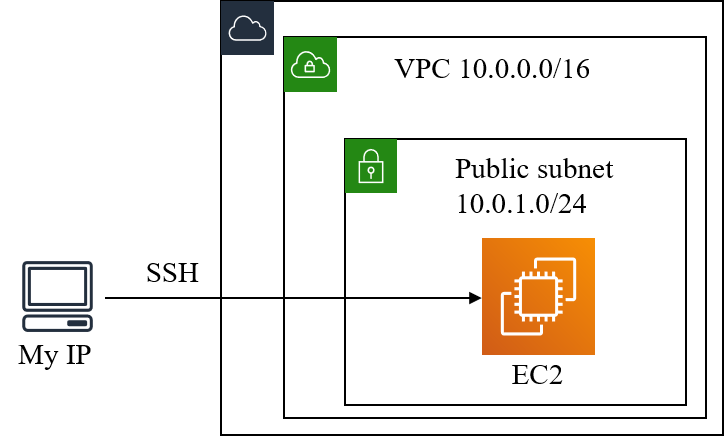
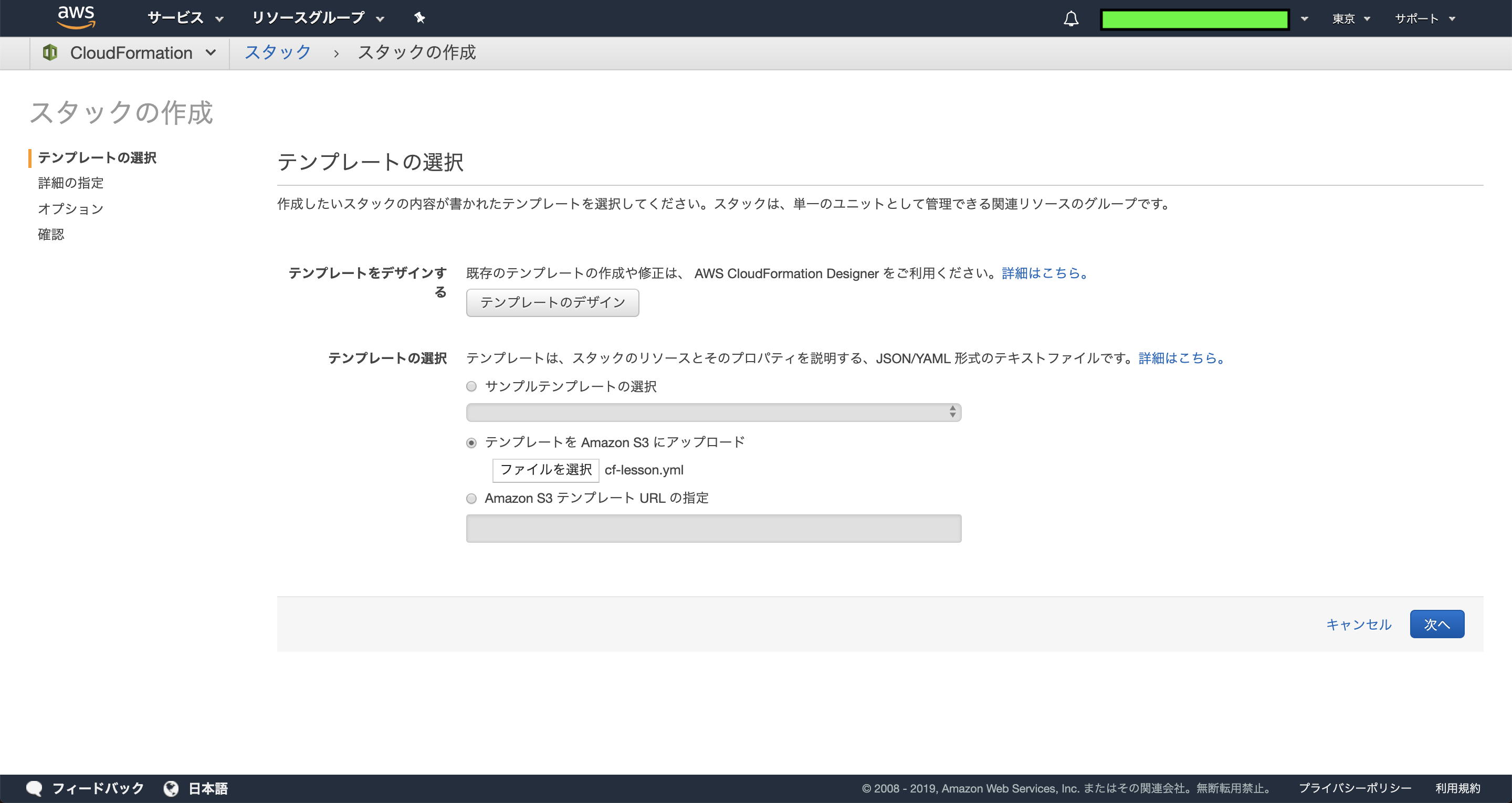
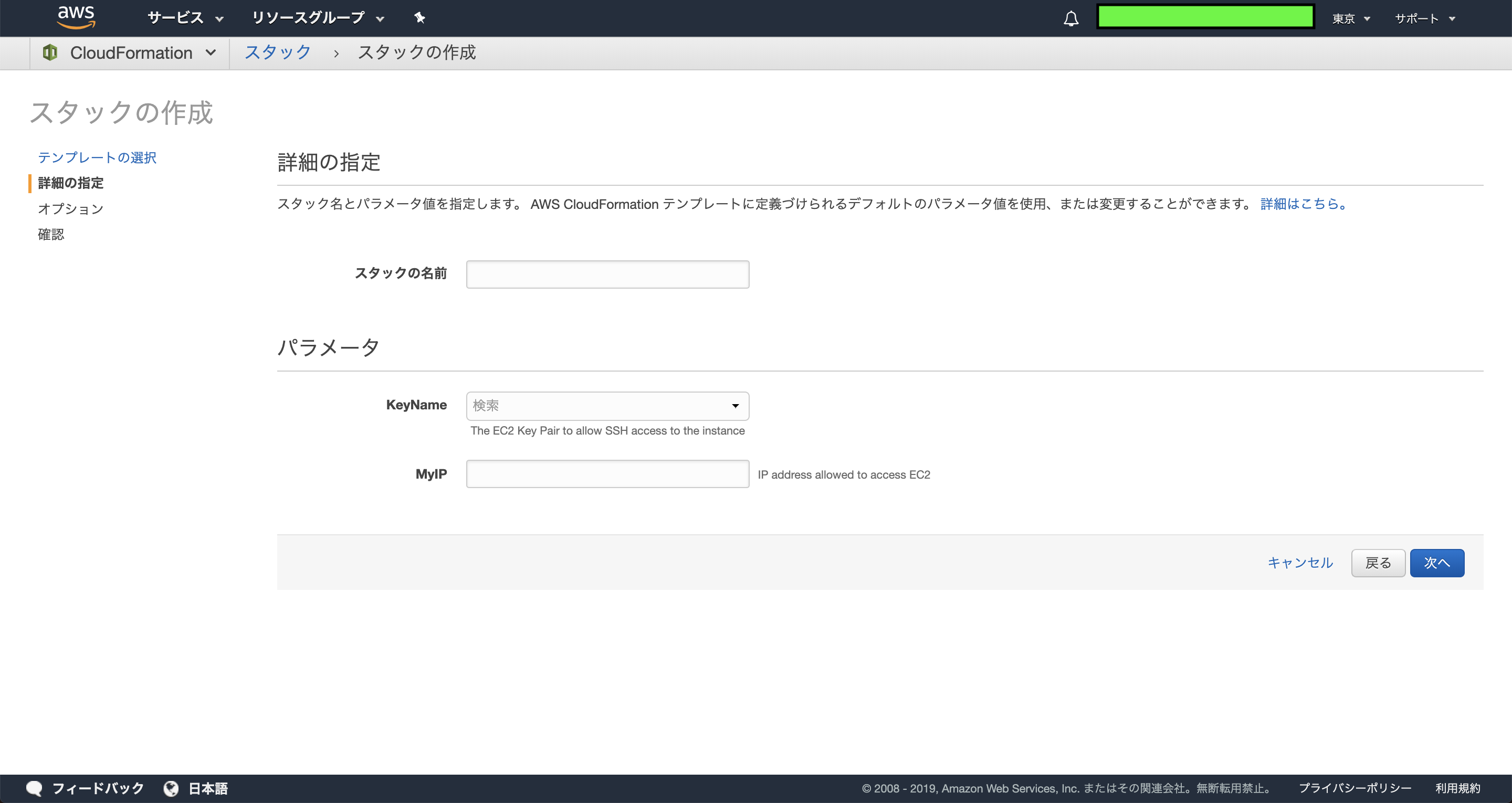
Parameters:KeyName:Description:The EC2 Key Pair to allow SSH access to the instanceType:"AWS::EC2::KeyPair::KeyName"MyIP:Description:IP address allowed to access EC2Type:String
EC2SG:Type:AWS::EC2::SecurityGroupProperties:GroupName:ec2-sg-cfGroupDescription:Allow SSH and HTTP access only MyIPVpcId:!RefVPCSecurityGroupIngress:# http-IpProtocol:tcpFromPort:80ToPort:80CidrIp:!RefMyIP# ssh-IpProtocol:tcpFromPort:22ToPort:22CidrIp:!RefMyIP
$ sudo growpart /dev/xvda 1
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 16G 0 disk
└─xvda1 202:1 0 16G 0 part /
ファイルシステムのリサイズ
sudo resize2fs /dev/xvda1
ファイルシステムのリサイズを行います。これで全体が使えるようになりました。
$ sudo resize2fs /dev/xvda1
resize2fs 1.42.13 (17-May-2015)
Filesystem at /dev/xvda1 is mounted on /; on-line resizing required
old_desc_blocks = 1, new_desc_blocks = 1
The filesystem on /dev/xvda1 is now 4194043 (4k) blocks long.
拡張後の容量の確認
念の為dfコマンドで容量を確認します。
$ df -h
Filesystem Size Used Avail Use% Mounted on
...
/dev/xvda1 16G 6.5G 9.0G 43% /
...