- 投稿日:2021-03-08T23:25:00+09:00
AWS MediaServicesの具体的なサービスとユースケース
インターネットを介したストリーミングビデオ
現在主流のビデオは下記の2つのモードでストリーミングされます。
リアルタイムライブストリーミング
リアルタイムライブストリーミングとは、ライブイベントの放送、もしくは事前に記録されたファイルの組み合わせである可能性がありますが、開始時間と停止時間が定義されています。
ビデオオンデマンド(VOD)ストリーミング
ビデオオンデマンド(VOD)ストリーミングとは、いつでも視聴できる事前に記録されたファイルです。
共通するビデオワークフロー
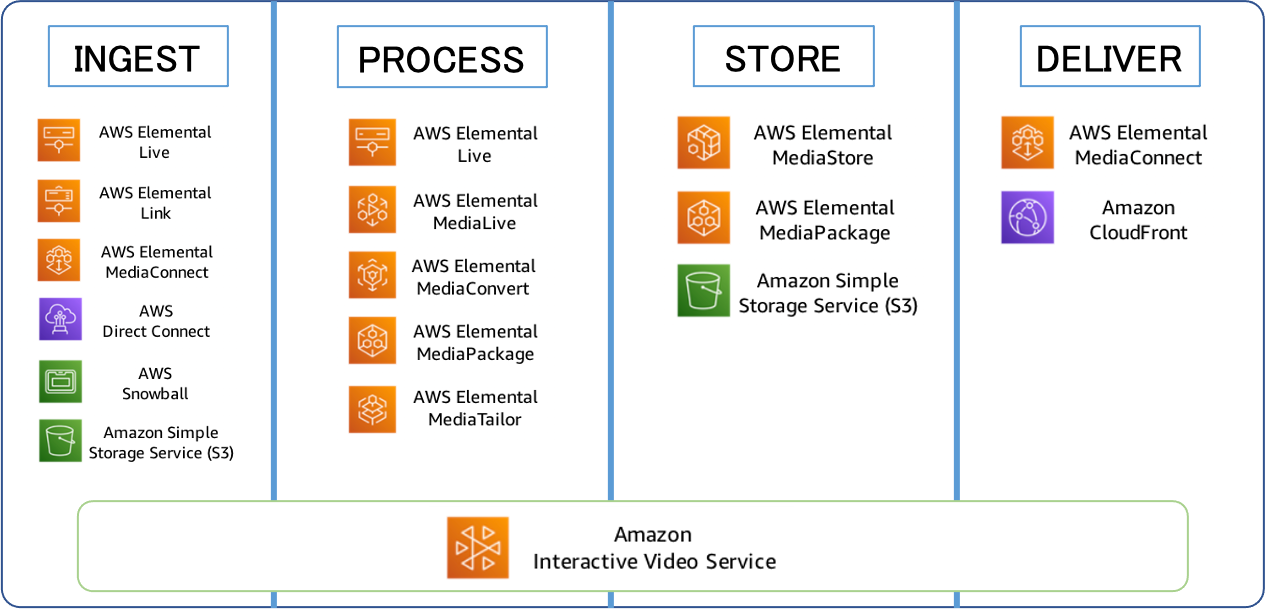
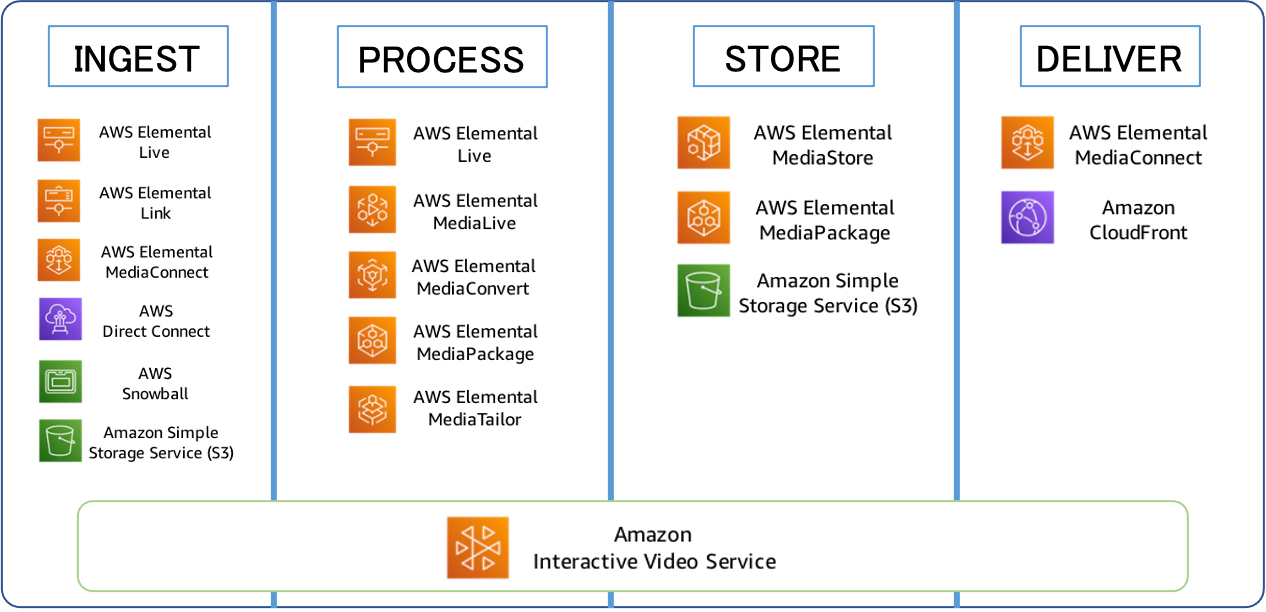
- ビデオワークフローにはさまざまなバリエーションがありますが、ライブ、オンデマンド、どちらであってもほとんどすべてに共通する4つの基本的な段階があります。 それが下記の、INGEST、PROCESS、STORE、DELIVERです。
INGEST
INGESTとは、ソースコンテンツをシステムに取り込む段階です。
ソースコンテンツとは、例えば下記のようなものです。
- ライブカメラ出力
- 他のプロバイダーからのビデオストリーム
- 録音済みファイル
- ユーザー生成コンテンツ(電話、タブレット)
- ウェブカメラ
PROCESS
コンテンツを操作または変換して利用可能にする段階です。
コンテンツを操作または変換とは、例えば下記のようなものです。
- 圧縮-帯域幅とファイルサイズの削減
- パッケージング-さまざまなプレーヤーデバイスのフォーマット
- 暗号化–アクセスの制限
- 収益化–広告挿入
STORE
視聴者のリクエストに先立ってコンテンツを保存またはキャッシュする段階です。
例えば、下記のようなものです。
- 「巻き戻し」のためのライブストリームの一時的なキャッシュ
- ビデオオンデマンドの長期
- 長期アーカイブ
DELIVER
多くの同時視聴者にコンテンツを配信する段階です。
AWSのサービスが4つの段階でどのように使用されるか
各AWSサービスの概要
AWS Elemental Live
高解像度の高帯域幅のソースコンテンツをより小さなバージョンに圧縮します。
AWS Elemental Link
カメラや動画制作機器などのライブ動画ソースを直接取得し、AWSのMediaLiveに送信します。
AWS Elemental MediaConnect
ライブビデオをAWSに取り込み、AWSグローバルネットワークを通じて安全に複数の送信先に送信できる新しいサービスです。
AWS Elemental MediaLive
複数のライブストリームを低解像度、低帯域幅バージョンへの圧縮をします。
これにより、ブロードキャストおよびストリーミング配信用のライブ出力を簡単に作成できます。AWS Elemental MediaConvert
複数のビデオファイルを低解像度、低帯域幅バージョンへの圧縮します。
AWS Elemental MediaPackage
接続されたTV、PC、タブレット、およびモバイルデバイスで再生するためにビデオストリームをフォーマットします。
また、暗号化によってコンテンツを保護します。AWS Elemental MediaStore
ビデオ、オーディオメディア用に最適化された高性能、低遅延のストレージサービスです。
AWS Elemental MediaTailor
ターゲットを絞った広告をビデオストリームにシームレスに挿入します。
ユースケース
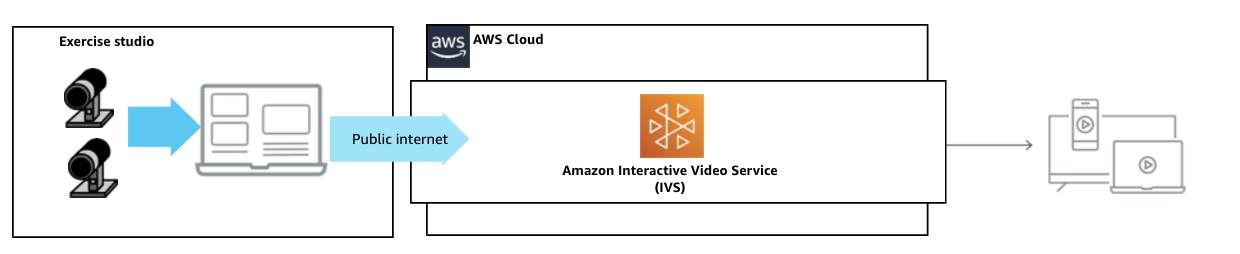
ライブのユースケース
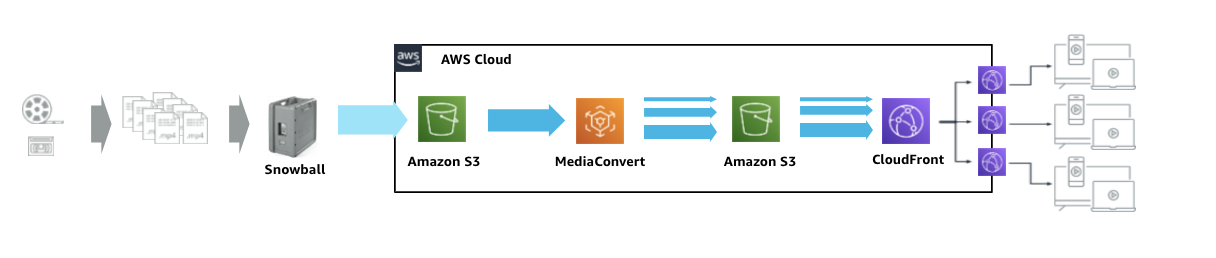
VODのユースケース
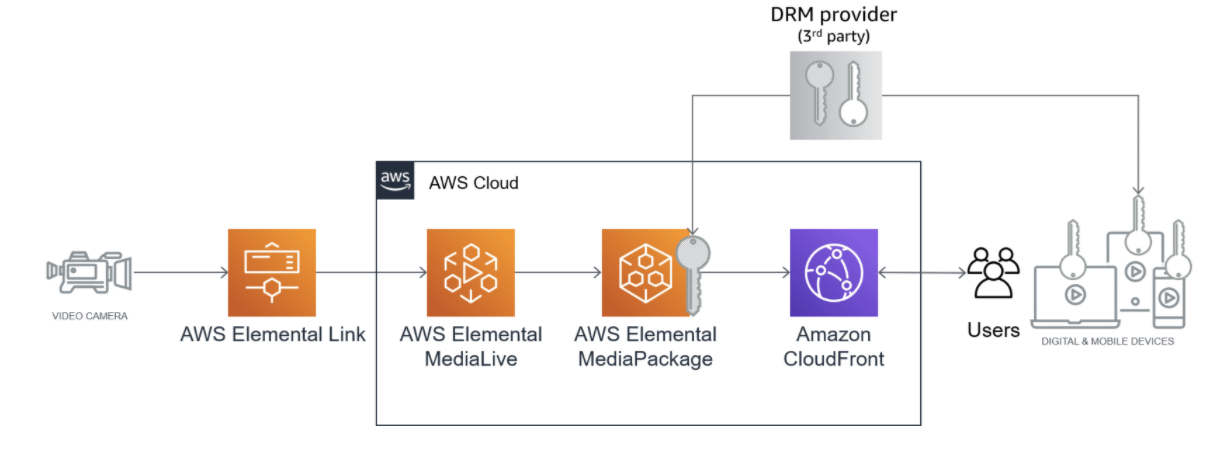
不正アクセスからコンテンツを保護するには?
- 一部のコンテンツは、自由に利用できるようになっています。
- 他のコンテンツへのアクセスは、収益または機密保持の理由で制限する必要がある場合があります。 => DRMと呼ばれているやつ。
DRMについては、AWS ElementalMediaPackageを使用して実装できます。
引用元: Protect Your Content from Unauthorized Access参考文献
- 投稿日:2021-03-08T23:25:00+09:00
AWS MediaServices の具体的なサービスとユースケース
インターネットを介したストリーミングビデオ
現在主流のビデオは下記の2つのモードでストリーミングされます。
リアルタイムライブストリーミング
リアルタイムライブストリーミングとは、ライブイベントの放送、もしくは事前に記録されたファイルの組み合わせである可能性がありますが、開始時間と停止時間が定義されています。
ビデオオンデマンド(VOD)ストリーミング
ビデオオンデマンド(VOD)ストリーミングとは、いつでも視聴できる事前に記録されたファイルです。
共通するビデオワークフロー
- ビデオワークフローにはさまざまなバリエーションがありますが、ライブ、オンデマンド、どちらであってもほとんどすべてに共通する4つの基本的な段階があります。 それが下記の、INGEST、PROCESS、STORE、DELIVERです。
INGEST
INGESTとは、ソースコンテンツをシステムに取り込む段階です。
ソースコンテンツとは、例えば下記のようなものです。
- ライブカメラ出力
- 他のプロバイダーからのビデオストリーム
- 録音済みファイル
- ユーザー生成コンテンツ(電話、タブレット)
- ウェブカメラ
PROCESS
コンテンツを操作または変換して利用可能にする段階です。
コンテンツを操作または変換とは、例えば下記のようなものです。
- 圧縮-帯域幅とファイルサイズの削減
- パッケージング-さまざまなプレーヤーデバイスのフォーマット
- 暗号化–アクセスの制限
- 収益化–広告挿入
STORE
視聴者のリクエストに先立ってコンテンツを保存またはキャッシュする段階です。
例えば、下記のようなものです。
- 「巻き戻し」のためのライブストリームの一時的なキャッシュ
- ビデオオンデマンドの長期
- 長期アーカイブ
DELIVER
多くの同時視聴者にコンテンツを配信する段階です。
AWSのサービスが4つの段階でどのように使用されるか
各AWSサービスの概要
AWS Elemental Live
高解像度の高帯域幅のソースコンテンツをより小さなバージョンに圧縮します。
AWS Elemental Link
カメラや動画制作機器などのライブ動画ソースを直接取得し、AWSのMediaLiveに送信します。
AWS Elemental MediaConnect
ライブビデオをAWSに取り込み、AWSグローバルネットワークを通じて安全に複数の送信先に送信できる新しいサービスです。
AWS Elemental MediaLive
複数のライブストリームを低解像度、低帯域幅バージョンへの圧縮をします。
これにより、ブロードキャストおよびストリーミング配信用のライブ出力を簡単に作成できます。AWS Elemental MediaConvert
複数のビデオファイルを低解像度、低帯域幅バージョンへの圧縮します。
AWS Elemental MediaPackage
接続されたTV、PC、タブレット、およびモバイルデバイスで再生するためにビデオストリームをフォーマットします。
また、暗号化によってコンテンツを保護します。AWS Elemental MediaStore
ビデオ、オーディオメディア用に最適化された高性能、低遅延のストレージサービスです。
AWS Elemental MediaTailor
ターゲットを絞った広告をビデオストリームにシームレスに挿入します。
ユースケース
ライブのユースケース
VODのユースケース
不正アクセスからコンテンツを保護するには?
- 一部のコンテンツは、自由に利用できるようになっています。
- 他のコンテンツへのアクセスは、収益または機密保持の理由で制限する必要がある場合があります。 => DRMと呼ばれているやつ。
DRMについては、AWS ElementalMediaPackageを使用して実装できます。
引用元: Protect Your Content from Unauthorized Access参考文献
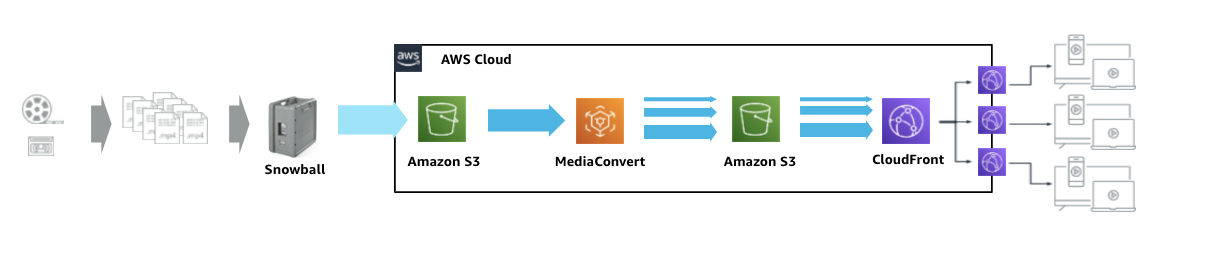
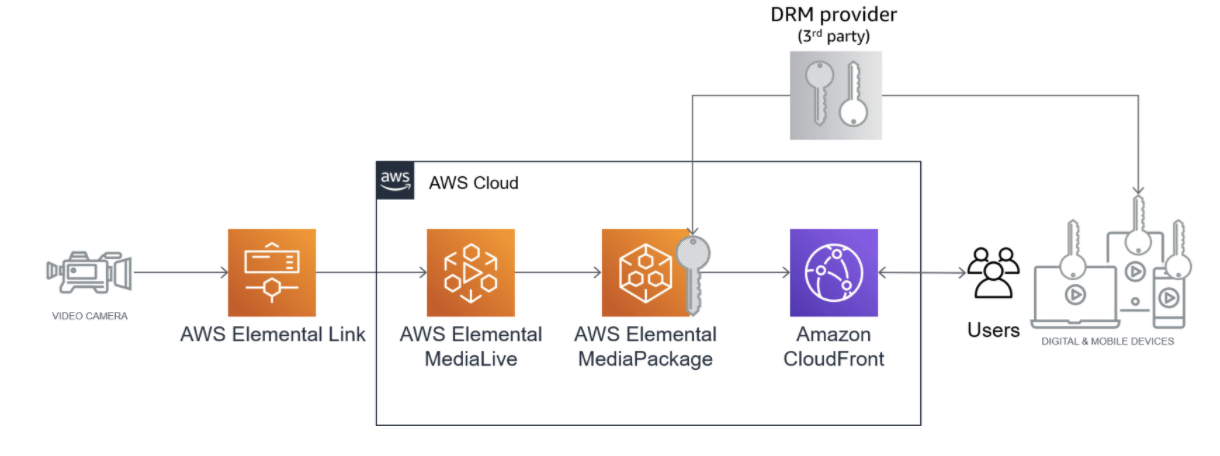
- 投稿日:2021-03-08T23:16:13+09:00
S3をWebサーバーにしてコンテンツを公開する①(S3パブリック編)
S3をWebサーバーにして静的コンテンツを公開する方法を紹介します。
- S3パブリック編 ←コレ!
- S3署名付きURL編
- CloudFrontパブリック編
- CloudFront署名付きURL編 (作成中)
- CloudFront署名付きCookie編 (作成中)
手順
バケットの作成
まずはバケットを作成しましょう。
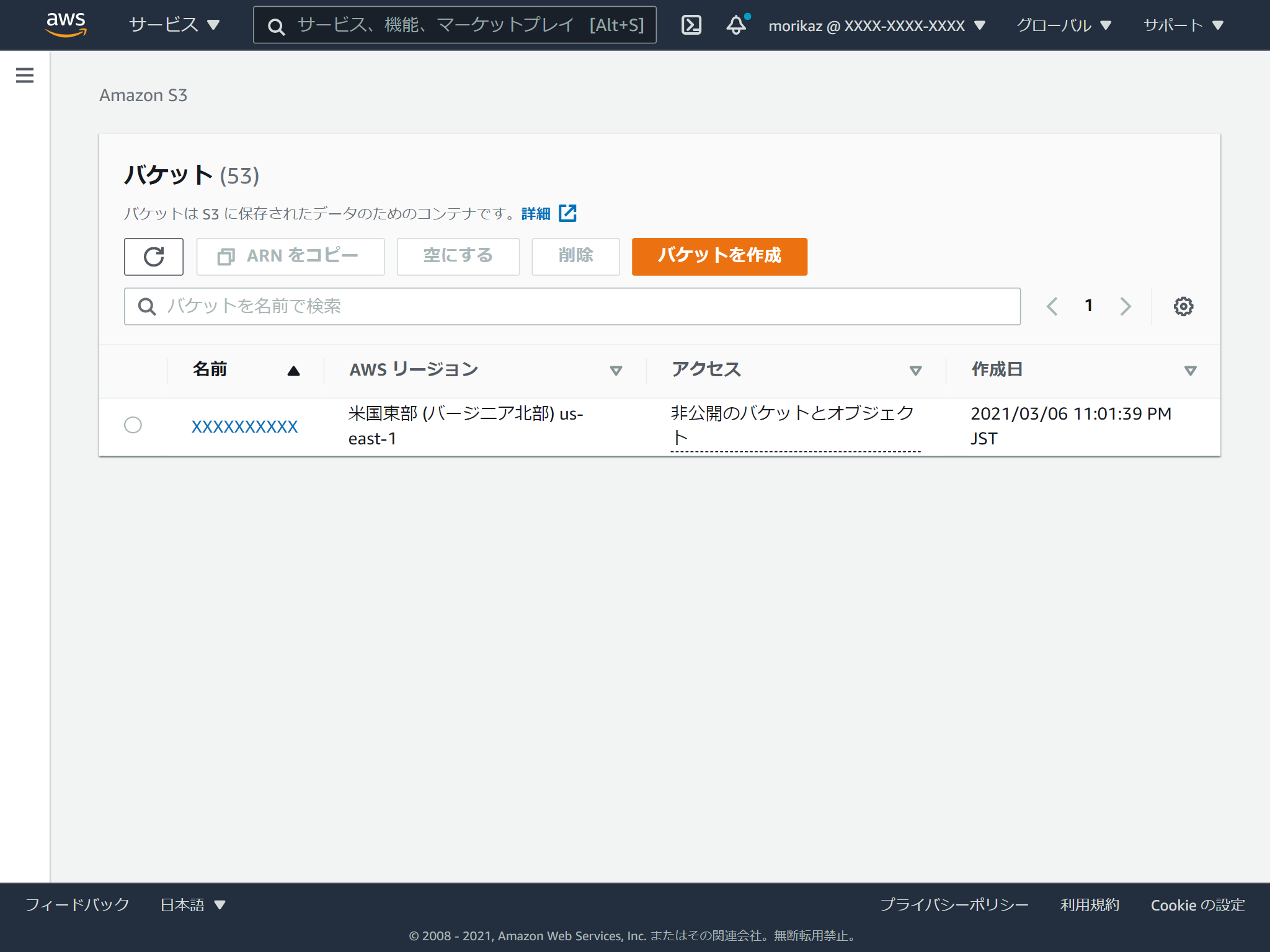
マネジメントコンソールでS3のページを開きます。
バケットを作成をクリックします。
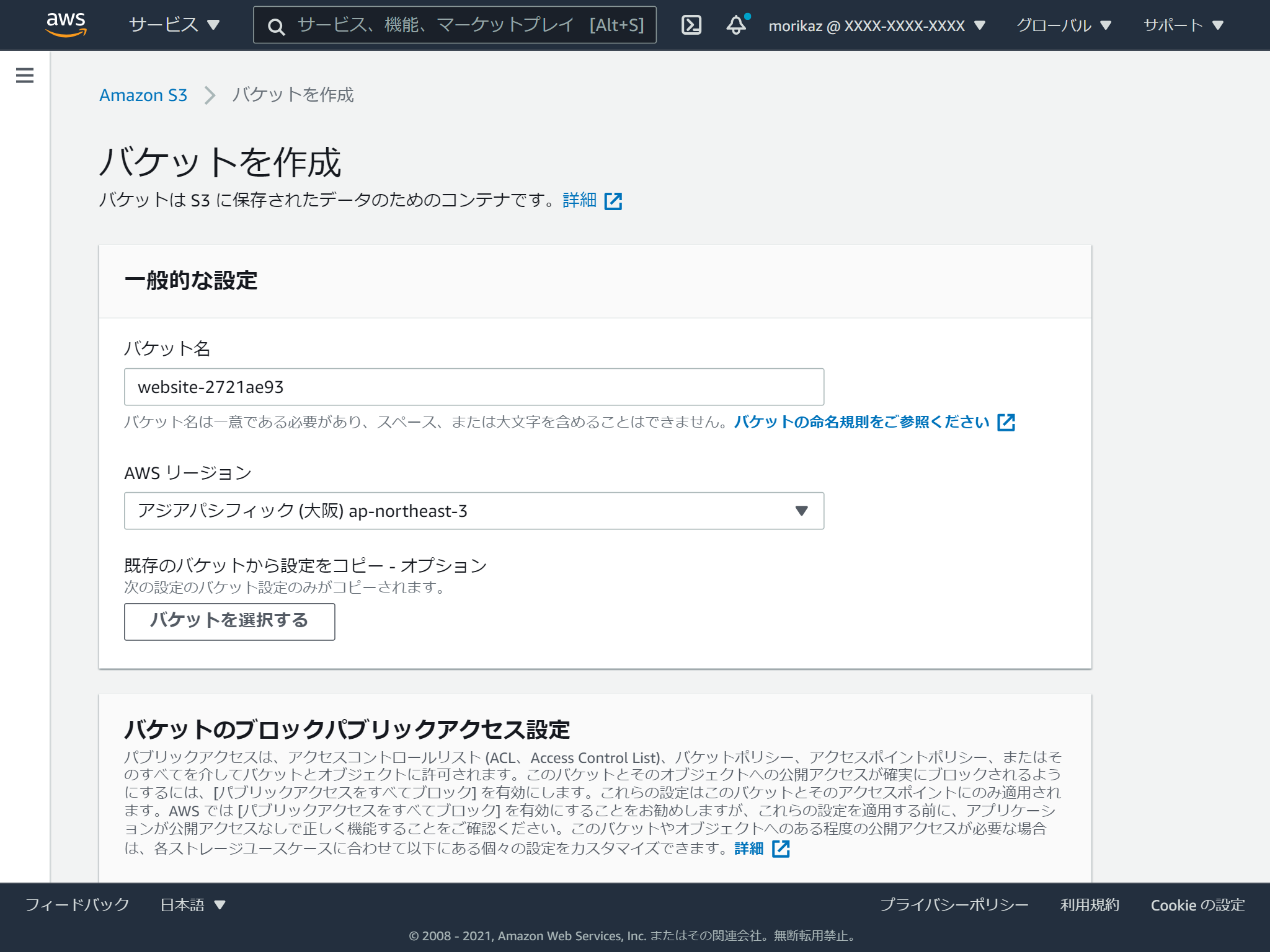
バケットの名前を入れて、リージョンを選択します。
バケット名は世界中のS3で一意である必要があります。
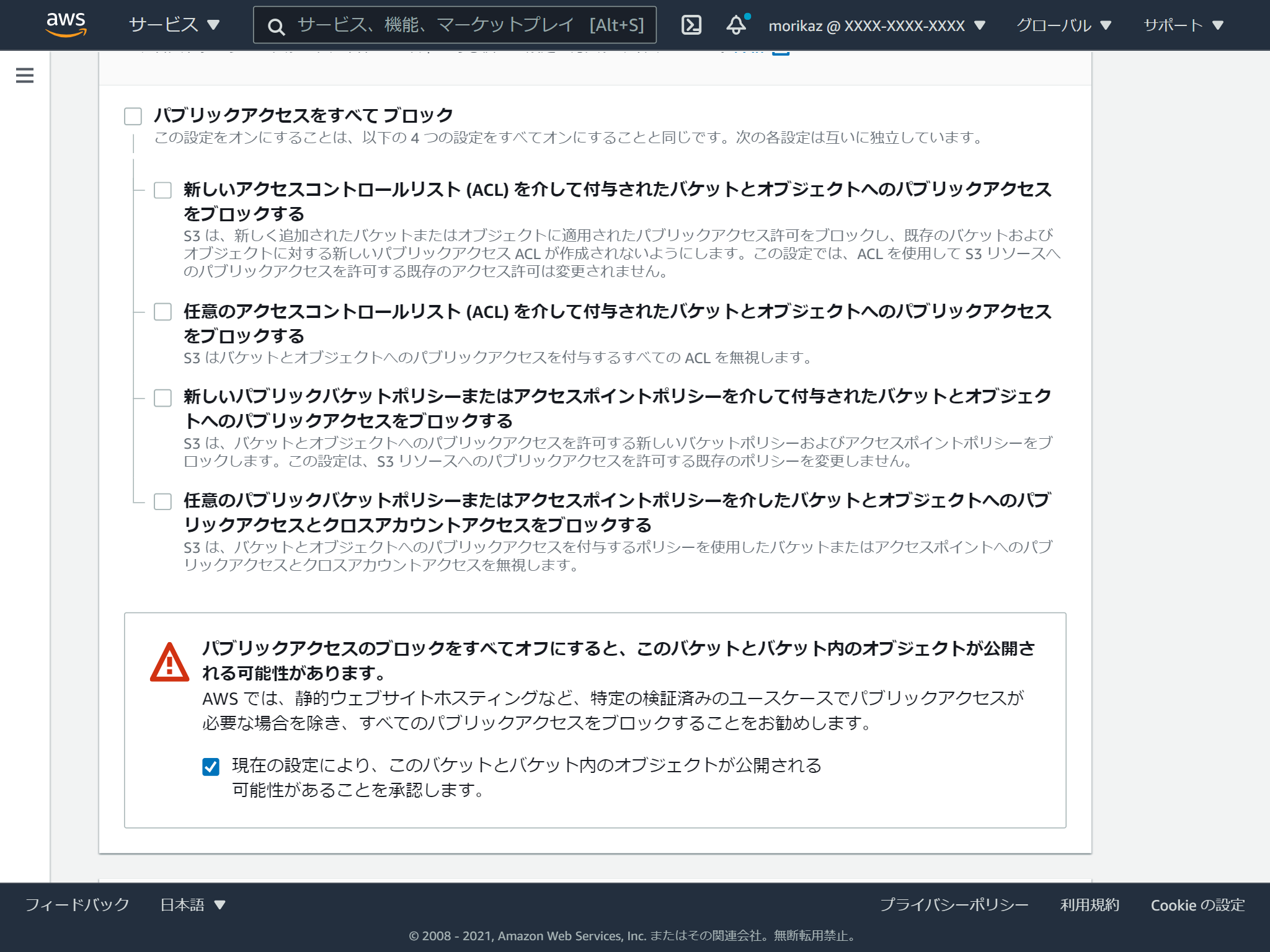
一般公開するので、パブリックアクセスを許可する必要があるため、「パブリックアクセスをすべてブロック」のチェックを外し、「現在の設定により、・・・」にチェックを入れます。
これでバケット作成は完了です。
HTMLの格納
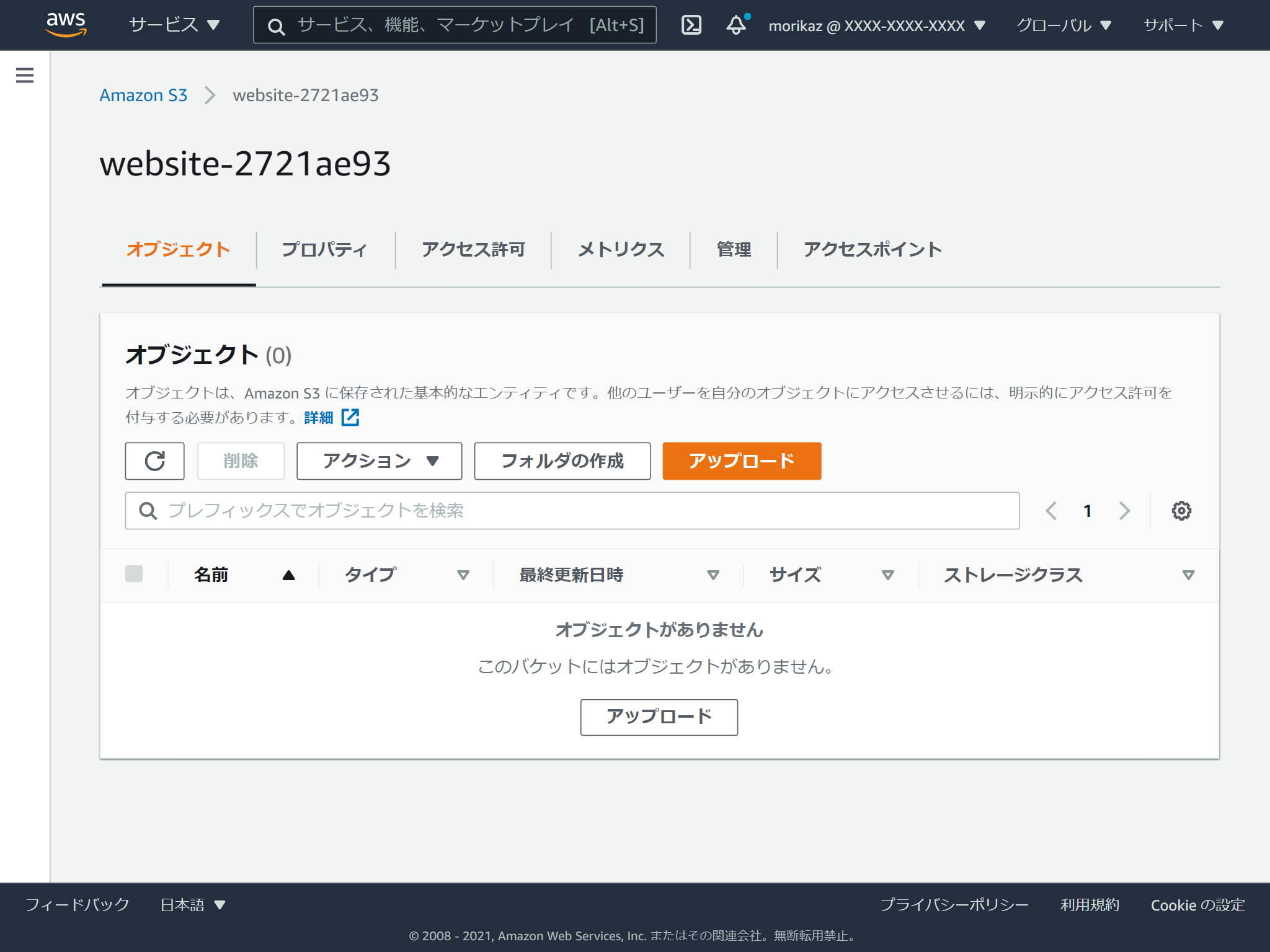
作成したバケットを選択します。
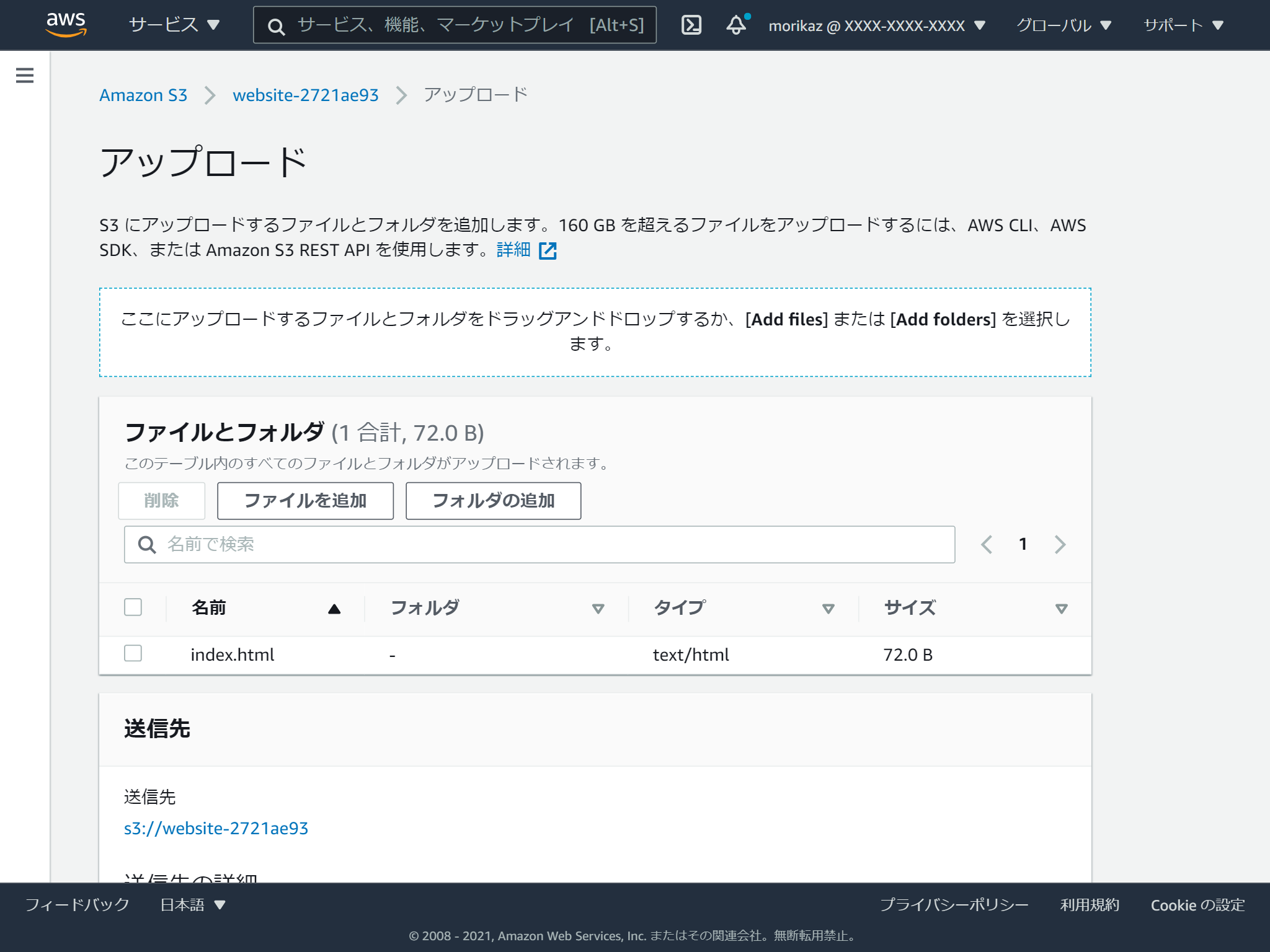
そして、HTMLファイルをドラッグアンドドロップします。
設定が色々ありますが、画面最下部のアップロードを実行します。
複数ファイルやフォルダーまるごとアップロードすることも可能です。
公開する
公開する方法は2種類あります。
- ウェブサイトエンドポイントとして公開
- REST API エンドポイント
ウェブサイトエンドポイントと REST API エンドポイントの主な違い
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/userguide/WebsiteEndpoints.html#WebsiteRestEndpointDiff公開する(ウェブサイトエンドポイント)
バケットの設定画面の「プロパティ」タブを選択します。
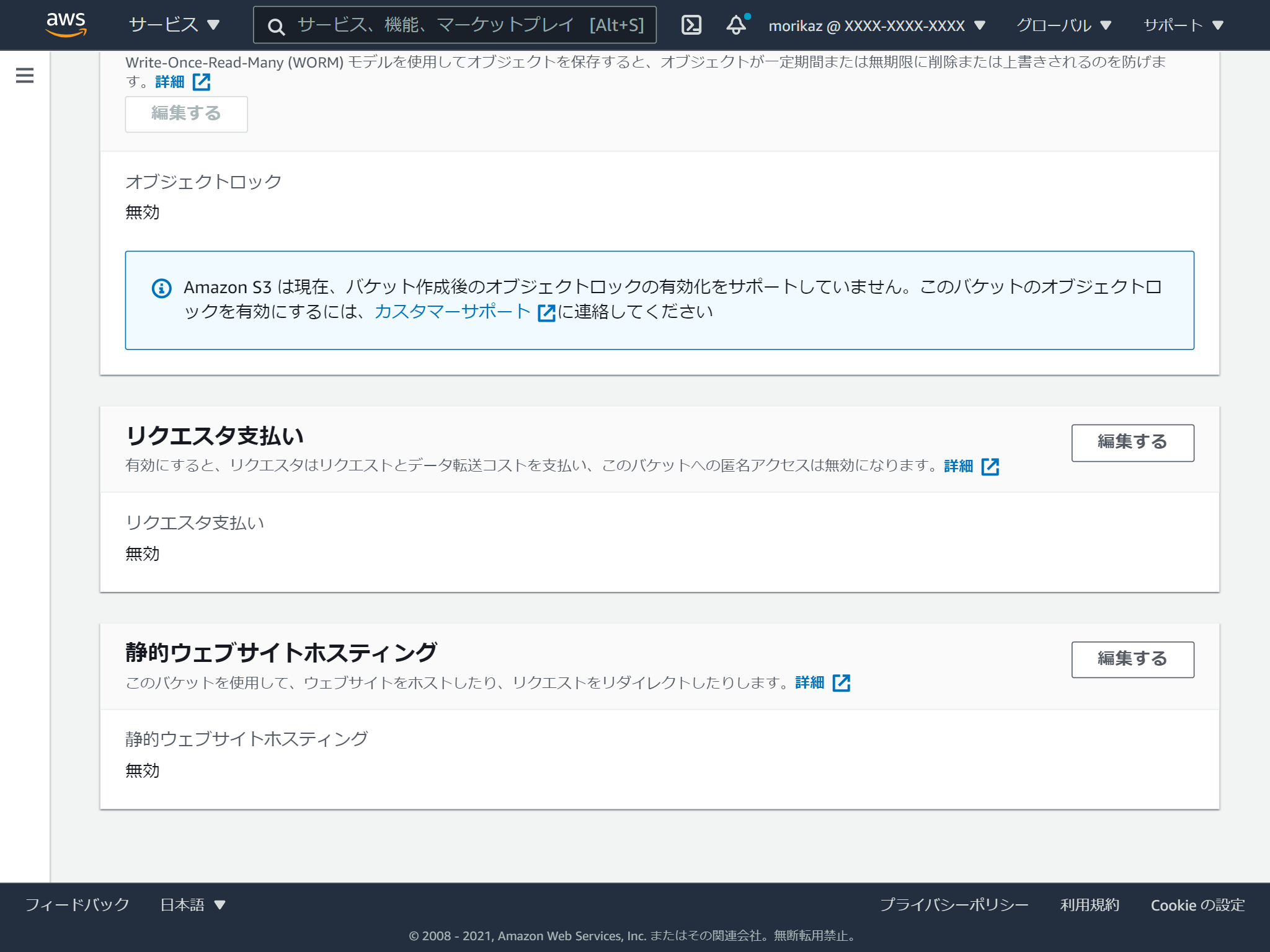
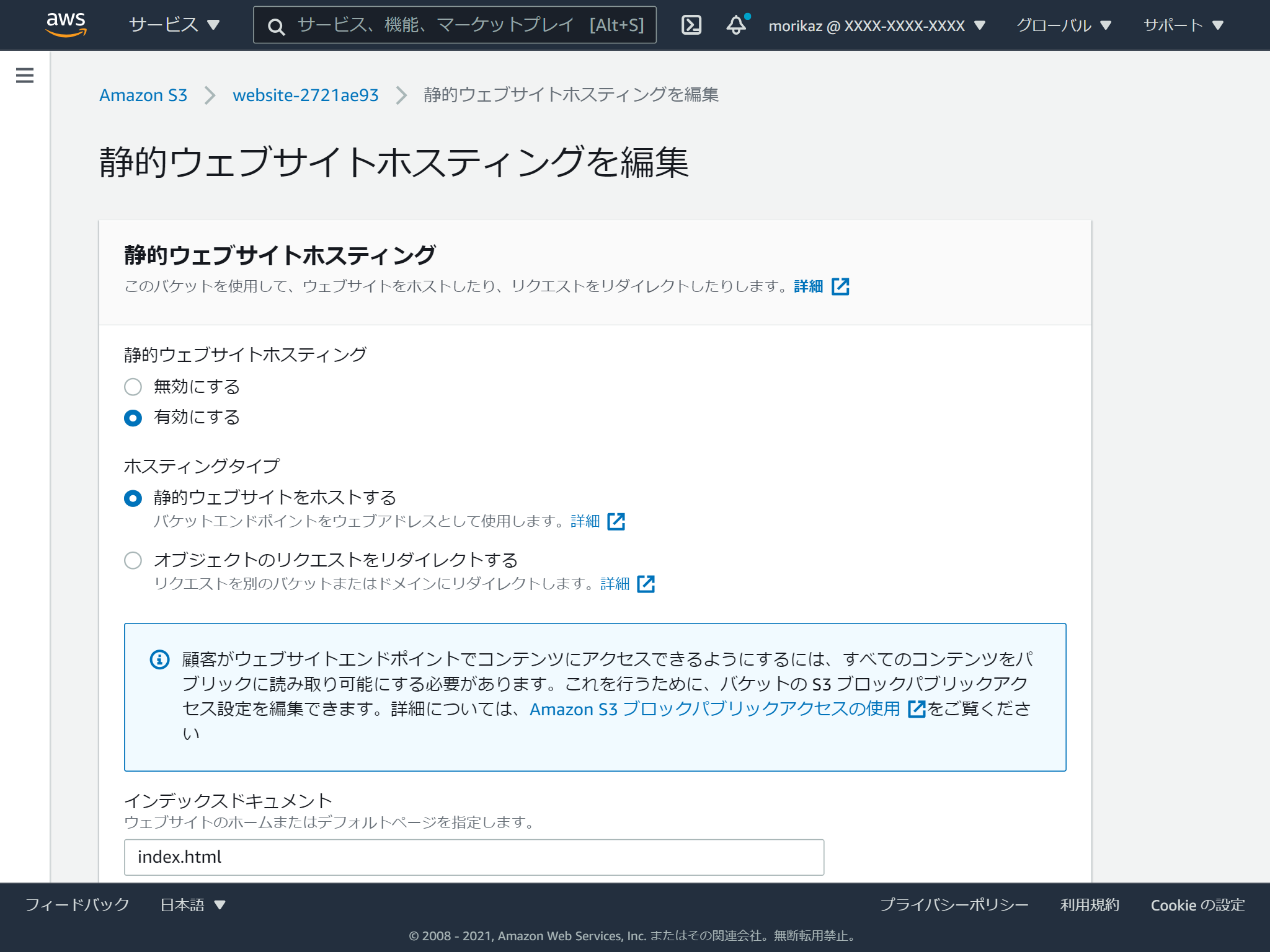
プロパティタブの一番下の「静的ウェブサイトホスティング」の「編集する」をクリックします。
静的ウェブサイトホスティングを有効にし、インデックスドキュメントを指定します。
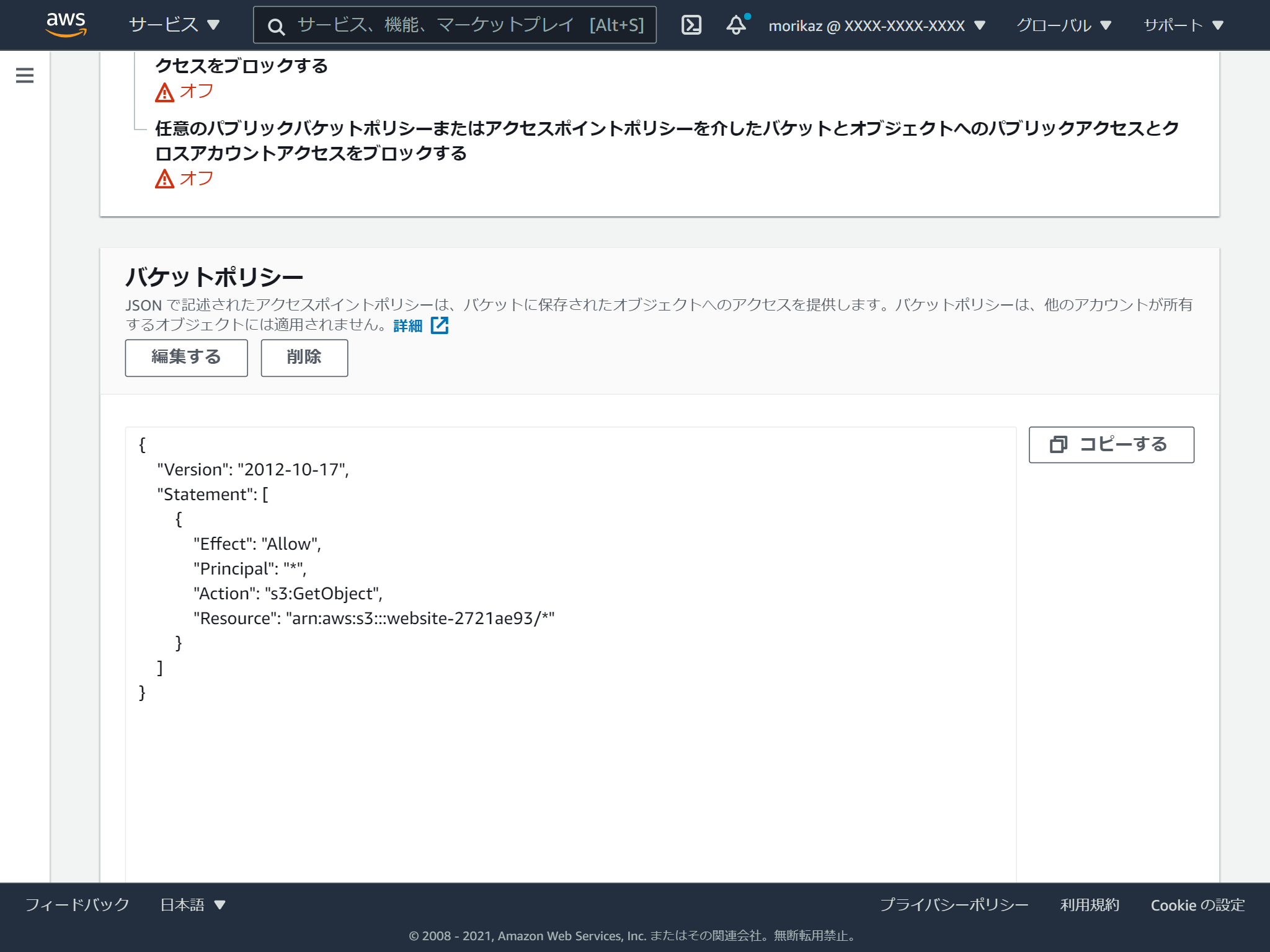
続いて、バケットの設定画面の「アクセス許可」タブを選択し、バケットポリシーに以下のJSONを指定します。(何故かコピペが使えず、一つ一つ手入力しました。。)
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::website-2721ae93/*" } ] }
これで設定完了です。
アクセスURLは以下となります。
http://[バケット名].s3-website.[リージョン名].amazonaws.com/公開する(REST API エンドポイント)
こちらは方法が2つあって、
- バケットポリシーで設定
- アクセスコントロールリスト(ACL)で設定
バケットポリシーで設定する方法は、先程のウェブサイトエンドポイントの手順で説明した、アクセス許可の設定だけすればOKです。
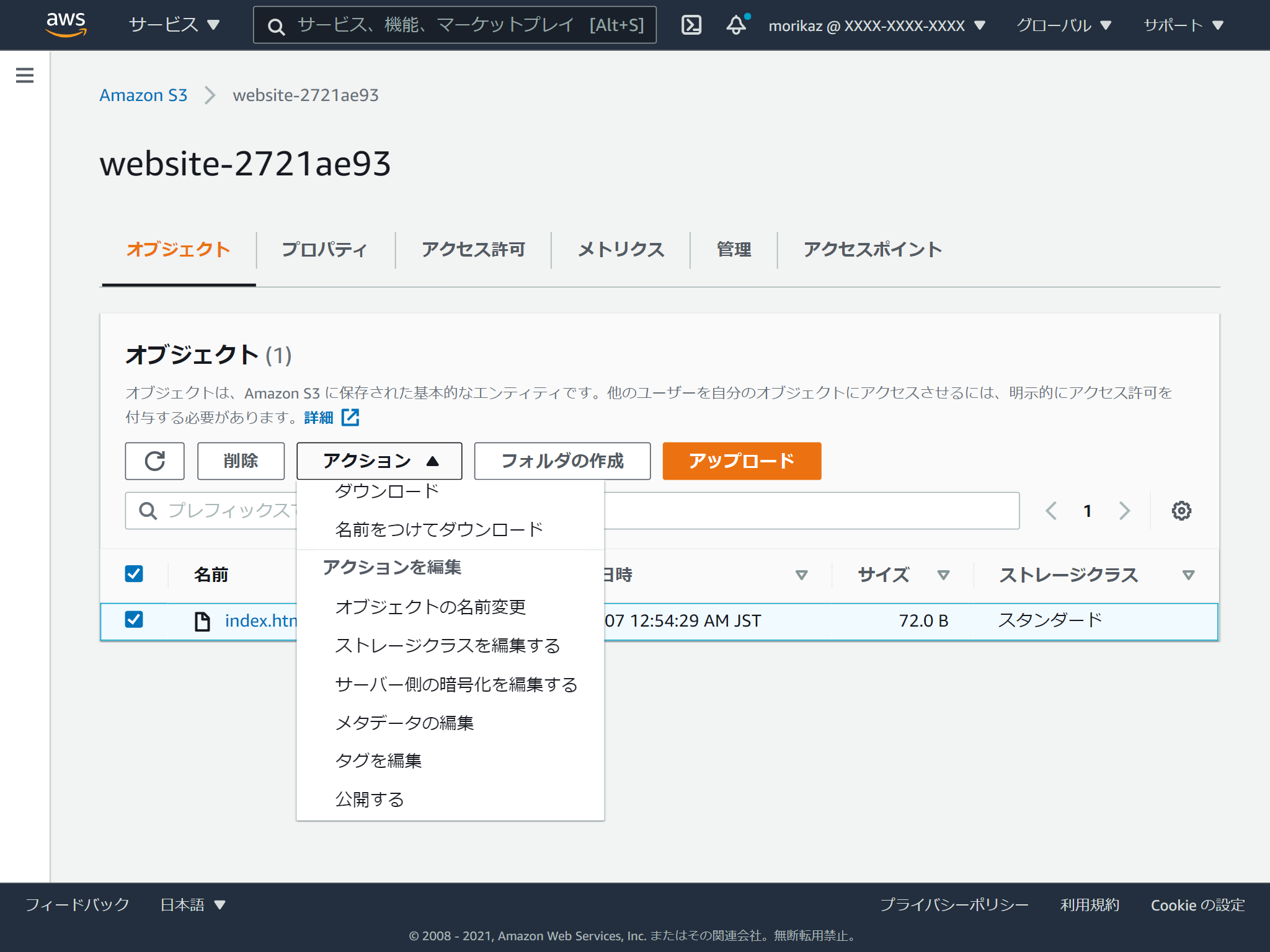
アクセスコントロールリスト(ACL)する方法は、公開したいオブジェクトを選択して、「アクション」の「公開する」を選択します。
アクセスURLは以下となります。
https://[バケット名].s3.[リージョン名].amazonaws.com/index.html
- 投稿日:2021-03-08T22:05:58+09:00
【学習メモ】Kinesis
Kinesis
ストリームデータを収集・処理するためのフルマネージド型サービスで主に3つのサービスで構成される。
・Amazon Kinesis Streams:ストリームデータを処理するアプリケーションを構築。
※主要なストリームデータはこのサービスによって使っていく。(代表サービス)
・Amazon Kinesis Firehose:ストリームデータをS3やRedshiftなどへ簡単に配信。
・Amazon Kinesis Analytics:ストリームデータを標準的なSQLクエリでリアルタイムに可視化・分析。
※残り二つのサービスは組み合わせで使う。Amazon Kinesis Streams
ストリーミング処理をシャードに分けて分散させて実行するため高速処理が可能。
(シャードの数によって、データ処理のスピードが変わる。数が多ければ、負荷を分散化して高速処理が可能。)
※シャード:Amazon Kinesis データストリームの基本的なスループットの単位。データプロデューサー:データ提供側。
データコンシューマー:データ利用側。Streamsへのデータの格納
reference:https://aws.amazon.com/jp/kinesis/data-streams/getting-started/?nc1=h_ls
データプロデューサーは、Amazon Kinesis データストリームに Amazon Kinesis Data Streams API、Amazon Kinesis Producer Library (KPL)、または Amazon Kinesis Agent を介してデータを格納できます。
Amazon Kinesis Firehose
各種DBに配信・蓄積するためのストリーム処理を実施する。Lambdaと連携するとETLとしても機能する
Amazon Kinesis Analytics
ストリームデータを標準的なSQLクエリでリアルタイムに分析

- 投稿日:2021-03-08T21:57:22+09:00
AWS Systems Manager とは
勉強前イメージ
AWSのシステム全体をまとめて管理するようなやつ?
管理系のサービスな気がするなぁ調査
AWS Systems Manager とは
AWSでインフラのサービスを管理や制御するためのサービスです。
複数のサービスのデータを表示して、リソース間でタスクを自動化する事が出来ます。AWS Systems Manager の特徴
- 複数のサービスのデータを一元化し、可視化させる
- リソース全体のタスクを自動化
- EC2とオンプレのサーバを管理することが出来る
AWS Systems Manager の機能
- 高速セットアップ
- 運用管理
- エクスプローラー
- OpsCenter
- Cloudwatch ダッシュボード
- PHD
- アプリケーション管理
- アプリケーションマネージャー
- AppConfig
- パラメータストア
- 変更管理
- 変更マネージャー
- 自動化
- カレンダーの変更
- メンテナンスウィンドウ
- ノード管理
- フリートマネージャー
- コンプライアンス
- インベントリ
- マネージドインスタンス
- ハイブリッドアクティベーション
- セッションマネージャー
- Run Command
- ステートマネージャー
- パッチマネージャー
- ディストリビューター
- 共有リソース
- ドキュメント
費用
以下以外は無料
- 運用管理
- エクスプローラー
- OpsCenter
- アプリケーション管理
- AppConfig
- パラメータストア
- 変更管理
- 変更マネージャー
- 自動化
- メンテナンスウィンドウ
- ノード管理
- コンプライアンス
- インベントリ
- ハイブリッドアクティベーション
- セッションマネージャー
- Run Command
- ステートマネージャー
- パッチマネージャー
- ディストリビューター
詳細の費用は こちら
勉強後イメージ
いろんな機能がありすぎてややこしいけど、
AWS全体のインフラを管理できて、オンプレも管理出来るよ。
あと自動化とかも出来るよ、って感じか・・・
使ってみないとピンと来ないかもなぁ参考
- 投稿日:2021-03-08T21:45:41+09:00
AWS VM Import/Export
VM Import/Exportってなんだろ?
AWSの模擬問題とかでもたまに出てくるVM Import/Exportというサービス。
名前は知ってるけどよく分からん!
ってことで調べてみました!仮想のこいつらをインポート、エクスポートするかんじかな?
とりあえず
仮想マシンって何?って方は、以下のリンクが分かりやすいと思います!
VMとは|「分かりそう」で「分からない」でも「分かった」気になれるIT用語辞典教えて公式
VM Import/Export を使用すると、仮想マシンイメージを既存の環境から Amazon EC2 インスタンスにインポートすることや、元のオンプレミス環境にエクスポートすることが簡単にできます。この機能によって、仮想マシンが Amazon EC2 のインスタンスとして移行されてすぐに使用できる状態になるので、IT セキュリティ、構成管理、コンプライアンスに関するお客様の要件に合わせて作成した仮想マシンへの、これまでの投資が無駄になることはありません。また、インポートしたインスタンスを元のオンプレミス仮想化インフラストラクチャにエクスポートすることもできるので、ワークロードを自社の IT インフラストラクチャにデプロイできるようになります。
VM Import/Export | AWSよりうん、なんか名前のまんまってかんじ!
オンプレ(会社など)にあるVM(Virtual Machine = 仮想マシン)を、
Import = AWSに持ち込んだり、
Export = AWSから外へ出したり
できるってことですね。Import = 持ち込むとどうなるの?
VM Import ではインポートプロセス中に VM が Amazon EC2 AMI に変換されます。Amazon EC2 AMI を使用すると、Amazon EC2 インスタンスを実行できます。VM のインポートが完了したら、Auto Scaling、Elastic Load Balancing、CloudWatch などのサービスを介して、Amazon の伸縮自在性、拡張性、モニタリングを活用し、インポートされたイメージをサポートできます。
なるほど!
会社にあった仮想マシンがAWSに入るとAMIになり、AMIからEC2を起動できるわけですね。そしてEC2になっちまえばこっちのもん。ELBとかAuto ScalingとかCloudWatchを使って負荷分散とか可用性向上とかモニタリングもできちゃうんだよってことか。Export = 持ち出すときはどうするの?
インポートした EC2 インスタンスをエクスポートするには、Amazon EC2 の API ツールを使用します。ターゲットのインスタンス、仮想マシンファイルフォーマット、出力先の S3 バケットを指定するだけで、インスタンスが自動的にその S3 バケットにエクスポートされます。このエクスポートされた VM は、ダウンロードしてオンプレミスの仮想化インフラストラクチャ内で起動できます。
EC2のAPI使って色々設定して、S3に出力するんだって。そうすると、S3からダウンロードできるから、ダウンロードした仮想マシンを会社のマシンで動かすって流れみたい。やったことないから実感わかないけど、S3に仮想マシンを出力してダウンロードするなんてことができるんですね!
どんな時に使うの?
主な用途としては、既存のVM環境のAWSへの移行や、よく使うVMイメージをカタログ化・保存してシステム罹災時などにおける復旧に備える、などが考えられます。
クラウド・オンプレミス間のデータ移行に役立つAWS Import/Export(Snowball)とVM Import/Exportとはよりオンプレのクラウド移行とバックアップなんかに使うみたい。
別の方法もあるの?
仮想マシン (VM) を Amazon EC2 インスタンスにインポートするには、次の 3 つのオプションを使用できます。
1. AWS Server Migration Service (SMS)
2. AWS VM Import/Export ツール
3. CloudEndure Migration
ローカルの仮想化環境と Amazon EC2 との間でインスタンスを移行する方法を教えてください。よりあるって!
SMSも名前は知ってて、サーバー移行できるよってことは知ってるけど、詳しくはまだ勉強不足です・・・。
CloudEndure Migrationは初耳です!
SMSもCloudEndure Migrationも今度調べてみます。まとめ
仮想マシンは個人的に少し触ったことがあるぐらいで、まだよくわかってない領域なので、ざっくりした内容になってしまいましたが、とりあえず仮想マシンをオンプレとAWSで出し入れできるサービスだよ!ってことは分かりました。一歩前進!
詳しい移行の話になってくると、まだ全然わからないので基本的なことも調べて記事にしたいと思います!
ご覧頂きありがとうございました!

- 投稿日:2021-03-08T20:06:19+09:00
[AWS] Windows版AWS Cliだけで、ECRにDockerイメージをPushする方法
ECRへのログイン
通常、ECRへのDockerイメージのPushは、ECRリポジトリ管理画面の「プッシュコマンドの表示」から行えます。
この中に、
- リポジトリへのログイン
- Dockerイメージのビルド
- Dockerイメージへのタグ付け
- ECRリポジトリへイメージPush
という手順が示されていますが、Windowsの場合、最のリポジトリへのログインが、PowerShellになってます。
AWS Tools for PowerShell
Windows PowerShell 用 AWS Tools を使用すると、デベロッパーと管理者が AWS のサービスとリソースを PowerShell スクリプト環境で管理できます。Windows、Linux、MacOS 環境の管理に使用するのと同じ PowerShell ツールを使用して、AWS リソースを管理できるようになりました。
となってます。そう、これは、あくまでPowerShell用であって、Windows版 AWS Cliとは別物なのです。
正直、AWS Cliだけで完結したいですよね。AWS Cliで最初のログインを突破する
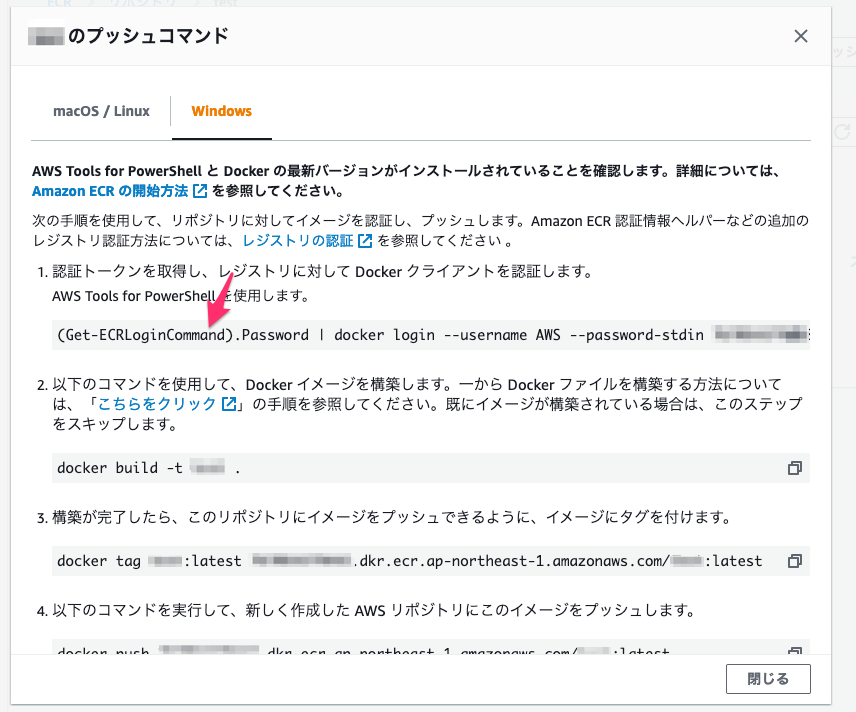
これさえできれば、このあとは、dockerコマンドのみでいけるのです。
ということで、AWS Cliコマンドのみでやる方法ですが、実に簡単です。PowerShell版
(Get-ECRLoginCommand).Password | docker login --username AWS --password-stdin {AWSアカウントID}.dkr.ecr.{リージョン}.amazonaws.comAWS Cli版
aws ecr get-login-password | docker login --username AWS --password-stdin {AWSアカウントID}.dkr.ecr.{リージョン}.amazonaws.com単純に、現在使用しているAWSアカウントでの、ECRのパスワードを標準出力経由で、
docker loginコマンドに渡してあげればいいだけです。
- 投稿日:2021-03-08T16:22:41+09:00
TerraformでBackendとProviderで別々のprofileを指定することにした
概要
TerraformでデプロイするIAMUserはAssumeRoleでそれぞれの必要な権限をもつIAMRoleにスイッチして
Terraform initからTerraform deploy/apply/destroyを実行するようにしてみた背景
- Terraformでデプロイするユーザのアクセスキーが万が一漏れても被害が最小限になるようにしたい
- 一々 AWS Cli でAssumeRoleコマンド実行してアクセスキーを切り替える(上書きする)のがめんどくさいのでそうしなくていいようにしたい
- 誰がリソースをいじったかわかるようにしたい
Terraform実行イメージ
terraform init時
- IAMUser → S3用IAMRoleにスイッチ
terraform plan/deploy/destroy時
- IAMUser → S3用IAMRoleにスイッチ → Deploy用IAMRoleにスイッチ
IAM関連で作成するもの
下記を作成していきます
IAMUserは社員毎に用意されているものとします。
AWSアカウント(アカウントID) IAM 名前 役割 Employee(111111111111) IAM User kaito IAMユーザ Employee(111111111111) IAM Poricy sample-service-assume-policy IAMユーザにAssumeRole権限を持つ ServiceA(999999999999) IAM Poricy sample-service-terraform-backend-policy S3に対する権限を持つ ServiceA(999999999999) IAM Role sample-service-terraform-backend-role S3に対する権限を持つ ServiceA(999999999999) IAM Role sample-service-terraform-deploy-role AWSの各サービスに対する権限を持つ S3用のIAM PoricyとIAM Roleの作成
sample-service-terraform-backend-policyを作成します。このIAM PoricyはTerraformが使用するstateファイルを管理する先としてS3を利用するための権限を与えるためのものになります。
その為、以下のようなポリシーを定義します。
- S3オブジェクトの読み込みと書き込み権限
Resourceにstateファイルを管理するS3バケットを指定ポリシー{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::sample-service-terraform-tfstate/*", "arn:aws:s3:::sample-service-terraform-tfstate" ] } ] }
sample-service-terraform-backend-roleを作成します。このIAM Roleは
sample-service-terraform-backend-policyがアタッチされます。
TerraformにはBackend周りはこのロールにAssumeRoleしてもらい処理を行ってもらいます。以下のようにRoleを定義します。
sample-service-terraform-backend-policyをアタッチします- 信頼する相手として「対象となるIAMユーザのAWSアカウント」を指定します
- よりセキュリティを強くするため条件を指定します
sts:RoleSessionNameでSessionNameとして実行するIAMUserの名前を指定するようにしますsts:ExternalId(外部ID)を指定します信頼関係{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::111111111111:root" }, "Action": "sts:AssumeRole", "Condition": { "StringEquals": { "sts:RoleSessionName": "${aws:username}", "sts:ExternalId": "sample-service-backend" } } } ] }デプロイ用のIAM Roleの作成
sample-service-terraform-backend-roleを作成します。このIAM RoleはTerraformにデプロイ時にAWSの各サービスに対する権限を与えるためのものになります。
TerraformにはDeploy周りはこのロールにAssumeRoleしてもらい処理を行ってもらいます。以下のようにRoleを定義します。
- 付与するアクセス権限を必要に応じて付与してください
- 信頼する相手として
sample-service-terraform-backend-roleを指定します
- こうすることで
sample-service-terraform-backend-roleにスイッチしてるIAMUserのみがスイッチできます- よりセキュリティを強くするため条件を指定します
sts:ExternalId(外部ID)を指定します信頼関係{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::999999999999:role/sample-service-terraform-backend-role" }, "Action": "sts:AssumeRole", "Condition": { "StringEquals": { "sts:ExternalId": "sample-service-deploy" } } } ] }IAMUserにそれぞれのRoleにスイッチできるようにする
sample-service-assume-policyを作成します。このIAM Policyは
sample-service-terraform-backend-roleにAssume Roleできるようにする為のものです。
その為、以下のようなポリシーを定義します。ポリシー{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": [ "arn:aws:iam::999999999999:role/sample-service-terraform-backend-role" ] } ] }動作確認
- aws profileの編集
sample-service-terraform-backend-roleにIAMUserのprofile経由でスイッチするprofileを追加します。sample-service-terraform-deploy-roleにsample-service-terraform-backend-role経由でスイッチするprofileを追加します。~/.aws/config[default] output = json region = ap-northeast-1 [profile sample-service-terraform-backend] region = ap-northeast-1 output = json [profile sample-service-terraform-deploy] region = ap-northeast-1 output = json~/.aws/credentials[default] aws_access_key_id = IAMUserのアクセスキー aws_secret_access_key = IAMUserのシークレットキー [sample-service-terraform-backend] role_arn = arn:aws:iam::999999999999:role/sample-service-terraform-backend-role role_session_name = kaito(IAMUserの名前) external_id = sample-service-backend source_profile = default [sample-service-terraform-deploy] role_arn = arn:aws:iam::999999999999:role/sample-service-terraform-deploy-role external_id = sample-service-deploy source_profile = sample-service-terraform-backend
- terraformの修正
providerのprofileにsample-service-terraform-deploy-roleにスイッチするprofile名を指定します。backend "s3"のprofileにsample-service-terraform-backend-roleにスイッチするprofile名を指定します。main.tfterraform { required_version = "= 0.14.7" required_providers { aws = { source = "hashicorp/aws" version = "= 3.9.0" } } backend "s3" { bucket = "sample-service-terraform-tfstate" key = "cloudfront/terraform.tfstate" region = "ap-northeast-1" profile = "sample-service-terraform-backend" } } provider "aws" { profile = "sample-service-terraform-deploy" region = "ap-northeast-1" }
terraform init,terraform plan/deploy/destroyを実行してみて正常に終了すれば成功です。おまけ
sample-service-terraform-backend-roleのスイッチにsession_nameの指定を強制しましたが、これをすることでCloudtrailに以下のように出力されます。ログの一部(cognito作成時){ "eventVersion": "1.08", "userIdentity": { "type": "AssumedRole", "principalId": "AAAAAAAAAAAAAAAAAAAAA:kaito", "arn": "arn:aws:sts::999999999999:assumed-role/sample-service-terraform-deploy/kaito", "accountId": "999999999999", "accessKeyId": "BBBBBBBBBBBBBBBBBBBB", "sessionContext": { "sessionIssuer": { "type": "Role", "principalId": "AAAAAAAAAAAAAAAAAAAAA:kaito", "arn": "arn:aws:iam::999999999999:role/sample-service-terraform-deploy", "accountId": "999999999999", "userName": "sample-service-terraform-deploy" }, "webIdFederationData": {}, "attributes": { "mfaAuthenticated": "false", "creationDate": "2021-03-07T14:48:29Z" } } }, "eventTime": "2021-03-07T14:48:32Z", "eventSource": "cognito-idp.amazonaws.com", "eventName": "CreateUserPool", "awsRegion": "ap-northeast-1", "sourceIPAddress": "2409:10:9780:c00:f09d:5f83:7147:9b65", "userAgent": "aws-sdk-go/1.34.26 (go1.14.5; darwin; amd64) APN/1.0 HashiCorp/1.0 Terraform/0.14.7 (+https://www.terraform.io)", "requestParameters": { "poolName": "Samplece_Service_Dev", "autoVerifiedAttributes": [ "email" ], "usernameAttributes": [ "email" ],
principalIdにIAMUserの名前が入るようになり、誰がリソースにどういった変更を加えたかなどがわかるようになります。まとめ
アクセスキーが流出した際のことを考慮に入れたデプロイ手法は色々あり、それを試してるうちにこんな感じになりました。
profileの設定を半ば強制してる感じで設定も共有する必要がありますが今のところは新人にもアクセスキーとprofileの設定さえ教えればアクセスキーの上書きとかなど細々としたこと教えずに済むので楽かなということでこれで運用してみようかなと思ってます
- 投稿日:2021-03-08T16:22:41+09:00
TerraformでBackendとProviderで別々のprofile/IAMRoleを使用することにした
概要
TerraformでデプロイするIAMUserはAssumeRoleでそれぞれの必要な権限をもつIAMRoleにスイッチして
Terraform initからTerraform deploy/apply/destroyを実行するようにしてみた背景
- Terraformでデプロイするユーザのアクセスキーが万が一漏れても被害が最小限になるようにしたい
- 一々 AWS Cli でAssumeRoleコマンド実行してアクセスキーを切り替える(上書きする)のがめんどくさいのでそうしなくていいようにしたい
- 誰がリソースをいじったかわかるようにしたい
Terraform実行イメージ
terraform init時
- IAMUser → S3用IAMRoleにスイッチ
terraform plan/deploy/destroy時
- IAMUser → S3用IAMRoleにスイッチ → Deploy用IAMRoleにスイッチ
IAM関連で作成するもの
下記を作成していきます
IAMUserは社員毎に用意されているものとします。
AWSアカウント(アカウントID) IAM 名前 役割 Employee(111111111111) IAM User kaito IAMユーザ(AssumeRoleしかできないユーザーが望ましい) Employee(111111111111) IAM Poricy sample-service-assume-policy IAMユーザにAssumeRole権限を持つ ServiceA(999999999999) IAM Poricy sample-service-terraform-backend-policy S3に対する権限を持つ ServiceA(999999999999) IAM Role sample-service-terraform-backend-role S3に対する権限を持つ ServiceA(999999999999) IAM Role sample-service-terraform-deploy-role AWSの各サービスに対する権限を持つ S3用のIAM PoricyとIAM Roleの作成
sample-service-terraform-backend-policyを作成します。このIAM PoricyはTerraformが使用するstateファイルを管理する先としてS3を利用するための権限を与えるためのものになります。
その為、以下のようなポリシーを定義します。
- S3オブジェクトの読み込みと書き込み権限
Resourceにstateファイルを管理するS3バケットを指定ポリシー{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::sample-service-terraform-tfstate/*", "arn:aws:s3:::sample-service-terraform-tfstate" ] } ] }
sample-service-terraform-backend-roleを作成します。このIAM Roleは
sample-service-terraform-backend-policyがアタッチされます。
TerraformにはBackend周りはこのロールにAssumeRoleしてもらい処理を行ってもらいます。以下のようにRoleを定義します。
sample-service-terraform-backend-policyをアタッチします- 信頼する相手として「対象となるIAMユーザのAWSアカウント」を指定します
- よりセキュリティを強くするため条件を指定します
sts:RoleSessionNameでSessionNameとして実行するIAMUserの名前を指定するようにしますsts:ExternalId(外部ID)を指定します信頼関係{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::111111111111:root" }, "Action": "sts:AssumeRole", "Condition": { "StringEquals": { "sts:RoleSessionName": "${aws:username}", "sts:ExternalId": "sample-service-backend" } } } ] }デプロイ用のIAM Roleの作成
sample-service-terraform-backend-roleを作成します。このIAM RoleはTerraformにデプロイ時にAWSの各サービスに対する権限を与えるためのものになります。
TerraformにはDeploy周りはこのロールにAssumeRoleしてもらい処理を行ってもらいます。以下のようにRoleを定義します。
- 付与するアクセス権限を必要に応じて付与してください
- 信頼する相手として
sample-service-terraform-backend-roleを指定します
- こうすることで
sample-service-terraform-backend-roleにスイッチしてるIAMUserのみがスイッチできます- よりセキュリティを強くするため条件を指定します
sts:ExternalId(外部ID)を指定します信頼関係{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::999999999999:role/sample-service-terraform-backend-role" }, "Action": "sts:AssumeRole", "Condition": { "StringEquals": { "sts:ExternalId": "sample-service-deploy" } } } ] }IAMUserにそれぞれのRoleにスイッチできるようにする
sample-service-assume-policyを作成します。このIAM Policyは
sample-service-terraform-backend-roleにAssume Roleできるようにする為のものです。
その為、以下のようなポリシーを定義します。ポリシー{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": [ "arn:aws:iam::999999999999:role/sample-service-terraform-backend-role" ] } ] }動作確認
- aws profileの編集
sample-service-terraform-backend-roleにIAMUserのprofile経由でスイッチするprofileを追加します。sample-service-terraform-deploy-roleにsample-service-terraform-backend-role経由でスイッチするprofileを追加します。~/.aws/config[default] output = json region = ap-northeast-1 [profile sample-service-terraform-backend] region = ap-northeast-1 output = json [profile sample-service-terraform-deploy] region = ap-northeast-1 output = json~/.aws/credentials[default] aws_access_key_id = IAMUserのアクセスキー aws_secret_access_key = IAMUserのシークレットキー [sample-service-terraform-backend] role_arn = arn:aws:iam::999999999999:role/sample-service-terraform-backend-role role_session_name = kaito(IAMUserの名前) external_id = sample-service-backend source_profile = default [sample-service-terraform-deploy] role_arn = arn:aws:iam::999999999999:role/sample-service-terraform-deploy-role external_id = sample-service-deploy source_profile = sample-service-terraform-backend
- terraformの修正
providerのprofileにsample-service-terraform-deploy-roleにスイッチするprofile名を指定します。backend "s3"のprofileにsample-service-terraform-backend-roleにスイッチするprofile名を指定します。main.tfterraform { required_version = "= 0.14.7" required_providers { aws = { source = "hashicorp/aws" version = "= 3.9.0" } } backend "s3" { bucket = "sample-service-terraform-tfstate" key = "cloudfront/terraform.tfstate" region = "ap-northeast-1" profile = "sample-service-terraform-backend" } } provider "aws" { profile = "sample-service-terraform-deploy" region = "ap-northeast-1" }
terraform init,terraform plan/deploy/destroyを実行してみて正常に終了すれば成功です。おまけ
sample-service-terraform-backend-roleのスイッチにsession_nameの指定を強制しましたが、これをすることでCloudtrailに以下のように出力されます。ログの一部(cognito作成時){ "eventVersion": "1.08", "userIdentity": { "type": "AssumedRole", "principalId": "AAAAAAAAAAAAAAAAAAAAA:kaito", "arn": "arn:aws:sts::999999999999:assumed-role/sample-service-terraform-deploy/kaito", "accountId": "999999999999", "accessKeyId": "BBBBBBBBBBBBBBBBBBBB", "sessionContext": { "sessionIssuer": { "type": "Role", "principalId": "AAAAAAAAAAAAAAAAAAAAA:kaito", "arn": "arn:aws:iam::999999999999:role/sample-service-terraform-deploy", "accountId": "999999999999", "userName": "sample-service-terraform-deploy" }, "webIdFederationData": {}, "attributes": { "mfaAuthenticated": "false", "creationDate": "2021-03-07T14:48:29Z" } } }, "eventTime": "2021-03-07T14:48:32Z", "eventSource": "cognito-idp.amazonaws.com", "eventName": "CreateUserPool", "awsRegion": "ap-northeast-1", "sourceIPAddress": "2409:10:9780:c00:f09d:5f83:7147:9b65", "userAgent": "aws-sdk-go/1.34.26 (go1.14.5; darwin; amd64) APN/1.0 HashiCorp/1.0 Terraform/0.14.7 (+https://www.terraform.io)", "requestParameters": { "poolName": "Samplece_Service_Dev", "autoVerifiedAttributes": [ "email" ], "usernameAttributes": [ "email" ],
principalIdにIAMUserの名前が入るようになり、誰がリソースにどういった変更を加えたかなどがわかるようになります。まとめ
アクセスキーが流出した際のことを考慮に入れたデプロイ手法は色々あり、それを試してるうちにこんな感じになりました。
profileの設定を半ば強制してる感じで設定も共有する必要がありますがアクセスキーとprofileの設定さえ教えればアクセスキーの上書きなど細々としたことやらずに済むので楽かなということでこれで運用してみようかなと思ってます
- 投稿日:2021-03-08T16:00:52+09:00
S3のアクセス制御を理解するためのロードマップ
記事の目的
S3のアクセス制限を理解するためのロードマップをまとめます!
各機能についてわかりやすい記事などはたくさんあるのですが、全体像を掴める感じのものがなかったため作成しました。
機能が多くてややこしいS3のアクセス制御を理解するために、何をどの順で理解していけばいいかというところに焦点を当てています。各機能の説明については他の良記事にお任せするスタイルですm(_ _)m想定対象読者
- AWS初心者
- S3のアクセス制御を体系的に理解したい方
- S3のアクセス制御がややこしくて頭を抱えている人(<-私)
ロードマップ
=================================================================================== = 1. 全体像を掴む(SGのアクセス制御に関連する機能が何か把握する) =================================================================================== S3のアクセス制御の手法いろいろありますよね。まずは「何があるのか?」、「それで何ができるのか?」を把握しましょう。 =================================================================================== = 2. 各機能について理解する =================================================================================== 全体像を掴んだ後は、各機能について以下の観点で理解しましょう。 - 「何ができるのか?」 - 「どういった用途で使われるのか?」 - 「各機能の違いは?」 =================================================================================== = 3. 複数の機能を使用したケースについて理解する =================================================================================== S3では複数の機能を用いてアクセス制御を行う機会が多くあります。 複数の機能が適用された場合、どのような挙動になるのか理解しておきましょう。 =================================================================================== = 4. ポリシー(IAMポリシー/バケットポリシー)を深く理解する =================================================================================== IAMポリシーとバケットポリシーはJSON形式で定義します。 複雑で柔軟な定義ができる分、理解するのは一苦労します。 理解して使用できるポリシーパターンを徐々に増やして、幅広いアクセス制御を実現できるようにしましょう。前提知識
基本的なことなので、わかる人はスキップしましょう♪
S3バケット
ファイルを格納するオブジェクトストレージ
オブジェクト
S3バケットに格納されるファイル
1. 全体像を掴む
S3のアクセス制御に関連する機能は以下の4つになります。
No 機能 概要 1 ACL 簡単に設定できるが、その分柔軟なアクセス制御はできない。オブジェクトにも適用することが可能 2 バケットポリシー 設定は複雑だが、柔軟なアクセス制御が可能。 3 IAM S3への操作権限をIAMユーザー/グループに対して付与する 4 パブリックブロックアクセス バケットがパブリックに公開されることを防止するというシンプルな制御機能 まずは、この4つについて理解しておけばOKということを意識しておきましょう。
2. 各機能について理解する
2-1. ACL
利用シーン
一番古くから存在しているアクセス制御機能であり、簡単に設定できる分大雑把な制御しかできないため、以下のケース以外ではあまり利用されないです。
- バケットの所有者とオブジェクトの所有者が異なっている場合に、オブジェクトに対してアクセス制御を施したい
- 簡易的にアクセス制御を施したい
- S3アクセスログを格納するS3バケットへアクセス制御を施したい
概要
- バケットポリシーに比べて簡単に設定できるが、その分柔軟なアクセス制御をすることはできない
- バケットだけでなく、オブジェクト単位で適用することが可能
- ユーザーはAWSアカウント単位(IAMユーザー、グループでの制御はできない)
設定は、被付与者(制御対象)に対してアクセス許可(許可する操作)を指定するだけです。
被付与者
- バケット所有者 (AWS アカウント)
- 全員 (パブリックアクセス)
- Authenticated Users グループ (AWS アカウントを持つすべてのユーザー)
- S3 ログ配信グループ
- 他のAWSアカウント
アクセス許可(制御対象のアクション)
- FULL_CONTROL
- READ
- WRITE
- READ_AC
- WRITE_ACP
参考
被付与者とアクセス許可については、公式のドキュメントが一番まとまっている気がします。
あとはこの辺の記事がわかりやすいです。
2-2. バケットポリシー
利用シーン
バケットに対するアクセス制御を施す時は基本的にバケットポリシーを利用します。(簡易的な制御で良い場合はACLを選ぶこともあります)
概要
- バケットに適用できる
- 設定が難しい分、柔軟で複雑なアクセス制御を実現できる
- ポリシードキュメントと言うJSON形式のフォーマットで設定する
ポリシードキュメントは奥が深いので、最初はググってサンプルをゲットして、それを使いましょう。
参考
以下の記事がわかりやすいです。
2-3. IAM
利用シーン
「このIAMユーザー/グループはこのS3バケットにアクセスできる(できない)ように....」というIAMユーザー/グループ視点でアクセス制御をかけたい時に利用します。
概要
S3の設定ではないため、S3のバケットを作成する限りでは意識しにくいところです。ただし、S3のアクセス制御に関わる大切なところです。
(S3に限れば)ActionとResourceを定義することで、S3へのアクセス制御を施すことができます。
- Action:制御対象のS3への操作(オブジェクトのアップロードや、削除など)
- Resource:制御対象のS3バケット、フォルダ、オブジェクト
参考
公式ドキュメントのサンプルを見るとイメージしやすいと思います。
2-4. パブリックブロックアクセス
利用シーン
パブリックに公開することを防止したい時に有効化します。デフォルトでは有効になっているため、パブリックに公開したいバケットである場合は設定を無効化します。
概要
- 設定できることはシンプルで「パブリックアクセスを許可するか/否か」
- バケット単位だけでなく、AWSアカウント全体(全てのバケット)に設定することもできる。
外部に公開しないバケットは有効化しておくことが必須です。
参考
以下がわかりやすいかなと。
各機能の比較
それぞれの機能について理解したところで、まとめとして比較を記載します。
No 機能 設定対象 設定形式 AWSアカウント単位の適用 IAMユーザー/グループ単位の適用 1 ACL バケット、オブジェクト 選択式 ○ x 2 バケットポリシー バケット json形式 x ○ 3 IAM IAMユーザー/グループ json形式 ○ x 4 パブリックブロックアクセス バケット、AWSアカウント(全てのバケット) 選択式 対象外 対象外 3. 複数の機能を使用したケースについて理解する
複数の機能が併用された際に、一番大切になるポイントは
「明示的な拒否が1つでも定義された場合は、アクセス制御は拒否になる」ということです。ACLは許可しかできないため、バケットポリシーかIAMのどちらかで拒否された対象は、問答無用で拒否されます。
以下参考にしてください。
4. ポリシーを深く理解する
こちらに関しては他の記事に丸投げする形ですw
バケットポリシー
基本的にやりたい制御方法をググって調べて、サンプルからパクる。
それを色々繰り返して行くと、自分のナレッジとして貯まるのかなと思います。なのでサンプルをどんどん読んで、色々なパターンに触れていきましょう。
サンプル
Tips
否定条件を複数定義したポリシーを作る際は、以下必読です。
IAMポリシー
IAMポリシーはS3に限ってはAction、Resourceを意識すれば、ある程度の設定はできるかと思います。
ただIAMポリシー自体に関しては、奥が深すぎるので、ここではこれ以上深入りしないですm(_ _)m所感
クラメソさんのDevelopersIO、やっぱりわかりやすい
参考
- アクセスコントロールリスト (ACL) の概要 (aws 開発者ガイド)
- ユーザーポリシーの例 (aws 開発者ガイド)
- バケットポリシーの例 (aws 開発者ガイド)
- AWS/S3のバケットポリシー入門
- S3バケットポリシーの具体例で学ぶAWSのPolicyドキュメント (DevelopersIO produced by Classmethod)
- S3のアクセスコントロールまとめ (Qitta)
- AWS S3 運用 権限設定を逆引形式で整理してみる (cloud link)
- S3 バケットへのアクセス制御方式の違い
- S3のブロックパブリックアクセス設定について分かりやすく説明する (Hatena Blog)
- S3で誤ったデータの公開を防ぐパブリックアクセス設定機能が追加されました (DevelopersIO produced by Classmethod)
- S3バケットポリシーとIAMポリシーの関係を整理する
- S3 バケットポリシーいろいろ (Qitta)
- 【AWS】S3のBucket-ACLとObject-ACLとバケットポリシーどれが強いのか? (Qitta)
- 複数の否定条件を使ったS3バケットポリシーを正しく理解してますか? (DevelopersIO produced by Classmethod)
- S3のアクセスコントロールが多すぎて訳が解らないので整理してみる (DevelopersIO produced by Classmethod)
- 投稿日:2021-03-08T15:58:17+09:00
Greengrass(V1)をクイックスタートでインストールしてみる
はじめに
Greengrass(V1)をクイックスタート手順でインストールしてみたので、その手順をまとめます。
以下の手順を参考にしました。
参考:AWS IoT Greengrass > 開発者ガイド、バージョン 1 > クイックスタート: Greengrass デバイスのセットアップなお、今回Greengrass CoreをインストールするデバイスはJetson nanoのDevelopers kitです。
作業はWindowsで行い、Jetson nanoに対する作業は主にTeraTermで接続して行っています。1 Greengrassのインストール
今回、下記手順の実行時にエラーが発生しましたが実施時通りの流れで記載します。
成功した手順は1-4からです1-1 インストール事前準備
1.インストールに利用するため、AWS CLIで一時認証情報を取得
aws sts get-session-token #結果は以下の通り返ってくる { "Credentials": { "AccessKeyId": "[アクセスキーID]", "SecretAccessKey": "[シークレットアクセスキー]", "SessionToken": "[セッショントークン]", "Expiration": "[有効期限]" } }2.クレデンシャル情報を環境変数に設定する
#環境変数の設定 export AWS_ACCESS_KEY_ID=[アクセスキー] export AWS_SECRET_ACCESS_KEY=[シークレットアクセスキー] export AWS_SESSION_TOKEN=[セッショントークン] #設定されていることを確認 echo $AWS_ACCESS_KEY_ID echo $AWS_SECRET_ACCESS_KEY echo $AWS_SESSION_TOKEN1-2 インストール用スクリプトの起動(エラー発生)
1.以下のコマンドでスクリプトのダウンロードと実行を行う
※手順にはwgetとcurlの両コマンドが用意されているwget -q -O ./gg-device-setup-latest.sh https://d1onfpft10uf5o.cloudfront.net/greengrass-device-setup/downloads/gg-device-setup-latest.sh && chmod +x ./gg-device-setup-latest.sh && sudo -E ./gg-device-setup-latest.sh bootstrap-greengrass-interactive1-3 エラーの調査と試行したこと(未解決)
スクリプトの最後で以下のエラーが発生しました。
Unexpected error: An error occurred (InvalidClientTokenId) when calling the CreateRole operation: The security token included in the request is invalid1.スクリプト実行時のログを確認
#ログを確認 view GreengrassDeviceSetup-20210308-140514.log #ログの末尾を抜粋 2021-03-08 14:05:17,234 - __main__ - DEBUG - There is no Greengrass Service Role attached to this AWS account. Attaching a service role to the account... 2021-03-08 14:05:17,300 - __main__ - DEBUG - Creating a Greengrass service role for the account.Greengrassサービスのロールがアタッチされていないとのこと。
2.IoT Coreのマネジメントコンソールで設定をクリックし、最下部のGreengrassサービスロールで「ロールをアタッチ」をクリック
3.「Greengrass_ServiceRole」を選択して「保存」をクリック
3.スクリプトを再試行
※既にスクリプトは取得済かつ権限付与済なので、実行コマンドのみsudo -E ./gg-device-setup-latest.sh bootstrap-greengrass-interactive同様のエラーが出てしまったので、今回は別の方法を試すことにしました。
1-4 IAMユーザのアクセスキーとセキュリティキーで再試行(成功)
1.環境変数にIAMユーザのアクセスキーとセキュリティキーを設定
#環境変数の設定 export AWS_ACCESS_KEY_ID=[アクセスキー] export AWS_SECRET_ACCESS_KEY=[シークレットアクセスキー] #セッションキーは使わなくなる export AWS_SESSION_TOKEN= #設定されていることを確認 echo $AWS_ACCESS_KEY_ID echo $AWS_SECRET_ACCESS_KEY echo $AWS_SESSION_TOKEN2.スクリプトを再試行
※「1-2 インストール用スクリプトの起動(エラー発生)」で既にスクリプトを取得・権限付与もしているため、実施コマンドのみsudo -E ./gg-device-setup-latest.sh bootstrap-greengrass-interactive3.CLI上で入力が求められるので以下の通り対応
※ちなみに今までの実行でも入力は求められており、最後にエラーメッセージが表示されていた#以降でGreengrassグループ名などを対話形式で設定 [GreengrassDeviceSetup] Forwarding command-line parameters: bootstrap-greengrass-interactive #環境変数を指定しているので、ここから3つはEnterで次へ Enter your AWS access key ID, or press 'Enter' to read it from your environment variables. Enter your AWS secret access key, or press 'Enter' to read it from your environment variables. Enter your AWS session token, which is required only when you are using temporary security credentials. Press 'Enter' to read it from your environment variables or if the session token is not required. #東京リージョンを使うため、ap-northeast-1と入力 Enter the AWS Region where you want to create a Greengrass group, or press 'Enter' to use 'us-west-2'. ap-northeast-1 #Greengrassグループ名とGreengrass Core名は指定した Enter a name for the Greengrass group, or press 'Enter' to use 'GreengrassDeviceSetup_Group_1b07fde8-fbe6-4c78-a2d6-048ea082319c'. [Greengrassグループ名] Enter a name for the Greengrass core, or press 'Enter' to use 'GreengrassDeviceSetup_Core_fdd7444e-64df-4450-b888-defe360031fa'. [Greengrass Core名] Enter the installation path for the Greengrass core software, or press 'Enter' to use '/'. #Hello World Lambda関数はデプロイした Do you want to include a Hello World Lambda function and deploy the Greengrass group? Enter 'yes' or 'no'. yes Enter a deployment timeout (in seconds), or press 'Enter' to use '180'. Enter the path for the Greengrass environment setup log file, or press 'Enter' to use './'.4.以下の表示が出てインストール完了
You can now use the AWS IoT Console to subscribe to the 'hello/world' topic to receive messages published from your Greengrass core.2 Greengrass Coreのデプロイ
マネジメントコンソールでIot Coreに移動し、Greengrass Coreをデプロイする
2-1 Greengrass Coreのデプロイ
1.IoT Coreマネジメントコンソールの左のメニューから Greengrass > クラシック(V1) > グループ の順にクリック
2.作成されたGreengrass Coreをクリックし、コアをクリック
3.アクション > デプロイ の順にクリック
2-2 Lambda実行と疎通の確認
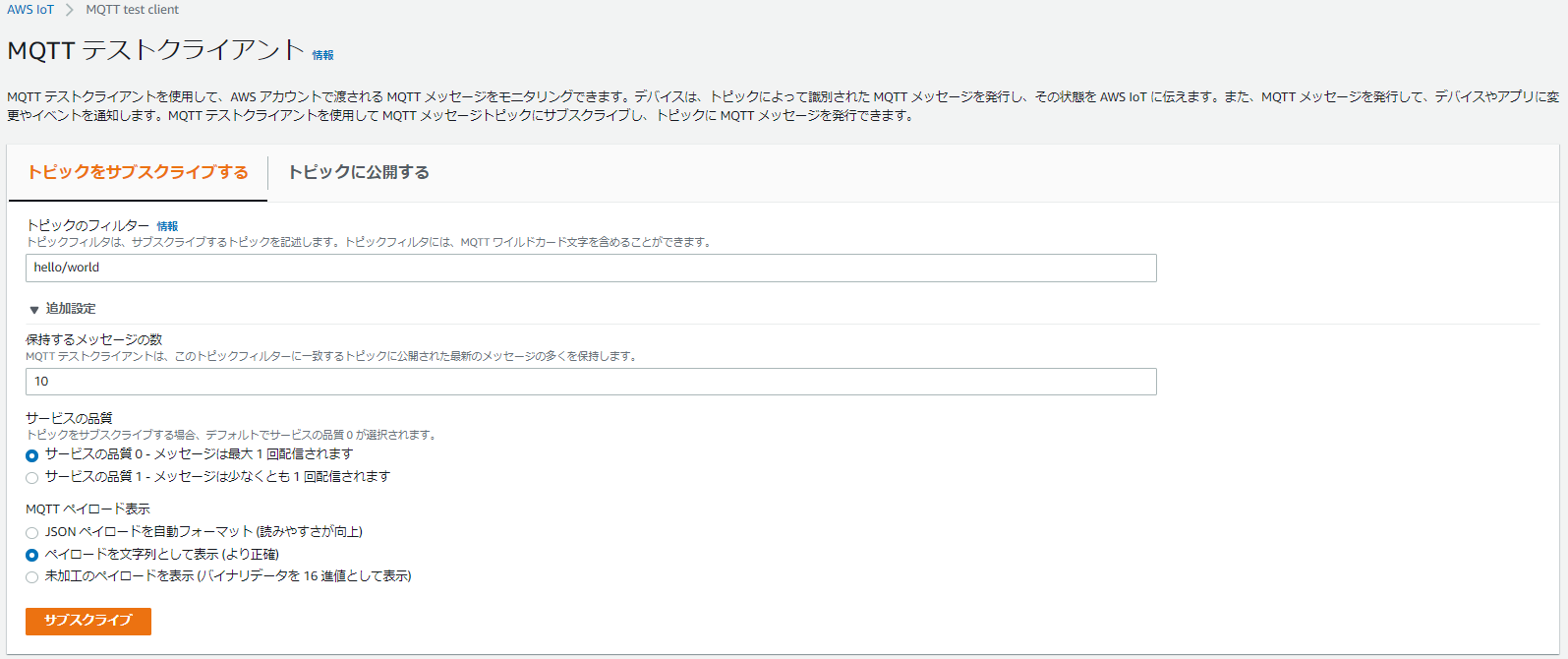
1.IoT Coreマネジメントコンソールでの左のメニューから テスト をクリック
2.トピックのフィルターを「hello/world」、追加設定のMQTTペイロード表示を「ペイロードを文字列として表示(より正確)」として「サブスクライブ」をクリック
※デプロイしたHelloWorld関数が hello/world 宛てにパブリッシュし続けることを確認
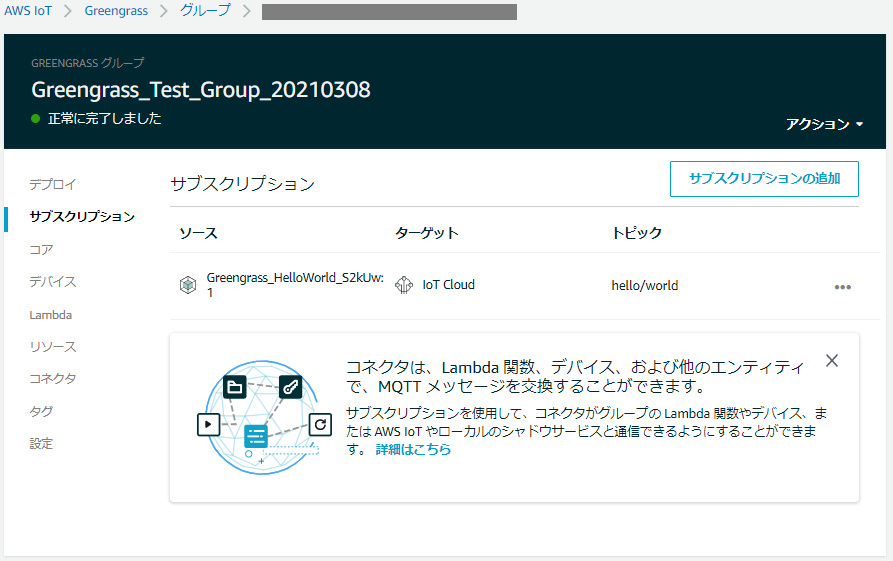
3.以下のようなメッセージが表示されるHello world! Sent from the Lambda function - Greengrass_HelloWorld_S2kUw running on platform: Linux-4.9.201-tegra-aarch64-with-Ubuntu-18.04-bionic※左のメニューからGreengrass > クラシック(v1) > グループ > 作成したグループ > サブスクリプション と移動すると、ローカルのLambdaからIoT Cloudをターゲットとして、hello/world へのMQTTメッセージのルーティングが定義されていることが分かる
2-3 Greengrassの起動と終了を確認
「2-2 Lambda実行と疎通の確認」で実施したサブスクライブはそのままとして、Greengrassの起動/終了でメッセージが止まるかどうか確認しました。
1.Greengrassを以下のコマンドで終了する
#停止コマンド sudo /greengrass/ggc/core/greengrassd stop #成功すると以下の通り返ってくる Waiting.......... Stopped greengrass daemon, exiting with success2.IoT Coreのマネジメントコンソールで「hello/world」にメッセージが届かなくなったことを確認する
3.Greengrassを以下のコマンドで再度開始する#開始コマンド sudo /greengrass/ggc/core/greengrassd start #成功すると以下の通り返ってくる Setting up greengrass daemon Validating hardlink/softlink protection Waiting for up to 1m10s for Daemon to start Greengrass successfully started with PID: 291834.再びIoT Coreのマネジメントコンソールで「hello/world」にメッセージが届くことを確認する
3 おわりに
以下の通り設定時に環境変数に設定するAWSアカウントの認証情報は一時的なセキュリティ認証情報が推奨とのことですが、今回は上手くいかなかったため、IAMユーザの認証情報を利用しました。
再度、試行して上手くいった際には原因と解消法をまとめます。
参考:Greengrass デバイスセットアップ設定オプション
4 参考文献(文中で登場していないもの)

- 投稿日:2021-03-08T15:51:59+09:00
EIP(Elastic IP)が解放できない際等の逆引きアドレス確認方法
どこにも関連付けてないはずのEIPなのに解放しようとすると
123.345.567.789: The address with allocation id [eip-0123456789abcdefg] cannot be released because it is locked to your account. Please contact AWS Support to unlock it.
Service: AmazonEC2; Status Code: 400; Error Code: InvalidAddress.Locked; Request ID: 12345678-9ab-cdef-ghij-klmnopqrstuv)みたいなことを言われて失敗することがあります。
今回がまさにそうだったんですが、EIPを関連付けたEC2からメール送信を行う等の理由でIPアドレスの逆引き設定をしてもらっている場合などが該当します。
この逆引き設定がされているかどうかはお手元のコンソールから確認することができます。
$ host 123.345.567.789 123.345.567.789.in-addr.arpa domain name pointer sample.example.com.こんな感じなら逆引き設定されているということになります。
この場合はAWSの専用サポートのUse Caseに「rDNSを削除してちょ」って書くと削除してもらえます。
Please remove following rDNS lookup settings: 789.567.345.123.in-addr.arpa domain name pointer sample.example.com.逆引きが設定されていない、または設定が削除されたかどうかも同じくお手元のコンソールから確認できます。
$ host 123.345.567.789 789.567.345.123.in-addr.arpa domain name pointer ec2-123-345-567-789.ap-northeast-1.compute.amazonaws.com.こんな感じになってれば逆引き設定がされていない状態なのでEIPも解放できると思います。
- 投稿日:2021-03-08T15:48:14+09:00
Laravel + Cogntitoでサインイン時にエラー"The security token included in the request is invalid."
事象
Laravel環境にCognitoを使用したサインアップ/サインイン機能を搭載したのですが、新規登録・メール検証済みユーザーでサインインしようとした時に全くもってサインインできませんでした。うんともすんとも動かねえぜ。
前提条件として、Cognitoのアプリクライアントの設定で「認証用の管理 API のユーザー名パスワード認証を有効にする(ALLOW_ADMIN_USER_PASSWORD_AUTH)」を使用した場合でのエラーです。
結論を言うと環境変数に設定していたAWS_ACCES_KEY_IDが間違っていただけなのですが、なんとこのミスに気づかず6時間以上を無駄にしてしまったため、備忘録として残します。
以下、Laravel+Cognito構築で参考にさせて頂いた記事
・https://blackbits.io/blog/laravel-authentication-with-aws-cognito
・https://qiita.com/suzumurakk/items/efe4543cf0df2cd31659原因
タイトルにもある通りで、裏では以下のエラーが返ってきていました。
The security token included in the request is invalid.(リクエストに含まれているセキュリティトークンが無効です。)このエラーでググると、AWSに送信しているアクセスキーIDもしくはシークレットアクセスキーが無効とのことでした。
Laravelの.envを確認したところ、アクセスキーID(AWS_ACCES_KEY_ID)に余計な文字が入っておりました。チクショー!!
上記解決後、無事にサインインできることを確認しました。
反省点
- Laravelの認証周り(Guardやプロバイダー)の理解が浅く、原因追求に時間がかかりました。
- 真っ先にAWSからのレスポンスを確認すべきでした。次からは必ずそうします!!!
そのうちLaravel+Cognitoを使った認証/メール検証/サインアップの実装記事を書こうと思います。
- 投稿日:2021-03-08T15:48:14+09:00
Laravel+Cognitoでサインイン時にエラー"The security token included in the request is invalid."
事象
Laravel環境にCognitoを使用したサインアップ/サインイン機能を搭載したのですが、新規登録・メール検証済みユーザーでサインインしようとした時に全くもってサインインできませんでした。うんともすんとも動かねえぜ。
前提条件として、Cognitoのアプリクライアントの設定で「認証用の管理 API のユーザー名パスワード認証を有効にする(ALLOW_ADMIN_USER_PASSWORD_AUTH)」を使用した場合でのエラーです。
結論を言うと環境変数に設定していたAWS_ACCES_KEY_IDが間違っていただけなのですが、なんとこのミスに気づかず6時間以上を無駄にしてしまったため、備忘録として残します。
以下、Laravel+Cognito構築で参考にさせて頂いた記事
・https://blackbits.io/blog/laravel-authentication-with-aws-cognito
・https://qiita.com/suzumurakk/items/efe4543cf0df2cd31659原因
タイトルにもある通りで、裏では以下のエラーが返ってきていました。
The security token included in the request is invalid.(リクエストに含まれているセキュリティトークンが無効です。)このエラーでググると、AWSに送信しているアクセスキーIDもしくはシークレットアクセスキーが無効とのことでした。
Laravelの.envを確認したところ、アクセスキーID(AWS_ACCES_KEY_ID)に余計な文字が入っておりました。チクショー!!
上記解決後、無事にサインインできることを確認しました。
反省点
- Laravelの認証周り(Guardやプロバイダー)の理解が浅く、原因追求に時間がかかりました。
- 真っ先にAWSからのレスポンスを確認すべきでした。次からは必ずそうします!!!
そのうちLaravel+Cognitoを使った認証/メール検証/サインアップの実装記事を書こうと思います。
- 投稿日:2021-03-08T15:26:47+09:00
AWSとAzureの差異について
AWS と Azureって何が違うの
設計や構築メインで担当してます。個人的な感触を纏めていきます。わりとAWS側の人間なのですがAzureやることになりましたので、Azureで気づいた部分など踏まえガンガン更新していきます。
AWS
・IaaSとしての利用でもインフラ設計をあんまり考えなくても詰まない。
・UI/UXが素晴らしく、直感的に触っていれば慣れる。
・クラウド初心者向けで余計なことはあまり考えずAWSがやってくれるAzure
・IaaSとしてはインフラ設計をがっつりしないと詰む。
・UI/UXがわかりにくい。各単語が意味不明。
・オンプレからがっつり移行したいケースだと細かいパラメータ多いから似た構成を再現しやすい。
- 投稿日:2021-03-08T13:10:11+09:00
Kubernetes on Amazon EC2 リソース作成編 ~新人がやってみた(2)~
このシリーズは、入社1年目の新人がEC2上にKubernetes環境構築を色々試行錯誤してやってみて、上手くいった手順をまとめたものです。 はじめに 前の記事では、Amazon EC2上にKubernetesクラスターを構築しました。 Kubernetesをデプロイするだけでは意味がないので、今回はKubernetesクラスターに色んなリソースを作成してみます。 Kubernetes on Amazon EC2 環境構築編 ~新人がやってみた(1)~の続きになります。 この記事の前後の記事は以下です。 Kubernetes on Amazon EC2 環境構築編 Kubernetes on Amazon EC2 リソース作成編 (本記事) Kubernetes on Amazon EC2 運用監視編(今後公開予定) ※この記事は手順に焦点を当てているので、Kubernetesに関する用語の詳細な説明は省略しています。 目次 0.本記事で構築する環境について 1.Namespaceの作成 2.Deploymentの作成 3.Serviceの作成 4.PersistentVolumeの作成 5.Role(ユーザー)の作成 0. 本記事で構築する環境について 前回の記事で作成したKubernetes on EC2環境上に以下5つのリソースを作成します。 Namespace Deployment Service PersistentVolume Role 作成する流れは、以下のようになっています。 まずNamespaceを1つ作成し、Deploymentを使ってpodをデプロイします。 podの中にはそれぞれNGINXコンテナをデプロイし、アクセスできるようにServiceを設定します。 次に、MasterノードにEBSをアタッチし、NFSサーバとして設定し、PersistentVolumeを作成します。 EBSボリュームの中に自作のhtmlファイルを格納し、PVをマウントするようなPodをデプロイして自作htmlにアクセスできるようにします。 最後にClusterRoleやRoleBindingを使用して、Namespace1におけるReadOnly権限を持つユーザーを作成します。 本記事で紹介している手順を全て行うと、以下のようになると思います。 ※本記事では、各リソースをyamlで定義して作成しています。 どのリソースも、作成するまでの流れは基本的に同じで、 yamlを作成して、kubectl createコマンドでリソースをデプロイするという感じです。 1. Namespaceの作成 本章では、Namespaceを1つ作成する手順を紹介します。 Namespaceとは、Kubernetesクラスターの中に仮想クラスターを作成するものです。 Namespaceを作成することで、各Namespace上に作成されたリソースを独立させることができます。 Namespaceを作成したい場合、以下のコマンド1つで作成できます。 本記事では、namespace1という名前のNamespaceを作成しています。 $ kubectl create namespace namespace1 2. Deploymentの作成 本章では、NGINXのpodを2起動させるDeploymentを作成する手順を紹介します。 Deploymentとは、Podのロールバックやローリングアップデート等を管理することができるものです。 Deploymentを作成すると、コンテナイメージがアップデートされた場合などに アップデートしたコンテナイメージを使用して、自動でPodを再起動してくれます。 本記事では、NGINXコンテナを1台起動するpodをレプリカ数2でデプロイしています。 (1)yamlを作成します。 $ sudo vi nginx-deployment.yaml nginx-deployment.yaml apiVersion: apps/v1 #APIのバージョン kind: Deployment #リソースの種類 metadata: name: test-nginx #podの名前 namespace: namespace1 #デプロイするNamespaceを指定 spec: selector: #どのPodを起動するか matchLabels: app: nginx #テンプレートを指定 replicas: 2 #レプリカ数(起動するPodの数) template: #作成されるPodのテンプレート metadata: labels: app: nginx #Labelを付ける spec: containers: - name: nginx # コンテナに名前を付ける image: nginx:latest # イメージを指定する ports: - containerPort: 80 #コンテナが開くポートを指定 (2)作成したyamlを使用して、podをデプロイします。 $ kubectl create -f nginx-deployment.yaml 3. Serviceの作成 本章では、2.Deploymentの作成で起動させたPodを外部に公開するためのServiceを作成する手順を紹介します。 Serviceとは、デプロイされたPodの公開ポリシーや接続方法を定義するものです。 Serviceには、以下のように4つの公開タイプがあります。 ClusterIP : Kubernetesクラスター内でのみ有効なタイプです。外部からアクセスできません。 NodePort : Workerノードのポートを指定して、外部に公開します。 LoadBalancer : 外部からのリクエストを複数のPodへ負荷分散するタイプです。 ExtarnalName : 任意のドメインをServiceに紐づけ、Podをドメインで外部に公開します。 本記事では、NodePortタイプのServiceを作成し、Podを公開します。 (1)yamlを作成します。外部に公開するポート番号は、30000から32767の間で自由に指定できます。 ポート番号を指定しない場合は、30000から32767の間で自動で割り当たります。 $ sudo vi nginx-service.yaml nginx-service.yaml apiVersion: v1 kind: Service metadata: name: nginx # Serviceの名前 labels: app: nginx # Serviceのラベル spec: type: NodePort #Serviceのタイプ ports: - port: 80 # Serviceが受け取るポート protocol: TCP targetPort: 80 # コンテナが開いているポート nodePort: 30001 # 外部に公開するWorkerノードのポート selector: app: nginx # Serviceを紐づけるPodのラベルを指定します (2)作成したyamlを使用して、Serviceをデプロイします。 $ kubectl create -f nginx-service.yaml (3)以下のコマンドを使用して、PodがどのWorkerノードで起動しているかを調べます。 $ kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE test-nginx 2/2 Running 0 6m 10.244.1.10 worker1 (4)「http://NGINXのPodが起動しているWorkerノードのIPアドレス:30001」にアクセスして、以下のように表示されることを確認します。 4. PersistentVolumeの作成 本章では、EBSを使用してPersistentVolumeを作成する手順を紹介します。 PersistentVolume(PV)とは、Kubernetesクラスターから利用可能なボリュームのことです。 しかしPVだけではPodにマウントできないため、 PersistnetVolumeClaim(PVC)というボリュームの使用要求リソースと一緒に使用します。 PVはPVCから呼び出されることによって、Podにマウントできるようになります。 MasterノードにアタッチしたEBSをNFSサーバーとして設定し、それをPersistentVolumeとしてPodからアクセスできるようにします。 本記事では、EBSの作成からPVをマウントするPodの公開まで、以下のような流れで作成します。 1. EBSの作成とアタッチ 2. NFSサーバの設定 3. NFSサーバの動作確認 4. PersistentVolumeの作成 5. PersistentVolumeClaimの作成 6. PVをマウントするpodの作成 7. podを外部に公開するServiceの作成 4-1. EBSの作成とアタッチ GUIを使用してEBSを作成することもできますが、本記事ではAWS CLIを使用して作成しています。 Masterノードにて、以下の手順を行います。(Workerノードでも可能です。) (1)aws configureを設定します。使用しているIAMユーザーのアクセスキーとシークレットキーを入力してください。 $ aws configure AWS Access Key ID [None]: アクセスキー AWS Secret Access Key [None]: シークレットキー Default region name [None]: ap-northeast-1 Default output format [None]: json ※IAMユーザーのアクセスキーは、AWSコンソールの「IAMサービス > ユーザー > 認証情報」で確認できます。 しかし、シークレットキーはアクセスキーを作成したときにしか表示、保存できません。 シークレットキーが見つからないという場合は、新規にアクセスキーを作成し、使用してください。 (2)EBSを作成します。 --availability-zoneはNFSサーバーとして設定する予定のEC2インスタンスと同様のアベイラビリティゾーンを入力してください。(本記事では、Masterノードです。) 実行結果のVolumeId:の後ろに表示されているvol-XXXXXXXXXをコピーしておいてください。 $ aws ec2 create-volume --size=10 --volume-type=gp2 --availability-zone ap-northeast-1d { "AvailabilityZone": "ap-northeast-1c", "CreateTime": "2020-12-15T10:59:55.000Z", "Encrypted": false, "Size": 10, "SnapshotId": "", "State": "creating", "VolumeId": " vol-07ebc41e508b23485",★この部分★ "Iops": 100, "Tags": [], "VolumeType": "gp2" } (3)EBSをMasterノードにアタッチします。MasterノードのEC2インスタンスIDと上記ボリュームIDを入力してください。 実行結果のStateがattachingになっていることを確認します。 $ aws ec2 attach-volume --instance-id MasterノードのEC2インスタンスID --device /dev/xvdf --volume-id vol-07ebc41e508b23485 --region ap-northeast-1 { "AttachTime": "2020-12-15T11:08:26.251Z", "InstanceId": "MasterノードのインスタンスID", "VolumeId": "vol-07ebc41e508b23485", "State": "attaching",★ "Device": "/dev/xvdf" } (4)EBSがアタッチされている(xvdfが認識されている)ことを確認します。 $ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 8G 0 disk └─xvda1 202:1 0 8G 0 part / xvdf 202:80 0 10G 0 disk★ 4-2. NFSサーバの設定 MasterノードにアタッチしたEBSをNFSサーバとしてKubernetesクラスター間で共有できるように設定します。 (1)/dev/xvdfパーティションをファイルシステムext4でフォーマットします。 $ sudo mkfs -t ext4 /dev/xvdf (2)マウントポイントを作成します。 $ sudo mkdir -p /export/nfs (3)/etc/fstabの最後の行にマウント情報を追加します。 $ sudo vi /etc/fstab /etc/fstab /dev/xvdf /export/nfs ext4 defaults,nofail 1 2 (4)EBSを/export/nfsにマウントします。 $ sudo mount /export/nfs (5)/etc/exportsの最後の行にexportポイント情報を追加します。本記事では、/export/nfsをVPC内で共有できるように設定します。 $ sudo vi /etc/exports /etc/exports /export/nfs VPCのCIDER(rw,no_root_squash) (6)NFSを起動します。 $ sudo systemctl start nfs ※NFSがすでに起動済みの場合は以下のコマンドで設定を反映できます。 $ sudo exportfs -ar (7)ディレクトリ(/export/nfs)が共有されているか確認します。 $ showmount -e Export list for master: /export/nfs VPCのCIDER (8)EBSがマウントされている(xvdfのMOUNTPOINT欄に/export/nfsが表示されている)ことを確認します。 $ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 8G 0 disk └─xvda1 202:1 0 8G 0 part / xvdf 202:80 0 10G 0 disk /export/nfs ^^^^^^^^^^^ (9)表示させるhtmlを作成し、共有ディレクトリ(/export/nfs)に配置します。 $ sudo vi /export/nfs/index.html index.html <html> <head> <title>Volume Test</title> </head> <body> <h1>Hello Persistent Volume!</h1> </body> </html> 4-3. NFSサーバの動作確認 (1)全Workerノードにnfsがインストールされていることを確認してください。インストールされていない場合、インストールを行ってください。 $ yum list | grep nfs (省略) nfs-utils.x86_64 1:1.3.0-0.54.amzn2.0.2 installed nfs4-acl-tools.x86_64 0.3.3-17.amzn2 amzn2-core (省略) (2)Workerノードで、NFSサーバから共有されているディレクトリをマウントできることを確認します。 NFSサーバーのIPアドレスには、NFSサーバとして設定したEC2インスタンス(本記事では、Masterノード)のプライベートIPアドレスを入力します。 $ sudo mount -t nfs NFSサーバのIPアドレス:/export/nfs /mnt/nfs $ df Filesystem 1K-blocks Used Available Use% Mounted on NFSサーバのIPアドレス:/export/nfs 503839744 128 503839616 1% /mnt/nfs ※マウントを解除するには、下記コマンドを実行してください。 $ umount /mnt/nfs 4-4. PersistentVolumeの作成 本節では、前々節で作成したNFSサーバーをPersistentVolumeとして、Kubernetesクラスターに作成します。 (1)PersistentVolumeのyamlを作成します。 server欄にNFSサーバのIPアドレスを入力し、path欄に設定したマウントポイントを入力します。 $ sudo vi nfs-pv.yaml nfs-pv.yaml apiVersion: v1 kind: PersistentVolume metadata: name: nfs-pv # PVの名前 spec: capacity: storage: 8Gi # ストレージの容量指定 accessModes: - ReadWriteOnce #ボリュームをアタッチできるノード数の指定 persistentVolumeReclaimPolicy: Recycle nfs: server: NFSサーバのIPアドレス path: /export/nfs #マウントポイント (2)作成したyamlを使用して、PVをデプロイします。 $ kubectl create -f nfs-pv.yaml 4-5. PersistentVolumeClaimの作成 4-4.で作成したPVをPodからマウントできるように、PVCを作成します。 (1)yamlを作成します。 $ sudo vi nfs-pvc.yaml nfs-pvc.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: nfs-pvc # PVCの名前 spec: accessModes: - ReadWriteOnce #ボリュームをアタッチできるノード数の指定 resources: requests: storage: 2Gi (2)作成したyamlを使用して、PVCをデプロイします。 $ kubectl create -f nfs-pvc.yaml 4-6. PVをマウントするpodの作成 podのyamlを作成します。 Pod内のNGINXコンテナの/usr/share/nginx/html ディレクトリにPVをマウントさせるyamlを作成します。 4-5.で作成したPVCを指定することで、PVをマウントできるようになります。 (1)yamlを作成します。 $ sudo vi nginx-pv.yaml nginx-pv.yaml apiVersion: v1 kind: Pod metadata: name: nginx-pv # Podの名前 namespace: namespace1 #デプロイするNamespaceを指定 labels: app: nginx-pv # Podのラベル spec: containers: - name: nginx-container # コンテナの名前 image: nginx # コンテナイメージ ports: - containerPort: 80 # コンテナが開くポート name: "http-server" # ポートの名前 volumeMounts: - mountPath: "/usr/share/nginx/html" # コンテナ側のマウントポイント name: nginx-vm #ボリューム名 volumes: - name: nginx-vm # PVCで呼び出したボリューム名 persistentVolumeClaim: claimName: nfs-pvc # PVCを指定 (2)作成したyamlを使用して、podをデプロイします。 $ kubectl create -f nginx-pv.yaml 4-7. podを外部に公開するServiceの作成 本節では、NodePortタイプのServiceを作成して、30002ポートを外部に公開します。 (1)yamlを作成します。 $ sudo vi nginx-svc-pv.yaml nginx-svc-pv.yaml apiVersion: v1 kind: Service metadata: name: nginx-svc-pv # Serviceの名前 labels: app: nginx-svc-pv # Serviceのラベル spec: type: NodePort # NodePortタイプを指定 ports: - port: 80 # Serviceが受け取るポート protocol: TCP targetPort: 80 # コンテナ側のポート nodePort: 30002 # 外部に公開用のポート selector: app: nginx-pv # 公開するpodのラベルを指定 (2)作成したyamlを使用して、Serviceをデプロイします。 $ kubectl create -f nginx-svc-pv.yaml (3)以下のコマンドを使用して、podがどのWorkerノードで起動しているかを調べます。 $ kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE nginx-pv 1/1 Running 0 3m 10.244.1.11 worker2 (4)「http://NGINXのpodがデプロイされているノードのIPアドレス:30002」にアクセスして、作成したhtmlが表示されていることを確認します。 5. Role(ユーザー)の作成 本章では、Kubernetesクラスター上のリソースに対して、ReadOnly権限のみを付与したRoleを作成する手順を紹介します。 Kubernetesには、RBAC(Role-Based Access Control)というアクセス制御機能があり、以下の4つのリソースがあります。 Role ClusterRole RoleBinding ClusterRoleBinding RoleとClusterRoleは、どのリソースに対するどんな操作を許可するかを定義するもので、 RoleBindingとClusterRoleBindingは、RoleやClusterRoleをどのユーザー等に紐づけるかを定義するものです。 そして、それぞれClusterが付いていないリソース(Role,RoleBinding)と付いているリソース(ClusterRole,ClusterRoleBinding)の違いは、前者が特定のNamespaceに属するリソースで、後者がNamespaceに属さずクラスター内で使用できることです。 本記事では、ClusterRoleとRoleBindingを使用して、Namespace1におけるReadOnly権限を持つユーザーを作成します。 以下のような流れで、ユーザーを作成します。 1. ユーザー認証情報の作成 2. コンテキストの作成 3. ClusterRoleとRoleBinding作成 5-1. ユーザー認証情報の作成 ※本記事で作成している認証情報は、自己署名証明書です。 (1)秘密鍵を作成します。 $ sudo openssl genrsa -out ns1user.key 2018 Generating RSA private key, 2018 bit long modulus .......+++ ...............+++ e is 65537 (0x10001) (2)作成した秘密鍵を元に、証明書発行リクエストファイルを作成します。Organization Nameに所属グループ名、Common Nameにユーザー名を入力し、それ以外は空欄で大丈夫です。 $ sudo openssl req -new -key ns1user.key -out ns1user.csr (略) ----- Country Name (2 letter code) [XX]: State or Province Name (full name) []: Locality Name (eg, city) [Default City]: Organization Name (eg, company) [Default Company Ltd]:test Organizational Unit Name (eg, section) []: ^^^^ Common Name (eg, your name or your server's hostname) []:ns1user Email Address []: ^^^^^^^ Please enter the following 'extra' attributes to be sent with your certificate request A challenge password []: An optional company name []: (3)作成した証明書発行リクエストファイルとPKI証明書を使って、SSL証明書を作成します。 $ sudo openssl x509 -req -in ns1user.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out ns1user.crt -days 10000 Signature ok subject=/C=XX/L=Default City/O=test/CN=ns1user Getting CA Private Key (4)ns1userというユーザー名で、(1)から(3)で作成した証明書情報をKubernetesクラスターに登録します。 $ kubectl config set-credentials ns1user --client-certificate=ns1user.crt --client-key=ns1user.key --embed-certs=true 5-2. コンテキストの作成 コンテキストを作成し、Namespaceとユーザー、クラスターを紐づけます。 本手順書では例として、ns1userというコンテキスト名で、各項目を紐づけています。 $ kubectl config set-context ns1user --user=ns1user --cluster=Kubernetes --namespace=namespace1 5-3. ClusterRoleとRoleBinding作成 ユーザーの権限を作成します。Namespace1におけるReadOnly権限(get, watch, list)を持つns1userを作成します。 (1)ClusterRoleとRoleBindingを定義するyamlを作成します。 $ sudo vi ns1user.yaml ns1user.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: readonly-for-all # ClusterRoleの名前 rules: - apiGroups: ["*"] # resources: ["*"] # 操作を許可するリソースを指定 verbs: ["get", "list", "watch"] # 許可する操作を指定 - nonResourceURLs: ["*"] verbs: ["get", "list", "watch"] # 許可する操作を指定 --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: readonly-ns1user # RoleBindingの名前 namespace: namespace1 # RoleBindingを作成するNamespaceを指定 subjects: - kind: User name: ns1user # ユーザー名を指定 apiGroup: rbac.authorization.k8s.io roleRef: kind: ClusterRole name: readonly-for-all # ClusterRoleを指定 apiGroup: rbac.authorization.k8s.io (2)作成したyamlを使用して、ClusterRoleとRoleBindingをデプロイします。 $ kubectl create -f ns1user.yaml 5-4. 動作確認 (1)作成したコンテキストに切り替えます。 $ kubectl config use-context ns1user Switched to context "ns1user" (2)Namespace1内のPodが見られることを確認します。 $ kubectl get pod NAME READY STATUS RESTARTS AGE nginx-pv 1/1 Running 0 90m (3)podの作成はできないことを確認します。 (使用しているyamlファイルは、2.章で作成したものです。) $ kubectl create -f nginx-deployment.yaml Error from server (Forbidden): pods is forbidden: User "ns1user" cannot create resource "pods" in API group "" in the namespace "namespace1" あとがき 最初は、NamespaceやDeployment、Pod作成だけをまとめていたのですが、せっかく勉強する機会があるのに、これだけでは勿体ないと思い、PersistentVolumeとRoleの作成手順を追加しました。 手順を検証していく中で、EC2上のKubernetes環境でPVを作るのに大変苦労しました。 AWS CLIでEBSを作成してアタッチする方法やEBSをPVとして認識させる方法など、分からないことだらけでした。 先輩方や色んなWebサイトに助けられて、何とか上手くいきましたが、AWS CLIやNFSの勉強もできたので、大変いい経験でした。 ※商標類について: - Amazon Web Services、“Powered by Amazon Web Services”ロゴ、[およびかかる資料で使用されるその他のAWS商標]は、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。 - DockerおよびDockerロゴは、Docker Inc. の米国およびその他の国における登録商標もしくは商標です。 - NGINXはNGINX, Inc.の登録商標です。 - Kubernetesは、The Linux Foundationの米国およびその他の国における登録商標または商標です。 - その他記載されている会社名、製品名はそれぞれ各社の商標および登録商標です。
- 投稿日:2021-03-08T13:09:48+09:00
Kubernetes on Amazon EC2 環境構築編 ~新人がやってみた(1)~
このシリーズは、入社1年目の新人がEC2上にKubernetes環境構築を色々試行錯誤して、上手くいった手順をまとめたものです。 はじめに 本シリーズは、EC2上にKubernetesクラスターを構築する環境構築編(本記事)と KubernetesクラスターにPodやServiceなど5つのリソースを作成するリソース作成編、 最後に、KubernetesクラスターにElasticSearchとKibanaを導入する運用監視編の三部構成になっています。 この記事ではEC2上にKubernetesクラスターを構築するまでの手順を書いてます。 リソース作成編や運用監視編の記事は、以下になります。 Kubernetes on Amazon EC2 環境構築編 (本記事):EC2上にKubernetesクラスターを構築するまでの手順を書いてます。 Kubernetes on Amazon EC2 リソース作成編(今後公開予定):Kubernetesの5つのリソース(PodやServiceなど)を作成する手順を書いてます。 Kubernetes on Amazon EC2 運用監視編(今後公開予定):Kubernetes環境にElasticSearchとKibanaを導入するまでの手順を書いてます。 ※この記事は手順に焦点を当てているので、Kubernetesに関する用語の詳細な説明は省略しています。 目次 全体的な作業の流れ 0.本記事で構築する環境について 1.Kubernetes on Amazon EC2環境構築に必要な事前準備 2.Kubernetes on Amazon EC2環境構築 全体的な作業の流れ この記事で行う作業の全体的な流れは、以下のようになってます。 EC2を3台起動させます。(Master1台、Worker2台) 全ノードにDocker、kubelet、kubeadm、kubectlをインストールします。 Masterノードでkubeadmを初期化して、Masterノードの設定をします。 Workerノードをクラスターに追加します。 0. 本記事で構築する環境について 本記事では、新人が勉強の目的で構築した手順を紹介するため、シンプルな構築になっています。 Masterノード1台、Workerノード2台で全3台構成のKubernetes環境を構築します。 コンテナランタイムはDockerを使用します。 使用したものは以下になります。 docker-CE 19.03.6-ce Kubernetes v1.20.1 Flannel v0.13.0-rc2 1. Kubernetes on Amazon EC2環境構築に必要な事前準備 事前準備では、EC2インスタンスとセキュリティグループを作成します。 ※EC2を作成する前に、VPCとパブリックサブネットを作成しておきます。 1. EC2インスタンスを作成します。 本記事ではAMIにAmazon Linux2を選択しています。 インスタンスタイプはt2.medium以上の性能を選択してください。 ※Kubernetesを導入するのに、メモリ2GB以上、2CPU以上が必要なためです。 https://kubernetes.io/ja/docs/setup/production-environment/tools/kubeadm/install-kubeadm/ 2. MasterノードとWorkerノードで開くポートが異なるため、セキュリティグループを2つ作成します。 Masterノードにアタッチするセキュリティグループは以下のように設定してください。 ポート番号 用途 アクセス許可元 6443/TCP Kubernetes API VPCのCIDR 2379,2380/TCP etcd server client API VPCのCIDR 10250/TCP kubelet API VPCのCIDR 10251/TCP kube-scheduler VPCのCIDR 10252/TCP kube-controller-manager VPCのCIDR 3. Workerノードにアタッチするセキュリティグループは以下のように設定してください。 ポート番号 用途 アクセス許可元 10250/TCP kubelet API VPCのCIDR 30001-30003/TCP Node Port Service 自PCのIPアドレス 2. Kubernetes on Amazon EC2環境構築 本章では、大まかに以下の流れで環境構築をしていきます。 1. 必要なモジュールをインストール(Dockerやkubeletなど) 2. kubeadmを使用して、Masterノードを構築 3. kubeadmを使用して、Workerノードを構築し、クラスターに追加 事前準備で作成したEC2インスタンスに接続します。 以下のように、接続するインスタンスを選択し、「接続」を押下することでEC2インスタンスに接続できます。 本記事ではEC2への接続に、AWS Systems Managerを使用しています。 2-1. (全ノード)Dockerのインストール まず、全ノードにDockerをインストールします。 (1)デフォルトでインストールされているパッケージをアップデートします。 $ sudo yum update -y (2)amazon-linux-extrasコマンドを使用して、Dockerをインストールします。 $ sudo amazon-linux-extras install -y docker (3)インストールが終わったらDockerを起動し、EC2インスタンスを再起動しても、Dockerが自動で起動するように設定します。 $ sudo systemctl start docker && sudo systemctl enable docker 2-2. (全ノード)kubelet、kubeadm、kubectlのインストール Kubernetes環境を構築するのに必要なモジュールをインストールします。 (1)kubelet、kubeadm、kubectlをインストールするためにレポジトリを作成します。 $ sudo vi /etc/yum.repos.d/kubernetes.repo /etc/yum.repos.d/kubernetes.repo [kubernetes] name=kubernetes baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg exclude=kube* (2)kubelet, kubeadm, kubectlをインストールします。 $ sudo yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes ※SELinuxが有効の場合、SELinuxを無効化してから上記コマンドを叩いてください。 $ setenforce 0 (3)kubeletを起動させ、EC2インスタンスを再起動しても自動で起動するようにします。 $ sudo systemctl enable kubelet && sudo systemctl start kubelet 2-3. (Masterノード)kubeadm kubeadmを初期化して、Masterノードの設定を行います。 この手順は、Masterノードのみで行ってください。 (1)kubeadmを初期化します。 実行結果の最後に、以下のような文が表示されるので、kubeadm join ~の一文をコピーしておきます。 (後で、Workerノードをクラスターに追加するときに使用します。) $ sudo kubeadm init --pod-network-cidr=10.244.0.0/16 (省略) Then you can join any number of worker nodes by running the following on each as root: kubeadm join MaserノードのプライベートIPアドレス:6443 --token トークン番号 --discovery-token-ca-cert-hash sha256:XXXXXXXXXX (2)非rootユーザがkubectlコマンドを実行できるように、以下のコマンドを叩きます。 $ mkdir -p $HOME/.kube $ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config $ sudo chown $(id -u):$(id -g) $HOME/.kube/config (3)flannelをデプロイします。 ※falnnelとは、Kubernetesクラスターのネットワークモデルを構築するプラグインの1つです。 $ kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml (4)STATUSがReadyになっていることを確認してください。 $ kubectl get nodes NAME STATUS ROLES AGE VERSION master Ready control-plane,master 5m v1.20.1 2-4. (Workerノード)クラスターにWorkerノードを追加 kubeadmを使用して、WorkerノードをKubernetesクラスターに追加します。 この手順は、クラスターに追加する全Workerノードで行ってください。 (1)kubeadmの初期化の(1)でコピーしておいたkubeadm join ~の一文をペーストし、root権限で実行します。 $ sudo kubeadm join MasterノードのプライベートIPアドレス:6443 --token トークン番号 --discovery-token-ca-cert-hash sha256:XXXXXXXXXX (2)Workerノードがクラスターに追加されたことを確認します。 $ kubectl get nodes NAME STATUS ROLES AGE VERSION master Ready control-plane,master 14m v1.20.1 worker1 Ready <none> 11m v1.20.1 worker2 Ready <none> 11m v1.20.1 これで、Kubernetesクラスターの構築が完了です。 次は、構築したKubernetesクラスター上にpodやserviceを作成していきます。 Kubernetes on Amazon EC2 リソース作成編(今後公開予定) あとがき なぜEC2上にKubernetes環境を構築したのかというと、新人研修後にAWS、コンテナ技術などを勉強していると、先輩に「AWS上にKubernetes環境を構築したら、AWSとKubernetesの勉強が一緒にできるね」とアドバイスを頂き、やってみたという流れです。 AWSもKubernetesも分からなかった当時の私には、EC2の作成やクラスターの構築方法が分からず困りました。 その中でも特に苦労したのは、EC2のセキュリティグループの設定でした。 セキュリティグループで設定しなければいけないポートがどこなのかが分からず、大変でした。 ※商標類について: - Amazon Web Services、“Powered by Amazon Web Services”ロゴ、[およびかかる資料で使用されるその他のAWS商標]は、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。 - DockerおよびDockerロゴは、Docker Inc. の米国およびその他の国における登録商標もしくは商標です。 - KubernetesおよびKubernetesロゴは、The Linux Foundationの米国およびその他の国における登録商標または商標です。 - その他記載されている会社名、製品名はそれぞれ各社の商標および登録商標です。
- 投稿日:2021-03-08T12:49:05+09:00
AWS CloudFormationのデプロイ済みスタックのテンプレートを取得
CloudFormationのデプロイ済みスタックのテンプレートをawscliでYAMLやJSONのフォーマットで取得する方法です。
aws cloudformation get-templateコマンドでテンプレートを取得できるのですが、デプロイ時YAMLとJSONのどちらを使ったかによって返ってくるフォーマットが違い、毎回試行錯誤してしまうので、メモしておきます。テンプレートを取得するワンライナー
YAMLでデプロイしたスタックをYAMLで取得
$ aws cloudformation get-template --stack-name $STACKNAME | jq .TemplateBody -rJSONでデプロイしたスタックをJSONで取得
$ aws cloudformation get-template --stack-name $STACKNAME | jq .TemplateBodyYAMLでデプロイしたスタックをJSONで取得
$ aws cloudformation get-template --stack-name $STACKNAME | jq .TemplateBody -r | yq $ aws cloudformation get-template --stack-name $STACKNAME | ruby -rjson -ryaml -e 'puts JSON.pretty_generate(YAML.load(JSON.load(ARGF)["TemplateBody"]))' $ aws cloudformation get-template --stack-name $STACKNAME | jq .TemplateBody -r | python -c 'import sys; import json; from awscli.customizations.cloudformation.yamlhelper import yaml_parse; print(json.dumps(yaml_parse(sys.stdin.read()), indent=4))'1つ目と2つ目は
!GetAttみたいなのには非対応です。Pythonのboto3がある環境では、3つ目のようにがんばれば!GetAttみたいなのに対応できます。JSONでデプロイしたスタックをYAMLで取得
$ aws cloudformation get-template --stack-name $STACKNAME | yq .TemplateBody -y $ aws cloudformation get-template --stack-name $STACKNAME | ruby -ryaml -e 'puts YAML.dump(YAML.load(ARGF)["TemplateBody"])'試してみる
テンプレートファイル
RDSのインスタンスを作るシンプルなテンプレートで試します。
AWSTemplateFormatVersion: '2010-09-09' Resources: SampleRDS: Type: AWS::RDS::DBInstance Properties: Engine: postgres EngineVersion: 12.5 DBInstanceIdentifier: samplerdsinstance1 DBInstanceClass: db.t3.micro StorageType: gp2 AllocatedStorage: 20 # GiB DBName: mydb MasterUsername: myuser MasterUserPassword: mypassword Outputs: SampleRDSEndpoint: Value: !GetAtt SampleRDS.Endpoint.Address{ "AWSTemplateFormatVersion": "2010-09-09", "Resources": { "SampleRDS": { "Type": "AWS::RDS::DBInstance", "Properties": { "Engine": "postgres", "EngineVersion": 12.5, "DBInstanceIdentifier": "samplerdsinstance2", "DBInstanceClass": "db.t3.micro", "StorageType": "gp2", "AllocatedStorage": 20, "DBName": "mydb", "MasterUsername": "myuser", "MasterUserPassword": "mypassword" } } }, "Outputs": { "SampleRDSEndpoint": { "Value": { "Fn::GetAtt": ["SampleRDS", "Endpoint.Address"] } } } }デプロイ
$ aws cloudformation deploy --template-file template.yaml --stack-name sample-yaml$ aws cloudformation deploy --template-file template.json --stack-name sample-jsonaws cloudformation get-templateコマンド
デプロイ時のYAML/JSONでコマンドの出力がだいぶ違うんですよね。。。
YAMLの場合は、YAMLのコードがそのまま文字列になってJSONに埋め込まれている。JSONの場合は、そのままJSON。
$ aws cloudformation get-template --stack-name sample-yaml { "TemplateBody": "AWSTemplateFormatVersion: '2010-09-09'\n\nResources:\n SampleRDS:\n Type: AWS::RDS::DBInstance\n Properties:\n Engine: postgres\n EngineVersion: 12.5\n DBInstanceIdentifier: samplerdsinstance1\n DBInstanceClass: db.t3.micro\n StorageType: gp2\n AllocatedStorage: 20 # GiB\n DBName: mydb\n MasterUsername: myuser\n MasterUserPassword: mypassword\n\nOutputs:\n SampleRDSEndpoint:\n Value: !GetAtt SampleRDS.Endpoint.Address\n", "StagesAvailable": [ "Original", "Processed" ] }$ aws cloudformation get-template --stack-name sample-json { "TemplateBody": { "AWSTemplateFormatVersion": "2010-09-09", "Resources": { "SampleRDS": { "Type": "AWS::RDS::DBInstance", "Properties": { "Engine": "postgres", "EngineVersion": 12.5, "DBInstanceIdentifier": "samplerdsinstance2", "DBInstanceClass": "db.t3.micro", "StorageType": "gp2", "AllocatedStorage": 20, "DBName": "mydb", "MasterUsername": "myuser", "MasterUserPassword": "mypassword" } } }, "Outputs": { "SampleRDSEndpoint": { "Value": { "Fn::GetAtt": [ "SampleRDS", "Endpoint.Address" ] } } } }, "StagesAvailable": [ "Original", "Processed" ] }テンプレート取得
YAMLデプロイのスタックをYAMLで取得。YAML自体がJSONの文字列になっているのでjqコマンドに
-rオプションを付ける。$ aws cloudformation get-template --stack-name sample-yaml | jq .TemplateBody -r AWSTemplateFormatVersion: '2010-09-09' Resources: SampleRDS: Type: AWS::RDS::DBInstance Properties: Engine: postgres EngineVersion: 12.5 DBInstanceIdentifier: samplerdsinstance1 DBInstanceClass: db.t3.micro StorageType: gp2 AllocatedStorage: 20 # GiB DBName: mydb MasterUsername: myuser MasterUserPassword: mypassword Outputs: SampleRDSEndpoint: Value: !GetAtt SampleRDS.Endpoint.AddressJSONデプロイのスタックをJSONで取得。
$ aws cloudformation get-template --stack-name sample-json | jq .TemplateBody { "AWSTemplateFormatVersion": "2010-09-09", "Resources": { "SampleRDS": { "Type": "AWS::RDS::DBInstance", "Properties": { "Engine": "postgres", "EngineVersion": 12.5, "DBInstanceIdentifier": "samplerdsinstance2", "DBInstanceClass": "db.t3.micro", "StorageType": "gp2", "AllocatedStorage": 20, "DBName": "mydb", "MasterUsername": "myuser", "MasterUserPassword": "mypassword" } } }, "Outputs": { "SampleRDSEndpoint": { "Value": { "Fn::GetAtt": [ "SampleRDS", "Endpoint.Address" ] } } } }YAMLとJSONを変換したければ、冒頭に書いた通りyqコマンドやワンライナーで変換できます。
コマンドのインストール
jqコマンド
jqのインストールはUbuntuならば$ sudo apt install -y jqCentOS 8ならば
$ sudo yum install -y jqyqコマンド
yqはPythonで書かれており、pipでインストールできます。$ pip install yq内部で
jqを呼び出しているようで、jqがないと次のようなエラーになります。yq: Error starting jq: FileNotFoundError: [Errno 2] No such file or directory: 'jq'. Is jq installed and available on PATH?
- 投稿日:2021-03-08T12:46:09+09:00
AWS RedShiftを学んでみた
(追記していきます。)
AWS Redshift
いわゆるデータウェアハウスですね。
- マネージド型
- 高速でスケーラブル
- PostgreSQL互換
- 列志向データモデル
- 複数ノードをまとめたクラスター構成
そもそもデータウェアハウスとは
(クラスターについてもう少し書く)
課金
- 一般的なデータウェアハウスよりは安いはず
- 1テラバイトあたり年間1000USDで利用可能
インスタンスタイプ
- RA3インスタンス
- DC2インスタンス
列志向
- 高速にIO処理できる
- RDSは業務用データベースで行志向
- RedShiftは分析用なので列志向
マテリアライズドビュー
TBW
機械学習
TBW
ワークロード管理
TBW
スケーリング
- 32個までノードを追加
- クラスターの追加もできる
未整理
- データはS3バケットに保存
- S3との関係
- 投稿日:2021-03-08T12:25:19+09:00
AWSへデプロイ後にユーザー情報が更新できない現象への対処法
AWSへデプロイ後に、user.saveでユーザー情報が保存できない現象についての対処法
とあるプログラミング学習サイトを利用してRailsを学び、作成したアプリケーションをサーバーへデプロイしたところまでは良かったのですが、その後作成したユーザーのアイコンを変更できない現象に遭遇しました。手探りでの対処で苦戦しましたので、同じことを繰り返さないためにも投稿に残したいと思います。
現象が発生した元のコード
app/controllers/users_controller.rbdef update @user = User.find_by(id: params[:id]) @user.name = params[:name] @user.user_id = params[:user_id] @user.email = params[:email] if params[:image] @user.image_name = "#{@user.id}.jpg" image = params[:image] File.binwrite("public/user_images/#{@user.image_name}", image.read) end if params[:password] != nil @user.password = params[:password] end if @user.save flash[:notice] = "ユーザー情報を編集しました" redirect_to("/users/#{@user.user_id}") else render("users/#{@user.user_id}/edit") end endこのコードでローカルではうまくいっていたのですが、サーバーへデプロイ後はユーザー画像のみ保存されて、MySQLのデータは更新されませんでした。
試したこと
エラーが吐き出されていないか確認しましたが、log/production.logにはエラーらしきものはなく、mysql.logを確認しようとしましたがどこにあるのかわからず、できませんでした。
このためはじめはrails consoleで状況を確認しようとしましたが、RDSのデータベースには接続されていないのか、users = User.allでユーザー情報を取得しようとしても、users.count = 0の状態でした。
そこで直接MySQLへログインして、テーブルのデータをSQLで更新してみたところ、こちらはできましたので、MySQLを使用して更新する方法を取ることにしました。
現象が改善した後のコード
app/controllers/users_controller.rbdef update id = @current_user.id updated = 0 update_name_sql = "update users set name = '#{params[:name]}' where id =#{id};" updated = ActiveRecord::Base.connection.execute(update_name_sql) update_email_sql = "update users set email = '#{params[:email]}' where id =#{id};" updated = ActiveRecord::Base.connection.execute(update_email_sql) if params[:image] update_image_name_sql = "update users set image_name = '#{id}.jpg' where id =#{id};" updated = ActiveRecord::Base.connection.execute(update_image_name_sql) image = params[:image] File.binwrite("public/user_images/#{id}.jpg", image.read) end if params[:password] hashed_password = BCrypt::Password.create(params[:password]) update_password_sql = "update users set encrypted_password = '#{hashed_password}' where id =#{@current_user.id};" ActiveRecord::Base.connection.execute(update_password_sql) end if updated =! nil flash[:notice] = "ユーザー情報を編集しました" redirect_to("/users/#{@user.id}") else flash[:notice] = "データベースへの保存に失敗しました" render("users/edit") end endSQLを直に作成して、ActiveRecord::Base.connection.execute(SQL)でMySQLのデータベースを直接更新する方法へ変えました。
(パスワードに関してもトラブルがありましたので、直接暗号化してから保存するコードに書き換えました)まとめ
プログラミング学習サイトの良いところは、手軽に言語の学習に手をつけられるところですね。しかし現実には実用レベルに達するためにいくつもの壁を越えなければいけないものなのだと実感しています。ローカルでは動いていたけれど、サーバー環境ではうまくいかないことが普通にあるのだとわかりました。これに懲りずにポートフォリオ作りに励もうと思います!
- 投稿日:2021-03-08T11:01:31+09:00
TerraformでAWS 大阪リージョンを使う設定
現状
これを書いている2021年3月8日現在、本家からは大阪リージョンに対応したAWSプロバイダーがリリースされています。
aws-provider no support for ap-northeast-3 region that became generally available on 1/03/21 #17882This has been released in version 3.31.0 of the Terraform AWS provider. Please see the Terraform documentation on provider versioning or reach out if you need any assistance upgrading. For further feature requests or bug reports with this functionality, please create a new GitHub issue following the template for triage. Thanks! (これは、TerraformAWSプロバイダーのバージョン3.31.0でリリースされています。 プロバイダーのバージョン管理に関するTerraformのドキュメントを参照するか、アップグレードについてサポートが必要な場合はお問い合わせください。 この機能に関するその他の機能リクエストまたはバグレポートについては、トリアージのテンプレートに従って新しいGitHubの問題を作成してください。 ありがとう!)というわけで、AWSプロバイダーのバージョンを3.31.0以上にアップグレードすればいいです。
設定
provider "aws" { region = "ap-northeast-3" } terraform { required_providers { aws = "3.31.0" } }バックエンドにS3を使用している場合は、S3バックエンドのバリデーションで引っかかるので、
skip_region_validation = trueが必要になります。provider "aws" { region = "ap-northeast-3" } terraform { backend "s3" { bucket = "xxxxxxxxxxxx" key = "xxxxxxxxxxx" dynamodb_table = "xxxxxxxxxx" region = "ap-northeast-3" skip_region_validation = true } required_providers { aws = "3.31.0" } }上記内容で設定した後
$ terraform initで、使えるようになるはずです。
メモとして書いたけど、そのうち必要なくなる内容ですね。
- 投稿日:2021-03-08T10:40:47+09:00
AWS IoT Coreに「1-Click証明書作成」と「CSRによる作成」の2つの方法でプロビジョニングを実施してみる
はじめに
IoT Coreにプロビジョニングする方法のうち、以下2点を試したので、その備忘録です。
- 1-Click証明書作成
- CSRによる作成
なお、今回プロビジョニングするデバイスはJetson nanoのDevelopers kitです。
作業はWindowsで行い、Jetson nanoに対する作業は主にTeraTermで接続して行っています。
※ファイルのやりとりはFileZillaで実施以下の記事を参考に、事前にOSインストール済です。
参考:はじめてみよう!NVIDIA Jetson nano まずは知識と最初の起動!事前準備
AWS IoTのCAルートを取得
このページからAWS IoTのCAルートを取得します。
「RSA 2048 ビットキー: Amazon Root CA 1」を右クリックして、「名前を付けてリンク先を保存」で取得できます。mosquittoのインストール
プロビジョニング後の疎通テスト用にmosquittoをインストールしておきます。
参考:UbuntuにMosquittoをインストールしてMQTTブローカーを構築#パッケージにmosquittoのレポジトリを追加 sudo add-apt-repository ppa:mosquitto-dev/mosquitto-ppa #パッケージリストの更新 sudo apt-get update #クライアントのインストール sudo apt-get install mosquitto-clients #ブローカーのインストール sudo apt-get install mosquitto1.「1-Click証明書作成」でプロビジョニング
今回は証明書作成→モノの作成、という順で実施したので、その通り記載します。
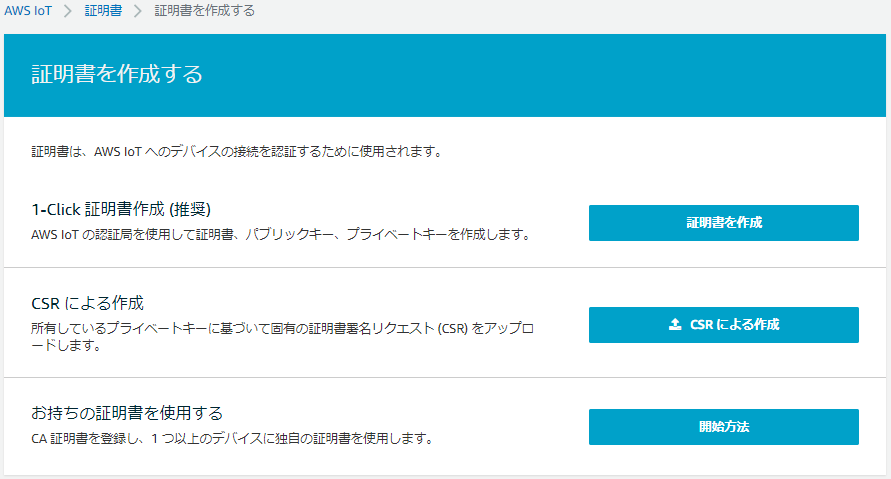
※モノの作成で「1-Click証明書作成」の方が手数は少なく済むはずです1-1 証明書の作成
1.マネジメントコンソールでIoT Coreに移動
2.左のメニューから 安全性 > 証明書 > 証明書を作成する の順にクリック
3.以下の画面で 1-Click証明書作成(推奨)の「証明書を作成」をクリック
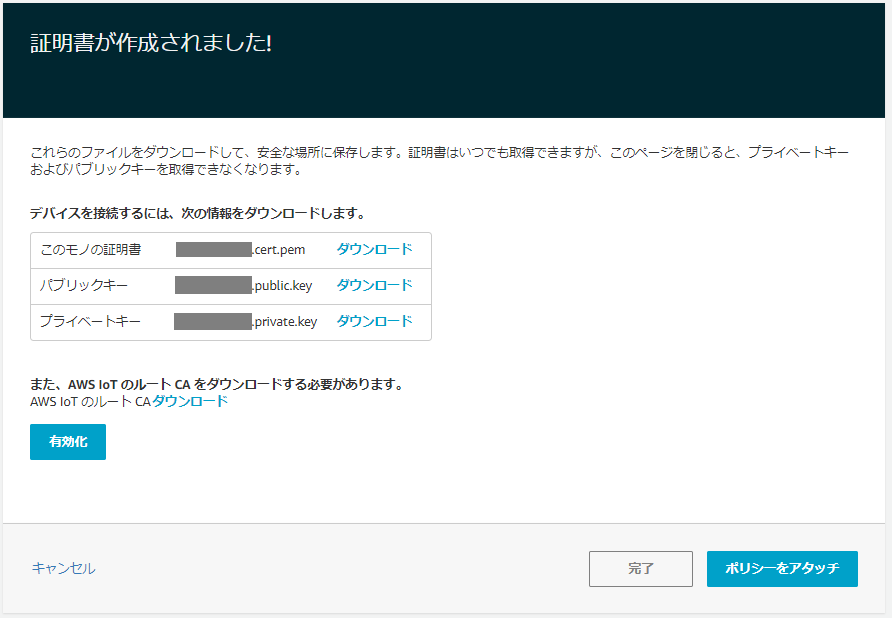
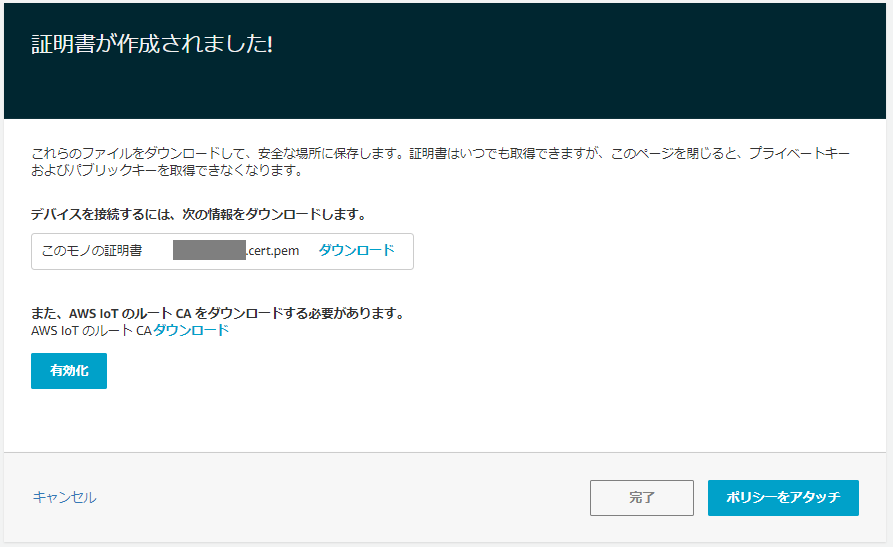
4.証明書が作成されるので、すべてダウンロードし「有効化」をクリック
5.「ポリシーをアタッチ」をクリック
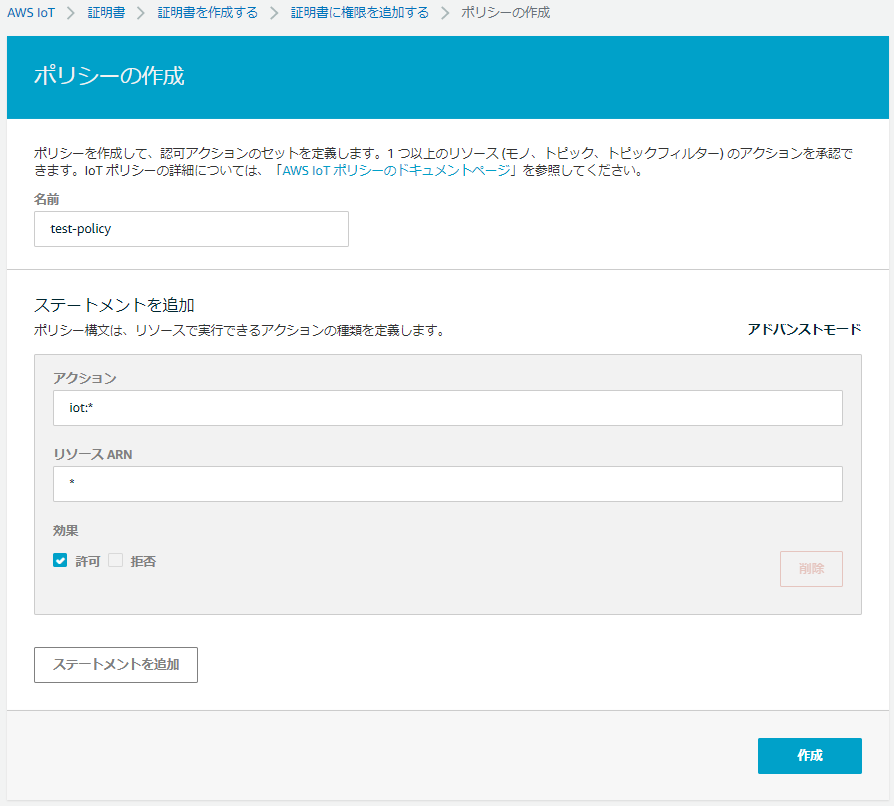
6.「新規ポリシーの作成」をクリック
7.今回は検証用なので、以下の通り特に権限を絞らずアクションとリソースを指定して、「作成」をクリック
- 名前:任意のポリシー名
- アクション:iot:*
- リソースARN:*
- 許可にチェック
1-2 モノの作成
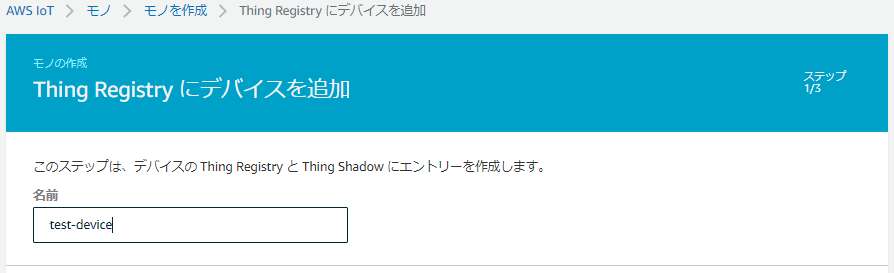
1.左のメニューから 管理 > モノ > モノの登録 の順にクリック
2.「単一のモノを作成する」をクリック
3.「名前」に任意の名前を入力し、他はそのままで「次へ」をクリック
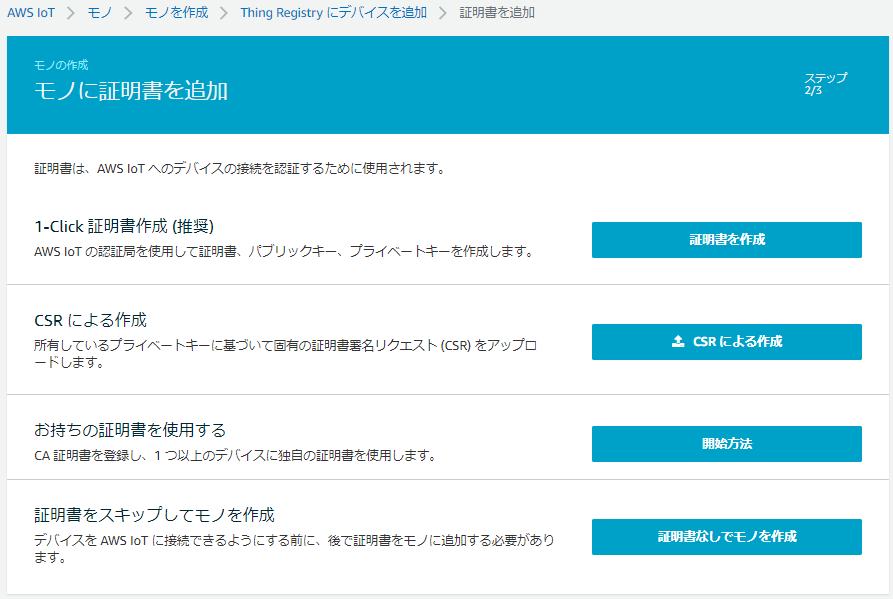
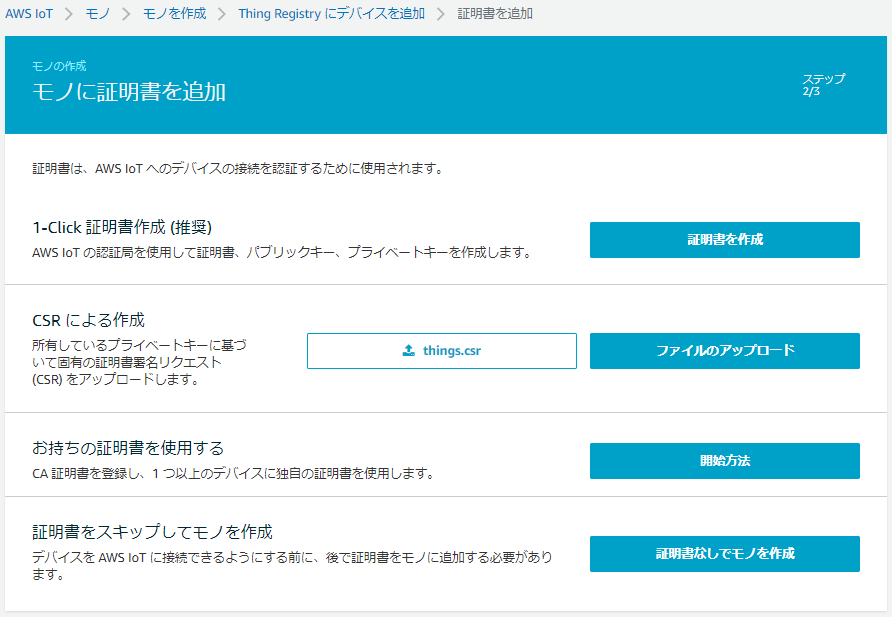
4.今回は先に証明書を作成しているので、「証明書なしでモノを作成」をクリック
1-3 証明書のアタッチ
ここまでの手順で作成したモノと証明書を関連付けます。
1.左のメニューから 安全性 > 証明書 とクリック
※一覧に先ほど作成した証明書が表示される
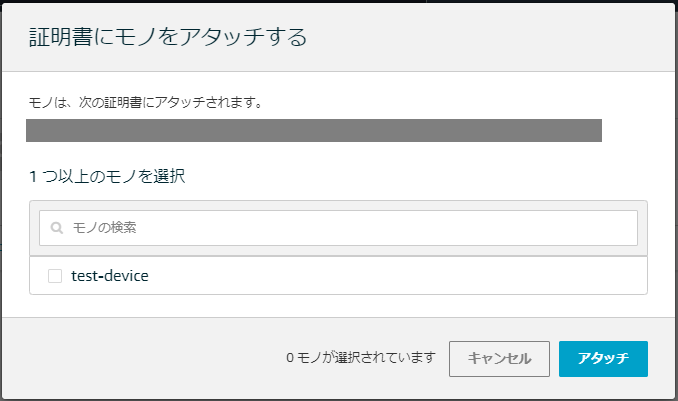
2.作成した証明書をチェックして アクション > モノをアタッチ
3.作成したモノをチェックして「アタッチ」をクリック
1-4 疎通確認
取得したモノの証明書、秘密鍵、AWS IoTのCAルートを使ってIoT CoreにMQTTでメッセージを送信します。
1.証明書等を格納するディレクトリを作成
mkdir .certs2.作成したディレクトリに以下のファイルをアップロード
- 秘密鍵:xxxxx-private.pem.key
- 証明書:xxxxx-certificate.pem.crt
- IoT CoreのCA:AmazonRootCA1.pem
3.マネジメントコンソールで 左メニューからテストをクリック
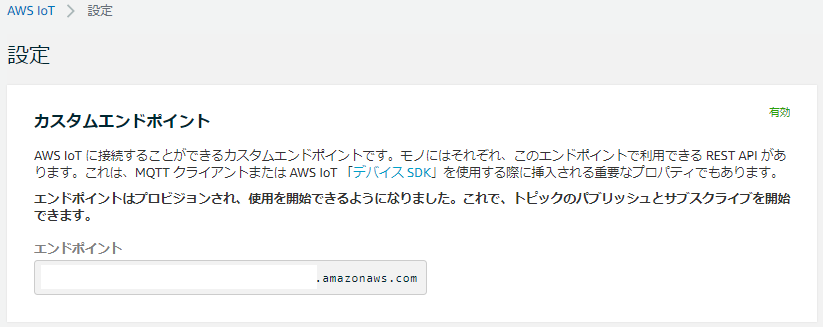
4.左のメニューの設定をクリックし、エンドポイントを控えておく
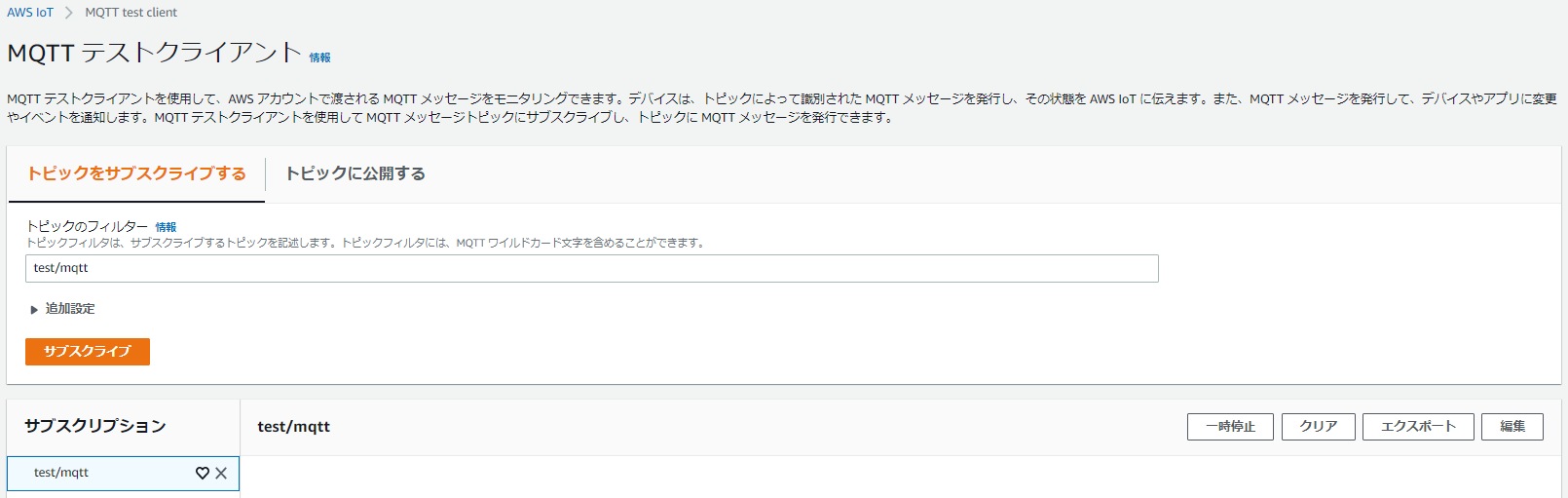
5.トピックのフィルターに「test/mqtt」と入力して、「サブスクリプション」をクリック
※test/mqtt宛てにパブリッシュされたメッセージをサブスクライブできるかテストする
6.Jetson nanoからmosquittoでtest/mqtt宛てにメッセージをパブリッシュ#証明書等を格納したディレクトリに移動 cd .certs #MQTTメッセージをパブリッシュ mosquitto_pub --cafile [IoT CoreのCA] --cert [モノの証明書] --key [秘密鍵] \ -i [デバイス名] --tls-version tlsv1.2 -h [エンドポイント] -p 8883 -q 1 \ -t test/mqtt -m "{\"message\":\"Hello world\"}" -d7.マネジメントコンソールで設定したサブスクリプションにメッセージが届ていることを確認する
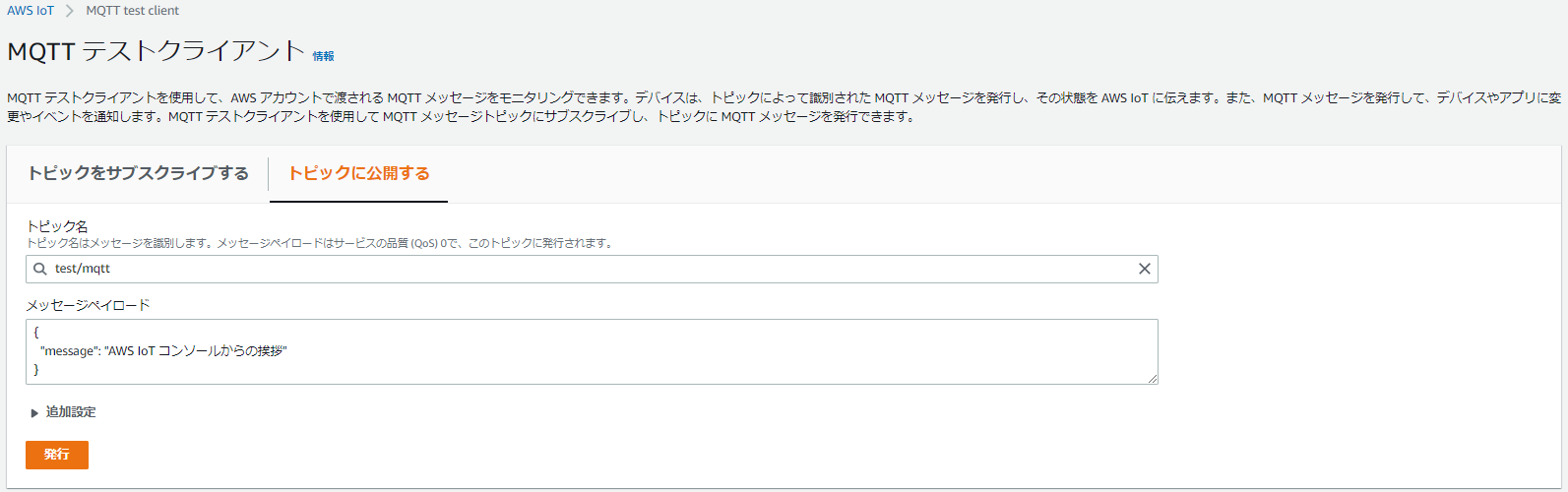
8.Jetson nanoで今度はサブスクライブを行うmosquitto_sub --cafile [IoT CoreのCA] --cert [モノの証明書] --key [秘密鍵] \ -i [デバイス名] --tls-version tlsv1.2 -h [エンドポイント] -p 8883 -q 1 -t test/mqtt -d9.マネジメントコンソールで左のメニューから テスト > トピックに公開する をクリック
10.トピック名を「test/mqtt」として「発行」をクリック
11.Jetson nanoでサブスクライブ出来たことを確認する
※Ctrl + C でサブスクライブを終了1-5 備忘録
証明書を格納したディレクトリ以外でmosquittoコマンドを実行したところ「Error: Problem setting TLS options.」というエラーが発生しました。
以下の記事を参考に、上記の通りディレクトリを移動したところ解消しました。
参考:【Raspberry Pi】AWS IoTとRaspberry PiでIoTをやってみよう2 CSRによる作成
上記の作業後、同じJetson nanoで作業をするにあたって以下を削除しています。
マネジメントコンソールから
- モノ
- 証明書
Jetson nanoから
- モノの証明書
- 秘密鍵
2-1 秘密鍵とCSRの作成
今回は「CSRによる作成」でモノの証明書作成を行うため、以下の記事を参考に秘密鍵とCSRを作成しました。
参考:Apache + OpenSSL CSR生成手順 (新規)1.Jetson nanoで秘密鍵とCSRを生成
#opensslが使えることを確認 openssl version OpenSSL 1.1.1 11 Sep 2018 #作業ディレクトリに移動 cd .certs #秘密鍵の生成 openssl genrsa -des3 -out private.key 2048 #CSRの生成 openssl req -new -key private.key -out things.csr2.作成したCSRを取得
2-2 モノの作成
1.左のメニューから 管理 > モノ > モノの登録 の順にクリック
2.「単一のモノを作成する」をクリック
3.「名前」に任意の名前を入力し、他はそのままで「次へ」をクリック
4.今回は「CSR」による作成をクリック
5.ファイル選択画面が開くので、先ほど作成・取得したCSRファイルを選択
6.「ファイルのアップロード」ボタンをクリック
7.作成されたモノの証明書をダウンロードし、「有効化」をクリック
8.「ポリシーのアタッチ」をクリック
9.「1-1 証明書の作成」で作成したポリシーを残しているので、今回はこれを選択して「モノの登録」をクリック2-3 疎通確認
以下は1-4で実施した手順と同じになります。
1.取得したモノの証明書をJetson nanoの.certsディレクトリにアップロード
2.マネジメントコンソールで 左メニューからテストをクリック
3.トピックのフィルターに「test/mqtt」と入力して、「サブスクリプション」をクリック
※test/mqtt宛てにパブリッシュされたメッセージをサブスクライブできるかテストする
4.Jetson nanoからmosquittoでtest/mqtt宛てにメッセージをパブリッシュ#証明書等を格納したディレクトリに移動 cd .certs #MQTTメッセージをパブリッシュ mosquitto_pub --cafile [IoT CoreのCA] --cert [モノの証明書] --key [秘密鍵] \ -i [デバイス名] --tls-version tlsv1.2 -h [エンドポイント] -p 8883 -q 1 \ -t test/mqtt -m "{\"message\":\"Hello world\"}" -d5.マネジメントコンソールで設定したサブスクリプションにメッセージが届ていることを確認する
6.Jetson nanoで今度はサブスクライブを行うmosquitto_sub --cafile [IoT CoreのCA] --cert [モノの証明書] --key [秘密鍵] \ -i [デバイス名] --tls-version tlsv1.2 -h [エンドポイント] -p 8883 -q 1 -t test/mqtt -d7.マネジメントコンソールで左のメニューから テスト > トピックに公開する をクリック
8.トピック名を「test/mqtt」として「発行」をクリック
9.Jetson nanoでサブスクライブ出来たことを確認する2-4 備忘録
「2-2 モノの作成」の手順6で「ファイルのアップロード」をクリックした際に以下の挙動に何度か発生しました。
- 作成された証明書の画面を飛ばしてポリシーのアタッチの画面に飛ばされる
- ポリシーを選択して「モノの登録」をクリック後、モノが登録されていない
作成された証明書の画面が飛ばされた際は戻って「ファイルのアップロード」を再試行しました。
モノが登録されていなかった場合は モノを登録 → 証明書をアタッチ という順で対応しました。3 おわりに
今回は上記2つの方法でデバイスをプロビジョニングし、MQTTメッセージのパブリッシュ/サブスクライブができるところまでを確認しました。
確認が目的だったので作成した以下のものは作業後削除しています。
※AWS IoT CoreのCAは今後また検証で使うことを見越して残しています
- ポリシー
- モノの証明書
- モノ
- 秘密鍵とCSRファイル
4 参考文献(文中で登場していないもの)
- 投稿日:2021-03-08T09:43:39+09:00
terraformerを使って複数のDatadog Organizationを統合する
概要
監視、モニタリングで使用している複数のDatadogの環境(Organization)がある。
これらを1つにOrganizationをまとめて管理しやすくしたい。でも、、、全部手作業でやるのは
めんどくs工数が掛かる!
そこでterraformを使って一気にできたらいいなぁなんて思ってやってみました。前提条件
Orgaqnizationは2つあり、以下のダッシュボードのみを持つ。
記事簡略化のためダッシュボード以外のリソースは持たないことにする。また、各Organizationでは共通のメトリクスが取得できているものとする。
既存Datadogリソースのtf化については以下の方法が考えられた。
- 手動で全部書く
terraform importでリソースを取得し、tfファイルに記載するterraformerというインポートツールを使用して自動インポートする結果、3の
terraformerを使用する方法を採用した。Datadog公式ページにて推奨されていることと、リソースが多い場合一括でimportできるので結果的に一番手間が少ないと判断したためである。Datadog環境(example)
- Organizetion1: Yojo_Dog
- resourse: Dog_moniter_dashboard
- Organization2: Yojo_Cat
- resourse: Cat_moniter_dashboard
今回は、
Yojo_Cat環境のCat_moniter_dashboardをterraformerを使ってtfファイルとして出力し、Yojo_Dog環境にterraformからapplyすることで、2つのdashboardがある状態を作ります!
使用ツール
Terraform: コンピュータやネットワークを自動構築するツール。Datadog用のモジュールが用意されているためDatadogの環境をコード化、自動化できる。
terraformer: 構築済みの既存リソース(AWSやDatadogなど)を読み取り、terraformのコードとして出力してくれるインポートツール
tfenv: 複数のTerraformバージョンを切り替えして使用できる管理ツール
構築作業手順
ツールのインストール、セットアップ
local環境は
Mac
Widows
Macを買ってください
WSLのUbuntuとかでできるんじゃないですかねぇ(投げやり)tfenvのインストール
#Terraformがインストールされている場合エラーになるので一旦消す $ brew uninstall terraform #tfenvをインストール $ brew install tfenv #tfenvの確認 $ tfenv --version tfenv 2.2.0tfenvからterraformをインストール
今回はterraformer用に
v0.13.6を使用します。#tfenvからterraformをインストール $ tfenv install 0.13.6 Installing Terraform v0.13.6 Downloading release tarball from https://releases.hashicorp.com/terraform/0.13.6/terraform_0.13.6_darwin_amd64.zip ##################################################################################################################### 100.0% Downloading SHA hash file from https://releases.hashicorp.com/terraform/0.13.6/terraform_0.13.6_SHA256SUMS No keybase install found, skipping OpenPGP signature verification Archive: tfenv_download.TOSAgI/terraform_0.13.6_darwin_amd64.zip inflating: /usr/local/Cellar/tfenv/2.2.0/versions/0.13.6/terraform Installation of terraform v0.13.6 successful. To make this your default version, run 'tfenv use 0.13.6' #インストールされたか確認 $ tfenv list * 0.13.6 (set by /usr/local/Cellar/tfenv/2.2.0/version) #インストールしたterraformバージョンを使用する $ tfenv use 0.13.6 #terraformコマンドの確認 $ terraform --version Terraform v0.13.6terraformerのインストール
$ brew install terraformer $ terraformer version Terraformer v0.8.10Datadogリソースをインポートする準備
terraformerでDatadogリソースをインポートするにはAPI KeyとAPP Keyが必要になります。
以下手順で確認します。API Keyの確認
Datadogのコンソールにログインし、左のメニューから
Integrations → APIsを選択します。
以下画面に遷移しますので、API Keysを展開しKeyを控えておきます。
APP Keyの確認
同様のページから
Application Keys have moved to the Teams pageを選択するとApp Keyの作成、確認ページに遷移します。
作成済みのKeyがあっても作成時に一度しかKeyは確認できないようです。
また、Key作成の際は自身のユーザの権限のみを持ちますので個人ではなく会社でやる際は偉い人を脅す確認しましょう。
+New Keyボタンを押すとKey作成されクリップボードにコピーすることができます。控えておいてください。
これでこのOrganizationからterraformerでtfファイルをインポートする準備ができました!!ヨシっ!!

同様の手順でもう一つのOrganizationのKeyを控えておきます。
terraformerの実行
terraformの初期設定
まずはterraformを実行できるようにサクっと環境を作りましょう。
#実行ディレクトリの作成(自由に) terraform └── datadogmain.tfの作成
Datadog公式ドキュメント通りに書いていきます。
api_keyapp_keyはDatadogリソースをインポートする準備で取得したリソースを書き出したい方のOrganizationのものを記載します。
この記事ではkeyを直接記載しますので間違えてgithubに公開しないように気をつけてくださいね
Yojo_CatのリソースをYojo_Dogに追加するので以下のようになります。terraform/datadog/main.tfterraform { required_providers { datadog = { source = "Datadog/datadog" } } } provider "datadog" { api_key = "Yojo_Dog_api_key" app_key = "Yojo_Dog_app_key" }initする
Datadog用のprovidersをインストールするため、
initします。$ terraform init Terraform has been successfully initialized!1つ目のOrganizationのリソースを
terraformer importする今回はdashboardだけですが、その他のリソースがある場合は
--resorces=hoge,fuga,piyoとカンマ区切りで指定できます。
また、特定のリソースだけを出力する場合は--filter=dashboard=Dog_moniter_dashboardIDのように指定できます。1#Yojo_Dog Organizationのリソースを出力 $ terraformer import datadog --resources=dashboard --api-key "Yojo_Dog_api_key" --app-key "Yojo_Dog_app_key" 2021/03/05 02:58:27 datadog importing... dashboard 2021/03/05 02:58:28 Refreshing state... datadog_dashboard.tfer--dashboard_<Dog_moniter_dashboardID> 2021/03/05 02:58:36 datadog Connecting.... 2021/03/05 02:58:36 datadog save dashboard 2021/03/05 02:58:37 datadog save tfstate for dashboard #generateディレクトリとファイルが出力される ./generated └── datadog └── dashboard ├── dashboard.tf ├── outputs.tf ├── provider.tf └── terraform.tfstate2つ目のOrganizationのリソースを
terraformer importするこのまま実行するとなんと全部上書きされてしまいます・・・What's!?
なので、別のディレクトリに一旦退避させましょうterraform └── datadog ├── Yojo_Dog │ └── generated │ └── datadog │ └── dashboard │ ├── dashboard.tf │ ├── outputs.tf │ ├── provider.tf │ └── terraform.tfstate └── main.tf #Yojo_Cat Organizationのリソースを出力 $ terraformer import datadog --resources=dashboard --api-key "Yojo_Cat_api_key" --app-key "Yojo_Cat_app_key" 2021/03/05 03:16:40 datadog importing... dashboard 2021/03/05 03:16:44 Refreshing state... datadog_dashboard.tfer--dashboard_<Cat_moniter_dashboardID> 2021/03/05 03:16:55 datadog save dashboard 2021/03/05 03:16:56 datadog save tfstate for dashboard #generateディレクトリとファイルが出力される . ├── Yojo_Dog │ └── generated │ └── datadog │ └── dashboard │ ├── dashboard.tf │ ├── outputs.tf │ ├── provider.tf │ └── terraform.tfstate ├── generated │ └── datadog │ └── dashboard │ ├── dashboard.tf │ ├── outputs.tf │ ├── provider.tf │ └── terraform.tfstate └── main.tf #統一感だしていこ???笑笑笑 . ├── Yojo_Cat (略) ├── Yojo_Dogリソースファイルの修正
出力したファイルはそのままでは使うことができません。これを使用するために2つのことをファイル追加修正します。
- tfファイルのバージョンアップを行う
- 競合するIDを削除する
tfファイルのバージョンアップを行う
これはDatadog公式ドキュメントの手順で推奨されているので実行します。
terraformerでimportしたtfファイルのバージョンをv0.13.xに調整します。#Yojo_Catに実行 $ pwd /datadog/Yojo_Cat/datadog/dashboard $ terraform 0.13upgrade . Would you like to upgrade the module in the current directory? Only 'yes' will be accepted to confirm. Enter a value: yes #yesを入力してエンター ----------------------------------------------------------------------------- Upgrade complete! #なんか変わってる。まぁ任せた!! $ git status Changes not staged for commit: modified: provider.tf Untracked files: (use "git add <file>..." to include in what will be committed) versions.tf #initする $ terraform init Terraform has been successfully initialized . ├── dashboard.tf ├── outputs.tf ├── provider.tf ├── terraform.tfstate └── versions.tf #忘れずにYojo_Dogにも適用する $ pwd /terraform/datadog/Yojo_Dog/generated/datadog/dashboard $ terraform 0.13upgrade . $ terraform init競合するIDを削除する
terraformerの弱点の一つとして、リソースの固有IDまでtfファイルにもってきてしまうことです。
このままapplyしようとしても既存リソースと競合してしまいエラーとなります。ちょっと状況を確認してみましょう。
$ terraform plan Error: "widget.10.id": this field cannot be set on dashboard.tf line 125, in resource "datadog_dashboard" "tfer--dashboard_<dashboard_ID>": 125: resource "datadog_dashboard" "tfer--dashboard_<dashboard_ID>" { Error: "widget.10.id": this field cannot be set . . . . echo '天才の僕「ぎゃーーー!!!!」'・・・とご丁寧にどのリソースやウィジットがエラーになってるか書いているのでtfファイルを修正していきましょう
以下は"爆速なお仕事(笑)"が特技の筆者の方法です。$ ls dashboard.tf outputs.tf provider.tf terraform.tfstate versions.tf #伝説の武器、VSCodeを起動!!俺のターーーン!!!!!(エンターキーをターン!する) $ code dashboard.tf
ID = .*$で検索してみると。。。
なんかいた!!!!これが入ってるとapplyできません。
全部いらないので置換で消しちゃいましょう。神経質な方は確認してから消しましょう。
筆者はできなきゃ戻せばいいやみたいな悪いエンジニアなのでそのまま全部置換
エラーが出なくなるまで特定して修正します。
$ terraform plan Error: api_key and app_key must be set unless validate = false上記は大丈夫なやつです。generated配下でplanしているのでキーがなくて正常です。
エラーが出なくなったらもう一つのOrganizationも修正しましょう。
 $ terraform plan Error: "widget": required field is not set 6731: resource "datadog_dashboard" "tfer--dashboard_<dashboard_ID>" {
$ terraform plan Error: "widget": required field is not set 6731: resource "datadog_dashboard" "tfer--dashboard_<dashboard_ID>" {見たところ、widgetが無いテストみたいなダッシュボードでした。
からっぽのdashboardはGUIから保存できてしまいますがコード上は許されていないようです。ただファイルから削除しただけだとtfstateとの整合性が取れなくなりややこしくなります。
その辺りは、今回は触れません。つまり、、、GUIから物理削除してimportしなおしました!
(exampleだとdashboardが1個になってますが、こういうエラーもあるよということで例外紹介でした)リソースを統合する
いよいよ最終章です。2つのOrganizatioのdashboardをおまとめして、Yojo_Dog環境を最強にします。
ファイルの移動
importしたデータメインディレクトリに移動しましょう。
dashboard.tterraform.tfstateversions.tfが対象です。$ pwd /datadog/Yojo_Cat/datadog/dashboard $ cp dashboard.tf terraform.tfstate versions.tf ../../../ . ├── Yojo_Cat │ └── datadog │ └── dashboard │ ├── dashboard.tf │ ├── outputs.tf │ ├── provider.tf │ ├── terraform.tfstate │ └── versions.tf ├── Yojo_Dog │ └── generated │ └── datadog │ └── dashboard │ ├── dashboard.tf │ ├── outputs.tf │ ├── provider.tf │ ├── terraform.tfstate │ └── versions.tf ├── dashboard.tf ├── main.tf ├── terraform.tfstate └── versions.tfplanで内容を確認する。
注意:このログは良く確認してください。適当に実行してしまうと・・・
破壊と創造
を行うシステム障害の神になりえます。
しっっかっかっかっかりとログを確認して念のため退職届を書いておきましょう。#ファイルが増えているので一旦initしておく $ terraform init $ terraform plan #変更のあるリソースを確認 datadog_dashboard.tfer--dashboard_<Cat_moniter_dashboard_ID>: Refreshing state... [id=Cat_moniter_dashboard_ID] ------------------------------------------------------------------------ #Createdのみなはず。deleteがあるなら要確認 An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: + create Terraform will perform the following actions: # datadog_dashboard.tfer--dashboard_<Cat_moniter_dashboard_ID> will be created + resource "datadog_dashboard" "<Cat_moniter_dashboard_ID>" { + dashboard_lists_removed = (known after apply) + description = <<~EOT ## Overall Dashbord for (略) # +が追加される部分です。リソース、ウィジットなど変更点を確認しましょう。 #最後に変更点のカウントが出ます。 Plan: 1 to add, 0 to change, 0 to destroy. ------------------------------------------------------------------------applyする
ここまで問題がなければapplyすることでリソースの統合ができるはずです。
Yojo_DogにYojo_Catの全てをぶっこんであげましょう!!!$ terraform apply datadog_dashboard.tfer--dashboard_<Cat_moniter_dashboard_ID>: Refreshing state... [id=<Cat_moniter_dashboard_ID>] An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: + create (略) #実行するか聞かれるのでyesを入力します。 Do you want to perform these actions? Terraform will perform the actions described above. Only 'yes' will be accepted to approve. Enter a value: yes Apply complete! Resources: 7 added, 0 changed, 0 destroyed. Outputs: datadog_dashboard_tfer--dashboard_<Cat_moniter_dashboard_ID>_id = datadog_dashboard.tfer--dashboard_<Cat_moniter_dashboard_ID>.idApply complete!が出ていれば成功です!お疲れ様でした
結果をGUIから確認する
ナイスー!!!!!
勝ち申した!!!!
Twitterやってます!エンジニアアカウントも音楽アカウントもフォローしてね

わんわんもにゃんにゃんもかわいいけど、どっちかだったら…??
— 天才ハッカー幼女こはるちゃん (@koharu_infra) March 4, 2021
わんわんが好きです?????????✨✨✨✨
????????
--filterで使用するIDはリソースのnameではなく個別にDatadogから振られているIDを使います。ブラウザから例えば対象のダッシュボードを開くとブラウザのURLにIDが表示されているのでそれを使用します。 ↩
- 投稿日:2021-03-08T08:29:08+09:00
React+Amplify+AppSync+TypeScript+Recoilで認証機能つきチャットアプリを作る
React+Amplify+AppSync+TypeScript+Recoilで認証機能つきチャットアプリを作る方法を紹介します。
完成するアプリのデモは以下です。
左右の画面に異なるユーザーでログインし、チャットを行っています。
本記事で作成するアプリのアーキテクチャーは下記です。
Amplify Console Static Web Site Hostingでフロンドエンドのコードをホスティングします。
AWS AppsyncでGraphQL APIを提供し、データベースはDynamoDBを使用します。
Amazon Cognitoをユーザー認証に用いています。
バージョン
使用した環境は以下の通りです。
$ npx create-react-app --version 4.0.3 $ node -v v14.16.0 $ npm -v 6.14.11 $ amplify -v 4.44.2Amplify CLIが未インストールの場合は、公式ドキュメントを参考にインストールします。
アプリの雛形作成
create-react-appでアプリの雛形を作ります。$ npx create-react-app chat --template typescript
yarn startでサンプルアプリが起動すれば成功です。$ cd chat $ yarn start
続いて、
amplify initでプロジェクトにAmplify用の設定を追加します。$ amplify init ? Enter a name for the project chat ? Enter a name for the environment production ? Choose your default editor: Visual Studio Code ? Choose the type of app that you're building javascript ? What javascript framework are you using react ? Source Directory Path: src ? Distribution Directory Path: build ? Build Command: npm run-script build ? Start Command: npm run-script start ? Do you want to use an AWS profile? Yes ? Please choose the profile you want to use default ← amplify configureで指定したプロファイル名を指定アプリの雛形作成は以上で完了です。
認証機能の実装
認証機能を実装していきます。
バックエンド/インフラ
amplify add authで認証機能を追加します。$ amplify add auth ? Do you want to use the default authentication and security configuration? Default configuration ? Warning: you will not be able to edit these selections. ? How do you want users to be able to sign in? Username ? Do you want to configure advanced settings? No, I am done.続いて、
amplify pushでクラウドへ変更を反映します。$ amplify push ? Are you sure you want to continue? Yesバックエンド/インフラの実装は以上で完了です。
フロントエンド
パッケージインストール
まずはAmplify関連のパッケージをインストール。
$ yarn add aws-amplify @aws-amplify/ui-react続いて、Material-UIをインストール。
$ yarn add @material-ui/core @material-ui/icons最後に、Recoilをインストール。
$ yarn add recoilコンポーネントの実装
App.tsxを下記のように書き換えます。
ログイン画面は@aws-amplify/ui-reactのコンポーネントを用いて作成しています。
ログアウトはhandleClick内でaws-amplifyのAuth.signOut()することで実現しています。
また、後述するRecoilのatomにログインユーザー名を格納しています。App.tsximport React, { useState } from "react"; import Amplify, { Auth } from "aws-amplify"; import { AmplifyAuthenticator, AmplifySignUp } from "@aws-amplify/ui-react"; import { AuthState, onAuthUIStateChange, CognitoUserInterface, } from "@aws-amplify/ui-components"; import awsconfig from "./aws-exports"; import { RecoilRoot } from "recoil"; import { createStyles, Theme, makeStyles } from "@material-ui/core/styles"; import AppBar from "@material-ui/core/AppBar"; import Toolbar from "@material-ui/core/Toolbar"; import Typography from "@material-ui/core/Typography"; import IconButton from "@material-ui/core/IconButton"; import ExitToAppIcon from "@material-ui/icons/ExitToApp"; Amplify.configure(awsconfig); const useStyles = makeStyles((theme: Theme) => createStyles({ appBar: { zIndex: theme.zIndex.drawer + 1, }, toolBar: { display: "flex", }, signOut: { marginLeft: "auto", display: "flex", }, }) ); const App = () => { const classes = useStyles(); const [authState, setAuthState] = useState<AuthState>(); const [user, setUser] = useState<CognitoUserInterface | undefined>(); React.useEffect(() => { return onAuthUIStateChange((nextAuthState, authData) => { setAuthState(nextAuthState as AuthState); setUser(authData as CognitoUserInterface); }); }, []); const handleClick = () => { Auth.signOut(); }; return authState === AuthState.SignedIn && user ? ( <div> <RecoilRoot> <AppBar className={classes.appBar}> <Toolbar className={classes.toolBar}> <Typography variant="h6" noWrap> ChatApp </Typography> <div onClick={handleClick} className={classes.signOut}> <IconButton aria-label="display more actions" edge="end" color="inherit" > <ExitToAppIcon /> </IconButton> </div> </Toolbar> </AppBar> </RecoilRoot> </div> ) : ( <AmplifyAuthenticator> <AmplifySignUp slot="sign-up" formFields={[ { type: "username" }, { type: "password" }, { type: "email" }, ]} /> </AmplifyAuthenticator> ); }; export default App;Recoilの実装
src/recoil/ChatState.tsxを作成し、下記のように書きます。
1件の投稿を意味するpostStateと投稿リストを意味するpostListStateを作成します。
また、投稿のメッセージだけをget/setするためにmessageStateを作成しています。ChatState.tsximport { atom, selector, DefaultValue, RecoilState } from "recoil"; import produce from "immer"; export interface PostState { id: string; message: string; owner: string; user: string; createdAt: string; } const defaultValue: PostState = { id: "", message: "", owner: "", user: "", createdAt: "", }; const atomKeyName: string = "postState"; export const postState = atom({ key: atomKeyName, default: defaultValue, }); export const messageState: RecoilState<string> = (() => { const propName: keyof PostState = "message"; return selector<string>({ key: atomKeyName + "/" + propName, get: ({ get }) => { return get(postState)[propName]; }, set: ({ set, get }, newValue) => { const tempValue: string = newValue instanceof DefaultValue ? defaultValue[propName] : newValue; const imValue = produce<PostState>(get(postState), (draft) => { draft[propName] = tempValue; }); set(postState, imValue); }, }); })(); const postListDefaultValue: PostState[] = []; export const postListState = atom({ key: "postListState", default: postListDefaultValue, });以上で認証機能の実装は完了です。
下記の手順で動作確認してみましょう。
- yarn start
- ブラウザで http://localhost:3000 にアクセスする
- Create acccountをクリックする
- Username、Password、Emailを入力し、CREATE ACCOUNTをクリックする
- 入力したメールアドレスに送付されたConfirmation Codeを入力し、CONFIRMをクリックする
- Username、Passwordを入力しログインする
- ヘッダーにChatAppと表示されればログイン成功です

チャットの実装
続いて、チャットの実装をしていきます。
バックエンド/インフラ
GraphQL APIの作成
amplify add apiでGraphQL APIを作成します。$ amplify add api ? Please select from one of the below mentioned services: GraphQL ? Provide API name: chat ? Choose the default authorization type for the API Amazon Cognito User Pool ? Do you want to configure advanced settings for the GraphQL API No, I am done. ? Do you have an annotated GraphQL schema? No ? Choose a schema template: Single object with fields (e.g., “Todo” with ID, name, description) ? Do you want to edit the schema now? NoGraphQLのスキーマを編集
amplify/backend/api/chat/build/schema.graphqlに生成されたスキーマを編集します。
すべての投稿を作成日順に取得するために@keyを使用しています。type Post @model @key( name: "SortByCreatedAt" fields: ["owner", "createdAt"] queryField: "listPostsSortedByCreatedAt" ) { id: ID! message: String! owner: String user: String createdAt: AWSDateTime }
@model、@keyの説明は公式ドキュメントをご確認ください。
https://docs.amplify.aws/cli/graphql-transformer/model
https://docs.amplify.aws/cli/graphql-transformer/keyGraphQL APIのデプロイ
amplify pushでクラウドにGraphQL APIをデプロイします。$ amplify push ? Are you sure you want to continue? Yes ? Do you want to generate code for your newly created GraphQL API Yes ? Choose the code generation language target typescript ? Enter the file name pattern of graphql queries, mutations and subscriptions src/graphql/**/*.ts ? Do you want to generate/update all possible GraphQL operations - queries, mutations and subscriptions Yes ? Enter maximum statement depth [increase from default if your schema is deeply nested] 2 ? Enter the file name for the generated code src/API.ts GraphQL endpoint: https://xxxxxxxxx.appsync-api.us-east-1.amazonaws.com/graphql最後の行のURLがApp Syncが提供するGraphQL APIのURLになります。
このURLは自動生成されるsrc/aws-exports.jsというファイルに自動で書き込まれています。フロントエンド
コンポーネントの実装
チャット機能をもつ
Contentコンポーネントを実装します。
src/Content.tsxを作成し、下記コードのように書きます。
登録ボタン押下時にGraphQLのmutationsによりデータをDynamoDBに登録しています。
また、Contentコンポーネントの初回呼び出し時にGraphQLのqueriesにより投稿一覧を取得しています。全投稿を作成日時順に取得するため、ownerにchatという固定の値を入れています。
さらに、Contentコンポーネントの初回呼び出し時にGraphQLのsubscriptionsを呼び出すことで、新規投稿をsubscribeしています。自分自身の投稿の場合もsubscribeしているので、自分自身の投稿の場合はsetPostしないようにする必要があります。Content.tsximport React, { useEffect } from "react"; import { useRecoilState } from "recoil"; import { postListState, messageState, PostState } from "./recoil/ChatState"; import { API, graphqlOperation } from "aws-amplify"; import { GraphQLResult } from "@aws-amplify/api"; import { listPostsSortedByCreatedAt } from "./graphql/queries"; import { createPost } from "./graphql/mutations"; import { onCreatePost } from "./graphql/subscriptions"; import List from "@material-ui/core/List"; import ListItem from "@material-ui/core/ListItem"; import Chip from "@material-ui/core/Chip"; import Button from "@material-ui/core/Button"; import TextField from "@material-ui/core/TextField"; import { createStyles, Theme, makeStyles } from "@material-ui/core/styles"; import Container from "@material-ui/core/Container"; import { CreatePostMutation, ListPostsSortedByCreatedAtQuery } from "./API"; const useStyles = makeStyles((theme: Theme) => createStyles({ container: { paddingTop: theme.spacing(10), paddingBottom: theme.spacing(10), backgroundColor: "white", }, input: { display: "flex", }, myMessage: { display: "flex", justifyContent: "flex-start", }, otherMessage: { display: "flex", justifyContent: "flex-end", }, }) ); interface ContentProps { userName?: string; } const Content = (props: ContentProps) => { const classes = useStyles(); const [posts, setPosts] = useRecoilState(postListState); const [message, setMessage] = useRecoilState(messageState); const handleClick = () => { postPost(); }; const postPost = async () => { const post = (await API.graphql( graphqlOperation(createPost, { input: { message: message, owner: "chat", user: props.userName }, }) )) as GraphQLResult<CreatePostMutation>; const postData = post.data?.createPost as PostState; setPosts([...posts, postData]); setMessage(""); }; const handleChange = (event: React.ChangeEvent<HTMLInputElement>) => { setMessage(event.target.value); }; useEffect(() => { async function getPosts() { const res = (await API.graphql( graphqlOperation(listPostsSortedByCreatedAt, { owner: "chat" }) )) as GraphQLResult<ListPostsSortedByCreatedAtQuery>; const postData = res?.data?.listPostsSortedByCreatedAt ?.items as PostState[]; setPosts(postData); } getPosts(); }, [setPosts]); useEffect(() => { // @ts-ignore const subscription = API.graphql(graphqlOperation(onCreatePost)).subscribe({ next: (eventData: any) => { const post = eventData.value.data.onCreatePost; if (post !== undefined && post.user !== props.userName) { setPosts([...posts, post]); } }, }); return () => subscription.unsubscribe(); }, [posts]); const postList: JSX.Element[] = []; for (const post of posts) { if (post.user === props.userName) { postList.push( <ListItem key={post.id} className={classes.myMessage}> <Chip label={post.message}></Chip> </ListItem> ); } else { postList.push( <ListItem key={post.id} className={classes.otherMessage}> <Chip label={post.message}></Chip> </ListItem> ); } } return ( <Container maxWidth="lg" className={classes.container}> <div className={classes.input}> <TextField value={message} onChange={handleChange} /> <Button variant="contained" color="secondary" onClick={handleClick}> 登録する </Button> </div> <List>{postList}</List> </Container> ); }; export default Content;作成した
ContentコンポーネントをAppコンポーネントから呼び出します。App.tsximport React, { useState } from "react"; import Amplify, { Auth } from "aws-amplify"; import { AmplifyAuthenticator, AmplifySignUp } from "@aws-amplify/ui-react"; import { AuthState, onAuthUIStateChange, CognitoUserInterface, } from "@aws-amplify/ui-components"; import awsconfig from "./aws-exports"; import Content from "./Content"; import { RecoilRoot } from "recoil"; import { createStyles, Theme, makeStyles } from "@material-ui/core/styles"; import AppBar from "@material-ui/core/AppBar"; import Toolbar from "@material-ui/core/Toolbar"; import Typography from "@material-ui/core/Typography"; import IconButton from "@material-ui/core/IconButton"; import ExitToAppIcon from "@material-ui/icons/ExitToApp"; Amplify.configure(awsconfig); const useStyles = makeStyles((theme: Theme) => createStyles({ appBar: { zIndex: theme.zIndex.drawer + 1, }, toolBar: { display: "flex", }, signOut: { marginLeft: "auto", display: "flex", }, }) ); const App = () => { const classes = useStyles(); const [authState, setAuthState] = useState<AuthState>(); const [user, setUser] = useState<CognitoUserInterface | undefined>(); React.useEffect(() => { return onAuthUIStateChange((nextAuthState, authData) => { setAuthState(nextAuthState as AuthState); setUser(authData as CognitoUserInterface); }); }, []); const handleClick = () => { Auth.signOut(); }; return authState === AuthState.SignedIn && user ? ( <div> <RecoilRoot> <AppBar className={classes.appBar}> <Toolbar className={classes.toolBar}> <Typography variant="h6" noWrap> ChatApp </Typography> <div onClick={handleClick} className={classes.signOut}> <IconButton aria-label="display more actions" edge="end" color="inherit" > <ExitToAppIcon /> </IconButton> </div> </Toolbar> </AppBar> <Content userName={user.username} /> </RecoilRoot> </div> ) : ( <AmplifyAuthenticator> <AmplifySignUp slot="sign-up" formFields={[ { type: "username" }, { type: "password" }, { type: "email" }, ]} /> </AmplifyAuthenticator> ); }; export default App;以上でチャット機能の実装は完了です。
下記手順で動作確認してみましょう。
- yarn start
- ログイン
- 投稿内容をテキストボックスに入力
- 投稿する ボタンを押す
- 投稿内容がリスト表示されていることを確認
- 別のユーザーでログインする
- 投稿内容をテキストボックスに入力
- 投稿する ボタンを押す
- 自分の投稿内容が左側に、別のユーザーの投稿が右側に表示されていれば成功

フロントエンドをホスティング
最後に、作成したフロントエンドのコードをAmplify Console Static Web Site Hostingでホスティングしましょう。
$ amplify hosting add ? Select the plugin module to execute Hosting with Amplify Console (Managed hosting with custom domains, Continuous deployment) ? Choose a type Manual deployment $ amplify publish ? Are you sure you want to continue? Yesコンソールに出力されたURLにアクセスできれば成功です。
以上で、本記事で作成する認証機能つきチャットアプリの作成は完了です。
最後に
作成した環境を削除するには下記を実行してください。
$ amplify delete ? Are you sure you want to continue? This CANNOT be undone. (This will delete all the environments of the project from the cloud and wipe out all the local files created by Amplify CLI) Yes本記事で作成した認証機能つきチャットアプリの全体のソースコードは下記で公開しています。
https://github.com/shimi7o/chat



- 投稿日:2021-03-08T00:59:51+09:00
Direct Connect Gateway へ接続変更を行った際の手順概要
はじめに
AWS パートナーが提供する 共有型 Direct Connect 接続サービスを利用して VPC ごとの
仮想プライベートゲートウエイ (VGW) と接続していた環境を Direct Connecat Gateway (DXGW) 経由の
接続につなぎ替える機会がありました。その際の手順および流れをメモ程度ですが残しておきます。
Direct Connect Gateway 自体の作成方法は本記事では触れません。変更前の構成
複数のプライベート VIF によるマルチ VPC 接続 を行っていました。
接続サービスを提供するキャリアから VGW 毎に仮想インターフェースの払い出しをうけて VPC と接続します。
変更後の構成
利用していたサービスが Direct Connect Gateway タイプのプライベート接続もサポートしていたため
DXGW 経由で複数の VPC に接続する方式へ切り替えました。
1つの DXGW で リージョンを問わず 10 VPC まで接続することが可能です。
DXGW と接続先の VPC は別アカウントでも問題ありません。
ただし、Private VIF と DXGW は同一アカウントである必要があります。
以降の手順も、DXGW と接続先 VPC が別アカウントである前提で記載しています。公式ドキュメントで案内されている手順
公式ドキュメントでは 既存のアタッチ済み VGW に DXGW を関連付けたあとに
VGW に関連付けられている仮想インターフェースを削除する手順が案内されています。3. 仮想プライベートゲートウェイを Direct Connect ゲートウェイに関連付けます。
4. 仮想プライベートゲートウェイに関連付けられた仮想インターフェイスを削除します。
キャリアの接続サービスを利用しているため、仮想インターフェースもキャリアにて作成されたものです。
自身で再作成ができないため、切り戻しも考慮して新規の VGW を付け替える手順で実施することにしました。実際に実施した手順
おおよそ以下のような流れで実施しました。
接続先アカウント: DXGW で接続する VPC が存在するアカウント
DXGW 管理アカウント: Private VIF および DXGW が存在するアカウント
- 接続先アカウントで新規 VGW の作成
- 接続先アカウントで VPC から既存 VGW をデタッチする
- 接続先アカウントで VPC に新規 VGW をアタッチする
- 接続先アカウントで DXGW への関連付け提案を作成する
- DXGW 管理アカウントで関連付け提案を承諾する
- ルートテーブルの変更
接続断が発生するのは 2 - 6 の間です。実際にかかる時間は環境に依存すると思いますが
参考までにある 1 つの VPC をつなぎ替えた際にかかった時間はおおよそ 30 分でした。
そのうち VGW のデタッチに 10 分程度、 DXGW と VGW の関連付けに 10 分程度かかっています。以降は各手順の補足です。
1. 接続先アカウントで新規 VGW の作成
特筆すべき点はありません。
VGW に対して、DXGW の関連付けを行う必要があるため、新規の VGW を作成します。2. 接続先アカウントで VPC から既存 VGW をデタッチする
前述のとおり、デタッチが完了するまで少し時間がかかります。
3. 接続先アカウントで新規 VGW を VPC にアタッチする
アタッチは瞬時に完了します。
2 および 3 の手順を DXGW の関連付け完了後に実施することで、接続断の時間を減らせるようにも見えますが
DXGW の関連付けリクエストを設定するには VGW が VPC にアタッチされている必要があるため
このタイミングで実施します。4. 接続先アカウントで DXGW への関連付け提案を作成する
DirectConnect コンソールの仮想プライベートゲートウェイから、新規作成した VGW の詳細に進みます。
Direct Connect ゲートウェイの関連付けタブを選択し、Direct Conenct ゲートウェイを関連付ける を
クリックします。
関連付けアカウントのタイプのアカウント所有者で 別のアカウント を選択し
関連付けの設定で下記の情報を入力し、Direct Conect ゲートウェイに関連付ける をクリックします。• DirectConnectゲートウェイ ID
• DirectConnectゲートウェイ所有者アカウント ID
• 許可されたプレフィックス (オプション)
これにより、DXGW を管理するアカウントに関連付けの提案が送られます。
5. DXGW 管理アカウントで関連付けの提案を承認する
Direct Connect コンソールの Direct Connect ゲートウエイから対象の DXGW を選択し、詳細を表示します。
Pending proposals (保留中の提案) タブで提案を選択し、提案を許可 を選びます。
許可後、関連付けのステータスが、associatedとなることを確認します。
6. ルートテーブルの変更
各サブネットに関連付けられたルートテーブルを変更します。
Blackhole になっている既存の VGW への経路を削除し、新規 VGW への経路を設定し直します。
手順的には 3 の後であれば問題ありません。
実際は DXGW の関連付けが完了するまでに時間を要すため、その間に実施しておくのがよいかと思います。留意点など
DXGW に接続しているオンプレミス同士、VPC 同士の折返し通信はできません。
(Transit Gateway に接続している場合を除く)Direct Connect ゲートウェイでは、同じ Direct Connect ゲートウェイ上にあるゲートウェイの関連付けが相互にトラフィックを送信することはできません (たとえば、仮想プライベートゲートウェイから別の仮想プライベートゲートウェイへ)。
キャリアが提供する接続サービスで 複数のプライベート VIF によるマルチ VPC 接続を行っている場合
キャリア網内での折返しによってVPC 同士での通信が行えるケースがありますが、
同一 DXGW に接続する場合は折返し通信が不可となります。
通信が必要な場合は VPC Peering 等で代替する必要があります。以上です。
参考になれば幸いです。
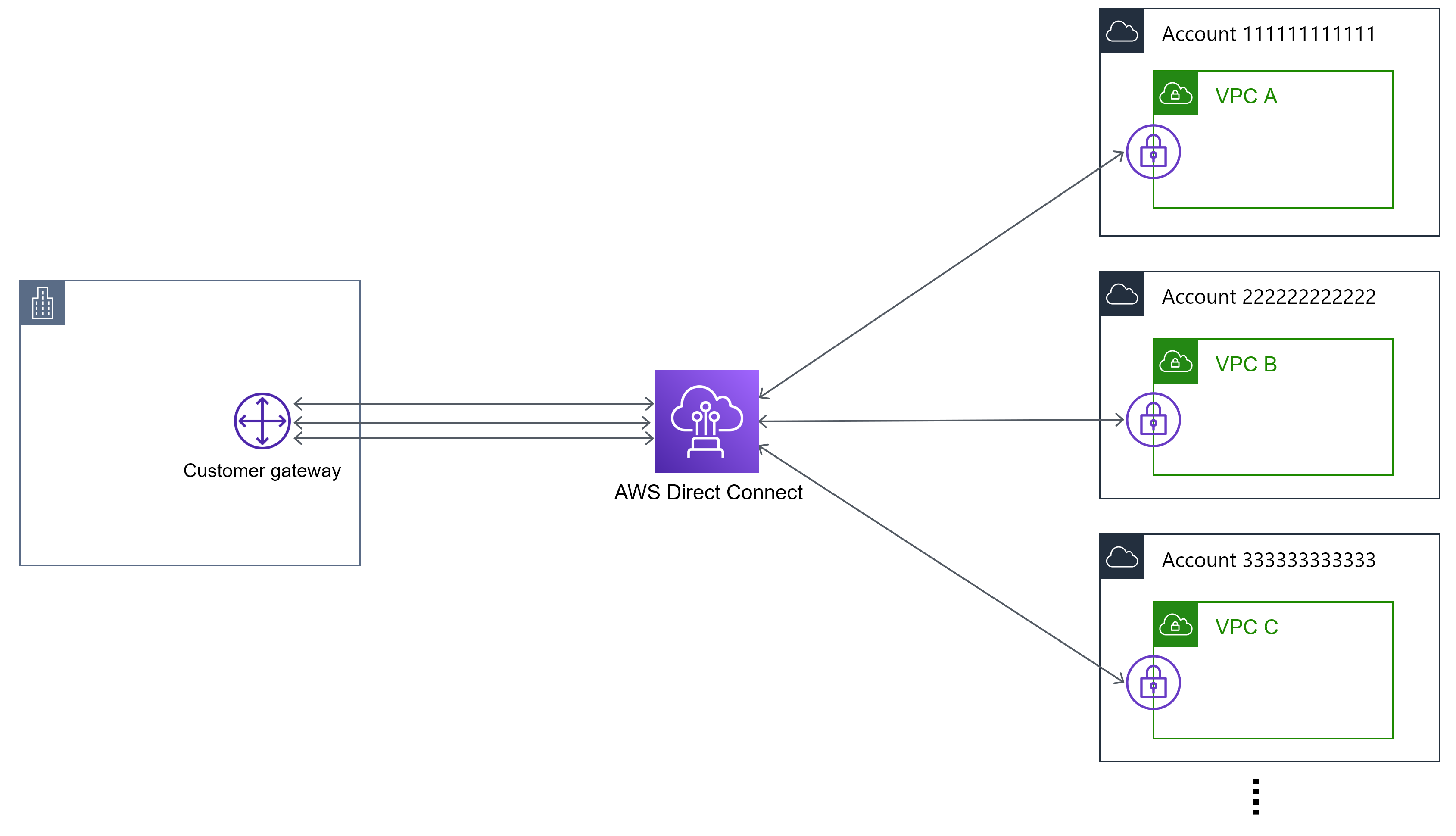
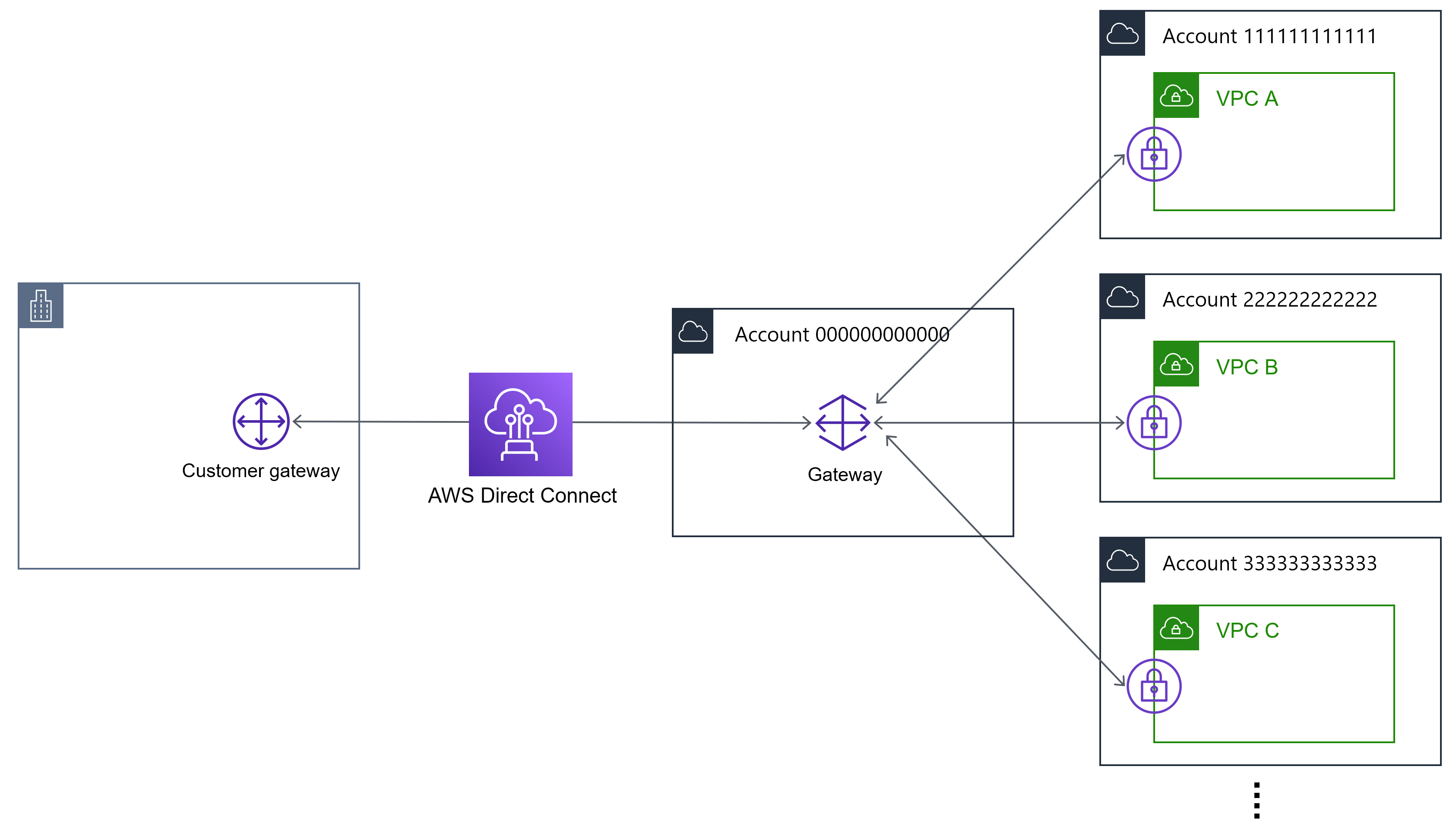
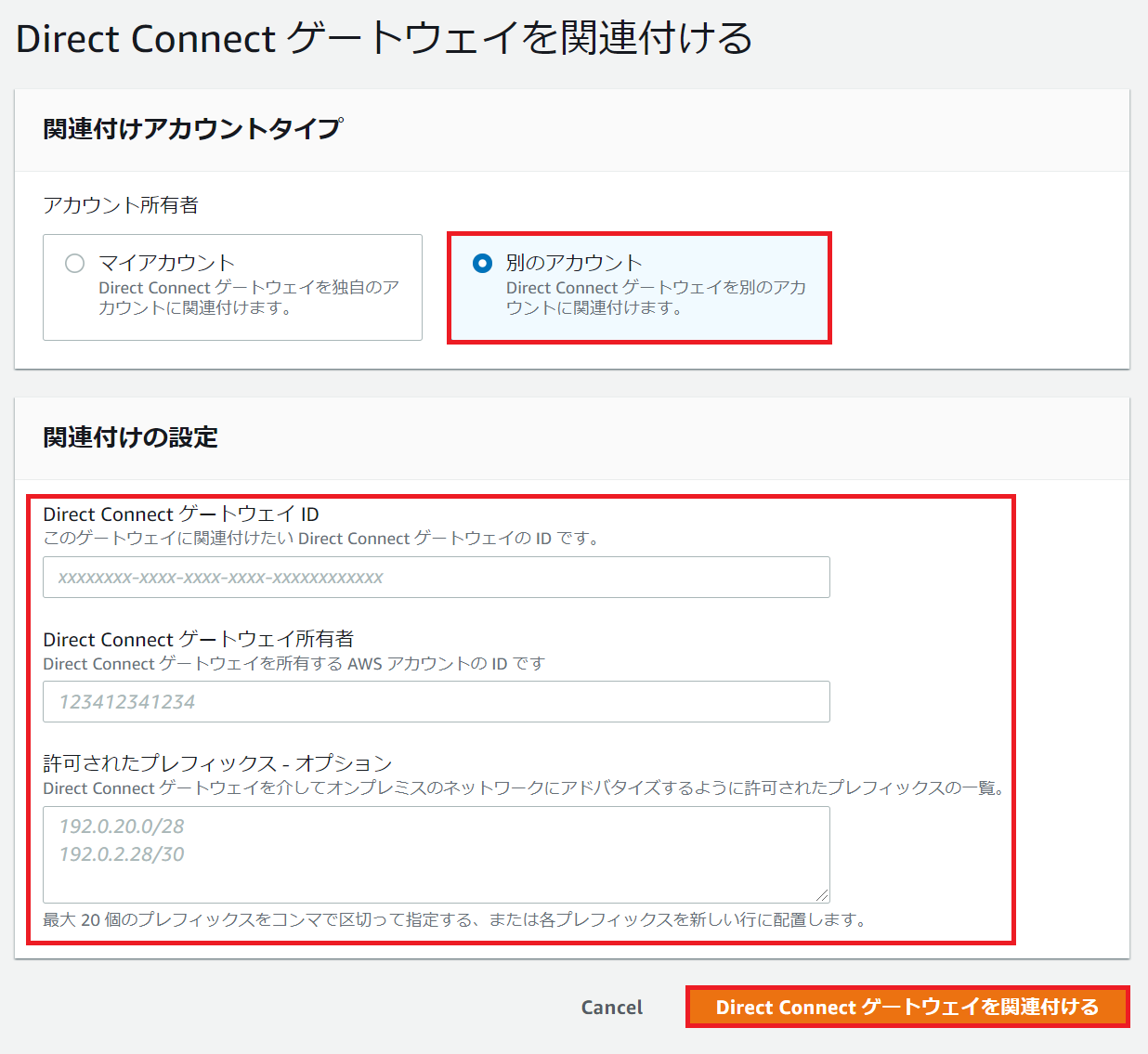
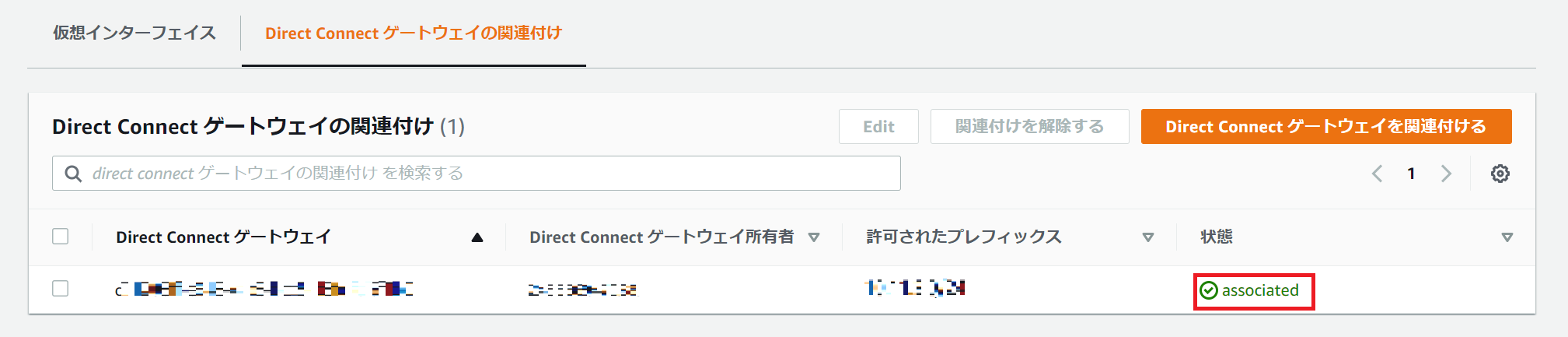
- 投稿日:2021-03-08T00:52:20+09:00
サブネットマスク、ネットワークアドレス、ブロードキャストアドレスの計算
問題
192.168.1.68/28が属するサブネットマスク、ネットワークアドレス、ブロードキャストアドレスの値を答えなさい
解答
サブネットマスク
IPv4の場合は32ビットで、/28は左から28ビットが1。よって↓
11111111 11111111 11111111 11110000
第4オクテットを10進数で表すと240
A. 255.255.255.240ネットワークアドレス
IPアドレス(2進数)とサブネットマスクをAND演算
IPアドレス(192.168.1.68)を2進数に変換
11000000 10101000 00000001 01000100AND演算
11000000 10101000 00000001 01000100
11111111 11111111 11111111 11110000
↓
11000000 10101000 00000001 01000000
これを2進数に変換
A. 192.168.1.64ブロードキャストアドレス
IPアドレス(2進数)とサブネットマスクを反転したものをOR演算
IPアドレス(192.168.1.68)を2進数に変換
11000000 10101000 00000001 01000100OR演算
11000000 10101000 00000001 01000100
00000000 00000000 00000000 00001111
↓
11000000 10101000 00000001 01001111
これを2進数に変換
A. 192.168.1.79
- 投稿日:2021-03-08T00:18:46+09:00
Railsチュートリアル6.0に沿って、AWS Cloud9上にRailsの開発環境作ってみた
Railsチュートリアル6.0を実施するにあたって、記載があった手順でAWS Cloud9でクラウド統合開発環境を作ってみました。
Cloud上とPC上で説明が混ざっていたので、こちらにまとめてすっきりさせたい意図で本記事を作成しました。(あと、記事の画面が若干古かったため)なお、アカウントは既に作成済みで、使用機材はwindowsです。(クラウドなので、差異はない気がしています)
以下が参照した手順
https://railstutorial.jp/chapters/beginning?version=6.0#sec-development_environment手順1:AWSのCloud9にアクセスする
ルートユーザーでログインし、AWSマネジメントコンソールにアクセス。
上の検索窓から「Cloud9」を入力し、Cloud9に遷移します。
手順2:「Create environment」を押下
Cloud9の画面で「Create environment」を押下する。
手順3:Name environmentを設定
Name environmentの「Name」と「Description」に適当な値を設定します。
自分の場合は
Name:rails-tutorial
Description:rails-tutorial
と値を設定しました。値設定後「Next step」を押下します。
手順4:各種設定
ここでの設定ですが、
Platform:Ubuntu Server 18.04 LTS
を設定して、他はデフォルトのままで「Next step」を押下します。
手順5:Review
設定した内容を確認し、「Create environment」を押下。
これでCloud9で開発環境の構築は完了です。
補足:インデントのデフォルトを変えておく
Rubyはインデントに2つのスペースを使うの通例らしいので、エディタのインデント設定をデフォルトから2に変更します。
手順としては、Cloud 9の右上歯車マークを押下し、Project Settingを開きます。
その後、CodeEditer(Ace)のsofttabを2に設定すれば完了です。
Railsインストール
下記コマンドをCloud 9のターミナルで走らせます。
まず、Rubyドキュメントをインストールしないよう.gemrcファイルを設定します。
$ echo "gem: --no-document" >> ~/.gemrcバージョンを指定してRailsをインストールします。(Railsチュートリアルではv 6.0.3をインストールしているのでそれに倣います)
$ gem install rails -v 6.0.3下記コマンドを入力して、Railsのバージョンが返ってくれば、Railsのインストールは完了です。
$ rails -vYarnインストール
もう一つだけ、javascriptのパッケージマネージャーの「Yarn」をインストールしていきます。
$ source <(curl -sL https://cdn.learnenough.com/yarn_install)もし警告メッセージが出た場合は、メッセージ通り下記を入力すればOKです。
$ yarn install --check-filesこちらもバージョンを確認して、表示されたらOKです。
$ yarn -vこれでRailsチュートリアルで実施されていたクラウド統合開発環境構築はいったん完了です。
Gitやherokuなどセットアップはまた別の機会に。







- 投稿日:2021-03-08T00:18:46+09:00
Railsチュートリアル6.0に沿って、AWSのCloud9上でRailsの開発環境作ってみた
Railsチュートリアル6.0を実施するにあたって、記載があった手順でAWS Cloud9でクラウド統合開発環境を作ってみました。
Cloud上とPC上で説明が混ざっていたので、こちらにまとめてすっきりさせたい意図で本記事を作成しました。(あと、記事の画面が若干古かったため)なお、アカウントは既に作成済みで、使用機材はwindowsです。(クラウドなので、差異はない気がしています)
以下が参照した手順
https://railstutorial.jp/chapters/beginning?version=6.0#sec-development_environment手順1:AWSのCloud9にアクセスする
ルートユーザーでログインし、AWSマネジメントコンソールにアクセス。
上の検索窓から「Cloud9」を入力し、Cloud9に遷移します。
手順2:「Create environment」を押下
Cloud9の画面で「Create environment」を押下する。
手順3:Name environmentを設定
Name environmentの「Name」と「Description」に適当な値を設定します。
自分の場合は
Name:rails-tutorial
Description:rails-tutorial
と値を設定しました。値設定後「Next step」を押下します。
手順4:各種設定
ここでの設定ですが、
Platform:Ubuntu Server 18.04 LTS
を設定して、他はデフォルトのままで「Next step」を押下します。
手順5:Review
設定した内容を確認し、「Create environment」を押下。
これでCloud9で開発環境の構築は完了です。
補足:インデントのデフォルトを変えておく
Rubyはインデントに2つのスペースを使うの通例らしいので、エディタのインデント設定をデフォルトから2に変更します。
手順としては、Cloud 9の右上歯車マークを押下し、Project Settingを開きます。
その後、CodeEditer(Ace)のsofttabを2に設定すれば完了です。
Railsインストール
下記コマンドをCloud 9のターミナルで走らせます。
まず、Rubyドキュメントをインストールしないよう.gemrcファイルを設定します。
$ echo "gem: --no-document" >> ~/.gemrcバージョンを指定してRailsをインストールします。(Railsチュートリアルではv 6.0.3をインストールしているのでそれに倣います)
$ gem install rails -v 6.0.3下記コマンドを入力して、Railsのバージョンが返ってくれば、Railsのインストールは完了です。
$ rails -vYarnインストール
もう一つだけ、javascriptのパッケージマネージャーの「Yarn」をインストールしていきます。
$ source <(curl -sL https://cdn.learnenough.com/yarn_install)もし警告メッセージが出た場合は、メッセージ通り下記を入力すればOKです。
$ yarn install --check-filesこちらもバージョンを確認して、表示されたらOKです。
$ yarn -vこれでRailsチュートリアルで実施されていたクラウド統合開発環境構築はいったん完了です。
Gitやherokuなどセットアップはまた別の機会に。