- 投稿日:2021-02-27T22:44:22+09:00
Railsポートフォリオ #3 herokuにデプロイ
こんにちは
今回はherokuへのデプロイを行いました。(前回記事(#3 DB設計))私は、前職(ホテルの料飲部)における、コミュニケーションの課題を解決するアプリを作っているのですが、今回は、
herokuへのデプロイを行いました
元々はAWSでデプロイするつもりだったのですが(やったことあったので)、難しすぎて、一旦諦め、herokuで手を打つことにしました。。。
感じたこと
- AWSの勉強不足
Qiita記事等を参考にしながら行ったのですが、知識不足でやってるので、どこで間違ったのかわからん、、、、、
もう少し勉強してから出直そうと思いました。
こちらの記事(【画像付きで丁寧に解説】AWS(EC2)にRailsアプリをイチから上げる方法【その1〜ネットワーク,RDS環境設定編〜】)とかを参考に行ったのですが、敗北しました。
非常に悔しいです。さらに
実際にアプリの中身を作っていたら、作っておいたER図が全然的外れだったと言うことにも気づきました。
こちらもやり直さねば。。。次は、ER図を修正し、基本機能を実装していきます
- 投稿日:2021-02-27T22:32:02+09:00
AppSyncコンソールからクエリ変数の利用する
概要
Amplifyのワークショップを行った際のメモ
ゴール
Amplifyコンソールから
クエリ変数を利用し、コメントを投稿するGraphQLリクエストを実行する背景
Amplifyの学習で公式のワークショップで学習をする機会がありました。
事前準備
今回は、事前にaws_consoleというユーザを作成しています。
該当範囲
MVPを作ろう!-POST機能: BACK-END(1)
AWSマネジメントコンソールを開き、初めてのクエリ実行としてコメントの投稿を行います。
基本的には、AppSyncのクエリ操作は、Explorerから以下の操作を行うことでリクエスト可能です。
▶︎ createPostを押下し開く▼ createPostに値を入力する前提条件
ここまで
amplify add apiが実行済みなので、src/graphql/mutations.jsが生成されています。TODO
- 自動生成されたファイルの内容を確認する
- リクエストの内容をAppSyncコンソールに貼り付ける
- 実行する
1. 自動生成されたファイルの内容を確認する
src/graphql/mutations.js内には下記のような箇所が見当たります。export const createPost = /* GraphQL */ ` mutation CreatePost( ~省略~ ) { createTimeline(input: $input, condition: $condition) { ~省略~ } } `;生成されている上記のコードを利用してGraphQLリクエストが実行可能です。
2. リクエストの内容をAppSyncコンソールに貼り付ける
- (上記の)
mutation CreatePost (~略~) {~略~}をコピーし、AppSyncのクエリに貼り付ける- クエリ変数の欄に
$input内の変数:値を記載するまずは、下記の内容をクエリとして貼り付けます。
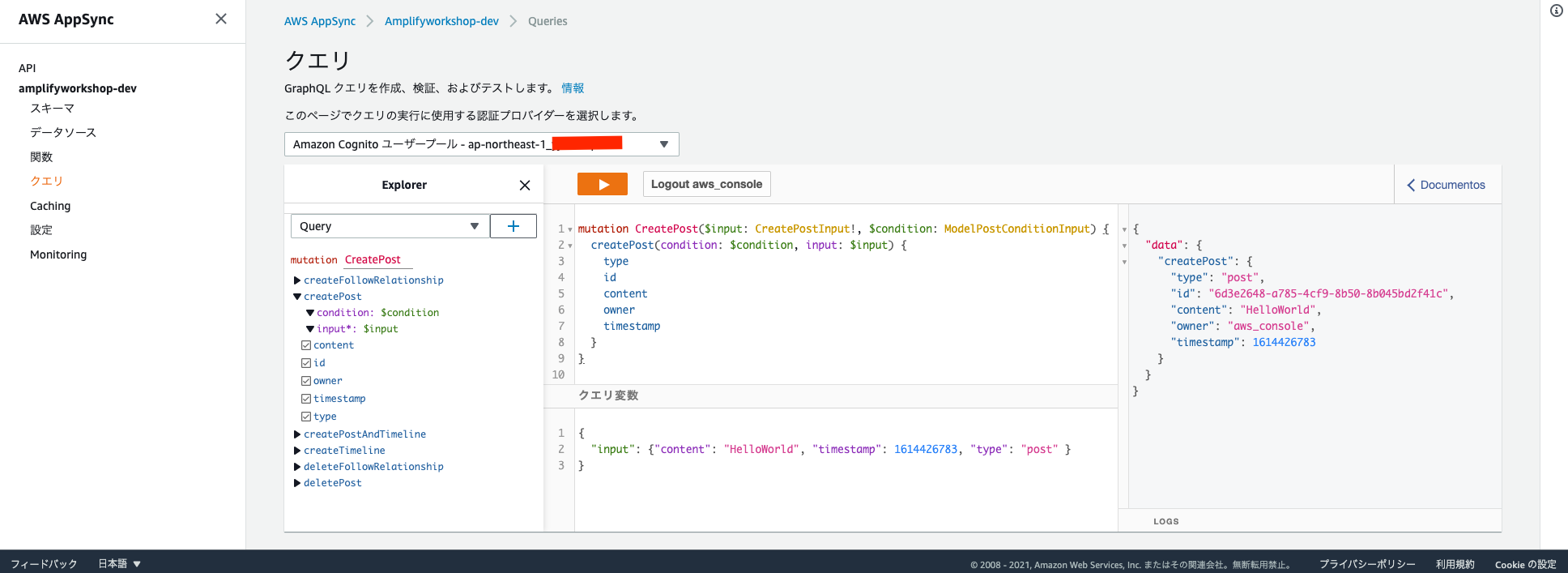
mutation CreatePost($input: CreatePostInput!, $condition: ModelPostConditionInput) { createPost(condition: $condition, input: $input) { type id content owner timestamp } }次に、下記の内容をクエリ変数の欄に貼り付けます。
(timestampは
10などでも問題ありませんが、date +%sで出力し、貼り付けて利用してください。){ "input": {"content": "HelloWorld", "timestamp": 1614426783, "type": "post" } }3. 実行する
実行すると、以下の画像のようになります。
Queryの操作について下記の記事が参考になったので載せておきます。
https://qiita.com/shunp/items/d85fc47b33e1b3a88167#comments4. 確認
Subscription
- AWSマネジメントコンソールを計2枚開く
- onCreatePostを実行する
- mutationでcreatePostを実行する
1. AWSマネジメントコンソールを計2枚開く
一方(左)は先程のcreatePostです。
他方(右)はSubscriptionであるonCreatePostです。以下を貼り付けます。
subscription OnCreatePost { onCreatePost { type id content owner timestamp } }2. onCreatePostを実行する
(画像:右)のSubscriptionであるonCreatePostを実行すると、
1個のミューテーションにサブスクライブしました
と表示され、ボタンの ▶︎ が ■ に変わります。
3. mutationでcreatePostを実行する
(画像:左)のcreatePostを実行すると、onCreatePostがPostされたメッセージを受け取ります。


- 投稿日:2021-02-27T21:49:03+09:00
AWSでJava開発環境を構築する
概要
最近PGする機会がめっきり減ってきたので、コーディング力を維持する(というか成長させる)ために、Javaでも書いてみようと思いました。
せっかくなのでクラウドの統合開発環境の代表格(?)であるAWSを使ってみます。やること一覧
- Gitでリポジトリ作成
- Cloud9 の環境作成
- READMEをGitにpush
- プログラムを一本push
1. Gitでリポジトリ作成
いつもの画面が出てきます。
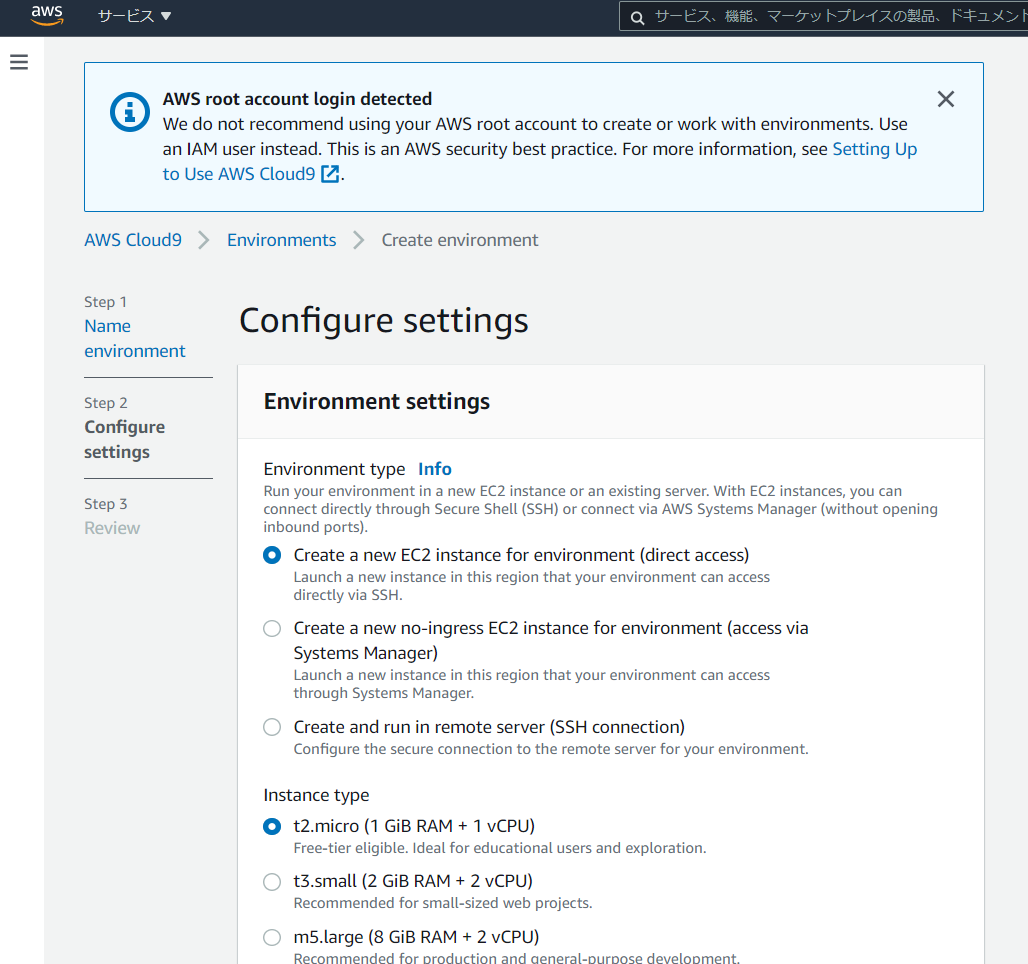
2. Cloud9 の環境構築
- AWSマネジメントコンソールの検索バーにCloud9と入力
- Cloud9が選択肢に出てくるのでクリック
- 「Create environment」をクリック
- 名前と概要を書いて「Next step」をクリック
高性能でなくていいですし、デフォルトからセッティングをいじる必要もなさそうと判断してそのまま「Next step」をクリック
確認画面が出てきます。Cloud9環境を使用するにあたっての注意事項が書いてあるので、読んでから「Create environment」をクリック
数分待ちます。
できました!
3. READMEをGitにpush
Gitリポジトリに書いてある始め方に沿って進めます。
$ git init $ git add README.md $ git commit -m "first commit" $ git config --global user.name "Mick Danjoh" $ git config --global user.email *****@gmail.com $ git branch -M main $ git remote add origin https://github.com/danjo-m/lemon.git $ git push -u origin mainリポジトリにpushできました。
4. プログラムを一本push
まじで何でもないプログラムを作ってpushします。
あらかじめJDKが入っていることを確認。$ java -version openjdk version "11.0.10" 2021-01-19 LTS OpenJDK Runtime Environment Corretto-11.0.10.9.1 (build 11.0.10+9-LTS) OpenJDK 64-Bit Server VM Corretto-11.0.10.9.1 (build 11.0.10+9-LTS, mixed mode)いつものHello World
Sample1.javapublic class Sample1 { public static void main(String[] args) { System.out.println("Hello World!"); } }$ ls README.md Sample1.java $ javac Sample1.java $ java Sample1 Hello World!Hello Worldできました。
こいつをpushしておきます。$ git add Sample1.java $ git commit -m "Create first pg" $ git push origin maingitignoreやクラスファイルの整理はおいおい。
おまけ:Gitコマンド
Githubで情報提供されていたコマンドのオプションをすっかり忘れていたので、
使ったものだけでも整理。
- git commit -m "comment"
- -mで単一コメントを記述する。
- 対象ファイルを書かない場合はステージされている(addした)全ファイルをコミット。
- git branch -M <branch_name>
- 「branch_name」のカレントブランチの名前を変更。
- -mだと上書き禁止。-Mだと強制上書き。
- git push -u <remote_path> <local_branch>:<remote_branch> *「remote_path」へ「local_branch」を「remote_branch」へpush。 *ブランチ名はローカルとリモートが同じ場合は1つに省略可。
- -uオプションで、次回から
git pushだけで今回と同じ操作ができる。- 「remote_path」は省略名で指定可能。省略名は
git remote -vで確認。$ git remote -v origin https://github.com/danjo-m/lemon.git (fetch) origin https://github.com/danjo-m/lemon.git (push)参考リンク
Gitチートシート
[Git]git branch コマンドの -m と -M オプションの違い
git pushのオプション -u とは以上!お疲れさまでした。




- 投稿日:2021-02-27T21:44:04+09:00
AWS認定DevOpsエンジニア – プロフェッショナル 合格体験記
はじめに
SOMPOホールディングスでチーフエンジニアをしているy-sugichanです。
※最近、エンジニアリングマネージャー(SRE)的なロールになってきました。今回、AWS認定DevOpsエンジニア-プロフェッショナル試験に合格したので、勉強法などを残しておきたいと思います。
ソリューションアーキテクト-プロフェッショナル試験(以下SAP)の合格体験記はこちらです。
AWS認定ソリューションアーキテクト – プロフェッショナル 合格体験記今回も、みなさまのご参考になれば幸いです。
まずは結果から
スコア:782(750で合格)
▶ぎ、ギリギリすぎます・・・!試験結果詳細:以下のとおりです。
セクション スコア 再学習の必要あり 十分な知識を有する 分野 1:SDLCの自動化 22% ○ 分野 2:構成管理および Infrastructure as Code 18% ○ 分野 3:監視およびロギング 15% ○ 分野 4:ポリシーと標準の自動化 11% ○ 分野 5:インシデントおよびイベントへの対応 18% ○ 分野 6:高可用性、フォールトトレランス、およびディザスタリカバリ 18% ○ インシデント対応できないって致命的では・・・!?
再学習の必要あり、については勉強し直します(反省私について(再掲
- エンジニア歴13年
- 主にWEBアプリ開発を経験
- AWSの実務は3年以上5年未満くらい
- サーバーレスやElasticBeanstalksなどでの開発メイン。GlueやAthenaとかも使ってました。
- CloudFormationのテンプレートも書いてたり(今は中々機会が・・・
- 家ではAlexaスキルを作って遊んだりもしてました(Lambda+DynamoDB)
- AWS認定ソリューションアーキテクト-プロフェッショナル取得済み
- インフラエンジニアとしてキャリアを積んだわけではないのでそこらへんは未熟
取ろうと思った動機
それはもちろん、SAPを取ったことで、試験代が半額になる特典をもらったからです。
冗談です。以下のような感じです。
- PoCを主に実施するチームではあるが、チームもプロダクトもスケーリングしてきた
- もっとDevOpsを実践していきたい
- Slack通知だけではなく、ログ可視化とか色々やりたい
- 金融機関だし、コンプライアンスやセキュリティインシデント防止策も兼ねたい
- みんなが安心して使える環境を整えたい
- そのあたりを踏まえると、一度DevOpsの資格にチャレンジしておきたい
- せっかくなのでプロフェッショナル二冠を名乗りたい
たぶん最後の不純な動機が一番です。
取得してみて
サービスの組み合わせが難しすぎる・・・
言葉のとおりです。これ系の資格試験の運命かもしれませんが、いくつかの問題は「ここの用語だけ微妙に違う」という選択肢が待っています。
これは統合していないよな・・・?などの正確な知識が明確に求められます。
そういう意味で、取得したことで「AWSのサービスを組み合わせたDevOpsソリューション」を的確に導き出せるようになった気がします(DevOpsソリューションってなんだまた、普通にGitのマージ戦略とか、デプロイ方法などの一般的な考え方も出てくるため、ここらへんが曖昧な人は間違いなく落ちるという意味でも、取得した甲斐がありました。
IaCは当たり前、開発もしてますという方であれば、AWSのサービス組み合わせさえ覚えれば合格できると思います。あと、「あなたはCEOに〜CIOに〜求められました、どうしますか」という問題が75問続くので、メンタルが鍛えられました。なりきりプレイです。
勉強期間と教材
勉強期間
前回の試験終了後、1月中旬から開始しました。1ヶ月半くらいです。
今回は長期休暇などはなかったものの、2月の飛び石連休をうまく使いました。
(途中、結構サボりましたが・・・)合計時間は前回のSAP150時間に比べると短く、体感では50〜60時間くらいだと思います。
また、SAPでの勉強も活かせているため、大幅に勉強時間を削減できたと考えています。教材
基本戦略はSAPと同じです!
【書籍】
- なし
今回つらかったのは、書籍がなかったことです。
正直、書籍が出てから勉強したほうがコスパは良いと思います!
出るのかは・・・わかりませんが・・・(泣)【公式】
- Black Belt
- 前回に続き、AWS サービス別資料のYou Tubeリンクが非常に便利です!
今回はDevOpsに関連する以下のシリーズを徹底して学びました。
- CloudFormation
- YAML書いたことがない人は書けるレベルにしておいたほうがいいです
- ベストプラクティスだけではなく、各要素の使い方まで把握しておかないと詰みます
- ECS
- ECSにとどまらず、そもそもDockerイメージどう扱いますかなどを知らないと詰みます
- ECSの細かい挙動も知っておいた方がおすすめです
- Codeシリーズ
- Pipelineをメインにどのようにビルド・デプロイしていくか叩き込みましょう
- CloudWatch
- 実務でやってないときついかもしれませんが、とにかく叩き込みましょう
- Eventsやアラーム作ったことない方は作りましょう
- OpsWorks
- 最近全然動画などもありませんが、基礎として流しておきましょう(私は未だに苦手です
- ElasticBeanstalks
- まだまだ試験的には現役っぽいので、動画はありませんがPDFを見ておきましょう
- AWS Well-Architected
- SAP同様、まだ読まれていない方はAWS Well-Architectedの5つの柱を一読しましょう。問題で何を聞かれているのか?を理解できるため、遠回りなようで捗ります。
- 各サービス公式ドキュメント
- SAP同様、実務でもお世話になる公式ドキュメントに必ず答えがあります。Black Beltのお供にフル活用しましょう。
【問題集】
今回は色々調べていて書籍もないことから、AWS WEB問題集で学習しようにお世話になりました。
過去問らしいですが、今回の私の試験では似た問題が10問あったかないかくらいで、ほぼ自力でがんばるしかありませんでした・・・合格体験記見ると、これだけでイケる的な方もいるみたいですので、試験日によるのかもしれません。
しかし、10問近くあるだけでもかなり助かります!ただ、資格を取ることを目的にするのではなく、サービス理解などを深めることが目的であれば、公式が一番でしょうか。
勉強方法
ここからは具体的に試験までの流れに沿って勉強方法を記載してみます。
これも基本的にはSAPと同じです!が、書籍はありません!試験内容の把握
SAP同様、まずは試験内容です。公式の試験ガイドで明確に示されています。
試験時間:180分(3時間)
問題数:75問
分野 試験における比重 分野 1: SDLCの自動化 22% 分野 2: 構成管理および Infrastructure as Code 19% 分野 3: 監視およびロギング 15% 分野 4: ポリシーと標準の自動化 10% 分野 5: インシデントおよびイベントへの対応 18% 分野 6: 高可用性、フォールトトレランス、およびディザスタリカバリ 16% 合計 100% 冒頭のスコアと見比べると微妙に配分が違うため、当日の問題内容で増減するのだと思います。
と思ったら、冒頭のスコアを合計すると100%ではないため、採点対象外問題があったのですかね。
目安ですということで。SAP同様、長文問題を一問2分~3分以内で解かないといけないため気合が必要ですが、自身の業務によってだいぶ受け取り方が変わる気がします。
開発やってれば、ビルドとかデプロイとかコンテナを聞かれるDevOpsのほうが簡単に感じました。が、ノリで回答してスコアは悪くなりました(泣)
合格体験記の調査
SAPに比べると非常に少ないです。正直、困りました。
なのでこの記事が少しでも参考になれば幸いです。書籍での勉強・・・はできない!
SAPの問題を見返そうかなと思ったのですが、自分を信じてやめました。
結果として、問題傾向が全く違うので振り返らなくてよかったと思います。Black Beltをひたすら見る
今回は書籍もないため、基本はこれ頼みです。
話はずれますが、deep dive系は見ていて面白くなってきますよね。ドキュメントを読む
今回は「よくある質問」を単体で読んでいました。
特にAuto Scalingはよく読んでおいたほうがいいです!奥が深い。すごいぜAuto Scalling...
AWS Well-Architectedを読んでいない場合は、ここで併せて読んでおきましょう。WEB問題集を解く
動画とドキュメントを読むのと並行しながら問題を解いてみました。
傾向が少し古いのかなぁ・・・というのが正直なところです。
新しい問題セットを1周、2周目は新しい方から20セットを解き直しましたが、前述したとおりあまり似た問題が出ませんでした・・・ただ、傾向をつかむには良いと思います。問題解くよりドキュメント読み直す
今回に限っては、書籍もなく問題集もあまりないため、模擬試験を受けるか悩みましたが・・・
最後まで自分の苦手分野に関するドキュメントを読んでいました。
特に、サーバーレスでオラオラ攻めていた私はAuto Scallingの奥の深さを噛み締めていました。
CloudFormationも活用したら何でもできるのでは????という小並感に至った次第です。当日について
簡単なふりかえりです。
- やっぱり180分も集中力は続かない
- SAPより実務っぽい感じではあるのですが、半分あたりで知恵熱出てきます。
- 長文はSAPより少ない(体感)ので抵抗感は減った
- 国語力のある方にとっては、長文が少ないのでSAPより楽に感じるかもしれません。
- ただし、SAPに比べてというだけで、基本的には24インチモニタ全面を埋め尽くす文章量です(白目
- 見直しフラグはない代わりに、残り15分しかなかった
- 時間かかりました・・・その代わり、トップに戻って4問程度見直してフィニッシュでした。
- SAPとの難易度比較は自身の業務にかなり依存する
- 資格の名前を体現していると思います。
- 日本語訳がSAPより良かった
- SAPは英語原文を表示させることが多々ありましたが、今回は一つもありませんでした!
アンケート回答中は「気づいたら試験が終わってた。SAPに比べて受かった気がしない」と思っていましたが、合格が見えて不思議な気持ちでした。
ただ、スコアを見るとごもっともかと・・・最後に
「SAPと比べて難易度はどうか?」というのは、前述したとおり自身の業務によると思います。
また取得価値についても、アーキテクトの方であればSAPがあれば十分かもしれません。
開発に携わるなら取っておいて損はありません!なによりプロフェッショナル二冠というのは気持ちいいです!(本音二冠ともに一発で取れましたが、今後はセキュリティかDBあたりを攻めたいと思っています。
セキュリティは・・・書籍があるんです!やったー(しつこい
また金融機関にいる以上、セキュリティはどれだけ知っていても損はありませんので。以上、お読みいただきありがとうございました!
- 投稿日:2021-02-27T21:17:16+09:00
Rails6.0アプリに独自ドメインを付与
始めに
Railsアプリを本番環境にデプロイさせる工程は今回の内容で最後になります。
今まではElastic IPアドレスを使ってブラウザに入力していましたが、ドメインを取得してよりわかりやすいURLに変えていきます。
ドメインは有料ですが,こだわらなければ初年度は数百円程度で取得できます。
この記事では「お名前.com」というサービスを利用してドメインを取得します。用意するもの
- クレジットカード
- AWSのアカウント
- AWSでデプロイ済みのEC2インスタンス
目次
1.ドメインを購入
2.IPアドレスとドメインの関連付け
3.ネームサーバーの設定
4.Nginxの設定1. ドメインを購入
①お名前.com (https://www.onamae.com/) にアクセスします。
②取得したいドメインを検索バーで検索します。
- 注意
- 先に誰かが使用しているドメインは取得できません。
- ドメインに使用できる文字は
「半角英数字」と「ハイフン -」です- また"_"や"!"といった特殊な記号は使用できないことがあります。

③希望のドメインを選択。
こだわりがなければ初年度の安いドメインを取得をおすすめします。
僕自身は.workというドメインを選択し最安値の1円に押さえました。
- 購入処理の際の注意
- 「サーバー」は「利用しない」をチェック
- 「Whois情報公開代行メール転送オプション」などは全てチェック不要
④その後、会員登録を済ませドメインを購入。 会員登録した際に入力したメールアドレスに以下のメールが来たら、取得可能です。

2. IPアドレスとドメインの関連付け
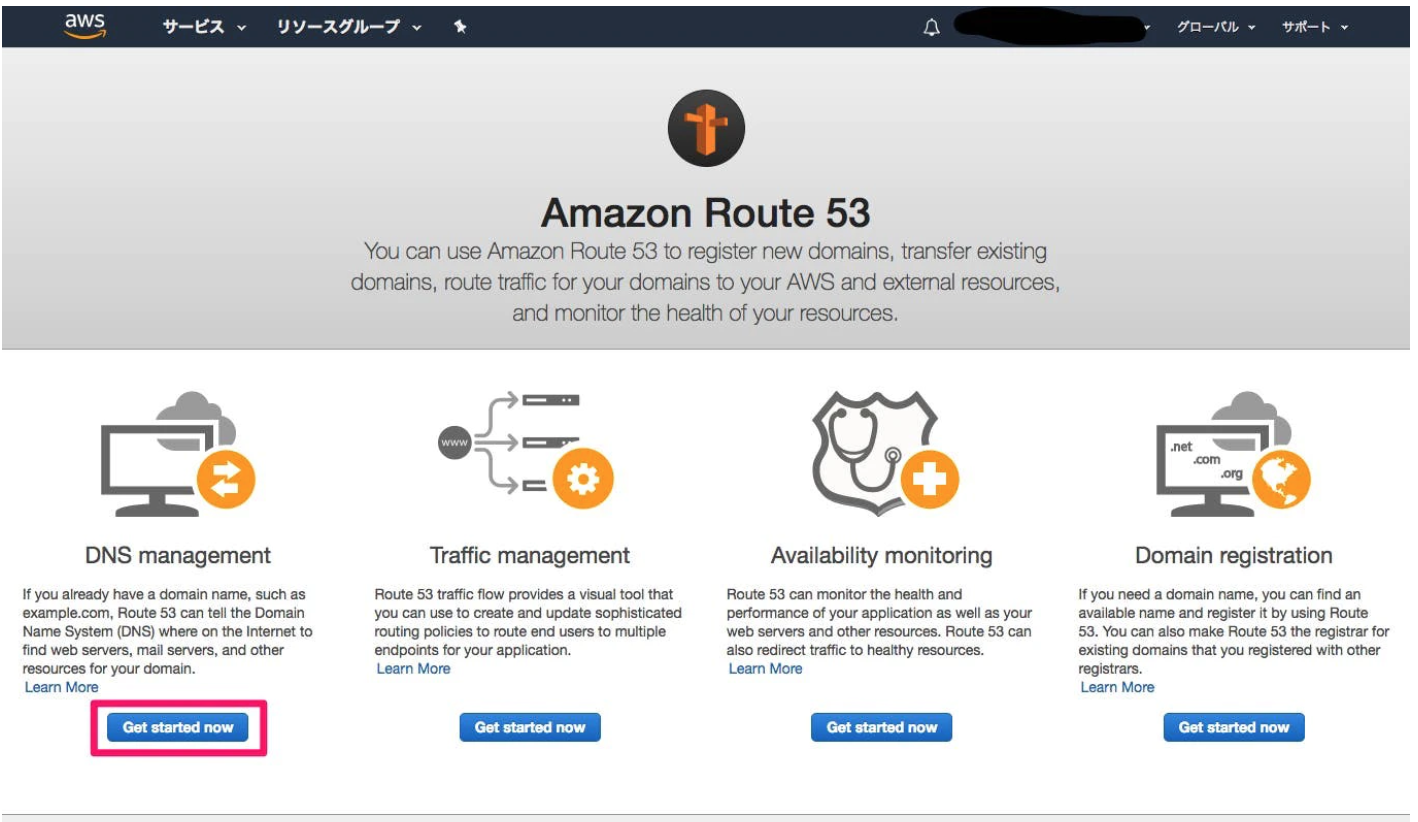
①サービスでRoute53を選択
先ほど購入したドメインをIPアドレスに変換することができます。②一番左のDNS managementを選択。
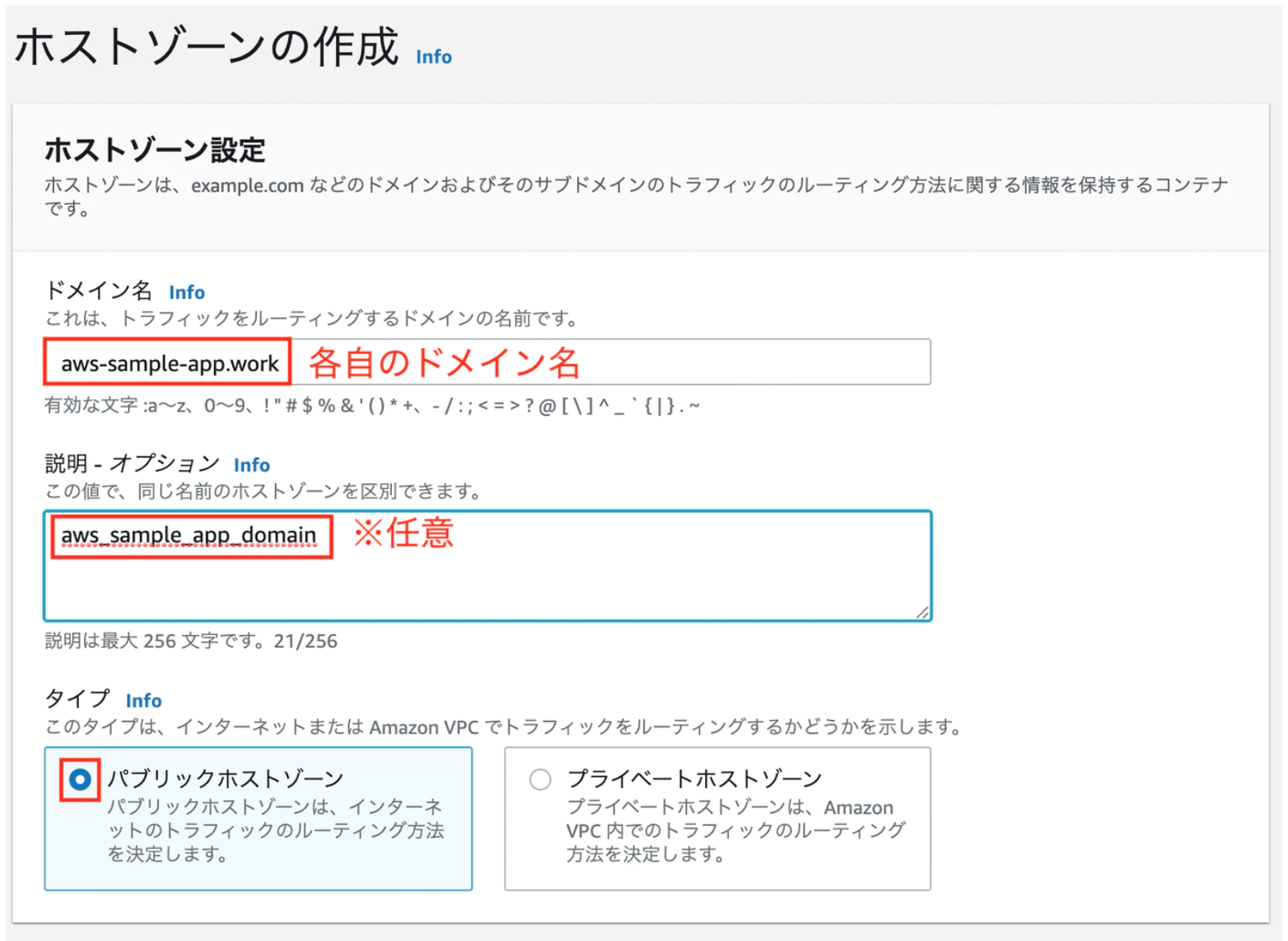
③ホストゾーンの作成。
キー 値 ドメイン名 取得したドメイン名 説明-オプション アプリ名_domein Type Public Hostes Zone
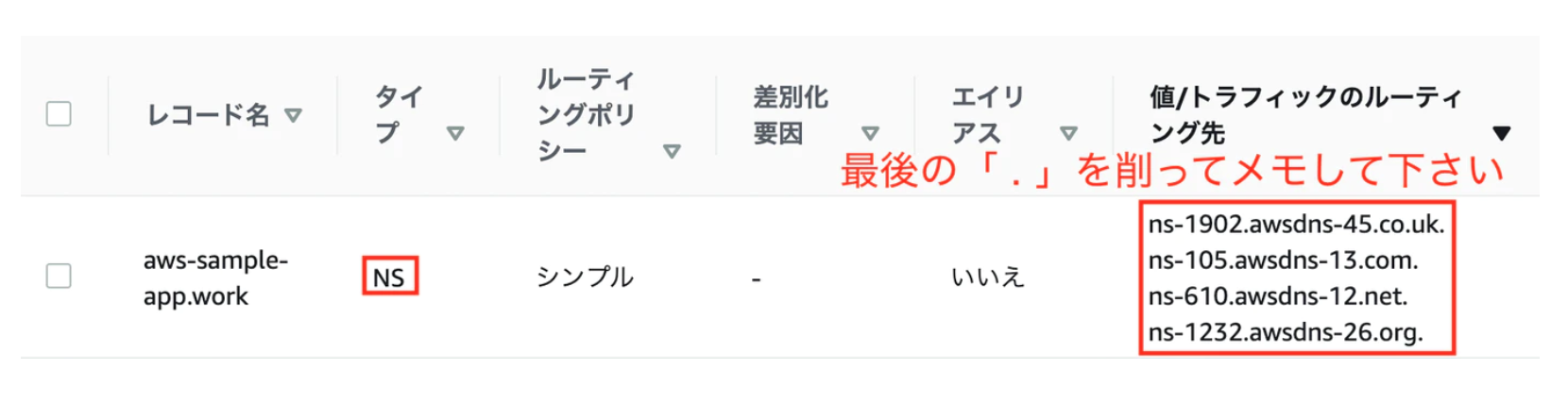
上記を入力したらホストゾーン作成をクリックホストゾーンが作成されると「値/トラフィックのルーティング先」というものが作成されます。
このうちタイプがNSで表示されている4つをネームサーバーとしてメモしておきましょう。
メモする際に,それぞれの最後についている「ドット .」は削除して下さい!
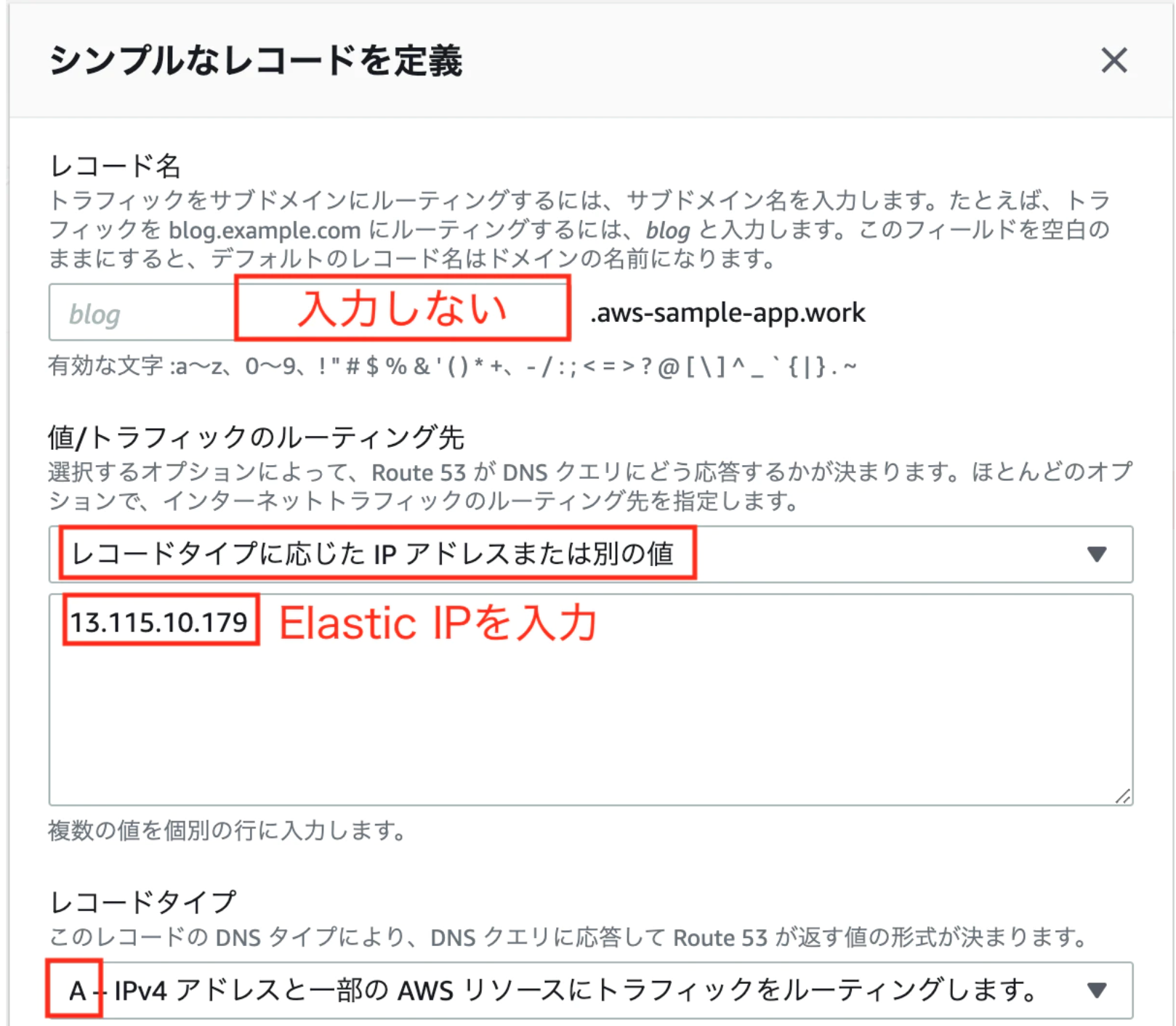
④レコードセットの作成。
Route53の画面から、「レコードを作成」をクリック
キー 値 レコード名 入力しない 値/トラフィックのルーティング先 「レコードタイプに応じた IP アドレス または別の値」をクリックし, Elastic IP を入力 レコードタイプ A
Aタイプのレコードが作成されたら完了です!3. ネームサーバーの設定
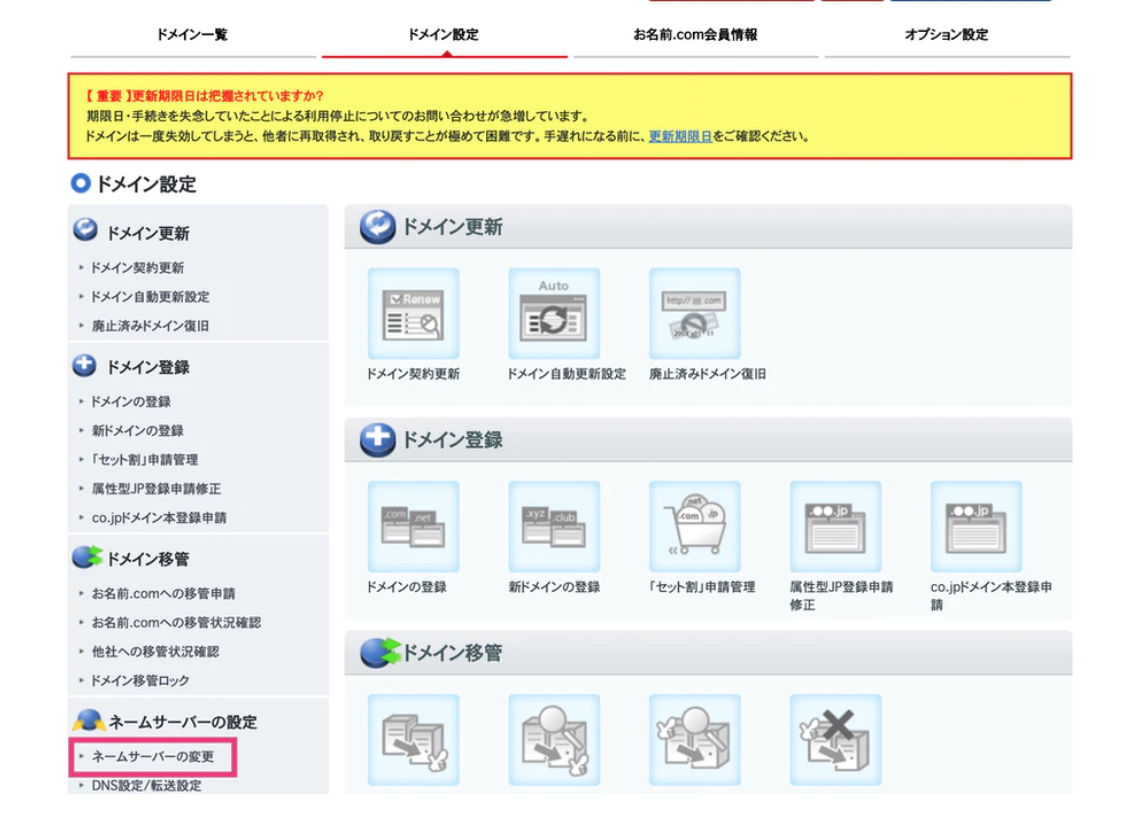
①お名前.comに戻ってログインします。
②ログインしたらドメインの設定から
ネームサーバーの変更を選択してください。
③他のネームサーバーを利用を選択。
ネームサーバー情報を入力する欄に先ほどAWSで取得したNSタイプのレコード(4つ)を入力。
デフォルトでは2つしか枠がないので、追加入力を2回クリックして枠を追加します。
ネームサーバーの確認
ローカル環境のターミナルから以下のコマンドを実行して下さい。
登録した4つのドメインが入っていればOKです。(順番が入れ替わっていてもOK)ターミナル$ dig ドメイン名 NS +shortまた、ターミナルでdig xxxxx.xxx(←自分のドメイン名)と入力してみましょう。
AWSで取得したレコードが表示されていれば成功です!ターミナル$dig xxxxxxx.com ; <<>> DiG 9.10.6 <<>> xxxxxxx.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 31076 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;xxxxxx.com. IN A ;; ANSWER SECTION: xxxxxxx.com. 278 IN A xx.xxx.xx.xxxここまででドメインの設定は完了です!
ドメインの浸透には5分~30分ほど時間がかかる場合があるので、しばらくしたらブラウザにIPアドレスではなくドメイン名を入力して確認してみましょう。4. Nginxの設定
本番環境にNginxを採用している場合は設定を変更しないとエラーがおきてしまいます。
nginx.confのserver_nameを変更しましょう。/etc/nginx/conf.d/rails.confupstream app_server { # Unicornと連携させるための設定。 server unix:/var/www/xxxxxx/shared/tmp/sockets/unicorn.sock; } # サーバの設定 server { # このプログラムが接続を受け付けるポート番号 listen 80; # Elastic IPアドレスを独自ドメインに変更 server_name xxxx.com; # 接続が来た際のrootディレクトリ root /var/www/xxxxxx/current/public; # assetsファイル(CSSやJavaScriptのファイルなど)にアクセスが来た際に適用される設定 location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; root /var/www/xxxxxx/current/public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html;以上で終了です!
ブラウザで確認してみましょう。
- 投稿日:2021-02-27T21:17:16+09:00
【 Ruby on Rails 6.0 】 AWS + Nginx + Unicornでデプロイ⑧
始めに
Railsアプリを本番環境にデプロイさせる工程は今回の内容で最後になります。
今まではElastic IPアドレスを使ってブラウザに入力していましたが、ドメインを取得してよりわかりやすいURLに変えていきます。
ドメインは有料ですが,こだわらなければ初年度は数百円程度で取得できます。
この記事では「お名前.com」というサービスを利用してドメインを取得します。用意するもの
- クレジットカード
- AWSのアカウント
- AWSでデプロイ済みのEC2インスタンス
目次
目次 内容 セクション1 EC2インスタンス作成 セクション2 Linuxサーバー構築 セクション3 データベース設定 セクション4 EC2上でGemをインストールし環境変数を設定 セクション5 Railsアプリを起動 セクション6 Nginxの導入 セクション7 自動デプロイ セクション8 独自ドメイン取得(今回の内容) 1. ドメインを購入
①お名前.com (https://www.onamae.com/) にアクセスします。
②取得したいドメインを検索バーで検索します。
- 注意
- 先に誰かが使用しているドメインは取得できません。
- ドメインに使用できる文字は
「半角英数字」と「ハイフン -」です- また"_"や"!"といった特殊な記号は使用できないことがあります。
③希望のドメインを選択。
こだわりがなければ初年度の安いドメインを取得をおすすめします。
僕自身は.workというドメインを選択し最安値の1円に押さえました。
- 購入処理の際の注意
- 「サーバー」は「利用しない」をチェック
- 「Whois情報公開代行メール転送オプション」などは全てチェック不要
2. IPアドレスとドメインの関連付け
①サービスでRoute53を選択
先ほど購入したドメインをIPアドレスに変換することができます。②一番左のDNS managementを選択。
③ホストゾーンの作成。
キー 値 ドメイン名 取得したドメイン名 説明-オプション アプリ名_domein Type Public Hostes Zone
上記を入力したらホストゾーン作成をクリックホストゾーンが作成されると「値/トラフィックのルーティング先」というものが作成されます。
このうちタイプがNSで表示されている4つをネームサーバーとしてメモしておきましょう。
メモする際に,それぞれの最後についている「ドット .」は削除して下さい!
④レコードセットの作成。
Route53の画面から、「レコードを作成」をクリック
キー 値 レコード名 入力しない 値/トラフィックのルーティング先 「レコードタイプに応じた IP アドレス または別の値」をクリックし, Elastic IP を入力 レコードタイプ A
Aタイプのレコードが作成されたら完了です!3. ネームサーバーの設定
①お名前.comに戻ってログインします。
②ログインしたらドメインの設定から
ネームサーバーの変更を選択してください。
③他のネームサーバーを利用を選択。
ネームサーバー情報を入力する欄に先ほどAWSで取得したNSタイプのレコード(4つ)を入力。
デフォルトでは2つしか枠がないので、追加入力を2回クリックして枠を追加します。
ネームサーバーの確認
ローカル環境のターミナルから以下のコマンドを実行して下さい。
登録した4つのドメインが入っていればOKです。(順番が入れ替わっていてもOK)ターミナル$ dig ドメイン名 NS +shortまた、ターミナルでdig xxxxx.xxx(←自分のドメイン名)と入力してみましょう。
AWSで取得したレコードが表示されていれば成功です!ターミナル$dig xxxxxxx.com ; <<>> DiG 9.10.6 <<>> xxxxxxx.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 31076 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;xxxxxx.com. IN A ;; ANSWER SECTION: xxxxxxx.com. 278 IN A xx.xxx.xx.xxxここまででドメインの設定は完了です!
ドメインの浸透には5分~30分ほど時間がかかる場合があるので、しばらくしたらブラウザにIPアドレスではなくドメイン名を入力して確認してみましょう。4. Nginxの設定
本番環境にNginxを採用している場合は設定を変更しないとエラーがおきてしまいます。
nginx.confのserver_nameを変更しましょう。/etc/nginx/conf.d/rails.confupstream app_server { # Unicornと連携させるための設定。 server unix:/var/www/xxxxxx/shared/tmp/sockets/unicorn.sock; } # サーバの設定 server { # このプログラムが接続を受け付けるポート番号 listen 80; # Elastic IPアドレスを独自ドメインに変更 server_name xxxx.com; # 接続が来た際のrootディレクトリ root /var/www/xxxxxx/current/public; # assetsファイル(CSSやJavaScriptのファイルなど)にアクセスが来た際に適用される設定 location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; root /var/www/xxxxxx/current/public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html;以上で終了です!
ブラウザで確認してみましょう。
- 投稿日:2021-02-27T20:56:08+09:00
AWS S3とは?
S3(Simple Storage Service)とは?
S3は、99.999999999%の耐久性を実現したストレージサービス。
料金安く、保存できるデータ量無制限。【活用方法】
・AWSサービスの利用ログの保存
・静的Webサイト構築
・ビッグデータの分析のデータソースとしての活用
・自動スケーリング設計されたEC2インスタンスのログ保存
など、様々な場面で活用されています。S3冗長化構成
結果整合性採用。
保存したデータは、保存した際に自動的に複数のデータセンターに同期される。
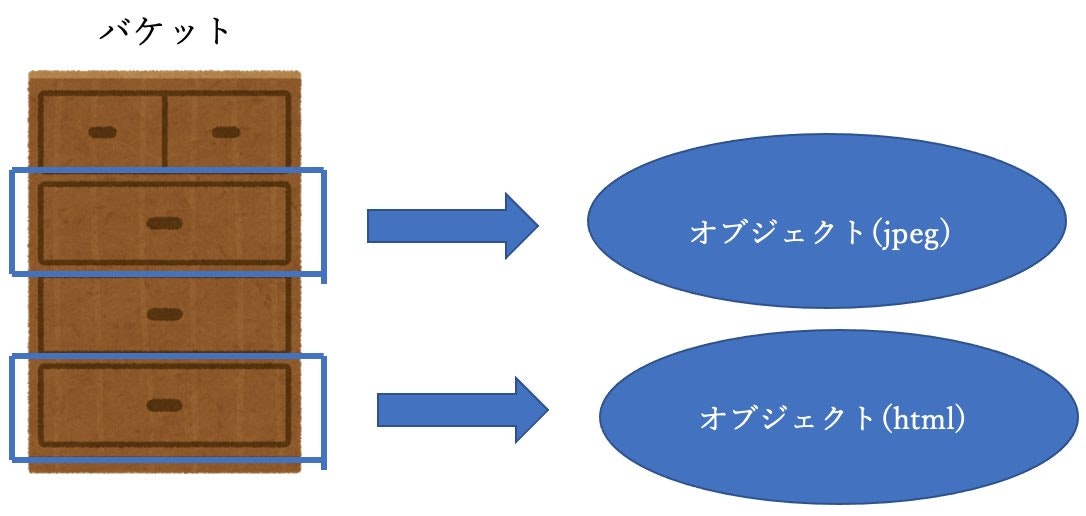
要するに、「更新したら勝手に全体に反映される」ということ。バケットとオブジェクト
データ保存は、バケットを作成して、オブジェクトとしてデータを保存する。
バケットは複数個作成可能で、バケット単位で参照、作成、削除等のアクセス制限を設定する。
オブジェクトの最大サイズ 5TBで、保存できる数に制限はありません。
ストレージオプション
①標準ストレージ
指定された1年間に99.999999999%の堅牢性と99.99%の可用性を提供、2拠点で同時にデータ損失起きてもデータが維持されるように設定されている。②低冗長化ストレージ指定された1年間に99.99%の堅牢性と99.99%の可用性を提供、単一の施設でデータ損失を防ぐように設定されている。コスト削減を目的とする場合選択。
Webホスティング機能
静的コンテンツに限ってWebサイトとしてホスティングする環境を簡単に設定作成することが可能。
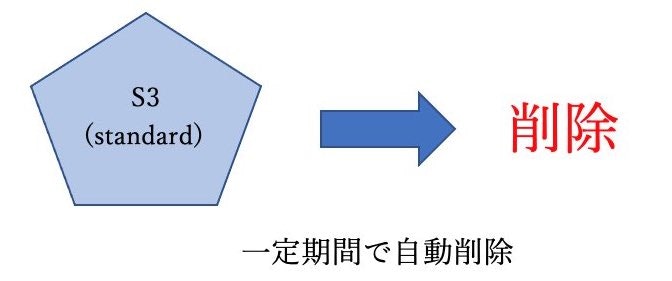
動的なコンテンツは、Webホスティングを使用することはできない。ライフサイクル設定
オブジェクトの作成から、上書き・削除までの期間をライフサイクルとしてどのように管理するか設定できる機能。
【管理方法】
・スケジューリングによる削除処理
・Amazon Glacierへのアーカイブ
Amazon Glacier
S3と同様に99.999999999%の耐久性を持ちながら、さらに低下価格で利用できるアーカイブストレージサービス。
低価格であるが、データ取り出しに時間がかかります。
長期間保存し、アクセス頻度が低く取り出し時間がかかっても問題のないデータを保存することに適している。
- 投稿日:2021-02-27T18:50:36+09:00
TerraformでCodeBuildのレポート機能を使ってみる
はじめに
昨年5月に CodeBuild のレポート機能が追加されたが、自分の所属するプロジェクトでは自動テストやカバレッジのレポートは既に別のソリューションを導入していたのであまり触っていなかった。
今回、別の記事を書くにあたり、この辺りの機能を試してみたくなったので、併せて使ってみた。なお、本記事の前提知識として、
- CodeBuild のプロジェクトを IaC で書いたことがある
- CodeBuild のレポート機能の概要を知っている
ことが前提となる。
※CodeBuild のレポート機能の概要は例によってクラスメソッド先生が分かりやすい必要な Terraform リソース
必要なリソースは、
aws_codebuild_report_groupだ。
テストレポートとカバレッジレポートで出力が違うため、typeプロパティで指定ができる。一癖あるのが
nameプロパティで、AWS公式ドキュメントによると、「CodeBuildのプロジェクト名」-「Buildspec の reports セクションで指定するグループ名」という名前が適用されるらしい(変更できるかはよく分からない)。
そんな感じなので、以下のように定義する。################################################################################ # S3 # ################################################################################ resource "aws_s3_bucket" "test" { bucket = local.s3_testreport_bucket_name acl = "private" } resource "aws_s3_bucket" "coverage" { bucket = local.s3_coveragereport_bucket_name acl = "private" } ################################################################################ # CodeBuild # ################################################################################ resource "aws_codebuild_report_group" "test" { name = "${local.codebuild_project_name}-${local.codebuild_test_reportgroup_name}" type = "TEST" export_config { type = "S3" s3_destination { bucket = aws_s3_bucket.test.id encryption_disabled = false encryption_key = data.aws_kms_key.aws_s3.arn } } } resource "aws_codebuild_report_group" "code_coverage" { name = "${local.codebuild_project_name}-${local.codebuild_codecoverage_reportgroup_name}" type = "CODE_COVERAGE" export_config { type = "S3" s3_destination { bucket = aws_s3_bucket.coverage.id encryption_disabled = false encryption_key = data.aws_kms_key.aws_s3.arn } } }そんなに難しいことはないが、公式ドキュメントによると、
Note: the API does not currently allow setting encryption as disabled
とのことで、encryption_disabled が無効にできないんだとか。
ということは、KMS が必要になるが、ここは別に AWS マネージドな KMS でも良いので、お手軽にやるなら
data "aws_kms_key" "aws_s3" { key_id = "alias/aws/s3" }な感じで S3 バケット用のエイリアスを引っ張ってきて設定しよう。
当然ながら、S3 バケットに PutObject をするための権限を CodeBuild のサービスロールに付与するのを忘れないように。ちなみに、
export_configでNO_EXPORTを指定することも可能だが、エラーが出たときにプレーンなファイルが残っていないと調査が困難なので、最初は出力しておくのがオススメ。Buildspec での指定
レポートを出力するには、出力形式に合わせたフォーマットで Buildspec 上でファイルを渡してあげなければいけない。
テストとカバレッジであれば以下ように両方を指定する。reports: ${TEST_REPORTGROUP_NAME}: files: - "report/report.xml" file-format: "JUNITXML" ${COVERAGE_REPORTGROUP_NAME}: files: - "report/coverage.xml" file-format: "COBERTURAXML"環境変数になっている部分が、グループ名だ。
↑で作ったグループ名の書き換え忘れがないように、CodeBuild の環境変数で渡すようにしている。################################################################################ # CodeBuild # ################################################################################ resource "aws_codebuild_project" "test" { (中略) environment { environment_variable { name = "TEST_REPORTGROUP_NAME" value = local.codebuild_test_reportgroup_name } environment_variable { name = "COVERAGE_REPORTGROUP_NAME" value = local.codebuild_codecoverage_reportgroup_name } } (後略)実際に出力するファイルの形式については、言語によっても異なるので、それぞれの言語に合わせて対応してもらいたい。
詳細は AWS の公式ドキュメントに書かれている。いざ、動かす!
さて、これで CodeBuild を実行すれば、レポートのタブから以下のように結果が確認できるようになる。
さらに、ここからレポートに飛ぶことで、以下のようにテストとカバレッジのレポートを確認できる。
テストレポート
また、グループのトップに行けば、エラーの推移等も確認可能だ。
カバレッジレポート
こちらもグループのトップから推移の確認が可能。
余談
ちなみに、レポートグループにレポートが残っていると、
aws_codebuild_report_groupのdestroy時にInvalidInputException: Report group could only be deleted after its reports are deletedなエラーが出て消せない。S3バケットの
force_destroyプロパティみたいなものが出てほしい……。
※実運用上ではこのリソースを消すことはあまりなさそうなので、実質問題ないとは思うが。



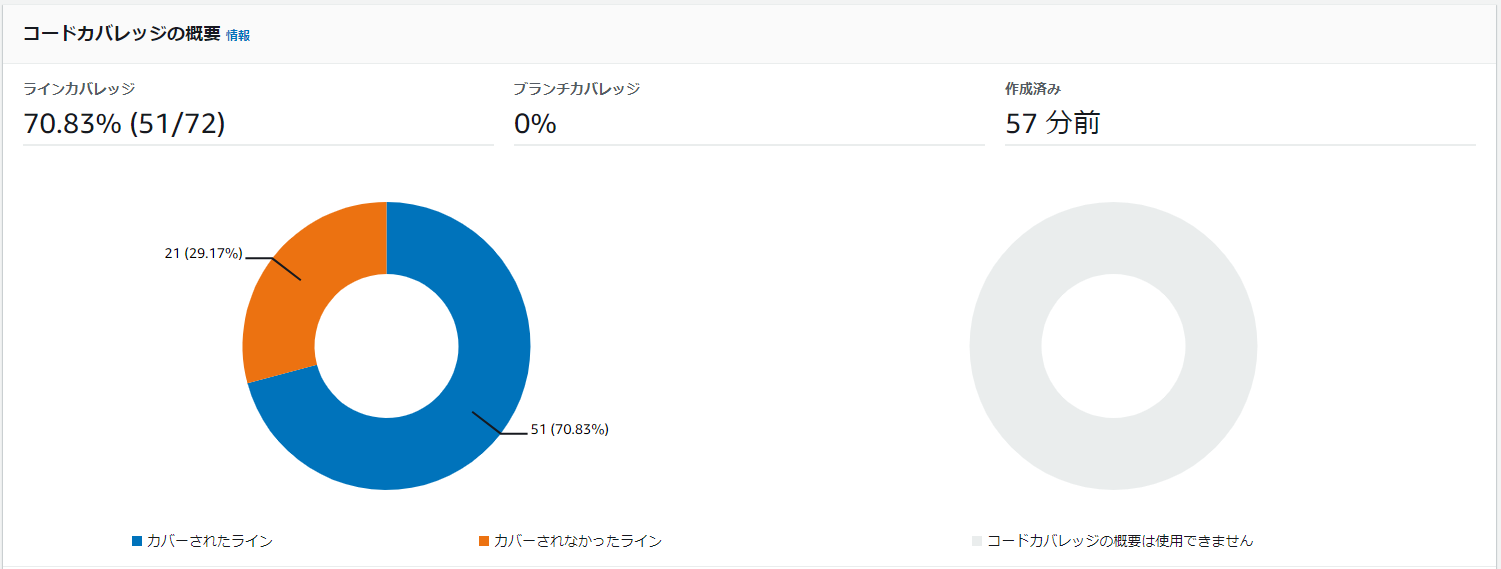

- 投稿日:2021-02-27T18:40:46+09:00
パッチマネージャー で hooks をかけれるように
内容
[Feb 3, 2021]パッチインストール時の安全性を向上させるパッチ適用の前と後のアクション
パッチの前後にhooksをかけて、アクションを実行出来るようになりました。
例えば、Windowsにパッチをあてる前に、WindowsUpdateサービスが立ち上がっているか確認してあげたり、あるいは、パッチ実行後にインスタンスが正常に動いているか確認してあげたりアクションを指定してあげることが可能になったようです。
なお、SSM Agent 3.0.502 以降 に対応している必要があります。コンソール画面を確認してみると、「今すぐパッチ適用」から次のような項目が新しくできていました。
現時点では、自己所有の Run Command ドキュメントのみ指定可能なようです。
こちらにやって見た系の記事がありました。
AWS Systems Manager Patch Manager でパッチ適用前後にアクションが実行できるようになりました!方法によっては、動作に若干の差があることに注意が必要そうです。
A. AWS System Manager >>> パッチマネージャー >>> 今すぐパッチ適用
B. AWS Systems Manager >>> Run Command >>> コマンドの実行A.の方法で実施した場合は、「On Exit」にRun Command ドキュメントを指定しても、デフォルトの AWS-Noop のまま変化がないようです。。。
やってみた系
本件のアップデートとは関係ないですが、パッチマネージャーの関連リソースについて上手くまとめられていたので、理解のために。。。
【AWS Systems Manager】パッチマネージャーの パッチベースライン と パッチグループ の概念を勉強する
【AWS Systems Manager】パッチマネージャー実行時の関連リソースを、絵で見て(完全に)理解する。パッチマネージャーを指定した場合の関連リソースについての関係をおっていうことが目的なので、細かなところは画面を見て行けばいいので、割愛する。
パッチマネージャー
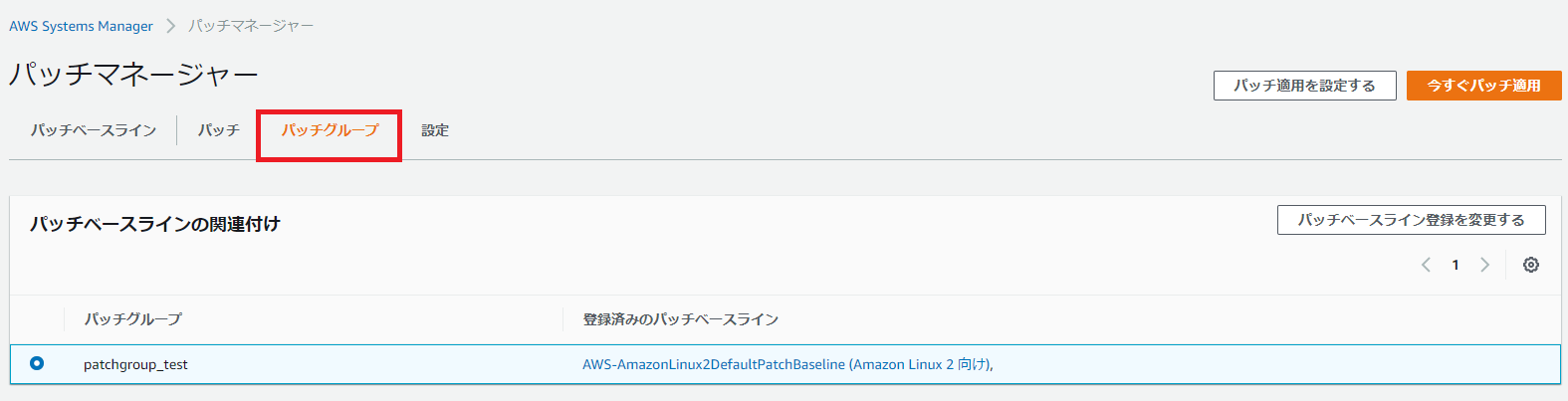
パッチグループ
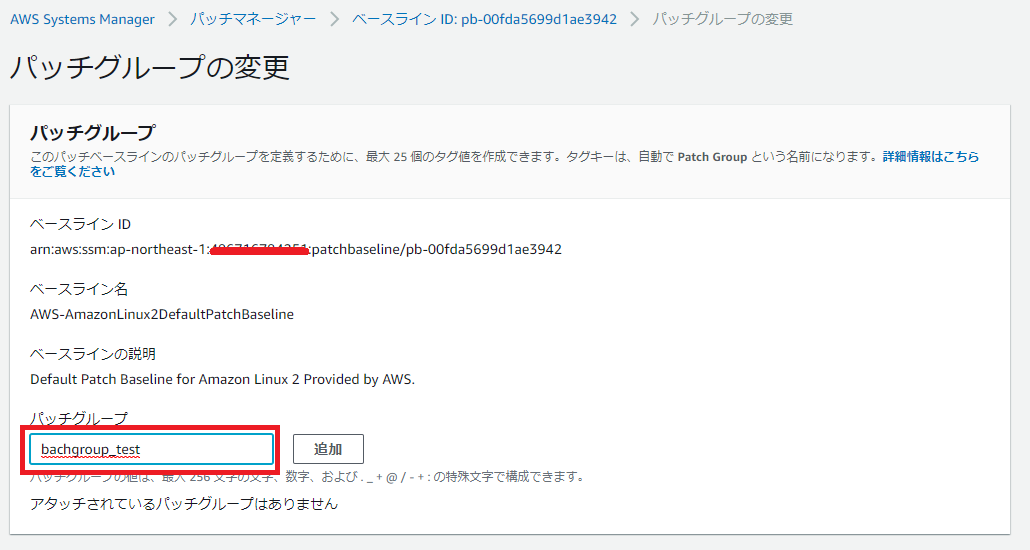
パッチベースラインタブより、AWS-AmazonLinux2DefaultPatchBaseline を選択し、「アクション」から「バッチグループの変更」。
「パッチグループ」名を入力し追加。
パッチグループ タブで作成されていることを確認。なお、パッチグループ タブから新規で作成するということはできないようだ。
このパッチグループに所属させたいEC2インスタンスには、次のようにタグを付与しておく。
・キー:patch group
・値:patchgroup_test(指定したパッチグループ名)パッチ適用
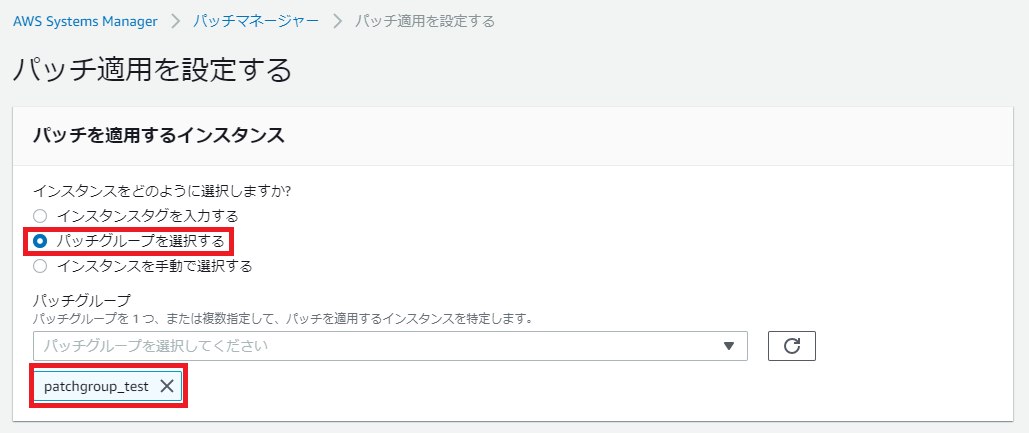
パッチを適用するインスタンス
「パッチグループを選択する」で、先程作成したパッチグループを指定する。
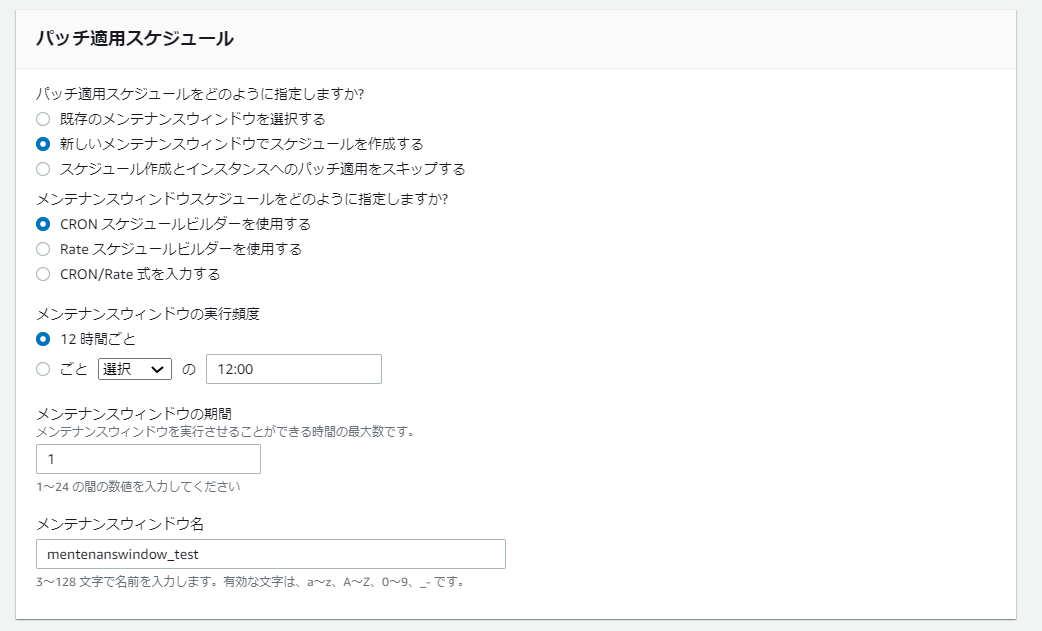
メンテナンスウィンドウの実行頻度
特に細かな指定はありませんが、次の時間に実行されるように指定。
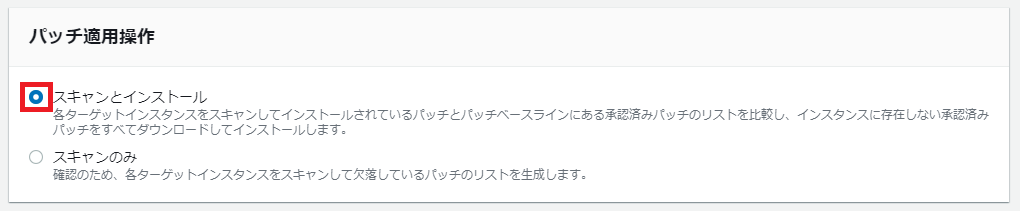
パッチ適用操作
「スキャンとインストール」を選択。
毎日0時、12時間おきに実行されるように指定したので、次はこれをメンテナンスウィンドウで詳細を確認してみる。
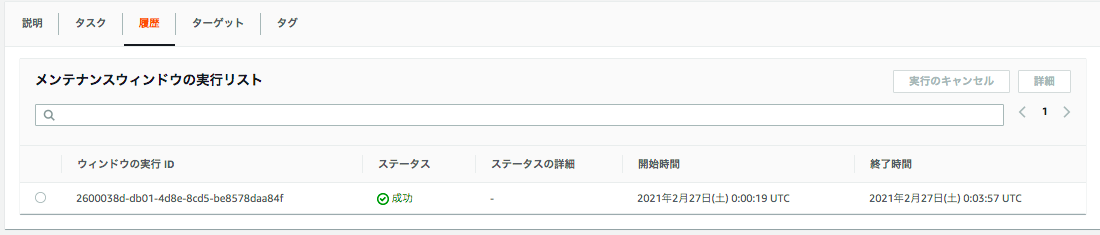
メンテナンスウインドウ
先程パッチ適用で作成したものが、メンテナンスウィンドウから確認することが出来る。
実際に1度実行された後なので、履歴 タブを開くと、実行履歴を確認できる。
では、この実行は Run Command で実行されているはずなので、Run Command を確認してみる。
Run Command
コマンド履歴 タブを確認する。
AWS-RunPatchBaseline が実行されていることがわかる。
では、AWS-RunPatchBaseline はどのような内容が実行されるのか、ドキュメントで詳細を確認してみると。
ドキュメント
AWS-RunPatchBaseline を検索して、コンテンツ タブを開く実行される内容がわかる。
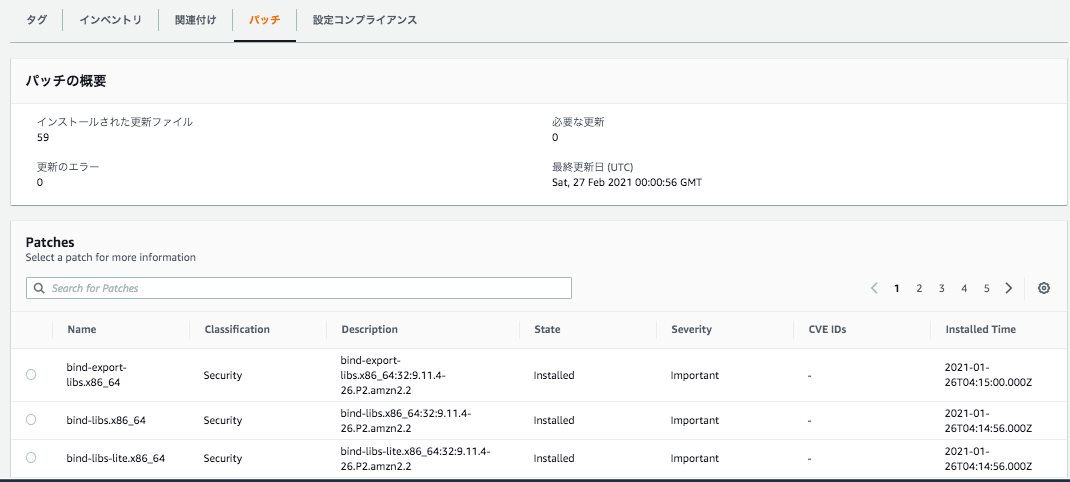
最後にインスタンスごとに実行された内容、結果をマネージドインスタンスから確認してみると。
マネージドインスタンス
パッチ タブを選択すれば、インスタンスごとにインストールされたなどを確認することができる。





- 投稿日:2021-02-27T18:09:12+09:00
USキーボードでAWS (EC2) を使う。manpath: can't set the locale; の解決策。
問題
EC2でログインすると、以下のエラーが表示される。
manpath: can't set the locale; make sure \$LC_* and $LANG are correct(USキーボードを使用している記事があまり見当たらずに苦労したため、メモとして残しておきます。)
エラー内容
~ % ssh aws_key_rsa Last login: Sat Feb 27 17:21:44 2021 from kd059138042141.ppp-bb.dion.ne.jp __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ -bash: warning: setlocale: LC_CTYPE: cannot change locale (us_US.UTF-8): No such file or directory -bash: warning: setlocale: LC_COLLATE: cannot change locale (us_US.UTF-8): No such file or directory -bash: warning: setlocale: LC_MESSAGES: cannot change locale (us_US.UTF-8): No such file or directory -bash: warning: setlocale: LC_NUMERIC: cannot change locale (us_US.UTF-8): No such file or directory -bash: warning: setlocale: LC_TIME: cannot change locale (us_US.UTF-8): No such file or directory manpath: can't set the locale; make sure $LC_* and $LANG are correct [user@ip-address ~]$エラーが起きた時の状況
インスタンス作成後は、以下のようにタイムゾーンにUTC(世界協定時刻)がデフォルト設定されていました。
$ timedatectl Local time: Sun 2019-08-25 10:27:53 UTC ……① Universal time: Sun 2019-08-25 10:27:53 UTC RTC time: Sun 2019-08-25 10:27:52 Time zone: UTC (UTC, +0000) ……② System clock synchronized: yes NTP service: active RTC in local TZ: no私は、上の ①Local time と ②Time zone に変更を加えました。
$ timedatectl list-timezones | grep Asia/Tokyo Asia/Tokyo # 日本時間がタイムゾーンに設定可能かどうかを確認するコマンド。 $ sudo timedatectl set-timezone Asia/Tokyo # Time zone を Asia/Tokyo に変更する。その結果が、以下の ①’ と ②’ です。
[user@ip-address ~]$ timedatectl Local time: 日 2021-02-28 08:31:59 JST ……①’ Universal time: 土 2021-02-27 23:31:59 UTC RTC time: 土 2021-02-27 23:31:59 Time zone: Asia/Tokyo (JST, +0900) ……②’ NTP enabled: yes NTP synchronized: yes RTC in local TZ: no DST active: n/aこのあたりで、ログイン時にエラーが出るようになりました。
※複数の設定を同時に変更していたため、デフォルトから上の状況だけを試した場合、再現性がない場合があります。エラーが起こる時の環境変数
[user@ip-address ~]$ locale locale: Cannot set LC_CTYPE to default locale: No such file or directory locale: Cannot set LC_MESSAGES to default locale: No such file or directory locale: Cannot set LC_ALL to default locale: No such file or directory LANG=us_US.UTF-8 LC_CTYPE="us_US.UTF-8" LC_NUMERIC="us_US.UTF-8" LC_TIME="us_US.UTF-8" LC_COLLATE="us_US.UTF-8" LC_MONETARY="us_US.UTF-8" LC_MESSAGES="us_US.UTF-8" LC_PAPER="us_US.UTF-8" LC_NAME="us_US.UTF-8" LC_ADDRESS="us_US.UTF-8" LC_TELEPHONE="us_US.UTF-8" LC_MEASUREMENT="us_US.UTF-8" LC_IDENTIFICATION="us_US.UTF-8" LC_ALL= [user@ip-address ~]$ localectl System Locale: LANG=us_US.UTF-8 #この列を、以下で編集していきます。 VC Keymap: us X11 Layout: us X11 Model: pc105+inet X11 Options: terminate:ctrl_alt_bksp [user@ip-address ~]$ timedatectl Local time: 日 2021-02-28 08:19:29 JST ……①’ Universal time: 土 2021-02-27 23:19:29 UTC RTC time: 土 2021-02-27 23:19:29 Time zone: Asia/Tokyo (JST, +0900) ……②’ NTP enabled: yes NTP synchronized: yes RTC in local TZ: no DST active: n/a [user@ip-address ~]$ vim /etc/locale.conf Lang=us_US.UTF-8解決策
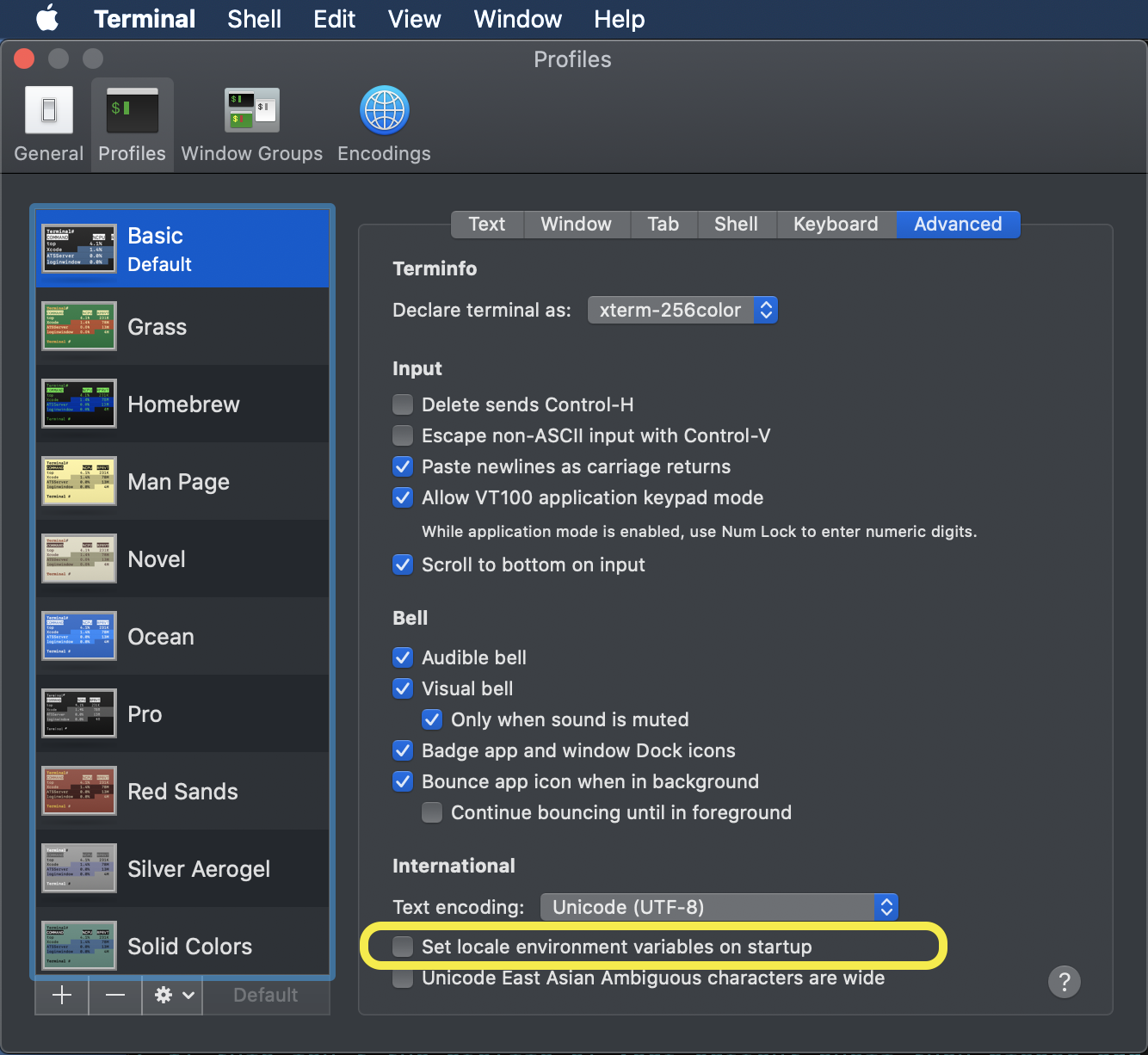
①Terminal の設定を変える
Terminal > Preferences > Profiles > Advanced > Set locale environment variables on starup のチェックを外す。
②Language & Region の確認
Region が Japan に、そして Preffered languages のトップが English にしています。③ $LANG の変更
vim /etc/locale.conf Lang=ja_JP.utf8④System Locale を変更する
[user@ip-address ~]$ sudo localectl set-locale LANG=ja_JP.utf8 [user@ip-address ~]$ localectl System Locale: LANG=ja_JP.utf8 #先ほどの LANG=us_US.UTF-8 から変わりました。 VC Keymap: us X11 Layout: us X11 Model: pc105+inet X11 Options: terminate:ctrl_alt_bksp [user@ip-address ~]$ vi /etc/locale.conf⑤rebootして、再度ログインする。
$ sudo reboot Connection to {IPアドレス} closed by remote host. Connection to {IPアドレス} closed. % ssh aws_key_rsa Last login: (略) __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ [user@ip-address ~]$これでエラーがなく、EC2にログインできました。
補足①
[user@ip-address ~]$ locale LANG=ja_JP.utf8 LC_CTYPE="ja_JP.utf8" LC_NUMERIC="ja_JP.utf8" LC_TIME="ja_JP.utf8" LC_COLLATE="ja_JP.utf8" LC_MONETARY="ja_JP.utf8" LC_MESSAGES="ja_JP.utf8" LC_PAPER="ja_JP.utf8" LC_NAME="ja_JP.utf8" LC_ADDRESS="ja_JP.utf8" LC_TELEPHONE="ja_JP.utf8" LC_MEASUREMENT="ja_JP.utf8" LC_IDENTIFICATION="ja_JP.utf8" LC_ALL=LC_*が自動で切り替わっていることが確認できました。
補足② (当時の私の .bash_profile の状況です。)
[user@ip-address ~]$vim .bash_profile # Get the aliases and functions if [ -f ~/.bashrc ]; then . ~/.bashrc fi # User specific environment and startup programs PATH=$PATH:$HOME/.local/bin:$HOME/bin export PATH export PATH="$HOME/.rbenv/bin:$PATH" eval "$(rbenv init -)"環境変数についての投稿のため、補足しておきます。

- 投稿日:2021-02-27T18:02:13+09:00
AWS 公式 User Guide のすすめ
AWS はとかく難しい。
ネットを検索するとAWSに関する記事は山ほど見つかる。ところが、AWS自体が急速に進化しているために、内容が古くなっているものも多い。記述が断片的だったり、不正確な記事もまた多い。というわけで、AWSに関する正確な情報を得るのは案外難しい。
…と思っていた。この公式 User Guide に出会うまでは。
英語 https://docs.aws.amazon.com/
日本語 https://docs.aws.amazon.com/ja_jp/このサイトには、AWSのサービスごとに極めて詳細なガイドブックがすべて無料で公開されている。おすすめはPDF版。これはもはや一冊の本である。体系的な知識が学べる。しかも無料で読み放題なのだ!読まない手はないだろう。
Amazon は米国の企業であり、すべてのドキュメントはもともと英語で書かれている。その後、日本語訳されているものも多い。だが、正直、日本語訳は文体がこなれておらず、読みにくい。可能な限り、英語で読むことをおすすめする。それが難しい場合は、日本語版を読みながら、ときどき対応する箇所を英語版で読むといい。
私はとりあえず、
を中心にいま読み進めているところだ。私の考えでは、AWS の各リソースへの権限周りの話が一番ややこしく、セキュリティ上も極めて重要だからだ。AWSの肝ではないかと思っている。
- 投稿日:2021-02-27T17:03:59+09:00
はい、CodePipelineのビルドで「An error occurred (AccessDeniedException) ~」と怒られた人集合
DockerのコンテナをいちいちビルドしてECRにプッシュするの面倒くさいなと思い、CodePipelineというサービスを使ったのですが、何回ビルドしても以下のようなエラーが起きるんです。
An error occurred (AccessDeniedException) when calling the GetAuthorizationToken operation: User: arn:aws:sts::***:assumed-role/zaemonia/AWSCodeBuild-*** is not authorized to perform: ecr:GetAuthorizationToken on resource: * Error: Cannot perform an interactive login from a non TTY device [Container] 2021/02/27 06:47:26 Command did not exit successfully aws ecr get-login --no-includeemail --region a--northeast-1 exit status 1 [Container] 2021/02/27 06:47:26 Phase complete: PRE_BUILD State: FAILED要するにECRのリポジトリにアクセスする権限が無いんですね。
じゃあ追加してあげましょう!!
サービス検索欄で「CodePipeline」と検索。
「ビルド」→「ビルドプロジェクト」→任意のビルドプロジェクトをクリック。
このような画面になると思います。
ここから「ビルドの詳細」タブから「環境」→「サービスロール」をクリック。
「ポリシーをアタッチします」→「AmazonEC2ContainerRegistryPowerUser」を追加してください!
これでビルド無事ビルドを行うことができます。
ちゃっかり時間かかったのでくれぐれもお気を付けください。
以上、「はい、CodePipelineのビルドで「An error occurred (AccessDeniedException) ~」と怒られた人集合」でした!
また、何か間違っていることがあればご指摘頂けると幸いです。
他にも初心者さん向けに記事を投稿しているので、時間があれば他の記事も見て下さい!!
あと、最近「ココナラ」で環境構築のお手伝いをするサービスを始めました。
気になる方はぜひ一度ご相談ください!
Thank you for reading

- 投稿日:2021-02-27T16:37:12+09:00
GraphQLのマネージド・サービス AWS AppSyncを軽く触ってみた
はじめに
以前、Node.js+MongoDB構成で簡単なGraphQLサーバをつくりました。Schema, Query, Mutationの作成に意外と時間がかかったので、もっと簡単に構築できる方法がないか調べたところ、AWSにAppSyncというサービスがあることを知りました。AppSyncを使うと、Schemaを作成するだけでQueryとMutationの作成やDB接続を簡単にできるということだったので、学習のために触ってみることにしました。
AWS AppSyncとは
AppSyncはGraphQLのマネージド・サービスです。
以下の特徴があり、このサービスを使うと拡張性高くセキュアなリアルタイムアプリケーションを簡単に作ることができます。
- Schemaを定義するだけでQueryとMutationとSubscriptionを自動作成
- DBとの自動接続
- 複数のDBの切り替え
- データへのセキュアなアクセス
- オフラインアクセス
*Subscriptionというのは、リアルタイムでデータを取得するために使われるものです。これを使うと、例えばクライアントAがデータ登録を行ったときに、クライアントBの表示がデータ登録後の値にリアルタイムで切り替わります。
Black Beltの資料にもっと詳しい内容が載っています。
API作成手順
AWSマネジメントコンソールでAWS AppSyncを検索し、
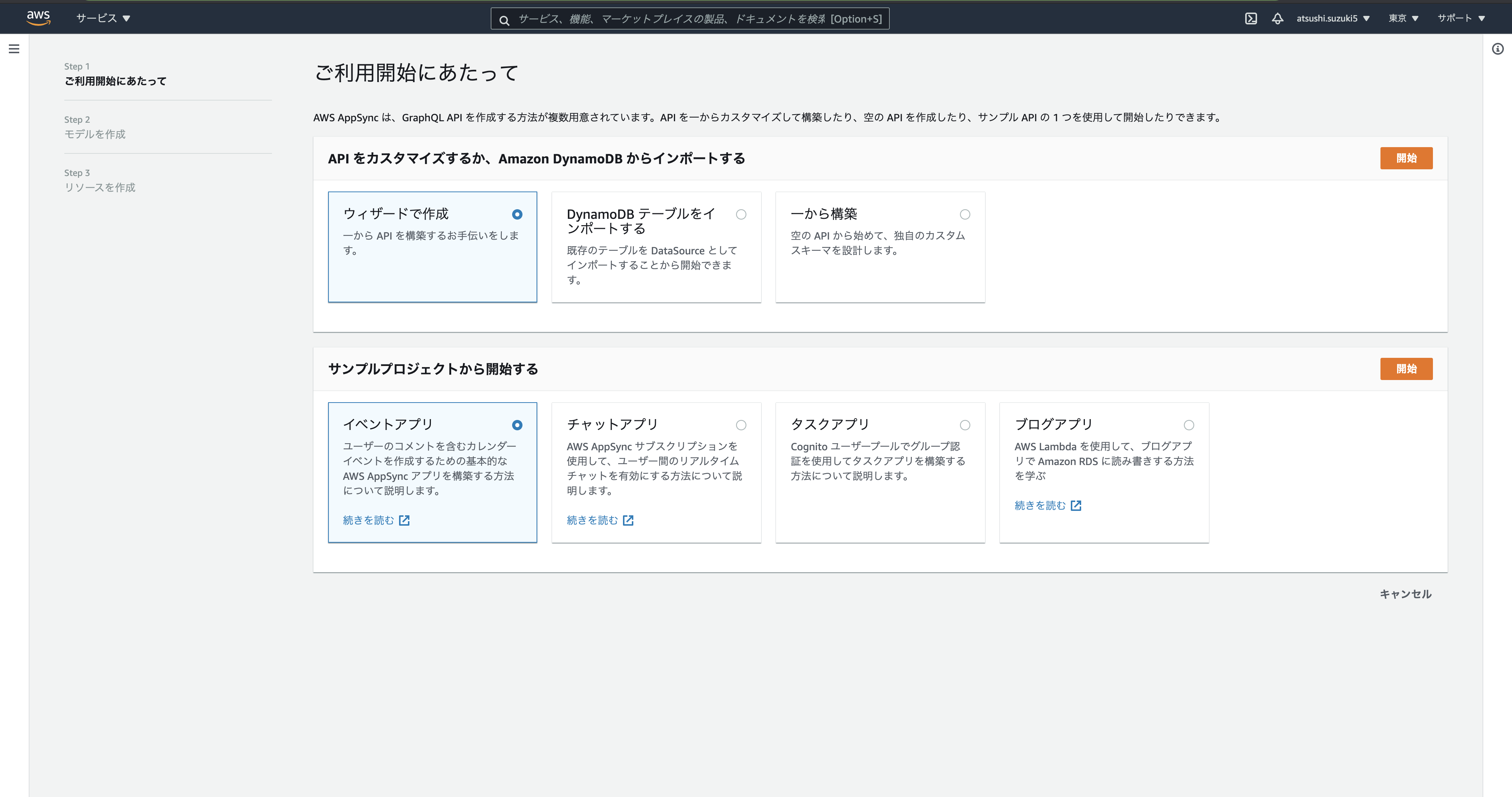
APIを作成を選択すると以下の画面になります。
APIを作成する方法が6つあるのですが、今回は1からAPI構築する手順を学ぶのが目的なので、ウィザードで作成を選択します。
モデルを作成する画面になります。モデルはGraphQLのSchemaにあたるもので、ここで名前やフィールドの設定を行います。モデルテーブルは対応するDBのテーブルにあたります。
API名を入力して
作成を押します。
以下の画面になります。スキーマの画面にMutationとQueryが作成されていることを確認できます。
また、データソースをみるとDynamoDBにテーブルが自動で作成されていることも確認できます。
試しにクエリからMutation(CreatePracticeAppType)を実行すると、ちゃんとDBにデータが登録されています。
AWSコンソールにログインしてからここまでなんと3分しか経っていません。すげー。
resolverのカスタマイズ
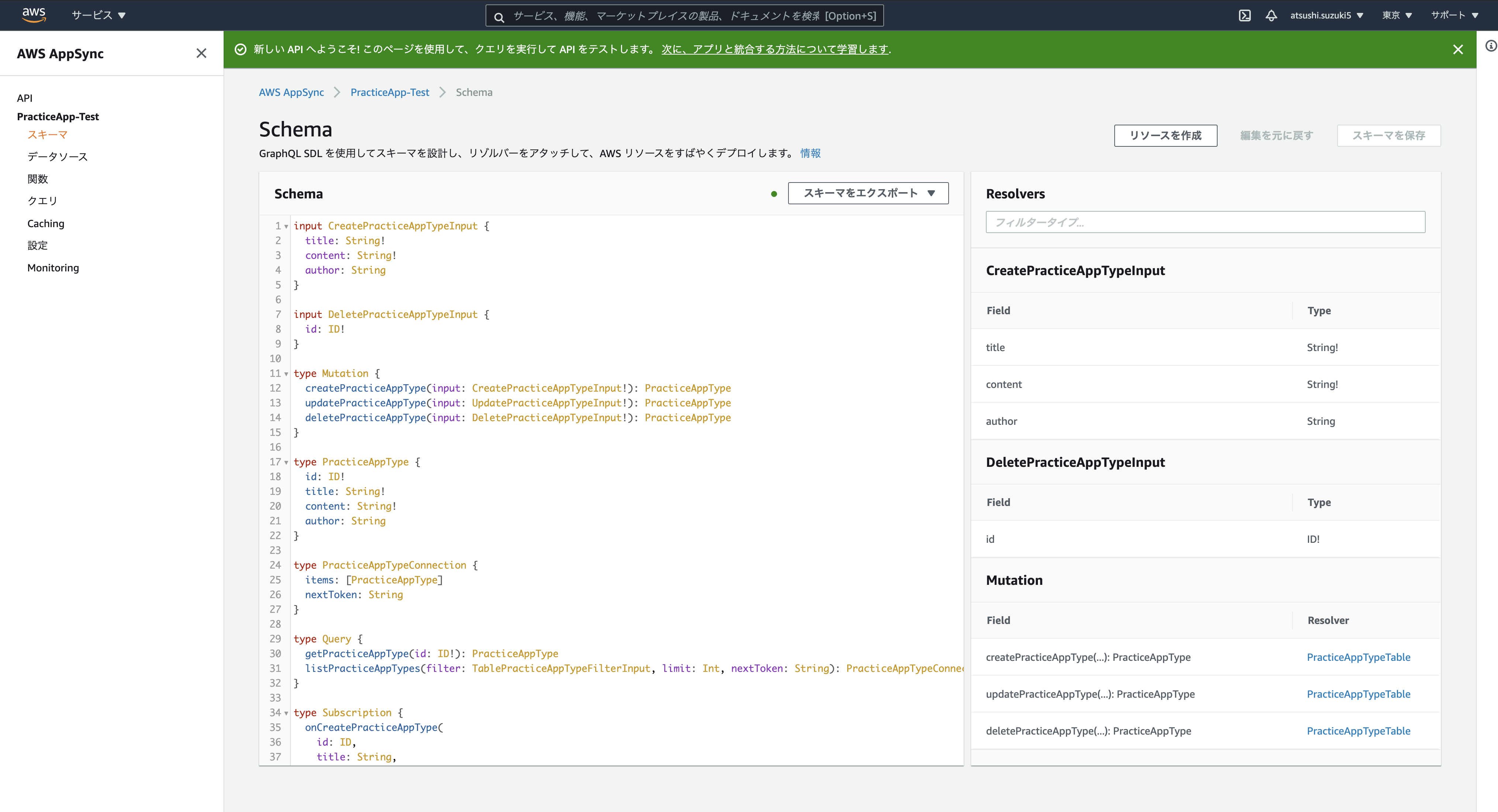
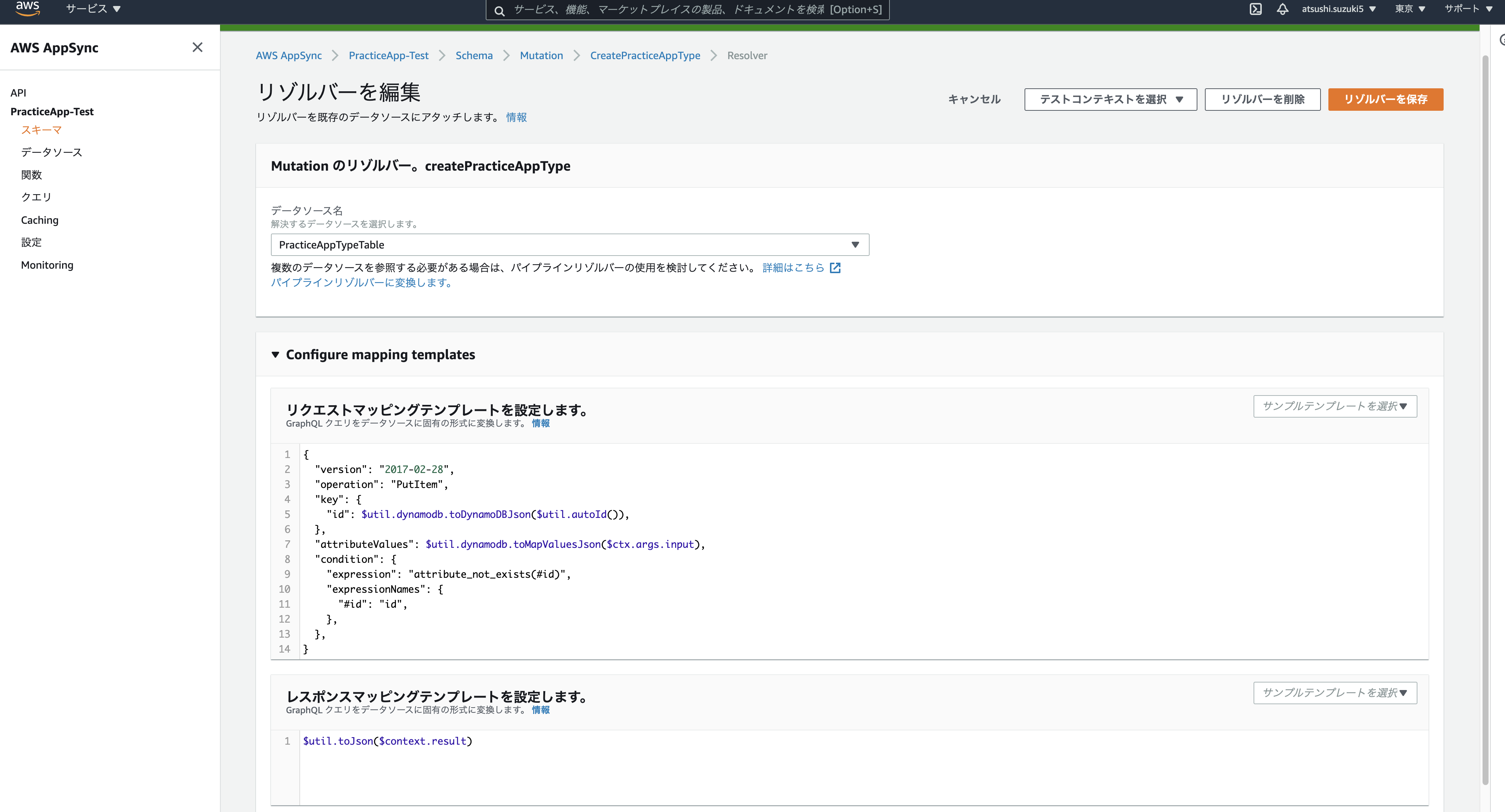
Muttionを実行できたのでresolverも自動で設定されているわけですが、こちらのカスタマイズも自由に行うことができます。GraphQLリクエストをデータソースの命令に変換する側(リクエストマッピングテンプレート)と、データソースからの応答をGraphQLレスポンスの応答に変換する側(レスポンスマッピングテンプレート)の2つをVTLという言語で好きにカスタマイズすることができます。
クライアント(アプリ)との接続
amplifyというサーバレスなバックエンドを簡単に構築するためのJavaScriptライブラリを使うことで、AppSyncで作成したGraphQL APIを自分のアプリと接続することができるようになります。
おわりに
今度はAWS Amplifyを使って、APIを含めたバックエンドの構築をやってみたいと思います。





- 投稿日:2021-02-27T14:00:55+09:00
Sagemakerの公式コンテナに好きなパッケージを追加して使う方法
概要
AWS の Sagemaker で
公式に用意されているもの以外に好きなパッケージを追加して使いたいと思った時
あまり日本語の情報が無かったので、
今回私が公式のコンテナを拡張するためにやった方法をまとめてみました。(1回やっただけで細かい動作確認などはまだ行っていないので、間違ってる所があったらごめんなさいm(__)m)
方法
1. 拡張したいコンテナのURLを探す
以下のサイトから自分が拡張したいコンテナのURLを選びます。
deep-learning-containers/available_images.md at master · aws/deep-learning-containers · GitHub大体の場合はGeneral Framework Containersの中から選べばいいと思います。
Elastic Inferenceを使いたい場合は多分Elastic Inference Containersから選べばOKです。
学習時に使うコンテナの場合はJob Typeがtrainingのものを、推論時に使うならinferenceのものを選んでください。
また、自分の使うpythonのバージョンに合ったものを選んでください。ページ上部にあるリージョンの表から、作ったコンテナを使いたいリージョンを選択し、
URLの前半部分は該当するURLに差し替えてください。例)東京リージョンで使う予定で、CPUインスタンスでTensorflow2.3.1を使って推論を実行したいなら
763104351884.dkr.ecr.ap-northeast-1.amazonaws.com/tensorflow-inference:2.3.1-cpu-py37-ubuntu18.042. Dockerfileの作成
コンテナを作るためのDockerfileを作成します。
DockerfileFROM <1.で選んだURL> RUN pip install <入れたいパッケージ> RUN apt-get install -y <入れたいもの>というように、
拡張したいdocker imageをFROMで呼び出してから、
RUNを使って追加したいパッケージを入れるようにします。3. コンテナの構築とECRへのアップロード
コマンドラインで
docker build -t <新しいコンテナの名前(任意)> .を実行し、新しいコンテナを構築します。
次に、
aws ecr get-login-password --region <1.で選んだリージョン> | docker login --username AWS --password-stdin <自分のアカウントID>.dkr.ecr.<1.で選んだリージョン>.amazonaws.comを実行してECRにログインした後、コマンドラインで以下の内容を実行してください。
(シェルスクリプト化してshコマンドで実行してもOK)push_docker_image.shalgorithm_name=<作ったコンテナの名前> region=<1.で選んだリージョン> account=$(aws sts get-caller-identity --query Account --output text) fullname="${account}.dkr.ecr.${region}.amazonaws.com/${algorithm_name}:latest" # If the repository doesn't exist in ECR, create it. aws ecr describe-repositories --repository-names "${algorithm_name}" > /dev/null 2>&1 if [ $? -ne 0 ] then aws ecr create-repository --repository-name "${algorithm_name}" > /dev/null fi # Build the docker image locally with the image name and then push it to ECR # with the full name. docker build -t ${algorithm_name} . docker tag ${algorithm_name} ${fullname} docker push ${fullname}これで作ったコンテナがECRにアップロードされたはずです。
4. 作ったコンテナを使ってSagemakerを使用する
例えば、Tensorflowの学習済みモデルを使ってSagemakerのモデルを作りたいなら、
モデルのオブジェクトを作る時のimage_uri引数として
さっきのfullnameにあたるURLを指定してやれば使えます。from sagemaker.tensorflow.model import TensorFlowModel model = TensorFlowModel(model_data="hoge.tar.gz", role=role, image_uri="<自分のアカウント番号>.dkr.ecr.<1.で選んだリージョン>.amazonaws.com/<作ったコンテナ名>")参考ページ
コンテナの拡張方法を説明したAWS公式のガイド:
構築済みのコンテナの拡張 - Amazon SageMaker公式コンテナのURLのリスト(1.で使ったものです):
deep-learning-containers/available_images.md at master · aws/deep-learning-containers · GitHub以下のサイトではSagemakerのモデルを作る時に使うクラスの仕様(引数などについて)が解説されてます。
全てのフレームワークで共通の仕様
Model — sagemaker 2.26.0 documentation各フレームワークごとの仕様
Frameworks — sagemaker 2.26.0 documentation例えば、Tensorflowを使うなら以下のページ
TensorFlow — sagemaker 2.26.0 documentation
- 投稿日:2021-02-27T13:34:37+09:00
matplotlibで描いたグラフをAWS LambdaでS3にアップロードする
lambda
権限の問題によりtmpディレクトリ下に保存する。
lambda_function.pyimport matplotlib.pyplot as plt import boto3 def upload(): fig = plt.figure() plt.plot([1, 2, 3], [4, 5, 6]) fig.savefig('/tmp/sample.png') client = boto3.client('s3') client.upload_file( '/tmp/sample.png', 'lambda-upload-test-0227', 'sample.png' ) def lambda_handler(event, context): upload() return 0matplotlibのインポート
こちらの記事を参考にmatplotlibのARNをレイヤーに追加する。
参考記事
- 投稿日:2021-02-27T13:34:37+09:00
AWS Lambdaでmatplotlibでグラフ作成、S3にアップロードする
lambda
権限の問題によりtmpディレクトリ下に保存する。
lambda_function.pyimport matplotlib.pyplot as plt import boto3 def upload(): fig = plt.figure() plt.plot([1, 2, 3], [4, 5, 6]) fig.savefig('/tmp/sample.png') client = boto3.client('s3') client.upload_file( '/tmp/sample.png', 'lambda-upload-test-0227', 'sample.png' ) def lambda_handler(event, context): upload() return 0matplotlibのインポート
こちらの記事を参考にmatplotlibのARNをレイヤーに追加する。
参考記事
- 投稿日:2021-02-27T13:34:37+09:00
AWS Lambda matplotlibでグラフ作成、S3にアップロードする
lambda
権限の問題によりtmpディレクトリ下に保存する。
lambda_function.pyimport matplotlib.pyplot as plt import boto3 def upload(): fig = plt.figure() plt.plot([1, 2, 3], [4, 5, 6]) fig.savefig('/tmp/sample.png') client = boto3.client('s3') client.upload_file( '/tmp/sample.png', 'lambda-upload-test-0227', 'sample.png' ) def lambda_handler(event, context): upload() return 0matplotlibのインポート
こちらの記事を参考にmatplotlibのARNをレイヤーに追加する。
参考記事
- 投稿日:2021-02-27T13:14:50+09:00
AWS認定クラウドプラクティショナー 合格するまでにやったこと
久々の投稿です。タイトルに記載の資格を取ったので、何したら受かったかを書きます。
資格概要
AWS認定クラウドプラクティショナーとはどんな資格か、出題範囲、試験形式、試験時間、料金等概要は以下をご覧ください。
https://aws.amazon.com/jp/certification/certified-cloud-practitioner/私についてと受検に至る背景
- 分析・ITコンサル見習い。
- AWSサービスの構築は未経験。AWS
- Azureでの分析基盤構築ならちょこっと経験あるけど、主にSQL ServerでやらETLツールでデータ前処理したり分析事例調査したりしてました。
- EC2, S3とか単語はなんとなく知ってる程度。
- ベンダー資格(VMware Certified Professional)は約7年前に取ったことあるので、ベンダー資格特有の日本語文章のおかしさは体験済み。
- 何故受検したかというと、仕事で必要になったから。プロダクト企画支援案件(お客さんが新しくプロダクト作りたいけどどこから手をつけていいかわからないので、うちらは話聞きながら何から始めるか、ゴールは何かをまとめていきましょう案件)で、お客さんの環境がAWSで会話するとき必須の知識なので急いで基礎部分だけでも習得の必要がありました。
勉強期間とかけた時間
以下状況で、思い立ってから約1ヶ月、1日0〜4時間、約30時間かけました。
- 妊娠8ヶ月、妊娠してないときと比べ体力がもたず休憩を挟まなければならない、動きにくい、集中力低下ぎみらしいので作業時間減少、効率も低下していたと思われます。
- 仕事はたまに定時では終わらない程度の忙しさ。
使った教材と所感
テキスト
(1) AWS認定資格試験テキスト AWS認定 クラウドプラクティショナー
動画
(2) AWS Cloud Practitioner Essentials (Japanese)
https://www.aws.training/Details/eLearning?id=66479(3) Udemy「この問題だけで合格可能!AWS認定クラウドプラクティショナー模擬試験問題集」
https://www.udemy.com/share/101SaAAEMaeFlRQn8J/上記に加え、AWS公式YouTubeの Black Belt シリーズやAWS公式ドキュメントを必要に応じて確認しました。
1〜3の順番でやりました。
テキストについては要点はまとまってるけど、内容はこれだけでは不充分かなと思います。普段からAWS触ってる人にはわかりやすいのかもしれないかけど、私には頭に入ってきづらいと感じました。動画はコーヒーショップを例にわかりやすく解説してくれていて、簡単なテストを挟んで理解度を確かめながら進むので内容も頭に入ってきやすい、とても良かった。
ただまともに観ると6時間かかるので、ほぼ倍速で聴いてた。
動画から始めれば良かったのかも。他のブログにもあるようにUdemyも良かった教材。有料ですが、たまたまセールで1500円になっててラッキー!
最後の1週間はひたすら過去問やって、間違えたところはAWSのドキュメントやBlack Belt、テキストで復讐、を繰り返してました。
ただ、実際の試験に比べて全体的に難易度高めです。基礎と応用(とそれ以上)がありますが、応用レベルの問題はほぼ出てなかったと思います。
試験前日に応用レベルの問題を解いて正答率44%で絶望的な気持ちになりましが、1000点満点中917点取れたので、それくらいの正答率でも気を抜かずに諦めなければ大丈夫だと思います(笑)ホワイトペーパーやマネジメントコンソール、AWSの全サービスの確認もやらなきゃと思いつつできませんでした。。
試験当日の流れ
試験実施業者はピアソン VUEを選択し自宅で受検することにしました。初めて自宅で資格試験を受けたのですが、後述の通りちょっとしたトラブルがありました。
試験官とのコミュニケーション言語は英語と日本語が選べたので日本語にしました。メールの案内に従い、試験に使うピアソンVUEアプリをインストール、システムチェックを事前に完了する必要があり、忘れそうだったので1週間前にテストも無事完了。
しかし当日、試験30分前にチェックインしようとしたらアプリが古いらしく再インストール。
その後、部屋の写真、身分証明書、自分の顔写真をアップロードしチェックイン完了。
- チャットにて挨拶、部屋とデスクの様子をカメラに映す
- 腕を見せる、時計してないか確認するため
などしました。
このへんでチャット画面がめちゃめちゃ重くなり、最初の挨拶以外に、ウェルカム画面は見えてますか?とか聞かれたけど返答できず。最初の秘密保持的な同意画面も上手く操作できず時間切れで閉じてしまいました。。
試験をまともに受けられるか不安だったけど、試験中は普通に動作して回答できました。むちゃくちゃ焦った。。。
あとで気づきましたが、古いバージョンのアプリも立ち上がってて固まってたことも要因だったかも。。
次回以降の教訓として、システムテストは前日くらいにやっておこうと思いました。。かなりじっくり考えて解いても50分ほど時間が余ったので、30分ほどまたじっくり見直すことができました。
終わりに
初めてのAWSの資格、初めての自宅受検で色々不安でしたが、受検申し込み時に比べてかなり知識がついたと感じていて、受検して良かったです。これからIT業界行きたいと思ってる方、IT業界にいるけど開発してない、けどエンジニアとコミュニケーションする必要がある方(マネージャ、営業あたり?)にはおすすめの資格だと感じました。
今後はちょっと考え中です。1つ上の資格にソリューションアーキテクト(アソシエイト) があるけど、話を聞く限りかなりハードルが上がるので。。
引き続きゆるゆる頑張ります。
- 投稿日:2021-02-27T12:13:47+09:00
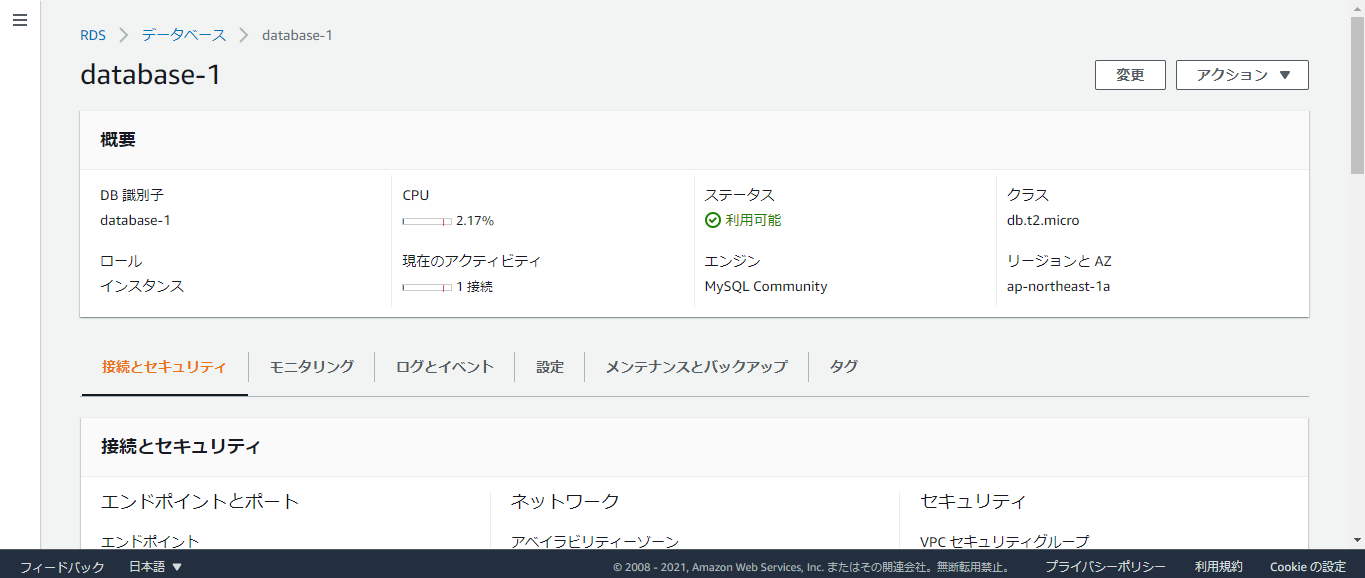
【AWS】EC2インスタンスで作成したLaravelとRDS(MySQL)を連携させる方法
今回はAWSのRDS(MySQL)についてい書いていきます。
AWSにもDockerにも段々慣れてきたのですが、まだまだ知らない機能の方が多いですね。
さて、早速説明していきましょう。
はじめに
まず初めに前提条件として以下の条件を満たしている前提で話を進めめていきます。
・ECSで既にLaravelに関するコンテナの環境が構築済み
・EC2インスタンスへのSSH接続が可能上記2つの条件を満たしていな場合は下記の記事にすべてやり方が書いてあるので是非ご覧ください!
【AWS】AWS超初心者が、頑張ってDockerで作ったLaravelプロジェクトをECR、ECS、EC2を使ってAWS上で動かしてみた
RDSでMySQLのデータベースを作成
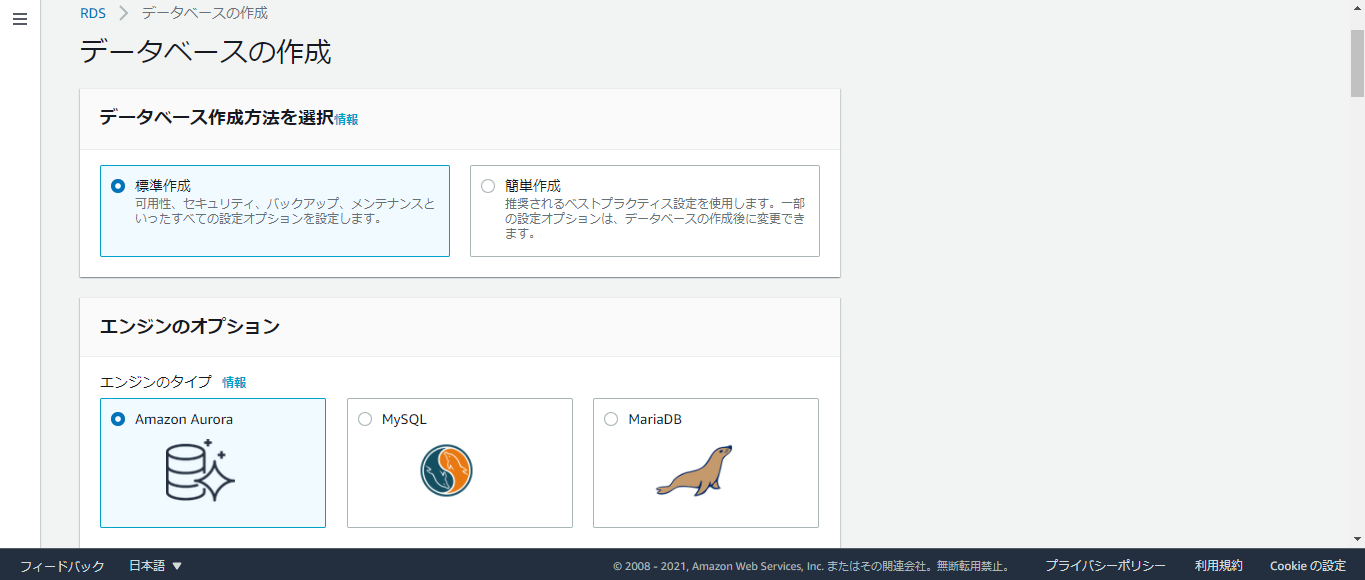
サービス検索欄から「RDS」と検索してください。
そして、「データベースの作成」をクリック。
するとこのような画面になると思います。
そしたら以下の条件を元にデータベースを作成してください。
データベースの作成方法 標準作成 エンジンのオプション MySQL バージョン 任意(大体8.*か5.7) テンプレート 本番稼働用 DBクラスター識別子 database-1 マスターユーザー名・マスターパスワード 任意 Virtual Private Cloud (VPC) 利用するEC2インスタンスと同じVPCを選択 パブリックアクセス可能 あり VPCセキュリティグループ 既存の選択 追加設定 最初のデータベース名(ローカル環境で使っていたデータベース名を入れるところ) 注意すべきポイントを2つ解説します。
1つ目は「Virtual Private Cloud (VPC)」です。
これは、書いてる通りEC2インスタンスと同じVPCを必ず選択してください。選択しないとEC2インスタンスへSSH接続したときにMySQLへアクセスできないのでくれぐれもご注意を。2つ目は追加設定の「最初のデータベース名」です。
「DBクラスター識別子」ではdatabase-1と設定しましたが、これとは全く別物です。
例えばローカル環境でexample_databaseという名前のデータベースを利用していた場合は、example_databaseを「DBクラスター識別子」ではなく、「最初のデータベース名」に書いて下さい。また、ローカルでのデータベース名と本番環境用のデータベース名を分けたい場合でも「最初のデータベース名」に入力してください。
「データベースの作成」をクリックし、しばらくするとデータベースが作成されます。
SSH接続でMySQLのアクセス確認
次に、EC2インスタンスにSSH接続を行いMySQLへアクセスしてみます。
その前に先ほど作成したデータベースの画面へ行ってください。
「セキュリティ」の「VPCセキュリティグループ」をクリックしてください(sg-から始まるもの)
※注意 「ネットワーク」のVPCではございませんのでご注意を。
そしたらインバウンドルールの編集を行います。
SSH接続でMySQLにアクセスするために、利用するEC2インスタンスの「プライベート IPv4 アドレス」をコピーして、「すべてのトラフィック」で「IPv4アドレス/32」として追加してください。
例:10.0.0.0/32
また、LaravelからもMySQLのデータベースにアクセスできるようにタイプで「MYSQL/Aurora」を選んで「0.0.0.0/0」もしくはALBのセキュリティグループを選んでください。
そしてルールを保存してください。
これでSSH接続でMySQLにアクセスが可能になり、Laravelからもデータベースにアクセスすることができます。
試しにSSH接続でMySQLにアクセスしてみましょう!
ssh -i "C:~\zaemonia-ec2-key.pem" ec2-user@ec2-xxx.ap-northeast-1.compute.amazonaws.commysql -u{マスターユーザー名} -p -h{MySQLのエンドポイント} Enter password:{マスターパスワード} #パスワード入力は文字が出力されないのでコピペするのが良いかと無事MySQLにアクセス出来たら成功です!
これでアクセスできない場合は以下の事項を再確認してください。
・マスターユーザー名、マスターパスワード
・セキュリティグループのインバウンドルールこれら2つがしっかりと合っていれば必ずアクセスできます。
諦めずに頑張りましょう!!
以上、「【AWS】EC2インスタンスで作成したLaravelとRDS(MySQL)を連携させる方法」でした!
良ければ、LGTM、コメントお願いします。
また、何か間違っていることがあればご指摘頂けると幸いです。
他にも初心者さん向けに記事を投稿しているので、時間があれば他の記事も見て下さい!!
あと、最近「ココナラ」で環境構築のお手伝いをするサービスを始めました。
気になる方はぜひ一度ご相談ください!
Thank you for reading
- 投稿日:2021-02-27T11:44:27+09:00
AWS LambdaからS3にファイルをアップロードする
サンプルコード
- Body・・・ファイルに書きたい内容
- Bucket・・・アップロード先のバケット
- Key・・・アップロードしたときのファイル名
lambda_function.pyimport boto3 def upload(): client = boto3.client('s3') response = client.put_object( Body='Hello from Lambda!', Bucket='my-bucket', Key='sample.txt', ) def lambda_handler(event, context): upload() return 0サンプルロール
既存のラムダロールに追加する。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "s3:PutObject", "Resource": "arn:aws:s3:::my-bucket/*" } ] }参考記事
- boto3 ドキュメント
- 投稿日:2021-02-27T11:44:27+09:00
AWS Lambdaでファイルを作成しS3にアップロードする
サンプルコード
- Body・・・ファイルに書きたい内容
- Bucket・・・アップロード先のバケット
- Key・・・アップロードしたときのファイル名
lambda_function.pyimport boto3 def upload(): client = boto3.client('s3') response = client.put_object( Body='Hello from Lambda!', Bucket='my-bucket', Key='sample.txt', ) def lambda_handler(event, context): upload() return 0サンプルロール
既存のラムダロールに追加する。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "s3:PutObject", "Resource": "arn:aws:s3:::my-bucket/*" } ] }参考記事
- boto3 ドキュメント
- 投稿日:2021-02-27T11:44:27+09:00
AWS Lambdaでファイルを作成・編集しS3にアップロードする
サンプルコード
- Body・・・ファイルに書きたい内容
- Bucket・・・アップロード先のバケット
- Key・・・アップロードしたときのファイル名
lambda_function.pyimport boto3 def upload(): client = boto3.client('s3') response = client.put_object( Body='Hello from Lambda!', Bucket='my-bucket', Key='sample.txt', ) def lambda_handler(event, context): upload() return 0サンプルロール
既存のラムダロールに追加する。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "s3:PutObject", "Resource": "arn:aws:s3:::my-bucket/*" } ] }参考記事
- boto3 ドキュメント
- 投稿日:2021-02-27T10:48:02+09:00
全Terraformユーザーにおすすめしたいtfsec
全Terraformユーザーにおすすめしたいツール、それが tfsec !!
Technology Radarでも取り上げられてるので、最近知名度は上がってきたのでご存知の方は多いのではないでしょうか?
tfsecとは?
Terraformコードの静的解析ツールです。
https://tfsec.dev/
セキュリティ的にベストプラクティスに反している点などを指摘してくれます。
AWS, GCP, Azureのリソースに対応しています。
(以降は特にAWSでの利用について述べます)
おすすめする理由
こんな経験ないでしょうか?
SecurityHub導入してAWSのベストプラクティスに則っていくぞ!
→ 「RDSを暗号化しましょう」
→ 「既存のRDSを暗号化するにはスナップショットから再作成する必要があります」
→ メンテナンス入れてサービス止めないと対応できない!!
→ なんで初期構築時に暗号化してなかったんだ!!こんな人におすすめ
- 既存のRDSが暗号化されていなくて絶望したことがある人
- 安価にPaaSのセキュリティを高めたい人
- セキュリティ対策を勉強したい人
逆に、手動でマネジメントコンソールから作ったリソースに対しては無力です。
そういった実リソースの検知はSecurityHub等を利用しましょう。
令和の時代にIaCしてないエンジニアはいないと思いますが。使い方
インストール
brewでインストールするかリリースページからバイナリを取得しましょう。
$ brew install tfsecコード
このようなS3バケットのリソースがあったとします。
resource "aws_s3_bucket" "my-bucket" { acl = "public-read" }実行結果
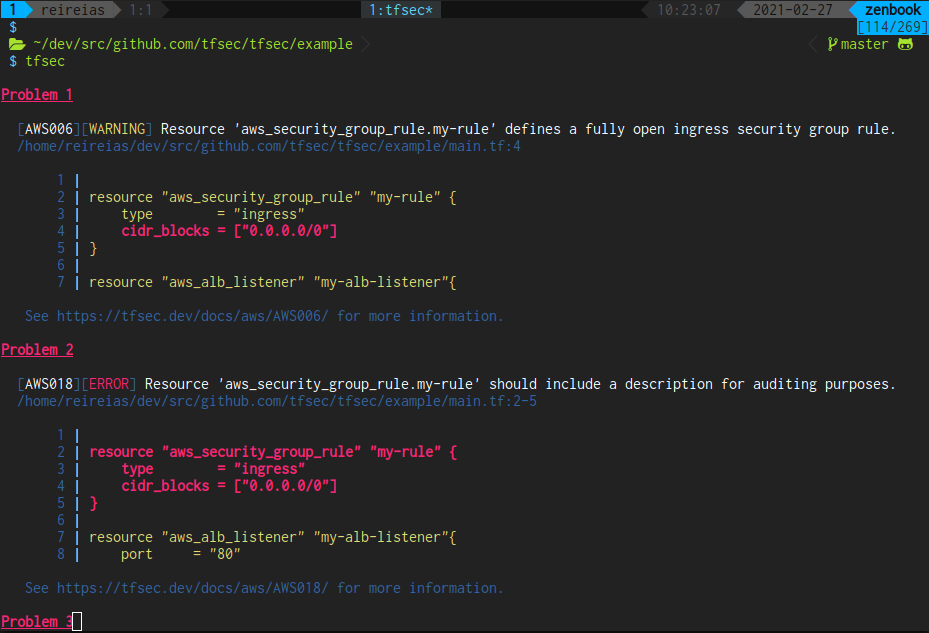
tfsecコマンドを実行すると、3件検出されました。
検出されたエラーは以下の通りです。セキュリティのベストプラクティスに準拠していない点が指摘されますね。
$ tfsec Problem 1 [AWS001][WARNING] Resource 'aws_s3_bucket.my-bucket' has an ACL which allows public access. /tmp/tfsec/s3.tf:2 1 | resource "aws_s3_bucket" "my-bucket" { 2 | acl = "public-read" 3 | } 4 | See https://tfsec.dev/docs/aws/AWS001/ for more information. Problem 2 [AWS002][ERROR] Resource 'aws_s3_bucket.my-bucket' does not have logging enabled. /tmp/tfsec/s3.tf:1-3 1 | resource "aws_s3_bucket" "my-bucket" { 2 | acl = "public-read" 3 | } 4 | See https://tfsec.dev/docs/aws/AWS002/ for more information. Problem 3 [AWS017][ERROR] Resource 'aws_s3_bucket.my-bucket' defines an unencrypted S3 bucket (missing server_side_encryption_configuration block). /tmp/tfsec/s3.tf:1-3 1 | resource "aws_s3_bucket" "my-bucket" { 2 | acl = "public-read" 3 | } 4 | See https://tfsec.dev/docs/aws/AWS017/ for more information. times ------------------------------------------ disk i/o 1.009268ms parsing HCL 13.505µs evaluating values 126.152µs running checks 459.172µs counts ------------------------------------------ files loaded 1 blocks 1 evaluated blocks 1 modules 0 module blocks 0 3 potential problems detected.GitHub Actionsで実行する
毎回手動で実行してもいいのですが、人間絶対に忘れます。
当然、CIで実行したいと思うでしょう。tfsecを実行してくれるActionsはいくつか公開されています。
https://github.com/marketplace?type=actions&query=tfsec私はterraform-security-scanを利用することが多いです。
以下のActionsの設定でPull Requestに対してActionsで
tfsecを実行できます。
警告があった場合はPull Requestにコメントが投稿されます。.github/workflows/tfsec.ymlname: tfsec on: [pull_request] jobs: tfsec: name: tfsec runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Terraform security scan uses: triat/terraform-security-scan@v2.1.0 env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}Vimで実行する
Actionsで実行されるからと言って、手元で実行しないということはありません。
手元でサクッと実行して確認したいですよね?私はNeovimを使用しているのですが、こういった解析ツールはターミナルからではなくNeovim上で実行することが多いです。
tfsecに関してもtfファイル編集中に実行エディタ上で実行したいのですが、あいにくpluginが存在しませんでした。なので、自作しました!
検出したエラーをQuickfix Listに追加しているので、Quicklistの操作で次のエラーに移動できます。
tfsecで検出できないもの
冒頭でも述べましたが手動で作成したリソースなどには無力です。
また、Terraformで管理しない(できない)リソースに対するセキュリティ警告は検出できません。
たとえば、「rootアカウントにはMAFデバイスを設定する」等の検出はできません。上記を検出するためにはSecurityHubを利用することを推奨します。
SecurityHubは企業で利用するAWSアカウントだったら必ず設定すべき項目だと個人的には思います。まとめ
tfsecはプロジェクト初期から是非導入することをおすすめします!!


- 投稿日:2021-02-27T07:54:25+09:00
【 Ruby on Rails 6.0 】 AWS + Nginx + Unicornでデプロイ⑦
始めに
前回の内容でNginxというWebサーバーを導入しRailsアプリを本番環境で起動出来ました。
しかし、現状だと開発環境で変更したものを本番環境に反映させるのに工数が多く不便です。
そこで、Capistranoという自動デプロイツールを導入しコマンドひとつでデプロイ作業を完了できるように設定していきます。目次
目次 内容 セクション1 EC2インスタンス作成 セクション2 Linuxサーバー構築 セクション3 データベース設定 セクション4 EC2上でGemをインストールし環境変数を設定 セクション5 Railsアプリを起動 セクション6 Nginxの導入 セクション7 自動デプロイ(今回の内容) セクション8 独自ドメイン取得 Capistranoの導入
必要なGemをインストールし、Capistranoを動かすために必要な設定ファイルを生成します。
Gemfile(ローカル)group :development, :test do gem 'capistrano' gem 'capistrano-rbenv' gem 'capistrano-bundler' gem 'capistrano-rails' gem 'capist endターミナル(ローカル)$ bundle install # gemを読み込めたら、下記のコマンドを打ちます。 $ bundle exec cap installするとデプロイについての設定を書くファイルが自動で生成されます。
Capfileを編集
Capfileは、capistrano全体の設定ファイルです。
Capifilerequire "capistrano/setup" require "capistrano/deploy" require 'capistrano/rbenv' require 'capistrano/bundler' require 'capistrano/rails/assets' require 'capistrano/rails/migrations' require 'capistrano3/unicorn' Dir.glob("lib/capistrano/tasks/*.rake").each { |r| import r }デプロイについての設定ファイルを編集
cap installコマンドを打つと、config/deploy配下にproduction.rbとstaging.rbの2 種類のファイルが生成されます。production.rbですが2つファイルがあります
❌ config/environment/production.rb
⭕️ config/deploy/production.rb今回作業はするのはconfig/deploy/production.rbです。
production.rbを下記のように編集
config/deploy/production.rb# 最下部に追記 server 'XX.XXX.XX.XXX(Elastic IP)', user: 'ec2-user', roles: %w{app db web}deploy.rbを編集
config/deploy.rb# 全て削除して以下を追記 # config valid only for current version of Capistrano # capistranoのバージョンを記載。固定のバージョンを利用し続け、バージョン変更によるトラブルを防止する lock '○.○○.○(Capistranoのバージョン)' # Capistranoのログの表示に利用する set :application, '○○○(自身のアプリケーション名)' set :deploy_to, '/var/www/○○○(アプリ名)' # どのリポジトリからアプリをpullするかを指定する set :repo_url, 'git@github.com:○○○(Githubのユーザー名)/○○○(レポジトリ名.git' # バージョンが変わっても共通で参照するディレクトリを指定 set :linked_dirs, fetch(:linked_dirs, []).push('log', 'tmp/pids', 'tmp/cache', 'tmp/sockets', 'vendor/bundle', 'public/system', 'public/uploads') set :rbenv_type, :user set :rbenv_ruby, '○.○.○(rubyのバージョン)' #カリキュラム通りに進めた場合、2.5.1か2.3.1です # どの公開鍵を利用してデプロイするか set :ssh_options, auth_methods: ['publickey'], keys: ['~/.ssh/○○○○○.pem(ローカルPCのEC2インスタンスのSSH鍵(pem)へのパス 例:~/.ssh/key_pem.pem))'] # プロセス番号を記載したファイルの場所 set :unicorn_pid, -> { "#{shared_path}/tmp/pids/unicorn.pid" } # Unicornの設定ファイルの場所 set :unicorn_config_path, -> { "#{current_path}/config/unicorn.rb" } set :keep_releases, 5 # デプロイ処理が終わった後、Unicornを再起動するための記述 after 'deploy:publishing', 'deploy:restart' namespace :deploy do task :restart do invoke 'unicorn:restart' end end以下の5点は書き換えが必須です。
- 3行目のはご自身のバージョンを記述しましょう。
- 6行目の<自身のアプリケーション名>はご自身のものを記述しましょう。
- 9行目の/<レポジトリ名>も同様に、ご自身のもの記述してください。
- 15行目の<このアプリで使用しているrubyのバージョン>はご自身のものを確認して 記述してください。
- 19行目の<ローカルPCのEC2インスタンスのSSH鍵(pem)へのパス>も同様に、ご自 身のもの記述してください。
Capistranoのバージョン確認
capistranoのバージョンは、gemfile.lockに記載されています。
capistrano(3.11.0)ように記載されています。rubyのバージョンの確認
ローカルのターミナルで以下のように確認します。
ターミナル$ ruby -v # 実行結果 ruby2.6.5....unicorn.rbの記述を編集
capistrano導入後はアプリケーションのディレクトリ構造が変化するので以下のように記述を編集します。
config/unicorn.rbapp_path = File.expand_path('../../', __FILE__) worker_processes 1 working_directory app_path pid "#{app_path}/tmp/pids/unicorn.pid" listen "#{app_path}/tmp/sockets/unicorn.sock" stderr_path "#{app_path}/log/unicorn.stderr.log" stdout_path "#{app_path}/log/unicorn.stdout.log" # 以下のように変更↓ # ../が一つ増えている app_path = File.expand_path('../../../', __FILE__) worker_processes 1 # currentを指定 working_directory "#{app_path}/current" # それぞれ、sharedの中を参照するよう変更 listen "#{app_path}/shared/tmp/sockets/unicorn.sock" pid "#{app_path}/shared/tmp/pids/unicorn.pid" stderr_path "#{app_path}/shared/log/unicorn.stderr.log" stdout_path "#{app_path}/shared/log/unicorn.stdout.log"Nginxの設定ファイルの記述を編集
同様に、Nginxの設定ファイルもディレクトリで構造が変化しているので編集します。
ターミナル(EC2)# SSHログインしてから実行 [ec2-user@ip-172-31-25-189 ~]$ $ sudo vim /etc/nginx/conf.d/rails.confrails.confupstream app_server { # sharedの中を参照するよう変更(/shared/tmp/sockets/unicorn.sock;) server unix:/var/www/○○○○○(アプリケーション名)/shared/tmp/sockets/unicorn.sock; } server { listen 80; server_name XX.XXX.XX(Elastic IP); # currentの中を参照するよう変更(/current/public;) root /var/www/○○○○○(アプリケーション名)/current/public; location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; # currentの中を参照するよう変更(/current/public;) root /var/www/○○○○○○(アプリケーション名)/current/public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }編集し終わったら、
escキーを押して:wqで保存します。
Nginxの設定を変更したら、忘れずに再読込・再起動をします。ターミナル(EC2)# nginx起動 [ec2-user@ip-172-31-25-189 ~]$ sudo systemctl reload nginx [ec2-user@ip-172-31-25-189 ~]$ sudo systemctl restart nginx # nginxのステータスを確認(active runningであれば成功) $ sudo systemctl status nginx.service ● nginx.service - The nginx HTTP and reverse proxy server Loaded: loaded (/usr/lib/systemd/system/nginx.service; disabled; vendor preset: disabled) Active: active (running) since 水 2021-02-17 11:28:00 UTC; 7h ago # エラーが出た場合はnginxのエラーログを確認 [ec2-user@ip-172-31-45-167 アプリ名]$ sudo cat /var/log/nginx/error.logデータベースの起動を確認
データベースが立ち上がっていないとデプロイが失敗するので起動します。
ターミナル(EC2)[ec2-user@ip-172-31-25-189 ~]$ sudo systemctl restart mariadb # ステータスを確認(active runningなら成功) [ec2-user@ip-172-31-25-189 ~]$ sudo systemctl status mariadbunicornのプロセスをkill
自動デプロイを実行する前にunicornのコマンドをkillします。
ターミナル(EC2)# プロセスを確認 [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn # 一番上のunicorn_rails masterをkillしたいので、下記を実施 [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill 17877ローカルでの修正を全てmasterにpush
ローカルでのコードの変更が、全てmasterにpushされていることを確認しましょう。
自動デプロイ実行
これで、ローカルのターミナルからコマンド一発でデプロイできるようになりました。
ターミナル(ローカル)# アプリケーションのディレクトリで実行する $ bundle exec cap production deployエラーがなく完了したらデプロイ完了です!
ブラウザからElastic IPでアクセスすると、アプリケーションにアクセスできます!
確認してみましょう。もし途中でエラーが出たら
- EC2のターミナルで
less log/unicorn.stderr.logコマンドでエラーログを確認- ローカルでの編集のpushやpullを忘れていないか確認
- mariaDBやNginxを再起動してみる
- EC2インスタンスを再起動してみる
終わりに
ここまででRailsアプリを本番環境にデプロイする工程が終了しました!
ただ、IPアドレスだと覚えにくいので次回で独自ドメインを取得方法をまとめたいと思います。
お疲れさまでした。。。次回
独自ドメイン取得

- 投稿日:2021-02-27T01:20:00+09:00
EC2上のエラーログをS3に移してAthenaで分析する
エラーログをAthenaでお手軽に見やすくしたい
ALBのアクセスログをAthenaで可視化してみたら非常に便利だったので、エラーログでもやってみました。
エラーログ、見るの手間だけどほっとくと増えてるんだよな…。環境と要件
Apache/2.4.46 ()
PHP 7.0.33そこまでリアルタイム性は求めてないですが、毎日更新はさせたいです。
さすがにFatalが出ていたら気づきたいですし、Warningも無理のない範囲でつぶしていきたいです。
ログファイルはLogrotateで日付ごとのファイル分割と.gzファイルへの圧縮は対応済みです。
良い感じの記事が見つからなかったのでテーブルは自作します。エラーログをS3におく
必ずしも漏らさず拾う必要もないので、ログファイルは適当に定時でS3に移動するようにします。
S3上のエラーログからAthenaでテーブルを作成する
エラーログは以下のような形式です。
[Fri Feb 26 06:50:56.127563 2021] [:error] [pid 26587] [client 127.0.0.1:21111] PHP Warning: strlen() expects parameter 1 to be string, array given in /home/example.jp/test.php on line 20, referer: https://example.jp/そしてテーブルの作成クエリがこちら。テーブル名とS3バケット名は任意のものに変更してください。
CREATE EXTERNAL TABLE IF NOT EXISTS in_error_logs ( time string, theme string, pid string, user_name string, ip string, type string, detail string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( 'input.regex' = '([^ ]* [^ ]* [^ ]* [^ ]* [^ ]*) ([^ ]*) [^ ]* ([^ ]*) ([^ ]*) ([^ ]*) (.+?): ((.+ on line [0-9]+)(.+))' ) LOCATION 's3://in-log/error-log/';以下、考慮した部分です。
同じ内容をGROUP BYでまとめるために、発生個所にreferer情報が出る場合を考慮してカラムを作成しています。
エラーのレベルと内容が分かれば十分なので、ほかの情報はあまり細かく分割していません。
例えば今回ログファイルを日付ごとに分割しているので、記録日時は重要ではないと判断しました。
参考 php エラーログの読み方必要な情報だけを取り出す
Queryは例えばこんな感じです。
SELECT COUNT(TIME) AS COUNT, error_level, detail FROM elblogdb.media_in_error_logs GROUP BY error_level, detail ORDER BY error_level DESC, COUNT DESC;するとこうなります。めでたしめでたし?
エラー解消していきましょう。
BIツールで可視化
共有したかったのでBIツールで可視化しました。
AWSアカウントのないメンバーでも、ログの確認と対応ができます。
個人的にはRedash気に入ってまして、実際はここまでのクエリ操作もすべてRedash上で行っています。
Fatalないよね?とか、急に件数増えてる!とかわかりやすいです。やってみて
アクセスログの分析をやっていれば問題なくできると思います。
エラーログを見るハードルがぐんと下がりました。やったね?
