- 投稿日:2021-02-20T23:50:59+09:00
MacのPython開発環境作成メモ
はじめに
Python環境作成時の自分用メモです。下記を参考にしました。
Macにpyenv + AnacondaでPython環境作成の備忘録
【初心者向け】Anacondaで仮想環境を作ってみる
pyenv-virtualenvを使って都合のいいように Pythonパッケージ環境を行き来する話
Macに0からpyenv + pyenv-virtualenvでpython環境を作る動作環境
macOS Catalina 10.15.7
1. pyenv, pyenv-virtualenvのinstall
pyenvとpyenv-virtualenvはすでに入っていたので、実際にはinstall作業していないけれど、必要な作業は下記。
zsh$ brew install pyenv pyenv-virtualenvpyenvにPathを通す。.zshrcに以下を追加して
source .bash_profileで設定を適用する。vimexport PATH="$HOME/.pyenv/bin:$PATH" eval "$(pyenv init -)" eval "$(pyenv virtualenv-init -)"2. Anacondaのinstall
pyenvでAnacondaをinstallする。
zsh#install可能なpythonは下記で検索可能。Anacondaだけではなくいろいろ。 $ pyenv install --list #anaconda3-5.1.0をinstall $ pyenv install anaconda3-5.1.0 #installされたpythonのversionを確認 $ pyenv versions * system (set by /Users/user/.pyenv/version) anaconda3-5.1.03. virtualenvを作成する
pyenv virtualenv installしたpython 環境名で環境を作成する。zsh$ pyenv virtualenv anaconda3-5.1.0 anaconda3-510env #installされるパッケージの名前とかいろいろ出てくるworkディレクトリにvirtualenvをあてる。
zsh$ pyenv versions system * anaconda3-5.1.0 (set by /Users/user/.pyenv/version) #Anacondaをglobalに切り替え $ pyenv global anaconda3-5.1.0 #workディレクトリを作成する。プロンプトの前に現在のpythonの環境が出てくる。便利 (anaconda3-5.1.0) $ mkdir anaconda3-510env (anaconda3-5.1.0) $ cd anaconda3-510env #workディレクトリにanaconda環境をあてる。workディレクトリに移動するとanacondaが使えるようになる (anaconda3-5.1.0) $ pyenv local anaconda3-5.1.0 (anaconda3-5.1.0) $ pyenv versions system * anaconda3-5.1.0 (set by /Users/user/anaconda3-510env/.python-version) #condaで仮想環境を作る (anaconda3-5.1.0) $ conda create --name py36 python=3.6 (anaconda3-5.1.0) $ pyenv versions system * anaconda3-5.1.0 (set by /Users/user/anaconda3-510env/.python-version) anaconda3-5.1.0/envs/py36 #py36用のworkディレクトリを作成 (anaconda3-5.1.0) $ mkdir py36 (anaconda3-5.1.0) $ cd py36 #py36workディレクトリにpy36環境をあてる (anaconda3-5.1.0) $ pyenv local anaconda3-5.1.0/envs/py36 (anaconda3-5.1.0/envs/py36) $ pyenv versions system anaconda3-5.1.0 * anaconda3-5.1.0/envs/py36 (set by /Users/user/anaconda3-510env/py36/.python-version) #ディレクトリを移動するとpython環境が変わる。すごい、便利 (anaconda3-5.1.0/envs/py36) $ cd ../ (anaconda3-5.1.0) $ pyenv versions system * anaconda3-5.1.0 (set by /Users/user/anaconda3-510env/.python-version) anaconda3-5.1.0/envs/py36 #systemをglobalに戻す(必要に応じて) (anaconda3-5.1.0) $ pyenv global system4. Jupyter Notebookの設定
condaで作成した仮想環境py36にはJupyter Notebookが入っていない。Jupyter Notebookのカーネルを設定する上で必要なので、インストールして諸々設定を行う。
zsh#py36環境にjupyterをinstall $ cd py36 $ pip install jupyter #baseに戻って、environment_kernelsをinstall $ cd ../ $ pip install environment_kernels #設定ファイル作成 $ jupyter notebook --generate-config Writing default config to: /Users/achi/.jupyter/jupyter_notebook_config.py $ echo "c.NotebookApp.kernel_spec_manager_class = 'environment_kernels.EnvironmentKernelSpecManager'" >> ~/.jupyter/jupyter_notebook_config.py $ echo "c.EnvironmentKernelSpecManager.conda_env_dirs=['/Users/user/.pyenv/versions/anaconda3-5.1.0/envs/']" >> ~/.jupyter/jupyter_notebook_config.pyJupyter Notebookを開いて、設定した環境が出てきたら設定完了。
お疲れ様でした。

- 投稿日:2021-02-20T23:11:49+09:00
spaCy + GiNZAではじめて形態素解析してみた
What is this?
- 自然言語処理の超初心者である筆者が(ほぼ)はじめて形態素解析してみました
- spaCy + GiNZAを利用して実施してみました
- 想像以上に簡単にできました!
- はじめてにしては上出来なレベル
実施環境
- Debian GNU/Linux 10
- Python: 3.9.1
- ginza:4.0.5
spaCyとは?
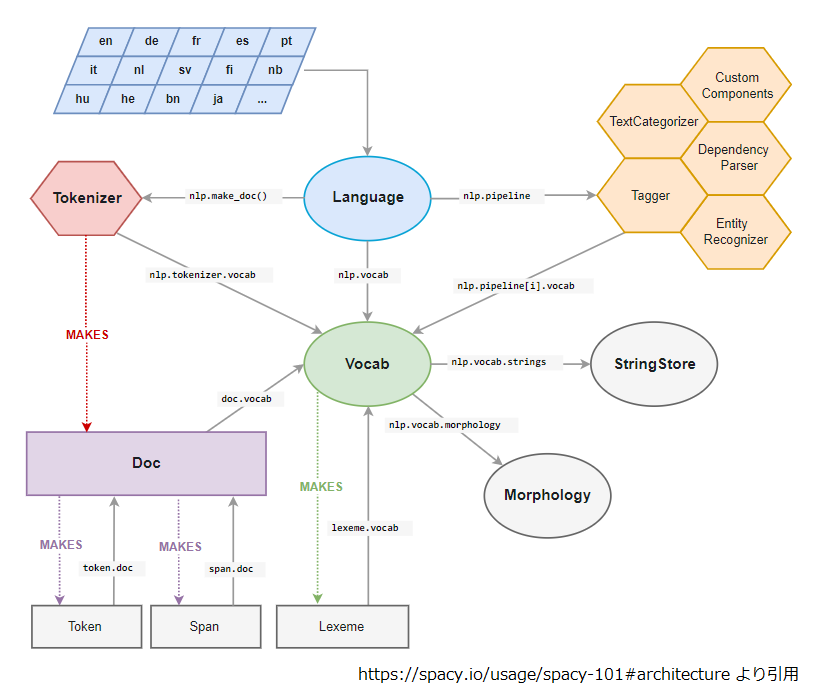
オージス総研によるオブジェクトの広場での解説が個人的にわかりやすかったため、引用させていただきました。
spaCy は Explosion AI 社の開発する Python/Cython で実装されたオープンソースの自然言語処理ライブラリで MIT ライセンスで利用が可能です。多くの言語をサポートし、学習済みの統計モデルと単語ベクトルが付属しています。
(https://www.ogis-ri.co.jp/otc/hiroba/technical/similar-document-search/part4.html より引用)名前の通り、Cythonで実装されているんですね。また、同記事内のspaCyの構造図に関しても、細かくは理解できていないものの、わかった気になれます。
ただし、GiNZAが登場するまでは、日本語を解析する際に工夫が必要だったようです。
しかし最近まで spaCy の学習済みモデルには日本語に対応したものがなく、バックエンドに MeCab を用いた形態素解析ができる程度でした。その為、spaCy を利用して記述された自然言語処理のアプリケーションやライブラリでは日本語の文書を処理することができない状況が続いていました。
(https://www.ogis-ri.co.jp/otc/hiroba/technical/similar-document-search/part4.html より引用)GiNZAとは?
こちらも同記事の解説がわかりやすいです。
ここで、2019年4月にリクルートと国立国語研究所の研究成果である GiNZA が登場します。主な特徴をリクルート社のリリース*1から引用すると、
1. 高度な自然言語処理をワンステップで導入完了
2. 高速・高精度な解析処理と依存構造解析レベルの国際化に対応
3. 国立国語研究所との共同研究成果の学習モデルを提供
とのことで、早い話が spaCy を日本語で利用できるようになった!pip install 一発でインストールできるので導入も簡単!!ということでよいかと思います。
(https://www.ogis-ri.co.jp/otc/hiroba/technical/similar-document-search/part4.htmlより引用)なお、scaPyとGiNZAの関係性としては、GiNZAは上記scaPyの構造における図内では"Language"にあたる機能を提供しているようです。
余談ですが、spaCyを始めようと思って調べ始めたら、GiNZAというのが出てきたので、思考停止でそのままGoogle検索したら「銀座 日本 東京の地名」が検索結果で表示されました。そりゃそうですよね。実行環境のセットアップ
なにかと環境構築に躓きやすいイメージのある自然言語ですが、私の環境ではpipにて簡単に構築することができました!
pip install -U ginza*実際にはDocker環境にてrequirements.txtに
spacyとginzaを記載してインストールを行いましたが、問題なく動作しました。使い方
こちらを参考に実行しました。
https://note.com/npaka/n/n5c3e4ca67956import spacy import ginza import pandas as pd nlp = spacy.load('ja_ginza') # spacyにginzaを使用することを指定 txt = '私は機械学習を勉強しています。' # 入力文字列 doc = nlp(txt) # モデルへ適応 ginza.set_split_mode(nlp, "C") # 形態素の分割モード指定 # 結果をデータフレームに格納 result_list = [] for sent in doc.sents: result_list = result_list + [[str(token.i), token.text, token.lemma_, token.pos_, token.tag_] for token in sent] df_result = pd.DataFrame(result_list, columns = ['token_no', 'text', 'lemma', 'pos', 'tag'])
doc.sentsにて各文のイテレータを取得します(今回の例は1文なので、要素は1つです。)。また、sent自身をさらにループに回すことで各単語での要素を取得できます。結果
今回はデータフレームに結果を格納したため、このようなテーブルが出力されます。
token_no text lemma pos tag 0 私 私 PRON 代名詞 1 は は ADP 助詞-係助詞 2 機械学習 機械学習 NOUN 名詞-普通名詞-一般 3 を を ADP 助詞-格助詞 4 勉強 勉強 VERB 名詞-普通名詞-サ変可能 5 し する AUX 動詞-非自立可能 6 て て SCONJ 助詞-接続助詞 7 い いる AUX 動詞-非自立可能 8 ます ます AUX 助動詞 9 。 。 PUNCT 補助記号-句点 特に違和感なく、形態素解析ができているかと思います。自然言語処理の素人として感じたことは、「勉強する」の「勉強」という部分が名詞タグだけれども、文の中では動詞として認識されていることが、すごいなと感じました。
参考文献

- 投稿日:2021-02-20T23:05:38+09:00
Pythonで数式を書く_02(tanh)
数式
以下がtanh関数(hyperbolic tangent function)です。
※tanhはハイパボリックタンジェントやタンエイチと読みます。日本語では双曲線正接関数と呼びます。y\ = \frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}Pythonで記述
import numpy as np # tanh関数 y = (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))上の記述方法の他に次のような方法もあります。
import numpy as np # tanh関数 y = np.tanh(x)一番最初の記載方法だと長いので、
以降は np.tanh(x) の方で記載していきます。import numpy as np x = -1 y = np.tanh(x) print(y)x=-1の出力結果-0.7615941559557649コードを省略しますが、x = 0 と x = 1 のときは以下のように出力されます。
x=0の出力結果0.0x=1の出力結果0.7615941559557649tanh関数を視覚化
先ほどの入力と出力を表にまとめると次のようになります。
x = -1 x = 0 x = 1 出力結果 y -0.76 0.0 0.76 表だけだとわかりにくいですが、
グラフにするとtanhの出力は -1 ~ 1 の間になることがわかります。
ちなみに、上のグラフは以下のコードで描くことができます。
import matplotlib.pyplot as plt import numpy as np x = np.arange(-5, 5, 0.1) y = np.tanh(x) plt.plot(x, y) plt.title("tanh") plt.xlabel("x") plt.ylabel("y") plt.show()シグモイド関数と同様にtanhもニューラルネットワークの活性化関数として利用されますので、
その方面に興味のある方はこちらも覚えておいてもよいかもしれません。

- 投稿日:2021-02-20T23:03:52+09:00
SOMPO HD プログラミングコンテスト2021(AtCoder Beginner Contest 192) 参戦記
SOMPO HD プログラミングコンテスト2021(AtCoder Beginner Contest 192) 参戦記
ABC192A - Star
1分で突破. 書くだけ.
X = int(input()) print(100 - X % 100)ABC192B - uNrEaDaBlE sTrInG
3分で突破. 書くだけだけど、0-indexed と 1-indexed で偶奇が入れ替わるのを間違えて無駄に時間を取った.
S = input() for i in range(0, len(S), 2): if S[i] != S[i].lower(): print('No') exit() for i in range(1, len(S), 2): if S[i] != S[i].upper(): print('No') exit() print('Yes')ABC192C - Kaprekar Number
6分で突破. 書くだけだったけど、計算量が計算できなくて、大丈夫かなってなった.
def g1(x): return int(''.join(sorted(str(x), reverse=True))) def g2(x): return int(''.join(sorted(str(x)))) def f(x): return g1(x) - g2(x) N, K = map(int, input().split()) a = N for i in range(K): a = f(a) print(a)ABC192E - Train
24分で突破. WA1. 最初、特定の都市間には一つしか路線がないように書いて WA した、まぬけ. まあ、ダイクストラすればいいだけですね.
from sys import stdin from heapq import heappop, heappush readline = stdin.readline INF = 10 ** 18 N, M, X, Y = map(int, readline().split()) links = [{} for _ in range(N)] for _ in range(M): A, B, T, K = map(int, readline().split()) links[A - 1].setdefault(B - 1, []) links[B - 1].setdefault(A - 1, []) links[A - 1][B - 1].append((T, K)) links[B - 1][A - 1].append((T, K)) dp = [INF] * N dp[X - 1] = 0 q = [(0, X - 1)] while len(q) != 0: n, i = heappop(q) link = links[i] for j in link: for t, k in link[j]: d = (n + k - 1) // k * k if d + t >= dp[j]: continue dp[j] = d + t heappush(q, (d + t, j)) if dp[Y - 1] == INF: print(-1) else: print(dp[Y - 1])ABC192D - Base n
48分半で突破. WA5. Xが1桁のときの特別性に気づくのに時間がかかったし、気づいた後も求められているのがn進法表記の数とみなして得られる値の種類数であることになかなか気づかなかった. やらかしたなあ.
def f(s, n): result = 0 b = 1 for c in s[::-1]: result += int(c) * b b *= n return result INF = 10 ** 19 X = input() M = int(input()) d = int(max(X)) ok = d ng = INF + 1 while ng - ok > 1: m = ok + (ng - ok) // 2 if f(X, m) <= M: ok = m else: ng = m if ok == INF: print(1) else: print(ok - d)
- 投稿日:2021-02-20T22:54:55+09:00
Pythonで学ぶ制御工学 第4弾:状態空間モデル
#Pythonで学ぶ制御工学< 状態空間モデル >
はじめに
基本的な制御工学をPythonで実装し,復習も兼ねて制御工学への理解をより深めることが目的である.
その第4弾として状態空間モデルを扱う.状態空間モデル
行列表現とすることで,多元高階の微分方程式を1階の微分方程式で表現するもの
伝達関数との違いや,状態空間モデルの一般式を次の図で示す.
次に1入力1出力である場合の状態空間モデルを示す.
状態空間モデルの計算
以下では,前々回から扱っている制御モデルについて状態空間モデルをそれぞれ求める過程を示す.なお,ここで扱う制御モデルは1入力1出力である.
状態空間モデル①:台車
状態空間モデル②:アーム
状態空間モデル③:RLC回路
状態空間モデル④:増幅回路
実装
ここでは,Python上で状態空間モデルを表現する方法を学ぶために実装する.そのため,適当な値を用いて実装している.以下にソースコードとそのときの出力を示す.
ソースコード
state_space_model.py""" 2021/02/20 @Yuya Shimizu 状態空間モデル """ from control import ss, ssdata ##ss関数では,MATLAB表記が可能 #状態空間モデル構築 A = '0 1; -1 -1' B = '0 ; 1' C = '1 0' D = '0' state_model = ss(A, B, C, D) print(f"<状態空間モデル>\n{state_model}\n") #状態空間モデルからA~D行列の抽出 print("<定数行列A~D>") print('A=', state_model.A) print('B=', state_model.B) print('C=', state_model.C) print('D=', state_model.D) #もしくは,以下の方法でまとめて抽出できる sysA, sysB, sysC, sysD = ssdata(state_model)出力
<状態空間モデル> A = [[ 0. 1.] [-1. -1.]] B = [[0.] [1.]] C = [[1. 0.]] D = [[0.]] <定数行列A~D> A= [[ 0. 1.] [-1. -1.]] B= [[0.] [1.]] C= [[1. 0.]] D= [[0.]]感想
状態空間モデルの構成を復習することができた.ここでは,状態空間モデルをPython上で表現する方法についても学ぶことができた.これにより,状態空間モデルを扱うことが可能となった.ただ,状態空間モデルの定数行列はあらかじめ計算しておく必要がありそうだ.ここは,伝達関数のときと同じである.だから,また同じように物理量などを引数にするなどしてある制御モデル特有の状態空間モデル生成関数も作成できそうである.
参考文献
Pyhtonによる制御工学入門 南 祐樹 著 オーム社






- 投稿日:2021-02-20T22:47:31+09:00
scikit-learnを使ってみる(2)
前の記事「scikit-learnを使ってみる」で三角関数の学習がうまくできなかった。トレーニングデータではそこそこ学習できても、テストデータの結果はボロボロだった。
今回は方法を変更して、sin関数で作成した連続した3つの値から次の値を学習させていく。下図で説明すると、緑の点3つから赤の点を学習させることになる。これを順次行う。
三角関数(2)
import numpy as np from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression import matplotlib.pyplot as plt look_back = 3 def make_data(y, look_back): X = [] Y = [] for i in np.arange(len(y) - look_back): X.append(y[i:i+look_back]) Y.append(y[i+look_back]) return X, Y # 三角関数 Y = sin(X)を求める。 x = np.linspace(0, 20, num=200) y = np.sin(x) X, Y = make_data(y, look_back=look_back) X_train, X_test, Y_train, Y_test = train_test_split(X, Y, shuffle=False) lr = LinearRegression() lr.fit(X_train, Y_train) print(f'回帰係数={lr.coef_}') print(f'切片={lr.intercept_}') print(f'決定係数={lr.score(X_train, Y_train)}') plt.scatter(x, y, label='data') plt.plot(x[look_back:look_back+len(X_train)], lr.predict(X_train), color='green', label='train') plt.plot(x[look_back+len(X_train):], lr.predict(X_test), color='red', label='test') plt.legend() plt.savefig('linear_regression6.png') plt.show()さて結果は...
うまく学習できたようだ。


- 投稿日:2021-02-20T22:35:21+09:00
[PyTorch]Upsampleクラスのalign_cornersの動作
はじめに
画像セグメンテーションや敵対的生成ネットワーク等で利用されるPyTorch Upsampleクラスのalign_cornersの動作が気になったので、メモを残します。
環境
- Windows 10 home
- Python(3.7.6)
- Numpy(1.19.4)
Upsampleクラスのalign_corners
PyTorch Upsampleクラスは、scale_factorサイズにより、画像データであれば、縦横を拡大するものです。拡大のためには、増加する点を補間する必要があります。補間方法には、大きく分けると、近傍の値と同一ものをとるか(nearest)、線形補間するか(linear, bilinearなど)があります。
今回は、線形補間系に機能する、align_cornersの話です。align_cornersは、公式ドキュメントでは、以下のように説明しています。align_corners (bool, optional) – if
True, the corner pixels of the input and output tensors are aligned, and thus preserving the values at those pixels.exampleでは、
>>> input = torch.arange(1, 5, dtype=torch.float32).view(1, 1, 2, 2) >>> input tensor([[[[ 1., 2.], [ 3., 4.]]]]) >>> m = nn.Upsample(scale_factor=2, mode='bilinear') # align_corners=False >>> m(input) tensor([[[[ 1.0000, 1.2500, 1.7500, 2.0000], [ 1.5000, 1.7500, 2.2500, 2.5000], [ 2.5000, 2.7500, 3.2500, 3.5000], [ 3.0000, 3.2500, 3.7500, 4.0000]]]]) >>> m = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True) >>> m(input) tensor([[[[ 1.0000, 1.3333, 1.6667, 2.0000], [ 1.6667, 2.0000, 2.3333, 2.6667], [ 2.3333, 2.6667, 3.0000, 3.3333], [ 3.0000, 3.3333, 3.6667, 4.0000]]]])と書かれています。cornerの値は、align_corners=Trueとalign_corners=Falseに違いがないような気がして、何がalignされているのか、私はよくわかりませんでした。
調べてみると、PyTorchのdiscussionに、以下の説明がありました。
When
align_corners=True, pixels are regarded as a grid of points. Points at the corners are aligned.When
align_corners=False, pixels are regarded as 1x1 areas. Area boundaries, rather than their centers, are aligned.どうも元となる配列の値を、拡大した配列のどこに配置し補間するかが違いのようです。では、この図をもとに、Numpyを使って検証してみます。
検証
Numpyに直接bilinearを扱う関数がなかったので、PyTorch Upsample クラスのexamplesの左端の列を対象に、線形補間をする関数のnumpy.interpで、Upsampleの結果を再現します(下図)。
図1:PyTorch Upsample examplesで検証に利用する列。Upsamleクラスexamplesより抜粋。align_corners=Trueの場合
align_cornersをTrueにすると、拡大配列の端の点と、元配列の端の点を合わせて、拡大配列の値を内挿します。
図2:align_corners=Trueの時の動作イメージnumpy.interpを用いて、拡大配列を計算します。
import numpy as np before = np.array([1, 3]) after = np.interp([0, 1, 2, 3], [0, 3], [before[0], before[1]]) print(after.reshape(4, 1))#見た目を合わせるためにreshape
図3:numpy.interpでの計算結果。左:numpy.interp、右:PyTorch Upsample align_corners=True。PyTorch Upsamle align_corners=Trueのexamplesと同じになりました。
align_corners=Falseの場合
align_cornersをFalseにすると、元配列の値を、拡大した配列の節に配置し、拡大配列の値を線形補間することになります。
図4: align_corners=Falseの時の動作イメージnumpy.interpを用いて、拡大配列を計算します。align_corners=Trueでは、拡大配列での元配列の値の位置を[0, 3]しましたが、align_corners=Falseでは、[0.5, 2.5]となっています。
import numpy as np before = np.array([1, 3]) after = np.interp([0, 1, 2, 3], [0.5, 2.5], [before[0], before[1]]) print(after.reshape(4, 1)) # 見た目を合わせるためにreshape
図5:numpy.interpでの計算結果。左:numpy.interp、右:PyTorch Upsample align_corners=False。これも、PyTorch Upsample align_corners=False examplesと同じになりました。
なお、numpy.interpは、与えられた点の外では、境界の値を出力するようです。align_corners=Falseの例だと、与えられた点の外は、after[0]やafter[-1]に当たり、それぞれafter[0] = before[0](= 1.0)とafter[-1] = before[-1](=3.0)となります。計算結果が同じなので、PyTorch Upsampleも類似の操作をしているのでしょう。
最後に、numpy.interp を組み合わせたbilinearで、PyTorch Upsampleのexamplesの2x2→4x4拡大の再現をしてみます。Numpy interpを使ってPyToch Upsample examplesを再現
align_corners=True
# align_corners=True import numpy as np column0 = np.interp([0, 1, 2, 3], [0, 3], [1, 3]) column3 = np.interp([0, 1, 2, 3], [0, 3], [2, 4]) row0 = np.interp([0,1,2,3], [0,3], [1,2]) row3 = np.interp([0,1,2,3], [0,3], [3,4]) row1 = np.interp([0,1,2,3], [0,3], [column0[1], column3[1]]) row2 = np.interp([0,1,2,3], [0,3], [column0[2], column3[2]]) align_corners_true = np.vstack([row0, row1, row2, row3]) print(align_corners_true)
図6:numpy.interpでのPyTorch Upsample align_corners=True examplesの拡大の再現。上段:numpy.interp、下段:PyTorch Upsample。align_corner=False
# align_corners=False import numpy as np column0 = np.interp([0,1,2,3], [0.5, 2.5], [1,3]) column3 = np.interp([0,1,2,3], [0.5, 2.5], [2,4]) row0 = np.interp([0,1,2,3], [0.5, 2.5], [1,2]) row3 = np.interp([0,1,2,3], [0.5, 2.5], [3,4]) row1 = np.interp([0,1,2,3], [0.5, 2.5], [column0[1], column3[1]]) row2 = np.interp([0,1,2,3], [0.5, 2.5], [column0[2], column3[2]]) align_corners_false = np.vstack([row0, row1, row2, row3]) print(align_corners_false)
図7: numpy.interpでのPyTorch Upsample align_corners=False examplesの拡大の再現。上段:numpy.interp、下段:PyTorch Upsample。numpy.interpでPyTorchのdiscussion説明内容の操作を行って、PyTorch Upsampleクラスexamplesと同じ結果となることが確認できました。
参考
https://discuss.pytorch.org/t/what-we-should-use-align-corners-false/22663/6












- 投稿日:2021-02-20T22:17:10+09:00
webdriver_manager マジ便利
何が便利なの?
仕事してると定期的に、これブラウザ操作で勝手にやってくれんかな・・って時あるよね
自分は本当に楽をしたい気持ちがいっぱいなので、定期的にこれ思います。
そんな時に使うのがseleniumさん。
ただ、ブラウザ操作するためにwebドライバー必要だよね。
しかもバージョンをしっかり合わせたやつ・・・。使おう!って思った時に、あ・・なんか動かないわ・・手動でやるか・・ってことが多かったんですが、webdriver_managerを入れてからそんなことがなくなりました
webdriver_managerとは?
ファイル実行時に、適合するwebドライバーを勝手にダウンロードしてきてくれるやつ!
実行時に何やらキャッシュがどうこうっていうのが出てくるから、一回使ったドライバーはキャッシュとして保存しておいてくれてるっぽい(調べてはないけど)インストール方法は?
pip install webdriver-managerさいごに
ちょっとだけセレニウム使おうとして、ドライバーがあってなくて動かない時、もうほんとにストレスですよね。
ダウンロードするほどじゃないんよ・・・みたいな。これ入れとくことで、気軽にセレニウム使えてます
- 投稿日:2021-02-20T21:49:55+09:00
データテーブルの横方向への連結 2(内部結合)
テーブルとテーブルの連結には、縦方向(行が増える)と横方向(列が増える)の場合があります。
縦方向の場合は集合、横方向の場合は結合と言います。結合には以下のパターンがあります。
完全外部結合:共通しないレコードをすべて含めて列を増やす。
右(左)外部結合:右(左)側のテーブルの共通しないレコードを含めて列を増やす。
内部結合:共通するレコードを対象として列を増やす。
今回は、内部結合について、SAS プログラムと SQL、および Python (Pandas) をそれぞれ用いた例を紹介します。行いたい操作は下記です。
A列をキーとして、値が一致するレコードのみを取り出して、横方向に連結します。① SAS プログラムでの内部結合
data table_3; merge table_1 (in=flg1) table_2 (in=flg2); by A; if flg1=1 and flg2=1 then output; run;merge ステートメントで横に重ねて、 by でキーとなる変数を指定します。
in は、一時変数を指定するオプションです。
具体的には例えば、table_1 ( in =flg1) では、一時変数名をflg1として設定しており、
・table_1 由来のレコードでは flg1=1
・それ以外では flg1=0
となります。
さらに一時変数として指定した flg1 と flg2 は、出力テーブルには出力されません。例えば、下記プログラムでは、
data table_4; merge table_1 (in=flg1) table_2 (in=flg2); by A; val1=flg1; val2=flg2; run;出力は下記となります。一時変数の値を強制的に表示させるため、val1, val2 でそれぞれ値を引き継がせています。
val1 が table_1 起因、val2 が table_2 起因であることがわかると思います。
改めて下記プログラムに戻ると、
data table_3; merge table_1 (in=flg1) table_2 (in=flg2); by A; if flg1=1 and flg2=1 then output; run;if flg1=1 and flg2=1 then output; で、flg1 (=val1) と flg2 (=val2) が共に 1 であるレコードを出力 (then output) させることで、内部結合に相当するテーブルが得られます。
② SQL での内部結合
create table table_3 as select table_1.A, B, C from table_1 inner join table_2 on table_1.A = table_2.A;SELECT 取り出す変数名 from データセット1 inner join データセット2 on 結合条件
(inner は省略してもOK)
結合したいテーブルどうしを inner join でつなぎ、on 以下でどの列を基準にデータを一致させるかを指定します。
また、inner join ~ on を使わずに、where句を使って次のように記述することもできます。create table table_3 as select table_1.A, B, C from table_1, table_2 where table_1.A = table_2.A;③ Python (Pandas) での完全外部結合
import pandas as pd table_1 = pd.DataFrame({'A': [1, 2], 'B': ['AA', 'BB']}) table_2 = pd.DataFrame({'A': [2, 3], 'C': [10, 20]}) table_3 = pd.merge(table_1, table_2, on = "A", how="inner").merge で結合、on にキー列を指定、how で様式(内部なので "inner")を指定します。
出力結果
ちなみに how の様式指定では、 "outer" が完全外部結合、"left" ("right") が左 (右) 外部結合となります。関連記事




- 投稿日:2021-02-20T21:49:55+09:00
データテーブルの連結ー横方向2(内部結合)
テーブルとテーブルの連結には、縦方向(行が増える)と横方向(列が増える)の場合があります。
縦方向の場合は集合、横方向の場合は結合と言います。結合には以下のパターンがあります。
完全外部結合:共通しないレコードをすべて含めて列を増やす。
右(左)外部結合:右(左)側のテーブルの共通しないレコードを含めて列を増やす。
内部結合:共通するレコードを対象として列を増やす。
今回は、内部結合について、SAS プログラムと SQL、および Python (Pandas) をそれぞれ用いた例を紹介します。行いたい操作は下記です。
A列をキーとして、値が一致するレコードのみを取り出して、横方向に連結します。① SAS プログラムでの内部結合
data table_3; merge table_1 (in=flg1) table_2 (in=flg2); by A; if flg1=1 and flg2=1 then output; run;merge ステートメントで横に重ねて、 by でキーとなる変数を指定します。
in は、一時変数を指定するオプションです。
具体的には例えば、table_1 ( in =flg1) では、一時変数名をflg1として設定しており、
・table_1 由来のレコードでは flg1=1
・それ以外では flg1=0
となります。
さらに一時変数として指定した flg1 と flg2 は、出力テーブルには出力されません。例えば、下記プログラムでは、
data table_4; merge table_1 (in=flg1) table_2 (in=flg2); by A; val1=flg1; val2=flg2; run;出力は下記となります。一時変数の値を強制的に表示させるため、val1, val2 でそれぞれ値を引き継がせています。
val1 が table_1 起因、val2 が table_2 起因であることがわかると思います。
改めて下記プログラムに戻ると、
data table_3; merge table_1 (in=flg1) table_2 (in=flg2); by A; if flg1=1 and flg2=1 then output; run;if flg1=1 and flg2=1 then output; で、flg1 (=val1) と flg2 (=val2) が共に 1 であるレコードを出力 (then output) させることで、内部結合に相当するテーブルが得られます。
② SQL での内部結合
create table table_3 as select table_1.A, B, C from table_1 inner join table_2 on table_1.A = table_2.A;SELECT 取り出す変数名 from データセット1 inner join データセット2 on 結合条件
(inner は省略してもOK)
結合したいテーブルどうしを inner join でつなぎ、on 以下でどの列を基準にデータを一致させるかを指定します。
また、inner join ~ on を使わずに、where句を使って次のように記述することもできます。create table table_3 as select table_1.A, B, C from table_1, table_2 where table_1.A = table_2.A;③ Python (Pandas) での完全外部結合
import pandas as pd table_1 = pd.DataFrame({'A': [1, 2], 'B': ['AA', 'BB']}) table_2 = pd.DataFrame({'A': [2, 3], 'C': [10, 20]}) table_3 = pd.merge(table_1, table_2, on = "A", how="inner").merge で結合、on にキー列を指定、how で様式(内部なので "inner")を指定します。
出力結果
ちなみに how の様式指定では、 "outer" が完全外部結合、"left" ("right") が左 (右) 外部結合となります。関連記事(本記事含む)
データテーブルの連結-縦方向 1(異なる列名をそのまま残す場合)
データテーブルの連結-縦方向 2(異なる列名を統合する場合)
データテーブルの連結-縦方向 3(積集合と差集合)
データテーブルの連結-横方向 1(完全外部結合)
データテーブルの連結-横方向 2(内部結合)




- 投稿日:2021-02-20T21:45:22+09:00
転移学習・ファインチューニング【実装】
はじめに
今回は、学習済モデルを使った「転移学習及びファインチューニング」の実装をしていきます!!
ディープラーニングや畳み込みニューラルネットワークの基本については、下記の記事を参照してください。
?基本となるディープラーニング
https://qiita.com/hara_tatsu/items/c0e59b388823769f9704?ディープラーニングの実装及び過学習対策
https://qiita.com/hara_tatsu/items/b7423e90574cf7730978?「畳み込みニューラルネットワーク(CNN)まとめ」
https://qiita.com/hara_tatsu/items/8dcd0a339ad2f67932e7?畳み込みニューラルネットワーク(CNN)の実装
https://qiita.com/hara_tatsu/items/d2c6536ae35cca5e97ab学習済モデルを使う理由
ディープラーニングで新しいモデルを作成するときの最大の悩みは、学習用データのデータ量。
少ないデータ量だと、限られた学習用データからの特徴抽出しかできない。そのため精度が悪く、過学習も起こりやすい。そんなときに使われる手法が「転移学習又はファインチューニング」。
大量のデータセットで学習されている学習済モデルの特徴抽出を利用することで、少ないデータ量でも精度の良いモデルを作成することができる。
転移学習とは
学習済モデルを特徴抽出器として利用する方法。
学習済モデル(特徴抽出) → 追加する層(畳み込み層・全結合層) → 出力層
学習済モデルから特徴を抽出した後に学習させる。
転移学習【実装】
今回は題材として、「【SIGNATE】画像ラベリング(10種類)」を使います。
https://signate.jp/competitions/133画像データに映っているものを10種類のラベルから分類するものです。
データの前処理
必要なライブラリーをインポート
python.pyimport numpy as np import pandas as pd from PIL import Image import glob目的変数と説明変数の処理
目的変数を読み込んでカテゴリー変数へ変換
python.pytrain_Y = pd.read_csv('train_master.tsv', delimiter='\t') train_Y = train_Y.drop('file_name', axis=1) # カテゴリー変数へ変換 from tensorflow.keras.utils import to_categorical Y = to_categorical(train_Y) print(Y.shape) print(Y[:5]) (5000, 10) array([[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.], [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.]], dtype=float32)説明変数(画像データ)は、「glob」を使って読み込めるが画像データの並びがバラバラに読み込まれてしまう。そのため、読み込み後に小さい数字の順番に並び替える。
python.pytrain_file = glob.glob('train_images/t*') # 0埋めでない数値を小さい順に並び替える関数 import re from collections import OrderedDict def sortedStringList(array=[]): sortDict=OrderedDict() for splitList in array: sortDict.update({splitList:[int(x) for x in re.split("(\d+)",splitList)if bool(re.match("\d*",x).group())]}) return [sortObjKey for sortObjKey,sortObjValue in sorted(sortDict.items(), key=lambda x:x[1])] # 小さい順に並び替え sort_file = sortedStringList(train_file) print(sort_file[:5]) ['train_images/train_0.jpg', 'train_images/train_1.jpg', 'train_images/train_2.jpg', 'train_images/train_3.jpg', 'train_images/train_4.jpg']説明変数(画像データ)の前処理
現在は、「glob」で画像データのファイル名を取得している状態。
PIL形式で読み込み後にnumpy化する。※※CPU環境では学習に時間がかかる場合があるため、「image = load_img(image, target_size = (32, 32)) 」とすれば画像サイズを小さくできるので計算時間が減る。(予測精度は悪くなる可能性あり)
python.pyfrom tensorflow.keras.preprocessing.image import load_img, img_to_array, array_to_img X = [] for image in sort_file: # 画像ファイルのPIL形式で読み込み image = load_img(image) #image = load_img(image, target_size = (32, 32)) 学習時間を短縮したい場合 # PIL形式からnumpy形式へ image = img_to_array(image) # データをリストへ格納 X.append(image) #Xはリスト型のためnumpy型へ変換 X_np = np.array(X) print(X_np.shape) (5000, 96, 96, 3)学習用データ、検証用データ、テストデータへ分割
python.py# データの分割 from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(X_np, Y, test_size=0.2, random_state=0) X_train, X_valid, Y_train, Y_valid = train_test_split(X_train, Y_train, test_size=0.2, random_state=0) # 形状を確認 print("Y_train=", Y_train.shape, ", X_train=", X_train.shape) print("Y_valid=", Y_valid.shape, ", X_valid=", X_valid.shape) print("Y_test=", Y_test.shape, ", X_test=", X_test.shape) Y_train= (3200, 10) , X_train= (3200, 96, 96, 3) Y_valid= (800, 10) , X_valid= (800, 96, 96, 3) Y_test= (1000, 10) , X_test= (1000, 96, 96, 3)学習用データの拡張と水増し
python.pyfrom tensorflow.keras.preprocessing.image import ImageDataGenerator # 学習用データの拡張設定 image_gen = ImageDataGenerator(rotation_range=45, #45°回転 horizontal_flip = True, #左右反転 rescale=1./255 #正規化 ) # 拡張データの生成 train_data_gen = image_gen.flow(X_train, Y_train, batch_size = 32, shuffle = False) # 拡張データを表示する関数 def plotImages(images_arr): fig, axes = plt.subplots(1, 5, figsize=(20,20)) axes = axes.flatten() for img, ax in zip( images_arr, axes): ax.imshow(img) ax.axis('off') plt.tight_layout() plt.show() augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
python.py#学習用データの状態確認 #3200 / 32 print(len(train_data_gen)) 100検証用データを学習用データの状態に合わせる
python.pyvalid_gen = ImageDataGenerator(rescale=1./255 #正規化) valid_data_gen = valid_gen.flow(X_valid, Y_valid, batch_size = 32) #800 / 32 print(len(valid_data_gen)) 25転移学習の実装
畳み込みニューラルネットワークの学習済モデルとして有名な「VGG16」を利用します。
他にも「Inception」,「ResNet」などあります。
※「ResNet」でも試したが、「VGG16」の方が精度が良かった。
python.pyfrom tensorflow.keras.applications.vgg16 import VGG16 base_model = VGG16(weights = 'imagenet', #学習済みの重みを使用する include_top = False, #出力層は使わない input_shape = (96, 96, 3)) #入力する画像サイズの指定 base_model.summary()VGG16の構造は以下のとおり
(畳み込み層のブロックが5つ)Model: "vgg16" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 96, 96, 3)] 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 96, 96, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 96, 96, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 48, 48, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 48, 48, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 48, 48, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 24, 24, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 24, 24, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 24, 24, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 24, 24, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 12, 12, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 12, 12, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 12, 12, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 12, 12, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 6, 6, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 6, 6, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 6, 6, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 6, 6, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 3, 3, 512) 0 ================================================================= Total params: 14,714,688 Trainable params: 14,714,688 Non-trainable params: 0 _________________________________________________________________転移学習では学習済モデルの重みは固定したままにするので以下の処理を行う。
?重みの固定をしないと全ての重みが更新されてしまうため、学習済モデルを使うメリットがなくなってしまう。
python.py# 全ての重みを固定(freeze) for layer in base_model.layers[:19]: layer.trainable = False # 重みが固定されているかの確認 for layer in base_model.layers: print(layer, layer.trainable)全てが「Flase」となっていれば重みの固定が成功している。
<tensorflow.python.keras.engine.input_layer.InputLayer object at 0x7f5cc984ff60> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f5cc984fb38> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f5cbe758fd0> False <tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7f5cbd716f28> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f5cbd738080> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f5cbd738e10> False <tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7f5cbd73d4e0> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f5cbd745048> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f5cbd74b400> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f5cbd752908> False <tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7f5cbd752ac8> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f5cbd745358> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f5cbd6d9f98> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f5cbd6dc5f8> False <tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7f5cbd6e4e48> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f5cbd6e9b00> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f5cbd6f1a90> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f5cbd6f1198> False <tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7f5cbd6f8940> False転移学習モデルの作成
python.pymodel = keras.Sequential() # VGG16モデル model.add(base_model) # 層を追加 model.add(Conv2D(64, kernel_size=3, padding="same", activation="relu")) model.add(MaxPooling2D()) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(256, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(128, activation="relu")) model.add(Dense(64, activation="relu")) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax')) model.summary()転移学習モデルの構造
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= vgg16 (Functional) (None, 3, 3, 512) 14714688 _________________________________________________________________ conv2d (Conv2D) (None, 3, 3, 64) 294976 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 1, 1, 64) 0 _________________________________________________________________ dropout (Dropout) (None, 1, 1, 64) 0 _________________________________________________________________ flatten (Flatten) (None, 64) 0 _________________________________________________________________ dense (Dense) (None, 256) 16640 _________________________________________________________________ dropout_1 (Dropout) (None, 256) 0 _________________________________________________________________ dense_1 (Dense) (None, 128) 32896 _________________________________________________________________ dropout_2 (Dropout) (None, 128) 0 _________________________________________________________________ dense_2 (Dense) (None, 64) 8256 _________________________________________________________________ dropout_3 (Dropout) (None, 64) 0 _________________________________________________________________ dense_3 (Dense) (None, 10) 650 ================================================================= Total params: 15,068,106 Trainable params: 353,418 Non-trainable params: 14,714,688 _________________________________________________________________訓練されるパラメーターの確認をします。
python.pyfor layer in model.layers: print(layer, layer.trainable ) print(len(model.trainable_weights))10個のパラメータが訓練される。
<tensorflow.python.keras.engine.functional.Functional object at 0x7f5cbd6fe978> True <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f5cc984f668> True <tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7f5cbd6d4f98> True <tensorflow.python.keras.layers.core.Dropout object at 0x7f5cbd6d4c88> True <tensorflow.python.keras.layers.core.Flatten object at 0x7f5cbd238f98> True <tensorflow.python.keras.layers.core.Dense object at 0x7f5cbd238240> True <tensorflow.python.keras.layers.core.Dropout object at 0x7f5cbd240518> True <tensorflow.python.keras.layers.core.Dense object at 0x7f5cbd240d68> True <tensorflow.python.keras.layers.core.Dropout object at 0x7f5cbd240710> True <tensorflow.python.keras.layers.core.Dense object at 0x7f5cbd252588> True <tensorflow.python.keras.layers.core.Dropout object at 0x7f5cbd25a550> True <tensorflow.python.keras.layers.core.Dense object at 0x7f5cbd25afd0> True 10python.pymodel.compile(loss='categorical_crossentropy',optimizer= 'rmsprop', metrics=['accuracy']) %%time # 学習の実施 log = model.fit_generator(train_data_gen, #学習用データ steps_per_epoch = 100, epochs = 5000, #繰り返し計算する回数 callbacks = [keras.callbacks.EarlyStopping(monitor='val_loss',#監視する値 min_delta=0, #改善とみなされる最小の量 patience=50, #設定したエポック数改善がないと終了 verbose=1, mode='auto' #監視する値が増減どうなったら終了か自動で推定 )], validation_data = valid_data_gen, #検証用データ validation_steps = 25)結果の確認
python.pyacc = log.history['accuracy'] val_acc = log.history['val_accuracy'] loss = log.history['loss'] val_loss = log.history['val_loss'] #学習回数によって変更 epochs_range = range(55) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Training Accuracy') plt.plot(epochs_range, val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.title('Training and Validation Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Training Loss') plt.plot(epochs_range, val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.title('Training and Validation Loss') plt.show()
python.py#テストデータの正規化 X_test = X_test / 255.0 # 予測 Y_pred = model.predict(X_test) Y_pred = np.argmax(Y_pred,axis=1) print('予測データ') print(Y_pred[:5]) # カテゴリー変数の復元 Y_test_ = np.argmax(Y_test, axis=1) print('正解データ') print(Y_test_[:5]) # モデルの評価 from sklearn.metrics import classification_report print(classification_report(Y_test_, Y_pred)) 予測データ [2 6 0 2 1] 正解データ [2 5 0 9 1] precision recall f1-score support 0 0.92 0.83 0.87 93 1 0.70 0.85 0.77 100 2 0.98 0.82 0.89 99 3 0.55 0.67 0.60 103 4 0.78 0.65 0.71 117 5 0.73 0.41 0.52 93 6 0.70 0.77 0.73 101 7 0.68 0.69 0.69 110 8 0.79 0.83 0.81 88 9 0.71 0.90 0.79 96 accuracy 0.74 1000 macro avg 0.75 0.74 0.74 1000 weighted avg 0.75 0.74 0.74 1000正解率74%!!
ファインチューニングとは
学習済モデルの出力層に近い部分だけを再学習することでより作成したいモデルに適合させる。
学習済モデル(特徴抽出) → 学習済モデル(再学習) → 新しい層(畳み込み層・全結合層) → 出力層
?出力層に近い部分は、学習済データにより具体的な特徴量を持っている。そのため、この部分を再学習することで今回の学習用データにフィットした特徴量を生み出すことができる。
ファインチューニング【実装】
?前処理は転移学習を参照してください!!
python.pyfrom tensorflow.keras.applications.vgg16 import VGG16 base_model = VGG16(weights = 'imagenet', #学習済の重みを使用する include_top = False, #出力層を除外する(全結合層) input_shape = (96, 96, 3)) #入力する画像サイズ転移学習とは違い最後のConv2D層の重みを解凍して再学習します。
python.py# 最後の畳み込み層の直前までの層を固定 for layer in base_model.layers[:15]: layer.trainable = False # 重みが固定されているかの確認 for layer in base_model.layers: print(layer, layer.trainable )最後の畳み込み層のみ「True」となっていれば成功。
※「True」となっている部分が再学習される。<tensorflow.python.keras.engine.input_layer.InputLayer object at 0x7f4214e33f98> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f420a83b710> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f4209f874a8> False <tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7f4209fb3a90> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f4209fba9e8> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f4209fb3cc0> False <tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7f4208f3fcc0> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f4208f46dd8> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f4208f4b518> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f4208f46828> False <tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7f4208f55eb8> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f4208f59b70> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f4208f59400> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f4208f466a0> False <tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7f4208f659b0> False <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f4208f653c8> True <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f4208f60be0> True <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f4208f726a0> True <tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7f4208f7ae48> Trueファインチューニングモデルの作成
python.py# VGG16のモデルに全結合分類を追加する model = keras.Sequential() # VGG16モデル model.add(base_model) model.add(Conv2D(64, kernel_size=3, padding="same", activation="relu")) model.add(MaxPooling2D()) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(256, activation='relu')) model.add(Dropout(0.25)) model.add(Dense(128, activation="relu")) model.add(Dropout(0.25)) model.add(Dense(64, activation="relu")) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax')) model.summary()?転移学習よりも訓練するパラメーター(Trainable params)が多くなっていることがわかる。
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= vgg16 (Functional) (None, 3, 3, 512) 14714688 _________________________________________________________________ conv2d_1 (Conv2D) (None, 3, 3, 64) 294976 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 1, 1, 64) 0 _________________________________________________________________ dropout_4 (Dropout) (None, 1, 1, 64) 0 _________________________________________________________________ flatten_2 (Flatten) (None, 64) 0 _________________________________________________________________ dense_6 (Dense) (None, 256) 16640 _________________________________________________________________ dropout_5 (Dropout) (None, 256) 0 _________________________________________________________________ dense_7 (Dense) (None, 128) 32896 _________________________________________________________________ dropout_6 (Dropout) (None, 128) 0 _________________________________________________________________ dense_8 (Dense) (None, 64) 8256 _________________________________________________________________ dropout_7 (Dropout) (None, 64) 0 _________________________________________________________________ dense_9 (Dense) (None, 10) 650 ================================================================= Total params: 15,068,106 Trainable params: 7,432,842 Non-trainable params: 7,635,264 _________________________________________________________________訓練されるパラメーターの確認。
python.pyfor layer in model.layers: print(layer, layer.trainable ) print(len(model.trainable_weights))16個のパラメータで訓練が行われる。
<tensorflow.python.keras.engine.functional.Functional object at 0x7f4208f462b0> True <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7f4225e4a390> True <tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7f40e0c9d080> True <tensorflow.python.keras.layers.core.Dropout object at 0x7f40df0d65f8> True <tensorflow.python.keras.layers.core.Flatten object at 0x7f40e0c9d7b8> True <tensorflow.python.keras.layers.core.Dense object at 0x7f40df07d780> True <tensorflow.python.keras.layers.core.Dropout object at 0x7f40e0bc2da0> True <tensorflow.python.keras.layers.core.Dense object at 0x7f40df07d978> True <tensorflow.python.keras.layers.core.Dropout object at 0x7f40df08f2e8> True <tensorflow.python.keras.layers.core.Dense object at 0x7f40df08f470> True <tensorflow.python.keras.layers.core.Dropout object at 0x7f40df083278> True <tensorflow.python.keras.layers.core.Dense object at 0x7f40df097978> True 16python.pymodel.compile(loss='categorical_crossentropy', optimizer= keras.optimizers.SGD(lr=1e-4, momentum=0.9), #ファインチューニング時は学習率が低いものを選択 metrics=['accuracy']) %%time # 学習の実施 log = model.fit_generator(train_data_gen, #学習用データ steps_per_epoch = 100, epochs = 5000, #繰り返し計算する回数 callbacks = [keras.callbacks.EarlyStopping(monitor='val_loss',#監視する値 min_delta=0, #改善とみなされる最小の量 patience=30, #設定したエポック数改善がないと終了 verbose=1, mode='auto' #監視する値が増減どうなったら終了か自動で推定 )], validation_data = valid_data_gen, #検証用データ validation_steps = 25)結果の確認
python.pyacc = log.history['accuracy'] val_acc = log.history['val_accuracy'] loss = log.history['loss'] val_loss = log.history['val_loss'] epochs_range = range(55) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Training Accuracy') plt.plot(epochs_range, val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.title('Training and Validation Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Training Loss') plt.plot(epochs_range, val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.title('Training and Validation Loss') plt.show()
python.py# 予測 Y_pred = model.predict(X_test) Y_pred = np.argmax(Y_pred,axis=1) # モデルの評価 print(classification_report(Y_test_, Y_pred)) precision recall f1-score support 0 0.89 0.92 0.91 93 1 0.79 0.87 0.83 100 2 0.89 0.94 0.91 99 3 0.65 0.73 0.68 103 4 0.76 0.82 0.79 117 5 0.73 0.47 0.58 93 6 0.74 0.81 0.77 101 7 0.81 0.71 0.76 110 8 0.91 0.89 0.90 88 9 0.90 0.86 0.88 96 accuracy 0.80 1000 macro avg 0.81 0.80 0.80 1000 weighted avg 0.80 0.80 0.80 1000正解率80%!!
まとめ
転移学習:計算コスト低い・精度落ちる
ファインチューニング:計算コスト高い・精度は高い?いずれにせよGPU環境での学習でないと計算時間が非常に長くなる。



- 投稿日:2021-02-20T21:42:02+09:00
Pythonで数式を書く_01(シグモイド関数)
数式
以下がシグモイド関数(sigmoid function)です。
y\ = \frac{1}{1+e^{-ax}} \ \ (a>0)a = 1 のときは標準シグモイド関数(standard sigmoid function)と呼びます。
今回はPythonで a = 1 のときのシグモイド関数を記述します。
※ちなみに、本やネットを見ていると、y は h(x) やς(x) と表記していたりもします。Pythonで記述
import numpy as np # シグモイド関数 y = 1 / (1 + np.exp(-x))これがPythonで記述したときのシグモイド関数です。
x = 1 のときは以下のように出力されます。import numpy as np x = 1 y = 1 / (1 + np.exp(-x)) print(y)x=1の出力結果0.7310585786300049コードを省略しますが、x = -1 や x = 0 のときは以下のように出力されます。
x=-1の出力結果0.5x=0の出力結果0.2689414213699951シグモイド関数を視覚化
先ほどの入力と出力を表にまとめると次のようになります。
x = -1 x = 0 x = 1 出力結果 y 0.27 0.5 0.73 表だけだとわかりにくいですが、
グラフにするとシグモイド関数の出力は 0 ~ 1 の間になることがわかります。
ちなみに、上のグラフは以下のコードで描くことができます。
import matplotlib.pyplot as plt import numpy as np x = np.arange(-15, 15, 0.1) y = 1 / (1 + np.exp(-x)) plt.plot(x, y) plt.title("standard sigmoid function") plt.xlabel("x") plt.ylabel("y") plt.show()シグモイド関数はニューラルネットワークの活性化関数としても利用されますので、
その方面に興味のある方はシグモイド関数の数式とPythonでの記述方法を覚えておいてもよいかもしれません。

- 投稿日:2021-02-20T20:47:30+09:00
pylance(pyright)でfrom requests.packages.urllib3.util.retry import Retryに対して「reportMissingModuleSource」の警告が出る
環境
- Language Server version: 2021.2.3
- OS : Windows
- Python version 3.9
内容
インポートは正常に機能しますが
from requests.packages.urllib3.util.retry import Retryに対して「reportMissingModuleSource」の警告が出てしまう解決方法
from requests.packages.urllib3.util.retry import Retryを
from urllib3.util.retry import Retryに修正するだけ再現方法
仮想環境を作成 requestsモジュールをインポート
python -m venv venv.\venv\Scripts\activate.batpip install requestsコード
from requests.packages.urllib3.util.retry import Retry r = Retry print(r)実行
>python test.py <class 'urllib3.util.retry.Retry'>インポートは正常にできていることがわかる
「reportMissingModuleSource」の警告
pylance(pyright)では以下のような警告が出てしまう
原因調査
ソースを見てみると
requests/packages/urllib3/util/retry.pyがあると期待してたが
実際にはrequests/packages.pyのみで以下の記述があったhttps://github.com/psf/requests/blob/master/requests/packages.py
packages.pyimport sys # This code exists for backwards compatibility reasons. # I don't like it either. Just look the other way. :) for package in ('urllib3', 'idna', 'chardet'): locals()[package] = __import__(package) # This traversal is apparently necessary such that the identities are # preserved (requests.packages.urllib3.* is urllib3.*) for mod in list(sys.modules): if mod == package or mod.startswith(package + '.'): sys.modules['requests.packages.' + mod] = sys.modules[mod] # Kinda cool, though, right?これで
requests.packages.urllib3.をurllib3.に読み替えているのでimportは正常におこなえてpylanceがrequests.packages.urllib3.util.retryの実際のソースを見つけることはが出来きずに警告が出てい理由が分かるなので解決方法としてはどうせ読み替えられるので
from urllib3.util.retry import Retryでインポートするのがいいのかもしれません。ほかに解決策があれば

- 投稿日:2021-02-20T20:38:51+09:00
MonowirelessのTWELITE PalからのデータをRaspiで受け取って、DBへ格納→Streamlitで表示する
背景
タイトルの通りのことを実現したい。
イメージ図は以下の通り。
準備するもの
PC:TWELITE pal および Monostick設定変更
Raspberry pi:今回はRaspi 4(4GB)にRasbian OS を導入したものを用いました
TWILITER2:センサへの設定書き込み用
センサデータ送受信関係
TWELITE PAL(Blue or red):センサ側の通信部分(データ送信)
Ambient pal:環境センサモジュール
MONOSTICK(Blue or red):Raspi側の通信部分(データ受信)環境設定
Raspbian OS GNU/Linux 10 (buster)
Python 3.7.3
mariadb 10.3
Streamlit 0.62.0: Raspberry piでstreamlitを導入しようとするとpyarrowのインストールでコケたので0.62.0を指定しました。
mysql-connector-python 8.0.23センサのデータ送受信テスト
MONOWIRELESSさんから提供されている種々ソフトウェアを用いてセンサの送受信テストを行います。
受信側MONOSTICK(親機)およびセンサ側(子機)の設定
子機から送信されたデータを親機で受信するためには、チャンネルなどを適切に設定する必要があります。MONOWIRELESSさんが提供しているTWELITESTAGE SDKに含まれるMWSTAGEを用いて子機と親機の設定をしていきます。
今回は、Windowsにてセンサの設定を行います。続いて、DLしたTWILITESTAGE SDKを解凍します。TWILITER2をPCへと接続し、センサとTWILITER2も接続した状態で、解凍フォルダ内に含まれるTWELITESTAGE.exeを立ち上げます。
TWILITER2→アプリ書き換え→BINから選択→MONO WIRELESS APP_PAL(Endevice) V1-00-2
の順に選択するとセンサ側のファームウェアが書き込まれます。続いてインタラクティブモードへ移行するので、適宜設定します。ここでの設定の詳細は公式の解説(PALアプリインタラクティブモード)に譲ることとしますが、わからなければチャンネルをメモして、データ送信間隔を好みの感覚にいじっておけばいいでしょう。(tを入力後、好みの数字を入力)
続いて、MONOSTICKをPCへと接続し、TWELITESTAGE.exeを立ち上げます。
MONOSTICK→アプリ書き換え→BINから選択→APP_PAL-PARENT
の順に選択すると親機側のファームウェアが書き込まれます。続いてインタラクティブモードモードへ移行します。ここでは、センサ側とチャンネル設定の数字があっていることが確認できれば問題ありません。もし異なっていれば、先ほどメモした数字に書き換えましょう。Raspiを用いたデータ取得テスト
MONOWIRELESSさんによるPython用のデータ取得スクリプトを用いてセンサで取得したデータを通信によってRaspiに取得し表示するテストを行います。Raspi側では、Python3を使用するので、pyserialを導入しておきます。
>pip3 install pyserial続いて、まず、ソースコード(PAL_Script.py)と実行に必要なライブラリ(MNLib)をRaspiへと移します。
この時PAL_Script.pyとライブラリは同一のディレクトリ内に存在する必要があります。それさえ気をつけておけば、PAL_Script.pyが存在するディレクトリにおいて、>python3 PAL_Script.pyと実行しその後、子機に電池を挿入することで受信したデータが表示されます。
*** MONOWIRELESS App_PAL_Viewer 1.0.1 *** {'ArriveTime': datetime.datetime(2021, 2, 6, 21, 19, 6, 51703), 'LogicalID': 1, 'EndDeviceSID': '82014DC1', 'RouterSID': '80000000', 'LQI': 132, 'SequenceNumber': 10, 'Sensor': 128, 'PALID': 2, 'PALVersion': 1, 'Power': 2790, 'ADC1': 2373, 'Temperature': 26.85, 'Humidity': 49.06, 'Illuminance': 4}ちなみに子機側のデータ送信間隔を長く設定してしまった場合、子機のLEDの隣にあるボタンを押すと、データ送信間隔を待たずして強制的にデータが送信されます。強制送信によってもデータの送受信が確認できます。
センサのデータのMariaDBへの格納
MariaDBの導入
RaspiにMariaDBを導入します。
>sudo apt-get install mariadb-server設定周りはP.H (id:raspberrypi)さんのブログを参考にrootのパスワード設定までを実行しておきましょう。
データベースの作成
PALアプリから得られたデータを格納するためのtableを作成します。上記の通り多くのデータが無線で送信されてきますが、ここでは、センサデータとして最低限必要なものとして、
- time:受信日時(datetime) 主キーとして指定
- sensorid:センサーID(varchar(128))
- humidity:湿度(float)
- temperature:気温(float)
- lqi:受信強度(int)
を登録することとします。(カッコ内は指定する型)
>mysql -u root -p Enter password: #パスワードを入力 >create database monowireless; >create table monowireless.amb (time datetime not null primary key, sensorid varchar(128), humidity float, temperature float,lqi int);以上で必要なデータを格納するためのテーブルの作成が完了しました。
センサで取得したデータをデータベースへ登録
データ取得テストで使用したPAL_Script.pyを書き換えて取得データをデータベースへ登録します。pythonからのDB操作にはmysql-connector-pythonを用いることとします。使い方等はこちらを参考にさせていただきました。
>pip install mysql-connector-pythonまずPAL_Script.pyの冒頭のライブラリインポート部分に以下を追記します。
import mysql.connector続いて、取得したデータを記録するために、PAL_Script.py下部の「# なにか処理を記述する場合はこの下に書く」以降に、次の内容を追記します。ここに記述することでデータを取得、書き込みごとにデータベースと接続して得られたセンサデータを記録する形式となります。
conn = mysql.connector.connect( host='localhost', port='3306', user='root', password='password',#パスワード設定を変えた場合はその通りに変更 database='monowireless' ) cur = conn.cursor() cur.execute("INSERT INTO amb VALUES (%s,%s,%s,%s,%s)",(Data["ArriveTime"],Data["EndD eviceSID"] ,Data["Humidity"], Data["Temperature"],Data["LQI"])) conn.commit() cur.close() conn.close()ここまで修正したうえでPAL_Script.pyを実行し、強制送信によってデータの送受信を確認します。
>python3 PAL_Script.py受信したデータはMariaDBへ直接記録されていくので表示は出てきません。記録されたデータを確認してみます。
>mysql -u root -p Enter password: #パスワードを入力 >select * from monowireless.amb; #以下に格納されたデータが表示されるデータが確認できれば、データの格納までは完了です。
MariaDBへ格納したデータをStreamlitで表示
最後にDBに格納されたデータをStreamlitで表示しましょう。グラフ等様々な出力がありますが、ここではひとまず表形式のデータを出力することとします。
まず、streamlitの動作確認をしてみます。>streamlit helloすると、以下のようなエラーメッセージが出て怒られます。
Original error was: libf77blas.so.3: cannot open shared object file: No such file or directory調べてみるとこういう記述にぶち当たりました。どうやらライブラリが足りない模様です。
>sudo apt-get install libatlas-base-devとして必要なライブラリを導入します。これでいけるはずなので再度動作確認。
>streamlit hello RequestsDependencyWarning) Welcome to Streamlit. Check out our demo in your browser. Network URL: http://xxx.xxx.xxx.xxx:8501 External URL: http://yyy.yyy.yyy.yyy:8501 Ready to create your own Python apps super quickly? Just head over to https://docs.streamlit.io May you create awesome apps!ラズベリーパイには別のPCからsshで接続している状況を想定しています。ラズベリーパイ上で構築されたwebアプリにアクセスするにはNetwork URLに記されているURLを任意のブラウザに入力します。すると、streamlitのアプリサンプルが表示されるかと思います。確認出来たらアプリを停止して、DBからデータを取得して表示する処理を記述していきます。
amb_steamlit.pyimport mysql.connector import pandas as pd import streamlit as st def get_df_by_sql(): conn = mysql.connector.connect( host='localhost', port='3306', user='root', password='password',#パスワード設定を変えた場合はその通りに変更 database='monowireless' ) sql = 'SELECT * FROM amb' df = pd.io.sql.read_sql(sql,conn) conn.close return df st.table(get_df_by_sql())上記をsteramlitで実行します。
>streamlit run amb_steamlit.pyテスト時と同様に得られたURLに接続すると以下のような画面になります。
無事streamlitで取得データを表示することができました。
まとめ
以上で、「MonowirelessのTWELITE PalからのデータをRaspiで受け取って、DBへ格納→Streamlitで表示する」ことができました。グラフ等にしたければStreamlitの書式に従って適宜作っていきましょう。
参考
MONOWIRELESS
Raspberry Pi & Python 開発ブログ ☆彡
DBOnline MySQLの使い方
Qiita Python + mysql-connector-python の使い方まとめ


- 投稿日:2021-02-20T20:37:43+09:00
Github Actions 使ったらPypiへのリリースがめちゃくちゃ楽になった
Github Actions 使ったらめちゃくちゃ楽になった
Python Packageのリリース (Pypi)
https://github.com/tys-hiroshi/backlogprocessing を例に挙げると、
今まで、setup.cfg ファイルの
versionパラメータを修正し、
以下のコマンドをUbuntuで叩いていた。pipenv shell pipenv install --dev twine python3 setup.py sdist --formats=zip twine upload dist/*GithubからCloneしてこないといけないし、Releaseできる環境が常にあるわけではないので、
それなりにしんどい作業だった。.github/workflos/[名前は何でも良いよ].yml
を作成し、以下のように記載すると、PypiへReleaseできる。
PYPI_API_TOKEN は Pypiで発行したAPI TokenをGithubのSecretsに登録すること!
name: Upload pypi package release on: # Trigger the workflow on push or pull request, # but only for the master branch push: branches: - master release: types: - created jobs: deploy: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Set up Python uses: actions/setup-python@v2 with: python-version: '3.x' - name: Install dependencies run: | python -m pip install --upgrade pip pip install pipenv pip install wheel - name: Build run: | python3 setup.py sdist --formats=zip - name: Publish a Python distribution to PyPI if: startsWith(github.event.ref, 'refs/tags') || github.event_name == 'release' uses: pypa/gh-action-pypi-publish@master with: user: __token__ password: ${{ secrets.PYPI_API_TOKEN }}Thank you for Reference:
https://help.github.com/en/actions/reference/events-that-trigger-workflows
- 投稿日:2021-02-20T19:30:17+09:00
Macのpyenv installエラー
環境
- MacOSX 11.2.1 BigSur
エラー内容
MacOSXでのzlibエラー。
pyenv install 3.8.5を叩くとエラーがでた。$ pyenv install 3.8.5errorpython-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Installing Python-3.8.5... python-build: use readline from homebrew python-build: use zlib from xcode sdk BUILD FAILED (OS X 11.2.1 using python-build 20180424)ログのtailはこんな感じ。
log__import__(pkg_name) File "<frozen zipimport>", line 241, in load_module File "<frozen zipimport>", line 709, in _get_module_code File "<frozen zipimport>", line 570, in _get_data zipimport.ZipImportError: can't decompress data; zlib not available make: *** [install] Error 1対処法
Tipsによく転がっているxcode-selectや、pkgのインストールなどではうまくいかなかったが、下記でうまくいった。
LDFLAGS="-L$(xcrun --show-sdk-path)/usr/lib" pyenv install 3.8.5参考にした記事
こちらの記事に書いてあった。
https://github.com/pyenv/pyenv/issues/1219#issuecomment-727951276
- 投稿日:2021-02-20T19:30:17+09:00
pyenv installしたときのZipImportError
環境
- MacOSX 11.2.1 BigSur
エラー内容
MacOSXでのzlibエラー。
pyenv install 3.8.5を叩くとエラーがでた。$ pyenv install 3.8.5errorpython-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Installing Python-3.8.5... python-build: use readline from homebrew python-build: use zlib from xcode sdk BUILD FAILED (OS X 11.2.1 using python-build 20180424)ログのtailはこんな感じ。
log__import__(pkg_name) File "<frozen zipimport>", line 241, in load_module File "<frozen zipimport>", line 709, in _get_module_code File "<frozen zipimport>", line 570, in _get_data zipimport.ZipImportError: can't decompress data; zlib not available make: *** [install] Error 1対処法
Tipsによく転がっているxcode-selectや、pkgのインストールなどではうまくいかなかったが、下記でうまくいった。
LDFLAGS="-L$(xcrun --show-sdk-path)/usr/lib" pyenv install 3.8.5参考にした記事
こちらの記事に書いてあった。
https://github.com/pyenv/pyenv/issues/1219#issuecomment-727951276
- 投稿日:2021-02-20T17:46:20+09:00
Python ExcelデータをGoogle翻訳からスクレイピング翻訳
0. はじめに
以前YouTubeで紹介した仕事や課題のさぼり方について解説する。エクセルに羅列された日本語を英語に翻訳するプログラムだ。WebDriverを用いてgoogle翻訳からスクレイピングで翻訳する。動作環境はChromで行う。
1. 必要ライブラリ
openpyxl、selenium、timeを用いる。openpyxlとseleniumは予めpip等でインストールする必要がある。又、ブラウザ操作をするためChromDriverをダウンロードしpathを通しておく必要がある。python -m pip install openpyxl python -m pip install seleniumimport openpyxl as excel from selenium import webdriver import time2. Excelファイルの読み込みとDriverの設定
次にエクセルファイルを指定する。
book = excel.load_workbook("<Excelファイルのパス>", data_only=True) sheet = book.worksheets[0] #データのsheetを選択 driver = webdriver.Chrome() #DriverをChromに設定 count = 1 #セルの行指定3. データの読み込みとスクレイピングによる翻訳
先ほどを見込んだファイルからセルのデータを抽出し、Google翻訳で英訳する。返ってきた英語を受け取りExcelに書き込む。
while True: cell = sheet["A" + str(count)] #cellの指定 if cell.value: #もしcellにデータがあれば url = "https://translate.google.co.jp/?hl=ja&sl=ja&tl=en&text={}&op=translate".format(cell.value) #Google翻訳に日本語を入力済みのURLを作成 driver.get(url) #上記URLを開く time.sleep(1) #サーバ負荷軽減 ja = driver.find_element_by_css_selector("span[jsname='W297wb']") sheet["B" + str(count)] = ja.text count += 1 else: break #cellにデータがなければループを抜ける4. Excelファイルを保存し実行
最後にExcelファイルを保存する。
実際にデバッグしてみるとChromが立ち上がり順次翻訳されるだろう。デバッグする際はExcelファイルは閉じてデバッグする。book.save("<Excelファイルのパス>")5. 最後に
課題をさぼれるが何の役にも立たない。課題はしっかりやって身に着けるべき。
- 投稿日:2021-02-20T17:41:01+09:00
Pythonコードと可視化で確認するマハラノビス距離
はじめに
この記事ではマハラノビス距離の計算と可視化を通して、
マハラノビス距離を用いた異常検知のイメージを確認します。
理論や数式は省いて、ソースコードと可視化を中心に、定性的な理解に重きを置いています。この記事ですること
・相関のあるデータの生成と可視化
・分散共分散行列の計算と可視化
・マハラノビス距離の計算と可視化マハラノビス距離の定義等については、既にQiita内でも解説してくださっている方がいらっしゃるので、
そちらを参考にされると良いと思います。
教師なし学習による異常値検知: マハラノビス距離 (理論編)
scipyを使って特徴量の相関を考慮したマハラノビス距離を計算するscikit-learnでの公式ページの解説はこちらからご確認ください。
Robust covariance estimation and Mahalanobis distances relevance本論
ライブラリ
バージョン確認
import numpy import matplotlib import scipy import sklearn print("numpy: {0}".format(numpy.__version__)) print("matplotlib: {0}".format(matplotlib.__version__)) print("scipy: {0}".format(scipy.__version__)) print("sklearn: {0}".format(sklearn.__version__))筆者環境では以下のバージョンがインストールされております。
numpy: 1.17.0 matplotlib: 3.2.2 scipy: 1.5.0 sklearn: 0.23.1使用する部分のインポート
import numpy as np import matplotlib.pyplot as plt from scipy.stats import multivariate_normal from sklearn.covariance import EmpiricalCovariance相関のあるデータの生成と可視化
今回は正の相関を持つ2次元正規分布のデータを生成して学習データとして利用します。
分散をそれぞれ1.0、共分散を0.7に設定しています。mean = np.array([0,0]) # 平均 cov_org = np.array([[1.0,0.7],[0.7,1.0]]) # 分散共分散行列 np.random.seed(0) X = multivariate_normal(mean, cov_org).rvs(size=1000) # データ生成生成したデータを散布図で可視化します。
fig,ax = plt.subplots(figsize=(8,6)) ax.plot(X[:,0], X[:,1] ,'.') ax.set_xlim([-4,4]) ax.set_ylim([-4,4]) ax.set_xlabel('X[0]') ax.set_ylabel('X[1]') ax.set_aspect('equal') ax.set_title('Fig.1') plt.savefig('fig1.png')
正の相関を持つデータが生成できていることが確認できます。
分散共分散行列の計算と可視化
生成したデータから分散共分散行列を再計算してみます。
これがデータの「学習」に相当します。empCov = EmpiricalCovariance().fit(X) cov_cal = empCov.covariance_ヒートマップで可視化してみます。
fig, ax = plt.subplots(figsize=(8,6)) im = ax.imshow(cov_cal, vmin=0, cmap='Reds') cbar = ax.figure.colorbar(im, ax=ax) ax.set_xticks(np.arange(cov_cal.shape[0])) ax.set_yticks(np.arange(cov_cal.shape[1])) ax.tick_params(top=True, bottom=False,labeltop=True, labelbottom=False) for i in range(cov_cal.shape[0]): for j in range(cov_cal.shape[1]): text = ax.text(i, j, cov_cal[i, j], ha='center', va='center', color='w') ax.set_title('Fig.2') plt.savefig('fig2.png')
データの生成時に設定した分散共分散行列に従ってデータが生成されていることが確認できます。マハラノビス距離の計算と可視化
テスト用にデータを生成します。
今回は[-2,-2]~[2,2]の範囲で1間隔の格子状にデータを生成しています。
説明の都合上、A:[-2,-2],B:[-1,-2],C:[0,-2],…,M:[0,0],…,Y:[2,2]と対応付けることにします。Y0,Y1 = np.meshgrid(np.arange(-2,3),np.arange(-2,3)) Y = np.array([Y0.reshape(-1),Y1.reshape(-1)]).T labels = ['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y']これを先ほど使用したEmpiricalCovarianceクラスのmahalanobis()に入れるとマハラノビス距離の2乗が計算できます。
md = np.sqrt(empCov.mahalanobis(Y)) print('Mahalanobis Distance') print(md)実行結果
Mahalanobis Distance [2.24902063 2.12256063 2.84114155 3.96970512 5.25020799 2.16386194 1.13576907 1.42031549 2.61997568 3.97880646 2.88870249 1.45353983 0.0246127 1.41706927 2.85223012 4.00562162 2.64077329 1.42197552 1.09086983 2.11604144 5.27100616 3.98405422 2.84280177 2.10000179 2.20412 ]棒グラフで可視化するとこのようになります。
fig,ax = plt.subplots(figsize=(8,6)) ax.bar(labels, md) ax.set_xlabel('Label') ax.set_ylabel('Mahalanobis Distance') ax.set_title('Fig.3') plt.savefig('fig3.png')
この結果を詳しく見ていくことにします。
先ほどの散布図に、テスト用データおよびラベルと、マハラノビス距離の等高線も含めて可視化します。### 等高線用データ cX, cY = np.meshgrid(np.linspace(-4, 4, 100), np.linspace(-4.0, 4.0, 100)) cZ = np.sqrt(empCov.mahalanobis(np.array([cX.reshape(-1),cY.reshape(-1)]).T)).reshape(100,100) ### 散布図 + 等高線 fig,ax = plt.subplots(figsize=(8,6)) # 学習データ ax.plot(X[:,0], X[:,1], '.', alpha=0.3) # テストデータ ax.plot(Y[:,0], Y[:,1], 'x', color='red') # 等高線用データ ax.clabel(ax.contour(cX, cY, cZ, np.arange(0, 10, 1), cmap='jet'), inline=True, fontsize=10) for i in range(Y.shape[0]): text = ax.text(Y[i,0]+0.1, Y[i,1]+0.1, labels[i], color='r') ax.set_xlim([-4,4]) ax.set_ylim([-4,4]) ax.set_xlabel('X[0]') ax.set_ylabel('X[1]') ax.set_aspect('equal') ax.set_title('Fig.4') plt.savefig('fig4.png')
M[0,0]の点は分布の中央に位置しているので、マハラノビス距離はほぼ0となります。
つまり、異常度は極めて低いと言うことができます。
E[2,-2]とU[2,-2]が相関から外れているため、マハラノビス距離が5.3程度と大きくなっています。
そのため、例えば「マハラノビス距離5以上を異常とみなす」と設定した場合は、
E・Uの2点を異常として検知することができます。
また、A[-2,-2]とE[2,-2]を比べてみると、中心からの画像上の距離(=ユークリッド距離)は同じですが、
Aの方は相関から外れていないのでマハラノビス距離も2.2と小さくなっています。
他に、A[-2,-2]とI[1,-1]を比べてみると、ユークリッド距離が小さいのはIですが、相関から外れているため、
マハラノビス距離は2.6とAより大きくなっています。
以上のように相関を考慮した異常検知ができていることが確認できると思います。まとめ
以上、コードと可視化を交えたマハラノビス距離の解説でした。
どなたかのお役に立てれば幸いです。
お気づきの点がありましたらご指摘ください。付録
使用したコード全体
## ライブラリ ### バージョン確認 import numpy import matplotlib import scipy import sklearn print("numpy: {0}".format(numpy.__version__)) print("matplotlib: {0}".format(matplotlib.__version__)) print("scipy: {0}".format(scipy.__version__)) print("sklearn: {0}".format(sklearn.__version__)) ### 使用する部分のインポート import numpy as np import matplotlib.pyplot as plt from scipy.stats import multivariate_normal from sklearn.covariance import EmpiricalCovariance ## データの生成と可視化 ### データの生成 mean = np.array([0,0]) # 平均 cov_org = np.array([[1.0,0.7],[0.7,1.0]]) # 分散共分散行列 np.random.seed(0) X = multivariate_normal(mean, cov_org).rvs(size=1000) # データ生成 ### 散布図 fig,ax = plt.subplots(figsize=(8,6)) ax.plot(X[:,0], X[:,1] ,'.') ax.set_xlim([-4,4]) ax.set_ylim([-4,4]) ax.set_xlabel('X[0]') ax.set_ylabel('X[1]') ax.set_aspect('equal') ax.set_title('Fig.1') plt.savefig('fig1.png') ## 分散共分散行列の計算と可視化 ### 分散共分散行列の再計算(学習) empCov = EmpiricalCovariance().fit(X) cov_cal = empCov.covariance_ ### ヒートマップ fig, ax = plt.subplots(figsize=(8,6)) im = ax.imshow(cov_cal, vmin=0, cmap='Reds') cbar = ax.figure.colorbar(im, ax=ax) ax.set_xticks(np.arange(cov_cal.shape[0])) ax.set_yticks(np.arange(cov_cal.shape[1])) ax.tick_params(top=True, bottom=False,labeltop=True, labelbottom=False) for i in range(cov_cal.shape[0]): for j in range(cov_cal.shape[1]): text = ax.text(i, j, cov_cal[i, j], ha='center', va='center', color='w') ax.set_title('Fig.2') plt.savefig('fig2.png') ## マハラノビス距離の計算と可視化 ### テスト用データ生成(格子点) Y0,Y1 = np.meshgrid(np.arange(-2,3),np.arange(-2,3)) Y = np.array([Y0.reshape(-1),Y1.reshape(-1)]).T labels = ['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y'] ### マハラノビス距離計算 md = np.sqrt(empCov.mahalanobis(Y)) print('Mahalanobis Distance') print(md) ### 棒グラフ fig,ax = plt.subplots(figsize=(8,6)) ax.bar(labels, md) ax.set_xlabel('Label') ax.set_ylabel('Mahalanobis Distance') ax.set_title('Fig.3') plt.savefig('fig3.png') ### 等高線用データ cX, cY = np.meshgrid(np.linspace(-4, 4, 100), np.linspace(-4.0, 4.0, 100)) cZ = np.sqrt(empCov.mahalanobis(np.array([cX.reshape(-1),cY.reshape(-1)]).T)).reshape(100,100) ### 散布図 + 等高線 fig,ax = plt.subplots(figsize=(8,6)) # 学習データ ax.plot(X[:,0], X[:,1], '.', alpha=0.3) # テストデータ ax.plot(Y[:,0], Y[:,1], 'x', color='red') # 等高線用データ ax.clabel(ax.contour(cX, cY, cZ, np.arange(0, 10, 1), cmap='jet'), inline=True, fontsize=10) for i in range(Y.shape[0]): text = ax.text(Y[i,0]+0.1, Y[i,1]+0.1, labels[i], color='r') ax.set_xlim([-4,4]) ax.set_ylim([-4,4]) ax.set_xlabel('X[0]') ax.set_ylabel('X[1]') ax.set_aspect('equal') ax.set_title('Fig.4') plt.savefig('fig4.png')




- 投稿日:2021-02-20T17:15:40+09:00
【Python】2次元配列で隣接している座標を求める その1【NumPy】
Python 勉強中です
時間があるので Python の勉強をしています。NumPyってのが、いい感じにややこしくて、おもしろいなぁ。というレベル感の記事です。Google Colaboratory で動作させながら記事を書いてます。
数学的な知見があまりないので「Numpy 隣接」などで検索してもそれじゃない感じの概念の解説しかみつけられなかったので、自分で考えてみたので残しておこうと思います。
ゲーム系のプログラマーでもないし座標計算?な、ゆるい記事です。まずは2次元配列を作成して表示する。
import numpy as np l = np.arange(15).reshape(3,5) print(l) # [[ 0 1 2 3 4] # [ 5 6 7 8 9] # [10 11 12 13 14]]これだけで簡単にできるのはなかなか嬉しい。Python, NumPy が人気なのも納得。
まずは
6に隣接する1,5,7,11を求めていきます。
6の座標は(1,1)です。上下左右とはそれぞれ(-1,0)(+1,0)(0,-1)(0,+1)を座標と演算して(0,1)(2,1)(1,0)(1,2)ですね。
ファーストステップは点pから4つの座標がわかるところまで。可読性がいいかなと思い、座標はタプルを利用します。p = (1,1) print( l[p], l[(0,1)], l[(2,1)], l[(1,0)], l[(1,2)] ) # 6 1 11 5 7最初の呪文「ブロードキャスト!」
ここで早速、NumPyさんの呪文「ブロードキャスト」が活躍しそうです。
細かい解説はしませんが、要素が一つのものと複数のものとを演算するといい感じにしてくれる呪文だと思っています。
そもそも(1,1)+(0,1)で(1,2)を簡単に求めてくれるのも NumPyさんのおかげ。以下にコードをprint( p + (0,1) ) # (1, 1, 0, 1) # 通常タプル同士の + はただ連結される print( p + np.array((0,1)) ) # [1 2] # どちらかがNumPy化?しているとそれぞれ足してくれる。不思議! # Up Right Down Left # 時計回り u_r_d_l = [(-1,0), (0,1), (1,0), (0,-1)] print( p + np.array(u_r_d_l) ) # [[0 1] # [1 2] # [2 1] # [1 0]] # アメージング!for文っぽいループなしに4つの座標の演算結果をゲットすることができました。コメントでNumPy化という謎の言葉を使いましたが、みんなどんな感じで呼んでますか?うちらはこうだな、などなどありましたらぜひコメントください。
おもしろいと感じたのは「+」の前後どちらかだけでもうまくいくところですね。ちなみに座標部分はタプル
(1,1)で記述していますが、リスト[1,1]でも問題ないはずです。座標を扱う際にタプル(a,b)に特別な機能があるわけではない(と思う)。同じように Python 勉強中の方がいたら混乱するかもしれないので、念のため言及しておきます。断言してないのはまだ僕も勉強中で書いている記事なので。また演算結果はタプルではなくなってしまいますが
[*map(tuple, xxx)]で、xxx に入れるとタプルを持ったリストに変換できます。わざわざタプルにする必要がない場合も、print()で表示したときに見やすいかもなって時などに、この方法を利用していきます。
map関数?はっ?て人も、このコードは[[],[],...]を[(),(),...]に変換してるんだなぐらいで考えてればOKです。(この記事では map関数の説明をする気がないです。。。ごめんなさい。ちなみにどなたか詳しい方でlist(map(...))と[*map(...)]の違いってあるのか、ご教授いただけたら嬉しいです。)# [[],[],...] → [(),(),...] へ変換 print( [*map(tuple, p + np.array(u_r_d_l)] ) # [(0, 1), (1, 2), (2, 1), (1, 0)]これでかんせーい!ではないですね。
今は点p が中心あたりなので大丈夫ですが、これがはじっこにずれると範囲外の座標を示してしまいます。
(-1,0)などのマイナス座標は Pythonはうまい具合に後ろから処理してくれますが、(3,0)や(0,5)はエラーになってしまいます。
次の呪文で、この辺りのケアをしていきたいと思いますが、ここまでのコードをちょっと書き換えて一度、記述しておきます。まぁまぁなことやってるはずなのですが、短くてすごいですね。
2次元配列に壁の概念があって、点p にはじっこが入力されない場合はこれでおしまいですからね。import numpy as np l = np.arange(15).reshape(3,5) p = (1,1) u_r_d_l = np.array([(-1,0), (0,1), (1,0), (0,-1)]) print( [*map(tuple, p + u_r_d_l] ) # [(0, 1), (1, 2), (2, 1), (1, 0)]思ってたよりこの後が長くなっているので、一度投稿しておきます。 つづく
- 投稿日:2021-02-20T16:42:47+09:00
kivyに関する備忘録
Androidアプリを作っている際にpythonでGUIを作成したいなと思ったので、kivyというライブラリを使ってGUIを作成することにしました!
今回はメモ代わりに書いているので、正直書いている項目に順番はありません。また、今回は
Widgetクラスとウィジェットを区別して書くことにします。カタカナでウィジェットになっている場合は、ButtonやLabelなどのウィジェットだと思ってください。開発環境
- Visual Studio Code 1.53.2
- MacOS Darwin x64 20.3.0
- python 3.7.7(anaconda)
参考記事
こちらの記事がわかりやすかったので、参考にさせていただきました。
Kivy 超入門(6):動的配置 – float レイアウト
Python: Kivy と Matplotlib でデータセットの確認ツールを書いてみる
Kv Languageを使ったKivyの動かし方
Kv言語の基本
Python: Kivy で Matplotlib のグラフをプロットする
Python3入門〜Kivy による GUI アプリケーション開発,サウンド入出力,ウェブスクレイピング〜GUIを構築するためのプログラミング言語
まず、最初にAndroidアプリを作る時には、Androidアプリを作るための統合開発環境である、Android Studioというものが良く使われているみたいです。
しかし、これで作る場合は、言語はJavaかKotlinというもので作る必要があるのですが、自分はPythonで書く方が慣れているため、なんとかpythonで作る方法を探してみたところ、見つかったのが、このkivyというライブラリです。
kivyの役割
kivyライブラリを使って、GUIを作成する際は、
①pythonファイルだけを作成して、そこにkivyライブラリを読み込んで、GUIを作っていく方法
②pythonファイルとkvファイルの2つを作成して、pythonファイルには機能だけを、kvファイルにはレイアウトだけを加えていき、GUIを作成していく方法(この場合もpythonファイルにはkivyライブラリを読み込む)②の場合は、HTMLとCSSのような書き方になっておりますね。
日本語表記するための最強のライブラリ
KV Languageを使って日本語表記を行おうと思っている方は多いと思います。
しかし、kvはデフォルトでは英語表記になっておりますので、日本語表記にするために色々面倒くさそうなことをしなければありません。そこで活躍するのが、
japanize_kivyになります!!pip install japanize-kivy import japanize_kivyこれを行うだけで、他には何もしなくても日本語で表示することが可能です。
Python: インポートするだけで Kivy が日本語を表示できるようになる japanize-kivy を作った
Widgetとは
まず、Kivyを勉強していて思ったのが、
Widgetクラスを親クラスとして継承して、Buttonなどを作っている人もいれば、継承せずに作っている人もいるという不思議。どうやら、Widgetクラスとは
ButtonやLabelなどの総称のことではないかと自分は理解しました。
なので、Widgetクラスを継承しておけば、他を包括しているので、万能!みたいな感じかなと。ルートウィジェットとは
ウィジェットのことは少しわかったのですが、次によくわからなかった部分が、
ルートウィジェットになります。ズバリ結論から言いますと、
ルートウィジェットというのは、全てのウィジェットの1番基盤の部分になります。少しわかりにくいと思いますので、具体例を見ながら確認していきましょう。
Application.pyfrom kivy.app import App from kivy.uix.widget import Widget class MyWidget(Widget): pass class MyApp(App): def build(self): return MyWidget() if __name__ == '__main__': MyApp().run()こちらの
pythonファイルの方で、Widgetクラスを継承して、新しいMyWidgetクラスを作成しています。my.kv<MyWidget>: BoxLayout: orientation: 'vertical' Label: GridLayout: rows:1 cols:4 Button: Button: Button: Button:上の場合ですと、
ルートウィジェットというのは、MyWidgetになります。
ルートウィジェットというのはアプリケーションのなかに、必ず1つだけしか存在しないという特徴があります。
MyWidgetという1番大きなWidgetを定義する- その中に
BoxLayoutという2番目に大きなWidgetを定義するBoxLayoutの中に、LabelやGridLayoutやButtonなどの細かいウィジェットが入っているこのような構造になっております。
MyWidgetが親だとすると、BoxLayoutは子ども、LabelやGridLayout
やButtonは孫みたいな感じになりますね。selfとrootの違い
先程のコードのkvファイルのみを用いて説明をしたいと思います。
my.kv<MyWidget>: BoxLayout: orientation: 'vertical' Label: GridLayout: rows:1 cols:4 Button: Button: Button: Button:まず、
selfとは個々のウィジェット自身を指します。
GridLayoutの部分にself.を書けば、GridLayout自身を指しますし、Button
の部分に書けば、Button自身を指します。次に
rootですね。
正直、rootに関してはあまり確信を持てていない状態です。
個人的な認識としては、rootウィジェットを指していると考えております。確信を持てていない理由
なぜ、確信を持てていないのかというと、例えば、下で説明するような画面の切り替えを行う場合に、rootは結局1番根っこの
rootウィジェットを指しているのか、それともrootウィジェットに追加されたウィジェットを指しているのかわからないからです。pos_hintとsize_hint
アプリケーションを作るということになった場合、PCとスマホで画面の大きさが違うという問題にぶち当たりますよね。
通常は、以下のように、
ピクセル単位で数字を指定していくのですが、これだと、PCの時は良いかもしれないが、スマホの時はサイズが合わないというふうになってしまいます。pos: 20, 50 size: 500, 300そこで、活躍してくれるのが、
pos_hintとsize_hintというものになります。pos_hint: {'x':0, 'top':1} size_hint: 0.3, 0.4のような形で、
size_hintは全画面に対してどれくらいの割合の大きさか、pos_hintは画面の左下を(0,0)として、どれくらいの割合の場所に位置するかというのを指定します。pos_hintの変数
pos_hintはx, y, right, topを変数として指定することができます。xはウィジェットの左の部分の位置を指定
yはウィジェットの下部分の位置を指定
rightはウィジェットの右部分の位置を指定
topはウィジェットの上部分の位置を指定を行うことができます。
root.sizeとhint_sizeはどう使い分ければ良い?
個人的によくわかりにくかったのが、この2つを使い分けることですね。
root.sizeは1番大きい外枠のWidgetの大きさを基準にするhint_sizeは今現在のWidgetの大きさを基準にする少し文字だとわかりにくいので、具体例を使って説明していきたいと思います。
Application.pyfrom kivy.app import App from kivy.uix.widget import Widget class MyWidget(Widget): pass class MyApp(App): def build(self): return MyWidget() if __name__ == '__main__': MyApp().run()my.kv<MyWidget>: BoxLayout: orientation: 'vertical' size: root.size Label: id: txt01 text: root.text size_hint: 1, 0.1
BoxLayoutでまず、root.sizeを使用しているのですが、これは、ルートウィジェットの大きさまで大きくするという認識で考えております。
Labelの方で、size_hintを使用していますが、こちらは、Labelより1つ外側のWidget(今回は、BoxLayout)の大きさを基準にして、調整する形になります。もしも、
Labelでroot.sizeを使った場合は、MyWidgetの大きさのLabelができあがります。(間違っていたらすみません。)つまづいた点
こちらは、GUIアプリを作っている際に、つまづいて、Teratailにも質問してみた内容です。
Application.pyimport japanize_kivy import pandas_datareader.data as web import numpy as np import matplotlib.pyplot as plt import datetime import talib import mplfinance as mpf import time import pandas as pd import tensorflow as tf import schedule import traceback import sys from sklearn import preprocessing from StockApp import * from matplotlib import gridspec from kivy.app import App from kivy.config import Config from kivy.uix.widget import Widget from kivy.uix.boxlayout import BoxLayout from kivy.properties import * from kivy.resources import resource_add_path from kivy.core.text import LabelBase, DEFAULT_FONT from kivy.uix.screenmanager import ScreenManager, Screen from kivy.garden.matplotlib.backend_kivyagg import FigureCanvasKivyAgg from kivy.graphics import * from kivy.factory import Factory # マルチタッチを無効化する => 右クリックしても赤い点が残らない Config.set('input', 'mouse', 'mouse, disable_multitouch') Config.set('modules', 'inspector', '') Name = ['A', 'B'] # csvファイルを読み込む Hello01 = pd.read_csv('graph01.csv') Hello02 = pd.read_csv('graph02.csv') Hello03 = pd.read_csv('graph03.csv') Hello01['Date'] = pd.to_datetime(Hello01['Date']) Hello02['Date'] = pd.to_datetime(Hello02['Date']) Hello03['Date'] = pd.to_datetime(Hello03['Date']) # DataFrameの状態では、インデックス番号で指定できないからnp.arrayで配列に変換する A_Hello = np.array(Hello01).T B_Hello = np.array(Hello02).T C_Hello = np.array(Hello03).T class FirstPage(BoxLayout): text = StringProperty() # プロパティの追加 graph = NumericProperty(0) def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self.text = ' ' # リストに入れる self.d_list = [] self.w_list = [] self.m_list = [] self.numbers = 0 with open('File01.txt', 'r', encoding='utf-8') as day: self.day = day.readlines() with open('File02.txt', 'r', encoding='utf-8') as week: self.week = week.readlines() with open('File03.txt', 'r', encoding='utf-8') as month: self.month = month.readlines() # ActionBarの次へボタンを押したら次の会社に行くようにする処理 def Next(self, index_num): if 0 <= index_num < len(Name) - 1: self.numbers = index_num self.text = self.day[self.numbers] # 月のグラフの表示を更新する処理 def update01(self): self.text = self.month[self.numbers] # 週のグラフの表示を更新する処理 def update02(self): self.text = self.week[self.numbers] # 日の表示を更新する処理 def update03(self): self.text = self.day[self.numbers] class GraphView(BoxLayout): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) # データをrootウィジェットの方に呼び出すようにする => このクラスがインスタンス化された時に1番最初に呼び出される self.A_Hello = A_Hello self.B_Hello = B_Hello self.C_Hello = C_Hello self.d_data = Hello01 self.w_data = Hello02 self.m_data = Hello03 self.num = 0 # figとaxだけで表す必要あり self.fig, self.ax = plt.subplots(2, 1, gridspec_kw={ 'height_ratios':[4,1] }) self.Update(self.A_Hello[self.num+1], self.d_data[Name[self.num]], Hello['Date']) self.add_widget(FigureCanvasKivyAgg(self.fig)) def Update(self, data, signal, times): # 前にプロットされたグラフを消去する self.ax[0].clear() self.ax[1].clear() period = 30 upper, middle, lower = talib.BBANDS(signal, timeperiod=period, nbdevup=1, nbdevdn=1, matype=0) # 引数としてHelloを取得するからselfをつける必要はない rsi = talib.RSI(signal, timeperiod=period) # 取得したデータを元にプロットする self.ax[0].plot(times, data) self.ax[0].set_ylabel('price', fontsize=15) self.ax[0].plot(times, upper) self.ax[0].plot(times, lower) self.ax[0].legend([Name[self.num]]) self.ax[0].tick_params(labelsize=10) self.ax[1].plot(times, rsi) self.ax[1].set_xlabel('time', fontsize=20) self.ax[1].set_ylabel('persentage', fontsize=15) self.ax[1].legend(['RSI']) self.ax[1].tick_params(labelsize=10) # 再描画する self.fig.canvas.draw() self.fig.canvas.flush_events() time.sleep(0.1) # 0.1秒だけ開ける # ActionBarの次へボタンを押したら次に行くようにする処理 def Next(self, index_num): if 0 <= index_num < len(Name) - 1: self.num = index_num A_Hello = self.A_Hello[self.num+1] data = self.d_data[Name[self.num]] self.Update(A_Hello, data, Hello['Date']) # 月のグラフの表示を更新する処理 def update01(self): C_Hello = self.C_Hello[self.num+1] m_data = self.m_data[Name[self.num]] self.Update(C_Hello, m_data, Hello03['Date']) # 上で変更された変数を元にしてメソッドが実行される # 週のグラフの表示を更新する処理 def update02(self): B_Hello = self.B_Hello[self.num+1] w_data = self.w_data[Name[self.num]] self.Update(B_Hello, w_data, Hello02['Date']) # 日毎の表示を更新する処理 def update03(self): A_Hello = self.A_Hello[self.num+1] d_data = self.d_data[Name[self.num]] self.Update(A_Hello, d_data, Hello['Date']) class TextWidget(Widget): sm = ScreenManager() print(Name[0]) def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) def change_page(self): self.clear_widgets() self.add_widget(FirstPage()) def change_page2(self): self.clear_widgets() page2 = Factory.SecondPage() self.add_widget(page2) class CopyHelloApp(App): def __init__(self, **kwargs): super().__init__(**kwargs) self.title = 'HelloWold' # ウィンドウの名前を変更する def build(self): return TextWidget() if __name__ == '__main__': CopyHelloApp().run()copyhello.kv#:kivy 2.0.0 # TextWidget rootウィジェットに指定されている TextWidget: <TextWidget>: FirstPage: id: page1 <page1>: orientation: 'vertical' size: root.size # BoxLayoutのサイズ rootウィジェット(TextWidget)の大きさに合わせる # メニューバー ActionBar: ActionView: ActionPrevious: title: 'ページタイトル1' with_previous: False # 戻るボタンを表示する ActionButton: text: '次のページ' on_release: app.root.change_page2() ActionGroup: text: 'グループ名' mode: 'spinner' ActionButton: text: 'A' on_release: app.root.ids['graph_view'].Next(0) on_release: app.root.ids['page1'].Next(0) on_release: name.text = 'A' ActionButton: text: "B" on_release: app.root.ids['graph_view'].Next(1) on_release: app.root.ids['page1'].Next(1) on_release: name.text = 'B' BoxLayout: orientation: 'horizontal' size_hint_y: 0.1 Label: id: name text: 'A' Label: id: show text: app.root.ids['page1'].text # グラフをここで表示する GraphView: size_hint_y: 0.9 id: graph_view GridLayout: cols: 3 rows: 1 size_hint_y: 0.1 Button: id: button11 text: '月' font_size: 48 on_release: app.root.ids['graph_view'].update01() on_release: app.root.ids['page1'].update01() Button: id: button12 text: '週' font_size: 48 on_release: app.root.ids['graph_view'].update02() on_release: app.root.ids['page1'].update02() Button: id: button13 text: '日' font_size: 48 on_release: app.root.ids['graph_view'].update03() on_release: app.root.ids['page1'].update03() <GraphView>: <SecondPage@BoxLayout>: id: page2 size: root.size orientation: 'horizontal' # 画面の切り替えを行う ActionBar: ActionView: ActionPrevious: title: 'ページタイトル2' with_previous: False # 戻るボタンを表示する ActionButton: text: '前のページ' on_release: app.root.change_page() MyLabel: id: first_button text: 'Hello' MyLabel: id: second_button text: 'World' <MyLabel@Label>: font_size: 60 size_hint_y: 1 '''このコードですと、なぜか画面が真っ暗になってしまったので、なんでかなと思いつつ、エラーになる前の状態から1つずつ機能を追加していきました。
Application.pyimport japanize_kivy import pandas_datareader.data as web import numpy as np import matplotlib.pyplot as plt import datetime import talib import mplfinance as mpf import time import pandas as pd import tensorflow as tf import schedule import traceback import sys from sklearn import preprocessing from StockApp import * from matplotlib import gridspec from kivy.app import App from kivy.config import Config from kivy.uix.widget import Widget from kivy.uix.boxlayout import BoxLayout from kivy.properties import * from kivy.resources import resource_add_path from kivy.core.text import LabelBase, DEFAULT_FONT from kivy.uix.screenmanager import ScreenManager, Screen from kivy.garden.matplotlib.backend_kivyagg import FigureCanvasKivyAgg from kivy.graphics import * from kivy.factory import Factory # マルチタッチを無効化する => 右クリックしても赤い点が残らない Config.set('input', 'mouse', 'mouse, disable_multitouch') Config.set('modules', 'inspector', '') Name = ['A', 'B'] # csvファイルを読み込む Hello01 = pd.read_csv('graph01.csv') Hello02 = pd.read_csv('graph02.csv') Hello03 = pd.read_csv('graph03.csv') Hello01['Date'] = pd.to_datetime(Hello01['Date']) Hello02['Date'] = pd.to_datetime(Hello02['Date']) Hello03['Date'] = pd.to_datetime(Hello03['Date']) # DataFrameの状態では、インデックス番号で指定できないからnp.arrayで配列に変換する A_Hello = np.array(Hello01).T B_Hello = np.array(Hello02).T C_Hello = np.array(Hello03).T class FirstPage(BoxLayout): text = StringProperty() # プロパティの追加 graph = NumericProperty(0) def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self.text = ' ' # リストに入れる self.d_list = [] self.w_list = [] self.m_list = [] self.numbers = 0 with open('File01.txt', 'r', encoding='utf-8') as day: self.day = day.readlines() with open('File02.txt', 'r', encoding='utf-8') as week: self.week = week.readlines() with open('File03.txt', 'r', encoding='utf-8') as month: self.month = month.readlines() # ActionBarの次へボタンを押したら次の会社に行くようにする処理 def Next(self, index_num): if 0 <= index_num < len(Name) - 1: self.numbers = index_num self.text = self.day[self.numbers] # 月のグラフの表示を更新する処理 def update01(self): self.text = self.month[self.numbers] # 週のグラフの表示を更新する処理 def update02(self): self.text = self.week[self.numbers] # 日の表示を更新する処理 def update03(self): self.text = self.day[self.numbers] class GraphView(BoxLayout): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) # データをrootウィジェットの方に呼び出すようにする => このクラスがインスタンス化された時に1番最初に呼び出される self.A_Hello = A_Hello self.B_Hello = B_Hello self.C_Hello = C_Hello self.d_data = Hello01 self.w_data = Hello02 self.m_data = Hello03 self.num = 0 # figとaxだけで表す必要あり self.fig, self.ax = plt.subplots(2, 1, gridspec_kw={ 'height_ratios':[4,1] }) self.Update(self.A_Hello[self.num+1], self.d_data[Name[self.num]], Hello['Date']) # グラフを初期化する => ここは日毎のデータにする # ax[0].set_title('HelloPredict') self.add_widget(FigureCanvasKivyAgg(self.fig)) def Update(self, data, signal, times): # 前にプロットされたグラフを消去する self.ax[0].clear() self.ax[1].clear() period = 30 upper, middle, lower = talib.BBANDS(signal, timeperiod=period, nbdevup=1, nbdevdn=1, matype=0) # 引数としてHelloを取得するからselfをつける必要はない rsi = talib.RSI(signal, timeperiod=period) # 取得したデータを元にプロットする self.ax[0].plot(times, data) self.ax[0].set_ylabel('price', fontsize=15) self.ax[0].plot(times, upper) self.ax[0].plot(times, lower) self.ax[0].legend([Name[self.num]]) self.ax[0].tick_params(labelsize=10) self.ax[1].plot(times, rsi) self.ax[1].set_xlabel('time', fontsize=20) self.ax[1].set_ylabel('persentage', fontsize=15) self.ax[1].legend(['RSI']) self.ax[1].tick_params(labelsize=10) # 再描画する self.fig.canvas.draw() self.fig.canvas.flush_events() time.sleep(0.1) # 0.1秒だけ開ける # ActionBarの次へボタンを押したら次に行くようにする処理 def Next(self, index_num): if 0 <= index_num < len(Name) - 1: self.num = index_num A_Hello = self.A_Hello[self.num+1] data = self.d_data[Name[self.num]] self.Update(A_Hello, data, Hello['Date']) # 月のグラフの表示を更新する処理 def update01(self): C_Hello = self.C_Hello[self.num+1] m_data = self.m_data[Name[self.num]] self.Update(C_Hello, m_data, Hello03['Date']) # 上で変更された変数を元にしてメソッドが実行される # 週のグラフの表示を更新する処理 def update02(self): B_Hello = self.B_Hello[self.num+1] w_data = self.w_data[Name[self.num]] self.Update(B_Hello, w_data, Hello02['Date']) # 日毎の表示を更新する処理 def update03(self): A_Hello = self.A_Hello[self.num+1] d_data = self.d_data[Name[self.num]] self.Update(A_Hello, d_data, Hello['Date']) class DisplayCompany(BoxLayout): pass class TextWidget(BoxLayout): sm = ScreenManager() print(Name[0]) def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self.page1 = Factory.FirstPage() self.page2 = Factory.SecondPage() def change_page(self): self.clear_widgets() self.add_widget(self.page1) def change_page2(self): self.clear_widgets() self.add_widget(self.page2) class CopyHelloApp(App): def __init__(self, **kwargs): super().__init__(**kwargs) self.title = 'HelloWold' # ウィンドウの名前を変更する def build(self): return TextWidget() if __name__ == '__main__': CopyHelloApp().run()copyhello.kv#:kivy 2.0.0 # TextWidget rootウィジェットに指定されている TextWidget: <TextWidget>: PredictShow: id: page1 <PredictShow>: orientation: 'vertical' size: root.size # BoxLayoutのサイズ rootウィジェット(TextWidget)の大きさに合わせる # メニューバー ActionBar: ActionView: ActionPrevious: title: 'ページタイトル1' with_previous: False # 戻るボタンを表示する ActionButton: text: '次のページ' on_release: app.root.change_page2() ActionGroup: text: 'グループ名' mode: 'spinner' ActionButton: text: 'A' on_release: root.ids.graph_view.Next(0) on_release: app.root.ids['page1'].Next(0) on_release: name.text = 'A' ActionButton: text: "B" on_release: root.ids.graph_view.Next(1) on_release: app.root.ids['page1'].Next(1) on_release: name.text = 'B' BoxLayout: orientation: 'horizontal' size_hint_y: 0.1 Label: id: name text: 'A' Label: id: show text: root.text # グラフをここで表示する GraphView: size_hint_y: 0.9 id: graph_view GridLayout: cols: 3 rows: 1 size_hint_y: 0.1 Button: id: button11 text: '月' font_size: 48 on_release: root.ids.graph_view.update01() on_release: app.root.ids['page1'].update01() Button: id: button12 text: '週' font_size: 48 on_release: root.ids.graph_view.update02() on_release: app.root.ids['page1'].update02() Button: id: button13 text: '日' font_size: 48 on_release: root.ids.graph_view.update03() on_release: app.root.ids['page1'].update03() <GraphView>: <DisplayCompany>: id: page2 size: root.size orientation: 'horizontal' # 画面の切り替えを行う ActionBar: ActionView: ActionPrevious: title: 'ページタイトル2' with_previous: False # 戻るボタンを表示する ActionButton: text: '前のページ' on_release: app.root.change_page() MyLabel: id: first_button text: 'Hello' MyLabel: id: second_button text: 'World' <MyLabel@Label>: font_size: 60 size_hint_y: 1変更点
・rootウィジェットである、TextWidgetの親クラスをBoxLayoutに変更。
・カスタムウィジェットであるの部分をに変更。
・Labelのtextをapp.root.ids['page1'].textからroot.textに変更
・TextWidgetクラス内で、__init__メソッドを追加し、self.page1=Factory.FirstPage()とself.page2=Factory.SecondPage()を記述。
・rootウィジェット内にidを置いたウィジェット(今回ではFirstPage)のメソッドにアクセスする際に、app.root.ids['ID名'].メソッド名を使用する
・rootウィジェットのメソッドにアクセスする際に、root.メソッド名を使用する。
・rootウィジェットの下のウィジェットのメソッドにアクセスする際に、root.ids.ID名.メソッド名を使用する。わかった点(個人的に解釈しているだけで確証はない)
・画面を切り替えるときは、
Widgetクラスじゃなくて、BoxLayoutクラスを継承する方が上手くいく。
・textやsizeなどイベントでは無い部分に対して、app.rootは使わない。root.sizeやroot.textという記述をする。
・TextWidgetクラスの初期化部分で、self.ページ名を記述しておくと、別のページに移動しても元の画面の情報が失われない。
・rootウィジェットに追加したウィジェットのメソッドにアクセス→app.root.ids['ID名'].メソッド名
・rootウィジェットクラスのメソッドにアクセス→app.root.メソッド名
・rootウィジェットの下のウィジェットのメソッドにアクセス→root.ids.ID名.メソッド名まとめ
Kivyの記事は少ないとのことで、自分も理解するのが大変でした。
わかりやすい記事があって助かりました。自分の記事も皆さんのお助けになればと思います。
- 投稿日:2021-02-20T16:32:22+09:00
[Python] 日時に関するtimeとdatetimeのまとめ
初めに
Pythonにおける日時に関するモジュールをまとめた。
UNIX時間を取得するならtimeモジュール、日時を取得するならdatetimeモジュールを使う。
pandasのTimestamp型はdatetime.datetimeとほぼ同一なので、取り扱う場合はdatetime型を意識する。
本記事ではtimeとdatetimeモジュールを取り扱う。
- time : 実行時間計測
- datetime:日付利用
- pandas.Timestamp:データ解析
- numpy.datetime64:データ解析
time
時間に関するpythonの標準モジュール。
このモジュールでは、時刻に関するさまざまな関数を提供します。
[公式] 時刻データへのアクセスと変換時刻はUNIX時間[秒]で表現されたもの。
time.time() はUNIX時間を示しており、この時間を用いてプログラムの実行時間計測などに使用する。
time.strftime() は日時などを文字列で表現するが、個人的には使用しない。
time.ctime() は日時を含めた表現。こちらもdatetimeを用いるので、個人的には使用しない。
理由としては後述するdatetimeに類似する型がpandasやnumpyなどの演算系ライブラリで使用されているため。
コード type value time.time() float 1612560000.0000000 time.strftime('%Y/%m/%d %H:%M:%S') string 2021/01/02 03:04:05 time.ctime() string Sat Feb 2 03:04:05 2021 import time def data_print(value): print(' type: ', type(value)) print(' value: ', value) print('time') data_print(time.time()) data_print(time.strftime('%Y/%m/%d %H:%M:%S')) data_print(time.ctime()) # time # type: <class 'float'> # value: 1612560000.0000000 # type: <class 'str'> # value: 2021/01/02 03:04:05 # type: <class 'str'> # value: Sat Feb 2 03:04:05 2021なお、文字に関するフォーマットは以下の通り。
[公式] 時刻データへのアクセスと変換 time.strftime(format[, t])
ディレクティブ 意味 %a ロケールの短縮された曜日名 %A ロケールの曜日名 %b ロケールの短縮された月名 %B ロケールの月名 %c ロケールの日時の適切な形式 %d 月中の日にちの 10 進表記[01,31] %H 時 (24 時間表記) の 10 進表記[00,23] %I 時 (12 時間表記) の 10 進表記 [01,12] %j 年中の日にちの 10 進表記[001,366] %m 月の 10 進表記 [01,12] %M 分の 10 進表記[00,59] %p ロケールの AM もしくは PM と等価な文字列 %S 秒の 10 進表記 [00,61] %U 年の初めから何週目か (日曜を週の始まりとします) を表す 10 進数 [00,53] %w 曜日の 10 進表記[0 (日曜日),6] %W 年の初めから何週目か (月曜を週の始まりとします) を表す 10 進数 [00,53] %x ロケールの日付を適切な形式 %X ロケールの時間を適切な形式 %y 西暦の下 2 桁の 10 進表記 [00,99] %Y 西暦 ( 4桁) の 10 進表記 %z タイムゾーンと UTC/GMT との時差を表す正または負の時間を +HHMM、-HHMM で表します。[-23:59, +23:59] %Z タイムゾーンの名前 %% 文字 '%' UNIX時間
UNIX時間とは、時刻の起点(エポック:epoch)からの経過秒数。
時刻の起点は協定世界時 (UTC) の1970年1月1日午前0時0分0秒。
なお、UTC時間とは異なり、閏秒の存在を無視している。
例えば、UTC時間で閏秒+1秒が挿入された+2秒において、UTC時間は+1秒が挿入される。
これは、日時を表現するときに数秒の差が発生することを意味するが、その影響は意識することはあまりない。UTC時間
UTC時間(UTC:Coordinated Universal Time)とは、国際原子時 (TAI) に由来する原子時系の時刻。協定世界時ともいう。
エポックからの経過秒数を示しており、閏秒も考慮している。
各国における時間は(主に)UTCからの時差を算出することでその国における時間を規定している。
日本の標準時刻を日本標準時 (JST)といい、UTCに対して9時間進めた時間を採用している。
タイムゾーン(地域における同一の標準時を使用する規定地域)を指定することで、その時刻差を規定し、補正した値を使用する。協定世界時は国際度量衡局 (BIPM) が国際地球回転・基準系事業 (IERS) の支援を受けて維持する時刻系。
世界各地の標準時は協定世界時を基準としている。日本標準時 (JST) は協定世界時より9時間進めた時間である。
@wiki実行時間を計測する
あるプログラムのの実行時間を計測する場合、演算を行う関数などを挟んで、そのUNIX時間を取得し、その時間差を実行時間とする。
実行速度を検証する際や、演算速度比較を行う際に使用する。main.pyimport time def func1(): values = [] for val in range(10**6): values.append(val) def func2(): values = [0] * 10**6 for num, val in enumerate(range(10**6)): values[num] = val def func3(): values = [val for val in range(10**6)] time1 = time.time() func1() time2 = time.time() func2() time3 = time.time() func3() time4 = time.time() print('func1: {:.3f} sec'.format(time2 - time1)) print('func2: {:.3f} sec'.format(time3 - time2)) print('func3: {:.3f} sec'.format(time4 - time3)) # func1: 0.120 sec # func2: 0.095 sec # func3: 0.073 secdatetime
datetimeモジュールは、日時を操作する際に使用されるモジュール。
日付や時刻などを取り扱う場合はtimeモジュールでなく、こちらをよく使う。
オブジェクトはstringではないので、表示の際は注意する。
また、よく使用されるdatetime.datetimeとdatetime.dateオブジェクトは別なので注意する。datetime モジュールは、日付や時刻を操作するためのクラスを提供しています。
日付や時刻に対する算術がサポートされている一方、実装では出力のフォーマットや操作のための効率的な属性の抽出に重点を置いています。
[公式] 基本的な日付型および時間型: datetime
オブジェクト 概要 datetime.datetime 年月日と時刻 datetime.date 年月日 datetime.time 時刻 datetime.timedelta 時間差・経過時間 datetime.timezone タイムゾーン datetime.date:年月日
datetime.dateオブジェクトは、日付のみの情報を使用する。
時間などの細かい情報が必要ない場合に使用する。date オブジェクトは、両方向に無期限に拡張された現在のグレゴリオ暦という理想化された暦の日付 (年月日) を表します。
1 年 1 月 1 日は日番号 1、1 年 1 月 2 日は日番号 2 と呼ばれ、他も同様です。
[公式] date オブジェクト
コード type value (example) datetime.date.today() datetime.date 2021-01-02 datetime.date(year=2021, month=1, day=2) datetime.date 2021-01-02 >>> import datetime >>> today = datetime.date.today() >>> today datetime.date(2021, 1, 2) >>> type(today) <class 'datetime.date'> >>> test = datetime.date(year = 2021, month = 1, day = 2) >>> test datetime.date(2021, 1, 2) >>> type(test) <class 'datetime.date'>datetime.datetime:年月日と時刻
datetimeオブジェクトは、日時を表す。
dateおよびtimeが単一に含まれている。datetime オブジェクトは date オブジェクトおよび time オブジェクトの全ての情報が入っている単一のオブジェクトです。
[公式] datetime オブジェクト
コード type value (example) datetime.datetime.now() datetime.datetime datetime.datetime(2021, 1, 2, 3, 4, 5, 666666) datetime.datetime(year = 2021, month = 1, day = 2, hour = 3, minute = 4, second = 5, microsecond = 6) datetime.datetime datetime.datetime(2021, 1, 2, 3, 4, 5, 6) >>> import datetime >>> now = datetime.datetime.now() >>> now datetime.datetime(2021, 2, 6, 18, 28, 50, 729471) >>> type(now) <class 'datetime.datetime'> >>> test = datetime.datetime(year = 2021, month = 1, day = 2, hour = 3, minute = 4, second = 5, microsecond = 6) >>> test datetime.datetime(2021, 1, 2, 3, 4, 5, 6) >>> type(test) <class 'datetime.datetime'>datetime.timedelta:時刻差
datetime.timedelta オブジェクトは、2つのdatetimeの時刻差を表すオブジェクト。
二つの日付や時刻間の差を使用する場合に用いる。全ての引数がオプションで、デフォルト値は 0 です。 引数は整数、浮動小数点数でもよく、正でも負でも可。
datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)
[公式] timedelta オブジェクト使用する場合は、対象となるdatetimeオブジェクトに対して、演算子を用いて演算を行う。
基本的には時刻差や日時の差を操作する際に使用する。>>> import datetime >>> test = datetime.datetime(year = 2021, month = 1, day = 2, hour = 3, minute = 4, second = 5, microsecond = 6) >>> datetime.timedelta(days=1) datetime.timedelta(days=1) >>> test + datetime.timedelta(days=1) datetime.datetime(2021, 1, 3, 3, 4, 5, 6)datetime型 ↔ string型
datetimeと文字列の変換は、日時を取り扱っているため、使用することが多い。
文字列化する際は、datetime.strftime()を使用し、
文字列からdatetimeオブジェクト化する際は、datetime.strptime()を使用する。date, datetime, time オブジェクトは全て strftime(format) メソッドをサポートし、時刻を表現する文字列を明示的な書式文字列で統制して作成しています。
逆に datetime.strptime() クラスメソッドは日付や時刻に対応する書式文字列から datetime オブジェクトを生成します。
[公式] strftime() と strptime() の振る舞い
datetime.strftime() datetime.strptime() 使用法 与えられた書式に従って文字列に変換 指定された書式で文字列を構文解析して datetime オブジェクトに変換 メソッドの種類 インスタンスメソッド クラスメソッド メソッドを持つクラス date, datetime, time datetime シグネチャ strftime(format) strptime(date_string, format)
指定子 format文中の意味 %a ロケールの曜日名を短縮形。 %A ロケールの曜日名 %w 曜日を10進表記した文字列を表示します。0 が日曜日で、6 が土曜日を表します。 %d 0埋めした10進数で表記した月中の日にち %b ロケールの月名を短縮形 %B ロケールの月名を表示 %m 0埋めした10進数で表記した月 %y 0埋めした10進数で表記した世紀無しの年 %Y 西暦 (4桁) の 10 進表記 %H 0埋めした10進数で表記した時 (24時間表記) %I 0埋めした10進数で表記した時 (12時間表記) %p ロケールの AM もしくは PM と等価な文字列 %M 0埋めした10進数で表記した分 %S 0埋めした10進数で表記した秒 %f 10進数で表記したマイクロ秒 (左側から0埋めされます) %z UTCオフセットを ±HHMM[SS[.ffffff]] の形式で表示します (オブジェクトがnaiveであれば空文字列) %Z タイムゾーンの名前を表示します (オブジェクトがnaiveであれば空文字列) %j 0埋めした10進数で表記した年中の日にち %U 0埋めした10進数で表記した年中の週番号 (週の始まりは日曜日とする) %W 0埋めした10進数で表記した年中の週番号 (週の始まりは月曜日とする) %c ロケールの日時を適切な形式 %x ロケールの日付を適切な形式 %X ロケールの時間を適切な形式 %% 文字 '%' を表します。 datetime型 → 文字列型
文字列化に関して、実施例を示す。
指定子に従って、文字列化できる。>>> import datetime >>> now = datetime.datetime.now() >>> now.strftime('%Y-%m-%d %H:%M:%S') '2021-02-06 19:01:48'文字列型 → datetime型
datetimeオブジェクト化に関して、実施例を示す。
指定子に従った解釈でdatetimeオブジェクトに変換できる。>>> import datetime >>> datetime.datetime.strptime('2021-02-06 19:01:48', '%Y-%m-%d %H:%M:%S') datetime.datetime(2021, 2, 6, 19, 1, 48)datetime型 → date型
datetime型とdate型は直接比較演算が実施できない。
したがって、比較演算などを行う場合は変換が必要となる。
また、取り扱う場合は混ざらないようにする必要がある。datetime型でdate()を実行すると、date型で返してくれる。
>>> test = datetime.datetime(year = 2021, month = 1, day = 2, hour = 3, minute = 4, second = 5, microsecond = 6) >>> test.date() datetime.date(2021, 1, 2)最後に
関数の実行時間確認や時系列データの処理などに利用することはよくある。
利用の際に本記事を思い出しの参考にする予定。
また、pandasとnumpyに関しても変換が必要になるので、別途まとめたい。参考・引用
【time】
[公式] 時刻データへのアクセスと変換
[公式] 時刻データへのアクセスと変換 time.strftime(format[, t])【datetime】
[公式] 基本的な日付型および時間型: datetime
[公式] datetime オブジェクト
[公式] strftime() と strptime() の振る舞い
[公式] timedelta オブジェクト
- 投稿日:2021-02-20T16:05:30+09:00
pythonとopenCVを用いて文庫本のテクスチャを作成する
概要
Blenderにおいて使う目的で本のテクスチャを作成してみました。
openCVの練習目的でもあります。グダグダコードですが、参考になれば幸いです。コード
import cv2 import random import numpy as np from PIL import Image,ImageFont,ImageDraw #参考資料 #https://watlab-blog.com/2019/08/25/image-text/ #https://python-no-memo.blogspot.com/2021/01/opencvcv2rectangle.html ###以下の部分はmainで使うデータを定めているだけです。 JapaneseWordsList=['間', '相手', '合います', '会います', '青', '青い', '赤', '赤い', '赤ちゃん', '明るい', '秋', '開きます', '開けます', '上げます', '朝', '朝ごはん', '足', '味', '遊びます', '頭', '新しい', '暑い', '', '熱い', '厚い', '集めます', '兄', '姉', 'あの方', 'あの人', '危ない', '甘い', '網棚', '雨', '洗います', '歩いて', '歩きます', '暗証番号', '安心します', '案内します', '胃', '位', '言います', '家', '以下', '医学', '行きます', 'いくつ', '池', '生け花', '意見', '医者', '以上', '以上です', '伊豆', '忙しい', '急ぎます', '痛いです', '一度', '一度も', '5日', '一生懸命', '5つ', '行ってきます', '田舎', '犬', '今', '今いいですか', 'います', 'います', '今にも', '今の', '電車', '意味', '妹', '妹さん', '入口', '要ります', '入れます', '入れます', '色', '上', '植えます', '伺います', '受付', '受けます', '動きます', '薄い', '歌', '歌います', '宇宙', '美しい', '馬', '生まれます', '海', '梅', '裏', '売り場', '売ります', '売れます', '上着', '運転します', '運動会', '運動します', '絵', '映画', '営業', '英語', 'ATM', '駅', '駅員', '駅前', '枝', '絵はがき', '絵本', '偉い', '選びます', '-円', '鉛筆', '遠慮なく', 'お忙しいですか', '応援します', '大きい', '大きさ', '大きな', '大勢', 'お母さん', 'お帰りなさい', '多くの', '大阪城', '大阪城公園', 'お金', '置き場', '起きます', '置きます', '起きます', 'お客様', '奥', '億', '奥様', '奥さん', '屋上', '国', '送ります', '送ります', '遅れます', 'お元気ですか', 'お子さん', '行います', 'お先に', 'どうぞ', '押し入れ', '教えます', '教えます', '押します', '押します', 'お知らせ', 'お世話になりました', '遅い', '遅く', 'お大事に', 'お宅', 'お茶', 'お茶をたてます', 'お疲れさまでした', '夫', 'お釣り', 'お手洗い', 'お出かけですか', '音', 'お父さん', '弟', '弟さん', '男の子', '男の人', 'お年玉', '落とします', '踊ります', '同じ', 'お名前は?', 'お兄さん', 'お姉さん', 'お願いがあるんですが', 'お願いします', 'おはようございます', 'お引き出しですか', '覚えて', 'いません', '覚えます', 'お孫さん', 'お待たせしました', 'お待ちください', '見舞い', 'お目にかかります', '重い', '思い出します', '思います', '重さ', '表', 'お休みなさい', '泳ぎます', '折ります', '降ります', '折れます', '降ろします', '終わり', '終わりましょう', '終わります', '音楽', '音楽家', '温泉', '温度', '女の子', '女の人', '家', '-階', '-回', '海外', '海岸', '会議', '会議室', '外国', '会社', '会社', '会社員', '会場', '階段', '懐中電灯', '買います', '飼います', '買い物します', '回覧', '会話', '返します', '帰って', '来ます', '換えます', '変えます', '帰り', '帰ります', '顔', '科学', '鏡', '係員', '掛かります', '書きます', '家具', '学生', '確認', '-か月', '掛けます', '掛けます', '掛けます', '傘', '飾ります', '菓子', '火事', '貸してください', '貸します', '歌手', '風', '数えます', '家族', '方', '方', '硬い', '形', '片つきます', '片づけます', '勝ちます', '課長', '-月', '学校', '葛飾北斎', '角', '家内', '悲しい', '必ず', '彼女', '花瓶', '歌舞伎', '壁', '紙', '髪', '雷', '通います', '火曜日', '辛い', 'から来ました', '体', '体にいい', '借ります', '軽い', '彼', '川', '側', '乾きます', '変わります', '缶', '間', '考えます', '缶切り', '漢字', '感謝します', '缶詰', '乾杯', '頑張ります', '管理人', '木', '機', '黄色', '消えます', '機会', '聞きます', '聞きます', '危険', '聞こえます', '傷', '季節', '規則', '北', '汚い', '喫茶店', '切手', '切符', '厳しい', '気分がいい', '気分が悪い', '来ます', '着ます', '君', '決めます', '気持ち', '気持ちが', '気持ちが', '着物', '救急車', '休憩します', '急行', '牛どん', '急に', '牛肉', '牛乳', '給料', '教育', '教会', '教師', '教室', '教室', '兄弟', '興味', '許可', '曲', '去年', '切ります', '切ります', '切れます', '気をつけます', '金', '金色', '禁煙', '金額', '金閣寺', '銀行', '銀行員', '近所', '緊張します', '金曜日', '具合', '空気', '空港', '腐ります', '薬', '果物', '口', '靴', '靴下', '国', '組み立てます', '曇り', '曇ります', '暗い', '車', '黒', '黒い', '詳しい', '君', '芸', '警官', '経験', '経済', '警察', '計算します', '景色', '消しゴム', '消します', 'けっこうです', '結婚式', '結婚します', '月曜日', '県', '原因', '見学します', '玄関', '元気', '研究室', '研究します', '研究者', '現金', '健康', '剣道', '原料', '個', '語', '後', '濃い', '恋人', '号', '公園', '豪華', '坑外', '合格します', '講義', '航空便', '高校', '交差点', 'ー号室', '工場', '紅茶', '交通', '交番', '声', '国際', '午後', '9日', '9つ', '心', '心から', 'ご主人', '故障', '午前', 'ご存じです', '答え', '答えます', 'ご注文は?', '国会議事堂', '子ども', '子どもたち', 'この間', 'この辺', '細かい', '細かい', 'お金', '困ります', 'ごみ箱', '込みます', '米', 'ご覧になります', '怖い', '壊します', '壊れます', '紺', '今月', '今週', '今度', '今晩', '今夜', '婚約します'] #ネットから拾った日本語リストを整形したものです names_List=['浅井蔵屋', '油川夫人', '足利氏姫', '朝日殿', '綾木大方', '阿南姫', '饗庭局', '井伊直虎', '市場姫', '市川局', '出雲阿国', '市場姫', '飯坂の局', '池田せん', '伊勢姫', '一の台', '一之臺', '犬山殿', '内海照日', '栄輪院', '園光院', '円珠尼', '円信院殿', '円融院', 'お市の方', 'お犬の方', '黄梅院', '大井の方', '大政所', '大宮姫', '奥山ひよ', 'おさい', '尾崎殿', '尾崎局', 'お船の方', '於大の方', '阿南姫', '小野お通', '小野殿', '小幡殿', '於フ子', '小見の方', '尾崎局', '御南', '於フ子', '小見の方', '花舜夫人', '海津局', '片倉喜多', '勝子', '含笑院', '蒲池徳子', '菊姫', '菊姫', '北川殿', '吉川夫人', '恭雲院', '京極竜子', '櫛橋光', '久保姫', 'くらの方', '慶誾尼', '慶寿院', '桂峯院', '月静院', '華陽院', '見性院', '見性院', '高台院', '小少将', '小松姫', '五龍局', '芳春院', '西郷局', '三条の方', '慈光院', '島津常盤', '下山殿', '秋悦院', '寿桂尼', '珠光', '青岳尼', '定恵院', '常高院', '浄光院', '信松尼', '新庄局', '信徳院', '真竜院', '常高院', '信松尼', '瑞雲院', '瑞渓院', '随念院', '崇源院', '杉大方', '清円院', '青岩院', '積翠院', '善応院', '仙桃院', '雪窓夫人', '絶姫', '相応院', '大匠院', '大頂院', '高瀬姫', '多劫姫', '智雲院', '長慶院', '趙州院', '長勝院', '長生院', '長齢院', '築山殿', '妻木煕子', '鶴姫', '天遊永寿', '問田大方', '洞松院', '土田御前', '中の丸', '奈多夫人', '七曲殿', '七曲殿', '南呂院', '日秀尼', '沼田麝香', '禰々', '乃夫殿', '乃美大方', '初音姫', '早川殿', '東向殿', '彦姫', '宝光院', '法秀院', '芳春院', '北条夫人', '真木花藻', '南の局', '妙印尼', '妙玖', '妙向尼', '妙寿尼', '妙林尼', '深芳野', '宗像色姫', '愛姫', '元親夫人', '安井御前', '山手殿', '祐椿尼', '養珠院殿', '陽泰院', '養徳院', '義姫', '淀殿', '理慶尼', '龍勝院', '嶺松院', '若狭', '若政所'] #同様 ここでは歴史上の人物の名前を使いました hiragana=["あ","い","う","え","お","か","き","く","け","こ","さ","し","す","せ","そ","た","ち","つ","て","と", "な","に","ぬ","ね","の","は","ひ","ふ","へ","ほ","ま","み","む","め","も", "や","ゆ","よ","ら","り","る","れ","ろ","わ","を","ん"] digits=["1","2","3","4","5","6","7","8","9"] #半角文字ならstring.digitsなどが便利 colors_cRGB=[[255,175,18,61],[255,277,54,74],[0,228,78,77],[0,233,83,84], [0,218,155,84],[0,206.174,53],[0,207,212,118],[0,97,199,214], [0,52,172,75],[0,41,187,150],[255,0,104,117],[255,1,112,165], [255,9,35,72],[255,13,44,88],[255,10,10,10]] #clip studio paintを用いてネット上の画像から色を採取 colors=[color[::-1] for color in colors_cRGB] #BGR and color of character ###以上までデータ部分 def img_add_msg(img, message, position, color, fontsize=20): #position must be 2d-tuple, such as (50,50) #この部分は殆ど参考資料にあげさせていただいたサイトにあるコードです。 fontpath = 'C:\Windows\Fonts\msmincho.ttc' # Windowsのフォントファイルへのパス font = ImageFont.truetype(fontpath, fontsize) # PILでフォントを定義 img = Image.fromarray(img) # cv2(NumPy)型の画像をPIL型に変換 draw = ImageDraw.Draw(img) # 描画用のDraw関数を用意 # テキストを描画(位置、文章、フォント、文字色(BGR+α)を指定) draw.text(position, message, font=font, fill=(color, color, color, 0)) img = np.array(img) # PIL型の画像をcv2(NumPy)型に変換 return img # 文字入りの画像をリターン def random_japanese_string(): #架空の題名をrandomを用いて定めます。 n=random.choice([1,1,2,2,2]) return "\n".join([_ for _ in "".join([random.choice(JapaneseWordsList) for i in range(n)])]) #日本語を縦書きで画像に書き込む方法が分からなかったので改行(\n)で代用します def random_name(): #作者名 return "\n".join([_ for _ in random.choice(names_List)]) def random_sign(): #図書記号 全然正式じゃないですが、雰囲気だけrandomに定めます random_sing_List=[random.choice(hiragana),random.choice(hiragana),random.choice(digits)] return "\n".join(random_sing_List) if __name__=="__main__": # Create a black image opencvの公式ドキュメント参照 for counter in range(10): #10枚分の画像を生成していきます img = np.zeros((512,512,3), np.uint8) color=random.choice(colors) numOfBooks=random.choice((9,10,11)) margin=2 shift=10 #この辺りの挙動はよく分からなかったが、試行錯誤を繰り返して適切な値を見つけました for i in range(numOfBooks): img = cv2.rectangle(img,(int(i*(512/numOfBooks)+margin),0),(int((i+1)*(512/numOfBooks))-margin,1023),color[:3],-1) #長方形を描画 img = img_add_msg(img, random_japanese_string(), (int((i+0.5)*(512/numOfBooks))-shift,10),color[3]) #題名 img = img_add_msg(img, random_name(), (int((i+0.5)*(512/numOfBooks))-shift,270),color[3]) #作者名 img = cv2.rectangle(img,(int(i*(512/numOfBooks)+margin*7),370),(int((i+1)*(512/numOfBooks))-margin*7,420),[255,255,255],-1) img = img_add_msg(img, random_sign(), (int((i+0.5)*(512/numOfBooks))-shift*0.8,370),0,15) img = img_add_msg(img, "ネ\nコ\n文\n庫", (int((i+0.5)*(512/numOfBooks))-shift*0.8,430),color[3],12) #文庫名はネコ文庫にしました。私は犬派ですが cv2.imwrite("books texture.{0:03}.jpg".format(counter+1),img) #画像を保存 #cv2.imshow('Test', img) ここは画像を一時的に表示するために使っていました forループ中は不要なのでコメントアウトしました #cv2.waitKey(0) #cv2.destroyAllWindows()実行結果
作業中のファイルに10枚画像が保存されました。
個々の写真はこのような感じです。
比較的満足してますが、ハイライトなどを加えられたらよりよくなるでしょう。
ただ、その辺りの処理はクリスタなどを用いた方が圧倒的に速いかも知れません。おまけ
使用例のようなものです。先述の通りblenderの画像です。
遠目から見ればヘンテコ日本語もバレませんね。一安心。
最後までご覧いただきありがとうございました(o*。_。)oペコッ参考文献
再掲です。
https://watlab-blog.com/2019/08/25/image-text/
https://python-no-memo.blogspot.com/2021/01/opencvcv2rectangle.html



- 投稿日:2021-02-20T16:01:27+09:00
Project Euler 問題9「三辺の和が1000となるピタゴラスのトリプレット」
問題
a < b < c、 a*2 + b*2 = c*2 となるようなa、b、cの組のうち、a + b + c = 1000となる唯一の組の積(a * b * c)を求めよ。
A Pythagorean triplet is a set of three natural numbers, a < b < c, for which,
a2 + b2 = c2
For example, 32 + 42 = 9 + 16 = 25 = 52.There exists exactly one Pythagorean triplet for which a + b + c = 1000.
Find the product abc.コード(Python)
# 以下の条件を持つa、b、cの積を求める: # (1) a、b、cは整数 # (2) a < b < c # (3) a + b + c = 1000 # (4) a**2 + b**2 = c**2 def isEven(num): return num % 2 == 0 def getMaxOfB(a): remain = 1000 - a return remain - 1 // 2 # (1)〜(3)からaの最大値は332 for a in range(1, 332): # bの最小はa + 1 # bの最大は1000からaを引いた残りからさらに1を引き(cを超えないようにするため)、2で割った値(小数点以下切り捨て) for b in range(a + 1, (999 - a)//2): c = 1000 - (a + b) if (a**2 + b**2 == c**2): print(a * b * c)
- 投稿日:2021-02-20T15:10:49+09:00
マクドナルドで一日分の栄養を取れる組み合わせを計算したら衝撃の結果に
マックで一日分の栄養を取りたい!
マクドナルド。関東ではマック、関西ではマクドと呼ばれている、おなじみのファーストチェーン店です。全国津々浦々にありますので、よく食べる方もいらっしゃるでしょう。私も大好きで、よく食べています。
ところで、マクドナルドって栄養的にどうなんでしょう?ファーストフードばかり食べていると体に悪いという話をよく聞きますが、そんなに偏っているのでしょうか?メニューの組み合わせさえ気を付ければ大丈夫なのでしょうか。
そこで、マクドナルドで一日に必要な栄養素を取るための商品の組み合わせを調べてみました。
計算は簡単
式を立てる
組み合わせを見つけるのはそれほど難しくありません。線形計画法という手法を用いれば簡単に解くことができます。特に最低限必要な栄養素を求める問題はダイエット問題という名前で知られています。
マクドナルドの商品の栄養素は公開されているデータを使用します。
日本人が一日必要な栄養素は厚生労働省が公表しています。年齢や性別によって基準量が異なりますが、30歳男子をターゲットとすると以下のようになります。「20~25g」のように基準量に幅がある場合は中央値を取りました。
栄養素 基準量 たんぱく質 (g) 0.65 脂質 (g) 25 炭水化物 (g) 62.5 ナトリウム (mg) 5000 カリウム (mg) 3000 カルシウム (mg) 738 リン (mg) 600 鉄 (mg) 6.3 ビタミンA (μg) 625 ビタミンB1 (mg) 1.4 ビタミンB2 (mg) 1.6 ナイアシン (mg) 15 ビタミンC (mg) 100 コレステロール (mg) 0 食物繊維 (g) 21 食塩相当量 (g) 5 コレステロールは最低摂取基準量はないので0としています(実はこれが伏線になっている)。
そして目的は、一日必要な栄養素を満たす最もカロリーの低い商品の組み合わせとします。金に糸目はつけません。健康第一!
解く
商品の数が96個、栄養素の数が16個なので、とても人間の手では解けません。そこでコンピューターの力を借ります。幸いPuLPというPythonで無料で利用できるソルバーがあるので、これで計算します。ちなみにExcelにもソルバーが搭載されていますが、この程度の数の決定変数でもエラーになって計算できませんでした。
hello.mac# Import PuLP modeler functions from pulp import * # A new LP problem prob = LpProblem(name="mac", sense=LpMinimize) # Variables AA = LpVariable(name = "AA", lowBound = 0, cat="Integer") AB = LpVariable(name = "AB", lowBound = 0, cat="Integer") AC = LpVariable(name = "AC", lowBound = 0, cat="Integer") AD = LpVariable(name = "AD", lowBound = 0, cat="Integer") AE = LpVariable(name = "AE", lowBound = 0, cat="Integer") AF = LpVariable(name = "AF", lowBound = 0, cat="Integer") AG = LpVariable(name = "AG", lowBound = 0, cat="Integer") AH = LpVariable(name = "AH", lowBound = 0, cat="Integer") AI = LpVariable(name = "AI", lowBound = 0, cat="Integer") AJ = LpVariable(name = "AJ", lowBound = 0, cat="Integer") AK = LpVariable(name = "AK", lowBound = 0, cat="Integer") AL = LpVariable(name = "AL", lowBound = 0, cat="Integer") AM = LpVariable(name = "AM", lowBound = 0, cat="Integer") AN = LpVariable(name = "AN", lowBound = 0, cat="Integer") AO = LpVariable(name = "AO", lowBound = 0, cat="Integer") AP = LpVariable(name = "AP", lowBound = 0, cat="Integer") AQ = LpVariable(name = "AQ", lowBound = 0, cat="Integer") AR = LpVariable(name = "AR", lowBound = 0, cat="Integer") AS = LpVariable(name = "AS", lowBound = 0, cat="Integer") AT = LpVariable(name = "AT", lowBound = 0, cat="Integer") AU = LpVariable(name = "AU", lowBound = 0, cat="Integer") AV = LpVariable(name = "AV", lowBound = 0, cat="Integer") AW = LpVariable(name = "AW", lowBound = 0, cat="Integer") AX = LpVariable(name = "AX", lowBound = 0, cat="Integer") AY = LpVariable(name = "AY", lowBound = 0, cat="Integer") AZ = LpVariable(name = "AZ", lowBound = 0, cat="Integer") BA = LpVariable(name = "BA", lowBound = 0, cat="Integer") BB = LpVariable(name = "BB", lowBound = 0, cat="Integer") BC = LpVariable(name = "BC", lowBound = 0, cat="Integer") BD = LpVariable(name = "BD", lowBound = 0, cat="Integer") BE = LpVariable(name = "BE", lowBound = 0, cat="Integer") BF = LpVariable(name = "BF", lowBound = 0, cat="Integer") BG = LpVariable(name = "BG", lowBound = 0, cat="Integer") BH = LpVariable(name = "BH", lowBound = 0, cat="Integer") BI = LpVariable(name = "BI", lowBound = 0, cat="Integer") BJ = LpVariable(name = "BJ", lowBound = 0, cat="Integer") BK = LpVariable(name = "BK", lowBound = 0, cat="Integer") BL = LpVariable(name = "BL", lowBound = 0, cat="Integer") BM = LpVariable(name = "BM", lowBound = 0, cat="Integer") BN = LpVariable(name = "BN", lowBound = 0, cat="Integer") BO = LpVariable(name = "BO", lowBound = 0, cat="Integer") BP = LpVariable(name = "BP", lowBound = 0, cat="Integer") BQ = LpVariable(name = "BQ", lowBound = 0, cat="Integer") BR = LpVariable(name = "BR", lowBound = 0, cat="Integer") BS = LpVariable(name = "BS", lowBound = 0, cat="Integer") BT = LpVariable(name = "BT", lowBound = 0, cat="Integer") BU = LpVariable(name = "BU", lowBound = 0, cat="Integer") BV = LpVariable(name = "BV", lowBound = 0, cat="Integer") BW = LpVariable(name = "BW", lowBound = 0, cat="Integer") BX = LpVariable(name = "BX", lowBound = 0, cat="Integer") BY = LpVariable(name = "BY", lowBound = 0, cat="Integer") BZ = LpVariable(name = "BZ", lowBound = 0, cat="Integer") CA = LpVariable(name = "CA", lowBound = 0, cat="Integer") CB = LpVariable(name = "CB", lowBound = 0, cat="Integer") CC = LpVariable(name = "CC", lowBound = 0, cat="Integer") CD = LpVariable(name = "CD", lowBound = 0, cat="Integer") CE = LpVariable(name = "CE", lowBound = 0, cat="Integer") CF = LpVariable(name = "CF", lowBound = 0, cat="Integer") CG = LpVariable(name = "CG", lowBound = 0, cat="Integer") CH = LpVariable(name = "CH", lowBound = 0, cat="Integer") CI = LpVariable(name = "CI", lowBound = 0, cat="Integer") CJ = LpVariable(name = "CJ", lowBound = 0, cat="Integer") CK = LpVariable(name = "CK", lowBound = 0, cat="Integer") CL = LpVariable(name = "CL", lowBound = 0, cat="Integer") CM = LpVariable(name = "CM", lowBound = 0, cat="Integer") CN = LpVariable(name = "CN", lowBound = 0, cat="Integer") CO = LpVariable(name = "CO", lowBound = 0, cat="Integer") CP = LpVariable(name = "CP", lowBound = 0, cat="Integer") CQ = LpVariable(name = "CQ", lowBound = 0, cat="Integer") CR = LpVariable(name = "CR", lowBound = 0, cat="Integer") CS = LpVariable(name = "CS", lowBound = 0, cat="Integer") CT = LpVariable(name = "CT", lowBound = 0, cat="Integer") CU = LpVariable(name = "CU", lowBound = 0, cat="Integer") CV = LpVariable(name = "CV", lowBound = 0, cat="Integer") CW = LpVariable(name = "CW", lowBound = 0, cat="Integer") CX = LpVariable(name = "CX", lowBound = 0, cat="Integer") CY = LpVariable(name = "CY", lowBound = 0, cat="Integer") CZ = LpVariable(name = "CZ", lowBound = 0, cat="Integer") DA = LpVariable(name = "DA", lowBound = 0, cat="Integer") DB = LpVariable(name = "DB", lowBound = 0, cat="Integer") DC = LpVariable(name = "DC", lowBound = 0, cat="Integer") DD = LpVariable(name = "DD", lowBound = 0, cat="Integer") DE = LpVariable(name = "DE", lowBound = 0, cat="Integer") DF = LpVariable(name = "DF", lowBound = 0, cat="Integer") DG = LpVariable(name = "DG", lowBound = 0, cat="Integer") DH = LpVariable(name = "DH", lowBound = 0, cat="Integer") DI = LpVariable(name = "DI", lowBound = 0, cat="Integer") DJ = LpVariable(name = "DJ", lowBound = 0, cat="Integer") DK = LpVariable(name = "DK", lowBound = 0, cat="Integer") DL = LpVariable(name = "DL", lowBound = 0, cat="Integer") DM = LpVariable(name = "DM", lowBound = 0, cat="Integer") DN = LpVariable(name = "DN", lowBound = 0, cat="Integer") DO = LpVariable(name = "DO", lowBound = 0, cat="Integer") DP = LpVariable(name = "DP", lowBound = 0, cat="Integer") DQ = LpVariable(name = "DQ", lowBound = 0, cat="Integer") DR = LpVariable(name = "DR", lowBound = 0, cat="Integer") # Objective prob += 395*AA+ 545*AB+ 532*AC+ 441*AD+ 498*AE+ 478*AF+ 387*AG+ 311*AH+ 1067*AI+ 428*AJ+ 527*AK+ 489*AL+ 776*AM+ 38*AN+ 389*AO+ 475*AP+ 395*AQ+ 457*AR+ 307*AS+ 431*AT+ 345*AU+ 364*AV+ 465*AW+ 256*AX+ 60*AY+ 979*AZ+ 659*BA+ 525*BB+ 323*BC+ 292*BD+ 374*BE+ 319*BF+ 121*BG+ 419*BH+ 420*BI+ 550*BJ+ 396*BK+ 695*BL+ 1*BM+ 553*BN+ 768*BO+ 728*BP+ 486*BQ+ 594*BR+ 693*BS+ 655*BT+ 542*BU+ 655*BV+ 406*BW+ 584*BX+ 498*BY+ 709*BZ+ 356*CA+ 724*CB+ 434*CC+ 473*CD+ 642*CE+ 625*CF+ 471*CG+ 579*CH+ 558*CI+ 83*CJ+ 31*CK+ 287*CL+ 23*CM+ 10*CN+ 1034*CO+ 252*CP+ 8*CQ+ 249*CR+ 6*CS+ 243*CT+ 275*CU+ 148*CV+ 810*CW+ 270*CX+ 109*CY+ 145*CZ+ 33*DA+ 161*DB+ 304*DC+ 211*DD+ 1057*DE+ 1844*DF+ 44*DG+ 517*DH+ 410*DI+ 225*DJ+ 235*DK+ 337*DL+ 59*DM+ 257*DN+ 295*DO+ 232*DP+ 108*DQ+ 7*DR # Constraints prob += 12.5*AA+ 14.5*AB+ 19*AC+ 16.7*AD+ 20.2*AE+ 15.5*AF+ 22.3*AG+ 19.2*AH+ 61.9*AI+ 19.9*AJ+ 26.5*AK+ 27.3*AL+ 39.5*AM+ 0*AN+ 14.2*AO+ 21.5*AP+ 15*AQ+ 26.5*AR+ 15.8*AS+ 17.1*AT+ 14*AU+ 15.2*AV+ 20*AW+ 12.8*AX+ 0*AY+ 34.1*AZ+ 26.2*BA+ 26*BB+ 14.4*BC+ 15.9*BD+ 17.7*BE+ 8*BF+ 0*BG+ 17.2*BH+ 10.4*BI+ 20.3*BJ+ 15.7*BK+ 29.7*BL+ 0*BM+ 19.4*BN+ 35.3*BO+ 25.8*BP+ 30*BQ+ 33.3*BR+ 39.8*BS+ 40.6*BT+ 23.2*BU+ 42*BV+ 23.5*BW+ 26.1*BX+ 23*BY+ 34.8*BZ+ 20.6*CA+ 41.4*CB+ 22.7*CC+ 25.5*CD+ 27.2*CE+ 39*CF+ 26.7*CG+ 21.4*CH+ 32.4*CI+ 5.2*CJ+ 0.2*CK+ 3*CL+ 0.4*CM+ 0.5*CN+ 13.4*CO+ 15.3*CP+ 0.5*CQ+ 15*CR+ 0.2*CS+ 14.8*CT+ 5*CU+ 3.8*CV+ 47.3*CW+ 15.8*CX+ 0.3*CY+ 1.2*CZ+ 0.2*DA+ 3.8*DB+ 3.7*DC+ 1.9*DD+ 38.2*DE+ 60.6*DF+ 0.4*DG+ 6.7*DH+ 5.3*DI+ 2.9*DJ+ 5.9*DK+ 8*DL+ 3.2*DM+ 5.4*DN+ 5.9*DO+ 5.3*DP+ 0.4*DQ+ 0.4*DR >= 0.65 prob += 17.4*AA+ 29.4*AB+ 21.1*AC+ 20*AD+ 23.2*AE+ 30.2*AF+ 18.9*AG+ 13.5*AH+ 65.5*AI+ 21.7*AJ+ 30.7*AK+ 26.6*AL+ 43.1*AM+ 0*AN+ 20.2*AO+ 30.6*AP+ 25.1*AQ+ 25*AR+ 13.4*AS+ 23*AT+ 15.5*AU+ 17.3*AV+ 21.9*AW+ 9.4*AX+ 6.7*AY+ 51.3*AZ+ 42.7*BA+ 28.3*BB+ 13.9*BC+ 13.3*BD+ 20.8*BE+ 8.6*BF+ 0*BG+ 23.7*BH+ 23.8*BI+ 33.2*BJ+ 18.1*BK+ 49.7*BL+ 0*BM+ 25.5*BN+ 36.1*BO+ 50*BP+ 26.5*BQ+ 34.2*BR+ 43.2*BS+ 39.1*BT+ 28.7*BU+ 40.1*BV+ 21*BW+ 31.6*BX+ 24*BY+ 34.7*BZ+ 16.9*CA+ 43.4*CB+ 18.6*CC+ 28.4*CD+ 43.5*CE+ 36.2*CF+ 23.7*CG+ 38.3*CH+ 33.1*CI+ 3*CJ+ 1.5*CK+ 18*CL+ 0*CM+ 0.1*CN+ 51.8*CO+ 13.1*CP+ 0.2*CQ+ 12.9*CR+ 0*CS+ 12.8*CT+ 18.9*CU+ 3.9*CV+ 51.6*CW+ 17.2*CX+ 11.2*CY+ 9.6*CZ+ 0.1*DA+ 4.4*DB+ 18.1*DC+ 10.7*DD+ 60.3*DE+ 103.4*DF+ 2.3*DG+ 25.9*DH+ 20.6*DI+ 11.3*DJ+ 7*DK+ 10.6*DL+ 0.8*DM+ 5.5*DN+ 10.7*DO+ 5.5*DP+ 10.9*DQ+ 0*DR >= 25 prob += 47.7*AA+ 55.8*AB+ 66.6*AC+ 48.4*AD+ 52.4*AE+ 36.4*AF+ 31*AG+ 27.1*AH+ 57.5*AI+ 38.9*AJ+ 36.8*AK+ 35.5*AL+ 57.5*AM+ 9.5*AN+ 38.1*AO+ 27.3*AP+ 27.2*AQ+ 31.4*AR+ 30.8*AS+ 39.2*AT+ 37.7*AU+ 37*AV+ 47.3*AW+ 30.3*AX+ 0*AY+ 92.9*AZ+ 40.2*BA+ 41.8*BB+ 35.8*BC+ 26.4*BD+ 29.1*BE+ 52.7*BF+ 30.2*BG+ 34.3*BH+ 41.9*BI+ 42.4*BJ+ 42.4*BK+ 31.2*BL+ 0.1*BM+ 62.8*BN+ 76*BO+ 44.1*BP+ 31*BQ+ 38.9*BR+ 36.8*BS+ 35.5*BT+ 48*BU+ 31.4*BV+ 30.8*BW+ 49.1*BX+ 47.6*BY+ 64.4*BZ+ 30.3*CA+ 41.8*CB+ 45*CC+ 29.1*CD+ 35.5*CE+ 36.3*CF+ 38.2*CG+ 37.6*CH+ 32.7*CI+ 9.6*CJ+ 4.3*CK+ 28.3*CL+ 5.6*CM+ 2.3*CN+ 128.5*CO+ 18.2*CP+ 1.1*CQ+ 18.3*CR+ 1.2*CS+ 17.2*CT+ 21.1*CU+ 24.7*CV+ 39.2*CW+ 13.1*CX+ 1.6*CY+ 13.3*CZ+ 7.7*DA+ 26.4*DB+ 31.5*DC+ 26.8*DD+ 90.4*DE+ 167.7*DF+ 5.2*DG+ 64.3*DH+ 51*DI+ 28*DJ+ 37.7*DK+ 53.4*DL+ 9.7*DM+ 46.8*DN+ 44.1*DO+ 40.6*DP+ 2*DQ+ 1.2*DR >= 62.5 prob += 919*AA+ 986*AB+ 1296*AC+ 994*AD+ 1216*AE+ 829*AF+ 813*AG+ 649*AH+ 2326*AI+ 816*AJ+ 1052*AK+ 1129*AL+ 1714*AM+ 4*AN+ 996*AO+ 789*AP+ 722*AQ+ 1132*AR+ 747*AS+ 1060*AT+ 850*AU+ 813*AV+ 1139*AW+ 542*AX+ 36*AY+ 1673*AZ+ 962*BA+ 1007*BB+ 644*BC+ 636*BD+ 837*BE+ 711*BF+ 1*BG+ 890*BH+ 971*BI+ 1193*BJ+ 1030*BK+ 1358*BL+ 254*BM+ 1309*BN+ 2082*BO+ 1308*BP+ 965*BQ+ 987*BR+ 1223*BS+ 1300*BT+ 1501*BU+ 1435*BV+ 898*BW+ 1565*BX+ 1355*BY+ 1778*BZ+ 693*CA+ 1310*CB+ 816*CC+ 989*CD+ 1142*CE+ 1428*CF+ 1340*CG+ 1245*CH+ 1554*CI+ 84*CJ+ 2*CK+ 222*CL+ 210*CM+ 1*CN+ 830*CO+ 791*CP+ 152*CQ+ 730*CR+ 91*CS+ 639*CT+ 55*CU+ 83*CV+ 1517*CW+ 506*CX+ 283*CY+ 307*CZ+ 182*DA+ 318*DB+ 154*DC+ 217*DD+ 1426*DE+ 2346*DF+ 182*DG+ 415*DH+ 329*DI+ 181*DJ+ 155*DK+ 268*DL+ 37*DM+ 135*DN+ 118*DO+ 118*DP+ 222*DQ+ 384*DR >= 25 prob += 119*AA+ 237*AB+ 328*AC+ 212*AD+ 343*AE+ 255*AF+ 297*AG+ 183*AH+ 860*AI+ 366*AJ+ 432*AK+ 379*AL+ 536*AM+ 7*AN+ 262*AO+ 235*AP+ 170*AQ+ 358*AR+ 232*AS+ 277*AT+ 246*AU+ 258*AV+ 345*AW+ 214*AX+ 0*AY+ 730*AZ+ 477*BA+ 372*BB+ 198*BC+ 148*BD+ 230*BE+ 254*BF+ 0*BG+ 266*BH+ 167*BI+ 256*BJ+ 172*BK+ 415*BL+ 2*BM+ 138*BN+ 610*BO+ 433*BP+ 405*BQ+ 551*BR+ 617*BS+ 565*BT+ 445*BU+ 574*BV+ 340*BW+ 460*BX+ 430*BY+ 596*BZ+ 322*CA+ 588*CB+ 342*CC+ 338*CD+ 428*CE+ 523*CF+ 467*CG+ 294*CH+ 401*CI+ 206*CJ+ 7*CK+ 30*CL+ 103*CM+ 137*CN+ 2260*CO+ 256*CP+ 5*CQ+ 259*CR+ 8*CS+ 251*CT+ 191*CU+ 179*CV+ 786*CW+ 262*CX+ 6*CY+ 194*CZ+ 45*DA+ 112*DB+ 219*DC+ 55*DD+ 1654*DE+ 3046*DF+ 14*DG+ 1130*DH+ 897*DI+ 492*DJ+ 280*DK+ 347*DL+ 118*DM+ 235*DN+ 253*DO+ 215*DP+ 16*DQ+ 30*DR >= 3000 prob += 64*AA+ 33*AB+ 20*AC+ 103*AD+ 38*AE+ 51*AF+ 146*AG+ 171*AH+ 259*AI+ 42*AJ+ 134*AK+ 217*AL+ 250*AM+ 1*AN+ 33*AO+ 183*AP+ 158*AQ+ 216*AR+ 121*AS+ 124*AT+ 31*AU+ 62*AV+ 39*AW+ 30*AX+ 1*AY+ 257*AZ+ 123*BA+ 143*BB+ 75*BC+ 137*BD+ 122*BE+ 134*BF+ 0*BG+ 50*BH+ 79*BI+ 188*BJ+ 174*BK+ 200*BL+ 1*BM+ 97*BN+ 48*BO+ 76*BP+ 149*BQ+ 47*BR+ 140*BS+ 223*BT+ 39*BU+ 223*BV+ 124*BW+ 130*BX+ 37*BY+ 48*BZ+ 33*CA+ 149*CB+ 80*CC+ 125*CD+ 73*CE+ 232*CF+ 139*CG+ 231*CH+ 394*CI+ 27*CJ+ 4*CK+ 10*CL+ 4*CM+ 13*CN+ 45*CO+ 33*CP+ 23*CQ+ 12*CR+ 2*CS+ 10*CT+ 134*CU+ 121*CV+ 31*CW+ 10*CX+ 4*CY+ 5*CZ+ 2*DA+ 60*DB+ 44*DC+ 5*DD+ 43*DE+ 76*DF+ 5*DG+ 22*DH+ 18*DI+ 10*DJ+ 174*DK+ 181*DL+ 89*DM+ 143*DN+ 144*DO+ 136*DP+ 3*DQ+ 3*DR >= 738 prob += 102*AA+ 149*AB+ 319*AC+ 214*AD+ 320*AE+ 149*AF+ 274*AG+ 211*AH+ 596*AI+ 171*AJ+ 300*AK+ 334*AL+ 428*AM+ 1*AN+ 227*AO+ 211*AP+ 121*AQ+ 318*AR+ 184*AS+ 301*AT+ 222*AU+ 225*AV+ 319*AW+ 109*AX+ 2*AY+ 273*AZ+ 273*BA+ 275*BB+ 205*BC+ 235*BD+ 215*BE+ 0*BF+ 1*BG+ 172*BH+ 372*BI+ 535*BJ+ 499*BK+ 245*BL+ 0*BM+ 143*BN+ 588*BO+ 246*BP+ 332*BQ+ 273*BR+ 402*BS+ 436*BT+ 400*BU+ 435*BV+ 242*BW+ 475*BX+ 395*BY+ 583*BZ+ 167*CA+ 392*CB+ 328*CC+ 273*CD+ 265*CE+ 422*CF+ 312*CG+ 296*CH+ 461*CI+ 80*CJ+ 4*CK+ 26*CL+ 8*CM+ 16*CN+ 497*CO+ 282*CP+ 18*CQ+ 266*CR+ 3*CS+ 264*CT+ 140*CU+ 125*CV+ 758*CW+ 253*CX+ 10*CY+ 47*CZ+ 5*DA+ 0*DB+ 75*DC+ 23*DD+ 754*DE+ 1255*DF+ 11*DG+ 249*DH+ 198*DI+ 108*DJ+ 187*DK+ 218*DL+ 70*DM+ 154*DN+ 167*DO+ 151*DP+ 7*DQ+ 9*DR >= 600 prob += 0.8*AA+ 0.9*AB+ 0.8*AC+ 1.1*AD+ 0.9*AE+ 1.1*AF+ 2.1*AG+ 1.3*AH+ 5.2*AI+ 1.9*AJ+ 2.1*AK+ 1.9*AL+ 3.1*AM+ 0*AN+ 0.8*AO+ 1.7*AP+ 0.8*AQ+ 2*AR+ 1.2*AS+ 0.8*AT+ 0.7*AU+ 0.7*AV+ 0.9*AW+ 1.2*AX+ 0*AY+ 6.2*AZ+ 2.9*BA+ 2.2*BB+ 0.5*BC+ 1.3*BD+ 1.3*BE+ 3.3*BF+ 0*BG+ 1.1*BH+ 2*BI+ 3.1*BJ+ 2.5*BK+ 2.3*BL+ 0*BM+ 1*BN+ 1.4*BO+ 1.8*BP+ 2.8*BQ+ 3.2*BR+ 3.4*BS+ 3.2*BT+ 1.1*BU+ 3.5*BV+ 1.9*BW+ 1.1*BX+ 1*BY+ 1.3*BZ+ 1.9*CA+ 3.8*CB+ 0.6*CC+ 2.1*CD+ 1.7*CE+ 3.2*CF+ 2.2*CG+ 1.1*CH+ 2*CI+ 1.1*CJ+ 0*CK+ 0.1*CL+ 0.1*CM+ 0.2*CN+ 2.6*CO+ 0.5*CP+ 0*CQ+ 0.5*CR+ 0*CS+ 0.4*CT+ 0.3*CU+ 0*CV+ 1.4*CW+ 0.5*CX+ 0*CY+ 0.3*CZ+ 0.1*DA+ 1.4*DB+ 2.9*DC+ 0.3*DD+ 2.2*DE+ 4*DF+ 0.1*DG+ 1.3*DH+ 1*DI+ 0.6*DJ+ 0.5*DK+ 1.5*DL+ 0*DM+ 0.2*DN+ 0.4*DO+ 0.1*DP+ 0.1*DQ+ 0.1*DR >= 6.3 prob += 8*AA+ 10*AB+ 11*AC+ 60*AD+ 10*AE+ 11*AF+ 131*AG+ 118*AH+ 149*AI+ 63*AJ+ 114*AK+ 147*AL+ 127*AM+ 0*AN+ 25*AO+ 118*AP+ 48*AQ+ 118*AR+ 61*AS+ 62*AT+ 13*AU+ 13*AV+ 12*AW+ 14*AX+ 99*AY+ 141*AZ+ 141*BA+ 74*BB+ 28*BC+ 118*BD+ 61*BE+ 0*BF+ 0*BG+ 8*BH+ 9*BI+ 125*BJ+ 115*BK+ 123*BL+ 0*BM+ 9*BN+ 14*BO+ 17*BP+ 141*BQ+ 78*BR+ 129*BS+ 161*BT+ 35*BU+ 137*BV+ 71*BW+ 72*BX+ 22*BY+ 16*BZ+ 23*CA+ 93*CB+ 30*CC+ 71*CD+ 14*CE+ 124*CF+ 82*CG+ 108*CH+ 217*CI+ 7*CJ+ 1*CK+ 7*CL+ 9*CM+ 27*CN+ 0*CO+ 7*CP+ 3*CQ+ 10*CR+ 6*CS+ 4*CT+ 255*CU+ 42*CV+ 69*CW+ 23*CX+ 3*CY+ 0*CZ+ 3*DA+ 8*DB+ 4*DC+ 1*DD+ 46*DE+ 69*DF+ 1*DG+ 0*DH+ 0*DI+ 0*DJ+ 61*DK+ 61*DL+ 10*DM+ 47*DN+ 47*DO+ 47*DP+ 5*DQ+ 0*DR >= 625 prob += 0.09*AA+ 0.16*AB+ 0.13*AC+ 0.11*AD+ 0.16*AE+ 0.19*AF+ 0.13*AG+ 0.13*AH+ 0.31*AI+ 0.17*AJ+ 0.24*AK+ 0.18*AL+ 0.23*AM+ 0*AN+ 0.11*AO+ 0.18*AP+ 0.15*AQ+ 0.13*AR+ 0.1*AS+ 0.11*AT+ 0.12*AU+ 0.15*AV+ 0.16*AW+ 0.1*AX+ 0*AY+ 0.25*AZ+ 0.25*BA+ 0.17*BB+ 0.11*BC+ 0.14*BD+ 0.14*BE+ 0*BF+ 0*BG+ 0.26*BH+ 0.3*BI+ 0.32*BJ+ 0.23*BK+ 0.28*BL+ 0*BM+ 0.1*BN+ 0.26*BO+ 0.32*BP+ 0.16*BQ+ 0.21*BR+ 0.28*BS+ 0.22*BT+ 0.16*BU+ 0.18*BV+ 0.13*BW+ 0.16*BX+ 0.17*BY+ 0.26*BZ+ 0.12*CA+ 0.22*CB+ 0.17*CC+ 0.16*CD+ 0.39*CE+ 0.19*CF+ 0.25*CG+ 0.2*CH+ 0.14*CI+ 0.1*CJ+ 0*CK+ 0.04*CL+ 0.02*CM+ 0.03*CN+ 0.61*CO+ 0.1*CP+ 0*CQ+ 0.31*CR+ 0.22*CS+ 0.09*CT+ 0.05*CU+ 0.05*CV+ 0.28*CW+ 0.09*CX+ 0.01*CY+ 0.05*CZ+ 0.01*DA+ 0*DB+ 0.08*DC+ 0.05*DD+ 0.5*DE+ 0.9*DF+ 0.01*DG+ 0.31*DH+ 0.24*DI+ 0.13*DJ+ 0.07*DK+ 0.09*DL+ 0.03*DM+ 0.07*DN+ 0.07*DO+ 0.07*DP+ 0.01*DQ+ 0.01*DR >= 1.4 prob += 0.06*AA+ 0.16*AB+ 0.09*AC+ 0.14*AD+ 0.12*AE+ 0.19*AF+ 0.36*AG+ 0.31*AH+ 0.54*AI+ 0.16*AJ+ 0.25*AK+ 0.3*AL+ 0.38*AM+ 0*AN+ 0.09*AO+ 0.37*AP+ 0.17*AQ+ 0.28*AR+ 0.16*AS+ 0.16*AT+ 0.09*AU+ 0.1*AV+ 0.12*AW+ 0.09*AX+ 0*AY+ 0.51*AZ+ 0.51*BA+ 0.24*BB+ 0.09*BC+ 0.31*BD+ 0.18*BE+ 0*BF+ 0*BG+ 0.21*BH+ 0.2*BI+ 0.46*BJ+ 0.41*BK+ 0.45*BL+ 0*BM+ 0.08*BN+ 0.2*BO+ 0.35*BP+ 0.42*BQ+ 0.26*BR+ 0.35*BS+ 0.4*BT+ 0.14*BU+ 0.39*BV+ 0.22*BW+ 0.21*BX+ 0.14*BY+ 0.2*BZ+ 0.15*CA+ 0.35*CB+ 0.13*CC+ 0.23*CD+ 0.36*CE+ 0.37*CF+ 0.24*CG+ 0.32*CH+ 0.41*CI+ 0.06*CJ+ 0.01*CK+ 0.01*CL+ 0.01*CM+ 0.02*CN+ 0.07*CO+ 0.09*CP+ 0.01*CQ+ 0.09*CR+ 0.01*CS+ 0.08*CT+ 0.24*CU+ 0.2*CV+ 0.31*CW+ 0.1*CX+ 0.01*CY+ 0.01*CZ+ 0*DA+ 0*DB+ 0.03*DC+ 0*DD+ 0.24*DE+ 0.38*DF+ 0*DG+ 0.03*DH+ 0.03*DI+ 0.01*DJ+ 0.29*DK+ 0.3*DL+ 0.13*DM+ 0.23*DN+ 0.26*DO+ 0.23*DP+ 0*DQ+ 0.01*DR >= 1.6 prob += 1*AA+ 3.3*AB+ 7.9*AC+ 2.3*AD+ 8.1*AE+ 3.6*AF+ 2.6*AG+ 1.2*AH+ 10.7*AI+ 3.9*AJ+ 4.8*AK+ 4.3*AL+ 6.2*AM+ 0*AN+ 5*AO+ 2.9*AP+ 2.9*AQ+ 4.1*AR+ 2.5*AS+ 5*AT+ 5.3*AU+ 5.6*AV+ 8.2*AW+ 2.5*AX+ 0*AY+ 3.9*AZ+ 3.9*BA+ 4.4*BB+ 1.4*BC+ 1.3*BD+ 2.6*BE+ 0*BF+ 0*BG+ 4.3*BH+ 4.2*BI+ 4.2*BJ+ 2.6*BK+ 5.4*BL+ 0*BM+ 1.3*BN+ 15.8*BO+ 6.6*BP+ 4.1*BQ+ 6.6*BR+ 7.5*BS+ 7*BT+ 9.5*BU+ 7.2*BV+ 4.1*BW+ 9.5*BX+ 9.8*BY+ 15.7*BZ+ 4*CA+ 7.5*CB+ 2.1*CC+ 4.1*CD+ 7.3*CE+ 6.4*CF+ 4.9*CG+ 3.6*CH+ 4.1*CI+ 1*CJ+ 0*CK+ 0.1*CL+ 0.3*CM+ 0.2*CN+ 12.5*CO+ 7.7*CP+ 0.1*CQ+ 7.6*CR+ 0*CS+ 7.6*CT+ 0.2*CU+ 0.2*CV+ 21.3*CW+ 7.1*CX+ 0*CY+ 0.9*CZ+ 0.2*DA+ 0*DB+ 0.8*DC+ 0.3*DD+ 20.5*DE+ 33.9*DF+ 0.1*DG+ 6.3*DH+ 5*DI+ 2.7*DJ+ 0.3*DK+ 0.6*DL+ 0.1*DM+ 0.4*DN+ 0.4*DO+ 0.3*DP+ 0.1*DQ+ 0.1*DR >= 15 prob += 1*AA+ 1*AB+ 1*AC+ 6*AD+ 1*AE+ 1*AF+ 1*AG+ 0*AH+ 2*AI+ 6*AJ+ 17*AK+ 7*AL+ 2*AM+ 0*AN+ 1*AO+ 0*AP+ 0*AQ+ 1*AR+ 1*AS+ 1*AT+ 0*AU+ 0*AV+ 1*AW+ 1*AX+ 0*AY+ 1*AZ+ 1*BA+ 2*BB+ 0*BC+ 6*BD+ 7*BE+ 0*BF+ 0*BG+ 6*BH+ 0*BI+ 0*BJ+ 5*BK+ 6*BL+ 0*BM+ 1*BN+ 2*BO+ 2*BP+ 1*BQ+ 6*BR+ 17*BS+ 7*BT+ 1*BU+ 1*BV+ 1*BW+ 1*BX+ 0*BY+ 1*BZ+ 1*CA+ 2*CB+ 0*CC+ 7*CD+ 6*CE+ 0*CF+ 17*CG+ 1*CH+ 1*CI+ 8*CJ+ 5*CK+ 0*CL+ 19*CM+ 15*CN+ 40*CO+ 0*CP+ 0*CQ+ 0*CR+ 0*CS+ 0*CT+ 0*CU+ 0*CV+ 3*CW+ 1*CX+ 0*CY+ 1*CZ+ 1*DA+ 0*DB+ 0*DC+ 0*DD+ 22*DE+ 43*DF+ 0*DG+ 20*DH+ 16*DI+ 9*DJ+ 0*DK+ 0*DL+ 0*DM+ 3*DN+ 0*DO+ 0*DP+ 0*DQ+ 0*DR >= 100 prob += 66*AA+ 56*AB+ 49*AC+ 47*AD+ 50*AE+ 56*AF+ 248*AG+ 231*AH+ 187*AI+ 49*AJ+ 73*AK+ 74*AL+ 109*AM+ 0*AN+ 37*AO+ 255*AP+ 45*AQ+ 76*AR+ 38*AS+ 50*AT+ 35*AU+ 35*AV+ 49*AW+ 26*AX+ 18*AY+ 478*AZ+ 458*BA+ 69*BB+ 40*BC+ 228*BD+ 47*BE+ 21*BF+ 0*BG+ 54*BH+ 30*BI+ 254*BJ+ 227*BK+ 294*BL+ 0*BM+ 126*BN+ 93*BO+ 105*BP+ 274*BQ+ 93*BR+ 118*BS+ 119*BT+ 69*BU+ 127*BV+ 64*BW+ 82*BX+ 66*BY+ 92*BZ+ 52*CA+ 121*CB+ 68*CC+ 73*CD+ 103*CE+ 113*CF+ 68*CG+ 79*CH+ 99*CI+ 0*CJ+ 0*CK+ 7*CL+ 0*CM+ 0*CN+ 23*CO+ 44*CP+ 1*CQ+ 43*CR+ 0*CS+ 43*CT+ 116*CU+ 12*CV+ 188*CW+ 63*CX+ 7*CY+ 4*CZ+ 0*DA+ 11*DB+ 5*DC+ 2*DD+ 136*DE+ 210*DF+ 2*DG+ 11*DH+ 9*DI+ 5*DJ+ 17*DK+ 17*DL+ 4*DM+ 14*DN+ 14*DO+ 14*DP+ 6*DQ+ 0*DR >= 0 prob += 2.9*AA+ 0.8*AB+ 1.9*AC+ 0.9*AD+ 2.8*AE+ 1.7*AF+ 1.5*AG+ 1.7*AH+ 3.2*AI+ 2.3*AJ+ 2.4*AK+ 1.9*AL+ 3.2*AM+ 0.2*AN+ 2.2*AO+ 1.7*AP+ 1.7*AQ+ 1.7*AR+ 1.5*AS+ 2.2*AT+ 1.9*AU+ 2.5*AV+ 2.8*AW+ 1.5*AX+ 0*AY+ 6.1*AZ+ 3.2*BA+ 2.6*BB+ 2.1*BC+ 1.1*BD+ 1.7*BE+ 2.8*BF+ 0*BG+ 1.5*BH+ 1.6*BI+ 1.7*BJ+ 1.8*BK+ 2*BL+ 0*BM+ 3.9*BN+ 4*BO+ 1.8*BP+ 1.6*BQ+ 2.3*BR+ 2.5*BS+ 2*BT+ 2.9*BU+ 1.8*BV+ 1.6*BW+ 2.9*BX+ 2.5*BY+ 3.9*BZ+ 1.6*CA+ 2.7*CB+ 3*CC+ 1.8*CD+ 1.5*CE+ 1.8*CF+ 2.3*CG+ 1.7*CH+ 1.7*CI+ 2.9*CJ+ 0*CK+ 0.5*CL+ 0.4*CM+ 0.8*CN+ 12*CO+ 1.1*CP+ 0*CQ+ 1.2*CR+ 0.1*CS+ 1.1*CT+ 0.2*CU+ 0.3*CV+ 2.6*CW+ 0.9*CX+ 0.1*CY+ 1.5*CZ+ 0.3*DA+ 1.3*DB+ 2.3*DC+ 1*DD+ 7.7*DE+ 14.6*DF+ 0.3*DG+ 6*DH+ 4.8*DI+ 2.6*DJ+ 0.7*DK+ 1.7*DL+ 0.1*DM+ 1*DN+ 1.1*DO+ 0.7*DP+ 0.1*DQ+ 0.1*DR >= 21 prob += 2.3*AA+ 2.5*AB+ 3.3*AC+ 2.5*AD+ 3.1*AE+ 2.1*AF+ 2.1*AG+ 1.6*AH+ 6*AI+ 2.1*AJ+ 2.7*AK+ 2.9*AL+ 4.4*AM+ 0*AN+ 2.5*AO+ 2*AP+ 1.8*AQ+ 2.9*AR+ 1.9*AS+ 2.7*AT+ 2.2*AU+ 2.1*AV+ 2.9*AW+ 1.4*AX+ 0.1*AY+ 4.2*AZ+ 2.4*BA+ 2.6*BB+ 1.6*BC+ 1.6*BD+ 2.1*BE+ 1.8*BF+ 0*BG+ 2.3*BH+ 2.5*BI+ 3*BJ+ 2.6*BK+ 3.4*BL+ 0.6*BM+ 3.3*BN+ 5.3*BO+ 3.3*BP+ 2.4*BQ+ 2.5*BR+ 3.1*BS+ 3.3*BT+ 3.8*BU+ 3.6*BV+ 2.3*BW+ 4*BX+ 3.4*BY+ 4.5*BZ+ 1.8*CA+ 3.3*CB+ 2.1*CC+ 2.5*CD+ 2.9*CE+ 3.6*CF+ 3.4*CG+ 3.2*CH+ 3*CI+ 0.2*CJ+ 0*CK+ 0.6*CL+ 0.5*CM+ 0*CN+ 2.1*CO+ 2*CP+ 0.4*CQ+ 1.9*CR+ 0.2*CS+ 1.6*CT+ 0.1*CU+ 0.2*CV+ 3.9*CW+ 1.3*CX+ 0.7*CY+ 0.8*CZ+ 0.5*DA+ 0.8*DB+ 0.4*DC+ 0.6*DD+ 3.6*DE+ 6*DF+ 0.5*DG+ 1.1*DH+ 0.8*DI+ 0.5*DJ+ 0.4*DK+ 0.7*DL+ 0.1*DM+ 0.3*DN+ 0.3*DO+ 0.3*DP+ 0.6*DQ+ 1*DR >= 5 # Solve the problem using the default solver prob.solve() print(LpStatus[prob.status]) # Print the value of the variables at the optimum print("Result") print("えびフィレオ:", AA.value()) print("ごはんてりやき:", AB.value()) print("ごはんチキンフィレオ:", AC.value()) print("ごはんベーコンレタス:", AD.value()) print("てりやきチキンフィレオ:", AE.value()) print("てりやきマックバーガー:", AF.value()) print("エグチ(エッグチーズバーガー):", AG.value()) print("エッグマックマフィン:", AH.value()) print("ギガビッグマック®:", AI.value()) print("グラン ガーリックペッパー:", AJ.value()) print("グラン クラブハウス:", AK.value()) print("グラン ベーコンチーズ:", AL.value()) print("グランドビッグマック®:", AM.value()) print("ストロベリージャム:", AN.value()) print("スパチキ(スパイシーチキンバーガー):", AO.value()) print("ソーセージエッグマフィン:", AP.value()) print("ソーセージマフィン:", AQ.value()) print("ダブルチーズバーガー:", AR.value()) print("チーズバーガー:", AS.value()) print("チキチー(チキンチーズバーガー):", AT.value()) print("チキンクリスプ:", AU.value()) print("チキンクリスプマフィン:", AV.value()) print("チキンフィレオ:", AW.value()) print("ハンバーガー:", AX.value()) print("バターパット:", AY.value()) print("ビッグブレックファスト デラックス(ハッシュポテト含む):", AZ.value()) print("ビッグブレックファスト(ハッシュポテト含む):", BA.value()) print("ビッグマック®:", BB.value()) print("フィレオフィッシュ:", BC.value()) print("ベーコンエッグマックサンド:", BD.value()) print("ベーコンレタスバーガー:", BE.value()) print("ホットケーキ:", BF.value()) print("ホットケーキシロップ:", BG.value()) print("マクポ(ベーコンマックポーク):", BH.value()) print("マックグリドル ソーセージ:", BI.value()) print("マックグリドル ソーセージエッグ:", BJ.value()) print("マックグリドル ベーコンエッグ:", BK.value()) print("メガマフィン:", BL.value()) print("塩・コショウ:", BM.value()) print("倍えびフィレオ:", BN.value()) print("倍てりやきチキンフィレオ:", BO.value()) print("倍てりやきマックバーガー:", BP.value()) print("倍エグチ(倍エッグチーズバーガー):", BQ.value()) print("倍グラン ガーリックペッパー:", BR.value()) print("倍グラン クラブハウス:", BS.value()) print("倍グラン ベーコンチーズ:", BT.value()) print("倍スパチキ(倍スパイシーチキンバーガー):", BU.value()) print("倍ダブルチーズバーガー:", BV.value()) print("倍チーズバーガー:", BW.value()) print("倍チキチー(倍チキンチーズバーガー):", BX.value()) print("倍チキンクリスプ:", BY.value()) print("倍チキンフィレオ:", BZ.value()) print("倍ハンバーガー:", CA.value()) print("倍ビッグマック®:", CB.value()) print("倍フィレオフィッシュ:", CC.value()) print("倍ベーコンレタスバーガー:", CD.value()) print("倍マクポ(倍ベーコンマックポーク):", CE.value()) print("炙り醤油風 ダブル肉厚ビーフ:", CF.value()) print("炙り醤油風 ベーコントマト肉厚ビーフ:", CG.value()) print("チーズチーズてりやきマックバーガー:", CH.value()) print("チーズチーズダブルチーズバーガー:", CI.value()) print("えだまめコーン:", CJ.value()) print("りんご&クリーム:", CK.value()) print("クリームブリュレパイ:", CL.value()) print("ケチャップ:", CM.value()) print("サイドサラダ:", CN.value()) print("シェアポテト:", CO.value()) print("シャカチキ チェダーチーズ:", CP.value()) print("シャカチキ チェダーチーズ味シーズニング:", CQ.value()) print("シャカチキ レッドペッパー:", CR.value()) print("シャカチキ レッドペッパー味シーズニング:", CS.value()) print("シャカチキ(チキンのみ):", CT.value()) print("スジャータアイスバニラ:", CU.value()) print("ソフトツイスト:", CV.value()) print("チキンマックナゲット 15ピース:", CW.value()) print("チキンマックナゲット 5ピース:", CX.value()) print("トリュフ香るパルメザンチーズソース:", CY.value()) print("ハッシュポテト:", CZ.value()) print("バーベキューソース:", DA.value()) print("プチパンケーキ:", DB.value()) print("ベルギーショコラパイ:", DC.value()) print("ホットアップルパイ:", DD.value()) print("ポテナゲ大:", DE.value()) print("ポテナゲ特大:", DF.value()) print("マスタードソース:", DG.value()) print("マックフライポテト(L):", DH.value()) print("マックフライポテト(M):", DI.value()) print("マックフライポテト(S):", DJ.value()) print("マックフルーリー® オレオ®クッキー:", DK.value()) print("マックフルーリー® 超 オレオ®:", DL.value()) print("ヨーグルト:", DM.value()) print("ワッフルコーン ストロベリー:", DN.value()) print("ワッフルコーン チョコ&アーモンド:", DO.value()) print("ワッフルコーン プレーン:", DP.value()) print("伊勢海老と紅ズワイガニソース:", DQ.value()) print("低カロリー玉ねぎ:", DR.value())結果
さあ計算しましょう。なんだかワクワクしてきました。
kekka.txtResult - Optimal solution found Objective value: 972.00000000 Enumerated nodes: 0 Total iterations: 117 Time (CPU seconds): 0.10 Time (Wallclock seconds): 0.10条件を満たす組み合わせは存在するようです!マクドナルドだけで生きていけるかもしれません!これで一人暮らしでも健康に生きていける!
マイスーパーコンピューターがはじき出した商品の種類は5種類。5種類だけ食べれば健康になれるようです。すげー。以下がその商品です!
バター(1個)
いきなり変化球です。朝マック以外ではお目にかかりません。
トリュフ香るパルメザンチーズソース(1個)
またまた変化球です。期間限定のナゲットのソース。
低カロリー玉ねぎ(1個)
サイドサラダのドレッシングです。
塩・コショウ(6個)
マクドナルドに塩・コショウなんてあるんですね。初めて知りました。
そして最後が・・・
サイドサラダ(79個)
圧倒的ですね。ギャル曽根でも助走つけて殴るレベルの量です。
ポテトもハンバーガーも食べず、ひたすらサラダを食えとのお達しです。この組み合わせによって以下の通り、一日必要な栄養素を満たす極めて健康的な栄養を摂取することができます。
栄養素 摂取量 エネルギー(kcal) 1944 たんぱく質 (g) 80.4 脂質 (g) 51.6 炭水化物 (g) 370.2 ナトリウム (mg) 4612 カリウム (mg) 21742 カルシウム (mg) 2082 リン (mg) 2570 鉄 (mg) 31.8 ビタミンA (μg) 4470 ビタミンB1 (mg) 4.78 ビタミンB2 (mg) 3.2 ナイアシン (mg) 31.8 ビタミンC (mg) 2370 コレステロール (mg) 50 食物繊維 (g) 126.8 食塩相当量 (g) 10.8 kekka.txtえびフィレオ: 0.0 ごはんてりやき: 0.0 ごはんチキンフィレオ: 0.0 ごはんベーコンレタス: 0.0 てりやきチキンフィレオ: 0.0 てりやきマックバーガー: 0.0 エグチ(エッグチーズバーガー): 0.0 エッグマックマフィン: 0.0 ギガビッグマック®: 0.0 グラン ガーリックペッパー: 0.0 グラン クラブハウス: 0.0 グラン ベーコンチーズ: 0.0 グランドビッグマック®: 0.0 ストロベリージャム: 0.0 スパチキ(スパイシーチキンバーガー): 0.0 ソーセージエッグマフィン: 0.0 ソーセージマフィン: 0.0 ダブルチーズバーガー: 0.0 チーズバーガー: 0.0 チキチー(チキンチーズバーガー): 0.0 チキンクリスプ: 0.0 チキンクリスプマフィン: 0.0 チキンフィレオ: 0.0 ハンバーガー: 0.0 バターパット: 1.0 ビッグブレックファスト デラックス(ハッシュポテト含む): 0.0 ビッグブレックファスト(ハッシュポテト含む): 0.0 ビッグマック®: 0.0 フィレオフィッシュ: 0.0 ベーコンエッグマックサンド: 0.0 ベーコンレタスバーガー: 0.0 ホットケーキ: 0.0 ホットケーキシロップ: 0.0 マクポ(ベーコンマックポーク): 0.0 マックグリドル ソーセージ: 0.0 マックグリドル ソーセージエッグ: 0.0 マックグリドル ベーコンエッグ: 0.0 メガマフィン: 0.0 塩・コショウ: 6.0 倍えびフィレオ: 0.0 倍てりやきチキンフィレオ: 0.0 倍てりやきマックバーガー: 0.0 倍エグチ(倍エッグチーズバーガー): 0.0 倍グラン ガーリックペッパー: 0.0 倍グラン クラブハウス: 0.0 倍グラン ベーコンチーズ: 0.0 倍スパチキ(倍スパイシーチキンバーガー): 0.0 倍ダブルチーズバーガー: 0.0 倍チーズバーガー: 0.0 倍チキチー(倍チキンチーズバーガー): 0.0 倍チキンクリスプ: 0.0 倍チキンフィレオ: 0.0 倍ハンバーガー: 0.0 倍ビッグマック®: 0.0 倍フィレオフィッシュ: 0.0 倍ベーコンレタスバーガー: 0.0 倍マクポ(倍ベーコンマックポーク): 0.0 炙り醤油風 ダブル肉厚ビーフ: 0.0 炙り醤油風 ベーコントマト肉厚ビーフ: 0.0 チーズチーズてりやきマックバーガー: 0.0 チーズチーズダブルチーズバーガー: 0.0 えだまめコーン: 0.0 りんご&クリーム: 0.0 クリームブリュレパイ: 0.0 ケチャップ: 0.0 サイドサラダ: 79.0 シェアポテト: 0.0 シャカチキ チェダーチーズ: 0.0 シャカチキ チェダーチーズ味シーズニング: 0.0 シャカチキ レッドペッパー: 0.0 シャカチキ レッドペッパー味シーズニング: 0.0 シャカチキ(チキンのみ): 0.0 スジャータアイスバニラ: 0.0 ソフトツイスト: 0.0 チキンマックナゲット 15ピース: 0.0 チキンマックナゲット 5ピース: 0.0 トリュフ香るパルメザンチーズソース: 1.0 ハッシュポテト: 0.0 バーベキューソース: 0.0 プチパンケーキ: 0.0 ベルギーショコラパイ: 0.0 ホットアップルパイ: 0.0 ポテナゲ大: 0.0 ポテナゲ特大: 0.0 マスタードソース: 0.0 マックフライポテト(L): 0.0 マックフライポテト(M): 0.0 マックフライポテト(S): 0.0 マックフルーリー® オレオ®クッキー: 0.0 マックフルーリー® 超 オレオ®: 0.0 ヨーグルト: 0.0 ワッフルコーン ストロベリー: 0.0 ワッフルコーン チョコ&アーモンド: 0.0 ワッフルコーン プレーン: 0.0 伊勢海老と紅ズワイガニソース: 0.0 低カロリー玉ねぎ: 1.0サイドサラダ王になる!
いかがでしたか?ビッグマックもポテトも食べずに、ひたすらサイドサラダを食べる。これが健康への近道です!私も無人島に食べ物を一種類だけ持っていくとしたら間違いなくサイドサラダを選びます。完全食です。最高!
でも、カリウムを22gも取って大丈夫なのか?そういえば日本人の食事摂取基準には過剰摂取に由来する健康障害のリスクも載っていたような?・・・そもそもここであげた12種類以外にも人類に必要な栄養素があるのでは?(さっきの伏線回収)
と、ツッコミどころを上げたらきりがありません。頭使ったらお腹が減ってきたので、今からビッグマック食べにいこっと。





- 投稿日:2021-02-20T15:10:49+09:00
マクドナルトで一日分の栄養を取れる組み合わせを計算する
マックで一日分の栄養を取りたい!
マクドナルド。関東ではマック、関西ではマクドと呼ばれている、おなじみのファーストチェーン店です。全国津々浦々にありますので、よく食べる方もいらっしゃるでしょう。私も大好きで、よく食べています。
ところで、マクドナルドって栄養的にどうなんでしょう?ファーストフードばかり食べていると体に悪いという話をよく聞きますが、そんなに偏っているのでしょうか?メニューの組み合わせさえ気を付ければ大丈夫なのでしょうか。
そこで、マクドナルドで一日に必要な栄養素を取るための商品の組み合わせを調べてみました。
計算は簡単
式を立てる
組み合わせを見つけるのはそれほど難しくありません。線形計画法という手法を用いれば簡単に解くことができます。特に最低限必要な栄養素を求める問題はダイエット問題という名前で知られています。
マクドナルドの商品の栄養素は公開されているデータを使用します。
日本人が一日必要な栄養素は厚生労働省が公表しています。年齢や性別によって基準量が異なりますが、30歳男子をターゲットとすると以下のようになります。「20~25g」のように基準量に幅がある場合は中央値を取りました。
栄養素 基準量 たんぱく質 (g) 0.65 脂質 (g) 25 炭水化物 (g) 62.5 ナトリウム (mg) 5000 カリウム (mg) 3000 カルシウム (mg) 738 リン (mg) 600 鉄 (mg) 6.3 ビタミンA (μg) 625 ビタミンB1 (mg) 1.4 ビタミンB2 (mg) 1.6 ナイアシン (mg) 15 ビタミンC (mg) 100 コレステロール (mg) 0 食物繊維 (g) 21 食塩相当量 (g) 5 コレステロールは最低摂取基準量はないので0としています(実はこれが伏線になっている)。
そして目的は、一日必要な栄養素を満たす最もカロリーの低い商品の組み合わせとします。金に糸目はつけません。健康第一!
解く
商品の数が96個、栄養素の数が16個なので、とても人間の手では解けません。そこでコンピューターの力を借ります。幸いPuLPというPythonで無料で利用できるソルバーがあるので、これで計算します。ちなみにExcelにもソルバーが搭載されていますが、この程度の数の決定変数でもエラーになって計算できませんでした。
hello.mac# Import PuLP modeler functions from pulp import * # A new LP problem prob = LpProblem(name="mac", sense=LpMinimize) # Variables AA = LpVariable(name = "AA", lowBound = 0, cat="Integer") AB = LpVariable(name = "AB", lowBound = 0, cat="Integer") AC = LpVariable(name = "AC", lowBound = 0, cat="Integer") AD = LpVariable(name = "AD", lowBound = 0, cat="Integer") AE = LpVariable(name = "AE", lowBound = 0, cat="Integer") AF = LpVariable(name = "AF", lowBound = 0, cat="Integer") AG = LpVariable(name = "AG", lowBound = 0, cat="Integer") AH = LpVariable(name = "AH", lowBound = 0, cat="Integer") AI = LpVariable(name = "AI", lowBound = 0, cat="Integer") AJ = LpVariable(name = "AJ", lowBound = 0, cat="Integer") AK = LpVariable(name = "AK", lowBound = 0, cat="Integer") AL = LpVariable(name = "AL", lowBound = 0, cat="Integer") AM = LpVariable(name = "AM", lowBound = 0, cat="Integer") AN = LpVariable(name = "AN", lowBound = 0, cat="Integer") AO = LpVariable(name = "AO", lowBound = 0, cat="Integer") AP = LpVariable(name = "AP", lowBound = 0, cat="Integer") AQ = LpVariable(name = "AQ", lowBound = 0, cat="Integer") AR = LpVariable(name = "AR", lowBound = 0, cat="Integer") AS = LpVariable(name = "AS", lowBound = 0, cat="Integer") AT = LpVariable(name = "AT", lowBound = 0, cat="Integer") AU = LpVariable(name = "AU", lowBound = 0, cat="Integer") AV = LpVariable(name = "AV", lowBound = 0, cat="Integer") AW = LpVariable(name = "AW", lowBound = 0, cat="Integer") AX = LpVariable(name = "AX", lowBound = 0, cat="Integer") AY = LpVariable(name = "AY", lowBound = 0, cat="Integer") AZ = LpVariable(name = "AZ", lowBound = 0, cat="Integer") BA = LpVariable(name = "BA", lowBound = 0, cat="Integer") BB = LpVariable(name = "BB", lowBound = 0, cat="Integer") BC = LpVariable(name = "BC", lowBound = 0, cat="Integer") BD = LpVariable(name = "BD", lowBound = 0, cat="Integer") BE = LpVariable(name = "BE", lowBound = 0, cat="Integer") BF = LpVariable(name = "BF", lowBound = 0, cat="Integer") BG = LpVariable(name = "BG", lowBound = 0, cat="Integer") BH = LpVariable(name = "BH", lowBound = 0, cat="Integer") BI = LpVariable(name = "BI", lowBound = 0, cat="Integer") BJ = LpVariable(name = "BJ", lowBound = 0, cat="Integer") BK = LpVariable(name = "BK", lowBound = 0, cat="Integer") BL = LpVariable(name = "BL", lowBound = 0, cat="Integer") BM = LpVariable(name = "BM", lowBound = 0, cat="Integer") BN = LpVariable(name = "BN", lowBound = 0, cat="Integer") BO = LpVariable(name = "BO", lowBound = 0, cat="Integer") BP = LpVariable(name = "BP", lowBound = 0, cat="Integer") BQ = LpVariable(name = "BQ", lowBound = 0, cat="Integer") BR = LpVariable(name = "BR", lowBound = 0, cat="Integer") BS = LpVariable(name = "BS", lowBound = 0, cat="Integer") BT = LpVariable(name = "BT", lowBound = 0, cat="Integer") BU = LpVariable(name = "BU", lowBound = 0, cat="Integer") BV = LpVariable(name = "BV", lowBound = 0, cat="Integer") BW = LpVariable(name = "BW", lowBound = 0, cat="Integer") BX = LpVariable(name = "BX", lowBound = 0, cat="Integer") BY = LpVariable(name = "BY", lowBound = 0, cat="Integer") BZ = LpVariable(name = "BZ", lowBound = 0, cat="Integer") CA = LpVariable(name = "CA", lowBound = 0, cat="Integer") CB = LpVariable(name = "CB", lowBound = 0, cat="Integer") CC = LpVariable(name = "CC", lowBound = 0, cat="Integer") CD = LpVariable(name = "CD", lowBound = 0, cat="Integer") CE = LpVariable(name = "CE", lowBound = 0, cat="Integer") CF = LpVariable(name = "CF", lowBound = 0, cat="Integer") CG = LpVariable(name = "CG", lowBound = 0, cat="Integer") CH = LpVariable(name = "CH", lowBound = 0, cat="Integer") CI = LpVariable(name = "CI", lowBound = 0, cat="Integer") CJ = LpVariable(name = "CJ", lowBound = 0, cat="Integer") CK = LpVariable(name = "CK", lowBound = 0, cat="Integer") CL = LpVariable(name = "CL", lowBound = 0, cat="Integer") CM = LpVariable(name = "CM", lowBound = 0, cat="Integer") CN = LpVariable(name = "CN", lowBound = 0, cat="Integer") CO = LpVariable(name = "CO", lowBound = 0, cat="Integer") CP = LpVariable(name = "CP", lowBound = 0, cat="Integer") CQ = LpVariable(name = "CQ", lowBound = 0, cat="Integer") CR = LpVariable(name = "CR", lowBound = 0, cat="Integer") CS = LpVariable(name = "CS", lowBound = 0, cat="Integer") CT = LpVariable(name = "CT", lowBound = 0, cat="Integer") CU = LpVariable(name = "CU", lowBound = 0, cat="Integer") CV = LpVariable(name = "CV", lowBound = 0, cat="Integer") CW = LpVariable(name = "CW", lowBound = 0, cat="Integer") CX = LpVariable(name = "CX", lowBound = 0, cat="Integer") CY = LpVariable(name = "CY", lowBound = 0, cat="Integer") CZ = LpVariable(name = "CZ", lowBound = 0, cat="Integer") DA = LpVariable(name = "DA", lowBound = 0, cat="Integer") DB = LpVariable(name = "DB", lowBound = 0, cat="Integer") DC = LpVariable(name = "DC", lowBound = 0, cat="Integer") DD = LpVariable(name = "DD", lowBound = 0, cat="Integer") DE = LpVariable(name = "DE", lowBound = 0, cat="Integer") DF = LpVariable(name = "DF", lowBound = 0, cat="Integer") DG = LpVariable(name = "DG", lowBound = 0, cat="Integer") DH = LpVariable(name = "DH", lowBound = 0, cat="Integer") DI = LpVariable(name = "DI", lowBound = 0, cat="Integer") DJ = LpVariable(name = "DJ", lowBound = 0, cat="Integer") DK = LpVariable(name = "DK", lowBound = 0, cat="Integer") DL = LpVariable(name = "DL", lowBound = 0, cat="Integer") DM = LpVariable(name = "DM", lowBound = 0, cat="Integer") DN = LpVariable(name = "DN", lowBound = 0, cat="Integer") DO = LpVariable(name = "DO", lowBound = 0, cat="Integer") DP = LpVariable(name = "DP", lowBound = 0, cat="Integer") DQ = LpVariable(name = "DQ", lowBound = 0, cat="Integer") DR = LpVariable(name = "DR", lowBound = 0, cat="Integer") # Objective prob += 395*AA+ 545*AB+ 532*AC+ 441*AD+ 498*AE+ 478*AF+ 387*AG+ 311*AH+ 1067*AI+ 428*AJ+ 527*AK+ 489*AL+ 776*AM+ 38*AN+ 389*AO+ 475*AP+ 395*AQ+ 457*AR+ 307*AS+ 431*AT+ 345*AU+ 364*AV+ 465*AW+ 256*AX+ 60*AY+ 979*AZ+ 659*BA+ 525*BB+ 323*BC+ 292*BD+ 374*BE+ 319*BF+ 121*BG+ 419*BH+ 420*BI+ 550*BJ+ 396*BK+ 695*BL+ 1*BM+ 553*BN+ 768*BO+ 728*BP+ 486*BQ+ 594*BR+ 693*BS+ 655*BT+ 542*BU+ 655*BV+ 406*BW+ 584*BX+ 498*BY+ 709*BZ+ 356*CA+ 724*CB+ 434*CC+ 473*CD+ 642*CE+ 625*CF+ 471*CG+ 579*CH+ 558*CI+ 83*CJ+ 31*CK+ 287*CL+ 23*CM+ 10*CN+ 1034*CO+ 252*CP+ 8*CQ+ 249*CR+ 6*CS+ 243*CT+ 275*CU+ 148*CV+ 810*CW+ 270*CX+ 109*CY+ 145*CZ+ 33*DA+ 161*DB+ 304*DC+ 211*DD+ 1057*DE+ 1844*DF+ 44*DG+ 517*DH+ 410*DI+ 225*DJ+ 235*DK+ 337*DL+ 59*DM+ 257*DN+ 295*DO+ 232*DP+ 108*DQ+ 7*DR # Constraints prob += 12.5*AA+ 14.5*AB+ 19*AC+ 16.7*AD+ 20.2*AE+ 15.5*AF+ 22.3*AG+ 19.2*AH+ 61.9*AI+ 19.9*AJ+ 26.5*AK+ 27.3*AL+ 39.5*AM+ 0*AN+ 14.2*AO+ 21.5*AP+ 15*AQ+ 26.5*AR+ 15.8*AS+ 17.1*AT+ 14*AU+ 15.2*AV+ 20*AW+ 12.8*AX+ 0*AY+ 34.1*AZ+ 26.2*BA+ 26*BB+ 14.4*BC+ 15.9*BD+ 17.7*BE+ 8*BF+ 0*BG+ 17.2*BH+ 10.4*BI+ 20.3*BJ+ 15.7*BK+ 29.7*BL+ 0*BM+ 19.4*BN+ 35.3*BO+ 25.8*BP+ 30*BQ+ 33.3*BR+ 39.8*BS+ 40.6*BT+ 23.2*BU+ 42*BV+ 23.5*BW+ 26.1*BX+ 23*BY+ 34.8*BZ+ 20.6*CA+ 41.4*CB+ 22.7*CC+ 25.5*CD+ 27.2*CE+ 39*CF+ 26.7*CG+ 21.4*CH+ 32.4*CI+ 5.2*CJ+ 0.2*CK+ 3*CL+ 0.4*CM+ 0.5*CN+ 13.4*CO+ 15.3*CP+ 0.5*CQ+ 15*CR+ 0.2*CS+ 14.8*CT+ 5*CU+ 3.8*CV+ 47.3*CW+ 15.8*CX+ 0.3*CY+ 1.2*CZ+ 0.2*DA+ 3.8*DB+ 3.7*DC+ 1.9*DD+ 38.2*DE+ 60.6*DF+ 0.4*DG+ 6.7*DH+ 5.3*DI+ 2.9*DJ+ 5.9*DK+ 8*DL+ 3.2*DM+ 5.4*DN+ 5.9*DO+ 5.3*DP+ 0.4*DQ+ 0.4*DR >= 0.65 prob += 17.4*AA+ 29.4*AB+ 21.1*AC+ 20*AD+ 23.2*AE+ 30.2*AF+ 18.9*AG+ 13.5*AH+ 65.5*AI+ 21.7*AJ+ 30.7*AK+ 26.6*AL+ 43.1*AM+ 0*AN+ 20.2*AO+ 30.6*AP+ 25.1*AQ+ 25*AR+ 13.4*AS+ 23*AT+ 15.5*AU+ 17.3*AV+ 21.9*AW+ 9.4*AX+ 6.7*AY+ 51.3*AZ+ 42.7*BA+ 28.3*BB+ 13.9*BC+ 13.3*BD+ 20.8*BE+ 8.6*BF+ 0*BG+ 23.7*BH+ 23.8*BI+ 33.2*BJ+ 18.1*BK+ 49.7*BL+ 0*BM+ 25.5*BN+ 36.1*BO+ 50*BP+ 26.5*BQ+ 34.2*BR+ 43.2*BS+ 39.1*BT+ 28.7*BU+ 40.1*BV+ 21*BW+ 31.6*BX+ 24*BY+ 34.7*BZ+ 16.9*CA+ 43.4*CB+ 18.6*CC+ 28.4*CD+ 43.5*CE+ 36.2*CF+ 23.7*CG+ 38.3*CH+ 33.1*CI+ 3*CJ+ 1.5*CK+ 18*CL+ 0*CM+ 0.1*CN+ 51.8*CO+ 13.1*CP+ 0.2*CQ+ 12.9*CR+ 0*CS+ 12.8*CT+ 18.9*CU+ 3.9*CV+ 51.6*CW+ 17.2*CX+ 11.2*CY+ 9.6*CZ+ 0.1*DA+ 4.4*DB+ 18.1*DC+ 10.7*DD+ 60.3*DE+ 103.4*DF+ 2.3*DG+ 25.9*DH+ 20.6*DI+ 11.3*DJ+ 7*DK+ 10.6*DL+ 0.8*DM+ 5.5*DN+ 10.7*DO+ 5.5*DP+ 10.9*DQ+ 0*DR >= 25 prob += 47.7*AA+ 55.8*AB+ 66.6*AC+ 48.4*AD+ 52.4*AE+ 36.4*AF+ 31*AG+ 27.1*AH+ 57.5*AI+ 38.9*AJ+ 36.8*AK+ 35.5*AL+ 57.5*AM+ 9.5*AN+ 38.1*AO+ 27.3*AP+ 27.2*AQ+ 31.4*AR+ 30.8*AS+ 39.2*AT+ 37.7*AU+ 37*AV+ 47.3*AW+ 30.3*AX+ 0*AY+ 92.9*AZ+ 40.2*BA+ 41.8*BB+ 35.8*BC+ 26.4*BD+ 29.1*BE+ 52.7*BF+ 30.2*BG+ 34.3*BH+ 41.9*BI+ 42.4*BJ+ 42.4*BK+ 31.2*BL+ 0.1*BM+ 62.8*BN+ 76*BO+ 44.1*BP+ 31*BQ+ 38.9*BR+ 36.8*BS+ 35.5*BT+ 48*BU+ 31.4*BV+ 30.8*BW+ 49.1*BX+ 47.6*BY+ 64.4*BZ+ 30.3*CA+ 41.8*CB+ 45*CC+ 29.1*CD+ 35.5*CE+ 36.3*CF+ 38.2*CG+ 37.6*CH+ 32.7*CI+ 9.6*CJ+ 4.3*CK+ 28.3*CL+ 5.6*CM+ 2.3*CN+ 128.5*CO+ 18.2*CP+ 1.1*CQ+ 18.3*CR+ 1.2*CS+ 17.2*CT+ 21.1*CU+ 24.7*CV+ 39.2*CW+ 13.1*CX+ 1.6*CY+ 13.3*CZ+ 7.7*DA+ 26.4*DB+ 31.5*DC+ 26.8*DD+ 90.4*DE+ 167.7*DF+ 5.2*DG+ 64.3*DH+ 51*DI+ 28*DJ+ 37.7*DK+ 53.4*DL+ 9.7*DM+ 46.8*DN+ 44.1*DO+ 40.6*DP+ 2*DQ+ 1.2*DR >= 62.5 prob += 919*AA+ 986*AB+ 1296*AC+ 994*AD+ 1216*AE+ 829*AF+ 813*AG+ 649*AH+ 2326*AI+ 816*AJ+ 1052*AK+ 1129*AL+ 1714*AM+ 4*AN+ 996*AO+ 789*AP+ 722*AQ+ 1132*AR+ 747*AS+ 1060*AT+ 850*AU+ 813*AV+ 1139*AW+ 542*AX+ 36*AY+ 1673*AZ+ 962*BA+ 1007*BB+ 644*BC+ 636*BD+ 837*BE+ 711*BF+ 1*BG+ 890*BH+ 971*BI+ 1193*BJ+ 1030*BK+ 1358*BL+ 254*BM+ 1309*BN+ 2082*BO+ 1308*BP+ 965*BQ+ 987*BR+ 1223*BS+ 1300*BT+ 1501*BU+ 1435*BV+ 898*BW+ 1565*BX+ 1355*BY+ 1778*BZ+ 693*CA+ 1310*CB+ 816*CC+ 989*CD+ 1142*CE+ 1428*CF+ 1340*CG+ 1245*CH+ 1554*CI+ 84*CJ+ 2*CK+ 222*CL+ 210*CM+ 1*CN+ 830*CO+ 791*CP+ 152*CQ+ 730*CR+ 91*CS+ 639*CT+ 55*CU+ 83*CV+ 1517*CW+ 506*CX+ 283*CY+ 307*CZ+ 182*DA+ 318*DB+ 154*DC+ 217*DD+ 1426*DE+ 2346*DF+ 182*DG+ 415*DH+ 329*DI+ 181*DJ+ 155*DK+ 268*DL+ 37*DM+ 135*DN+ 118*DO+ 118*DP+ 222*DQ+ 384*DR >= 25 prob += 119*AA+ 237*AB+ 328*AC+ 212*AD+ 343*AE+ 255*AF+ 297*AG+ 183*AH+ 860*AI+ 366*AJ+ 432*AK+ 379*AL+ 536*AM+ 7*AN+ 262*AO+ 235*AP+ 170*AQ+ 358*AR+ 232*AS+ 277*AT+ 246*AU+ 258*AV+ 345*AW+ 214*AX+ 0*AY+ 730*AZ+ 477*BA+ 372*BB+ 198*BC+ 148*BD+ 230*BE+ 254*BF+ 0*BG+ 266*BH+ 167*BI+ 256*BJ+ 172*BK+ 415*BL+ 2*BM+ 138*BN+ 610*BO+ 433*BP+ 405*BQ+ 551*BR+ 617*BS+ 565*BT+ 445*BU+ 574*BV+ 340*BW+ 460*BX+ 430*BY+ 596*BZ+ 322*CA+ 588*CB+ 342*CC+ 338*CD+ 428*CE+ 523*CF+ 467*CG+ 294*CH+ 401*CI+ 206*CJ+ 7*CK+ 30*CL+ 103*CM+ 137*CN+ 2260*CO+ 256*CP+ 5*CQ+ 259*CR+ 8*CS+ 251*CT+ 191*CU+ 179*CV+ 786*CW+ 262*CX+ 6*CY+ 194*CZ+ 45*DA+ 112*DB+ 219*DC+ 55*DD+ 1654*DE+ 3046*DF+ 14*DG+ 1130*DH+ 897*DI+ 492*DJ+ 280*DK+ 347*DL+ 118*DM+ 235*DN+ 253*DO+ 215*DP+ 16*DQ+ 30*DR >= 3000 prob += 64*AA+ 33*AB+ 20*AC+ 103*AD+ 38*AE+ 51*AF+ 146*AG+ 171*AH+ 259*AI+ 42*AJ+ 134*AK+ 217*AL+ 250*AM+ 1*AN+ 33*AO+ 183*AP+ 158*AQ+ 216*AR+ 121*AS+ 124*AT+ 31*AU+ 62*AV+ 39*AW+ 30*AX+ 1*AY+ 257*AZ+ 123*BA+ 143*BB+ 75*BC+ 137*BD+ 122*BE+ 134*BF+ 0*BG+ 50*BH+ 79*BI+ 188*BJ+ 174*BK+ 200*BL+ 1*BM+ 97*BN+ 48*BO+ 76*BP+ 149*BQ+ 47*BR+ 140*BS+ 223*BT+ 39*BU+ 223*BV+ 124*BW+ 130*BX+ 37*BY+ 48*BZ+ 33*CA+ 149*CB+ 80*CC+ 125*CD+ 73*CE+ 232*CF+ 139*CG+ 231*CH+ 394*CI+ 27*CJ+ 4*CK+ 10*CL+ 4*CM+ 13*CN+ 45*CO+ 33*CP+ 23*CQ+ 12*CR+ 2*CS+ 10*CT+ 134*CU+ 121*CV+ 31*CW+ 10*CX+ 4*CY+ 5*CZ+ 2*DA+ 60*DB+ 44*DC+ 5*DD+ 43*DE+ 76*DF+ 5*DG+ 22*DH+ 18*DI+ 10*DJ+ 174*DK+ 181*DL+ 89*DM+ 143*DN+ 144*DO+ 136*DP+ 3*DQ+ 3*DR >= 738 prob += 102*AA+ 149*AB+ 319*AC+ 214*AD+ 320*AE+ 149*AF+ 274*AG+ 211*AH+ 596*AI+ 171*AJ+ 300*AK+ 334*AL+ 428*AM+ 1*AN+ 227*AO+ 211*AP+ 121*AQ+ 318*AR+ 184*AS+ 301*AT+ 222*AU+ 225*AV+ 319*AW+ 109*AX+ 2*AY+ 273*AZ+ 273*BA+ 275*BB+ 205*BC+ 235*BD+ 215*BE+ 0*BF+ 1*BG+ 172*BH+ 372*BI+ 535*BJ+ 499*BK+ 245*BL+ 0*BM+ 143*BN+ 588*BO+ 246*BP+ 332*BQ+ 273*BR+ 402*BS+ 436*BT+ 400*BU+ 435*BV+ 242*BW+ 475*BX+ 395*BY+ 583*BZ+ 167*CA+ 392*CB+ 328*CC+ 273*CD+ 265*CE+ 422*CF+ 312*CG+ 296*CH+ 461*CI+ 80*CJ+ 4*CK+ 26*CL+ 8*CM+ 16*CN+ 497*CO+ 282*CP+ 18*CQ+ 266*CR+ 3*CS+ 264*CT+ 140*CU+ 125*CV+ 758*CW+ 253*CX+ 10*CY+ 47*CZ+ 5*DA+ 0*DB+ 75*DC+ 23*DD+ 754*DE+ 1255*DF+ 11*DG+ 249*DH+ 198*DI+ 108*DJ+ 187*DK+ 218*DL+ 70*DM+ 154*DN+ 167*DO+ 151*DP+ 7*DQ+ 9*DR >= 600 prob += 0.8*AA+ 0.9*AB+ 0.8*AC+ 1.1*AD+ 0.9*AE+ 1.1*AF+ 2.1*AG+ 1.3*AH+ 5.2*AI+ 1.9*AJ+ 2.1*AK+ 1.9*AL+ 3.1*AM+ 0*AN+ 0.8*AO+ 1.7*AP+ 0.8*AQ+ 2*AR+ 1.2*AS+ 0.8*AT+ 0.7*AU+ 0.7*AV+ 0.9*AW+ 1.2*AX+ 0*AY+ 6.2*AZ+ 2.9*BA+ 2.2*BB+ 0.5*BC+ 1.3*BD+ 1.3*BE+ 3.3*BF+ 0*BG+ 1.1*BH+ 2*BI+ 3.1*BJ+ 2.5*BK+ 2.3*BL+ 0*BM+ 1*BN+ 1.4*BO+ 1.8*BP+ 2.8*BQ+ 3.2*BR+ 3.4*BS+ 3.2*BT+ 1.1*BU+ 3.5*BV+ 1.9*BW+ 1.1*BX+ 1*BY+ 1.3*BZ+ 1.9*CA+ 3.8*CB+ 0.6*CC+ 2.1*CD+ 1.7*CE+ 3.2*CF+ 2.2*CG+ 1.1*CH+ 2*CI+ 1.1*CJ+ 0*CK+ 0.1*CL+ 0.1*CM+ 0.2*CN+ 2.6*CO+ 0.5*CP+ 0*CQ+ 0.5*CR+ 0*CS+ 0.4*CT+ 0.3*CU+ 0*CV+ 1.4*CW+ 0.5*CX+ 0*CY+ 0.3*CZ+ 0.1*DA+ 1.4*DB+ 2.9*DC+ 0.3*DD+ 2.2*DE+ 4*DF+ 0.1*DG+ 1.3*DH+ 1*DI+ 0.6*DJ+ 0.5*DK+ 1.5*DL+ 0*DM+ 0.2*DN+ 0.4*DO+ 0.1*DP+ 0.1*DQ+ 0.1*DR >= 6.3 prob += 8*AA+ 10*AB+ 11*AC+ 60*AD+ 10*AE+ 11*AF+ 131*AG+ 118*AH+ 149*AI+ 63*AJ+ 114*AK+ 147*AL+ 127*AM+ 0*AN+ 25*AO+ 118*AP+ 48*AQ+ 118*AR+ 61*AS+ 62*AT+ 13*AU+ 13*AV+ 12*AW+ 14*AX+ 99*AY+ 141*AZ+ 141*BA+ 74*BB+ 28*BC+ 118*BD+ 61*BE+ 0*BF+ 0*BG+ 8*BH+ 9*BI+ 125*BJ+ 115*BK+ 123*BL+ 0*BM+ 9*BN+ 14*BO+ 17*BP+ 141*BQ+ 78*BR+ 129*BS+ 161*BT+ 35*BU+ 137*BV+ 71*BW+ 72*BX+ 22*BY+ 16*BZ+ 23*CA+ 93*CB+ 30*CC+ 71*CD+ 14*CE+ 124*CF+ 82*CG+ 108*CH+ 217*CI+ 7*CJ+ 1*CK+ 7*CL+ 9*CM+ 27*CN+ 0*CO+ 7*CP+ 3*CQ+ 10*CR+ 6*CS+ 4*CT+ 255*CU+ 42*CV+ 69*CW+ 23*CX+ 3*CY+ 0*CZ+ 3*DA+ 8*DB+ 4*DC+ 1*DD+ 46*DE+ 69*DF+ 1*DG+ 0*DH+ 0*DI+ 0*DJ+ 61*DK+ 61*DL+ 10*DM+ 47*DN+ 47*DO+ 47*DP+ 5*DQ+ 0*DR >= 625 prob += 0.09*AA+ 0.16*AB+ 0.13*AC+ 0.11*AD+ 0.16*AE+ 0.19*AF+ 0.13*AG+ 0.13*AH+ 0.31*AI+ 0.17*AJ+ 0.24*AK+ 0.18*AL+ 0.23*AM+ 0*AN+ 0.11*AO+ 0.18*AP+ 0.15*AQ+ 0.13*AR+ 0.1*AS+ 0.11*AT+ 0.12*AU+ 0.15*AV+ 0.16*AW+ 0.1*AX+ 0*AY+ 0.25*AZ+ 0.25*BA+ 0.17*BB+ 0.11*BC+ 0.14*BD+ 0.14*BE+ 0*BF+ 0*BG+ 0.26*BH+ 0.3*BI+ 0.32*BJ+ 0.23*BK+ 0.28*BL+ 0*BM+ 0.1*BN+ 0.26*BO+ 0.32*BP+ 0.16*BQ+ 0.21*BR+ 0.28*BS+ 0.22*BT+ 0.16*BU+ 0.18*BV+ 0.13*BW+ 0.16*BX+ 0.17*BY+ 0.26*BZ+ 0.12*CA+ 0.22*CB+ 0.17*CC+ 0.16*CD+ 0.39*CE+ 0.19*CF+ 0.25*CG+ 0.2*CH+ 0.14*CI+ 0.1*CJ+ 0*CK+ 0.04*CL+ 0.02*CM+ 0.03*CN+ 0.61*CO+ 0.1*CP+ 0*CQ+ 0.31*CR+ 0.22*CS+ 0.09*CT+ 0.05*CU+ 0.05*CV+ 0.28*CW+ 0.09*CX+ 0.01*CY+ 0.05*CZ+ 0.01*DA+ 0*DB+ 0.08*DC+ 0.05*DD+ 0.5*DE+ 0.9*DF+ 0.01*DG+ 0.31*DH+ 0.24*DI+ 0.13*DJ+ 0.07*DK+ 0.09*DL+ 0.03*DM+ 0.07*DN+ 0.07*DO+ 0.07*DP+ 0.01*DQ+ 0.01*DR >= 1.4 prob += 0.06*AA+ 0.16*AB+ 0.09*AC+ 0.14*AD+ 0.12*AE+ 0.19*AF+ 0.36*AG+ 0.31*AH+ 0.54*AI+ 0.16*AJ+ 0.25*AK+ 0.3*AL+ 0.38*AM+ 0*AN+ 0.09*AO+ 0.37*AP+ 0.17*AQ+ 0.28*AR+ 0.16*AS+ 0.16*AT+ 0.09*AU+ 0.1*AV+ 0.12*AW+ 0.09*AX+ 0*AY+ 0.51*AZ+ 0.51*BA+ 0.24*BB+ 0.09*BC+ 0.31*BD+ 0.18*BE+ 0*BF+ 0*BG+ 0.21*BH+ 0.2*BI+ 0.46*BJ+ 0.41*BK+ 0.45*BL+ 0*BM+ 0.08*BN+ 0.2*BO+ 0.35*BP+ 0.42*BQ+ 0.26*BR+ 0.35*BS+ 0.4*BT+ 0.14*BU+ 0.39*BV+ 0.22*BW+ 0.21*BX+ 0.14*BY+ 0.2*BZ+ 0.15*CA+ 0.35*CB+ 0.13*CC+ 0.23*CD+ 0.36*CE+ 0.37*CF+ 0.24*CG+ 0.32*CH+ 0.41*CI+ 0.06*CJ+ 0.01*CK+ 0.01*CL+ 0.01*CM+ 0.02*CN+ 0.07*CO+ 0.09*CP+ 0.01*CQ+ 0.09*CR+ 0.01*CS+ 0.08*CT+ 0.24*CU+ 0.2*CV+ 0.31*CW+ 0.1*CX+ 0.01*CY+ 0.01*CZ+ 0*DA+ 0*DB+ 0.03*DC+ 0*DD+ 0.24*DE+ 0.38*DF+ 0*DG+ 0.03*DH+ 0.03*DI+ 0.01*DJ+ 0.29*DK+ 0.3*DL+ 0.13*DM+ 0.23*DN+ 0.26*DO+ 0.23*DP+ 0*DQ+ 0.01*DR >= 1.6 prob += 1*AA+ 3.3*AB+ 7.9*AC+ 2.3*AD+ 8.1*AE+ 3.6*AF+ 2.6*AG+ 1.2*AH+ 10.7*AI+ 3.9*AJ+ 4.8*AK+ 4.3*AL+ 6.2*AM+ 0*AN+ 5*AO+ 2.9*AP+ 2.9*AQ+ 4.1*AR+ 2.5*AS+ 5*AT+ 5.3*AU+ 5.6*AV+ 8.2*AW+ 2.5*AX+ 0*AY+ 3.9*AZ+ 3.9*BA+ 4.4*BB+ 1.4*BC+ 1.3*BD+ 2.6*BE+ 0*BF+ 0*BG+ 4.3*BH+ 4.2*BI+ 4.2*BJ+ 2.6*BK+ 5.4*BL+ 0*BM+ 1.3*BN+ 15.8*BO+ 6.6*BP+ 4.1*BQ+ 6.6*BR+ 7.5*BS+ 7*BT+ 9.5*BU+ 7.2*BV+ 4.1*BW+ 9.5*BX+ 9.8*BY+ 15.7*BZ+ 4*CA+ 7.5*CB+ 2.1*CC+ 4.1*CD+ 7.3*CE+ 6.4*CF+ 4.9*CG+ 3.6*CH+ 4.1*CI+ 1*CJ+ 0*CK+ 0.1*CL+ 0.3*CM+ 0.2*CN+ 12.5*CO+ 7.7*CP+ 0.1*CQ+ 7.6*CR+ 0*CS+ 7.6*CT+ 0.2*CU+ 0.2*CV+ 21.3*CW+ 7.1*CX+ 0*CY+ 0.9*CZ+ 0.2*DA+ 0*DB+ 0.8*DC+ 0.3*DD+ 20.5*DE+ 33.9*DF+ 0.1*DG+ 6.3*DH+ 5*DI+ 2.7*DJ+ 0.3*DK+ 0.6*DL+ 0.1*DM+ 0.4*DN+ 0.4*DO+ 0.3*DP+ 0.1*DQ+ 0.1*DR >= 15 prob += 1*AA+ 1*AB+ 1*AC+ 6*AD+ 1*AE+ 1*AF+ 1*AG+ 0*AH+ 2*AI+ 6*AJ+ 17*AK+ 7*AL+ 2*AM+ 0*AN+ 1*AO+ 0*AP+ 0*AQ+ 1*AR+ 1*AS+ 1*AT+ 0*AU+ 0*AV+ 1*AW+ 1*AX+ 0*AY+ 1*AZ+ 1*BA+ 2*BB+ 0*BC+ 6*BD+ 7*BE+ 0*BF+ 0*BG+ 6*BH+ 0*BI+ 0*BJ+ 5*BK+ 6*BL+ 0*BM+ 1*BN+ 2*BO+ 2*BP+ 1*BQ+ 6*BR+ 17*BS+ 7*BT+ 1*BU+ 1*BV+ 1*BW+ 1*BX+ 0*BY+ 1*BZ+ 1*CA+ 2*CB+ 0*CC+ 7*CD+ 6*CE+ 0*CF+ 17*CG+ 1*CH+ 1*CI+ 8*CJ+ 5*CK+ 0*CL+ 19*CM+ 15*CN+ 40*CO+ 0*CP+ 0*CQ+ 0*CR+ 0*CS+ 0*CT+ 0*CU+ 0*CV+ 3*CW+ 1*CX+ 0*CY+ 1*CZ+ 1*DA+ 0*DB+ 0*DC+ 0*DD+ 22*DE+ 43*DF+ 0*DG+ 20*DH+ 16*DI+ 9*DJ+ 0*DK+ 0*DL+ 0*DM+ 3*DN+ 0*DO+ 0*DP+ 0*DQ+ 0*DR >= 100 prob += 66*AA+ 56*AB+ 49*AC+ 47*AD+ 50*AE+ 56*AF+ 248*AG+ 231*AH+ 187*AI+ 49*AJ+ 73*AK+ 74*AL+ 109*AM+ 0*AN+ 37*AO+ 255*AP+ 45*AQ+ 76*AR+ 38*AS+ 50*AT+ 35*AU+ 35*AV+ 49*AW+ 26*AX+ 18*AY+ 478*AZ+ 458*BA+ 69*BB+ 40*BC+ 228*BD+ 47*BE+ 21*BF+ 0*BG+ 54*BH+ 30*BI+ 254*BJ+ 227*BK+ 294*BL+ 0*BM+ 126*BN+ 93*BO+ 105*BP+ 274*BQ+ 93*BR+ 118*BS+ 119*BT+ 69*BU+ 127*BV+ 64*BW+ 82*BX+ 66*BY+ 92*BZ+ 52*CA+ 121*CB+ 68*CC+ 73*CD+ 103*CE+ 113*CF+ 68*CG+ 79*CH+ 99*CI+ 0*CJ+ 0*CK+ 7*CL+ 0*CM+ 0*CN+ 23*CO+ 44*CP+ 1*CQ+ 43*CR+ 0*CS+ 43*CT+ 116*CU+ 12*CV+ 188*CW+ 63*CX+ 7*CY+ 4*CZ+ 0*DA+ 11*DB+ 5*DC+ 2*DD+ 136*DE+ 210*DF+ 2*DG+ 11*DH+ 9*DI+ 5*DJ+ 17*DK+ 17*DL+ 4*DM+ 14*DN+ 14*DO+ 14*DP+ 6*DQ+ 0*DR >= 0 prob += 2.9*AA+ 0.8*AB+ 1.9*AC+ 0.9*AD+ 2.8*AE+ 1.7*AF+ 1.5*AG+ 1.7*AH+ 3.2*AI+ 2.3*AJ+ 2.4*AK+ 1.9*AL+ 3.2*AM+ 0.2*AN+ 2.2*AO+ 1.7*AP+ 1.7*AQ+ 1.7*AR+ 1.5*AS+ 2.2*AT+ 1.9*AU+ 2.5*AV+ 2.8*AW+ 1.5*AX+ 0*AY+ 6.1*AZ+ 3.2*BA+ 2.6*BB+ 2.1*BC+ 1.1*BD+ 1.7*BE+ 2.8*BF+ 0*BG+ 1.5*BH+ 1.6*BI+ 1.7*BJ+ 1.8*BK+ 2*BL+ 0*BM+ 3.9*BN+ 4*BO+ 1.8*BP+ 1.6*BQ+ 2.3*BR+ 2.5*BS+ 2*BT+ 2.9*BU+ 1.8*BV+ 1.6*BW+ 2.9*BX+ 2.5*BY+ 3.9*BZ+ 1.6*CA+ 2.7*CB+ 3*CC+ 1.8*CD+ 1.5*CE+ 1.8*CF+ 2.3*CG+ 1.7*CH+ 1.7*CI+ 2.9*CJ+ 0*CK+ 0.5*CL+ 0.4*CM+ 0.8*CN+ 12*CO+ 1.1*CP+ 0*CQ+ 1.2*CR+ 0.1*CS+ 1.1*CT+ 0.2*CU+ 0.3*CV+ 2.6*CW+ 0.9*CX+ 0.1*CY+ 1.5*CZ+ 0.3*DA+ 1.3*DB+ 2.3*DC+ 1*DD+ 7.7*DE+ 14.6*DF+ 0.3*DG+ 6*DH+ 4.8*DI+ 2.6*DJ+ 0.7*DK+ 1.7*DL+ 0.1*DM+ 1*DN+ 1.1*DO+ 0.7*DP+ 0.1*DQ+ 0.1*DR >= 21 prob += 2.3*AA+ 2.5*AB+ 3.3*AC+ 2.5*AD+ 3.1*AE+ 2.1*AF+ 2.1*AG+ 1.6*AH+ 6*AI+ 2.1*AJ+ 2.7*AK+ 2.9*AL+ 4.4*AM+ 0*AN+ 2.5*AO+ 2*AP+ 1.8*AQ+ 2.9*AR+ 1.9*AS+ 2.7*AT+ 2.2*AU+ 2.1*AV+ 2.9*AW+ 1.4*AX+ 0.1*AY+ 4.2*AZ+ 2.4*BA+ 2.6*BB+ 1.6*BC+ 1.6*BD+ 2.1*BE+ 1.8*BF+ 0*BG+ 2.3*BH+ 2.5*BI+ 3*BJ+ 2.6*BK+ 3.4*BL+ 0.6*BM+ 3.3*BN+ 5.3*BO+ 3.3*BP+ 2.4*BQ+ 2.5*BR+ 3.1*BS+ 3.3*BT+ 3.8*BU+ 3.6*BV+ 2.3*BW+ 4*BX+ 3.4*BY+ 4.5*BZ+ 1.8*CA+ 3.3*CB+ 2.1*CC+ 2.5*CD+ 2.9*CE+ 3.6*CF+ 3.4*CG+ 3.2*CH+ 3*CI+ 0.2*CJ+ 0*CK+ 0.6*CL+ 0.5*CM+ 0*CN+ 2.1*CO+ 2*CP+ 0.4*CQ+ 1.9*CR+ 0.2*CS+ 1.6*CT+ 0.1*CU+ 0.2*CV+ 3.9*CW+ 1.3*CX+ 0.7*CY+ 0.8*CZ+ 0.5*DA+ 0.8*DB+ 0.4*DC+ 0.6*DD+ 3.6*DE+ 6*DF+ 0.5*DG+ 1.1*DH+ 0.8*DI+ 0.5*DJ+ 0.4*DK+ 0.7*DL+ 0.1*DM+ 0.3*DN+ 0.3*DO+ 0.3*DP+ 0.6*DQ+ 1*DR >= 5 # Solve the problem using the default solver prob.solve() print(LpStatus[prob.status]) # Print the value of the variables at the optimum print("Result") print("えびフィレオ:", AA.value()) print("ごはんてりやき:", AB.value()) print("ごはんチキンフィレオ:", AC.value()) print("ごはんベーコンレタス:", AD.value()) print("てりやきチキンフィレオ:", AE.value()) print("てりやきマックバーガー:", AF.value()) print("エグチ(エッグチーズバーガー):", AG.value()) print("エッグマックマフィン:", AH.value()) print("ギガビッグマック®:", AI.value()) print("グラン ガーリックペッパー:", AJ.value()) print("グラン クラブハウス:", AK.value()) print("グラン ベーコンチーズ:", AL.value()) print("グランドビッグマック®:", AM.value()) print("ストロベリージャム:", AN.value()) print("スパチキ(スパイシーチキンバーガー):", AO.value()) print("ソーセージエッグマフィン:", AP.value()) print("ソーセージマフィン:", AQ.value()) print("ダブルチーズバーガー:", AR.value()) print("チーズバーガー:", AS.value()) print("チキチー(チキンチーズバーガー):", AT.value()) print("チキンクリスプ:", AU.value()) print("チキンクリスプマフィン:", AV.value()) print("チキンフィレオ:", AW.value()) print("ハンバーガー:", AX.value()) print("バターパット:", AY.value()) print("ビッグブレックファスト デラックス(ハッシュポテト含む):", AZ.value()) print("ビッグブレックファスト(ハッシュポテト含む):", BA.value()) print("ビッグマック®:", BB.value()) print("フィレオフィッシュ:", BC.value()) print("ベーコンエッグマックサンド:", BD.value()) print("ベーコンレタスバーガー:", BE.value()) print("ホットケーキ:", BF.value()) print("ホットケーキシロップ:", BG.value()) print("マクポ(ベーコンマックポーク):", BH.value()) print("マックグリドル ソーセージ:", BI.value()) print("マックグリドル ソーセージエッグ:", BJ.value()) print("マックグリドル ベーコンエッグ:", BK.value()) print("メガマフィン:", BL.value()) print("塩・コショウ:", BM.value()) print("倍えびフィレオ:", BN.value()) print("倍てりやきチキンフィレオ:", BO.value()) print("倍てりやきマックバーガー:", BP.value()) print("倍エグチ(倍エッグチーズバーガー):", BQ.value()) print("倍グラン ガーリックペッパー:", BR.value()) print("倍グラン クラブハウス:", BS.value()) print("倍グラン ベーコンチーズ:", BT.value()) print("倍スパチキ(倍スパイシーチキンバーガー):", BU.value()) print("倍ダブルチーズバーガー:", BV.value()) print("倍チーズバーガー:", BW.value()) print("倍チキチー(倍チキンチーズバーガー):", BX.value()) print("倍チキンクリスプ:", BY.value()) print("倍チキンフィレオ:", BZ.value()) print("倍ハンバーガー:", CA.value()) print("倍ビッグマック®:", CB.value()) print("倍フィレオフィッシュ:", CC.value()) print("倍ベーコンレタスバーガー:", CD.value()) print("倍マクポ(倍ベーコンマックポーク):", CE.value()) print("炙り醤油風 ダブル肉厚ビーフ:", CF.value()) print("炙り醤油風 ベーコントマト肉厚ビーフ:", CG.value()) print("チーズチーズてりやきマックバーガー:", CH.value()) print("チーズチーズダブルチーズバーガー:", CI.value()) print("えだまめコーン:", CJ.value()) print("りんご&クリーム:", CK.value()) print("クリームブリュレパイ:", CL.value()) print("ケチャップ:", CM.value()) print("サイドサラダ:", CN.value()) print("シェアポテト:", CO.value()) print("シャカチキ チェダーチーズ:", CP.value()) print("シャカチキ チェダーチーズ味シーズニング:", CQ.value()) print("シャカチキ レッドペッパー:", CR.value()) print("シャカチキ レッドペッパー味シーズニング:", CS.value()) print("シャカチキ(チキンのみ):", CT.value()) print("スジャータアイスバニラ:", CU.value()) print("ソフトツイスト:", CV.value()) print("チキンマックナゲット 15ピース:", CW.value()) print("チキンマックナゲット 5ピース:", CX.value()) print("トリュフ香るパルメザンチーズソース:", CY.value()) print("ハッシュポテト:", CZ.value()) print("バーベキューソース:", DA.value()) print("プチパンケーキ:", DB.value()) print("ベルギーショコラパイ:", DC.value()) print("ホットアップルパイ:", DD.value()) print("ポテナゲ大:", DE.value()) print("ポテナゲ特大:", DF.value()) print("マスタードソース:", DG.value()) print("マックフライポテト(L):", DH.value()) print("マックフライポテト(M):", DI.value()) print("マックフライポテト(S):", DJ.value()) print("マックフルーリー® オレオ®クッキー:", DK.value()) print("マックフルーリー® 超 オレオ®:", DL.value()) print("ヨーグルト:", DM.value()) print("ワッフルコーン ストロベリー:", DN.value()) print("ワッフルコーン チョコ&アーモンド:", DO.value()) print("ワッフルコーン プレーン:", DP.value()) print("伊勢海老と紅ズワイガニソース:", DQ.value()) print("低カロリー玉ねぎ:", DR.value())結果
さあ計算しましょう。なんだかワクワクしてきました。
kekka.txtResult - Optimal solution found Objective value: 972.00000000 Enumerated nodes: 0 Total iterations: 117 Time (CPU seconds): 0.10 Time (Wallclock seconds): 0.10条件を満たす組み合わせは存在するようです!マクドナルドだけで生きていけるかもしれません!これで一人暮らしでも健康に生きていける!
マイスーパーコンピューターがはじき出した商品の種類は5種類。5種類だけ食べれば健康になれるようです。すげー。以下がその商品です!
バター(1個)
いきなり変化球です。朝マック以外ではお目にかかりません。
トリュフ香るパルメザンチーズソース(1個)
またまた変化球です。期間限定のナゲットのソース。
低カロリー玉ねぎ(1個)
サイドサラダのドレッシングです。
塩・コショウ(6個)
マクドナルドに塩・コショウなんてあるんですね。初めて知りました。
そして最後が・・・
サイドサラダ(79個)
圧倒的ですね。ギャル曽根でも助走つけて殴るレベルの量です。
ポテトもハンバーガーも食べず、ひたすらサラダを食えとのお達しです。この組み合わせによって以下の通り、一日必要な栄養素を満たす極めて健康的な栄養を摂取することができます。
栄養素 摂取量 エネルギー(kcal) 1944 たんぱく質 (g) 80.4 脂質 (g) 51.6 炭水化物 (g) 370.2 ナトリウム (mg) 4612 カリウム (mg) 21742 カルシウム (mg) 2082 リン (mg) 2570 鉄 (mg) 31.8 ビタミンA (μg) 4470 ビタミンB1 (mg) 4.78 ビタミンB2 (mg) 3.2 ナイアシン (mg) 31.8 ビタミンC (mg) 2370 コレステロール (mg) 50 食物繊維 (g) 126.8 食塩相当量 (g) 10.8 kekka.txtえびフィレオ: 0.0 ごはんてりやき: 0.0 ごはんチキンフィレオ: 0.0 ごはんベーコンレタス: 0.0 てりやきチキンフィレオ: 0.0 てりやきマックバーガー: 0.0 エグチ(エッグチーズバーガー): 0.0 エッグマックマフィン: 0.0 ギガビッグマック®: 0.0 グラン ガーリックペッパー: 0.0 グラン クラブハウス: 0.0 グラン ベーコンチーズ: 0.0 グランドビッグマック®: 0.0 ストロベリージャム: 0.0 スパチキ(スパイシーチキンバーガー): 0.0 ソーセージエッグマフィン: 0.0 ソーセージマフィン: 0.0 ダブルチーズバーガー: 0.0 チーズバーガー: 0.0 チキチー(チキンチーズバーガー): 0.0 チキンクリスプ: 0.0 チキンクリスプマフィン: 0.0 チキンフィレオ: 0.0 ハンバーガー: 0.0 バターパット: 1.0 ビッグブレックファスト デラックス(ハッシュポテト含む): 0.0 ビッグブレックファスト(ハッシュポテト含む): 0.0 ビッグマック®: 0.0 フィレオフィッシュ: 0.0 ベーコンエッグマックサンド: 0.0 ベーコンレタスバーガー: 0.0 ホットケーキ: 0.0 ホットケーキシロップ: 0.0 マクポ(ベーコンマックポーク): 0.0 マックグリドル ソーセージ: 0.0 マックグリドル ソーセージエッグ: 0.0 マックグリドル ベーコンエッグ: 0.0 メガマフィン: 0.0 塩・コショウ: 6.0 倍えびフィレオ: 0.0 倍てりやきチキンフィレオ: 0.0 倍てりやきマックバーガー: 0.0 倍エグチ(倍エッグチーズバーガー): 0.0 倍グラン ガーリックペッパー: 0.0 倍グラン クラブハウス: 0.0 倍グラン ベーコンチーズ: 0.0 倍スパチキ(倍スパイシーチキンバーガー): 0.0 倍ダブルチーズバーガー: 0.0 倍チーズバーガー: 0.0 倍チキチー(倍チキンチーズバーガー): 0.0 倍チキンクリスプ: 0.0 倍チキンフィレオ: 0.0 倍ハンバーガー: 0.0 倍ビッグマック®: 0.0 倍フィレオフィッシュ: 0.0 倍ベーコンレタスバーガー: 0.0 倍マクポ(倍ベーコンマックポーク): 0.0 炙り醤油風 ダブル肉厚ビーフ: 0.0 炙り醤油風 ベーコントマト肉厚ビーフ: 0.0 チーズチーズてりやきマックバーガー: 0.0 チーズチーズダブルチーズバーガー: 0.0 えだまめコーン: 0.0 りんご&クリーム: 0.0 クリームブリュレパイ: 0.0 ケチャップ: 0.0 サイドサラダ: 79.0 シェアポテト: 0.0 シャカチキ チェダーチーズ: 0.0 シャカチキ チェダーチーズ味シーズニング: 0.0 シャカチキ レッドペッパー: 0.0 シャカチキ レッドペッパー味シーズニング: 0.0 シャカチキ(チキンのみ): 0.0 スジャータアイスバニラ: 0.0 ソフトツイスト: 0.0 チキンマックナゲット 15ピース: 0.0 チキンマックナゲット 5ピース: 0.0 トリュフ香るパルメザンチーズソース: 1.0 ハッシュポテト: 0.0 バーベキューソース: 0.0 プチパンケーキ: 0.0 ベルギーショコラパイ: 0.0 ホットアップルパイ: 0.0 ポテナゲ大: 0.0 ポテナゲ特大: 0.0 マスタードソース: 0.0 マックフライポテト(L): 0.0 マックフライポテト(M): 0.0 マックフライポテト(S): 0.0 マックフルーリー® オレオ®クッキー: 0.0 マックフルーリー® 超 オレオ®: 0.0 ヨーグルト: 0.0 ワッフルコーン ストロベリー: 0.0 ワッフルコーン チョコ&アーモンド: 0.0 ワッフルコーン プレーン: 0.0 伊勢海老と紅ズワイガニソース: 0.0 低カロリー玉ねぎ: 1.0サイドサラダ王になる!
いかがでしたか?ビッグマックもポテトも食べずに、ひたすらサイドサラダを食べる。これが健康への近道です!私も無人島に食べ物を一種類だけ持っていくとしたら間違いなくサイドサラダを選びます。完全食です。最高!
でも、カリウムを22gも取って大丈夫なのか?そういえば日本人の食事摂取基準には過剰摂取に由来する健康障害のリスクも載っていたような?・・・そもそもここであげた12種類以外にも人類に必要な栄養素があるのでは?(さっきの伏線回収)
と、ツッコミどころを上げたらきりがありません。頭使ったらお腹が減ってきたので、今からビッグマック食べにいこっと。
- 投稿日:2021-02-20T15:06:35+09:00
chainer+CUDA(11.0)+cuDNN(8.0)で畳み込みする際にPerformanceWarningが出る
概要
chainerでGPUを使ってCNNをする際に,以下のようなWarningが出てきました.
PerformanceWarning: The best algo of conv fwd might not be selected due to lack of workspace size (8388608)実行自体は問題ないのですが,Warningが出るのは気持ちが悪いので修正方法を探しました.
実行環境
- chainer version 7.7.0
- CUDA 11.0
- cuDNN 8.0
原因
同じような問題に遭遇している方がいらっしゃいました.
chainerでTensorcoreを使って学習の高速化どうやらcuDNNがGPUのメモリ(workspace)を確保する際にサイズが不足していることが原因らしいです.
解決策
解決するには以下のようにworkspaceのサイズを設定することで,必要なメモリサイズを確保してあげれば良いそうです.
ws_size = 256 * 1024 * 1024 # 256MB chainer.cuda.set_max_workspace_size(ws_size)この例の場合256MBを確保しています.
確保するサイズを調整することによっていづれPerformanceWarningが出なくなります.私の場合は512MBを確保したらPerformanceWarningが出なくなりました.
参考記事
chainerでTensorcoreを使って学習の高速化
chainer.backends.cuda.set_max_workspace_size
ChainerでTensorコア(fp16)を使いこなす後書き
他の複数の環境では出たことがなかったので環境依存なんですかね?
- 投稿日:2021-02-20T14:11:52+09:00
VS CodeでOpenCVする時に、MacBook内蔵Facetimeカメラが使えない(セキュリティーとプライバシー)
とりあえず、最短距離でOpenCVを試してみたい
Mac/iMacで、OpenCVやってみたい、さぁ、とりあえずサンプルを、と思ったとき、以下のような最短手順で、内蔵Facetimeカメラを使った顔認識を試すことができます。
ダウンロード/インストール
pip3 install -U opencv-contrib-python curl -OL https://github.com/opencv/opencv/archive/4.5.1.zip unzip 4.5.1.zip実行
cd opencv-4.5.1/samples/python python3 facedetect.py カメラへのアクセスが必要と言われたら、[OK]を押して、もう一度実行。 自分の顔で試したり、そのへんに転がっていた集合写真などをかざせば、オッケー。 (escキーで終了)(蛇足)ダウンロードは、curlでもwgetでもお好きな方で。
wgetが好きな人は、curlの代わりに、 wget https://github.com/opencv/opencv/archive/4.5.1.zip brewでwgetをインストールする場合は、 brew install wgetVS Codeでやってみると、あれ???
VS Code便利!、ターミナルもVS Codeで、となっている人も多いと思います。
で、やってみると、んんー、と考えた後、エラーが出ます。Abort trap: 6なにこのエラーメッセージ。そっけない。ググッてみたら、C++コード実行時例外発生、ということで、いろいろな局面で出る模様。
Facetime HD Camera関係でググると、カメラのアクセスがシステムによって許可されていないから、ということ。「システム環境設定/セキュリティーとプライバシー/カメラ」で、登録するやつですね。
ターミナルアプリは、許可されているのでオッケー。はい、ここにVS Codeも登録したら良いです。とはならない。。
例えば、ブラウザ経由で動いているJupyterがカメラ/マイクを使おうとするとき、Jupyterからリクエストがでて、ここに登録する流れができますが、VS Codeはそれがないことが問題。マイクへのアクセスも同様。
とりあえずの解決策
ターミナルから、
code .とコマンドを打ってVS Codeを起動すればよい。カメラ/マイクへのアクセスは、起動した親のアクセス権が適応される、ということ。codeコマンドを有効にするには、
1. VS Codeのコマンドパレットから、shellと入力。
2. 「シェル コマンド: PATH内に'code'コマンドをインストールします」をクリック。
根本的な解決
VS CodeのGitHub.comリポジトリで、issueが上がっています。
'VSCode terminal doesn't allow/request permissions to access media devices #95062'
https://github.com/microsoft/vscode/issues/95062問題は認識されているが、未解決。
根本的な解決は、VS Codeが「セキュリティーとプライバシー」に登録される流れを実装すること。しばし待て、ですね。危険なゴニョゴニョ
おとなしく、待つ方が賢明です。それでもやりたい人は、データベースを直接書き換えます。アップデートなどでデータベースの構造が変化していたりすると、バグります。
リカバリーモードでシステム再起動(cmd+R長押し)して、System Integrity Protection(SIP、システム整合性保護)を一時的に無効化しないとダメ、というサイトが多数見られますが、不要です。
代わりに、ターミナルにフルディスクアクセスの権限を与えます。
Mojaveは、これで行けました。
# TCC.dbを念の為バックアップして、データベースを編集 cd ~/Library/Application\ Support/com.apple.TCC/ cp TCC.db TCC.db.bak sqlite3 TCC.db # sqlite>プロンプトが出ます。 # Mojaveの場合: # VS Codeにカメラへのアクセス権を追加 INSERT into access VALUES('kTCCServiceCamera',"com.microsoft.VSCode",0,1,1,NULL,NULL,NULL,'UNUSED',NULL,0,1541440109); # マイクへのアクセス権を追加 INSERT into access VALUES('kTCCServiceMicrophone','com.microsoft.VSCode',0,1,1,NULL,NULL,NULL,'UNUSED',NULL,0,1541440109);
BigSurの場合(すみません、未検証です。どなたか、冒険心と興味あれば追試を。危険です。)
# BigSurの場合: INSERT into access (service, client, client_type, auth_value, auth_reason, auth_version) VALUES ("kTCCServiceCamera","com.microsoft.VSCode",0,2,0,1); INSERT into access (service, client, client_type, auth_value, auth_reason, auth_version) VALUES ("kTCCServiceMicrophone","com.microsoft.VSCode",0,2,0,1);おまけ。OpenCVのサンプル実行
色々試すには、メニューアプリdemo.pyを使う。
cd opencv-4.5.1/samples/python python3 samples/python/demo.py
読みにくかったので、フォントやフォントサイズを改変しました。各エントリーが、かなりいい加減に作られていて、ボロが出ます。もうちょっとメンテしても良さそうな。。
ビデオソースを使うデモとしてわかりやすいのは、こんなところで。
facedetect.py mosse.py edge.py基本的に
escキーで終了、となっているものが多いかな?レナさんファンは、チュートリアルにある、こちらなど、どうぞ。
cd opencv-4.5.1/samples/python python3 tutorial_code/ImgTrans/Filter2D/filter2D.py









- 投稿日:2021-02-20T13:31:44+09:00
【matplotlib入門】3dプロットで遊んでみた♬
何度も描いてきたような気がするが、今回も探したので、3dプロットの簡単な例をまとめておきます。
やったこと
・欲しかった図
・オリジナルのデータ
・カラーバーの合成
・hexbinで描画・欲しかった図
なんの変哲もない以下の右の図を探しました。
ありそうで、matplotlibのexampleからもなかなか見つからないので、以下の過去記事から見つけて、
ax4.pcolormesh(f(x1, y1), cmap='hsv')を採用。
【参考】
・【matplotlib基本】動的グラフを書いてみる♬~動画出力;Gifアニメーション
pcolormeshの使い方のコード
from matplotlib import cm import matplotlib.pyplot as plt import numpy as np from mpl_toolkits.mplot3d import Axes3D #--- from mpl_toolkits.mplot3d.axes3d import get_test_data X, Y, Z = get_test_data(0.05) fig = plt.figure(figsize=(12, 6)) ax1 = fig.add_subplot(1, 2, 1, projection='3d') hs = ax1.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='hsv') # cm.viridis #fig.colorbar(hs, ax=ax1) ax2 = fig.add_subplot(1, 2, 2) hv = ax2.pcolormesh(X,Y,Z, cmap='hsv') fig.colorbar(hv, ax=ax2) plt.pause(1) plt.savefig('orijinal.png') plt.close()・オリジナルのデータ
参考は、3dプロットをsubplotとして並べられる(配置アレンジできる)ことを有意義としているようだが、今では普通にいろいろなところで使われている。むしろ、オリジナルデータの使い方が美味しそうです。
【参考】
・What's New 1 Subplot3d
オリジナルデータの使い方のコード
fig = plt.figure(figsize=(12, 6)) ax = fig.add_subplot(1, 2, 1, projection='3d') X = np.arange(-5, 5, 0.25) Y = np.arange(-5, 5, 0.25) X, Y = np.meshgrid(X, Y) R = np.sqrt(X**2 + Y**2) Z = np.sin(R) surf = ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap=cm.viridis, linewidth=0, antialiased=False) ax.set_zlim3d(-1.01, 1.01) fig.colorbar(surf, shrink=0.5, aspect=5) ax = fig.add_subplot(1, 2, 2, projection='3d') #X, Y, Z = get_test_data(0.05) ax.plot_wireframe(X, Y, Z, rstride=2, cstride=2) plt.pause(1) plt.savefig('orijinal2.png') plt.close()・カラーバーの合成
ここでは、負値と正値で一度描画して、それを合成したものを示している。
単純な合成だと思っていたが、3つ目の絵を見ると再計算しているようだ。
因みに、最後のものはcmap='RdBu'で描画している。
単純に'hsv'で描画したものが、上のように書けているので異なっているようだ。
【参考】
・Colorbar
カラーバーの合成のコード
#https://matplotlib.org/stable/gallery/color/colorbar_basics.html#sphx-glr-gallery-color-colorbar-basics-py import numpy as np import matplotlib.pyplot as plt # setup some generic data N = 37 #X, Y, Z = get_test_data(0.05) #x, y = X, Y #np.mgrid[:N, :N] #Z = Z #(np.cos(x*0.2) + np.sin(y*0.3)) x, y = np.mgrid[:N, :N] Z = (np.cos(x*0.2) + np.sin(y*0.3)) # mask out the negative and positive values, respectively Zpos = np.ma.masked_less(Z, 0) Zneg = np.ma.masked_greater(Z, 0) fig, (ax1, ax2, ax3) = plt.subplots(figsize=(13, 3), ncols=3) # plot just the positive data and save the # color "mappable" object returned by ax1.imshow pos = ax1.imshow(Zpos, cmap='Blues', interpolation='none') # add the colorbar using the figure's method, # telling which mappable we're talking about and # which axes object it should be near fig.colorbar(pos, ax=ax1) # repeat everything above for the negative data neg = ax2.imshow(Zneg, cmap='Reds_r', interpolation='none') fig.colorbar(neg, ax=ax2) # Plot both positive and negative values between +/- 1.2 pos_neg_clipped = ax3.imshow(Z, cmap='RdBu', vmin=-1.2, vmax=1.2, interpolation='none') # Add minorticks on the colorbar to make it easy to read the # values off the colorbar. cbar = fig.colorbar(pos_neg_clipped, ax=ax3, extend='both') cbar.minorticks_on() plt.savefig('AddClolorbar.png') plt.pause(1) plt.close()・hexbinで描画
これは、調べていると見つけたので、示しておく。コードは分かるがやっている処理内容は完全には理解できない。以下の参考では、scatterをhexbinで置き換えるとと言っているが、上記のX,Y,Zで描画しても綺麗な絵は得られない。
【参考】
・Hexbin Demo
hexbinで描画のコード
#https://matplotlib.org/stable/gallery/statistics/hexbin_demo.html#sphx-glr-gallery-statistics-hexbin-demo-py import numpy as np import matplotlib.pyplot as plt # Fixing random state for reproducibility np.random.seed(19680801) n = 100000 x = np.random.standard_normal(n) y = 2.0 + 3.0 * x + 4.0 * np.random.standard_normal(n) xmin = x.min() xmax = x.max() ymin = y.min() ymax = y.max() fig, axs = plt.subplots(ncols=2, sharey=True, figsize=(7, 4)) fig.subplots_adjust(hspace=0.5, left=0.07, right=0.93) ax = axs[0] hb = ax.hexbin(x, y, gridsize=50, cmap='inferno') ax.set(xlim=(xmin, xmax), ylim=(ymin, ymax)) ax.set_title("Hexagon binning") cb = fig.colorbar(hb, ax=ax) cb.set_label('counts') ax = axs[1] hb = ax.hexbin(x, y, gridsize=50, bins='log', cmap='inferno') ax.set(xlim=(xmin, xmax), ylim=(ymin, ymax)) ax.set_title("With a log color scale") cb = fig.colorbar(hb, ax=ax) cb.set_label('log10(N)') plt.pause(1) plt.savefig('hexbin.png') plt.close()まとめ
・3dプロットで遊んでみた♬
・3d描画、2dマップ、ワイヤーフレーム、そしてclorbarを使えるようになった
、






- 投稿日:2021-02-20T13:18:11+09:00
Prometheus Pushgateway に プログラムからメトリクスをpushする
Pushgateway にプログラムからメトリクスをpushする方法を紹介します。
各言語向けライブラリ
「Prometheus」のクライアントライブラリに「Pushgateway」へのメトリクスpushメソッドがしれっと実装されていますので若干盲点ですが、各言語向けのライブラリがあります。
以下ドキュメントで紹介されています。サンプルコードも記載されているので取り入れやすいです。
通常は上記のライブラリを使うのが良いと思います。以下は車輪の再発明をしたい方向けの情報です。
メトリクスをPOSTする処理を実装するだけなのでわざわざライブラリ使わなくても、、という方には参考になるかも知れません。Prometheus Client Data の仕様
以下ドキュメントにPrometheus Client Dataのフォーマットが記載されています。
POSTリクエスト送信処理を実装するには、リクエストボディの最後に改行(空行)を付与することに気をつけると良いです。
この仕様についてはThe last line must end with a line-feed character.と記述されています。最後に改行がないとレスポンスコード
400 Bad Requestが返り、レスポンスメッセージはtext format parsing error in line 1: invalid metric name\nとなっていました。curl によるPOST手順の確認
README.mdに以下のように記載されています。
このcurlコマンドで送信されるPOSTリクエストと同じPOSTリクエストをプログラムで生成することを考えると良さそうです。cat <<EOF | curl --data-binary @- http://pushgateway.example.org:9091/metrics/job/some_job/instance/some_instance # TYPE some_metric counter some_metric{label="val1"} 42 # TYPE another_metric gauge # HELP another_metric Just an example. another_metric 2398.283 EOF以下、サンプルコードです。
Pythonによるメトリクスpush処理の実装例
import requests import textwrap def push(): some_metric = 42 another_metric = 2398.283 data = textwrap.dedent(''' # TYPE some_metric counter some_metric{label="val1"} {some_metric} # TYPE another_metric gauge # HELP another_metric Just an example. another_metric {another_metric} '''.format(some_metric=some_metric, another_metric=another_metric )) # 最終行に改行を入れないと400が返るので注意 res = post(data) def post(data): headers = {'Content-Type': 'application/x-www-form-urlencoded'} res = requests.post( "http://pushgateway.example.org:9091/metrics/job/some_job/instance/some_instance", headers=headers, data=data) if res.status_code != 200: raise Exception("failed : {}".format(res.status_code)) return resなお、curlコマンドによるPOSTリクエストヘッダは、
Content-Typeがapplication/x-www-form-urlencodedでしたので、このプログラムでも合わせていますが、この指定は特になくても良いようです。