- 投稿日:2020-11-04T23:06:59+09:00
Youtube Data API使って動画検索してみた(初心者)
はじめに
データ分析の勉強はインプットも大事だけど実践が1番ってことで、練習になるいいデータはないかなーと思っていました。Youtubeのデータがいいものなのかは、正直今の僕には判断ができません。でも、よくYoutube見るし、興味のある分野なので「Youtube Data API」を使って分析用のデータ抽出ができるようになることを目標に使い方をまとめてボチボチまとめて行こうかと思います。APIの学習には以下のページ(APIリファレンス)を利用しました。
https://developers.google.com/youtube/v3/docs?hl=ja検索処理
今回は手始めに以下の条件で動画を検索し、結果をcsvファイルに出力します。
- 指定したキーワードで動画を検索(キーワードは第1引数で指定)
- 検索結果は再生回数で降順に表示
また、検索結果の動画がどのチャンネルのものかを度数分布化し、csvファイルに出力します。
ソースコード
ソースは以下の通りです。プログラム内の変数「DEVELOPER_KEY」は、自身のAPIキーを入力してください。APIキーの発行方法はここでは割愛します。
searchKeyword.py# import library from apiclient.discovery import build from apiclient.errors import HttpError import argparse import numpy as np import pandas as pd # Set Yotube Data API key DEVELOPER_KEY = "YOUR API KEY!!!" YOUTUBE_API_SERVICE_NAME = "youtube" YOUTUBE_API_VERSION = "v3" def searchKeyword(options): # キーワード検索処理 youtube = build(YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION, developerKey=DEVELOPER_KEY) searchResults = youtube.search().list(q=options.sw, type="video", part="id,snippet", maxResults=options.max_results, order="viewCount" ).execute() # 検索結果分類処理 videos = [] others = [] for searchResult in searchResults["items"]: if (searchResult["id"]["kind"] == "youtube#video"): videos.append(searchResult) else : others.append(searchResult) #動画、チャンネル情報整形、csvファイル出力 videoTitles = [] viewCounts = [] likeCounts = [] dislikeCounts = [] favoriteCounts = [] commentCounts =[] videoChannelTitles = [] stat_list = [viewCounts, likeCounts, dislikeCounts, favoriteCounts, commentCounts] stat_keywords = ['viewCount', 'likeCount', 'dislikeCount', 'favoriteCount', 'commentCount'] for video in videos: videoDetail = youtube.videos().list( part="statistics, snippet", id = video["id"]["videoId"] ).execute() channelDetail = youtube.channels().list(part="snippet", id=videoDetail["items"][0]["snippet"]["channelId"] ).execute() videoTitles.append(videoDetail["items"][0]["snippet"]["title"]) for stat, stat_keyword in zip(stat_list, stat_keywords): try: stat.append(videoDetail["items"][0]["statistics"][stat_keyword]) except KeyError: stat.append(0) videoChannelTitles.append(channelDetail["items"][0]["snippet"]["title"]) df_videos = pd.DataFrame({"title":videoTitles, "ViewCount":viewCounts, "channelTitle":videoChannelTitles,"likeCount":likeCounts, "dislikeCount":dislikeCounts, "favoriteCount":favoriteCounts, "commentCount":commentCounts}) df_videos.to_csv("Search_result_{}.csv".format(options.sw),encoding="utf-8_sig") df_videos_countbyChannel = df_videos["channelTitle"].value_counts() df_videos_countbyChannel.to_csv("ChannelTitle_{}.csv".format(options.sw),encoding="utf-8_sig") return df_videos, df_videos_countbyChannel if __name__ == "__main__": # parse Argument parser = argparse.ArgumentParser("search Youtube Program...") parser.add_argument("sw", help="search Keyword in Youtube") parser.add_argument("--max_results", type=int, help="max of search results", default=50) options = parser.parse_args() searchKeywordResults = searchKeyword(options)実行してみた
実際に動かしてみました。今回は「量子コンピュータ」を検索キーワードに指定して実行します。
$ python searchKeyword.py "量子コンピュータ"「searchKeyword.py」を配置したディレクトリに「Search_result_量子コンピュータ.csv」と「ChannelTitle_量子コンピュータ.csv」ができた。この2つのファイルの内容を確認してみる。
- Search_result_量子コンピュータ.csv(冒頭部分のみ記載)
No title ViewCount channelTitle likeCount dislikeCount favoriteCount commentCount 0 Quantum Computers Explained – Limits of Human Technology 12915763 Kurzgesagt – In a Nutshell 310808 3405 0 16871 1 [マインクラフト]疑似量子ビット計算機[理論上世界最速?] 4483432 田辺魅癒喜 60153 2057 0 9898 2 量子コンピューターは通常のコンピューターと何が違うのか?【日本科学情報】【科学技術】 622469 日本科学情報 8019 435 0 647 3 世界を変える「量子コンピューター」とは?ホリエモンが解説!【NewsPicksコラボ】 232913 堀江貴文 ホリエモン 1443 121 0 275 4 この世界はシミュレーション⁉もし量子コンピュータが完成したら...【都市伝説】 211623 ミルクティー飲みたい 2722 142 0 411 5 【驚愕】量子コンピュータの衝撃「想像を絶する勘違い」 144126 イチゼロシステム 1898 121 0 199 6 スパコンを遥かに凌駕!国産量子コンピューター発表(17/11/20) 121514 ANNnewsCH 1085 47 0 0 7 【量子力学】「量子コンピューター」と「シュテルン・ゲルラッハの実験」を学ぼう 117389 イケハヤ大学 1311 214 0 95 8 【挑戦】10分でわかる「量子コンピュータ」 110234 NEX工業 1579 178 0 187 9 【量子コンピュータ】第一回「量子ビットと重ね合わせ」(10分) 105738 量子コイン 0 0 0 58 10 ビットコインが崩壊か⁉Googleが量子コンピュータ開発でどのようになるのか?ブロックチェーンの安全性など解説 99405 もふもふ不動産 1675 121 0 192 うまい具合に動画情報が取得できたようです。
- ChannelTitle_量子コンピュータ.csv(冒頭部分のみ記載)
チャンネル名 Count 量子コイン 7 慶應義塾Keio University 5 DENSO Official Channel 2 神王TV 2 報道SAMURAI 2 もふもふ不動産 2 jstsciencechannel 1 EE Times Japan 1 ミルクティー飲みたい 1 ブライトサイド Bright Side Japan こちらもうまい具合に情報取得できたようです。
最後に
これを応用していけば色々面白いことが出来そうです。もうちょっと色々できるように機能を少しずつ拡張していこうと思います。
- 投稿日:2020-11-04T22:39:02+09:00
PyTorchでXORを実装してみる
はじめに
Kerasでやりたいことをやろうとすると、結局tensorflowを使わざるを得ず、それならPyTorchの方がいいんじゃね?ということで早速、XORを実装してみた。
環境
- Python 3.6
- pytorch 1.7.0
ソース
import torch import torch.nn as nn import torch.optim as optim class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.fc1 = torch.nn.Linear(2, 8) self.fc2 = torch.nn.Linear(8, 8) self.fc3 = torch.nn.Linear(8, 1) self.sigmoid = nn.Sigmoid() def forward(self, x): x = torch.nn.functional.relu(self.fc1(x)) x = torch.nn.functional.relu(self.fc2(x)) x = self.fc3(x) x = self.sigmoid(x) return x def main(): import numpy as np x = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) y = np.array([[0], [1], [1], [0]]) num_epochs = 10000 # convert numpy array to tensor x_tensor = torch.from_numpy(x).float() y_tensor = torch.from_numpy(y).float() # crate instance net = Net() # set training mode net.train() # set training parameters optimizer = torch.optim.SGD(net.parameters(), lr=0.01) criterion = torch.nn.MSELoss() # start to train epoch_loss = [] for epoch in range(num_epochs): print(epoch) # forward outputs = net(x_tensor) # calculate loss loss = criterion(outputs, y_tensor) # update weights optimizer.zero_grad() loss.backward() optimizer.step() # save loss of this epoch epoch_loss.append(loss.data.numpy().tolist()) print(net(torch.from_numpy(np.array([[0, 0]])).float())) print(net(torch.from_numpy(np.array([[1, 0]])).float())) print(net(torch.from_numpy(np.array([[0, 1]])).float())) print(net(torch.from_numpy(np.array([[1, 1]])).float())) if __name__ == "__main__": main()結果
tensor([[0.0511]], grad_fn=<SigmoidBackward>) tensor([[0.9363]], grad_fn=<SigmoidBackward>) tensor([[0.9498]], grad_fn=<SigmoidBackward>) tensor([[0.0666]], grad_fn=<SigmoidBackward>)お、いい感じだ。
感想
まだ、ほんの触り程度だが、KerasやTensorflowに比べると、ブラックボックス感がなくPythonからシームレスに使える感じがすごくいい。
例えば、モデルの中にprint文を入れても, そのまま出力される。実行中の可視化なんかもすごくやりやすそう。
- 投稿日:2020-11-04T22:20:52+09:00
Pythonを使って円周率を求める #モンテカルロ法
初めに
この記事では
ラムダさんの動画を見てそのまま、深夜テンションで書いたモンテカルロ法を用いて円周率を求めるプログラムを解説する記事です。深夜テンションなのであまり期待しないで下さい!コードが酷い
import matplotlib.pyplot as plt import random Xlist=[] Ylist=[] Number_list=[] pi=0 pi_list=[] for i in range(15000): Xlist.append(random.uniform(0,1)) Ylist.append(random.uniform(0,1)) if (i+1)%10 == 0: Number_list.append(i+1) pi_list.append((pi/(i+1))*4) if Xlist[i]**2+Ylist[i]**2 <= 1 and (i+1)%10 == 0: Number_list.append(i+1) pi_list.append((pi/(i+1))*4) pi+=1 elif Xlist[i]**2+Ylist[i]**2 <= 1: pi+=1 print((pi/(i+1))*4) plt.plot(Number_list,pi_list) plt.show()
何これ汚ない
一応動くちゃ動くけど、同じ処理が何回も書かれいるし流石にやばいので結局朝に書き直しました。import matplotlib.pyplot as plt import random Xlist=[] Ylist=[] Number_list=[] pi=0 pi_list=[] for i in range(15000): Xlist.append(random.uniform(0,1)) Ylist.append(random.uniform(0,1)) if (i+1)%10 == 0: Number_list.append(i+1) pi_list.append((pi/(i+1))*4) if Xlist[i]**2+Ylist[i]**2 <= 1: pi+=1 print((pi/(i+1))*4) plt.plot(Number_list,pi_list) plt.show()少しはマシになりましたね。
それでは1行ずつコードを解説して行きましょう。import matplotlib.pyplot as plt import random一行目ではmatplotlibと言うグラフを作図する時に便利なライブラリーをpltと言う名前で使える様にしました。
二行目ではrandomと言うランダムな値を生成できるライブラリーをインポートしています。Xlist=[] Ylist=[] Number_list=[] pi=0 pi_list=[]ここでは諸々円周率の計算に必要な変数を宣言をしています。
XlistとYlistにはランダムに生成した点の座標を格納して後の計算で、点が円内部に入っているか否かを判定します。Number_listではグラフ作成に必要な等差数列を作成しています。本当はnumpyを使って先に等差数列を作った方が早いですが、今回は方法を調べるのがめんどくさいのでパスしました(サボり魔)。piには合計で円内部にプロットされた点の数の合計をpi_listにはそれぞれ計算で求めた円周率ををリスト形式で保存する時に使います。for i in range(15000): Xlist.append(random.uniform(0,1)) Ylist.append(random.uniform(0,1)) if (i+1)%10 == 0: Number_list.append(i+1) pi_list.append((pi/(i+1))*4) if Xlist[i]**2+Ylist[i]**2 <= 1: pi+=1ここではfor文を使って以下の処理を15,000回繰り返します(人間がやったら死んじゃう)。
XlistとYlistにramdomモジュールを使って点の座標を格納します。
説明の都合先にif Xlist[i]2+Ylist[i]2 <= 1:のブロックを解説します。
ここでは面倒臭い説明は省きますが
$x^2+y^2=r^2$
より取り敢えずXlistとYlistの最後に格納されている数をそれぞれ二乗して足して半径の二乗以下だったら、円の中に点が入っている事が分かります。これを数式として表したのが上のif文です。このif文で点が円の中にいる事が分かったので、piに1加えます。最後にif (i+1)%10 == 0:のブロックについてです。ここでは十回に一回円周率を計算してpi_listに格納し、ついでにNumber_listを等差数列にするために数を追加します。plt.plot(Number_list,pi_list)
plt.show()
これはグラフを作成するだけのプログラムですので解説はしません(手抜き)。終わりに
多分いらないと思いますが、PDFにして今回の内容をまとめて見ました。
プログラム歴はびっくりするほど浅いので間違っていたら気軽にコメントで教えてください!!
後よかったらコメントもくだい。

- 投稿日:2020-11-04T22:16:22+09:00
PythonでいろいろPOSTしてFlaskで受け取る
pythonでjsonとか画像とかPOSTしたくなってきたので, 全部まとめました。全部Flaskで受け取ってます。
まずは普通にdataをPOST
post.pyimport requests import json post_url = "http://127.0.0.1:5000/callback" #postしたいデータ data = "wowwowwowwow" #POST送信 response = requests.post( post_url, data = data ) print(response.json())server.pyfrom flask import * import os from PIL import Image import json app=Flask(__name__) @app.route("/") def hello(): return "hello" @app.route("/callback",methods=["POST"]) def callback(): print(request.data.decode()) return jsonify({"kekka": "受け取ったよ!"}) if __name__=="__main__": port=int(os.getenv("PORT",5000)) app.debug=True app.run()JSON形式でPOST
post.pyimport requests import json post_url = "http://127.0.0.1:5000/callback" json = {"data": "ウオオオオお"} #POST送信 response = requests.post( post_url, json = json, ) print(response.json())server.pyfrom flask import * import os from PIL import Image import json app=Flask(__name__) @app.route("/") def hello(): return "hello" @app.route("/callback",methods=["POST"]) def callback(): data = request.data.decode('utf-8')#デコード data = json.loads(data) print(data["data"]) return jsonify({"kekka": "受け取ったよ!"}) if __name__=="__main__": port=int(os.getenv("PORT",5000)) app.debug=True app.run()画像をPOST
post.pyimport requests import json post_url = "http://127.0.0.1:5000/callback" #POSTするファイルの読込 files = { "image_file": open('./sample.jpg', 'rb') } #POST送信 response = requests.post( post_url, files = files, ) print(response.json())server.pyfrom flask import * import os from PIL import Image import json app=Flask(__name__) @app.route("/") def hello(): return "hello" @app.route("/callback",methods=["POST"]) def callback(): #画像の読み込み im = Image.open(request.files["image_file"]) #表示 im.show() return jsonify({"kekka": "受け取ったよ!"}) if __name__=="__main__": port=int(os.getenv("PORT",5000)) app.debug=True app.run()感想
これであなたもPOSTマスター。
- 投稿日:2020-11-04T22:08:09+09:00
Existence from the viewpoint of Python
- 投稿日:2020-11-04T20:52:58+09:00
競プロのライブラリ整理~二元一次不定方程式~
Codeforces Round #592 (Div.2)-C The Football Seasonを二元一次不定方程式で解く際に苦労したので、この記事で解法を整理していこうと思います。また、拡張ユークリッドの互除法による特殊解の求め方は扱わないので、詳しくは参考記事4を読んでください。
(1)二元一次不定方程式の解き方
目標
$ax+by=c$ ($a,b,c$:整数)における$x,y$の一般解を求める
①前提条件
$c$が$gcd(a,b)$の倍数でない場合は解が存在しません。逆に$c$が$gcd(a,b)$の倍数の場合は必ず解が存在します。
(↓以下では、$g=gcd(a,b)$として表記します。)
②特殊解を求める
拡張ユークリッドの互除法により求めることができます。詳しくは参考記事4とコードを見てください。また、拡張ユークリッドの互除法により求まるのは$ax+by=g$の特殊解なので、求まった特殊解をそれぞれ$\frac{c}{g}$倍する必要があります。
(↓以下では、求まった特殊解を$x_0,y_0$として表記します。)
③一般解を求める
まず、$ax_0+by_0=c$かつ$ax+by=c$より、$a(x-x_0)+b(y-y_0)=0$が成り立ちます。そして、$a,b$を$a^{'}=\frac{a}{g},b^{'}=\frac{b}{g}$に置き換えて変形することで、$a^{'}(x-x_0)=-b^{'}(y-y_0)$になります。
前述の変形により$a^{'}$と$b^{'}$は互いに素なので、$x-x_0$は$b^{'}$の倍数であることが必要です。よって、$m$を整数として$x-x_0=m b^{'}$として表すことができます。したがって、先ほどの式に代入すれば、$x=x_0+m b^{'},y=y_0-m a^{'}$として一般解が求まります。
(2)コード
構造体(Pythonはクラス)でコードを書きました。コンストラクタを呼ぶだけで一般解を求められるようになります。また、変数名はこの記事の表記に準拠しているので、適宜変えて使ってください。
Codeforces Round #592 (Div.2)-C The Football Seasonにおいてverifyしましたが1$^,$2、バグがあればご連絡ください。
C++
extgcd.cc/* 二元一次不定方程式(Linear Diophantine equation) 初期化すると、x=x0+m*b,y=y0-m*aで一般解が求められる(m=0で初期化) 掛け算でオーバーフローする可能性があるので… a,b,cが32bit整数に収まらないとき→llに__int128_tを使って出力でcastする a,b,cが64bit整数に収まらないとき→Pythonを使う */ struct LDE{ ll a,b,c,x0,y0; ll m=0; bool check=true;//解が存在するか //初期化 LDE(ll a_,ll b_,ll c_): a(a_),b(b_),c(c_){ //llが128bit整数の可能性があるのでlong longにキャスト ll g=gcd(static_cast<long long>(a),static_cast<long long>(b)); if(c%g!=0){ check=false; }else{ //ax+by=gの特殊解を求める extgcd(a,b,x0,y0); //ax+by=cの特殊解を求める(オーバフローに注意!) x0*=c/g;y0*=c/g; //一般解を求めるために割る a/=g;b/=g; } } //拡張ユークリッドの互除法 //返り値:aとbの最大公約数 ll extgcd(ll a,ll b,ll &x,ll &y){ if(b==0){ x=1; y=0; return a; } ll d=extgcd(b,a%b,y,x); y-=a/b*x; return d; } //パラメータmの更新(書き換え) void m_update(ll m_){ x0+=(m_-m)*b; y0-=(m_-m)*a; m=m_; } };Python
基本的にはC++と同じ挙動をするようにしてあるはずです。
ただし、$x,y$は整数ではなく整数を格納した長さ1の配列です。これは整数(イミュータブルなオブジェクト)を関数内で書き換えようとすると別のオブジェクトになることを避けるために、ミュータブルなオブジェクトとして整数を扱う必要があるからです。詳しくは参考記事の1~3を読んでください。
extgcd.py''' 二元一次不定方程式(Linear Diophantine equation) 初期化すると、x=x0+m*b,y=y0-m*aで一般解が求められる(m=0で初期化) ''' class LDE: #初期化 def __init__(self,a,b,c): self.a,self.b,self.c=a,b,c self.m,self.x0,self.y0=0,[0],[0] #解が存在するか self.check=True g=gcd(self.a,self.b) if c%g!=0: self.check=False else: #ax+by=gの特殊解を求める self.extgcd(self.a,self.b,self.x0,self.y0) #ax+by=cの特殊解を求める self.x0=self.x0[0]*c//g self.y0=self.y0[0]*c//g #一般解を求めるために self.a//=g self.b//=g #拡張ユークリッドの互除法 #返り値:aとbの最大公約数 def extgcd(self,a,b,x,y): if b==0: x[0],y[0]=1,0 return a d=self.extgcd(b,a%b,y,x) y[0]-=(a//b)*x[0] return d #パラメータmの更新(書き換え) def m_update(self,m): self.x0+=(m-self.m)*self.b self.y0-=(m-self.m)*self.a self.m=m(3)二元一次不定方程式を使う問題
ACL Contest 1-B Sum is Multiple
→自分の解説記事Codeforces Round #592 (Div.2)-C The Football Season
→自分の解説記事(更新中です)(4)参考記事
1:Pythonの組み込みデータ型の分類表(ミュータブル等)
2:【python】immutableを参照渡ししたい
3:共有渡しと参照の値渡しと
4:拡張ユークリッドの互除法 〜 一次不定方程式 ax + by = c の解き方 〜
- 投稿日:2020-11-04T20:20:28+09:00
競プロ用テンプレート(Python)
C++用のテンプレートに引き続きPythonのテンプレートも作ることにしました。
最近ハマっているCodeforcesでinputの高速化が要求されるので、やむを得ず導入することにしました。テンプレートの説明
(1)itertools
競プロで一番有能なモジュールです。使い方を知らない人は僕の記事を読みましょう。
ちなみに、combinations_with_replacementも使ったことがありますが、関数名が長いので省略しました。(2)collections
両方向から追加・削除可能なdeque、要素ごとに個数を保存できるCounter、どっちも有能なデータ構造です。
ちなみに、Counterは辞書のサブクラスなので、辞書っぽく使えます。(3)bisect
二分探索で使うモジュールです。使い方を知らない人は僕の記事を読みましょう。
(4)math
gcd,lcm,sqrtくらいしか実際は使いません。
とは言うものの、コドフォで三角関数を使ったことがあります(参照)。(5)fractions,decimal
小数点誤差を回避するために使うモジュールです。fractionsは有理数を誤差なしで保持して,decimalは10進小数を誤差なしで保持します。ABC169-C Multiplication 3で使ったのが最初で最後な気がします(僕の解説記事はこちら)。
(6)sys,input
inputを高速化します。コドフォでは必須と言っても過言ではありません。
(7)MOD,INF
両者とも競プロをやっていれば頻繁に使います。適宜、値を変えて使ってください。
追記・修正・削除の履歴
追記(2020/11/04)
setrecursionlimitにより再帰回数の上限が上がります。適当に$10^7$回にしておきました。
ちなみに、CodeforcesでPyPy3でsetrecursionlimitを含めて提出するとMLEになるので、コメントアウトしてあります(謎…)。
コード
template.pyfrom itertools import accumulate,chain,combinations,groupby,permutations,product from collections import deque,Counter from bisect import bisect_left,bisect_right from math import gcd,lcm,sqrt,sin,cos,tan,degrees,radians from fractions import Fraction from decimal import Decimal import sys input=sys.stdin.readline().rstrip #from sys import setrecursionlimit #setrecursionlimit(10**7) MOD=10**9+7 INF=10**20
- 投稿日:2020-11-04T20:12:31+09:00
GCPのCloud Shell EditorでPythonの開発環境ぐちゃって詰んだので更地にして再構築したらなんとかなった件
概要
2019年末くらいからGCPのCloud Shell上でPython開発してCloud Functionにデプロイする作業してました。
ある程度開発終わって数ヶ月放置した後、最近新しい開発案件が発生したのでちょろっといじってデプロイしてテストするかーと思ったらデプロイ時に色々エラーを吐き始めてしまいます。
エラー見つつ対処進めたけどまあうまくいかず、最終的に環境リセットしたらうまく行ったのでまとめます。Pythonとpipのアップデートとバージョン切り替えが一番手詰まりポイントでした
手順
- バックアップをとる
- 公式の手順にしたがって環境をリセットする
- Pythonをpyenvでアップデートする
- pipをpip3に切り替えてアップデートする
- 公式の手順にしたがってgcloudをアップデートする
- 作業ファイルを復元する
- requirements.txtから更新する
- あとはdeployして適宜バグを潰す
1. バックアップをとる
pip freeze > requirements.txtでインストール済みパッケージを書き出したのち、Cloud Sell Editor上にあるファイルを一括ダウンロードしておきましょう。
ファイルはtarで落ちてきます。後でtarのまま上げなおすので、解凍する必要は特にないです。2. 公式の手順にしたがって環境をリセットする
Cloud Shell の無効化またはリセット
https://cloud.google.com/shell/docs/resetting-cloud-shell?hl=ja曰く、
sudo rm -rf $HOME
でリセットのちShell再起動でいけるらしいです。3. Pythonをpyenvでアップデートする
こちらのQiita参考になりました、書いた方ありがとうございます。
GCPのCloud Shellのpythonバージョンの更新方法
https://qiita.com/greenteabiscuit/items/cbecdf4f84f0b73ff96e私はpython 3.7.9 で実行しています。
4. pipをpip3に切り替えてアップデートする
そのままpipするとpython v2だから気をつけてね的な表示がでます。
放置するとCloud Functionデプロイ時にエラー吐いたので多分ここもpip3にした方がよいと思われ。
下記サイトのコマンド参考に切り替え
https://www.it-swarm-ja.tech/ja/pip/pip3%E3%82%B3%E3%83%9E%E3%83%B3%E3%83%89%E3%82%92pip%E3%81%AB%E5%A4%89%E6%9B%B4%E3%81%99%E3%82%8B%E3%81%AB%E3%81%AF%E3%81%A9%E3%81%86%E3%81%99%E3%82%8C%E3%81%B0%E3%82%88%E3%81%84%E3%81%A7%E3%81%99%E3%81%8B%EF%BC%9F/831723093/
alias pip=pip3
でいけます。そのあとは、
pip install -U pipで最新版にしましょう。5. 公式の手順にしたがってgcloudをアップデートする
さらにgcloudもアップデートしないとダメでした。
公式的にはこちらの手順です:gcloud components update
https://cloud.google.com/sdk/gcloud/reference/components/update
gcloud components update
が当該コマンド。
しかしShell上だとこれでアップデートはできず、sudo apt-get update && sudo apt-get --only-upgrade install google-cloud-sdk-app-engine-python-extras google-cloud-sdk-kpt google-cloud-sdk-minikube google-cloud-sdk-app-engine-java google-cloud-sdk-datalab google-cloud-sdk-kind google-cloud-sdk-app-engine-grpc google-cloud-sdk-firestore-emulator google-cloud-sdk-bigtable-emulator google-cloud-sdk-skaffold kubectl google-cloud-sdk-cbt google-cloud-sdk-pubsub-emulator google-cloud-sdk-anthos-auth google-cloud-sdk google-cloud-sdk-datastore-emulator google-cloud-sdk-app-engine-python google-cloud-sdk-spanner-emulator google-cloud-sdk-cloud-build-local google-cloud-sdk-app-engine-goというvery longなコマンドを実行しろと言われます。
実行するとちゃんとアップデートされました。6. 作業ファイルを復元する
1でDLしたtarをアップロードしましょう。
D&Dか、ファイル一覧の何もないところ右クリック→Upload Filesでいけます。
アップロード後、tarコマンドで解凍します。
やり方はこちらのQiitaを参考にしてました:[Linux]ファイルの圧縮、解凍方法
https://qiita.com/supersaiakujin/items/c6b54e9add21d375161f
tar -xvf xxxx.tar
コマンド的には上記7. requirements.txtから更新する
あとはpipパッケージを再インストールしましょう。
私は下記サイトを参考にしました。Python, pipでrequirements.txtを使ってパッケージ一括インストール
https://note.nkmk.me/python-pip-install-requirements/
pip install -r requirements.txtたまーに「別のパッケージないとこのパッケージインストールできんぞ」的なエラー出ますが、その時はパッケージ名指定してinstallすればなんとかなります。
ただbigqueryのapi使ってるのですが、関連のパッケージは以下でインストールしないとダメだった:
pip install google-cloud-bigquery8. あとはdeployして適宜バグを潰す
あとは
gcloud functions deployして無限にバグを産みましょう潰しましょう。追記
もしかすると、Editor画面下の青いバーでバージョン変更したらめんどくさいことしなくてもいけるのかもしれない。
- 投稿日:2020-11-04T20:10:19+09:00
Redhat7でFlask/MySql/Apache/mod_wsgi/virtualenvの環境構築(Python2.7)2020年11月
検証環境
- Red Hat Enterprise Linux Server release 7.9 (Maipo)
- Python 2.7.5
- Apache/2.4.6 (Red Hat Enterprise Linux)
- Flask 1.1.2
- MySql mysql Ver 8.0.22 for Linux on x86_64 (MySQL Community Server - GPL)
- pip 20.2.4
- virtualenv 20.1.0
インストールとアプリケーションファイルの作成
Apache/mod_wsgiのインストール
$ sudo su $ yum install httpd $ chkconfig httpd on $ service httpd start $ service httpd status # 確認 $ yum install mod_wsgi # mod_wsgiのインストールpipのインストール
$ curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py $ python get-pip.pyvirtualenvのインストール
$ pip install virtualenvアプリケーションのディレクトリを作成
$ mkdir /var/www/myapp $ cd /var/www/myapp $ virtualenv venv # virtualenv環境の構築 $ source venv/bin/activate # virtualenv有効化 $ pip install flask # flaskのインストール $ touch app.py # アプリケーションのファイルを作成 $ touch app.wsgi # アプリケーションのファイルを作成app.pyfrom flask import Flask, jsonify app = Flask(__name__) @app.route("/") def hello(): return jsonify("Hello World!"), 201 if __name__ == "__main__": app.run()app.wsgiimport os import sys DIR=os.path.dirname(__file__) sys.path.append(DIR) activate_this = os.path.join(DIR, 'venv/bin/activate_this.py') execfile(activate_this, dict(__file__=activate_this)) from app import app as application最終的に下記の様なファイル構成になる
$ tree -L 2 . ├── app.py ├── app.wsgi └── venv ├── bin ├── lib ├── lib64 └── pyvenv.cfgApache/mod_wsgiの設定
$ vi /etc/httpd/conf/httpd.conf下記の行を追加
Listen 8888port 8888を加えて、apacheを再起動すると下記のようにエラーが出る
(13)Permission denied: AH00072: make_sock: could not bind to address [::]:8888 (13)Permission denied: AH00072: make_sock: could not bind to address 0.0.0.0:8888selinuxでポートを追加する
参考 http://hetarena.com/archives/495$ semanage port -a -t http_port_t -p tcp 8888アプリケーション用の環境を構築
$ vi /etc/httpd/conf.d/myenv.confmyenv.conf<VirtualHost *:8888> WSGIDaemonProcess wsgi_flask user=apache group=apache threads=10 WSGIScriptAlias / /var/www/myapp/app.wsgi WSGIScriptReloading On <Directory "/var/www/myapp"> WSGIProcessGroup wsgi_flask WSGIApplicationGroup %{GLOBAL} Order deny,allow Allow from all </Directory> </VirtualHost>
- 設定ファイルの確認
$ apachectl configtesthttps://deep-blog.jp/engineer/12317/
$ service httpd gracefulmysqlのインストール
$ sudo su $ rpm -Uvh https://repo.mysql.com/mysql80-community-release-el7-3.noarch.rpm $ yum install mysql-community-server $ service mysqld start $ service mysqld status # 確認mysqlのログイン
$ sudo su $ tail /var/log/mysqld.log # パスワードをログから確認 $ mysql -uroot $ mysql> ALTER USER 'root'@'localhost' IDENTIFIED WITH caching_sha2_password BY 'YQM3rCyae8Ft?';参考 https://dev.classmethod.jp/articles/how-to-serve-flask-with-apache-mod_wsgi-virtualenv-on-ec2/
- 投稿日:2020-11-04T19:49:51+09:00
discordでデータ保存してみた
discord のチャンネルにファイルを上げてそれを取得します
(初心者が作ったので変なところがあるかもしれません)環境
python 3.8.2
discord.py 1.5.1作ろうとしたきっかけ
discord でデータを保存できたらいいなーと思っていて
heroku で稼働しているため 約24時間で自動再起動します
なのでファイルを保存すると消えるので
使うとしたらデータサーバーを借りるしかないのですが
いろんな記事を見てもいまいちわからず・・
ここで たしかdiscord でファイルを上げれるはず・・
こんな感じで作成しましたBOT作成
まずdiscord.py とはどんなものなのかわからない方はこちらを参考にしてください
https://qiita.com/1ntegrale9/items/9d570ef8175cf178468f基本設定
まずBOTの設定等が終わり使える状況を前提とします
次にデータを保存するチャンネルを作ります
名前はなんでもいいです
次にするのが一番重要な保存するファイルです
ファイルはjson で作ってください
今回使用するjsonファイルです{ "goban":[ 12345, 123456, 1234678 ] }最初に読み込むコード
まずファイルを読み込むコードはこちらです
@bot.event async def on_ready(): mass = bot.get_channel(作ったチャンネルのID) id = mass.last_message_id msg = await mass.fetch_message(id) await msg.attachments[0].save("goban.json")これが読み込んで保存するコードです
セーブする名前は各自で変えてください
あとはこれのコードの後ろにファイルを開けてlist などに
入れると使えるようになります
使う用途に合わせて追加してくださいファイルに追加するコード
ファイルに追加するコードはこうです
@bot.command() async def tui(ctx,ss): global motolist with open("goban.json", "r",encoding="utf-8") as moto: moto = json.load(moto) for da in (moto['goban']): motolist += [f"{da}"]まず jsonに追加しようとすると上書きになってしまうので
それでは使えないでまずファイルを開いてリストなどに追加しておきます
次に大事な追加するコードですwith open("goban.json","w",encoding="utf-8") as data: data.write('{\n') data.write('"goban":[\n') for moto in motolist: data.write(f'"{str(moto)}"') data.write(", \n") data.write(f'"{ss}"\n ]') data.write('\n}') await bot.get_channel(作ったチャンネルID).send(file=discord.File('goban.json'))これとさっきのコードを繋げるとこうなります
@bot.command() async def tui(ctx,ss): global motolist with open("goban.json", "r",encoding="utf-8") as moto: moto = json.load(moto) for da in (moto['goban']): motolist += [f"{da}"] with open("goban.json","w",encoding="utf-8") as data: data.write('{\n') data.write('"goban":[\n') for moto in motolist: data.write(f'"{str(moto)}"') data.write(", \n") data.write(f'"{ss}"\n ]') data.write('\n}') await bot.get_channel(作ったチャンネルID).send(file=discord.File('goban.json'))こうなりましたねこれで追加したり自由にできます
このあとにもっかい開きなおすと 更新できます
いままでのコードを全部繋げるとimport discord from discord.ext import commands import json bot = commands.Bot(command_prefix='.') client = discord.Client() motolist = [] @bot.event async def on_ready(): mass = bot.get_channel()作ったチャンネルID) id = mass.last_message_id msg = await mass.fetch_message(id) await msg.attachments[0].save("goban.json") @bot.command() async def tui(ctx,ss): global motolist with open("goban.json", "r",encoding="utf-8") as moto: moto = json.load(moto) for da in (moto['goban']): motolist += [f"{da}"] with open("goban.json","w",encoding="utf-8") as data: # ス data.write('{\n') data.write('"goban":[\n') for moto in motolist: data.write(f'"{str(moto)}"') data.write(", \n") data.write(f'"{ss}"\n ]') data.write('\n}') await bot.get_channel(作ったチャンネルID).send(file=discord.File('goban.json')) motolist = [] bot.run("TOKEN")最後に
python 初心者が使ったプログラムです 間違っている場合などは
言ってください
- 投稿日:2020-11-04T19:35:15+09:00
GCP Cloud Vision APIでテキスト抽出やーる(Python3.6)
はじめに
GCP Cloud Vision APIで画像からテキスト抽出やってみました
開発環境
- Windows 10
- Anaconda
- Python 3.6
- OpenCV 4.4.0
導入
画像内のテキストを検出するを参考にします。
1.Cloud Consoleからプロジェクトを作成します。
2.課金が有効になっていることを確認します。
3.Vision API を有効にします。
4.認証の設定をし、JSONファイルがPCにダウンロードされます。
5.環境変数 GOOGLE_APPLICATION_CREDENTIALS にJSONファイルのパスを設定します。
6.anaconda promptを開き、Python 3.6環境を作成します。$ conda create -n py36 python=3.6 $ conda activate py367.ライブラリをインストールします
$ pip install numpy $ pip install pillow $ pip install opencv-python $ pip install --upgrade google-cloud-vision8.下記のコードを実行してみましょう
from google.cloud import vision import io import os import cv2 import numpy as np from PIL import ImageFont, ImageDraw, Image def detect_text(image): """Detects text in the file.""" client = vision.ImageAnnotatorClient() content = cv2.imencode(".png", image)[1].tostring() tmp = vision.Image(content=content) response = client.text_detection(image=tmp) texts = response.text_annotations if response.error.message: raise Exception( '{}\nFor more info on error messages, check: ' 'https://cloud.google.com/apis/design/errors'.format( response.error.message)) return texts filename = "338px-Atomist_quote_from_Democritus.png" root, ext = os.path.splitext(filename) image = cv2.imread(filename, cv2.IMREAD_COLOR) texts = detect_text(image) fontpath ='C:\Windows\Fonts\meiryo.ttc' font = ImageFont.truetype(fontpath, 10) image_pil = Image.fromarray(image) for text in texts: print(text.description) vertices = [(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices] # cv2.putText(image, text.description, vertices[0], cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA) # cv2.rectangle(image, vertices[0], vertices[2], (0, 255, 0)) draw = ImageDraw.Draw(image_pil) w, h = draw.textsize(text.description, font = font) draw.text((vertices[0][0], vertices[0][1]-h), text.description, font=font, fill=(255, 255, 255, 0)) # draw.text(vertices[0], text.description, font=font, fill=(255, 255, 255, 0)) draw.rectangle((vertices[0], vertices[2]), outline=(0, 255, 0)) image = np.array(image_pil) cv2.imshow("image", image) cv2.imwrite(root+"_ocr"+ext, image) cv2.waitKey(0)
input PIL PIL(OpenCV風) OpenCV OpenCVだと全角英語(日本語)が文字化けするのでPILを用いてテキスト表示しました。
お疲れ様でした。




- 投稿日:2020-11-04T18:57:02+09:00
【AIアルゴリズム】次元削減(t-SNE)について
今回は機械学習の教師なし学習、「次元削減(t-SNE)」のアルゴリズムについて記事を書いていきます。
次元削減にはいくつかの有名なアルゴリズムがありますが、ここでは多次元データに適した手法のt-SNEについて書いていきたいと思います。次元削減とは入力データの説明変数を少なくする変換のことで、元の入力データの情報を保ちつつも少ない変数で元のデータの特徴を説明できるようにすることです。
例えば、Aさんの年齢(目的変数y)を予想したいと考えた時にAさんの情報として身長(説明変数x1)、体重(説明変数x2)のみ与えられているものとします。大人になると子供よりも身長、体重がともに高くなっていくのである程度年齢と相関がありそうです。この時の身長、体重という2つの変数を次元削減しようとするとこの2つの変数の情報をある程度保ちつつも変数を1つにすることを考えます。そうすると、身長、体重の関係から「体格」という一つの変数を作れそうです。そして、その体格という変数を用いて年齢を予想することもできそうです。このように、いくつかある変数を一つにまとめることを次元削減といいます。
通常は変数が何十何百とある多変数データを2つ、3つの変数までに削減することが一般的です。
では、なぜわざわざ次元削減を行うかというと理由は大きく2つあります。1つ目は多次元データを視覚化するためです。視覚化することによってパッとみよくわからないデータでも人間の頭の中で把握しやすくなります。データの傾向をとらえやすくなれば、EDAや分析結果の評価などでもより説明しやすくなります。2つ目は「次元の呪い」を防ぐことです。次元の呪いとはおおまかにいうとデータの持つ変数の数が多すぎる(次元数が多い)と機械学習の色々なアルゴリズムにおいて性能が低下してしまうことです。私も次元の呪いについてさほど詳しくないのですが、全データの持つ情報は変わらないとして、変数が多いよりも変数が少なく、一つの変数あたりの情報量が多いほうがアルゴリズムの性能が高まりやすいそうです。
では、t-SNEのアルゴリズムについて考えていきたいと思います。改めて、PCAのようないくつかある次元削減手法の中でt-SNEは使い勝手がいいです。t-SNEの特徴は、多様体空間(部分的に多次元空間でも2点間の距離が表せるような空間)に分布したデータを次元圧縮して可視化できることです。ちなみにPCAは線形のデータ全体をみて次元削減することが得意ですが、t-SNEは非線形データを局所的(2点間)をみて削減するのが得意です。つまり、t-SNEは多次元の構造を極力残してデータ間の距離の着目することで2~3次元へ削減します。
t-SNEのベースはSNEというアルゴリズムなのでまずこちらから説明します。
SNEは
の数式です。
これは、与えられたiという条件におけるjの条件付確率です。あくまでも表しているのは確率ですが、これにより、高次元空間のデータ間の近さを表現します。
その中身はそっくりそのまま多変量でのガウス分布の式になっています。3次元以上で扱われる正規分布のようなものだと理解していますが、詳しくは別記事を参照ください。
重要なのはxとは圧縮前のデータ集合Xの中の一つのデータ点です。
- 投稿日:2020-11-04T17:28:49+09:00
古のTensorFlow1.xで部分的にパラメータの読み込みをする
ありがたいことに、世にTensorFlow2.xが公開されてずいぶん経ちました。
これまでv1.xで随分もがいていましたが、v2.xではデコレータで簡単にtf的なグラフに変更できるようになるなど大変素晴らしい機能がたくさん実装され、我々開発者もスピーディにモデルの学習、評価等を行えるようになりました。しかし一部にv2.xとの互換性の問題からそのままv1.xを使用しなければならない人もいますよね(何を隠そう私のことです)。
今や更新されるドキュメントはみんな2.xについて言及していて1.xのドキュメントは増えにくく、適切な情報にたどり着けなくなってきています。
私は今(2020/11/4 17:10現在)、実際v1.xでパラメータを部分的に読み込む場合の処理についてヒットするまで時間がかかってしまいました。
単にResNetとかMobileNetとか、公開されているモデルをそのまま使用する場合なら計算グラフ全部で読み込んでしまえるのでそこまで苦労しないでしょうが、事前に学習したResNetを画像エンコーダとして後続の自作ネットワークに使用したい...という場合には部分的にパラメータの読み込みをする必要があります。
今後v1.xで部分的にパラメータの読み込みをする方へむけて(何を隠そう私のことです)、タイトルに記載の通り部分的なパラメータ読み込みの方法について記録しておきます。やること
原則、以下のコードで可能です。
... with tf.Session() as sess: saver = tf.train.Saver({'読み込みたいモデルのノード名': そのノード名をつけたtf.Variableの変数, ...}) saver.restore(sess, 'path/to/checkpoint')ただし、「tf.train.Saverに渡すノード名と変数の辞書どうやって作ればいいんだよ!」となるので、その場合は
variables = tf.trainable_variables() restore_variables = {} for v in variables: if 'モデルの名前空間' in v.name: restore_variables[v.name] = vとすることで、現在使用しているノードから特定のノードだけ取り出して辞書に入れることができます。
学習する時、勝手に
:0とかが付与されることがあるので、その場合はfixed_name = v.name[:-2] restore_variables[fixed_name] = vみたいに対応することで、読み込み可能になります。
補足
事前学習したときのcheckpointにそれぞれ変数名がどのように保存されているのか確認する場合は、
tensorflow.python.tools.inspect_checkpoint.print_tensors_in_checkpoint_fileが便利です。import print_tensors_in_checkpoint_file print_tensors_in_checkpoint_file(file_name='path/to/checkpoint', tensor_name='', all_tensors=False) # beta1_power (DT_FLOAT) [] # beta2_power (DT_FLOAT) [] # cae/conv0/convolution2d/biases (DT_FLOAT) [64] # cae/conv0/convolution2d/biases/Adam (DT_FLOAT) [64] # cae/conv0/convolution2d/biases/Adam_1 (DT_FLOAT) [64] # cae/conv0/convolution2d/weights (DT_FLOAT) [7,7,3,64] # cae/conv0/convolution2d/weights/Adam (DT_FLOAT) [7,7,3,64] # cae/conv0/convolution2d/weights/Adam_1 (DT_FLOAT) [7,7,3,64] # cae/conv1/convolution2d/biases (DT_FLOAT) [32] # cae/conv1/convolution2d/biases/Adam (DT_FLOAT) [32] # cae/conv1/convolution2d/biases/Adam_1 (DT_FLOAT) [32] # cae/conv1/convolution2d/weights (DT_FLOAT) [5,5,64,32] # cae/conv1/convolution2d/weights/Adam (DT_FLOAT) [5,5,64,32] # cae/conv1/convolution2d/weights/Adam_1 (DT_FLOAT) [5,5,64,32]参考
以下の記事を参考にしました。
https://blog.metaflow.fr/tensorflow-saving-restoring-and-mixing-multiple-models-c4c94d5d7125
- 投稿日:2020-11-04T17:18:44+09:00
pythonによる機械学習(2) 単回帰分析
前回の記事で機械学習の全体的な分類についてまとめたので今回からはそれぞれの具体的な実装について記して行く。
前回の記事はこちらから
https://qiita.com/U__ki/items/4ae54da6cadec8a84d1b単回帰分析の実装
今回のテーマは、
「部屋の大きさにあうテレビサイズは?」です。
春から引越しが決まっている人もいるのでないでしょうか。
新しい部屋の大きさにふさわしいテレビのサイズをどうやって決めようかと思う人のために部屋の大きさにあうテレビサイズを単回帰分析を用いて求めてみたいと思う。せっかくなのでpandasを用いて模擬データを作成し、そのあとそのデータを基にして分析することにした。
pandasによるcsvファイル作成
まずこちらの記事(https://www.olive-hitomawashi.com/lifestyle/2019/10/post-294.html) を参考に部屋のサイズにあうオススメのテレビサイズのデータを以下のようにした。
(これあるならこの記事いらなくない)【テレビサイズ】
6乗: 24インチ
8畳: 32インチ
10畳: 40インチ
12畳: 50インチこのデータをpandasを用いてcsvファイルとして出力する。
create_csv.py#csv作成pandas import pandas as pd df=pd.DataFrame([ ["6", "24"], ["8", "32"], ["10", "40"], ["12", "50"]], columns=["room_size", "tv_inch"] ) df.to_csv("room_tv.csv", index=False)dfはdata flameの略。
またindex=Falseとすることでcsv内のインデックス番号を無くした。
これで同一フォルダ上に新しくroom_tv.csvというファイルが作成された。以上でフォルダの中に以下のファイルが生成されていたら成功だ。
room_tv.csvroom_size,tv_inch 6,24 8,32 10,40 12,50これで今回用いるcsvファイルが用意できた。
単回帰分析
続いて今回のメインである単回帰分析を行っていく。
単回帰分析は次の3つの構成となる。
・モデルの決定
・評価関数を設定する
・評価関数を最小化する(傾きの決定)モデルの決定
まずcsvを読み込む。
main.pydf=pd.read_csv("room_tv.csv")これでjupyter notebookを用いているなら以下のように先ほど作成したデータが表示される。
次に一旦今回のデータを図示して見る。pythonで図示するにはmatplotlibがわかりやすい。
main.pyx=df["room_size"] y=df["tv_inch"] import matplotlib.pyplot as plt plt.scatter(x,y) plt.show()ここでxには部屋の大きさを、yにはテレビのサイズを入れた。
扱いやすそうなデータが取れた。
今回は一次関数で対応できそう(モデルの決定)。現状このデータをそのまま用いてもいいのだが、このデータをもちいると
y=ax+b
となり、a,bの2つの変数が出てくる。このままでも計算はできるのだが、変数を一つ減らすためにデータの平均化を行う。データの平均化
全てのデータの平均値を取り、データからそれぞれ引き算した値を用いる。
pandasではデータの平均値をとったり全てのデータに対して引き算することが極めて簡単にできる。
これを行うことでy=axのみを考えることができる。main.py#データの平均値の取得 xm=x.mean() ym=y.mean() #全てのデータから平均値を引くことで中心化 xc=x-xm yc=y-ym #再表示 plt.scatter(xc,yc) plt.show()以上のコードで以下のような図に変化した。
先ほどのグラフとあまり変化がないようだが切片(b)を考えずに済むので今後の計算がかなり楽になる。
\hat{y}=axについてのaを求めればよい。
評価関数の決定
実測値に対して予測値(機械学習を用いたもの)が一番小さくなるように式を決定したい。そのためのものが評価関数の決定という。データサイエンスでいう「損失関数」と意味は同じ。
ここでは説明は少なくするが二乗誤差を確かめて小さいもので決定する。
yを実測値、y^(ワイハット)を予測値として\begin{align} L&=(y_1-\hat{y_1})^2+(y_2-\hat{y_2})^2+....+(y_N-\hat{y_1N})^2\\ &=\sum_{n=1}^{N}(y_n-\hat{y_n})^2 \end{align}で表すことができる。この時Lのことを評価関数という。
評価関数の最小化
評価関数は先ほど見た通り二次関数で現れる。
したがって傾きが0の点が最小となり、二乗誤差が小さい点となる。高校数学の範囲になるが二次方程式の傾きが0となる点を求めるなら微分を行い「=0」となる点を探せばいい。
変数はaなので
\frac{\partial}{\partial a}(L)=0を求める。これに先ほどの数式を代入し展開すると
\begin{align} L&=\sum_{n=1}^{N}y_n^2-2(\sum_{n=1}^{N}x_ny_n)a+(\sum_{n=1}^{N}x_n^2)a^2\\ &=c_o-2c_1a+c_2a^2 \end{align}代入して
\frac{\partial}{\partial a}(c_o-2c_1a+c_2a^2)=0\\ \\ a=\frac{\sum_{n=1}^{N}x_ny_n}{\sum_{n=1}^{N}x_n^2}これについてコードを作成して行く。
main.py#式よりそれぞれの二乗の値を求める xx=xc*xc xy=xc*yc #aを求める a=xy.sum()/xx.sum() #プロットしてみる plt.scatter(xc,yc, label="y") plt.plot(x,a*x, label="y_hat", color="green") plt.legend() plt.show()以下にそのグラフを記す。
実測値の範囲でxが定まってるので線分が短くなっているがaを求めれた。
以上により傾きaが求まった。しかし中心化しているので実際に当てはめる際は
x(x値)-x(平均値)をしたものにaをかけて最後にy(平均値)をすることを忘れないこと。
最後にこれをまとめたものを記す。
main.pyimport pandas as pd import matplotlib.pyplot as plt df=pd.read_csv("room_tv.csv") x=df["room_size"] y=df["tv_inch"] #平均化 xm=x.mean() ym=y.mean() #中心化 xc=x-xm yc=y-ym xx=xc*xc xy=xc*yc a=xy.sum()/xx.sum() plt.scatter(xc,yc, label="y") plt.plot(x,a*x, label="y_hat", color="green") plt.legend() plt.show()
おまけ
main.py#データの概要把握 df.describe()これにより以下のようにデータの解析を行ってくれる。
より複雑で大量なデータの処理の際に役立つ。
最後に
コードとしては短いものであったがとても意味のあるものだった。
次回は重回帰分析を行ってみたいと思います。
今後の展開としてはコーディング、エラー処理などのプログラミング関連だけでなく、神経科学と結びつけたものも投稿していきます。





- 投稿日:2020-11-04T17:18:44+09:00
pythonによる機械学習(2) 単回帰分析
前回の記事で機械学習の全体的な分類についてまとめたので今回からはそれぞれの具体的な実装について記して行く。
前回の記事はこちらから
https://qiita.com/U__ki/items/4ae54da6cadec8a84d1b単回帰分析の実装
今回のテーマは、
「部屋の大きさにあうテレビサイズは?」です。
春から引越しが決まっている人もいるのでないでしょうか。
新しい部屋の大きさにふさわしいテレビのサイズをどうやって決めようかと思う人のために部屋の大きさにあうテレビサイズを単回帰分析を用いて求めてみたいと思う。せっかくなのでpandasを用いて模擬データを作成し、そのあとそのデータを基にして分析することにした。
pandasによるcsvファイル作成
まずこちらの記事(https://www.olive-hitomawashi.com/lifestyle/2019/10/post-294.html) を参考に部屋のサイズにあうオススメのテレビサイズのデータを以下のようにした。
(これあるならこの記事いらなくない)【テレビサイズ】
6乗: 24インチ
8畳: 32インチ
10畳: 40インチ
12畳: 50インチこのデータをpandasを用いてcsvファイルとして出力する。
create_csv.py#csv作成pandas import pandas as pd df=pd.DataFrame([ ["6", "24"], ["8", "32"], ["10", "40"], ["12", "50"]], columns=["room_size", "tv_inch"] ) df.to_csv("room_tv.csv", index=False)dfはdata flameの略。
またindex=Falseとすることでcsv内のインデックス番号を無くした。
これで同一フォルダ上に新しくroom_tv.csvというファイルが作成された。以上でフォルダの中に以下のファイルが生成されていたら成功だ。
room_tv.csvroom_size,tv_inch 6,24 8,32 10,40 12,50これで今回用いるcsvファイルが用意できた。
単回帰分析
続いて今回のメインである単回帰分析を行っていく。
単回帰分析は次の3つの構成となる。
・モデルの決定
・評価関数を設定する
・評価関数を最小化する(傾きの決定)モデルの決定
まずcsvを読み込む。
main.pydf=pd.read_csv("room_tv.csv")これでjupyter notebookを用いているなら以下のように先ほど作成したデータが表示される。
次に一旦今回のデータを図示して見る。pythonで図示するにはmatplotlibがわかりやすい。
main.pyx=df["room_size"] y=df["tv_inch"] import matplotlib.pyplot as plt plt.scatter(x,y) plt.show()ここでxには部屋の大きさを、yにはテレビのサイズを入れた。
扱いやすそうなデータが取れた。
今回は一次関数で対応できそう(モデルの決定)。現状このデータをそのまま用いてもいいのだが、このデータをもちいると
y=ax+b
となり、a,bの2つの変数が出てくる。このままでも計算はできるのだが、変数を一つ減らすためにデータの平均化を行う。データの平均化
全てのデータの平均値を取り、データからそれぞれ引き算した値を用いる。
pandasではデータの平均値をとったり全てのデータに対して引き算することが極めて簡単にできる。
これを行うことでy=axのみを考えることができる。main.py#データの平均値の取得 xm=x.mean() ym=y.mean() #全てのデータから平均値を引くことで中心化 xc=x-xm yc=y-ym #再表示 plt.scatter(xc,yc) plt.show()以上のコードで以下のような図に変化した。
先ほどのグラフとあまり変化がないようだが切片(b)を考えずに済むので今後の計算がかなり楽になる。
\hat{y}=axについてのaを求めればよい。
評価関数の決定
実測値に対して予測値(機械学習を用いたもの)が一番小さくなるように式を決定したい。そのためのものが評価関数の決定という。データサイエンスでいう「損失関数」と意味は同じ。
ここでは説明は少なくするが二乗誤差を確かめて小さいもので決定する。
yを実測値、y^(ワイハット)を予測値として\begin{align} L&=(y_1-\hat{y_1})^2+(y_2-\hat{y_2})^2+....+(y_N-\hat{y_1N})^2\\ &=\sum_{n=1}^{N}(y_n-\hat{y_n})^2 \end{align}で表すことができる。この時Lのことを評価関数という。
評価関数の最小化
評価関数は先ほど見た通り二次関数で現れる。
したがって傾きが0の点が最小となり、二乗誤差が小さい点となる。高校数学の範囲になるが二次方程式の傾きが0となる点を求めるなら微分を行い「=0」となる点を探せばいい。
変数はaなので
\frac{\partial}{\partial a}(L)=0を求める。これに先ほどの数式を代入し展開すると
\begin{align} L&=\sum_{n=1}^{N}y_n^2-2(\sum_{n=1}^{N}x_ny_n)a+(\sum_{n=1}^{N}x_n^2)a^2\\ &=c_o-2c_1a+c_2a^2 \end{align}代入して
\frac{\partial}{\partial a}(c_o-2c_1a+c_2a^2)=0\\ \\ a=\frac{\sum_{n=1}^{N}x_ny_n}{\sum_{n=1}^{N}x_n^2}これについてコードを作成して行く。
main.py#式よりそれぞれの二乗の値を求める xx=xc*xc xy=xc*yc #aを求める a=xy.sum()/xx.sum() #プロットしてみる plt.scatter(xc,yc, label="y") plt.plot(x,a*x, label="y_hat", color="green") plt.legend() plt.show()以下にそのグラフを記す。
実測値の範囲でxが定まってるので線分が短くなっているがaを求めれた。
以上により傾きaが求まった。しかし中心化しているので実際に当てはめる際は
x(x値)-x(平均値)をしたものにaをかけて最後にy(平均値)をすることを忘れないこと。
最後にこれをまとめたものを記す。
main.pyimport pandas as pd import matplotlib.pyplot as plt df=pd.read_csv("room_tv.csv") x=df["room_size"] y=df["tv_inch"] #平均化 xm=x.mean() ym=y.mean() #中心化 xc=x-xm yc=y-ym xx=xc*xc xy=xc*yc a=xy.sum()/xx.sum() plt.scatter(xc,yc, label="y") plt.plot(x,a*x, label="y_hat", color="green") plt.legend() plt.show()
おまけ
main.py#データの概要把握 df.describe()これにより以下のようにデータの解析を行ってくれる。
より複雑で大量なデータの処理の際に役立つ。
最後に
コードとしては短いものであったがとても意味のあるものだった。
次回は重回帰分析を行ってみたいと思います。
今後の展開としてはコーディング、エラー処理などのプログラミング関連だけでなく、神経科学と結びつけたものも投稿していきます。
- 投稿日:2020-11-04T15:19:09+09:00
住所から位置情報(緯度経度)を求める.PythonでGeocode 〜Geocoderとpydams〜
Google Colaboratory使用
Geocoder
https://qiita.com/yoshi_yast/items/bb75d8fceb712f1f49d1
を参照pydams
詳細は以下
https://github.com/hottolink/pydams
http://newspat.csis.u-tokyo.ac.jp/geocode/modules/dams/index.php?content_id=2
https://www.hottolink.co.jp/blog/20180823_98734/準備
!wget http://newspat.csis.u-tokyo.ac.jp/download/dams-4.3.4.tgz !tar -xzvf dams-4.3.4.tgz!git clone https://github.com/hottolink/pydams.git !patch -d ./dams-4.3.4 -p1 < ./pydams/patch/dams-4.3.4.diff%cd dams-4.3.4 !./configure; make!make install !ldconfig !ldconfig -v | grep dams!ldconfig -v | grep dams!make dic !make install-dic%cd ../ ![ ! -d 'pydams' ] && git clone https://github.com/hottolink/pydams.git %cd pydams !make all !make install!pip freeze | grep pydams #実行結果 #pydams==1.0.4from pydams import DAMS from pydams.helpers import pretty_print DAMS.init_dams() address = u"東京都港区芝公園4丁目2−8" # geocode() method geocoded = DAMS.geocode(address) pretty_print(geocoded) # geocode_simplify() method geocoded = DAMS.geocode_simplify(address) pretty_print(geocoded) """実行結果 score: 5 candidates: 1 candidate: 0, address level: 7 address:東京都, lat:35.68949890136719, long:139.69163513183594 address:港区, lat:35.65850067138672, long:139.75155639648438 address:芝公園, lat:35.65782928466797, long:139.75172424316406 address:四丁目, lat:35.65620422363281, long:139.7484588623047 address:2番, lat:35.658538818359375, long:139.74542236328125 score: 5 candidates: 1 candidate: 0, address level: 7 address:東京都港区芝公園四丁目2番, lat:35.658538818359375, long:139.74542236328125 """住所を入力とし,緯度経度を返す関数
def GEOCODE(address): DAMS.init_dams() # geocode() method geocoded = DAMS.geocode_simplify(address) res = geocoded['candidates'][0] return [res['y'], res['x']]print(GEOCODE('東京都港区芝公園4丁目2−8')) #[35.658538818359375, 139.74542236328125]
- 投稿日:2020-11-04T15:14:49+09:00
Serverless FrameworkでLINE Botを作ってみた!
Serverless Frameworkとは
Serverless Framework はFaaS(Function as a Service)やクラウドのDB,Storageでアプリケーションを構成するためのフレームワークです。AWS以外にもGCP, Azureにも対応しています。
導入方法などは、こちらの記事を参考にしてください。注意事項
・コマンドはMacを想定しているのでWindowsの方は、設定方法が異なると思います。
・AWSのアカウントを持っていないと、できません。
・LambdaやAPI Gatewayの設定を簡単に出来過ぎてしまうため、初めて触る方には、あまり理解できないかと思います。LINE Botを作成
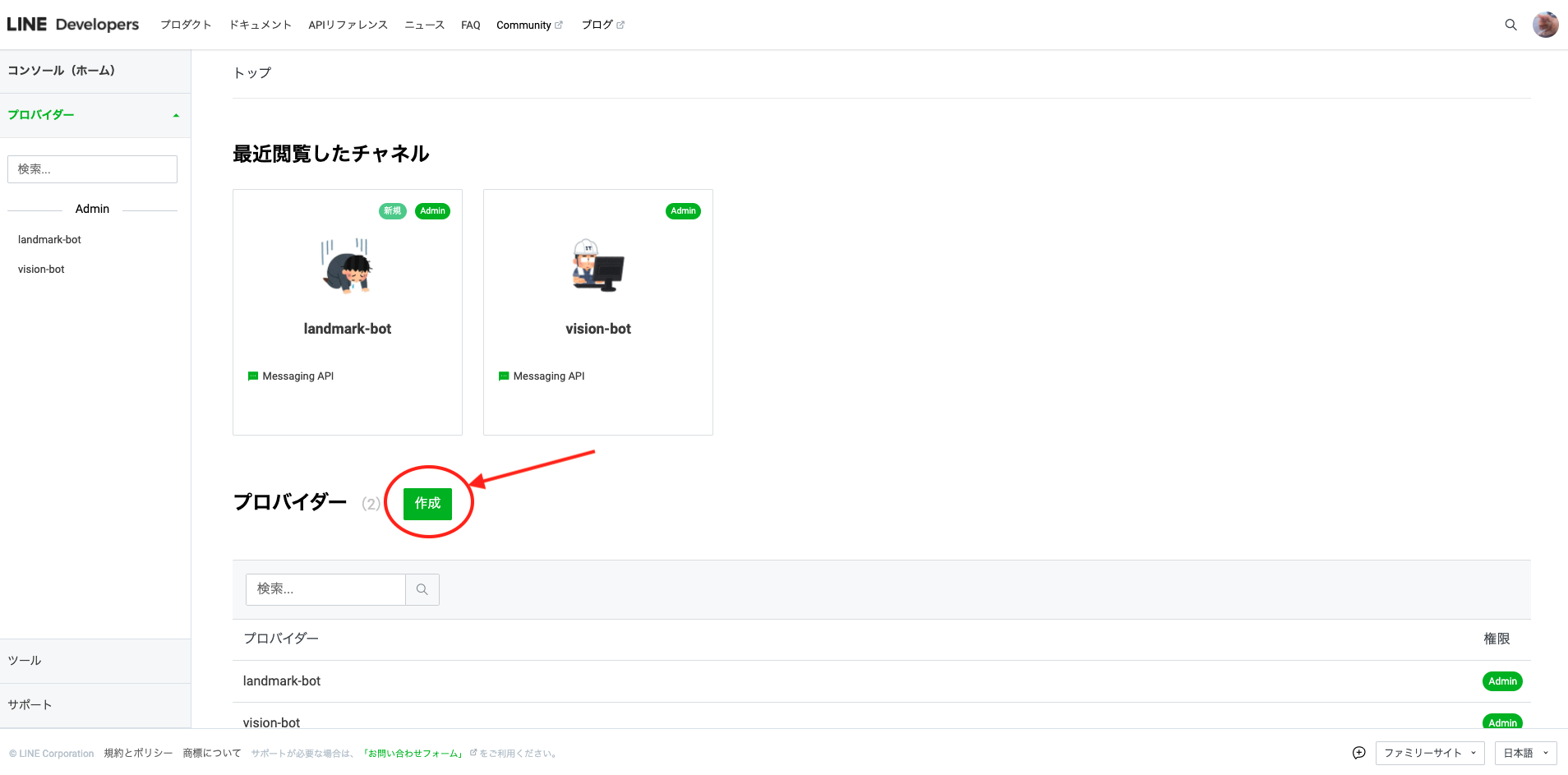
LINE DvelopersでLINE Botを作成します。
ログインしたら、画面下の作成をクリックします。
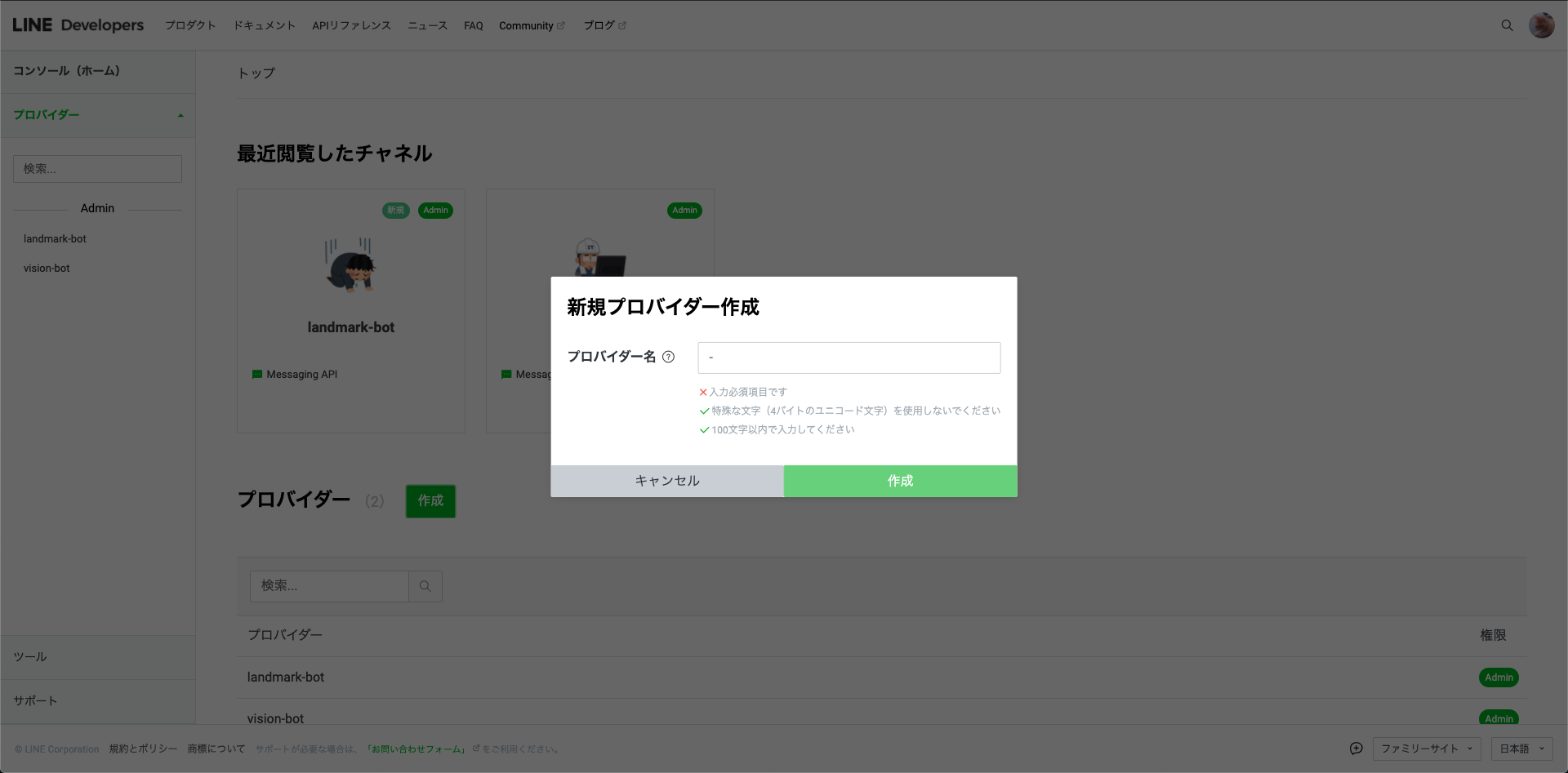
そうすると、プロバイダー名を入力する画面が表示されるので、好きな名前を入力します。
これでプロバイダーを作成できました。
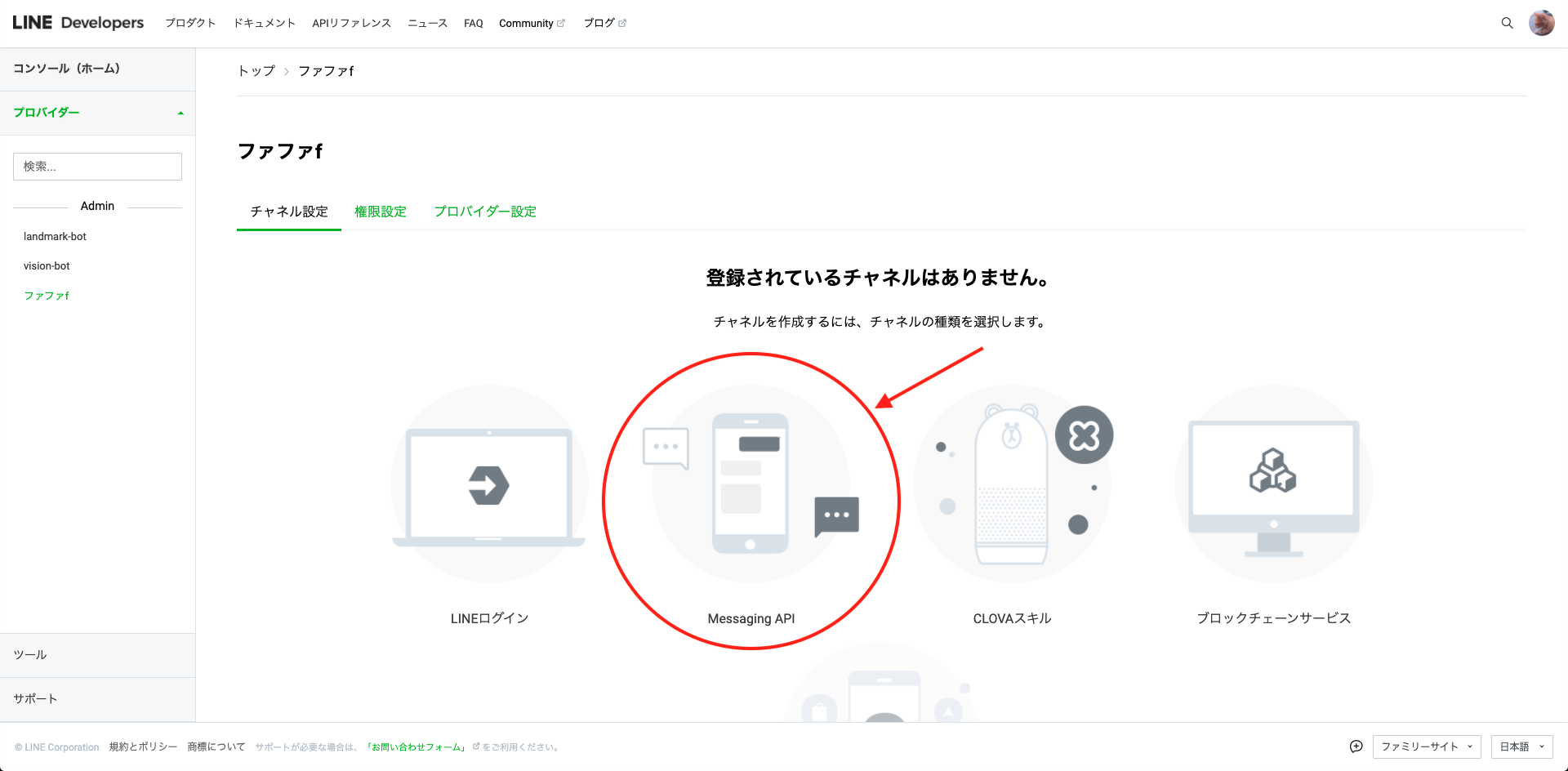
次にチャネル(LINE Bot)を作成します。今回はおうむ返しするLINE Botを作成するのでMessaging APIを選択します。
LINE Botのアイコンや名前を入力する画面が出てくるので、入力します。
これでLINE Botの作成は終了です。
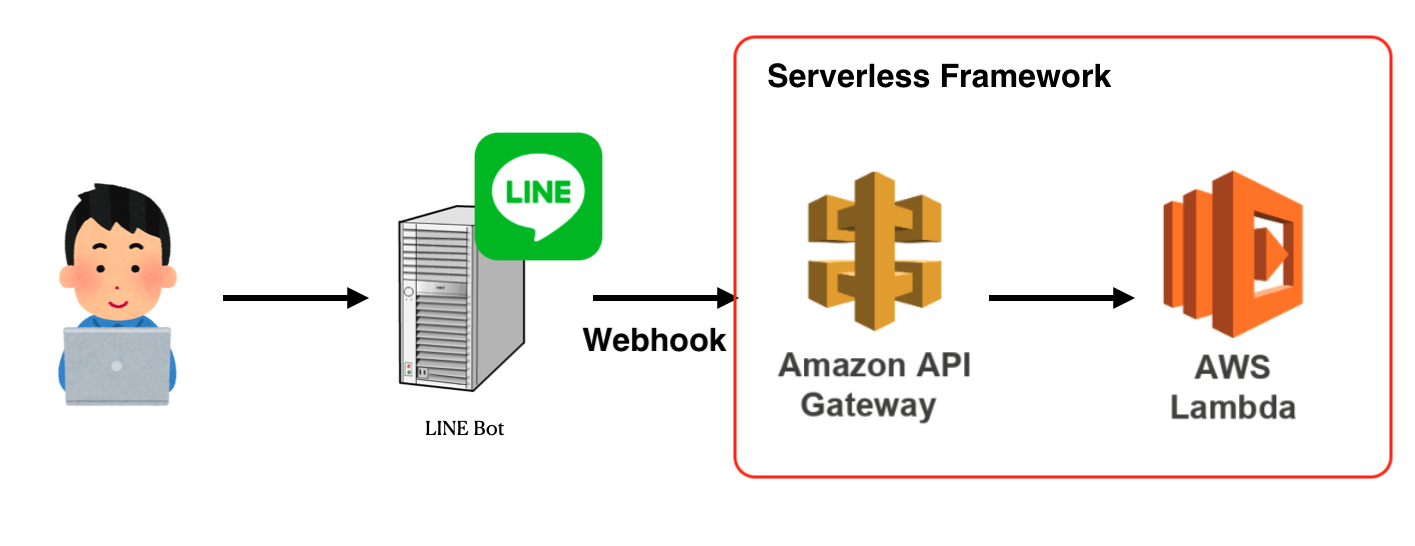
システム構成
今回作成するシステムは、ユーザーがLINE Botにメッセージを送信すると、WebhookでLambdaの関数が実行されるという感じです。
赤く囲っているところをServerless Frameworkで実装します。
AWSのアカウントをPCに関連付ける
AWS-CLIを利用してPCにAWSの情報を設定しておきます。
この記事を参考にLet's Serverless
Serverless FrameworkをPCに導入したら、ターミナルで作業ディレクトリに移動して、以下のコマンドを実行します。
--templateオプションで指定しているのは、Lambdaで使用するプログラミング言語で、--pathオプションで指定しているのは、プロジェクト名とプロジェクトの配置場所です。適宜変更してください。$ serverless create --template aws-python3 --path line-botコマンドを実行すると以下のディレクトリ構成でプロジェクトが作成されると思います。
line-bot ├ .gitignore ├ handler.py └ serverless.ymlserverless.ymlを書き換える
serverless.ymlを以下に書き換えます。
serverless.ymlservice: line-bot frameworkVersion: '2' provider: name: aws runtime: python3.8 region: ap-northeast-1 # 東京リージョンを指定 # Lambda関数の設定 functions: callback: handler: handler.callback # API Gatewayの設定 events: - http: path: callback method: postこれで、API GatewayとLambdaの設定が終わりです。
簡単すぎますね...Lambda関数を実装
次にLambdaが実行する関数を実装します。
Pythonの仮想環境を作成
Pythonなので、まず仮想環境を作ります。
自分は、venvで仮想環境を作りますが、conda や virtualenvで作る方もいると思うので、そこは適宜変更してください。$ python3 -m venv line-botこれを実行すると、line-botというディレクトリが生成されると思います。
line-bot ├ line-bot/ <-- 仮想環境用ディレクトリ ├ .gitignore ├ handler.py └ serverless.yml生成されたら、以下のコマンドでactivateしてください。
$ source line-bot/bin/activateLINE Botに使用するライブラリ
LINE Botの操作には、line-bot-sdkというライブラリを使用します。
$ pip3 install line-bot-sdkhandler.pyに実装
これで準備は完了なので、実際にコードを書きます。
handler.pyfrom linebot.models import ( MessageEvent, TextMessage, TextSendMessage, ImageMessage ) from linebot.exceptions import ( InvalidSignatureError ) from linebot import ( LineBotApi, WebhookHandler ) import os access_token = os.environ['LINE_CHANNEL_ACCESS_TOKEN'] // Lambdaの環境変数から取得 secret_key = os.environ['LINE_CHANNEL_SECRET'] // Lambdaの環境変数から取得 line_bot_api = LineBotApi(access_token) handler = WebhookHandler(secret_key) // LINE BotのWebhookで実行される関数 def callback(event, context): try: signature = event["headers"]["x-line-signature"] event_body = event["body"] handler.handle(event_body, signature) except InvalidSignatureError as e: logger.error(e) return {"statusCode": 403, "body": "Invalid signature. Please check your channel access token/channel secret."} except Exception as e: logger.error(e) return {"statusCode": 500, "body": "exception error"} return {"statusCode": 200, "body": "request OK"} // おうむ返しをする関数 @handler.add(MessageEvent, message=TextMessage) def handle_message(event): line_bot_api.reply_message( event.reply_token, TextSendMessage(text=event.message.text) )これで、Lambda関数の実装は終了です。
ひとまずデプロイ
ここまで来たら、一回デプロイをして見ましょう
以下のコマンドでデプロイできます。
slsは、serverlessの短縮形です。$ sls deployこれを実行したら、AWSのコンソール画面にいき、東京リージョンのLambdaを見にいきましょう
すると、実際にデプロイされていることが分かると思います。LINE Botのアクセストークンとシークレットキーを見にいく
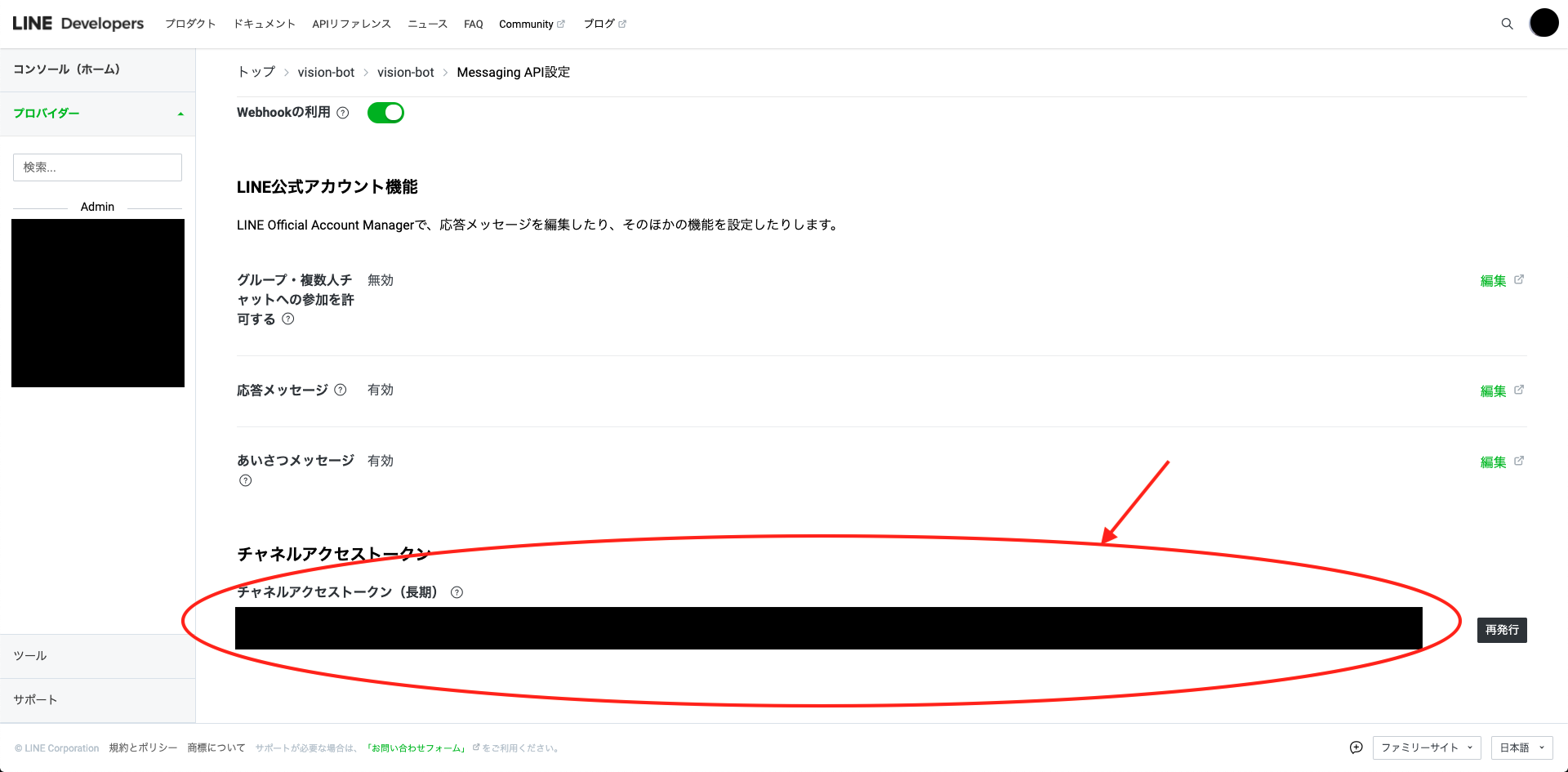
実装したLambda関数を実行するためには、LINE Botのアクセストークンとシークレットキーが必要になるので、LINE Developersのコンソール画面で見ます。
アクセストークンは、Messaging API設定の下の方にあります。
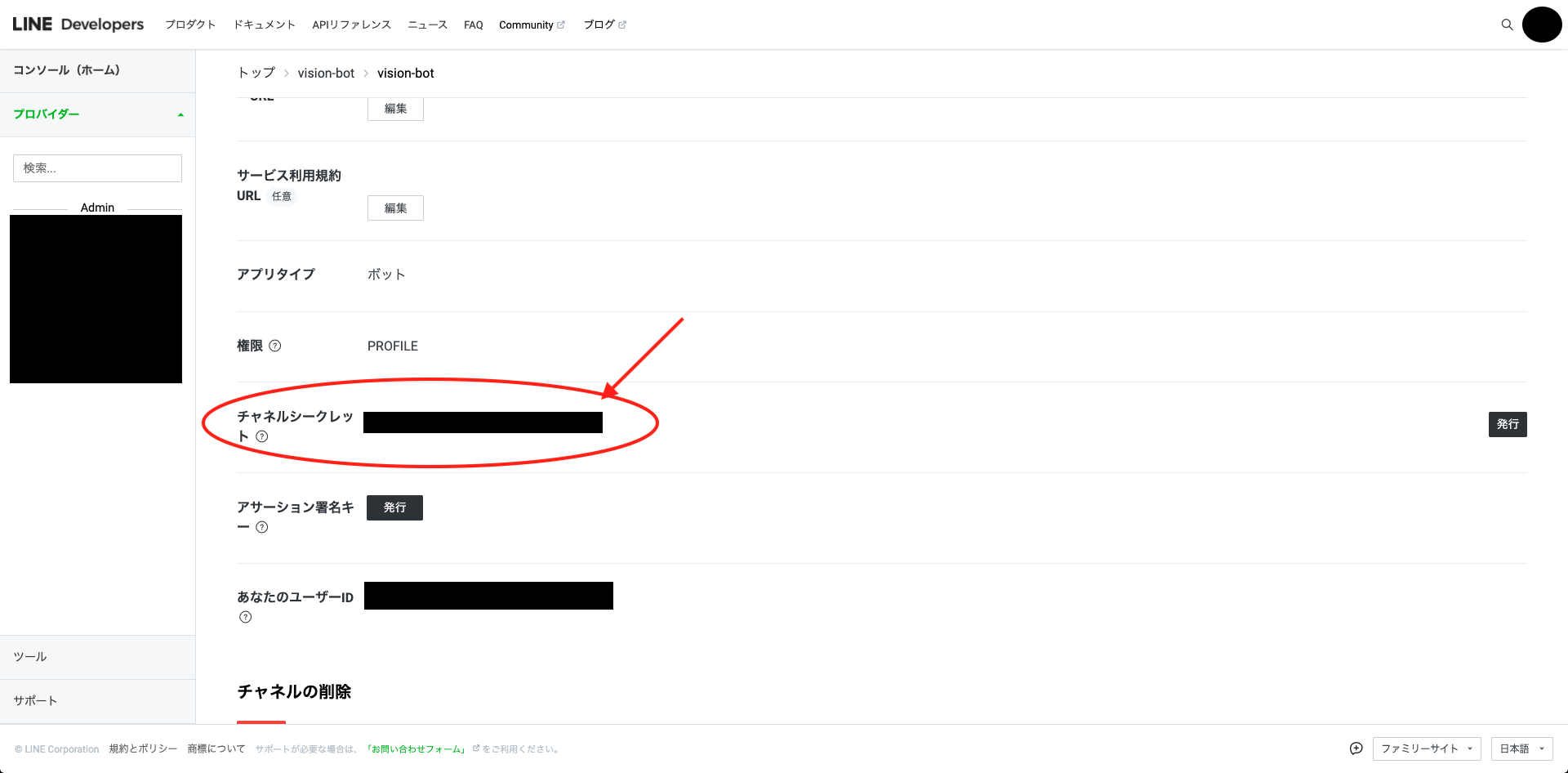
シークレットキーは、チャネル基本設定の下の方にあります。
Lambdaに環境変数を設定
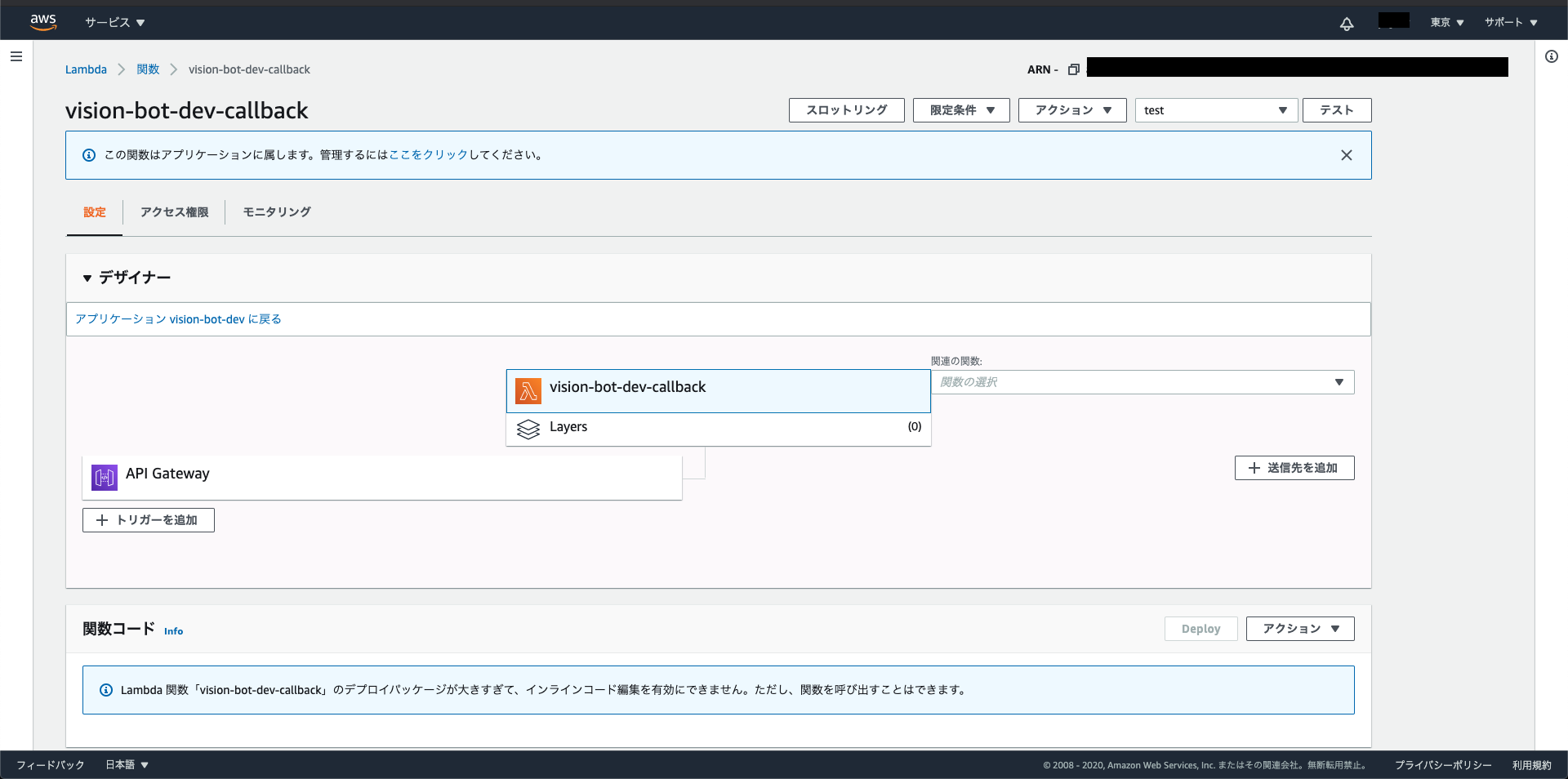
上記で見た値をLambdaの環境変数にセットします。
この画面の少し下に、環境変数を設定できるところがあるので、このような形で保存します。
キー 値 LINE_CHANNEL_ACCESS_TOKEN ✖️✖️✖️✖️✖️✖️ LINE_CHANNEL_SECRET ✖️✖️✖️✖️✖️✖️
API GatewayのURLを見る
以下のところをクリックすると、API Gatewayから発行されているURLを確認できるので、見ておきましょう。
LINE BotのWebhookにLambda関数のURLを設定
LINE BotのMessaging API設定の画面のWebhookにAPI GatewayのURLを入力します。
入力後、検証ボタンをクリックして、成功画面が表示されたら、終了です。
LINE BotのQRコードが上の方に表示されていると思うのうで、そこから友達追加をすれば、おうむ返しBotで遊べると思います。もしも、詰まったら
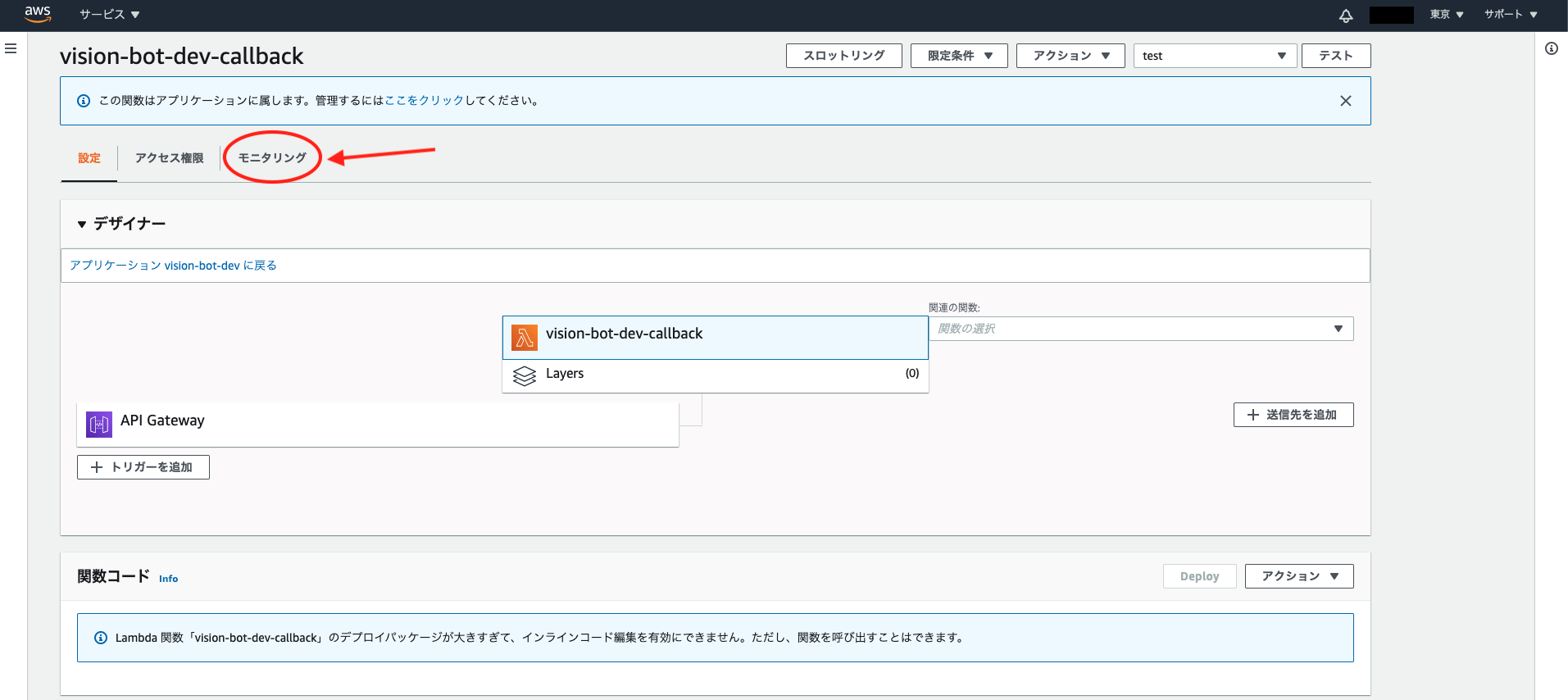
上記の検証をクリックして、レスポンスエラーが表示されたら、Lambda関数でエラーが出ていると思うので、以下のモニタリングのところから
この「CloudWatchのログを表示」をクリックすると、Lambda関数のログを見ることができるので、それを見てデバッグをして見てください。





- 投稿日:2020-11-04T14:42:40+09:00
PythonでPDFを生成するライブラリ比較まとめ
この記事の目的
PDFで見積書を出力するにあたって関連ライブラリのメリデメを洗い出してみました。
そのライブラリの中で実装方法とアウトプットを提示し、比較できる状態にしすることが本稿の目的です。この記事は2つの手法のPDF出力ライブラリをリスト化して比較しました。その手法と、各種ライブラリは次のとおりです。
- HTMLをPDFを化して出力する
- django-wkhtmltopdf
- django_xhtml2pdf
- WeasyPrint
- コードからPDFを生成するもの
- reportlab
また比較に関しては次の点に注目しています。
- ライブラリの使いやすさ
- 使うのは容易か
- コードは複雑にならないか
- 動作は重くないか
- 動作させるために別途ソフトウェアのインストールは必要か
自由度
- A4一枚の見積書を作成するのは容易か
- レイアウトに対して細かい設定が可能か
保守性
- メンテナンスはしやすいか
- ライブラリの更新頻度
- 出力されたPDFのクオリティは問題なさそうか
- ネット上の情報は多いか
TL;DR.
個人的な主観的な比較を置いておきます。
ライブラリ名 使いやすさ 自由度 保守性 備考 django-wkhtmltopdf ○ ○ △ django_xhtml2pdf ○ × △ WeasyPrint ○ △ △ reportlab × ◎ ○ HTML to PDF
django-wkhtmltopdf
ドキュメント django-wkhtmltopdf 3.2.0 documentation
グーグル検索で
Python PDFで検索したときに検索上位に出るwkhtmltopdfをdjango向けにラップされたライブラリです。
Djangoのクラスベースビューに対応しており非常に安易に導入できます。
生成されるPDFもデフォルトできれいに出力されています。ただ、別途ソフトウェアのインストールが必要なのでAppEngineでの導入の手間は大変そうです(要検証)。インストール方法
$ pipenv install django-wkhtmltopdf別途wkhtmltopdfからソフトウェアインストールが必要。
SampleCode
from wkhtmltopdf.views import PDFTemplateView class PdfSampleView(PDFTemplateView): filename = 'my_psdf.pdf' template_name = "pdf_sample/sample.html"生成されたPDF
django_xhtml2pdf
PythonでHTMLをPDFに変換するライブラリ
django_xhtml2pdfをDjango向けにラップしたライブラリです。
クラスベースビュー向けのmixinを提供されていて簡単に使用できます。またデコレーターが標準でサポートされています。
ただしドキュメントが少なく、オプションはほとんど無い。またCSSの解釈が独特なためか通常のHTMLとは違う構成で出力されます。インストール方法
$ pipenv install django_xhtml2pdfSampleCode
from django_xhtml2pdf.views import PdfMixin class Xhtml2pdfSampleView_(PdfMixin, TemplateView): template_name = "pdf_sample/sample.html"生成されたPDF
WeasyPrint
wkhtmltopdfに近いPDF生成ツールとライブラリ。ドキュメントが充実しています。
wkhtmltopdfほどではないがxhtmlよりかは高品質なPDFが出力されます。xhtmlとくらべ相対的にHTMLとの出力に差分がすくない。ただ、インストールドキュメントを見るとパッケージとは別にインストールが必要とのためAppEngineではむずかしそうです(要調査)。WeasyPrint — WeasyPrint 51 documentation
SampleCode
from weasyprint import HTML, CS from django.http import HttpResponse from django.template.loader import get_templat class WeasyPrintView(TemplateView): template_name = 'pdf_sample/sample.html' def get(self, request, *args, **kwargs): html_template = get_template('pdf_sample/sample.html') context = super().get_context_data(**kwargs) html_str = html_template.render(context) pdf_file = HTML(string=html_str, base_url=request.build_absolute_uri()).write_pdf( ) response = HttpResponse(pdf_file, content_type='application/pdf') response['Content-Disposition'] = 'filename="fuga.pdf"' return response生成されたPDF
HardCodePDF
reportlab
Pythonのコード上で実際にレイアウトを指定して生成するライブラリです。
スタイルを含めコード上で起こすため必然的に長くなる。PDFの生成は問題なく実行できます。
またすべてのデータをコードで挿入できるため実装の自由度は非常に高いです。
オプションとドキュメントも充実しているため一通りの帳簿などの作成は可能です。ReportLab - Content to PDF Solutions
インストール方法
$ pipenv install reportlabSampleCode
from django.views.generic import TemplateView from django.http import HttpResponse from reportlab.pdfgen import canvas from reportlab.pdfbase import pdfmetrics from reportlab.pdfbase.cidfonts import UnicodeCIDFont from reportlab.lib.pagesizes import A4, portrait from reportlab.platypus import Table, TableStyle from reportlab.lib.units import mm from reportlab.lib import colors class ReportlabView(TemplateView): template_name = 'pdf_sample/sample.html' def get(self, request, *args, **kwargs): response = HttpResponse(status=200, content_type='application/pdf') response['Content-Disposition'] = 'filename="example.pdf"' # response['Content-Disposition'] = 'attachment; filename="example.pdf"' self._create_pdf(response) return response def _create_pdf(self, response): # 日本語が使えるゴシック体のフォントを設定する font_name = 'HeiseiKakuGo-W5' pdfmetrics.registerFont(UnicodeCIDFont(font_name)) # A4縦書きのpdfを作る size = portrait(A4) # pdfを描く場所を作成:pdfの原点は左上にする(bottomup=False) pdf_canvas = canvas.Canvas(response) # ヘッダー font_size = 24 # フォントサイズ pdf_canvas.setFont("HeiseiKakuGo-W5", font_size) pdf_canvas.drawString(93 * mm, 770, "見積書") font_size = 10 pdf_canvas.setFont("HeiseiKakuGo-W5", font_size) pdf_canvas.drawString( 150 * mm, 813, f"見積発行日: " ) pdf_canvas.drawString( 150 * mm, 800, "xxxxxxxxxxx-xxxxxxxxxx", ) # (4) 社名 data = [ [f"ほげほげ会社御中", ""], ["案件名", "ほげほげ案件"], ["御見積有効限:発行日より30日", ""], ] table = Table(data, colWidths=(15 * mm, 80 * mm), rowHeights=(7 * mm)) table.setStyle( TableStyle( [ ("FONT", (0, 0), (-1, -1), "HeiseiKakuGo-W5", 12), ("LINEABOVE", (0, 1), (-1, -1), 1, colors.black), ("VALIGN", (0, 0), (1, -1), "MIDDLE"), ("VALIGN", (0, 1), (0, -1), "TOP"), ] ) ) table.wrapOn(pdf_canvas, 20 * mm, 248 * mm) table.drawOn(pdf_canvas, 20 * mm, 248 * mm) pdf_canvas.drawString(20 * mm, 238 * mm, "下記の通り御見積申し上げます") # (4) 社名 data = [ ["合計金額(消費税込)", f"1000 円"], ] table = Table(data, colWidths=(50 * mm, 60 * mm), rowHeights=(7 * mm)) table.setStyle( TableStyle( [ ("FONT", (0, 0), (1, 2), "HeiseiKakuGo-W5", 10), ("BOX", (0, 0), (2, 3), 1, colors.black), ("INNERGRID", (0, 0), (1, -1), 1, colors.black), ("VALIGN", (0, 0), (1, 2), "MIDDLE"), ("ALIGN", (1, 0), (-1, -1), "RIGHT"), ] ) ) table.wrapOn( pdf_canvas, 20 * mm, 218 * mm, ) table.drawOn( pdf_canvas, 20 * mm, 218 * mm, ) # 品目 data = [["内容", "開始月", "終了月", "単価", "数量", "金額"]] for idx in range(13): data.append([" ", " ", " ", " ", " ", ""]) data.append([" ", " ", " ", "合計", "", f"{1000:,}"]) data.append([" ", " ", " ", "消費税", "", f"{1000 * 0.10:,.0f}"]) data.append([" ", " ", " ", "税込合計金額", "", f"{1000 * 1.10:,.0f}"]) data.append( [" ", " ", " ", "", "", ""], ) table = Table( data, colWidths=(70 * mm, 25 * mm, 25 * mm, 20 * mm, 20 * mm, 20 * mm), rowHeights=6 * mm, ) table.setStyle( TableStyle( [ ("FONT", (0, 0), (-1, -1), "HeiseiKakuGo-W5", 8), ("BOX", (0, 0), (-1, 13), 1, colors.black), ("INNERGRID", (0, 0), (-1, 13), 1, colors.black), ("LINEABOVE", (3, 11), (-1, 18), 1, colors.black), ("VALIGN", (0, 0), (-1, -1), "MIDDLE"), ("ALIGN", (1, 0), (-1, -1), "RIGHT"), ] ) ) table.wrapOn(pdf_canvas, 17 * mm, 100 * mm) table.drawOn(pdf_canvas, 17 * mm, 100 * mm) pdf_canvas.drawString(17 * mm, 100 * mm, "<備考>") table = Table( [[""]], colWidths=(180 * mm), rowHeights=90 * mm, ) table.setStyle( TableStyle( [ ("FONT", (0, 0), (-1, -1), "HeiseiKakuGo-W5", 8), ("BOX", (0, 0), (-1, -1), 1, colors.black), ("INNERGRID", (0, 0), (-1, -1), 1, colors.black), ("VALIGN", (0, 0), (-1, -1), "TOP"), ] ) ) table.wrapOn(pdf_canvas, 17 * mm, 5 * mm) table.drawOn(pdf_canvas, 17 * mm, 5 * mm) pdf_canvas.showPage() # pdfの書き出し pdf_canvas.save()生成されたPDF生成
参照
python + reportlab で 履歴書フォーマットPDFを作成 - Qiita
python 2.7 - HTML to PDF on Google AppEngine - Stack Overflow




- 投稿日:2020-11-04T14:38:36+09:00
Twitter API:フォローしているがフォローバックされてないアカウント一覧の取得
Twitter API:フォローしているがフォローバックされてないアカウント一覧の取得
フォロワーが多くなると手作業でこの作業をするのは厳しくなってくる。時間も無駄だし…。ということで半自動化することにする。なお、まだフォロワー数1万までは達していない状態なので、アンフォローする作業は実際に対象アカウントを視認しながら手作業で行いたい。アカウント一覧取得までをスクリプト化する。
※ ネット上にそういうことができるWebアプリ/Webサイトが転がっているが、使うのはちょっと怖いので自作することにする。
pythonとPIPをインストール
割愛
tweepyをインストール
$ pip install tweepyTwitter APIのキーをお手元に準備
https://developer.twitter.com/en/portal/dashboard より。
コード
#unfollow_list.py import tweepy keys = dict( screen_name = '[ツイッターアカウント名(screen_name)]', consumer_key = '[コンシューマーキー]', consumer_secret = '[コンシューマーシークレット]', access_token = '[アクセストークン]', access_token_secret = '[アクセストークンシークレット]', ) SCREEN_NAME = keys['screen_name'] CONSUMER_KEY = keys['consumer_key'] CONSUMER_SECRET = keys['consumer_secret'] ACCESS_TOKEN = keys['access_token'] ACCESS_TOKEN_SECRET = keys['access_token_secret'] auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET) auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET) api = tweepy.API(auth) followers = api.followers_ids(SCREEN_NAME) friends = api.friends_ids(SCREEN_NAME) for f in friends: if f not in followers: print(api.get_user(f).screen_name)実行
$ python unfollow_list.py結果
ファイルに落としたかったらコピペ。
補足
自動でプログラムにリムらせたかったら、
print(api.get_user(f).screen_name)の後にapi.destroy_friendship(f)文を追記。
※ しかし最初のうちはひとつひとつ手動でチェックしてみた方が良い。けっこうリストアップエラーがある(ちゃんとフォロバされているのに対象リストに入ってくる)


- 投稿日:2020-11-04T12:20:38+09:00
ラズパイやディープラーニングを用いてハムスターの行動を監視するシステムを作ってみた【概要】
動機
ペットのハムスターの活動の様子を知りたい。
具体的には..
- 外出時、ハムスターがちゃんと動いていることを知って安心したい。
- 夜行性のため、飼い主が寝ている時間帯にどれだけ動いていたかを知りたい。
→ 手持ちのラズパイに物体検出ディープラーニングモデルを埋め込み、監視システムを作成。
ラズパイカメラをスマホアームで固定して飼育ケージをストリーミング撮影しています。できたもの
3つの機能により、ハムスターの活動の様子を見守れるようにしています?
Githubにコード一式をまとめています(実装の詳細は作り方の記事にて解説)。1. 飼育ケージをラズパイカメラで撮影しストリーミング
?が巣穴から出てきてカメラに映ったら物体検出モデルが働いてくれます(↓Gif)
使ったもの: Python(Flask), OpenCV, PyTorch, YOLOv5
※ 夜行性なので、暗がりでも撮影できる赤外線カメラを導入。全体的に紫がかってます。
※ かなりカクカクしていますが、行動把握や↓のLINE通知目的ならこれで十分と判断..2. ハムスターを検出したらLINE通知
?が映ってるときに常に通知すると大変なことになるので、10分おきに判定をかけています。
使ったもの: LINE Notify API3. BIツールによる活動時間帯の可視化
なんとなくですがいつ動いてたか、がわかります。
※ 回し車(wheel)にどのくらい滞在してたかも可視化したいのですが、現状あまりうまく行ってないですね..
使ったもの: GCP(IoTCore, Pub/Sub, Cloud Functions, BigQuery), Googleデータポータルシステム構成図
ごちゃごちゃしてますが全体像はこんな感じです。
※ 最初はObject Detection APIでモデルを作成したのですが、後にYOLOv5に乗り換えました。
準備したもの&協力者
- Raspberry Pi 4B ※ Jetson nanoとかでも試したい..
- Kuman カメラモジュール Raspberry Pi用 夜間 赤外線可視 ラズベリーパイ 500W画素 Pi 4B 3 2 SC15
- ジャンガリアンハムスター
作り方
それぞれ長くなりそうなので各記事で紹介します(近日投稿予定)
- ラズパイカメラでハムスターの動きを検出し、ストリーミング&LINE通知してみた【YOLOv5】
- ラズパイカメラでハムスターの動きを検出し、ストリーミング&LINE通知してみた【Object Detection API】
- ラズパイカメラ検出したハムスターの動きをGoogleデータポータルで可視化してみた。





- 投稿日:2020-11-04T11:51:18+09:00
EV3×Pyrhon 機械学習その3 分類編
本記事の内容はベータ公開としているので内容が変更される場合があります。
本記事では、教育版 LEGO® MINDSTORMS EV3(以降EV3)とPython環境を利用して色の識別を分類を用いて行っていく。
環境構築に関しては環境構築編の記事を参照してほしい。
また、前回の記事ではライントレースと線形回帰を合わせた内容を行っている。EV3で機械学習その1 環境構築編:こちら
EV3で機械学習その2 線形回帰編:こちら
EV3で機械学習その3 分類編:本記事参考
本記事の内容は以下の書籍を参考にしている。
Pythonを使ったEV3の基本的な制御等については以下に網羅されている。本記事内での環境
PC
Windows10
Python 3.7.3
開発環境 VisualStudioCodeEV3
ev3dev目次
- 分類手法
- やること
- EV3のモデルと読み取る色
- プログラムの作成
- プログラムの実行
- 実行結果
- まとめ
分類手法
SVM(サポートベクターマシン)
データの散布があったとき、それらを分けるための境界線を引くための手法。
境界線を引く=分類の予測をする ということになるが、予測には過去のデータを利用する。
その際に外れ値のような余計なデータまで使ってしまうと精度が下がる可能性がある。
そこでSVMは本当に予測に必要となる一部のデータのみ利用する。予測に必要となるデータのことをサポートベクトルと呼び、サポートベクトルを用いた機械学習法がサポートベクターマシンとなる。
やること
今回はカラーセンサーでRGB(赤緑青の度合い)と何色かのラベル番号をセットで採取する。EV3のカラーセンサーはRGB値は0~255の数値で取得できる。採取したデータ群をもとにそのデータが何色なのか境界を定めさせデータをもとに推論を行う。
以下は今回採取するデータの例
EV3のモデルと読み取る色
前回使用したコースの端にあるカラーを読み取っていく。プログラム内でラベルの定義を変更することである程度の色を学習データとして利用することは可能なので好きな色を分類させることができる。

また今回も前回と同様のEV3のモデル「ベースロボ」を利用する。今回はモーターを動かすわけではないのでインテリジェントブロックとカラーセンサーさえあれば問題ないが、カラーセンサーは読み取る面から0.5cm~1cm程度の隙間が空いている必要があるため安定してカラーセンサーを固定できるモデルを利用する。

プログラムの作成
今回は以下の2つのプログラムを作成する。
- EV3側プログラム
data_get_color.py- PC側プログラム
Classification.py
前回同様データの処理や推論自体はPC側プログラムで行い、EV3側ではカラーのRGB値の取得や送信を行う。
それぞれのプログラムの関係性を以下の図に示す。
EV3側プログラム
EV3側プログラム
data_get_color.pyはVSCode上のワークスペースで作成する。ワークスペースの作成やEV3への転送方法については以下の記事を参照してほしい。
EV3×Pyrhon 機械学習その1 環境構築編data_get_color.pyimport time import socket import sys from ev3dev2.button import Button from ev3dev2.sensor import INPUT_3 from ev3dev2.sensor.lego import ColorSensor def dataget(color_dic, color_num): _rgb_data = color.raw _rgb_data = list(_rgb_data) _rgb_data.append(color_num) _rgb_data_str = ','.join(map(str, _rgb_data)) s.send(_rgb_data_str.encode()) print('\n'+'rgb_color = {}'.format(_rgb_data_str)) def predict(): _rgb_data = color.raw _rgb_data = list(_rgb_data) _rgb_data_str = ','.join(map(str, _rgb_data)) s.send(_rgb_data_str.encode()) pre_color = s.recv(1024).decode() print('\n'+'predict_color = {}'.format(color_dic[int(pre_color[0])])) # sensors&motors definition button = Button() color = ColorSensor(INPUT_3) # gyro initialize color.mode = 'RGB-RAW' # variable initialize color_dic = { 1: 'RED', 2: 'GREEN', 3: 'BLUE' } color_num = 1 color_max = len(color_dic) # get gyrodate and into array with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: s.connect(('169.254.85.105', 50010)) # your PC's Bluetooth IP & PORTpy for cnt in range(color_max): s.send((color_dic[cnt+1]).encode()) time.sleep(0.1) s.send(('END').encode()) print('Start program...') while not(button.backspace): if button.up: color_num += 1 time.sleep(0.1) if color_num > color_max: color_num = color_max elif button.down: color_num -= 1 time.sleep(0.1) if color_num < 1: color_num = 1 elif button.right: msg = 'save' s.send(msg.encode()) dataget(color_dic, color_num) elif button.left: msg = 'predict' s.send(msg.encode()) predict() print('\r'+'save_color = {} '.format(color_dic[color_num]), end='') time.sleep(0.1) print('\n'+'End program') sys.exit()※EV3側環境は日本語でコメントアウトすると文字コードの性質上エラーが発生するので注意が必要。
後半に記述しているs.connect(('169.254.207.161', 50010))は、前回と同様に環境に応じて書き換える。
以下のRED、GREEN、BLUEの箇所を変更することでデータとして記録する際のラベル名を変更できる。
今回は赤、緑、青を読み取るので以下のままにする。data_get_color.py# variable initialize color_dic = { 1: 'RED', 2: 'GREEN', 3: 'BLUE' }PC側プログラム
PC側プログラムではEV3から送られてくるカラーの値とラベルをセットにCSVファイルに記録するのと、EV3側から推論のメッセージが送られてきたらデータ群を元に現在見ている色が何色か推論を行い結果を表示する。
前回同様
programフォルダにClassification.pyをテキストドキュメントとして作成し、以下の内容を記述する。Classification.pyimport socket import sys import csv import numpy as np import pandas as pd import os.path from sklearn.model_selection import train_test_split from sklearn.svm import SVC from sklearn.multiclass import OneVsRestClassifier from sklearn.ensemble import RandomForestClassifier as RFC from sklearn.metrics import accuracy_score # setting svm C = 1. kernel = 'rbf' gamma = 0.01 estimator = SVC(C=C, kernel=kernel, gamma=gamma) clf = OneVsRestClassifier(estimator) x_data = np.zeros(0) y_data = np.zeros(0) color_elements = None color_dic = {} color_cnt = 1 # データファイルの作成 if os.path.exists('color_data.csv') == False: writedata = ['red', 'green', 'blue', 'color'] f = open('color_data.csv', 'w', newline='') # ファイルを開く writer = csv.writer(f) writer.writerow(writedata) # データの書き込み f.close() data = pd.read_csv("color_data.csv", sep=",") # csvファイルの読み込み # 読み込んだデータを入力データとラベルに分ける x_data = data.loc[:, ["red", "green", "blue"]] y_data = data.loc[:, "color"] with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: s.bind(('169.254.85.105', 50010)) # your PC's Bluetooth IP & PORT s.listen(1) print('Start program...') while True: conn, addr = s.accept() with conn: # EV3側のプログラムで作成した色の辞書と同じものを作成 while True: color_elements = conn.recv(1024).decode() if color_elements == 'END': break color_dic[color_cnt] = color_elements color_cnt += 1 print('color_dic = {}'.format(color_dic)) # メッセージによって動作を変化 while True: rgb_data = conn.recv(1024).decode() if not rgb_data: break # 溜めたデータを用いて、推論後、値をEV3に送信 elif rgb_data == 'predict': train_x, test_x, train_y, test_y = train_test_split(x_data, y_data) clf.fit(train_x, train_y) y_pred = clf.predict(test_x) rgb_data = conn.recv(1024).decode() rgb_data = rgb_data.split(',') pre_color = clf.predict([rgb_data]) print('predict_color = {}'.format(color_dic[pre_color[0]])) conn.send(str(pre_color[0]).encode()) # EV3から送られてきたデータを保存 elif rgb_data == 'save': rgb_data = conn.recv(1024).decode() rgb_data = rgb_data.split(',') print('rgb_data = {}'.format(rgb_data)) np.append(y_data, rgb_data[0:2]) np.append(y_data, int(rgb_data[3])) writedata = rgb_data f = open('color_data.csv', 'a', newline='') writer = csv.writer(f) writer.writerow(writedata) f.close() print('End program') sys.exit()後半に記述している
s.bind(('169.254.207.161', 50010))はEV3側プログラム同様環境に合わせて変更する。
環境の確認と変更方法は前回の記事もしくは以下を確認してほしい。
ソケット通信のIP設定プログラムの実行
2つのプログラムを作成できたらそれぞれ実行していく。
コマンドプロンプトから
cd Desktop\programを実行する(\は¥マークと同義)
続けてコマンドプロンプトにて
python Classification.pyを実行する
※実行後Start program...と表示され待機状態になる
VSCode上で接続しているEV3のSSHターミナルを開き
cd ev3workspace/を実行するSSHターミナルにて
python3 data_get_gyro.pyを実行する
コースに付属している色の上にEV3を設置し、カラーセンサーでRGB値をを取得しPCに送信する。EV3の各ボタンに操作が設定されているため応じてボタンを押下してデータを採取する。

- 上:保存する色(ラベル)を切り替える
- 下:保存する色(ラベル)を切り替える
- 右:ボタンが押されたら、その時のカラーセンサーの値とラベルをPCに送信する(データ採取)
- 左:ボタンがおされたら、その時のカラーセンサーの値をPCに送信する(推論)
上記のように操作が設定されているので、採取したい色に上下ボタンでラベルを合わせて、右ボタンを押してデータを採取する。
上下ボタンを押すとVSCode上で採取するラベルの名前が切り替わる。
右ボタンでカラーのデータを採取するとVSCode上とコマンドプロンプト上に以下のようにRGB値とラベルが出力され、、CSVファイルに保存される。
同じように各ラベルである程度データを集める。
実行結果
ある程度データを採取できたらEV3の左上のボタンを押して一度プログラムを終了する。
CSVが作成されているのを確認する。
再度同じ手順でPC側、EV3側のプログラムをそれぞれ実行し、
それぞれ採取した色の上で左ボタンを押して推論結果をPC側で確認する。

それぞれの色が判別できているのが確認できる。
まとめ
実際にロボットから受け取ったデータで分類を行うことができた。今回はSVMの手法を用いたが、Scikit-learnのモデル指定の記述を変更することでランダムフォレストなど他の分類手法で機械学習を実装することも可能だ。
昨今の機械学習ではPC内で簡潔してしまうものが多いが、今回のようにエッジ(ロボット側)で実行結果を確認できる点や自分で採取したデータを利用する点においては身近に感じることができるのではないだろうか。Appendix
3次元データのプロット
今回取得したRGBのような3次元のデータを以下のようなプログラムでプロットする。
プロットには前回の記事でインストールしたライブラリmatpolotlib必要なので注意color_data.csvがあるフォルダ下に
3d_graph.pyを作成する。3d_graph.pyfrom mpl_toolkits.mplot3d import Axes3D import matplotlib.pyplot as plt import numpy as np from sklearn.svm import SVC from sklearn.metrics import r2_score import math import itertools from sklearn.multiclass import OneVsRestClassifier from sklearn.metrics import accuracy_score file = 'color_data.csv' def main(): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') data = np.loadtxt(file,delimiter=",",skiprows=1) print('data = {}'.format(data)) print('data max= {}'.format(np.amax(data,axis=0))) print('data min= {}'.format(np.amin(data,axis=0))) for xs, xy, zs, c in data: #print('xs = {}, xy = {}, zs = {}, c = {}'.format(xs, xy, zs, c)) if c == 1: color = "r" marker="o" elif c == 2: color = "g" marker="^" elif c == 3: color = "b" marker="," ax.scatter(xs, xy, zs, c=color, marker=marker) ax.set_xlabel('red') ax.set_ylabel('green') ax.set_zlabel('blue') plt.show() if __name__ == '__main__': main()コマンドプロンプトより
cd コマンドで作成したフォルダに移動する。
python 3d_graph.pyで実行するとcsvファイルを読み込み以下のように3次元のグラフをプロットすることができ、データの分布を確認することができる。

















- 投稿日:2020-11-04T11:43:27+09:00
Apache Flink の課題とチャンス
このブログ記事では、Apache Flinkとそのエコシステムが、多くの課題を抱えながらも、機械学習の分野で何か素晴らしいことが起こるであろう、その可能性について論じています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
Jian Feng著
Apache Flink のエコシステムについて議論する前に、まずエコシステムとは何かを見てみましょう。ITの世界では、エコシステムとは、共通のコアコンポーネントから派生したコンポーネントのコミュニティであり、このコアコンポーネントを直接または間接的に利用し、このコアコンポーネントと一緒に利用することで、より大きな、あるいはより特殊な種類のタスクを達成することができると理解することができます。続いて、Flinkのエコシステムとは、コアコンポーネントとしてのFlinkを取り巻くエコシステムのことを指します。
ビッグデータのエコシステムの中では、Flinkは計算側のみを扱う計算コンポーネントであり、独自のストレージシステムは一切関与しないということになります。しかし、多くの実用的なシナリオでは、Flinkだけでは要件を満たすことができないことに気づくかもしれません。例えば、データをどこから読み込むか、Flinkで処理されたデータをどこに保存するか、データをどのように消費するか、垂直的なビジネス分野で特殊なタスクを達成するためにFlinkをどのように使用するかなどを検討する必要があるかもしれません。下流と上流の両方の側面に加えて、より高い抽象度を伴うこれらのタスクを達成するためには、1つの強力なエコシステムが必要になります。
Flinkエコシステムの現状
エコシステムとは何かを理解したところで、Flinkエコシステムの現状について話してみましょう。全体的に見て、Flinkエコシステムはまだ黎明期にあります。現在、Flinkのエコシステムは主にアップストリームとダウンストリームの様々なコネクタと数種類のクラスタをサポートしています。
Flinkが現在サポートしているコネクタを一日中リストアップすることができます。しかし、いくつか挙げるとすれば、Kafka、Cassandra、Elasticsearch、Kinesis、RabbitMQ、JDBC、HDFSです。次に、Flinkはほぼすべての主要なデータソースをサポートしています。クラスタに関しては、現在FlinkはStandaloneとYARNをサポートしています。このエコシステムの現状を踏まえると、Flinkは主にストリームデータの計算に使われています。他のシナリオ(機械学習や対話型分析など)でFlinkを使用することは比較的複雑な作業になる可能性があり、これらのシナリオでのユーザーエクスペリエンスにはまだ多くの希望が残されています。しかし、このような課題の中にあっても、Flinkエコシステムには多くのチャンスがあることは間違いありません。
Flinkエコシステムの課題と機会
Flinkは主にバッチ処理やストリーム処理に使用されるビッグデータ・コンピューティング・プラットフォームとしての役割を果たしていますが、それ以外の用途にも大きな可能性を秘めています。私の考えでは、Flinkの可能性を最大限に引き出すためには、より強力で堅牢なエコシステムが必要だと考えています。Flinkをよりよく理解するために、2つの異なるスケーリング次元からエコシステムを評価することができます。
1、水平方向のスケーリング。水平方向のスケーリングという点では、エコシステムは、すでに持っているものに対して、より完全なエンドツーエンドのソリューションを構築する必要があります。例えば、このソリューションには、上流と下流の異なるデータソースを接続するさまざまなコネクタや、下流の機械学習フレームワークとの統合、さらには下流のBIツールとの統合、Flinkジョブの提出とメンテナンスを簡素化するツールや、よりインタラクティブな分析体験を提供するノートブックなどが含まれるかもしれません。
2、垂直的なスケーリング。他の分野へのスケールアウトという意味では、より抽象的なFlinkエコシステムは、当初意図した計算シナリオを超えた要件を満たす必要がありました。たとえば、垂直方向のエコシステムには、バッチおよびストリームコンピューティング、テーブルAPI(より高度な計算抽象化レイヤーを持つ)、CEP(複雑なイベント処理エンジン)、Flink ML(機械学習のためのより高度なコンピューティングフレームワークを持つ)、さまざまなクラスタフレームワークへの適応などがあります。
以下の図は、上記のようにFlinkのエコシステムが水平・垂直方向にスケールした場合を想定したものです。
FlinkとHiveの統合
Apache Hiveは10年近く前に開発されたトップレベルのApacheプロジェクトです。このプロジェクトは当初、MapReduceの上にSQL文をカプセル化していました。ユーザーは、複雑なMapReduceジョブを書かなくても、使い慣れたシンプルなSQL文を書くだけで済むようになりました。ユーザーからのSQL文は、1つまたは複数のMapReduceジョブに変換されます。プロジェクトの継続的な進化の過程で、Hiveのコンピューティングエンジンはプラグイン可能になりました。現在、Hiveは3つのコンピューティングエンジンをサポートしています。MR、Tez、Sparkの3つのコンピューティングエンジンをサポートしています。Apache Hiveは、Hadoopエコシステムにおけるデータウェアハウスの業界標準となっています。多くの企業が何年も前からデータウェアハウスシステムをHive上で運用しています。
Flinkはバッチ処理とストリーム処理を統合したコンピューティングフレームワークなので、当然ながらHiveと統合する必要があります。例えば、Flinkを使ってETLを実行してリアルタイムデータウェアハウスを構築する場合、リアルタイムデータクエリにはHiveのSQLを使う必要があります。
Flinkコミュニティでは、Hiveとのより良い統合とサポートを可能にするために、FLINK-10556がすでに作成されています。その主な機能は以下の通りです。
- FlinkがHiveのメタデータにアクセスできるようにします。
- FlinkがHiveのテーブルデータにアクセスできるようにします。
- FlinkはHiveのデータ型と互換性があります。
- FlinkでHive UDFを使用できます。
- FlinkでHive SQLを使用できます(DMLやDDLを含む)。
Flinkコミュニティでは、上記のような機能を実装するための段階的なステップを踏んでいます。これらの機能を事前に試してみたいという方は、アリババクラウドが開発したオープンソースのBlinkプロジェクトを試してみると良いでしょう。オープンソースのBlinkプロジェクトでは、FlinkとHiveをメタデータ層とデータ層で接続しています。ユーザーはFlink SQLを直接使ってHive内のデータをクエリしたり、実際の意味でHiveとFlinkをシームレスに切り替えることができます。メタデータに接続するために、BlinkはFlinkカタログの実装を再構築し、メモリベースのFlinkInMemoryCatalogと、Hive MetaStoreに接続するHiveCatalogの2つのカタログを追加しました。このHiveCatalogを使用すると、FlinkのジョブはHiveからメタデータを読み取ることができます。データに接続するために、BlinkにはHiveTableSourceが実装されており、FlinkのジョブがHiveの通常のテーブルやパーティションテーブルから直接データを読み込めるようになっています。そのため、Blinkを利用することで、ユーザーはFlinkのSQLを利用して既存のHiveのメタデータやデータを読み込んでデータ処理を行うことができるようになります。アリババは今後、Hive固有のクエリ、データ型、Hive UDFのサポートなど、FlinkとHiveの互換性を向上させていく予定です。これらの改善は、徐々にFlinkコミュニティに貢献していく予定です。
Flinkでのインタラクティブな解析をサポート
バッチ処理もFlinkの一般的なアプリケーションシナリオです。インタラクティブな分析はバッチ処理の大部分を占めており、データアナリストやデータサイエンティストにとっては特に重要です。
インタラクティブな分析プロジェクトやツールに関しては、Fink 自体もパフォーマンス要件を改善するための更なる強化が必要です。FLINK-11199を例に考えてみましょう。現在、複数のジョブにまたがる同じFlinkアプリ内のデータを共有することはできません。各ジョブのDAGは分離されたままです。FLINK-11199はこの問題を解決するために設計されており、インタラクティブな分析をよりフレンドリーにサポートします。
さらに、データアナリストやデータサイエンティストがFlinkをより効率的に利用できるようにするためには、インタラクティブな分析プラットフォームが必要です。Apache Zeppelinはこの点で多くのことを行ってきました。Apache Zeppelinは、対話型の開発環境を提供し、Scala、Python、SQLなどの複数のプログラミング言語をサポートするApacheの最上位プロジェクトでもあります。また、Zeppelinは高度なスケーラビリティをサポートしており、Spark、Hive、Pigなど多くのビッグデータエンジンをサポートしています。Alibabaは、ZeppelinでFlinkのより良いサポートを実装するために多大な努力をしてきました。ユーザーは、Zeppelinで直接Flinkコード(Scala言語またはSQL言語)を書くことができます。また、ローカルでパッケージングしてからbin/flinkスクリプトを実行して手動でジョブを投入するのではなく、ユーザーはZeppelinで直接ジョブを投入してジョブ結果を見ることができます。ジョブ結果は、テキストで表示することも、可視化することもできます。SQL結果の場合は、特に可視化が重要です。Zeppelinでは、主に以下のようなFlinkのサポートを提供しています。
- 3つのrunモード ローカル、リモート、ヤーン
- Scala、バッチSQL、ストリームSQL
- 静的・動的テーブルの可視化
- ジョブURLとの自動関連付け
- ジョブキャンセル
- フリンクのSavepointの求人情報
- コントロールの作成など、ZeppelinContextの高度な機能
- 3つのチュートリアルノート ストリーミングETL、Flinkバッチチュートリアル、Flinkストリームチュートリアル
これらの変更のいくつかは Flink に実装されており、いくつかは Zeppelin に実装されています。これらの変更がすべて Flink コミュニティと Zeppelin コミュニティに貢献される前に、この Zeppelin Docker イメージを使用して、これらの機能をテストして使用することができます。Zeppelin Docker イメージのダウンロードとインストールの詳細については、Blink ドキュメントに記載されている例を参照してください。ユーザーがこれらの機能をより簡単に試すことができるように、このバージョンのZeppelinでは3つの組み込みFlinkチュートリアルを追加しました。1つはStreaming ETLの例を示し、他の2つはFlink BatchとFlink Streamの例を示しています。
#Flinkでの機械学習のサポート
ビッグデータのエコロジーにおいて最も重要なコンピューティングエンジンのコンポーネントとして、Flinkは現在、主にデータコンピューティングと処理の伝統的なセグメント、つまり従来のビジネスインテリジェンス(またはBI)(例えば、リアルタイムのデータウェアハウスやリアルタイムの統計レポート)に使用されています。しかし、21世紀は人工知能(AI)の時代です。いくつかの異なる業界の企業が、ビジネスのやり方を根本的に変えるためにAI技術を選択するケースが増えてきています。このようなビジネス界全体の変化の波に、ビッグデータコンピューティングエンジンFlinkは欠かせない存在であると言えるのではないでしょうか。Flinkが機械学習専用に開発されているわけではないにしても、Flinkのエコシステムの中で機械学習がかけがえのない役割を果たしていることに変わりはありません。そして今後、Flinkが機械学習をサポートするための3つの大きな機能を提供していくことが期待されています。
- 機械学習のためのパイプラインの構築
- 従来の機械学習アルゴリズムをサポート
- 他のディープラーニングフレームワークとの統合を可能にする 機械学習のパイプラインを見ていると、機械学習は単純にトレーニングと予測の2つの主要なフェーズに煮詰めることができると簡単に思い込むことができます。しかし、トレーニングと予測は機械学習のごく一部に過ぎません。トレーニングの前に、機械学習モデルのためにデータを準備するプロセスでは、データのクリーニング、データの変換、正規化などの作業が不可欠です。そして、訓練後には、モデルの評価も重要なステップです。予測段階でも同じことが言えます。複雑な機械学習システムでは、個々のステップを適切に組み合わせることが、ロバストでスケーラブルな機械学習モデルを生成するための鍵となります。多くの点で、FLINK-11095はこの目標を実現するためにコミュニティが現在取り組んでいるものであり、Flinkはこれらのすべてのステップを通して機械学習モデルを構築する上で重要な役割を果たしています。
現在、Flinkのflink-mlモジュールは、いくつかの伝統的な機械学習アルゴリズムを実装していますが、さらなる改善が必要です。
Flinkコミュニティでは、ディープラーニングのサポートが積極的に行われています。AlibabaはTensorFlow on Flinkプロジェクトを提供しており、ユーザーはFlinkのジョブでTensorFlowを実行し、Flinkをデータ処理に使用し、処理されたデータをTensorFlowのPythonプロセスに送って深層学習のトレーニングを行うことができます。プログラミング言語については、FlinkコミュニティがPythonのサポートに取り組んでいます。現在、FlinkはJavaとScalaのAPIのみをサポートしています。どちらの言語もJVMベースです。そのため、現在のところFlinkはシステムのビッグデータ処理には適していますが、データ分析や機械学習にはあまり適していません。一般的にデータ分析や機械学習の分野の人たちは、PythonやRなどのより高度な言語を使うことを好みますが、Flinkのコミュニティでも近い将来、これらの言語のサポートを計画しています。FlinkがまずPythonをサポートするのは、Pythonは近年、AIやディープラーニングの発展に伴い、急速な発展を遂げているからです。現在、TensorFlow、Pytorch、Kerasなど、人気のあるディープラーニングライブラリはすべてPythonのAPIを提供しています。FlinkでPythonがサポートされるようになれば、ユーザーは機械学習のためのすべてのパイプラインをたった1つの言語で接続できるようになり、開発が飛躍的に向上するはずです。
Flinkジョブの送信とメンテナンス
開発環境では、Flink のジョブは一般的にシェルコマンド bin/flink run で投入されます。しかし、本番環境で使用する場合、このジョブ投入方法は実際には多くの問題を引き起こす可能性があります。例えば、ジョブのステータスの追跡と管理、失敗したジョブの再試行、複数のFlinkジョブの開始、ジョブパラメータの変更と送信などが困難な場合があります。これらの問題は、もちろん手動での介入で解決することは可能ですが、手動での介入は、時間がかかることは言うまでもなく、生産現場では非常に危険なことです。理想的には、自動化できるすべての操作を自動化する必要があります。残念ながら、現在のところFlinkのエコシステムには適切なツールは見当たりません。アリババはすでに社内向けに適切なツールを開発しており、長い間本番で稼働しており、Flinkジョブの提出と維持のための安定した信頼性の高いツールであることが証明されています。現在、アリババは、アリババが内部的に依存しているいくつかのコンポーネントを削除し、このプロジェクトのソースコードを公開する予定です。このプロジェクトは2019年前半にオープンソース化される予定です。
要約すると、現在の Flink のエコシステムには多くの問題がありますが、同時に多くの開発の余地があります。Apache Flink のコミュニティは人間的なもので、Flink の可能性を最大限に引き出すために、より強力な Flink のエコシステムを構築するために、常に大きな努力をしています。
アイデアをお持ちですか?インスピレーションを感じていますか?コミュニティに参加して、より良いFlinkエコシステムを一緒に構築しましょう。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。


- 投稿日:2020-11-04T11:32:08+09:00
宇宙背景X線放射(CXB)をフラックス範囲を指定してpythonで計算する方法
背景
宇宙背景X線放射(CXB)を推定する場合に、トータルの明るさはいくつかを知りたいだけではなくて、撮像観測した場合は、撮像により検出された明るい点源は除いた場合に、どのくらいが空間分解せずに残っているか?を推定する必要がある。
ここでは、https://iopscience.iop.org/article/10.1086/374335 に従って、soft (1-2 keV) と hard (2-10 keV) のそれぞれをpythonで計算する方法を紹介する。
ソースコード
コードを読めばわかる人は、calc_cxbのColab を参照ください。
#!/bin/evn python import matplotlib.pyplot as plt import numpy as np # THE RESOLVED FRACTION OF THE COSMIC X-RAY BACKGROUND A. Moretti, # The Astrophysical Journal, Volume 588, Number 2 (2003) # https://iopscience.iop.org/article/10.1086/374335 smax = 1e-1 # maxinum of flux range (erg cm^-2 c^-1) smin = 1e-17 # minimum of flux range (erg cm^-2 c^-1) n = int(1e5) # number of grid in flux fcut = 5e-14 # user-specified maxinum flux (erg cm^-2 c^-1) def calc_cxb(s,fcut=5e-14, ftotal_walker=2.18e-11, plot=True, soft=True): if soft: # 1-2 keV print("..... soft X-ray 1-2 keV is chosen") a1=1.82; a2=0.6; s0=1.48e-14; ns=6150 foutname="soft" else: # hard 2-10 keV print("..... hard X-ray 2-10 keV is chosen") a1=1.57; a2=0.44; s0=4.5e-15; ns=5300 foutname="hard" n_larger_s = ns * 2.0e-15 ** a1 / (s**a1 + s0**(a1-a2)*s**a2) # Moretti et al. 2013, eq(2) if plot: F = plt.figure(figsize=(6,6)) ax = plt.subplot(1,1,1) plt.plot(s, n_larger_s, ".", label="test") plt.xscale('log') plt.ylabel(r"$N(>S)/deg^2$") plt.xlabel(r"$S (erg cm^{-2} s^{-1})$") plt.yscale('log') plt.savefig(foutname + "_ns.png") plt.show() diff_n_larger_s = np.abs(np.diff(n_larger_s)) diff_s = np.diff(s) div_ns = np.abs(diff_n_larger_s/diff_s) s_lastcut = s[:-1] totalflux = np.sum(div_ns*s_lastcut*diff_s) # Moretti et al. 2013, eq(4) fluxcut = np.where(s > fcut)[0][:-1] particalflux = np.sum(div_ns[fluxcut]*s_lastcut[fluxcut]*diff_s[fluxcut]) fdiff = totalflux - particalflux fcxb = ftotal_walker - particalflux # Walker et al. 2016, eq(1) print("totalflux = ", "%.4e"%totalflux, " [erg cm^-2 c^-1]", " from ", "%.4e"%smin, " to ", "%.4e"%smax) print("particalflux = ", "%.4e"%particalflux, " [erg cm^-2 c^-1]", " from ", "%.4e"%fcut, " to ", "%.4e"%smax) print("fdiff = totalflux - particalflux = ", "%.4e"%fdiff, " [erg cm^-2 c^-1]", " from ", "%.4e"%smin, " to ", "%.4e"%fcut) print("fcxb(2-10keV)= ftotal_walker - particalflux = ", "%.4e"%fcxb, " [erg cm^-2 c^-1]") if plot: F = plt.figure(figsize=(6,6)) ax = plt.subplot(1,1,1) plt.plot(s[:-1], div_ns, ".", label="test") plt.xscale('log') plt.ylabel(r"$dN/dS/deg^2$") plt.xlabel(r"$S (erg cm^{-2} s^{-1})$") plt.yscale('log') plt.savefig(foutname + "_nsdiff.png") plt.show() return s, n_larger_s, diff_n_larger_s, div_ns, diff_s #s = np.linspace(sexcl,smax,n) s = np.logspace(np.log10(smin),np.log10(smax),n) # plot soft band s, n_larger_s, diff_n_larger_s, div_ns, diff_s = calc_cxb(s,fcut=fcut) # plot hard band s, n_larger_s, diff_n_larger_s, div_ns, diff_s = calc_cxb(s,fcut=fcut,soft=False)実行結果
1-2 keV
2-10 keV
計算方法
さすがにリニアだとメモリが足りずに計算できないので、s(erg cm^-2 s^-1)空間のログで、積分はただの長方形近似を用いた。
この関数は、n_larger_s = ns * 2.0e-15 ** a1 / (s*a1 + s0(a1-a2)*s*a2) で計算している。
この積分は、totalflux = np.sum(div_ns*s_lastcut*diff_s) で計算している。
fcxb = ftotal_walker - particalflux # Walker et al. 2016, eq(1) の部分はおまけで、この論文の 2-10 keV のCXBの推定をしており、それに準じた計算を出しておいた。
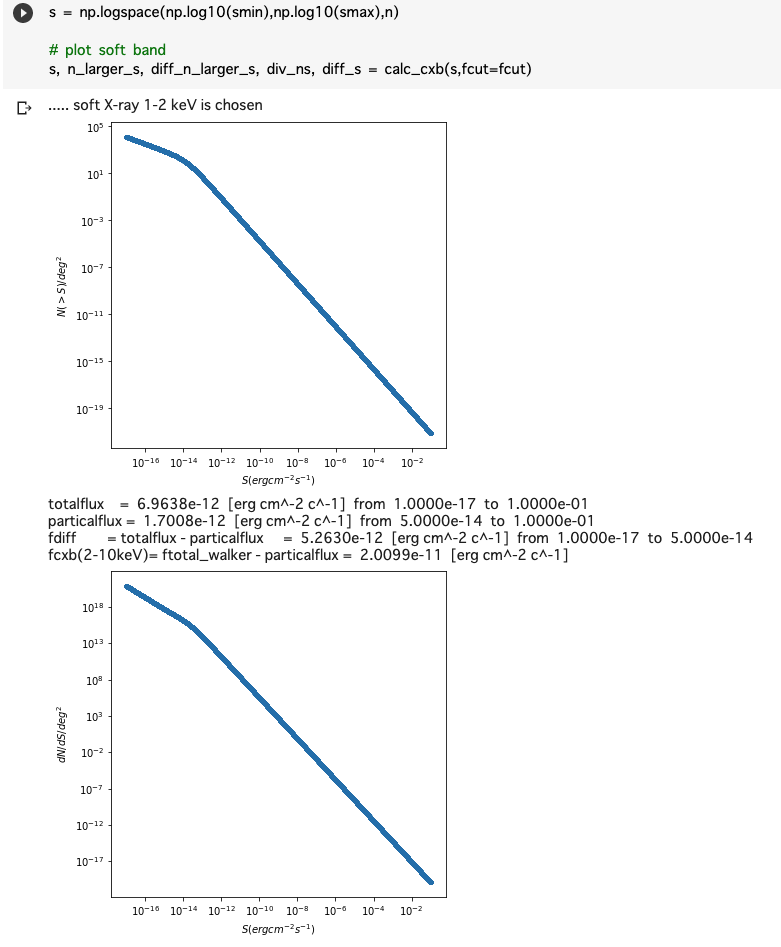
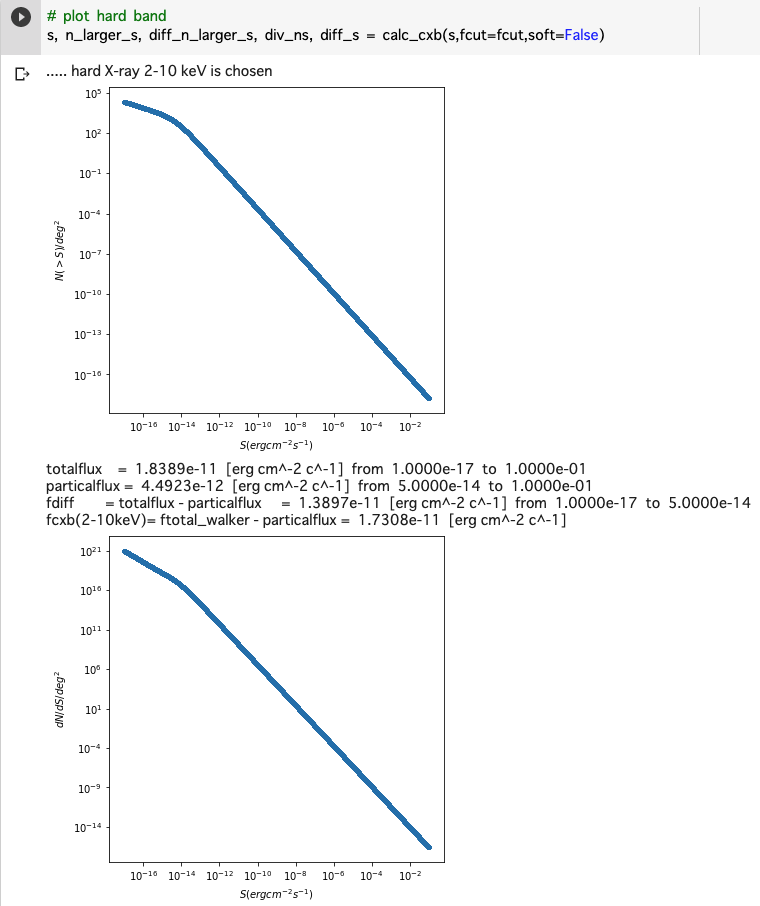
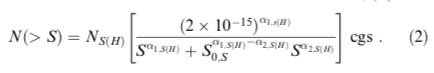

- 投稿日:2020-11-04T08:33:52+09:00
argparse のヘルプでオプションの書式とその説明が被って読みづらい現象をどうにかする
はじめに
こんにちは rtanpo440 です。
Python の標準コマンドラインパーサ argparse はいいですね! 自分は Python を最近はじめたばかりでまだ慣れていないところもありますが、コマンドラインパーサはこんなに簡単に書けるんだなぁと思いました。
そして argparse はヘルプを自動で生成してくれます。自分で
add_argumentしなくても-h--helpオプションは自動的に追加され、いい感じに表示できます。ドキュメント : https://docs.python.org/ja/3/library/argparse.html
問題点
しかし 1 個だけこまったことがあります。それは、各オプションの書式と説明が被ってしまい、読みづらい状態になってしまうことです。
before#!/usr/bin/python3 import argparse parser = argparse.ArgumentParser() parser.add_argument('-m', '--foo', help='Foo foo foo.') parser.add_argument('-l', '--bar', nargs='+', help='Bar bar bar.') parser.add_argument('-o', '--long-long-long-option', action='store_true', help='Just a so long option, but do nothing') parser.parse_args()
デフォルトでは各オプションの説明は、書式がどれくらいの文字数であるかにかかわらず、固定の位置から表示される仕様になっているようです。書式が長い場合でも折り返しはされず説明が次の行に表示されるため、書式が説明の列にはみ出しています。
これは読みづらい!! どうしよう……ということでドキュメントを眺めていたら、
HelpFormatterというものがあるようです。その名の通りヘルプのフォーマットをカスタマイズするというもので、具体的にはデフォルト値を表示するようにしたり、改行を保持したりするといった機能を持つ 4 つのサブクラスがデフォルトで提供されているようです。……が、公式ドキュメントにはデフォルトで用意されている 4 つのサブクラスについては説明されていましたが、
HelpFormatterを自前で継承してカスタマイズする方法がわからなかったので、その実装を参照しながら手探りでやってみました。HelpFormatter を見てみる
右側の説明は、画面左端を 0 とすると 24 の位置に表示されるので、24 で検索をかけてみたら、ズバリそれっぽいのが出てきました。
self._max_help_positionがこの問題に関係しているようです。なら、無理やりだけどこのクラスを継承してself._max_help_positionを上書きしちゃえ!! ということでやってみます。解決方法
色々試した結果、下のコードでうまくいきました。
HelpFormatterを継承してForceOneLineHelpFormatterを作成します。after#!/usr/bin/python3 import argparse class ForceOneLineHelpFormatter(argparse.HelpFormatter): def __init__(self, *args, **namedargs): super().__init__(*args, **namedargs) self._max_help_position = 999 parser = argparse.ArgumentParser(formatter_class=ForceOneLineHelpFormatter) parser.add_argument('-m', '--foo', help='Foo foo foo.') parser.add_argument('-l', '--bar', nargs='+', help='Bar bar bar.') parser.add_argument('-o', '--long-long-long-option', action='store_true', help='Just a so long option, but do nothing') parser.parse_args()
self._max_help_positionをなぜか 999 にしていますが、内部で左側の書式と右側の説明の間が広がりすぎないよう自動で調整されるようです。つまりこの値は想定される画面幅よりただ十分に大きければ問題ないということになります。そして実際に
--helpつきで実行した結果がこちらです。
おお~! いい感じ! しかしもっといいやり方があるかもしれない……
まとめ
- argparse のヘルプでオプションの書式と説明が被って読みづらいときは、
argparse.HelpFormatterのサブクラスを作成する。- そして
__init__内で_max_help_positionを 999 など大きな値に設定する。- すると説明の位置が自動的に調整され、書式の右側にきれいに説明が表示される。



- 投稿日:2020-11-04T03:06:35+09:00
そもそもPythonで依存性逆転の法則(DIP)を実現できるのか?
はじめに
最近設計やアーキテクチャについて悩むことが多いのですが、動的型付き言語であるPythonでも依存性逆転の法則について実現できるのかについて自分なりの意見を書いてみました。私の意見が絶対正しいというわけではないのですが、少しでも参考になれば幸いです。
※Pythonの解説記事ですがC++のコードも出てきますのでご了承ください(内容は難しくありません)
ポリモーフィズムとは?
まず、依存性逆転の法則を理解する前にポリモーフィズムについての理解が必要です。
説明をWikipediaから引用します。ポリモーフィズム(英: Polymorphism)とは、プログラミング言語の型システムの性質を表すもので、プログラミング言語の各要素(定数、変数、式、オブジェクト、関数、メソッドなど)についてそれらが複数の型に属することを許すという性質を指す。ポリモルフィズム、多態性、多相性、多様性とも呼ばれる。
内容が分かりにくいので詳細に解説します。本質は「それらが複数の型に属することを許すという性質を指す」の部分です。Pythonなどの動的型付き言語の場合はあまり意識することはありませんが、静的型付き言語の場合変数の型が限定されるため基本的には複数の型に属することは許されません。
例えば以下の例を見てください。(C++のコードですが、内容は難しくないと思います)
main.cpp#include <iostream> using namespace std; int main() { int a = 1; string b = "hello"; a = b; // error }aという変数はintで定義しており、bという変数はstringで定義しています。「a = b」で「int型の変数aにstring型の変数bを代入」しようとしています。この操作でエラーになります。これは、変数aがint型として定義されており、複数の型に属することができないため、となります。
つまり、変数などは原則複数の型に属することはできません。しかし、ポリモーフィズムの場合は特別に複数の型に属することを許容する、という内容がWikipediaの引用部分の解説になります。
では、実際にポリモーフィズムの例を見てみましょう。(C++のコードですがコード自体を理解する必要はありません)
main.cpp#include <iostream> using namespace std; class Human{ public: string name; int age; Human(const string _name, const int _age){ name = _name; age = _age; }; virtual void print_gender(){}; void print_info(){ cout << "name: " << name << ", age: " << age << endl; }; }; class Man: public Human{ public: Man(const string _name, const int _age): Human(_name,_age){}; void print_gender() override { cout << "I am man." << endl; }; }; class Woman: public Human{ public: Woman(const string _name, const int _age): Human(_name,_age){}; void print_gender() override { cout << "I am woman." << endl; }; }; int main() { Man* taro = new Man("taro", 12); Woman* hanako = new Woman("hanako", 23); Human* human = taro; human->print_gender(); human->print_info(); }重要な部分は下記になります。
Man* taro = new Man("taro", 12); Woman* hanako = new Woman("hanako", 23); Human* human = taro;Humanクラスで定義しているhumanという変数にManクラスのtaroという変数を代入しています。上記の説明で変数は一つの型(クラス)にしか属することができないということを書きましたが、humanという変数はHumanというクラスとManというクラスの両方に属するように見えます。(厳密にはHumanのみに属します)
なぜこのようなことが可能になっているかというと、ManクラスはHumanクラスの派生クラスになっているからです。ManクラスとHumanクラスには関係があるので、関係があるものについては同じように扱うことを許可する、というイメージですかね。
ポリモーフィズムのメリットは、同じ性質をもったものを同じように扱うことができるため、きれいなコードを書くことができる、という部分かと思います。(具体例については解説しません。すみません。)
抽象と具象について
事前知識として「抽象」と「具象」についても少し理解しておく必要があります。単語について少し解説します。
抽象とは
抽象とはインターフェイスと言い換えることもできますが、要するに型定義のことです(正確には正しくないかもしれません)。
例えば、以下のような関数を考えます。main1.pydef add_number(a: int, b: int) -> int: """二つの引数を足した結果を返す""" return a + badd_numberという関数はintの引数を取り、intの結果を変えすというインターフェイスが定義されています。抽象の観点からすると実装の内部は考えないのでadd_numberという関数名だが内部で足し算ではなく掛け算が行われていても気にしません。あくまで、インプットとアウトプット(インターフェイス)のみしか考えません。
具象とは
具象では実装の内部まで考えます。なので、add_number関数の内部実装が足し算か掛け算か、ということも踏まえて考えることになります。
依存性逆転の法則とは?
前提知識の説明が長くなってしまいました。しかも、Pythonのコードもほとんど出てこないし、、、
まず、「依存」という言葉の意味がややこしいのでそこから解説します。例えば、以下のコードを見てください。
main2.py(抜粋)def main(): taro: Man = Man('taro', 12) taro.print_gender() taro.print_info()main関数内でどうやらManというクラスを使っているようです。この状態は「main関数がManクラスに依存している」ということができます。つまり、Manクラスの内容が変更されるとmain関数にも影響が及ぶ可能性がある、と言い換えることもできます。
では、ここで依存性逆転の法則の説明をwikipediaから引用しましょう。
オブジェクト指向設計において、依存性逆転の原則、または依存関係逆転の原則[1](dependency inversion principle) とはソフトウエアモジュールを疎結合に保つための特定の形式を指す用語。この原則に従うとソフトウェアの振る舞いを定義する上位レベルのモジュールから下位レベルモジュールへの従来の依存関係は逆転し、結果として下位レベルモジュールの実装の詳細から上位レベルモジュールを独立に保つことができるようになる
A. 上位レベルのモジュールは下位レベルのモジュールに依存すべきではない。両方とも抽象(abstractions)に依存すべきである。
B. 抽象は詳細に依存してはならない。詳細が抽象に依存すべきである。またまた難解な説明が。。。
まず、「上位」と「下位」という言葉ですが、先ほどの例でいうとmain関数が上位でManクラスが下位に当たります。つまり、「上位レベルのモジュールは下位レベルのモジュールに依存すべきではない。」は具体的に言うと、「main関数はManクラスに依存するべきではない」という意味になります。
つぎに、「両方とも抽象(abstractions)に依存すべき」という部分ですが、言い換えると内部の実装に依存するのではなくインターフェイス(型)に依存するべき、という意味になります。先ほどのコードとほぼ同じですが、以下の例を見てください。
main3.py(抜粋)def main(): taro: Human = Man('taro', 12) taro.print_gender() taro.print_info()違いは、main関数がManクラスへの依存からHumanクラスへの依存に代わっている、という点です。
では、HumanクラスとManクラスの実装を見てみましょう。(内容は抜粋です、全文は末尾に載せます)main3.py(抜粋)@dataclass class Human(metaclass=ABCMeta): name: str age: int # 抽象メソッド @abstractmethod def print_gender(self) -> None: pass # 共通メソッド def print_info(self) -> None: print(f'name: {self.name}, age: {self.age}') class Man(Human): def print_gender(self): print('I am man.')Humanクラスはベースとなるクラスであり、複雑なビジネスロジックは含まれていません。つまり、抽象的なクラスということができます。逆にManクラスは内部実装が含まれるクラスのなので具象クラスとなります。HumanクラスとManクラスで何が違うかというとHumanクラスは変更される頻度が少なくManクラスは変更される頻度が多い、という部分です。理由は当然でHumanクラスはインターフェイスの定義のみ(正確には違いますが、、、)、Manクラスは内部実装、ビジネスロジックが含まれるからです。
ここまでくると、main関数がManクラス(具象)からHumanクラス(抽象)へ依存するように変えることのメリットが理解頂けると思います。Manクラスに依存する場合、main関数はManクラスの変更の影響を受けるわけですから、Manクラスの変更頻度が多いので多大な影響を受けます。逆にHumanクラスに依存する場合は、もちろんHumanクラスが変更された場合は影響を受けますが、Manクラスと比較すると変更頻度が少ないので影響が少ない、ということになります。
つまり、抽象に依存することでより変更に対して堅牢なコードを書くことができる、ということになります。
結局Pythonで依存性逆転の法則は実現できるのか?
できますが、完全ではありません。
具体的には抽象クラスabcとリント、型チェックツールを併用することで可能です。
ただし、Pythonの場合は型情報が間違っていてもプログラム自体は動きますので、他の静的型付き言語と同レベルのことを実現することはできません。
より高レベルを目指すのであれば、チームで開発環境をそろえる、プレコミットで型、リントのチェックを実施する、などを徹底すれば実現可能かと思います。
実用レベルで利用する分には問題ないレベルの機能が提供されていると思ってます。最後に
少し急いで書いたのであまり分かりやすい内容ではないかと思います。この辺りは理解するのが難しい分野ですので、少しでも参考になれればなと。コメントで質問頂ければできる限り回答させて頂きます。間違い、アドバイスもご指摘頂けると助かります。
実装コード全文
main3.pyfrom abc import ABCMeta, abstractmethod from dataclasses import dataclass @dataclass class Human(metaclass=ABCMeta): name: str age: int # 抽象メソッド @abstractmethod def print_gender(self) -> None: pass # 共通メソッド def print_info(self) -> None: print(f'name: {self.name}, age: {self.age}') class Man(Human): def print_gender(self): print('I am man.') class Woman(Human): def print_gender(self): print('I am woman.') def main(): taro: Human = Man('taro', 12) taro.print_gender() taro.print_info()
- 投稿日:2020-11-04T03:06:35+09:00
そもそもPythonで依存性逆転の原則(DIP)を実現できるのか?
はじめに
最近設計やアーキテクチャについて悩むことが多いのですが、動的型付き言語であるPythonでも依存性逆転の原則について実現できるのかについて自分なりの意見を書いてみました。私の意見が絶対正しいというわけではないのですが、少しでも参考になれば幸いです。
※Pythonの解説記事ですがC++のコードも出てきますのでご了承ください(内容は難しくありません)
ポリモーフィズムとは?
まず、依存性逆転の原則を理解する前にポリモーフィズムについての理解が必要です。
説明をWikipediaから引用します。ポリモーフィズム(英: Polymorphism)とは、プログラミング言語の型システムの性質を表すもので、プログラミング言語の各要素(定数、変数、式、オブジェクト、関数、メソッドなど)についてそれらが複数の型に属することを許すという性質を指す。ポリモルフィズム、多態性、多相性、多様性とも呼ばれる。
内容が分かりにくいので詳細に解説します。本質は「それらが複数の型に属することを許すという性質を指す」の部分です。Pythonなどの動的型付き言語の場合はあまり意識することはありませんが、静的型付き言語の場合変数の型が限定されるため基本的には複数の型に属することは許されません。
例えば以下の例を見てください。(C++のコードですが、内容は難しくないと思います)
main.cpp#include <iostream> using namespace std; int main() { int a = 1; string b = "hello"; a = b; // error }aという変数はintで定義しており、bという変数はstringで定義しています。「a = b」で「int型の変数aにstring型の変数bを代入」しようとしています。この操作でエラーになります。これは、変数aがint型として定義されており、複数の型に属することができないため、となります。
つまり、変数などは原則複数の型に属することはできません。しかし、ポリモーフィズムの場合は特別に複数の型に属することを許容する、という内容がWikipediaの引用部分の解説になります。
では、実際にポリモーフィズムの例を見てみましょう。(C++のコードですがコード自体を理解する必要はありません)
main.cpp#include <iostream> using namespace std; class Human{ public: string name; int age; Human(const string _name, const int _age){ name = _name; age = _age; }; virtual void print_gender(){}; void print_info(){ cout << "name: " << name << ", age: " << age << endl; }; }; class Man: public Human{ public: Man(const string _name, const int _age): Human(_name,_age){}; void print_gender() override { cout << "I am man." << endl; }; }; class Woman: public Human{ public: Woman(const string _name, const int _age): Human(_name,_age){}; void print_gender() override { cout << "I am woman." << endl; }; }; int main() { Man* taro = new Man("taro", 12); Woman* hanako = new Woman("hanako", 23); Human* human = taro; human->print_gender(); human->print_info(); }重要な部分は下記になります。
Man* taro = new Man("taro", 12); Woman* hanako = new Woman("hanako", 23); Human* human = taro;Humanクラスで定義しているhumanという変数にManクラスのtaroという変数を代入しています。上記の説明で変数は一つの型(クラス)にしか属することができないということを書きましたが、humanという変数はHumanというクラスとManというクラスの両方に属するように見えます。(厳密にはHumanのみに属します)
なぜこのようなことが可能になっているかというと、ManクラスはHumanクラスの派生クラスになっているからです。ManクラスとHumanクラスには関係があるので、関係があるものについては同じように扱うことを許可する、というイメージですかね。
ポリモーフィズムのメリットは、同じ性質をもったものを同じように扱うことができるため、きれいなコードを書くことができる、という部分かと思います。(具体例については解説しません。すみません。)
抽象と具象について
事前知識として「抽象」と「具象」についても少し理解しておく必要があります。単語について少し解説します。
抽象とは
抽象とはインターフェイスと言い換えることもできますが、要するに型定義のことです(正確には正しくないかもしれません)。
例えば、以下のような関数を考えます。main1.pydef add_number(a: int, b: int) -> int: """二つの引数を足した結果を返す""" return a + badd_numberという関数はintの引数を取り、intの結果を変えすというインターフェイスが定義されています。抽象の観点からすると実装の内部は考えないのでadd_numberという関数名だが内部で足し算ではなく掛け算が行われていても気にしません。あくまで、インプットとアウトプット(インターフェイス)のみしか考えません。
具象とは
具象では実装の内部まで考えます。なので、add_number関数の内部実装が足し算か掛け算か、ということも踏まえて考えることになります。
依存性逆転の原則とは?
前提知識の説明が長くなってしまいました。しかも、Pythonのコードもほとんど出てこないし、、、
まず、「依存」という言葉の意味がややこしいのでそこから解説します。例えば、以下のコードを見てください。
main2.py(抜粋)def main(): taro: Man = Man('taro', 12) taro.print_gender() taro.print_info()main関数内でどうやらManというクラスを使っているようです。この状態は「main関数がManクラスに依存している」ということができます。つまり、Manクラスの内容が変更されるとmain関数にも影響が及ぶ可能性がある、と言い換えることもできます。
では、ここで依存性逆転の法原則の説明をwikipediaから引用しましょう。
オブジェクト指向設計において、依存性逆転の原則、または依存関係逆転の原則[1](dependency inversion principle) とはソフトウエアモジュールを疎結合に保つための特定の形式を指す用語。この原則に従うとソフトウェアの振る舞いを定義する上位レベルのモジュールから下位レベルモジュールへの従来の依存関係は逆転し、結果として下位レベルモジュールの実装の詳細から上位レベルモジュールを独立に保つことができるようになる
A. 上位レベルのモジュールは下位レベルのモジュールに依存すべきではない。両方とも抽象(abstractions)に依存すべきである。
B. 抽象は詳細に依存してはならない。詳細が抽象に依存すべきである。またまた難解な説明が。。。
まず、「上位」と「下位」という言葉ですが、先ほどの例でいうとmain関数が上位でManクラスが下位に当たります。つまり、「上位レベルのモジュールは下位レベルのモジュールに依存すべきではない。」は具体的に言うと、「main関数はManクラスに依存するべきではない」という意味になります。
つぎに、「両方とも抽象(abstractions)に依存すべき」という部分ですが、言い換えると内部の実装に依存するのではなくインターフェイス(型)に依存するべき、という意味になります。先ほどのコードとほぼ同じですが、以下の例を見てください。
main3.py(抜粋)def main(): taro: Human = Man('taro', 12) taro.print_gender() taro.print_info()違いは、main関数がManクラスへの依存からHumanクラスへの依存に代わっている、という点です。
では、HumanクラスとManクラスの実装を見てみましょう。(内容は抜粋です、全文は末尾に載せます)main3.py(抜粋)@dataclass class Human(metaclass=ABCMeta): name: str age: int # 抽象メソッド @abstractmethod def print_gender(self) -> None: pass # 共通メソッド def print_info(self) -> None: print(f'name: {self.name}, age: {self.age}') class Man(Human): def print_gender(self): print('I am man.')Humanクラスはベースとなるクラスであり、複雑なビジネスロジックは含まれていません。つまり、抽象的なクラスということができます。逆にManクラスは内部実装が含まれるクラスのなので具象クラスとなります。HumanクラスとManクラスで何が違うかというとHumanクラスは変更される頻度が少なくManクラスは変更される頻度が多い、という部分です。理由は当然でHumanクラスはインターフェイスの定義のみ(正確には違いますが、、、)、Manクラスは内部実装、ビジネスロジックが含まれるからです。
ここまでくると、main関数がManクラス(具象)からHumanクラス(抽象)へ依存するように変えることのメリットが理解頂けると思います。Manクラスに依存する場合、main関数はManクラスの変更の影響を受けるわけですから、Manクラスの変更頻度が多いので多大な影響を受けます。逆にHumanクラスに依存する場合は、もちろんHumanクラスが変更された場合は影響を受けますが、Manクラスと比較すると変更頻度が少ないので影響が少ない、ということになります。
つまり、抽象に依存することでより変更に対して堅牢なコードを書くことができる、ということになります。
結局Pythonで依存性逆転の原則は実現できるのか?
できますが、完全ではありません。
具体的には抽象クラスabcとリント、型チェックツールを併用することで可能です。
ただし、Pythonの場合は型情報が間違っていてもプログラム自体は動きますので、他の静的型付き言語と同レベルのことを実現することはできません。
より高レベルを目指すのであれば、チームで開発環境をそろえる、プレコミットで型、リントのチェックを実施する、などを徹底すれば実現可能かと思います。
実用レベルで利用する分には問題ないレベルの機能が提供されていると思ってます。最後に
少し急いで書いたのであまり分かりやすい内容ではないかと思います。この辺りは理解するのが難しい分野ですので、少しでも参考になれればなと。コメントで質問頂ければできる限り回答させて頂きます。間違い、アドバイスもご指摘頂けると助かります。
実装コード全文
main3.pyfrom abc import ABCMeta, abstractmethod from dataclasses import dataclass @dataclass class Human(metaclass=ABCMeta): name: str age: int # 抽象メソッド @abstractmethod def print_gender(self) -> None: pass # 共通メソッド def print_info(self) -> None: print(f'name: {self.name}, age: {self.age}') class Man(Human): def print_gender(self): print('I am man.') class Woman(Human): def print_gender(self): print('I am woman.') def main(): taro: Human = Man('taro', 12) taro.print_gender() taro.print_info()
- 投稿日:2020-11-04T01:21:58+09:00
windowsでのpython開発環境構築例(wsl2, vscode, pipenv)
背景
- windows上でpython開発環境を構築
- プロジェクト毎に環境を分けたい
- Anacondaを使いたくない
- too much感がある
- 調べ物をするときに、conda前提で書かれている例が少ない(ような気がする)
Summary
- いろいろ試しましたが、WSL2, Ubuntu20.04, pipenv, VisualStudioCodeが使いやすいと判断
- 試した過程は記述していません
- 手順だけ記述します、慣れれば5分くらいで構築できます
前提
- Windows 10 Home (2020/10ぐらい)
- VisualStudioCode(以下、VSCODE)がインストールされていること
手順
- WSL2の環境をセットアップする(ここが一番時間かかる)
- ※InsiderProgramに入らなくても、いつの間にかWin10HomeでもWSL2が使えるようになっていた
- 手順はこちらが一番参考になる
- MicrosoftStoreからUbuntu20.04を探してインストールしておく
- 無事にUbuntu20.04が起動できたら、更新しておく
$ sudo apt update$ sudo apt upgrade- ※BIOSでCPUの仮想化がENABLEになっていないと、起動時にエラーが発生するので要注意
- python3がデフォルトでインストールされている
- pip3をインストール
sudo apt install python3-pip- pip3でpipenvをインストール
- sudoでインストールすること
- 任意のプロジェクトフォルダを作成しておく
- 例:
$ mkdir ~/work/python-test$ cd ~/work/python-test- 初期化
- プロジェクトフォルダ直下で下記を実行
pipenv --python=/usr/bin/python3
- FIXME: pipenv --python 3をやろうとするとwindowsのpythonを見に行ってしまうので明示的に指定
- Pipfileが生成されていることを確認
- 使いたい任意のパッケージをインストール
pipenv install [package]- Pipfile.lockファイルが生成されていることを確認
- VSCODEの拡張機能をインストール
- 「Remote - WSL」
- VSCODEとWSLの接続
- いろいろやり方がある。
- 方法1:VSCODEの左下のバーから接続して、VSCODEにてUbuntu上のフォルダを開く
- 方法2:Ubuntu上で
$ codeしてから、VSCODEにてUbuntu上のフォルダを開く- 方法3:Ubuntu上でプロジェクトフォルダ内に移動して
$ code .- ※初回のcodeコマンド実行時にVSCODEのサーバープログラムが自動でインストールされる
- VSCODE内でpython開発用の拡張機能をインストール
- 最低限「ms-python.python」だけあればよい
- ※拡張機能自体は接続先毎にインストールが必要になるので要注意
- プロジェクトフォルダ内に適当なpythonファイルを作成して開発スタート(**.py)
- 左下のpython interpereterで、([directory name]: pipenv)のものを選ぶ(初回は大体pipenvになっていない) -


- 以上で実行、デバッグ可能となる!
- 実行方法、デバッグ方法の説明は割愛
おまけ
- バージョン管理
- PipfileとPipfile.lockは両方ともバージョン管理すること
- gitなどで、別の環境で開発を開始する場合は、両ファイルが置いてあるフォルダで、
$ pipenv installすれば自動的に依存モジュールがインストールされて開発環境が作られる- 仮想環境を削除する場合
$ pipenv --rm- インストールされるモジュールの場所
- デフォルト
~/.local/share/virtualenvs/[フォルダ名]-[ランダム文字列]- プロジェクトフォルダ配下に置きたい場合
$ export PIPENV_VENV_IN_PROJECT=true- プロジェクトフォルダ配下で初期化
- プロジェクトフォルダ配下に.venvフォルダができて、その中に設置されるようになる
- 投稿日:2020-11-04T01:00:53+09:00
camelotで点線を実線として処理する(ハフ変換)
はじめに
camelotは点線が苦手でよく失敗するので調べてみると以下の参考の記事が見つかりました
camelotはopencvで抽出しているので点線を書き換えればいいみたいなのでハフ変換で点線を抽出し実線で上書きしてみたらうまくいきました
参考
Pythonを使えばテキストを含むPDFの解析は簡単だ・・・そんなふうに考えていた時期が俺にもありました
こちらの記事の横の点線のPDFを使わせていただきます
https://github.com/mima3/yakusyopdf/blob/master/20200502/%E5%85%B5%E5%BA%AB%E7%9C%8C.pdf
ハフ変換
ハフ変換で直線抽出
千葉のGo To Eatの加盟店一覧のPDF
ハフ変換で水平の直線のみ抽出
プログラム
import cv2 import numpy as np import camelot # パッチ作成 def my_threshold(imagename, process_background=False, blocksize=15, c=-2): img = cv2.imread(imagename) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) edges = cv2.Canny(gray, 50, 150, apertureSize=3) lines = cv2.HoughLinesP( edges, rho=1, theta=np.pi / 180, threshold=80, minLineLength=3000, maxLineGap=50 ) for line in lines: x1, y1, x2, y2 = line[0] # 水平の場合はy1 == y2、垂直の場合はx1 == x2のifでフィルタする cv2.line(img, (x1, y1), (x2, y2), (0, 0, 0), 1) if process_background: threshold = cv2.adaptiveThreshold( gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, blocksize, c ) else: threshold = cv2.adaptiveThreshold( np.invert(gray), 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, blocksize, c, ) return img, threshold camelot.parsers.lattice.adaptive_threshold = my_threshold tables = camelot.read_pdf("data.pdf", pages="all") tables[0].dfパッチ摘要前
点線部分が反応しないため縦に結合してしまっている
パッチ摘要後


{kind=link}