- 投稿日:2020-09-06T22:41:23+09:00
Docker Swarm + Traefik(1.7) で構築したクラスタで、REMOTE_ADDRが取得できない問題に対処した話
Docker Swarmクラスタ上で、リバースプロキシとしてTraefikコンテナを立て、nodeコンテナでコンテンツを配信する構成で運用しようとしたところ、どうにもREMOTE_ADDRが取得できなくて困りました。
そのときの対処方法をメモしておきます。
Dockerのバージョン:19.03.12
当初のdocker-compose.ymlファイルは以下のとおりです。
version: '3.4' services: socket-proxy: image: tecnativa/docker-socket-proxy networks: - internal volumes: - /var/run/docker.sock:/var/run/docker.sock environment: - SERVICES=1 - TASKS=1 - NETWORKS=1 - LOGSPOUT=ignore deploy: placement: constraints: - node.hostname == manager traefik: image: traefik:1.7-alpine command: - "--logLevel=error" - "--entryPoints=Name:http Address::80 Redirect.EntryPoint:https" - "--entryPoints=Name:https Address::443 TLS" - "--defaultentrypoints=http,https" - "--web" - "--web.address=:8080" - "--acme" - "--acme.storage=certs.json" - "--acme.entrypoint=https" - "--acme.httpchallenge.entrypoint=http" - "--acme.onHostRule=true" - "--acme.email=hashimoto@bagooon.com" - "--docker" - "--docker.endpoint=tcp://socket-proxy:2375" - "--docker.swarmMode" - "--docker.watch" ports: - 80:80 - 443:443 networks: - internal - overlay volumes: - ./certs/certs.json:/certs.json deploy: placement: constraints: - node.hostname == web restart_policy: condition: on-failure web: image: hoge/fuga:dev networks: - overlay deploy: replicas: 1 placement: constraints: - node.hostname == web labels: - "traefik.enable=true" - "traefik.backend=web" - "traefik.frontend.rule=Host:sample.com" - "traefik.frontend.entryPoints=https" - "traefik.frontend.passHostHeader=true" - "traefik.docker.network=overlay" - "traefik.protocol=http" - "traefik.port=3000" networks: overlay: external: true internal: internal: true今回の本題ではありませんが、上記の設定では「docker-socket-proxy」を使って、Traefikのendpointを別のコンテナに割り振っています。一般的にTraefikはマネージャノードで実行し、endpointにdocker.sockを指定して使用するのですが、もしTraefikにセキュリティホールが見つかったりすると、クラスタ全体を乗っ取られてしまう危険性が指摘されています。docker-socket-proxyを使用することで、ワーカーノード上でTraefikを実行でき、さらにdocker-socket-proxyで権限を絞ることでセキュリティを高めた運用が可能になります。
以前あるサイトを運用していて、悪質なアクセスに悩まされた経験がありますので、是非ともREMOTE_ADDRはログとして残しておきたいのですが、どうにも取得できません。
Traefikは、各コンテナで「traefik.frontend.passHostHeader=true」を指定すれば、バックエンドにヘッダー情報等をそのまま送り届けてくれるはずです。User-Agent等は正しく取得できますので、どうやらこの設定は生きているようです。
原因
いろいろ調べていたところ、海外の掲示板で、Docker SwarmのオーバーレイネットワークがREMOTE_ADDRを運ばないらしいという情報を見つけました。そして、Nginxの事例ではありましたが、ポートをhostモードでマウントするといいよ、という解決策も示されていました。
解決策
そこで、Traefikのポートの設定を以下のように書き換えてみました。
ports: - mode: host protocol: tcp published: 80 target: 80 - mode: host protocol: tcp published: 443 target: 443テストしたところ、無事にREMOTE_HOSTを取得できるようになりました。
Nginx等でも同じ対応で解決できるものと思います。
同じ問題でお困りの方がいらっしゃいましたら、是非お試しください。
- 投稿日:2020-09-06T20:58:15+09:00
Docker-composeを使用したDjangoの開発環境構築(個人的備忘録)
はじめに
データベースサーバには「postgres」環境構築に主眼を置いているため、pythonやDjangoに精通している必要はない。プロジェクトを開始するにあたり、任意の場所に作業ディレクトリを作成する。docker-composeを使用する場合、docker-compose.ymlファイルが置いてあるディレクトリ名が、コンテナ名やボリューム名の接頭辞として使用されるため、実際の環境においてはプロジェクト名などの意味のあるディレクトリ名を作成する。
ディレクトリの作成
-# djangoというディレクトリの作成 % mkdir django -# djangoディレクトリに移動 % cd djangodjangoディレクトリをビルドコンテキストにするため不要なファイルは含めないようにする。
Pythonの実行環境のイメージを作成するためのDockerfileを作成する。
% vim DockerfileDockerfile# python3の実行環境のイメージを指定 FROM python:3 # PYTHONUNBUFFEREDという環境変数に1を指定。この環境変数に何かしら設定しておくとバッファーを無効化できる。 ENV PYTHONUNBUFFERED 1 # codeディレクトリを作成 RUN mkdir /code # 作業ディレクトリをcodeディレクトリに移動 WORKDIR /code # ビルドコンテキスト上にあるrequirements.txtをcodeディレクトリ内に置く COPY requirements.txt /code/ # pipインストールを実行している。pipはpythonのパッケージツールで、 # -rで指定したrequirements.txtに記載されているパッケージのインストールを実行する。 # requirements.txtは、ビルドコンテキスト内に作成するがdjangoとPostgresのドライバーのパッケージ名を記述する。 RUN pip install -r requirements.txt # ビルドコンテキストの内容を全て/code内に置いている。 COPY . /code/requirements.txtの作成
% vim requirements.txt -# version2.0のDjangoのインストール Django==2.0 -#pythonでpostgresに接続するためのドライバー psycopg2docker-compose.ymlの作成
docker-compose.ymlversion: '3' services: db: image: postgres environment: POSTGRES_USER: postgres POSTGRES_PASSWORD: password web: build: . command: python3 manage.py runserver 0.0.0.0:8000 volumes: - .:/code ports: - "8000:8000" depends_on: - dbservices には「db」と「web」の2つのコンテナが起動する想定。
web にはbuildにドットが定義されているので先ほど定義したDockerfileからイメージをbuildして使用する。dbには「postgres」SQLのイメージを使用。
command はコンテナ起動時に実行されるコマンドを意味している。ここでは「python3」で「manage.py」を実行し、引数に開発用の軽量のサーバを立ち上げる「runserver」とリッスンするIPアドレス、ポート番号を指定している。「manage.py」はDjangoをインストールすると自動で生成されるファイル。しかし、ここに記載したコマンドは、コンテナ実行時にコマンドが渡された場合に上書きされる。そのため引数にコマンドを渡さなかった場合にdocker-composeのコマンドが実行される。
valunes はカレントディレクトリを/codeにバインドマウントしている。
ports は8000番で公開して、コンテナの8000番に転送されるように指定。転送先のポート番号は「runserver」のポート番号を合わせる必要がある。
depends_on「web」サービスを起動する前に「db」サービスが起動するように依存関係を定義する。Djangoプロジェクトの作成
% docker -compose run web django-admin.py startproject examplepj .docker-compose runの引数にはymlに定義した「web」サービスを指定。以降はwebサービスのコンテナ起動時に実行するコマンド。django-admin.pyもDjangoのインストールによって作成されるもの。ここではdjango-admin.pyを実行して、「startproject」でdjangoのプロジェクトを作成している。プロジェクト名はexamplepjで保存先をカレントディレクトリにしている。カレントディレクトリはDockerfileで指定した/codeディレクトリになる。
% ls -l現在のカレントディレクトリとコンテナの/codeディレクトリがバインドマウントされてことが確認できる。
データベースの設定を記述して開発用のwebサーバを起動する。
% vim examplepj/settings.pysettings.pyALLOWED_HOSTS = ['*'] ----省略---- DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql', #ENGINEにpostgresqlを指定 'NAME': 'postgres', #postgresの指定 'USER': 'postgres', #postgresの指定 'PASSWORD': 'password', 'HOST': 'db', #docker-composeで立ち上げたコンテナはサービス名で名前解決を行うことができるのでHOSTの指定はdbとすることができる。 'PORT': 5432, #postgresqlのデフォルトの5432番ポートを指定 } }各サービスの起動
% docker-compose up -d Starting django_db_1 ... done Creating django_web_1 ... doneIp:8000で接続されていることが確認できる。manage.pyなどの管理用のスクリプトを実行する場合はコンテナで実行しないと失敗する可能性があることに注意する。あくまでpythonの実行環境はコンテナに用意されているため、pythonのスクリプト実行自体はコンテナ内で実行する。
Djangoのチュートリアルのpollsアプリケーション作成
-# pollsアプリケーションのファイルをプロジェクト内に作成 % docker-compose run web python3 manage.py startapp polls -# views.pyページの変更 % vim polls/views.pyviews.pyfrom django.http import HttpResponse # Create your views here. def index(request): return HttpResponse("Hello, world. You're at the polls index.")これで「polls」というURLにアクセスが来た場合に表示されるメッセージを定義。
polls.indexのルート設定
% vim polls/urls.pyurls.pyfrom django.urls import path from . import views urlpatterns = [ path('', views.index, name='index'), ]作成したindexメソッドの結果を表示することを定義している。
作成したurls.pyをメインのurls.pyから読み込むように設定する。
% vim examplepj/urls.pyurls.pyurlpatterns = [ path('polls/', include('polls.urls')), path('admin/', admin.site.urls), ]これでip:8000/polls/でindexページが表示される。このようにソースコードを追加することでコンテナでdjangoを動作させながら、開発を進めることができる。
コンテナの停止
% docker-compose stop
- 投稿日:2020-09-06T19:28:02+09:00
GitHub Container Registry を試す
Docker Hub が無料プランでの制限を強化する1一方、GitHub Container Registry が発表された2。
2019年から提供されるようになった GitHub Package Registry3 でも Docker Image は扱えたのだけど、GitHub Container Registry として独立させることで、ユーザ体験とパフォーマンスの向上を目指すとのこと。GitHub Container Registry(以下 ghcr.io)は2020/09/06時点ではまだ、Public Beta だけど、Github自身が公開しているGithub Action Super-LinterのDocker Imageはすでに ghcr.io のパブリック・イメージとして公開されている。スター5.5k の Github Action のイメージに使用しようとしているのでそれなりに安定稼働が期待できるのかな?4
利用料金については次の様になっている。
- パブリック・イメージの公開は無料
- GAまでの間はプライベートイメージも無料
(GAしたら GitHub Packages の一部として同様のプライスモデルで課金)パブリック・イメージを公開してみた
Prontoを実行するGithub Actionを作ったで紹介したGithub Action Pronto Actionで利用している Docker Image は元々、Docker Hub でイメージを公開していた。ところが、Pullの回数にも制限がかかるとの発表があったので、パブリックイメージなら無料な ghcr.io に移行してみた。
Docker Hubの場合には、Docker Hubの自動ビルド機能を利用して、masterへのPushやタグをプッシュしたときにイメージをビルドするようにしていた。
ghcr.io で公開するイメージは Github Action でビルドするのが手軽。公開の手順は次の通り。
- ghcr.io アクセス用の Personal Access Token を作る
- イメージをビルドする(Dockerfile を含む)リポジトリに Github Workflow を追加する
- パッケージをパブリックに設定変更する
一度、仕組みを作ってしまえば、後は自動でビルド、自動で公開してくれる。
ghcr.io アクセス用の Personal Access Token を作る
Pushing and pulling Docker imagesに ghcr.io への読み書きについて基本的なことが書いてある。
それによると、パスワードの代わりに Personal Access Token(以下PAT)を使うと書いてある。
もちろん、パブリック・イメージをPullするだけならログインする必要はないのだけど、Pushしたいので用意する必要がある。
Github Workflow でPushするなら、secrets.GITHUB_TOKENが使えるでは?と思うかもしれないが、ドキュメントにダメって書いてある5。ghcr.io で読み書きするためにはNew personal access tokenにアクセスして、
write:packagesを許可したPATを作成する。
下のスクリーンショットではwrite:packages以外も有効にしているが、write:packagesを有効にしたら自動的に他も有効になる。セットで必要なようだ。
作成したPATは、イメージをビルドするリポジトリの Settings > Secrets にアクセスして、後でWorkflow内で参照できるように登録しておく。
このエントリではGHCR_TOKENというキーで登録したという体で説明する。イメージをビルドする(Dockerfile を含む)リポジトリに Github Workflow を追加する
Introducing GitHub Container Registryでは、starter-workflows/docker-publish.ymlの利用が紹介されているのだけど、Github ActionのドキュメントPublishing Docker imagesで紹介されているDocker社謹製の Build and push Docker imagesのほうが、ビルドしたイメージのタグをよしなに調整してくれたり便利なのでこちらを使った。
で、Docker Image をビルドして ghcr.io に Push する Workflow は次の通り。
name: Publish Docker image on: push: branches: - master - develop tags: - '[0-9]+.[0-9]+.[0-9]+' jobs: push_to_registry: name: Push Docker image to GitHub Container Registry runs-on: ubuntu-latest steps: - name: Check out the repo uses: actions/checkout@v2 - name: Push to GitHub Container Registry uses: docker/build-push-action@v1 with: username: ${{ github.actor }} password: ${{ secrets.GHCR_TOKEN }} registry: ghcr.io repository: heromo/pronto-action tag_with_ref: true
masterブランチまたはdevelopブランチにpushした場合、あるいはフィルターパターン'[0-9]+.[0-9]+.[0-9]+'にマッチするGitのタグ(例:1.0.0,1.4.0)をpushした時に実行される。
masterブランチまたはdevelopブランチにpushした場合というのは、これらのブランチにコミットが追加された時というのと同意なので、プルリクエストをマージした場合にも実行される。
registryにはghcr.ioを指定する。
passwordには先程、 Secrets に登録したキーGHCR_TOKENへの参照を設定する。
repositoryには オーナー名/イメージ名 の形式でPush先を指定する。これはすべて小文字である必要がある(私はGithubのオーナー名に大文字を使っているのでそのまま大文字で設定したらエラーになった)。
tag_with_ref: trueを設定していると、ビルドした Docker Image のタグを次の様によしなに設定してくれる6。
- ブランチ
master->latest- ブランチ
develop->develop- タグ
1.4.0->1.4.0パッケージをパブリックに設定変更する
Pushされたイメージは、リポジトリには紐付いておらず、自分のGithubプロファイルページの Packages を開くと見つけることができる。できたばかりのパッケージはプライベートとなっている。
Configuring visibility of container images for your personal accountに書いてあるとおり、ページの右上の Edit package プルダウンで、Package Setting を選択すると設定ページが開く。
後は、Danger Zone の Make public ボタンをクリックすればパブリックになる。一度、パブリックにするとプライベートには戻せないので注意。Github Action で利用するイメージであればパブリックにする必要がある。そうしないと、Workflowを実行した時にpullできなくてエラーとなる。
自分のための自分しか使わないイメージならプライベートにしておいても構わないのだけど、GAになったら課金されることに注意が必要。
まとめ
今回、Docker Hub で公開していたイメージを ghcr.io で公開してみた。
Github Actionで利用しているイメージを公開する場合、Github内ですべて閉じるので ghcr.io を使ったほうが手間が少ないと感じた。
パブリックだと無料で、回数制限もなさそうなのもよい。
https://www.docker.com/pricing/resource-consumption-updates ↩
https://github.blog/2020-09-01-introducing-github-container-registry/ ↩
https://github.blog/2019-05-10-introducing-github-package-registry/ ↩
リポジトリを調べてみると、2020/09/06時点ではmasterではghcr.ioからイメージをpullするように変更されているものの、Actionとして公開されているものはまだ、DockerHubかpullするようになっている様子。 ↩
https://docs.github.com/en/packages/getting-started-with-github-container-registry/migrating-to-github-container-registry-for-docker-images#updating-your-github-actions-workflow ↩

- 投稿日:2020-09-06T19:03:33+09:00
Dockerの個人的なメモ
- 投稿日:2020-09-06T19:03:33+09:00
個人的用語メモリストを共有する
ゲッター
ゲッターはある属性の値を取得するメソッド
セッター
セッターは属性に値を設定するメソッド
イミュータブルなオブジェクト
変更不可能
ミュータブルなオブジェクト
変更可能
イメージとコンテナの違い
プログラミングで例えるとイメージがクラスでコンテナがオブジェクト(インスタンス)
docker-composeの役割
複数コンテナをコマンド一つで作成、削除、停止できる。
docker runだとそのコンテナ一つごとにコマンドを叩かなければならない。その他
dockerコマンドを叩けるターミナルなどをdockerクライアント、dockerサーバーをdockerDemonと呼ぶ
また追記します。アドバイスあればよろしくお願いします。
- 投稿日:2020-09-06T19:03:33+09:00
個人的な疑問だった用語のメモリストを共有する
ゲッター
ゲッターはある属性の値を取得するメソッド
セッター
セッターは属性に値を設定するメソッド
イミュータブルなオブジェクト
変更不可能なオブジェクト
ミュータブルなオブジェクト
変更可能なオブジェクト
イメージとコンテナの違い
プログラミングで例えるとイメージがクラスでコンテナがオブジェクト(=インスタンス)
docker-composeの役割
複数コンテナをコマンド一つで作成、削除、停止できる。
docker runだとそのコンテナ一つごとにコマンドを叩かなければならない。その他
dockerコマンドを叩けるターミナルなどをdockerクライアント、dockerサーバーをdockerDemonと呼ぶ
また追記します。アドバイスあればよろしくお願いします。
- 投稿日:2020-09-06T17:08:16+09:00
macOS CatalinaでDocker上のlilypondを動かして楽譜を作成する
背景
基本的に以下の先行事例と同じ動機。
- Running Lilypond on MacOS 10.15 (Catalina) | Kyle W. Baldwin
- macOS Catalinaで死んだLilypondをDocker上で動かす - Qiita
楽譜作成ソフトlilypondはmacOSの64bit版が存在しないためCatalina以降では実行できない。公式サイトには非公式バイナリも紹介されているが、いつまでメンテナンスされているかわからない。
ただし上記2サイトはdockerhubでイメージが管理され、いまいち現時点ではDockerfileの作り方もわからないDocker初心者にはよくわからないところもあったので、特に1つ目を参考にしつつ0から作れる方法を以下にメモ。
たぶんDocker hubを理解すればそちらの方が楽に思えるのだろうけれど。
環境はMacBook Air 13-inch 2018。
Dockerをインストールしてイメージを作成
Running Lilypondのページで紹介されているように Install Docker Desktop on MacからDockerのインストーラをダウンロードし、ドラッグアンドドロップでインストールしてDocker hubにアカウントを作成してログイン。ログインは必要ないかもしれない。
次に
% docker pull ubuntuでイメージをダウンロードし、
% docker run -it ubuntuでそのubuntuイメージからコンテナを作成・起動・アタッチ。オプション-itはそれぞれ標準入力利用可能と端末(TTY)利用可能。起動したままdettachしたい場合はCtrl+P, Ctro+Q。停止させたい場合はexit。
参考: Dockerコンテナの作成、起動〜停止まで - Qiita
lilypondをDockerコンテナ上にインストール
アタッチしたコンテナ上で
Kyle Baldwinさんのgithubにあるように、
- apt-get update
- apt-get install locales
- apt-get update
- apt-get install wget
- lilypondのバイナリをwget
- shでインストール。
% sh lilypond-2.20.0-1.linux-64.sh以上でこのコンテナ上では普通にlilypondが実行できるようになった。
lilypondがインストールされたUbuntuコンテナをイメージとして保存する
Ctrl+P, Ctrl+Qでコンテナからdettachする。
Docker ps で起動しているコンテナの一覧を表示し、ハッシュ値を得て、docker コミットしてdocker-lilypondという名前のimageを作成。
% docker commit <hash> docker-lilypondDockerイメージ一覧にdocker-lilypondが表示された。
% docker images REPOSITORY TAG IMAGE ID CREATED SIZE docker-lilypond latest b77f9ee3467e 4 days ago 303MB ubuntu latest 4e2eef94cd6b 2 weeks ago 73.9MBMac上からDockerコンテナ上のlilypondを実行して楽譜を取り出す
以下のコマンドで一回ごとにイメージを起動してlilypond を実行できる。カレントディレクトリ(pwd)を/app にマウントし、sample.lyファイルに対してlilypondコマンドを実行する。
% docker run --rm -v $(pwd):/app -w /app docker-lilypond lilypond sample.lyすると端末にlilypondのメッセージが表示され、カレントにsample.pdfが作成される。このコマンドをファイルに保存してchmod +xして/usr/local/binに置く。
lilypond.sh#! /bin/bash docker run --rm -v "$(pwd)":/app -w /app docker-lilypond lilypond "$@"以降は
lilypond.sh aaa.lyでaaa.pdfが作成できる。
lilypond.sh --versionのような実行も可能。
- 投稿日:2020-09-06T13:53:50+09:00
Docker × Laravel コードを自動整形するコンテナを構築する
PHP CS Fixer とは
PHP CS Fixer (PHP Coding Standards Fixer) とは、その名の通りPHPのコードをコーディング規約に沿うよう修正してくれるツールです。
前提
当記事は上記の記事の補足になる記事です。
docker-compose.ymlの編集
docker-compose.ymlservices: cs: image: herloct/php-cs-fixer volumes: - ./backend:/project
services.csを追記します。コマンド
# 自動整形しない(差分表示のみ) $ docker-compose run cs fix --dry-run -v --diff --diff-format udiff . # 自動整形する $ docker-compose run cs fix -v --diff --diff-format udiff .Makefile
コマンドが長いのでMakefileを用意しておくと良いです。
dry-cs: docker-compose run cs fix --dry-run -v --diff --diff-format udiff . fix-cs: docker-compose run cs fix -v --diff --diff-format udiff .下記のコマンドで実行できるようになります。
$ make dry-cs $ make fix-cs参考
- 投稿日:2020-09-06T11:54:18+09:00
データサイエンス100本ノック解説(P081~100)
1. はじめに
前回に引き続き、データサイエンス100本ノックの解説を行う。
データサイエンス100本ノック解説(P001~020)
データサイエンス100本ノック解説(P021~040)
データサイエンス100本ノック解説(P041~060)
データサイエンス100本ノック解説(P061~080)導入についてはこちらの記事を参考に進めてください(※ MacでDockerを扱います)
2. 解説編
P-081: 単価(unit_price)と原価(unit_cost)の欠損値について、それぞれの平均値で補完した新たなdf_product_2を作成せよ。なお、平均値について1円未満は四捨五入とし、0.5については偶数寄せでかまわない。補完実施後、各項目について欠損が生じていないことも確認すること。
P-081# fillnaで欠損値を補完する。 # np.roundで偶数よせの四捨五入。np.nanmeanで欠損値の値を除いた平均値 df_product_2 = df_product.fillna({'unit_price':np.round(np.nanmean(df_product['unit_price'])), 'unit_cost':np.round(np.nanmean(df_product['unit_cost']))}) # isnull().sum()で欠損を確認する df_product2.isnull().sum()参考: pandasで数値を丸める(四捨五入、偶数への丸め)
参考: NumPyで欠損値np.nanを含む配列ndarrayの合計や平均を算出P-082: 単価(unit_price)と原価(unit_cost)の欠損値について、それぞれの中央値で補完した新たなdf_product_3を作成せよ。なお、中央値について1円未満は四捨五入とし、0.5については偶数寄せでかまわない。補完実施後、各項目について欠損が生じていないことも確認すること。
P-082# 欠損値はfillnaを用いる # np.roundで偶数よせの四捨五入。中央値np.nanmedianで補完する df_product_3 = df_product.fillna({'unit_price':np.round(np.nanmedian(df_product['unit_price'])), 'unit_cost':np.round(np.nanmedian(df_product['unit_cost']))}) # isnull().sum()で欠損を確認する df_product_3.isnull().sum()参考: pandasで数値を丸める(四捨五入、偶数への丸め)
参考: [NumPy] 11. NumPy配列のNaNに関するいろいろな処理P-083: 単価(unit_price)と原価(unit_cost)の欠損値について、各商品の小区分(category_small_cd)ごとに算出した中央値で補完した新たなdf_product_4を作成せよ。なお、中央値について1円未満は四捨五入とし、0.5については偶数寄せでかまわない。補完実施後、各項目について欠損が生じていないことも確認すること。
P-083# (解法1) # 各商品の小区分(category_small_cd)ごとに中央値を出す df_tmp = df_product.groupby('category_small_cd').agg({'unit_price': 'median', 'unit_cost': 'median'}).reset_index() # カラム名を変更する df_tmp.columns = ['category_small_cd', 'median_price', 'median_cost'] # 商品データフレーム(df_product)と中央値が入ったデータフレーム(df_tmp)を結合する df_product_4 = pd.merge(df_product, df_tmp, how='inner', on='category_small_cd') # 単価(unit_price)の欠損値に中央値を補完する(axis=1で各行に適用) df_product_4['unit_price'] = df_product_4[['unit_price', 'median_price']]. \ apply(lambda x: np.round(x[1]) if np.isnan(x[0]) else x[0], axis=1) # 原価(unit_cost)の欠損値に中央値を補完する(axis=1で各行に適用) df_product_4['unit_cost'] = df_product_4[['unit_cost', 'median_cost']]. \ apply(lambda x: np.round(x[1]) if np.isnan(x[0]) else x[0], axis=1) # isnull().sum()で欠損を確認する df_product_4.isnull().sum()P-083# (解法2) # 各商品の小区分(category_small_cd)ごとに中央値を出す df_tmp = df_product.groupby('category_small_cd').agg(median_price=('unit_price', 'median'), median_cost=('unit_cost', 'median')).reset_index() # 商品データフレーム(df_product)と中央値が入ったデータフレーム(df_tmp)を結合する df_product_4 = pd.merge(df_product, df_tmp, how='inner', on='category_small_cd') # maskを用いて欠損値(Nan)の部分はマスク(見えないように)して、中央値を代入する # mask(隠す条件, 埋める値)、roundで四捨五入 df_product_4['unit_price'] = (df_product_4['unit_price'].mask(df_product_4['unit_price'].isnull(), df_product_4['median_price'].round())) df_product_4['unit_cost'] = (df_product_4['unit_cost'].mask(df_product_4['unit_cost'].isnull(), df_product_4['median_price'].round())) # isnull().sum()で欠損を確認する df_product_4.isnull().sum()P-083# (解法3) # 商品データフレーム(df_product)をコピーする df_product_4 = df_product.copy() # 単価(unit_price)と原価(unit_cost)それぞれの処理を行う # fillnaを用いて欠損値を補完する。 # 各商品の小区分(category_small_cd)ごとに中央値を出す。transformを用いる。 for x in ['unit_price', 'unit_cost']: df_product_4[x] = df_product_4[x].fillna(df_product_4.groupby('category_small_cd')[x] .transform('median').round()) # isnull().sum()で欠損を確認する df_product_4.isnull().sum()参考: [NumPy] 11. NumPy配列のNaNに関するいろいろな処理
参考: Python pandas データ選択処理をちょっと詳しく <後編>
参考: Pandas の transform と apply の基本的な違いP-084: 顧客データフレーム(df_customer)の全顧客に対し、全期間の売上金額に占める2019年売上金額の割合を計算せよ。ただし、販売実績のない場合は0として扱うこと。そして計算した割合が0超のものを抽出せよ。 結果は10件表示させれば良い。また、作成したデータにNAやNANが存在しないことを確認せよ。
P-084# レシート明細データフレーム(df_receipt)のsales_ymdが2019年のものを抽出する(df_tmp1) df_tmp_1 = df_receipt.query('20190101 <= sales_ymd <= 20191231') # 顧客データフレーム(df_customer)のcustomer_idと2019年のみを抽出したレシート明細データフレーム(df_tmp1)を左結合 # customer_idごとにグループ分け(結合時に増えている)し、売上金額(amount)を合計する # カラム名を変更する(rename) df_tmp_1 = pd.merge(df_customer['customer_id'], df_tmp_1[['customer_id', 'amount']], how='left', on='customer_id'). \ groupby('customer_id').sum().reset_index().rename(columns={'amount': 'amount_2019'}) # 全期間の売上金額を顧客別に合計する df_tmp_2 = pd.merge(df_customer['customer_id'], df_receipt[['customer_id', 'amount']], how='left', on='customer_id'). \ groupby('customer_id').sum().reset_index() # df_tmp1とdf_tmp2を結合する(2019年と全ての期間の売上高(amount)の比較用) df_tmp = pd.merge(df_tmp1, df_tmp_2, how='inner', on='customer_id') # # 欠損値をそれぞれ0で補完する df_tmp['amount_2019'] = df_tmp['amount_2019'].fillna(0) df_tmp['amount'] = df_tmp['amount'].fillna(0) # 割合(amount_rate)を求め、欠損値を補完する df_tmp['amount_rate'] = df_tmp['amount_2019'] / df_tmp['amount'] df_tmp['amount_rate'] = df_tmp['amount_rate'].fillna(0) # 割合(amount_rate)が0を超えるものを10件表示する df_tmp.query('amount_rate > 0').head(10)参考: pandasの使い方(merge、join、concat編)
参考: pandas.DataFrameの行名・列名の変更P-085: 顧客データフレーム(df_customer)の全顧客に対し、郵便番号(postal_cd)を用いて経度緯度変換用データフレーム(df_geocode)を紐付け、新たなdf_customer_1を作成せよ。ただし、複数紐づく場合は経度(longitude)、緯度(latitude)それぞれ平均を算出すること。
P-085# 顧客データフレーム(df_customer)と経度緯度変換用データフレーム(df_geocode)を結合する df_customer_1 = pd.merge(df_customer[['customer_id', 'postal_cd']], df_geocode[['postal_cd', 'longitude' ,'latitude']], how='inner', on='postal_cd') # 経度緯度変換用データフレームに重複があるため、複数紐づいている。 # customer_idでグループ分けし、経度(longitude)、緯度(latitude)それぞれ平均 # カラム名を変更する df_customer_1 = df_customer_1.groupby('customer_id'). \ agg({'longitude':'mean', 'latitude':'mean'}).reset_index(). \ rename(columns={'longitude':'m_longitude', 'latitude':'m_latitude'}) # 顧客データフレーム(df_customer)と重複がない(df_customer_1)を結合する df_customer_1 = pd.merge(df_customer, df_customer_1, how='inner', on='customer_id') df_customer_1.head(3)参考: pandasの使い方(merge、join、concat編)
参考: pandas.DataFrameの行名・列名の変更P-086: 前設問で作成した緯度経度つき顧客データフレーム(df_customer_1)に対し、申込み店舗コード(application_store_cd)をキーに店舗データフレーム(df_store)と結合せよ。そして申込み店舗の緯度(latitude)・経度情報(longitude)と顧客の緯度・経度を用いて距離(km)を求め、顧客ID(customer_id)、顧客住所(address)、店舗住所(address)とともに表示せよ。計算式は簡易式で良いものとするが、その他精度の高い方式を利用したライブラリを利用してもかまわない。結果は10件表示すれば良い。
$$
緯度(ラジアン):\phi \
経度(ラジアン):\lambda \
$$
$$
距離L = 6371 * arccos(sin \phi_1 * sin \phi_2
+ cos \phi_1 * cos \phi_2 * cos(\lambda_1 − \lambda_2))
$$P-086# 計算式の関数を作成 def calc_distance(x1, y1, x2, y2): x1_r = np.radians(x1) x2_r = np.radians(x2) y1_r = np.radians(y1) y2_r = np.radians(y2) return 6371 * np.arccos(np.sin(y1_r) * np.sin(y2_r) + np.cos(y1_r) * np.cos(y2_r) * np.cos(x1_r - x2_r)) # 緯度経度つき顧客データフレーム(df_customer_1)と店舗データフレーム(df_store)と結合 df_tmp = pd.merge(df_customer_1, df_store, how='inner', left_on=['application_store_cd'], right_on=['store_cd']) # 距離を求める df_tmp['distance'] = calc_distance(df_tmp['m_longitude'], df_tmp['m_latitude'], df_tmp['longitude'], df_tmp['latitude']) df_tmp[['customer_id', 'address_x', 'address_y', 'distance']].head(10) # (別解) mathを使ったパターン def calc_distance(x1, y1, x2, y2): distance = 6371 * math.acos(math.sin(math.radians(y1)) * math.sin(math.radians(y2)) + math.cos(math.radians(y1)) * math.cos(math.radians(y2)) * math.cos(math.radians(x1) - math.radians(x2))) return distance df_tmp = pd.merge(df_customer_1, df_store, how='inner', left_on='application_store_cd', right_on='store_cd') df_tmp['distance'] = df_tmp[['m_longitude', 'm_latitude','longitude', 'latitude']]. \ apply(lambda x: calc_distance(x[0], x[1], x[2], x[3]), axis=1) df_tmp[['customer_id', 'address_x', 'address_y', 'distance']].head(10)P-087: 顧客データフレーム(df_customer)では、異なる店舗での申込みなどにより同一顧客が複数登録されている。名前(customer_name)と郵便番号(postal_cd)が同じ顧客は同一顧客とみなし、1顧客1レコードとなるように名寄せした名寄顧客データフレーム(df_customer_u)を作成せよ。ただし、同一顧客に対しては売上金額合計が最も高いものを残すものとし、売上金額合計が同一もしくは売上実績の無い顧客については顧客ID(customer_id)の番号が小さいものを残すこととする。
P-087# レシート明細データフレーム(df_receipt)を顧客ごとにグループ分けして売り上げ金額を合計する df_tmp = df_receipt.groupby('customer_id').agg({'amount': sum}).reset_index() # 顧客データフレーム(df_customer)と先ほど作成した顧客ごとの売り上げ金額を結合する # 顧客データフレーム(df_customer)のキーを全て残すため左結合(how='left') # 顧客ごとに昇順を行い、金額を降順でソートする df_customer_u = pd.merge(df_customer, df_tmp, how='left', on='customer_id'). \ sort_values(['amount', 'customer_id'], ascending=[False, True]) # 1顧客1レコードとなるように名前(customer_name)と郵便番号(postal_cd)の重複を削除する。(ソートした結果、重複のものは最初のものを残す) df_customer_u.drop_duplicates(subset=['customer_name', 'postal_cd'], keep='first', inplace=True) # 減少した数を出力する print('減少数: ', len(df_customer) - len(df_customer_u))参考: Python pandas 図でみる データ連結 / 結合処理
参考: pandas.DataFrame, Seriesをソートするsort_values, sort_index
参考: pandas.DataFrame, Seriesの重複した行を抽出・削除P-088: 前設問で作成したデータを元に、顧客データフレームに統合名寄IDを付与したデータフレーム(df_customer_n)を作成せよ。ただし、統合名寄IDは以下の仕様で付与するものとする。
重複していない顧客:顧客ID(customer_id)を設定
重複している顧客:前設問で抽出したレコードの顧客IDを設定P-088# 顧客データフレーム(df_customer)と名寄せした名寄顧客データフレーム(df_customer_u)を結合する # ※名前(customer_name)と郵便番号(postal_cd)が一致するものを結合する df_customer_n = pd.merge(df_customer, df_customer_u[['customer_id', 'customer_name', 'postal_cd']], how='inner', on=['customer_name', 'postal_cd']) # カラム名を変更 df_customer_n.rename(columns={'customer_id_x': 'customer_id', 'customer_id_y': 'integration_id'}, inplace=True) # IDの差を求める print('ID数の差', len(df_customer_n['customer_id'].unique()) - len(df_customer_n['integration_id'].unique()))参考: pandasでユニークな要素の個数、頻度(出現回数)をカウント
P-089: 売上実績のある顧客に対し、予測モデル構築のため学習用データとテスト用データに分割したい。それぞれ8:2の割合でランダムにデータを分割せよ。
P-089# 売り上げ実績のある顧客データを作成(df_customerとdf_receiptを結合) df_tmp = pd.merge(df_customer, df_receipt['customer_id'], how='inner', on='customer_id') # df_customerを学習用データとテスト用データに分割 (train_test_split)を用いる df_train, df_test = train_test_split(df_tmp, test_size=0.2, random_state=71) # 学習用データとテスト用データそれぞれの割合を出す print('学習データ割合: ', len(df_train) / len(df_tmp)) print('テストデータ割合: ', len(df_test) / len(df_tmp))参考: scikit-learnでデータを訓練用とテスト用に分割するtrain_test_split
P-090: レシート明細データフレーム(df_receipt)は2017年1月1日〜2019年10月31日までのデータを有している。売上金額(amount)を月次で集計し、学習用に12ヶ月、テスト用に6ヶ月のモデル構築用データを3セット作成せよ。
P-090# レシート明細データフレーム(df_receipt)をコピーする df_tmp = df_receipt.copy() # sales_ymdをint64からstr型へ変更し、スライスを用いて年月を取り出す df_tmp['sales_ymd'] = df_tmp['sales_ymd'].astype('str').str[:6] # sales_ymd(年月)でグループ分けして、売上金額(amount)を合計する df_tmp = df_tmp.groupby('sales_ymd').agg({'amount': sum}).reset_index() # 学習データとテストデータに分ける関数 def split_date(df, train_size, test_size, slide_window, start_point): train_start = start_point * slide_window test_start = train_start + train_size return df[train_start:test_start], df[test_start:test_start+test_size] # モデル構築用データを3セット作成 df_train_1, df_test_1 = split_date(df_tmp, train_size=12, test_size=6, slide_window=6, start_point=0) df_train_2, df_test_2 = split_date(df_tmp, train_size=12, test_size=6, slide_window=6, start_point=1) df_train_3, df_test_3 = split_date(df_tmp, train_size=12, test_size=6, slide_window=6, start_point=2)(補足: 問題を理解する)
学習用は12ヶ月データでテスト用は6ヶ月データとするモデルは3つ
モデル 学習データ 学習データ範囲 テストデータ テストデータ範囲 モデル1 df_train_1 2017/01月〜2017/12月 df_train_1 2017/01月〜2017/12月 モデル2 df_train_2 2017/06月〜2018/06月 df_train_2 2018/06月〜2018/12月 モデル3 df_train_3 2018/01月〜2018/12月 df_train_3 2019/01月〜2019/06月 参考: scikit-learnでデータを訓練用とテスト用に分割するtrain_test_split
P-091: 顧客データフレーム(df_customer)の各顧客に対し、売上実績のある顧客数と売上実績のない顧客数が1:1となるようにアンダーサンプリングで抽出せよ。
P-091# レシート明細データフレーム(df_receipt)を顧客ごとにグループ分けし、売り上げを合計する df_tmp = df_receipt.groupby('customer_id').agg({'amount': sum}).reset_index() # 顧客データフレーム(df_customer)とレシート明細データフレーム(df_receipt)を結合(左結合) df_tmp = pd.merge(df_customer, df_tmp, how='left', on='customer_id') # 売り上げ実績(amount)がある場合は1、ない場合は0を入れる df_tmp['buy_flg'] = df_tmp['amount'].apply(lambda x: 0 if np.isnan(x) else 1) # 売上実績のある顧客数と売上実績のない顧客数の件数を出力する print('0の件数', len(df_tmp.query('buy_flg==0'))) print('1の件数', len(df_tmp.query('buy_flg==1'))) # RandomUnderSampler でアンダーサンプリングする rs = RandomUnderSampler(random_state=71) df_sample, _ = rs.fit_sample(df_tmp, df_tmp.buy_flg) # 売上実績のある顧客数と売上実績のない顧客数の件数を出力する print('0の件数', len(df_sample.query('buy_flg==0'))) print('1の件数', len(df_sample.query('buy_flg==1')))参考: 【Kaggle】imbalanced-learn を使ってアンダーサンプリングをしてみた
参考: 多クラス分類の不均衡データのdownsamplingP-092: 顧客データフレーム(df_customer)では、性別に関する情報が非正規化の状態で保持されている。これを第三正規化せよ。
P-092# 顧客データフレーム(df_customer)のgender_cdの重複を取り除く df_gender = df_customer[['gender_cd', 'gender']].drop_duplicates() # 性別のデータフレーム(df_gender)を作成したので顧客データフレームからgenderカラムを削除する df_customer_s = df_customer.drop(columns='gender')参考: pandas.DataFrame, Seriesの重複した行を抽出・削除
P-093: 商品データフレーム(df_product)では各カテゴリのコード値だけを保有し、カテゴリ名は保有していない。カテゴリデータフレーム(df_category)と組み合わせて非正規化し、カテゴリ名を保有した新たな商品データフレームを作成せよ。
P-093# 商品データフレーム(df_product)とカテゴリデータフレーム(df_category)を結合する df_product_full = pd.merge(df_product,df_category[['category_small_cd', 'category_major_name', 'category_medium_name', 'category_small_name']], how='inner', on='category_small_cd') df_product_full.head()キーを"category_small_cd"としているのは、"category_major_cd"や"category_medium_cd"ではカテゴリーとなっており、細かく分類できないからである。
P-094: 先に作成したカテゴリ名付き商品データを以下の仕様でファイル出力せよ。なお、出力先のパスはdata配下とする。
・ファイル形式はCSV(カンマ区切り)
・ヘッダ有り
・文字コードはUTF-8P-094# to_csv(ファイル形式はCSV)を用いて出力する df_product_full.to_csv('./data/P_df_product_full_UTF-8_header.csv', encoding='UTF-8', index=False) # (別解) # コード例2(BOM付きでExcelの文字化けを防ぐ) df_product_full.to_csv('./data/P_df_product_full_UTF-8_header.csv', encoding='utf_8_sig', index=False)参考: pandasでcsvファイルの書き出し・追記(to_csv)
P-095: 先に作成したカテゴリ名付き商品データを以下の仕様でファイル出力せよ。なお、出力先のパスはdata配下とする。
・ファイル形式はCSV(カンマ区切り)
・ヘッダ有り
・文字コードはCP932P-095# to_csv(ファイル形式はCSV)を用いて出力する df_product_full.to_csv('./data/P_df_product_full_CP932_header.csv', encoding='CP932', index=False)CP932とは?
Microsoft コードページ 932(CP932)は、マイクロソフト及び、MS-DOSのOEMベンダがShift_JISを独自に拡張した文字コードである。参考: pandasでcsvファイルの書き出し・追記(to_csv)
P-096: 先に作成したカテゴリ名付き商品データを以下の仕様でファイル出力せよ。なお、出力先のパスはdata配下とする。
・ファイル形式はCSV(カンマ区切り)
・ヘッダ無し
・文字コードはUTF-8P-096# to_csv(ファイル形式はCSV)を用いて出力する df_product_full.to_csv('./data/P_df_product_full_UTF-8_noh.csv', header=False ,encoding='UTF-8', index=False)参考: pandasでcsvファイルの書き出し・追記(to_csv)
P-097: 先に作成した以下形式のファイルを読み込み、データフレームを作成せよ。また、先頭10件を表示させ、正しくとりまれていることを確認せよ。
・ファイル形式はCSV(カンマ区切り)
・ヘッダ有り
・文字コードはUTF-8P-097# read_csvを用いて読み込む df_tmp = pd.read_csv('./data/P_df_product_full_UTF-8_header.csv') df_tmp.head(10)参考: pandasでcsv/tsvファイル読み込み(read_csv, read_table)
P-098: 先に作成した以下形式のファイルを読み込み、データフレームを作成せよ。また、先頭10件を表示させ、正しくとりまれていることを確認せよ。
・ファイル形式はCSV(カンマ区切り)
・ヘッダ無し
・文字コードはUTF-8P-098# read_csvを用いて読み込む df_tmp = pd.read_csv('./data/P_df_product_full_UTF-8_noh.csv', header=None) df_tmp.head(10)参考: pandasでcsv/tsvファイル読み込み(read_csv, read_table)
P-099: 先に作成したカテゴリ名付き商品データを以下の仕様でファイル出力せよ。なお、出力先のパスはdata配下とする。
・ファイル形式はTSV(タブ区切り)
・ヘッダ有り
・文字コードはUTF-8P-099# to_csv(ファイル形式はCSV)を用いて出力する # タブ文字\tで区切ったtsvファイルとして保存 df_product_full.to_csv('./data/P_df_product_full_UTF-8_header.tsv', sep='\t', encoding='UTF-8', index=False)参考: pandasでcsvファイルの書き出し・追記(to_csv)
P-100: 先に作成した以下形式のファイルを読み込み、データフレームを作成せよ。また、先頭10件を表示させ、正しくとりまれていることを確認せよ。
・ファイル形式はTSV(タブ区切り)
・ヘッダ有り
・文字コードはUTF-8P-100# TSVの読み込みはread_tableを用いる df_tmp = pd.read_table('./data/P_df_product_full_UTF-8_header.tsv', encoding='utf-8') df_tmp.head(10)参考: pandasでcsv/tsvファイル読み込み(read_csv, read_table)
3. 参考文献
データサイエンス100本ノック
Macでデータサイエンス100本ノックを動かす方法4. 所感
081-093までは非常に歯応えがある内容であった。
解説が浅いところもあるので復習しながら解説を充実させていきます。

- 投稿日:2020-09-06T11:43:56+09:00
raspberry pi2 b+でdockerインストールできなかった.
きっかけ
余っているPi2を,録画サーバのチューナサーバとして使う際,
- mirakc
- mirakurun
のいずれかのチューナサーバアプリケーションを使わないといけない.
これらは,Dockerコンテナで動かすことを推奨しているので,どちらを使うにせよ,
ラズパイでDockerが使える環境をセットアップしたほうが良さそう.目標
次の2つが使えるようにする.
- docker
- docker-compose
前提条件
- Raspbian Lite 2020-0820
- Raspberry Pi 2B+以上.
(ただし,今回使ったRaspberry Piは2B+なので,armhf7lである.
arm64のPi3以上だと同様の動作をするかはわからない.)作業内容
パッケージ更新
まずは最低限更新周り.
$ sudo raspi-config #諸々のラズパイの初期設定をしておく.CPUを1GHzにするなど. $ sudo apt update &&\ sudo apt upgrade -y &\ sudo apt autoremove -yDockerインストール
Dockerのインストール.公式通り.
$ curl -sSL https://get.docker.com | sh注意点として,上記処理によって走るスクリプトは,必ず
E: Sub-process /usr/bin/dpkg returned an error code (1)
というエラーを吐いてしまう.
そのため,まずはインストールされたdockerと関連パッケージを削除する.$ sudo apt purge -y docker* && sudo apt autoremove今回のこのエラーの原因は,今日(2020年09月06日)時点でのコミットに問題がありそう.
コミットハッシュは→ 26ff363bcf3b3f5a00498ac43694bf1c7d9ce16c
みてみるとやはりIssueがあがってた.https://github.com/docker/for-linux/issues/1035ここで
journalctl -xeしてみると,dockerデーモンをstartした直後,次のログが出ていた.The unit docker.socket has successfully entered the 'dead' state.ソケットがそもそもなんかよろしくないっぽい.
ちょっとjournalctl -uしてもうちょいみてみる.Sep 06 10:47:57 raspberrypi dockerd[1135]: time="2020-09-06T10:47:57.586700264+09:00" level=error msg="failed to mount overlay: no such device" storage-driver=overlay2 Sep 06 10:47:57 raspberrypi dockerd[1135]: time="2020-09-06T10:47:57.647312450+09:00" level=error msg="AUFS was not found in /proc/filesystems" storage-driver=aufs Sep 06 10:47:57 raspberrypi dockerd[1135]: time="2020-09-06T10:47:57.708413639+09:00" level=error msg="failed to mount overlay: no such device" storage-driver=overlay Sep 06 10:47:57 raspberrypi dockerd[1135]: time="2020-09-06T10:47:57.913269270+09:00" level=warning msg="Your kernel does not support swap memory limit" Sep 06 10:47:57 raspberrypi dockerd[1135]: time="2020-09-06T10:47:57.933919334+09:00" level=warning msg="Your kernel does not support cgroup cfs period" Sep 06 10:47:57 raspberrypi dockerd[1135]: time="2020-09-06T10:47:57.937300344+09:00" level=warning msg="Your kernel does not support cgroup cfs quotas" Sep 06 10:47:57 raspberrypi dockerd[1135]: time="2020-09-06T10:47:57.940482354+09:00" level=warning msg="Your kernel does not support cgroup rt period" Sep 06 10:47:57 raspberrypi dockerd[1135]: time="2020-09-06T10:47:57.940913356+09:00" level=warning msg="Your kernel does not support cgroup rt runtime" Sep 06 10:47:57 raspberrypi dockerd[1135]: time="2020-09-06T10:47:57.941234357+09:00" level=warning msg="Unable to find cpuset cgroup in mounts" Sep 06 10:47:57 raspberrypi dockerd[1135]: time="2020-09-06T10:47:57.941741358+09:00" level=warning msg="mountpoint for pids not found"カーネルが古いからこのようなエラーが出てるっぽいので,カーネル更新してみる.
また,dockerまわりがうまく動いていないままなので,modprove周りのせいだと思うが,カーネル更新できない.
予め削除しておく.ちなみにこの対処法にたどり着くのにかなり時間がかかった…$ sudo apt purge -y docker* && sudo apt -y autoremove $ sudo apt install linux-image-rpi2 #sudo apt search linux-image-*し,自分の環境に合うものを選ぼう. $ sudo reboot再起動後,もう一度Dockerをインストールしてみたがだめだった.
よろしければ…
よろしければ助言お願いします…
armhfな環境でDockerを使うのが初めてなので,ここまで詰まると解決策がもうわからない.
もしも解決できる方がいらっしゃったらコメントなど頂けますと非常にありがたいです.
- 投稿日:2020-09-06T10:20:41+09:00
Docker環境でvite+Nginxを動作させた時に詰まったポイント
TL;DR
vite + Nginxの構成をDokcer上で作成したいと思ったんですが、
一部詰まったポイントがあったので備忘録的に残しておきます。なおライブラリのソースを直接弄ってごまかしているので、
基本的には公式のアップデートを待つのが吉かと思います。viteについて
公式リポジトリ
viteはVue.jsの作者のEvan You氏が作成したビルドツールです。Vue-cliでは諸々のバンドルツールをいれてましたがviteは不要なため、
devサーバーが高速に動作するのが一番の特徴かと思います。
マジで早い。ちなみにビルドにはRollupを利用しているようです。
Docker環境で動かす
さて今回の本題に入りたいと思います。
Dokcer環境上にNginx+viteの環境を構築するために準備をします。
HOST(8080) => Nginx(80) => vite(3000)で通信をする想定です。※Docker環境の構築そのものの説明は割愛します。
最終的なディレクトリ構成は以下のような形になります。
. ├── config │ └── nginx │ └── dev.conf ├── docker-compose.yml ├── index.html ├── logs │ └── nginx │ └── error.log ├── package.json ├── public │ └── favicon.ico ├── src │ ├── App.vue │ ├── assets │ │ └── logo.png │ ├── components │ │ └── HelloWorld.vue │ ├── index.css │ └── main.js └── yarn.lock現時点でのdocker-compose.ymlとNginxの設定ファイルは以下のような状態。
docker-compose.ymlversion: "3" services: vite: image: node:12.6.0 container_name: vite working_dir: /var/local/app volumes: - .:/var/local/app:cached environment: - HOST=0.0.0.0 command: /bin/sh -c "yarn cache clean && yarn install && yarn dev" proxy_nginx_vite: image: nginx:1.19.1 volumes: - ./config/nginx/dev.conf:/etc/nginx/nginx.conf:cached - ./logs/nginx:/var/log/nginx:cached container_name: proxy_nginx_vite ports: - 8080:80 depends_on: - vitedev.conferror_log /var/log/nginx/error.log; events{ } http { server { listen 80; server_name localhost; location / { proxy_pass http://vite:3000/; proxy_intercept_errors on; } } }Docker環境の立ち上げ(1回目)
環境の準備をしたら以下のコマンドで立ち上げます。
docker-compose -f docker-compose.yml up --buildこの時点では以下のエラーが出て表示されません。
NginxでWebSocketを使うには設定が必要だったので早々にNginxのconfファイルを修正します。
NginxでWebsocket通信を使うための修正
以下のあたりを参考に修正します。
以下をconfファイルに追加します。
dev.confmap $http_upgrade $connection_upgrade { default upgrade; '' close; } ~~中略~~ proxy_http_version 1.1; proxy_set_header Host $host; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection $connection_upgrade;この時点のNginxのconfファイル
dev.conferror_log /var/log/nginx/error.log; events{ } http { map $http_upgrade $connection_upgrade { default upgrade; '' close; } server { listen 80; server_name localhost; location / { proxy_pass http://vite:3000/; proxy_intercept_errors on; proxy_http_version 1.1; proxy_set_header Host $host; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection $connection_upgrade; } } }Docker環境の立ち上げ(2回目)
ここでdokcerを立ち上げ直します。
docker-compose -f docker-compose.yml up --build先程のエラーは解消されて表示自体はされますが、繰り返しページのリフレッシュが走ります。
consoleを見ると以下のエラーが出ています。
先程のエラーとは異なっているようですがこれもWebSocket関連のようです。
viteのWebSocket通信のPORTの向き先を変更する
hostからはポート8080でDockerコンテナに接続しているんですが、
vite自体はポート3000で起動しているもんだから、
WebSocket通信でlocalhost:3000を見に行こうとしてつながらない=>繰り返しリフレッシュされている模様。↓此処から先は自己責任↓
ライブラリ内のファイルを直接弄って編集
node_modules/vite/dist/client/client.ts内のファイルの33行目でWebsocket通信に使うURLを生成しているんですが、ここで引いてきているPORTが3000のままのためおきているようです。viteのリポジトリにもISSUEが立っていたので参考に無理やりつながるようにしてみます。
WebSocket connection can not work inside Docker container
公式リポジトリのコードの該当箇所// dockerコンテナ内でコマンドを実行 docker exec -it vite bash // vimがなければインストール apt-get update apt-get install vim // 以下のファイルを編集 vi node_modules/vite/dist/client/client.js // before const socketUrl = `${socketProtocol}://${location.hostname}:${__PORT__}`; ↓↓↓以下に変更↓↓↓ // after // HOSTから見に行く先のPORT番号を具体的に指定 const socketUrl = `${socketProtocol}://${location.hostname}:8080`;Docker環境の立ち上げ(3回目)
もっかい再起動
docker-compose -f docker-compose.yml up --build
リフレッシュもせずに無事動きました。
今後どうなっていきそうか
正直この状態で動かすのは好ましくありません。
ただ先程のISSUEにぶら下がっているPR見てみると
WebSocket用のconfigが追加されそうな気配を感じます。feat(dev): add config for websocket connection
どう反映されるかわかりませんが、以下はこんな感じになりそうかな?という想像です。
vite.config.jsmodule.exports = { socketPort: 8080 }結論
とりあえず動作するとこまでは行きましたが、
さすがにこのままつかっていくのは厳しいなとは思っています。
今回のような構成にしなければこういう問題は発生しないんですけどね、、、。まだ絶賛開発中なところもあるので、色々と手間をかける部分は必要そうです。
趣味や個人で使う分にはローカルでのサーバー起動も早くすごく快適ですので、
Vue使っている人は是非試してみてください!参考



- 投稿日:2020-09-06T09:40:50+09:00
【Folio LSP】チュートリアル Single Server Deployment(complete版)をEC2で
前置き
- この記事では、Folioのチュートリアルのうち、Single Server DeploymentをEC2で実行する場合の紹介をします。
- ここでは、Complete版をデプロイします。
- Edge modulesは対象外としています。
Core版と比較すると以下が違ってきますが、この記事に沿って作っていけば大丈夫です。
- cloneしてくるリポジトリとそれに伴うパスの変更
- 必要なRAMの容量
- runbookのスクリプトの種類(core版ではなくcomlete版を使う)
記事内のパスについては、エラーになったら適宜変更してください。
先に以下に目を通しておくと理解しやすいかと思います。
- Vagrant/VirtualBoxでSingle Server Deploymentチュートリアルを実行する(https://qiita.com/ayungn/items/f84e55893b7817af15a7)
- チュートリアルで出てくるCURLオプション(https://qiita.com/ayungn/items/f713f3a142f093a63e0e)
凡例
参考情報
Q&A
- 元ネタの中にmainbar/sidebarとありますが、mainbar/sidebarとは何ですか?
- sidebarを実行すると「最新スナップショット」をもとにしたビルドができます。mainbarは四半期に一度のリリースをもとにビルドします。
- plartform-core/platform-completeとは何ですか?
- platform-coreは基本機能、platform-comleteは全機能をビルドします。バックエンドモジュールの数でいうとplatform-coreは25、platform-completeは55です。この記事では、platform-coreのビルドについて説明します。
大まかな流れ
- EC2を準備する
- EC2内に環境を整える(Okapi、Postgre、Java、Dockerエンジンなど)
- Folioのテナント(diku)を作る
- Stripesのビルド
- テナントの使うモジュールのDockerをOkapi経由でpull
- サンプルレコードの準備
EC2の準備
インスタンスを起動
選択
インスタンスタイプはt2.2xlarge(8vCPU, 32GiB)を選択。
「確認と作成」押下
「起動」押下
ローカルからEC2にSSH接続をしたいので、キーペアを取得しておく。
任意のキーペア名を入力し、「キーペアのダウンロード」を押下して秘密鍵を取得する。
「インスタンスの生成」押下。
インスタンスが作成されるまでしばらく待つ。
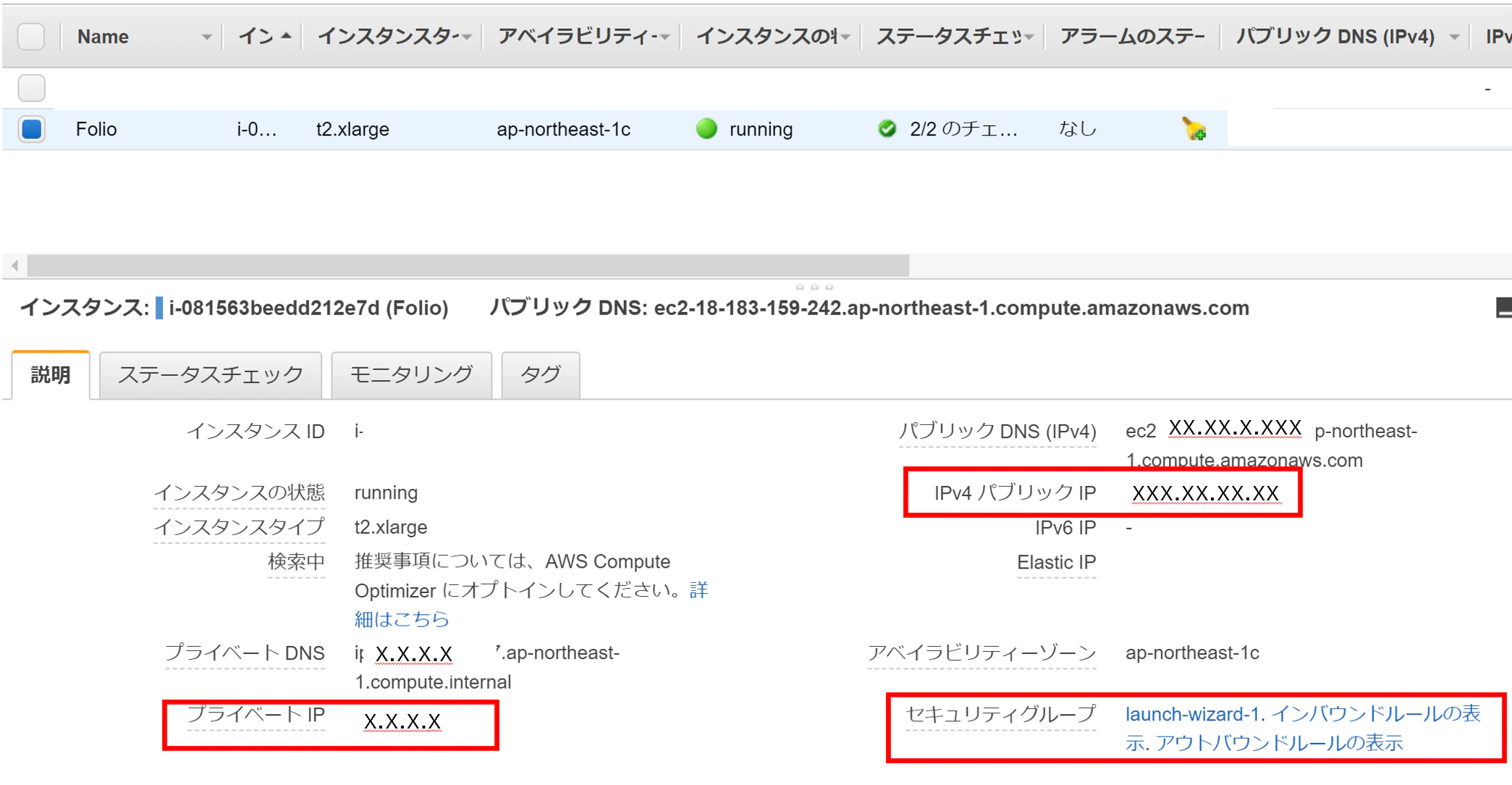
インスタンスの確認
パブリックIP、プライベートIPを確認します。
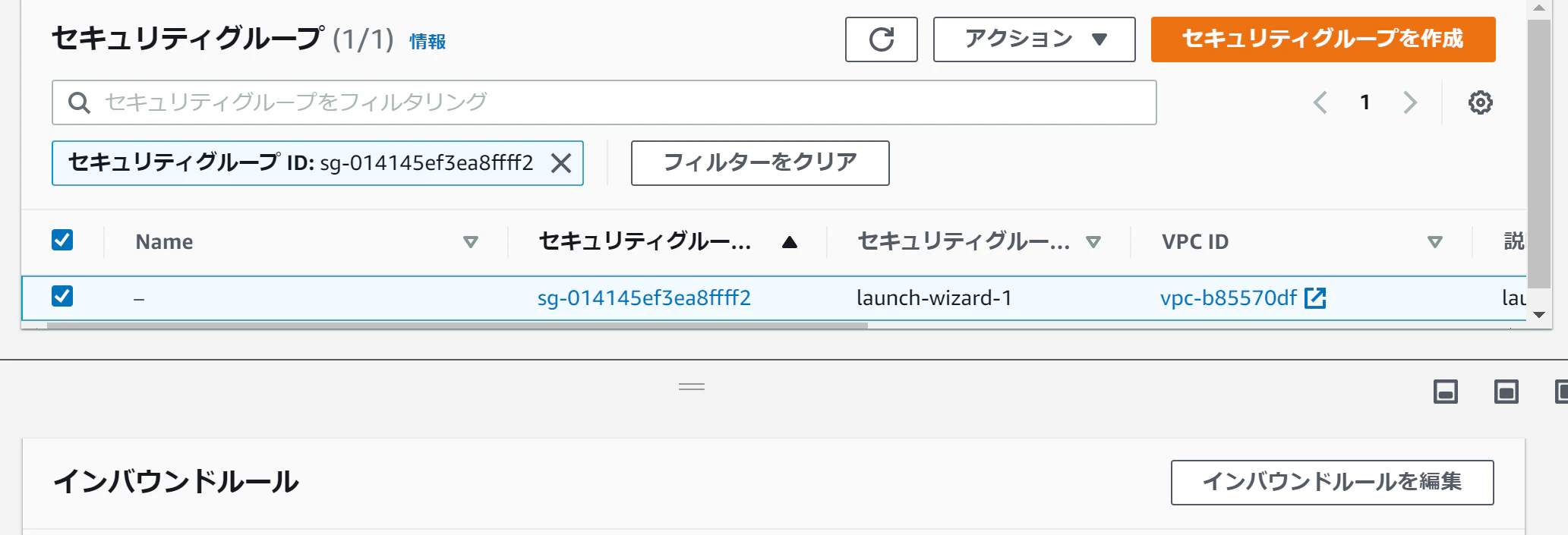
セキュリティグループはここからリンクしています。
セキュリティグループの設定
ポートを開けます。
上記の「セキュリティグループ」から、
「インバウンドルールを編集」を押下
「ルールを追加」を押下
以下のルールを記述(これだと開けすぎ。後日編集します)
「ルールを保存」を押下
SSHでEC2に接続する
インスタンスの設定時に取得した秘密鍵とパブリックIPを利用し、お好きな方法で。
Win10 Powershellからなら、下記で接続できます。ssh -i <保存した秘密鍵へのパス> ubuntu@<パブリックIP>Linuxホストのビルド
①適当なディレクトリに、このチュートリアル用のスクリプトなどが入っているリポジトリをクローンします。
git clone https://github.com/folio-org/folio-install cd folio-install git checkout q2-2020 cd runbooks/single-server
cp ~/folio-install/runbooks/single-server/scripts/nginx-stripes-complete.conf ~/folio-install/runbooks/single-server/scripts/nginx-stripes.conf必要なパッケージをインストールして構成する
実行環境の要件: Java 8, nginx(エンジンエックス), PostgreSQL 10, Docker
①apt cacheのアップデート
sudo apt-get update②Java8とnginxをインストールし、Java8をシステムデフォルトにする
sudo apt-get -y install openjdk-8-jdk nginx sudo update-java-alternatives --jre-headless --jre --set java-1.8.0-openjdk-amd64③PostgreSQLのキーをインポートし、PostgreSQL aptリポジトリを追加し、PostgreSQLをインストールする
※ここがVitrutalBox版とちょっと違うsudo add-apt-repository "deb http://security.ubuntu.com/ubuntu xenial-security main" sudo apt-get update sudo apt-get install libicu55 wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add - sudo add-apt-repository "deb http://apt.postgresql.org/pub/repos/apt/ xenial-pgdg main" sudo apt-get update sudo apt-get -y install postgresql-10 postgresql-client-10 postgresql-contrib-10 libpq-dev④Dockerから接続できるようにPostgreSQLを構成する。
- /etc/postgresql/10/main/postgresql.confの「Connection Settings」に
listen_addresses = '*'を追記- /etc/postgresql/10/main/pg_hba.confに
host all all 0.0.0.0/0 md5を追記- PostgreSQLを
sudo systemctl restart postgresqlでリスタートsudo vim /etc/postgresql/10/main/postgresql.conf sudo vim /etc/postgresql/10/main/pg_hba.conf sudo systemctl restart postgresql⑤DockerのキーをインポートしてDocker aptリポジトリを追加し、Dockerエンジンをインストールする
sudo apt-get -y install apt-transport-https ca-certificates gnupg-agent software-properties-common wget --quiet -O - https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - sudo add-apt-repository "deb https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" sudo apt-get update sudo apt-get -y install docker-ce docker-ce-cli containerd.io⑥Dockerエンジンの構成
sudo mkdir -p /etc/systemd/system/docker.service.d sudo cp ~/folio-install/runbooks/single-server/scripts/docker-opts.conf /etc/systemd/system/docker.service.d sudo systemctl daemon-reload sudo systemctl restart docker⑦docker-composeのインストール
sudo curl -L \ "https://github.com/docker/compose/releases/download/1.26.2/docker-compose-$(uname -s)-$(uname -m)" \ -o /usr/local/bin/docker-compose sudo chmod +x /usr/local/bin/docker-composeビルド要件のインストール:git, curl, NodeJS, npm, Yarn, libjson-perl, libwww-perl libuuid-tiny-perl
①Ubuntuのaptリポジトリからインストール
sudo apt-get -y install git curl nodejs npm libjson-perl libwww-perl libuuid-tiny-perl②npmからnをインストール
※nというのは、nodeの管理コマンドです。sudo npm install n -g③Yarnのキーをインポートし、Yarn aptレジストリを追加し、Yarnをインストールする
wget --quiet -O - https://dl.yarnpkg.com/debian/pubkey.gpg | sudo apt-key add - sudo add-apt-repository "deb https://dl.yarnpkg.com/debian/ stable main" sudo apt-get update sudo apt-get -y install yarnApache KafkaとApache ZooKeeperのインストール
※上記はmod-subpubで必要です。
~/folio-install/runbooks/single-server/scripts/docker-compose-kafka-zk.ymlを修正する。修正前
KAFKA_ADVERTISED_LISTENERS: INTERNAL://10.0.2.15:9092,LOCAL://localhost:29092
修正後KAFKA_ADVERTISED_LISTENERS: INTERNAL://<PRIVATE IP ADDRESS>:9092,LOCAL://localhost:29092
sudo mkdir /opt/kafka-zk sudo cp ~/folio-install/runbooks/single-server/scripts/docker-compose-kafka-zk.yml /opt/kafka-zk/docker-compose.yml cd /opt/kafka-zk sudo docker-compose up -d cd -データベースとロールの作成
PostgreSQLにスーパーユーザーでログイン
sudo su -c psql postgres postgresOkapiとテナントのDBとロールを作成する。
CREATE ROLE okapi WITH PASSWORD 'okapi25' LOGIN CREATEDB; CREATE DATABASE okapi WITH OWNER okapi; CREATE ROLE folio WITH PASSWORD 'folio123' LOGIN SUPERUSER; CREATE DATABASE folio WITH OWNER folio;
\qでpsqlを抜ける。Okapiのインストールと構成
wget --quiet -O - https://repository.folio.org/packages/debian/folio-apt-archive-key.asc | sudo apt-key add - sudo add-apt-repository "deb https://repository.folio.org/packages/ubuntu xenial/" sudo apt-get update sudo apt-get -y install okapi=3.1.2-1 sudo apt-mark hold okapi①Okapiの構成
/etc/folio/okapi/okapi.confの以下を編集する
- role="dev"
- port_end="9230"
- host="<PRIVATE IP ADDRESS>"
- storage="postgres"
- okapiurl="http://<PRIVATE IP ADDRESS>:9130"
②Okapiのリスタート
sudo systemctl daemon-reload sudo systemctl restart okapi③module descriptorsをセントラルレジストリからプル
curl -w '\n' -D - -X POST -H "Content-type: application/json" -d '{"urls":["http://folio-registry.aws.indexdata.com"]}' http://localhost:9130/_/proxy/pull/modules
※Registoryに以下の記述がありますAs part of the continuous integration process, each ModuleDescriptor.json is published to the FOLIO Registry at https://folio-registry.aws.indexdata.com/
Folioテナントを作成する
テナント初期化をOkapiにポストする
curl -w '\n' -D - -X POST -H "Content-type: application/json" -d '{"id" : "diku","name" : "Datalogisk Institut","description" : "Danish Library Technology Institute"}' http://localhost:9130/_/proxy/tenants
Okapiの内部モジュールをテナント用に有効化する。
curl -w '\n' -D - -X POST -H "Content-type: application/json" -d '{"id":"okapi"}' http://localhost:9130/_/proxy/tenants/diku/modulesFolioStripesプラットフォームの最新版をビルドする
n <バージョン> で指定したNodeのバージョンに更新できます。
ここではltsに更新します。sudo n ltscd ~ git clone https://github.com/folio-org/platform-complete cd platform-complete git checkout q2-2020 yarn install
@folio:registry=https://repository.folio.org/repository/npm-folio/の記述があります
~/platform-complete/stripes.config.jsを以下のように修正する。修正前:
okapi: { 'url':'http://localhost:9130', 'tenant':'diku' },
修正後:okapi: { 'url':'http://<YOUR PUBLIC IP>:9130', 'tenant':'diku' },
その場合、上記修正と以下のビルドをし直す必要があります。NODE_ENV=production yarn build output cd ..ウェブサーバを構成してStripes webpackをサーブする
nginxサーバを構成する。
folio-install/runbooks/single-server/scripts/nginx-stripes.confの#Set pathの箇所を以下のように書き換える。
修正前:/home/vagrant/platform-complete/output;
修正後:/home/ubuntu/platform-complete/output;sudo cp folio-install/runbooks/single-server/scripts/nginx-stripes.conf /etc/nginx/sites-available/stripes sudo ln -s /etc/nginx/sites-available/stripes /etc/nginx/sites-enabled/stripes sudo rm /etc/nginx/sites-enabled/default sudo systemctl restart nginx対応するFolioバックエンドをデプロイしてテナントに有効にする
① デプロイしたモジュールが利用するデータベースの情報をOkapiにポストする
curl -w '\n' -D - -X POST -H "Content-Type: application/json" -d "{\"name\":\"DB_HOST\",\"value\":\"<PRIVATE IP ADDRESS>\"}" http://localhost:9130/_/env curl -w '\n' -D - -X POST -H "Content-Type: application/json" -d "{\"name\":\"DB_PORT\",\"value\":\"5432\"}" http://localhost:9130/_/env curl -w '\n' -D - -X POST -H "Content-Type: application/json" -d "{\"name\":\"DB_DATABASE\",\"value\":\"folio\"}" http://localhost:9130/_/env curl -w '\n' -D - -X POST -H "Content-Type: application/json" -d "{\"name\":\"DB_USERNAME\",\"value\":\"folio\"}" http://localhost:9130/_/env curl -w '\n' -D - -X POST -H "Content-Type: application/json" -d "{\"name\":\"DB_PASSWORD\",\"value\":\"folio123\"}" http://localhost:9130/_/env②バックエンドモジュールのリストをポストして有効にする。テナントパラメータをセットして、サンプルデータと参照データをロードする。
※platform-completeは作業ディレクトリに応じて変更してください。これはPWDがhome/ubuntuの場合です。curl -w '\n' -D - -X POST -H "Content-type: application/json" \ -d @platform-complete/okapi-install.json \ http://localhost:9130/_/proxy/tenants/diku/install?deploy=true\&preRelease=false\&tenantParameters=loadSample%3Dtrue%2CloadReference%3Dtrue注意:Docker HubからDocker imageを持ってくるため、これは時間がかかります。
進捗を見る→Okapi log at /var/log/folio/okapi/okapi.log または sudo docker ps | grep -v "^CONTAINER" | wc -l
③Stripesモジュールのリストをポストして有効にする
※platform-completeは作業ディレクトリに応じて変更してください。これはPWDがhome/ubuntuの場合です。curl -w '\n' -D - -X POST -H "Content-type: application/json" \ -d @platform-complete/stripes-install.json \ http://localhost:9130/_/proxy/tenants/diku/install?preRelease=falseFolioのスーパーユーザを作成し、パーミッションをロードする
perl folio-install/runbooks/single-server/scripts/bootstrap-superuser.pl --tenant diku --user diku_admin --password admin --okapi http://localhost:9130done!と表示されればOK。
サンプルデータのロード
MODSレコードをロードする
inventory用のサンプルデータをロードします。サンプルデータは https://github.com/folio-org/folio-install/tree/master/runbooks/single-server/sample-data/mod-inventory にあります。
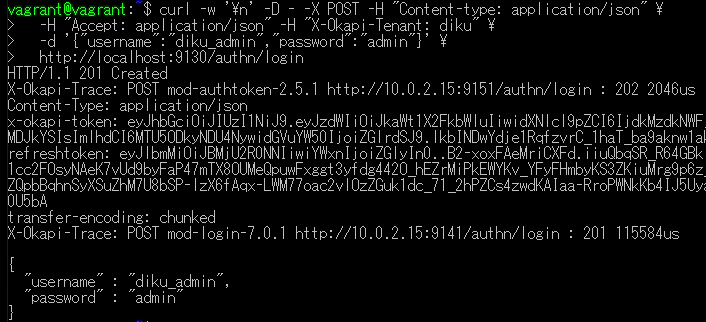
curl -w '\n' -D - -X POST -H "Content-type: application/json" -H "Accept: application/json" -H "X-Okapi-Tenant: diku" -d '{"username":"diku_admin","password":"admin"}' http://localhost:9130/authn/login
下記の<okapi token>には、返ってきたtokenの値を入れる。
※
./folio-install/runbooks/single-serverはディレクトリに応じて変更してください。これはPWDがhome/ubuntuの場合です。for i in ./folio-install/runbooks/single-server/sample-data/mod-inventory/*.xml; do curl -w '\n' -D - -X POST -H "Content-type: multipart/form-data" -H "X-Okapi-Tenant: diku" -H "X-Okapi-Token: <okapi token>" -F upload=@${i} http://localhost:9130/inventory/ingest/mods; doneEC2のパブリックIPにブラウザからアクセス
diku_admin/adminでログイン










- 投稿日:2020-09-06T09:40:50+09:00
【Folio LSP】チュートリアル Single Server Deployment(complete版)
前置き
- この記事では、Folioのチュートリアルのうち、Single Server DeploymentをEC2で実行する場合の紹介をします。
- ここでは、Complete版をデプロイします。
Core版と比較すると以下が違ってきますが、この記事に沿って作っていけば大丈夫です。
- cloneしてくるリポジトリとそれに伴うパスの変更
- 必要なRAMの容量
- runbookのスクリプトの種類(core版ではなくcomlete版を使う)
※記事内のパスについては、エラーになったら適宜変更してください。
先に以下に目を通しておくと理解しやすいかと思います。
- Vagrant/VirtualBoxでSingle Server Deploymentチュートリアルを実行する(https://qiita.com/ayungn/items/f84e55893b7817af15a7)
Q&A
- 元ネタの中にmainbar/sidebarとありますが、mainbar/sidebarとは何ですか?
- sidebarを実行すると「最新スナップショット」をもとにしたビルドができます。mainbarは四半期に一度のリリースをもとにビルドします。
- plartform-core/platform-completeとは何ですか?
- platform-coreは基本機能、platform-comleteは全機能をビルドします。バックエンドモジュールの数でいうとplatform-coreは25、platform-completeは55です。この記事では、platform-coreのビルドについて説明します。
EC2の準備
インスタンスを起動
選択
インスタンスタイプはt2.2xlarge(8vCPU, 32GiB)を選択。
→Dockerをpullする際にno space leftとなったため、ボリュームを追加。
適宜対応してください。
「確認と作成」押下
「起動」押下
ローカルからEC2にSSH接続をしたいので、キーペアを取得しておく。
任意のキーペア名を入力し、「キーペアのダウンロード」を押下して秘密鍵を取得する。
「インスタンスの生成」押下。
インスタンスが作成されるまでしばらく待つ。
インスタンスの確認
パブリックIP、プライベートIPを確認します。
セキュリティグループはここからリンクしています。
パブリックIPはインスタンスをstopすると変わるので注意。セキュリティグループの設定
ポートを開けます。
上記の「セキュリティグループ」から、
「インバウンドルールを編集」を押下
「ルールを追加」を押下
以下のルールを記述(これだと開けすぎ。後日編集します)
「ルールを保存」を押下
SSHでEC2に接続する
インスタンスの設定時に取得した秘密鍵とパブリックIPを利用し、お好きな方法で。
Win10 Powershellからなら、下記で接続できます。ssh -i <保存した秘密鍵へのパス> ubuntu@<パブリックIP>Linuxホストのビルド
①適当なディレクトリに、このチュートリアル用のスクリプトなどが入っているリポジトリをクローンします。
git clone https://github.com/folio-org/folio-install cd folio-install git checkout q2-2020 cd runbooks/single-server
cp ~/folio-install/runbooks/single-server/script/nginx-stripes-complete.conf ~/folio-install/runbooks/single-server/script/nginx-stripes.conf必要なパッケージをインストールして構成する
実行環境の要件: Java 8, nginx(エンジンエックス), PostgreSQL 10, Docker
①apt cacheのアップデート
sudo apt-get update②Java8とnginxをインストールし、Java8をシステムデフォルトにする
sudo apt-get -y install openjdk-8-jdk nginx sudo update-java-alternatives --jre-headless --jre --set java-1.8.0-openjdk-amd64③PostgreSQLのキーをインポートし、PostgreSQL aptリポジトリを追加し、PostgreSQLをインストールする
※ここがVitrutalBox版とちょっと違うsudo add-apt-repository "deb http://security.ubuntu.com/ubuntu xenial-security main" sudo apt-get update sudo apt-get install libicu55 wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add - sudo add-apt-repository "deb http://apt.postgresql.org/pub/repos/apt/ xenial-pgdg main" sudo apt-get update sudo apt-get -y install postgresql-10 postgresql-client-10 postgresql-contrib-10 libpq-dev④Dockerから接続できるようにPostgreSQLを構成する。
- /etc/postgresql/10/main/postgresql.confの「Connection Settings」に
listen_addresses = '*'を追記- /etc/postgresql/10/main/pg_hba.confに
host all all 0.0.0.0/0 md5を追記- PostgreSQLを
sudo systemctl restart postgresqlでリスタートsudo vim /etc/postgresql/10/main/postgresql.conf sudo vim /etc/postgresql/10/main/pg_hba.conf sudo systemctl restart postgresql⑤DockerのキーをインポートしてDocker aptリポジトリを追加し、Dockerエンジンをインストールする
sudo apt-get -y install apt-transport-https ca-certificates gnupg-agent software-properties-common wget --quiet -O - https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - sudo add-apt-repository "deb https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" sudo apt-get update sudo apt-get -y install docker-ce docker-ce-cli containerd.io⑥Dockerエンジンの構成
sudo mkdir -p /etc/systemd/system/docker.service.d sudo cp /vagrant/scripts/docker-opts.conf /etc/systemd/system/docker.service.d sudo systemctl daemon-reload sudo systemctl restart docker⑦docker-composeのインストール
sudo curl -L \ "https://github.com/docker/compose/releases/download/1.26.2/docker-compose-$(uname -s)-$(uname -m)" \ -o /usr/local/bin/docker-compose sudo chmod +x /usr/local/bin/docker-composegit, curl, NodeJS, npm, Yarn, libjson-perl, libwww-perl libuuid-tiny-perl
①Ubuntuのaptリポジトリからインストール
sudo apt-get -y install git curl nodejs npm libjson-perl libwww-perl libuuid-tiny-perl②npmからnをインストール
※nというのは、nodeの管理コマンドです。sudo npm install n -g③Yarnのキーをインポートし、Yarn aptレジストリを追加し、Yarnをインストールする
wget --quiet -O - https://dl.yarnpkg.com/debian/pubkey.gpg | sudo apt-key add - sudo add-apt-repository "deb https://dl.yarnpkg.com/debian/ stable main" sudo apt-get update sudo apt-get -y install yarnApache KafkaとApache ZooKeeperのインストール
※上記はmod-subpubで必要です。
~/folio-install/runbooks/single-server/scripts/docker-compose-kafka-zk.ymlを修正する。修正前
KAFKA_ADVERTISED_LISTENERS: INTERNAL://10.0.2.15:9092,LOCAL://localhost:29092
修正後KAFKA_ADVERTISED_LISTENERS: INTERNAL://<PRIVATE IP ADDRESS>:9092,LOCAL://localhost:29092
※<PRIVATE IP ADDRESS>には、EC2インスタンスのプライベートIPアドレスを入れてください。sudo mkdir /opt/kafka-zk sudo cp /vagrant/scripts/docker-compose-kafka-zk.yml /opt/kafka-zk/docker-compose.yml cd /opt/kafka-zk sudo docker-compose up -d cd -データベースとロールの作成
PostgreSQLにスーパーユーザーでログイン
$ sudo su -c psql postgres postgresOkapiとテナントのDBとロールを作成する。
CREATE ROLE okapi WITH PASSWORD 'okapi25' LOGIN CREATEDB; CREATE DATABASE okapi WITH OWNER okapi; CREATE ROLE folio WITH PASSWORD 'folio123' LOGIN SUPERUSER; CREATE DATABASE folio WITH OWNER folio;
\qでpsqlを抜ける。Okapiのインストールと構成
wget --quiet -O - https://repository.folio.org/packages/debian/folio-apt-archive-key.asc | sudo apt-key add - sudo add-apt-repository "deb https://repository.folio.org/packages/ubuntu xenial/" sudo apt-get update sudo apt-get -y install okapi=3.1.2-1 sudo apt-mark hold okapiOkapiの構成
/etc/folio/okapi/okapi.confの以下を編集する
- role="dev"
- port_end="9230"
- host="<PRIVATE IP ADDRESS>"
- storage="postgres"
- okapiurl="http://<PRIVATE IP ADDRESS>:9130"
※<PRIVATE IP ADDRESS>には、EC2インスタンスのプライベートIPアドレスを入れてください。
Okapiのリスタート
sudo systemctl daemon-reload sudo systemctl restart okapimodule descriptorsをセントラルレジストリからプル
curl -w '\n' -D - -X POST -H "Content-type: application/json" -d '{"urls":["http://folio-registry.aws.indexdata.com"]}' http://localhost:9130/_/proxy/pull/modulesFolioテナントを作成する
テナント初期化をOkapiにポストする
curl -w '\n' -D - -X POST -H "Content-type: application/json" -d '{"id" : "diku","name" : "Datalogisk Institut","description" : "Danish Library Technology Institute"}' http://localhost:9130/_/proxy/tenantsOkapiの内部モジュールをテナント用に有効化する。
curl -w '\n' -D - -X POST -H "Content-type: application/json" -d '{"id":"okapi"}' http://localhost:9130/_/proxy/tenants/diku/modulesFolioStripesプラットフォームの最新版をビルドする
n <バージョン> で指定したNodeのバージョンに更新できます。
ここではltsに更新します。sudo n ltsgit clone https://github.com/folio-org/platform-complete cd platform-complete git checkout q2-2020 yarn install
~/platform-complete/stripes.confing.jsを以下のように修正する。修正前:
okapi: { 'url':'http://localhost:9130', 'tenant':'diku' },
修正後:okapi: { 'url':'http://<YOUR PUBLIC IP>:9130', 'tenant':'diku' },※<YOUR PUBLIC IP>にはEC2インスタンスのパブリックIPを入力してください。
その場合、上記修正と以下のビルドをし直す必要があります。NODE_ENV=production yarn build output cd ..ウェブサーバを構成してStripes webpackをサーブする
nginxサーバを構成する。
sudo cp folio-install/runbooks/single-server/scripts/nginx-stripes.conf /etc/nginx/sites-available/stripes sudo ln -s /etc/nginx/sites-available/stripes /etc/nginx/sites-enabled/stripes sudo rm /etc/nginx/sites-enabled/default sudo systemctl restart nginx対応するFolioバックエンドをデプロイしてテナントに有効にする
デプロイしたモジュールが利用するデータソースの情報をOkapiにポストする
※<PRIVATE IP ADDRESS>には、EC2インスタンスのプライベートIPアドレスを入れてください。curl -w '\n' -D - -X POST -H "Content-Type: application/json" -d "{\"name\":\"DB_HOST\",\"value\":\"<PRIVATE IP ADDRESS>\"}" http://localhost:9130/_/env curl -w '\n' -D - -X POST -H "Content-Type: application/json" -d "{\"name\":\"DB_PORT\",\"value\":\"5432\"}" http://localhost:9130/_/env curl -w '\n' -D - -X POST -H "Content-Type: application/json" -d "{\"name\":\"DB_DATABASE\",\"value\":\"folio\"}" http://localhost:9130/_/env curl -w '\n' -D - -X POST -H "Content-Type: application/json" -d "{\"name\":\"DB_USERNAME\",\"value\":\"folio\"}" http://localhost:9130/_/env curl -w '\n' -D - -X POST -H "Content-Type: application/json" -d "{\"name\":\"DB_PASSWORD\",\"value\":\"folio123\"}" http://localhost:9130/_/envバックエンドモジュールのリストをポストして有効にする。テナントパラメータをセットして、サンプルデータと参照データをロードする。
※platform-completeは作業ディレクトリに応じて変更してください。これはPWDがhome/ubuntuの場合です。curl -w '\n' -D - -X POST -H "Content-type: application/json" \ -d @platform-complete/okapi-install.json \ http://localhost:9130/_/proxy/tenants/diku/install?deploy=true\&preRelease=false\&tenantParameters=loadSample%3Dtrue%2CloadReference%3Dtrue注意:Docker HubからDocker imageを持ってくるため、これは時間がかかります。
進捗を見る→Okapi log at /var/log/folio/okapi/okapi.log または sudo docker ps | grep -v "^CONTAINER" | wc -lStripesモジュールのリストをポストして有効にする
※@platform-completeは作業ディレクトリに応じて変更してください。これはPWDがhome/ubuntuの場合です。curl -w '\n' -D - -X POST -H "Content-type: application/json" \ -d @platform-complete/stripes-install.json \ http://localhost:9130/_/proxy/tenants/diku/install?preRelease=falseFolioのスーパーユーザを作成し、パーミッションをロードする
perl folio-install/runbooks/single-server/scripts/bootstrap-superuser.pl --tenant diku --user diku_admin --password admin --okapi http://localhost:9130done!と表示されればOK。
サンプルデータのロード
MODSレコードをロードする
inventory用のサンプルデータをロードします。サンプルデータはhttps://github.com/folio-org/folio-install/tree/master/runbooks/single-server/sample-data/mod-inventoryにあります。
```
curl -w '\n' -D - -X POST -H "Content-type: application/json" -H "Accept: application/json" -H "X-Okapi-Tenant: diku" -d '{"username":"diku_admin","password":"admin"}' http://localhost:9130/authn/login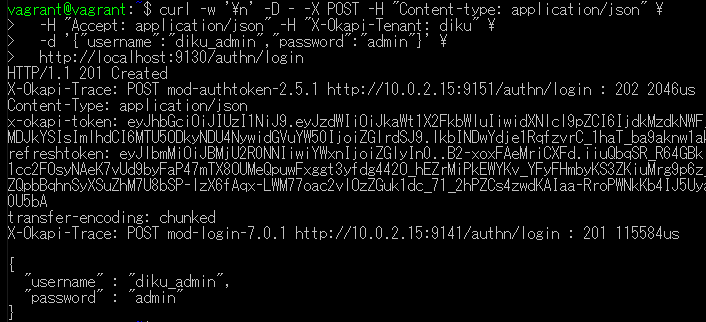 下記の\<okapi token>には、返ってきたtokenの値を入れる。 ※`./folio-install/runbooks/single-server`はディレクトリに応じて変更してください。これはPWDがhome/ubuntuの場合です。for i in ./folio-install/runbooks/single-server/sample-data/mod-inventory/*.xml; do curl -w '\n' -D - -X POST -H "Content-type: multipart/form-data" -H "X-Okapi-Tenant: diku" -H "X-Okapi-Token: " -F upload=@${i} http://localhost:9130/inventory/ingest/mods; done
```
localhost:3000にブラウザからアクセス
diku_admin/adminでログイン

- 投稿日:2020-09-06T08:49:46+09:00
Dockerfile、docker-compose.ymlを更新した後にやること
はじめに
Dockerfileやdocker-compose.ymlを編集して更新した後、イメージやコンテナに反映させるためのコマンドのメモです。
案外シンプルでした。
なお、当記事でご紹介するのはdocker-composeで複数コンテナを管理している場合のものになります。Dockerfileの更新を反映させる
$ docker-compose up -d --build※-dオプションは、バックグラウンドで起動するオプション
docker-compose upコマンドに
--buildオプションを追加しています。通常docker-compose upを実行すると、
①Dockerイメージをbuildして、
②runが実行されるという処理が実行されますが、もし既にDockerイメージがbuildされている場合は、
②のrunだけが実行されるようになっています。
そのため、Dockerfileを更新した後にdocker-compose up -dコマンドを実行しても、
新しいDockerイメージがbuildされず、古いイメージを元にrunが実行されてしまいます。
そこで、--buildオプションを追加することで、buildとrunを一緒に実行することができるようになるのです。docker-compose.ymlの更新を反映させる
$ docker-compose up -d※-dオプションは、バックグラウンドで起動するオプション
こちらは、普段docker-composeでコンテナを起動するコマンドと変わらないですね。
更新後のdocker-compose.ymlを元に、コンテナの再構築が行われます。
- 投稿日:2020-09-06T02:51:24+09:00
AWSで割とモダンな技術使う大学生日記①
前置き
terraformで構成しようとしたが、まずはAWSを理解するためコンソールから構築
本記事は私自身が少し悩んだ、ネットワークの構成やトラブルシューティングについて重点的に記載されております。ハンズオン形式の記事はQiita等にも多くございますのでそちらを参照しつつ、こちらの記事でより理解を深めていただければな、と思います。
使用技術 Laravel6.x AWS ECS(Fargate), RDS, ElasticCache Docker, docker-compose ネットワーク構成
VPCは10.1.0.0/16を利用。
サブネットの利用感は下記みたいな感じ
サブネット 用途 10.1.0.0/24, 10.1.1.0/24 Publicサブネット。LBに使うサブネット 10.1.2.0/24, 10.1.3.0/24 Privateサブネット。LBからECSに行くサブネット 10.1.4.0/24, 10.1.5.0/24 ECS~RDS間のサブネット。ECSからDBに接続するサブネット 10.1.6.0/24 EC2~RDS間のサブネット。EC2からDBに接続するサブネット migrationはDockerfileには置かないのでDB接続用のEC2インスタンスを用意する。
(userのデータとかも取得できるので)ルートテーブルでInternetGatewayと接続するのはLBとDB接続用のEC2インスタンスのみ。
appサーバーとDBサーバー(RDS)はローカルでしか接続できないように設定する。
※ネットワークの軽い知識があれば上記のサブネットや、CIDRを理解できます。
30分とかで理解できると思うのでYouTubeとかでおさらいしておいてください。
Fargateタイプにおいてのコンテナ間通信について
webコンテナは
Nginx(読み方はエンジンエックスっていうらしい、最近までエヌジンクスって読んでた)を利用していてappコンテナはPHPでフレームワークはLaravel。
そのためwebコンテナからappコンテナへの通信が必要。
ローカル内では下記のように.confファイルを記述する。
ポートはwebはHTTP通信のため80、appは9000。
(docker-compose.ymlで名前をそれぞれwebとappで指定しておく)default.conf01:server { 02: listen 80; 03: root /work/public; 04: index index.php; 05: charset utf-8; 06: 07: location / { 08: root /work/public; 09: try_files $uri $uri/ /index.php$is_args$args; 10: } 11: 12: location ~ \.php$ { 13: fastcgi_split_path_info ^(.+\.php)(/.+)$; 14: fastcgi_pass app:9000; 15: fastcgi_index index.php; 16: include fastcgi_params; 17: fastcgi_param SCRIPT_FILENAME /work/public/index.php; 18: fastcgi_param PATH_INFO $fastcgi_path_info; 19: } 20:}上記のような設定だとAWS ECSのFargate起動タイプだとヘルスチェックで
Taskが実行できません。
というエラーが出ます。そこで14行目を下記のように変更します。default.conf14: fastcgi_pass localhost:9000;上記のようにする理由としては、Fargate起動タイプは同じローカルネットワーク内でtaskが実行されるためlocalhostは共有している。そのためコンテナ間通信は
localhost:ポート番号で指定する。トラブルシューティング
ヘルスチェックが通らない。
ECSを起動する際に、ヘルスチェックが通らず、taskが実行できなかったとき。
Dockerfileへの知見が甘かったため、
待つポート番号やコピーするディレクトリを間違えていたりした。
Dockerfileの最後の行にEXPOSE <ポート番号>を指定すること。
また、ローカルでコンテナを起動し期待するディレクトリにソースが入っているかを確認するといい。ヘルスチェックは通るがLBのDNSに接続してもログインページが表示されない
ECS起動後にヘルスチェックが通るがログインページは表示されない場合。
ヘルスチェックは通っている ↓ ローカル内での通信はできている ↓ ネットワークの構成を確認し、落ちているところを確認主に原因はネットワーク。
SGのインバウンドルールは適切か。ルートテーブルは適切か。再度確認する。
この過程が割と大事でCloudFomationとかで構成すると割と曖昧になりがちなネットワーク構成を理解できる。私の場合は、LBのターゲットグループを複数作成しており、利用したいターゲットグループの優先順位が一番ではなかったため、ログインページが表示されていなかった。セッションの共有
可用性のために、複数のタスクを実行し、AutoScallingをオンにしていると思うので
セッションの共有をしておかなければいけない。
Laravelのセッションはデフォルトでfileを選択しておりProject/storage/sessionsに保存されている。実行されるタスクが複数でセッションの保存先がfileの場合、それぞれのappコンテナの中に保存されてしまうので、セッションの共有をしなければいけない。
今回は、AWSのマネージドサービスであるElasticCacheを利用する。
※実装の工数上、現状(2020/09/06)では未構築のため後日追記する。
その際には上記のネットワーク構成にも修正を加える予定。
Dockerfileとdocker-compose.yml
いや、GitHub載せろよ。って思うよね。
僕的に、Qiita見ながらコピペできるのが理想なのでDockerfileとdocker-compose.ymlはここに書きます。default.confは上記に記載済み。Fargate起動タイプの時はlocalhost指定してください。
ディレクトリ構成も載せておきます。| ├── docker | | │ ├── nginx | | ├── Dockerfile │ │ └── default.conf │ └── php │ ├── Dockerfile │ └── php.ini ├── docker-compose.yml | ├── .env | ├── .gitignore | └── livedocker-compose.ymlversion: "3" services: app: build: context: . dockerfile: ./docker/php/Dockerfile args: - TZ=${TZ} ports: - ${APP_PORT}:9000 volumes: - ./live:/work - ./logs:/var/log/php - ./docker/php/php.ini:/usr/local/etc/php/php.ini working_dir: /work environment: # ここは要設定 - DB_CONNECTION={DB_CONNECTION} - DB_HOST=${DB_HOST} - DB_DATABASE=${DB_DATABASE} - DB_USERNAME=${DB_USERNAME} - DB_PASSWORD=${DB_PASSWORD} - TZ=${TZ:-Asia/Tokyo} web: build: context: . dockerfile: ./docker/nginx/Dockerfile depends_on: - app ports: - ${WEB_PORT:-80}:80 volumes: - ./live:/work - ./logs:/var/log/nginx - ./docker/nginx/default.conf:/etc/nginx/conf.d/default.conf environment: - TZ=${TZ:-Asia/Tokyo} volumes: db-store:docker/nginx/DockerfileFROM nginx:1.19-alpine COPY ./docker/nginx/default.conf /etc/nginx/conf.d/default.conf EXPOSE 80dokcer/php/DockerfileFROM php:7.4-fpm-alpine ARG PSYSH_DIR=/usr/local/share/psysh ARG PHP_MANUAL_URL=http://psysh.org/manual/ja/php_manual.sqlite ARG TZ ENV COMPOSER_ALLOW_SUPERUSER 1 ENV COMPOSER_HOME /composer RUN set -eux && \ apk update && \ apk add --update --no-cache --virtual=.build-dependencies \ autoconf \ gcc \ g++ \ make \ tzdata && \ apk add --update --no-cache \ icu-dev \ oniguruma-dev \ libzip-dev && \ cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime && \ echo ${TZ} > /etc/timezone && \ pecl install xdebug && \ apk del .build-dependencies && \ docker-php-ext-install intl pdo_mysql mbstring zip bcmath && \ docker-php-ext-enable xdebug && \ mkdir $PSYSH_DIR && wget $PHP_MANUAL_URL -P $PSYSH_DIR && \ curl -sS https://getcomposer.org/installer | php -- --install-dir=/usr/bin --filename=composer && \ composer config -g repos.packagist composer https://packagist.jp && \ composer global require hirak/prestissimo RUN apk add --no-cache freetype libpng libjpeg-turbo freetype-dev libpng-dev libjpeg-turbo-dev && \ docker-php-ext-configure gd \ --with-jpeg=/usr/include/ \ --with-freetype=/usr/include/ && \ NPROC=$(grep -c ^processor /proc/cpuinfo 2>/dev/null || 1) && \ docker-php-ext-install -j${NPROC} gd && \ apk del --no-cache freetype-dev libpng-dev libjpeg-turbo-dev RUN chmod -R 777 /work/storage \ /work/bootstrap/cache RUN php artisan key:generate RUN php artisan config:clear RUN php artisan config:cache # RUN php artisan migrate # RUN php artisan db:seed EXPOSE 9000php.iniは自分で検索してください。笑
.envファイルがないと起動できないので各々の用途に合わせて記述してください。
一応下記に書いておきます。TZ=Asia/Tokyo APP_PORT=9000 DB_CONNECTION=mysql DB_HOST=<RDSのエンドポイント> DB_PORT=3306 DB_DATABASE=<DB名> DB_USERNAME=<username, rootでもいい> DB_PASSWORD=<セキュアなやつにしてね>以上です。
まだ、CI/CDとかできていないので別記事にでも書こうと思っております。
AWS第一弾でした。
docker/php/Dockerfileは割と書きすぎてる気がするのでこれいらんよ、とかあったら教えて欲しいです。未熟者の記事ですが読んでいただいてありがとうございます。
- 投稿日:2020-09-06T01:00:51+09:00
macでSSTP接続するために、Windowsにsquidを入れてproxyにした話
なぜこんなことをしたのか
発端は、この方と同じような状況です。
VPNがsoftetherで作成されたのが発端でした。当初はiSSTPが信頼できるアプリケーションなのかが判断つかなかったので、softetherのL2TP接続でmacから接続できないか、VPN作成側に依頼をしていました。
残念ながら接続はうまくいかず、結局iSSTPを導入して接続してみました。
- CONNECTを連打しないと繋がらない
- つながっても速度が異常に遅い
- macの調子が悪いので再起動したら、Appleマークが出て起動に時間がかかる
など不安なことが多く発生し、「家にWindowsがあるのだからこれをproxyにして接続できるはずだ」という思いつきから始まりました。
Windowsをproxyサーバーにする
まずWindowsをどうproxyサーバーにすればいいかです。
導入の手間が最小のdockerイメージに、何かないかを探してみたところ、ちょうどよさそうな sameersbn/docker-squidがみつかりました。以下の手順でdockerを導入し、Windowsをproxyサーバー化します。
1.Windowsに docker for Windows のインストール
2.Windowsの power shell を開く
3.以下のコマンドでdockerイメージを起動docker run --name squid -d --restart=always --publish 3128:3128 sameersbn/squid:3.5.27-2これで、power shellから
curl example.com -Proxy localhost:3128でプロキシ経由でアクセスできるか試したのですが、エラーが発生。。。
以下のコマンドでsquidのログを確認。
docker exec -it squid tail -f /var/log/squid/access.logすると
...(略)... 172.17.0.1 TCP_DENIED/403 ...(略)...というエラーが出ていました。
このエラーをググってこの方の記事に辿り着き、squid.confにhttp_accessとaclの指定がないとダメそうだなとわかりました。
dockerイメージのsquid.confの差し替え
まずコンテナ内の既存のconfをホストにコピーします。
docker cp squid:/etc/squid/squid.conf .コピーしたsquid.confに、ログに出力されていたIPを通すように以下を追記します。
acl docker src 172.17.0.1 http_access allow docker変更したconfでdockerを再起動します。
($pwdに関してはこの方の記事を参考)# 既存に動作しているイメージを削除 docker rm -f squid # pwdの指定 $pwd = "/$((pwd).Drive.Name.ToLowerInvariant())/$((pwd).Path.Replace('\', '/').Substring(3))" # conf付きでイメージ起動 docker run --name squid -d --restart=always \ --publish 3128:3128 \ --volume ${pwd}/squid.conf:/etc/squid/squid.conf \ sameersbn/squid:3.5.27-2これで先ほどの以下のコマンドが成功するようになりました。
curl example.com -Proxy localhost:3128macのproxyにWindowsを指定する
ここの公式の説明を参考に、
ネットワーク環境設定 > WiFi > 詳細 > プロキシの
- Webプロキシ(HTTP)
- 保護されたWebプロキシ(HTTPS)
それぞれに
{WindowsのIPアドレス}:3128を指定することで、proxyの設定は完了です。これでブラウザからはVPN経由で接続でき、アクセス元のIP制限がされているWebページがmacから閲覧できるようになりました。
gitもproxy経由で接続する
本プロジェクトのgitも接続元IPが制限されていました。
上記のmacの設定では、gitはproxyを経由しないので、この方の記事を参考に、以下の指定をします。
git config --global http.[https://{gitドメイン}/].proxy http://{WindowsのIPアドレス}:3128これで
git cloneでソースを落としてくることができるようになりました。まとめ
同じように困っている方の助けになれば嬉しいです。
macからsoftetherにL2TPで接続する方法を教えてください 泣