- 投稿日:2020-09-06T23:47:09+09:00
Pythonで内外判定➁:ドーナツ型ポリゴンについて
やりたいこと
以下のようなドーナツ型ポリゴンのshpファイルについて、任意の地点の内外判定を行う方法について整理しました。
(出典:https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-A31-v2_1.html)下記の順に解説していきます。
Step1:ドーナツ型ポリゴンデータの読み込み
Step2:内外判定モジュールドーナツ型ポリゴンデータの読み込み
shpファイルにおいて、ドーナツ型ポリゴンは、複数の凹凸ポリゴン(パーツ)の重ね合わせにより構築されています。したがって、まずは、各パーツの節点座標を抽出する必要があります。
import numpy import shapefile import matplotlib.pyplot as plt # def outLS(pnt,fig): #ポリゴンの節点データつなげたラインデータを描画 print(*pnt) xs,ys = zip(*pnt) plt.plot(xs,ys) return 0 # fname="test.shp" #入力ファイル src=shapefile.Reader(fname,encoding='SHIFT-JIS') #ファイル読み込み SRS=src.shapes() #地物情報取得 # for srs in SRS: IP=srs.parts #各地物のパーツを取得 NP=len(IP) #パーツの数を取得 pnt=srs.points #節点データを取得 pnts=[] #パーツ毎に、パーツの節点座標を整理 for ip in range(NP-1): pnts.append(pnt[IP[ip]:IP[ip+1]]) pnts.append(pnt[IP[NP-1]:]) # fig = plt.figure() #各パーツの外形線情報を描画 for np in range(NP): outLS(pnts[np],fig) plt.show() plt.clf()実行結果
以下のように、ドーナツ型ポリゴンを構成する各パーツの外形線情報を区別して取得できました。
内外判定モジュール
内外判定は、実は簡単です。対象地点を始点とする半直線と、ドーナツ型ポリゴンを構成する全パーツの外形線の交差回数をチェックすればよいです。交差回数が奇数であれば、内側判定、偶数であれば外側判定になります。ソースコードにすると、以下のような感じです。下の例では、対象地点から東に向かって引いた半直線と外形線の交差回数をカウントしています。
import sys import numpy as np import shapefile import matplotlib.pyplot as plt # def naig(long,lat,pnts,boxs): #内外判定:対象地点から東向き水平方向に半直線(=A)を引いたときに直線と地物の外形線が交差する数をカウント NPS=len(pnts) ccount=0 for nps in range(NPS): pnt=pnts[nps] box=boxs[nps] # if long<=box[2] and box[1]<=lat<=box[3]: #矩形を用いて交差する可能性のあるパーツを絞り込み NP=len(pnt) for np in range(NP-1): xx1=pnt[np][0] #線分の始点X yy1=pnt[np][1] #線分の始点Y xx2=pnt[np+1][0] #線分の終点X yy2=pnt[np+1][1] #線分の終点Y miny=min([yy1,yy2]) #線分の最小Y maxy=max([yy1,yy2]) #線分の最大Y minx=min([xx1,xx2]) #線分の最小X maxx=max([xx1,xx2]) #線分の最大X if abs(xx1-xx2)<1.E-7: #線分が南北方向に垂直 if xx1>long and miny<=lat<maxy: #対象地点Y座標が線分の最小Y以上、最大Y未満 ccount=ccount+1 elif abs(yy1-yy2)<1.E-7: #線分がほぼ水平 ccount=ccount #水平な線分に対しては交差判定は不要 else: aa=(yy2-yy1)/(xx2-xx1) #線分を通る直線の傾き bb=yy2-aa*xx2 #線分を通る直線の切片 yc=lat #直線とAの交点Y座標 xc=(yc-bb)/aa #直線とAの交点X座標 #交点X座標は対象地点X座標よりも大きくなければならず、交点Y座標は線分の最小Y以上、最大Y未満でなければならない if xc>long and miny<=yc<maxy: ccount=ccount+1 return ccount # fname="test.shp" #入力ファイル src=shapefile.Reader(fname,encoding='SHIFT-JIS') #ファイル読み込み SRS=src.shapes() #地物情報取得 SRR=src.shapeRecords() #地物情報取得 # #地物情報を取得 pntall=[] for srs in SRS: IP=srs.parts #各地物のパーツを取得 NP=len(IP) #パーツの数を取得 pnt=srs.points #節点データを取得 pnts=[] #パーツ毎に、パーツの節点座標を整理 for ip in range(NP-1): pnts.append(pnt[IP[ip]:IP[ip+1]]) pnts.append(pnt[IP[NP-1]:]) pntall.append(pnts) # #属性情報を取得 recall=[] for srr in SRR: recall.append(srr.record) if len(pntall)!=len(recall): print("属性情報の数と地物の数の不一致!!") sys.exit() # #各パーツを包有する矩形を求めておく(矩形情報取得) NPA=len(pntall) #地物数 boxall=[] for npa in range(NPA): pnts=pntall[npa] NPS=len(pnts) #パーツ数 boxs=[] for nps in range(NPS): #各パーツの節点の緯度、経度の最小値・最大値を取得 pp=np.array(list(pnts[nps]),dtype=np.float32) bbox=[pp[:,0].min(),pp[:,1].min(),pp[:,0].max(),pp[:,1].max()] boxs.append(bbox) boxall.append(boxs) # #交点数をカウントする LON=[130.60533882626782543,130.59666405110618825,130.60918282680634661,130.60550819793903088,130.60379578346410767] LAT=[32.76515635424413375,32.77349238606328896,32.77375748954870716,32.76751282967006063,32.77819292046771693] NPP=len(LON) #地点数 for npp in range(NPP): #地点についてのループ for npa in range(NPA): #地物についてのループ ic=naig(LON[npp],LAT[npp],pntall[npa],boxall[npa]) if ic % 2==0: #外側にある場合 print("地点{0}は地物{1}の外! (交差数:{2})".format(npp+1,npa+1,ic)) else: #内側にある場合 print("地点{0}は地物{1}の中! (交差数:{2})".format(npp+1,npa+1,ic))実行結果
以下のように、判定できました。内外判定は、sympyを用いる方法よりも、こちらの自作モジュールの方が大分早そうです。地点1は地物1の外! (交差数:14) 地点2は地物1の外! (交差数:18) 地点3は地物1の中! (交差数:3) 地点4は地物1の外! (交差数:4) 地点5は地物1の中! (交差数:1)


- 投稿日:2020-09-06T23:32:28+09:00
pythonをWindowsにインストールせずにchromeを操作する環境構築手順(selenium使用)
概要
仕事でブラウザの自動化をした方がいいのではないかという場面があった。
ただ、会社から貸与されたWindowsは、自由にソフトをインストールすることが出来ない。
その為、ソフトのインストールをせずに自動化をする必要がありました。
なので、ZipのPythonをダウンロードして、そこにSeleniumをインストールという方法で実行環境を構築しました。
その際の手順を以下に記載する。
(プロキシサーバで制限を掛けられている環境下では難しいかもしれません。)手順
1. pythonのzipをダウンロードする
1-1. https://www.python.org/ へアクセスする
1-2. Downloads → Windowsをクリックする
1-3. 最新バージョンをクリックする
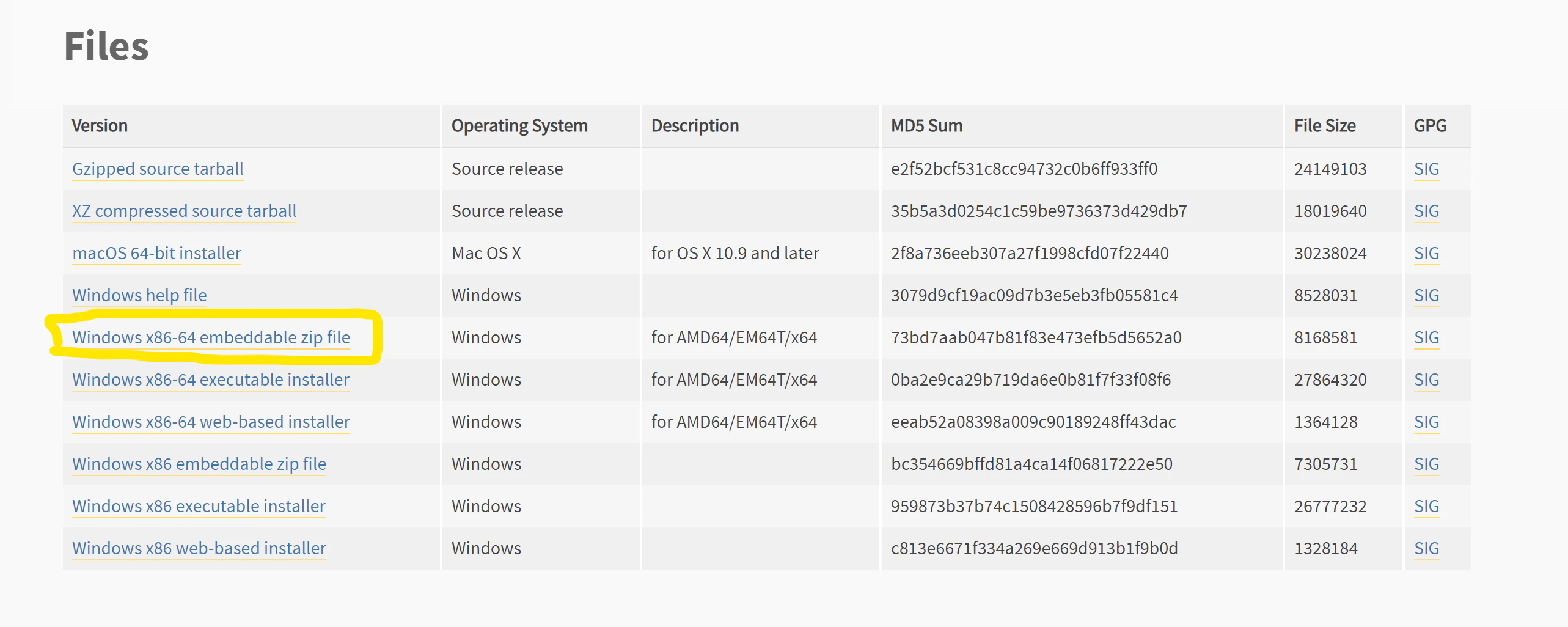
1-4. 最下部までスクロールして、「Windows x86-64 embeddable zip file」をクリックする
1-5. Zipを適当なフォルダに展開する(今回は、C:\00_myspace\tool\に展開する)
<展開対象>
<展開先>
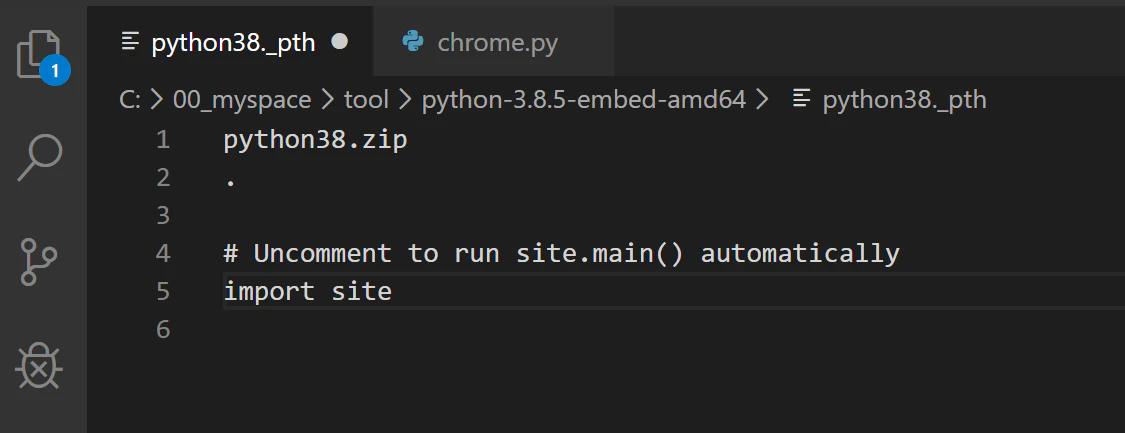
2. seleniumをインストールできるようにする為、「python38._pth」を書き換える
2-1. importのコメントアウトを削除する
変更前
変更後
3. chromeのドライバーをダウンロードする
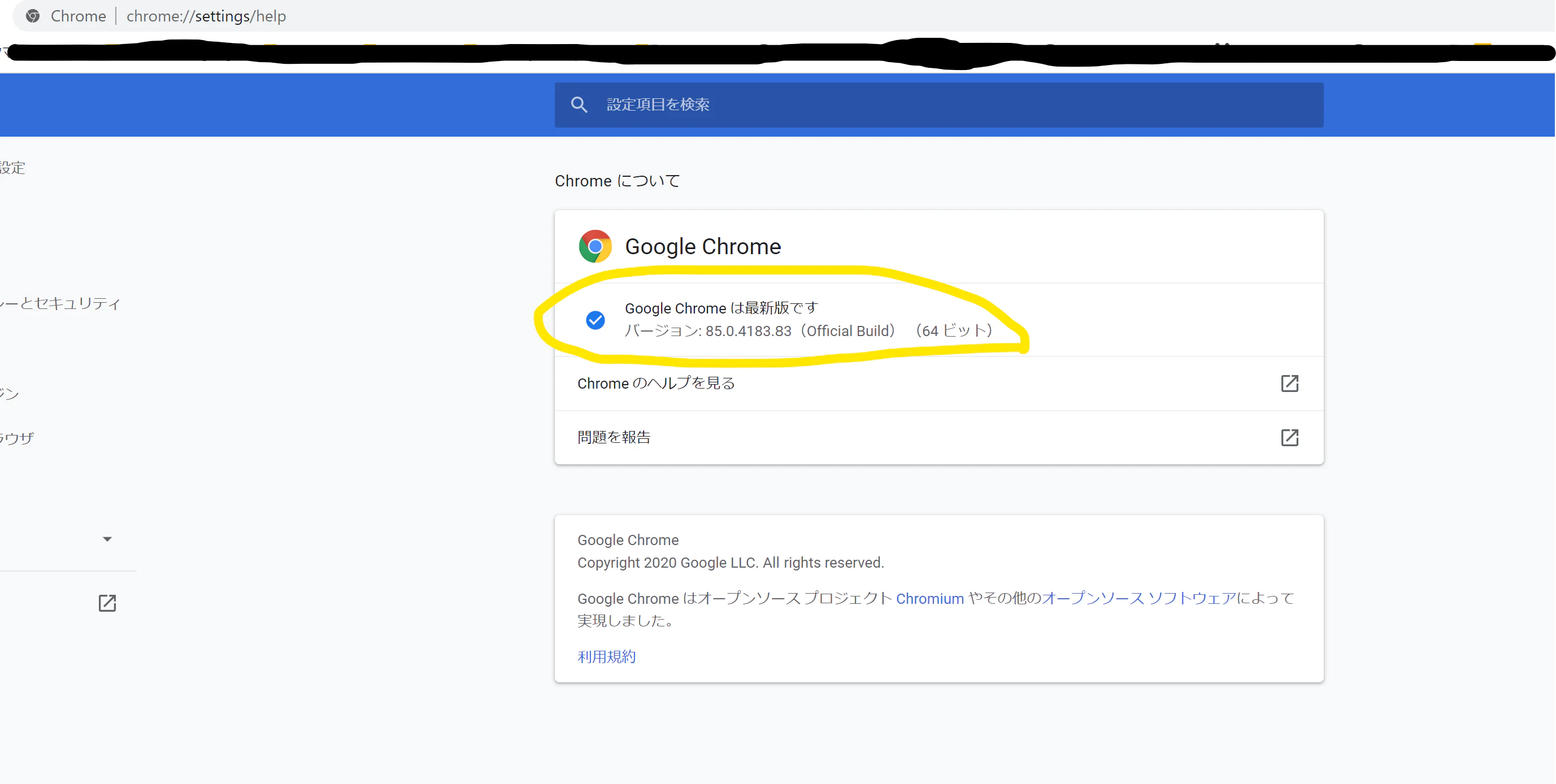
3-1. chromeのバージョンを確認する
3-2. https://sites.google.com/a/chromium.org/chromedriver/ へアクセスする
https://sites.google.com/a/chromium.org/chromedriver/
3-3. 確認したChromeのバージョンと同じものをクリックする(今回は、85.0.4183.87を選択する)
3-4.chromedriver_win32.zipをクリックする
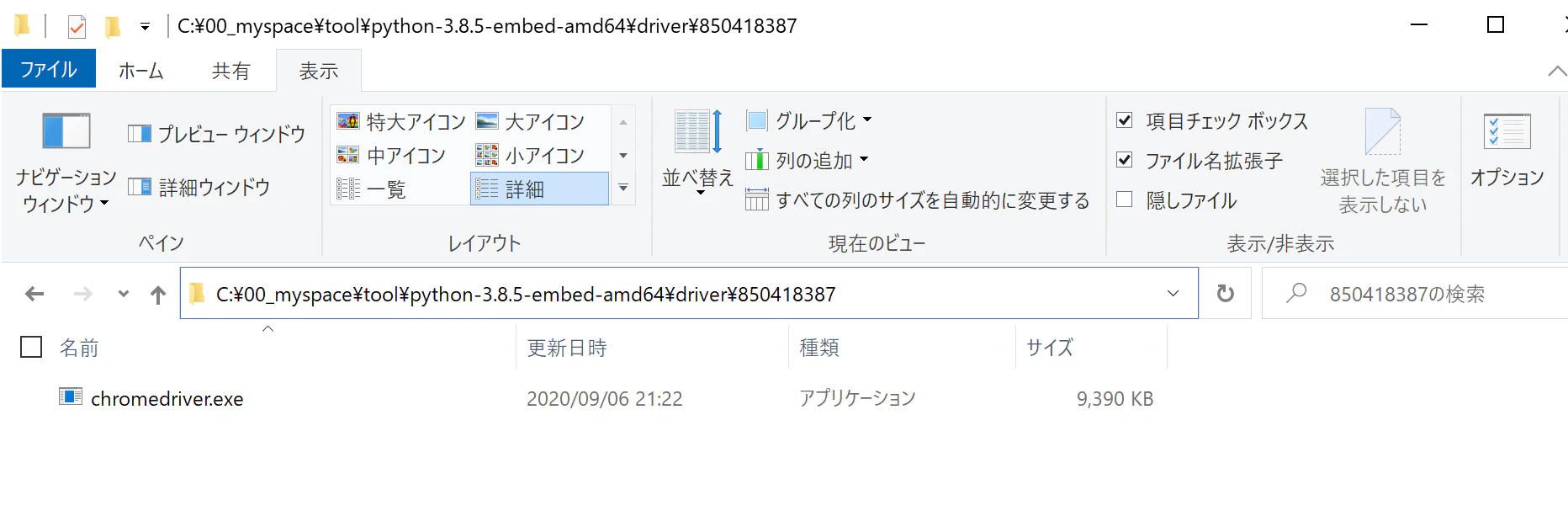
3-5.先ほど展開したpythonのフォルダ内にdriverフォルダ + バージョンフォルダを作成して、その中にダウンロードしたドライバーを格納する
C:\00_myspace\tool\python-3.8.5-embed-amd64\driver\850418387
4. seleniumをインストールする
4-1. powershellを起動する
4-2. pythonをインストールしたフォルダへ移動する
4-3. wget "https://bootstrap.pypa.io/get-pip.py" -O "get-pip.py" でpipをダウンロードする
コマンド : wget "https://bootstrap.pypa.io/get-pip.py" -O "get-pip.py"
4-4. python get-pip.py を実行する(実行しなくてもいいかもしれません)
4-5. コマンドプロンプトを起動して、pythonをインストールしたフォルダへ移動し、以下のコマンドを実行する
コマンド : python -m get-pip install selenium
4-6. python用のプログラムを格納するフォルダをpythonフォルダ内に作成する
※ ここでは、「pyfile」フォルダとしておく
4-7. サンプルファイル(chrome.py)を格納する
chrome.pyimport time from selenium import webdriver #ドライバーを読み込む driver = webdriver.Chrome('./driver/850418387/chromedriver') #googleのURLを設定 driver.get('http://www.google.com/') #1秒sleep(sleepを入れる意味はありません。技術メモの為入れています) #検索ボックスを指定 search_box = driver.find_element_by_name('q') #search_box.send_keys('成田ゆめ牧場 オートキャンプ場') #検索ボックスに検索ワード設定 search_box.send_keys('yahoo') #検索実行 search_box.submit() #先頭の検索結果を選択 search_box = driver.find_element_by_class_name('LC20lb') #クリック search_box.click() #yahooニュース等に指定されているクラスの一覧を取得 search_box = driver.find_elements_by_class_name('_2bBRLhI5ZpVYu0tuHZEFrn') #yahooニュースをクリック search_box[9].click() print('10秒後にブラウザを終了します。') #10秒sleep time.sleep(10) #終了(ブラウザを閉じる) driver.quit()
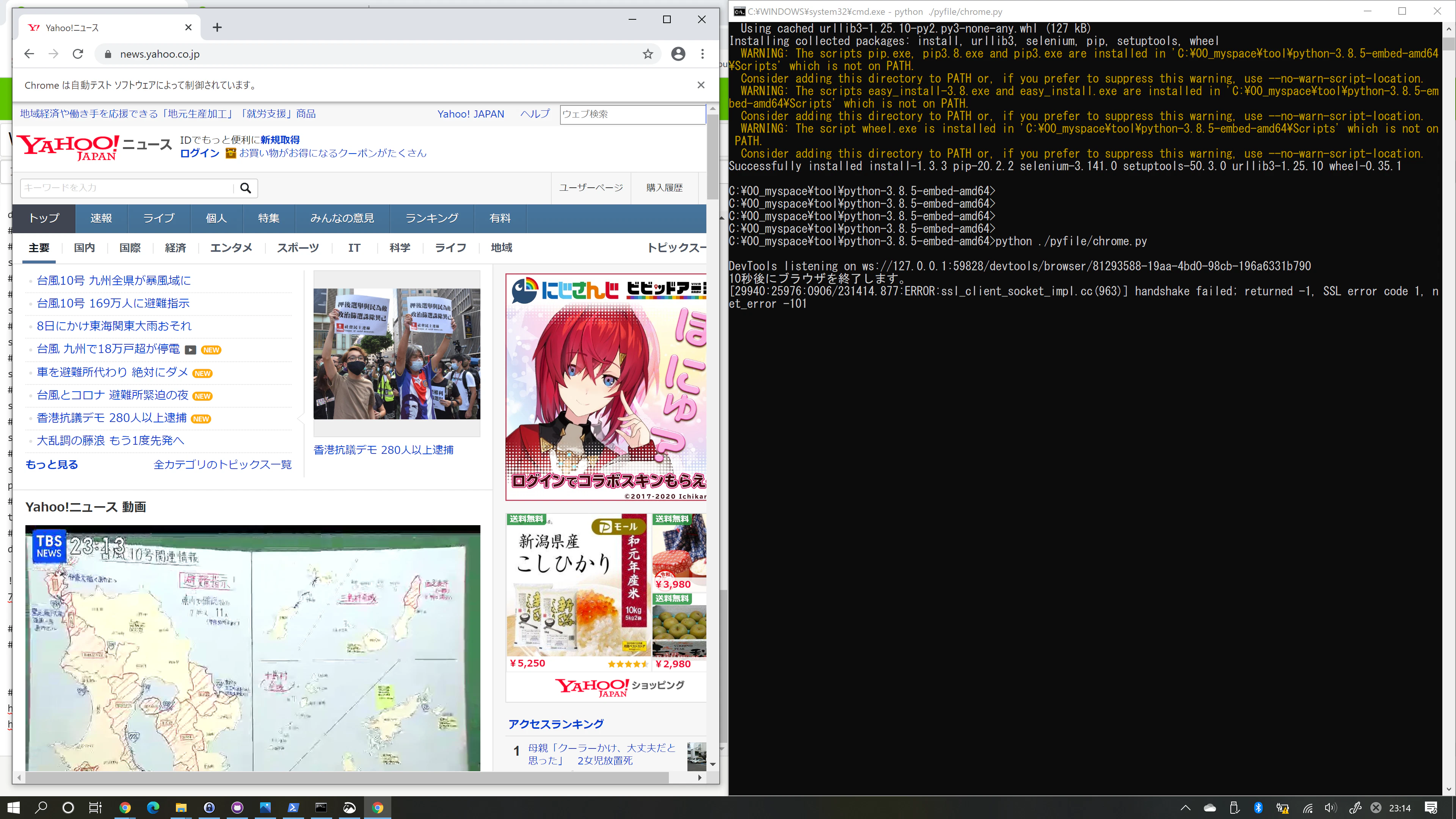
5. 実行する(例:googleでyahooを検索してyahooニュースをのページまで遷移する)
5-1. コマンドプロンプトでPythonフォルダに移動し、以下のコマンドで実行する
コマンド : python ./pyfile/chrome.py
※ 実行許可を求めるアラートが表示された場合は、許可をする
以上がWindowsでpythonをインストールせずに自動化を実施する手順となります。
Github
https://github.com/KOJI-YAMAMOTO-GitHub/python-selenium-chrome-sample
参考サイト
https://qiita.com/mm_sys/items/1fd3a50a930dac3db299
https://sites.google.com/a/chromium.org/chromedriver/getting-started










- 投稿日:2020-09-06T23:23:44+09:00
クラスタ計算機にpythonをインストールする
概要
クラスタ計算機にpython3系をインストールする方法を確立したのでシェアします。
備考
この記事は研究室用のドキュメントとして作成したものとなります。研究室外の方は、「クラスタ計算機」や後述の「大学のVPB」を適宜読み替えてください。
また、基本的にはローカルのmacであっても同じコマンドでpythonをインストールできます。メモ
クラスタ計算機の変更点としては、git v2系、openssl v1.1系をインストールしたことです。
参考文献
要約
python 3.8.5をインストールする場合の手順のまとめです。
※ここで話しているzsh、bashについて不安があるひとは「手順」の章から順に進めていってください。
zshのひと$ git clone https://github.com/pyenv/pyenv.git ~/.pyenv $ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshrc $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshrc $ echo 'eval "$(pyenv init -)"' >> ~/.zshrc $ source ~/.zshrc $ CONFIGURE_OPTS="--with-openssl=/usr/local/openssl-1.1.1/" pyenv install 3.8.5 $ source ~/.zshrc $ pyenv global 3.8.5 $ python --version
bashのひと$ git clone https://github.com/pyenv/pyenv.git ~/.pyenv $ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile $ source ~/.bash_profile $ CONFIGURE_OPTS="--with-openssl=/usr/local/openssl-1.1.1/" pyenv install 3.8.5 $ source ~/.bash_profile $ pyenv global 3.8.5 $ python --version手順
- 環境構築
- pyenvのインストール
- pyenvのパスを通す
- pyenvでpythonのインストール
- pythonのバージョン変更
1. 環境構築
まずは大学のVPNに接続します。そしてmacのターミナルを開き、クラスタ計算機にsshし、シェルの確認をします。
{{username}}には自分のクラスタ計算機のユーザー名を代入してください。{{ip}}にはクラスタ計算機のIPアドレスを代入してください。$ ssh -Y {{username}}@{{ip}} $ echo $SHELLおそらく
/bin/tcshが返ってくると思います。シェルはmacと揃えておいたほうがmacの環境をそのままクラスタ計算機に移すことができて便利だと思います。したがって、macのシェルがzshならクラスタ計算機もzsh、macがbashならクラスタ計算機もbashにするのが良いと思います。
※個人的にはmacもクラスタ計算機もzshにするのが良いと思います。zshのほうが簡単だし、便利です。というわけで、クラスタ計算機のシェルの変更をします。
zshの人は{{shell}}のところに、zsh、bashの人は{{shell}}のところに、bashを代入してください。$ chsh -s /bin/{{shell}}シェルの変更には一旦ログアウトしなければならないため、ログアウトします。
$ exit再度クラスタ計算機にログインし、シェルの確認をします。先程変更したシェルとなっていればOKです。
$ ssh -Y {{username}}@{{ip}} $ echo $SHELL2. pyenvのインストール
git cloneするだけです。
$ git clone https://github.com/pyenv/pyenv.git ~/.pyenv3. pyenvのパスを通す
シェルによって手順が異なるので、自分のシェルが
zsh、bashのどちらであるかを確認した上で以降の手順を行ってください。
zshのひと$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshrc $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshrc $ echo 'eval "$(pyenv init -)"' >> ~/.zshrc $ source ~/.zshrc
bashのひとecho 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile echo 'eval "$(pyenv init -)"' >> ~/.bash_profile source ~/.bash_profileこれは共通の手順です。念の為、pyenvがちゃんとインストールされているか確認します。何かしらのバージョン番号が返ってくればOKです。
$ pyenv --version4. pyenvでpythonのインストール
openssl1.1系でないとpythonのインストールが正常に行われないらしいので、openssl1.1系のフルパスを指定した上でpythonをインストールします。
{{version}}のところには、インストールしたいpythonのバージョンを代入してください。$ CONFIGURE_OPTS="--with-openssl=/usr/local/openssl-1.1.1/" pyenv install {{version}}以降はシェルによって手順が異なるので、自分のシェルが
bash、zshのどちらであるかを確認した上で以降の手順を行ってください。
- zshのひと
$ source ~/.zshrc
- bashのひと
$ source ~/.bash_profile5. pythonのバージョン変更
最後にpythonのバージョンを変更し、インストールしたバージョンとなっているかを確認します。
{{version}}のところは先程インストールしたpythonのバージョンを代入してください。$ pyenv global {{version}} $ python --version無事インストールしたバージョンが返ってくればインストールは成功です。お疲れさまでした。
- 投稿日:2020-09-06T23:13:09+09:00
Python(Kivy)で作るオセロアプリ(iOSアプリ)
はじめに
Pythonでマルチタップアプリを開発するためのオープンソースライブラリkivyを使ってオセロアプリを作成してみました。
また、最終的にiOSのSimulatorで(xcode)でビルドしました。環境
python: 3.7.7
kivy: 1.11.1
xcode: 11.7作成物
完成形
ソースコード解説
今回作成したオセロアプリを開発した順番を追いながら説明します。
1. オセロ盤面と初期石を配置
下記の状態まで作成
class OthelloApp(App): title = 'オセロ' def build(self): return OthelloGrid() OthelloApp().run()APPクラスの中でOthelloGridクラスをreturnしている。
今回のアプリの処理はこのOthelloGridクラスの中で行うようにしている。class OthelloGrid(Widget): def __init__(self, **kwargs): super().__init__(**kwargs) self.num = 8 self.tile = [[' ' for x in range(self.num)] for x in range(self.num)] self.turn = 'W' self.grid = GridLayout(cols=self.num, spacing=[3,3], size=(Window.width, Window.height)) for x in range(self.num): for y in range(self.num): if x == 3 and y == 3 or x == 4 and y == 4: self.grid.add_widget(WhiteStone()) self.tile[x][y] = 'W' elif x == 4 and y == 3 or x == 3 and y == 4: self.grid.add_widget(BlackStone()) self.tile[x][y] = 'B' else: self.grid.add_widget(PutButton(background_color=(0.451,0.3059,0.1882,1), background_normal='', tile_id=[x, y])) self.add_widget(self.grid)
self.numはオセロ盤面の縦、横のマスの数である。
self.tileは盤面の状態を記憶しておくためのリストで白が置かれている時'W'、黒が置かれている時'B'、何も置かれていない時' 'の値をとる。
self.turnは現在のターンが黒か白かを記憶しているもので、初期は白ターンから始まるようにしている。
実際に画面に描画する盤面はself.grid(GridLayout)で定義しており、既に石が置かれているマスには白の石の場合WhiteStoneクラス、黒の石の場合BlackStoneクラスをadd_widgetしており、まだ石が置かれていないマスにはPutButtonクラスをadd_widgetしています。class WhiteStone(Label): def __init__(self, **kwargs): super().__init__(**kwargs) self.bind(pos=self.update) self.bind(size=self.update) self.update() def update(self, *args): self.canvas.clear() self.canvas.add(Color(0.451,0.3059,0.1882,1)) self.canvas.add(Rectangle(pos=self.pos, size=self.size)) self.canvas.add(Color(1,1,1,1)) self.canvas.add(Ellipse(pos=self.pos, size=self.size)) class BlackStone(Label): def __init__(self, **kwargs): super().__init__(**kwargs) self.bind(pos=self.update) self.bind(size=self.update) self.update() def update(self, *args): self.canvas.clear() self.canvas.add(Color(0.451,0.3059,0.1882,1)) self.canvas.add(Rectangle(pos=self.pos, size=self.size)) self.canvas.add(Color(0,0,0,1)) self.canvas.add(Ellipse(pos=self.pos, size=self.size)) class PutButton(Button): def __init__(self, tile_id, **kwargs): super().__init__(**kwargs) self.tile_id = tile_id
WhiteStone、BlackStoneクラスはLabelクラスを継承しており、単純にマスRectangle(pos=self.pos, size=self.size)の上に楕円の石Ellipse(pos=self.pos, size=self.size)を描画しているだけです。
PutButtonクラスはButtonクラスを継承しており、まだ押した時の処理はありません。
tile_idとして、grid上のどの位置のマスかをインスタンス自身が記憶できるようにしています。2.マスをタップした時に石を置く
下記の状態まで作成
下記のように
PutButtonクラスにon_pressファンクションを作成し、マスをタップされた時の処理を追加する。PutButtonクラスdef on_press(self): put_x = self.tile_id[0] put_y = self.tile_id[1] turn = self.parent.parent.turn self.parent.parent.tile[put_x][put_y] = turn self.parent.parent.put_stone()
put_x、put_yにタップされたマスの番号を代入し、turnに現在のターンを代入する。
親のクラス(OthelloGrid)のtileのタップされたマスの場所にturnの値を代入し、put_stoneファンクションを呼び出す。
put_stoneはOthelloGridに下記のように作成したファンクションで、tileの中身から盤面を再作成するファンクションである。OthelloGridクラスdef put_stone(self): self.clear_widgets() self.grid = GridLayout(cols=self.num, spacing=[3,3], size=(Window.width, Window.height)) next_turn = 'W' if self.turn == 'B' else 'B' for x in range(self.num): for y in range(self.num): if self.tile[x][y] == 'W': self.grid.add_widget(WhiteStone()) elif self.tile[x][y] == 'B': self.grid.add_widget(BlackStone()) else: self.grid.add_widget(PutButton(background_color=(0.451,0.3059,0.1882,1), background_normal='', tile_id=[x, y]))3.挟んだ石をひっくり返す(ひっくり返せないマスをタップした場合は何もしない)
下記の状態まで作成
下記のように
OthelloGridクラスにマスの座標と現在のターンを起点にひっくり返すことができる石があるかをチェックするファンクションcan_reverse_checkとreverse_listを追加する。OthelloGridクラスdef can_reverse_check(self, check_x, check_y, turn): check =[] # 左上確認 check += self.reverse_list(check_x, check_y, -1, -1, turn) # 上確認 check += self.reverse_list(check_x, check_y, -1, 0, turn) # 右上確認 check += self.reverse_list(check_x, check_y, -1, 1, turn) # 右確認 check += self.reverse_list(check_x, check_y, 0, 1, turn) # 右下確認 check += self.reverse_list(check_x, check_y, 1, 1, turn) # 下確認 check += self.reverse_list(check_x, check_y, 1, 0, turn) # 左下確認 check += self.reverse_list(check_x, check_y, 1, -1, turn) # 左確認 check += self.reverse_list(check_x, check_y, 0, -1, turn) return check def reverse_list(self, check_x, check_y, dx, dy, turn): tmp = [] while True: check_x += dx check_y += dy if check_x < 0 or check_x > 7: tmp = [] break if check_y < 0 or check_y > 7: tmp = [] break if self.tile[check_x][check_y] == turn: break elif self.tile[check_x][check_y] == ' ': tmp = [] break else: tmp.append((check_x, check_y)) return tmp
can_reverse_checkでは石を置こうとしているマスにからそれぞれの方向に対して、ひっくり返すことができる石があるかをチェックするファンクションであるreverse_listを呼んでいる。
戻り値として、ひっくり返すことができる石の座標のリストが返ってくるようにしている。下記のように、この
can_reverse_checkをPutButtonクラスがタップされた時に(on_press内で)呼び出し、戻り値のリストの中身があった場合tileの値を更新して、盤面を作り直す(put_stoneを呼び出す)。
リストの中身が無かった場合は何もしない。PutButtonクラスdef on_press(self): put_x = self.tile_id[0] put_y = self.tile_id[1] check =[] turn = self.parent.parent.turn check += self.parent.parent.can_reverse_check(self.tile_id[0], self.tile_id[1], turn) if check: self.parent.parent.tile[put_x][put_y] = turn for x, y in check: self.parent.parent.tile[x][y] = turn self.parent.parent.put_stone()4.パス機能とゲーム終了時の処理の追加
石を置く場所がなくなった時のパス機能
ゲーム終了時の勝敗判定
OthelloGridクラスのput_stoneを下記のように拡張するOthelloGridクラスdef put_stone(self): pass_flag = True finish_flag = True check = [] self.clear_widgets() self.grid = GridLayout(cols=self.num, spacing=[3,3], size=(Window.width, Window.height)) next_turn = 'W' if self.turn == 'B' else 'B' for x in range(self.num): for y in range(self.num): if self.tile[x][y] == 'W': self.grid.add_widget(WhiteStone()) elif self.tile[x][y] == 'B': self.grid.add_widget(BlackStone()) else: self.grid.add_widget(PutButton(background_color=(0.451,0.3059,0.1882,1), background_normal='', tile_id=[x, y])) for x in range(self.num): for y in range(self.num): if self.tile[x][y] == ' ': finish_flag = False check += self.can_reverse_check(x, y, next_turn) if check: pass_flag = False break if finish_flag: content = Button(text=self.judge_winner()) popup = Popup(title='Game set!', content=content, auto_dismiss=False, size_hint=(None, None), size=(Window.width, Window.height/3)) content.bind(on_press=popup.dismiss) popup.open() else: if pass_flag: skip_turn_text = 'White Turn' if self.turn == 'B' else 'Black Turn' content = Button(text='OK') popup = Popup(title=skip_turn_text+' Skip!', content=content, auto_dismiss=False, size_hint=(None, None), size=(Window.width, Window.height/3)) content.bind(on_press=popup.dismiss) popup.open() else: self.turn = next_turn self.add_widget(self.grid)
pass_flagとfinish_flagを用意し、パスするかゲームを終了するかの判定に用いる。
tileの中の何も置かれていない全てのマス(値が' 'のマス)に対して、次のターンのプレイヤーがそのマスに石を置いた時にひっくり返す石があるかを確認し、もしなければ次のターンをスキップする。
その際にPopupでスキップしたことを画面に表示するようにする。もし、
tileの中の何も置かれていないマスがなければゲーム終了とみなし、下記のjudge_winnerファンクションでどちらが勝ったかを判別して、Popupで画面に表示する。OthelloGridクラスdef judge_winner(self): white = 0 black = 0 for x in range(self.num): for y in range(self.num): if self.tile[x][y] == 'W': white += 1 elif self.tile[x][y] == 'B': black += 1 print(white) print(black) return 'White Win!' if white >= black else 'Black Win!'ここまでで、オセロの処理としては一通り終わりとなります。
ソースコード全体
他にもResetButtonやターンを表示するラベルなども追加していますが、その辺りは下記のソースコード全体でご確認ください。
(gitにもあげています。https://github.com/fu-yuta/kivy-project/tree/master/Othello)main.pyfrom kivy.app import App from kivy.uix.widget import Widget from kivy.core.window import Window from kivy.uix.gridlayout import GridLayout from kivy.uix.boxlayout import BoxLayout from kivy.uix.button import Button from kivy.uix.label import Label from kivy.uix.popup import Popup from kivy.graphics import Color, Ellipse, Rectangle class OthelloGrid(Widget): def __init__(self, **kwargs): super().__init__(**kwargs) self.num = 8 self.tile = [[' ' for x in range(self.num)] for x in range(self.num)] self.turn = 'W' self.grid = GridLayout(cols=self.num, spacing=[3,3], size_hint_y=7) for x in range(self.num): for y in range(self.num): if x == 3 and y == 3 or x == 4 and y == 4: self.grid.add_widget(WhiteStone()) self.tile[x][y] = 'W' elif x == 4 and y == 3 or x == 3 and y == 4: self.grid.add_widget(BlackStone()) self.tile[x][y] = 'B' else: self.grid.add_widget(PutButton(background_color=(0.451,0.3059,0.1882,1), background_normal='', tile_id=[x, y])) self.creat_view('White Turn') def put_stone(self): self.grid = GridLayout(cols=self.num, spacing=[3,3], size_hint_y=7) pass_flag = True finish_flag = True check = [] next_turn = 'W' if self.turn == 'B' else 'B' for x in range(self.num): for y in range(self.num): if self.tile[x][y] == 'W': self.grid.add_widget(WhiteStone()) elif self.tile[x][y] == 'B': self.grid.add_widget(BlackStone()) else: self.grid.add_widget(PutButton(background_color=(0.451,0.3059,0.1882,1), background_normal='', tile_id=[x, y])) for x in range(self.num): for y in range(self.num): if self.tile[x][y] == ' ': finish_flag = False check += self.can_reverse_check(x, y, next_turn) if check: pass_flag = False break if finish_flag: content = Button(text=self.judge_winner()) popup = Popup(title='Game set!', content=content, auto_dismiss=False, size_hint=(None, None), size=(Window.width, Window.height/3)) content.bind(on_press=popup.dismiss) popup.open() self.restart_game() else: if pass_flag: skip_turn_text = 'White Turn' if self.turn == 'B' else 'Black Turn' content = Button(text='OK') popup = Popup(title=skip_turn_text+' Skip!', content=content, auto_dismiss=False, size_hint=(None, None), size=(Window.width, Window.height/3)) content.bind(on_press=popup.dismiss) popup.open() else: self.turn = next_turn turn_text = 'Black Turn' if self.turn == 'B' else 'White Turn' self.creat_view(turn_text) def can_reverse_check(self, check_x, check_y, turn): check =[] # 左上確認 check += self.reverse_list(check_x, check_y, -1, -1, turn) # 上確認 check += self.reverse_list(check_x, check_y, -1, 0, turn) # 右上確認 check += self.reverse_list(check_x, check_y, -1, 1, turn) # 右確認 check += self.reverse_list(check_x, check_y, 0, 1, turn) # 右下確認 check += self.reverse_list(check_x, check_y, 1, 1, turn) # 下確認 check += self.reverse_list(check_x, check_y, 1, 0, turn) # 左下確認 check += self.reverse_list(check_x, check_y, 1, -1, turn) # 左確認 check += self.reverse_list(check_x, check_y, 0, -1, turn) return check def reverse_list(self, check_x, check_y, dx, dy, turn): tmp = [] while True: check_x += dx check_y += dy if check_x < 0 or check_x > 7: tmp = [] break if check_y < 0 or check_y > 7: tmp = [] break if self.tile[check_x][check_y] == turn: break elif self.tile[check_x][check_y] == ' ': tmp = [] break else: tmp.append((check_x, check_y)) return tmp def judge_winner(self): white = 0 black = 0 for x in range(self.num): for y in range(self.num): if self.tile[x][y] == 'W': white += 1 elif self.tile[x][y] == 'B': black += 1 print(white) print(black) return 'White Win!' if white >= black else 'Black Win!' def restart_game(self): print("restart game") self.tile = [[' ' for x in range(self.num)] for x in range(self.num)] self.turn = 'W' self.grid = GridLayout(cols=self.num, spacing=[3,3], size_hint_y=7) for x in range(self.num): for y in range(self.num): if x == 3 and y == 3 or x == 4 and y == 4: self.grid.add_widget(WhiteStone()) self.tile[x][y] = 'W' elif x == 4 and y == 3 or x == 3 and y == 4: self.grid.add_widget(BlackStone()) self.tile[x][y] = 'B' else: self.grid.add_widget(PutButton(background_color=(0.451,0.3059,0.1882,1), background_normal='', tile_id=[x, y])) self.creat_view('White Turn') def creat_view(self, turn_text): self.clear_widgets() self.turn_label = Label(text=turn_text, width=Window.width , size_hint_y=1, font_size='30sp') self.restart_button = RestartButton(text='Restart') self.layout = BoxLayout(orientation='vertical', spacing=10, size=(Window.width, Window.height)) self.layout.add_widget(self.turn_label) self.layout.add_widget(self.grid) self.layout.add_widget(self.restart_button) self.add_widget(self.layout) class WhiteStone(Label): def __init__(self, **kwargs): super().__init__(**kwargs) self.bind(pos=self.update) self.bind(size=self.update) self.update() def update(self, *args): self.canvas.clear() self.canvas.add(Color(0.451,0.3059,0.1882,1)) self.canvas.add(Rectangle(pos=self.pos, size=self.size)) self.canvas.add(Color(1,1,1,1)) self.canvas.add(Ellipse(pos=self.pos, size=self.size)) class BlackStone(Label): def __init__(self, **kwargs): super().__init__(**kwargs) self.bind(pos=self.update) self.bind(size=self.update) self.update() def update(self, *args): self.canvas.clear() self.canvas.add(Color(0.451,0.3059,0.1882,1)) self.canvas.add(Rectangle(pos=self.pos, size=self.size)) self.canvas.add(Color(0,0,0,1)) self.canvas.add(Ellipse(pos=self.pos, size=self.size)) class PutButton(Button): def __init__(self, tile_id, **kwargs): super().__init__(**kwargs) self.tile_id = tile_id def on_press(self): print(self.tile_id) put_x = self.tile_id[0] put_y = self.tile_id[1] check =[] turn = self.parent.parent.parent.turn check += self.parent.parent.parent.can_reverse_check(self.tile_id[0], self.tile_id[1], turn) if check: self.parent.parent.parent.tile[put_x][put_y] = turn for x, y in check: self.parent.parent.parent.tile[x][y] = turn self.parent.parent.parent.put_stone() class RestartButton(Button): def __init__(self, **kwargs): super().__init__(**kwargs) def on_press(self): content = Button(text='OK') popup = Popup(title='Restart Game!', content=content, auto_dismiss=False, size_hint=(None, None), size=(Window.width, Window.height/3)) content.bind(on_press=popup.dismiss) popup.open() self.parent.parent.restart_game() class OthelloApp(App): title = 'オセロ' def build(self): return OthelloGrid() OthelloApp().run()iOS Simulaterでのビルド
下記の記事を参考にさせていただきました。
https://qiita.com/sobassy/items/b06e76cf23046a78ba05Xcodeのコマンドラインツールが入っていない場合は下記コマンドを実行してください。
xcode-select --install依存関係をインストールする
brew install autoconf automake libtool pkg-config brew link libtoolCythonをインストールする
pip install cythonkivy-iosをgit cloneする。
git clone https://github.com/kivy/kivy-ios.git cd kivy-iosiOS用のkivyをビルドするために下記コマンドを実行する(完了までに数十分ほどかかるかも)
python toolchain.py build kivy上記が完了したらkivyプログラムをXcode用にビルドする。
python toolchain.py create [Xcodeのプロジェクト名(任意の名前)] [kivyプログラムのフォルダ名]この時、kivyプログラムのファイルの名前は
main.pyにしておかなければならない。
Xcodeのプロジェクト名をAppとした場合、App-iosというディレクトリが作成されており、その中にApp.xcodeprojが作成されている。
このプロジェクトをXcodeで開く。open App.xcodeprojXcodeでSimulatorを指定してビルドすれば、アプリが立ち上がるハズである。
もし、kivyプログラムを更新した場合には、下記コマンドでXcodeのプロジェクトも更新しなければならない。python toolchain.py update App終わりに
pythonのライブラリの1つであるkivyを使って、オセロアプリを作成し、iOSのSimulaterでビルドしてみました。
今回は、main.pyの中で全ての処理を書いていましたがkivyにはkv言語というもので、wighetなどを分けて書くことができるので、そちらへの移植も今後考えていきたい。
また、オセロのAIを組み込んでプレイヤー対CPUの対戦機能も今後追加していきたい。参考
https://qiita.com/sobassy/items/b06e76cf23046a78ba05
https://github.com/PrestaMath/reverse_tile






- 投稿日:2020-09-06T22:51:47+09:00
Kaggle備忘録 ~NLP with Disaster Tweets第一回~
Kaggleに挑戦
しばらく手を付けていなかったKaggleに久々にトライしてみました。
挑戦するのはこちら↓
Real or Not? NLP with Disaster Tweets
https://www.kaggle.com/c/nlp-getting-startedまずはデータセットをDataFrameに落とし込む。
import os import pandas as pd for dirname, , filenames in os.walk('../input/nlp-getting-started'): for filename in filenames: path = os.path.join(dirname, filename) exec("{0}df = pd.read_csv(path)".format(filename.replace(".csv","")))特定の単語と災害発生Tweetに相関があるんじゃないかと考えて以下のコードを作成。
# Tweet文を単語ごとに区切り、DataFrameに格納する words_df = pd.DataFrame([], columns = ['words' , 'target_count']) for index,item in train_df[['text','target']].iterrows(): word_df = pd.DataFrame([], columns = ['words' , 'target_count']) word_df['words'] = item[0].split(' ') word_df['target_count'] = item[1] words_df = pd.concat([words_df,word_df]) # ストップワードを除外するために5文字以上の単語に絞る long_words_df = words_df[words_df['words'].str.len() > 5] # 同一の単語をGroupByしてその集計結果を表示する long_words_df.groupby(['words']).sum().sort_values("target_count", ascending=False)結果は以下の通り。
Hiroshimaって単語が上位に食い込んでいるのが気になりますね。
words target_count California 86 killed 86 people 83 suicide 71 disaster 59 Hiroshima 58
- 投稿日:2020-09-06T22:39:21+09:00
pylintでワイルドカード指定が動かないとき
概要
カレントディレクトリ直下のpythonファイルを一括でpylintかけようとしてはまった話。
同じことで悩んでいそうな方に、一応の解決策を提供します。結論
解決策は以下。
- 空の__init__.pyをまず作る。
- コマンド実行時に..で一階層上がってからフォルダ指定する。(理由はわからないです)環境
- OS ... Windows 10 64bit(Home)
- Python実行環境 ... Minicondaでconda仮想環境を作成
- pylint 2.5.2
- astroid 2.4.1
- Python 3.7.9 (default, Aug 31 2020, 17:10:11) [MSC v.1916 64 bit (AMD64)]
やったこと
最初フォルダ構成はこんな感じ。
C:\Users\{ユーザー名}\Desktop\project └aaa.pyコマンドプロンプトから以下を実行してみた。
(dev) C:\Users\{ユーザー名}\Desktop\project>pylint *.py ************* Module *.py *.py:1:0: F0001: No module named *.py (fatal)あれ。。。ワイルドカード使えない?
いろいろ調べて、
__init__.pyを同じ階層に作れば行けそうな雰囲気を感じた。
__init__.pyは空のファイルで良い。C:\Users\{ユーザー名}\Desktop\project ├__init__.py └aaa.pyこれなら以下で行けるか?
(dev) C:\Users\{ユーザー名}\Desktop\project>pylint . (dev) C:\Users\{ユーザー名}\Desktop\project>これもダメ。。。
念のため1階層上でも試してみる。(dev) C:\Users\{ユーザー名}\Desktop\project>cd .. (dev) C:\Users\{ユーザー名}\Desktop>pylint project ************* Module project.aaa.py project\aaa.py:24:0: C0301: Line too long (109/100) (line-too-long) (そのほか多数) ----------------------------------- Your code has been rated at 2.20/10 (dev) C:\Users\snkmr\Desktop\repo>お、できた!!!でも階層上がらないとできないの不便すぎる...
もしかしてワンチャンこれならいける??(dev) C:\Users\{ユーザー名}\Desktop>cd project (dev) C:\Users\{ユーザー名}\Desktop\project>pylint ..\project ************* Module project.aaa.py project\aaa.py:24:0: C0301: Line too long (109/100) (line-too-long) (そのほか多数) ----------------------------------- Your code has been rated at 2.20/10 (dev) C:\Users\snkmr\Desktop\repo>行けた!!!これが正しい解決法かわからないけど、一応解決した。
結論(再掲)
解決策は以下。
- 空の__init__.pyをまず作る。
- コマンド実行時に..で一階層上がってからフォルダ指定する。(理由はわからないです)
- 投稿日:2020-09-06T22:33:37+09:00
Twitterで20倍ファミチキを当てやすくする方法をPythonで発見しました
はじめに
ファミチキを当てたかったら日付変わった瞬間に応募するな.
ツイッターでファミマの抽選を当てたい人はこれを見ろ!
— 電気野菜 (@YasaiDev) August 30, 2020
日付変わった瞬間に応募するのはやめようね!!!!
youtubeでめっちゃ詳しく解説したので見てくれ!!!https://t.co/VBI5hUSeNO pic.twitter.com/svHqMGlfmPTwitterでファミチキ?
Twitterでファミチキを当てるってなんの話かと思う人もいると思いますが,下の画像を見れば分かる人もいるのではないでしょうか.
広告の画像が引用ツイートではでなかったので貼ってます.
【本日最終日】?7日間連続✨
— ファミリーマート (@famima_now) August 16, 2020
このアカウントをフォローして、#ファミチキたべたい と #ファミマ でツイートしてくれた人の中から
毎日抽選で1万名様に
?ファミチキ(骨なし)無料引換券?が当たる!これに限らず,Twitter上ではリプライで毎日ホニャララ名様に当たるキャンペーンが多く開催されています.できるならこれを当てたいというのが人の性です.
そこで,今回ファミチキキャンペーンに関して,すべての抽選参加者とその結果を集計し当てるコツを調査しました.
調査手法
ファミチキの当選結果は,ファミマ公式(famima_now)ではなくファミリーマート公式返信用アカウント(famima_reply)が通知しています.
@rngn0710 ご応募ありがとうございます!
— ファミリーマート公式返信用アカウント (@famima_reply) July 24, 2020
残念はずれ…!
でも!はずれた方にも【先着100万名】に
「ファミチキ(骨なし)20円割引券」をプレゼント中!
※予定引換数に達し次第、Famiポートでの発券はできなくなります※
▼Famiポートの使い方はこちらhttps://t.co/GihPGGELuG pic.twitter.com/I8AMb8miC0なのでTwintという最強のツイート収集用のライブラリを使い,ひたすら(famima_reply)のツイートを収集しました.
Q.なぜTwintは最強なのか?
A.期間や取得数上限なくツイートを収集可能だから.公式APIのフリープランだと期間は直近1週間,上限は3000程度であるはず...収集したデータ: 7/26~7/29のfamima_replyの全ツイート(150万以上)
そして,収集後のデータをPandasでうまいこと整形して,TweepyでTwitterAPIからデータ(FF数・アカウント開設日)を取得し可視化を行いました.
結果
これは7/26~7/29のキャンペーンの抽選結果に基づきます.
おおまかに分析
- 一日あたりの応募者数: 約38000人
- 一日あたりの当選者: 10000人(公式情報)
- 一日あたりの当選確率: 約2.6%
- 一週間(キャンペーン期間)中に当たる確率: 約17%
1-(1-0.026)^7=17\%一週間連続で外れる以外の可能性
時系列で分析(7/26だけ)
どの日付でもおんなじ傾向だったので,7/26だけを見ます.データを30分ごとに当選者・落選者に分けて分析します.
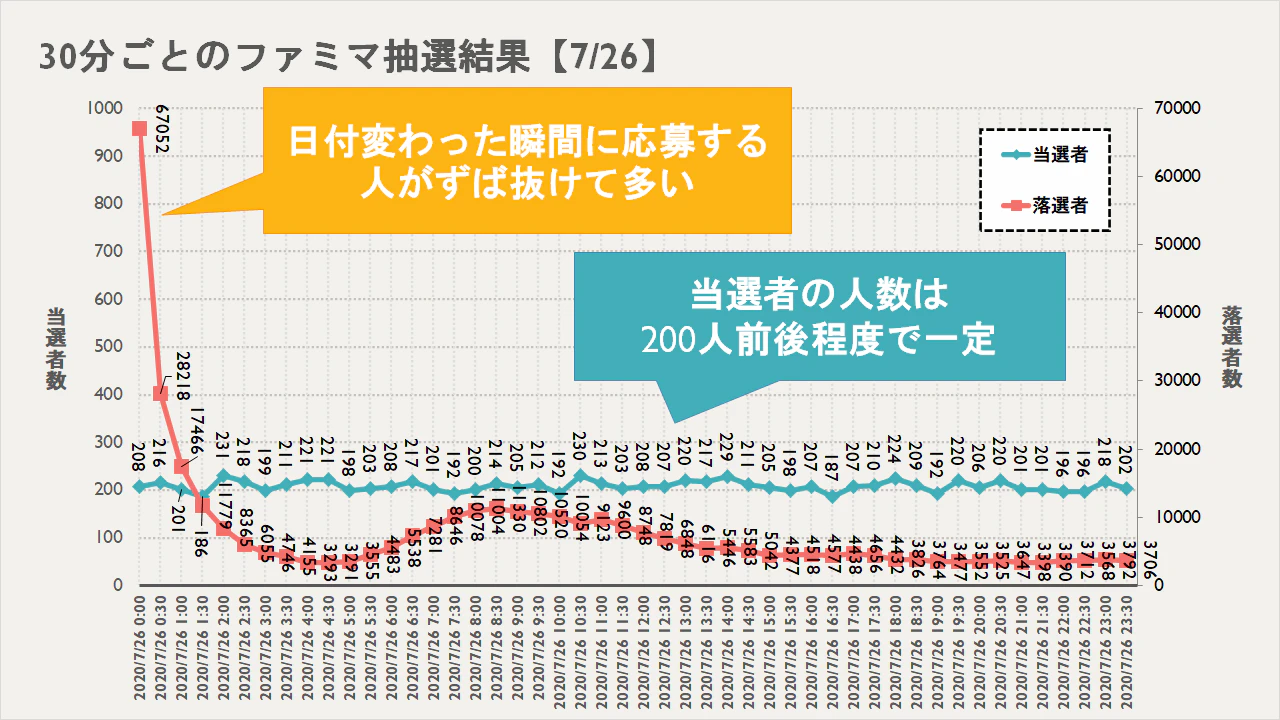
30分ごとのファミマ抽選結果
日付を変わった瞬間や,起床する時間帯に応募する人がめっちゃくっちゃ多いみたいに応募者は時間帯ごとに偏りがあるのに,当選者は200人前後で一定ですね.おそらく,意図的に時間帯ごとに偏りなく当選者が出るように設定されていると考えられますね.Q.なせ応募者は30分ごとに200人なのか?
A.1日を30分に分割して10000人で割ると,大体208人になる.30分ごとのファミマ当選確率
したがって,当選確率は応募者の少ない時間帯が高くなります.なので一枚目の画像になるわけですね.
ファミチキをほしけりゃ3時から4時・19時以降に応募しろってことですね.
当たる"アカウント"を分析
7/26~7/29の抽選結果を当選者・落選者からそれぞれ1000アカウント分ランダムサンプリングして分析を進めました.アカウントのデータは分析日(8/28)に準じるので,キャンペーン期間中とはややズレがあるかもしれません.
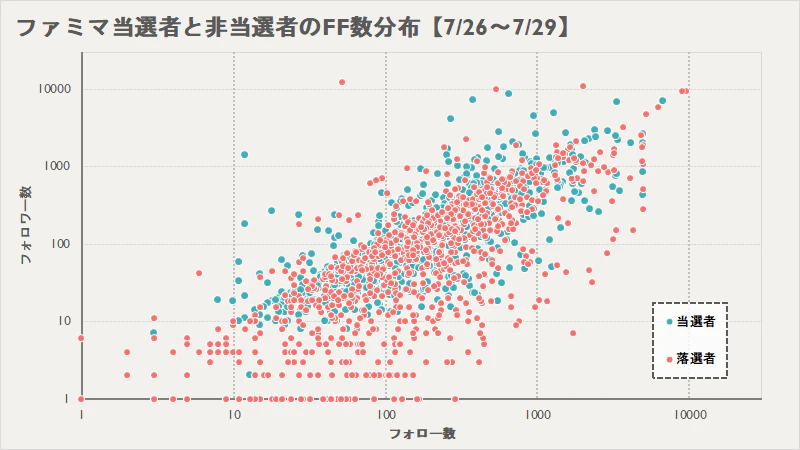
当選者と非当選者のFF数分布
対数グラフで表してるので,実際には0でも1の軸にデータが表示されてしまっている部分もあります.当選者・落選者が重なっているゾーンは抽選に参加できているということですね.注目すべきなのは,当選者と落選者が別れてしまっているゾーンです.
やはり,FF数の偏っているアカウント,特にフォロワー数が0のアカウントはフォロー数によらずすべて落選しており,明らかに異常だと考えられます.したがって,当てたければフォロワー数1以上のアカウントで応募すべきですね.
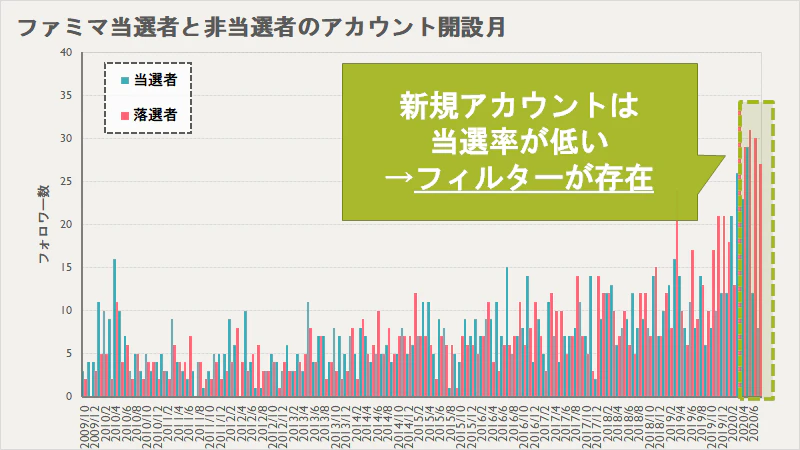
アカウント開設時期
少し見づらいのですが,キャンペーン時期(2020/7)の直近(2020/5~2020/6)に開設されたアカウントに関しては,当選者と落選者に乖離があります.直近に開設されたアカウントはフォロー数も少ないと考えられるので,「フォロワー数が0のアカウントはフォロー数によらずすべて落選」と繋がります.また,抽選応募用の捨てアカウント等を防ぐためのフィルターがあるのではと考えられますね.(強引な推測ですけど...)当たるコツまとめ
- 3時から4時・19時以降に応募
- フォロワー数1以上のアカウントで応募
- 捨てアカウントでは応募しない



- 投稿日:2020-09-06T22:29:42+09:00
ディープラーニングを学び始めた方へ 東京大学/松尾豊 教授の動画
1.はじめに
ディープラーニングを学び始めた方にとって、東京大学/松尾教授の動画を見ることは、とても刺激的で勉強になり面白いものだと思います。今回、松尾教授の講演に加えて対談やパネルディスカッションも含めた動画のリンクをまとめましたので、よろしかったら見て下さい。
特におすすめは、01, 05, 18, 23, 27 です。2.動画リンク
講演には★の表示がしてあります。
□2012年
★01.Computer will be more clever than human beings
東京大学版TEDです(もちろん日本語です)。ウェブを利用した情報の利用と人工知能の可能性についてコンパクトにまとめています。ディープラーニングには触れていませんが、若々しい松尾教授の姿が見れて、内容も興味深いです。<おすすめです。>(15分)□2013年
02.IT融合シンポジウム ~企業・研究者による先端事例紹介~
ウェブにおけるビッグデータ活用と人工知能についての講演です。(20分)★03.平成25年度市民講座 第8回 :「ソーシャルメディアからの社会予測」
国立情報研究所での講演(63分)□2014年
04.人工知能が閻魔大王になる日【PART1】【PART2】
ニュース専門ネット局 ビデオニュース・ドットコムでの対談。素人の質問に、実に分かりやすくコメントする松尾教授が印象的。本当に頭の良い人は、難しいことを簡単に話せる人なんだと思います。(126分)□2015年
★05.『人工知能は人間を超えるか ディープラーニングの先にあるもの』
東京大学で行った超有名な講演です。<おすすめです。>(102分)06.人工知能の最前線~人口減・職の減少・ビジネスに与えるインパクト
グロービスG1サミットでのパネルディスカッション。東京大学・松尾豊氏×IBM・中林紀彦氏×はこだて未来大学・中島秀之氏×スマートニュース・鈴木健氏(76分)07.人工知能を使ったビジネス・軍事技術
グロービスでのパネルディスカッション。茂木健一郎×松尾豊×佐藤航陽(45分)★08.人工知能の未来~ディープラーニングの先にあるもの 【Part1/2】【Part2/2】
東京大学での講演のグロービス版(76分)09.人工知能は日本企業の好機となるか~ディープラーニングが変える社会~
グロービスパネルディスカッション。UBIC CTO・武田 秀樹氏×東京大学・松尾 豊氏×楽天・森 正弥氏×経営共創基盤パートナー・木村 尚敬氏(74分)10.意識と人工知能のギャップから 見えてきた未来
茂木健一郎×松尾豊の対談(10分)★11.2015 日本未来学会 セッション1
東京大学での講演の短縮版□2016年
12.AIF2015 【静かなる変革 - テクノロジー進化と未来】
Asia Innovation Forum パネルディスカッション。東京大学・松尾豊×ヤフー・安宅和人×オムロン・立石文雄×東京大学・郷治友孝×カーネギーメロン大学・川上和也×経営共創基盤・富山和彦(90分)13.人工知能が変える3年後の未来
グロービスG1サミット パネルディスカッション。ソニー・北野宏明×東京大学・松尾豊×UBIC・守本正宏×ワークアプロケーションズ・牧野正幸(58分)★14.【SoftBank World 2016】 人工知能は人間を超えるか
東京大学での講演のソフトバンク版(41分)★15.第9回 人工知能の未解決問題とディープラーニング
東京大学のOpen Course Ware。「ビッグデータ時代の人工知能学と情報社会のあり方」の第9回講義。(92分)★16.第10回 記号とパターンのはざまに
東京大学のOpen Course Ware。「ビッグデータ時代の人工知能学と情報社会のあり方」の第10回講義。(108分)□2018年
17.日本企業が世界で勝つための「AI戦略」とは?
グロービスG1サミット パネルディスカッション。PFN・西川氏×東京大学・松尾豊×村田機械・村田氏×DNA・守安氏×経営共創基盤・木村氏(60分)
松尾教授曰く「希望的観測と客観的観測は分けた方がいい。Googleとfacebookが抱えるエンジニアの数, コンピューティングパワー, 今までの知見をどうやって逆転するのかを具体的に教えて欲しい」と西川氏へ切り込みが鋭い。★18.日本文明研究所シンポジウム第12回<特別講演>
東京大学での講演のアップデート版です。<おすすめです。>(120分)★19.先端研究者が語る人工知能の現状 -札幌市立大学公開講座-
リレー形式講演。札幌市立大学・中島秀之, 東京大学・松尾豊, 公立はこだて未来大学・松原仁。0:19〜0:45(26分)□2019年
20.「AIの社会実装」最新事例と今後の課題
グロービスのパネルディスカッション。ジンズ・田中氏×東京大学・松尾氏×ブレインパッド・草野氏。
松尾教授曰く「AIの必勝法が分かって来た。1つは競合がやる気を失うほどモデルを数多く作ること。もう1つは現場で起こっていた不具合を解消し新たなフローを生み出すこと。」は興味深い。(50分)21.「ディープラーニングの現在地 AI研究の第一人者に聞く【前編】 【後編】
TBSニュースのDOOでのインタビュー(37分)22.AIとビッグデータを活用した「デジタル戦略」「サステイナビリティ」
グロービスパネルディスカッション。川邊健太郎×住隆幸×松尾豊×島田太郎。(60分)★23.「意味理解と想像」ー深層学習の先にあるもの – 記号推論との融合を目指して
東京大学での講演。<おすすめです。>(25分)□2020年
24.【CafeSta】「山田太郎のおけまるチャンネル」
自民党/山田太郎 参議院議員との対談。(52分)25.社会はAIでいかに読み解けるのか? 柳川範之×松尾豊
テンミニッツTV - 1話10分で学ぶ大人の教養講座。(10分)26.人工知能が日本の産業力を強くする~イノベーションは辺境から起きる!
グロービスG1サミットパネルディスカッション。PFN・西川氏×東京大学・松尾氏×経営共創基盤・木村氏。(61分)★27.JDLA合格者の会 2020 松尾豊特別講演
00:16〜1:06が特別講演。<おすすめです。>(45分)
- 投稿日:2020-09-06T22:29:42+09:00
ディープラーニングを学び始めた方へ 東京大学/松尾豊教授の動画
1.はじめに
ディープラーニングを学び始めた方にとって、東京大学/松尾教授の動画を見ることは、とても刺激的で勉強になり面白いものだと思います。今回、松尾教授の講演に加えて対談やパネルディスカッションも含めた動画のリンクをまとめましたので、よろしかったら見て下さい。
特におすすめは、01, 05, 08, 14, 18, 23, 27 です。2.動画リンク
講演には★の表示がしてあります。
□2012年
★01.Computer will be more clever than human beings
東京大学版TEDです(もちろん日本語です)。ウェブを利用した情報の利用と人工知能の可能性についてコンパクトにまとめています。ディープラーニングには触れていませんが、若々しい松尾教授の姿が見れて、内容も興味深いです。<おすすめです。>(15分)□2013年
02.IT融合シンポジウム ~企業・研究者による先端事例紹介~
ウェブにおけるビッグデータ活用と人工知能についての講演です。(20分)★03.平成25年度市民講座 第8回 :「ソーシャルメディアからの社会予測」
国立情報研究所での講演(63分)□2014年
04.人工知能が閻魔大王になる日【PART1】【PART2】
ニュース専門ネット局 ビデオニュース・ドットコムでの対談。素人の質問に、実に分かりやすくコメントする松尾教授が印象的。本当に頭の良い人は、難しいことを簡単に話せる人なんだと思います。(126分)□2015年
★05.『人工知能は人間を超えるか ディープラーニングの先にあるもの』
東京大学で行った伝説的な講演です。<おすすめです。>(102分)06.人工知能の最前線~人口減・職の減少・ビジネスに与えるインパクト
グロービスG1サミットでのパネルディスカッション。東京大学・松尾豊氏×IBM・中林紀彦氏×はこだて未来大学・中島秀之氏×スマートニュース・鈴木健氏(76分)07.人工知能を使ったビジネス・軍事技術
グロービスでのパネルディスカッション。茂木健一郎×松尾豊×佐藤航陽(45分)★08.人工知能の未来~ディープラーニングの先にあるもの 【Part1/2】【Part2/2】
東京大学での講演のアップデート版です(76分)<おすすめです。>09.人工知能は日本企業の好機となるか~ディープラーニングが変える社会~
グロービスパネルディスカッション。UBIC CTO・武田 秀樹氏×東京大学・松尾 豊氏×楽天・森 正弥氏×経営共創基盤パートナー・木村 尚敬氏(74分)10.意識と人工知能のギャップから 見えてきた未来
茂木健一郎×松尾豊の対談(10分)★11.2015 日本未来学会 セッション1
東京大学での講演の短縮版□2016年
12.AIF2015 【静かなる変革 - テクノロジー進化と未来】
Asia Innovation Forum パネルディスカッション。東京大学・松尾豊×ヤフー・安宅和人×オムロン・立石文雄×東京大学・郷治友孝×カーネギーメロン大学・川上和也×経営共創基盤・富山和彦(90分)13.人工知能が変える3年後の未来
グロービスG1サミット パネルディスカッション。ソニー・北野宏明×東京大学・松尾豊×UBIC・守本正宏×ワークアプロケーションズ・牧野正幸(58分)★14.【SoftBank World 2016】 人工知能は人間を超えるか
東京大学での講演のアップデート版。<おすすめです>。(41分)★15.第9回 人工知能の未解決問題とディープラーニング
東京大学のOpen Course Ware。「ビッグデータ時代の人工知能学と情報社会のあり方」の第9回講義。(92分)★16.第10回 記号とパターンのはざまに
東京大学のOpen Course Ware。「ビッグデータ時代の人工知能学と情報社会のあり方」の第10回講義。(108分)□2018年
17.日本企業が世界で勝つための「AI戦略」とは?
グロービスG1サミット パネルディスカッション。PFN・西川氏×東京大学・松尾豊×村田機械・村田氏×DNA・守安氏×経営共創基盤・木村氏(60分)
松尾教授曰く「希望的観測と客観的観測は分けた方がいい。Googleとfacebookが抱えるエンジニアの数, コンピューティングパワー, 今までの知見をどうやって逆転するのかを具体的に教えて欲しい」と西川氏へ切り込みが鋭い。★18.日本文明研究所シンポジウム第12回<特別講演>
05.東京大学での講演のアップデート版です。<おすすめです。>(120分)★19.先端研究者が語る人工知能の現状 -札幌市立大学公開講座-
リレー形式講演。札幌市立大学・中島秀之, 東京大学・松尾豊, 公立はこだて未来大学・松原仁。0:19〜0:45(26分)□2019年
20.「AIの社会実装」最新事例と今後の課題
グロービスのパネルディスカッション。ジンズ・田中氏×東京大学・松尾氏×ブレインパッド・草野氏。
松尾教授曰く「AIの必勝法が分かって来た。1つは競合がやる気を失うほどモデルを数多く作ること。もう1つは現場で起こっていた不具合を解消し新たなフローを生み出すこと。」は興味深い。(50分)21.「ディープラーニングの現在地 AI研究の第一人者に聞く【前編】 【後編】
TBSニュースのDOOでのインタビュー(37分)22.AIとビッグデータを活用した「デジタル戦略」「サステイナビリティ」
グロービスパネルディスカッション。川邊健太郎×住隆幸×松尾豊×島田太郎。(60分)★23.「意味理解と想像」ー深層学習の先にあるもの – 記号推論との融合を目指して
東京大学での新バージョン講演です。<おすすめです。>(25分)□2020年
24.【CafeSta】「山田太郎のおけまるチャンネル」
自民党/山田太郎 参議院議員との対談。(52分)25.社会はAIでいかに読み解けるのか? 柳川範之×松尾豊
テンミニッツTV - 1話10分で学ぶ大人の教養講座。(10分)26.人工知能が日本の産業力を強くする~イノベーションは辺境から起きる!
グロービスG1サミットパネルディスカッション。PFN・西川氏×東京大学・松尾氏×経営共創基盤・木村氏。(61分)★27.JDLA合格者の会 2020 松尾豊特別講演
00:16〜1:06が特別講演、最新版です。<おすすめです。>(45分)
- 投稿日:2020-09-06T22:28:24+09:00
ArcFaceによる画像分類の超(簡潔な)まとめ
はじめに
本記事ではArcFaceを用いた画像分類の大枠について簡潔にまとめます。
理論的な背景やコードなどは適宜参考サイトを示しますので、ぜひご確認ください。超まとめ
- 画像の分類では距離学習(metric learning)という学習手法がよくつかわれる。
- 距離学習は空間に埋め込んだデータについて、同じクラス同士はまとまって、違うクラス同士は離れて配置されるように学習すること。
- 単純な分類器では、新しいクラスが追加された際にモデルの再学習が必要だが、距離学習では既存のモデルをそのまま使える。
- 新しいクラスは、既存のクラスと遠くに配置される(ことが理想的)ので、新しいクラスは新しいクラス同士で特異な場所に集まる。
- 空間的に集まったデータに対して、未知のデータをプロットして最も近くにあるクラスを予測値として返すのが基本的な考え(後述)。
- ArcFaceはSOTAな距離学習アルゴリズムのひとつ。
- 空間の点同士の距離を離すには各点の原点からの距離を伸ばすか、角度を大きくすればよい。
- ArcFaceは角度に注目したアプローチ。
- 特徴としては、点同士の距離が超平面の距離と同じになるので幾何的解釈が容易らしい。
- その他には伝統的なcentre loss、contrastive loss、triplet lossや、最近登場したSphereFace、CosFaceなどがある
- 詳しくは:モダンな深層距離学習 (deep metric learning) 手法: SphereFace, CosFace, ArcFace
- 角度を用いた深層距離学習(deep metric learning)を徹底解説 -PytorchによるAdaCos実践あり-
- ArcFaceは分類器の後半にレイヤーとして追加することで動作する
- predictではArcFaceを取り除いた学習モデルを使用
- 出力は各データに対して1つのベクトル(一次元配列)
- testデータの出力ベクトルと、(あらかじめ計算してある)trainデータの出力ベクトルの距離を計算し、最も距離が近いtrainデータのラベルをpredict結果とする
- 投稿日:2020-09-06T22:26:56+09:00
区間DP(だるま落とし)の説明記事を個人的に咀嚼してみた
区間DPの解説記事で(参考)、個人的に理解できない箇所があったので、個人的に咀嚼して説明してみる。
(理解に誤りがあるかもしれないが。。。)理解できなかった箇所は以下の2点
1.なぜ右側解放?
2.2ケースに分けているが、他のケースは無いのか?1.なぜ右側解放?
・ただ単にindexが0始まりだから
・0<=l,r<nの場合は以下の表現でも良さそう
※AOJでTLEするけど、それっぽいソースを最下部に張り付けておく。
- dp[l][r] := 区間[l , r]で取り除くことのできるブロックの数
・区間分割点(上記参考記事ではmid)をそのまま使って再帰表現をしたいから
両側が閉じた表現にした場合(つまり区間[l , r])、以下の分け方になる。
- [l,mid] , [mid+1 , r]に区間を分ける
2.2ケースに分けているが、他のケースは無いのか?
参考記事では以下の様にケース分けをしていた。
- 1. lのブロックとr - 1のブロックが対になれる
- 2. [l,mid) , [mid , r)に区間を分ける
1.のケースは、両端に挟まれている箇所がすべて消えて、さらに残った両端が消えるケース。ぷよぷよの連鎖みたいに。
2.のケースは、2分割してそれぞれのパート毎に最大の除去数を求めるケース自分の疑問は、他にケースは無いのか?ということ。2ケースでMECEとなる理由が分からなかった。
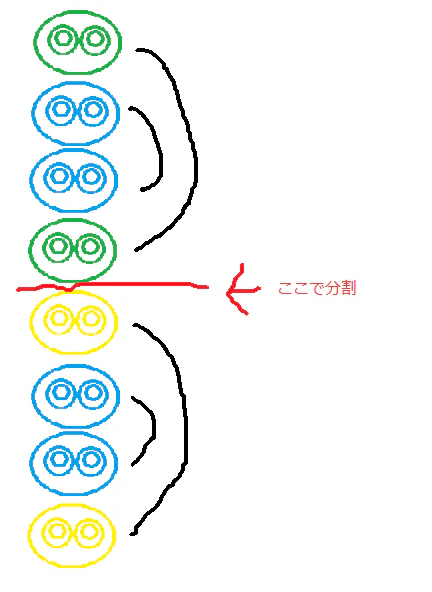
たとえば、両端に挟まれている箇所が2個を残し消えて、さらに残った2個が両端とともに消えるケースはどうなのか?(ケースA)
両端に挟まれている箇所が1個を残し消えて、さらに残った1個が両端のいずれかとともに消えるケースはどうなのか?(ケースB)図に書いてみると、2のケースに含まれることがわかった。
(2ケースに収まるという証明ができたわけではない)
ケースA
ケースB  import sys sys.setrecursionlimit(250000) input = sys.stdin.readline dp = [] w =[] def rec(l,r): #既に探索済の場合はその値を返す if dp[l][r] >= 0: return dp[l][r] #単一ケースは落とせないので0 if l == r: dp[l][r] = 0 return 0 #連続している箇所の場合 if l + 1 == r: if abs(w[l] - w[r]) <= 1: dp[l][r] = 2 return 2 else: dp[l][r] = 0 return 0 res = 0 #Case1 両端に挟まれている箇所がすべて消えて、さらに残った両端が消える if abs(w[l] - w[r]) <= 1 and rec(l+1, r-1) == (r - 1) - (l + 1) + 1: res = (r - 1) - (l + 1) + 1 + 2 else: #Case2 両端に挟まれている箇所が消えない for mid in range(l,r): res = max(res, rec(l,mid)+rec(mid+1,r)) dp[l][r]=res return res def main(): global w global dp n_list=[] w_list=[] while True: n = int(input()) if n == 0 : break w_tmp = list(map(int, input().split())) n_list.append(n) w_list.append(w_tmp) for i in range(len(n_list)): dp = [[-1] * n_list[i] for j in range(n_list[i])] w = w_list[i] print(rec(0,n_list[i]-1)) main()
import sys sys.setrecursionlimit(250000) input = sys.stdin.readline dp = [] w =[] def rec(l,r): #既に探索済の場合はその値を返す if dp[l][r] >= 0: return dp[l][r] #単一ケースは落とせないので0 if l == r: dp[l][r] = 0 return 0 #連続している箇所の場合 if l + 1 == r: if abs(w[l] - w[r]) <= 1: dp[l][r] = 2 return 2 else: dp[l][r] = 0 return 0 res = 0 #Case1 両端に挟まれている箇所がすべて消えて、さらに残った両端が消える if abs(w[l] - w[r]) <= 1 and rec(l+1, r-1) == (r - 1) - (l + 1) + 1: res = (r - 1) - (l + 1) + 1 + 2 else: #Case2 両端に挟まれている箇所が消えない for mid in range(l,r): res = max(res, rec(l,mid)+rec(mid+1,r)) dp[l][r]=res return res def main(): global w global dp n_list=[] w_list=[] while True: n = int(input()) if n == 0 : break w_tmp = list(map(int, input().split())) n_list.append(n) w_list.append(w_tmp) for i in range(len(n_list)): dp = [[-1] * n_list[i] for j in range(n_list[i])] w = w_list[i] print(rec(0,n_list[i]-1)) main()
- 投稿日:2020-09-06T22:16:13+09:00
PythonのMatplotlibで二次関数のグラフを描写する
概要
PythonのライブラリMatplotlibの練習です。
何番煎じかわからないくらいありふれてますがご容赦ください。Matplotlibのインストール
pipでインストールします。
pip install matplotlib描写
import matplotlib.pyplot as plt import numpy as np # -20 < x < 20 x = np.arange(-20, 20, 0.1) # a, b, cにそれぞれ値を代入 a = int(input("a : ")) b = int(input("b : ")) c = int(input("c : ")) # y = ax^2 + bx + c y = a*x**2 + b*x + c # x軸, y軸のラベル表示 plt.xlabel("x") plt.ylabel("y", rotation=0) # グラフへのプロット実行 plt.plot(x, y) plt.show()実行結果
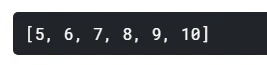
a=1, b=2, c=2 | y=x^2+2x+2
a=4, b=5, c=2 | y=4x^2+5x+2
しっかり描写することができました。


- 投稿日:2020-09-06T21:34:12+09:00
モンテカルロ法入門
導入
昨今では、ベイズ的アプローチもはやっておらず、いかにして学習データを集めてDeep Learning にぶっこむかが流行っていますが、たまにはこういう古典的な計算をするのもありでしょう。
MCMC についても説明するつもりでしたが、単純なシミュレーションについて説明するのもそこそこしんどかったので、いったん単純なシミュレーションについて説明します。
MCMC についても、近いうちに書きたいなと個人的には思っています。本記事では、大体 PRML の 11 章を参考にしています。
モンテカルロ法
機械学習に携わっていると、モンテカルロシミュレーション、もしくは、モンテカルロ法という単語をよく耳にすると思います。「あー、MCMCでしょ」とこの記事を書く前の僕は漠然と思っていたのですが、具体的に説明しようとすると答えに詰まってしまいました。こういうときは、Wikipedia さんに聞けば大体なことがわかりますので、とりあえず Wikipedia の記事見てみたいと思います。
モンテカルロ法(モンテカルロほう、(英: Monte Carlo method、MC)とはシミュレーションや数値計算を乱数を用いて行う手法の総称。 カジノで有名な国家モナコ公国の4つの地区(カルティ)の1つであるモンテカルロから名付けられた。モンテカルロはただの地名でした。カジノという言葉を聞くと、カジノで勝とうとしている人たちがシミュレーションを行おうとして生み出したのかなと
計算理論の分野において、モンテカルロ法とは誤答する確率の上界が与えられる乱択アルゴリズム(ランダム・アルゴリズム)と定義される[1]。つまり、乱数を用いれば大抵のことはモンテカルロシミュレーションやモンテカルロ法と名乗ることができるわけです。実際、「ミラー-ラビン素数判定法」という確率的に素数かどうかを判断するアルゴリズムもモンテカルロ法であると、記事には書いてあります。ですが、今回は機械学習に主眼を置いており、素数判定法なんぞにうつつを抜かしている暇はありません。
そのため、考える対象を以下に限定したいと思います。
ある確率分布 P を決めたときに、P の分布に従っている乱数 X を生成するアルゴリズムを考える上の問題設定に出てくる乱数 $X$ を生成することができれば、様々なシミュレーションや数値計算に応用することができます。
目次
- 変数変換法
- 指数分布
- 正規分布
- コーシー分布
- 棄却サンプリング法
- ガンマ分布
全体を通して、$[0, 1]$ の一様分布の乱数 $U$ を生成することは可能であるとします。この $U$ から有名な確率分布に従う乱数を
変数変換法
生成したい確率分布を $P$ とします。
一様分布の乱数 $U$ に対して、「$Y = F_{P}(U)$ が $P$ の分布に従う」ような関数 $F_{P}$ を探す手法のことを変数変換法と言います。
「$Y = F_{P}(U)$ が $P$ の分布に従う」と書きましたが、これは以下の数式と同じ意味です。$$ du = p(y) dy $$
$u, y$ が同時に出てきているため、わかったようなわからないような気分にさせてくれます。ですが、$Y = F_{P}(U)$ という関係があるので、$F_{p}$ の逆関数 $F_{p}^{-1}$ を用いると、$U = F_{p}^{-1}(Y)$ と書けます。この式を用いると、$p(y) = du / dy = d(F_{p}^{-1}(y)) / dy$ と書けることがわかります。
実際、この式変形はかなりトリッキーだと思います。少なくとも初見では理解しづらいです。なぜ、逆関数が現れるのか不思議だと思いますが、以下の例を見ながら少しずつ慣れていきましょう。例: 指数分布
指数分布の確率密度関数 $p$ は以下の式で表されます。
$$p(x)=\frac{1}{\lambda} e^{-x/\lambda}$$
$G(x) = \int_{0}^{x} p(x)dx$ とおきます。積分した関数を微分すると元の関数に戻るので、$dG/dx = p(x)$ が成り立ちます。$p(y) = d(F_{p}^{-1}(y)) / dy$ を満たす関数を見つけたかったので、なんとなく $G$ の逆関数が $F$ である気がします (実際そうです)。
$G$ を具体的に計算すると、
$$ u = G(x) = \bigg[-\exp \bigg(-\frac{x}{\lambda}\bigg) \bigg]^{x} = 1 - \exp \bigg(-\frac{x}{\lambda}\bigg) $$
となるので、逆関数 $F$ は、
$$ F(u) = - \lambda \log(1 - u) $$
となります。
この関数 $F$ を用いて、乱数を生成する Python スクリプトを実際に書いてみました。import numpy as np import matplotlib.pyplot as plt Lambda = 0.1 N = 100000 u = np.random.rand(N) y = - Lambda * np.log(1 - u) plt.hist(y, bins=200) plt.show()
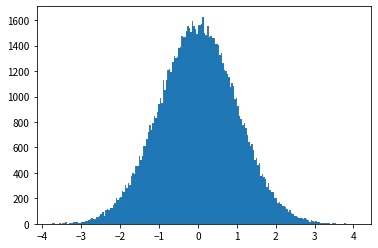
ヒストグラムの結果を見る限り、指数分布の確率密度関数と似た形になっており、指数分布に従う乱数が生成できていることがわかります。
例: 正規分布
次に、標準正規分布の乱数を作成する有名なアルゴリズムである「Box-Muller アルゴリズム」を紹介します。
半径 1 の円板上の一様分布 $(z_1, z_2)$ から天下り的に式を与えたのは、この式を導出することを諦めてしまったからです。。
この関数 $F$ を用いて、乱数を生成する Python スクリプトを実際に書いてみました。
import numpy as np import matplotlib.pyplot as plt N = 100000 z = np.random.rand(N * 2, 2) * 2 - 1 z = z[z[:, 0] ** 2 + z[:, 1] ** 2 < 1] z = z[:N] r = z[:, 0] ** 2 + z[:, 1] ** 2 y = z[:, 0] / (r ** 0.5) * ((-2 * np.log(r)) ** 0.5) plt.hist(y, bins=200) plt.show()
コーシー分布
最後に、コーシー分布に従う乱数を生成してみます。
コーシー分布は指数分布や正規分布と比較すると、統計学的にもほとんど利用されません。ですが、次節のガンマ分布の項でコーシー分布に従う乱数を利用するため、ここで紹介します。
コーシー分布の確率密度関数は以下の式で表されます。p(x; c) = \frac{1}{1 + (x - c)^2}コーシー分布の累積分布関数 $G$ は $\arctan$ という $\tan$ 関数の逆関数を用いれば、以下のように簡単に書くことができます。
u = G(x) = \int_{-\infty}^{x} p(x; c) = \frac{1}{\pi} \arctan (x - c) + \frac{1}{2}よって、$G$ の逆関数 $F$ は以下のように書けます。
F(u) = \tan \bigg(\pi \bigg(u - \frac{1}{2} \bigg)\bigg) + cつまり、$$ F(u) = \tan \bigg(\pi \bigg(u - \frac{1}{2} \bigg)\bigg) + c$$
を $[0, 1]$ の一様乱数を $U$ とすると、$F(U)$ がコーシー分布に従う乱数であることがわかります。この関数 $F$ を用いて、実際に乱数を生成した結果を見てみましょう。
cauchy_F = lambda x: np.tan(x * (np.pi / 2 + np.arctan(c)) - np.arctan(c)) + c N = 100000 u = np.random.rand(N) y = cauchy_F(u) y = y[y < 10] plt.hist(y[y < 10], bins=200) plt.show()
ヒストグラムの結果を見る限り、指数分布の確率密度関数と似た形になっており、指数分布に従う乱数が生成できていることがわかります。
ですが、スクリプトをよく見てみると、y = y[y < 10]という気になる一行が入っています。
この一行を外して実行すると、とんでもないことになります。つまり、とんでもなく大きい外れ値が生成される可能性があることを示しています。この結果は、コーシー分布の平均値が発散するという事実を思い出してみると、なんとなく納得できるかと思います。
乱数値を 10 以下で制限すると平均値は 2 前後かと思うのですが、きわめて大きい値がまれに発生してしまうために、平均値を上側にずり上げてしまっています。収入の平均値と中央値が乖離している話を思い出しますね。
変数変換法のポイント
分布の特性をよく知っている必要があります。
大体の場合は累積分布関数が簡単な形に書ける必要があります。
それ以外の方法で求めるのは相当骨が折れるかと思います。
また、F が簡単に計算できる関数でなければ、結局意味がありません。棄却サンプリング法
例: ガンマ分布
ガンマ分布の確率密度関数は以下の式で表されます。
p(x; a, b) = b^{a} z^{a-1} \exp(-bz) / \Gamma(a)$ \Gamma $ 関数の値を求めるのは大変なので、$\Gamma $ の部分を無視した $\tilde{p}$ を利用します。
\tilde{p}(x; a) = z^{a-1} \exp(-z)ここで、コーシー分布を超える k を求めましょう。手計算で求めるのが面倒だったので、今回はスクリプトに頼りました。
gamma_p_tilda = lambda x: (x ** (a - 1)) * np.exp(-x) cauchy_p = lambda x: 1 / (1 + ((x - c) ** 2)) / (np.pi / 2 + np.arctan(c)) z = np.arange(0, 100, 0.01) gammas = gamma_p_tilda(z) cauchys = cauchy_p(z) k = np.max(gammas / cauchys) cauchys *= k plt.plot(z, gammas, label='gamma') plt.plot(z, cauchys, label='cauchy') plt.legend() plt.show()
上述のスクリプトに格納されている $k$ の値は $2.732761944808582$ でした。
N = 100000 u = np.random.rand(N * 3) y = cauchy_F(u) u0 = np.random.rand(N * 3) u0 *= k * cauchy_p(y) y = y[u0 < gamma_p_tilda(y)] y = y[:N] plt.hist(y, bins=200) plt.show()
棄却サンプリングの適用条件
乱数を簡単に生成することができる提案分布 $Q$ を用意する必要があります。
また、$kq \geq p$ を満たす $k$ を算出しなければいけません。$k$ の値を不用意に大きくしすぎると、せっかく生成した乱数を棄却しなければいけないため、できるかぎり $k$ をぎりぎりの小さい値に取りたいわけです。
しかし、そうなると関数の具体的な形から導出するか、精密に値を計算する必要があり、そこそこの苦労を伴います。
また、$k$ の値を決める場合や棄却するかを計算するときに、$P$, $Q$ ともに確率密度関数の値を使うため、確率密度関数自体が簡単に計算できる必要があります。そのため、複数の変数が複雑に絡み合ったモデル等、確率密度関数の計算自体が難しい場合には、この手法を適用することはできません。MCMC に向けて
ここまで、標準的な乱数生成手法を概観してきました。
一通り見てきたところ、大元の確率分布がある程度扱いやすい形をしている必要があることが見て取れるかと思います。正規分布や指数分布、ガンマ分布等、統計学的に重要な乱数が一様分布から一通り生成できることはわかりました。これだけでも十分いろいろなことができるかと思いますが、世の中にはベイズ的アプローチを用いたより複雑なモデルがうじゃうじゃ存在しています。
今回の生成手法だけでは、複雑なベイズ的モデルに対抗するだけの武器を持ち合わせてはいません。そこで、MCMC と呼ばれる、より複雑なモデルに対して、乱数を生成することができるアルゴリズムが出てきます。
次回は、MCMC を適用する主領域であるグラフィカルモデルと MCMC の具体的な手法について説明したいと思います。





- 投稿日:2020-09-06T20:36:27+09:00
優勝コードから学ぶ―メルカリコンペ編①―
はじめに
Kaggleの勉強をするにあたり、過去のコンペで1位をとった人のコードから勉強しようということで、今回はメルカリコンペの1位の方のコードを題材に勉強しました。
学んだこと
・コンテキストマネージャを使った時間計測
・Pipeline化とFunctionTransformer
・TF-IDF, itemgetter, TfidfVectorizer
・4層MLP(Multilayer perceptron)でも精度がでる
・partialを使用してy_trainは固定してx_trainだけ変えるメルカリコンペ概要
内容
出品時の妥当な値段を予測するモデルの作成
意義
出品時に商品情報から適切な値段を自動的に提示することで出品時の手間を削減する。出品が簡単になる。
背景
メルカリの相場から外れて、高い値段で出品した場合売れない
逆にメルカリの相場より低い値段で出品してしまった場合、お客さまが損をするコンペの制約
カーネルコンペ:ソースコード自体をKaggleに提出。提出するとKaggle上で実行されてスコアが算出される。
計算機資源と計算時間の制約があるCPU: 4 cores
Memory: 16GB
Disk: 1GB
制限時間: 1時間
GPU: なし評価
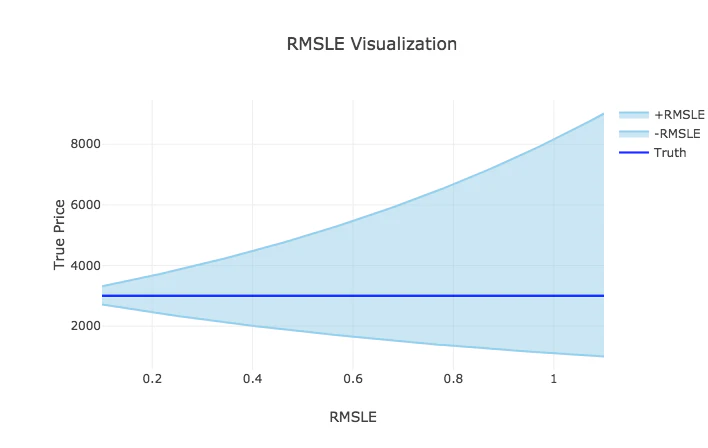
RMLSE:Root Mean Squared Logarithmic Error
スコアが低ければ低いほど、小さい誤差で値段を推定できたことになる
一位の方のモデルはRMLSE: 0.3875
使用データ
列名 説明 name 商品名 item_condition_id 中古、新品など、商品の状態。(1~5)、大きい方が状態が良い。 category_name 大まかなカテゴリ/詳細なカテゴリ/より詳細なカテゴリ brand_name ブランド名。例: Nike, Apple price 過去の販売価格(USD) shipping 送料を出品者か購入者のどちらが支払うか。1 -> 出品者が払う, 0 -> 購入者が払う。 item_description 商品の詳細 出力形式
Test_idとprice
1位のコードの要点
・100行という短さ。シンプル。
・4層MLP。精度でている。この時代はまだニューラルネットワークは使用されていなかった?
・TF-IDF。 df['name'].fillna('') + ' ' + df['brand_name'].fillna('')で文字列を結合したことで精度UP?
・y_trainの標準化
・4コアで4モデルを学習->アンサンブル教師データの準備
各処理にかかる時間の計測
1時間との制約があるため、どこの処理でどれだけの時間を使っているか計測する工夫が入れられている。
各処理の箇所にwith timerが入れられている。with timerの説明。
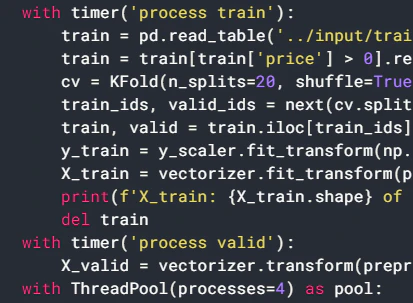
教師データの作成
qiita.rbwith timer('process train'): #ロード train = pd.read_table('../input/train.tsv') #0ドルのpriceが存在しているためはじいている train = train[train['price'] > 0].reset_index(drop=True) #データを学習用と検証用で分割するための準備 cv = KFold(n_splits=20, shuffle=True, random_state=42) #データを学習用と検証用で分割 #.split()でイテラブルなオブジェクトが帰ってくる。学習用の「インデックスと検証用のインデックスが取り出せる。 #next()でイテレータ内から要素を取得 train_ids, valid_ids = next(cv.split(train)) #取得したインデックスで学習と検証用に分割 train, valid = train.iloc[train_ids], train.iloc[valid_ids] #価格は1行n列をn行1列に変換。log(a+1)で変換。正規化 y_train = y_scaler.fit_transform(np.log1p(train['price'].values.reshape(-1, 1))) #パイプラインで処理 X_train = vectorizer.fit_transform(preprocess(train)).astype(np.float32) print(f'X_train: {X_train.shape} of {X_train.dtype}') del train #検証用データも同様に前処理 with timer('process valid'): X_valid = vectorizer.transform(preprocess(valid)).astype(np.float32)前処理
ブランド名には欠損値があるため、空白に置き換えている。そのうえで、商品名とブランド名を結合している。あとでTF-IDFしやすいようにする為。新しくtextという要素を作っている。'name', 'text', 'shipping', 'item_condition_id'はこの後のPipelineの処理で使用する。
qiita.rbdef preprocess(df: pd.DataFrame) -> pd.DataFrame: df['name'] = df['name'].fillna('') + ' ' + df['brand_name'].fillna('') df['text'] = (df['item_description'].fillna('') + ' ' + df['name'] + ' ' + df['category_name'].fillna('')) return df[['name', 'text', 'shipping', 'item_condition_id']]文字の抽出とTF-IDFの算出を一連の流れで行えるようにPipeline化している。
qiita.rbdef on_field(f: str, *vec) -> Pipeline: return make_pipeline(FunctionTransformer(itemgetter(f), validate=False), *vec) def to_records(df: pd.DataFrame) -> List[Dict]: return df.to_dict(orient='records') vectorizer = make_union( on_field('name', Tfidf(max_features=100000, token_pattern='\w+')), on_field('text', Tfidf(max_features=100000, token_pattern='\w+', ngram_range=(1, 2))), on_field(['shipping', 'item_condition_id'], FunctionTransformer(to_records, validate=False), DictVectorizer()), n_jobs=4) y_scaler = StandardScaler() X_train = vectorizer.fit_transform(preprocess(train)).astype(np.float32)文字種類分(200000)のスコア(Bag of Words)と'shipping', 'item_condition_id'のスコア合計200002が出力となる。
学習
4コア4スレッドで学習し、その後平均をとってアンサンブルを行っている。
学習の際はy_trainはpartialで固定してxsだけを変えている。qiita.rbdef fit_predict(xs, y_train) -> np.ndarray: X_train, X_test = xs config = tf.ConfigProto( intra_op_parallelism_threads=1, use_per_session_threads=1, inter_op_parallelism_threads=1) with tf.Session(graph=tf.Graph(), config=config) as sess, timer('fit_predict'): ks.backend.set_session(sess) model_in = ks.Input(shape=(X_train.shape[1],), dtype='float32', sparse=True)#MLPの設計 out = ks.layers.Dense(192, activation='relu')(model_in) out = ks.layers.Dense(64, activation='relu')(out) out = ks.layers.Dense(64, activation='relu')(out) out = ks.layers.Dense(1)(out) model = ks.Model(model_in, out) model.compile(loss='mean_squared_error', optimizer=ks.optimizers.Adam(lr=3e-3)) for i in range(3):#3エポック with timer(f'epoch {i + 1}'): model.fit(x=X_train, y=y_train, batch_size=2**(11 + i), epochs=1, verbose=0)#バッチサイズは指数関数的に増加させる return model.predict(X_test)[:, 0]#予想を返す with ThreadPool(processes=4) as pool: #4つのスレッドにする Xb_train, Xb_valid = [x.astype(np.bool).astype(np.float32) for x in [X_train, X_valid]] xs = [[Xb_train, Xb_valid], [X_train, X_valid]] * 2 y_pred = np.mean(pool.map(partial(fit_predict, y_train=y_train), xs), axis=0)#4コアで学習したものの平均をとっている y_pred = np.expm1(y_scaler.inverse_transform(y_pred.reshape(-1, 1))[:, 0])#logで変換していたものを価格に戻す print('Valid RMSLE: {:.4f}'.format(np.sqrt(mean_squared_log_error(valid['price'], y_pred))))参考




- 投稿日:2020-09-06T20:27:25+09:00
任意のディレクトリ配下のCSVファイルをすべてDataFrameに落とし込む
DataFrameに落とし込みたいCSVファイルが大量にある場合は
下記コマンドを使うことで『ファイル名_df』という変数名でDataFrameを定義できます。import os import pandas as pd for dirname, _, filenames in os.walk(ディレクトリ名): for filename in filenames: path = os.path.join(dirname, filename) # execコマンドを用いてファイル名を変数名として動的に定義していく exec("{0}_df = pd.read_csv(path)".format(filename.replace('.csv','')))
- 投稿日:2020-09-06T20:19:17+09:00
partialの使い方
きっかけ
メルカリコンペ1位のコードに出てきたpartialが良く分からなかったから。
まとめ
partial→一部の引数は可変、一部の引数は固定で処理を実行できる。
使用例
下記例の参考
bを5で固定して、aの引数を0~5で変化させて処理させる。qiita.rbfrom functools import partial def add_func(a, b): return a + b add_list = list(map(partial(add_func, b=5), [0,1,2,3,4,5])) print(add_list)
メルカリコンペ1位のコードでの例
y_trainの値は固定して、fit_predictに入るxsの値だけを変えている。qiita.rbdef fit_predict(xs, y_train) -> np.ndarray: X_train, X_test = xs config = tf.ConfigProto( intra_op_parallelism_threads=1, use_per_session_threads=1, inter_op_parallelism_threads=1) with tf.Session(graph=tf.Graph(), config=config) as sess, timer('fit_predict'): ks.backend.set_session(sess) model_in = ks.Input(shape=(X_train.shape[1],), dtype='float32', sparse=True) out = ks.layers.Dense(192, activation='relu')(model_in) out = ks.layers.Dense(64, activation='relu')(out) out = ks.layers.Dense(64, activation='relu')(out) out = ks.layers.Dense(1)(out) model = ks.Model(model_in, out) model.compile(loss='mean_squared_error', optimizer=ks.optimizers.Adam(lr=3e-3)) for i in range(3): with timer(f'epoch {i + 1}'): model.fit(x=X_train, y=y_train, batch_size=2**(11 + i), epochs=1, verbose=0) return model.predict(X_test)[:, 0] with ThreadPool(processes=4) as pool: #4つのスレッドにする Xb_train, Xb_valid = [x.astype(np.bool).astype(np.float32) for x in [X_train, X_valid]] xs = [[Xb_train, Xb_valid], [X_train, X_valid]] * 2 y_pred = np.mean(pool.map(partial(fit_predict, y_train=y_train), xs), axis=0)
- 投稿日:2020-09-06T20:05:10+09:00
pythonでフォルダ作成・ファイル移動,圧縮,削除の操作
フォルダ作成makedirs
exist_okでフォルダが存在している場合には作らない。
指定しなければエラー。import os dir_path = os.path.join('C:\\Users\\username\\Desktop','00') os.chdir(dir_path) os.makedirs('new_made', exist_ok=True) dir_path_sub_folder = os.path.join(dir_path,'new_made')一旦操作するファイルを作成
from sklearn.datasets import load_iris import pandas as pd iris = load_iris() irisDF = pd.DataFrame(iris.data) csv_name='iris.csv' irisDF.to_csv(csv_name,header=False,index=False)フォルダ内のファイル名を取得
import glob files = glob.glob(dir_path+"\\"+csv_name)ファイルの移動
import shutil move_csv_path = shutil.move(files[0], dir_path_sub_folder+"\\"+csv_name)zipに圧縮
import zipfile zip_name=dir_path_sub_folder+'\\iris.zip' with zipfile.ZipFile(zip_name, 'w', compression=zipfile.ZIP_DEFLATED) as new_zip: new_zip.write(move_csv_path, arcname=csv_name)ファイルの削除
os.remove(move_csv_path)圧縮ファイルの解凍
zip_file = zipfile.ZipFile(zip_name) zip_file.extractall()解凍先を指定
os.makedirs('extract_zip', exist_ok=True) zip_file.extractall('extract_zip')フォルダやファイルの削除
中身の入ったフォルダはremoveで削除できない
os.remove(dir_path_sub_folder)PermissionError: [WinError 5] アクセスが拒否されました。シェルユーティリティー(shutil)を使えば完全に削除できる
shutil.rmtree(dir_path_sub_folder)完全でなく、ゴミ箱に送って復元もできるようにする。
import send2trash send2trash.send2trash(dir_path_sub_folder)以上
- 投稿日:2020-09-06T19:22:36+09:00
スコープ厨のお前らならば余裕で実行できるね〜♪
- 投稿日:2020-09-06T19:18:29+09:00
Pythonで解く【初中級者が解くべき過去問精選 100 問】(024 - 027 深さ優先探索)
1. 目的
初中級者が解くべき過去問精選 100 問をPythonで解きます。
すべて解き終わるころに水色になっていることが目標です。本記事は「024 - 027 深さ優先探索」です。
2. 総括
下記の記事では簡単に書いてますが、もともと
BFSとDFSを理解するためにかなり時間がかかりました。
BFSとDFSの基本形をおさえるまでに、最初は解説を読んでもまったくわからず、理解するまでに1週間くらい(1日10時間以上悩むこともあった)かかっています。理解するために行ったこととしては、解説記事を読むのは当然ですが、
ACで通っているコードをデバックしてみて、一行ずつ、どのようにデータが動いているかを確認するということを理解できるまでやりました。
再帰については、実際にノートにすべての再帰計算を書き出したりもしました。すると、ある時を境に、頭の中で
BFSとDFSのデータ構造ができあがって、ノートに何も書かなくても、頭の中でBFS、DFS的にデータを動かせるようになっていました。
おそらくこの瞬間が訪れるのは個人差があるとは思いますが、一定量の思考(試行?)をしないと訪れないのでは、と思います。なお、デバックはVS codeのデバッカーを使っています。便利です。こんな感じ。
3. 本編
024 - 027 深さ優先探索
024. ALDS_11_B - 深さ優先探索
回答
N = int(input()) graph = [[] for _ in range(N+1)] for _ in range(N): i, num, *nodes = map(int, input().split()) graph[i] = nodes # 有向グラフ go_time = [0] * (N+1) back_time = [0] * (N+1) def dfs(node, t): # 行きの記録 t += 1 go_time[node] = t for next_node in graph[node]: if go_time[next_node] == 0: t = dfs(next_node, t) # 帰りの記録 t += 1 back_time[node] = t return t t = 0 for node in range(1, N+1): # すべての点からスタートを試す if go_time[node] == 0: t = dfs(node, t) print(node, go_time[node], back_time[node])まず、データの受け取りがめんどくさいです。
グラフ情報の受け取り方ですが、長さが可変の個所はi, num, *nodes = map(int, input().split())のように、一番最後の*nodesに*を付けることでnodesに残り部分を全部渡すことができます。参考-> Pythonでタプルやリストをアンパック(複数の変数に展開して代入)こちら提出してみるとわかりますが、1からスタートしてもたどり着けない箇所が存在する可能性があるので(これが問題文のどこで読み取れるかわからない・・・)、すべての点をスタートの候補として試す必要があります。
今回書いた再帰による
dfsも、deque(pythonの場合)によるdfsもまずは基本の型を覚える必要があり、基本の型の説明は僕にはなかなか難しいので省略します。
とりあえず、この基本形を覚える、で最初は進めていきます。
025. AOJ 1160 - 島はいくつある?
回答
from collections import deque def main(w, h, MAP, visited): count = 0 # すべての点からスタートを試す for start_y in range(h): for start_x in range(w): if MAP[start_y][start_x] == 0: # 海の場合は飛ばす continue if visited[start_y][start_x] != -1: # 探索済みは飛ばす continue q = deque() q.append((start_y, start_x)) visited[start_y][start_x] = 1 while q: y, x = q.pop() for dy in range(-1, 2): for dx in range(-1, 2): moved_y = y + dy moved_x = x + dx if moved_y < 0 or h-1 < moved_y or moved_x < 0 or w-1 < moved_x: # 地図外への移動は飛ばす continue if MAP[moved_y][moved_x] == 0: # 海の場合は飛ばす continue if visited[moved_y][moved_x] != -1: # 探索済みは飛ばす continue visited[moved_y][moved_x] = 1 q.append((moved_y, moved_x)) count += 1 # whileを抜けたら1つの島 return count if __name__ == "__main__": answer_list =[] while True: w, h = map(int, input().split()) MAP = [list(map(int, input().split())) for _ in range(h)] visited = [[-1] * w for _ in range(h)] if w == 0 and h == 0: break answer = main(w, h, MAP, visited) answer_list.append(answer) for answer in answer_list: print(answer)個人的には再帰よりもデック(デキュー?)による
dfsのほうが書きやすいです。
これもdfsの基本形(だと思う)なので、そのまま書くだけです。
026. AtCoder Beginner Contest 138 D - Ki
回答
from collections import deque # -------------- [入力] -------------- N, Q = map(int, input().split()) # Nは頂点の数、Qは操作の回数 graph = [[] for _ in range(N+1)] for _ in range(N-1): a, b = map(int, input().split()) graph[a].append(b) graph[b].append(a) counts = [0] * (N+1) for _ in range(Q): p, x = map(int, input().split()) counts[p] += x visited = [-1] * (N+1) # -------------- [1からスタート] -------------- q = deque() q.append(1) visited[1] = 1 # -------------- [DFS] -------------- while q: node = q.pop() next_nodes = graph[node] for next in next_nodes: if visited[next] != -1: continue q.append(next) visited[next] = 1 counts[next] += counts[node] # 親のスコアをプラスする print(*counts[1:])この問題は、AtCoder Beginner Contest 176 D - Wizard in Maze (僕の回答の記事はこちら→AtCoder ABC 176 Python (A~E)) に少し似ていると感じました。この問題のほうが簡単ですが・・・。
どこが似ているかと、この問題でいうところの
counts[next] += counts[node]この部分で、ABC 176でいうとvisited[moved_y][moved_x] = visited[y][x]ここ。どうして似ていると思ったかというと、
q.pop()で抽出してきた探索対象(①とする)から、探索対象①の次の探索対象(②とする)に移る際に、①の情報を使って②の情報をアップデートするという処理が似ているからです。通常(?)の
DFS、BFSでは、上記でいう②の情報のアップデートは、ほかのリストや単なるインクリメントであることが多いと思いますが、同じリストの情報でアップデートするという方法は、一回やっておかないとなかなか思いつくのが難しいかなと思いました。
この点さえわかれば、あとはBFSの基本形とあまりかわらないです。
027. JOI 2009 予選 4 - 薄氷渡り
回答
import sys sys.setrecursionlimit(10**9) # -------------- [初期値] -------------- def dfs(count, start_y, start_x, visited): ans = count for dy, dx in moves: moved_y = start_y + dy moved_x = start_x + dx if moved_y < 0 or n-1 < moved_y or moved_x < 0 or m-1 < moved_x: continue if grid[moved_y][moved_x] == 0: continue if visited[moved_y][moved_x] != -1: continue visited[start_y][start_x] = 1 ans = max(ans, dfs(count+1, moved_y, moved_x, visited)) # 始点から行ける最大値をとってくる visited[start_y][start_x] = -1 return ans if __name__ == "__main__": # -------------- [入力] -------------- m = int(input()) # 横 n = int(input()) # 縦 grid = [list(map(int, input().split())) for _ in range(n)] # 1: 氷、0: 氷無し moves = [(1, 0), (0, 1), (-1, 0), (0, -1)] # 上下左右のみ visited = [[-1] * m for _ in range(n)] # -------------- [すべての点をスタート地点として試す] -------------- answer = 0 for start_y in range(n): for start_x in range(m): if grid[start_y][start_x] == 0: continue answer = max(answer, dfs(1, start_y, start_x, visited)) print(answer)
sys.setrecursionlimit(10**9)はなくても通りますが、備忘として残します。
これも基本形とやっていることは大体同じで、異なるのはans = max(ans, dfs(count+1, moved_y, moved_x, visited)) # 始点から行ける最大値をとってくる visited[start_y][start_x] = -1ここだけです。
これで、各始点からいける最長距離を返します。







- 投稿日:2020-09-06T19:15:13+09:00
Python,AI関連の英語読解力を上げる(文章の意味を逆に感じると心が折れるので。。。注意 例:however,・・・)
目的
今生、英語が身につくかどうかは、非常に、微妙だが。。。
これ以上の英語力の低下は避けたい!!!⇒わずかな抵抗として、記事を書く。
(正しい答えは、多読!!! たぶん)ここでは、英語が逆の意味に読めて、読む気を失うことがよくあるので、
そうならない留意点をまとめる(まだ、1件ですが。。。)英文が逆の意味に感じられる例
「however」
出典1のpythonでのprivateについての記載において
引用
This is not strict privacy, however, as such names can still be accessed with other import statement forms.
Google翻訳(ママ)
ただし、これは厳密なプライバシーではありません。そのような名前は他のインポートステートメントフォームで引き続きアクセスできます。
誤った意味のとりかた、
howeverの前と後ろを分断して、それを、howeverでつなぐ「これは厳密なプライベートではない」(前半)
+
しかしながら(= however)
+
「このような名前は、別の方法でまだアクセスできる」(後半)⇒ これで、????が沢山。何が、しかしながら(however)なの????
ポイント(間違わないための留意点!!) howeverは、文頭でなくて、少し、下がった場所にくる場合あり。この場合のhoweverは、ここ以前の文章に対するもの!! 出典
出典1
Python Pocket Reference, 5th Edition
Python In Your Pocket
By Mark Lutz
Publisher: O'Reilly Mediaまとめ
とくにありません。
全然、英語、詳しくないので、正しい解釈等、コメント頂けると幸甚です。
- 投稿日:2020-09-06T19:15:13+09:00
Python,AI関連の英語読解力を上げる(意味を逆に感じると心が折れるので。。。注意 例:however,・・・)
目的
今生、英語が身につくかどうかは、非常に、微妙だが。。。
これ以上の英語力の低下は避けたい!!!⇒わずかな抵抗として、記事を書く。
(正しい答えは、多読!!! たぶん)ここでは、英語が逆の意味に読めて、読む気を失うことがよくあるので、
そうならない留意点をまとめる(まだ、1件ですが。。。)英文が逆の意味に感じられる例
ケース1、「however」
出典1のpythonでのprivateについての記載において
引用
This is not strict privacy, however, as such names can still be accessed with other import statement forms.
Google翻訳(ママ)
ただし、これは厳密なプライバシーではありません。そのような名前は他のインポートステートメントフォームで引き続きアクセスできます。
誤った意味のとりかた、
howeverの前と後ろを分断して、それを、howeverでつなぐ「これは厳密なプライベートではない」(前半)
+
しかしながら(= however)
+
「このような名前は、別の方法でまだアクセスできる」(後半)⇒ これで、????が沢山。何が、しかしながら(however)なの????
ポイント(間違わないための留意点!!) howeverは、文頭でなくて、少し、下がった場所にくる場合あり。この場合のhoweverは、ここ以前の文章に対するもの!! 出典
出典1
Python Pocket Reference, 5th Edition
Python In Your Pocket
By Mark Lutz
Publisher: O'Reilly Mediaまとめ
とくにありません。
全然、英語、詳しくないので、正しい解釈等、コメント頂けると幸甚です。
- 投稿日:2020-09-06T19:15:02+09:00
【Python】いい書き方と悪い書き方を知って中級者を目指す?
Pythonでコードを書くときのGood/Badプラクティス
こちらの記事は、DuomlyによりDev.to上で公開された『 Good and Bad Practices of Coding in Python 』の邦訳版です(原著者から許可を得た上での公開です)
元記事:Good and Bad Practices of Coding in Python
(以下、翻訳した本文)
この記事は元々 https://www.blog.duomly.com/good-and-bad-practices-of-coding-in-python/ に公開されたものです。
Pythonは可読性を重視した高水準のマルチパラダイムプログラミング言語です。Pythonは、「Pythonの禅」、別名ではPEP 20と呼ばれるルールに従って開発、保守され、幅広く使用されている言語です。
この記事では、頻繁に会う可能性が高いPythonでのコーディングの良い例と悪い例のいくつか示しています。
アンパック(unpacking)を使用して簡潔にコードを記述する
パック(packing)とアンパック(unpacking)は強力なPythonの特長です。アンパックを使用することで、複数の値を複数の変数に割り当てることが可能です。
良い例>>> a, b = 2, 'my-string' >>> a 2 >>> b 'my-string'この動作を利用して、コンピュータープログラミングの世界全体でおそらく最も簡潔でエレガントな変数スワップを実装することができます。
良い例>>> a, b = b, a >>> a 'my-string' >>> b 2アンパックは、より複雑な場合の複数の変数への割り当てに使うことができます。たとえば、次のように変数へ値を割り当てることはできます。
悪い例>>> x = (1, 2, 4, 8, 16) >>> a = x[0] >>> b = x[1] >>> c = x[2] >>> d = x[3] >>> e = x[4] >>> a, b, c, d, e (1, 2, 4, 8, 16)しかし、代わりに、より簡潔で間違いなく読みやすいアプローチを使うことができます。
良い例>>> a, b, c, d, e = x >>> a, b, c, d, e (1, 2, 4, 8, 16)イケてますよね?でも、これはさらにイケてます。
さらに良い例>>> a, *y, e = x >>> a, e, y (1, 16, [2, 4, 8])ポイントは、
*付きの変数が他に割り当てられていない値をまとめているという点です。チェーンを使用して簡潔にコードを記述する
Pythonでは、比較演算をチェーンさせることができます。したがって、2つ以上の比較演算が
Trueであるかどうかを使用して確認する必要はありません。悪い例>>> x = 4 >>> x >= 2 and x <= 8 True代わりに、数学者のように、これをよりコンパクトな形式で書くことができます。
良い例>>> 2 <= x <= 8 True >>> 2 <= x <= 3 FalsePythonは連鎖割り当てもサポートしています。したがって、複数の変数に同じ値を割り当てる場合は、簡単に行うことができます。
悪い例>>> x = 2 >>> y = 2 >>> z = 2よりエレガントな方法は、アンパックを使用することです。
良い例>>> x, y, z = 2, 2, 2ただし、連鎖割り当てを使用すると、状況はさらに改善されます。
さらに良い例>>> x = y = z = 2 >>> x, y, z (2, 2, 2)値がミュータブルな型の場合は注意してください。すべての変数は同じインスタンスを参照します。
Noneのチェック
NoneはPythonでは特別でユニークなオブジェクトです。Cライクな言語でのnullと同じような目的があります。変数が
Noneを参照しているかは比較演算子の==および!=で確認することができます。悪い例>>> x, y = 2, None >>> x == None False >>> y == None True >>> x != None True >>> y != None Falseしかし、よりPython的で望ましいのは
isおよびis notを使うやり方です。良い例>>> x is None False >>> y is None True >>> x is not None True >>> y is not None Falseさらに、より可読性の低い代替手段の
not (x is None)よりも、is not構文であるx is not Noneを使用することをお勧めします。シーケンスと連想配列の繰り返し
Pythonでは、いくつかのやり方で繰り返しとforループを実装できます。Pythonはそれを容易にするためにいくつかの組み込みクラスを提供しています。
ほとんどすべての場合、範囲を使用して整数を生成するイテレータを取得できます。
悪い例>>> x = [1, 2, 4, 8, 16] >>> for i in range(len(x)): ... print(x[i]) ... 1 2 4 8 16ただし、シーケンスを繰り返すより良い方法があります。
良い例>>> for item in x: ... print(item) ... 1 2 4 8 16しかし、逆の順序で繰り返しをしたい場合はどうでしょうか?もちろん、範囲をまた使うことができます。
悪い例>>> for i in range(len(x)-1, -1, -1): ... print(x[i]) ... 16 8 4 2 1シーケンスを逆にする方がよりエレガントなやり方です。
良い例>>> for item in x[::-1]: ... print(item) ... 16 8 4 2 1この場合、Python的なやり方は、
reversedを使用して、シーケンスのアイテムを逆の順序で生成するイテレーターを取得することです。さらに良い例>>> for item in reversed(x): ... print(item) ... 16 8 4 2 1シーケンスの要素と対応するインデックスの両方が必要になる場合があります。
悪い例>>> for i in range(len(x)): ... print(i, x[i]) ... 0 1 1 2 2 4 3 8 4 16
enumerateを使用して、インデックスとアイテムを含むタプルを生成する別のイテレーターを取得するやり方の方が良いとされています。良い例>>> for i, item in enumerate(x): ... print(i, item) ... 0 1 1 2 2 4 3 8 4 16イケてます。しかし、2つ以上のシーケンスを反復処理したい場合はどうでしょうか。もちろん、範囲をここでも使うことができます。
悪い例>>> y = 'abcde' >>> for i in range(len(x)): ... print(x[i], y[i]) ... 1 a 2 b 4 c 8 d 16 eこの場合、またPythonはより良いソリューションを提供しています。
zipを適用して、対となる要素のタプルを取得できます。良い例>>> for item in zip(x, y): ... print(item) ... (1, 'a') (2, 'b') (4, 'c') (8, 'd') (16, 'e')アンパックと組み合わせることができます。
さらに良い例>>> for x_item, y_item in zip(x, y): ... print(x_item, y_item) ... 1 a 2 b 4 c 8 d 16 e範囲は非常に役に立つものであることを覚えておいてください。ただし、(上記のような)より便利な代替手段がある場合もあります。
辞書を反復処理すると、キーが生成されます。
悪い例>>> z = {'a': 0, 'b': 1} >>> for k in z: ... print(k, z[k]) ... a 0 b 1ただし、メソッド
.items()を適用して、キーと対応する値を持つタプルを取得できます。良い例>>> for k, v in z.items(): ... print(k, v) ... a 0 b 1また、メソッド
.keys()を使うことでキーを、.values()を使うことで値を反復処理することもできます。
0との比較数値データがあり、数値がゼロに等しいかどうかを確認する必要がある場合は、比較演算子
==および!=を使用できますが、そうする必要はありません。悪い例>>> x = (1, 2, 0, 3, 0, 4) >>> for item in x: ... if item != 0: ... print(item) ... 1 2 3 4Python的なのは、ブール値のコンテキストで
0がFalseとして解釈される一方、他の全ての数字はTrueとして見なされるという事実を利用するやり方です。0以外の数字は全て真>>> bool(0) False >>> bool(-1), bool(1), bool(20), bool(28.4) (True, True, True, True)これを念頭に置いて、
if item ! = 0の代わりにただif itemを使えば良いのです。良い例>>> for item in x: ... if item: ... print(item) ... 1 2 3 4同じロジックに従い、
if item == 0の代わりにif not itemを使用できます。ミュータブルなオプション引数を避ける
Pythonには、関数とメソッドに引数を提供するための非常に柔軟なシステムがあります。オプション引数はこのシステムの一部です。ただし、注意が必要です。通常、ミュータブルなオプション引数を使用しない方が賢明です。次の例について考えてみます。
悪い例?>>> def f(value, seq=[]): ... seq.append(value) ... return seq
seqを指定しない場合、f()は空のリストに値を追加し、[value]のようなものを返します。これは一見すると、うまくいくように見えます。>>> f(value=2) [2]問題なさそうですね?そんなことはありません!次の例を検討してみましょう。
>>> f(value=4) [2, 4] >>> f(value=8) [2, 4, 8] >>> f(value=16) [2, 4, 8, 16]驚いたでしょうか?混乱していますか?もしそうなら、あなただけではありません。
オプション引数(この場合はリスト)の同じインスタンスが、関数が呼び出されるたびに使われているようです。時には上のコードがしていることと全く同じことをしたい場合があるかもしれません。しかし、それを回避する必要がある場合の方がはるかに多いことでしょう。いくつかの追加ロジックを使うと、これを避けることができます。方法のうちの1つは次です。良い例>>> def f(value, seq=None): ... if seq is None: ... seq = [] ... seq.append(value) ... return seqさらに短いバージョンは次のとおりです。
さらに良い例>>> def f(value, seq=None): ... if not seq: ... seq = [] ... seq.append(value) ... return seqようやく、異なる動作が得られます。
>>> f(value=2) [2] >>> f(value=4) [4] >>> f(value=8) [8] >>> f(value=16) [16]ほとんどの場合、これが欲しい結果です。
従来のゲッターとセッターの使用を避ける
Pythonでは、C++やJavaと同様にゲッターメソッドとセッターメソッドを定義できます。
悪い例>>> class C: ... def get_x(self): ... return self.__x ... def set_x(self, value): ... self.__x = value次が、ゲッターとセッターを使用してオブジェクトの状態を取得および設定する方法です。
悪い例>>> c = C() >>> c.set_x(2) >>> c.get_x() 2場合によっては、これがやりたいことを実現するための最良の方法です。ただし、特に単純なケースでは、プロパティを定義して使用する方が洗練されていることがよくあります。
良い例>>> class C: ... @property ... def x(self): ... return self.__x ... @x.setter ... def x(self, value): ... self.__x = valueプロパティは、従来のゲッターやセッターよりもPython的と考えられています。C#と同様に、つまり通常のデータ属性と同じように使用できます。
良い例>>> c = C() >>> c.x = 2 >>> c.x 2したがって、一般的には、可能な場合はプロパティを使用し、どうしても必要な場合はC++ライクなゲッターとセッターを使用することがグッドプラクティスとされています。
保護されたクラスメンバーへのアクセスを避ける
Pythonには本当のプライベートなクラスメンバーはありません。ただし、インスタンスの外でアンダースコア(_)で始まるメンバーにアクセスしたり変更したりしてはならないという規約があります。Pythonのプライベートなクラスメンバーは既存の動作を保持していることが保証されていません。
たとえば、次のコードを考えます。
>>> class C: ... def __init__(self, *args): ... self.x, self._y, self.__z = args ... >>> c = C(1, 2, 4)クラスCのインスタンスには、
.x、._y、._C__zの3つのデータメンバーが存在します。メンバーの名前が2つのアンダースコアで始まる場合は、難号化(mangled)され、変更されます。そのため、.__zの代わりに._C__zができます。.xには直接アクセスまたは変更しても問題ありません。
良い例>>> c.x # OK 1インスタンスの外部から
._yにアクセスまたは変更することもできますが、これはバッドプラクティスと見なされています。悪い例>>> c._y # 可能だが悪い 2
.__zにアクセスすることはできません。zは難号化されているからです。しかし、._C__zにアクセスまたは変更することはできます。さらに悪い例>>> c.__z # エラー! Traceback (most recent call last): File "", line 1, in AttributeError: 'C' object has no attribute '__z' >>> c._C__z # 可能だが、1個前の例よりさらに悪い! 4 >>>これは避けてください。クラスの作者は、おそらく名前をアンダースコアで始めて、「使用するな」と伝えています。
コンテキストマネージャーを使用してリソースを解放する
リソースを適切に管理するためのコードを記述する必要がある場合があります。これは、ファイル、データベース接続、または管理されていないリソースを持つ他のエンティティを操作する場合によく見られます。
たとえば、ファイルを開いて次のように処理することができます。
悪い例>>> my_file = open('filename.csv', 'w') >>> # do something with `my_file`メモリを適切に管理するには、ジョブ終了後にこのファイルを閉じる必要があります。
悪い例>>> my_file = open('filename.csv', 'w') >>> # do something with `my_file and` >>> my_file.close()ファイルを閉じることは、閉じないよりもマシです。しかし、ファイルの処理中に例外が発生した場合はどうでしょうか?その後、
my_file.close()は決して実行されません。この場合、例外処理構文または
withコンテキストマネージャーで対応できます。2番目の方法は、コードをwithブロック内に配置することを意味します。良い例>>> with open('filename.csv', 'w') as my_file: ... # do something with `my_file`
withブロックを使用するということは、特殊メソッドの.__enter__()と.__exit()__が例外が発生した場合でも呼び出されます。これらのメソッドがリソースの面倒を見てくれるはずです。コンテキストマネージャーと例外処理を組み合わせることで、特に堅牢な構成を実現できます。文体に関してのアドバイス
Pythonコードは、エレガントで簡潔で読みやすいものにする必要があります。それは美しいはずです。
美しいPythonコードの書き方に関する究極のリソースは、「Style Guide for Python Code」、またの名を「PEP 8」です。Pythonでコーディングする場合は、必ず読むべきです。
結論
この記事では、より効率的で読みやすく、より簡潔なコードを書く方法についていくつかのアドバイスを提供しています。つまり、Python的(Pythonic)なコードの記述方法を示しています。さらに、PEP 8はPythonコードのスタイルガイドを提供し、PEP 20はPython言語の原則を示しています。
Pythonicで役立つ美しいコードを書くことを楽しみましょう!

- 投稿日:2020-09-06T18:31:30+09:00
大槻班長のチンチロ不正を暴け ~統計基礎その2~
はじめに
みなさんは大槻班長をご存じでしょうか。
そうです、漫画カイジの地下強制労働施設で登場する極悪班長です。知らない人でも、カイジが生ビールを飲んだ際の名言「キンキンに冷えてやがるっ・・・!!」「犯罪的だ・・・うますぎる・・・」は誰かが言っているのを聞いたことがあるのではないでしょうか。その生ビールをカイジにあげた人です。
実はこの大槻班長、一部のファンの間で大人気でスピンオフ漫画もすでに9巻まで販売されています。読みましたが犯罪的におもしろいです。
今回は大槻班長が地下強制労働施設でやっていたチンチロリンの不正を見破るという題材で、2項分布の検定をやってみます。
知り合いに書いてもらった大槻班長です。すごくうまい。
チンチロリンのルール(地下ver)
地下強制労働施設で行われていた賭博がチンチロリン(略してチンチロ)です。そのルールはいたってシンプルでサイコロ3つをどんぶりの中に投げ入れ、その出た役の強さで勝敗が決まります。参加者は下図のように円形で座り、まず親が振り次に子たちが左回りに振り、親の目対子の目どっちが強いかでペリカ(地下労働施設の通貨で1円=10ペリカ)が行き来します。
だいたい下図のようなイメージです。
役の強さは下の表のようになっています。
基本的には目の大きい方が強くて、ぞろ目やシゴロはその上の役といった感じでしょうか。ちなみに、上の表のようにパワポで同じパーツを平行位置(上下左右)に大量にコピーしたい場合は、Ctrl+Shift+マウスドラッグを使えばとても楽です。
ハンチョウのいかさまサイコロ
さて、ここでハンチョウが使ったイカサマサイコロを見てみましょう。いかさまサイコロには出目が4~6しかないのですが、同じ数字は真反対側に位置するように置かれているため、振られたサイコロを一見するだけではいかさまだと気づかれないようになっています。
さらにハンチョウはイカサマの露見を防ぐため、以下の2つの対策も取っています。
1、いつも使っていてはバレるから、1度の勝負で使うのは勝負所の2回だけ。
2、親番で使うときは子にも振らせるようにし、違和感を消す。サイコロの出目で検定
推定統計を使って大槻班長のイカサマを見破る方法を検討していこうと思います。推定統計の有名な逸話であるポアンカレとパン屋の話についてはこちらの記事で紹介しています。
推定統計の検定は簡単に言うと、事前に母集団に関して仮説をたてておいて、得られた標本が現実的な範囲に入ってるか確かめる手法です。漫画の設定では、1勝負中にイカサマサイコロを2回使うということですが「1回の勝負」の定義が分からなかったので、10人でプレイして1周親をまわすことを「1回の勝負」と仮定してます。
サイコロの出目はPythonのrandom関数を使って実装しました。10日間毎日記録を取り続けた場合の結果(計回分のサイコロの目)を下に示しています。1度に3つのサイコロを振るのですが、簡単のために全て独立に考えています。なんとなく4~6が多く出てるのが分かりますが・・・
普通のサイコロであれば、振って4~6が出る確率は1/2であるはずですので、帰無仮説は「このサイコロを300回(10日×10回で1周×3つのサイコロ)振ったときに4~6の目が出るのは半分の150回である」とします。
成功確率がpの試行をn回行ったときの成功回数は二項分布に従います。二項分布での成功回数(4~6がでる回数)の期待値はE(X)=npで、分散はV(x)=np(1-p)です。そして、二項分布を下記の式で標準化することで標準正規分布N(0, 1)に近似します。両側検定として棄却率は1%とするので、下記式のzが-2.68~2.68に入れば帰無仮説は正しいと考えます。
\begin{align} z=\frac{X-np}{\sqrt{np(1-p)} \\} \end{align}さて、結果はどうでしょうか。
残念ながら、帰無仮説が正しい範囲となってしまい、不正を見破ることはできませんでした。(通常サイコロでも現実的にありえる出方)
自分から見えるサイコロの3面の目の組み合わせで検定
次の検討として、いかさまサイコロは4~6の値しか取らないため、「振られたサイコロの自分から見える3面の目×3つのサイコロの確率変数」を検定することを考えてみます。※角度によっては3面見えないときもある気がしますが、とりあえず進めます
自分から見えるサイコロの目の組み合わせは通常のサイコロ構造であれば、以下の8パターンのどれかになります。
(1,2,3)、(1,2,4)、(1,3,5)、(1,4,5)、(2,3,6)、(2,4,6)、(3,5,6)、(4,5,6)
そして、通常のサイコロでは見え方が(4,5,6)となる確率は1/8です。
下図が観測された値です。さきほどと同じランダム変数を使いましたが、偏りがより顕著になりました。
同様に二項分布の期待値の検定を行いました。結果はどうでしょうか。
はい、完全に不正をしているという結果になりました。
(帰無仮説が棄却されるため、班長はいかさまサイコロを使っている)ということで、もしも怪しいサイコロゲームを持ち掛けられた場合は、見えるサイコロの目の全てを記録しておくことをお勧めいたします。
コード
import math import random import numpy as np import matplotlib.pyplot as plt #自分から見えるサイコロの目の見える目のパターン look_pattern = {1:[1,2,3], 2:[1,2,4], 3:[1,3,5], 4:[1,4,5], 5:[2,3,6], 6:[2,4,6], 7:[3,5,6], 8:[4,5,6]} counts_single = [0 for _ in range(7)] counts_multi = [0 for _ in range(9)] #10日間 for day in range(10): #通常 for normal in range(8): #3つのサイコロ for dice_num in range(3): #サイコロ見え方 result = random.randint(1,8) counts_multi[result] += 1 #サイコロ出目 result = look_pattern[result][random.randint(0,2)] counts_single[result] += 1 #イカサマ for ikasama in range(2): #3つのサイコロ for dice_num in range(3): #サイコロ見え方 result = 8 counts_multi[result] += 1 #サイコロ出目 result = look_pattern[result][random.randint(0,2)] counts_single[result] += 1 #サイコロ出目 plt.scatter(range(len(counts_single[1:])),counts_single[1:]) plt.plot(range(len(counts_single[1:])),counts_single[1:]) plt.ylim(0,100) plt.show() #自分から見えるサイコロの目 plt.scatter(range(len(counts_multi[1:])),counts_multi[1:]) plt.plot(range(len(counts_multi[1:])),counts_multi[1:]) plt.ylim(0,100) plt.show() #検定 n = sum(counts_multi) p = 1/8 X = counts_multi[8] z = (X - n*p) / (n*p*(1-p))**0.5 ok_Xs = np.linspace(-2.68, 2.68, num = 50) f = lambda x: (math.exp(-x**2/2)) / math.sqrt(2*math.pi) plt.plot([i*0.1-5 for i in range(100)],[f(i*0.1-5) for i in range(100)], color = "black") plt.fill_between(ok_Xs, np.zeros_like(ok_Xs),list(map(f, ok_Xs)),facecolor='darkred',alpha=0.5) plt.plot([z,z],[0,1], color = "blue") plt.ylim(0,0.4) plt.xlim(-4,10) plt.show()参考
終わりに
最後まで読んで頂きありがとうございました。「1日外出録ハンチョウ」おもしろいので、読んでみてください。よろしければLGTMをお願いします。











- 投稿日:2020-09-06T18:31:30+09:00
ハンチョウのチンチロ不正を見破れ ~統計基礎その2~
はじめに
みなさんは大槻班長をご存じでしょうか。
そうです、漫画カイジの地下強制労働施設で登場する極悪班長です。知らない人でも、カイジが生ビールを飲んだ際の名言「キンキンに冷えてやがるっ・・・!!」「犯罪的だ・・・うますぎる・・・」は誰かが言っているのを聞いたことがあるのではないでしょうか。その生ビールをカイジにあげた人です。
実はこの大槻班長、一部のファンの間で大人気でスピンオフ漫画もすでに9巻まで販売されています。読みましたが犯罪的におもしろいです。
今回は大槻班長が地下強制労働施設でやっていたチンチロの不正を統計的に見破るということで、2項分布の検定をやってみます。
知り合いに書いてもらったイラストです。うますぎる…
チンチロリンのルール(地下ver)
地下強制労働施設で行われていた賭博がチンチロリン(略してチンチロ)です。そのルールはいたってシンプルでサイコロ3つをどんぶりの中に投げ入れ、その出た役の強さで勝敗が決まります。参加者は下図のように円形で座り、まず親が振り次に子たちが左回りに振り、親の目対子の目どっちが強いかでペリカ(地下労働施設の通貨で1円=10ペリカ)が行き来します。
だいたい下図のようなイメージです。
役の強さは下の表のようになっています。
基本的には目の大きい方が強くて、ぞろ目やシゴロはその上の役といった感じでしょうか。ちなみに、上の表のようにパワポで同じパーツを平行位置(上下左右)に大量にコピーしたい場合は、Ctrl+Shift+マウスドラッグを使えばとても楽です。
ハンチョウのいかさまサイコロ
さて、ここでハンチョウが使ったイカサマサイコロを見てみましょう。いかさまサイコロには出目が4~6しかないのですが、同じ数字は真反対側に位置するように置かれているため、振られたサイコロを一見するだけではいかさまだと気づかれないようになっています。
さらにハンチョウはイカサマの露見を防ぐため、以下の2つの対策も取っています。
1、いつも使っていてはバレるから、1度の勝負で使うのは勝負所の2回だけ。
2、親番で使うときは子にも振らせるようにし、違和感を消す。サイコロの出目で検定
推定統計を使って大槻班長のイカサマを見破る方法を検討していこうと思います。推定統計の有名な逸話であるポアンカレとパン屋の話についてはこちらの記事で紹介しています。
推定統計の検定は簡単に言うと、事前に母集団に関して仮説をたてておいて、得られた標本が現実的な範囲に入ってるか確かめる手法です。漫画の設定では、1勝負中にイカサマサイコロを2回使うということですが「1回の勝負」の定義が分からなかったので、10人でプレイして1周親をまわすことを「1回の勝負」と仮定してます。
サイコロの出目はPythonのrandom関数を使って実装しました。10日間毎日記録を取り続けた場合の結果(計回分のサイコロの目)を下に示しています。1度に3つのサイコロを振るのですが、簡単のために全て独立に考えています。なんとなく4~6が多く出てるのが分かりますが・・・
普通のサイコロであれば、振って4~6が出る確率は1/2であるはずですので、帰無仮説は「このサイコロを300回(10日×10回で1周×3つのサイコロ)振ったときに4~6の目が出るのは半分の150回である」とします。
成功確率がpの試行をn回行ったときの成功回数は二項分布に従います。二項分布での成功回数(4~6がでる回数)の期待値はE(X)=npで、分散はV(x)=np(1-p)です。そして、二項分布を下記の式で標準化することで標準正規分布N(0, 1)に近似します。両側検定として棄却率は1%とするので、下記式のzが-2.68~2.68に入れば帰無仮説は正しいと考えます。
\begin{align} z=\frac{X-np}{\sqrt{np(1-p)} \\} \end{align}さて、結果はどうでしょうか。
残念ながら、帰無仮説が正しい範囲となってしまい、不正を見破ることはできませんでした。(通常サイコロでも現実的にありえる出方)
自分から見えるサイコロの3面の目の組み合わせで検定
次の検討として、いかさまサイコロは4~6の値しか取らないため、「振られたサイコロの自分から見える3面の目×3つのサイコロの確率変数」を検定することを考えてみます。※角度によっては3面見えないときもある気がしますが、とりあえず進めます
自分から見えるサイコロの目の組み合わせは通常のサイコロ構造であれば、以下の8パターンのどれかになります。
(1,2,3)、(1,2,4)、(1,3,5)、(1,4,5)、(2,3,6)、(2,4,6)、(3,5,6)、(4,5,6)
そして、通常のサイコロでは見え方が(4,5,6)となる確率は1/8です。
下図が観測された値です。さきほどと同じランダム変数を使いましたが、偏りがより顕著になりました。
同様に二項分布の期待値の検定を行いました。結果はどうでしょうか。
はい、完全に不正をしているという結果になりました。
(帰無仮説が棄却されるため、班長はいかさまサイコロを使っている)ということで、もしも怪しいサイコロゲームを持ち掛けられた場合は、見えるサイコロの目の全てを記録しておくことをお勧めいたします。
コード
import math import random import numpy as np import matplotlib.pyplot as plt #自分から見えるサイコロの目の見える目のパターン look_pattern = {1:[1,2,3], 2:[1,2,4], 3:[1,3,5], 4:[1,4,5], 5:[2,3,6], 6:[2,4,6], 7:[3,5,6], 8:[4,5,6]} counts_single = [0 for _ in range(7)] counts_multi = [0 for _ in range(9)] #10日間 for day in range(10): #通常 for normal in range(8): #3つのサイコロ for dice_num in range(3): #サイコロ見え方 result = random.randint(1,8) counts_multi[result] += 1 #サイコロ出目 result = look_pattern[result][random.randint(0,2)] counts_single[result] += 1 #イカサマ for ikasama in range(2): #3つのサイコロ for dice_num in range(3): #サイコロ見え方 result = 8 counts_multi[result] += 1 #サイコロ出目 result = look_pattern[result][random.randint(0,2)] counts_single[result] += 1 #サイコロ出目 plt.scatter(range(len(counts_single[1:])),counts_single[1:]) plt.plot(range(len(counts_single[1:])),counts_single[1:]) plt.ylim(0,100) plt.show() #自分から見えるサイコロの目 plt.scatter(range(len(counts_multi[1:])),counts_multi[1:]) plt.plot(range(len(counts_multi[1:])),counts_multi[1:]) plt.ylim(0,100) plt.show() #検定 n = sum(counts_multi) p = 1/8 X = counts_multi[8] z = (X - n*p) / (n*p*(1-p))**0.5 ok_Xs = np.linspace(-2.68, 2.68, num = 50) f = lambda x: (math.exp(-x**2/2)) / math.sqrt(2*math.pi) plt.plot([i*0.1-5 for i in range(100)],[f(i*0.1-5) for i in range(100)], color = "black") plt.fill_between(ok_Xs, np.zeros_like(ok_Xs),list(map(f, ok_Xs)),facecolor='darkred',alpha=0.5) plt.plot([z,z],[0,1], color = "blue") plt.ylim(0,0.4) plt.xlim(-4,10) plt.show()参考
終わりに
最後まで読んで頂きありがとうございました。「1日外出録ハンチョウ」おもしろいので、読んでみてください。よろしければLGTMをお願いします。
- 投稿日:2020-09-06T18:31:30+09:00
ハンチョウのチンチロ不正を見破る ~統計基礎その2~
はじめに
みなさんは大槻班長をご存じでしょうか。
そうです、漫画カイジの地下強制労働施設で登場する極悪班長です。知らない人でも、カイジが生ビールを飲んだ際の名言「キンキンに冷えてやがるっ・・・!!」「犯罪的だ・・・うますぎる・・・」は聞いたことがあるのではないでしょうか。その生ビールをカイジにあげた人です。
実はこの大槻班長、一部のファンの間で大人気でスピンオフ漫画もすでに9巻まで販売されています。読みましたが犯罪的におもしろいです。
今回は大槻班長が地下強制労働施設でやっていたチンチロの不正を統計的に見破るということで、2項分布の検定をやってみます。
知人に書いてもらったイラストです。うますぎる…
チンチロリンのルール(地下ver)
地下強制労働施設で行われていた賭博がチンチロリン(略してチンチロ)です。そのルールはいたってシンプルでサイコロ3つをどんぶりの中に投げ入れ、その出た役の強さで勝敗が決まります。参加者は下図のように円形で座り、まず親が振り次に子たちが左回りに振り、親の目対子の目どっちが強いかでペリカ(地下労働施設の通貨で1円=10ペリカ)が行き来します。
だいたい下図のようなイメージです。
役の強さは下の表のようになっています。
基本的には目の大きい方が強くて、ぞろ目やシゴロはその上の役といった感じでしょうか。ちなみに、上の表のようにパワポで同じパーツを平行位置(上下左右)に大量にコピーしたい場合は、Ctrl+Shift+マウスドラッグを使えばとても楽です。
ハンチョウのいかさまサイコロ
さて、ここでハンチョウが使ったイカサマサイコロを見てみましょう。いかさまサイコロには出目が4~6しかないのですが、同じ数字は真反対側に位置するように置かれているため、振られたサイコロを一見するだけではいかさまだと気づかれないようになっています。
さらにハンチョウはイカサマの露見を防ぐため、以下の2つの対策も取っています。
1、いつも使っていてはバレるから、1度の勝負で使うのは勝負所の2回だけ。
2、親番で使うときは子にも振らせるようにし、違和感を消す。サイコロの出目で検定
推定統計を使って大槻班長のイカサマを見破る方法を検討していこうと思います。推定統計の有名な逸話であるポアンカレとパン屋の話についてはこちらの記事で紹介しています。
推定統計の検定は簡単に言うと、事前に母集団に関して仮説をたてておいて、得られた標本が現実的な範囲に入ってるか確かめる手法です。漫画の設定では、1勝負中にイカサマサイコロを2回使うということですが「1回の勝負」の定義が分からなかったので、10人でプレイして1周親をまわすことを「1回の勝負」と仮定してます。
サイコロの出目はPythonのrandom関数を使って実装しました。10日間毎日記録を取り続けた場合の結果(計回分のサイコロの目)を下に示しています。1度に3つのサイコロを振るのですが、簡単のために全て独立に考えています。なんとなく4~6が多く出てるのが分かりますが・・・
普通のサイコロであれば、振って4~6が出る確率は1/2であるはずですので、帰無仮説は「このサイコロを300回(10日×10回で1周×3つのサイコロ)振ったときに4~6の目が出るのは半分の150回である」とします。
成功確率がpの試行をn回行ったときの成功回数は二項分布に従います。二項分布での成功回数(4~6がでる回数)の期待値はE(X)=npで、分散はV(x)=np(1-p)です。そして、二項分布を下記の式で標準化することで標準正規分布N(0, 1)に近似します。両側検定として棄却率は1%とするので、下記式のzが-2.68~2.68に入れば帰無仮説は正しいと考えます。
\begin{align} z=\frac{X-np}{\sqrt{np(1-p)} \\} \end{align}さて、結果はどうでしょうか。
残念ながら、帰無仮説が正しい範囲となってしまい、不正を見破ることはできませんでした。(通常サイコロでも現実的にありえる出方)
自分から見えるサイコロの3面の目の組み合わせで検定
次の検討として、いかさまサイコロは4~6の値しか取らないため、「振られたサイコロの自分から見える3面の目×3つのサイコロの確率変数」を検定することを考えてみます。※角度によっては3面見えないときもある気がしますが、とりあえず進めます
自分から見えるサイコロの目の組み合わせは通常のサイコロ構造であれば、以下の8パターンのどれかになります。
(1,2,3)、(1,2,4)、(1,3,5)、(1,4,5)、(2,3,6)、(2,4,6)、(3,5,6)、(4,5,6)
そして、通常のサイコロでは見え方が(4,5,6)となる確率は1/8です。
下図が観測された値です。さきほどと同じランダム変数を使いましたが、偏りがより顕著になりました。
同様に二項分布の期待値の検定を行いました。結果はどうでしょうか。
はい、完全に不正をしているという結果になりました。
(帰無仮説が棄却されるため、班長はいかさまサイコロを使っている)ということで、もしも怪しいサイコロゲームを持ち掛けられた場合は、見えるサイコロの目の全てを記録しておくことをお勧めいたします。
コード
import math import random import numpy as np import matplotlib.pyplot as plt #自分から見えるサイコロの目の見える目のパターン look_pattern = {1:[1,2,3], 2:[1,2,4], 3:[1,3,5], 4:[1,4,5], 5:[2,3,6], 6:[2,4,6], 7:[3,5,6], 8:[4,5,6]} counts_single = [0 for _ in range(7)] counts_multi = [0 for _ in range(9)] #10日間 for day in range(10): #通常 for normal in range(8): #3つのサイコロ for dice_num in range(3): #サイコロ見え方 result = random.randint(1,8) counts_multi[result] += 1 #サイコロ出目 result = look_pattern[result][random.randint(0,2)] counts_single[result] += 1 #イカサマ for ikasama in range(2): #3つのサイコロ for dice_num in range(3): #サイコロ見え方 result = 8 counts_multi[result] += 1 #サイコロ出目 result = look_pattern[result][random.randint(0,2)] counts_single[result] += 1 #サイコロ出目 plt.scatter(range(len(counts_single[1:])),counts_single[1:]) plt.plot(range(len(counts_single[1:])),counts_single[1:]) plt.ylim(0,100) plt.show() #自分から見えるサイコロの目 plt.scatter(range(len(counts_multi[1:])),counts_multi[1:]) plt.plot(range(len(counts_multi[1:])),counts_multi[1:]) plt.ylim(0,100) plt.show() #検定 n = sum(counts_multi) p = 1/8 X = counts_multi[8] z = (X - n*p) / (n*p*(1-p))**0.5 ok_Xs = np.linspace(-2.68, 2.68, num = 50) f = lambda x: (math.exp(-x**2/2)) / math.sqrt(2*math.pi) plt.plot([i*0.1-5 for i in range(100)],[f(i*0.1-5) for i in range(100)], color = "black") plt.fill_between(ok_Xs, np.zeros_like(ok_Xs),list(map(f, ok_Xs)),facecolor='darkred',alpha=0.5) plt.plot([z,z],[0,1], color = "blue") plt.ylim(0,0.4) plt.xlim(-4,10) plt.show()参考
終わりに
最後まで読んで頂きありがとうございました。「1日外出録ハンチョウ」おもしろいので、読んでみてください。よろしければLGTMをお願いします。
- 投稿日:2020-09-06T18:31:30+09:00
チンチロリン不正を統計検定で見破る
はじめに
みなさんは大槻班長をご存じでしょうか。
そうです、漫画カイジの地下強制労働施設で登場する極悪班長です。知らない人でも、カイジが生ビールを飲んだ際の名言「キンキンに冷えてやがるっ・・・!!」「犯罪的だ・・・うますぎる・・・」は聞いたことがあるのではないでしょうか。その生ビールをカイジにあげた人です。
実はこの大槻班長、一部のファンの間で大人気でスピンオフ漫画もすでに9巻まで販売されています。読みましたが犯罪的におもしろいです。
今回は大槻班長が地下強制労働施設でやっていたチンチロの不正を統計的に見破るということで、2項分布の検定をやってみます。
知人に書いてもらったイラストです。うますぎる…
チンチロリンのルール(地下ver)
地下強制労働施設で行われていた賭博がチンチロリン(略してチンチロ)です。そのルールはいたってシンプルでサイコロ3つをどんぶりの中に投げ入れ、その出た役の強さで勝敗が決まります。参加者は下図のように円形で座り、まず親が振り次に子たちが左回りに振り、親の目対子の目どっちが強いかでペリカ(地下労働施設の通貨で1円=10ペリカ)が行き来します。
だいたい下図のようなイメージです。
役の強さは下の表のようになっています。
基本的には目の大きい方が強くて、ぞろ目やシゴロはその上の役といった感じでしょうか。ちなみに、上の表のようにパワポで同じパーツを平行位置(上下左右)に大量にコピーしたい場合は、Ctrl+Shift+マウスドラッグを使えばとても楽です。
ハンチョウのいかさまサイコロ
さて、ここでハンチョウが使ったイカサマサイコロを見てみましょう。いかさまサイコロには出目が4~6しかないのですが、同じ数字は真反対側に位置するように置かれているため、振られたサイコロを一見するだけではいかさまだと気づかれないようになっています。
さらにハンチョウはイカサマの露見を防ぐため、以下の2つの対策も取っています。
1、いつも使っていてはバレるから、1度の勝負で使うのは勝負所の2回だけ。
2、親番で使うときは子にも振らせるようにし、違和感を消す。サイコロの出目で検定
推定統計を使って大槻班長のイカサマを見破る方法を検討していこうと思います。推定統計の有名な逸話であるポアンカレとパン屋の話についてはこちらの記事で紹介しています。
推定統計の検定は簡単に言うと、事前に母集団に関して仮説をたてておいて、得られた標本が現実的な範囲に入ってるか確かめる手法です。漫画の設定では、1勝負中にイカサマサイコロを2回使うということですが「1回の勝負」の定義が分からなかったので、10人でプレイして1周親をまわすことを「1回の勝負」と仮定してます。
サイコロの出目はPythonのrandom関数を使って実装しました。10日間毎日記録を取り続けた場合の結果(計回分のサイコロの目)を下に示しています。1度に3つのサイコロを振るのですが、簡単のために全て独立に考えています。なんとなく4~6が多く出てるのが分かりますが・・・
普通のサイコロであれば、振って4~6が出る確率は1/2であるはずですので、帰無仮説は「このサイコロを300回(10日×10回で1周×3つのサイコロ)振ったときに4~6の目が出るのは半分の150回である」とします。
成功確率がpの試行をn回行ったときの成功回数は二項分布に従います。二項分布での成功回数(4~6がでる回数)の期待値はE(X)=npで、分散はV(x)=np(1-p)です。そして、二項分布を下記の式で標準化することで標準正規分布N(0, 1)に近似します。両側検定として棄却率は1%とするので、下記式のzが-2.68~2.68に入れば帰無仮説は正しいと考えます。
\begin{align} z=\frac{X-np}{\sqrt{np(1-p)} \\} \end{align}さて、結果はどうでしょうか。
残念ながら、帰無仮説が正しい範囲となってしまい、不正を見破ることはできませんでした。(通常サイコロでも現実的にありえる出方)
自分から見えるサイコロの3面の目の組み合わせで検定
次の検討として、いかさまサイコロは4~6の値しか取らないため、「振られたサイコロの自分から見える3面の目×3つのサイコロの確率変数」を検定することを考えてみます。※角度によっては3面見えないときもある気がしますが、とりあえず進めます
自分から見えるサイコロの目の組み合わせは通常のサイコロ構造であれば、以下の8パターンのどれかになります。
(1,2,3)、(1,2,4)、(1,3,5)、(1,4,5)、(2,3,6)、(2,4,6)、(3,5,6)、(4,5,6)
そして、通常のサイコロでは見え方が(4,5,6)となる確率は1/8です。
下図が観測された値です。さきほどと同じランダム変数を使いましたが、偏りがより顕著になりました。
同様に二項分布の期待値の検定を行いました。結果はどうでしょうか。
はい、完全に不正をしているという結果になりました。
(帰無仮説が棄却されるため、班長はいかさまサイコロを使っている)コード
import math import random import numpy as np import matplotlib.pyplot as plt #自分から見えるサイコロの目の見える目のパターン look_pattern = {1:[1,2,3], 2:[1,2,4], 3:[1,3,5], 4:[1,4,5], 5:[2,3,6], 6:[2,4,6], 7:[3,5,6], 8:[4,5,6]} counts_single = [0 for _ in range(7)] counts_multi = [0 for _ in range(9)] #10日間 for day in range(10): #通常 for normal in range(8): #3つのサイコロ for dice_num in range(3): #サイコロ見え方 result = random.randint(1,8) counts_multi[result] += 1 #サイコロ出目 result = look_pattern[result][random.randint(0,2)] counts_single[result] += 1 #イカサマ for ikasama in range(2): #3つのサイコロ for dice_num in range(3): #サイコロ見え方 result = 8 counts_multi[result] += 1 #サイコロ出目 result = look_pattern[result][random.randint(0,2)] counts_single[result] += 1 #サイコロ出目 plt.scatter(range(len(counts_single[1:])),counts_single[1:]) plt.plot(range(len(counts_single[1:])),counts_single[1:]) plt.ylim(0,100) plt.show() #自分から見えるサイコロの目 plt.scatter(range(len(counts_multi[1:])),counts_multi[1:]) plt.plot(range(len(counts_multi[1:])),counts_multi[1:]) plt.ylim(0,100) plt.show() #検定 n = sum(counts_multi) p = 1/8 X = counts_multi[8] z = (X - n*p) / (n*p*(1-p))**0.5 ok_Xs = np.linspace(-2.68, 2.68, num = 50) f = lambda x: (math.exp(-x**2/2)) / math.sqrt(2*math.pi) plt.plot([i*0.1-5 for i in range(100)],[f(i*0.1-5) for i in range(100)], color = "black") plt.fill_between(ok_Xs, np.zeros_like(ok_Xs),list(map(f, ok_Xs)),facecolor='darkred',alpha=0.5) plt.plot([z,z],[0,1], color = "blue") plt.ylim(0,0.4) plt.xlim(-4,10) plt.show()参考
終わりに
最後まで読んで頂きありがとうございました。もしも怪しいサイコロゲームを持ち掛けられた場合は、見えるサイコロの目の全てを記録しておくことをお勧めいたします、という謎コメントで終わろうと思います。
- 投稿日:2020-09-06T18:31:30+09:00
ハンチョウのチンチロ不正を見破れ
はじめに
みなさんは大槻班長をご存じでしょうか。
そうです、漫画カイジの地下強制労働施設で登場する極悪班長です。知らない人でも、カイジが生ビールを飲んだ際の名言「キンキンに冷えてやがるっ・・・!!」「犯罪的だ・・・うますぎる・・・」は聞いたことがあるのではないでしょうか。その生ビールをカイジにあげた人です。
実はこの大槻班長、一部のファンの間で大人気でスピンオフ漫画もすでに9巻まで販売されています。読みましたが犯罪的におもしろいです。
今回は大槻班長が地下強制労働施設でやっていたチンチロの不正を統計的に見破るということで、2項分布の検定をやってみます。
知人に書いてもらったイラストです。うますぎる…
チンチロリンのルール(地下ver)
地下強制労働施設で行われていた賭博がチンチロリン(略してチンチロ)です。そのルールはいたってシンプルでサイコロ3つをどんぶりの中に投げ入れ、その出た役の強さで勝敗が決まります。参加者は下図のように円形で座り、まず親が振り次に子たちが左回りに振り、親の目対子の目どっちが強いかでペリカ(地下労働施設の通貨で1円=10ペリカ)が行き来します。
だいたい下図のようなイメージです。
役の強さは下の表のようになっています。
基本的には目の大きい方が強くて、ぞろ目やシゴロはその上の役といった感じでしょうか。ちなみに、上の表のようにパワポで同じパーツを平行位置(上下左右)に大量にコピーしたい場合は、Ctrl+Shift+マウスドラッグを使えばとても楽です。
ハンチョウのいかさまサイコロ
さて、ここでハンチョウが使ったイカサマサイコロを見てみましょう。いかさまサイコロには出目が4~6しかないのですが、同じ数字は真反対側に位置するように置かれているため、振られたサイコロを一見するだけではいかさまだと気づかれないようになっています。
さらにハンチョウはイカサマの露見を防ぐため、以下の2つの対策も取っています。
1、いつも使っていてはバレるから、1度の勝負で使うのは勝負所の2回だけ。
2、親番で使うときは子にも振らせるようにし、違和感を消す。サイコロの出目で検定
推定統計を使って大槻班長のイカサマを見破る方法を検討していこうと思います。推定統計の有名な逸話であるポアンカレとパン屋の話についてはこちらの記事で紹介しています。
推定統計の検定は簡単に言うと、事前に母集団に関して仮説をたてておいて、得られた標本が現実的な範囲に入ってるか確かめる手法です。漫画の設定では、1勝負中にイカサマサイコロを2回使うということですが「1回の勝負」の定義が分からなかったので、10人でプレイして1周親をまわすことを「1回の勝負」と仮定してます。
サイコロの出目はPythonのrandom関数を使って実装しました。10日間毎日記録を取り続けた場合の結果(計回分のサイコロの目)を下に示しています。1度に3つのサイコロを振るのですが、簡単のために全て独立に考えています。なんとなく4~6が多く出てるのが分かりますが・・・
普通のサイコロであれば、振って4~6が出る確率は1/2であるはずですので、帰無仮説は「このサイコロを300回(10日×10回で1周×3つのサイコロ)振ったときに4~6の目が出るのは半分の150回である」とします。
成功確率がpの試行をn回行ったときの成功回数は二項分布に従います。二項分布での成功回数(4~6がでる回数)の期待値はE(X)=npで、分散はV(x)=np(1-p)です。そして、二項分布を下記の式で標準化することで標準正規分布N(0, 1)に近似します。両側検定として棄却率は1%とするので、下記式のzが-2.68~2.68に入れば帰無仮説は正しいと考えます。
\begin{align} z=\frac{X-np}{\sqrt{np(1-p)} \\} \end{align}さて、結果はどうでしょうか。
残念ながら、帰無仮説が正しい範囲となってしまい、不正を見破ることはできませんでした。(通常サイコロでも現実的にありえる出方)
自分から見えるサイコロの3面の目の組み合わせで検定
次の検討として、いかさまサイコロは4~6の値しか取らないため、「振られたサイコロの自分から見える3面の目×3つのサイコロの確率変数」を検定することを考えてみます。※角度によっては3面見えないときもある気がしますが、とりあえず進めます
自分から見えるサイコロの目の組み合わせは通常のサイコロ構造であれば、以下の8パターンのどれかになります。
(1,2,3)、(1,2,4)、(1,3,5)、(1,4,5)、(2,3,6)、(2,4,6)、(3,5,6)、(4,5,6)
そして、通常のサイコロでは見え方が(4,5,6)となる確率は1/8です。
下図が観測された値です。さきほどと同じランダム変数を使いましたが、偏りがより顕著になりました。
同様に二項分布の期待値の検定を行いました。結果はどうでしょうか。
はい、完全に不正をしているという結果になりました。
(帰無仮説が棄却されるため、班長はいかさまサイコロを使っている)コード
import math import random import numpy as np import matplotlib.pyplot as plt #自分から見えるサイコロの目の見える目のパターン look_pattern = {1:[1,2,3], 2:[1,2,4], 3:[1,3,5], 4:[1,4,5], 5:[2,3,6], 6:[2,4,6], 7:[3,5,6], 8:[4,5,6]} counts_single = [0 for _ in range(7)] counts_multi = [0 for _ in range(9)] #10日間 for day in range(10): #通常 for normal in range(8): #3つのサイコロ for dice_num in range(3): #サイコロ見え方 result = random.randint(1,8) counts_multi[result] += 1 #サイコロ出目 result = look_pattern[result][random.randint(0,2)] counts_single[result] += 1 #イカサマ for ikasama in range(2): #3つのサイコロ for dice_num in range(3): #サイコロ見え方 result = 8 counts_multi[result] += 1 #サイコロ出目 result = look_pattern[result][random.randint(0,2)] counts_single[result] += 1 #サイコロ出目 plt.scatter(range(len(counts_single[1:])),counts_single[1:]) plt.plot(range(len(counts_single[1:])),counts_single[1:]) plt.ylim(0,100) plt.show() #自分から見えるサイコロの目 plt.scatter(range(len(counts_multi[1:])),counts_multi[1:]) plt.plot(range(len(counts_multi[1:])),counts_multi[1:]) plt.ylim(0,100) plt.show() #検定 n = sum(counts_multi) p = 1/8 X = counts_multi[8] z = (X - n*p) / (n*p*(1-p))**0.5 ok_Xs = np.linspace(-2.68, 2.68, num = 50) f = lambda x: (math.exp(-x**2/2)) / math.sqrt(2*math.pi) plt.plot([i*0.1-5 for i in range(100)],[f(i*0.1-5) for i in range(100)], color = "black") plt.fill_between(ok_Xs, np.zeros_like(ok_Xs),list(map(f, ok_Xs)),facecolor='darkred',alpha=0.5) plt.plot([z,z],[0,1], color = "blue") plt.ylim(0,0.4) plt.xlim(-4,10) plt.show()参考
終わりに
最後まで読んで頂きありがとうございました。もしも怪しいサイコロゲームを持ち掛けられた場合は、見えるサイコロの目の全てを記録しておくことをお勧めいたします、という謎コメントで終わろうと思います。
- 投稿日:2020-09-06T18:27:26+09:00
機械学習は平行四辺形を予測できるか?(2)内挿みたいなのに外挿ってどうなるかな??
前の記事
機械学習は平行四辺形を予測できるか?(1)外挿ってできるかな?前の記事を書いて思ったのですが、あまりプログラムテクニックが書いてありませんでした。でも、一応pyhtonで計算しているので、タグはpythonにしてあります。pythonで機械学習している人も多いだろうから、qiitaへの投稿でも良いですよね。。。
この計算は、scikit-learnで計算しています。さて、前の記事で外挿ができないことはわかりました。
じゃぁ、次のような問題は、どうなるでしょうか?問3:小さい値と大きい値で学習して、その間は予測できるか?
a b 角度c 学習用 0~50 and 1000~1100 0~100 0~90 内挿?外挿? 150~900 50 45 簡単な問題です。底辺の長さaを0~50、1000~1100で予測して、その間の150~900は予測ができるのでしょうか?
線形回帰のLassoは、たぶん予測できるのでしょう。でもランダムフォレストやニューラルネットワークは、どうなるのでしょうか?
このデータセットがあったら、0~1100まで予想できると、ついつい思ってしまいます。現実のデータは、こういう例がありそうです。結果です。
まず、学習の結果の決定係数とグラフです。
決定係数 学習 テスト Lasso回帰 0.686 0.661 ランダムフォレスト 0.999 0.975 ニューラルネットワーク 0.997 0.997 Lasso
ランダムフォレスト
ニューラルネットワーク
底辺aの値は、小さい値と大きい値にしてありますが、bと角度cがランダムに作られているため、面積のareaの領域はつながって見えます。グラフで見ると、ランダムフォレストの2つのはずれ値がなぜ出たのかはわかりませんが、でも、これらのグラフと決定係数をみれば、Lassoを選ぶ必要はないと感じてしまいますし、ランダムフォレスト最高!ニューラルネットワーク最高!って思いますよね。
では、底辺aで学習した間の値を予測するとどうなるか?です。
とりあえずグラフを見てみましょう。
Lasso
ランダムフォレスト
ニューラルネットワーク
底辺aの数値を学習の間に入れていますが、ニューラルネットワークは全然ダメです。これを見ると、ディープラーニングでの回帰予測は、しっかり内挿で予測しないと危ないですね。
ランダムフォレストもそうです。内挿、外挿をしっかり見極めないといけません。Lassoは、みてわかるように、近い値で予測できています。少しでも外挿の恐れがある場合は、線形回帰が良いということかもしれません。
結論
機械学習で外挿の予想はやめましょう。特に、内挿のように見える外挿が要注意です。少しで外挿の予想をしていると思ったら、線形であると仮定を立て、線形回帰で頑張りましょう。
ということかもしれません。
次は、記述子設計を検討してみます。


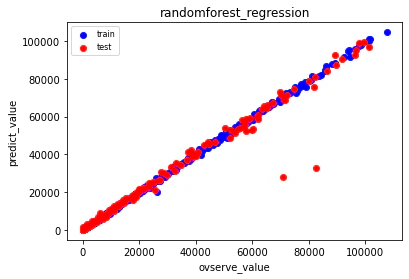
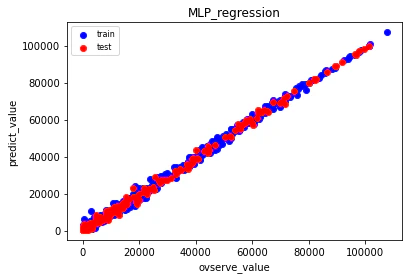
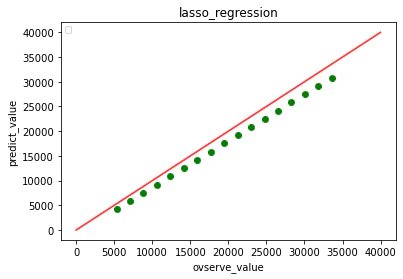

- 投稿日:2020-09-06T18:01:56+09:00
マッチングアプリの足跡自動化について勉強(Python, Selenium, BeautifulSoup,)
#!/usr/bin/env python # coding: utf-8 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from bs4 import BeautifulSoup from time import sleep driver = webdriver.Chrome('chromedriver') # ログイン自動化 # driver.get('https://with.is/auth/facebook') # id = driver.find_element_by_id("email") # id.send_keys('') # password = driver.find_element_by_id('pass') # password.send_keys('') # login_button = driver.find_element_by_id("loginbutton") # login_button.click() # login2 = driver.find_element_by_id('u_0_f') # login2.click() # code = driver.find_element_by_id('approvals_code') # val1 = input() # code.send_keys(val1) # nextlogin = driver.find_element_by_id('checkpointSubmitButton') # nextlogin.click() driver.get("https://with.is/#_=_") # ページ下部の更新 for i in range(10): driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") sleep(2) soup = BeautifulSoup(driver.page_source, 'html.parser') # リンクだけを取得 links = [url.get('href') for url in soup.find_all('a')] # リンクからユーザのみ抽出 links = [s for s in links if "users" in s] # ユーザの数だけアクセス for link in links: href = 'https://with.is/' + link driver.get(href) driver.back() sleep(1) driver.refresh()課題
- ログイン自動化がスマートじゃない
- 無限スクロールがスマートじゃない
- 投稿日:2020-09-06T17:33:38+09:00
Gmailでネタメールを一斉送信
動機
ラジオでネタ投稿を本格的にやろうと決意した。
採用数を上げるにはたくさんの投稿をするのは必須、いっぱい送らないと。
そんな中思ったのが、メールがめんどくさい。
基本的にネタはメールで投稿。1通につき1ネタ。10個のネタ送るのに10通のメール・・・。
ということで、一括でネタメールを一斉送信するものを作ろうと思った次第。準備
- 自動送信をするアカウントの「Googleシート」と「Googleドライブ」のAPIを有効化し、JSONファイルを入手する
- JSONファイルを Renameする。
- コードを書くファイルを作成する。
- jsonをファイルを同じフォルダに格納する
スプレッドシート
使うsheetは2つで、sheet名は「Index」、「Main」としました。内容は次の通り。
・Index:カウントのメールアドレスとパスワード、送信先、送信元、ラジオネーム、住所、名前
・Main:件名、ネタ、作成日、送信日、状態、結果Index
Main
ライブラリインストール
$ pip install gspread oauth2clientコード
send.py#メール送信関係 from email.mime.text import MIMEText from email.utils import formatdate import smtplib #API連携関係 import gspread from oauth2client.service_account import ServiceAccountCredentials import datetime from pprint import pprint scope = ["https://spreadsheets.google.com/feeds",'https://www.googleapis.com/auth/spreadsheets',"https://www.googleapis.com/auth/drive.file","https://www.googleapis.com/auth/drive"] creds = ServiceAccountCredentials.from_json_keyfile_name("creds.json", scope) client = gspread.authorize(creds) SPREADSHEET_KEY = '******************************************' sheet1= client.open_by_key(SPREADSHEET_KEY).worksheet('Index') sheet2= client.open_by_key(SPREADSHEET_KEY).worksheet('Main') # Index _id = sheet1.cell(2,1).value _pass = sheet1.cell(2,2).value _from = sheet1.cell(4,1).value _to = sheet1.cell(4,2).value _radioName = sheet1.cell(4,3).value _name = sheet1.cell(6,1).value _address = sheet1.cell(8,1).value # 全ての値を、dataという変数に代入しています。 data = sheet2.get_all_records() # データ数を取得 last_number = len(data) # pprint(data) for row in range(last_number): # 送信判定 status = data[row]["結果"] if status == "完了": continue # メール送信に必要な情報を抽出 body = data[row]["ネタ"] radioName = "ラジオネーム:" + _radioName msg = MIMEText(body + "\n\n" + radioName + "\n\n" + _address + "\n\n" + _name) # sheet更新 now = datetime.datetime.now() sheet2.update_cell(row + 2, 5 , now.strftime("%Y/%m/%d %H:%M:%S.%f")) sheet2.update_cell(row + 2, 6, "送信済み") sheet2.update_cell(row + 2, 7, "完了") msg['Subject'] = data[row]["件名"] msg['From'] = _from msg['To'] = _to msg['Date'] = formatdate() # pprint(msg) smtp = smtplib.SMTP('smtp.gmail.com', 587) smtp.ehlo() smtp.starttls() smtp.ehlo() smtp.login(_id, _pass) smtp.send_message(msg) smtp.close()補足
Python2系だと、次のエラーがでます。
Traceback (most recent call last): File "send.py", line 6, in <module> import gspread ModuleNotFoundError: No module named 'gspread'対応としては3系をインストールすればいいだけなんですが、Pythonに関して勉強不足なもんで、数時間詰まってしまいました。
参考

