- 投稿日:2020-09-06T22:29:37+09:00
AWS Batchでコンテナの実行方法および実行結果の確認
概要
自前で作成したコンテナをAWS Batchで使えるようにするためにいろいろ調べて試した流れのメモです。
rdkitを使いたかったのでrdkitを使えるコンテナを使用しています。事前準備
Dockerimage の作成
- 起動させるDockerコンテナのイメージを作成します。
FROM mcs07/rdkit:2020.03.2 # https://github.com/mcs07/docker-rdkit RUN apt-get update && apt-get upgrade -y RUN apt-get install python3-pip -y RUN pip3 install pandas && \ pip3 install numpy && \ pip3 install hashids && \ pip3 install xlsxwriter && \ pip3 install Pillow WORKDIR /dev/app COPY module . ENTRYPOINT ["python3", "src/pandasTest.py"]
- ディレクトリは以下のようになっています。
dockerfile module\data module\data\signal-datas_1.csv module\src module\src\logger.py module\src\pandasTest.py
- pandasTest.py
data/signal-datas_1.csvを読み込んで出力するだけの内容です。import pandas as pd from logger import LoggerObj if __name__ == "__main__": logObj=LoggerObj() log=logObj.createLog() log.info('処理開始') test=pd.read_csv('data/signal-datas_1.csv') log.info(test.head()) log.info('処理終了')
- looger.py
- ログ出力用のプログラム
長いので折りたたんでます
from logging import Formatter, handlers, StreamHandler, getLogger, DEBUG,INFO from datetime import datetime import configparser import os # ログの出力処理 class LoggerObj: loggers={} logger=None def __init__(self, name=__name__,logFilename='log_'): print('log作成:'+name+':'+logFilename) pass def createLog(self, name=__name__,logFilename='log_'): if len(self.loggers)!=0: if name in self.loggers: # すでに作成済みなら重複して作成しないようにする return self.loggers[name] self.logger = getLogger(name) self.logger.setLevel(DEBUG) formatter = Formatter("[%(levelname)s]:[%(asctime)s]: %(message)s") needoutput=True # stdout handler = StreamHandler() handler.setLevel(DEBUG) handler.setFormatter(formatter) self.logger.addHandler(handler) logdirectory='logs' os.makedirs(logdirectory,exist_ok=True) fileNamePath=logdirectory+'/'+logFilename if needoutput: logFileName=fileNamePath+datetime.now().strftime("%Y%m%d%H%M%S")+'.log' # file handler = handlers.RotatingFileHandler(filename = logFileName, maxBytes = 1048576, backupCount = 3) handler.setLevel(DEBUG) handler.setFormatter(formatter) self.logger.addHandler(handler) self.loggers[name]=self.logger return self.logger def debug(self, msg): self.logger.debug(msg) def info(self, msg): self.logger.info(msg) def warn(self, msg): self.logger.warning(msg) def error(self, msg): self.logger.error(msg) def critical(self, msg): self.logger.critical(msg)
- Docker imageの作成
- dockerfile を格納しているディレクトリに移動して以下のコマンドを実行します。
docker build -t pandastest/0.1 .ECRの作成
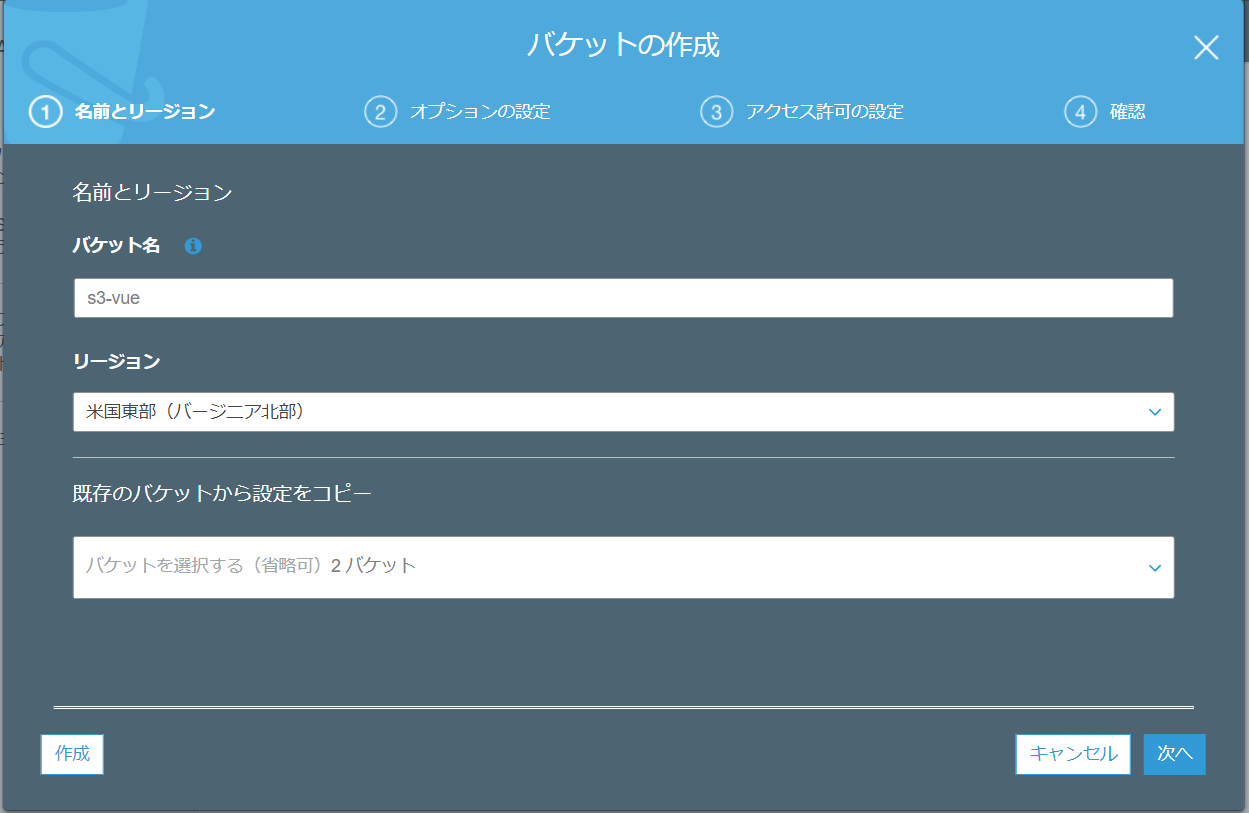
- AWSのコンソールからリポジトリを作成する。
- リポジトリの名前を設定します。
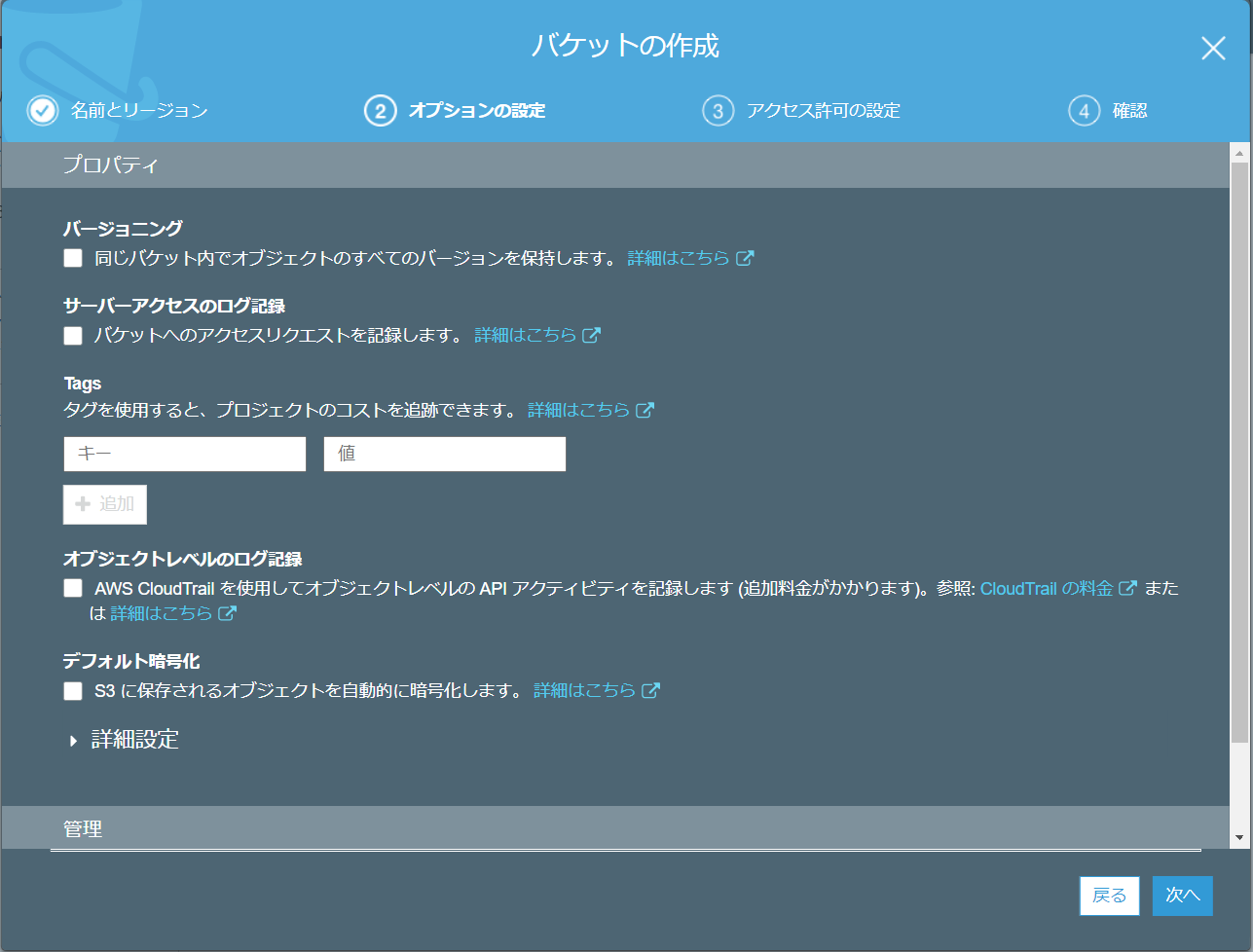
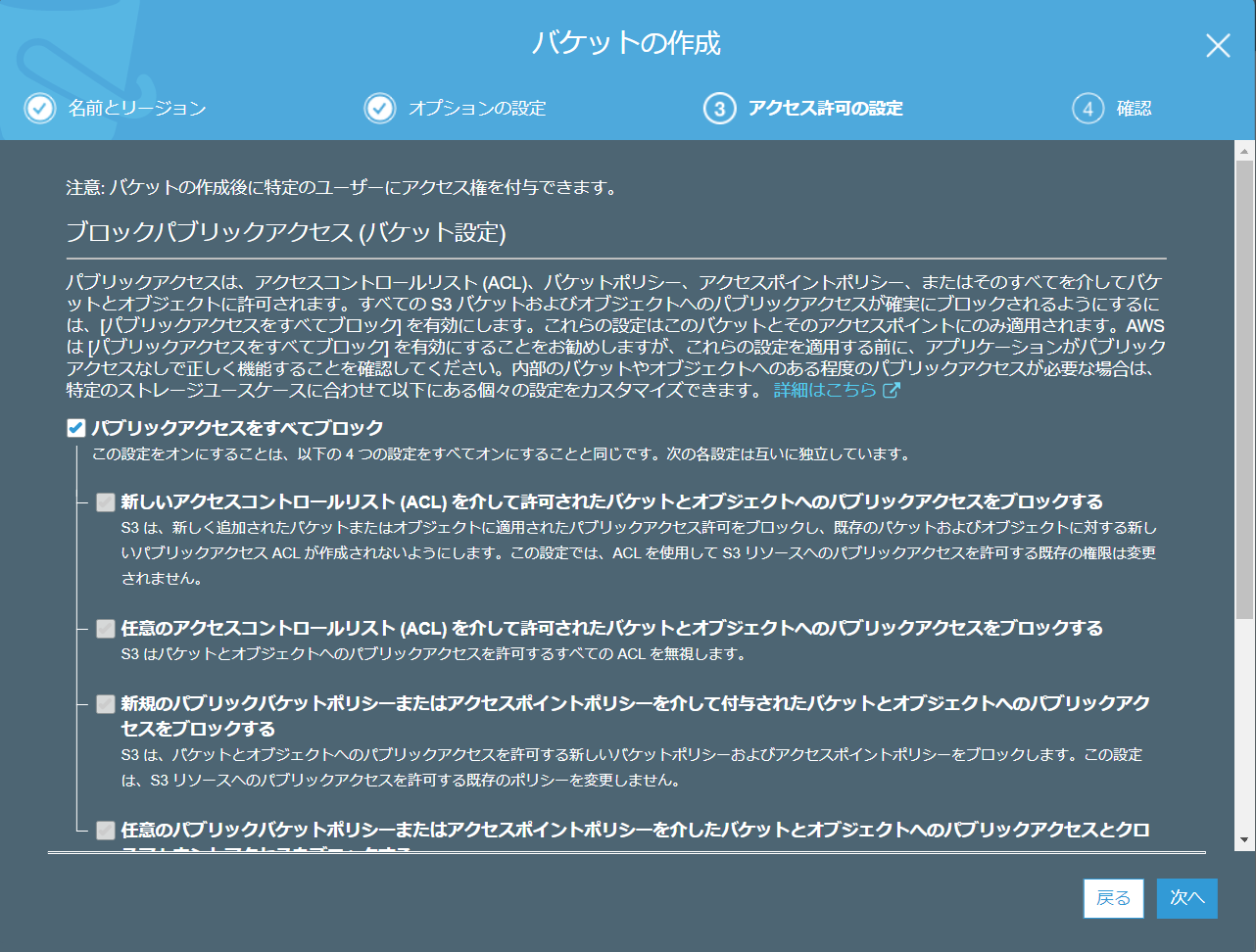
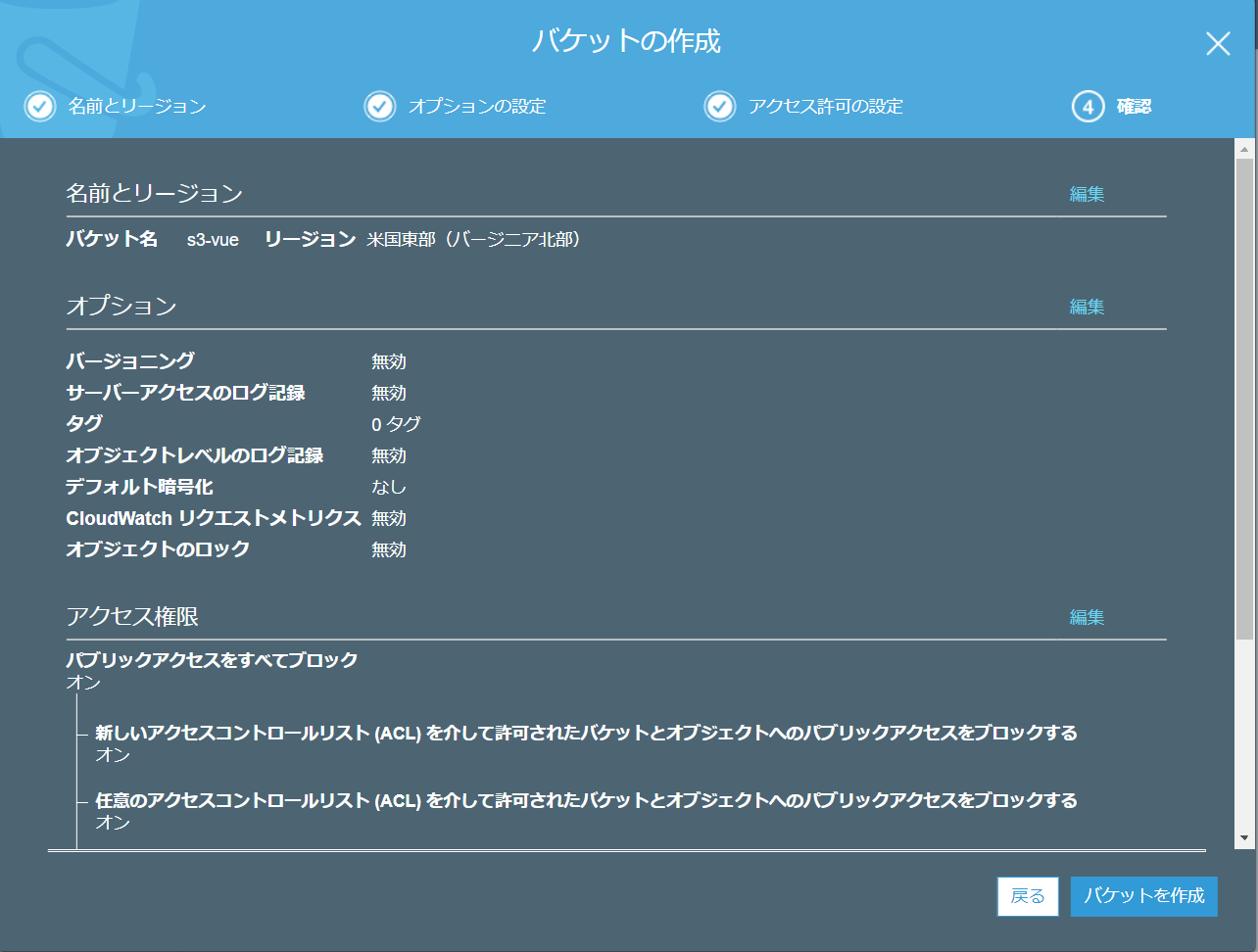
- コンテナのスキャンや暗号化は状況に応じて設定します。 今回はお試しなので省略しています。
ECRへのプッシュ
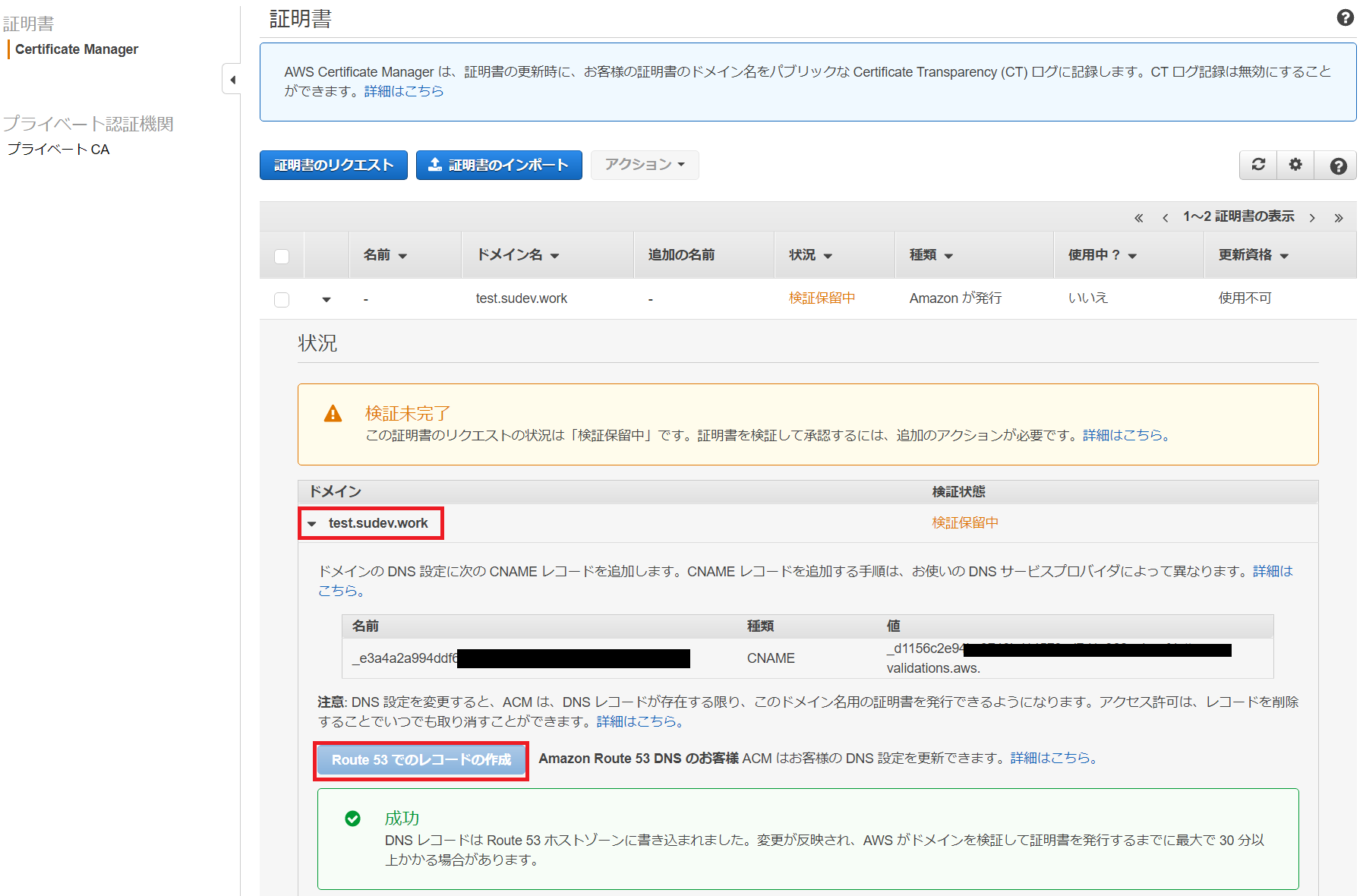
- 作成したリポジトリの
プッシュコマンドの表示ボタンを押下するとプッシュするための方法が出てきます。- 認証トークンの取得の部分がうまくいかなかったのでこちらを参考にログインコマンドを発行しました。そうするとdockerログイン用の情報が取得できます。すごく長いのでtextに吐き出すのがよさそうです
aws ecr get-login --no-include-email --region ap-northeast-1 > text.text
- AWS CLIでAWSに接続して操作できるようにcredentialsの設定が必要です。
- dockerログイン用のコマンドを実行します。吐き出したtextの内容をそのままコピペします。
docker login -u AWS -p xxxxxxxx https://yyyyyyyy.dkr.ecr.ap-northeast-1.amazonaws.com- docker imageにtagを付与します。ここはイメージ名などに合わせてください。
プッシュコマンドの表示で出てくる内容を使えばいいはずですが名前についてはの状況に合わせてください。
docker tag pandastest/0.1 yyyyyyyy.dkr.ecr.ap-northeast-1.amazonaws.com/pandastest:latest- imageに付与したtagを指定してECRへのプッシュします。
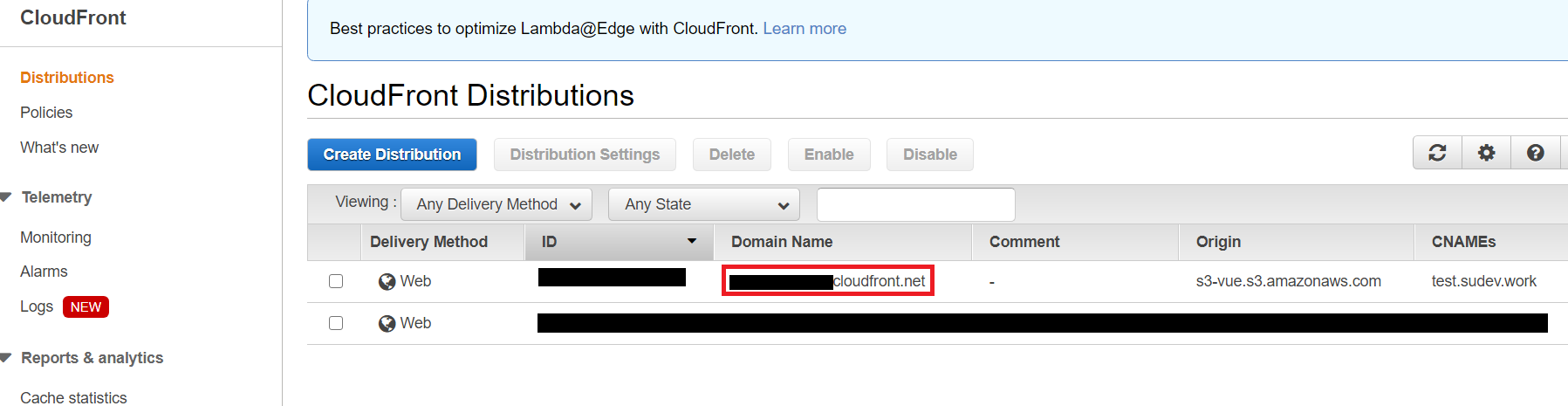
docker push yyyyyyyy.dkr.ecr.ap-northeast-1.amazonaws.com/pandastest:latest- ECRの画面でプッシュしたコンテナimageが登録されていることを確認します。 ## AWSBatchの作成
- AWSコンソール上から
Batchを選択します。- コンテナイメージにはECRに登録されているコンテナimageの
イメージの URIを設定します。ほかの項目については必要に応じて環境変数や引数などを設定します。- 作成後
ジョブの送信から作成したジョブを選択して実行します。- 結果は CloudWatch Log で確認できます。
- 投稿日:2020-09-06T18:01:46+09:00
AWX on AWS(EC2) を構築する
背景
AWXを触ってみたいとAWSに構築しようと思いましたところ、公式の構成はかなり冗長化されてて課金やばそう
ということでEC2にインストールして実行してみます
やること
EC2 を立てて、そこにAWXを導入します
AWS環境
項目 バージョン AMI Ubuntu Server 18.04 LTS (HVM), SSD Volume Type - ami-08046c40513c3265e (64 ビット x86) Ubuntu Ubuntu Server 18.04 LTS (HVM) 構築
EC2を立てる
以下の要件に従って作成します。
私は
Ubuntu Server 18.04 LTS (HVM), SSD Volume Typeをt2.midiumで立ち上げましたポートは80, 443, 22を開けてます
System Requirements
The system that runs the AWX service will need to satisfy the following requirements
- At least 4GB of memory
- At least 2 cpu cores
- At least 20GB of space
- Running Docker, Openshift, or Kubernetes
- If you choose to use an external PostgreSQL database, please note that the minimum version is 10+.
AWXを導入する
以下のAWX公式リポジトリのマークダウンに方法が書いてありますので、これを基準に進めます
https://github.com/ansible/awx/blob/devel/INSTALL.md
AWSのインストールをする前に以下のパッケージが必要になりますので、準備していきます
Prerequisites
Before you can run a deployment, you'll need the following installed in your local environment:
- Ansible Requires Version 2.8+
- Docker
A recent version
- docker Python module
This is incompatible with docker-py. If you have previously installed docker-py, please uninstall it.
We use this module instead of docker-py because it is what the docker-compose Python module requires.
- GNU Make
― Git Requires Version 1.8.4+
- Python 3.6+
- Node 10.x LTS version
This is only required if you're building your own container images with use_container_for_build=false
- NPM 6.x LTS
This is only required if you're building your own container images with use_container_for_build=false
Ansibleのインストール
リポジトリを更新して最新版をインストールします
sudo apt update sudo apt install software-properties-common sudo apt-add-repository --yes --update ppa:ansible/ansible sudo apt install ansible -yapt標準のリポジトリだとVersionが2.8まで上がらないので以下のようなエラーが表示されるので注意
hoge@hogehoge:~/awx/installer$ ansible-playbook -i inventory install.yml /usr/lib/python2.7/dist-packages/ansible/parsing/vault/__init__.py:44: CryptographyDeprecationWarning: Python 2 is no longer supported by the Python core team. Support for it is now deprecated in cryptography, and will be removed in a future release. from cryptography.exceptions import InvalidSignature ERROR! no action detected in task. This often indicates a misspelled module name, or incorrect module path. The error appears to have been in '/home/ubuntu/awx/installer/roles/local_docker/tasks/compose.yml': line 39, column 7, but may be elsewhere in the file depending on the exact syntax problem. The offending line appears to be: - block: - name: Start the containers ^ hereDockerのインストール
https://docs.docker.com/engine/install/ubuntu/
sudo apt-get remove docker docker-engine docker.io containerd runcsudo apt-get update sudo apt-get install \ apt-transport-https \ ca-certificates \ curl \ gnupg-agent \ software-properties-commoncurl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -Verify that you now have the key with the fingerprint 9DC8 5822 9FC7 DD38 854A E2D8 8D81 803C 0EBF CD88, by searching for the last 8 characters of the fingerprint.
sudo apt-key fingerprint 0EBFCD88sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable"sudo apt-get update sudo apt-get install docker-ce docker-ce-cli containerd.io -yGNU Makeのバージョン確認
これはたぶんデフォで入っているはず
$ make --version GNU Make 4.1 Built for x86_64-pc-linux-gnu Copyright (C) 1988-2014 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law.Gitのバージョン確認
これもデフォで入っとった。
$ git --version git version 2.17.1Python3.7 のインストール
$ python3 --version Python 3.6.93.6はすでに入っているようですが、もうすぐEOLになるので3.7にしときます。
この後でawxをgit pullした後にpipenvでバージョン固定します
(いる人は)pipのインストールとDocker pythonモジュールのインストール
sudo apt install python-pip -y pip install dockernode, npmのインストール
sudo apt install nodejs npm -y sudo npm install npm --globalAWXをGitリポジトリからpull
git clone https://github.com/ansible/awx.gitpythonのバージョン固定
# 必要なライブラリのインストール sudo apt-get install git gcc make openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-dev zlib1g-dev -y # pyenvをGitリポジトリからクローン git clone https://github.com/pyenv/pyenv.git ~/.pyenv # バッシュ設定 echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc echo 'eval "$(pyenv init -)"' >> ~/.bashrc source ~/.bashrc # 3.7.9インストール pyenv install 3.7.9 # ローカルは3.7.9に固定 cd awx/ pyenv local 3.7.9こんな感じ
~/awx$ python --version Python 3.7.9これをしないと
TASK [local_docker : Start the containers] ***************************************************************************************fatal: [localhost]: FAILED! => {"changed": false, "msg": "Failed to import the required Python library (Docker SDK for Python: docker (Python >= 2.7) or docker-py (Python 2.6)) on ip-10-2-1-31's Python /usr/bin/python3. Please read module documentation and install in the appropriate location. If the required library is installed, but Ansible is using the wrong Python interpreter, please
consult the documentation on ansible_python_interpreter, for example via `pip install docker` or `pip install docker-py` (Python 2.6). The error was: No module named 'requests'"}
各種設定を実施
インストールする際のパスワードやポートの設定を、inventoryファイルに行います
vi ~/awx/installer/inventoryinstall用のplaybookを実行
インストーラ実行
cd ~/awx/installer sudo ansible-playbook -i inventory install.ymlトラブル
この時に以下のような問題で少しと間取りましたので、同じかた見えましたら以下参照ください
pyenvでpython3を標準利用にしてたが、そのせいで動作しない
~/awx/installer/inventoryにはpython3を使うようなコマンドが入っているためこれをpythonにするように変更pipでdocker-pyとdockerを両方実行してしまった
docker-pyはdockerに含まれるようになったので、一度両方削除してからdockerのみ実行する
https://qiita.com/hasegit/items/e0bd58eff8e4ab2bde3e
まとめ
何とかインストールできました。
いろいろ触ってみたいと思います

- 投稿日:2020-09-06T16:41:40+09:00
【忘備録】AmazonLinux2にseleniumを導入し、GUIで操作する。
概要
内容
- EC2をデスクトップ化して、seleniumを導入する
メリット
- EC2環境で、seleniumの挙動をGUIで確認できる。
- 他の記事では、headressで起動しないとできないと記載されていたが、この方法を使えばGUIで挙動を確認できる
参考資料
https://qiita.com/hitomatagi/items/e63dd8c4b879de156628
https://qiita.com/onorioriori/items/4fa271daa3621e8f6fd9
https://qiita.com/natsu_san/items/e8b17306385d5ab72969作業工程
AmazonLinux2にデスクトップ環境を作成する
Python3を導入する
MATE上部にあるAplication→System Tools→Mate Terminalを起動
- yumを最新の状態にする
$ sudo yum -y update $ sudo yum -y install gcc openssl-devel bzip2-devel libffi-devel
- Pythonをダウンロードする
- バージョンは問わない。今回は3.8.1
$ wget https://www.python.org/ftp/python/3.8.1/Python-3.8.1.tgz $ tar xzf Python-3.8.1.tgz
- Python3をインストールする。
$ cd Python-3.8.1 $ sudo ./configure --enable-optimizations $ sudo make altinstall
- インストールされているか確認する
$ python3.8 --version Python 3.8.1 $ pip3.8 --version pip 19.2.3 from /usr/local/lib/python3.8/site-packages/pip (python 3.8)
- PATHを差し替える
- rootからもPython3.8を使えるようにパスを通しシンボリックリンクをはっておく
$ sudo visudo (Before) Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin (After) Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin:/usr/local/sbin:/usr/local/bin
- シンボリックリンクを作成する
$ sudo ln -s /usr/local/bin/python3.8 /usr/local/bin/python3 $ sudo ln -s /usr/local/bin/pip3.8 /usr/local/bin/pip3seleniumを導入する
- Google Chromeをインストール
$ curl https://intoli.com/install-google-chrome.sh | bash
- GConf2のインストール
- ChromeDriverを実行する時はGConf2がないと動作しない。
- yum install GConf2を行っても「No package GConf2 available.」となるので、 リポジトリを追加する。
$ sudo vim /etc/yum.repos.d/centos.repocentos.repo[CentOS-base] name=CentOS-6 - Base mirrorlist=http://mirrorlist.centos.org/?release=6&arch=x86_64&repo=os gpgcheck=1 gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-6 #released updates [CentOS-updates] name=CentOS-6 - Updates mirrorlist=http://mirrorlist.centos.org/?release=6&arch=x86_64&repo=updates gpgcheck=1 gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-6 #additional packages that may be useful [CentOS-extras] name=CentOS-6 - Extras mirrorlist=http://mirrorlist.centos.org/?release=6&arch=x86_64&repo=extras gpgcheck=1 gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-6
- これでインストールができるようになる。
$ yum -y install GConf2
- Google Chromeのバージョンを確認
$ google-chrome-stable -version Google Chrome 84.0.4147.135
- 上記のバージョンに合わせたKeyをこちらに合わせて導入
$ wget https://chromedriver.storage.googleapis.com/{chromeのバージョン番号}/chromedriver_linux64.zip
- 解凍してchromedriverを移動
$ unzip chromedriver_linux64.zip $ sudo mv chromedriver /usr/local/bin/
- そのままでは文字化けするため、google-notoをインストール
sudo yum install google-noto* -y
- seleniumを導入
$ sudo pip3 install selenium
- seleniumをテスト起動
test.py# Library from selenium import webdriver from selenium.webdriver.chrome.options import Options # Options options = Options() options.add_argument('--disable-extensions') options.add_argument('--proxy-server="direct://"') options.add_argument('--proxy-bypass-list=*') options.add_argument('--start-maximized') # Chrome driver = webdriver.Chrome(options=options) driver.get('https://www.google.co.jp/')
- 日本語が文字化けせずに、表示されれば成功
- 投稿日:2020-09-06T15:56:16+09:00
Azure Cloud Shellを最強のAWS CLI環境にする
最近Azureも触りだしましたが、AWSにない便利な機能の一つに
Azure Cloud Shellがあります。Azure Cloud Shellとは
Azure Cloud Shell は、Azure リソースを管理するための、ブラウザーでアクセスできる対話形式の認証されたシェルです。 Bash または PowerShell どちらかのシェル エクスペリエンスを作業方法に合わせて柔軟に選択できます。
https://docs.microsoft.com/ja-jp/azure/cloud-shell/overview
ブラウザからちょっとしたコマンドが実行できるので便利ですね。また、Windows ターミナルやスマホアプリからも使用することができます。
Azure Cloud shellの環境にAWS CLIをインストールしてしまおうという作戦です。
Azure Cloud Shellの概要
公式サイトからの引用です
概念
- Cloud Shell は、ユーザーごとにセッション単位で一時的に提供されるホスト上で実行されます。
- Cloud Shell は、無操作状態で 20 分経過するとタイムアウトとなります。
- Cloud Shell では、Azure ファイル共有がマウントされている必要があります
- Cloud Shell では、Bash と PowerShell に対して同じ Azure ファイル共有が使用されます
- Cloud Shell には、ユーザー アカウントごとに 1 台のマシンが割り当てられます。
- Cloud Shell はファイル共有に保持されている 5 GB のイメージを使用して $HOME を永続化します
- Bash では、標準の Linux ユーザーとしてアクセス許可が設定されます。
Bashが使え、5GBのファイル領域があり、$HOMEは永続化されるところがポイントです。
価格
Cloud Shell のホストとなるマシンは無料です。ただし、前提条件として Azure Files 共有をマウントする必要があります。 ストレージのコストは通常どおりに適用されます。
月額約¥6.72/Giなので5G使っても月35円ぐらいです。
AWS CLI V2のインストール
Linux での AWS CLI バージョン 2 のインストールを参考にしますが、ポイントは
- ホームディレクトリ内にインストールする
です。
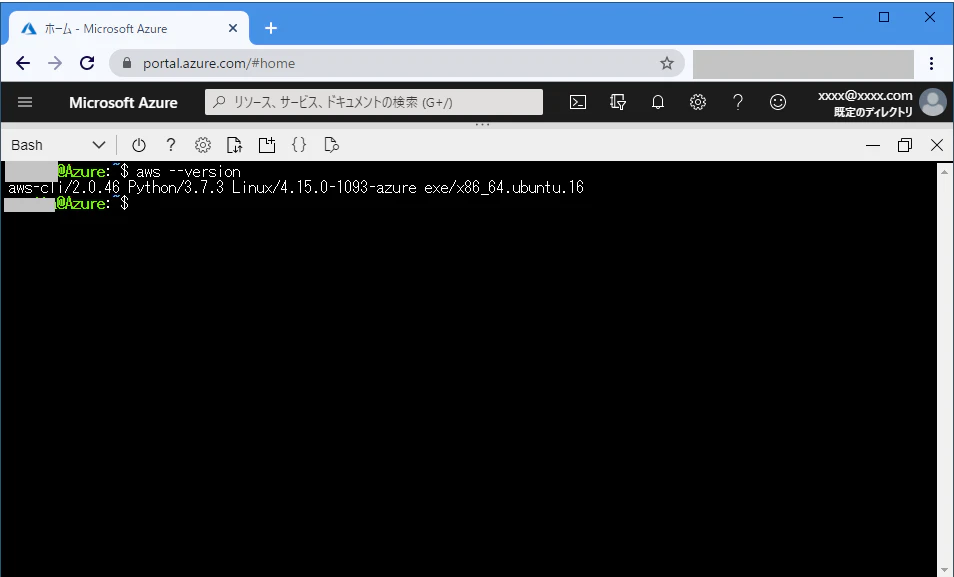
@Azure:~$ curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 31.9M 100 31.9M 0 0 102M 0 --:--:-- --:--:-- --:--:-- 102M @Azure:~$ unzip -q awscliv2.zip @Azure:~$ ./aws/install -i ~/aws-cli -b ~/bin You can now run: /home/xxxxxx/bin/aws --version @Azure:~$ rm -rf aws @Azure:~$ rm -rf awscliv2.zip @Azure:~$@Azure:~$ ~/bin/aws --version aws-cli/2.0.46 Python/3.7.3 Linux/4.15.0-1093-azure exe/x86_64.ubuntu.16 @Azure:~$
~/binディレクトリにパスが通るように、.bashrcに書いておきましょう@Azure:~$ echo 'export PATH=~/bin:$PATH' >> .bashrc @Azure:~$@Azure:~$ source .bashrc @Azure:~$ aws --version aws-cli/2.0.46 Python/3.7.3 Linux/4.15.0-1093-azure exe/x86_64.ubuntu.16 @Azure:~$これでインストールは完了です。
認証情報の設定
通常、AWSの認証情報は
~/.awsに保管されますが、Azure Cloud Shellの説明にSSH キーなどのシークレットを格納するときは、ベスト プラクティスを使用します。 Azure Key Vault などのサービスには、設定用のチュートリアルが用意されています。
とありますので、これを使って認証情報を保存してみましょう。
Key Vaultの作成と認証情報の登録
Key Vaultの作成
cloud-shell-aws-cliがKey Vaultの名称です。@Azure:~$ az keyvault create --name cloud-shell-aws-cli --resource-group [リソースグループ名] --location japaneastAWS アクセスキーの登録
@Azure:~$ az keyvault key create --vault-name cloud-shell-aws-cli --name aws-access-key-id --protection software @Azure:~$ az keyvault secret set --vault-name cloud-shell-aws-cli --name aws-access-key-id --value [AWS アクセスキー]シークレットキーの登録
@Azure:~$ az keyvault key create --vault-name cloud-shell-aws-cli --name aws-secret-access-key --protection software az keyvault secret set --vault-name cloud-shell-aws-cli --name aws-access-key-id --value [シークレットキー]AWS リージョンの登録(機密性はありませんが。。)
@Azure:~$ az keyvault key create --vault-name cloud-shell-aws-cli --name aws-default-region --protection software @Azure:~$ az keyvault secret set --vault-name cloud-shell-aws-cli --name aws-default-region --value ap-northeast-1Key Vaultに登録した値の取得
登録した値の取得は以下でできます。
@Azure:~$ az keyvault secret show --vault-name cloud-shell-aws-cli --id https://cloud-shell-aws-cli.vault.azure.net/secrets/aws-default-region { "attributes": { "created": "2020-09-06T02:02:45+00:00", "enabled": true, "expires": null, "notBefore": null, "recoveryLevel": "Recoverable+Purgeable", "updated": "2020-09-06T02:02:45+00:00" }, "contentType": null, "id": "https://cloud-shell-aws-cli.vault.azure.net/secrets/aws-default-region/28db5ad04abf4a1a92d43f7ae9cccae8", "kid": null, "managed": null, "name": "aws-default-region", "tags": { "file-encoding": "utf-8" }, "value": "ap-northeast-1" } @Azure:~$このままだと扱いづらいので必要な値だけを取得します。
@Azure:~$ az keyvault secret show --vault-name cloud-shell-aws-cli --id https://cloud-shell-aws-cli.vault.azure.net/secrets/aws-default-region --output tsv --query "[value]" ap-northeast-1 @Azure:~$余談となりますが、
az keyvault secret showのパラメーターで必要なidはhttps://[Key Vault名].vault.azure.net/secrets/[Key名]の書式ですが、以下のコマンドで取得することも可能です。@Azure:~$ az keyvault secret list --vault-name cloud-shell-aws-cli [ { "attributes": { "created": "2020-09-06T02:01:33+00:00", "enabled": true, "expires": null, "notBefore": null, "recoveryLevel": "Recoverable+Purgeable", "updated": "2020-09-06T02:01:33+00:00" }, "contentType": null, "id": "https://cloud-shell-aws-cli.vault.azure.net/secrets/aws-access-key-id", "managed": null, "name": "aws-access-key-id", "tags": { "file-encoding": "utf-8" } }, { "attributes": { "created": "2020-09-06T02:02:45+00:00", "enabled": true, "expires": null, "notBefore": null, "recoveryLevel": "Recoverable+Purgeable", "updated": "2020-09-06T02:02:45+00:00" }, "contentType": null, "id": "https://cloud-shell-aws-cli.vault.azure.net/secrets/aws-default-region", "managed": null, "name": "aws-default-region", "tags": { "file-encoding": "utf-8" } }, { "attributes": { "created": "2020-09-06T02:01:44+00:00", "enabled": true, "expires": null, "notBefore": null, "recoveryLevel": "Recoverable+Purgeable", "updated": "2020-09-06T02:01:44+00:00" }, "contentType": null, "id": "https://cloud-shell-aws-cli.vault.azure.net/secrets/aws-secret-access-key", "managed": null, "name": "aws-secret-access-key", "tags": { "file-encoding": "utf-8" } } ] @Azure:~$ここまでで認証情報をKey Vaultに登録及び取得ができました。
なのでこれも
.bashrcに登録しちゃいましょう。@Azure:~$ echo 'export AWS_ACCESS_KEY_ID=`az keyvault secret show --vault-name cloud-shell-aws-cli --id https://cloud-shell-aws-cli.vault.azure.net/secrets/aws-access-key-id --output tsv --query "[value]"`' >> .bashrc @Azure:~$ echo 'export AWS_SECRET_ACCESS_KEY=`az keyvault secret show --vault-name cloud-shell-aws-cli --id https://cloud-shell-aws-cli.vault.azure.net/secrets/aws-secret-access-key --output tsv --query "[value]"`' >> .bashrc @Azure:~$ echo 'export AWS_DEFAULT_REGION=`az keyvault secret show --vault-name cloud-shell-aws-cli --id https://cloud-shell-aws-cli.vault.azure.net/secrets/aws-default-region --output tsv --query "[value]"`' >> .bashrc @Azure:~$@Azure:~$ source .bashrc @Azure:~$動作確認
@Azure:~$ aws sts get-caller-identity { "UserId": "XXXXXXXXXXXXXXXXXXX", "Account": "999999999999", "Arn": "arn:aws:iam::999999999999:user/XXXXXXXXXX" }うまくいきました。
- 投稿日:2020-09-06T14:16:05+09:00
【AWS】課金料金をなるべくなくす【初心者】
はじめに(ターゲット層の方)
・初めてWebアプリケーションをAWSを使いデプロイした後、料金が発生してしまい困っている方
・ポートフォリオとして使っていたWebアプリを転職成功などの理由により使用しなくなった方CloudTrail、CloudWatch
・課金が発生したリージョンを選択。
・「CloudTrail」「CloudWatch」該当ページに行き、以前設定したファイルを削除するだけでいい。EC2
料金画面
Amazon Elastic Compute Cloud running Linux/UNIX
実行しているインスタンスを停止するだけでOK。EBS
料金画面
停止されたものも含めてインスタンスが4つ以上あり、容量オーバーによって料金が発生している。
4つ以上から料金が発生してしまう模様。3つ以下にインスタンスを減らすこと。
参考:https://gattsu09.hatenadiary.com/entry/2017/11/11/094102Elastic IP Addresses
料金画面
・Elastic IPによる料金が発生している。インスタンスに関連づけられていたElastic IPを開放すればOK。使用していないEIPを解放しないまま放置してしまうと料金が発生してしまうため注意
・自動的にEC2内でスナップショットを保存している時があるため、そちらを削除する。
→紐づけられているAMIがあるため削除できないと言われたら、EC2内の左選択バー内にあるAMIを選択し、該当のAMIを削除すればスナップショットを削除できるようになる。
参考:https://qiita.com/Yuji-Ishibashi/items/bb1c0042fd16a9350c5aRDS
料金画面
・起動しているRDSを削除すれば課金が止まる。停止しても7日間経てば自動的に起動してしまうため注意。
・削除する際、スナップショット(バックアップのようなもの)を作成すること。
参考①:https://dev.classmethod.jp/articles/aws-rds-startandstop/
参考②:https://sys-guard.com/post-7264/Route53
料金画面
Route53の画面に行き、該当のホストゾーンを削除すればOK。S3
料金画面
該当のリージョンにあるS3のバケットを削除すればOK。






- 投稿日:2020-09-06T13:25:22+09:00
AWS認定ソリューションアーキテクトプロフェッショナルを受験した時の話
この記事の概要
2020/09/06と2021/02/28の2回
AWS認定ソリューションアーキテクト - プロフェッショナル
(AWS Certified Solution Architect - Professional (SAP-C01))
を受験したので、その時の記録1度不合格となり、約半年後に再挑戦しなんとか合格しました。
その時の反省も踏まえて、振り返ります。試験の概要
プロフェッショナルレベル(一番上)の設計者向け試験です。
「AWSプラットフォームでの分散アプリケーションおよびシステムの設計における高度な技術スキルと経験を認定します。」
AWS公式より引用:引用元◼︎ 試験要項
問題数 :75問
試験時間 :180分
受験料 :¥30,000(税別)
合格ライン:100~1000点中750点(約72%)
受験資格 :なし
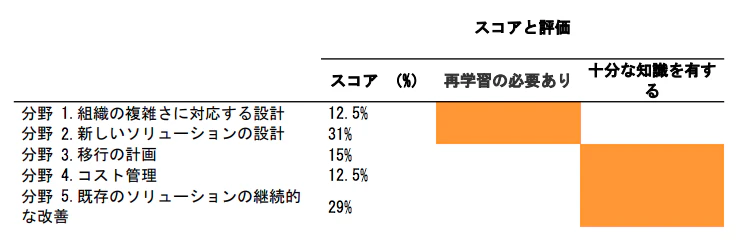
有効期限 :3年◼︎ 出題範囲
分野 出題割合 分野 1: 組織の複雑さに対応する設計 12.5% 分野 2: 新しいソリューションの設計 31% 分野 3: 移行の計画 15% 分野 4: コスト管理 12.5% 分野 5: 既存のソリューションの継続的な改善 29% 2021/02時点の最新バージョン(Ver.1.3)のものです。
バージョンアップで範囲等は変更されるので、受験時は公式で確認してください。
AWS 認定 ソリューションアーキテクト - プロフェッショナル | AWS勉強開始前の状態
AWSで動いているアプリ開発の業務経験3年(SDKによる開発を2年、インフラの設計構築は半年程度)
半年ほど前までにアソシエイト3資格を取得済み
AWSソリューションアーキテクトを受験した時の話
https://qiita.com/aminosan000/items/24c6dff9532658a5c4d5
https://qiita.com/aminosan000/items/89bc76f77626314f3182
https://qiita.com/aminosan000/items/b1765260e8ad1435a366勉強に使ったもの
1. 試験対策本
AWS認定ソリューションアーキテクト-プロフェッショナル ~試験特性から導き出した演習問題と詳細解説
2020/08時点での唯一のプロフェッショナル対策本、前回SysOps受験時に購入した3資格対策本のシリーズなので期待して購入。
内容的にはSAA保有程度の知識を持っている人向けにSAP取得に必要なサービスと考え方を順に解説する内容が2割、問題集が4割、問題集の解答に対する解説が4割程度。オンライン問題集だと解説がないため、この解説が結構ありがたい。2. オンライン練習問題(非公式)
AWS Certified Solution Architect Professional | Whizlabs
アソシエイト試験でもお世話になり、おもはやおなじみとなった「Whizlabs」
最新のバージョンの問題が400問(80問×5パターン)用意されています。
プロフェッショナルはアソシエイトより少し高いようで 29.95USD の 50%off で 14.97USD でした。(アソシエイト系も私が購入したときより 5USD 値上げされて 24.95USD になってました。それでも書籍の問題集の半額程度なのでやっぱりコスパ抜群!)
前回同様、Google翻訳で翻訳しながら日本語が怪しい部分は原文とあわせながら利用。
3. AWS公式模擬試験
4. AWSアカウント
今回はアソシエイト系に比べるときちんとした理解が必要そうなので、現時点での不足知識を補う意味で書籍の前半をゆっくり読むところから開始。
あとはひたすら問題集を解き、書籍や問題集で知らないサービスやワードが出てきたらググる、イメージが沸かないものは実際にマネコンでも触るってみる〜の流れで勉強しました。(この辺は今までと一緒)
アソシエイトの時に利用したAWS WEB問題集で学習しよう
は、フリープランだとプロフェッショナルの問題数は7問と少なく、全問(350問)利用するためにはダイヤモンドプラン:90日/¥5,480(税抜き)の登録が必要なので、今回は利用せず。〜〜〜〜〜ここからは1回目試験受験後の追加勉強〜〜〜〜〜
5. AWS公式デジタルトレーニング「Exam Readiness: AWS Certified Solutions Architect – Professional (Japanese)」
公式から公開されているSAPの学習動画です。なんと日本語!
https://www.aws.training/Details/eLearning?id=424036. Udemyの模擬試験
AWS 認定ソリューションアーキテクト プロフェッショナル模擬試験問題集(全5回分375問)
https://www.udemy.com/share/1020WGBkAfc1xWQ3o=/5回分解いて、解答・解説を読みながら理解の浅い部分をBlackBeltなどで勉強。
忘れそうな部分や、より理解を深めたい部分は自分の言葉で要約しながら記事にまとめてみたり、要点だけメモとしてアウトプットして、何度も見返す。勉強時間
1回目30時間、2回目70時間のトータルで100時間ぐらい
受験後
■1回目
仕事の都合で受験日を決めてしまっていたので、Whizlabsの最後の確認テストは実施せずに受験。
勉強時間30時間程度、あと20点足りず…
おおよその内訳はこんな感じ
- 分野1「組織の複雑さに対応する設計」: IAMの権限決定ロジックやOrganizationsやCloudFormation/サービスカタログによる複数アカウントの管理、Direct ConnectとVPNを利用したハイブリッドアーキテクチャに対する理解が足りていなかった。
- 分野2「新しいソリューションの設計」: この分野は特定のサービスとかではなく、AWSのいろいろなサービスを組み合わせてセキュリティ・信頼性・パフォーマンスの高い設計ができることを求める。 類似のサービスの細かな違いやパフォーマンス向上のための機能や手法に対する理解が足りていなかった。
■2回目
1度目の受験から約5ヶ月経ってから再勉強開始、さすがに2度目の不合格は避けたかったので、追加で勉強約70時間。
今度は問題集5回分+理解の浅い部分(IAM, Organizations, Direct Connect, CloudFormationなど)をBlackBeltやネット上の記事を読み漁り、苦手分野を克服。
※Kinesisファミリーも結構勉強したんですが、ほぼ出ませんでした。
分野1と分野2は「十分な知識を有する」になりました。
正直、AWS認定試験は日本語翻訳が結構怪しくて、謎の単語が出てきたり、英語がそのままカタカナになっていたりするので、すっきり自信を持って回答できない問題もあって結構焦りました。
(「workload→作業負荷」とか、「promote→プロモート」とか)今回の受験でいろいろと消耗したので、しばらくはAWS認定は受けないと思います…
受けるとしても、比較的軽そうな「AWS 認定セキュリティ - 専門知識(SCS-C01)」あたりですかね。勉強になったことメモ
試験のために勉強しながら忘れないように書き溜めたメモたち
※ここに書いてあることは、あくまで私が理解が足りないと感じ、覚えたかったことで、必ずしも試験で出る範囲ではありません。試験範囲を網羅はしていません。■組織の管理
クロスアカウント認証とアクセス戦略
IAMによる認証
ユーザ/グループ/ロール/ポリシーの違いとフェデレーション,SSOについては頻出(というかいろんな問題に絡んでくる)っぽいので要理解。
同じような選択肢で違いが「IAMユーザ」「IAMグループ」「IAMロール」のみの場合に引っかからなくなるだけでも得点率が上がる。↓IAMは覚えることが多いので別途まとめ
AWS IAM再入門AWS Organizations
SCPとIAMによる権限の制御については要理解
↓これも頻出、かつ普段利用機会が少ないので個別でまとめ
AWS Organization再入門AWS Directory Service
AWS Directory Serviceを利用することで既存の組織のADとAWSの権限管理の統合など、ユーザ管理を効率化することができる。
選択肢 概要 AWS Managed Microsoft AD AWS上にMicrosoft ADを構築することができる、ライセンス料が含まれるためコストは高め。 Active Directory Connector オンプレ等の既存のADと接続/統合することで新規ユーザ管理を不要とする、この機能を利用して社内の既存ユーザIDを利用したAWS WorkSpaceやマネコンのSSOも実現できる。 Simple Active Directory AWS上にシンプルなマネージドのADを構築できる。Microsoft AD等と比べ機能が少ない。例えばMFAなどは利用できない。 AWS RAM(Resource Access Manager)
特定のAWSリソースを他のAWSアカウントと共有できる。
ハイブリッドアーキテクチャ
オンプレとVPCの接続
ハイブリッドアーキテクチャの実現や、社内イントラからAWSへのパブリックなNWを経由しないアクセスの実現のための選択肢は2つある
選択肢 概要 メリット デメリット Direct Connect データセンターや社内イントラとVPCを物理的に専用線で接続する ・専用線なのでNW帯域を確保しやすい ・開通までに時間がかかる
・高コストVPN接続 暗号化された仮想の専用線を経由する ・即時構築、接続可能
・低コスト・物理線はインターネットを経由するのでNW輻輳の影響を受ける それぞれにメリット・デメリットがあるので、要件に応じて選択する。
また、2つを組み合わせた冗長構成も可能なので、Direct Connectを主系経路とし、VPNを副系経路とすることで、高可用性とコスト削減を両立できる。この場合平常時はDirect Connectを優先し、障害時はVPNに自動的にフェイルオーバーさせることができる。
- 複数リージョンや複数VPCに専用線接続したい場合はDirect Connectゲートウェイを利用。
- S3やDynamoDBへのアクセスはパブリック仮想インターフェース(VPCゲートウェイエンドポイントを作成してもDirect Connectからのアクセスはできない)、VPC内へのアクセスはプライベート仮想インターフェース
■LAG(Link Aggregation Group)
LACP(Link Aggregation Control Protocol)を利用し、複数のDirect Connect接続をまとめる機能。
LAGにはいくつかルールがある。
- 全ての接続は同じ帯域幅を使用する必要がある。
- 最大4個の接続。
- すべての接続は同じDirect Connectエンドポイントで終了する必要がある。
AWS Storage Gateway
標準的なストレージプロトコルを利用してオンプレミスからAWSのストレージサービスへのアクセスを可能にするハイブリッドストレージサービス
種類 概要 ファイルゲートウェイ ・NFSインターフェース
・S3オブジェクトをバックエンドとしたファイルストレージ
ボリュームゲートウェイ ・iSCSIブロックインターフェース
・S3およびEBSスナップショットをバックエンドとしたブロックストレージ
・オンプレのディスクデータのスナップショットをS3上に作成しDRに利用したり、ストレージの拡張として利用テープゲートウェイ ・iSCSI仮想テープライブラリ(VTL)インターフェース
・S3とGlacierにデータを保管する仮想テープストレージとVTL管理■ボリュームゲートウェイの2つのタイプ
タイプ 特徴 保管型(Gateway-Stored Volumes) メインデータはローカルに保存、非同期でAWSにバックアップ。データ全体が高耐久ストレージに保管され、低レイテンシでアクセスできる。DRなどの目的で全体をバックアップする用途で利用する。 キャッシュ型(Gateway-Cached Volumes) プライマリデータをS3に保存、頻繁にアクセスされるデータはキャッシュしてローカルに保存。頻繁にアクセスされるデータは低レイテンシで利用できる。ローカルにキャッシュを持つ分S3利用コストは下がる。オンプレミスのストレージを低コストで拡張する目的で利用する。 VPCエンドポイント
VPCの内外を接続する手段、2種類に分類される
種類 概要 インターフェイスエンドポイント(PrivateLink) 実態はプライベートIPを持ったENI、CloudWatch LogsやSSMなどに利用、EC2上で動かす独自サービスにも利用可能(NLBにエンドポイントをアタッチ)、冗長化を考慮した設計が必要 ゲートウェイエンドポイント グローバルIPを持つタイプのサービス(S3やDynanoDBなど)にVPCの外を経由せずに接続できる Amazon RDS on VMware
オンプレミス環境のRDBをRDSにより管理できる。通常のRDSと同様下記のような機能が利用できる。
- AWS上のRDSへのレプリケーション
- 自動バックアップ
- CloudWatchメトリクスの利用
■データベース
Amazon Auroraのメリット
通常のMulti-AZの場合セカンダリはスタンバイ状態のためアクセスできない(Active-Stundby型)が、AuroraではプライマリDBインスタンス(Writer)とレプリカ(Reader)を同時に利用(Active-Active型)できるため、平常時もセカンダリを無駄にしない。
RDSの読み取りパフォーマンスを向上させる方法
- Amazon RDSリードレプリカを追加して、読取処理をレプリカで分散処理できるようにする。
- Elasticacheによるキャッシュ処理を追加して、読取処理が集中しているデータをキャッシュとして処理することで高速な処理を実現し、RDSへの負荷を減少させる。
- ストレージタイプをIOPSの大きなサイズに変更することで、RDS本体のI/Oパフォーマンスを向上させる。
費用対効果が高いのはRDSリードレプリカ
Aurora以外のRDBの読み込みオートスケーリング
Amazon Auroraを利用してAurora以外のRDB(RDS for MySQLやEC2上で動作するMySQL等)をオートスケーリングさせることができる。
やりかた:Auroraのクラスターを作成し、オートスケーリングを設定した上でマスターとなるRDBのレプリケーションスレーブに設定する。
スケーリングするのはレプリケーションなのでこの方法で拡張できるのは読み込みのみ。RDSのクロスリージョンレプリケーション
RDSのクロスリージョンレプリケーションは非同期が推奨、リージョン間の距離により生じるレイテンシーによりデータベース付加が高くなるため。
AWSのグラフDB
NeptuneというマネージドグラフDBサービスがある、グラフDBはデータのリレーションシップやその方向性を探索するのに適しており、SNSの友人同士の繋がりを探索し、新しいつながりを提案するなどに利用される。
DynamoDBのグローバルテーブル
リージョンをまたいだ冗長化が可能、グローバルテーブルを使わずに複数リージョンにレプリケーションする方法として、DynamoDBストリームを生成し、ワーカー(Lambda等)で他リージョンに書き込む方法もある。
DynamoDBのセカンダリインデックス
パーティションキーを変えたい時はグローバルセカンダリインデックス、既存テーブルへの追加はできない、もう一つテーブルを作るようなもの。
ソートキーだけ追加したいときはローカルセカンダリインデックス、既存テーブルへ追加できる。DynamoDBの1項目の上限とCU
忘れやすいのでメモ
- DynamoDBの1項目の上限は400KB
- 1RCU=4KB以下の場合、結果整合性2回/秒、強い整合性1回/秒
- 1WCU=1KB以下の場合、1回/秒
Amazon Redshift
列(カラム)指向データベース、SQLによるデータ分析に利用。
Amazon Redshiftはデータの静的な分析向けに設計されており、リアルタイムの継続的なデータ取り込み(ストリーミングデータ等)には向かない。ElastiCache
Type 特徴 Redis ・レプリケーショングループで高可用性を実現できる。
・暗号化できる。
・リアルタイムゲーム処理のキャッシュ等に向いている。Memcached ・シンプルなキャッシュ向け。
・レプリケーションなどはできない。Redisのキャッシュ戦略
Type 特徴 書き込みスルー ・書き込みor更新時に必ずキャッシュにも反映する。
・キャッシュミスがない。
・キャッシュの量が膨らむ、ほぼ読み込まれないデータもキャッシュされる。遅延読み込み ・リクエストされて初めてキャッシュにデータが読み込まれる。
・キャッシュミスがある。
・初回は読み込みが遅くなる、キャッシュミス時も読み込みが遅くなる。
・同一のデータを連続で読み込むようなケースでないとパフォーマンスは向上しない。■アナリティクス
CloudSearch
マネージド型の検索機能サービス、検索機能の実装・運用工数を減らせる。
QuickSight
マネージド型のBIサービス、AWSの各サービスの利用状況などを監視するダッシュボードの提供などができる。
DataDogなどのサードパーティ製品に比べ、AWSの各サービスとの統合をしやすいというメリットがある。AWS Glue
ETL(Extract/Transform/Load)処理(データ分析基盤構築のためのデータの読み込みや加工)をマネージド型で提供するサービス。
データをクロールし、メタデータをデータカタログに出力、このデータカタログをもとに変換を実行、という流れ。■アプリケーション統合
Amazon SES(Simple Email Service)
マネージド型のSMTPサーバを提供する。
あんまり使わなそう(個人的感想)
通常のメールサーバとの違いとして、その他のAWSサービスとの連携が行える。
会員制サービスなどで宛先が大量にある場合はSNSよりSESを利用がベストプラクティス。
(SNS=運用者向け/SES=コンシューマ向けと覚える)SESとSNS比較
サービス 特徴 SES ・マルチメディアファイルの添付やHTMLメールの送信も可能
・受信者の事前同意は不要
・大量の一般ユーザ向けSNS ・事前に受信者側から登録(Subscribe)する必要あり。送信側が特定ユーザを指定して特定のメールを送信するようなやり方には向いていない。
・一つのSNSトピックからマルチチャネルのファンアウト(メール、Chatbot、SQS、アプリPUSHなど)が可能
・運用者や管理者への通知向けAmazon SWF(Simple Workflow)
マネージド型のワークフロー実行基盤サービス。
AWS Step Functions
Lambda,ECS,AWS Batch, SNS, SQSなどの複数のサービスによる一連の処理をステートマシンとしてJSONで定義し、構築・管理することができる。SWFの後継の位置付けらしい。プロセスに介入する外部信号が必要な場合と結果を親に返す子プロセスを定義したい場合、Step Functionsで実現できないのでSWFを選択することになる。それ以外はStep Functionsの利用を推奨。
■Step Functionsの2つのワークフロー
- 標準ワークフロー: 長時間実行、高耐久性、監査可能
- Expressワークフロー: 大量イベント処理ワークロード
Amazon Elastic Transcoder
マネージド型の動画の変換処理サービス。
AWS MQ
メッセージブローカー、Apache ActiveMQのマネージド。
AWSのキューイングサービスと言えばSQSだが、オンプレで既にActiveMQを利用している場合の移行先などに利用(リプラットフォーム)。■AI
Amazon Rekognition
画像・動画認識サービス。結構新し目なのでGoogleとかWATSONに追いつくにはまだ掛かりそう?(個人的感想)
Amazon Comprehend
テキストから感情を推論するサービス。レビューなどからユーザの感情を分析するためなどに利用できる。
Amazon Personalize
ユーザ情報から「おすすめ」を推論するためのサービス。
Amazon Forecast
時系列予測サービス。需要予測などに利用できる。
Amazon Lex
テキスト・音声をインプットとするインターフェースを提供するサービス。Alexaスキルなどの対話型のアプリケーション開発に利用できる。
その他AI系
- テキストto音声:Amazon Polly
- 音声toテキスト:Amazon Transcribe
- 画像toテキスト:Amazon Textract
- 翻訳:Amazon Translate
■セキュリティ
Amazon CloudHSM
暗号化キーを生成・管理するための専用ハードウェア・キーの保管庫。セキュリティーポリシーによりパブリッククラウドでのキーの保存が許可されない場合などに利用できる。
ELBのSSL/TLS処理をオフロードすることもできる。AWS Secrets Manager
データベースの認証情報やAPIキーなどのシークレットを管理するためのサービス。
自動ローテーションや有効期限設定の機能を備える。SSMパラメータストア経由で取得することもできる。
(/aws/reference/secretsmanager/をプレフィックスとしてIDを指定する)
SSMパラメータストアのセキュア文字列と非常に用途が近いので自動ローテーション等要件に応じて使い分ける。
参考:https://qiita.com/tomoya_oka/items/a3dd44879eea0d1e3ef5Amazon GuardDuty
AWS上での操作や動作をモニタリングし、セキュリティ脅威を検出する。CloudTrailのログなどを解析し検知するので、AWS上で公開しているWebサービスなどへの攻撃ではなくAWSアカウントやAWS上に保存しているリソースに対する不正アクセス等から守ることが目的。
Amazon Inspector
EC2インスタンスの脆弱性を診断・検出するサービス。
Amazon Macie
AWS上に保存されている機密データを自動的に検出・分類・保護するサービス。
■管理
AWS Config
AWS上の構成変更のロギング・特定の変更操作発生時の通知、変更操作がされた場合の修復アクションの設定などができる。
AWS System Manager(SSM)
EC2インスタンスの運用・管理のための色々な機能がある
- インベントリ:インストールされたソフトウェアの情報を収集する
- オートメーション:定期的に実行が必要な運用管理タスクを自動化する
- 実行コマンド:インスタンスに対するコマンドの実行を自動化する
- セッションマネージャー:マネコンでインスタンスにSSHできる
- メンテナンスウインドウ:運用管理タスクを実行するための時間枠をスケジューリング
- パッチマネージャー:OSやSWへのパッチ適用
- ステートマネージャー:サーバ設定、ファイアウォール設定など指定された状態を維持(定期的にスクリプト実行など)
- パラメータストア:パラメータ管理
- AppConfig: アプリケーションの設定データを管理、LambdaやEC2上のアプリケーションを停止することなく安全に、設定を更新できる
AWS Personal Health Dashboard
AWSで発生している障害の状況などを確認できる。
Amazon DLM(Data Lifecycle Manager)
EBSボリュームのスナップショット取得を定期的に実行できる。
SSHポートを開けずにEC2/ECSを管理する方法
SSMのセッションマネージャー/Run Commandを利用し、マネコンから操作できる。SSMのこれらの機能はSSMの前提条件を満たして(HTTPSのアウトバウンドポートが空いている、SSMエージェントがインストールされいてる等)いれば利用できる。
CloudFormationによるIaC
↓覚えることが多いので別ページでまとめ
AWS CloudFormation再入門OpsWorksのコンポーネント
OpsWorksはネストされたコンポーネントを持つ
スタック:最上位のコンポーネント、LB/APサーバ/DBサーバなどをまとめた1サービス単位、複数のレイヤーを含む
↓
レイヤー:その名の通り多層アーキテクチャの各層(LB/AP/DB)単位、複数のレシピを含む
↓
レシピ:LBやインスタンス内の設定やAPサーバ上のAPP定義CloudTrail Insights
CloudTrailで取得した証跡に対し、異常なアクティビティを自動的に検出し、CloudWatch LogsとS3に出力することができる機能。2019/11~公開
2つの請求アラート
AWSの利用料が予算を超過しないようにするために通知させる手段は2つある。
- CloudWatchの請求アラーム: 請求額に対する金額やパーセンテージによる条件設定ができる
- AWS Budgetsの予算アラート: 請求額以外にもリソースごとの利用状況を細かく設定できる
コスト配分タグ
請求ダッシュボード内の「コスト配分タグ」機能を利用するとCost Explorerや請求ダッシュボードでタグ名によるフィルタリングを行い、特定のタグの付いたリソースにかかったコストを確認できる。
コスト配分タグは有効化が必要で、有効化前の請求に関してはフィルタリングできない。
Organizationsを利用している場合、マスターアカウントでコスト配分タグを有効化することで、各部門ごとの利用料管理もできる。
※タグポリシーなどで部門ごとのタグ付けが標準化されている必要がある。コストと使用状況レポート
コストと使用状況レポートはRedshiftに取り込むかAmazon QuickSightにアップロードすることでコスト状況の分析が可能。また、Athenaとの統合を有効化することで圧縮されたレポートがS3に自動配信される。
統合請求が有効な場合、これを閲覧できるのはマスターアカウントのみ。■移行
AWS DMS(Database Migration Service)
DBの移行のためのサービス、AWStoAWS, オンプレtoAWSどちらも対応、異なるDBエンジン間の移行も可能。移行だけでなくレプリケーションの目的でも利用できる。S3のCSVとDynamoDBのレプリケーションなども可能。
移行対象テーブル、移行方式をタスクとして設定できる。
テーブルマッピング、DMSコンソール、JSONが利用できる。Amazon SCT(Schema Conversion Tool)
DBエンジン間でスキーマの変換を行うサービス。
AWS SMS(Server Migration Service)
オンプレ等で稼働しているVMをAMIへ変換するサービス。「リホスト」方式をサポート
下記の流れでマイグレーションを行う。
1. Server Migration Connectorをオンプレ環境にインストール
2. IAMユーザの設定
3. AWS側からコネクタへの接続をセットアップ
4. サーバーカタログをSMSへインポート
5. 出来上がったAMIからEC2の起動AWS Application Discovery Service
AWSへの移行の前準備として、オンプレ環境のアプリケーションやインフラ情報を収集するためのサービス。
VMware環境の場合エージェントレス型、それ以外の場合エージェント型(エージェントのインストールが必要)。AWS Migration Hub
サードパーティのマイグレーションツールとの連携を行うためのサービス。
VM Import/Export
インスタンスとVMを相互変換するためのサービス。
移行戦略の6R
オンプレからクラウドへの移行にはRから始まる6つの移行戦略がある、既存のアプリケーションやインフラ構成、コンプライアンス等を考慮し、適切な戦略を選択する。複数の移行戦略を組み合わせることもある。(一部のアプリケーションのみ移行が難しい場合Replatform+Retainなど)
移行戦略 概要 例 移行難度 Rehost
(インフラの置き換え)アプリケーションには手を加えない、インフラのみ移行。(リフト・アンド・シフト」とも言う。) アプリケーションを稼働させるサーバをEC2に移行する。 低 Replatform
(プラットフォームも含めた置き換え)ミドルウェアのPaaSへの移行を行う。 DBをRDSに移行する。 中 Repurchase
(再購入)既存のアプリケーションをSaaS等に置き換える。(「使用廃止と購入」とも言う。) 社内の業務システムをKintoneに置き換える。 中 Refactor/Re-Architect
(リファクタリング/再設計)アプリケーションの修正やアーキテクチャの再設計を行い、クラウドネイティブな構成にする。 夜間のバッチ処理を行っていたシステムをAWS BatchやLambdaでサーバレスに置き換える。 高 Retire
(廃止)不必要な機能やアプリケーション自体を廃止する。 利用者が少ないのでサービス終了する。 移行なし Retain
(保持)オンプレで稼働を続ける。 社内ルール上データをクラウドに置けないのでDBはそのままオンプレを維持する。 移行なし AWS Snowファミリー
オンプレからAWSへのデータ移行の際に、対象のデータ量がTBを超えるようなケース(ネットワーク経由の移行で1週間以上かかる場合など)はSnowファミリーの利用を検討
大きく分けて4種類
サービス 特徴 Snowcone ・テラバイト規模のデータ移行
・A5サイズの小型デバイス
・8TB
※2020/06に発表、そろそろ試験でもでるかも?(2021/02)Snowball ・ペタバイト規模のデータ移行
・S3へのインポートorS3からのエクスポート用
・データはクライアント側で暗号化してから書き込み
・80TBSnowball Edge ・Snowball+コンピュート+α
・データの暗号化をEdge内で実施
・書き込み時にLambdaによる処理が可能
・Edge内でEC2インスタンスを起動可能
・100TB or 42TB
・クラスター構成にしてローカルストレージとしての利用も可Snowmobile エクサバイト規模のデータ移行、セミトレーラートラックが牽引する長さ14mの丈夫な輸送コンテナがやってくる
Snowball Edgeはさらに2種類に分かれる
種類 特徴 Snowball Edge Storage Optimized ・ブロックストレージとS3両方と互換性のあるストレージ
・24個のvCPU搭載(EC2 m4.4xlargeと同等)
・100TBSnowball Edge Compute Optimized ・移行中の高度な機械学習やビデオ分析などに利用
・52個のvCPU搭載
・オプションでGPUも提供
・42TB※2020/04/07以降、通常のSnowballはSnowball Storage Optimizedに移行(公式ブログ参照)したので、「Snowball」というサービスの中で「Snowball Edge Storage Optimized」「Snowball Edge Compute Optimized」の2つから選択する形(ややこしい、試験ではいつから統合された名称になるか不明)
AWS Licence Manager
クラウド移行の際にBring-Your-Own-License(BYOL)によりコストを削減をしつつ、ライセンス移動プロセスを効率化するためのサービス。
あたりまえだが、マネージドのサービスに移行するとライセンスを継続利用できない。■ストレージ
S3のストレージクラス
IAとかRRSとかが忘れやすいのでメモ
ストレージクラス 特徴 標準 低レイテンシーかつ高スループットで高耐久(99.999999999%) 標準IA(Infrequent Access) 低頻度アクセス用、ストレージ料金は標準より安い。 1ゾーンIA 低冗長化、低頻度アクセス(RRSは非推奨になり、低冗長は1ゾーンIAに)、ストレージ料金が標準IAよりさらに安い。 Glacier 長期保存、かつほぼアクセスしない場合用、ストレージ料金が安い代わりに読み込みが非常に遅い。(数分〜数時間※↓の表参照) Glacier Deep Archive Glacierよりさらに遅い(12時間以内or48時間以内※↓の表参照)、代わりにさらに安い。 S3 Intelligent-Tiering アクセス頻度に応じて自動的にコスト最適化してくれる、アクセス頻度が流動的で予測不可能な場合のコスト最適化に利用できる。
- 1ゾーン以外は3つのAZで冗長化される
- 低頻度アクセスとGlacierは取り出し時容量に応じた料金がかかる
- 標準以外は30日間~180日間の最低ストレージ期間料金(途中で移行や削除した場合も請求される料金)がある
(30日以内に削除するデータに標準以外を利用したり、コスト最適化のためにクラスを短期間で変えるのは逆にコストを上げてしまう可能性があるので注意)Gracierの取り出しオプション
種類 概要 迅速(Expedited) ・コストは上がるが読み込みが早くなる
・通常1〜5分以内
・Deep Archiveの場合利用不可標準(Standard) ・デフォルトの取り出し方
・通常3〜5時間以内
・Deep Archiveの場合12時間以内大量取り出し(Bulk) ・最も安価
・通常5〜12時間以内
・Deep Archiveの場合48時間以内■コンピューティング
EC2インスタンスタイプ
これも忘れやすい
インスタンスタイプ 特徴 汎用(T3, M5等) バランスの取れたコンピューティング、メモリ、ネットワークのリソースを提供
Txはアイドル状態のときにCPUクレジットを蓄積し、アクティブなときにCPUクレジットを消費するバーストが可能。コンピューティング最適化(C5等)
※Compute=Cで覚えるバッチ処理ワークロード、メディアトランスコード、高性能ウェブサーバー向け。 メモリ最適化(R5, X1等) メモリ内の大きいデータセットを処理するワークロード向け。 高速コンピューティング(G3, P4等)
※GPU=Gで覚える最新世代のGPUベースのインスタンス、機械学習トレーニングやグラフィック処理向け。 ストレージ最適化(I3, D3等)
※I/O=Iで覚える低レイテンシー、高いランダムI/Oパフォーマンスと高いシーケンシャル読み取りスループット。 スポットフリート
EC2の購入オプションとして最もコスト効率の良いスポットインスタンスだが、インスタンス価格の高騰により、起動できなかったり、稼働中のインスタンスが中断されるリスクがある。それをカバーする方法として、「スポットフリート」というオプションがある「スポットフリート」を利用することであらかじめインスタンス数またはvCPU数を指定しておき、指定したキャパシティを維持するよう、スポットインスタンスとオンデマンドを組み合わせて起動させることができる。
プレイスメントグループ
複数のEC2インスタンス間のレイテンシを下げるための仕組みとして「プレイスメントグループ」がある。同一のプレイスメントグループ内のインスタンスは物理的に近いハードウェア上に配置され、インスタンス間で広いNW帯域が確保される。プレイスメントグループへの追加はインスタンスが停止中でないとできない。
3種類のプレイスメントグループがある。
グループ 説明 クラスタープレイスメントグループ 単一AZ内のインスタンスを論理的にグループ化したもの パーティションプレイスメントグループ 論理的なパーティションに分散されているインスタンスのグループ(複数AZにまたがる) スプレッド(分散)プレイスメントグループ それぞれ異なるハードウェアに配置されるインスタンスのグループ HVM(Hardware-assited VM)とPV(ParaVirtual)
HVMは完全仮想化でPVは準仮想化、HVMはCPU/NW/ストレージなどのHW拡張機能を利用できる。
遅延を減らしたい場合HVM、パフォーマンス改善の問題でまれに出る。AWS Batch
大規模計算処理の実行・管理をするためのマネージドサービス、実際の処理はECS上で行われる。
定型業務の逐次実行などのバッチ処理向けではない。■ネットワーク
VPCピアリング
複数のVPCを接続し、インターネット経由なしで通信可能にする。
- VPCピアリング接続は2つ以上のVPC間の推移的なピア接続をサポートしない
(VPC AとVPC B,VPC BとVPC Cがピアリングされていても、VPC AとVPC Cは通信できない)- 異なるリージョン間のピアリング機能を「インターリージョンVPCピアリング」という
(クロスリージョンではなく、インターリージョンと呼ぶらしい)セカンダリCIDRブロック
VPC内のプライベートIPが枯渇しそうな時は、「セカンダリCIDRブロック」により拡張できる。
例えば、既存のCIDRブロック10.0.0.0/16にセカンダリCIDRブロック10.1.0.0/16を追加することで両方の範囲を利用できるVPCになる。
※セカンダリといいつつ複数つけられる。(元のCIDRがプライマリでそれ以外は全てセカンダリ)VPCのCIDRブロック内の予約済みIP
プライベートネットワークにおいて先頭と末尾はネットワークアドレスとブロードキャストアドレスだが、VPCの場合それ以外にも3つ使えないIPがある。
各サブネット CIDR ブロックの最初の 4 つの IP アドレスと最後の IP アドレスは使用できず、インスタンスに割り当てることができません。たとえば、CIDR ブロック 10.0.0.0/24 を持つサブネットの場合、次の 5 つの IP アドレスが予約されます。
10.0.0.0: ネットワークアドレスです。
10.0.0.1: VPC ルーター用に AWS で予約されています。
10.0.0.2: AWS で予約されています。DNS サーバーの IP アドレスは、VPC ネットワーク範囲のベースにプラス 2 したものです。複数の CIDR ブロックを持つ VPC の場合、DNS サーバーの IP アドレスはプライマリ CIDR にあります。また、VPC 内のすべての CIDR ブロックに対して、各サブネットの範囲 + 2 のベースを予約します。詳細については、「Amazon DNS サーバー」を参照してください。
10.0.0.3: 将来の利用のために AWS で予約されています。
10.0.0.255: ネットワークブロードキャストアドレスです。VPC ではブロードキャストがサポートされないため、このアドレスを予約します。引用元:VPCとサブネット
拡張ネットワーキングによるI/Oパフォーマンスの向上
シングルルートI/O仮想化(SR-IOV)を使用してネットワーク性能を上げることができる。
下記いずれかのメカニズムを選択
- ENA(Elastic Network Adapter):最大100Gpbs
- Intel 82599 Virtual Function(VF)インターフェイス:最大10Gbps
ELBの使い分け
キーワード 概要 ALB(Application Load Balancer) ・HTTP/HTTPSのみに対応した(TCPには対応していない)L7ロードバランサー
・パスやクエリなどのコンテンツベースのルーティングが可能NLB(Network Load Balancer) ・TCP/UDPに対応したL4ロードバランサー
・高可用性/高スループット/低レイテンシ
・ソースIP/Portがターゲットまで保持される
・SGは設定できないCLB(Classic Load Balancer) ・TCPおよびSSLリスナーが利用可能ト
・アプリケーション生成の独自Cookieを使用したスティッキーセッションが可能(ALBの場合「AWSELB」という名前のCookieが自動生成される)
- ALB/CLBでクライアントのIPを取得したい場合「X-Forwarded-For」ヘッダーから取得
BYOIP(Bring Your Own IP: 保有IP持ち込み)
既存グローバルIPをEIPとして利用できる。RIR(Regional Internet Registry)に登録し、RDAP(Registry Data Access Protocol)で証明書(ROA(Route Origin Authorization))を発行する。
■その他
障害復旧モデル
DR対策として、RTO/RPOとコストの要件に応じていくつかの方式がある。
下に行くほどコストが上がる代わりにRTO(復旧にかかる時間)が短くなる。
方式 概要 バックアップ&リストア バックアップのみを別リージョンに退避しておく。障害発生時はバックアップから復旧。 パイロットライト メインのリージョンよりスペックの低いDBを別リージョンに起動しデータを同期しておき、障害発生時DBをスケールアップしつつAPを立ち上げる。(DBだけは起動しておくので「コールドスタンバイ」ではない) ウォームスタンバイ AP等含めた構成を別リージョンにも起動しておき(このときコスト削減のためスペックの低い構成やインスタンス数を減らしておく)、障害発生時はスケールアップ/スケールアウトさせる。 マルチサイト(ホットスタンバイ) AP等含めメインのリージョンと同等の構成を別リージョンでも稼働させておき、障害発生時はRoute53等で向き先を切り替えるのみ。 Kinesisシリーズ
サービス名 概要 Kinesis Data Streams 低レイテンシのスタンダードなデータストリーム、順序付けが可能。 Kinesis Firehose データを直接S3やRedshift, ElasticSearchに流しこめる。
(Lambdaによるデータの変換もできる)Kinesis Analytics 入力データにSQL等を適用し、再度ストリームとして出力できる。 Kinesis Video Streams 動画用、Rekognitionで画像解析をしたり、そのままURLを発行しストリーミング配信等が可能。 Kinesis Agent サーバ等にインストールしておくことで、ログファイル等の指定したファイルへの書き込み発生時に書き込まれたデータを自動的にKinesisストリームとして送信してくれる。データに対し、フィルター適用などの送信前の事前処理を設定することも可能。 Kinesis Producer Library 独自のアプリケーションからKinesisストリームを生成/送信するためのライブラリ。 Kinesis Consumer Library 独自のアプリケーションでKinesisストリームを受信するためのライブラリ。
- KinesisとSQSの違い:SQSはシンプルなデータキュー、Kinesisは大量データを高速に処理するためのストリーム
- Kinesisのストリーミングデータ保存期間:デフォルト24時間、最大7日間
Kinesisのようなストリーミングサービスはプロデューサー(送信側)とコンシューマー(データ処理側)を組み合わせて利用する。
■Kinesisのプロデューサー/コンシューマー
どれがプロデューサーでどれがコンシューマーか覚えておくだけでも、消去法で解答しやすくなる。
プロデューサー コンシューマー ・Kinesis Data Streams
・Kinesis Video Streams
・Kinesis Producer Library(KPL)
・Kineis Agent
・Kinesis Analytics・Kinesis Firehose
・Kinesis Client Library(KCL)
・Kinesis Analytics※Kinesis Analyticsはストリームに対し、SQLを実行した上で再度ストリームを出力するため、コンシューマー兼プロデューサー
引用元:AWS Black Belt Online Seminar 2017 Amazon KinesisKinesis Video Streamsの3つの利用方法
プロデューサー コンシューマー GetMedia 独自アプリケーションからKinesis Video Streamsのストリーミングデータを取得する方式、GetMedia APIを利用。 HLS(HTTP Live Streaming) 業界標準のHTTPベースのメディアストリーミング通信プロトコル。
GetHLSStreamingSession URL APIによってHLSストリーミングURLを取得できる。
このURLを利用してブラウザやHLS対応メディアプレイヤで直接再生できる。MPEG-DASH(Dynamic Adaptive Streaming over HTTP) 従来のHTTPウェブサーバーから配信されたインターネット経由で高品質のストリーミングを可能にする適応ビットレートストリーミングプロトコル。
GetDASHStreamingSession URL APIによってMPEG-DASHストリーミングURLを取得できる。■HLSとDASHの違い:
- エンコード形式:MPEG-DASHでは、任意のエンコード標準を使用できる。一方、HLSではH.264またはH.265の使用が必須。
- デバイスのサポート:HLSは、Appleデバイスでサポートされている唯一の形式。iPhone、MacBook、およびその他のApple製品は、MPEG-DASHで配信された動画を再生できない。
Cognitoの2つのプール
紛らわしいのでメモ
- ユーザープール:ユーザそのものを登録するプール、Cognitoのみで認証をする場合に必要
- IDプール:ユーザに一意のIDを作成し保存するプール、その他のSAMLやWEBIDフェデレーションで認証した結果に対し、認可をするのに利用
リモート向けの機能
- Amazon Workspace:DaaS
- Amazon AppStream:デスクトップ全体でなくアプリ単位で提供
ブロックチェーン
ブロックチェーン関連のAWSサービスについても出題されるようなのでキーワードをメモ
キーワード 概要 Amazon QLDB(Quantum Ledger Database) フルマネージドの台帳データベース Amazon Managed Blockchain フルマネージドの分散型ブロックチェーンサービス AWS Blockchain Template CloudFormationテンプレートを利用し、簡単にブロックチェーンネットワークを作成できる Amazon Managed BlockChainでは
Hyperledger FabricとEthereumの2つのフレームワークに対応。AWSの知識ではないけれど知らなかったこととか、覚えておきたいこと
- PoC:概念検証、新しいソリューションの前に実現性、効果とコストなどを検証すること、アプリケーション開発の場合プロトタイピングが該当する。
- コンバージョン率:ビジネスとして成果につながった割合のこと、商品の売り上げや会員登録などそのビジネスの目的により「成果」は異なる。
- ワークロード:英語の意味そのままだと仕事量、作業量。AWSでは「ワークロードは、リソースと、ビジネス価値をもたらすコード (顧客向けアプリケーションやバックエンドプロセスなど) の集まりです。」らしい。
参考:https://docs.aws.amazon.com/ja_jp/wellarchitected/latest/userguide/workloads.htmlDR用語
どっちがどっちかわからなくなるやつ
- RPO(Recovery Point Objective):目標復旧時点(どれぐらい新しいデータまで復旧する必要があるか、大きいほど巻き戻りを許容)
- RTO(Recovery Time Objective):目標復旧時間(ダウンタイムをどれぐらい許容するか、大きいほど復旧作業に余裕ができる)
「Time」はダウンタイム、「Point」は復旧時点の点で覚える。
RAID
これもどれがどれだか忘れるのでメモ、0と1以外はこの試験ではおそらく出ないので気にしない。
- RAID0: ストライピング、信頼性は上がらないが読み書きの性能は上がる
- RAID1: ミラーリング、読み書きの性能は上がらないが、信頼性が上がる
DNSのレコードの種類
これもすぐ忘れるのでメモ、他にもあるけど省略
レコード 概要 Aレコード ドメインとIPを直接紐付けるレコード NSレコード ドメインの頂点(APEX)につくレコード example.comのようにサブドメインを持たないドメインには必須CNAMEレコード ドメインとFQDNを紐付けるレコード
Aレコードでつけたドメインをさらに別のドメインに紐付けるなどで利用ALIASレコード CNAME同様FQDNに別のドメインを紐付けるためのものだが、CNAMEレコードでがつけられないような時(CNAMEは他のレコードと共存できないため、Zone ApexにはNSレコードが付いているのでつけられない、などの理由)に利用できる。
※DNS自体の仕様ではなくRoute53のエイリアス機能のためのレコードORACLE DBの機能
- Oracle RAC(Real Application Clusters):複数台のORACLE DBサーバを1つのDBとして利用する構成、RDSでは利用不可(EC2のMarket prace AMIで利用可能)
- Oracle RMAN:バックアップ/リカバリを行うツール。RDSではバックアップからの復元はできるが、バックアップ取得は不可、RDSの自動バックアップ機能の利用を推奨。





- 投稿日:2020-09-06T11:45:14+09:00
Amplifyアプリのリダイレクト設定をaws-cliで行う
create-react-appとamplify-cliでアプリを作成していたところ、ここをみてリダイレクトの設定をしようと思ったのですが、AWS Consoleからしかできなくて調べました。
amplify-cliの設定でうまくやる方法が無いようでした1が、aws-cliではできました。方法
まずリダイレクトのルールを書いたJSONファイルを作成します。
custom-rules.json[{"source": "</^[^.]+$|\\.(?!(css|gif|ico|jpg|js|png|txt|svg|woff|ttf|map|json)$)([^.]+$)/>", "status": "200", "target": "index.html"}]以下のようにappIdを指定してコマンドを実行します。
aws amplify update-app --app-id <appid> --custom-rules file://custom-rules.jsonappIdは、以下のコマンドで確認できます。
aws amplify list-apps
amplify-cliのソースでAWS.Amplify.createAppしているところで、CustomRulesのパラメタは渡していないので、今のところは無理っぽいと判断。 ↩
- 投稿日:2020-09-06T11:43:57+09:00
AWS認定ソリューションアーキテクトプロフェッショナルに合格するまで〜アソシエイト編〜
はじめに
AWS認定試験の勉強を始めて1ヶ月でソリューションアーキテクトアソシエイト(以下SAA)を取得し、その後4ヶ月でソリューションアーキテクトプロフェッショナル(以下SAP)を取得したので、勉強方法や利用した教材、勉強方法などについて書こうと思います。これから受験を考えている方の役に立てば幸いです。
勉強を始めた時点での知識・スキル・経験など
- 入社2年目終わりの2月。ITエンジニア(Android)歴4ヶ月
- AWSの業務経験はほぼ0。プロジェクトではAWSを利用してインフラ構築しているため、不具合の切り分けなどでたまにcloudwatchでログを見る程度
- ネットワークの知識は基礎レベル(CCNAは持っていない)
- サーバー関連知識はLPIC LEVEL1程度
AWS認定とは
最も基礎的なレベルのクラウドプラクティショナー、アーキテクト、運用、開発者に分類されたアソシエイトレベル、そしてアーキテクト、DevOpsのプロフェッショナルレベルのAWSについて幅広い知識が問われる6試験と、専門知識の6試験が用意されています。
AWS 認定より抜粋
SAAについて
AWS 認定 ソリューションアーキテクト – アソシエイト
に詳しい情報が記載されています。
- 実施形式
テストセンターまたはオンラインプロクター試験- 時間
130分間- 受験料金
15,000 円(税別)/ 模擬試験 2,000円(税別)- 言語
英語、日本語、韓国語、中国語 (簡体字)あるあるかもしれないですが、日本語は怪しいところが結構あります。試験問題は英語で作成されて、日本語問題はそれをエキサイトな感じで翻訳しているだけなんでしょうか、わかりません。日本語受験を選んでも英語と切り替えながら試験を受けることができるので、相当英語に自信があるとかでなければ日本語での受験をお勧めします。
利用した教材など
勉強を始めるにあたって、「AWS SAA 勉強法」とかでググって合格してる人の勉強方法を参考にしました。結果的に、いくつかブログやqiitaなどの合格体験記で名前が挙がっていた以下の2つの講座をUdemyで購入して勉強しました。
これだけでOKの方は主要なサービスの解説とハンズオンが中心ですが、最後に模擬試験3回分(内1つは一問一答の小テスト形式ですが)もついていて、AWS入門用としても試験対策としてもちょうどよかったと思います。また、
これだけでOKのみだと演習が足りないと感じたため、同じ講師の方が出している演習問題中心のアソシエイト模擬試験問題集も利用しました。業務で既にAWSを利用していて、ある程度主要サービスの知識や構築経験がある人はこちらの講座の方がおすすめです。Udemyは頻繁にセールをやってるので必ずセール時に買うようにしましょう。勉強の流れ
全体の流れは以下の通りです。
これだけでOKを3週間(座学&ハンズオンパート2週間、付録の模擬試験1週間)アソシエイト模擬試験問題集を1週間計4週間やってから本番に臨みました。公式の模擬試験はお金がかかるので受けませんでした。本番に合わせて購入した講座はきっちりやり切りました。期限を決めた方が短期集中できて効率が良いかと思います。
これだけでOKのハンズオンではよくあるアーキテクチャパターンをコンソール上でぽちぽちやって構築していくのですが、「こんなに簡単にできるんだ」って驚きがあって楽しかったです。AWSってどういうものなのかを理解するのに役立ちました。
ハンズオンで一通りサービスに関する知識と手を動かす経験を身に付けたら、付録の模擬試験をやってみました。1回目は確か60%くらいしか取れなかったと思います。資格取得のためには演習を繰り返すことが大事だと痛感したので、これだけでOKの模擬試験とアソシエイト模擬試験問題集で演習を繰り返しました。全て9割くらいは取れるまで繰り返してたと思います。
演習問題は時間を計って解く、間違えた部分を公式のドキュメントを読む、などして試験で問われる部分を強化しました。よくある質問はかなり参考になりましたね。試験本番では結構落ち着いて問題を解くことができ、微妙な問題は最後に見直しをして無事合格できました。と言ってもやはり模擬試験やってる時よりは本番の方が時間はかかりましたし、見直しマークのつく問題も多かった気がします。
おわりに
- 資格取得のためには演習を効率よく繰り返すべし
- 知識の補強はよくある質問が役に立つ
- SAAはほぼ0から始めても1か月で取得できる
- 投稿日:2020-09-06T11:01:31+09:00
Flutterアプリのユーザー認証システムにAmazon Cognitoを使う(OAuth 2, Google, LINEなど)
Special Thanks! : @to-jiki と共同でこの記事を作成しました.
結構長いのでご注意!
Flutterを使ったアプリで, ユーザー認証のシステムを作りたいと思い, バックエンドをAWSで実装する必要があったため, Amazon Cognitoを使うことになりました. ただ, Flutter+Firebaseの情報は結構出てくるのですが, Flutter+Amazon Cognitoの方があまり出てこなくて困ったのでメモ程度にまとめたいと思います. 個人的に結構困った, Flutter部分も結構詳しめに書いています.
1つ注意していただきたいのが, FlutterもAWSも初心者の状態でいろいろ手探りなため, 正直遠回しなところや, よくない事をしているところもあるかもしれません. 参考程度にとどめて, あくまで自己責任でやっていただきたいと思います.
また, この記事ではバックエンドとの通信はAPI Gateway+Lambdaを用いたフルサーバーレスなアプリケーションの作成を想定しています(furaiev/amazon-cognito-identity-dart-2).
その他のアーキテクチャの場合は, furaiev/amazon-cognito-identity-dart-2のReadmeをご覧ください.
以下, リージョンはすべてus-east-1でやっていますが, そこは適宜読み替えてください.
Amazon Cognitoの設定
AWSのアカウントの作成等の作業はここでは省略します.IAMユーザーを作って作業をすることは忘れずに
ここでは
- メールアドレスとパスワードによる認証
- Googleアカウントによる認証
- LINEアカウントによる認証
のCognito及び関連(GCP,LINE Developer)の設定方法についてそれぞれ紹介します.
上記二つの設定の大半はmakotomiさんの記事を参考にさせていただきました.似たような内容になってしまったのですが細かい設定や,後に使用したプラグインなどで異なる部分はあるので参考にされる方々は両方目を通していただけると幸いです.
メールアドレスとパスワードによる認証
ユーザープールの作成
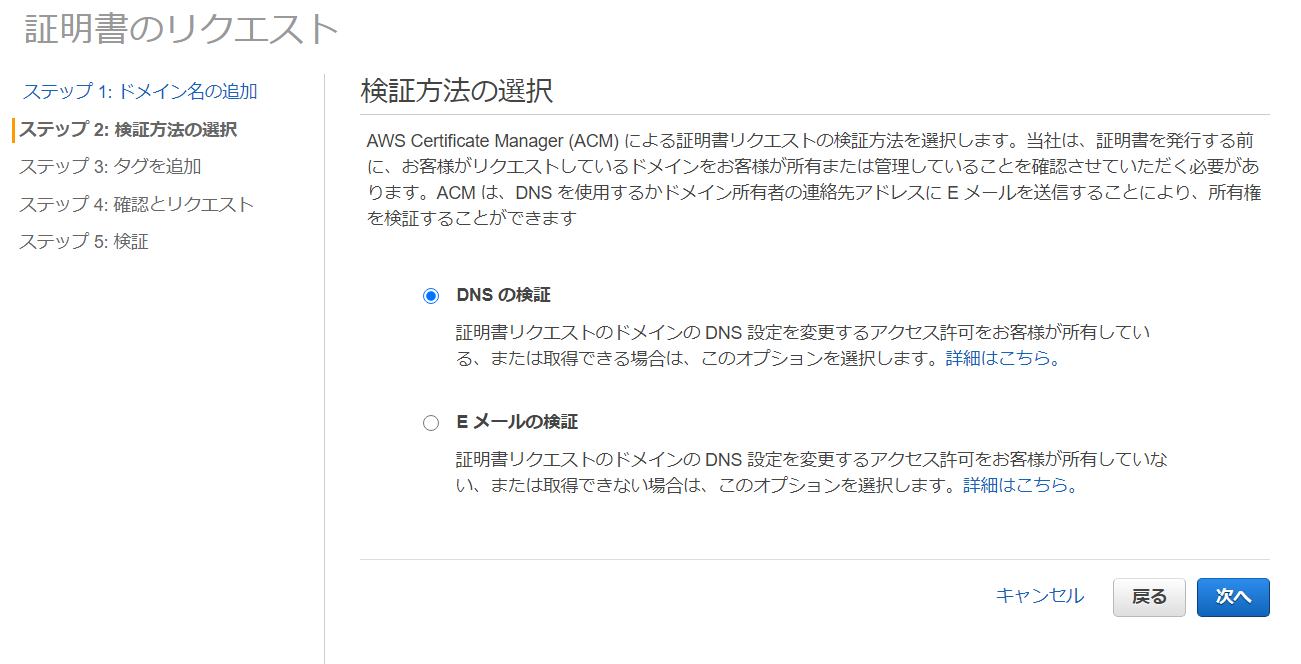
初めに認証したユーザーを保存しておくユーザープールを作成します.これはGoogle,LINEによる認証でも使用します.
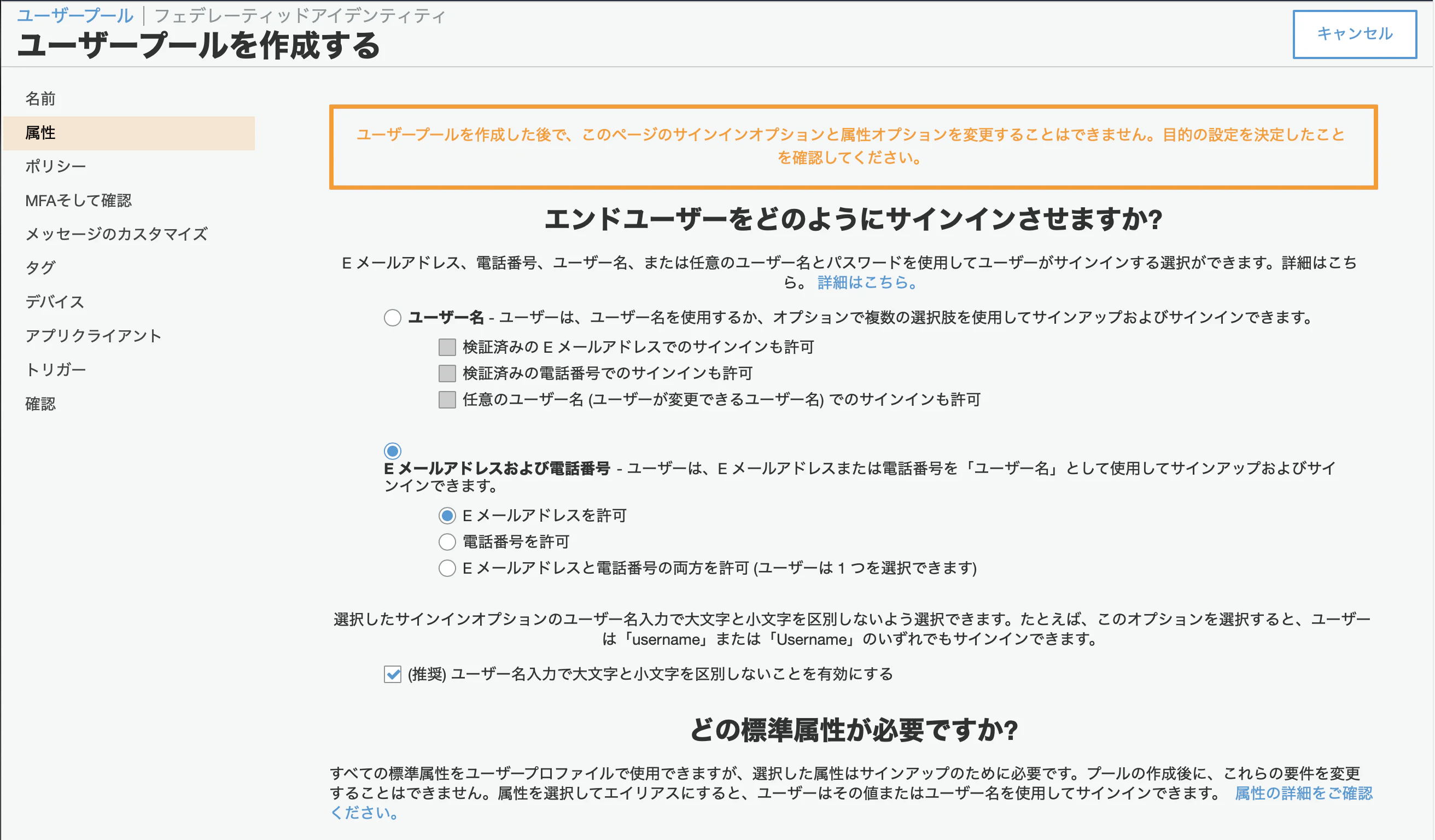
(1) ユーザープール名を決め,デフォルトを確認するを選択します.
(2) 属性で設定したい認証方法に沿った項目を設定します.(今回は、Eメールアドレスおよび電話番号)
ここの設定はプール作成をしてしまうと変更することはできないので,よく確認してください.
また下の方にある標準属性でemailを選択するとうまく動かないことがあります.
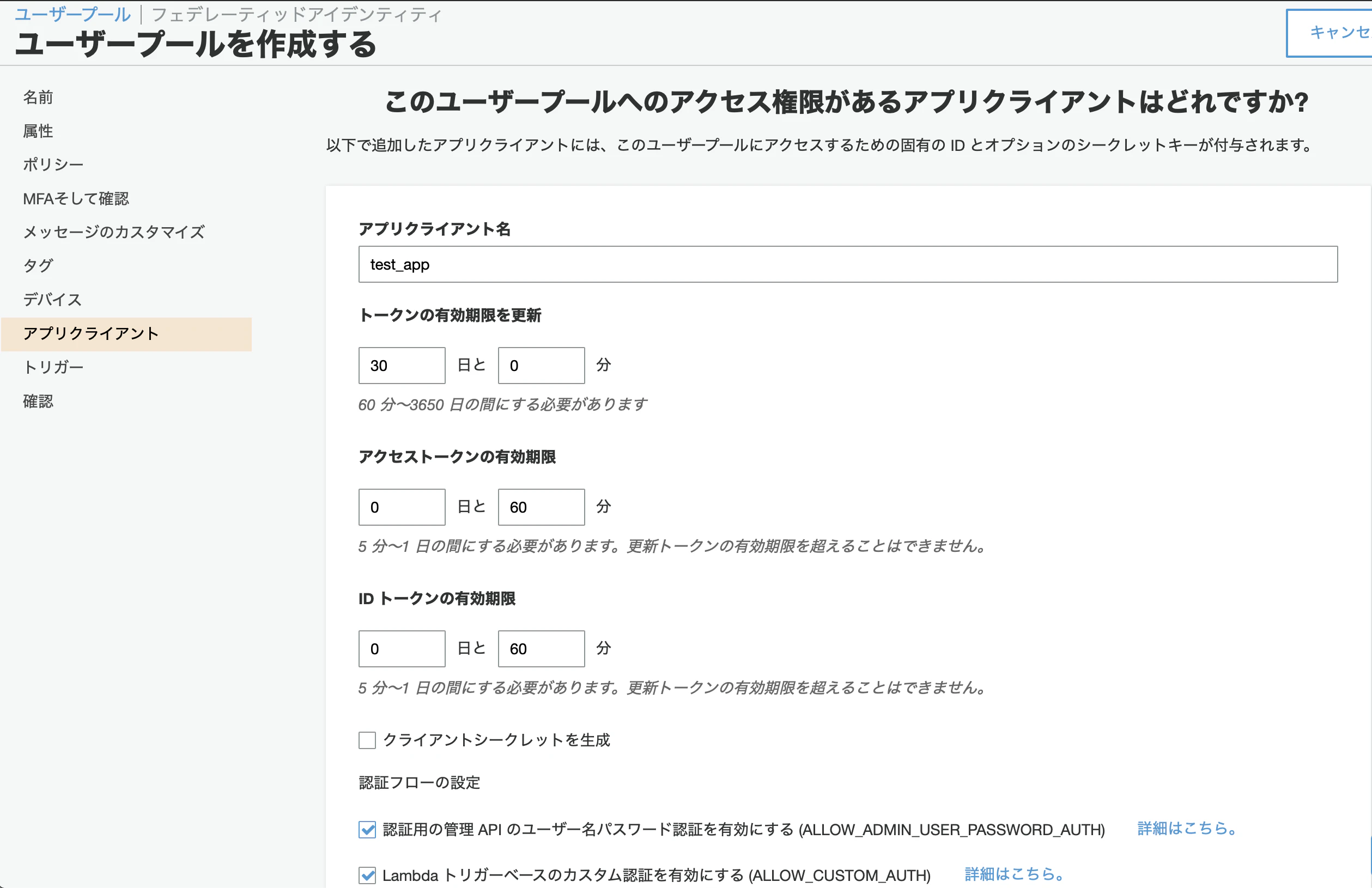
(3) アプリクライアントの作成をしてアプリごとに紐付けを行うID(アプリクライアントID)を発行します.ユーザープール作成後に表示されます.
クライアントシークレットは外して,あとはお好みで設定してください.
(4) ポリシー等でパスワードの条件等を設定できるので欲しい要件にあった設定を行いプールの作成を押してください.
(5) 作成後,後で必要になるプールIDとアプリクライアントIDは控えておいてください.
メールアドレスとパスワードによる認証のCognito側の準備は以上です.
コードの中でどのように使うかは設定を全部した後で話そうと思います.Googleアカウントによる認証
Googleとの認証の連携ではGoogle Cloud Platformを使用します.自分のGoogleアカウントを用いて登録してください.
(1) 初めにProjectの作成をします.
(2) APIとサービス➞OAuth同意画面でアプリケーションの作成を行います.
設定はデフォルトで大丈夫です.
(3) 認証情報➞+認証情報を作成➞OAuthクライアントIDを選択して,
ウェブアプリケーションの種類と名前を決め作成します.
~.apps.googleusercontent.comというクライアントIDとクライアントシークレットが作成されます.Cognitoとの連携で使用するのでメモしておいてください.
(4) 一旦Cognitoのほうに戻ります.
ダッシュボードの下のほうにあるIDプロバイダーを開きGoogleを選択します.
ここで先ほどメモしたIDを使用します.
- GoogleアプリID → クライアントID
- アプリシークレット → クライアントシークレット
- 承認スコープ → profile email openid
のように入力をして,有効化を押します.
(5) アプリクライアントの設定の有効なプロバイダですべてを有効にして以下のように設定します.
コールバックURL(Flutter側の設定ではcallbackSchemeと呼んでいます)はログインの処理が終わった時の遷移先のことです. 今回の記事の中ではmyapp://としています.コールバックURLはCognito側とアプリ側で統一すればどんなものでも構いませんが, すこしややこしいので最後が
://で終わるようにしてください. また, 本当はmyapp://という簡易的なものではなく, ほかにスマホにインストールされているアプリのコールバックスキームと重複しない固有なものにするべきです. 今回はわかりやすさのためmyapp://としていますが, 実際にアプリを作る際は, 一意なものになるようにしてください. 例えば,jp.foo.bar.ci78mls2://などランダムな文字列を入れたりすると良いかもしれません.
(6) ドメイン名を選択しプールの場所を示してくれるAmazon Cognito ドメイン作成します.使用可能なドメインかチェックをして変更の保存をしてください.
再びGoogleの設定へ戻ります.
(7) GCPのAPIとサービス → 認証情報で先ほど作成したクライアントの承認済みURLに,6で作成したドメインに/oauth2/idpresponseを付加した
https://[自分で決めたドメイン].auth.us-east-1.amazoncognito.com/oauth2/idpresponse
を入力して保存します.
以上でGoogelアカウントによるログインでのCognito,GCPの設定は以上です.
LINEアカウントによる認証
LINEによる認証ではLINE Developer を使用します. 特別に何か登録する必要はないので自身のLINEアカウントでログインするだけで大丈夫です.
(1) 初めにプロバイダーを作成します.LINE Login → Start now → Console home を開きます.ここでは自分たちが実際に利用したプロバイダーがありますが,最初は何もない状態だと思いますので新しく作成してください.
(2) プロバイダーを開いたらCreate a LINE Login Channelを選択します.
Channel Typeの選択ではLINE Loginを,以下のような入力画面が出てくるのでうちのApp typesではWeb App を選択.後の名前などは自分のプロダクトにあった名前を付けてください.
optional の項目は入力しなくて大丈夫です.
(3) createをした後表示される画面でChannel IDとChannel secretの値はまたCoginito側の設定をするときに必要なのでメモしておいてください.
(4) Basic settings の隣にあるLINE Loginの中にあるCallback URLにGoogleの時と同様に
https://[自分で決めたドメイン].auth.us-east-1.amazoncognito.com/oauth2/idpresponse
を入力します.
最後にDevelpoingをPublishedにしてLINE側の設定は終わりです.
Cognitoの設定に移動します.
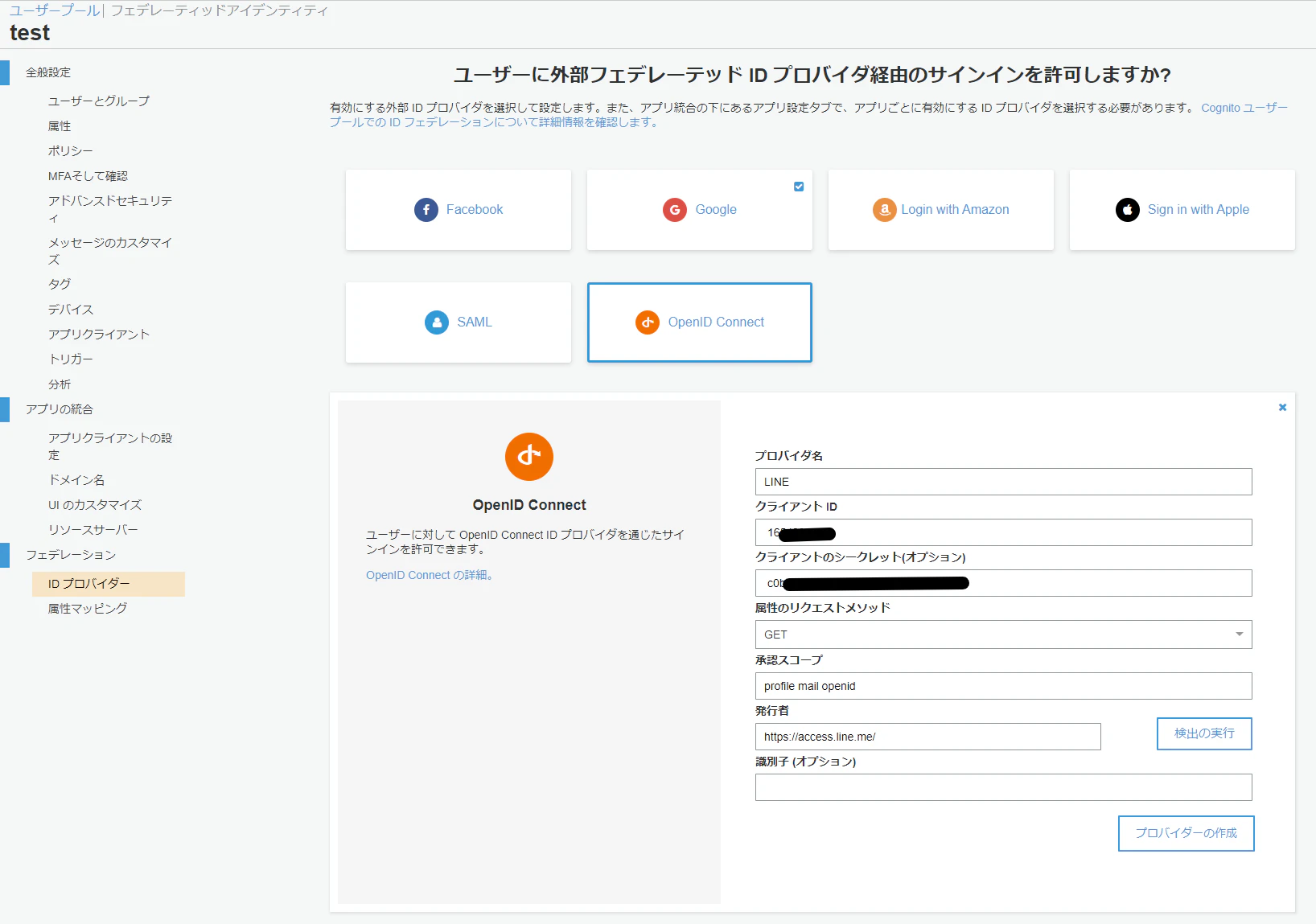
(5) IDプロバイダーを開いて今度はLINE専用のプロバイダはないのでOpenID Connect選択します.クライアントIDとシークレットに4のLINEのChannelでメモしたIDとシークレットを入力.
承認スコープにはprofile mail openid
発行者には https://access.line.me/
このままプロバイダーを作成しようとすると,
検出により結果は返されませんでした。発行者を確認し、もう一度検出を実行するか、以下の必須のフィールドを手動で追加します。
と表記されるので,
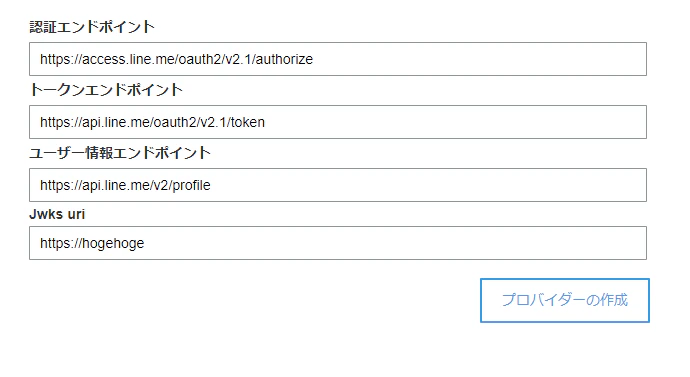
- 認証エンドポイント → https://access.line.me/oauth2/v2.1/authorize
- トークンエンドポイント → https://api.line.me/oauth2/v2.1/token
- ユーザ情報エンドポイント → https://api.line.me/v2/profile
を入力.
Jwks uriは特に入力する必要はないのですが,https:// から始まるURLを入れないとエラーが出るので適当に入れておきましょう.
(6) 後はアプリクライアントの設定で有効なIDプロバイダで作成したLINEを選択して保存すれば設定は完了です.
おまけ
後のアプリとの連携でつかうのでIDプールも作成しておきます.
認証プロバイダーにそれぞれメモしたIDを入力して作成プールの作成を行います.
作成後の画面でIDプールのIDが表示されるのでこれもメモしておきましょう.
Flutterの設定
ユーザー認証付きのアプリを作成する場合, ユーザーが登録・ログインしたタイミングでユーザーごとに一意なIDを取得し, それを使ってAPIコールをしたりすると思います.
ここでは, 登録・ログインしてから, 一意なユーザーIDを取得するところまでを解説します. また, おまけとして, Cognitoで認証されたユーザーのみがアプリ内からAPIコールを呼び出す方法についても見てみます.
これ以下のコードでは例外は
try-catchでキャッチして,print()しているだけですので, 必要な処理は書き足すようにしてください. また,async-await文もawaitの部分のみ書いているところも注意してください.また, これ以下で書いていることを使って簡単なユーザー認証アプリのデモを作ったので, もし良ければご覧ください. コードを見ながら, 実際に使いながらのほうがわかりやすいかもしれません.
https://github.com/Log4Rhythm/flutter_cognito_auth
ただし
auth.dartにはダミーの文字列が入れてあるので, 実際に動かすには上記のCognitoで設定した各値が必要- デモアプリなので
onPressed:に直に書いていますが, 実際はメソッド化するべき- ログインに成功したりしても, トークンを
print()したりするだけの簡易的なものなので, 続きは必要に応じて書いていく必要ありであることに注意してください.
ユーザー認証のおおまかな流れは以下のようになります. 3種類のトークンについてはすぐ下に記載しています.
メールアドレス・パスワード認証の場合
- 登録・ログイン時に更新トークンを取得する.
- 更新トークンを利用して, トークンエンドポイントから, 残り2種類のトークンを取得する.
- 一意なユーザーIDを取得する(IDトークンをデコードする or IDプールのIDを取得する).
- 2で取得したIDトークンとアクセストークンを利用して, APIコールをする.
サードパーティ認証の場合
- 登録・ログイン時にAuthorization Codeを取得する. このコードは1回きりしか使用できない.
- Authorization Codeを利用して, トークンエンドポイントから, 3種類のトークンを取得する.
- 一意なユーザーIDを取得する(IDトークンをデコードする or IDプールのIDを取得する).
- 2で取得したIDトークンとアクセストークンを利用して, APIコールをする.
更新トークン・IDトークン・アクセストークン
Amazon Cognitoのトークンエンドポイントから取得できる3種類のトークンについては, 以下の記事などを参考にしてください.
- Cognitoのサインイン時に取得できる、IDトークン・アクセストークン・更新トークンを理解する
- Refresh Token: どのような場合に使用し、どのように JWT と相互作用するか
- OAuth 2.0/OpenID Connectの2つのトークンの使いみち
イメージとしては,
- 更新トークンを取得
- その更新トークンを利用して, IDトークン・アクセストークンを取得
- IDトークンとアクセストークンを利用してCognitoの認証を行う
という感じだと思っています. 更新トークンはどこかに保管しておいて, APIコールを呼び出すタイミングでIDトークンやアクセストークンの有効期限が切れていれば, トークンエンドポイントからそれらを取得して使うという感じだと思います.
更新トークン IDトークン アクセストークン 設定可能な有効期限 60分~3650日 5分~1日 5分~1日 主な用途(?) IDトークン・アクセストークンを取得する APIコールなどに使用 APIコールなどに使用 使用するパッケージ
いつも通り
pubspec.yamlに以下を追記してflutter pub getします(バージョンは最新のものを使用してください).pubspec.yamlhttp: ^0.12.2 amazon_cognito_identity_dart_2: ^0.1.16 flutter_web_auth: ^0.2.4 jwt_decode: ^0.1.0また, この記事だけでは情報が十分でないところは多々あると思いますので, 各パッケージのAPI Referenceも参照するようにしてください.
ユーザープール, IDプールの情報をまとめておく
毎回これらの情報を直接打ち込むのは運用・保守の観点からしてもよろしくないので, 何か1つのDartファイルにまとめて書いておきます. 自分たちの設定したものに書き換えてください.
*callbackSchemeには://を除いたものを入れていることに注意してください. FlutterWebAuthパッケージに渡す際に://が含まれないものを渡す必要があるため, このようにしています.
*cognitoUserPoolはamazon_cognito_identity_dart_2パッケージのCognitoUserPoolオブジェクトです. これに付随するメソッド(.getRegion(), .getClientId())を利用するために定義しています.これ以降の説明ではこの変数を使っていきます. これらを使用するDartファイルに, このDartファイルをimportしてください. このファイルを
auth.dartと呼ぶことにします.auth.dartimport 'package:amazon_cognito_identity_dart_2/cognito.dart'; // Cognito User Pool // 自分で決めたドメイン // ex.) 'foo-bar123' const cognitoDomain = 'foo-bar123'; // ユーザープールID // ex.) 'us-east-1_XXXXXXXXX' const cognitoUserPoolId = 'us-east-1_XXXXXXXXX'; // アプリクライアントID // ex.) 'xxxxxxxxxxxxxxxxxxxxxxxxxx' const cognitoClientId = 'xxxxxxxxxxxxxxxxxxxxxxxxxx'; // コールバックURL // "://"が含まれないことに注意 const callbackScheme = 'myapp'; // 今回はAUthorization Codeでのレスポンスが欲しいので'code'を指定 // ほかにも'token'なども指定可能 const cognitoOAuthResponseType = 'code'; // ユーザープールで設定したScopeのうちここで使いたいScopeをスペースで区切って入力 const cognitoScope = 'openid email'; // Create Cognito User Pool // 上で設定したプールIDとアプリクライアントIDをつかって, CognitoUserPoolクラスのオブジェクトを作成. // これ以降, このオブジェクトを使いまくります final cognitoUserPool = CognitoUserPool(cognitoUserPoolId, cognitoClientId); // Cognito ID Pool // IDプールのID // ex.) 'us-east-1:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx' const cognitoIdentityPoolId = 'us-east-1:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx'; // Lambda / API Gateway // ex.) 'https://xxxxxxxxxx.execute-api.us-east-1.amazonaws.com' const apiEndpoint = 'https://xxxxxxxxxx.execute-api.us-east-1.amazonaws.com';メールアドレスとパスワードで認証
新規登録
ユーザーが入力したメールアドレス・パスワードが
userEmail,userPasswordだとします. また, ユーザーが入力したレジストレーションキーがuserRegistrationKeyだとします.
- 上(
auth.dart)で定義した,cognitoUserPoolに対して,signUp()メソッドで登録を行います. 戻り値は,CognitoUserPoolData型のオブジェクトであり, ここではcognitoUserPoolDataとします. メールアドレスに不備があったり, パスワードの要件を満たさなかったりした場合は,CognitoClientExceptionが発生します. エラーなく実行できた場合は,userEmailのメールアドレス宛にレジストレーションキーが送信されています.- 上で返ってきた,
cognitoUserPoolDataのuserプロパティはCognitoUser型のオブジェクトです. これに対して,confirmRegistration()メソッドで, レジストレーションキーの確認をすることができます. ここでも, 例外が発生した場合は,CognitoClientExceptionでキャッチできます.import 'package:amazon_cognito_identity_dart_2/cognito.dart'; // Registration try { CognitoUserPoolData cognitoUserPoolData = await cognitoUserPool.signUp(userEmail, userPassword); } on CognitoClientException catch (e) { print(e); } // Confirm Registration Key try { await cognitoUserPoolData.user.confirmRegistration(userRegistrationKey); } on CognitoClientException catch (e) { print(e); }ログイン
ユーザーが入力したメールアドレス・パスワードが
userEmail,userPasswordだとします.
userEmailと, 上(auth.dart)で定義した,cognitoUserPoolからCognitoUser型のオブジェクトcognitoUserを作成します.userEmailとuserPasswordからAuthenticationDetails型のオブジェクトauthenticationDetailsを作成します.cognitoUserに対して,authenticationDetailsを引数に渡したauthenticateUser()メソッドでユーザーを認証できます. パスワードが違うなどの例外もキャッチできます. 戻り値は,CognitoUserSession型のオブジェクトであり, ここではcognitoUserSessionとします.- (optional)
cognitoUserSessionには各種トークンの情報が含まれるため, それらを取得して,userIdを取得するのに使えます(後述の 一意なユーザーIDを取得する を参照).import 'package:amazon_cognito_identity_dart_2/cognito.dart'; CognitoUser cognitoUser = CognitoUser(userEmail, cognitoUserPool); final authenticationDetails = AuthenticationDetails(username: userEmail, password: userPassword); try { final cognitoUserSession = await cognitoUser.authenticateUser(authenticationDetails); // 以下の3つは必要に応じて使ってください. final refreshToken = cognitoUserSession.getRefreshToken().token; final idToken = cognitoUserSession.getIdToken().jwtToken; final accessToken = cognitoUserSession.getAccessToken().jwtToken; } catch (e) { print(e); }パスワードを忘れた場合
ユーザーが入力したメールアドレス・パスワードが
userEmail,userNewPasswordだとします. また, ユーザーが入力したリセットコードがuserResetCodeだとします.
userEmailと, 上(auth.dart)で定義した,cognitoUserPoolからCognitoUser型のオブジェクトcognitoUserを作成します.cognitoUserに対して,forgotPassword()メソッドを実行し,userEmailのメールアドレス宛にリセットコードを送信します. ただ, このメソッドでは,userEmailがCognitoに存在するか(すでに登録されたものか)を判別していないため, 登録されていないメールアドレスを入力しても例外が発生しないことに注意してください.- 2が問題なく実行できた場合,
cognitoUserに対して,confirmPassword()メソッドを実行して新しいパスワードを登録します. 引数は,userResetCodeとuserNewPasswordです. ここでもパスワードが要件を満たしていないなどの例外をキャッチできます.import 'package:amazon_cognito_identity_dart_2/cognito.dart'; CognitoUser cognitoUser = CognitoUser(userEmail, cognitoUserPool); try { await cognitoUser.forgotPassword(); } catch (e) { print(e); } // Create New Password try { await cognitoUser.confirmPassword(userResetCode, userNewPassword); } catch (e) { print(e); }パスワードの変更
ここでは詳しく紹介しませんが, 上と同様に
cognitoUserに対してchangePassword()メソッドを実行すればパスワードの変更ができます.
CognitoUserクラスにはほかにも様々なメソッドがあるので, 是非API Referenceを確認してみてください.サードパーティで認証(Google, LINEでログイン・新規登録)
サードパーティで認証を行う場合, ログイン・新規登録の流れは以下のようになります. ログインの場合でも新規登録の場合でも挙動は同じです.
- 認証エンドポイントにアクセス
- ユーザーがサードパーティのアカウントでログインすると, Authorization Codeが返ってくる.→アプリにリダイレクト
- Authorization Codeを利用して, トークンエンドポイントから, 3種類のトークンを取得する.
1. 認証エンドポイント
認証エンドポイントは, 以下のようになり, Cognitoユーザープールでの設定により変わります.
アプリ内で「Googleでログイン」などのボタンをユーザーが押すと, このURLにアクセスさせ, 認証が終わればresponse_typeに従ったレスポンスが返ってきます.
{}の部分は上(auth.dart)で定義した変数に置き換えます. もちろんですが, すべて文字列として結合するので, ''は含まれません.cognitoRegionは上(auth.dart)で定義した変数ではありませんが, ここでは便宜上このように書いています.final cognitoRegion = 'us-east-1'などに定義しておいても良いのですが, 先述のように,cognitoUserPool.getRegion()と,cognitoUserPoolに対してgetRegion()メソッドを使えばとってくることができるので, わざわざ定義していません.redirect_uriはCognitoユーザープールで設定したものと正確に一致している必要があり,callbackSchemeに://を書き足していることに注意してください.https://{cognitoDomain}.auth.{cognitoRegion}.amazoncognito.com/login?response_type={cognitoOAuthResponseType}&client_id={cognitoClientId}&scope={cognitoScope}&redirect_uri={callbackScheme}://
このままでも使えるのですが, どのサードパーティアカウントで認証したいのかをもう一度ユーザーが選ばなければならないのが不満だったので, 以下のURLに直接アクセスさせるようにしました.
identityProviderは, どのサードパーティアカウントで認証させるかにより変わります. 例えばGoogleであればidentityProviderとなります.https://{cognitoDomain}.auth.{cognitoRegion}.amazoncognito.com/oauth2/authorize?response_type={cognitoOAuthResponseType}&client_id={cognitoClientId}&identity_provider={identityProvider}&scope={cognitoScope}&redirect_uri={callbackScheme}://
2. アプリにリダイレクト
上の認証エンドポイントのURLをインターナルブラウザで開いて, レスポンスを受け取るところまでを, flutter_web_authに任せます.
使い方は簡単で, アクセスさせたい
urlとredirect_uri(callbackScheme)をFlutterWebAuth.authenticate()に渡すだけです. 戻り値の型はもちろんFuture型なのでasync-awaitで使います.
ユーザーがアクセスしたにも関わらず, ログインせずに戻ってきた場合はPlatformExceptionを吐くので, エラーを検出するためにtry-catch文で書くと例えば以下のようになります.try { final result = await FlutterWebAuth.authenticate(url: url, callbackUrlScheme: callbackScheme); } on PlatformException catch (e) { print(e); }ここでの,
callbackSchemeは上で変数に格納したように,://を含まないことに注意してください.ここで返ってくる
resultは以下のような形になります.myapp://?code=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxこれの
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxの部分がAuthorization Codeです.
これを以下のようにparseしてとってきます.final cognitoAuthCode = Uri.parse(result).queryParameters['code'];Androidの場合はAndroidManifest.xmlの編集が必要
Androidでアプリにリダイレクトさせるためには追加の設定が必要です.
android/app/src/main/AndroidManifest.xmlに以下を追記します. 上と同じですが,myappの部分は設定したコールバックスキームに書き換えてください.://は含みません.android/app/src/main/AndroidManifest.xml<!-- Flutter Web Auth --> <activity android:name="com.linusu.flutter_web_auth.CallbackActivity"> <intent-filter android:label="flutter_web_auth"> <action android:name="android.intent.action.VIEW"/> <category android:name="android.intent.category.DEFAULT"/> <category android:name="android.intent.category.BROWSABLE"/> <!-- ここは書き換える --> <data android:scheme="myapp"/> </intent-filter> </activity>追記する場所ですが,
<manifest>→<application>タグの中に書きます. デフォルトであれば,<application>タグの中には, 最初に<activity android:name=".MainActivity" …で始まる<activity>タグがあると思いますが, その<activity>タグと並列になるように追記します.3. トークンエンドポイントからトークンを取得する
2で取得したAuthorization Codeを使ってトークンエンドポイントにhttpリクエストを送り(ここで, httpパッケージを使います), トークンを受け取ります. 詳細はトークンエンドポイント - Amazon Cognitoを参照してください.
トークンエンドポイントは, 以下のようになります.
https://{cognitoDomain}.auth.{cognitoRegion}.amazoncognito.com/oauth2/token
また, ヘッダーは固定で,
{'Content-Type': 'application/x-www-form-urlencoded'}
となっています.あと必要な情報は, リクエストのbodyですが, ここでは,
- Authorization Codeから更新トークン・IDトークン・アクセストークンを取得する方法
- 更新トークンからIDトークン・アクセストークンを取得する方法
を解説します.
Authorization Codeから更新トークン・IDトークン・アクセストークンを取得する
bodyに必要な中身は以下のようになります.
'grant_type'は'authorization_code'で固定です. 下4つのパラメータの値は, 上(auth.dart)で定義した変数を使っています.- こちらの
'redirect_uri'もCognito ユーザープールで設定したものと正確に一致する必要があり,'myapp://'のように://が含まれるため, 下の表ではcallbackSchemeと'://'を連結していることに注意してください.|パラメータ|値|
|-|-|
|'grant_type'|'authorization_code'|
|'client_id'|cognitoUserPool.getClientId()(cognitoCliendIdでも同じ)|
|'code'|cognitoAuthCode|
|'redirect_uri'|callbackScheme + '://'|
|'scope'|cognitoScope|全体としてまとめて, httpリクエストを送ってresponseを受け取るところまでを書くと, 以下のようになります.
responseはhttp.Response型です.import 'package:http/http.dart' as http; // tokenEndPointのURLを作成 final tokenEndpoint = Uri.https(cognitoDomain + '.auth.' + cognitoUserPool.getRegion() + '.amazoncognito.com', '/oauth2/token'); http.Response response; try { response = await http.post( tokenEndpoint, headers: {'Content-Type': 'application/x-www-form-urlencoded'}, body: { 'grant_type': 'authorization_code', 'client_id': cognitoUserPool.getClientId(), 'code': cognitoAuthCode, 'redirect_uri': callbackScheme + '://', 'scope': cognitoScope, }, ); } catch (e) { print(e); }この
responseから, 各種トークンを取得するには以下のように,dart:convertに含まれるjson.decode()を利用して(importが必要です),import 'dart:convert'; final refreshToken = json.decode(response.body)['refresh_token']; final idToken = json.decode(response.body)['id_token']; final accessToken = json.decode(response.body)['access_token'];となります.
更新トークンからIDトークン・アクセストークンを取得する
bodyに必要な中身は以下のようになります.
*'grant_type'は'refresh_tokenで固定です.'client_id'は上(auth.dart)で定義した変数を使っています.
*'refresh_token'は, これ以前にどこかで(例えば上のAuthorization Codeなどから)取得したものを指定します. ここでは,refreshTokenという変数に格納されているとします.|パラメータ|値|
|-|-|
|'grant_type'|'refresh_token'|
|'client_id'|cognitoUserPool.getClientId()(cognitoCliendIdでも同じ)|
|'refresh_token'|refreshToken|全体としてまとめて, httpリクエストを送ってresponseを受け取るところまでを書くと, 以下のようになります.
responseはhttp.Response型です.import 'package:http/http.dart' as http; // tokenEndPointのURLを作成 final tokenEndpoint = Uri.https(cognitoDomain + '.auth.' + cognitoUserPool.getRegion() + '.amazoncognito.com', '/oauth2/token'); http.Response response; try { response = await http.post( tokenEndpoint, headers: {'Content-Type': 'application/x-www-form-urlencoded'}, body: { 'grant_type': 'refresh_token', 'client_id': cognitoUserPool.getClientId(), 'refresh_token': refreshToken, }, ); } catch (e) { print(e); }この
responseから, 各種トークンを取得するには以下のように,dart:convertに含まれるjson.decode()を利用して(importが必要です),import 'dart:convert'; final idToken = json.decode(response.body)['id_token']; final accessToken = json.decode(response.body)['access_token'];となります.
一意なユーザーIDを取得する
ここでは, ユーザーを識別するために必要な一意なユーザーIDを取得する方法を解説します. 以下の2つの方法を見ていきます.
- 取得したIDトークンをデコードして, ユーザープールでいう
subを取得する- 取得した更新トークンを利用して, IDプールのユーザーIDを取得する
上記2つのIDは別物であるため, どちらを使うかはアプリ内で統一してください.
IDトークンをデコードする
取得したIDトークンは, 単純にエンコードされたものなので, デコードすることで中身を知ることができます. デコードに, jwt_decodeパッケージを使用します.
ここでは,
idTokenに取得したIDトークンが格納されているとします.
1.idTokenをamazon_cognito_identity_dart_2のCognitoIdTokenオブジェクトにします.
2.getJwtToken()メソッドでJwtTokenに変換します.
3. それをJwt.parseJwt()でデコードします.
4.payloadはMapで, 今回はその中のsubを取得する.import 'package:amazon_cognito_identity_dart_2/cognito.dart'; import 'package:jwt_decode/jwt_decode.dart'; final cognitoIdToken = CognitoIdToken(idToken); final payload = Jwt.parseJwt(cognitoIdToken.getJwtToken()); final userId = payload['sub']これで, 一意なユーザーID(
userId)を取得することができました.ちなみに,
payloadにはsubだけでなく, 例えば参考(再掲) : Cognitoのサインイン時に取得できる、IDトークン・アクセストークン・更新トークンを理解する
IDプールのユーザーIDを取得する
先述の
subでも構いませんが, こちらのIDもユーザーごとに一意なのでユーザーを識別するためのIDとして利用できますここでは,
idTokenに取得したIDトークンが格納されているとします.
1.idTokenをCognitoIdTokenオブジェクトにします.
2.CognitoCredentialsオブジェクトを作成します. ここでの引数は, 上(auth.dart)で定義したString型のcognitoIdentityPoolIdと,CognitoUserPoolオブジェクトのcognitoUserPoolです.
3.cognitoCredentials.getAwsCredentials()にJwtTokenを渡して,AwsCredentialsを取得します.
4.cognitoCredentialsのuserIdentityIdプロパティがIDプールのユーザーIDです.import 'package:amazon_cognito_identity_dart_2/cognito.dart'; final cognitoIdToken = CognitoIdToken(idToken); CognitoCredentials cognitoCredentials = CognitoCredentials(cognitoIdentityPoolId, cognitoUserPool); await cognitoCredentials.getAwsCredentials(cognitoIdToken.getJwtToken()); final userId = cognitoCredentials.userIdentityId;これで, 一意なユーザーID(
userId)を取得することができました.(おまけ) APIコールについて
この記事はAPIに関することがメインではないので, ここでは実際にLambda関数を作ったりするようなことはしません. また, 前提としてLambdaとAPI Gatewayはつながっているとします.
AWS側の設定
AWS側で少し設定が必要です.
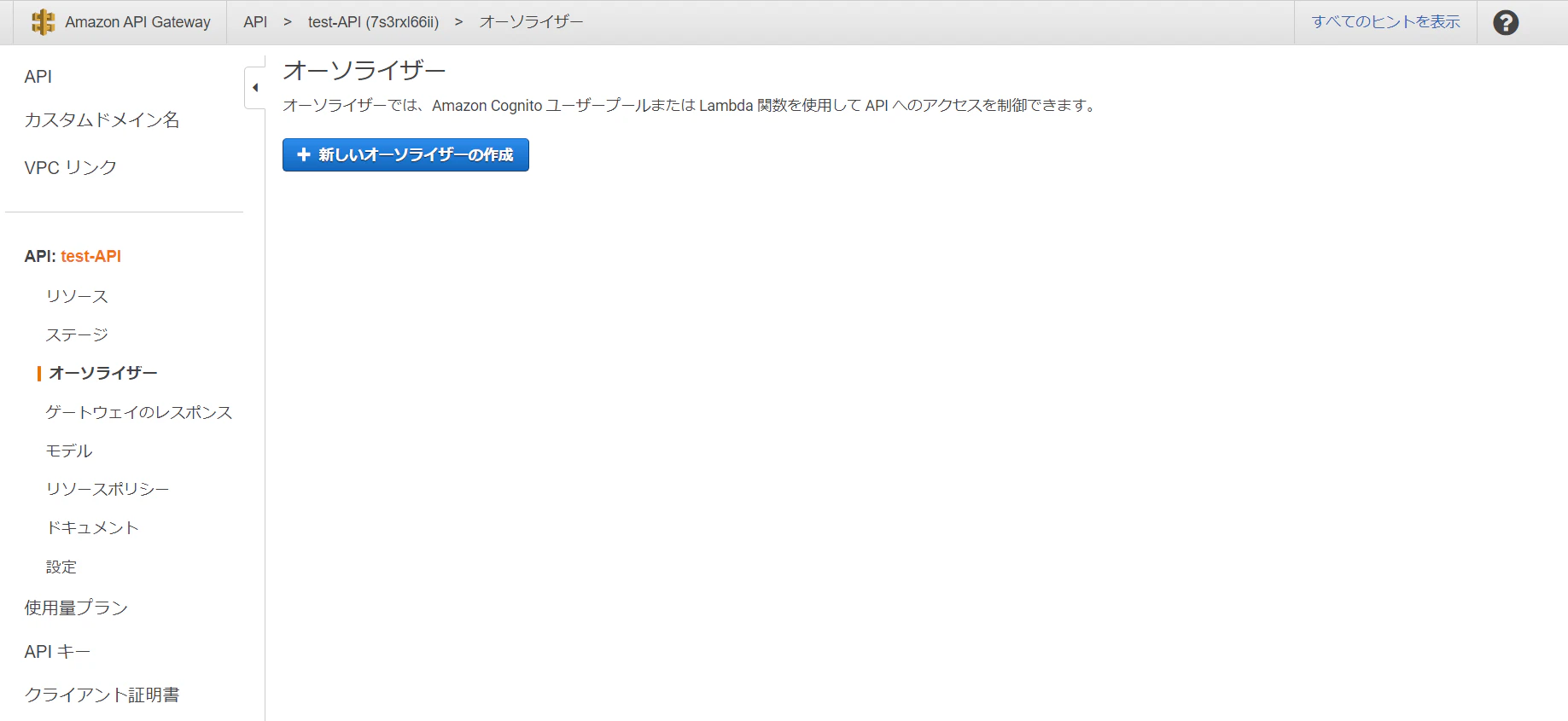
1. オーソライザーを作成する
- 下のように, 左のメニューからオーソライザーを選び, 「新しいオーソライザーの作成」をクリックします.
- 名前は適当につけ, タイプは「Cognito」にし, 上で作成したCognitoユーザプールを選びます(リージョンを選んで右のフィールドをクリックすればユーザープール一覧が出てきます. 出てこない場合はリージョンを確認してください). トークンのソースも適当なものを入力してください. 終わったら, 「作成」をクリックしてください.
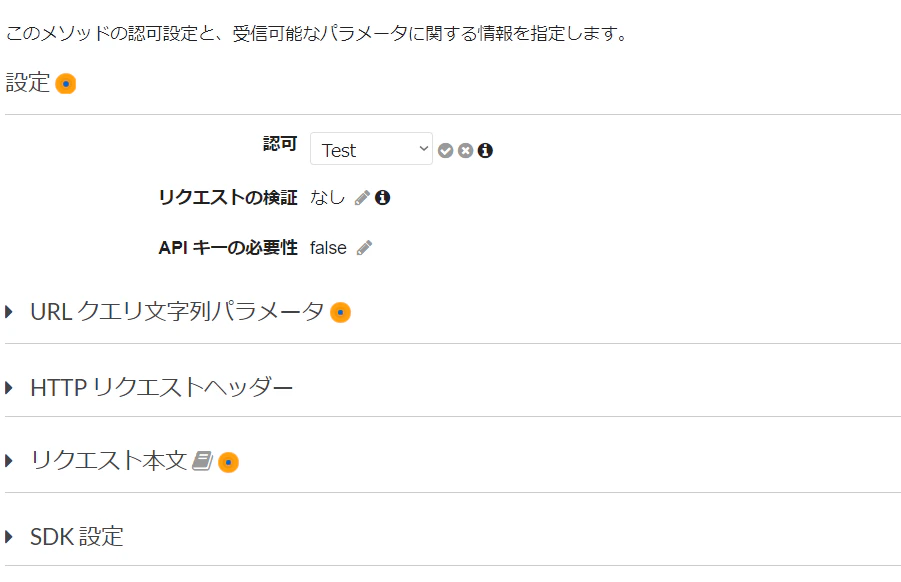
2. リソースに認可を与える
左のメニューから「リソース」を選び, 認可を与えたいリソースのメソッドを選択してください.
「メソッドリクエスト」をクリックしてください.
- 「認可 なし」となっているところの横のペンマークをクリックして, ドロップダウンから先ほど作成したオーソライザーを選択してください. 出てこない場合は, ページを再読み込みしてください. 選択できたら, 横のチェックマークをクリックしてください。
Flutter側からhttpリクエストを送る
idToken,accessTokenは上で取得したものです. また,apiEndpointはauth.dartで定義した変数です.
APIによっても様々なので一例として
* リソースパスが/testapiというAPI Gateway内のリソースに対して
*methodがPOST
*headersがrequestHeaders
*bodyがrequestBodyのリクエストを送る場合を書いています.
responseがもちろんレスポンスです. ちなみに, リソースパスは, 以下の部分で確認できます.
import 'package:amazon_cognito_identity_dart_2/cognito.dart'; CognitoUserSession cognitoUserSession = CognitoUserSession(idToken, accessToken); final cognitoCredentials = CognitoCredentials(cognitoIdentityPoolId, cognitoUserPool); await cognitoCredentials.getAwsCredentials(cognitoUserSession.getIdToken().getJwtToken()); final awsSigV4Client = AwsSigV4Client(cognitoCredentials.accessKeyId, cognitoCredentials.secretAccessKey, apiEndpoint, sessionToken: cognitoCredentials.sessionToken, region: cognitoUserPool.getRegion()); final signedRequest = SigV4Request(awsSigV4Client, method: 'POST', path: '/testapi', headers: requestHeaders, body: requestBody); http.Response response; try { response = await http.post( signedRequest.url, headers: signedRequest.headers, body: signedRequest.body, ); } catch (e) { print(e); }(正しくないかも?) ログイン状態の保持について
ここまで見てきたように, 例えばユーザーのパスワード変更や, APIコールにはIDトークンやアクセストークンなどが必要でした. しかし, 更新トークン・IDトークン・アクセストークンのところで見たように, これらのトークンの有効期限は長くても1日です. つまり, ユーザーは1日ごとにログインしなくてはならないわけです. そうなるととても不便なので, ログイン状態を保持したいとなります.
そこで, この解決方法が正しいのかはわかりませんが, 私たちは更新トークンの期限を3650日にして, shared_preferencesというパッケージを使い, 更新トークンをSharedPreferencesに保存することにしています. 更新トークンさえあれば, 「更新トークンからIDトークン・アクセストークンを取得する」に従ってID必要なものをすべて取得できます.
他には, amazon_cognito_identity_dart_2の
CognitoUserクラスにはcacheTokens()メソッドや,clearCachedTokens()メソッドがあるので, これらを使うことができるかもしれません(やったことはないです).何かもっと安全な方法を知っている方はぜひ教えてください!



















- 投稿日:2020-09-06T10:31:36+09:00
【サーバーレス初心者向け】Serverless Framework + SwaggerでWeb APIを作る!第3回 Dynamo編(全3回)
はじめに
こんにちは!
本記事は先日公開した本記事は先日公開した【サーバーレス初心者向け】Serverless Framework + SwaggerでWeb APIを作る!第2回 WAF適用編の続きとなります。前回はWAFを適用し、特定のIPアドレスにのみAPI Gatewayへのアクセスを許可するようにしました。
第3回となる今回は、Lambda関数からDynamoDBにアクセスするAPIのロジック部分を実装したいと思います。
過去の記事はこちら
- 【サーバーレス初心者向け】Serverless Framework + SwaggerでWeb APIを作る!第1回(全3回)
- 【サーバーレス初心者向け】Serverless Framework + SwaggerでWeb APIを作る!第2回 WAF適用編(全3回)
今回作るもの(再掲)
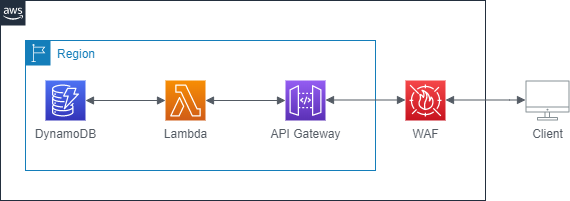
今回は以下のアーキテクト図のようなWeb APIバックエンドを作っていきます。
API GatewayでクライアントからのAPIリクエストを受信し、該当するLambda関数を呼び出し、必要に応じてDynamoDBからのデータ読み出しおよび書き込みを行います。さらに、WAFを適用することでセキュアにします。
APIとしては、ID・名前・身長・体重・年齢の情報を持つPersonモデルを登録・取得・更新・削除するAPIを作りたいと思います。
- GET dev/slsTestApp/v1/api/person/{personId}
- POST dev/slsTestApp/v1/api/person
- PUT dev/slsTestApp/v1/api/person/{personId}
- DELETE dev/slsTestApp/v1/api/person/{personId}
実装手順
今回はGET APIを例に以下の手順で実装していきたいと思います。
- DynamoDBのテンプレート実装→デプロイ
- IAM Roleのテンプレート実装→デプロイ
- Lambda関数の実装→デプロイDynamoDBのテンプレート実装→デプロイ
DynamoDBのテンプレートは以下のようになります。
dynamodb.ymlResources: SlsTestAppPersonTable: Type: AWS::DynamoDB::Table Properties: TableName: SlsTestAppPersonTable-${self:provider.stage} AttributeDefinitions: - AttributeName: personId AttributeType: S - AttributeName: age AttributeType: S KeySchema: - AttributeName: personId KeyType: HASH - AttributeName: age KeyType: RANGE BillingMode: PAY_PER_REQUESTレコードのIDとなる
PersonIdをパーティションキー、ageをソートキーにしたテーブルとします。BillingModeで課金モードを指定できます。今回はテストアプリのためアクセスはほとんどしないため、使った分だけ課金されるPAY_PER_REQUESTを指定しています。もしたくさんのアクセスが予想されるシステムへ流用するならあらかじめキャパシティユニットを指定するPROVISIONEDのほうが安く済む場合もあります。
両モードの料金比較はクラスメソッドさんに記事がありますのでこちらを参照してみてください。DynamoDB料金比較
https://dev.classmethod.jp/articles/reinvent2018-compare-dynamodb-on-demand-price-with-provisioned-price/その他の記載方法は以下を参照してください。
DynamoDB CloudFormation
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/aws-resource-dynamodb-table.htmlテンプレートが完成したら、一度デプロイします。DBはステートフルリソースなので、Lambda関数とはスタックを分けたほうが良いです。そのため、前回の記事で取り上げたWAFのデプロイのように、
dynamodbフォルダを作り、その下に先ほどのdynamodb.ymlとserverless.ymlを作成します。serverless.ymlは以下のような感じです。serverless.yml(dynamodbスタック用)# Welcome to Serverless! # # 中略 service: slsTestAppDynamoDb # app and org for use with dashboard.serverless.com #app: your-app-name # 中略 provider: name: aws runtime: nodejs12.x # you can overwrite defaults here stage: dev region: ap-northeast-1 # 中略 # you can add packaging information here package: # include: # - include-me.js # - include-me-dir/** exclude: - templates/** #functions: # functionsは記載しない # you can add CloudFormation resource templates here resources: - ${file(./templates/dynamodb.yml)}ここまでできたら、
dynamodbフォルダまでコマンドプロンプトを起動し、デプロイコマンドを実行します。sls deploy -vIAM Roleのテンプレート実装→デプロイ
Lambda関数からDynamoDBにアクセスするにはIAM Roleでアクセス権限をつける必要がありますので、そのテンプレートを作成します。
テンプレートは以下のようになります。
iam.ymlResources: GetPersonRole: Type: AWS::IAM::Role Properties: RoleName: "GetPersonRole-${self:provider.stage}" AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: Service: "lambda.amazonaws.com" Action: sts:AssumeRole ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole Path: "/" Policies: - PolicyName: "GetPersonPolicy-${self:provider.stage}" PolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Action: - dynamodb:Query Resource: - "arn:aws:dynamodb:${self:provider.region}:${self:provider.environment.ACCOUNT}:table/SlsTestAppPersonTable-${self:provider.stage}" - "arn:aws:dynamodb:${self:provider.region}:${self:provider.environment.ACCOUNT}:table/SlsTestAppPersonTable-${self:provider.stage}/index/*"まず、
ManagedPolicyとして、AWSLambdaBasicExecutionRoleを付けます。これをつけることで実行結果がCloudWatch Logsに出力されるようになり、デバッグがしやすくなります。
GET APIではバックエンドでDynamoのQueryを使用する想定なので、dynamodb:Queryを許可する記載にしています。ResourceにはアクセスしたいDyanmoDBのArnを指定しますが、Queryやセカンダリーインデックスを使ったアクセスの許可の場合には{DynamoDBのArn}/index/*も追加する必要があることに注意してください。それではデプロイしていきます。Lambda関数定義が記載されたsrerverless.ymlの
resourcesにiam.ymlへのパスを指定し、デプロイコマンドを実行してください。
なお、IAM RoleもDynamoDBやWAFと同様にスタックを分けて作成しても構いません。Lambda関数の実装→デプロイ
ここまで来たらロジックを実装していきます。
まずはDynamoDBにアクセスする関数を実装していきます。
コードは以下の通りです。personTable.js"use strict"; module.exports = class PersonTable { constructor(serviceClient) { this.client = serviceClient; } getPerson(personId) { const params = { TableName: process.env.PERSON_TABLE_NAME, KeyConditionExpression: "#hash = :personId", ExpressionAttributeNames: { "#hash": "personId", }, ExpressionAttributeValues: { ":personId": personId, }, }; return new Promise((resolve, reject) => { this.client.query(params, (err, data) => { if (err) { console.log(err); reject(err); } else { console.log("getPerson Success!"); resolve(data); } }); }); } };少し特殊かもしれませんが、DynamoDBにアクセスする関数をまとめたクラス
PersonTableの中にAPI別にメソッドを実装しています。メソッドを使用するときは呼び出し元でDynamoDBクライアントを作りそれをコンストラクターに渡してあげます。次に、API Gatewayから呼び出されるLambda関数を実装していきます。
第1回で作成したindex.jsを以下のように変更します。index.js"use strict"; var AWS = require("aws-sdk"); AWS.config.update({ region: process.env.region }); //ここでDynamoDBのクライアントを作る var docClient = new AWS.DynamoDB.DocumentClient({ apiVersion: "2012-08-10" }); //先ほどのPersonTableをインポート var PersonTable = require("../../aws/personTable"); var Validator = require("../../util/validator"); var Formatter = require("../../util/formatter"); module.exports.handler = async (event, context, callback) => { //ここでクライアントを渡す const personTable = new PersonTable(docClient); const validator = new Validator(); const formatter = new Formatter(); try { //DynamoDBからPersonモデルを取得する const res = await personTable.getPerson(event.pathParameters.personId); if (validator.checkDyanmoQueryResultEmpty(res)) { const errorModel = { errorCode: "STA00001", errorMessage: "Not Found", }; callback(null, { statusCode: 404, body: JSON.stringify({ errorModel, }), }); } callback(null, { statusCode: 200, body: JSON.stringify(formatter.getPersonFormatter(res)), }); } catch (err) { console.log("getPersonTable-index error"); } };コメント残している箇所がDynamoDBアクセスに関係する箇所です。
eventにパスパラメータ(personId)が入っているのでそれを取得してPersonTable.getPersonに渡しています。
validatorやformatterは詳しくは述べませんが、それぞれDynamoDBアクセスの結果をバリデーションするクラス/フォーマットするクラスです。ここまでできたらデプロイしてください。
動作確認
では早速動作確認していきましょう。GET APIなので、DynamoDBに手動でレコードを登録しておきます。例えば以下のような内容です。
PersonModel{ "personId": "aaa", "age": "28", "height": "178", "name": "tarou", "weight": "70" }GET APIをcurlで実行し、先ほどのjsonが返ってくれば成功です!
> curl GET https://XXX.execute-api.ap-northeast-1.amazonaws.com/dev/slsTestApp/v1/api/person/aaa {"personId": "aaa","age": "28","height": "178","name": "tarou","weight": "70"}おわりに
最後までご覧いただきありがとうございました。
ここまでのサンプルコード一式や、紹介しきれなかったその他のPOST/PUT/DELETEのAPI実装、単体テストなどなど以下のGitHubに置いておきましたので、参考していただければ幸いです。
- 投稿日:2020-09-06T09:59:20+09:00
(Python)Trelloから期限が近づいているタスクを通知するアプリをLambdaで作ってみた。
前説
うちのチームは、全員がやらなければならないタスクをTrelloで管理しています。
(カードにタスク、チェックリストに個人名が並び、タスク完了者は☑をつける形式)上司は、毎回Trello開いて、各カード開いて、進捗を確認しなければなりません。
絶対面倒くさい。
そして、Trello Alertでは、カードの変更や新規作成、リストに☑をつけた時などにslack通知を出せますが、☑を付けるたびに通知が来るし、完了者と未完了者が一覧で見れるわけではありません。
基本的に、通知はslackのチャンネルを汚していきます(個人的な見解)。
そして、一覧で見れないのはやっぱり面倒くさい。じゃあ、定期的に(チャンネルを汚さない範囲で)タスク未完了者を通知するアプリを作ってしまおう。
そして、やるならAWS使って実装しよう。と思いつき、作ってみました。
(2020/09/06現在、権限の関係でSlackに通知を出しておりません。今後実装予定)開発
開発フロー
大まかな開発フローは、
①TrelloのAPI叩く
②コード書く
③AWS lambdaに実装
④EventBridge(CloudWatch Events)をトリガーにする
⑤Slack appを作成する
⑥コード書く(実装予定)というような感じです。一つずつ見ていきます。
TrelloのAPI叩く
ここにアクセスします。
Trello API Keys
一番上にあるKeyをコピーしておきます。(メモ帳なんかにおいておくと◎)
Trello API Token
Key:の下のToKen:内にあるTokenのリンクをクリック。
そうすると、
Would you like to give the following application access to your account?
と聞いてくるので、スクロールしてAllowします。
上記ページに移動したら、Token Keyが書いてあるので、これもコピーしておきます。次は、ライブラリ(py-trello)のインストールをしていきましょう。
今回は、Lambdaを使う予定なので、ライブラリをpythonコードと同じフォルダ内(trello_alert)にインストールします。(フォルダ内が汚くなるのは置いておきます)powershellmkdir trello_alert cd trello_alert pip install py-trello --target .これで、APIをたたく準備ができました。
実際に叩いていきましょう。trello_api.pyfrom trello import TrelloClient #trelloにAPI接続 client=TrelloClient( api_key='ここにAPI Key書く', api_secret='ここにAPI Token書く' ) print(client.list_boards())これで実行して、trelloのリストの一覧が出力されていればAPIをたたくタスクは完了です。
コード書く
では、リストを取得して、期限が近いタスクが未完了な人を出力していきます。
基本的に、このGitHubにTrelloClientのクラスのコードが上がっているので、必要に応じて確認してみてください。
自分の書いたコードを参考に挙げておきます。
(lamdaに上げるので、lamda用のコードになってます)lambda_function.py#Dateが近づいているTask未完了者を取得 import re import datetime from trello import TrelloClient import json def lambda_handler(event, context): result = {} #今日と来週の日付を取得 today = datetime.date.today() next_week = today + datetime.timedelta(weeks=1) #trelloにAPI接続 client = TrelloClient( api_key='ここにAPI Key書く', api_secret='ここにAPI Token書く' ) #trelloのカードを取得する board = client.get_board(`注①:ここにボードidを書く`) #ボードを取得 target_list = board.get_list(`注②:ここにリストidを書く`) #リストを取得 cards = target_list.list_cards() #リスト上のカードの一覧を取得 #カード毎のタスク未完了者と期限を取得 #期限が1週間後のものと今日のものを通知 for c in cards: #カードを取得 card = client.get_card(c.id) card.fetch() #カードの期限を取得 due = re.match("[0-9]{4}-[0-9]{2}-[0-9]{2}", c.due).group() #期限が今日のものと1週間後のもののチェックリストを取得 if(str(due) == str(today) or str(due) == str(next_week)): #チェックリストを1件ずつ取得 for checklist in card.checklists: not_finish = [] for i, item in enumerate(checklist.items): #タスク未完了者を出力 if(item["checked"]== False): not_finish.append(item["name"]) #カード名とタスク未完了者を辞書形式で格納 result[c.name] = not_finish return { 'statusCode': 200, 'body': json.dumps(result, ensure_ascii=False) }注1:trelloのboardを開いたときのurlのbの後ろがボードidです。
https://trello.com/b/ボードid/ボード名
注2:boardクラスにall_list関数があるので、それを出力してリストidを探します。
print(board.all_list())こんな感じで、期限の近いタスクとタスク未完了者を取得することができました。
(ローカルで実行してみたいよという方は、8行目、45行目~48行目をコメントアウトして`print(result)を最後に付け加えれば実行できます。)
ファイル名を'lambda_function'にしておかないと、lamdaにアップしたときに動かないので注意しましょう。とりあえず、コードができました。
lambdaに上げていきます。AWS lambdaに実装
zipファイル化
lambdaにコードを上げるのにzipファイルにする必要があるので、
trello_alertフォルダ内にあるすべてを選択し、圧縮し、zipファイルにしましょう。
zipファイル名はtrelloとかにしておきましょう。AWSにログイン
Find Servicesからlambdaと検索するとAWS Lambdaが候補に出てくるので選択。
このページに移動したら、
create functionをクリック。
次のページでは、一番左を選択し、下にスクロール。
こんな感じに記入します。(trello_alert既にあるよって言われてるので赤字ですね)
そして、create functionをクリック。
Lambdaのところに、trello_alertが追加されます。
trello_alertをクリックして、コードをアップしていきます。
このページに移動したら、右下のActionの部分をクリック。
Upload a .zip fileを選択し、先ほど作っておいたtrello.zipをアップロードします。
こんな感じで、ファイルがアップされます。
(デフォルトで用意されているlambda_functionが邪魔してきたらdeleteしておきましょう)
あとは、上記画面のsaveを押して、testを実行します。
テストを押すと以下のような画面になるので、Event nameをtestにして、createします。
前の画面に戻るので、もう一度testを実行します。Execution Resultに200応答が返ってきていればlambdaにアップ完了です。
環境変数設定(オプション)
API KeyやAPI Tokenを生のままコードに書いておくのは..という方は、
Function codeの下に、Enviroment variablesがあるので、
そこに環境変数を設定し、コード上では、
api_key=os.environ['API_KEY']
と書けば、問題なく実行されます。EventBridge(CloudWatch Events)をトリガーにする
定期実行したいのでCloudWatch Eventsを利用します。
Slack appを作成
以下の記事を参考にSlack appを作成しました。
【2020年版】slackAPIでメッセージ投稿するボットアプリ作成・設定(スコープ権限を詳細解説)実装予定
⑥コード書く(実装予定)
まとめ
AWSも使えて、APIも叩けて、業務も改善が見込めていい経験でした。









- 投稿日:2020-09-06T08:18:58+09:00
SQSでCognitoユーザー一覧をS3に作成するキュー処理を行う関数とAPIをLambdaにSAMでデプロイする
日本語が不自由なタイトルになりましたが順に設定していきます。
AWSのCognitoで管理されているユーザー一覧のCSVファイルをS3上に自動で作成する関数をLambda上に構築します。
そのLambdaを発動させるトリガーにSQSを設定し、SQSにメッセージキューを追加するAPIも別のLambdaに実装しAPI Gateway経由でHTTPリクエストを受け取るようにします。
- Cognito: ユーザー管理サービス。多要素認証(MFA)やSNS連携などを簡単に実装できる。
- S3: クラウドストレージ。バージョニングや一時的に利用可能なダウンロードURL作成などもできる。
- SQS: AWS上でキューを管理する。非同期処理などに利用される。
- Lambda: サーバーレスの関数実行環境
- API Gateway: LambdaやEC2にAPIのインターフェースを提供する。
構成図は以下のとおりです。
AWS-CLIのインストールとIAMの設定
$ brew install awscli $ aws configure AWS Access Key ID [None]: ************ AWS Secret Access Key [None]: ************************ Default region name [None]: ap-northeast-1 Default output format [None]: jsonSAMのインストール
※ Dockerも必要になるためインストールと起動をしてください。
$ brew tap aws/tap $ brew install aws-sam-cli $ sam --version SAM CLI, version 1.0.0SAMプロジェクトの初期化
今回はPython3.8でHello Worldテンプレートをベースに実装を進めます
% sam init Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 Which runtime would you like to use? 1 - nodejs12.x 2 - python3.8 3 - ruby2.7 ・・・ Runtime: 2 Project name [sam-app]: sample-app Cloning app templates from https://github.com/awslabs/aws-sam-cli-app-templates.git AWS quick start application templates: 1 - Hello World Example 2 - EventBridge Hello World ・・・ Template selection: 1 ----------------------- Generating application: ----------------------- Name: sample-app Runtime: python3.8 Dependency Manager: pip Application Template: hello-world Output Directory: . Next steps can be found in the README file at ./sample-app/README.mdCognitoのユーザープールの作成
今回はひとまずデフォルト設定で作成して、適当なユーザーを一つ手動で追加しました。
作成したユーザープールIDをファイル作成時に利用します。
実装
主要なファイルを以下のように実装しました。
app.pyimport json import requests import boto3 from datetime import datetime import pandas as pd def lambda_handler(event, context): try: sqs_client = boto3.client("sqs") # 一度SQSをデプロイすると自動でSQSにキューが作成されるのでそれを設定します queue_url = "https://sqs.ap-northeast-1.amazonaws.com/********/**********" print(queue_url) now = datetime.now() date_str = now.strftime('%Y/%m/%d-%H:%M:%S') sqs_response = sqs_client.send_message( QueueUrl=queue_url, MessageBody=json.dumps(date_str) ) except requests.RequestException as e: # Send some context about this error to Lambda Logs print(e) raise e return { "statusCode": 200, "body": json.dumps({ "message": "hello world" }), } def csv_create_handler(event, context): for record in event['Records']: payload=record["body"] date_str = str(payload) s3 = boto3.resource('s3') bucket = s3.Bucket('arkth-user-list-files') cognito_client = boto3.client('cognito-idp') response = cognito_client.list_users( UserPoolId = 'ap-northeast-***********', AttributesToGet = ['email','sub'] ) data = [] for user in response["Users"]: data.append([user['Username'], user['Enabled']]) Coulum = ['Username', 'Enabled'] df = pd.DataFrame(data, columns=Coulum) df_csv = df.to_csv(index=None) objkey = 'user-list.csv' print(objkey) putobj = bucket.Object(objkey) putobj.put(Body=df_csv) def support_datetime_default(obj): if isinstance(obj, datetime): return obj.isoformat() raise TypeError(repr(obj) + " is not JSON serializable")template.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > sample-app Sample SAM Template for sample-app # More info about Globals: https://github.com/awslabs/serverless-application-model/blob/master/docs/globals.rst Globals: Function: Timeout: 3 Runtime: python3.8 Resources: HelloWorldFunction: Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction Properties: CodeUri: hello_world/ Handler: app.lambda_handler Events: HelloWorld: Type: Api # More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api Properties: Path: /hello Method: get UsersCsv: Type: AWS::SQS::Queue Properties: VisibilityTimeout: 60 CsvCreateFunction: Properties: CodeUri: hello_world/ Handler: app.csv_create_handler Events: MySQSEvent: Type: SQS Properties: Queue: !GetAtt UsersCsv.Arn BatchSize: 10 Type: AWS::Serverless::Functionrequirement.txtrequests boto3 pandasSAMのビルド
$ sam build Building function 'HelloWorldFunction' Running PythonPipBuilder:ResolveDependencies Running PythonPipBuilder:CopySource Building function 'CsvCreateFunction' Running PythonPipBuilder:ResolveDependencies Running PythonPipBuilder:CopySource Build Succeeded Built Artifacts : .aws-sam/build Built Template : .aws-sam/build/template.yaml Commands you can use next ========================= [*] Invoke Function: sam local invoke [*] Deploy: sam deploy --guidedローカルでSAMの起動
$ sam local start-api Mounting HelloWorldFunction at http://127.0.0.1:3000/hello [GET] You can now browse to the above endpoints to invoke your functions. You do not need to restart/reload SAM CLI while working on your functions, changes will be reflected instantly/automatically. You only need to restart SAM CLI if you update your AWS SAM template 2020-09-05 22:11:22 * Running on http://127.0.0.1:3000/ (Press CTRL+C to quit)SQSのエンドポイントがダミーのためエラーになりますが、ブラウザから
http://127.0.0.1:3000/helloにアクセスしてSyntax Errorなどがないか確かめます。SAMのデプロイ
初回は --guided でデプロイすることで対話式で、samconfig.tomlが作成されます。
$ sam deploy --guided Configuring SAM deploy ====================== Looking for samconfig.toml : Not found Setting default arguments for 'sam deploy' ========================================= Stack Name [sam-app]: sample-app AWS Region [us-east-1]: ap-northeast-1 #Shows you resources changes to be deployed and require a 'Y' to initiate deploy Confirm changes before deploy [y/N]: y #SAM needs permission to be able to create roles to connect to the resources in your template Allow SAM CLI IAM role creation [Y/n]: Y HelloWorldFunction may not have authorization defined, Is this okay? [y/N]: y Save arguments to samconfig.toml [Y/n]: Y ・・・・ ・・・・ ・・・・少し時間がかかりますが、IAMやApi Gatewayなども適当に設定してデプロイしてくれます。
環境設定
- app.py内のSQSのエンドポイントを、作成されたSQSのエンドポイントに書き換えます。
ファイル作成のLambda関数に割りてられているIAMのRoleにSQSとS3にアクセスする権限を付与します。
以下のように、APIの方のLambda関数のDestinationに作成されたSQSを設定します。ここはSAMで設定できるのかもしれないのですが、今回は手動で行いました。
その後、再度build & deployします。
$ sam build $ sam deploy動作確認
HelloWorldの方のLambda関数に設定されているAPI Gatewayのエンドポイントにブラウザでアクセスします。
その後S3のBucketにアクセスすると、以下のようなCSVファイルが作成されています。




- 投稿日:2020-09-06T08:15:57+09:00
【JavaScript】String配列の要素をキーとするオブジェクトを作成する方法
はじめに
ループしながら、配列内の要素をキーとするオブジェクトを作成する方法を紹介します。
方法
const array = ['key1', 'key2', 'key3',] const createObj = (array) => { const obj = new Object(); array.forEach(item => (Object.defineProperty(obj, item, { enumerable: true, // ループのために必要! value: 'ここに値' }))); return obj; } console.log(createObj(array)); // {key1: 'ここに値', key2: 'ここに値', key3: 'ここに値'}オプションとして設定する、
enumerable: trueが重要です。
これがないと動きません。まとめ
配列内の要素をキーとするオブジェクトを作成することができました。
- 投稿日:2020-09-06T02:51:24+09:00
AWSで割とモダンな技術使う大学生日記①
前置き
terraformで構成しようとしたが、まずはAWSを理解するためコンソールから構築
本記事は私自身が少し悩んだ、ネットワークの構成やトラブルシューティングについて重点的に記載されております。ハンズオン形式の記事はQiita等にも多くございますのでそちらを参照しつつ、こちらの記事でより理解を深めていただければな、と思います。
使用技術 Laravel6.x AWS ECS(Fargate), RDS, ElasticCache Docker, docker-compose ネットワーク構成
VPCは10.1.0.0/16を利用。
サブネットの利用感は下記みたいな感じ
サブネット 用途 10.1.0.0/24, 10.1.1.0/24 Publicサブネット。LBに使うサブネット 10.1.2.0/24, 10.1.3.0/24 Privateサブネット。LBからECSに行くサブネット 10.1.4.0/24, 10.1.5.0/24 ECS~RDS間のサブネット。ECSからDBに接続するサブネット 10.1.6.0/24 EC2~RDS間のサブネット。EC2からDBに接続するサブネット migrationはDockerfileには置かないのでDB接続用のEC2インスタンスを用意する。
(userのデータとかも取得できるので)ルートテーブルでInternetGatewayと接続するのはLBとDB接続用のEC2インスタンスのみ。
appサーバーとDBサーバー(RDS)はローカルでしか接続できないように設定する。
※ネットワークの軽い知識があれば上記のサブネットや、CIDRを理解できます。
30分とかで理解できると思うのでYouTubeとかでおさらいしておいてください。
Fargateタイプにおいてのコンテナ間通信について
webコンテナは
Nginx(読み方はエンジンエックスっていうらしい、最近までエヌジンクスって読んでた)を利用していてappコンテナはPHPでフレームワークはLaravel。
そのためwebコンテナからappコンテナへの通信が必要。
ローカル内では下記のように.confファイルを記述する。
ポートはwebはHTTP通信のため80、appは9000。
(docker-compose.ymlで名前をそれぞれwebとappで指定しておく)default.conf01:server { 02: listen 80; 03: root /work/public; 04: index index.php; 05: charset utf-8; 06: 07: location / { 08: root /work/public; 09: try_files $uri $uri/ /index.php$is_args$args; 10: } 11: 12: location ~ \.php$ { 13: fastcgi_split_path_info ^(.+\.php)(/.+)$; 14: fastcgi_pass app:9000; 15: fastcgi_index index.php; 16: include fastcgi_params; 17: fastcgi_param SCRIPT_FILENAME /work/public/index.php; 18: fastcgi_param PATH_INFO $fastcgi_path_info; 19: } 20:}上記のような設定だとAWS ECSのFargate起動タイプだとヘルスチェックで
Taskが実行できません。
というエラーが出ます。そこで14行目を下記のように変更します。default.conf14: fastcgi_pass localhost:9000;上記のようにする理由としては、Fargate起動タイプは同じローカルネットワーク内でtaskが実行されるためlocalhostは共有している。そのためコンテナ間通信は
localhost:ポート番号で指定する。トラブルシューティング
ヘルスチェックが通らない。
ECSを起動する際に、ヘルスチェックが通らず、taskが実行できなかったとき。
Dockerfileへの知見が甘かったため、
待つポート番号やコピーするディレクトリを間違えていたりした。
Dockerfileの最後の行にEXPOSE <ポート番号>を指定すること。
また、ローカルでコンテナを起動し期待するディレクトリにソースが入っているかを確認するといい。ヘルスチェックは通るがLBのDNSに接続してもログインページが表示されない
ECS起動後にヘルスチェックが通るがログインページは表示されない場合。
ヘルスチェックは通っている ↓ ローカル内での通信はできている ↓ ネットワークの構成を確認し、落ちているところを確認主に原因はネットワーク。
SGのインバウンドルールは適切か。ルートテーブルは適切か。再度確認する。
この過程が割と大事でCloudFomationとかで構成すると割と曖昧になりがちなネットワーク構成を理解できる。私の場合は、LBのターゲットグループを複数作成しており、利用したいターゲットグループの優先順位が一番ではなかったため、ログインページが表示されていなかった。セッションの共有
可用性のために、複数のタスクを実行し、AutoScallingをオンにしていると思うので
セッションの共有をしておかなければいけない。
Laravelのセッションはデフォルトでfileを選択しておりProject/storage/sessionsに保存されている。実行されるタスクが複数でセッションの保存先がfileの場合、それぞれのappコンテナの中に保存されてしまうので、セッションの共有をしなければいけない。
今回は、AWSのマネージドサービスであるElasticCacheを利用する。
※実装の工数上、現状(2020/09/06)では未構築のため後日追記する。
その際には上記のネットワーク構成にも修正を加える予定。
Dockerfileとdocker-compose.yml
いや、GitHub載せろよ。って思うよね。
僕的に、Qiita見ながらコピペできるのが理想なのでDockerfileとdocker-compose.ymlはここに書きます。default.confは上記に記載済み。Fargate起動タイプの時はlocalhost指定してください。
ディレクトリ構成も載せておきます。| ├── docker | | │ ├── nginx | | ├── Dockerfile │ │ └── default.conf │ └── php │ ├── Dockerfile │ └── php.ini ├── docker-compose.yml | ├── .env | ├── .gitignore | └── livedocker-compose.ymlversion: "3" services: app: build: context: . dockerfile: ./docker/php/Dockerfile args: - TZ=${TZ} ports: - ${APP_PORT}:9000 volumes: - ./live:/work - ./logs:/var/log/php - ./docker/php/php.ini:/usr/local/etc/php/php.ini working_dir: /work environment: # ここは要設定 - DB_CONNECTION={DB_CONNECTION} - DB_HOST=${DB_HOST} - DB_DATABASE=${DB_DATABASE} - DB_USERNAME=${DB_USERNAME} - DB_PASSWORD=${DB_PASSWORD} - TZ=${TZ:-Asia/Tokyo} web: build: context: . dockerfile: ./docker/nginx/Dockerfile depends_on: - app ports: - ${WEB_PORT:-80}:80 volumes: - ./live:/work - ./logs:/var/log/nginx - ./docker/nginx/default.conf:/etc/nginx/conf.d/default.conf environment: - TZ=${TZ:-Asia/Tokyo} volumes: db-store:docker/nginx/DockerfileFROM nginx:1.19-alpine COPY ./docker/nginx/default.conf /etc/nginx/conf.d/default.conf COPY ./live /work EXPOSE 80dokcer/php/DockerfileFROM php:7.4-fpm-alpine ARG PSYSH_DIR=/usr/local/share/psysh ARG PHP_MANUAL_URL=http://psysh.org/manual/ja/php_manual.sqlite ARG TZ ENV COMPOSER_ALLOW_SUPERUSER 1 ENV COMPOSER_HOME /composer RUN set -eux && \ apk update && \ apk add --update --no-cache --virtual=.build-dependencies \ autoconf \ gcc \ g++ \ make \ tzdata && \ apk add --update --no-cache \ icu-dev \ oniguruma-dev \ libzip-dev && \ cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime && \ echo ${TZ} > /etc/timezone && \ pecl install xdebug && \ apk del .build-dependencies && \ docker-php-ext-install intl pdo_mysql mbstring zip bcmath && \ docker-php-ext-enable xdebug && \ mkdir $PSYSH_DIR && wget $PHP_MANUAL_URL -P $PSYSH_DIR && \ curl -sS https://getcomposer.org/installer | php -- --install-dir=/usr/bin --filename=composer && \ composer config -g repos.packagist composer https://packagist.jp && \ composer global require hirak/prestissimo RUN apk add --no-cache freetype libpng libjpeg-turbo freetype-dev libpng-dev libjpeg-turbo-dev && \ docker-php-ext-configure gd \ --with-jpeg=/usr/include/ \ --with-freetype=/usr/include/ && \ NPROC=$(grep -c ^processor /proc/cpuinfo 2>/dev/null || 1) && \ docker-php-ext-install -j${NPROC} gd && \ apk del --no-cache freetype-dev libpng-dev libjpeg-turbo-dev ADD ./live /work WORKDIR /work RUN chmod -R 777 /work/storage \ /work/bootstrap/cache RUN composer install RUN php artisan key:generate RUN php artisan config:clear RUN php artisan config:cache # RUN php artisan migrate # RUN php artisan db:seed EXPOSE 9000php.iniは自分で検索してください。笑
.envファイルがないと起動できないので各々の用途に合わせて記述してください。
一応下記に書いておきます。TZ=Asia/Tokyo APP_PORT=9000 DB_CONNECTION=mysql DB_HOST=<RDSのエンドポイント> DB_PORT=3306 DB_DATABASE=<DB名> DB_USERNAME=<username, rootでもいい> DB_PASSWORD=<セキュアなやつにしてね>以上です。
まだ、CI/CDとかできていないので別記事にでも書こうと思っております。
AWS第一弾でした。
docker/php/Dockerfileは割と書きすぎてる気がするのでこれいらんよ、とかあったら教えて欲しいです。未熟者の記事ですが読んでいただいてありがとうございます。
- 投稿日:2020-09-06T02:13:31+09:00
NUXTJS公式:S3 と CloudFront を使用して AWS へデプロイするには?の補足
はじめに
※画像多めです
公式ドキュメント内のAWS: S3 バケットと CloudFront Distribution の設定の参考記事が古く、そのままの手順では動かなかったので、画像多めで手順をまとめたいと思います。(公式ドキュメント)S3 と CloudFront を使用して AWS へデプロイするには?
(参考記事)S3 と CloudFront をセットアップするためのチュートリアル(次の記事でデプロイをdocker-composeコマンド1つでできるようにカスタマイズする記事を書く予定です。)
前提
- AWSアカウントを作成済み
- Route53に作成予定のドメインを設定済み
- サブドメインを作成して公開する
AWSの環境準備
S3、CloudFront、Route53、Certificate Managerを使用します。
1. S3バケットを作成する
バケット名は任意の文字列を入力します。
今回はcloudFrontを使用し、S3自体を公開するわけではないので公開するドメインと同じである必要はありません。
例としてs3-devというバケットを作成します。
デフォルトのまま次へ。
パブリックアクセスもデフォルト(全てブロック)。
内容を確認し、問題なければバケットを作成します。
作成が完了したら動作確認用に適当なファイルをアップロードしておきます。
2. AWS Certificate ManagerでCDNドメインのSSL証明書を取得する
SSL証明書は、リクエストから発行まで時間がかかるので、こちらを優先で実施します。
リージョン
US-East-1のAWS Certificate Managerコンソールを開き、証明書のリクエストを実施します。
パブリック証明書のリクエストを選択し、証明書のリクエストを実施します。
公開するドメイン名を入力します。
今回はRoute53に所持しているテスト用ドメインsudev.workにtestというサブドメインを指定して使用します。
test.sudev.work
今回使用するドメインはRoute53で管理するため、
DNSの検証を選択します。
タグの指定は特にしないのでそのまま次へ。
内容を確認し、問題なければ
確定とリクエストを実施。
この時点ではまだRoute53でサブドメインを作成していないので、検証保留になっています。
そのまま続行を押下します。
赤枠の部分を押下し、Route53にレコードを作成します。
画像の通り成功と出たら完了です。
※作成完了までに時間がかかるので、完了後にCloudFrontセットアップにすすむ
3. CloudFrontをセットアップ
Create Distributionを押下し、次画面でWebのGet Startedを押下します。
Origin Settings
- Origin Domain Name:S3のバケット名を入力し、プルダウンで選択
- Origin Path:空白
- Restrict Bucket Access:YES
- Origin Access Identity:Create a New Identity
- Grant Read Permissions on Bucket:Yes, Update Bucket Policy
Default Cache Behavior Settings
- Viewer Protocol Policy:Redirect HTTP to HTTPS
- Compress Objects Automatically:オブジェクトを自動圧縮する場合はYes
- Grant Read Permissions on Bucket:Yes, Update Bucket Policy
Distribution Settings
- Alternate Domain Names:test.sudev.work
- SSL Certificate:Custom SSL Certificate (example.com):
- プルダウンで先ほど作成したSSL証明書
test.sudev.workを選択- ※作成までに時間がかかるので、出てこない場合は時間をおいて再度実施
- Default Root Object:index.html
他はデフォルトでCreateを押下し、作成します。
S3でアップロードしたテストファイルが
CloudFrontのドメイン/ファイル名でで表示されれば完了です。
次の手順でRoute53の設定でCloudFrontのドメインをRoute53のサブドメインと紐づけます。
赤枠のドメインを控えておいてください。
4. Route53でCloudFrontを指定のドメインで公開する
Route53 > ホストゾーン > 対象ドメイン(sudev.work) > レコード作成 >
シンプルルーティング > シンプルなレコードを定義
- レコード名:公開するドメイン
test.sudev.work- レコードタイプ:CNAME
- ルーティング先:レコードタイプに応じたIPアドレスまたは別の値
- 値:先ほどメモ控えたCloudFrontのドメイン
接続確認
S3でアップロードしたテストファイルがhttpsで
Route53のドメイン:test.sudev.work/ファイル名でで表示されれば完了です。
手順は以上になります。
補足
サブドメインで公開したURLでF5を押すとエラーになるので、下記を参考に対策をしたほうが良いと思います。
https://qiita.com/Safire/items/505cdf9b981c58ad38f6