- 投稿日:2020-08-17T23:49:07+09:00
【初心者向け】「return」がイマイチ分からない2年前の自分に向けての記事(if-elseの話も少し)
この記事を読んで習得できること
・プログラミングを初めてまだ「return」の使い方が分からない方々
・3年前の私経緯
大学院でプログラムを書いていた3年前のボク。
大学の研究で実験の解析で必要だったため、必死で書いていたのをなんとなく覚えている。ひとまず、自分の行いたい解析プログラムは動くようになり、
喜びながらそのプログラムを使って解析を行っていた。ひと段落してから、プログラムを見てみると、
「結構ソース汚いな…」と思い、修正しようと試みた。しかし、ソースのスパゲッティ感*が半端なく、
なかなか修正が出来ずに、前回と同じようなソースなのに、
一から書き直したのを覚えている。3年前のソースで何が起こっていたのか
おおよそのイメージだが、こんな感じ。
sample.swiftfunc yabaiCode() { if 条件1 { 処理1(15行以上) 処理A(10行以上) 処理4(10行以上) } else if 条件2 { 処理2(15行以上) 処理A`(10行以上) 処理5(10行以上) } if 条件3 { 処理3(15行以上) 処理A``(10行以上) 処理6(10行以上) } else { 処理7(20行以上) } }何が言いたいかって、条件分岐の中の処理がとんでもなく長いのだ。
しかし、処理を分けたいのだが、分け方がイマイチ分からない。
どうやら、メソッドで分割していけば、もっと簡単に処理ができるとのことだ。でも、メソッドで分けることが出来なかった。
メソッド間での、値の受け渡しが分からなかったのだ…んで、結局分からないまま、このままのコードを残して卒業してしまったわけだが(後輩ちゃんごめん)、
今になって(流石に)return文がある程度分かった自分が、過去の自分にreturnを教えるために、この記事を書いたってわけです。returnの主な使い方は2つ
1.メソッドを終了させる
sample.swiftfunc return1() { num = 5 // 好きな数値を入れる if num == 4 { print("4です") return } else if num == 5 { print("5です") return // このメソッドはここで終了するはず // これ以降は処理されない } if num == 6 { print("6です") return } else { print("分からない") return } }このreturnは、無駄な処理を省くことができる。
途中で答えが出たら、その時点で処理を終了させればいいし、
また、returnがあるおかげで、if-elseを使わなくてよくなる。if-elseは、処理が多くなる上に、ifとelseが同時でいることが前提になるため、
1メソッドあたりの処理が多くなることがある。
読みにくくなったりもする。
職場によっては、「if-else禁止!」なんてところもあるだろう。
(自分の部署はそうでした)どんだけif-elseがないとコードが読みやすくなるか。
FizzBuzz文を参考にしてみたいと思う。まずは、if-else文を使用したもの。
FizzBuzz.swiftfunc fizzBuzz() { for i in 1...30 { judgeFizzBuzz(num: i) } } func judgeFizzBuzz(num : Int) { if num % 15 == 0 { print("FizzBuzz") } else if num % 3 == 0 { print("Fizz") } else if num % 5 == 0 { print("Buzz") } else { print(num) } }めっちゃ悪いわけではないが、もし仮に、7の倍数の時の処理を入れるなんて時は、
気をつけないと、全ての処理がぶっ壊れてしまう。
(return使うときももちろん気をつける必要があるが)では、return文を使ってみる。
FizzBuzz.swiftfunc fizzBuzz() { for i in 1...30 { judgeFizzBuzz(num: i) } } func judgeFizzBuzz(num : Int) { if num % 15 == 0 { print("FizzBuzz") return } if num % 3 == 0 { print("Fizz") return } if num % 5 == 0 { print("Buzz") return } print(num) }if文がパーツ化されるので、実に見やすい。本当に素晴らしい。
何もなければnumがprintされるってことも一目瞭然だ。2.値を返してくれる
ここでは、数値を返してくれるメソッドを使用する
sample.swiftfunc say() { num = 5 doubleNum = doubleNum(num) // 10が返ってくる } // 2倍した数値を返してくれる関数 func doubleNum(num :Int) -> Int { return num * 2 //数値を返す }別のメソッドで計算して、処理結果を返してもらうってことも容易になる。
FizzBuzz使うとさらにお分りいただけるかもしれない。
FizzBuzz.swiftfunc fizzBuzz() { for i in 1...30 { print(judgeFizzBuzz(num: i)) } } func judgeFizzBuzz(num : Int) -> String { if num % 15 == 0 { return "FizzBuzz" } if num % 3 == 0 { return "Fizz" } if num % 5 == 0 { return "Buzz" } return String(num) }1で書いたものよりも、さらに見やすくなったと思う。
judgeFizzBuzzがStringを返すようになったということで、全体としてのコード量も減った(print)まとめ
returnをうまく使わないとメソッドが盛り盛りになってしまうので、もし使っていない方がいたら是非使って欲しい。
これを知らないで、よく大学卒業できたな、俺…
- 投稿日:2020-08-17T23:22:34+09:00
「桜井さん」をAPI Gateway + LambdaでLINE BOT化してみた
はじめに
これは前回作成した記事「「アイネクライネナハトムジーク」に出てくる斉藤さんをミスチルの桜井さんとして再現してみた」の続きになります。
気になった方は上記の記事をまず読むことをおすすめします。作ったもの
まずはどんなものを作ったか紹介します。
こちらで友達登録したら試すことができます!
使い方はシンプルです。
桜井さんに何か話しかけます。
そうするとその心境に合うようなミスチルの曲の一部を桜井さんが歌ってくれます。(正確にはテキストで返信してくれます)
裏でCOTOHAの感情分析APIを活用していて、
送信した文章と感情スコアの近い歌詞の一部を返すようになっています。
なのであまり内容が一致してないことも多々あることはご了承ください。(お遊び感覚でお使いください。。)
コロナによる自粛疲れを希望がちらつかすといった表現で励ましているような気がします。
システム概要
歌詞フレーズと感情スコアを格納するDBへの登録部分は前回の記事を参照してください。
今回はLINEから送って返信が返ってくるまでの構成を紹介します。
構成はシンプルでLINEのMessaging API、AWSのAPI Gateway、Lambda、RDS、COTOHAのAPIを利用しています。
① - ②:LINE Messaging APIを使ってLINEからWeb HookによりAPI Gatewayを呼び出すようにする
③:API Gatewayの設定により作成したLambda関数を呼び出す
④:COTOHA APIを呼び出して送ったメッセージの感情スコアを取得
⑤:感情スコアの近い歌詞のフレーズをRDS上に作成したDBから取得
⑥ - ⑦:取得したフレーズをLINEの返信としてMessaging APIにより返す各サービスの詳細説明
設定に手こずりそうなAPI Gateway、Lambda、LINE Messaging APIの説明をします。
RDSとCOTOHAについては特に難しい設定はないため、省略させていただきます。API Gatewayの設定
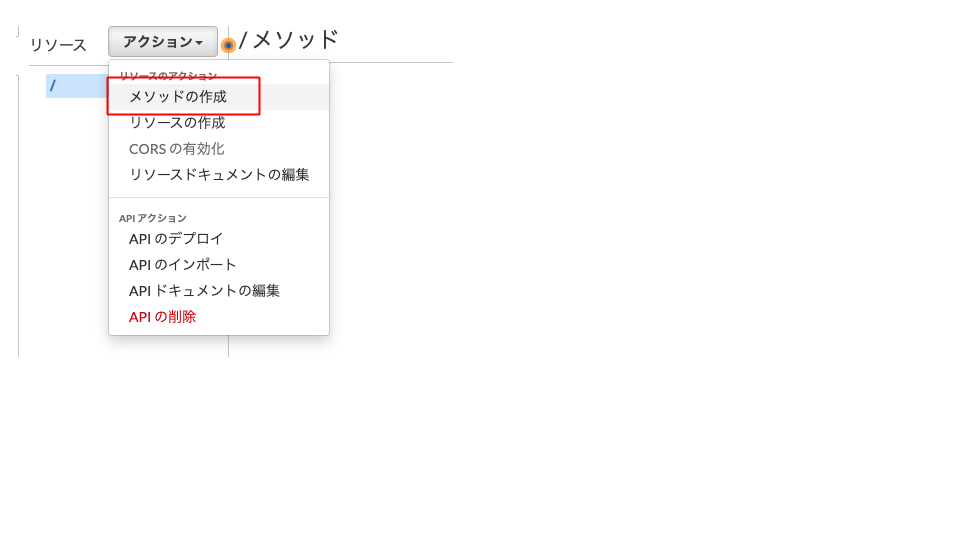
(1) API Gatewayから新規にAPIを作成
(2) RESTの新しいAPIとして作成
(3) 新しいメソッドの作成
POSTで作成します。
(4) Lambdaの登録
Lambdaが実行できるように統合タイプを「Lambda関数」、Lambda関数にLambda名を入力
(5) 統合リクエストをクリック
(6) HTTPヘッダーの設定
名前をAuthentication、マッピング元を'Bearer <LINEのアクセストークン>' として登録します。
LINEのアクセストークンの取得については後述します。
登録したらこちらに入力しましょう。
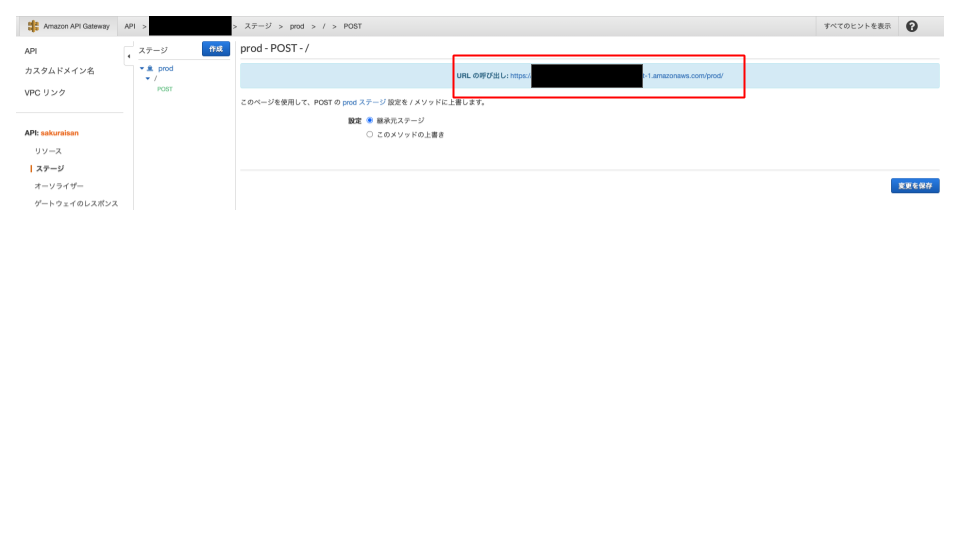
(7) APIのデプロイ
「アクション」→APIのデプロイをクリックし、
ステージ名を入力してデプロイします。(ここではprodとする)
(8) APIのURIの発行
デプロイされると左メニューのステージ→prod→POSTにURLが発行されているはずです。
後のLINE Messaging APIのWebhookとして登録するのでどこかにURLをコピーしておきましょう。
Lambdaの設定
ソースコードはGitHubのlambda/lambda.pyを参照してください。
注意点としては、DBの接続情報、COTOHA APIの接続情報、LINE APIのトークン情報はLambdaの環境変数に登録していることです。
また、デフォルトでmysql-connector-pythonが入っていないためLambda上に入れる必要があります。
今回はLambdaのレイヤーを利用しました。
使い方はここを参照すると良いでしょう。LINE Messaging APIの設定
初めて使う方は、チャネル作成についてはこちらを参照してください。
最低限必要な設定は以下です。
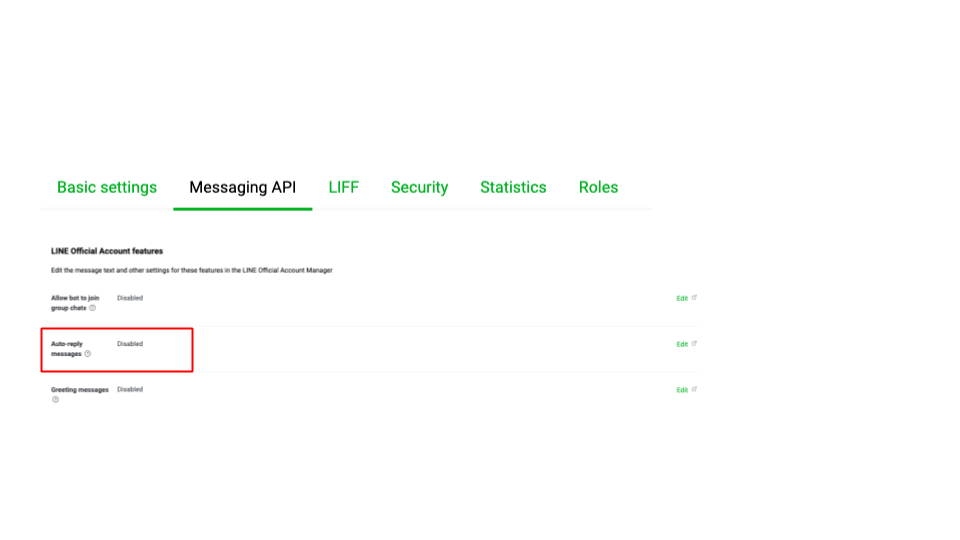
(1) Webhookの設定
事前にAPI Gatewayで作成したURLを登録します。
(2) アクセストークンの発行
(3) 自動応答の設定をオフにする
これを設定しないと関係ない返信をしてしまいます。
(4) Messaging APIの設定確認
LINE Official Account Managerに飛び、
左メニューのMessaging APIをクリックし、Webhook URLが登録されているか確認してください。
登録されていなければ(1)同様にAPIのURLを入力します。
参考
以下記事を参考にさせていただきました。













- 投稿日:2020-08-17T23:16:34+09:00
ファイルの書き込み読み込み
ファイルの読み込みと書き込みを同時に行いたい場合
w+を使う場合
"w+"は読み込みと書き込みが可能
sの内容をファイルに書き込み
seekで先頭に戻り、読み込んでいる
ここでseekを用いないとエラーが発生するqiita.pys="""\ AAA BBB CCC DDD """ with open("test.text", "w+") as f: f.write(s) f.seek(0) print(f.read())実行結果
AAA BBB CCC DDD注意点
"w+"で書き込み、読み込みはできるが
実行した時点でファイルの中身が消えてしまう
次のように読み込みのみしようとするとqiita.pys="""\ AAA BBB CCC DDD """ with open("test.text", "w+") as f: # f.write(s) # f.seek(0) print(f.read())実行結果
r+を使う場合
wのときとは違い読み込むファイルがないとエラーになるので注意
qiita.pys="""\ AAA BBB CCC DDD """ with open("test.text", "r+") as f: print(f.read()) f.seek(0) f.write(s)
- 投稿日:2020-08-17T23:15:51+09:00
2020年Arduino・Raspberry Pi/Python・マイコンのC言語を学ぶなら
私が独断でお勧めの本を紹介します。
Pythonでハードウェア(Raspberry Pi)を触る
ラズパイ4対応 カラー図解 最新 Raspberry Piで学ぶ電子工作 作る、動かす、しくみがわかる!
https://www.amazon.co.jp/dp/4065193397
Pythonでハードウェア(RaspberryPi)を触るならこの一冊です。
難点は、本のサイズが小さい事
読みながらコードを打つのには向いていません・・・ESP32とArduinoを学ぶなら
ESP32&Arduino 電子工作 プログラミング入門
https://www.amazon.co.jp/dp/4297112051/
ここ数年の中で一番のArduino本でありながら、ESP32の詳細本でもあります。
Arduino本は、あれどESP32をキチンと取り扱っている本が少ないですが
本書は、ESP32とネイティブなArduinoを比較しながら解説しています。
初心者でプログラムを触りたい人にも満足できると思います。
もっと、深く書いても良いと思いますが、贅沢な悩みな気がします。C言語でマイコンを深く触ろう
基板付きキット 絵解き マイコンCプログラミング教科書
https://www.amazon.co.jp/dp/4789845273/
マイコンボードをとりあえず触りたい、C言語って難しそう
と言う方や初心者の方には、上のESP32&Arduino 電子工作 プログラミング入門をお勧めします。
Arduinoを触ったことがあるがもっとマイコンを触りたい、C言語を学びたいと言う人には、本書をお勧めします。
基板もついており、本書だけでC言語を学ぶ事が可能です。
私が経営者ならば、本書を使って新人教育をします。2020年にはベストなArm本、ROSの本がまだ出ていないのが残念です。
- 投稿日:2020-08-17T23:15:51+09:00
2020年Arduino・Raspberry Pi/Python・マイコンのC言語を学ぶなら~お勧めの本~
私が独断でお勧めの本を紹介します。
Pythonでハードウェア(Raspberry Pi)を触る
ラズパイ4対応 カラー図解 最新 Raspberry Piで学ぶ電子工作 作る、動かす、しくみがわかる!
https://www.amazon.co.jp/dp/4065193397
Pythonでハードウェア(RaspberryPi)を触るならこの一冊です。
難点は、本のサイズが小さい事
読みながらコードを打つのには向いていません・・・ESP32とArduinoを学ぶなら
ESP32&Arduino 電子工作 プログラミング入門
https://www.amazon.co.jp/dp/4297112051/
ここ数年の中で一番のArduino本でありながら、ESP32の詳細本でもあります。
Arduino本は、あれどESP32をキチンと取り扱っている本が少ないですが
本書は、ESP32とネイティブなArduinoを比較しながら解説しています。
初心者でプログラムを触りたい人にも満足できると思います。
もっと、深く書いても良いと思いますが、贅沢な悩みな気がします。C言語でマイコンを深く触ろう
基板付きキット 絵解き マイコンCプログラミング教科書
https://www.amazon.co.jp/dp/4789845273/
マイコンボードをとりあえず触りたい、C言語って難しそう
と言う方や初心者の方には、上のESP32&Arduino 電子工作 プログラミング入門をお勧めします。
Arduinoを触ったことがあるがもっとマイコンを触りたい、C言語を学びたいと言う人には、本書をお勧めします。
基板もついており、本書だけでC言語を学ぶ事が可能です。
私が経営者ならば、本書を使って新人教育をします。2020年にはベストなArm本、ROSの本がまだ出ていないのが残念です。
- 投稿日:2020-08-17T22:56:57+09:00
巡回セールスマン問題について
最近、仕事の都合で「数理最適化」というものに触れる機会に恵まれています。
折角なので、ちょっとだけプライベートで触れてみた結果を載せてみたいと思います。やったことは、数理最適化の1例、「巡回セールスマン問題」
これを、なんと無料の環境pulpで実装できるということで、その環境を整えつつ、実装までやってみました。やってみたい問題は以下のもの。
◆2.12 巡回セールスマン問題
https://www.msi.co.jp/nuopt/docs/v19/examples/html/02-12-00.html以下に簡単に絵を描いて見ました。
A,B,C,Dが地図上のポイント。
Aを出発して、一筆書きをして帰ってくるとき、その距離の総和が一番小さいのはどのルートか???
という最適化問題のことを「巡回セールスマン問題」というらしいです。
NP困難と呼ばれて、結構難しいらしい。しかし、python環境で触れるpulpというモデラーでのアプローチが無料で!!!簡単に出来るということで、以下の記事を参考にさせていただきます。
◆巡回セールスマン問題から始まる数理最適化
https://qiita.com/panchovie/items/6509fb54e3d53f4766aa素晴らしいことに、pulpのインストールから、サンプルコードまで置いてあります。
早速、最初の設定をサンプルコードに入れてみます。
とりあえずコンパイルが通りそうな以下のようなコードでどうでしょうか。import pulp as pp # 最適化モデルの定義 mip_model = pp.LpProblem("tsp_mip", pp.LpMinimize) N = 4 BigM = 10000 c_ = [ [0,6,5,5], # pointA > [pointA,pointB,pointC,pointD] [6,0,7,4], # pointB > [pointA,pointB,pointC,pointD] [5,7,0,3], # pointC > [pointA,pointB,pointC,pointD] [5,4,3,0], # pointD > [pointA,pointB,pointC,pointD] ] # 変数の定義 x = [[pp.LpVariable("x(%s,%s)"%(i, j), cat="Binary") for i in range(N)] for j in range(N)] u = [pp.LpVariable("u(%s)"%(i), cat="Continuous", lowBound=1.0, upBound=(N)) for i in range(N)] # 評価指標(式(1))の定義&登録 objective = pp.lpSum(c_[i][j] * x[i][j] for i in range(N) for j in range(N) if i != j) mip_model += objective # 条件式(2)の登録 for i in range(N): mip_model += pp.lpSum(x[i][j] for j in range(N) if i != j) == 1 # 条件式(3)の登録 for i in range(N): mip_model += pp.lpSum(x[j][i] for j in range(N) if i != j) == 1 for i in range(N): mip_model += x[i][i] == 0 # 条件式(4) (MTZ制約) for i in range(N): for j in range(N): if i != j: mip_model += u[i] + 1.0 - BigM * (1.0 - x[i][j]) <= u[j] # 最適化の実行 status = mip_model.solve() # 結果の把握 print("Status: {}".format(pp.LpStatus[status])) print("Optimal Value [a.u.]: {}".format(objective.value())) for i in range(N): for j in range(N): if i != j: print("x[%d][%d]:%f" % (i,j,x[i][j].value())) for i in range(len(u)): print("u[%d] %f" % (i,u[i].value()))この状態で実行すると・・・
Status: Infeasible Optimal Value [a.u.]: 18.0 x[0][1]:0.000000 x[0][2]:1.000000 x[0][3]:0.000000 x[1][0]:0.999800 x[1][2]:0.000000 x[1][3]:0.000200 x[2][0]:0.000200 x[2][1]:0.000000 x[2][3]:0.999800 x[3][0]:0.000000 x[3][1]:1.000000 x[3][2]:0.000000と出てきて、どうやら上手く計算できていないようです。
制約条件が上手く満たせていないような感じなので、色々と検討すると、どうやらこのままではMTZ制約の式がおかしくなるようでした。
最終状態のxからuについての式を4本全て書くと以下になります。u[0] < u[2]\\ u[1] < u[0]\\ u[2] < u[3]\\ u[3] < u[1]これを全部満たすとなると、
u[0] < u[2] < u[3] < u[1] < u[0] < ...なんだか無限に増えていきますが、uの有効範囲は1~4の間のため矛盾が出てしまったようです。
そこで、最後にA地点に戻る変数についての制約を取り除くことで、以下のように式を構成しなおしてみます。u[0] < u[2]\\ u[2] < u[3]\\ u[3] < u[1]これによって、実装も変わり、MTZ条件の式は以下に変更となります。
# 条件式(4) (MTZ制約) for i in range(N): for j in range(1,N): if i != j: mip_model += u[i] + 1.0 - BigM * (1.0 - x[i][j]) <= u[j]ソースコードをまとめると以下になります。
sample_route.pyimport pulp as pp # 最適化モデルの定義 mip_model = pp.LpProblem("tsp_mip", pp.LpMinimize) N = 4 BigM = 10000 c_ = [ [0,6,5,5], # pointA > [pointA,pointB,pointC,pointD] [6,0,7,4], # pointB > [pointA,pointB,pointC,pointD] [5,7,0,3], # pointC > [pointA,pointB,pointC,pointD] [5,4,3,0], # pointD > [pointA,pointB,pointC,pointD] ] # 変数の定義 x = [[pp.LpVariable("x(%s,%s)"%(i, j), cat="Binary") for i in range(N)] for j in range(N)] u = [pp.LpVariable("u(%s)"%(i), cat="Continuous", lowBound=1.0, upBound=(N)) for i in range(N)] # 評価指標(式(1))の定義&登録 objective = pp.lpSum(c_[i][j] * x[i][j] for i in range(N) for j in range(N) if i != j) mip_model += objective # 条件式(2)の登録 for i in range(N): mip_model += pp.lpSum(x[i][j] for j in range(N) if i != j) == 1 # 条件式(3)の登録 for i in range(N): mip_model += pp.lpSum(x[j][i] for j in range(N) if i != j) == 1 for i in range(N): mip_model += x[i][i] == 0 # 条件式(4) (MTZ制約) for i in range(N): for j in range(1,N): if i != j: mip_model += u[i] + 1.0 - BigM * (1.0 - x[i][j]) <= u[j] # 最適化の実行 status = mip_model.solve() # 結果の把握 print("Status: {}".format(pp.LpStatus[status])) print("Optimal Value [a.u.]: {}".format(objective.value())) for i in range(N): for j in range(N): if i != j: print("x[%d][%d]:%f" % (i,j,x[i][j].value())) for i in range(len(u)): print("u[%d] %f" % (i,u[i].value()))結果は以下になります。
Status: Optimal Optimal Value [a.u.]: 18.0 x[0][1]:0.000000 x[0][2]:1.000000 x[0][3]:0.000000 x[1][0]:1.000000 x[1][2]:0.000000 x[1][3]:0.000000 x[2][0]:0.000000 x[2][1]:0.000000 x[2][3]:1.000000 x[3][0]:0.000000 x[3][1]:1.000000 x[3][2]:0.000000 u[0] 1.000000 u[1] 4.000000 u[2] 2.000000 u[3] 3.000000無事に収束してくれました。
結果はグラフィカルに出ていませんが、A地点 → C地点 → D地点 → B地点 → A地点
が最短らしく、その距離は18とのことでした。
問題が載っていたところには、A地点 → B地点 → D地点 → C地点 → A地点
で、やはり、距離は18で最短らしいので、いくつか答えがあるということになるのですね。
数理最適化は、今まで触れてこなかった分野だけに、とても新鮮です。
気軽に試せる環境があるので、これを機に色々と勉強してみようと思います。

- 投稿日:2020-08-17T22:45:57+09:00
AtCoder ABC 175 Python
総括
ABC解けました。
D,Eは方針まで立てられたのですが時間内に解けず。
今回は初めてF問題まで考えることができました(解けるか否かはまた別の話・・・)
後日Eは解けましたが、DはWAをつぶしきれずいまだACしていません。問題
https://atcoder.jp/contests/abc175
A. Rainy Season
回答
S = tuple(input()) if S == ('R', 'R', 'R'): print(3) elif S == ('R', 'R', 'S') or S == ('S', 'R', 'R'): print(2) elif S == ('S', 'S', 'S'): print(0) else: print(1)上手い具合の解き方がないか考えましたが、思いつかず。
全部列挙してif文で解きました。コンテスト時はわざわざtupleにいれましたが、文字列をそのまま判定してよいですね。
B. Making Triangle
回答
from itertools import combinations N = int(input()) L = list(map(int, input().split())) count = 0 for C in combinations(L, 3): l_list = list(C) l_list.sort() if l_list[2] > l_list[1] and l_list[1] > l_list[0]: if l_list[2] < l_list[1] + l_list[0]: count += 1 print(count)三角形の条件なので、
最大の辺 < その他の2辺の和で解けます。
制約が小さいので全部列挙しました。C. Walking Takahashi
回答
X, K, D = map(int, input().split()) new_X = abs(X) % D new_K = K - abs(X) // D if new_K <= 0: answer = abs(X) - K*D else: if new_K % 2 == 0: answer = new_X else: answer = abs(new_X - D) print(answer)まず制約がきつすぎるので、for文は絶対に使いたくないです。
これだけ大きい数字を処理するのですから、「大きい数を何かの数で割り算を行う」という処理がどこかに入ってくると予想ができます。そう考えると、座標
Xを移動距離Dでとりあえず割ってみたくなります。
X // Dの意味を考えてみると、「X距離進むために必要な距離Dの移動の回数」であるとわかります。
「移動の回数」ときたらKから引き算をしたくなりますね。次に、いくつか入力サンプルで実験すると、DがXより十分に大きい場合は原点付近で振動することがわかります。
振動するということは、答えは二通りだなとわかります。ここまでくるとだいぶ方針が固まってきました。
1.K - X // Dを行い残りの回数を算出
2. 原点付近で振動するのでその2通りの場合分けを行い、答え算出
3. あとは正負の扱いに注意して、XがDより十分に大きい場合の例外を処理これをコードに落とします。
D. Moving Piece
回答(これは半分WAとなります)
N, K = map(int, input().split()) P = [0] + list(map(int, input().split())) C = [0] + list(map(int, input().split())) answer = -float('inf') for start_p in range(1, N+1): cycle_total_score = 0 cycle_in_score = -float('inf') cycle_count = 0 next_p = P[start_p] while True: cycle_total_score += C[next_p] cycle_in_score = max(cycle_in_score, cycle_total_score) cycle_count += 1 if next_p == start_p: # print('start_p:', start_p, ' cycle_total_score:', cycle_total_score, 'cycle_in_score:', cycle_in_score, 'cycle_count:', cycle_count) break next_p = P[next_p] max_score = 0 if K == cycle_count: max_score = cycle_in_score else: #あふれたK % cycle_count回数分だけスコアを足すためにmaxを探さす add_max_count = K % cycle_count add_total_score = 0 add_score = -float('inf') add_count = 0 add_next_p = P[start_p] while True: add_total_score += C[add_next_p] add_score = max(add_score, add_total_score) add_count += 1 if add_count == add_max_count: break add_next_p = P[add_next_p] if K < cycle_count: #最大の試行回数がcycle_countよりも小さい場合K % cycle_countまでで一番良いところでbeak max_score = add_total_score else: if cycle_total_score >= 0: #1サイクルでプラスの場合はできるだけサイクルを回してK % cycle_countまでで一番良いところでbeak max_score = (K // cycle_count) * cycle_total_score + add_total_score else: #1サイクルでマイナスの場合はサイクルを回さないで、K % cycle_countまでで一番良いところでbreak max_score = add_total_score # print('max_score', max_score) answer = max(answer, max_score) print(answer)いまだにACをとることができていません。上記コードではテスト入力はすべて通るのですが、本番では半分がWAとなります。
考え方はあっていると思うのですが、WAの原因を特定しきれていません・・・。文字だけだと何を言っているかわからないので図を描きます。下記は入力例1を図示化したものです。
この図の特徴を考えると、サイクルを持ったグラフが1つ以上作成できることがわかります。
解く方針は愚直に全通りを試します。
1. まずはスタートする場所を決める=>これをN通り試す
2. スタートから一回りしてみて、下記のスコアを記録しておく
2.1 . 1サイクルの合計のスコア
2.2. 1サイクル内で最大となる瞬間のスコア
2.3. 1サイクルに必要な移動の数
3. Kが1サイクルの移動数の整数倍であれば簡単ですが、中途半端の時があり得るのでその場合に下記スコアを探しに行きます
3.1. 中途半端となる数
3.2. 中途半端となる数のなかで最大となるときのスコアたぶんこれで解けるはずなのですが、最後まで解けきれていません(ということはこれで解けないのでは?)。
E. Picking Goods
回答(通常版 TLEです)
R, C, K = map(int, input().split()) scores = [[0] * (C + 1) for _ in range(R+1)] for _ in range(K): r, c, v = map(int, input().split()) scores[r][c] = v dp = [[[0] *4 for _ in range(C+1)] for _ in range(R+1)] for i in range(1, R+1): for j in range(1, C+1): for k in range(4): dp[i][j][k] = max(dp[i][j-1][k], dp[i-1][j][3]) for k in range(3, 0, -1): dp[i][j][k] = max(dp[i][j][k], dp[i][j][k-1] + scores[i][j]) answer = dp[R][C][3] print(answer)回答(高速化ver ACです)
from numba import jit import numpy as np @jit def main(): R, C, K = map(int, input().split()) scores = np.zeros((R,C), np.int64) for _ in range(K): r, c, v = map(int, input().split()) scores[r-1][c-1] = v dp = np.zeros((R+1,C+1,4), np.int64) for i in range(1, R+1): for j in range(1, C+1): for k in range(4): dp[i][j][k] = max(dp[i][j-1][k], dp[i-1][j][3]) for k in range(3, 0, -1): dp[i][j][k] = max(dp[i][j][k], dp[i][j][k-1] + scores[i-1][j-1]) return dp[R][C][3] print(main())これは時間内に解きたかったです。
Pythonで普通に組んでしまうと時間がギリギリ間に合いませんが、numpyと@jitでもとのコードを改良すれば通ります。まずは問題を読んでDPであることがわかりました。しかし僕が解けるのはまだ2次元のDPまで・・・。
とりあえず「同じ行で3個まで」の制約を無視してDPを書いてみます。
すると下記のようになります。
(2次元のDPテーブルを可視化する際はpandasを使うと縦横が見やすくなるのでデバック用としてpandasとnumpyをいれてます)R, C, K = map(int, input().split()) scores = [[0] * (C + 1) for _ in range(R+1)] for _ in range(K): r, c, v = map(int, input().split()) scores[r][c] = v dp = [[0] *(C+1) for _ in range(R+1)] for i in range(1, R+1): for j in range(1, C+1): dp[i][j] = max(dp[i-1][j] + scores[i][j], dp[i][j-1] + scores[i][j]) print(dp[R][C]) # import numpy as np # import pandas as pd # show_dp = np.array(dp) # show_dp = pd.DataFrame(show_dp) # print(show_dp)ここまでは簡単です。
(と言いつつ、1週間前の僕ではここまでくるのは不可能でしたが、ここ1週間でここ>>レッドコーダーが教える、競プロ・AtCoder上達のガイドライン【中級編:目指せ水色コーダー!】のDP問題を解いていたのでそう言えるのですが・・・。)コンテスト時はここから「同じ行で3個まで」の制約を組み込むことができませんでした。
dpテーブルの次元を一つ増やして「何か」すればよいということはわかったのですが、この「何か」を思つくことができませんでした。「横に行くときは3回目まではscoreを追加し、それ以外は追加しない」をそのまま書いてみます。
僕はdpを解くときは実際にdpテーブルを紙に書いて視覚化しないとうまくイメージがつかないので、3次元のdpテーブルはなかなかしっくりこないです・・・。
習うより慣れろというところでしょうか。ところで、pythonでは普通にdpでコード化するとTLEになります。
方針としてはnumpyを使ってfor文で書いているところを一括で計算するか、pypyを使うか、jitを使うか、と思います。
強い人は当然にnumpyで上手いこと計算しているようですが、僕はまだそこまでは書けません。
今回のコードではpypyでも通りませんでしたので、関数化して@jitを使ってみました。すると、下記のように「少量の計算は格段に遅く、大量の計算は格段に速く」なり、なんとかAC通りました。どうしてこうなるのかわかりませんが、とりあえずdpで通らない場合は同じようにjitで試してみます。
【普通のコードの場合】
【@jitを使用したコードの場合】








- 投稿日:2020-08-17T22:39:50+09:00
ファイルの読み込み、seekを使った移動
ファイルをまとめて読み込み
qiita.pywith open("test.text", "r") as f: print(f.read())一行ずつ読み込む
1行ずつ読み込みたい時はreadlineを使う
print関数でend=""とする理由としてはprint関数で改行が行われてしまうからqiita.pywith open("test.text", "r") as f: while True: line = f.readline() print(line,end="") if not line: break実行結果
AAA BBB CCC DDDend=""を使わないと
qiita.pywith open("test.text", "r") as f: while True: line = f.readline() print(line) if not line: break実行結果
AAA BBB CCC DDD特定の文字数ごと読み込む
chunkを設定する
ネットワークの読み込みに使われる事もqiita.pywith open("test.text", "r") as f: while True: chunk = 2 line = f.read(chunk) print(line) if not line: break実行結果
AA A BB B CC C DD Dseekを使った移動
teil 現在の位置を返す
seek 任意の位置に移動することができるqiita.pywith open("test.text", "r") as f: print(f.tell()) #0 print(f.read(1)) #A f.seek(5) print(f.read(1)) #B f.seek(14) print(f.read(1)) #D
- 投稿日:2020-08-17T22:36:16+09:00
Pythonで画像のコントラストを調整する方法
学習メモです。
やったこと
画像のコントラストを調整するPythonスクリプトを書きました。
コード
import cv2 import numpy as np import matplotlib.pyplot as plt img = cv2.imread('画像.jpg') #コントラスト contrast = 128 #コントラスト調整ファクター factor = (259 *(contrast + 255)) / (255 *(259 - contrast)) #float型に変換 newImage = np.array(img, dtype = 'float64') #コントラスト調整。(0以下 or 255以上)はクリッピング newImage = np.clip((newImage[:,:,:] - 128) * factor + 128, 0, 255) #int型に戻す newImage = np.array(newImage, dtype = 'uint8') #出力 cv2.imwrite('out.png', newImage)結果
レナさんの画像で試してみます。
オリジナル画像
コントラスト+128で調整後
参考URL
IMAGE PROCESSING ALGORITHMS PART 5: CONTRAST ADJUSTMENT
Algorithms for Adjusting Brightness and Contrast of an Image


- 投稿日:2020-08-17T22:22:44+09:00
英文PDFの翻訳を試す その1
「続【Python】英文PDF(に限らないけど)をDeepLやGoogle翻訳で自動で翻訳させてテキストファイル、いやHTMLにしてしまおう。」
https://qiita.com/Cartelet/items/a00d4cec8216d04f9274を試してみました。
環境
- Ubuntu 18.04
- Python 3.6.9
- コード:
記事にはいくつかのバージョンが示されてますが、今回は8/11追記分の「文章分解強化版コード」を使用しました。
Word通さずともある程度段落を分解できるようにしました。
(だいたい)段落ごとに翻訳するため、1文ずつに比べ翻訳速度もだいぶマシになりました。このコードを pdftrans.py として保存しました。
ライブラリ設定など
$ python3 pdftrans.pyとして実行すると
Traceback (most recent call last): File "pdftrans.py", line 1, in <module> from selenium import webdriver ModuleNotFoundError: No module named 'selenium'と出たので
$ sudo pip3 install seleniumとしてインストール。pyperclip も同様に必要だったので、
$ sudo pip3 install pyperclipとしてインストール。
Traceback (most recent call last): File "/usr/local/lib/python3.6/dist-packages/selenium/webdriver/common/service.py", line 76, in start stdin=PIPE) File "/usr/lib/python3.6/subprocess.py", line 729, in __init__ restore_signals, start_new_session) File "/usr/lib/python3.6/subprocess.py", line 1364, in _execute_child raise child_exception_type(errno_num, err_msg, err_filename) FileNotFoundError: [Errno 2] No such file or directory: 'chromedriver.exe': 'chromedriver.exe' During handling of the above exception, another exception occurred: Traceback (most recent call last): File "pdftrans.py", line 165, in <module> TranslateFromClipboard(*args) File "pdftrans.py", line 75, in TranslateFromClipboard chrome_options=options) File "/usr/local/lib/python3.6/dist-packages/selenium/webdriver/chrome/webdriver.py", line 73, in __init__ self.service.start() File "/usr/local/lib/python3.6/dist-packages/selenium/webdriver/common/service.py", line 83, in start os.path.basename(self.path), self.start_error_message) selenium.common.exceptions.WebDriverException: Message: 'chromedriver.exe' executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/homeとなったので、
https://sites.google.com/a/chromium.org/chromedriver/homeから
chromedriver_linux64.zip
をダウンロードして展開。$ ls -alh 合計 16M drwxrwxr-x 2 nanbuwks nanbuwks 4.0K 8月 17 21:07 . drwxrwxr-x 91 nanbuwks nanbuwks 56K 8月 17 21:06 .. -rwxr-xr-x 1 nanbuwks nanbuwks 11M 5月 29 06:05 chromedriver -rw-rw-r-- 1 nanbuwks nanbuwks 5.1M 8月 17 21:06 chromedriver_linux64.zip -rw-r--r-- 1 nanbuwks nanbuwks 8.0K 8月 17 16:53 pdftrans.pyとして、pdftrans.py と同じディレクトリに配置しました。
その上で pdftrans.py の9行目
DRIVER_PATH = 'chromedriver.exe'となっているところを以下のように変更。
DRIVER_PATH = './chromedriver'PATHの 設定を簡略化してとりあえず pdftrans.py はスクリプトのあるディレクトリで実行することにしました。
Traceback (most recent call last): File "pdftrans.py", line 165, in <module> TranslateFromClipboard(*args) File "pdftrans.py", line 75, in TranslateFromClipboard chrome_options=options) File "/usr/local/lib/python3.6/dist-packages/selenium/webdriver/chrome/webdriver.py", line 81, in __init__ desired_capabilities=desired_capabilities) File "/usr/local/lib/python3.6/dist-packages/selenium/webdriver/remote/webdriver.py", line 157, in __init__ self.start_session(capabilities, browser_profile) File "/usr/local/lib/python3.6/dist-packages/selenium/webdriver/remote/webdriver.py", line 252, in start_session response = self.execute(Command.NEW_SESSION, parameters) File "/usr/local/lib/python3.6/dist-packages/selenium/webdriver/remote/webdriver.py", line 321, in execute self.error_handler.check_response(response) File "/usr/local/lib/python3.6/dist-packages/selenium/webdriver/remote/errorhandler.py", line 242, in check_response raise exception_class(message, screen, stacktrace) selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 84と出たので Chromeは Version 83 を使用していたのですが、最新版にアップデートしてバージョン: 84.0.4147.125(Official Build) (64 ビット)としました。
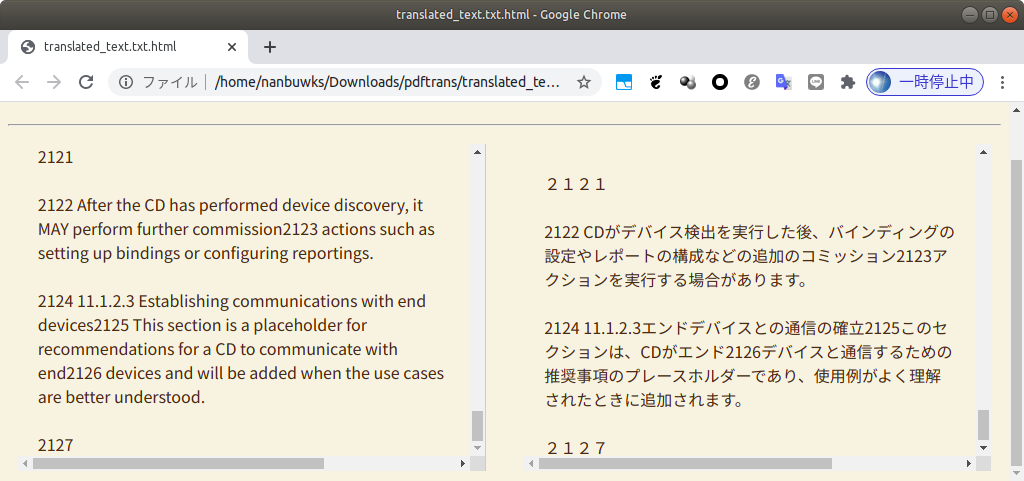
実行
$ python3 pdftrans.py 1. 英語 → 日本語 2. 日本語 → 英語 1 1. DeepL 2.GoogleTranslate 1 翻訳結果を書き出しますか? y/n y 1. txt 2. HTML 3. both 2 出力ファイルにつける名前を入力してください(デフォルトは'translated_text.html') (論文の)タイトルを入力してください zigbeebdb 翻訳経過をここに表示しますか? y/n n 準備ができたらEnterを押してください 1/900 0% done 2/900 0% done 3/900 0% done 4/900 0% done ・ ・ ・結果
使ってみて
- 今回は87ページのPDFを試してみました。
- 上記例ではGoogle ChromeでPDFを開きクリップボードにコピーした所900センテンスで処理されました。後ほどevinceでPDFを開きクリップボードにコピーしたところ1249センテンスで処理されました。
- 1249センテンス処理で約30分。
- DeepLだと全体の1/20ぐらいでTimeUpぽくGoogleTranslateで実行しました。
- どうせGoogleTranslateにするなら8/16版の高速版で試した方が方が良かったかも。
8/16追記
マルチスレッドで大量にChromeを開く力技高速化を施しました。
こちらは書き出しはHTMLのみとなっています。
またDeepLの場合、多く開きすぎると制限がかかって翻訳止まりますのでご注意ください。
- 時間かかっても他の作業すればまあいいかと思っていましたが、クリップボードがコントロールされるので並行作業はコツがいる感じ。
- 参照した記事の更に元になった記事に使い方が書いてあったのですが、ちゃんと読まずに使おうとして、あれれーとなりました。 ちゃんと読んで事前にPDF文字情報をクリップボードにコピーしておけばちゃんと動きました!
「【Python】英文PDF(に限らないけど)をDeepLやGoogle翻訳で自動で翻訳させてテキストファイルにしてしまおう。」
https://qiita.com/Cartelet/items/c56477033cda17a2a28a追記 8/16版の高速版で試してみた
同時並行30にしたら、上記と同じ87ページ1249センテンスの文書が10分程度で翻訳できましたが、ロードアベレージがえらいことになりました。
オーバーヘッドのロスがかからないように環境に応じて工夫するのが良さそうです。
実際に、同時並行10にしてみたら6分程度で処理できました。
- 投稿日:2020-08-17T22:20:03+09:00
[AWS] Step Functionsで遊んでみる(SAM + Lambda) Part.3(分岐編)
Part.2のおさらい
Part2では、主に以下のことを行いました。
- Lambdaに固定引数を渡してみる
- Lambdaに外部からの引数を渡してみる
- Lambdaにコンテキストオブジェクトを渡してみる
- Lambdaの戻り値を、別のTaskの引数に渡してみる
今回は、その続きからはじめてみます。
ここから始める方は、
https://github.com/hito-psv/sam-demo-005
のコードをgit cloneしてもらっても大丈夫ですし、Part2からやってみてもらっても構いません。今回のターゲット
- Lambdaでランダムな結果を返す
- 結果に応じて、次に実行するタスクを変える
- リトライ時は、しばらく時間が経ってから再実行する
をターゲットにしてみたいと思います。
Lambda部分については、Part2で作成した「HelloWorld」の関数を少しだけいじって、色々試してみたいと思います。準備
Lambda関数を修正する
現在のコードに、乱数でいくつかのパターンの文字列を返すようにしてみたいと思います。
hello_world/app.pyimport logging import random logger = logging.getLogger() logger.setLevel(logging.INFO) def lambda_handler(event, context): logger.info(event) message_array = [ "hello world", "retry" ] message = random.choice(message_array) logger.info(message) return { "statusCode": 200, "body": { "message": message, } }これで、結果のメッセージには
- hello_world
- retry
のいずれかの文字列が返されます。
ビルド・デプロイする
この状態で、
sam build、sam deploy --guidedを実行し、Lambda関数をデプロイしましょう。Lambda関数の戻り値によって振る舞いを変える
ステートマシン定義の修正
まずは、ステートマシンの定義を修正します。
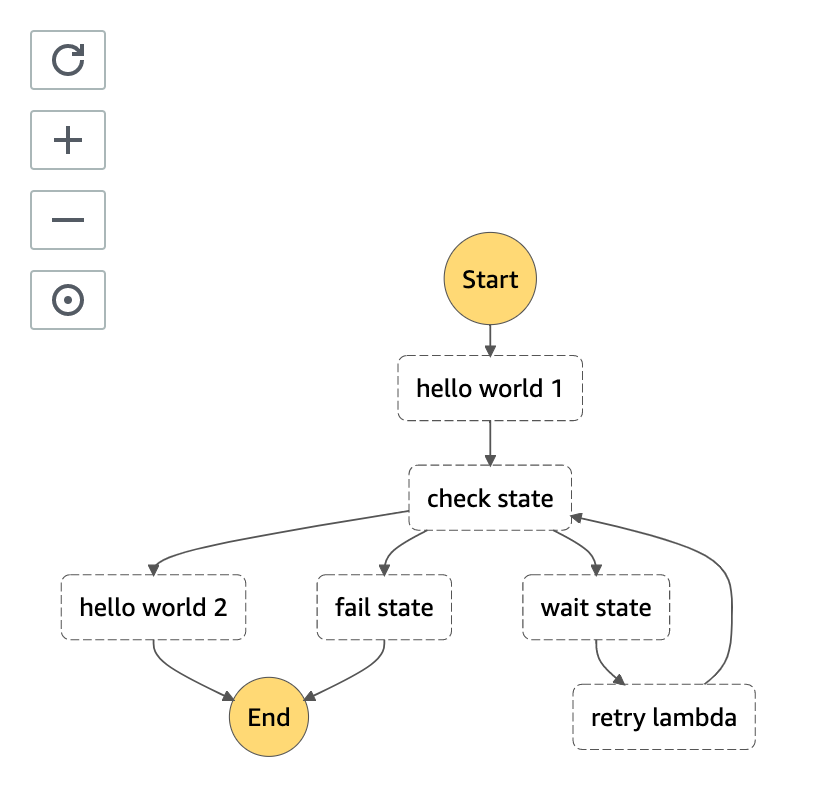
修正内容は後ほど説明しますので、まずは、このように修正してみます。step_functions/state_machine.json{ "StartAt": "hello world 1", "States": { "hello world 1": { "Type": "Task", "Resource": "${HelloWorldFunction}", "Parameters": { "p1.$": $.p1, "p2.$": "$.p2", "p3": { "p3-1": 20, "p3-2": "xyz" }, "all.$": "$" }, "ResultPath": "$.hello_world_result", "OutputPath": "$", "Next": "check state" }, "retry lambda": { "Type": "Task", "Resource": "${HelloWorldFunction}", "InputPath": "$", "ResultPath": "$.hello_world_result", "OutputPath": "$", "Next": "check state" }, "check state": { "Type" : "Choice", "Choices": [ { "Variable": "$.hello_world_result.body.message", "StringEquals": "hello world", "Next": "hello world 2" }, { "Variable": "$.hello_world_result.body.message", "StringEquals": "retry", "Next": "wait state" } ], "Default": "fail state" }, "wait state": { "Type": "Wait", "Seconds": 5, "Next": "retry lambda" }, "hello world 2": { "Type": "Task", "Resource": "${HelloWorldFunction}", "InputPath": "$", "End": true }, "fail state": { "Type": "Fail", "Cause": "No Matches!" } } }
- 「hello world 1」は次のステートに「check state」のステートを実行する
- 「check state」は「$.hello_world_result.body.message」の値が「hello world」なら、次のステートに「hello world 2」を実行する
- 「check state」は「$.hello_world_result.body.message」の値が「retry」なら、次のステートに「wait state」を実行する
- 「check state」は「$.hello_world_result.body.message」の値が「hello world」「retry」以外なら、次のステートに「fail state」を実行する(今回は起こり得ない)
- 「wait state」は、5秒経ったら「retry lambda」のステートを実行する
- 「retry lambda」は、lambda関数をコールした後、「check state」のステートを実行する
- 「hello world 2」はlambda関数をコールした後、ステート実行を終了する
- 「fail state」は、異常終了としてステート実行を終了する
という記述になっています。
「Choices」の中で
Variable:チェック対象StringEquals:文字列がこの値と同じならNext:次に実行するステートを指定します。
なお、StringEqualsの箇所に指定できる演算は、AWS Step Functions開発者ガイドを参照ください。ビルド・デプロイする
この状態で、
sam build、sam deploy --guidedを実行し、デプロイしましょう。ステートマシンの確認
まずは、ステートマシンの定義更新によって、可視化されたステートマシンがどのようになっているかをみてみましょう。
変更したように、「check state」から分岐し、「retry lambda」の後「check state」に戻っていることが確認できたと思います。
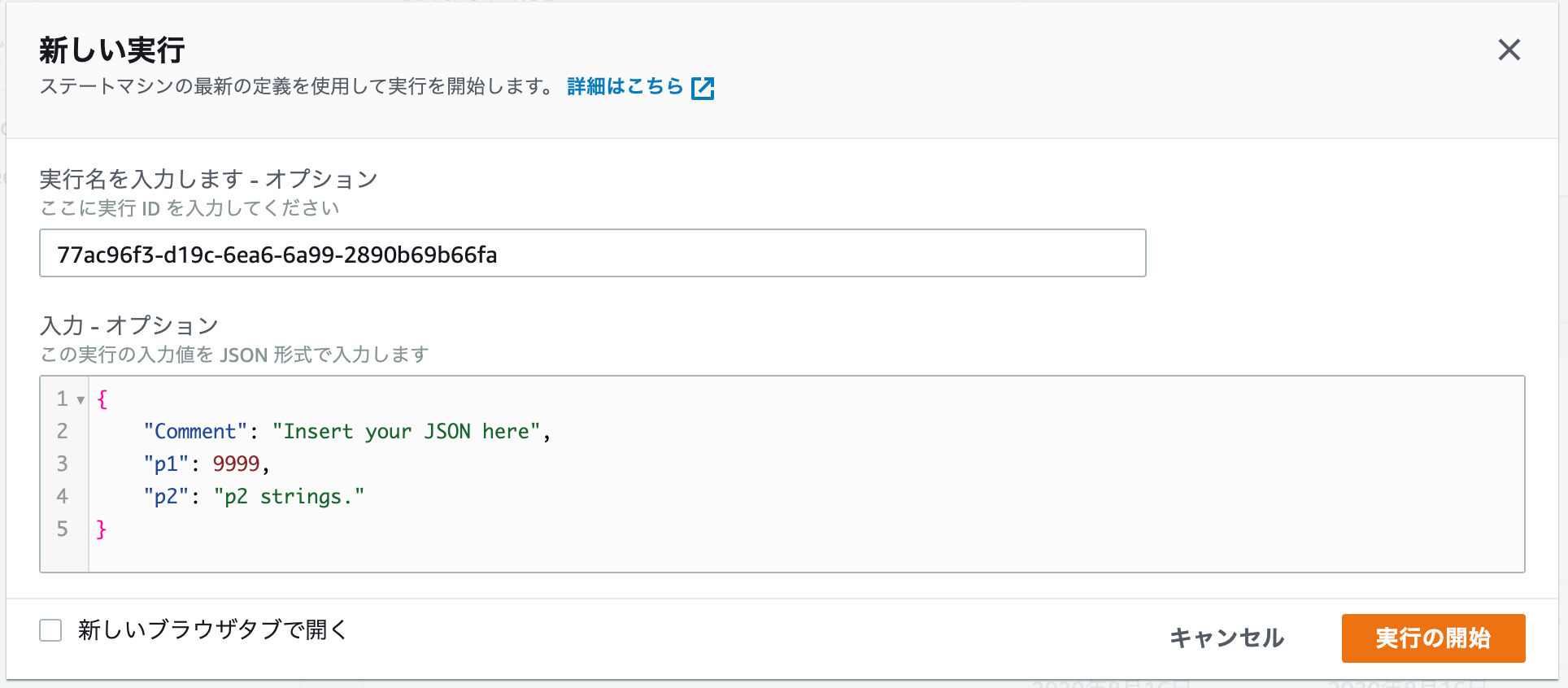
ステートマシンを実行してみる
マネジメントコンソールから、ステートマシンを実行してみましょう。
Part.2からの修正のため、入力値のp1、p2を使用するため、入力蘭を以下のように指定してください。
- p1に、9999数値を指定
- p2に「p2 strings.」という文字列を指定
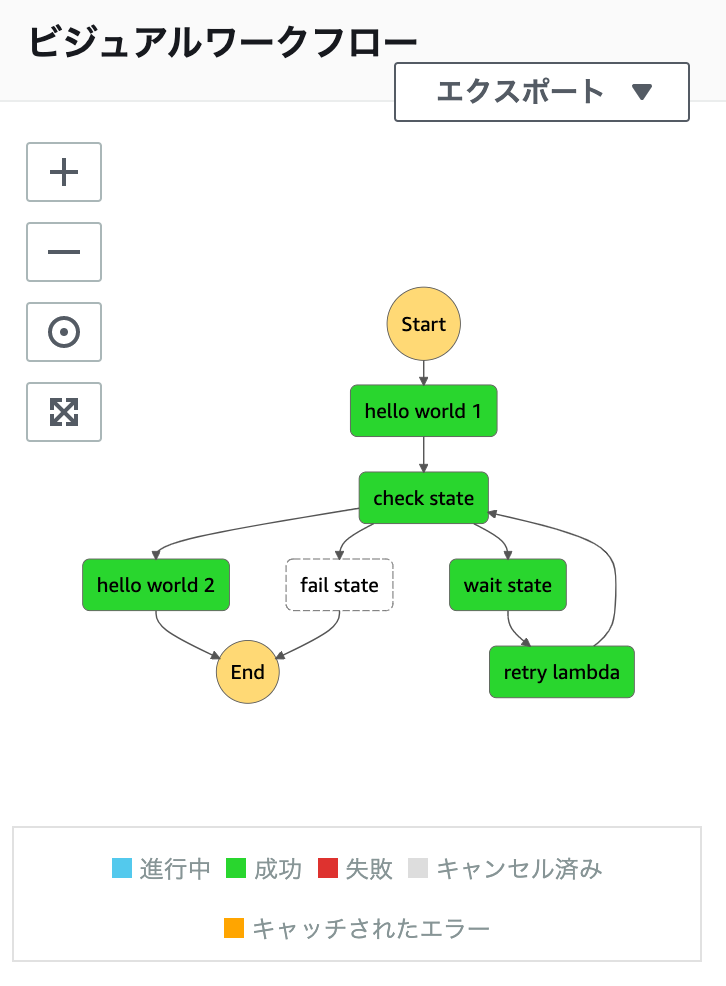
結果をみてみる
まずは、ビジュアルフローを確認してみましょう。
見事に、全パスが通ってくれてます(ランダムなので、「hello world 1」→「check state」→「hello world 2」という流れもありえます)。
では、
Choiceの処理が正しく動作しているのか、確認してみましょう。
まずは、「hello world 1」のステートから呼び出されたLambda関数の戻りがこちらです。
bodyのmessage部が「retry」であることが確認できます。
その結果、次に「wait state」が実行され、5秒後(#10と#11の時間をチェック)「retry lambdaのステートが実行されています。
実は、この後、更に2回連続して「retry」が返ってきますが、3回目に「hello world」が返されます。
その後は「hello world 2」のステートが実行されていることがわかります。
そして、そのままステートが終了します。
新しく追加された「Choice」ステート
2020/8/13に、アップデートされた内容があります。
値のテスト(型チェック)
- IsNull
- IsString
- IsNumeric
- IsBoolean
- IsTimestamp
によって、
Variableの型をChoiceで確認することができます。例"Variable": "$.foo", "IsNull|IsString|IsNumeric|IsBoolean|IsTimestamp": true|false存在チェック
- IsPresent
によって、
Variableそのものの存在チェックを行うことができます。例"Variable": "$.foo", "IsPresent": true|falseワイルドカードチェック
- StringMatches
によって、ワイルドカードを使用した判定チェックが行えます。
例"Variable": "$.foo", "StringMatches": "log-*.txt"別の入力フィールドとの比較
- StringEqualsPath
によって、入力フィールドを別の入力フィールドと比較できます。状態の変更などを確認するときに使用できます。
例"Variable": "$.foo", "StringEqualsPath": "$.bar"詳細
こちらから確認できます。
まとめ
今回は
Choiceによる分岐を行なってみましたが、ここまで来ると、ようやくワークフローっぽくなってきた感じがしますね。
ここまでのPart.1〜Part.3の内容だけでも、ある程度のステートマシンが定義できるようになっているかと思います。
次回は、Lambda以外のサービスをタスク定義で呼び出してみたいと思います。サンプルコードリポジトリ



- 投稿日:2020-08-17T22:11:18+09:00
ファイルの作成、withステートメント
次のように書くとtest.textというファイルが作成されその中にtestと書き込まれる
qiita.pyf = open("test.text", "w") f.write("test") f.close()追加で書き込む際は'w'を'a'と書き換える必要がある
'w'のままにしておくと上書きされてしまうqiita.pyf = open("test.text", "a") f.write("test2") f.close()ファイルの状態
testtest2print関数
print関数を使ってもファイルに書き込むことが可能
qiita.pyf = open("test.text", "w") f.write("test\n") print("print関数での書き込み", file=f) f.close()ファイルの状態
test print関数での書き込み,で区切って書くとスペース開けて書き込まれる
qiita.pyf = open("test.text", "w") f.write("test\n") print('print','関数','での','書き込み', file=f) f.close()ファイルの状態
test print 関数 での 書き込みsep,endも使うことが可能
qiita.pyf = open("test.text", "w") f.write("test\n") print('print','関数','での','書き込み',sep="#",end="@", file=f) f.close()ファイルの状態
test print#関数#での#書き込み@withステートメント
ファイルをf.closeを忘れるとメモリが消費されてしまう
withステートメントを使用することでcloseを使わずに済むqiita.pywith open("test.text", "w") as f: f.write("test\n") print('print','関数','での','書き込み',sep="#",end="@", file=f)
- 投稿日:2020-08-17T21:45:32+09:00
Educational Codeforces Round 93 バチャ復習(8/17)
今回の成績
今回の感想
やはりDを通せないところがまだ安定感のなさを感じます。
非想定解でゴリゴリやろうとして行き詰まってしまいました。
ゴリゴリやろうとする場合も見通しをちゃんと持ってから実装するようにします。A問題
問題を誤読しかけました。問題は三角形を構成しないような三つの数の組を答えるというもので、数列$a$は昇順ソート済みなので、$a_i+a_j<a_k (i<j<k)$が存在するかを確かめます。これは$a_i+a_j$を小さく$a_k$を大きくすることを考えれば良いので、$(i,j,k)=(1,2,n)$で成り立つかを確かめれば良いです。
A.pyfor _ in range(int(input())): n=int(input()) a=list(map(int,input().split())) if a[0]+a[1]<=a[-1]: print(f"1 2 {n}") else: print(-1)B問題
一瞬難しそうで身構えましたが、簡単でした。
どちらも選ぶ1の個数を最大化することを目指すので、長い1の連続部分列から順に交互に選んでいきます。したがって、文字列$S$に含まれる1の連続部分列の長さを
ansに格納した後に値の降順でソートして、奇数番目のものの合計がAliceのスコアの最大値となります。二つ飛ばしを選ぶのにPythonではans[::2]だけで書けるので非常に便利ですね。B.pyfor _ in range(int(input())): s=input() n=len(s) ans=[0] for i in range(n): if s[i]=="1": ans[-1]+=1 else: if ans[-1]!=0: ans.append(0) ans.sort(reverse=True) print(sum(ans[::2]))C問題
足し算の遷移としての扱いやすさからDPを疑いましたが、状態の管理ができないのでDPは難しいです(結果的にD問題がDPでした。悔しいです。)。
ここでは、区間を扱うので累積和の差分を考えることにしました。したがって、$x$番目までの和を$S_x$とおきます。この時、題意の条件は$S_r- S_{l-1}=r-l+1 \leftrightarrow S_r-r=S_{l-1}-(l-1)$となります。よって、$S_0-0=0$とすれば、任意の$i(0 \leqq i \leqq n)$について$S_i-i$が等しいもの同士は組になります。したがって、これはCounterなどの辞書を用いて同じになるもの同士に分け、$S_i-i=k$となるような$i$が$l$個ある時は$_l C _2$がそれらの$i$の組み合わせの個数となります。それぞれの$k$でこの計算を行い、和をとったものが答えとなります。
AtCoderでも最近出た気がするので高速に解くことができました。おそらく1ヶ月前は30分くらいかかっているので、精進の大切さと成長を感じました。
C.pyfor _ in range(int(input())): n=int(input()) a=list(map(int,input().split())) if a==[i+1 for i in range(n)]: print(0) continue #端は除く for i in range(n): if a[i]!=i+1: break for j in range(n-1,-1,-1): if a[j]!=j+1: break #インデックス間違い for k in range(i,j+1): if a[k]==k+1: print(2) break else: print(1)D問題
一つの考察のズレが大きな差を生むと感じました。もっと精度を高めた考察をしたいです。
まず容易に思いつく方針として値の大きいものから貪欲に組みにしていくというものがあります。つまり、$r,g,b$の辺の組ををそれぞれ長い順でpriority_queueに突っ込んで長いものから組にしていきます。しかし、この方法をとった場合は一つの色の辺だけ余ってしまいます。この場合はどうするべきでしょうか。一つ目の方法は、余った辺を後付けで組み込むことです。しかし、貪欲法を行っている(自分で選び順を恣意的に決めている)ので、後付けにより貪欲法が崩れる可能性があります。自分は崩さないように考えたのですが、コーナーケースを踏みそうで実装できませんでした。このようにある程度考えても難しく、他にも方針が立ちうる場合はいったん別の方法を考えてみるべきです。
ここで、先述の貪欲法ではかなり実行時間に対して余裕があるので、貪欲法にこだわらずとも考えることができます。次に考えつく方法としてはDPではないでしょうか。選ぶという遷移を考えることに加え、$r,g,b$は高々200なので$R \times G \times B=8 \times 10^6$程度の状態数しかなさそうというところから、かなりDPは有効な手段ではないかと考えられます。
ここで考えるDPは以下です。また、$r,g,b$はそれぞれ大きいものから選んでいくのが最適なので、降順ソートされているものとして議論を進めます。
$dp[i][j][k]:=$($r$の$i$個,$g$の$j$個,$b$の$k$個を組にした時に最大の長方形の合計の面積)
さらに、通常の遷移では一つずつ要素を加えることを考えますが、今回は組にすることで長方形を作れるので、組を加える遷移を考えます。したがって、以下のようになります。
(1)$i<R$かつ$j<G$の時
$r$及び$g$から組を選ぶことができるので、選べる中で一番大きい$r[i]$と$g[j]$を選びます($i,j$は0-indexedであることに注意が必要です。)。
$dp[i+1][j+1][k]=max(dp[i+1][j+1][k],dp[i][j][k]+r[i]*g[j])$(2)$i<R$かつ$k<B$の時
$r$及び$b$から組を選ぶことができるので、選べる中で一番大きい$r[i]$と$b[k]$を選びます($i,k$は0-indexedであることに注意が必要です。)。
$dp[i+1][j][k+1]=max(dp[i+1][j][k+1],dp[i][j][k]+r[i]*b[k])$(3)$j<G$かつ$k<B$の時
$g$及び$b$から組を選ぶことができるので、選べる中で一番大きい$g[j]$と$b[k]$を選びます($j,k$は0-indexedであることに注意が必要です。)。
$dp[i][j+1][k+1]=max(dp[i][j+1][k+1],dp[i][j][k]+g[j]*b[k])$(4)その他の時
組として選べるものがないので、以下がそれぞれ答えとなります。
[1]$i<R$の時、$dp[i+1][j][k]=max(dp[i+1][j][k],dp[i][j][k])$
[2]$j<G$の時、$dp[i][j+1][k]=max(dp[i][j+1][k],dp[i][j][k])$
[3]$k<B$の時、$dp[i][j][k+1]=max(dp[i][j][k+1],dp[i][j][k])$D.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll R,G,B;cin>>R>>G>>B; vector<ll> r(R);REP(i,R)cin>>r[i];sort(ALL(r),greater<ll>()); vector<ll> g(G);REP(i,G)cin>>g[i];sort(ALL(g),greater<ll>()); vector<ll> b(B);REP(i,B)cin>>b[i];sort(ALL(b),greater<ll>()); vector<vector<vector<ll>>> dp(R+1,vector<vector<ll>>(G+1,vector<ll>(B+1,0))); REP(i,R+1){ REP(j,G+1){ REP(k,B+1){ //pairごとで選ぶ、配るDP //思いつければ楽だけど //dp[i][j][k]:=i番目j番目k番目まで組にした時の bool f=false; if(i<R and j<G){ dp[i+1][j+1][k]=max(dp[i+1][j+1][k],dp[i][j][k]+r[i]*g[j]); f=true; } if(i<R and k<B){ dp[i+1][j][k+1]=max(dp[i+1][j][k+1],dp[i][j][k]+r[i]*b[k]); f=true; } if(j<G and k<B){ dp[i][j+1][k+1]=max(dp[i][j+1][k+1],dp[i][j][k]+g[j]*b[k]); f=true; } if(!f){ if(i<R)dp[i+1][j][k]=max(dp[i+1][j][k],dp[i][j][k]); if(j<G)dp[i][j+1][k]=max(dp[i][j+1][k],dp[i][j][k]); if(k<B)dp[i][j][k+1]=max(dp[i][j][k+1],dp[i][j][k]); } } } } cout<<dp[R][G][B]<<endl; }E問題以降
今回は飛ばします

- 投稿日:2020-08-17T21:41:06+09:00
クラス変数、クラスメソッドとスタティスティックメソッド
qiita.pyclass Person(object): kind = 'human' def __init__(self,name): self.name = name def who_are_you(self): print(self.name,self.kind) a = Person('A') a.who_are_you() #A human b = Person('B') b.who_are_you() #B human注意点
クラス変数は全てのオブジェクトで共有される
qiita.pyclass T(object): words = [] def add_word(self,word): self.words.append(word) c = T() c.add_word('add1') c.add_word('add2') d = T() d.add_word('add3') d.add_word('add4') print(c.words) #['add1', 'add2', 'add3', 'add4']このように書き換える必要がある
initで初期化するqiita.pyclass T(object): def __init__(self): self.words = [] def add_word(self,word): self.words.append(word) c = T() c.add_word('add1') c.add_word('add2') print(c.words) #['add1', 'add2'] d = T() d.add_word('add3') d.add_word('add4') print(d.words) #['add3', 'add4']クラスメソッド
qiita.pyclass Person(object): kind = 'human' def __init__(self): self.x = 100 a = Person() print(a) b = Person print(b)実行すると
aでは『オブジェクトだと表示』され、
bでは『クラスのみを示し、オブジェクト化されていない』と表示される。<__main__.Person object at 0x7fc0558d6210> <class '__main__.Person'>self.xにアクセスしようとすると
aでは100と表示されるが
bではinitが実行されていない為エラーが発生するqiita.pyclass Person(object): kind = 'human' def __init__(self): self.x = 100 a = Person() print(a.x) b = Person print(b.x)100 Traceback (most recent call last): File "/Users/kirinboy96/PycharmProjects/untitled1/lesson_package/NEW1.py", line 11, in <module> print(b.x) AttributeError: type object 'Person'ただ、この場合でもkindには$\color{red}{\rm アクセス可能}$
qiita.pyclass Person(object): kind = 'human' def __init__(self): self.x = 100 a = Person() print(a.kind) # 実行結果:human b = Person print(b.kind) # 実行結果:humanクラスメソッド
オブジェクト化されていなくても、アクセスする方法としてクラスメソッドが存在する
qiita.pyclass Person(object): kind = 'human' def __init__(self): self.x = 100 @classmethod def what_is_your_kind(cls): return cls.kind a = Person() print(a.what_is_your_kind()) # 実行結果:human b = Person print(b.what_is_your_kind()) # 実行結果:humanスタティックメソッド
スタティックメソッドにはcls,selfなど使わなくてもOK
qiita.pyclass Person(object): kind = 'human' def __init__(self): self.x = 100 @classmethod def what_is_your_kind(cls): return cls.kind @staticmethod def about(): print("about human") print(Person.about()) # 実行結果:about human引数をとる事もできる
qiita.pyclass Person(object): kind = 'human' def __init__(self): self.x = 100 @classmethod def what_is_your_kind(cls): return cls.kind @staticmethod def about(year): print("about human {}".format(year)) print(Person.about(2020)) # 実行結果:about human 2020
- 投稿日:2020-08-17T21:17:07+09:00
0からはじめる「Python AIプログラミング」 for Google Colab
はじめに
ここでは、クラウド(Google Colab)でAIプログラミングを「手っ取り早く動かしてイメージをつかみたいと思っている方」向けの手順を説明いたします。
初心者向けのもので、目的は開発環境を整えてプログラム (プログラミングはしません。コピペでOKです^^;) を実行し、「ほぉ、AIプログラミングってこんな感じか~」というところがGOALです。
※ローカルPC版の『【0からはじめる「Python AIプログラミング」 for PC』は、こちらです
どんなことをやるか
まず
手書きの数字0~9とその正解ラベル(0~9)がセットになった教師データ60,000枚をAIに学習させます。その後、
手書きの数字0~9とその正解ラベル(0~9)がセットになった検証データ10,000枚をAIに検証させて、認識率や検証データの手書き数字がAIによって0~9のどの数字と認識したのかを試してみます。(1) AIに学習させる
教師データ(60,000枚)を使用して、手書き画像を正解ラベルに沿って、0~9の数字として覚えさせます。
(2) AIに検証させる
検証データ(10,000枚)`を利用して、手書き画像をAIにより0~9の数字に分類(クラス分類)させ、正解データと比較し当たったかどうかを判定。
※上記データは プログラム実行時に MNISTデータベース から自動的にダウンロードされますので、
画像ファイルの収集や正解ラベリング(画像データと正解ラベルの結びつけ)等の前準備は一切不要となっています。開発環境準備
Google Colabが全部用意してくれるので、今回はインストールなどはありません。
「Google Colabサービス」を利用するのに「googleアカウント」が必要なだけです。
No. 開発環境 説明 1 Googleアカウント Google Colab利用のためにGoogleアカウントを使用します。無料です。 2 Google Colabサービス Googleのクラウド仮想マシン上で動くPython実行環境。使用料は無料です。インストール等の作業などは不要です。GPUも無料で使用でき、AI学習も素早く計算が可能です。 作業フロー
1.Googleのサービスから「
ドライブ」をクリック
2.ドライブの「
新規」->「その他」->「Google Colaboratory」をクリック
3.「
ランタイム」->「ランタイムのタイプを変更」をクリック
4.ノートブックの設定でハードウェアアクセラレータを「
GPU」を選択し「保存」をクリック
5. AIプログラムをコピペ
以下のプログラムをGoogle Colabのコードのところへ
コピペしてください。# ------------------------------------------------------------------------------------------------------------ # CNN(Convolutional Neural Network)でMNISTを試す # ------------------------------------------------------------------------------------------------------------ import numpy as np import matplotlib.pyplot as plt from sklearn.metrics import confusion_matrix from keras.datasets import mnist from keras import backend as ke from keras.utils import np_utils from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D # ------------------------------------------------------------------------------------------------------------ # ハイパーパラメータ # ------------------------------------------------------------------------------------------------------------ # ハイパーパラメータ ⇒ バッチサイズ、エポック数 # 例えば、訓練データが60,000個で、batch_sizeを6,000とした場合、 # 学習データをすべて使うのに60,000個÷6,000=10回のパラメータ更新が行われる。 # これを1epochと言う。epochが10であれば、10×10=100回のパラメータ更新が行われることとなる。 # epoch数は損失関数(コスト関数)の値がほぼ収束するまでに設定する。 batch_size = 6000 # バッチサイズ epochs = 20 # エポック数 # ------------------------------------------------------------------------------------------------------------ # 正誤表関数 # ------------------------------------------------------------------------------------------------------------ def show_prediction(): n_show = 100 # 全部は表示すると大変なので一部を表示 y = model.predict(X_test) plt.figure(2, figsize=(10, 10)) plt.gray() for i in range(n_show): plt.subplot(10, 10, (i+1)) # subplot(行数, 列数, プロット番号) x = X_test[i, :] x = x.reshape(28, 28) plt.pcolor(1 - x) wk = y[i, :] prediction = np.argmax(wk) plt.text(22, 25.5, "%d" % prediction, fontsize=12) if prediction != np.argmax(y_test[i, :]): plt.plot([0, 27], [1, 1], color='red', linewidth=10) plt.xlim(0, 27) plt.ylim(27, 0) plt.xticks([], "") plt.yticks([], "") # ------------------------------------------------------------------------------------------------------------ # keras backendの表示 # ------------------------------------------------------------------------------------------------------------ # print(ke.backend()) # print(ke.floatx()) # ------------------------------------------------------------------------------------------------------------ # MNISTデータの取得 # ------------------------------------------------------------------------------------------------------------ # 初回はダウンロードが発生するため時間がかかる # 60,000枚の28x28ドットで表現される10個の数字の白黒画像と10,000枚のテスト用画像データセット # ダウンロード場所:'~/.keras/datasets/' # ※MNISTのデータダウンロードがNGとなる場合は、PROXYの設定を見直してください # # MNISTデータ # ├ 教師データ (60,000個) # │ ├ 画像データ # │ └ ラベルデータ # │ # └ 検証データ (10,000個) # ├ 画像データ # └ ラベルデータ # ↓教師データ ↓検証データ (X_train, y_train), (X_test, y_test) = mnist.load_data() # ↑画像 ↑ラベル ↑画像 ↑ラベル # ------------------------------------------------------------------------------------------------------------ # 画像データ(教師データ、検証データ)のリシェイプ # ------------------------------------------------------------------------------------------------------------ img_rows, img_cols = 28, 28 if ke.image_data_format() == 'channels_last': X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1) X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1) input_shape = (img_rows, img_cols, 1) else: X_train = X_train.reshape(X_train.shape[0], 1, img_rows, img_cols) X_test = X_test.reshape(X_test.shape[0], 1, img_rows, img_cols) input_shape = (1, img_rows, img_cols) # 配列の整形と、色の範囲を0~255 → 0~1に変換 X_train = X_train.astype('float32') X_test = X_test.astype('float32') X_train /= 255 X_test /= 255 # ------------------------------------------------------------------------------------------------------------ # ラベルデータ(教師データ、検証データ)のベクトル化 # ------------------------------------------------------------------------------------------------------------ y_train = np_utils.to_categorical(y_train) # 教師ラベルのベクトル化 y_test = np_utils.to_categorical(y_test) # 検証ラベルのベクトル化 # ------------------------------------------------------------------------------------------------------------ # ネットワークの定義 (keras) # ------------------------------------------------------------------------------------------------------------ print("") print("●ネットワーク定義") model = Sequential() # 入力層 28×28×3 model.add(Conv2D(16, kernel_size=(3, 3), activation='relu', input_shape=input_shape, padding='same')) # 01層:畳込み層16枚 model.add(Conv2D(32, (3, 3), activation='relu', padding='same')) # 02層:畳込み層32枚 model.add(MaxPooling2D(pool_size=(2, 2))) # 03層:プーリング層 model.add(Dropout(0.25)) # 04層:ドロップアウト model.add(Conv2D(32, (3, 3), activation='relu', padding='same')) # 05層:畳込み層64枚 model.add(MaxPooling2D(pool_size=(2, 2))) # 06層:プーリング層 model.add(Flatten()) # 08層:次元変換 model.add(Dense(128, activation='relu')) # 09層:全結合出力128 model.add(Dense(10, activation='softmax')) # 10層:全結合出力10 # model表示 model.summary() # コンパイル # 損失関数 :categorical_crossentropy (クロスエントロピー) # 最適化 :Adam model.compile(loss='categorical_crossentropy', optimizer='Adam', metrics=['accuracy']) print("") print("●学習スタート") f_verbose = 1 # 0:表示なし、1:詳細表示、2:表示 hist = model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(X_test, y_test), verbose=f_verbose) # ------------------------------------------------------------------------------------------------------------ # 損失値グラフ化 # ------------------------------------------------------------------------------------------------------------ # Accuracy (正解率) plt.plot(range(epochs), hist.history['accuracy'], marker='.') plt.plot(range(epochs), hist.history['val_accuracy'], marker='.') plt.title('Accuracy') plt.ylabel('accuracy') plt.xlabel('epoch') plt.legend(['train', 'test'], loc='lower right') plt.show() # loss (損失関数) plt.plot(range(epochs), hist.history['loss'], marker='.') plt.plot(range(epochs), hist.history['val_loss'], marker='.') plt.title('loss Function') plt.ylabel('loss') plt.xlabel('epoch') plt.legend(['train', 'test'], loc='upper right') plt.show() # ------------------------------------------------------------------------------------------------------------ # テストデータ検証 # ------------------------------------------------------------------------------------------------------------ print("") print("●検証結果") t_verbose = 1 # 0:表示なし、1:詳細表示、2:表示 score = model.evaluate(X_test, y_test, verbose=t_verbose) print("") print("batch_size = ", batch_size) print("epochs = ", epochs) print('Test loss:', score[0]) print('Test accuracy:', score[1]) print("") print("●混同行列(コンフュージョンマトリックス) 横:識別結果、縦:正解データ") predict_classes = model.predict_classes(X_test[1:60000, ], batch_size=batch_size) true_classes = np.argmax(y_test[1:60000], 1) print(confusion_matrix(true_classes, predict_classes)) # ------------------------------------------------------------------------------------------------------------ # 正誤表表示 # ------------------------------------------------------------------------------------------------------------ show_prediction() plt.show()こんな感じ ↓ になりましたか?
6. AIプログラムを実行
「
ランタイム」->「すべてのセルを実行」をクリックして、AIプログラムを実行してください。
7. 実行結果
さすがGPUです?とても処理が早いです!
以上
Google ColabはGPUを使用できるので、AIの学習が比較的早く終わります。
自前のノートPCだと5epocくらいでイライラしちゃうのに、Google Colabだと20epocでもへっちゃらです?
- お疲れ様でした!









- 投稿日:2020-08-17T21:09:27+09:00
Djangoでセッションを使った情報記録メモ
セッションから記録情報を引き出す方法
下記のように取得し、定義などは考える必要なし (空の場合は以降の処理で場合分けを行う)。
変数 = request.session.get('セッション記憶情報変数名')ex) cart = request.session.get('cart')セッションの情報を追加する方法
下記のように追加情報を変数に追加してからセッションを上書きする。
変数.append(追加情報) request.session['セッション記憶情報変数名'] = 変数ex) cart.append(product_id) request.session['cart'] = cartセッションの情報を削除する方法
下記のように削除情報を持たない仮変数を作ってからセッションを上書きする。
for 仮数(何でも良い) in 変数: if 仮数 != 削除情報: 仮変数.append(仮数) request.session['セッション記憶情報変数名'] = 仮変数ex) for p in cart: if p != product_id: filtered.append(p) request.session['cart'] = filtered
- 投稿日:2020-08-17T21:03:28+09:00
6ドルの激安LiDAR(Camsense X1)を使ってみる
2000円のLidarって大丈夫?
Aliexpressで2千円のLidarが売っている事を知りましたが、怪しすぎて買うのを躊躇っていました。
そんなところ、買った方のコメントや、Qiita記事を見て自分も購入してみました。・camsense-X1
https://github.com/Vidicon/camsense-X1
・激安LiDAR(Camsense X1)を使ってみる
https://qiita.com/junp007/items/819aced4d48efd97c79f
届いたのは?
2個購入した所
左はNG品、右は正常品でした。
NGと書いてあったり、本体にCamsense X1のロゴが無いのはNG品です。
NG品は、修正が入っていますね。動作させる
今回は、USB-Serialアダプタを使って接続します。
電源は5V、USB-Serialの接続先はRXです。
(TX⇒RX)
こういう時に使用するのは
スルホール用テストワイヤ TT-200 (10本入)
http://akizukidenshi.com/catalog/g/gC-09831/TeraTermの受信内容
接続します。
ボーレート:115200
TeraTermの表示内容はこんな感じです。
これを見て壊れていると思ってしまいますよね・・・
使えるようにしてみよう
「激安LiDAR(Camsense X1)を使ってみる」に
https://qiita.com/junp007/items/819aced4d48efd97c79f
「距離と強度データが8ステップずつ入った36バイトのパケットになっていて」と記載されています。
つまり、このままではダメです。
記載されているとおり、Pythonで動かしてみましょう。Windowsで動かす・・・camsenseX1.py
必要なのはpython、pyserial、matplotlibです。
これらをインストールします。
私は、Windows標準のコマンドプロンプトを使用しており
まずは、pipをインストールし、Python、pyserial、matplotlibをインストールしていきます。
最後に、こちらのプログラムを起動します。
コマンドプロンプトの最後に、シリアルポートを選択しますC:\Users\user\Desktop\camsenseX1.py COM2シリアルポートを指定しないと、こんなメッセージが出ます。
無事起動
ちょっと、怪しい挙動がありますが、動きました。
これで2000円なら満足ですね。配線するよ
それでは、キチンと使えるようにしましょう。
というのは、コネクタの品種がわからず、使えないからです。
本来はL型のピンヘッダが必要ですが無いので普通のを曲げました。
買う人は、秋月電子のこちらなど
ピンヘッダ (L型) 1×6 (6P)
http://akizukidenshi.com/catalog/g/gC-05336/はんだ付け
脚をつけるよ
M2.5X20を選択しました。
今や6ドル未満
今は6ドル未満で売っています。
送料がかかるので実際は1000円です。
この価格は何でしょうか?
非常に困ってしまいますね・・・お勧めはしない
ここまで見ると動きそうだと思われますね
ですが、正直お勧めできません
ふつうの人であれば、動かない商品を買うのは嫌でしょう
私ですら嫌です。
なので、動かない可能性が高い本商品は、2個のうち1個動けばいいやと思えるかが重要です。2000円の時に2個買った私は、6ドルならば6個買ってもほぼ一緒ですが・・・
動かない前提で試してみる気があるならば・・・












- 投稿日:2020-08-17T19:50:21+09:00
NumPyの操作方法
https://www.udemy.com/course/ds_for_python/
をやってるなかで、コマンド忘れそうなのでimportimport numpy as npflatten()
flattenarray1=np.array([[1,2,3],[4,5,6],[7,8,9]]) array1.flatten()結果
array([1, 2, 3, 4, 5, 6, 7, 8, 9])squeeze
squeezearray1=np.array([[1,2,3]]) array1.shape
(1, 3)squeezenp.squeeze(array1)
(3,)次元を減らす。
expand_dims
expand_dimsndarray1=np.array([1,2,3]) ndarray1.shape expand_axis=np.expand_dims(ndarray1, axis=-1) expand_axis.shape expand_axis(3,) (3, 1) array([[1], [2], [3]])逆に、次元を増やす。
axisの引数で増やす場所が変わる。
- 投稿日:2020-08-17T19:17:33+09:00
個人で使ってもMLflow Trackingは良い
はじめに
MLOpsという、「機械学習モデルが陳腐化してシステムがゴミにならないように、ちゃんと機械学習の技術が含まれたシステムを運用するための基盤をつくりましょうね」というような話がある。
参考記事:小さく始めて大きく育てるMLOps2020その助けになるように作られたツールとしてMLFlowというものがある。
MLflowの一つの機能、MLflow Trackingを使う機会があったので、いろいろ調べながら使ってみたらこれは良いものだなぁ、と思ったのでここに記す。まあ使い方自体は他にたくさん記事があるのでそれを見ていただくとして、「こういう感じでモデル作成の記録を残していくのはどうよ?」とモデル構築のログの残し方のアイデアの種にでもなればハッピー。MLflowはバージョン1.8.0を使った。
MLflowについては以下の記事がわかりやすい。
mlflowを使ってデータ分析サイクルの効率化する方法を考える
MLflow 1.0.0 リリース!機械学習ライフサイクルを始めよう!使用データ
KaggleのTelco Customer Churnのデータを使用する。
https://www.kaggle.com/blastchar/telco-customer-churn
これは電話会社の顧客に関するデータであり、解約するか否かを目的変数とした2値分類問題。
各行は顧客を表し、各列には顧客の属性が含まれている。使うパッケージと関数の定義
集計結果を可視化する関数や、モデルを作る関数などを作成。
本題ではないので説明は省略。使用パッケージ
# package import numpy as np import scipy import matplotlib as mpl import matplotlib.pyplot as plt import matplotlib.gridspec as gridspec import seaborn as sns import pandas as pd from pandas.plotting import register_matplotlib_converters import xgboost import xgboost.sklearn as xgb import sklearn from sklearn.model_selection import train_test_split from sklearn.model_selection import KFold from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import precision_score from sklearn.metrics import recall_score from sklearn.metrics import accuracy_score from sklearn.metrics import f1_score from sklearn.metrics import auc from sklearn.metrics import roc_curve from sklearn.metrics import log_loss from sklearn.model_selection import StratifiedKFold from sklearn.model_selection import cross_validate from sklearn.cluster import KMeans from sklearn.metrics import confusion_matrix from sklearn.metrics import make_scorer from sklearn.metrics import precision_recall_curve import time import os import glob from tqdm import tqdm import copy import mlflow from mlflow.sklearn import log_model from mlflow.sklearn import load_model定義した関数群
# ヒストグラム作成 def plot_many_hist(df_qiita,ex_col,ob_col,clip=[0, 99.],defalt_bin=10,png='tmp.png', visual = True): fig=plt.figure(figsize=(15,10)) for i in range(len(ex_col)): df_qiita_clip=df_qiita.copy() col=ex_col[i] # クリッピング upperbound, lowerbound = np.percentile(df_qiita[col].values, clip) col_clip = np.clip(df_qiita[col].values, upperbound, lowerbound) df_qiita_clip['col_clip']=col_clip # ビンの数調整 if len(df_qiita_clip['col_clip'].unique())<10: bins=len(df_qiita_clip['col_clip'].unique()) else: bins=defalt_bin # ヒストグラムプロット ax=plt.subplot(3,3,i+1) for u in range(len(df_qiita_clip[ob_col].unique())): ln1=ax.hist(df_qiita_clip[df_qiita_clip[ob_col]==u]['col_clip'], bins=bins,label=u, alpha=0.7) ax.set_title(col) h1, l1 = ax.get_legend_handles_labels() ax.legend(loc='upper right') ax.grid(True) plt.tight_layout() fig.suptitle("hist", fontsize=15) plt.subplots_adjust(top=0.92) plt.savefig(png) if visual == True: print('Cluster Hist') plt.show() else: plt.close() # 標準化 def sc_trans(X): ss = StandardScaler() X_sc = ss.fit_transform(X) return X_sc # kmeansモデル作成 def km_cluster(X, k): km=KMeans(n_clusters=k,\ init="k-means++",\ random_state=0) y_km=km.fit_predict(X) return y_km,km # 円グラフ作成 def pct_abs(pct, raw_data): absolute = int(np.sum(raw_data)*(pct/100.)) return '{:d}\n({:.0f}%)'.format(absolute, pct) if pct > 5 else '' def plot_chart(y_km, png='tmp.png', visual = True): km_label=pd.DataFrame(y_km).rename(columns={0:'cluster'}) km_label['val']=1 km_label=km_label.groupby('cluster')[['val']].count().reset_index() fig=plt.figure(figsize=(5,5)) ax=plt.subplot(1,1,1) ax.pie(km_label['val'],labels=km_label['cluster'], autopct=lambda p: pct_abs(p, km_label['val']))#, autopct="%1.1f%%") ax.axis('equal') ax.set_title('Cluster Chart (ALL UU:{})'.format(km_label['val'].sum()),fontsize=14) plt.savefig(png) if visual == True: print('Cluster Structure') plt.show() else: plt.close() # 表作成 def plot_table(df_qiita, cluster_name, png='tmp.png', visual = True): fig, ax = plt.subplots(figsize=(10,10)) ax.axis('off') ax.axis('tight') tab=ax.table(cellText=np.round(df_qiita.groupby(cluster_name).mean().reset_index().values, 2),\ colLabels=df_qiita.groupby(cluster_name).mean().reset_index().columns,\ loc='center',\ bbox=[0,0,1,1]) tab.auto_set_font_size(False) tab.set_fontsize(12) tab.scale(5,5) plt.savefig(png) if visual == True: print('Cluster Stats Mean') plt.show() else: plt.close() # XGBモデル作成 def xgb_model(X_train, y_train, X_test): model = xgb.XGBClassifier() model.fit(X_train, y_train) y_pred=model.predict(X_test) y_pred_proba=model.predict_proba(X_test)[:, 1] y_pred_proba_both=model.predict_proba(X_test) return model, y_pred, y_pred_proba, y_pred_proba_both # 学習データとテストデータ作成 def createXy(df, exp_col, ob_col, test_size=0.3, random_state=0, stratify=True): dfx=df[exp_col].copy() dfy=df[ob_col].copy() print('exp_col:',dfx.columns.values) print('ob_col:',ob_col) if stratify == True: X_train, X_test, y_train, y_test = train_test_split(dfx, dfy, test_size=test_size, random_state=random_state, stratify=dfy) else: X_train, X_test, y_train, y_test = train_test_split(dfx, dfy, test_size=test_size, random_state=random_state) print('Original Size is {}'.format(dfx.shape)) print('TrainX Size is {}'.format(X_train.shape)) print('TestX Size is {}'.format(X_test.shape)) print('TrainY Size is {}'.format(y_train.shape)) print('TestY Size is {}'.format(y_test.shape)) return X_train, y_train, X_test, y_test # 分類評価指標の結果返す def eval_list(y_test, y_pred, y_pred_proba, y_pred_proba_both): # eval log_loss_=log_loss(y_test, y_pred_proba_both) accuracy=accuracy_score(y_test, y_pred) precision=precision_score(y_test, y_pred) recall=recall_score(y_test, y_pred) # FPR, TPR, thresholds fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba) # AUC auc_ = auc(fpr, tpr) # roc_curve fig, ax = plt.subplots(figsize=(10,10)) ax.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %.2f)'%auc_) ax.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') plt.legend() plt.title('ROC curve') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.grid(True) plt.savefig('ROC_curve.png') plt.close() return log_loss_, accuracy, precision, recall, auc_ # Recall-Precision曲線返す def threshold_pre_rec(test, prediction, save_name='threshold_pre_rec.png'): precision, recall, threshold = precision_recall_curve(test, prediction) thresholds = threshold user_cnt=[prediction[prediction>=i].shape[0] for i in thresholds] fig=plt.figure(figsize=(10,6)) ax1 = plt.subplot(1,1,1) ax2=ax1.twinx() ax1.plot(thresholds, precision[:-1], color=sns.color_palette()[0],marker='+', label="precision") ax1.plot(thresholds, recall[:-1], color=sns.color_palette()[2],marker='+', label="recall") ax2.plot(thresholds, user_cnt, linestyle='dashed', color=sns.color_palette()[6], label="user_cnt") handler1, label1 = ax1.get_legend_handles_labels() handler2, label2 = ax2.get_legend_handles_labels() ax1.legend(handler1 + handler2, label1 + label2, loc='lower left') ax1.set_xlim(-0.05,1.05) ax1.set_ylim(-0.05,1.05) ax1.set_xlabel('threshold') ax1.set_ylabel('%') ax2.set_ylabel('user_cnt') ax2.grid(False) plt.savefig(save_name) plt.close() # 予測確率-実測確率曲線を返す def calib_curve(y_tests, y_pred_probas, save_name='calib_curve.png'): y_pred_proba_all=y_pred_probas.copy() y_tests_all=y_tests.copy() proba_check=pd.DataFrame(y_tests_all.values,columns=['real']) proba_check['pred']=y_pred_proba_all s_cut, bins = pd.cut(proba_check['pred'], list(np.linspace(0,1,11)), right=False, retbins=True) labels=bins[:-1] s_cut = pd.cut(proba_check['pred'], list(np.linspace(0,1,11)), right=False, labels=labels) proba_check['period']=s_cut.values proba_check = pd.merge(proba_check.groupby(['period'])[['real']].mean().reset_index().rename(columns={'real':'real_ratio'})\ , proba_check.groupby(['period'])[['real']].count().reset_index().rename(columns={'real':'UU'})\ , on=['period'], how='left') proba_check['period']=proba_check['period'].astype(str) proba_check['period']=proba_check['period'].astype(float) fig=plt.figure(figsize=(10,6)) ax1 = plt.subplot(1,1,1) ax2=ax1.twinx() ax2.bar(proba_check['period'].values, proba_check['UU'].values, color='gray', label="user_cnt", width=0.05, alpha=0.5) ax1.plot(proba_check['period'].values, proba_check['real_ratio'].values, color=sns.color_palette()[0],marker='+', label="real_ratio") ax1.plot(proba_check['period'].values, proba_check['period'].values, color=sns.color_palette()[2], label="ideal_line") handler1, label1 = ax1.get_legend_handles_labels() handler2, label2 = ax2.get_legend_handles_labels() ax1.legend(handler1 + handler2, label1 + label2, loc='center right') ax1.set_xlim(-0.05,1.05) ax1.set_ylim(-0.05,1.05) ax1.set_xlabel('period') ax1.set_ylabel('real_ratio %') ax2.set_ylabel('user_cnt') ax2.grid(False) plt.savefig(save_name) plt.close() # 混合行列を出力 def print_cmx(y_true, y_pred, save_name='tmp.png'): labels = sorted(list(set(y_true))) cmx_data = confusion_matrix(y_true, y_pred, labels=labels) df_cmx = pd.DataFrame(cmx_data, index=labels, columns=labels) plt.figure(figsize = (10,6)) sns.heatmap(df_cmx, annot=True, fmt='d', cmap='coolwarm', annot_kws={'fontsize':20},alpha=0.8) plt.xlabel('pred', fontsize=18) plt.ylabel('real', fontsize=18) plt.savefig(save_name) plt.close()データの読み込み
本題ではないので、欠損行はそのまま削除。
# データ読み込み df=pd.read_csv('WA_Fn-UseC_-Telco-Customer-Churn.csv') churn=df.copy() # 半角空白をNanに変更 churn.loc[churn['TotalCharges']==' ', 'TotalCharges']=np.nan # floatに変更 churn['TotalCharges']=churn['TotalCharges'].astype(float) # 面倒なので欠損行がある場合、その行は削除する churn=churn.dropna() print(churn.info()) display(churn.head())MLflowでクラスタリング結果を記録
kmenasなどでクラスタリングした後は、クラスタごとの特徴を見て、人間がクラスタリング結果の解釈を行う。しかし試行錯誤していく中で毎回可視化したり表を作ったりしてクラスタの特徴を見るのは面倒だし、前の結果がどんなものだったのか忘れてしまうかもしれない。この問題を解決するためにMLflowを活用できる。説明変数を連続値の'tenure', 'MonthlyCharges', 'TotalCharges'に絞ってクラスタリングを実施して、その結果をMLflowに記録する。
#### クラスタリング実施 exp_col=['tenure','MonthlyCharges','TotalCharges'] df_km=churn.copy()[exp_col] df_cluster=df_km.copy() cluster_name = 'My_Cluster' k=5 ob_col = cluster_name # クラスタリング結果をmlflowに記録 mlflow.set_experiment('My Clustering')# 実験の名前を定義 with mlflow.start_run():# mlflow記録開始 # 標準化 X=sc_trans(df_cluster) # kmeansモデル作成 y_km, km=km_cluster(X, k) # paramsをmlflowに記録 mlflow.log_param("method_name",km.__class__.__name__) mlflow.log_param("k", k) mlflow.log_param("features", df_cluster.columns.values) # modelをmlflowに保存 log_model(km, "model") df_cluster[cluster_name]=y_km # クラスタリング結果を可視化 # クラスタ構成比 plot_chart(y_km, png='Cluster_Chart.png', visual = False)# カレントディレクトリに図を保存 mlflow.log_artifact('Cluster_Chart.png')# カレントディレクトリにある図を記録 os.remove('Cluster_Chart.png')# 記録した後にカレントディレクトリの図は削除した # クラスタごとの平均値 plot_table(df_cluster, ob_col, png='Cluster_Stats_Mean.png', visual = False)# カレントディレクトリに図を保存 mlflow.log_artifact('Cluster_Stats_Mean.png')# カレントディレクトリにある図を記録 os.remove('Cluster_Stats_Mean.png')# 記録した後にカレントディレクトリの図は削除した # クラスタごとのヒストグラム plot_many_hist(df_cluster,exp_col,ob_col,clip=[0, 99.],defalt_bin=20, png='Cluster_Hist.png', visual = False)# カレントディレクトリに図を保存 mlflow.log_artifact('Cluster_Hist.png')# カレントディレクトリにある図を記録 os.remove('Cluster_Hist.png')# 記録した後にカレントディレクトリの図は削除した上記のように、アルゴリズム名や、説明変数名、ハイパラの値、クラスタごとの特徴を可視化した図表を記録するように記述したコードを実行すると、カレントディレクトリに"mlruns"というフォルダが作成される。記録した結果はすべてこの"mlruns"というフォルダに保存されている。
"mlruns"フォルダがあるディレクトリでターミナルを開き"mlflow ui"と記述して実行すると、localhostの5000番が立ち上がる。ブラウザでlocalhostの5000番にアクセスすると、MLflowのリッチなUIを通して作ったモデルの記録を確認できる。"mlruns"フォルダ
"mlruns"というフォルダがあるディレクトリで"mlflow ui"と記述
mlflow uiトップ画面
My Clusteringという名前の部屋にクラスタリング結果は記録されている。記録した内容を見るため、記録日時が書かれたリンクの中を確認してみる。
Parameters, Metrics
Artifacts
Artifacts
Artifacts
記録するように設定したアルゴリズム名や、説明変数名、ハイパラの値はParametersに記録されていることが確認できる。また図表などはArtifactsに記録されている。
このように記録していくと、説明変数を変えたり、kの値を変えたりした時も、以前のモデルの結果と比較することが容易くなる。予測結果をMLflowに記録
分類モデルを作るときも同様に記録できる。
#### 予測モデルを構築 exp_col=['tenure','MonthlyCharges','TotalCharges'] ob_col = 'Churn' df_pred=churn.copy() df_pred.loc[df_pred[ob_col]=='Yes', ob_col]=1 df_pred.loc[df_pred[ob_col]=='No', ob_col]=0 df_pred[ob_col]=df_pred[ob_col].astype(int) df_pred[cluster_name]=y_km X_tests, y_tests, y_preds, y_pred_probas, y_pred_proba_boths = [],[],[],[],[] for cluster_num in np.sort(df_pred[cluster_name].unique()): # 1つのクラスタのデータを抽出 df_n=df_pred[df_pred[cluster_name]==cluster_num].copy() # 学習データとテストデータ作成 X_train, y_train, X_test, y_test=createXy(df_n, exp_col, ob_col, test_size=0.3, random_state=0, stratify=True) # モデル作成 model, y_pred, y_pred_proba, y_pred_proba_both = xgb_model(X_train, y_train, X_test) # 評価指標計算 log_loss_, accuracy, precision, recall, auc_ = eval_list(y_test, y_pred, y_pred_proba, y_pred_proba_both) # データを空のリストに挿入 X_tests.append(X_test) y_tests.append(y_test) y_preds.append(y_pred) y_pred_probas.append(y_pred_proba) y_pred_proba_boths.append(y_pred_proba_both) # 混合行列 print_cmx(y_test.values, y_pred, save_name='confusion_matrix.png') # Recall-Precision曲線 threshold_pre_rec(y_test, y_pred_proba, save_name='threshold_pre_rec.png') # Pred Prob曲線 calib_curve(y_test,y_pred_proba, save_name='calib_curve.png') # 予測結果をmlflowに記録 mlflow.set_experiment('xgb_predict_cluster'+str(cluster_num))# 実験の名前を定義 with mlflow.start_run():# mlflow記録開始 mlflow.log_param("01_method_name", model.__class__.__name__) mlflow.log_param("02_features", exp_col) mlflow.log_param("03_objective_col", ob_col) mlflow.log_params(model.get_xgb_params()) mlflow.log_metrics({"01_accuracy": accuracy}) mlflow.log_metrics({"02_precision": precision}) mlflow.log_metrics({"03_recall": recall}) mlflow.log_metrics({"04_log_loss": log_loss_}) mlflow.log_metrics({"05_auc": auc_}) mlflow.log_artifact('ROC_curve.png') os.remove('ROC_curve.png') mlflow.log_artifact('confusion_matrix.png') os.remove('confusion_matrix.png') mlflow.log_artifact('threshold_pre_rec.png') os.remove('threshold_pre_rec.png') mlflow.log_artifact('calib_curve.png') os.remove('calib_curve.png') log_model(model, "model") # クラスタごとのデータをconcatして全データをまとめる y_pred_all=np.hstack((y_preds)) y_pred_proba_all=np.hstack((y_pred_probas)) y_pred_proba_both_all=np.concatenate(y_pred_proba_boths) y_tests_all=pd.concat(y_tests) # 評価指標計算 log_loss_, accuracy, precision, recall, auc_ = eval_list(y_tests_all.values, y_pred_all, y_pred_proba_all, y_pred_proba_both_all) # 混合行列 print_cmx(y_tests_all.values, y_pred_all, save_name='confusion_matrix.png') # Pred Prob曲線 calib_curve(y_tests_all, y_pred_proba_all, save_name='calib_curve.png') # 全データでの予測結果をmlflowに記録 mlflow.set_experiment('xgb_predict_all')# 実験の名前を定義 with mlflow.start_run():# mlflow記録開始 mlflow.log_param("01_method_name", model.__class__.__name__) mlflow.log_param("02_features", exp_col) mlflow.log_param("03_objective_col", ob_col) mlflow.log_params(model.get_xgb_params()) mlflow.log_metrics({"01_accuracy": accuracy}) mlflow.log_metrics({"02_precision": precision}) mlflow.log_metrics({"03_recall": recall}) mlflow.log_metrics({"04_log_loss": log_loss_}) mlflow.log_metrics({"05_auc": auc_}) mlflow.log_artifact('ROC_curve.png') os.remove('ROC_curve.png') mlflow.log_artifact('confusion_matrix.png') os.remove('confusion_matrix.png') mlflow.log_artifact('calib_curve.png') os.remove('calib_curve.png')上記のコードを実行すると、先ほどのクラスタごとにモデルが作られ、MLflowに記録される。
アルゴリズム名や、説明変数名、ハイパラの値、損失関数、様々な指標の分類精度、ROCカーブ、Calibrationカーブ、Recall, Precisionカーブ、混合行列などを記録できる。mlflowトップ画面
Parameters
Metrics
Artifacts
このように記録していくと、説明変数を変えたり、ハイパラ調整をしたり、アルゴリズムを変えたりした時などに、以前のモデルの結果と比較することが容易くなる。
おわりに
備忘録的なことも兼ねているが、MLflowの説明は一切せず、こんな感じで使えるよという活用方法をメインに示した。これから使おうかなと考えている人の活用イメージが湧くような内容になっていたら嬉しい。興味が湧いた人は他の記事などでも調べて使ってみることをオススメ。
おまけ
"mlruns"フォルダの中身
1をクリック
b3fa3eb983044a259e6cae4f149f32c8をクリック
artifactsをクリック
図が保存されている
mlflow uiで確認できるものはこのようにLocalに保存されている。
クラウドサービスと連携していろんな人とモデルの記録を共有することもできるみたい。
個人で使う分にはLocalで問題ないかな。以上!











- 投稿日:2020-08-17T18:54:51+09:00
日本語諸方言コーパスをDB化して遊ぶ (8) ファイル形式変換機能をつける
連載記事です。前回までに談話・話者ごとの発話総覧を作ったので、今回は最後の機能「サイト上での Excel と TextGrid の相互変換」を実装します。完全に自分用の作業メモで、説明もいろいろ足りていないと思いますが、ご容赦ください。
先述のとおり、今回は既に TextGrid と Excel を変換する Python スクリプトが存在しているので(内容には詳しく触れません)、これを Laravel アプリに組み込んでサーバー上で実行することを目指します。
- 第1回: 日本語諸方言コーパスをDB化して遊ぶ (1) 構成を考える
- 第2回: 日本語諸方言コーパスをDB化して遊ぶ (2) SQLite3 で DB 化
- 第3回: 日本語諸方言コーパスをDB化して遊ぶ (3) PHP Laravel で操作する
- 第4回: 日本語諸方言コーパスをDB化して遊ぶ (4) サービスの全体像を決める
- 第5回: 日本語諸方言コーパスをDB化して遊ぶ (5) データベースの移行とモデルの作成
- 第6回: 日本語諸方言コーパスをDB化して遊ぶ (6) 談話ごとの発話総覧を作る
- 第7回: 日本語諸方言コーパスをDB化して遊ぶ (7) 話者ごとの発話総覧を作る
- 第8回: 日本語諸方言コーパスをDB化して遊ぶ (8) ファイル形式変換機能をつける ←今ここ
- 第9回: 日本語諸方言コーパスをDB化して遊ぶ (9) Heroku でデプロイする
事前準備
今回はサーバー上のストレージにファイルを保存し、それを変換し、ダウンロードする仕組みを作るので、最初にそのあたりの設定をしておきます。アップロードしたファイルは
storageフォルダに保存されますが、一般公開されるのはpublicフォルダなので、慣例に従いpublic/storageからstorage/app/publicへシンボリックリンクを張ります。下記の artisan コマンドで勝手に貼ってくれます1。cmdphp artisan storage:link画面遷移図
画面遷移図を再掲します。1ページですけど。
コンポーネントのルーティング
コンポーネントがひとつしかないので、特に解説することはありません。
resources/js/app.js+ import ConvertComponent from "./components/ConvertComponent"; + { + path: "/convert", + name: "convert", + component: ConvertComponent + }コンポーネントの作成
1画面ではありますが、たくさん機能をつけるので前回までよりは複雑です。
resouces/js/components/ConvertComponent.vue<template> <div> <form enctype="multipart/form-data"> <input type="file" name="file" id="fileRef" style="display: none" @change="fileSelected" /> <div class="input-group"> <input type="text" id="fileShow" class="form-control" placeholder="select file..." readonly /> <div class="input-group-append"> <span class="input-group-btn"> <button type="button" class="btn btn-outline-success" onclick="fileRef.click()" > Browse </button> </span> <button type="button" class="btn btn-success" @click="fileUpload" > Upload </button> </div> </div> </form> <div class="pt-3"> <table class="table table-sm table-striped"> <thead> <tr class="thead-dark"> <th colspan="2"> <div class="text-center">ファイル一覧</div> </th> </tr> </thead> <tbody> <tr v-for="file of files" v-bind:key="file.name"> <td> <span class="pl-3">{{ file.replace("public/", "") }}</span> </td> <td> <div class="text-right"> <span class="btn btn-success btn-sm" @click="toTextgrid(file)" v-if="file.indexOf('.xls') != -1" > to TextGrid </span> <span class="btn btn-outline-success btn-sm disabled" v-else > to TextGrid </span> <span class="btn btn-success btn-sm" @click="toExcel(file)" v-if="file.indexOf('.txt') != -1 || file.indexOf('.TextGrid') != -1" > to Excel </span> <span class="btn btn-outline-success btn-sm disabled" v-else > to Excel </span> <a v-bind:href="'./storage' + file.replace('public', '')" v-bind:download="file.replace('public', '')" > <span class="btn btn-warning btn-sm"> download </span> </a> <span class="btn btn-danger btn-sm" @click="deleteFile(file)" > delete </span> </div> </td> </tr> </tbody> </table> </div> </div> </template> <script> export default { data: function() { return { files: [], uploadingFileInfo: "" }; }, methods: { fileSelected(event) { this.uploadingFileInfo = event.target.files[0]; fileShow.value = fileRef.value.replace("C:\\fakepath\\", ""); }, fileUpload() { if (this.uploadingFileInfo) { const formData = new FormData(); formData.append("file", this.uploadingFileInfo); axios.post("/api/toolkit/upload", formData).then(res => { fileRef.value = ""; fileShow.value = ""; this.uploadingFileInfo = ""; this.getFileList(); }); } else { alert("アップロードするファイルを選択してください"); } }, getFileList() { axios.get("/api/convert/files").then(res => { this.files = res.data; }); }, to_textgrid(path) { axios.post("/api/convert/toTextgrid", { filepath: path }).then(() => { this.getFileList(); }); }, to_excel(path) { axios.post("/api/convert/toExcel", { filepath: path }).then(() => { this.getFileList(); }); }, deleteFile(path) { axios.post("/api/convert/delete", { filepath: path }).then(() => { this.getFileList(); }); } }, mounted() { this.getFileList(); } }; </script>ファイル選択フォーム
fileフォームは bootstrap のみではあまりいい感じになりません。いくつか簡便な手法が考案されていますが、今回は以下のサイトを参考にしました。変換ボタン
[to TextGrid] や [to Excel] のボタンはファイルの拡張子によって切り替えて、適切な拡張子のときのみ、クリックで発火するようにしています。TextGrid とかいう形式があるせいで
mimetypeによる場合分けが使えないので、単純にファイル名に.txtや.TextGridなどの文字列が含まれるかどうかで場合分けしています2。場合分け自体はv-if・v-elseでパパっと。<!-- .txt/.TextGrid なら上の有効ボタンを表示する --> <span class="btn btn-success btn-sm" @click="toExcel(file)" v-if="file.indexOf('.txt') != -1 || file.indexOf('.TextGrid') != -1" > to Excel </span> <!-- そうでないなら下の無効ボタンを表示する --> <span class="btn btn-outline-success btn-sm disabled" v-else > to Excel </span>ダウンロードボタン
各種変換や削除はクリックで関数を実行するようにしていますが、ダウンロードだけはファイルに直接リンクを貼っています。Laravel のサーバーからファイルをダウンロードする方法はいくつかあるのですが、
Storageファサードやresponse()を使った手法はどうもうまくいかなかったので(数敗)3、直接リンクを貼る方法を採用しました。ファイルパスは後述のようなシンプルな方法で取得すると
/storage/app以下のパスを返す(=/public/filename.extのようなパスが返る)ので、適当に置換してシンボリックリンク先の(/public)/storage/filename.extに直接リンクを貼ります。downloadリンク<a v-bind:href="'./storage' + file.replace('public', '')" v-bind:download="file.replace('public', '')" > <span class="btn btn-warning btn-sm"> download </span> </a>コントローラへのルーティング
すべて
FileControllerに実装するので、関数名を適当に考えてルーティングをapi.phpに書いておきます。routes/api.php+ Route::get('/convert/files', 'FileController@getFileList'); + Route::post('/convert/upload', 'FileController@upload'); + Route::post('/convert/e_t', 'FileController@toTextgrid'); + Route::post('/convert/t_e', 'FileController@toExcel'); + Route::post('/convert/delete', 'FileController@deleteFile');コントローラの作成
先ほど使用することにした5つの機能を実装します。
<?php namespace App\Http\Controllers; use Illuminate\Http\Request; use Illuminate\Http\Response; use Illuminate\Support\Facades\Storage; class FileController extends Controller{ // ファイルをアップロードして保存する public function upload(Request $request){ $filename = $request->file('file')->getClientOriginalName(); $request->file('file')->storeAs('public/',$filename); } // Excel を TextGrid に変換して保存 public function toTextgrid(Request $request) { exec("which python", $pythonpath); $scriptpath = app_path('Python/excel_to_textgrid.py'); $filepath = storage_path('app/' . $request->input('filepath')); $command = $pythonpath[0] . ' ' . $scriptpath . ' ' . $filepath; exec($command); } // TextGrid を Excel に変換して保存;上とほぼ同じ public function toExcel(Request $request) { exec("which python", $pythonpath); $scriptpath = app_path('Python/textgrid_to_excel.py'); $filepath = storage_path('app/' . $request->input('filepath')); $command = $pythonpath[0] . ' ' . $scriptpath . ' ' . $filepath; exec($command); } // ファイルのリストを取得する public function getFileList(){ // true は .gitignore などの dotfile を除外する $files = Storage::allfiles('public/', true); // SplFileInfo 型は javascript 上で扱いにくいので、ファイルパス文字列にして返す(悪?) $filepaths = explode('#', implode('#', $files)); return $filepaths; } // ファイルを削除する public function deleteFile(Request $request){ $filepath = $request->input('filepath'); Storage::delete($filepath); } }Python スクリプトの実行
サーバーに Python がインストールされていさえすれば、PHP の
execコマンドで Python を動かすことができます。後述しますが、Heroku ビルド時に Python と使用するモジュールを忘れずにインストールしておきましょう。Heroku は Linux 系なので4、Linux コマンドを意識して書いていきます。今回はコンテナ仮想化などはせず Windows10 で開発しましたが、本記事で扱うのはちょっとしたものなので、大きな問題はありませんでした。
実行までの手順はシンプルです。今回使用するスクリプトは「対象ファイルのパスを与えると、そのファイルを変換して、同ディレクトリに保存する」ものですので、Python 実行ファイルのパス・スクリプトのパス・対象ファイルのパスを取得して、それをもとにコマンドを組み立てるだけです。今回、スクリプトは
/app/Python下に入れてあるので、app_pathなどのパスヘルパを使用して無難にパスを取得します(ヘルパを使わないとルートのずれに対して不安定になる)。<?php // Excel を TextGrid に変換して保存 public function toTextgrid(Request $request) { // 実行環境での python へのパスを取得 // Windows cmd なら exec("where python", $pythonpath); exec("which python", $pythonpath); // 実行したい python スクリプトのパスを取得 $scriptpath = app_path('Python/excel_to_textgrid.py'); // POST されてきた filepath を取得して適切な相対パスに変換 $filepath = storage_path('app/' . $request->input('filepath')); // コマンドを組み立てて実行 // 環境に複数バージョンの Python がある場合は index に注意 $command = $pythonpath[0] . ' ' . $scriptpath . ' ' . $filepath; exec($command); }なお、ここで使用したスクリプトは入力ファイルと同じディレクトリに出力ファイルを保存する設定になっています。
完成図
こんな感じになっているはずです。
/convert
改善点
既に言及したエラーハンドリングなどはもとより、セキュリティ上は
execが大きな問題です。一般にユーザーが改竄できるデータを PHP のexec関数にそのままぶち込むのは大変危険ですので、適切にエスケープする必要があります。今回はいちおう Laravel のパスヘルパを通しているので大丈夫じゃないかな、と思いますが、ヘルパの正確な挙動を把握していない限りは万全を期したほうがよいでしょう。次回
Heroku に上げていきます(最終回)。
後述しますが、ローカルで張ったシンボリックリンクが Heroku 上で勝手に張られることはないので、必要な命令を
composer.jsonに書き込んでおいて、ビルド時にシンボリックリンクが張られるようにしておく必要があります。 ↩ほんとうはこんなフロントエンドのなんちゃって検証ではなく、サーバ側でちゃんと入力ファイルを検証しないとダメ。 ↩
パス解決に失敗したり、403エラーが出たり、POSTレスポンスにファイル内容は積まれてくるけどダウンロードまで行けなかったりしました。 ↩
Heroku では Dyno という、Amazon EC2 の巨大インスタンス上で動作する軽量 Linux コンテナが使われています。 ↩


- 投稿日:2020-08-17T18:47:49+09:00
日本語諸方言コーパスをDB化して遊ぶ (4) サービスの全体像を決める
連載記事です。第4回は前回お試しで作成した Laravel アプリを いったん反故にして 、サービスの全体像を決めて、ルーティングを作るところまで。完全に自分用の作業メモで、説明もいろいろ足りていないと思いますが、ご容赦ください。
- 第1回: 日本語諸方言コーパスをDB化して遊ぶ (1) 構成を考える
- 第2回: 日本語諸方言コーパスをDB化して遊ぶ (2) SQLite3 で DB 化
- 第3回: 日本語諸方言コーパスをDB化して遊ぶ (3) PHP Laravel で操作する
- 第4回: 日本語諸方言コーパスをDB化して遊ぶ (4) サービスの全体像を決める ←今ここ
- 第5回: 日本語諸方言コーパスをDB化して遊ぶ (5) データベースの移行とモデルの作成
- 第6回: 日本語諸方言コーパスをDB化して遊ぶ (6) 談話ごとの発話総覧を作る
- 第7回: 日本語諸方言コーパスをDB化して遊ぶ (7) 話者ごとの発話総覧を作る
- 第8回: 日本語諸方言コーパスをDB化して遊ぶ (8) ファイル形式変換機能をつける
- 第9回: 日本語諸方言コーパスをDB化して遊ぶ (9) Heroku でデプロイする
実現したい機能
COJADS は現在、コーパス検索アプリケーション「中納言」にてモニター版が利用可能ですので、これとは機能的に差別化したいところです。
「談話/話者」ごとの発話総覧
「中納言」版では検索機能をメインに据えており、テキストデータを「談話」や「話者」といったまとまりでは提供していません。また、前述のとおり COJADS の公式サイトで提供されている生データは「談話」を軸に全結合してあり、取り回しが不便です。したがって、これをエンティティごとに分離して、サイト上で閲覧できるようにする、たとえば「談話」だけでなく「話者」ごとに発話を総覧できる機能を提供することには、一定の価値があると考えられます。
「発話」の編集
わざわざ SQL を書くことなく、サイト上からデータベースを操作し、発話を編集する機能をつけます。ログもとります1。そこまで必要性は感じられませんが、データベースの勉強がてら実装したいと思います。
Excel と TextGrid の相互変換
COJADS では音声・方言テキスト・標準語テキストが発話を単位に紐づけられていますが、公式サイトでは CSV 形式の生データのみが配布されており、音声データや TextGrid 形式(音声分析ソフト Praat 専用形式)のテキストデータは配布されていません。音声と直接紐づいているのは TextGrid ファイルであり、CSV と音声ファイルがあったところでうまく対応を観察することができません。
また TextGrid がいずれ配布されたとしても、CSV データを各自で編集してしまうと対応が崩れてしまい、音声分析が困難になります。そこで Excel ファイルと TextGrid ファイルを相互変換する機能をつけたいと思います。
既に手元に Excel と TextGrid を相互変換する Python スクリプトがありましたので、これを最大限に活かすべく、
- ファイルをアップロードして
- サーバー上で Python スクリプトにかけて変換して
- それをダウンロードする
という仕組みにします。
使用技術
AWS を利用するほどでもないので、今回は Heroku のフリープランを利用して完全無料で上記の機能を実装します。ウェブフレームワークとしては前述のとおり PHP Laravel を使用します。また Heroku は本番環境で SQLite が使えないので2、データベースとしては Heroku PostgreSQL のフリープランを利用します。
Heroku は非常に簡便に利用開始できるサービスですが、その分ビルド後に root 権限が使えなかったり、特にフリープランでは制限されている部分も多く、初心者には難しい点がいくつかありましたので、そこらへんは第9回に説明を試みます。
また、せっかくなので SPA (Single Page Application) 化します。SPA を実現するフレームワークはいくつかありますが、今回は学習コストの低そうな Vue Router を採用します。下記のチュートリアルが大いに参考になりました。
画面遷移図
必要となるページを数え上げて、簡単な画面遷移図を作ります。Qiita で表示しても不快にならないよう、いくつかに分けて描いてみます。
エレガントではないですが、アイコニックで分かりやすく作画コストも低いので draw.io を使用しました。
「談話」ごとの発話総覧と編集機能は以下のようにしましょう。「談話」テーブルには非常に多くの情報が含まれている(ファイル記号、データ名、収録年月日、収録場所、収録担当者、編集担当者、話題、談話ジャンル)ため、これをすべて一画面に表示すると邪魔になります。そこで「談話一覧」ページには、データの性質に影響を与えない要素(収録担当者、編集担当者など)は表示しないようにして、「発話詳細」ページでだけ確認できるようにします。また、「発話編集」ページで更新処理を行なったら「発話詳細」ページに遷移させます。
「話者」ごとの発話総覧は、単純に発話をまとめるだけではつまらないので、簡単な文字列処理を噛ませて、発話ごとではなく文ごとに提示するようにしましょう。
ファイル変換画面は、とりあえずアップロードして、変換して、ダウンロードして、削除できればよいので、素朴なのを用意しておきます。
プロジェクトの準備
では作成していきましょう。まずは Laravel プロジェクトを作っていきます。やることは基本的に上記参考サイトと同じで、適当なフォルダで
composerにプロジェクトを作ってもらい、必要なパッケージ等を Laravel (php artisan) やnpmの助けを借りて導入していきます。composer create-project laravel/laravel --prefer-dist cojads composer require laravel/ui php artisan ui vue npm install npm install --save vue-routerこれからプロジェクトの内実を作っていきますが、ガワ(ルーティングやテンプレート)から作り始めて、内実(コンポーネントやコントローラ)はあとで作りこむ、という手順を貫きます。
SPA のテンプレート作成
今回は SPA を作るので、ガワ(テンプレート)として唯一のページ
app.blade.phpを作成します。Laravel プロジェクトではウェブサイトとして通常アクセスした際のルーティングがweb.phpで規定されるので、まずここを編集して任意のパスをapp.blade.phpにルーティングします。ただし今回のサービスはあとで/storageに直接アクセスする必要が出てくるので、/storage以下にだけは特別なルーティングをかけないようにしておきます。routes/web.php<?php use Illuminate\Support\Facades\Route; Route::get('/{any}', function() { return view('app'); })->where('any', '^(?!storage).*');そうしたら SPA のガワ
app.blade.phpを作ります。Vue Router の処理で<header-component>位置にヘッダーが、<footer-component>位置にフッターが、<router-view>位置に各ページの内容が読み込まれるようになっています。bootstrap で固定ヘッダーを作る関係で、
<rooter-view>の上下に適当に余白を設けています(汚い)。resources/views/app.blade.php<!doctype html> <html lang="{{ str_replace('_', '-', app()->getLocale()) }}"> <head> <base href="/" /> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1"> <meta name="robots" content="noindex"> <meta name="csrf-token" content="{{ csrf_token() }}"> <title>{{ config('app.name', 'COJADS App') }}</title> <link href="{{ mix('/css/app.css') }}" rel="stylesheet"> </head> <body> <div id="app"> <header-component></header-component> <div class="px-5 py-5"><div class="py-3"> <router-view></router-view> </div></div> <footer-component></footer-component> </div> <script src="{{ mix('/js/app.js') }}" defer></script> </body> </html>コンポーネントのルーティング
続いてテンプレートに挿入されるコンポーネントのルーティングを行ないます。コンポーネントの登録とそのルーティングは
app.jsで管理されているので、ここを編集します。以下ではヘッダー・フッター・表紙ページ・談話一覧ページの要素を読み込んで適切なルーティングを行なっています。resources/js/app.jsimport VueRouter from "vue-router"; // register components import HeaderComponent from "./components/HeaderComponent"; import FooterComponent from "./components/FooterComponent"; import HomeComponent from "./components/HomeComponent"; import DiscourseIndexComponent from "./components/DiscourseIndexComponent"; require("./bootstrap"); window.Vue = require("vue"); Vue.use(VueRouter); // routing const router = new VueRouter({ mode: "history", routes: [ { // ルートにアクセスすると HomeComponent をロードする path: "/", name: "home", component: HomeComponent }, { // /discourse にアクセスすると DiscourseIndexComponent をロードする path: "/discourse", name: "discourse.index", component: DiscourseIndexComponent } ] }); // ヘッダー・フッター用のカスタムエレメントを定義して、コンポーネントを読み込む Vue.component("header-component", HeaderComponent); Vue.component("footer-component", FooterComponent); const app = new Vue({ el: "#app", router });各コンポーネントの作成
ルーティングの構想ができたらページの内容を作っていきます。先ほど
app.jsで使用することにした4つのコンポーネント(.vueファイル)を/resources/js/components下に作成します(discourseは次回)。以下のファイルを作成する+ resources/js/components/HeaderComponent.vue + resources/js/components/FooterComponent.vue + resources/js/components/HomeComponent.vue + resources/js/components/DiscourseIndexComponent.vueヘッダー
bootstrap でページ上部に固定するタイプのヘッダーを作ります。先取りになりますが、ヘッダーには
<router-link>で各コンポーネントへのリンクを張っておきましょう。とはいえ、まだリンク先を用意していないので、この段階でコンパイルするなら適当にコメントアウトする必要があります。resources/js/components/HeaderComponent.vue<template> <header class="navbar fixed-top navbar-dark bg-dark"> <span class="navbar-brand mb-0 h1">COJADS APP</span> <div> <span> <router-link v-bind:to="{ name: 'home' }"> <button class="btn btn-success btn-sm">Top Page</button> </router-link> <router-link v-bind:to="{ name: 'discourse.index' }"> <button class="btn btn-success btn-sm">Discourse List</button> </router-link> <router-link v-bind:to="{ name: 'speaker.index' }"> <button class="btn btn-success btn-sm">Speaker List</button> </router-link> <router-link v-bind:to="{ name: 'convert' }"> <button class="btn btn-success btn-sm">Toolkits</button> </router-link> </span> </div> </header> </template> <script> export default {}; </script>フッター
フッターも適当に作ります。
resources/js/components/FooterComponent.vue<template> <footer class="navbar fixed-bottom navbar-dark bg-dark"> <span class="navbar-brand mb-0 h1">(c) 2020 @a_eau_</span> </footer> </template> <script> export default {}; </script>ホーム画面
特に書くこともないので、最小限だけ作ります。
resources/js/components/HomeComponent.vue<template> <div> Welcome to COJADS App! </div> </template> <script> export default {}; </script>コンパイル・ローカルサーバで確認
以上のコードを書き終えたら、一度コンパイルして確認しましょう。以下のコマンドを実行すると、もろもろの必要なものを取り込んでいい感じにコンパイルしてくれます。
cmdnpm run dev あるいは npm run productionコンパイルが済んだら Laravel の以下コマンドでローカルサーバを立ち上げて、
localhost:8000にアクセスしてみましょう。404 や 500 エラーが出ずに想定通りのページが表示されれば成功です。cmdphp artisan serve次回
Heroku で SQLite が使えないことを知って PostgreSQL に乗り換える回です。



- 投稿日:2020-08-17T18:05:02+09:00
Pythonの特徴について
Pythonで出来ること
自身がPythonを学ぶ上で出来ることをまとめてみました。
AI
PythonはAI・機械学習の開発に使えるライブラリがたくさん揃っており、その開発が現在進行系で進んでいる。AIや機械学習は数学的処理の塊です。行列計算や統計処理など山のように用いられます。それらを逐一実装していると時間がいくらあっても足りません。ライブラリが整っているおかげで効率よく学習でき、Pythonであれば効率よく開発ができます。AIや機械学習のプログラミングをする際は、すべての計算を自分で書くわけではない。特に教育現場でのロボット制御が有名で、レゴのマインドストリーム EV3もPythonを使って制御することが可能です。
予測モデルを作成し、価格予測を行ったり、株式や債券などのポートフォリオ最適によって、投資リスクを最小にしてリターンを最大にする銘柄の算出なども行えます。Webサイト作成
Pythonはシステム寄りの言語と思われがちですが、Webサイトを作成することが可能です。
素のHTML/CSSを使うよりもはるかに高機能かつ保守性の高いサイトを作れます。
DjangoやFlaskといったフレームワークを利用することで効率的に開発することが可能です。ただし、WebアプリケーションにおいてはHTML/CSS、
Javascriptなど他の技術と組み合わせて利用することが一般的です。Web上の情報収集ツールの作成
クローリング、スクレイピングという技術を使って、例えば自身が気になる情報を自動定期的に収集するなどの操作がPythonは可能です。
有名な技術としてSeeniumというライブラリがあり、これを用いることで情報収集やブラウザ操作やテキスト入力が可能になります。自分が定期的にチェックしているWebサイトのデータを取ることで、手動でアクセスする手間が省けます。Webサイトの更新を自動的にチェックしたり、定期的に価格情報を取得して保存するなどの行動も可能なので、競合サイトのチェック作業を短縮することができます。
[YouTube][Instagram]にもPythonが使用されています。データ処理・分析・解析
Pythonの強みとして、数値計算能力と連携可能なシステムの多さが挙げられます。
大量にあるデータベースのデータを内部計算して読みやすい行列表に計算したり、競馬や株価の予測プログラムや自動取引アルゴリズムが作成できたり、別アプリにコピーしたりする柔軟なデータ処理が可能です。
Excelはデータの整理やグラフ化を行うためのツールですが、同じ処理を毎日のように行うのは大変な作業です。ExcelにはVBAと呼ばれるプログラミング言語が用意されていますが、活用範囲が限定的なことから他の言語学習に時間を割く方は多い、Pythonを使用すればExcel操作の自動化を実施できます、一度プログラムを作成すればデータの集計・削除・統合やグラフなどを自動化できるようになります。スマホアプリ制作
Pythonのみを用いて、iOS/Android両方に対応したスマホアプリを作ることができます。
Kivyなどのマルチプラットフォームを使うとPythonでiPhone用のアプリやAndroid用のアプリを開発することも可能です。
SwiftやJavaなどのネイティブ言語と違い使用できない機能の制限もありますが、複数のライブラリが存在しています。ゲーム制作
Pythonでゲームを実装すると言ったら、まず名前が挙がるのがこのPYgameです。
Pygameを活用すれば、Pythonだけでゲーム開発ができます。Pygameに慣れれば手軽にPythonの機械学習アプリのデモを作ることもできるようになります
Pythonを使うと、2Dのレトロゲームから3Dのゲーム開発まで可能となります。
ゲーム開発といえばUnityですが、ゲームエンジンを使うとPythonでも本格的なゲームを作成することができます。 ディズニー社でも使われた実績があります。
実用的なUnityなどのフレームワークに比べると導入している企業は少ないです。Pythonの特徴
文法はやさしく、初心者にも学びやすく、コードが読みやすいことから、学校などでのプログラミング教育用にも使われています。
シンプルな必要最低限のコードで多くの処理ができます。
強力な標準ライブラリやフレームワークと充実した外部ライブラリ
Pythonでは多くのタスクをサポートするライブラリやフレームワークが豊富にあります。 また、AI分野を主とする外部ライブラリが充実しているため、これらをふんだんに活用することにより、生産性の高い開発が可能になります。様々なハードウェアとOSに対応できる移植性の高さ
Windows、Mac、Linux、PlayStationなどに対応することができ、どの機種・OSにおいてもPythonで作ったプログラムは同じ動きをします。
- 投稿日:2020-08-17T18:01:06+09:00
プログラミング言語を学ぶ時には、はじめにプログラミング言語の家系図を見ておくとよいよ、という話
プログラミミング言語の家系図ってなに
あるプログラミングがいつ、どのような言語に影響を受けて誕生したかを表す系譜のことです。
プログラミミング言語の家系図はここにある
プログラミング家系図を載せているサイトはいくつかあるのですが、今回はこちらのサイトを紹介します。
diagram & history of programming languages (プログラミング言語の系譜)
主要言語のみものと、150以上の言語を載せているバージョンの2種類が記載されています。
2020年8月時点で、2018年の分まで記載されています。いくつかの言語をピックアップ
主要言語の図から、いくつかの言語をピックアップしてみましょう。
C言語(K&R)
- 誕生: 1978年
- 影響を受けた言語: Algol 60
- 影響を与えた言語: C++, Python (他、子孫多数)
注)
C言語の誕生は1972年であるが、リンク先の図では、『プログラミング言語C』(原題:The C Programming Language、通称 K&R)が出版された年を採用している。(参考: C言語 - Wikipedia, プログラミング言語C - Wikipedia)Python
- 誕生: 1991年
- 影響を受けた言語: C, C++, Pascal
- 影響を与えた言語: Ruby
Ruby
- 誕生: 1995年
- 影響を受けた言語: Perl, Eiffel, Python
- 影響を与えた言語: Swift
Java
- 誕生: 1995年
- 影響を受けた言語: C++
- 影響を与えた言語: JavaScript, C#, Kotlin
JavaScript
- 誕生: 1995年
- 影響を受けた言語: Java
- 影響を与えた言語: Kotlin
プログラミング言語(2言語目以降)を学ぶ時には、はじめにプログラミング言語の家系図を見ておくとよいよ
さて表題の件ですが、2言語目以降のプログラミング言語を学ぶときにはこの家系図を最初に確認することをおすすめします。
理由は
- 自分がすでに知っているプログラミング言語と、新しく学ぶ言語がどのくらい離れているかによって習得難易度を把握することができるから
- 自分がすでに知っているプログラミング言語より新しい場合、新しくて便利な構文があることを期待しながら学習を進められるから
- 自分がすでに知っているプログラミング言語より古い場合、便利な機能がないことを覚悟しながら学習を進めることができるから
です。
自分の場合は、Java歴5年、Perlはバッチ程度ならで少し書ける程度のときに、Rubyを習得しようとしました。
そのときに、RubyはPerlから影響を受けていることを知ったので構文の理解に役立ちました。
一方、関数型言語の知識はほぼ無かったのでその部分は苦労しましたが、そのことを事前に予測できたのはよかったと思います。あとがき
『はじめてのRuby』(著: Yugui) にRubyに関係する部分のプログラミング言語家系図が記載されていました。この図はRubyの理解に大変役に立ちました。
ほかの言語の図も探していたところリンク先のものが見つかりました。
プログラミング言語はここ数十年で大幅に進化しているのだなあ。

- 投稿日:2020-08-17T17:59:37+09:00
Python初心者によるDjango超入門!その4 超シンプルな日記アプリケーションを作ってみた(クラスベース汎用ビューを利用しないで関数のみで作成)
本記事について
UdemyでDjangoについて学習した結果のアウトプットページです。
前の記事はこちらです。今回は、Djangoで超シンプルな日記アプリケーションを作成したいと思います。
また、今回はDjangoの動作について理解を深めるためにクラスベース汎用ビューを利用せず、関数のみで作ります。成果物
トップページ
詳細ページ
更新ページ
削除ページ
事前準備
まずは環境構築から。
Secondというプロジェクトを作成し、diaryというDjangoアプリを作成します。
プロジェクト名は任意ですが、可能なら半角英数字のみにしておいた方が無難です。
アンダーバーや空白スペースがプロジェクト名にあると後述の手順で謎のエラーが発生することがあります。django-admin startproject Second cd diary_project py .\manage.py startapp diarysettings.pyにdiaryアプリを登録して、日本時間をセット
Second\Second\sattings.pyINSTALLED_APPS = [ 'diary', 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ] LANGUAGE_CODE = 'ja' TIME_ZONE = 'Asia/Tokyo'models.py
今回はDjangoのDBにデータを登録する処理が発生するので、models.pyでDBにどんなデータを入れるのか定義します。
逆に言うと、models.pyを見れば、DjangoのDBにどんなデータフィールドが用意されているのか分かるということです。
また、models.pyで明示的に主キーを設定しなかった場合、idという主キーが自動でセットされます。Second\Second\models.pyfrom django.db import models from django.utils import timezone class Day(models.Model): #ここで宣言はしていないけど、idという主キーが自動で登録されている title = models.CharField('タイトル', max_length=200) text = models.TextField('本文') date = models.DateField('日付', default=timezone.now)models.pyの入力が終わったら、manage.pyでDBに登録します。
manage.pyが保存されているフォルダに移動して、以下のコマンドで登録してください。py .\manage.py makemigrations py .\manage.py migratemakemigrations実行時に、RecursionErrorが表示されることがあります。
RecursionError: maximum recursion depth exceeded while calling a Python objectエラーの原因の1つとして、プロジェクト名に半角英数字以外の文字があったり、
パスの中に空白スペースが含まれている場合に発生することがあります。
OneDirveなどの特殊なフォルダに保存していると空白スペースがパスに含まれることがありますので、注意してください。urls.py
プロジェクト直下にあるurls.pyで、アプリ直下にあるurls.pyに行くように設定します。
Second\Second\urls.pyfrom django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('diary/', include('diary.urls')), ]アプリ直下にあるurls.pyを以下のように記入。
Second\diary\urls.pyfrom django.urls import path from . import views app_name = 'diary' urlpatterns = [ path('', views.index, name='index'), #一覧ページ path('add/', views.add, name='add'), #追加ページ path('update/<int:pk>/', views.update, name='update'), #更新ページ path('delete/<int:pk>', views.delete, name='delete'), #削除ページ path('detail/<int:pk>', views.detail, name='detail'), #詳細ページ ]アプリ直下のurls.pyにはURLを登録。
今回は一覧、追加、更新、削除、詳細の5ページを作成します。
<int:pk>というのは、それぞれの記事に紐づいている主キーという意味です。models.pyの説明時にidという主キーが自動登録されていると書きましたが、
Djangoではそのidをpkという変数で表現することが慣例となっています。
<int:id>と表現しても良いのですが、<int:pk>としておきましょう。例えば、pkが1の詳細ページにアクセスする場合は、
diary/detail/1/になります。
特定の記事に紐づいていない、一覧ページや追加ページには不要です。forms.py
views.pyの作成の前に、forms.pyというファイルを新規に作成します。
views.pyと同じフォルダ(Second\diary)にforms.pyというファイルを作成し、
内容を以下のようにしてください。Second\diary\forms.pyfrom django import forms from .models import Day class DayCreateForm(forms.ModelForm): class Meta: model = Day fields = '__all__'記事を作成したり、更新したりする場合、当然ですがHTMLファイルに入力欄が必要になります。
その入力欄を作成するにあたり、HTMLファイルにFormというものを構成する必要があります。そのFormに対して、どんなデータを渡すのかを定義するのがこのforms.pyです。
今回はmodels.pyで定義されているDayクラスの全てのデータを渡すことにしましょう。
全てを渡す場合はfields = '__all__'としてください。DayCreateFormというクラス名は任意ですが、
その中にあるMetaというクラスは定型文です。
変更しないようにしましょう。views.py
views.pyに一覧、追加、更新、削除、詳細のページを表示するための関数を作成します。
本来であれば、クラスベース汎用ビューというDjangoの神機能を使うことで簡単に書けるのですが、
今回の記事は関数で書いてみようというものなので、あえて関数で書きます。Second\diary\views.pyfrom django.shortcuts import render, redirect, get_object_or_404 from .forms import DayCreateForm from .models import Day def index(request): """ 日記の一覧を表示 """ context = { 'day_list':Day.objects.all(), } return render(request, 'diary/day_index.html', context) def add(request): """ 日記の記事を追加 """ # 送信内容を元にフォームを作る。POSTじゃなければ空のフォームを作成。 form = DayCreateForm(request.POST or None) # method==POSTとは送信ボタンが押されたとき。form.is_validは入力内容に問題が無い場合Trueになる。 if request.method == 'POST' and form.is_valid(): form.save() return redirect('diary:index') # 通常時のアクセスや入力内容に誤りがあれば、再度day_form.htmlを表示 context = { 'form':form } return render(request, 'diary/day_form.html', context) def update(request, pk): """ 日記の記事を変更 """ # urlのpkを基に、Dayを取得(pkはidと同じ) day = get_object_or_404(Day, pk=pk) # formに取得したDayを紐づける form = DayCreateForm(request.POST or None, instance=day) # method=POST(送信ボタン押下)、でかつ、入力内容に問題がなければフォームを保存する。 if request.method == 'POST' and form.is_valid(): form.save() return redirect('diary:index') # 通常時のアクセスや入力内容に問題があった場合は最初のページを表示 context = { 'form':form } return render(request, 'diary/day_form.html', context) def delete(request, pk): """ 日記の記事を削除 """ # URLのPKを基に、Dayを取得(pkはidと同じ) day = get_object_or_404(Day, pk=pk) # method=POST(送信ボタン押下) if request.method == 'POST': day.delete() return redirect('diary:index') # 通常時のアクセス。または問題があった場合のアクセス。 context = { 'day':day } return render(request, 'diary/day_delete.html', context) def detail(request, pk): """ 日記の詳細ページ """ # URLのPKを基に、Dayを取得 day = get_object_or_404(Day, pk=pk) context = { 'day':day } return render(request, 'diary/day_detail.html', context)
def index(request):は記事の一覧を表示するための関数です。
models.pyにあるDayクラスの全てのデータを、contextに代入します。
render関数を使って、day_index.htmlに作成したcontextを渡しています。
def add(request):は記事を新規作成するための関数です。
form = DayCreateForm(request.POST or None)で送信内容を元にフォームを作ります。送信前の状態だと、空のフォームになります。
if request.method == 'POST' and form.is_valid():は、送信ボタンが押され、かつ、内容に問題が無い場合の処理です。
問題が無いので、form.save()で保存して、index.htmlのページにリダイレクトします。
通常時のアクセスの場合や入力に誤りがあった場合は、render関数でday_form.htmlにcontextを渡します。
def update(request, pk):は記事の内容を変更するための関数です。
このupdateページを表示する場合、URLはdiary/update/<記事のpk>になります。
更新対象となる記事の主キーが必要になるので、pkを引数に渡します。
URLで受け取ったpkをDayクラスに紐づけて記事の内容を以下のコードで取得します。
day = get_object_or_404(Day, pk=pk)
後の処理はadd関数と同じ流れです。
def delete(request, pk):は記事を削除するための関数です。
ほとんどupdateと同じ処理ですが、削除なのでformを操作する必要が無いので、作成しません。
day.delete()で記事を削除し、index.htmlへリダイレクトします。
def detail(request, pk):は記事の詳細ページを表示するための関数です。
formも作成する必要が無いのでシンプルです。htmlファイルの作成
最後にhtmlファイルを作成します。
diaryフォルダの下にtemplatesフォルダを作成し、更にdiaryフォルダを作成します。
※<プロジェクト名>/<アプリ名>/templates/<アプリ名>と覚えると楽です。base.htmlの作成
まずbase.htmlを作成します。
すべての大本となるhtmlファイルです。
※CSSやJavaScriptはBootstrapを利用しています。nav部分で一覧ページと記事の新規作成をリンクしておきます。
リンクは{% url '<アプリ名>:<urls.pyで定義したnameの値>'%}でリンクしましょう。Second\diary\templates\diary\base.html<!doctype html> <html lang="ja"> <head> <title>日記アプリケーション</title> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0-beta.2/css/bootstrap.min.css" integrity="sha384-PsH8R72JQ3SOdhVi3uxftmaW6Vc51MKb0q5P2rRUpPvrszuE4W1povHYgTpBfshb" crossorigin="anonymous"> </head> <body> <div class="container"> <nav class="nav"> <a class="nav-link active" href="{% url 'diary:index' %}">一覧</a> <a class="nav-link" href="{% url 'diary:add' %}">追加</a> </nav> {% block content %} {% endblock %} </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.2.1.slim.min.js" integrity="sha384-KJ3o2DKtIkvYIK3UENzmM7KCkRr/rE9/Qpg6aAZGJwFDMVNA/GpGFF93hXpG5KkN" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.12.3/umd/popper.min.js" integrity="sha384-vFJXuSJphROIrBnz7yo7oB41mKfc8JzQZiCq4NCceLEaO4IHwicKwpJf9c9IpFgh" crossorigin="anonymous"></script> <script src="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0-beta.2/js/bootstrap.min.js" integrity="sha384-alpBpkh1PFOepccYVYDB4do5UnbKysX5WZXm3XxPqe5iKTfUKjNkCk9SaVuEZflJ" crossorigin="anonymous"></script> </body> </html>day_index.htmlの作成
記事の一覧ページです。
views.pyから、day_listがKeyのcontextを渡されているので、
day_listを使ってDBに保存されている記事のタイトルと日付にアクセスできます。
これをfor文を使って表示させています。updateとdeleteにはday.pkを渡して、それぞれの記事の更新ページへアクセスする仕組みです。
Second\diary\templates\diary\day_index.html{% extends 'diary/base.html' %} {% block content %} <h1>日記一覧</h1> <table class="table"> <thead> <tr> <th>タイトル</th> <th>日付</th> <th>更新処理</th> <th>削除処理</th> </tr> </thead> <tbody> {% for day in day_list %} <tr> <td><a href="{% url 'diary:detail' day.pk %}">{{ day.title }}</a></td> <td>{{ day.date }}</td> <td><a href="{% url 'diary:update' day.pk %}">更新</a></td> <td><a href="{% url 'diary:delete' day.pk %}">削除</a></td> </tr> {% endfor %} </tbody> </table> {% endblock %}day_detail.htmlの作成
詳細ページです。
title、text、dateを表示しています。
textの後に、linebreaksbrと付け足しているのは、
HTML上で改行を表現するためです。無くても問題はありません。Second\diary\templates\diary\day_detail.html.html{% extends 'diary/base.html' %} {% block content %} <table class="table"> <tr> <th>タイトル</th> <td>{{ day.title }}</td> </tr> <tr> <th>本文</th> <td>{{ day.text | linebreaksbr}}</td> </tr> <tr> <th>日付</th> <td>{{ day.date }}</td> </tr> </table> <a href="{% url 'diary:update' day.pk %}"><button class="btn btn-primary">更新</button></a> <a href="{% url 'diary:delete' day.pk %}"><button class="btn btn-danger">削除</button></a> {% endblock %}day_form.htmlの作成
フォームの作成です。
記事の作成・更新で利用します。Second\diary\templates\diary\day_form.html{% extends 'diary/base.html' %} {% block content %} <form action="" method="POST"> <table class="tabel"> <tr> <th>タイトル</th> <td>{{ form.title }}</td> </tr> <tr> <th>本文</th> <td>{{ form.text }}</td> </tr> <tr> <th>日付</th> <td>{{ form.date }}</td> </tr> </table> <button type="submit" class="btn btn-primary">送信</button> {% csrf_token %} </form> {% endblock %}day_delete.htmlの作成
似たような内容が続きますが、これで最後です。
最後は削除ページです。Second\diary\templates\diary\day_delete.html{% extends 'diary/base.html' %} {% block content %} <form action="" method="POST"> <table class="table"> <tr> <th>タイトル</th> <td>{{ day.title }}</td> </tr> <tr> <th>本文</th> <td>{{ day.text }}</td> </tr> <tr> <th>日付</th> <td>{{ day.date }}</td> </tr> </table> <p>こちらのデータを削除します。</p> <button type="submit" class="btn btn-primary">削除</button> {% csrf_token %} </form> {% endblock %}動作確認
あとはpy manage.py runserverで動作確認しましょう。
記事の作成・更新・削除が出来たら成功です。


- 投稿日:2020-08-17T17:34:43+09:00
AIやるうえで知っといた方がよい線形代数の知識
※すいませんが数式(一部の行列)の表示がおかしくなり修正方法を調べ中のため、一旦、画像でどんと掲載します^^;

- 投稿日:2020-08-17T17:11:49+09:00
暇なので『RPAツール』を作る #4 selenium編 テキストの取得
はじめに
皆さん、今回は早めに投稿できたと思っています。enp(えん)です。恋愛がしたいです。
この記事は『RPAツール』を作ろうとする人の進捗報告になります。
RPAやRPAツールの作り方が書いてあるものではございませんので、ご了承ください。(もしかしたら、ソースは少しだけ載せるかもしれません。気分次第です)
今回はseleniumと仲良くなろうPart.2です。やったこととしては『住所から郵便番号への変換』と『郵便番号から住所への変換』です。
また長い記事になってしまいますが、お付き合いいただければ幸いです。僕はテキストを取得したいだけなんですッ!!
はい。タイトルそのまんまです。
ブログに書いてある文字やウィキペディアに記載されている文字などを取得したい。今回の記事はそれだけです。
じゃあ、なんで住所から郵便番号取得しようとしてんの? ってなりますよね。
それは仕事で必要なインターネット上の情報を僕の偏見と独断で考えた結果、郵便番号だったからです。
仕事内容によって他にインターネットで必要な情報はあると思います。
ですが、仕事内容関係なく郵便番号って調べそうだと思いました。あくまで私の偏見です。
また、扱うテキスト多そうという単純な理由も含みます。
じゃあ、なんで郵便番号から住所を取得しようとしてんの? 住所から郵便番号分かればいいじゃん。そうです。
しかし、逆の機能がないと不便かもしれないじゃないですか。あと、なんか逆の機能がないと落ち着きませんでした。
という訳で今回は『住所から郵便番号への変換』と『郵便番号から住所への変換』という二つの機能を実装しました。(はっきり言って、探せば住所や郵便番号を扱うライブラリはあると思います。しかし、今回はselenium学習のために実装するのでライブラリで住所を探す等の行為は行いません。seleniumで実装していきます)
まずはサイトの仕様を知ろう
サイトの仕様が分からなければ実装の仕様がありません。なので郵便番号検索等について学びましょう。
まずは郵便番号から住所の検索についてです。
上記は郵便番号検索の検索バーです。まぁ、テキストボックスに郵便番号いれてボタンを押せば終了ですよね。分かりやすい。
では、検索した後はどうでしょう?
こんな感じに表示されます。表の中から住所を抜き出せば取得できそうですね。次に住所から郵便番号の検索です。
さて、ここで気になるのが都道府県の選択です。選択をseleniumで実装するのは少し骨が折れそうなイメージ。
しかし、日本郵便局は大変親切です。市区町村などを入力する欄に必要な住所全て入れても検索可能なのです。
有難い。今年は年賀状を出すか検討することにしましょう。送る人はいませんが。
検索後は以下のようになります。
郵便番号は記載されていませんね。町域にある住所をクリックした場合はどうなるのでしょうか?
上記のようになります。ここでようやく郵便番号が出てきます。住所から郵便番号への変換の方がひと手間増えますね。以上がサイトの仕様です。
(『検索後、他に候補がない』ことを前提として実装していきます。郵便番号で検索した場合、郵便番号が対応している住所は一つに定まるはずです。また、一部を除き住所検索でも曖昧検索をしなければ一つに定まるはずです。曖昧検索をする場合、『ユーザーが選択する前提』で検索を行っているので『自動化』ではないと思います。そのため、曖昧検索には対応しないことにしました)
要素取得の限界
じゃあ、早速実装していきましょう! と言いたいところですが、ここで問題が発生しました。
今までは要素の属性名を使ってテキストボックスに文字を入力したり、ボタンをクリックしたりしてきました。
(要素とはdivやinput、属性はclassやidのことを指します)
では、属性名が複数の要素で使われていたらどうなるでしょうか?
例えばclassにsampleという名前がいろんなdivに使われている場合です。
その場合、入力したい場所やクリックしたい場所を正確に特定することができません。
属性名で要素を特定したいときはid名やname名を使うのですが、必ずidやnameが使われている保証はありません。
また、属性名を使用していない場合もあります。
要素名を使って指定することもできますが、Webページにはdivという要素が多用されていて一つを特定するのには不向きです。
じゃあ、どうすればいいんや!! そういう時はXPathを使いましょう。
XPath? なにそれ? バンド? と思われるかもしれません。その人が想像しているのはX JAPANかもしれない。
ということで、次の項目ではXPathについて軽く説明します。XPathとは何ぞや?
XPathとは簡単に言うと要素の住所のことです。
ちょっとサンプルを用いて説明しましょう。<html> <head> <title>Sample HTML</title> </head> <body> <h1>HTMLのサンプル</h1> <p>This is HTML Sample.</p> <p>This is HTML Sample.</p> </body> </html>上記はHTMLのサンプルプログラムです。サンプルであることを過剰に主張しています。
HTMLの説明をしているわけではないので、どのようなHTMLなのかというところは省きますが、
重要なのは属性が使われておらず、要素が複数使われているものがあるということです。
さぁ、ここで皆さんに質問です。<○○></○○>で一個の塊に見えないでしょうか?
見方としてはhtmlの中にbodyがあるような感じです。その感じがXPath。
htmlの中のbodyの中の二番目のpと聞くと、サンプルプログラムでの8行目のことかな? となんとなく分かるはずです。
同じことがseleniumでも出来るということです。
じゃあ、どうやって書くの? 文字で書けなければプログラムに書けませんね。
書き方としては下記のとおりです。/html/body/p[2]言ってることはさっきと一緒です。『htmlの中のbodyの中の二番目のp』を指しています。
しかし、いちいちhtmlから書いていくのは難しいです。
全てのHTMLがサンプルのように短ければ出来るかもしれませんが、長いと頭がこんがらがってきます。
そのため、必要な部分までのXPathを『//』で省略することができます。
以上XPathの説明でした。もっと詳しいことが知りたい方は自分でお調べください。実装!
さぁ、いよいよ実装しましょう。プログラムは以下の通りです。
# ライブラリインポート from selenium import webdriver from selenium.webdriver.common.keys import Keys import time import psutil import re # 郵便番号または住所の入力 postHint = input("郵便番号または住所:") # ドライバーインポート chrome = webdriver.Chrome(r".\driver\chromedriver.exe") # JPの郵便番号検索ページへ移動 chrome.get("https://www.post.japanpost.jp/zipcode/") # 『郵便番号から住所』か『住所から郵便番号』かの条件分岐 while True : if re.fullmatch("((\d{3})-(\d{4}))|(\d+)", postHint) : # 郵便番号から住所を検索する場合 if re.fullmatch("(\d{3})-(\d{4})", postHint) : # -ありの場合、-を削除 postNumber = postHint.replace("-", "") else : postNumber = postHint # 郵便番号から住所を検索する textarea = chrome.find_element_by_name("zip") # 郵便番号を入力するテキストボックス textarea.send_keys(postNumber) # 郵便番号を入力 textarea.send_keys(Keys.ENTER) # エンターで決定 # 住所を取得 ken = chrome.find_element_by_xpath("//table[@class='prefList sp-b10']/tbody/tr[2]/td[2]/small").get_attribute("textContent") si = chrome.find_element_by_xpath("//table[@class='prefList sp-b10']/tbody/tr[2]/td[3]/small").get_attribute("textContent") machi = chrome.find_element_by_xpath("//table[@class='prefList sp-b10']/tbody/tr[2]/td[4]/div/p/small/a").get_attribute("textContent") # 住所の結合 address = ken + si + machi # 結果 print("検索結果:" + address) # ループを抜ける break elif re.fullmatch(".+?県.+?\d*?-?\d*?-?\d*?-?\d*?-?\d*?", postHint) : # 住所から郵便番号の場合 # 住所の数字部分を削除 if re.search("\d", postHint) : postAddress = re.sub("\d+?-?\d*?-?\d*?-?\d*?-?\d*?", "", postHint) else : postAddress = postHint # 住所から郵便番号を検索する textarea = chrome.find_element_by_name("addr") # 住所を入力するテキストボックス textarea.send_keys(postAddress) textarea.send_keys(Keys.ENTER) #一秒間待機(ブラウザの処理が追い付かないため) time.sleep(1) # 郵便番号の取得 button = chrome.find_element_by_xpath("//table[@class='prefList sp-b10']/tbody/tr[2]/td[2]/div/p/a") # リンクを取得 button.click() addressNumber = chrome.find_element_by_xpath("//table[@class='zip-detail']/tbody/tr[2]/td[1]/span").get_attribute("textContent") # 結果の出力 print("検索結果:" + re.sub("\s*?", "", addressNumber)) # ループを抜ける break else : postHint = repr(input("郵便番号または住所:")) p = psutil.Process(chrome.service.process.pid) p.terminate()シンタックスハイライトを無効にしたので少し見辛いかもしれません。
しかし、シンタックスハイライトを有効にしたらもっと見辛かったので無効にしました。
待機処理についてはsleepよりも良いものがるのですが、今回はsleepにしました。理由は特にありません。本題ではないので。
プログラムがやってることは簡単です。検索して情報を取得する。以上! シンプル!
ですが、このプログラムには致命的な欠点が二つほどあります。
そもそもエラーハンドリングしてませんからね。厳密には二つどころじゃないでしょうが。さて、致命的な欠点一つ目は住所での検索時、候補がいくつかあったらバグります。
全ての住所を正しく入力しても候補が出てくる事があります。その場合、正しい郵便番号を出力しない可能性があります。
原因はXPathで第一候補を選択するようにしているからです。
第一候補以外ない状況を想定していた為のバグと言えるでしょう。
解決策の一つとして、候補それぞれの住所とユーザーが入力した住所を比較するという方法があります。致命的な欠点の二つ目は住所検索の正規表現が緩いです。
問題の正規表現は『.+?県.+?\d*?-?\d*?-?\d*?-?\d*?-?\d*?』。
文字化け? と一瞬思いそうな文字たちですね。
正規表現については説明しませんが、表していることは『○○県の後ろに何かしらの文字があればOK』というものです。
つまり『熊本県桜』と書いても正しいと認識します。究極『まる県か』でもOKです。
しかし『東京都』や『京都府』など『○○県』でないものは検索してくれません。
ユルユル過ぎて話にならない。もちろん検索して何もヒットしなかったらエラーを吐いてプログラムは終了します。
正規表現がユルユルな理由は住所の書き方は都道府県で違うからです。
○○県○○市○○があれば○○県○○市○○区○○、○○県○○群○○などなど。
その全てを調べて対応するのは不可能です。何かしらのリストがあれば出来るかもしれません。
しかし、今のところ個人で調べるしか方法はないのでユルユルな正規表現になりました。
また、東京都などを検索してくれない問題は単純に私が忘れていただけです。申し訳ない。RPAツールを実装する上で必要なこと
さて、今回も今までの経験に基づき、実装にかかわる内容を列挙したいと思います。
以下、箇条書きです。
- 要素の取得にXPathが使えないと限界がある
- プログラミングができない人のためにXPathが何か説明が必要
- プログラミングができない人のためにXPathの書き方には工夫が必要
- 待機処理がないとうまく動かない場合がある
- 条件分岐や繰り返しができた方がRPAの幅が広がると感じた
- 繰り返しについてbreakなどが使えたら便利
- 正規表現が使えた方がいい
- プログラミングができない人のために正規表現が何か説明が必要
- プログラミングができない人のために正規表現の書き方には工夫が必要
- テキスト取得にはget_attribute("textContent")を使った方が良い
- 文字列の結合機能も欲しい
- 結構しっかりとエラーハンドリングしないとすぐ壊れそう
現在、思いつく限りでは以上です。
get_attribute("textContent")はブラウザに表示されていない文字も取得できるため、
エラーを吐きにくくなると考えています。最後に
最後までお付き合いいただきありがとうございます。
今回でseleniumさんとは結構仲良く出来るかなと思っています。
しかし、最後にseleniumさんとやりたいことがあるので、まだしばらくselenium編が続きます。
次回の記事は『seleniumと仲良くなろう Part.3』になると思いますので、よろしくお願いいたします。
以上、enpがお送りいたしました。




- 投稿日:2020-08-17T16:35:12+09:00
Pythonで1000個くらいのボールの衝突判定をハッシュを使って軽くする(新型コロナウィルス関連)
Pythonで千個くらいのボールの衝突判定をハッシュを使って軽くする(新型コロナウィルス関連)
ワシントンポスト-オンラインの記事
この↓ワシントンポストの新型コロナウィルスの感染シミュレーションの記事(現象の説明)
に刺激されて、沢山のボールが衝突するプログラムをPythonで作ってみた。
(ちなみにこの記事はワシントンポストのオンラインで、それまでで最も見られた記事になったようです。)overshoot.py
スペースキーをプレスすると、最初の感染が始まる。
Pythonista バージョン
Pythonisitaバージョンはspawnで感染スタート
ボールの衝突そのものは、 Simpson College Computer Scienceの以下の記事などを
参考にした。
http://programarcadegames.com/python_examples/f.php?file=bouncing_balls.py問題は、ボールが1000個くらいになったら、とても動きがスローになる。常に一つのボールが他の
すべてのボールと衝突判定をしているためである。そこで、近傍のボールとだけの衝突判定をすればいいわけだが、この近傍のボール同士を決めるの
にPythonのハッシュ関数を使う。
レイトレーシングなどでレイとオブジェクトの交差判定の計算をする場合も、Oct Treeなどで、
空間分割をするのに似ている。ハッシュとは?
ハッシュとは、乱暴に言うと、ある変数(文字列、数値など)を与えると、それが入る箱の名前を決める
関数(関数と言っていいのか?)で変数は複数でもよい。今回の場合、ボールの二次元座標(x,y)を与え
るとその座標値からその位置が入る箱の番号を与える。たとえば、x,yが、1.24と3.24とすると、それぞれ
の小数点以下を切り捨てて、(1,3)という名前の箱に入れることができる。この箱には(1.55, 1.99)の位置
のボールも同じ名前の箱に入る。箱の名前を決定する計算式は用途に合わせて適宜考える。
Pythonにはこのハッシュが用意されているので便利!こうして、交差判定を同じ箱に入っているもの同士のボールに限れば計算がぐっと軽くなる。
しかし、実際はボールに大きさがあるので、隣あう箱どうしにボールの中心が存在して、それと
衝突する可能性も考慮する。一応動いたのが以下のコードであるが、Pygameを用いているので、そのモジュールも
インストールする必要がある。このコードではただボールが衝突して衝突したら必ず感染する
のですぐに爆発的に感染するが、潜伏期、発症期、死亡、抗体獲得、再生産数、などを設定し
なければならない。(ただしこのコードがすべてボールの衝突を完全に正しく反映しているかは保証できない。)
コード
overshoot.pyimport pygame import random import math #import numpy as np #import copy # Define colors BLACK = (0, 0, 0) WHITE = (255, 255, 255) BLUE = (90, 90, 180) GREEN = (0, 255, 0) RED = (255, 0, 0) GREY = (50, 50, 255) SCREEN_WIDTH = 700 SCREEN_HEIGHT = 650 start_time = pygame.time.get_ticks() class Ball: """ Class to keep track of a ball's location and vector. """ def __init__(self): # radius self.r = 4 # diameter self.d = self.r * 2 # position self.x = 0 self.y = 0 # velocity self.vx = 0 self.vy = 0 # color self.color = (0, 255, 0) # neighbour self.px = False self.mx = False self.py = False self.my = False def make_ball(): """ Function to make a new, random ball. """ ball = Ball() # Starting position of the ball. # Take into account the ball size so we don't spawn on the edge. ball.x = random.randrange(ball.d, SCREEN_WIDTH - ball.d) ball.y = random.randrange(ball.d, SCREEN_HEIGHT - ball.d - 200) # Speed and direction of rectangle ball.vx = float(random.randrange(-2, 2)) * 0.2 ball.vy = float(random.randrange(-2, 2)) * 0.2 return ball def main(): """ main program. """ pygame.init() xval = 0 bcount = 0 #redcount = 0 # Set the height and width of the screen size = [SCREEN_WIDTH, SCREEN_HEIGHT] screen = pygame.display.set_mode(size) pygame.display.set_caption("OverShoot") # Loop until the user clicks the close button. done = False # Used to manage how fast the screen updates clock = pygame.time.Clock() # dictionary results = {} cell_size = 40 ball_amount = 800 # Spawn many balls for i in range(ball_amount): ball = make_ball() results.setdefault((int(ball.x/cell_size), int(ball.y/cell_size)), []).append(ball) print(len(results.keys())) #print(results) screen.fill((20,20,20), rect=(0,SCREEN_HEIGHT - 250, SCREEN_WIDTH,SCREEN_HEIGHT)) # -------- Main Program Loop ----------- while not done: # --- Event Processing for event in pygame.event.get(): if event.type == pygame.QUIT: done = True elif event.type == pygame.KEYDOWN: # Space bar! Spawn a new ball. if event.key == pygame.K_SPACE: ball = make_ball() ball.color = RED results.setdefault((int(ball.x/cell_size), int(ball.y/cell_size)), []).append(ball) # if event.key == pygame.K_g: ball = make_ball() ball.color = (255,0,255) results.setdefault((int(ball.x/cell_size), int(ball.y/cell_size)), []).append(ball) # --- Drawing # Set the screen background screen.fill(GREY, rect=(0,0,SCREEN_WIDTH,SCREEN_HEIGHT - 200 + ball.d)) # Draw the balls cresults = {} for ky in results: blist = results[ky] blist2 = blist.copy() # for bl in blist: blist2.remove(bl) if bl.px: k = (ky[0]+1,ky[1]) if k in results: ek = results[k] blist2.extend(ek) if bl.mx: k = (ky[0]-1,ky[1]) if k in results: ek = results[k] blist2.extend(ek) if bl.py: k = (ky[0],ky[1]+1) if k in results: ek = results[k] blist2.extend(ek) if bl.my: k = (ky[0],ky[1]-1) if k in results: ek = results[k] blist2.extend(ek) if bl.px and bl.py: k = (ky[0]+1,ky[1]+1) if k in results: ek = results[k] blist2.extend(ek) if bl.mx and bl.py: k = (ky[0]-1,ky[1]+1) if k in results: ek = results[k] blist2.extend(ek) if bl.px and bl.my: k = (ky[0]+1,ky[1]-1) if k in results: ek = results[k] blist2.extend(ek) if bl.mx and bl.my: k = (ky[0]-1,ky[1]-1) if k in results: ek = results[k] blist2.extend(ek) # for bl2 in blist2: #if bl == bl2: # continue # Circle Intersect sqDist = (bl2.x-bl.x)*(bl2.x-bl.x)+(bl2.y-bl.y)*(bl2.y-bl.y) #if sqDist > 0 and sqDist <= ((BALL_SIZE)+(BALL_SIZE)): #print(sqDist, math.sqrt(sqDist)) if sqDist > 0 and sqDist <= (bl.d*bl.d): # detect collision dist = math.sqrt(sqDist) # vCollison vc = ([bl2.x-bl.x, bl2.y-bl.y]) # vCollisonNorm vcn = ([vc[0]/dist, vc[1]/dist]) # vRelativeVelocity vrv = ([bl.vx-bl2.vx, bl.vy-bl2.vy]) speed = vrv[0]*vcn[0] + vrv[1]*vcn[1] #print(speed) if speed > 0: bl.vx -= speed * vcn[0] bl.vy -= speed * vcn[1] bl2.vx += speed * vcn[0] bl2.vy += speed * vcn[1] # #infection if bl.color == RED and bl2.color != RED: bl2.color = RED bcount += 1 if bl2.color == RED and bl.color != RED: bl.color = RED bcount += 1 # col = bl.color pygame.draw.circle(screen, col, [round(bl.x), round(bl.y)], bl.r) bl.x += bl.vx bl.y += bl.vy # avoid line y if bl.y > SCREEN_HEIGHT - 200 + bl.r: bl.y = SCREEN_HEIGHT - 200 bl.vy = -bl.vy if bl.y < bl.r : bl.y = bl.r bl.vy = -bl.vy if bl.x < bl.r: bl.x = bl.r bl.vx = -bl.vx if bl.x <= 0 : bl.vx = 0.1 if bl.x > SCREEN_WIDTH - bl.r: bl.x = SCREEN_WIDTH - bl.r bl.vx = -bl.vx # #Bounce the ball if needed if bl.y > SCREEN_HEIGHT - 200 or bl.y < bl.r: bl.vy *= -1 if bl.x > SCREEN_WIDTH - bl.r or bl.x < bl.r: bl.vx *= -1 # set key and get hash and append cresults.setdefault((int(bl.x/cell_size), int(bl.y/cell_size)), []).append(bl) # # check neighbour with new key bl.px = int((bl.x+bl.r)/cell_size) > int(bl.x/cell_size) bl.mx = int((bl.x-bl.r)/cell_size) < int(bl.x/cell_size) bl.py = int((bl.y+bl.r)/cell_size) > int(bl.y/cell_size) bl.my = int((bl.y-bl.r)/cell_size) < int(bl.y/cell_size) results.clear() results.update(cresults) # show stat timepassed = pygame.time.get_ticks()-start_time if timepassed % 12 == 0: if bcount > 0 and bcount < ball_amount: pygame.draw.line(screen,(200,0,0),(xval*2,SCREEN_HEIGHT-10),(xval*2,SCREEN_HEIGHT-int(bcount/5)-10),2) xval += 1 #for res in results: # a = results[res] # for bl in a: # pygame.draw.circle(screen, WHITE, [round(bl.x), round(bl.y)], BALL_SIZE) # break # Go ahead and update the screen with what we've drawn. clock.tick(60) pygame.display.flip() # Close everything down pygame.quit() if __name__ == "__main__": main()pythonistaバージョン
overshoot.pyimport ui from scene import * import random import math import time import sys import os # Define colors BLACK = (0, 0, 0) WHITE = (1, 1, 1) BLUE = (0.5, 0.5, 0.8) GREEN = (0, 1, 0) RED = (1, 0, 0) GREY = (0.5, 0.5, 0.5) CELL_SIZE = 20 BALL_AMOUNT = 800 class Ball: """ Class to keep track of a ball's location and vector. """ def __init__(self): # radius self.r = 3 # diameter self.d = self.r * 2 # position self.x = 0 self.y = 0 # velocity self.vx = 0 self.vy = 0 # color self.color = (0, 1, 0) # neighbour self.nb = (False,False,False,False) def make_ball(self): """ Function to make a new, random ball. """ ball = Ball() # Starting position of the ball. # Take into account the ball size so we don't spawn on the edge. ball.x = random.randrange(ball.d, self.size.width - ball.d) ball.y = random.randrange(270, self.size.height- ball.d-200) # Speed and direction of rectangle ball.vx = float(random.randrange(-2, 2)) * 0.2 ball.vy = float(random.randrange(-2, 2)) * 0.2 return ball def button_tapped(sender): #print('hhh') os.abort() class MyScene2(Scene): def setup(self): self.val = (0,0) self.bar = [] self.last = 0 def add(self): self.bar.append(self.val[1]) print(self.val[1]) def draw(self): #print(self.val) background(0.5,0.5,0.5) fill(0.9,0.0,0.5) # for i in range(len(self.bar)): rect(40+i*2, 4, 2, 4+self.bar[i]/4) class MyScene(Scene): def setup(self): self.startTime = time.time() self.xval = 0 self.bcount = 0 self.last = 0 #self.MySprite = SpriteNode(color = 'red', size = (32,32), parent = self) #self.spot=ShapeNode(path=ui.Path.rect (100,0,50 ,30),parent=self) #self.spot.position = (200,500) self.results = {} self.cell_size = CELL_SIZE self.ball_amount = BALL_AMOUNT # Spawn many balls for i in range(self.ball_amount): ball = make_ball(self) self.results.setdefault((int(ball.x/self.cell_size), int(ball.y/self.cell_size)), []).append(ball) # red ball #aball = make_ball(self) #aball.color = RED #self.results.setdefault((int(ball.x/self.cell_size), int(ball.y/self.cell_size)), []).append(aball) print("cell number = ",len(self.results.keys())) # disp hashmap data cnt = 0 ad = 0 ocl = 0 for aky in self.results.keys(): ad += len(aky) cnt += 1 if len(aky) == 1: ocl += 1 print("balls / cell = ", ad/cnt) print("1 ball cell = ", ocl) # scene view for stat self.sv = SceneView(frame=(0, self.view.height-250,self.view.width,250),flex='WH') self.s2 = MyScene2() self.sv.scene = self.s2 self.view.add_subview(self.sv) self.sv.border_color = (0.9,0.6,0.7) self.sv.border_width = 3 # button = ui.Button() button.frame = (110,100,120,30) button.action = self.button_tapped button.title = 'spawn' button.background_color = (0.6,0.3,0.5) button.tint_color = ('white') self.view.add_subview(button) def button_tapped(self,sender): #print('hhhgggg') aball = make_ball(self) aball.r= 3 aball.d = 60 aball.color = RED self.results.setdefault((int(aball.x/self.cell_size), int(aball.y/self.cell_size)), []).append(aball) def draw(self): cell_size = CELL_SIZE #bcount = self.bcount background(0, 0, 150) fill(110,10,10) tint(200,5,5) # Draw the balls #self.cresults = {} cresults = {} for ky in self.results: blist = self.results[ky] blist2 = blist.copy() # for bl in blist: blist2.remove(bl) skip = True if bl.nb[0] and bl.nb[1]: k = (ky[0]+1,ky[1]+1) if k in self.results: blist2.extend(self.results[k]) skip = False if skip and bl.nb[2] and bl.nb[1]: k = (ky[0]-1,ky[1]+1) if k in self.results: blist2.extend(self.results[k]) skip = False if skip and bl.nb[0] and bl.nb[2]: k = (ky[0]+1,ky[1]-1) if k in self.results: blist2.extend(self.results[k]) skip = False if skip and bl.nb[2] and bl.nb[2]: k = (ky[0]-1,ky[1]-1) if k in self.results: blist2.extend(self.results[k]) # if bl.nb[0]: k = (ky[0]+1,ky[1]) if k in self.results: blist2.extend(self.results[k]) if bl.nb[2]: k = (ky[0]-1,ky[1]) if k in self.results: blist2.extend(self.results[k]) if bl.nb[1]: k = (ky[0],ky[1]+1) if k in self.results: blist2.extend(self.results[k]) if bl.nb[3]: k = (ky[0],ky[1]-1) if k in self.results: blist2.extend(self.results[k]) # for bl2 in blist2: #if bl == bl2: # continue # Circle Intersect sqDist = (bl2.x-bl.x)*(bl2.x-bl.x)+(bl2.y-bl.y)*(bl2.y-bl.y) #if sqDist > 0 and sqDist <= ((BALL_SIZE)+(BALL_SIZE)): #print(sqDist, math.sqrt(sqDist)) if sqDist > 0 and sqDist <= ((bl.r+bl2.r)*(bl.r+bl2.r)): # detect collision dist = math.sqrt(sqDist) # vCollison vc = ([bl2.x-bl.x, bl2.y-bl.y]) # vCollisonNorm vcn = ([vc[0]/dist, vc[1]/dist]) # vRelativeVelocity vrv = ([bl.vx-bl2.vx, bl.vy-bl2.vy]) speed = vrv[0]*vcn[0] + vrv[1]*vcn[1] #print(speed) if speed > 0: bl.vx -= speed * vcn[0] bl.vy -= speed * vcn[1] bl2.vx += speed * vcn[0] bl2.vy += speed * vcn[1] # #infection if bl.color == RED and bl2.color != RED: bl2.color = RED self.bcount += 1 if bl2.color == RED and bl.color != RED: bl.color = RED self.bcount += 1 # # draw shape fill(bl.color) ellipse(int(bl.x)-bl.r, int(bl.y)-bl.r, bl.r*2, bl.r*2) bl.x += bl.vx bl.y += bl.vy # avoid line y if bl.y > self.size.height - 200 + bl.r: bl.y = self.size.height - 200 bl.vy = -bl.vy if bl.y < bl.r : bl.y = bl.r bl.vy = -bl.vy if bl.x < bl.r: bl.x = bl.r bl.vx = -bl.vx if bl.x <= 0 : bl.vx = 0.1 if bl.x > self.size.width - bl.r: bl.x = self.size.width - bl.r bl.vx = -bl.vx # #Bounce the ball if needed if bl.y > self.size.height - 200 or bl.y < bl.r + 260: bl.vy *= -1 if bl.x > self.size.width - bl.r or bl.x < bl.r: bl.vx *= -1 # set key and get hash and append cresults.setdefault((int(bl.x/cell_size), int(bl.y/cell_size)), []).append(bl) # # check neighbour with new key px = int((bl.x+bl.r)/cell_size) > int(bl.x/cell_size) mx = int((bl.x-bl.r)/cell_size) < int(bl.x/cell_size) py = int((bl.y+bl.r)/cell_size) > int(bl.y/cell_size) my = int((bl.y-bl.r)/cell_size) < int(bl.y/cell_size) bl.nb =(px,py,mx,my) self.results.clear() self.results.update(cresults) #print((selfself.spot.position = (100,800).now-dt.now).seconds)) timepassed = time.time()-self.startTime #print(int(timepassed)) if int(timepassed) != self.last and self.ball_amount > self.bcount: self.s2.add() self.s2.val = (self.xval, self.bcount) self.last = int(timepassed) self.xval += 1 s=MyScene() #Scene.run(s, show_fps=True) main_view = ui.View() scene_view = SceneView(frame=main_view.bounds, flex='WH') main_view.title = 'OverShoot' main_view.tint_color = (0,0,0) main_view.add_subview(scene_view) scene_view.scene = s button = ui.Button() button.frame = (10,100,main_view.width-20,30) button.action = button_tapped button.title = 'quit' button.background_color = (0.6,0.3,0.5) button.tint_color = ('white') main_view.add_subview(button) #scene_view.add_subview(sv) #sv.background_color = (1,0,0) main_view.present(hide_title_bar=False, animated=False)


- 投稿日:2020-08-17T16:19:45+09:00
【超入門レベル】Pythonの基本シート
Pythonの基本チートシート
キノコードさんの動画とブログを参考にしています。
目次
- Pythonの特徴
- 環境構築
- プログラムの実行
- 変数
- データ型
- 演算子
- 関数
- クラス
- 総まとめ
Pythonの特徴
- 1991年開発オランダのグイド・ヴァンロッサム
- プログラミング言語
- オブジェクト指向言語→データと処理を1セット→「カプセル化」「多態性」「継承」
- 「人工知能開発」「データ分析」「Webアプリケーション開発」ができる
- 「文章を読むようにわかりやすいコード」を意識
- スクリプト言語
- 人気の言語→Googleは社内の標準プログラミング言語
- ライブラリが豊富→「人工知能」「データ解析」「数値計算」
環境構築
- VSCodeと拡張機能
- anaconda→Pythonのディストリビューション→様々なライブラリが入っている
VSCode拡張機能
「Python」→補完機能やデバッグ機能
anaconda
「anaconda」→「Python3系」のものをダウンロード
Graphical Installerのほうが簡単※ 後々「.py」というファイルを作成したときに「Python」のコマンドラインツールが作成される。
プログラムの実行
- ファイルの実行→拡張子は「.py」
- ソースコードの記述
- ソースコードの保存
- ソースコードの実行
- 順次進行の確認
ソースコードの記述
print("Good morning")ソースコードの実行
python ファイル名変数
変数の宣言
num = 1 print(num) =>1変数名のルール
- アルファベット、数字、アンダースコアが使える
- 数字から始めることができない
- アンダースコア以外の記号が使えない
- 大文字と小文字は区別される
- 予約語は使えない(returnやclass、for、whileなど)
データ型
変数に入れるデータの種類のこと。
- 数値型、文字列型、ブール型
- Pythonでは、変数にデータを入れるときにデータ型をしていしなくてもいい。→動的型付け言語。数値型
- 整数のint型
- 小数のfloat型
- typeで、データ型を表示することができる
文字列型
- " "か' 'で囲む
ブール型
- TrueかFalseのどちらかを持つ型
リスト
- 複数のデータを格納することができるもの。
- 添字は「順番 - 1」
リストの作り方
a = ["sato","suzuki","takahashi"] a[1] = "tanaka" print(a[0]) print(a[1]) print(a[2])多次元リスト
arr = [["sato","suzuki"],["takahashi","tanaka"]] print(a[0][0]) print(a[0][1]) print(a[1][0]) print(a[1][1])演算子
- 算術演算子→+,-,*,/,%
- 関係演算子→>,<,>=,<=,==,!=
- 論理演算子→and,or
- 代入演算子→=
- 複合代入演算子→+=,-=,*=,/=
条件分岐
if文
age = 0 if age >= 20: print("adult") elif age == 0: print("baby") else: print("child")反復
for文
for i in range(5): print(i)break文→処理を終了
for i in range(5): if i == 3: break print(i)continue文→処理をスキップ
for i in range(5): if i == 3: continue print(i)ネスト
for i in range(3): for j in range(3): print(i, j, sep="-")※sep引数というものがある。
リストの繰り返し
arr = [2,4,6,8,10] sum = 0 for i in arr sum += i print(sum)関数
関数の定義
def sayHello(greeting) print(greeting) sayHello("Good evening")def sayHello(greeting) print(greeting) hello = sayHello hello("Good evening")変数に関数を代入することもできる。
def add(num01,num02): print(num01 + num02) add(6,2)def add(num01,num02): return (num01 + num02) print(add(6,2))def add(num01,num02): return (num01 + num02) add_result = add(6,2) print(add_result)クラス
データと処理をセットにしたもの。
Pythonのクラス
- データをアトリビュートという→クラス内の変数
- 処理をメソッドという→クラス内の関数
クラスの定義方法
class Student: def avg(self): print((80 + 70) / 2)関数の場合は引数は空欄でOK。
メソッドの場合は必ず引数を一つ渡す必要がある。→必要ない場合はselfと書くのが慣習。クラスの使い方(インスタンス化)
class Student: def avg(self): print((80 + 70) / 2) a001 = Student() a001.avg()メソッドに引数を渡す
class Student: def avg(self, math, english): print((math,+ english)/2) a001 = Student() a001.avg(80,70)アトリビュートの定義→「インスタンス名.アトリビュート」で定義することができる。
class Student: def avg(self, math, english): print((math + english)/2) a001 = Student() a001.avg(80,70) a001.name = "sato" print(a001.name)class Student: def avg(self, math, english): print((math + english)/2) a001 = Student() a001.avg(80,70) a001.name = "sato" print(a001.name) a002 = Student() print(a002.name)これはエラーになる!?
→Rubyのときと違って、インスタンスごとにアトリビュートを定義しないといけない。
→新しいインスタンス(生徒)を作成するごとに、同様のアトリビュート(名前)を作成しないといけない。
→つまり、以下の記述ならOKclass Student: def avg(self, math, english): print((math + english)/2) a001 = Student() a001.avg(80,70) a001.name = "sato" print(a001.name) a002 = Student() a002.name = "tanaka" print(a002.name)ただ、これだと不便さがある。
→コンストラクタを使う。
→初期化メソッドのこと。コンストラクタ→アトリビュートの自動生成
- インスタンス化するときに、自動的に実行されるメソッド。
- rubyのinitializaメソッドみたいなもの。
class Student: def __init__(self): self.name = "" def avg(self, math, english): print((math + english)/2) a001 = Student() a001.name = "sato" print(a001.name) a002 = Student() a001.name = "tanaka" print(a002.name)以下のようにすると便利。
class Student: def __init__(self,name): self.name = name def avg(self, math, english): print((math + english)/2) a001 = Student("sato") print(a001.name) a002 = Student("tanaka") print(a001.name)総まとめ
- クラスを定義
- コンストラクタの定義
- 平均を計算するメソッドを定義
- テスト結果を判定するメソッドを定義
- インスタンス化する
- リストに点数を格納
- 変数に平均点を代入
- 変数に判定結果を代入
- それぞれ表示させる
class Student: def __init__(self,name): self.name = name def calculateAvg(self, data): sum = 0 for num in data: sum += num avg = sum / len(data) return avg def jedge(self, avg): if (avg >= 60): result = "passed" else: result = "failed" return result a001 = Student("sato") data = [70, 65, 50, 90, 30] avg = a001.calculateAvg(data) result = a001.jedge(avg) print(avg) print(a001.name + " " + result)まとめ
rubyに続き、pythonの文法について学んでみたが
けっこう雰囲気は似ているなと感じた。ただ、rubyの方が雰囲気扱いやすく感じた。記述の仕方に慣れているからかな?
pythonのほうがendがなくていいなど、色々あるので、それぞれの良さがあるのかなと感じた。rubyとpythonは似ているんだなと思う。
そして、おそらく簡単な方なんだなと思う。rubyは簡単にアプリケーションを作成するもの。
pythonは人工知能を扱うための言語という感じかな?
- 投稿日:2020-08-17T15:54:42+09:00
たくさんのAWS Glue Jobを実行している環境で実行履歴を一覧表示するPythonスクリプト
Glue Jobの実行履歴をコマンドラインのワンライナーで見る方法を以前にブログに書きました。
が、日時の表示がイケてなくて、使いづらかったので、Pythonのスクリプトで書き直しました。
import boto3 # default以外のprofileを使う場合はここで指定 profile = "default" session = boto3.session.Session(profile_name = profile) client = session.client("glue") jobs = client.get_jobs() header = [ "started", "completed", "executionTime", "status", "name", "allocatedCapacity", "maxCapacity", "glueVersion", "errorMessage", ] result = [] for job in jobs["Jobs"]: name = job["Name"] history = client.get_job_runs(JobName = name) for run in history["JobRuns"]: started = run["StartedOn"].strftime("%Y-%m-%d %H:%M:%S") if "CompletedOn" in run: completed = run["CompletedOn"].strftime("%Y-%m-%d %H:%M:%S") else: completed = "" executionTime = str(run["ExecutionTime"]) if executionTime == "0": executionTime = "" status = run["JobRunState"] if "ErrorMessage" in run: errorMessage = run["ErrorMessage"] else: errorMessage = "" allocatedCapacity = str(run["AllocatedCapacity"]) maxCapacity = str(run["MaxCapacity"]) glueVersion = str(run["GlueVersion"]) result.append([ started, completed, executionTime, status, name, allocatedCapacity, maxCapacity, glueVersion, errorMessage, ]) # 起動時間でソート result.sort(key = lambda r: r[0]) # タブ区切りで出力 print("\t".join(header)) for r in result: print("\t".join(r))起動時刻と終了時刻を表示しますが、環境変数
TZに依存したローカルタイムで表示されるようです。
- 投稿日:2020-08-17T15:23:07+09:00
Pythonでホップフィールドネットワークによる連想記憶を実装してみる
はじめに
ホップフィールドネットワークは1980年代前半にアメリカの物理学者ホップフィールドによって提案されました。ホップフィールドはニューラルネットワークにエネルギーの概念を導入しました。さらに、連想記憶だけでなく巡回セールスマン問題のような最適化問題にも応用できることを示したのです。ここでは、連想記憶について扱います。ニューラルネットワークにパターンを記憶(記銘過程)させ、思い出させます(想起過程)。具体的には、以下の白黒画像(文字列に特に意味はありません)をニューラルネットワークに埋め込み、ノイズを加えたパターンを与えて想起させてみます。
ノイズを加えたパターンを初期パターン(下記の左画像)として設定し、更新を繰り返すと記憶パターンが想起されます(下記の右画像)。
連想記憶をPythonで実装しました。googleアカウントをお持ちであれば、こちら(Google Colab)からすぐに実行できます。
モデル [1][2]
ホップフィールドネットワークの構造は次のようになります(ニューロン数5個の場合)。両矢印は相互結合を表しています。以下の図は自己結合を考慮していない構造です。
記銘過程
ニューラルネットワークの結合荷重を変化させてパターンを記憶させます。そのパターンをベクトル$ \boldsymbol{x} =(x_1,...,x_N) (x_i:1 \leqq i \leqq N)$で表します。$N$はニューロン数(ユニット数)です。記憶させたいベクトルが$P$個$( \boldsymbol{x}^{(1)} ,..., \boldsymbol{x}^{(P)} )(\boldsymbol{x}^{(k)}:1 \leqq k \leqq P)$あるとき、行列で
X = \begin{bmatrix} \boldsymbol{x}^{(1)} \\ \vdots \\ \boldsymbol{x}^{(P)} \end{bmatrix} = \begin{bmatrix} x_1^{(1)} & \cdots & x_N^{(1)} \\ \vdots & \ddots & \vdots \\ x_1^{(P)} & \cdots & x_N^{(P)} \end{bmatrix} (P×N行列) \tag{1}と表します。
記憶させたいパターンを記憶パターンとよびます。記憶パターンを用意出来たら、ニューラルネットワークに埋め込んでいきます。記憶させるときは一つずつ覚えてもらいます。一つのパターンをニューラルネットワークに与えるたびに結合荷重を変化させます。ニューロン$i$からニューロン$j$へとつながる結合荷重$w_{ij}$は以下の式の$\Delta w$だけ変化します。$$x_i^{(k)}=0,1 \hspace{10pt}(1 \leqq i \leqq N,1 \leqq k \leqq P)の場合$$
\Delta w = (2x_i^{(k)} - 1)(2x_j^{(k)} - 1) \tag{2}(2)式は埋め込むパターンベクトルの要素が1か0の二値である場合です。もし、パターンベクトルの要素が-1,0,1であるならば$\Delta w$は以下の式になります。
$$x_i^{(k)}=-1,0,1 \hspace{10pt}(1 \leqq i \leqq N,1 \leqq k \leqq P)の場合$$
\Delta w = x_i^{(k)} x_j^{(k)} \tag{3}上記の(2),(3)式はヘッブ則といわれる学習則です。同じ出力をするニューロン同士の結合荷重を強くし、異なる出力をするニューロン同士の結合荷重は弱くさせます。ニューロン数が$N$個であるとき、結合荷重$w_{ij}$は$N×N$本存在します。(1)式で用意したパターンを(2),(3)式で埋め込むならば、行列形式の結合荷重$W$は以下の式のように表現できます。
$$x_i^{(k)}=0,1 \hspace{10pt}(1 \leqq i \leqq N,1 \leqq k \leqq P)の場合$$
W = \begin{bmatrix} w_{11} & \cdots & w_{1N} \\ \vdots & \ddots & \vdots \\ w_{N1} & \cdots & w_{NN} \end{bmatrix} = (2X-1)^T(2X-1) \hspace{10pt} (N×N行列) \tag{4}$$x_i^{(k)}=-1,0,1 \hspace{10pt}(1 \leqq i \leqq N,1 \leqq k \leqq P)の場合$$
W = \begin{bmatrix} w_{11} & \cdots & w_{1N} \\ \vdots & \ddots & \vdots \\ w_{N1} & \cdots & w_{NN} \end{bmatrix} = X^TX \hspace{10pt} (N×N行列) \tag{5}想起過程
想起過程は、任意の入力パターン$\boldsymbol{x'}=(x_1',...,x_N')$をニューラルネットワークの初期状態として設定することから始まります。この入力パターン$\boldsymbol{x'}$を初期パターンとよびます。初期パターンと記憶パターンがどれほど違うかを示すのにハミング距離を用います。以下に記憶パターン$\boldsymbol{x}$と初期パターン$\boldsymbol{x'}$のハミング距離$d$の定義を示します。$x_i^{(k)}=-1,0,1$の場合は以下の式に1/2がつきます。
$$x_i^{(k)}=0,1 \hspace{10pt}(1 \leqq i \leqq N,1 \leqq k \leqq P)の場合$$d = \sum_{i=1}^N |x_i - x_i'| \tag{6}初期パターンを初期状態に設定したら、以下の更新手順①,②を指定した回数繰り返します。
①ニューロンの中からランダムに一つ、ニューロン$m$を選びます。次にニューロン$m$の出力$y_m(t)$を求めます。s(u):ステップ関数 \\ s(u) = \left\{ \begin{array}{ll} 1 & (u > 0) \\ 0 & (u \leqq 0) \end{array} \right. \hspace{10pt} もしくは \hspace{10pt} s(u) = \left\{ \begin{array}{lll} 1 & (u > 0) \\ 0 & (u = 0) \\ -1 & (u < 0) \end{array} \right. \\ \boldsymbol{w_m}:ニューロンmへの結合荷重 \\ b_m:バイアス(しきい値、閾値)y_m(t)=s(u)=s(\boldsymbol{x} \boldsymbol{w_m} + b_m) \tag{7}②ニューロン$m$の次の状態$y_m(t+1)$を(7)式により求まった値に更新します。ニューロン$m$以外は更新せずそのままです。
y_m(t+1)←y_m(t) \tag{8}このような、ニューロン一つだけを更新していく方法を非同期的な更新といいます。ホップフィールドネットワークは非同期的な更新のことを指すようです。更新を繰り返すときネットワークのエネルギーは下がり続けることが理論的に示されています。エネルギーは以下のように定義されます。
E(t) = -\frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N w_{ij}x_i(t)x_j(t) - \sum_{j=1}^N b_jx_j(t) \tag{9}クラスと関数
- クラス
Pattern:パターンを読み込むクラスです。
- 関数
weight_cal1(X):パターンベクトルの要素が0,1の場合の結合荷重を設定します。
weight_cal2(X):パターンベクトルの要素が-1,0,1の場合の結合荷重を設定します。
hamming(ptn_vec1, ptn_vec2):引数に与えた2つのパターンベクトルのハミング距離を返します。
set_ptn_vec1(ptn_vec, difference_rate):パターンベクトルの要素が0,1の場合の初期パターン生成関数です。
set_ptn_vec2(ptn_vec, difference_rate):パターンベクトルの要素が-1,0,1の場合の初期パターン生成関数です。
step_function1(x):0,1を返すステップ関数です。
step_function2(x):-1,0,1を返すステップ関数です。
sync(ptn_vec, weight, bias, func):同期的更新を行う関数です。
async(ptn_vec, weight, bias, func):非同期的な更新を行う関数です。
energy_cal(output, weight, bias):ニューラルネットワークのエネルギーを計算します。
display_pattern(ptn_vec):引数に与えられたパターンベクトルを画面に出力します。
display_pattern_all(ptn):引数に与えられたパターンすべてを画面に出力します。使用するモジュールは以下の3つです。
HopfieldNetwork.ipynbimport numpy as np import random import matplotlib.pyplot as plt実践
まずはパターンの読み込みと結合荷重の設定を行います。
HopfieldNetwork.ipynbptn = np.array([[0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0]]) #パターンを読み込む row = column = 8 pattern = Pattern(row, column, ptn) #読み込んだパターンを表示する display_pattern_all(pattern.X) #結合荷重を決定する weight = weight_cal1(pattern.X) #バイアスはすべて0 bias = np.zeros(pattern.unit)実行結果
次にk = 1の場合について想起してみます。記憶パターンと初期パターンのハミング距離は10に設定しました。
HopfieldNetwork.ipynb%%time #更新回数の上限を設定 time = 1000 #パターンを選択 k = 1 #初期パターンを生成 hamming_distance = 10 ini_ptn_vec = set_ptn_vec1(pattern.X[k-1], hamming_distance/pattern.unit) #初期パターンを表示 print("初期パターン") display_pattern(ini_ptn_vec) #初期パターンのエネルギー energy = [] energy.append(energy_cal(ini_ptn_vec, weight, bias)) #上限1000回まで更新を続ける for i in range(time): #非同期的更新 async(ini_ptn_vec, weight, bias, step_function1) #更新途中のエネルギーをリストに追加していく energy.append(energy_cal(ini_ptn_vec, weight, bias)) #記憶パターンを想起できたらループを抜ける if(hamming(ini_ptn_vec, pattern.X[k-1]) == 0): print("更新回数 time =", i) break #最終的に想起されたパターンを表示 print("想起されたパターン") display_pattern(ini_ptn_vec)実行結果
energyに追加していったエネルギーの推移を確認します。HopfieldNetwork.ipynbplt.plot(energy) plt.ylabel("energy", fontsize=18) plt.xlabel("time", fontsize=18) plt.show()実行結果
とりあえず、ホップフィールドネットワークによる連想記憶の流れは以上のようになります。後日、いくつかの実験したものを載せたいと思います。
参考文献
[1] Hopfield, J.J. (1982): “Neural networks and physical systems with emergent collective computational abilities”, Proc. Natl. Sci. USA, 79, 2554-2558.
[2] 中野 馨 他共著 (1990): ニューロコンピュータの基礎 コロナ社






