- 投稿日:2020-08-17T22:20:03+09:00
[AWS] Step Functionsで遊んでみる(SAM + Lambda) Part.3(分岐編)
Part.2のおさらい
Part2では、主に以下のことを行いました。
- Lambdaに固定引数を渡してみる
- Lambdaに外部からの引数を渡してみる
- Lambdaにコンテキストオブジェクトを渡してみる
- Lambdaの戻り値を、別のTaskの引数に渡してみる
今回は、その続きからはじめてみます。
ここから始める方は、
https://github.com/hito-psv/sam-demo-005
のコードをgit cloneしてもらっても大丈夫ですし、Part2からやってみてもらっても構いません。今回のターゲット
- Lambdaでランダムな結果を返す
- 結果に応じて、次に実行するタスクを変える
- リトライ時は、しばらく時間が経ってから再実行する
をターゲットにしてみたいと思います。
Lambda部分については、Part2で作成した「HelloWorld」の関数を少しだけいじって、色々試してみたいと思います。準備
Lambda関数を修正する
現在のコードに、乱数でいくつかのパターンの文字列を返すようにしてみたいと思います。
hello_world/app.pyimport logging import random logger = logging.getLogger() logger.setLevel(logging.INFO) def lambda_handler(event, context): logger.info(event) message_array = [ "hello world", "retry" ] message = random.choice(message_array) logger.info(message) return { "statusCode": 200, "body": { "message": message, } }これで、結果のメッセージには
- hello_world
- retry
のいずれかの文字列が返されます。
ビルド・デプロイする
この状態で、
sam build、sam deploy --guidedを実行し、Lambda関数をデプロイしましょう。Lambda関数の戻り値によって振る舞いを変える
ステートマシン定義の修正
まずは、ステートマシンの定義を修正します。
修正内容は後ほど説明しますので、まずは、このように修正してみます。step_functions/state_machine.json{ "StartAt": "hello world 1", "States": { "hello world 1": { "Type": "Task", "Resource": "${HelloWorldFunction}", "Parameters": { "p1.$": $.p1, "p2.$": "$.p2", "p3": { "p3-1": 20, "p3-2": "xyz" }, "all.$": "$" }, "ResultPath": "$.hello_world_result", "OutputPath": "$", "Next": "check state" }, "retry lambda": { "Type": "Task", "Resource": "${HelloWorldFunction}", "InputPath": "$", "ResultPath": "$.hello_world_result", "OutputPath": "$", "Next": "check state" }, "check state": { "Type" : "Choice", "Choices": [ { "Variable": "$.hello_world_result.body.message", "StringEquals": "hello world", "Next": "hello world 2" }, { "Variable": "$.hello_world_result.body.message", "StringEquals": "retry", "Next": "wait state" } ], "Default": "fail state" }, "wait state": { "Type": "Wait", "Seconds": 5, "Next": "retry lambda" }, "hello world 2": { "Type": "Task", "Resource": "${HelloWorldFunction}", "InputPath": "$", "End": true }, "fail state": { "Type": "Fail", "Cause": "No Matches!" } } }
- 「hello world 1」は次のステートに「check state」のステートを実行する
- 「check state」は「$.hello_world_result.body.message」の値が「hello world」なら、次のステートに「hello world 2」を実行する
- 「check state」は「$.hello_world_result.body.message」の値が「retry」なら、次のステートに「wait state」を実行する
- 「check state」は「$.hello_world_result.body.message」の値が「hello world」「retry」以外なら、次のステートに「fail state」を実行する(今回は起こり得ない)
- 「wait state」は、5秒経ったら「retry lambda」のステートを実行する
- 「retry lambda」は、lambda関数をコールした後、「check state」のステートを実行する
- 「hello world 2」はlambda関数をコールした後、ステート実行を終了する
- 「fail state」は、異常終了としてステート実行を終了する
という記述になっています。
「Choices」の中で
Variable:チェック対象StringEquals:文字列がこの値と同じならNext:次に実行するステートを指定します。
なお、StringEqualsの箇所に指定できる演算は、AWS Step Functions開発者ガイドを参照ください。ビルド・デプロイする
この状態で、
sam build、sam deploy --guidedを実行し、デプロイしましょう。ステートマシンの確認
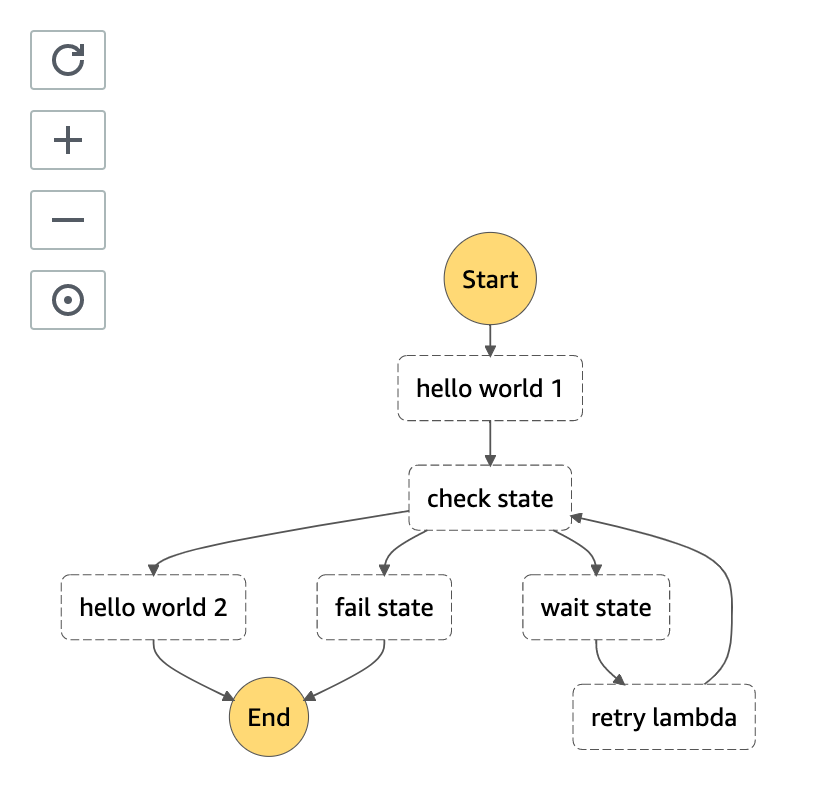
まずは、ステートマシンの定義更新によって、可視化されたステートマシンがどのようになっているかをみてみましょう。
変更したように、「check state」から分岐し、「retry lambda」の後「check state」に戻っていることが確認できたと思います。
ステートマシンを実行してみる
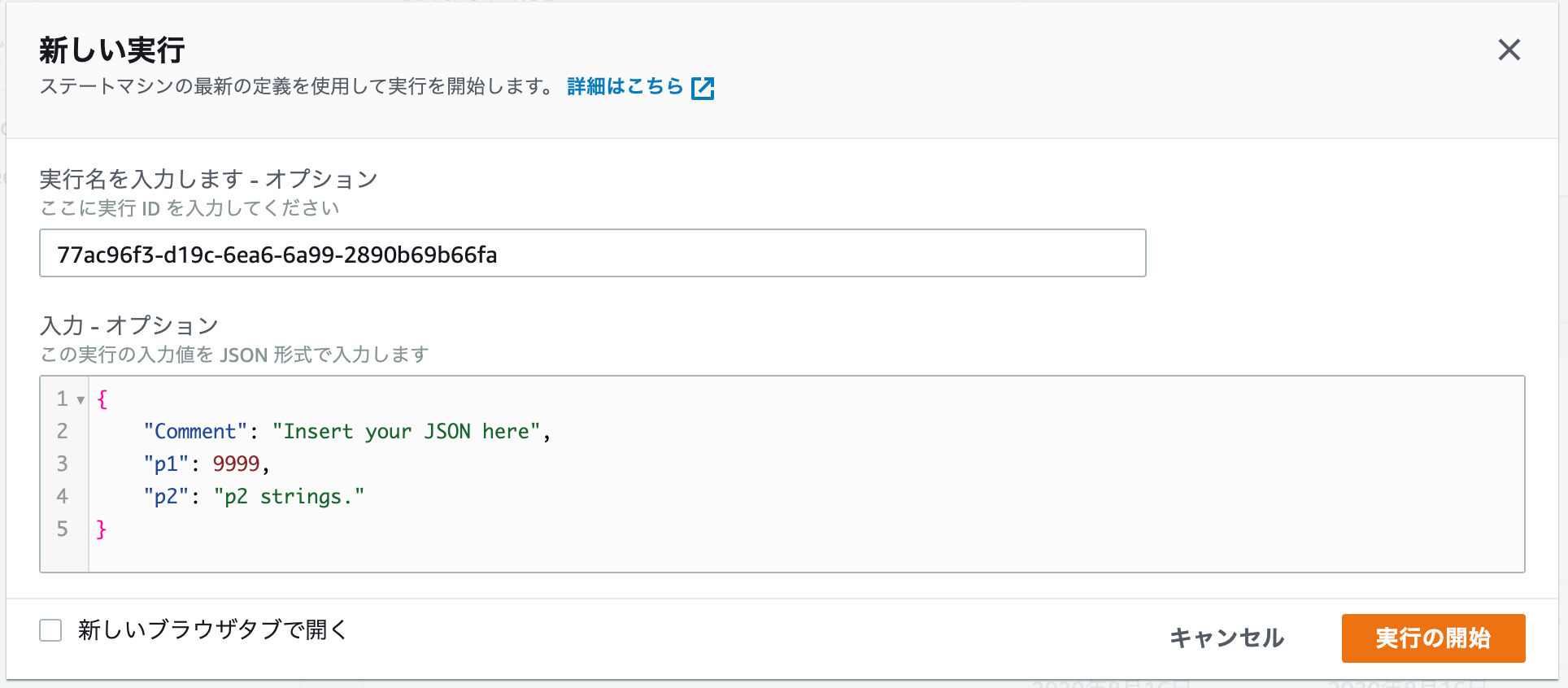
マネジメントコンソールから、ステートマシンを実行してみましょう。
Part.2からの修正のため、入力値のp1、p2を使用するため、入力蘭を以下のように指定してください。
- p1に、9999数値を指定
- p2に「p2 strings.」という文字列を指定
結果をみてみる
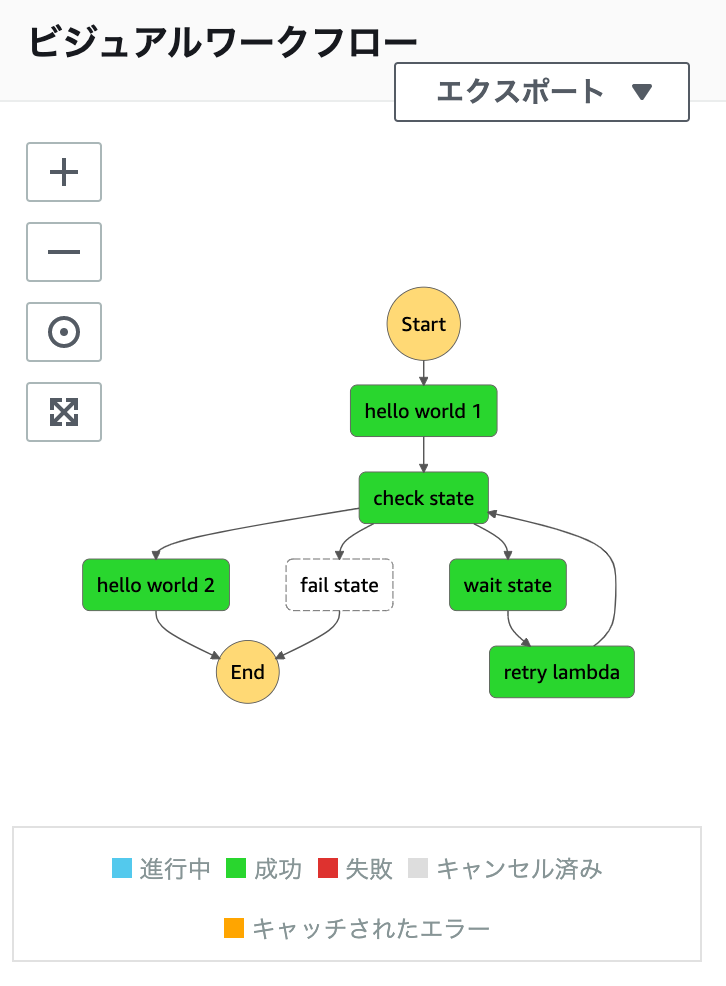
まずは、ビジュアルフローを確認してみましょう。
見事に、全パスが通ってくれてます(ランダムなので、「hello world 1」→「check state」→「hello world 2」という流れもありえます)。
では、
Choiceの処理が正しく動作しているのか、確認してみましょう。
まずは、「hello world 1」のステートから呼び出されたLambda関数の戻りがこちらです。
bodyのmessage部が「retry」であることが確認できます。
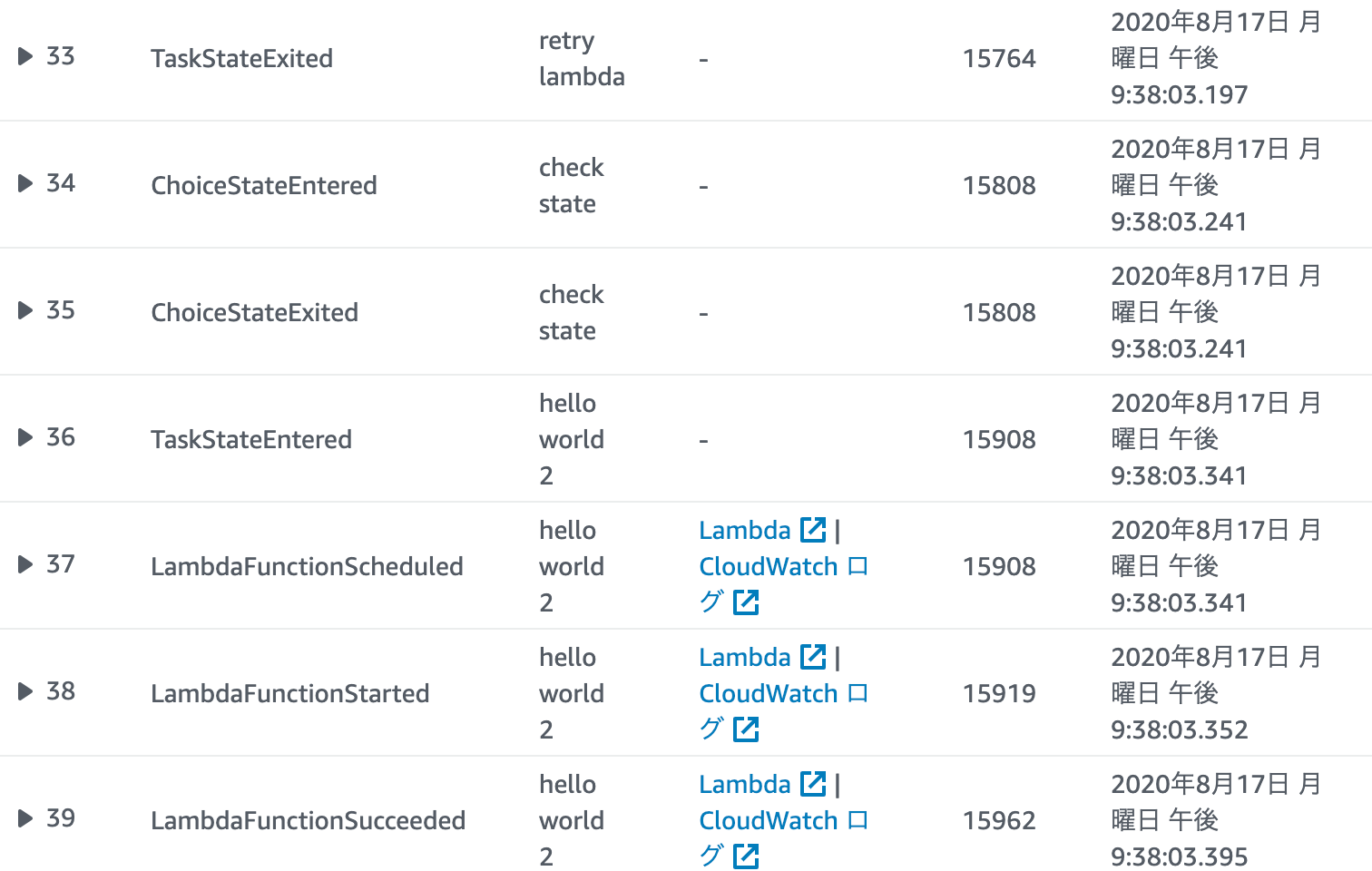
その結果、次に「wait state」が実行され、5秒後(#10と#11の時間をチェック)「retry lambdaのステートが実行されています。
実は、この後、更に2回連続して「retry」が返ってきますが、3回目に「hello world」が返されます。
その後は「hello world 2」のステートが実行されていることがわかります。
そして、そのままステートが終了します。
新しく追加された「Choice」ステート
2020/8/13に、アップデートされた内容があります。
値のテスト(型チェック)
- IsNull
- IsString
- IsNumeric
- IsBoolean
- IsTimestamp
によって、
Variableの型をChoiceで確認することができます。例"Variable": "$.foo", "IsNull|IsString|IsNumeric|IsBoolean|IsTimestamp": true|false存在チェック
- IsPresent
によって、
Variableそのものの存在チェックを行うことができます。例"Variable": "$.foo", "IsPresent": true|falseワイルドカードチェック
- StringMatches
によって、ワイルドカードを使用した判定チェックが行えます。
例"Variable": "$.foo", "StringMatches": "log-*.txt"別の入力フィールドとの比較
- StringEqualsPath
によって、入力フィールドを別の入力フィールドと比較できます。状態の変更などを確認するときに使用できます。
例"Variable": "$.foo", "StringEqualsPath": "$.bar"詳細
こちらから確認できます。
まとめ
今回は
Choiceによる分岐を行なってみましたが、ここまで来ると、ようやくワークフローっぽくなってきた感じがしますね。
ここまでのPart.1〜Part.3の内容だけでも、ある程度のステートマシンが定義できるようになっているかと思います。
次回は、Lambda以外のサービスをタスク定義で呼び出してみたいと思います。サンプルコードリポジトリ



- 投稿日:2020-08-17T22:17:57+09:00
S3の静的ウェブサイトホスティングをRoute53のプライベートホストゾーンからエイリアスする
はじめに
S3の静的ウェブサイトホスティングは便利。
でもエンドポイントがhttp://バケット名.s3-website-ap-northeast-1.amazonaws.comになってしまったりhttps://s3-ap-northeast-1.amazonaws.com/バケット名.comになってしまってイケてない。内部通信くらいはちゃんとしたサービス名をつけてあげたいけど内部通信にドメイン使用量は払いたくない。そんなワガママなあなたに、良い感じの名前でアクセスするコツを書いておく。
さらに、今回の記事では、作った静的ウェブサイトホスティングに対してクロスアカウントでセキュアにアクセスする方法まで書いておく。
Route53のプライベートホストゾーンを使おう
良い感じの名前を付けるのであれば、Route53のプライベートホストゾーンを使えば良い。
プライベートホストゾーンを設定する方法は以前の記事に書いている。
一つ注意しなければいけないのは、S3のエイリアスを作る場合は、「ホスト名=バケット名」になっている必要があるということだ。これをやっておかないと、Route53のホストゾーンでAレコードをS3に紐付けることができない。
Terraformで格納であればこんな感じになる。
name = aws_s3_bucket.my.idとしているのがキモだ。
lifecycleについては後述する。resource "aws_route53_zone" "s3" { provider = aws.to_account name = local.zone_name vpc { vpc_id = data.aws_vpc.to.id } } resource "aws_route53_record" "s3" { provider = aws.to_account zone_id = aws_route53_zone.s3.zone_id name = aws_s3_bucket.my.id type = "A" alias { name = aws_s3_bucket.my.website_domain zone_id = aws_s3_bucket.my.hosted_zone_id evaluate_target_health = true } }作ったエイリアスレコードを他のAWSアカウントと共有してクロスアカウントアクセスを可能にする
さて、せっかく作ったエイリアスレコードなのだから、複数のサービスで共通で使用したくなることがあるかもしれない。ないかもしれないしその可能性が高い。
だが、もしそういう事態が訪れた時には、AWS公式がやり方を紹介してくれている。
このリンクお貼っておくだけでは芸がないので、Terraformで書くとこうなる、を置いておく。resource "aws_route53_vpc_association_authorization" "s3" { provider = aws.to_account vpc_id = data.aws_vpc.from.id zone_id = aws_route53_zone.s3.id } resource "aws_route53_zone_association" "s3" { provider = aws.from_account vpc_id = aws_route53_vpc_association_authorization.s3.vpc_id zone_id = aws_route53_vpc_association_authorization.s3.zone_id }これでterraform applyすると、aws_route53_zoneに指定したVPCが追加される。
しかし、VPCが追加されるということは、aws_route53_zone.s3の.tfファイルとプロパティが合わなくなってしまうということだ。
すると、何が起こるかと言うと、次にapplyするタイミングで、実際のリソースとの差分を検知して、せっかく設定したVPCの設定が削除されてしまう。これを避けるために、aws_route53_zone_association でクロスアカウント設定する場合は、aws_route53_zone に以下の設定を追加する。
resource "aws_route53_zone" "s3" { provider = aws.to_account name = local.zone_name vpc { vpc_id = data.aws_vpc.to.id } lifecycle { ★追加 ignore_changes = [ ★追加 vpc, ★追加 ] ★追加 } ★追加 }これにより、vpcの変更は無視されるようになるため、次に関係のないリソースをapplyする際に差文検知しなくなる。
クロスアカウントアクセスをセキュアにする
さて、静的Webサイトホスティングの用途は千差万別だが、内部のためにクロスアカウントアクセスを設定したのであれば、以下のようにVPCエンドポイント経由のアクセスにして、該当VPCエンドポイント以外からのアクセスを制限をしよう。バケットポリシーでAllowするのであれば、バケット全体のACL自体は
privateでも問題ない。resource "aws_vpc_endpoint" "s3" { provider = aws.from_account vpc_id = data.aws_vpc.from.id service_name = "com.amazonaws.ap-northeast-1.s3" } resource "aws_vpc_endpoint_route_table_association" "s3" { provider = aws.from_account route_table_id = data.aws_route_table.from.id vpc_endpoint_id = aws_vpc_endpoint.s3.id } resource "aws_s3_bucket_policy" "my" { provider = aws.to_account bucket = aws_s3_bucket.my.id policy = <<POLICY { "Version": "2012-10-17", "Statement": [ { "Sid": "AllowVPCEndPointRead", "Effect": "Allow", "Principal": "*", "Action": "s3:*", "Resource": [ "arn:aws:s3:::${local.bucket_name}", "arn:aws:s3:::${local.bucket_name}/*" ], "Condition": { "StringEquals": { "aws:sourceVpce": "${aws_vpc_endpoint.s3.id}" } } } ] } POLICY }
- 投稿日:2020-08-17T19:52:45+09:00
AWS CDKのデプロイで複数のAWSアカウントを使い分ける方法
やりたいこと
- AWS CDKでデプロイする際に、何も設定しない場合、AWS CLIで指定されているアカウントでデプロイを行います
- ただし、お仕事とプライベートでAWS CLIのアカウントを分けたかったり、開発環境と本番環境で異なるアカウントを使用したいということがあるかと思います
- AWS CDKでデプロイする際に、使用するAWSアカウントを明示的に指定できるようにしてみましょう
--profileオプション
- --profileオプションを使えば、AWS CDKを実行するアカウントを指定できます
- こちらの使い方を説明していきます
configを設定する
- ローカルのawsフォルダ以下にコンフィグファイルを新規作成します
- VS Codeを使用する場合は以下コマンドで作成できます
code ~/.aws/config
- 作成されたconfigファイルに以下を記述します
- 「profile XXXX」の「XXXX」に適当な分かりやすい名前をつけましょう
[profile personal] aws_access_key_id = XXXXXXXXX aws_secret_access_key = XXXXXXXX region = ap-northeast-1 [profile work] aws_access_key_id = XXXXXXXX aws_secret_access_key = XXXXXXXX region = ap-northeast-1AWS CDKを実行する
- AWS CDKコマンドに
--profileオプションを付けて実行すれば、指定したアカウントで実行するようになりますcdk diff --profile personal cdk deploy --profile personal cdk destroy --profile personal
- 投稿日:2020-08-17T19:17:52+09:00
dockerでelasticsearchクラスターの検証
dockerでelasticsearchクラスターの検証
前提
- 今回は検証なので色々おかしいとろがあると思います。
検証環境
- cloud
- AWS EC2
- machine type
- Rhel8
- instance type
- t2.xlarge
目的
今回は検証なので
docker hostで
curl 0.0.0.0:9200/_cat/health?v↑叩いた時以下のような出力が得られるようにする
cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent elasctic green 2 1 0 0 0 0 0 0 - 100.0%elastic search container 構築
- とりあえずalpineにjavaとesを入れてみた、imageが大きくなったがとりあえず良しとする
FROM alpine:3.10 ENV ES_HOME=elasticsearch-7.8.1 ENV JAVA_HOME=/usr/lib/jvm/default-jvm/jre EXPOSE 9200 EXPOSE 9300 RUN apk update \ && apk upgrade \ && apk add perl-utils \ su-exec \ openjdk11-jre \ bash \ && wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.8.1-linux-x86_64.tar.gz \ && wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.8.1-linux-x86_64.tar.gz.sha512 \ && shasum -a 512 -c elasticsearch-7.8.1-linux-x86_64.tar.gz.sha512 \ && tar -xzf elasticsearch-7.8.1-linux-x86_64.tar.gz \ && rm -rf /elasticsearch-7.8.1/modules/x-pack-ml \ && rm -rf elasticsearch-7.8.1-linux-x86_64.tar.gz \ && rm -rf elasticsearch-7.8.1-linux-x86_64.tar.gz.sha512 \ && adduser -DH -s /sbin/nologin elasticsearch \ && chown -R elasticsearch:elasticsearch /elasticsearch-7.8.1/docker network 作成
docker network create --driver=bridge --subnet=10.10.0.0/24 escontainer 起動
- node-1(master)
docker run --rm --net es -itd --name alpine-esm1 --privileged -p 9200:9200 -p 9300:9300 --ip 10.10.0.10 alpine-es- node-2(data)
docker run --rm --net es -itd --name alpine-esm2 --privileged --ip 10.10.0.11 alpine-esconfig/elasticsearch.yml
master
cluster.name: elasctic node.name: ${HOSTNAME} network.host: _site_ discovery.seed_hosts: - "10.10.0.10" cluster.initial_master_nodes: - "10.10.0.10" node.master: true node.data: false node.ingest: false node.remote_cluster_client: falsedata
cluster.name: elasctic node.name: ${HOSTNAME} network.host: _site_ discovery.seed_hosts: - "10.10.0.10" cluster.initial_master_nodes: - "10.10.0.10" node.master: false node.data: true node.ingest: false node.remote_cluster_client: falseelasticsearch 起動
su-exec elasticsearch /elasticsearch-7.8.1/bin/elasticsearch↑を各containerで実行
docker host で
curl 0.0.0.0:9200/_cat/health?vまとめ
- 今までそれほど考えていなかったdocker networkの勉強になった。
- ec2上での開発は楽しい。
- 投稿日:2020-08-17T15:54:42+09:00
たくさんのAWS Glue Jobを実行している環境で実行履歴を一覧表示するPythonスクリプト
Glue Jobの実行履歴をコマンドラインのワンライナーで見る方法を以前にブログに書きました。
が、日時の表示がイケてなくて、使いづらかったので、Pythonのスクリプトで書き直しました。
import boto3 # default以外のprofileを使う場合はここで指定 profile = "default" session = boto3.session.Session(profile_name = profile) client = session.client("glue") jobs = client.get_jobs() header = [ "started", "completed", "executionTime", "status", "name", "allocatedCapacity", "maxCapacity", "glueVersion", "errorMessage", ] result = [] for job in jobs["Jobs"]: name = job["Name"] history = client.get_job_runs(JobName = name) for run in history["JobRuns"]: started = run["StartedOn"].strftime("%Y-%m-%d %H:%M:%S") if "CompletedOn" in run: completed = run["CompletedOn"].strftime("%Y-%m-%d %H:%M:%S") else: completed = "" executionTime = str(run["ExecutionTime"]) if executionTime == "0": executionTime = "" status = run["JobRunState"] if "ErrorMessage" in run: errorMessage = run["ErrorMessage"] else: errorMessage = "" allocatedCapacity = str(run["AllocatedCapacity"]) maxCapacity = str(run["MaxCapacity"]) glueVersion = str(run["GlueVersion"]) result.append([ started, completed, executionTime, status, name, allocatedCapacity, maxCapacity, glueVersion, errorMessage, ]) # 起動時間でソート result.sort(key = lambda r: r[0]) # タブ区切りで出力 print("\t".join(header)) for r in result: print("\t".join(r))起動時刻と終了時刻を表示しますが、環境変数
TZに依存したローカルタイムで表示されるようです。
- 投稿日:2020-08-17T13:59:29+09:00
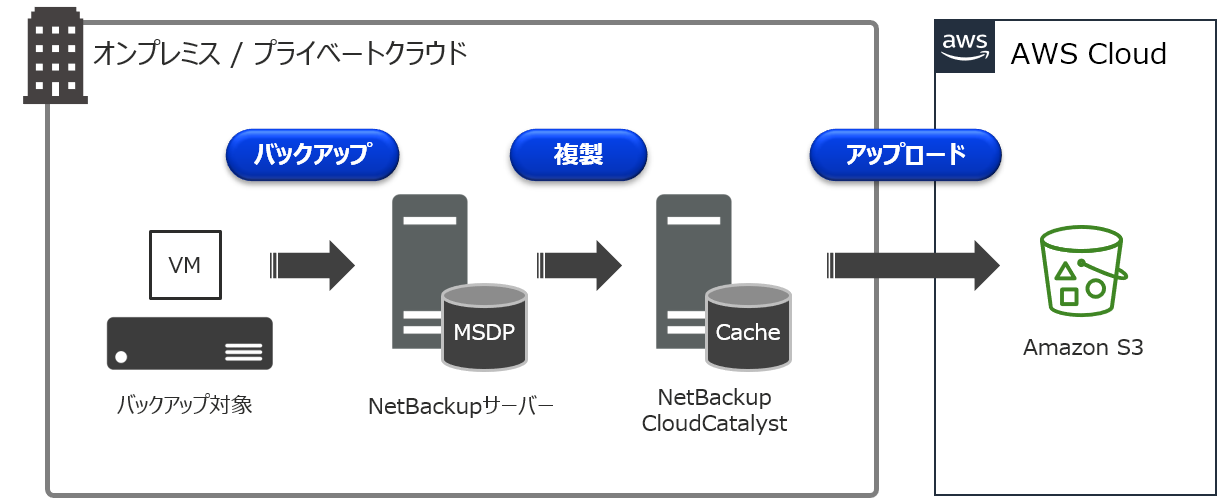
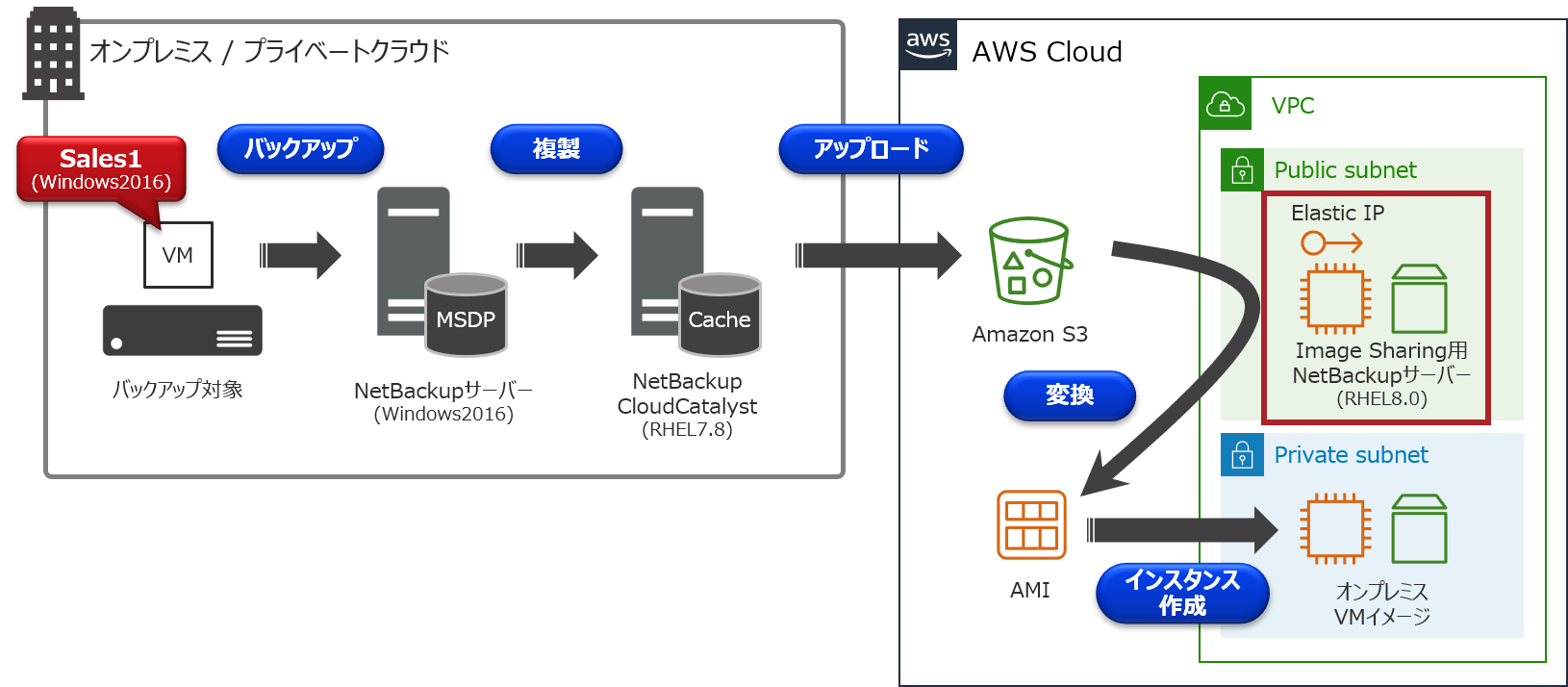
クラウドストレージに保管されたバックアップデータをAWS移行に利用しませんか?【CloudCatalyst編】
はじめに
以前、「NetBackup CloudCatalyst for AWS入門」で、CloudCatalystについて解説を行いました。
CloudCatalystの詳細については、こちらのまとめ記事をご参照下さい。CloudCatalystでは、重複排除されたバックアップデータをAmazon S3などのクラウドストレージに保管することが可能です。
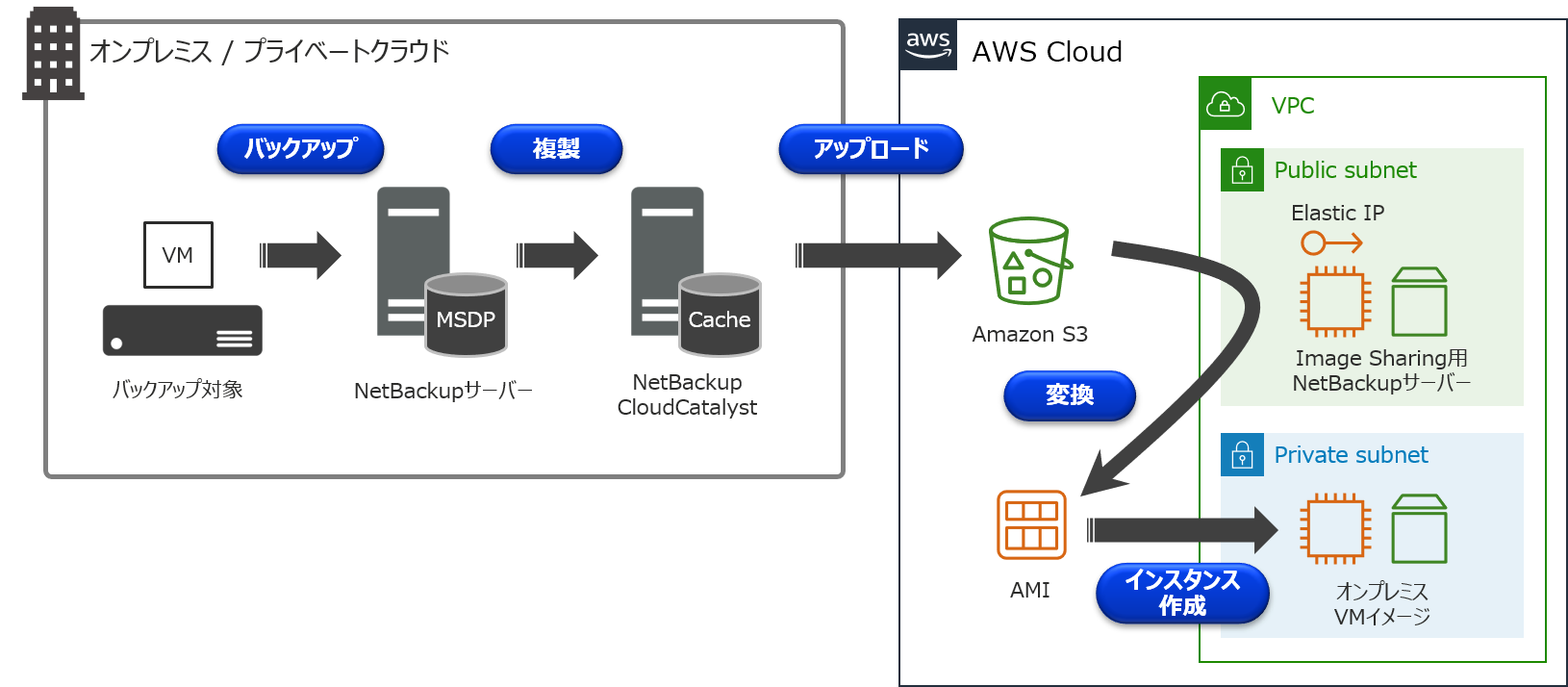
通常、クラウドストレージに保管されたバックアップデータは、オンプレミスに存在するNetBackupサーバーでバックアップ/リストアなどの操作を行うことになります。オンプレミスではなく、クラウド上にNetBackupサーバーを構築することで、このクラウドストレージに保管されているバックアップデータを共有することが可能で、この機能を「Image sharing」と呼んでいます。
ちなみに、NetBackup 8.2でも同様の機能があり、その頃は「Automated disaster recovery」という名称でした。このImage sharingを利用することで、オンプレミス側で取得したVMwareの仮想マシンバックアップ(VADPバックアップ)を、AWSのAMIに変換して、Amazon EC2インスタンスとして起動させるといった使い方が出来ます!
今回は、Image sharing用NetBackupサーバーの構築手順からEC2インスタンス作成までの手順についてお伝えしたいと思います。【 備考:MSDP-Cloudについて 】
重複排除されたバックアップデータをクラウドストレージに複製するには、上述の通り、別途、CloudCatalystサーバーを準備して頂く必要がありました。NetBackup 8.3からMSDP-Cloudという新機能が追加されたのですが、このMSDP-Cloudを利用することで、重複排除およびクラウドストレージへの複製が、1台のメディアサーバーで構成することが可能となりました。(CloudCatalystとは別機能)
MSDP-CloudのサポートOSは、現状、RHELとCentOSになりますが、細かなバージョンや制限事項などは、マニュアルやSCLをご確認下さい。このMSDP-Cloudについては、別記事でご紹介させて頂きます。
Image sharing設定手順
注意事項
今回、ご紹介する手順はあくまで一例となります。
必ず、マニュアルやHardware and Cloud Storage Compatibility Listを参照し、Image sharingの詳細・制限事項について確認するようにして下さい。
- Veritas NetBackup Deduplication Guide - About image sharing in cloud using CloudCatalyst
- Hardware and Cloud Storage Compatibility List
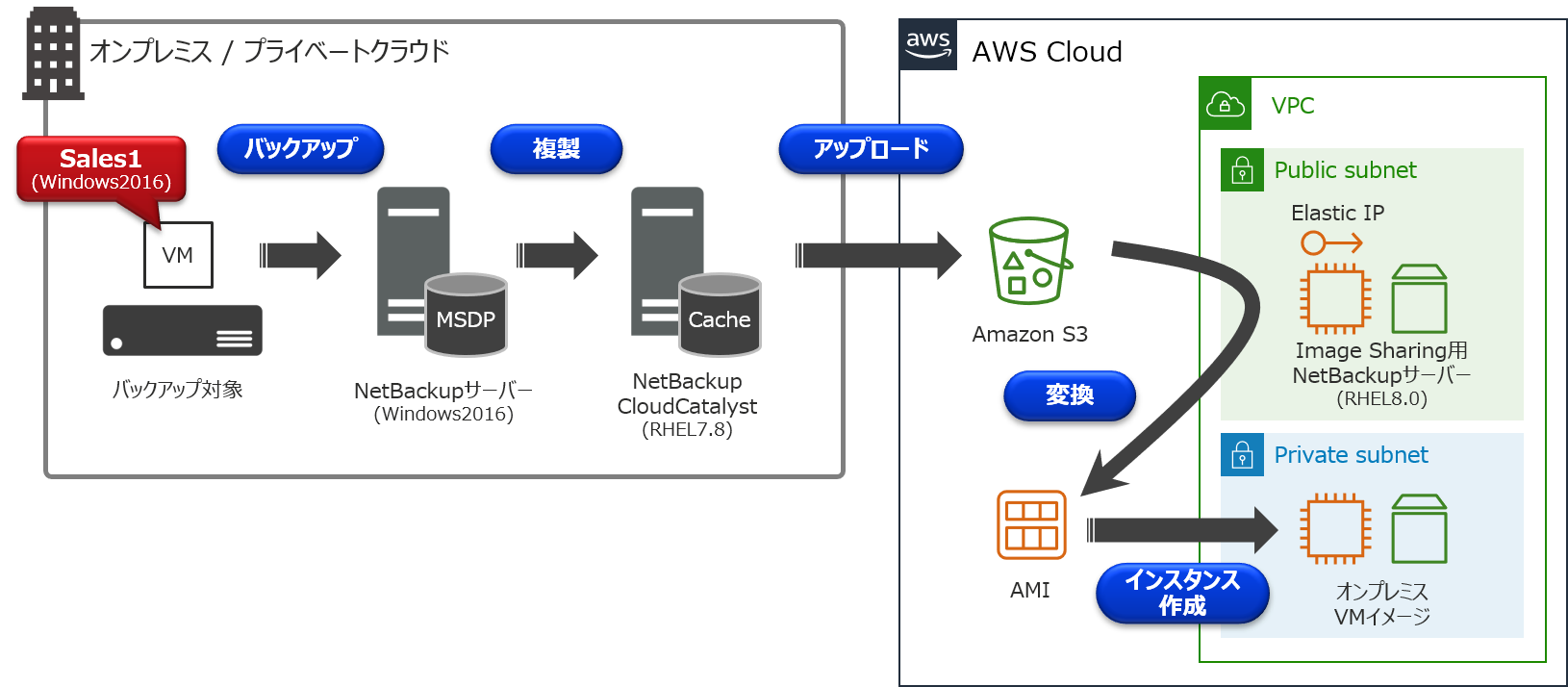
環境について
今回は以下のCloudCatalyst環境を例に、オンプレミスにあるVMware仮想マシンの「Sales1」を、EC2インスタンスとして起動するまでの手順について説明を行います。
- オンプレミス側
- バックアップ対象(VMware仮想マシン)
- ホスト名:Sales1
- Windows 2016
- 80GB HDD:Thin Provision(実使用量 12GB)
- NetBackupサーバー(マスターサーバー 兼 メディアサーバー)
- Windows 2016
- NetBackup 8.3
- NetBackup CloudCatalystサーバー
- RHEL 7.8
- NetBackup 8.3
- AWS側
- Image Sharing用NetBackupサーバー
- Elastic IPアドレス付与
- RHEL 8.0
- NetBackup 8.3
手順の流れ
①オンプレミス側でVADPバックアップを取得
②AWS側でEC2インスタンスを構築
③NetBackup 8.3のインストール
④Image sharing用NetBackupサーバーの構成
⑤Amazon S3に保存されているバックアップデータの確認
⑥バックアップデータをAMIに変換
⑦AMIからAmazon EC2インスタンスを起動詳細手順
①オンプレミス側でVADPバックアップを取得
オンプレミス側で「Sales1」のVADPバックアップを取得します。
CloudCatalystの構築やバックアップ手順などは、まとめ記事をご参照下さい。なお、NetBackupの管理コンソールですが、現時点では、日本語化パッチが出ていないため、メニューが英語表記となっておりますが、後日、提供される日本語化パッチを適用することで、メニューの日本語化が可能です。
一点、注意事項として、移行元の仮想マシンのファームウェアタイプは「BIOS」にして下さい。
「UEFI」の場合、AMI変換時に失敗しますので、ご注意下さい。②AWS側でEC2インスタンスを構築
Image Sharing用NetBackupサーバーを構築するため、AWS側でEC2インスタンスを構築します。
OSは、RHEL7.3 から RHEL8.0までがサポートされています。
また、以下の設定を実施するようにして下さい。
- セキュリティグループでHTTPSポート:443を有効にします。
- ホスト名を外部のFQDNに変更します。
# hostname ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com
- /etc/hostsファイルを編集します。外部IPアドレス/内部IPアドレス、どちらも外部ホスト名で登録します。
# cat /etc/hosts 18.180.xxx.xxx ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com 192.168.20.238 ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com
- /etc/resolv.confを編集します。内部ドメインの前に外部ドメインを検索するように変更します。
# cat /etc/resolv.conf search ap-northeast-1.compute.amazonaws.com ap-northeast-1.compute.internal nameserver 192.168.0.2
- Python 2.x系がインストールされていることを確認します。もし、インストールされていない場合、Python 2.x系を導入して下さい。
# which python /usr/bin/python # python -V Python 2.7.16③NetBackup 8.3のインストール
NetBackup8.3のインストールガイドに従って、マスターサーバーとしてインストールを行います。
また、NetBackupのサーバー名は先ほど設定したホスト名にして下さい。④Image sharing用NetBackupサーバーの構成
Image sharing用NetBackupサーバーの構成を行います。
ims_system_config.pyスクリプトを実行することで、Image sharingの構成が可能です。今回は、アクセスキー、シークレットアクセスキーを用いて実行しています。
もし、リージョンが異なるといったエラーが発生する場合は、「-r」オプションを付与して、Amazon S3のリージョンを指定して実行してみて下さい。構成完了までに10分ほど掛かります。
【実行コマンド】 # python /usr/openv/pdde/pdag/scripts/ims_system_config.py -k <AWS_access_key> -s <AWS_secret_access_key> -b <name_S3_bucket> -r <bucket_region> 【実行例】 # python /usr/openv/pdde/pdag/scripts/ims_system_config.py -k ***** -s ***** -b vrts-cloudcatalyst-test001 -r ap-northeast-1 *****************************IMPORTANT TIPS!********************************* Ensure that the hostname "ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com" is in the FQDN format. If the hostname is not in the FQDN format, the webservice might fail. Enter Y to continue or any other key to reset:Y INFO - Confirm hostname same to FQDN INFO - Begin checking the KMS encryption status in the cloud storage... WARNING - KMS encryption is disabled in the cloud storage. Disaster recovery will not use the KMS mode. INFO - Completed checking the KMS encryption status in the cloud storage. INFO - Begin syncing up sys inodes... INFO - Completed syncing up sys inodes. INFO - Begin configuring web service... INFO - Completed configuring web service. INFO - Begin creating storage server... INFO - [CMD]:/usr/openv/netbackup/bin/admincmd/csconfig cldinstance -as -in amazon.com -sts ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -ssl 2 INFO - [CMD]:/usr/openv/netbackup/bin/admincmd/nbdevconfig -creatests -storage_server ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -stype PureDisk_amazon_rawd -media_server ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -st 9 INFO - [CMD]:/usr/openv/volmgr/bin/tpconfig -dsh -stype PureDisk_amazon_rawd INFO - [CMD]:/usr/openv/volmgr/bin/tpconfig -add -storage_server ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -stype PureDisk_amazon_rawd -sts_user_id xxx INFO - [CMD]:/usr/openv/netbackup/bin/admincmd/nbdevconfig -getconfig -stype PureDisk_amazon_rawd -storage_server ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com INFO - [CMD]:/usr/openv/netbackup/bin/admincmd/nbdevconfig -setconfig -stype PureDisk_amazon_rawd -storage_server ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -configlist /tmp/imagesharing_sts_config.txt INFO - [CMD]:/usr/openv/netbackup/bin/admincmd/nbdevconfig -previewdv -storage_server ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -stype PureDisk_amazon_rawd -media_server ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -dv vrts-cloudcatalyst-test001 -dvlist /tmp/imagesharing_dvlist.txt INFO - [CMD]:/usr/openv/netbackup/bin/admincmd/nbdevconfig -createdv -storage_server ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -stype PureDisk_amazon_rawd -dv vrts-cloudcatalyst-test001 -config 'region:ap-northeast-1' INFO - [CMD]:/usr/openv/netbackup/bin/admincmd/nbdevconfig -createdp -storage_servers ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -stype PureDisk_amazon_rawd -dp amazon_dp -dvlist /tmp/imagesharing_dvlist.txt INFO - [CMD]:/usr/openv/netbackup/bin/admincmd/bpstuadd -label amazon_dp_stu -odo 0 -dt 6 -dp amazon_dp -nodevhost -cj 20 -mfs 51200 INFO - Completed creating storage server. INFO - Begin verifying web service... INFO - [CMD]:/usr/openv/pdde/vpfs/bin/vpfs_config.sh --create_spws_self_signed_certs --storagepath /storage/storage --hostname ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com --upgrade INFO - [CMD]:/usr/openv/pdde/vpfs/bin/nb_admin_tasks --get_self_cert INFO - Completed verifying web service.⑤Amazon S3に保存されているバックアップデータの確認
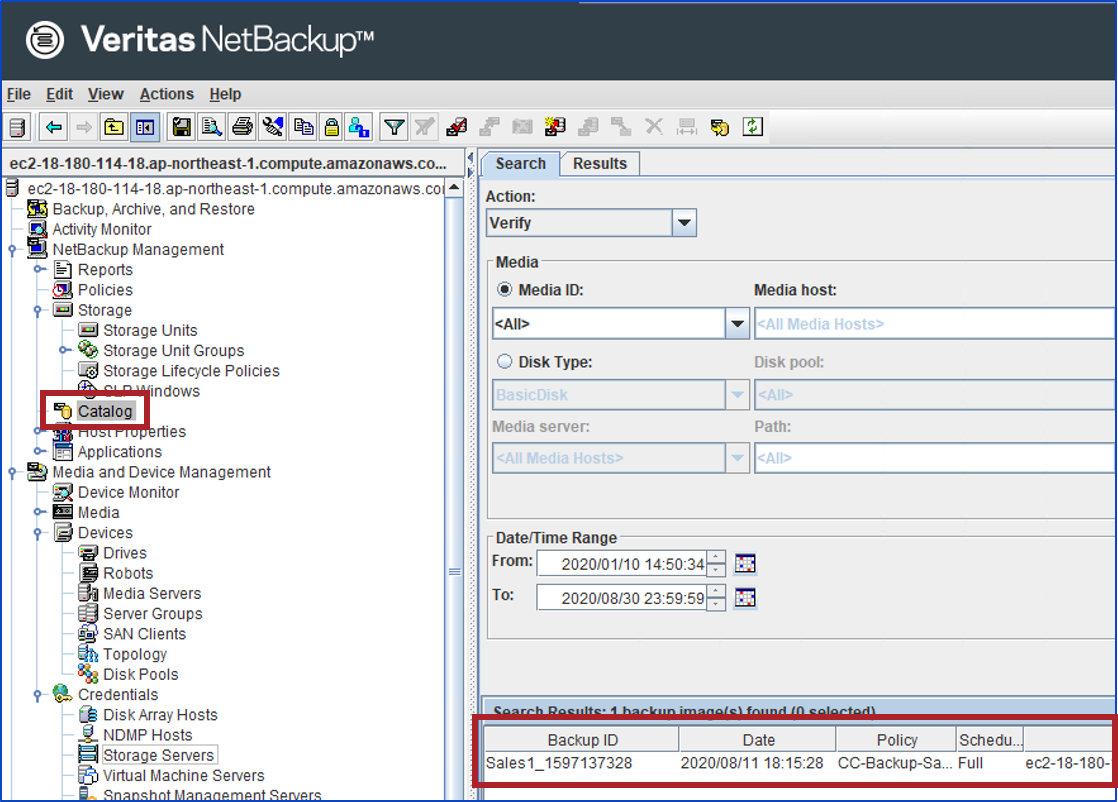
④のスクリプトが正常完了すれば、Amazon S3に保管されているバックアップデータを確認することが出来ます!
では、実際にSales1が表示されるかを確認してみましょう。まず、NetBackupにログインします。
もし、パスワードに特殊文字を用いている場合、シングルクォーテーション「'」で囲んで下さい。【実行コマンド】 # /usr/openv/netbackup/bin/admincmd/nbimageshare --login <username> <password> 【実行例】 # /usr/openv/netbackup/bin/admincmd/nbimageshare -login root 'PASSWORD' Login successful.Amazon S3に保管されているバックアップデータを確認してみます。
【実行コマンド】 # /usr/openv/netbackup/bin/admincmd/nbimageshare -listimage 【実行例】 # /usr/openv/netbackup/bin/admincmd/nbimageshare -listimage { "meta": { "pagination": { "count": 1, "last": 0, "next": 0, "limit": 0, "offset": 0, "prev": 0, "first": 0 } }, "data": [ { "attributes": { "backupTime": 1597137328, "resumeNumber": 1, "importStatus": "NotImported", "copyNumber": 2, "client": "Sales1", "policyType": "VMware", "policy": "CC-Backup-Sales1", "backupID": "Sales1_1597137328", "scheduleType": "Full" }, "type": "cloudImages", "id": "0" } ] }無事、オンプレミスでバックアップしたSales1が、AWS側にあるNetBackupから確認出来ました!!!
⑥バックアップデータをAMIに変換
無事にバックアップデータが確認出来ましたので、Sales1をAMIに変換したいと思います。
まず、NetBackupにバックアップイメージのインポートを行います。
⑤で出力された値を、引数として渡します。★注意事項★
マニュアルでは、オプションが「--singleimport」となっていますが、正しくは「--single-import」(singleとimportの間にハイフンが入る)となりますので、ご注意下さい。【実行コマンド】 # /usr/openv/netbackup/bin/admincmd/nbimageshare --single-import <client> <policy> <backupID> 【実行例】 # /usr/openv/netbackup/bin/admincmd/nbimageshare --single-import Sales1 CC-Backup-Sales1 Sales1_1597137328 { "type": "importResponse", "id": "6", "attributes": { "images": [ { "status": "0", "policy": "CC-Backup-Sales1", "backupID": "Sales1_1597137328" } ] } }bpdbjobsコマンドで、ジョブの実行状態が分かります。
StateがDoneで、Status 0で終了することを確認します。# /usr/openv/netbackup/bin/admincmd/bpdbjobs JobID Type State Status Policy Schedule Client Dest Media Svr Active PID FATPipe 6 Import Done 0 CC-Backup-Sales1 Sales1 ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com 22437ちなみに、リモート管理コンソールなどで、NetBackupサーバーに接続し、カタログ検索を行うと、バックアップ情報が表示されることを確認することが出来ます。(こちらのリモート管理コンソールも、①での説明と同様、後日、提供される日本語化パッチを適用することで、メニューの日本語化が可能です)
これで、準備万端です!
以下のコマンドを実行して、Sales1のAMI変換を行います。★注意事項★
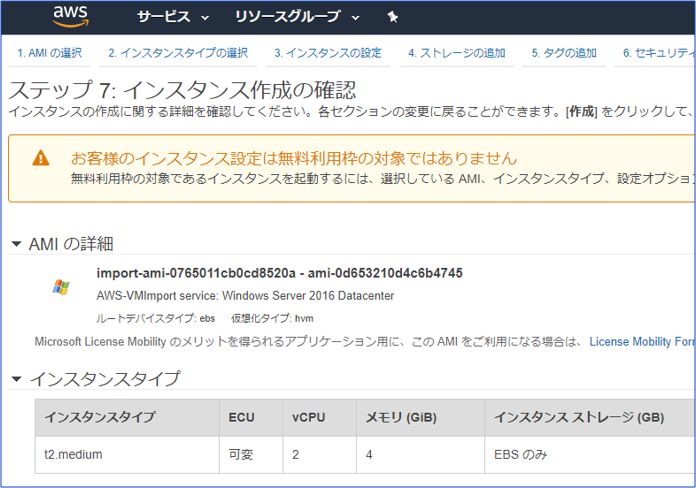
マニュアルでは、オプションが「--recovervm」となっていますが、正しくは「--recover-vm」(recoverとvmの間にハイフンが入る)となりますので、ご注意下さい。【実行コマンド】 # /usr/openv/netbackup/bin/admincmd/nbimageshare --recover-vm <client> <policy> <backupID> 【実行例】 # /usr/openv/netbackup/bin/admincmd/nbimageshare --recover-vm Sales1 CC-Backup-Sales1 Sales1_1597137328 { "type": "recoverEc2Response", "id": "7", "attributes": { "status": "0", "policy": "CC-Backup-Sales1", "backupId": "Sales1_1597137328" } }上記コマンド実行後、バックアップデータがAMIに変換され、AWS管理コンソールから確認することが可能です。
なお、AMI変換までに少し時間が掛かります。
今回の環境の場合、上記ジョブが完了するのに27分25秒の時間が掛かりました。⑦AMIからAmazon EC2インスタンスを起動
AWS管理コンソールにログインし、Sales1のAMIが登録されていることを確認します。
無事に登録されてますね!ここまで来れば、バックアップデータのAMI変換は無事に終わっていますので、EC2インスタンスとして正常に起動するかを確認します。
【EC2インスタンスの作成画面】
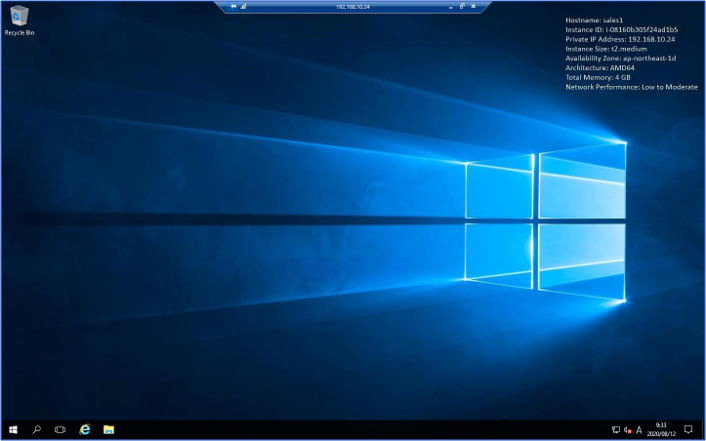
【Sales1のデスクトップ画面】
AWS上で無事にSales1インスタンスが起動していますね!
この後は環境に合わせて、アプリの動作確認などを実施して下さい。おわりに
いかがでしたでしょうか?
思いのほか、簡単にAWSへ移行することが実感頂けたのではないでしょうか。AWSへの移行は様々な方法がありますが、今回ご紹介した方法であれば、既存環境に手を加える必要はありません。
そのため、既存環境への影響を与えることなく、安全にAWSへの移行が可能です。有事の際のバックアップだけではなく、AWS移行にもバックアップを是非ご活用下さい!
商談のご相談はこちら
本稿からのお問合せをご記入の際には「コメント/通信欄」に#GWCのタグを必ずご記入ください。
ご記入いただきました内容はベリタスのプライバシーポリシーに従って管理されます。その他のリンク
【まとめ記事】ベリタステクノロジーズ 全記事へのリンク集もよろしくお願い致します!

- 投稿日:2020-08-17T13:17:17+09:00
aws sts get-caller-identityしたときにunknown output typeが表示されたはなし
はじめに
aws sts get-caller-identityをしたらunknown output typeが表示されて、ちょっとはまったので忘れないようにメモ。おきたこと
そもそも
aws sts get-caller-identityをしようとしたら、間違えてaws configureをしてしまいました。(なぜかよくやっちゃう。)なので、いつも通りそのままEnter押していきます。C:\>aws configure AWS Access Key ID [******************ID]: AWS Secret Access Key [*****************KEY]: Default region name [ap-northeast-1]: Default output format [JSON]:そして、ようやくやりたかったコマンドを打ってみたらUnknown output typeと言われてしまいました。
C:\>aws sts get-caller-identity Unknown output type: JSONJSON であってるのにおかしいなと思いながら、とりあえずもう1回
aws configureをして小文字の json に変更してみます。C:\>aws configure AWS Access Key ID [******************ID]: AWS Secret Access Key [*****************KEY]: Default region name [ap-northeast-1]: Default output format [JSON]: jsonできた。
C:\>aws sts get-caller-identity { "UserId": "**********UserId", "Account": "*********Account", "Arn": "arn:aws:iam::**************:user/me" }おわりに
なるほど。小文字なのか。
(じゃあなんでこの前aws configureしたときは何も問題なかったんだろう…?)
- 投稿日:2020-08-17T13:15:41+09:00
AWS Chatbot + Lambda(Go)でSlackからRDSを操作する
はじめに
RDSを常時起動させておく必要がないシステムがあります。そのシステムを使う時だけRDSを起動させたいのですが、使用する人はIAMユーザを持っていないため、コンソールから起動、停止できない、ということがありました!
そこで、SlackからRDSの操作をできるようにしました!
Chatbotを紐づけたSlackのチャンネルからコマンドを実行し、Lambda関数を呼び出すことで、RDSの操作をします。
やりたいこと
Slackからやりたいことは以下の3つです。
- RDSの起動
- RDSの停止
- RDSのステータスの確認
方法検討
調べてみると、Slackから実行する方法が2つ見つかりました。
- API Gatewayを使う方法(Slash Commandsの作成)
- AWS Chatbotを使う方法
今回は、2020年4月にGAになった、使ってみたかった、Slackとの組み合わせが素晴らしいらしいという観点からAWS Chatbotを使ってみることにしました!
AWS Chatbotってなに?
公式サイトによると、次のように説明されています。
AWS Chatbot は、Slack チャンネルや Amazon Chime チャットルームで AWS のリソースを簡単にモニタリングおよび操作できるようにしてくれるインタラクティブエージェントです。AWS Chatbot を使用すると、アラートを受信することや、診断情報の取得、AWS Lambda 関数の呼び出し、AWS サポートケースの作成を行うコマンドを実行することができるようになります。
Chatbotでできること
今回は、Slackチャンネルから操作を行うようにしたいです。
AWS Chatbotは、AWSサービスの読み取り専用コマンドをサポートしています。AWSリソースを作成、削除、または構成するコマンドは実行できません。ただし、一部のサービスは読み取りもサポートしていません。IAM、AWS Security Token Service、AWS Key Management ServiceなどはChatbotを通じて読み取りコマンドの呼び出しも行えません。もちろん作成、削除、構成のコマンドも使えません。
RDSの起動/停止はChatbotから操作できず、ステータスの確認はChatbotからコマンドで操作できます。ただし、取得できる大量の情報からステータスのみを抽出したかったのでChatbotでLambda関数の呼び出しを実行し、Lambda関数からそれぞれの操作を行うようにします。
参考
料金
Chatbot自体には料金はかかりません!
AWS Chatobot には追加料金はかかりません。お支払いは基盤となるサービス (Amazon Simple Notification Service、AWS GuardDuty、AWS Security Hub など) の使用に対してのみであり、AWS Chatbot を使用していない場合と同様です。また、最低料金や前払いの義務はありません。
参考:https://aws.amazon.com/jp/chatbot/pricing/
今回の構成だとLambdaの料金のみがかかります。
構成図
構成は下図の通りです。本記事では、Slack、AWS Chatbot、Lambdaにフォーカスしています。
やってみる
Lambda関数の作成
今回は操作ごとに3つのLambda関数を作成しました。
- RDSの起動
- RDSの停止
- RDSのステータスの確認
IAMロール
ターゲットRDSの起動、停止、情報を取得するポリシーを作成してアタッチします。今回作る3つのLambda関数にこのロールを設定しました。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "rds:DescribeDBInstances", "rds:StopDBInstance", "rds:StartDBInstance" ], "Resource": "<ターゲットRDSのarn>" } ] }ソースコード
※それぞれクリックしたらソースコードが見れます。
RDS起動
package main import ( "fmt" "log" "os" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/rds" "github.com/aws/aws-sdk-go/service/rds/rdsiface" ) func StartDBInstance(svc rdsiface.RDSAPI) { // os.Getenv()でLambdaの環境変数を取得 InstanceID := os.Getenv("InstanceID") // DB識別子 InstanceIDP := aws.String(InstanceID) input := &rds.StartDBInstanceInput{ DBInstanceIdentifier: InstanceIDP, } result, err := svc.StartDBInstance(input) if err != nil { panic(err.Error()) } // 結果を出力 fmt.Println(result) } /************************** 処理実行 **************************/ func run() (interface{}, error) { log.Println("--- RDS自動起動バッチ 開始") log.Println("----- セッション作成") svc := rds.New(session.Must(session.NewSession())) log.Println("----- インスタンス起動 実行") StartDBInstance(svc) log.Println("--- RDS自動起動バッチ 完了") res := "RDSを起動しています。" return res, nil } /************************** メイン **************************/ func main() { lambda.Start(run) }
RDS停止
package main import ( "fmt" "log" "os" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/rds" "github.com/aws/aws-sdk-go/service/rds/rdsiface" ) func StopDBInstance(svc rdsiface.RDSAPI) { // os.Getenv()でLambdaの環境変数を取得 InstanceID := os.Getenv("InstanceID") // DB識別子 InstanceIDP := aws.String(InstanceID) input := &rds.StopDBInstanceInput{ DBInstanceIdentifier: InstanceIDP, } result, err := svc.StopDBInstance(input) if err != nil { panic(err.Error()) } // 結果を出力 fmt.Println(result) } /************************** 処理実行 **************************/ func run() (interface{}, error) { log.Println("--- RDS自動停止バッチ 開始") log.Println("----- セッション作成") svc := rds.New(session.Must(session.NewSession())) log.Println("----- インスタンス停止 実行") StopDBInstance(svc) log.Println("--- RDS自動停止バッチ 完了") res := "RDSを停止しています。" return res, nil } /************************** メイン **************************/ func main() { lambda.Start(run) }
RDSステータス取得
package main import ( "fmt" "log" "os" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/rds" "github.com/aws/aws-sdk-go/service/rds/rdsiface" ) func DescribeDBStatus(svc rdsiface.RDSAPI) interface{} { // os.Getenv()でLambdaの環境変数を取得 InstanceID := os.Getenv("InstanceID") // DB識別子 InstanceIDP := aws.String(InstanceID) input := &rds.DescribeDBInstancesInput{ DBInstanceIdentifier: InstanceIDP, } result, err := svc.DescribeDBInstances(input) if err != nil { panic(err.Error()) } status := *result.DBInstances[0].DBInstanceStatus return status } /************************** 処理実行 **************************/ func run() (interface{}, error) { log.Println("--- RDSステータス取得バッチ 開始") log.Println("----- セッション作成") svc := rds.New(session.Must(session.NewSession())) log.Println("----- RDSステータス取得 実行") status := DescribeDBStatus(svc) log.Println("--- RDSステータス取得バッチ 完了") return status, nil } /************************** メイン **************************/ func main() { lambda.Start(run) }Slackのチャンネル準備
まずは自分のDMの中で試してみようと思いましたが、上手くいきませんでした。
WebhookでSlackに通知するときは自分のDMに送信することができますが、Chatbotは自分のDMで動かすことができません!なのでチャンネルを作成するようにしましょう。操作できる人を限定するために、今回はプライベートチャンネルを作成しました。プライベートチャンネルの場合は、下記のコマンドを対象のチャンネルで実行して、Chatbotユーザを招待してください。(試せていませんが、パブリックチャンネルの場合は不要みたいです。)
/invite @aws
マスキング部分にはチャンネル名が入ります。
Slackの準備はこれでOKです!Chatbotの作成
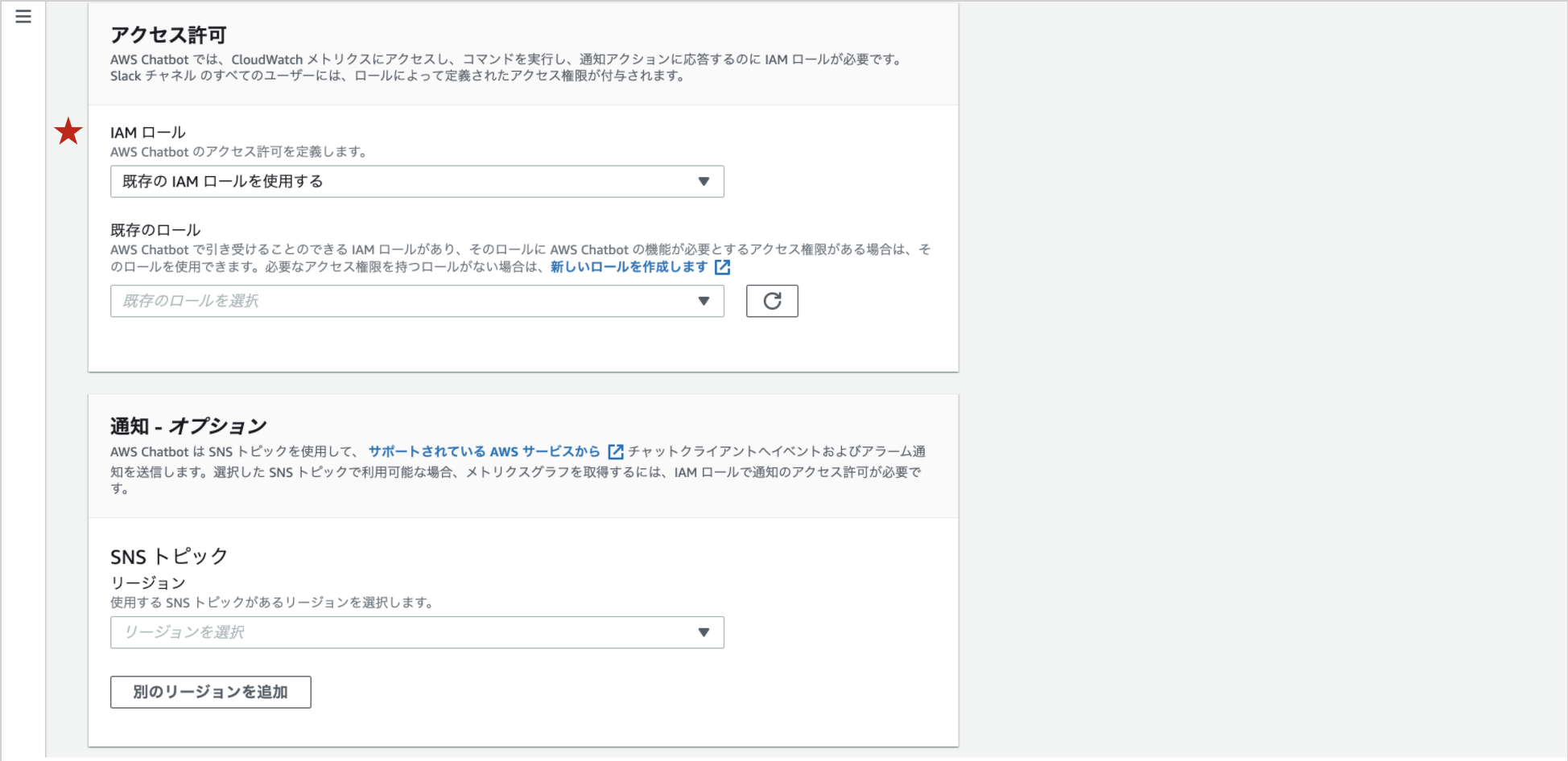
IAMロール
Chatbotのチャンネル設定時に、いくつかポリシーテンプレートが用意されており、その中のLambda呼び出しコマンドのアクセス許可というポリシーを選択してIAMロールを簡単に作成することができます。
Lambda呼び出しコマンドのアクセス許可のポリシーテンプレートを使用すると下記のようなポリシーが作成されます。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "lambda:invokeAsync", "lambda:invokeFunction" ], "Resource": [ "*" ] } ] }ただ、リソースは選択できないので、全てのLambda関数の実行権限があるポリシーがアタッチされます。また、非推奨?とされている
invokeAsyncの権限もついています。ポリシーテンプレートで作成したとしても作成後に編集は可能ですが、実行できるLambda関数も絞りたかったので、今回は自分で作成しました。
ユースケースは
AWS Chatbot - AWS Chatbotを選択します。そして、このポリシーを作成して、Chatbot用のロールにアタッチします。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "lambda:InvokeFunction", "Resource": [ "<RDS起動Lambdaのarn>", "<RDS停止Lambdaのarn>", "<RDSステータス取得Lambdaのarn>" ] } ] }Chatbotの作成
Chatbotの作成を行います!
チャットクライアントで
Slackを選択し、クライアント設定をクリックします。そして、先ほど作成したチャンネルのあるワークスペースにサインインして、AWS Chatbotがワークスペースにアクセスできるように権限付与します。
新しいチャネルを設定から設定を行います。
補足事項に沿って名前の設定、Slackのチャンネルの登録を行います。ちなみに、ここで設定する名前はAWS上で識別するのために使うもので、SlackのApp Nameではないです。
IAMロールには先ほど作成したロールを選択します。
今回は通知は行わないので、通知欄は特に設定しません。これでChatbotの作成も完了です!
実行結果
実行はSlackのメッセージで下記のようにコマンドを送信します。
@aws service command --options今回は、ChatbotでLambda関数の呼び出しを行うので次のコマンドを実行します。
@aws lambda invoke --function-name <Lambda関数名> --region ap-northeast-1Lambda関数名にはそれぞれの関数名を入力してください。
RDSの起動
起動
起動用のLambda関数名を入れて上記のコマンドを実行するとWould you like me to do so?と確認されるので、[Yes]を選択します。
これでRDSを起動させることができます。
ステータス確認
起動が完了しました。ステータスを確認してみましょう。
ターゲットのRDSステータスのみが返ってきて、Payloadに入るようになっています。availableになっているのでRDSの起動が完了して利用可能なことがわかります!
ステータスの種類と意味はこちらへ
RDSの停止
停止
停止用のLambda関数名を入れたコマンドを実行して、[Yes]を選択します。
ステータス確認
停止が完了しました。ステータスを確認してみましょう。
PayloadがstoppedになっているのでRDSが停止していることがわかります。
無事Slackから操作ができていることを確認できました!
その他のコマンド
Chatbotのコマンドの全体的なことが知りたいときは次のコマンドを実行します。
@aws helpRDSのコマンドオプションが知りたいとき
あるAWSサービスについてのコマンドオプションが知りたいときは次のコマンドを実行します。
@aws rds --helpただ、一覧に表示されてもChatbotに実行権限をつけていないと実行はできません。また、実行権限をつけていてもChatbotでできることで記載した通り、基本的には読み取り専用コマンドをサポートしているので、作成、削除、または構成するコマンドなどは実行できません。
もっと簡単に実行したい
今回使ったSlackは無料版だったので使えなかったのですが、有料版だとワークフロービルダーというSlackの機能を使うことができます。このワークフローを使うとコマンドを打たなくて良く、やりたい操作を選択するだけで実行できるので良さそうです。
参考
おわりに
すごく簡単にSlackとAWSを連携することができました!Chatbot自体にもロールを付与するので、指定した操作以外はできなくなっています。IAMユーザーがない人でも、操作できるようになるのは魅力的ですね!他のサービスでも応用ができるので、今後もいろんなところで使えそうです!
おまけ
ステータスの確認をLambdaを介さずに行ってみます。
Chatbotのポリシー追加
先ほど作成したChatbot用のポリシーに、RDSインスタンスの情報を取得する権限を追加します。
{ "Sid": "VisualEditor1", "Effect": "Allow", "Action": "rds:DescribeDBInstances", "Resource": "*" }実行結果
@aws rds describe-db-instances --db-instance-identifier <DB識別子> --region ap-northeast-1
取得した情報はまだまだこの下も続いています。
結果は長いですが、DBInstanceStatusを確認することでステータスの確認ができます。今回はステータスのみを抽出するためにLambda関数を使いましたが、AWS CLIのように
--queryが使えるようになるといいなあと思いました。












- 投稿日:2020-08-17T12:44:58+09:00
AWSアカウントを作成したら最低限にやること(アカウント保護)
AWS Organizationsを個人利用の中で使う際に、久しぶりにAWSアカウントを複数作成したので、その際にアカウント保護の最低限の項目をまとめてみました。
最低限やること(rootユーザーのアカウント保護)
AWSアカウントを作成したら
①【マイアカウント】から、AWSアカウント(rootユーザー)のパスワードを変更する。パスワードは長めがオススメ(個人的には40桁の英数字特殊記号ランダム)
②IAMへ移動し、【ダッシュボードを確認】し5つの✅項目を満たす。
②-1) MFAの有効化を設定
②-2) IAMパスワードポリシーの適用
②-3) IAMユーザーの作成
②-4) グループを指定したアクセス許可の割り当てIAMユーザーの作成に際して(IAMユーザーのアカウント保護)
上記の②-3でIAMユーザーを作成した際にも注意が必要です。IAMユーザーの作成においては、個人利用に際しても不用意に強い権限を与えないことと、ユーザー自体の保護が重要です。
やることとしては
【アカウント保護】
・IAMユーザーのパスワードを強化(IAMパスワードポリシーに準拠)
・IAMユーザーのMFA有効化
【最低限の権限】
・権限のポリシーはユーザーにではなく、グループにアタッチする。
・グループにアタッチする権限は、Admin権限ではなく、読み取り専用のAWS管理ポリシーと、Adminロールにスイッチロールするためのカスタマー管理ポリシーをアタッチする。普段は読み取り専用のAWS管理ポリシーでコンソールを自由に閲覧し、何か作成や削除などの作業をする際に、スイッチロールをしてAdmin権限をもったAdminロールにスイッチロールをして作業をするとよい。
その後
上記の項目を全て満たしたら、とりあえずrootユーザーからはサインアウトをし、作成したIAMユーザーでログインし操作をすることで、極力rootユーザーでの操作は控える。
今回は簡単なアカウント保護の超最低限の項目だけ書きましたが、アカウントの管理にはまだまだ取り入れるサービスが山程あります。予算管理も重要です。次回は、予算系の管理や、AWSの各種サービスを使ってのアカウントの監視や通知などの記事も書けたら書こうと思います〜。
- 投稿日:2020-08-17T09:50:10+09:00
AWS CLIで出力される文字列のダブルクォートを外す方法
--output textをつければ外れます。つけない場合.sh$ aws lambda get-function \ --function-name $NAME \ --query "Configuration.FunctionArn" > "arn:aws:lambda:ap-northeast-1:1234567890:hoge"つけた場合.sh$ aws lambda get-function \ --function-name $NAME \ --query "Configuration.FunctionArn" \ --output text > arn:aws:lambda:ap-northeast-1:1234567890:hogeデフォルトのJSON形式は常にダブルクォートに囲まれているため、前のコマンドで出力された値を次のコマンドにパイプするには不都合です。
--output textをつけることで出力内容がJSONからテキストに変更され、ダブルクォートが外れます。
- 投稿日:2020-08-17T08:10:28+09:00
【AWS】RDS ProxyをCloudFormationで構築する
RDS Proxyが2020/6/30にGAされましたね。
最近RDS Proxyに触れる機会があり、サクッと消せるようにCloudFormation(以下CFnと略)を使って構築しました。その時書いたCFnテンプレートを一例としてご紹介します。RDS Proxyの詳細や運用の勘所については説明しませんので、公式ドキュメントなどを参照してください。
要件
- プロキシ先はAurora
- ユーザとパスワードの一般的な認証
- Secrets Managerを利用
- TLSは必須ではない
CFnテンプレート
テンプレートが100行超えたのでGitHub Gistにアップロードしました。
テンプレートの全容を見たい方はhomoluctus/rds_proxy.ymlを参照してください。解説
Parameters
Parameters: # DB Proxy ProxyName: Type: String ProxyEngineFamily: Type: String AllowedValues: - MYSQL - POSTGRESQL ProxyIdleClientTimeout: Type: Number ProxyRequireTLS: Type: String AllowedValues: - true - false Default: false ProxyVpcSecurityGroupIds: Type: List<AWS::EC2::SecurityGroup::Id> ProxyVpcSubnetIds: Type: List<AWS::EC2::Subnet::Id> # DB Proxy Target Group ProxyTargetConnectionBorrowTimeout: Type: Number ProxyTargetMaxConnectionsPercent: Type: Number ProxyTargetMaxIdleConnectionsPercent: Type: Number ProxyTargetDBClusterIdentifiers: Type: CommaDelimitedList # Secrets Manager SecretsManagerRoleName: Type: String SecretsManagerName: Type: String SecretsManagerKMSKeyId: Type: String SecretsManagerManagedPolicyName: Type: StringResources
DB Proxy
RDSProxy: Type: "AWS::RDS::DBProxy" Properties: Auth: # Secrets Managerを利用してユーザ名とパスワードで認証 # 予めSecretsは作成しておく必要があり - AuthScheme: SECRETS IAMAuth: DISABLED SecretArn: !Sub "arn:aws:secretsmanager:${AWS::Region}:${AWS::AccountId}:secret:${SecretsManagerName}" # 作成するRDS Proxyの名前 DBProxyName: !Ref ProxyName # 2020/08/17時点でMySQLとPostgreSQLがサポートされている EngineFamily: !Ref ProxyEngineFamily # Proxyとクライアント間の接続がアイドル状態の時に接続切断するまでの秒数 IdleClientTimeout: !Ref ProxyIdleClientTimeout # TLSが必須かどうか RequireTLS: !Ref ProxyRequireTLS # RDS Proxyに設定するIAM Role # 今回はSecrets Managerから値を取得して復号可能なRoleをアタッチ RoleArn: !GetAtt SecretsManagerRole.Arn # RDS Proxyにアタッチするセキュリティグループ VpcSecurityGroupIds: !Ref ProxyVpcSecurityGroupIds # RDS Proxyを構築するVPC Subnet VpcSubnetIds: !Ref ProxyVpcSubnetIdsDB Proxy Target Group
今回はRDS Proxyの裏にはRDS Auroraが存在すると仮定します。
RDSProxyTargetGroup: Type: "AWS::RDS::DBProxyTargetGroup" Properties: # コネクションプールの設定 ConnectionPoolConfigurationInfo: # コネクションプールが使用可能になるまでの待機秒数 # Proxyが使用可能な最大接続数を使い切っていて、その全接続を使用中の場合に適用される ConnectionBorrowTimeout: !Ref ProxyTargetConnectionBorrowTimeout # RDS 最大接続数のうちProxyが使用可能な接続数の割合 MaxConnectionsPercent: !Ref ProxyTargetMaxConnectionsPercent # RDSへの接続数のうちアイドル状態の接続数の割合 # 上限はMaxConnectionsPercentで値が大きければ再度接続するオーバーヘッドが減少する MaxIdleConnectionsPercent: !Ref ProxyTargetMaxIdleConnectionsPercent # Proxyが接続するRDS Auroraクラスターの識別子 DBClusterIdentifiers: !Ref ProxyTargetDBClusterIdentifiers # AWS::RDS::DBProxyで作成したRDS Proxyの名前 DBProxyName: !Ref RDSProxy # ターゲットグループ名はdefaultを無条件に指定 # 2020/08/17時点ではdefaultであることが必須 TargetGroupName: defaultIAM Policy
SecretsManagerManagedPolicy: # 使いまわせるようにインラインポリシーではなくユーザ管理のポリシーを作成 Type: "AWS::IAM::ManagedPolicy" Properties: Description: "Get values from Secrets Manager" ManagedPolicyName: !Ref SecretsManagerManagedPolicyName Path: / PolicyDocument: Version: "2012-10-17" Statement: # Secrets ManagerからRDS Proxy用に作成したSecretsを取得 - Effect: Allow Action: - "secretsmanager:GetSecretValue" Resource: !Sub "arn:aws:secretsmanager:${AWS::Region}:${AWS::AccountId}:secret:${SecretsManagerName}" # 取得したSecretsを復号する - Effect: Allow Action: - "kms:Decrypt" Resource: !Sub "arn:aws:kms:${AWS::Region}:${AWS::AccountId}:key/${SecretsManagerKMSKeyId}" Condition: StringEquals: kms:ViaService: !Sub "secretsmanager.${AWS::Region}.amazonaws.com"IAM Role
SecretsManagerRole: Type: "AWS::IAM::Role" Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: # RoleをRDSに渡す - Effect: Allow Principal: Service: - "rds.amazonaws.com" Action: - "sts:AssumeRole" Description: "Use for RDS Proxy" # 作成したユーザ管理ポリシーを指定 ManagedPolicyArns: - !Ref SecretsManagerManagedPolicy Path: / RoleName: !Ref SecretsManagerRoleName終わりに
アンチパターンとされてきたLambda + RDSの構成を解決するRDS Proxyは素晴らしい


ただSQLによってはピン留めとか発生するのでプロダクションで運用する際には慎重に検討した方がいいでしょうReference
- 投稿日:2020-08-17T02:17:58+09:00
S3のアクセスを特定のサービスロールに制限する
概要
AWSのS3に設定するバケットポリシーのお話です。
2パターン用意したので好きな方使うとよいです。特定のサービスロールのみを許可する方法
{ "Version": "2012-10-17", "Id": "{POLICY_ID}", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::{ACCOUNT_ID}:role/{ROLE_NAME}" ] }, "Action": "s3:GetObject", "Resource": "arn:aws:s3:::{REPOSITORY_NAME}/*" } ] }特定のAWSアカウントからのサービスロールを全て許可する方法
{ "Version": "2012-10-17", "Id": "{POLICY_ID}", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": [ "*" ] }, "Action": "s3:GetObject", "Resource": "arn:aws:s3:::{REPOSITORY_NAME}/*", "Condition": { "ArnLike": { "aws:PrincipalArn": [ "arn:aws:iam::{ACCOUNT_ID}:role/*" ] } } } ] }備考
1個目で
{ROLE_NAME}にワイルドカード設定すればいけそうなもんだけどダメでした。