- 投稿日:2020-07-20T23:52:31+09:00
【技術書】独学プログラマー -第1部(1)-
はじめに
他の言語をある程度知っている上で、Pythonの覚えておきたいことを書いています。
目次
- 第1章 イントロダクション
- 第2章 さあ、はじめよう!
- 第3章 プログラミング入門
- 第4章 関数
第1章 イントロダクション
- 作者が、ソフトウェアエンジニアになるために学ばなければならなかったことを全て記している。
プログラミング入門書を読み終えたあと、「次はどうすればいいのか」といった疑問に答えている。
本書の構成
第一部:プログラミング(Python)入門
第二部:オブジェクト指向プログラミング入門
第三部:プログラミングツール入門
第四部:コンピュータサイエンス入門(特に、データ構造とアルゴリズム)
第五部:エンジニアとして仕事を得ること。成長すること。働くときのコツ等情報系の学生は一般に、たっぷり時間をかけて理論を学ぶが、プログラミングの仕方を知らないまま卒業する。しかし、先にプログラミングを学び、それがどんな理論で動いているのか知りたいと強く思ってから理論を学んだほうが、効率的である。
独学のプログラマーの強みは、自ら「学びたい」という強い欲求。
継続が大切。テクニックの1つとして、友人や家族にお金を渡しておいて、ある一定期間のうちに目標を達成したら自分に戻してもらい、失敗したら自分の嫌いな組織に寄付するよう依頼しておく、というものが有効。
第2章 さあ、はじめよう!
- Pythonは、オランダのプログラマーが開発し、イギリスのコメディアングループ「モンティ・パイソン」から名前を採った。
- Pythonには、「IDLE(Interactive DeveLompemnt Environment)」と呼ばれる開発環境が用意されている。macOSなら、Spotlight検索でIDLE.appと検索すると、立ち上がる。
- 対話シェルでは、ちょっとしたお試しコードを少し書いては動かす、といった使い方ができるのが利点。
- Pythonでプログラムを書くことは、エディタで入力したテキストをファイルに保存し、対話シェルで実行することである。IDLEの実行中に、メニューバーの「New File」をクリックすると白いテキストエディタが現れる。ここにコードを書いて保存し、「Run Module」でそのプログラムがIDLE上の対話シェルで実行される。
file_hozon.py# 普通に入力した場合 >>> print("Hello, World!") >> 'Hello, World!' #保存したプログラムを実行した場合 =============== RESTART: /Users/any_path/hello_world.py =============== >> 'Hello, World! '第3章 プログラミング入門
- コメントは、「#」記号で始める。誰かがコードを読んだ時、そこで何をしているのか理解しやすいようなコメントを記す。コードを読めば分かる場合など、必要以上にはいらない。
- Pythonのプログラムは行単位で解釈されるため、ペースト機能などで複数行を一気貼り付けると期待通りにならない。コードが長いときは、以下のように書く。
hukusuugyou.py# 三重クォート(""")で囲んだり、() {} [] で、改行して複数行に跨って書ける print("""こんにちは。これは、とても 長いコードです。複数行にわたって、 書かれています。""")
- Pythonでは、スペースでコードブロックの開始と終了を意味する。インデントには、4つのスペースを用いている。
- データや性質でグループ分けしたものをデータ型と呼び、 2 や "Hello, World!"などの値はオブジェクトと呼ばれる
- Pythonのデータ型については、次のリンクが参考になる。(https://pycamp.pycon.jp/textbook/3_types.html)
- 変数定義は、非常にシンプル。代入演算子を使って値を割り当てたとき、変数は作られる。Pythonのキーワードは変数名に使えないので注意。(https://docs.python.org/ja/3/reference/lexical_analysis.html#keywords)
hensuu.pyb = 100 b >> 100
- エラーには、「構文エラー(Syntax Error)と例外(Exception)の2種類がある。
- 論理演算子は、論理積なら「True and False」のように、記号のみならず英語風にも書ける。
- 条件分(if文)は、if、elif、そしてelseのキーワードを用いて書く。条件式の後の「:」を忘れずに書くこと。
sample4.py# Pythonでif文 x = 15 if x % 2 == 0: print("数値は偶数です。") elif x % 2 != 0: print("数値は奇数です。") else: ...
- 2種類の文「単純文(1行のコードで表現)」と「複合文」がある。複合文は、1つ以上の「節」で構成される。forなどのキーワードを含む「ヘッダー」部分と、それに続く「スイート」部分からなる。
sentences.py# 3つの「節(ヘッダー+スイート)」からなる「複合文」 x = 100 if x == 10: # ヘッダー行の最後は、セミコロンで終わる print("10") # 1つのスイートは1行のコード elif x == 20: print("20") else print("分かりません")第4章 関数
- 関数は、1つのことだけをすべき。それを徹底した方がよい。
- 関数とは、入力を受け取り、命令を実行し、出力を返す「複合文」のこと。
- <関数名>(<引数>) で呼び出す(f(x, y)のように)
kansuu_teigi.py# def [関数名]([引数]): # [〜関数定義〜] def f(x, y): return x * y
- Pythonでは、組み込み関数という最初から用意された関数があり、includeなしですぐに使用できる。例えば、print関数や、len関数など。(使いながら覚えよう)
- input関数 は、シェル内でプログラム使用者に返事(レスポンス)を要求する。
- 例外処理 tryとexcept
except.pya = input("type a number:") b = input("type another:") a = int(a) b = int(b) # 0が分母にある可能性 try: print(a / b) except ZeroDivisionError: # 起こりうるエラー print("b cannot be zero.")このように書いておけば、プログラムは中断しない。
- 関数宣言の次の行に、引数や返り値のデータ型を知らせる"docstring(ドキュメンテーション文字列)"を置くと、それを読む人の手助けになる。
doctoring.pydef add(x, y): """ Returns x + y. :param x: int. :param y: int. :return : int sum of x and y. """ return x + y #本体感想
構文は、暗記しようとせずとも、コードをたくさん書けば身に付く。
- 投稿日:2020-07-20T23:50:45+09:00
IQ Bot テーブルの抽出応用編まとめ
IQ Botのテーブル抽出は、カスタムロジックを組み合わせるとかなりフレキシブルに行うことができます。
ここでは、以下のような帳票に対して、カスタムロジックを使ってフレキシブルにテーブルの抽出結果を成形するやりかたを解説します。
サンプル帳票
通常の抽出結果
上記のような帳票をIQ Botで抽出すると、以下のような結果が得られます。
カスタムロジックを使ってできること
カスタムロジックを使うと、以下のようなことができます。
各項目をクリックすると、やりかたのリンクに飛べます。(1)空欄行の中身を埋める
(2)下X桁を小数として扱う
(3)金額欄から金額部分だけを抽出する(税額は不要):リンク先準備中
(4)金額欄を金額/区分/税率に分割する:リンク先準備中
(5)明細の不要な行を除外する:リンク先準備中







- 投稿日:2020-07-20T23:32:27+09:00
IQ Bot:明細の下X桁を小数として扱う
実務で扱う帳票の中には、以下のように、罫線の位置が小数点を表しているケースがあります。
このようなケースも、IQ Botのカスタムロジックを使えば処理できます。
サンプルコード
カスタムロジック(小数点付加)の実装例# 値を保存する変数: table_values #表の操作をするときに必ず入れるコード(最初) import pandas as pd df = pd.DataFrame(table_values) ############################################# # ↓↓↓ ここからが今回の処理 ↓↓↓ ############################################# import re def decimalAdd(num, digit): num = re.sub("\\D","",num) seisu = str(num)[:-digit] shosu = str(num)[-digit:] result = str(seisu) + "." + str(shosu) return result df["単価"] = df["単価"].apply(decimalAdd,digit=2) ############################################# # ↑↑↑ ここまでが今回の処理 ↑↑↑ ############################################# #表の操作をするときに必ず入れるコード(最後) table_values = df.to_dict()応用例
上記のサンプルコードの細かい説明は省きますが、応用する場合に変える必要があるのは以下の部分だけです。
カスタムロジック(小数点付加)の実装例df["単価"] = df["単価"].apply(decimalAdd,digit=2)変更箇所は2か所。
"単価"の部分を処理したい列名に変えます。(2つあるので2つとも)digit=2は、下2桁を小数とみなすという意味です。下3桁を小数にしたい場合は、digit=3というふうに変えます。コードの意味がどうしても気になる人は……
以下の記事を読みながら上記のコードを眺めてみると、意味がわかると思います。

- 投稿日:2020-07-20T22:50:30+09:00
【#2 Python】Pythonで一番注意すべきポイントはインデント!!
Pythonは分かりやすい言語だと言われていますが、
JavaやC言語から入った私は「インデント(字下げ)」に少し苦しめられました・・・。JavaやC言語だと、波括弧{}で囲まれているのでインデントにそこまで気を配る必要はありません。
CTRL + A、CTRL + Iで一発だしね。
しかし波括弧を使わないPythonではインデントは超大切!!
コードの見た目がそのままプログラムの動作に影響するので、気を付けなければなりません。score = 50 if score == 100: print("よくできました!") print("次も頑張りましょう!") # 条件式が成り立たないため実行されないscore = 50 if score == 100: print("よくできました!") print("次も頑張りましょう!") #インデントがないため、if文の外と見なされる # 次も頑張りましょう!私はここで少し引っかかりました。
言語が違うとやっぱりちょっとあれ?ってなりますね。気を付けよう。
- 投稿日:2020-07-20T22:43:25+09:00
【Python】LINEからYoutubeの曲や動画を落としたい1/3
概要
・【Python】LINEからYoutubeの曲や動画を落としたい1/3
経緯について
Androidに曲を落としたいがYoutubeの曲落とすアプリだと広告うざい。
かと言ってWEBから落とせるのもあるが、ずっと変換終わるまで待たないといけない。
もういっそ、自分でアレンジして作ってみようって考えた末、開発に至りました。本プログラムについて
・Youtubeの曲、SoundCloud、ニコニコ動画に対応しています。
・Youtubeのプレイリストからでも曲の複数ダウンロードに対応しています。
・データはGoogleDrive上に保管されます。
・LINEを閉じようが何しようが、一旦コマンドを送れば自動的に処理が終わります。
・LINE MessageAPIとWebhook、GoogleDriveAPI、Youtube-dlを使用します。
・さくらのVPSサーバを使用しています。出来上がりの状態
仕様について
・SoundCloudのURLで動画を取得しようとした際の例外処理は入っていません。
(そもそも取得できないですから・・・前提条件
・GoogleDriveAPI(GCPを使用)が使用できること。参考にした記事
・LINE MessageAPIが使用できること。参考
・ngrokが利用できること。参考にした記事
・Pythonの基礎知識があること。(なくてもほぼコピペで動くようには書くつもり)動作環境
・Python 3.8.4 (3系なら動く)
・CentOS Linux release 7.8.2003 (Core) (7系ならOK)
・ngrok version 2.3.35
・pip 20.1.1
・line-bot-sdk 1.16.0
・google-api-python-client 1.9.3
・PyDrive 1.3.1
・youtube-dl 2020.06.16.1
・ffmpeg 2.8.15・httplib 0.15.0 (最新の0.16.0では大きい動画だとGoogleDriveへアップロード時に以下のエラーが出ます)
Redirected but the response is missing a Location: header.詳細はこちらディレクトリ構造
$HOME/ ┝ line/ ┝ app.py ┝ youtube.py ┝ start.sh ┝ credentials.json ┝ settings.yaml ┕ youtube/ ┕ sound.mp3,movie.mp4実装に必要なライブラリ等のインストール
# pip install line-bot-sdk # pip install google-api-python-client # pip install PyDrive # pip install youtube-dl //もしhttplibが入ってしまっていた場合は、一旦アンインストールしてバージョン指定してください。 # pip uninstall httplib # pip install httplib==0.15.0Firewalldの設定(ngrokで解放するポートの穴あけ)
※今回9000で解放して説明します。
firewall-cmd --permanent --add-port=9000/tcp firewall-cmd --reload以下から一般ユーザーで作成しています。
ディレクトリ作成
$ mkdir $HOME/line/youtube $ cd $HOME/lineでは早速、youtube-dlのプログラムから作成していきます。
オプション設定についてはこちらをご参考ください。youtube.pyの作成
$ vim youtube.pl#!/bin/env python3 import youtube_dl import sys import os import glob import re def option_setting(opt,dl_dir): options = { 'outtmpl':dl_dir + '%(title)s.%(ext)s', 'restrictfilenames':'True', 'quiet':'True', 'default_search':'error' } options.update(opt) return options def download(option,url): try: with youtube_dl.YoutubeDL(option) as ydl: ydl.download([url]) except Exception as e: return e def main(operation,url,dl_dir): if operation == "/mp3": #ニコニコ動画は変換なし if "nicovideo" in url: opt = {} else: opt = ({'format':'bestaudio[ext=mp3]/bestaudio[ext=m4a]/bestaudio'}) option = option_setting(opt,dl_dir) msg = download(option,url) #ニコニコ動画のRetry対策 if "retries" in str(msg): while True: msg = download(option,url) if not "retries" in str(msg): break #ディレクトリ内の特定の拡張子を持つファイルのリストアップ m4afiles = glob.glob(dl_dir + '*.m4a') mp4files = glob.glob(dl_dir + '*.mp4') #m4aファイル群の変換 for m4afile in m4afiles: root, ext = os.path.splitext(m4afile) cnv_mp3 = '%s.mp3' % root cmd = 'ffmpeg -y -i "%s" -ab 256k "%s" -loglevel quiet' % (m4afile, cnv_mp3) os.system(cmd) os.remove(m4afile) #mp4ファイル群の変換 for mp4file in mp4files: root, ext = os.path.splitext(mp4file) cnv_mp3 = '%s.mp3' % root cmd = 'ffmpeg -y -i "%s" -ab 256k "%s" -loglevel quiet' % (mp4file, cnv_mp3) os.system(cmd) os.remove(mp4file) #MP3ファイルのリストアップ filename = [] mp3files = glob.glob(dl_dir + '*.mp3') for mp3file in mp3files: filename += [mp3file.strip(dl_dir)] return filename elif operation == "/mov" or operation == "/nomov": if "nicovideo" in url: opt = {} else: opt = ({'format':'bestvideo+bestaudio'}) option = option_setting(opt,dl_dir) msg = download(option,url) filename = [] #ニコニコ動画のRetry対策 if "retries" in str(msg): while True: msg = download(option,url) if not "retries" in str(msg): mp4files = glob.glob(dl_dir + '*.mp4') filename += [mp4files[0].strip(dl_dir)] break mkvfiles = glob.glob(dl_dir + '*.mkv') webmfiles = glob.glob(dl_dir + '*.webm') for files in mkvfiles: if operation == "/mov": root, ext = os.path.splitext(files) mp4file = '%s.mp4' % root #無劣化で変換 cmd = 'ffmpeg -y -i "%s" -vcodec copy "%s" -loglevel quiet' % (files, mp4file) os.system(cmd) os.remove(files) files = mp4file filename += [files.strip(dl_dir)] for files in webmfiles: if operation == "/mov": root, ext = os.path.splitext(files) mp4file = '%s.mp4' % root #HighQuality(0 - 51) # cmd = 'ffmpeg -i "%s" crf 0 "%s" -loglevel quiet' % (files, mp4file) #Default cmd = 'ffmpeg -y -i "%s" "%s" -loglevel quiet' % (files, mp4file) #VeryFast # cmd = 'ffmpeg -i "%s" -preset veryfast "%s" -loglevel quiet' % (files, mp4file) os.system(cmd) os.remove(files) files = mp4file filename += [files.strip(dl_dir)] return filename #if __name__ == "__main__": # dl_dir = "youtube/" # main("/mp3","https://www.youtube.com/watch?v=9swXEd6SWjA",dl_dir)一番下の3行のコメント部分を外して実際に動くか確認してみるといいです。
フリーBGMの[Shall we meet?.mp3]が取得できればまずは成功です。今回は一旦ここまでとします。次回はこのyoutube-dlを使ってプログラムを組んでいきます。

- 投稿日:2020-07-20T22:37:40+09:00
【#1 Python】分かりやすいと噂のPythonを触ってみた
最近ProgateにてPythonの勉強を始めました。
Pythonは最近よく使われるようになってきたプログラミング言語で、とにかく人間が使いやすいように考えられたものだそう。
例えば、Javaだと出力する際に「System.out.println();」とつらつら書かなくてはなりませんが、Pythonでは一言(後述)!
また、初心者にありがちなセミコロンの付け忘れも、Pythonならそもそもつける必要がないので考慮する必要がありません。
プログラミングを始めたいけど何からしたらいいか分からない・・・という方は、とりあえずPythonから始めてみてもいいかも。文字列の出力
Pythonでは、文字列はシングルクォーテーション(')かダブルクォーテーション(")どちらで囲んでも構いません。
ただ、囲まないとエラーになるので気を付けましょう。
また、実行されないコメント(コードに関するメモ)は、行頭に「#」をつけることで書くことが出来ます。print('Hello Python') # Hello Python print("Hello Python") # Hello Python print(Hello Python) # SyntaxError: invalid syntax
数値の出力
数値はクォーテーションで囲む必要はありません。
計算もその場で出来ます。分かりやすい、、。
ちなみに計算式をクォーテーションで囲むと、文字列となります。print(5) #5 print(3 + 5) #8 print("3 + 5") #3 + 5
変数
「変数名=値」で変数を定義できます。変数名はクォーテーションで囲む必要はありません。
プログラミングの「=」は、「等しい」という意味ではなく「右辺を左辺に代入する」という意味になるので注意!name = "John" number = 10 print(name) #John print("name") #name print(number) #10
変数を使うメリット
- データに名前をつけることで、扱っているデータの中身が何を表しているかが明確になる
- 同じデータを繰り返し利用できる
- 変数の値を変更する際直すところが少なくて済む
変数のデータ型
通常、文字列型と数値型は一緒に扱えません。
しかし型変更を行えば大丈夫です。price = 100 price("りんごの価格は" + price + "円です") #TypeError: Can't convert 'int' object to str implicitly price("りんごの価格は" + str(price) + "円です") #りんごの価格は100円です ※数値型を文字列に変更したため連結できる!!count = "3" price = 100 total_price = price + int(count) #数値型に変更 print(total_price) #300基本的なことは他のプログラミング言語と一緒です。
文字列型と数値型を連結する際は少し手を加えなければなりませんが、それ以外はとても簡潔で分かりやすいなという印象を受けました。
- 投稿日:2020-07-20T22:15:48+09:00
IQ Bot:印影の重なった社名にカスタムロジックで対応する
印影の重なった社名をOCRにかけると、印影と重なった部分が文字化けしたり、文字として認識できずに欠けてしまったりすることがあります。
例えば以下のサンプル帳票の右上の部分などです。
こうした部分を正しく読む方法として、ひとつは前処理で印影除去などをする方法があります。
ですが、前処理で印影除去を行った場合でも、もともと印影が重なっていなかった部分に比べると精度が下がる場合が多いです。この記事では、もっと手軽にできてパワフルな、カスタムロジックを使って対応する方法を説明します。
前提
この方法を使うためには、以下の条件が揃っている必要があります。
- 社名のうち、印影が重なっていない部分は正しく読めている
- その正しく読めた部分を根拠に、社名の全体が判断できる
たとえば以下のような場合です。
やりかた
カスタムロジックに、以下の処理を入れます。
カスタムロジック実装例# 値を保存する変数: field_value if "ふるさとエニ" in field_value: field_value = "ふるさとエニウエア商事株式会社"上記は取得結果に「ふるさとエニ」という文字列が含まれていたら、取得結果を「ふるさとエニウエア商事株式会社」に置き換えるという処理です。
"ふるさとエニ"と"ふるさとエニウエア商事株式会社"を置き換えるだけで、簡単に様々なケースに応用できます。
社名が特殊フォントで書かれている場合など、請求元の名称からはまともに情報がとれない場合もあります。
(特殊フォントは誤読したり、文字として認識できない場合が多い)
そのような場合は、振込先の口座名義などを根拠に検出する方法もとれます。


- 投稿日:2020-07-20T21:49:28+09:00
Tkinter 汎用的に使えるMenuBarを考えてみる
TkinterなどのGUIアプリケーションでMenuBarを作るときはいつも同じ苦労をしている気がする…
という事で、何らかのテンプレートを作っておけば再度Menuを作る場合に早く作れるのではないかと思い下記の通りまとめてみました。
Tkinter Menuを継承した、NormalMenuを作り必要なコールバックを登録する仕組みで作ってみました。
こちらもアプリケーション毎にカスタマイズが必要となりますが、1から組み立てるより早く
作れるのではないかと思います。
メインアプリから最小限のソースコードでやりたい事を実現させるべく、メインコードは下記のようにシンプルにまとめられるようにしてみました。
個人的にMenuのHelpを押して、助かった事がないので入れてません。--main application frame--
menu_bar=NormalMenu(win) menu_bar.file_menu(open_cmd=open, saveas_cmd=save) menu_bar.arduino_menu(connect_cmd=open, disconnect_cmd=save) menu_bar.log_menu() menu_bar.version_menu()以下作ってみたソースコード
NormalMenu.pyimport sys import tkinter as tk from tkinter import filedialog from tkinter import messagebox #Version Infomation Version = "1.0" #Open File Type Open_type = [('text_file','*.txt')] #Default Directory Default_dir = None class NormalMenu(tk.Menu): def __init__(self, master): super().__init__(master) master.config(menu=self) def file_menu(self, new_cmd=None, open_cmd=None, save_cmd=None, saveas_cmd=None): def open_handler(): file = filedialog.askopenfilenames(filetypes = Open_type) open_cmd(file) def save_handler(): file = filedialog.asksaveasfilename(filetypes = Open_type) file_menu = tk.Menu(self, tearoff=0) file_menu.add_command(label='New', command=new_cmd) if new_cmd!= None else "" file_menu.add_command(label='Open', command=open_handler) if open_cmd!= None else "" file_menu.add_command(label='Save', command=save_cmd) if save_cmd!= None else "" file_menu.add_command(label='Save As', command=save_handler) if saveas_cmd!= None else "" self.add_cascade(label="File", menu=file_menu) def arduino_menu(self, connect_cmd=None, disconnect_cmd=None): arduino_menu = tk.Menu(self, tearoff=0) arduino_menu.add_command(label='Connect', command=connect_cmd) if connect_cmd!= None else "" arduino_menu.add_command(label='Disconnect', command=disconnect_cmd) if disconnect_cmd!= None else "" self.add_cascade(label="Arduino", menu=arduino_menu) def log_menu(self, log_cmd=None): log_menu = tk.Menu(self, tearoff=0) log_menu.add_command(label="Log WIndow", command=log_cmd) if log_cmd!=None else "" self.add_cascade(label="Log", menu=log_menu) def version_menu(self): def push(): tk.messagebox.showinfo("Version Infomation", Version) ver_menu = tk.Menu(self, tearoff=0) ver_menu.add_command(label="Version Infomation", command=push) self.add_cascade(label="Version", menu=ver_menu) if __name__ == '__main__': def open( filename ): print(filename) def save( filename ): print(filename) def connect(): print("connect") def disconnect(): print("disconnect") win = tk.Tk() menu_bar=NormalMenu(win) menu_bar.file_menu(open_cmd=open, saveas_cmd=save) menu_bar.arduino_menu(connect_cmd=open, disconnect_cmd=save) menu_bar.log_menu() menu_bar.version_menu() win.mainloop()ファイルメニューを開くと、たまにシステム毎落ちてしまう事がありました。
何らかの終了処理を入れる必要があるかもしれません。
もう少し研究してみます。
あと、他のGUIではMenuそのものを押すとコールバックできるのですが(Log)を押すと動くなど、Tkinterは一度メニュー表示させてからでないと動かない仕様なのでしょうか。
- 投稿日:2020-07-20T21:32:50+09:00
PythonにおけるSQLインジェクション対策
セキュリティを学ぶ機会があったので、自分なりに調べたことをこれからまとめていこうと思います。
初回はPythonにおけるSQLインジェクション対策について調べたことを書いていきます。
SQLインジェクションとは
データベース(以下DB)へアクセスする際にSQL文を用いることで情報を得たり、追加したり、削除したりすることができます。
DBを用いるWebアプリケーションにおいては、ユーザが入力した情報をもとにSQL文を通じてデータベース入っている値を読み取り、その結果が画面に出力されます。例えば、
user_name = "入力フォームから受け取った名前" sql_input_text = "SELECT * from user_data_table where user ='" + user_name + "'"のようにユーザの入力値をプログラミング言語を通じてSQL文を構築し、そのSQL文でDBへアクセスすることによって情報を抜き出すことができます。
通常
user_nameにはtakeshiなどのユーザ名が入力され、sql_input_text = "SELECT * from user_data_table where user = 'takeshi'"となりデータベースから
takeshiに紐づく情報が取り出されます。しかし、悪意のある人が
user_nameに'OR 'A' = 'Aを入力した場合sql_input_text = "SELECT * from user_data_table where user = ''OR 'A' = 'A'"となりuser = '' または A = Aの条件を満たす情報すべてが出力されます。
この時、A = A は必ず成り立つので、user_data_tableに入っているすべての情報が抜き出されてしまいますね。
結果第三者はユーザ名を知ることなく情報を取得できてしまいます。このように、悪意あるユーザの入力値によって、webアプリ作成者が意図していない動作を行う可能性があることを、SQLインジェクションの脆弱性が存在するといいます。
SQLインジェクション対策
このSQLインジェクションの脆弱性をなくすためにはプレイスホルダーというものを使います。事前にSQL構文を確定しておいて、あとからユーザの入力値をその確定した構文のプレイスホルダーにはめ込んでDBへアクセスします。これによってユーザの入力値はSQL構文を変えることがないので、webアプリ作成者が意図した形で値を受け取ることができるようになります。
PythonにおけるSQLインジェクション対策
今回は、Pythonでよく使用されるDBであるSQLiteへ、アクセスする際にプレイスホルダーを活用する方法を紹介します。
SQLインジェクションの脆弱性が存在するコーディング
cursor.execute("SELECT * from user_data_table where user ='" + user_name + "'")SQLインジェクションの脆弱性が存在しないコーディング
cursor.execute("SELECT * from user_data_table where user ='?'",(user_name,))1つ目のコードはuser_nameが代入されてからSQL文が確定しています。
それに対して、2つ目のコードはSQL文が確定されてからプレイスホルダーである?の部分にuser_nameが代入されます。
ちなみに、プレイスホルダー?に値を代入することをバインドするといいます。今回はこのくらいにします。
参考文献
Python3でSQLite3を使う – 基本操作からエラー処理までサンプルコード付
SQLインジェクション
【初心者向け】SQLインジェクションの概要と対策方法
SQLインジェクションの対策
- 投稿日:2020-07-20T21:22:43+09:00
IQ Bot テーブルの空欄を埋める
IQ Botを使って、空欄行を埋めるやりかたを解説します。
イメージ
以下のような処理を行います。
やりかた
テーブルに対するカスタムロジックを使って、以下のように処理します。
空欄埋めのカスタムロジック実装例# 値を保存する変数: table_values #表の操作をするときに必ず入れるコード(最初) import pandas as pd df = pd.DataFrame(table_values) ############################################# # ↓↓↓ ここからが今回の処理 ↓↓↓ ############################################# #日付の空欄埋め vDate = "" for i in range(len(df)): if df.at[str(i),"日付"] != "": vDate = df.at[str(i),"日付"] else: df.at[str(i),"日付"] = vDate #伝票番号の空欄埋め vDenpyoNo = "" for i in range(len(df)): #df.at[str(i),"伝票番号"] = "aaa" if df.at[str(i),"伝票番号"] != "": vDenpyoNo = df.at[str(i),"伝票番号"] else: df.at[str(i),"伝票番号"] = vDenpyoNo ############################################# # ↑↑↑ ここまでが今回の処理 ↑↑↑ ############################################# #表の操作をするときに必ず入れるコード(最後) table_values = df.to_dict()解説
上記のカスタムロジックを読んで、何をやっているか想像がついた方は、解説は読み飛ばしてOKです。
処理のポイント
上記の日付、伝票番号とも、処理の仕組みとしてはまったく同じことをやっています。
日付なら日付、伝票番号なら伝票番号の列を1行ずつ読んでいき、値が入っていればそれを変数に格納し、空欄であれば変数の値を代入するという処理です。空欄埋めのカスタムロジック抜粋#日付の空欄埋め vDate = "" # 変数の初期化 for i in range(len(df)): # 抽出結果のテーブルを1行1行処理する(処理中の行をi番目とする) if df.at[str(i),"日付"] != "": # i番目の行の日付欄の値が空欄でなかったら(★) vDate = df.at[str(i),"日付"] # → 変数に日付欄の値を入れる else: # ★以外の場合(=i番目の行の日付欄の値が空欄だったら) df.at[str(i),"日付"] = vDate # → 変数の値で日付欄を埋める応用ポイント
上記のロジックを自分の業務に当てはめて応用したい場合、基本的に変える部分は
df.at[str(i),"日付"]の中の"日付"の部分だけでOKです。この部分を、自分が処理したいIQ Botのテーブル項目名に変えます。
IQ Botの項目名にスペースが含まれている場合は、スペース部分はアンダースコア(_)に置き換えます。
「伝票番号」という項目に対して処理したい場合は
df.at[str(i),"伝票番号"]に、
「明細 消費税」という項目に対して処理したい場合はdf.at[str(i),"明細_消費税"]に変えるという要領です。上記の例の
vDateやvDenpyoNoはただの変数名なので変えなくても動きますが、見た目のわかりやすさを考えると、しかるべき名前に変えておいた方がいいでしょう(消費税欄ならvTaxなど)。

- 投稿日:2020-07-20T21:06:06+09:00
papermillで、Notebookの実行結果を返り値として取得
papermillでnotebookを実行した時に、こんな感じでnotebookの最後のセルの出力を値として取得できます。
nb = papermill.execute_notebook('index.ipynb', ...) nb['cells'][-1]['outputs'][0]['text']使い方
環境
- python: 3.8.3-slim (Docker)
- notebook: 6.0.3
- papermill: 2.1.2
使い方の例
下記のような、fizzbuzzを実行するだけのnotebookを定義してみます。
上記notebookをpapermillで実行するコードを記述します。別途papermillのパラメータ機能を使って引数を定義することで、notebookを引数と返り値を持つひとつの関数のように利用できます。
main.pyimport papermill def notebook_result(path, param): nb = papermill.execute_notebook(path, '/dev/null', dict(num=param)) return nb['cells'][-1]['outputs'][0]['text'] print(notebook_result('fizzbuzz.ipynb', 15)) #=> fizzbuzz$ poetry run python main.py (中略) fizzbuzz参考
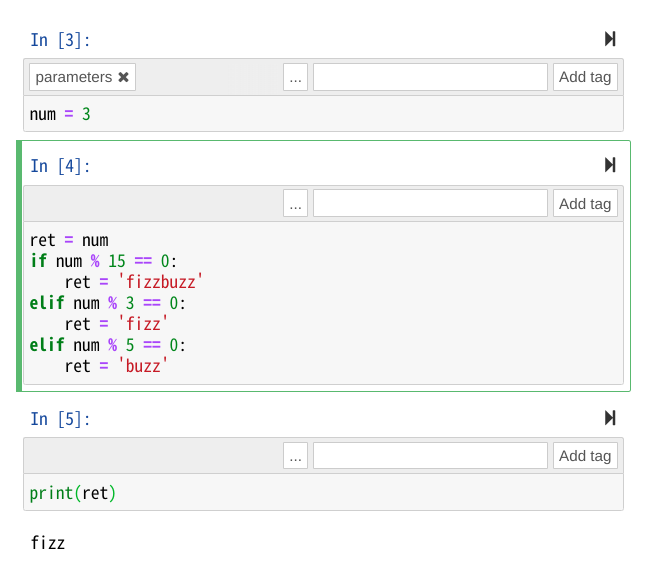
- 投稿日:2020-07-20T20:30:45+09:00
Google APIを使ってリマインドの機能を持つ音声認識アプリを作ってみた
物忘れがひどいので定期的に音声で通知するモノを作りたいと思い立ち、音声認識に挑戦しました。人生初の実装経験で未熟なため、あくまでも参考程度にして下さい。
開発環境
os : windows10
使用言語 : Python 3.6.3
jupyter notebook全体の流れ
①「テスト」とパソコンに呼びかけ、要件を言って音声を取得→テキスト変換する。
e.x「15時30分に歯医者」
②音声に含まれる時間の情報を抽出し、15時30分になるまで30分置きにe.xを通知させる。上記の作業を行うために音声をテキスト変換する必要があります。また、精度の高い出力を目指してGoogleが提供するcloud speech text to apiを利用しようと考えました。そこで以下のサイトを参考にして、google apiとpythonを用いて音声をテキスト変換しました。
https://qiita.com/yoshiokaCB/items/9e2e968756beb53fa452
音声を録音してwavファイルに書き出すプログラムは以下のサイトを参考にしました。
https://ai-trend.jp/programming/python/voice-record/
jsonファイルの取得と読み込みは以下のspeech to text のドキュメントを参照しました。
https://cloud.google.com/speech-to-text/docs?hl=ja①用と、②用の2つのpythonファイルを用いて実行しました。
利用したデータ
・自分の声の音声ファイル(通知用の音声)
・効果音用の音声ファイル①のプログラムの全体の流れと補足
必要なライブラリとモジュールのインポート
import base64 from googleapiclient import discovery import httplib2 import pyaudio #録音機能を使うためのライブラリ import wave #wavファイルを扱うためのライブラリ from pygame import mixer import os import threading from datetime import datetime mixer.init() #初期化 mixer.music.load("button03b.mp3")・import base64でバイナリデータをテキストデータに変換します。
・from googleapiclient import discoveryで必要なAPIの情報を与えることで指定したAPIを用いることが出来ます。
・pygameは音声再生のためのモジュール。pyaudioでも可能ですがpygameの方が精度が高いですし、mp3形式のファイルを再生することが出来ます。今回使った効果音の音声ファイルがmp3形式なので都合がいいです。
・①と②の2つのpythonファイルを実行するためthreadingをインポートします。録音とAPIに関する基本情報
key = "apiキー" #APIキーを設定 WAVE_OUTPUT_FILENAME = "hello.wav" #音声を保存するファイル名 RECORD_SECONDS = 5 #録音する時間の長さ(秒) iDeviceIndex = 0 #録音デバイスのインデックス番号 DISCOVERY_URL = ('https://{api}.googleapis.com/$discovery/rest?' 'version={apiVersion}') #APIのURL情報録音された時間の情報の条件分岐の構文の作成
import re def get_time(t): if "時" in t and "分" not in t: time_data = t.split("時") return time_data[0]+":00" elif "時" and "分" in t: time_data = re.split('["時" "分"]',t) return time_data[0] + ":"+time_data[1] else: return Noneこの構文によって指定した時刻を、分単位での音声再生が可能になります。
複数の区切り文字を指定するのでreモジュールを使用します。録音の情報の入力
def clone( time,filename ): os.system("python clone.py "+time +" "+filename ) def record(): #基本情報の設定 FORMAT = pyaudio.paInt16 #音声のフォーマット CHANNELS = 1 #モノラル RATE = 44100 #サンプルレート CHUNK = 2**11 #データ点数 audio = pyaudio.PyAudio() stream = audio.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, input_device_index = iDeviceIndex, #録音デバイスのインデックス番号 frames_per_buffer=CHUNK)・pyaudio.paInt16 について。1秒を何個も分割することによって任意の分割Δが小さくなり、より良い音を提供できます。そして整数intで十分可能です。
・RATE = 44100は1秒間に取得するデータ数のことです。
・CHUNK = 2**11はバッファサイズを指定します。一度に取り出すデータの塊のことです。
・streamに関してです。inputは入力ストリームを行うための引数で、録音データを受け取るデータストリームとしてTrueを渡す必要があります。
・frames_per_buffer=CHUNKでデータを取得する間隔を指定します。録音のやり方を定義
#--------------録音開始--------------- print ("recording...") frames = [] for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)): data = stream.read(CHUNK) frames.append(data) print ("finished recording")RATE / CHUNK * RECORD_SECONDSはデータを読み取る総回数を求めています。1秒間におけるデータを読み取る回数はRATE / CHUNKで求められます。例えば5秒間の音声であれば、RATE / CHUNK*5とすれば良いです。
録音の終了の仕方を定義
#--------------録音終了--------------- stream.stop_stream() stream.close() audio.terminate() waveFile = wave.open(WAVE_OUTPUT_FILENAME, 'wb') waveFile.setnchannels(CHANNELS) waveFile.setsampwidth(audio.get_sample_size(FORMAT)) waveFile.setframerate(RATE) waveFile.writeframes(b''.join(frames)) waveFile.close() def get_speech_service(): #APIの情報を返す関数 http = httplib2.Http() return discovery.build( 'speech', 'v1', http=http, discoveryServiceUrl=DISCOVERY_URL, developerKey=key)・stream.stop_stream()でストリームの停止を行います。書き込みや読み取りを行うことが出来なくなります。
・stream.close()でストリームを閉じます。⇔ リソースの解放
・pyaudioはPortAudioへのインターフェースとして提供しているため、PortAudio を終了することを宣言しています。録音した音声をテキストして音声認識を行う
def SpeechAPI(flag = False): with open(WAVE_OUTPUT_FILENAME, 'rb') as speech: #音声ファイルを開く speech_content = base64.b64encode(speech.read()) service = get_speech_service() #APIの情報を取得して、音声認識を行う service_request = service.speech().recognize( body={ 'config': { 'encoding': 'LINEAR16', 'sampleRateHertz': 44100, 'languageCode': 'ja-JP', #日本語に設定 'enableWordTimeOffsets': 'false', }, 'audio': { 'content': speech_content.decode('UTF-8') } }) #SpeechAPIによる認識結果を保存 response = service_request.execute()・config=設定
・②のpythonファイル名はclone.py
・上記のコードは以下のサイトを参考にしました。
https://cloud.google.com/speech-to-text/docs/basics?hl=ja喋った音声のファイルを生成
if flag: text = response["results"][0]["alternatives"][0]["transcript"] time = get_time(text) if time != None: #今保存している音声ファイル(喋った内容)を別のファイルとして保存をします #ここで別のファイル名を作成します new_filename = datetime.now().strftime("%Y-%m-%d-%H-%M.wav") #hello.wav を new_filename に変更して保存します # ファイル名の変更 os.rename("hello.wav", new_filename) #clone.pyを実行させます t1 = threading.Thread(name='clone', target=clone , args=([time , new_filename ])) t1.start() if not("results" in response): return・flagはオン(True)かオフ(False)のどちらかの状態を表す値が入る変数です。
・上記のコードは②のプログラムと大きく関連しています。②のプログラムの詳細は下に記載されてます。見やすいようにコンソール画面で出力
for i in response["results"]: if "テスト" in i["alternatives"][0]["transcript"]: print("テストが入力されました") mixer.music.play(1) record() SpeechAPI(True) while True: record() SpeechAPI()②のプログラムの流れと補足
import sys from datetime import datetime,timedelta #時間の計算をするのに必要 import winsound #windows用の音声再生のモジュール args = sys.argvコマンドライン引数を受け取ります。ソースコード名がclone.pyとしてコマンドラインで実行する場合、python clone.py と入力しますが、これがいわゆるコマンドライン引数で、args[0]= clone.pyが格納されます。
target_time = datetime.now().strftime("%Y-%m-%d ") + args[1] filename = args[2] target_time = datetime.strptime(target_time,'%Y-%m-%d %H:%M' ) back_time = datetime.now() #実行した時間 print(back_time) X = 30 from pygame import mixer mixer.init() #初期化 mixer.music.load( filename ) while True: now_time = datetime.now() if now_time.strftime("%H:%M") == (back_time + timedelta(minutes=X)).strftime("%H:%M"): print("hello") mixer.music.play(1) X += 30 #30分おきに通知させる if now_time > target_time: break・args[1]は時刻の情報が格納されます。
・target_time = 15:30でnow_timeは現在時刻。now_time > target_timeになったら、プログラムを終了させます。結果
テスト」とパソコンに向かって言ったら、「ポンッ」と、効果音が流れます。そして効果音が流れた後に、要件を言うと、その文章が精度が高い音声としてちゃんと30分おきに再生されました。
結果の考察と改善点
出力される音声がアナウンサーの声であればより良いと感じました。またスマホのアプリで利用できたらよいと思いました。現実的にスマホからいきなり音声が流れると利用者がびっくりするので厳しいらしいですが...
- 投稿日:2020-07-20T18:07:25+09:00
Python版 螺旋本(『プログラミングコンテスト攻略のためのアルゴリズムとデータ構造』) 解答例
※この記事は随時更新していきます。
はじめに
最近、競技プログラミング(AtCoder)をはじめてみました。が、がむしゃらにコンテストに出てみたり過去問を解いても実力の伸びがゆるいような気がしたので、ある程度体系的な知識を得るために螺旋本に手を出してみることにしました。
ただ、螺旋本の解答例はC++なので、Pythonで挑戦している人の参考(反面教師?)のため、また自身の備忘録代わりに投稿させていただきます。
初心者・初投稿なので不備等あるかもしれません。あたたかくご指摘いただけると幸いです。
なお、問題を解くにあたっては出来るだけ題意(本文の教育的配慮)に沿うように、敢えて便利なライブラリ等使っていないところもありますのでご了承ください。(もちろん、知識不足で知らないだけのことが多いのですが…)環境
python3
AOJでACを確認2章 アルゴリズムと計算量
2.5 導入問題
ALDS1_1_D: Maximum Profit
ALDS1_1_D.pyR = [int(input()) for i in range(int(input()))] dfmx = -10 ** 10 mn = 10 ** 10 for i in range(len(R)): dfmx = max(R[i] - mn, dfmx) mn = min(R[i], mn) print(dfmx)3章 初等的整列
3.2 挿入ソート
ALDS1_1_A: Insertion Sort
ALDS1_1_A.pyn = int(input()) A = list(map(int, input().split())) for i in range(1, n): print(' '.join(map(str, A))) temp = A[i] j = i - 1 while A[j] > temp and j >= 0: A[j + 1] = A[j] j -= 1 A[j + 1] = temp print(' '.join(map(str, A)))3.3 バブルソート
ALDS1_2_A: Bubble Sort
ALDS1_2_A.pyn = int(input()) A = list(map(int, input().split())) cnt = 0 flg = 1 while flg: flg = 0 for i in range(n - 1, 0, -1): if A[i] < A[i - 1]: A[i], A[i - 1] = A[i - 1], A[i] cnt += 1 flg = 1 print(' '.join(map(str, A))) print(cnt)3.4 選択ソート
ALDS1_2_B: Selection Sort
ALDS1_2_B.pyn = int(input()) A = list(map(int, input().split())) cnt = 0 for i in range(n): minj = i for j in range(i, n): if A[j] < A[minj]: minj = j A[i], A[minj] = A[minj], A[i] if minj != i: cnt += 1 print(' '.join(map(str, A))) print(cnt)3.5 安定なソート
ALDS1_2_C: Stable Sort
ALDS1_2_C.pydef bblsrt(cards): cards1 = cards.copy() for i in range(len(cards1)): for j in range(len(cards1) - 1, i, -1): if cards1[j][1] < cards1[j - 1][1]: cards1[j], cards1[j - 1] = cards1[j - 1], cards1[j] return cards1 def slcsrt(cards): cards2 = cards.copy() for i in range(len(cards2)): minj = i for j in range(i, len(cards2)): if cards2[j][1] < cards2[minj][1]: minj = j cards2[i], cards2[minj] = cards2[minj], cards2[i] return cards2 n = int(input()) C = list(input().split()) print(' '.join(bblsrt(C))) print('Stable') print(' '.join(slcsrt(C))) print('Stable' if slcsrt(C) == bblsrt(C) else 'Not stable')
- 投稿日:2020-07-20T17:58:49+09:00
numpy配列から別配列を取り出す練習
はじめに
numpyの多次元配列の次元を落としたり,任意の2つの一元配列を取り出して分散図を書く練習をします.
ここではサイズ2×3×4の3次元の配列を題材とします.
インデックスはdata[z][y][x]のように,zからx方向に並びます.zは最大1,yは最大2,xは最大3となります.本記事における配列の図はすべて,奥行きをz,下方向yを,右方向をxとしています.
練習
練習1 題材となる3次元配列の生成
問題
以下の図のようにdata[z][y][x]=(z+1)*100+(y*10)+(z+1)という値が設定されている3次元配列を生成してください.
解答例
3重ループ文で書く場合
q0.py>>> data=np.zeros((2,3,4),dtype=np.int) >>> for x in range(4): ... for y in range(3): ... for z in range(2): ... data[z][y][x]=(z+1)*100+(y+1)*10+x+1内包表記でも書けます
q1.py>>> import numpy as np >>> data=np.array([[[(z+1)*100+(y+1)*10+x+1 for x in range(4)] for y in range(3)] for z in range(2)]) >>> data array([[[111, 112, 113, 114], [121, 122, 123, 124], [131, 132, 133, 134]], [[211, 212, 213, 214], [221, 222, 223, 224], [231, 232, 233, 234]]]) >>> data[1,2,3] 234
練習2 1次元配列(ベクトル)の取り出し
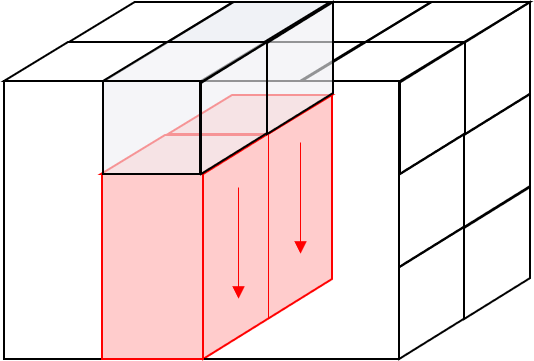
問題2-1 赤色部分のデータを1元配列として取り出してください
解答例2-1
q2-1.py>>> data[1,2,:] array([231, 232, 233, 234]) #省略形 >>> data[1,2] array([231, 232, 233, 234])問題2-2 赤色部分のデータを1元配列として取り出してください
解答例2-2
q2-2.py>>> data[1,:,2] array([213, 223, 233])問題2-3 赤色部分のデータを1元配列として取り出してください
解答例2-3
q2-3.py>>> data[:,1,2] array([123, 223])練習3 2次元配列の取り出し
問題3-1 赤色部分のデータを2元配列として取り出してください
解答例3-1
q3-1.py>>> data[1,:,:] array([[211, 212, 213, 214], [221, 222, 223, 224], [231, 232, 233, 234]]) #省略形 >>> data[1] array([[211, 212, 213, 214], [221, 222, 223, 224], [231, 232, 233, 234]])問題3-2 赤色部分のデータを2元配列として取り出してください
解答例3-2
q3-2.py>>> data[:,1,:] array([[121, 122, 123, 124], [221, 222, 223, 224]]) #省略形 >>> data[:,1] array([[121, 122, 123, 124], [221, 222, 223, 224]])問題3-3 赤色部分のデータを2元配列として取り出してください
解答例3-3
q3-3.py>>> data[:,:,1] array([[112, 122, 132], [212, 222, 232]])練習4 スライス
問題4-1 図のZ方向に取り出した1次元配列の最初の要素をスライスします
解答例4-1
q4-1.py>>> data[1:,1,2] array([223])上の通り結果はスカラではなく配列です.
問題4-2 図ように取り出した2次元配列のyの最初の要素をスライスします
解答例4-2
q4-2.py>>> data[:,1:,1] array([[122, 132], [222, 232]])問題4-3 図ようにもとの配列をスライスします
解答例4-3
q4-3.py>>> data[:,:,1:3] array([[[112, 113], [122, 123], [132, 133]], [[212, 213], [222, 223], [232, 233]]])練習5 分散図
問題5-1 図の赤い部分を2つの1次元配列とみなして,その関係を分散図として表示してください.
解答例5-1
q5-1.py>>> import matplotlib.pyplot as plt >>> (data[0,1,:],data[1,1,:]) (array([121, 122, 123, 124]), array([221, 222, 223, 224])) >>> plt.scatter(data[0,1,:],data[1,1,:]) <matplotlib.collections.PathCollection object at 0x0000019ACC48C208> >>> plt.show()
問題5-2 図の赤い部分を2つの1次元配列とみなして,その関係を分散図として表示してください
解答例5-2
q5-2.py>>> (data[0,:,1],data[1,:,1]) (array([112, 122, 132]), array([212, 222, 232])) >>> plt.scatter(data[0,:,1],data[1,:,1]) <matplotlib.collections.PathCollection object at 0x0000019AC6F14A08> >>> plt.show()
問題5-3 図の赤い部分を2つの1次元配列とみなして,その関係を分散図として表示してください
解答例5-3
q5-3.py>>> (data[:,1,2],data[:,2,2]) (array([123, 223]), array([133, 233])) >>> plt.scatter(data[:,1,2],data[:,2,2]) <matplotlib.collections.PathCollection object at 0x0000019AC70D1808> >>> plt.show()















- 投稿日:2020-07-20T17:42:14+09:00
LibreOffice を Python で操作: 入出力フィルタ
使用バージョン
- LibreOffice 6.4.4
- Python 3.7.7
概要
LibreOffice で文書を読み込むまたは書き出す際には入出力フィルタによりファイル形式と内部データとの変換を行う。
フィルタは --convert-to スイッチによりコマンドラインからファイル形式を変換する 時とマクロないしプログラムからファイルを読み書きする際にフィルタ名とフィルタオプションで指定する。
フィルタの一覧は LibreOffice のインストールディレクトリ下のファイルもしくは UNO インタフェースにて取得できる。Python-UNO bridge からの入出力フィルタの利用
文書読み込み
文書はcom.sun.star.frame.Desktop インタフェースが XComponentLoader インタフェースから継承している loadComponentFromURL() メソッドにより読み込む。
第4引数の Arguments の中でフィルタ名やフィルタオプションを指定できる。Arguments の型はsequence< com::sun::star::beans::PropertyValue >となっているが、Python-UNO bridge の場合は com.sun.star.beans.PropertyValue インスタンスのタプルということになる。
Arguments についてはcom::sun::star::document::MediaDescriptor参照とされていて、
FilterName は TypeDetection の構成にマッチしなければいけないと書いてあるが実際には TypeDetection ではなく FilterFactory サービスの Element に一致する必要がある。同じページからリンクされているフィルタ名の一覧も正しくないようだ。Arguments でフィルタ名を指定しない場合、ファイルの内容により可能であれば自動判定される。
import uno url = uno.systemPathToFileUrl('test.ods') desktop = XSCRIPTCONTEXT.getDesktop() document = desktop.loadComponentFromURL(url, '_blank', 0, ())自動判定は必ずしも有効ではなく、CSV ファイルを指定すると Calc の CSVインポートのダイアログが立ち上がる。
フィルタ名とフィルタオプションを指定することでプログラムからインポート方法を指定できる。import uno from com.sun.star.beans import PropertyValue url = uno.systemPathToFileUrl('test.csv') desktop = XSCRIPTCONTEXT.getDesktop() argument = (PropertyValue(Name='FilterName', Value='Text - txt - csv (StarCalc)'), PropertyValue(Name='FilterOptions', Value='44,34,76')) document = desktop.loadComponentFromURL(url, '_blank', 0, argument)文書書き出し
文書の書き出しは XComponent インタフェースが継承している XStorable インタフェースの store(), storeAsURL(), storeToURL() メソッドで行う。
store() は GUI からの save (保存) 相当で読み込んだファイルに書き出すのでフィルタも読み込みと同じ物が用いられる。
storeAsURL() は save as 相当で、書き出し先のファイルを指定して保存。書き出し先のファイルとフィルタが新たなファイル、フィルタとして文書に記録される。使用するフィルタは入力(インポート)と出力(エクスポート)の両方ができる必要がある。
storeToURL() は export 相当で、書き出し先のファイルを指定してエキスポート。文書のファイル名とフィルタは更新されない。出力専用フィルタが使用できる。
フィルタを指定しない場合デフォルトのフィルタが使用される。出力ファイル形式は ODF となる。import uno from com.sun.star.beans import PropertyValue document = XSCRIPTCONTEXT.getDocument() url = uno.systemPathToFileUrl('test.csv') argument = (PropertyValue(Name='FilterName', Value='Text - txt - csv (StarCalc)'), PropertyValue(Name='FilterOptions', Value='44,34,76,,,,,,true')) document.storeAsURL(url, argument)使用できるフィルタ名
Python-UNO bridge からの取得
入出力フィルタは FilterFactory サービスにて一覧できる。
各フィルタは名前で識別される。フィルタのプロパティにすいては Apache OpenOffice Wiki の Properties of a Filter に記述がある。
FilterFactory サービスは、LibreOffice が元々持っているフィルタに加えて拡張機能が追加したフィルタも一括して管理している。DocumentService プロパティは対象とする文書の種類を識別する。com.sun.star.text.TextDocument なら Writer文書、com.sun.star.sheet.SpreadsheetDocument なら Calcスプレッドシート。これは各文書の getIdentifier() メソッドの返す値と一致する。
Type プロパティは入出力されるファイルの型を識別する。このプロパティに保持されるのは Type の名前であり、各 Type については TypeDetection サービスでプロパティを取得できる。
Flags プロパティは複数のフラグを合わせた物である。IMPORT フラグは入力フィルタであることを示し EXPORT フラグは出力フィルタであることを示す。DEFAULT フィルタは DocumentService のデフォルトのフィルタであることを示し、PREFERRED フィルタは Type に対して優先して使用されるフィルタであることを示す。TypeDetection サービスはファイルの型を定義する。
各 Type は名前で識別される。
Extensions プロパティは対象とするファイルの拡張子を列記している。以下は FilterFactory サービスから取得したフィルタの一覧で、一部のプロパティと対応する Type の一部のプロパティの表である。Flags は IMPORT, EXPORT, DEFAULT, PREFERRED に限定している。
Name DocumentService UIName Flags Type Extensions MediaType StarOffice XML (Base) Report Chart com.sun.star.chart2.ChartDocument OpenOffice.org 1.0 レポートグラフ IMPORT EXPORT DEFAULT StarBaseReportChart odc application/vnd.sun.xml.report.chart StarOffice XML (Chart) com.sun.star.chart2.ChartDocument OpenOffice.org 1.0 グラフ IMPORT chart_StarOffice_XML_Chart sxs application/vnd.sun.xml.chart chart8 com.sun.star.chart2.ChartDocument ODF グラフ IMPORT EXPORT DEFAULT PREFERRED chart8 odc application/vnd.oasis.opendocument.chart BMP - MS Windows com.sun.star.drawing.DrawingDocument BMP - Windows Bitmap IMPORT bmp_MS_Windows bmp image/x-MS-bmp ClarisWorks_Draw com.sun.star.drawing.DrawingDocument ClarisWorks/AppleWorks 図形描画 IMPORT PREFERRED draw_ClarisWorks cwk application/clarisworks Corel Draw Document com.sun.star.drawing.DrawingDocument Corel Draw IMPORT PREFERRED draw_CorelDraw_Document cdr application/vnd.corel-draw Corel Presentation Exchange com.sun.star.drawing.DrawingDocument Corel Presentation Exchange IMPORT PREFERRED draw_Corel_Presentation_Exchange cmx image/x-cmx DXF - AutoCAD Interchange com.sun.star.drawing.DrawingDocument DXF - AutoCAD Interchange Format IMPORT dxf_AutoCAD_Interchange dxf image/vnd.dxf EMF - MS Windows Metafile com.sun.star.drawing.DrawingDocument EMF - Enhanced Metafile IMPORT emf_MS_Windows_Metafile emf image/x-emf EPS - Encapsulated PostScript com.sun.star.drawing.DrawingDocument EPS - Encapsulated PostScript IMPORT eps_Encapsulated_PostScript eps image/x-eps Freehand Document com.sun.star.drawing.DrawingDocument Adobe/Macromedia Freehand IMPORT PREFERRED draw_Freehand_Document fh fh1 fh2 fh3 fh4 fh5 fh6 fh7 fh8 fh9 fh10 fh11 image/x-freehand GIF - Graphics Interchange com.sun.star.drawing.DrawingDocument GIF - Graphics Interchange Format IMPORT gif_Graphics_Interchange gif image/gif JPG - JPEG com.sun.star.drawing.DrawingDocument JPEG - Joint Photographic Experts Group IMPORT jpg_JPEG jpg jpeg jfif jif jpe image/jpeg MET - OS/2 Metafile com.sun.star.drawing.DrawingDocument MET - OS/2 Metafile IMPORT met_OS2_Metafile met image/x-met MOV - MOV com.sun.star.drawing.DrawingDocument MOV - QuickTime ファイルフォーマット IMPORT mov_MOV mov MOV application/movie MWAW_Bitmap com.sun.star.drawing.DrawingDocument 古いMacのビットマップ IMPORT PREFERRED MWAW_Bitmap * MWAW_Drawing com.sun.star.drawing.DrawingDocument 古いMacのドロー形式 IMPORT PREFERRED MWAW_Drawing * OpenDocument Drawing Flat XML com.sun.star.drawing.DrawingDocument Flat XML ODF 図形描画 IMPORT EXPORT draw_ODG_FlatXML fodg odg xml application/vnd.oasis.opendocument.graphics-flat-xml PBM - Portable Bitmap com.sun.star.drawing.DrawingDocument PBM - Portable Bitmap IMPORT pbm_Portable_Bitmap pbm image/x-portable-bitmap PCT - Mac Pict com.sun.star.drawing.DrawingDocument PCT - Mac Pict IMPORT pct_Mac_Pict pct pict image/x-pict PCX - Zsoft Paintbrush com.sun.star.drawing.DrawingDocument PCX - Zsoft Paintbrush IMPORT pcx_Zsoft_Paintbrush pcx image/x-pcx PGM - Portable Graymap com.sun.star.drawing.DrawingDocument PGM - Portable Graymap IMPORT pgm_Portable_Graymap pgm image/x-portable-graymap PNG - Portable Network Graphic com.sun.star.drawing.DrawingDocument PNG - Portable Network Graphic IMPORT png_Portable_Network_Graphic png image/png PPM - Portable Pixelmap com.sun.star.drawing.DrawingDocument PPM - Portable Pixelmap IMPORT ppm_Portable_Pixelmap ppm image/x-portable-pixmap PSD - Adobe Photoshop com.sun.star.drawing.DrawingDocument PSD - Adobe Photoshop IMPORT psd_Adobe_Photoshop psd image/vnd.adobe.photoshop PageMaker Document com.sun.star.drawing.DrawingDocument Adobe PageMaker IMPORT PREFERRED draw_PageMaker_Document p65 pm pm6 pmd application/x-pagemaker Publisher Document com.sun.star.drawing.DrawingDocument Microsoft Publisher 98-2010 IMPORT PREFERRED draw_Publisher_Document pub application/x-mspublisher QXP Document com.sun.star.drawing.DrawingDocument QuarkXPress IMPORT PREFERRED draw_QXP_Document qxd qxt RAS - Sun Rasterfile com.sun.star.drawing.DrawingDocument RAS - Sun Raster Image IMPORT ras_Sun_Rasterfile ras image/x-cmu-raster SVG - Scalable Vector Graphics Draw com.sun.star.drawing.DrawingDocument SVG - スケーラブル・ベクター・グラフィックス IMPORT PREFERRED svg_Scalable_Vector_Graphics_Draw svg svgz image/svg+xml SVM - StarView Metafile com.sun.star.drawing.DrawingDocument SVM - StarView Metafile IMPORT svm_StarView_Metafile svm image/x-svm StarOffice XML (Draw) com.sun.star.drawing.DrawingDocument OpenOffice.org 1.0 図形描画 IMPORT PREFERRED draw_StarOffice_XML_Draw sxd application/vnd.sun.xml.draw StarOffice_Drawing com.sun.star.drawing.DrawingDocument 古い StarOffice 図形描画 IMPORT PREFERRED StarOffice_Drawing sda TGA - Truevision TARGA com.sun.star.drawing.DrawingDocument TGA - Truevision Targa IMPORT tga_Truevision_TARGA tga image/x-targa TIF - Tag Image File com.sun.star.drawing.DrawingDocument TIFF - Tagged Image File Format IMPORT tif_Tag_Image_File tif tiff image/tiff Visio Document com.sun.star.drawing.DrawingDocument Microsoft Visio 2000-2013 IMPORT PREFERRED draw_Visio_Document vdx vsd vsdm vsdx application/vnd.visio WMF - MS Windows Metafile com.sun.star.drawing.DrawingDocument WMF - Windows Metafile IMPORT wmf_MS_Windows_Metafile wmf image/x-wmf WordPerfect Graphics com.sun.star.drawing.DrawingDocument WordPerfect Graphics IMPORT PREFERRED draw_WordPerfect_Graphics wpg image/x-wpg XBM - X-Consortium com.sun.star.drawing.DrawingDocument XBM - X Bitmap IMPORT xbm_X_Consortium xbm image/x-xbitmap XHTML Draw File com.sun.star.drawing.DrawingDocument XHTML EXPORT XHTML_File html xhtml application/xhtml+xml XPM com.sun.star.drawing.DrawingDocument XPM - X PixMap IMPORT xpm_XPM xpm image/x-xpixmap ZMF Document com.sun.star.drawing.DrawingDocument Zoner Callisto/図形描画 IMPORT PREFERRED draw_ZMF_Document zmf draw8 com.sun.star.drawing.DrawingDocument ODF 図形描画 IMPORT EXPORT DEFAULT PREFERRED draw8 odg application/vnd.oasis.opendocument.graphics draw8_template com.sun.star.drawing.DrawingDocument ODF 図形描画テンプレート IMPORT EXPORT draw8_template otg application/vnd.oasis.opendocument.graphics-template draw_PCD_Photo_CD_Base com.sun.star.drawing.DrawingDocument PCD - Kodak Photo CD (768x512) IMPORT pcd_Photo_CD_Base pcd image/x-photo-cd draw_PCD_Photo_CD_Base16 com.sun.star.drawing.DrawingDocument PCD - Kodak Photo CD (192x128) IMPORT pcd_Photo_CD_Base16 pcd image/x-photo-cd draw_PCD_Photo_CD_Base4 com.sun.star.drawing.DrawingDocument PCD - Kodak Photo CD (384x256) IMPORT pcd_Photo_CD_Base4 pcd image/x-photo-cd draw_StarOffice_XML_Draw_Template com.sun.star.drawing.DrawingDocument OpenOffice.org 1.0 図形描画テンプレート IMPORT draw_StarOffice_XML_Draw_Template std application/vnd.sun.xml.draw.template draw_bmp_Export com.sun.star.drawing.DrawingDocument BMP - Windows Bitmap EXPORT bmp_MS_Windows bmp image/x-MS-bmp draw_emf_Export com.sun.star.drawing.DrawingDocument EMF - Enhanced Metafile EXPORT emf_MS_Windows_Metafile emf image/x-emf draw_eps_Export com.sun.star.drawing.DrawingDocument EPS - Encapsulated PostScript EXPORT eps_Encapsulated_PostScript eps image/x-eps draw_flash_Export com.sun.star.drawing.DrawingDocument Macromedia Flash (SWF) EXPORT graphic_SWF swf draw_gif_Export com.sun.star.drawing.DrawingDocument GIF - Graphics Interchange Format EXPORT gif_Graphics_Interchange gif image/gif draw_html_Export com.sun.star.drawing.DrawingDocument HTML ドキュメント (Draw) EXPORT graphic_HTML html htm text/html draw_jpg_Export com.sun.star.drawing.DrawingDocument JPEG - Joint Photographic Experts Group EXPORT jpg_JPEG jpg jpeg jfif jif jpe image/jpeg draw_pdf_Export com.sun.star.drawing.DrawingDocument PDF - Portable Document Format EXPORT pdf_Portable_Document_Format application/pdf draw_pdf_addstream_import com.sun.star.drawing.DrawingDocument PDF - Portable Document Format IMPORT pdf_Portable_Document_Format application/pdf draw_pdf_import com.sun.star.drawing.DrawingDocument PDF - Portable Document Format (Draw) IMPORT PREFERRED pdf_Portable_Document_Format application/pdf draw_png_Export com.sun.star.drawing.DrawingDocument PNG - Portable Network Graphic EXPORT png_Portable_Network_Graphic png image/png draw_svg_Export com.sun.star.drawing.DrawingDocument SVG - Scalable Vector Graphics EXPORT svg_Scalable_Vector_Graphics svg svgz image/svg+xml draw_tif_Export com.sun.star.drawing.DrawingDocument TIFF - Tagged Image File Format EXPORT tif_Tag_Image_File tif tiff image/tiff draw_wmf_Export com.sun.star.drawing.DrawingDocument WMF - Windows Metafile EXPORT wmf_MS_Windows_Metafile wmf image/x-wmf MathML XML (Math) com.sun.star.formula.FormulaProperties MathML 2.0 IMPORT EXPORT math_MathML_XML_Math mml application/mathml+xml MathType 3.x com.sun.star.formula.FormulaProperties MathType3.x IMPORT EXPORT math_MathType_3x xxx StarOffice XML (Math) com.sun.star.formula.FormulaProperties OpenOffice.org 1.0 数式 IMPORT math_StarOffice_XML_Math sxm application/vnd.sun.xml.math math8 com.sun.star.formula.FormulaProperties ODF 数式 IMPORT EXPORT DEFAULT math8 odf application/vnd.oasis.opendocument.formula math_pdf_Export com.sun.star.formula.FormulaProperties PDF - Portable Document Format EXPORT pdf_Portable_Document_Format application/pdf Apple Keynote com.sun.star.presentation.PresentationDocument Apple Keynote IMPORT PREFERRED impress_AppleKeynote key application/x-iwork-keynote-sffkey CGM - Computer Graphics Metafile com.sun.star.presentation.PresentationDocument CGM - Computer Graphics Metafile IMPORT impress_CGM_Computer_Graphics_Metafile cgm image/cgm ClarisWorks_Impress com.sun.star.presentation.PresentationDocument ClarisWorks/AppleWorks プレゼンテーション IMPORT PREFERRED impress_ClarisWorks cwk application/clarisworks Impress MS PowerPoint 2007 XML com.sun.star.presentation.PresentationDocument PowerPoint 2007–365 IMPORT EXPORT PREFERRED MS PowerPoint 2007 XML pptx application/vnd.openxmlformats-officedocument.presentationml.presentation Impress MS PowerPoint 2007 XML AutoPlay com.sun.star.presentation.PresentationDocument PowerPoint 2007–365 オートプレイ IMPORT EXPORT PREFERRED MS PowerPoint 2007 XML AutoPlay ppsx application/vnd.openxmlformats-officedocument.presentationml.slideshow Impress MS PowerPoint 2007 XML Template com.sun.star.presentation.PresentationDocument PowerPoint 2007–365 テンプレート IMPORT EXPORT PREFERRED MS PowerPoint 2007 XML Template potx potm application/vnd.openxmlformats-officedocument.presentationml.template Impress MS PowerPoint 2007 XML VBA com.sun.star.presentation.PresentationDocument PowerPoint 2007–365 VBA IMPORT EXPORT PREFERRED MS PowerPoint 2007 XML VBA pptm application/vnd.ms-powerpoint.presentation.macroEnabled.main+xml Impress Office Open XML com.sun.star.presentation.PresentationDocument Office Open XML プレゼンテーション IMPORT EXPORT PREFERRED Office Open XML Presentation pptx pptm application/vnd.openxmlformats-officedocument.presentationml.presentation Impress Office Open XML AutoPlay com.sun.star.presentation.PresentationDocument Office Open XML プレゼンテーションオートプレイ IMPORT EXPORT PREFERRED Office Open XML Presentation AutoPlay ppsx application/vnd.openxmlformats-officedocument.presentationml.slideshow Impress Office Open XML Template com.sun.star.presentation.PresentationDocument Office Open XML プレゼンテーションテンプレート IMPORT EXPORT PREFERRED Office Open XML Presentation Template potx potm application/vnd.openxmlformats-officedocument.presentationml.template MS PowerPoint 97 com.sun.star.presentation.PresentationDocument PowerPoint 97–2003 IMPORT EXPORT impress_MS_PowerPoint_97 ppt dps application/vnd.ms-powerpoint MS PowerPoint 97 AutoPlay com.sun.star.presentation.PresentationDocument PowerPoint 97–2003 オートプレイ IMPORT EXPORT impress_MS_PowerPoint_97_AutoPlay pps application/vnd.ms-powerpoint MS PowerPoint 97 Vorlage com.sun.star.presentation.PresentationDocument PowerPoint 97–2003 テンプレート IMPORT EXPORT impress_MS_PowerPoint_97_Vorlage pot dpt application/vnd.ms-powerpoint MWAW_Presentation com.sun.star.presentation.PresentationDocument 古いMacのプレゼンテーション IMPORT PREFERRED MWAW_Presentation * OpenDocument Presentation Flat XML com.sun.star.presentation.PresentationDocument Flat XML ODF プレゼンテーション IMPORT EXPORT impress_ODP_FlatXML fodp odp xml application/vnd.oasis.opendocument.presentation-flat-xml PowerPoint 3 com.sun.star.presentation.PresentationDocument Microsoft PowerPoint 1-4および95 IMPORT impress_PowerPoint3 ppt pot SVG - Scalable Vector Graphics com.sun.star.presentation.PresentationDocument SVG - Scalable Vector Graphics IMPORT PREFERRED svg_Scalable_Vector_Graphics svg svgz image/svg+xml StarOffice XML (Impress) com.sun.star.presentation.PresentationDocument OpenOffice.org 1.0 プレゼンテーション IMPORT PREFERRED impress_StarOffice_XML_Impress sxi application/vnd.sun.xml.impress StarOffice_Presentation com.sun.star.presentation.PresentationDocument 古いStarOfficeプレゼンテーション IMPORT PREFERRED StarOffice_Presentation sdd UOF presentation com.sun.star.presentation.PresentationDocument Unified Office Format プレゼンテーション IMPORT EXPORT Unified_Office_Format_presentation uop uof XHTML Impress File com.sun.star.presentation.PresentationDocument XHTML EXPORT XHTML_File html xhtml application/xhtml+xml impress8 com.sun.star.presentation.PresentationDocument ODF プレゼンテーション IMPORT EXPORT DEFAULT PREFERRED impress8 odp application/vnd.oasis.opendocument.presentation impress8_draw com.sun.star.presentation.PresentationDocument ODF 図形描画 (Impress) IMPORT EXPORT draw8 odg application/vnd.oasis.opendocument.graphics impress8_template com.sun.star.presentation.PresentationDocument ODF プレゼンテーションテンプレート IMPORT EXPORT impress8_template otp application/vnd.oasis.opendocument.presentation-template impress_StarOffice_XML_Draw com.sun.star.presentation.PresentationDocument OpenOffice.org 1.0 図形描画 (Impress) IMPORT draw_StarOffice_XML_Draw sxd application/vnd.sun.xml.draw impress_StarOffice_XML_Impress_Template com.sun.star.presentation.PresentationDocument OpenOffice.org 1.0 プレゼンテーションテンプレート IMPORT impress_StarOffice_XML_Impress_Template sti application/vnd.sun.xml.impress.template impress_bmp_Export com.sun.star.presentation.PresentationDocument BMP - Windows Bitmap EXPORT bmp_MS_Windows bmp image/x-MS-bmp impress_emf_Export com.sun.star.presentation.PresentationDocument EMF - Enhanced Metafile EXPORT emf_MS_Windows_Metafile emf image/x-emf impress_eps_Export com.sun.star.presentation.PresentationDocument EPS - Encapsulated PostScript EXPORT eps_Encapsulated_PostScript eps image/x-eps impress_flash_Export com.sun.star.presentation.PresentationDocument Macromedia Flash (SWF) EXPORT graphic_SWF swf impress_gif_Export com.sun.star.presentation.PresentationDocument GIF - Graphics Interchange Format EXPORT gif_Graphics_Interchange gif image/gif impress_html_Export com.sun.star.presentation.PresentationDocument HTML ドキュメント (Impress) EXPORT graphic_HTML html htm text/html impress_jpg_Export com.sun.star.presentation.PresentationDocument JPEG - Joint Photographic Experts Group EXPORT jpg_JPEG jpg jpeg jfif jif jpe image/jpeg impress_pdf_Export com.sun.star.presentation.PresentationDocument PDF - Portable Document Format EXPORT pdf_Portable_Document_Format application/pdf impress_pdf_addstream_import com.sun.star.presentation.PresentationDocument PDF - Portable Document Format IMPORT pdf_Portable_Document_Format application/pdf impress_pdf_import com.sun.star.presentation.PresentationDocument PDF - Portable Document Format (Impress) IMPORT PREFERRED pdf_Portable_Document_Format application/pdf impress_png_Export com.sun.star.presentation.PresentationDocument PNG - Portable Network Graphic EXPORT png_Portable_Network_Graphic png image/png impress_svg_Export com.sun.star.presentation.PresentationDocument SVG - Scalable Vector Graphics EXPORT svg_Scalable_Vector_Graphics svg svgz image/svg+xml impress_tif_Export com.sun.star.presentation.PresentationDocument TIFF - Tagged Image File Format EXPORT tif_Tag_Image_File tif tiff image/tiff impress_wmf_Export com.sun.star.presentation.PresentationDocument WMF - Windows Metafile EXPORT wmf_MS_Windows_Metafile wmf image/x-wmf StarOffice XML (Base) Report com.sun.star.report.ReportDefinition ODF データベースレポート IMPORT EXPORT DEFAULT StarBaseReport orp application/vnd.sun.xml.report StarOffice XML (Base) com.sun.star.sdb.OfficeDatabaseDocument ODF データベース IMPORT DEFAULT StarBase odb application/vnd.sun.xml.base ADO Rowset XML com.sun.star.sheet.SpreadsheetDocument ADO Rowset XML IMPORT calc_ADO_rowset_XML xml Apple Numbers com.sun.star.sheet.SpreadsheetDocument Apple Numbers IMPORT PREFERRED calc_AppleNumbers numbers application/x-iwork-numbers-sffnumbers Calc MS Excel 2007 Binary com.sun.star.sheet.SpreadsheetDocument Microsoft Excel 2007 バイナリ IMPORT PREFERRED MS Excel 2007 Binary xlsb Calc MS Excel 2007 VBA XML com.sun.star.sheet.SpreadsheetDocument Excel 2007–365 (マクロ有効) IMPORT EXPORT PREFERRED MS Excel 2007 VBA XML xlsm application/vnd.ms-excel.sheet.macroEnabled.12 Calc MS Excel 2007 XML com.sun.star.sheet.SpreadsheetDocument Excel 2007–365 IMPORT EXPORT PREFERRED MS Excel 2007 XML xlsx application/vnd.openxmlformats-officedocument.spreadsheetml.sheet Calc MS Excel 2007 XML Template com.sun.star.sheet.SpreadsheetDocument Excel 2007–365 テンプレート IMPORT EXPORT MS Excel 2007 XML Template xltx xltm application/vnd.openxmlformats-officedocument.spreadsheetml.template Calc Office Open XML com.sun.star.sheet.SpreadsheetDocument Office Open XML 表計算ドキュメント IMPORT EXPORT PREFERRED Office Open XML Spreadsheet xlsx xlsm application/vnd.openxmlformats-officedocument.spreadsheetml.sheet Calc Office Open XML Template com.sun.star.sheet.SpreadsheetDocument Office Open XML 表計算ドキュメントテンプレート IMPORT Office Open XML Spreadsheet Template xltx xltm application/vnd.openxmlformats-officedocument.spreadsheetml.template ClarisWorks_Calc com.sun.star.sheet.SpreadsheetDocument ClarisWorks/AppleWorks 表計算ドキュメント IMPORT PREFERRED calc_ClarisWorks cwk application/clarisworks Claris_Resolve_Calc com.sun.star.sheet.SpreadsheetDocument ClarisResolve ドキュメント IMPORT PREFERRED calc_Claris_Resolve cwk application/clarisworks DIF com.sun.star.sheet.SpreadsheetDocument Data Interchange Format IMPORT EXPORT calc_DIF dif Gnumeric Spreadsheet com.sun.star.sheet.SpreadsheetDocument Gnumeric 表計算ドキュメント IMPORT PREFERRED Gnumeric XML gnumeric gnm application/x-gnumeric HTML (StarCalc) com.sun.star.sheet.SpreadsheetDocument HTML ドキュメント (Calc) IMPORT EXPORT generic_HTML html xhtml htm text/html Lotus com.sun.star.sheet.SpreadsheetDocument Lotus 1-2-3 IMPORT PREFERRED calc_Lotus wk1 wks 123 application/vnd.lotus-1-2-3 MS Excel 2003 XML com.sun.star.sheet.SpreadsheetDocument Microsoft Excel 2003 XML EXPORT calc_MS_Excel_2003_XML xml xls MS Excel 2003 XML Orcus com.sun.star.sheet.SpreadsheetDocument Microsoft Excel 2003 XML IMPORT PREFERRED calc_MS_Excel_2003_XML xml xls MS Excel 4.0 com.sun.star.sheet.SpreadsheetDocument Microsoft Excel 4.0 IMPORT PREFERRED calc_MS_Excel_40 xls xlw xlc xlm application/vnd.ms-excel MS Excel 4.0 Vorlage/Template com.sun.star.sheet.SpreadsheetDocument Microsoft Excel 4.0 テンプレート IMPORT calc_MS_Excel_40_VorlageTemplate xlt application/vnd.ms-excel MS Excel 5.0/95 com.sun.star.sheet.SpreadsheetDocument Microsoft Excel 5.0 IMPORT PREFERRED calc_MS_Excel_5095 xls xlc xlm xlw application/vnd.ms-excel MS Excel 5.0/95 Vorlage/Template com.sun.star.sheet.SpreadsheetDocument Microsoft Excel 5.0 テンプレート IMPORT calc_MS_Excel_5095_VorlageTemplate xlt application/vnd.ms-excel MS Excel 95 com.sun.star.sheet.SpreadsheetDocument Microsoft Excel 95 IMPORT PREFERRED calc_MS_Excel_95 xls xlc xlm xlw application/vnd.ms-excel MS Excel 95 Vorlage/Template com.sun.star.sheet.SpreadsheetDocument Microsoft Excel 95 テンプレート IMPORT calc_MS_Excel_95_VorlageTemplate xlt application/vnd.ms-excel MS Excel 97 com.sun.star.sheet.SpreadsheetDocument Excel 97–2003 IMPORT EXPORT PREFERRED calc_MS_Excel_97 xls xlc xlm xlw xlk et application/vnd.ms-excel MS Excel 97 Vorlage/Template com.sun.star.sheet.SpreadsheetDocument Excel 97–2003 テンプレート IMPORT EXPORT calc_MS_Excel_97_VorlageTemplate xlt ett application/vnd.ms-excel MS_Works_Calc com.sun.star.sheet.SpreadsheetDocument Microsoft Works ドキュメント IMPORT calc_MS_Works_Document wks wdb MWAW_Database com.sun.star.sheet.SpreadsheetDocument 古いMacのデータベース IMPORT PREFERRED MWAW_Database * MWAW_Spreadsheet com.sun.star.sheet.SpreadsheetDocument 古いMacの表計算 IMPORT PREFERRED MWAW_Spreadsheet * Mac_Works_Calc com.sun.star.sheet.SpreadsheetDocument Microsoft Works for Mac 表計算ドキュメント (v1 - v4) IMPORT PREFERRED calc_Mac_Works wps application/vnd.ms-works Microsoft Multiplan com.sun.star.sheet.SpreadsheetDocument Microsoft Multiplan IMPORT PREFERRED calc_MS_Multiplan mp OpenDocument Spreadsheet Flat XML com.sun.star.sheet.SpreadsheetDocument Flat XML ODF 表計算ドキュメント IMPORT EXPORT calc_ODS_FlatXML fods ods xml application/vnd.oasis.opendocument.spreadsheet-flat-xml Quattro Pro 6.0 com.sun.star.sheet.SpreadsheetDocument Quattro Pro 6.0 IMPORT PREFERRED calc_QPro wb2 Rich Text Format (StarCalc) com.sun.star.sheet.SpreadsheetDocument Rich Text Format (Calc) IMPORT writer_Rich_Text_Format rtf application/rtf SYLK com.sun.star.sheet.SpreadsheetDocument SYLK IMPORT EXPORT calc_SYLK slk sylk text/spreadsheet StarOffice XML (Calc) com.sun.star.sheet.SpreadsheetDocument OpenOffice.org 1.0 表計算ドキュメント IMPORT calc_StarOffice_XML_Calc sxc application/vnd.sun.xml.calc StarOffice_Spreadsheet com.sun.star.sheet.SpreadsheetDocument 古い StarOffice 表計算ドキュメント IMPORT PREFERRED StarOffice_Spreadsheet sdc Text - txt - csv (StarCalc) com.sun.star.sheet.SpreadsheetDocument テキスト CSV IMPORT EXPORT generic_Text csv tsv tab txt text/plain UOF spreadsheet com.sun.star.sheet.SpreadsheetDocument Unified Office Format 表計算ドキュメント IMPORT EXPORT Unified_Office_Format_spreadsheet uos uof WPS_Lotus_Calc com.sun.star.sheet.SpreadsheetDocument Lotus ドキュメント IMPORT calc_WPS_Lotus_Document wk1 wk3 wk4 123 WPS_QPro_Calc com.sun.star.sheet.SpreadsheetDocument QuattroPro ドキュメント IMPORT calc_WPS_QPro_Document wb1 wb2 wq1 wq2 XHTML Calc File com.sun.star.sheet.SpreadsheetDocument XHTML EXPORT XHTML_File html xhtml application/xhtml+xml calc8 com.sun.star.sheet.SpreadsheetDocument ODF 表計算ドキュメント IMPORT EXPORT DEFAULT calc8 ods application/vnd.oasis.opendocument.spreadsheet calc8_template com.sun.star.sheet.SpreadsheetDocument ODF 表計算ドキュメントテンプレート IMPORT EXPORT calc8_template ots application/vnd.oasis.opendocument.spreadsheet-template calc_HTML_WebQuery com.sun.star.sheet.SpreadsheetDocument Webページ クエリー (Calc) IMPORT PREFERRED generic_HTML html xhtml htm text/html calc_StarOffice_XML_Calc_Template com.sun.star.sheet.SpreadsheetDocument OpenOffice.org 1.0 表計算ドキュメントテンプレート IMPORT calc_StarOffice_XML_Calc_Template stc application/vnd.sun.xml.calc.template calc_jpg_Export com.sun.star.sheet.SpreadsheetDocument JPEG - Joint Photographic Experts Group EXPORT jpg_JPEG jpg jpeg jfif jif jpe image/jpeg calc_pdf_Export com.sun.star.sheet.SpreadsheetDocument PDF - Portable Document Format EXPORT pdf_Portable_Document_Format application/pdf calc_pdf_addstream_import com.sun.star.sheet.SpreadsheetDocument PDF - Portable Document Format IMPORT pdf_Portable_Document_Format application/pdf calc_png_Export com.sun.star.sheet.SpreadsheetDocument PNG - Portable Network Graphic EXPORT png_Portable_Network_Graphic png image/png calc_svg_Export com.sun.star.sheet.SpreadsheetDocument SVG - Scalable Vector Graphics EXPORT svg_Scalable_Vector_Graphics svg svgz image/svg+xml dBase com.sun.star.sheet.SpreadsheetDocument dBASE IMPORT EXPORT calc_dBase dbf Text (encoded) (StarWriter/GlobalDocument) com.sun.star.text.GlobalDocument 文書 - エンコードの選択 (マスタードキュメント) IMPORT EXPORT generic_Text csv tsv tab txt text/plain writer_globaldocument_StarOffice_XML_Writer com.sun.star.text.GlobalDocument OpenOffice.org 1.0 文書ドキュメント writer_StarOffice_XML_Writer sxw application/vnd.sun.xml.writer writer_globaldocument_StarOffice_XML_Writer_GlobalDocument com.sun.star.text.GlobalDocument OpenOffice.org 1.0 マスタードキュメント IMPORT PREFERRED writer_globaldocument_StarOffice_XML_Writer_GlobalDocument sxg application/vnd.sun.xml.writer.global writer_globaldocument_pdf_Export com.sun.star.text.GlobalDocument PDF - Portable Document Format EXPORT pdf_Portable_Document_Format application/pdf writerglobal8 com.sun.star.text.GlobalDocument ODF マスタードキュメント IMPORT EXPORT PREFERRED writerglobal8 odm application/vnd.oasis.opendocument.text-master writerglobal8_HTML com.sun.star.text.GlobalDocument HTML (Writer/Global) EXPORT generic_HTML html xhtml htm text/html writerglobal8_template com.sun.star.text.GlobalDocument ODF マスタードキュメントテンプレート IMPORT EXPORT writerglobal8_template otm application/vnd.oasis.opendocument.text-master-template writerglobal8_writer com.sun.star.text.GlobalDocument ODF 文書ドキュメント EXPORT DEFAULT writer8 odt application/vnd.oasis.opendocument.text AbiWord com.sun.star.text.TextDocument AbiWord ドキュメント IMPORT writer_AbiWord_Document abw zabw application/x-abiword Apple Pages com.sun.star.text.TextDocument Apple Pages IMPORT PREFERRED writer_ApplePages pages application/x-iwork-pages-sffpages BroadBand eBook com.sun.star.text.TextDocument BroadBand eBook IMPORT PREFERRED writer_BroadBand_eBook lrf application/x-sony-bbeb ClarisWorks com.sun.star.text.TextDocument ClarisWorks/AppleWorks 文書ドキュメント IMPORT PREFERRED writer_ClarisWorks cwk application/clarisworks DocBook File com.sun.star.text.TextDocument DocBook IMPORT EXPORT writer_DocBook_File xml application/docbook+xml DosWord com.sun.star.text.TextDocument Microsoft Word for DOS IMPORT writer_DosWord doc EPUB com.sun.star.text.TextDocument EPUB文書 EXPORT writer_EPUB_Document epub application/epub+zip FictionBook 2 com.sun.star.text.TextDocument FictionBook 2.0 IMPORT PREFERRED writer_FictionBook_2 fb2 zip application/x-fictionbook+xml HTML (StarWriter) com.sun.star.text.TextDocument HTML ドキュメント (Writer) IMPORT EXPORT generic_HTML html xhtml htm text/html LotusWordPro com.sun.star.text.TextDocument Lotus WordPro ドキュメント IMPORT PREFERRED writer_LotusWordPro_Document lwp application/vnd.lotus-wordpro MS WinWord 5 com.sun.star.text.TextDocument Microsoft WinWord 1/2/5 IMPORT writer_MS_WinWord_5 doc application/msword MS WinWord 6.0 com.sun.star.text.TextDocument Microsoft Word 6.0 IMPORT writer_MS_WinWord_60 doc application/msword MS Word 2003 XML com.sun.star.text.TextDocument Word 2003 XML IMPORT EXPORT writer_MS_Word_2003_XML xml doc MS Word 2007 XML com.sun.star.text.TextDocument Word 2007–365 IMPORT EXPORT writer_MS_Word_2007 docx application/msword MS Word 2007 XML Template com.sun.star.text.TextDocument Word 2007–365 テンプレート IMPORT EXPORT writer_MS_Word_2007_Template dotx dotm application/msword MS Word 2007 XML VBA com.sun.star.text.TextDocument Word 2007–365 VBA IMPORT EXPORT writer_MS_Word_2007_VBA docm application/msword MS Word 95 com.sun.star.text.TextDocument Microsoft Word 95 IMPORT writer_MS_Word_95 doc application/msword MS Word 95 Vorlage com.sun.star.text.TextDocument Microsoft Word 95 テンプレート IMPORT writer_MS_Word_95_Vorlage dot application/msword MS Word 97 com.sun.star.text.TextDocument Word 97–2003 IMPORT EXPORT PREFERRED writer_MS_Word_97 doc wps application/msword MS Word 97 Vorlage com.sun.star.text.TextDocument Word 97–2003 テンプレート IMPORT EXPORT writer_MS_Word_97_Vorlage dot wpt application/msword MS_Works com.sun.star.text.TextDocument Microsoft Works ドキュメント IMPORT writer_MS_Works_Document wps application/vnd.ms-works MS_Write com.sun.star.text.TextDocument Microsoft Write IMPORT writer_MS_Write wri application/x-mswrite MWAW_Text_Document com.sun.star.text.TextDocument 古いMacの文書ドキュメント IMPORT PREFERRED MWAW_Text_Document * MacWrite com.sun.star.text.TextDocument MacWrite ドキュメント IMPORT PREFERRED writer_MacWrite mw mcw application/macwriteii Mac_Word com.sun.star.text.TextDocument Microsoft Word for Mac (v1 - v5) IMPORT PREFERRED writer_Mac_Word doc application/msword Mac_Works com.sun.star.text.TextDocument Microsoft Works for Mac 文書ドキュメント (v1 - v4) IMPORT PREFERRED writer_Mac_Works wps application/vnd.ms-works Mariner_Write com.sun.star.text.TextDocument Mariner Write Mac Classic v1.6 - v3.5 IMPORT PREFERRED writer_Mariner_Write mwd Office Open XML Text com.sun.star.text.TextDocument Office Open XML 文書 IMPORT EXPORT writer_OOXML docx docm application/vnd.openxmlformats-officedocument.wordprocessingml.document Office Open XML Text Template com.sun.star.text.TextDocument Office Open XML 文書テンプレート IMPORT writer_OOXML_Text_Template dotx dotm application/vnd.openxmlformats-officedocument.wordprocessingml.template OpenDocument Text Flat XML com.sun.star.text.TextDocument Flat XML ODF 文書ドキュメント IMPORT EXPORT writer_ODT_FlatXML fodt odt xml application/vnd.oasis.opendocument.text-flat-xml PalmDoc com.sun.star.text.TextDocument PalmDoc eBook IMPORT PREFERRED writer_PalmDoc pdb application/x-aportisdoc Palm_Text_Document com.sun.star.text.TextDocument Palm 文書ドキュメント IMPORT PREFERRED Palm_Text_Document pdb application/vnd.palm Plucker eBook com.sun.star.text.TextDocument Plucker eBook IMPORT PREFERRED writer_Plucker_eBook pdb application/prs.plucker Rich Text Format com.sun.star.text.TextDocument Rich Text IMPORT EXPORT PREFERRED writer_Rich_Text_Format rtf application/rtf StarOffice XML (Writer) com.sun.star.text.TextDocument OpenOffice.org 1.0 文書ドキュメント IMPORT PREFERRED writer_StarOffice_XML_Writer sxw application/vnd.sun.xml.writer StarOffice_Writer com.sun.star.text.TextDocument 古い StarOffice 文書ドキュメント IMPORT PREFERRED StarOffice_Writer sdw T602Document com.sun.star.text.TextDocument T602 ドキュメント IMPORT PREFERRED writer_T602_Document 602 txt application/x-t602 Text com.sun.star.text.TextDocument テキスト IMPORT EXPORT PREFERRED generic_Text csv tsv tab txt text/plain Text (encoded) com.sun.star.text.TextDocument 文書 - エンコードの選択 IMPORT EXPORT generic_Text csv tsv tab txt text/plain UOF text com.sun.star.text.TextDocument Unified Office Format テキスト IMPORT EXPORT Unified_Office_Format_text uot uof WordPerfect com.sun.star.text.TextDocument WordPerfect ドキュメント IMPORT PREFERRED writer_WordPerfect_Document wpd application/vnd.wordperfect WriteNow com.sun.star.text.TextDocument WriteNow ドキュメント IMPORT PREFERRED writer_WriteNow wn nx^d XHTML Writer File com.sun.star.text.TextDocument XHTML EXPORT XHTML_File html xhtml application/xhtml+xml writer8 com.sun.star.text.TextDocument ODF 文書ドキュメント IMPORT EXPORT DEFAULT PREFERRED writer8 odt application/vnd.oasis.opendocument.text writer8_template com.sun.star.text.TextDocument ODF 文書ドキュメントテンプレート IMPORT EXPORT writer8_template ott application/vnd.oasis.opendocument.text-template writer_MIZI_Hwp_97 com.sun.star.text.TextDocument Hangul WP 97 IMPORT writer_MIZI_Hwp_97 hwp application/x-hwp writer_StarOffice_XML_Writer_Template com.sun.star.text.TextDocument OpenOffice.org 1.0 文書ドキュメントテンプレート IMPORT writer_StarOffice_XML_Writer_Template stw application/vnd.sun.xml.writer.template writer_jpg_Export com.sun.star.text.TextDocument JPEG - Joint Photographic Experts Group EXPORT jpg_JPEG jpg jpeg jfif jif jpe image/jpeg writer_layout_dump com.sun.star.text.TextDocument Writer Layout XML EXPORT writer_layout_dump_xml xml writer_pdf_Export com.sun.star.text.TextDocument PDF - Portable Document Format EXPORT pdf_Portable_Document_Format application/pdf writer_pdf_addstream_import com.sun.star.text.TextDocument PDF - Portable Document Format IMPORT pdf_Portable_Document_Format application/pdf writer_pdf_import com.sun.star.text.TextDocument PDF - Portable Document Format (Writer) IMPORT PREFERRED pdf_Portable_Document_Format application/pdf writer_png_Export com.sun.star.text.TextDocument PNG - Portable Network Graphic EXPORT png_Portable_Network_Graphic png image/png writer_svg_Export com.sun.star.text.TextDocument SVG - Scalable Vector Graphics EXPORT svg_Scalable_Vector_Graphics svg svgz image/svg+xml HTML com.sun.star.text.WebDocument HTML ドキュメント IMPORT EXPORT PREFERRED generic_HTML html xhtml htm text/html Text (StarWriter/Web) com.sun.star.text.WebDocument 文書 (Writer/Web) IMPORT EXPORT generic_Text csv tsv tab txt text/plain Text (encoded) (StarWriter/Web) com.sun.star.text.WebDocument 文書 - エンコードの選択 (Writer/Web) IMPORT EXPORT generic_Text csv tsv tab txt text/plain writer_web_HTML_help com.sun.star.text.WebDocument Help コンテンツ IMPORT writer_web_HTML_help writer_web_StarOffice_XML_Writer com.sun.star.text.WebDocument OpenOffice.org 1.0 文書ドキュメント (Writer/Web) EXPORT writer_StarOffice_XML_Writer sxw application/vnd.sun.xml.writer writer_web_StarOffice_XML_Writer_Web_Template com.sun.star.text.WebDocument OpenOffice.org 1.0 HTML テンプレート IMPORT writer_web_StarOffice_XML_Writer_Web_Template stw application/vnd.sun.xml.writer.web writer_web_jpg_Export com.sun.star.text.WebDocument JPEG - Joint Photographic Experts Group EXPORT jpg_JPEG jpg jpeg jfif jif jpe image/jpeg writer_web_pdf_Export com.sun.star.text.WebDocument PDF - Portable Document Format EXPORT pdf_Portable_Document_Format application/pdf writer_web_png_Export com.sun.star.text.WebDocument PNG - Portable Network Graphic EXPORT png_Portable_Network_Graphic png image/png writerweb8_writer com.sun.star.text.WebDocument 文書 (Writer/Web) EXPORT writer8 odt application/vnd.oasis.opendocument.text writerweb8_writer_template com.sun.star.text.WebDocument HTML ドキュメントテンプレート IMPORT EXPORT writerweb8_writer_template oth application/vnd.oasis.opendocument.text-web この表を出力するのには以下のマクロを使用した。
このマクロは LibreOffice Calc のスプレッドシートを作成するので CSV に出力して MarkDown に編集した。filters.py"""list import/expot filters from FilterFactory and TypeDetection services """ """ (C) Copyright 2020 Shojiro Fushimi, all rights reserved Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: - Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. - Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDER ``AS IS'' AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE AUTHOR OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. """ from functools import reduce import uno from com.sun.star.awt.FontWeight import BOLD ALL_FIELDS = False FIELDS = ['DocumentService', 'UIName', 'Flags'] ALL_FLAGS = False FLAGS = ['IMPORT', 'EXPORT', 'DEFAULT', 'PREFERRED'] KEY_FIELD = 'DocumentService' SHOW_TYPE_FIELDS = True ALL_TYPE_FIELDS = False TYPE_FIELDS = ['Extensions', 'MediaType'] # Flags are defined in <source directory>/include/comphelper/documentconstants.hxx # with exception of3RDPARTYFILTER is STARONEFILTER and READONLY is OPENREADONLY there FLAG_LABELS = [(0x00000001, 'IMPORT'), (0x00000002, 'EXPORT'), (0x00000004, 'TEMPLATE'), (0x00000008, 'INTERNAL'), (0x00000010, 'TEMPLATEPATH'), (0x00000020, 'OWN'), (0x00000040, 'ALIEN'), (0x00000100, 'DEFAULT'), (0x00000400, 'SUPPORTSSELECTION'), (0x00001000, 'NOTINFILEDIALOG'), (0x00010000, 'READONLY'), (0x00020000, 'MUSTINSTALL'), (0x00040000, 'CONSULTSERVICE'), (0x00080000, '3RDPARTYFILTER'), (0x00100000, 'PACKED'), (0x00200000, 'EXOTIC'), (0x00800000, 'COMBINED'), (0x01000000, 'ENCRYPTION'), (0x02000000, 'PASSWORDTOMODIFY'), (0x04000000, 'GPGENCRYPTION'), (0x10000000, 'PREFERRED'), (0x20000000, 'STARTPRESENTATION'), (0x40000000, 'SUPPORTSSIGNING'), ] def main(*args, **kwds): ctx = XSCRIPTCONTEXT.getComponentContext() smgr = ctx.ServiceManager # get filter information from filter factory SERVICE_FILTERFACTORY = 'com.sun.star.document.FilterFactory' SERVICE_TYPEDETECTION = 'com.sun.star.document.TypeDetection' filter_factory = smgr.createInstanceWithContext(SERVICE_FILTERFACTORY, ctx) filter_dict = {} for filter_name in filter_factory.getElementNames(): try: property_dict = {} for property in filter_factory.getByName(filter_name): property_dict[property.Name] = property.Value filter_dict[filter_name] = property_dict except: continue fields = sorted(list(reduce(lambda x,y:x|y, (set(v.keys()) for v in filter_dict.values()), set()))) if not ALL_FIELDS: fields = [f for f in FIELDS if f in fields] if SHOW_TYPE_FIELDS and 'Type' not in fields: fields.append('Type') # if SHOW_TYPE_FIELDS: type_detection = smgr.createInstanceWithContext(SERVICE_TYPEDETECTION, ctx) type_dict = {} for type_name in type_detection.getElementNames(): try: property_dict = {} for property in type_detection.getByName(type_name): property_dict[property.Name] = property.Value type_dict[type_name] = property_dict except: continue type_fields = sorted(list(reduce(lambda x,y:x|y, (set(v.keys()) for v in type_dict.values()), set()))) if not ALL_TYPE_FIELDS: type_fields = [f for f in TYPE_FIELDS if f in type_fields] else: type_dict = {} type_fields = [] # head = ['Name'] + fields + type_fields filter_table = [] for filter_name, property_dict in filter_dict.items(): filter_values = [filter_name] + [property_dict.get(f) for f in fields] if 'Flags' in fields: idx = head.index('Flags') if filter_values[idx] is not None: flag_value = filter_values[idx] flag_names = [] for n, name in FLAG_LABELS: if flag_value & n == n: if ALL_FLAGS or name in FLAGS: flag_names.append(name) flag_value &= ~n if flag_value != 0: # found an unknown flag flag_names.append('%8.8x' % flag_value) filter_values[idx] = ' '.join(flag_names) type_values = [type_dict.get(property_dict.get('Type'), {}).get(n) for n in type_fields] if 'Extensions' in type_fields: idx = type_fields.index('Extensions') if type_values[idx] is not None: type_values[idx] = ' '.join(type_values[idx]) filter_table.append(filter_values + type_values) # if KEY_FIELD in fields: idx = head.index(KEY_FIELD) key = lambda r:(r[idx], r) else: key = None filter_table.sort(key=key) filter_table.insert(0, head) # table to spreadsheet NEWSHEET_URL = 'private:factory/scalc' desktop = XSCRIPTCONTEXT.getDesktop() spreadsheet = desktop.loadComponentFromURL(NEWSHEET_URL, '_blank', 0, ()) sheet = spreadsheet.getSheets().getByIndex(0) for i, row in enumerate(filter_table): for j, col in enumerate(row): cell = sheet.getCellByPosition(j, i) cell.String = str(col) # set column width optimal columns = sheet.getColumns() for i in range(len(head)): columns.getByIndex(i).OptimalWidth = True # make head line characters bold for i in range(len(head)): cell = sheet.getCellByPosition(i, 0) cell.CharWeight = BOLD # freeze head row (column 0, row 1) spreadsheet.CurrentController.freezeAtPosition(0, 1) # set auto filter cell_range = sheet.getCellRangeByPosition(0, 0, len(head) - 1, len(filter_table) - 1) range_name = 'filter range' spreadsheet.DatabaseRanges.addNewByName(range_name, cell_range.getRangeAddress()) filter_range = spreadsheet.DatabaseRanges.getByName(range_name) filter_range.AutoFilter = TrueLibreOffice インストールディレクトリからの取得
FilterFactory, TypeDetection サービスから取得できるのと同内容は、<LibreOfficeインストールディレクトリ>/share/registry ディレクトリ下の .xcd ファイルに定義がある。
こちらに定義されているのは LibreOffice が元から持っているフィルタのみで、拡張機能のフィルタの定義は拡張機能のインストールディレクトリ下の .xcu ファイルにある。下記は .xcd ファイルからフィルタの表を作成するプログラムであるが、UIName の地域化(日本語名)には対応していない。地域化データは <LibreOfficeインストールディレクトリ>/share/registry/res ディレクトリ下にある。
filter_registry.py#!/usr/bin/env python """list import/expot filters from registry """ """ (C) Copyright 2020 Shojiro Fushimi, all rights reserved Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: - Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. - Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDER ``AS IS'' AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE AUTHOR OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. """ import sys from argparse import ArgumentParser from re import compile as re_compile from functools import reduce import csv import xml.etree.ElementTree DEFAULT_FIELDS = ['DocumentService', 'UIName', 'Flags'] DEFAULT_FLAGS = ['IMPORT', 'EXPORT', 'DEFAULT', 'PREFERRED'] DEFAULT_KEY_FIELD = 'DocumentService' DEFAULT_TYPE_FIELDS = ['Extensions', 'MediaType'] NS_RE = re_compile(r'\{(.*?)\}') def component_data_dict(file_name: str, component_name: str, node_name: str): tree = xml.etree.ElementTree.parse(file_name) root = tree.getroot() namespace_mo = NS_RE.match(root.tag) if namespace_mo is None: return {} namespace = {'oor': namespace_mo.group(1)} data_dict = {} for component_data in root.findall(f'.//oor:component-data[@oor:name="{component_name}"]', namespace): component_node = component_data.find(f'node[@oor:name="{node_name}"]', namespace) if component_node is None: continue oor_name = f'{{{namespace["oor"]}}}name' for data_node in component_node.findall('node'): name = data_node.attrib.get(oor_name) if name is None: continue prop_dict = {} for prop in data_node.findall('prop'): prop_name = prop.attrib.get(oor_name) if prop_name is None: continue value = prop.find('value') if value is not None: value_text = value.text else: value_text = None prop_dict[prop_name] = value_text data_dict[name] = prop_dict return data_dict def main(argv): aparser = ArgumentParser() aparser.add_argument('files', nargs='*') aparser.add_argument('--out', '-o', dest='out', action='store', default=None) aparser.add_argument('--fields', dest='fields', action='store', default=','.join(DEFAULT_FIELDS)) aparser.add_argument('--flags', dest='flags', action='store', default=','.join(DEFAULT_FLAGS)) aparser.add_argument('--all-fields', dest='all_fields', action='store_true', default=False) aparser.add_argument('--all-flags', dest='all_flags', action='store_true', default=False) aparser.add_argument('--key-field', dest='key_field', action='store', default=DEFAULT_KEY_FIELD) aparser.add_argument('--show-type-fields', dest='show_type_fields', action='store_true', default=False) aparser.add_argument('--type-fields', dest='type_fields', action='store', default=','.join(DEFAULT_TYPE_FIELDS)) aparser.add_argument('--all-type-fields', dest='all_type_fields', action='store_true', default=False) args = aparser.parse_args(argv[1:]) filter_dict = reduce(lambda x,y:dict(x, **y), (component_data_dict(file_name, 'Filter', 'Filters') for file_name in args.files), {}) fields = sorted(list(reduce(lambda x,y:x|y, (set(v.keys()) for v in filter_dict.values()), set()))) if not args.all_fields: fields = [f.strip() for f in args.fields.split(',') if f.strip() in fields] if args.show_type_fields and 'Type' not in fields: fields.append('Type') # if 'Flags' in fields and not args.all_flags: for d in filter_dict.values(): if 'Flags' in d: d['Flags'] = ' '.join([f for f in d['Flags'].split() if f in args.flags]) # if args.show_type_fields: type_dict = reduce(lambda x,y:dict(x, **y), (component_data_dict(file_name, 'Types', 'Types') for file_name in args.files), {}) type_fields = sorted(list(reduce(lambda x,y:x|y, (set(v.keys()) for v in type_dict.values()), set()))) if not args.all_type_fields: type_fields = [f.strip() for f in args.type_fields.split(',') if f.strip() in type_fields] else: type_dict = {} type_fields = [] # head = ['Name'] + fields + type_fields try: keyidx = head.index(args.key_field) key = lambda r:(r[keyidx], r) except: key = None table = sorted([[k] + [v.get(f) for f in fields] + [type_dict.get(v.get('Type'), {}).get(n) for n in type_fields] for k, v in filter_dict.items()], key=key) table.insert(0, head) # if args.out is not None: outfp = open(args.out, 'w', newline='') else: outfp = sys.stdout csv.writer(outfp).writerows(table) if args.out is not None: outfp.close() return 0 if __name__ == '__main__': rc = main(sys.argv) sys.exit(rc)
- 投稿日:2020-07-20T17:25:41+09:00
OpenCVでトラックバーを利用して画像の閾値調整
はじめに
OpenCVのトラックバーを使用して、
画像処理時のパラメータを調整するためのテストプログラム。
今回は、ガンマ補正した画像に対して二値化を行う。テスト用画像の読み込み
カメラから取得した画像を使用する。
取得した画像をグレースケールに変換して画素値の最大を取得(ガンマ補正用)import cv2 import sys cameraId = 0 capCam = cv2.VideoCapture(cameraId) if not capCam.isOpened(): sys.exit() ret, frame = capCam.read() gray = cv2.cvtColor(frame, cv2.COLOR_RGBA2GRAY) grayMax = gray.max()トラックバーを生成する
ガンマ補正値(gamma)と閾値(threshold1)を調整するためのトラックバーを生成する
gamma = 0.5 threshold = 28 def nothing(x): pass cv2.namedWindow('window') cv2.createTrackbar('gamma','window', int(gamma*10) , 50, nothing) cv2.createTrackbar('threshold1','window', threshold , 255, nothing)引数は以下のようになっている
CreateTrackbar(trackbarName, windowName, value, count, onChange)
- trackbarname : 作成されるトラックバーの名前
- windowName : 作成されるトラックバーの親として用いられるウィンドウの名前(事前に生成しておく)
- value : 作成時のスライダー位置
- count : スライダーの最大値(最小値は0固定)
- onChange : スライダーの位置変更時のコールバックgammaには0.1刻みの値を適用したいため、
トラックバー上は10倍した値としている。トラックバーと画像の表示
トラックバーから値を取得して画像に適用する
import numpy as np delay = 1 ESC_KEY = 27 while True: # ESCキーを入力したら終了 if cv2.waitKey(delay) == ESC_KEY: break # トラックバーから値を取得 gamma = cv2.getTrackbarPos('gamma','window') threshold = cv2.getTrackbarPos('threshold1','window') if gamma > 0: gamma /= 10 else: gamma = 0.1 # ガンマ補正 lut = np.zeros((256, 1), dtype='uint8') for i in range(256): lut[i][0] = grayMax * pow(float(i)/grayMax, 1.0/gamma) gray_gamma = cv2.LUT(gray, lut) # 二値化 ret, threshold = cv2.threshold(gray_gamma, threshold, 255, cv2.THRESH_BINARY) # 描画 cv2.imshow("window", threshold)gammaは1/10にした値を使用する。
0は許容できない(div/0で落ちる)ため、0.1に補正する。表示させると以下のようなイメージとなる。
スライダーでパラメータを変更すると適用された値で描画される。

- 投稿日:2020-07-20T17:00:12+09:00
ESPNetのAttributeError: module 'warpctc_pytorch' has no attribute 'gpu_ctc'解決法
実行環境
- Ubuntu18.04(Docker 19.03.12)
- Python3.7
- CUDA 10.0
ESPNetのStage4(Network Training)で以下のエラーが発生
dictionary: data/lang_1char/train_nodup_sp_units.txt stage 4: Network Training run.pl: job failed, log is in exp/train_nodup_sp_pytorch_train_rnn/train.logexp/train_nodup_sp_pytorch_train_rnn/train.log# asr_train.py --config conf/tuning/train_rnn.yaml --ngpu 1 --backend pytorch --outdir exp/train_nodup_sp_pytorch_train_rnn/results --tensorboard-dir tensorboard/train_nodup_sp_pytorch_train_rnn --debugmode 1 --dict data/lang_1char/train_nodup_sp_units.txt --debugdir exp/train_nodup_sp_pytorch_train_rnn --minibatches 0 --seed 1 --verbose 0 --resume --train-json dump/train_nodup_sp/deltafalse/data.json --valid-json dump/train_dev/deltafalse/data.json # Started at Mon Jul 20 06:07:11 UTC 2020 # /espnet/tools/venv/lib/python3.7/site-packages/librosa/util/decorators.py:9: NumbaDeprecationWarning: An import was requested from a module that has moved location. Import requested from: 'numba.decorators', please update to use 'numba.core.decorators' or pin to Numba version 0.48.0. This alias will not be present in Numba version 0.50.0. from numba.decorators import jit as optional_jit /espnet/tools/venv/lib/python3.7/site-packages/librosa/util/decorators.py:9: NumbaDeprecationWarning: An import was requested from a module that has moved location. Import of 'jit' requested from: 'numba.decorators', please update to use 'numba.core.decorators' or pin to Numba version 0.48.0. This alias will not be present in Numba version 0.50.0. from numba.decorators import jit as optional_jit 2020-07-20 06:07:12,362 (asr_train:555) WARNING: Skip DEBUG/INFO messages 2020-07-20 06:07:12,614 (nets_utils:417) WARNING: Subsampling is not performed for vgg*. It is performed in max pooling layers at CNN. Exception in main training loop: module 'warpctc_pytorch' has no attribute 'gpu_ctc' Traceback (most recent call last): File "/espnet/tools/venv/lib/python3.7/site-packages/chainer/training/trainer.py", line 316, in run update() File "/espnet/espnet/asr/pytorch_backend/asr.py", line 242, in update self.update_core() File "/espnet/espnet/asr/pytorch_backend/asr.py", line 206, in update_core data_parallel(self.model, x, range(self.ngpu)).mean() / self.accum_grad File "/espnet/tools/venv/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py", line 185, in data_parallel return module(*inputs[0], **module_kwargs[0]) File "/espnet/tools/venv/lib/python3.7/site-packages/torch/nn/modules/module.py", line 489, in __call__ result = self.forward(*input, **kwargs) File "/espnet/espnet/nets/pytorch_backend/e2e_asr.py", line 363, in forward self.loss_ctc = self.ctc(hs_pad, hlens, ys_pad) File "/espnet/tools/venv/lib/python3.7/site-packages/torch/nn/modules/module.py", line 489, in __call__ result = self.forward(*input, **kwargs) File "/espnet/espnet/nets/pytorch_backend/ctc.py", line 112, in forward self.loss = to_device(self, self.loss_fn(ys_hat, ys_true, hlens, olens)).to( File "/espnet/espnet/nets/pytorch_backend/ctc.py", line 62, in loss_fn return self.ctc_loss(th_pred, th_target, th_ilen, th_olen) File "/espnet/tools/venv/lib/python3.7/site-packages/torch/nn/modules/module.py", line 489, in __call__ result = self.forward(*input, **kwargs) File "/espnet/tools/venv/lib/python3.7/site-packages/warpctc_pytorch/__init__.py", line 93, in forward self.length_average, self.blank, self.reduce) File "/espnet/tools/venv/lib/python3.7/site-packages/warpctc_pytorch/__init__.py", line 23, in forward loss_func = warp_ctc.gpu_ctc if is_cuda else warp_ctc.cpu_ctc Will finalize trainer extensions and updater before reraising the exception. Traceback (most recent call last): File "/espnet/egs/csj/asr1/../../../espnet/bin/asr_train.py", line 628, in <module> main(sys.argv[1:]) File "/espnet/egs/csj/asr1/../../../espnet/bin/asr_train.py", line 614, in main train(args) File "/espnet/espnet/asr/pytorch_backend/asr.py", line 830, in train trainer.run() File "/espnet/tools/venv/lib/python3.7/site-packages/chainer/training/trainer.py", line 349, in run six.reraise(*exc_info) File "/espnet/tools/venv/lib/python3.7/site-packages/six.py", line 703, in reraise raise value File "/espnet/tools/venv/lib/python3.7/site-packages/chainer/training/trainer.py", line 316, in run update() File "/espnet/espnet/asr/pytorch_backend/asr.py", line 242, in update self.update_core() File "/espnet/espnet/asr/pytorch_backend/asr.py", line 206, in update_core data_parallel(self.model, x, range(self.ngpu)).mean() / self.accum_grad File "/espnet/tools/venv/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py", line 185, in data_parallel return module(*inputs[0], **module_kwargs[0]) File "/espnet/tools/venv/lib/python3.7/site-packages/torch/nn/modules/module.py", line 489, in __call__ result = self.forward(*input, **kwargs) File "/espnet/espnet/nets/pytorch_backend/e2e_asr.py", line 363, in forward self.loss_ctc = self.ctc(hs_pad, hlens, ys_pad) File "/espnet/tools/venv/lib/python3.7/site-packages/torch/nn/modules/module.py", line 489, in __call__ result = self.forward(*input, **kwargs) File "/espnet/espnet/nets/pytorch_backend/ctc.py", line 112, in forward self.loss = to_device(self, self.loss_fn(ys_hat, ys_true, hlens, olens)).to( File "/espnet/espnet/nets/pytorch_backend/ctc.py", line 62, in loss_fn return self.ctc_loss(th_pred, th_target, th_ilen, th_olen) File "/espnet/tools/venv/lib/python3.7/site-packages/torch/nn/modules/module.py", line 489, in __call__ result = self.forward(*input, **kwargs) File "/espnet/tools/venv/lib/python3.7/site-packages/warpctc_pytorch/__init__.py", line 93, in forward self.length_average, self.blank, self.reduce) File "/espnet/tools/venv/lib/python3.7/site-packages/warpctc_pytorch/__init__.py", line 23, in forward loss_func = warp_ctc.gpu_ctc if is_cuda else warp_ctc.cpu_ctc AttributeError: module 'warpctc_pytorch' has no attribute 'gpu_ctc' # Accounting: time=27 threads=1 # Ended (code 1) at Mon Jul 20 06:07:38 UTC 2020, elapsed time 27 seconds要するにwarpctc_pytorch周りでエラーが起きている
解決法
ESPNetはvenv環境内で実行しているため、まずvenv環境に入る。
source /espnet/tools/venv/bin/activatewarp ctcの再インストール
git clone https://github.com/espnet/warp-ctc -b pytorch-1.1 cd warp-ctc && mkdir build && cd build && cmake .. && make -j cd ../pytorch_binding && python(もしくはpython3) setup.py install
- 以下のエラー出た場合は、3-Aを実行した後、
python setup.py installを再実行running install running bdist_egg running egg_info creating warpctc_pytorch10_cuda100.egg-info writing warpctc_pytorch10_cuda100.egg-info/PKG-INFO writing dependency_links to warpctc_pytorch10_cuda100.egg-info/dependency_links.txt writing top-level names to warpctc_pytorch10_cuda100.egg-info/top_level.txt writing manifest file 'warpctc_pytorch10_cuda100.egg-info/SOURCES.txt' reading manifest file 'warpctc_pytorch10_cuda100.egg-info/SOURCES.txt' writing manifest file 'warpctc_pytorch10_cuda100.egg-info/SOURCES.txt' installing library code to build/bdist.linux-x86_64/egg running install_lib running build_py creating build/lib.linux-x86_64-3.7 creating build/lib.linux-x86_64-3.7/warpctc_pytorch copying warpctc_pytorch/__init__.py -> build/lib.linux-x86_64-3.7/warpctc_pytorch creating build/lib.linux-x86_64-3.7/warpctc_pytorch/lib copying warpctc_pytorch/lib/libwarpctc.so -> build/lib.linux-x86_64-3.7/warpctc_pytorch/lib running build_ext building 'warpctc_pytorch._warp_ctc' extension creating build/temp.linux-x86_64-3.7 creating build/temp.linux-x86_64-3.7/src gcc -pthread -B /espnet/tools/venv/compiler_compat -Wl,--sysroot=/ -Wsign-compare -DNDEBUG -g -fwrapv -O3 -Wall -Wstrict-prototypes -fPIC -I/warp-ctc/include -I/espnet/tools/venv/lib/python3.7/site-packages/torch/lib/include -I/espnet/tools/venv/lib/python3.7/site-packages/torch/lib/include/torch/csrc/api/include -I/espnet/tools/venv/lib/python3.7/site-packages/torch/lib/include/TH -I/espnet/tools/venv/lib/python3.7/site-packages/torch/lib/include/THC -I/usr/local/cuda/include -I/espnet/tools/venv/include/python3.7m -c src/binding.cpp -o build/temp.linux-x86_64-3.7/src/binding.o -std=c++11 -fPIC -DWARPCTC_ENABLE_GPU -DTORCH_API_INCLUDE_EXTENSION_H -DTORCH_EXTENSION_NAME=_warp_ctc -D_GLIBCXX_USE_CXX11_ABI=0 cc1plus: warning: command line option ‘-Wstrict-prototypes’ is valid for C/ObjC but not for C++ src/binding.cpp:11:11: fatal error: c10/cuda/CUDAGuard.h: No such file or directory #include "c10/cuda/CUDAGuard.h" ^~~~~~~~~~~~~~~~~~~~~~ compilation terminated. error: command 'gcc' failed with exit status 1
- 以下のエラーが出る場合は、3-Bを実行した後、
python setup.py installを再実行running install running bdist_egg running egg_info writing warpctc_pytorch12_cuda100.egg-info/PKG-INFO writing dependency_links to warpctc_pytorch12_cuda100.egg-info/dependency_links.txt writing top-level names to warpctc_pytorch12_cuda100.egg-info/top_level.txt reading manifest file 'warpctc_pytorch12_cuda100.egg-info/SOURCES.txt' writing manifest file 'warpctc_pytorch12_cuda100.egg-info/SOURCES.txt' installing library code to build/bdist.linux-x86_64/egg running install_lib running build_py copying warpctc_pytorch/lib/libwarpctc.so -> build/lib.linux-x86_64-3.6/warpctc_pytorch/lib running build_ext building 'warpctc_pytorch._warp_ctc' extension x86_64-linux-gnu-gcc -pthread -DNDEBUG -g -fwrapv -O2 -Wall -g -fstack-protector-strong -Wformat -Werror=format-security -Wdate-time -D_FORTIFY_SOURCE=2 -fPIC -I/warp-ctc/include -I/usr/local/lib/python3.6/dist-packages/torch/include -I/usr/local/lib/python3.6/dist-packages/torch/include/torch/csrc/api/include -I/usr/local/lib/python3.6/dist-packages/torch/include/TH -I/usr/local/lib/python3.6/dist-packages/torch/include/THC -I/usr/local/cuda/include -I/usr/include/python3.6m -c src/binding.cpp -o build/temp.linux-x86_64-3.6/src/binding.o -std=c++11 -fPIC -DWARPCTC_ENABLE_GPU -DTORCH_API_INCLUDE_EXTENSION_H -DTORCH_EXTENSION_NAME=_warp_ctc -D_GLIBCXX_USE_CXX11_ABI=0 In file included from /usr/local/lib/python3.6/dist-packages/torch/include/torch/csrc/Device.h:3:0, from /usr/local/lib/python3.6/dist-packages/torch/include/torch/csrc/api/include/torch/python.h:8, from /usr/local/lib/python3.6/dist-packages/torch/include/torch/extension.h:6, from src/binding.cpp:6: /usr/local/lib/python3.6/dist-packages/torch/include/torch/csrc/python_headers.h:9:10: fatal error: Python.h: No such file or directory #include <Python.h> ^~~~~~~~~~ compilation terminated. error: command 'x86_64-linux-gnu-gcc' failed with exit status 13-A. 自分のCUDAバージョンにあったPytorchのインストール
pip install torch===1.2.0 torchvision===0.4.0 -f https://download.pytorch.org/whl/torch_stable.html3-B. python3.7-devのインストール
apt-get install software-properties-common add-apt-repository ppa:deadsnakes/ppa apt-get update apt-get install python3.7(自分のpythonのバージョンに合わせる)-dev
- 投稿日:2020-07-20T16:59:23+09:00
2. Pythonで綴る多変量解析 4-1. 因子分析(scikit-learn)
因子分析は、多数ある変量の間に共通する因子を探り出して、それらの共通因子を使ってデータを評価するための技法です。
たとえば、マーケティングリサーチでは、ある質問の回答データ(多肢選択型でそれも選択肢が何十もある)について因子分析を行ない、ずっと少ない数の因子に置き換えます。それを今度はデータとして、クラスター分析(人分け)を行ない、つまりタイプ分類をしてプロファイリングをやったりします。各クラスターの性別・年齢別の構成比はどうなっているか、どのような特性をもった人たちなのか、市場全体に占めるボリュームは何%か、というようなことをやるわけです。
さて、12教科のテストの得点が1000人分、というダミーデータを因子分析用に作成しました。
以下、scikit-learnを利用して、因子分析の大筋をつかみます。⑴ ライブラリを読み込む
import numpy as np # 数値計算 import pandas as pd # データフレーム操作 import matplotlib.pyplot as plt # グラフ描画 %matplotlib inline # Notebook内にグラフ描画⑵ ダミーデータを読み込む
url = 'https://raw.githubusercontent.com/yumi-ito/sample_data/master/subject_scores.csv' df = pd.read_csv(url) df.head()GitHubに保管してあるcsvファイル
subject_scores.csvを読み込み、冒頭5行を表示して中身を確認します。
⑶ データを概観する ➀基本統計量
df.describe().apply(lambda s: s.apply(lambda x: format(x, 'g')))標本数(count)、平均値(mean)、標準偏差(std)、最小値(min)、四分位数(25%, 50%, 75%)、最大値(max)となっています。
なお、基本統計量の取得はdescribe()で事足りますが、それだと小数点以下6桁に0が並び、とても見づらいので.apply()以下で調節しています。
⑷ データを概観する ➁散布図
# matplotlibを日本語表示に対応させるモジュール !pip install japanize-matplotlib import japanize_matplotlib # pandasのplottingメソッドをインポート from pandas import plotting # 散布図行列を表示 plotting.scatter_matrix(df, figsize=(12, 12), alpha=0.8)pandasのplottingメソッドは、通常のplotメソッドよりも高度なグラフを描画することができます。
それはさておき、これは因子分析のために作成したダミーデータなので、実際にはあり得ないような高い相関が見てとれます(というか、そのように仕組んであります)。
⑸ データを標準化する
# sklearnの標準化メソッドをインポート from sklearn.preprocessing import StandardScaler # fitを使ってデータを変換する計算式を作成 sc = StandardScaler() sc.fit(df) # fitの結果を使って実際にデータを変換 z = sc.transform(df) print(z) print(z.shape)標準化とは、平均が0、分散が1(標準偏差も1)となるようにデータを変換してやることです。標準化は、次の式で行います。
$\displaystyle\frac{x-\bar{x}}{s}$
データの各値$x$から、その変数列の平均$\bar{x}$を引き、標準偏差$s$で割ります。
かりに、ある生徒の得点が、日本史が70点で倫理が60点だったとすると、
$日本史:\displaystyle\frac{70-65.574}{4.31545}=1.025617$
$倫 理:\displaystyle\frac{60-49.588}{9.0544}=1.149938$
つまり、得点だけを見ると日本史のほうが上のようですが、倫理のほうが上だとわかります。このように平均や標準偏差、あるいは単位の異なる変数間で大小を評価することができるようになります。
これを標準化得点(standard score)とかz得点などといい、行列の形状はもとのデータと同じ1000名×12変数(12教科)になっています。⑹ モデルを生成し、因子得点を算出する
# sklearnの因子分析モジュールをインポート from sklearn.decomposition import FactorAnalysis as FA # 因子数を指定 n_components=3 # 因子分析の実行 fa = FA(n_components, max_iter=5000) # モデルを定義 fitted = fa.fit_transform(z) # fitとtransformを一括処理 print(fitted) print(fitted.shape)もとは1000名×12変数であったデータが、1000名×3因子に変換されています。すなわち、各人のテストの得点は、各人の因子得点に変換されたわけです。
⑺ 因子負荷量行列を取得する
fa.components_.T生成されたモデル
faに対しcomponents_メソッドで因子負荷量を取得し、.Tで行列を転置して表示しています。
因子の解釈をやり易いように、行名・列名を付与してデータフレームに変換します。# 変数Factor_loading_matrixに格納 Factor_loading_matrix = fa.components_.T # データフレームに変換 pd.DataFrame(Factor_loading_matrix, columns=["第1因子", "第2因子", "第3因子"], index=[df.columns])因子負荷量は、共通因子が各変数に与える影響度を表わします。ある共通因子が潜在的にはたらいて、変数のそれぞれに影響を与えているから、それがテストの得点に反映しているという考え方です。
➀因子負荷量の絶対値の大きさ、➁因子負荷量のプラス・マイナス、にもとづいて因子の解釈をおこないます。
第1因子は、すべての変数がプラスになっているので、この因子が高くなると全変数が足並みをそろえて高くなります。そこで「総合学力」とか「基礎学力」などと命名できそうです。
第2因子は、国語・英語の絶対値が大きく、いずれもプラスで、また倫理もプラスでやや高めとなっています。そこで「言語能力」と命名しておきましょう。
第3因子は、数学・物理の絶対値がずば抜けて大きく、いずれもプラスになっているので、この因子は「数理能力」といえます。

因子分析って、こうしてライブラリを使えば、いとも手早くできてしまうのですが、実はかなり中ではいろいろな事をやっているんですよね。また、因子数の決め方はどうするとか、回転がどうであるとか、寄与率は、等など気にしておきたいポイントも少なくないです。計算は機械がやってくれますけど、そこから意味を見いだすのは人間の仕事なので・・・。




- 投稿日:2020-07-20T16:10:33+09:00
3D 形状の簡易ビューワーをFreeCADのpython モジュールで作りたい(調査中メモ)
解決したい問題
外面が平面で構成される立体についての計算をExcel上で行うのだが、入力ミスをし易く、穴の開いた形状となったり、面がダブったりし易い。
その確認をしたいのだが、Excelは3Dのソリッド形状をグラフ化する機能がない。手段の選択
gnuplotを使うことも考えたのだが、以下の理由からFreeCADのpythonモジュールを使うこととした。
- FreeCADのデータ、またはそれから変換したCADデータにすれば、寸法の確認をCADアプリ上で行うことや、データの2次利用などが可能となる
- Excelとpythonの連携はxlwingsを用いることで実装可能
- pythonスクリプト中でデータのチェックを補助する計算を加えることもできる
python.exeのバージョン
Anacondaでインストールしたpython.exeを使って簡単な例を実行してみたら、バージョンの差異により実行できなかった。また、FreeCADのドキュメントの中で、一部の機能を使うには、FreeCADをビルドした時に使ったのと同じCコンパイラでコンパイルしたpython.exeが必要との記述を見つけた。
よって、FreeCADに同梱のpython.exeを使うこととする。これにより、Anacondaをインストールしていなくても、FreeCADさえインストールしていれば、実行できる、というオマケもついた。参考:python.exeのバージョン
- Anacoonda版 : 3.7
- FreeCAD同梱 : 3.6
開発ステップ
中途段階でも利用可能とするよう、以下のステップで開発することとする。
- pythonのオブジェクト(変数)として定義されて3D形状データから、FreeCADのオブジェクトを生成し、FreeCADのネーティブファイルで保存するモジュールの実装
- 3D形状を定義するテキストファイルを読み込み、FreeCADのネーティブファイルで保存するスクリプトの実装
- Excelから3D形状を定義するテキストファイルの生成を簡易化するExcelシートの作成
- xlwingsを用いて、Excel上から3DデータをFreeCADのネーティブファイルで保存する機能の実装
- 3D形状を表示する簡易ビューワーの実装
以下、調査中メモ
FreeCADの外部で実行するpythonスクリプトから、FreeCAD関連のモジュールを利用する場合には、pythonのモジュール検索パスに、パスの追加が必要。Windowsに標準インストールした場合には、以下
FREECADPATH = r'C:\Program Files\FreeCAD 0.18\bin' import sys sys.path.append(FREECADPATH)
FreeCAD関連のメインのモジュールは、FreeCADとFreeCADGui。モジュールFreeCADがファイルIOその他全般、モジュールFreeCADGuiがGUI関連。importするとそれぞれ、AppとGuiという別名からアクセスできる。(ドキュメント中の例などがApp, Guiで書かれているので、このことを知らないと理解しづらい。)
3D View関連は過去の経緯から、OpenCASCADEではなく、OpenInvertor standardを実装したCoin3Dを使用。そのpython側のラップモジュールがpivy。
pivyモジュールを直接使って、boxなどを3Dシーンに追加することは可能。但し、これは同時にFreeCADのGeometryオブジェクトを作っているわけではないので、注意が必要。寸法線などの説明的要素の表示を追加するなどのために設けられた裏口的なものと思った方が良い。
ビューワー的なものを実現方法の例がいくつか、ここ Embedding FreeCADGuiにあり。現状、一番下の例が良いらしい。
- 投稿日:2020-07-20T16:10:27+09:00
PyAutoItをちょっとだけ触ってみた
業務でPyAutoItを使ってみたので、備忘録として記事にしておきます。
PyAutoItとは
Python用のAutoItのラッパーで。WindwosのGUIを操作することができます1
※似たようなものにPythonGUIというものがありますが、私は詳しくないです。
公式:https://pypi.org/project/PyAutoIt/そもそもAutoItとは・・・
AutoItはWindows用プログラムのGUI自動操作機能を主な特徴としている。スクリプトは実行形式にコンパイル可能であり、コンパイルしたものはAutoItインタプリタのインストールされていない環境でも動作する。フリーウェアであり非常に多くのライブラリ、開発ツールが存在する。
Wikipedia公式:https://pypi.org/project/autoit/
とのことらしいです。PyAutoItを使うのに必要な環境情報
# 名前 説明 1 Python3 PyAutoItはPythonで動くので当然必要になります 2 エディタツール VSCode,pycharm,ATOM等お好きなもの 3 PyAutoIT インストールしないと使えません 1. PyautoItのインストール
- コマンドプロンプトを起動する
- pip install pyautoit と入力する
PyAutoItのインストール$ pip install pyautoit2. AutoItのインストール
AutoItに入っている「Au3Info.exe2」を使いたいので、本家のAutoItもインストールします。
- AutoItの公式サイトのDownloadから最新版をダウンロードします。v3.3.14.5(2020年7月時点)
- ダウンロードしたSetup.exeを開き、インストールする
- Next -> Agree -> 画面に沿ってインストール 4.C:\Program Files (x86)\AutoIt3 の中にAu3Info.exe / Au3Info_64.exeが入っていることを確認する ※インストール先を変更した場合は、変更先で確認してください。
参考したページ:http://auto-pc.neginukide.com/?p=27
PyAutoItの使い方
PyAutoItはあくまでも自動化することしかできません。
その自動化する対象(GUI)の情報を取得するのには、Au3Info.exeを使用します。
※Au3Info.exe / Au3Info_64.exeの2種類存在しますが、自身のPCのbit数と同じものを使ってください。
Au3Info.exe:32bit / Au3Info_64.exe:64bitPyAutoItで使える関数
基本的にAutoItと同じ関数が使えるそうです。
ただし、少しだけ使い方が異なるので注意してください。例)ControlTreeView関数の場合
AutoIt:ControlTreeView
PyAutoIt:Control_Tree_View (autoit.Control_Tree_View(hoge,hogehoge,hogehogehoge)と使うそうです)https://open-shelf.appspot.com/AutoIt3.3.6.1j/html/functions.htm
Au3Info.exeの使い方はこちらの記事を参考にしてください。
■■■Au3Info.exeの利用方法■■■操作例(Au3Info.exe)
Au3Info.exeを起動するとこのような画面が表示されます
赤枠の部分をドラッグして、操作したいウインドウの場所までもっていきます
Controlタブを選択すると、ドラッグした箇所のウィンドウ情報を取得することができます。
取得したウィンドウ情報をもとにコードを書いてみます
サンプルコード
ここでは、メモ帳に"Hello World!"と入力するサンプルコードを記述します。
PyAutoItサンプルコード(Python)import autoit autoit.run("notepad.exe") autoit.win_wait_active("[CLASS:Notepad]", 3) autoit.control_send("[CLASS:Notepad]", "Edit1", "hello world{!}") autoit.win_close("[CLASS:Notepad]") autoit.control_click("[Class:#32770]", "Button2")実際に動かしてみた(デモ動画)
操作の内容
1. メモ帳を開く
2. "Hello World!"と入力する
3. 保存せずにメモ帳を閉じる
AutoItの使い方
このページはPyAutoItのことをメインにしているので、
もし本家のAutoItに興味のある方は、下記の記事を読んでみてください。
https://cfautog.tokyo/2020/02/27/autoit-howtouse/



- 投稿日:2020-07-20T15:47:20+09:00
Pythonプロジェクトを開始する時にやること
はじめに
Pythonを使ったプロジェクトを開始する際にやることのメモです。
必要なものインストール
anyenv
env系を管理するもの
*envを入れるなら入れておいた方が便利brew install anyenv anyenv init*envを一括でアップデートできる以下のプラグインも便利
https://github.com/znz/anyenv-updatepyenv
pythonを複数バージョン扱うのを可能にしてくれるもの
anyenv install pyenvPoetry
プロジェクト毎のpythonのバージョンやパッケージの管理をするもの
curl -sSL https://raw.githubusercontent.com/python-poetry/poetry/master/get-poetry.py | python # シェル再読み込み exec $SHELL -l # 仮想環境をプロジェクトフォルダに作成するように変更 poetry config virtualenvs.in-project true環境作成
pyenv local 3.7.7 # poetryは自動でpythonのバージョンを切り替えてくれないので、手動で変える poetry init # pyenvのpythonは使わないので、.python-versionを削除 rm .python-version # 2回目以降 poetry shellフォーマッター等インストール
which python # poetryのpythonを使っているかチェック poetry add -D yapf flake8 pep8-naming
- 投稿日:2020-07-20T14:13:12+09:00
【初心者向け】VSCodeでDjango-htmlを自動整形したいときに躓いたのでメモ
はじめに
この記事ではDjango-htmlのフォーマッター(厳密に言うと違うけど)をVisual Studio Code上で動かすのに困った点などをまとめる。
Django-girlsとかから取り敢えず初めて見たけど、
「there is no formatter for 'django-html' files installed('django-html' ファイルのフォーマッタがインストールされていません。)」って出て苦戦してる人向け。Formatterとは
コーディングは見やすさが命。
記述パターンを統一することで可読性が上がり、純粋な作業効率のUPだけでなく
スムーズなチーム間共有にも繋がる。あと見やすいとモチベも向上する。それを自動でお手伝いしてくれる拡張機能(とか)が、いわゆるコードフォーマッター。
便利な世の中になったよね。実行環境
- Windows10 64bit
- Visual Studio Code v1.47.2
留意点
手順的には割とあっさりなので、仕組みが分からずなんでやねんと試行錯誤した部分を先に走り書きとしてまとめておく。
- VSCodeの内部にもjs-beautifyというフォーマッターがあり、実は結構これで色々できる。けど使用するスタイルを変更する機能がないので断念。
- Extensionsとしてはprettierとかが有名。だけどhtml,css,jsとかに対応してる一方でDjango-htmlはこちらも非対応だった為断念。(settingうまく弄ればいけたかも?
- beautifyはjs-beautifyで出来ない設定を可能にし、拡張性をもたらすアドオン。今回はこれを使用。
- 留意点として、Django-html用のformatterは、2020年7月現時点では存在しない(多分)。 今回はhtml扱いのなかで、Django-htmlをフォーマットしているため、Djangoテンプレートとの融和性は低め。なのですべてがきれいに整えられるわけではないことに注意。
導入手順
1.Ctrl+Shift+xで
beautifyを検索、install
2.Ctrl+,でsettingsから、右上の.jsonで開き以下を追記
setting.json"beautify.language": { "html": [ "htm", "html", "django-html" ] }3.保存してVSCodeを再起動
4.編集中のdjango-htmlでフォーマットしたい範囲を
Ctrl+K Ctrl+Fで選択、フォーマット。(全体で行うときはShift + Alt + F)終わり。
思ったこと
最初は「拡張子htmlなのにエンコードされない、ぐぬぬ..」とかれこれ1時間ほど設定を見直していたが、Django-html用のformatterがないという初歩的な勘違いだった。おかげでjs-beautifyとprettierの特徴や違いが学べたから良しとしよう。
Djangoはbeautifyでjsはprettierとか言語別でフォーマットをしておくと便利かも。
ちなみにVSCode内蔵のformatを指定するときはこう↓
"editor.defaultFormatter": "vscode.html-language-features"最後までお読みいただきありがとうございました。
よかったらLGTMしてね。参考にしたサイト
GitHub - There is no document formatter for 'django-html'-files installed. #65189
stackoverflow - There is no document formatter for 'django-html'-files installed
Beautify HookyQR - VisualStudio Marketplace
VSCodeにおけるDjango-htmlのformatterについて

- 投稿日:2020-07-20T13:44:03+09:00
ReadTheDocsでno module namedのエラーが出た時
はじめに
ReadTheDocsというサービスがあります。
これはどうやら
- Sphinxでドキュメントを作るのを、ReadTheDocs上でGitHubからTravisなどで自動化してビルドし、そのままパブリックに公開する
というもののようです。
https://cookiecutter-pypackage.readthedocs.io/en/latest/tutorial.html
このライブラリを用いて現在パッケージを作成していますが、どうやらこのチュートリアルもReadTheDocsで公開されているようです。
エラー
ReadTheDocsのビルド上で
no module named `numpy`のように、numpyのパッケージがないからdocsのビルドのときに参照先が分からずエラー出てるよ!が発生しているようです。
よって、ビルドのときにこれらの内部で使っているパッケージをインストールしてあげれば良さそうです。対処法
https://docs.readthedocs.io/en/stable/config-file/v2.html
こちらを参照して修正します。
.readthedocs.ymlにpython: install: - requirements: docs/requirements.txtを追加して、docs/requirements.txtに必要なパッケージを書いてあげれば、ビルド前にインストールしてくれます。
- 投稿日:2020-07-20T12:23:44+09:00
[python]pandasのto_sql()を使わずにXML文字列を生成して、SQLServerのストアドプロシージャ内でOPENXML関数を用いてデータ更新処理をするまわり
1.概要
pandasにはcsvやExcelファイル、あるいはリレーショナルデータベース(RDB)やGoogleのBigQueryなど各種データソースのデータ書き込み/読み込みを行うメソッドが用意されていて、例えばSQLServerなどのRDBMSのテーブルにデータを書き込みしたい場合は、pandasのto_sql()なるメソッドを使えば簡単にテーブルにデータ更新ができる訳だが。既にテーブルに格納したデータを2回目の更新処理の際に同じデータをテーブルに再度書き込みしようとした場合、データが重複してしまうのでそうした重複するデータに関してはテーブル書き込みをしないよう、テーブル上でデータが一意になる形でデータ更新をしたい場合に、pandasのto_sql()だとやや小回りが効かない感が否めない。さりとてreplaceモードでto_sql()を実行するわけにもいかなく...
ということで今回はpandasのto_sql()を使わずに、以下の流れでSQLServer上のテーブルに差分データのみ更新する方法について試作/考察してみた。1:pythonにてpandasのdfデータフレームからelementTreeでXML文字列を生成・・・(1)
2:(1)のXML文字列を引数にしてSQLAlchemyでSQLServerのストアドプロシージャを実行
3:(1)のXML文字列をSQLServerのOPENXML関数で読み込んでデータ展開・・・(2)
4:(2)のデータを一時テーブル#tableに格納して、実テーブルとJOINして差分のみ更新なおこの上記のイメージでデータ更新が可能なのは、MicrosoftのRDBMS製品であるSQLServerに標準で用意されているXML文字列を操作する機能であるOPENXML関数なるサポートがあることが前提であり、他のRDBMS製品では、OPENXML関数みたいなXML文字列を操作する機能があるのかないのか定かではないがどうなんでしょうか?(注:自分はMySQLやpostgresなどが詳しくないのであれだが、方向性としてはXML文字列をRDB上で簡単に操作する機能がMySQLやpostgresなどにもしあれば、それらの機能で代替できるのではないかなと、なんとなく思ったりしつつ...)
従ってこのイシューはSQLServer限定で実装可能な方法である点をご留意していただきたく!2.前半部分(python上でXML文字列を生成)
file1.pyimport pandas as pd import xml.etree.ElementTree as ET #サンプルデータ lei = ['353800PIEETYXIDK6K51','5493006W3QUS5LMH6R84','not found'] cname = ['トヨタ自動車','極洋','さくらインターネット'] isin = [' JP3633400001' , 'JP3257200000','JP3317300006'] sic =['7203','1301','3778'] #df生成 Pythondata={'sic': sic, 'isin': isin, 'cname': cname ,'lei': lei } df = pd.DataFrame(data) columns = ['sic', 'isin', 'cname', 'lei' ] df.columns = columns print(df) #XML文字列の生成 roots = ET.Element('root') for i in range(len(df)): f0 = ET.SubElement(roots, 'sb') f1 = ET.SubElement(f0, 'hoge') f1.set('sic', df.iloc[i,0]) f1.set('isin', df.iloc[i,1]) f1.set('cname', df.iloc[i,2]) f1.set('lei', df.iloc[i,3]) tree = ET.tostring(roots) tree = tree.decode() tree = "'" + tree + "'" print(tree)まず上記のサンプルデータ3件(トヨタ自動車、極洋、さくらインターネット)は、JPX東証のページからコード等を調べた。またLEIのコードはGLEIFのページで調べた。
上記のpythonコードを実行すると、まずpandasデータフレームdfが生成され、そのdfからXML文字列を生成する。上記ではXMLオブジェクトを生成して操作するためのpythonモジュールelementTreeを利用して、XMLオブジェクトを生成して、rootタグから逐次XMLタグ(正確にはXMLの属性情報)をforループで追加している。以下は上記のサンプルpythonコードの実行結果↓
※ 簡易的にGoogle Colabratoryでスクショ取ったが、実際は後述するSQLServerにデータを更新する処理が後続にあるので、Google Colabratoryではなく、利用するSQLServerにアクセスできる環境のpython実行環境にてスクリプトを実行するべし!上記のサンプルpythonコードで生成したXML文字列は以下の通り↓
'<root><sb><hoge cname="トヨタ自動車" isin=" JP3633400001" lei="353800PIEETYXIDK6K51" sic="7203" /></sb><sb><hoge cname="極洋" isin="JP3257200000" lei="5493006W3QUS5LMH6R84" sic="1301" /></sb><sb><hoge cname="さくらインターネット" isin="JP3317300006" lei="not found" sic="3778" /></sb></root>'XML文字列をもう少し可読性を上げて改行して記述すると、以下のようなXML構造となる↓
'<root> <sb> <hoge cname="トヨタ自動車" isin="JP3633400001" lei="353800PIEETYXIDK6K51" sic="7203" /> </sb> <sb> <hoge cname="極洋" isin="JP3257200000" lei="5493006W3QUS5LMH6R84" sic="1301" /> </sb> <sb> <hoge cname="さくらインターネット" isin="JP3317300006" lei="not found" sic="3778" /> </sb> </root>'上記のXMLでは、要素(element)で定義するのではなく、属性(attribute)で定義をしている。これは後述のSQLServerのOPENXML関数でXMLを読み込むときの仕様に基づいて属性(attribute)で定義付けを行なっている。あとはXML文字列を生成するときに、NULL(NaN/None)をどう処理するかがキモになるのかなと。pandasで扱うデータで欠損値は当然出てくると思うが、その際NULL(NaN/None)のたぐいは、XMLの文字列で定義付けする際に上手く扱えないので、何かしらの文字列を付与してあげるとかの回避策を考える必要がある。
(例えば上記のサンプルでは、1301極洋と7203トヨタ自動車はLEIのコードを保有しているが、一方の3778さくらインターネットはLEIのコードを持っていなくて、XML文字列を生成するために無理やりNULLのデータを「not found」などの文字に無理やり変換して、後述のSQLServerでのOPENXML関数での読み込み後にそれらを上手に対応するなどが必要かと。ここは改良の余地あり)3.後半部分(SQLServer上でOPENXML関数でXML文字列からデータを読み込み/組成)
file2.sqlDECLARE @idoc INT DECLARE @xml AS NVARCHAR(MAX) SET @xml = '<root><sb><hoge cname="トヨタ自動車" isin=" JP3633400001" lei="353800PIEETYXIDK6K51" sic="7203" /></sb><sb><hoge cname="極洋" isin="JP3257200000" lei="5493006W3QUS5LMH6R84" sic="1301" /></sb><sb><hoge cname="さくらインターネット" isin="JP3317300006" lei="not found" sic="3778" /></sb></root>' --SELECT @xml DROP TABLE IF EXISTS #temp; EXEC sp_xml_preparedocument @idoc OUTPUT, @xml; SELECT * INTO #temp FROM OPENXML(@idoc, '/root/sb/hoge',1) WITH (SIC varchar(50) './@sic' , ISIN varchar(50) './@isin' , CNAME varchar(50) './@cname' , LEI varchar(50) './@lei' ); SELECT * FROM #temp; DROP TABLE IF EXISTS #temp;上記のSQLクエリーの実行結果↓
SQLServerにはOPENXML関数というXML文字列を操作する機能が標準装備でサポートしており、このOPENXML関数を用いて、上記のpythonで生成したXML文字列をSQLで操作可能な状態のデータにした上で、一時テーブル#tempにデータを格納(SELECT * INTO〜句)してあげれば、あとはその#tempと格納先テーブルをJOINして、まだ格納先テーブルに存在していない#tempのレコードを差分レコードとして格納先テーブルにInsert処理するトランザクションクエリーを記述してあげれば、データの一意性を担保しつつテーブルのデータ更新が実現できるのではないかと思われる。なお前半部分で生成したXML文字列(のXMLの構造)と、後半のSQLのOPENXML関数で読み込む際のXMLの読み込み記述の箇所は完全に同一である必要があって、扱うXMLの構造は前半のXML文字列吐き出し部分と後半のXML読み込み部分が同じである必要があるので、ここが注意点であると思われる。(このSQLServerのOPENXML関数での読み込み部分でXML文字列が上手に読み込めない場合は、大抵XMLの記述の箇所で前半のpython上で生成した文字列と、SQLServer上でOPENXMLで読み込む箇所がシンクロしてない可能性がある)
4.SQLAlchemyでSQLServerのストアドプロシージャを実行
file1.pyimport sqlalchemy # DB接続設定文字列 CONNECT_INFO = 'mssql+pyodbc://hoge' #hoge=ODBC名 engine = sqlalchemy.create_engine(CONNECT_INFO, encoding='utf-8') #...(中略)... ## DB更新 Session = sqlalchemy.orm.sessionmaker(bind=engine) session = Session() ## ストアド実行 query = 'EXEC dbo.spUpdatehoge @prm = {0}'.format(tree) res = session.execute(query) #sp実行 print(res.fetchall()) session.commit() #コミット session.close()SQLServerのストアドプロシージャをpython(のSQLAlchemy)で実行する際、上記クエリーの
session.execute(query)の箇所で、ストアドプロシージャを実行した戻り値(レスポンス)をpython上で取得して表示させたい場合、ストアドプロシージャ内ではReturn句ではなくSelect文で更新結果状態を返すようにすると、python上でストアド実行した結果が即分かるのではないかと思う。どうやらストアドプロシージャ内にてReturn句で返した結果を、SQLAlchemyのResultProxyオブジェクトは、上手く取得ができない模様。
今回記した更新方法は、前半部分のPythonスクリプトでXML文字列を生成する箇所と、後半部分のSQLServerでのストアドプロシージャ内のOPENXML処理の箇所と、処理の前半/後半とで分かれてしまっているので、ストアドプロシージャの処理結果(成功失敗有うんぬん)がPythonのSQLAlchemyで取得表示できると、安心できるのではないかなと思われ。

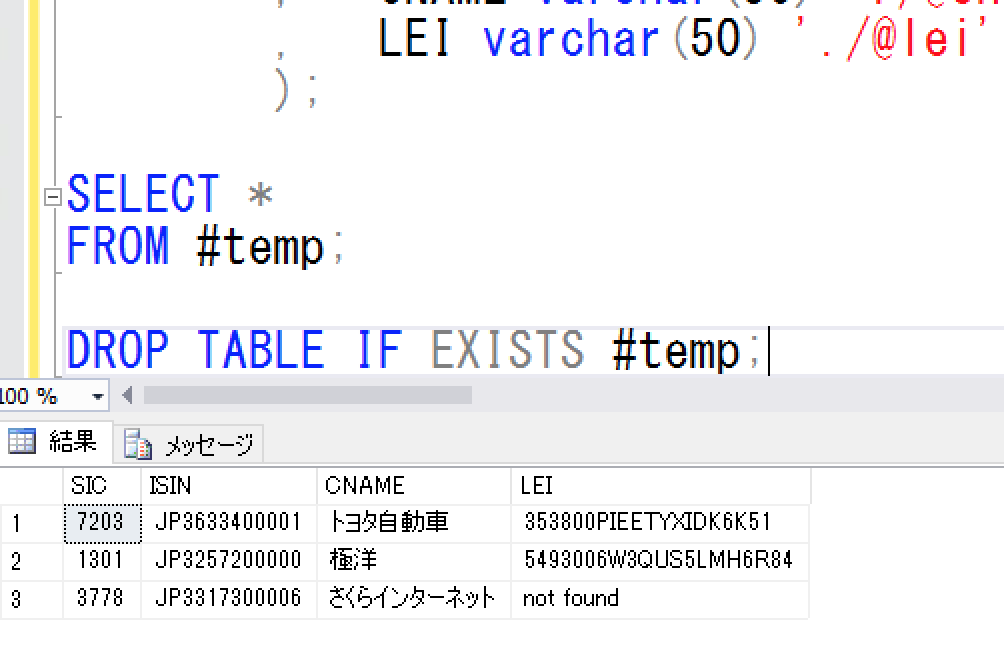
- 投稿日:2020-07-20T12:11:53+09:00
入試の「受験者平均点」「合格者平均点」「倍率」から「合格最低点」を求める
目的
中学・高校・大学等の入試の過去問を解く際、「受験者平均点」「合格者平均点」「倍率(合格者数 / 受験者数)」が公開されているが「合格最低点」が非公開の場合がある。
ここではその合格最低点を予測することを考える。手法
以下のサイトで公開されているM中学の入試データ(2013~2019年度)を利用した。
ゴロゴロ中学受験
https://www.goro-goro.net/2019-musashi各年度のデータについて、受験者平均点を $\mu_a$ 、合格者平均点を $\mu_p$ 、倍率を $r$ として、以下の操作を行った。
(各操作は次項で詳細に説明する。)
- $\sigma$ の値を決める。受験者の得点が平均が $\mu_a$ 、標準偏差が $\sigma$ の正規分布に従うと仮定する。
- 正規分布において、 $x > b$ の面積が $\frac{1}{r}$ となるような $b$ を暫定の合格最低点とする。
- 分布の $x > b$ の部分の平均を求め、暫定の合格者平均点 ${\mu_p}^{\prime}$ とする。
- ${\mu_p}^{\prime}$ と $\mu_p$ の大小関係から、標準偏差 $\sigma$ を更新し、1に戻る。これを繰り返す。
- ${\mu_p}^{\prime}=\mu_p$ となったら、その時点での合格最低点 $b$ を予測値とする。
その後、合格最低点の予測値と実際の値をプロットし、簡単な予測(※)の場合と精度を比較した。
(※)合格最低点 = (受験者平均点 + 合格者平均点) / 2 であるという予測手法の詳細
1. $\sigma$ の値を決める。受験者の得点が平均が $\mu_a$ 、標準偏差が $\sigma$ の正規分布に従うと仮定する。
受験人数が十分に多く、満点や零点の受験者がいない場合、この仮定は有効であると考えた。
もちろん、本当の得点分布は離散分布であるが、これを連続分布として考えている。
最初の $\sigma$ はてきとうに決めてよく、後々更新され最適値に近づいていく。
なお、上のグラフを「一人の受験生の得点の確率分布」と見るならば $y$ 軸は「確率密度(積分すると確率になる)」であり、「全受験生の得点分布」と見るならば $y$ 軸は「確率密度×人数(積分すると人数になる)」である。
2. 正規分布において、 $x > b$ の面積が $\frac{1}{r}$ となるような $b$ を暫定の合格最低点とする。これは数式で表すと
\int^{b}_{\infty} \frac{1}{\sqrt{2\pi{\sigma}^2}}\exp{\left(-\frac{(x-\mu_a)^2}{2\sigma^2}\right)} \mathrm{d}x = 1-\frac{1}{r}を満たす $b$ を求めることに相当する。
左辺は、今回の正規分布の累積分布関数に $b$ を代入したものとなっている。
この式は解析的に解くことができないため、今回プログラミング(Python)を利用した(コードは後述)。
直線 $x=b$ が、得点分布で合格者と不合格者を分けているイメージである。
3. 分布の $x > b$ の部分の平均を求め、暫定の合格者平均点 ${\mu_p}^{\prime}$ とする。これは、切断正規分布の平均(期待値)を求めることに相当し、
{\mu_p}^{\prime} = \mu_a + \sigma\frac{\phi\left(\frac{b - \mu_a}{\sigma}\right)}{1-\Phi\left(\frac{b - \mu_a}{\sigma}\right)}と表される( $\phi (\cdot)$ は標準正規分布の確率密度関数、 $\Phi (\cdot)$ はその累積分布関数を表す)。
参考:https://bellcurve.jp/statistics/blog/18075.html
4. ${\mu_p}^{\prime}$ と $\mu_p$ の大小関係から、標準偏差 $\sigma$ を更新し、1に戻る。これを繰り返す。
上図のように、最初に決めた標準偏差 $\sigma$ が大きいほど ${\mu_p}^{\prime}$ は大きくなる(単調増加)ため、二分法を使い、${\mu_p}^{\prime} = \mu_p$ となる $\sigma$ を探索する。
上図のように毎回探索範囲が半分になるため、100回ほど繰り返すと十分な精度で目的の値にたどりつく。
(注)実は $\sigma$ と ${\mu_p}^{\prime}$ は上図の通り、1次関数の関係にある。そのため、実際には二分法を使わずに ${\mu_p}^{\prime} = \mu_p$ となる $\sigma$ を求めることができる。このことに解析後に気付いたが、計算精度や計算時間はほとんど変わらないため、二分法での解析をそのまま掲載した。
5. ${\mu_p}^{\prime}=\mu_p$ となったら、その時点での合格最低点 $b$ を予測値とする。コードと結果
上記の「正規分布を使った予測」を行い、「合格最低点 = (受験者平均点 + 合格者平均点) / 2 であるという予測」と精度を比較した。
import numpy as np from scipy.stats import norm import matplotlib.pyplot as plt from sklearn.metrics import r2_score, mean_absolute_error # 2013-2019年度のデータ from https://www.goro-goro.net/2019-musashi jukensya = [433, 556, 519, 590, 577, 541, 569] goukakusya = [177, 177, 185, 183, 187, 185, 186] juken_heikin = [138.5, 173.3, 172.9, 167.0, 165.5, 186.9, 170.5] goukaku_heikin = [166.5, 210.7, 210.3, 202.0, 197.0, 221.5, 205.2] goukaku_saitei = [146, 192, 188, 184, 180, 201, 185] goukaku_saitei_pred = [] for i in range(7): # 2013-2019年度の7回分を解析 r = jukensya[i] / goukakusya[i] # 倍率 mu_a = juken_heikin[i] # 受験者平均点 mu_p = goukaku_heikin[i] # 合格者平均点 sigma_l = 0.1 sigma_r = 1000 sigma = (sigma_l + sigma_r) / 2 # 標準偏差を、0.1~1000の範囲で探索 for i in range(100): # 二分法を100回繰り返す b = norm.isf(1 / r, mu_a, sigma) # 暫定の合格最低点 mu_p_prime = mu_a + sigma * norm.pdf((b - mu_a) / sigma) \ / (1 - norm.cdf((b - mu_a) / sigma)) # 暫定の合格者平均点 if mu_p_prime < mu_p: sigma_l = sigma else: sigma_r = sigma sigma = (sigma_l + sigma_r) / 2 goukaku_saitei_pred.append(b) # 受験者平均点と合格者平均点のちょうど中間点が合格最低点であるという予測 goukaku_saitei_pred_rough = [(goukaku_heikin[i] + juken_heikin[i]) / 2 for i in range(7)] ## R^2とMAEの確認 ## print("Pred 1: 正規分布を使った予測の結果") print("R^2: {:.4f}".format(r2_score(goukaku_saitei, goukaku_saitei_pred))) print("MAE: {:.4f}".format(mean_absolute_error(goukaku_saitei, goukaku_saitei_pred))) print("") print("Pred 2: (受験者平均点 + 合格者平均点) / 2 であるという予測の結果") print("R^2: {:.4f}".format(r2_score(goukaku_saitei, goukaku_saitei_pred_rough))) print("MAE: {:.4f}".format(mean_absolute_error(goukaku_saitei, goukaku_saitei_pred_rough))) ## 実測値-予測値プロットの作成 ## fig = plt.figure(figsize=(10, 5)) lim = [140, 220] # 両軸の範囲 s = 17 # フォントサイズ # Pred 1: 正規分布を使った予測の結果 ax0 = fig.add_subplot(1,2,1) ax0.plot(goukaku_saitei, goukaku_saitei_pred, "o", markersize=8) ax0.plot(lim, lim, "k-") ax0.set_title('Pred 1', fontsize=s) ax0.set_xlabel('True', fontsize=s) ax0.set_ylabel('Predicted', fontsize=s) ax0.tick_params(labelsize=s) ax0.set_xlim(lim) ax0.set_ylim(lim) ax0.set_aspect('equal') # Pred 2: (受験者平均点 + 合格者平均点) / 2 であるという予測の結果 ax1 = fig.add_subplot(1,2,2) ax1.plot(goukaku_saitei, goukaku_saitei_pred_rough, "o", markersize=8) ax1.plot(lim, lim, "k-") ax1.set_title('Pred 2', fontsize=s) ax1.set_xlabel('True', fontsize=s) ax1.set_ylabel('Predicted', fontsize=s) ax1.tick_params(labelsize=s) ax1.set_xlim(lim) ax1.set_ylim(lim) ax1.set_aspect('equal') # PNGとして保存 fig.tight_layout() fig.savefig("plot.png")出力
R^2値は決定係数であり、1に近いほど精度が良いことを意味する。
MAEは予測誤差の絶対値を平均したものであり、0に近いほど精度が良いことを意味する。Pred 1: 正規分布を使った予測の結果 R^2: 0.9892 MAE: 1.4670 Pred 2: (受験者平均点 + 合格者平均点) / 2 であるという予測の結果 R^2: 0.9583 MAE: 2.5571
考察
正規分布を利用した予測であるPred 1は、簡単な予測であるPred 2より高精度であるといえる。
予測誤差の平均は約1.5点であり、実際の勉強の際の目安にも十分使えそうである。
また、Pred 2のプロットを見ると左下の145点付近のデータで予測誤差が大きくなっている。
これは、Pred 2では受験倍率に関係なく「受験者平均点と合格者平均点の中点の数値」を採用しているため、倍率の変化に対応できないことが原因と考えられる(この年だけ倍率が2.4倍と低い、他の年は2.8~3.2倍)。
一方、Pred 1では予測誤差が他データと同程度以下に抑えられており、正規分布を利用した手法は倍率の変化に対応できているといえる。なお、Pred 1では多くのデータが「予測値が実際の値より1~2程度小さい」という似たようなずれ方をしている。
そのため、データが十分ある場合は、今回の「1~2程度」にあたる定数を求め、それを予測値に足す補正を加えることで、さらに良い精度となる可能性がある。参考
scipy.stats - scipyの統計関数群のAPI - keisukeのブログ
http://kaisk.hatenadiary.com/entry/2015/02/17/1929553-5. 歪度と尖度 | 統計学の時間 | 統計WEB
https://bellcurve.jp/statistics/course/17950.html





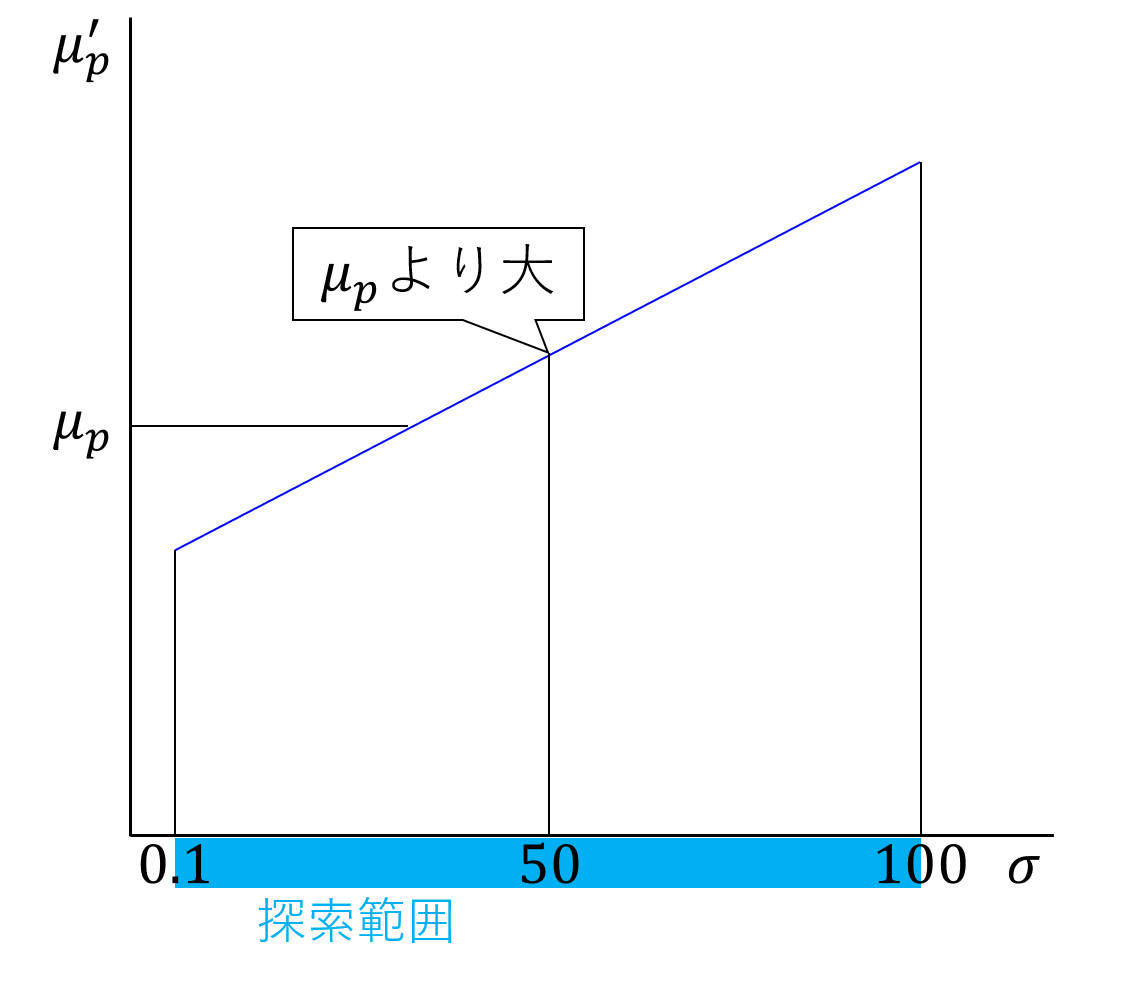



- 投稿日:2020-07-20T11:11:08+09:00
Machine Learning : Supervised - Linear Regression
目標
線形回帰、Ridge回帰、LASSO、Elastic-Net を数式で理解して、scikit-learn で実装する。
微分積分、線形代数、統計学が既習であることを前提としています。
理論
回帰とは、1つまたは複数の説明変数 $x$ からなる入力値から、1つまたは複数の目標変数 $y$ の値を予測することです。
線形回帰
単回帰
まずは説明変数 $x$ と目的変数 $y$ が 1つの単回帰を考えます。パラメータを $a, b$ とすると、推定値 $\hat{y}$ は以下のように 1次関数で表せます。
\hat{y} = a x + b回帰問題では $a, b$ を調整して $y$ を予測するため、$\hat{y}$ と $y$ の差が 0 になることを目指します。
そこで最初に思い浮かぶのは差 $y - \hat{y}$ ですが、これは正負の値を持ちます。正の値だけを扱うようにするには $|y - \hat{y}|$ のように絶対値をとる方法がありますが、絶対値は場合分けする必要があるため不便です。そこで、2乗する方法を用いるのが最小2乗法です。
従って解くべき数式は以下のように表せます。ここで、$n$ はデータの総数を表します。
L = \sum^n_{i=1} \{y_i - (ax_i + b) \}^2$L$ の最小値を求めたいので、$a, b$ で微分します。
\begin{align} \frac{\partial L}{\partial a} &= \frac{\partial}{\partial a} \sum^n_{i=1} (y_i - ax_i - b)^2 \\ &= \sum^n_{i=1} \{ 2 \cdot (-x_i) \cdot (y_i - ax_i - b) \} \\ &= 2 \left\{ a \sum^n_{i=1} x^2_i + b \sum^n_{i=1} x_i - \sum^n_{i=1} x_iy_i \right\}\\ \frac{\partial L}{\partial b} &= \frac{\partial}{\partial b} \sum^n_{i=1} (y_i - ax_i - b)^2 \\ &= \sum^n_{i=1} \{ 2 \cdot (-1) \cdot (y_i - ax_i - b) \} \\ &= 2 \left\{ a \sum^n_{i=1} x_i + nb - \sum^n_{i=1} y_i \right\} \\ \end{align}$a, b$ に関する微分を 0 として解くと、以下の連立方程式が得られます。
a \sum^n_{i=1} x^2_i + b \sum^n_{i=1} x_i - \sum^n_{i=1} x_iy_i = 0 \\ a \sum^n_{i=1} x_i + nb - \sum^n_{i=1} y_i = 0これを解いていきます。まず、下の式を $b$ について式変形すると、
b = \frac{1}{n} \sum^n_{i=1}y_i - a \frac{1}{n} \sum^n_{i=1} x_iここで、
\frac{1}{n} \sum^n_{i=1}y_i = \bar{y}, \frac{1}{n} \sum^n_{i=1} x_i = \bar{x}とおくと、
b = \bar{y} - a \bar{x}次に、もう一方の式を $n$ で割ってから代入すると、
a = \frac{ \frac{1}{n} \sum^n_{i=1} x_iy_i - \bar{x} \bar{y} }{ \frac{1}{n} \sum^n_{i=1} x^2_i - \bar{x}^2 }ここで、分母・分子は以下のように式変形できます。
\begin{align} \frac{1}{n} \sum^n_{i=1} x^2_i - \bar{x}^2 &= \frac{1}{n} \sum^n_{i=1} x^2_i - 2\bar{x}^2 + \bar{x}^2 \\ &= \frac{1}{n} \sum^n_{i=1} x^2_i - 2 \bar{x} \frac{1}{n} \sum^n_{i=1} \bar{x} + \bar{x}^2 \\ &= \frac{1}{n} \left\{ \sum^n_{i=1} x^2_i - 2 \bar{x} \sum^n_{i=1} x_i + n \bar{x}^2 \right\} \\ &= \frac{1}{n} \sum^n_{i=1} \left( x^2_i - 2 \bar{x}x_i + \bar{x}^2 \right) \\ &= \frac{1}{n} \sum^n_{i=1} \left( x_i - \bar{x} \right)^2 \\ \frac{1}{n} \sum^n_{i=1} x_iy_i - \bar{x}\bar{y} &= \frac{1}{n} \sum^n_{i=1} x_iy_i - 2\bar{x}\bar{y} + \bar{x}\bar{y} \\ &= \frac{1}{n} \left( \sum^n_{i=1}x_iy_i - 2n \bar{x}\bar{y} + n \bar{x}\bar{y} \right) \\ &= \frac{1}{n} \left( \sum^n_{i=1} x_iy_i - n \frac{1}{n} \sum^n_{i=1}x_i \bar{y} - n \frac{1}{n} \sum^n_{i=1} y_i \bar{x} - n\bar{x}\bar{y} \right) \\ &= \frac{1}{n} \sum^n_{i=1} \left( x_iy_i - \bar{y}x_i - \bar{x}y_i + \bar{x}\bar{y} \right) \\ &= \frac{1}{n} \sum^n_{i=1} \left\{ (x_i - \bar{x} )( y_i - \bar{y} ) \right\} \\ \end{align}よって、
a = \frac{\frac{1}{n} \sum^n_{i=1} \left\{ (x_i - \bar{x} )( y_i - \bar{y} ) \right\}}{\frac{1}{n} \sum^n_{i=1} \left( x_i - \bar{x} \right)^2} = \frac{Cov[x, y]}{\mathbb{V}[x]}ここで、$Cov[x, y]$ は共分散、$\mathbb{V}[x]$ は分散を表します。したがって、単回帰は以下の式で求まることが分かりました。
y = \frac{Cov[x, y]}{\mathbb{V}[x]} x + \left( \bar{y} - \frac{Cov[x, y]}{\mathbb{V}[x]} \bar{x} \right)重回帰
次に説明変数が 2つ以上の重回帰を考えます。説明変数 $x = (x_1, x_2, ..., x_m)$、目的変数 $y$、パラメータを $w = (w_0, w_1, ..., w_m)$ とすると、推定値 $\hat{y}$ は以下のように表せます。
\hat{y}(w, x) = w_0 + w_1x_1 + \cdots + w_mx_m$w_0$ は単回帰における切片 $b$ を表しており、$w_0$ に対応する疑似説明変数 $x_0 = 1$ を導入すると、上式をベクトルで表すことができるようになります。
\hat{y}(w, x) = w_0x_0 + w_1x_1 + \cdots + w_mx_m = {\bf x}^T {\bf w} \\ {\bf x}^T = (1, x_1, ..., x_m), {\bf w} = \begin{pmatrix} w_0 \\ w_1 \\ \vdots \\ w_m \end{pmatrix}また、$x$ はデータ数 $n$ だけ存在するので、行方向をデータ数、列方向を説明変数として行列 $\bf{X}$ で表すことにします。
\hat{y} = {\bf X} {\bf w} \\ {\bf X} = \begin{pmatrix} 1 & x_{11} & \cdots & x_{1m} \\ \vdots & & \ddots & \vdots \\ 1 & x_{n1} & \cdots & x_{nm} \end{pmatrix}単回帰と同様に最小2乗法を用いて、パラメータ $w$ に対して最小値を求めます。表記を簡便にするためにボールド表記をやめています。
\min_w || Xw - y ||^2これを式変形すると、
\begin{align} L &= || Xw - y ||^2 \\ &= (Xw - y)^T(Xw - y) \\ &= (w^TX^T - y^T)(Xw - y) \\ &= w^TX^TXw - w^TX^Ty - y^TXw + y^Ty \\ &= w^TX^TXw - 2w^TX^Ty + y^Ty \end{align}となるので、$w$ について微分して 0 を求めると、
\frac{\partial L}{\partial w} = 2X^TXw - 2X^Ty = 0 \\ w = (X^TX)^{-1}X^Tyしたがって、パラメータ $w$ はデータから求めることができることが分かりました。ただし、$X^TX$ が逆行列を持たない場合は解を定めることができません。
Ridge回帰
線形回帰にパラメータ $w$ に関する L2項を加えたものが Ridge回帰です。解くべき式は以下の式になります。
\min_w ||Xw - y||^2 + \alpha||w||^2_2これを $w$ に関して微分して 0 として解くと、
\frac{\partial L}{\partial w} = 2X^TXw - 2X^Ty + 2 \alpha w = 0 \\ w = (X^TX + \alpha I)^{-1} X^T yここで、$I$ は単位行列を表しています。
線形回帰では $X^TX$ が逆行列を持たない場合は解を定めることができませんでしたが、Ridge回帰では L2項を加えたことで逆行列を持つことを保証することができます。
逆行列をもつことを正則であるといい、L2項を加えることで必ず逆行列をもつようになるため、正則化と呼ばれています。
また、パラメータ $w$ に関する L2項を加えることは重み減衰として知られています。その効果を確認するため、ここで具体的な例を計算してみます。L2項が作用するのは実質 $(X^TX + \alpha I)^{-1}$ の部分だけなので、以下のような説明変数が 2つのデータが得られた場合を考えます。1列目は切片に対応するので疑似説明変数になっています。
X = \begin{pmatrix} 1 & 2 & 3 \\ 1 & 4 & 5 \\ 1 & 3 & 2 \\ \end{pmatrix}このとき、$X^TX$ は以下のように求まり、逆行列は以下のようになります。
X^TX = \begin{pmatrix} 3 & 9 & 10 \\ 9 & 29 & 32 \\ 10 & 32 & 38 \\ \end{pmatrix} , (X^TX)^{-1} = \begin{pmatrix} 4.875 & -1.375 & -0.125 \\ -1.375 & 0.875 & -0.375 \\ -0.125 & -0.375 & 0.375 \end{pmatrix}ここで、L2項の係数 $\alpha = 1$ のとき、(1行1列目は疑似説明変数なので 0 とします)
\alpha I = \begin{pmatrix} 0 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \\ \end{pmatrix}を $X^TX$ に加えると、
X^TX + \alpha I = \begin{pmatrix} 3 & 9 & 10 \\ 9 & 30 & 32 \\ 10 & 32 & 39 \\ \end{pmatrix} , (X^TX + \alpha I)^{-1} = \begin{pmatrix} 3.744 & -0.795 & -0.308 \\ -0.795 & 0.436 & -0.154 \\ -0.308 & -0.154 & 0.231 \end{pmatrix}確かに値が小さくなっており、重みを減衰させる効果があることが分かります。
LASSO
線形回帰にパラメータ $w$ に関する L1項を加えたものは LASSO (Least Absolute Shrinkage and Selection Operator) [1] と呼ばれています。解くべき式は以下の式になります。
\min_w \frac{1}{2}|| Xw - y ||^2 + \alpha ||w||_1上式には絶対値が含まれているため、場合分けをする必要があります。そこでまず、$w_0$ について考えます。
正則化が切片 $w_0$ には働かないことを考慮すると、
L_0 = \frac{1}{2} \left\{ \sum^n_{i=1} \left( w_0 + \sum^m_{j=1} x_{ij} w_j - y_i \right) \right\}^2これまでと同様に、$L_0$ を $w_0$ について微分して 0 として解くと、
\frac{\partial L_0}{\partial w_0} = \sum^n_{i=1} \left( w_0 + \sum^m_{j=1} x_{ij} w_j - y_i \right) = 0 \\ w_0 = \frac{1}{n} \sum^n_{i=1} \left( y_i - \sum^m_{j=1} x_{ij} w_j \right)次に、$w_1, ..., w_m$ について考えます。絶対値を含んでいるので $w_k$ に関して右微分と左微分で場合分けします。
\frac{\partial L}{\partial w^+_k} = \sum^n_{i=1} \left( w_0 + \sum^m_{j=1} x_{ij} w_j - y_i \right)x_{ik} + \alpha \\ \frac{\partial L}{\partial w^-_k} = \sum^n_{i=1} \left( w_0 + \sum^m_{j=1} x_{ij} w_j - y_i \right)x_{ik} - \alphaこれまでと同様に 0 として解くと、
w_k = \left\{ \begin{array}{ll} \frac{\sum^n_{i=1} \left( y_i - w_0 - \sum^m_{j=1, (j \neq k)} x_{ij} w_j \right)x_{i} - \alpha}{\sum^n_{i=1} x^2_{ik}} & (w_k > 0) \\ \frac{\sum^n_{i=1} \left( y_i - w_0 - \sum^m_{j=1, (j \neq k)} x_{ij} w_j \right)x_{i} + \alpha}{\sum^n_{i=1} x^2_{ik}} & (w_k < 0) \end{array} \right.となります。ただし上式の $w_k$ には条件が付いており、条件を満たさない場合は $w_k$ を 0 にします。
w_k = \left\{ \begin{array}{ll} \frac{\sum^n_{i=1} \left( y_i - w_0 - \sum^m_{j=1, (j \neq k)} x_{ij} w_j \right)x_{ik} - \alpha}{\sum^n_{i=1} x^2_{ik}} & \left(\sum^n_{i=1} \left( y_i - w_0 - \sum^m_{j=1, (j \neq k)} x_{ij} w_j \right)x_{ik} > \alpha \right) \\ 0 & \left( -\alpha \leq \sum^n_{i=1} \left( y_i - w_0 - \sum^m_{j=1, (j \neq k)} x_{ij} w_j \right)x_{ik} \leq \alpha \right) \\ \frac{\sum^n_{i=1} \left( y_i - w_0 - \sum^m_{j=1, (j \neq k)} x_{ij} w_j \right)x_{ik} + \alpha}{\sum^n_{i=1} x^2_{ik}} & \left( \sum^n_{i=1} \left( y_i - w_0 - \sum^m_{j=1, (j \neq k)} x_{ij} w_j \right)x_{ik} < - \alpha \right) \end{array} \right.また、以下のようにソフト閾値関数を定義することができます。
S(z, \alpha) = \left\{ \begin{array}{ll} z - \alpha & (z > \alpha) \\ 0 & (-\alpha \leq z \leq \alpha) \\ z + \alpha & (z < -\alpha) \end{array} \right. \\ z = \sum^n_{i=1} \left( y_i - w_0 - \sum^m_{j=1, (j \neq k)} x_{ij} w_j \right)x_{ik} \\なお、scikit-learn における LASSO は、座標降下法で実装されています。座標降下法では、説明変数に 0 を代入してソフト閾値関数を適用することをすべての説明変数に 1つずつ実行することを繰り返すことで近似解を求めます。
LASSO はパラメータの多くを 0 にすることでスパースな表現の獲得と特徴選択を行いますが、データ数 $n$ が説明変数 $m$ よりも少ない ($n < m$) 場合、データ数までしか特徴選択ができないことに注意が必要です。
また、説明変数間に高い相関があるとその内の 1つしか選択しないため、説明変数間を無相関にしておくとともに、入力特徴量を平均 0、分散 1 に標準化しておくとよいです。
Elastic-Net
線形回帰にパラメータに関する L1項と L2項を加えたものは、Elastic-Net [2] と呼ばれています。解くべき式は以下の式になります。
\min_w \frac{1}{2}||Xw - y||^2 + \alpha \rho ||w||_1 + \frac{\alpha(1 - \rho)}{2} ||w||^2_2Elastic-Net では、L1項だけでなく L2項も加えることで LASSO の欠点を改善しています。
なお、scikit-learn における Elastic-Net は、LASSO 同様に座標降下法で実装されています。
L1制約と L2制約の幾何学
下図は説明変数を 2つのとして、橙色の楕円は $||Xw - y||^2$ を、青色のひし形は L1制約を、円は L2制約を表しています。そして橙色の楕円と青い色の図形の交点である黄色の点が最適解を表しています。
L1制約では $w_1$ が 0 となっており、パラメータの多くがこのように 0 となることでスパースな解が得られます。
回帰問題のデータセット
scikit-learn には回帰問題のデータセットとして、diabates dataset が提供されているので、これを用いることにします。
データ数 特徴量数 目標値 442 10 [25, 346] 回帰モデルの定量評価
回帰モデルの定量評価として、Mean Squared Error と R2 Score が挙げられます。
Mean Squared Error
Mean Squared Error (MSE) は訓練データから推定したパラメータを用いて予測した $\hat{y}$ とテストデータ $y$ との平均2乗誤差を求めます。
MSE = \frac{1}{n} \sum^n_{i=1} (y_i - \hat{y}_i)^2MSE が小さいほどモデルの精度が高いことを示します。
R2 Score
R2 Score (Coefficient of Determination) は説明変数が目的変数をどの程度説明できているかを表します。訓練データから推定したパラメータを用いて予測した値を $\hat{y}$ 、テストデータの値を $y$ とすると、R2 Score は以下の式から求まります。
R^2 = 1 - \frac{SS_{residual}}{SS_{total}} \\ SS_{residual} = \sum^n_{i=1} (y_i - \hat{y}_i)^2, SS_{total} = \sum^n_{i=1} (y_i - \bar{y})^2R2 Score は [0, 1] の値をもち、1 に近づくほどモデルの精度が高いことを示します。
実装
実行環境
ハードウェア
・CPU Intel(R) Core(TM) i7-6700K 4.00GHz
ソフトウェア
・Windows 10 Pro 1909
・Python 3.6.6
・scikit-learn 0.23.0実行するプログラム
実装したプログラムは GitHub で公開しています。
linear_regression.py結果
実行結果は以下のようになります。
Linear Regression Mean Squared Error: 3424.32 R2 score: 0.33 Ridge Regression Mean Squared Error: 3427.67 R2 score: 0.33 LASSO Mean Squared Error: 3434.59 R2 score: 0.33 Elastic-Net Mean Squared Error: 3295.57 R2 score: 0.36この中では、Elastic-Net が他のモデルよりも精度が高いようです。
参考
1.1.1 Ordinary Least Squares
1.1.2 Ridge Regression and Classification
1.1.3 Lasso
1.1.5 Elastic-Net
- Robert Tibshirani. "Regression Shrinkage and Selection via the Lasso", Journal of the Royal Statistical Society: Series B (Methodological) Vol.58, No.1 (1996), p. 267-288.
- Hui Zou and Trevor Hastie. "Regularization and variable selection via the elastic net", Journal of the Royal Statistical Society: Series B (Statistical Methodology) Vol.67, No.2 (2005), p. 301-320.

- 投稿日:2020-07-20T10:07:06+09:00
【S3】PythonをつかってS3でCRUDする【Python】
アクセスするのに必要なキーを取得する
1.AWSのセキュリティ認証情報ページへ移動。
2.アクセス管理タグの「ユーザー」をクリック
3.「ユーザーを追加」を押して、ユーザー名を入力し、プログラムによるアクセスにチェック。
グループが無ければ作成し、AmazonS3FullAccessを選択する。
4.タグの追加はそのまま何も入力せずに次のステップへ
5.「ユーザー作成」で作成完了。CSVダウンロードやアクセスキーIDとシークレットアクセスキーのメモをしておく。boto3のインストール
pip install boto3CRUD
ここで利用されるaccesskey及びsecretkeyは、環境変数によって指定してください。
誰かに知られると大変なことになります。
regionは利用している地域名です。例)オハイオならus-east-2Create(ファイルの保存)
def create_img_s3(path, img):#画像の保存 s3 = boto3.client('s3', aws_access_key_id=accesskey, aws_secret_access_key=secretkey, region_name=region) img.thumbnail((900, 1200), Image.ANTIALIAS) out = BytesIO() img.save(out, "PNG") s3.put_object(Bucket=bucket_name, Key=path, Body=out.getvalue()) url = "https://"+bucket_name+".s3-"+region+".amazonaws.com/"+path return url def create_csv_s3(path, dataframe):#DataFrameからCSVに変換し、CSV保存 out2 = StringIO() dataframe.to_csv(out2, encoding='utf_8_sig') s3 = boto3.client('s3', aws_access_key_id=accesskey, aws_secret_access_key=secretkey, region_name=region) s3.put_object(Bucket=bucket_name, Key=path, Body=out2.getvalue().encode("utf-8_sig")) url = "https://" + bucket_name + ".s3-" + region + ".amazonaws.com/" + path return urlRead(ファイルの読み込み)
def readImg_s3(imgpath): s3 = boto3.client('s3', aws_access_key_id=accesskey, aws_secret_access_key=secretkey, region_name=region) obj = s3.Object(Bucket=bucket_name, Key=imgpath) print(obj) print(obj["Body"]) def readDir_s3(dirpath):#特定のフォルダにあるデータをリストで取得する s3 = boto3.client('s3', aws_access_key_id=accesskey, aws_secret_access_key=secretkey, region_name=region) res = s3.list_objects_v2(Bucket=bucket_name, Prefix=dirpath, Delimiter='/') urls = [] for data in res["Contents"]: data_url = data["Key"] if dirpath != data_url: url = "https://" + bucket_name + ".s3-" + region + ".amazonaws.com/" + data_url urls.append(url) return urls
- 投稿日:2020-07-20T09:33:59+09:00
Codeforces Round #657 (Div. 2) 復習
今回の成績
今回の感想
2ヶ月ぶりくらいにcodeforcesに参加しました。A問題がずっと解けず激冷を覚悟していたのですが、なぜかかなり温まりました。地力がついてきたのかもしれません。
ともかく久しぶりに色変を果たしたので、成功体験としてはよかったと思います。AtCoder:青,Coderforces:紫、を目指して頑張りたいと思います。
A問題
A問題に配置されていたので冷静さを失って解けませんでした。
原理としては何も難しくない…。$O(t \times n^2)$の計算量が許容されるのであまり難しくありません。まずは、"abacaba"(以降、文字列Sとします)が文字列のどの部分に出てくる可能性かをチェックします。チェックしたときにすでに二回以上文字列Sが出てくる場合は"No"を出力し、一回のみ文字列Sが出てくる場合は"?"を"d~z"に変えて出力すれば良いです。その他の場合は、"?"を変えることで文字列Sになりうるもののうち文字列Sを一つだけ作り出すようなものがあるかをチェックしていきます。
また、文字列Sになりうる部分文字列のチェックと文字列Sが一つのみになるかを別々に分ければわかりやすい実装になります。
A.py#abacaのできる可能性のあるところにチェック #おかしい #インデックスミスなど… a=["a","b","a","c","a","b","a"] t=int(input()) for _ in range(t): n=int(input()) s=list(input()) check=[0]*(n-6) for i in range(n-6): for j in range(i,i+7): if s[j]!=a[j-i] and s[j]!="?": break else: if s[i:i+7]==a: check[i]=2 else: check[i]=1 if check.count(2)>1: print("No") continue elif check.count(2)==1: print("Yes") print(("".join(s)).replace("?","z")) continue #?を変えて一個だけのパターン g=False for i in range(n-6): if check[i]==1: f=False cand=[a[j-i] if i<=j<=i+6 else s[j] if s[j]!="?" else "z" for j in range(n)] for j in range(n-6): if i!=j: for k in range(j,j+7): if cand[k]!=a[k-j]: break else: f=True if not f: print("Yes") print("".join(cand)) g=True break if not g:print("No")B問題
まず$a,b,c$で表現できる範囲を考えます。これは$l$以上$r$以下なので、与式にそれぞれ当てはめて考えます。すると、以下のようになります。
このもとで、①と②について片方を固定して考えます。②は連続的で考えやすいので、①を固定することを考えます。
すると、①はmに近づけることが最適なので、$ceil(\frac{m}{a}) \times a$または$floor(\frac{m}{a}) \times a$になります。
よって、この値と$m$との絶対値の差が$r-l$となれば、$b,c$も存在し、答えとなります。
これを任意の$a$について探して答えとなるものを一つでも求めれば良いです。
また、計算量は$O(t \times (r-l))$となり、答えは必ず求まることが問題文中に書かれているので、コードを書いて以下のようになります。
B.pyt=int(input()) for _ in range(t): l,r,m=map(int,input().split()) f=False for a in range(l,r+1): n1,n2=m//a,-((-m)//a) if l-r<=m-n1*a<=r-l: for c in range(l,r+1): b=m-n1*a+c if l<=b<=r: if m+c-b!=0: print(a,b,c) f=True break if f:break if l-r<=m-n2*a<=r-l: for c in range(l,r+1): b=m-n2*a+c if l<=b<=r: if m+c-b!=0: print(a,b,c) f=True break if f:breakC問題
方針は難しくないと思いますが、Pythonだとギリギリですかね??怖いのでC++で通しました。
$n$が大きいので全てを試行できません。しかし、ある程度の回数の試行を行った後はある$b_i$のみを選べば良いです。ここで、最大の$b_i$を取るのが最適だと思ったのですがサンプルが合いませんでした。良く考えると、$b_i$を選ぶ時$a_i$も選ぶ必要がありその値次第では最大の$b_i$を取るのが最適となりません。したがって、どの$b_i$を取り続けるか全通り($m$通り)試すことにしました。
また、$b_i$を取らない時は$n \leqq m$が成り立ち、この時は$a$のうち大きい方から$n$個を選べば良いです。また、$a_i$は昇順で並んでいる必要がありますが、$b_i$に対応する$a_i$があとで必要になるので、$a_i$が昇順で並ぶ配列$c$を用意します。
ここで、$b_i$を選ぶ時、$a$の中で$b_i$より大きいものも選分のが和を最大にするのに最適で、配列$c$をupper_boundで探した要素以上の要素を全て選べば良いです。この時、それらの要素の和を毎回計算するのは非効率的なので、累積和により求めておきます。
また、$b_i$と同時に$a_i$を選ぶ必要があり、$a_i$が先ほど選ばれているかどうかで場合分けします。以上を繰り返して最大となるものを答えとして求めれば良いです。
C.cc//コンパイラ最適化用 #pragma GCC optimize("Ofast") //インクルード(アルファベット順) #include<algorithm>//sort,二分探索,など #include<bitset>//固定長bit集合 #include<cmath>//pow,logなど #include<complex>//複素数 #include<deque>//両端アクセスのキュー #include<functional>//sortのgreater #include<iomanip>//setprecision(浮動小数点の出力の誤差) #include<iostream>//入出力 #include<iterator>//集合演算(積集合,和集合,差集合など) #include<map>//map(辞書) #include<numeric>//iota(整数列の生成),gcdとlcm(c++17) #include<queue>//キュー #include<set>//集合 #include<stack>//スタック #include<string>//文字列 #include<unordered_map>//イテレータあるけど順序保持しないmap #include<unordered_set>//イテレータあるけど順序保持しないset #include<utility>//pair #include<vector>//可変長配列 using namespace std; typedef long long ll; //マクロ //forループ関係 //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() //sortなどの引数を省略したい #define SIZE(x) ll(x.size()) //sizeをsize_tからllに直しておく //定数 #define INF 1000000000000 //10^12:極めて大きい値,∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange(素数列挙などで使用) //略記 #define PB push_back //vectorヘの挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 #define Umap unordered_map #define Uset unordered_set signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll t;cin>>t; while(t--){ ll n,m;cin>>n>>m; vector<ll> a(m); vector<ll> b(m); vector<ll> c(m); REP(i,m){cin>>a[i]>>b[i];c[i]=a[i];} //aのソート済みのやつ sort(ALL(c)); //cの累積和を求める(逆方向から) vector<ll> d(m+1);d[m]=0; REPD(i,m)d[i]=c[i]+d[i+1]; ll ans=0; //aのみを選ぶ時 if(n<=m)ans=max(ans,d[m-n]); //どのbの要素を選ぶか REP(i,m){ auto as=upper_bound(ALL(c),b[i]); ll anum=distance(c.begin(),as); if(a[i]>b[i] and m-anum<=n)ans=max(d[anum]+b[i]*(n-(m-anum)),ans); if(a[i]<=b[i] and m-anum<=n-1)ans=max(d[anum]+b[i]*(n-(m-anum)-1)+a[i],ans); } cout<<ans<<endl; } }D問題以降
今回は飛ばします


- 投稿日:2020-07-20T07:16:30+09:00
Githubのプルリク本文に貼られた画像を一括ダウンロードする
スクリーンショットはDroidKaigi/conference-app-2020のものをお借りしています。
なぜするか
自社サービスのアプリ開発をしています。アプリアップデータリリース時の速報として、新しく作られたり変更があった画面のスクリーンショット一覧を、企画、運用部門と共有することを一部自動化したいです。また、あとで文章にまとめるときにも、すでに収集されたスクリーンショット集があるので効率的に作れます。
私が所属する開発チームではプルリクのレビュー依頼時にプルリクの本文にスクリーンショットやGifアニメーションを貼る習慣あるので、その画像を企画、運用部門と共有します。Pythonを使って一括ダウンロードする
事前準備
shmkdir Downloads pip install PyGithub BeautifulSoup4 requests実行Pythonソースコード
main.pyimport os from datetime import datetime, timedelta # マークダウンからHTMLに変換 import markdown # Github API クライアント from github import Github # HTMLパーサー from bs4 import BeautifulSoup # HTTPクライアント import requests # MIMEタイプから拡張子を取得 import mimetypes # 保存先ディレクトリ save_dir = "Downloads" # マークダウンをHTMLに変換する担当オブジェクト作成 md = markdown.Markdown() # アクセストークンはこちらで作る # https://github.com/settings/tokens access_token = os.environ['GITHUB_API_ACCESS_TOKEN'] # アクセストークンを持ってGithubオブジェクトを作成 g = Github(access_token) # リポジトリを取得 gr = g.get_organization('DroidKaigi').get_repo('conference-app-2020') # 個人のリポジトリの場合は # gr = g.get_user().get_repo('repository_name') # ダウンロードする範囲(プルリク作成日基準) start_datetime = datetime(2020, 1, 1) end_datetime = datetime(2020, 1, 13) # 閉じられたプルリクエスト一覧を取得 prs = gr.get_pulls(state='close', base='master') for pr in prs: # 順番は作成日降順 if pr.created_at < start_datetime: # これ以上は遡らなくて良い break if pr.created_at < end_datetime: # ダウンロードする範囲に入った # マージされたPRに限定する if pr.merged != True: continue print("#%d %s" % (pr.number, pr.title)) # プルリク本文のマークダウンをHTMLに変換する html = md.convert(pr.body) # HTMLをパースする soup = BeautifulSoup(html, features='html.parser') # すべてのimgタグに対して for img_index, img in enumerate(soup.find_all('img')): # src属性の値を画像urlとして取得して url = img.get('src') # src属性が空のケース対応 if len(url) == 0: continue # URLをダウンロードする r = requests.get(url) if r.ok: # ダウンロード成功 # ファイルのmimeタイプを取得する content_type = r.headers['Content-Type'] # mimeタイプから拡張子を取得する ext = mimetypes.guess_extension(content_type) # ファイル名にプルリクタイトルを含めたいが # スラッシュがファイル名に含まれているとファイルを作れないので # 全角に変換する title = pr.title.replace('/', '/') # 保存先パスを作成 path = "%s/%04d_%s_%02d.%s" % (save_dir, pr.number, title, img_index, ext) # 画像を保存する with open(path, 'wb') as f: f.write(r.content) else: # ダウンロード失敗 message = "Image download error\n%s\n%d %s" % ( url, r.status_code, r.reason) raise RuntimeError(message)状況に応じてカスタマイズ
上記ソースコードはとりあえずローカルPCで動かしてローカルフォルダに一括ダウンロードしています。組織やプロジェクトの状況に応じて例えばこのようなカスタマイズを行うと良いと思います。
- 継続的デリバリーのワークフローで実行する
- SlackBotにする
- 画像はGoogle Driveにアップロードする
バージョンアップの差分だけ画像をダウンロードする
自作アプリのリリースワークフローでは前バージョンリリース以後にマージされたPR一覧を取得してリリースノートを自動で作るPythonスクリプトを動かしています。そのPR一覧から本文を取得して上記と同じような処理を行えばバージョンアップの差分だけ画像をダウンロードできます。
注意点
他部門と共有するスクリーンショットにAWSアクセスキーにような秘密の情報が含まれていないかご注意ください。

- 投稿日:2020-07-20T05:23:14+09:00
ゼロから始めるLeetCode Day92 「4. Median of Two Sorted Arrays」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day91「153. Find Minimum in Rotated Sorted Array」Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!お知らせ
Day 100でQiitaでの投稿はひとまず区切りを付けようかと思います。
タグの記事が僕の記事ばかりになってしまうのもいかがなものかと思いましたし、他に有益な情報を提供している方の邪魔になってしまうこともあると考えたので、こうすることにしました。
至らない部分は多々ありましたが、今までお付き合い頂きありがとうございました。問題を解いて記事を書く、というのは上記の個人ブログで続けるつもりですし、興味ある方はたまにそちらを覗いていただけると嬉しいです。
Twitterの方のアカウントはほとんど更新通知用と化しているので、Leetcodeを解く記事について気になる方はそちらも合わせてフォローいただくと良いかもしれません。問題
4. Median of Two Sorted Arrays
難易度はHard。問題としては、サイズ
mとnの2つのソートされた配列nums1とnums2がある。2つの並べ替え配列の中央値を求めよ。
なお、全体の実行時間の複雑さは,O(log (m+n))でなければならず、nums1とnums2はどちらも空ではないと仮定してもよい。Example 1:
nums1 = [1, 3]
nums2 = [2]
The median is 2.0Example 2:
nums1 = [1, 2]
nums2 = [3, 4]
The median is (2 + 3)/2 = 2.5解法
O(log(m+n))である、ということは二分探索が使えますね。
ただ、難易度がHardということで、扱うリストが二つになっています。
これで書くコードの量が増えますし、書く量が増えるということは凡ミスも増える可能性が高くなります。
そして、二つとも同じ大きさのリストとは限らないのでその点もきちんと頭に入れておきましょう。class Solution: def obtain_kth_num(self, nums1, nums2, k): nums1_len, nums2_len = len(nums1), len(nums2) nums1 = [-2**31] + nums1 + [2**31-1] nums2 = [-2**31] + nums2 + [2**31-1] left, right = max(0, k-nums2_len), min(nums1_len, k) while left <= right: i = (left+right) // 2 j = k - i if nums1[i] > nums2[j+1]: right = i - 1 elif nums2[j] > nums1[i+1]: left = i + 1 else: return max(nums1[i], nums2[j]) def findMedianSortedArrays(self, nums1: List[int], nums2: List[int]) -> float: nums_len = len(nums1) + len(nums2) mid = self.obtain_kth_num(nums1, nums2, (nums_len+1)//2) if nums_len % 2 == 0: mid = (mid+self.obtain_kth_num(nums1, nums2, (nums_len+1)//2+1)) / 2.0 return mid # Runtime: 116 ms, faster than 35.51% of Python3 online submissions for Median of Two Sorted Arrays. # Memory Usage: 13.9 MB, less than 92.38% of Python3 online submissions for Median of Two Sorted Arrays.DFSなどと同様に別に関数を実装してからメインで呼び出す、という形式を取りました。
-2**31や2**31-1というのはPython3にはlong型が存在しないためこういった方式を取っている、というのを以前も解説した気がします。
obtain_kth_num関数は与えられたnums1とnum2を入力として受け取り,配列のk番目に小さい数を返すための関数です。なお、二分探索をする上で根底となる考え方はこの動画を参考にしました。
こういう動画を作れるくらい強くなりたい・・・では今回はここまで。お疲れ様でした。