- 投稿日:2020-07-20T23:46:32+09:00
API GatewayでLambdaのエラーハンドリング
題材とするアーキテクチャ
Lambda (2) → API Gateway → Lambda (1)
API Gatewayの返り値を整形する。
エラー時に400/500台のステータスコードを付してDescriptionをつけて返したい。
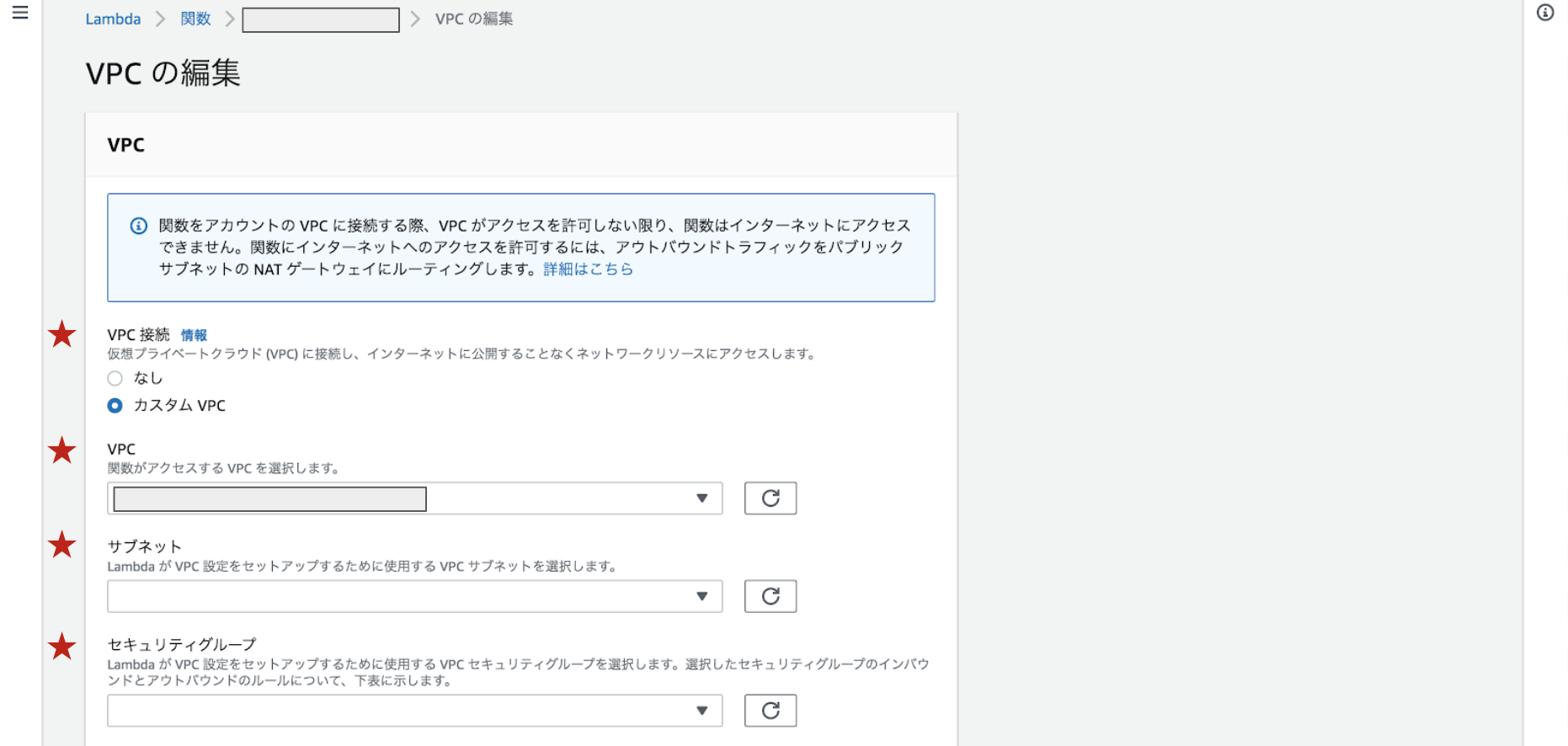
1 Exceptionクラスを継承して拡張した例外クラスを作る。
2 エラー時にraiseする。Lambda1import json import boto3 import logging import traceback logger = logging.getLogger() logger.setLevel(logging.INFO) dynamodb = boto3.resource('dynamodb') # 例外クラスを拡張 class ExtendException(Exception): def __init__(self, statusCode, description): self.statusCode = statusCode self.description = description def __str__(self): obj = { "statusCode": self.statusCode, "description": self.description } return json.dumps(obj) def lambda_handler(event, context): # validation check if not "key" in event or not isinstance(event["key"], int): raise ExtendException(400, "Bad Request") # 何らかの処理 return 0テスト
response{ "errorMessage": "{\"statusCode\": 400, \"description\": \"Bad Request\"}", "errorType": "ExtendException", "stackTrace": [ " File \"/var/task/lambda_function.py\", line 29, in lambda_handler\n raise ExtendException(400, \"Bad Request\")\n" ] }3 API Gatewayのレスポンスをマッピング
Lambdaエラーの正規表現では
.*statusCode: 400,.*を指定。
Lambdaから返されるエラーレスポンスのerrorMessageの部分のみ返している。テスト
response{ "statusCode": 400, "description": "Bad Request" }別Lambdaからコールした時にエラー内容を表示する。
以下のようにしてエラーレスポンスを拾うことができる。
try: pass except urllib.error.HTTPError as err: res = err.read().decode("utf-8")Lambda2import json import urllib.request, urllib.error import logging import traceback logger = logging.getLogger() logger.setLevel(logging.INFO) class ExtendException(Exception): def __init__(self, statusCode, description): self.statusCode = statusCode self.description = description def __str__(self): obj = { "statusCode": self.statusCode, "description": self.description } return json.dumps(obj) request_url = "https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/v1" api_key = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" def lambda_handler(event, context): try: headers = {'x-api-key': api_key, "Content-Type":"application/json"} method = "POST" # validation errorするようにAPIをコールする。 request_json = { "notExistKey": 1 } req = urllib.request.Request(url=request_url, method=method, headers=headers, data=json.dumps(request_json).encode()) with urllib.request.urlopen(req) as res: body = res.read().decode("utf-8") except urllib.error.HTTPError as err: traceback.print_exc() res = err.read().decode("utf-8") res = json.loads(res) logger.info("------------------") logger.info(res) logger.info("------------------") raise ExtendException(500, "[ERROR] {} : {}".format(res["statusCode"], res["description"])) except urllib.error.URLError as err: traceback.print_exc() res = err.read().decode("utf-8") res = json.loads(res) logger.info("------------------") logger.info(res) logger.info("------------------") raise ExtendException(500, "[ERROR] {} : {}".format(res["statusCode"], res["description"])) except: traceback.print_exc() raise ExtendException(500, "Internal Error") return json.loads(body)テスト
response{ "errorMessage": "{\"statusCode\": 500, \"description\": \"[ERROR] 400 : Bad Request\"}", "errorType": "ExtendException", "stackTrace": [ " File \"/var/task/lambda_function.py\", line 45, in lambda_handler\n raise ExtendException(500, \"[ERROR] {} : {}\".format(res[\"statusCode\"], res[\"description\"]))\n" ] }


- 投稿日:2020-07-20T21:05:14+09:00
【裏技】RDS for MySQL において sql_mode を空白にする【非推奨】
背景
RDS for MySQL の 5.5 から 5.6 にバージョンアップするにあたり、
極力後方互換性を保って移行したいと思い、MySQL 5.5 と同じような動作となるようにパラメータの値を検討していた。sql_mode についても 5.5 ではデフォルト値 (= 空白) に設定していたため、同様の設定を 5.6 にも引き継ぎたいが
MySQL 5.6.6 以降においてデフォルト値は NO_ENGINE_SUBSTITUTION が適用されることになる。これをなんとか空白にしたかった
無理やり空白にする方法
パラメータグループにおいて、sql_mode を 「,」 カンマだけを入力して登録する
そうすると、許可されていない空白が値として登録できました。
"ParameterValue": ""となっていますね。urabe:~ $ aws rds describe-db-parameters --db-parameter-group-name test-mysql-56-params| jq '.Parameters[]| select(.ParameterName == "sql_mode")' { "ParameterName": "sql_mode", "ParameterValue": "", "Description": "Current SQL Server Mode.", "Source": "user", "ApplyType": "dynamic", "DataType": "list", "AllowedValues": "ALLOW_INVALID_DATES,ANSI_QUOTES,ERROR_FOR_DIVISION_BY_ZERO,HIGH_NOT_PRECEDENCE,IGNORE_SPACE,NO_AUTO_CREATE_USER,NO_AUTO_VALUE_ON_ZERO,NO_BACKSLASH_ESCAPES,NO_DIR_IN_CREATE,NO_ENGINE_SUBSTITUTION,NO_FIELD_OPTIONS,NO_KEY_OPTIONS,NO_TABLE_OPTIONS,NO_UNSIGNED_SUBTRACTION,NO_ZERO_DATE,NO_ZERO_IN_DATE,ONLY_FULL_GROUP_BY,PAD_CHAR_TO_FULL_LENGTH,PIPES_AS_CONCAT,REAL_AS_FLOAT,STRICT_ALL_TABLES,STRICT_TRANS_TABLES,ANSI,DB2,MAXDB,MSSQL,MYSQL323,MYSQL40,ORACLE,POSTGRESQL,TRADITIONAL", "IsModifiable": true, "ApplyMethod": "immediate" } urabe:~ $ご注意
AWS としては動作保証するものではないので、ふーん そんな挙動あるんだ、とだけ思っておいてください。
2020/7/20 現在たまたまそういう動作があったということで、今後動作が変わるかもしれません。
実運用では使わないでくださいね。使われたとしても、どういう問題が起こるか保証できかねます!m(_ _)m!NO_ENGINE_SUBSTITUTION が有効であっても、正しく動作するように対処するのがベストだと思います。
- 投稿日:2020-07-20T20:31:09+09:00
AWS SDK のリクエストヘッダを見る方法
- AWS SDK for PHP の場合
例えばsqsクライアントの場合$client = new SqsClient([ 'region' => ***, 'version' => ***, 'credentials' => [ 'key' => ***, 'secret' => *** ], 'debug' => true, # ←コレを追加 ]);debugを
trueにすることで標準出力にログが出力される。
参考: https://docs.aws.amazon.com/ja_jp/sdk-for-php/v3/developer-guide/faq.html
- AWS SDK for JavaScript の場合
例えばsesクライアントの場合new AWS.SES().sendEmail(sesParams, function(err, data){ if(error){ console.log(this.httpResponse); // ← コレを追加 } else { console.log(this.httpResponse); } });
thisというのはAWS.Responseのことらしい。基本的にはレスポンスの情報を参照出来るらしいけど、リクエストした情報(AWS.Request)も見れる。
参考: https://docs.aws.amazon.com/sdk-for-javascript/v2/developer-guide/using-a-callback-function.html
- 投稿日:2020-07-20T19:23:57+09:00
amplify+AppSyncの開発でRDSを使いたかった話
AppSyncのデータソースにRDSを指定できるので
amplifyでDynamoDBの代わりに使えるのではないか?
という期待から色々調べた結果、期待通りには出来なかった話。結論から言うと、以下の通り。
- RDSに自動的にテーブルはできない
- RDSの既存テーブルをモデルとしてGraphqlで利用することはできる
- amplifyで作成したモデルはDynamoDBにテーブルが生成される
筆者のスキルレベル
AWS自体触り始めて半年。
amplify+AppSync初めて触った。理解が割とあやふやなので、間違った事を書いている可能性があります。
よろしくお願いします。amplify api add-graphql-datasource
このコマンドでデータソースをRDSにできるんじゃね?
って思ったので調査開始。とりあえず叩く
# amplify api add-graphql-datasource Using datasource: Aurora Serverless, provided by: awscloudformation You must create an AppSync API in your project before adding a graphql datasource. Please use "amplify api add" to create the API.APIを作っていない場合怒られた。
作ってから再挑戦。# amplify api add-graphql-datasource Using datasource: Aurora Serverless, provided by: awscloudformation ? Provide the region in which your cluster is located: ? us-east-1 us-east-2 us-west-2 ap-northeast-1 eu-west-1AppSyncで対応しているRDSはAurora Serverlessしかないため、それがある場所を指定する。
また、接続に使用する認証はSecretで先に定義しておく必要がある。# amplify api add-graphql-datasource Using datasource: Aurora Serverless, provided by: awscloudformation ? Provide the region in which your cluster is located: ap-northeast-1 ? Select the Aurora Serverless cluster that will be used as the data source for your API: sil-database-1 ? Select the secret used to access your Aurora Serverless cluster: silsecret ? Fetched Aurora Serverless cluster. No properly configured databases found.データベースが作成されていないと怒られる。
なのでデータベースを作成# aws rds-data execute-statement --resource-arn "arn:aws:rds:ap-northeast-1:1234567890xx:cluster:sil-database-1" \ --schema "mysql" --secret-arn "arn:aws:secretsmanager:ap-northeast-1:1234567890xx:secret:silsecret-AaBbCc" \ --region ap-northeast-1 --sql "create DATABASE TESTDB" { "generatedFields": [], "numberOfRecordsUpdated": 1 }作成したので再挑戦。
# amplify api add-graphql-datasource Using datasource: Aurora Serverless, provided by: awscloudformation ? Provide the region in which your cluster is located: ap-northeast-1 ? Select the Aurora Serverless cluster that will be used as the data source for your API: sil-database-1 ? Select the secret used to access your Aurora Serverless cluster: silsecret ? Fetched Aurora Serverless cluster. ? Select the database to use as the datasource: TESTDB Successfully added the Aurora Serverless datasource locally Some next steps: "amplify push" will build all your local backend resources and provision it in the cloud "amplify publish" will build all your local backend and frontend resources (if you have hosting category added) and provision it in the cloud The following types do not have '@auth' enabled. Consider using @auth with @model - Todo Learn more about @auth here: https://docs.amplify.aws/cli/graphql-transformer/directives#auth (node:571) UnhandledPromiseRejectionWarning: Error: Type Query must define one or more fields. Type Mutation must define one or more fields. Type Subscription must define one or more fields. at assertValidSchema (/usr/local/lib/node_modules/@aws-amplify/cli/node_modules/graphql/type/validate.js:71:11) at Object.validate (/usr/local/lib/node_modules/@aws-amplify/cli/node_modules/graphql/validation/validate.js:54:35) at Object.exports.validateModelSchema (/usr/local/lib/node_modules/@aws-amplify/cli/node_modules/graphql-transformer-core/src/validation.ts:143:10) at GraphQLTransform.transform (/usr/local/lib/node_modules/@aws-amplify/cli/node_modules/graphql-transformer-core/src/GraphQLTransform.ts:240:20) at _buildProject (/usr/local/lib/node_modules/@aws-amplify/cli/node_modules/graphql-transformer-core/src/util/amplifyUtils.ts:63:35) at ensureMissingStackMappings (/usr/local/lib/node_modules/@aws-amplify/cli/node_modules/graphql-transformer-core/src/util/amplifyUtils.ts:137:23) at Object.buildProject (/usr/local/lib/node_modules/@aws-amplify/cli/node_modules/graphql-transformer-core/src/util/amplifyUtils.ts:30:3) at transformGraphQLSchema (/usr/local/lib/node_modules/@aws-amplify/cli/node_modules/amplify-provider-awscloudformation/lib/transform-graphql-schema.js:451:29) (Use `node --trace-warnings ...` to show where the warning was created) (node:571) UnhandledPromiseRejectionWarning: Unhandled promise rejection. This error originated either by throwing inside of an async function without a catch block, or by rejecting a promise which was not handled with .catch(). To terminate the node process on unhandled promise rejection, use the CLI flag `--unhandled-rejections=strict` (see https://nodejs.org/api/cli.html#cli_unhandled_rejections_mode). (rejection id: 1) (node:571) [DEP0018] DeprecationWarning: Unhandled promise rejections are deprecated. In the future, promise rejections that are not handled will terminate the Node.js process with a non-zero exit code.データベースを作成しただけではだめだった。
ローカルで定義したモデルがないよ、とかそもそもフィールドの定義が変だよとか言われてる?この辺でやっとdocumentを見つける
私は説明書を読まないタイプなので、最初に読めばよかったとかよく後悔します。
https://docs.amplify.aws/cli/graphql-transformer/relationalデータソースとして利用できるテーブルを作っておけばいけるらしいのでテーブルを作る。
# aws rds-data execute-statement --resource-arn "arn:aws:rds:ap-northeast-1:1234567890xx:cluster:sil-database-1" \ --schema "mysql" --secret-arn "arn:aws:secretsmanager:ap-northeast-1:1234567890xx:secret:silsecret-AaBbCc" \ --region ap-northeast-1 \ --sql "CREATE TABLE Customers ( id int(11) NOT NULL PRIMARY KEY, name varchar(50) NOT NULL, phone varchar(50) NOT NULL, email varchar(50) NOT NULL)" --database "TESTDB" { "generatedFields": [], "numberOfRecordsUpdated": 0 } # aws rds-data execute-statement --resource-arn "arn:aws:rds:ap-northeast-1:1234567890xx:cluster:sil-database-1" \ --schema "mysql" --secret-arn "arn:aws:secretsmanager:ap-northeast-1:1234567890xx:secret:silsecret-AaBbCc" \ --region ap-northeast-1 \ --sql "CREATE TABLE Orders ( id int(11) NOT NULL PRIMARY KEY, customerId int(11) NOT NULL, orderDate datetime DEFAULT CURRENT_TIMESTAMP, KEY \`customerId\` (\`customerId\`), CONSTRAINT \`customer_orders_ibfk_1\` FOREIGN KEY (\`customerId\`) REFERENCES \`Customers\` (\`id\`))" --database "TESTDB" { "generatedFields": [], "numberOfRecordsUpdated": 0 }テーブルを作ったので再度
# amplify api add-graphql-datasource Using datasource: Aurora Serverless, provided by: awscloudformation ? Provide the region in which your cluster is located: ap-northeast-1 ? Select the Aurora Serverless cluster that will be used as the data source for your API: sil-database-1 ? Select the secret used to access your Aurora Serverless cluster: silsecret ? Fetched Aurora Serverless cluster. ? Select the database to use as the datasource: TESTDB Successfully added the Aurora Serverless datasource locally Some next steps: "amplify push" will build all your local backend resources and provision it in the cloud "amplify publish" will build all your local backend and frontend resources (if you have hosting category added) and provision it in the cloud The following types do not have '@auth' enabled. Consider using @auth with @model - Todo Learn more about @auth here: https://docs.amplify.aws/cli/graphql-transformer/directives#auth GraphQL schema compiled successfully. Edit your schema at /root/boardapp/amplify/backend/api/boardapp/schema.graphql or place .graphql files in a directory at /root/boardapp/amplify/backend/api/boardapp/schemaなんとか正常終了しました。
未定義モデルはDynamoDBのテーブルが作られる
amplify pushしてみたところ、データソースが二つ登録されました。
追加したTESTDBと、メッセージで色々言われてたTodoのテーブル。
TodoはTESTDBになかったため、push時にDynamoDBに自動生成されたようです。
というわけで、当初やりたかった「DynamoDBではなくRDSをデータソースとして利用する」
というのはamplifyではちょっと難しいらしいことがわかりました。
できなくはないですが、RDSのテーブルとamplifyソースを別々に管理する必要がありそうです。何か間違った事を書いてしまっていたら、ご指摘願います。
参考
チュートリアル: Aurora Serverless - AWS AppSync
API (GraphQL) - Relational Databases - Amplify Docs
Aurora Serverless の Data API の使用 - Amazon Aurora
AWS AppSync + RDS を試してみた - Qiita
【爆速】React+Amplify+AppSyncでリアルタイム掲示板アプリを15分で作り上げる 〜これが最高のDeveloper Experienceだ〜 - Qiita

- 投稿日:2020-07-20T17:09:41+09:00
Elastic BeanstalkでSSM ParameterStoreからパラメータ取得しようとして詰まったこと
経緯
- EBのマルチコンテナ環境って結局裏でECS動いてるだけだから、大体ECSの機能使えるだろと思ってた
- もともとEBの環境プロパティにDBの接続情報をぶち込んでいたが、平文であんまりよろしくないので、ParameterStoreに移そうと話が上がった。
- ECSでParameterStoreを利用したケースはあり、EBのMultiContainerは実質ECSで動作するがわかっていたため、タスク定義に指定すればおわりやろとおもっていた。
Dockerrun.aws.jsonで指定した場合
- EBのDockerrun.aws.jsonのContainerDifinissionのformatはECSとおなじとのことで、containerDefinitionsにsecretを追加して、EBのサービスRoleにParameterStoreを取得できるようポリシー設定した。
executionRoleArnはECSタスク実行用のRole、ここを参考にIAMポリシーを付与したRolearnを設定- 結果的に
executionRoleArnはDockerrun.aws.jsonでは無効なプロパティ扱いされ、executionRoleArnを指定しろというECSのエラーが表示された。フォーマットが一緒のため検証時点ではエラーにならないが、適用されない模様。- ECSタスクの実行Roleは指定できず、最終的は別の方法をとった
Dockerrun.aws.json{ "AWSEBDockerrunVersion": 2, "executionRoleArn": "arn:aws:iam::aws_account_id:role/ecsTaskExecutionRole" "containerDefinitions": [ { "name": "api", "image": "xxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/eb-secret:latest", "essential": true, "memory": 128, "portMappings": [ { "hostPort": 80, "containerPort": 5000 } ], "environment": [], "secrets": [{ "name": "environment_variable_name", "valueFrom": "arn:aws:ssm:region:aws_account_id:parameter/parameter_name" }] } ] }entrypoint.shでコンテナの環境変数に展開する方法
― この方法ではコンテナ内にAWSCLI(とjq)を用意する必要がある
- 最終的にこの方法を利用したentrypoint.sh#!/bin/bash export AWS_DEFAULT_REGION = ap-northeast-1 export AWS_DEFAULT_OUTPUT = json export ENVIRONMENT_VARIABLE = $(aws ssm get-parameter --name parameter_name \ --with-decryption | jq -r '.Parameters[].Value')要約
- Elastic BeanstalkのMultiContainer環境ではコンテナ定義によってSSM ParameterStoreから取得したパラメータを環境変数に格納することはできないっぽい?
- ParameterStoreからDBの接続情報を取得するためには、コンテナ起動時にentorypoint.shでawscliを利用して、環境変数に格納する
- もしくは、アプリから直接SSM ParameterStoreに取りに行く必要がある
- 複数台一気にアプリを立ち上げるような場合はParameterStoreのスループット上限を気にするように。標準は40tps、引き上げは可能
- 投稿日:2020-07-20T16:05:16+09:00
WORKSPACESに繋がらなくなった話とパウリ効果
何もしてないのに壊れた
※技術的にはしょーもない話なのですがご了承ください。
はい皆さんこんにちは
このタイトルをあまりITに詳しくない人間に言われたエンジニアは結構な数いるのではないでしょうか。
かくいう私もその一人です。
理不尽な内容から、エンジニアなんだからプリンターも直せるでしょ?という広告が思い浮かびます。
起
ある日WORKSPACESに接続出来なくなったとユーザーから連絡がありました。
話を聞いてみると、
・いつもの作業端末で接続しているが繋がらない
・最後に繋がったのは結構前
・端末には何もしてない等と供述しており・・・
調査をすることに。承
WORKSPACESのアクセスログを見ると確かに、最後にログインした日付が古い。
⇒これはClouwdWatchのイベント・ルール監視で"WorkSpaces Access"を見てます。インスタンスは起動している。
⇒これはWORKSPACESのステータスが”AVAILABLE”になっていればOKです。なんなら自分の環境からはWORKSPACESにログインできる
⇒WORKSPACESのIP アクセスコントロールグループは未設定でした。
⇒”信頼された Windows デバイスのみに WorkSpaces へのアクセスを許可”の設定は有効でした。転
というわけでユーザーに証明書は端末に入ってますか?という返事をしました。
(証明書って何処で見るんだっけとか色々あったのはカットして)
すると翌日、証明書インストールし直したら接続出来ましたと連絡がありました。
結
直って良かったね!という感じでクローズしましたが、
何もしてないのに壊れた というのは世の中無いわけで、何かしら原因があるんですよね。
この現象に名前とか付いているのか?という疑問があったので調べてみたら
パウリ効果 だったわけです。
感想
証明書じゃなくて、IP制限の方にしたったら良かったなぁと思いました
ありがとうございました。
- 投稿日:2020-07-20T15:45:18+09:00
AWS 認定ソリューションアーキテクト試験当日までの流れと注意
先日以下の記事を投稿させていただきましたが思った以上に高評価をいただくことができました
AWS初心者がAWS 認定ソリューションアーキテクト アソシエイトを取得するまで
今回は前回の記事に補足する形で試験当日までの流れと当日の注意点を記事にしようと思います。試験への申し込み
アカウントの作成
試験への申し込みにはamazonのアカウントを作成後に、Amazonアカウントからシングルサインオンで認定用アカウント登録します。
登録完了後、対象となる各試験への申し込みを行うことができます。
- 以下のリンクより試験のスケジュールを立てるをクリック
AWS 認定 ソリューションアーキテクト – アソシエイト- ログイン画面が表示されるのでamazonアカウントまたはAPNパートナー用のアカウントを保持している場合はそのままログインへ、ない場合はamazonアカウントの作成を行う
- 入力したamazonアカウントからAWS認定用アカウントの作成を行う
試験のスケジュールを立てる
AWS認定アカウントの登録を行うとAWS認定アカウント用のダッシュボード画面を利用することができます。
試験の申し込みはコンソール画面内の試験の申し込みタブを選択肢、対象の試験を選択します
※今回の場合であればAWS Certified Solutions Architect - AssociateをのPSIによるスケジュールをクリック
※上記ではPSIによるスケジュール(最寄りのテストセンター)での受験を選択しておりますが、ピアソンVUE(オンライン試験)の選択も可能です(ただしこちらは英語での案内となりますので英語に自信がない方はPSIによるスケジュールを推奨いたします)PSIによるスケジュールを選択した場合の流れは以下になります
- 対象試験の画面に移動するので
日程の決定をクリック(ちなみに右上に言語設定の変更項目があるので日本語にしておく)- 確認画面が出るので
続行をクリック- 言語の選択と試験場の選択画面が出てくるので任意の場所を選択
※試験場によって試験中にカメラで常に監視が入るテストセンターとそうでない場所があるそうです
ちなみに都内では私が受験した新宿と銀座ではカメラでの監視はないのでおすすめします- 対象の場所を選ぶと日付の選択が表示されるので任意の日付を選択後
続行をクリック ※試験日の変更は登録後2回目まで変更が可能です・また24時間前までであれば試験のキャンセルを行うことも可能です- 支払い画面に移動しますのでカード決済にて支払い後申し込み完了です
※支払い方法は現状クレジットカードのみとなります試験当日まで
とにかくお勉強あるのみです!
試験の勉強法については先日投稿した以下を参考にしてみてください!
AWS初心者がAWS 認定ソリューションアーキテクト アソシエイトを取得するまで試験当日
試験前の流れと注意
- 持ち物の確認
試験では以下の2種類の身分証明書を提出する必要があります(電子ファイル不可)
1:自署、正式な氏名、および顔写真が含まれる、現行の有効な政府発行の身分証明書(免許証・パスポート)
2:自署および正式な氏名が含まれている証明書(クレジットカード・銀行カード・社員証など)- 試験会場へ移動(試験開始の15分前までにつくように移動すること)
- 身分証明書の提示・持ち物を身分証明書以外全て指定されたロッカーにしまう(ポケットの中までチェックされますので注意)
- ★試験会場は寒くトイレにいきたくなることがありますので忘れずに事前にいっておきましょう(私はトイレを我慢しながらの受験となってしまいました...)
試験中
案内されたPCでの受験となります。
試験前にメモ用紙を渡されますのでメモを取りながらテストを進めることができます(※ただし最後に回収されますのであくまでテスト用として活用してください)
また、試験の画面では問題にチェックマークを入れたり、問題を飛ばし後から解くことも可能です(自信がない問題・その時点ではわからない問題は飛ばしながら最後の方で余裕を持って解くのが良いかと思います)
- 試験時間:130分
- 問題数:65問
- 合格点:720~ (1000点満点)
※ちなみに私は732点というギリギリの範囲で合格となりました。上記で書いたようにわからない問題にチェックを入れて後から見返してギリギリ取れたような気がしますので最後まで諦めない心が大事です試験後
一通り問題をとき終わり終了ボタンを押すと簡単なアンケートが出てきます。
アンケートに答えると試験結果が画面上に表示されます
その後正式な通知は試験を完了してから5営業日以内に試験結果が記載されたメールが届きます
また詳細な点数などについてはAWS認定アカウント用のダッシュボード画面のこれまでの受験履歴から確認することができます


- 投稿日:2020-07-20T15:10:00+09:00
【AWS】MFAを有効にしているユーザでCLIを利用する方法
はじめに
MFAを設定しているユーザでAWS CLIを利用してみたいと思ったので、試してみました。
利用方法
アクセストークンの設定
ユーザのCLIアクセストークン等の情報は事前に発行しておいてください。
基本情報設定コマンドaws configure下記4点の情報について入力を求められるので、ユーザの認証情報を入力してください。
基本情報設定コマンド実行結果AWS Access Key ID [None]: AKIAIOSFODNN7EXAMPLE AWS Secret Access Key [None]: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY Default region name [None]: us-west-2 Default output format [None]: jsonCLI上でMFA認証
ターミナル上で下記の文を実行します。
MFA認証を実行するaws sts get-session-token --serial-number [[自分のMFAデバイスのARN]] --duration-seconds 86400 --token-code [[MFAデバイスの認証コード]]自分のMFAデバイスのARNの確認方法
AWSマネジメントコンソールのユーザータブから、確認したいユーザのページを開きます。
認証情報のタブを開き、赤枠内に記載されているARNを利用します。
--token-codeの確認方法
自分が設定しているMFAの認証機器上でコードを確認してください。MFA認証実行後の設定
MFA認証を実行すると、下記のような認証結果が返却されます。
MFA認証の実行結果{ "Credentials": { "AccessKeyId": "AccessKeyIdxxxxxxxxxxxxxxxxxxx", "SecretAccessKey": "SecretAccessKeyxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", "SessionToken": "SessionTokenxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", "Expiration": "202X-XX-XXTXX:XX:XX+00:00" } }実行結果を元に、認証情報を設定します。
--profileで名前を付けて認証情報を設定します。
今回は、「mfa-user」という名前で認証情報を登録します。
~/.aws/credentialsに情報を登録します。credentialsの末尾に追加する内容[mfa-user] output = json region = ap-northeast-1 aws_access_key_id = AccessKeyIdxxxxxxxxxxxxxxxxxxx aws_secret_access_key = SecretAccessKeyxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx aws_session_token = SessionTokenxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx実行確認
上記の設定で、
mfa-userというプロファイルでCLIが動作するようになっていると思います。実行できるか確認してみましょう。
確認用コマンドaws s3 ls --profile mfa-user正常に設定されていた場合、エラーでは無く、s3のバケット一覧が表示されるはずです!
s3のバケットが1つも無い場合は1つも無い旨のメッセージが表示されます。まとめ
MFA認証を有効にしたまま、CLIを利用する方法をまとめてみました。
今までは、AWSマネジメントコンソールから操作していましたが、今後は、CLIを積極的に利用していきたいと思います。

- 投稿日:2020-07-20T14:40:11+09:00
Elastic Beanstalkでデプロイする際に、No such file or directory: '/var/app/ondeck/' と表示される
はじめに
Elastic Beanstalkに構築したLaravelアプリケーションのデプロイの際に「No such file or directory: '/var/app/ondeck/'」と表示され、デプロイに失敗しました
環境
$ php artisan -V Laravel Framework 6.18.25Elastic Beanstalkプラットフォームバージョン : PHP 7.3 running on 64bit Amazon Linux2
エラー内容
$ eb logs ---------------------------------------- /var/log/eb-engine.log ---------------------------------------- ・ ・ ・ 2020/07/20 14:17:25.467640 [ERROR] Error occurred during build: [Errno 2] No such file or directory: '/var/app/ondeck/storage' 2020/07/20 14:17:25.467671 [ERROR] An error occurred during execution of command [app-deploy] - [PostBuildEbExtension]. Stop running the command. Error: Container commands build failed. Please refer to /var/log/cfn-init.log for more details.対応方法
プラットフォームのバージョンを「PHP 7.3 running on 64bit Amazon Linux2」から「PHP 7.3 running on 64bit Amazon Linux」に変更して、対処しました
(Amazon Linux2系を使用するのをやめました)まとめ
Amazon Linux2では、「/var/app/ondeck」のフォルダがなくなったようです
抜本的な解決になっていませんが、お困りの方は参考にしてみてください参考
AWS Developer Forums: Server stuck in a loop (eb-engine.log)
- 投稿日:2020-07-20T14:32:05+09:00
Amplifyでpush前のバックエンドに強制的に戻す方法
はじめに
Amplifyで作成したバックエンドは、権限設定などリソースが複雑に絡み合ってくると、誤ったリソースの削除を行ってしまった場合など、
$amplify pushのコマンドを入力しても途中でエラーになってしまい、もうどうしようもない、、、ということが起きがちです。何も知らなかった開発段階では、泣く泣く
$amplify deleteをして、一から作り直していたことも有りました、、、。(これが辛いのなんのって。)本番環境をリリースしてから、そんなスクラップ&ビルドはできませんので、今回はそんなときの対処法を記録として共有します。
(これも暫定的な方法なので、早くamplifyさんこのあたり改善してくれないかな、、、)対処法の流れ
事実を受け止める
修復する方法ないか出来る限り検証はしたほうがいいですが、素直に自分がやってしまった過ちを受け入れましょう。
過ちを正す
$amplify pushが一切できなくなってしまった要因を見つけだし、動いていた頃のコードに修正します。新しい出会い
ここでenvコマンドの登場です。
以下の流れで、別のバックエンドの環境を構築し乗り換えます。$ amplify env add Do you want to use an existing environment? No ? Enter a name for the environment testdev // 名前は適当でOK $ amplify env checkout testdev $ amplify push過去との決別
壊れて動かなくなってしまったこれまでの環境に別れを告げます。
ありがとう、、、そしてさようなら、、、$ amplify env remove devこのとき以下のようなエラーが出て、お別れに失敗することがあります。
App d1bqk0orw288u not found.これは、GUIのamplify設定でホスティングの登録した際の紐付けが怒られています。GUIからamplifyを開き、紐付けを解除しましょう。
その後、アプリID(上記の場合はd1bqk0orw288u)をローカルのamplifyフォルダで検索をかけると2箇所出てきますので、その項目を削除します。
再度removeコマンドを打てば、完全にお別れができます。復縁
やっぱり、君じゃなきゃだめだ、、。
$ amplify env add Do you want to use an existing environment? No ? Enter a name for the environment dev $ amplify env checkout dev $ amplify pushそしてお別れ
この子のおかげで、また出会うことができました。本当にありがとう。
これで壊れた関係を無事修復することができました。$ amplify env remove testdevアフターフォロー
これでバックエンドは完全復活しました!!1から自分で作り直すことを考えれば、めちゃめちゃ早くシンプルに解決できました。
ただ、amplify以外のGUIで設定した箇所については、再度設定し直す必要があります。
以下は参考までに記載しておきます。Amplifyコンソール
再度gitのブランチと復活したバックエンドを結び直します。
API Gateway
Lambda関数は、同じfunction名で作成されていますが、全く別物になるため、再度functionの紐付けを全て行いましょう。
- functionの再度紐付け
- オーソライザーの再設定
CROSのエラーがでることあり。再度CROSの有効化をやってデプロイしたら解消しました。
Cognito
結構GUIで設定してしまっていること多いので、注意が必要です。
- ソーシャルログイン設定
- OpenID Connect設定
- マッピング
- 検証メール設定
- Lambdaトリガー(サインアップ前にcreateUserを紐付け)
- デバイス
DynamoDB
DBも完全に初期化されているため、必要な初期データの流し込みを行います。これ忘れているとエラーいっぱい起きますので、ちゃんと行いましょう。
aws-exports.js
こちらのフォイルも更新されているため、開発メンバーに周知しましょう。
おわりに
できればこれもやりたくはない作業ですが、dev環境であれば、修復ができるようになりました。もしprodでこれがおきたら、、、
必ず開発環境内で検証をしっかりと行っていきましょう!!
引き続き、効率的な開発に向けてamplifyとはより深いお友達になっていきたいと思います!
参考
- 投稿日:2020-07-20T14:31:54+09:00
AWSでデプロイして放置してたらアクセス拒否された件
初デプロイから2週間、スプリントレビューでメンターさんに動作確認してもらおうとしたら・・・
そんな不思議なトラブルのお話です。
TECH CAMP最終課題カリキュラム中、私はデプロイ担当をしております。
そして迎える初スプリントレビュー、本番環境見せようとしたら・・・
アクセスが拒否されました(確かこんな文面)
スクショ撮っておけばよかった。???
おそらく私含め、チームメンバーもそんな顔してたような気がします。
ハナからできてなかったんならまだしも、一度は成功してたんですから。よくわからないのでインスタンスの再起動やら一度停止、起動を経てもういいやと再デプロイ、すると・・・
ググったところ、NGINXのホーム画面のようで、これが出るということは、
Elastic IP設定するファイルにElastic IPがちゃんと書けてない(誤字ってる)
という記述を発見、ならイージーモード。秒で直せばいい。いやElastic IP合ってるんですけど?
デプロイの勉強会用のQiitaをいくら見ても何が間違ってるのかわからない。
ググってもわからん。チームメンバーもあれこれ助言してくれますが、解決に至らず...
メンターさんへの相談も視野に入れつつ、3度目の正直の再デプロイ。作りかけのほぼ白紙のwebページが見事表示できましたとさ。
ここで仮説。
デプロイ後、一定時間放置してたら、AWS側で「これいらないのかな?」と判断してアクセス弾く説。
大穴の考えとしてはアクセス集中で弾かれるということもありますが、Elastic IPなんざそんな誰も彼も知ってるわけじゃないんだから。この線は薄いと思います。
仮に総当たり攻撃的な感じで打って入ったんだとしても、Basic認証もあるので、一定の硬さはあるはず。体感で思っただけなので、むしろその辺り知ってる人いたら教えてください。
お願いします。

- 投稿日:2020-07-20T12:38:33+09:00
【3分で設定】MacでAWSのアクセスキーを暗号化して管理
前提
Homebrew, aws-cliは導入済みとして記載します。
手順
Homebrewを使用してaws-vaultを入れる。
brew cask install aws-vaultaws-vaultにアクセスキーを登録。
パスワードの設定が求められる。# 以下の "foobar" は任意の文字列 aws-vault add foobaraws-vaultの情報を使用するように
~/.aws/credencialsを設定する。[default] credential_process=aws-vault exec -j foobar挙動を確認。
先ほど設定したパスワードの入力が求められる。aws s3 ls以上。簡単&安心ですね。
詳細
Macにはキーチェーンという認証情報管理用のアプリケーションが含まれます。そこでAWSのアクセスキーを管理するためのOSSが今回使用したaws-vaultです。
デザインのクラウドソーシング大手である99designsがメンテしており、2020/07時点でGitHubのスターは3700ほどついており開発も活発です。備考
以下は便利な使い方です。お好みでご利用ください。
セッションの持続時間を伸ばす
アクセスキーのローテーション
aws-vault rotate -n foobarSTSを用いずアクセスキーをそのまま使う
-nオプションを付加しないと私の環境ではエラーとなりました。
ベストプラクティスとして、アクセスキーは定期的にローテーションしたほうが良いので簡単なエイリアスを作成して気軽にローテーションできるようにしておきましょう。
以下はZ Shellでavrというエイリアスを貼っています。(aws-vault rotateの略)echo "alias avr='aws-vault rotate -n foobar'" >> ~/.zshrc source ~/.zshrcブラウザでログイン
aws-vault login foobar環境
- sw_vers
- ProductName: Mac OS X
- ProductVersion: 10.15.6
- BuildVersion: 19G73
- aws-vault: v5.4.4
- aws-cli: aws-cli/2.0.32 Python/3.8.4 Darwin/19.6.0 botocore/2.0.0dev35
関連リンク
- 投稿日:2020-07-20T12:10:12+09:00
祝GA‼︎【Go】Lambda + RDS 接続にRDS Proxyを使ってみた
はじめに
2019年末に行われたre:Invent 2019で発表されたRDS Proxyが先日正式リリースになりました!API Gateway + Lambda + RDSを使ってWebアプリケーションを作っていて、そこでRDS Proxyを使ってみたので、備忘録です。
RDS Proxyって何?
公式サイトによると、次のように説明されています。
Amazon RDS プロキシは、Amazon Relational Database Service (RDS) 向けの高可用性フルマネージド型データベースプロキシで、アプリケーションのスケーラビリティやデータベース障害に対する回復力と安全性を高めます。
詳細は公式サイトをご確認ください!
RDS Proxyで何をするのか
RDS Proxyでデータベースへのコネクションプールを確立、管理することで、アプリケーションからのデータベース接続数を少なく抑えることができるというので、今回使ってみました!
Lambda関数は、呼び出すごとに新しいコネクションを作成する必要があります。しかし、LambdaからRDSへの同時接続数には上限があり、これまではコネクション数が上限に達しないようにする必要がありました。これを解決してくれるのがこのRDS Proxyです。RDS Proxyを利用することで、既存のコネクションを再利用することができ、コネクション数を抑えることができます。
つまり、Lambda + RDSの構成が避けられていた原因の1つの同時接続数問題がRDS Proxyで解決できるのです!
料金
料金は有効になっているデータベースインスタンスの vCPU あたり0.018USD/時間(東京リージョン)となります。ただし、最低料金として、2つのvCPU分の料金がかかるので、1つのvCPUの場合でも0.018 × 2 = 0.036USD/時間かかります。
参考:https://aws.amazon.com/jp/rds/proxy/pricing/結論
とても記事が長くなってしまったので、先に結論をまとめます。
- RDS Proxyを介してRDSに接続できることが確認できた
- VPC内にLambdaを設置したときのコールドスタートが改善されていることがわかった
→ IAM認証接続ではパブリックサブネットに置いていたRDSをプライベートサブネットに配置できるようになった- VPCLambda + RDSで構築していたものはエンドポイントをRDS Proxyに向けるだけでOK(コードの修正が不要)
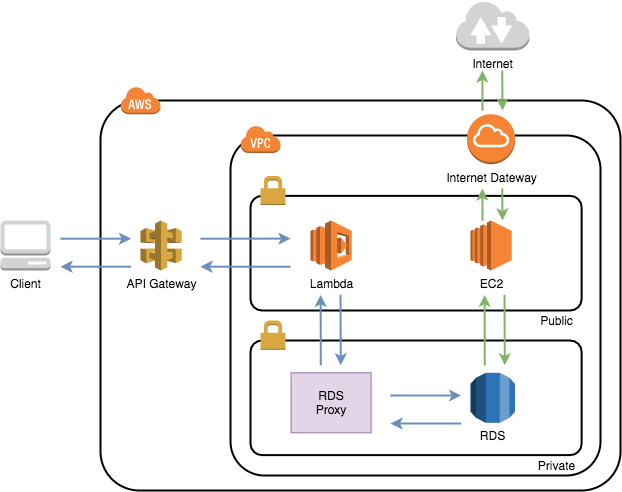
それでは、本題に入っていきます!構成図
このような構成で作成しました!本記事では、Lambda、RDS Proxy、RDS、踏み台のEC2にフォーカスしています。
手順
下記の流れで進めていきます。
- VPC、サブネットの作成
- セキュリティグループの作成
- RDSの構築
- 踏み台EC2の構築
- テーブル作成
- DBユーザの作成
- RDS Proxyの構築
- Lambda関数の作成
やってみる
1. VPC、サブネットの作成
事前準備として、VPCを作成し、作成したVPCの中にプライベートサブネット、パブリックサブネットを作成します。特別な設定は不要なので作成方法は省略します。
2. セキュリティグループの作成
事前準備として、各リソースのセキュリティグループの作成を行います。
Lambda
セキュリティグループ name : sg-lambda
インバウンド
タイプ ポート ソース ー ー ー 特にどこからも許可していなくてもAPI Gatewayからは叩くことができます!
EC2
セキュリティグループ name : sg-ec2-bastion
インバウンド
タイプ ポート ソース SSH 22 許可したいIPアドレス RDS Proxy
セキュリティグループ name : sg-rdsproxy
インバウンド
タイプ ポート ソース MySQL/Aurora 3306 sg-lambda RDS
セキュリティグループ name : sg-rds
インバウンド
タイプ ポート ソース MySQL/Aurora 3306 sg-ec2-bastion MySQL/Aurora 3306 sg-rdsproxy 3. RDSの構築
プライベートサブネットにRDSを立てます。
今回使用したMySQLのバージョン : MySQL 5.7.22
セキュリティグループは2で作成したsg-rdsを選択してください。その他、特に特別な設定は不要なので省略します。
4. 踏み台EC2の構築
RDSに接続して、ユーザやテーブルを作成するための踏み台EC2をたてます。
今回使用したOS : Amazon Linux 2
セキュリティグループは2で作成したsg-ec2-bastionを選択してください。こちらも、特に特別な設定は不要なので省略します。
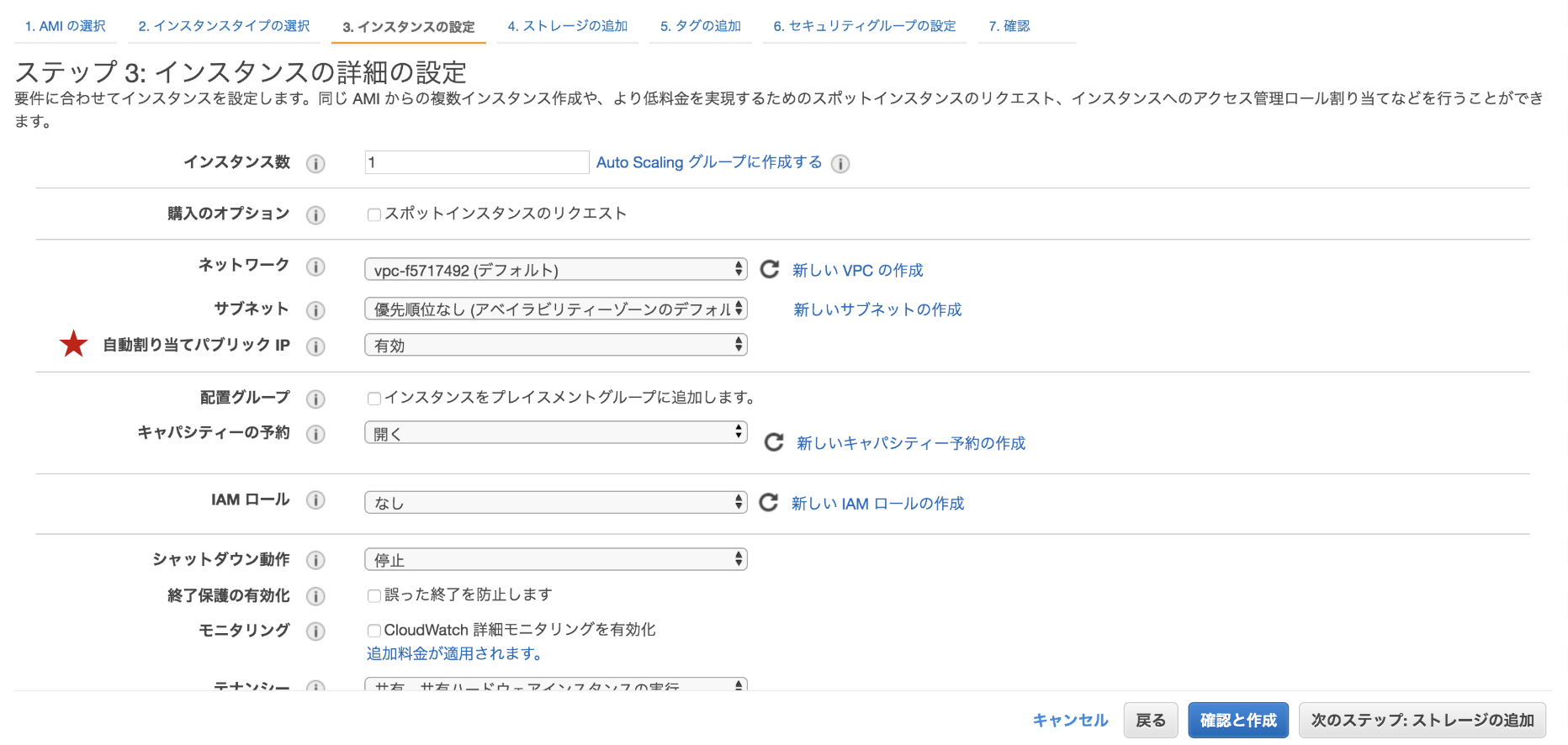
ただ、IPv4パブリックIPを使ってsshで接続するため、自動割り当てパブリックIPは有効に設定します。(これをせずに、プライベートIPで接続を試みましたが、できませんでした。)※上記の方法(自動割り当てパブリックIP)では、EC2を再起動するごとにパブリックIPアドレスが変更になるのでお気をつけてください。
5. テーブル作成
RDS内にテーブルを作成します。
テーブル内のデータはcsvファイルから取り込むようにしたかったので、今回はcsvファイルを準備しましたが、ただデータをRDSに保存するだけです。csvファイルのアップロード
ローカルから踏み台のEC2にcsvファイルを移動させました。
$ scp -i [キーペア名].pem [ファイル名].csv ec2-user@[パブリックIP]:/home/ec2-user/(EC2内の保存したいディレクトリを指定)EC2にssh接続
$ ssh -i [キーペア名].pem ec2-user@[IPv4パブリックIP]MySQLのインストール
$ sudo yum update $ sudo yum install mysqlRDSへ接続
$ mysql --local-infile=1 -h [RDSエンドポイント] -u [マスタユーザ名] -pテーブル内のデータはcsvファイルから読み込むために、
--local-infile=1のオプションをつけました。テーブルの作成
まず、テーブルの枠を作成します。
> CREATE TABLE [テーブル名] ([カラムの指定]); # 例 > CREATE TABLE m1_champion (id INT(2) AUTO_INCREMENT NOT NULL PRIMARY KEY, name VARCHAR(30) NOT NULL, champion YEAR NOT NULL, formed YEAR NOT NULL, note VARCHAR(30));次に、下記のようなcsvファイルをインポートします。
> LOAD DATA LOCAL INFILE "[ファイルパス]/[ファイル名].csv" INTO TABLE [テーブル名] FIELDS TERMINATED BY ',' LINES TERMINATED BY '\r\n';これでテーブルが完成しました。
id name champion formed note 1 ミルクボーイ 2019 2007 コーンフレーク 2 霜降り明星 2018 2013 NULL 3 とろサーモン 2017 2002 NULL 6. DBユーザの作成
上記の手順通り進めば、現在DBにログインしているので、このままLambdaから接続したときに使うユーザを作成します。
> CREATE USER '[ユーザ名]'@'%' IDENTIFIED BY '[パスワード]'; > GRANT SELECT, INSERT, UPDATE, DELETE ON [対象のDB].[対象のテーブル] TO '[ユーザー名]'@'%';上記はSELECT, INSERT, UPDATE, DELETEの権限を許可しています。また、ホスト名には
%=ワイルドカードを使用し、どこからのアクセスも受け入れるように設定しています。ちなみに、全てのDBとテーブルが対象の場合は*.*とします。7. RDS Proxyの構築
いよいよRDS Proxyの構築に入ります。
Secrets Manager シークレットの作成
先ほど作成したDBのユーザ名とパスワードを入力し、作成します。
下記URLのAWSの公式ブログに沿って作成してください。
参考:AWS LambdaでAmazon RDS Proxyを使用するIAMロールの作成
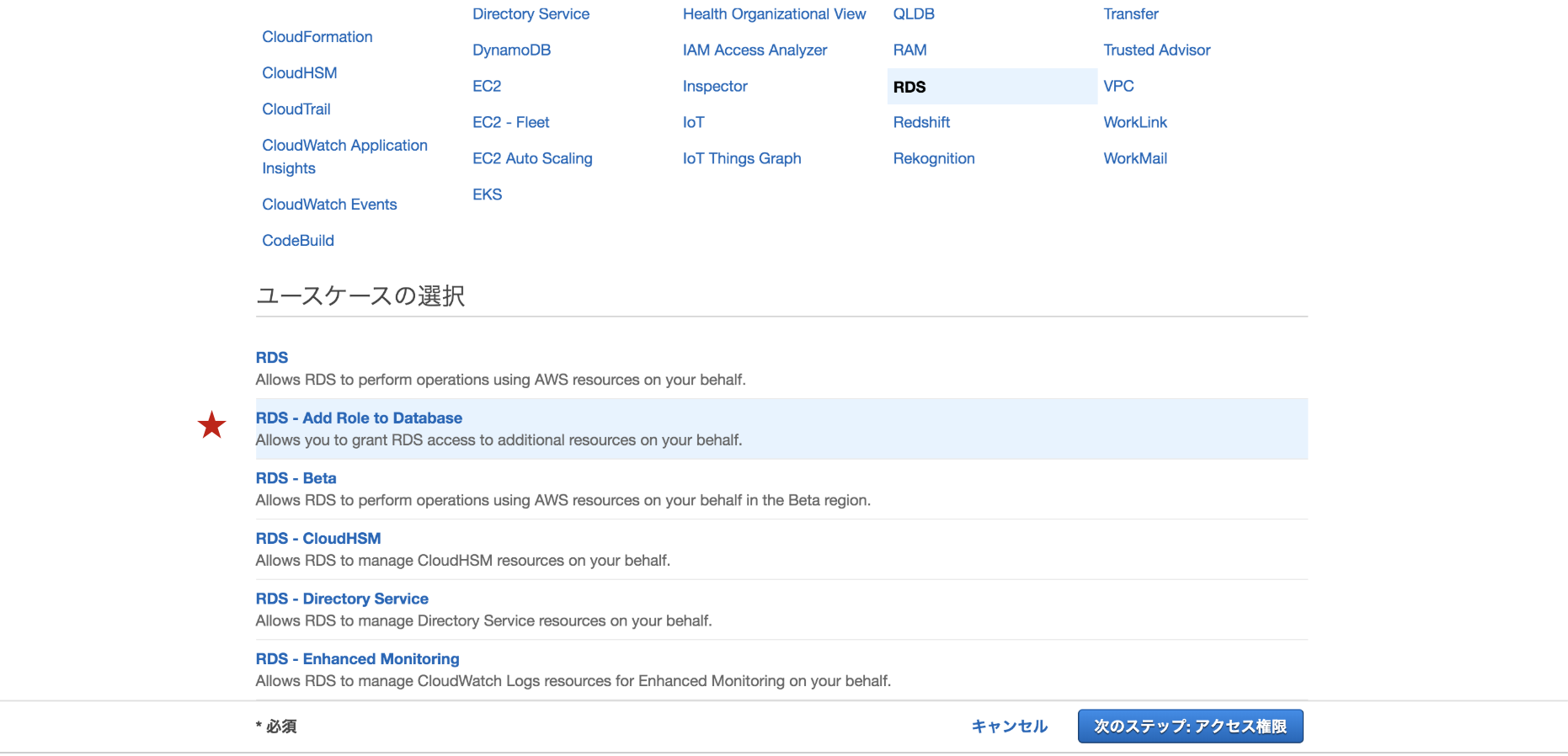
ユースケースは
RDS - Add Role to Databaseを選択します。
そして、必要なポリシーをアタッチします。
Secrets Managerへのアクセス権限のポリシー
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Action": [ "secretsmanager:GetResourcePolicy", "secretsmanager:GetSecretValue", "secretsmanager:DescribeSecret", "secretsmanager:ListSecretVersionIds" ], "Resource": "[シークレットARN]" } ] }拡張ログを取得したい場合はCloud Watch Logsへのアクセス権限も必要です。ただ、以下のログに関しては、Cloud Watch Logsへのアクセス権限がなくてもロググループに出力されます。
- RDS Proxyの起動終了
- DBへの接続開始終了
- 警告
RDS Proxyの作成
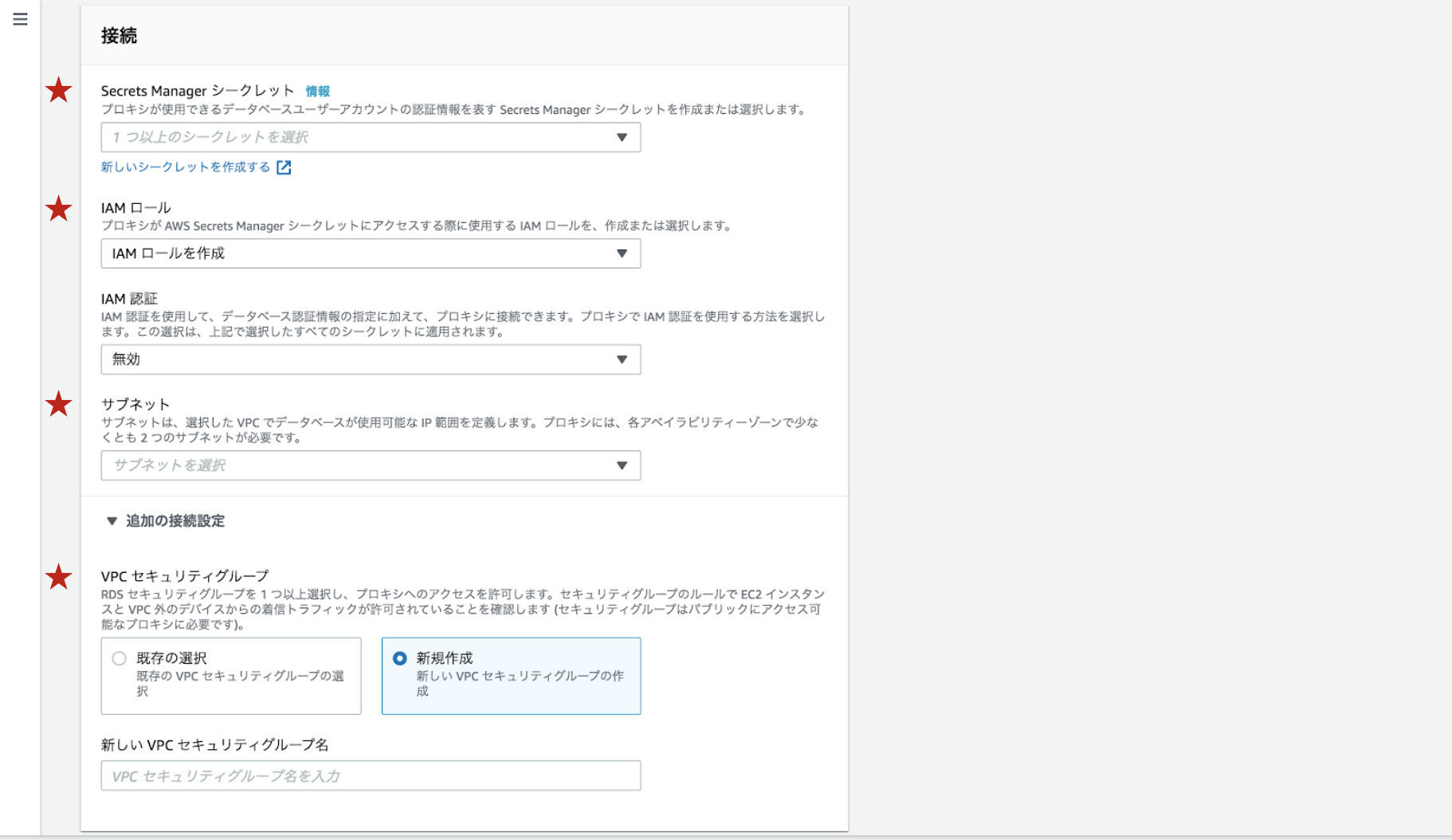
今回はRDS Proxyのコンソールから作成します。
ちなみに、Lambda関数のコンソール上からも作成でき、IAM認証で接続する場合はLambdaと紐付ける手間を省くことができます。ただ、今回のようにDBのユーザ名とパスワードを用いて接続する場合は紐付けは必要ないようなので、RDS Proxyのコンソールから作成しました。
プロキシ識別子(名前)を入力します。
エンジンの互換性ではMySQLとPostgreSQLが選べるようになっていました。ここでプロキシが接続できるDBのタイプを設定します。今回はMySQLなので、MySQLを選択しました。
先ほど作成したRDSを選択します。
先ほど作成したSecrets ManagerシークレットとIAMロールを選択します。
サブネットはRDSと同じプライベートサブネットを選択します。
セキュリティグループは2で作成したsg-rdsproxyを選択してください。
Cloud Watch Logsでデバッグログを取得したい場合は拡張されたログ記録を有効にするにチェックを入れてください。(Cloud Watch Logsへのアクセス権限も必要です。)
8. Lambda関数の作成
IAMロール
LambdaはVPC内にあるのでENI生成用のポリシーを作成してアタッチします。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Action": [ "ec2:DescribeNetworkInterfaces", "ec2:DeleteNetworkInterface", "ec2:CreateNetworkInterface" ], "Resource": "*" } ] }ログを取得したい場合はCloud Watch Logsへのアクセス権限も必要です。
VPC
Lambda関数の編集画面で設定できます。
カスタムVPCを選択し、RDSとRDS Proxyと同様のVPCとパブリックサブネットを選択します。
セキュリティグループは2で作成したsg-lambdaを選択してください。ソースコード
package main import ( "database/sql" "encoding/json" "fmt" "github.com/aws/aws-lambda-go/lambda" _ "github.com/go-sql-driver/mysql" "os" ) type Response struct { ID int `json:"id"` Name string `json:"name"` Champion string `json:"champion"` Formed string `json:"formed"` Note sql.NullString `json:"note"` } // os.Getenv()でLambdaの環境変数を取得 var dbUser = os.Getenv("dbUser") // DBに作成したユーザ名 var dbPass = os.Getenv("dbPass") // パスワード var dbEndpoint = os.Getenv("dbEndpoint") // RDS Proxyのプロキシエンドポイント var dbName = os.Getenv("dbName") // テーブルを作ったDB名 func RDSConnect() (*sql.DB, error) { connectStr := fmt.Sprintf( "%s:%s@tcp(%s:%s)/%s?charset=%s", dbUser, dbPass, dbEndpoint, "3306", dbName, "utf8", ) db, err := sql.Open("mysql", connectStr) if err != nil { panic(err.Error()) } return db, nil } func RDSProcessing(db *sql.DB) (interface{}, error) { var id int var name string var champion string var formed string var note sql.NullString responses := []Response{} responseMap := Response{} getData, err := db.Query("SELECT * FROM m1_champion") defer getData.Close() if err != nil { return nil, err } for getData.Next() { if err := getData.Scan(&id, &name, &champion, &formed, ¬e); err != nil { return nil, err } fmt.Println(id, name, champion, formed, note) responseMap.ID = id responseMap.Name = name responseMap.Champion = champion responseMap.Formed = formed responseMap.Note = note responses = append(responses, responseMap) } params, _ := json.Marshal(responses) fmt.Println(string(params)) defer db.Close() return string(params), nil } func run() (interface{}, error) { fmt.Println("RDS接続 start!") db, err := RDSConnect() if err != nil { panic(err.Error()) } fmt.Println("RDS接続 end!") fmt.Println("RDS処理 start!") response, err := RDSProcessing(db) if err != nil { panic(err.Error()) } fmt.Println("RDS処理 end!") return response, nil } /************************** メイン **************************/ func main() { lambda.Start(run) }実行結果
上記の手順でRDS Proxyを用いての接続は完了です。(あれ意外と簡単)
Lambdaでの実行結果がこちらです。
RDSから値が取得できました!
びっくりするのは応答時間!!!コールドスタートで接続に10秒程度かかるのでご法度とされていたVPCLambdaですが、こんなにはやくなっているんです。
参考:[発表] Lambda 関数が VPC 環境で改善されます
これは使わない手はない!
おわりに
無事、LambdaからRDS Proxyを介してRDSに接続が可能になりました!これで同時接続数問題も気にしなくていい!!また、VPC内にLambdaを設置したときのコールドスタートが改善されたので、Lambdaを非VPCに設置しなくてもいけるし、RDSがプライベートサブネットに置ける!!素晴らしい!
また、RDSのセキュリティグループにLambdaのセキュリティグループを付加し、コード中のエンドポイントの向きをRDS ProxyからRDSに変更するだけで、このコードのままRDSに接続できることが確認できました。つまり、Lambda + RDSで構築していたものは簡単にRDS Proxyを経由することができるんです!
わたしはこれまでIAM認証でのLambda + RDS接続しか経験がなく、コードの実装に手間取ってしまいましたが、上手く接続できないときの問題の切り分け方などとても勉強になりました!GAになったので、これから活用できる場所が増えるのではないかなと思います!





- 投稿日:2020-07-20T12:05:46+09:00
VPCとサブネット
本記事の対象者
この記事はAWSを使用した事があり、VPCとサブネットとCIDR表記について再確認したいという方向けです。
目標
VPCのネットマスクとサブネットのネットマスクを決定した時、
手動でサブネット内で使えるIPアドレスの個数を求める。VPC
簡単に、リージョン上に構築する仮想ネットワーク
サブネット
簡単に、VPCのIPアドレス範囲の中で、更に小さな仮想ネットワークを作成するAWSのサービス
VPCからサブネットのIPアドレスは裏でどうやって分割されてるの??
この章がこの記事の主旨です。
視覚的に、
サブネットのネットマスクを大きくする事で実現しているという事になるのですが、
これをもっと具体的に、IPアドレスで見ていきます。CIDR表記で、IPアドレスからIPアドレスの範囲の求め方は知っている前提で進めます。
VPCのIPアドレスが「172.31.0.0/16」だったとすると、
IPアドレスの範囲は、「172.31.0.0〜172.31.255.255」ここで、サブネットが「172.31.0.0/20」の場合を考えます。
IPアドレスの範囲は、「172.31.0.0,〜172.31.15.255」まとめます
VPCのIPアドレスが「172.31.0.0/16」
サブネットのネットマスクが20の時、
CIDR IPアドレス範囲 VPC 172.31.0.0/16 172.31.0.0〜172.31.255.255 サブネット1 172.31.0.0/20 172.31.0.0〜172.31.15.255 サブネット2 172.31.16.0/20 172.31.16.0〜172.31.31.255 サブネット3 172.31.32.0/20 172.31.32.0〜172.31.47.255 サブネット4 172.31.48.0/20 172.31.48.0〜172.31.63.255 サブネット5 172.31.64.0/20 172.31.64.0〜172.31.81.255 すなわち、
VPCのネットワークアドレス部が16でサブネットのネットワークアドレス部が20の時、
サブネットは、2*2*2*2=16個作成可能サブネット内で使用できるIPアドレスの個数は、
ホストアドレス部の(16*255=4080)
+
サブネットの個数の(16)
ー
VPCのサブネットでは、1つのサブネットに対して5つのIPアドレスが特定の用途で使われるため(5)
=
4091最後に
VPCのネットマスクが16で例えば、172.31.0.0/16のような時、
サブネットのネットマスク IPアドレス表記 1サブネット内で使えるIPアドレスの個数 作成できるサブネットの数(VPCのネットマスクが/16の場合) /16 255.255.0.0 65531 1 /17 255.255.128.0 32763 2 /18 255.255.192.0 16379 4 /19 255.255.224.0 8187 8 /20 255.255.240.0 4091 16 /21 255.255.248.0 2043 32 /22 255.255.252.0 1019 64 /23 255.255.254.0 507 128 /24 255.255.255.0 251 256 /25 255.255.255.128 123 512 /26 255.255.255.192 59 1024 /27 255.255.255.224 27 2048 /28 255.255.255.240 11 4096
- 投稿日:2020-07-20T10:07:06+09:00
【S3】PythonをつかってS3でCRUDする【Python】
アクセスするのに必要なキーを取得する
1.AWSのセキュリティ認証情報ページへ移動。
2.アクセス管理タグの「ユーザー」をクリック
3.「ユーザーを追加」を押して、ユーザー名を入力し、プログラムによるアクセスにチェック。
グループが無ければ作成し、AmazonS3FullAccessを選択する。
4.タグの追加はそのまま何も入力せずに次のステップへ
5.「ユーザー作成」で作成完了。CSVダウンロードやアクセスキーIDとシークレットアクセスキーのメモをしておく。boto3のインストール
pip install boto3CRUD
ここで利用されるaccesskey及びsecretkeyは、環境変数によって指定してください。
誰かに知られると大変なことになります。
regionは利用している地域名です。例)オハイオならus-east-2Create(ファイルの保存)
def create_img_s3(path, img):#画像の保存 s3 = boto3.client('s3', aws_access_key_id=accesskey, aws_secret_access_key=secretkey, region_name=region) img.thumbnail((900, 1200), Image.ANTIALIAS) out = BytesIO() img.save(out, "PNG") s3.put_object(Bucket=bucket_name, Key=path, Body=out.getvalue()) url = "https://"+bucket_name+".s3-"+region+".amazonaws.com/"+path return url def create_csv_s3(path, dataframe):#DataFrameからCSVに変換し、CSV保存 out2 = StringIO() dataframe.to_csv(out2, encoding='utf_8_sig') s3 = boto3.client('s3', aws_access_key_id=accesskey, aws_secret_access_key=secretkey, region_name=region) s3.put_object(Bucket=bucket_name, Key=path, Body=out2.getvalue().encode("utf-8_sig")) url = "https://" + bucket_name + ".s3-" + region + ".amazonaws.com/" + path return urlRead(ファイルの読み込み)
def readImg_s3(imgpath): s3 = boto3.client('s3', aws_access_key_id=accesskey, aws_secret_access_key=secretkey, region_name=region) obj = s3.Object(Bucket=bucket_name, Key=imgpath) print(obj) print(obj["Body"]) def readDir_s3(dirpath):#特定のフォルダにあるデータをリストで取得する s3 = boto3.client('s3', aws_access_key_id=accesskey, aws_secret_access_key=secretkey, region_name=region) res = s3.list_objects_v2(Bucket=bucket_name, Prefix=dirpath, Delimiter='/') urls = [] for data in res["Contents"]: data_url = data["Key"] if dirpath != data_url: url = "https://" + bucket_name + ".s3-" + region + ".amazonaws.com/" + data_url urls.append(url) return urls
- 投稿日:2020-07-20T09:18:02+09:00
【AWS】【SSM】【Terraform】環境変数の管理
DBのホスト名、ユーザー名、パスワードを環境変数で管理する場合
AWS SSMパラメータストアを用いて管理すると良い
コンソールやaws-cliから登録できるaws-cli# 暗号化した値(--type SecureString)を保存するときに叩くコマンド $ aws ssm put-parameter --name 'name' --value 'password' --type SecureString # 暗号化した値を複合して(--with-decryption)参照するときに叩くコマンド $ aws ssm get-parameter --output text --query Parameter.Value --name 'name' --with-decryption => passwordTerraformによるコード化を行う場合の注意点
暗号化するコードがソースコードに平文で書かれてしまうと暗号化する意味がなくなってしまうので、
Terraformではダミーの値を設定して、あとでaws-cliから更新する戦略が有効。ssm.tfresource "aws_ssm_parameter" "db_password" { name = "/db/password" value = "password" type = "SecureString" description = "DB_PASSWORD" lifecycle { ignore_changes = [value] # 上書きして変更するので無視する } }aws-cli$ aws ssm put-parameter --name 'db/password' --type 'SecureString' --value 'overwrite-password' --overwrite参考
実践Terraform AWSにおけるシステム設計とベストプラクティス
Resource: aws_ssm_parameter
AWS CLI Command Reference
- 投稿日:2020-07-20T08:51:24+09:00
ドメイン駆動設計における戦略的デザインについて解説
ドメイン駆動設計における戦略的デザインとは
ドメイン駆動設計における戦略的デザインとは、エリックエヴァンスが提唱した以下の概念のことである。
境界付けられたコンテキスト
コンテキストマップ
組織パターン
戦略的設計戦略的デザインをまとめると、複数の異なるチームが共通のドメイン認識を持ち、異なるドメイン層の連携、開発、テストを進めるためのデザインのことである。
ドメイン駆動設計の戦略的デザインとは、異なるアプリ間のドメイン層を連携する際に使用される概念である。
そのため、ドメイン駆動設計のドメイン層を他のアプリ間で連携しない場合、戦略的デザインの概念は不要となる。
今回の記事では、ドメイン駆動設計で提唱されている戦略的デザインを解説、適用する方法を提示し、ドメイン駆動設計を戦略レベルで運用する方法を説明しようと思う。戦略とは何か
戦略とはソ連赤軍の大将軍であるアレクサンドル・スヴェチンが提唱した概念である。
スヴェチンの著書、「戦略」では戦略とは以下の行動と定義されている。
戦争の準備と作戦のグループ化を組み合わせて、軍が戦争によって提唱した目標を達成する技術。
スヴェチンが定義した戦略をドメイン駆動設計が定義している戦略的デザインに適用すると以下のようになる。
戦略的デザインとは、異なるアプリ間のドメイン層を戦略的目標ごとにグルーピング、連携を行い戦略的目標を達成するための技術。戦略的目標
1.定義
戦略的目標を以下のように定義する。
・作戦レベルのアプリを円滑に運用するための環境を用意する。2.戦略的目標を達成するための手段
・アプリ運用を円滑に行うためのインフラサービスを提供する。
・別アプリで発生した業務エラーデータが他のアプリに波及する場合、エラーデータを修正、削除するロジックを開発する。
・ビジネスルールに違反しているユーザーの監視、検知、通知を行う。
・特定の期間中に実施するキャンペーンイベントを準備するため、キャンペーンデータの登録、イベント通知を行う。ユビキタス言語
戦略的目標を達成するためには、異なるチーム同士で共通認識を持ち、共同開発を行っていく必要がある
そのために、以下のようなドメイン層の全体の見取り図を作成し、開発チームの共通の言語であるユビキタス言語とする。1.境界付けられたコンテキスト
境界付けられたコンテキストとは特定のモデルを定義・適用する境界を明示的に示したもの。
簡単に説明するとアプリ内で使用するドメイン層の境界線を定めたコンテキストのことである。2.コンテキストマップ
コンテキストマップとは、境界づけられたコンテキスト間の関係を俯瞰する地図であり、システムの全体像や相互関係を把握する際に使用する。
3.組織パターン
戦略的目標を達成するためにアプリ間のドメイン層を連携するロジックをチーム間でマネジメントし、作成、テストを行う必要がある。
チーム間の関係をパターン化、カタログ化したもの。3.1.パートナーシップ
計画から連携試験までマネジメント、管理を行い、チーム間のインターフェイス部を共通にし最適な状態になるよう発展させる。
3.2.順応者
上流のドメイン層のメソッドを担当するチームと下流のドメイン層のメソッドを担当するチームの関係。上流チームの都合に合わせて、下流チームのメソッドを作成、変更を行う。
3.3.別々の道
両者のチームでドメインを共有できていない場合、ドメインを統合する必要がないため、別々のコンテキストで開発を行っていく。
4.戦略的設計
戦略手目標を達成するために、アプリ間のドメイン層を連携するロジックを作成、開発するための設計手法。
4.1.共有カーネル
複数のコンテキスト間で、共有のドメインクラス、メソッドを包括したモデルを持つパターン。カーネルはどのチームでも変更できるが、最初に他のチームに相談する必要がある。
4.2.腐敗防止層
アプリ間のドメインモデルが共有化できない場合、アプリごとに異なるモデルを変換、提供する腐敗防止層を設ける。腐敗防止層の構築には大きなコストがかかるので注意が必要。
4.3.公開ホストサービス
数多くのアプリで戦略的目標を達成するロジックを共有する場合、インターフェースなどを公開し、共有サービスという形にする。
5.戦略的設計のイメージ
以下が戦略的設計のイメージ図となる。
戦略レベルに該当する戦略的設計と作戦レベルである各アプリの境界付けられたコンテキストの境界性戦をイメージすることが重要。
戦略的デザインの全体図
戦略的デザイン全体の流れ。以下の順番で設計、開発、テスト、リリースを行う
1.境界づけられたコンテキスト、コンテキストマップの作成
2.戦略的目標の定義・・・戦略上、達成したい目標を定義する
3.組織パターンを考える・・・戦略レベルのビジネスロジックを管理、運用、メンテンナスするチーム間の関係を考える
4.戦略的設計・・・戦略レベルのビジネスロジックを作成する際の設計方法を考える
5.ビジネスロジックの作成
7.テスト
8.リリース戦略的目標を達成するためのビジネスロジック
戦略的目標を達成するためのビジネスロジックでは、サブゴールと呼ばれる中間目標の設定が重要である。
サブゴール内で作戦レベルのアプリのメソッドを実行し、実行結果が正常であるならば処理を継続し、それ以外の場合、処理を終了する。
サブゴールを全て達成した場合、トランザクションをコミットし、処理を終了する。以下が戦略的目標を達成するためのビジネスロジックのイメージ図となる。


- 投稿日:2020-07-20T02:01:00+09:00
[Terraform]CodeBuildでTerraformリポジトリのCIを行う
概要
CodeBuildサービスを利用してterraformリポジトリの継続的インテグレーションが行えるようになるまでの設定手順をハンズオンライクに記載します。
前提
- Githubでtfファイルを管理している
- AWSアカウントを保持している
- ステートファイルをS3バケットで管理している
実施すること
AWS上の
CodeBuildサービスを用いて、Githubで管理しているterraformコードに修正が行われた際、修正プルリクエストの更新等をトリガーとして、自動的に以下を行うようなプロジェクトを作成します。
- フォーマット確認(format)
- バリデーション(validate)
- 静的解析(lint)
- 実行計画(plan)
- 実行計画の通知(tfnotify)
フォーマット確認
terraform fmtコマンドではファイルにフォーマットをかけたり、未フォーマットのファイルを検知を行ったりします。Terminal$ terraform fmt -recursive -check
-recursiveオプション:現在のディレクトリから再帰的にtfファイルを探して実行する-checkオプション:formatの正しくないファイルがあった場合にexit codeが0以外になるなお、
-checkオプションをつけない場合は、自動的に全ファイルのフォーマットが行われ、フォーマット対象となったファイル名一覧が返却されます。バリデーション
terraform validateコマンドで、変数が未定義かどうか、構文にエラーが存在するかといったことをチェックします。
ただし、validateを行う前にinitを実行しておく必要があります。Terminal$ terraform init $ terraform validate
validateをはじめ、これ以降のコマンドに関してはfmtのように再帰的に実行可能なオプションが用意されていないため、自前でtfファイルが存在するディレクトリ一覧を取得し、それぞれのディレクトリに対してコマンド実行するといった工夫が必要となります。
シェルコマンドでこれを解決する一例を以下に示しておきます。Terminal$ find ${base_dir} -type f -name "*.tf" -exec dirname {} \; | sort -u | xargs -I {} terraform validate {}静的解析
tflintを用いることでtfファイルの静的解析を行います。
手元で使う場合はbrewによるインストールが必要となります。Terminal$ brew install tflintたとえば、次のように存在しないリソース種別を定義しているファイルを検知することが可能です。
main.tfresource aws_instance tutorial { ami = data.aws_ami.latest.image_id instance_type = "t2.micro2" # 存在しないEC2インスタンスタイプを指定 iam_instance_profile = "unknown_profile" # 存在しないプロファイルを指定 }Terminal$ tflint 1 issue(s) found: Error: "t2.micro2" is an invalid value as instance_type (aws_instance_invalid_type) on main.tf line 33: 33: instance_type = "t2.micro2"AWS APIを用いてより詳細な解析を行うために
--deepオプションが用意されています。
上記の例では、このオプションを付与することでiam_instance_profileが不正であることも検知することが可能となります。
なお、--deepオプションを利用する際にはAWS APIを利用するため、実行時のregion指定およびAWSへのCredentials設定が必要となります。Terminal$ tflint --deep --region=ap-northeast-1 2 issue(s) found: Error: "t2.micro2" is an invalid value as instance_type (aws_instance_invalid_type) on main.tf line 33: 33: instance_type = var.aws_instance_type Error: "unknown_profile" is invalid IAM profile name. (aws_instance_invalid_iam_profile) on main.tf line 34: 34: iam_instance_profile = "unknown_profile"
validatetflintのそれぞれに得意・不得意があるようなので、組み合わせて使うのが良いのではないかと考えています。実行計画
terraform planを利用することで、実行計画を取得します。
通常実行するケースでは特にオプションをつける必要性はありませんが、今回のCodeBuildやcircleci上で実行する場合、実行結果ログを見やすくするために-no-colorオプションを付与することが好ましいです。(実行結果が色つきではなくANSIエスケープコードで表示されるため)
また、planを行うためにはinitが前提となります。Terminal$ terraform init $ terraform plan Refreshing Terraform state in-memory prior to plan... The refreshed state will be used to calculate this plan, but will not be persisted to local or remote state storage. data.aws_ami.latest: Refreshing state... ------------------------------------------------------------------------ An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: + create Terraform will perform the following actions: # aws_instance.tutorial will be created + resource "aws_instance" "tutorial" { + ami = "ami-0a1c2ec61571737db" + arn = (known after apply) + associate_public_ip_address = (known after apply) + availability_zone = (known after apply) + cpu_core_count = (known after apply) + cpu_threads_per_core = (known after apply) + get_password_data = false + host_id = (known after apply) + id = (known after apply) + instance_state = (known after apply) + instance_type = "t2.micro" ・・・(中略) } Plan: 1 to add, 0 to change, 0 to destroy. ------------------------------------------------------------------------実行計画の通知
tfnotifyを用いることで、GithubのPRやSlackへ
planの実行結果を通知することができます。あらかじめ実行計画を見ることができる点が非常に便利です。
対象が複数環境となる場合でGithub PRへの通知設定を行っている場合、ややPRのコメントが流れやすくなってしまうため多少運用面での工夫が必要となるかもしれません。
terraform planをパイプラインで渡して実行します。Terminal$ terraform plan | tfnotify plan --config tfnotify.yml
通知先や通知内容の設定は任意のymlファイルに記載することができます。(詳細はこちらを参照)
なお、Githubへ連携を行うためにはアクセス用トークンを発行する必要があります。(後述)
一例を以下に示します。tfnotify.ymlci: codebuild # ciを行う場所 circleciならcircleci notifier: github: # 今回はgithubへ通知 token: $GITHUB_TOKEN # github連携用トークン repository: owner: "mintak21" # 通知先リポジトリのオーナーユーザー名称 name: "terraform" # 通知先リポジトリ名称 terraform: plan: # 通知結果表示テンプレートを定義(html利用可能) template: | {{ .Title }} {{ .Message }} {{if .Result}}<pre><code> {{ .Result }} </pre></code>{{end}} <details><summary>Details (Click me)</summary> <pre><code> {{ .Body }} </pre></code></details> # 実行結果ごとのアクション定義(Github限定) when_add_or_update_only: # addかupdateだけの場合、add-or-updateラベルをつける label: "add-or-update" when_no_changes: label: "no-changes" when_destroy: # destroyがある場合、destroyラベルをつけ、WARNINGを付記 label: "destroy" template: | ## :warning: WARNING: Resource Deletion will happen :warning: This plan contains **resource deletion**. Please check the plan result very carefully! when_plan_error: label: "error"使用できるテンプレート変数
変数 概要 {{ .Title }} ## Plan result {{ .Message }} tfnotify コマンド実行時の --messageオプションで指定した内容{{ .Result }} plan最後の1行 ex:Plan: 1 to add, 0 to change, 0 to destroy.{{ .Body }} planの内容{{ .Link }} tfnotifyを実行したCIページへのリンクCodeBuildプロジェクトの作成
CIにて確認したい内容、確認の方法を上記で見ることができたので、ここからそれを実行するためのCodeBuildプロジェクトを作成していきましょう。もちろん
terraformで作成します。
次のようなディレクトリ構成とします。
コードの全容はリポジトリをご参照ください。├── cicd/ # CodeBuild設定管理ファイル │ ├── backend.tf │ ├── buildspec.yml # ビルドフェーズ定義ファイル │ ├── main.tf # エントリポイント │ ├── output.tf # 出力定義 │ ├── providers.tf │ ├── terraform.tfvars │ ├── tfnotify.yml # tfnotify設定 │ └── variables.tf ├── files/ # CIの対象とするファイル群(階層はイメージ) │ ├── development/ │ │ └── main.tf │ └── staging/ │ └── main.tf ├── module/ # モジュール └── scripts/ # CodeBuildビルドフェーズで使用するスクリプト群 └── ci/ ├── format.sh ├── install_packages.sh ├── lint_aws.sh ├── plan.sh ├── settings.sh └── validate.sh1. Github連携トークンの払い出し
githubと連携を行うため必要なトークンを作成します。
こちらを参照して発行を行ってください。2. パラメータストアへのトークン登録
連携トークンは秘匿情報にあたります。
CodeBuildの環境変数に設定してもよいのですが、よりセキュアに管理するためトークン情報はAWS Systems Manager パラメータストアに保存し、CodeBuildからパラメータ参照することとします。ここではaws-cliコマンドを使用して保存します。Terminalaws ssm put-parameter --type SecureString --name パラメータ名 --value Githubトークン3. CodeBuild用IAMロール払い出し
CodeBuild用のIAMロール作成を行います。
モジュールの詳細を割愛しますが、指定したポリシードキュメントを持つIAMポリシーを作成、サービスロールとしてIAMロールを作成し、これらの関連付けを行っています。
また、少し楽をするため、アタッチするポリシーはCodeBuild全権限としています。通常は必要な権限を絞って適用すべきである点ご注意ください。main.tfdata aws_iam_policy administrator { arn = "arn:aws:iam::aws:policy/AWSCodeBuildAdminAccess" // !!!CodeBuildAdmin権限注意!!! } module service_role_for_continuous_check { source = "./../module/aws/iam" role_name = var.codebuild_role_name policy_name = var.codebuild_role_policy_name policy = data.aws_iam_policy.administrator.policy principal_service_identifiers = ["codebuild.amazonaws.com"] }4. CodeBuildプロジェクト定義
次にCodeBuildプロジェクト作成のためのコードを書いていきます。
4.1. CI実行用スクリプトの作成
ビルドフェーズで
lintやplanを行うにあたり対象とするディレクトリに対して再帰的に実行したいため、ラッパーシェルを作成します。例えばplanを行うシェルは以下のように作成しています。
なおここで使用しているCODEBUILD_SRC_DIRという環境変数を使用することでCodeBuildでビルドする際のルートディレクトリを取得することが可能です。plan.shtarget_dirs=`find ../../${base_dir} -type f -name "*.tf" -exec dirname {} \; | sort -u` for target in ${target_dirs} do cd ${target} terraform init -input=false -no-color terraform plan -input=false -no-color | \ tfnotify --config ${CODEBUILD_SRC_DIR}/cicd/tfnotify.yml plan --message "$(date)" doneまた、今回ベースイメージにterraform:lightを使用しますが、
tflintやtfnotifyは含まれていないため、installフェーズでこれらを取得するためのスクリプトも作成しておきます。(専用のカスタムイメージを作成し、これを使用するようにすればinstallフェーズ自体のスキップすることができるかもしれません)install_packages.shTF_LINT_VER="v0.16.2" TF_NOTIFY_VER="v0.6.2" function install_tflint() { REPO_URL="https://github.com/terraform-linters/tflint/releases/download" DL_LINK="${REPO_URL}/${TF_LINT_VER}/tflint_linux_amd64.zip" wget ${DL_LINK} -P /tmp unzip /tmp/tflint_linux_amd64.zip -d /tmp mv /tmp/tflint /bin/tflint echo "install tflint" } function install_tfnotify() { REPO_URL="https://github.com/mercari/tfnotify/releases/download" DL_LINK="${REPO_URL}/${TF_NOTIFY_VER}/tfnotify_linux_amd64.tar.gz" wget ${DL_LINK} -P /tmp tar zxvf /tmp/tfnotify_linux_amd64.tar.gz -C /tmp mv /tmp/tfnotify /bin/tfnotify echo "install tfnotify" } install_tflint install_tfnotify4.2. ビルドフェーズ定義ファイルの作成
CodeBuildでのビルドはSUBMITTEDフェーズ〜FINALIZINGフェーズまで、一連のフェーズにて行われます。
これら各種フェーズで何を行うかをymlファイルで設定することが可能です。
今回はINSTALLフェーズで必要となるパッケージをインストールし、BUILDフェーズでformat/validate/lint/planを行う(シェルを呼び出す)ように設定します。buildspec.ymlversion: 0.2 env: parameter-store: GITHUB_TOKEN: "2で指定したパラメータ名" phases: install: commands: - ${CODEBUILD_SRC_DIR}/scripts/ci/install_packages.sh build: commands: - ${CODEBUILD_SRC_DIR}/scripts/ci/format.sh - ${CODEBUILD_SRC_DIR}/scripts/ci/validate.sh - ${CODEBUILD_SRC_DIR}/scripts/ci/lint_aws.sh - ${CODEBUILD_SRC_DIR}/scripts/ci/plan.sh4.3. プロジェクトの作成ファイル
一例を示しますが、重要な項目は次となります。
service_role:紐付けるサービスロール。払い出したロールのarn値を指定するsourceブロック:CIの実行対象とするリポジトリの定義
report_build_status:true: CI結果の通知を行う。デフォルトfalseなので有効化しない限りGithub側へ反映されないenvironmentブロック:CIを行う環境の準備
image:使用するDockerイメージcompute_type:マシンスペック。特に意識しなければ最小構成のBUILD_GENERAL1_SMALLを選択すべしlogs_configブロック:ログ出力設定。CloudWatchはONにしておくとよいかとmain.tfresource aws_codebuild_project continuous_check { // プロジェクトの設定 name = var.codebuild_project_name description = "continuous integration project for terraform repogistory" badge_enabled = false tags = { Author = "mintak21" } // ソース source { type = "GITHUB" location = var.github_repository_location git_clone_depth = 1 report_build_status = true // リポジトリ側へ結果通知 buildspec = var.buildspec_settings } // 環境 environment { image = "hashicorp/terraform:light" // カスタムイメージURL type = "LINUX_CONTAINER" // 環境タイプ compute_type = "BUILD_GENERAL1_SMALL" // コンピューティングタイプ privileged_mode = false } // サービスロール service_role = module.service_role_for_continuous_check.this_aws_iam_role_arn // タイムアウト build_timeout = "30" // キュータイムアウト queued_timeout = "60" // アーティファクト artifacts { type = "NO_ARTIFACTS" } // キャッシュ cache { type = "LOCAL" modes = ["LOCAL_SOURCE_CACHE"] } // ログ logs_config { cloudwatch_logs { status = "ENABLED" group_name = "mintak" stream_name = "logs-for-${var.codebuild_project_name}" } s3_logs { status = "DISABLED" } } }5. Webhook作成ファイル
プロジェクトを作成しましたが、このままでは
GithubにpushやPRの作成等を行っても、CodeBuildへ連携されることがありません。そこでこれらのイベントをトリガーとしてプロジェクトのビルドが実行されるようにWebhookを作成します。
filterブロックで検知するイベントの種別、パターンを記述します。ここでは以下をトリガーとしてビルド実行される設定を行います。
- PR作成・更新
- developブランチへのpush
- masterブランチへのpush
main.tfresource aws_codebuild_webhook continuous_check { project_name = aws_codebuild_project.continuous_check.name // PR作成・更新時 filter_group { filter { type = "EVENT" pattern = "PULL_REQUEST_CREATED" } } filter_group { filter { type = "EVENT" pattern = "PULL_REQUEST_UPDATED" } } // developブランチpush時 filter_group { filter { type = "EVENT" pattern = "PUSH" } filter { type = "HEAD_REF" pattern = "develop" } } // masterブランチpush時 filter_group { filter { type = "EVENT" pattern = "PUSH" } filter { type = "HEAD_REF" pattern = "master" } } }6. プロジェクト作成
ここまでで必要なコード類がそろったので、いよいよ
applyでプロジェクトを作成します。Terminal$ cd cicd $ terraform init $ terraform apply7. Githubブランチの設定
ここまででCIは実行されるようになりましたが、CIに失敗した場合にPRがマージが可能な状態は避けたいものです。
そこでGithubリポジトリのブランチ保護設定を行い、PRのマージ可能条件に「CIの成功」を設定します。masterブランチおよびdevelopブランチに設定するのが良いでしょう。
試してみる
では実際に
filesディレクトリ以下のtfファイルに任意の変更を行い、プルリクエストを作成してみましょう。
CodeBuildが実行され、以下が通知されれば正しく設定が完了しています。
tfnotifyによりplan結果(コメント)- ビルドステータス

おつかれさまでした!
References


