- 投稿日:2020-02-09T15:15:42+09:00
RaspberryPi4/3のCPUで爆速DeepLearning (レアデバイスもあるよ)
これは connpass - 2020/02/15(土) 第2回ディープラーニングガジェット品評会 の発表資料です。 プレゼン用に箇条書きが多いですがご容赦願います。 なお、私の全成果物は Github と Qiita にフルコミットしてあります。 詳しく知りたい方はAppendixをご覧下さい。 この記事はプレゼンが終わったらその場でQiitaへ公開します。
https://deepgatget.connpass.com/event/156270/
1. PINTO
名古屋に住んでいます。 しがないビルドジャンキーです。 ありきたりじゃないのが死ぬほど好きです。 RaspberryPi はビルド専用端末です。
2. おことわり
- 撮影OK
- SNS共有OK
- アドバイスOK
- 飲み会のお誘い歓迎
- プルリク歓迎
- ディスりNG
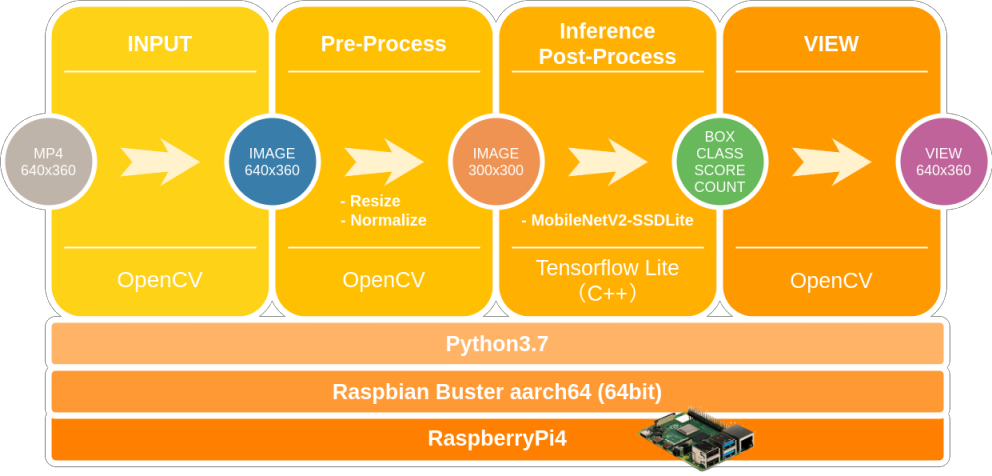
3. 今回トライしたこと
- RaspberryPi4 の CPUのみ でDeepLearning (EdgeTPU, NCS2使わない縛り)
- 公式公開モデルのMobileNetV2-SSDLite データセット変更
- MS-COCO (90class) -> Pascal-VOC (20class)
- Tensorflow v2.1.0 の v1-API 対応 (セルフビルドしてインストールするだけ)
- モデルの 8bit量子化 (Integer Quantization)
- Tensorflow LiteのPythonAPIを 改造
- RaspberryPi4 を Raspbian Buster 64bit 化
- RaspberryPi4 の オーバークロック (1.5GHz->1.75GHz)
- 2020/02/07のkernelアップデートで1.8GHz対応されていました
- https://www.raspberrypi.org/blog/a-new-raspbian-update/
4. 公式モデル MobileNetV2-SSDLite (MS-COCO) を Pascal-VOC でリトレーニング
大したことはしません。 データセットを変更していちからトレーニングするだけです。 クラス数が 90クラス から 20クラス へ減少することにより、 RaspberryPi4 の CPUによる後処理で 5ms ほどパフォーマンスが改善しました。 手順は下記のQiita記事をご覧ください。
MobileNetV2-SSDLiteのPascal-VOCデータセットによる学習 [Docker版リメイク]
Dockerを使用してこんな感じの環境でガガガッと学習します。 ヒュ〜、無駄にカッコイイ。
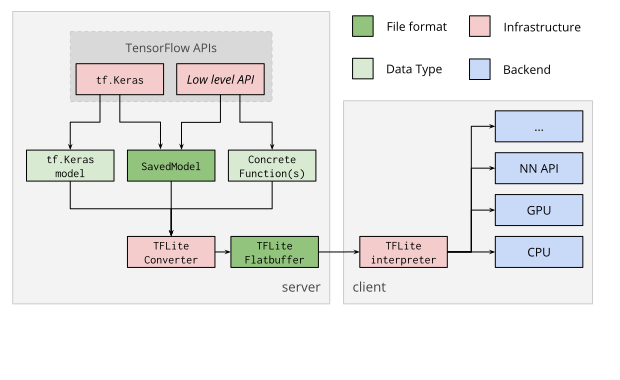
5. Tensorflow Lite
- 軽量・高速推論に最適化されたフレームワーク
- モデルの量子化・実行
- カスタムオペレータ対応
- 非対応のオペレータは Flex Delegate によりTensorflow側へオフロード可能
- モデルのプルーニング
- EdgeTPU
- ARM64 に最適化
5-1. 普通のTensorflow Liteのワークフロー
Tensorflow v2.x.x 以降、標準では従来資産の .pb (GraphDef) ファイルを .tflite 形式に変換できません。 でも、 Tensorflow v2.1.0 の最新のオペレーターに対応させたうえで .pb の変換も行いたいですよね。
5-2. 改造後のTensorflow Liteのワークフロー
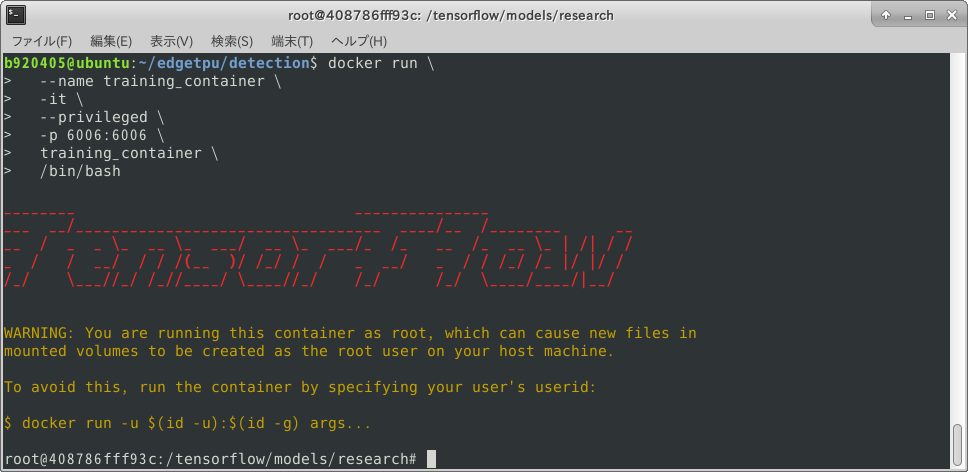
ですので、 「そうだ、京都へ行こう。」 的なノリで、 Tensorflow v2.1.0 のワークフローを変更しました。
--config=v1オプションを指定して Tensorflow をフルビルドするだけです。 いつもめちゃくちゃな発想ばかりしていますので、そのうちGoogleの中の人に怒られそうです。
v1-API版 Ubuntu 18.04 x86_64用 Tensorflow v2.1.0インストーラ tensorflow-2.1.0-cp36-cp36m-linux_x86_64.whl
5-3. Tensorflow v2.1.0 for v1-API のWheelインストーラフルビルド
ビルドの下準備なども含めた全手順は コチラのREADME をご覧ください。
ワークフローを変更するためのビルドコマンドだけを抜き出したものは下記です。v1-APIを有効にしたTensorflow_v2.1.0のフルビルドコマンド$ sudo bazel build \ --config=opt \ --config=noaws \ --config=nohdfs \ --config=nonccl \ --config=v1 \ //tensorflow/tools/pip_package:build_pip_package
5-4. モデルの量子化
公式チュートリアルによると、
"モデルサイズが4倍に削減され、CPUパフォーマンスが3〜4倍に向上します。 さらに、完全に量子化されたモデルは、整数演算特化のハードウェアアクセラレータで使用できます。"だそうです。整数演算特化のハードウェアアクセラレータは EdgeTPU のことですね。 爆速なのは知っています。 バナナもプルプルしちゃうほどです。
Tensorflow for Mobile/IoT - Post-training integer quantization チュートリアル
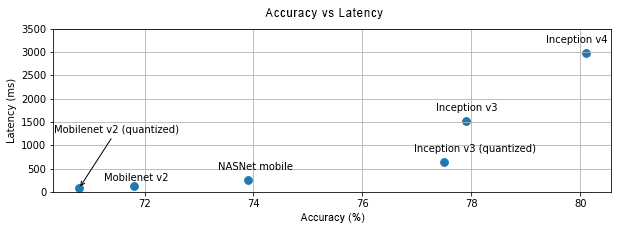
5-5. 量子化モデルの精度とレイテンシ
8bit量子化を行うことで、若干の精度劣化を伴う代わりにレイテンシは 2分の1 〜 4分の1 になります。
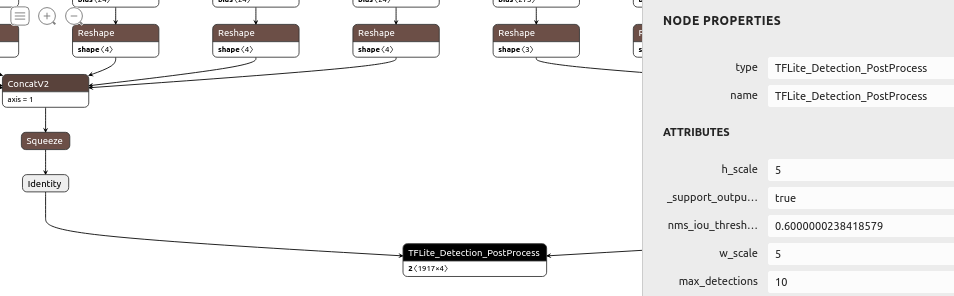
5-6. MobileNetV2-SSDLite の.pbファイルへのエクスポート (Post-Process有り)
Post-Process がモデルの末尾にくっついた .tflite ファイルを生成します。 Post-Process はカスタムオペレータです。
Export_model$ python3 object_detection/export_tflite_ssd_graph.py \ --pipeline_config_path=pipeline.config \ --trained_checkpoint_prefix=model.ckpt-44548 \ --output_directory=export \ --add_postprocessing_op=True
5-7. MobileNetV2-SSDLite の .pb の8bit量子化 (Integer Quantization)
Integer_Quantization_from_.pb_fileimport tensorflow as tf import tensorflow_datasets as tfds import numpy as np def representative_dataset_gen(): for data in raw_test_data.take(100): image = tf.image.resize(data['image'].numpy(), (300, 300)) image = image[np.newaxis,:,:,:] yield [(image - 127.5) * 0.007843] tf.compat.v1.enable_eager_execution() raw_test_data, info = tfds.load(name="voc/2007", with_info=True, split="validation", data_dir="~/TFDS", download=True) graph_def_file="tflite_graph_with_postprocess.pb" input_arrays=["normalized_input_image_tensor"] output_arrays=['TFLite_Detection_PostProcess','TFLite_Detection_PostProcess:1', 'TFLite_Detection_PostProcess:2','TFLite_Detection_PostProcess:3'] input_tensor={"normalized_input_image_tensor":[1,300,300,3]} ################################### ↓ ココ TF v2 では本来使用できないAPI converter = tf.lite.TFLiteConverter.from_frozen_graph(graph_def_file, input_arrays, output_arrays,input_tensor) converter.allow_custom_ops=True converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset_gen tflite_quant_model = converter.convert() with open('./ssdlite_mobilenet_v2_voc_300_integer_quant_with_postprocess.tflite', 'wb') as w: w.write(tflite_quant_model)
6. Tensorflow Liteランタイムの改造
Tensorflow Lite の PythonAPI を改造してマルチスレッド推論に対応させます。
tensorflow/lite/python/interpreter.pydef set_num_threads(self, i): return self._interpreter.SetNumThreads(i)tensorflow/lite/python/interpreter_wrapper/interpreter_wrapper.ccPyObject* InterpreterWrapper::SetNumThreads(int i) { interpreter_->SetNumThreads(i); Py_RETURN_NONE; }tensorflow/lite/python/interpreter_wrapper/interpreter_wrapper.hPyObject* SetNumThreads(int i);いじょ。 簡単ですね。
7. Raspbian Buster 64bit
Tensorflow Liteの公式チュートリアルやベンチマークはAndroidスマホのものばかりです。 何故か? 64bit ARMへの最適化があるからだと思います。 てことで、Raspbianを64bit化します。 後の動画で結果は明らかです。 sakaki-さんのリポジトリのREADMEどおりに導入するだけです。
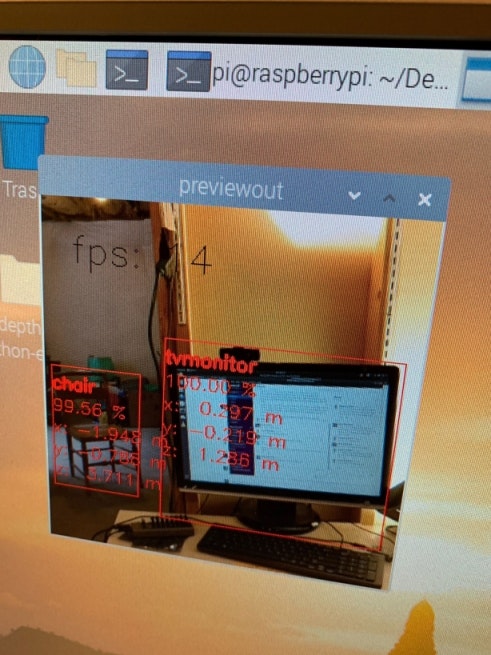
8. CPU推論 - Object Detection
レッツ推論!!
— Super PINTO (@PINTO03091) February 8, 2020
— Super PINTO (@PINTO03091) February 8, 2020
9. 深度推定+DeepLearningデバイス 〈DepthAI〉
VPU MyriadX と RaspberryPi3 と ステレオカメラ を一体にしたとんでもデバイスを Luxonis の Brandonさん から試験用にご提供頂きました。 NCS2 と RaspberryPi3 がハードウェアレベルで一体になっているのと同じです。 本日は展示デモを行います。 量産化前だそうなので世界に10台しかないうちの1台です。
DepthAI https://luxonis.com/depthai
DepthAI Documentation https://docs.luxonis.com/
Brandonさんから頂いたDepthAIの性能です。 RaspberryPi3+MyriadX (NCS2同等) の本来のパフォーマンスです。 深度も取れます。 USB2.0を経由せず直接バイパスしています。 モデルにもよると思いますがサンプルPGは 25FPS です。#RaspberryPi #DepthAI #MyriadXhttps://t.co/QNPIWFxwbd
— Super PINTO (@PINTO03091) February 12, 2020
Cool !!!!
Calibrating the camera is extremely difficult and struggling. However, RaspberryPi3 + ObjectDetection + Depth estimation seems to be working properly.?#DepthAI #RaspberryPi #MyriadXhttps://t.co/lwNcxu40mH
— Super PINTO (@PINTO03091) February 12, 2020
10. RaspberryPi4 + NCS2 のPINTO実装
去年作成した NCS2 x1本 + RaspberryPi4 の動画がコレですからね。 やっぱりエッジアクセラレータは特化していて強いです。https://t.co/tEYBwyhTlu
— Super PINTO (@PINTO03091) February 8, 2020
11. 最後に
この界隈は技術の移り変わりがとても激しいです。 ですので、新しいものが出てきたら次へ次へと思考シフトしていける柔軟なフットワークが必要だと考えています。 そんな中、何故あえて数年前に提案されたモデル等を高速化するのか。 最新の技術と準最新の技術を組み合わせると意外とかつては解決が難しかった課題が解決することもあると思っているからです。 課題はコストだったのかもしれないし、パフォーマンスだったのかもしれない。 でも、シンプルで長年洗練された技術は新しい技術で少し味付けするだけで、機材調達コストが大幅に下がったうえにパフォーマンスが著しく上がって極端に優位性が高くなったり、当時はとても実業務には適応できなかったようなものでもとたんに息を吹き替えしたりする。 そういうものにロマンを感じます。 そんな時代にあっても、私は一生、生み出す側ではなく利用する側でいるに違いないわけですけれども。。。
12. Appendix
- RaspberryPi4/3用 Tensorflow フルビルドインストーラ
- RaspberryPi4/3 armv7l,aarch64用 PythonAPI改造済みの Tensorflow Lite Wheelインストーラ
- Tensorflow LiteのFlex Delegate対応済みバイナリ
- <お手製> 量子化モデルZOO
- RaspberryPi用 Bazel








- 投稿日:2020-02-09T14:07:47+09:00
TensorFlow 2.0 の Dataset を無理やり使って MNIST
PyTorch全盛の今ですが、TensorFlowが2.0になりkerasが統合されたなら試してみなきゃ!ということで試してみました第2弾です。第1弾はこちら。
今回は tf.data.Datasetの構築 をしてみよう!ということで、今後メモリに入りきらないデータの学習やData Augmentationをバリバリ使いたいなあというのがモチベーションです。
こちらの公式を参考にしています。
ソースは GITHUB で公開しています。Google Colaboratory で実行可能です。import
Google Colaboratory ではまだデフォルトのTensorFlowは1.xなので、2.0に変更してインポート(近々デフォルトがアップデートされる予定のようです。)
try: %tensorflow_version 2.x except Exception: pass import tensorflow as tfData
Google Colaboratory の sample_dataフォルダ に用意されている MNIST_small(csvファイル)を使います。
最初の列がラベルになっていて、残りは28*28=784列になっているようなので、reshapeなどしてとりあえずndarrayにしておきます。mnist_train_small = pd.read_csv('sample_data/mnist_train_small.csv', header=None) mnist_test = pd.read_csv('sample_data/mnist_test.csv', header=None) y_train = mnist_train_small.iloc[:, 0].to_numpy() x_train = mnist_train_small.drop(columns=0).to_numpy().reshape(-1,28,28) y_test = mnist_test.iloc[:, 0].to_numpy() x_test = mnist_test.drop(columns=0).to_numpy().reshape(-1,28,28)import matplotlib.pyplot as plt %matplotlib inline plt.figure() plt.imshow(x_train[0]) plt.colorbar() plt.show()
/255 します。
x_train, x_test = x_train / 255.0, x_test / 255.0MNISTの画像を確認
plt.figure(figsize=(8,8)) for i in range(4*4): plt.subplot(4,4,i+1) plt.xticks([]) plt.yticks([]) plt.imshow(x_train[i], cmap=plt.cm.binary) plt.xlabel(y_train[i]) plt.show()
Dataset
いよいよメインの tf.data.Datasetの構築 です。
tf.data.Dataset.from_tensor_slices で (image, label)のペアのデータセット を作ります。
データがメモリに収まらない場合のために、cacheメソッドでキャッシュファイルを使用してみました。(今回は不要ですが)
バッチサイズ、シャッフル、リピートを指定しておきます。バリデーションデータについても Dataset オブジェクトにしてバッチサイズを指定しておきます。(学習時のバリデーションに必要ですが、バリデーションになぜ必要なのか正直良く分かりません。)
image_label_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)) ds = image_label_ds.cache(filename='./cache.tf-data') ds = ds.apply( tf.data.experimental.shuffle_and_repeat(buffer_size=image_count)) AUTOTUNE = tf.data.experimental.AUTOTUNE BATCH_SIZE = 32 ds = ds.batch(BATCH_SIZE).prefetch(1) ds_valid = tf.data.Dataset.from_tensor_slices((x_test, y_test)) ds_valid = ds_valid.batch(BATCH_SIZE).prefetch(buffer_size=AUTOTUNE)Model
第1弾と同じく、CNNですらない、シンプルなモデルで試します。
model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation='softmax') ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) model.summary()Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten (Flatten) (None, 784) 0 _________________________________________________________________ dense (Dense) (None, 128) 100480 _________________________________________________________________ dropout (Dropout) (None, 128) 0 _________________________________________________________________ dense_1 (Dense) (None, 10) 1290 ================================================================= Total params: 101,770 Trainable params: 101,770 Non-trainable params: 0 _________________________________________________________________Train
学習します。
学習データ、バリデーションデータに Datasetオブジェクトを指定しています。
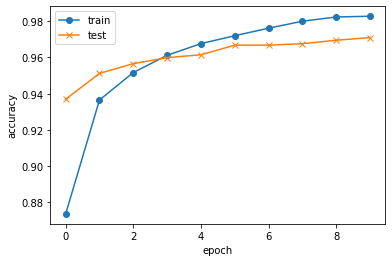
steps_per_epochは 学習データ/バッチサイズ にしています。history = model.fit(ds, epochs=10, steps_per_epoch=625, workers=0, validation_data=ds_valid)Train for 625 steps, validate for 313 steps Epoch 1/10 625/625 [==============================] - 3s 5ms/step - loss: 0.4385 - accuracy: 0.8737 - val_loss: 0.2224 - val_accuracy: 0.9370 Epoch 2/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2197 - accuracy: 0.9366 - val_loss: 0.1707 - val_accuracy: 0.9512 Epoch 3/10 625/625 [==============================] - 2s 4ms/step - loss: 0.1646 - accuracy: 0.9517 - val_loss: 0.1521 - val_accuracy: 0.9566 Epoch 4/10 625/625 [==============================] - 2s 4ms/step - loss: 0.1354 - accuracy: 0.9612 - val_loss: 0.1284 - val_accuracy: 0.9599 Epoch 5/10 625/625 [==============================] - 2s 4ms/step - loss: 0.1089 - accuracy: 0.9676 - val_loss: 0.1299 - val_accuracy: 0.9615 Epoch 6/10 625/625 [==============================] - 2s 4ms/step - loss: 0.0942 - accuracy: 0.9720 - val_loss: 0.1095 - val_accuracy: 0.9668 Epoch 7/10 625/625 [==============================] - 2s 4ms/step - loss: 0.0790 - accuracy: 0.9761 - val_loss: 0.1143 - val_accuracy: 0.9668 Epoch 8/10 625/625 [==============================] - 2s 4ms/step - loss: 0.0680 - accuracy: 0.9800 - val_loss: 0.1037 - val_accuracy: 0.9676 Epoch 9/10 625/625 [==============================] - 2s 4ms/step - loss: 0.0580 - accuracy: 0.9823 - val_loss: 0.1073 - val_accuracy: 0.9695 Epoch 10/10 625/625 [==============================] - 2s 4ms/step - loss: 0.0545 - accuracy: 0.9827 - val_loss: 0.1002 - val_accuracy: 0.9710学習の推移を確認
plt.plot(history.history["accuracy"], label="train", ls="-", marker="o") plt.plot(history.history["val_accuracy"], label="test", ls="-", marker="x") plt.ylabel("accuracy") plt.xlabel("epoch") plt.legend(loc="best") plt.show()
Test
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=1)10000/10000 [==============================] - 1s 67us/sample - loss: 0.1004 - accuracy: 0.9710結果をいくつか確認しましょう。
import numpy as np plt.figure(figsize=(16,16)) for i in range(10): plt.subplot(1, 10, i+1) plt.xticks([]) plt.yticks([]) plt.imshow(x_test[i], cmap=plt.cm.binary) plt.xlabel(y_test[i]) plt.show() print(np.argmax(model.predict(x_test[0:10]), axis=1))
[7 2 1 0 4 1 4 9 5 9]
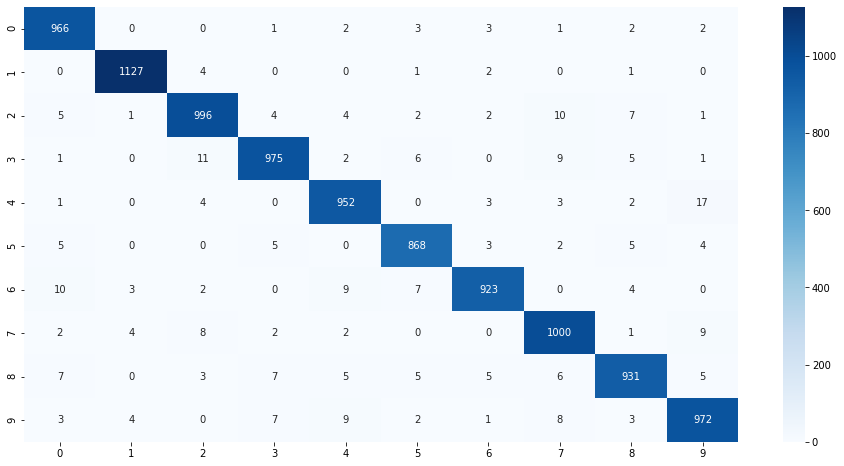
10個全部あってます。混合行列で確認
from sklearn.metrics import confusion_matrix import seaborn as sns cm = confusion_matrix(y_test,np.argmax(preds,axis=1)) plt.figure(figsize=(16,8)) sns.heatmap(cm, annot=True, fmt='d', cmap='Blues') plt.show()
次回は DataAugumentation か 学習済みモデルの転移学習 か TensorflowHUB のどれやろうかな。
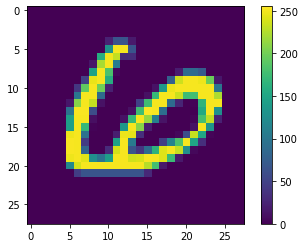

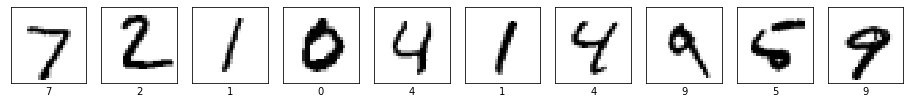
- 投稿日:2020-02-09T05:52:38+09:00
tf.kerasのcustom layerに対してtf.keras.layers.TimeDistributedを使う時の注意
本記事の目的
tf.kerasで定義したcustom layerに対してtf.keras.layers.TimeDistributedを用いるとエラーを吐いたので、その内容と解決策を共有します。version
- Python: 3.6.9
- Tensorflow: 2.1.0
目次
- tf.keras.layers.TimeDistributedとは
- custom layerとは
- custom layerに対してtf.keras.layers.TimeDistributedを作用させたときのエラー内容紹介
- 上記の解決法
tf.keras.layers.TimeDistributedとは
時間方向に1つのlayerを繰り返し作用させたいときなどに用います。 (参考)
from tensorflow.keras import Input, Model from tensorflow.keras.layers import TimeDistributed, Dense temporal_dim = 4 emb_dim = 16 inputs = Input((temporal_dim, 8)) outputs = TimeDistributed(Dense(emb_dim))(inputs) model = Model(inputs, outputs) model.summary() """ _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 4, 8)] 0 _________________________________________________________________ time_distributed (TimeDistri (None, 4, 16) 144 ================================================================= Total params: 144 Trainable params: 144 Non-trainable params: 0 _________________________________________________________________ """注)
tf.keras.layers.Denseは最後の次元にしか作用しないので、上記結果はtf.keras.layers.TimeDistributedの有無に依らないです。ありがたみを感じられるのは、tf.keras.layers.Embeddingのようなinput_shapeに制限があるlayerに対して使った時です。
tf.keras.layers.Embeddingはbatch_sizeこみで2D tensorにしか使えないので、もしも、3D tensorを埋め込みたい場合は、tf.keras.layers.TimeDistributedを使って足りない余計な1次元方向に繰り返し作用させる必要があります。(recommendのモデルで使います)custom layerとは
tf.kerasでは、tf.keras.layers.Layerを継承してcustom layerを定義できます。
tf.kerasにはたくさんの便利なlayerが実装されており、それらを組み合わせてtf.keras.Modelを作り上げていきます。標準のlayerだけでも非常に多くのモデルが実装できます。より柔軟な処理を行いたい場合には、custom layerとして実装することで
tf.kerasっぽさを損なわずにすみます。(参考)例.1: 標準の
tf.keras.layersを組み合わせるこの場合、
.__init__()でtf.keras.layersのinstanceを生成しておき、.call()にて実際のlayerの処理を定義します。(以下のlayerは、
tf.keras.layers.Denseと同じものです)import tensorflow as tf from tensorflow.keras.layers import Dense class Linear(tf.keras.layers.Layer): def __init__(self, emb_dim, *args, **kwargs): super(Linear_error, self).__init__(*args, **kwargs) self.dense = Dense(emb_dim) def call(self, x): return self.dense(x)例.2: 学習可能な変数を定義する
より低レベルAPIを使用する方法として、以下の様に、書けます。
class Linear(tf.keras.layers.Layer): def __init__(self, emb_dim): super(Linear, self).__init__() self.emb_dim = emb_dim def build(self, input_shape): self.kernel = self.add_weight( "kernel", shape=[int(input_shape[-1]), self.emb_dim] ) def call(self, x): return tf.matmul(x, self.kernel)Error: custom layerに対するtf.keras.layers.TimeDistributedが動かない
以下の様にcustom layerに対して
tf.keras.layers.TimeDistributedを使います。from tensorflow.keras import Input from tensorflow.keras.layers import TimeDistributed temporal_dim = 4 emb_dim = 16 inputs = Input((temporal_dim, 8)) outputs = TimeDistributed(Linear(emb_dim))(inputs) assert outputs.shape.rank == 3 assert outputs.shape[1] == temporal_dim assert outputs.shape[2] == emb_dimすると、以下のエラーが返ってきます。(一部抜粋)
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/engine/base_layer.py:773: in __call__ outputs = call_fn(cast_inputs, *args, **kwargs) /usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/layers/wrappers.py:270: in call output_shape = self.compute_output_shape(input_shape).as_list() /usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/layers/wrappers.py:212: in compute_output_shape child_output_shape = self.layer.compute_output_shape(child_input_shape) > raise NotImplementedError E NotImplementedError /usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/engine/base_layer.py:564: NotImplementedErrorこれは、custom layerの
.compute_output_shape()の中身がないので自分で実装して下さいというメッセージです。tf.keras.layersは
.build()か、.call()が呼ばれるまでinput_shapeとoutput_shapeが定まらないです。しかし、tf.keras.layers.TimeDistributedは引数に入れたlayerのouput_shapeをinstance生成時(つまり、.build()や.call()の前)に知ろうとします。tf.keras.layersはそんな時のために.compute_output_shape()というメソッドを用意しています。コードを見た限りbuildしようとしていますが、custom layerだとbuildに成功せずに、NotImplementedErrorがraiseしています。解決策
custom layerの定義時に
.compute_output_shape()をoverrideして陽にoutput_shapeを定義します。class Linear(tf.keras.layers.Layer): def __init__(self, emb_dim, *args, **kwargs): super(Linear, self).__init__(*args, **kwargs) self.emb_dim = emb_dim self.dense = Dense(self.emb_dim) def call(self, x): return self.dense(x) def compute_output_shape(self, input_shape): output_shape = input_shape[0:-1] + [self.emb_dim] return output_shapeこちらのcustom layerであれば、
tf.keras.layers.TimeDistributedにわたしても正常に動いてくれます。