- 投稿日:2020-02-09T22:04:34+09:00
Goでシグナルを監視する君を書いた
tl;dt
https://github.com/nozo-moto/signal_kansitai
目的
ちょっとした調査、アプリケーションにどんなシグナルが送られてくるか知りたかった
方法
Go言語は以下のようにすると作成したgoroutineにシグナルがあるとハンドリングできます。
c := make(chan os.Signal) signal.Notify(c) go func() { for { s := <-c log.Println("signal :", s) } } }()よしなにロギング
標準出力とログファイルに書き出したかったのでio.MultiWriterを利用logfile, err := os.OpenFile("./signal.log", os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0666) if err != nil { panic("cannnot create log :" + err.Error()) } defer logfile.Close() log.SetOutput(io.MultiWriter(logfile, os.Stdout)) log.SetFlags(log.Ldate | log.Ltime)こんな感じでシグナルをハンドリングして流してくれる
% tail -f signal.log 2020/02/09 21:48:01 alive : 2020/02/09 21:49:01 alive : 2020/02/09 21:50:01 alive : 2020/02/09 21:50:33 signal : hangup falseSIGTERMが送られてきたら落とすようにしました。60秒に一回生存確認をしています。
また、SIGKILLとかのハンドリングできない系はハンドリングできずに死にます。知見
SIGWINCHというターミナルのWindowサイズの変更のシグナルがあることを知った。
- 投稿日:2020-02-09T20:04:46+09:00
Linuxとは?
今回はLinuxについて学習したのでまとめておきます。
LinuxとはMacOsやwindowsOsと同じくOSのことです。そしてLinuxは主にサーバー用として使うOSです。
オープンソースなので誰でも無料で使用できます。
- 投稿日:2020-02-09T19:32:30+09:00
bsdiff/bspatchを利用したパッチツールを作ってみる(1)
はじめに
以前にudm差分ファイル作成ツールを使った自動アップデート機能の作り方という記事で、
「udm差分ファイル作成ツール」を紹介しましたが、
このツールはプロプライエタリであり、また最新のWindowsをサポートできていないという問題があります。
将来的に使っていけるようにbsdiff/bspatchを使ったパッチツールを自作してみようかなと思い、
調査内容を何回かにわけてまとめていきます。最終的なゴール
- ディレクトリの差分を適用する自己解凍方式のパッチを作る(udm差分ファイル作成ツールの代替)
- 圧縮効率の高いbsdiff/bspatchを流用する
- Windows対応
今回はbsdiff/bspatchに関する調査内容を記載します。
bsdiff/bspatchとは
bsdiff/bspatchはUNIXやLinuxで利用されているバイナリの差分作成ツールです。
この仕組みはどうやらGoogle Chromeのアップデートパッチでも利用されているようです。
(参考記事:Google Chromeアップデート高速化の秘密、bsdiffと逆アセンブラ | マイナビニュース)コマンドラインでの使い方
bsdiffコマンドの使い方: UNIX/Linuxの部屋 からの引用ですが、使い方は単純で下記のように実行すればよさそうです。
bsdiff はバイナリファイルのパッチ (差分ファイル) を生成する。
% bsdiff bin.old bin.new bin.bsdiff
⇒ bin.old と bin.new の差分を抽出し、パッチファイル bin.bsdiff を生成する。
生成したパッチをあてるには bspatch を使う。
% bspatch bin.old bin.new bin.bsdiff
⇒ bin.old にパッチファイル bin.bsdiff をあて、bin.new を生成する。bsdiff/bspatchを実際に使ってみる
インストールと基本的な動作の確認
ためしに手持ちのMac(Mojave 10.14.5)にbsdiffをインストールして使ってみます。
# インストール $ brew install bsdiff ==> Downloading https://homebrew.bintray.com/bottles/bsdiff-4.3.mojave.bottle.tar.gz ######################################################################## 100.0% ==> Pouring bsdiff-4.3.mojave.bottle.tar.gz ? /usr/local/Cellar/bsdiff/4.3: 4 files, 21.5KB # テストファイル作成 $ echo "version 1.00" > v1.dat $ echo "version 2.00" > v2.dat # パッチ作成 $ bsdiff v1.dat v2.dat patch_v1_to_v2 # 中身を覗いてみる。中身はバイナリデータ。 $ less patch_v1_to_v2 BSDIFF40+^@^@^@^@^@^@^@(^@^@^@^@^@^@^@^M^@^@^@^@^@^@^@BZh91AY&SY<B3>7-<87>^@^@^E<C0>@T @^@ ^@!<80>^L^A<D6>M[qw$S<85> ^K3r<D8>pBZh91AY&SoI}^@^@^B<C0>^@d^@ ^@0<CC> 4<CA>^Gaw$S<85> ^@<86><F4><97><D0>BZh9^WrE8P<90>^@^@^@^@ patch_v1_to_v2 (END) # パッチ適用のために、v1.datをコピーしておく $ cp v1.dat src.dat # パッチ適用 $ bspatch src.dat dst.dat patch_v1_to_v2 # 確認 $ cat dst.dat version 2.00たしかに変わってますね。
コマンドライン引数を確認
bsdiff/bspatchのコマンドライン引数を見てみます。
$ bsdiff --help bsdiff: usage: bsdiff oldfile newfile patchfile $ man bsdiff BSDIFF(1) BSD General Commands Manual BSDIFF(1) NAME bsdiff -- generate a patch between two binary files SYNOPSIS bsdiff <oldfile> <newfile> <patchfile> DESCRIPTION bsdiff compares <oldfile> to <newfile> and writes to <patchfile> a binary patch suitable for use by bspatch(1). When <oldfile> and <newfile> are two versions of an executable program, the patches produced are on average a factor of five smaller than those produced by any other binary patch tool known to the author. bsdiff uses memory equal to 17 times the size of <oldfile>, and requires an absolute minimum working set size of 8 times the size of oldfile. SEE ALSO bspatch(1) AUTHORS Colin Percival <cperciva@freebsd.org> FreeBSD May 18, 2003 FreeBSD (END)オプションとか特になさそう…?
$ bspatch --help bspatch: usage: bspatch oldfile newfile patchfile $ man bspatch BSPATCH(1) BSD General Commands Manual BSPATCH(1) NAME bspatch -- apply a patch built with bsdiff(1) SYNOPSIS bspatch <oldfile> <newfile> <patchfile> DESCRIPTION bspatch generates <newfile> from <oldfile> and <patchfile> where <patchfile> is a binary patch built by bsdiff(1). bspatch uses memory equal to the size of <oldfile> plus the size of <newfile>, but can tolerate a very small working set without a dramatic loss of performance. SEE ALSO http://www.daemonology.net/bsdiff/ AUTHORS Colin Percival <cperciva@freebsd.org> FreeBSD May 18, 2003 FreeBSDこちらも特にない。
なぜコマンドライン引数を見たかというと、GNUの
sedコマンドの-iのようなファイルをそのまま置き換えるといったオプションがあるかどうか確認したかったからです。
どうやらなさそうなので、パッチを適用時に古いものと新しいものを混在させておいて最後に切り替えるのが良さそうです。ディレクトリに適用できるのか確認
コマンドライン引数を見ると、その可能性はなさそうにみえますが、、、一応やってみます。
$ mkdir v1 v2 $ echo "version 1.00" > v1/data $ echo "version 2.00" > v2/data $ echo "additional data" > v2/data_additional $ bsdiff v1 v2 patch_v1_to_v2 bsdiff: v1: Is a directoryですよね。。。なので、差分生成のアルゴリズムとしてbsdiff/bspatchは使えるが、
ファイルやディレクトリも含めた差分を出すには自力で頑張る必要がありそうです。diff/patchコマンドでディレクトリ構造を含めてパッチが作れるけど?
サブタイトルのような疑問をいだいた方はいると思います。
例えばdiffコマンドでは下記のようにディレクトリを含めてパッチを作ることができます。$ diff -crN -a --binary v1 v2 > patch_v1_to_v2 # 検証用にディレクトリをコピー $ cp -R v1 v1_test # パッチ適用 $ cd v1_test && patch < ../patch_v1_to_v2 && cd .. patching file data patching file data_additional # 確認 $ cat v1_test/data version 2.00 $ cat v1_test/data_additional additional dataではなぜこれを使わないのでしょうか?
理由はdiff/patchは改行を想定しているためです。
いままでのテストでは普通のテキストデータしか出てきませんでしたが、バイナリデータを作って検証してみます。$ mkdir v1 v2 # 1MBのバイナリデータを作成 $ head -c 1048576 /dev/urandom > v1/data # \rと\nを除く $ vim v1/data # :%s/\r/A/g # :%s/\n/B/g # :wq $ ll v1/data -rw-r--r-- 1 USER GROUP 1048578 2 9 17:31 v1/data # 2バイト増えているので2バイト削る $ head -c 1048576 v1/data > v1/data.2 $ mv v1/data.2 v1/data ll v1/data -rw-r--r-- 1 USER GROUP 1048576 2 9 17:32 v1/data # v2では1バイトだけいじってみる $ head -c 1000000 v1/data > v2/data $ echo -n "a" >> v2/data $ tail -c 48575 v1/data >> v2/dataこの状態でdiffとbsdiffで比較してみます。
$ diff -c -a --binary v1/data v2/data > diff_v1_v2 $ bsdiff v1/data v2/data bsdiff_v1_v2 # 比較結果 $ ll *diff_v1_v2 -rw-r--r-- 1 USER GROUP 153 2 9 17:34 bsdiff_v1_v2 -rw-r--r-- 1 USER GROUP 2097348 2 9 17:33 diff_v1_v21行ずつ比較をとるdiffではバイナリパッチには不向きであることがわかります。
bsdiff/bspatchをどうやって組み込むか?
ソースコードについて
bsdiff/bspatchは下記にソースコードが公開されております。
https://github.com/mendsley/bsdiffライセンスは「2条項BSDライセンス」となっており、下記を満たせばソースやバイナリの再配布が可能です。
変更の有無を問わず、ソースやバイナリ形式での再配布や利用は、次の条件を満たせば許可される。
・ソースコードの再配布は、上記の著作権表示、ここに列挙された条件、および下記の免責条項を保持すること。
・バイナリ形式の再配布は、上記の著作権表示、ここに列挙された条件、および下記の免責条項は、ドキュメントまたは他の資料で配布すること。GPL/LGPL等のようにソースコードの公開は必須ではないので安心して使えますね。
ソースコードを読み解く - bsdiff.c
アルゴリズムについて知っておきたい気もしますが…
やりたいのはただbsdiffの機能を拝借するだけなので、とりあえずmain関数を見てみます。int main(int argc,char *argv[]) { int fd; int bz2err; uint8_t *old,*new; off_t oldsize,newsize; uint8_t buf[8]; FILE * pf; struct bsdiff_stream stream; BZFILE* bz2; memset(&bz2, 0, sizeof(bz2)); stream.malloc = malloc; stream.free = free; stream.write = bz2_write;この辺は変数の宣言とメモリの初期化。
if(argc!=4) errx(1,"usage: %s oldfile newfile patchfile\n",argv[0]); /* Allocate oldsize+1 bytes instead of oldsize bytes to ensure that we never try to malloc(0) and get a NULL pointer */ if(((fd=open(argv[1],O_RDONLY,0))<0) || ((oldsize=lseek(fd,0,SEEK_END))==-1) || ((old=malloc(oldsize+1))==NULL) || (lseek(fd,0,SEEK_SET)!=0) || (read(fd,old,oldsize)!=oldsize) || (close(fd)==-1)) err(1,"%s",argv[1]); /* Allocate newsize+1 bytes instead of newsize bytes to ensure that we never try to malloc(0) and get a NULL pointer */ if(((fd=open(argv[2],O_RDONLY,0))<0) || ((newsize=lseek(fd,0,SEEK_END))==-1) || ((new=malloc(newsize+1))==NULL) || (lseek(fd,0,SEEK_SET)!=0) || (read(fd,new,newsize)!=newsize) || (close(fd)==-1)) err(1,"%s",argv[2]);この辺は与えられた引数(ファイル)に関するバリデーションです。
メモリが足りない場合もエラーになります。/* Create the patch file */ if ((pf = fopen(argv[3], "w")) == NULL) err(1, "%s", argv[3]);ここで書き込むパッチファイルをオープンしています。
/* Write header (signature+newsize)*/ offtout(newsize, buf); if (fwrite("ENDSLEY/BSDIFF43", 16, 1, pf) != 1 || fwrite(buf, sizeof(buf), 1, pf) != 1) err(1, "Failed to write header");ヘッダです。bspatchを叩くときに使うのでしょう。
シグネチャとパッチ適用後のファイルサイズ(64bit)が入ります。if (NULL == (bz2 = BZ2_bzWriteOpen(&bz2err, pf, 9, 0, 0))) errx(1, "BZ2_bzWriteOpen, bz2err=%d", bz2err);bsdiffは内部的にbzip2を使っているようです。
bzip2についてはこちらを参考にさせていただきました。
libbzip2 の使い方 - 矢田 晋
なお、bzip2はBSDライクなライセンスなので組み込んでもソースコードの開示は不要です。stream.opaque = bz2; if (bsdiff(old, oldsize, new, newsize, &stream)) err(1, "bsdiff");ここで実際にbsdiffを使った差分を抽出して、データに書き出しています。
BZ2_bzWriteClose(&bz2err, bz2, 0, NULL, NULL); if (bz2err != BZ_OK) err(1, "BZ2_bzWriteClose, bz2err=%d", bz2err);bzip2の説明をみると、このクローズのタイミングで圧縮データをファイルに保存していそうです。
if (fclose(pf)) err(1, "fclose"); /* Free the memory we used */ free(old); free(new); return 0; }ファイルにフラッシュして終了。
bsdiff.cは単一の実行プログラムなので、これでは利便性が低いですが、
main関数と同様に、比較対象2つとパッチデータの出力先を引数とする関数を.a/.libや.so/.dllに公開すれば、アプリケーション側で好きに利用ができそうですね。
Windowsへのビルドにはmingw-w64等を使うか、Visual Studioに対応させるかは後ほど考えます。ソースコードを読み解く - bspatch.c
同様にしてこちらもみてみます。
int main(int argc,char * argv[]) { FILE * f; int fd; int bz2err; uint8_t header[24]; uint8_t *old, *new; int64_t oldsize, newsize; BZFILE* bz2; struct bspatch_stream stream; struct stat sb;この辺は変数の宣言とメモリの初期化。
if(argc!=4) errx(1,"usage: %s oldfile newfile patchfile\n",argv[0]); /* Open patch file */ if ((f = fopen(argv[3], "r")) == NULL) err(1, "fopen(%s)", argv[3]);ここで与えられた引数に対するバリデーション。
/* Read header */ if (fread(header, 1, 24, f) != 24) { if (feof(f)) errx(1, "Corrupt patch\n"); err(1, "fread(%s)", argv[3]); } /* Check for appropriate magic */ if (memcmp(header, "ENDSLEY/BSDIFF43", 16) != 0) errx(1, "Corrupt patch\n"); /* Read lengths from header */ newsize=offtin(header+16); if(newsize<0) errx(1,"Corrupt patch\n");ヘッダの整合性をチェック。合わせて、出力後のファイルサイズも取得。
/* Close patch file and re-open it via libbzip2 at the right places */ if(((fd=open(argv[1],O_RDONLY,0))<0) || ((oldsize=lseek(fd,0,SEEK_END))==-1) || ((old=malloc(oldsize+1))==NULL) || (lseek(fd,0,SEEK_SET)!=0) || (read(fd,old,oldsize)!=oldsize) || (fstat(fd, &sb)) || (close(fd)==-1)) err(1,"%s",argv[1]);適用前のファイルサイズを取得し、適用前のファイルのデータを読み込む
if((new=malloc(newsize+1))==NULL) err(1,NULL);適用後のバッファを用意。
if (NULL == (bz2 = BZ2_bzReadOpen(&bz2err, f, 0, 0, NULL, 0))) errx(1, "BZ2_bzReadOpen, bz2err=%d", bz2err);bzip2で圧縮したので、bzip2を解凍するための準備です。
第2引数のfはパッチファイル(ヘッダ部分を読み飛ばしたところにカーソルがある)です。stream.read = bz2_read; stream.opaque = bz2; if (bspatch(old, oldsize, new, newsize, &stream)) errx(1, "bspatch");ここが実際にbsdiffを使って抽出した差分を適用する処理です。
/* Clean up the bzip2 reads */ BZ2_bzReadClose(&bz2err, bz2); fclose(f);読み込んでいたファイルを解放。
/* Write the new file */ if(((fd=open(argv[2],O_CREAT|O_TRUNC|O_WRONLY,sb.st_mode))<0) || (write(fd,new,newsize)!=newsize) || (close(fd)==-1)) err(1,"%s",argv[2]); free(new); free(old); return 0;ファイルに書き込んで終了。
自己解凍形式にするなら、第1引数のファイル名と第3引数のデータを
自分のプログラム中にデータを埋め込むように作り直せばいけそうですね。
データの埋め込みはパッチを作る際にソースコードをビルドするでも良いし、
Windowsならリソースという機能を使って埋め込むことができます。
方針は後ほど考えます。今後の方針
- bsdiff/bspatchはそのままの形では使えないのでアルゴリズムを流用する
- bsdiffはライブラリ化して、パッチ作成ツールから呼び出せるようにする
- bspatchで引数で与えていたbsdiffで作ったパッチ情報を実行可能ファイルに内包するようにして、自己解凍パッチを作る
- 投稿日:2020-02-09T17:25:18+09:00
user毎にiptablesでsshを制限
お客さんからあるサーバを一般ユーザとして使ってもらうが、sshの踏み台みたいには使われないで欲しいという要件があったのでiptablesで対応した。
環境
- OS : ubuntu18.04.3
iptablesでユーザ毎にsshを制限
iptables -A OUTPUT -p tcp --dport 22 -m owner --uid-owner {USERNAME} -j DROPなお相手サーバのLISTENポートが22番以外だった場合、無意味なので環境によって適時変えて欲しい。
設定の永続化
apt install iptables-persistent /etc/init.d/iptables-persistent save
- 投稿日:2020-02-09T15:35:39+09:00
(初心者)SSHやLinuxコマンド ssh-keygen がよくわからないのでまとめた
入社1week目の個人的メモ。
ssh接続について
ssh-keygenコマンドは「OpenSSH」で使う公開鍵と秘密鍵や、CA鍵(Certificate Authority、認証局による鍵)を使った「証明書」と呼ばれるファイルを作成できます。
OpenSSH とは
ネットワーク経由通信を暗号化する「SSH」のオープンソース実装です。
おもにUNIX/Linuxサーバに対するネットワーク経由でのリモートログインに使用します。SSH とは
「SSH(Secure Shell)」は、暗号や認証の技術を利用してセキュアにリモートコンピュータと通信するためのプロトコルです。
パスワードなどの認証情報を含む通信を暗号化します。プロトコル とは
定められた、データ通信を行うための規約。情報フォーマット、交信手順。引用:https://www.ossnews.jp/oss_info/OpenSSH
なぜssh接続が必要なのか
引用:https://www.kagoya.jp/howto/rentalserver/ssh/
VPS(バーチャル・プライベート・サーバー.)などの各種サーバー機器は、ほとんどの場合、操作をする人から離れた場所にあります。
そのため、この操作をする人だけが安全にインターネット経由で接続できる手段が必要になります。なぜなら、万一悪意をもった人がサーバーにログインできてしまうと、サーバー内ではやりたい放題となり、さまざまなリスクの原因となるからです。
なおふだん使うSSHという用語には、以下のような複数の意味があるため、どれを指しているかを明確にする必要あり。
- SSHでサーバーにログインするための情報(ホスト名、パスワード、認証用ファイルなど)
- ソフトウェアとしてはサーバーとクライアントの両方ある
- WindowsなどのOSからは、専用のクライアントソフトを使って接続する
sshとsslの違い
SSH
目的:サーバーへの接続
主な対象者:サーバー管理者SSL
目的:Webサイトを安全に表示
主な対象者:Webサイトの閲覧者SSHの認証方法について
離れた場所にあるサーバーへ安全に接続するため、SSHは複雑にできている。
さらに、サーバーへのログインが適正かどうかチェックする認証方法は、複数用意されている。代表的なものは
パスワード認証方式と公開鍵認証方式。
- パスワード認証方式 この場合のパスワードは、サーバーのユーザーアカウントに設定しているもの。 手軽だが、パスワードが流出すると、悪意をもった第三者からサーバーにログインされてしまう可能性があり、危険でもある。
※ 実際にはパスワードのみを単純に確認しているわけではなく、複雑な動きをしている。
詳しくは引用元参照。
- 公開鍵認証方式 初期設定作業が大変だが、通信の安全性はとても高い方式。 方法はいくつかありますが、
「鍵」と呼ばれるファイルをしっかり保管さえすれば、「鍵」のないユーザーからのログインは原則できません。これにより、悪意をもった第三者からの不正なログインを防ぐことができます。公開鍵認証方式は、ざっくり言うと以下のような流れ。
- 「鍵」作成(「鍵」は、SSHサーバーかSSHクライアントかどちらかで作成します。)
- サーバーとクライアントで必要な「鍵」をそれぞれ保管 「鍵」は1つではなく、必ず
サーバー用(公開鍵)とクライアント用(秘密鍵)とをペアで作成します。- SSHクライアントを操作し、
SSHサーバーにログインしたい意思を伝える- 相互に「鍵」を照合し、合っているか確認
- 通信の暗号化などの手続き(暗号化や復号化、それらをするための情報のやりとり)
- 暗号化された通信が開始
ssh-keygen コマンドとオプション
Linuxコマンド
ssh-keygen秘密鍵と公開鍵をのセットを発行するLinuxコマンド。
ファイル場所とデフォルトのファイル名は以下の通り。秘密鍵:/root/.ssh/id_rsa
公開鍵:/root/.ssh/id_rsa.pub自分の場合は
~/.ssh/ディレクトリが存在しなかったので、mkdirで作成した。手順書で出てきた以下のコマンドについて
手順書のコマンド
ssh-keygen -f stash_rsa -t rsa -b 2048基本文法
ssh-keygen [オプション] [-f 鍵ファイル]
※[ ]は省略可能な引数各種オプションの意味
引用元:https://www.atmarkit.co.jp/ait/articles/1503/20/news007.html
-fオプション
ファイルを指定する。
今回はstash_rsaという名前にしたかったので、使っていると思われる。
(指定しないとid_rsaという名前で生成される。)
-tオプション
鍵の種類 rsa1, dsa, ecdsa, ed25319, rsa (-tで指定しない場合はバージョンにもよるけど大抵rsaがデフォルト)
-bオプション
鍵の長さを指定する(最低値は768bit、初期値は2048bit)
上記コマンドでも2048bitが指定されている。
(初期値が2048bitと引用元に書いてあるが、あえて指定している理由は不明)秘密鍵と公開鍵を生成した後の設定
疲れたので後日記載しよう。
- 投稿日:2020-02-09T14:54:42+09:00
【備忘録】Windows 10にUbuntu+Docker Desktopをインストールするまでの手順
手順
- Windows Subsystem for Linux(WSL)機能の有効化
- Ubuntuのインストール
- Windows 10 Insider Preview ビルドのインストール
- WSL 2に切り替え
- Dockerインストール
1. Windows Subsystem for Linux(WSL)機能の有効化
- 設定>Windowsの機能の有効化または無効化で「Windows Subsystem for Linux」を有効化
- Windowsを再起動
2. Ubuntuのインストール
- Microsoft StoreでUbuntuを検索、インストール
- Ubuntuを起動、ユーザー名とパスワードの設定
sudo apt update・・・インストール可能なパッケージ一覧をアップデートsudo apt upgrade・・・インストール済みパッケージを更新sudo apt install task-japanese・・・日本語関連パッケージのインストールsudo dpkg-reconfigure locales・・・ロケールを日本語に設定exit・・・Ubuntuを終了- Ubuntuを再起動
sudo dpkg-reconfigure tzdata・・・タイムゾーンをJSTに設定sudo apt install man・・・日本語ツールなどのインストール3. Windows 10 Insider Preview ビルドのインストール
2020年2月10日現在、WSL 2(Windows Subsystem for Linux Version2)はPreview ビルドでのみ利用可能となっている。
そのため、以下の手順でWindows 10 Insider Preview ビルドをインストールする。
- 設定>Windows Insider Programの設定で、Windows Insiderとして登録
- Microsoftアカウントのリンク
- Windows Update
4. WSL 2に切り替え
- 管理者権限でWindows PowerShellを開く
Enable-WindowsOptionalFeature -Online -FeatureName VirtualMachinePlatform・・・仮想マシンプラットフォームの有効化- Windowsの再起動
- Windows PowerShellを開く(管理者権限でなくて良い)
wsl -l -v・・・Linuxディストリビューションのバージョン確認wsl --set-version Ubuntu 2・・・WSL 2に切り替えwsl --set-default-version 2・・・WSL 2をデフォルト化(オプション)5. Dockerインストール
この記事が詳しかった。
Windows10 HomeとWSL2でdocker-composeができるようにする参考文献
- 投稿日:2020-02-09T14:54:42+09:00
【備忘録】Windows 10にUbuntuをインストールするまでの手順
1. Windows Subsystem for Linux(WSL)機能の有効化
- 設定>Windowsの機能の有効化または無効化で「Windows Subsystem for Linux」を有効化
- Windowsを再起動
2. Ubuntuのインストール
- Microsoft StoreでUbuntuを検索、インストール
- Ubuntuを起動、ユーザー名とパスワードの設定
sudo apt update・・・インストール可能なパッケージ一覧をアップデートsudo apt upgrade・・・インストール済みパッケージを更新sudo apt install task-japanese・・・日本語関連パッケージのインストールsudo dpkg-reconfigure locales・・・ロケールを日本語に設定exit・・・Ubuntuを終了- Ubuntuを再起動
sudo dpkg-reconfigure tzdata・・・タイムゾーンをJSTに設定sudo apt install man・・・日本語ツールなどのインストール参考文献
- 投稿日:2020-02-09T14:54:42+09:00
【備忘録】Windows 10にUbuntuを入れる
「Linuxの勉強をしたいなー」と思い、Virtual Boxをインストールしたらめちゃくちゃ重くて触る気がおきず。
「他に良い方法はないものか」と探していたら、ノコテック・ラボさんの以下の記事を発見。Windows10にはLinuxの実行環境をインストールできる
非常に分かり易い記事であった。
以下、同記事を参照にインストールした際のメモ。
詳しくは記事参照。≪2020年2月10日追記≫
日本語化の部分はこちらの記事の方が詳しい。
WSLのDebian環境を日本語化する【メモ】
- 設定>「Windowsの機能の有効化または無効化」で「Windows Subsystem for Linux」を有効化
- 再起動
- Microsoft Storeで「Linux」と検索
- Ubuntuをインストール
- Ubuntu起動後、初期設定(ユーザー名とパスワード)
- インストール可能なパッケージ一覧をアップデート(sudo apt update)
- インストール済みパッケージを更新(sudo apt upgrade)
- 日本語関連パッケージのインストール(sudo apt install task-japanese)
- ロケールを日本語に設定(sudo dpkg-reconfigure locales)
- exitコマンドで終了後、再起動
- タイムゾーンをJSTに設定(sudo dpkg-reconfigure tzdata)
- 日本語ツールなどのインストール(sudo apt install man)
- 投稿日:2020-02-09T13:11:53+09:00
Linuxのスワップしやすさを調整する
はじめに
たまにサーバ速度がなんとなく遅いので、topやps等を使って状態を調べてたところ、どうやらswapを使っていたみたいでした。
Swap: 1.0G 278M 742Mこれはメモリを増やした方がいいかなーとぱっと考えていましたが、freeコマンドの全体はこんな感じでした。
onodes@Balthazar:~$ free -h total used free shared buff/cache available Mem: 985M 309M 311M 33M 364M 495M Swap: 1.0G 278M 742Mavailableを見ればわかるとおり、物理メモリの利用可能量も十分ある中で、278MBのswap inが発生していました。
スワップとは
改めてここでいうスワップ(swap)とは、物理メモリが不足した場合に、メモリ内のデータをディスク(HDD/SSD等)に移動させる機能のことです。
つまり、考え方としては物理メモリが不足していなければ、swapは発生しないことになります。swappiness
物理メモリが空いているのにswapが利用される背景として、swappinessの設定があります。
swappinessはLinuxカーネルのパラメータで、スワップ処理を行う頻度変更、調整に用いるパラメータです。
Linuxカーネル2.6以上(大体世の中そうだと思いますが...)のLinuxで実装、採用されています。onodes@Balthazar:~$ cat /proc/sys/vm/swappiness 60未調整だとデフォルトで60が入っているはずです。この値は0から100までの調整が可能で値が大きいほどswapしやすくなります。
また、0にするとメモリが枯渇するまでswapを利用しないという設定になります。
値 頻度 swappiness = 0 メモリが一杯(枯渇)するまでswapをしない swappiness = 60 デフォルト swappiness = 100 積極的にswapする。全体のパフォーマンス影響が出るレベル ここだけ見ると、swappiness = 0にしたほうがメモリをガンガン使ってパフォーマンスが上がりそうですが、0にしたら今度はOOM Killerが発生しやすくなりプロセスダウンが起きるので、やりすぎは禁物。
今回は若干日和って、swappiness = 10にしてみます。
swappinessの変更と反映
OSはUbuntu18.04です。
$ sudo vim /etc/sysctl.conf下部に追記
vm.swappiness = 10そして反映
$ sudo sysctl -p vm.swappiness = 10確認とswapの開放
freeを打ちます。
onodes@Balthazar:~$ free -h total used free shared buff/cache available Mem: 985M 384M 181M 56M 419M 396M Swap: 1.0G 276M 744Mswapの値は変わっていない...ここではswapは開放されません。
swap usedの容量よりも実メモリの空き容量のほうが大きい場合はswapをオフにして開放して、再びオンにします。
もし、実メモリが少ない場合は色々プロセスを停止させて実メモリに空きを作りましょう。
そこまでメモリが有効活用されていれば、この記事の作業自体いらない気もします。結果
onodes@Balthazar:~$ free -h total used free shared buff/cache available Mem: 985M 578M 95M 34M 311M 224M Swap: 1.0G 0B 1.0Gスワップを開放した直後なので、0Bになっています。
ここから、経過観察をしてみます。
- 投稿日:2020-02-09T12:48:58+09:00
ARM の CPU 情報を得るためのデバイスドライバ
Main ID (MIDR) などの取得
x86 の CPUID 命令みたいなことを ARM で行いたいのですが、Raspbian のユーザー空間では CPU 情報を得る命令(MRC)が実行できなかったので、カーネル モジュールを作る。
MRC 命令を実行するデバイス ドライバ
ARM の MRC 命令のオペランドのうち、Rt を除いた
coproc, #opcode1, CRn, CRm, #opcode2
を、アドレス空間+-----+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ |...20|19|18|17|16|15|14|13|12|11|10| 9| 8| 7| 6| 5| 4| 3| 2| 1| 0| +-----+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ |0..01| coproc |opcode1 | CRn | CRm |opcode2 | | +-----+-----------+--------+-----------+-----------+--------+-----+に見立てた、キャラクタ デバイスのファイル /dev/arm_mrc で読めるようにします。
データは4バイトだから下位2ビットがデータ内のバイト位置になります。
アドレスは lseek 関数で指定します。先頭からの範囲は 0x100000 〜 0x1FFFFF です。
データは read 関数で取得します。
注意点
カーネル モジュール内で実行した MRC 命令の結果である
カーネル/ユーザーで共通となる情報とは限りません。カーネル モジュール内での未定義命令実行
領域によっては未定義命令の実行になって処理が中断します。Linux カーネル モジュール
ファイルは3つ。 "make insmod" で "/dev/arm_mrc" が現れます。
環境は Raspbian buster, Kernel Version 4.19 で行っています。
Raspbian 用ソースコード
arm_mrc.c#include <uapi/linux/fs.h> #include <linux/kernel.h> #include <linux/module.h> #include <linux/uaccess.h> #include <linux/slab.h> #include <linux/vmalloc.h> #include <linux/init.h> #include <linux/cdev.h> #include <linux/fs.h> #include <asm/cacheflush.h> MODULE_LICENSE("Dual BSD/GPL"); MODULE_AUTHOR("ikiuo"); MODULE_DESCRIPTION("Invoke MRC instruction"); MODULE_VERSION("0.1.0"); #if defined(DEBUG) #define debug(x) printk x #else #define debug(x) #endif typedef struct class class_type; typedef struct device device_type; typedef struct cdev chrdev_type; typedef struct inode inode_type; typedef struct file file_type; typedef struct file_operations file_handler; typedef unsigned int (*mrc_func)(void); static void *mrc_proc = NULL; #define INS_MRC 0xee100010 #define INS_MOV_PC_LR 0xe1a0f00e /* MOV PC,LR */ #define INS_BX_LR 0xe12fff1e /* BX LR */ /* addr = [1:mode][4:cop][3:op1][4:CRn][4:CRm][3:op2][2:00] */ static const loff_t offset_max = (1 << (1+4+3+4+4+3+2)); static loff_t device_llseek (file_type *file, loff_t offset, int mode) { debug((KERN_INFO "lseek(%p, %Ld, %d): call\n", file, offset, mode)); switch (mode) { default: return -EINVAL; case SEEK_SET: offset += file->f_pos; break; case SEEK_CUR: break; case SEEK_END: offset += offset_max; break; } if (offset < 0) return -EINVAL; if (offset > offset_max) return -EINVAL; file->f_pos = offset; debug((KERN_INFO "lseek(%p, %Ld, %d): end\n", file, offset, mode)); return offset; } static ssize_t device_read (file_type *file, char *buffer, size_t size, loff_t *offset) { loff_t addr, rem, pos = *offset; ssize_t total = 0; size_t res_size; loff_t res_pos; unsigned int *ins = (unsigned int *) mrc_proc; unsigned int cop, CRn, op1, CRm, op2; loff_t mode; unsigned int status; if (pos < 0) return -EIO; if (pos >= offset_max) return -EIO; rem = offset_max - pos; if (size > rem) size = rem; while (size > 0) { addr = pos >> 2; op2 = (addr >> 0) & 7; CRm = (addr >> 3) & 15; CRn = (addr >> 7) & 15; op1 = (addr >> 11) & 7; cop = (addr >> 14) & 15; mode = (addr >> 18); debug((KERN_INFO "read(%p, %p, %d, %Ld)\n", file, buffer, size, *offset)); status = 0; if (mode != 1) return -EIO; ins[0] = INS_MRC | (op1 << 21) | (CRn << 16) | (cop << 8) | (op2 << 5) | CRm; ins[1] = INS_MOV_PC_LR; flush_kernel_vmap_range (ins, 16); flush_icache_range ((unsigned long)ins,16); status = ((mrc_func)ins) (); res_pos = pos & 3; res_size = 4 - res_pos; if (res_size > size) res_size = size; __copy_to_user (buffer, ((char*)&status) + res_pos, res_size); buffer += res_size; size -= res_size; pos += res_size; total += res_size; } *offset = pos; return total; } static int device_open (inode_type *inode, file_type *file) { return (try_module_get (THIS_MODULE) ? 0 : -EBUSY); } static int device_release (inode_type *inode, file_type *file) { module_put (THIS_MODULE); return 0; } static file_handler handler = { .llseek = device_llseek, .read = device_read, .open = device_open, .release = device_release, }; static chrdev_type cdev_mrc; #define DEVICE_NAME "arm_mrc" static const int arm_ins_buffer_type = 1; static const char *device_name = DEVICE_NAME; static int major_number = 0; static int minor_base = 0; static int minor_count = 1; static class_type *device_class = NULL; static device_type *sys_device = NULL; static void * arm_alloc_ins_buffer (void) { if (arm_ins_buffer_type) return __vmalloc (256, GFP_KERNEL, PAGE_KERNEL_EXEC); else return kmalloc (256, GFP_KERNEL); } static void arm_free_ins_buffer (void *p) { if (p == NULL) return; if (arm_ins_buffer_type) vfree (p); else kfree (p); } static void arm_mrc_exit_chrdev (void) { dev_t dev = MKDEV (major_number, minor_base); unregister_chrdev_region (dev, minor_count); arm_free_ins_buffer (mrc_proc); } static void arm_mrc_exit_cdev_chrdev (void) { cdev_del (&cdev_mrc); arm_mrc_exit_chrdev (); } static void arm_mrc_exit_all (void) { device_destroy (device_class, MKDEV (major_number, minor_base)); class_destroy (device_class); arm_mrc_exit_cdev_chrdev (); } static int __init arm_mrc_init (void) { dev_t dev; int stat; mrc_proc = arm_alloc_ins_buffer (); if (mrc_proc == NULL) return -ENOMEM; stat = alloc_chrdev_region (&dev, minor_base, minor_count, device_name); if (stat < 0) { printk (KERN_ERR DEVICE_NAME ": alloc_chrdev_region failed: %d\n", stat); return stat; } major_number = MAJOR (dev); cdev_init (&cdev_mrc, &handler); cdev_mrc.owner = THIS_MODULE; stat = cdev_add (&cdev_mrc, dev, minor_count); if (stat < 0) { printk (KERN_ERR DEVICE_NAME ": cdev_add failed: %d\n", stat); arm_mrc_exit_chrdev (); return stat; } device_class = class_create (THIS_MODULE, device_name); if (IS_ERR(device_class)) { printk (KERN_ERR DEVICE_NAME ": class_create failed\n"); arm_mrc_exit_cdev_chrdev (); return -1; } sys_device = device_create(device_class, NULL, dev, NULL, DEVICE_NAME); if (IS_ERR(sys_device)) { arm_mrc_exit_all (); return -1; } return 0; } static void __exit arm_mrc_exit (void) { arm_mrc_exit_all (); } module_init (arm_mrc_init); module_exit (arm_mrc_exit);Makefile# Makefile #MOD_DIR = /lib/modules/4.9.0-6-rpi #MOD_DIR = /lib/modules/4.19.93+ #MOD_DIR = /lib/modules/4.19.93-v7+ MOD_DIR = /lib/modules/4.19.93-v7l+ DEVNAME = arm_mrc KMOD = $(DEVNAME).ko obj-m += $(DEVNAME).o all: build build: $(KMOD) $(KMOD): $(DEVNAME).c make -C $(MOD_DIR)/build M=$(PWD) modules clean: make -C $(MOD_DIR)/build M=$(PWD) clean insmod: build sudo cp 99-arm_mrc.rules /etc/udev/rules.d/ sudo insmod $(KMOD) rmmod: sudo rmmod $(KMOD)99-arm_mrc.rulesKERNEL=="arm_mrc", GROUP="root", MODE="0666"
テスト プログラム
test.c#include <stdio.h> #include <stdlib.h> #include <errno.h> #include <fcntl.h> #include <unistd.h> int main (int argc, char **argv) { int debug = 0; int coproc = 0; int opcode1 = 0; int CRn = 0; int CRm = 0; int opcode2 = 0; int fd; off_t addr, spos; ssize_t rdsz; unsigned int value; int exitcode = 0; if (argc < 2) { printf ("Usage: %s coproc [opcode1 [CRn [CRm [opcode2]]]]\n", argv[0]); return 1; } if (argc > 1) coproc = strtol (argv[1], NULL, 10); if (argc > 2) opcode1 = strtol (argv[2], NULL, 10); if (argc > 3) CRn = strtol (argv[3], NULL, 10); if (argc > 4) CRm = strtol (argv[4], NULL, 10); if (argc > 5) opcode2 = strtol (argv[5], NULL, 10); if ((coproc > 15) || (opcode1 > 7) || (CRn > 15) || (CRm > 15) || (opcode2 > 7)) { printf ("invalid argument.\n"); printf ("coproc=%d, opcode1=%d, CRn=%d, CRm=%d, opcode2=%d\n", coproc, opcode1, CRn, CRm, opcode2); return 1; } addr = ((1 << 20) | (coproc << 16) | (opcode1 << 13) | (CRn << 9) | (CRm << 5) | (opcode2 << 2)); fd = open ("/dev/arm_mrc", O_RDONLY); if (fd < 0) { printf ("Can't open '/dev/arm_mrc': error=%d (%d)\n", fd, errno); return 2; } spos = lseek (fd, addr, SEEK_SET); if (addr != spos) { printf ("seek error: error=%d (%d)\n", spos, errno); exitcode = 2; } else { rdsz = read (fd, &value, sizeof (value)); if (rdsz != sizeof (value)) { printf ("read error: error=%d (%d)\n", spos, errno); exitcode = 2; } else { printf ("MRC p%d,#%d,Rt,c%d,c%d,#%d; Rt=%#010x\n", coproc, opcode1, CRn, CRm, opcode2, value); } } close (fd); return 0; }RaspberryPi 4 でのテスト プログラムの実行結果
MIDR_EL1$ ./test 15 0 0 0 0 MRC p15,0,Rt,c0,c0,0; Rt=0x410fd083ID_PFR0_EL1./test 15 0 0 1 0 MRC p15,0,Rt,c0,c1,0; Rt=0x00000131ID_PFR1_EL1$ ./test 15 0 0 1 1 MRC p15,0,Rt,c0,c1,1; Rt=0x00011011
- 投稿日:2020-02-09T11:35:09+09:00
Linux環境に固定IPを設定する
目的
Hyper-Vに作ったCentOS8の仮想マシンに固定IPを設定する
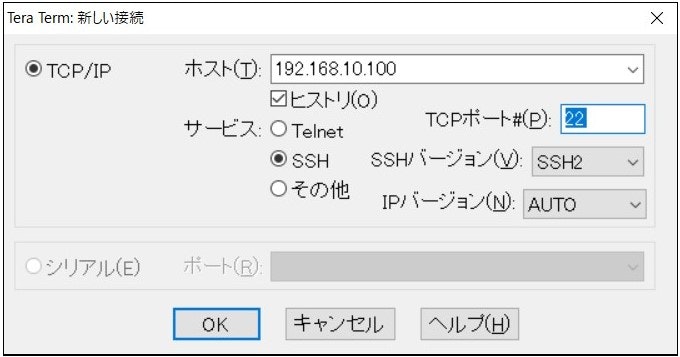
仮想マシンにTera Termで接続する環境
CentOS 8.1.1911
手順
現在の状態確認
●コマンドで状態を確認
# ip a # ip a show dev eth0eth0: inet 192.168.10.4/24
これで現在のプライベートIPアドレスがわかります。
ネットワークアドレス "192.168.10"
ホストアドレス "4"
※最後の"24"はプレフィックス長といい、先頭24ビットがネットワークアドレスであることを表す。設定ファイル編集
●インタフェース設定ファイルを以下のように編集します。
※書いてないパラメータはそのまま。/etc/sysconfig/network-scripts/ifcfg-eth0IPV6INIT="no" #IPV6_AUTOCONF="yes" #IPV6_DEFROUTE="yes" #IPV6_FAILURE_FATAL="no" #IPV6_ADDR_GEN_MODE="stable-privacy" BOOTPROTO="none" IPADDR=192.168.10.100 PREFIX=24 GATEWAY=192.168.10.1 DNS1=192.168.10.1 DNS2=8.8.8.8IPV6は使わないのでIPV6INITを"yes"から"no"に変更しました。
ほかのIPV6絡みのパラメータは除きました。・BOOTPROTO:
IPアドレスの指定方法 [none/dhcp/bootp]
固定IPを指定する場合は"none"、もしくは"static"でもいいみたいです。・IPADDR:
指定するIPアドレス
さっきのネットワークアドレスに適当なホストアドレスつける。・PREFIX:
プレフィックス長
これはたぶんNETMASKってパラメータでもどっちでもいいのかな?たぶん。。。・GATEWAY:
ルーターのIP・DNS
"8.8.8.8"はGoogle Public DNS●設定してからネットワーク再起動
# systemctl restart NetworkManager状態確認すると...
eth0: inet 192.168.10.100/24ipv6無効化
さっきの手順で再起動したあとで確認しても、inet6が設定されていました。
別に問題ないのかもしれませんが、設定で使わないとしたつもりだったので無効化します。●以下のファイルを作成
/etc/sysctl.d/disable_ipv6.confnet.ipv6.conf.all.disable_ipv6 = 1 net.ipv6.conf.default.disable_ipv6 = 1●反映
# sysctl -p/etc/sysctl.d/disable_ipv6.conf状態確認するとinet6が消えていました。
確認
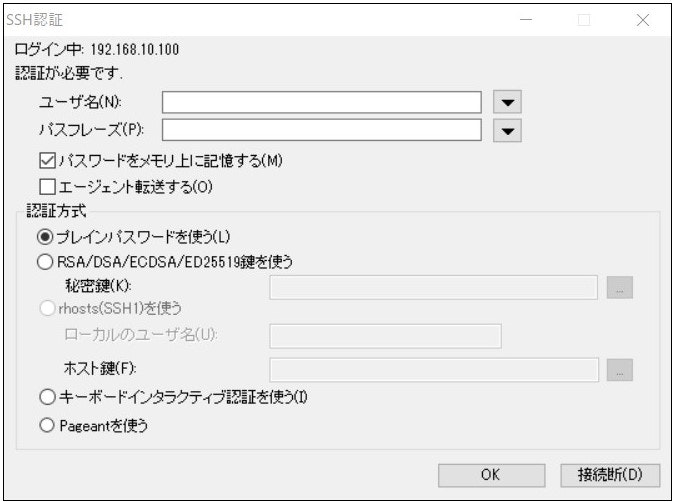
●設定したIPアドレスを入力
●ユーザとパスワード入力後、接続
接続できました。
ひとまずこれで、やりたいことが出来たこととします。
- 投稿日:2020-02-09T00:17:01+09:00
Linuxのswap度合いを調整する
はじめに
たまにサーバ速度がなんとなく遅いので、topやps等を使って状態を調べてたところ、どうやらswapを使っていたみたいでした。
Swap: 1.0G 278M 742Mこれはメモリを増やした方がいいかなーとぱっと考えていましたが、freeコマンドの全体はこんな感じでした。
onodes@Balthazar:~$ free -h total used free shared buff/cache available Mem: 985M 309M 311M 33M 364M 495M Swap: 1.0G 278M 742Mavailableを見ればわかるとおり、物理メモリの利用可能量も十分ある中で、278MBのswap inが発生していました。
スワップとは
改めてここでいうスワップ(swap)とは、物理メモリが不足した場合に、メモリ内のデータをディスク(HDD/SSD等)に移動させる機能のことです。
つまり、考え方としては物理メモリが不足していなければ、swapは発生しないことになります。swappiness
物理メモリが空いているのにswapが利用される背景として、swappinessの設定があります。
swappinessはLinuxカーネルのパラメータで、スワップ処理を行う頻度変更、調整に用いるパラメータです。
Linuxカーネル2.6以上(大体世の中そうだと思いますが...)のLinuxで実装、採用されています。onodes@Balthazar:~$ cat /proc/sys/vm/swappiness 60未調整だとデフォルトで60が入っているはずです。この値は0から100までの調整が可能で値が大きいほどswapしやすくなります。
また、0にするとメモリが枯渇するまでswapを利用しないという設定になります。
値 頻度 swappiness = 0 メモリが一杯(枯渇)するまでswapをしない swappiness = 60 デフォルト swappiness = 100 積極的にswapする。全体のパフォーマンス影響が出るレベル ここだけ見ると、swappiness = 0にしたほうがメモリをガンガン使ってパフォーマンスが上がりそうですが、0にしたら今度はOOM Killerが発生しやすくなりプロセスダウンが起きるので、やりすぎは禁物。
今回は若干日和って、swappiness = 10にしてみます。
swappinessの変更と反映
OSはUbuntu18.04です。
$ sudo vim /etc/sysctl.conf下部に追記
vm.swappiness = 10そして反映
$ sudo sysctl -p vm.swappiness = 10確認とswapの開放
freeを打ちます。
onodes@Balthazar:~$ free -h total used free shared buff/cache available Mem: 985M 384M 181M 56M 419M 396M Swap: 1.0G 276M 744Mswapの値は変わっていない...ここではswapは開放されません。
swap usedの容量よりも実メモリの空き容量のほうが大きい場合はswapをオフにして開放して、再びオンにします。
もし、実メモリが少ない場合は色々プロセスを停止させて実メモリに空きを作りましょう。
そこまでメモリが有効活用されていれば、この記事の作業自体いらない気もします。結果
onodes@Balthazar:~$ free -h total used free shared buff/cache available Mem: 985M 578M 95M 34M 311M 224M Swap: 1.0G 0B 1.0Gスワップを開放した直後なので、0Bになっています。
ここから、経過観察をしてみます。
- 投稿日:2020-02-09T00:02:44+09:00
pthread_mutex_init()の戻り値について
はじめに
ライブラリ関数pthread_mutex_init()の戻り値について調べてみました。
背景
仕事でBP(ビジネスパートナー)さんが書いたコードを見ていた。
するとpthead_mutex_init()の戻り値チェックをhoge.cif (r == -1) { //エラー処理 }と書いていた。
私「・・・・ -1 だと !?」
調べた結果
ページによって様々だが、だいたい以下の三つだった。
・pthread_mutex_init()は常に0を返す。
or
・pthread_mutex_init()は正常時0を、異常時-1を返す。
or
・pthread_mutex_init()は正常時0を、異常時非ゼロを返す。環境依存なのかな。
最後に
とりあえず、戻り値のチェックに関しては
hoge.cif (r != 0) { //エラー処理 }という風に非ゼロにかけるべきかなと。