- 投稿日:2019-12-30T23:45:38+09:00
TensorflowのFreezeGraph済み.pbファイルのINPUTのPlaceholderを置き換えつつモデルを再生成するTips [置換・置き換え・変換・変更・更新・差し替え]
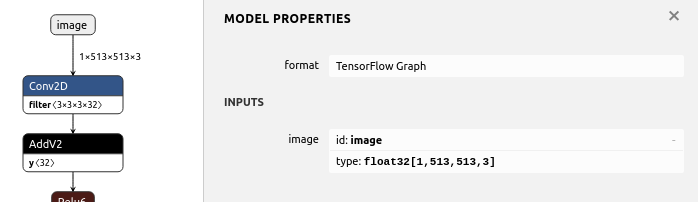
[1, ?, ?, 3]の入力サイズで定義されている .pbファイル のPlaceholderを[1, 513, 513, 3]のPlaceholderに強制的に置き換えて、.pbを再生成するサンプルプログラム。
name='image'の部分は置き換え後のPlaceholderの名前を自由に指定する。
input_map={'image:0': inputs}のimage:0の部分は、変換前のモデルのPlaceholder名を指定する。replacement_of_input_placeholder.pyimport tensorflow as tf from tensorflow.tools.graph_transforms import TransformGraph with tf.compat.v1.Session() as sess: # shape=[1, ?, ?, 3] -> shape=[1, 513, 513, 3] # name='image' specifies the placeholder name of the converted model inputs = tf.compat.v1.placeholder(tf.float32, shape=[1, 513, 513, 3], name='image') with tf.io.gfile.GFile('./model-mobilenet_v1_101.pb', 'rb') as f: graph_def = tf.compat.v1.GraphDef() graph_def.ParseFromString(f.read()) # 'image:0' specifies the placeholder name of the model before conversion tf.graph_util.import_graph_def(graph_def, input_map={'image:0': inputs}, name='') print([n for n in tf.compat.v1.get_default_graph().as_graph_def().node if n.name == 'image']) # Delete Placeholder "image" before conversion # see: https://github.com/tensorflow/tensorflow/tree/master/tensorflow/tools/graph_transforms # TransformGraph( # graph_def(), # input_op_name, # output_op_names, # conversion options # ) optimized_graph_def = TransformGraph( tf.compat.v1.get_default_graph().as_graph_def(), 'image', ['heatmap','offset_2','displacement_fwd_2','displacement_bwd_2'], ['strip_unused_nodes(type=float, shape="1,513,513,3")']) tf.io.write_graph(optimized_graph_def, './', 'model-mobilenet_v1_101_513.pb', as_text=False)Result[name: "image" op: "Placeholder" attr { key: "dtype" value { type: DT_FLOAT } } attr { key: "shape" value { shape { dim { size: 1 } dim { size: 513 } dim { size: 513 } dim { size: 3 } } } } ]
- 変換前

- 変換後
Graph Transform Tool
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/tools/graph_transforms
- 投稿日:2019-12-30T20:34:27+09:00
TensorFlow2 + Keras による画像分類に挑戦3 ~MNISTデータを可視化してみる~
はじめに
TensorFlow2 + Keras を利用した画像分類(Google Colaboratory 環境)についての勉強メモ(第3弾)です。題材は、ド定番である手書き数字画像(MNIST)の分類です。
- TensorFlow2 + Keras による画像分類に挑戦 シリーズ
前回は、MNISTデータを取得し、そのデータの構造や内容について確認しました。手書きの数字の画像データに相当する入力データは、28x28pixelの256段階グレースケールでした。このデータの型は
numpy.ndarrayの2次元配列で、そのまま
データの正規化
MNISTのデータは、0~255の整数値を使って、256段階グレースケール(白を0、黒を255に割り当てたグレースケール)を表現していました(詳しくは前回参照)。しかし、TensorFlow を使った画像分類のサンプルコード(公式HPのチュートリアル参照)では、機械学習させる都合上、次のように 0.0~1.0 の範囲になるように正規化を施しています。
import tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 # 正規化処理ここから先は、0.0~1.0 に正規化されたデータを対象に進めていきたいと思います。
とりあえず表示
トレーニング用の入力データの1個目
x_train[0]をグレースケール画像として出力してみたいと思います。このデータは、正解データy_train[0]に格納されているように「5」を表現した画像になります。import matplotlib.pyplot as plt plt.figure(dpi=96) plt.imshow(x_train[0],interpolation='nearest',vmin=0.,vmax=1.,cmap='Greys')
実行環境によっては、
interpolation='nearest'は省略できます(Google Colab.では省略してもOKです、他環境で実行してぼやけた出力になったら、このオプションを明示しましょう)。また、
vmin=0.,vmax=1.は、当該データx_train[?]の内部要素の最小値が 0.0、最大値が 1.0 の場合は省略してもOKです(cmap='Greys'により0.0に白、1.0に黒が割り当てられます)。そうでない場合、例えば、薄文字などを表現していてx_train[?]の内部要素の最大値が0.7のようなときは、このオプションを指定しないと、薄文字の感じが反映されません。キーワード引数
cmapの値を変えると、出力に使用するカラーマップを変えることができます。プリセットとして用意されているカラーマップ一覧は、matplotlibのリファレンスで確認することができます。例えば、cmap='Greens'とすると次のような出力になります(0.0のところも薄緑になります)。
カラーマップをカスタマイズすることも可能です。具体的な方法は「相関行列をキレイにカスタマイズしたヒートマップで出力したい。matplotlib編 @ Qiita」を参照ください。
特定の数字についての手書き画像を並べて出力
特定の数字(例えば「7」)について、どんなで手書きデータが存在するのか確認したいときには、次のようなコードで出力することができます。
import numpy as np import matplotlib.pyplot as plt x_subset = x_train[ y_train == 7 ] # (1) fig, ax = plt.subplots(nrows=8, ncols=8, figsize=(5, 5), dpi=120) for i, ax in enumerate( np.ravel(ax) ): ax.imshow(x_subset[i],interpolation='nearest',vmin=0.,vmax=1.,cmap='Greys') ax.tick_params(axis='both', which='both', left=False, labelleft=False, bottom=False, labelbottom=False) # (2)実行結果は次のようになります。7以外の数値について出力したい場合は、上記コードの (1) の
y_train == 7の数値を変更してください。(2) のax.tick_params(...)は、X軸・Y軸の目盛を消すためのものです。
一覧で眺めてみると、この64枚のなかであっても、どうみても「1」にしか見えないものが少なくとも2、3個は含まれているということが分かります(つまり、正答率 1.0000 は極めて難しい)。
整形して表示
非常に短いコードで入力データを画像化して出力できることが分かりました。
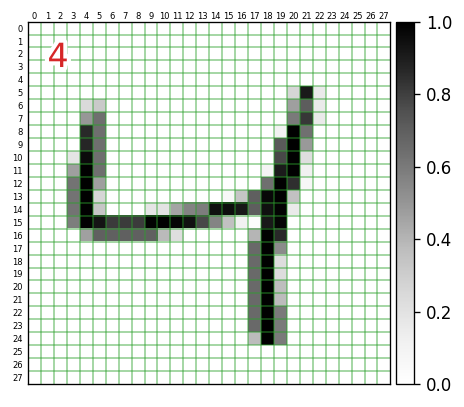
ここでは、次のように、各入力データの何行何列目の要素がどんな値になっているのか?までを確認できるように手を加えていきます。左上の赤文字は、対応する正解データの値です。
import numpy as np import matplotlib.pyplot as plt import matplotlib.patheffects as pe import matplotlib.transforms as ts i = 2 # 表示するデータのインデックス plt.figure(dpi=120) plt.imshow(x_train[i],interpolation='nearest',vmin=0.,vmax=1.,cmap='Greys') h, w = 28, 28 plt.xlim(-0.5,w-0.5) # X軸方向の描画範囲 plt.ylim(h-0.5,-0.5) # Y軸方向の・・・ # plt.tick_params(axis='both', which='major', left=False, labelleft=False, bottom=False, labelbottom=False) plt.tick_params(axis='both', which='minor', left=False, labelleft=True, top=False, labeltop=True, bottom=False, labelbottom=False) # 各軸のグリッド設定 plt.gca().set_xticks(np.arange(0.5, w-0.5,1)) # 1ドット単位でグリッド plt.gca().set_yticks(np.arange(0.5, h-0.5,1)) plt.grid( color='tab:green', linewidth=1, alpha=0.5) # 各軸のラベル設定 plt.gca().set_xticks(np.arange(0, w),minor=True) plt.gca().set_xticklabels(np.arange(0, w),minor=True, fontsize=5) plt.gca().set_yticks(np.arange(0, h),minor=True) plt.gca().set_yticklabels(np.arange(0, h),minor=True, fontsize=5) # ラベルの位置の微調整 offset = ts.ScaledTranslation(0, -0.07, plt.gcf().dpi_scale_trans) for label in plt.gca().xaxis.get_minorticklabels() : label.set_transform(label.get_transform() + offset) offset = ts.ScaledTranslation(0.03, 0, plt.gcf().dpi_scale_trans) for label in plt.gca().yaxis.get_minorticklabels() : label.set_transform(label.get_transform() + offset) # 正解データを左上に表示(白色で縁取り) t = plt.text(1, 1, f'{y_train[i]}', verticalalignment='top', fontsize=20, color='tab:red') t.set_path_effects([pe.Stroke(linewidth=5, foreground='white'), pe.Normal()]) plt.colorbar( pad=0.01 ) # 右側にカラーバー表示グレースケール値のヒストグラム
入力データは、$28\times 28 = 784$ 個の要素から構成され、各要素には 0.0 から 1.0 の値が含まれますが、それはどんな分布になっているかヒストグラムを作成してみたいと思います。
import numpy as np import matplotlib.pyplot as plt i = 0 # 表示するデータのインデックス h = plt.hist(np.ravel(x_train[i]), bins=10, color='black') plt.xticks(np.linspace(0,1,11)) print(h[0]) # 実行結果 -> [639. 11. 6. 11. 6. 9. 11. 12. 11. 68.] print(h[1]) # 実行結果 -> [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. ]
plt.hist(...)の戻値には、各階級の度数が含まれます。上記の例だと、範囲 $0.0\le v < 0.1 $ の値を持つピクセルが 639個存在することが分かります。なお、一番右端のみ、範囲は $0.9\le v \le 1.0 $ となり、値がちょうど 1.0 のデータも含んだものになります。実際に
print(h[0].sum())にすれば、784.0が得られ、値がちょうど 1.0 の要素もちゃんとカウントされていることが確認できます。次回
- 学習済みのモデルを使って実際に予測を行ないます。




- 投稿日:2019-12-30T18:45:29+09:00
ubuntu18.04 LTS + RTX2060 + CUDA + tensorflow で機械学習環境を構築する
はじめに
こんにちは, @tbashiyy です. 普段はwebアプリケーションエンジニアをしています.
今回は,研究用途で手元に機械学習環境が欲しくなり,自宅PCにRTX2060を導入しました.
(GTX1660tiと悩みましたが,最終的にはtensor coreが搭載されているRTX2060にしました.)
そこで,tensorflowとCUDAを使って,Ubuntu上に機械学習環境を構築する手順を備忘録としてまとめておきます.環境
- OS: Ubuntu 18.04.3 LTS
- Memory: 8GB
- CPU: Core i5-6500(3.2GHz x 4)
- GPU: GeForce RTX2060
- python: 3.7.5
- 仮想環境: pipnev
python仮想環境上にtensorflowをインストール
まず,tensorflowを使えるように,任意のディレクトリにpythonの仮想環境を作成していきます.
仮想環境は,pipenvを使います.任意のディレクトリ上で
$ pipenv --python 3.7$ pipenv shellで,仮想環境に入ります.そして,
$ pipenv install tensorflow-gpu仮想環境にGPUを利用するtensorflowのパッケージをインストールします.
$ pip freezeで下記のようにインストールが確認できれば成功です.tensorboard==2.0.2 tensorflow-estimator==2.0.1 tensorflow-gpu==2.0.0※後ほどjupyter notebookを利用します. もしインストールされていない場合は,
$ pipenv install jupyterで,jupyterも入ります.
GPU周りに必要なソフトウェア群のインストール
(参考) https://www.tensorflow.org/install/gpu
上記URLのtensorflow公式通り,必要なソフトウェアをインストールしていきます.1. 環境変数の設定
$ vi ~/.bashrcで.bashrcを開いて,下記を追加します../bashrcexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/extras/CUPTI/lib64追加して保存したら,
$ source ~/.bashrcします.
2. NVIDAのdriver,CUDA類のインストール
ここでは下記の5つをインストールしていきます.
- NVIDIA GPU drivers
- CUDA Toolkit
- CUPTI
- cuDNN SDK
- TensorRT 5.0下記を実行.
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-repo-ubuntu1804_10.0.130-1_amd64.deb $ sudo dpkg -i cuda-repo-ubuntu1804_10.0.130-1_amd64.deb $ sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub $ sudo apt-get update $ wget http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb $ sudo apt install ./nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb $ sudo apt-get update $ sudo apt-get install --no-install-recommends nvidia-driver-418ここまで終わった段階で,
$ sudo rebootして再起動する.再起動後,
$ nvidia-smiを実行して下記のような表示が出れば成功.
+-----------------------------------------------------------------------------+ | NVIDIA-SMI 440.33.01 Driver Version: 440.33.01 CUDA Version: 10.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce RTX 2060 On | 00000000:01:00.0 On | N/A | | 47% 30C P8 12W / 160W | 470MiB / 5933MiB | 3% Default | +-------------------------------+----------------------+----------------------+そして,下記コマンドを実行する.
$ sudo apt-get install --no-install-recommends \ cuda-10-0 \ libcudnn7=7.6.2.24-1+cuda10.0 \ libcudnn7-dev=7.6.2.24-1+cuda10.0 $ sudo apt-get install -y --no-install-recommends libnvinfer5=5.1.5-1+cuda10.0 \ libnvinfer-dev=5.1.5-1+cuda10.0ここまでで,インストールが完了です.(この段階で再度rebootすると良いかもしれません.)
tensorflowでGPUが使えているか確認する
(参考)https://thr3a.hatenablog.com/entry/20180113/1515820265
先程作った
pipenvの仮想環境に入り,$ jupyter notebookで,ブラウザが立ち上がり,下記のような画面が出てきます.
右上のNew -> Python3 で新規ファイルを作成します.作成したファイルで,
from tensorflow.python.client import device_lib device_lib.list_local_devices()を実行して,下記のような結果の中に,
device_type: "GPU"があればtensorflow上からGPUが認識できています.[name: "/device:CPU:0" device_type: "CPU" memory_limit: 268435456 locality { } incarnation: 7162619330375723357, name: "/device:XLA_CPU:0" device_type: "XLA_CPU" memory_limit: 17179869184 locality { } incarnation: 9655519139365664409 physical_device_desc: "device: XLA_CPU device", name: "/device:XLA_GPU:0" device_type: "XLA_GPU" memory_limit: 17179869184 locality { } incarnation: 16357788976776791373 physical_device_desc: "device: XLA_GPU device", name: "/device:GPU:0" device_type: "GPU" memory_limit: 5294129152 locality { bus_id: 1 links { } } incarnation: 3083761924213793354 physical_device_desc: "device: 0, name: GeForce RTX 2060, pci bus id: 0000:01:00.0, compute capability: 7.5"]実際にGPUを使っているかモニタリングしてみる
tensorflowにあるチュートリアルを実行してみます.
その際に,$ nvidia-smi -lをしておくと,リアルタイムでGPU使用率をモニタリングできます.
結果
ProcessesのPID6933で5233MiBのビデオメモリを利用していることが確認できますね.
+-----------------------------------------------------------------------------+ | NVIDIA-SMI 440.33.01 Driver Version: 440.33.01 CUDA Version: 10.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce RTX 2060 On | 00000000:01:00.0 On | N/A | | 47% 34C P2 33W / 160W | 5818MiB / 5933MiB | 21% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | 0 6660 C ...rew/.linuxbrew/opt/python/bin/python3.7 83MiB | | 0 6933 C ...rew/.linuxbrew/opt/python/bin/python3.7 5233MiB | +-----------------------------------------------------------------------------+最後に
- 実はかなり試行錯誤して,何度もやり直しをしました.最終的には公式ドキュメントにたどり着きました. 公式ドキュメントをはじめからちゃんと読みましょう.(自戒)
- 公式にはCUDA10.0が推奨,調べていると10.2で動作しないなどの報告をちらほら見つけましたが,公式のとおりにインストールするとなぜかCUDA10.2になってしまいました. 動いているっぽいのでいいのか...?(詳しい方教えていただけると嬉しいです.)
参考
- 投稿日:2019-12-30T16:22:51+09:00
TensorFlow2 + Keras による画像分類に挑戦2 ~入力データを詳しくみてみる~
はじめに
手書き数字画像(MNIST)の分類を、Google Colaboratory 環境の TensorFlow2 + Keras でやってみよう(+Pythonや深層学習の理解も深めよう)という内容です。前回 は、TensorFlow の 公式HPのチュートリアル からサンプルコードを持ってきて、実際に実行してみる、というところまでやりました。
- TensorFlow2 + Keras による画像分類に挑戦 シリーズ
なお、MNIST(エムニスト)は、「図解速習DEEP LEARNING(著:増田知彰)」によれば、次のような由来があるデータだそうです。ここでは直接関係ありませんが、生のデータは、http://yann.lecun.com/exdb/mnist/ から入手できます。
NIST(National Institute of Standards and Technology database)の1つに、米国の国勢調査局職員と高校生が手書きした数字を持つデータセットがありました。それを機械学習でより使いやすく改変(Modified)したものが、"M"NISTです。
今回は、前回に示したサンプルコードのなかの トレーニング用データ(
x_train、y_train)、テスト用データ(x_test、y_test)について、その内容を詳しく見てみたり、matplotlib を使って可視化してみたりします。それにあたり、まずは「多クラス分類問題」と「深層学習」について整理しておきます(トレーニング用データとテスト用データの位置づけを確認します)。
多クラス分類問題
手書き数字の認識は、多クラス分類問題というものに属します。多クラス分類問題とは、入力データに対して、そのカテゴリ(クラス)を予測するという問題です。カテゴリは、問題設定のなかで「犬」「猫」「鳥」のようにあらかじめ与えられており、入力データ(例えば画像)に対してそれが「犬」「猫」「鳥」のうち、どのカテゴリになるかを求める、といった問題になります。
多クラス分類問題に対して様々なアプローチが提案されていますが、ここでは深層学習(ディープラーニング)を使って解決していきます。
深層学習
深層学習(ディープラーニング)は、教師付き機械学習という手法に属します。教師付き機械学習は、大きく「学習フェーズ」と「予測フェーズ(推論フェーズ、適用フェーズ)」という2段階から構成されます。
はじめに、学習フェーズでは、入力データと正解データ(=教師データ、正解データ、正解値、正解ラベル)をペアにしたものをモデルに大量に与えて、それらの関係を学習させます。これらの入力データと正解データのペア集合をトレーニング用データ(=学習用データ)と呼びます。そして、トレーニング用データを使って学習させたモデルを「学習済みモデル」といいます。
つづく予測フェーズでは、学習済みモデルに対して、未知の入力データを与えて出力の予測(Predict)を行ないます。多クラス問題であれば、カテゴリ(例えば「犬」など)が予測出力となります。
そして、「学習済みモデルにどの程度の性能があるか」を測るのが評価(Evaluate)というプロセスになります。評価では、まず、トレーニングに使ったものとは異なる入力データと正解データを用意して、このうち入力データだけを学習済みモデルに与えて、予測データを得ます。そして、この得られた予測データについて、正解データを使って答え合わせ、採点をして評価値とします。具体的な評価指標としては、前回出てきた正答率(accuracy)、損失関数値(loss)のほかに、適合率や再現率など必要に応じて様々なものが採用されます。
MNISTのトレーニング用データ、テスト用データ
次のコードで、MNISTデータをダウンロードして、各変数(
x_train、y_train、x_test、y_test)に格納しています(プログラム全体は前回 を参照)。mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data()ここで、
*_trainがトレーニング用(学習用)に割り当てられた入力&正解データ、*_testがテスト用(モデル評価用)に割り当てられた入力&正解データとなります。トレーニング用は 60,000件、テスト用は 10,000件 あります。また、
x_***には入力データ(つまり手書き画像を表すデータ:28x28の256段階グレースケール)、y_***には正解データ(「0」から「9」までのカテゴリ)が、配列的に格納されています。まずは、実際に、それぞれが 60,000件、10,000件 のデータから構成されていることを
len()で確認してみます。# トレーニング用データ print(len(x_train)) # 実行結果 -> 60000 print(len(y_train)) # 実行結果 -> 60000 # テスト用データ print(len(x_test)) # 実行結果 -> 10000 print(len(y_test)) # 実行結果 -> 10000次に、各データのタイプ(型)を確認してみます。
print(type(x_train)) # 実行結果 -> <class 'numpy.ndarray'> print(type(y_train)) # 実行結果 -> <class 'numpy.ndarray'> print(type(x_test)) # 実行結果 -> <class 'numpy.ndarray'> print(type(y_test)) # 実行結果 -> <class 'numpy.ndarray'>次に、
y_train(=トレーニング用の正解データ)の内容を確認してみます。print(y_train) # 実行結果 -> [5 0 4 ... 5 6 8]0件目のデータの正解値は「5」、1件目のデータの正解値は「0」・・・、59,999件目のデータの正解値は「8」ということが分かりました。
次に、
x_train(=トレーニング用の手書き画像を表すもの)の内容を確認してみます。全件を表示するととんでもないことになるので、先頭のx_train[0]のみを対象にします。(x_train, y_train), (x_test, y_test) = mnist.load_data() print(x_train[0].shape) # 実行結果 -> (28, 28) print(x_train[0]) # 実行結果 -> 下記参照numpy.ndarray のデータは、
.shapeで大きさが確認できます。(28, 28)、ということは、x_train[0]が28行28列の2次元配列で構成されていることが分かります。また、print(x_train[0])の出力は次のようになります。薄眼で眺めていただくと、ややいびつな手書きの「5」という数字が浮かんできます。これは、
y_train[0]に格納されている「5」と一致しますね。
各ピクセルデータは、0から255の範囲の値で構成されて、0が背景(白)で、255が最も濃い文字部(黒)になっていることが分かります。
60,000個の全てのデータについて、それを確認してみたいと思います。
import numpy as np print(x_train.min()) # 最小値を抽出 # 実行結果 -> 0 print(x_train.max()) # 最大値を抽出 # 実行結果 -> 255すべてのデータは0から255の範囲で構成されていることが確認できます。
ところで、60,000件のトレーニング用データのなかに、「0」から「9」までの各数字は何件ずつ存在するのでしょうか?基本的には、0から9までの10パターンがほぼ均等に存在していると思いますが、確認してみます。集計にpandasを利用します。
pandas版import pandas as pd tmp = pd.DataFrame({'label':y_train}) tmp = tmp.groupby(by='label').size() display(tmp) print(f'総数={tmp.sum()}')実行結果label 0 5923 1 6742 2 5958 3 6131 4 5842 5 5421 6 5918 7 6265 8 5851 9 5949 dtype: int64 総数=60000「5」が少なくて「1」が多いといった多少のバラつきがあるようです。
なお、次のように pandas を使わなくても求めることができます。
numpy版import numpy as np tmp = list([np.count_nonzero(y_train==p) for p in range(10)]) print(tmp) # 実行結果 -> [5923, 6742, 5958, 6131, 5842, 5421, 5918, 6265, 5851, 5949] print(f'総数={sum(tmp)}') # 実行結果 -> 総数=60000次回
- matplotlib を使って入力データをグラフィカルに表示するところまで進めたかったのですが、記事が長くなってしまったので、それは次回にしたいと思います。




- 投稿日:2019-12-30T10:54:46+09:00
React + TensorFlow.jsで手書き数字認識アプリを作ってみた
はじめに
サークルの講習会で、kivyとTensorFlow?を使って手書きの数字を認識するアプリを作っている先輩がいたので、これをReactでやってみたいなと思ったので、今回やってみました。このアプリを作る中で、こちらのサイトを非常に参考にさせていただきました。また、僕は機械学習についてあまり知識がないので、今回はpythonを全く書きません。機会があれば、モデルの作成からやってみたいと思います。
完成物
インストールしたパッケージ
TensorFlow.js: https://www.tensorflow.org/js/
react-signature-canvas: https://www.npmjs.com/package/react-signature-canvas
material-ui: https://material-ui.com/"@material-ui/core": "^4.8.1", "@tensorflow/tfjs": "^0.12.6", "react-signature-canvas": "^1.0.3",※ tensorflow/tfjsは上記のバージョンに合わせてください。
ファイル構造
create-react-appコマンドで作成したプロジェクトをベースに話を進めます。以下のファイル構造は、編集または新規作成したファイルのみ書いています。
src- |-components | |-Accuracy.js | |-AccuracyTable.js | |-App.js |-App.csscomponents/Accuracy.jsimport React from "react"; const Accuracy = props => { const { no, content } = props; return ( <tr> <th>{no}</th> <td className="accuracy" data-row-index={`${no}`}> {content} </td> </tr> ); }; export default Accuracy;components/AccuracyTable.jsimport React from "react"; import Accuracy from "./Accuracy"; const AccuracyTable = () => ( <table className="table"> <thead> <tr> <th>数字</th> <th>精度</th> </tr> </thead> <tbody> <Accuracy no={0} content="-" /> <Accuracy no={1} content="-" /> <Accuracy no={2} content="-" /> <Accuracy no={3} content="-" /> <Accuracy no={4} content="-" /> <Accuracy no={5} content="-" /> <Accuracy no={6} content="-" /> <Accuracy no={7} content="-" /> <Accuracy no={8} content="-" /> <Accuracy no={9} content="-" /> </tbody> </table> ); export default AccuracyTable;App.jsimport React from "react"; import "./App.css"; import * as tf from "@tensorflow/tfjs"; import SignatureCanvas from "react-signature-canvas"; import { Button } from "@material-ui/core"; import AccuracyTable from "./components/AccuracyTable"; class App extends React.Component { constructor() { super(); this.state = { is_loading: "is-loading", model: null, maxNumber: null, maxScore: null }; this.onRef = this.onRef.bind(this); this.getImageData = this.getImageData.bind(this); this.getAccuracyScores = this.getAccuracyScores.bind(this); this.predict = this.predict.bind(this); this.reset = this.reset.bind(this); } componentDidMount() { tf.loadModel( "https://raw.githubusercontent.com/tsu-nera/tfjs-mnist-study/master/model/model.json" ).then(model => { this.setState({ is_loading: "", model }); }); } onRef(ref) { this.signaturePad = ref; } getAccuracyScores(imageData) { const scores = tf.tidy(() => { const channels = 1; let input = tf.fromPixels(imageData, channels); input = tf.cast(input, "float32").div(tf.scalar(255)); input = input.expandDims(); return this.state.model.predict(input).dataSync(); }); return scores; } getImageData() { return new Promise(resolve => { const context = document.createElement("canvas").getContext("2d"); const image = new Image(); const width = 28; const height = 28; image.onload = () => { context.drawImage(image, 0, 0, width, height); const imageData = context.getImageData(0, 0, width, height); for (let i = 0; i < imageData.data.length; i += 4) { const avg = (imageData.data[i] + imageData.data[i + 1] + imageData.data[i + 2]) / 3; imageData.data[i] = avg; imageData.data[i + 1] = avg; imageData.data[i + 2] = avg; } resolve(imageData); }; image.src = this.signaturePad.toDataURL(); }); } predict() { this.getImageData() .then(imageData => this.getAccuracyScores(imageData)) .then(accuracyScores => { const maxAccuracy = accuracyScores.indexOf( Math.max.apply(null, accuracyScores) ); const elements = document.querySelectorAll(".accuracy"); elements.forEach(el => { el.parentNode.classList.remove("is-selected"); const rowIndex = Number(el.dataset.rowIndex); if (maxAccuracy === rowIndex) { el.parentNode.classList.add("is-selected"); } el.innerText = Math.round(accuracyScores[rowIndex] * 1000) / 1000; }); this.setState({ maxNumber: maxAccuracy, maxScore: accuracyScores[maxAccuracy] }); console.log(accuracyScores); }); } reset() { this.setState({ maxNumber: null }); this.signaturePad.clear(); const elements = document.querySelectorAll(".accuracy"); elements.forEach(el => { el.parentNode.classList.remove("is-selected"); el.innerText = "-"; }); } render() { let text = "数字を入力してください"; if (this.state.maxNumber !== null) { if (this.state.maxScore > 0.999) { text = `この数字は確実に${this.state.maxNumber}です。`; } else if (this.state.maxScore > 0.9) { text = `この数字はほぼ間違いなく${this.state.maxNumber}です。`; } else if (this.state.maxScore > 0.5) { text = `この数字は多分${this.state.maxNumber}です。`; } else { text = `この数字は${this.state.maxNumber}かもしれないです。`; } } return ( <div className="container"> <h2>{text}</h2> <div className="canbas"> <SignatureCanvas ref={this.onRef} minWidth={15} maxWidth={15} penColor="white" backgroundColor="black" canvasProps={{ width: 420, height: 420, className: "sigCanvas" }} onEnd={this.predict} /> </div> <div className="button"> <Button variant="contained" onClick={this.reset}> reset </Button> </div> <AccuracyTable /> </div> ); } } export default App;App.css.container { margin-bottom: 120px; text-align: center; } .canbas { display: inline; } .button { display: block; margin-top: 20px; margin-bottom: 60px; } .table { display: inline; border-collapse: collapse; border-spacing: 0; } .table th, .table td { padding: 10px 0; width: 200px; text-align: center; } .table tr:nth-child(odd) { background-color: #eee; } .is-selected { color: red; }終わりに
PCでは、うまくいったのですが、スマホからアクセスするとうまくいきませんでした。今後の課題としては、スマホアプリ(Expo+ReactNative)にしてみたいなと思っています。あとは、機械学習を勉強してモデルの作成もいちからやってみたいです。
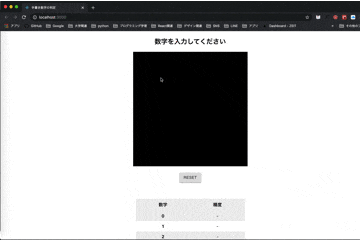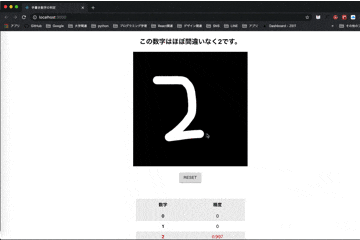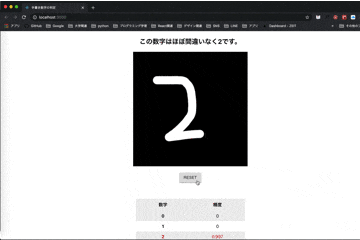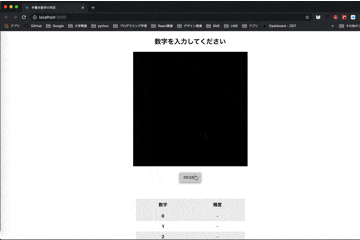
- 投稿日:2019-12-30T10:38:05+09:00
TensorFlow2 + Keras による画像分類に挑戦1 ~とりあえず動かす~
はじめに
TensorFlow2 + Keras を利用した画像分類(Google Colaboratory 環境)についての勉強メモ(第1弾)です。題材は、ド定番である手書き数字画像(MNIST)の分類です。
- TensorFlow2 + Keras による画像分類に挑戦 シリーズ
具体的には、こんな手書き数字を取り込んだ画像(28x28pixel)を対象に、
それぞれの画像が「0」から「9」のどれに分類できるか?という問題(=多クラス分類問題)について、TensorFlow2 + Keras によるディープラーニング(深層学習)でアプローチしてみようという内容です。開発・実行の環境には、簡単・便利で無料の Google Colabo. を利用します。Google Colabo. の導入については、こちら を参照ください。
今回の記事では、TensorFlow の 公式HP に掲載されているサンプルコードを持ってきて、Google Colab. のコードセルに貼り付け、問題なく実行できることを確認します。
そのうえで「コードの各部分では何をやっているのか」「実行時にで表示されるテキストは何を伝えているのか」を緩くぼんやりと解説しています。
TensorFlowとは
- 「テンソルフロー」または「テンサーフロー」と読む。
- Googleが開発した機械学習ライブラリで、ニューラルネットワーク(NN)の構築とトレーニング(=学習/訓練)ができる。無論、トレーニングしたNNモデルを使って予測もできる。
- 2017年2月に 1.0 がリリース、2019年10月に 2.0 がリリースされた。
- TF2.0 では、Keras(後述)を統合して Pythonとの親和性が高まり、より使いやすく洗練されたものとなった(とのこと)。GPU対応も強化された(とのこと)。
- PyTorch などの後発の機械学習ライブラリ勢力に負けないように開発が続いている。
Keras
- 「ケラス」と読む。
- TensorFlow のほか、Theano にも対応したハイレベルのAPI。ラッパー。
- Python で書かれている。
- Keras 経由で TF を使うことで、簡潔で短いコードにより機械学習が実現できる。
サンプルコードを試す
TensorFlowの公式HPの「初心者のための TensorFlow 2.0 入門」に、手書き数字の画像データセット(MINIST)を対象とした画像分類のサンプルコード(わずか十数行)があります。これを Google Colab. に貼り付けて実行します。
TFのバージョンを 1.x から 2.x に切り替える
TensorFlow2 を利用するため、次のマジックコマンドをコードセルのなかで実行します(コードセルに貼り付けて Ctrl+Enter)。これは、Google Colab.(2019/12/27の時点)では TensorFlow 1.x がデフォルトになっているので、それを 2.x を利用するように切り替えるためのものです。
GoogleColab.での準備%tensorflow_version 2.x問題なければ「
TensorFlow 2.x selected.」と表示されます。なお、1.x の TF を実行すると「The default version of TensorFlow in Colab will soon switch to TensorFlow 2.x.」とメッセージがでるので、近いうちにこの手続きは不要になると思います(2.x がデフォルト環境になると思います)。サンプルコードと実行
公式HPのサンプルコードに少しだけコメントを付けています。
import tensorflow as tf # (1) 手書き数字画像のデータセット(MNIST)をダウンロード、変数に格納 mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() # (2) データの正規化(データに対する前処理) x_train, x_test = x_train / 255.0, x_test / 255.0 # (3) NNモデルの構築 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation='softmax') ]) # (4) モデルのコンパイル(学習に関する設定も含む) model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy']) # (5) モデルのトレーニング(学習・訓練) model.fit(x_train, y_train, epochs=5) # (6) モデルの評価 model.evaluate(x_test, y_test, verbose=2)この短いプログラムのなかで、次のことを行なっています。
- 手書き数字画像のデータセットをダウンロードして、各変数に格納(データの準備)
*_train:トレーニング用(学習用、訓練用)のデータ*_test:テスト用(評価用)のデータ- これらデータについての解説は次回で
- データの正規化(データに対する前処理)
- 0~255 の範囲の整数値を、0.0~1.0 の範囲の実数値に変換
- 機械学習のためのニューラルネットワークモデルの構築
- モデルのコンパイル(学習に関する設定も含む)
- トレーニング用データを使ったモデルの学習(→ 学習済みモデルが完成)
- テスト用データ(
*_test)を使ったモデルの評価(学習済みモデルによる画像分類の実行と、答え合わせ(採点))プログラムの実行結果は、次のようになります。
実行結果Train on 60000 samples Epoch 1/5 60000/60000 [==============================] - 5s 82us/sample - loss: 0.2992 - accuracy: 0.9134 Epoch 2/5 60000/60000 [==============================] - 5s 78us/sample - loss: 0.1457 - accuracy: 0.9561 Epoch 3/5 60000/60000 [==============================] - 5s 78us/sample - loss: 0.1096 - accuracy: 0.9659 Epoch 4/5 60000/60000 [==============================] - 5s 78us/sample - loss: 0.0876 - accuracy: 0.9730 Epoch 5/5 60000/60000 [==============================] - 5s 80us/sample - loss: 0.0757 - accuracy: 0.9765 10000/10000 - 0s - loss: 0.0766 - accuracy: 0.9762 [0.07658648554566316, 0.9762]意味的には・・・
Train on 60000 samples:60,000枚の手書き文字画像を使ってトレーニングしますよ。Epoch x/5:全体で5回繰り返して学習させるうちの x回目の学習ですよ。5s 82us/sample - loss: 0.2992 - accuracy: 0.9134:画像1枚あたり82$\mu$秒、全体(60,000枚)では約5秒の学習時間がかかりましたよ。そうやって学習させたモデルについて(トレーニング用データを使って評価した)性能は、損失関数値(loss)が 0.2992、正答率(accuracy)が0.9134 でしたよ。
- 0.9134 ということは、$60,000\times0.9134=54,804$ 枚の画像について正しく 0~9 の分類できて、残りの $60,000-54,804=5,196$ 枚の画像については正しい分類ができなかったということ。
10000/10000 - 0s - loss: 0.0766 - accuracy: 0.9762:(トレーニング用として使ったものとは別の)テスト用の 10,000枚の画像で分類予測のテストをしました。テストには 0秒の時間がかかって、損失関数値(loss)が 0.0766、正答率(accuracy)が 0.9762 でしたよ。正答率(accuracy)とは
「精度」や「正解率」とも呼ばれます。正しく分類できた画像の割合を表します。例えば、100枚の画像のうち、98枚について正しく分類できれば正答率は 0.98(=98%)となります。0.0 から 1.0 までの範囲をとり、値が大きいほど(1.0に近いほど)優れたモデルといえます。
損失関数値(loss)とは
正答率という観点だけではモデル(分類器)の優劣を測れない部分があります。例えば、次のような1枚の画像(正解は「3」)について、異なる2つのモデルを使って分類(予測)を行なうとします。
この画像に対して、モデルAは「3」と予測し、モデルBも「3」と予測したとします。正解は「3」なので、いずれのモデルも正答率は 1.0 となります。この正答率という指標を見れば、2つのモデルは同じ程度に優れたモデルといえます。
しかし、モデルAの予測は「8である確信が10%、3である確信が90%というなかで、3を選択したもの」であり、一方で、モデルBの予測は「8である確信が45%、3である確信が55%というなかで、3を出力したもの」だったとしたら、どうでしょうか?
同じ正答率 1.0 でも、モデルAのほうが優れていると言えます。
しかし、正答率という指標では、このようなことは考慮できません。それを評価するためのものが損失関数値(loss)になります。
今回の手書き数字分類は「多クラス分類問題」というタイプに属し、その場合、損失関数には交差エントロピー(クロスエントロピー)という指標がよく使用されます。交差エントロピーは、ニューラルネットワークの出力層の各値と正解データを使って計算します)。詳しくは丁寧に解説している記事が多数ありますので、そちらを参照してください。
基本的に損失関数値は0以上の値をとり、損失関数値が小さいほど(0.0に近いほど)優れたモデルと見なします。
次回
- 今回はここまでで、次回は、トレーニング用データ(
x_train、y_train)、テスト用データ(x_test、y_test)の解説と matplotlib を使った可視化をしたいと思います。


- 投稿日:2019-12-30T01:36:40+09:00
tensorflowのインストール
tensorflowのインストール
tensorflowのインストールはpythonのバージョンとtensorflowのバージョンが適合することが必要になる。
(anacondaを使用すると楽だが、ここでは直で入れる場合とする)今回Ubuntu18.04.3にpython3.6.9が入っていた。
https://qiita.com/yasushi00/items/3e5a299b0a6a808e4af3
このサイトによると、python3.6.9に適合するtensorflowのバージョンは2.0.0とあったので、以下を実行。pip3 install tensorflow==2.0.0※pipではなくpip3でやらないとダメだった。
すると下記のようなメッセージが出た。Collecting tensorflow==2.0.0
Could not find a version that satisfies the requirement tensorflow==2.0.0 (from versions: 0.12.1, 1.0.0, 1.0.1, 1.1.0rc0, 1.1.0rc1, 1.1.0rc2, 1.1.0, 1.2.0rc0, 1.2.0rc1, 1.2.0rc2, 1.2.0, 1.2.1, 1.3.0rc0, 1.3.0rc1, 1.3.0rc2, 1.3.0, 1.4.0rc0, 1.4.0rc1, 1.4.0, 1.4.1, 1.5.0rc0, 1.5.0rc1, 1.5.0, 1.5.1, 1.6.0rc0, 1.6.0rc1, 1.6.0, 1.7.0rc0, 1.7.0rc1, 1.7.0, 1.7.1, 1.8.0rc0, 1.8.0rc1, 1.8.0, 1.9.0rc0, 1.9.0rc1, 1.9.0rc2, 1.9.0, 1.10.0rc0, 1.10.0rc1, 1.10.0, 1.10.1, 1.11.0rc0, 1.11.0rc1, 1.11.0rc2, 1.11.0, 1.12.0rc0, 1.12.0rc1, 1.12.0rc2, 1.12.0, 1.12.2, 1.12.3, 1.13.0rc0, 1.13.0rc1, 1.13.0rc2, 1.13.1, 1.13.2, 1.14.0rc0, 1.14.0rc1, 1.14.0, 2.0.0a0, 2.0.0b0, 2.0.0b1)
No matching distribution found for tensorflow==2.0.0そのため、下記を実行
pip3 install tensorflow==2.0.0a0インストールが実行された。
pip3 listでバージョンを確認すると
tensorflow (2.0.0a0)
と表示されたのでこれでOK。