- 投稿日:2019-12-30T23:56:28+09:00
【Python】scheduleを使ってモジュールを定期実行させよう
モジュールを定期的に実行させるのに便利なscheduleモジュールを紹介します。scheduleは一定の間隔(数分・数時間・数日おき)に同じ作業を実行するような場合に便利なモジュールです。webスクレイピングで情報収集を行う場面などで便利なモジュールとなります。
今回は基本的なscheduleモジュールの使用法をまとめた後、スクレイピングを定期的に実行するモジュールを実装例としてご紹介します。
scheduleのインストール
scheduleモジュールはpipコマンドで入手可能です。コマンドプロンプト上で以下のコマンドを実行するとインストールされます。
pip install scheduleサンプルコード
sample_schedule.pyimport schedule import time # 実行job関数 def job(): print("job実行") #1分毎のjob実行を登録 schedule.every(1).minutes.do(job) #1時間毎のjob実行を登録 schedule.every(1).hours.do(job) #AM11:00のjob実行を登録 schedule.every().day.at("11:00").do(job) #日曜日のjob実行を登録 schedule.every().sunday.do(job) #水曜日13:15のjob実行を登録 schedule.every().wednesday.at("13:15").do(job) # jobの実行監視、指定時間になったらjob関数を実行 while True: schedule.run_pending() time.sleep(1)scheduleのサンプルモジュールです。ある間隔ごとにjob関数が実行され、「job実行」が表示されるモジュールとなります。
schedule.everyは実行するjobと実行間隔を登録する記述となります。数分ごとや数時間ごと、さらに特定日時の実行も可能です。# 1分毎にjobを実行 schedule.every(1).minutes.do(job)上記の
schedule.everyで登録したjobは以下のschedule.run_pending()で実行されます。普通にschedule.run_pending()を呼び出しただけでは、一度jobを実行した時点で、モジュールが終了してしまうため、while文で無限ループ状態にする必要があります。無限ルール状態にすることで、同じ処理を一定間隔で実し続けることが可能です。while True: schedule.run_pending() time.sleep(1)scheduleを使ってYahooニュースの採取を定期実行
今回紹介したscheduleモジュールを使用して、定期的にスクレイピングを実行するようなモジュールを作成しました。1時間ごとにYahooニュースにアクセスし、ニュースのタイトルとURLを取得するようなモジュールです。
scraping_schedule.pyfrom urllib.request import urlopen from urllib.error import HTTPError from urllib.error import URLError from bs4 import BeautifulSoup import re import schedule import time def job(): try: html = urlopen('https://news.yahoo.co.jp/topics') except HTTPError as e: print(e) except URLError as e: print(e) else: # Yahooトピックスにアクセスし、ニュース情報を採取 bs = BeautifulSoup(html.read(), 'lxml') newsList = bs.find('div', {'class': 'topicsListAllMain'}).find_all('a') # 取得したListからニュースのタイトルとURLを取得して表示 for news in newsList: if re.match('^(https://)', news.attrs['href']): print(news.get_text()) print(news.attrs['href']) #1時間毎にjobを実行 schedule.every(1).hours.do(job) while True: schedule.run_pending() time.sleep(1)まとめ
今回は定例的ないjobを一定間隔で実行させることができるscheduleモジュールをご紹介しました。私は主にスクレイピングなどで活用することが多いですが、作業の定期実行にも使えるモジュールではあるので、使用用途はとても広いと思います。
参考文献
Python Scheduleライブラリでジョブ実行
scheduleライブラリを使ってPythonスクリプトを定期実行しよう
- 投稿日:2019-12-30T23:45:38+09:00
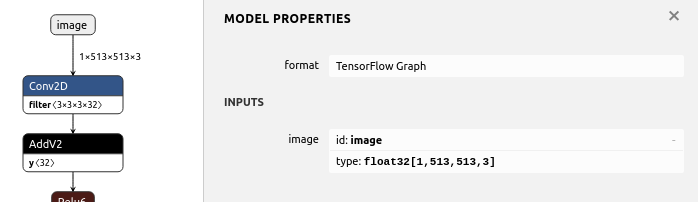
TensorflowのFreezeGraph済み.pbファイルのINPUTのPlaceholderを置き換えつつモデルを再生成するTips [置換・置き換え・変換・変更・更新・差し替え]
[1, ?, ?, 3]の入力サイズで定義されている .pbファイル のPlaceholderを[1, 513, 513, 3]のPlaceholderに強制的に置き換えて、.pbを再生成するサンプルプログラム。
name='image'の部分は置き換え後のPlaceholderの名前を自由に指定する。
input_map={'image:0': inputs}のimage:0の部分は、変換前のモデルのPlaceholder名を指定する。replacement_of_input_placeholder.pyimport tensorflow as tf from tensorflow.tools.graph_transforms import TransformGraph with tf.compat.v1.Session() as sess: # shape=[1, ?, ?, 3] -> shape=[1, 513, 513, 3] # name='image' specifies the placeholder name of the converted model inputs = tf.compat.v1.placeholder(tf.float32, shape=[1, 513, 513, 3], name='image') with tf.io.gfile.GFile('./model-mobilenet_v1_101.pb', 'rb') as f: graph_def = tf.compat.v1.GraphDef() graph_def.ParseFromString(f.read()) # 'image:0' specifies the placeholder name of the model before conversion tf.graph_util.import_graph_def(graph_def, input_map={'image:0': inputs}, name='') print([n for n in tf.compat.v1.get_default_graph().as_graph_def().node if n.name == 'image']) # Delete Placeholder "image" before conversion # see: https://github.com/tensorflow/tensorflow/tree/master/tensorflow/tools/graph_transforms # TransformGraph( # graph_def(), # input_op_name, # output_op_names, # conversion options # ) optimized_graph_def = TransformGraph( tf.compat.v1.get_default_graph().as_graph_def(), 'image', ['heatmap','offset_2','displacement_fwd_2','displacement_bwd_2'], ['strip_unused_nodes(type=float, shape="1,513,513,3")']) tf.io.write_graph(optimized_graph_def, './', 'model-mobilenet_v1_101_513.pb', as_text=False)Result[name: "image" op: "Placeholder" attr { key: "dtype" value { type: DT_FLOAT } } attr { key: "shape" value { shape { dim { size: 1 } dim { size: 513 } dim { size: 513 } dim { size: 3 } } } } ]
- 変換前

- 変換後
Graph Transform Tool
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/tools/graph_transforms
- 投稿日:2019-12-30T22:37:42+09:00
pandas.DataFrameで、特定の列だけ代入するときでも、indexがついていれば、データの順番は気にしなくていい
発見したこと
DataFrameに列単位で、DataFrame型の値を代入するとき、データ順がばらばらでも、indexが一致していれば、そのまま代入できます。
DataFrameから一部の列を抜き出して、条件により加工し、戻す、というときに、知っておくと便利かもです。試した環境
- python 3.7.4
- pandas 0.25.3
コード例
モジュールとデータの準備をして
import numpy as np import pandas as pd # 0-19の数列を4*5に整形し、dataframe化 df = pd.DataFrame(np.arange(20).reshape((4,5)), columns = list("abcde")) # a b c d e # 0 0 1 2 3 4 # 1 5 6 7 8 9 # 2 10 11 12 13 14 # 3 15 16 17 18 19一部の列を抜き出したDataFrameを作って、値を加工します
df_e_1 = df.loc[[0,2], ["e"]] # e # 0 4 # 2 14 df_e_1["e"] += 300 # e # 0 304 # 2 314一部の列を抜き出したDataFrameを作って、上で加工したデータと結合します。
df_e_2 = df.loc[[1,3], ["e"]] # e # 1 9 # 3 19 df_e = pd.concat([df_e_1, df_e_2]) # e # 0 304 # 2 314 # 1 9 # 3 19ここでdf_eをindex順に整列しないともとのDataFrameに代入してもデータ順がばらばらになってしまう、と思っていたけれど・・
そのまま代入しても、indexを一致させて自動で並べ替えて代入してくれます。
以下のe欄に注目くださいdf["e"] = df_e print(df) # a b c d e # 0 0 1 2 3 304 # 1 5 6 7 8 9 # 2 10 11 12 13 314 # 3 15 16 17 18 19
- 投稿日:2019-12-30T21:04:28+09:00
東京大学大学院情報理工学系研究科 創造情報学専攻 2013年度冬 プログラミング試験
2013年度冬の院試の解答例です
※記載の内容は筆者が個人的に解いたものであり、正答を保証するものではなく、また東京大学及び本試験内容の提供に関わる組織とは無関係です。出題テーマ
- 真理値表
- マクロ
問題文
※ 東京大学側から指摘があった場合は問題文を削除いたします。
(1)
def solve1(file_path): with open(file_path, 'r') as f: text = f.read() if text[-1] == '\n': text = text[:-1] ret = text.split('+') return ret def print1(ret): for txt in ret: print(txt)(2)
def solve1(file_path): with open(file_path, 'r') as f: text = f.read() if text[-1] == '\n': text = text[:-1] ret = text.split('+') return ret def solve2(file_path): txts = solve1(file_path) al_set = set() groups = [] for index, txt in enumerate(txts): als = txt.split('&') group = [] for al in als: group.append(al) al_set.add(al) group.sort() groups.append(group) al_set2 = [] for al in al_set: al_set2.append(al) al_set2.sort() answers = set() for group in groups: ans = [''] for al in al_set2: if al in group: for i in range(len(ans)): ans[i] += '{0}=true '.format(al) # print(ans) else: tmp = len(ans) ans = ans * 2 for i in range(tmp): ans[i] += '{0}=true '.format(al) ans[i+tmp] += '{0}=false '.format(al) for txt in ans: answers.add(txt) if len(answers) > 0: for a in answers: print(a) else: print('none')(3)
def solve1(file_path): with open(file_path, 'r') as f: text = f.read() if text[-1] == '\n': text = text[:-1] ret = text.split('+') return ret # a&!aが存在するかどうか # groupでは!aをa!の形で持っている def isNone(group): for al in group: if (al+'!') in group: return True return False def solve3(file_path): txts = solve1(file_path) al_set = set() groups = [] for index, txt in enumerate(txts): als = txt.split('&') group = [] for al in als: last = al[-1] if (len(al) % 2) == 0: group.append(last+'!') else: group.append(last) al_set.add(last) group.sort() groups.append(group) al_set2 = [] for al in al_set: al_set2.append(al) al_set2.sort() # print(al_set2) # print(groups) # return answers = set() for group in groups: if not isNone(group): ans = [''] for al in al_set2: if al in group: for i in range(len(ans)): ans[i] += '{0}=true '.format(al) elif (al+'!') in group: for i in range(len(ans)): ans[i] += '{0}=false '.format(al) else: tmp = len(ans) ans = ans * 2 for i in range(tmp): ans[i] += '{0}=true '.format(al) ans[i+tmp] += '{0}=false '.format(al) for txt in ans: answers.add(txt) if len(answers) > 0: for a in answers: print(a) else: print('none')(4)
from N_DIGIT import baseNumbers alpha = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'x', ] def get_alpha_set(text): ret = [] for al in alpha: if al in text: ret.append(al) ret.sort() return ret def macro(text): text = text.replace('!', ' not ') text = text.replace('&', ' and ') text = text.replace('+', ' or ') return text def solve4(file_path): with open(file_path, 'r') as f: text = f.read() if text[-1] == '\n': text = text[:-1] al_set = get_alpha_set(text) al_dic = {} for index, al in enumerate(al_set): al_dic[al] = index bs = baseNumbers(1 << len(al_set), 2, len(al_set)) ans = [] for b in bs: tmp = text for al in al_set: tmp = tmp.replace(al, str(b[al_dic[al]])) formatted_tmp = macro(tmp) if eval(formatted_tmp): ans.append(b) for a in ans: txt = '' for index, boolean in enumerate(a): if boolean: al = al_set[index] txt += '{0}=true '.format(al) else: al = al_set[index] txt += '{0}=false '.format(al) print(txt)(5)
from N_DIGIT import baseNumbers alpha = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'x', ] def get_alpha_set(text): ret = [] for al in alpha: if al in text: ret.append(al) ret.sort() return ret def macro(text): text = text.replace('!', ' not ') text = text.replace('&', ' and ') text = text.replace('+', ' or ') return text def solve5(file_path): with open(file_path, 'r') as f: text = f.read() if text[-1] == '\n': text = text[:-1] al_set = get_alpha_set(text) al_dic = {} for index, al in enumerate(al_set): al_dic[al] = index bs = baseNumbers(1 << len(al_set), 2, len(al_set)) ans = [] for b in bs: tmp = text for al in al_set: tmp = tmp.replace(al, str(b[al_dic[al]])) formatted_tmp = macro(tmp) if eval(formatted_tmp): ans.append(b) txt = '' for a in ans: tmp = '' for index, boolean in enumerate(a): if boolean: al = al_set[index] tmp += (al+'&') else: al = al_set[index] tmp += ('!'+al+'&') txt += (tmp[:-1]+'+') print(txt[:-1])(6)
from N_DIGIT import baseNumbers alpha = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'x', ] def get_alpha_set(text): ret = [] for al in alpha: if al in text: ret.append(al) ret.sort() return ret def macro(text): text = text.replace('!', ' not ') text = text.replace('&', ' and ') text = text.replace('+', ' or ') return text def solve6(file_path): with open(file_path, 'r') as f: text = f.read() if text[-1] == '\n': text = text[:-1] al_set = get_alpha_set(text) al_dic = {} for index, al in enumerate(al_set): al_dic[al] = index bs = baseNumbers(1 << len(al_set), 2, len(al_set)) ans = [] for b in bs: tmp = text for al in al_set: tmp = tmp.replace(al, str(b[al_dic[al]])) formatted_tmp = macro(tmp) if not eval(formatted_tmp): ans.append(b) txt = '' for a in ans: tmp = '(' for index, boolean in enumerate(a): if boolean: al = al_set[index] tmp += ('!'+al+'+') else: al = al_set[index] tmp += (al+'+') txt += (tmp[:-1]+')&') print(txt[:-1])感想
- コンパイラと見せかけた真理値表の問題
- (3)までは解析を実装して、そこから解を求めていく形にしたが(4)から()が登場し、これの何がまずいかというと()内()がこの場合ありえてしまうのでsplitなどによって単純に分割できなくなった。実際に()つきの解析プログラムを実装することは可能(当たり前)だがそれは言語処理論の分野であり、導出木の作成が必要で非常に厄介と感じたため、全探索とマクロを使う形にした(最初からこのやり方の方が実は楽)。
- ただ全探索とマクロを組み合わせたやり方だと最後までこのやり方でできてしまうので、出題者の意図に反しているのではないかと迷ったので筆者は(3)まではきちんと解析を実装した形にした。
- 全探索の場合は最大で2^26(アルファベット分)の約10^7~10^8の計算量が必要であるがこれはまぁ現実的な範囲では一応ある。
- 大抵のプログラミング言語はnot > and > orの優先順位であるのでマクロの利用を想定しているとも取れる。
- 加法の方はまぁ(4)そのままでいいだろう、乗法の方はこれも論理回路の教科書などには必ず載っている内容であるので知っていると加法同様に(4)を利用してすぐに実装ができる。知らないとド・モルガンの法則から自力で気付くのは結構きついと思う。

- 投稿日:2019-12-30T20:55:41+09:00
JupyterNotebookでの「No module named '〇〇'」エラーの対処法|!pipでインストールしよう!
JupyterNotebook初心者向けの記事です。
※記事内のミスがありましたら、コメントにてお教えください。事象:No module named 'pandas'のようなエラーが発生
import pandas as pdのようなコードを実行し、
ModuleNotFoundError Traceback (most recent call last) <ipython-input-23-7dd3504c366f> in <module> ----> 1 import pandas as pd ModuleNotFoundError: No module named 'pandas'のエラーが発生したとき。
原因:モジュールがjupyternotebook上にインストールされていない
実行しようとしていたモジュール(numpyやpandasなど)が、jupyternotebook上でインストールされていない可能性があります。
※terminal上や、その他IDEでインストールしていても、jupyternotebook上でモジュールを動かしたいときは、別途インストールが必要です。対処法:!pip installでインストールし直し
!pip install pandas
!pipというコマンドを使って、モジュールをインストールし直しましょう。「!」を先頭につけることで、jupyternotebook上でも、システムコマンドを実行できます。結果:Successfully installed 〇〇と出ていれば成功
Collecting numpy Downloading https://files.pythonhosted.org/packages/7c/cd/5243645399c09bb5081e8d2847583f7a6b7cca55eb096a880eda0b602d4d/numpy-1.18.0-cp36-cp36m-macosx_10_9_x86_64.whl (15.2MB) |████████████████████████████████| 15.2MB 48kB/s eta 0:00:016 Installing collected packages: numpy Successfully installed numpy-1.18.0このようにインストールが完了すれば成功です。
再インストール後は、↑のように再度使いたいモジュールを
importを使って呼び出してみてください。

- 投稿日:2019-12-30T20:34:27+09:00
TensorFlow2 + Keras による画像分類に挑戦3 ~MNISTデータを可視化してみる~
はじめに
Google Colaboratory 環境で TensorFlow2 + Keras を利用した画像分類の勉強メモです。ド定番である手書き数字画像(MNIST)の分類を題材にします。
前回は、MNISTデータを取得し、そのデータの構造や内容について確認しました。手書きの数字の画像データに相当する入力データは、28x28pixelの256段階グレースケールでした。このデータの型は
numpy.ndarrayの2次元配列で、そのまま
データの正規化
MNISTのデータは、0~255の整数値を使って、256段階グレースケール(白を0、黒を255に割り当てたグレースケール)を表現していました(詳しくは前回参照)。しかし、TensorFlow を使った画像分類のサンプルコード(公式HPのチュートリアル参照)では、機械学習させる都合上、次のように 0.0~1.0 の範囲になるように正規化を施しています。
import tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 # 正規化処理ここから先は、0.0~1.0 に正規化されたデータを対象に進めていきたいと思います。
とりあえず表示
トレーニング用の入力データの1個目
x_train[0]をグレースケール画像として出力してみたいと思います。このデータは、正解データy_train[0]に格納されているように「5」を表現した画像になります。import matplotlib.pyplot as plt plt.figure(dpi=96) plt.imshow(x_train[0],interpolation='nearest',vmin=0.,vmax=1.,cmap='Greys')
実行環境によっては、
interpolation='nearest'は省略できます(Google Colab.では省略してもOKです、他環境で実行してぼやけた出力になったら、このオプションを明示しましょう)。また、
vmin=0.,vmax=1.は、当該データx_train[?]の内部要素の最小値が 0.0、最大値が 1.0 の場合は省略してもOKです(cmap='Greys'により0.0に白、1.0に黒が割り当てられます)。そうでない場合、例えば、薄文字などを表現していてx_train[?]の内部要素の最大値が0.7のようなときは、このオプションを指定しないと、薄文字の感じが反映されません。キーワード引数
cmapの値を変えると、出力に使用するカラーマップを変えることができます。プリセットとして用意されているカラーマップ一覧は、matplotlibのリファレンスで確認することができます。例えば、cmap='Greens'とすると次のような出力になります(0.0のところも薄緑になります)。
カラーマップをカスタマイズすることも可能です。具体的な方法は「相関行列をキレイにカスタマイズしたヒートマップで出力したい。matplotlib編 @ Qiita」を参照ください。
特定の数字についての手書き画像を並べて出力
特定の数字(例えば「7」)について、どんなで手書きデータが存在するのか確認したいときには、次のようなコードで出力することができます。
import numpy as np import matplotlib.pyplot as plt x_subset = x_train[ y_train == 7 ] # (1) fig, ax = plt.subplots(nrows=8, ncols=8, figsize=(5, 5), dpi=120) for i, ax in enumerate( np.ravel(ax) ): ax.imshow(x_subset[i],interpolation='nearest',vmin=0.,vmax=1.,cmap='Greys') ax.tick_params(axis='both', which='both', left=False, labelleft=False, bottom=False, labelbottom=False) # (2)実行結果は次のようになります。7以外の数値について出力したい場合は、上記コードの (1) の
y_train == 7の数値を変更してください。(2) のax.tick_params(...)は、X軸・Y軸の目盛を消すためのものです。
一覧で眺めてみると、この64枚のなかであっても、どうみても「1」にしか見えないものが少なくとも2、3個は含まれているということが分かります(つまり、正答率 1.0000 は極めて難しい)。
整形して表示
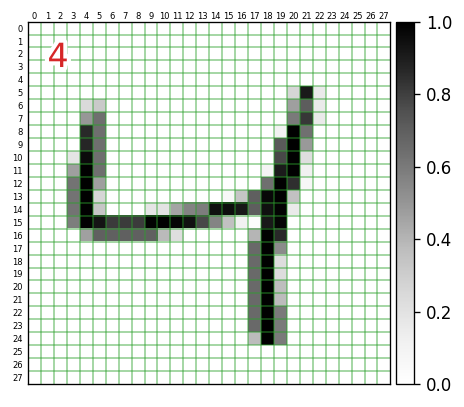
非常に短いコードで入力データを画像化して出力できることが分かりました。
ここでは、次のように、各入力データの何行何列目の要素がどんな値になっているのか?までを確認できるように手を加えていきます。左上の赤文字は、対応する正解データの値です。
import numpy as np import matplotlib.pyplot as plt import matplotlib.patheffects as pe import matplotlib.transforms as ts i = 2 # 表示するデータのインデックス plt.figure(dpi=120) plt.imshow(x_train[i],interpolation='nearest',vmin=0.,vmax=1.,cmap='Greys') h, w = 28, 28 plt.xlim(-0.5,w-0.5) # X軸方向の描画範囲 plt.ylim(h-0.5,-0.5) # Y軸方向の・・・ # plt.tick_params(axis='both', which='major', left=False, labelleft=False, bottom=False, labelbottom=False) plt.tick_params(axis='both', which='minor', left=False, labelleft=True, top=False, labeltop=True, bottom=False, labelbottom=False) # 各軸のグリッド設定 plt.gca().set_xticks(np.arange(0.5, w-0.5,1)) # 1ドット単位でグリッド plt.gca().set_yticks(np.arange(0.5, h-0.5,1)) plt.grid( color='tab:green', linewidth=1, alpha=0.5) # 各軸のラベル設定 plt.gca().set_xticks(np.arange(0, w),minor=True) plt.gca().set_xticklabels(np.arange(0, w),minor=True, fontsize=5) plt.gca().set_yticks(np.arange(0, h),minor=True) plt.gca().set_yticklabels(np.arange(0, h),minor=True, fontsize=5) # ラベルの位置の微調整 offset = ts.ScaledTranslation(0, -0.07, plt.gcf().dpi_scale_trans) for label in plt.gca().xaxis.get_minorticklabels() : label.set_transform(label.get_transform() + offset) offset = ts.ScaledTranslation(0.03, 0, plt.gcf().dpi_scale_trans) for label in plt.gca().yaxis.get_minorticklabels() : label.set_transform(label.get_transform() + offset) # 正解データを左上に表示(白色で縁取り) t = plt.text(1, 1, f'{y_train[i]}', verticalalignment='top', fontsize=20, color='tab:red') t.set_path_effects([pe.Stroke(linewidth=5, foreground='white'), pe.Normal()]) plt.colorbar( pad=0.01 ) # 右側にカラーバー表示グレースケール値のヒストグラム
入力データは、$28\times 28 = 784$ 個の要素から構成され、各要素には 0.0 から 1.0 の値が含まれますが、それはどんな分布になっているかヒストグラムを作成してみたいと思います。
import numpy as np import matplotlib.pyplot as plt i = 0 # 表示するデータのインデックス h = plt.hist(np.ravel(x_train[i]), bins=10, color='black') plt.xticks(np.linspace(0,1,11)) print(h[0]) # 実行結果 -> [639. 11. 6. 11. 6. 9. 11. 12. 11. 68.] print(h[1]) # 実行結果 -> [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. ]
plt.hist(...)の戻値には、各階級の度数が含まれます。上記の例だと、範囲 $0.0\le v < 0.1 $ の値を持つピクセルが 639個存在することが分かります。なお、一番右端のみ、範囲は $0.9\le v \le 1.0 $ となり、値がちょうど 1.0 のデータも含んだものになります。実際に
print(h[0].sum())にすれば、784.0が得られ、値がちょうど 1.0 の要素もちゃんとカウントされていることが確認できます。次回
- 学習済みのモデルを使って実際に予測を行ないます。自作の手書きでデータを入力とした予測も行ないます。




- 投稿日:2019-12-30T20:21:42+09:00
東京大学大学院情報理工学系研究科 創造情報学専攻 2015年度夏 プログラミング試験
2015年度夏の院試の解答例です
※記載の内容は筆者が個人的に解いたものであり、正答を保証するものではなく、また東京大学及び本試験内容の提供に関わる組織とは無関係です。出題テーマ
- 文字列探索
問題文
※ 東京大学側から指摘があった場合は問題文を削除いたします。
(1)
def solve1(file_path): cnt = 0 with open(file_path, 'r') as f: txt = f.read() if txt[-1] == '\n' and len(txt) > 1: txt = txt[:-1] for ch in txt: if ch == ';': cnt += 1 return cnt(2)
def solve2(file_path): with open(file_path, 'r') as f: txts = f.readlines() ret = [] for index, txt in enumerate(txts): if 'main' in txt: print('{0}行目: {1}'.format(index+1, txt))(3)
def solve3(file_path): with open(file_path, 'r') as f: text = f.readlines() txts = [] for index, txt in enumerate(text): if txt[-1] == '\n': txts.append(txt[:-1]) else: txts.append(txt) s = set() for index, txt in enumerate(txts): if index < len(txts) - 1: next_txt = txts[index + 1] if txt == next_txt: s.add(txt) for txt in s: print(txt)(4)
class Line(object): def __init__(self, txt, initial_appear, appear_times): self.txt = txt self.initial_appear = initial_appear self.appear_times = appear_times def __lt__(self, line): self.initial_appear < line.initial_appear def __repr__(self): return '初登場行: {0}, 登場回数: {1}, txt: {2}'.format(self.initial_appear, self.appear_times, self.txt) def solve4(file_path): with open(file_path, 'r') as f: text = f.readlines() txts = [] for index, txt in enumerate(text): if txt[-1] == '\n': txts.append(txt[:-1]) else: txts.append(txt) dic = {} # 'txt': [初登場行, 登場回数] for index, txt in enumerate(txts): if txt in dic.keys(): dic[txt][1] += 1 else: dic[txt] = [index+1, 1] ret = [] for key in dic.keys(): obj = dic[key] initial_appear = obj[0] appear_times = obj[1] if appear_times > 1: ret.append(Line(key, initial_appear, appear_times)) sorted(ret) for line in ret: print(line)(5)
def formatnptxt(nparray): txt = '' for ch in nparray: txt += ch return txt def solve5(file_path, minimum_len): with open(file_path, 'r') as f: text = f.readlines() txts = [] max_len = 0 for index, txt in enumerate(text): if txt[-1] == '\n': if len(txt[:-1]) >= minimum_len: txts.append(txt[:-1]) max_len = max(max_len, len(txt[:-1])) else: if len(txt) >= minimum_len: txts.append(txt) max_len = max(max_len, len(txt)) formatted_txts = np.array([[' ' for _ in range(max_len)] for _ in range(len(txts))]) for i, txt in enumerate(txts): for j, ch in enumerate(txt): formatted_txts[i, j] = ch ret = set() sames = 0 for i in range(0, len(formatted_txts) - 1): txt1 = formatted_txts[i] for j in range(i+1, len(formatted_txts)): txt2 = formatted_txts[j] booleans = (txt1 == txt2) same_scores = booleans.sum() if same_scores < max_len and (max_len - same_scores) < 5: sames += 1 pair1 = '{0}\n{1}'.format(formatnptxt(txt1), formatnptxt(txt2)) pair2 = '{0}\n{1}'.format(formatnptxt(txt2), formatnptxt(txt1)) if (not (pair1 in ret)) and (not (pair2 in ret)): ret.add(pair1) for set_ele in ret: set_ele_array = set_ele.split('\n') print('{0}, {1}'.format(set_ele_array[0], set_ele_array[1])) print(sames)(6)
from LCS import LCS def solve6(file_path, minimu_len): with open(file_path, 'r') as f: text = f.readlines() txts = [] for index, txt in enumerate(text): if txt[-1] == '\n': if len(txt[:-1]) >= minimu_len: txts.append(txt[:-1]) else: if len(txt) >= minimu_len: txts.append(txt) s = set() sames = 0 for i in range(len(txts) - 1): txt1 = txts[i] txt1_len = len(txt1) for j in range(i + 1, len(txts)): txt2 = txts[j] txt2_len = len(txt2) if txt1 != txt2: lcs = LCS(txt1, txt2) lcs_len = len(lcs) diff = abs(txt1_len - txt2_len) + min(txt1_len - lcs_len, txt2_len - lcs_len) if diff < 4: sames += 1 pair1 = '{0}\n{1}'.format(txt1, txt2) pair2 = '{0}\n{1}'.format(txt2, txt1) if (not (pair1 in s)) and (not (pair2 in s)): s.add(pair1) for set_ele in s: set_ele_array = set_ele.split('\n') print('{0}, {1}'.format(set_ele_array[0], set_ele_array[1])) print(sames)(7) 時間内に解き終わりませんでした...
やり方をちょっと考えたのですが, n行とすると
4,5,6...n/2ブロックサイズで順に探索して, 例えば4のとき、[1,4]と[12,15]が一致して5のとき
[1,5]と[12,16]が一致したら、前者を削除するみたいな感じでやればできそうな気がします。感想
- (6)ではtext1からtext2またはその逆の変換コストは等しいので、ここでは短い方を長い方に作り変える視点で考えて、まずLCS(最長共通部分列)をみて、短い方との差(min(txt1_len - lcs_len, txt2_len - lcs_len))をまず長い方に合わせて作り変えると、短い方の長さの文字列ができ、あとは長い方との文字数差分abs(txt1_len - txt2_len)を追加することでできるのでコード上のような内容が最小ステップ数となります。(たぶん笑)
- (7)は純粋に時間足りなかったです...


- 投稿日:2019-12-30T20:18:08+09:00
【python】outlookでメール送信
はじめに
仕事でexcelでメール作成マクロ作ったけど
「excelだと起動わずらわしいし、excelありきになるからなんかやだな…」
と思い、業務外ってことでリラックスした気持ちで探したら
神がかり的にわかりやすいサイトが見つかったので作ってみた。参考サイト
https://towel-memo.com/python/email_python/
#ライブラリ import win32com.client #Outlookのオブジェクト設定 outlook = win32com.client.Dispatch('Outlook.Application') mymail = outlook.CreateItem(0) #署名 sign = ''' 株式会社 ホゲホゲドットコム 世界のナベヒロ ''' #メールの設定 mymail.BodyFormat = 1 mymail.To = 'foo@hoge.co.jp; bar@hoge.co.jp' mymail.cc = 'foo@hoge.com' mymail.Bcc = 'bar@hoge.com' mymail.Subject = '件名' mymail.Body = '''各位 お疲れ様です。 以上、よろしくお願いいたします。 '''+ '\n' +sign path = r'C:\\Users\watya\Desktop\hogehoge.txt' # 添付ファイルは絶対パスで指定 mymail.Attachments.Add (path) #出来上がったメール確認 mymail.Display(True) #確認せず送信する場合は、mymail.Display(True)を消して、下記コードを使用する #mymail.Send()実行結果
mymail.Display(True)
で実行したので、メールは作成されたけど
送信まではされず下書き状態でストップしてくれた。やさしい。。。
これはテンプレ通りのメールを作成するのに便利ですね。しかもfromはログイン時のOutlookアドレスを使用してくれるので
プログラム作成時に意識する必要もないのでとっても楽。
これは便利!
- 投稿日:2019-12-30T19:18:45+09:00
今日のpython error:
プログラムちょい替え(2)Python3: URLをコマンドライン引数で(wikipedia)
https://qiita.com/kaizen_nagoya/items/fc095b0c580a35001ea7の作業をdockerで実施中。
docker(89) dockerでpython2, python3
https://qiita.com/kaizen_nagoya/items/ecbe11a4d743357134d5docker/ubuntu# pip install bs4 DEPRECATION: Python 2.7 will reach the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 won't be maintained after that date. A future version of pip will drop support for Python 2.7. More details about Python 2 support in pip, can be found at https://pip.pypa.io/en/latest/development/release-process/#python-2-support Collecting bs4 Downloading https://files.pythonhosted.org/packages/10/ed/7e8b97591f6f456174139ec089c769f89a94a1a4025fe967691de971f314/bs4-0.0.1.tar.gz Collecting beautifulsoup4 Downloading https://files.pythonhosted.org/packages/c5/48/c88b0b390ae1f785942fc83413feb1268a1eb696f343d4d55db735b9bb39/beautifulsoup4-4.8.2-py2-none-any.whl (106kB) |################################| 112kB 1.7MB/s Collecting soupsieve>=1.2 Downloading https://files.pythonhosted.org/packages/81/94/03c0f04471fc245d08d0a99f7946ac228ca98da4fa75796c507f61e688c2/soupsieve-1.9.5-py2.py3-none-any.whl Collecting backports.functools-lru-cache; python_version < "3" Downloading https://files.pythonhosted.org/packages/da/d1/080d2bb13773803648281a49e3918f65b31b7beebf009887a529357fd44a/backports.functools_lru_cache-1.6.1-py2.py3-none-any.whl Building wheels for collected packages: bs4 Building wheel for bs4 (setup.py) ... done Created wheel for bs4: filename=bs4-0.0.1-cp27-none-any.whl size=1273 sha256=79b8b3765197c5d2662611ba7f1199b00147c4741c41f4dc9cdc82d0f08f0609 Stored in directory: /root/.cache/pip/wheels/a0/b0/b2/4f80b9456b87abedbc0bf2d52235414c3467d8889be38dd472 Successfully built bs4 Installing collected packages: backports.functools-lru-cache, soupsieve, beautifulsoup4, bs4 Successfully installed backports.functools-lru-cache-1.6.1 beautifulsoup4-4.8.2 bs4-0.0.1 soupsieve-1.9.5 # pip3 install bs4 Collecting bs4 Cache entry deserialization failed, entry ignored Cache entry deserialization failed, entry ignored Downloading https://files.pythonhosted.org/packages/10/ed/7e8b97591f6f456174139ec089c769f89a94a1a4025fe967691de971f314/bs4-0.0.1.tar.gz Collecting beautifulsoup4 (from bs4) Cache entry deserialization failed, entry ignored Downloading https://files.pythonhosted.org/packages/cb/a1/c698cf319e9cfed6b17376281bd0efc6bfc8465698f54170ef60a485ab5d/beautifulsoup4-4.8.2-py3-none-any.whl (106kB) 100% |################################| 112kB 2.4MB/s Collecting soupsieve>=1.2 (from beautifulsoup4->bs4) Cache entry deserialization failed, entry ignored Cache entry deserialization failed, entry ignored Downloading https://files.pythonhosted.org/packages/81/94/03c0f04471fc245d08d0a99f7946ac228ca98da4fa75796c507f61e688c2/soupsieve-1.9.5-py2.py3-none-any.whl Building wheels for collected packages: bs4 Running setup.py bdist_wheel for bs4 ... done Stored in directory: /root/.cache/pip/wheels/a0/b0/b2/4f80b9456b87abedbc0bf2d52235414c3467d8889be38dd472 Successfully built bs4 Installing collected packages: soupsieve, beautifulsoup4, bs4 Successfully installed beautifulsoup4-4.8.2 bs4-0.0.1 soupsieve-1.9.5 # python2.7 wia.py Traceback (most recent call last): File "wia.py", line 9, in <module> from urllib.request import urlopen ImportError: No module named request # python3.8 wib.py Traceback (most recent call last): File "wib.py", line 8, in <module> from bs4 import BeautifulSoup ModuleNotFoundError: No module named 'bs4' # pip install urllib ERROR: Could not find a version that satisfies the requirement urllib (from versions: none) ERROR: No matching distribution found for urllib # pip3 install urllib Collecting urllib Exception: Traceback (most recent call last): File "/usr/lib/python3/dist-packages/pip/basecommand.py", line 215, in main status = self.run(options, args) File "/usr/lib/python3/dist-packages/pip/commands/install.py", line 353, in run wb.build(autobuilding=True) File "/usr/lib/python3/dist-packages/pip/wheel.py", line 749, in build self.requirement_set.prepare_files(self.finder) File "/usr/lib/python3/dist-packages/pip/req/req_set.py", line 380, in prepare_files ignore_dependencies=self.ignore_dependencies)) File "/usr/lib/python3/dist-packages/pip/req/req_set.py", line 554, in _prepare_file require_hashes File "/usr/lib/python3/dist-packages/pip/req/req_install.py", line 278, in populate_link self.link = finder.find_requirement(self, upgrade) File "/usr/lib/python3/dist-packages/pip/index.py", line 465, in find_requirement all_candidates = self.find_all_candidates(req.name) File "/usr/lib/python3/dist-packages/pip/index.py", line 423, in find_all_candidates for page in self._get_pages(url_locations, project_name): File "/usr/lib/python3/dist-packages/pip/index.py", line 568, in _get_pages page = self._get_page(location) File "/usr/lib/python3/dist-packages/pip/index.py", line 683, in _get_page return HTMLPage.get_page(link, session=self.session) File "/usr/lib/python3/dist-packages/pip/index.py", line 795, in get_page resp.raise_for_status() File "/usr/share/python-wheels/requests-2.18.4-py2.py3-none-any.whl/requests/models.py", line 935, in raise_for_status raise HTTPError(http_error_msg, response=self) requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://pypi.org/simple/urllib/
- 投稿日:2019-12-30T19:18:45+09:00
今日のpython error: ModuleNotFoundError: No module named 'bs4'
プログラムちょい替え(2)Python3: URLをコマンドライン引数で(wikipedia)
https://qiita.com/kaizen_nagoya/items/fc095b0c580a35001ea7の作業をdockerで実施中。
docker(89) dockerでpython2, python3
https://qiita.com/kaizen_nagoya/items/ecbe11a4d743357134d5docker/ubuntu# pip install bs4 DEPRECATION: Python 2.7 will reach the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 won't be maintained after that date. A future version of pip will drop support for Python 2.7. More details about Python 2 support in pip, can be found at https://pip.pypa.io/en/latest/development/release-process/#python-2-support Collecting bs4 Downloading https://files.pythonhosted.org/packages/10/ed/7e8b97591f6f456174139ec089c769f89a94a1a4025fe967691de971f314/bs4-0.0.1.tar.gz Collecting beautifulsoup4 Downloading https://files.pythonhosted.org/packages/c5/48/c88b0b390ae1f785942fc83413feb1268a1eb696f343d4d55db735b9bb39/beautifulsoup4-4.8.2-py2-none-any.whl (106kB) |################################| 112kB 1.7MB/s Collecting soupsieve>=1.2 Downloading https://files.pythonhosted.org/packages/81/94/03c0f04471fc245d08d0a99f7946ac228ca98da4fa75796c507f61e688c2/soupsieve-1.9.5-py2.py3-none-any.whl Collecting backports.functools-lru-cache; python_version < "3" Downloading https://files.pythonhosted.org/packages/da/d1/080d2bb13773803648281a49e3918f65b31b7beebf009887a529357fd44a/backports.functools_lru_cache-1.6.1-py2.py3-none-any.whl Building wheels for collected packages: bs4 Building wheel for bs4 (setup.py) ... done Created wheel for bs4: filename=bs4-0.0.1-cp27-none-any.whl size=1273 sha256=79b8b3765197c5d2662611ba7f1199b00147c4741c41f4dc9cdc82d0f08f0609 Stored in directory: /root/.cache/pip/wheels/a0/b0/b2/4f80b9456b87abedbc0bf2d52235414c3467d8889be38dd472 Successfully built bs4 Installing collected packages: backports.functools-lru-cache, soupsieve, beautifulsoup4, bs4 Successfully installed backports.functools-lru-cache-1.6.1 beautifulsoup4-4.8.2 bs4-0.0.1 soupsieve-1.9.5 # pip3 install bs4 Collecting bs4 Cache entry deserialization failed, entry ignored Cache entry deserialization failed, entry ignored Downloading https://files.pythonhosted.org/packages/10/ed/7e8b97591f6f456174139ec089c769f89a94a1a4025fe967691de971f314/bs4-0.0.1.tar.gz Collecting beautifulsoup4 (from bs4) Cache entry deserialization failed, entry ignored Downloading https://files.pythonhosted.org/packages/cb/a1/c698cf319e9cfed6b17376281bd0efc6bfc8465698f54170ef60a485ab5d/beautifulsoup4-4.8.2-py3-none-any.whl (106kB) 100% |################################| 112kB 2.4MB/s Collecting soupsieve>=1.2 (from beautifulsoup4->bs4) Cache entry deserialization failed, entry ignored Cache entry deserialization failed, entry ignored Downloading https://files.pythonhosted.org/packages/81/94/03c0f04471fc245d08d0a99f7946ac228ca98da4fa75796c507f61e688c2/soupsieve-1.9.5-py2.py3-none-any.whl Building wheels for collected packages: bs4 Running setup.py bdist_wheel for bs4 ... done Stored in directory: /root/.cache/pip/wheels/a0/b0/b2/4f80b9456b87abedbc0bf2d52235414c3467d8889be38dd472 Successfully built bs4 Installing collected packages: soupsieve, beautifulsoup4, bs4 Successfully installed beautifulsoup4-4.8.2 bs4-0.0.1 soupsieve-1.9.5 # python2.7 wia.py Traceback (most recent call last): File "wia.py", line 9, in <module> from urllib.request import urlopen ImportError: No module named request # python3.8 wib.py Traceback (most recent call last): File "wib.py", line 8, in <module> from bs4 import BeautifulSoup ModuleNotFoundError: No module named 'bs4' # pip install urllib ERROR: Could not find a version that satisfies the requirement urllib (from versions: none) ERROR: No matching distribution found for urllib # pip3 install urllib Collecting urllib Exception: Traceback (most recent call last): File "/usr/lib/python3/dist-packages/pip/basecommand.py", line 215, in main status = self.run(options, args) File "/usr/lib/python3/dist-packages/pip/commands/install.py", line 353, in run wb.build(autobuilding=True) File "/usr/lib/python3/dist-packages/pip/wheel.py", line 749, in build self.requirement_set.prepare_files(self.finder) File "/usr/lib/python3/dist-packages/pip/req/req_set.py", line 380, in prepare_files ignore_dependencies=self.ignore_dependencies)) File "/usr/lib/python3/dist-packages/pip/req/req_set.py", line 554, in _prepare_file require_hashes File "/usr/lib/python3/dist-packages/pip/req/req_install.py", line 278, in populate_link self.link = finder.find_requirement(self, upgrade) File "/usr/lib/python3/dist-packages/pip/index.py", line 465, in find_requirement all_candidates = self.find_all_candidates(req.name) File "/usr/lib/python3/dist-packages/pip/index.py", line 423, in find_all_candidates for page in self._get_pages(url_locations, project_name): File "/usr/lib/python3/dist-packages/pip/index.py", line 568, in _get_pages page = self._get_page(location) File "/usr/lib/python3/dist-packages/pip/index.py", line 683, in _get_page return HTMLPage.get_page(link, session=self.session) File "/usr/lib/python3/dist-packages/pip/index.py", line 795, in get_page resp.raise_for_status() File "/usr/share/python-wheels/requests-2.18.4-py2.py3-none-any.whl/requests/models.py", line 935, in raise_for_status raise HTTPError(http_error_msg, response=self) requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://pypi.org/simple/urllib/URLlibのエラーは
pip3でurllibをインストール
http://rongonxp.hatenablog.jp/entry/2018/02/01/000816# pip3 install urllib3 Collecting urllib3 Downloading https://files.pythonhosted.org/packages/b4/40/a9837291310ee1ccc242ceb6ebfd9eb21539649f193a7c8c86ba15b98539/urllib3-1.25.7-py2.py3-none-any.whl (125kB) 100% |################################| 133kB 1.7MB/s Installing collected packages: urllib3 Successfully installed urllib3-1.25.7 # python3 wib.py Traceback (most recent call last): File "wib.py", line 15, in <module> url = "https://ja.wikipedia.org/wiki/" + urllib.parse.quote(args[1]) IndexError: list index out of range文書履歴(document history)
ver. 0.01 初稿 20191230 午後
ver. 0.02 urllib3 追記 20191230 夜
- 投稿日:2019-12-30T19:04:25+09:00
スマホ/PCからラズパイ4にbluetooth 接続する時のメモ
スマホ/PCからラズパイにbluetooth 接続し、ラズパイ側でpython を使った制御を行う時の一通りの手順をまとめてみました。
(外のサイトを参照していて嵌ったところもあったので、改めて。。。)動作環境
- Raspberry PI 4 & Rasubian
- Windows 10
環境のインストール
参考:
https://qiita.com/shippokun/items/0953160607833077163f# pyBluez の依存パッケージをインストール $ sudo apt-get install -y python-dev libbluetooth3-dev # pyBluez のインストール $ sudo pip3 install pybluez # sudo apt-get install bluetooth blueman -y # bluez-tool $ sudo apt install libusb-dev $ sudo apt install libdbus-1-dev $ sudo apt install libglib2.0-dev $ sudo apt install libudev-dev -y $ sudo apt install libical-dev -y $ sudo apt install libreadline-dev -y $ sudo apt install libdbus-glib-1-dev -y $ sudo apt install libbluetooth-devラズパイのBluetooth macアドレスを確認する(必要に応じて)
$ hciconfig hci0: Type: Primary Bus: UART BD Address: DC:A6:32:37:3D:60 ACL MTU: 1021:8 SCO MTU: 64:1 UP RUNNING PSCAN RX bytes:3163 acl:22 sco:0 events:92 errors:0 TX bytes:3627 acl:21 sco:0 commands:64 errors:0未使用のチャンネルを調べる(必要に応じて)
$ sudo sdptool browse local | grep Channel Channel: 17 Channel: 16 Channel: 15 Channel: 14 Channel: 10 Channel: 9 Channel: 24 Channel: 12 Channel: 3sudo sdptool browse local だけ実行すると何にどのチャンネルが使われているのがわかると思います。
$ sudo sdptool browse local ... Service Name: Headset Voice gateway Service RecHandle: 0x10005 Service Class ID List: "Headset Audio Gateway" (0x1112) "Generic Audio" (0x1203) Protocol Descriptor List: "L2CAP" (0x0100) "RFCOMM" (0x0003) Channel: 12 Profile Descriptor List: "Headset" (0x1108) Version: 0x0102 ...未使用のチャンネルを指定してシリアルポートサービスを追加。
(当然のことながら、使用済みのチャンネルを指定するとこの後のステップで失敗します。これに気づかずに最初嵌りました…)sudo sdptool add --channel=22 SPチャンネルを指定せずにシリアルポートサービスを追加する場合は、上記の代わりに以下を実行する。
sudo sdptool add SPシリアルポートサービスを追加できたかどうか確認する。
sudo sdptool browse local上記を実行すると以下のような
Service Name: Serial Port
という出力が得られるはず。ここに
Channel: 1
のようにチャンネル番号が表示されているので確認しておくこと。Service Name: Serial Port Service Description: COM Port Service Provider: BlueZ Service RecHandle: 0x10001 Service Class ID List: "Serial Port" (0x1101) Protocol Descriptor List: "L2CAP" (0x0100) "RFCOMM" (0x0003) Channel: 1 Language Base Attr List: code_ISO639: 0x656e encoding: 0x6a base_offset: 0x100 Profile Descriptor List: "Serial Port" (0x1101) Version: 0x0100設定ファイルを編集して、起動直後にBluetoothでシリアル通信ができるようにする。
sudo nano /etc/systemd/system/dbus-org.bluez.serviceExecStart ... の行に --compat を追記する(互換モードで動作するようにする)。
また、ExecStartPost=/usr/bin/sdptool add SP # チャンネルを指定する場合は上記の代わりに以下を記述する。 # 使用済のチャンネルを指定しないように注意。 # ExecStartPost=/usr/bin/sdptool add --channel=22 SPを追記してシリアル通信プロトコル(SPP)が起動時に追加されるようにしておく。
チャンネル番号の指定は任意で。[Unit] Description=Bluetooth service Documentation=man:bluetoothd(8) ConditionPathIsDirectory=/sys/class/bluetooth [Service] Type=dbus BusName=org.bluez ExecStart=/usr/lib/bluetooth/bluetoothd --compat ExecStartPost=/usr/bin/sdptool add SP # チャンネルを指定する場合は上記の代わりに以下を記述する。 # 使用済のチャンネルを指定しないように注意。 # ExecStartPost=/usr/bin/sdptool add --channel=22 SP NotifyAccess=main #WatchdogSec=10 #Restart=on-failure CapabilityBoundingSet=CAP_NET_ADMIN CAP_NET_BIND_SERVICE LimitNPROC=1 ProtectHome=true ProtectSystem=fullラズパイを再起動する。
$ sudo reboot -hペアリングする
ラズパイのBluetoothをONし、server側でBluetooth が検索されるのを許可する。
sudo bluetoothctl [bluetooth] power on [bluetooth] discoverable on [bluetooth] agent on [bluetooth] default-agentこの状態で接続しようとすると以下のようなパスキー確認やサービス認証の確認を求められるので、yes/no を入力する。
参考:
https://qiita.com/oko1977/items/9f53f3b11a1b033219ea[CHG] Device 80:19:34:31:CD:1E Connected: yes Request confirmation [agent] Confirm passkey 291086 (yes/no): yes Authorize service [agent] Authorize service 0000110e-0000-1000-8000-00805f9b34fb (yes/no): yes Authorize service [agent] Authorize service 0000110d-0000-1000-8000-00805f9b34fb (yes/no): yes [CHG] Device 80:19:34:31:CD:1E UUIDs: 00001000-0000-1000-8000-00805f9b34fb ... [CHG] Device 80:19:34:31:CD:1E UUIDs: c7f94713-891e-496a-a0e7-983a0946126e [CHG] Device 80:19:34:31:CD:1E Connected: no [CHG] Device 80:19:34:31:CD:1E Connected: yes [CHG] Device 80:19:34:31:CD:1E Connected: no [bluetooth]#ここで、
上記画像のように、サウンドデバイスとして認識される場合、デバイスとプリンターからraspberrypi を選んで、
- シリアルポート(SPP)'SerialPort'
- リモートで制御可能なデバイス
- リモート制御
以外の項目のチェックを外しておく。
(外しておかないと、サウンドデバイスとして扱われる。筆者の環境では、元々使っていたサウンドデバイスが不活性化して音が鳴らなくなった。。。)
ちなみに、「シリアルポート(SPP) 'SerialPort'」が出てこない場合は、序盤の手順で
sdptool add SP
を実行してシリアル通信サービスを有効いるかどうかを再度確認すること。受信してみる
以下を実行する。
sudo rfcomm listen /dev/rfcomm0チャンネル番号を指定する場合は以下のように実行する(チャンネル番号22の場合)。
sudo rfcomm listen /dev/rfcomm0 22別コンソールを立ち上げて、Raspberry Pi側でメッセージを確認するために、/dev/rfcomm0をcatする。
$ sudo cat /dev/rfcomm0また、さらに別コンソールを立ち上げて
Raspberry Pi上で/dev/rfcomm0デバイスにメッセージをechoしてみる。$ sudo echo abcd > /dev/rfcomm0python & bluez で受信してみる
1 # -*- coding: utf-8 -*- 2 # Author: Shinsuke Ogata 3 4 import sys 5 import traceback 6 import time 7 import bluetooth 8 import threading 9 10 class SocketThread(threading.Thread): 11 ''' 12 @param client_socket accept の結果返ってきたクライアントソケット. 13 @param notify_receive シリアル通信で受信したデータを処理する関数・メソッド. 14 @param notify_error エラー時の処理を実行する関数・メソッド 15 ''' 16 def __init__(self, server_socket, client_socket, notify_receive, notify_error, debug): 17 super(SocketThread, self).__init__() 18 self._server_socket = server_socket 19 self._client_socket = client_socket 20 self._receive = notify_receive 21 self._error = notify_error 22 self._debug = debug 23 24 def run(self): 25 while True: 26 try: 27 data = self._client_socket.recv(1024) 28 if self._receive != None: 29 self._receive(data) 30 except KeyboardInterrupt: 31 self._client_socket.close() 32 self._server_socket.close() 33 break 34 except bluetooth.btcommon.BluetoothError: 35 self._client_socket.close() 36 self._server_socket.close() 37 if self._debug: 38 print('>>>> bluetooth.btcommon.BluetoothError >>>>') 39 traceback.print_exc() 40 print('<<<< bluetooth.btcommon.BluetoothError <<<<') 41 break 42 except: 43 self._client_socket.close() 44 self._server_socket.close() 45 if self._debug: 46 print('>>>> Unknown Error >>>>') 47 traceback.print_exc() 48 print('<<<< Unknown Error <<<<') 49 break 50 51 class BluetoothServer(threading.Thread): 52 53 ''' 54 @param notify_receive シリアル通信で受信したデータを処理する関数・メソッド. 55 @param notify_error エラー時の処理を実行する関数・メソッド 56 @param debug デバッグメッセージを出すときTrue をセット 57 ''' 58 def __init__(self, notify_receive, notify_error=None, debug=False): 59 super(BluetoothServer, self).__init__() 60 self._port =1 61 self._receive = notify_receive 62 self._error = notify_error 63 self._server_socket = None 64 self._debug = debug 65 66 def run(self): 67 try: 68 self._server_socket=bluetooth.BluetoothSocket( bluetooth.RFCOMM ) 69 70 if self._debug: 71 print("BluetoothServer: binding...") 72 73 self._server_socket.bind( ("",self._port )) 74 75 if self._debug: 76 print("BluetoothServer: listening...") 77 78 self._server_socket.listen(1) 79 80 client_socket,address = self._server_socket.accept() 81 82 if self._debug: 83 print("BluetoothServer: accept!!") 84 task = SocketThread(self._server_socket, client_socket, self._receive, self._error, self._debug) 85 task.start() 86 except KeyboardInterrupt: 87 if self._debug: 88 print("BluetoothServer: KeyboardInterrupt") 89 except: 90 if self._debug: 91 print('>>>> Unknown Error >>>>') 92 traceback.print_exc() 93 print('<<<< Unknown Error <<<<') 94 95 96 def receive(data): 97 print("receive [%s]" % data) 98 99 def error(data): 100 print("error") 101 102 if __name__ == '__main__': 103 task = BluetoothServer(receive, error, True) 104 task.start()



- 投稿日:2019-12-30T19:03:52+09:00
PythonのためにVimにALEを導入するときにハマった点
環境
Windows 10
Vim
Windows Terminal
deinハマったこと
vim+dein+aleを導入しようとした。
そこで、ALELintやALEFifxを実行してみたがソースコードには何の変化もなかった。
pip installしていて、blackなどはインストールされていた。3時間ほどかけて見つけた原因は、
でした。
以下のように変更する必要がありました。
g:python3_host_progが(windowsの)pathのイメージだったので、ディレクトリ指定だと思い込んでいました...
python.exeのpathを指定しないといけないというお話でした。参考文献


- 投稿日:2019-12-30T18:56:04+09:00
いつ,どこで,どのファイルを実行したのか自動で記録する
はじめに
日頃からシェルスクリプトとPythonのファイルを実行していると,
いつ,どこで,どのような処理をしたのか,残しておきたくなります.
ここでは,これらを記録するための,私なりの工夫をご紹介します.その日のための作業用ディレクトリ
まず,その日のための作業用ディレクトリを作成します.
以下ではこれを「DF (Day Folder)」と呼ぶことにします.
ドキュメントの下にその月のディレクトリを作成し,
その中にさらに,その日のためのディレクトリを作成します.
DFの作成は,bashrcに以下のように記載して,自動化しています.~/.bashrcexport DF=/home/Username/Documents/`date '+%m'`/`date '+%m%d'` mkdir -p $DF私はDFを,その日の汎用的なフォルダとして,様々な書類の保存に使用しています.
たとえばあるコードを書き換える際には,更新前のコードを$ cp main.c $DFと,念のため保存しています.
ジョブファイルを保存して実行するコマンドの定義
次に,シェルスクリプトとPythonのジョブファイルを実行した際に,
エラーにならなかった場合にそのファイルをDFにコピーし,
実行した時間と実行した場所を記録して,区別できるようにします.
私はジョブファイルのファイル名の先頭に実行した時間を付加し,
ジョブファイルの一番先頭の行に実行した場所を挿入しています.bashrcに次の項目を追記して,コマンド「ana」を定義します.
~/.bashrcfunction ana(){ DFFILE=$DF/`date '+%H%M%S'`$1 if [ "'`echo ${1##*.}`'" = "'sh'" ]; then sh $1 && cp $1 $DFFILE && sed -i 1i`pwd`$1 $DFFILE elif [ "'`echo ${1##*.}`'" = "'py'" ]; then python $1 && cp $1 $DFFILE && sed -i 1i`pwd`$1 $DFFILE else echo "the extension of job file must be 'sh' or 'py' with command ana" echo "the extension of input file:'`echo ${1##*.}`'" fi }anaコマンドの引数は,拡張子が ".sh" もしくは ".py" のジョブファイルです.
引数の拡張子を判別して,sh もしくは python のコマンドを実行します.$ ana hoge.sh #or hoge.py具体例
$ cd $DF #ここではDFで作業することにします. $ ls #".sh" と ".py" の二つのファイルを用意しました. main.sh hoge.py $ cat main.sh #main.sh を実行すると, echo "This is a pen" #"This is the pen" と表示します. $ ana main.sh #「ana」で実行してみます. This is a pen #たしかにシェルスクリプトが実行されました. $ ls $DF # DFの中には,main.shに時間がついたファイルがあります. 182115main.sh main.sh hoge.py $ head $DF/182115main.sh #このファイルの一行目には,実行した場所が記載されています. /home/Username/Documents/12/1230main.sh echo "This is a pen" $ cat hoge.py #以下,Pythonでも同様の操作になります. print("Is this a pen?") $ ana hoge.py Is this a pen? $ ls $DF/Executed 182115main.sh 182329hoge.py main.sh hoge.py $ head $DF/182329hoge.py /home/Username/Documents/12/1230hoge.py print("Is this a pen?")
- 投稿日:2019-12-30T18:29:38+09:00
UbuntuでMeCabのユーザ辞書に単語を追加してPythonで使えるようにする
はじめに
最近、研究でpythonとMeCabを使用した解析し始めたものの、単語をユーザ辞書に追加する際に苦労したので自分用にまとめてみました。
環境
- Ubuntu 16.04
- Python 3.6 (anacondaの仮想環境)
- MeCab 0.996 (pip install mecab-python3で導入)
1. 辞書を用意する
辞書はcsvファイルで作成しておきます。辞書のフォーマットは
表層形,左文脈ID,右文脈ID,コスト,品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原型,読み,発音
の順で並べます。vim add_term.csv アナと雪の女王,,,1,名詞,一般,*,*,*,*,アナと雪の女王,アナトユキノジョオウ,アナトユキノジョオー左文脈IDと右文脈IDは空欄にしておくと自動で入力してくれます。また、コストはその単語がどれだけ出現しやすいかを示しており、小さいほど出現しやすいという意味になります。コストの推定法もあるようですが、今回は1にしました。不要なものは「*」でオーケーです。
※文字コードは必ず「UTF-8」で作成すること!「Shift-jis」や「EUC-jp」にすると上手くいきませんでした。2. ユーザ辞書を作成する
作成したcsvファイルからユーザ辞書を作成します。辞書の作成にはMeCabをインストールした際に付属のmecab-dict-indexを使います。
#ユーザ辞書保存先ディレクトリの作成 mkdir /usr/local/lib/mecab/dic/userdic #辞書作成 sudo /usr/lib/mecab/mecab-dict-index \ -d /usr/local/mecab/dic/ipadic \ -u /usr/local/lib/mecab/dic/userdic/add.dic \ -f utf-8 \ -t utf-8 \ add_term.csvオプションは以下の通りです。
-d システム辞書が入っているディレクトリ
-u ユーザ辞書の保存先
-f csvファイルの文字コード
-t ユーザ辞書の文字コード
csvファイルmecab-dict-indexはフルパスで実行します。この時も文字コードはUTF-8を指定します。
reading add_term.csv ... 1 emitting double-array: 100% |###########################################| done!と表示されると成功です。
3. MeCabの設定ファイルに作成したユーザ辞書を追加する
設定ファイルに以下の文を追記します。
sudo vim /etc/mecabrc userdic = /usr/local/lib/mecab/dic/userdic/add.dic公式サイトでは
/usr/local/lib/mecab/dic/ipadic/dicrc
/usr/local/etc/mecabrc
のどちらかに追記するように書いてありますが、筆者の環境では上手くいかず、上記場所にmecabrcがあったのでそちらに追記することで正しく動作しました。複数辞書を登録したい場合は,userdic = AAA.dic,BBB.dicとすれば登録できました。
動作確認
- コマンドラインから確認する
#追加前 mecab アナと雪の女王 アナ 名詞,一般,*,*,*,*,アナ,アナ,アナ と 助詞,並立助詞,*,*,*,*,と,ト,ト 雪 名詞,一般,*,*,*,*,雪,ユキ,ユキ の 助詞,連体化,*,*,*,*,の,ノ,ノ 女王 名詞,一般,*,*,*,*,女王,ジョオウ,ジョオー EOS #追加後 アナと雪の女王 アナと雪の女王 名詞,一般,*,*,*,*,アナと雪の女王,アナトユキノジョオウ,アナトユキノジョオー EOS
- pythonのMeCabで使用する
python3>>> import MeCab >>> m_t = MeCab.Tagger('-Ochasen \ -u /usr/local/lib/mecab/dic/userdic/add.dic') >>> txt = 'アナと雪の女王を観に行こう。' >>> print(m_t.parse(txt)) アナと雪の女王 を 観 に 行こ う 。インストール済みのmecab-ipadic-neologdと一緒に使いたい場合は
python3>>> import MeCab >>> m_t = MeCab.Tagger('-Ochasen \ -d /usr/lib/mecab/dic/mecab-ipadic-neologd \ -u /usr/local/lib/mecab/dic/userdic/add.dic')と変更すれば同時に読み込んでくれます。
結論
試行錯誤しましたが、python上で上手く動作するところまで確認できました。もし間違っている点などありましたらご指摘をいただけますと幸いです。
参考サイト
- 投稿日:2019-12-30T18:18:39+09:00
python DSのデバッグ
◆pdb
デフォルトのデバッグ機能◆helpコマンド
help(なんかオブジェクト)でだいたいの説明が出てきます◆対話的なデバッグも
https://recruit-tech.co.jp/blog/2018/10/16/jupyter_notebook_tips/#b31◆言語ごとのDumpの違い
https://hydrocul.github.io/wiki/programming_languages_diff/io/dump.html
pprintがpythonでは紹介されてます。ーーー継続して書いていきますーーー
- 投稿日:2019-12-30T18:05:43+09:00
第7章 [誤差逆伝播法] P275~(中盤) 【Pythonで動かして学ぶ! あたらしい機械学習の教科書】
誤差逆伝播法(バックプロパゲーション)
この誤差逆伝播法では、ネットワークの出力で生じる誤差(教師信号との差)の情報を使って、出力層の重み$v_{kj}$から中間層への重み$w_{ji}$へと入力法こと逆向きに重みを更新していくことから、この名前がつけられている。
しかし、この誤差逆伝播法は勾配法そのもので、勾配法をフィードフォワードニューラルネットに適用すると誤差逆伝播ほうが自然と導出される。クラス分類をさせるので、誤差函数には式7-18の平均交差エントロピー誤差を考える(P266)
$$
E(w,v)=-\frac{1}{N}\sum_{n=0}^{N-1}\sum_{k=0}^{K-1}t_{nk}log(y_{nk})\hspace{40pt}(7-18)
$$・ここでやりたいことは$\partial{E}/ \partial{w_{ji}}$(平均交差エントロピー誤差)を求めたい。
・データが1つの時の交差エントロピー$E_n$を考えたときに、その微分は$\partial{E_n} /
\partial{w_{ji}}$で求まるから、本命の$\partial{E}/ \partial{w_{ji}}$(平均交差エントロピー誤差)はデータの個数分の$\partial{E_n} / \partial{w_{ji}}$を求めてそれを平均すれば良い
・ここでtはt=[0,0,1]とかで表していた、教師信号(なんのクラスを表すかの信号)それが↓
$$
\frac{\partial{E}}{\partial{w_{ji}}}=\frac{\partial}{\partial{w_{ji}}}\frac{1}{N}
\sum_{n=0}^{N-1}E_n
=\frac{1}{N}\sum_{n=0}^{N-1}
\frac{\partial{E_n}}{\partial{w_{ji}}}
$$今回はD=2,M=2,K=3の場合を考える。
D:入力値の個数
M:中間層の個数
K:出力の個数
w,v:重み重みは、w,vの二つあるので、まず$E_n$を$v_{kj}$で偏微分した式を求める。その次に$E_n$を$w_{ji}$で偏微分した式を求める。(
順番に特に意味はなさそう。誤差逆伝播法では、誤差を元に逆順に式展開が伝播するため逆から行っている。)$
\frac{\partial{E}}{\partial{v_{kj}}}
$
の$E_n$の部分は7-22の$E_n(w,v)=-\sum_{k=0}^{K-1}t_{nk}log(y_{nk})$なので、$\frac{\partial{E}}{\partial{v_{kj}}}$これは連鎖律で偏微分を求めることができる。連鎖律↓
$$
\frac{\partial{E}}{\partial{v_{kj}}}=
\frac{\partial{E}}{\partial{a_k}}\frac{\partial{a_k}}{\partial{v_{kj}}}
$$$a_k$は入力値とダミー変数の総和
ここでは、まず左側の$\frac{\partial{E}}{\partial{a_k}}$から考える。
Eの部分は$E_n$が省略されているものなので、ここを式7-22で置き換えると、(k=0の場合で考える[データ数0個?])$$
\frac{\partial{E}}{\partial{a_0}}= \
\frac{\partial}{\partial{a_0}}(-t_0logy_0-t_1logy_1-t_2logy_2)
$$となる。
ここで対数の微分の公式を使うと
・説明にあるようにtは教師信号でyは入力総和の出力なので、$a_0$と関係があるため。
・ここでtはt=[0,0,1]とかで表していた、教師信号(なんのクラスを表すかの信号)対数の微分:
$
\begin{align*} (\log x)' = \frac{1}{x} \end{align*}
$と表せる↓
$$
\frac{\partial{E}}{\partial{a_0}}=\
-t_0\frac{1}{y_0}\frac{\partial{y_0}}{\partial{a_0}}
-t_1\frac{1}{y_1}\frac{\partial{y_1}}{\partial{a_0}}
-t_2\frac{1}{y_2}\frac{\partial{y_2}}{\partial{a_0}}
\hspace{40pt}(7-27)
$$第7章(前半)で説明したように$\partial{y_0} / \partial{a_0}$の部分ではソフトマックス関数が使用されている。
そこで、4-130で導いた、ソフトマックス関数の偏微分の公式通りにすると、
公式4-130:
$\frac{\partial{y_j}}{\partial{x_i}}=y_j(l_{ij}-y_i)$
・iは入力値の係数、jは出力値の係数
ここで、lは$i=j$のとき1、$i\neq{j}$の時0式7-28のようになります。
$$
\frac{\partial{y_0}}{\partial{a_0}}=y_0(1-y_0)
$$
今回はダミー変数を含めるとM=K=3なのでlの部分は1残りの二つは、入力値の係数と、出力値の係数が異なるのでそれぞれ
$$
\frac{\partial{y_1}}{\partial{a_0}}=-y_0y_1
$$
$$
\frac{\partial{y_2}}{\partial{a_0}}=-y_0y_2
$$
となる。それぞれ3つを代入すると
よって、式7-27は以下のようになる(7-31):\begin{align} \frac{\partial{E}}{\partial{a_0}}&= -t_0\frac{1}{y_0}\frac{\partial{y_0}}{\partial{a_0}} -t_1\frac{1}{y_1}\frac{\partial{y_1}}{\partial{a_0}} -t_2\frac{1}{y_2}\frac{\partial{y_2}}{\partial{a_0}}\\ &=-t_0(1-y_0)+t_1y_0+t_2y_0\\ &=(t_0+t_1+t_2)y_0-t_0\\ &=y_0-t_0 \end{align}最後は$t_0+t_1+t_2=1$を使った。
$y_0$が1番目のノードのニューロンの出力で、$t_0$がそれに対する教師信号なので$y_0-t_0$は誤差を表している。
同じようにk番目のデータ(k=1,2)を考えると式(7-32)のようになる。
そして、式7-25の連鎖律の左側の部分は7-33のように表せる。(偏微分左側)
式7-25の $\partial{a_k} / \partial{v_kj}$ の部分を考える。
k=0の場合を考えると、総和の$a_0$は中間層の出力(z)と中間層から出力層への重みvの総和なので、
$$
a_0=v_{00}z_0+v_{01}z_1+v_{02}z_{02}
$$なので、$a_0$をそれぞれのv($v_0,v_1,v_2$)について解くと7-37のようになる。
それで、7-37をまとめて書くと、7-38にになる。
k=1,k=2の場合でも同様な結果が得られるので、全てまとめて式7-39のようになる
$$
\frac{\partial{a_k}}{\partial{v_{kj}}}=z_j\hspace{40pt}(7-39)
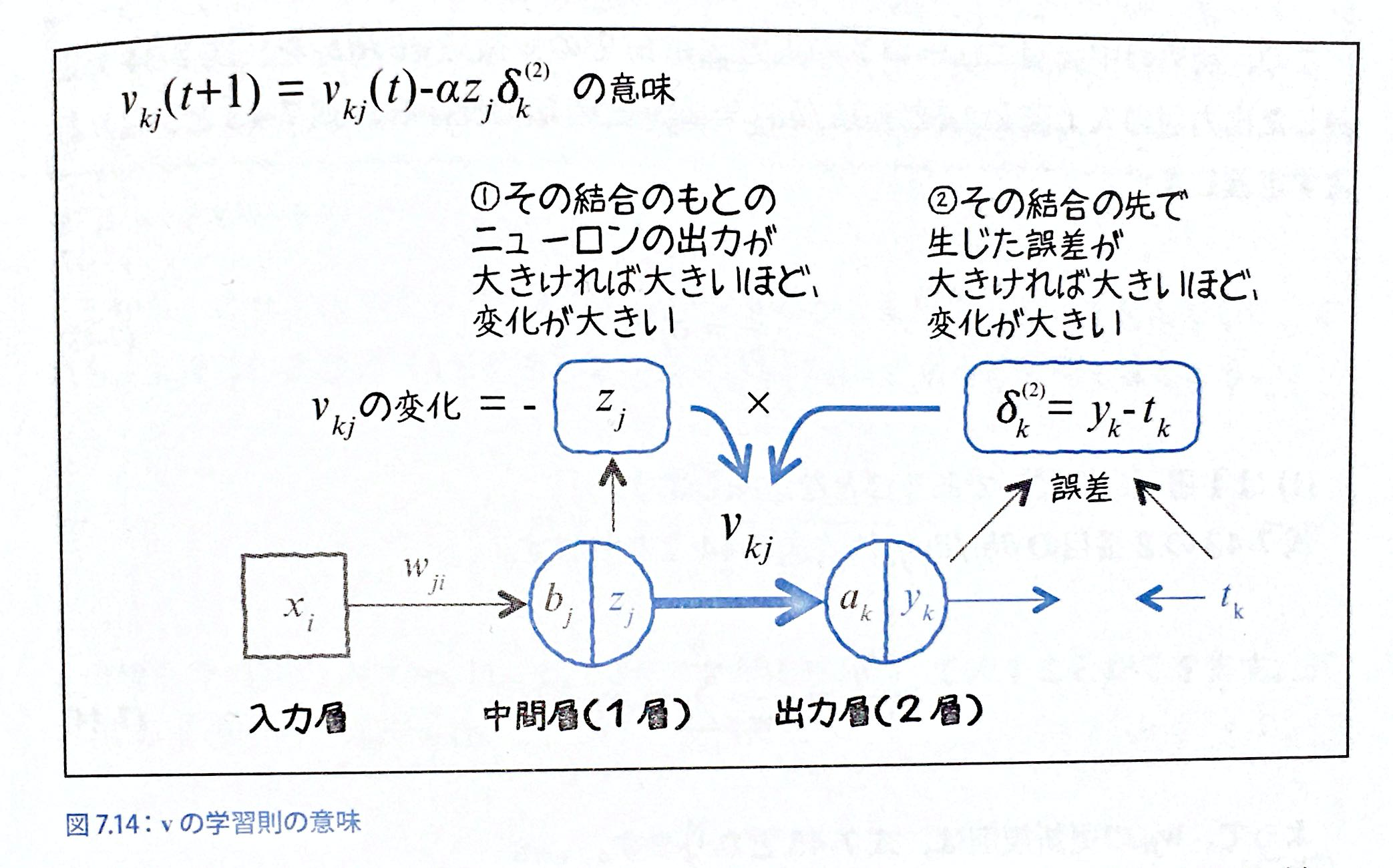
$$これで偏微分の左側、右側が揃ったので、組み合わせると式7-40のようになる。
式7-41で言っていることは、今欲しい値は$v_{kj}$という適切な重みの値が欲しいので、その値を適切に調整する時の理論が図で表していること。
・zは(シグモイドを通しているから)0~1の値をとる確率で出力yと教師信号tの誤差分をなくすようなvになりたい分けだから、誤差($\delta_k^{(2)}$のぶんだけvの値を変更する。)
・誤差($\delta_k^{(2)}$)が0の場合 = 出力$y_k$と目標データ(教師信号)$t_k$ が一致していれば,($y_k-t_k=0$)変更分の$-\alpha\delta_k^{(2)}z_j$は0となる。(重要)P281:
目標データ$t_k$が0なのに、出力$y_k$が0よりも大きかった場合、誤差$\delta_k^{(2)}=(y_k-t_k)$は正の値となります。$z_j$は常に正のですから、結果、$-\alpha\delta_k^{(2)}z_j$は負の数となり、$v_{kj}$は減る方向へ修正される。つまり、出力が大きすぎて誤差が生じたので、ニューロン$z_j$からの影響を絞る方向へ重みが変更されると解釈できます。また、入力$z_j$が大きかったら、その結合からの出力への寄与が大きかったことになるので、$v_{kj}$の変更量もその分大きくするようになっていると解釈できます。
ここの部分が非常に重要で、ここで言っていることは、
・目的データtよりも出力データyの方が大きければ、vの変更はその出力yを減らす方に変化する(v=0.2とかになるのかな?)
・そして、誤差(y-t=0)がなければ、vは変わらない
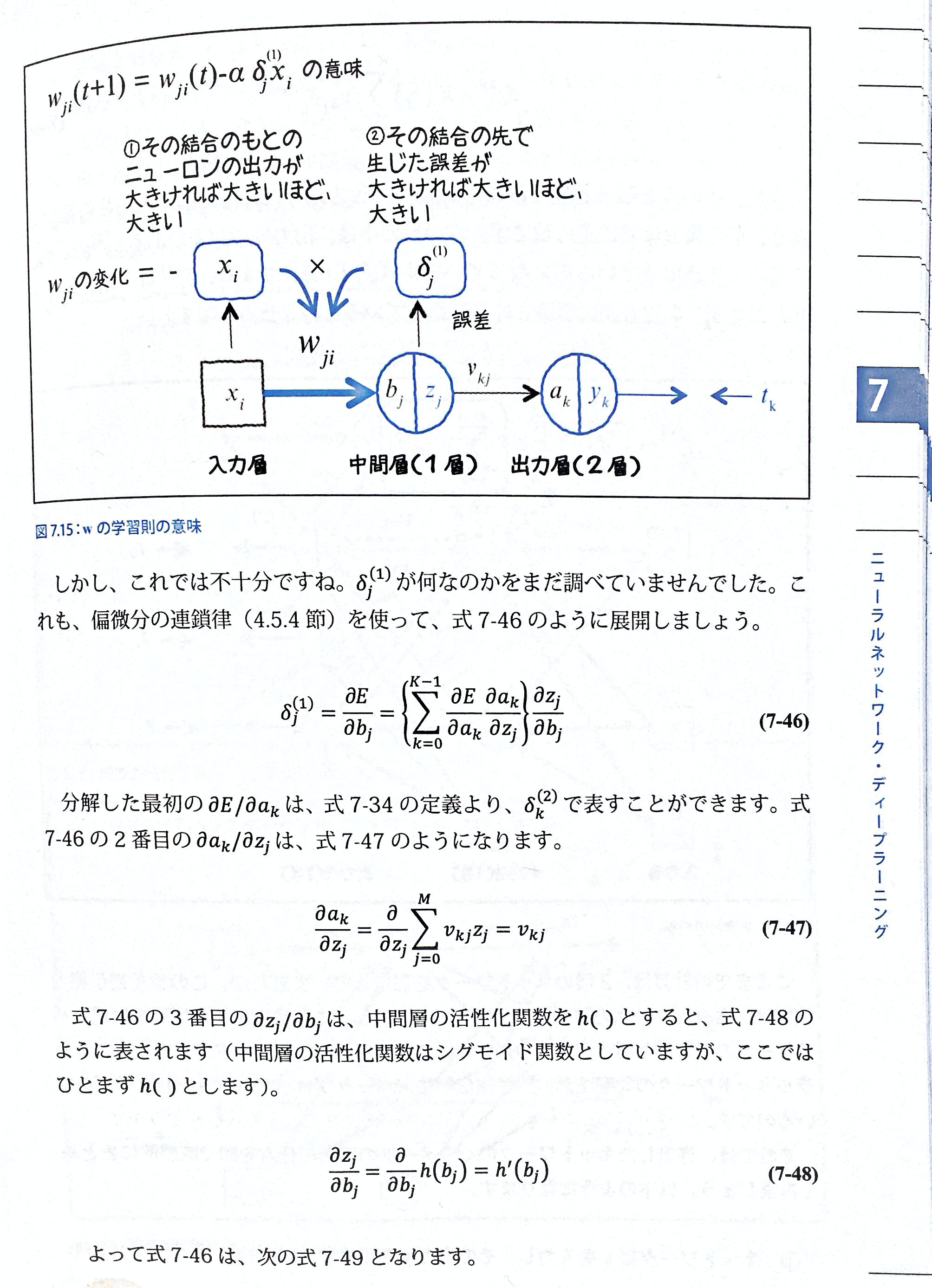
・また、入力値z(これは確率を表す)が大きければvの変更量もその分大きくなるEのwで微分を求める。
$\partial{E}/\partial{w_{ji}}$を求める
・式7-43は7-34と同じ
・式7-44は7-39と同じ
・なので、同様に式7-45は7-41と同じ
として処理できる。$\delta_{j}^{(1)}$をとりあえずとしておいたで、それが何かを求める。
まず、最初に7-43の式を連鎖律で偏微分すると:
$$
\delta_j^{(1)}=\frac{\partial{E}}{\partial{b_j}}=
\biggl(
\sum_{k=0}^{K-1}\frac{\partial{E}}{\partial{a_k}}
\frac{\partial{a_k}}{\partial{z_j}}
\biggr)
\frac{\partial{z_j}}{\partial{b_j}}
$$
なるのを理解するのに、以下を理解する必要がある。・ここでは、$g_0$と$g_1$が$w_0$とw_1$の関数で、fがg_0$とg_1$の関数となっている場合となっているので、これを置き換える。
$$
E(a_k(z_0,z_1))
$$
(k=0~2の3つ)なので、(4-62)が適用できる。
という関数になる。
$$
\frac{\partial}{\partial{z_j}}E(a_0(z_0,z_1),a_1(z_0,z_1),a_2(z_0,z_1))=\sum_{k=0}^{K-1}\frac{\partial{E}}{\partial{a_k}}\frac{\partial{a_k}}{\partial{z_j}}
$$
となる。これを組み合わせると、式7-46のように展開できる。
式7-47がなぜ$v_{kj}$になるかわかりませんが、P283で説明している通り、$\delta_{j}^{(1)}$は以下のようになる
・式7-47では、$z_j$について偏微分しろと言っているので、それ以外のvは定数とおく、z=1として残るところのvだけ定数も残るので、$v_{kj}$が残る。それらを合わせると↓
$$
\delta_{j}^{(1)}=h'(b_j)\sum_{k=0}^{K-1}v_{kj}\delta_{k}^{(2)}
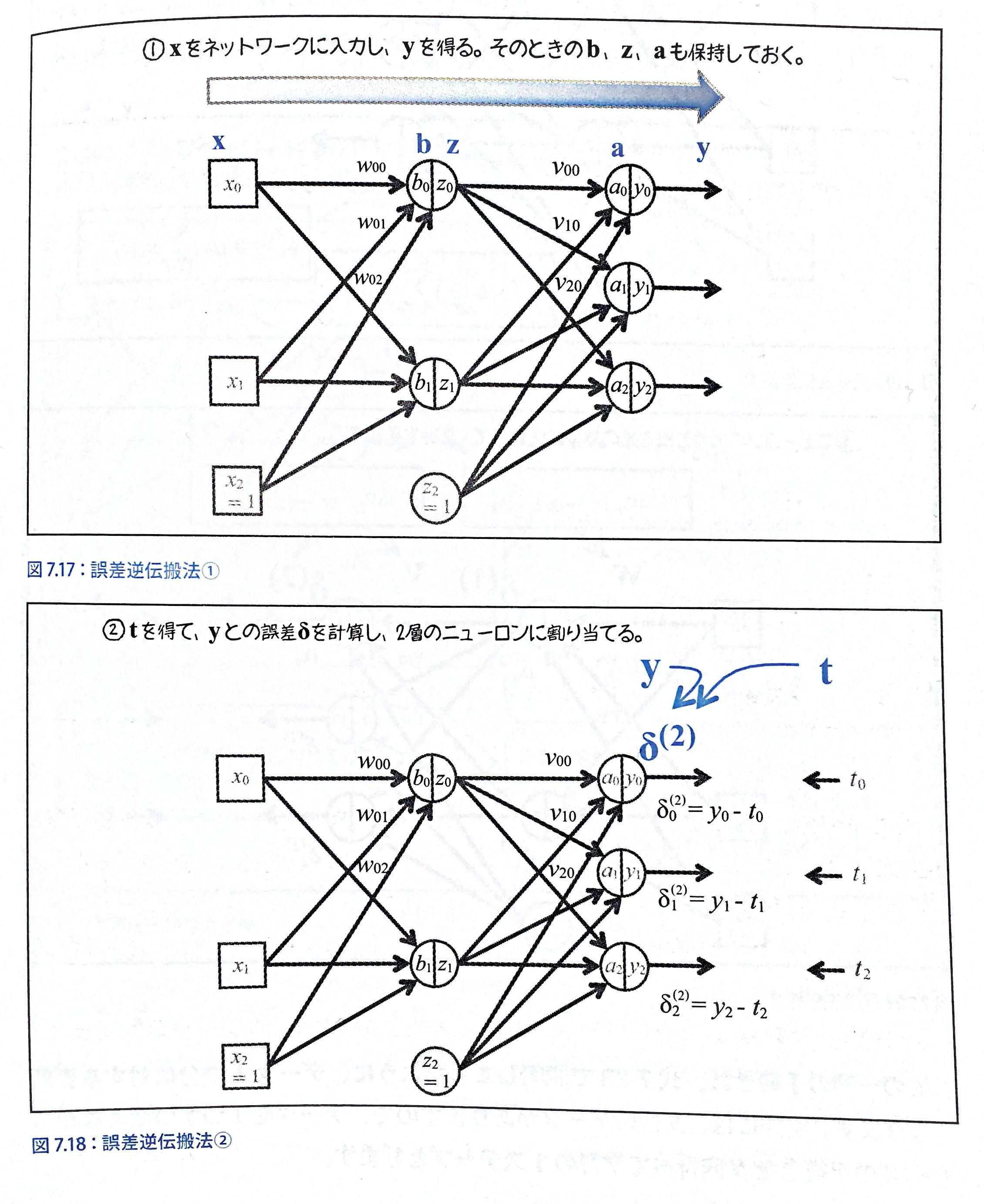
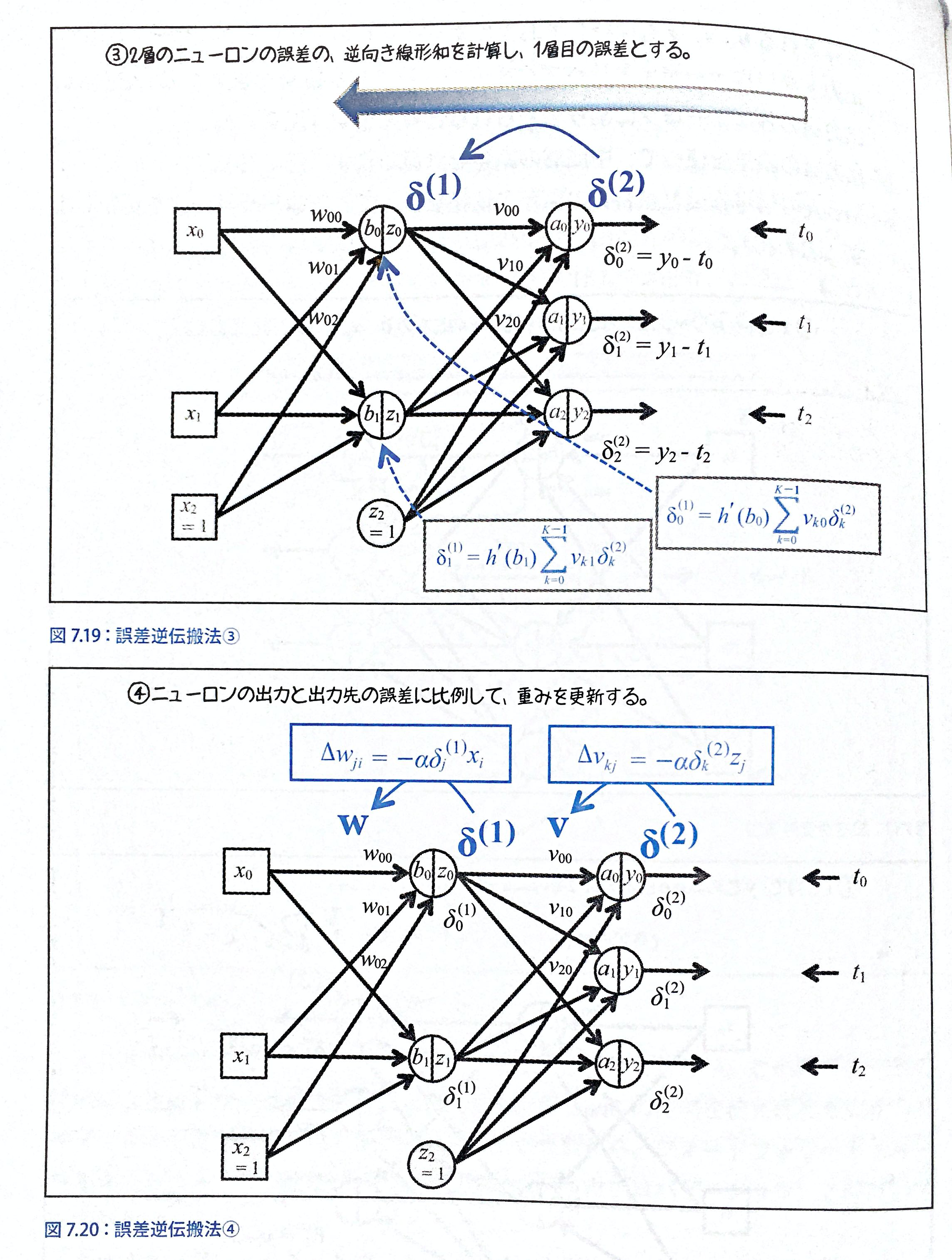
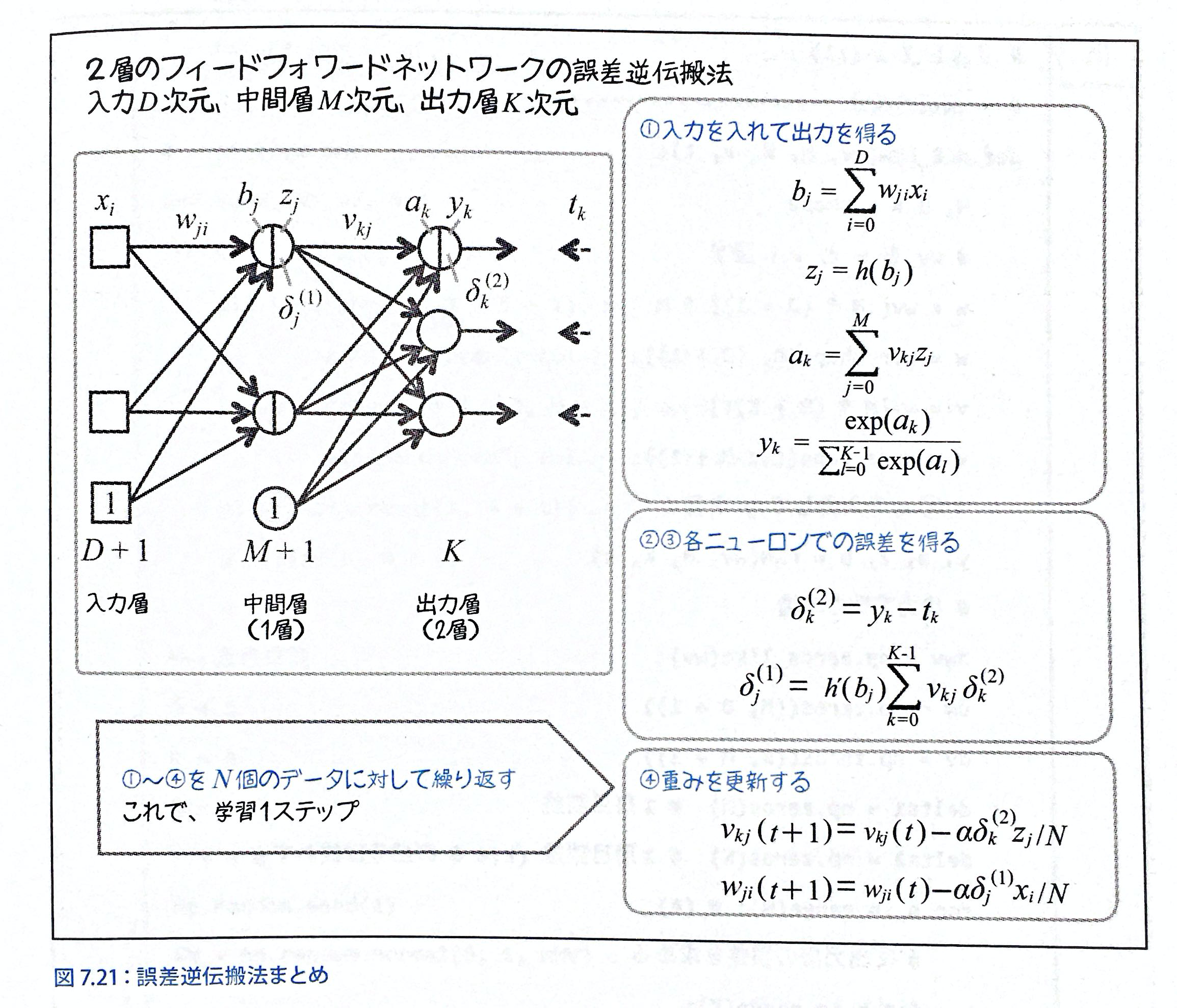
$$P284~ 誤差逆伝播法まとめ
誤差逆伝播法で行いたいことは、w,vなどの重みパラメータの最適化であり、逆向きに伝播させることでそれを可能にしている。
・最初の$h'(b_j)$は、シグモイド関数で変換されたものなので、$b_j$は0~1の値をとっている、そのため、この値は常に正の値をとる。
・$\frac{\partial{E}}{\partial{a_k}}=
\delta_{k}^{(2)}=
(y_k-t_k)h'(a_k)$なので、出力層の出力yに重みvをかけて集めてきているものです。(出力層での誤差が大きければ、v*(大きい値)となり、vが大きく働く。)①では、まず、適当にw,vを設定して、出力yを得る。
②教師信号のtがあるので、そのtとyを比較する。
③今まで導出した式を用いて誤差を逆向きに伝播する。具体的には全ての誤差(y-t)と重みv(2層目)をかけて総和をとり、それを中間層のシグモイド関数を通した総和$h'(b_0)$をかける。(それが③の図の式)
④誤差が0になるようにw,vを更新する。(誤差がわかったので、その分が0になるようにする。)
誤差逆伝播法式まとめ


- 投稿日:2019-12-30T17:21:50+09:00
文書のベクトル化を応用して街の「地域色」を可視化する
概要
自然言語処理における文書ベクトル化の手法を応用して、テキストで記述された地域情報をもとに各地域を色分けした地図を作成する、ということを行いました。
具体的には、首都圏の都市計画(整備、開発、保全の方針:いわゆる整開保)の文書をトピックモデル(LDA)で分類した結果を、RGB値で地図上に表現するというものです。
これにより、「この地域とあの地域は地理的には離れているけど意外と同じ様な特性がある」といった概念的な発見に繋げられないか、と考えて実施しています。
現状はデータが整理しきれておらず歯抜け状態ですが、例えば茨城県は紫色っぽいのが多いのに対し、千葉県・埼玉県は緑・茶系が多い。しかし、埼玉でも秩父など西側は茨城県と近い色を示しています。また君津と所沢なども意外と近そう。なぜ埼玉市の中心(大宮)も紫なのかは謎、、などなど。データ数が増えれば精度の納得感は向上するかもしれません。
元のデータ
国土交通省都市計画マスタープランリンク集から千葉・埼玉・茨城の都市計画文書を取り繕ってきました。ただし、全ての地域は網羅できておらず、あくまでサンプルとなります。こんな感じのデータセット(CSV形式)をインプットとして作成しました。
name description 1 竜ヶ崎・牛久 竜ヶ崎・牛久都市計画(龍ケ崎市,牛久市,利根町)都市計画区域の〜(略)〜近隣都市間の連携を強化し,豊かな自然・田園環境と共生しながら,職・住が一体となった〜 (略) 2 飯能市 飯能都市計画(飯能市)都市計画区域の〜(略)〜公共交通の利用促進やみどりの創出などにより、低炭素社会の実現を図る。地域の個性ある発展〜 (略) 文書のベクトル化
実際に作成したコードは下記となります。MeCabで形態素解析、gensimでトピックモデルによるベクトル化、scikit-learnでTSNEによる次元削減を行っています。改善点は多いかもですが、その辺りは随時修正したいと思います。
- 実行環境>> OS: MacOS Catalina | 言語: python3.6.6
visualizer.pyfrom sklearn.manifold import TSNE from gensim import corpora, models import string import re import MeCab import pandas as pd import numpy as np #Text Tokenizer by MeCab def text_tokenizer(text): token_list = [] tagger = MeCab.Tagger() tagger.parse('') node = tagger.parseToNode(text) while node: pos = node.feature.split(",") if pos[0] in ["名詞", "動詞", "形容詞"]: #target word-class if pos[6] != '*': #lemma is added when it exists token_list.append(pos[6]) else: token_list.append(node.surface) node = node.next return list(token_list) #Loading input dataset df = pd.read_csv('input.csv', encoding="utf-8") df['text'] = df['description'] #set target column #Remove https-links df['text_clean'] = df.text.map(lambda x: re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', "", x)) #Remove numerals df['text_clean'] = df.text_clean.map(lambda x: re.sub(r'\d+', '', x)) #Converting all letters into lower case df['text_clean'] = df.text_clean.map(lambda x: x.lower()) #Creating DataFrame for Token-list df['text_tokens'] = df.text_clean.map(lambda x: text_tokenizer(x)) #LDA np.random.seed(2000) texts = df['text_tokens'].values dictionary = corpora.Dictionary(texts) corpus = [dictionary.doc2bow(text) for text in texts] ldamodel = models.ldamodel.LdaModel(corpus, id2word=dictionary, num_topics=20, passes=5, minimum_probability=0) ldamodel.save('lda_bz.model') print(ldamodel.print_topics()) #Converting Topic-Model result into numpy matrix hm = np.array([[y for (x,y) in ldamodel[corpus[i]]] for i in range(len(corpus))]) #Dimensionality reduction by tsne tsne = TSNE(n_components=3, init='pca', verbose=1, random_state=2000, perplexity=50, method='exact', early_exaggeration=120, learning_rate=200, n_iter=1000) embedding = tsne.fit_transform(hm) x_coord = embedding[:, 0] y_coord = embedding[:, 1] z_coord = embedding[:, 2] #RGB conversion with normalization def std_norm(x, axis=None): xmean = x.mean(axis=axis, keepdims=True) xstd = np.std(x, axis=axis, keepdims=True) y = (x-xmean)/xstd min = y.min(axis=axis, keepdims=True) max = y.max(axis=axis, keepdims=True) norm_rgb = (y-min)/(max-min) * 254 result = norm_rgb.round(0) return result x_rgb = std_norm(x_coord, axis=0) y_rgb = std_norm(y_coord, axis=0) z_rgb = std_norm(z_coord, axis=0) embedding = pd.DataFrame(x_coord, columns=['x']) embedding['y'] = pd.DataFrame(y_coord) embedding['z'] = pd.DataFrame(y_coord) embedding["r"] = pd.DataFrame(x_rgb) embedding["g"] = pd.DataFrame(y_rgb) embedding["b"] = pd.DataFrame(z_rgb) embedding['description'] = df.description #export to csv embedding.to_csv("output.csv", encoding="utf_8")
基本的なコンセプトは、自然言語処理においてよく行われる”文書ベクトルの3次元可視化”を実施し、その3次元ベクトル(x,y,z値)をRGB値に変換しています。
今回、文書のベクトル化ではトピックモデルを採用しています。その理由として、その他のベクトル化手法(例えばtf-idfやword2vecベース)では次元削減後のxyz値に外れ値が出てくるケースが多く、0〜255のRGB値に変換した際にその影響が大きすぎたためです。トピックモデルの場合、パラメータを適切に設定すれば外れ値が生じにくく、この問題をクリアできると考えました。
地図上での可視化
文書情報をRGB値に変換したあとは、各市町村のRGB値をマップ上で可視化します。
私の場合、QGISで地理情報との紐付けを行い、Leafletを使って描画しました。こちらは今回は省略しますが要すれば別記事にて詳述します。QGISで属性情報にあるRGB値をそのまま色で表現する方法があるのか、どなたかご存知であれば教えてください。
留意点と今後の課題
文書ベクトルは大まかに言って、語られている内容(単語の出現傾向やトピックなど)が近ければベクトルとしても近い距離に現れるため、それを色に変換すれば、似た様な色合いの街は語られている内容も近いと判断できるかなと考えています。このあたり、もしカウンターパンチがあれば謹んでお受け致しますのでご指摘ください。
この色は地域同士の相対的な関係性を示すため、初期値を変えて解析をするとその度に色が変わります。「毎年この作業を実施して経年で変化を追う」といった場合に使いづらいので、このあたりの解決策も模索したい。
今回とりあえず試験的に都市計画文書を用いていますが、まだ全ての市町村をカバーできていないことだけでなく、それ以前にこれらが「街の特色」を表しているかというと、一般的な感覚とは乖離があると思います。ゆくゆくは、観光客の声や住民参加型ワークショップの協議録などを反映させたものができたら面白いと思っています。

- 投稿日:2019-12-30T16:45:58+09:00
年賀状作成をPythonに任せたかった
年末
僕自身は年賀状を毎年作成するのを諦めたのですが、アルバイトで家族の分の年賀状を毎年パソコンでつくっています。毎年この時期になるとExcelとワードの差し込み印刷と格闘しながら年賀状を作っているのですが...
Excelのお気持ちが理解できないので、もはやPandasで年賀状の住所録管理と宛名作成したい?
— Capchii (@Capchii) December 28, 2019
- Excelの関数ワカラーン、せっかく勉強してるしPandasでやらせてほしい。
- 差し込み印刷の柔軟さが微妙、例えば差出人とかも連名で場合分けしたい
...というわけで、Pythonで年賀状作成をしてみることにしました。
やろうとしたこと
- Pandasで住所録データの前処理
- OpenCVではがきの印刷位置指定 (住所とか郵便番号とか)
- Pillowで宛名面・通信面作成
- 印刷 (失敗)
住所録データの前処理
ダミーデータ
まず、実験用にダミーの住所録データを作ります。
https://yamagata.int21h.jp/tool/testdata/
こちらで50人分のアドレスを作り、CSVにしました。import pandas as pd df = pd.read_csv("address.csv") df.columns = ["index", "name", "address"]
名前と住所の分割
次に、今後の連名対応の為、氏名を姓と名に分けます。また、住所をいい感じに段組するために住所を2分割します。具体的には
- 建物・マンション名がない場合→住所の数字以降 (丁目, 番地など) で分割
- 建物・マンション名がある場合→建物・マンション名で分割
という感じで分けていきます
df["sei"]=df["name"].str.split(expand=True)[0] df["mei"]=df["name"].str.split(expand=True)[1] import re def split_address(address): if " " in address: pos = int(address.find(" ")) return [address[:pos],address[pos:]] else: pos = int(re.search("\d", address).start()) return [address[:pos],address[pos:]] df["address_1"] = df.address.apply(lambda x: split_address(x)[0]) df["address_2"] = df.address.apply(lambda x: split_address(x)[1])先にdataframeの列を初期化してれば、二列いっぺんに代入できるらしいですね
郵便番号取得
こちらの郵便番号取得APIを使います。map関数を使うと続々とリクエストを送ってしまいますので、適度にsleepを挟みながら取得していきます。
import json import requests import time def get_postal(address): pos = int(re.search("\d", address).start()) address = address[:pos] try: res = requests.get("http://geoapi.heartrails.com/api/json?method=suggest&matching=prefix&keyword="+address) postal = json.loads(res.text)["response"]["location"][0]["postal"] time.sleep(1) return postal except: return "" df["postal"] = df["address"].map(lambda x: get_postal(x))最終的にこんな感じになります。
get_postal()は例外が発生した場合、空の郵便番号を返すようになっています。リクエストの送りすぎの可能性もありますが、住所の妥当性チェックもできると思います。はがきの印刷位置指定
こんな感じにはがきを一枚用意し、住所とかを印刷したい箇所を黒塗りにし、雑に写真を撮ります。
アフィン変換
これをまずアフィン変換による台形補正で、はがきを綺麗に抜き出します。コードはこちらのサイトのコードをほぼそのまま使わせていただきました。
まず輪郭抽出
img = np.array(Image.open("nengajo.jpg")) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) ret,thresh = cv2.threshold(gray,128,255,cv2.THRESH_BINARY) contours, hierarchy = cv2.findContours(thresh , cv2.RETR_TREE, cv2.RETR_LIST) new_img = img.copy() plt.imshow(cv2.drawContours(new_img, contours, -1, (128,0,0), 30))
次に、一番 (面積の) 大きな輪郭の四隅を抽出します。
menseki=[ ] for i in range(0, len(contours)): menseki.append([contours[i],cv2.contourArea(contours[i])]) menseki.sort(key=lambda x: x[1], reverse=True) epsilon = 0.1*cv2.arcLength(menseki[0][0],True) approx = cv2.approxPolyDP(menseki[0][0],epsilon,True) new_img = img.copy() plt.imshow(cv2.drawContours(new_img, approx, -1,(0, 0, 255),100))
最後に、はがきを真正面から見るようにアフィン変換し、切り抜きます。また、はがきの推奨ピクセルサイズが
2362x3496pxということなので、それに合わせます。approx=approx.tolist() left = sorted(approx,key=lambda x:x[0]) [:2] right = sorted(approx,key=lambda x:x[0]) [2:] left_down= sorted(left,key=lambda x:x[0][1]) [0] left_up= sorted(left,key=lambda x:x[0][1]) [1] right_down= sorted(right,key=lambda x:x[0][1]) [0] right_up= sorted(right,key=lambda x:x[0][1]) [1] perspective1 = np.float32([left_down,right_down,right_up,left_up]) perspective2 = np.float32([[0, 0],[1378, 0],[1378, 2039],[0, 2039]]) psp_matrix = cv2.getPerspectiveTransform(perspective1,perspective2) img_psp = cv2.warpPerspective(img, psp_matrix,(1378,2039)) plt.imshow(img_psp)
綺麗に抜き出せましたね、すごい!
塗りつぶし領域の抽出
OpenCVの
cv2.threshold()により画像の閾値処理をし、塗りつぶした領域をマスクします。cv2.threshold()はグレースケールの画像を投げる事もできますが、HEIGHT×WIDTHの形の、uint8のnumpy行列ならなんでも投げられます。また、自分の経験上、閾値処理はBGRでやるよりもHSVのどれかに注目してやるとうまくいくことが多いです。
今回画像をHSVの3チャンネル画像HEIGHT×WIDTH×3にまず変換します、そのうち、V成分のチャンネルのみを抜き出し、HEIGHT×WIDTHの行列を閾値処理する事で、うまく塗りつぶした部分を抽出することができました。_, v_img = cv2.threshold(cv2.cvtColor(img_psp,cv2.COLOR_BGR2HSV)[:,:,2], 128, 255, cv2.THRESH_BINARY) plt.imshow(v_img)
ここで、マスクの輪郭を抽出します。輪郭を抽出する前に、マスク自体のノイズをまずモルフォロジー変換で除去します。また、輪郭の面積が一定以下のものをリスト内包表記でフィルタしています。
_, v_img = cv2.threshold(cv2.cvtColor(img_psp,cv2.COLOR_BGR2HSV)[:,:,2], 128, 255, cv2.THRESH_BINARY) kernel = np.ones((8, 8),np.uint8) v_img = cv2.morphologyEx(v_img, cv2.MORPH_CLOSE, kernel) contours, hierarchy = cv2.findContours(v_img, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE) menseki=[ ] for i in range(0, len(contours)): menseki.append([contours[i],cv2.contourArea(contours[i])]) menseki = [m[0] for m in menseki if m[1] > 800] contours=menseki cont_vis = cv2.drawContours(v_img, contours, -1, (128,0,0), 30) for idx, con in enumerate(contours): cont_vis = cv2.putText(cont_vis, str(idx), (con[2][0][0], con[2][0][1]), cv2.FONT_HERSHEY_PLAIN, 3, (64, 64, 64), 5) plt.figure(figsize=(15,20)) plt.imshow(cont_vis)輪郭抽出の結果はこんな感じ
ここで、モルフォロジー変換をかけない結果はこんな感じになります。
今回輪郭の誤検知はあまりありませんが、マスクに乗っている細かいノイズが除去されていることがわかります。
あとはこの画像を見ながら、どのデータをどこに配置したいか定義します。
address_conts = { "to_postal":list(map(cv2.boundingRect, [contours[17],contours[18],contours[16], contours[14], contours[12], contours[13], contours[15]])), "to_address1":cv2.boundingRect(contours[10]), "to_address2":cv2.boundingRect(contours[9]), "to_name":cv2.boundingRect(contours[11]), "from_address":cv2.boundingRect(contours[8]), "from_name":cv2.boundingRect(contours[7]), "from_postal":list(map(cv2.boundingRect, [contours[6],contours[0],contours[2], contours[3], contours[5], contours[4], contours[1]])), }
cv2.bouundingRect()で輪郭を外接する長方形で囲い、xywh座標 ($(x,y)$は長方形の左上の座標, $(w,h)$は長方形のの縦横の長さ) で保持します。この結果を見て思ったのですが、cv2.findContours()って画像の下にあるものから輪郭を検出してるんですかね...
印刷面の作成
Pillowで印刷面を作っていきます。
宛名面
先ほどの座標をもとに、文字を縦書きで置いていきます。とりあえず今回は住所録から一件だけ取り出して作ってみます。「Pillow 縦書き」とかでググるとこちらの記事が出てくるのですが、この記事の方のおかげで、Pillowのv6以上ではttb指定で縦書きが可能になっています。あとはraqmの環境構築が必要です。フォントの.otfファイルは今回の実行ディレクトリ (jupyter labを使いました) におきます。
def calc_start_pos(cont): x = cont[0] y = cont[1] return (x, y) from PIL import Image, ImageDraw, ImageFont data = df.loc[2] fnt1 = ImageFont.truetype("GenEiAntique.otf", 80) fnt2 = ImageFont.truetype("GenEiAntique.otf", 150) fnt3 = ImageFont.truetype("GenEiAntique.otf", 50) address = Image.new('RGBA', (v_img.shape[1],v_img.shape[0]), (255,255,255,255)) d = ImageDraw.Draw(address) d.text(calc_start_pos(address_conts["to_address1"]), data["address_1"].replace("-","|"), font=fnt1, fill=(0,0,0,255), direction="ttb") d.text(calc_start_pos(address_conts["to_address2"]), data["address_2"].replace("-","|"), font=fnt1, fill=(0,0,0,255), direction="ttb") d.text(calc_start_pos(address_conts["to_name"]), data["name"] + " 様", font=fnt2, fill=(0,0,0,255), direction="ttb") d.text(calc_start_pos(address_conts["from_address"]), "東京都新宿区歌舞伎町127-0-1".replace("-","|"), font=fnt3, fill=(0,0,0,255), direction="ttb") d.text(calc_start_pos(address_conts["from_name"]), "某山某太郎", font=fnt1, fill=(0,0,0,255), direction="ttb") for num, rect in zip(data["postal"], address_conts["to_postal"]): d.text(calc_start_pos(rect), num, font=fnt1, fill=(0,0,0,255), direction="ttb") for num, rect in zip("1600021", address_conts["from_postal"]): d.text(calc_start_pos(rect), num, font=fnt1, fill=(0,0,0,255), direction="ttb")
calc_start_pos()で文字を書き始める位置を計算しようと思ったのですが、先ほど抽出した矩形の左上座標をそのまま指定すればうまく配置できました。こんな感じで描いた宛名面を、先ほどのはがきに載せてみます。あらかじめ黒く塗り潰したところはマスクを使い、はがきの色っぽく塗り戻しています。
address_array = np.array(address) final_image = np.zeros_like(img_psp) letter_image = img_psp.copy() for i in range(3): letter_image[:,:,i] = np.where( v_img < 129, 222, img_psp[:,:,i] ) for i in range(3): final_image[:,:,i] = np.where( address_array[:,:,i] ==0, address_array[:,:,i], letter_image[:,:,i] ) plt.figure(figsize=(7,10)) plt.imshow(final_image)
細かい調整はまだできそうですが、そこそこいい感じになりましたね。
np.where()はマスクを元にあれこれ処理するときに便利です。裏面
いい感じにOpenCVで書きます。
ura = np.zeros_like(final_image)+255 pts = np.array([[400,500],[1100,500],[750,1500]], np.int32) pts = pts.reshape((-1,1,2)) ura = cv2.fillPoly(ura,[pts],(128,128,128)) ura = cv2.circle(ura,(400,500), 200, (72, 72, 72), -1) ura = cv2.circle(ura,(1100,500), 200, (72, 72, 72), -1) ura = cv2.circle(ura,(750,1500), 50, (72, 72, 72), -1) ura = cv2.circle(ura,(750,1500), 50, (72, 72, 72), -1) ura = cv2.circle(ura,(670,900), 50, (72, 72, 72), -1) ura = cv2.circle(ura,(850,900), 50, (72, 72, 72), -1) ura = cv2.line(ura,(750,1500),(900,1400),(72, 72, 72),20) ura = cv2.line(ura,(750,1500),(900,1500),(72, 72, 72),20) ura = cv2.line(ura,(750,1500),(900,1600),(72, 72, 72),20) ura = cv2.line(ura,(750,1500),(600,1400),(72, 72, 72),20) ura = cv2.line(ura,(750,1500),(600,1500),(72, 72, 72),20) ura = cv2.line(ura,(750,1500),(600,1600),(72, 72, 72),20) ura = cv2.putText(ura, "A Happy New Year!!", (50, 1800), cv2.FONT_HERSHEY_PLAIN, 8, (64, 64, 64), 10) ura = cv2.putText(ura, "2020", (450, 2000), cv2.FONT_HERSHEY_PLAIN, 13, (64, 64, 64), 20) plt.figure(figsize=(10,15)) plt.imshow(ura)?
印刷
コマンドラインの
lprコマンドから印刷を試みます。指定できるオプションはlpoptions -p [プリンタ名] -lでコマンドラインから確認できます。あとはご使用のプリンターの公式サイトを見れば、いい感じに印刷できるはず...?import subprocess from PIL import Image from io import BytesIO buf = BytesIO() Image.fromarray(ura).save(buf, 'PNG') # print out p = subprocess.Popen('lpr -P Canon_TS5100_series -o media=Postcard -o InputSlot=rear -o MediaType=any'.split(), stdin=subprocess.PIPE) p.communicate(buf.getvalue()) p.stdin.close() buf.close()おもて面も同様に指定すれば、いい感じに印刷できるはずです。
結果
↓裏面、いい感じ
↓おもて面、二回印刷してフチなしとフチありを試したのですがいうまくいかず...
印刷までこぎつけたのですが、サイズが合わない悔しい結果になってしまいました。アフィン変換したときに小さく切り出してしまい、誤差が生じている可能性や、プリンタ側で拡大縮小している可能性があります... (フチなしの時とフチありの時のちょうど中間に印刷できれば、ちょうどよくなるはず?)
まとめ
印刷がうまくできませんでした。どなたか知見をお持ちでしたら教えていただきたく思います。ExcelとWord万々歳。良いお年を!









- 投稿日:2019-12-30T16:31:48+09:00
FlaskとReact使ったTwitter認証をWebSocket使ってめっちゃ強引に行う
概要
reactにおける認証は下記のページなどで行っている人が複数人いる。
React Authentication with Twitter, Google, Facebook and Github
ReactでSPAを作り、Twitter認証(OAuth)でログインする。バックエンドはRails
ただ、自分は馬鹿なのでいまいちよくわからなかった(後、上記ページはサーバーサイドがexpressとかRailsでflaskは見つからなかった)。
そのため、小手先でめっちゃ強引な認証を書いた。WebSocket使うのもReactのuseEffect使うのも、Flask使うのも初めてなので、参考程度にみてもらえると良い(後々、ちゃんとしたコードで書き直したい)
流れ
今回は「連携アプリ認証」のボタンを押すと連携が始まるようになっているので、そこの部分は適当に変えて欲しい。
- 認証を行うボタンをおす(js内handleClick関数)
- サーバーに"Twitter"の文字列が飛ぶ(js内handleClick関数)
- URLをサーバーが返す(Twitter認証用)(python内pipe関数)
- jsでURLで移動(js内ws.onmessage = function(e)内)
- Twitter認証画面
- 認証する
- クライアント側のページにredirect
- サーバーにauth_tokenとauth_verifierの情報がいく(useEffect内ws.onopenより)
- サーバーはtokenとverifierを使ってaccess_token_secretを作成する(python内user_timeline)
- Twitterから認証ユーザの最新のタイムライン一件を持ってくる(python内user_timeline)
認証などにはtweepyを用いている。
実際のコード
index.pyimport os import json import sys import tweepy from flask import Flask, session, redirect, render_template, request, jsonify, abort, make_response from flask_cors import CORS, cross_origin from os.path import join, dirname from gevent import pywsgi from geventwebsocket.handler import WebSocketHandler app = Flask(__name__) CORS(app) #勝手に決める app.secret_key = "" #TwitterAppから持ってくる CONSUMER_KEY = "" CONSUMER_SECRET = "" @app.route('/pipe') def pipe(): if request.environ.get('wsgi.websocket'): ws = request.environ['wsgi.websocket'] while True: message = ws.receive() # print(message) #ボタンを押すとTwitterがwebsocketで送られるので送られたら発火 if message == "Twitter": auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET) try: # 連携アプリ認証用の URL を取得 redirect_url = auth.get_authorization_url() session['request_token'] = auth.request_token except Exception as ee: # except tweepy.TweepError: sys.stderr.write("*** error *** twitter_auth ***\n") sys.stderr.write(str(ee) + "\n") #websocketでurlを送り返す ws.send(redirect_url) ws.close() #return無いとエラーが出るため return redirect_url elif message != None: messages = json.loads(message) # print(messages) user_timeline(messages, ws) def user_timeline(auths, ws): # tweepy でアプリのOAuth認証を行う auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET) verifier = str(auths["oauth_verifier"]) # Access token, Access token secret を取得. auth.request_token['oauth_token'] = str(auths["oauth_token"]) auth.request_token['oauth_token_secret'] = verifier try: access_token_secret = auth.get_access_token(verifier) except Exception as ee: print(ee) return "" print(access_token_secret) # tweepy で Twitter API にアクセス api = tweepy.API(auth) # user の timeline 内のツイートのリストを1件取得して返す for status in api.user_timeline(count=1): text = status.text # user の timeline 内のツイートのリストを1件取得して返す ws.send(text) ws.close() def main(): app.debug = True server = pywsgi.WSGIServer(("", 5000), app, handler_class=WebSocketHandler) server.serve_forever() if __name__ == "__main__": main()app.jsimport React from 'react'; import './App.css'; import { useState, useEffect } from 'react'; function App() { const [flag, setFlag] = useState(false); const [userData, setUserData] = useState(''); const [data, setData] = useState(''); //webSocketとの通信 const ws = new WebSocket('ws://localhost:5000/pipe'); // レンダー前にwsがopenした後にurl内のverifierを返す useEffect(() => { ws.onopen = event => { if (userData == false && window.location.search.includes('verifier')) { setFlag(true); ws.send(getParam('oauth_verifier')); } }; setUserData('true'); }); //url内の特定の要素を持ってくるためのコード function getParam(name, url) { if (!url) url = window.location.href; name = name.replace(/[\[\]]/g, '\\$&'); var regex = new RegExp('[?&]' + name + '(=([^&#]*)|&|#|$)'), results = regex.exec(url); if (!results) return null; if (!results[2]) return ''; return decodeURIComponent(results[2].replace(/\+/g, ' ')); } // サーバー側からメッセージが送られてきた際に受け取り、関数を発動する(Twitterの認証用URLに飛ぶため) ws.onmessage = e => { console.log(e); if (e.data.includes('oauth_token')) { window.location.href = e.data; } else { console.log(e); setData(e.data); } }; //クリックした時(今回は文字をbuttonをクリックしたらサーバーにTwitterのもじが送られる) function handleClick() { console.log('rest'); ws.send('Twitter'); } console.log(flag); //レンダー要素の切替 let render = flag ? ( <div>{data}</div> ) : ( <button onClick={handleClick}>連携アプリ認証</button> ); return <>{render}</>; } export default App;正直、めっちゃ適当なコードなので参考にできればする程度がちょうどいいと思う(後、websocketのエラーが出る。closedの状態で通信を行ってしまっているためだと思うので修正できたら編集します)
- 投稿日:2019-12-30T16:22:51+09:00
TensorFlow2 + Keras による画像分類に挑戦2 ~入力データを詳しくみてみる~
はじめに
手書き数字画像(MNIST)の分類を、Google Colaboratory 環境の TensorFlow2 + Keras でやってみよう(+Pythonや深層学習の理解も深めよう)という内容です。前回 は、TensorFlow の 公式HPのチュートリアル からサンプルコードを持ってきて、実際に実行してみる、というところまでやりました。
なお、MNIST(エムニスト)は、「図解速習DEEP LEARNING(著:増田知彰)」によれば、次のような由来があるデータだそうです。ここでは直接関係ありませんが、生のデータは、http://yann.lecun.com/exdb/mnist/ から入手できます。
NIST(National Institute of Standards and Technology database)の1つに、米国の国勢調査局職員と高校生が手書きした数字を持つデータセットがありました。それを機械学習でより使いやすく改変(Modified)したものが、"M"NISTです。
今回は、前回に示したサンプルコードのなかの トレーニング用データ(
x_train、y_train)、テスト用データ(x_test、y_test)について、その内容を詳しく見てみたり、matplotlib を使って可視化してみたりします。それにあたり、まずは「多クラス分類問題」と「深層学習」について整理しておきます(トレーニング用データとテスト用データの位置づけを確認します)。
多クラス分類問題
手書き数字の認識は、多クラス分類問題というものに属します。多クラス分類問題とは、入力データに対して、そのカテゴリ(クラス)を予測するという問題です。カテゴリは、問題設定のなかで「犬」「猫」「鳥」のようにあらかじめ与えられており、入力データ(例えば画像)に対してそれが「犬」「猫」「鳥」のうち、どのカテゴリになるかを求める、といった問題になります。
多クラス分類問題に対して様々なアプローチが提案されていますが、ここでは深層学習(ディープラーニング)を使って解決していきます。
深層学習
深層学習(ディープラーニング)は、教師付き機械学習という手法に属します。教師付き機械学習は、大きく「学習フェーズ」と「予測フェーズ(推論フェーズ、適用フェーズ)」という2段階から構成されます。
はじめに、学習フェーズでは、入力データと正解データ(=教師データ、正解データ、正解値、正解ラベル)をペアにしたものをモデルに大量に与えて、それらの関係を学習させます。これらの入力データと正解データのペア集合をトレーニング用データ(=学習用データ)と呼びます。そして、トレーニング用データを使って学習させたモデルを「学習済みモデル」といいます。
つづく予測フェーズでは、学習済みモデルに対して、未知の入力データを与えて出力の予測(Predict)を行ないます。多クラス問題であれば、カテゴリ(例えば「犬」など)が予測出力となります。
そして、「学習済みモデルにどの程度の性能があるか」を測るのが評価(Evaluate)というプロセスになります。評価では、まず、トレーニングに使ったものとは異なる入力データと正解データを用意して、このうち入力データだけを学習済みモデルに与えて、予測データを得ます。そして、この得られた予測データについて、正解データを使って答え合わせ、採点をして評価値とします。具体的な評価指標としては、前回出てきた正答率(accuracy)、損失関数値(loss)のほかに、適合率や再現率など必要に応じて様々なものが採用されます。
MNISTのトレーニング用データ、テスト用データ
次のコードで、MNISTデータをダウンロードして、各変数(
x_train、y_train、x_test、y_test)に格納しています(プログラム全体は前回 を参照)。mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data()ここで、
*_trainがトレーニング用(学習用)に割り当てられた入力&正解データ、*_testがテスト用(モデル評価用)に割り当てられた入力&正解データとなります。トレーニング用は 60,000件、テスト用は 10,000件 あります。また、
x_***には入力データ(つまり手書き画像を表すデータ:28x28の256段階グレースケール)、y_***には正解データ(「0」から「9」までのカテゴリ)が、配列的に格納されています。まずは、実際に、それぞれが 60,000件、10,000件 のデータから構成されていることを
len()で確認してみます。# トレーニング用データ print(len(x_train)) # 実行結果 -> 60000 print(len(y_train)) # 実行結果 -> 60000 # テスト用データ print(len(x_test)) # 実行結果 -> 10000 print(len(y_test)) # 実行結果 -> 10000次に、各データのタイプ(型)を確認してみます。
print(type(x_train)) # 実行結果 -> <class 'numpy.ndarray'> print(type(y_train)) # 実行結果 -> <class 'numpy.ndarray'> print(type(x_test)) # 実行結果 -> <class 'numpy.ndarray'> print(type(y_test)) # 実行結果 -> <class 'numpy.ndarray'>次に、
y_train(=トレーニング用の正解データ)の内容を確認してみます。print(y_train) # 実行結果 -> [5 0 4 ... 5 6 8]0件目のデータの正解値は「5」、1件目のデータの正解値は「0」・・・、59,999件目のデータの正解値は「8」ということが分かりました。
次に、
x_train(=トレーニング用の手書き画像を表すもの)の内容を確認してみます。全件を表示するととんでもないことになるので、先頭のx_train[0]のみを対象にします。(x_train, y_train), (x_test, y_test) = mnist.load_data() print(x_train[0].shape) # 実行結果 -> (28, 28) print(x_train[0]) # 実行結果 -> 下記参照numpy.ndarray のデータは、
.shapeで大きさが確認できます。(28, 28)、ということは、x_train[0]が28行28列の2次元配列で構成されていることが分かります。また、print(x_train[0])の出力は次のようになります。薄眼で眺めていただくと、ややいびつな手書きの「5」という数字が浮かんできます。これは、
y_train[0]に格納されている「5」と一致しますね。
各ピクセルデータは、0から255の範囲の値で構成されて、0が背景(白)で、255が最も濃い文字部(黒)になっていることが分かります。
60,000個の全てのデータについて、それを確認してみたいと思います。
import numpy as np print(x_train.min()) # 最小値を抽出 # 実行結果 -> 0 print(x_train.max()) # 最大値を抽出 # 実行結果 -> 255すべてのデータは0から255の範囲で構成されていることが確認できます。
ところで、60,000件のトレーニング用データのなかに、「0」から「9」までの各数字は何件ずつ存在するのでしょうか?基本的には、0から9までの10パターンがほぼ均等に存在していると思いますが、確認してみます。集計にpandasを利用します。
pandas版import pandas as pd tmp = pd.DataFrame({'label':y_train}) tmp = tmp.groupby(by='label').size() display(tmp) print(f'総数={tmp.sum()}')実行結果label 0 5923 1 6742 2 5958 3 6131 4 5842 5 5421 6 5918 7 6265 8 5851 9 5949 dtype: int64 総数=60000「5」が少なくて「1」が多いといった多少のバラつきがあるようです。
なお、次のように pandas を使わなくても求めることができます。
numpy版import numpy as np tmp = list([np.count_nonzero(y_train==p) for p in range(10)]) print(tmp) # 実行結果 -> [5923, 6742, 5958, 6131, 5842, 5421, 5918, 6265, 5851, 5949] print(f'総数={sum(tmp)}') # 実行結果 -> 総数=60000次回
- matplotlib を使って入力データをグラフィカルに表示するところまで進めたかったのですが、記事が長くなってしまったので、それは次回にしたいと思います。




- 投稿日:2019-12-30T16:14:43+09:00
CloudComposerでML Pipelineを構築してみた
本記事でやること
Google Cloud PlatformのCloud Composerを用いて以下のような機械学習を行う際の一連のタスクをオーケストレーションします。
- BigQueryから抽出したTrain/TestデータをCSVファイルにしてGCSへ置く
- ML EngineへTrainingのジョブを送る
- モデルのデプロイを行う
- ML EngineへPredictionのジョブを送る
- GCSに置かれているPrediction結果をBigQueryへLoadする
作成するAirflow上のノードとワークフローは下図の様になります。
対象読者
- CloudComposer/AirFlowを触ったことのある方
- ML Engine/DataFlowを触ったことのある方
使用言語とフレームワーク
- Python 3.6.3
- tensorflow 1.15
Airflowのバージョン
- 1.10.6
GCPの各サービスのアーキテクチャ
上記AirflowのタスクをGCPのサービスでそれぞれを表現すると以下の様になります。
1. Cloud Composerの環境設定を行う
以下のbashコマンドでは3つのことを行なっています。
1.Cloud Composerの環境構築
Cloud Composerの環境構築時に注意しないといけないこととしては、引数に
--python-version 3を指定することです。デフォルトではpython2系が設定されています。2.airflowへのライブラリーのインストール
冒頭で示したタスク一覧の中でSlackでメッセージをpostする箇所がありました。このタスクを実行する為にairflowに
slackclientライブラリーをインストールする必要があります。
--update-pypi-packages-from-file引数にライブラリーの設定ファイルを指定します。requirements.txtslackclient~=1.3.23.airflow上の環境変数を設定
先述の通り、slackclientライブラリーを使ってslackへメッセージをpostする際に
acccess_tokenが必要になるのでairflowの環境変数にaccess_tokenを設定しおくと便利なので予め設定しておきます。(dagファイルにaccess_tokenをベタ書きするのはあまりよろしくない)#!/usr/bin/env bash ENVIRONMENT_NAME=dev-composer LOCATION=us-central1 # 変数を読み込む eval `cat airflow/config/.secrets.conf` echo ${slack_access_token} # cloud composerの環境作成 gcloud composer environments create ${ENVIRONMENT_NAME} \ --location ${LOCATION} \ --python-version 3 # airflowの環境にライブラリーをインストール gcloud composer environments update ${ENVIRONMENT_NAME} \ --update-pypi-packages-from-file airflow/config/requirements.txt \ --location ${LOCATION} # airflow上の環境変数を設定 gcloud composer environments run \ --location=${LOCATION} \ ${ENVIRONMENT_NAME} \ variables -- \ --set slack_access_token ${slack_access_token} project_id ${project_id}dagファイルの実装
今回作成したdagファイルは以下の通りになっています。
これだけだと説明が不十分なので、タスク毎にコードを切り分けて説明をしていきます。import os import airflow import datetime from airflow.models import Variable from airflow.operators.bash_operator import BashOperator from airflow.operators.dummy_operator import DummyOperator from airflow.contrib.operators.dataflow_operator import DataFlowPythonOperator from airflow.operators.slack_operator import SlackAPIPostOperator from airflow import configuration from airflow.utils.trigger_rule import TriggerRule from airflow.contrib.operators.mlengine_operator \ import MLEngineTrainingOperator, MLEngineBatchPredictionOperator BUCKET = 'gs://your_bucket' PROJECT_ID = Variable.get('project_id') REGION = 'us-central1' YESTERDAY = datetime.datetime.now() - datetime.timedelta(days=1) PACKAGE_URI = BUCKET + '/code/trainer-0.1.tar.gz' OUTDIR = BUCKET + '/trained_model' DATAFLOW_TRAIN_FILE = os.path.join( configuration.get('core', 'dags_folder'), 'dataflow', 'extract_train_data.py') DATAFLOW_PRED_FILE = os.path.join( configuration.get('core', 'dags_folder'), 'dataflow', 'extract_pred_data.py') DATAFLOW_LOAD_FILE = os.path.join( configuration.get('core', 'dags_folder'), 'dataflow', 'load.py') DEFAULT_ARGS = { 'owner': 'Composer Example', 'depends_on_past': False, 'email': [''], 'email_on_failure': False, 'email_on_retry': False, 'retries': 1, 'retry_delay': datetime.timedelta(minutes=5), 'start_date': YESTERDAY, 'project_id': Variable.get('project_id'), 'dataflow_default_options': { 'project': Variable.get('project_id'), 'temp_location': 'gs://your_composer_bucket/temp', 'runner': 'DataflowRunner' } } def get_date(): jst_now = datetime.datetime.now() dt = datetime.datetime.strftime(jst_now, "%Y-%m-%d") return dt with airflow.DAG( 'asl_ml_pipeline', 'catchup=False', default_args=DEFAULT_ARGS, schedule_interval=datetime.timedelta(days=1)) as dag: start = DummyOperator(task_id='start') #### # ML Engineでのtrainingを行うタスク #### job_id = 'dev-train-{}'.\ format(datetime.datetime.now().strftime('%Y%m%d%H%M')) job_dir = BUCKET + '/jobs/' + job_id submit_train_job = MLEngineTrainingOperator( task_id='train-model', project_id=PROJECT_ID, job_id=job_id, package_uris=[PACKAGE_URI], region=REGION, training_python_module='trainer.task', training_args=[f'--output_dir={OUTDIR}', f'--job_dir={job_dir}', '--dropout_rate=0.5', '--batch_size=128', '--train_step=1' ], scale_tier='BASIC_GPU', python_version='3.5' ) #### # modelをdeployするタスク #### BASE_VERSION_NAME = 'v1_0' VERSION_NAME = '{0}_{1}'.\ format(BASE_VERSION_NAME, datetime.datetime.now().strftime('%Y_%m_%d')) MODEL_NAME = 'dev_train' deploy_model = BashOperator( task_id='deploy-model', bash_command='gcloud ml-engine versions create ' '{{ params.version_name}} ' '--model {{ params.model_name }} ' '--origin $(gsutil ls gs://your_bucket/trained_model/export/exporter | tail -1) ' '--python-version="3.5" ' '--runtime-version=1.14 ', params={'version_name': VERSION_NAME, 'model_name': MODEL_NAME} ) #### # ML Engineでバッチ予測を行うタスク #### today = get_date() input_path = BUCKET + f'/preprocess/{today}/prediction/prediction-*' output_path = BUCKET + f'/result/{today}/' batch_prediction = MLEngineBatchPredictionOperator( task_id='batch-prediction', data_format='TEXT', region=REGION, job_id=job_id, input_paths=input_path, output_path=output_path, model_name=MODEL_NAME, version_name=VERSION_NAME ) #### # DataFlowでデータ抽出を行うタスク #### job_args = { 'output': 'gs://your_bucket/preprocess' } create_train_data = DataFlowPythonOperator( task_id='create-train-data', py_file=DATAFLOW_TRAIN_FILE, options=job_args ) create_pred_data = DataFlowPythonOperator( task_id='create-pred-data', py_file=DATAFLOW_PRED_FILE, options=job_args ) #### # DataFlowでBigQueryへデータをloadするタスク #### load_results = DataFlowPythonOperator( task_id='load_pred_results', py_file=DATAFLOW_LOAD_FILE ) post_success_slack_train = SlackAPIPostOperator( task_id='post-success-train-to-slack', token=Variable.get('slack_access_token'), text='Train is succeeded', channel='#feed' ) post_fail_slack_train = SlackAPIPostOperator( task_id='post-fail-train-to-slack', token=Variable.get('slack_access_token'), trigger_rule=TriggerRule.ONE_FAILED, text='Train is failed', channel='#feed' ) #### # SlackへメッセージをPOSTするタスク #### post_success_slack_pred = SlackAPIPostOperator( task_id='post-success-pred-to-slack', token=Variable.get('slack_access_token'), text='Prediction is succeeded', channel='#feed' ) post_fail_slack_pred = SlackAPIPostOperator( task_id='post-fail-pred-to-slack', token=Variable.get('slack_access_token'), trigger_rule=TriggerRule.ONE_FAILED, text='Prediction is failed', channel='#feed' ) end = DummyOperator(task_id='end') start >> [create_train_data, create_pred_data] >> submit_train_job \ >> [post_fail_slack_train, post_success_slack_train] post_fail_slack_train >> end post_success_slack_train >> deploy_model >> batch_prediction \ >> load_results \ >> [post_success_slack_pred, post_fail_slack_pred] >> endBigQueryからのデータ抽出及びGCSへの書き出し
Training Phaseで行なっている最初のタスクです。(以下図の赤枠)
BigQueryからDataFlowを使ってデータの抽出及びGCSの適当なバケットへデータを置くという処理を行なっています。
Dagファイルの説明
定数
DATAFLOW_TRAIN_FILE/DATAFLOW_PRED_FILE
- DataFlowの実行ファイルが置かれているファイルパス
- Cloud Composerの環境構築時に作成された
Bucket内のdagsディレクトリ以下のファイルは数秒間隔でairflowのworkerによって同期されています。定数
DEFAULT_ARGS
dataflow_default_optionsの引数にDataFlow実行時の環境変数を設定します。
DataFlowPythonOperatorクラス
- DataFlowをpythonファイル使用してJOBを実行する際のクラス
py_file引数に実行ファイルが置かれているパスをしているするoptions引数に実行ファイルに渡す引数を指定する
- 今回はGCSにデータを置く際のファイルパスを指定しています
DATAFLOW_TRAIN_FILE = os.path.join( configuration.get('core', 'dags_folder'), 'dataflow', 'extract_train_data.py') DATAFLOW_PRED_FILE = os.path.join( configuration.get('core', 'dags_folder'), 'dataflow', 'extract_pred_data.py') DEFAULT_ARGS = { 'owner': 'Composer Example', 'depends_on_past': False, 'email': [''], 'email_on_failure': False, 'email_on_retry': False, 'retries': 1, 'retry_delay': datetime.timedelta(minutes=5), 'start_date': YESTERDAY, 'project_id': Variable.get('project_id'), 'dataflow_default_options': { 'project': Variable.get('project_id'), 'temp_location': 'gs://your_composer_bucket/temp', 'runner': 'DataflowRunner' } } #### # DataFlowでデータ抽出を行うタスク #### # GCSにデータを置く際のファイルパス job_args = { 'output': 'gs://your_bucket/preprocess' } create_train_data = DataFlowPythonOperator( task_id='create-train-data', py_file=DATAFLOW_TRAIN_FILE, options=job_args ) create_pred_data = DataFlowPythonOperator( task_id='create-pred-data', py_file=DATAFLOW_PRED_FILE, options=job_args )DataFlow実行ファイルの説明
以下のファイルは、Trainingを行うための、
train dataとtest dataに分割しGCSへ置く処理となっています。
(また、記事の簡略化のためtrain dataとtest dataに分割するためのクエリの解説は割愛させて頂きます。timestampのカラムがあることを前提にハッシュ化を行い、除算した余りの値で分割しております)ここで気をつけたいポイントは2点です。
CSVファイルへの変換
- 最終的にCSVファイルとして出力したいのでBigQueryから抽出したデータをカンマ区切りの形式に変換する必要があります。
- ここでは、
to_csvという関数を用意しております。DataFlowのPythonバージョン
- DataFlowのPythonは3.5.xなので3.6から追加された
f-stringsなどの文法は使えません。import os import argparse import logging from datetime import datetime import apache_beam as beam from apache_beam.options.pipeline_options import \ PipelineOptions PROJECT = 'your_project_id' def create_query(phase): base_query = """ SELECT *, MOD(ABS(FARM_FINGERPRINT(CAST(timestamp AS STRING))), 10) AS hash_value FROM `dataset.your_table` """ if phase == 'TRAIN': subsumple = """ hash_value < 7 """ elif phase == 'TEST': subsumple = """ hash_value >= 7 """ query = """ SELECT column1, column2, column3, row_number()over() as key FROM ({0}) WHERE {1} """.\ format(base_query, subsumple) return query def to_csv(line): csv_columns = 'column1,column2,column3,key'.split(',') rowstring = ','.join([str(line[k]) for k in csv_columns]) return rowstring def get_date(): jst_now = datetime.now() dt = datetime.strftime(jst_now, "%Y-%m-%d") return dt def run(argv=None): parser = argparse.ArgumentParser() parser.add_argument( '--output', required=True ) known_args, pipeline_args = \ parser.parse_known_args(argv) options = PipelineOptions(pipeline_args) with beam.Pipeline(options=options) as p: for phase in ['TRAIN', 'TEST']: query = create_query(phase) date = get_date() output_path = os.path.join(known_args.output, date, 'train', "{}".format(phase)) read = p | 'ExtractFromBigQuery_{}'.format(phase) >> beam.io.Read( beam.io.BigQuerySource( project=PROJECT, query=query, use_standard_sql=True ) ) convert = read | 'ConvertToCSV_{}'.format(phase) >> beam.Map(to_csv) convert | 'WriteToGCS_{}'.format(phase) >> beam.io.Write( beam.io.WriteToText(output_path, file_name_suffix='.csv')) if __name__ == '__main__': logging.getLogger().setLevel(logging.INFO) run()ML Engineでのtraining及びdeploy
ここでは、ML Engineを使ったtraining及び学習したモデルのdeployを行うタスクの説明を行いまいす。
また、今回はML Engineで使用する実行ファイルtask.pyやモデルファイルmodel.pyについての説明は割愛させて頂きます。
今回ML Engine用にバケットを用意しております。
なので、Cloud Composerの環境構築時で作成されるバケットと合わせると合計2つバケットを使い分けているので注意してください。. ├── your_bucket │ ├── code // 学習に必要なmodel.pyやtask.py等を固めたgzファイルを置く │ │ │ └── trainde_model // 学習済みのmodelファイルが置かれる │ └── your_composer_bucket // cloud composerの環境構築時に作成されるバケットDagファイルの説明
定数
PACKAGE_URI
- ML Engineの実行ファイルが置いてあるファイルパス
- 今回は
trainer.pyやmodel.pyなどを固めたgzファイルを上記のgs://your_bucket/code以下に置いています。MLEngineTrainingOperatorクラスのpackage_uris引数にこの定数を指定しています。
BashOperatorクラス
- bashコマンドを実行する際のクラス
- 今回は学習済みのモデルファイルをdeployする際にbashコマンド使用しています。
gcloud ml-engine versions createを実行することでmodelのdeployを行なっています- (おそらく)
MLEngineVersionOperatorクラスでも同様のことが行えると思いますが、今回はbashコマンドを利用しました。PACKAGE_URI = BUCKET + '/code/trainer-0.1.tar.gz' OUTDIR = BUCKET + '/trained_model' job_id = 'dev-train-{}'.\ format(datetime.datetime.now().strftime('%Y%m%d%H%M')) job_dir = BUCKET + '/jobs/' + job_id submit_train_job = MLEngineTrainingOperator( task_id='train-model', project_id=PROJECT_ID, job_id=job_id, package_uris=[PACKAGE_URI], region=REGION, training_python_module='trainer.task', training_args=[f'--output_dir={OUTDIR}', f'--job_dir={job_dir}', '--dropout_rate=0.5', '--batch_size=128', '--train_step=1' ], scale_tier='BASIC_GPU', python_version='3.5' ) today = get_date() BASE_VERSION_NAME = 'v1_0' VERSION_NAME = '{0}_{1}'.\ format(BASE_VERSION_NAME, datetime.datetime.now().strftime('%Y_%m_%d')) MODEL_NAME = 'dev_model' deploy_model = BashOperator( task_id='deploy-model', bash_command='gcloud ml-engine versions create ' '{{ params.version_name}} ' '--model {{ params.model_name }} ' '--origin $(gsutil ls gs://your_bucket/trained_model/export/exporter | tail -1) ' '--python-version="3.5" ' '--runtime-version=1.14 ', params={'version_name': VERSION_NAME, 'model_name': MODEL_NAME} )ML Engineでのバッチ予測
ここでは、先でdeployしたモデルを使ってバッチ予測を行うタスクについて説明をします。
定数
input_path
- 先で行なった予測用に抽出しGCSにおいたCSVファイルのパス
定数
output_path
- 予測した結果を置くGCSのファイルパス
Dagファイルの説明
input_path = BUCKET + f'/preprocess/{today}/prediction/prediction-*' output_path = BUCKET + f'/result/{today}/' batch_prediction = MLEngineBatchPredictionOperator( task_id='batch-prediction', data_format='TEXT', region=REGION, job_id=job_id, input_paths=input_path, output_path=output_path, model_name=MODEL_NAME, version_name=VERSION_NAME )バッチ予測結果のBigQueryへのLoad
ここでは、先で予測した予測結果をDataFlowを使ってBigQueryにLoadするタスクについて説明します。
Dagファイルの説明
Dagファイルについて、冒頭で説明した"BigQueryからデータを抽出する"タスクと同様になります。
定数DATAFLOW_LOAD_FILEにDataFlowの実行ファイルがおかれているGCSのファイルパスを指定しています。DATAFLOW_LOAD_FILE = os.path.join( configuration.get('core', 'dags_folder'), 'dataflow', 'load.py') load_results = DataFlowPythonOperator( task_id='load_pred_results', py_file=DATAFLOW_LOAD_FILE )DataFlow実行ファイルの説明
以下のファイルでは、GCSに置かれているファイル読み込み、Json形式へと変換しBigQueryの適当なテーブルへloadをしております。
ここで気をつけたいこととしては
- バッチ予測結果はjson形式のテキストファイルとしてGCSに置かれます。
- テキストファイルに書かれているpredictionの出力結果の値などはリスト形式として記載されているのでそのままloadしようとすると型が合わなくてエラーが生じます。
{"key": [0], "prediction: [3.45...]"}import logging import argparse import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions BUCKET_NAME = 'your_bucket' INPUT = 'gs://{}/result/prediction.results-*'.format(BUCKET_NAME) def convert(line): import json record = json.loads(line) return {'key': record['key'][0], 'predictions': record['predictions'][0]} def run(argv=None): parser = argparse.ArgumentParser() known_args, pipeline_args = \ parser.parse_known_args(argv) options = PipelineOptions(pipeline_args) with beam.Pipeline(options=options) as p: dataset = 'your_dataset.results' read = p | 'ReadPredictionResult' >> beam.io.ReadFromText(INPUT) json = read | 'ConvertJson' >> beam.Map(convert) json | 'WriteToBigQuery' >> beam.io.Write(beam.io.BigQuerySink( dataset, schema='key:INTEGER, predictions:FLOAT', create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED, write_disposition=beam.io.BigQueryDisposition.WRITE_TRUNCATE)) if __name__ == '__main__': logging.getLogger().setLevel(logging.INFO) run()おわりに
普段はAWSを使っていますが、GCPのサービスについて触れる機会があったのでML関係のサービスについてまとめてみました。MLのワークフローについて悩まれている方の参考になれば幸いです。
MLEngineでtrainingしたmodelをそのままdeployする箇所がありますが、あまりオススメできません。なにがしか学習したモデルの精度を測る/比較する機構を作り、そのタスクを挟んでからdeployすることをオススメします。




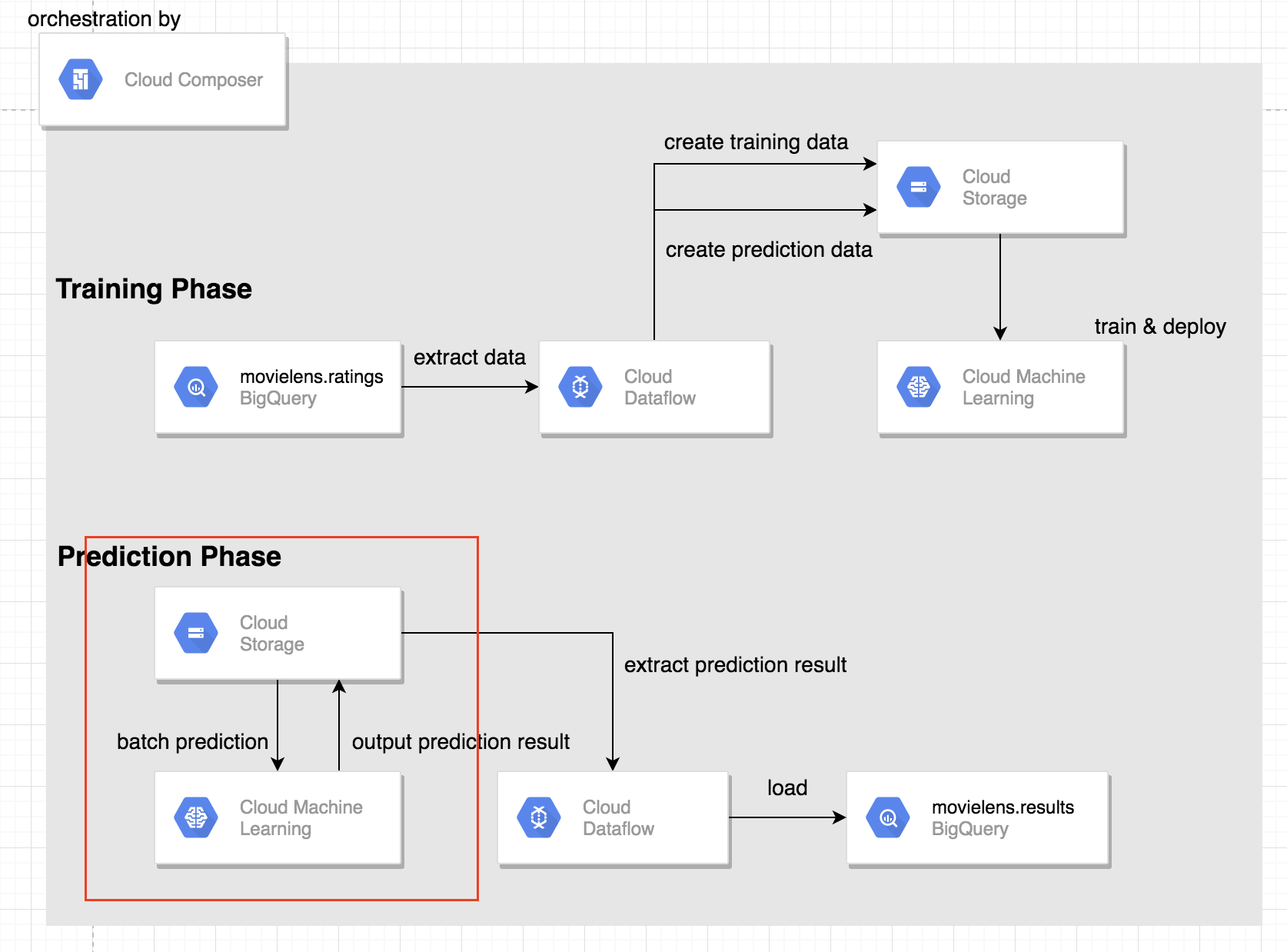

- 投稿日:2019-12-30T15:36:09+09:00
Python学習ノート_006
第4章のサンプルコードは下記のようです。
- ポイント
- リストの長さはlen()で計算して、forループにインデックスの上限値として使える
- printにコンマで区切った複数の値の間に1スペースがあるため、それを回避する方法は文字列の連結で1つ文字列として出力する
sample04.pyscores = [60, 50, 60, 58, 54, 54, 58, 50, 52, 54, 48, 69, 34, 55, 51, 52, 44, 51, 69, 64, 66, 55, 52, 61, 46, 31, 57, 52, 44, 18, 41, 53, 55, 61, 51, 44] length = len(scores) for i in range(length): print("テストの案 #" + str(i),"のscore:",scores[i]) high_score = max(scores) max_list = [] for i in range(length): if scores[i] == high_score: max_list.append(i) print("テストの総数:",length) print("最高の点数:",max(scores)) print("最大値のインデックス:",max_list)
- 出力結果

- 投稿日:2019-12-30T15:34:28+09:00
宿題がめんどくさかったのでPythonで管理会計をする
私は大学では経営学を学んでいるのでもちろん会計的な授業もあります。その中の一つである管理会計の授業の問題がめんどくさいのでプログラミングでできないかなと考えました。テストの時には使えないので結局計算式は暗記しないといけないのですが、まぁ今回はいいでしょう。
管理会計とは?
管理会計(かんりかいけい、英語:management accounting)は、企業会計の一種。主として、会計情報を経営管理者の意思決定や組織内部の業績測定・業績評価に役立てることを目的としている。対義語は財務会計である。企業外部の利害関係者に対する情報提供を目的とする財務会計とは、大きく性格が異なっている。
引用 wikipedia
簡単にいうと一般的な簿記試験などである商業簿記などの会計は企業の外部の人にむけて作られているものなんです。なので規則に乗っ取って作らないといけません。しかし、管理会計の目的は企業の意思決定に役に立つ様な会計的な情報を測定し、レポートを作成することなので目的が全く違うのです。
投資可能(受託可能)な案件かどうか判定する
nowは現在の生産量
capacity_percentは現在の操業度
trade_request_amountは相手の求めている生産量def Investable(now, capacity_percent, trade_request_amount): max_amount= now / capacity_percent now_can_use = max_amount- now if now_can_use >trade_request_amount: print('Investable') else: print('No') Investable(42500, 85, 7000 ) #実行結果 No実行の結果この投資案は実行できないということが分かりました。
差額原価収益分析
差額原価収益分析とは、安値受注のような特殊な非反復的意思決定を行うときに、追加的に発生する収益及び原価・費用のみを抽出して差額利益を計算し、迅速な意思決定を行う手法である。
productive_volume 生産個数
revenue_per_item 製品1個あたりの利益
produce_cost_per_item 製品1個あたりの生産コスト
sales_cost 販売費
fixed_cost 固定費def Differential_cost_revenue(productive_volume, revenue_per_item, produce_cost_per_item, sales_cost, fixed_cost): a = revenue_per_item * productive_volume b = produce_cost_per_item * productive_volume c = sales_cost * productive_volume cost = b+c +fixed_cost if a- cost >0: print('think voting') return(a-cost) else: print('stop voting') Differential_cost_revenue(6500, 450, 230, 30, 435000) #実行結果 think voting 800000まとめ
今回は大学の授業の管理会計の宿題を簡単にやってくれるプログラムを作って見ました。このコードを書いたときは手元に問題のプリントがあったのですが、今はないので細かい問題の条件を忘れてしまいましたがコードが残っていたので想像でコードを書いて見ました笑
- 投稿日:2019-12-30T15:09:58+09:00
[2−1]作成したQRコードを読み取り識別する
この記事は"QRコードを使った入場システムを自作する"シリーズの記事です。
前回
"[1]独自のフォーマットに基づいてQRコードを発行する"では独自のフォーマットのQRコードを発行してデータベースに登録することができました。
今回はデータベースに登録したQRコードの読み取り方です。QRコードを読み取るには
スキャナーを用意する予算がなかったのiOSアプリのPythonista3を利用してQRコードを読み取ります。
手順
Pythonista3を利用しなくてもなんでも読み取った後の処理は同じです。
- QRコードをスキャン
- 読み取ったコードを文字列に変換
- MySQLで検索をかける
Pythonista3でQRコードを読み取る方法
今回一番きつかったのがこの部分で、objective-cをPython上で動かさなければいけませんでした。
Pythonistaには標準でobjc_utilというモジュールが入っているのでそれを利用します。とは言っても...
objective-cなんか生まれてから一度も利用したことがなくswiftが主流?になってきているので今回はこちらを流用させていただいた。(一部改変)
ということで
以下がソースコードになる。
QRscanner1.py# Barcode scanner demo for Pythonista from objc_util import * from ctypes import c_void_p import mysql.connector as testdb import ui import sound found_codes = set() main_view = None AVCaptureSession = ObjCClass('AVCaptureSession') AVCaptureDevice = ObjCClass('AVCaptureDevice') AVCaptureDeviceInput = ObjCClass('AVCaptureDeviceInput') AVCaptureMetadataOutput = ObjCClass('AVCaptureMetadataOutput') AVCaptureVideoPreviewLayer = ObjCClass('AVCaptureVideoPreviewLayer') dispatch_get_current_queue = c.dispatch_get_current_queue dispatch_get_current_queue.restype = c_void_p #QRコードの読み取り def captureOutput_didOutputMetadataObjects_fromConnection_(_self, _cmd, _output, _metadata_objects, _conn): objects = ObjCInstance(_metadata_objects) for obj in objects: s = str(obj.stringValue()) if s not in found_codes: found_codes.add(s) #読み取り終了後にWindowを閉じる。 main_view.close() MetadataDelegate = create_objc_class('MetadataDelegate', methods=[captureOutput_didOutputMetadataObjects_fromConnection_], protocols=['AVCaptureMetadataOutputObjectsDelegate']) @on_main_thread def main(): global main_view delegate = MetadataDelegate.new() main_view = ui.View(frame=(0, 0, 400, 400)) main_view.name = 'Barcode Scanner' session = AVCaptureSession.alloc().init() device = AVCaptureDevice.defaultDeviceWithMediaType_('vide') _input = AVCaptureDeviceInput.deviceInputWithDevice_error_(device, None) if _input: session.addInput_(_input) else: print('Failed to create input') return output = AVCaptureMetadataOutput.alloc().init() queue = ObjCInstance(dispatch_get_current_queue()) output.setMetadataObjectsDelegate_queue_(delegate, queue) session.addOutput_(output) output.setMetadataObjectTypes_(output.availableMetadataObjectTypes()) prev_layer = AVCaptureVideoPreviewLayer.layerWithSession_(session) prev_layer.frame = ObjCInstance(main_view).bounds() prev_layer.setVideoGravity_('AVLayerVideoGravityResizeAspectFill') ObjCInstance(main_view).layer().addSublayer_(prev_layer) session.startRunning() main_view.present('sheet') main_view.wait_modal() session.stopRunning() delegate.release() session.release() output.release() #QRコードを読み取った際の処理 if found_codes: #cur = conn.cursor() scan_code = str(''.join(found_codes)) #table: QRidのデータを照合 table = 'QRid' cur.execute("select * from QRid where QR=%s",(scan_code,)) result = cur.fetchall() if len(result) == 0: sound.play_effect('digital:PhaserUp4') print('該当するデータがありません。') vibrate([50,0,50,0,50,0,50]) else: sound.play_effect('arcade:Coin_5') print('ID'+'{:>15}'.format('DATE')+'{:>11}'.format('TIME')) for i in result: print(*i) if __name__ == '__main__': #MySQLへ接続 conn = testdb.connect( user = 'test', password = '12345', host = '192.168.x.x', port = '3306', database='QRtest' ) #接続ステータスを確認 conn.ping(reconnect=True) print('[Status] ', end='') print(conn.is_connected()) cur = conn.cursor() main() #MySQLへの接続を終了 cur.close() conn.commit() conn.close()スクリプトを走らせるとカメラウィンドウが表示されます。
正常に読み取られるとこのウィンドウが閉じてコンソールが開きます。
MySQL上に登録されている情報が表示されれば成功です。
次回予告
[2-2]作成したQRコードを読み取り識別する。でよりわかりやすいGUIを追加します。読み取り機は次回で完成です。

- 投稿日:2019-12-30T15:07:37+09:00
【忘備録】Minimum Covariance Determinantを使用したマーケットの異常探知
Minimum Covariance Determinant or MLEで求めた共分散行列による異常探知比較
飛んだ値に思いっ切り引きずられるのを避けるためにも、マーケットデータと相性良いメソッドかと
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import warnings from sklearn.covariance import EmpiricalCovariance, MinCovDet from sklearn.covariance import EmpiricalCovariance warnings.filterwarnings('ignore') plt.style.use('seaborn-darkgrid') plt.rcParams['axes.xmargin'] = 0.01 plt.rcParams['axes.ymargin'] = 0.01ReadDFに週次の各種マーケットリターン(為替、株、債券etc)
# ルックバック過去50週間リターンを用いて算出 ts_out = pd.DataFrame() for date in ReadDF.dropna(axis=0)[50:].index: x = ReadDF[:date][-50:] x = (x/x.std()).dropna(axis=0) mcd.fit(x[:-1]) anomaly_score_mcd = mcd.mahalanobis(x[-1:]) mle.fit(x[:-1]) anomaly_score_mle = mle.mahalanobis(x[-1:]) out = pd.DataFrame([anomaly_score_mcd, anomaly_score_mle]).T out.columns = ['mcd', 'mle'] out.index = [date] ts_out = pd.concat([ts_out, out], axis=0)fig = plt.figure(figsize=(15, 10), dpi=80) out = pd.DataFrame(ts_out/ts_out.std()) # 規格化 sns.set_palette("hls", len(out.columns)) ax1 = fig.add_subplot(1, 1, 1) ax1.plot(out, alpha=0.6) plt.legend(out.columns) plt.show()

- 投稿日:2019-12-30T14:14:52+09:00
【AWS IoT】モノにアタッチされていない証明書を削除する
目的
AWS IoTにおいて、モノにアタッチされていない証明書を削除する。
不要な証明書を大量に作成してしまった場合用。クラス
import boto3 class CertKiller(): def __init__(self): # AWS IoTを操作するクラスをインスタンス化 self.client = boto3.client('iot') return def delete_not_attached_cert_all(self): ''' モノにアタッチされていない証明書を削除 ''' # 証明書情報のリストを取得 list_cert = self.get_list_cert() # モノにアタッチされていない証明書を削除 for cert in list_cert: self.__delete_not_attached_cert(cert) return def get_list_cert(self): ''' 証明書情報のリストを取得 ''' list_cert = self.client.list_certificates(pageSize=100)['certificates'] return list_cert def __delete_not_attached_cert(self, cert): ''' 証明書がどのモノにもアタッチされていなかった場合、削除 ''' # 証明書情報を取得 cert_arn = cert['certificateArn'] cert_id = cert['certificateId'] # 証明書をアタッチしてあるモノの一覧を取得 thing_attached_cert = self.client.list_principal_things(principal=cert_arn)['things'] print(cert_arn, thing_attached_cert) # 証明書がどのモノにもアタッチされていなかった場合、削除 if len(thing_attached_cert) == 0: self.__delete_cert(cert_arn, cert_id) else: pass return def __delete_cert(self, cert_arn, cert_id): ''' 証明書を削除 ''' # 削除前に無効化する必要がある self.client.update_certificate(certificateId=cert_id, newStatus='INACTIVE') # 削除前にポリシーをデタッチする必要がある self.__detach_all_policy(cert_arn, cert_id) # 削除 self.client.delete_certificate(certificateId=cert_id, forceDelete=False) print('{} has been deleted.'.format(cert_arn)) return def __detach_all_policy(self, cert_arn, cert_id): ''' 証明書にアタッチされている全てのポリシーをデタッチ ''' # 証明書にアタッチされているポリシーのリストを取得 list_policy = self.client.list_attached_policies(target=cert_arn)['policies'] # デタッチ for policy in list_policy: policy_name = policy['policyName'] self.client.detach_policy(policyName=policy_name, target=cert_arn) return実行
cert_killer = CertKiller() cert_killer.delete_not_attached_cert_all()備考
- もし使用いただける場合は自己責任でお願いします。
- デバイスにアタッチされている証明書が削除される心配はありません。
(delete_certificate() で forceDelete=Falseとしているため)- モノにアタッチされていない=不要 とは限らないと思いますので、
複数名でAWS IoTを使用している場合は、削除前に他のユーザーに確認を取ると良いと思います。感想
めちゃめちゃ初心者なので、本当に些細なことでもご指摘・コメント等いただけますと幸いです。
参照
- 投稿日:2019-12-30T12:26:49+09:00
selenium/pythonだってAzure DevOps pipelineでヘッドレス実行したいよね?そうだよね?
本投稿はAzure DevOps Advent Calendar 2019の22日目の投稿になります。
DevOpsを推進するうえで重要な要素となる自動化ですが、様々な方法が考えられますし、組織に応じて導入を進めていく必要があります。組織のカルチャーを無視してコンセンサスが得られない状況で独自のツールが乱立してそれが運用に与える効果を測ることができればいいなと考えているsasukehです。皆様いかがお過ごしでしょうか?
巷では、seleniumを使って自動化という記事がかなりの数上がってくるようになりました。その効果もあり、WebのE2Eテストをseleniumで自動化するというかたも増えてきているように思えます。Test Driven Developmentもめちゃくちゃ重要でソフトウェアを検証、計測することで、その開発が正しい方向を向いているかの指標となります。なので、TDD始めましょう!というのは簡単だけど、じゃあどうすればいいの?という目的はわかったけど、手段がわからないという状況にいる方もいるのでは?と思います。とくにAzure DevOpsを使ってSeleniumでUIのテスト自動化したいけど、やっぱりagentにGUIが必要で、CLIは向いてないよね?みたいな解釈をしているかたがいらっしゃいますが、実は、seleniumには、headless実行と呼ばれる、GUIなしで実行する方法があります。また、Screenshotも取れるので、ZipでまとめてBlobでアップロードする方法もあります。
今年の初め頃に社内のチームメンバーとハッカソンしたときのコードなりtipsがあったのですが、なかなか公開できていなかったので、今日これをまとめようと思います。
つづく
- 投稿日:2019-12-30T11:55:35+09:00
【python】argparseを使ってコマンドラインで動く簡単なプログラムを作ってみた
ArgumentParser (argparse)
Pythonで書いたプログラムをコマンドラインで実行する時、ArgumentParser (argparse)を用いれば簡単にコマンドライン引数を使うことができます。
コマンドライン引数とは
コマンドライン引数とは次のようなもののことを言います。
python test.py -t 10使ってみる
瞬時式について
瞬時式は一般に
e=V_{m} \sin(2 \pi f t \pm \phi)で表されます。今回は
V_{m}[V],f[Hz],\phi[deg]をコマンドライン変数で変更([]内はプログラム中での単位)し、様々なグラフの描画を試みます。
ソース
ライブラリの読み込み。argparseを読めば使えます。
import argparseそれぞれの引数の初期値などを定義
parser = argparse.ArgumentParser() parser.add_argument('--phase', '-p', type=float, default=0, help='Definition of a point in time') parser.add_argument('--voltage', '-v', type=float, default=100, help='Definition of a effective value') parser.add_argument('--frequency', '-f', type=float, default=60, help='Definition of a frequency') parser.add_argument('--sampletime', '-t', type=float, default=0.0001, help='Definition of sampletime') args = parser.parse_args()指定した数値の表示
print('phase : {}\n'.format(args.phase)) print('voltage : {}\n'.format(args.voltage)) print('frequency : {}\n'.format(args.frequency))グラフの描画
t = np.arange(0, 1/60, args.sampletime) y1 = args.voltage * np.sqrt(2) * np.sin(2 * np.pi * args.frequency * t + np.deg2rad(args.phase)) y2 = args.voltage * np.sqrt(2) * np.sin(2 * np.pi * args.frequency * t) plt.plot(t, y1) plt.plot(t, y2) plt.grid(True) plt.show() #plt.savefig("img.png")コマンドラインで
python test.py -p 45とすれば
を得ます。
コード全体
import numpy as np import argparse import matplotlib.pyplot as plt def main(): parser = argparse.ArgumentParser() parser.add_argument('--phase', '-p', type=float, default=0, help='Definition of a point in time') parser.add_argument('--voltage', '-v', type=float, default=100, help='Definition of a effective value') parser.add_argument('--frequency', '-f', type=float, default=60, help='Definition of a frequency') parser.add_argument('--sampletime', '-t', type=float, default=0.0001, help='Definition of sampletime') args = parser.parse_args() print('phase : {}\n'.format(args.phase)) print('voltage : {}\n'.format(args.voltage)) print('frequency : {}\n'.format(args.frequency)) t = np.arange(0, 1/60, args.sampletime) y1 = args.voltage * np.sqrt(2) * np.sin(2 * np.pi * args.frequency * t + np.deg2rad(args.phase)) y2 = args.voltage * np.sqrt(2) * np.sin(2 * np.pi * args.frequency * t) plt.plot(t, y1) plt.plot(t, y2) plt.grid(True) plt.show() if __name__ == '__main__': main()

- 投稿日:2019-12-30T11:55:35+09:00
【Python】argparseを使ってコマンドラインで動く簡単なプログラムを作ってみた
ArgumentParser (argparse)
Pythonで書いたプログラムをコマンドラインで実行する時、ArgumentParser (argparse)を用いれば簡単にコマンドライン引数を使うことができます。
コマンドライン引数とは
コマンドライン引数とは次のようなもののことを言います。
python test.py -t 10使ってみる
瞬時式について
瞬時式は一般に
e=V_{m} \sin(2 \pi f t \pm \phi)で表されます。今回は
V_{m}[V],f[Hz],\phi[deg]をコマンドライン変数で変更([]内はプログラム中での単位)し、様々なグラフの描画を試みます。
ソース
ライブラリの読み込み。argparseを読めば使えます。
import argparseそれぞれの引数の初期値などを定義
parser = argparse.ArgumentParser() parser.add_argument('--phase', '-p', type=float, default=0, help='Definition of a point in time') parser.add_argument('--voltage', '-v', type=float, default=100, help='Definition of a effective value') parser.add_argument('--frequency', '-f', type=float, default=60, help='Definition of a frequency') parser.add_argument('--sampletime', '-t', type=float, default=0.0001, help='Definition of sampletime') args = parser.parse_args()指定した数値の表示
print('phase : {}\n'.format(args.phase)) print('voltage : {}\n'.format(args.voltage)) print('frequency : {}\n'.format(args.frequency))グラフの描画
t = np.arange(0, 1/60, args.sampletime) y1 = args.voltage * np.sqrt(2) * np.sin(2 * np.pi * args.frequency * t + np.deg2rad(args.phase)) y2 = args.voltage * np.sqrt(2) * np.sin(2 * np.pi * args.frequency * t) plt.plot(t, y1) plt.plot(t, y2) plt.grid(True) plt.show() #plt.savefig("img.png")コマンドラインで
python test.py -p 45とすれば
を得ます。
コード全体
import numpy as np import argparse import matplotlib.pyplot as plt def main(): parser = argparse.ArgumentParser() parser.add_argument('--phase', '-p', type=float, default=0, help='Definition of a point in time') parser.add_argument('--voltage', '-v', type=float, default=100, help='Definition of a effective value') parser.add_argument('--frequency', '-f', type=float, default=60, help='Definition of a frequency') parser.add_argument('--sampletime', '-t', type=float, default=0.0001, help='Definition of sampletime') args = parser.parse_args() print('phase : {}\n'.format(args.phase)) print('voltage : {}\n'.format(args.voltage)) print('frequency : {}\n'.format(args.frequency)) t = np.arange(0, 1/60, args.sampletime) y1 = args.voltage * np.sqrt(2) * np.sin(2 * np.pi * args.frequency * t + np.deg2rad(args.phase)) y2 = args.voltage * np.sqrt(2) * np.sin(2 * np.pi * args.frequency * t) plt.plot(t, y1) plt.plot(t, y2) plt.grid(True) plt.show() if __name__ == '__main__': main()
- 投稿日:2019-12-30T11:15:48+09:00
なろう小説の評価点から順位を付けてみた
概要
なろう作品の平均評価点を元にした順位です。
ジャンルは全て、四半期と月間ランキングにある小説のみが対象のため、好きな作品が順位に載っていない可能性も多々あります。ご了承下さい。この記事で得た結果を載せます。
注)2019/12/30現在の、小説家になろうランキング上位作品の「個人的な解析による」順位です。
上位のべ600作品だけを分析しているため、順位が低いものはつまらない、ということでは決してありません。分析対象になったのは既にランキング上位にある選ばれし作品なのです。
結果を見て気分を害される場合があるかもしれませんが、あくまで個人的な解析方法で行った順位付けなのであしからずご了承ください。
では1位から順に発表です。
全データ数:600
評価外件数(評価数500未満):120
重複抜き純データ数:405
平均評価点:931位
『本好きの下剋上 ~司書になるためには手段を選んでいられません~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:98.044
評価偏差値:71.9
文中会話率:50%
レビュー数:1202位
『 お隣の天使様にいつの間にか駄目人間にされていた件』
ジャンル:現実世界〔恋愛〕
評価点:97.989
評価偏差値:71.67
文中会話率:48%
レビュー数:2163位
『シャングリラ・フロンティア〜クソゲーハンター、神ゲーに挑まんとす〜』
ジャンル:VRゲーム〔SF〕
評価点:97.671
評価偏差値:70.37
文中会話率:49%
レビュー数:454位
『エリスの聖杯』
ジャンル:異世界〔恋愛〕
評価点:97.51
評価偏差値:69.71
文中会話率:44%
レビュー数:175位
『リビルドワールド』
ジャンル:アクション〔文芸〕
評価点:97.492
評価偏差値:69.63
文中会話率:46%
レビュー数:366位
『嘆きの亡霊は引退したい 〜最弱ハンターは英雄の夢を見る〜【Web版】』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:97.398
評価偏差値:69.25
文中会話率:27%
レビュー数:237位
『オタク同僚と偽装結婚した結果、毎日がメッチャ楽しいんだけど!』
ジャンル:現実世界〔恋愛〕
評価点:97.15
評価偏差値:68.23
文中会話率:32%
レビュー数:28位
『貴腐人ローザは陰から愛を見守りたい』
ジャンル:異世界〔恋愛〕
評価点:96.859
評価偏差値:67.03
文中会話率:26%
レビュー数:119位
『昏き宮殿の死者の王【Web版】』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:96.823
評価偏差値:66.89
文中会話率:18%
レビュー数:1710位
『悪役令嬢の執事様 ~俺が育てた彼女はとても可愛い~ (連載版)』
ジャンル:異世界〔恋愛〕
評価点:96.809
評価偏差値:66.83
文中会話率:38%
レビュー数:1111位
『魔導具師ダリヤはうつむかない』
ジャンル:異世界〔恋愛〕
評価点:96.791
評価偏差値:66.75
文中会話率:44%
レビュー数:2212位
『Re:ゼロから始める異世界生活』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:96.777
評価偏差値:66.7
文中会話率:41%
レビュー数:15613位
『最凶の支援職【話術士】である俺は世界最強クランを従える』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:96.615
評価偏差値:66.03
文中会話率:53%
レビュー数:2014位
『狼は眠らない』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:96.56
評価偏差値:65.81
文中会話率:54%
レビュー数:3815位
『やり直し令嬢は竜帝陛下を攻略中』
ジャンル:異世界〔恋愛〕
評価点:96.543
評価偏差値:65.74
文中会話率:49%
レビュー数:216位
『禁断師弟でブレイクスルー~勇者の息子が魔王の弟子で何が悪い~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:96.506
評価偏差値:65.58
文中会話率:51%
レビュー数:2317位
『ガリ勉地味萌え令嬢は、俺様王子などお呼びでない』
ジャンル:異世界〔恋愛〕
評価点:96.345
評価偏差値:64.92
文中会話率:56%
レビュー数:818位
『時使い魔術師の転生無双 ~魔術学院の劣等生、実は最強の時間系魔術師でした~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:96.315
評価偏差値:64.8
文中会話率:37%
レビュー数:6419位
『悪役令嬢、ブラコンにジョブチェンジします』
ジャンル:異世界〔恋愛〕
評価点:96.299
評価偏差値:64.74
文中会話率:33%
レビュー数:420位
『悪役令嬢なのでラスボスを飼ってみました』
ジャンル:異世界〔恋愛〕
評価点:96.196
評価偏差値:64.31
文中会話率:54%
レビュー数:1421位
『無職転生 - 異世界行ったら本気だす -』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:96.187
評価偏差値:64.28
文中会話率:22%
レビュー数:16322位
『ホラー女優が天才子役に転生しました ~今度こそハリウッドを目指します!~』
ジャンル:現実世界〔恋愛〕
評価点:96.075
評価偏差値:63.82
文中会話率:55%
レビュー数:223位
『シャバの「普通」は難しい』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:96.042
評価偏差値:63.68
文中会話率:34%
レビュー数:1524位
『難攻不落の魔王城へようこそ~デバフは不要と勇者パーティーを追い出された黒魔導士、魔王軍の最高幹部に迎えられる~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:96.039
評価偏差値:63.67
文中会話率:33%
レビュー数:2225位
『俺は星間国家の悪徳領主!』
ジャンル:宇宙〔SF〕
評価点:95.925
評価偏差値:63.2
文中会話率:32%
レビュー数:1226位
『転生した大聖女は、聖女であることをひた隠す』
ジャンル:異世界〔恋愛〕
評価点:95.892
評価偏差値:63.06
文中会話率:29%
レビュー数:1827位
『聖女様はイケメンよりもアンデッドがお好き⁈ 〜 死霊術師として忌み嫌われていた男、英雄の娘に転生して〝癒しの聖女″となる 〜』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:95.874
評価偏差値:62.99
文中会話率:36%
レビュー数:228位
『乙女ゲー世界はモブに厳しい世界です』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:95.75
評価偏差値:62.48
文中会話率:39%
レビュー数:2229位
『懐いた後輩がうるさくて寝れないので、意地悪して嫌われようと思う〜それ意地悪じゃなくて惚れさせてますよ?』
ジャンル:現実世界〔恋愛〕
評価点:95.731
評価偏差値:62.4
文中会話率:33%
レビュー数:430位
『ティアムーン帝国物語 ~断頭台から始まる、姫の転生逆転ストーリー~』
ジャンル:異世界〔恋愛〕
評価点:95.671
評価偏差値:62.16
文中会話率:32%
レビュー数:931位
『転生王女は今日も旗を叩き折る。』
ジャンル:異世界〔恋愛〕
評価点:95.668
評価偏差値:62.14
文中会話率:34%
レビュー数:1832位
『マジカル★エクスプローラー エロゲの友人キャラに転生したけど、ゲーム知識使って自由に生きる』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:95.652
評価偏差値:62.08
文中会話率:43%
レビュー数:1033位
『薬屋のひとりごと』
ジャンル:推理〔文芸〕
評価点:95.652
評価偏差値:62.08
文中会話率:34%
レビュー数:3234位
『モブ高生の俺でも冒険者になればリア充になれますか?』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:95.624
評価偏差値:61.96
文中会話率:31%
レビュー数:935位
『社畜男はB人お姉さんに助けられて――』
ジャンル:現実世界〔恋愛〕
評価点:95.559
評価偏差値:61.7
文中会話率:60%
レビュー数:1236位
『魔法世界の受付嬢になりたいです』
ジャンル:異世界〔恋愛〕
評価点:95.524
評価偏差値:61.55
文中会話率:39%
レビュー数:1737位
『最強出涸らし皇子の暗躍帝位争い~帝位に興味ないですが、死ぬのは嫌なので弟を皇帝にしようと思います~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:95.509
評価偏差値:61.49
文中会話率:45%
レビュー数:938位
『私はご都合主義解決担当の王女である』
ジャンル:異世界〔恋愛〕
評価点:95.407
評価偏差値:61.07
文中会話率:31%
レビュー数:239位
『元・世界1位のサブキャラ育成日記 ~廃プレイヤー、異世界を攻略中!~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:95.397
評価偏差値:61.03
文中会話率:44%
レビュー数:3340位
『転生したらスライムだった件』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:95.39
評価偏差値:61.0
文中会話率:14%
レビュー数:9141位
『その悪役令嬢は攻略本を携えている』
ジャンル:異世界〔恋愛〕
評価点:95.362
評価偏差値:60.89
文中会話率:32%
レビュー数:042位
『元マフィア幹部の少年、超競争社会の魔法学園で成り上がる~頭脳最強の知略無双~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:95.309
評価偏差値:60.67
文中会話率:43%
レビュー数:143位
『反逆のソウルイーター ~弱者は不要といわれて剣聖(父)に追放されました~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:95.264
評価偏差値:60.49
文中会話率:23%
レビュー数:1644位
『王妃レオノーラ』
ジャンル:純文学〔文芸〕
評価点:95.24
評価偏差値:60.39
文中会話率:25%
レビュー数:245位
『隣の席になった美少女が惚れさせようとからかってくるがいつの間にか返り討ちにしていた』
ジャンル:現実世界〔恋愛〕
評価点:95.206
評価偏差値:60.25
文中会話率:48%
レビュー数:446位
『勇者召喚に巻き込まれたけど、異世界は平和でした』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:95.153
評価偏差値:60.03
文中会話率:53%
レビュー数:7447位
『落ちこぼれ子竜の縁談 ~閣下に溺愛されるのは想定外ですが!?~』
ジャンル:異世界〔恋愛〕
評価点:95.125
評価偏差値:59.92
文中会話率:28%
レビュー数:248位
『村づくりゲームのNPCが生身の人間としか思えない』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:95.081
評価偏差値:59.74
文中会話率:28%
レビュー数:1549位
『現代社会で乙女ゲームの悪役令嬢をするのはちょっと大変』
ジャンル:現実世界〔恋愛〕
評価点:95.064
評価偏差値:59.67
文中会話率:24%
レビュー数:150位
『魔王学院の不適合者 ~史上最強の魔王の始祖、転生して子孫たちの学校へ通う~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.983
評価偏差値:59.33
文中会話率:43%
レビュー数:3051位
『地球さんはレベルアップした~非匿主義少女の英雄譚~』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:94.975
評価偏差値:59.3
文中会話率:21%
レビュー数:152位
『ずたぼろ令嬢は姉の元婚約者に溺愛される』
ジャンル:異世界〔恋愛〕
評価点:94.94
評価偏差値:59.16
文中会話率:47%
レビュー数:453位
『陰の実力者になりたくて!【web版】』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.857
評価偏差値:58.82
文中会話率:39%
レビュー数:5154位
『北の傭兵の息子が南の魔法学院に入学する話。』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.843
評価偏差値:58.76
文中会話率:39%
レビュー数:1255位
『氷の令嬢の溶かし方 ~クールで素っ気ないお隣さんがデレるとめちゃくちゃ可愛い件~』
ジャンル:現実世界〔恋愛〕
評価点:94.829
評価偏差値:58.7
文中会話率:38%
レビュー数:456位
『とある策士の三國志(仮)~天下人の軍師~』
ジャンル:歴史〔文芸〕
評価点:94.8
評価偏差値:58.58
文中会話率:32%
レビュー数:957位
『信者ゼロの女神サマと始める異世界攻略 クラスメイト最弱の魔法使い』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.79
評価偏差値:58.54
文中会話率:36%
レビュー数:958位
『奴隷堕ちした追放令嬢のお仕事』
ジャンル:異世界〔恋愛〕
評価点:94.788
評価偏差値:58.53
文中会話率:45%
レビュー数:259位
『Dジェネシス ダンジョンができて3年(旧:ダンジョンが出来て3年。いきなり世界ランク1位になった俺は、会社を辞めてゆるゆると生きてます。)』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:94.728
評価偏差値:58.29
文中会話率:55%
レビュー数:1760位
『視える令嬢とつかれやすい公爵【連載】』
ジャンル:異世界〔恋愛〕
評価点:94.708
評価偏差値:58.2
文中会話率:30%
レビュー数:061位
『やたらと察しのいい俺は、毒舌クーデレ美少女の小さなデレも見逃さずにグイグイいく』
ジャンル:現実世界〔恋愛〕
評価点:94.691
評価偏差値:58.13
文中会話率:48%
レビュー数:362位
『『北土聖伐』顛末記~異世界転生者が奴隷少女を前にして必死過ぎる件~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.686
評価偏差値:58.11
文中会話率:98%
レビュー数:163位
『僕は婚約破棄なんてしませんからね』
ジャンル:異世界〔恋愛〕
評価点:94.672
評価偏差値:58.06
文中会話率:55%
レビュー数:764位
『ハズレ枠の【状態異常スキル】で最強になった俺がすべてを蹂躙するまで』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.662
評価偏差値:58.01
文中会話率:29%
レビュー数:4665位
『悪役令嬢は引き籠りたい~転生したら修羅場が多い~』
ジャンル:異世界〔恋愛〕
評価点:94.659
評価偏差値:58.0
文中会話率:24%
レビュー数:466位
『婚活ダンジョンちゃん、東京に巣食う』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:94.641
評価偏差値:57.93
文中会話率:26%
レビュー数:367位
『大事なものは失くしてわかる。』
ジャンル:現実世界〔恋愛〕
評価点:94.574
評価偏差値:57.65
文中会話率:39%
レビュー数:168位
『おまえだけしか愛せない』
ジャンル:異世界〔恋愛〕
評価点:94.439
評価偏差値:57.1
文中会話率:58%
レビュー数:069位
『田中家、転生する。』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.43
評価偏差値:57.06
文中会話率:31%
レビュー数:270位
『突然パパになった最強ドラゴンの子育て日記 〜かわいい娘、ほのぼのと人間界最強に育つ〜』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.429
評価偏差値:57.06
文中会話率:39%
レビュー数:171位
『ありふれた職業で世界最強』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.394
評価偏差値:56.91
文中会話率:40%
レビュー数:9172位
『漆黒のダークヒーロー~ヒーローに憧れた俺が、あれよあれよとラスボスに!? ~』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:94.378
評価偏差値:56.85
文中会話率:43%
レビュー数:473位
『許嫁が出来たと思ったら、その許嫁が学校で有名な『悪役令嬢』だったんだけど、どうすればいい?』
ジャンル:現実世界〔恋愛〕
評価点:94.372
評価偏差値:56.82
文中会話率:77%
レビュー数:274位
『現代で異能バトルが始まったので、異世界で学んだ魔法で無双していたら、魔法少女が参戦してきた。』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:94.327
評価偏差値:56.64
文中会話率:44%
レビュー数:275位
『サッカーと恋愛 〜普通に生きてきた俺が、ある日サッカーをした事がきっかけで、超美形の兄妹から惚れられてしまうお話〜』
ジャンル:現実世界〔恋愛〕
評価点:94.319
評価偏差値:56.61
文中会話率:37%
レビュー数:176位
『転生! 竹中半兵衛 マイナー武将に転生した仲間たちと戦国乱世を生き抜く』
ジャンル:歴史〔文芸〕
評価点:94.302
評価偏差値:56.54
文中会話率:35%
レビュー数:1077位
『スキル『台所召喚』はすごい!~異世界でごはん作ってポイントためます~』
ジャンル:異世界〔恋愛〕
評価点:94.285
評価偏差値:56.47
文中会話率:36%
レビュー数:278位
『ライブダンジョン!』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.279
評価偏差値:56.44
文中会話率:51%
レビュー数:2679位
『創世のアルケミスト~前世の記憶を持つ私は崩壊した日本で成り上がる~』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:94.255
評価偏差値:56.34
文中会話率:21%
レビュー数:180位
『元ホームセンター店員の異世界生活 ~称号《DIYマスター》《グリーンマスター》《ペットマスター》を駆使して異世界を気儘に生きます~』
ジャンル:異世界〔恋愛〕
評価点:94.228
評価偏差値:56.23
文中会話率:42%
レビュー数:281位
『影の英雄の日常譚 ~勇者の裏で暗躍していた最強のエージェント、組織が解体されたので、正体隠して人並みの日常を謳歌する~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.194
評価偏差値:56.09
文中会話率:37%
レビュー数:582位
『異世界のんびり農家』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.176
評価偏差値:56.02
文中会話率:14%
レビュー数:3083位
『外れスキル「影が薄い」を持つギルド職員が、実は伝説の暗殺者』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.15
評価偏差値:55.91
文中会話率:47%
レビュー数:584位
『もふもふを知らなかったら人生の半分は無駄にしていた【Web版】』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.141
評価偏差値:55.88
文中会話率:54%
レビュー数:385位
『貧乏令嬢の勘違い聖女伝 ~お金のために努力してたら、王族ハーレムが出来ていました!?~』
ジャンル:異世界〔恋愛〕
評価点:94.12
評価偏差値:55.79
文中会話率:33%
レビュー数:586位
『逆行した悪役令嬢は、なぜか魔力を失ったので深窓の令嬢になります』
ジャンル:異世界〔恋愛〕
評価点:94.11
評価偏差値:55.75
文中会話率:31%
レビュー数:187位
『人間不信の冒険者達が世界を救うようです』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.105
評価偏差値:55.73
文中会話率:53%
レビュー数:288位
『世界最高の暗殺者、異世界貴族に転生する』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.093
評価偏差値:55.68
文中会話率:29%
レビュー数:1389位
『貴族転生~恵まれた生まれから最強の力を得る』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.089
評価偏差値:55.66
文中会話率:46%
レビュー数:2090位
『異世界最強の大魔王、転生し冒険者になる』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:94.082
評価偏差値:55.63
文中会話率:34%
レビュー数:091位
『出遅れテイマーのその日ぐらし』
ジャンル:VRゲーム〔SF〕
評価点:94.055
評価偏差値:55.52
文中会話率:51%
レビュー数:2592位
『打撃系鬼っ娘が征く配信道!』
ジャンル:VRゲーム〔SF〕
評価点:94.011
評価偏差値:55.34
文中会話率:36%
レビュー数:293位
『冰剣の魔術師が世界を統べる〜世界最強の魔術師である少年は、魔術学院に入学する〜』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.978
評価偏差値:55.21
文中会話率:49%
レビュー数:294位
『モンスターがあふれる世界になったので、好きに生きたいと思います』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:93.899
評価偏差値:54.88
文中会話率:26%
レビュー数:1895位
『俺は全てを【パリイ】する 〜逆勘違いの世界最強は冒険者になりたい〜』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.898
評価偏差値:54.88
文中会話率:20%
レビュー数:1196位
『黄金の経験値』
ジャンル:VRゲーム〔SF〕
評価点:93.883
評価偏差値:54.82
文中会話率:28%
レビュー数:197位
『III count Dead END 【旧タイトル転生者のSF戦記。あれ?でもココ転生者の意味無くね?】』
ジャンル:宇宙〔SF〕
評価点:93.88
評価偏差値:54.8
文中会話率:57%
レビュー数:198位
『一億年ボタンを連打した俺は、気付いたら最強になっていた~落第剣士の学院無双~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.763
評価偏差値:54.32
文中会話率:38%
レビュー数:299位
『悪役令嬢後宮物語』
ジャンル:異世界〔恋愛〕
評価点:93.715
評価偏差値:54.13
文中会話率:56%
レビュー数:13100位
『メリーさんから家に向かってるって電話がかかってきたんだが、俺今旅行中なんだよな』
ジャンル:現実世界〔恋愛〕
評価点:93.712
評価偏差値:54.12
文中会話率:55%
レビュー数:3101位
『寝取られ勇者は魔王と駆け落ちする』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.667
評価偏差値:53.93
文中会話率:36%
レビュー数:0102位
『王女様に婚約を破棄されましたが、おかげさまで幸せです。』
ジャンル:異世界〔恋愛〕
評価点:93.648
評価偏差値:53.85
文中会話率:36%
レビュー数:0103位
『失格から始める成り上がり魔導師道!~呪文開発ときどき戦記~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.635
評価偏差値:53.8
文中会話率:37%
レビュー数:4104位
『不死者の弟子~邪神の不興を買って奈落に落とされた俺の英雄譚~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.629
評価偏差値:53.77
文中会話率:29%
レビュー数:2105位
『私の名はマルカ』
ジャンル:異世界〔恋愛〕
評価点:93.601
評価偏差値:53.66
文中会話率:42%
レビュー数:0106位
『異世界でも無難に生きたい症候群』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.597
評価偏差値:53.64
文中会話率:51%
レビュー数:4107位
『聖女の魔力は万能です』
ジャンル:異世界〔恋愛〕
評価点:93.548
評価偏差値:53.44
文中会話率:26%
レビュー数:3108位
『クラスで陰キャの俺が実は大人気バンドのボーカルな件』
ジャンル:現実世界〔恋愛〕
評価点:93.544
評価偏差値:53.43
文中会話率:40%
レビュー数:1109位
『異世界で妹天使となにかする。』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.52
評価偏差値:53.33
文中会話率:49%
レビュー数:3110位
『転生した最強の錬金術師は、劣等とされる錬金術で無双する』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.512
評価偏差値:53.29
文中会話率:39%
レビュー数:0111位
『転生先で捨てられたので、もふもふ達とお料理します ~お飾り王妃はマイペースに最強です~』
ジャンル:異世界〔恋愛〕
評価点:93.505
評価偏差値:53.27
文中会話率:30%
レビュー数:2112位
『婚約破棄から始まる悪役令嬢の監獄スローライフ【Web版】』
ジャンル:異世界〔恋愛〕
評価点:93.482
評価偏差値:53.17
文中会話率:57%
レビュー数:15113位
『復讐を誓った白猫は竜王の膝の上で惰眠をむさぼる』
ジャンル:異世界〔恋愛〕
評価点:93.442
評価偏差値:53.01
文中会話率:35%
レビュー数:0114位
『ソシャゲキャラになった彼女の日常』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:93.422
評価偏差値:52.92
文中会話率:51%
レビュー数:0115位
『冒スキ(WEB連載版)』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:93.412
評価偏差値:52.88
文中会話率:20%
レビュー数:7116位
『幼馴染の妹の家庭教師をはじめたら疎遠だった幼馴染が怖い 〜学年のアイドルが俺のことを好きだなんて絶対に信じられない〜』
ジャンル:現実世界〔恋愛〕
評価点:93.412
評価偏差値:52.88
文中会話率:59%
レビュー数:4117位
『わたしの幸せな結婚』
ジャンル:異世界〔恋愛〕
評価点:93.403
評価偏差値:52.85
文中会話率:39%
レビュー数:0118位
『悪役令嬢は天使の皮を被ってます!!』
ジャンル:異世界〔恋愛〕
評価点:93.393
評価偏差値:52.81
文中会話率:40%
レビュー数:0119位
『貧乏貴族ノードの冒険譚』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.376
評価偏差値:52.74
文中会話率:22%
レビュー数:7120位
『追放悪役令嬢の旦那様』
ジャンル:異世界〔恋愛〕
評価点:93.354
評価偏差値:52.65
文中会話率:40%
レビュー数:2121位
『目覚めたら最強装備と宇宙船持ちだったので、一戸建て目指して傭兵として自由に生きたい』
ジャンル:宇宙〔SF〕
評価点:93.346
評価偏差値:52.61
文中会話率:62%
レビュー数:4122位
『ラスボス、やめてみた ~主人公に倒されたふりして自由に生きてみた~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.334
評価偏差値:52.56
文中会話率:40%
レビュー数:0123位
『私、能力は平均値でって言ったよね!』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.315
評価偏差値:52.49
文中会話率:34%
レビュー数:31124位
『メリリース・スペンサーの苦難の日々』
ジャンル:異世界〔恋愛〕
評価点:93.256
評価偏差値:52.24
文中会話率:34%
レビュー数:16125位
『白豚貴族だったどうしようもない私に前世の記憶が生えた件 (書籍:白豚貴族ですが前世の記憶が生えたのでひよこな弟育てます)』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.242
評価偏差値:52.19
文中会話率:42%
レビュー数:6126位
『望まぬ不死の冒険者』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.236
評価偏差値:52.16
文中会話率:22%
レビュー数:27127位
『【驚愕】貧乏さん、奇跡的に手に入れたスマホがワケありすぎて覚醒してしまう・・・からの現代無双』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:93.155
評価偏差値:51.83
文中会話率:46%
レビュー数:3128位
『神達に拾われた男(改訂版)』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.139
評価偏差値:51.76
文中会話率:55%
レビュー数:0129位
『公爵令嬢の嗜み』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.121
評価偏差値:51.69
文中会話率:43%
レビュー数:23130位
『極めた錬金術に、不可能はない。 ~万能スキルで異世界無双~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.055
評価偏差値:51.42
文中会話率:27%
レビュー数:0131位
『聖女じゃなかったので、王宮でのんびりご飯を作ることにしました』
ジャンル:異世界〔恋愛〕
評価点:93.05
評価偏差値:51.4
文中会話率:37%
レビュー数:0132位
『魔石グルメ ~魔物の力を食べたオレは最強!~(Web版)』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:93.002
評価偏差値:51.2
文中会話率:46%
レビュー数:10133位
『転生しまして、現在は侍女でございます。』
ジャンル:異世界〔恋愛〕
評価点:92.977
評価偏差値:51.1
文中会話率:34%
レビュー数:5134位
『デスマーチからはじまる異世界狂想曲( web版 )』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.964
評価偏差値:51.04
文中会話率:38%
レビュー数:23135位
『転生して田舎でスローライフをおくりたい』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.928
評価偏差値:50.9
文中会話率:40%
レビュー数:8136位
『追放者食堂へようこそ! 【書籍2巻発売!!!】』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.813
評価偏差値:50.42
文中会話率:49%
レビュー数:7137位
『ポーション頼みで生き延びます!』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.798
評価偏差値:50.36
文中会話率:29%
レビュー数:14138位
『暗殺スキルで異世界最強 ~錬金術と暗殺術を極めた俺は、世界を陰から支配する~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.757
評価偏差値:50.19
文中会話率:27%
レビュー数:2139位
『召喚された先は、私を殺した国でした』
ジャンル:異世界〔恋愛〕
評価点:92.75
評価偏差値:50.17
文中会話率:42%
レビュー数:1140位
『ニートの逆襲 〜俺がただのニートから魔王と呼ばれるまで〜』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:92.748
評価偏差値:50.16
文中会話率:28%
レビュー数:1141位
『中卒探索者ですけど今更最強になったのでダンジョンをクリアしたいと思います!』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:92.729
評価偏差値:50.08
文中会話率:55%
レビュー数:1142位
『ギルド追放された雑用係の下克上 ~超万能な"雑用スキル"で世界最強~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.727
評価偏差値:50.07
文中会話率:50%
レビュー数:3143位
『D級冒険者の俺、なぜか勇者パーティーに勧誘されたあげく、王女につきまとわれてる』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.723
評価偏差値:50.06
文中会話率:35%
レビュー数:1144位
『転生貴族の異世界冒険録~自重を知らない神々の使徒~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.677
評価偏差値:49.87
文中会話率:41%
レビュー数:7145位
『社畜騎士がSランク冒険者に拾われてヒモになる話 ~養われながらスローライフ~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.665
評価偏差値:49.82
文中会話率:41%
レビュー数:5146位
『誰かこの状況を説明してください』
ジャンル:異世界〔恋愛〕
評価点:92.649
評価偏差値:49.75
文中会話率:44%
レビュー数:3147位
『アンデッドから始める産業革命』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.648
評価偏差値:49.75
文中会話率:43%
レビュー数:1148位
『パソコン持ち転生令嬢ですが、推しキャラと永遠の独房生活を満喫中です。』
ジャンル:異世界〔恋愛〕
評価点:92.623
評価偏差値:49.64
文中会話率:26%
レビュー数:3149位
『嘘が見抜ける令嬢は愛人を脅し婚約者への復讐を決意する』
ジャンル:異世界〔恋愛〕
評価点:92.616
評価偏差値:49.62
文中会話率:51%
レビュー数:0150位
『没落予定の貴族だけど、暇だったから魔法を極めてみた』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.61
評価偏差値:49.59
文中会話率:45%
レビュー数:7151位
『不遇職『鍛冶師』だけど最強です ~気づけば何でも作れるようになっていた男ののんびりスローライフ~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.609
評価偏差値:49.59
文中会話率:34%
レビュー数:0152位
『転生領主の優良開拓〜前世の記憶を生かしてホワイトに努めたら、有能な人材が集まりすぎました〜』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.605
評価偏差値:49.57
文中会話率:54%
レビュー数:4153位
『異世界のんびり素材採取生活』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.602
評価偏差値:49.56
文中会話率:34%
レビュー数:3154位
『俺はまだ、本気を出していない』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.587
評価偏差値:49.5
文中会話率:45%
レビュー数:6155位
『転生したら小魚だったけど龍になれるらしいので頑張ります』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.451
評価偏差値:48.94
文中会話率:17%
レビュー数:0156位
『王妃ベルタの肖像 ~うっかり陛下の子を妊娠してしまいました~』
ジャンル:異世界〔恋愛〕
評価点:92.446
評価偏差値:48.92
文中会話率:33%
レビュー数:6157位
『今度は絶対に邪魔しませんっ!』
ジャンル:異世界〔恋愛〕
評価点:92.443
評価偏差値:48.91
文中会話率:32%
レビュー数:37158位
『追放されたので洞窟掘りまくってたら、いつのまにか最強賢者になってて、最強国家ができてました』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.437
評価偏差値:48.88
文中会話率:27%
レビュー数:1159位
『だから俺は〇〇なんかじゃない!~高嶺の花をナンパから助けたら正体がばれました~』
ジャンル:現実世界〔恋愛〕
評価点:92.417
評価偏差値:48.8
文中会話率:58%
レビュー数:4160位
『外れスキルをもらったけど、敵の攻撃食らってたら最強になってた ~Fランク冒険者は最強英雄候補です~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.414
評価偏差値:48.79
文中会話率:29%
レビュー数:2161位
『たかが子爵嫡男に高貴な人たちがグイグイきて困る』
ジャンル:異世界〔恋愛〕
評価点:92.38
評価偏差値:48.65
文中会話率:56%
レビュー数:3162位
『レベル1の最強賢者 ~ 呪いで最下級魔法しか使えないけど、神の勘違いで無限の魔力を手に入れ、最強に ~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.347
評価偏差値:48.51
文中会話率:33%
レビュー数:2163位
『最弱テイマーはゴミ拾いの旅を始めました。』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.312
評価偏差値:48.37
文中会話率:37%
レビュー数:3164位
『栽培チートで最強菜園 ~え、ただの家庭菜園ですけど?~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.282
評価偏差値:48.24
文中会話率:47%
レビュー数:6165位
『【web版】最強の魔導士。ひざに矢をうけてしまったので田舎の衛兵になる』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.276
評価偏差値:48.22
文中会話率:51%
レビュー数:9166位
『くま クマ 熊 ベアー』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.227
評価偏差値:48.02
文中会話率:45%
レビュー数:21167位
『二度転生した少年はSランク冒険者として平穏に過ごす ~前世が賢者で英雄だったボクは来世では地味に生きる~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.196
評価偏差値:47.89
文中会話率:46%
レビュー数:2168位
『装備枠ゼロの最強剣士 でも、呪いの装備(可愛い)なら9999個つけ放題』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.192
評価偏差値:47.88
文中会話率:47%
レビュー数:2169位
『異世界転移で女神様から祝福を! ~いえ、手持ちの異能があるので結構です~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.191
評価偏差値:47.87
文中会話率:38%
レビュー数:16170位
『婚約破棄された令嬢は野獣辺境伯へ嫁ぐ!【連載版】』
ジャンル:異世界〔恋愛〕
評価点:92.185
評価偏差値:47.85
文中会話率:41%
レビュー数:0171位
『虐げられた令嬢は、実は最強の聖女~もう愛してくれなくて構いません、私は隣国の民を癒します』
ジャンル:異世界〔恋愛〕
評価点:92.141
評価偏差値:47.67
文中会話率:27%
レビュー数:0172位
『異世界でスローライフを(願望)』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.124
評価偏差値:47.6
文中会話率:49%
レビュー数:9173位
『漆黒使いの最強勇者 〜仲間全員に裏切られたので最強の魔物と組みます〜』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.122
評価偏差値:47.59
文中会話率:51%
レビュー数:11174位
『目が覚めたら戦国時代‼︎そしてオレは南部晴政⁉︎』
ジャンル:歴史〔文芸〕
評価点:92.094
評価偏差値:47.47
文中会話率:27%
レビュー数:0175位
『射程極振り弓おじさん』
ジャンル:VRゲーム〔SF〕
評価点:92.093
評価偏差値:47.47
文中会話率:14%
レビュー数:3176位
『泡になって消えた。』
ジャンル:異世界〔恋愛〕
評価点:92.084
評価偏差値:47.43
文中会話率:15%
レビュー数:0177位
『世界で唯一の男魔術師』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:92.079
評価偏差値:47.41
文中会話率:45%
レビュー数:1178位
『レベル1だけどユニークスキルで最強です』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.061
評価偏差値:47.34
文中会話率:42%
レビュー数:17179位
『盾の勇者の成り上がり』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.01
評価偏差値:47.13
文中会話率:44%
レビュー数:43180位
『とんでもスキルで異世界放浪メシ』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:92.008
評価偏差値:47.12
文中会話率:36%
レビュー数:109181位
『転生したら第七王子だったので、気ままに魔術を極めます』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.971
評価偏差値:46.97
文中会話率:35%
レビュー数:0182位
『実は俺、最強でした? ~転生直後はどん底スタート、でも万能魔法で逆転人生を上昇中!~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.966
評価偏差値:46.95
文中会話率:41%
レビュー数:1183位
『加護なし令嬢の小さな村』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.964
評価偏差値:46.94
文中会話率:41%
レビュー数:2184位
『従弟の尻拭いをさせられる羽目になった』
ジャンル:異世界〔恋愛〕
評価点:91.956
評価偏差値:46.91
文中会話率:66%
レビュー数:0185位
『お姉さま、それちょうだい?』
ジャンル:異世界〔恋愛〕
評価点:91.942
評価偏差値:46.85
文中会話率:49%
レビュー数:2186位
『「攻略本」を駆使する最強の魔法使い ~〈命令させろ〉とは言わせない俺流魔王討伐最善ルート~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.883
評価偏差値:46.61
文中会話率:35%
レビュー数:3187位
『俺のスライムから放たれる攻撃魔法は威力がおかしいらしい 〜え、今倒したの人類滅亡クラスの災厄だったんすか?〜』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.851
評価偏差値:46.48
文中会話率:26%
レビュー数:3188位
『悪役令嬢は隣国の王太子に溺愛される』
ジャンル:異世界〔恋愛〕
評価点:91.851
評価偏差値:46.48
文中会話率:44%
レビュー数:1189位
『捨てられ白魔法使いの紅茶生活』
ジャンル:異世界〔恋愛〕
評価点:91.837
評価偏差値:46.42
文中会話率:41%
レビュー数:0190位
『クズ異能 〜【温度を変える者】の俺が無双するまで〜 WEB版』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:91.832
評価偏差値:46.4
文中会話率:35%
レビュー数:1191位
『植物魔法チートでのんびり領主生活始めます~前世の知識を駆使して農業したら、逆転人生始まった件~ 』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.814
評価偏差値:46.32
文中会話率:34%
レビュー数:0192位
『王女殿下はお怒りのようです<WEB版>』
ジャンル:異世界〔恋愛〕
評価点:91.802
評価偏差値:46.27
文中会話率:47%
レビュー数:2193位
『転生したら宿屋の息子でした。田舎街でのんびりスローライフをおくろう』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.767
評価偏差値:46.13
文中会話率:42%
レビュー数:0194位
『異世界賢者の転生無双 ~ゲームの知識で異世界最強~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.723
評価偏差値:45.95
文中会話率:30%
レビュー数:4195位
『転生したら乙女ゲーの世界?いえ、魔術を極めるのに忙しいのでそういうのは結構です。』
ジャンル:異世界〔恋愛〕
評価点:91.717
評価偏差値:45.93
文中会話率:31%
レビュー数:2196位
『いつでも自宅に帰れる俺は、異世界で行商人をはじめました ~等価交換スキルで異世界通貨を日本円へ~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.713
評価偏差値:45.91
文中会話率:44%
レビュー数:12197位
『 100人の英雄を育てた最強預言者は、冒険者になっても世界中の弟子から慕われてます』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.708
評価偏差値:45.89
文中会話率:42%
レビュー数:0198位
『ブラックな騎士団の奴隷がホワイトな冒険者ギルドに引き抜かれてSランクになってました』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.706
評価偏差値:45.88
文中会話率:39%
レビュー数:1199位
『現代ダンジョンで、生き残るには!? 日本にダンジョンが溢れた結果、最強チートを手に入れたので退職冒険者に!』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:91.689
評価偏差値:45.81
文中会話率:44%
レビュー数:0200位
『転生賢者の異世界ライフ ~第二の職業を得て、世界最強になりました~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.654
評価偏差値:45.67
文中会話率:36%
レビュー数:5201位
『転生魔導王は、底辺職の黒魔術士が、実は最強職だと知っている』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.652
評価偏差値:45.66
文中会話率:33%
レビュー数:0202位
『達人達はおっさんを見過ごせない。 〜追放されたおっさんは『融合』でオリジナルを創りだす〜』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.59
評価偏差値:45.4
文中会話率:27%
レビュー数:0203位
『聖女のはずが、どうやら乗っ取られました』
ジャンル:異世界〔恋愛〕
評価点:91.583
評価偏差値:45.38
文中会話率:22%
レビュー数:0204位
『俺の前世の知識で底辺職テイマーが上級職になってしまいそうな件について 』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.518
評価偏差値:45.11
文中会話率:27%
レビュー数:3205位
『0歳児スタートダッシュ物語』
ジャンル:異世界〔恋愛〕
評価点:91.491
評価偏差値:45.0
文中会話率:39%
レビュー数:1206位
『テイマーの限界を超えたみたいなので女の子をテイムして最強パーティーをつくります 〜俺にテイムされると強くなるらしくSランクの獣人も伝説の聖女もエルフの女王も最強の龍王も自分からテイムされにくる〜』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.483
評価偏差値:44.96
文中会話率:60%
レビュー数:1207位
『冒険者をクビになったので、錬金術師として出直します! 〜辺境開拓? よし、俺に任せとけ!』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.468
評価偏差値:44.9
文中会話率:50%
レビュー数:2208位
『攻略難易度ハードモードの地球産ダンジョンは、ボッチが異世界から買う奴隷少女らにとっては生温いようです!!』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:91.458
評価偏差値:44.86
文中会話率:32%
レビュー数:0209位
『勿論、慰謝料請求いたします!』
ジャンル:異世界〔恋愛〕
評価点:91.455
評価偏差値:44.85
文中会話率:48%
レビュー数:1210位
『ルイ16世に転生してしまった俺はフランス革命を全力で阻止してマリーと末永くお幸せに暮らしたい』
ジャンル:歴史〔文芸〕
評価点:91.454
評価偏差値:44.85
文中会話率:23%
レビュー数:3211位
『前世聖女は手を抜きたい よきよき』
ジャンル:異世界〔恋愛〕
評価点:91.404
評価偏差値:44.64
文中会話率:30%
レビュー数:0212位
『二度と家には帰りません!~虐げられていたのに恩返ししろとかムリだから~』
ジャンル:異世界〔恋愛〕
評価点:91.366
評価偏差値:44.48
文中会話率:32%
レビュー数:1213位
『神々の加護で生産革命 ~異世界の片隅でまったりスローライフしてたら、なぜか多彩な人材が集まって最強国家ができてました~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.313
評価偏差値:44.27
文中会話率:48%
レビュー数:0214位
『傷心公爵令嬢レイラの逃避行』
ジャンル:異世界〔恋愛〕
評価点:91.298
評価偏差値:44.21
文中会話率:41%
レビュー数:1215位
『アラフォー男の異世界通販生活』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.246
評価偏差値:43.99
文中会話率:47%
レビュー数:1216位
『失格紋の最強賢者 ~世界最強の賢者が更に強くなるために転生しました~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.226
評価偏差値:43.91
文中会話率:34%
レビュー数:9217位
『精霊の愛子の婚約者』
ジャンル:異世界〔恋愛〕
評価点:91.225
評価偏差値:43.91
文中会話率:36%
レビュー数:0218位
『真の仲間じゃないと勇者のパーティーを追い出されたので、辺境でスローライフすることにしました』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.222
評価偏差値:43.89
文中会話率:40%
レビュー数:11219位
『【修復】スキルが万能チート化したので、武器屋でも開こうかと思います』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.186
評価偏差値:43.75
文中会話率:38%
レビュー数:6220位
『真実の愛に目覚めたので婚約破棄をしました』
ジャンル:異世界〔恋愛〕
評価点:91.16
評価偏差値:43.64
文中会話率:18%
レビュー数:0221位
『解雇された暗黒兵士(30代)のスローなセカンドライフ』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.135
評価偏差値:43.54
文中会話率:39%
レビュー数:3222位
『《最強ステータス》を引き継いだ転生少年、勇者の婚約者(お姫様)をうっかり寝取ってしまう』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.079
評価偏差値:43.31
文中会話率:32%
レビュー数:0223位
『よくわからないけれど異世界に転生していたようです』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.073
評価偏差値:43.28
文中会話率:38%
レビュー数:6224位
『地味で目立たない私は、今日で終わりにします。』
ジャンル:異世界〔恋愛〕
評価点:91.068
評価偏差値:43.26
文中会話率:43%
レビュー数:0225位
『おっさん冒険者ケインの善行』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.053
評価偏差値:43.2
文中会話率:39%
レビュー数:14226位
『転生勇者の気まま旅 ~伝説の最強勇者は第二の人生でさらに強くなるようです~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.031
評価偏差値:43.11
文中会話率:41%
レビュー数:2227位
『八男って、それはないでしょう! 』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:91.018
評価偏差値:43.06
文中会話率:41%
レビュー数:37228位
『異世界帰りの大賢者様はそれでもこっそり暮らしているつもりです』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:90.987
評価偏差値:42.93
文中会話率:37%
レビュー数:1229位
『転生したら兵士だった?!〜赤い死神と呼ばれた男〜』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:90.902
評価偏差値:42.58
文中会話率:33%
レビュー数:1230位
『転生貴族、鑑定スキルで成り上がる~弱小領地を受け継いだので、優秀な人材を増やしていたら、最強領地になってた~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:90.883
評価偏差値:42.5
文中会話率:33%
レビュー数:0231位
『呪いの魔剣で高負荷トレーニング!? 知られちゃいけない仮面の冒険者』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:90.868
評価偏差値:42.44
文中会話率:39%
レビュー数:2232位
『勇者パーティーを追放されたビーストテイマー、最強種の猫耳少女と出会う』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:90.738
評価偏差値:41.91
文中会話率:45%
レビュー数:2233位
『新米オッサン冒険者、最強パーティに死ぬほど鍛えられて無敵になる。※コミカライズ連載中!!』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:90.737
評価偏差値:41.9
文中会話率:40%
レビュー数:1234位
『駆除人』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:90.659
評価偏差値:41.58
文中会話率:53%
レビュー数:10235位
『高一から始める探索者生活』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:90.635
評価偏差値:41.48
文中会話率:37%
レビュー数:1236位
『世界でただ一人の魔物使い~転職したら魔王に間違われました~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:90.624
評価偏差値:41.44
文中会話率:48%
レビュー数:0237位
『最強タンクの迷宮攻略』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:90.608
評価偏差値:41.37
文中会話率:38%
レビュー数:5238位
『地獄の業火で焼かれ続けた少年。最強の炎使いとなって復活する。』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:90.589
評価偏差値:41.29
文中会話率:58%
レビュー数:0239位
『悪役令嬢(予定)らしいけど、私はお菓子が食べたい~ブロックスキルで穏やかな人生目指します~』
ジャンル:異世界〔恋愛〕
評価点:90.584
評価偏差値:41.27
文中会話率:27%
レビュー数:1240位
『脇役キャラに転生したので知識を活かして暮らしてたら、英雄たちに頼りにされる伝説の錬金術師になってた』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:90.582
評価偏差値:41.27
文中会話率:38%
レビュー数:1241位
『魔物を従える"帝印"を持つ転生賢者 ~かつての魔法と従魔でひっそり最強の冒険者になる~【WEB連載版】』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:90.422
評価偏差値:40.61
文中会話率:34%
レビュー数:3242位
『【web版】ここは俺に任せて先に行けと言ってから10年がたったら伝説になっていた。』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:90.395
評価偏差値:40.5
文中会話率:49%
レビュー数:11243位
『ダンジョン暮らし!スキル【ダンジョン図鑑】で楽々攻略?』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:90.268
評価偏差値:39.98
文中会話率:41%
レビュー数:1244位
『その劣等生、実は最強賢者』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:90.192
評価偏差値:39.66
文中会話率:28%
レビュー数:0245位
『のんべんだらりな転生者~貧乏農家を満喫す~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:90.184
評価偏差値:39.63
文中会話率:44%
レビュー数:0246位
『姉が剣聖で妹が賢者で』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:90.069
評価偏差値:39.16
文中会話率:36%
レビュー数:0247位
『すみません、今さら無理です』
ジャンル:異世界〔恋愛〕
評価点:90.048
評価偏差値:39.07
文中会話率:33%
レビュー数:0248位
『異世界の貧乏農家に転生したので、レンガを作って城を建てることにしました』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:89.987
評価偏差値:38.82
文中会話率:27%
レビュー数:3249位
『賢者の孫』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:89.969
評価偏差値:38.75
文中会話率:53%
レビュー数:13250位
『地球に出戻りした元勇者は、チートなスキルや魔法を駆使して第3の人生を謳歌する!』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:89.885
評価偏差値:38.4
文中会話率:36%
レビュー数:1251位
『勇者パーティーを追放された錬金術師、SSSランクダンジョンを創造する(書籍版:追放された錬金術師さん、最強のダンジョンを創りませんか?)』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:89.839
評価偏差値:38.22
文中会話率:44%
レビュー数:3252位
『異世界迷宮で奴隷ハーレムを』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:89.804
評価偏差値:38.07
文中会話率:26%
レビュー数:39253位
『追放されたけど、スキル『ゆるパク』で無双する』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:89.759
評価偏差値:37.89
文中会話率:38%
レビュー数:2254位
『バートレット英雄譚 〜スローライフしたいのにできない弱小貴族奮闘記〜』
ジャンル:ヒューマンドラマ〔文芸〕
評価点:89.522
評価偏差値:36.91
文中会話率:47%
レビュー数:7255位
『ざまぁ系悪役令嬢の元凶母に転生したようなので、可愛い娘のために早めのお掃除頑張ります』
ジャンル:異世界〔恋愛〕
評価点:89.5
評価偏差値:36.82
文中会話率:20%
レビュー数:0256位
『現代ダンジョンをチート職「忍者」で無双する。』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:89.405
評価偏差値:36.43
文中会話率:29%
レビュー数:0257位
『薔薇とすみれ』
ジャンル:異世界〔恋愛〕
評価点:89.366
評価偏差値:36.27
文中会話率:44%
レビュー数:0258位
『公爵令嬢は婚約破棄したい』
ジャンル:異世界〔恋愛〕
評価点:89.348
評価偏差値:36.2
文中会話率:34%
レビュー数:0259位
『死に戻り、全てを救うために最強へと至る』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:89.324
評価偏差値:36.1
文中会話率:35%
レビュー数:3260位
『乙女ゲームを降りる事にしました』
ジャンル:異世界〔恋愛〕
評価点:89.144
評価偏差値:35.36
文中会話率:43%
レビュー数:0261位
『砂漠だらけの世界で、おっさんが電子マネーで無双する』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:89.111
評価偏差値:35.23
文中会話率:44%
レビュー数:0262位
『虐待されていた商家の令嬢は聖女の力を手に入れ、無自覚に容赦なく逆襲する【本編完結】』
ジャンル:異世界〔恋愛〕
評価点:89.058
評価偏差値:35.01
文中会話率:14%
レビュー数:2263位
『偽聖女と虐げられた公爵令嬢は二度目の人生は復讐に生きる【本編完結】』
ジャンル:異世界〔恋愛〕
評価点:88.996
評価偏差値:34.76
文中会話率:22%
レビュー数:2264位
『運命の愛なんて知らない』
ジャンル:異世界〔恋愛〕
評価点:88.879
評価偏差値:34.27
文中会話率:49%
レビュー数:0265位
『没落貴族の嫡男なので好きに生きようと思います~最強な血筋なのにどうしてこうなった~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:88.67
評価偏差値:33.42
文中会話率:53%
レビュー数:0266位
『史上最強の大魔王、村人Aに転生する ~村人(規格外)による、普通だけど普通じゃない英雄譚~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:88.62
評価偏差値:33.21
文中会話率:32%
レビュー数:2267位
『天空の城を貰ったので異世界で楽しく遊びたい』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:88.475
評価偏差値:32.62
文中会話率:41%
レビュー数:1268位
『戦鬼と呼ばれた男、王家に暗殺されたら娘を拾い、一緒にスローライフをはじめる』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:88.471
評価偏差値:32.6
文中会話率:30%
レビュー数:3269位
『帰ってきた元奴隷の男』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:88.435
評価偏差値:32.45
文中会話率:47%
レビュー数:1270位
『2位では意味がないと貴族の家から勘当された少年、実は剣技や魔法、すべてにおいてハイレベル。~無自覚に無双しながら、好き勝手に生きたいと思います~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:88.4
評価偏差値:32.31
文中会話率:35%
レビュー数:2271位
『完全回避ヒーラーの軌跡』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:88.367
評価偏差値:32.17
文中会話率:47%
レビュー数:1272位
『私、興味がないので(連載版)』
ジャンル:異世界〔恋愛〕
評価点:88.338
評価偏差値:32.05
文中会話率:49%
レビュー数:0273位
『この色に誓って』
ジャンル:異世界〔恋愛〕
評価点:88.153
評価偏差値:31.29
文中会話率:42%
レビュー数:0274位
『聖女の奇跡』
ジャンル:異世界〔恋愛〕
評価点:88.135
評価偏差値:31.22
文中会話率:49%
レビュー数:0275位
『裏切りのその末は』
ジャンル:異世界〔恋愛〕
評価点:88.012
評価偏差値:30.72
文中会話率:28%
レビュー数:0276位
『私はおとなしく消え去ることにします』
ジャンル:異世界〔恋愛〕
評価点:88.007
評価偏差値:30.7
文中会話率:52%
レビュー数:0277位
『なんとなく歩いてたらダンジョンらしき場所にいた俺の話』
ジャンル:ローファンタジー〔ファンタジー〕
評価点:87.885
評価偏差値:30.19
文中会話率:44%
レビュー数:1278位
『ニトの怠惰な異世界症候群 ~最弱職〈ヒーラー〉なのに最強はチートですか?~』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:87.846
評価偏差値:30.03
文中会話率:39%
レビュー数:9279位
『限界レベル1からの成り上がり ~廃棄された限界レベル1の俺、スキル【死体吸収】の力で最強になる~』
ジャンル:アクション〔文芸〕
評価点:87.541
評価偏差値:28.78
文中会話率:33%
レビュー数:0280位
『貧乏国の悪役令嬢、金儲けに必死になってたら婚約破棄されました』
ジャンル:異世界〔恋愛〕
評価点:87.425
評価偏差値:28.31
文中会話率:31%
レビュー数:1281位
『不遇らしいけど何とかなりそうなので無難にやってます』
ジャンル:VRゲーム〔SF〕
評価点:87.337
評価偏差値:27.94
文中会話率:57%
レビュー数:0282位
『ガベージブレイブ【異世界に召喚され捨てられた勇者の復讐物語】』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:87.296
評価偏差値:27.78
文中会話率:36%
レビュー数:0283位
『婚約破棄をされた令嬢は、全てを見捨てる事にした』
ジャンル:ハイファンタジー〔ファンタジー〕
評価点:86.224
評価偏差値:23.38
文中会話率:30%
レビュー数:0284位
『ハッピーエンドのそのまえに』
ジャンル:異世界〔恋愛〕
評価点:85.284
評価偏差値:19.52
文中会話率:32%
レビュー数:1285位
『番だと気づいたのは、婚約破棄した後でした』
ジャンル:異世界〔恋愛〕
評価点:83.634
評価偏差値:12.74
文中会話率:31%
レビュー数:0