- 投稿日:2019-10-04T23:13:27+09:00
ジョイスティック操縦プログラム
はじめに
このページは,
の1ページです.
全体を見たい場合は上記ページへお戻りください.概要
前回の記事では,tello.pyのTelloクラスを使って,Telloをキーボードで操縦するプログラムを作りました.
しかし,キーを押しっぱなしにして操作することはできない仕様だったので,リアルタイムにラジコンを操縦する感覚ではありませんでした.本企画は「OpenCVの画像処理を用いてTelloを自律ロボット化する」のが本筋なのですが,今回はちょっと寄り道してジョイパッド/ジョイスティックでTelloを操縦してみます.
(「Tello-Pythonでどこまでできるのか,可能性を見せる」という感じ?)前提条件
ホームフォルダにTello-Pythonがインストールされているという前提で話を進めます.
Linuxマシンであれば
/home/(ユーザー名)/に,Tello-Pythonというフォルダがあることになります.詳しくは Tello-Pythonのダウンロード を御覧ください.
ジョイスティックを準備しよう
アナログ入力が少なくとも4軸あるジョイパッドまたはジョイスティックを用意しましょう.
プレイステーションのコントローラの様に,2つのアナログスティックが付いていればOKです.USB接続の製品であれば,Linuxでも問題なく認識してくれると思います.
Bluetooth接続は,製品に依存するのでオススメできません.(それぞれの製品をLinuxで使う,的な記事を探して設定する必要があります.)この記事では,古いデバイスをたくさん引っ張り出してきて遊びました(笑
- ロジクール F710
- プレイステーション3のコントローラ(DualShock3)をUSB接続
- プレイステーション4のコントローラ(DualShock4)をUSB接続
- XBOXコントローラそっくりの中国製の安いやつ
- サンワサプライの古いジョイパッド
- エレコムの古いジョイパッド
- Madcatz Cyborg F.L.Y.5
- Saitek X52 Pro
- Thrustmaster HOTAS couger
- Thrustmaster Top Gun Afterburner
いつか鉄騎コントローラでTelloを操縦したいなあ...
Telloをジョイスティックで操縦するプログラム
ディレクトリの作成
まずは,
Tello-Pythonディレクトリの下に,新しいディレクトリTello-joyを作ります.
(前回のTello-keyに名前が似ているので注意)Tello-joyディレクトリを作成$ cd ~/Tello-Python/ $ mkdir Tello-joy $ cd Tello-joyファイルをコピー
tello.pyとlibh264decoder.soを,前々回の
Tello-batteryからコピーしてきましょう.重要なファイルをコピー$ cp ../Tello-battery/tello.py ./ $ cp ../Tello-battery/libh264decoder.so ./ジョイスティックを管理するツール
ジョイパッドやジョイスティックは,製品に応じてボタン番号やアナログ軸番号が異なるので,プログラムするまえに動作を確認する必要があります.
そんな時に便利なのがjstest-gtkです.インストールは以下のコマンドです.
jstest-gtkのインストール$ sudo apt install jstest-gtkちなみにRaspberry Piでも問題なく使えるアプリです.
下図のように,Linuxのスタートメニューに「jstest-gtk」が追加されているはずです.
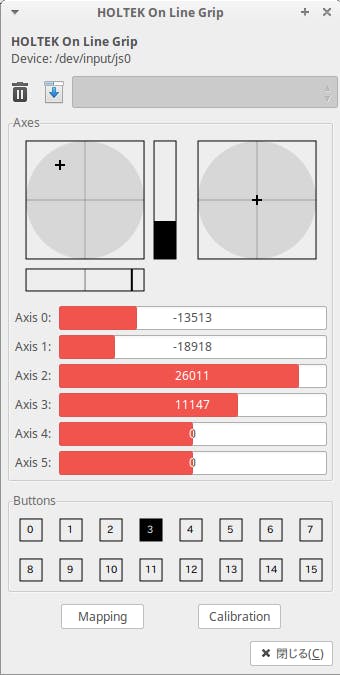
アプリを起動すると,PCに接続されているジョイスティックを列挙した画面が表示されます.
調べたいジョイスティックをダブルクリックすると,アナログスティックやボタンの情報を見ることができます.
GUIのウィンドウアプリケーションなので,お手軽に使えます.
Windowsの[ゲームコントローラの設定]みたいな機能です.jstest-gtkには,番号順序を変更(リマップ)したり,アナログ軸の方向を反転(リバース)させたりする機能もありますが,今回は使いません.
システム側でイジるよりも,プログラム側で対応することに慣れておいたほうが今後のためにも良いでしょう.Pythonでジョイスティック入力を取る方法
Pythonでジョイスティック入力を取る方法はいくつかありますが,今回は
pygameというライブラリを使います.pygameは,Pythonでグラフィカルなゲームを作るときに使うライブラリで,GUIウィンドウの生成や描画,サウンド,入出力などの多彩な機能を持っています.ですが今回は,pygameのジョイスティックを読む機能だけを使います.
Tello操作のキー配置
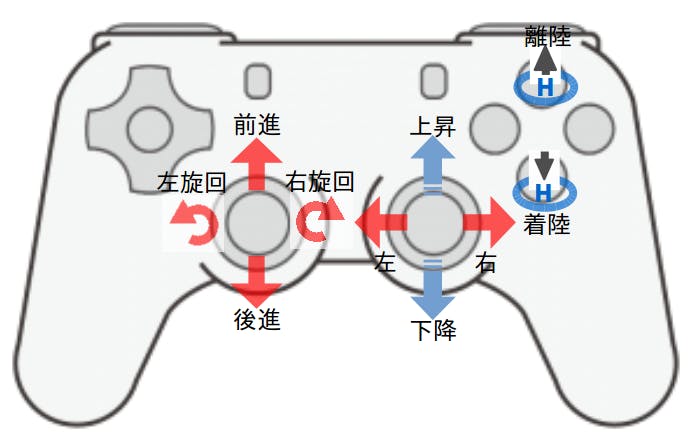
ジョイパッドの場合
ジョイパッドのスティックの使い方は,ラジコンのモード1と同じ配置にしました.
というか,筆者はモード1しか飛ばせないので(T_T
モード2の人は,適宜プログラムを変えてください.ジョイスティックの場合
ジョイスティックの場合は,実機ヘリコプターと同様のイメージにしました.
右スティックがサイクリックピッチ(前後左右移動),
左のスロットルレバーがコレクティブピッチ(上昇下降),のつもりです.
フットペダルが左右旋回なのですが,ペダルはオプションなので所有していない人のほうが多いです.その場合は「左レバーに付いているアナログ軸」あるいは「右スティックの『ねじり』軸」などに割り当てると良いでしょう.
こうして見ると,プロポのモード2というのは実機ヘリに近いことがわかりますね.
「プロポ モード2」で画像検索Tello SDKのラジコン操作コマンド
前回のキー入力と同様に,
forward,back,left,rightなどのコマンドを使っても良いのですが,これらの移動コマンドは応答が遅いです.Tello SDKのPDFをよく見ると,ラジコンの様にスティックの状態を流し込めるコマンドがあります.
コマンド名 解説 備考 rc a b c d 4チャンネル分のリモコン操作をセット “a” = left/right (-100〜100)
“b” = forward/backward (-100〜100)
“c” = up/down (-100〜100)
“d” = yaw (-100〜100)このコマンドを使うには,Telloクラスの
send_command関数を利用して,以下の様に書きます.send_commandを使ってrcコマンドを実装drone.send_command('rc %s %s %s %s'%(a, b, c, d) ) # a,b,c,dには±100以内の操作量を入れるa,b,c,dという変数には,ジョイスティックの値を入れてあげれば良いわけです.
ただし,数値は±100の範囲内に収める必要があります.main.py
それでは,プログラム本体である
main.pyです.以下のコードをコピー&ペーストするか,
ここ を右クリックして[名前を付けて保存]機能でファイル保存してください.main.py#!/usr/bin/env python # -*- coding: utf-8 -*- import tello # tello.pyをインポート import time # time.sleepを使いたいので import pygame # pygameでジョイスティックを読む def main(): # pygameの初期化とジョイスティックの初期化 pygame.init() joy = pygame.joystick.Joystick(0) # ジョイスティック番号はjstest-gtkで確認しておく joy.init() # Telloクラスを使って,droneというインスタンス(実体)を作る # コマンドの応答タイムアウトを0.01秒(10ms)にして,rcコマンドの連送に耐えられるようにする drone = tello.Tello('', 8889, command_timeout=.01 ) time.sleep(0.5) # 通信が安定するまでちょっと待つ #Ctrl+cが押されるまでループ try: while True: # Joystickの読み込み # get_axisは -1.0〜0.0〜+1.0 で変化するので100倍して±100にする # プラスマイナスの方向が逆の場合は-100倍して反転させる a = int( joy.get_axis(2)*100 ) # aは左右移動 b = int( joy.get_axis(1)*-100 ) # bは前後移動 c = int( joy.get_axis(3)*-100 ) # cは上下移動 d = int( joy.get_axis(0)*100 ) # dは旋回 btn0 = joy.get_button(0) btn1 = joy.get_button(1) btn2 = joy.get_button(2) btn3 = joy.get_button(3) pygame.event.pump() # イベントの更新 # プラスマイナスの方向や離陸/着陸に使うボタンを確認するためのprint文 #print("l/r=%d f/b=%d u/d=%d cw/ccw=%d btn0=%d btn1=%d btn2=%d btn3=%d"%(a, b, c, d, btn0, btn1, btn2, btn3)) # rcコマンドを送信 drone.send_command( 'rc %s %s %s %s'%(a, b, c, d) ) if btn1 == 1: # 離陸 drone.takeoff() elif btn2 == 1: # 着陸 drone.land() time.sleep(0.03) # 適度にウェイトを入れてCPU負荷を下げる except( KeyboardInterrupt, SystemExit): # Ctrl+cが押されたら離脱 print( "SIGINTを検知" ) # telloクラスを削除 del drone # "python main.py"として実行された時だけ動く様にするおまじない処理 if __name__ == "__main__": # importされると"__main__"は入らないので,実行かimportかを判断できる. main() # メイン関数を実行プログラムの実行
プログラム本体はmain.pyです.
プログラムの実行$ python main.pyctrl+cを押すことで,プログラムを終了できます.
実行結果
問題なく動作すれば,以下の様になるはずです.
実行結果$ python main.py pygame 1.9.6 Hello from the pygame community. https://www.pygame.org/contribute.html sent: command sent: streamon [h264 @ 0x195ba40] non-existing PPS 0 referenced [h264 @ 0x195ba40] non-existing PPS 0 referenced [h264 @ 0x195ba40] decode_slice_header error [h264 @ 0x195ba40] no frame! (略) >> send cmd: rc 0 0 0 0 >> send cmd: rc 0 0 0 0 >> send cmd: rc 0 0 0 0 >> send cmd: rc 38 82 86 99 >> send cmd: rc 29 82 86 99 . . .main.pyの解説
ではmain.pyの中身を見てみます.
import部分
まずはインポート部分です。
インポートimport tello # tello.pyをインポート import time # time.sleepを使いたいので import pygame # pygameでジョイスティックを読むpygameを読み込んでいます。
Raspberry Piだとpygameはデフォルトで入っているのですが、普通のPC Linuxだと入っていない事もあります。pygameのインストール$ pip install pygameLinuxの環境によっては、sudoを付ける必要があったり、pipをpip2と書いたりする必要があります。
メイン関数
メイン関数の中身は大きく分けて3つの部分に分かれています.
「初期化」「ループ」「終了処理」です.メイン関数# メイン関数本体 def main(): 初期化部 ループ部 終了処理部それぞれ解説していきます.
初期化部
初期化処理部# pygameの初期化とジョイスティックの初期化 pygame.init() joy = pygame.joystick.Joystick(0) # ジョイスティック番号はjstest-gtkで確認しておく joy.init() # Telloクラスを使って,droneというインスタンス(実体)を作る # コマンドの応答タイムアウトを0.01秒(10ms)にして,rcコマンドの連送に耐えられるようにする drone = tello.Tello('', 8889, command_timeout=.01 ) time.sleep(0.5) # 通信が安定するまでちょっと待つpygameの初期化とジョイスティックのインスタンス作成,ジョイスティックの初期化をしています.
今回はTelloクラスの呼び出し時の引数に
command_timeout=.01を追加してあります.
これはtakeoffなどのコマンドに対するTelloの応答を待つ時間「タイムアウト時間」の指定です.
デフォルト値は0.3なので300ミリ秒の待ちですが,0.01で10ミリ秒しか待たないようにしました.
こうすることで,ラジコンのプロポでドローンを動かしている様な感覚で操縦できるようになります.また,前回のキー入力で操縦の際に行った「5秒おきに
commandを送って,Telloが止まるのを回避する」機能はありません.というのは,ジョイスティックの値をrcコマンドで常時タレ流しにするので,コマンドが来なくなる状況には成り得ないからです.ループ部
while Trueで永久ループを作っています.
ctrl+cを検知してループを終了させるのはtry exceptにお任せです.ループ部#Ctrl+cが押されるまでループ try: while True: # Joystickの読み込み # get_axisは -1.0〜0.0〜+1.0 で変化するので100倍して±100にする # プラスマイナスの方向が逆の場合は-100倍して反転させる a = int( joy.get_axis(2)*100 ) # aは左右移動 b = int( joy.get_axis(1)*-100 ) # bは前後移動 c = int( joy.get_axis(3)*-100 ) # cは上下移動 d = int( joy.get_axis(0)*100 ) # dは旋回 btn0 = joy.get_button(0) btn1 = joy.get_button(1) btn2 = joy.get_button(2) btn3 = joy.get_button(3) pygame.event.pump() # イベントの更新 # プラスマイナスの方向や離陸/着陸に使うボタンを確認するためのprint文 #print("l/r=%d f/b=%d u/d=%d cw/ccw=%d btn0=%d btn1=%d btn2=%d btn3=%d"%(a, b, c, d, btn0, btn1, btn2, btn3)) # rcコマンドを送信 drone.send_command( 'rc %s %s %s %s'%(a, b, c, d) ) if btn1 == 1: # 離陸 drone.takeoff() elif btn2 == 1: # 着陸 drone.land() time.sleep(0.03) # 適度にウェイトを入れてCPU負荷を下げる except( KeyboardInterrupt, SystemExit): # Ctrl+cが押されたら離脱 print( "SIGINTを検知" )joyクラスには
get_axis(軸番号)とget_button(ボタン番号)で値を取るメンバがあります.
rc a b c dコマンドのa,b,c,dに対応する軸番号が何番なのかをprint文で探しました.プラスマイナスの方向もこのprint文で確認します.また,ボタン番号も確認して,離陸/着陸に使いたいボタンがどれかを調べました.
必要な情報を集めたら,print文はコメントアウトします.
drone.send_command( 'rc %s %s %s %s'%(a, b, c, d) )でジョイスティックの値を送信しています.今回はボタン1と2が離陸と着陸だったので,if文でボタンが押された時の処理を書いてあります.
終了処理部
終了処理はクラスを削除だけです.
終了処理部del drone # telloクラスを削除おわりに
今回はちょっと脇道にそれてジョイスティックでTelloを操縦しました.
Telloをプログラムで動かすには,
forward,back,left,right,up,downで移動距離を指定する方法rcで,直接移動量を指定する方法の2種類があることが分かりました.
画像処理のプログラムでTelloを動かすときには,目的に応じてどちらを使うべきなのか考えると良いでしょう.次回は,本筋に戻って画像処理の入門をやります.



- 投稿日:2019-10-04T22:56:48+09:00
Qisikitでアダマールゲートを実装する
```
はじめに、仮想環境を構築します。
create_env$ conda create -n envname python=3envnameには、仮想環境の名前を入れます。
conda info -eで自分の作った仮想環境の一覧を見ることが出来ます。
$ conda info -e$ source activate name_of_my_envqiskitをインストールします。
$ pip install qiskitimport numpy as np from qiskit import * %matplotlib inline量子回路を作成するにはQiskit内のQuantumCircuitというモジュールを使います。()の中は使用するqubitの数です。
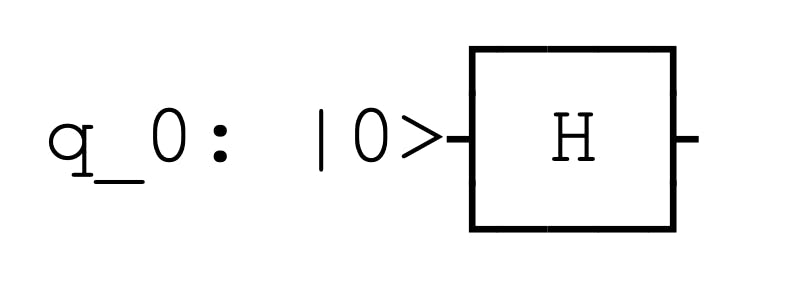
circ = QuantumCircuit(3)続いてアダマールゲートの実装の仕方です。hがアダマールゲートを指し、()内の数字は何qubit目の量子ゲートを使用するかを表しています。
circ.h(0)結果はこのようになります。
こうしてアダマールゲートをqiskit上で実装することが出来ました。
Qiskitのインストール
https://qiskit.org/documentation/locale/ja/install.html
Qiskitでアダマールゲートを実装する
https://github.com/Qiskit/qiskit-iqx-tutorials/blob/master/qiskit/fundamentals/1_getting_started_with_qiskit.ipynb

- 投稿日:2019-10-04T20:50:19+09:00
量子情報理論の基本:量子チャネル
$$
\def\bra#1{\mathinner{\left\langle{#1}\right|}}
\def\ket#1{\mathinner{\left|{#1}\right\rangle}}
\def\braket#1#2{\mathinner{\left\langle{#1}\middle|#2\right\rangle}}
$$はじめに
周囲の環境と相互作用する開いた量子系は、環境からの雑音(ノイズ)の影響を受けながら、一般に非ユニタリで時間発展していきます。前回の記事で説明した通り、この状態変化は「全体系に対する部分トレース」「Kraus表現」「CPTPマップ」といった形で理論的に記述できるのでした。現実の量子系への応用を考える際には、単なる抽象理論だけでなく、雑音の影響で量子系自体がどのように壊れていくのかをパターン化・モデル化して理解していくことが重要です。通信技術の分野で入力と出力の間をつなぐ通信路=雑音過程のことを「チャネル」と表現したりしますが、そのアナロジーで量子系のこの状態変化のことを「量子チャネル」と言うようです。今回の記事では、その「量子チャネル」の典型的なパターンをいくつか取り上げて、その特徴を記述してみたいと思います。さらに、量子計算シミュレータqlazyで、そのうちの一つを再現してみます。
参考にさせていただいたのは、以下の文献です。
- ニールセン、チャン「量子コンピュータと量子通信(2)」オーム社(2005年)
- ニールセン、チャン「量子コンピュータと量子通信(3)」オーム社(2005年)
- 石坂、小川、河内、木村、林「量子情報科学入門」共立出版(2012年)
- 富田「量子情報工学」森北出版(2017年)
ブロッホ表示
量子チャネルの特徴を理解するために、密度演算子の「ブロッホ表示」を知っておく必要があるので、その説明からはじめます。1量子ビットの量子状態は、3次元空間上の単位球=ブロッホ球の球面上の1点で表現することができます。球面の北極を$\ket{0}$、南極を$\ket{1}$とし、Z軸とのなす角を$\theta$、XY平面への射影とX軸とのなす角を$\phi$とすると、任意の量子状態(純粋状態)は、
\ket{\psi} = \cos\frac{\theta}{2} \ket{0} + e^{i\phi} sin\frac{\theta}{2} \ket{1} \tag{1}と表すことができます。これに対応した密度演算子は、
\rho = \frac{1}{2} (\sigma_0 + u_1 \sigma_1 + u_2 \sigma_2 + u_3 \sigma_3) \tag{2}と書くことができ、この表現のことを密度演算子の「ブロッホ表示」と呼び、ベクトル$(u_1,u_2,u_3)$を「ブロッホ・ベクトル」と呼びます。ここで、$\sigma_0,\sigma_1,\sigma_2,\sigma_3$はパウリ行列($\sigma_0$は単位行列)を表しており、$u_1,u_2,u_3$は、
\begin{align} u_1 &= \sin\theta \cos\phi \\ u_2 &= \sin\theta \sin\phi \\ u_3 &= \cos\theta \tag{3} \end{align}です1。つまり、純粋状態のブロッホ・ベクトル$(u_1,u_2,u_3)$は、ブロッホ球面上の点であり、これは、量子状態をブロッホ球上で表現したときの座標値に等しいです。
ブロッホ表示は、混合状態にも拡張できます。$\{\sigma_i\}$には、$Tr(\sigma_{i} \sigma_{j})=\delta_{ij}$という関係があるので、$u_1,u_2,u_3$は$\rho$から、
u_i = Tr(\sigma_{i} \rho) \tag{4}のように求めることができます。混合状態は純粋状態の線形和(正確には係数の和が1になるので「凸結合」)として表現されるので、式(4)で計算されたブロッホ・ベクトルは、もはや球面上には存在しません。この後、見ていきますが、量子チャンネルによる密度演算子の変化は、このブロッホ・ベクトルの変化として視覚化して理解することができます。
量子チャネルの典型例
それでは本題に入ります。量子チャネルの典型的な例として、
- ビット反転
- 位相反転
- 分極解消
- 振幅ダンピング
- 位相ダンピング
を取り上げ、ブロッホ・ベクトルの変化のパターンや物理的なイメージについて見ていきます。
ビット反転
密度演算子が、確率$p$で以下のように変化する場合を考えます。
\Gamma(\rho) = (1-p) \rho + p \sigma_1 \rho \sigma_1 \tag{5}右辺第2項の$\sigma_1 \rho \sigma_1$は、パウリのX行列を密度演算子に適用する(量子回路でいうと、1量子ビットにXゲートを演算する)ことに相当しますので、全体として、確率$p$で「ビット反転(bit flip)」する量子チャネルを表しています。例えば、量子コンピュータの1つの量子ビットが、何らかの外部からの雑音によって、確率的にビット反転するようなことをイメージしておけば良いです。
式(5)を見ながらKraus表現を思い出していただくと、この量子チャネルに対するKraus演算子が見えてきます。書き出すと、
\begin{align} M_0 &= \sqrt{1-p} I \\ M_1 &= \sqrt{p} \sigma_1 \tag{6} \end{align}です。
さて、先程説明したブロッホ・ベクトルは、この量子チャネルでどう変化するでしょうか。式(4)を使えば、簡単に計算できます。変化する前後のブロッホ・ベクトルを各々$(u_1,u_2,u_3),\space (u_1^{\prime},u_2^{\prime},u_3^{\prime})$とすると、
\begin{align} u_{1}^{\prime} &= Tr((1-p) \sigma_{1} \rho + p \rho \sigma_{1}) \\ &= Tr((1-p) \sigma_{1} \rho + p \sigma_{1} \rho) \\ &= Tr(\sigma_{1} \rho) \\ &= u_1 \\ u_{2}^{\prime} &= Tr((1-p) \sigma_{2} \rho + p \sigma_{2} \sigma_{1} \rho \sigma_{1}) \\ &= Tr((1-p) \sigma_{2} \rho - p \sigma_{1} \sigma_{2} \rho \sigma_{1}) \\ &= (1-p) Tr(\sigma_{2} \rho) - p Tr(\sigma_{1} \sigma_{2} \rho \sigma_{1}) \\ &= (1-p) u_2 - p u_2 \\ &= (1-2p) u_2 \\ u_{3}^{\prime} &= (1-2p) u_3 \tag{7} \end{align}となります2。ブロッホ・ベクトルのX成分は変わらず、Y,Z成分が$(1-2p)$倍になります。ということは、ブロッホ球面上にあった純粋状態は、ビット反転の量子チャネルによって、Y,Z方向に縮小した楕円体上に移動することになります。
位相反転
密度演算子が、確率$p$で以下のように変化する場合を考えます。
\Gamma(\rho) = (1-p) \rho + p \sigma_3 \rho \sigma_3 \tag{8}先程の$\sigma_1$が$\sigma_3$に変わりました。$\sigma_3$はパウリのZ行列なので、全体として、確率$p$で「位相反転(phase flip)」する量子チャネルを表しています。先程と同様に、量子コンピュータの1つの量子ビットがノイズの影響で、確率的に位相を変えるというイメージをもっていただいて良いです。
式(8)より、Kraus演算子は、
\begin{align} M_0 &= \sqrt{1-p} I \\ M_1 &= \sqrt{p} \sigma_3 \tag{9} \end{align}です。ブロッホ・ベクトルの変化は、結果だけを示すと(先程と同様の計算なので省略します)、
\begin{align} u_1^{\prime} &= (1-2p) u_1 \\ u_2^{\prime} &= (1-2p) u_2 \\ u_3^{\prime} &= u_3 \tag{10} \end{align}となります。この量子チャネルによって、ブロッホ球面上にあった純粋状態は、X,Y方向に縮小した楕円体上に移動することになります。
分極解消
密度演算子が、確率$p$で以下のように変化する場合を考えます。
\Gamma(\rho) = p \frac{I}{2}+ (1-p) \rho \tag{11}これは確率$p$で完全な混合状態である$I/2$に変化することに相当しています3。この量子チャネルは「分極解消(depolarizing)」と呼ばれています。なぜ「分極」の「解消」かというと、ブロッホ球上で特定の方向を向いている純粋状態というのは、例えば、すべての電子のスピンが特定の方向を向いた状態です(当たり前ですが)。つまり、この物理系を外から見ると「分極」しているように見えます。これが完全な混合状態になるということは、全体としてスピンがどっちを向いているかわからない状態(=完全にランダムにあっち向いたり、こっち向いたりしている状態)です。つまり、「分極」が「解消」している状態になります。
さて、改めて、式(10)の形を見ていただくと、ビット反転や位相反転の場合と違って、Kraus表現の格好になっていません。が、密度演算子に対する恒等式4、
\frac{1}{2} (\rho + \sigma_{1} \rho \sigma_{1} + \sigma_{2} \rho \sigma_{2} + \sigma_{3} \rho \sigma_{3}) = I \tag{12}を使うことで、以下のように式変形できます($q=3p/4$とおきました)。
\Gamma(\rho) = (1-q) \rho + \frac{q}{3} (\sigma_{1} \rho \sigma_{1} + \sigma_{2} \rho \sigma_{2} + \sigma_{3} \rho \sigma_{3}) \tag{13}ということで、Kraus演算子が見えてきました。
M_0 = \sqrt{1-q} I, \space M_1 = \sqrt{\frac{q}{3}} \sigma_{1}, \space M_2 = \sqrt{\frac{q}{3}} \sigma_{2}, \space M_3 = \sqrt{\frac{q}{3}} \sigma_{3} \tag{14}です。ブロッホ・ベクトルの変化は、これも結果だけ示すと、
\begin{align} u_{1}^{\prime} &= (1-p) u_{1} \\ u_{2}^{\prime} &= (1-p) u_{2} \\ u_{3}^{\prime} &= (1-p) u_{3} \tag{15} \end{align}となります。したがって、この量子チャネルによって、ブロッホ球面上にあった純粋状態は、全体に縮小した球面上に移動することになります。
振幅ダンピング
次に、もう少し、現実の物理現象として想起できそうな量子チャネルについて見ていきます。まず、「振幅ダンピング(amplitude dumping)」です。
例えば、フォトンを自然放出する原子や、スピン多体系が環境と相互作用しながら平衡状態に近づく現象や、干渉計や共振器を通して散乱や減衰を受けるフォトンなど、何らかの相互作用によって、考えている量子系からエネルギーが散逸する過程を具体的にイメージすれば良いです。
一例として、フォトンが何かに当たって確率的に散乱するプロセスを考えてみます。具体的には「ビームスプリッタ」と呼ばれる光学素子にフォトンが入射することを考えます。
ということで、振幅ダンピングの説明の前に、ちょっとだけ「ビームスプリッタ」とは何か、について説明しておきます。2つのプリズムを合わせて、その境界面をハーフミラーにしたような光学素子がビームスプリッタです。境界面に斜め45度から入射した光(A)は、ある確率で斜め45度の角度で反射するか、あるいはそのまま透過します。一方、境界面に対して(A)とは反対の斜め45度から入射する別の光(B)を考えると、同じようにある確率で反射したり透過したりします。入射する2つの光の強度を各々$A,B$とすると、その光たちは、境界面の反射率(透過率)に応じて各々混じり合って出射することになります。その強度を$A^{\prime},B^{\prime}$とすると、以下のような関係が成り立ちます($\theta$は、境界面の反射率(透過率)から決まるパラメータです)。要するに、Aが減った分だけBが増え、あるいはAが増えた分だけBが減る関係の直交変換(A,Bをベクトル成分とした回転)です。
\begin{align} A^{\prime} &= A \cos\theta + B \sin\theta \\ B^{\prime} &= -A \sin\theta + B \cos\theta \tag{16} \end{align}ここまでは、古典光学におけるビームスプリッタの説明です。が、ここは量子チャネルを説明するところなので、大量の光が一度に入射するのではなく、量子効果が現れるように、ゼロ個または1個のフォトンが入射するようなプロセスを考えてみます。したがって、ここで光の量子化についての知識が必要になるのですが、一から説明すると長くなってしまうので、天下ります。光の量子化は、生成演算子$a^{\dagger}$、消滅演算子$a$によって定義される数演算子$a^{\dagger} a$の固有状態$\ket{n}$を使って、記述することができます。結果、以下が成り立ちます。
\begin{align} a^{\dagger} a \ket{n} &= n \ket{n} \\ a^{\dagger} \ket{n} &= \sqrt{n+1} \ket{n+1} \\ a \ket{n} &= \sqrt{n} \ket{n-1} \\ [a,a^{\dagger}] &= 1 \tag{17} \end{align}ここで、$\ket{n}$の中の$n$はフォトンの数を表していると思ってください(電子スピンの上向き、下向きのイメージではないのでご注意)。とすると、確かに$a^{\dagger} a$は数演算子の名にふさわしい動きをしていますし、生成演算子も消滅演算子も、確かにその名の通り、フォトンを増やしたり減らしたりする動きをしていることがわかります。
それでは、前置きが長くなりましたが、振幅ダンピングの説明に移ります。先程のビームスプリッタでは光が通る経路としてAとBを考えて、両方から光が入射するという想定でした。いまゼロ個あるいは1個のフォトンを考え、そのエネルギー損失を評価してみたいので、経路Aを環境系(S)、経路Bを注目系(S)として、この2つの経路にゼロ個または1個のフォトンが入射する想定にします。そうすると、入射のパターンは、$\ket{0}_E \ket{0}_S, \ket{1}_E \ket{0}_S, \ket{0}_E \ket{1}_S$の3パターンになります($\ket{1}_E \ket{1}_S$はフォトンが2個のパターンになるので考えません)。古典光学のビームスプリッタの変換式から、この3パターンは各々、以下のように変化します。
\begin{align} \ket{0}_E \ket{0}_S &\rightarrow \ket{0}_E \ket{0}_S \\ \ket{1}_E \ket{0}_S &\rightarrow \cos\theta \ket{1}_E \ket{0}_S - \sin\theta \ket{0}_E \ket{1}_S \\ \ket{0}_E \ket{1}_S &\rightarrow \sin\theta \ket{1}_E \ket{0}_S + \cos\theta \ket{0}_E \ket{1}_S \tag{18} \end{align}この変換を演算子$U$と表すと、
U = \ket{0}_E \ket{0}_S \bra{0}_E \bra{0}_S + (\cos\theta \ket{1}_E \ket{0}_S - \sin\theta \ket{0}_E \ket{1}_S) \bra{1}_E \bra{0}_S + (\sin\theta \ket{1}_E \ket{0}_S + \cos\theta \ket{0}_E \ket{1}_S) \bra{0}_E \bra{1}_S \tag{19}と書けます。計算すればわかるように、これはユニタリ演算子です5。ということで、全体系に対するユニタリ演算子がわかったので、Kraus演算子は、定義から、以下のように求めることができます。
\begin{align} M_0 &= \bra{0}_E U \ket{0}_E = \ket{0}_S \bra{0}_S + \cos\theta \ket{1}_S \bra{1}_S \\ M_1 &= \bra{1}_E U \ket{0}_E = \sin\theta \ket{0}_S \bra{1}_S \tag{20} \end{align}ここで、$\gamma = \sin^{2} \theta$とおくと、$\gamma$はフォトンを失う確率を表すパラメータとなり、上のKraus演算子は、以下のように書き直せます。
\begin{align} M_0 &= \ket{0}_S \bra{0}_S + \sqrt{1-\gamma} \ket{1}_S \bra{1}_S \\ M_1 &= \sqrt{\gamma} \ket{0}_S \bra{1}_S \tag{21} \end{align}これより、Kraus表現は、
\begin{align} \Gamma(\rho) &= M_{0} \rho M_{0}^{\dagger} + M_{1} \rho M_{1}^{\dagger} \\ &= (\ket{0} \bra{0} + \sqrt{1-\gamma} \ket{1} \bra{1}) \rho (\ket{0} \bra{0} + \sqrt{1-\gamma} \ket{1} \bra{1}) + \sqrt{\gamma} \ket{0} \bra{1} \rho \ket{1} \bra{0} \tag{22} \end{align}となります(面倒なので注目系を表す添字Sは省略しました)。式(21)(22)をじっと見ていただくと、なんとなくわかってきますが、$M_0$は、$\ket{0}$が来たらそのまま出して、$\ket{1}$が来たらその確率を減らす効果を表していて、一方、$M_1$は、$\ket{1}$が来たら$\ket{0}$に遷移させる効果を表しています。全体として、入ってきたフォトンがそのまま出ていく確率を減らす、つまり減衰させる効果を表す量子チャネルになっています。
ブロッホ・ベクトルの変化を見てみると、
\begin{align} u_1 &= \sqrt{1-\gamma} u_1 \\ u_2 &= \sqrt{1-\gamma} u_2 \\ u_3 &= \gamma + \sqrt{1-\gamma} u_3 \tag{23} \end{align}と計算できます。これより、ブロッホ球は、$\gamma$が大きくなるに従い、X軸、Y軸方向に縮小していき、同時にZ軸成分は1に近づいていきます。すなわち、$\ket{0}$=北極に向かって、どんどん縮小していくパンケーキのイメージですね。
位相ダンピング
現実の物理現象として想起できそうな量子チャネルのもう一つの例は、「位相ダンピング(phase dumping)」です。環境との相互作用によって量子状態の位相が変化する過程なので、これは量子系固有の雑音過程と言えます。一般に、量子状態をエネルギー固有状態の重ね合わせで表現したとき、各々の固有状態はその固有エネルギーの値に比例する形で位相変化していきます。雑音によってその固有状態間の相対位相がずれていくというのが位相ダンピングのイメージです。
先程の振幅ダンピングと同様に、ビームスプリッタに入射するフォトンの散乱過程として位相ダンピングを記述してみます。ただし、今回はフォトンは減衰しません。つまり、散乱によってフォトンがなくなることはないので、ハミルトニアンに
\ket{1}_S \bra{1}_Sという因子がないといけません。また、この散乱によって環境系でフォトンが生成される過程を表す
\ket{1}_E \bra{0}_Eという因子もありえます6。そうだとすると、さらに、全体をエルミートにするために
\ket{0}_E \bra{1}_Sという因子(逆に消滅を表す因子)もハミルトニアンには必要です。この条件を満たす、最も簡単なものは、
H = \chi \ket{1}_S \bra{1}_S (\ket{1}_E \bra{0}_E + \ket{0}_E \bra{1}_E) \tag{24}です7。
このハミルトニアンで表される系の時間発展は、以下のユニタリ演算子で記述できます。
U = exp(iHt) = exp(i \chi t \ket{1}_S \bra{1}_S (\ket{1}_E \bra{0}_E + \ket{0}_E \bra{1}_E)) \tag{25}指数関数のテイラー展開を使いながら、地道に計算すると、
U = \ket{0}_S \bra{0}_S (\ket{0}_E \bra{0}_E + \ket{1}_E \bra{1}_E) + \cos(\chi t) \ket{1}_S \bra{1}_S (\ket{1}_E \bra{0}_E + \ket{0}_E \bra{1}_E) + i \sin(\chi t) \ket{1}_S \bra{1}_S (\ket{1}_E \ket{0}_E + \ket{0}_E \bra{1}_E) \tag{26}となります8。$\gamma = \sin^{2}(\chi t)$とおくと、
U = \ket{0}_S \bra{0}_S (\ket{0}_E \bra{0}_E + \ket{1}_E \bra{1}_E) + \sqrt{1-\gamma} \ket{1}_S \bra{1}_S (\ket{1}_E \bra{0}_E + \ket{0}_E \bra{1}_E) + i \sqrt{\gamma} \ket{1}_S \bra{1}_S (\ket{1}_E \ket{0}_E + \ket{0}_E \bra{1}_E) \tag{27}となり、Kraus演算子は、
\begin{align} M_0 &= \bra{0}_E U \ket{0}_E = \ket{0} \bra{0} + \sqrt{1-\gamma} \ket{1} \bra{1} \\ M_1 &= \bra{1}_E U \ket{0}_E = i \sqrt{\gamma} \ket{1} \bra{1} \tag{28} \end{align}となります(面倒なので添字Sは省略しました)。したがって、位相ダンピングの量子チャネルは、
\Gamma(\rho) = (\ket{0} \bra{0} + \sqrt{1-\gamma} \ket{1} \bra{1}) \rho (\ket{0} \bra{0} + \sqrt{1-\gamma} \ket{1} \bra{1}) + \gamma \ket{1} \bra{1} \rho \ket{1} \bra{1} \tag{29}と書くことができます。
さて、ここで面白い補足をしておきます。実は、この量子チャネルは、位相反転とまったく同じ効果を表しています。位相反転の式を再度掲載します。
\Gamma(\rho) = (1-p) \rho + p \sigma_3 \rho \sigma_3 \tag{7}これと、式(29)は同じです。一見違って見えますが、ちょっと式変形してみます。まず、式(29)です。
\begin{align} \Gamma(\rho) &= \ket{0}\bra{0}\rho\ket{0}\bra{0} + \sqrt{1-\gamma} \ket{0}\bra{0}\rho\ket{1}\bra{1} + \sqrt{1-\gamma} \ket{1}\bra{1}\rho\ket{0}\bra{0} + (1-\gamma) \ket{1}\bra{1}\rho\ket{1}\bra{1} + \gamma \ket{1}\bra{1}\rho\ket{1}\bra{1} \\ &= \ket{0}\bra{0}\rho\ket{0}\bra{0} + \sqrt{1-\gamma} \ket{0}\bra{0}\rho\ket{1}\bra{1} + \sqrt{1-\gamma} \ket{1}\bra{1}\rho\ket{0}\bra{0} + \ket{1}\bra{1}\rho\ket{1}\bra{1} \tag{30} \end{align}次に、式(7)です。途中で、$\sum_{i} \ket{i}\bra{i} = 1$を使います。
\begin{align} \Gamma(\rho) &= (1-p) \rho + p (\ket{0}\bra{0} - \ket{1}\bra{1}) \rho (\ket{0}\bra{0} - \ket{1}\bra{1}) \\ &= (1-p) (\ket{0}\bra{0} + \ket{1}\bra{1}) \rho (\ket{0}\bra{0} + \ket{1}\bra{1}) + p (\ket{0}\bra{0} - \ket{1}\bra{1}) \rho (\ket{0}\bra{0} - \ket{1}\bra{1}) \\ &= \ket{0}\bra{0} \rho \ket{0}\bra{0} + (1-2p) \ket{0}\bra{0} \rho \ket{1}\bra{1} + (1-2p) \ket{1}\bra{1} \rho \ket{0}\bra{0} + \ket{1}\bra{1} \rho \ket{1}\bra{1} \tag{31} \end{align}式(30)と式(31)を比較すると、
p = \frac{(1-\sqrt{1-\gamma})}{2} \tag{32}とおけば一致することがわかります。したがって、ブロッホ球の変化も位相反転の場合とまったく同じになります。
歴史的に位相ダンピングは、何らかの散乱過程による連続的な位相誤差の結果として生じると理解されていたので、確率的に起きる離散的な位相反転の結果と同等というこの知見は、ちょっとした発見だったようで、これによって始めて量子誤り訂正が発展しました(とニールセン、チャンに書いてありました)9。
シミュレータによる量子チャネルの再現
それでは、いままで説明した中から、振幅ダンピングを取り上げて、その効果をqlazyで確認してみます。
振幅ダンピング
最初の純粋状態を$(u_1,u_2,u_3)=(1/\sqrt{3},1/\sqrt{3},1/\sqrt{3})$、減衰率を表すパラメータ$\gamma$をとりあえず0.5として、この量子チャネルの前後で、密度演算子と密度演算子の2乗トレース(純粋状態か混合状態かの確認)とブロッホ・ベクトルの値を出力するようにしました。また、$a^{\dagger}a$の期待値、つまりエネルギーの期待値(正確にはフォトン数の期待値ですが光の周波数を固定すればエネルギーに比例しているので代用)も合わせて計算して表示するようにしました。
全体のPythonコードを以下に示します。
import math import numpy as np from qlazypy import DensOp # Pauli Matrix Sigma_0 = np.eye(2) Sigma_1 = np.array([[0,1],[1,0]]) Sigma_2 = np.array([[0,-1j],[1j,0]]) Sigma_3 = np.array([[1,0],[0,-1]]) def get_coordinate(densop=None): u_1 = densop.expect(matrix=Sigma_1) u_2 = densop.expect(matrix=Sigma_2) u_3 = densop.expect(matrix=Sigma_3) return (u_1,u_2,u_3) def make_densop_matrix(u_1,u_2,u_3): matrix = (Sigma_0+u_1*Sigma_1+u_2*Sigma_2+u_3*Sigma_3) / 2.0 return matrix def make_kraus(gamma=0.0): transmit = math.sqrt(1.0-gamma) reflect = math.sqrt(gamma) kraus = [] kraus.append(np.array([[1,0],[0,0]])+transmit*np.array([[0,0],[0,1]])) kraus.append(reflect*np.array([[0,1],[0,0]])) return kraus def make_hamiltonian(): return np.array([[0,0],[0,1]]) if __name__ == '__main__': print("== parameter ==") gamma = 0.5 H = make_hamiltonian() print("gamma =", gamma) print("== initial density operator ==") u_1 = math.sqrt(1/3) u_2 = math.sqrt(1/3) u_3 = math.sqrt(1/3) D = make_densop_matrix(u_1,u_2,u_3) de = DensOp(matrix=D) de.show() print("square trace =",de.sqtrace()) print("(u_1,u_2,u_3) = ({0:.3f},{1:.3f},{2:.3f})".format(u_1,u_2,u_3)) print("expect value of energy =", de.expect(matrix=H)) [M_0,M_1] = make_kraus(gamma=gamma) print("== finail density operator ==") de.instrument(kraus=[M_0,M_1]) de.show() print("square trace =", de.sqtrace()) (u_1,u_2,u_3) = get_coordinate(densop=de) print("(u_1,u_2,u_3) = ({0:.3f},{1:.3f},{2:.3f})".format(u_1,u_2,u_3)) print("expect value of energy =", de.expect(matrix=H)) de.free()何をやっているか、ざっくり説明します。
print("== parameter ==") gamma = 0.5 H = make_hamiltonian() print("gamma =", gamma)$\gamma$の値を設定して、フォトン数演算子の行列表現を作っています(ハミルトニアンの代用品として)。この演算子の固有状態$\{\ket{n}\} \space (n=0,1)$の基底で$a,a^{\dagger},a^{\dagger}a$を行列表現すると、
a = \begin{pmatrix} 0 & 1 \\ 0 & 0 \end{pmatrix}, \space a^{\dagger} = \begin{pmatrix} 0 & 0 \\ 1 & 0 \end{pmatrix}, \space a^{\dagger} a = \begin{pmatrix} 0 & 0 \\ 0 & 1 \end{pmatrix} \tag{33}です。make_hamiltonian関数で、$a^{\dagger} a$の行列表現を設定しています。
print("== initial density operator ==") u_1 = math.sqrt(1/3) u_2 = math.sqrt(1/3) u_3 = math.sqrt(1/3) D = make_densop_matrix(u_1,u_2,u_3) de = DensOp(matrix=D)ブロッホ・ベクトルの成分を$(1/\sqrt{3},1/\sqrt{3},1/\sqrt{3})$に設定します(何でも良かったのですが適当です)。make_densop_matrix関数でそれに対応した密度演算子の行列表現を計算して、変数Dに格納します。Dから密度演算子クラスのインスタンスdeを作成します。
de.show() print("square trace =",de.sqtrace()) print("(u_1,u_2,u_3) = ({0:.3f},{1:.3f},{2:.3f})".format(u_1,u_2,u_3)) print("expect value of energy =", de.expect(matrix=H))「密度演算子の各要素」「2乗トレース」「ブロッホ・ベクトルの成分」「ハミルトニアンの期待値」の初期値を表示します。
[M_0,M_1] = make_kraus(gamma=gamma) print("== finail density operator ==") de.instrument(kraus=[M_0,M_1])make_kraus関数で、設定した$\gamma$に対するKraus演算子をリスト[M_0,M_1]に格納します。そして、insutrumentメソッド10でKraus表現にします。つまり、量子チャネルに通します。
de.show() print("square trace =", de.sqtrace()) (u_1,u_2,u_3) = get_coordinate(densop=de) print("(u_1,u_2,u_3) = ({0:.3f},{1:.3f},{2:.3f})".format(u_1,u_2,u_3)) print("expect value of energy =", de.expect(matrix=H))量子チャネル通過後の「密度演算子の各要素」「2乗トレース」「ブロッホ・ベクトルの成分」「ハミルトニアンの期待値」を表示します。
実行結果は以下です。まず$\gamma=0.5$の場合です。
== parameter == gamma = 0.5 == initial density operator == elm[0][0] = +0.7887+0.0000*i : 0.6220 |+++++++ elm[0][1] = +0.2887-0.2887*i : 0.1667 |+++ elm[1][0] = +0.2887+0.2887*i : 0.1667 |+++ elm[1][1] = +0.2113+0.0000*i : 0.0447 |+ square trace = 1.0 (u_1,u_2,u_3) = (0.577,0.577,0.577) expect value of energy = 0.21132487 == finail density operator == elm[0][0] = +0.8943+0.0000*i : 0.7998 |+++++++++ elm[0][1] = +0.2041-0.2041*i : 0.0833 |++ elm[1][0] = +0.2041+0.2041*i : 0.0833 |++ elm[1][1] = +0.1057+0.0000*i : 0.0112 |+ square trace = 0.9776709 (u_1,u_2,u_3) = (0.408,0.408,0.789) expect value of energy = 0.10566243ブロッホ・ベクトルを見ると、北極に少し近づいていることがわかります。また、エネルギー期待値は半分になっています。次に、$\gamma=0.8$としてみると、以下のようになりました(最終状態のみ切り出して表示)。
== finail density operator == elm[0][0] = +0.9577+0.0000*i : 0.9173 |++++++++++ elm[0][1] = +0.1291-0.1291*i : 0.0333 |+ elm[1][0] = +0.1291+0.1291*i : 0.0333 |+ elm[1][1] = +0.0423+0.0000*i : 0.0018 |+ square trace = 0.98570938 (u_1,u_2,u_3) = (0.258,0.258,0.915) expect value of energy = 0.04226497さらに、北極に近づき、エネルギーも減衰しました。最後に$\gamma=1.0$としてみると、以下のようになりました(最終状態のみ切り出して表示)。
== finail density operator == elm[0][0] = +1.0000+0.0000*i : 1.0000 |+++++++++++ elm[0][1] = +0.0000+0.0000*i : 0.0000 | elm[1][0] = +0.0000+0.0000*i : 0.0000 | elm[1][1] = +0.0000+0.0000*i : 0.0000 | square trace = 1.0 (u_1,u_2,u_3) = (0.000,0.000,1.000) expect value of energy = 0.0というわけで、全エネルギーを使い切ってしまいましたが、ついに北極点に到達しました。おめでとうございます!
おわりに
量子チャネルの物理的イメージも含めて、基本的な理解ができました。この勢いで「量子誤り訂正」に進みたい気がしてきましたが、その前におさえておくべき基本事項(「シュミット分解」とか「純粋化」とか「エントロピー」とか諸々)がいくつか残っているので、次回以降、順に見ていきたいと思います。
以上
$\sigma_0=\ket{0}\bra{0}+\ket{1}\bra{1},\sigma_1=\ket{0}\bra{1}+\ket{1}\bra{0},\sigma_2=-i\ket{0}\bra{1}+i\ket{1}\bra{0},\sigma_3=\ket{0}\bra{0}-\ket{1}\bra{1}$に注意しながら、三角関数の半角公式、倍角公式を使えば、式(1)から式(2)は導けます。 ↩
パウリ行列の性質:$\sigma_{i} \sigma_{i} = I, \space \{\sigma_{i},\sigma_{j}\}=\sigma_{i} \sigma_{j} + \sigma_{j} \sigma_{i} = 0$、およびトレースの性質:$Tr(aA+bB)=aTr(A)+bTr(B), \space Tr(ABC) = Tr(BCA) = Tr(CAB)$を使いました。 ↩
この場合の完全な混合状態は、$\ket{0}$と$\ket{1}$が半々に混ざりあった状態なので、密度演算子の定義から、$I/2$になるのは簡単にわかりますね。 ↩
パウリ行列の定義と密度演算子のトレースが1であることを使って、左辺を地道に計算すれば、わかります。 ↩
参考文献4にもユニタリです、と書いてありますが、$\ket{1}_E \ket{1}_S$を入れていないので、ユニタリの次元は3ということになります。2のべきではない次元は、量子情報的にはあまり出てこないと思うのですが、こんな場合もあって良いのでしょうか。わかりませんが、今の場合、特に問題なさそうです。 ↩
無から有が生まれる過程ですね。生成消滅演算子を導入して第2量子化するというのは、要はこういう状況も記述する必要に迫られて編み出された方法と言えます。もともとのシュレーディンガー方程式(第1量子化)では粒子の生成消滅は記述できなかったので、、 ↩
振幅ダンピングの説明のときは、古典光学の現象と対応させる形で散乱過程を行列表現しましたが、位相ダンピングの場合、ハミルトニアンをいきなり人為的に作ってしまっています。位相雑音は量子系特有の現象なので、うまく対応づけられるような古典光学の現象がないからだと思います。なんとなく釈然としないですが、ここは我慢です。 ↩
長くなるので計算過程はバッサリ省略しました。どうしても自分で導出したいという方は、参考文献4を見てください。もう少し式変形のヒントが書いてあります。 ↩
ニールセン、チャンの本では、Kraus演算子のユニタリな自由度に基づき両者相互に変換できるということで同等、という説明がなされていました。どんなユニタリ変換?という具体的な式変形が示されおらず、自力導出もちょっと面倒な気がしたので、ここでは、$\Gamma(\rho)$が両者同じになるよね、という説明の仕方にしました。 ↩
この演算のことを「CP-instrument」と言ったりするので、それに従いメソッド名としました。 ↩
- 投稿日:2019-10-04T20:47:59+09:00
【顔認識入門】顔識別して「ウワンさん、こんにちわ」♪
昨夜のコードに前回のtext2speakを追加すると、念願の「ウワンさん、こんにちわ」ができました。
【参考】
①【Speak入門】text2speakとQRcode2speakを自作して遊んでみた♪
話は簡単なので、昨夜のコードの差分だけ説明します。
ストーリーは、顔識別したらその識別結果に「txt+さんこんにちわ」として、それをtext2speakに渡すということです。コード全体は以下に置きました
・face_recognition/recognize_vgg16_camera_ohayo.py
コード解説
利用する追加Libは以下のとおりです。
import pyaudio import wave import time import retext2speak関数は丸々追加します。
def text2speak(num0): ...text2speakの追加個所は以下のとおりです。
yomikomi関数で顔識別した結果をtxtに代入して、それをnum0=txt+"さんこんにちわ"として、このnum0を渡します。こうして「ウワンさんこんにちわ」と発話できます。
※ここでちょっとロジック入れれば「おはよう」とか「おつかれさま」とか発話出来ますtry: roi = cv2.resize(roi, (int(224), 224)) cv2.imshow('roi',roi) txt, preds=yomikomi(model,roi) print("txt, preds",txt,preds*100 ," %") txt2=conv.do(txt) cv2.imwrite(path+"/"+label+"/"+str(sk)+'_'+str(txt2)+'_'+str(int(preds*100))+'.jpg', roi) num0=txt+"さんこんにちわ" print(num0) text2speak(num0)センテンスが短いので、はっきり綺麗に発話できました。
また、「まゆゆさんこんにちわ」「あかりんだーすーさんこんにちわ」と変化してくれました。まとめ
・「ウワンさんこんにちわ」などと識別結果に基づいて変化してくれました
・笑顔、悲しい顔、怒り顔、普通の顔などの情感変化に基づいた発話させたい
・もう少し複雑な会話形式のロジックと識別結果と連携して発話させたい
- 投稿日:2019-10-04T20:16:13+09:00
Pythonを学ぶ理由
Pythonを学ぶ理由
1.案件の数が多い
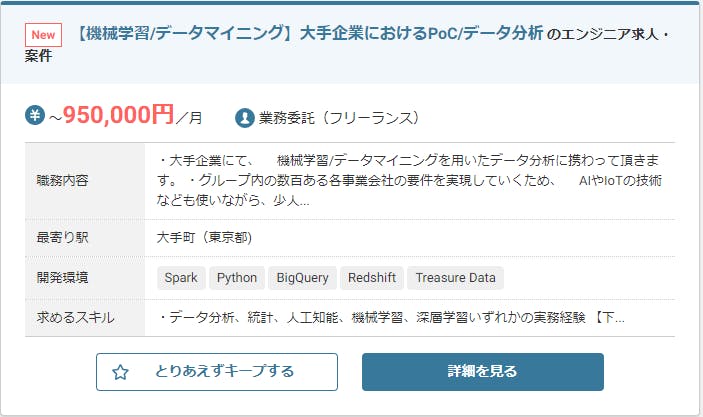
YouTubeなど日常生活でよく使うアプリケーションの開発にPythonが使われてきています。- AIブームなどで注目を集める
Pythonは需要が高く、近年では案件が多く存在する傾向にあります。- 上記の画像はレバテックというフリーランスエンジニアの求人サイトです。
Pythonの求人で検索をかけたところ528件がヒットしました。- このことから
Pythonの案件が多いことがわかるかと思います。2.案件の単価が他言語と比較して大差がない
- フリーランスの求人サイトを見ると
Pythonの案件が年々増加する傾向にあります。- 案件が増加する一方で
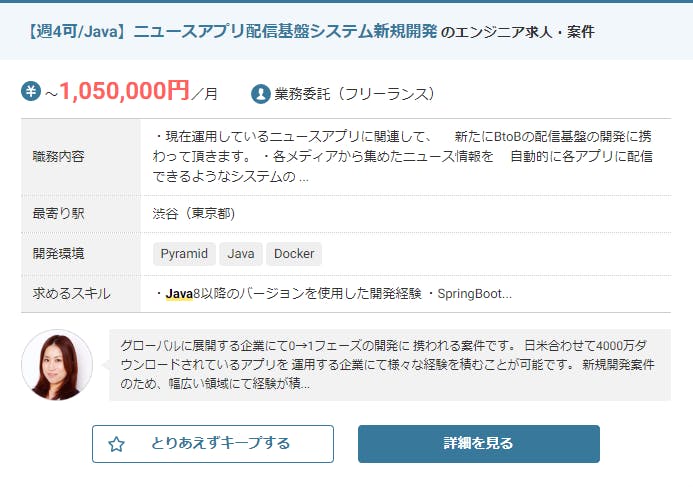
Pythonを扱えるエンジニアの不足から需要は高まっている状況です。- 上記の画像は レバテック のPython(上)とJava(下)の一番高い求人の比較です。
- Python(上)が
~95万円、Java(下)が~105万円と大差がないように感じます。3.他言語と比べて習得難易度が低い
Pythonでは、$や括弧などの記号を極力廃して、シンプルなコードを書くことができるように設計されています。- そのため、
コード量が減り、シンプルで生産性が高いコードを書くことが可能となります。- また、
ライブラリが豊富なため、ほとんど覚えることは少なく、比較的習得しやすい言語になっています。まとめ
案件の数が多い
案件の単価が他言語と比較して大差がない
他言語と比べて習得難易度が低い
以上のことから投資対効果に期待でき、比較的習得難易度が低いPythonを習得することをおすすめします。

- 投稿日:2019-10-04T19:45:15+09:00
アノテーションツール"doccano"をWindows10homeで動かすまで
あらすじ
テキストのアノテーションを行うのってかなり大変ですよね。
師の教えにより、古来より伝わるExcelを使う方法でやってましたが我慢の限界です。TISがOSSとして公開している「doccano(ドッカーノ)」がかなり便利そうだったので使ってみようと思いました!
しかし、OSはWindows10Homeです。果たして導入できるのか。
方法
結論から言うと無事動かせましたので、その手順を残しておきます。
1.Dockerのインストール
まずはWindowsにdockerを導入します。
重要なポイントとして、Windows10HomeだとHyper-Vの機能が使えないので、Docker for Windowsはインストールできません。
代わりに、Docker Toolboxをインストールします。
こちらの サイト から"DockerToolbox-19.03.1.exe"をダウンロードしてインストールするだけです。
↓のようなダイアログが出るので、チェックボックスを入力していくだけです。
2.Docker Quickstart Terminalの起動
インストールが終わったら、Docker Quickstart Terminalを起動します。
しばらく待って、下のようにクジラが表示されたら準備完了です。
3.doccanoの導入
基本的には、本家様の丁寧な案内の通りにすれば導入できます。
まずは、dockerイメージをpullしてきます$ docker pull chakkiworks/doccano↓下のような画面が完了したら準備OKです。
4.doccanoの立ち上げ
次にdoccanoを立ち上げていきます。
↓を入力します。usenameやpasswordは任意に変更しても大丈夫でした。$ docker run -d --rm --name doccano \ > -e "ADMIN_USERNAME=admin" \ > -e "ADMIN_EMAIL=admin@example.com" \ > -e "ADMIN_PASSWORD=password" \ > -p 8000:8000これで起動完了です。あとはブラウザで開いていきます。
5.ブラウザで開く(失敗)
公式ガイドでは、
でログイン画面に入れると書いてあります。
おや?しかし、自分の環境ではうまくいきませんでした。。6.ブラウザで開く(解決策)
どうやらIPアドレスが良くないみたいです。
$ docker-machine ipと入力するとIPアドレスの確認ができます。
そのIPアドレスで差し替えて。。http://<確認したIPアドレス>:8000/login/
でログイン画面に入れます。
Great!これでバッチリですね!アノテーションしてみる
これでバリバリつかえるようになりました。実際にやってみます。
まずはCreate Projectでプロジェクトを立ち上げます。
Labelのページからアノテーションのタグやショートカットキーを指定できます。
あとはショートカットキーを使ってサクサクアノテーションです。最高ですね!
体感で10倍くらい違います....!!
系列ラベリングや文書分類など用途によって使い分けられるので、是非使ってみてください!
参考サイト
1.https://www.tis.co.jp/news/2018/tis_news/20181106_1.html
2.https://qiita.com/KIYS/items/8ac37f6757a6b7f84569








- 投稿日:2019-10-04T19:19:01+09:00
Atcoder Beginner Selection 回答メモ
Atcoder Beginner Selectionで提出した回答です。
回答日2019/10/04ABC086A - Product
a, b = map(int, input().split()) if a*b % 2 == 0: print('Even') else: print('Odd')ABC081A Placing Marbles
n = str(input()) print(n.count('1'))ABC081B Shift only
n=int(input()) a = list(map(int, input().split())) ans=0 while all(x%2==0 for x in a): a = [x/2 for x in a] ans += 1 print(ans)ABC087B Coins
A = int(input()) B = int(input()) C = int(input()) X = int(input()) ans = 0 for a in range(A+1): for b in range(B+1): for c in range(C+1): if a*500 + b*100 + c*50 == X: ans+=1 print(ans)ABC083B Some Sums
n, a, b = map(int, input().split()) ans = 0 for x in range(n+1): x_str = str(x) x_digit_sum = 0 for z in x_str: x_digit_sum += int(z) if a<= x_digit_sum <= b: ans += x print(ans)ABC088B Card Game for Two
n = int(input()) A = map(int, input().split()) Alice = 0 Bob = 0 A_d = sorted(A, reverse = True) Alice += sum(A_d[0::2]) Bob += sum(A_d[1::2]) dif = Alice -Bob print(dif)ABC085B Kagami Mochi
n = int(input()) D = [] for d in range(n): D.append(input()) X = list(set(D)) ans = len(X) print(ans)ABC085C Otoshidama
n, y = map(int, input().split()) for a in range(n+1): for b in range(n-a+1): c = n-a-b if 0<=c<=2000 and 10000*a + 5000*b + 1000*c == y: print(a,b,c) exit() print(-1,-1,-1)ABC049C 白昼夢 / Daydream
S = str(input()) a = S.count('dreamer') b = S.count('eraser') c = S.count('dream') d = S.count('erase') e = S.count('dreamerase') dreamer = a-e dream = c-a+e eraser = b erase = d-b x = 7*dreamer + 5*dream + 6*eraser + 5*erase if len(S) == x: print('YES') else: print('NO')ABC086C Traveling
n = int(input()) t = [0] * n x = [0] * n y = [0] * n for i in range(n): t[i], x[i], y[i] = map(int, input().split()) s = 0 if n == 1: if t[0] < x[0]+y[0] or (x[0]+y[0]) % 2 != t[0] % 2: s += 1 elif n > 1: for j in range(1, n): if t[j]-t[j-1] < abs(x[j]-x[j-1]+y[j]-y[j-1]) or abs(x[j]-x[j-1]+y[j]-y[j-1]) % 2 != (t[j]-t[j-1]) % 2: s += 1 if s == 0: print('Yes') else: print('No')
- 投稿日:2019-10-04T18:51:00+09:00
Pythonによるフォルマント分析と音声認識
今回,株式会社サイシードのインターンシップで音声認識の仕組みを学び,音声認識システムをゼロから作るということにチャレンジしてみました.
この記事では音声認識に関する基本的な仕組みを実際に実装し,母音をクラス分類した結果までの一連の流れを書きます.目次
- 音声認識の仕組み
- Julius
- フォルマント
- フォルマント分析とは
- 母音のフォルマントの抽出に関する実装
- フォルマントを用いた母音のクラス分類
- k近傍法による母音のクラス分類
- SVMによる母音のクラス分類
- 考察
- まとめ
- 参考
音声認識の仕組み
音声認識では連続的な音声を認識する場合,音響モデルと言語モデルを用意します.
音響モデルは音声波形から音素の音響的特徴を求め,各単語の標準のパターンを作成します.
言語モデルはそれぞれの単語間・音素間のつながりを統計的に処理を行い,もっともらしい文章や単語列を生成します.
音声認識ではこの二つのモデルを用いて音素から単語を予測し,単語から文章の繋がりを予測していきます.
今回は,音響モデルの中で音素の特徴を求める手法の一つであるLPC分析を行い,母音のフォルマント抽出とその分類に挑戦していきます.ちなみに
今回,音素抽出にはJuliusを用いています.
Juliusは音声認識システムの開発・研究のためのオープンソースの音声認識エンジンです.
音声認識はGoogleやIBM,Microsoftなどで試すことができますが無料で行うには制限があります. そういった面で,Juliusでは音声認識に触れてみたい人にとってオススメの音声認識エンジンとなっています.
Julius自体は音声認識エンジンであり,別途音響モデルや単語辞書,言語モデルが必要となりますが,そちらに関しても標準のモデルが提供されています.フォルマントとは
人の音声は声帯の振動で生成され,声道を通り,口唇から発せられます.その声道には複数の共鳴周波数があり,特定の周波数の音声が強くなります.この強くなった周波数をフォルマント周波数と呼びます.フォルマント周波数は低いものから順に,第一フォルマント(F1),第二フォルマント(F2),・・・と呼ばれ,母音を特徴づけるのに大きく関わっています.
『英語リスニング科学的上達法』の148ページ今回は文章を読み上げた音声データから音素を抽出し,母音の音素に関してフォルマント分析していきます.
母音のフォルマントの抽出に関する実装
まず,集めた音声データをJuliusのsegmentation-kitを用いて音声データを音素に分割します.分割する際に,音声データに対応するテキストデータを用意し,segment_julius.plを実行すると以下のようなlabファイルが作成されます.
0.0000000 0.6325000 silB 0.6325000 0.7025000 s 0.7025000 0.8225000 e 0.8225000 0.8925000 ts 0.8925000 0.9525000 u 0.9525000 1.0125000 m 1.0125000 1.1425000 e 1.1425000 1.1825000 i 1.1825000 1.2325000 k 1.2325000 1.3325000 a 1.3325000 1.3725000 i 1.3725000 2.0075000 silE※Juliusではサンプリング周波数16kHz,量子化ビット数16ビット固定,チャンネル数1チャンネル(モノラル)の音声データ(wav形式)に対応しているのでffmpegなどで変換してください.(コードは以下のようにすれば整えられます.)
$ ffmpeg -i input.wav -ac 1 -ar 16000 -acodec pcm_s16le output.wav次に,segmentation-kitによって得られた各音素の発声タイミングのデータを使い,音声データを切り出し,音素波形を確認します.
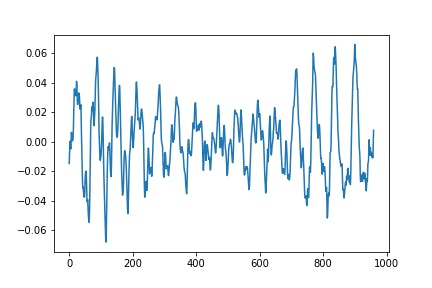
phoneme_img.py# 使用するパッケージ import matplotlib.pyplot as plt import cis from collections import defaultdict #音素部分の画像出力 for i in range(100,150,1): data_list = [] open_file = "lab_and_text/sound-"+str(i)+".lab" filename = "wav/sound-"+str(i) v ,fs = cis.wavread(filename+".wav") #labファイルの音素データに関する情報を格納 with open(open_file,"r") as f: data = f.readline().split() while data: data_list.append(data) data = f.readline().split() #各音素毎に保存したいので,alphabetの辞書を作成 saisei_dic = defaultdict(list) #音素ラベル,開始・終了タイミングを辞書に追加 for j in range(len(data_list)): label = data_list[j][2] if label != "silB" and label != "silE": x1 = int(fs * float(data_list[j][0])) x2 = int(fs * float(data_list[j][1])) saisei_dic[label].append([x1, x2]) #音素の波形画像を出力 for j in saisei_dic: for k in range(len(saisei_dic[j])): fig = plt.figure() ax = fig.add_subplot(1, 1, 1) ax.plot(v[saisei_dic[j][k][0]:saisei_dic[j][k][1]]) plt.savefig('Phoneme_file/' + j + '_' + str(i) + '_' + str(k) + '.png')得られた音素波形は以下のようになっています.(x軸,y軸のスケールは調整していません.)
母音(/a/)に関してうまく出ていると以下のような画像が出力されます.
図1.母音aの音声波形子音(/b/)に関しては以下のような画像が出力されます.
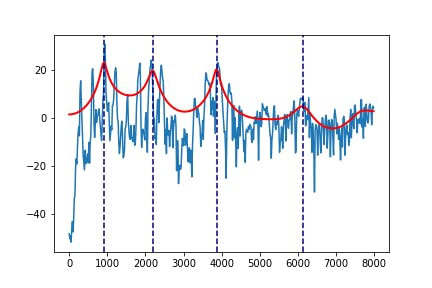
図2.子音bの音声波形次に,母音の音素に対してフォルマントを求め,線形予測分析(LPC)を使ってフォルマントの包絡とそのピークを抽出していきます.
formant_analysis.py#使用するパッケージ import cis import numpy as np import scipy.signal from levinson_durbin import autocorr, LevinsonDurbin #プリエンファシス(高域強調) def preEmphasis(wave, p=0.97): # 係数 (1.0, -p) のFIRフィルタを作成 return scipy.signal.lfilter([1.0, -p], 1, wave) #母音の音素データの辞書作成 voice_dict = {"a":[],"i":[],"u":[],"e":[],"o":[]} boin_list = ["a","i","u","e","o"] #データの読み込み, 音素ごとに辞書化 for i in range(100,150,1): data_list = [] open_file = "lab_and_text/sound-"+str(i)+".lab" filename = "wav/sound-"+str(i) v ,fs = cis.wavread(filename+".wav") with open(open_file,"r") as f: data = f.readline().split() while data: data_list.append(data) data = f.readline().split() saisei_dic = defaultdict(list) for j in range(len(data_list)): label = data_list[j][2] if label in boin_list: x1 = int(fs * float(data_list[j][0])) x2 = int(fs * float(data_list[j][1])) saisei_dic[label].append([x1, x2]) for j in saisei_dic: for k in range(len(saisei_dic[j])): # LPC係数を求める(lpcの次数は要調整) lpcOrder = 16 #短すぎるデータは扱いづらいので削除 start = saisei_dic[j][k][0] end = saisei_dic[j][k][1] if (end - start) <= fs//200: continue fig = plt.figure() ax = fig.add_subplot(1, 1, 1) #センター部分を使う center = (end + start) // 2 cuttime = 0.04 voice_data = v[center - int(cuttime / 2 * fs) : center + int(cuttime / 2 * fs)] #正規化 voice_data = voice_data/max(abs(voice_data)) #プリエンファシス p = 0.97 voice_data = preEmphasis(voice_data, p) #ハミング窓 hammingWindow = np.hamming(len(voice_data)) voice_data = voice_data * hammingWindow r = autocorr(voice_data, lpcOrder + 1) a, e = LevinsonDurbin(r, lpcOrder) # LPC係数の振幅スペクトルを求める sample = len(voice_data) fscale = np.fft.fftfreq(sample, d = 1.0 / fs)[:sample//2] # オリジナル信号の対数スペクトル spec = np.abs(fft(voice_data, sample)) logspec = 20 * np.log10(spec) ax.plot(fscale, logspec[:sample//2]) # LPC対数スペクトル w, h = scipy.signal.freqz(np.sqrt(e), a, sample, "whole") lpcspec = np.abs(h) loglpcspec = 20 * np.log10(lpcspec) #出力をプロットしてみて出力 ax.plot(fscale, loglpcspec[:sample//2], "r", linewidth=2) maxId = scipy.signal.argrelmax(loglpcspec[:sample//2],order=3) maxId = maxId[0] #とりあえず4つ分ぐらいのフォルマントの位置を出力 ax.axvline(fscale[maxId[0]], ls = "--", color = "navy") ax.axvline(fscale[maxId[1]], ls = "--", color = "navy") ax.axvline(fscale[maxId[2]], ls = "--", color = "navy") ax.axvline(fscale[maxId[3]], ls = "--", color = "navy") plt.savefig('formant_file/'+j+'_'+str(i)+'_'+str(k)+'.png')例えば,図1の母音aのフォルマントは次のように出力されます.
図3.図1の母音aの波形の包絡また,本プログラムで利用したlevinson_durbin,LPCは人工知能に関する断創録さんのプログラムを参考にしています.
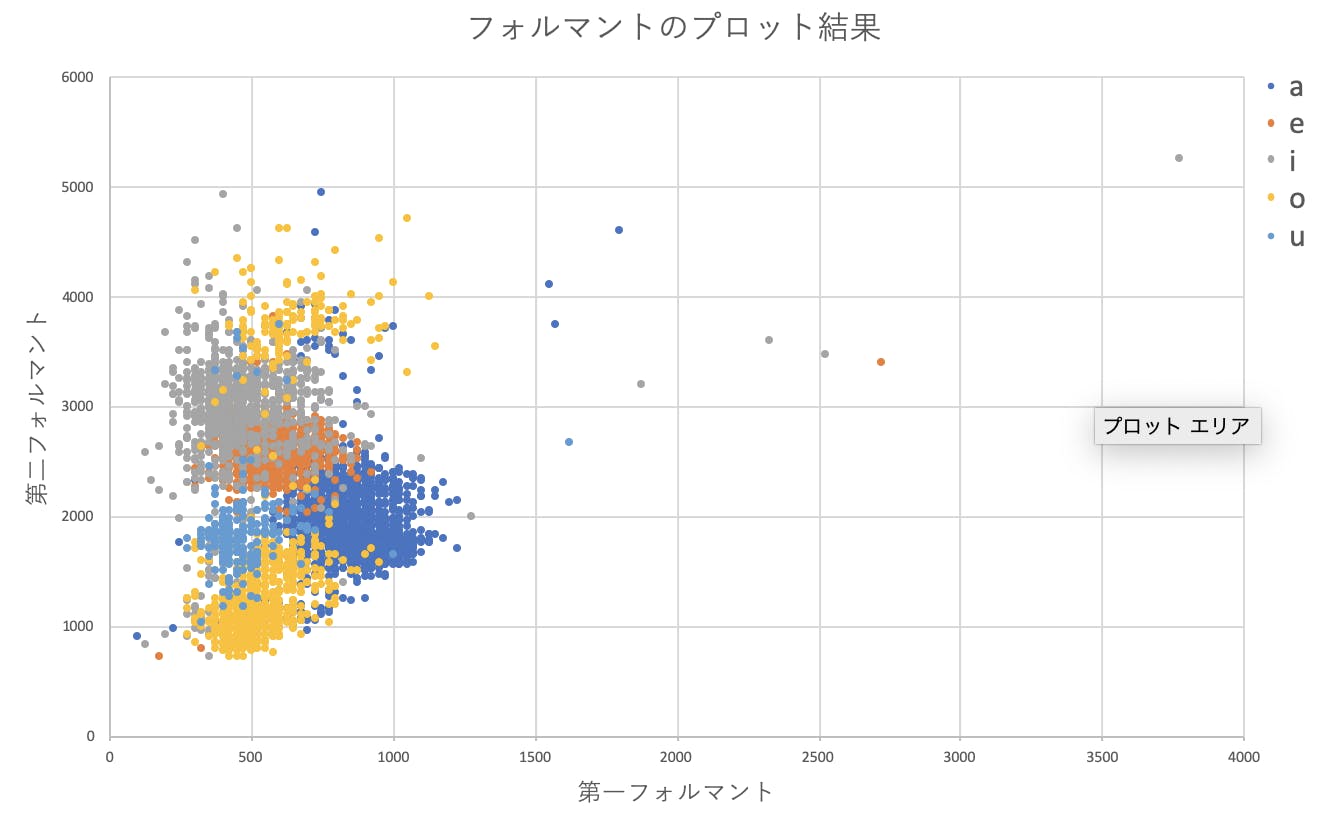
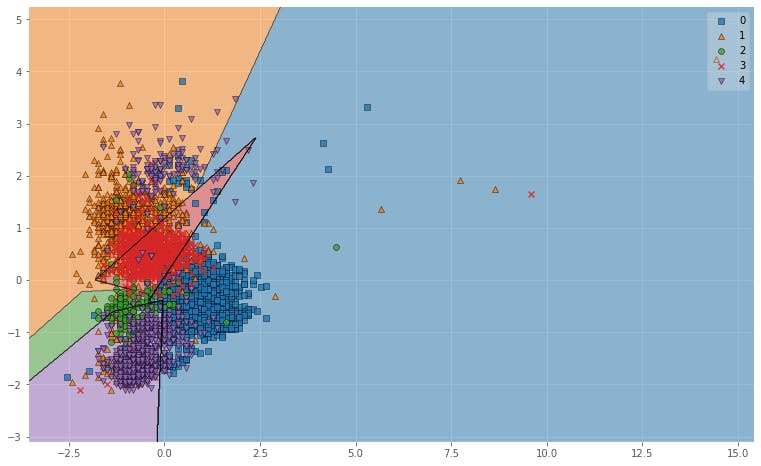
全てのデータ(5000程度)の第1,第2フォルマントをplotした結果は次のようになります.
図4.フォルマントのプロット結果明らかな外れ値もありますが,パッと見6分類ぐらいでいけそうな・・・
とりあえず分類してみましょう.k近傍法による母音のクラス分類
まずはkNNを試していきます.
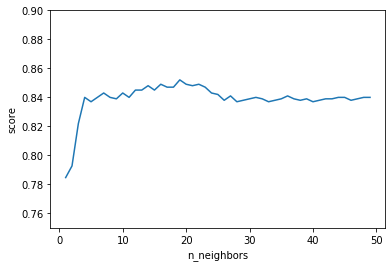
knn.py#k-近傍法 import matplotlib.pyplot as plt import pandas as pd from sklearn.neighbors import KNeighborsClassifier as KNN #データセットの読み込み formant_df = pd.read_csv("formant5.csv", encoding="shift-jis") # データのシャッフル formant_df = formant_df.sample(frac = 1).reset_index(drop=True) #教師データとテストデータの境目を決める use_row_limit = int(formant_df.shape[0] * 0.8) use_column = list(range(formant_df.shape[1]))[1:] train_data = formant_df.iloc[:use_row_limit,:] test_data = formant_df.iloc[use_row_limit:,:] list_nn = [] list_score = [] max_score = 0 for k in range(1,50): knn = KNN(n_neighbors = k,n_jobs = -1) knn.fit( train_data.iloc[:,use_column].values, train_data["vowel"].values, ) pred_target = knn.predict( test_data.iloc[:,use_column].values ) list_nn.append(k) score = sum(test_data["vowel"] == pred_target) / len(pred_target) list_score.append(score) if score >= max_score: max_score = score #プロット plt.ylim(0.75, 0.90) plt.xlabel("n_neighbors") plt.ylabel("score") plt.plot(list_nn, list_score) print(max_score)今回
k=1~50で回してみた結果一番いい精度は
0.852112676056338
プロット結果は以下のようになっています.
図5. kNNの精度
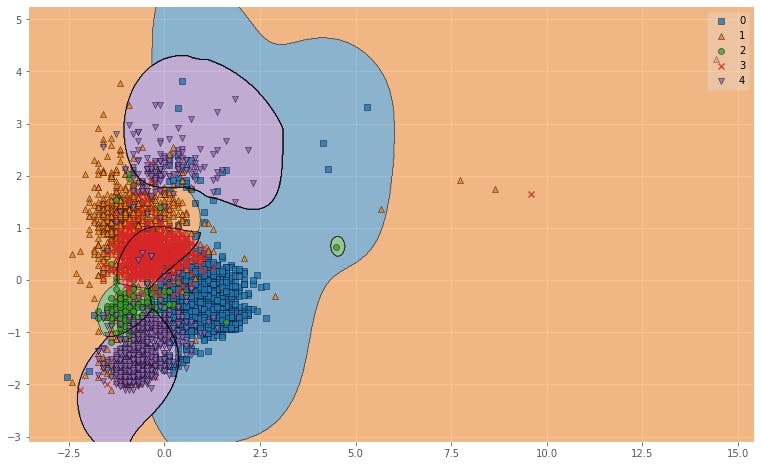
元の状態から考えるとなかなかいい精度で分類できてそうです.SVMによる母音のクラス分類
続いて,SVMでクラス分類してみます.
カーネルが簡単に選択できるので,とりあえず3つほど試してみます.svm.py#SVM #必要なパッケージ import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.svm import SVC from sklearn.metrics import accuracy_score #データセットの読み込み formant_df = pd.read_csv("formant5.csv", encoding="shift-jis") # データのシャッフル formant_df = formant_df.sample(frac = 1).reset_index(drop=True) x = formant_df.iloc[:, [1,2]]#F1とF2 y = formant_df.iloc[:, 0]#a,i,u,e,oのラベル #ラベルは一旦数字に変更 y[y == "a"] = 0 y[y == "i"] = 1 y[y == "u"] = 2 y[y == "e"] = 3 y[y == "o"] = 4 y = np.array(y, dtype = "int") #教師データとテストデータの境目を決める x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = None) #データの標準化 sc = StandardScaler() sc.fit(x_train) x_train_std = sc.transform(x_train) x_test_std = sc.transform(x_test) #SVMのインスタンスを生成 model_linear = SVC(kernel = 'linear', random_state = None) model_poly = SVC(kernel = "poly") model_rbf = SVC(kernel = "rbf") model_linear.fit(x_train_std, y_train) model_poly.fit(x_train_std, y_train) model_rbf.fit(x_train_std, y_train) pred_linear_train = model_linear.predict(x_train_std) pred_poly_train = model_poly.predict(x_train_std) pred_rbf_train = model_rbf.predict(x_train_std) accuracy_linear_train = accuracy_score(y_train, pred_linear_train) accuracy_poly_train = accuracy_score(y_train, pred_poly_train) accuracy_rbf_train = accuracy_score(y_train, pred_rbf_train) print("train_result") print("Linear : " + str(accuracy_linear_train)) print("Poly : " + str(accuracy_poly_train)) print("RBF : " + str(accuracy_rbf_train)) pred_linear_test = model_linear.predict(x_test_std) pred_poly_test = model_poly.predict(x_test_std) pred_rbf_test = model_rbf.predict(x_test_std) accuracy_linear_test = accuracy_score(y_test, pred_linear_test) accuracy_poly_test = accuracy_score(y_test, pred_poly_test) accuracy_rbf_test = accuracy_score(y_test, pred_rbf_test) print("-" * 40) print("test_result") print("Linear : " + str(accuracy_linear_test)) print("Poly : " + str(accuracy_poly_test)) print("RBF : " + str(accuracy_rbf_test))実行した結果は次のようになります.
train_result Linear : 0.8109896432681243 Poly : 0.7206559263521288 RBF : 0.8550057537399309 ---------------------------------------- test_result Linear : 0.7825503355704698 Poly : 0.6932885906040268 RBF : 0.8308724832214766今回のデータにはRBFを指定したほうがよさそうですね.
次元数が多くなってきたら,Linearを使うといいそうです.
また,kernelは指定なしでは通常RBFが指定されます.
中身がどうなっているのかよくわからないので図にプロットしてみます.plot_svm_result.pyimport matplotlib.pyplot as plt from mlxtend.plotting import plot_decision_regions plt.style.use('ggplot') X_combined_std = np.vstack((x_train_std, x_test_std)) X_combined_std y_combined = np.hstack((y_train, y_test)) fig = plt.figure(figsize = (13,8)) plot_decision_regions(X_combined_std, y_combined, clf = model_linear) plt.show() fig = plt.figure(figsize = (13,8)) plot_decision_regions(X_combined_std, y_combined, clf = model_poly) plt.show() fig = plt.figure(figsize = (13,8)) plot_decision_regions(X_combined_std, y_combined, clf = model_rbf) plt.show()プログラムはKazuki Hayakawaさんの記事に詳しく記載されています.
図6. Linearによる母音の分類結果
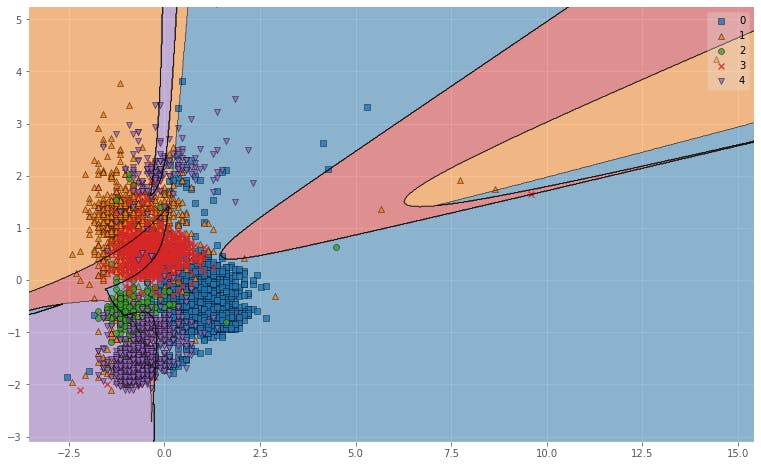
図6. Polyによる母音の分類結果
図6. RBFによる母音の分類結果図示してみるとRBFがよかった理由がわかりやすいですね.
RBFはデータを非線形空間(ガウス関数)に変換し,複雑なデータ群をよりシンプルに捉えることができるので,
単純に線引きをするよりも精度が上がります.考察
音声データからの音素抽出・音素のフォルマント分析・母音のクラス分類という基本的な音声認識の流れをプログラムを作りながら,追ってみました.
今回,音声認識データの母音分類結果としては85%前後の精度を得ることができました.
これは用いた音声データが一人の音声から集められているものなのでこのような結果を得ることができたと考えられます.たくさんの人の音声を集めて同じことをやると精度は落ちていくことが考えられます.
一方で,音素のセグメンテーションでは日本語訳と音声の不一致や音素抽出部分のずれなどの影響により母音の単音発声と比べるとノイズの多いものとなっています.これらの影響でうまくフォルマント分析することができていないデータ群が存在していることが考えられ,それが認識精度の減少に繋がっていると思います.実環境で応用していくには,ある程度の長文音声データにも対応する必要があります.そのためには,より正確な音素セグメンテーションとより高い精度の分析手法が求められます.
今後はそれらの分析手法に関しても実装していきたいと考えています.まとめ
本記事では音声データを音素に分解するところから実際に母音をフォルマント分析してみるまでを書いてみました.
部分部分に関しては詳しく書いてある記事があると思いますが,実際にゼロベースから分類までを記載している記事というのは少ないと思います.
音声認識の分析を過程への理解したい方,とりあえず試してみたいという方のための記事になれば幸いです.今後はMFCCなどを用いてより本格的な音声認識を実装していきたいと思います.
参考
- 人工知能に関する断創録
- Kazuki Hayakawaさんの記事
- 音声認識(MLPシリーズ)
- Pythonで学ぶ実践画像・音声処理入門

- 投稿日:2019-10-04T18:40:48+09:00
コマンドプロンプトでpythonファイル(.py)を開く方法
当たり前過ぎてどこにも書いてなかったので。
当該.pyファイルのディレクトリに移動し、
open pythonfile.pyで開けます。
当たり前ですけれど。
- 投稿日:2019-10-04T17:26:15+09:00
文系大学生が機械学習を0から始めて9か月でKaggle銀メダルを獲得するまで
今回自分は0から始めて9か月でコンペで銀メダル(6385分の249位,top4パーセント)を獲得できました。
自分の今までの流れをおさらいしていきます。それまでの僕のスペック
・数3と行列はほぼ何も分からない
・プログラムはrubyとjavaはそこそこに書ける、pythonは知らん勉強の流れ
12月末
機械学習を始めると決心、とりあえず何をやればいいかよく分からないがpythonが必要らしいのでprogateでpythonをやってみる
1月
数学が必要らしいので、行列と微分積分について1から学んでみる。今から考えると、行列の基礎をさらえたのは良かったですが、それ以外はこの時間は絶対いらなかったなと考えています。
行列
https://www.amazon.co.jp/よ・く・わ・か・る-線形代数-Primary大学ノート-藤田-岳彦/dp/44073251272月
Udemyで多くの講座を受ける、詳細は以下の記事にまとまっています
https://qiita.com/HayatoYamaguchi/items/c8051baa0f7b0ec681a1
機械学習にはnumpyとpandasが必要らしいということでPYQをやってみるまたここで1年休学を決意。
3月
courseraのmachine learningコースがいいらしいと聞いて、これを完走。行列などを学ばなければこれはできなかったのでその意味では数学を学んだのは良かったかも
4月
オライリーの専門本をここで勉強します。
今考えると2冊目はかなり無駄だったかなという面もあります・また、ここで始めてkaggleに参加します。
titanicチュートリアルとhouse priceを行いました。
タイタニック
https://qiita.com/HayatoYamaguchi/items/ed13171372d3043e42aa
house price
https://qiita.com/HayatoYamaguchi/items/30e93a43d519f8c8aea05月
この辺で普通のコンペに参加すべきだったのですが、ハードルを感じてしまい、結局もう一つメルカリコンペを行いました。
https://qiita.com/HayatoYamaguchi/items/ad41b20b2e61ea30827eまた、課金してCourseraのDeepLearningコースも学びました。ここで始めてCNNやRNNなどについて学びました。
また、6月の統計検定2級に備えて統計の勉強もしました。
6月
機械学習系の業務委託を受けたりインターンをやり始めて試用期間で切られたりする(ここから先はインターンで機械学習をやりながらそれと平行)
courseraのHow to Win a Data Science Competition: Learn from Top Kagglersをやる
これで、kaggleの細かい実践的なことを学びました。
また、いよいよ本格的にコンペに初参戦しました。Instant Gratificationに参加してラスト1週間ほどでやりましたが、結局公開カーネルを真似したものを提出しただけになってしまいました、、、
また、統計検定2級を受験し、無事に合格しました。7月
他のインターンも始める
ここからSignateの飯田産業コンペに注力し始めます。これではカーネルがないので、実際に自分で特徴量を1から作り出していく必要があり、初めての経験のためかなり大変でした。8月
飯田産業コンペ終了、順位は189 位 / 593
validationなどにこだわってしまったので、特徴をもっと作らなかったことを反省9月
始めからIEEE-CIS Fraud Detectionに参加してコミットしました。
チームを組んで、最終的なモデルは自分が作ったものを採用し、無事それでスコアを出すことができました。コンペの詳細については後日投稿しようと思います。ここまでの反省点など
・pythonやudemyや数学に時間を使いすぎた
初心者エンジニアあるあるですが完璧に理解してコードを書けることを重視しすぎて、実践の中で吸収していこうという考えが少なかった
・動画教材などのインプットに重きを置きすぎた
同じくわかってから進めたい病炸裂
・もっと早い時期からコンペに参加するべきだった
これもコンペ参加のハードルを上げすぎました、、、
多くのkaggleマスターなどがtaitanicが終わったらもうコンペに参加した方がいいと述べていますが、それは的確だと考えています。
・最初の頃はダラダラ勉強しすぎた
正直4月くらいまでの内容はちゃんと自分を追い込めば2ヶ月でできる内容だったのかなと考えています。おそらくこの辺ちゃんと解決できれば、フルコミットすればかなり厳しい道のりになりますが完全初心者から3,4か月でメダル取るのは不可能ではないのかなと考えています。同じようなことをやりたいと考えている人の参考になれば幸いです。
- 投稿日:2019-10-04T17:08:01+09:00
GCP Cloud FunctionsでMeCab + Neologdの分かち書きAPIをデプロイする(Python)
背景
Neologdの辞書が重すぎて、Cloud Functionsに乗らない。
でも、サーバ料金を押さえたいので、なんとかして乗せたい。お金ない。・環境
Mac macOS Mojave(10.14.2)・Cloud Functions
言語はPython3、トリガーはhttpです。参考記事
https://qiita.com/carrotflakes/items/d3bab5a81817c7e7edc0
方針
参考記事に書かれているように、neologd辞書を
--eliminate-redundant-entryで縮小し、zip化することで100MB以下に納め、デプロイするという作戦です。--eliminate-redundant-entry オプションとは
mecab-ipadic-NEologd"--eliminate-redundant-entry" オプションを指定した場合は、正規化済みの日本語テキストを単語分割するための別称・異表記・表記揺れなどを一切考慮できない辞書を、512MByte 程度の空きメモリ領域があればインストールできます。
Functionのデプロイ方法
- APIのコードとneologd辞書をzip化(mecab.zip)してCloud Storageに配置
- Storageのパスを指定してFunctionを作成します
デプロイコマンドはこんな感じ。
gcloud beta functions deploy mecab \ --source=gs://<バケット名>/mecab.zip \ --stage-bucket=<バケット名> \ --trigger-http \ --memory=512MB \ --runtime=python37 \ --region=asia-northeast1 \ --project=<プロジェクト名>mecab.zip
mecab.zipは下記ファイルとフォルダを一つのzipにしたものです。
このmecab.zipは、上記デプロイコマンドを打つ前にStorageにデプロイしておきます。$ tree . ├── main.py # Functionのコード ├── neologd-light # 辞書 │ ├── char.bin │ ├── dicrc │ ├── left-id.def │ ├── matrix.bin │ ├── pos-id.def │ ├── rewrite.def │ ├── right-id.def │ ├── sys.dic │ └── unk.dic └── requirements.txt下記コマンドでmecab.zipを作成します。
$ zip -r mecab.zip *$ tree . ├── main.py ├── mecab.zip # 作成されたmecab.zip ├── neologd-light │ ├── char.bin │ ├── dicrc │ ├── left-id.def │ ├── matrix.bin │ ├── pos-id.def │ ├── rewrite.def │ ├── right-id.def │ ├── sys.dic │ └── unk.dic └── requirements.txt各ファイルの説明
neologd-light(辞書)
Mac上でMeCabとNeologdをインストールし、作られた辞書データを使用します。
環境依存だと思っていたのでダメ元だったのですが、Cloud Functions上でそのまま動作しました。ここでは、MeCabのインストール方法は割愛させてください。
Neologdを
--eliminate-redundant-entryオプション付きでビルドします。$ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git $ cd mecab-ipadic-neologd/ $ ./bin/install-mecab-ipadic-neologd -y -p $HOME/neologd-light -n --eliminate-redundant-entryホームディレクトリに
neologd-lightが作成されました。main.py
import os import json import MeCab # MeCab準備 # リクエスト毎ではなく、インスタンスが立った時にだけ読み込まれる neologd_path = os.path.join(os.path.abspath( os.path.dirname(__file__)), "neologd-light") mcb = MeCab.Tagger('-d ' + neologd_path) mcb.parse('') def mecab(request): if request.method == 'GET': if request.args and 'text' in request.args: text = request.args.get('text') parsed_text = mcb.parse(text) return json.dumps({'p_text': parsed_text}, ensure_ascii=False) else: print('No text.') return ('Bad Request', 400)requirements.txt
mecab-python3==0.996.2
- 投稿日:2019-10-04T16:51:17+09:00
OpenpyxlでExcel操作入門&TIPS
pythonでExcelを操作できるライブラリはいくつかありますが、
私が調べた中で唯一「.xlsm」の拡張子を扱うことのできたライブラリOpenpyxlについて記事にします。Openpyxl概要
公式ドキュメント:https://openpyxl.readthedocs.io/en/stable/index.html
最新バージョン:2.6.2(2019/9/27現在)
ライセンス:MITライセンス
対応officeバージョン:office2010~
xlsx、xlsm等には対応できるが、xlsは非対応。
インストール
以下のように、pipコマンドでインストールするだけ。
cmdpip install openpyxlExcelを開いてみる
from openpyxl import Workbook, load_workbook # xlsm形式ファイルを開く場合 wb = load_workbook(filename="Excelファイルのパス", read_only=False, keep_vba=True) ws = self.wb['シート名']最低限、Excelファイルのパスを指定してload_workbookの引数に渡せば、pythonでExcelファイルを開くことはできる。
read_only = False
読み取り専用(True)か書き込み可能(False)かを指定する。
keep_vba = True
開いたExcelのVBマクロを読み込むかどうかを指定する。
読み込む → True、読み込まない → False
※ここで、Falseを指定すると、保存時にVBマクロが動かなくなるので、保存後もマクロを有効にしたい場合は、Trueを指定する。Excelを編集してみる
# 書き込み ws['A1'] = 'A1' # R1C1形式でも指定可能 # 列数、行数は1から開始 ws.cell(row=2, column=3).value = 'C2' # 読み取り data1 = ws['A1'] data2 = ws.cell(row=2, column=3).value # Bookの保存 wb.save("保存先Excelファイルのパス")簡単な読み書きだけであれば、以上のことを覚えておくだけで完結する。
より複雑な編集をしてみる
以下にただの読み書きよりも少し高度なExcel編集をTIPSとして羅列する。
まず、importしなければならないライブラリfrom openpyxl.workbook.protection import WorkbookProtection from openpyxl.styles.borders import Border, Side from openpyxl.styles import Alignment from openpyxl.styles.fonts import Font from openpyxl.worksheet.datavalidation import DataValidation from openpyxl.styles.fills import PatternFill以下、ソースコード抜粋
# 罫線の適用 # 罫線を定義 thinside = Side(style='thin', color='000000') thisborder = Border(top=thinside, bottom=thinside, left=thinside, right=thinside) ws['A1'].border = thisborder # セルの塗りつぶし # 塗りつぶしルールを定義 fill = PatternFill(patternType='solid', start_color='ffff0000', end_color='ffff0000') ws['A1'].fill = fill # ズームの変更 ws.sheet_view.zoomScale = 75 # 75%に変更 # データの入力規則の適用 # 選択肢A~Dで空白を許可する data_valid = DataValidation(type='list', formula1='"選択肢A,選択肢B,選択肢C,選択肢D"', allow_blank=True) data_valid.add(ws['A1']) # シートの保護 ws.protection.enable() # ブックの保護 wb.security = WorkbookProtection() wb.security.lockStructure = Trueさいごに
今回は、xlsmのファイルを扱うためにOpenpyxlを使用したが、
他のExcel操作のpythonライブラリも試して、
各ライブラリの比較とかできたらよいなと心の片隅に思った…(思っただけ)
- 投稿日:2019-10-04T16:38:47+09:00
PythonでJSON 読み込み
下準備
使用するjsonファイルを作成しておきます。
ファイル名はqitta_json.jsonにしました。{ "section1":{ "key":"key1", "number": 1 }, "section2":{ "key":"key2", "number": 2 } }モジュールをインポート
まずはモジュールをインポートしましょう。
import jsonファイルを開く
下のように読み込みたいファイルを指定してopen関数で開いてあげます。
rはreadのrです。
変数1 = open('読み込みたいjsonファイルのパス','r')json_open = open('qitta_json.json', 'r')開いたファイルをJSONとして読み込む
先ほど開いたファイル(変数1)をjson.load関数でJSONにします。
変数2 = json.load(変数1)json_load = json.load(json_open)一旦見てみましょう
ではここまでの成果を確認してみましょう。
import json json_open = open('qitta_json.json', 'r') json_load = json.load(json_open) print(json_load)実行結果
作業ディレクトリ>python qitta_json.py {'section1': {'key': 'key1', 'number': 1}, 'section2': {'key': 'key2', 'number': 2}}無事読み込めましたね!
とりあえず何か値を取り出してみる
次は読み込んだJSONから欲しいデータを取り出します。
例)section1のkeyの値を出力する。import json json_open = open('qitta_json.json', 'r') json_load = json.load(json_open) print(json_load['section1']['key'])実行結果
key1はい、ちゃんと取れましたね!
このようにJSONで読み込むとpythonの辞書型として保存されます。
辞書型が不安な人はどっかで確認しておきましょう。for文で値をとる
import json json_open = open('qitta_json.json', 'r') json_load = json.load(json_open) #valuesで値をとってくる for v in json_load.values(): print(v)実行結果
{'key': 'key1', 'number': 1} {'key': 'key2', 'number': 2}
sectionごとの値が取れましたね!!
でも多分これだと実用的じゃないので更にnumberの値だけとってこれるようにしましょう。
print(v)をprint(v['number'])に変えるだけでおけです。import json json_open = open('qitta_json.json', 'r') json_load = json.load(json_open) for v in json_load.values(): #ここを変えました。 print(v['number'])実行結果
1 2はい、できましたね!!
疲れたので書き込み編は今度書きます!!
お疲れさまでした!!参考
・【Python入門】JSON形式データの扱い方
・Pythonの辞書(dict)のforループ処理(keys, values, items)
- 投稿日:2019-10-04T16:08:55+09:00
pyTorchでlist(torch.Tensor, torch.Tensor, ...)をtorch.Tensorにまとめる
全ての要素がlistで完結しているなら何も問題はないと思いますが、tensor in list -> tensorsの際にひっかかったため
なお、list内のtensorは全て同じshapeを持つとします。arrs = [torch.Tensor(), torch.Tensor(), torch.Tensor(), ...] arrs = torch.cat(arrs).reshape(len(arrs), *arrs[0].shape)
- 投稿日:2019-10-04T16:05:49+09:00
django + Bootstrap4 + Apache +mod_wsgi でタスク管理アプリを作った
サーバサイドにDjangoを利用したタスク管理アプリを結構前に作りました。
というか今も鋭意開発中です。
アプリを作る際にハマったところとか、参考にしたサイトや知識なんかをまとめておきたいと思います。タスク管理アプリ「gantt」のご紹介
まずはじめに、こういうものが作れましたの紹介をさせてください。
僕が作ったのがタスク管理アプリ「gantt」です。
https://gantt.work/
- 登録したタスクをガントチャートで表示することができます。
- 期限のないミニマルなタスクを登録するTODO機能を使うことができます。
- Twitter、GitHub、LINEでのソーシャルログインに対応しています。
- 期限切れのタスクがある場合に、TwitterへのDMで通知することができます。
タダだよ!よかったらつかってね!
タスクの期限切れはいずれLINEのプッシュ通知とかでもできるようにするつもり。事前知識の習得
WEBアプリの作成知識は全くのゼロの状態から初めたので、どのサイトを使って勉強したかから書いていきます。
Paizaラーニング
エンジニア向けの転職サイトのPaizaが出しているWEB学習サービスです。環境構築不要で、動画を見ながら問題をときつつ学ぶことができるので効率がいいです。このサービスでPython、SQL、HTML/CSS、Bootstrap、Flask、Bash、Gitなんかをざっと学びました。
有料会員になると、動画を早回しする機能を使えるようになるので有料会員になるのもありかもしれません。
ちなみに僕は有料会員です。正直djangoを使う場合はSQL文は書けなくてもなんとかなります。でもDBがどういうものか知っておいたほうがイメージつくんじゃないかなーと思うので、余裕があったら見ておいたらいいかも。
Djangoの使い方
Djangoの使い方はこちらの記事を参考にして勉強しました。
簡単な書籍管理アプリをイチから作り方を教えてくれるので、初心者でも簡単に一個アプリを作ることができるのでおすすめです。
「Djangoでなにか作りたかったらこの記事を読んでおけばいいんじゃない? んで作ればいいんじゃない?」っていうくらいおすすめです。WEBアプリの作成(実践)
何ヶ月かかかって作っていて、どういう順序で作っていったか覚えていないので、実装している機能ごとに「こんなもの使ってるよー。こういうサイトを参考にしてつくったよー」位を書いていきます。
ソーシャルログイン周り
django-allauthを使っています。pipでインストールできます。
pip install django-allauth海外のプロジェクト?なのであまり情報がなくて困りました。
特にLINEのログインはドキュメントがほとんどなくてしかもハマったので、また今度記事にしたいと思います。標準ログイン周りは爆速で作れるDjangoユーザ認証機能【django-allauth】を、twitterログインなんかはこっちの記事を読むとわかりやすいかも。
ガントチャートの表示
Google Chartsのgantt chartをそのまま使用しています。
これはドキュメントを見た気がしないので、公式ドキュメントを見てもらうといいかも。
英語だらけで分けわからないですが、ソースコードコピペで意外となんとかなるから大丈夫。タスク入力画面のデータタイムピッカー
これはdjango-bootstrap-datepicker-plusを利用しています。
これもpipでインストールできます。pip install django-bootstrap-datepicker-plusこちらの記事を参考に作りました。
[Django] 日付入力欄をカレンダー形式にする (bootstrap-datetimepicker)参照先で丁寧に説明してくれているので、ここでの説明は割愛します。
djangoプロジェクトのデプロイ
ドメインとかサーバとかを借りる
ganttはお名前.comでドメインを取得しています。
サーバーはConoHaで借りています。「AWSじゃないの?」という人もいると思いますが、AWSは従量課金制で万が一サイトが流行ったらお金が払えないのでやめました。(そんなにはやってないよ!)どういうサイトを参考に設定したか忘れたんですけど(多分いろんな参考情報のキメラ)、今調べたらこちらのサイトがわりかしわかりやすそうでした。
Conohaサーバと独自ドメインを連携ドメインとサーバの連携は設定自体は簡単なんですけど、情報の反映に時間がかかるので、「失敗かも!?」と焦って設定を変えまくるんじゃなくて、設定した後放置しておくくらいが丁度いいです。
ConoHaでサーバを建てる
初めは僕も「CentOSサーバをたてて、そこにdjangoなりなんなりを入れていこう!」としましたが、ConoHaはdjango用のイメージを用意していてくれるので、間違いなく使った方がいいです。
イメージを指定して「作成!」とボタンを押すだけでだいたいサーバイメージができるので簡単です。
これからConoHaでdjangoをデプロイする人が居たら、迷うことなく既存イメージを使いましょう。djangoのアプリをデプロイする
ここもだいぶ悩んだので、色んなサイトを見ました。
いくつか参考になったサイトを載せておきます。ConoHaのVPSにDjango環境を作る
DjangoGirlsで作ったWebアプリを、ConoHa VPSでデプロイおわりに
とりあえずこれでデプロイまでです。
後はSSL通信化したり、メールサーバ構築してシステムメールをくるようにしていますけどそれは別の機会に。あと、もういちど、gantt使ってください!(切実)
お問合せフォームから開発要望とか随時受け付けています!
- 投稿日:2019-10-04T15:44:58+09:00
Blackできれいに自動整形!flake8とBlack導入と実行
こんにちは!
とあるITベンチャーで長期インターンをしている京都の学生です。
今回はBlackを導入しろ!というカリキュラムがあったので、実際にやって、ちょこっとBlackのアウトプットをしようかなと思っています。
基本的に参考文献に書いてあること書いているだけなので、詳細を見たい方は参考文献を見てください。Blackについて
僕のインターン先ではflake8とBlackを組み合わせて使用しています。
flake8についてのアウトプットに書いたとおり、flake8はコーディングチェックツールのラッパーです。
flake8はコードのチェックにはとても便利で優秀です。
しかし、エラーの修正まではできません。
そこで、このエラーを自動で修正してくれるのがBlackというわけですね。Blackの導入
Blackを導入するには下記のコマンドを打ちます。
$ pip install blackしかし、僕だけかもしれませんが次にようなエラーが出ました。
Cannot pip install black: No matching distribution found for black
ただ、一瞬で解決する方法があったのでそちらも一緒に紹介します。
こちらを参考にして下記のコマンドを打つだけでいけました。笑python3.6 -m pip install blackBlackは
Python3.6より新しいものでないと機能しないみたいなので、これでも駄目だったら、一度Python3のバージョンを確認してみてください。VSCodeの設定
Blackのインストールが完了したら、次にVSCodeの設定をいじっていきます。
僕はこちらを参考にしたので、詳しく知りたい方は一度目を通してください。
VSCodeのsettingsの設定を以下のようにしていきます。
設定名 機能 設定値 python.linting.enabled Lint機能を有効にするかどうか true python.linting.pylintEnabled Linterにpylintを使用するかどうか false python.linting.flake8Enabled Linterにflake8を使用するかどうか true python.linting.lintOnSave ファイル保存時にLintを実行するか true python.formatting.provider Pythonコードの整形に何を使用するか black editor.formatOnSave ファイル保存時に自動整形するかどうか true →引用元(丸パクリ)
上記の引用元から引っ張ってきた表です。
変えたところとしてはpython.formatting.providerの設定値を僕のインターン先ではBlackを使用しているのでBlackに変えたくらいです。
この設定を行うことでflake8についてのアウトプットでインストールしたflake8とBlackを使用できます。
引用元には上記の設定の一つ一つの解説をしてくれているので一度見ることをおすすめします。実際に使ってみる
では、実際に使ってみましょう。
foo(): print( "Hello" "World" )上記のコードを保存したときに、下記のコードのようにきれいな状態になっていれば導入成功です。
def foo(): print("Hello" "World")まとめ
今回はBlackについて書きました。
flake8に関してはflake8についてのアウトプットに書いてあるので今回ははしょりました。
僕が書いたことはほとんどコピペなのでもっと詳しく知りたいという方は参考文献を見てください!!
最後まで読んでいただきありがとうございます。参考文献
【VS Code】BlackとFlake8を使ってきれいなPythonコードを書く!!
VSCodeのPython開発環境でpylintの代わりにflake8を導入し自動整形を設定する
もうPythonの細かい書き方で議論しない。blackで自動フォーマットしよう
- 投稿日:2019-10-04T15:09:39+09:00
tf-pose-estimationを使って動画の姿勢推定と軌道描画
はじめに
前回の記事「https://qiita.com/fugunoko/items/299cfde96126007c6274」
では、tf-pose-estimation(https://github.com/ildoonet/tf-pose-estimation)
を使って、動画から姿勢推定と2D座標の出力を行いました。今回は、出力した2D座標を用いて、動画(gif)上に節毎の軌道を描くようにします(結果は冒頭のgifのようになります。)
目次
- データ準備
- 軌道gif作成
- ご参考サイト
データ準備
前回の記事「https://qiita.com/fugunoko/items/299cfde96126007c6274」
を参考に、2D座標データリスト、frame毎の画像を出力しておきます。軌道gif作成
これらのデータを用いて、frame毎の画像に2D座標データリストから各節の点を上書きプロットします。nframe目には、nframe,(n-1)frame...の節をプロットしています。これらの画像を集めてgifとすることで、軌道が分かるようなgifが作成されるようにしています。
jupyter notebook環境で実行しました。
graph.pyimport pandas as pd import numpy as np import os import codecs import cv2 import glob from PIL import Image #2D座標リスト df= pd.read_csv('cmu_dance_2ddata.csv') #各節の軌道の色設定(0~18節) colors = [[255,0,0],[0,255,0],[0,0,255],[255,255,0],[255,0,255] ,[0,255,255],[0,255,0],[0,0,255],[255,255,0],[255,0,255] ,[0,255,255],[0,255,0],[0,0,255],[255,255,0],[255,0,255] ,[0,255,255],[0,255,0],[0,0,255]] #合計frameとframe間隔設定 frame = 135 term = 5 sizex = 1280 sizey = 720 for m in range(0,frame+term,term): #各frameの画像読み込み img = cv2.imread('brabra/cmu_dance_' + str(m) + '_data.jpg') #サイズ変換 img = cv2.resize(img,(sizex,sizey)) #そのframeまでの節を画像に上書き描画 for i in range(0,m+5,5): dfa = df[(df['flame']==i)] try: max(dfa['human']) except: continue for j in range(1,max(dfa['human'])+1): dfb = dfa[(dfa['human']==j)] for k in range(0,19): dfc = dfb[(dfb['point'] == k)] try: cv2.circle(img, (int(dfc['x']), int(dfc['y'])), 3, colors[k], -1) except: continue #各frameで画像保存 cv2.imwrite('brabra/cmu_dance_' + str(m) + '_data_curve.jpg', img) #gif化 files = [] for i in range(0,frame+term,term): filepath = 'brabra/cmu_dance_' + str(i) + '_data_curve.jpg' files.append(filepath) images = list(map(lambda file: Image.open(file), files)) images[0].save('C:brabra/cmu_dance_curve' + str(term) + '.gif', save_all=True, append_images=images[1:], interval=330, loop=0)実行すれば冒頭のgifのような軌道が描画されたものが作成されます。
動作の軌道から得られるものは多いと思うのでどんどん使っていきたいです。ご参考サイト

- 投稿日:2019-10-04T14:54:53+09:00
Windows10でPythonの環境構築
Windows10でPythonの環境構築
概要
WindowsにPython環境作る手順と、Macとの違い
MacとWindowsの違い
Mac:
- pyenvがある
- Homebrewでインストールできる
Windows:
- pyenvない、その代わり(?)Pythonランチャーなるものがある
- 公式からインストーラをダウンロードする
pipコマンドとかがpython -m pipとかpy -m pipになって使いづらい1. インストール
python.jpの案内に従ってインストール
https://www.python.jp/install/windows/index.html2. 実行
スクリプト/プロジェクトごとのバージョン切り替えとか気にしないよって人は
pyコマンドで実行するだけ
(インストール時に"Add Python 3.x to PATH"にチェックを入れた場合pythonでもいける)# インタプリタを立ち上げる > py Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> print('Hello World!') Hello World! >>> exit() # exit()で終了 ># スクリプトを実行 > py example.py Hello World!複数の異なるバージョンを扱う場合
スクリプトごとやプロジェクトごとにバージョンやモジュールを使い分けたい人用
■ Python自体のバージョンだけ切り替えたい場合
使いたいバージョンをすべてインストール(インストール時、PATHを通さない)して
実行時のオプションでバージョンを指定PowerShell> py -3.5 example.py > py -3.7 -m pip list■ Pythonのバージョンは同じでも、モジュールのバージョンは切り替えたい場合
venvで仮想環境つくる仮想環境を作ると
- Pythonバージョンや扱うモジュールとそのバージョンをプロジェクトごとに切り替えられる
- MacやLinuxと同様
pip listとかでいけるようになるPowerShell# プロジェクト(環境を切り替えたい単位)のディレクトリに移動 > cd ./ProjectDir # 引数でバージョンを指定して環境を作る(最後の引数はこの環境用に作るディレクトリ名) > py -3.7 -m venv venv # 仮想環境の中に入る(activate) > venv/Scripts/activate (venv) ~> # プロンプトに"(ディレクトリ名)"がつく (venv) ~> pip list Package Version ---------- ------- pip 19.0.3 setuptools 40.8.0 # 仮想環境から出る(deactivate) (venv) ~> deactivate > # プロンプトの"(ディレクトリ名)"がなくなる※activateがエラーになるとき
WindowsではデフォルトでPowerShellのスクリプトの実行ポリシーが厳しくなっているので以下のエラーが出ることがある。
venv/Scripts/activate : ファイル C:\Users\user01\venv\Scripts\Activate.ps1 を読み込めません。 ファイル C:\Users\user01\venv\Scripts\Activate.ps1 はデジタル署名されていません。このスクリプトは現在のシステムでは実行できません。スクリプトの実行および実行ポリシーの設定の詳細については、「about_Execution_Polic ies」(https://go.microsoft.com/fwlink/?LinkID=135170) を参照してください。下記コマンドで現在ログイン中のユーザに対し、実行ポリシーを「RemoteSigned」にする
PowerShell> Set-ExecutionPolicy RemoteSigned -Scope CurrentUser参考になったサイト
pyとpythonの違いや、バージョンの切り替えについて
https://gammasoft.jp/python/python-version-management/
Set-ExecutionPolicyについて
https://qiita.com/kikuchi/items/59f219eae2a172880ba6
- 投稿日:2019-10-04T14:28:05+09:00
【Tweepy】TwitterAPIでのデータ収集で少し間違えた話
はじめに
最近TwitterからPythonでデータ収集して解析することがあったのですが、
使い方で少し間違えた部分があったので備忘録的に残しておきます。0.TwitterAPIへの登録
PythonでTwitterからデータ収集するためには、TwitterAPIに登録する必要があります。
使用目的など聞かれるので英語で少し書けばその日中に申請が通ります。。詳しくは下記のサイトがとても参考になりました。↓
Twitter API 登録 (アカウント申請方法) から承認されるまでの手順まとめ ※2019年8月時点の情報
1.Twitterからのデータ収集(今回のミス)
あとは簡単なコードでTwitterからデータを収集できます。
今回勘違いしてたのが↓のコード。1000件集めるつもりだったのですが。。import tweepy #keyなどを指定 Consumer_key = '********' Consumer_secret = '********' Access_token = '********' Access_secret ='********' auth = tweepy.OAuthHandler(Consumer_key, Consumer_secret) auth.set_access_token(Access_token, Access_secret) api = tweepy.API(auth, wait_on_rate_limit = True) #検索ワードを設定 #リツイートを除外したいときは、'検索ワード -RT' keyword='検索ワード' #tweetを収納するリスト tweets_data=[] for tweet in tweepy.Cursor(api.search,count=1000, q=q,tweet_mode='extended',lang='ja').items(): #つぶやきテキスト(FULL)を取得 tweets_data.append(tweet.full_text.strip().replace('\n','。') + '\n') #集めたツイート数を表示 print('Twitterからの収集完了:{}件'.format(len(tweets_data))↓出力
Twitterからの収集完了:7196件おや?7000件超も集まってしまいました(泣)
2.Twitterからのデータ収集(正)
勘違いしてたのはこの部分です。
for tweet in tweepy.Cursor(api.search,count=1000, q=q,tweet_mode='extended',lang='ja').items():'count='の部分はユーザー数の指定みたいですね。件数で指定したい場合には'items()'の部分で指定するらしいです。
for tweet in tweepy.Cursor(api.search, q=q,tweet_mode='extended',lang='ja').items(1000):これで無事1000件集められました。
おわりに
今回はシンプルにTwitterからのテキスト収集をしましたが、フォローやいいねの情報も収集できるみたいです。奥が深い.....
- 投稿日:2019-10-04T14:22:09+09:00
キー入力操縦プログラム
はじめに
このページは,
の1ページです.
全体を見たい場合は上記ページへお戻りください.概要
前回の記事では,tello.pyのTelloクラスを使って,Tello本体のバッテリー残量を取得して表示しました.
...でも情報を見るだけなんて,つまらないですね.
やはりドローンを飛ばさなければ面白くありません.今回は,キーボード入力でTelloを離着陸,移動させてみます.
前提条件
ホームフォルダにTello-Pythonがインストールされているという前提で話を進めます.
Linuxマシンであれば
/home/(ユーザー名)/に,Tello-Pythonというフォルダがあることになります.詳しくは Tello-Pythonのダウンロード を御覧ください.
Telloをキーボードで操縦するプログラム
ディレクトリの作成
まずは,
Tello-Pythonディレクトリの下に,新しいディレクトリTello-keyを作ります.Tello-keyディレクトリを作成$ cd ~/Tello-Python/ $ mkdir Tello-key $ cd Tello-keyファイルをコピー
tello.pyとlibh264decoder.soを,前回の
Tello-batteryからコピーしてきましょう.重要なファイルをコピー$ cp ../Tello-battery/tello.py ./ $ cp ../Tello-battery/libh264decoder.so ./キーボード入力を取る方法
kbhit.pyは,コンソールでキー入力が欲しい時に便利です.
tello_state.pyでも使っているcursesライブラリでもキー入力を取ることはできますが,コンソール画面にもう1枚別の黒スクリーンが貼られている感じが嫌いな人もいるかと思います.
C言語からの人間はkbhitとgetchで十分なんですよ(笑kbhit.pyについては, dronekitの記事 でも紹介しています.
まずは次のリンクを右クリックし,[名前を付けて保存]の機能を使って,
Tello_keyディレクトリにkbhit.pyを保存しましょう.kbhit.pyの使い方は,以下の3つを満たすように書くことです.
(1) kbhit.pyをインポートする
from kbhit import *(2) プログラムの冒頭(インポートの後)に,この2行を書く
atexit.register(set_normal_term) set_curses_term()(3) 永久ループ内でキー入力があるかどうかチェック(C言語と同じ書き方)
if kbhit(): # 何かキーが押されるのを待つ key = getch() # 1文字取得まさに
kbhitとgetch!,古い人間にはこれで十分です(爆Tello操作のキー配置
「Tello_Video」と「Tello_Video_With_Pose_Recognition」の操作パネルでは,矢印キーも使って操作するキー配置になっていました.モード2の操作に似せてある感じでした.
しかし,せっかくパソコンで操作するのですから,FPSの操作系で良いじゃないですか! やっぱり右手はマウスの上じゃないと.というわけで,今回作成するプログラムは,下図の様な操作系にしようと思います.
Takeoffの
tとLandのlだけ,頭文字のキーにしています.main.py
それでは,プログラム本体である
main.pyです.以下のコードをコピー&ペーストするか,
ここ を右クリックして[名前を付けて保存]機能でファイル保存してください.main.py#!/usr/bin/env python # -*- coding: utf-8 -*- import tello # tello.pyをインポート import time # time.sleepを使いたいので from kbhit import * # kbhit.pyをインポート # メイン関数本体 def main(): # kbhitのためのおまじない atexit.register(set_normal_term) set_curses_term() # Telloクラスを使って,droneというインスタンス(実体)を作る drone = tello.Tello('', 8889) current_time = time.time() # 現在時刻の保存変数 pre_time = current_time # 5秒ごとの'command'送信のための時刻変数 #Ctrl+cが押されるまでループ try: while True: if kbhit(): # 何かキーが押されるのを待つ key = getch() # 1文字取得 # キーに応じた処理 if key == 't': # 離陸 drone.takeoff() elif key == 'l': # 着陸 drone.land() elif key == 'w': # 前進 drone.move_forward(0.3) # 0.3mなので30cm動く elif key == 's': # 後進 drone.move_backward(0.3) elif key == 'a': # 左移動 drone.move_left(0.3) elif key == 'd': # 右移動 drone.move_right(0.3) elif key == 'q': # 左旋回 drone.rotate_ccw(20) # 20度旋回 elif key == 'e': # 右旋回 drone.rotate_cw(20) elif key == 'r': # 上昇 drone.move_up(0.3) elif key == 'f': # 下降 drone.move_down(0.3) time.sleep(0.3) # 適度にウェイトを入れてCPU負荷を下げる # 5秒おきに'command'を送って、Telloが自動終了しないようにする current_time = time.time() # 現在時刻を取得 if current_time - pre_time > 5.0 : # 前回時刻から5秒以上経過しているか? drone.send_command('command') # 'command'送信 pre_time = current_time # 前回時刻を更新 except( KeyboardInterrupt, SystemExit): # Ctrl+cが押されたら離脱 print( "SIGINTを検知" ) # telloクラスを削除 del drone # "python main.py"として実行された時だけ動く様にするおまじない処理 if __name__ == "__main__": # importされると"__main__"は入らないので,実行かimportかを判断できる. main() # メイン関数を実行こうして,
Tello_keyのディレクトリ内には,4つのファイルがあるはずです.ファイルは4つ$ ls kbhit.py libh264decoder.so main.py tello.pyプログラムの実行
「Tello_battery」の時と同様に,プログラム本体はmain.pyなので,コマンドラインから実行します.
プログラムの実行$ python main.pyctrl+cを押すことで,プログラムを終了できます.
操作は,キーをポンっと1回叩き,次のキーを押すまでは2秒ほど待つようにしてください.FPSゲームの様な感覚でキーを押しっぱなしにするのは厳禁です!
up,down,left,right,forward,back,cw,ccwのコマンドは,完了するまで数秒かかるので,キーを押しっぱなしにしていると先行入力が貯まって暴走します.1コマンドずつ動作確認するつもりでキーを打ってください.
実行結果
問題なく動作すれば,以下の様になるはずです.
実行結果$ python main.py sent: command sent: streamon [h264 @ 0x25db7a0] non-existing PPS 0 referenced [h264 @ 0x25db7a0] non-existing PPS 0 referenced [h264 @ 0x25db7a0] decode_slice_header error [h264 @ 0x25db7a0] no frame! [h264 @ 0x25db7a0] non-existing PPS 0 referenced [h264 @ 0x25db7a0] non-existing PPS 0 referenced [h264 @ 0x25db7a0] decode_slice_header error [h264 @ 0x25db7a0] no frame! >> send cmd: command >> send cmd: takeoff ←ここでtキーをおした >> send cmd: command [h264 @ 0x25db7a0] concealing 1670 DC, 1670 AC, 1670 MV errors in P frame >> send cmd: right 30 ←ここでdキーをおした >> send cmd: command >> send cmd: right 30 ←ここでdキーをおした >> send cmd: down 30 ←ここでfキーをおした >> send cmd: command >> send cmd: land ←ここでlキーをおした >> send cmd: command SIGINTを検知5秒おきに
commandが送信されているのがわかります.
Telloは15秒間コマンドがないと自動着陸するので,それを回避する機能が効いています.main.pyの解説
ではmain.pyの中身を見てみます.
shebangと文字コード指定
前回と同様にshebangと文字コード指定が書いてあります.
shebangと文字コード#!/usr/bin/env python # -*- coding: utf-8 -*-この2行は,「おまじない」として毎回書きましょう.
import部分
tello.pyのTelloクラスに加えて,kbhitを使いたいので,
from kbhit import *が書かれています.
こう書くことで,kbhit.pyの中にあるkbhitやgetchなどの全ての関数(*アスタリスクが全てを意味している)を使うことができるようになります.インポートimport tello # tello.pyをインポート import time # time.sleepを使いたいので from kbhit import * # kbhit.pyをインポートメイン関数
メイン関数の中身は大きく分けて3つの部分に分かれています.
「初期化」「ループ」「終了処理」です.メイン関数# メイン関数本体 def main(): 初期化部 ループ部 終了処理部それぞれ解説していきます.
初期化部
初期化処理部# kbhitのためのおまじない atexit.register(set_normal_term) set_curses_term() # Telloクラスを使って,droneというインスタンス(実体)を作る drone = tello.Tello('', 8889) # タイムアウト時間を短くし,なるべく早くキー入力に対応できるようにした time.sleep(0.5) # 通信が安定するまでちょっと待つ current_time = time.time() # 現在時刻の保存変数 pre_time = current_time # 5秒ごとの'command'送信のための時刻変数kbhitを使うためには,プログラム開始時に2つの関数を書いておく必要があります.
これは細かいことを考えず,「おまじない」として書くものだと思っておいたほうが良いです.
(中身を理解するのはPythonに精通してから)Telloクラスを元にdroneインスタンスを作っているのは,前回と同様です.
Telloとの通信が安定するのを待つ意味で,
time.sleepで0.5秒ほど待っています.
current_time(現在時刻)とpre_time(前回時刻)は,前回と現在との時間差を計算するために必要な変数です.ループ部でこの変数を使うときには異なる値が入るのですが,初期化部の段階では両方共に同じ値を入れています.ループ部
while Trueで永久ループを作っています.
ctrl+cを検知してループを終了させるのはtry exceptにお任せです.ループ部#Ctrl+cが押されるまでループ try: while True: if kbhit(): # 何かキーが押されるのを待つ key = getch() # 1文字取得 # キーに応じた処理 if key == 't': # 離陸 drone.takeoff() elif key == 'l': # 着陸 drone.land() (略) time.sleep(0.3) # 適度にウェイトを入れてCPU負荷を下げる # 5秒おきに'command'を送って、Telloが自動終了しないようにする current_time = time.time() # 現在時刻を取得 if current_time - pre_time > 5.0 : # 前回時刻から5秒以上経過しているか? drone.send_command('command') # 'command'送信 pre_time = current_time # 前回時刻を更新 except( KeyboardInterrupt, SystemExit): # Ctrl+cが押されたら離脱 print( "SIGINTを検知" )C言語と同様に,
kbhit()でキーボード入力の有無,key = getch()で入力されたキーのキーコードを取り出します.if文で,キーが押された時の処理を分岐させています.
Pythonにはswitch文は無いので,if 〜 elif(else ifの意味) 〜 elif 〜の様に書くしかありません.Telloクラスの中には,
takeoff()やland(),move_なんちゃらという移動に関する関数が予め用意されています(詳しくはtello.pyのソースを読むこと).ユーザーはdrone.takeoff()の様にドットを付けて呼びだすだけです.またループの最後に,現在時刻
current_timeと,前回時刻pre_timeとの差を調べて,5秒以上だったらTelloに'command'を送信しています.
Telloは15秒間コマンドが来ないと自動着陸して終了してしまうので,キー入力が無くても5秒おきにコマンドを出す様にしてあるのです.
コマンドを送信した時刻がpre_timeになるので,drone.send_command('command')と一緒にpre_time = current_timeを書いて時刻を更新しています.終了処理部
終了処理も簡単に1行です.
クラスを削除しているだけです.終了処理部del drone # telloクラスを削除おわりに
キーボード入力でTelloを操縦できるようにしました.
とは言え,キーを1個1個押していく感じなので,リアルタイムに操縦している感じではありませんね.次回は,ジョイパッド/ジョイスティックを使って,ほぼリアルタイムにTelloを動かしてみようと思います.
(FPSの様にキーボードでリアルタイムに動かすのは,次のジョイスティックをやれば作れるようになります)

- 投稿日:2019-10-04T14:02:20+09:00
Lambda(CloudWatch) + Pythonでシフト勤務の報告ページをConfluenceに自動作成する
はじめに
シフトページを自動化するPythonコードを書いてみた。
構造
テンプレート構造
親スペース[SPACE_KEY] ━ 親ページ[oya_page] ━ 月ページ[月テンプレート] ━ 日ページ[日テンプレートA]
┗ 日ページ[日テンプレートB]稼働後の構造:月と日のページが出来上がる
親スペース[SPACE_KEY] ━ 親ページ[oya_page] ━ 月ページ[YYYY/MM] ━ 日ページ[YYYY/MM/DD_A]
┗ 日ページ[YYYY/MM/DD_B]
※ページがYYYY/MM~となっているのはコンフルの一意制約対策コード
変数名はご愛敬
import requests import json import re import datetime BASE_URL = "https://★コンフルのURL★.atlassian.net/wiki/rest/api" AUTH = ("★コンフルのID★","★コンフルのPW★") HEADERS = {"content-type":"application/json"} SPACE_KEY = "★コンフルのスペースキー★" NEW_DATE = datetime.datetime.now() + datetime.timedelta(days=7) # 一週間後指定(lambdaでの実行はUTC+7日後) def lambda_handler(event, context): parent_id = monthpage_create() shiftpage_create("★日テンプレートAの名前★","★付属したい任意の文字(例:A)★", parent_id) shiftpage_create("★日テンプレートBの名前★","★付属したい任意の文字(例:B)★", parent_id) def monthpage_create(): template_title_month = "★月テンプレページの名前★" new_page_title_month = NEW_DATE.strftime("%Y/%m") oya_page = "★親ページのIDを指定" # 月初は新規ページ作成 if NEW_DATE.strftime("%d") == "01": # コピー元(月テンプレ)ページ情報取得 get_result_month = get_page(template_title_month) parent_id = post_page(new_page_title_month, get_result_month[1], oya_page) print("Create MonthPage : " + new_page_title_month + " PageId : " + parent_id) else: get_result_month = get_page(new_page_title_month) parent_id = get_result_month[0] return parent_id def shiftpage_create(template_title_day, shift, parent_id): # シフトのページタイトル作成 yobi = ["月","火","水","木","金","土","日"] dow = yobi[NEW_DATE.weekday()] # 曜日取得(day of the week) new_page_title_day = NEW_DATE.strftime("%Y/%m/%d") + ("(") + dow + (")") + shift # コピー元(シフトテンプレ)ページ情報取得 get_result_day = get_page(template_title_day) # シフトページ作成 shiftpage_id = post_page(new_page_title_day, get_result_day[1], parent_id) print("Create DayPage : " + new_page_title_day + " PageId : " + shiftpage_id) # ページを取得 # return: # [0] = id # [1] = contents def get_page(title): response_get = requests.get( BASE_URL+"/content", auth=AUTH, params={ "title":title, "spacekey":SPACE_KEY, "expand":"body.storage.value" } ) response_get.raise_for_status() json_contents = json.loads(response_get.content.decode("utf-8")) contents = json_contents["results"][0]["body"]["storage"]["value"] page_id = json_contents["results"][0]["id"] return page_id, contents # ページを新規作成 # return: id def post_page(title, contents, parent_id): payload = { "type": "page", "title": title, "ancestors": [{"id": parent_id}], "space": {"key": SPACE_KEY}, "body": { "storage": { "value": contents, "representation": "storage" } } } response_create = requests.post( BASE_URL + "/content", auth = AUTH, data = json.dumps(payload), headers = HEADERS ) response_create.raise_for_status() json_create_contents = json.loads(response_create.content.decode("utf-8")) create_id = json_create_contents["id"] return create_idLambda + CloudWatchへの登録
以下雑です。
1.以下コマンドをlinux環境で実行して上のソースと一緒にzip化する
pip install requests2.CloudWatchに時間登録
※CloudFormation使った登録は別で
- 投稿日:2019-10-04T13:34:57+09:00
Pythonで簡体字と繁体字を区別する
動機
インターンの業務で中国語を取り扱う案件があったのですが、
その際に簡体字と繁体字を別で処理してほしいとお願いされたのでその時の解決方法です。解決方法
さすが天下の中国ということでライブラリがありました。
zhconvのisscmpを使うと良さそうです。まずはインストールします。
> pip install zhconvコード
import zhconv # 簡体字の例文 kan_text = '承蒙关照了,今后还请多多关照。送走了一年的辛劳,迎来了又一个崭新的年月,祝您在新的一年里,大展宏图,财源广进!' # 簡体字の例文 han_text = '承蒙關照了,今後還請多多關照。送走了一年的辛勞,迎來了又一個嶄新的年月,祝您在新的一年裡,大展宏圖,財源廣進!' print('簡体字: ', zhconv.issimp(kan_text)) # True print('繁体字: ', zhconv.issimp(han_text)) # Falseこのように簡体字ならTrue, 繁体字ならFalseを返してくれます。
- 投稿日:2019-10-04T12:40:40+09:00
Azure Text to Speech REST API をやーる(Python 3.6.9)
AzureのCognitiveServicesを用いて、テキストから音声変換をやってみました。
はじめに
Azure Portalにログインして、リソースの作成から「音声」を検索し作成してください。
リソースグループ名、エンドポイントおよびsubscription keyを用いるのでコピペしてください。サンプルコード
'YOUR_RESOURCE_NAME'を作成したリソースグループ名に変更してください。
"YOUR_KEY_HERE"を作成したsubscription keyに変更してください。
fetch_token_urlやbase_urlを作成したリージョンのエンドポイントに合わせて変更してください。import os import requests import time from xml.etree import ElementTree try: input = raw_input except NameError: pass class TextToSpeech(object): def __init__(self, subscription_key): self.subscription_key = subscription_key self.tts = input("What would you like to convert to speech: ") self.timestr = time.strftime("%Y%m%d-%H%M") self.access_token = None def get_token(self): fetch_token_url = 'https://westus.api.cognitive.microsoft.com/sts/v1.0/issuetoken' headers = { 'Ocp-Apim-Subscription-Key': self.subscription_key } response = requests.post(fetch_token_url, headers=headers) self.access_token = str(response.text) # return self.access_token def save_audio(self): base_url = 'https://westus.tts.speech.microsoft.com/' path = 'cognitiveservices/v1' constructed_url = base_url + path headers = { 'Authorization': 'Bearer ' + self.access_token, 'Content-Type': 'application/ssml+xml', 'X-Microsoft-OutputFormat': 'riff-24khz-16bit-mono-pcm', 'User-Agent': 'speechsdk' } xml_body = ElementTree.Element('speak', version='1.0') xml_body.set('{http://www.w3.org/XML/1998/namespace}lang', 'en-us') voice = ElementTree.SubElement(xml_body, 'voice') voice.set('{http://www.w3.org/XML/1998/namespace}lang', 'en-US') voice.set( 'name', 'Microsoft Server Speech Text to Speech Voice (en-US, Guy24KRUS)') voice.text = self.tts body = ElementTree.tostring(xml_body) response = requests.post(constructed_url, headers=headers, data=body) if response.status_code == 200: with open('sample-' + self.timestr + '.wav', 'wb') as audio: audio.write(response.content) print("\nStatus code: " + str(response.status_code) + "\nYour TTS is ready for playback.\n") else: print("\nStatus code: " + str(response.status_code) + "\nSomething went wrong. Check your subscription key and headers.\n") if __name__ == "__main__": subscription_key = "YOUR_KEY_HERE" app = TextToSpeech(subscription_key) app.get_token() app.save_audio()結果
下記のように表示されれば成功です。フォルダの中にsample-yyyymmdd-hhmm.wavの音声ファイルが生成されているはずです。
(py36) D:\User\s-fujimoto\sts>python tts.py What would you like to convert to speech: hello world Status code: 200 Your TTS is ready for playback.参考文献
- 投稿日:2019-10-04T11:29:28+09:00
flake8についてのアウトプット
こんにちは!
現在インターン先でプログラミングの勉強をしている大学三回生です。
今回はflake8について勉強する機会があったので、それについてアウトプットしていこうと思います。
基本調べたことを書いているだけなので、詳細を知りたい方は参考文献を載せておくのでそちらを御覧ください。flake8と何なのか
flake8とは「pep8のチェック、pyflakesのチェック、及び循環的複雑度をチェックできるラッパー」→(引用元)のことらしいです。
つまり、広範囲カバーしてくれるPythonのコードチェックツールですね!
flake8は下記コードチェックツールのラッパーとなります。・
PyFlakes(pyflakes : コードのエラーチェック)
・pycodestyle(pycodestyle : PEP8に準拠しているかチェック)
・Ned Batchelder’s McCabe script(mccabe : 循環的複雑度のチェック)flake8を使ってみよう!
では実際にflake8を使ってみましょう!
そのためには、まずflake8をインストール必要があります。
下記コマンドでインストールできます。$ pip install flake8実際に使用するときは
$ flake8 ファイル名で実行できます。
また、ファイル名だけではなく、ディレクトリ名でも実行できます。
実際に僕のdjangoのblogsというアプリケーションで試してみたいと思います。$ flake8 blogs blogs/views.py:3:1: E302 expected 2 blank lines, found 1 blogs/views.py:4:47: W292 no newline at end of file blogs/urls.py:7:2: W292 no newline at end of file blogs/admin.py:5:1: W391 blank line at end of file blogs/models.py:4:1: E302 expected 2 blank lines, found 1 blogs/models.py:11:26: W292 no newline at end of file blogs/tests.py:1:1: F401 'django.test.TestCase' imported but unused blogs/migrations/0001_initial.py:17:80: E501 line too long (114 > 79 characters)このような結果が出てきます。
また、--show-sourceオプションをつけるとどこを修正すればいいのかわかりやすくなります。
では、実際に実行してみましょう。$ flake8 --show-source blogs blogs/views.py:3:1: E302 expected 2 blank lines, found 1 def index(request): ^ blogs/views.py:4:47: W292 no newline at end of file return render(request, 'blogs/index.html') ^ blogs/urls.py:7:2: W292 no newline at end of file ] ^ blogs/admin.py:5:1: W391 blank line at end of file ^ blogs/models.py:4:1: E302 expected 2 blank lines, found 1 class Blog(models.Model): ^ blogs/models.py:11:26: W292 no newline at end of file return self.title ^ blogs/tests.py:1:1: F401 'django.test.TestCase' imported but unused from django.test import TestCase ^ blogs/migrations/0001_initial.py:17:80: E501 line too long (114 > 79 characters) ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),このようにさっきよりもわかりやすくなりました。
まとめ
flake8を使用することで、より間違いも少なくでき、コードもきれいになるので頻繁に使っていこうと思います。
最後までお読みいただきありがとうございます。
もっと詳しく知りたい方は参考文献をお読みください。参考文献
Vimメモ : flake8でPythonのコードをチェックする
- 投稿日:2019-10-04T10:34:28+09:00
AWS Lambda + SSM Parameter Store でカウンターを作る
事の発端はこのツイートを見たこと。
目的外利用な気はしますが SSM Parameter Store はどうでしょう
— fujiwara (@fujiwara) September 19, 2019今まで Lambda を使っていて「データベースを用意するほどじゃないけどちょっとした情報を保存したい」と思うケースが多々あって、もっともカジュアルな方法はなんだろうかと考えていたところだった。
「ちょっとした情報の保存先」として SSM Parameter Store を使うアイデアは面白そうだと思ったので、試しに AWS Lambda + SSM Parameter Store でカウンターを作ってみた。
Lambda Function の実装
SSM Parameter Store に値を保持してカウントアップするだけの素朴な Lambda Function を作った。ランタイムは Python 3.7。
import boto3 ssm = boto3.client('ssm') def get_param(key: str) -> str: global ssm try: return ssm.get_parameter(Name=key)['Parameter']['Value'] except ssm.exceptions.ParameterNotFound: return None def set_param(key: str, value: str): global ssm ssm.put_parameter(Name=key, Value=value, Type='String', Overwrite=True) def lambda_handler(event, context): key = 'counter' count = int(get_param(key) or 0) count += 1 set_param(key, str(count)) return countRole の設定
このままでは Lambda Function から SSM Parameter Store にアクセスする権限がないので、以下のようなポリシーを持つ IAM Role を作成して Lambda Function に割り当てる。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ssm:PutParameter", "ssm:GetParameter" ], "Resource": "arn:aws:ssm:*:*:parameter/counter" } ] }権限を最小限にするために
counterという名前のパラメータの読み書きのみができるようにした。実行
Lambda Function を実行するたびにカウンターの値が 1 ずつ増えていくことが確認できると思う。
DynamoDB や S3 に保存するよりもはるかに簡単にできたので、「ちょっとした情報の保存先」として SSM Parameter Store を使うアイデアはかなりアリだなと思った。
- 投稿日:2019-10-04T10:29:10+09:00
Python is と == の違い
はじめに
投稿した記事のコメントで is と == の違い について教えていただきましたので、それについてまとめたいと思います。
(ミュータブル/イミュータブルとかの値のややこしい話とかは抜きにしてまとめてみました。)1.== で比較しているもの
今まで vba や C を書く機会が多く、比較するときには==を使う習慣が身についてしまっていたわけですが、、、
pythonにおいて==で比較しているのは変数の値そのものだそうです。ですので、次のような場合はTrueとなります。
code.pya=[1,2] b=[1,2] print(a==b)ResultTrue2.is で比較しているもの
Pythonに限らずオブジェクト指向のプログラミング言語には、オブジェクト、クラス、インスタンスといった概念があります。ざっくりいうと、オブジェクトは枠、クラスは設計書、インスタンスはモノといったイメージになると思います。
(オブジェクト=焼き菓子、クラス=クッキーの作り方、インスタンス=クッキー(完成品)的な関係)インスタンスとかややこしいことを言っていますが、 a = 10 とか何気なく変数に値を代入するだけでもインスタンスが作られています。
Pythonでは、isは、インスタンス同士のidが同じか否かを判断します。
idはid(変数)で調べることが出来ます。code.pya="cookies" #"cookies"のidをaに格納 b="cookies" #"cookies"のidをbに格納 A=["cookies"] #動的にメモリを確保し、確保したメモリに"cookies"を格納 → idは動的に確保した場所を示す B=["cookies"] #動的にメモリを確保し、確保したメモリに"cookies"を格納 → idは動的に確保した場所を示す print(id(a),id(b)) print(a is b) #idの比較 print(a==b) #値の比較 print(id(A),id(B)) print(A is B) print(A==B)Result2737112766312 2737112766312 #ここの二つの値が同じ True True 2737112556296 2737111787336 #ここの二つの値が異なる False Trueまとめ
is と == の二つの目線で変数を比較出来ることを学びました。
is は変数の id を比較し、 == は 変数の値そのもの を比較するようです。C言語とかのポインタとかアドレスとかの話を、オブジェクト指向プログラミングで話すと今回の内容のような話になりそうですね。すごくややこしい反面、こうゆうところを気にしてコーディングできると綺麗なコードがかけるんだろうな~とか思いました!
- 投稿日:2019-10-04T10:05:05+09:00
RaspberryPiで赤外線アレイセンサAMG8833(Grid-EYE)からデータ取得
必要なもの
- Raspberry Pi
- Raspberry Pi 3 model B+を使用しています
- Conta サーモグラフィー AMG8833搭載
- スイッチサイエンスで購入 https://www.switch-science.com/catalog/3395/
- ブレッドボードおよびジャンパーワイヤ
モジュールについて
- Panasonic製のAMG8833(愛称:Grid-EYE)を搭載
- 8×8の赤外線アレイセンサにより2次元画像取得可能
- 入出力はI2Cバス
- 検出温度範囲:0~80℃(各素子)
- AMG8833のデータシート
モジュールとRaspberry Piの接続
- AMG8833(3.3V) ⇔ GPIO1(3.3V)
- AMG8833(GND) ⇔ GPIO6(Ground)
- AMG8833(SDA) ⇔ GPIO3(SDA)
- AMG8833(SCL) ⇔ GPIO5(SCL)
(Raspberry PiのGPIOピン配置は https://pinout.xyz/ などを参照)
fritzingで書いた配線図は以下です。
Adafruit社が提供しているFritzing-Libraryを利用したのですが、基盤のピン配置が今回使用したものと少し違うので注意してください。
以降はRaspberry Piで作業します。
使用しているRaspberry PiのOSバージョンは以下の通りです。
$ lsb_release -a No LSB modules are available. Distributor ID: Raspbian Description: Raspbian GNU/Linux 10 (buster) Release: 10 Codename: busterI2Cを有効化します。
$ sudo raspi-config -> 5 Interfacing Options --> P5 I2C接続できているか確認します。
$ i2cdetect -y 1 0 1 2 3 4 5 6 7 8 9 a b c d e f 00: -- -- -- -- -- -- -- -- -- -- -- -- -- 10: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 20: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 30: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 40: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 50: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 60: -- -- -- -- -- -- -- -- 68 -- -- -- -- -- -- -- 70: -- -- -- -- -- -- -- --このように「68」が出ていれば問題ありません。
工場出荷時は68になっているようです。
変更したい場合はSJ1のソルダージャンパーをH側と接続すると「69」になります。データ取得
Adafruit社から提供されているCircuitPythonを使用します。
$ sudo pip3 install adafruit-circuitpython-amg88xxAdafruitのサンプルプログラムを参考にプログラムします。
https://learn.adafruit.com/adafruit-amg8833-8x8-thermal-camera-sensor/raspberry-pi-thermal-cameraamg8833.py# -*- coding: utf-8 -*- import time import busio import board import adafruit_amg88xx # I2Cバスの初期化 i2c_bus = busio.I2C(board.SCL, board.SDA) # センサーの初期化 sensor = adafruit_amg88xx.AMG88XX(i2c_bus) # センサーの初期化待ち time.sleep(.1) # 8x8の表示 print(sensor.pixels)ただし、このまま実行するとエラーになります。
$ python3 amg8833.py Traceback (most recent call last): File "/usr/local/lib/python3.7/dist-packages/adafruit_bus_device/i2c_device.py", line 68, in __init__ i2c.writeto(device_address, b'') File "/usr/local/lib/python3.7/dist-packages/busio.py", line 69, in writeto return self._i2c.writeto(address, buffer, stop=stop) File "/usr/local/lib/python3.7/dist-packages/adafruit_blinka/microcontroller/generic_linux/i2c.py", line 38, in writeto self._i2c_bus.write_bytes(address, buffer[start:end]) File "/usr/local/lib/python3.7/dist-packages/Adafruit_PureIO/smbus.py", line 244, in write_bytes self._device.write(buf) OSError: [Errno 121] Remote I/O error During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/usr/local/lib/python3.7/dist-packages/adafruit_bus_device/i2c_device.py", line 74, in __init__ i2c.readfrom_into(device_address, result) File "/usr/local/lib/python3.7/dist-packages/busio.py", line 59, in readfrom_into return self._i2c.readfrom_into(address, buffer, stop=stop) File "/usr/local/lib/python3.7/dist-packages/adafruit_blinka/microcontroller/generic_linux/i2c.py", line 44, in readfrom_into readin = self._i2c_bus.read_bytes(address, end-start) File "/usr/local/lib/python3.7/dist-packages/Adafruit_PureIO/smbus.py", line 155, in read_bytes return self._device.read(number) OSError: [Errno 121] Remote I/O error During handling of the above exception, another exception occurred: Traceback (most recent call last): File "amg8833.py", line 12, in <module> sensor = adafruit_amg88xx.AMG88XX(i2c_bus) File "/usr/local/lib/python3.7/dist-packages/adafruit_amg88xx.py", line 131, in __init__ self.i2c_device = I2CDevice(i2c, addr) File "/usr/local/lib/python3.7/dist-packages/adafruit_bus_device/i2c_device.py", line 76, in __init__ raise ValueError("No I2C device at address: %x" % device_address) ValueError: No I2C device at address: 69I2Cのアドレスが69でないといけないようです。
ソルダージャンパーを変更してアドレスを69にしてもいいですが、https://github.com/adafruit/Adafruit_CircuitPython_AMG88xx を見たらオプションでアドレス変更できると書いてあるので、センサーの初期化のときにアドレスを68に指定します。amg8833.py# -*- coding: utf-8 -*- import time import busio import board import adafruit_amg88xx # I2Cバスの初期化 i2c_bus = busio.I2C(board.SCL, board.SDA) # センサーの初期化 # アドレスを68に指定 sensor = adafruit_amg88xx.AMG88XX(i2c_bus, addr=0x68) # センサーの初期化待ち time.sleep(.1) # 8x8の表示 print(sensor.pixels)これで8x8の温度が取得できます。
$ python3 amg8833.py [[27.25, 26.75, 26.75, 27.25, 27.75, 26.75, 27.75, 29.75] [27.0, 27.25, 27.25, 26.75, 27.25, 27.5, 29.75, 32.5] [27.25, 26.5, 26.75, 27.25, 27.0, 27.5, 27.75, 28.75] [26.75, 25.5, 26.5, 23.5, 27.0, 24.75, 27.5, 33.5] [26.75, 26.75, 26.75, 27.0, 27.25, 26.75, 27.25, 32.0] [26.5, 26.5, 26.5, 27.25, 26.75, 27.0, 28.0, 32.25] [26.5, 26.5, 26.5, 27.0, 27.0, 27.25, 28.0, 31.0] [26.0, 26.5, 26.0, 26.5, 26.5, 26.75, 26.75, 27.75]]見やすいように改行したり空白を入れたりしましたが、実際は一列で表示されます。


- 投稿日:2019-10-04T09:56:15+09:00
pipで更新可能なパッケージを一括でアップデートする
pipでアップデートがあるパッケージの一覧を表示する.
pip list -oつぎのコマンドで一括アップデートができる.
pip list -o | tail -n +3 | awk '{ print $1 }' | xargs pip install -U出力をフォーマットして,アップデートするコマンドに渡すことで実現している.
コマンドのaliasを追加するとより便利.
~/.bash_profile,~/zprofileなどに次の一行を追加すると,pip-update-allですべてのパッケージをアップデートできる.alias pip-update-all="pip list -o | tail -n +3 | awk '{ print $1 }' | xargs pip install -U"
- 投稿日:2019-10-04T07:58:51+09:00
CNNの畳み込み処理(主にim2col)をpython素人が解説(機械学習の学習 #5)
0. はじめに
CNN(畳み込みニューラルネットワーク)の「畳み込み処理」のうち、im2col周りを中心に説明します。サンプルソースはpythonで書かれているわけで、python素人には難易度が高い!筆者の理解の過程を共有します。
全体を通して、以下書籍を参考にしながら記載をしています。
「ゼロからつくるDeepLearning」斎藤 康毅著 オライリージャパン
誰もが知るすばらしい本です。説明がめちゃめちゃわかりやすいです。尚、本ページに変な記載があったら、すべて私の無知・誤りによるのものです。
1. 全体像
1.1. CNNとは
・・・について、細かい説明は省きます(これを読んでいる人がCNN知らないことはないと思いますので)。
【参考ページ】
Convolutional Neural Networkとは何なのか1.2. 扱う範囲
CNNのうち、「画像データから最初に畳み込む」部分のみです。im2colについても記載します。
pythonでどう実装しているのか、に焦点をあてています。1.3. 畳み込みとは
パディング処理を施した画像データに対し、ストライド幅でフィルタを掛け合わせて特徴マップを作る処理です。
上述参考ページのほか、以下ページもわかりやすかったです。
・・・ということで、説明は省きます。【参考ページ】
畳み込みニューラルネットワーク(Convolutional neural network)2. 前提知識:numpyの配列
2.1. 高次元配列のデータ指定方法
以下で、「配列の指定方法」と「それがどこを指すのかのイメージ」を持っておきます。
例は、3次元配列の場合です。
2.2. 配列の形式変換(reshape)
配列を変換したとき、値がどのような順番で格納されるかをみてみます。
例は、3次元配列を1次元配列にしています。
A.shapeが(2, 4, 3)、Aを1次元配列にしたB.shapeが(24)で、
A[1, 0, 3] =B[1*(4*3) + 0*(3) + 3] = B[15] となる点がポイントです。値(インデックス)の指定方法、格納のされかた、上述のイメージ図を関連づけて理解しておくとよいと思います。
説明やプログラムの中でreshape(A*B*C, -1)などと書く際、引数の掛け算の順は、上記の値の取り方を考慮して記載します(約束事なのではと思います)。
2.3. 補足
配列の並び順(reshapeでどの順で並ぶか)については、ndarrayのデフォルト設定を前提としています。
reshapeでorderという引数を使うと、reshape時の値の取る順番が変わります。詳しくは以下にて。【参考ページ】
配列を形状変換するNumPyのreshapeの使い方3. 畳み込み処理
3.1. やっていること
画像データに対し、フィルタを適用させて(畳み込み)、データの特徴を抽出します。
3.2. 処理高速化→行列演算化→im2col
画像データにフィルタをそのまま直感的にコーディングすると計算時間がかかります(、みたいですね)。
numpyは行列計算が高速にできるようになっており、逆にfor文には時間がかかるとされています。
そこで、これを極力行列演算で実現しよう!という発想になります。
おおよそ、
①高次元配列を行列(二次元配列)に変換する。
②行列積を求める。
③行列を高次元配列に変換する。
となります。
im2colは、画像データ(の集まり)を1つの行列にする、という関数になります。4. im2col
4.1. フィルタの行列変換
フィルタのデータも多次元です。im2colを考える前に、このフィルタをどのように行列化するかを考えます。
前節でみた図を、まずは配列表記にしましょう。filter_org(FN, C, FH, FW)と記載することとします。
フィルタの数がFN個あり、これらを画像データ群に適用させる必要があります。
直感的に「一つのフィルタの情報」×「フィルタの数」と考えるのがシンプルです。
画像データの配列と行列積をなすためには、縦方向に「一つのフィルタの情報」を格納し、そのフィルタ情報を横に並べる形をとります。
行列の縦方向は「フィルタのデータ(C*FH*FW)」が入ります。
つまり、フィルタの行列としては、filter_col(C*FH*FW, FN)としたいわけです。
結論として、フィルタの行列変換は
filter_col = filter_org.reshape(FN, -1).Tとなります。いきなり、filter_org.reshape(-1, FN)としてはいけません。2.の前提知識でふれたとおり、(FN, C, FH, FW)の順番を考慮せずにreshapeすると、思った通りに値が取り出せなくなります。
im2colはこのフィルタの形式ありき、という点を覚えておいてください。4.2. 画像データの行列変換
どのようなサイズの行列にすべきかを考えます。
先ほど行列の形式はフィルタの形式ありきといいましたが、フィルタのサイズはfilter_col(C*FH*FW, FN)です。行列変換後の画像ファイルをim_colとすると、im_colとfilter_colとの行列積を求めるためには、im_colの列のサイズはfilter_colの行のサイズと等しくする必要があります。つまり、C*FH*FWです。
次に、im_colの縦方向にはどのような値を入れるのがふさわしいかを考えます。
filter_colの行列積を取ることを考えると、1列目にはフィルタ"0000"が掛け合わされます。2列目にはフィルタ"0001”、3列目は、・・・・というふうにつながります。1列目を例にとると、フィルタ"0000"と掛け合わされる画像データを上から順に格納する必要があります。つまり、畳み込みの計算方法を考えると、画像データの最初から、フィルタ"0000"を縦横にストライド分飛ばした値を並べたものになります。
値の個数はいくつでしょうか。それは(N*OH*OW)です。
Nは画像データの数です。OH,OWですが、これは畳み込み後のデータサイズ(の縦と横)を表します。
- 画像 高さH×幅W
- フィルタ 高さFH×幅FH
- ストライド 縦横ともにS
- パディング 縦横ともにP
のとき、畳み込み後のサイズは、以下で求められます。
- OH = (H + 2P - FH)/S +1
- OW = (W + 2P - FW)/S +1
結論として、画像データの変換後サイズは im_col(N*OH*W, C*FH*FW) となります。
ここまでくれば、im2colの実装が読めてきます(長かった・・・!)
4.3. im2colの実装
以上を踏まえてim2colです。
よく知られた実装ではありますが、キーとなるところだけコードで記載します。雰囲気だけつかんでください。実装は「ゼロつく本」などでご確認ください。まず、関数とその引数です。
# 関数の引数は # 画像データ群、フィルタの高さ、フィルタの幅、縦横のストライド、縦横のパディング def im2col(im_org, FH, FW, S, P):各データのサイズを規定しましょう。
N, C, H, W = im_org.shape OH = (H + 2 * P - FH)//S + 1 OW = (W + 2 * P - FW)//S + 1画像データはパディングしておきます。
画像データフィルタを適用させます。
まず、im2colの戻り値を定義しておきます。im_col = np.zeros((N, C, FH, FW, OH, OW))フィルタの各要素(FH、FWの二次元データ)に適用させる画像データを、
ストライドずつづらしながら取得(OH、OWの二次元データ)し、im_colに格納します。# (y,x)は(FH,FW)のフィルタの各要素。 for y in range(FH): y_max = y + S * OH for x in range(FW): x_max = x + S * OW im_col[:, :, y, x, :, :] = img_org[:, :, y:y_max:S, x:x_max:S]for文の一番内側では、以下の黄色部分を取得していることになります。
あとは、目的の形に変形しておしまいです。
# (N, C, FH, FW, OH, OW) →軸入替→ (N, OH, OW, C, FH, FW) # →形式変換→ (N*OH*CH, C*FH*FW) im_col = im_col.transpose(0, 4, 5, 1, 2, 3) im_col = im_col.reshape(N * out_h * out_w, -1) return im_col5. im2colの後
あとは、フィルタを行列変換し、掛け合わせて、結果の行列を多次元配列に戻します。
要はこういうことです(雑!)。
6. おわりに(蛇足)
im2col本当に難しかったんです、私には…。忘れる前にまとめられてよかったです。
機械学習において、python,numpyの理解は大事やな、と痛感しております。
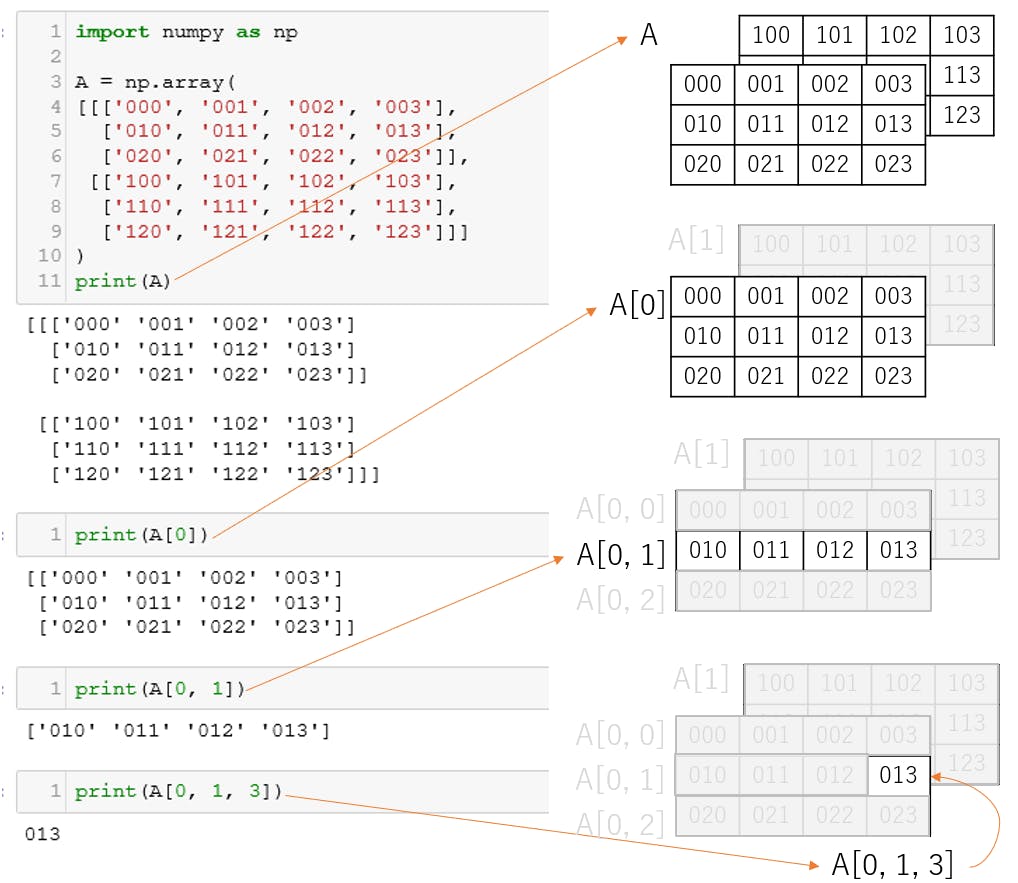
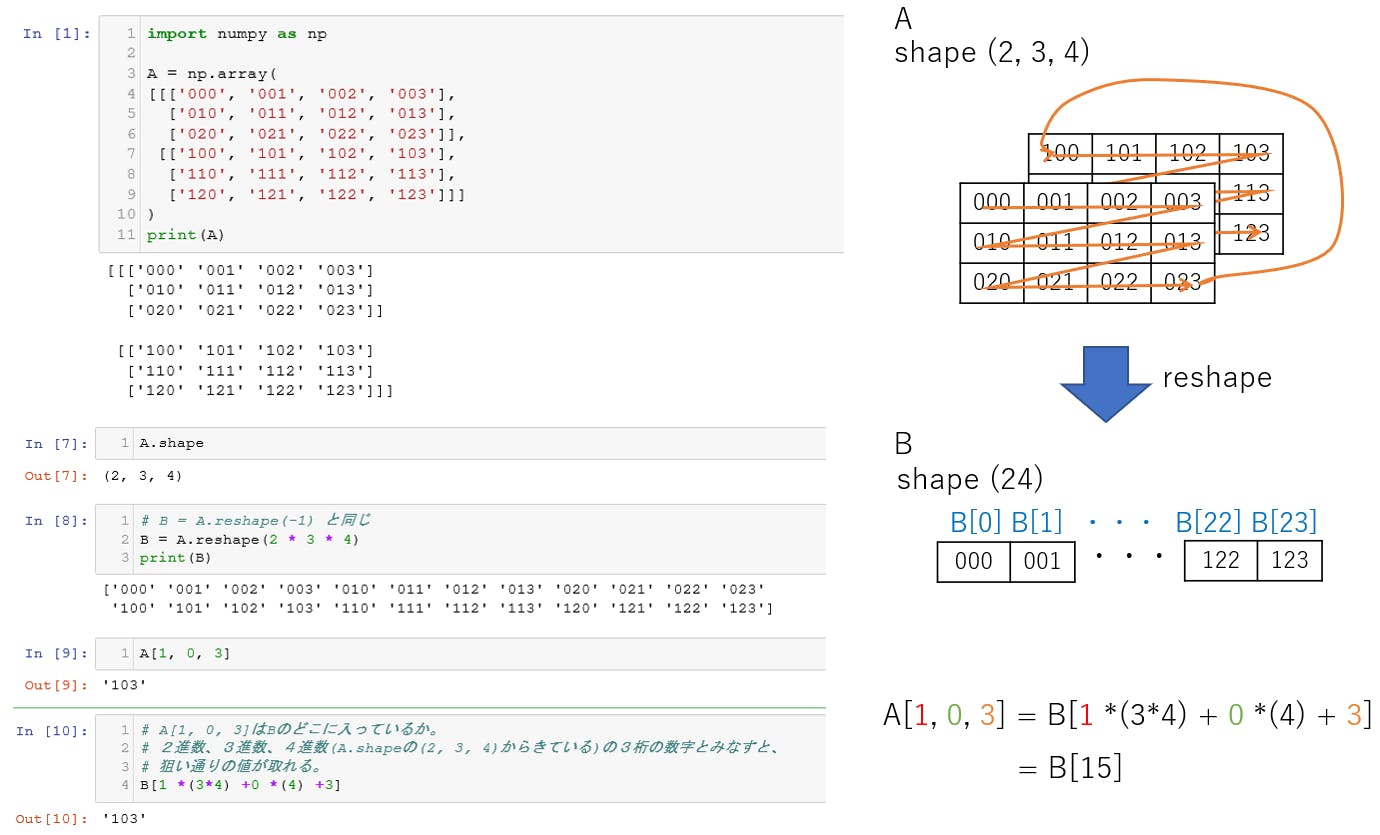
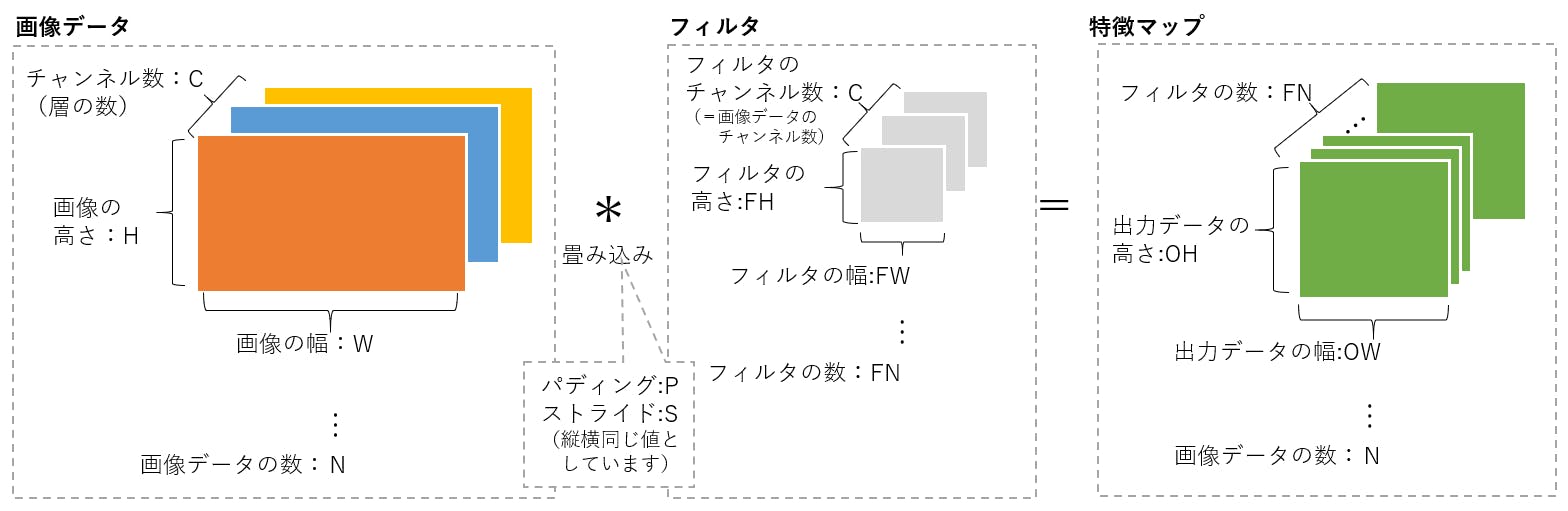
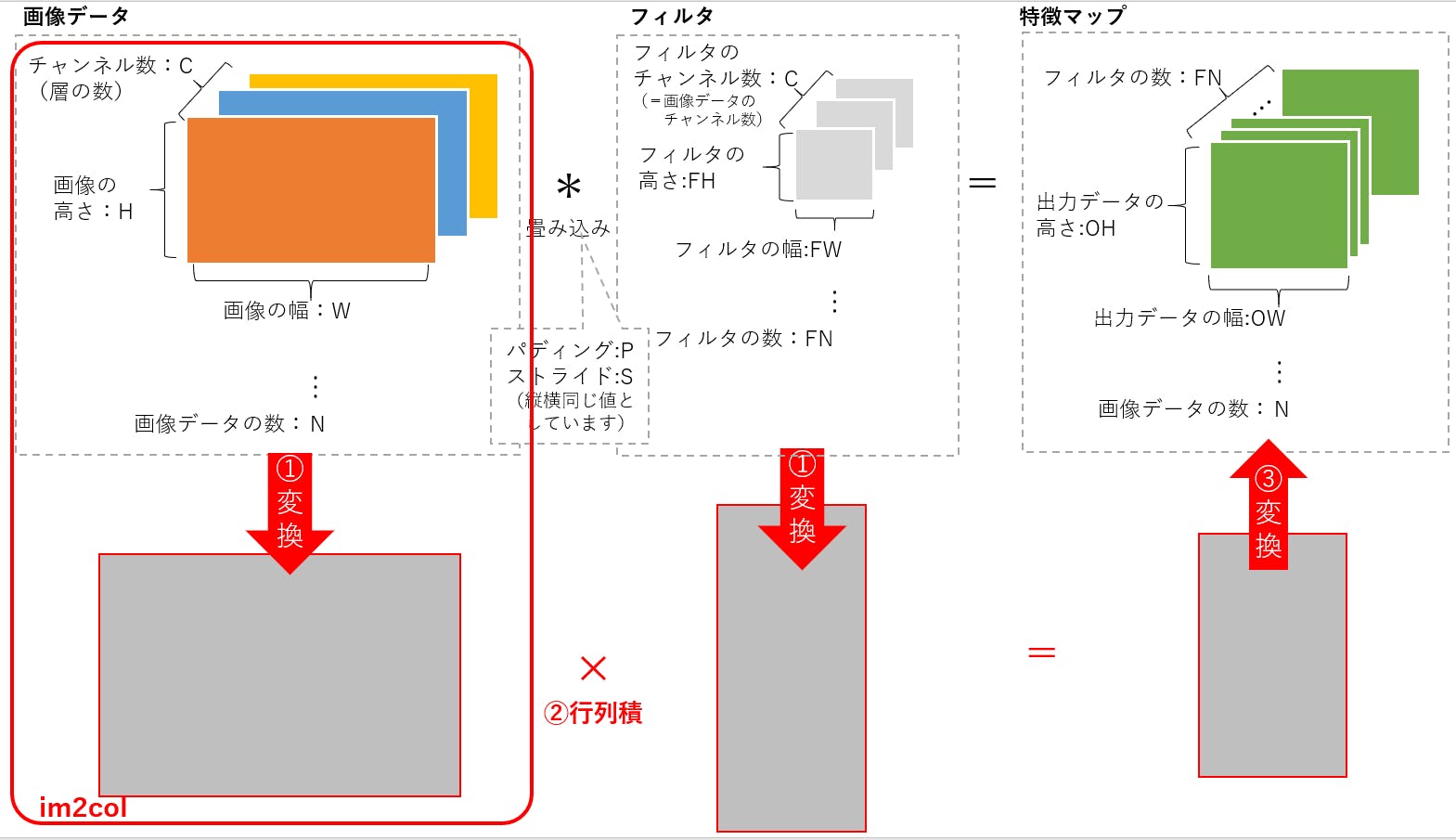
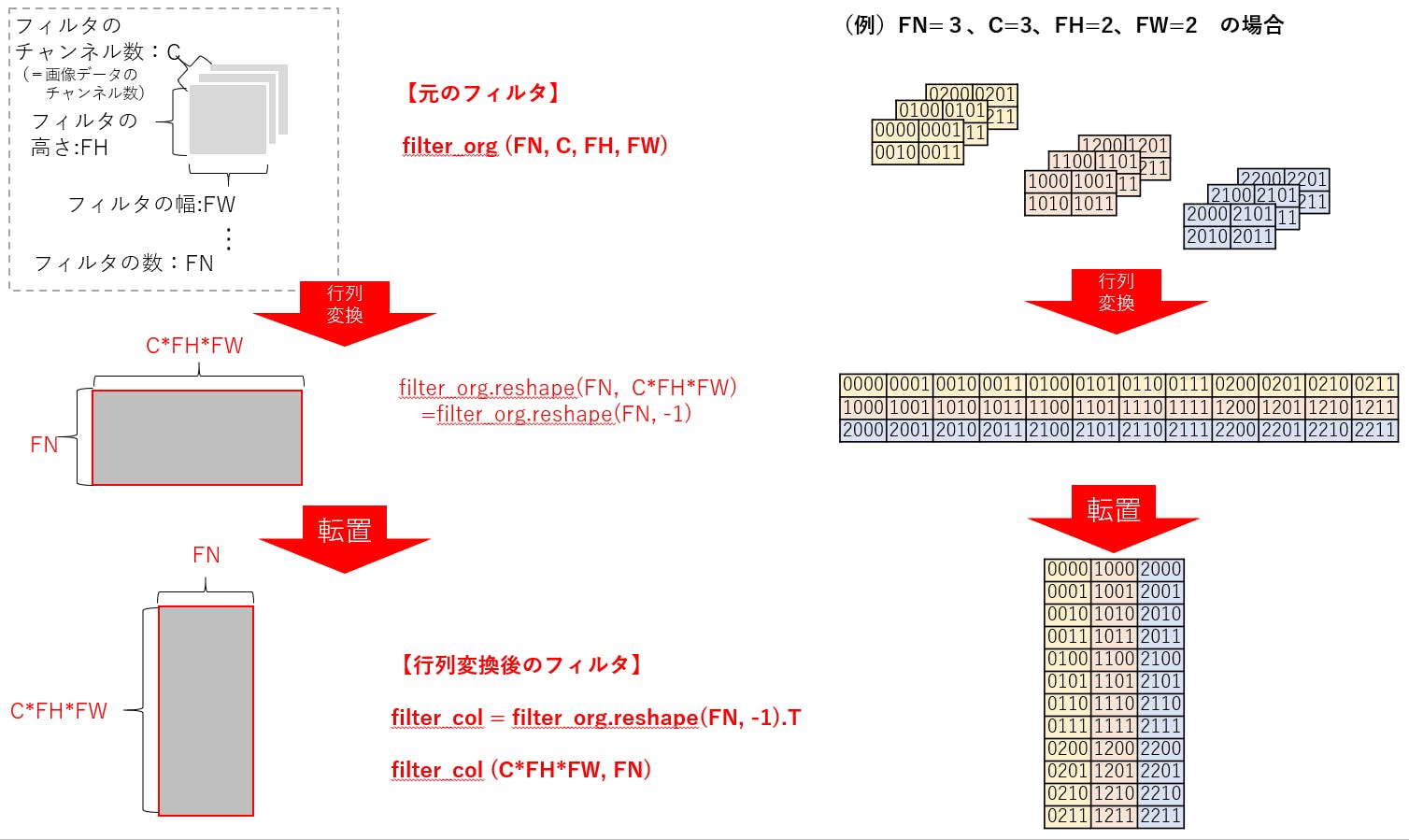
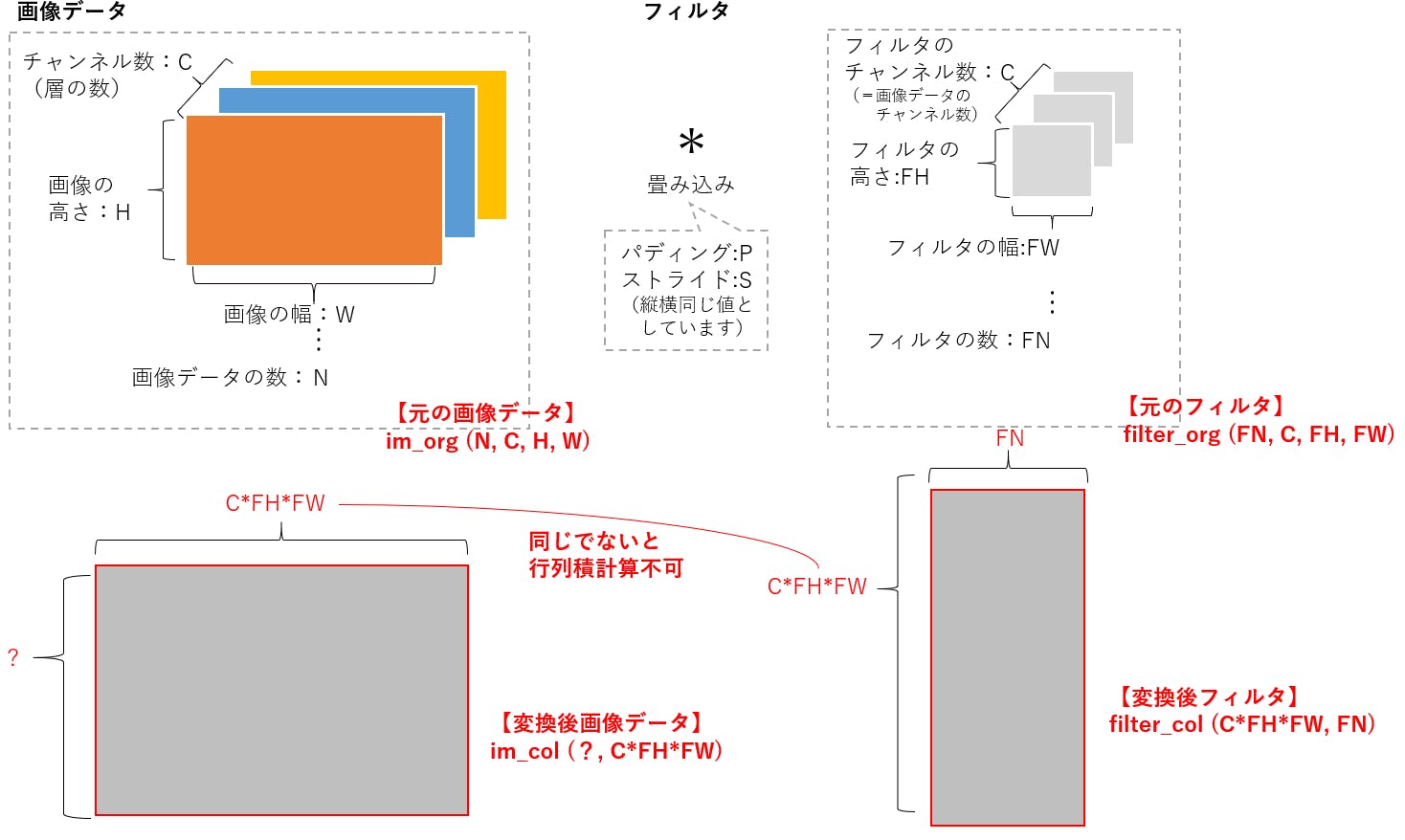
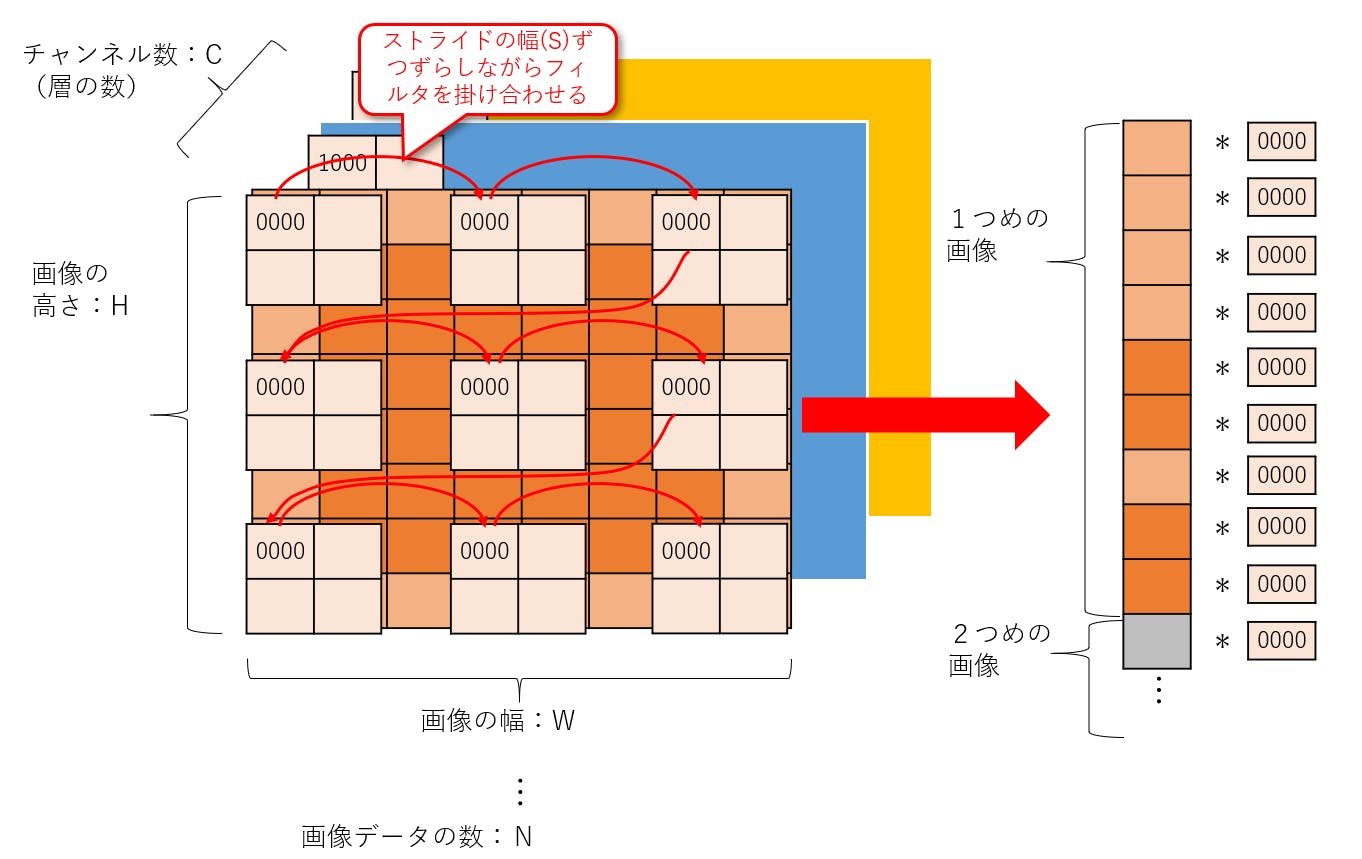
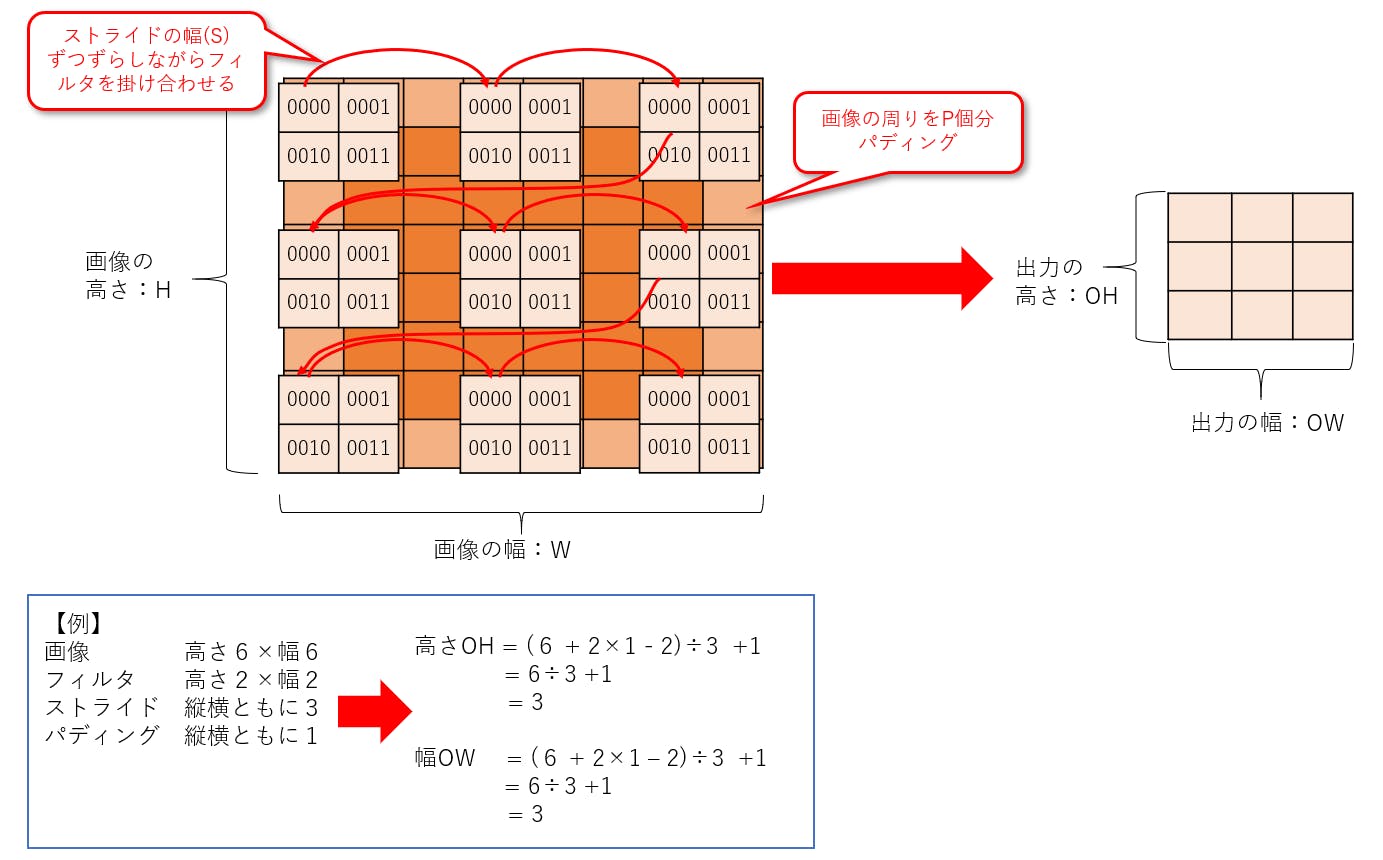
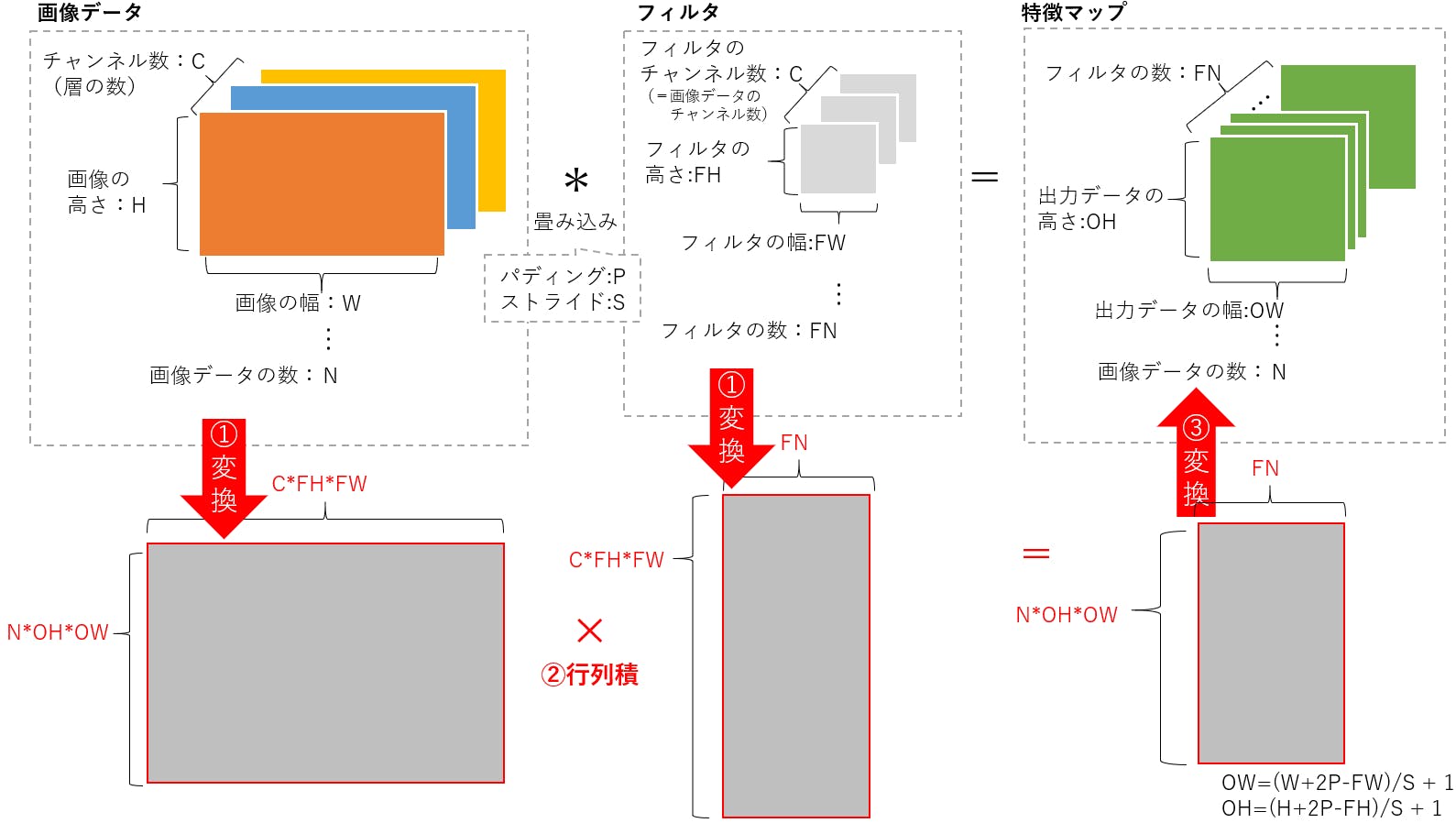
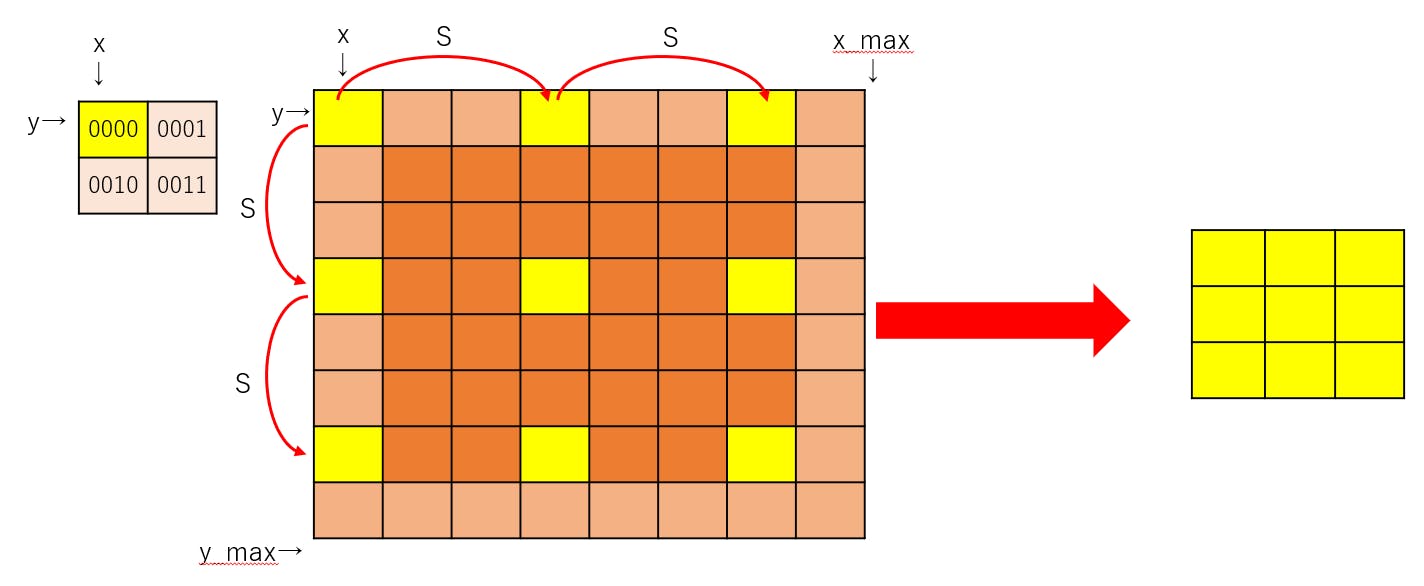
- 投稿日:2019-10-04T03:23:41+09:00
FlaskでAPIを実装し REST Clientからファイルをアップロードした話
TL; DR
Flaskで作ったAPIをREST Clientで叩きました。
環境
Python 3.7
Flask 1.1
VSCode 1.38ディレクトリ構成
/
├ data/
├ __init__.py
├ api.py
├ call.http
├ face.png
└ requirements.txt1. APIの実装(JSONのGET)
FlaskでのAPIの実装マジで簡単。やったぜ。
1-1. 実装
api.pyfrom flask import Flask, jsonify app = Flask(__name__) @app.route('/api/item', methods=['GET']) def get_item(): item = {"item_name": 'hogehoge'} return jsonify(item) if __name__ == '__main__': app.run(debug=True)これだけ。やったぜ。
1-2. 叩く
さっそく試しに叩いてみよう!
......あれよく考えたらあんまり叩き方知らないな?(情弱)1-2-0. REST Client
ググってみたら次の記事を見つけました。
REST Client allows you to send HTTP request and view the response in Visual Studio Code directly.
VSCode上で HTTP リクエストができるとな?便利そう。
早速 REST Client を入れて叩いてみました。1-2-1. Flask起動
$ python api.py * Serving Flask app "api" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: on * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 111-858-1521-2-2. リクエスト
call.http### GET item GET http://localhost:5000/api/itemCmd + Option + R で送信! (Windows は Ctl + Alt + R)
1-2-3. 結果
responseHTTP/1.0 200 OK Content-Type: application/json Content-Length: 30 Server: Werkzeug/0.16.0 Python/3.7.3 Date: Thu, 03 Oct 2019 16:54:12 GMT { "item_name": "hogehoge" }やったぜ。
2. API 実装(ユーザー情報のPOST)
GET はうまくいったので POST も試してみよう。
ということでまずはFlaskでAPIを実装。2-1. 実装
api.pyfrom flask import Flask, jsonify, request import bleach app = Flask(__name__) TOKEN = 'YOUR_TOKEN' @app.route('/api/v1/user', methods=['POST']) def add_user(): # check token header = request.headers.get('Authorization', None) _, token = header.split() if token != TOKEN: return jsonify({'Forbidden': 'Access is denied'}), 403 # method check if request.method != 'POST': return jsonify({'Method Not Allowed': 'Method is invalid.'}), 405 # create new user new_user = {} for key in request.form.keys(): new_user[key] = bleach.clean(request.form.get(key)) return jsonify(new_user) if __name__ == '__main__': app.run(debug=True)これだけ。やったぜ。
ほんとはDBと繋いで new_user を登録したりしたんですけど、今回は割愛。Flask でリクエストを受け取る時は request を使用します。
今回は Content-Type は multipart/form-data で送信するつもりなので、request.form を使用しています。
他にもパラメータを受け取る場合は request.args 、json を受け取る時は request.form を使用します。2-2. 叩く
2-2-1. Flask起動
さっきと同じようにapi.pyを動かしておきましょう。
2-2-2. リクエスト
call.http####### ### POST user info POST http://localhost:5000/api/v1/user Authorization: Bearer YOUR_TOKEN Content-Type: multipart/form-data; boundary=HOGEHOGEBOUNDARY --HOGEHOGEBOUNDARY Content-Disposition: form-data; name=user_name SAKAMOTO RYOMA --HOGEHOGEBOUNDARY Content-Disposition: form-data; name=user_email ryoma.sakamoto@... --HOGEHOGEBOUNDARY--なるほど multipart 形式でPOSTする場合は boundary っていうのを設定するんですね。(情弱)
送信する要素ごとに --{your boundary} を記述して、
要素の最後は --{your boundary}-- で締めくくるんですねぇ。
このへんはRFC7578で規定されていますのでご確認ください。Content-Disposition の name が記述されていますが、これはHTMLの
html<form> <input name="user_name"> </form>と同じです。
2-2-3. 結果
responseHTTP/1.0 200 OK Content-Type: application/json Content-Length: 98 Server: Werkzeug/0.16.0 Python/3.7.3 Date: Thu, 03 Oct 2019 17:24:57 GMT { "user_email": "ryoma.sakamoto@...", "user_name": "SAKAMOTO RYOMA" }やったぜ。無事POSTできましたね。
3. APIの実装(アップロードファイルのPOST)
さて、ようやく本題です。
ユーザー情報送るなら顔写真とかも送れた方が良いよね?そうでもないですか?
ファイルアップロードのAPIって実装めんどくさいよなぁと思ってましたが超簡単でした!
そうFlaskとREST Clientならね。3-1. 実装
api.pyfrom flask import Flask, jsonify, request import bleach app = Flask(__name__) TOKEN = 'YOUR_TOKEN' @app.route('/api/v1/user', methods=['POST']) def add_user(): # check token header = request.headers.get('Authorization', None) _, token = header.split() if token != TOKEN: return jsonify({'Forbidden': 'Access is denied'}), 403 # method check if request.method != 'POST': return jsonify({'Method Not Allowed': 'Method is invalid.'}), 405 # create new user new_user = {} for key in request.form.keys(): new_user[key] = bleach.clean(request.form.get(key)) ### このへん追加 # save uploaded file into data folder for file in request.files: if file is None: break upload_file = request.files.get(file) upload_path = 'data/%s' % upload_file.filename upload_file.save(upload_path) new_user[file] = upload_file.filename return jsonify(new_user) if __name__ == '__main__': app.run(debug=True)これだけ。やったぜ。
Flaskでファイルを受け取る場合、 request.files の中に入っていきます。3-2. 叩く
3-2-1. Flask起動
さっきと同じようにapi.pyを動かしておきましょう。
また、事前に顔写真 face.png を api.py と同じディレクトリに置いておきましょう。3-2-2. リクエスト
call.http####### ### OK POST http://localhost:5000/api/v1/user Authorization: Bearer YOUR_TOKEN Content-Type: multipart/form-data; boundary=HOGEHOGEBOUNDARY --HOGEHOGEBOUNDARY Content-Disposition: form-data; name=user_name SAKAMOTO RYOMA --HOGEHOGEBOUNDARY Content-Disposition: form-data; name=user_email ryoma.sakamoto@... --HOGEHOGEBOUNDARY Content-Disposition: form-data; name="file"; filename="face.png" Content-Type: application/octet-stream < ./face.png --HOGEHOGEBOUNDARY--3-2-3. 結果
responseHTTP/1.0 200 OK Content-Type: application/json Content-Length: 98 Server: Werkzeug/0.16.0 Python/3.7.3 Date: Thu, 03 Oct 2019 18:01:26 GMT { "file": "face.png", "user_email": "ryoma.sakamoto@...", "user_name": "SAKAMOTO RYOMA" }dataフォルダをのぞいてみるとちゃんと face.png が保存されていました!
くぅ疲、これにて目的達成です。やったぜ。感想
ほんとFlask はAPI さくっと書けて優秀だなぁと思います。
情弱の弁解ですが、普段はAPIはJavascriptのAjaxだったり、Pythonのrequestsだったりで叩いているのですが、
curlについて調べているときにREST Clientについて知ったので使ってみた次第です。参考
Qiita
Auth0