- 投稿日:2019-10-01T23:57:36+09:00
Pythonで最大公約数を求めるコーディング
先日のABC142のD問題で、最大公約数を求める必要があった。
愚直にロジックを考えていたのだが、ほかの回答者のソースコードを見たらなんと既存の関数があるではないか。
ということで備忘録。from fractions import gcd
p = gcd(m,n)これだけ。
※なお、gcd = Greatest Common Divisor(最大公約数)とのこと。
- 投稿日:2019-10-01T23:28:40+09:00
メモ「Automate the Boring stuff -chapter4 Lists」
The List Data Type
The term list value refers to the list itself (which is a value that can be stored in a variable or passed to a function like any other value), not the values inside the list value.
Python will give you an IndexError error message if you use an index that exceeds the number of values in your list value.
Indexes can be only integer values, not floats. The following example will cause a TypeError error
>>> spam = [['cat', 'bat'], [10, 20, 30, 40, 50]] >>> spam[0] ['cat', 'bat'] >>> spam[0][1] 'bat' >>> spam[1][4] 50Negative Indexes
- The integer value -1 refers to the last index in a list, the value -2 refers to the second-to-last index in a list, and so on.
Getting Sublists with Slices
In a slice, the first integer is the index where the slice starts.
The second integer is the index where the slice ends.
A slice goes up to, but will not include, the value at the second index.
A slice evaluates to a new list value.
As a shortcut, you can leave out one or both of the indexes on either side of the colon in the slice.
Getting a List’s Length with len()
- The len() function will return the number of values that are in a list value passed to it, just like it can count the number of characters in a string value.
Changing Values in a List with Indexes
>>> spam = ['cat', 'bat', 'rat', 'elephant'] >>> spam[1] = 'aardvark' >>> spam ['cat', 'aardvark', 'rat', 'elephant'] >>> spam[2] = spam[1] >>> spam ['cat', 'aardvark', 'aardvark', 'elephant'] >>> spam[-1] = 12345 >>> spam ['cat', 'aardvark', 'aardvark', 12345]List Concatenation and List Replication
>>> [1, 2, 3] + ['A', 'B', 'C'] [1, 2, 3, 'A', 'B', 'C'] >>> ['X', 'Y', 'Z'] * 3 ['X', 'Y', 'Z', 'X', 'Y', 'Z', 'X', 'Y', 'Z'] >>> spam = [1, 2, 3] >>> spam = spam + ['A', 'B', 'C'] >>> spam [1, 2, 3, 'A', 'B', 'C']Removing Values from Lists with del Statements
>>> spam = ['cat', 'bat', 'rat', 'elephant'] >>> del spam[2] >>> spam ['cat', 'bat', 'elephant'] >>> del spam[2] >>> spam ['cat', 'bat']Working with Lists
catNames = [] while True: print('Enter the name of cat ' + str(len(catNames) + 1) + ' (Or enter nothing to stop.):') name = input() if name == '': break catNames = catNames + [name] # list concatenation print('The cat names are:') for name in catNames: print(' ' + name) Enter the name of cat 1 (Or enter nothing to stop.): Zophie Enter the name of cat 2 (Or enter nothing to stop.): Pooka Enter the name of cat 3 (Or enter nothing to stop.): Simon Enter the name of cat 4 (Or enter nothing to stop.): Lady Macbeth Enter the name of cat 5 (Or enter nothing to stop.): Fat-tail Enter the name of cat 6 (Or enter nothing to stop.): Miss Cleo Enter the name of cat 7 (Or enter nothing to stop.): The cat names are: Zophie Pooka Simon Lady Macbeth Fat-tail Miss Cleo
- catNames = [Zophie, Pooka, Simon, Lady Macbeth, Fat-tail, Miss Cleo]
- catNames contains 6 string values in the list, so the for Loops extract and print the values 6 times.
Using for Loops with Lists
>>> supplies = ['pens', 'staplers', 'flame-throwers', 'binders'] >>> for i in range(len(supplies)): print('Index ' + str(i) + ' in supplies is: ' + supplies[i]) Index 0 in supplies is: pens Index 1 in supplies is: staplers Index 2 in supplies is: flame-throwers Index 3 in supplies is: bindersThe in and not in Operators
myPets = ['Zophie', 'Pooka', 'Fat-tail'] print('Enter a pet name:') name = input() if name not in myPets: print('I do not have a pet named ' + name) else: print(name + ' is my pet.') The output may look something like this: Enter a pet name: Footfoot I do not have a pet named FootfootThe Multiple Assignment Trick
- The multiple assignment trick is a shortcut that lets you assign multiple variables with the values in a list in one line of code.
Instead of doing this: >>> cat = ['fat', 'orange', 'loud'] >>> size = cat[0] >>> color = cat[1] >>> disposition = cat[2] you could type this line of code: >>> cat = ['fat', 'orange', 'loud'] >>> size, color, disposition = catAugmented Assignment Operators
Augmented assignment statement Equivalent assignment statementspam += 1 spam = spam + 1
spam -= 1 spam = spam - 1
spam *= 1 spam = spam * 1
spam /= 1 spam = spam / 1
spam %= 1 spam = spam % 1Methods
A method is the same thing as a function, except it is “called on” a value.
Each data type has its own set of methods. The list data type, for example, has several useful methods for finding, adding, removing, and otherwise manipulating values in a list.
Finding a Value in a List with the index() Method
List values have an index() method that can be passed a value, and if that value exists in the list, the index of the value is returned. If the value isn’t in the list, then Python produces a ValueError error.
When there are duplicates of the value in the list, the index of its first appearance is returned.
Adding Values to Lists with the append() and insert() Methods
>>> spam = ['cat', 'dog', 'bat'] >>> spam.append('moose') >>> spam ['cat', 'dog', 'bat', 'moose']>>> spam = ['cat', 'dog', 'bat'] >>> spam.insert(1, 'chicken') >>> spam ['cat', 'chicken', 'dog', 'bat']
- Methods belong to a single data type. The append() and insert() methods are list methods and can be called only on list values, not on other values such as strings or integers.
Removing Values from Lists with remove()
>>> spam = ['cat', 'bat', 'rat', 'elephant'] >>> spam.remove('bat') >>> spam ['cat', 'rat', 'elephant']
If the value appears multiple times in the list, only the first instance of the value will be removed.
The del statement is good to use when you know the index of the value you want to remove from the list. The remove() method is good when you know the value you want to remove from the list.
Sorting the Values in a List with the sort() Method
>>> spam = [2, 5, 3.14, 1, -7] >>> spam.sort() >>> spam [-7, 1, 2, 3.14, 5] >>> spam = ['ants', 'cats', 'dogs', 'badgers', 'elephants'] >>> spam.sort() >>> spam ['ants', 'badgers', 'cats', 'dogs', 'elephants'] >>> spam.sort(reverse=True) >>> spam ['elephants', 'dogs', 'cats', 'badgers', 'ants'] >>> spam = [1, 3, 2, 4, 'Alice', 'Bob'] >>> spam.sort() Traceback (most recent call last): File "<pyshell#70>", line 1, in <module> spam.sort() TypeError: unorderable types: str() < int() >>> spam = ['Alice', 'ants', 'Bob', 'badgers', 'Carol', 'cats'] >>> spam.sort() >>> spam ['Alice', 'Bob', 'Carol', 'ants', 'badgers', 'cats'] >>> spam = ['a', 'z', 'A', 'Z'] >>> spam.sort(key=str.lower) >>> spam ['a', 'A', 'z', 'Z']Example Program: Magic 8 Ball with a List
List-like Types: Strings and Tuples
Mutable and Immutable Data Types
A list value is a mutable data type: It can have values added, removed, or changed. However, a string is immutable: It cannot be changed.
The proper way to “mutate” a string is to use slicing and concatenation to build a new string by copying from parts of the old string.
The Tuple Data Type
If you need an ordered sequence of values that never changes, use a tuple.
A second benefit of using tuples instead of lists is that, because they are immutable and their contents don’t change, Python can implement some optimizations that make code using tuples slightly faster than code using lists.
Converting Types with the list() and tuple() Functions
>>> tuple(['cat', 'dog', 5]) ('cat', 'dog', 5) >>> list(('cat', 'dog', 5)) ['cat', 'dog', 5] >>> list('hello') ['h', 'e', 'l', 'l', 'o']References
Passing References
When a function is called, the values of the arguments are copied to the parameter variables.
For lists (and dictionaries, which I’ll describe in the next chapter), this means a copy of the reference is used for the parameter.
The copy Module’s copy() and deepcopy() Functions
What exactly is the difference between shallow copy, deepcopy and normal assignment operation?
Summary
Comma Code
https://www.geeksforgeeks.org/iterate-over-a-list-in-python/
```
def takeAListValue(param):
length = len(param) -1
for i in range(length):
param[i] = param[i] + ', '
param[-1] = 'and ' + param[-1]
return paramspam = ['apples', 'bananas', 'tofu', 'cats']
code = ''
for j in takeAListValue(spam):
code = code + jprint(code)
```
- 投稿日:2019-10-01T23:14:33+09:00
Pythonクローリング&スクレイピング 読書録①
はじめに
現在作りたいと思っているWebアプリがあって、そのためにはある分野のWeb上のデータを自動で収集してくる必要があるため、「Pythonクローリング&スクレイピング[増補改訂版]
―データ収集・解析のための実践開発ガイドー」加藤耕太・著を購入した。自分はアウトプット不精なのでこの本を読み進めながら内容をまとめてQiitaに公開していくことにする。
並行してFlaskフレームワークでのWebアプリ開発についてもアウトプットしていけたらと考えている。
サブPCを購入したのでサンプルプログラムはSourceTreeでも使ってメインとサブで共有して行く予定。
第1章 クローリング・スクレイピングとは何か
クローラ
Web上のページの情報を取得するためプログラム。
高速でデータを取得することができるので、使用の際は相手側のサーバへの負荷を考えないといけない。クローリング
Webページのハイパーリンクをたどって次々にWebページをダウンロードする作業。
スクレイピング
ダウンロードしたWebページから必要な情報を抜き出す作業。
Linuxの環境構築
といった概要の説明があったところで、Pythonを使ったクローリング・スクレイピングの前に、Wgetというツールを使ったデータの取得を行うため、Linuxの環境構築が必要となるのだが
注釈にWindows Subsystem for Linux(WSL)を使っている方は、これでUbuntu 18.04を動かしても良いでしょう。ただし本書では検証を行っていないため不具合などが発生してもサポートできません。
とありましたのでじゃあWSLでやってやるか、ということでMicrosoft Storeからダウンロード。
↑WSLでUbuntu18.04を動かしている様子こちらのサイトを参考にして日本語化。結構時間がかかるので注意。
WSLのUbuntu環境を日本語化する:Tech TIPSWgetでクローリング
といったところでWgetを使ってWebサイトをクローリングする項目へ
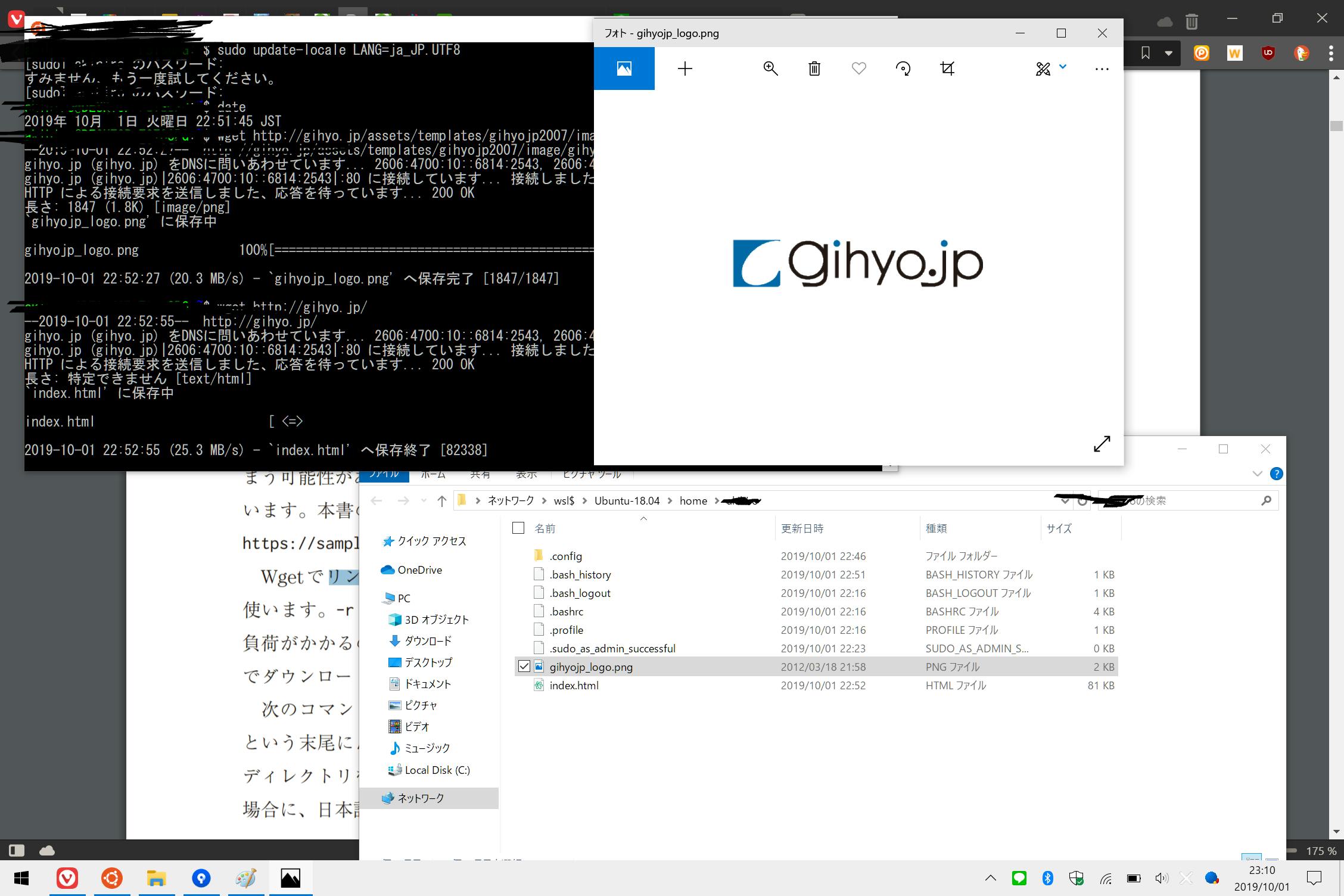
まず最初はこの本の版元の技術評論社からロゴ画像とトップページのデータを取得するというもの。
$ wget <URL>
で取得が可能取得データについては↓
WindowsからLinuxファイルへのアクセスが可能に ~「Windows 10 19H1」におけるWSLの改善
を参考にしexplorer.exe .コマンドでカレントディレクトリをWindowsのエクスプローラーで開いて、きちんと保存されていることを確認。
(続く)
- 投稿日:2019-10-01T22:50:21+09:00
技術書典の本を検索できるアプリを作ってみた~サーバーサイド 編(Python, Go)~
はじめに
この記事は、時間ができた学生が暇つぶしに「技術書典の本を検索できるアプリを作ってみた」というものです。
技術書典に参加する前にある程度購入する本を決めると思うのですが、その際に欲しい技術について書いてある本を探したいと思うはずです。サークル一覧から本を探すのはとても大変で時間が足りません。そこでスクレーピングしてデータ収集し、検索できるアプリを開発してみました(自己満)。
この記事ではサーバーサイドについて書きます。次の記事で「Androidアプリを作ってみた」を書きたいと思います。サーバーサイドの流れ
- Pythonでデータを収集する
I.技術書典のサークルリスト からURL情報を収集する
II. 集めたURLにアクセスしてそれぞれのサークルが出している本の情報を収集する- 収集したデータをDBに保存する
- Goでサーバーを立てる
1. Pythonでデータ収集
I. 技術書典のサークルリスト からURL情報を収集する
技術書典のサークルリストの<a>タグをひたすら保存するコード
collect_url.py# coding: UTF-8 from bs4 import BeautifulSoup from selenium import webdriver import chromedriver_binary from selenium.webdriver.chrome.options import Options # ブラウザのオプションを格納する変数 options = Options() # Headlessモードを有効にする options.set_headless(True) # ブラウザを起動する driver = webdriver.Chrome(chrome_options=options) # ブラウザでアクセスする driver.get("https://techbookfest.org/event/tbf07/circle") # HTMLを文字コードをUTF-8に変換してから取得 html = driver.page_source.encode('utf-8') # BeautifulSoupで扱えるようにパース soup = BeautifulSoup(html, "html.parser") # ファイル出力 file_text = open("url_data.txt", "w") elems = soup.find_all("a") for elem in elems: print(elem.get('href'),file=file_text) file_text.close()II. 集めたURLにアクセスしてそれぞれのサークルが出している本の情報を収集する
1.で集めたURLにアクセスし、
出店しているサークル名、配置場所、ジャンル、ジャンル詳細、サークル画像、出品している本の名前、内容
のデータを収集する。(残念ながらペンネームは集められなかった。html にclass or idを貼って無いから面倒)collect_data.py# coding: UTF-8 from bs4 import BeautifulSoup from selenium import webdriver import chromedriver_binary from selenium.webdriver.chrome.options import Options import pickle import sys # データを保存する i = 0 sys.setrecursionlimit(10000) with open('../data/getData.txt', 'wb') as ff: # 保存するデータ save_datas = [] # ブラウザのオプションを格納する変数 options = Options() # Headlessモードを有効にする options.set_headless(True) # ブラウザを起動する driver = webdriver.Chrome(chrome_options=options) urlHeader = "https://techbookfest.org" pathfile = "../data/url_data.txt" with open(pathfile) as f: for _path in f: i += 1 url = urlHeader + _path print(i,url) # ブラウザでアクセスする driver.get(url) # HTMLを文字コードをUTF-8に変換してから取得 html = driver.page_source.encode('utf-8') # BeautifulSoupで扱えるようにパース soup = BeautifulSoup(html, "html.parser") circle = soup.find(class_="circle-name").string arrange = soup.find(class_="circle-space-label").string genre = soup.find(class_="circle-genre-label").string keyword = soup.find(class_="circle-genre-free-format").string circle_image = soup.find(class_="circle-detail-image").find(class_="ng-star-inserted") book_title = [] for a in soup.find_all(class_="mat-card-title"): book_title.append(a.string) book_content = [] for a in soup.find_all(class_="products-description"): book_content.append(a.string) for title, content in zip(book_title, book_content): data = [circle,circle_image['src'],arrange,genre,keyword,title,content,url] save_datas.append(data) pickle.dump(save_datas,ff)2. 収集したデータをDBに保存する
ファイルに保存したデータを取得し、MySQLにInsertするだけのプログラムです。Insertするだけなので適当なプログラムになってしまった。
insertDB.py# coding: UTF-8 import MySQLdb import pickle # データベースへの接続とカーソルの生成 connection = MySQLdb.connect( host='0.0.0.0', user='user', passwd='password', db='techBook') cursor = connection.cursor() # id, circle, circle_image, arr, genere, keyword, title, content with open('../data/getData.txt','rb') as f: load_datas = pickle.load(f) for load_data in load_datas: data = [] if load_data[6] == None: for dd in load_data: if dd == None: continue dd = dd.replace('\'','') data.append(dd) sql = "INSERT INTO circle (circle, circle_image, arr, genere, keyword, title, circle_url) values ('" + data[0] + "','" + data[1] + "','" + data[2]+"','" + data[3]+"','" + data[4]+"','" + data[5]+"','" + data[6]+"')" else: for dd in load_data: dd = dd.replace('\'','') data.append(dd) sql = "INSERT INTO circle (circle, circle_image, arr, genere, keyword, title, content, circle_url) values ('" + data[0] + "','" + data[1] + "','" + data[2]+"','" + data[3]+"','" + data[4]+"','" + data[5]+"','" + data[6]+"','" + data[7]+"')" print(sql) cursor.execute(sql) # 保存を実行 connection.commit() # 接続を閉じる connection.close()3. Goでサーバーを立てる
Pythonで書いてもよかったのですが、気分的にGoで書きました。
レイアードアーキテクチャで書いています。(宣伝)
ファイル数が多いので全部載せることはできませんでした。Githubを参照ください。
検索はSQLの部分一致検索で行います。SELECT * FROM circle where content like '%swift%';取得したデータをjson形式で返して終わりです!!
[request] { "keyword":"..." } [response] { "result": [ { "CircleURL": "...", "Circle": "...", "CircleImage": "...", "arr": "...", "Genere": "...", "Keyword": "...", "Title": "...", "Content": "..." }, ] }終わりに
久々にPythonを書いた気がします。全体的に書いてて楽しかったです。今回書いたコードはこちら。
読んでいただきありがとうございました。次回のAndroid編をお楽しみに!!
- 投稿日:2019-10-01T22:46:07+09:00
[Tensorflow] Tensorflow 2
Tensorflow 2.0が発表されて、変化点を見る事も楽しいですね。
Kerasを基本に使えるようになって、便利になりますたね。Release 2.0.0
Major Features and Improvements
TensorFlow 2.0 focuses on simplicity and ease of use, featuring updates like:
- Easy model building with Keras and eager execution.
- Robust model deployment in production on any platform.
- Powerful experimentation for research.
- API simplification by reducing duplication and removing deprecated endpoints.
For details on best practices with 2.0, see the Effective 2.0 guide
For information on upgrading your existing TensorFlow 1.x models, please refer to our Upgrade and Migration guides. We have also released a collection of tutorials and getting started guides.
Highlights
- TF 2.0 delivers Keras as the central high level API used to build and train models. Keras provides several model-building APIs such as Sequential, Functional, and Subclassing along with eager execution, for immediate iteration and intuitive debugging, and
tf.data, for building scalable input pipelines. Checkout guide for additional details.- Distribution Strategy: TF 2.0 users will be able to use the
tf.distribute.StrategyAPI to distribute training with minimal code changes, yielding great out-of-the-box performance. It supports distributed training with Keras model.fit, as well as with custom training loops. Multi-GPU support is available, along with experimental support for multi worker and Cloud TPUs. Check out the guide for more details.- Functions, not Sessions. The traditional declarative programming model of building a graph and executing it via a
tf.Sessionis discouraged, and replaced with by writing regular Python functions. Using thetf.functiondecorator, such functions can be turned into graphs which can be executed remotely, serialized, and optimized for performance.- Unification of
tf.train.Optimizersandtf.keras.Optimizers. Usetf.keras.Optimizersfor TF2.0.compute_gradientsis removed as public API, useGradientTapeto compute gradients.- AutoGraph translates Python control flow into TensorFlow expressions, allowing users to write regular Python inside
tf.function-decorated functions. AutoGraph is also applied in functions used with tf.data, tf.distribute and tf.keras APIs.- Unification of exchange formats to SavedModel. All TensorFlow ecosystem projects (TensorFlow Lite, TensorFlow JS, TensorFlow Serving, TensorFlow Hub) accept SavedModels. Model state should be saved to and restored from SavedModels.
- API Changes: Many API symbols have been renamed or removed, and argument names have changed. Many of these changes are motivated by consistency and clarity. The 1.x API remains available in the compat.v1 module. A list of all symbol changes can be found here.
- API clean-up, included removing
tf.app,tf.flags, andtf.loggingin favor of absl-py.- No more global variables with helper methods like
tf.global_variables_initializerandtf.get_global_step.- Add toggles
tf.enable_control_flow_v2()andtf.disable_control_flow_v2()for enabling/disabling v2 control flow.- Enable v2 control flow as part of
tf.enable_v2_behavior()andTF2_BEHAVIOR=1.- Fixes autocomplete for most TensorFlow API references by switching to use relative imports in API
__init__.pyfiles.- Auto Mixed-Precision graph optimizer simplifies converting models to
float16for acceleration on Volta and Turing Tensor Cores. This feature can be enabled by wrapping an optimizer class withtf.train.experimental.enable_mixed_precision_graph_rewrite().- Add environment variable
TF_CUDNN_DETERMINISTIC. Setting toTRUEor "1" forces the selection of deterministic cuDNN convolution and max-pooling algorithms. When this is enabled, the algorithm selection procedure itself is also deterministic.Breaking Changes
- Many backwards incompatible API changes have been made to clean up the APIs and make them more consistent.
Toolchains:
- TensorFlow 1.15 is built using devtoolset7 (GCC7) on Ubuntu 16. This may lead to ABI incompatibilities with extensions built against earlier versions of TensorFlow.
- Tensorflow code now produces 2 different pip packages: tensorflow_core containing all the code (in the future it will contain only the private implementation) and tensorflow which is a virtual pip package doing forwarding to tensorflow_core (and in the future will contain only the public API of tensorflow). We don't expect this to be breaking, unless you were importing directly from the implementation. Removed the
freeze_graphcommand line tool;SavedModelshould be used in place of frozen graphs.
tf.contrib:
tf.contribhas been deprecated, and functionality has been either migrated to the core TensorFlow API, to an ecosystem project such as tensorflow/addons or tensorflow/io, or removed entirely.- Remove
tf.contrib.timeseriesdependency on TF distributions.- Replace contrib references with
tf.estimator.experimental.*for apis inearly_stopping.py.
tf.estimator:
- Premade estimators in the tf.estimator.DNN/Linear/DNNLinearCombined family have been updated to use
tf.keras.optimizersinstead of thetf.compat.v1.train.Optimizers. If you do not pass in anoptimizer=arg or if you use a string, the premade estimator will use the Keras optimizer. This is checkpoint breaking, as the optimizers have separate variables. A checkpoint converter tool for converting optimizers is included with the release, but if you want to avoid any change, switch to the v1 version of the estimator:tf.compat.v1.estimator.DNN/Linear/DNNLinearCombined*.- Default aggregation for canned Estimators is now
SUM_OVER_BATCH_SIZE. To maintain previous default behavior, please passSUMas the loss aggregation method.- Canned Estimators don’t support
input_layer_partitionerarg in the API. If you have this arg, you will have to switch totf.compat.v1 canned Estimators.Estimator.export_savedmodelhas been renamed toexport_saved_model.- When saving to SavedModel, Estimators will strip default op attributes. This is almost always the correct behavior, as it is more forwards compatible, but if you require that default attributes to be saved with the model, please use
tf.compat.v1.Estimator.- Feature Columns have been upgraded to be more Eager-friendly and to work with Keras. As a result,
tf.feature_column.input_layerhas been deprecated in favor oftf.keras.layers.DenseFeatures. v1 feature columns have direct analogues in v2 except forshared_embedding_columns, which are not cross-compatible with v1 and v2. Usetf.feature_column.shared_embeddingsinstead.
tf.keras:
OMP_NUM_THREADSis no longer used by the default Keras config. To configure the number of threads, usetf.config.threadingAPIs.tf.keras.model.save_modelandmodel.savenow defaults to saving a TensorFlow SavedModel. HDF5 files are still supported.- Deprecated
tf.keras.experimental.export_saved_modelandtf.keras.experimental.function. Please usetf.keras.models.save_model(..., save_format='tf')andtf.keras.models.load_modelinstead.- Layers now default to float32, and automatically cast their inputs to the layer's dtype. If you had a model that used float64, it will probably silently use float32 in TensorFlow 2, and a warning will be issued that starts with
Layer <layer-name>is casting an input tensor from dtype float64 to the layer's dtype of float32. To fix, either set the default dtype to float64 withtf.keras.backend.set_floatx('float64'), or passdtype='float64'to each of the Layer constructors. Seetf.keras.layers.Layerfor more information.
tf.lite:
- Removed
lite.OpHint,lite.experimental, andlite.constantfrom 2.0 API.Tensors are no longer hashable, but instead compare element-wise with
==and!=. Usetf.compat.v1.disable_tensor_equality()to return to the previous behavior.Performing equality operations on Tensors or Variables with incompatible shapes an exception is no longer thrown. Instead
__eq__returns False and__ne__returns True.Removed
tf.string_splitfrom v2 API.Deprecated the use of
constraint=and.constraintwith ResourceVariable.Add
UnifiedGRUas the new GRU implementation for tf2.0. Change the default recurrent activation function for GRU fromhard_sigmoidtosigmoid, andreset_afterto True in 2.0. Historically recurrent activation ishard_sigmoidsince it is fast than 'sigmoid'. With new unified backend between CPU and GPU mode, since the CuDNN kernel is using sigmoid, we change the default for CPU mode to sigmoid as well. With that, the default GRU will be compatible with both CPU and GPU kernel. This will enable user with GPU to use CuDNN kernel by default and get a 10x performance boost in training. Note that this is checkpoint breaking change. If user want to use their 1.x pre-trained checkpoint, please construct the layer with GRU(recurrent_activation='hard_sigmoid', reset_after=False) to fallback to 1.x behavior.
CUDNN_INSTALL_PATH,TENSORRT_INSTALL_PATH,NCCL_INSTALL_PATH,NCCL_HDR_PATHare deprecated. UseTF_CUDA_PATHSinstead which supports a comma-separated list of base paths that are searched to find CUDA libraries and headers.Refer to our public project status tracker and issues tagged with
2.0on GitHub for insight into recent issues and development progress.If you experience any snags when using TF 2.0, please let us know at the TF 2.0 Testing User Group. We have a support mailing list as well as weekly testing meetings, and would love to hear your migration feedback and questions.
Bug Fixes and Other Changes
tf.contrib:
- Expose
tf.contrib.proto.*ops intf.io(they will exist in TF2)
tf.data:
- Add support for TensorArrays to
tf.data Dataset.- Integrate Ragged Tensors with
tf.data.- All core and experimental tf.data transformations that input user-defined functions can span multiple devices now.
- Extending the TF 2.0 support for
shuffle(..., reshuffle_each_iteration=True)andcache()to work across different Python iterators for the same dataset.- Removing the
experimental_numa_awareoption fromtf.data.Options.- Add
num_parallel_readsand passing in a Dataset containing filenames intoTextLineDatasetandFixedLengthRecordDataset.- Add support for defaulting the value of
cycle_lengthargument oftf.data.Dataset.interleaveto the number of schedulable CPU cores.- Promoting
tf.data.experimental.enumerate_datasetto core astf.data.Dataset.enumerate.- Promoting
tf.data.experimental.unbatchto core astf.data.Dataset.unbatch.- Adds option for introducing slack in the pipeline to reduce CPU contention, via
tf.data.Options().experimental_slack = True- Added experimental support for parallel batching to
batch()andpadded_batch(). This functionality can be enabled throughtf.data.Options().- Support cancellation of long-running
reduce.- Now we use
datasetnode name as prefix instead of the op name, to identify the component correctly in metrics, for pipelines with repeated components.- Improve the performance of datasets using
from_tensors().- Promoting
unbatchfrom experimental to core API.- Adding support for datasets as inputs to
from_tensorsandfrom_tensor_slicesand batching and unbatching of nested datasets.
tf.distribute:
- Enable
tf.distribute.experimental.MultiWorkerMirroredStrategyworking in eager mode.- Callbacks are supported in
MultiWorkerMirroredStrategy.- Disable
run_eagerlyand distribution strategy if there are symbolic tensors added to the model usingadd_metricoradd_loss.- Loss and gradients should now more reliably be correctly scaled w.r.t. the global batch size when using a
tf.distribute.Strategy.- Set default loss reduction as
AUTOfor improving reliability of loss scaling with distribution strategy and custom training loops.AUTOindicates that the reduction option will be determined by the usage context. For almost all cases this defaults toSUM_OVER_BATCH_SIZE. When used in distribution strategy scope, outside of built-in training loops such astf.kerascompileandfit, we expect reduction value to be 'None' or 'SUM'. Using other values will raise an error.- Support for multi-host
ncclAllReducein Distribution Strategy.
tf.estimator:
- Replace
tf.contrib.estimator.add_metricswithtf.estimator.add_metrics- Use
tf.compat.v1.estimator.inputsinstead oftf.estimator.inputs- Replace contrib references with
tf.estimator.experimental.*for apis in early_s in Estimator- Canned Estimators will now use keras optimizers by default. An error will be raised if tf.train.Optimizers are used, and you will have to switch to tf.keras.optimizers or tf.compat.v1 canned Estimators.
- A checkpoint converter for canned Estimators has been provided to transition canned Estimators that are warm started from
tf.train.Optimizerstotf.keras.optimizers.- Losses are scaled in canned estimator v2 and not in the optimizers anymore. If you are using Estimator + distribution strategy + optimikzer v1 then the behavior does not change. This implies that if you are using custom estimator with optimizer v2, you have to scale losses. We have new utilities to help scale losses
tf.nn.compute_average_loss,tf.nn.scale_regularization_loss.
tf.keras:
- Premade models (including Linear and WideDeep) have been introduced for the purpose of replacing Premade estimators.
- Model saving changes
model.saveandtf.saved_model.savemay now save to the TensorFlow SavedModel format. The model can be restored usingtf.keras.models.load_model. HDF5 files are still supported, and may be used by specifyingsave_format="h5"when saving.- Raw TensorFlow functions can now be used in conjunction with the Keras Functional API during model creation. This obviates the need for users to create Lambda layers in most cases when using the Functional API. Like Lambda layers, TensorFlow functions that result in Variable creation or assign ops are not supported.
- Add support for passing list of lists to the
metricsargument in Kerascompile.- Add
tf.keras.layers.AbstractRNNCellas the preferred implementation for RNN cells in TF v2. User can use it to implement RNN cells with custom behavior.- Keras training and validation curves are shown on the same plot when using the TensorBoard callback.
- Switched Keras
fit/evaluate/predictexecution to use only a single unified path by default unless eager execution has been explicitly disabled, regardless of input type. This unified path places an eager-friendly training step inside of atf.function. With this- All input types are converted to
Dataset.- The path assumes there is always a distribution strategy. when distribution strategy is not specified the path uses a no-op distribution strategy.
- The training step is wrapped in
tf.functionunlessrun_eagerly=Trueis set in compile. The single path execution code does not yet support all use cases. We fallback to the existing v1 execution paths if your model contains the following:
sample_weight_modein compileweighted_metricsin compile- v1 optimizer
- target tensors in compile If you are experiencing any issues because of this change, please inform us (file an issue) about your use case and you can unblock yourself by setting
experimental_run_tf_function=Falsein compile meanwhile. We have seen couple of use cases where the model usage pattern is not as expected and would not work with this change.- output tensors of one layer is used in the constructor of another.
- symbolic tensors outside the scope of the model are used in custom loss functions. The flag can be disabled for these cases and ideally the usage pattern will need to be fixed.
- Mark Keras
set_sessionascompat.v1only.tf.keras.estimator.model_to_estimatornow supports exporting totf.train.Checkpoint format, which allows the saved checkpoints to be compatible withmodel.load_weights.keras.backend.resize_images(and consequently,keras.layers.Upsampling2D) behavior has changed, a bug in the resizing implementation was fixed.- Add an
implementation=3mode fortf.keras.layers.LocallyConnected2Dandtf.keras.layers.LocallyConnected1Dlayers usingtf.SparseTensorto store weights, allowing a dramatic speedup for large sparse models.- Raise error if
batch_sizeargument is used when input is dataset/generator/keras sequence.- Update TF 2.0
keras.backend.name_scopeto use TF 2.0name_scope.- Add v2 module aliases for losses, metrics, initializers and optimizers:
tf.losses = tf.keras.losses&tf.metrics = tf.keras.metrics&tf.initializers = tf.keras.initializers&tf.optimizers = tf.keras.optimizers.- Updates binary cross entropy logic in Keras when input is probabilities. Instead of converting probabilities to logits, we are using the cross entropy formula for probabilities.
- Added public APIs for
cumsumandcumprodkeras backend functions.- Add support for temporal sample weight mode in subclassed models.
- Raise
ValueErrorif an integer is passed to the training APIs.- Added fault-tolerance support for training Keras model via
model.fit()withMultiWorkerMirroredStrategy, tutorial available.- Custom Callback tutorial is now available.
- To train with
tf.distribute, Keras API is recommended over estimator.steps_per_epochandstepsarguments are supported with numpy arrays.- New error message when unexpected keys are used in sample_weight/class_weight dictionaries
- Losses are scaled in Keras compile/fit and not in the optimizers anymore. If you are using custom training loop, we have new utilities to help scale losses
tf.nn.compute_average_loss,tf.nn.scale_regularization_loss.Layerapply and add_variable APIs are deprecated.- Added support for channels first data format in cross entropy losses with logits and support for tensors with unknown ranks.
- Error messages will be raised if
add_update,add_metric,add_loss, activity regularizers are used inside of a control flow branch.- New loss reduction types:
AUTO: Indicates that the reduction option will be determined by the usage context. For almost all cases this defaults toSUM_OVER_BATCH_SIZE. When used withtf.distribute.Strategy, outside of built-in training loops such astf.kerascompileandfit, we expect reduction value to beSUMorNONE. UsingAUTOin that case will raise an error.NONE: Weighted losses with one dimension reduced (axis=-1, or axis specified by loss function). When this reduction type used with built-in Keras training loops likefit/evaluate, the unreduced vector loss is passed to the optimizer but the reported loss will be a scalar value.SUM: Scalar sum of weighted losses. 4.SUM_OVER_BATCH_SIZE: ScalarSUMdivided by number of elements in losses. This reduction type is not supported when used withtf.distribute.Strategyoutside of built-in training loops liketf.kerascompile/fit.- Wraps losses passed to the
compileAPI (strings and v1 losses) which are not instances of v2Lossclass inLossWrapperclass. => All losses will now useSUM_OVER_BATCH_SIZEreduction as default.model.add_loss(symbolic_tensor)should work in ambient eager.- Update metric name to always reflect what the user has given in compile. Affects following cases
- When name is given as 'accuracy'/'crossentropy'
- When an aliased function name is used eg. 'mse'
- Removing the
weightedprefix from weighted metric names.- Allow non-Tensors through v2 losses.
- Add v2 sparse categorical crossentropy metric.
- Add v2 APIs for
AUCCurveandAUCSummationMethodenums.add_updatecan now be passed a zero-arg callable in order to support turning off the update when settingtrainable=Falseon a Layer of a Model compiled withrun_eagerly=True.- Standardize the LayerNormalization API by replacing the args
norm_axisandparams_axiswithaxis.- Fixed critical bugs that help with DenseFeatures usability in TF2
tf.lite:
- Added evaluation script for
COCOminival- Add delegate support for
QUANTIZE.- Add
GATHERsupport to NN API delegate.- Added support for TFLiteConverter Python API in 2.0. Contains functions from_saved_model, from_keras_file, and from_concrete_functions.
- Add
EXPAND_DIMSsupport to NN API delegate TEST.- Add
narrow_rangeattribute to QuantizeAndDequantizeV2 and V3.- Added support for
tflite_convertcommand line tool in 2.0.- Post-training quantization tool supports quantizing weights shared by multiple operations. The models made with versions of this tool will use INT8 types for weights and will only be executable interpreters from this version onwards.
- Post-training quantization tool supports fp16 weights and GPU delegate acceleration for fp16.
- Add delegate support for
QUANTIZED_16BIT_LSTM.- Extracts
NNAPIDelegateKernelfrom nnapi_delegate.ccTensorRT
- Add TensorFlow 2.0-compatible
TrtGraphConverterV2API for TensorRT conversion. TensorRT initialization arguments are now passed wrapped in a named-tuple,TrtConversionParams, rather than as separate arguments as inTrtGraphConverter.- Changed API to optimize TensorRT enginges during graph optimization. This is now done by calling
converter.build()where previouslyis_dynamic_op=Falsewould be set.converter.convert()no longer returns atf.function. Now the funtion must be accessed from the saved model.- The
converter.calibrate()method has been removed. To trigger calibration, acalibration_input_fnshould be provided toconverter.convert().Other:
- Fix accidental quadratic graph construction cost in graph-mode
tf.gradients().- ResourceVariable's gather op supports batch dimensions.
- ResourceVariable support for
gather_nd.ResourceVariableandVariableno longer acceptsconstraintin the constructor, nor expose it as a @property.- Added gradient for
SparseToDenseop.- Expose a flag that allows the number of threads to vary across Python benchmarks.
image.resizein 2.0 now supports gradients for the new resize kernels.image.resizenow considers proper pixel centers and has new kernels (incl. anti-aliasing).- Renamed
tf.imagefunctions to remove duplicate "image" where it is redundant.- Variadic reduce is supported on CPU Variadic reduce is supported on CPU
- Remove unused
StringViewVariantWrapper.- Delete unused
Fingerprint64Mapop registration- Add broadcasting support to
tf.matmul.- Add C++ Gradient for
BatchMatMulV2.- Add
tf.math.cumulative_logsumexpoperation.- Add ellipsis (...) support for
tf.einsum().- Add expand_composites argument to all
nest.*methods.- Added
strings.byte_split.- Add a new "result_type" parameter to
tf.strings.split.- Add name argument to
tf.string_splitandtf.strings_split.- Extend
tf.strings.splitto support inputs with any rank.- Added
tf.random.binomial.- Added
keyandskipmethods torandom.experimental.Generator.- Extend
tf.functionwith basic support for CompositeTensors arguments (such asSparseTensorandRaggedTensor).parallel_for.pfor: add converters for Softmax, LogSoftmax, IsNaN, All, Any, and MatrixSetDiag.parallel_for: add converters for LowerTriangularSolve and Cholesky.parallel_for: add converters forLogMatrixDeterminantandMatrixBandPart.parallel_for: Add converter forMatrixDiag.parallel_for: Add converters forOneHot,LowerBound,UpperBound.parallel_for: add converter forBroadcastTo.- Add
pforconverter forSqueeze.- Add
RaggedTensor.placeholder().- Add ragged tensor support to
tf.squeeze.- Update RaggedTensors to support int32 row_splits.
- Allow
LinearOperator.solveto take aLinearOperator.- Allow all dtypes for
LinearOperatorCirculant.- Introduce MaxParallelism method
- Add
LinearOperatorHouseholder.- Adds Philox support to new stateful RNG's XLA path.
- Added
TensorSpecsupport for CompositeTensors.- Added
tf.linalg.tridiagonal_solveop.- Added partial_pivoting input parameter to
tf.linalg.tridiagonal_solve.- Added gradient to
tf.linalg.tridiagonal_solve.- Added
tf.linalg.tridiagonal_mul op.- Added GPU implementation of
tf.linalg.tridiagonal_matmul.- Added
LinearOperatorToeplitz.- Upgraded LIBXSMM to version 1.11.
- Uniform processing of quantized embeddings by Gather and EmbeddingLookup Ops.
- Correct a misstatement in the documentation of the sparse softmax cross entropy logit parameter.
- Add
tf.ragged.boolean_mask.tf.switch_caseadded, which selects a branch_fn based on a branch_index.- The C++ kernel of gather op supports batch dimensions.
- Fixed default value and documentation for
trainablearg of tf.Variable.EagerTensornow supports numpy buffer interface for tensors.- This change bumps the version number of the
FullyConnectedOp to 5.- Added new op:
tf.strings.unsorted_segment_join.- Added HW acceleration support for
topK_v2.- CloudBigtable version updated to v0.10.0 BEGIN_PUBLIC CloudBigtable version updated to v0.10.0.
- Expose
Headas public API.- Added
tf.sparse.from_denseutility function.- Improved ragged tensor support in
TensorFlowTestCase.- Added a function
nested_value_rowidsfor ragged tensors.- Added
tf.ragged.stack.- Makes the a-normal form transformation in Pyct configurable as to which nodes are converted to variables and which are not.
ResizeInputTensornow works for all delegates.tf.condemits a StatelessIf op if the branch functions are stateless and do not touch any resources.- Add support of local soft device placement for eager op.
- Pass partial_pivoting to the
_TridiagonalSolveGrad.- Add HW acceleration support for
LogSoftMax.- Add guard to avoid acceleration of L2 Normalization with input rank != 4
- Fix memory allocation problem when calling
AddNewInputConstantTensor.- Delegate application failure leaves interpreter in valid state
tf.while_loopemits a StatelessWhile op if the cond and body functions are stateless and do not touch any resources.tf.cond,tf.whileand if and while in AutoGraph now accept a nonscalar predicate if has a single element. This does not affect non-V2 control flow.- Fix potential security vulnerability where decoding variant tensors from proto could result in heap out of bounds memory access.
- Only create a GCS directory object if the object does not already exist.
- Introduce
dynamicconstructor argument in Layer and Model, which should be set toTruewhen using imperative control flow in thecallmethod.- Begin adding Go wrapper for C Eager API.
- XLA HLO graphs can be inspected with interactive_graphviz tool now.
- Add dataset ops to the graph (or create kernels in Eager execution) during the python Dataset object creation instead doing it during Iterator creation time.
- Add
batch_dimsargument totf.gather.- The behavior of
tf.gatheris now correct whenaxis=Noneandbatch_dims<0.- Update docstring for gather to properly describe the non-empty
batch_dimscase.- Removing of dtype in the constructor of initializers and partition_info in call.
- Add
tf.math.nextafterop.- Turn on MKL-DNN contraction kernels by default. MKL-DNN dynamically dispatches the best kernel implementation based on CPU vector architecture. To disable them, build with
--define=tensorflow_mkldnn_contraction_kernel=0.tf.linspace(start, stop, num)now always uses "stop" as last value (for num > 1)- Added top-k to precision and recall to keras metrics.
- Add a ragged size op and register it to the op dispatcher
- Transitive dependencies on :
pooling_opswere removed. Some users may need to add explicit dependencies on :pooling_opsif they reference the operators from that library.- Add
CompositeTensorbase class.- Malformed gif images could result in an access out of bounds in the color palette of the frame. This has been fixed now
- Add templates and interfaces for creating lookup tables
Tensor::UnsafeCopyFromInternaldeprecated in favorTensor::BitcastFrom.- In
map_vectorizationoptimization, reduce the degree of parallelism in the vectorized map node.- Add variant wrapper for
absl::string_view.- Add OpKernels for some stateless maps.
- DType is no longer convertible to an int. Use
dtype.as_datatype_enuminstead ofint(dtype)to get the same result.- Support both binary and -1/1 label input in v2 hinge and squared hinge losses.
- Added
LinearOperator.adjointandLinearOperator.H(alias).- Expose CriticalSection in core as
tf.CriticalSection.- Enhanced graphviz output.
- Add opkernel templates for common table operations.
- Fix callbacks do not log values in eager mode when a deferred build model is used.
SignatureDefutil functions have been deprecated.- Update
Fingerprint64Mapto use aliases- Add legacy string flat hash map op kernels.
- Add support for
add_metricin the graph function mode.- Updating cosine similarity loss - removed the negate sign from cosine similarity.
- Changed default for gradient accumulation for TPU embeddings to true.
- Adds summary trace API for collecting graph and profile information.
- The
precision_modeargument toTrtGraphConverteris now case insensitive.
- 投稿日:2019-10-01T22:43:39+09:00
Mac購入からPython環境を整える
概要
Pythonの開発環境を整える。
環境
MacOS Mojava 10.14.5
git hub 2.23.0手順
- pyenvのインストール
- anacondaのインストール
- anacondaの仮想環境を構築
pyenvのインストール
公式を参照した。
$ git clone https://github.com/pyenv/pyenv.git ~/.pyenv
- パスの設定
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile
- pyenvのおまじない
$ echo -e 'if command -v pyenv 1>/dev/null 2>&1; then\n eval "$(pyenv init -)"\nfi' >> ~/.bash_profile
- シェルの再起動
$ exec "$SHELL"anacondaのインストール
$ pyenv install anaconda3-5.3.0$ pyenv global anaconda3-5.3.0
.bashrcにanacondaの設定を付け足す。#for anaconda3-5.3.0 . ~/.pyenv/versions/anaconda3-5.3.0/etc/profile.d/conda.shanacondaの仮想環境を構築
$ conda create -n temp python=3.7 numpy matplotlib pandas jupyter
- activate
$ conda activate temp
- pythonのバージョン確認
(temp)$ python -V python 3.7.4最後に
これで最低限の環境は整ったと思います。あとはJupyterの環境も整えて万全ですね。
- 投稿日:2019-10-01T22:00:02+09:00
Djangoのプロジェクト途中からDBを消さずにカスタムユーザーモデルへ変更する
はじめに
業務の関係上新たにDjangoのユーザーモデルをカスタムする必要が生じたので調べてみるとプロジェクトの途中からは変更するのが難しいという情報が……
Djangoの公式ページですら以下のような調子です。
プロジェクト途中からのカスタムユーザーモデルへの変更
AUTH_USER_MODEL をデータベーステーブルの作成後に変更することは、たとえば、外部キーや多対多の関係に影響するため、非常に困難となります。この変更は自動的には行うことができません。手動でのスキーマ修正、古いユーザーテーブルからのデータ移動、一部のマイグレーションの手動による再適用をする必要があります。ステップの概要は #25313 を参照してください。
……
一番簡単な方法はDBを消して再マイグレーションすることですが、
もう既に稼働中のDBを消すのは無理……という状況だったので上記のDjango公式ページで紹介された#25313の方法を試してなんとかDBを消さずに済みました。
基本的には、この手順に従っていればできるのですが、手順がざっくりしているのと私のマイグレーションの知識が乏しかったせいで色々苦労したのでこの記事でまとめます。目次
手順
#25313で書かれている手順(原文)は以下の通りです。
- Create a custom user model identical to auth.User, call it User (so many-to-many tables keep the same name) and set db_table='auth_user' (so it uses the same table)
- Throw away all your migrations
- Recreate a fresh set of migrations
- Sacrifice a chicken, perhaps two if you're anxious; also make a backup of your database
- Truncate the django_migrations table
- Fake-apply the new set of migrations
- Unset db_table, make other changes to the custom model, generate migrations, apply them
これでふーんなるほど分かったぜ、という人はこの記事でなく元の文書を見てみた方がいいです。
ちなみに私は初見全く意味が分かりませんでした…
上記の内容をもうちょっと補足してまとめると以下のようになります。
- 組み込みユーザモデルauth.UserがDBに登録する時に使用するテーブル名
auth_userと同じテーブル名に登録するようなカスタムユーザーモデルを作成- 既にある全てのmigrationsを削除する
- migrationsの新しいセットを再作成
- DBバックアップ
- DB内のdjango_migrationsテーブルのデータを削除する
- migrationsの新しいセットを
--fake-initialオプションを付けてマイグレーション- カスタムユーザーの登録するテーブル名を
auth_userにするの設定部分を削除し、カスタムユーザーモデルに任意の変更を加え、migrationsを作成&適用これ以降は、Djangoのバージョンが 2.2 で以下のようなプロジェクトがあるという想定で手順の詳細をまとめていきます。
(プロジェクト内容はDjango girlsのパクリです。)djangogirls ├── blog │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ └── __init__.py │ ├── models.py │ ├── tests.py | ├── urls.py │ └── views.py ├── db.sqlite3 ├── manage.py └── mysite ├── __init__.py ├── settings.py ├── urls.py └── wsgi.py$ python manage.py showmigrations admin [X] 0001_initial [X] 0002_logentry_remove_auto_add [X] 0003_logentry_add_action_flag_choices auth [X] 0001_initial [X] 0002_alter_permission_name_max_length [X] 0003_alter_user_email_max_length [X] 0004_alter_user_username_opts [X] 0005_alter_user_last_login_null [X] 0006_require_contenttypes_0002 [X] 0007_alter_validators_add_error_messages [X] 0008_alter_user_username_max_length [X] 0009_alter_user_last_name_max_length blog [X] 0001_initial [X] 0002_post_author contenttypes [X] 0001_initial [X] 0002_remove_content_type_name sessions [X] 0001_initial組み込みユーザモデルと同一テーブルを使用するカスタムユーザーモデルを作成
ユーザモデルに関する前知識
この手順を説明する前に知っているとなんとなくやっている内容が分かると思うのでちょっとだけユーザーモデルについて説明します。
(手っ取り早く手順だけ知りたい!という人は仮のカスタムユーザーモデル作成へ)
そもそもDjangoのユーザーモデルは、django.contrib.authのAUTH_USER_MODELで設定されたモデルをUserモデルとして使用するようになっており、
このAUTH_USER_MODELは、デフォルトではauth.Userになっています。このUserモデル定義はmanage.pyのinspectdbのオプションでみることができます。
$ python manage.py inspectdb ... class AuthUser(models.Model): password = models.CharField(max_length=128) last_login = models.DateTimeField(blank=True, null=True) is_superuser = models.BooleanField() username = models.CharField(unique=True, max_length=150) first_name = models.CharField(max_length=30) email = models.CharField(max_length=254) is_staff = models.BooleanField() is_active = models.BooleanField() date_joined = models.DateTimeField() last_name = models.CharField(max_length=150) class Meta: managed = False db_table = 'auth_user'プロジェクトの途中でカスタムユーザーに変更することが困難なのは、初回のマイグレーション時(0001)にこの
AuthUserモデルを他のDjangoの組み込みモデルが外部キーとして登録してしまうことが原因となっています。
ここで注目するポイントは上記のMetaクラスに含まれているdb_tableです。
このdb_tableは、モデルをDBに登録する時のテーブル名を表しています。
つまりカスタムユーザーモデルのdb_tableをauth_userにしてしまえば一時的に外部キーの依存問題は解決できます。
初回のマイグレーションさえ通してしまえば、このテーブル名の偽装は後で元に戻すことが可能です。仮のカスタムユーザーモデル作成
ここから手順の説明です。
まず最初に仮のカスタムユーザーモデルを作成します。
ここで「仮」と付けているのは、DBの依存関係を解決するためだけの一時的な存在だからです。
カスタムユーザーの作成手順は、この記事を参考にしていきます。カスタムユーザー用のアプリを作成
(この手順は任意。今回はusersというカスタムユーザー用のアプリを作るものとする。)$ python manage.py startapp usersmodels.pyに組み込みのユーザーモデルと同一名のテーブルに登録するような仮のカスタムユーザーモデルを作成
(ここではAbstractBaseUserではなく、必ずAbstractUserを継承すること。)users/models.pyfrom django.db import models from django.contrib.auth.models import AbstractUser class User(AbstractUser): class Meta: db_table = 'auth_user'既存のプログラム内で
auth.Userをimportしている部分を全てカスタムユーザーモデルをimportするように書き換えるfrom django.contrib.auth.models import User↓
from users.models import User
- 追加したアプリを
INSTALLED_APPSに追加mysite/settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ・・・ 'users.apps.UsersConfig', ]使用するカスタムユーザーモデルを
AUTH_USER_MODELにセットmysite/settings.pyAUTH_USER_MODEL = 'users.User'既にある全てのmigrationsを削除する
一旦migrationsを消します。
ちまちま消してもいいですが、複雑なディレクトリ構成をしていなければアプリのトップディレクトリで以下のコマンドを実行すればOKなはずです。$ find . -path "*/migrations/*.py" -not -name "__init__.py" -deletemigrationsの新しいセットを再作成
新たにmigrationsを生成します。
$ python manage.py makemigrations今回の例の場合だとこんな感じで新たに作成したカスタムユーザーのみ、未適応の状態になるはずです。
$ python manage.py showmigrations admin [X] 0001_initial [X] 0002_logentry_remove_auto_add [X] 0003_logentry_add_action_flag_choices auth [X] 0001_initial [X] 0002_alter_permission_name_max_length [X] 0003_alter_user_email_max_length [X] 0004_alter_user_username_opts [X] 0005_alter_user_last_login_null [X] 0006_require_contenttypes_0002 [X] 0007_alter_validators_add_error_messages [X] 0008_alter_user_username_max_length [X] 0009_alter_user_last_name_max_length blog [X] 0001_initial [X] 0002_post_author contenttypes [X] 0001_initial [X] 0002_remove_content_type_name sessions [X] 0001_initial users [ ] 0001_initialDBをバックアップ
このタイミングでDBのバックアップをとります。
バックアップ方法はDB毎に異なるのでここでは割愛します。DB内のdjango_migrationsをTRUNCATEする
migrationsを消してもマイグレーション履歴自体はDBに残ったままなので、ここで履歴を削除します。
方法としては
$ python manage.py migrate --fake APP_NAME zeroで消すdbshellでdjango_migrationsテーブルのデータを消すのいずれかでOKですが、全アプリのマイグレーション履歴を消さなければいけないので後者のDBテーブルのデータを直接消す方法をオススメします。
その場合は当たり前ですが、django_migrations以外のテーブルのデータを消さないように注意してください。
DBテーブルの削除手順もDB毎に異なるのでここでは割愛します。今回の例の場合だとこんな感じで全てのマイグレーションが未適応の状態になるはずです。
$ python manage.py showmigrations admin [ ] 0001_initial [ ] 0002_logentry_remove_auto_add [ ] 0003_logentry_add_action_flag_choices auth [ ] 0001_initial [ ] 0002_alter_permission_name_max_length [ ] 0003_alter_user_email_max_length [ ] 0004_alter_user_username_opts [ ] 0005_alter_user_last_login_null [ ] 0006_require_contenttypes_0002 [ ] 0007_alter_validators_add_error_messages [ ] 0008_alter_user_username_max_length [ ] 0009_alter_user_last_name_max_length blog [ ] 0001_initial [ ] 0002_post_author contenttypes [ ] 0001_initial [ ] 0002_remove_content_type_name sessions [ ] 0001_initial users [ ] 0001_initialmigrationsの新しいセットを
--fake-initialオプションを付けてマイグレーション今回の肝であるマイグレーションをします。
まずはDjango組み込みのアプリであるadmin、auth、contenttypes、sessionsだけ--fakeオプションを付けてマイグレーションします。
--fakeは、DBスキーマを変更せずにマイグレーションを適用済みにするためのオプションです。
これをつけないと既に同じテーブルがあるぞ的なエラーが出ます。$ python manage.py migrate --fake APP_NAME次に自作アプリを
--fake-initialオプションをつけてマイグレーションします。
この--fake-initialは、先頭のマイグレーションだけ--fakeを適用するオプションです。$ python manage.py migrate --fake-initial APP_NAMEここのマイグレーションの実行順番によっては色々エラーが出る可能性があります。
(実際私もここを通すのが一番大変でした……)
マイグレーション時のエラーに関しては以下の記事がかなり参考になったので、もし詰まったら一度見てみてください。
Django 1.8: Create initial migrations for existing schema - Stack Overflow最終的に全てのマイグレーションが適応済みになっていたらOKです。
$ python manage.py showmigrations admin [X] 0001_initial [X] 0002_logentry_remove_auto_add [X] 0003_logentry_add_action_flag_choices auth [X] 0001_initial [X] 0002_alter_permission_name_max_length [X] 0003_alter_user_email_max_length [X] 0004_alter_user_username_opts [X] 0005_alter_user_last_login_null [X] 0006_require_contenttypes_0002 [X] 0007_alter_validators_add_error_messages [X] 0008_alter_user_username_max_length [X] 0009_alter_user_last_name_max_length blog [X] 0001_initial [X] 0002_post_author contenttypes [X] 0001_initial [X] 0002_remove_content_type_name sessions [X] 0001_initial users [X] 0001_initialちなみにDBテーブルを見てみるとこの時点では
auth_userが残っています。auth_group blog_post auth_group_permissions django_admin_log auth_permission django_content_type auth_user django_migrations auth_user_groups django_session auth_user_user_permissionsdb_tableの設定を解除し、カスタムユーザーモデルに他の変更を加え、migrationsを作成&適用
仮のカスタムユーザーモデル作成でカスタムユーザーモデルにくっつけていた
db_tableを削除し、
後は思い思いにカスタムユーザーモデルの変更を加えていきます。
ここではベタに住所と生年月日を付与してみます。users/models.pyfrom django.db import models from django.contrib.auth.models import AbstractUser class User(AbstractUser): class Meta: db_table = 'auth_user'↓
users/models.pyfrom django.db import models from django.contrib.auth.models import AbstractUser class User(AbstractUser): address = models.CharField(max_length=50, blank=True) birthday = models.DateTimeField(null=True, blank=True)その後カスタムユーザーモデルの変更分のmigrationsを作成&適用します。
$ python manage.py makemigrations users Migrations for 'users': users/migrations/0002_auto_20191001_1229.py - Change Meta options on user - Add field address to user - Add field birthday to user - Rename table for user to (default) $ python manage.py migrate Operations to perform: Apply all migrations: admin, auth, blog, contenttypes, sessions, users Running migrations: Applying users.0002_auto_20191001_1229... OKDBテーブルを見てみると組み込みユーザモデルの
auth_userテーブルが消えて新たにカスタムユーザー用のテーブル (今回の場合だとusers_user) が増えていることが確認できます。auth_group django_migrations auth_group_permissions django_session auth_permission users_user blog_post users_user_groups django_admin_log users_user_user_permissions django_content_typeモデルも増えています。
$ python manage.py inspectdb ... class UsersUser(models.Model): id = models.IntegerField(primary_key=True) # AutoField? password = models.CharField(max_length=128) last_login = models.DateTimeField(blank=True, null=True) is_superuser = models.BooleanField() username = models.CharField(unique=True, max_length=150) first_name = models.CharField(max_length=30) last_name = models.CharField(max_length=150) email = models.CharField(max_length=254) is_staff = models.BooleanField() is_active = models.BooleanField() date_joined = models.DateTimeField() address = models.CharField(max_length=50) birthday = models.DateTimeField(blank=True, null=True) class Meta: managed = False db_table = 'users_user'最後に一応ログインしてDBのデータが残っているかなどを確認してみてください。
ここまでできたら完了です!最後に
Django歴半年未満でチュートリアルを一通り触ってみてなんとなく使っている状態だったのでマイグレーション関係は個人的にとても勉強になりました。
ただ、微妙に理解が曖昧な所が多いので記事に不備があるかもしれないです。
何かここがおかしいという所があればどんどんコメントください。参考
- 投稿日:2019-10-01T21:32:08+09:00
scrapyでスクレイピング。spiderをscrapinghubで管理
スクレイピングの管理
みなさん、スクレイピングの管理はどのようにしていますか。
自分でサーバで立ち上げたり面倒な作業がいらない方法をご紹介します。scrapyでスクレイピングする部分を作成する。
プロジェクトの作成
pip install scrapy scrapy startproject yahoo_scrapy cd yahoo_scrapy scrapy genspider yahoo yahoo.co.jpspiderの作成(スクレイピング部分)
cd yahoo_scrapy scrapy genspider yahoo yahoo.co.jpyahoo_scrapy/items.pyclass YahooScrapyItem(scrapy.Item): link = scrapy.Field()yahoo_scrapy/spiders/yahoo.py# -*- coding: utf-8 -*- import scrapy from ..items import YahooScrapyItem class YahooSpider(scrapy.Spider): name = 'yahoo' allowed_domains = ['yahoo.co.jp'] start_urls = ['http://yahoo.co.jp/'] def parse(self, response): for sel in response.css("a"): article = YahooScrapyItem() article['link'] = sel.css('a::attr(href)').extract_first() yield articleローカルでの動作確認
scrapy crawl yahoo標準出力に、結果が出力されます。
scrapinghub
https://app.scrapinghub.com
こちらのほうに登録してください。ログインして、プロジェクトを作成します。
yahooをスクレイピングしようかと思うので、yahooプロジェクトにします。
Code & Deploys で作成したレポジトリと接続します。
接続完了後に、Gitのほうを、コミットしてプッシュしちゃってください。
SPIDERSメニューのDashboardをみると、yahooのspiderが登録されます。
RUNボタンを押して動かしてみましょう。
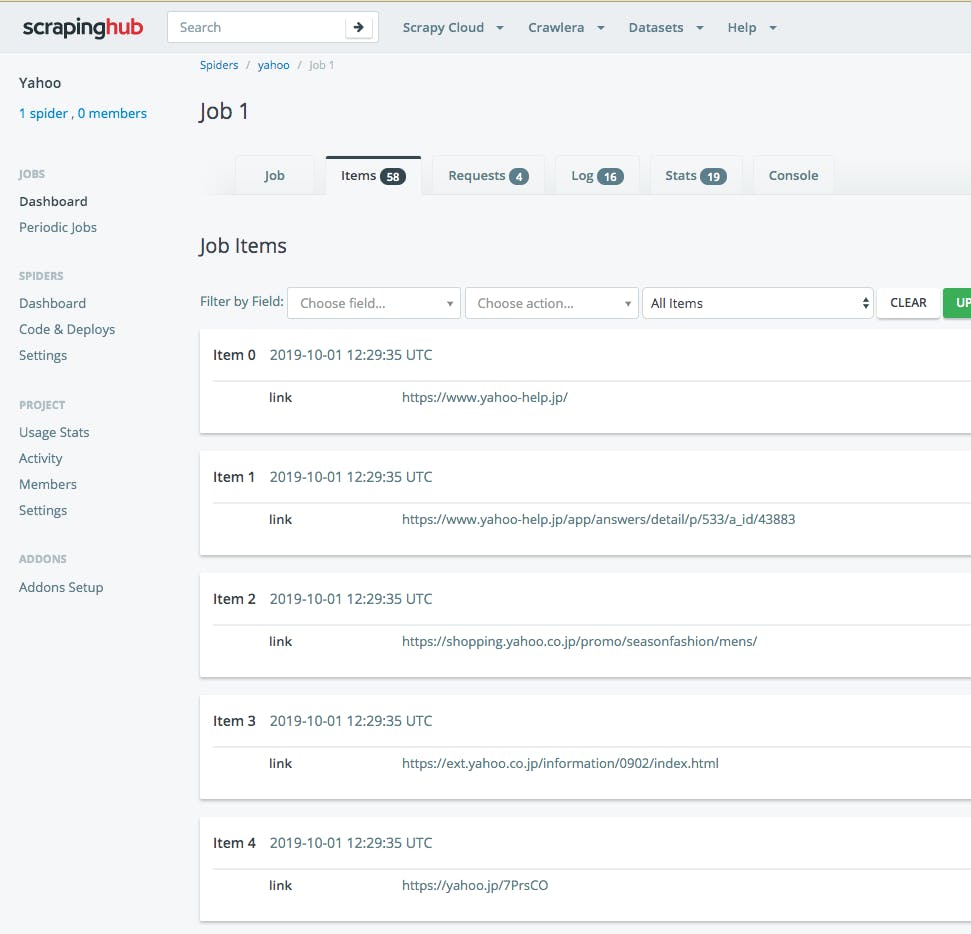
終了するとこんな感じで、結果が出ます。
さらにItemsを押すと、1つずつ見れます。
EXPORTからCSVやJSONなどに出力できます。便利です。
このScrapinghubには、apiもあり、結果がすぐAPIの結果して提供されます。
そちらも時間があれば書こうかと思います。




- 投稿日:2019-10-01T19:49:35+09:00
pythonのnumpyについてまとめてみた
はじめに
今回は自分がpythonのnumpyについてまとめた記事になっています。
numpyについては多くの人がまとめているため、特に目新しい点はないかもしれませんが、お付き合い頂ければ幸いです。
arrayの作成
numpyのarrayを作成してみましょう。
arrayの簡単な作り方のひとつは、arrayメソッドにリストを渡すことです。
import numpy as np lesson_list = [1, 2, 3, 4] lesson_array = np.array(lesson_list) print(lesson_array) print(type(lesson_array))[1 2 3 4]
<class 'numpy.ndarray'>次は二次元配列を作成してみましょう。
また、arrayオブジェクトのshape変数には次元の情報が格納されています。
また、detype変数には格納されているデータの型が入っています。
lesson_list1 = [1, 2, 3, 4] lesson_list2 = [5, 6, 7, 8] lesson_array = np.array([lesson_list1, lesson_list2]) print(lesson_array) print(lesson_array.shape) print(lesson_array.dtype)[[1 2 3 4]
[5 6 7 8]]
(2, 4)
int32numpyのarrayは全てのデータ型がそろっていなければならないことに注意してください。
zeros, onesについて
次のようにすれば、決められた次元の、データが全て0または1のarrayを作成できます。
print(np.zeros([2, 2])) print(np.ones([2, 2]))[[0. 0.]
[0. 0.]]
[[1. 1.]
[1. 1.]]データ型を確認してみましょう。
print(np.zeros([2, 2]).dtype) print(np.ones([2, 2]).dtype)float64
float64このように、numpyのzerosやonesを用いて配列を生成すると、float64型のデータ型で配列が生成されます。
ちなみに、zerosやonesの引数はリストではなくタプルでも大丈夫です。
print(np.zeros((2, 2))) print(np.ones((2, 2)))[[0. 0.]
[0. 0.]]
[[1. 1.]
[1. 1.]]zeros_like、ones_like
np.zeros_likeやnp.ones_likeを使えば、引数として渡した配列と同じ次元のデータが0または1のデータを作成できます。zerosやonesとはデータ型が異なることに注意してください。
test_array = np.array([[1, 2], [3, 4]]) like_zeros_array = np.zeros_like(test_array) like_ones_array = np.ones_like(test_array) print(like_zeros_array) print(like_ones_array) print(like_zeros_array.dtype) print(like_ones_array.dtype)[[0 0]
[0 0]]
[[1 1]
[1 1]]
int32
int32空っぽの配列の作成
numpyのemptyを使えば、空っぽの配列を作成できます。
print(np.empty((2, 2))) print(np.empty((2, 2)).dtype)[[1.95821574e-306 1.60219035e-306]
[1.37961506e-306 1.37961913e-306]]
float64なぜemptyで空の配列を作成する必要があるのかは、こちらの記事を参考にしてください。
簡単にまとめると、zerosやonesで初期化する場合と比べて若干高速になる点、また明示的に初期化する必要がないことをコードを読む人に伝えることができる点が挙げられます。
単位行列の生成
以下のようにすると単位行列を生成できます。
print(np.eye(3))[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]arangeを使ったarrayの生成
次の用にしてもarrayを生成できます。
print(np.arange(10))[0 1 2 3 4 5 6 7 8 9]
arrayを使った計算について
以下のようにすればarray同士の掛け算ができます。
array1 = np.array([[1, 2, 3, 4], [5, 6, 7, 8]]) print(array1 * array1)[[ 1 4 9 16]
[25 36 49 64]]結果をみればわかるように、同じ次元のarrayを掛け算すると、各々の要素を掛け算した値が返ってきます。
和や差も同じなので、ここでは割愛します。
行列の積について
np.matmulを用いれば行列の積を計算できます。
np.dotでも二次元配列においては同様の挙動を示しますが、次元により細かい挙動が違うので、二次元以下の場合はこちらの記事を、三次元以上の場合はこちらの記事を参考にしてください。しかし、ここで気をつけなければならないのが、一次元のarrayは縦ベクトルと横ベクトルを区別しないということです。
行列の掛け算を行うときには、通常線形代数でもそうであるように次元に注意する必要がありますが、一次元配列は縦ベクトルと横ベクトルを区別しないため、多少ガバガバでも計算できてしまうのです。
以下の例で確認しましょう。
array1 = np.array([[1, 1], [1, 1]]) array2 = np.array([1, 1]) result = np.matmul(array1, array2) print(array1.shape) print(array2.shape) print(result.shape)(2, 2)
(2,)
(2,)2×2の行列であるarray1には2×1の縦ベクトルをかける必要があるのですが、細かいことを考えずとも計算できてしまいます。
array2はこの場合、2×1の縦ベクトルなのか1×2の横ベクトルなのかの区別はありません。以下のように行列の掛け算の順番を逆にしても計算できます。
array1 = np.array([[1, 1], [1, 1]]) array2 = np.array([1, 1]) result = np.matmul(array2, array1) # ここが前の例とは逆になっています print(array1.shape) print(array2.shape) print(result.shape)(2, 2)
(2,)
(2,)このように、ベクトルの掛け算の順序を逆にしたにも関わらず計算が成功してしまいました。
以上のことから分かるように、numpyにおいては一次元配列は縦ベクトルでもあり、横ベクトルでもあるのです。
個人的にはこのガバガバさに慣れてしまうと怖いので、明示的にベクトルの形を揃えてあげた方が良い気がします。
ちなみに、tensorflowで用いるtensorオブジェクトはここの部分の区切りがしっかりとしているので、numpyの感覚で操作していたら痛い目を見ます(経験談)。
以下のように縦ベクトルと横ベクトルを意識して使い分けましょう。
array1 = np.array([[1], [1], [1]]) # これは縦ベクトル array2 = np.array([[1, 1, 1]]) # これは横ベクトル print(array1.shape) print(array2.shape)(3, 1)
(1, 3)この縦ベクトルと横ベクトルの使い方には慣れておきましょう。
また、numpyのarrayにはreshapeというメソッドが存在し、要素の数さえ合っていれば無理やり形を変えることができます。
array1 = np.array([1, 1, 1]).reshape((3, 1)) # これは縦ベクトル array2 = np.array([1, 1, 1]).reshape((1, 3)) # これは横ベクトル print(array1.shape) print(array2.shape)(3, 1)
(1, 3)転置行列について
numpyのarrayのTメソッドを使うことで、転置行列にアクセスできます。
array1 = np.array([[1, 2], [3, 4]]) print(array1.T)[[1 3]
[2 4]]ベクトルの内積について
転置行列を利用することで、以下のように縦ベクトル同士の内積を計算することができます。
array1 = np.array([1, 2, 3]).reshape([3, 1]) array2 = np.array([4, 5, 6]).reshape([3, 1]) result = np.matmul(array1.T, array2) print(result)[[32]]
また、
np.innerを用いても内積を計算できます。array1 = np.array([1, 2, 3]) array2 = np.array([4, 5, 6]) print(np.inner(array1, array2))32
ユークリッド距離について
距離とは集合二つの近さを測る尺度を指すので、距離といっても様々なものが存在します。
距離についてはこちらの記事を参考にしてください。
ユークリッド距離とは、2つのベクトルの差のノルムを表します。人が定規で測るような、一般的な距離のことだと考えて差し支えないです。
また、ノルムとは大きさのことなのですが、$L^2$ノルムや$L^3$ノルム呼ばれるものが存在します。
ノルムについてはこちらの記事を参考にしてください。
$L^2$ノルムや$L^3$ノルムは、
numpy.linalg.normを用いて計算することができます。以下のように第一引数にarrayを、第二引数に何乗ノルムなのかを指定してください。
array1 = np.array([1, 2, 3]) print('L^2ノルム:', np.linalg.norm(array1, 2)) print('L^3ノルム:', np.linalg.norm(array1, 3))L^2ノルム: 3.7416573867739413
L^3ノルム: 3.3019272488946263$L^2$ノルムはユークリッドノルムと呼ばれます。
ユークリッド距離とは二つのベクトルの差の$L^2$ノルムであるので、以下のように計算できます。
array1 = np.array([1, 2, 3]) array2 = np.array([4, 5, 6]) dif_array = array2 - array1 print('ユークリッド距離は', np.linalg.norm(dif_array, 2))ユークリッド距離は 5.196152422706632
軸(axis)を指定して合計、平均
次のようにして三次元のarrayを生成しましょう。
array1 = np.arange(9).reshape(3, 3) print(array1)[[0 1 2]
[3 4 5]
[6 7 8]]この三次元のarrayを操作していきます。
縦方向に対しての合計を計算しましょう。
array1 = np.arange(9).reshape(3, 3) print(array1.sum(axis=0))[ 9 12 15]
横方向に対しての合計を計算しましょう。
array1 = np.arange(9).reshape(3, 3) print(array1.sum(axis=1))[ 3 12 21]
このように、二次元配列においては
axis=0を指定すると縦方向に対して計算し、axis=1を指定すると横方向に対して計算します。二次元配列に対してこの操作を行うと、一次元配列になるので注意してください。
三次元以降の挙動についてはこちらの記事を参考にしてください。
以下のようにすると縦方向に対しての平均を計算できます。
array1 = np.arange(9).reshape(3, 3) print(array1.mean(axis=0))[3. 4. 5.]
arrayの計算のための関数について
sqrtについて
np.sqrt関数を用いれば、平方根を計算できます。array1 = np.arange(9).reshape(3, 3) print(np.sqrt(array1))[[0. 1. 1.41421356]
[1.73205081 2. 2.23606798]
[2.44948974 2.64575131 2.82842712]]expについて
np.expを用いれば、底がeで指数がarrayの値を計算できます。array1 = np.arange(9).reshape(3, 3) print(np.exp(array1))[[1.00000000e+00 2.71828183e+00 7.38905610e+00]
[2.00855369e+01 5.45981500e+01 1.48413159e+02]
[4.03428793e+02 1.09663316e+03 2.98095799e+03]]randomメソッドについて
numpyのrandomメソッドには、乱数を生成できるメソッドが大量にあるので、ざっくりまとめていきます。
こちらの記事にかなり細かくまとまっているので、参考にしてください。numpy.random.rand
numpy.random.randは0~1の乱数を生成します。引数で次元を指定できます。array1 = np.random.rand(3, 3, 3) print(array1)[[[0.78207838 0.19169644 0.33656754]
[0.17286481 0.71234607 0.46828202]
[0.61559107 0.98703808 0.01870277]][[0.21355205 0.75614897 0.40712531]
[0.33383552 0.93449879 0.85846818]
[0.22658314 0.67313683 0.40054548]][[0.67963611 0.51894421 0.58826204]
[0.18928953 0.26114807 0.19811072]
[0.53317241 0.51059944 0.02840698]]]numpy.random.random_sample
numpy.random.random_sampleはnumpy.random.randとほぼ同じですが、引数にタプルを渡して次元を指定します。array1 = np.random.random_sample((3, 3, 3)) print(array1)[[[0.89149307 0.59828768 0.24341452]
[0.28129118 0.8939036 0.97494691]
[0.11672552 0.19523899 0.18622686]][[0.71346416 0.20468212 0.82842017]
[0.45043354 0.42185774 0.91783287]
[0.47859017 0.73222385 0.40167049]][[0.19947387 0.73663499 0.55214293]
[0.77191802 0.481025 0.8765084 ]
[0.90954102 0.90351289 0.80627643]]]numpy.random.randint
numpy.random.randintは先ほどの二つと異なり、最小値と最大値を指定することができ、また乱数は整数になっています。引数に「乱数の最小値」「乱数の最大値」「乱数の次元」を渡しましょう。
次元はタプルで渡す必要があります。
array1 = np.random.randint(-1, 1, (2, 2)) print(array1)[[-1 0]
[ 0 0]]numpy.random.randn
numpy.random.randnは、平均0、分散1の正規分布に従う乱数を返します。次数をタプルで指定する必要がありません。
numpy.random.randの正規分布に従うバージョンと考えてください。array1 = np.random.randn(2, 2) print(array1)[[0.32322902 0.66778836]
[1.66995707 1.39959764]]numpy.random.normal
numpy.random.normalは前回のnumpy.random.randの平均と標準偏差を指定できるバージョンです。最初の引数に「平均」を、二番目の引数に「標準偏差」を、三番目の引数に「次数」をタプルで渡してください。
array1 = np.random.normal(5, 3, (2, 2)) print(array1)[[ 6.76899252 2.45230625]
[11.92108624 5.89567182]]終わりに
今回はここまでになります。お付き合い頂きありがとうございました。
- 投稿日:2019-10-01T18:42:19+09:00
はじめてのWebスクレイピング
はじめに
こちらの記事でセブンイレブンの商品のカロリー情報を人力で収集したのですが、今後のメンテナンス(笑)を考えると楽したいので、スクレイピングのお勉強もかねてやってみました。
今回は、セブンイレブンの公式サイトから、カロリーが載っているページをスクレイピングしてみました。
今回もPythonで試してみます。
使用するモジュール
どうやら「BeautifulSoup」って奴がいいらしいので、そのまま鵜呑みにしてみました。
新しめの技術で、情報がいっぱいあるのがうれしいです。コーディング
まずはモジュールを宣言します。
import requests import pandas as pd from bs4 import BeautifulSoup取得した情報をDataFrameに登録するのでPandasも使います。
ソースを眺めてみる
とりあえずここで、目的のページのHTMLの構造を確認してみます。
# 取得したいURL url = "https://www.sej.co.jp/i/products/anshin/?pagenum=0" # urlを引数に指定して、HTTPリクエストを送信してHTMLを取得 response = requests.get(url) # 文字コードを自動でエンコーディング response.encoding = response.apparent_encoding # 取得したHTMLを表示 print(response.text)で、出てきたのがこちら。(一部分だけ)
<div class="pagerCtrl"> <div class="counter">54件中 1-15件表示 </div><div id="filter001" class="filter" ><form id="itemList001"><label class="filterOn" for="filterOn001">表示切替</label><input type="checkbox" id="filterOn001" name="filterOn001" /><div class="panel"><dl><dt>並べ替え</dt><dd><ul><li><a class="button" href="/i/products/anshin/?page=1&sort=n&limit=15">新商品</a></li></ul></dd></dl><dl><dt>表示件数</dt><dd><ul><li><a class="button" href="/i/products/anshin/?page=1&sort=f&limit=50">50件</a></li><li><a class="button" href="/i/products/anshin/?page=1&sort=f&limit=100">100件</a></li></ul></dd></dl></div></form></div><!--filter001--><div class="pager"><b> 1 </b>| <a href="/i/products/anshin/?pagenum=1&page=1&sort=f&limit=15">2</a> | <a href="/i/products/anshin/?pagenum=2&page=1&sort=f&limit=15">3</a> | <a href="/i/products/anshin/?pagenum=3&page=1&sort=f&limit=15">4</a> <a href="/i/products/anshin/?pagenum=1&page=1&sort=f&limit=15">[次へ]</a></div></div><!--pagerCtrl--><div class="itemArea"> <ul class="itemList"><li class="item"> <div class="image"><a href="/i/item/KA0000475130.html?category=1085&page=1"><img data-original="//sej.dga.jp/i/dispImage.php?id=92723" alt="商品画像" /></a></div> <div class="summary"><div class="itemName"><strong><a href="/i/item/KA0000475130.html?category=1085&page=1">もち麦もっちり!梅ひじきおむすび</a></strong></div><ul class="itemPrice"> <li class="price">115円(税込124円)</li> <li class="region"><em>販売地域</em>全国(北海道一部除く)</li> </ul> <ul class="attribute"> <li class="n1">158kcal ※地域によりカロリーが異なる場合があります。</li> <li class="n3">047513</li> </ul> <div class="text">もち麦を使ったおむすびです。昆布とかつお節から丁寧に取っただしで炊き込んだもち麦御飯に、ひじき煮を混ぜ込みました。ひじき、食感のよい梅チップ、香りのよい赤しその、素材のうま味が感じられる仕立てです。</div> <div class="ipr"></div> </div> </li><li class="item"> <div class="image"><a href="/i/item/KA0000405570.html?category=1085&page=1"><img data-original="//sej.dga.jp/i/dispImage.php?id=94071" alt="商品画像" /></a></div> <div class="summary"><div class="itemName"><strong><a href="/i/item/KA0000405570.html?category=1085&page=1">五穀ごはんおむすび 塩こんぶツナ</a></strong></div><ul class="itemPrice"> <li class="price">115円(税込124円)</li> <li class="region"><em>販売地域</em>北海道、東北、関東、東海、近畿、中国、四国、九州</li> </ul> <ul class="attribute"> <li class="n1">180kcal ※地域によりカロリーが異なる場合があります。</li> <li class="n3">040557</li> </ul> <div class="text">レタス1個分の食物繊維を摂ることができる、五穀ごはんのおむすびです。もち玄米、もち赤米、もち黒米、もちきびで、もちもちとした食感の五穀ごはんに仕上げました。中具には、黒胡椒でアクセントを加えたツナと、相性のよい塩こんぶを組み合わせました。</div> <div class="ipr"></div> </div> </li><li class="item"> <div class="image"><a href="/i/item/KA0000475120.html?category=1085&page=1"><img data-original="//sej.dga.jp/i/dispImage.php?id=92722" alt="商品画像" /></a></div> <div class="summary"><div class="itemName"><strong><a href="/i/item/KA0000475120.html?category=1085&page=1">もち麦もっちり!塩こんぶ枝豆おむすび</a></strong></div><ul class="itemPrice"> <li class="price">115円(税込124円)</li> <li class="region"><em>販売地域</em>全国</li> </ul> <ul class="attribute"> <li class="n1">160kcal ※地域によりカロリーが異なる場合があります。</li> <li class="n3">047512</li> </ul> <div class="text">もち麦を使ったおむすびです。昆布とかつお節から丁寧に取っただしを使い、風味のよいもち麦御飯に仕上げました。ミネラル豊富な塩昆布、彩りのよい枝豆、コク深い香りのごま油を混ぜ込んだ、食べ進みのよい仕立てです。</div> <div class="ipr"></div> </div> </li><li class="item"> <div class="image"><a href="/i/item/KA0001018120.html?category=1085&page=1"><img data-original="//sej.dga.jp/i/dispImage.php?id=94075" alt="商品画像" /></a></div> <div class="summary"><div class="itemName"><strong><a href="/i/item/KA0001018120.html?category=1085&page=1">1/2日分の野菜!だし香る鶏団子鍋</a></strong></div><ul class="itemPrice"> <li class="price">400円(税込432円)</li> <li class="region"><em>販売地域</em>北海道、東北、関東(埼玉一部除く)、甲信越、北陸、東海、岡山、広島一部、鳥取、島根一部、四国</li> </ul> <ul class="attribute"> <li class="n1">150kcal ※地域によりカロリーが異なる場合があります。</li> <li class="n3">101812</li> </ul> <div class="text">1日に必要な野菜の1/2を摂ることができる、鶏団子鍋です。だしと醤油のうま味が感じられるスープに仕立てました。</div> <div class="ipr"></div> </div> </li>この中で今回取得したいのは、以下の4つの情報になります。
- 商品名(<div class="itemName">~</div>)
- 価格(<li class="price">~</li>)
- 販売地域(<li class="region">~</li>)
- カロリー(<li class="n1">~</li>)
なお、各商品は「<li class="item">~</li>」に囲まれています。
情報の取得
それぞれをこんな感じで取得します。
# HTML解析 bs = BeautifulSoup(response.text, 'html.parser') items = bs.find_all("li", attrs={"class", "item"}) for item in items: # 商品名 itemName = item.find("div", attrs={"class", "itemName"}) item_text = itemName.find("a") # 価格 price = item.find("li", attrs={"class", "price"}) price_index = price.contents[0].find("円") # 販売地域 region = item.find("li", attrs={"class", "region"}) # カロリー calory = item.find("li", attrs={"class", "n1"}) calory_index = calory.contents[0].find("kcal") # 登録 addRow = pd.Series([item_text.contents[0], price.contents[0][:price_index], region.contents[1], calory.contents[0][:calory_index]], index=df.columns) df = df.append(addRow, ignore_index=True)「BeautifulSoup()」で、取得したHTMLをパースします。
で、タグや属性を指定して、その”ひとかたまり”を取り出します。
最初に見つかった一つだけを取り出す場合は「find()」、条件にあてはまるやつを全部取り出す場合は「find_all()」を使います。
”ひとかたまり”の中から表示している文字列は「contents」に設定されています。(複数設定されている場合あり)価格は税抜の金額部分(最初の「円」の前)を取り出しています。
カロリーも数字(「kcal」の前)を取り出しています取得した情報をDataFrameに登録してみましたが、いい感じに取得できているようです。
実は1ページだけでなく複数ページにまたがって表示されますので、そこもうまい具合にページ数を取得して、ぐりぐり回して取得しています。
# 取得したいURL url = "https://www.sej.co.jp/i/products/anshin/?pagenum=0" # urlを引数に指定して、HTTPリクエストを送信してHTMLを取得 response = requests.get(url) # 文字コードを自動でエンコーディング response.encoding = response.apparent_encoding # HTML解析 bs = BeautifulSoup(response.text, 'html.parser') pager_tag = bs.find("div", attrs={"class", "pager"}) link_tags = pager_tag.find_all("a") # 抽出したタグのテキスト部分を出力 num = 0 for link in link_tags: if (link.contents[0].isdigit()): num = int(link.contents[0])まとめ
少なくとも、HTMLの構造を確認して、必要な情報がどのタグのどの属性にあるのかを確認するのが大変ですね。
それさえ何とかなれば、あとは簡単だと思います。また、他のページもこんな感じでスクレイピングすれば、より一層情報収集がはかどりそうです。

- 投稿日:2019-10-01T17:53:48+09:00
tqdmの表示内容をカスタマイズしたい
なにをするか
- tqdmの表示内容を変えてみる
環境
- Python 3.7.0
- tqdm 4.32.1
- GNU bash, バージョン 4.3.48(1)-release (x86_64-pc-linux-gnu)
通常
いつもの
基本from tqdm import tqdm from time import sleep for i in tqdm(range(10)): sleep(0.1)アウトプット100%|██████████████████████████████████| 10/10 [00:01<00:00, 9.96it/s]forの中でprintすると大変
printありfor i in tqdm(range(10)): print(i) sleep(0.1)アウトプット0%| | 0/10 [00:00<?, ?it/s] 0 10%|███▌ | 1/10 [00:00<00:00, 9.98it/s] 1 20%|███████ | 2/10 [00:00<00:00, 9.98it/s] 2 30%|██████████▌ | 3/10 [00:00<00:00, 9.97it/s] 3 40%|██████████████ | 4/10 [00:00<00:00, 9.97it/s] 4 50%|█████████████████▌ | 5/10 [00:00<00:00, 9.97it/s] 5 60%|█████████████████████ | 6/10 [00:00<00:00, 9.97it/s] 6 70%|████████████████████████▌ | 7/10 [00:00<00:00, 9.97it/s] 7 80%|████████████████████████████ | 8/10 [00:00<00:00, 9.97it/s] 8 90%|███████████████████████████████▌ | 9/10 [00:00<00:00, 9.97it/s] 9 100%|██████████████████████████████████| 10/10 [00:01<00:00, 9.97it/s]工夫する
postfixの中に表示してしまえばいい
tqdmのpostfixに含めるwith tqdm(range(10)) as t: for i in t: sleep(0.1) t.postfix = str(i) t.update()アウトプット100%|███████████████████████████████| 10/10 [00:01<00:00, 9.97it/s, 9]postfixの別の書き方
別の書き方with tqdm(range(10)) as t: for i in t: sleep(0.1) t.set_postfix(i=i) t.update()アウトプット100%|█████████████████████████████| 10/10 [00:01<00:00, 9.94it/s, i=9]説明をつける
かっこいい?with tqdm(range(10), desc="RANGE(10)") as t: for i in t: sleep(0.1) t.set_postfix(i=i) t.update()アウトプットRANGE(10): 100%|██████████████████| 10/10 [00:01<00:00, 9.95it/s, i=9]postfixの位置を変えたい
postfixを変えたいbar_format = "{l_bar}{bar}| {n_fmt}/{total_fmt} [{elapsed}<{remaining}{postfix}{rate_fmt}]" with tqdm(range(10), desc="RANGE(10)", bar_format=bar_format) as t: for i in t: sleep(0.1) t.set_postfix(i=i) t.update()アウトプットRANGE(10): 100%|████████████████████| 10/10 [00:01<00:00, i=9 9.95it/s]プログレスバーを消したい
プログレスバーを消すbar_format = "{l_bar}{r_bar}" with tqdm(range(10), desc="RANGE(10)", bar_format=bar_format) as t: for i in t: sleep(0.1) t.set_postfix(i=i) t.update()アウトプットRANGE(10): 100%|| 10/10 [00:01<00:00, 9.95it/s, i=9]bar_formatの全体(メモのため)
{l_bar}{bar}{r_bar}と同じ{desc}: {percentage:3.0f}%|{bar}| {n_fmt}/{total_fmt} [{elapsed}<{remaining}{rate_fmt}{postfix}]その他variablesn, total, elapsed_s, ncols, desc, unit, rate, rate_fmt, rate_noinv, rate_noinv_fmt, rate_inv, rate_inv_fmt, unit_divisor, remaining_s実はshにも組み込める
tqdm$ seq 10 | tqdm | wc -l 100it [00:00, 81284.96it/s] 100もっと知りたい
- 公式へどうぞ
- 投稿日:2019-10-01T17:25:30+09:00
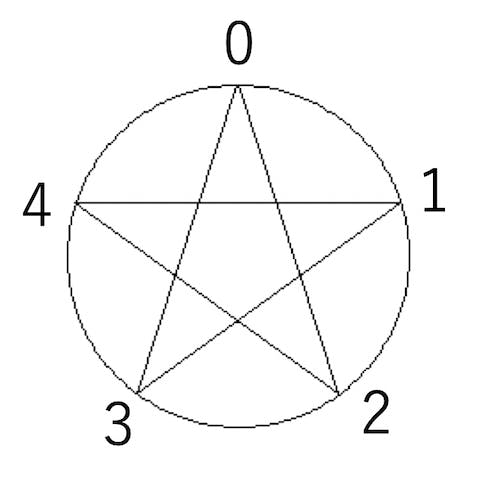
N芒星の数学的側面
はじめに
プログラムの講義で「N芒星の描画」をやりました。五芒星や七芒星はうまく描けますが、Nが偶数の時には工夫が必要で、特にN=6の時には 一筆書きの 六芒星はうまく描けません。そのあたりを説明してみます。「九九の一の位」の数学的側面と本質は同じ問題です。
コード
まず、N芒星を描画するコードを書いてみます。こんな感じです。
from math import cos, sin, pi from PIL import Image, ImageDraw from IPython.display import display def star(N, k): im = Image.new("L", (256, 256), 255) draw = ImageDraw.Draw(im) cx = 128 cy = 128 r = 96 draw.ellipse((cx - r, cy - r, cx + r, cy + r)) s = 2*pi/N for i in range(N): s1 = ((i*k) % N)*s - 0.5*pi s2 = s1 + s*k x1 = r*cos(s1)+cx y1 = r*sin(s1)+cy x2 = r*cos(s2)+cx y2 = r*sin(s2)+cy draw.line((x1, y1, x2, y2)) display(im)これは2つの数字、Nとkを指定すると、対応するN芒星を描画する関数です。五芒星を描くには(5,2)を指定します。
star(5,2)五芒星
Nが奇数の時にはkとしてN//2を指定すれば同様なN芒星が描けます。
七芒星
star(7,3)
九芒星
star(9,4)
Nが偶数の場合も、kの値を工夫すればN芒星になります。
八芒星
star(8,3)
十二芒星
star(12,5)
しかし、N=6の場合にはうまくN芒星が描けません。例えばk=3とすると、
star(6,3)
と縦棒になってしまいます。k=2は三角形になります。
star(6,2)
これはなぜでしょう、という問題です。
剰余類
まず、これは円をN等分し、その円周上の点を結ぶ問題になっています。
star(N, k)は、0に次々とkを足していき、Nで割った余りに対応する数字を線で結ぶ関数です。これを(N, k)と呼びましょう。例えば(5,2)なら、0に2を足していき、5で割った余りを追いかけます。
途中で6と1、5と0を同一視しています。このように「Nで割った余りが同じなら、元の数字を同一視する」ことでできる構造を Nを法とする 剰余類 と言います。剰余類は同値類の一種です。
さて、Nを法とする剰余類は、N等分した円周上の点で表現するのが自然です。先程の数字の通りに線を結んでいくと、五芒星が完成します。
0→2→4まで来て、次は4+2=6ですが、この円周上では6は1と同一視されるので次は1に行きます。
この円周上の数字を同値類の代表元と呼びます。
巡回群
もともと整数には加減算が定義されているため、「Nで割った余りの世界」である剰余類でも加減算ができます。しかし、整数は加算の逆元は減算ですが、剰余類は、加算だけで逆元を作ることができます。
例えば、5を法とする世界では、「3を足す」というのと「2を引く」は等価です。例えば、4に3を足すと7ですが、7を5で割った余りは2なので、「4 + 3 = 2 mod 5」となり、「3を足す」というのが「2を引く」のと同じ結果になることがわかります。したがって、剰余類の世界では加算だけで演算が閉じ、逆元も存在するので、加算が群を作ります。
特に今回は「毎回2を足す」というように、ただ一つだけの操作を考えます。このようにただ一つの要素から生成される群を 巡回群 と呼びます。(5, 2)で五芒星ができるのは、5を法とする世界で2を加算するという操作が作る巡回群の要素が、0から4まですべての数字を尽くすからです。
さて、Nを法とする剰余類で、kを足すという操作が作る巡回群(N, k)の要素が、0からN-1すべてを尽くすかどうかは、Nとkが互いに素であるかどうかで決まります。
先程うまくN芒星ができた(5,2)(7,3)(9,4)(8,3)(12,5)は、全て違いに素な数字の組でできていることがわかります。特にNが奇数の時には、N = 2k + 1とすれば、Nとkは必ず互いに素になるのでN芒星を作ることができます。
N芒星の性質
さて、N芒星は、Nを法としてkを加えていく操作で表現できるので、それを(N, k)と表現するのでした。この性質を見てみましょう。
まず、(N, k)と(N, N-k)は等価です。ただし、「書き順」が逆になります。
また、Nとkが互いに素でない場合には、「約分」ができます。たとえば(10,4)は(5,2)と等価です(コピペミスで図が(5,3)になってますが気にしないでください)。
一筆書きの六芒星ができない理由
ここまでで、一筆書きの六芒星ができない理由はわかるかと思います。(N,k)がN芒星になるためにはNとkが互いに素でなくてはいけませんが、N=6の時、6未満で6と互いに素な整数は1と5しかありません。5は6を法とする世界では-1と等価ですから、要するに自明なものしかない、ということです。というわけで、円周上の6つの点全てをめぐる組み合わせは(6,1)と(6,5)しかなく、それが作るのは単なる六角形になります。
また、(6,2)と(6,4)は互いに等価で、「約分」すると(3,1)ですから、三角形になってしまいます。
(6,3)にいたっては「約分」で(2,1)になるので、平面図形ではなくただの線分になってしまいます。
まとめ
円周をN等分して、k個ずつ進むことでN芒星を書くプログラムで遊んでみました。Nが奇数の時にはN=2k+1とすることでNとkが互いに素になり、N芒星になります。六芒星を一筆書きで作ることができないのは、6より小さい正の整数で6と互いに素なものが1,5という自明なものしかないからです。
この課題、プログラムが短いわりに絵も出るし数学的背景が面白いのでわりと気に入ってるんですが、どんなもんでしょう?











- 投稿日:2019-10-01T16:57:44+09:00
Pythonで動画再生する方法(自分用)
import cv2
import sysfile_path = 'file' //ファイル置いてる場所
delay = 1 //再生スピード調整
window_name = 'frame'cap = cv2.VideoCapture(file_path)
if not cap.isOpened():
sys.exit()while True:
ret, frame = cap.read()
if ret:
cv2.imshow(window_name, frame)
if cv2.waitKey(delay) & 0xFF == ord('q'):
break
else:
cap.set(cv2.CAP_PROP_POS_FRAMES, 0)cv2.destroyWindow(window_name)
- 投稿日:2019-10-01T16:42:48+09:00
Pythonでは何も指定されなかったのか明示的にNoneが指定されたのか区別できない問題
表題の通りです
Pythonでは関数にデフォルト引数を定義することができます。
def add(a, b=1): return a + b add(1, 2) # 3 add(1) # 2便利なんですが落とし穴が多いことでも有名です。
Pythonのデフォルト引数の挙動だいたいの問題はデフォルト引数の値は定義時に評価されることから来るのですが、今回またちょっと違う問題に当たってしまったのでご紹介します。
next(filter(...))
Pythonにはfilterもmapもありますが、findがないのは比較的有名だと思います。
多分製作者のこだわりだと思うんですが、itertoolsにもないのはちょっと理由がよくわからないです。割と必要とする場面が多いので、itertoolsのレシピ集にあるものをちょっといじって使っています。
(レシピ集に入れるのに実装はしないのはなぜ。。。?)def find(filter_f, iter_, default=None): return next(filter(filter_f, iter_), default)ようするにfilterの先頭から一つ取ろうという話なんですが、ここに罠がありました。
find(f, iterable) と next(filter(f, iterable))の結果が違う
簡単なサンプルをご紹介しますと、
find(lambda a: a > 10, range(10)) # None next(filter(lambda a: a > 10, range(10)) # Traceback (most recent call last): # File "<input>", line 1, in <module> # StopIterationはい、検索した項目が見つからなかった時の挙動が微妙に違いました。
next(iterable) と next(iterable, default)の違い
簡単にいうとnextは第二引数が指定されていない時はStopIterationをそのままraiseし、第二引数が指定されている時は、raiseする代わりにキャッチしてdefaultを返します。
しかし、今回の処理ではdefaultが指定されていればそれを、指定されていなければNoneを第二引数に指定する、という処理になってしまっているため、上のコードは1対1で対応せず、実際には以下のようになっていたのです。
find(lambda a: a > 10, range(10)) # None next(filter(lambda a: a > 10, range(10), None) # Noneだいたいの場面でこれが期待される動作として正しい気もするんですが、実際にはデフォルト値が定義されていないのに勝手にNoneを返すのはある意味
try: ... except Exception: passと同義であまり気持ちがいいものではありません。デフォルトのNoneと明示的なNoneをどう区別するか
上を踏まえると目指すべきコードとしては、
def find(filter_f, iter_, default=None): if ("""デフォルト値が設定されていないという条件"""): return next(filter(filter_f, iter_)) else: return next(filter(filter_f, iter_), default)のようになります。しかし、このままだとdefaultに明示的にNoneが指定されたか否かを判断する方法はありません。直感的にはdefaultには最初からNoneが代入されていて、指定された場合に上書きされる、というような挙動になっているからです。
これは-1や()でも同じような問題にぶち当たります。
解決法
https://stackoverflow.com/q/14749328/10299102
ここに来て伏線回収です。以下のコードをご覧ください
# https://stackoverflow.com/a/57628817/10299102 def f(value={}): if value is f.__defaults__[0]: print('default') else: print('passed in the call')パッと見てあぶない!と思った方、ここ進研ゼミでやったところだ!状態ですね。バッチリ予習されています。
なんのことかと言いますと、value={}の部分です。基本的には関数のデフォルト引数にmutableなオブジェクトを設定してはいけません。定義時にデフォルト引数の値が評価されるため、関数に引数を与えずに呼び出すたびに、同じオブジェクトが使われ、予期しない結果になるからです。ただ、今回はあえてオブジェクトを指定しています。定義時と全く同じオブジェクトが使われることを逆手にとり、isでidを比較することで、明示的に指定されたデータなのか、そうでないのかを区別することができます。上のコードを試しに実行すると、
f() # default f({}) # passed in the callとなり、値が同じものかに関わらず、指定されたか否かを正しく判断できていることがわかります。
改良版find
上のサンプルを見たときなるほどー!と思ったんですが、正直見づらいです。
f.__defaults__[0]という黒魔術っぽいものもあってちょっと、、という感じだったのですが、他の回答に改良方法が書いてあったので自分なりのアレンジを加えてお届けします。オブジェクトのid比較をしたいだけなので、デフォルトのオプションは
{}じゃなくても大丈夫です。DEFAULT=object() def find(filter_f, iter_, default=DEFAULT): if default is DEFAULT: return next(filter(filter_f, iter_)) else: return next(filter(filter_f, iter_), default)ただこれだけだとDEFAULTがただのobjectとしてしか見えず、デバッグのこととかを考えると型がobjectとしての情報しか持っていないのはちょっと嫌なので、専用のクラスを定義してあげます。
class Default: def __repr__(self): return "DEFAULT" DEFAULT=Default() def find(filter_f, iter_, default=DEFAULT): if default is DEFAULT: return next(filter(filter_f, iter_)) else: return next(filter(filter_f, iter_), default)だいたいこれでいいんですが、グローバル変数DEFAULTがどうしても残ってしまいます。
ちょっと気持ち悪いので、シングルトン化をすることでどこでクラスをインスタンス化しても、idが一意に定まるようにしてあげましょう!class Default: __singleton = None def __new__(cls, *args, **kwargs): if cls.__singleton is None: cls.__singleton = super(Default, cls).__new__(cls) return cls.__singleton def __repr__(self): return "DEFAULT" def find(filter_f, iter_, default=Default()): if default is Default(): return next(filter(filter_f, iter_)) else: return next(filter(filter_f, iter_), default)最後に、StopIterationを返すだけだと、検索をして見つからなかったという情報がないので、StopIterationのサブクラス、NotFoundを定義することで、その情報を明示します。
class Default: __singleton = None def __new__(cls, *args, **kwargs): if cls.__singleton is None: cls.__singleton = super(Default, cls).__new__(cls) return cls.__singleton def __repr__(self): return "DEFAULT" class NotFound(StopIteration): """見つからなかったことを明示する""" pass def find(filter_f, iter_, default=Default()): if default is Default(): try: return next(filter(filter_f, iter_)) except StopIteration: pass raise NotFound() else: return next(filter(filter_f, iter_), default)
ということでfind関数の改良版を作る記事でした(そうだっけ)
IteratorやGenerator周りは奥が深いのでこれからも色々と記事を書いていければなと思います。※記事の内容はニュアンスで書いているところが多いので、不正確な部分があるかもしれません、、随時ご指摘、編集リクエストお待ちしております。
- 投稿日:2019-10-01T16:38:29+09:00
Python 有村架純を主成分分析(PCA)してみる
1.はじめに
最近、sklearnの主成分分析(PCA)を勉強したので、ちょっと応用をやってみたくなった。
せっかくなので、題材は散布図の様なものより、画像が面白そう。なので、丁度手元にあった有村架純さんの顔画像にしたいと思います。
あっ、私、有村架純さんのファンではありません。たまたま、手元にデータがあっただけです。。。。
2.データの準備
カレントフォルダー(./arimura)に、223枚の有村架純さんの顔画像(png)を用意して、64*64のモノクロ画像に変換し、データにします。
import numpy as np import matplotlib.pyplot as plt import matplotlib.cm as cm from sklearn.decomposition import PCA from PIL import Image import glob # 初期設定 image_size = 64 # データ画像の読み込み x = [] files = glob.glob('./arimura'+'/*.png') for file in files: image = Image.open(file) image = image.convert('L') # カラーを白黒に image = image.resize((image_size, image_size)) # image_seize * image_size に縮小 data = np.asarray(image) x.append(data) X = np.array(x) X = X.reshape(X.shape[0], image_size * image_size) X = X / 255.0 # データ画像の表示(最初の50枚) print('X.shape =', X.shape) rows, cols = 5, 10 #5行10列 fig, aX_invs = plt.subplots(ncols=cols, nrows=rows, figsize=(18, 10)) for i in range(50): r = i // cols c = i % cols aX_invs[r, c].imshow(X[i].reshape(image_size,image_size),vmin=0.0,vmax=1.0, cmap = cm.Greys_r) aX_invs[r, c].set_title('data %d' % (i+1)) aX_invs[r, c].get_xaxis().set_visible(False) aX_invs[r, c].get_yaxis().set_visible(False) plt.show()
64*64モノクロの有村架純さんです。画像は全部で223枚ですが、ここでは最初の50枚のみ表示しています。PILは画像を読み込んでから、カラーから白黒へとか、サイズを変更したりとか、便利ですね。
最終的にデータは、X.shape = (223, 4096)にしています。
3. 主成分分析
さて、これをどの位、次元削減するかですが、思い切って 1/100 まで次元削減してみたいと思います。数字の切りの良いところで、64*64=4,096次元 → 40次元としましょう。
# PCA(主成分分析) N = 40 # 40成分でPCA pca = PCA(n_components=N) pca.fit(X) print('n_components = '+str(N)) print('explained_variance_ratio = ', pca.explained_variance_ratio_.sum()) # 第1〜第40成分の画像の表示 rows, cols = 5, 8 #5行8列 fig, aX_invs = plt.subplots(ncols=cols, nrows=rows, figsize=(18, 10)) for i in range(N): r = i // cols c = i % cols aX_invs[r, c].imshow(pca.components_[i].reshape(image_size,image_size),vmin=-0.05,vmax=0.05, cmap = cm.Greys_r) aX_invs[r, c].set_title('component %d' % (i+1)) aX_invs[r, c].get_xaxis().set_visible(False) aX_invs[r, c].get_yaxis().set_visible(False) plt.show()
components1 が第1主成分なのですが、ほとんど人間の顔の原型に近いですね。当たり前か。ただ、気のせいか第2主成分は、なんか有村架純の片鱗がある様な。。。。下位の成分に行くに従って、様々なバリエーションが現れますが、それが有村架純の特徴かと言われると、なんとも言えないですね。
explained_variance_ratio = 0.8631 なので、たった40次元ですが、これで全体の86%をカバーしている様です。結構なカバー率ですね。
4.画像の次元削減と復元
さあ、この40個の主成分情報を使って、有村架純の画像を1/100に次元削減してから、復元してみたいと思います。
# 次元削減と次元復元の係数 X_trans = pca.transform(X) X_inv = pca.inverse_transform(X_trans) print ('X.shape =', X.shape) print ('X_trans.shape =', X_trans.shape) print ('X_inv.shape =', X_inv.shape) # オリジナル画像と、次元削減後に復元した画像の表示 rows, cols = 2, 8 # 2行8列 fig, aX_invs = plt.subplots(ncols=cols, nrows=rows, figsize=(18,4)) for i in range(8): aX_invs[0, i].imshow(X[i,:].reshape(image_size, image_size),vmin=0.0,vmax=1.0, cmap = cm.Greys_r) aX_invs[0, i].set_title('original %d' % (i+1)) aX_invs[0, i].get_xaxis().set_visible(False) aX_invs[0, i].get_yaxis().set_visible(False) aX_invs[1, i].imshow(X_inv[i,:].reshape(image_size, image_size),vmin=0.0,vmax=1.0, cmap = cm.Greys_r) aX_invs[1, i].set_title('restore %d' % (i+1)) aX_invs[1, i].get_xaxis().set_visible(False) aX_invs[1, i].get_yaxis().set_visible(False)
オリジナル(original)と復元後(restore)に若干差はありますが、なんとかギリギリ有村架純らしさは残っているのではないでしょうか。情報を1/100にしてから戻しているのに、PCA凄いです!



- 投稿日:2019-10-01T15:41:37+09:00
【Python】スプレッドシート操作小技集
以下の形でクライアントを作成している前提で書いていきます。
※herokuでデプロイする想定で作っているので環境変数から読み込むようになっていますがよしなに読み替えてください。#2つのAPIを記述しないとリフレッシュトークンを3600秒毎に発行し続けなければならない scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive'] TYPE = os.getenv("GS_TYPE", "") CLIENT_EMAIL = os.getenv("GS_CLIENT_EMAIL", "") PRIVATE_KEY = os.getenv("GS_PRIVATE_KEY", "") PRIVATE_KEY_ID = os.getenv("GS_PRIVATE_KEY_ID", "") CLIENT_ID = os.getenv("GS_CLIENT_ID", "") key_dict = { 'type' : TYPE, 'client_email' : CLIENT_EMAIL, 'private_key' : PRIVATE_KEY, 'private_key_id': PRIVATE_KEY_ID, 'client_id' : CLIENT_ID, } SPREADSHEET_KEY = os.getenv("SPREADSHEET_KEY", "") credentials = ServiceAccountCredentials.from_json_keyfile_dict(key_dict, scope) #OAuth2の資格情報を使用してGoogle APIにログインします。 gc = gspread.authorize(credentials)新しいシート作成
gc.add_worksheet(title='test', rows=5000, cols=26)rowとcolは必須のようです。
シートが存在するかチェック
worksheets = gc.worksheets() # シートの一覧が取得できる for sheet in worksheets: if 'シート1' == sheet.title: return True else: return False調べた限りシートが存在するかを答えてくれる関数はなかったのでこんな感じでやってます。
- 投稿日:2019-10-01T15:28:30+09:00
よくあるPythonプロジェクトのREADME(開発手順の部分のみ)
Pythonプロジェクトを作るたびに、
README.mdやDEVELOPMENT.mdの開発手順 には毎回似た内容を書いている気がするので、コピペ用テンプレを残しておきます。# プロジェクト名 ## 開発手順 ### ブランチ戦略 Githubフローです。MR先はmasterブランチです。 ### 開発環境構築 `pipenv` で環境を作成します。 ```shell pipenv install --dev ``` ### テスト [pytest](https://docs.pytest.org/en/latest/)を使います。テストは以下のように実行できます。 ```shell pipenv run pytest --doctest-modules ``` ### スタイルチェック `mypy`, `black` などでテストします。`bin/lint`でまとめて実行できます。 ```shell bin/lint ``` ### リリース マージ後、担当者は以下の手順でリリースします。 **1. setup.cfg のバージョンを更新** `setup.cfg` 関数の引数のバージョンを更新します。 ```diff [metadata] name = hoge - version = 1.4.0 + version = 1.5.0 ``` 変更をコミットし、push してください。 ```shell $ git commit -m "バージョン 1.5.0" setup.cfg $ git push ``` **2. バージョンタグの追加** `setup` と同じバージョン番号のタグを作ってください。 ```shell $ git tag 1.5.0 $ git push --tag ``` **3. 社内PyPIへのデプロイ** ローカルマシンで `setup.py` を実行して公開物をビルドします。 ```shell $ pipenv run python setup.py sdist ``` twine を使って社内PyPIにデプロイします。環境変数を定義し忘れると公式PyPIに公開されるかもしれないので注意。 ```shell $ export TWINE_REPOSITORY_URL=https://packages.example.com/repository/pypi-internal/ $ export TWINE_USERNAME=ore-boku # LDAPユーザー名 $ pipenv run twine upload dist/hoge-1.5.0.tar.gz # 公開物を指定して実行 ``` **4. リリース連絡** slackなどで連絡してください。 ``` 各位 hoge のバージョン 1.0.0 をリリースしました。以下の機能を追加しています: - 機能の説明 - 機能の説明 - 機能の説明 なお、後方互換性を崩す変更は加えていません。 アップデートは、各チームごとに影響を判断した上で、以下のコマンドで行なってください。 pip install --upgrade hoge==1.0.0
- 投稿日:2019-10-01T15:21:51+09:00
Kintone アプリのレコードの作成日時を変更?してみる。
0.はじめに
Kintone アプリのレコードの作成日時を変更?してみる。としましたが…、
以下のページにもある様に、登録済みのレコードの作成日時は変更出来ない仕様みたいなので、
正確には、レコードの作成日時を指定して、新たに登録し直す。
になります。
今回は、上記機能の Python スクリプトを作成してみました。
1.Python スクリプト
Kintone_replicateRecords.py#!/usr/bin/python # -*- coding: utf-8 -*- # ---1----+----2----+----3----+----4----+----5----+----6----+----7----+----8---- # ============================================================================== # # Kintone_replicateRecords.py # # ============================================================================== # kintone REST APIの共通仕様 – cybozu developer network # https://developer.cybozu.io/hc/ja/articles/201941754-kintone-REST-API%E3%81%AE%E5%85%B1%E9%80%9A%E4%BB%95%E6%A7%98 # レコードの登録(POST) – cybozu developer network # https://developer.cybozu.io/hc/ja/articles/202166160 import sys import os import logging import codecs import json import datetime import requests import time sys.stdout = codecs.getwriter('utf_8')(sys.stdout) logging.basicConfig(level=logging.DEBUG, format="[%(asctime)s] %(levelname)-8s %(filename)-20.20s (%(lineno)06d) %(funcName)-12.12s | %(message)s", datefmt='%Y-%m-%d %H:%M:%S', filename=(__file__ + ".log"), filemode='w') sh = logging.StreamHandler() sh.setLevel(logging.DEBUG) formatter = logging.Formatter("[%(asctime)s] %(levelname)-8s (%(lineno)06d) | %(message)s") sh.setFormatter(formatter) logging.getLogger().addHandler(sh) logging.debug("<<<<<<<< %s Start >>>>>>>>", __file__) # ------------------------------------------------------------------------------ # Constant # ------------------------------------------------------------------------------ # cybozu.com Cybozu_Url_Base = 'https://****.cybozu.com' Src_App_ID = [移行元のKintoneアプリID] Src_API_Token = '[移行元のKintoneアプリのAPIトークン]' Src_Fields = [ 'AAA', 'BBB', 'CCC', 'DDD'] Dst_App_ID = [移行先のKintoneアプリID] Dst_API_Token = '[移行先のKintoneアプリのAPIトークン]' Dst_Fields = Src_Fields Base_DateTime = datetime.datetime(2000, 1, 1, 0, 0, 0) # ------------------------------------------------------------------------------ # Variables # ------------------------------------------------------------------------------ # ------------------------------------------------------------------------------ # Function # ------------------------------------------------------------------------------ def replicateRecords(): """Get Cybozu Monitors""" logging.debug("==== Replicate Records ====") logging.debug("==== Get Source Records ====") source_records = requests.get(Cybozu_Url_Base + '/k/v1/records.json', headers = { 'X-Cybozu-API-Token' : Src_API_Token, 'Content-Type' : 'application/json; charset=UTF-8', 'If-Modified-Since' : 'Thu, 01 Jun 1970 00:00:00 GMT' }, data = json.dumps({ 'app': Src_App_ID, 'query': '$id > 0 order by $id asc limit 500', 'fields': ['$id'] + Src_Fields, 'totalCount': 'true' }) ) source_records_json = source_records.json()['records'] logging.debug("source_records_json:[%s]", json.dumps(source_records_json, ensure_ascii=False)) logging.debug("====") for n, k in enumerate(sorted(source_records_json, key=lambda x:int(x[u'$id']['value']))): logging.debug("(%04d/%04d) Source Record | [%s] ", n + 1, len(source_records_json), json.dumps(k, ensure_ascii=False, sort_keys=True)) logging.debug("==== Post Destination Record ====") record = {} for nn, dst_field in enumerate(Dst_Fields): record[dst_field.decode('utf-8')] = { "value": k[Src_Fields[nn].decode('utf-8')]['value'] } dt = Base_DateTime + datetime.timedelta(minutes=n) dt_str = "{0:%Y-%m-%dT%H:%M:%SZ}".format(dt) record['作成日時'.decode('utf-8')] = { "value": dt_str.decode('utf-8') } record['更新日時'.decode('utf-8')] = { "value": dt_str.decode('utf-8') } logging.debug("(%04d/%04d) Destination Record | [%s] ", n + 1, len(source_records_json), json.dumps(record, ensure_ascii=False)) resp = requests.post(Cybozu_Url_Base + "/k/v1/record.json", headers = { 'X-Cybozu-API-Token' : Dst_API_Token, 'Content-Type' : 'application/json; charset=UTF-8', 'If-Modified-Since' : 'Thu, 01 Jun 1970 00:00:00 GMT' }, json = { 'app': Dst_App_ID, 'record': record } ) logging.debug("resp:[%s]", resp) # ------------------------------------------------------------------------------ # Program Start # ------------------------------------------------------------------------------ if __name__ == '__main__': replicateRecords() # ------------------------------------------------------------------------------ # Program End # ------------------------------------------------------------------------------ logging.debug("<<<<<<<< %s End >>>>>>>>", __file__) # ---1----+----2----+----3----+----4----+----5----+----6----+----7----+----8----
- 定数定義
Cybozu_Url_Base: ※任意 (ex : https://****.cybozu.com)Src_App_ID: [移行元のKintoneアプリID]Src_API_Token: [移行元のKintoneアプリのAPIトークン]Src_Fields: ※移行元のKintoneアプリのレコードの各フィールドコードのリストDst_App_ID: [移行先のKintoneアプリID]Dst_API_Token: [移行先のKintoneアプリのAPIトークン]Dst_Fields: ※移行先のKintoneアプリのレコードの各フィールドコードのリスト- 注意事項
- 今回の Python スクリプトでは、2000/01/01 00:00 から1分ずつ追加した作成日時を設定しています。
- 69行目 :
Base_DateTime = datetime.datetime(2000, 1, 1, 0, 0, 0)- 108行目 :
dt = Base_DateTime + datetime.timedelta(minutes=n)- 109行目 :
dt_str = "{0:%Y-%m-%dT%H:%M:%SZ}".format(dt)- レコード番号の制御はしていません。
- Src_Fields と Dst_Fields の順番は合わせる必要があります。
99.ハマりポイント
- ハマりポイントというか、Kintone の仕様ですね。
- 作成日時は、分単位でしか入力できない。
- kintone REST APIの共通仕様 – cybozu developer network
- Kintone の Rest API の仕様みたいです。
- アプリのAPIトークンの設定において、アプリ管理権限の設定が必要。
- レコードの登録(POST) – cybozu developer network
- Kintone の Rest API の仕様みたいで、以下のフィールドを登録する場合は必要とのこと。
- 作成者
- 更新者
- 作成日時
- 更新日時
XX.まとめ
作成日時を変更したい時もありますよね。
ということで、参考になれば♪
?♂️?♂️?♂️
- 投稿日:2019-10-01T14:51:44+09:00
python 勉強 複数ファイルの読込と日付の曜日表示
やりたいこと
1ファイルのみを集計対象として読み込んでいたが、
同じ形のデータが結構な日数分あるので同時に読み込んでしまいたい試したこと
1.対象ファイルをワイルドカードで指定して読み込み
2.日付から曜日を求めて曜日で集計
1.対象ファイルをワイルドカードで指定して読み込み
globを使用。
csv_files = glob.glob(r'インプットファイルがあるフォルダ\*.csv') list = [] for f in csv_files: list.append(pd.read_csv(f, index_col=0).drop(['企業コード','企業名称','店舗コード','店舗名称','支払番号','返金番号'], axis=1)) df = pd.concat(list)csvファイルの読み込みは記載した感じ。
ただ、読み込みする際に前回同様に要らない項目もあるのでdropでできるのかわからなかったが、
やってみたらできた。できた図はあまりにもみづらい。
そもそも私があまりプロットの知識がないので横に伸びず、下辺の文字がつぶれて見れない。。。2.日付から曜日を求めて曜日で集計
def get_week(dt): w_list = ['月', '火', '水', '木', '金', '土', '日'] return(w_list[dt.weekday()])なんて関数を用意したけど、うまく利用できていない。。。
あと、もともとのデータの日付が「"YYYY-MM-DD HH:MM:SS"」って形式だったので、
「"」を区切りにした1個目取得、「 (半角スペース)」を区切りにした1個目取得、さらに「to_datetime」に入れて形式変えて、
と面倒くさいにも程がある事この上ないったらありゃしない。
文字列から曜日算出できないかな。。。
もうちょっと模索が必要。。。あと、できた図は曜日が「月→日」じゃくてアルファベット順の並びだった。
修正が必要。
- 投稿日:2019-10-01T13:49:02+09:00
[Python]強化学習ライブラリKeras-RLでポリシーをカスタマイズする
はじめに
※本記事は、Keras-RLの基本的な使い方を理解している人向けに記載しています
Pythonの強化学習ライブラリであるKeras-RLを使っていると、
細かいところで独自にカスタマイズしたくなることがあります。ここでは例として強化学習のポリシー(方策)について考えたいと思います。
ポリシーとは、複数の行動の選択肢があった場合に、どの行動を選択するかを決めるルールです。例えば、
q_values = [1.3, 0.8, 1.2, 0.1]という行動の選択肢に対応するQ値のリストがあったとしましょう。
(行動1のQ値が1.3、行動2のQ値が0.8、・・)単純に考えれば最大のQ値である行動1を選択するのがよさそうですが、
もしかすると行動3を選んだほうが最終的にはよい報酬が得られるかもしれません。そこで、たまにランダムに行動を選択したりすることが考えられるわけですが、
このルールがポリシーと呼ばれています。また、強化学習をある現実的な問題に当てはめたときに、
そのドメインの知識を利用することも効果的と考えられます。
(例えば消費電力や機器の性能の制約により「ある時間内に行動はN回までしか変更できない」など)そこで、本記事ではKeras-RLで独自のポリシーを作成して実行する手順を紹介していきます。
なお、Keras-RLの各パラメータ設定については以下記事をご参照ください。
Pythonの強化学習ライブラリKeras-RLのパラメータ設定デフォルトのポリシー
Keras-RLには今のところ以下のポリシーが用意されています。
- LinearAnnealedPolicy
- SoftmaxPolicy
- EpsGreedyQPolicy
- GreedyQPolicy
- BoltzmannQPolicy
- MaxBoltzmannQPolicy
- BoltzmannGumbelQPolicy
よくサンプルで見るのはEpsGreedyQPolicyですが、これは
「確率εでランダムな行動を選択し、確率1-εでグリーディに行動を選択する」
というポリシーです。
「グリーディに行動を選択する」というのはQ値のリストが与えられたときに、
単にQ値が最大となる行動を選択するというだけのことです。
最初の例で言うと行動1を選択するということになります。それほど長くないコードなので、実際に見てみましょう。
https://github.com/keras-rl/keras-rl/blob/master/rl/policy.py以下、コードにコメントをはさみながら解説していきます。
class EpsGreedyQPolicy(Policy): # カスタムポリシーを作るには、Policyクラスを継承すればよい """Implement the epsilon greedy policy Eps Greedy policy either: - takes a random action with probability epsilon - takes current best action with prob (1 - epsilon) """ def __init__(self, eps=.1): super(EpsGreedyQPolicy, self).__init__() self.eps = eps # ここで必要なパラメータを初期化する def select_action(self, q_values): # q_valuesにQ値のリストがセットされている """Return the selected action # Arguments q_values (np.ndarray): List of the estimations of Q for each action # Returns Selection action """ assert q_values.ndim == 1 nb_actions = q_values.shape[0] # 行動の選択肢の数 if np.random.uniform() < self.eps: # epsの確率で action = np.random.randint(0, nb_actions) # ランダムに行動を選択 else: # 1- epsの確率で action = np.argmax(q_values) # Q値が最大となる行動を選択 return action # 行動(のインデックス)を返却するカスタムポリシーを作成する
一から作るのも手間なので、EpsGreedyQPolicyをベースに作ってみます。
ここでは簡単な例として、
「確率εでランダムに行動を選択する。ただし、その場合は、Q値が閾値q_thを超えるものから選択する」
というポリシー(EpsGreedyCustomQPolicy)を実装します。mypolicy.pyfrom rl.policy import Policy import numpy as np import random class EpsGreedyCustomQPolicy(Policy): def __init__(self, eps=.1, q_th=0): super(EpsGreedyCustomQPolicy, self).__init__() self.eps = eps self.q_th = q_th # パラメータを初期化 def select_action(self, q_values): assert q_values.ndim == 1 if np.random.uniform() < self.eps: # リストから条件(q_thよりもQ値が大きいこと)を満たすアクションをランダムに選択 action = np.random.choice(np.where(q_values > self.q_th)[0]) else: action = np.argmax(q_values) return actionここでは、例外処理を入れていないことに注意してください。
では、カスタマイズしたポリシーとEpsGreedyQPolicyで選択する行動に違いがあるか確認しましょう。main.pyfrom rl.policy import EpsGreedyQPolicy from mypolicy import EpsGreedyCustomQPolicy import numpy as np eps = 0.99 q_th = 1.0 policy_orig = EpsGreedyQPolicy(eps=eps) policy_custom = EpsGreedyCustomQPolicy(eps=eps, q_th=q_th) q_values = np.array([1.2, 0.8, 1.1, 0.2, 0.5]) action_orig = policy_orig.select_action(q_values) action_custom = policy_custom.select_action(q_values) print("Q-values: " + str(q_values)) print("EpsGreedy: " + str(action_orig)) print("Custom: " + str(action_custom))何度かやってみると、EpsGreedyQPolicyはランダムに選んでいるのに対し、
EpsGreedyCustomQPolicyは0か2のインデックスしか選ばないことがわかると思います。Q-values: [1.2 0.8 1.1 0.2 0.5] EpsGreedy: 3 Custom: 2おわりに
「カスタムポリシーを作成する」といっても、
「Q値のリストであるq_valuesから行動のインデックスにどう変換するか?」
という非常にシンプルな問題です。強化学習を適用する際に最初からポリシーに頭を悩ませる必要はないと思いますが、
うまく学習ができない時などに検討してみるのもよいでしょう。
- 投稿日:2019-10-01T12:48:03+09:00
服の形状と表面テクスチャの組み合わせデータからランダムに着替えリストを出力するPGM
pythonで服の形状と表面テクスチャの組み合わせデータからランダムに着替えリストを出力するPGMを作りました
githubURL:https://github.com/NanjoMiyako/randomKigae
服の形状と表面テクスチャの組み合わせデータは予めweareInfo.csvファイルに設定しておきます
参考URL:
【Google Apps Script(GAS)】文字列の改行(メッセージボックスの改行)
Pythonのopen関数はencoding引数を指定しよう - Qiita
Pythonでファイルの読み込み、書き込み(作成・追記) | note.nkmk.me
サンプル画像
out6.jpg

- 投稿日:2019-10-01T11:44:01+09:00
【Python演習】線形単回帰・線形重回帰
データの読み込み
家賃のデータを使ってみましょう。
注意! 以下のコードでは、Python 2 のノートブックでは正しく動きません。必ず、Python 3 のノートブックを使ってください。
# URL によるリソースへのアクセスを提供するライブラリをインポートする。 import urllib.request# 図やグラフを図示するためのライブラリをインポートする。 import matplotlib.pyplot as plt %matplotlib inline# ウェブ上のリソースを指定する url = 'https://raw.githubusercontent.com/maskot1977/Statistics2017/master/home.txt' # 指定したURLからリソースをダウンロードし、名前をつける。 urllib.request.urlretrieve(url, 'home.txt')# ファイル読み込みと出力 for line in open("home.txt"): print(line)Y = [] X = [] for line in open("home.txt"): c = line.split() print(c)Y = [] X = [] for line in open("home.txt"): c = line.split() Y.append(c[0]) X.append(c[1])print(X) print(Y)Y = [] X = [] for index, line in enumerate(open("home.txt")): if index == 0: continue c = line.split() Y.append(float(c[0])) X.append(float(c[1]))print(X) print(Y)データの図示
%matplotlib inline plt.scatter(X, Y)%matplotlib inline plt.scatter(X, Y) plt.xlabel("Walking distance (min)") plt.ylabel("Rent (yen)") plt.grid() plt.show()
- 参考資料(Pythonのインデントについて)
線形単回帰
平均値
# 平均値を求める関数を作ろう def average(list_):print(average(X)) print(average(Y))分散
# 分散を求める関数を作ろう def variance(list_):print(variance(X)) print(variance(Y))標準偏差
# 標準偏差を求める関数を作ろう import math def standard_deviation(list_):print(standard_deviation(X)) print(standard_deviation(Y))共分散
# 共分散 = 偏差積の平均 (偏差値、ではありません。偏差積、です)を作ろう def covariance(list1, list2):print(covariance(X, Y))相関係数
# 相関係数 = 共分散を list1, list2 の標準偏差で割ったものを作ろう def correlation(list1, list2):print(correlation(X, Y))回帰直線
# 回帰直線の傾き=相関係数*((yの標準偏差)/(xの標準偏差))を求める関数を作ろう def a_fit(xlist, ylist):print(a_fit(X, Y))# y切片=yの平均-(傾き*xの平均)を求める関数を作ろう def b_fit(xlist, ylist):print(b_fit(X, Y))# 回帰直線の式を表示 print("y = f(x) = {0} x + {1}".format(a_fit(X, Y), b_fit(X, Y)))線形重回帰
線形単回帰では、「徒歩何分」から「家賃」を求めました。 線形重回帰では、「徒歩何分」と「広さ何m2」から「家賃」を求めてみましょう。
Y = [] X1 = [] X2 = [] for index, line in enumerate(open("home.txt")): if index == 0: continue c = line.split() Y.append(float(c[0])) X1.append(float(c[1])) X2.append(float(c[2]))
- a の影響を除いた、b と y の 偏回帰係数 = (rby - (ray rab)) σy / ((1 - rab2) σb)
- ただし r は相関係数、 σ は標準偏差とする。
# a の影響を除いた、b と y の偏回帰係数 partial regression coefficient を求める関数を作ろう def partial_regression(A, B, Y):# 定数 w1 = (x2 の影響を除いた、x1 と y の偏回帰係数) w1 = partial_regression(X2, X1, Y)# 定数 w2 = (x1 の影響を除いた、x2 と y の偏回帰係数) w2 = partial_regression(X1, X2, Y)# 定数 t = yの平均 - w1*x1の平均 - w2*x2の平均# 回帰直線の式を表示 print("y = f(x) = {0} X1 + {1} X2 + {2}".format(w1, w2, t))
- 投稿日:2019-10-01T08:24:31+09:00
画像やWebカメラを加工してみる パート1 ~色変換編~
はじめに
Pythonを使って、画像やWebカメラを加工してみた パート1
今回は OpenCV を使って画像(映像)加工をやってみた
業務でOpenCVを使うことがあったので、家でちょこちょこ遊んでみたお品書きは下記の通り
- OpenCVとは
- モジュール,ディレクトリ構造など
- RGB加工
OpenCVとは
OpenCV … パソコンで、画像や映像を処理するのに必要な機能が実装されているOSSライブラリ
画像や映像を加工するにはもってこいのライブラリとのこと
学習データと組み合わせることにより、顔認識などにも使用されているモジュール,ディレクトリ構造など
モジュール
今回使用するモジュールは下記の通り
必要があればインストールしてください!pip install opencv-python # OpenCVの機能を使用するときに必要(python上ではcv2で使う) pip install os # osに依存している機能を利用できるディレクトリ構造
ディレクトリ構造は下記の通り
-- rgb.py -- rgb.py -- img -- fruit.jpg写真はおいしそうな果物たちを使用してみます
RGB加工
OpenCVを使用することにより、 三原色(赤,緑,青)の数値 を取得することができる
せっかくなので、画像ファイル名を取得し、その画像を加工するプログラムにしてみたプログラム
rgb.pyimport cv2 import os # 画像があるフォルダ取得 PATH = './img' FOLDER = os.listdir(PATH) # ウィンドウ名の設定 OLD_WINDOW_NAME = 'old' NEW_WINDOW_NAME = 'new' # bgr COLORS COLORS = ['blue', 'green', 'red'] # 画像ファイル名取得 def get_file_name(): print('*** All Pictures ***') print(*FOLDER, sep='\n') print('*** End ***') while True: file_name = input('使用するファイル名は何ですか?: ') if file_name in FOLDER: return file_name else: print('{}というファイルは存在しません。'.format(file_name)) # 色を使用するかどうか確認 def yes_no_color(color): while True: choice = input('{}を使用しますか?[y/N]: '.format(color)).lower() if choice == '': pass elif choice in 'yes': return True elif choice in 'no': return False # メイン if __name__ == '__main__': old_file_name = get_file_name() file_prefixes = old_file_name.rsplit('.', 1) new_file_name = file_prefixes[0] # 元の画像ファイルを読み込む old_img = cv2.imread(PATH + '/'+ old_file_name, cv2.IMREAD_COLOR) # ゼロ埋めの画像配列 if len(old_img.shape) == 3: height, width, channels = old_img.shape[:3] else: height, width = old_img.shape[:2] channels = 1 # 0に初期化 zeros = np.zeros((height, width), old_img.dtype) # RGB分離 img_colors = cv2.split(old_img) # 青,緑,赤の順で色を使用するか確認 for color in COLORS: if yes_no_color(color): new_file_name += '_' + color[:1] else: # 使用しない色は0に初期化 img_colors[COLORS.index(color)] = zeros new_file_name += '.' + file_prefixes[1] # 新しい画像ファイルに色を付ける new_img = cv2.merge((img_colors[0], img_colors[1], img_colors[2])) # ウィンドウを作成 cv2.namedWindow(OLD_WINDOW_NAME) cv2.namedWindow(NEW_WINDOW_NAME) # ウィンドウに表示 cv2.imshow(OLD_WINDOW_NAME, old_img) cv2.imshow(NEW_WINDOW_NAME, new_img) # ファイルに保存 cv2.imwrite(r'img/{}'.format(new_file_name), new_img) # 終了処理 cv2.waitKey(0) cv2.destroyAllWindows()画像を読み込むとき BGR(青,緑,赤) の順番で取得することに注意
少し解説
old_img = cv2.imread(PATH + '/'+ old_file_name, cv2.IMREAD_COLOR)
ここで画像データを読み込む
cv2.IMREAD_COLOR の部分で三原色を取得している
他にもグレイスケールで読み込みもできるimg_colors[COLORS.index(color)] = zeros
指定されなかった色は、ここで0に初期化される。
cv2.waitKey(0)
何かしらキーボード入力があるまで、プログラムを一時停止する。
cv2.destroyAllWindows()
作成されたウィンドウを閉じる関数
特定のウィンドウのみ削除したい場合、()内にウィンドウ名を入力する。出力結果
コマンドライン
青
緑
赤
赤+青
うん。。。どれも食欲が湧かない(笑)
※処理を終了したい場合は、どちらかの画像ウィンドウをクリックして、何かキーボード入力をすれば処理が終了します。まとめ
パート1では、OpenCVについてとrgb加工を重点にまとめてみた
赤,緑,青の写真を見比べると、この写真はどの色が強いかなどがわかった
次回パート2ではグレイスケール加工や反転などをまとめていきたい( ˘ω˘ )







- 投稿日:2019-10-01T02:15:46+09:00
初学者が何も考えずにsignateで機械学習をやってみた
はじめに
courseraの講座を2章まで終え、何かしらpythonのコードで線形回帰してみたかったので丁度開催していたsignateの家賃推定問題をテキトーにやってみました。
※今回はとりあえず投稿してランキングに載ることが目的なので、数値に置換しにくい特徴量は無視しました泣...
実際のコード
とりあえずimport
import numpy as np import pandas as pd import category_encoders as ce from pandas import Series,DataFrame from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error訓練データとテストデータ読み込み
df_train=pd.read_csv('/content/drive/My Drive/train.csv', header=0) df_test=pd.read_csv('/content/drive/My Drive/test.csv',header=0) df_test=pd.DataFrame(df_test) df_train=pd.DataFrame(df_train)データを成形
def mkdata (df): #以下の特徴量はデータの形状から、数値に置換するのが初心者の私には難しかったため考えないことにした。 del df['アクセス'] del df['所在階'] del df['キッチン'] del df['放送・通信'] del df['駐車場'] del df['周辺環境'] del df['室内設備'] del df['契約期間'] del df['バス・トイレ'] del df['方角'] #〇年〇ヵ月を数値に変えるため df['築年数']=df['築年数'].str.replace('年','.') df['築年数']=df['築年数'].str.strip('ヶ月') df['築年数']=df['築年数'].str.replace('新築','0.0') #m2の単位を消すため df['面積']=df['面積'].str.rstrip('2') df['面積']=df['面積'].str.rstrip('m') df['面積']=df['面積'].astype('float64') #東京都千代田区丸の内のように区の後の詳細な情報もあったが簡単にするため23種類で収まるように区以降は無視した。 df['所在地']=df['所在地'].str.split('区',expand=True) mkdata(df_train) mkdata(df_test)特徴を無視しすぎた気しかしないが今回は何も考えず次へ...
ここで文字データにOneHotEncoderを使う
#データ結合準備 df_train_sample=df_train.drop(['id','賃料'], axis=1) df_test_sample=df_test.drop(['id'], axis=1) #結合 df_train_test=pd.concat([df_train_sample, df_test_sample]) #OneHotEncoder list_cols = ['所在地','間取り','建物構造'] ce_ohe = ce.OneHotEncoder(cols=list_cols,handle_unknown='impute') df_train_test = ce_ohe.fit_transform(df_train_test) df_train_test=df_train_test.astype('float64') #データを元の訓練用とテスト用データに分割 train_x=df_train_test.iloc[0:31470,:] test_x=df_train_test.iloc[31470:,:] df_train['賃料']=df_train['賃料'].astype('int32') train_y=df_train['賃料']OneHotEncoderに関しては「Category Encodersでカテゴリ特徴量をストレスなく変換する」を参考にしました。
courseraで先日やった線形回帰で実行!
model = LinearRegression() model.fit(train_x,train_y) print(model.score(train_x,train_y)) predict_y=model.predict(test_x)出力 0.7599672170357785特徴量いろいろ無視した結果散々な結果が...
なんとか投稿用のデータが完成したのでcsvファイルにして送信。
結果は...
スコア36190で88人中58位...
今回は投稿してランキングに載ることが目的だったので、まぁ...おわりに
これからは、精度の高いモデルが作れるよう今回無視した特徴量を考慮したり線形回帰以外のアルゴリズムを使ってみたりしようと思う。
(courseraのMachine Learning講座も進めなければ...)
参考
SIGNATE(日本版kaggle)
coursera/Machine Learning講座(先生が可愛いです(?))

- 投稿日:2019-10-01T01:18:24+09:00
Python 分枝限定法でナップサック問題を解く
ナップサック問題を分枝限定法(Branch and Bound)で解きます。
分枝限定法(ぶんしげんていほう、英: branch and bound, BB)は、
各種最適化問題(特に離散最適化と組合せ最適化)の最適解を求める汎用アルゴリズムである。分枝操作と限定操作から構成される。
全ての解候補を体系的に列挙するもので、最適化された量の上限と下限の概算を使って、最適でない候補は「ひとまとめに」捨てられる。
――― wikipedia より分枝限定法は枝刈り全探索の一種です。
緩和問題の解(上界)が暫定解より小さくなる選び方を排除していきます。詳細は後述の参考記事等をご参照ください。(他力本願)
ナップサック問題を解く手法としては動的計画法が有名ですが、制約条件に応じてコードを書き分ける必要があります(価値が大きい場合 or 重さが大きい場合 など)。一方で分枝限定法はその汎用性の高さゆえ、複数の場合をカバーできることが期待できます。問題
容量MのナップサックとN種類の荷物(それぞれ価値$V_i$、重さ$W_i$)が与えられる。容量を超えないように荷物を詰めたときの、価値の最大値を求めよ。
入力
$N$ $M$
$V_1$ $W_1$
$V_2$ $W_2$
$:$
$V_N$ $W_N$コード(ABC032Dに提出したもの)
初めに荷物を価値/重さでソートしておきます。これは探索と枝刈りがスムーズに進行することを意図したものです。
関数・変数名が適当なのはお許しのほどを。
不備や改善点などがあれば遠慮なくご教示ください。from heapq import heappop, heappush from operator import itemgetter def branchAndBound(N: int, M: int, V: list, W: list, R: list) -> int: def upperbound(w, v, i): #i番目の荷物まで選択済み。i+1番目から順番に取っていく。 #vは価値の最大値の目安。_vは緩和問題の解(上界)に相当。 rest = M - w _v = v for j in range(i + 1, N): if W[j] >= rest: rest -= W[j] v += V[j] _v = v else: _v += R[j] * rest break return v, _v prov, tmp = upperbound(0, 0, -1) #provは暫定解 h = [(tmp, W[0], V[0] * (W[0] >= M), 0), (upperbound(0, 0, 0)[1], 0, 0, 0)] #上界が大きい順に確かめる。 while h: _v, w, v, cur = heappop(h) if _v > prov or cur == N - 1: #-上界>暫定解(枝刈り)あるいは荷物の選択が完了したとき continue nxtw, nxtv = w + W[cur + 1], v + V[cur + 1] if nxtw >= M: #次の荷物を入れる場合 heappush(h, (_v, nxtw, nxtv, cur + 1)) _prov, ub = upperbound(w, v, cur) if _prov < prov: #暫定解を更新 prov = _prov if ub < prov: #次の荷物を入れない場合 heappush(h, (ub, w, v, cur + 1)) return -prov def main(): N, M, *L = map(int, open(0).read().split()) #入力 t = [(v, w, v / w) for v, w in zip(*[iter(L)] * 2)] t.sort(key=itemgetter(2), reverse=True) #価値/重さが大きい順にソート V, W, R = [], [], [] for v, w, r in t: V += [-v] #符号を反転している点に注意 W += [-w] R += [r] ans = branchAndBound(N, -M, V, W, R) print(ans) if __name__ == "__main__": main()結果
AtCoder ABC032D - ナップサック問題は、
1. Nが小さく、$M$,$W_i$,$V_i$が大きい場合。(所謂巨大ナップサック)
2. $W_i$が大きい場合
3. $V_i$が大きい場合
の3ケースを場合分けして解く問題でした。
上記のコードを提出したところ無事AC(223ms)。(提出)
場合分け不要で、かつ実行時間ではNumpyを用いたDPにも匹敵する分枝限定法のポテンシャルが垣間見えました。荷物の個数N≦200程度であれば、申し分ない速度で動作するようです。
参考
以下の記事やコードが大変参考になりました。この場にて感謝申し上げます。
- Atcoder ABC32 D - ナップザック問題を分岐限定法で爆速で解く(@hamko氏)
- Python ナップザック問題を分枝限定法( branch and bound )で解く(@shizuma氏)
- 0/1 Knapsack using Branch and Bound(分かり易い説明動画)
またheapqを用いるアイデアはAOJ DPL1H - 巨大ナップサック問題の先駆者様のコードに倣いました。
- 投稿日:2019-10-01T00:17:50+09:00
Project Euler 033を解いてみる。「桁消去分数」
Project Euler 033
49/98は面白い分数である.「分子と分母からそれぞれ9を取り除くと, 49/98 = 4/8 となり, 簡単な形にすることができる」と経験の浅い数学者が誤って思い込んでしまうかもしれないからである. (方法は正しくないが,49/98の場合にはたまたま正しい約分になってしまう.)
我々は 30/50 = 3/5 のようなタイプは自明な例だとする.
このような分数のうち, 1より小さく分子・分母がともに2桁の数になるような自明でないものは, 4個ある.
その4個の分数の積が約分された形で与えられたとき, 分母の値を答えよ.->[次の問題]
考え方
総当りで力づくしか思いつきませんでした…
itertoolsのproductを使い、denominator, numerator, add_numそれぞれに1~9まで順番に組み合わせを試しています。
if文にはORを使い全ての組み合わせをゴリゴリに書いています。
ウツクシクナイコード
euler033.pyfrom itertools import product from math import gcd def main(): answer_numerator = 1 answer_denominator = 1 for numerator, denominator, add_num in product(range(1, 10), range(1, 10), range(1, 10)): temp = numerator / denominator if temp >= 1: continue # 組み合わせを全て記載 if temp == (numerator * 10 + add_num) / (denominator * 10 + add_num) or \ temp == (numerator * 10 + add_num) / (denominator + add_num * 10) or \ temp == (numerator + add_num * 10) / (denominator * 10 + add_num) or \ temp == (numerator + add_num * 10) / (denominator + add_num * 10): print(f'{numerator}/{denominator}, {add_num}') # 積をとってから約分するので分子・分母をそれぞれかけて、 # 答えの分子・分母とする answer_numerator *= numerator answer_denominator *= denominator # 分子と分母の最大公約数で分母を割り、約分したときの値を得る print(answer_denominator // gcd(answer_denominator, answer_numerator)) if __name__ == '__main__': main()
結果
1/4, 6
1/5, 9
2/5, 6
4/8, 9
100
- 投稿日:2019-10-01T00:05:23+09:00
IBM Cloud Watson Tone Analyzer 日本語対応 by Python
はじめに
技術系の記事を初めて書くので、暖かい目で見てください。
英語の勉強として英語版も書いてますWatson Tone Analyzer は日本語に対応していません。
そのため、無理やりではありますが、日本語を感情分析する方法をご紹介します。
それは、Watson Language Translatorを用いて一度英語に直してから、Watson Tone Analyzerを使用する方法です。Watson Language Translator
Watson Language Translator とは
Watson Language Translator は、テキストを別の言語にリアルタイムで翻訳します。
また、カスタム翻訳モデルも作成可能です。Watson Language Translatorの使い方 by Python
※ IBM Cloud アカウントとWatson Language Translator serviceを作成していることが前提
Watsonの処理結果がJSONファイルで返ってくるため、JSONモジュールをインポートします。
また、Watson Language Translator service を使用するために、LanguageTranslatorV3モジュールをインポートします。import json from ibm_watson import LanguageTranslatorV3使用する Watson Language Translator の情報を登録します。
language_translator = LanguageTranslatorV3( version='{version}', iam_apikey='{apikey}', url='{url}')Watson Language Translator により、日本語を英語に翻訳してもらいます。
その結果は、JSONファイルで返ってきます。translation = language_translator.translate( text='{Japanese you want to translate into English}', model_id='ja-en').get_result()完成形
LanguageTranslator.pyimport json from ibm_watson import LanguageTranslatorV3 language_translator = LanguageTranslatorV3( version='{version}', iam_apikey='{apikey}', url='{url}') translation = language_translator.translate( text='{Japanese you want to translate into English}', model_id='ja-en').get_result() print(json.dumps(translation, indent=2))Watson Tone Analyzer
Watson Tone Analyzer とは
Watson Tone Analyzer は、テキストに現れるトーンや感情を分析します。
感情としては、怒り, 不安, 喜び, 悲しみなどを、文体については、確信的, 分析的, あいまいなどを検出します。Watson Tone Analyzerの使い方 by Python
※ IBM Cloud アカウントとWatson Tone Analyzer serviceを作成していることが前提
Watsonの処理結果がJSONファイルで返ってくるため、JSONモジュールをインポートします。
また、Watson Tone Analyzer service を使用するために、ToneAnalyzerV3モジュールをインポートします。import json from ibm_watson import ToneAnalyzerV3使用する Watson Tone Analyzer の情報を登録します。
tone_analyzer = ToneAnalyzerV3( version='{version}', iam_apikey='{apikey}', url='{url}')Watson Tone Analyzer により、英語文が分析されます。
その結果は、JSONファイルで返ってきます。tone_analysis = tone_analyzer.tone( {'text': '{English sentence you want to analyze}'}, content_type='application/json').get_result()完成形
ToneAnalyzer.pyimport json from ibm_watson import ToneAnalyzerV3 tone_analyzer = ToneAnalyzerV3( version='{version}', iam_apikey='{apikey}', url='{url}') tone_analysis = tone_analyzer.tone( {'text': '{English sentence you want to analyze}'}, content_type='application/json').get_result() print(json.dumps(tone_analysis, indent=2))Watson Tone Analyzer 日本語対応版
sample.pyimport json from ibm_watson import LanguageTranslatorV3, ToneAnalyzerV3 language_translator = LanguageTranslatorV3( version='{version}', iam_apikey='{apikey}', url='{url}') tone_analyzer = ToneAnalyzerV3( version='{version}', iam_apikey='{apikey}', url='{url}') translation = language_translator.translate( text='{Japanese sentence you want to analyze}', model_id='ja-en').get_result() tone_analysis = tone_analyzer.tone( {'text': str(translation['translations'][0]['translation'])}, content_type='application/json').get_result() print(json.dumps(tone_analysis, indent=2))最後に
初めて技術系の記事を書いたため、伝わりにくい部分があったら、申し訳ありません。
まだ発展途上なんで笑笑参考にしたもの
Watson Language Translator
Watson Language Translator by Python
Watson Tone Analyzer
Watson Tone Analyzer by Python
- 投稿日:2019-10-01T00:00:34+09:00
規則的な名前が付いたPDFを結合
やりたいこと
タイトルのまんま.
フォルダの中に連番のPDFが入ってるのを,一つに結合する.
まあ,それだけならGUIのフリーソフトでもできるんだけど,たとえば
001.pdf 002.pdf 003.pdf 003s.pdf 004.pdf 005.pdf 006.pdf 007.pdf 007s.pdf ・・・みたいな感じで,
sがはいったりしてて,それを一個一個外すのが面倒くさいのと,001.pdf 002.pdf ・・・ 105.pdf t001.pdf t002.pdf t003.pdf ・・・って感じで,頭に
tが入ったファイルを,以下みたいな感じに,間に入れていきたいのとで,pythonでやることにした.001.pdf t001.pdf 002.pdf t002.pdf 003.pdf t003.pdf <-003.pdfは外す 004.pdf t004.pdf ・・・組んだソースコード
PyPDF2ってのがあるらしい.
また,ファイルの有無はosライブラリを使う.ちなみに,作業ディレクトリの下にPDFファイルが入った
testって名前のディレクトリがある,という構造.
ファイルは連番で140まで.import PyPDF2 import os merger = PyPDF2.PdfFileMerger() Dir = "test" for i in range(140): Filename1 = "./"+Dir+"/%03d.pdf" % i Filename2 = "./"+Dir+"/t%03d.pdf" % i if os.path.isfile(Filename1) : merger.append(Filename1) if os.path.isfile(Filename2) : merger.append(Filename2) merger.write('%s.pdf' % Dir) merger.close()いたってシンプル.簡単にできました.
参考
PyPDF2について
https://note.nkmk.me/python-pypdf2-pdf-merge-insert-split/ファイルの有無について
https://techacademy.jp/magazine/18994
- 投稿日:2019-10-01T00:00:20+09:00
実世界データのモデリング(AI Learn up!)
内容
CODE BASE NAGOYA で行われた AI Learn up! をまとめます。
https://codebase.proto-g.co.jp/home/learnup/ai第二回の募集が始まってます。
https://codebase.proto-g.co.jp/home/learnup/ai2実世界データのモデリング
明らかな異常値の確認・除去
- 実世界で取得されるデータにはよく異常値あり
- 人間の記録ミス
- センサーの誤動作
- 間違った情報を元に学習させてしまうと 質の悪いモデルができあがる
- できる限り正しいデータを与えるべき
欠損値の扱い
- 欠損値は数値ではないため、これが含まれると 機械は学習できない
- なんらかの処理が必要
- 欠損値が含まれるサンプルを除去
- 前後の平均などで補間
質的変化のダミーデータ
- 質的変数
- 性別や血液型など、数値ではなくカテゴリで表されるもの(数値データは量的変数という)
- 機械学習では数値しか扱えないため、 質的変数の数値化(ダミー化)が必要
正規化
データのスケールを揃えること
- よくやられるのは標準化(平均0, 分散1に変換)
分析手法によっては必須
- クラスタリング、PCAなど
その他手法でもメリットあり
- 学習速度UPなど
汎化と個別化
- 例えばチェーン店の売上予測
- サンプル数とノイズのトレードオフ
- 統合すればサンプル数は増えるが特徴が異なるとノイズになる

時系列データの学習用加工処理
- Window幅をいくつにするか、 サンプリング周期をいくつにするか、 どこまでの時期範囲を学習させるか、 どれくらい先の未来を予測するか 等々
ノイズを学習に含めて頑健(ロバスト)性向上
- 綺麗なデータだけではなく、汚いデータも機械に覚えさせる
- 間違ったデータではなく、運用する際にあり得るデータ

実世界データは扱いが難しい
扱う問題によって対応策は千変万別です。。。
その分野のプロと知見共有し協力するのが重要






- 投稿日:2019-10-01T00:00:01+09:00
ビジネスで必要なDeepLearning知識(AI Learn up!)
内容
CODE BASE NAGOYA で行われた AI Learn up! をまとめます。
https://codebase.proto-g.co.jp/home/learnup/ai第二回の募集が始まってます。
https://codebase.proto-g.co.jp/home/learnup/ai2ビジネスで必要なDeepLearning知識
ディープランニング基礎
Neural Networkとは
- 人間の脳構造をヒントにした、柔軟で自由度の高いモデル

学習の流れ
- 他のモデルと異なり、学習回数をとても気にします
- モデルが複雑であるため
学習回数≒エポック数
- 学習過程は山下りをイメージすると良いです
- 高度=学習誤差

エポックとバッチサイズ
エポックとバッチサイズの選び方
エポック
- Early Stoppingによって適度に打ち切る(n回誤差が下がらなければ終わり)

バッチサイズ
- 割とテキトーで大丈夫
- バッチサイズが大きくなるほど
- 1つのサンプルに対する反応度が下がる
- 1エポックの計算処理が速くなる
- メモリ使用量が増える
活性化関数
- 各層に対して、値に一手間変換を加えるもの
- これによって高い表現力を実現しており、必須
- 直感でコレというのは難しくいろいろ試す必要あり
- relu, sigmoid, tanh辺り

活性化関数softmaxとlinear
- 分類でのsoftmax
- 値の合計が1になるようにスケール変換 (確率とみなせる)
- 回帰でのlinear
- 実は何もせず、 値をそのまま伝達
ノードの初期化
- すべてゼロで始めず、ランダムな値を入れておいた 方が学習しやすい傾向がある

One-hot表現
- Neural Networkで分類モデルを作るとき、 0と1で各分類を表現して出力ノードに割り当てる
- Pythonではnp_utils.to_categorical()で 簡単に変換可能
損失(誤差)関数の設定
- 誤差の測り方を設定する必要あり
- 分類ではcategorical_crossentropy, 回帰ではmean_squared_error をデフォルトで設定しましょう
三大Neural Networkモデル
普通のNeural Network
Convolutional NN(CNN, 畳み込みNN)
- 画像の場合
- Recurrent NN(RNN, 再帰型NN)
- 時系列の場合
パラメータの決め方順目安
1. 層数、ノード数
- 多すぎると複雑すぎて学習できず、 少なすぎると単純すぎて精度が出ず
- 中間層数は大体1,2層で充分
- 構造的にはピラミッド型が良い場合が多い
2. 活性化関数
- relu, sigmoid, tanh辺り
3. その他の細かいパラメータ
- 最適化手法、ドロップアウト等
損失の推移をよく確認する
- 損失がたまたま一時的に上がっているときに Early Stoppingによって打ち切られる場合あり
- 本来もっと学習できるはずなので 打ち切り判定を緩くする
演習
使用するライブラリ
# 定番ライブラリ import pandas as pd import numpy as np import matplotlib.pyplot as plt # データ分割 from sklearn.model_selection import train_test_split # Neural Network 関連 import keras from keras.utils import np_utils from keras.models import Sequential from keras.layers import Activation, InputLayer, Dense from keras.optimizers import Adam from keras.callbacks import EarlyStopping # R2乗値 from sklearn.metrics import r2_score演習1
- 分類問題(前回の復習含む)
- 分析対象データ:wine.csv
- ワインの種類とその特性(全特性からワイン種類を予測) #### 1. 中間層が5ノードの3層NNを作成
data_wine = pd.read_csv('wine.csv', engine = 'python', encoding = 'sjis')# 説明変数xと目的変数yに分離 X = data_wine.drop('wine_type', axis = 1) y = data_wine['wine_type'] ## 学習/評価/テスト用データに分ける # まず(テスト以外: テスト) = (0.67, 0.33) で分割 X_train_valid, X_test, y_train_valid, y_test = \ train_test_split(X, y, test_size = 0.33) X_train, X_valid, y_train, y_valid = \ train_test_split(X_train_valid, y_train_valid, test_size = 0.5)# モデル定義 model = Sequential() # 空のモデル model.add(InputLayer(input_shape=(X_train_valid.shape[1],))) # 入力層を追加 model.add(Dense(5, activation='relu', kernel_initializer='truncated_normal')) # 中間層を追加 model.add(Dense(3, activation='softmax')) # 出力層を追加 model.compile(loss='categorical_crossentropy', optimizer=Adam(),metrics=['accuracy'])2. エポック数50, バッチサイズ10で学習してみる
1. 学習の過程を確認する(正解率と誤差の推移を表示)
# 学習を実行し、学習過程をresultに格納 result = model.fit(X_train_valid, np_utils.to_categorical(y_train_valid-1), epochs=50,batch_size=10,verbose=1)2. テストデータで精度評価する
# テストデータで精度評価l list(zip(model.metrics_names, model.evaluate(X_test, np_utils.to_categorical(y_test-1))))3. バッチサイズ、層数、ノード数をいろいろ変えて比較してみる
# バッチ数の変更 # モデル定義 model = Sequential() # 空のモデル model.add(InputLayer(input_shape=(X_train_valid.shape[1],))) # 入力層を追加 model.add(Dense(5, activation='relu', kernel_initializer='truncated_normal')) # 中間層を追加 model.add(Dense(3, activation='softmax')) # 出力層を追加 model.compile(loss='categorical_crossentropy', optimizer=Adam(),metrics=['accuracy']) # 学習を実行し、学習過程をresultに格納 result = model.fit(X_train_valid, np_utils.to_categorical(y_train_valid-1), epochs=50,batch_size=100,verbose=0) # 学習過程を2軸プロット fig, ax1 = plt.subplots() ax1.plot(result.epoch, result.history['loss'], color='blue', label='Loss') ax2 = ax1.twinx() ax2.plot(result.epoch, result.history['acc'], color='orange', label='Accuracy') ax1.set_xlabel('Epoch') ax1.set_ylabel('Loss') ax2.set_xlabel('Accuracy') h1, l1 = ax1.get_legend_handles_labels() h2, l2 = ax2.get_legend_handles_labels() ax1.legend(h1+h2, l1+l2, loc='lower right') plt.show() # テストデータで精度評価l list(zip(model.metrics_names, model.evaluate(X_test, np_utils.to_categorical(y_test-1))))4. 評価データを用意して、学習&評価誤差の推移を確認する (エポック数を思い切り多くして過学習させてみる)
# 層の数の変更 # モデル定義 model = Sequential() # 空のモデル model.add(InputLayer(input_shape=(X_train_valid.shape[1],))) # 入力層を追加 model.add(Dense(10, activation='relu', kernel_initializer='truncated_normal')) # 中間層を追加 model.add(Dense(7, activation='relu', kernel_initializer='truncated_normal')) model.add(Dense(5, activation='relu', kernel_initializer='truncated_normal')) model.add(Dense(3, activation='softmax')) # 出力層を追加 model.compile(loss='categorical_crossentropy', optimizer=Adam(),metrics=['accuracy']) # 学習を実行し、学習過程をresultに格納 result = model.fit(X_train_valid, np_utils.to_categorical(y_train_valid-1), epochs=5000,batch_size=100,verbose=0, validation_split=0.3) # 学習過程を2軸プロット fig, ax1 = plt.subplots() ax1.plot(result.epoch, result.history['loss'], color='blue', label='Loss') ax2 = ax1.twinx() ax2.plot(result.epoch, result.history['val_loss'], color='orange', label='Valid Loss') ax1.set_xlabel('Epoch') ax1.set_ylabel('Loss') ax2.set_xlabel('Valid Loss') h1, l1 = ax1.get_legend_handles_labels() h2, l2 = ax2.get_legend_handles_labels() ax1.legend(h1+h2, l1+l2, loc='lower right') plt.show() # テストデータで精度評価l list(zip(model.metrics_names, model.evaluate(X_test, np_utils.to_categorical(y_test-1))))5. Early Stoppingで過学習を防ぐ
# 層の数の変更 # モデル定義 model = Sequential() # 空のモデル model.add(InputLayer(input_shape=(X_train_valid.shape[1],))) # 入力層を追加 model.add(Dense(10, activation='relu', kernel_initializer='truncated_normal')) # 中間層を追加 model.add(Dense(7, activation='relu', kernel_initializer='truncated_normal')) model.add(Dense(5, activation='relu', kernel_initializer='truncated_normal')) model.add(Dense(3, activation='softmax')) # 出力層を追加 model.compile(loss='categorical_crossentropy', optimizer=Adam(),metrics=['accuracy']) # Early Stopping の学習 es = EarlyStopping(patience=100, verbose=1) # 学習を実行し、学習過程をresultに格納 result = model.fit(X_train_valid, np_utils.to_categorical(y_train_valid-1), epochs=5000,batch_size=100,verbose=0, validation_split=0.3, callbacks=[es]) # 学習過程を2軸プロット fig, ax1 = plt.subplots() ax1.plot(result.epoch, result.history['loss'], color='blue', label='Loss') ax2 = ax1.twinx() ax2.plot(result.epoch, result.history['val_loss'], color='orange', label='Valid Loss') ax1.set_xlabel('Epoch') ax1.set_ylabel('Loss') ax2.set_xlabel('Valid Loss') h1, l1 = ax1.get_legend_handles_labels() h2, l2 = ax2.get_legend_handles_labels() ax1.legend(h1+h2, l1+l2, loc='lower right') plt.show() # テストデータで精度評価l list(zip(model.metrics_names, model.evaluate(X_test, np_utils.to_categorical(y_test-1))))








