- 投稿日:2019-10-01T22:39:03+09:00
Homebridge-CMD4の使い方
Homebridge-CMD4とは?
homebridge-cmd4 - npm
Homebridge-CMD4とは、任意のコマンドをHomekitアクセサリのように登録し、実行可能になるプラグインです。
特長としては、Homekitのほぼすべてのアクセサリに対応しており、Homekitによって提供されるSiriでのコントロールなどの恩恵を最大限受けることが可能です。
インストール
Homebridge本体は既にあるものとします。
Step1 Homebridge-CMD4のインストール
State.jsについては後ほど解説します。
sudo npm install -g --unsafe-perm homebridge-cmdStep2 State.jsのインストール
mkdir $HOME/.homebridge mkdir $HOME/.homebridge/Cmd4Scripts cp /usr/lib/node_modules/homebridge-cmd4/Extras/Cmd4Scripts/State.js $HOME/.homebridge/Cmd4Scripts/ cp /usr/lib/node_modules/homebridge-cmd4/Extras/Cmd4Scripts/CheckYourScript.sh $HOME/.homebridge/Cmd4Scripts/ chmod 700 .homebridge/Cmd4Scripts/State.jsHomebridge-CMD4の基本概念
config.jsonの記述
Homebridge-CMD4も他のHomebridgeプラグインと同じように、config.jsonに設定を記述することで利用できます。
公式ページに載っているPS4の例を用いてこのプラグインの利用の基本について解説します。
こちらがそのconfig.jsonです。config.json... { "platform": "Cmd4", "name": "Cmd4", "accessories": [ { "type": "Switch", "name": "PS_4", "on": false, "state_cmd": "bash .homebridge/Cmd4Scripts/PS4.sh" "polling": true, <OR> "polling": [{"on": false, "interval": 5, "timeout": 4000} ], "interval": 5, "timeout": 4000, } ] } ...platform及びnameはHomebridgeの基本動作に必要なものですからそには触れずに、accessories以下にどんどん書き加えて増やしていく形になります。
利用可能なアクセサリー一覧はこちらにあります。
そして、このconfig.jsonで重要なのはstate_cmdのみです。
デバイス上からHomekitアクセサリを実行した時、実行されるのは上記の例ではbash .homebridge/Cmd4Scripts/PS4.shだけです。つまり、このプラグインではstate_cmdに設定したシェルスクリプトに、引数によってONにするかOFFにするかを与え、シェルスクリプト 内のif文によって実行するコマンドを変化させるのです。
state_cmdについて
ではサンプルの
PS4.shを見てみます。PS4.sh#!/bin/bash # Notes # 1) This script is called as defined by the config.json file as: # "state_cmd": "bash .homebridge/Cmd4Scripts/PS4.sh" # $1 = 'Get' # $2 = <Device name> DO NOT USE SPACES IN DEVICE NAME. It causes problems parsing the command line. # $3 = <Characteristic> # $4 = <Device option> # # 2) For a set of On, the command issued would be: # bash $HOME/.homebridge/Cmd4Scripts/PS4.sh Set PS_4 On false # or # bash $HOME/.homebridge/Cmd4Scripts/PS4.sh Set PS_4 On true # # 3) For a Get of On, the command issued would be: # bash $HOME/.homebridge/Cmd4Scripts/PS4.sh Get PS_4 On # # Homebridge-cmd4 will interpret the result of false to be 1 # and true to be 0 so either 0/1 or true/false can be returned. # echo "\$1='$1' \$2='$2' \$3='$3' \$4='$4'" # This is only here for the first run. if [ ! -f "/tmp/fileVariableHolder" ]; then echo "0" > "/tmp/fileVariableHolder" fi if [ "$1" = "Get" ]; then # This line is commented out and would be # interchangeable with ps4-waker. It is here # as an example # ps4-waker search | grep -i '200 Ok' cat /tmp/fileVariableHolder rc=$? if [ "$rc" = "0" ]; then exit 0 else echo "failed" exit -1 fi fi if [ "$1" = "Set" ]; then if [ "$3" = "On" ]; then if [ "$4" = "true" ]; then # This line is commented out and would be # interchangeable with ps4-waker. It is here # as an example # ps4-waker echo $4 > /tmp/fileVariableHolder exit $? else # This line is commented out and would be # interchangeable with ps4-waker. It is here # as an example # ps4-waker standby echo $4 > /tmp/fileVariableHolder exit $? fi fi fi exit -1Notesに書いてあることが全てです。
実際にどのようにこのシェルスクリプトが呼ばれるかというと、例えば、
PS4をONにする時、./PS4.sh Set My_PS4 On trueOFFにする時
./PS4.sh Set My_PS4 On falseまた現在の状況を得る時は
./PS4.sh Get My_PS4 Onのような形で実行されます。
config.jsonのstate_cmdに設定されたPS4.shが実行された時、まず最初の引数としてGetまたはSetが渡されます。
Getは特に頻繁に呼び出され、現在の状況を返します。
起動時などに必ず実行されます。
Setはステータスを変化させる際に呼ばれます。その次の引数はデバイスの名前です。あまり気にしなくても良いかと。
三番目のOnについてですが、ここでは必ずOnになっています。
Set My_PS4 onSet My_PS4 offとした方が分かりやすいのにこれでは冗長です。
ここの値はcharacteristicと呼ばれていて、今回はPS4の電源を切るかつけるかの二つしかないのでこうなりましたが、例えば明るさを変更できる照明のコントロールをする時などは、./light.sh Set My_Dimmable_Light Brightness 40のように、characteristicに
My_Dimmable_Lightが与えられてるのがわかると思います。
これを踏まえると、ここにOnがあるのは自然な事であることが分かります。Getされた時のコマンドと、Setされた時のコマンドをONとOFFで2パターン用意して、if文の中にif文入れてつらつら書いていけばいいです。
また、処理に成功したか失敗したかは必ず返すようにしましょう。
ここはちゃんとみられているので、ちゃんと返さないとデバイス上からは応答なしとか言われちゃいます。さらに、先ほどの明るさを変更できる照明のコントロールをする時
./light.sh Set My_Dimmable_Light Brightness 40だと、終了する
exit 0の前に、echo 40をなどを実行して、ちゃんと設定したその値も返してあげないといけません。終わりに
PS4を例に取った基本的な概念の解説は以上になります。
ここでようやくインストールしたStare.jsの解説なのですが、ここにはすべてのcharacteristicとその使用法が記述されています。
これを読んで、state_cmdで呼び出されるプログラムを書いて実行する、というのが基本です。
また感の良い方や公式のドキュメントに目を通した方は気づいているかもしれませんが、このPS4.shなどは別にシェルスクリプトである必要は全くありません。
python3 ~/.homebridge/Cmd4Scripts/PS4.pyみたいなんでもOKです。私が作った冷房をコントロールするためのプログラムをこちらに置いとくので、参考になるかは全く分かりませんが、もしよければご活用ください.
改善したらなんかかんか投げつけてください。本日はお読みいただきありがとうございました。

- 投稿日:2019-10-01T22:34:58+09:00
(mac)Zshをターミナルのデフォルトに設定したら、nodebrewのnodeが認識されなくなった
- 投稿日:2019-10-01T21:11:40+09:00
node.jsにおける非同期処理の順序
node.jsには、現在の処理を抜けた後に、即時実行するためのコマンドが4つある。
- setImmediate(f)
- setTimeout(f,0)
- process.nextTick(f)
- Promise.resolve().then(f)
どの順序で実行されるか、調べた結果をまとめておく。
先に結論を述べると、以下の順序になっている。(左が先に実行される)
process.nextTick(f) > Promise.resolve().then(f) > setTimeout(f,0) ≒ setImmediate(f)この順序で実行されることは、以下のページで説明されている。
https://nodejs.dev/コードで確認
実際にコードを書いて試してみる。
main.jssetImmediate(() => { console.log('setImmediate') }) setTimeout(() => { console.log('setTimeout0') }, 0) Promise.resolve().then(() => { console.log('Promise Job') }) process.nextTick(() => { console.log('nextTick') }) console.log('main')実行結果$ node main.js main nextTick Promise Job setTimeout0 setImmediatesetTimout(f,0)とsetImmediate(f)については、試した環境では常にsetTimeout(f,0)が先だったが、
説明によると確定ではないようである。
- 投稿日:2019-10-01T20:31:09+09:00
puppeteer初心者がTwitterブックマークをエクスポートするツールを作りながら、使い方をまとめてみた
ふと、puppeteerがおもしろそうだなと思い、前から欲しかった
TwitterブックマークをJSONファイルにエクスポートするツールを題材に、
いろいろ遊んでみた時に備忘録。puppeteerはサクッと使えるので、すてき(´ω`)
作ったもの
こんな感じで勝手に操作してエクスポートしてくれます(´ω`)
puppeteerで自動ログインして、ブクマをJOSNでエクスポートできるように(´ω`)
— 積読ハウマッチ?きらぷか (@kira_puka) October 1, 2019
わかりやすいように背景色を変えたりしてる(´ω`) pic.twitter.com/UJiGAiw5KN最終的なソースコードはGitHubで公開中。
- memory-lovers/export_twitter_bookmarks_puppeteer: Twitter Bookmark Export Tool using Puppeteerただ、注意事項がたくさんですが。。(-_-;)
puppeteerの使い方
インストール
$ npm install -S puppeteer基本的な雛形
基本的にはこんな感じ。
- ブラウザを起動
- ページを作成
- なんか処理する
- ブラウザの終了
const puppeteer = require("puppeteer"); const fs = require("fs"); async function main() { let browser = null; try { // ブラウザの起動 browser = await puppeteer.launch(); // ページの作成 const page = await browser.newPage(); // 何らかの処理 } catch (error) { console.error(`Error: ${error}`, error); } finally { // ブラウザの終了 if (!!browser) await browser.close(); } } main().then();puppeteerでできること
ブラウザの起動/停止
// ブラウザの起動: headlessで起動 const browser = await puppeteer.launch(); // ブラウザの起動: headlessじゃなく起動 const browser = await puppeteer.launch({ headless: false, slowMo: 10 }); // ブラウザの終了 await browser.close();
headless: falseにすると、ブラウザが立ち上がって、動作確認画できる。
slowMo: 10の値を大きくすると、スローモーションのように操作がゆっくりになる。ページの開く/閉じる
// 新規ページの作成 const page = await browser.newPage(); // 画面サイズの設定 await page.setViewport({ width: 1280, height: 1200 }); // ページを閉じる await page.close();指定したURLへ移動
// 指定したURLへ移動 await page.goto("https://www.google.com", { waitUntil: "networkidle2" }); // 指定したURLへ移動: waitを設定 await page.goto("https://www.google.com", { waitUntil: "networkidle2" });オプションの
waitUntilを指定すると、その条件が満たされるまでwaitする。
指定できるのは、以下の4つ。
load:loadイベントが発火するまでdomcontentloaded:DOMContentLoadedイベントが発火するまでnetworkidle0: ネットワーク接続が0個である状態が500ミリ秒続いたときnetworkidle2: ネットワーク接続が2個である状態が500ミリ秒続いたときSPAとかの場合は、
networkidle2とかまで待つと良さそう。参考: PuppeteerによるJavaScriptレンダリングされたHTMLの取得 - コードログ
要素の取得
// 最初の`.button`の要素を取得 const button = await page.$('.button'); // すべての`.button`の要素を取得 const buttonList = await page.$$('.button');実際はElementHandleが返ってくる。
1件取得と全件取得があるので注意。
セレクタの書き方はCSS selectorsが使える。XPATHで書ける
page.$x();というのもある。要素のクリック
// クリック: ページからセレクタで指定 await page.click('.button'); // クリック: ElementHandlerからクリック const button = await page.$('.button'); await button.click(); // クリック: ページからElementHandlerを使ってevaluate const button = await page.$('.button'); await page.evaluate(v => v.click(), button) // クリック: ElementHandlerからevaluateでクリック const button = await page.$('.button'); await button.evaluate(v => v.click())クリックなど、JavaScriptを実行する方法はいくつかある。
SPAなサイトだとうまく行かない場合があるが、page.evaluaateなどを使うとうまくいく時がある。入力する
// テキストを入力する: ページからセレクタで指定 await page.type('#text-input', "Hello"); // テキストを入力する: ElementHandlerで指定 const inputText = await page.$('#text-input'); await inputText.type("Hello");待つ/waitする
// 1000ms待つ await page.waitFor(1000); // 指定した要素が表示されるまで待つ await page.waitForSelector(`.foo`); // or await page.waitFor('.foo'); // 条件を満たすまで待つ await page.waitFor(() => !!document.querySelector('.foo')); // 移動するまで待つ await Promise.all([ page.waitForNavigation(), page.click('a.my-link'), ]); // or const navigationPromise = page.waitForNavigation(); await page.click('a.my-link'), await navigationPromise;その他もろもろ
evaluateを使うとHTML要素に対して実行できるので、いろいろできる// innerTextを取得 const innerText = await elm.evaluate(node => node.innerText); // textContentを取得 const textContent = await elm.evaluate(node => node.textContent); // href属性の取得 const href = await elm.evaluate(node => node.href); // 背景色変更 await elm.evaluate((v, color) => (v.style.backgroundColor = color), "gray"); // URLの取得 const url = await page.evaluate(_ => location.origin); // スクロール: 1画面分 await page.evaluate(_ => window.scrollBy(0, window.innerHeight)); // スクロール: 指定要素まで await page.evaluate(elm => window.scrollBy(0, elm.getBoundingClientRect().top), elm);スクリーンショットの取得
// スクリーンショットの取得: 表示範囲のみ await page.screenshot({ path: "screenshot.png" }); // スクリーンショットの取得: フルページを指定 await page.screenshot({ path: "screenshot.png", fullPage: true }); // スクリーンショットの取得: 指定要素のみ const element = await page.$('h1'); await element.screenshot({path: 'screenshot_h1.png'});描画されたHTMLの取得
const fs = require("fs"); // HTMLの取得: ページ全体 const html = await page.content(); fs.writeFileSync("output.html", html); // HTMLの取得: 指定要素のみ const bodyHandle = await page.$('body'); const html_body = await page.evaluate(body => body.innerHTML, bodyHandle); fs.writeFileSync("output_body.html", html_body);エクスポートするツールを作ってみる
やりたいことは、こんな感じ。
- ブラウザ起動
- ログイン
- ブックマークページに移動
- 以下繰り返し: 取得できる情報がなくなるまで
- ブックマークの情報を取得
- ブックマークの削除
- 取得した情報を.jsonファイルに書き出し
- ブラウザの停止
メインの処理はこんな感じ
async function exportBookmarkMain() { let browser = null; try { // ブラウザの起動 browser = await puppeteer.launch({ headless: false, slowMo: 10 }); // ページの作成 const page = await browser.newPage(); await page.setViewport({ width: 1280, height: 1200 }); // ログイン: ログインページに移動&認証 await login(page); // ブックマークのエクスポート: ブックマークページに移動&ツイート上の取得 const bookmarks = await getTwitterBookmarks(browser, page); console.log(`bookmarks size is ${bookmarks.length}`); // 取得した情報の書き出し const timestamp = dayjs().format("YYYYMMDD_HHmmss"); const outputFile = `twitter_bookmarks_${timestamp}.json`; fs.writeFileSync(`output/${outputFile}`, JSON.stringify(bookmarks)); } catch (error) { console.error(`Error: ${error}`, error); } finally { // ブラウザの停止 if (!!browser) await browser.close(); } }ログイン処理
/** * ログイン処理 */ async function login(page) { // dotenvからアカウント情報の取得 const account = process.env.TWITTER_ACCOUNT; const password = process.env.TWITTER_PASSWORD; // 指定したURLへ移動: waitを設定 await page.goto("https://twitter.com/", { waitUntil: "networkidle2" }); await page.waitForSelector(`.LoginForm > .LoginForm-username > .text-input`); // アカウントとパスワード入力 await page.type(`.LoginForm > .LoginForm-username > .text-input`, account); await page.type(`.LoginForm > .LoginForm-password > .text-input`, password); // ログインボタンを押して、ページ遷移するまで待つ const navigationPromise = page.waitForNavigation(); await page.click(` .LoginForm > .EdgeButton`); await navigationPromise; }ブックマークのエクスポート処理
くり返す処理はこんな感じ。
ツイートは<article>タグのようなので、それを起点に処理を進めていく。async function getTwitterBookmarks(browser, page) { const bookmarks = []; try { // ブックマークに移動 const bookmarksURL = "https://twitter.com/i/bookmarks"; await page.goto(bookmarksURL, { waitUntil: "networkidle2" }); // ブックマークしたツイートのHTML要素の取得 const articles = await page.$$("article"); for (let i = 0; i < articles.length; i++) { const article = articles[i]; // ツイートまでスクロール await page.evaluate(elm => window.scrollBy(0, elm.getBoundingClientRect().top), article); await page.waitFor(1000); // articleから情報を取得(別処理) const data = await toArticleData(browser, page, article); bookmarks.push(data); // ブックマークの削除(別処理) await deleteBookmark(browser, page, article); } } catch (error) { console.error(`** Error occuerred: ${error}`, error); } return bookmarks; }無限ローディングを持つような場合、適宜スクロールしないと要素が表示されないので、
ツイートごとにスクロールしている。ブックマークしたツイートから情報を取得
かなりTwitterの仕様によっているけど
- 取得したい要素を特定して、
- その要素を取得するセレクタを書き、
- innterTextやtextContentで文字を取得する
といった、感じのことをしている。
async function toArticleData(browser, page, article) => { // 初期化 const articleData = { accountName: "", accountId: "", accountURL: "", tweetText: "", tweetURL: "", links: [] }; // ツイートしたユーザのアカウント名とTwitterIdを取得 const account = "div > div:nth-of-type(2) > div:nth-of-type(2) > div:nth-of-type(1)"; const accountName = await article.$(`${account} a > div:nth-of-type(1) > div:nth-of-type(1)`); const accountId = await article.$(`${account} a > div:nth-of-type(1) > div:nth-of-type(2)`); articleData.accountName = await accountName.evaluate(node => node.innerText); articleData.accountId = await accountId.evaluate(node => node.innerText); // ツイートの内容を取得 const tweetData = "div > div:nth-of-type(2) > div:nth-of-type(2)"; const tweet = await article.$(`${tweetData} > div:nth-of-type(2)`); const tweetText = await tweet.evaluate(node => node.innerText); articleData.tweetText = tweetText; // ツイートに含まれるリンク(<a>)をすべて取得 const aTags = await article.$$(`${tweetData} a`); for (let i = 0; i < aTags.length; i++) { const aTag = aTags[i]; const text = await aTag.evaluate(node => node.textContent); const link = await aTag.evaluate(node => node.href); articleData.links.push({ link: link, text: text }); } // <a>の1つ目はユーザのURL articleData.accountURL = articleData.links[0].link; // <a>の2つ目はツイートのURL articleData.tweetURL = articleData.links[1].link; articleData.links.splice(0, 2); return articleData; };ブックマークの削除
async deleteBookmark(browser, page, article) { const waitTime = 1500; // 待ち時間 // 削除対象までスクロール await page.evaluate(elm => window.scrollBy(0, elm.getBoundingClientRect().top), article); await page.waitFor(1000); // 「ツイートを共有」ボタンをクリック const button = await article.$("div[aria-label='ツイートを共有']"); await page.evaluate(v => v.click(), button); // すこし待つ await page.waitFor(waitTime); // クリックするとメニューが出てくるので、取得 const menuItems = await page.$$("div[role='menuitem']"); // 非公開アカウントかどうかにより、メニューの数が変わるの処理を分ける if (menuItems.length === 3) { // 通常、メニューが3つあり、2つ目が削除ボタン await menuItems[1].click(); await page.waitFor(waitTime); } else if (menuItems.length === 1) { // 非公開の場合は、削除ボタンのみ表示 await menuItems[0].click(); await page.waitFor(waitTime); } };こんな感じで、「要素を探す→クリック→少し待つ」のくり返し。
ただ、ブラウザで操作しているときでも、削除されないときがある。。使ってみた感想
スクレイピング自体始めてだったけど、puppeteer自体がすごくよく、簡単に使うことができた(´ω`)
ただ、Twitterみたいなのを対象にするのは結構大変だった。。
1. どうセレクタを書けば、期待する要素をとってこれるのかを考えないといけない
特にscoped CSSを使っていて、class名がないdivばかりだとつらい
2. SPAなど動的に変わる部分が多いサイトだと、クリックなどがうまく動かないことがある
対象サイトのJavaScriptが正しく動作しない場合がある。。
3. 実行や動作確認に時間がかかるので、テストにかなり時間がかかる
あと、サイトのデザインが変わると追従対応しないといけない。。
便利だけど、かなり大変そうな感じ(´ω`)けど、ポイントを守ればかなり便利だなと、今更ながら体感(´ω`)
こんなのつくってます!!
積読用の読書管理アプリ 『積読ハウマッチ』をリリースしました!
積読ハウマッチは、Nuxt.js+Firebaseで開発してます!
もしよかったら、遊んでみてくださいヽ(=´▽`=)ノ
要望・感想・アドバイスなどあれば、
公式アカウント(@MemoryLoverz)や開発者(@kira_puka)まで♪参考にしたサイト様
- Puppeteerのセットアップから使い方まで〜ブラウザ操作の自動化〜 - Qiita
- Puppeteer v1.20.0
- PuppeteerによるJavaScriptレンダリングされたHTMLの取得 - コードログ
- puppeteerを使ったスクレイピング - Qiita
- 絶対顔本スクレイピングするマン
- puppeteerでの要素の取得方法 - Qiita
- CSSのnth-childとnth-of-typeについて基本から学ぼう | Stocker.jp / diary
- puppeteerでスクレイピング - Qiita
- puppeteerでよく使うであろう処理の書き方 - Qiita
- puppeteerを体験してみた - Qiita

- 投稿日:2019-10-01T18:26:44+09:00
Nginx+php7.2+laravel-echo-server環境を作成するまでの道のり
前の会社でとあるシステムを作成中、色々共有し合った部分をまとめる。
この作業で出来る事
GCMやpusherみたいな有料サービスを使用しないで自サーバー上でpush通知が使用可能になる。
おおまかにやる事
①laravel-echo-serverをインストールする。
こいつはnodejsで動くサーバーなのだが、supervisorでデーモン化+落ちたときに自動的に再起動するようにしておく。
②Nginxのリバースプロキシ機能を使ってポート80に対してWebSocketが来た場合はlaravel-echo-serverに処理を行わせる。
クライアント側から見るとhttpとwsをポート80で接続する事になる。
必要なもの バージョン情報 Ubuntu 16.04LTS nginx 任意のバージョン php-fpm php7.2 Laravel 5.5 LTS nodejs v10.16.3 npm 6.4.1 ※恐らくバージョンは古すぎなければあまり気にしなくても良いと思われます。
通知機能が動く所までを書いていく。
とりあえず、OSはubuntuを使った。
今回は備忘録用なのでvagrantでさくっと作った場合という前提で記載
下記コマンドでvagrant環境を作成し、接続> vagrant init bento/ubuntu-16.04 > vagrant up > vagrant sshざっと実行したコマンドを書いておく
vagrant@vagrant:~$ sudo apt install nginx unzip zip acl vagrant@vagrant:~$ sudo apt install xpdf curl vagrant@vagrant:~$ sudo systemctl enable nginx vagrant@vagrant:~$ sudo apt install software-properties-common vagrant@vagrant:~$ sudo add-apt-repository ppa:ondrej/php vagrant@vagrant:~$ sudo apt update vagrant@vagrant:~$ sudo apt install -y php7.2 php7.2-fpm php7.2-mysql php7.2-mbstring php7.2-zip php7.2-xml php7.2-dom php7.2-pgsql php7.2-curl vagrant@vagrant:~$ sudo apt install -y postgresql postgresql-contrib vagrant@vagrant:~$ curl -sS https://getcomposer.org/installer | php vagrant@vagrant:~$ sudo mv composer.phar /usr/local/bin/composer vagrant@vagrant:~$ sudo chmod +x /usr/local/bin/composer ※その他、php-fpm設定やらpostgresqlをLaravelから使用するための設定などは人それぞれ違うと思うので省略 nginxの設定はこんな感じ User:vagrant group:www-dataで、ここから結構ハマったというか自分の知識が不十分で色々苦労したので今後の為に書いておく。
Laravelのプロジェクト名:sample
nginx実行ユーザー:www-data
nginx実行グループ:www-data
sftpログインユーザー:vagrantnginxの実行ユーザーと実行グループに合わせてここは変わる。 僕は、vagrantユーザーでアップロードしたり色々やるので、nginxのユーザもvagrantにしたので下記のように設定 $ sudo usermod -aG www-data vagrant $ cd /var/www $ sudo chown -R vagrant:www-data /var/www $ composer create-project --prefer-dist laravel/laravel sample "5.5.*" $ cd sample $ sudo chown -R vagrant:www-data . $ sudo find . -type d -exec chmod 750 {} \; # この辺をやっておくと $ sudo find . -type f -exec chmod 640 {} \; # そのディレクトリで作られたファイルは $ sudo find storage -type d -exec chmod 775 {} \; # ここで強制的にそのディレクトリの所有者権限で $ sudo find bootstrap/cache -type f -exec chmod 664 {} \; # 保存されるようになる(知らなかった $ sudo setfacl -R -d -m g::rwx storage $ sudo setfacl -R -d -m g::rwx bootstrap/cache $ sudo systemctl enable postgresql@ $ sudo systemctl enable php7.2-fpm $ sudo rebootnginxの設定ファイルの中身、結構忘れるので書いておく。
server { listen 80 default_server; listen [::]:80 default_server; # root /var/www/html; root /var/www/sample/public; # index index.html index.htm index.nginx-debian.html; index index.html index.htm index.nginx-debian.html index.php; server_name _; location / { # try_files $uri $uri/ =404; try_files $uri $uri/ /index.php?$query_string; # auth_basic "Restricted"; # Basic認証をかけるとき # auth_basic_user_file /etc/nginx/.htpasswd; # Basic認証をかけるとき } location ~ \.php$ { fastcgi_pass unix:/run/php/php7.2-fpm.sock; fastcgi_index index.php; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; include fastcgi_params; } } server { listen 443; ssl on; server_name **********; root /var/www/sample/public; index index.php; location / { try_files $uri $uri/ /index.php?$query_string; auth_basic "Restricted"; # Basic認証をかけるとき auth_basic_user_file /etc/nginx/.htpasswd; # Basic認証をかけるとき } location ~ \.php$ { fastcgi_pass unix:/run/php/php7.2-fpm.sock; fastcgi_index index.php; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; include fastcgi_params; } ssl_certificate /etc/nginx/ssl/hogehoge.crt; ssl_certificate_key /etc/nginx/ssl/(省略; }Postgresqlのパスワード変更の仕方を忘れるのでメモ
postgres=# alter user postgres with encrypted password 'password';node.jsとnpmのインストール
nodejsはバージョン管理出来るようにしておいた方が良いと思ったので、手順を書いておく。
必要がなければ読み飛ばしてOK1.まずは通常通りnodejsとnpmを入れる
$ sudo apt install -y nodejs npm2.nというパッケージでバージョン管理が出来る模様なのでインストール
$ sudo npm -g install n3.バージョン指定をしてインストール(とりあえずこのバージョンで動作確認出来たので)
$ sudo n 10.12.04.nパッケージでnodejsをインストールしてしまった後は、手順1で入れたnodejsとnpmは用済みなので、消す
$ sudo apt -y purge nodejs npmRedis-Serverのインストール
この方の記事を参考にした。
とても丁寧で分かりやすかった。かいつまんで書いておく。$ sudo add-apt-repository ppa:chris-lea/redis-server $ sudo apt update $ sudo apt install redis-server $ sudo systemctl enable redis-server $ sudo systemctl start redis-server※執筆時は3.0.6をインストールした。
Laravel-Echo-Serverのインストール
$ sudo npm install -g laravel-echo-serverLaravelをインストールしたディレクトリで下記コマンドを実行する。 対話方式で進むので、空Enter対応してるとうまく繋がらないので注意 vagrant@vagrant:/var/www/sample$ laravel-echo-server init ? Do you want to run this server in development mode? No ? Which port would you like to serve from? 6001 ? Which database would you like to use to store presence channel members? redis ? Enter the host of your Laravel authentication server. http://localhost ? Will you be serving on http or https? http ? Do you want to generate a client ID/Key for HTTP API? Yes ? Do you want to setup cross domain access to the API? Yes ? Specify the URI that may access the API: 127.0.0.1:80 ? Enter the HTTP methods that are allowed for CORS: GET, POST ? Enter the HTTP headers that are allowed for CORS: Origin, Content-Type, X-Auth-Token, X-Requested-With, Accept, Authorization, X-CSRF-TOKEN, X-Socket-Id ? What do you want this config to be saved as? laravel-echo-server.json appId: c05b50863b4d4exx key: 083cac33e24033ddd495efffffffe1d Configuration file saved. Run laravel-echo-server start to run server.下記コマンドでlaravel-echo-serverが立ち上がる vagrant@vagrant:/var/www/sample$ laravel-echo-server start※こんなエラーを吐き続けた場合はRedis-serverが落ちているか、設定がなんかおかしいので見直す事
[ioredis] Unhandled error event: Error: connect ECONNREFUSED 127.0.0.1:6379 at TCPConnectWrap.afterConnect [as oncomplete] (net.js:1113:14)Supervisorのインストール
$ sudo apt install -y supervisorデーモン化とプロセス監視させるための設定 $ sudo vi /etc/supervisor/conf.d/laravel-echo-server.conf 中身はこんな --------------------------------------------------- 1 [program:laravel-echo-server] 2 directory=/var/www/sample/ 3 process_name=%(program_name)s_%(process_num)02d 4 command=laravel-echo-server start 5 autostart=true 6 autorestart=true 7 user=vagrant 8 numproces=1 9 redirect_stderr=true 10 stdout_logfile=/var/log/laravel-echo-server.log ---------------------------------------------------設定ファイルを作成したら下記コマンドを実行しないと読み込まない模様 vagrant@vagrant:~$ sudo supervisorctl reread設定ファイルを読み込ませたら下記コマンド実行 vagrant@vagrant:~$ sudo supervisorctl start all laravel-echo-server:laravel-echo-server_00: startedここまでがLaravel-Echo-Serverの設定
Redisライブラリインストール
再び、ディレクトリはLaravelのプロジェクトディレクトリ内のお話になる。 下記コマンドを実行 vagrant@vagrant:/var/www/sample$ composer require predis/predisLaravel-Echoとsocket.ioインストール
vagrant@vagrant:/var/www/sample$ npm install laravel-echo npm notice created a lockfile as package-lock.json. You should commit this file. + laravel-echo@1.5.2 added 1 package from 1 contributor and audited 1 package in 5.562s found 0 vulnerabilities ┌───────────────────────────────────────────────────────────┐ │ npm update check failed │ │ Try running with sudo or get access │ │ to the local update config store via │ │ sudo chown -R $USER:$(id -gn $USER) /home/vagrant/.config │ └───────────────────────────────────────────────────────────┘↑インストールしたらこんなメッセージが出たので、内容に沿ってコマンドを実行した。
vagrant@vagrant:/var/www/sample$ sudo chown -R $USER:$(id -gn $USER) /home/vagrant/.config vagrant@vagrant:/var/www/sample$ vagrant@vagrant:/var/www/sample$ vagrant@vagrant:/var/www/sample$ npm install laravel-echo + laravel-echo@1.5.2 updated 1 package and audited 1 package in 0.518s found 0 vulnerabilities vagrant@vagrant:/var/www/sample$ vagrant@vagrant:/var/www/sample$ vagrant@vagrant:/var/www/sample$ npm install socket.io-client + socket.io-client@2.2.0 added 28 packages from 22 contributors and audited 49 packages in 4.138s found 0 vulnerabilities vagrant@vagrant:/var/www/sample$config/app.phpの設定を変更
176行目にこんな内容がコメントアウトされてるのでコメントアウトを外す // App\Providers\BroadcastServiceProvider::class, # コメントアウトを外す.envの設定を変更
BROADCAST_DRIVER=log ↓ BROADCAST_DRIVER=redis QUEUE_DRIVER=sync ↓ QUEUE_DRIVER=redisちなみにQUEUE_DRIVERはsyncでも動く。
その代わり、php artisan queue:work(後程記載する)が落ちてる間にpushされた内容は消えるので、redisにしとくのが無難かと。イベントの作成
vagrant@vagrant:/var/www/sample$ php artisan make:event MessagePushソースを作成されたファイルを開き、少々変更
1 <?php 2 3 namespace App\Events; 4 5 use Illuminate\Broadcasting\Channel; 6 use Illuminate\Queue\SerializesModels; 7 use Illuminate\Broadcasting\PrivateChannel; 8 use Illuminate\Broadcasting\PresenceChannel; 9 use Illuminate\Foundation\Events\Dispatchable; 10 use Illuminate\Broadcasting\InteractsWithSockets; 11 use Illuminate\Contracts\Broadcasting\ShouldBroadcast; 12 13 class MessagePush implements ShouldBroadcast # 変更 14 { 15 use Dispatchable, InteractsWithSockets, SerializesModels; 16 17 public $messages; # 追加 18 19 public function __construct( $messages ) 20 { 21 $this->messages = $messages; # 追加 22 } 23 24 public function broadcastOn() 25 { 26 // PrivateChannelの場合、routes/channels.phpで認証ルールを定義 27 // PrivateChannelで使ったチャンネルはbootstrap.jsでもEcho.private('channel-name').listen...と書かないと取得できない 28 return new Channel('channel-name'); # 追加 29 # return new PrivateChannel('channel-name'); 30 } 31 32 public function broadcastAs() # 追加 33 { 34 return 'push-test'; 35 } 36 37 # public function broadcastWith() { 38 # return [ 'message' => $this->messages ]; 39 # } 40 }※ 13行目のインターフェースは大事
これがないと通知が飛んでいかない。
しばらくハマった。
このクラス内でpublic定義されている変数は全て通知のキー名として贈られる。
自分で定義したい場合はbroadcastWithを使えとの事。
参考:https://readouble.com/laravel/5.3/ja/broadcasting.html通知イベントを発行する為、routes.phpに下記を追加
route::get('/push', function() { event( new App\Events\MessagePush( 'Test Message : ' . date('Y-m-d H:i:s') ) ); });resources/assets/js/bootstrap.jsの変更
// 下記内容を追加 import Echo from 'laravel-echo' window.io = require('socket.io-client'); window.Echo = new Echo({ broadcaster: 'socket.io', host: window.location.hostname, }); $(function(){ if( window.Echo ) window.Echo.channel('channel-name') .listen('.push-test', function(e){ console.log(e); }); console.log('onload'); });コンパイルを行う
vagrant@vagrant:/var/www/sample$ npm run dev※もし、エラーが出た場合は下記コマンドを実行してから再度上記コマンドを実行
自分の場合はcross-envがないどうのこうのという内容だった(エビデンス取り忘れた)vagrant@vagrant:/var/www/sample$ npm installwelcome.blade.phpに追記
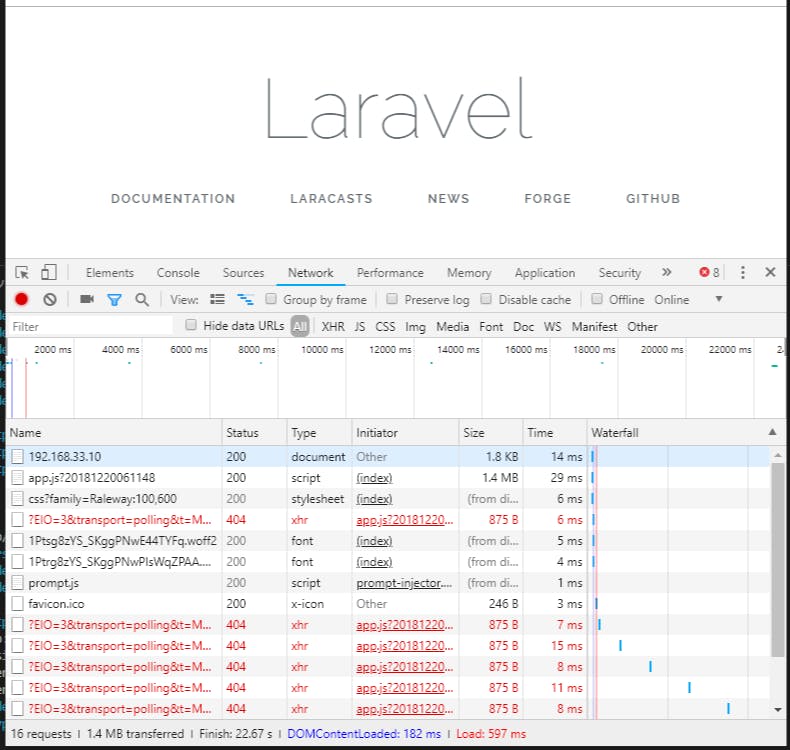
<script type="text/javascript" src="{{ asset('js/app.js') }}?{{ date('YmdHis') }}"></script>この状態でページにアクセスするとこんな感じで数秒ごとにエラーを吐いているのが確認出来る。
nginxの設定ファイルに追記
vagrant@vagrant:/var/www/sample$ sudo vim /etc/nginx/sites-enabled/default下記内容をserver{}の中に追記する
location /socket.io/ { proxy_pass http://127.0.0.1:6001; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; }nginx再起動
sudo systemctl restart nginxnginxを再起動すると同時にブラウザのNetworkログが変化するのを確認
送信した通知メッセージをWebSocketでレスポンスとして返すには下記コマンドを実行する
vagrant@vagrant:/var/www/sample$ php artisan queue:workすると、ブラウザ画面でF5押しまくった分が一気に通知されてくる。
しかし、このままだとphp artisan queue:workが実行中の時しか動かないので、こいつもsupervisorを使ってデーモン化する
/etc/supervisor/conf.d/artisan-queue.conf
[program:artisan-queue] directory=/var/www/sample/ process_name=%(program_name)s_%(process_num)02d command=php artisan queue:work --tries=3 autostart=true autorestart=true user=vagrant numprocs=1 redirect_stderr=true stdout_logfile=/var/log/artisan-queue.log作成したファイルをsupervisorに読むように設定する
vagrant@vagrant:~$ sudo supervisorctl reread artisan-queue: availablesupervisor再起動
vagrant@vagrant:~$ sudo supervisorctl stop all laravel-echo-server:laravel-echo-server_00: stopped vagrant@vagrant:~$ vagrant@vagrant:~$ vagrant@vagrant:~$ sudo supervisorctl start all artisan-queue:artisan-queue_00: started laravel-echo-server:laravel-echo-server_00: started vagrant@vagrant:~$Push通知の結果を保存させる
プッシュ通知に関するテーブルを作成する。
vagrant@vagrant:/var/www/sample$ php artisan queue:table vagrant@vagrant:/var/www/sample$ php artisan queue:failed-table vagrant@vagrant:/var/www/sample$ php artisan migrate長文疲れた。
手順の漏れはないと思うけど、あったらご指摘頂けると。
誰かの役に立ちますように。


- 投稿日:2019-10-01T15:45:14+09:00
Node.js シンプルなサーバー
index.jsconst express = require('express') const app = express() app.get('/', (req, res) => { res.send('Hello') }) app.listen(5000)
- 投稿日:2019-10-01T13:17:05+09:00
Docker for Mac で Kubernetes を試し、Nodeの環境を立ち上げる。
勉強用に書いときます。
参考にする資料
今こそ始めよう! Kubernetes入門 記事一覧
数時間で完全理解!わりとゴツいKubernetesハンズオン!!
Kubernetes道場 Advent Calendar 2018初期設定
kubernetesを有効化
DockerアプリのPreferences->Kubernetesから有効にする
[x] Enable Kubernetes にチェックを入れてApply
ここまででkubectlコマンドが有効になっている
$ kubectl version Client Version: version.Info{Major:"1", Minor:"14", GitVersion:"v1.14.6", GitCommit:"96fac5cd13a5dc064f7d9f4f23030a6aeface6cc", GitTreeState:"clean", BuildDate:"2019-08-19T11:13:49Z", GoVersion:"go1.12.9", Compiler:"gc", Platform:"darwin/amd64"} Server Version: version.Info{Major:"1", Minor:"14", GitVersion:"v1.14.6", GitCommit:"96fac5cd13a5dc064f7d9f4f23030a6aeface6cc", GitTreeState:"clean", BuildDate:"2019-08-19T11:05:16Z", GoVersion:"go1.12.9", Compiler:"gc", Platform:"linux/amd64"}contextsの設定
私の環境では2つある。
$ kubectl config get-contexts CURRENT NAME CLUSTER AUTHINFO NAMESPACE * docker-desktop docker-desktop docker-desktop docker-for-desktop docker-desktop docker-desktopcontextsは複数の異なるクラスタ、ユーザーを管理できるよう、接続先や使用するユーザーを切り替えるための仕組みで
2つともCLUSTERとAUTHINFOが指している物が同じな為、このままでも問題ないとは思うのだが、
ひとまず各種記事にある docker-for-desktopに変更する$ kubectl config use-context docker-for-desktop Switched to context "docker-for-desktop".確認
$ kubectl config get-contexts CURRENT NAME CLUSTER AUTHINFO NAMESPACE docker-desktop docker-desktop docker-desktop * docker-for-desktop docker-desktop docker-desktop状況確認
まだ立ち上げただけだが、この状態で、下記のようなPod(Podについてとkubectlの簡単な使い方)が動作している。
$ kubectl get pods --namespace=kube-system NAME READY STATUS RESTARTS AGE coredns-584795fc57-cvgn9 1/1 Running 0 15m coredns-584795fc57-j6kr5 1/1 Running 0 15m etcd-docker-desktop 1/1 Running 0 14m kube-apiserver-docker-desktop 1/1 Running 0 14m kube-controller-manager-docker-desktop 1/1 Running 0 14m kube-proxy-kxcxn 1/1 Running 0 15m kube-scheduler-docker-desktop 1/1 Running 0 14mどういったものなのかは下記のリンク先にわかりやすい図で説明してくれてる。
Kubernetesの概要構築作業
Dashbordの導入
Kubernetes Dashboardというものが用意されているそうなので、まずはこれを導入してみる。
Podの中身を見ながらやりたい為、一度ダウンロードする
$ wget https://raw.githubusercontent.com/kubernetes/heapster/master/deploy/kube-config/influxdb/influxdb.yaml$ kubectl apply -f kubernetes-dashboard.yaml.txt secret/kubernetes-dashboard-certs created serviceaccount/kubernetes-dashboard created role.rbac.authorization.k8s.io/kubernetes-dashboard-minimal created rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard-minimal created deployment.apps/kubernetes-dashboard created service/kubernetes-dashboard created$ kubectl proxy下記の長いURLでアクセスできる
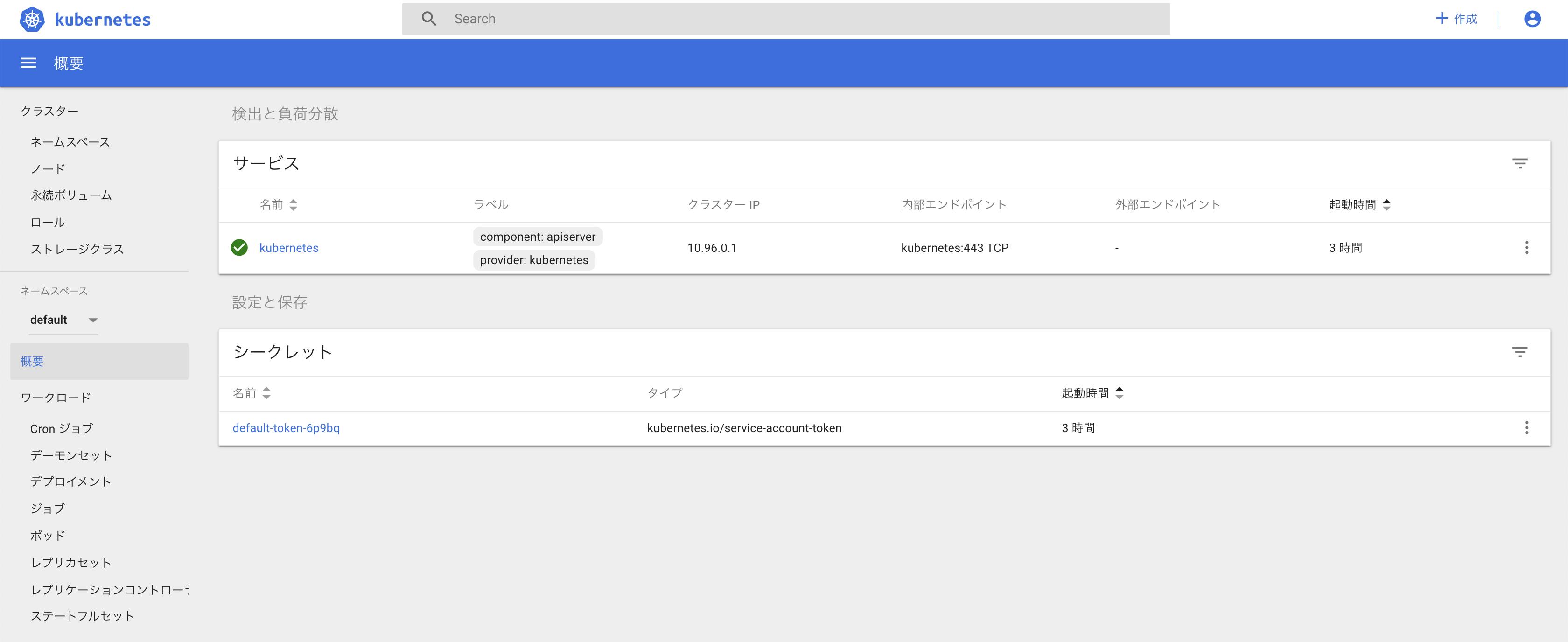
http://localhost:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/Dashbord 認証
Tokenを探す
「default-token-」から始まるsecretを探す。
$ kubectl -n kube-system get secret NAME ... TYPE DATA AGE default-token-r9tz9 kubernetes.io/service-account-token 3 3h45m ...「default-token-r9tz9」の詳細を確認し、Tokenをコピー
$ kubectl -n kube-system describe secret default-token-r9tz9 Name: default-token-r9tz9 Namespace: kube-system Labels: <none> Annotations: kubernetes.io/service-account.name: default kubernetes.io/service-account.uid: 90968fa6-db60-11e9-a391-025000000001 Type: kubernetes.io/service-account-token Data ==== token: eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.ey...先ほどの画面のToken欄に貼り付けてログイン
Node.jsの環境を立ててみる。
Node.js環境のDockerを作成。
ソースはnuxt-createとかで作成したものを利用FROM node:12.10.0-alpine WORKDIR /app COPY package*.json ./ RUN npm install COPY . . EXPOSE 3000 CMD [ "npm", "start" ]ビルドを実行
docker build --no-cache -t test-app .Deploymentを作成
k8s/deployment.yaml
apiVersion: apps/v1beta1 kind: Deployment metadata: name: test-app labels: app: test-app spec: replicas: 2 template: metadata: labels: app: test-app spec: containers: - name: test-app image: test-app imagePullPolicy: IfNotPresent # localのimageを利用する場合に必要 command: ports: - containerPort: 3000Serviceを作成
k8s/service.yaml
kind: Service apiVersion: v1 metadata: name: test-app-service spec: type: LoadBalancer selector: app: test-app ports: - protocol: TCP port: 3000 targetPort: 3000起動~確認〜削除
立ち上げ
$kubectl apply -f k8s/deployment.yaml $kubectl apply -f k8s/service.yaml確認、この状態でlocalhost:3000へ接続すれば画面が確認できる。
$ kubectl get pod NAME READY STATUS RESTARTS AGE test-app-5df7f6678c-hvzqg 1/1 Running 0 4m18s test-app-5df7f6678c-rrfc6 1/1 Running 0 4m18sダッシュボードを確認すると前回とは違い、グラフや動いているpodが確認できた。
削除
$kubectl delete -f k8s/deployment.yaml $kubectl delete -f k8s/service.yamlapply delete等は、ファイルが増えてくると大変なので、Makefileとかに書いとくのが良さそう。




- 投稿日:2019-10-01T13:05:39+09:00
Webサイト上の税率8%っぽい箇所を探すクローラーを作った
今日から消費税が10%になりました。
通販サイトなどでプログラムが税額を計算する部分はテスト済みかと思いますが、案外ベタ書きしている箇所も散在し、人の目で探すのは大変です。
- 利用ガイド(送料540円とか)
- ランディングページ
- 商品の説明欄
そういった抜け漏れを探す簡単なクローラーを作ってみました。
使い方
npm i -g taxmonkey taxmonkey 'https://www.ideamans.com/'
taxmonkey.tsvファイルに次のような結果が出力されます。URL 行番号 結果 詳細 HTML https://www.ideamans.com/ 0 該当なし https://www.ideamans.com/mt/sheetasset/ 0 該当なし https://www.ideamans.com/lightfile/managed/pricing/ 455 8%税込の可能性 [ 10,000円/サイト]は税別 9,260円 の8%税込金額を含む可能性があります 10,000円<small>/サイト</small>ロジック
以下のように8%っぽい金額を探します。
- HTMLのテキスト要素から数値を探す。
- その前後に
¥、円があれば金額表記とみなす。- ただし、前後に
税別や税抜がある場合は除外する。- 税別金額を逆算してキリのいい数字(10円単位)になったら8%表記の可能性あり。
ぶっちゃけ精度は高くありません。保険として使われることを想定してます。
カスタマイズ
簡単なオプションがあります。例えば税別価格が100円単位のサイトであれば、
-r 100とすることで少し精度が上がります。taxmonkey <url> URLを起点にクローリングを開始し、「税込8%っぽい」金額表記をリストアップします。 位置: url クローリングを開始するURL オプション: --help ヘルプを表示 [真偽] --version バージョンを表示 [真偽] --output, -o 出力先のファイルパス [デフォルト: "./taxmonkey.tsv"] --concurrency, -c 並列実行数 [デフォルト: 8] --limit, -l 最大ユニークURL数 [デフォルト: 1000] --device, -d クローリングを行うデバイス(mobile|pc)[デフォルト: "mobile"] --round, -r キリのいい金額の単位 [デフォルト: 10] --timeout 各ページのタイムアウト秒数 [デフォルト: 30] --rate 税率 [デフォルト: 0.08] --host 開始URL以外でリンクをたどるホスト名 [デフォルト: ""] --verbose, -v エラーや警告を標準エラーに出力 [真偽] [デフォルト: false] --quiet, -q プログレスバーを非表示 [真偽] [デフォルト: false] --ext HTMLドキュメントとみなす拡張子(カンマ区切り) [デフォルト: ".html,.htm,.php,.jsp,.asp,.aspx"] --index インデックスドキュメントとみなすファイル名(カンマ区切り) [デフォルト: "index.html,index.htm,index.php,index.jsp,index.asp,index.aspx"]
- 投稿日:2019-10-01T10:56:57+09:00
async/await(Promise)の並列と直列を関数型プログラミングで書く
前提とゴール
- よくあるasync/awaitのループの書き方がわかるようになる
- arrayのmapでasync使いたいが、直列で書きたい
- 普通にmapでasync使うと、前回の結果を待たないので、実は並列になります
- for文やmapのかわりに
reduce使います- 事前に回数のわからないasyncを、直列で書きたい
- おもにrestでページングがあり、何回で終わるのかrestしないとわからない時とか
- while文のかわりに
再帰します- 並列と直列を組み合わせたい
- 基本は直列になっていくとおもいますが、並列でやりたいところだけ並列にします
- Promise.allで並列の待ちあわせをし、flatでならします
- 関数型プログラミングについて
- あまり厳密な雰囲気ではないのでご容赦ください
- オブジェクトのシャローコピー、console、副作用じゃんみたいなのとか
- 本当にやりたいことは、for文やwhile文で必要になってしまう以下をスマートにすること
- mutableな変数を使わない
- 再代入しない
なにをするか
コードを書く上で、いい感じの要件なにかないかなーと思いましたが、
GitHubの単一のOrganization内にあるPRの一覧を出すことにします
自分が関係ないPR含めて何が進行しているか見たい、的な感じです
- GitHubのOrganizationのリポジトリ一覧を取得
- リポジトリの開いているPRを取得(直列のみ)
- リポジトリの開いているPRを取得(並列+直列)
- ちょっと見やすくして表示
GitHubのOrganizationのリポジトリ一覧を取得
id:passwordはbase64にして環境変数から取得
repository.getOrgReposでOrganizationのリポジトリ一覧をとっていますが、
APIの仕様として、デフォルトは30件までしか取れません!
GitHubRepository#getRecursiveにて全件取りきる再帰処理を書いています(async () => { // encode // new Buffer('a').toString('base64') // => YQ== // decode // new Buffer("YQ==",'base64').toString() // => a const auth: string = process.env["GITHUB_AUTH"] || ""; // "userId:password" のbase64 const owner: string = process.env["GITHUB_OWNER"] || ""; const repository = new GitHubRepository(auth); console.log({auth: auth ? "あり" : "", owner}); // 再帰で全件とる const rRepos: GitHubRepo[] = await repository.getOrgRepos(owner).catch(() => []); const repoNames: string[] = rRepos.map(r => r.name); console.log({repoNames}); // ... })();GitHubRepointerface GitHubRepo { name: string, }GitHubRepositoryimport fetch, {BodyInit, RequestInit} from "node-fetch"; import * as querystring from "querystring"; class GitHubRepository { constructor( readonly auth: string, ) { } createHeaders(usePostParam: boolean): object { return { "Authorization": `Basic ${this.auth}`, "Content-Type": usePostParam ? "application/json" : undefined, }; } async getRecursive<E>( baseUrl: string, baseParam: object = {}, page: number = 1, // 現在のページ per_page: number = 100, // 取得件数(デフォルト30, 最大100) beforeResult: E[] = [], ): Promise<E[]> { const url: string = baseUrl + "?" + querystring.stringify({ ...baseParam, page, per_page, }); const currentResult: E[] = await fetch(url, { method: "GET", headers: this.createHeaders(false), } as RequestInit).then(async r => { if (r.status !== 200) { console.error({url: r.url, status: r.status, text: await r.text()}); return []; } console.debug({url: r.url, status: r.status}); return r.json(); }); const totalResult = beforeResult.concat(currentResult); return currentResult.length === per_page // 最大件数まで取得したので、もう一度 ? this.getRecursive(baseUrl, baseParam, page + 1, per_page, totalResult) // 最大件数と取得件数が合わなければ終わり : totalResult; } async getOrgRepos(org: string): Promise<GitHubRepo[]> { return this.getRecursive(`https://api.github.com/orgs/${org}/repos`); } async getOwnerRepoPulls(owner: string, repo: string): Promise<GitHubPull[]> { return this.getRecursive(`https://api.github.com/repos/${owner}/${repo}/pulls`); } }(余談)再帰はスタックオーバーフローが起きうることを認識する
TS(JS)で再帰は、回数がかなり多い処理に使ってはいけません
普段スタックオーバーフローする件数を扱うことはほとんど無いはずなので、気にすることはないと思いますが、スタックオーバーフローが起きうることは覚えてはおきましょう末尾再帰最適化という挙動に言語やエンジンが対応していれば、問題はないのですが、
ES6の仕様に末尾再帰最適化がありつつも、ほとんど対応されていないようです
全体的な状況はきちんと調べなおしてはいませんが、少なくともTS3.6.3ではコンパイル後のjsでも再帰のままでした...詳細はほかの記事を読んだほうがいいです
末尾再帰による最適化
末尾再帰最適化についてこの部分return currentResult.length === per_page // 最大件数まで取得したので、もう一度 ? this.getRecursive(baseUrl, baseParam, page + 1, per_page, totalResult) // 最大件数と取得件数が合わなければ終わり : totalResult;リポジトリの開いているPRを取得(直列のみ)
件数の決まっているループについては、for文やmapではなく
reduceを使います(再帰でもいいですが)GitHubPullinterface GitHubPull { url: string, title: string, user: {login: string}, assignee: {login: string}, head: {label: string}, base: {label: string}, }(async () => { // ... const repoNames: string[] = rRepos.map(r => r.name); console.log({repoNames}); // ふつうの直列 const rPulls: GitHubPull[] = await mapSync(repoNames, cv => repository.getOwnerRepoPulls(owner, cv).catch(() => []), ); // ... })();mapSyncfunction mapSync<E, T>(base: T[], f: (currentValue: T) => Promise<E[]>): Promise<E[]> { return base.reduce(async (previousValue: Promise<E[]>, currentValue: T) => // 前のasyncをawaitしてから、次のasyncをawaitすることで直列になる (await previousValue).concat(await f(currentValue)) , Promise.resolve([])); }リポジトリの開いているPRを取得(並列+直列)
直列だけでリクエストしているとやっぱり遅いので、ちょっと並列も混ぜたいと思います
Promise.allで並列の待ちあわせをし、flatでならします
TSではflatだけlib指定しないと、デフォルトでは使えないので、設定に注意してくださいtsconfig.json{ "compilerOptions": { "module": "commonjs", "target": "es5", "lib": [ "esnext" ], ... } }(async () => { // ... const repoNames: string[] = rRepos.map(r => r.name); console.log({repoNames}); // 並列+直列にしたい const chunkedRepoNames: string[][] = chunk(repoNames, 3); console.log({chunkedRepoNames}); // Promise[]つくって、Promise.allでまちあわせ const readyPromise: Promise<GitHubPull[]>[] = chunkedRepoNames.map(async repoNames => mapSync(repoNames, cv => repository.getOwnerRepoPulls(owner, cv).catch(() => []), )); const rPulls: GitHubPull[] = (await Promise.all(readyPromise)).flat(); // ... })();chunkfunction chunk<E>(v: E[], parallel: number): E[][] { const chunked = v.reduce((pv, cv, ci) => { const chunkKey = ci % parallel; return { ...pv, [chunkKey]: (pv[chunkKey] || []).concat([cv]), }; }, {}); return Object.keys(chunked).map(key => chunked[key]); }ちょっと見やすくして表示
特別なことは何もないですが、見やすいように整形して表示して終わりです
うごくコードはこちらに
https://github.com/yakisuzu/sandbox-typescript-fpShowPullinterface ShowPull { url: string, title: string, user: string, branch: string, }(async () => { // ... const rPulls: GitHubPull[] = (await Promise.all(readyPromise)).flat(); const pulls: ShowPull[] = rPulls.map(p => ({ url: p.url, title: p.title, user: p.user.login, branch: `${p.head.label} to ${p.base.label}`, })); console.log({pulls}); })();
- 投稿日:2019-10-01T00:35:28+09:00
APIキーはハードコーディングせず.envファイルを活用しよう
対象の方
- プログラミング初心者
- .envを使用した事がない方
ハードコーディングって何?
ハードコーディングとは、本来プログラム中に記述すべきでないリソースを、直接ソースコード中に埋め込むことである。これらは本来、外部ソースから取得するか、実行時に生成するべきものであり、これをソフトコーディングという。
ウィキペディア# このようなコードの事 api_key = "xxxxxxxxxxxx"実際プログラミング初めて間もない頃は環境変数の言葉すら知らず、この様に直書きしてました笑
今考えると、Githubにpublicで上げるのに論外ですよね…ハードコーディングのここがダメ
- 特定のkeyが存在する場合はそれに関連する情報がコードの漏洩と共に盗まれる可能性がある。
- 複数箇所で使用する場合、毎回書くのは面倒く際
- などなど…
結果.envファイルを作成して、変数として管理しよう!!
使い方
- 隠しファイル.envを作業ディレクトリに作成しよう。
- 変数名=値の形で宣言しよう api_key="xxxxxxxx" #変数名 = 実際の値
手順としてはこれだけで後はこの値を使用したい箇所で呼び出すだけ!
とっても簡単!!こうする事で、apiキーだけでなくdockerで構築するdb情報を書いておけば
docker-compose.yml USER : ${変数名}の様に使用することが出来る。
また、node.jsなどで使用したい場合はdotenvを利用して.envを読み込み使用する事が出来る。
例 require('dotenv').config({path: ここに.envまでのパス}) process.env.変数名 #呼び出し後書き
初めてQiitaに記事を書いてみました。
読みづらい箇所が所々あったとは思いますが読んで頂きありがとうございます。
また、間違えがあればご指摘頂けると幸いです