- 投稿日:2019-09-09T23:49:58+09:00
[SIGNATE練習問題]自動車の評価をやってみた#2 〜Metric Learningしてみた〜
前回の試しにXGBoostでやってみた記事から、距離学習を入れてみた。
※前回記事:[SIGNATE練習問題]自動車の評価をやってみた
Label EncodingとOne-hot Encodingの違い
前回はいきなりOne-hot Encodingで、カテゴリ変数化したが
Label Encodingによるカテゴリ変数化でも良いのでは?と思われたかもしれない。
という訳で、今回はまずLabel EncodingとOne-hot Encodingの2つを
検証してみる。ライブラリを読み込み
#ライブラリインポート import numpy as np import pandas as pd import pandas_profiling as pdpf import matplotlib.pyplot as plt from tqdm import tqdm_notebook import umap import metric_learn from scipy.sparse.csgraph import connected_components from xgboost import XGBRFClassifier from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoderデータ読み込み
#train data train = pd.read_csv('./train.tsv',sep='\t') #test data test = pd.read_csv('./test.tsv', sep='\t')目的変数と説明変数に分離
#説明変数 train_df = train.drop(['id','class'], axis=1) #test用の説明変数 test_df = test.drop('id', axis=1) #目的変数 y = train['class'] #確認 print("train_df:",train_df.shape, "y:",y.shape, "test_df :",test_df.shape)TrainとTestを合体
# trainとtestでカテゴリーが異なるとダメだから、trainとtestをマージ length = train.shape[0] df = pd.concat([train_df, test_df], axis=0) print(df.columns)ようやく本題!
Label Encoding
df_le = pd.concat([train_df, test_df], axis=0) for i in list(df_le.columns): la_en = LabelEncoder() print(str(i)) la_en = la_en.fit(df_le[i]) la_en.fit(df_le[i]) df_le[i] = la_en.transform(df_le[i]) train_le = df_le.iloc[:length,:] test_le = df_le.iloc[length:,:] display(df_le)Label Encodingでは、それぞれ'0','1','2','3'などで、ただただカテゴリ変数化される。
buying maint doors persons lug_boot safety 0 1 2 2 0 2 1 1 1 0 2 2 2 2 2 3 0 0 0 2 2 3 0 0 2 2 0 2 4 0 0 2 0 1 0 ... ... ... ... ... ... ... 859 1 1 2 0 0 0 860 2 1 0 0 0 2 861 3 3 2 0 0 2 862 0 3 1 1 2 1 863 1 0 2 0 2 0 One-hot Encoding
一方、One-hot表現では、それぞれが[0,0,1],[0,1,0],[1,0,0]のように独立にラベル変数化されることがメリットである。
※ただのLabel Encodingでは、今回の'persons変数では
0:2人、1:4人、2:Moreとなるが、2人とMoreの平均が4人となってしまう。(ってことはMoreは6人??)この様な独立なラベルは、独立なまま特徴量にしたいからOne-hot Encodingを使う
df_oe = pd.concat([train_df, test_df], axis=0) df_dummy = pd.get_dummies(df_oe, prefix=df.columns) train_oe = df_dummy.iloc[:length,:] test_oe = df_dummy.iloc[length:,:] display(df_dummy)
目的変数もラベル化
#LabelEncoderのインスタンスを生成 le = LabelEncoder() #ラベルを覚えさせる le = le.fit(["unacc", "acc", "good", "vgood"]) #ラベルを整数に変換 y_label = le.transform(y) y_label_i = le.inverse_transform(y_label)XGBoostで学習
X_train_le, X_test_le, y_train_le, y_test_le = train_test_split(train_le,y_label,test_size = .2,random_state = 666,stratify = y_label) X_train_oe, X_test_oe, y_train_oe, y_test_oe = train_test_split(train_oe,y_label,test_size = .2,random_state = 666,stratify = y_label) import xgboost as xgb from sklearn.metrics import accuracy_score #### Label Encoding #### dtrain = xgb.DMatrix(X_train_le, label=y_train_le, feature_names=X_train_le.columns) dvalid = xgb.DMatrix(X_test_le, label=y_test_le, feature_names=train_le.columns) dtest = xgb.DMatrix(test_le, feature_names=train_le.columns) xgb_params = { 'objective': 'multi:softmax', 'num_class': 4, 'eval_metric': 'mlogloss', } evals = [(dtrain, 'train'), (dvalid, 'eval')] evals_result = {} bst_le = xgb.train(xgb_params, dtrain, num_boost_round=100, early_stopping_rounds=10, evals=evals, evals_result=evals_result ) #### One-hot Encoding #### dtrain_oe = xgb.DMatrix(X_train_oe, label=y_train_oe, feature_names=X_train_oe.columns) dvalid_oe = xgb.DMatrix(X_test_oe, label=y_test_oe, feature_names=train_oe.columns) dtest_oe = xgb.DMatrix(test_oe, feature_names=train_oe.columns) xgb_params = { 'objective': 'multi:softmax', 'num_class': 4, 'eval_metric': 'mlogloss', } evals = [(dtrain_oe, 'train'), (dvalid_oe, 'eval')] evals_result = {} bst_oe = xgb.train(xgb_params, dtrain_oe, num_boost_round=100, early_stopping_rounds=10, evals=evals, evals_result=evals_result )結果
微々たる差だが、One-hotが優勢っぽい
特徴量増加のためMetric Learningをトライ
微妙な差で勝利したOne-hot版の説明変数を使用。
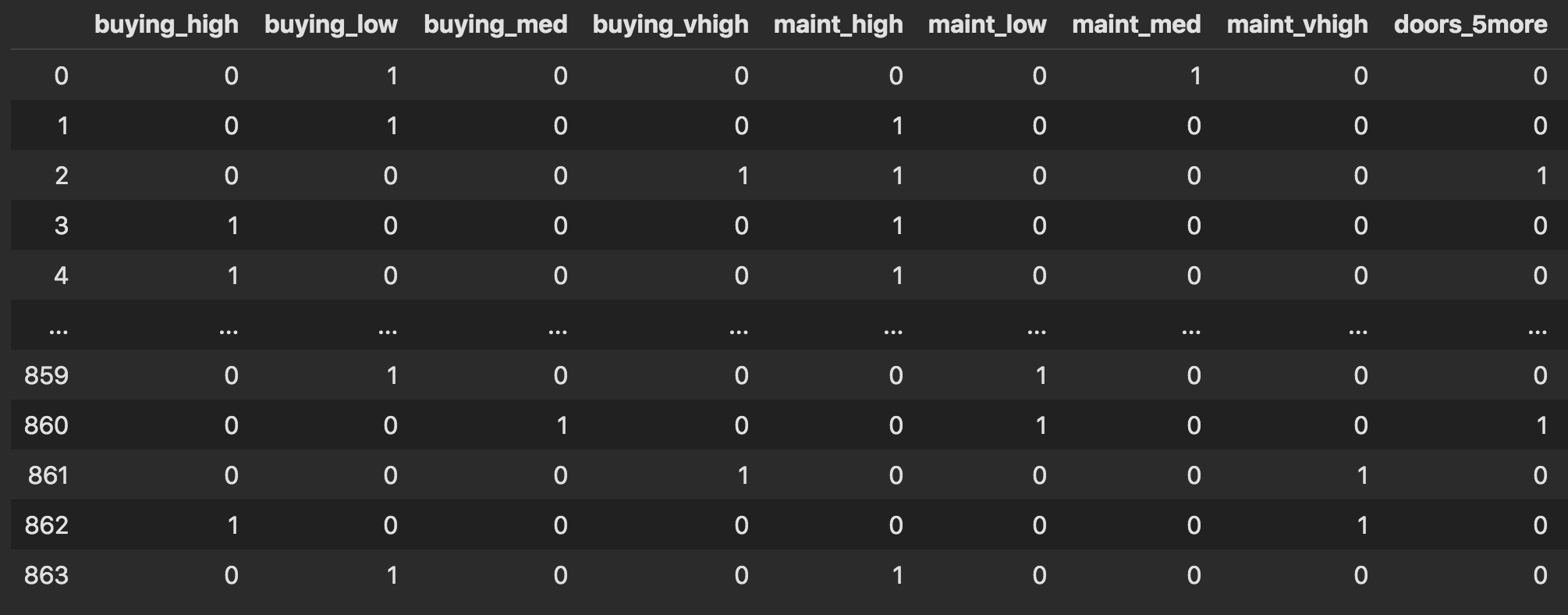
まずは、どんなデータになっているかを次元圧縮によって可視化(UMAPを使用)%time embedding = umap.UMAP().fit(train_oe) plt.scatter(embedding.embedding_[:,0], embedding.embedding_[:,1], c=y_label, cmap='plasma') plt.colorbar() plt.savefig('./fig/one-hot_umap.png', bbox_inches='tight') plt.show()
今回は、この変数をscikit-learnのmetric learnを使って次元圧縮。
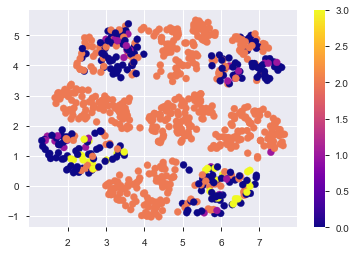
met_le = metric_learn.LMNN(k=5) met_le.fit(train_oe, y_label) %time X_met = met_le.transform(train_oe) %time X_met_test = met_le.transform(test_oe) %time met_embedding = umap.UMAP().fit(X_met) %time test_embedding = met_embedding.transform(X_met_test) plt.scatter(met_embedding.embedding_[:,0], met_embedding.embedding_[:,1], c=y_label, cmap='plasma') plt.colorbar() plt.savefig('./fig/metric_umap.png', bbox_inches='tight') plt.show()
何もしない時よりも綺麗に分かれてる!気がする。
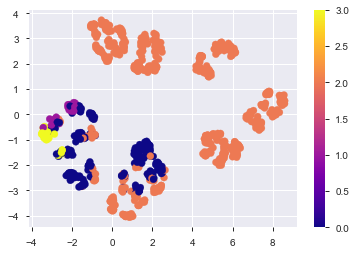
この分布上にTest用のデータを並べてみる。plt.scatter(met_embedding.embedding_[:,0], met_embedding.embedding_[:,1], c=y_label, cmap='plasma', label='train') plt.colorbar() plt.scatter(test_embedding[:,0], test_embedding[:,1], c='gold', edgecolor='black', linewidth=.7, marker='*', s=50, label='test') plt.legend() plt.savefig('./fig/metric_test_on.png', bbox_inches='tight') plt.show()
これだけでもなんとなく分離できそう...??
座標位置と距離を新たな特徴量として追加
元々のOne-hot encodingの説明変数に、今回作ってみた特徴量を追加。
X_met_df = pd.DataFrame(X_met, columns=np.arange(0,21,1).astype(str)) X_met_test_df = pd.DataFrame(X_met_test, columns=np.arange(0,21,1).astype(str)) embe = pd.DataFrame(met_embedding.embedding_, columns=['locate_x', 'locate_y']) test_embe = pd.DataFrame(test_embedding, columns=['locate_x', 'locate_y']) met_oe = pd.concat([train_oe, X_met_df], axis=1) met_oe = pd.concat([met_oe, embe], axis=1) met_test_oe = pd.concat([test_oe, X_met_test_df], axis=1) met_test_oe = pd.concat([met_test_oe, test_embe], axis=1) print(met_oe.shape, met_test_oe.shape) # (864, 44) (864, 44)再度XGBoostで学習
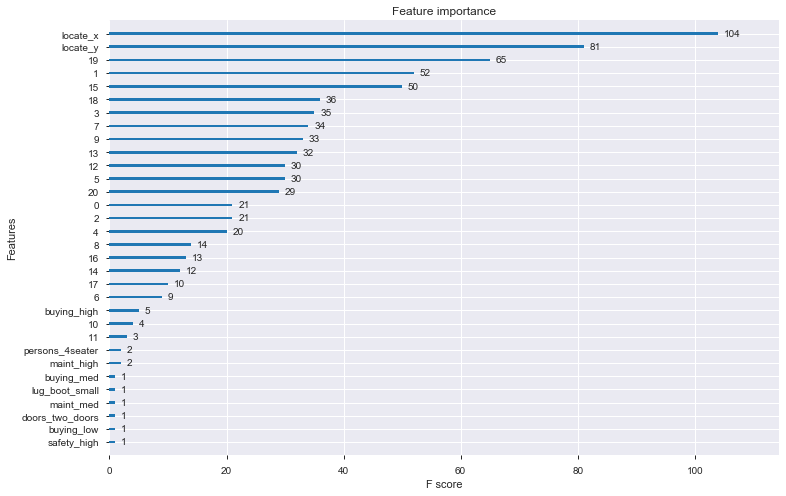
X_train_me, X_test_me, y_train_me, y_test_me = train_test_split(met_oe, y_label, test_size = .2, random_state = 666, stratify = y_label) dtrain_me = xgb.DMatrix(X_train_me, label=y_train_me, feature_names=X_train_me.columns) dvalid_me = xgb.DMatrix(X_test_me, label=y_test_me, feature_names=X_train_me.columns) dtest_me = xgb.DMatrix(met_test_oe, feature_names=met_test_oe.columns) xgb_params = { 'objective': 'multi:softmax', 'num_class': 4, 'eval_metric': 'mlogloss', } evals = [(dtrain_me, 'train'), (dvalid_me, 'eval')] evals_result = {} bst_me = xgb.train(xgb_params, dtrain_me, num_boost_round=100, early_stopping_rounds=10, evals=evals, evals_result=evals_result )ちなみに、特徴量寄与度はこんな感じ
_, ax = plt.subplots(figsize=(12, 8)) xgb.plot_importance(bst_me, ax=ax, importance_type='weight', show_values=True) plt.show()
座標位置が効いていそう...
結果出力
y_pred_me = bst_me.predict(dtest_me) y_pred_me = y_pred_me.astype(np.int) y_pred_me_i = le.inverse_transform(y_pred_me) submit_me = pd.read_csv('./sample_submit.csv', sep=',',header=None) submit_me.loc[:,1] = y_pred_me_i submit_me.to_csv("test_submit_me.csv", index = None, header = None)
あれ!!!なんか精度下がっている!!
過学習しているのか!?もう少し真面目に特徴量を増やすのと、過学習防止に5-foldでの検証など
まだまだやる余地はたくさんありそう。でもMetric Learningによる特徴量生成はうまくいく可能性がありそう。
to be continued.


- 投稿日:2019-09-09T23:23:05+09:00
Raspberry Pi ZERO WH + ACM1602NI LCD液晶 + BME280温湿度気圧センサーで色々表示してみる
ラズパイに液晶をくっつけて色々表示したら面白いんじゃないかと唐突に思いついたので作ってみました。
※最終的には魔改造の結果、ラズパイ起動後に自動実行され日付、時刻、温度、湿度、CPU使用率、メモリー使用率、IPアドレスが表示されるようになりました。
※pythonプログラミングは超初心者です。美しいコードとか一切意識してません。また作りたいから作っただけで実用性は無視です。基本的には自分用の覚書です。用意したもの
Raspberry Pi ZERO WH
http://akizukidenshi.com/catalog/g/gM-12958/
LCD液晶 ACM1602NI
http://akizukidenshi.com/catalog/g/gP-05693/
100kΩ半固定抵抗(↑のLCDを使うならこれが必要)
http://akizukidenshi.com/catalog/g/gP-08014/
温湿度気圧センサー BME280
http://akizukidenshi.com/catalog/g/gK-09421/
その他、ハンダゴテ、ブレッドボード、ラズパイ接続環境などの電子工作及びRaspberry Pi関連一般機器①I2C接続を有効にしてLCDに文字を出してみる
ラズパイではデフォルトではI2C接続が無効になっているはずです。
設定を行いI2Cを有効化、サンプルプログラムを使いなにか文字を投影しLCDの動作確認まで行います。
ポイントは、dtparam=i2c_baudrate=50000を設定すること、i2cdetectをしないことです。
私の場合はボーレートを設定するconfig.txt内でi2cに関する設定文のコメントアウトをはずしてやらないと動きませんでした。
その後https://github.com/yuma-m/raspi_lcd_acm1602ni.gitのサンプルプログラムで文字が表示されればOK
詳細な説明は参考ページをがわかりやすいです。↓
https://www.denshi.club/pc/raspi/i2caqmlcdarduinode1-aqm0802-2.html
http://yura2.hateblo.jp/entry/2016/02/13/Raspberry_Pi%E3%81%AB%E6%8E%A5%E7%B6%9A%E3%81%97%E3%81%9FLCD%28ACM1602NI%29%E3%82%92Python%E3%81%A7%E5%8B%95%E3%81%8B%E3%81%99
https://ameblo.jp/raspberrypi-iot/entry-12345308004.html②BME280を接続して温度、湿度、気圧を取得してみる
次にBME280センサーを接続してデータの取得をしてみます。
先にLCD液晶の回路があるはずなのでそこに追加する形でいきました。
I2C接続は線を共用できるので配線が少なく楽ですね。
配線後にhttps://github.com/SWITCHSCIENCE/BME280/blob/master/Python27/bme280_sample.pyのサンプルプログラムを使って各種データが取得できればOK
ポイントは、今回のようにACM1602NIをすでに接続した状態でテストをするならやっぱりi2cdetectはやってはいけません。
これをやると液晶が止まります・・・
詳細な説明は参考ページをがわかりやすいです。↓
https://deviceplus.jp/hobby/raspberrypi_entry_039/ここまでの配線状況
③BME280のデータをLCDに投影する
LCD表示のサンプルプログラムを見るとmain関数の中は次のようになっていました。
raspi_lcd.py(前略) def main(): if not 2 <= len(sys.argv) <= 3: print('Usage: python raspi_lcd.py "message for line 1" ["message for line 2"]') return else: lcd_controller = LCDController() lcd_controller.display_messages(sys.argv[1:3]) (後略)ここでコマンドラインから引数としてうけとった文字列の数を判定し、受け取った引数が1または2ならlcd_controller.display_messages(sys.argv[1:3])に渡してLCDに投影されるようです。
※ちなみに引数はsys.argvに格納されますがsys.argv[0]はプログラム名が入るらしいです。
・・・適当にリストを作ってそこに文字列を格納しlcd_controller.display_messagesに渡せば投影できるのでは?(単純
というわけでBME280のサンプルプログラムをLCD表示サンプルプログラムに無理やり追記しLCD表示に関するmain関数部分のみ次のように書き換えました
var_h,temperature,pressurear_h,temperature,pressureの各変数をグローバル変数化し参照できるように変えているので注意
また、このLCDは仕様上「℃」の文字が使えません。BME280のサンプルプログラムをそのまま使うと「℃」が表示できずエラーを起こしますのでなにかしら対策が必要です。私は代わりに「’C」を表示するようにしました。lcd.py(前略) def main(): while 1: lcddisp = [] #LCD表示文字列格納リスト readData() #BME280のデータ取得関数 lcdhum = ("HUM:%6.2f %" % (var_h)) #取得した湿度に表示用の文字列を追加 lcdtemp = ("TEMP: %-6.2f'C" % (temperature)) #取得した気温に表示用の文字列を追加 lcdpressure = ("pressure:%7.2fhPa" % (pressure/100)) #取得した気圧に表示用の文字列を追加 lcddisp.append(lcdtemp) #LCD表示文字列格納リストに気温を追加 lcddisp.append(lcdhum) #LCD表示文字列格納リストに湿度を追加 lcd_controller = LCDController() lcd_controller.display_messages(lcddisp[0:2]) #LCD表示文字列格納リストを表示関数に渡す time.sleep(2) #2秒待機後にLCD表示アップデート (後略)④日付と時刻を表示する
せっかくなので日付と時刻ぐらい表示したくね?(いきあたりばったりの思いつき)
main関数が以下のようになりました。(import datetime忘れないでね)lcd.py(前略) import datetime (中略) def main(): while 1: lcddisp = [] #LCD表示文字列格納リスト readData() #BME280のデータ取得関数 lcdhum = ("HUM:%6.2f %" % (var_h)) #取得した湿度に表示用の文字列を追加 lcdtemp = ("TEMP: %-6.2f'C" % (temperature)) #取得した気温に表示用の文字列を追加 lcdpressure = ("pressure:%7.2fhPa" % (pressure/100)) #取得した気圧に表示用の文字列を追加 lcddisp.append(lcdtemp) #LCD表示文字列格納リストに気温を追加 lcddisp.append(lcdhum) #LCD表示文字列格納リストに湿度を追加 lcd_controller = LCDController() lcd_controller.display_messages(lcddisp[0:2]) #LCD表示文字列格納リストを表示関数に渡す time.sleep(2) #2秒待機後にLCD表示アップデート lcddisp = [] #LCD表示文字列格納リストリセット dt_now = datetime.datetime.now() #現在時刻の取得 lcddisp.append(dt_now.strftime('DATE: %Y/%m/%d')) #年月日を格納 lcddisp.append(dt_now.strftime('TIME: %H:%M:%S')) #時分秒を格納 lcd_controller = LCDController() lcd_controller.display_messages(lcddisp[0:2]) #LCD表示文字列格納リストを表示関数に渡す time.sleep(2) #2秒待機後にLCD表示アップデート (後略)⑤CPU使用率とメモリー使用率を表示する
将来のヘッドレス運用に備えてCPU使用率とメモリー使用率も監視したいよね?
どうやらpsutilモジュールなるものを使うとできるらしい
参考↓
https://algorithm.joho.info/programming/python/psutil-cpu-memory-usage/
そして度重なるmain関数の魔改造lcd.py(前略) import psutil (中略) def main(): while 1: lcddisp = [] #LCD表示文字列格納リスト readData() #BME280のデータ取得関数 lcdhum = ("HUM:%6.2f %" % (var_h)) #取得した湿度に表示用の文字列を追加 lcdtemp = ("TEMP: %-6.2f'C" % (temperature)) #取得した気温に表示用の文字列を追加 lcdpressure = ("pressure:%7.2fhPa" % (pressure/100)) #取得した気圧に表示用の文字列を追加 lcddisp.append(lcdtemp) #LCD表示文字列格納リストに気温を追加 lcddisp.append(lcdhum) #LCD表示文字列格納リストに湿度を追加 lcd_controller = LCDController() lcd_controller.display_messages(lcddisp[0:2]) #LCD表示文字列格納リストを表示関数に渡す time.sleep(2) #2秒待機後にLCD表示アップデート lcddisp = [] #LCD表示文字列格納リストリセット dt_now = datetime.datetime.now() #現在時刻の取得 lcddisp.append(dt_now.strftime('DATE: %Y/%m/%d')) #年月日を格納 lcddisp.append(dt_now.strftime('TIME: %H:%M:%S')) #時分秒を格納 lcd_controller = LCDController() lcd_controller.display_messages(lcddisp[0:2]) #LCD表示文字列格納リストを表示関数に渡す time.sleep(2) #2秒待機後にLCD表示アップデート lcddisp = [] #LCD表示文字列格納リストリセット memory = psutil.virtual_memory() #メモリー使用率取得 cpu_percent = psutil.cpu_percent(interval=1) #CPU使用率取得 lcdmem = ('MEM: ' + str(memory.percent) + " %") #メモリ使用率に表示用の文字列を追加 lcdcpu = ('CPU: ' + str(cpu_percent) + " %") #CPU使用率に表示用の文字列を追加 lcddisp.append(lcdcpu) #CPU使用率を格納 lcddisp.append(lcdmem) #メモリー使用率を格納 lcd_controller = LCDController() lcd_controller.display_messages(lcddisp[0:2]) #LCD表示文字列格納リストを表示関数に渡す time.sleep(2) #2秒待機後にLCD表示アップデート (後略)⑥IPアドレスを表示する
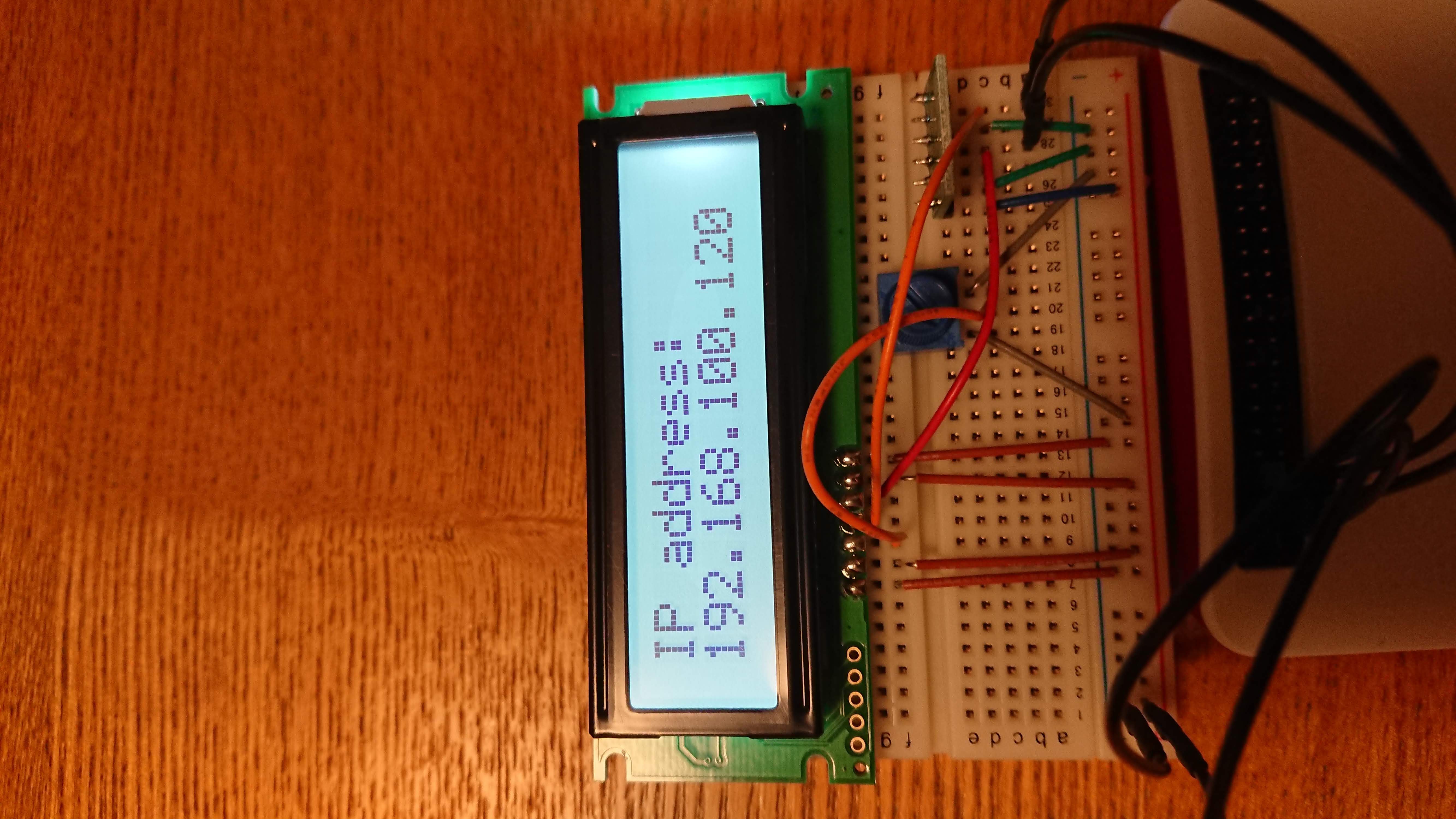
ラズパイ起動後にIPアドレス表示してくれたらSSHとかRDPとかするとき便利だよね、と思いついたので・・・
どうやらgethostnameを使うとできるとあるが127.0.0.1しか取得できない・・・
調べると以下のページに答えがあったので参考に↓
https://qiita.com/kjunichi/items/8e4967d04c3a1f6af35e
そしてmain関数を含めた最終的なコードの全容は次の通りlcd.py#!/usr/bin/env python # -*- coding: utf-8 -*- from __future__ import print_function from smbus2 import SMBus import sys import time import smbus import unicodedata import datetime import psutil import socket from config import BUS_NUMBER, LCD_ADDR, SLEEP_TIME, DELAY_TIME from character_table import INITIALIZE_CODES, LINEBREAK_CODE, CHAR_TABLE COMMAND_ADDR = 0x00 DATA_ADDR = 0x80 bus_number = 1 i2c_address = 0x76 bus = SMBus(bus_number) digT = [] digP = [] digH = [] t_fine = 0.0 pressure = 0.0 temperature = 0.0 var_h = 0.0 lcddisp = ["0","0"] def writeReg(reg_address, data): bus.write_byte_data(i2c_address,reg_address,data) def get_calib_param(): calib = [] for i in range (0x88,0x88+24): calib.append(bus.read_byte_data(i2c_address,i)) calib.append(bus.read_byte_data(i2c_address,0xA1)) for i in range (0xE1,0xE1+7): calib.append(bus.read_byte_data(i2c_address,i)) digT.append((calib[1] << 8) | calib[0]) digT.append((calib[3] << 8) | calib[2]) digT.append((calib[5] << 8) | calib[4]) digP.append((calib[7] << 8) | calib[6]) digP.append((calib[9] << 8) | calib[8]) digP.append((calib[11]<< 8) | calib[10]) digP.append((calib[13]<< 8) | calib[12]) digP.append((calib[15]<< 8) | calib[14]) digP.append((calib[17]<< 8) | calib[16]) digP.append((calib[19]<< 8) | calib[18]) digP.append((calib[21]<< 8) | calib[20]) digP.append((calib[23]<< 8) | calib[22]) digH.append( calib[24] ) digH.append((calib[26]<< 8) | calib[25]) digH.append( calib[27] ) digH.append((calib[28]<< 4) | (0x0F & calib[29])) digH.append((calib[30]<< 4) | ((calib[29] >> 4) & 0x0F)) digH.append( calib[31] ) for i in range(1,2): if digT[i] & 0x8000: digT[i] = (-digT[i] ^ 0xFFFF) + 1 for i in range(1,8): if digP[i] & 0x8000: digP[i] = (-digP[i] ^ 0xFFFF) + 1 for i in range(0,6): if digH[i] & 0x8000: digH[i] = (-digH[i] ^ 0xFFFF) + 1 def readData(): data = [] for i in range (0xF7, 0xF7+8): data.append(bus.read_byte_data(i2c_address,i)) pres_raw = (data[0] << 12) | (data[1] << 4) | (data[2] >> 4) temp_raw = (data[3] << 12) | (data[4] << 4) | (data[5] >> 4) hum_raw = (data[6] << 8) | data[7] compensate_T(temp_raw) compensate_P(pres_raw) compensate_H(hum_raw) def compensate_P(adc_P): global t_fine global pressure v1 = (t_fine / 2.0) - 64000.0 v2 = (((v1 / 4.0) * (v1 / 4.0)) / 2048) * digP[5] v2 = v2 + ((v1 * digP[4]) * 2.0) v2 = (v2 / 4.0) + (digP[3] * 65536.0) v1 = (((digP[2] * (((v1 / 4.0) * (v1 / 4.0)) / 8192)) / 8) + ((digP[1] * v1) / 2.0)) / 262144 v1 = ((32768 + v1) * digP[0]) / 32768 if v1 == 0: return 0 pressure = ((1048576 - adc_P) - (v2 / 4096)) * 3125 if pressure < 0x80000000: pressure = (pressure * 2.0) / v1 else: pressure = (pressure / v1) * 2 v1 = (digP[8] * (((pressure / 8.0) * (pressure / 8.0)) / 8192.0)) / 4096 v2 = ((pressure / 4.0) * digP[7]) / 8192.0 pressure = pressure + ((v1 + v2 + digP[6]) / 16.0) def compensate_T(adc_T): global t_fine global temperature v1 = (adc_T / 16384.0 - digT[0] / 1024.0) * digT[1] v2 = (adc_T / 131072.0 - digT[0] / 8192.0) * (adc_T / 131072.0 - digT[0] / 8192.0) * digT[2] t_fine = v1 + v2 temperature = t_fine / 5120.0 def compensate_H(adc_H): global t_fine global var_h var_h = t_fine - 76800.0 if var_h != 0: var_h = (adc_H - (digH[3] * 64.0 + digH[4]/16384.0 * var_h)) * (digH[1] / 65536.0 * (1.0 + digH[5] / 67108864.0 * var_h * (1.0 + digH[2] / 67108864.0 * var_h))) else: return 0 var_h = var_h * (1.0 - digH[0] * var_h / 524288.0) if var_h > 100.0: var_h = 100.0 elif var_h < 0.0: var_h = 0.0 def setup(): osrs_t = 1 #Temperature oversampling x 1 osrs_p = 1 #Pressure oversampling x 1 osrs_h = 1 #Humidity oversampling x 1 mode = 3 #Normal mode t_sb = 5 #Tstandby 1000ms filter = 0 #Filter off spi3w_en = 0 #3-wire SPI Disable ctrl_meas_reg = (osrs_t << 5) | (osrs_p << 2) | mode config_reg = (t_sb << 5) | (filter << 2) | spi3w_en ctrl_hum_reg = osrs_h writeReg(0xF2,ctrl_hum_reg) writeReg(0xF4,ctrl_meas_reg) writeReg(0xF5,config_reg) setup() get_calib_param() class LCDController: def __init__(self): self.bus = smbus.SMBus(BUS_NUMBER) pass def send_command(self, command, is_data=True): if is_data: self.bus.write_i2c_block_data(LCD_ADDR, DATA_ADDR, [command]) else: self.bus.write_i2c_block_data(LCD_ADDR, COMMAND_ADDR, [command]) time.sleep(DELAY_TIME) def initialize_display(self): for code in INITIALIZE_CODES: self.send_command(code, is_data=False) def send_linebreak(self): for code in LINEBREAK_CODE: self.send_command(code, is_data=False) def normalize_message(self, message): if isinstance(message, str): message = message.decode('utf-8') return unicodedata.normalize('NFKC', message) def convert_message(self, message): char_code_list = [] for char in message: if char not in CHAR_TABLE: error_message = 'undefined character: %s' % (char.encode('utf-8')) raise ValueError(error_message) char_code_list += CHAR_TABLE[char] if len(char_code_list) > 16: raise ValueError('Exceeds maximum length of characters for each line: 16') return char_code_list def display_one_line(self, line_no, message): message = self.normalize_message(message) char_code_list = self.convert_message(message) for code in char_code_list: self.send_command(code) def display_messages(self, message_list): self.initialize_display() time.sleep(SLEEP_TIME) for line_no, message in enumerate(message_list): if line_no == 1: self.send_linebreak() self.display_one_line(line_no, message) def main(): while 1: lcddisp = [] s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) s.connect(("8.8.8.8",80)) ip = s.getsockname()[0] lcddisp.append("IP address:") lcddisp.append(ip) lcd_controller = LCDController() lcd_controller.display_messages(lcddisp[0:2]) time.sleep(2) lcddisp = [] dt_now = datetime.datetime.now() lcddisp.append(dt_now.strftime('DATE: %Y/%m/%d')) lcddisp.append(dt_now.strftime('TIME: %H:%M:%S')) lcd_controller = LCDController() lcd_controller.display_messages(lcddisp[0:2]) time.sleep(2) lcddisp = [] readData() lcdhum = ("HUM:%6.2f %" % (var_h)) lcdtemp = ("TEMP: %-6.2f'C" % (temperature)) lcdpressure = ("pressure:%7.2fhPa" % (pressure/100)) lcddisp.append(lcdtemp) lcddisp.append(lcdhum) lcd_controller = LCDController() lcd_controller.display_messages(lcddisp[0:2]) time.sleep(2) lcddisp = [] memory = psutil.virtual_memory() cpu_percent = psutil.cpu_percent(interval=1) lcdmem = ('MEM: ' + str(memory.percent) + " %") lcdcpu = ('CPU: ' + str(cpu_percent) + " %") lcddisp.append(lcdcpu) lcddisp.append(lcdmem) lcd_controller = LCDController() lcd_controller.display_messages(lcddisp[0:2]) time.sleep(2) if __name__ == '__main__': main()クソコード臭が拭えませんが普通に動くので気にしません。
⑦ラズパイ起動後に自動起動させる
ヘッドレス運用時にラズパイ起動後に自動で起動してくれればIPアドレスとかとれるし正常起動したかわかるし便利そうなので設定してみました。
どうやらsystemdを設定すればいけるそうなので参考ページのとおりに設定したらあっさりいけました。
参考↓
https://qiita.com/molchiro/items/ee32a11b81fa1dc2fd8d
https://qiita.com/ikemura23/items/6f9adce99a3db555a0e4⑧動作の様子
こんな感じで動いてます
最終的にラズパイ起動時に自動実行されて日付、時刻、温度、湿度、cpu使用率、メモリー使用率、ipアドレスが自動表示される謎表示機になりました。
— しょうとくた (@syotokuta) September 9, 2019
ipアドレスやcpu使用率はヘッドレス運用時に便利かな pic.twitter.com/qAPwQ4F8pQ
- 投稿日:2019-09-09T23:00:14+09:00
Amazon Linux2 に Python3.7.4をインストール
最初からインストールされているのは3.6系だったので。
$ sudo yum install gcc openssl-devel bzip2-devel $ cd /usr/src $ sudo wget https://www.python.org/ftp/python/3.7.4/Python-3.7.4.tgz $ sudo tar xzf Python-3.7.4.tgz $ cd Python-3.7.4 $ sudo ./configure --enable-optimizations $ sudo make altinstall $ sudo rm /usr/src/Python-3.7.4.tgz $ python3.7 -V Python 3.7.4 $ vi /home/ec2-user/.bashrc # User specific aliases and functions alias python=python3.7 $ python -V Python 3.7.4
- 投稿日:2019-09-09T22:49:16+09:00
【Python】AWS Lambda + DynamoDBでTodoリスト用REST APIを構築した際にハマったこと
はじめに
AWS Lambda + DynamoDBでTodoリスト用REST APIを構築した際にハマったことのメモ。
構築したもの:https://github.com/r-wakatsuki/kadai4todo
ハマったこと
以下、ハマった際に遭遇した事象と解決方法を記載していく。
DynamoDBをまともに利用したのが初めてだったため、DynamoDBについてがほとんどである。1. DynamoDBに登録するデータの値には空文字は指定できないがnullは登録可能。ただしその場合は同じプロパティにNULL型とその他の型が混在することになる。
事象
contentプロパティに空文字が指定されている場合、空文字をString型のままDynamoDBに登録しようとすると、ClientError: An error occurred (ValidationException) when calling the PutItem operation: One or more parameter values were invalid: An AttributeValue may not contain an empty stringというエラーとなる。InputEvent: { "httpMethod": "POST", "resource": "/todo", "body": "{\"title\": \"たいとるですよ\",\"content\": \"\"}" } API:<Todo登録> #〜中略〜 #要素定義:content req_content = req_body_dict.get('content','') if req_content == None: req_content = '' #〜中略〜 #<Todo登録>実行 item = { "todoid": str(uuid.uuid4()), "title": req_title, "content": req_content, "priority": req_priority, "done": req_done, "created_at": current_date, "updated_at": current_date } table.put_item( Item = item ) #<Todo登録>実行結果リターン return(return200(item)) Response: { "errorMessage": "An error occurred (ValidationException) when calling the PutItem operation: One or more parameter values were invalid: An AttributeValue may not contain an empty string", "errorType": "ClientError", "stackTrace": [ " File \"/var/task/lambda_function.py\", line 72, in lambda_handler\n Item = item\n", " File \"/var/runtime/boto3/resources/factory.py\", line 520, in do_action\n response = action(self, *args, **kwargs)\n", " File \"/var/runtime/boto3/resources/action.py\", line 83, in __call__\n response = getattr(parent.meta.client, operation_name)(**params)\n", " File \"/var/runtime/botocore/client.py\", line 320, in _api_call\n return self._make_api_call(operation_name, kwargs)\n", " File \"/var/runtime/botocore/client.py\", line 623, in _make_api_call\n raise error_class(parsed_response, operation_name)\n" ] }
contentプロパティが空文字の場合にNULL型に変換する処理を入れ、NULL型でDynamoDBへの登録を試みると、登録処理は問題なく行われる。InputEvent: { "httpMethod": "POST", "resource": "/todo", "body": "{\"title\": \"たいとるですよ\",\"content\": \"\"}" } API:<Todo登録> #〜中略〜 #要素定義:content req_content = req_body_dict.get('content') if req_content == '':#空文字の場合はnull型を入れるようにする。 req_content = None #〜中略〜 #<Todo登録>実行 item = { "todoid": str(uuid.uuid4()), "title": req_title, "content": req_content, "priority": req_priority, "done": req_done, "created_at": current_date, "updated_at": current_date } table.put_item( Item = item ) #<Todo登録>実行結果リターン return(return200(item)) Response: { "statusCode": 200, "body": { "todoid": "0b19d07a-7f41-4d58-b179-45889e236743", "title": "たいとるですよ", "content": null, "priority": "normal", "done": 0, "created_at": "2019-09-07T22:39:00", "updated_at": "2019-09-07T22:39:00" } }しかし、DynamoDBのコンソール画面からテーブルを見ると登録したデータの
contentプロパティの値がtrueとなっている。
さらにDynamoDBのテーブルにデータが一つも登録されていない状態であったため、contentプロパティの型がNULL型となっている。
この状態で
contentプロパティにいくつか値を指定して登録し、取得してみると次のような結果となった。
ユーザーが登録しようとする値(型) DynamoDBに登録する際の値(型) DynamoDB管理画面上の値 実際にDynamoDBに登録された値(型) (String) null(NULL) true null(NULL) true(String) true(String) true true(String) 本文ですよ。(String) 本文ですよ。(String) 本文ですよ。 本文ですよ。(String) None(String) None(String) None None(String)
要するに登録時のデータの型をDynamoDB側で保持してくれている動作となる。これでも運用できなくはないがString型とNULL型が同じプロパティに混在しているのは気持ち悪い。
解決
Todoデータの登録時や更新時に
contentプロパティの末尾に</end>タグを必ず付与して、String型のみを扱うようにした。API:<Todo登録> #〜中略〜 #要素定義:content req_content = req_body_dict.get('content') if req_content == None: req_content = '</end>' else: req_content = req_content + '</end>' #〜中略〜 #<Todo登録>実行 item = { "todoid": str(uuid.uuid4()), "title": req_title, "content": req_content, "priority": req_priority, "done": int(req_done), #明示的にint型に設定 "created_at": current_date, "updated_at": current_date } table.put_item( Item = item )Todoデータの取得時には
content属性の末尾から</end>タグを除去する処理を入れた。import re API:<Todo個別取得> ##DBからTodoをtodoidで取得 todo = table.get_item( Key={ 'todoid': req_todoid } )['Item'] #contentから</end>タグ削除 todo['content'] = re.sub('</end>$', '', todo['content'])2. DynamoDBにint型で登録した値が取り出し時にDecimal型になる
事象
Todoステータス
doneプロパティの値は「未完了0」と「完了1」の2パターンとしている。
そこでDynamoDBへのTodo登録時の処理ではTodoのdoneプロパティの値を明示的にint型に設定してDynamoDBに登録するようにした。InputEvent: { "httpMethod": "POST", "resource": "/todo", "body": "{\"title\": \"内部定例\",\"done\": 0}" } API:<Todo登録> #〜中略〜 #<Todo登録>実行 item = { "todoid": str(uuid.uuid4()), "title": req_title, "content": req_content, "priority": req_priority, "done": int(req_done), #明示的にint型に設定 "created_at": current_date, "updated_at": current_date } table.put_item( Item = item ) Response: { "todoid": "35f047ba-1121-4473-8587-b893f0938389", "title": "内部定例", "content": "", "priority": "normal", "done": 0, "created_at": "2019-09-07T16:27:54", "updated_at": "2019-09-07T16:27:54" }しかし、登録したデータをDynamoDBから取得すると
doneプロパティの値がDecimal型<class 'decimal.Decimal'>となってしまっている。
また、取得したデータをレスポンスするためにjson.dumpsしようとするとTypeError:Object of type Decimal is not JSON serializableとなりJSONシリアライズできない。InputEvent: { "httpMethod": "GET", "resource": "/todo/{todoid}", "pathParameters": "{\"todoid\": \"35f047ba-1121-4473-8587-b893f0938389\"}" } API:<Todo個別取得> #〜中略〜 ##DBからTodoをtodoidで取得 todo = table.get_item( Key={ 'todoid': req_todoid } )['Item'] print(type(todo['done']))#型確認 #〜中略〜 #<Todo個別取得>実行結果リターン return{ 'statusCode': 200, 'body': json.dumps(todo) } Fanction Logs: <class 'decimal.Decimal'> Response: { "errorMessage": "Object of type Decimal is not JSON serializable", "errorType": "TypeError", "stackTrace": [ " File \"/var/task/lambda_function.py\", line 209, in lambda_handler\n 'body': json.dumps(item)\n", " File \"/var/lang/lib/python3.7/json/__init__.py\", line 231, in dumps\n return _default_encoder.encode(obj)\n", " File \"/var/lang/lib/python3.7/json/encoder.py\", line 199, in encode\n chunks = self.iterencode(o, _one_shot=True)\n", " File \"/var/lang/lib/python3.7/json/encoder.py\", line 257, in iterencode\n return _iterencode(o, 0)\n", " File \"/var/lang/lib/python3.7/json/encoder.py\", line 179, in default\n raise TypeError(f'Object of type {o.__class__.__name__} '\n" ] }解決
json.dumps時にDecimal型の値があればint型に変換するようにした。InputEvent: { "httpMethod": "GET", "resource": "/todo/{todoid}", "pathParameters": "{\"todoid\": \"35f047ba-1121-4473-8587-b893f0938389\"}" } API:<Todo個別取得> ##DBからTodoをtodoidで取得 todo = table.get_item( Key={ 'todoid': req_todoid } )['Item'] #〜中略〜 #Decimal型の場合はint型に変換 def decimal_default_proc(obj): if isinstance(obj, Decimal): return int(obj) raise TypeError #<Todo個別取得>実行結果リターン return{ 'statusCode': 200, 'body': json.dumps(todo,default=decimal_default_proc) } Response: { "todoid": "35f047ba-1121-4473-8587-b893f0938389", "title": "内部定例", "content": "", "priority": "normal", "done": 0, "created_at": "2019-09-07T16:27:54", "updated_at": "2019-09-07T16:27:54" }上記ではDecimal -> int変換用の関数を利用しているが、関数を使わなくてもDecimal型になることが事前に分かっている値は個別に
int(値)すればよい。参考
https://qiita.com/ekzemplaro/items/5fa8900212252ab554a3
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/GettingStarted.Python.03.html3.DynamoDBに登録されるデータのプロパティの並び順を定義できない。
事象
例えば、以下のようにプロパティの順番を整列させたTodoをDynamoDBに登録する。
API:<Todo登録> #〜中略〜 #<Todo登録>実行 item = { "todoid": str(uuid.uuid4()), "title": req_title, "content": req_content, "priority": req_priority, "done": req_done, "created_at": current_date, "updated_at": current_date } table.put_item( Item = item )登録したデータをDynamoDBから取得するとプロパティの並び順が整列されていない。
API:<Todo個別取得> ##DBからTodoをtodoidで取得 todo = table.get_item( Key={ 'todoid': req_todoid } )['Item'] #〜中略〜 #<Todo個別取得>実行結果リターン return{ 'statusCode': 200, 'body': json.dumps(todo) } Response: { "updated_at": "2019-09-01T21:38:37", "content": "定期券の更新ができた", "todoid": "6f9cd0e6-fbf0-48be-ac64-b4763c482d4d", "created_at": "2019-09-01T20:32:30", "priority": "normal", "done": 1, "title": "定期更新" }DynamoDB自体の設定でもプロパティの並び順をあらかじめ定義する設定は見当たらない。
解決
取得後にプロパティの並び順を整列する処理を入れる。
API:<Todo個別取得> ##DBからTodoをtodoidで取得 todo = table.get_item( Key={ 'todoid': req_todoid } )['Item'] #〜中略〜 #プロパティ並び順整列 item = { "todoid": todo['todoid'], "title": todo['title'], "content": todo['content'], "priority": todo['priority'], "done": todo['done'], "created_at": todo['created_at'], "updated_at": todo['updated_at'] } #<Todo個別取得>実行結果リターン return{ 'statusCode': 200, 'body': json.dumps(item) } Response: { "todoid": "6f9cd0e6-fbf0-48be-ac64-b4763c482d4d", "title": "定期更新", "content": "定期券の更新ができた", "priority": "normal", "done": 1, "created_at": "2019-09-01T20:32:30", "updated_at": "2019-09-01T21:38:37" }以上


- 投稿日:2019-09-09T22:35:01+09:00
乃木坂46起点のアーティスト関係図を描画する(Spotify API, Network X)
はじめに
Spotify APIで乃木坂46の関連アーティストを呼び出し、PythonライブラリのNetwork Xを使って、アーティスト関係図を描画したいと思います。
Spotify APIの利用方法や基本的な機能はこちら(Spotify APIで乃木坂46を分析したい)に投稿しています。参考
Spotify APIで好きなアーティストの繋がりを可視化してディグる
https://blog.aidemy.net/entry/2018/08/31/142408Spotipyのドキュメント(spotipyはSpotify APIをpythonで使用するためのライブラリ)
https://spotipy.readthedocs.io/en/latest/#Spotify APIのリファレンス
https://developer.spotify.com/documentation/web-api/reference-beta/Python使用環境
・spotipy 2.4.4
・numpy 1.15.4
・networkx 2.3
・matplotlib 3.0.2
・numpy 1.15.4アーティスト関係図の描画
アーティスト関係図について
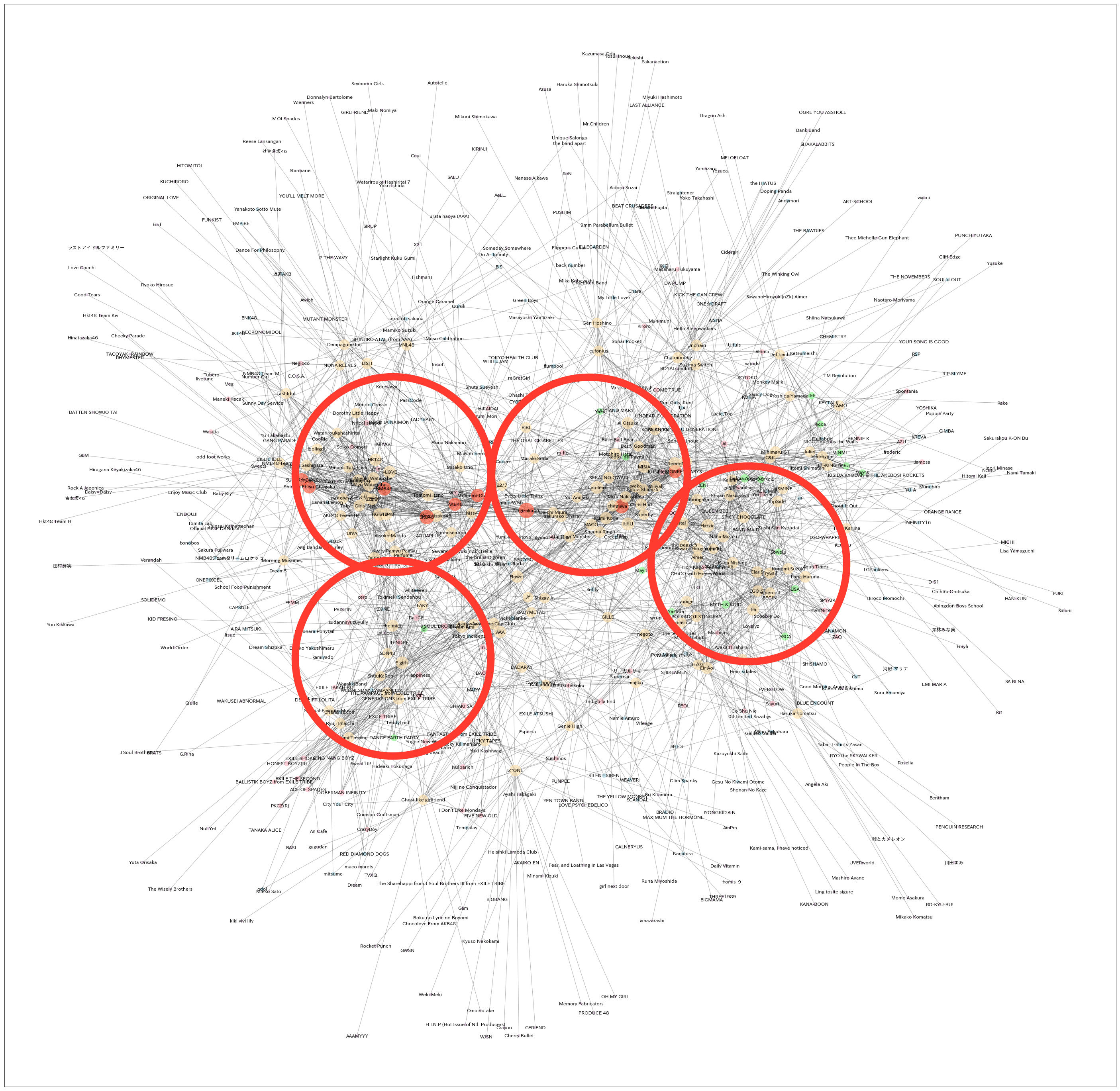
アーティスト関係図は乃木坂46を起点として、「乃木坂46の関連アーティスト」「乃木坂46の関連アーティストの関連アーティスト」という形式で辿っていくことで関係データを溜めていきます。それらを関係図の形で描画することで、乃木坂46を起点として「あるアーテイストを聞いている人が他によく聞いているアーティスト群」が一目でわかるのではないかという試みです。イメージはこんな感じです。
アーティスト関係図の描画実装
アーティスト関係図を描画するコードを実装します。
手順としては、まず起点となるアーティストのidからその関連アーティストのデータを取得します。
さらにその取得したアーティストの関連アーティストを辿って...という感じでぐるぐる回してデータを蓄積します。その後そのデータを用いて、networkxで関係図を描画すれば完成です。
下記が作成したコードです。至らない箇所も多いコードとは思いますがご了承ください。。。
事前に日本語が文字化けしないようにフォントを設定済みです。必要な方はこちらをご参照ください。import spotipy import matplotlib.pyplot as plt import networkx as nx from spotipy.oauth2 import SpotifyClientCredentials client_id = 'ここに自分のクライアントIDを記載' client_secret = 'ここに自分のシークレットキーを記載' client_credentials_manager = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret) spotipy.Spotify(client_credentials_manager=client_credentials_manager) spotify = spotipy.Spotify(client_credentials_manager=client_credentials_manager) class Spotify_Artists_info: def __init__(self, name): self.name = name self.related_artist = None #指定した名前のアーティストのidを取得する関数 def get_artist_uri(self): row = spotify.search(q='artist:' + self.name, type='artist')['artists']['items'][0]['uri'] uri = row.split(':')[2] #指定した名前のアーティストのuriを返す return uri #関連アーティストのデータを取得する関数 #sizeで何階層まで関連アーティストを辿るのかを指定 def relation_list(self, size): related_artist = [] #まず、指定のアーティストの直接の関連アーティストのデータを取得する for i in spotify.artist_related_artists(self.get_artist_uri())['artists']: related_artist.append([spotify.artist(self.get_artist_uri())['name'], i['name'], i['uri'].split(':')[2]]) #第二階層以上を辿る場合はここからぐるぐる回す if size > 1: count = 0 size = size-1 for i in range(size): head = count tail = len(related_artist) for uri in np.array(related_artist)[:,2][head:tail]: key_artist = spotify.artist(uri)['name'] for x in spotify.artist_related_artists(uri)['artists']: related_artist.append([key_artist,x['name'], x['uri'].split(':')[2]]) count += tail self.related_artist = related_artist else: self.related_artist = related_artist #描画の際のノードの色を変化させる関数 def fnc_color(self, siz): colorlist = ['tomato', "moccasin", "palegreen", "pink", "lightblue", "thistle","lightgrey", "w"] if siz >=1000: return colorlist[0] elif siz >=500: return colorlist[1] elif siz >=250: return colorlist[2] elif siz >= 100: return colorlist[3] elif siz >= 50: return colorlist[4] else: return colorlist[5] #アーティストの関係図を描画する関数 def generate_relation_map(self): for i in self.related_artist: G.add_edge(i[0], i[1]) plt.figure(figsize = [50, 50]) pos = nx.spring_layout(G, seed = 1, k = 0.2) #フォントは日本語が文字化けしないように、事前にダウンロード済み nx.draw_networkx_labels(G, pos, font_color='k', font_family='IPAexGothic') nx.draw_networkx_nodes(G, pos, alpha=0.7, node_shape="o", linewidths = 1, #次数中心性(そのノードから何本線が出ているか)を元にノードの大きさとサイズを指定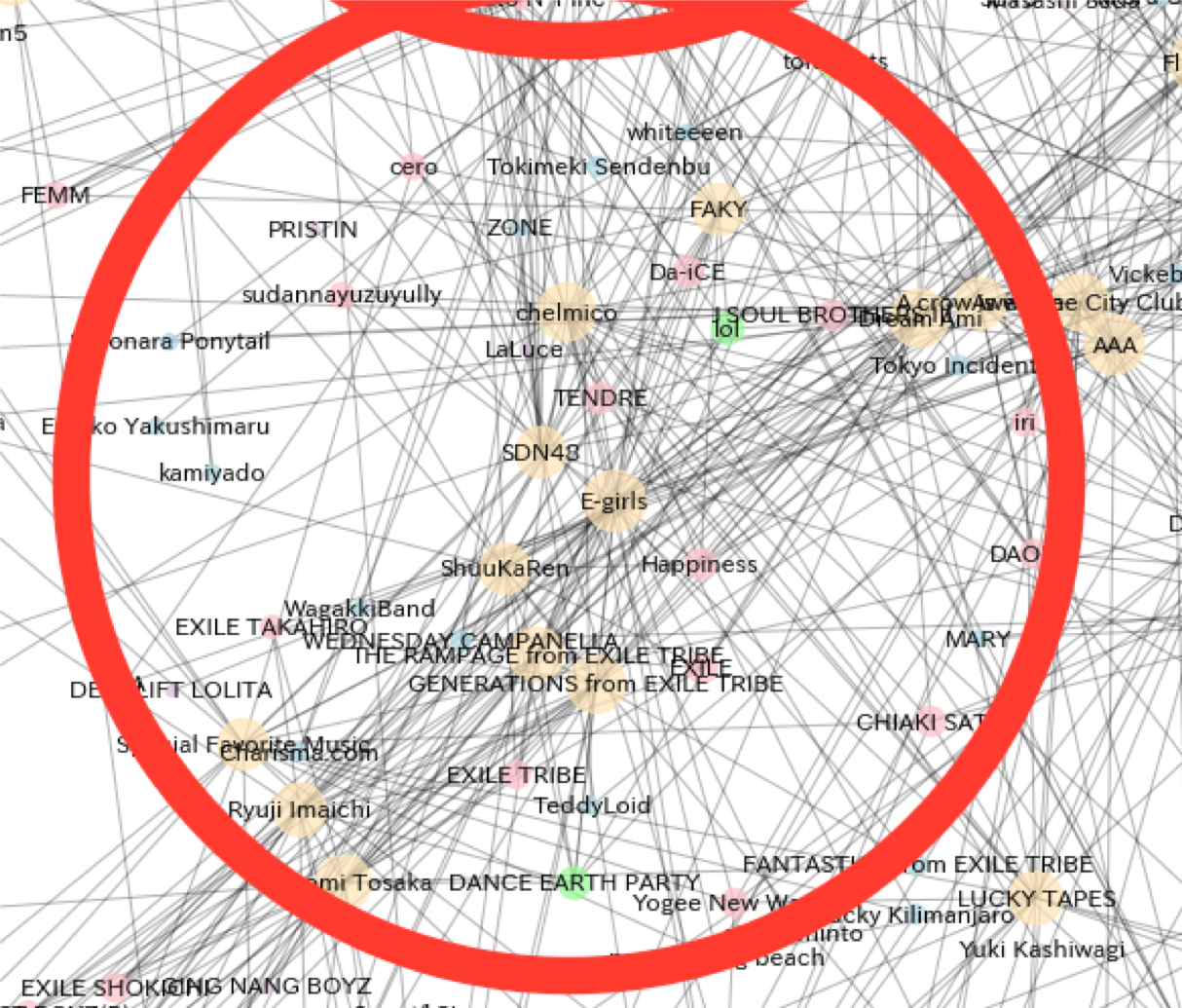 node_color = list(map(self.fnc_color ,[nx.degree_centrality(G)[i]*20000 for i in G.node])), node_size = [nx.degree_centrality(G)[i]*20000 for i in G.node]) nx.draw_networkx_edges(G, pos, alpha=0.3)描画
では、上記を用いて実際に乃木坂46を起点としてアーティスト関係図を描画してみます。
今回は、乃木坂を起点として第2階層までの描画とします。ちなみに階層を増やす毎にデータは指数関数的に増えていくため、その分非常に時間がかかります。s = Spotify_Artists_info('Nogizaka46') s.relation_list(2) s.generate_relation_map()描画した結果がこちら、
よくわからんけどなんかすごい。。。
アーティスト関係図の中身を分析
上記のアーティスト関係図ですが、よくよく見るとノード(丸のこと)が密集している箇所がいくつかあるのがわかります。
それぞれのクラスターについて少し詳しくみていきます。
①アイドルクラスター
まず、1つ目のクラスターを見ていきます。少し重なっている部分が見にくくて恐縮ですが、48系グループを中心にアイドルグループが集まっていることがわかります。48系やその派生ユニットだけでなく、「SUPER GIRLS」や「私立恵比寿中学」など他系統のアイドルグループ存在しています。そんな中、乃木坂46は少しクラスターから外れているのがお分りでしょうか。(画像の右端にあります。)前回の投稿にも記載しましたが、乃木坂46のファン層は所謂アイドルファン層のみ、という状況を脱しつつあることがわかります。
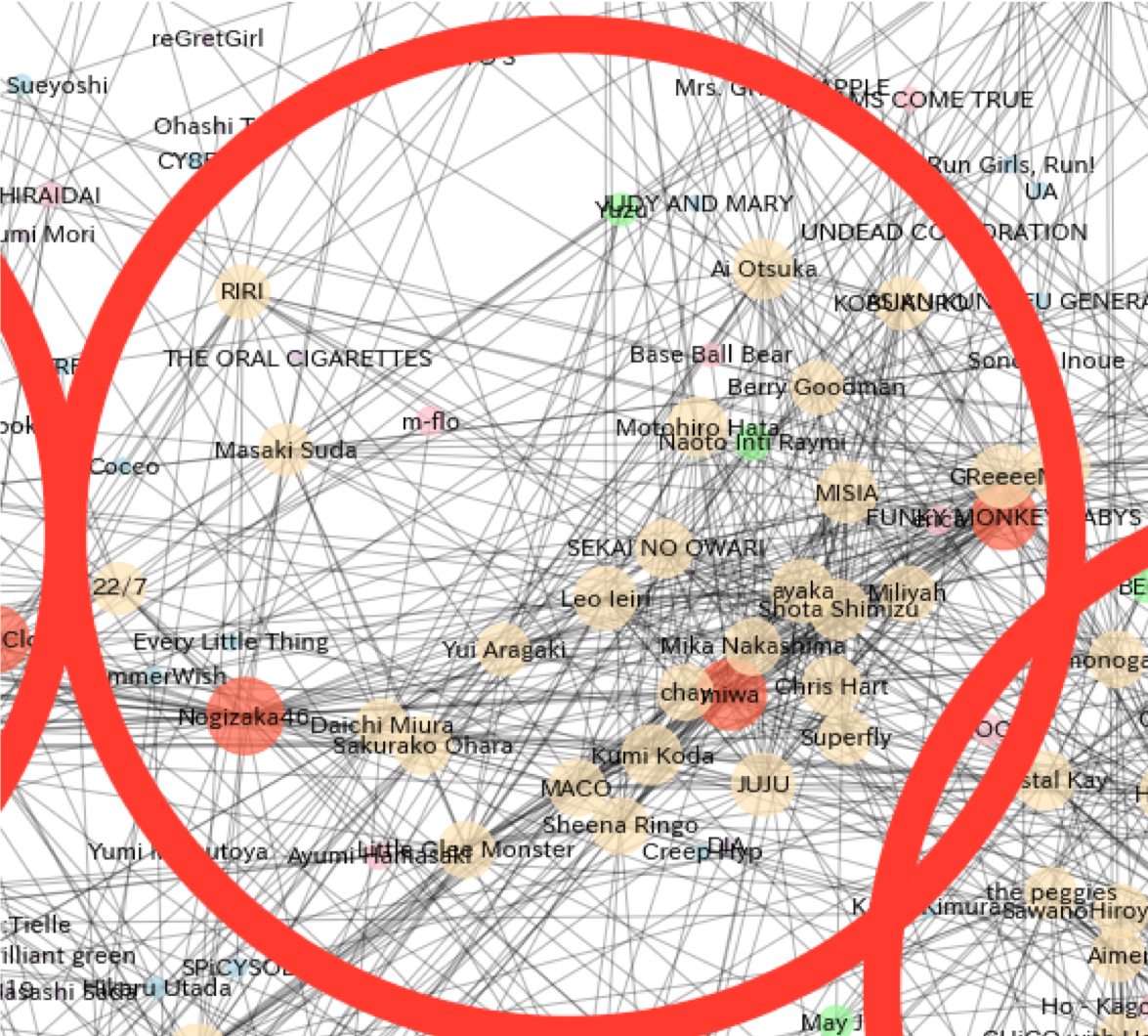
②人気J-POPクラスター
続いて、乃木坂46が属しているクラスターです。中には、「SEKAI NO OWARI」や「miwa」、「GReeeeN」や「Superfly」など、既に人口に膾炙しているような人気J-POPアーティストが目立ちます。(筆者はあまり音楽知識がないため、本当はもっと適切な定義付けが可能かもしれません。また、「SEKAI NO OWARI」はJ-POPなのか、みたいな問題もあるような気がするので、何となく大衆のレベルで認知度がある、というくくりの方がよいかもしれません。)また、その中に乃木坂46が入っているのを見ると、やはりアイドルと枠を脱して大衆レベルの認知度を獲得しつつあるのかとなと思います。
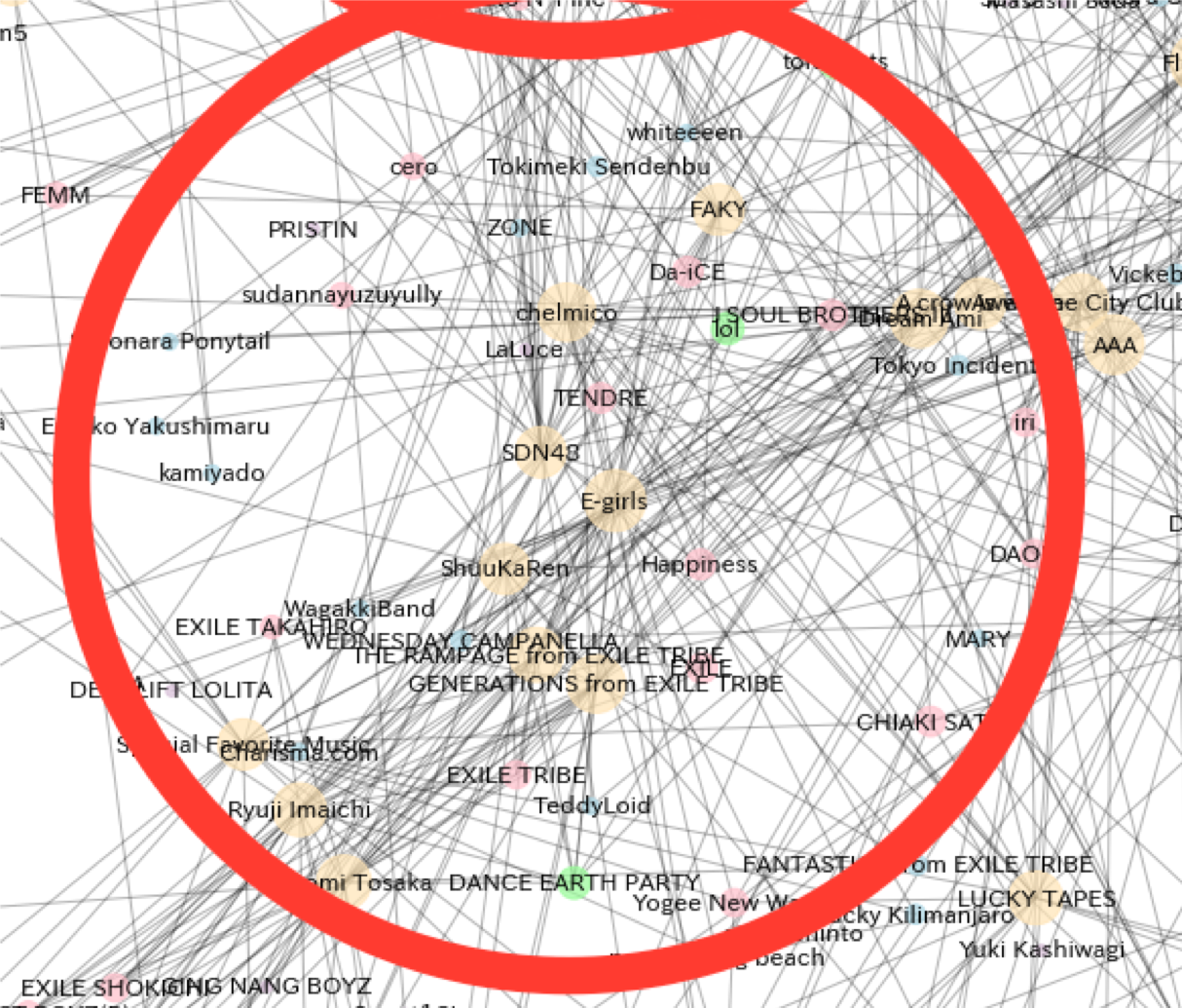
③EXILEクラスター
3つ目は、「EXILE」や「EXILE TRIBE」、「E-girls」など株式会社LDH JAPAN(EXILEのHIROが創業)に所属するグループのクラスターです。面白いのは、このクラスターがJ-POPクラスタとあまり近い位置にない、という点です。筆者としては、「EXILE」や「E-girls」はもっとJ-POP寄りのところにあっても良いのかな、という感覚なのですが、実際は割とはっきりファン層は分かれており、EXILE系グループを支持する層というのが明確に存在するということでなんでしょう。
もうひとつクラスターがあるのですが、筆者の音楽スキルが足りないため定義づけは諦めました。。。みなさんの方で色々試してみてどんな関係図が現れるのか試していただければ楽しいと思います!
おわりに
やっぱりSpotify APIは色々できて楽しいで、他の切り口の分析にもチャレンジしていければと思います。


- 投稿日:2019-09-09T22:34:53+09:00
PythonでHTML解析(スクレイピング)
サイトリニューアルのとき、よくあるデータ移行があります。
手動作業はできますが、コストかかりますので、
バッチでHTML取得⇒解析⇒新システムに投入 というような機能が役に立つ場合があります。Javaでは、jsoupというライブラリは有名です。
Pythonでは、beautifulsoup4 というライブラリは有名です。jsoup: https://jsoup.org/
beautifulsoup4: https://pypi.org/project/beautifulsoup4/VSCodeのターミナルからインストール
pip install beautifulsoup4HTMLのfragmentの解析
解析サンプル
from bs4 import BeautifulSoup html = "<body><h1>PythonでHTML解析</h1><p>HTML解析の説明</p></body>" soup = BeautifulSoup(html, "html5lib") print(soup.h1)結果
<h1>PythonでHTML解析</h1>一点注意したいのは、ライブラリにあるファイルを自分のプロジェクトフォルダーに作成するとエラーになる可能性があります。
例えば、「bs4.py」というファイルを作成して実行しようとするとエラーです。URLから解析
from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen("https://news.yahoo.co.jp/").read() soup = BeautifulSoup(html, 'html.parser') # print(soup.prettify()) # jQueryと同じにセレクターを書く elements = soup.select(".topicsList li.topicsListItem a") for element in elements: print("title: " + element.text + ", href: " + element.get("href"))解析結果
title: 日産・西川社長 16日付で辞任, href: https://news.yahoo.co.jp/pickup/6336028 title: 日産社長退任 裏に激しい攻防, href: https://news.yahoo.co.jp/pickup/6336027 title: 停電続く千葉「耐えるしか」, href: https://news.yahoo.co.jp/pickup/6336024 title: 上皇后さま 術後の経過順調, href: https://news.yahoo.co.jp/pickup/6336026 title: ヤマト 住所なしで発送可能に, href: https://news.yahoo.co.jp/pickup/6336019 title: 経費削減 減りゆくテレビCM, href: https://news.yahoo.co.jp/pickup/6335992 title: 騒然 ロッテ井口監督が即退場, href: https://news.yahoo.co.jp/pickup/6336025 title: 3選手がメッシとの会話拒否か, href: https://news.yahoo.co.jp/pickup/6336029詳しい情報のURL:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
以上
- 投稿日:2019-09-09T22:34:32+09:00
Raspberry PiとKV-7500で上位リンク通信
概要
Raspberry PiからKV-7500(keyence製PLC)にEtherNet/IPを利用してアクセスしてみました。
KV-7500の上位リンク通信機能を利用し、TCPサーバーとして機能します。
Raspberry PiはTCPクライアントとしてKV-7500と通信します。KV-7500の設定
ユニットエディタを開いて下記のように設定します。
機能
・ソケット通信:使用する
基本
・先頭DM番号:DM10000
・先頭リレー:R10000
・IPアドレス:固定IPアドレス(*)
・IPアドレス:192.168.0.10(デフォルトでOK)
・サブネットマスク:255.255.255.0(デフォルトでOK)ポート番号
・ポート番号(上位リンク):8501(デフォルトでOK)
あとの設定は特に変更する必要はなさそうです。
Raspberry Piの設定・プログラム
TCP/IPでKV-7500に接続して、コマンドを送信します。
KV-7500からの返答がきたら、結果を表示します。tcp-client.pyimport socket host_ip = '192.168.0.10' # kv-7500のIPアドレス host_port = 8501 # 上位リンク通信のポート番号 client = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # socket.AF_INETでip4を使うことを指定。socket.SOCK_STREAMでTCPを使うことを指定。 client.connect((host_ip,host_port)) # サーバーに接続(kv-7500にTCP接続/上位リンク通信) comand = "?K" # 上位リンク通信のコマンド(これは機種の問い合わせコマンド) separator = "\r" # 区切り符号CRの16進数表記 msg = comand + separator client.send(msg.encode("ascii")) # 上位リンク通信のデータコードがASCIIなのでエンコード print("send : " + msg) response = client.recv(1024) response = response.decode("UTF-8") # PLCからの返答がbyteデータなのでUTF-8にデコード client.close() print("Received :" ,response)「Received:55」と表示され、これは、KV-7500を意味します。
終わりに
上位リンク通信を利用してRaspberry PiからKV-7500にコマンドを送り、機種を確認することができました。
KV-7500には機種問い合わせのほかにも、データ読み出しやデータ書き込みなどのコマンドが用意されているので、随時試していきます。
- 投稿日:2019-09-09T22:28:20+09:00
Chainer+OptunaでFashion MNISTの正解率を90%以上にしたい
Optunaとは
ハイパーパラメータの自動最適化フレームワークです。
Pythonで利用できます。
Optunaには3つの特徴があります。
① Define by RunスタイルのAPI
② 学習曲線を用いた試行の枝刈り
③ 並列分散最適化
要はコードが簡単に書け、改修もしやすく、速いってことです。
詳しくは公式ページで確認できます。今回やること
Fashion MNISTのテスト正解率が90%以上となるハイパーパラメータを、Optunaにて探索します。
Qiita記事「ChainerでFashion mnistのテスト精度を90%以上にする」を参考にしました。実験条件
実験条件の縛りは上記記事と同様です。
- データセットはFashion MNIST(MNISTの衣類版。サイズ、枚数はMNISTと同じ。訓練50,000枚、テスト10,000枚。)
- Google Colaboratory上(GPU)で実行
- エポック数10以下
- 訓練時間100秒以内
- ネットワークは全結合層のみ
その他の確定条件は以下のようにします。
- 活性化関数はRelu関数
- 5エポック後、学習率に1/10をかける
- 試行回数は100
自動最適化を行うパラメータは以下のものとします。
- ネットワークの層数:1~6
- 各ユニットのノード数:100~4000
- オプティマイザ:MomentumSGD, Adam
- 学習率:1e-5~1e-1
- バッチサイズ:50, 100, 200, 500
また、PRUNER_INTERVALを3とします。
つまり、3エポック毎に学習曲線をチェックし、見込みがなければその試行を中止します。コード
コードは以下の通りです。
ほぼ、Optunaの公式exampleのコピーです。import chainer import chainer.functions as F import chainer.links as L import numpy as np import optuna from time import time EPOCH = 10 PRUNER_INTERVAL = 3 def create_model(trial): n_layers = trial.suggest_int('n_layers', 1, 6) layers = [] for i in range(n_layers): n_units = int(trial.suggest_loguniform( 'n_units_l{}'.format(i), 100, 4000)) layers.append(L.Linear(None, n_units)) layers.append(F.relu) layers.append(L.Linear(None, 10)) return chainer.Sequential(*layers) def create_optimizer(trial, model): optimizer_name = trial.suggest_categorical('optimizer', ['Adam', 'MomentumSGD']) if optimizer_name == 'Adam': adam_alpha = trial.suggest_loguniform('adam_alpha', 1e-5, 1e-1) optimizer = chainer.optimizers.Adam(alpha=adam_alpha) else: momentum_sgd_lr = trial.suggest_loguniform('momentum_sgd_lr', 1e-5, 1e-1) optimizer = chainer.optimizers.MomentumSGD(lr=momentum_sgd_lr) optimizer.setup(model) return optimizer def objective(trial): gpu_id = 0 model = L.Classifier(create_model(trial)) model.to_gpu(gpu_id) optimizer = create_optimizer(trial, model) rng = np.random.RandomState(0) batchsize = trial.suggest_categorical( 'batchsize', [50, 100, 200, 500]) train, test = chainer.datasets.fashion_mnist.get_fashion_mnist() train_iter = chainer.iterators.SerialIterator(train, batchsize) test_iter = chainer.iterators.SerialIterator( test, batchsize, repeat=False, shuffle=False) updater = chainer.training.StandardUpdater( train_iter, optimizer, device=gpu_id) trainer = chainer.training.Trainer(updater, (EPOCH, 'epoch')) optimizer_name = trial.params["optimizer"] if optimizer_name == "MomentumSGD": trainer.extend(chainer.training.extensions.ExponentialShift('lr', 0.1), trigger=(5, 'epoch')) else: trainer.extend(chainer.training.extensions.ExponentialShift('alpha', 0.1), trigger=(5, 'epoch')) trainer.extend(optuna.integration.ChainerPruningExtension( trial, "validation/main/loss", (PRUNER_INTERVAL, "epoch"))) trainer.extend(chainer.training.extensions.Evaluator( test_iter, model, device=gpu_id)) log_report_extension = chainer.training.extensions.LogReport(log_name=None) trainer.extend( chainer.training.extensions.PrintReport([ 'epoch', 'main/loss', 'validation/main/loss', 'main/accuracy', 'validation/main/accuracy' ])) trainer.extend(log_report_extension) trainer.run(show_loop_exception_msg=False) log_last = log_report_extension.log[-1] for key, value in log_last.items(): trial.set_user_attr(key, value) val_err = 1.0 - log_report_extension.log[-1]['validation/main/accuracy'] return val_err if __name__ == "__main__": start = time() study = optuna.create_study() study.optimize(objective, n_trials=100) elapsed_time = time() - start print("elapsed_time:", elapsed_time) print('Number of finished trials: ', len(study.trials)) print('Best trial:') trial = study.best_trial print(' Value: ', trial.value) print(' Params: ') for key, value in trial.params.items(): print(' {}: {}'.format(key, value)) print(' User attrs:') for key, value in trial.user_attrs.items(): print(' {}: {}'.format(key, value))実験結果
ベストパラメータは以下のようになりました。
- ネットワークの層数:2
- 各ユニットのノード数:[unit1: 3145, unit2: 3846]
- オプティマイザ:Adam
- 学習率:4.156e-4
- バッチサイズ:100
ベストパラメータでの結果は以下の通りです。
- 訓練正解率:94.42%
- テスト正解率:90.40%
- 学習時間:70秒
無事、条件を満たしつつテスト正解率を90%以上にすることができました。
考察
今回は特徴②の枝刈りを用いました。
100回の試行での総学習時間は2904秒でした。
単純計算で70x100=7,000秒程かかっておかしくないので、枝刈りが非常に時間短縮に役立っていると考えられます。ただ、オプティマイザは
- MomentumSGDは、学習は遅いが汎化性能が高い
- Adamは、学習は速いが汎化性能が低い
という特徴があるので、「MomentumSGDで学習が遅くても最終的に正解率が良くなるもの」も枝刈りされてしまった可能性があります。
そういった意味では、この枝仮はMomentumSGDにとって不利であったかもしれません。
そこらへんの枝刈り問題は、結構難しいらしいです。
(参照:OptunaのPruningが抱える課題)また、バッチサイズをある程度小さくすると正解率が良くなります。
上記のコードとは別に、今回の範囲よりも小さいバッチサイズを候補に入れたときは、正解率がより良くなりました。(バッチサイズが16のとき)
ただし、学習時間が100秒を余裕で超えてしまいました。
バッチサイズを小さくするとオプティマイザによる更新回数が増えるからなんでしょうね。
ここらへんは、時間との相談です。まとめ
Optunaは、ほんと便利です。
手動ではとてもできないようなハイパーパラメータを探し出してくれます。
ただし、ある程度のハイパーパラメータ調整に関する知識(モデルの大枠の組み方や学習率のスケジューリングなど)は必要です。
モデルやハイパーパラメータの大枠は自分で決めて、Optunaを使って細かい調整をしていくのが良い使い方なんだと思います。
- 投稿日:2019-09-09T21:54:48+09:00
【エラー対処】pyenvでinstallができなくなった
はじめに
以前pyenv, pyenv-virtualenvをインストールした記事を書いており、
これからはAnaconda依存ではなくバージョンごとに環境が変えられるなぁ〜と思っていました。しかし、すぐさまエラーが発生してしまいました。
原因は複数考えられますが
- 先日、Macのアカウント名を変更した(調べれば分かりますが、結構面倒で、アカウント変更後も不具合が多く出て、修復に大事時間が取られました。)
- bashをやめてfishにした。
が大きな要素かと思っています。
エラー内容
pyenv install 3.7.3 python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Downloading Python-3.7.3.tar.xz... -> https://www.python.org/ftp/python/3.7.3/Python-3.7.3.tar.xz Installing Python-3.7.3... python-build: use readline from homebrew python-build: use zlib from xcode sdk BUILD FAILED (OS X 10.14.5 using python-build 20180424) Inspect or clean up the working tree at /var/folders/q0/x66vgv1s6d1bf5rh1b0f79cc0000gn/T/python-build.20190909205347.67210 Results logged to /var/folders/q0/x66vgv1s6d1bf5rh1b0f79cc0000gn/T/python-build.20190909205347.67210.log Last 10 log lines: File "/var/folders/q0/x66vgv1s6d1bf5rh1b0f79cc0000gn/T/tmpqib00zdi/pip-19.0.3-py2.py3-none-any.whl/pip/_internal/cli/cmdoptions.py", line 22, in <module> File "/var/folders/q0/x66vgv1s6d1bf5rh1b0f79cc0000gn/T/tmpqib00zdi/pip-19.0.3-py2.py3-none-any.whl/pip/_internal/utils/hashes.py", line 10, in <module> File "/var/folders/q0/x66vgv1s6d1bf5rh1b0f79cc0000gn/T/tmpqib00zdi/pip-19.0.3-py2.py3-none-any.whl/pip/_internal/utils/misc.py", line 21, in <module> File "/var/folders/q0/x66vgv1s6d1bf5rh1b0f79cc0000gn/T/tmpqib00zdi/pip-19.0.3-py2.py3-none-any.whl/pip/_vendor/pkg_resources/__init__.py", line 35, in <module> File "/private/var/folders/q0/x66vgv1s6d1bf5rh1b0f79cc0000gn/T/python-build.20190909205347.67210/Python-3.7.3/Lib/plistlib.py", line 65, in <module> from xml.parsers.expat import ParserCreate File "/private/var/folders/q0/x66vgv1s6d1bf5rh1b0f79cc0000gn/T/python-build.20190909205347.67210/Python-3.7.3/Lib/xml/parsers/expat.py", line 4, in <module> from pyexpat import * ModuleNotFoundError: No module named 'pyexpat' make: *** [install] Error 1pythonを新しくpyenvでinstallしようとすると、エラーが発生し
ModuleNotFoundError: No module named 'pyexpat'がないと勧告されます。
とりあえずfishをやめる
fishはbashと同じでシェルの仲間ですが、.bash_profileを読み込んでくれないそうです。
正確には、文法が異なる、といったほうが正しいのかもしれません。よって、下記のコマンドでbashにデフォルトシェルを戻しました。
chsh -s /bin/bashchshはデフォルトシェルを変更するコマンドです。
XcodeのCommandLineToolのBeta版を入れる
https://qiita.com/karon9/items/875b8a0053fa1c685386
のサイトを参考にhttps://developer.apple.com/download/more/?=command%20line%20tools
からCommand Line Tools for Xcode Betaの最新版をダウンロード・インストールする。
その結果
ganariya$ pkgutil --pkg-info=com.apple.pkg.CLTools_Executables package-id: com.apple.pkg.CLTools_Executables version: 11.0.0.0.1.1565314599 volume: / location: / install-time: 1568031534 groups: com.apple.FindSystemFiles.pkg-groupとなり、バージョンが上がり
ganariya$ pyenv install 3.7.3 python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Installing Python-3.7.3... python-build: use readline from homebrew python-build: use zlib from xcode sdk Installed Python-3.7.3 to /usr/local/var/pyenv/versions/3.7.3無事インストール完了できた。うれしい。
まとめ
Fishを使うとBashの.bash_profileがきちんと読み込めない。
(これは、文法がちがうため)また、MacでCommand Lineツールのエラーで上記のエラーが出るので新しいバージョンを入れればきちんとインストールできる。
(ただ、もともとはうまく言ってて、アカウント名を変更したらこうなったので、多分アカウント名の変更時になんか変な事になってたんだと思う。)
- 投稿日:2019-09-09T21:14:14+09:00
selenium + python + chrome を用いたWebブラウザの操作(実サイトを用いたハンズオン)
はじめに
Pythonのseleniumモジュールを使用して、Chromeを操作する方法をまとめています。
Pythonの基礎がわかる人であれば理解できる内容にしています。
実在するサイトを用いて操作手順を記載しています。注意事項として、変なプログラム(連続してリクエストを投げるなど)を実行してしまうとWebサイトに負荷がかかる可能性があります。また、DoS攻撃と判断される可能性もあります。
プログラムを実行する前には間違いがないか注意してください。seleniumインストール
インストール方法は以下を参照してください。
[selenium向け] ChromeDriverをpipでインストールする方法(パス通し不要、バージョン指定可能)
https://qiita.com/hanzawak/items/2ab4d2a333d6be6ac760[超図解]AnacondaインストールからPythonプログラム実行までの手順(Windows版)
https://qiita.com/hanzawak/items/9dedcde1a43aa7d0e71aselenium概要
seleniumはWebサイトのテストを自動化するためのツールです。
以下の流れでブラウザを操作します。
- 操作したいブラウザを開く
- 操作したいページを開く
- 操作したい要素を確認する
- 操作したい要素を指定する
- 操作したい要素を操作する
selenium基本操作
0. seleniumインポート
from selenium import webdriver import chromedriver_binary # ChromeDriverをpipでインストールした場合はchromedriver_binaryもインポートしてください1. 操作したいブラウザを開く
まずはブラウザを開きます。
driver = webdriver.Chrome()以下のような画面が表示されます。
2. 操作したいページを開く
操作したいページを開きます。今回は楽天を開きます。
driver.get("https://rakuten.co.jp")楽天が開きます。
3. 操作したい要素を確認する
「キーワードから探す」の部分に文字を入力してみたいと思います。
「キーワードから探す」の要素を確認するには、ページのソースを見る必要があります。
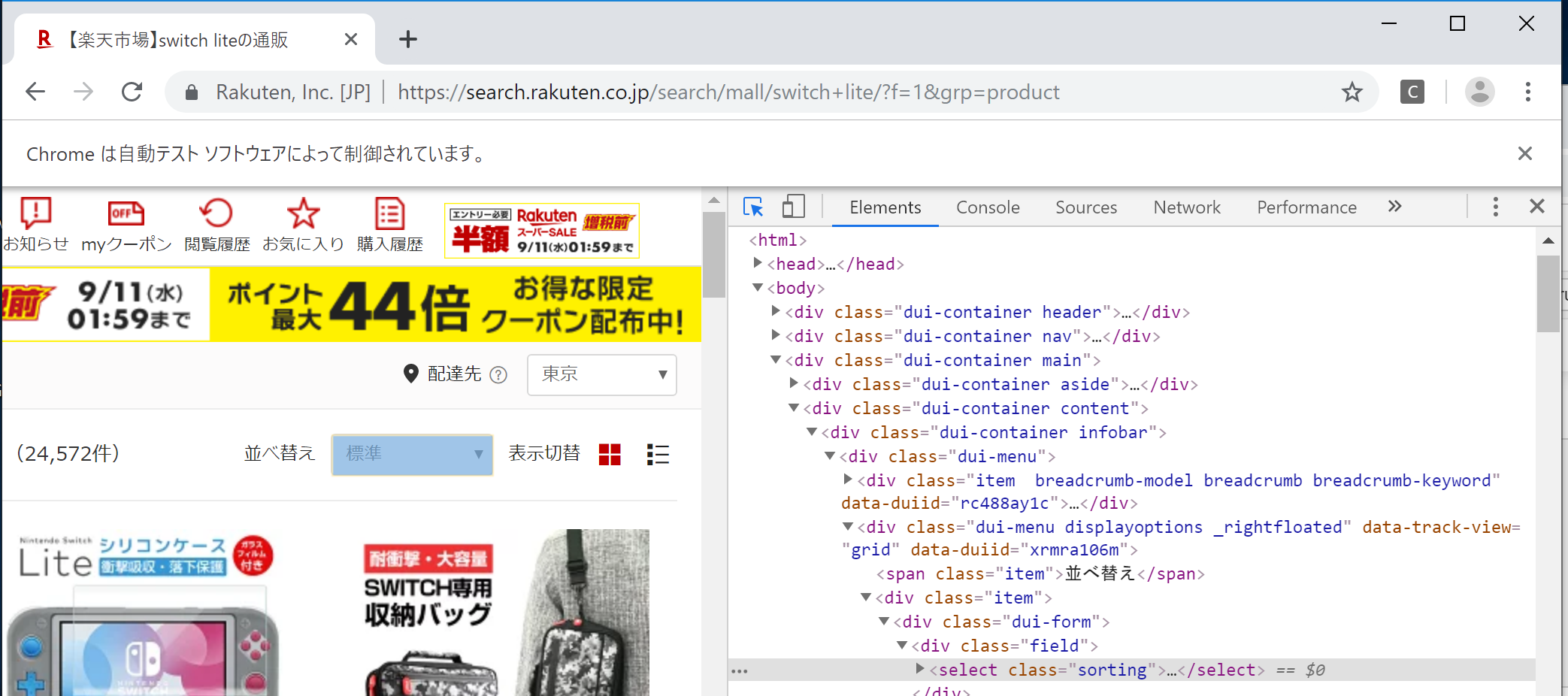
Chromeの場合は開発者ツールを用いることで簡単に確認できますので、その使用方法を記載します。I. F12キーをクリックする
画面右側に開発者ツールが開きます。
II. マウスカーソルボタンをクリックする
以下の赤丸部分を1回クリックしてください。するとマウスカーソルボタンが青色になります。
III. 要素を確認したい箇所をクリックする
マウスカーソルボタンが青色の状態の時に、左側の画面で要素を確認したい箇所をクリックしてください。
今回はキーワードを入力したいので、「キーワードから探す」の部分をクリックします。
IV. ソースを確認する
画面右側の一部が青くハイライトされています。
この部分が「キーワードから探す」のソースです。
V. 要素を確認する
以下は「キーワードから探す」のソースの部分です。
<input type="text" value="" name="sitem" size="40" class="searchInput" id="sitem" placeholder="キーワードから探す" autocomplete="off" maxlength="2048">seleniumで操作する際に使用できる要素としては以下がありました。
- name="sitem"
- class="searchInput"
- id="sitem"
上記以外にもXPathというXMLの特定の部分を指定する方法があります。
(XPathはソースに表示されません)
確認方法は、画面右側の青くハイライトされた部分を右クリックし、Copy→Copy XPath で確認できます。
コピーした内容は
//*[@id="sitem"]でした。4. 操作したい要素を指定する
前の項目で取得できた以下4つの要素のいずれかを用いて、操作したい要素を指定します。
- name="sitem"
- class="searchInput"
- id="sitem"
- XPath -> //*[@id="sitem"]
今回はclassで要素を指定します。
x = driver.find_element_by_class_name('searchInput')5. 操作したい要素を操作する
「switch lite」という文字を入力する場合は以下のようにします。
x.send_keys('switch lite')以上がseleniumを使用する際の基本操作です。
要素を確認して、指定して、操作する、というだけの流れです。selenium応用
まずはselenium基礎のコマンドについて、もう少し他の方法がありますのでその説明をします。
要素指定と要素の操作を1つにまとめる
「4. 操作したい要素を指定する」と「5. 操作したい要素を操作する」は2つの処理を1行にすることができます。
以下のように記載すると、「キーワードから探す」を指定して、「switch lite」を入力できます。driver.find_element_by_class_name('searchInput').send_keys('switch lite')class_name以外の要素の指定
「4. 操作したい要素を指定する」ではclass_nameを指定しましたが、name, id, XPathでは以下のようにして指定ができます。
driver.find_element_by_name('sitem').send_keys('switch lite') driver.find_element_by_id('sitem').send_keys('switch lite') driver.find_element_by_xpath('//*[@id="sitem"]').send_keys('switch lite')seleniumを使用した色々なブラウザ操作
入力されている文字を消す
「キーワードから探す」に入力されている文字を消す方法です。
class_name, name, id, xpathの順で記載しています。driver.find_element_by_class_name('searchInput').clear() driver.find_element_by_name('sitem').clear() driver.find_element_by_id('sitem').clear() driver.find_element_by_xpath('//*[@id="sitem"]').clear()ボタンのクリック
検索ボタンをクリックしてみたいと思います。
前の手順と同じように開発者ツールから検索ボタンの様子を確認すると、class=searchBtnでした。
そのためclass_nameでsearchBtnを指定し、末尾にclick()をつけるとボタンをクリックできます。driver.find_element_by_class_name('searchBtn').click()値段の一覧を取得
いつも通り開発者ツールからマウスカーソルボタンを押して、今度は値段の部分をクリックします。
するとclass=importantであることがわかります。
テキストの情報を取得するには以下のように記載します。末尾が
textになります。driver.find_element_by_class_name('important').textこれを実行すると「21,978円」と表示されます。
次に2件目の値段を取得するために、開発者ツールからマウスカーソルボタンを押して、2件目の値段の部分をクリックします。
まさかの2件目も
class=importantでした。
この場合、今までの方法ですと2件目の値段が取得できません。
どうやって解決するかというと、elementをelementsというように末尾にsをつけます。そして.textの前を[0][1]といったようにします。
以下のようにすると値段の1件目、2件目、3件目が取得できます。driver.find_elements_by_class_name('important')[0].text driver.find_elements_by_class_name('important')[1].text driver.find_elements_by_class_name('important')[2].textなぜか楽天の検索結果には「1〜45件」と記載されていますが、数えてみると48件表示されていますので、以下のようにすると
pricesに全ての価格を記録できます。prices = [] for i in range(48): prices.append(driver.find_elements_by_class_name('important')[i].text) print(prices)楽天が修正する可能性を考えると以下のようにtry-exceptを使用した方が安全かもしれません。
prices = [] i = 0 while True: try: prices.append(driver.find_elements_by_class_name('important')[i].text) i += 1 except: breakプルダウンメニューの操作
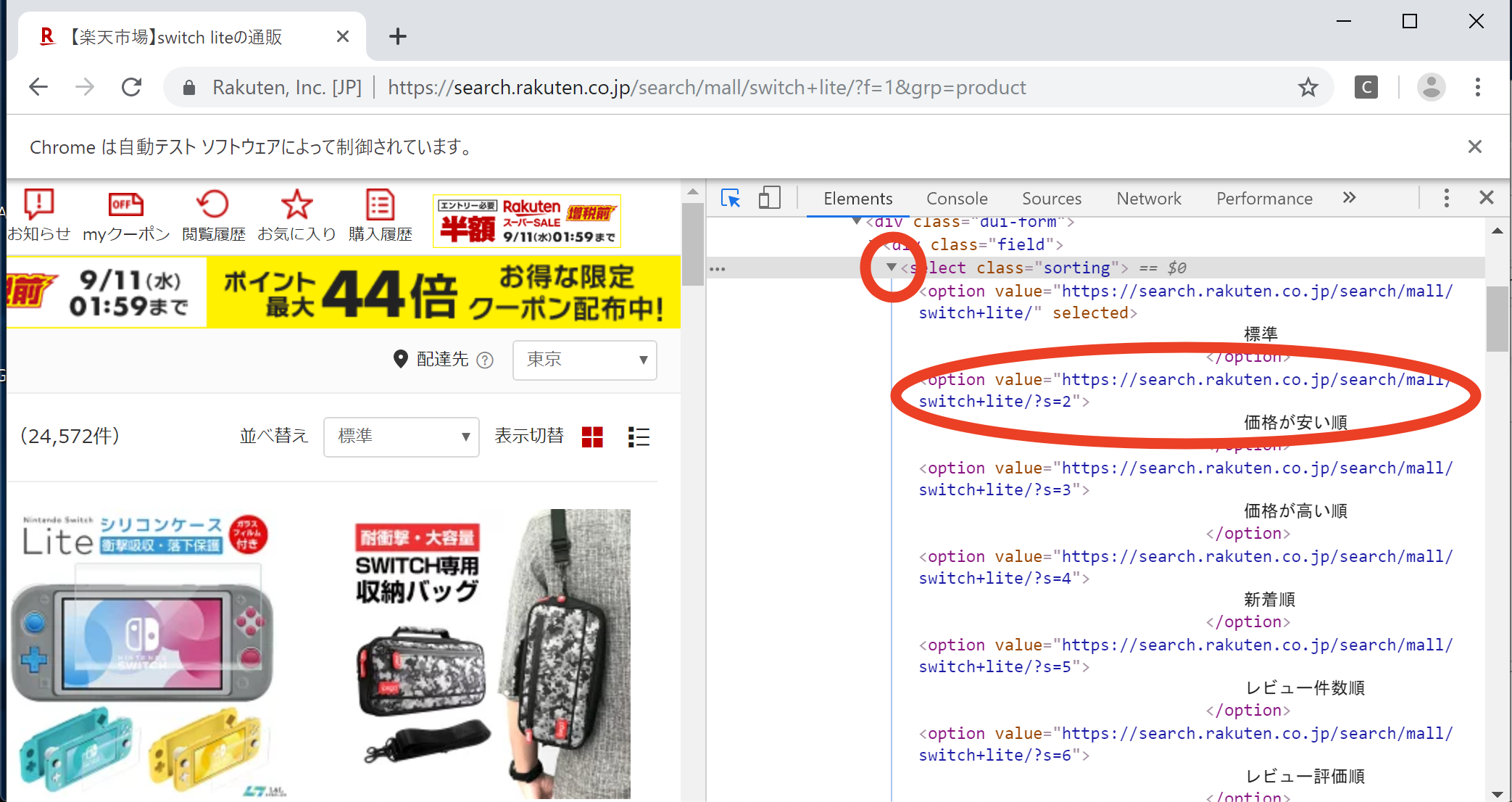
価格のソートをしてみようと思います。
プルダウンメニューを操作する時には、「要素」と「変更したいvalue」の情報が必要になります。「要素」はいつものように「並べ替え」の横の「標準」の部分で調べると、
class=sortingということがわかります。
「変更したいvalue」は
class=sortingの左側の三角ボタンを押して詳細を表示し、その中からvalueを選択します。
今回は「価格が安い順」にしてみたいのでvalueはhttps://search.rakuten.co.jp/search/mall/switch+lite/?s=2ということになります。
「要素」と「変更したいvalue」の情報が入手できましたのでプルダウンメニューを操作します。
以下のように記載すると「価格が安い順」が選択されます。
なおSelectをインポートする必要があります。from selenium.webdriver.support.ui import Select price_sort = driver.find_element_by_class_name('sorting') price_sort_select = Select(price_sort) price_sort_select.select_by_value('https://search.rakuten.co.jp/search/mall/switch+lite/?s=2')チェックボックスを操作
画面左側の「送料無料」のチェックボックスにチェックを入れたいと思います。
その場合はいつも通り要素を確認し、末尾にclick()を記載します。driver.find_element_by_name('f').click()チェックが付いた状態で再度上記を実行するとエラーになります。
そのため以下のようにしても良いと思います。try: driver.find_element_by_name('f').click() except: print('checked')前のページに戻る・先のページに進む
driver.back() # 前のページに戻る driver.forward() # 先のページに進むURLの取得
現在表示しているページのURLを取得できます。
driver.current_urlページタイトルの取得
現在表示しているページのタイトルを取得できます。
driver.titleマウス操作をする
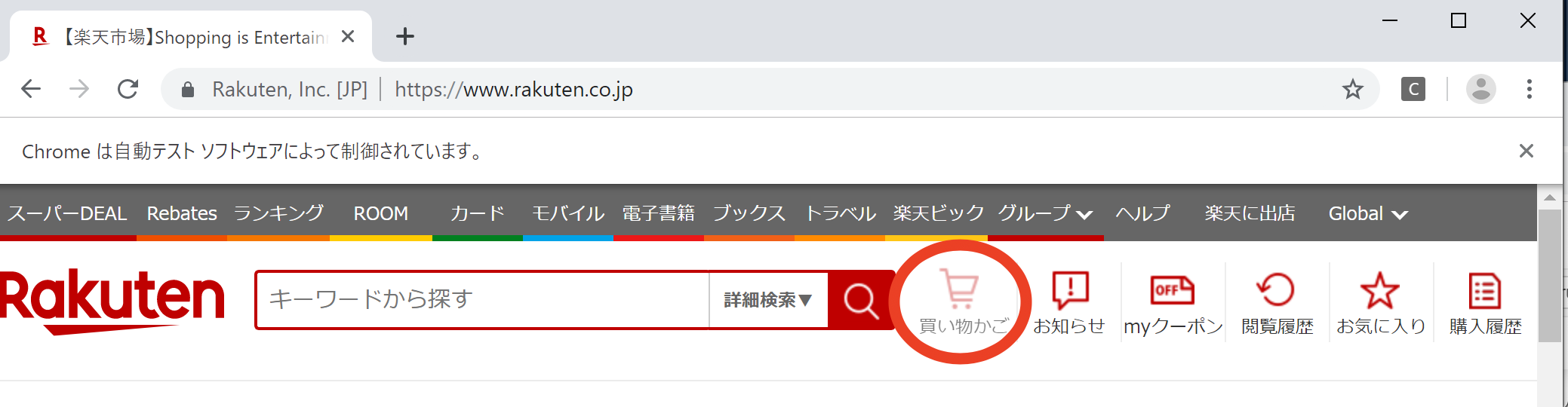
画面上部の「買い物かご」にマウスカーソルを合わせてみようと思います。
まずいつも通り「買い物かご」の要素を確認するとclass=basket-linkでした。
この情報を用いて以下のように記載して実行します。from selenium.webdriver.common.action_chains import ActionChains driver = webdriver.Chrome() driver.get("https://rakuten.co.jp") actions = ActionChains(driver) actions.move_to_element( driver.find_element_by_class_name("basket-link") ).perform()すると「買い物かご」の部分が色が薄くなっていると思います。
自分でマウスカーソルをいじってみるとわかりますが、「買い物かご」の上にマウスカーソルをあてると色が薄くなります。
マウスカーソルは表示されないですが、カーソルがあたった時と同じ動作になっていることがわかります。
スクリーンショットを撮る
同じフォルダにスクリーンショットが保存されます。
driver.save_screenshot('test.png')画面をスクロールする
driver.execute_script("window.scrollTo(0, 1000);")DoS攻撃と間違われないようにするために
サイトに負荷を与えないように、またDoS攻撃と間違われないようにするために、処理の途中にsleepをはさむのも良いと思います。
from selenium import webdriver import time driver = webdriver.Chrome() driver.get("https://rakuten.co.jp") time.sleep(5) driver.find_element_by_class_name('searchInput').send_keys('switch lite') time.sleep(5) driver.find_element_by_class_name('searchBtn').click()ブラウザを閉じる
driver.quit()
- 投稿日:2019-09-09T20:46:26+09:00
jsonスキーマの色々な機能を使用する
はじめに
pythonでjsonスキーマを使用するでは、jsonスキーマの簡単な使用方法をまとめました。
jsonスキーマには、さらに色々な機能がありますが、あまり知られていないためまとめようと思います。そのため、ここにまとめてあるのはjsonスキーマでチェックできる型や上限など良く知られているものは省略しています。環境
- python:3.6.5
- jsonschema:3.0.1
値チェックの色々
複数値内で値が合致しているものがあるかチェックする
入力値があらかじめ決まっている場合に
enumに設定してあげることで設定した値が入力されたらOK、入力された値が設定外ならエラーになります。schema.json{ "$schema": "http://json-schema.org/draft-07/schema#", "title": "PyJsonValidate", "description": "sample json for json validate", "type": "object", "properties" :{ "kind": { "type": "string", "enum": [ "dog", "cat" ] } } }サンプル用のpython
json_schema_main.pyimport json from jsonschema import validate, ValidationError with open('schema.json') as file_obj: json_schema = json.load(file_obj) item = { "kind": "mouse", } try: validate(item, json_schema) except ValidationError as e: print(e.message) print('END')結果
'mouse' is not one of ['dog', 'cat'] ENDjsonスキーマでkindキーの値はdog、catだと指定しているため、mouseを入力するとエラーして、mouseはdogでもcatでもないという旨のメッセージが表示されました。
同一キーで複数のチェックパターンを設定する
あまり仕様的に褒められたものではないですが、同じキーを再利用して全く別の値を入力することがあります。その際に、
anyOfを使用すると同じキーでありながら別パターンのチェックをすることができます。schema.json{ "$schema": "http://json-schema.org/draft-07/schema#", "title": "PyJsonValidate", "description": "sample json for json validate", "type": "object", "properties": { "kind": { "anyOf": [ {"type": "string"}, {"type": "integer"} ] } } }サンプル用のpythonは上と同じです。
itemの値だけ変更しています。結果
0.01 is not of type 'string' ENDjsonスキーマでkindキーの値は文字列と整数と指定しているため、0.01を入力するとエラーしました。また、当然ですが文字列と整数を入力した場合はエラーせずに終了しました。
今回は型の指定のみしましたが{}内に上限値など他の設定を入れるとその設定もそれぞれに有効になります。複数パターンのキーをチェックする
anyOfの応用です。これもあまり仕様的に褒められたものではないですが、場合によって入力されるキーのパターンが複数ある場合にも
anyOfを使うことでチェックできます。schema.json{ "$schema": "http://json-schema.org/draft-07/schema#", "title": "PyJsonValidate", "description": "sample json for json validate", "type": "object", "anyOf":[ {"additionalProperties": false, "properties":{"cat": {"type": "string"}}}, {"additionalProperties": false, "properties":{"dog": {"type": "string"}}} ] }サンプル用のpythonは上と同じです。
itemの値だけ変更しています。結果
Additional properties are not allowed ('mouse' was unexpected) ENDjsonスキーマでキーがcatまたはdogと指定しているため、itemのキーをmouseにして入力するとエラーしました。また、当然ですがdogとcatのキーを入力した場合はエラーせずに終了しました。
あるパターンのキーをチェックする
キーとキーの間の整合性を取るために2つのうちどちらかのキーのみ入力してほしい場合があります。その場合には
oneOfを使うことでチェックできます。schema.json{ "$schema": "http://json-schema.org/draft-07/schema#", "title": "PyJsonValidate", "description": "sample json for json validate", "type": "object", "oneOf":[ {"additionalProperties": false, "properties":{"cat": {"type": "string"}}}, {"additionalProperties": false, "properties":{"dog": {"type": "string"}}} ] }サンプル用のpythonは上と同じです。
itemの値だけ変更しています。json_schema_main.pyitem = { "dog": "pochi", "cat": "tama" }結果
Additional properties are not allowed ('dog' was unexpected) END正常パターン
json_schema_main.pyitem = { "dog": "pochi" }結果
ENDjsonスキーマでキーがcatとdogのパターンを禁止しているため、itemにdogとcatを入力するとエラーしました。また、当然ですがcatのキーだけを入力した場合はエラーせずに終了しました。anyOfと同様にこれも様々な設定をできます。
指定した以外の値を受け取る
ある値以外を欲しいという場合に
allOfとnotを使用してチェックできます。schema.json{ "$schema": "http://json-schema.org/draft-07/schema#", "title": "PyJsonValidate", "description": "sample json for json validate", "type": "object", "properties":{ "dog": { "allOf": [ {"type": "string"}, {"not": {"enum": ["pochi", "tama"]}} ] } } }サンプル用のpythonは上と同じです。
itemの値だけ変更しています。json_schema_main.pyitem = { "dog": "pochi" }結果
{'enum': ['pochi', 'tama']} is not allowed for 'pochi' END正常パターン
json_schema_main.pyitem = { "dog": "tibi" }結果
ENDenumでpochiとtamaだけの設定をnotで反転させ、pochiとtamaは受け付けないようにしました。また、allOfを使用して文字列と値の指定両方を満たすようにチェックしています。特にallOfを使用する必要はありませんが丁度良かったので使いました。
jsonスキーマの表記の色々
設定をリンクで指定する
設定が複雑になっていくと設定だけ別ファイルや別ブロックにまとめたい場合があります。その場合は、
$refに指定してあげることでリンクすることができます。schema.json{ "$schema": "http://json-schema.org/draft-07/schema#", "title": "PyJsonValidate", "description": "sample json for json validate", "type": "object", "$ref": "#/definitions/dog", "definitions": { "dog": { "properties" :{ "kind": { "type": "string", "enum": ["dog"] } } } } }item = { "kind": "cat", }結果
'cat' is not one of ['dog'] ENDrefで指定したdefinitions/dogの設定が反映されました。
上記例はあまり見やすくなった気がしないですが、anyOfやoneOfなど複雑になっていくとこの設定があるかないかで大きく見やすさが変わります。設定を別ファイルに分ける
次は別ファイルに分けていきます。json側では
$refにファイル名を指定してあげて、python側の設定で別ファイルのリンクを設定してあげます。
python側の設定はjsonschemaのライブラリのRefResolverクラスに設定ファイルがあるディレクトリと元のjsonスキーマを渡してあげてvalidate時に指定してあげる必要があります。schema.json{ "$schema": "http://json-schema.org/draft-07/schema#", "title": "PyJsonValidate", "description": "sample json for json validate", "type": "object", "$ref": "dog.json" }dog.json{ "properties" :{ "kind": { "type": "string", "enum": ["dog"] } } }json_schema_main.pyimport os import json from jsonschema import validate, ValidationError, RefResolver with open('schema.json') as file_obj: json_schema = json.load(file_obj) item = { "kind": "cat", } try: schema_path = 'file:///{0}/'.format((os.getcwd()).replace("\\", "/")) ref = RefResolver(schema_path, json_schema) validate(item, json_schema, resolver=ref) except ValidationError as e: print(e.message) print('END')結果
'cat' is not one of ['dog'] ENDjsonschemaライブラリの使い方が少しネックですが、jsonファイルはとても分かりやすくなりました。今回は設定まるまる別ファイルにしましたがやろうと思えばどんな設定も分けられるため、ルールを決めてファイル分けすると見やすくなるのではないかと思います。
おわりに
jsonスキーマの色々な使い方についてまとめました。おそらく、頭を使えばほとんどの入力値チェックがjsonスキーマで可能なほど汎用性のあるものでした。
ただ、ここまでやってしまうと人が見てわかりやすいjsonという利点をつぶしてしまいそうなので個人的にはよっぽどの理由がない限りは単純なjsonを使用しています。
開発の時に他の人の技術レベルを考えて開発していますが、技術レベルと開発のレベルはトレードオフの関係なので、どのレベルに抑えるのかがすごい悩みます。
- 投稿日:2019-09-09T20:46:26+09:00
jsonスキーマを色々な機能を使用する
はじめに
pythonでjsonスキーマを使用するでは、jsonスキーマの簡単な使用方法をまとめました。
jsonスキーマには、さらに色々な機能がありますが、あまり知られていないためまとめようと思います。そのため、ここにまとめてあるのはjsonスキーマでチェックできる型や上限など良く知られているものは省略しています。環境
- python:3.6.5
- jsonschema:3.0.1
値チェックの色々
複数値内で値が合致しているものがあるかチェックする
入力値があらかじめ決まっている場合に
enumに設定してあげることで設定した値が入力されたらOK、入力された値が設定外ならエラーになります。schema.json{ "$schema": "http://json-schema.org/draft-07/schema#", "title": "PyJsonValidate", "description": "sample json for json validate", "type": "object", "properties" :{ "kind": { "type": "string", "enum": [ "dog", "cat" ] } } }サンプル用のpython
json_schema_main.pyimport json from jsonschema import validate, ValidationError with open('schema.json') as file_obj: json_schema = json.load(file_obj) item = { "kind": "mouse", } try: validate(item, json_schema) except ValidationError as e: print(e.message) print('END')結果
'mouse' is not one of ['dog', 'cat'] ENDjsonスキーマでkindキーの値はdog、catだと指定しているため、mouseを入力するとエラーして、mouseはdogでもcatでもないという旨のメッセージが表示されました。
同一キーで複数のチェックパターンを設定する
あまり仕様的に褒められたものではないですが、同じキーを再利用して全く別の値を入力することがあります。その際に、
anyOfを使用すると同じキーでありながら別パターンのチェックをすることができます。schema.json{ "$schema": "http://json-schema.org/draft-07/schema#", "title": "PyJsonValidate", "description": "sample json for json validate", "type": "object", "properties": { "kind": { "anyOf": [ {"type": "string"}, {"type": "integer"} ] } } }サンプル用のpythonは上と同じです。
itemの値だけ変更しています。結果
0.01 is not of type 'string' ENDjsonスキーマでkindキーの値は文字列と整数と指定しているため、0.01を入力するとエラーしました。また、当然ですが文字列と整数を入力した場合はエラーせずに終了しました。
今回は型の指定のみしましたが{}内に上限値など他の設定を入れるとその設定もそれぞれに有効になります。複数パターンのキーをチェックする
anyOfの応用です。これもあまり仕様的に褒められたものではないですが、場合によって入力されるキーのパターンが複数ある場合にも
anyOfを使うことでチェックできます。schema.json{ "$schema": "http://json-schema.org/draft-07/schema#", "title": "PyJsonValidate", "description": "sample json for json validate", "type": "object", "anyOf":[ {"additionalProperties": false, "properties":{"cat": {"type": "string"}}}, {"additionalProperties": false, "properties":{"dog": {"type": "string"}}} ] }サンプル用のpythonは上と同じです。
itemの値だけ変更しています。結果
Additional properties are not allowed ('mouse' was unexpected) ENDjsonスキーマでキーがcatまたはdogと指定しているため、itemのキーをmouseにして入力するとエラーしました。また、当然ですがdogとcatのキーを入力した場合はエラーせずに終了しました。
あるパターンのキーをチェックする
キーとキーの間の整合性を取るために2つのうちどちらかのキーのみ入力してほしい場合があります。その場合には
oneOfを使うことでチェックできます。schema.json{ "$schema": "http://json-schema.org/draft-07/schema#", "title": "PyJsonValidate", "description": "sample json for json validate", "type": "object", "oneOf":[ {"additionalProperties": false, "properties":{"cat": {"type": "string"}}}, {"additionalProperties": false, "properties":{"dog": {"type": "string"}}} ] }サンプル用のpythonは上と同じです。
itemの値だけ変更しています。json_schema_main.pyitem = { "dog": "pochi", "cat": "tama" }結果
Additional properties are not allowed ('dog' was unexpected) END正常パターン
json_schema_main.pyitem = { "dog": "pochi" }結果
ENDjsonスキーマでキーがcatとdogのパターンを禁止しているため、itemにdogとcatを入力するとエラーしました。また、当然ですがcatのキーだけを入力した場合はエラーせずに終了しました。anyOfと同様にこれも様々な設定をできます。
指定した以外の値を受け取る
ある値以外を欲しいという場合に
allOfとnotを使用してチェックできます。schema.json{ "$schema": "http://json-schema.org/draft-07/schema#", "title": "PyJsonValidate", "description": "sample json for json validate", "type": "object", "properties":{ "dog": { "allOf": [ {"type": "string"}, {"not": {"enum": ["pochi", "tama"]}} ] } } }サンプル用のpythonは上と同じです。
itemの値だけ変更しています。json_schema_main.pyitem = { "dog": "pochi" }結果
{'enum': ['pochi', 'tama']} is not allowed for 'pochi' END正常パターン
json_schema_main.pyitem = { "dog": "tibi" }結果
ENDenumでpochiとtamaだけの設定をnotで反転させ、pochiとtamaは受け付けないようにしました。また、allOfを使用して文字列と値の指定両方を満たすようにチェックしています。特にallOfを使用する必要はありませんが丁度良かったので使いました。
jsonスキーマの表記の色々
設定をリンクで指定する
設定が複雑になっていくと設定だけ別ファイルや別ブロックにまとめたい場合があります。その場合は、
$refに指定してあげることでリンクすることができます。schema.json{ "$schema": "http://json-schema.org/draft-07/schema#", "title": "PyJsonValidate", "description": "sample json for json validate", "type": "object", "$ref": "#/definitions/dog", "definitions": { "dog": { "properties" :{ "kind": { "type": "string", "enum": ["dog"] } } } } }item = { "kind": "cat", }結果
'cat' is not one of ['dog'] ENDrefで指定したdefinitions/dogの設定が反映されました。
上記例はあまり見やすくなった気がしないですが、anyOfやoneOfなど複雑になっていくとこの設定があるかないかで大きく見やすさが変わります。設定を別ファイルに分ける
次は別ファイルに分けていきます。json側では
$refにファイル名を指定してあげて、python側の設定で別ファイルのリンクを設定してあげます。
python側の設定はjsonschemaのライブラリのRefResolverクラスに設定ファイルがあるディレクトリと元のjsonスキーマを渡してあげてvalidate時に指定してあげる必要があります。schema.json{ "$schema": "http://json-schema.org/draft-07/schema#", "title": "PyJsonValidate", "description": "sample json for json validate", "type": "object", "$ref": "dog.json" }dog.json{ "properties" :{ "kind": { "type": "string", "enum": ["dog"] } } }json_schema_main.pyimport os import json from jsonschema import validate, ValidationError, RefResolver with open('schema.json') as file_obj: json_schema = json.load(file_obj) item = { "kind": "cat", } try: schema_path = 'file:///{0}/'.format((os.getcwd()).replace("\\", "/")) ref = RefResolver(schema_path, json_schema) validate(item, json_schema, resolver=ref) except ValidationError as e: print(e.message) print('END')結果
'cat' is not one of ['dog'] ENDjsonschemaライブラリの使い方が少しネックですが、jsonファイルはとても分かりやすくなりました。今回は設定まるまる別ファイルにしましたがやろうと思えばどんな設定も分けられるため、ルールを決めてファイル分けすると見やすくなるのではないかと思います。
おわりに
jsonスキーマの色々な使い方についてまとめました。おそらく、頭を使えばほとんどの入力値チェックがjsonスキーマで可能なほど汎用性のあるものでした。
ただ、ここまでやってしまうと人が見てわかりやすいjsonという利点をつぶしてしまいそうなので個人的にはよっぽどの理由がない限りは単純なjsonを使用しています。
開発の時に他の人の技術レベルを考えて開発していますが、技術レベルと開発のレベルはトレードオフの関係なので、どのレベルに抑えるのかがすごい悩みます。
- 投稿日:2019-09-09T19:43:48+09:00
Project Euler 010を解いてみる。
Project Euler 010
10以下の素数の和は 2 + 3 + 5 + 7 = 17 である.
200万以下の全ての素数の和を求めよ.->[次の問題]
考え方
シンプルな問題ですね。
エラトステネスの篩で200万以下の素数を計算して合計すれば良さそうです。
篩のプログラムは以前に作ってmath_functions.pyに入れてあるのを使います。
なにかに応用できるかなと思ってboolean配列で返す関数と素数列で返す関数に分けてあります。
配列の数字を付け加えたり消したりといった処理やifによる分岐は重くなるようなので、boolean配列のTrue, Falseを切り替えることで値を表し、最後に数列に変換しています。
また、2,3以外の素数は6k±1であるので、少し探索範囲を減らしています。boolean_arr[4::2] = False #これはboolean_arrインデックス4から2個ずつ(4,6,8,...)をFalseにするという処理。 #bookean_arr[i*2::i] = Falseとすることでiより大きいiの倍数のインデックスをFalseにできる=非素数を消せる #if文を使わないので多分早いコード
math_functions.pyimport numpy as np def get_prime_arr_bool(n: int) -> np.ndarray: """ 自然数n未満の素数をboolean配列で返す関数 2,3,5 -> [False, False, True, True, False, True] :param n: int :return: numpy.ndarray """ boolean_arr = np.ones((n,), dtype=np.bool) # n個の要素をもつのboolean配列(0~n-1に対応)を生成、全てTrueとする boolean_arr[0:2] = False # [0,1]をFalseとする boolean_arr[4::2] = False # 2以外の偶数をFalseとする boolean_arr[6::3] = False # 3以外の3の倍数をFalseとする for i in range(5, ceil(sqrt(n)), 6): # iは初項5、公差6の等差数列とする if boolean_arr[i]: # 6k-1に対応。iに一致する要素がTrue=素数のとき boolean_arr[i * 2::i] = False # iの倍数の要素(非素数)をFalseとする if boolean_arr[i + 2]: # 6k+1に対応。 boolean_arr[(i + 2) * 2::(i + 2)] = False return boolean_arr # boolean配列を返す def get_prime_arr(n: int) -> np.ndarray: """ 自然数n未満の素数の配列を返す関数 :param n: int :return: numpy.ndarray """ return np.arange(n)[get_prime_arr_bool(n)] # 0~n-1の配列を生成、boolean配列でTrueとなっている数のみを返すeuler010.pyimport numpy as np from math_functions import get_prime_arr def main(): n = 200 * 10000 prime_arr = get_prime_arr(n+1) # 素数配列を生成(n未満を生成なので一応+1しておく) print(np.sum(prime_arr)) # 合計 if __name__ == '__main__': main()
結果
142913828922
main処理時間: 0.020266056060791016 sec.
できればforループの中のifもなくしたいところですが、どうやったらifなしで実現できるのか思いつかないので現状はこれが精一杯です。
- 投稿日:2019-09-09T19:43:48+09:00
Project Euler 010を解いてみる。「素数の和」
Project Euler 010
10以下の素数の和は 2 + 3 + 5 + 7 = 17 である.
200万以下の全ての素数の和を求めよ.->[次の問題]
Sympyにありました。
n = 200 * 10000 # sympy.primerange(a, b)でa以上b未満の素数を生成するgeneratorを返す prime_generator = sympy.primerange(2,n+1) print(sum(prime_generator))ただ、この書き方だと下記のエラトステネスの篩のほうが早いです。
考え方
シンプルな問題ですね。
エラトステネスの篩で200万以下の素数を計算して合計すれば良さそうです。
篩のプログラムは以前に作ってmath_functions.pyに入れてあるのを使います。
なにかに応用できるかなと思ってboolean配列で返す関数と素数列で返す関数に分けてあります。
配列の数字を付け加えたり消したりといった処理やifによる分岐は重くなるようなので、boolean配列のTrue, Falseを切り替えることで値を表し、最後に数列に変換しています。
また、2,3以外の素数は6k±1であるので、少し探索範囲を減らしています。boolean_arr[4::2] = False #これはboolean_arrインデックス4から2個ずつ(4,6,8,...)をFalseにするという処理。 #bookean_arr[i*2::i] = Falseとすることでiより大きいiの倍数のインデックスをFalseにできる=非素数を消せる #if文を使わないので多分早いコード
math_functions.pyimport numpy as np def get_prime_arr_bool(n: int) -> np.ndarray: """ 自然数n未満の素数をboolean配列で返す関数 2,3,5 -> [False, False, True, True, False, True] :param n: int :return: numpy.ndarray """ boolean_arr = np.ones((n,), dtype=np.bool) # n個の要素をもつのboolean配列(0~n-1に対応)を生成、全てTrueとする boolean_arr[0:2] = False # [0,1]をFalseとする boolean_arr[4::2] = False # 2以外の偶数をFalseとする boolean_arr[6::3] = False # 3以外の3の倍数をFalseとする for i in range(5, ceil(sqrt(n)), 6): # iは初項5、公差6の等差数列とする if boolean_arr[i]: # 6k-1に対応。iに一致する要素がTrue=素数のとき boolean_arr[i * 2::i] = False # iの倍数の要素(非素数)をFalseとする if boolean_arr[i + 2]: # 6k+1に対応。 boolean_arr[(i + 2) * 2::(i + 2)] = False return boolean_arr # boolean配列を返す def get_prime_arr(n: int) -> np.ndarray: """ 自然数n未満の素数の配列を返す関数 :param n: int :return: numpy.ndarray """ return np.arange(n)[get_prime_arr_bool(n)] # 0~n-1の配列を生成、boolean配列でTrueとなっている数のみを返すeuler010.pyimport numpy as np from math_functions import get_prime_arr def main(): n = 200 * 10000 prime_arr = get_prime_arr(n+1) # 素数配列を生成(n未満を生成なので一応+1しておく) print(np.sum(prime_arr)) # 合計 if __name__ == '__main__': main()
結果
142913828922
main処理時間: 0.020266056060791016 sec.
できればforループの中のifもなくしたいところですが、どうやったらifなしで実現できるのか思いつかないので現状はこれが精一杯です。
- 投稿日:2019-09-09T19:15:11+09:00
Anacondaと付き合うための情報を整理する(Pythonのインストール方法とパッケージ管理方法を中心に)
はじめに
PyCon JP 2019で「Anaconda環境運用TIPS」という15分のトークをします。
ドキュメントを当たったり、Anacondaの環境で実験したりして得た知見全てを15分のトークに収めることが難しかったので、別途記事にすることにしました。
正確性を重視したいので、誤った記載を見つけた場合は、コメントなどでご指摘いただけるとありがたいです。前提
この記事で扱うこと
- Pythonのインストール方法(Anaconda中心)
- AnacondaでPythonをインストールした場合のパッケージ管理方法の特徴
扱わないこと
- パッケージとは
- Anacondaの環境(base環境とは)
- condaコマンドの詳細な使い方(特に環境を分離する方法)
今後の更新や別記事でアップデート予定です。
おことわり
この記事を書く意図は、Anacondaをオススメすることではありません。
自分の中に蓄積されたAnacondaに関係する情報の整理が目的です。また、書き手はPythonを使った開発でAnacondaを使っているわけではありません。
Pythonを教える中で、Anaconda環境の問題を何件か解決し、この記事に記載した認識に至りました。
(誤りがあるかもしれませんので、お気づきの点はお知らせください)動作確認環境
- macOS 10.12.6
- conda 4.6.11
一部の検証にDockerイメージも使っています。
Pythonのインストール方法
Pythonには複数のインストール方法があります。
どういった方法があり、それぞれどのくらいの人が使っているかは、例えば、JetBrainsが調査したPython Developers Survey 2018 Resultsがあります(Python Installation and Upgradeという項目1)。
- 1位はOSごとに提供される方法(
apt-get,yum,brewなど)で38%- 2位はPython.orgで33%
- 3位がAnacondaで22%
また、2019年4月に「みんなのPython勉強会」で環境構築について話した際に参加者に挙手していただいたところ、AnacondaでPythonをインストールした方が半数で、Python.orgからインストールした方よりも多かったと記憶しています。
というわけで、ここでは、Pythonをインストールする際に、Anacondaという選択肢を選ぶ人が増えていることを確認しました。2
AnacondaでPythonをインストールする際の特徴
では、AnacondaでPythonをインストールした場合、他の方法と何が違うのでしょうか。
大きな特徴は、Pythonをインストールするだけでなく、科学計算に使うパッケージも合わせてインストールする3ということです。
Python.orgやbrewやaptでPythonをインストールする場合、科学計算に使うパッケージを別途インストールする必要があります。科学計算に使うパッケージ(numpy, scipy, pandas)が合わせてインストールされている例を見てみましょう。
AnacondaをインストールしたmacOSのターミナルでPythonを対話モードで起動します。(base) $ python Python 3.7.3 (default, Mar 27 2019, 16:54:48) [Clang 4.0.1 (tags/RELEASE_401/final)] :: Anaconda, Inc. on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import numpy, scipy, pandas >>>科学計算のパッケージに関連して、Anacondaでは機械学習のパッケージ(例:tensorflow)もインストールしやすいという特徴があります。
(macOSやLinuxを使った経験では、Python.orgからインストールしたPythonでも環境構築できました。私が未経験のWindowsでは苦労があるのかもしれません)他の特徴として、Anacondaはクロスプラットフォームであり、Windows・macOS・Linuxいずれでも動作する4という点も挙げられます。
これはbrewやaptなどOSごとに提供される方法でPythonをインストールする選択肢とは対照的ですね。
condaコマンドAnacondaにおけるパッケージ管理は
condaというコマンドで行われます。
AnacondaにおいてはPythonもパッケージとして扱われるため、Pythonのバージョンも管理5できます(脚注4のリンク参照)。AnacondaでPythonを導入するとbaseという名前の環境ができます。
そこに含まれるパッケージの一覧をconda listで表示してみましょう。(base) $ conda list # Name Version Build Channel numpy 1.16.2 py37hacdab7b_0 pandas 0.24.2 py37h0a44026_0 python 3.7.3 h359304d_0 scipy 1.2.1 py37h1410ff5_0200行を超える出力があるため、上では一部を抜粋しました。
AnacondaでPythonをインストールすると、200を超えるパッケージもすぐに使える状態というわけです。Anacondaを使わずにPythonをインストールした場合、
condaコマンドは使えず、pipというコマンドでパッケージを管理します。
混乱を招きやすいのですが、pipコマンドはAnacondaでも使うことができます(この点については理解して使っていただきたいため、詳細を後述します)
condapipAnaconda ◯(オススメしたい) △(使える) Anaconda以外 ☓(使えない) ◯(オススメしたい) なぜAnacondaが登場したか
Anacondaが登場した背景として、科学計算に用いるパッケージにはバイナリモジュールに依存するものがあり、
pipコマンドでインストールすることが難しい6ことがあったそうです。
このあたりの状況は改善してきている7と認識していますが、科学計算のパッケージのインストールのしにくさという問題により、今後もAnacondaは1つの選択肢として残り続けるのではないかと私自身は考えています。
condaとpipの違い上では
condaではPythonのバージョンを管理できるが、pipではできないという違いを見ました。
実はこの点よりも重要な違いがあります。
それは、配布されたパッケージをインストールする際の参照先のサイト(リポジトリ)が異なるということです。
condaでもpipでも、配布されたパッケージ(アーカイブされたファイル)をインターネット経由でダウンロードし、手元の環境にインストールします8。
pipでパッケージをインストールする場合は、デフォルトでPyPI(Python Package Index)にあるパッケージを参照します。
一方、condaでパッケージをインストールする場合、デフォルトではAnaconda社が管理するリポジトリ(repo.anaconda.com)を参照します9。PyPIは開発者に公開されており、誰でもPythonのパッケージを配布するために利用できます。
そのため、大量の多岐に渡るパッケージが集まっています。一方、Anaconda社のリポジトリは、開発者に公開されているわけではありません。
Anaconda社が管理しているため、PyPIに比べてパッケージはずっと少ないです。
また、PyPIにある最新版が必ずあるとは限りません。
この点への対応として、コミュニティが運営するconda-forgeなどのリポジトリからcondaコマンドでパッケージをインストールする方法が案内されています10。ここまで、
condaの場合もpipの場合もパッケージという同じ言葉を使ってきましたが、実はcondaとpipとでパッケージの形式は異なります11。
condaとpipは混ぜられる?Anacondaは導入がしやすい反面、パッケージのリポジトリという点でやや苦労するという印象を私は持っています。
対応として、conda-forgeを紹介しましたが、condaコマンドのドキュメントでは、conda-forgeで対応できない場合、pipを
使うことが案内されています12。この記載を見て、「condaとpip:混ぜるな危険」という2018年2月のエントリを思い出す方もいるでしょう。
「condaとpipを混ぜていいの?」と。ドキュメントの記載によれば、
condaの4.6以降ではcondaとpipが混ぜられる13ようです。
しかしながら、環境によっては壊れてしまうこともあるようなので、この記事の初公開の段階では積極的にオススメはしません。
(このあたり登壇当日までに結論を出し、アップデートします)(前略) conda now understands pip metadata more intelligently.
(注)リンク先には以下の2つが記載されており、ここで紹介しているのは後者の方です。
- experimentalな機能:
.condarc(condaの設定ファイルの編集)condaがpipのメタデータに対応した話後述の実験結果から、後者の機能はexperimentalの機能とは別に有効になっていると考えています。
(注 終わり)
Dockerイメージcontinuumio/anaconda3のタグ2019.07を用いて実験してみました。
- base環境に入っていないtensorflowのバージョン1.13.1を
conda install tensorflow=1.13.1でインストールpip install -U tensorflowで最新のバージョン1.14.0にアップデート- 対話モードやJuputer Notebookでtensorflowがimportできることを確認
Dockerイメージを用いた検証では、無事importできました。
しかしながら、macOSにてbaseと同様の環境を作って検証をしたところ、3に失敗する結果となりました。
(「Illegal instruction: 4」と表示されて対話モードが終了します。JuputerではKernelがRestartします)ドキュメント上は
condaとpipが混ぜられると記載されていますが、混ぜることで環境を壊さない可能性が絶対にないとは言えないという認識でいます。
そこで、Anacondaを使っている場合のパッケージ管理(暫定版)は
- まずAnaconda社のリポジトリやconda-forgeを検索
- 1で見つからない場合は、リスク承知でPyPIからインストール
という手順になりそうです。
そして、Anaconda社のリポジトリやconda-forgeからインストールしたパッケージのアップデートはcondaコマンドを使うことで、環境を壊すリスクは低減されると考えています。環境が壊れるリスクを抑える別の方法としては、Anacondaの環境を開発ごとに分離して使うことを私はオススメしたいです。
分離してあれば、ある環境が壊れたとしてもAnaconda自体の再インストールは発生しないと考えています。Anacondaを使った場合の環境の切り分けについては、PyCon JP当日のトーク(または別の記事で)お伝えします。
%の合計が100を超えるので、複数回答と考えています ↩
この理由について、JetBrainsの調査は「Pythonを使う他の種類の開発よりもデータサイエンスの人気が増していることを示している」と述べています。また、私の推測ですが、国内では毎月のように機械学習の入門書(やPythonの入門書)が刊行されており、そこでAnacondaが紹介されることが多いという理由もありそうです。後の節で触れますが、インストールする手順が簡単というのは著者にとって魅力なのでしょう。 ↩
https://docs.python.org/ja/3/using/windows.html#alternative-bundles ↩
https://packaging.python.org/guides/installing-scientific-packages/#the-conda-cross-platform-package-manager ↩
Pythonのバージョン管理は後述の
pipではできません ↩https://docs.python.org/ja/3/installing/index.html#install-scientific-python-packages ↩
numpy 1.10.4やscipy1.0.0以降はメジャーなOS向けにwheelフォーマットでパッケージがリリースされているそうですが、Windowsでは最適化された線形代数演算の性能が出ない可能性があるそうです ref:https://packaging.python.org/guides/installing-scientific-packages/ ↩
Distribution Packageの用語説明をもとにしています ↩
https://docs.conda.io/projects/conda/en/latest/user-guide/concepts/channels.html (ドキュメント上ではリポジトリのことをチャンネルと呼んでいるようです) ↩
ref:
condaで扱うパッケージ、pipで扱うパッケージ ↩https://docs.conda.io/projects/conda/en/latest/user-guide/concepts/channels.html#conda-channels ↩
https://docs.conda.io/projects/conda/en/latest/user-guide/configuration/pip-interoperability.html ↩
- 投稿日:2019-09-09T18:33:14+09:00
pythonで遊んだ
遊びました。Python歴2時間くらいです。
環境構築
Pythonは Colabというサービスを使えばブラウザ上でも簡単に動かすことができるようですが今回はちゃんと環境構築からします。
こちらのサイトを参考にさせて頂きました。
Pythonの開発環境を用意しよう!(Mac)まずはHomebrewをインストールします。
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"インストールできたらHomebrewのコマンドを使ってpyenvをインストールします。
brew install pyenv「.bash_profile」ファイルに設定用のコードを追加します。
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile echo 'eval "$(pyenv init -)"' >> ~/.bash_profile touch ~/.profileこれでpyenvコマンドが使えるようになったので
pyenv install --listで、最新のPythonのバージョンを確認して、インストールします。
pyenv install 3.XX.XX (使用するバージョンを入力する)最後に
pyenv global 3.XX.XXで先程インストールしたバージョンのPythonを使うようにします。
これで環境構築は終了です。
拡張子が.pyのファイルを作成してVSCodeなどで開いてみましょう。なお、コードを実行する方法はターミナルで
python XXXXX.py (ファイル名)です
あそぶ
環境ができたので適当にコードを書いてみます。
今回はPythonの機能の一つである辞書を使ってみました。dics = {'りんご': 'Apple', 'オレンジ': 'Orange'}辞書はこのように記述すれば作成することができるようです。
valuesの方にまた新たに辞書を指定してどんどん入れ子の形にすることも可能です。dics = { 'りんご': { '色': '赤', '形': '丸' }, 'オレンジ': 'Orange' }この機能を使って簡単なゲームを作ってみます。
問診を行って腹痛を訴える患者の病気を特定するゲームです。stomachache = { '腹膜炎': { 1: '今朝からです。', 2: 'お腹が全体てきに痛いです。', 3: '下痢はしていませんが、嘔吐しています。' }, '胃腸炎': { 1: '朝起きてからずっとです。', 2: '下の方、腸のあたりです。', 3: 'はい、しています。吐き気もあります。' }, '肺炎': { 1: '一昨日の夜からです。', 2: '上の方です。', 3: 'していません。少し熱っぽい気がします。' }, 'ストレス': { 1: 'もう何ヶ月も前からです。', 2: 'わからないです。胃のあたりな気がします。', 3: '偶にします。' } }このような感じで辞書を作成しました。
私は医者ではないので内容はかなり適当です。本気にしないでください。import random num = random.randint(0,3) lis = list(stomachache.values())import random num = random.randint(0,3) list = list(stomachache.values()) def question(): print('質問内容を選ぶ (1, 2 or 3)') print( '1: いつごろから痛みますか?\n2: どの辺りが痛みますか?\n3: 下痢はしていますか?') question = input('>> ') if question == '1': print(list(list[num].values())[0]) elif question == '2': print(list(list[num].values())[1]) elif question == '3': print(list(list[num].values())[2]) else: print("数字を選択して入力してください")0から3のランダムな数字を取得して、上で作成した辞書から質問部分のみをリスト化します。
プレイヤーに入力してもらった値を元に、listから患者の回答を表示します。print('病気を特定する (1, 2, 3 or 4)') print( '1: 腹膜炎\n2: 胃腸炎\n3: 肺炎\n4: ストレス') answer = input('>> ') if int(answer) == num + 1: print('正解です') else: print('不正解です')問診内容を元にプレイヤーに病名を特定させます。ランダムな数字は0..3なのでnumに+1しています。
最終的なコードはこのような形になりました。
import random stomachache = { '腹膜炎': { 1: '今朝からです。', 2: 'お腹が全体てきに痛いです。', 3: '下痢はしていませんが、嘔吐しています。' }, '胃腸炎': { 1: '朝起きてからずっとです。', 2: '下の方、腸のあたりです。', 3: 'はい、しています。吐き気もあります。' }, '肺炎': { 1: '一昨日の夜からです。', 2: '上の方です。', 3: 'していません。少し熱っぽい気がします。' }, 'ストレス': { 1: 'もう何ヶ月も前からです。', 2: 'わからないです。胃のあたりな気がします。', 3: '偶にします。' } } num = random.randint(0,3) lis = list(stomachache.values()) def question(): print('質問は二回までできます。質問内容を選ぶ (1, 2 or 3)') print( '1: いつごろから痛みますか?\n2: どの辺りが痛みますか?\n3: 下痢はしていますか?') question = input('>> ') if question == '1': print(list(lis[num].values())[0]) elif question == '2': print(list(lis[num].values())[1]) elif question == '3': print(list(lis[num].values())[2]) else: print("数字を選択して入力してください") question() question() print('病気を特定する (1, 2, 3 or 4)') print( '1: 腹膜炎\n2: 胃腸炎\n3: 肺炎\n4: ストレス') answer = input('>> ') if int(answer) == num + 1: print('正解です') else: print('不正解です')質問は二回までできます。質問内容を選ぶ (1, 2 or 3) 1: いつごろから痛みますか? 2: どの辺りが痛みますか? 3: 下痢はしていますか? >> 1 今朝からです。 質問は二回までできます。質問内容を選ぶ (1, 2 or 3) 1: いつごろから痛みますか? 2: どの辺りが痛みますか? 3: 下痢はしていますか? >> 2 お腹が全体てきに痛いです。 病気を特定する (1, 2, 3 or 4) 1: 腹膜炎 2: 胃腸炎 3: 肺炎 4: ストレス >> 1 正解ですもう少し細部をこだわればもっとまともな問診ゲームが作れそう。
- 投稿日:2019-09-09T18:21:37+09:00
Pythonではじめる機械学習 データ表現と特徴量エンジニアリング(交互作用・多項式)
学習内容の目次
データ表現と特徴量エンジニアリング
- 交互作用
- 多項式
要約
☆交互作用
- 線形モデルに特に有効で,交互作用特徴量加える方法
- 交互作用特徴量とは,ビンの指示子と元の特徴量の積
- 交互作用特徴量を加えることで,個々のビンがオフセットと傾きを持つ
交互作用特徴量を加える一連の流れ
In[1]: # ビニングされたデータを適用した線形モデルに,元の特徴量(グラフのx軸)を加える X_combined = np.hstack([X, X_binned]) print(X_combined.shape) Out[1]: # 11次元のデータセットになる (120, 11) In[2]: # 11次元のデータを適用する reg = LinearRegression().fit(X_combined, y) line_combined = np.hstack([line, line_binned]) plt.plot(line, reg.predict(line_combined), label='linear regression combined') for bin in bins: plt.plot([bin, bin], [-3, 3], ':', c='k') plt.legend(loc="best") plt.ylabel("Regression output") plt.xlabel("Input feature") plt.plot(X[:, 0], y, 'o', c='k')Out[2]:
- 上の図は傾きが全てのビンで共有されている状態
# 個々のビンが傾きを持つように,ビンと元の特徴量の積を求める In[3]: X_product = np.hstack([X_binned, X * X_binned]) print(X_product.shape) Out[3]: # 特徴量が20になることを確認 (120, 20) In[4]: reg = LinearRegression().fit(X_product, y) line_product = np.hstack([line_binned, line * line_binned]) plt.plot(line, reg.predict(line_product), label='linear regression product') for bin in bins: plt.plot([bin, bin], [-3, 3], ':', c='k') plt.plot(X[:, 0], y, 'o', c='k') plt.ylabel("Regression output") plt.xlabel("Input feature") plt.legend(loc="best")Out[4]:
- これによって個々のビンが傾きを持つ
☆多項式
- 線形モデルに特に有効で,多項式特徴量を加える方法
- 線形モデルのような単純なモデルには有効であるが,カーネル法を用いたSVMやランダムフォレストのような複雑なモデルには効果を発揮しない
- degreeメソッドで考慮する元の特徴量数を指定して,多項式特徴量を作る
多項式特徴量を加える一連の流れ
In[5]: from sklearn.preprocessing import PolynomialFeatures # degree=10でx ** 10までの多項式を加える # include_bias=Trueだと常に1となる特徴量を加えるためFalseにする poly = PolynomialFeatures(degree=10, include_bias=False) poly.fit(X) X_poly = poly.transform(X) print("X_poly.shape: {}".format(X_poly.shape)) Out[5]: # 特徴量が10になることを確認 X_poly.shape: (120, 10) In[6]: reg = LinearRegression().fit(X_poly, y) line_poly = poly.transform(line) plt.plot(line, reg.predict(line_poly), label='polynomial linear regression') plt.plot(X[:, 0], y, 'o', c='k') plt.ylabel("Regression output") plt.xlabel("Input feature") plt.legend(loc="best")Out[6]:
ポイント
- この分野はビンを応用したものであるため,ビンの概念を確実に理解することが重要
- 変換前・変換後でデータ配がどうなったのかを特に意識しないと理解が難しい
- 変換前・変換後のデータを実際にprintして確認してみるといいかも!
- fit(), transform(), fit_transform()など,メソッドが似ていてややこしいため注意
fit() transform() fit_transform() ・様々な統計情報を計算する
・計算後に保存,確定するイメージ
・どこでも使う!重要!・fit()で計算されたデータを基に,実際に変換する
・これを使ったあとに,変換前と変換後をprintして比較しみるといい・fit()を行った後でtransform()を行う
・1行で済むため便利だけど,テストデータの場合は訓練データの情報を使って処理を行うためこのメソッドは使わない!使用想定場面
- どうしてもモデルに線形モデルを使いたい!という時などに使う
- 線形モデルのような単純なモデルには有効であるが,ランダムフォレストなど複雑なモデルに対しては有効でないどころか精度低下の原因となるため使わない方が良い
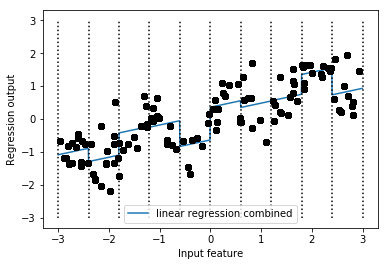
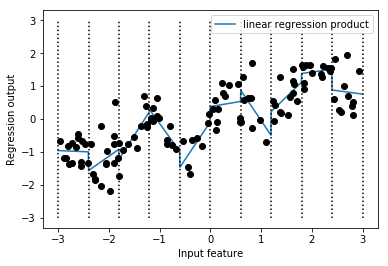
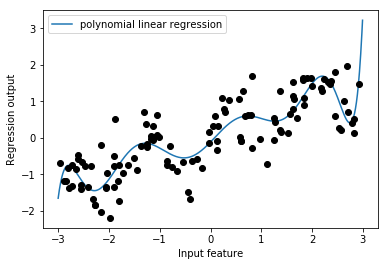
- 投稿日:2019-09-09T18:08:08+09:00
SymPy Geometry 学習メモ(多角形)
はじめに
sympy.geometry の学習メモ ~多角形~ です。「SymPy Geometory 学習メモ(点・直線)」のつづきです。複雑な形状(凸形・凹型)の多角形の面積や外周長さを求めることをゴールにします。
Pythonのバージョンは
3.6.8、SymPiのバージョンは1.3を使用しました。バージョン確認import sys import sympy print(f'Python {sys.version}') print(f'SymPi {sympy.__version__}')多角形
多角形(ポリゴン)は、点のリスト/タプルを与えて生成することができます。次のプログラムでは、凸多角形、凹多角形(非凸多角形)、自己交差する多角形のポリゴンを生成しています。また、この後の理解を助けるために、matplotlibでXY座標上に図示しています。
なお、SymPy 1.1.1 では「
GeometryError: Polygon has intersecting sides.」というエラーにより、自己交差する多角形は生成不能でした。from sympy.geometry import * import matplotlib.pyplot as plt %matplotlib inline # ポリゴン(多角形)の生成 tmp = ((1,1),(4,3),(5,1)) p0 = Polygon( *tmp ) # 凸多角形 tmp = ((1,4),(4,6),(5,4),(5,7),(1,7)) p1 = Polygon( *tmp ) # 凹多角形 tmp = ((5.5,2.0),(7.5,6.0),(6.0,6.0),(7.0,2.0)) p2 = Polygon( *tmp ) # 自己交差多角形 polygons = [p0,p1,p2] # グラフ描画 plt.figure(figsize=(5,5),dpi=96) for p in polygons : tmp = list(map(lambda p:(float(p.x),float(p.y)), p.vertices)) tmp = plt.Polygon(tmp,fc='red',alpha=0.5) plt.gca().add_patch(tmp) xRange=yRange=(0,8) plt.xlim(xRange) plt.ylim(yRange) plt.xticks(range(xRange[0],xRange[1]+1)) plt.yticks(range(yRange[0],yRange[1]+1)) plt.grid(color='blue', alpha=0.3) plt.show()
面積は
.areaで、外周はperimeterで、凸多角形かどうかは.is_convex()で簡単に知ることができます。for i,p in enumerate(polygons) : print( f'p{i} :',end=' ') print( f'面積 {float(p.area):5.1f}' ,end=' ') print( f'外周 {float(p.perimeter):5.1f}',end=' ') print( f'凸形か {p.is_convex()}')実行結果p0 : 面積 -4.0 外周 9.8 凸形か True p1 : 面積 8.0 外周 15.8 凸形か False p2 : 面積 0.0 外周 11.6 凸形か False面積については、注意が必要です。上記の結果をみると p0 の面積が「-4.0」と負の値になっています。多角形を生成する際に、時計回り(CW) に点を与えると面積が負になります。一方、反時計周り(CCW) に与えると面積は正になります。
tmp = [(1,1),(4,3),(5,1)] print(Polygon( *tmp ).area) # -4 tmp.reverse() print(Polygon( *tmp ).area) # 4つづいて、p3 の面積が 0.0 になっている理由ですが、これは自己交差により「時計周り領域」と「反時計周り領域」が形成され、面積が正負で相殺された結果です。今回は、上半分の逆三角形と、下半分の三角形の面積がたまたま一致したため 0.0 になっています。残念ながら自己交差を含んでいると面積を適切に求めることができません。
自己交差があるかを判定したい
凸多角形であるかは
.is_convex()で判定できるのですが、凹多角形のときに「自己交差を含むかどうか?」を判定するものは用意されていないようです(なお、凸多角形では自己交差はあり得ない)。ここでは、自己交差のある凹多角形を 不正なポリゴン と呼ぶことにして、それを判定する方法を考えます。たぶん効率の良い方法があるとは思うのですが、ここでは力業、つまり、多角形を構成する辺(線分)の全組合せについて「交差があるか」を総当たりで調べていきます。また、次のように「1点で3辺以上が接触している場合」も、ここでは不正なポリゴンに含めます(左側のポリゴンでも「$p1\to p3\to $ $p4\to p5$ $\to p3\to p2$」の順で点をつなげば自己交差はしていませんが、これと「$p1\to p3\to $ $p5\to p4$ $\to p3\to p2$」を区別することが難しいため)。
まず、多角形を構成数する辺は
p.sidesにより、Segment のリストとして取得できます。次に、このリストから2辺を組合せを取り出しますが、これにはitertools.combinationsを利用します。そして、前回に取り上げた.intersection()を使って交差があるかを調べます。ただし、次のように、多角形を構成している隣り合う2辺についてチェックした場合、その接点も交差と判定されてしまうので、それは無視する必要があります。
# 交差しない場合 s1 = Segment((0,0),(0,2)) s2 = Segment((2,0),(2,2)) print(s1.intersection(s2)) # [] # 隣り合う2辺の場合 → 端点の接触により交差が検出される s1 = Segment((0,0),(2,2)) s2 = Segment((2,2),(2,4)) print(s1.intersection(s2)) # [Point2D(2, 2)] # 辺の端点が、他方の線上(端点以外)に接する場合 →【不正なポリゴン】 s1 = Segment((0,2),(2,0)) s2 = Segment((0,0),(0,4)) print(s1.intersection(s2)) # [Point2D(0, 2)] # 交差する場合 →【不正なポリゴン】 s1 = Segment((1,0),(1,2)) s2 = Segment((0,1),(2,1)) print(s1.intersection(s2)) # [Point2D(1, 1)] # 辺が重なっている場合 →【不正なポリゴン】 s1 = Segment((0,0),(0,2)) s2 = Segment((0,0),(0,3)) print(s1.intersection(s2)) # [Segment2D(Point2D(0, 0), Point2D(0, 2))]これらを踏まえて、次のようにしました。
from sympy.geometry import * import matplotlib.pyplot as plt import itertools %matplotlib inline # ポリゴン(多角形)の生成 p0 = Polygon( (1,1),(2,3),(3,1) ) p1 = Polygon( (1,4),(2,6),(3,4),(3,7),(1,7) ) p2 = Polygon( (4,1),(5,3),(4,3),(5,1) ) p3 = Polygon( (6,3),(7,2),(6,1),(8,1),(7,2),(8,3) ) p4 = Polygon( (4,7),(4,4),(6,4),(4,5),(7,7) ) polygons = [p0,p1,p2,p3,p4] # グラフ描画 plt.figure(figsize=(5.5,5),dpi=96) for p in polygons : tmp = list(map(lambda p:(float(p.x),float(p.y)), p.vertices)) tmp = plt.Polygon(tmp,fc='red',alpha=0.5) plt.gca().add_patch(tmp) xRange=(0,9) yRange=(0,8) plt.xlim(xRange) plt.ylim(yRange) plt.xticks(range(xRange[0],xRange[1]+1)) plt.yticks(range(yRange[0],yRange[1]+1)) plt.grid(color='blue', alpha=0.3) plt.show() def is_valid(p) : if p.is_convex() : # 凸多角形の場合 return True if len(p.vertices) != len(set(p.vertices)) : return False for (s1,s2) in itertools.combinations(p.sides,2): cp = s1.intersection(s2) if len(cp) == 0 : continue if cp[0] in s1.points and cp[0] in s2.points : continue else : return False return True for i,p in enumerate(polygons) : print( f'p{i} :',end=' ') print( f'面積 {float(p.area):5.1f}' ,end=' ') print( f'外周 {float(p.perimeter):5.1f}',end=' ') print( f'凸形? {p.is_convex()}',end=' ') print( f'不正? {not is_valid(p)}')実行結果は、次のようになります。
実行結果p0 : 面積 -2.0 外周 6.5 凸形? True 不正? False p1 : 面積 4.0 外周 12.5 凸形? False 不正? False p2 : 面積 0.0 外周 6.5 凸形? False 不正? True p3 : 面積 2.0 外周 9.7 凸形? False 不正? True p4 : 面積 4.0 外周 13.8 凸形? False 不正? True$p2$ は明らかな自己交差により不正なポリゴン認定、$p3$ と $p4$ は自己交差はありませんが1点で3辺以上が接触しているので不正が認定されています。
点が多角形の内部にあるか調べたい
ある点が多角形の内部にあるかどうかは
.encloses_pointでチェック可能です。境界線上はFalseと判断されます。from sympy.geometry import * import matplotlib.pyplot as plt %matplotlib inline # ポリゴン(多角形)の生成 poly = Polygon( *((1,1),(3,2),(3,3),(2,3),(1,2),(1,4), (3,6),(2,7),(6,7),(5,5),(6,5),(7,4), (7,3),(5,3),(7,1)) ) # ポイント(点)の生成 p0 = Point(2.5, 2.9) p1 = Point(3.0, 7.0) # 境界線上 p2 = Point(5.9, 4.9) p3 = Point(5, 2) points = [p0, p1, p2, p3] # グラフ描画 plt.figure(figsize=(5,5),dpi=96) tmp = list(map(lambda p:(float(p.x),float(p.y)), poly.vertices)) tmp = plt.Polygon(tmp,fc='red',alpha=0.5) plt.gca().add_patch(tmp) for i,p in enumerate(points) : plt.plot(p.x, p.y, color='0.0',marker='.') plt.text(p.x, p.y + 0.2, 'p{0}'.format(i) , size=10, horizontalalignment='center', verticalalignment='bottom') xRange=yRange=(0,8) plt.xlim(xRange) plt.ylim(yRange) plt.xticks(range(xRange[0],xRange[1]+1)) plt.yticks(range(yRange[0],yRange[1]+1)) plt.grid(color='blue', alpha=0.3) plt.show() for i,p in enumerate(points) : print( f'p{i} : 多角形の内部に存在するか? {poly.encloses_point(p)}' )
実行結果p0 : 多角形の内部に存在するか? False p1 : 多角形の内部に存在するか? False p2 : 多角形の内部に存在するか? True p3 : 多角形の内部に存在するか? True
- 投稿日:2019-09-09T17:37:50+09:00
GCPでスケジューラから機械学習GAEを起動する
これは何?
Google Cloud Platformで、学習処理を定期的に実行したい時のアーキテクチャのお試し。
基本的には公式をなぞったもの。構成
Cloud Schedulerで1時間ごとにメッセージをパブリッシュする。
Pub/SubからAppEngineの機械学習処理エンドポイントへpushする。構築
App Engine
学習処理をつくる。
app.yamlruntime: python37requirements.txtFlask==1.0.2 scikit-learnmain.pyfrom flask import Flask app = Flask(__name__) @api.route('/api/v1/learn') def learn(req, resp): from sklearn import datasets from sklearn import svm from sklearn.metrics import accuracy_score iris = datasets.load_iris() from sklearn.model_selection import train_test_split X = iris.data y = iris.target X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=0) # 学習 model = svm.SVC(gamma='scale') model.fit(X_train, y_train) pred = model.predict(X_test) ac_score = accuracy_score(y_test, pred) resp.text = str(ac_score) if __name__ == '__main__': app.run(host='127.0.0.1', port=8080, debug=True)デプロイする。
$ gcloud app deployPub/Sub
GCPコンソールから作成する。
トピックトピックID: learningサブスクリプションサブスクリプションID: learning トピックの名前: projects/<プロジェクトID>/topics/learning 配信タイプ: push エンドポイント URL: https://<プロジェクトID>.appspot.com/api/v1/learn サブスクリプションの有効期限: 有効期限なしCloud Scheduler
ジョブを作成する。
名前: learn 頻度: 0 */1 * * * タイムゾーン: 日本 ターゲット: Pub/Sub トピック: learning ペイロード: {"type": "start"}テスト
Cloud Schedulerでジョブの[今すぐ実行]を押す。
結果: 成功
を確認する。
- 投稿日:2019-09-09T17:37:50+09:00
GCPでスケジューラから機械学習を起動する
これは何?
Google Cloud Platformで、学習処理を定期的に実行したい時のアーキテクチャのお試し。
基本的には公式をなぞったもの。構成
Cloud Schedulerで1時間ごとにメッセージをパブリッシュする。
Pub/SubからAppEngineの機械学習処理エンドポイントへpushする。構築
App Engine
学習処理をつくる。
app.yamlruntime: python37requirements.txtFlask==1.0.2 scikit-learnmain.pyfrom flask import Flask app = Flask(__name__) @api.route('/api/v1/learn') def learn(req, resp): from sklearn import datasets from sklearn import svm from sklearn.metrics import accuracy_score iris = datasets.load_iris() from sklearn.model_selection import train_test_split X = iris.data y = iris.target X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=0) # 学習 model = svm.SVC(gamma='scale') model.fit(X_train, y_train) pred = model.predict(X_test) ac_score = accuracy_score(y_test, pred) resp.text = str(ac_score) if __name__ == '__main__': app.run(host='127.0.0.1', port=8080, debug=True)デプロイする。
gcloud app deployPub/Sub
GCPコンソールから作成する。
トピックトピックID: learningサブスクリプションサブスクリプションID: learning トピックの名前: projects/<プロジェクトID>/topics/learning 配信タイプ: push エンドポイント URL: https://<プロジェクトID>.appspot.com/api/v1/learn サブスクリプションの有効期限: 有効期限なしCloud Scheduler
ジョブを作成する。
名前: learn 頻度: 0 */1 * * * タイムゾーン: 日本 ターゲット: Pub/Sub トピック: learning ペイロード: {"type": "start"}テスト
Cloud Schedulerでジョブの[今すぐ実行]を押す。
結果: 成功
を確認する。
- 投稿日:2019-09-09T17:05:20+09:00
アヤメデータの学習
他のところで使い回せるように、すごくシンプルな学習処理を書く。
- scikit-learnにバンドルされているアヤメデータセットを使う
- 学習データとテストデータに分割する
- サポートベクターマシンで学習する
- テストデータを使って予測する
- 正解率を表示する
iris.py# scikit-learnに入っているアヤメデータを分類する from sklearn import datasets # データの読込 iris = datasets.load_iris() # 学習データとテストデータへの振分 from sklearn.model_selection import train_test_split X = iris.data y = iris.target # X_train: 特徴量の学習データ # X_test: 特徴量のテストデータ # y_train: ラベルの学習データ # y_test: ラベルのテストデータ # train_size=0.8: 80%を学習データ、20%をテストデータに振り分ける # random_state=0: いつも同じ振分結果になるように固定値をセットする X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=0) # 学習 from sklearn import svm model = svm.SVC(gamma='scale') model.fit(X_train, y_train) # 予測 from sklearn.metrics import accuracy_score pred = model.predict(X_test) ac_score = accuracy_score(y_test, pred) print(ac_score)
- 投稿日:2019-09-09T16:49:01+09:00
【NLP入門】Pykakasiで文章をひらがなへのバラバラ変換して遊んでみた♪
先日は、ひらがなを与えれば、音声を発生させるアプリが出来た。
そこで次の難関は、文章をひらがな一文字毎に分割することだった。
今回、Pykakasiを使うと、漢字かな交じり文をひらがな一文字ずつ区切ることができたので、記事にしておこうと思う。
もちろん、このPykakasiはもう少し上等なこともできそうなものだということも記載したい。インストール
【参考】
日本語文字をローマ字に変換するpykakasiモジュールのインストールと利用について
参考の通り、2系は以下でインストール出来ました。$ pip install git+https://github.com/miurahr/pykakasi Successfully installed dill-0.3.0 klepto-0.1.7 pox-0.2.6 pykakasi-1.1b1 six-1.12.03系も同様に
$ pip3 install git+https://github.com/miurahr/pykakasi Successfully installed dill-0.3.0 klepto-0.1.7 pox-0.2.6 pykakasi-1.1b1 six-1.12.0インストール確認2系
ほぼ参考の通り、以下のコードで無事に出力できました。
コメントアウトした命令は、エラーはいて止まりましたが、次の二行で以下の出力がえられました。# coding: utf-8 from pykakasi import kakasi kakasi = kakasi() kakasi.setMode('H', 'a') kakasi.setMode('K', 'a') kakasi.setMode('J', 'a') conv = kakasi.getConverter() filename = '本日は晴天なり.jpg' #print(conv.do(filename)) # 本日は晴天なり.jpg print(type(filename.decode('utf-8'))) print(conv.do(filename.decode('utf-8')))$ python ex_pykakasi2.py <type 'unicode'> honjitsuhaseitennari.jpg3系も無事にインストール確認できました。
ということで、今回は3系で話を進めます。pykakasiの仕様について
以下の参考がオリジナルのページです。
【参考】
①miurahr/pykakasi pykakasi/COPYING
②PYKAKASI documentation参考②より以下のものが使えるみたいです。
Option Description Values Note K Katakana conversion a,H,None roman, Hiragana or non conversion H Hiragana conversion a,K,None roman, Katakana or non conversion J Kanji conversion a,H,K,None roman or Hiragana, Katakana or noconv a Roman conversion E,None JIS ROMAN or non conversion E JIS ROMAN conversion a,None ascii roman or non conversion 参考②を見ると、
v1.1b1_ (6, Sep, 2019) Added Add conversions: kya, kyu, kyo
なので、kya,kyu,kyoは、この6/9/19にリリースされたばかりなのね。参考①にはaFでローマ字の振り仮名がつくので、同様にHFでひらがなの振り仮名がつきます。
コードを試してみる
以下のコードを動かしてみます。
最初のコードはひらがな、かたかな、そして漢字を全てローマ字に変換します。# coding: utf-8 from pykakasi import kakasi kakasi_ = kakasi() kakasi_.setMode('H', 'a') # H(Hiragana) to a(roman) kakasi_.setMode('K', 'a') # K(Katakana) to a(roman) kakasi_.setMode('J', 'a') # J(Kanji) to a(roman) conv = kakasi_.getConverter() filename = '本日は晴天ナリ' print(type(filename)) print(filename) print(conv.do(filename))結果は以下のとおり、ベターとローマ字変換できました。
<class 'str'> 本日は晴天ナリ honjitsuhaseitennari次は、全てひらがなに変換します。
kakasi_.setMode('J', 'H') # J(Kanji) to H(Hiragana) kakasi_.setMode('H', 'H') # H(Hiragana) to None(noconversion) kakasi_.setMode('K', 'H') # K(Katakana) to a(Hiragana) conv = kakasi_.getConverter() print(filename) print(conv.do(filename))いい感じにひらがなになりました。
あとは分離してリストにすればいいのです。本日は晴天ナリ ほんじつはせいてんなり以下は振り仮名を付けます。
kakasi_.setMode("J","HF") # Japanese to furigana conv = kakasi_.getConverter() print(filename) print(conv.do(filename))以下のように振り仮名もつきました。
本日は晴天ナリ 本日[ほんじつ]は晴天[せいてん]なりwakatiとバラバラ分離をやってみる
wakatiは仕様にあるので、そのまま実施します。
一方、バラバラ分離は参考のような手法があるようです。
【参考】
python、rubyで文字列を1文字ずつのリストにする
コードは以下のとおりです。# coding: utf-8 from pykakasi import kakasi kakasi_ = kakasi() kakasi_.setMode('H', 'a') # H(Hiragana) to a(roman) kakasi_.setMode('K', 'a') # K(Katakana) to a(roman) kakasi_.setMode('J', 'a') # J(Kanji) to a(roman) kakasi_.setMode("s", True) #wakati conv = kakasi_.getConverter() filename = '本日は晴天ナリ' print(type(filename)) print(filename) print(conv.do(filename)) char_list = list(conv.do(filename)) print(char_list) kakasi_.setMode('J', 'H') # J(Kanji) to H(Hiragana) kakasi_.setMode('H', 'H') # H(Hiragana) to None(noconversion) kakasi_.setMode('K', 'H') # K(Katakana) to a(Hiragana) conv = kakasi_.getConverter() print(filename) print(conv.do(filename)) char_list = list(conv.do(filename)) print(char_list)ローマ字変換も分かち書きもバラバラ変換も両方できました。
<class 'str'> 本日は晴天ナリ honjitsu ha seiten nari ['h', 'o', 'n', 'j', 'i', 't', 's', 'u', ' ', 'h', 'a', ' ', 's', 'e', 'i', 't', 'e', 'n', ' ', 'n', 'a', 'r', 'i']ひらがな変換では分かち書きもバラバラ変換も両方まんま出来ました。
これが出来たので当初の目標達成です。
これで以前のアプリを使うと、音声変換までできます。
ただし、分かち書きするとスペースが入るので、入れないほうがいい場合もあると思います。本日は晴天ナリ ほんじつ は せいてん なり ['ほ', 'ん', 'じ', 'つ', ' ', 'は', ' ', 'せ', 'い', 'て', 'ん', ' ', 'な', 'り']最後は振り仮名付きの変換ですが、これも想像通りの結果になりました。
本日は晴天ナリ 本日[ほんじつ] は 晴天[せいてん] なり ['本', '日', '[', 'ほ', 'ん', 'じ', 'つ', ']', ' ', 'は', ' ', '晴', '天', '[', 'せ', 'い', 'て', 'ん', ']', ' ', 'な', 'り']分かち書きをやめると以下のように、スペースの無いバラバラ変換ができました。
なんか美しさを感じます♪<class 'str'> 本日は晴天ナリ honjitsuhaseitennari ['h', 'o', 'n', 'j', 'i', 't', 's', 'u', 'h', 'a', 's', 'e', 'i', 't', 'e', 'n', 'n', 'a', 'r', 'i'] 本日は晴天ナリ ほんじつはせいてんなり ['ほ', 'ん', 'じ', 'つ', 'は', 'せ', 'い', 'て', 'ん', 'な', 'り']最後にローマ字変換をひらがな変換の後で実施すると以下が得られます。
kakasi_.setMode('J', 'H') # J(Kanji) to H(Hiragana) kakasi_.setMode('H', 'H') # H(Hiragana) to None(noconversion) kakasi_.setMode('K', 'H') # K(Katakana) to a(Hiragana) kakasi_.setMode('a', 'H') # K(Katakana) to a(Hiragana) conv = kakasi_.getConverter() print(filename) print(conv.do(filename)) char_list = list(conv.do(filename)) print(char_list) kakasi_.setMode('H', 'a') # H(Hiragana) to a(roman) conv = kakasi_.getConverter() print(conv.do(char_list))なんかこれも美しい!
本日は晴天ナリ ほんじつはせいてんなり ['ほ', 'ん', 'じ', 'つ', 'は', 'せ', 'い', 'て', 'ん', 'な', 'り'] ['ho', 'n', 'ji', 'tsu', 'ha', 'se', 'i', 'te', 'n', 'na', 'ri']まとめ
・Pykakasiを使って遊んでみた
・漢字かな交じり文をひらがなリストへのバラバラ変換ができた・出力側はできたので入力側どうにかしよう。。。
- 投稿日:2019-09-09T16:07:11+09:00
mysqlclientをpipでインストールする際に出るerror: command 'gcc' failed with exit status 1の対処法
開発環境
OS: macOS Mojave 10.14.5
言語: python 3.7.2エラーの内容
ターミナルでmysqlclientをインストールするために以下のコードを実行しようとした。
$ pip install mysqlclientエラーが出た。
error: command 'gcc' failed with exit status 1対処法
$ sudo installer -pkg /Library/Developer/CommandLineTools/Packages/macOS_SDK_headers_for_macOS_10.14.pkg -target /再度インストール。
$ pip install mysqlclientUsing cached https://files.pythonhosted.org/packages/4d/38/c5f8bac9c50f3042c8f05615f84206f77f03db79781db841898fde1bb284/mysqlclient-1.4.4.tar.gz Installing collected packages: mysqlclient Running setup.py install for mysqlclient ... done Successfully installed mysqlclient-1.4.4解決!
- 投稿日:2019-09-09T14:30:19+09:00
Python3エンジニア認定基礎試験受験記
試験概要
実施団体:一般社団法人Pythonエンジニア育成推進協会
試験会場:オッデセイコミュニケーションズ
受験料 :10,500円(税込)
問題数 :40問
試験時間:60分
合否発表:即時下記から基本的な内容が出題される。Web版は無料なので、特段の拘りが無ければWeb版をお勧めする。
- (書籍)オライリー・ジャパン「Pythonチュートリアル 第3版」<\1,944>
- (Web)Python チュートリアル<無料>
個人的使用教材(おすすめ順)
- (Web)Dive into Code<無料>
- (書籍)詳細! Python 3 入門ノート<\2,894>
- (書籍)プログラミング超初心者が初心者になるためのPython入門(1)kindle版<尼会員無料?>
- (Web)PyQ<月額\2,980~>
勉強方法
当時のレベル:初学者、プログラミング経験なし
現在と変わっていない( ^ω^)・・・
1週目:チュートリアルを読み始めるも癖のある?翻訳で早々に閉じる。
2週目:「詳細! Python 3 入門ノート」を購入し、実際にコードを打ち込む。↑応用編は興味があれば。基礎編で試験範囲はカバーできます。
3週目:PyQがリリースされ興味をそそられ加入。基本写経に近いが楽しい。
↑ドットインストールやpaizaなど無料サービスもあるので自分に合うものを見つけてほしい。
4週目:チュートリアルを流し読みしDive into Codeで模試を受ける。
5週目:最寄りの試験会場を前日予約。当日は2-30分で解き終わり合格。後日談
- 会社からの報奨金が出なければ受験しない。
- 取得しても社会的には評価されない。
- プログラミングに興味を持つきっかけにはなった。
- 簡単なコードなら読めるようになる。
- このレベルの学習では凝ったものは作れない。
- 投稿日:2019-09-09T14:04:50+09:00
初心者の初心者による初心者のためのデータ分析!League of Legendsで下克上を目指せ!(穴場のチャンピオン探し編)
数ある記事の中からこのページを開いてくださりありがとうございます。
就労移行支援施設でpythonなどの勉強をしているまゆんごまゆまゆと申します。
第1回目の投稿ということでLeague of Legendsについてで簡単なデータ分析を行ったのでそれをあげます。
League of Legendsとは
League of Legends(以後lolと表記)は2009年にサービスが開始し世界中で多くの方にプレイされているオンラインゲームの1つです。
5vs5のチーム戦で各プレイヤーは自分の選んだキャラクター(チャンピオン)を動かして相手の陣地に入りターゲットを破壊した方が勝ちになります。
フィールド全体から見て左下に拠点を構えるチームがブルー、右上に拠点を構えるチームがレッドになります。
相手の陣地を攻めに行くのに道は全部で3つ(ミッドレーン、トップレーン、ボットレーン)ありチーム内でそれぞれ役割分担があります。
さらに各レーンを攻めるチャンピオンの手助けをするジャングルとサポートという役割があります。
さらなる詳細については公式サイトをご覧ください。
なんでデータ分析やろうと思った?
私事で2019年8月31日に障がいを持った方を対象にしたeスポーツの大会に出場しておりました。
この大会に参加することになったのが本番の10日前でアカウント作成から開始という状態でしたがチームメイトのお力もあり準優勝でした。
決勝まで進めたからには優勝したかったのでとても悔しかったです。
機会があればリベンジしたいという気持ちがあり現在も時間を見つけては練習しています。
現在就労移行支援施設でpythonの勉強をしているということもあり、データ分析というアプローチからlolの分析をし自分のような初心者でも参考になる資料を作りたいと考えました。
なぜ穴場のチャンピオン?
初心者でも勝率を上げる手軽な方法の1つとして大きな大会でよく使われ勝率の高いチャンピオンを選択することだと考えます。
しかしある程度経験のあるプレーヤーはそういったものを把握し既に対策している可能性があります。
それに対する対抗策は、使われる回数はそんなに多くはないけど勝率の高い「穴場」となるチャンピオンを使うことだと考えました。
検証方法
今回はKaggleにある過去の試合データを使いました。
言語はpython3でJupyterNotebookを使用します。
今回はブルー側(フィールドの左下側)のミッドレーンという真ん中の道の担当で選ばれたチャンピオンを見ていきます。
検証開始!
csvファイルをダウンロードしいらないものをカット
import pandas as pd match_data = pd.read_csv('matchinfo.csv') #コードとcsvファイルは同じフォルダで保存している blue_mid = match_data[['blueMiddleChamp','bResult']] #ここでブルーのミッドレーンで使われたチャンピオンと勝敗以外の情報はカット selected = blue_mid.groupby("blueMiddleChamp").agg({"bResult":"count"}) selected.reset_index(inplace=True) selected.columns = ["blueMiddleChamp", "Num of Selected"] #ここで各チャンピオンが使われた回数を数え上げた表を作成 winning = blue_mid.groupby(["blueMiddleChamp"])["bResult"].sum().reset_index() winning.reset_index(inplace=True) winning.rename(columns = {"bResult":"Total Winning"}, inplace = True) #勝敗は1と0で表記されているので各チャンピオンに獲得した数字の和を付与すればそのまま勝利回数になる #selectedと同様に表とするここでselected(各チャンピオンの選ばれた回数),winning(各チャンピオンが勝った回数)で表を作ったのでそれぞれの概観を見ていきましょう。
コード上では「変数名.describe()」を使います。1:selected
Num of Selected count 71.000000 mean 107.323944 std 162.849604 min 1.000000 25% 3.000000 50% 31.000000 75% 153.000000 max 643.000000 2:winning
Num of Winning count 71.000000 mean 58.394366 std 88.025561 min 0.000000 25% 2.000000 50% 17.000000 75% 80.000000 max 341.000000 これらの表にあるパーセンテージは数値において下位何%という風に見ていきます。
試合で使用されたと確認できるチャンピオンは全部で71種類。
どちらから見てもよく使われるチャンピオンと勝つ回数の多いチャンピオンはだいたい固まっていることがわかります。
作成した表を合体させさらに加工しよう!
2つの表ができたのでさらに手を加えていきます。
blue_mid_ddf = selected.merge(winning, left_on = 'blueMiddleChamp', right_on = 'blueMiddleChamp') #先程まで作った表2つを合体。ここではmergeを使用。ここでは各チャンピオンが選ばれた回数の右に勝った回数をくっつけるという形を取っている。 blue_mid_ddf["Winning Rate"] = blue_mid_ddf["Total Winning"] / blue_mid_ddf["Num of Selected"] * 100 blue_mid_ddf["Selected Rate"] = blue_mid_ddf["Num of Selected"] / 7620 * 100 #表を合体させたものの確率で見ないと比較は難しい。そこで新しくWinning RateとSelected Rateの2つを作り勝率、採用率それぞれを計算させる。7620は今回使用しているデータにある試合数。 blue_mid_ddf = blue_mid_ddf[['blueMiddleChamp','Num of Selected', 'Selected Rate', 'Total Winning', 'Winning Rate']] #表を並べ替え見やすくするこの状態で再度データの概観を見てみましょう。
Num of Selected Selected Rate Total Winning Winning Rate count 71.000000 71.000000 71.000000 71.000000 mean 107.323944 1.408451 58.394366 57.152692 std 162.849604 2.137134 88.025561 25.198421 min 1.000000 0.013123 0.000000 0.000000 25% 3.000000 0.039370 2.000000 49.359903 50% 31.000000 0.406824 17.000000 54.545455 75% 153.000000 2.007874 80.000000 66.666667 max 643.000000 8.438320 341.000000 100.000000 採用率を見ると75%(=上位25%)までいかないとほとんど使われないことがわかります。
勝率が高くてもそもそもの採用率の低いチャンピオンは足切りすることにしましょう。
やり方は非常にシンプルです。blue_mid_ddf = blue_mid_ddf[blue_mid_ddf['Selected Rate'] > 1.7]
Num of Selected Selected Rate Total Winning Winning Rate count 20.000000 20.000000 20.000000 20.000000 mean 324.050000 4.252625 176.100000 54.538742 std 163.551529 2.146346 87.295566 4.425204 min 131.000000 1.719160 72.000000 47.058824 25% 176.750000 2.319554 89.750000 51.921950 50% 322.500000 4.232283 172.500000 53.462437 75% 427.250000 5.606955 233.000000 56.954688 max 643.000000 8.438320 341.000000 64.122137 足切りラインを調整しチャンピオンをベスト20にまで絞り込むことができました。
あとは並べ替え実際に表示してみましょう。
blue_mid_ddf = blue_mid_ddf.sort_values(["Selected Rate"], ascending=False) #採用率の高い順に並べ替え blue_mid_ddf #JupyterNotebookではこれだけで表示される実際の結果がこちら!
blueMiddleChamp Num of Selected Selected Rate Total Winning Winning Rate Orianna 643 8.438320 341 53.032659 Viktor 621 8.149606 298 47.987118 Syndra 526 6.902887 299 56.844106 Azir 489 6.417323 285 58.282209 Corki 446 5.853018 232 52.017937 Leblanc 421 5.524934 221 52.494062 Cassiopeia 391 5.131234 217 55.498721 Taliyah 388 5.091864 236 60.824742 Ryze 366 4.803150 208 56.830601 Ahri 334 4.383202 185 55.389222 Vladimir 311 4.081365 160 51.446945 Lulu 225 2.952756 119 52.888889 Lissandra 199 2.611549 114 57.286432 Zed 183 2.401575 112 61.202186 Jayce 180 2.362205 89 49.444444 Kassadin 167 2.191601 90 53.892216 Galio 154 2.020997 81 52.597403 Karma 153 2.007874 72 47.058824 TwistedFate 153 2.007874 79 51.633987 Malzahar 131 1.719160 84 64.122137 Oriannaというチャンピオンが最も使われ勝率もある程度あることがわかります。
ではこのチャンピオンを使えば一番勝ちやすいかというと必ずしもそうでもありません。
最下位のMalzaharを見てみましょう。
勝率はトップの64.1%でOriannaと10%以上もの差があります。 あまり使われていないけれど勝率が高いものを選べば「穴場」になる可能性があります。
おわりに
今回はブルー側のミッドレーンでどのチャンピオンを使えばいいか過去の公式試合のデータを用いて「採用率」「勝率」という視点から検証してみました。
次回は使いたいチャンピオンがBANされた時の代替案を機械学習を用いて考えられるようにしていきます。
- 投稿日:2019-09-09T13:06:50+09:00
【備忘録】Pythonコマンドが認識してくれなくなった(Windows10のアップデートが関係?)
やっほー! こんにちはー!
物理好きのオザキ(@sena0801masato)です。今回は、Windows10で突然pythonコマンドを認識しなくなったので、その時の私が行った解決方法をお伝えしようと思います。
原因はいまいち分かりませんでした。Windowsのアップデートが影響しているような、私の環境の問題のような...
そのため、備忘録としてざっくりと書きます。もし同じようなことで、つまづいている方のお力になれれば幸いです。この記事の対象者
- 数か月前からpythonを使っている
- Windows10を最近アップデートした
- pythonコマンドを突然認識してくれなくなった
私の環境
- Windows10 Pro バージョン 1903 OSビルド 18362.295
- Anaconda
自分のWindows10のバージョンを確認する方法は、[スタート]ボタン > [設定] > [システム] > [バージョン情報] です
使用中の Windows オペレーティング システムのバージョンを確認する問題点
pythonを対話モードにしてみる。
コマンドプロンプトMicrosoft Windows [Version 10.0.18362.295] (c) 2019 Microsoft Corporation. All rights reserved. C:\Users\Owner>python --version (反応しないで処理が終わったことになる) C:\Users\Owner>python (Microsoft Storeのpythonをインストールしませんか?って画面が開かれる)ターミナル(gitのbash)$ python --version bash: /c/Users/Owner/AppData/Local/Microsoft/WindowsApps/python: Permission denied $ python bash: /c/Users/Owner/AppData/Local/Microsoft/WindowsApps/python: Permission denied今までは何も問題なく対話モードになっていたのに何かおかしい。
解決方法
Pathの順番を入れ替えてターミナルを起動し直したらうまく動作した。
Pathの確認は[コントロールパネル] > [システムとセキュリティ] > [システム] > [システムの詳細設定] > [環境変数]です。
入れ替えてというのは、[環境変数] > [Path]を選択 > [編集] > [上へ]や[下へ]をしました。入れ替え前
1. C:\Users\Owner\AppData\Local\Microsoft\WindowsApps
2. C:\Users\Owner\Anaconda3
3. C:\Users\Owner\Anaconda3\Scripts入れ替え後
1. C:\Users\Owner\Anaconda3
2. C:\Users\Owner\Anaconda3\Scripts
3. C:\Users\Owner\AppData\Local\Microsoft\WindowsAppsふたたび対話モードになるか確認してみる。
コマンドプロンプトC:\Users\Owner>python --version Python 3.6.1 :: Anaconda 4.4.0 (64-bit) C:\Users\Owner>python Python 3.6.1 |Anaconda 4.4.0 (64-bit)| (default, May 11 2017, 13:25:24) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> exit()ターミナル(gitのbash)$ python --version Python 3.6.1 :: Anaconda 4.4.0 (64-bit) $ python Python 3.6.1 |Anaconda 4.4.0 (64-bit)| (default, May 11 2017, 13:25:24) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> exit()原因
Pathは上の方にあるものが優先されます。そのため、Anacondaのpython.exeよりも先に、WindowsAppsでpython.exeが見つかったから、WindowsAppsのpython.exeを実行してしまったようです。
このWindowsAppsのpython.exeは私の環境では2019/09/06に作成されたらしいです。
"らしい"というのは、作成されるような操作をした心当たりがないためです。
こんなに最近にファイルが作成されていて、心当たりがあるのはWindows10のアップデートぐらいでした。
でも、Windows10のバージョン情報より、インストール日は2019/08/29と書いてあるから、ますます疑問です...Cドライブのすぐ下に2019/08/29に作成されたWindows.oldディレクトリや2019/09/01に作成されたWindowsディレクトリが、Windowsのアップデートで作成された気がするから、ここら辺が影響しているのかな...
また、WindowsAppsディレクトリに入っているpython.exeを削除するという方法もありますが、削除は怖いので今回はPathの順番を入れ替えるだけにしました。
Pathを勝手に入れ替えたのも怖いのですが、WindowsAppsディレクトリにはMicrosoft Storeを開くものだけで、大したものが入っていなさそうなので大丈夫だと思います。まとめ
コマンドを認識してくれなくなった!って思ったらとりあえずPathを確認すればなんとかなると思います。
ただWindowsAppsのpython.exeは何がきっかけで作成されたのか疑問です。ではでは!
参考文献
閲覧日2019/09/09 使用中の Windows オペレーティング システムのバージョンを確認する
https://support.microsoft.com/ja-jp/help/13443/windows-which-version-am-i-running
閲覧日2019/09/09 Python/python3 executes in Command Prompt, but does not run correctly
https://stackoverflow.com/questions/57485491/python-python3-executes-in-command-prompt-but-does-not-run-correctly
- 投稿日:2019-09-09T13:02:00+09:00
JupyterLabの拡張機能jupyterlab-lspの導入方法(macOS)
自分の環境
・macOS Mojave バージョン10.14.6
・zsh 5.7.1
・pip 19.2.3
・pyenv 1.2.13
・python 3.6.9
・JupyterLab 1.1.2インストール
JupyterLab
JupyterLab本体は$pip install jupyterlabでインストールしました。
nodebrew
Node.jsをインストールするために、Nodebrewを使用しました。
nodebrewとは、Node.jsのバージョン管理するためのものです。それではnodebrewのインストール方法です。
(https://github.com/hokaccha/nodebrew)
この公式のインストール方法を参考にしました。まず、
curlでnodebrewをインストールします。$ curl -L git.io/nodebrew | perl - setupインストール完了後、
PATHを通します。$echo 'export PATH=$HOME/.nodebrew/current/bin:$PATH' >> ~/.zshrc(
bashの方は.zshrcを.bashrcにしてください)構成ファイルを再読み込みします。
$source ~/.zshrc$nodebrew helpで確認します。
バージョンなどの情報が出てきたら、インストール成功です。Node.js
やっと本題の
Node.jsをnodebrewを使用し、インストールします。
JupyterLabの拡張機能はnpmを使用してインストールするので、Node.jsが必要です。$nodebrew install-binary latestでインストールします。
インストール終了後、$nodebrew ls v12.10.0でインストールされたバージョンを確認します。(私のバージョンは
v12.10.0でした。)
次に、使うバージョンを指定します。$nodebrew use v12.10.0
Node.jsのバージョンを確認してみましょう。$node -v v12.10.0このようになっているはずです。
完了したら、jupyterLabを起動します。$jupyter lab
起動後、上のパレットのようなアイコンを選択します。
その中の
を選択します。
選択するとこのようなポップアップが表示されるので[Enable]を選択します。
そうすると、
このようにチェックマークがつきます。さらに
このアイコンが追加されます。拡張機能をインストールする際はこのアイコンを選択して、@username/インストールしたい拡張機能で検索するか、
ターミナル上で$jupyter labextension install @username/インストールしたい拡張機能このようなコマンドを打つことでインストールすることができます。
jupyterlab-lsp
本命の拡張機能をインストールします。
(https://github.com/krassowski/jupyterlab-lsp )公式サイトを参考にインストールします。
ターミナル上で$jupyter labextension install @krassowski/jupyterlab-lspを実行すればインストールすることができます。
また、jupyterlab上では@krassowski/jupyterlab-lspと検索すればインストールすることができます。お好きな方でインストールしてください。
jupyterLabでインストールする際はRebuildとページの再読み込みは忘れず行ってください。
ターミナルでインストールする方もjupyterLabを起動したままの場合はページの再読み込みを行ってください。次にターミナル上で
$pip install 'python-language-server[all]'を実行し、インストールします。
次に、任意のディレクトリに
servers.ymlを作成します。私はhomeディレクトリに作成しました。$vi ~/servers.ymlで
servers.ymlを起動し、中に以下を記述します。langservers: python: - pyls R: - R - --slave - -e - languageserver::run()
:wqで保存が完了したら、作業は終了です。起動
jupyterlab-lspはjupyterlabを起動する前に"毎回"以下のコマンドを実行する必要があります。$node path_to_jupyterlab_staging/node_modules/jsonrpc-ws-proxy/dist/server.js --port 3000 --languageServers servers.yml
path_path_to_jupyterlab_stagingは
.pyenvの場合
~/.pyenv/versions/YOUR_VERSION_OR_VENV/share/jupyter/lab/staging/
ローカルインストールの場合
~/.local/lib/python3.6/site-packages/jupyterlab/staging/
となります。
私の場合は$node ~/.pyenv/versions/3.6.9/share/jupyter/lab/staging/node_modules/jsonrpc-ws-proxy/dist/server.js --port 3000 --languageServersとしました。
このコマンドを実行後、jupyterlabを起動すると動くはずです。エラーが出る場合
~/.pyenv/versions/YOUR_VERSION_OR_VENV/share/ディレクトリ以下にmanディレクトリしかない場合、internal/modules/cjs/loader.js:775 throw err; ^ Error: Cannot find module '/Users/USER_NAME/.pyenv/versions/YOUR_VERSION_OR_VENV/share/jupyter/lab/staging/node_modules/jsonrpc-ws-proxy/dist/server.js' at Function.Module._resolveFilename (internal/modules/cjs/loader.js:772:15) at Function.Module._load (internal/modules/cjs/loader.js:677:27) at Function.Module.runMain (internal/modules/cjs/loader.js:999:10) at internal/main/run_main_module.js:17:11 { code: 'MODULE_NOT_FOUND', requireStack: [] }このようなエラーが出ると思います。(というか私が初めて導入した際に出ました。)
出た場合は、ディレクトリを作成する必要があります。
share/ディレクトリ内で$mkdir jupyter/lab/staging/このような階層を作ります。(
zshならこれで一気に作成できます)
bashを使っている方は$mkdir -p jupyter/lab/staging/で一気に作成することができます。
その後staging/ディレクトリまで移動し、$npm initを実行します。このコマンドは
package.jsonファイルを作成するものです。実行した際、This utility will walk you through creating a package.json file. It only covers the most common items, and tries to guess sensible defaults. See `npm help json` for definitive documentation on these fields and exactly what they do. Use `npm install <pkg>` afterwards to install a package and save it as a dependency in the package.json file. Press ^C at any time to quit. package name: (share) version: (1.0.0) description: entry point: (index.js) test command: git repository: keywords: author: license: (ISC) About to write to /Users/USER_NAME/.pyenv/versions/YOUR_VERSION_OR_VENV/share/package.json: { "name": "share", "version": "1.0.0", "description": "", "main": "index.js", "directories": { "man": "man" }, "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "author": "", "license": "ISC" } Is this OK? (yes)このようなものが出ます。ここでは名前の設定など任意に設定できます。
しかし、めんどくさいので終わるまでenterを押して問題ありません。
作成が終了したら、このコマンドで、Server.jsをインストールします。$npm install server終了後、このコマンドで
jsonrpc-ws-proxyをインストールします。$npm i jsonrpc-ws-proxyこれで毎回打つコマンドのエラーは出ないと思います。
以上です。最後になりますが、
Tabを押さずにピリオドを打つだけで自動補完してくれる
jupyterlab-lspでpythonプログラミングを楽しみましょう!参考サイト
https://qiita.com/simonritchie/items/34504f03947bfb4f54f5
https://github.com/krassowski/jupyterlab-lsp
https://github.com/hokaccha/nodebrew
https://github.com/palantir/python-language-server
https://serverjs.io/tutorials/getting-started/
https://www.npmjs.com/package/jsonrpc-ws-proxy
https://jupyterlab.readthedocs.io/en/stable/user/extensions.html



- 投稿日:2019-09-09T13:02:00+09:00
JupyterLabの拡張機能jupyterlab-lspの導入方法(macOS、pipenv)
修正
9/9 16:10
・「自分の環境」
pipenvのバージョンを追加
・「jupyterlab-lsp」
そもそも私はpipenvで管理しているため、
.pyenvパスではなく、.localパスでした。
・「エラーが出る場合」
投稿時はjupyterlabのpathを勘違いしていたため、エラーが出ていました。
しかし、パスを見直したら出なくなったので一部削除自分の環境
・macOS Mojave バージョン10.14.6
・zsh 5.7.1
・pip 19.2.3
・pyenv 1.2.13
・pipenv 2018.11.26
・python 3.6.9
・JupyterLab 1.1.2インストール
JupyterLab
JupyterLab本体は$pipenv install jupyterlab #pipenvの方 $pip install jupyterlab #pipの方でインストールしました。
nodebrew
Node.jsをインストールするために、Nodebrewを使用しました。
nodebrewとは、Node.jsのバージョン管理するためのものです。それではnodebrewのインストール方法です。
(https://github.com/hokaccha/nodebrew)
この公式のインストール方法を参考にしました。まず、
curlでnodebrewをインストールします。$ curl -L git.io/nodebrew | perl - setupインストール完了後、
PATHを通します。$echo 'export PATH=$HOME/.nodebrew/current/bin:$PATH' >> ~/.zshrc(
bashの方は.zshrcを.bashrcにしてください)構成ファイルを再読み込みします。
$source ~/.zshrc$nodebrew helpで確認します。
バージョンなどの情報が出てきたら、インストール成功です。Node.js
やっと本題の
Node.jsをnodebrewを使用し、インストールします。
JupyterLabの拡張機能はnpmを使用してインストールするので、Node.jsが必要です。$nodebrew install-binary latestでインストールします。
インストール終了後、$nodebrew ls v12.10.0でインストールされたバージョンを確認します。(私のバージョンは
v12.10.0でした。)
次に、使うバージョンを指定します。$nodebrew use v12.10.0
Node.jsのバージョンを確認してみましょう。$node -v v12.10.0このようになっているはずです。
完了したら、jupyterLabを起動します。$jupyter lab
起動後、上のパレットのようなアイコンを選択します。
その中の
を選択します。
選択するとこのようなポップアップが表示されるので[Enable]を選択します。
そうすると、
このようにチェックマークがつきます。さらに
このアイコンが追加されます。拡張機能をインストールする際はこのアイコンを選択して、@username/インストールしたい拡張機能で検索するか、
ターミナル上で$jupyter labextension install @username/インストールしたい拡張機能このようなコマンドを打つことでインストールすることができます。
jupyterlab-lsp
本命の拡張機能をインストールします。
(https://github.com/krassowski/jupyterlab-lsp )公式サイトを参考にインストールします。
ターミナル上で$jupyter labextension install @krassowski/jupyterlab-lspを実行すればインストールすることができます。
また、
jupyterlab上では@krassowski/jupyterlab-lspと検索すればインストールすることができます。お好きな方でインストールしてください。
jupyterLabでインストールする際はRebuildとページの再読み込みは忘れず行ってください。
ターミナルでインストールする方もjupyterLabを起動したままの場合はページの再読み込みを行ってください。次にターミナル上で
$pipenv install 'python-language-server[all]' #pipenv の方 $pip install 'python-language-server[all]' #pip の方のどちらかを実行し、インストールします。
次に、任意のディレクトリに
servers.ymlを作成します。私はhomeディレクトリに作成しました。$vi ~/servers.ymlで
servers.ymlを起動し、中に以下を記述します。langservers: python: - pyls R: - R - --slave - -e - languageserver::run()
:wqで保存が完了したら、作業は終了です。起動
jupyterlab-lspはjupyterlabを起動する前に"毎回"以下のコマンドを実行する必要があります。$node path_to_jupyterlab_staging/node_modules/jsonrpc-ws-proxy/dist/server.js --port 3000 --languageServers servers.yml
path_path_to_jupyterlab_stagingは
.pyenvの場合
~/.pyenv/versions/YOUR_VERSION_OR_VENV/share/jupyter/lab/staging/
ローカルインストールの場合
~/.local/lib/python3.6/site-packages/jupyterlab/staging/
となります。
私の場合はpipenvで環境を管理しているので$node ~/.local/share/virtualenvs/3.6.9-KuE0SBuD/share/jupyter/lab/staging/node_modules/jsonrpc-ws-proxy/dist/server.js --port 3000 --languageServersとしました。
このコマンドを実行後、jupyterlabを起動するとjupyterlab-lspは動くはずです。
成功した際、このようにオレンジ色の点線が出てきます。
エラーが出る場合以下はならないはずです。internal/modules/cjs/loader.js:775 throw err; ^ Error: Cannot find module '/Users/USER_NAME/.pyenv/versions/YOUR_VERSION_OR_VENV/share/jupyter/lab/staging/node_modules/jsonrpc-ws-proxy/dist/server.js' at Function.Module._resolveFilename (internal/modules/cjs/loader.js:772:15) at Function.Module._load (internal/modules/cjs/loader.js:677:27) at Function.Module.runMain (internal/modules/cjs/loader.js:999:10) at internal/main/run_main_module.js:17:11 { code: 'MODULE_NOT_FOUND', requireStack: [] }このようなエラーが出ると思います。(というか私が初めて導入した際に出ました。)
出た場合は、server.jsまでのパスとserver.ymlまでのパスをしっかりと確認してください。最後に
以上です。最後になりますが、
Tabを押さずにピリオドを打つだけで自動補完してくれる
jupyterlab-lspでpythonプログラミングを楽しみましょう!参考サイト
https://qiita.com/simonritchie/items/34504f03947bfb4f54f5
https://github.com/krassowski/jupyterlab-lsp
https://github.com/hokaccha/nodebrew
https://github.com/palantir/python-language-server
https://serverjs.io/tutorials/getting-started/
https://www.npmjs.com/package/jsonrpc-ws-proxy
https://jupyterlab.readthedocs.io/en/stable/user/extensions.html

- 投稿日:2019-09-09T11:59:33+09:00
python Bottleの基本9 Form
このテーマは、入力フォームをサクッと作るです。特に日本語入力があるフォームは、文字化けしたりフォームが崩れたり、すべったり転んだりします。そこでテンプレートを作っておきます。
ex9.pyfrom bottle import * import json,os #HTML デコレーション(Bootstrap4) def Html(title): html=''' <!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8" /> <title>%s</title> <link rel="stylesheet" type="text/css" href="/static/content/bootstrap.min.css" /> <link href="static/content/jumbotron.css" rel="stylesheet" /> <link rel="stylesheet" type="text/css" href="/static/content/site.css" /> <script src="/static/scripts/modernizr-2.6.2.js"></script> <script src="/static/scripts/jquery-1.10.2.min.js"></script> <script src="/static/scripts/bootstrap.min.js"></script> <script src="/static/scripts/respond.min.js"></script> <script src="/static/scripts/mindmup-editabletable.js"></script> </head> <body> %s </body> </html>''' def f0(f): def f1(*a,**b): return html%(title,f(*a,**b)) return f1 return f0 def Body(): def f0(f): def f1(*a,**b): return '<div class="container body-content">%s</div>'%f(*a,**b) return f1 return f0 def Navi(menu): nav='''<nav class="navbar navbar-expand-md navbar-dark fixed-top bg-dark"> <a class="navbar-brand" href="/">%s</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarsExampleDefault" aria-controls="navbarsExampleDefault" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarsExampleDefault"> <ul class="navbar-nav mr-auto"> %s </ul> <form class="form-inline my-2 my-lg-0"> <input class="form-control mr-sm-2" type="text" placeholder="Search" aria-label="Search"> <button class="btn btn-outline-success my-2 my-sm-0" type="submit">Search</button> </form> </div> </nav>%s''' def f0(f): def f1(*a,**b): nm=''.join(['<li class="nav-item"><a class="nav-link" href="/%s">%s</a></li>'%(x,x) for x in menu[1:]]) return nav%(menu[0],nm,f(*a,**b)) return f1 return f0 def routes(menu): def f0(f): route('/','GET',f) [route("/%s"%x,'GET',f) for x in menu] def f1(*a,**b): return f(*a,**b) return f1 return f0 #JOMBOTRON デコレーション def Jumbotron(title,paragraph): jumbo='''<div class="jumbotron"> <div class="container"> <h1 class="display-3">%s</h1> <p>%s</p> </div> </div>%s''' def f0(f): def f1(*a,**b): return jumbo%(title,paragraph,f(*a,**b)) return f1 return f0 def form(nm): x0='''<div class="container" style="margin-top:2em;"> <form class="form" role="form" action="/form" method="post"> %s <button type="submit" class="btn btn-primary ">登録</button> </form> </div>''' x1='<div class="form-group row">%s</div>' x2='''<label for="{0}" class="col-sm-4 control-label">{0}</label> <div class="col-sm-8"> <input name="{0}" type="text" id="{0}" placeholder="{0}" class="form-control" autofocus> </div>''' ax=''.join([''.join([x1%x2.format(a) for a in x.split(' ')])for x in nm]) return x0%ax menu='Home,Form,Menu2,Menu3,Disp'.split(',') @routes(menu) @Html('Hello') @Navi(menu) @Jumbotron('Formテンプレート','これさえあればサクッと作ることができます') @Body() def Home(): p=request.urlparts[2] if p=='/Form': return form("名前,電話番号,メール,郵便番号,住所".split(',')) return "<h1>%s</h1><h1>Hello World</h1>"%(p) def vTable(d): b="\n".join(["<tr><th>%s</th><td>%s</td></tr>"%(x,d[x])for x in d]) h=["<table style='margin-top:3em;' class='table table-sm table-bordered table-striped table-responsive-sm table-hover'>", b,"</table>"] return "\n".join(h)+"<button class='btn btn-primary' onclick='history.back()'>戻る</button>" @route('/form',method="POST") @Html('Hello') @Jumbotron('Form表示テンプレート','これさえあればサクッと作ることができます') @Navi(menu) @Body() def form_post(): tbl={x: request.params.decode()[x] for x in request.params.decode()} htm=vTable(tbl) return htm #メニューの設定 #faviconの読み込み @route('/favicon.ico') def favcon(): return static_file('favicon.ico', root='./static') #staic ファイルの読み込み @route('/static/<filepath:path>') def server_static(filepath): return static_file(filepath, root='./static') #web server のhost portの設定 HOST,PORT='localhost',8080 if __name__ =='__main__': run(host=HOST,port=PORT)スニペット解説
return form("名前,電話番号,メール,郵便番号,住所".split(','))formのHtmlを生成しています。カンマ区切りの項目を変えれば自由にカスタマイズできます。
def form_post(): tbl={x: request.params.decode()[x] for x in request.params.decode()} htm=vTable(tbl) return htmPOSTされたデータをUTF-8にでコードしてdictを作っています。
vTableは、垂直方向に見出しするテーブルのhtmlを生成しています。
- 投稿日:2019-09-09T11:01:57+09:00
pip/pip3でのImportError: cannot import name mainについてとその対処。
説明なんていらねぇって人は、一番最後の最後に実行すべきコマンドをまとめます。へどうぞ。
結果
ここでは基本的にPython3での話です。(Python2でも同じやり方でできるはずですが…)
発生プロセスは、まず、Python2,Python3ともにosにデフォルトでインストールされていて、pip/pip3をインストールすると言う場面において、
$ sudo apt install python3-pipとすると、python3-pipつまりpip3がインストールされます。このとき、pip3のVersionは、おそらく「8.x.x」でしょう。
ここで何らかの理由(Version-9以上でなければならないとか、VersionをUpgradeするようpip/pip3に言われるなど)により、下のコマンドを実行します。
$ pip3 install --upgrade pipもしくは、
$ sudo -H pip3 install --upgrade pipすると全ての
pip3コマンドで、次のようなErrorがでる。ここでは例として-Vを実行する。
$ pip3 -Vすると、
Traceback (most recent call last): File "/usr/bin/pip", line 9, in <module> from pip import main ImportError: cannot import name mainこのような、Errorがでる。
原因
Errorが何を言っているのかと言うと、インポートエラーで「main」という名前のモデュールがインポートできない、そしてどこのことかと言うと
/usr/bin/pipのline 9にあるfrom pip import mainと言うところですよということである。
つまりあるべきところに「main」がないので、うまくimportできないのである。
このErrorの原因は他のwebサイトでも解説されているように、version-8以下とversion-9以上が非互換であるせいである。version-8仕様のファイルではversion-9以上は上手く動作することができない。pip(python-pip)とpip3(python3-pip)の違い
pipとpip3は基本的に同じものであるしかし、環境上にpython2とpython3が共存している場合pipだけでは、python2とpython3で互換がないライブラリなどがおかしくなったりそもそも、python2とpython3で別々に管理したいと言う場合に、
python2では、pip → python2用のpip
python3では、pip3(python3-pip) → python3用のpip
と言う使い分けをするのである。対処
一つ目の対処
他のwebサイトでは、まず
$ sudo python3 -m pip uninstall pipを行い、ライブラリは
$ python3 -m pip install numpyこのようにpython3を用いてインストールするようにと書かれているが、それはめんどくさいので、今までどおり
$ pip3 install numpyでライブラリをインストールできるようにする。
二つ目の対処
まず、
pip -upgrade pipでインストールしたpip3をアンインストールする。
$ sudo python3 -m pip uninstall pipそして、
aptでインストールしたpip3をアンインストールする。
$ sudo apt autoremove python3-pipこれで、
pip3は全てアンインストールされました。そして今度はaptではなくget-pip.pyというブートストラップを使って、標準インストールします。
まず、
$ curl https://bootstrap.pypa.io/get-pip.py -o get-pip.pyこれで、
get-pip.pyがダウンロードされます。そしてget-pip.pyを使ってpip3をインストールします。
$ python3 get-pip.py --userここで、
ModuleNotFoundError: No module named 'distutils.util'と言うようなErrorが出た場合、python3-distutilsをインストールします。
$ sudo apt install python3-distutilsそしてもう一度、
$ python3 get-pip.py --userそうすると
Successfully installed pip-19.2.3 setuptools-41.2.0 wheel-0.33.6pip-19.2.3インストールされるでしょう。(pip-19.x.xと言うべきですが)
最後に実行すべきコマンドをまとめます。
#Python2、Python3両方ともインストールし直す場合。------------------ # -upgradeでインストールされたpipをアンインストール。(No module named pipとでる場合はそのまま進む。) $ sudo python -m pip uninstall pip $ sudo python3 -m pip uninstall pip # aptでインストールされたpipをアンインストール。 $ sudo apt autoremove python3-pip $ sudo apt autoremove python-pip # get-pip.pyをダウンロード。 $ curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py # pipを標準インストール。(get-pip.pyがhome dirにあるとして、home dirで実行) $ python3 get-pip.py $ python get-pip.py # 「$ python3 get-pip.py」で「ModuleNotFoundError: No module named 'distutils.util'」と出てくる場合。 $ sudo apt install python3-distutils # もう一度「$ python3 get-pip.py」を実行する。 #Python3のみインストールし直す場合。------------------------------- radeでインストールされたpipをアンインストール。(No module named pipとでる場合はそのまま進む。) $ sudo python3 -m pip uninstall pip # aptでインストールされたpipをアンインストール。 $ sudo apt autoremove python3-pip # get-pip.pyをダウンロード。 $ curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py # pipを標準インストール。(get-pip.pyがhome dirにあるとして、home dirで実行) $ python3 get-pip.py # 「$ python3 get-pip.py」で「ModuleNotFoundError: No module named 'distutils.util'」と出てくる場合。 $ sudo apt install python3-distutils # もう一度「$ python3 get-pip.py」を実行する。以上。