- 投稿日:2019-09-09T23:24:02+09:00
UbuntuでEFSをマウントする
概要
Amazon Linuxでは多かったですが、Ubuntuでの解説がなかなか見つからなかったので、書いてみました。
EFS作成
この辺は情報が多いので、割愛します。
セキュリティグループの設定
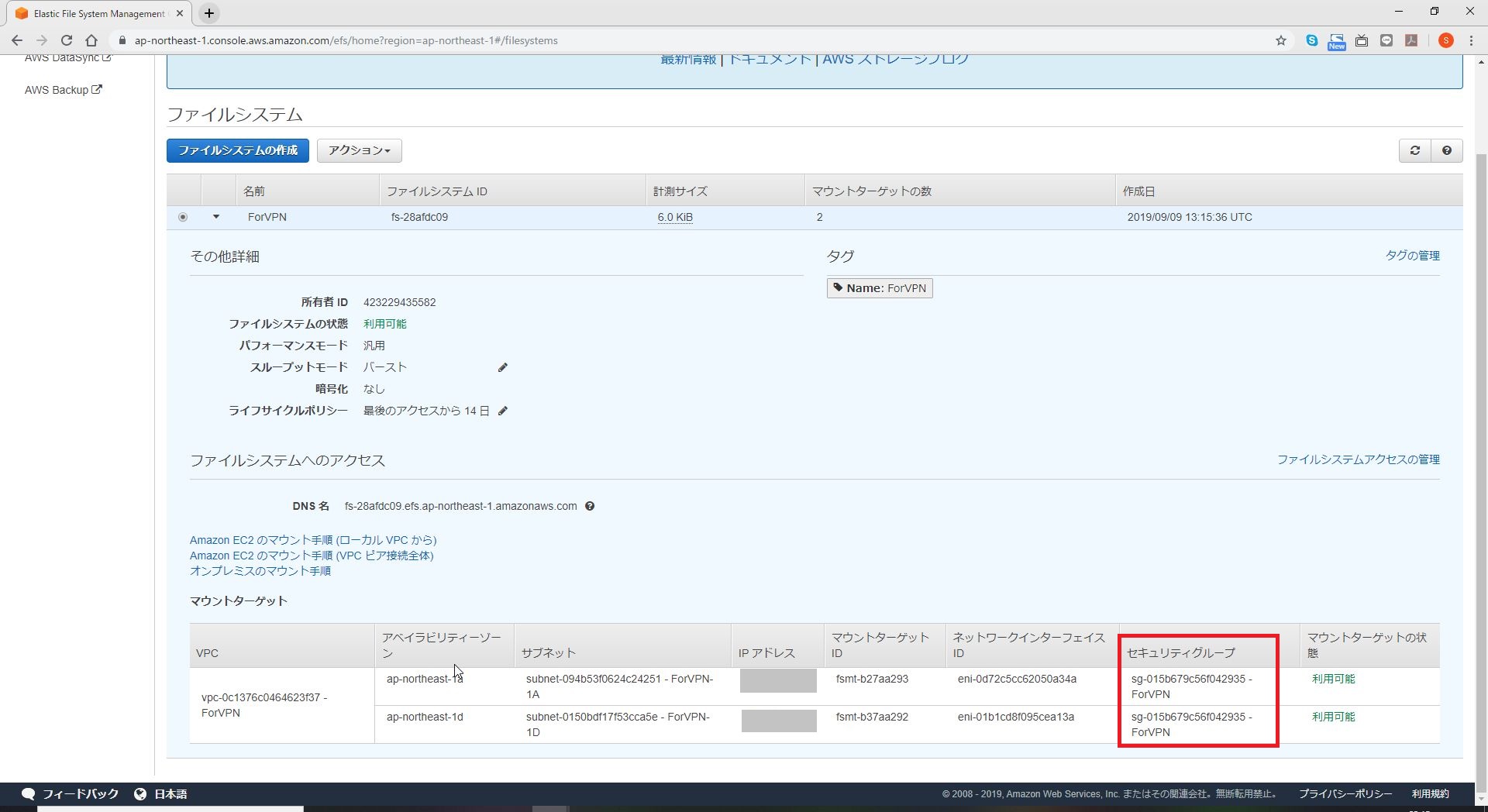
EFSのページにあるセキュリティグループを確認する。
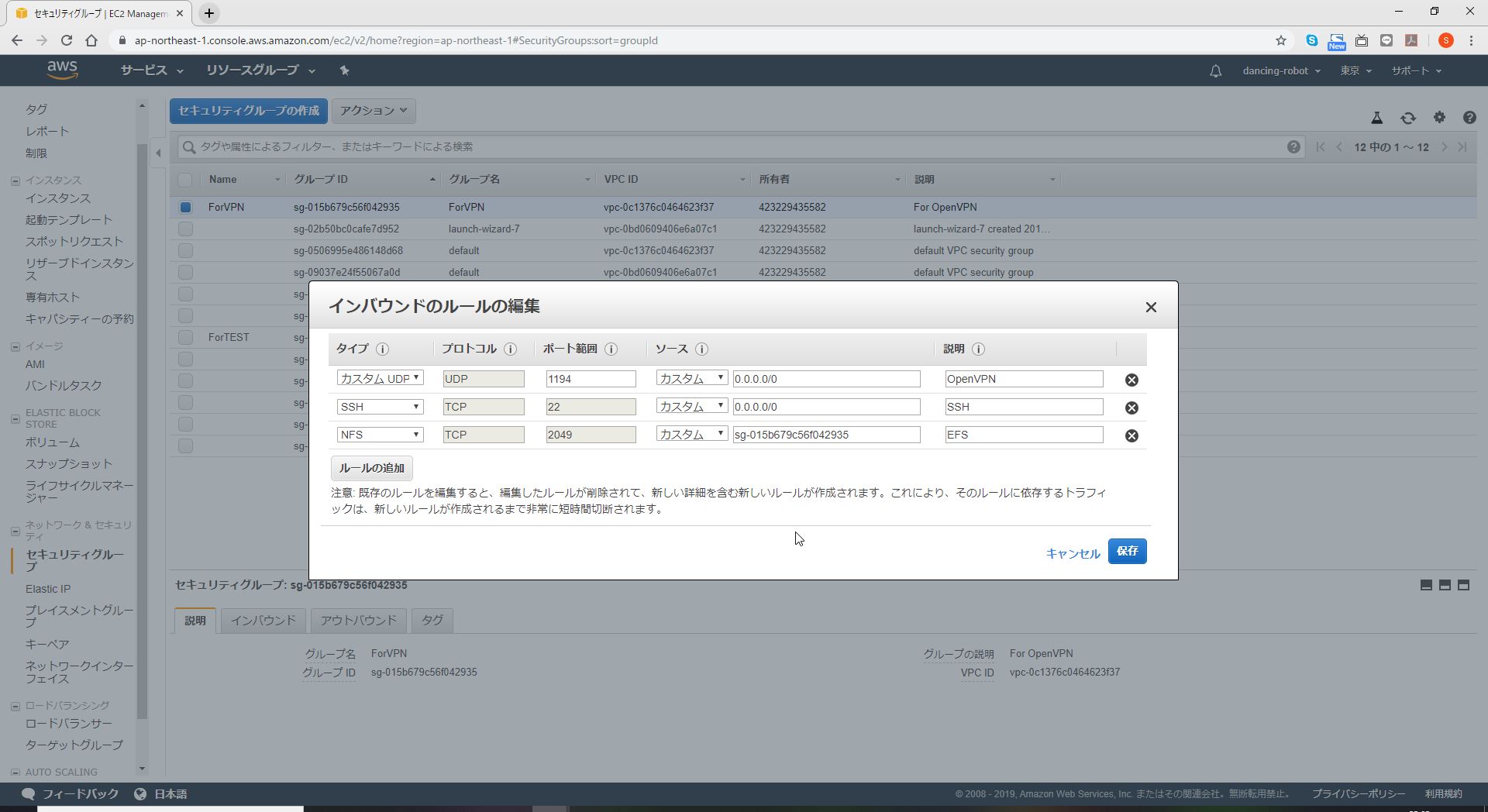
EFSのマウントターゲットのSecurityGroupに対して、EC2インスタンスからのNFSを許可する。
amazon-efs-utilsをインストール
binutilsをインストール
$ sudo apt-get -y install binutilsソースコードを GitHub から取得
$ git clone https://github.com/aws/efs-utils $ cd efs-utilsRPM パッケージをビルド&インストール
$ ./build-deb.sh # パッケージの確認 $ ls ./build/amazon-efs-utils*debDEV パッケージをビルド
# DEV パッケージをインストール $ sudo apt-get install -y ./build/amazon-efs-utils*deb ... Setting up amazon-efs-utils (1.3) ... Processing triggers for libc-bin (2.23-0ubuntu10) ... Processing triggers for systemd (229-4ubuntu21.2) ... Processing triggers for ureadahead (0.100.0-19) ... $マウントを実施
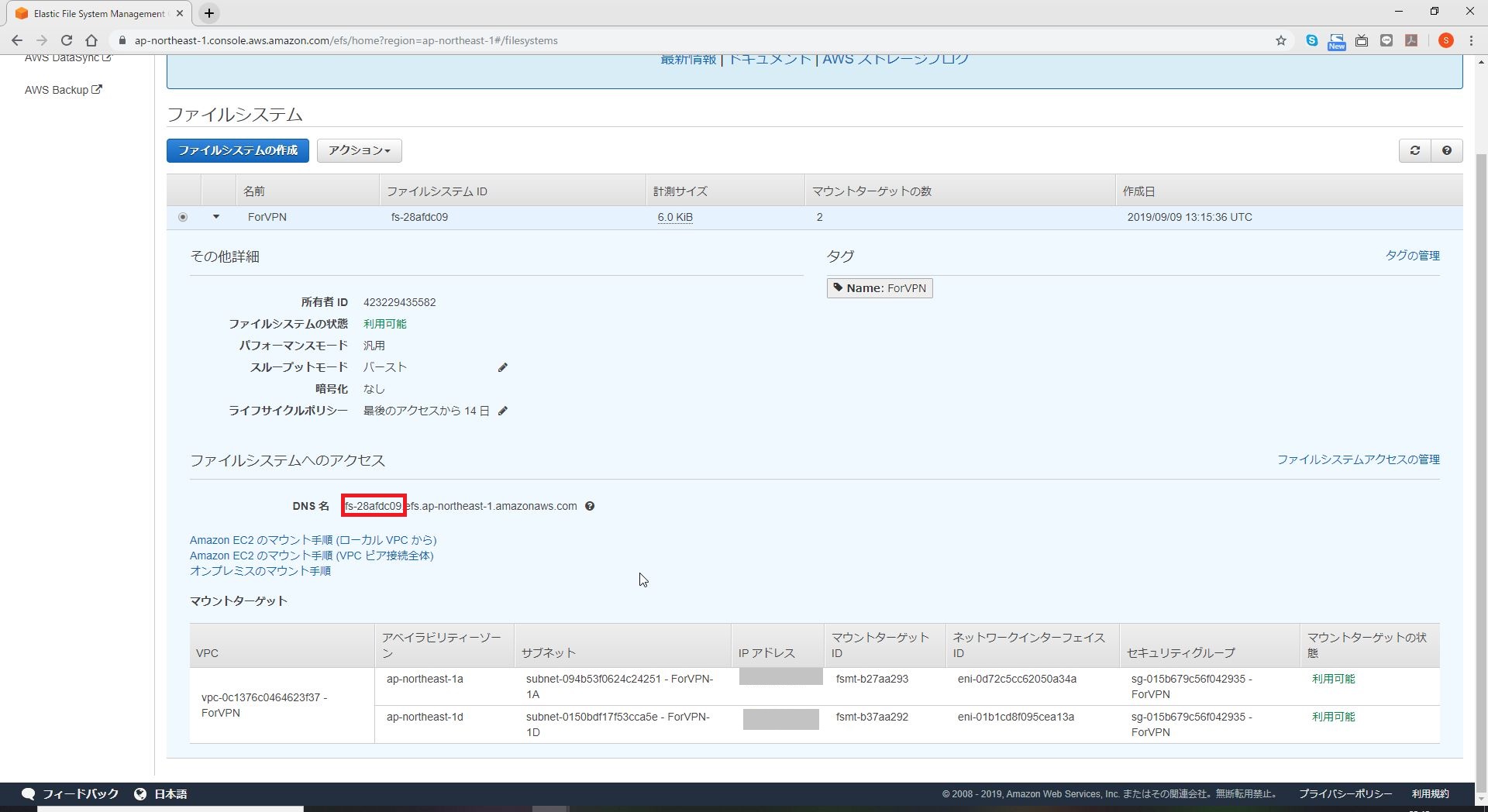
DNS名を確認します。
ディレクトリを作成します。
sudo mkdir /mnt/efsマウントを実行します。
sudo mount -t efs <DNS名>:/ /mnt/efs起動後に自動マウントを行う場合
/etc/fstabを編集
sudo vi /etc/fstab以下を追記します。
<DNS名>:/ /mnt/efs efs defaults,_netdev 0確認
df -h以上です。
参考
以下のサイトを参考にさせて頂きました。ありがとうございます。
https://dev.classmethod.jp/cloud/aws/install-amazon-efs-utils/
https://dev.classmethod.jp/etc/20181209-efs/
- 投稿日:2019-09-09T23:00:14+09:00
Amazon Linux2 に Python3.7.4をインストール
最初からインストールされているのは3.6系だったので。
$ sudo yum install gcc openssl-devel bzip2-devel $ cd /usr/src $ sudo wget https://www.python.org/ftp/python/3.7.4/Python-3.7.4.tgz $ sudo tar xzf Python-3.7.4.tgz $ cd Python-3.7.4 $ sudo ./configure --enable-optimizations $ sudo make altinstall $ sudo rm /usr/src/Python-3.7.4.tgz $ python3.7 -V Python 3.7.4 $ vi /home/ec2-user/.bashrc # User specific aliases and functions alias python=python3.7 $ python -V Python 3.7.4
- 投稿日:2019-09-09T22:49:16+09:00
【Python】AWS Lambda + DynamoDBでTodoリスト用REST APIを構築した際にハマったこと
はじめに
AWS Lambda + DynamoDBでTodoリスト用REST APIを構築した際にハマったことのメモ。
構築したもの:https://github.com/r-wakatsuki/kadai4todo
ハマったこと
以下、ハマった際に遭遇した事象と解決方法を記載していく。
DynamoDBをまともに利用したのが初めてだったため、DynamoDBについてがほとんどである。1. DynamoDBに登録するデータの値には空文字は指定できないがnullは登録可能。ただしその場合は同じプロパティにNULL型とその他の型が混在することになる。
事象
contentプロパティに空文字が指定されている場合、空文字をString型のままDynamoDBに登録しようとすると、ClientError: An error occurred (ValidationException) when calling the PutItem operation: One or more parameter values were invalid: An AttributeValue may not contain an empty stringというエラーとなる。InputEvent: { "httpMethod": "POST", "resource": "/todo", "body": "{\"title\": \"たいとるですよ\",\"content\": \"\"}" } API:<Todo登録> #〜中略〜 #要素定義:content req_content = req_body_dict.get('content','') if req_content == None: req_content = '' #〜中略〜 #<Todo登録>実行 item = { "todoid": str(uuid.uuid4()), "title": req_title, "content": req_content, "priority": req_priority, "done": req_done, "created_at": current_date, "updated_at": current_date } table.put_item( Item = item ) #<Todo登録>実行結果リターン return(return200(item)) Response: { "errorMessage": "An error occurred (ValidationException) when calling the PutItem operation: One or more parameter values were invalid: An AttributeValue may not contain an empty string", "errorType": "ClientError", "stackTrace": [ " File \"/var/task/lambda_function.py\", line 72, in lambda_handler\n Item = item\n", " File \"/var/runtime/boto3/resources/factory.py\", line 520, in do_action\n response = action(self, *args, **kwargs)\n", " File \"/var/runtime/boto3/resources/action.py\", line 83, in __call__\n response = getattr(parent.meta.client, operation_name)(**params)\n", " File \"/var/runtime/botocore/client.py\", line 320, in _api_call\n return self._make_api_call(operation_name, kwargs)\n", " File \"/var/runtime/botocore/client.py\", line 623, in _make_api_call\n raise error_class(parsed_response, operation_name)\n" ] }
contentプロパティが空文字の場合にNULL型に変換する処理を入れ、NULL型でDynamoDBへの登録を試みると、登録処理は問題なく行われる。InputEvent: { "httpMethod": "POST", "resource": "/todo", "body": "{\"title\": \"たいとるですよ\",\"content\": \"\"}" } API:<Todo登録> #〜中略〜 #要素定義:content req_content = req_body_dict.get('content') if req_content == '':#空文字の場合はnull型を入れるようにする。 req_content = None #〜中略〜 #<Todo登録>実行 item = { "todoid": str(uuid.uuid4()), "title": req_title, "content": req_content, "priority": req_priority, "done": req_done, "created_at": current_date, "updated_at": current_date } table.put_item( Item = item ) #<Todo登録>実行結果リターン return(return200(item)) Response: { "statusCode": 200, "body": { "todoid": "0b19d07a-7f41-4d58-b179-45889e236743", "title": "たいとるですよ", "content": null, "priority": "normal", "done": 0, "created_at": "2019-09-07T22:39:00", "updated_at": "2019-09-07T22:39:00" } }しかし、DynamoDBのコンソール画面からテーブルを見ると登録したデータの
contentプロパティの値がtrueとなっている。
さらにDynamoDBのテーブルにデータが一つも登録されていない状態であったため、contentプロパティの型がNULL型となっている。この状態で
contentプロパティにいくつか値を指定して登録し、取得してみると次のような結果となった。
ユーザーが登録しようとする値(型) DynamoDBに登録する際の値(型) DynamoDB管理画面上の値 実際にDynamoDBに登録された値(型) (String) null(NULL) true null(NULL) true(String) true(String) true true(String) 本文ですよ。(String) 本文ですよ。(String) 本文ですよ。 本文ですよ。(String) None(String) None(String) None None(String) 要するに登録時のデータの型をDynamoDB側で保持してくれている動作となる。これでも運用できなくはないがString型とNULL型が同じプロパティに混在しているのは気持ち悪い。
解決
Todoデータの登録時や更新時に
contentプロパティの末尾に</end>タグを必ず付与して、String型のみを扱うようにした。API:<Todo登録> #〜中略〜 #要素定義:content req_content = req_body_dict.get('content') if req_content == None: req_content = '</end>' else: req_content = req_content + '</end>' #〜中略〜 #<Todo登録>実行 item = { "todoid": str(uuid.uuid4()), "title": req_title, "content": req_content, "priority": req_priority, "done": int(req_done), #明示的にint型に設定 "created_at": current_date, "updated_at": current_date } table.put_item( Item = item )Todoデータの取得時には
content属性の末尾から</end>タグを除去する処理を入れた。import re API:<Todo個別取得> ##DBからTodoをtodoidで取得 todo = table.get_item( Key={ 'todoid': req_todoid } )['Item'] #contentから</end>タグ削除 todo['content'] = re.sub('</end>$', '', todo['content'])2. DynamoDBにint型で登録した値が取り出し時にDecimal型になる
事象
Todoステータス
doneプロパティの値は「未完了0」と「完了1」の2パターンとしている。
そこでDynamoDBへのTodo登録時の処理ではTodoのdoneプロパティの値を明示的にint型に設定してDynamoDBに登録するようにした。InputEvent: { "httpMethod": "POST", "resource": "/todo", "body": "{\"title\": \"内部定例\",\"done\": 0}" } API:<Todo登録> #〜中略〜 #<Todo登録>実行 item = { "todoid": str(uuid.uuid4()), "title": req_title, "content": req_content, "priority": req_priority, "done": int(req_done), #明示的にint型に設定 "created_at": current_date, "updated_at": current_date } table.put_item( Item = item ) Response: { "todoid": "35f047ba-1121-4473-8587-b893f0938389", "title": "内部定例", "content": "", "priority": "normal", "done": 0, "created_at": "2019-09-07T16:27:54", "updated_at": "2019-09-07T16:27:54" }しかし、登録したデータをDynamoDBから取得すると
doneプロパティの値がDecimal型<class 'decimal.Decimal'>となってしまっている。
また、取得したデータをレスポンスするためにjson.dumpsしようとするとTypeError:Object of type Decimal is not JSON serializableとなりJSONシリアライズできない。InputEvent: { "httpMethod": "GET", "resource": "/todo/{todoid}", "pathParameters": "{\"todoid\": \"35f047ba-1121-4473-8587-b893f0938389\"}" } API:<Todo個別取得> #〜中略〜 ##DBからTodoをtodoidで取得 todo = table.get_item( Key={ 'todoid': req_todoid } )['Item'] print(type(todo['done']))#型確認 #〜中略〜 #<Todo個別取得>実行結果リターン return{ 'statusCode': 200, 'body': json.dumps(todo) } Fanction Logs: <class 'decimal.Decimal'> Response: { "errorMessage": "Object of type Decimal is not JSON serializable", "errorType": "TypeError", "stackTrace": [ " File \"/var/task/lambda_function.py\", line 209, in lambda_handler\n 'body': json.dumps(item)\n", " File \"/var/lang/lib/python3.7/json/__init__.py\", line 231, in dumps\n return _default_encoder.encode(obj)\n", " File \"/var/lang/lib/python3.7/json/encoder.py\", line 199, in encode\n chunks = self.iterencode(o, _one_shot=True)\n", " File \"/var/lang/lib/python3.7/json/encoder.py\", line 257, in iterencode\n return _iterencode(o, 0)\n", " File \"/var/lang/lib/python3.7/json/encoder.py\", line 179, in default\n raise TypeError(f'Object of type {o.__class__.__name__} '\n" ] }解決
json.dumps時にDecimal型の値があればint型に変換するようにした。InputEvent: { "httpMethod": "GET", "resource": "/todo/{todoid}", "pathParameters": "{\"todoid\": \"35f047ba-1121-4473-8587-b893f0938389\"}" } API:<Todo個別取得> ##DBからTodoをtodoidで取得 todo = table.get_item( Key={ 'todoid': req_todoid } )['Item'] #〜中略〜 #Decimal型の場合はint型に変換 def decimal_default_proc(obj): if isinstance(obj, Decimal): return int(obj) raise TypeError #<Todo個別取得>実行結果リターン return{ 'statusCode': 200, 'body': json.dumps(todo,default=decimal_default_proc) } Response: { "todoid": "35f047ba-1121-4473-8587-b893f0938389", "title": "内部定例", "content": "", "priority": "normal", "done": 0, "created_at": "2019-09-07T16:27:54", "updated_at": "2019-09-07T16:27:54" }上記ではDecimal -> int変換用の関数を利用しているが、関数を使わなくてもDecimal型になることが事前に分かっている値は個別に
int(値)すればよい。参考
https://qiita.com/ekzemplaro/items/5fa8900212252ab554a3
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/GettingStarted.Python.03.html3.DynamoDBに登録されるデータのプロパティの並び順を定義できない。
事象
例えば、以下のようにプロパティの順番を整列させたTodoをDynamoDBに登録する。
API:<Todo登録> #〜中略〜 #<Todo登録>実行 item = { "todoid": str(uuid.uuid4()), "title": req_title, "content": req_content, "priority": req_priority, "done": req_done, "created_at": current_date, "updated_at": current_date } table.put_item( Item = item )登録したデータをDynamoDBから取得するとプロパティの並び順が整列されていない。
API:<Todo個別取得> ##DBからTodoをtodoidで取得 todo = table.get_item( Key={ 'todoid': req_todoid } )['Item'] #〜中略〜 #<Todo個別取得>実行結果リターン return{ 'statusCode': 200, 'body': json.dumps(todo) } Response: { "updated_at": "2019-09-01T21:38:37", "content": "定期券の更新ができた", "todoid": "6f9cd0e6-fbf0-48be-ac64-b4763c482d4d", "created_at": "2019-09-01T20:32:30", "priority": "normal", "done": 1, "title": "定期更新" }DynamoDB自体の設定でもプロパティの並び順をあらかじめ定義する設定は見当たらない。
解決
取得後にプロパティの並び順を整列する処理を入れる。
API:<Todo個別取得> ##DBからTodoをtodoidで取得 todo = table.get_item( Key={ 'todoid': req_todoid } )['Item'] #〜中略〜 #プロパティ並び順整列 item = { "todoid": todo['todoid'], "title": todo['title'], "content": todo['content'], "priority": todo['priority'], "done": todo['done'], "created_at": todo['created_at'], "updated_at": todo['updated_at'] } #<Todo個別取得>実行結果リターン return{ 'statusCode': 200, 'body': json.dumps(item) } Response: { "todoid": "6f9cd0e6-fbf0-48be-ac64-b4763c482d4d", "title": "定期更新", "content": "定期券の更新ができた", "priority": "normal", "done": 1, "created_at": "2019-09-01T20:32:30", "updated_at": "2019-09-01T21:38:37" }以上


- 投稿日:2019-09-09T20:32:01+09:00
【AWS】API Gatewayでカスタムドメインを利用する方法が紹介された記事を「ドメイン」「DNSサーバ」「SSL証明書」に着目して整理してみた
はじめに
API Gatewayでカスタムドメインを利用するにあたっては、AWS内のサービスもしくは外部サービスで以下の3つの要素を準備する必要がある。
- ドメイン(「contoso.com」などの独自ドメイン)
- DNSサーバ(ホスト名「apihost.contoso.com」からターゲットドメイン(カスタムドメインを利用したいREST APIに紐付いたホスト)への名前解決)
- SSL証明書(ホスト名「apihost.contoso.com」に対応したSSL証明書)
ググってもらえれば分かる通り、設定方法について紹介された記事はすでにいくつも出回っている。
しかし、上記3要素をAWS内・外のいずれで準備する手順となっているかが記事ごとに異なっており、AWS初心者にとってはそれが混乱のもとになりそうだと感じた。(少なくとも私はかなり混乱した)整理してみた
そこで、API Gatewayでカスタムドメインを設定する方法が紹介された記事を「ドメイン」「DNSサーバ」「SSL証明書」の3要素がAWSの内・外のいずれのサービスで準備される手順となっているかに着目して、以下の通り整理してみた。
No. ドメイン管理 DNSサーバ SSL証明書発行機関 記事 1 AWS
Route53AWS
Route53AWS
Certificate
ManagerAPI GatewayをカスタムドメインでHTTPS化する 2 外部サービス AWS
Route53外部サービス AWSのAPI Gatewayで独自ドメイン名を使うの難しかった (Regional) 3 (記載なし) AWS
Route53AWS
Certificate
ManagerAPI Gatewayでカスタムドメインを設定 4 外部サービス 外部サービス AWS
Certificate
Manager独自ドメイン名で API Gateway または EC2にアクセスする ※基本的には「API Gateway」「カスタムドメイン」でGoogle検索して1ページ目に表示される記事をピックアップしている。記載されている手順や仕様が明らかに古くなっている記事は省いている。
おわりに
私はNo.4の記事のように「ドメイン」「DNSサーバ」はムームードメイン、「SSL証明書」はAWS Certificate Managerで準備し、API Gatewayでカスタムドメインを利用する設定をした。
以上
- 投稿日:2019-09-09T20:27:27+09:00
kotlin/KtorでAmazonS3に画像ファイルを登録する
はじめに
サーバサイドkotlinを用いて、AWSのS3に画像ファイルを登録したい。
実装には、AmazonS3ClientBuilderを使用します。
https://docs.aws.amazon.com/AWSJavaSDK/latest/javadoc/com/amazonaws/services/s3/AmazonS3ClientBuilder.html
Javaの実装例を真似てkotlin/Ktorでやってみました。Ktorの構成例は以下と同じです。
https://github.com/raharrison/kotlin-ktor-exposed-starter実装
今回、アクセスキーなどの個人情報は、dotenvに記述していますが、
使わずにベタ書きしちゃっても問題ないです。また、画像ファイル送信の形式はmultipart/form-dataとBase64がありますが、
今回はmultipart/form-dataを採用しました。build.gradlecompile 'com.amazonaws:aws-java-sdk-s3:1.11.185' compile 'io.github.cdimascio:java-dotenv:5.1.1'.envS3_ACCESS_KEY = "" S3_SECRET_KEY = "" S3_SERVICE_END_POINT = "" S3_REGION = "" S3_BUCKET_ROOT = ""Env.ktobject Env { val dotenv = dotenv() val S3_ACCESS_KEY: String get() = dotenv["S3_ACCESS_KEY"]!! val S3_SECRET_KEY: String get() = dotenv["S3_SECRET_KEY"]!! val S3_SERVICE_END_POINT: String get() = dotenv["S3_SERVICE_END_POINT"]!! val S3_REGION: String get() = dotenv["S3_REGION"]!! val S3_BUCKET_ROOT: String get() = dotenv["S3_BUCKET_ROOT"]!! }AmazonS3Clientをオブジェクト化しています。
直接serviceクラスに書いてもいいので、好みです。AmazonS3Util.ktobject AmazonS3Util { fun makeClient(): AmazonS3 { return AmazonS3ClientBuilder .standard().withCredentials( AWSStaticCredentialsProvider( BasicAWSCredentials( Env.S3_ACCESS_KEY, Env.S3_SECRET_KEY ) ) ) .withClientConfiguration(ClientConfiguration().apply { protocol = Protocol.HTTPS }) .withEndpointConfiguration( AwsClientBuilder.EndpointConfiguration( Env.S3_SERVICE_END_POINT, Env.S3_REGION ) ) .build() } }multipart/form-data形式で受け取った画像をFileにパースし、S3に格納します。
今回は画像ファイルをパラメータ:idにリネームして登録しています。
名前を変える必要がない時は、part.originalFileNameだけで良いです。HogeService.ktsuspend fun addImage(multiPartData: MultiPartData, id: Int): { val file = makeImageFile(multiPartData, id) ?: return val client = AmazonS3Util.makeClient() val bucketName = Env.S3_BUCKET_ROOT + BUCKET_DIR client.putObject(PutObjectRequest(bucketName, file.name, file).apply { cannedAcl = CannedAccessControlList.PublicRead }) } private suspend fun makeImageFile(multiPartData: MultiPartData, id: Int): File? { val part = multiPartData.readPart() ?: return null if (part !is PartData.FileItem) { return null } val file = File("$id.${part.originalFileName?.substringAfterLast(".")}") part.streamProvider().use { inputStream -> file.outputStream().buffered().use { inputStream.copyTo(it) } } return file } companion object { const val BUCKET_DIR = "" }エンドポイントはこちら。
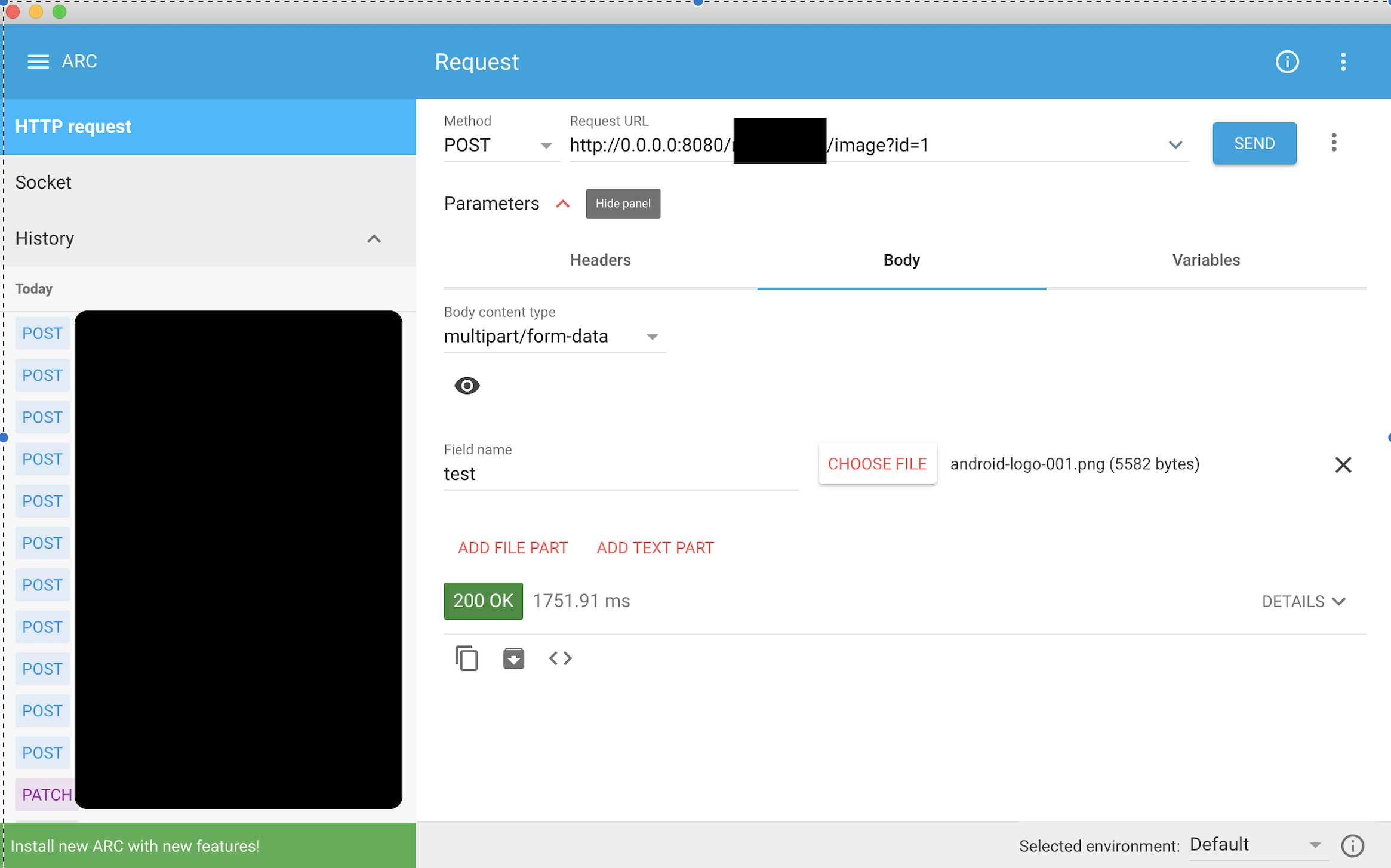
Ktorはcallメソッドでmultipartに対応してくれているので、楽ちんです。HogeResource.ktpost("/{id}/image") { val multiPartData = call.receiveMultipart() try { HogeService.addImage(multiPartData, call.parameters["id"]?.toInt()!!) call.respond(HttpStatusCode.OK) } catch (e: AmazonClientException) { call.respond(HttpStatusCode.BadRequest, e) } }動作確認は以下のRESTクライアントで行いました。
POSTメソッドのBody content typeをmultipart/form-dataにして画像を登録し、RequestURLを設定して実行すると簡単に確認できます。
Advanced REST Client(https://install.advancedrestclient.com/install)無事、登録に成功しました。


- 投稿日:2019-09-09T20:27:27+09:00
kotlin/ktorでAmazonS3に画像ファイルを登録する
はじめに
サーバサイドkotlinを用いて、AWSのS3に画像ファイルを登録したい。
実装には、AmazonS3ClientBuilderを使用します。
https://docs.aws.amazon.com/AWSJavaSDK/latest/javadoc/com/amazonaws/services/s3/AmazonS3ClientBuilder.html
Javaの実装例を真似てkotlin/ktorでやってみました。ktorの構成例は以下と同じです。
https://github.com/raharrison/kotlin-ktor-exposed-starter実装
今回、アクセスキーなどの個人情報は、dotenvに記述していますが、
使わずにベタ書きしちゃっても問題ないです。また、画像ファイル送信の形式はmultipart/form-dataとBase64がありますが、
今回はmultipart/form-dataを採用しました。build.gradlecompile 'com.amazonaws:aws-java-sdk-s3:1.11.185' compile 'io.github.cdimascio:java-dotenv:5.1.1'.envS3_ACCESS_KEY = "" S3_SECRET_KEY = "" S3_SERVICE_END_POINT = "" S3_REGION = "" S3_BUCKET_ROOT = ""Env.ktobject Env { val dotenv = dotenv() val S3_ACCESS_KEY: String get() = dotenv["S3_ACCESS_KEY"]!! val S3_SECRET_KEY: String get() = dotenv["S3_SECRET_KEY"]!! val S3_SERVICE_END_POINT: String get() = dotenv["S3_SERVICE_END_POINT"]!! val S3_REGION: String get() = dotenv["S3_REGION"]!! val S3_BUCKET_ROOT: String get() = dotenv["S3_BUCKET_ROOT"]!! }AmazonS3Clientをオブジェクト化しています。
直接serviceクラスに書いてもいいので、好みです。AmazonS3Util.ktobject AmazonS3Util { fun makeClient(): AmazonS3 { return AmazonS3ClientBuilder .standard().withCredentials( AWSStaticCredentialsProvider( BasicAWSCredentials( Env.S3_ACCESS_KEY, Env.S3_SECRET_KEY ) ) ) .withClientConfiguration(ClientConfiguration().apply { protocol = Protocol.HTTPS }) .withEndpointConfiguration( AwsClientBuilder.EndpointConfiguration( Env.S3_SERVICE_END_POINT, Env.S3_REGION ) ) .build() } }multipart/formdata形式で受け取った画像をFileにパースし、S3に格納します。
今回は画像ファイルをパラメータ:idにリネームして登録しています。
名前を変える必要がない時は、part.originalFileNameだけで良いです。HogeService.ktsuspend fun addImage(multiPartData: MultiPartData, id: Int): { val file = makeImageFile(multiPartData, id) ?: return val client = AmazonS3Util.makeClient() val bucketName = Env.S3_BUCKET_ROOT + BUCKET_DIR client.putObject(PutObjectRequest(bucketName, file.name, file).apply { cannedAcl = CannedAccessControlList.PublicRead }) } private suspend fun makeImageFile(multiPartData: MultiPartData, id: Int): File? { val part = multiPartData.readPart() ?: return null if (part !is PartData.FileItem) { return null } val file = File("$id.${part.originalFileName?.substringAfterLast(".")}") part.streamProvider().use { inputStream -> file.outputStream().buffered().use { inputStream.copyTo(it) } } return file } companion object { const val BUCKET_DIR = "" }エンドポイントはこちら。
ktorはcallメソッドでmultipartに対応してくれているので、楽ちんです。HogeResource.ktpost("/{id}/image") { val multiPartData = call.receiveMultipart() try { HogeService.addImage(multiPartData, call.parameters["id"]?.toInt()!!) call.respond(HttpStatusCode.OK) } catch (e: AmazonClientException) { call.respond(HttpStatusCode.BadRequest, e) } }動作確認は以下のRESTクライアントで行いました。
POSTメソッドのBody content typeをmultipart/form-dataにして画像を登録し、RequestURLを設定して実行すると簡単に確認できます。
Advanced REST Client(https://install.advancedrestclient.com/install)
無事、登録に成功しました。
- 投稿日:2019-09-09T18:36:49+09:00
データの受け渡しにS3を使う。2019-09-09
概要
世はまさに大データ時代です。
社内で分析している場合もありますが、外注して分析をしてもらっている場合もあります。
外注している場合はデータの受け渡しが発生します。
メール添付で送ったり、何か媒体に記録して送ったり、便利なクラウドサービスを利用したり、いろいろ手段はあります。今回は「データを受け取って分析をする側」にたって、データの受け渡しにS3を使うといろいろ便利かもしれない点について書きます。
前提・準備
状況整理
- 発注者、データを分析して欲しい人、データを準備する人、データを送る人
- 受注者、データを分析する人、データを授受する場を用意する人、データを受け取る人、すでにAWS利用中
ポイント: 「受注者」が "データを授受する場を用意する" ケースです
(「発注者」が「受注者」が用意したS3にデータを置きます)S3の準備
良い感じに特定のBucketだけ見られるようなポリシーを作ります。
「発注者」からは受け渡しに使うBucketのみ見える状態です。設定内容の詳細は割愛(画面からぽちぽちでも簡単に設定できるし、awsコマンドを使っても簡単にできるし、ググればやり方はたくさん見つかると思う!)
授受するデータ
例えば、 あるユーザの利用金額のデータの授受をすこぶるシンプルに考えます。
ファイルの形式は CSV で gzipで圧縮 されています。
ユーザID,利用金額
という内容です。具体的には以下の内容で、% gzcat test_data.csv.gz | head g,55777 n,14623 l,65655 t,92348 a,87128 m,74247 j,55425 j,44207 z,67019 j,5178サイズもそこそこあります。
% file test_data.csv.gz test_data.csv.gz: gzip compressed data, was "test_data.csv", last modified: Mon Sep 9 07:56:49 2019, from Unix, original size 788893425 % gzcat test_data.csv.gz | wc -l 100000000便利かもしれないポイント
すでにAWSを使っている場合、IAMをよしなにつかするだけでよい
すでにAWSを使っている場合、IAMをよしなにつかするだけでよいので楽

データの事前処理にAthenaを支えて便利、になるかも
例)不要なデータを抜く
例えば「1円のデータはテストデータだから分析対象には含めないでください」という指示が「発注者」からきた場合を考えます。
(結果の見やすさを考えて1円のデータが何件あるか数えます)そこで登場 Athena 先生
便利ポイント
- Athena先生がよしなにS3上にあるファイルを読んでくれる
- Athena先生がよしなにCSVをパースしてくれる
- Athena先生がよしなにgzip圧縮されているファイルを解凍してくれる
- Athena先生のSQLパワーでよしなに集計などが行える
上記の通りの便利ポイントがあります。
「発注者」にS3にファイルを置いてもらったら、「受注者」側では
- Athenaでcreate tableする
- Athenaでselectする
の2ステップで良い感じにデータの前処理ができます。
1. Athenaでcreate tableする
CREATE EXTERNAL TABLE `test_tb`( `id` string, `amount` int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' LOCATION 's3://バケット名/'2. Athenaでselectする
1円データを抜く
SELECT count(amount) FROM test_tb WHERE amount = 1
(Run time: 30.85 seconds, Data scanned: 353.52 MB)
_col0 1 954 集計例
idごとに集計してみたりも容易SELECT id, count(amount) FROM test_tb WHERE amount = 1 GROUP BY id
(Run time: 30.81 seconds, Data scanned: 353.52 MB)
id _col0 1 w 27 2 u 34 3 b 29 4 l 23 5 m 41 . . 略 その他のやり方も考える
コマンドで抜く
% time (gzcat test_data.csv.gz | egrep ',1$' | wc -l) 954 ( gzcat test_data.csv.gz | egrep ',1$' | wc -l; ) 32.62s user 0.43s system 111% cpu 29.753 total1円のデータを抜くだけの一例。
不要なデータを抜くだけならコマンドでも十分かもしれないが、もう少しカラムの多いCSVや、もう少し難しい条件の場合は大変そう。RDBを使う
割愛。たぶん S3 + Athena よりはいろいろ準備が必要なはず。
RDBを使う場合もAthenaである程度加工したデータをinsertした方が良いのではなかろうか。まとめ
データの受け渡しにS3を使うと、
- すでにAWSを使っている場合、IAMをよしなにつかするだけでよい
- データの事前処理にAthenaを支えて便利、になるかも
ということでS3を使ってみるというのはいかがでしょうか!
- 投稿日:2019-09-09T18:12:10+09:00
CloudFormationで変更なしのテンプレートを更新したい
解決策
メタデータを付与する
{ "AWSTemplateFormatVersion" : "2010-09-09", "Resources" : { "MyS3Bucket" : { "Type" : "AWS::S3::Bucket", "Metadata" : { "Object1" : "Location1", "Object2" : "Location2" } } } }AWSTemplateFormatVersion: '2010-09-09' Resources: MyS3Bucket: Type: AWS::S3::Bucket Metadata: Object1: Location1 Object2: Location2
- 投稿日:2019-09-09T16:59:16+09:00
AWS ECS で FireLens ログドライバを試したメモ
FireLens という ECS で EC2/Fargate のどちらの起動タイプでも使用できるログドライバが、パブリックプレビューで誰でも使用できるようになったので試してみたメモです。
Amazon ECS タスクから FluentBit, Fluentd を利用したログルーティングを可能にする "FireLens" ロギングドライバの Public Preview 開始です ???
— ポジティブな Tori (@toricls) August 31, 2019
ECS, Fargate が利用できる全リージョンで今日からお試しいただけます!
/ "Amazon ECS and AWS Fargate FireLens ..." https://t.co/ZJDxRyBalk個人的なこれまでの状況
Fargate のログドライバはしばらくの間 CloudWatch Logs しか使用できず、その他のログ基盤に連携を行いたい場合は CloudWatch Logs から Lambda を発火させるか、ログドライバを使用せず共有ボリュームにログファイルを出力してサイドカーの Fluentd に tail させる等、少々複雑な方法でしか実現できなさそうだった。
そんな中、FireLens は fluentd/fluent-bit にログを連携する事が可能なドライバということで、既存のログ基盤を活かせるのではないかと注目した。
また EC2 起動タイプでは fluentd ログドライバが以前から使用できていたが、今回の FireLens とどのような違いがあるのかも併せて確認したかった。
準備
下記サイトに基本的な手順が記載されているのでそれに沿って進めていく。
https://github.com/aws/containers-roadmap/tree/master/preview-programs/firelens
FireLens を動作させる上で必要な要素は
FireLensコンテナとしてマークしたログ収集コンテナ と ログドライバにawsfirelensを指定したアプリケーションコンテナ のみ。あとはログ収集コンテナがログを転送する先が必要で、今回は S3 にログを配置したかったので Kinesis Firehose を使用することにする。
ログ収集コンテナの設定
今回は手順でもオススメされている通りに fluent-bit を使用する。fluent-bit はプラグインの数や設定の自由度で fluentd より劣るが、C言語で実装されているため軽快に動作するので末端でのログ収集に向いている。
FireLens で使用する fluent-bit は AWS によって Kinesis Firehose と CloudWatch Logs の出力プライグインが追加されたカスタムイメージを使用する。この出力プライグインのオプションなどの詳細は下記リポジトで確認できる。
- https://github.com/aws/amazon-kinesis-firehose-for-fluent-bit
- https://github.com/aws/amazon-cloudwatch-logs-for-fluent-bit
FireLens コンテナとしてマークするにはタスク定義で
firelensConfigurationを設定すれば良い。現在は JSON からしか設定できないようだが、ウェブコンソール上でもJSONによる設定を押せば設定可能である。
firelensConfigurationはオプションでログにECSのメタデータを追加するかどうかを設定可能。アプリケーションコンテナの設定
ログ出力元のコンテナは標準出力にログを出すアプリケーションならなんでも良い。
logConfigurationのlogDriverにawsfirelensを設定すれば FireLens を使用することができるが、こちらも現在は JSON からしか設定できない模様。オプションは fluent-bit の設定ファイルで OUTPUT セクションに記述する内容をタスク定義で設定できる。ドキュメントに書かれているオプション以外にも
data_keysなど出力プラグインの設定は全て同様に記述できるようだ。Kinesis Firehose の設定
主題ではないので詳しくは書かないがウェブコンソール上で簡単にセットアップできるので使用したことがない方は是非使ってみてほしい。
実行
作成したタスク定義をECSでタスク実行させてみると、アプリケーションコンテナのログ設定が下記の表示になっていた。また、問題なく設定できていれば kinesis にもログが連携されていた。
実態の確認
実際にはどのようにしてログ連携されているのか気になったので、EC2 クラスターで FireLens を設定したタスクを実行して設定状態を確認してみた。
アプリケーションコンテナ
[ec2-user@ip-10-0-0-1 ~]$ docker inspect application-container ... "LogConfig": { "Type": "fluentd", "Config": { "fluentd-address": "unix:///var/lib/ecs/data/firelens/260d3686-c618-42bb-912d-c0878a18fb88/socket/fluent.sock", "fluentd-async-connect": "true", "tag": "test-firelens-260d3686-c618-42bb-912d-c0878a18fb88" } },
- FireLens の実態は fluentd ログドライバを使用している。
- ログ収集コンテナとの通信はECSエージェントが自動で用意した unix ソケットが設定されている。
ログ収集コンテナ
[ec2-user@ip-10-0-0-1 ~]$ docker inspect log-container "Mounts": [ { "Type": "bind", "Source": "/var/lib/ecs/data/firelens/82cd393b-0fd5-47a3-9dae-70f695e09acf/config/fluent.conf", "Destination": "/fluent-bit/etc/fluent-bit.conf", "Mode": "", "RW": true, "Propagation": "rprivate" }, { "Type": "bind", "Source": "/var/lib/ecs/data/firelens/82cd393b-0fd5-47a3-9dae-70f695e09acf/socket", "Destination": "/var/run", "Mode": "", "RW": true, "Propagation": "rprivate" } ],
- fluent-bit 設定ファイルと unix ソケット がログ収集コンテナに勝手にマウントされている。
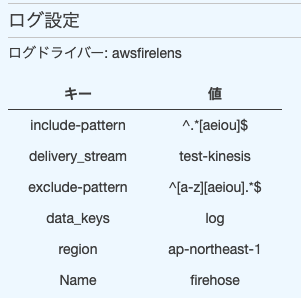
[ec2-user@ip-10-0-0-1 ~]$ cat /var/lib/ecs/data/firelens/82cd393b-0fd5-47a3-9dae-70f695e09acf/config/fluent.conf [INPUT] Name forward unix_path /var/run/fluent.sock [FILTER] Name grep Match test-firelens* Regex log ^.*[aeiou]$ [FILTER] Name grep Match coupon-firelens* Exclude log ^[a-z][aeiou].*$ [OUTPUT] Name firehose Match test-firelens* data_keys log delivery_stream test-kinesis region ap-northeast-1
- fluent-bit 設定ファイルはタスク定義で設定した内容が FILTER セクションと OUTPUT セクションに反映されていた。
- INPUT セクションはアプリケーションコンテナと同様に unix ソケットによる通信が設定されている。
まとめ
- FireLens の実態は fluentd ログドライバと fluent-bit をタスク定義に記述された内容をもとに自動で設定するラッパーのようなもの。
- メリット
- Fargate ではこれまで fluentd ログドライバを使用する選択肢がなかったので非常に大きなアップデート。
- unix ソケットを自動で設定してくれるので同一インスタンス内で複数のログ収集コンテナが起動しても問題ない。
- デメリット
- 現時点では fluent-bit 設定ファイルはECSエージェントによって強制的に上書きされるため、 タスク定義に設定可能な項目以外は独自の設定ができない。
- 特にバッファ周りなど SERVICE セクションが全く設定できないので、ログ自体が重要な役割を持つシステムに本番投入するには時期尚早な所感 (プレビューなので当たり前)
- プレビュー後にカスタム構成がサポートされると記載されているので今後に期待。
- https://github.com/aws/containers-roadmap/tree/master/preview-programs/firelens#3-specifying-your-own-configuration
書き殴ったメモなので認識間違い等ありましたらコメントください。
- 投稿日:2019-09-09T09:32:47+09:00
RDSに蓄積しているアクセスログを今すぐDataLakeに移行する
DataLakeとは
https://aws.amazon.com/jp/big-data/datalakes-and-analytics/what-is-a-data-lake/
AWS公式の記述を引用するとデータレイクは、規模にかかわらず、すべての構造化データと非構造化データを保存できる一元化されたリポジトリです。データをそのままの形で保存できるため、データを構造化しておく必要がありません。また、ダッシュボードや可視化、ビッグデータ処理、リアルタイム分析、機械学習など、さまざまなタイプの分析を実行し、的確な意思決定に役立てることができます。
当記事ではDataLakeのデータストアをS3とし、既存のRDSに蓄積されている既存ログ(レガシー)をGlueを使ってS3に移行する手順を紹介します。
なお、S3に移行したログの可視化や活用方法は当記事の対象範囲外です。
(ただしAthenaを使ってログを抽出できることは確認します)また、今後蓄積されるログはRDSではなくS3に蓄積し続けることになりますが、当記事では既存ログの移行方法を紹介するまでに留めます。
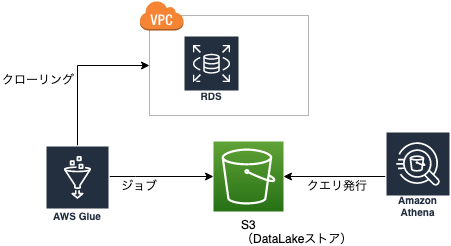
(やるとすればKinesisFirehoseを使うことになるでしょう)構成図
RDSはVPC内のプライベートサブネットに配置されています。
クローリング
GlueからVPC内のRDSへ接続しクローリングを行ないデータカタログを作ります。ジョブ
S3へ物理的にログを移行しますクエリ発行
S3へ移行されたログを抽出してみますGlueからRDSへ接続する
Glue設定
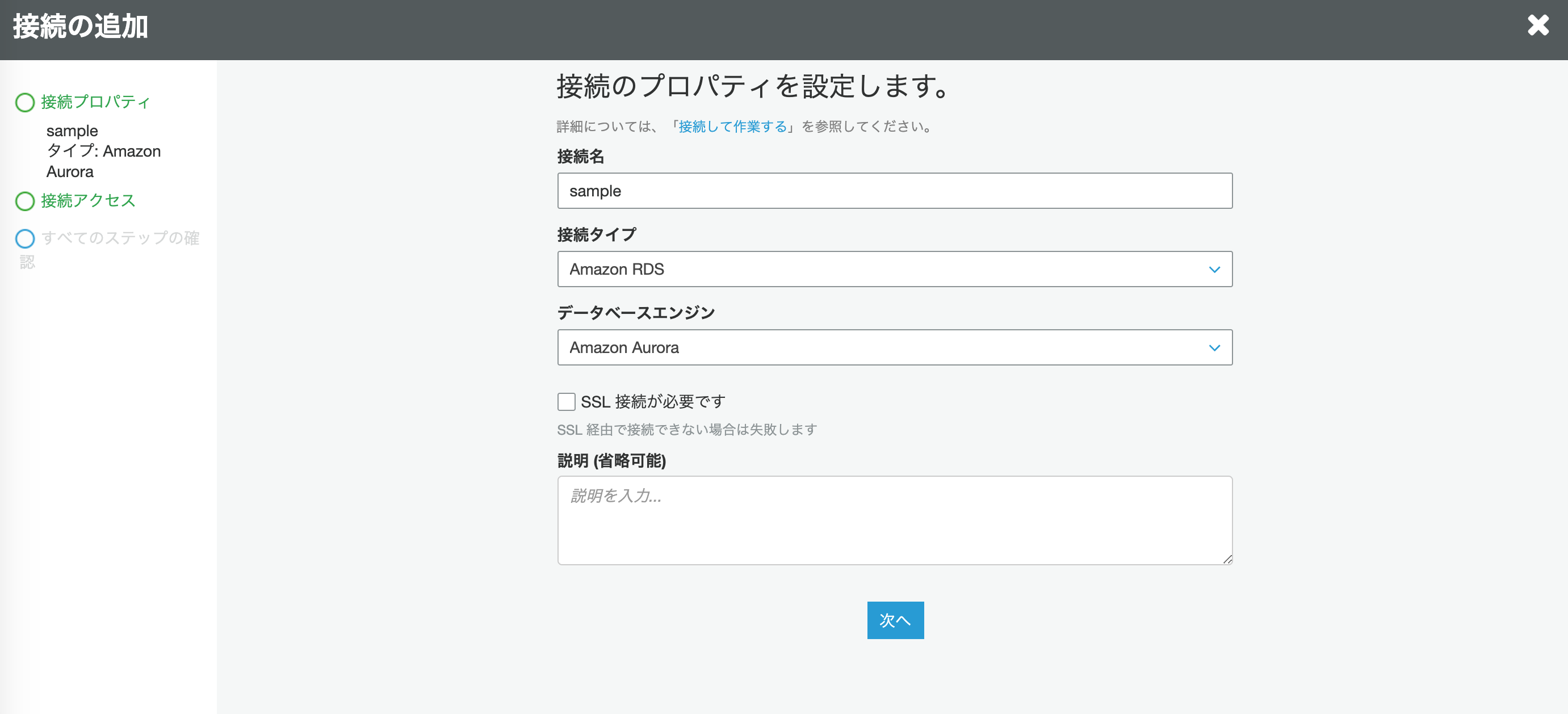
まずはGlueの
接続より接続の追加を押下します。
レガシーログが格納されているRDSを選択し、画面通りに設定を進めて完了します。
セキュリティグループ作成
RDSをVPCに配置している場合はセキュリティグループが必要です。
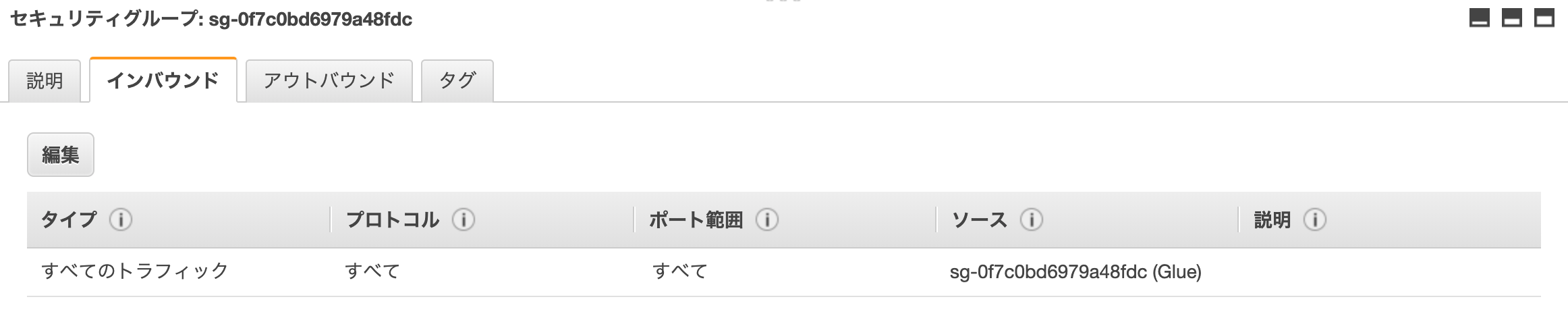
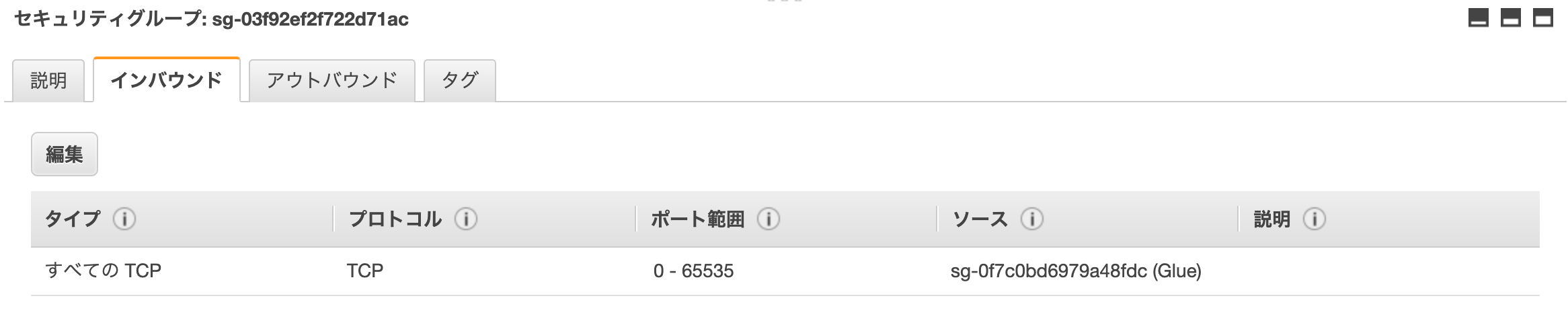
以下を参考に、Glueの自己参照型セキュリティグループを作成します。
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/setup-vpc-for-glue-access.html全てのトラフィックを、 自身のセキュリティグループからのみ呼ばれるように 設定します。
このセキュリティグループを、RDSのセキュリティグループに全てのTCPを開放して設定します。(以下はRDSにアタッチされているセキュリティグループの例)
接続テスト
ここまで進めればGlueの
接続より接続テストをしてみましょう。
ここで失敗すれば設定等に不備がある可能性があります。見直しましょう。クローリング①
データベース作成
Glueからデータベースの作成を行ないます。
クローリング実行
続いてクローラを作成し、実行します。
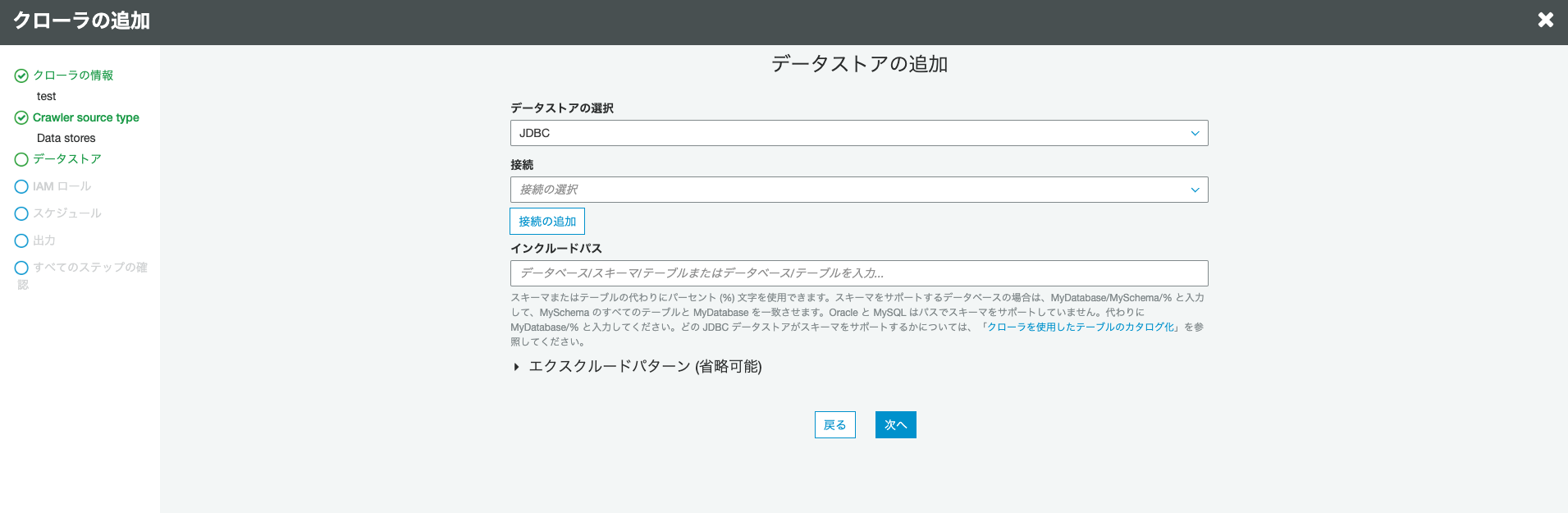
データストアは
JDBCを選択し、先ほど作成した接続を選択します。
実行はオンデマンドで実行とし、最後に手動実行します。
実行後、左メニューの
テーブルにテーブルが追加されていることを確認しましょう。S3バケット作成
Glueの
テーブルにクローリングの結果が格納されていますが、物理的なログの格納場所はS3となります。
この次の手順でジョブを作成しログを流し込みますが、そのためのS3バケットを事前に作成します。
適当なバケット名を指定して作成しておきましょう。Glueジョブ作成
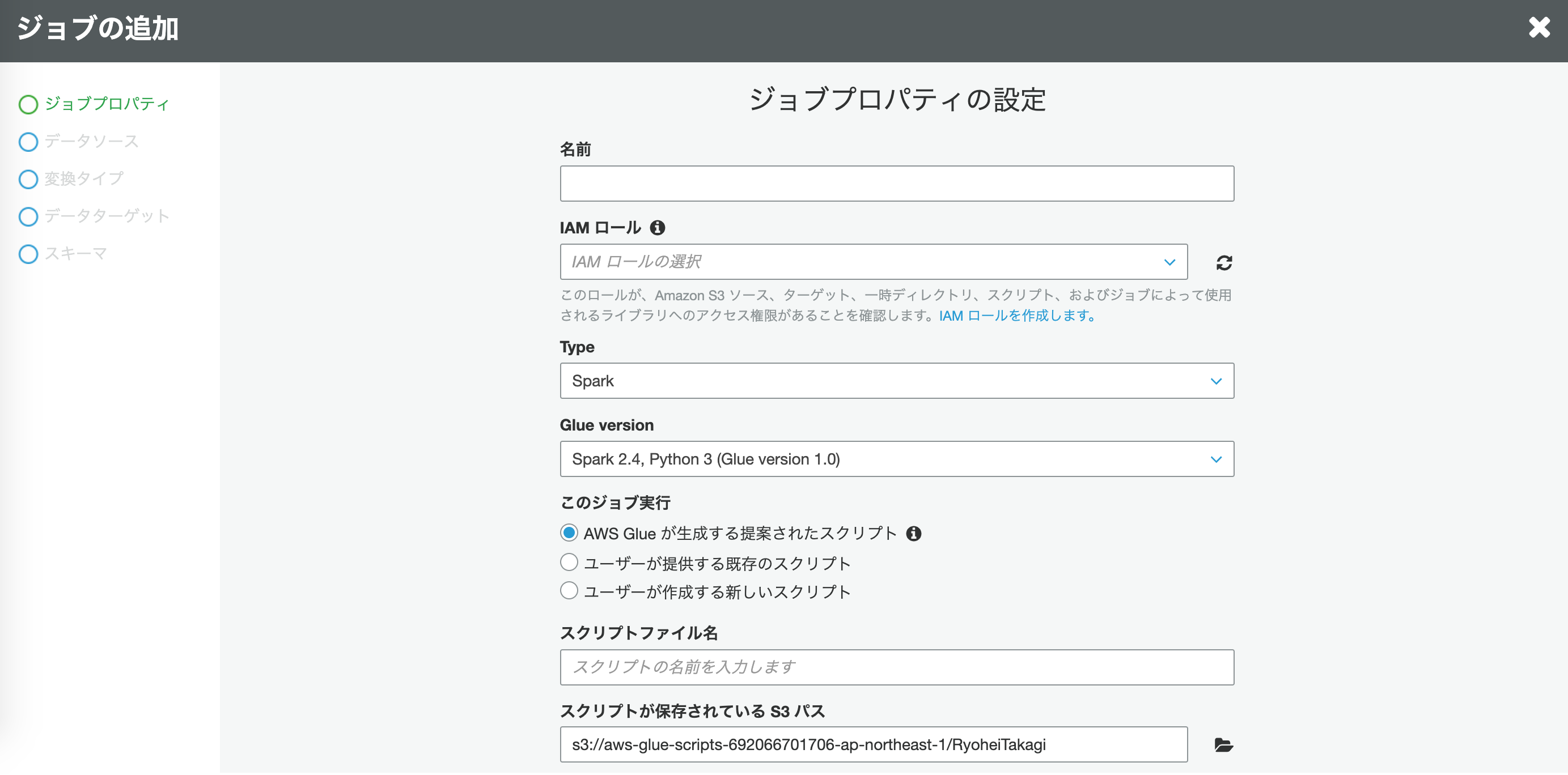
続いてS3へ物理的にログを移行するジョブを作成します。
ジョブにはスクリプトを作成する必要があります。
今回はAWS Glue が生成する提案されたスクリプトを選択して進めます。
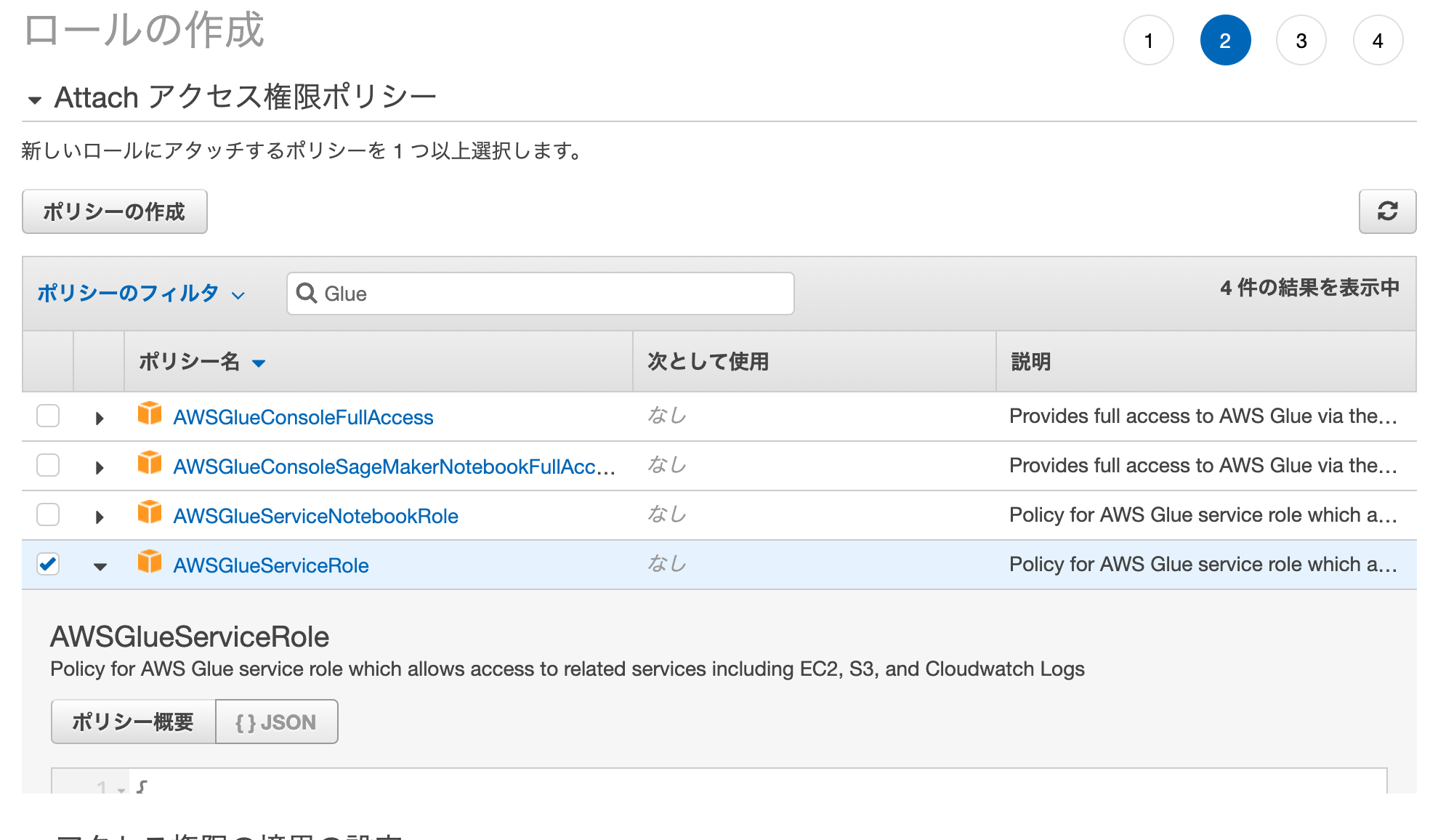
なお、IAMロールを作成する必要があるので存在しない場合は新規で作成します。
アタッチするポリシーはAWSGlueServiceRoleとAmazonS3FullAccessにします。
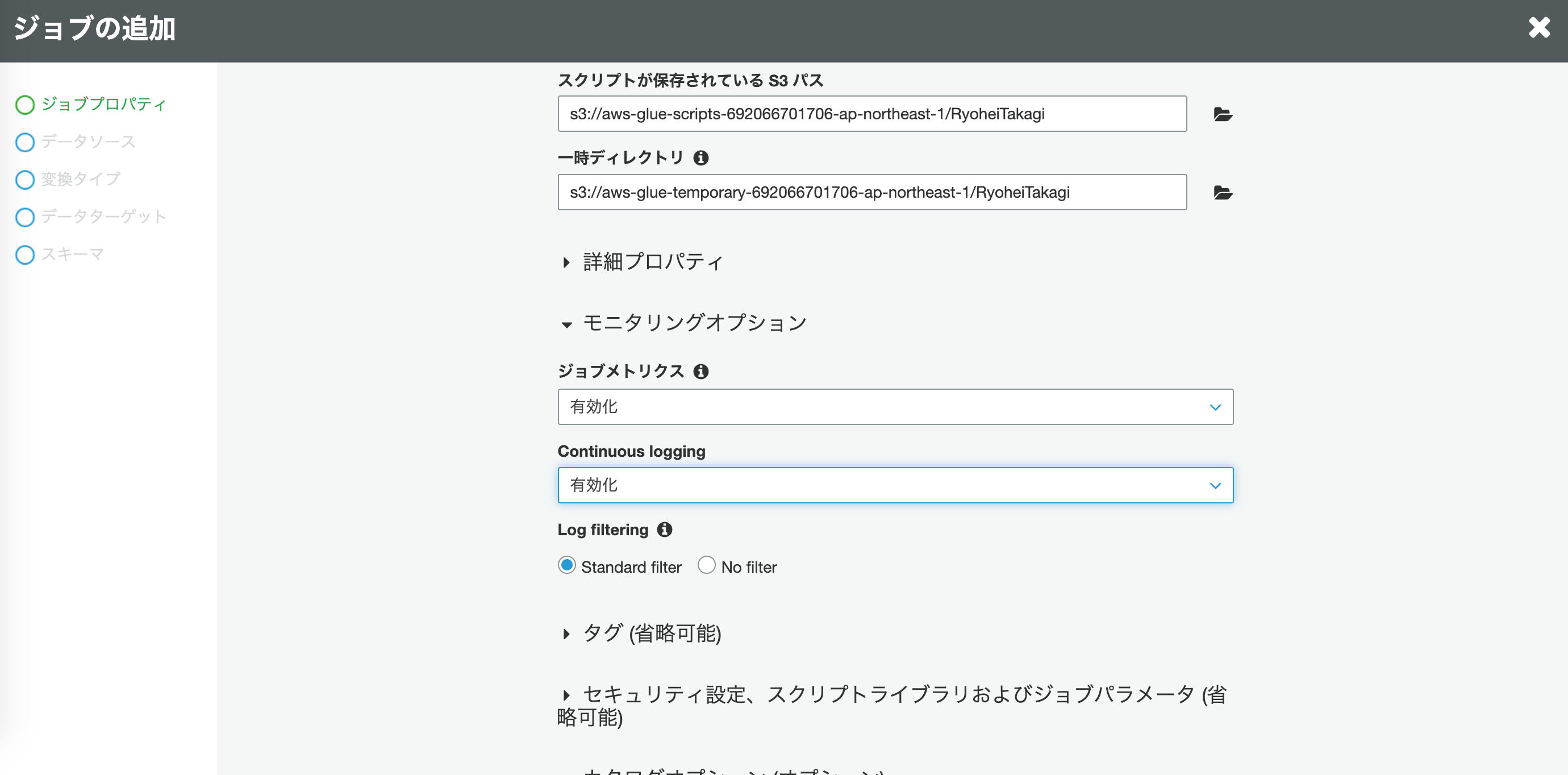
その他オプションについては自由ですが、モニタリングオプションは有効化しておくのがおすすめです。
エラーになった場合に原因が特定されやすくなります。
そして設定を進めていくとスクリプトの編集画面に進みます。
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job ## @params: [JOB_NAME] args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME'], args) 〜(省略)〜 ## @type: DataSink ## @args: [database = "xxxxx", table_name = "xxx_logs", transformation_ctx = "datasink5"] ## @return: datasink5 ## @inputs: [frame = resolvechoice4] # datasink5 = glueContext.write_dynamic_frame.from_catalog(frame = resolvechoice4, database = "xxxxx", table_name = "xxx_logs", transformation_ctx = "datasink5") datasink5 = glueContext.write_dynamic_frame.from_options(frame = resolvechoice4, connection_type = "s3", connection_options = {"path": "s3://xxx/yyy/zzz"}, format = "parquet", transformation_ctx = "datasink5") job.commit()最終行付近にある
glueContext.write_dynamic_frame.from_catalogの部分を編集します。
今回はS3に配置するため、以下のようにします。glueContext.write_dynamic_frame.from_options(frame = resolvechoice4, connection_type = "s3", connection_options = {"path": "s3://xxx/yyy/zzz"}, format = "parquet", transformation_ctx = "datasink5")
s3://xxxがバケット、yyy/zzzはキー(プレフィックス)になりますが、S3ではキーで区切ることでデータストアのパーティションとして定義することができます。パーティションについての解説は当記事の対象範囲外とします。クローリング②
ジョブの実行が完了すると、S3に
.parquet形式のログデータが格納されていると思います。
このデータをデータカタログとして登録するためにクローラの作成を行ないます。前回の手順ではデータストアをRDSとしましたが、今回はS3です。
クローラを実行し、左メニューの
テーブルにS3をデータストアとしたテーブルが追加されていることを確認しましょう。なお、クローラを実行しないとデータカタログが更新されませんので
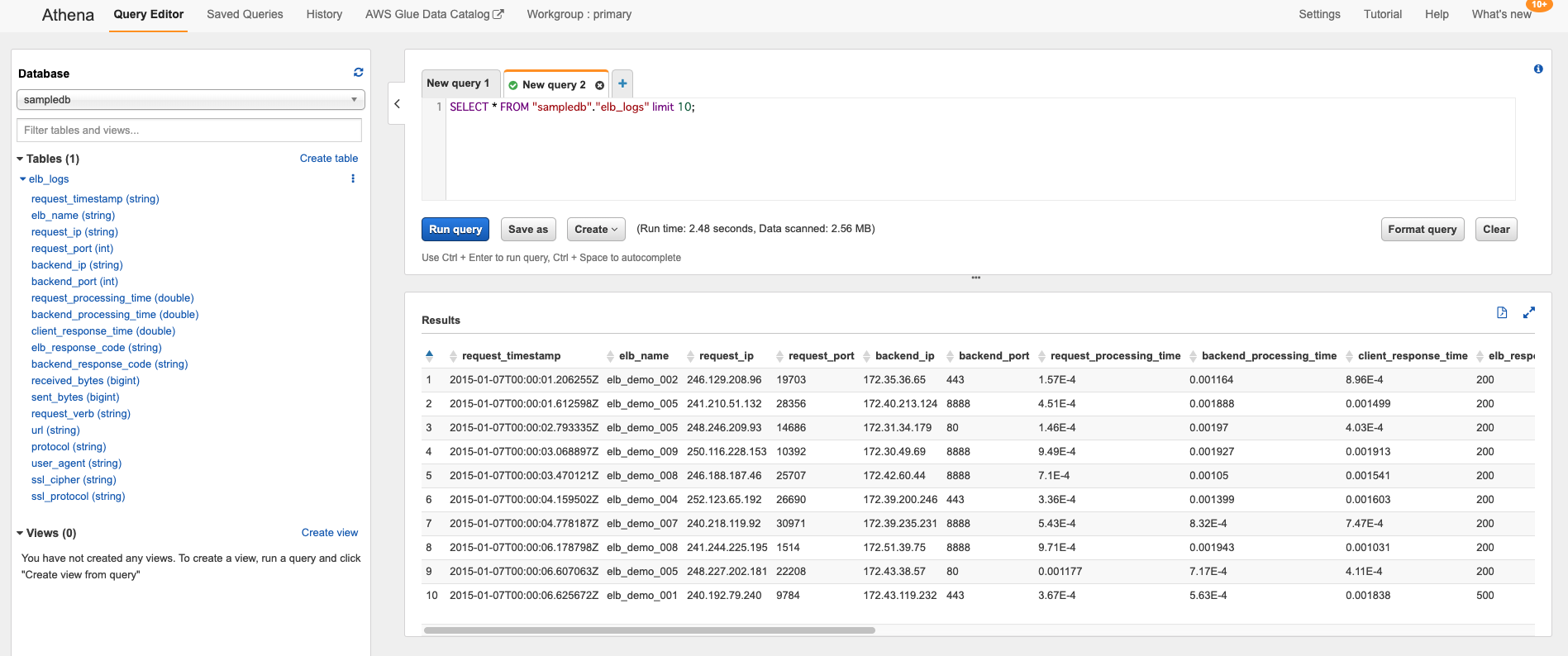
商用で活用する場合は定期的に実行するようにスケジュールを設定することをおすすめします。Athenaによるクエリ実行
Athenaによるログの抽出は簡単です。SQLとほぼ同じ形式で書けます。
クローリングしたデータが抽出できることを確認しましょう。※下記はAWSがあらかじめ用意したサンプルで例を提示しています。
- 投稿日:2019-09-09T05:05:34+09:00
awscliでStatusCheckFailedアラートを上げる設定を入れる
awscliで実行
GreaterThanThresholdで閾値が0より大きい場合、アラートが上がるようにaws cloudwatch put-metric-alarm --alarm-name "StatusCheckFailed" --namespace AWS/EC2 \ --metric-name StatusCheckFailed --dimensions Name=InstanceId,Value=i-0219028c30d71bee2 --period 300 \ --statistic Average --threshold 0 --comparison-operator GreaterThanThreshold \ --evaluation-periods 1 --alarm-actions arn:aws:sns:ap-northeast-1:697333814928:Default_CloudWatch_Alarms_Topic \ --ok-actions arn:aws:sns:ap-northeast-1:697333814928:Default_CloudWatch_Alarms_Topic
- 投稿日:2019-09-09T03:35:57+09:00
CodeBuildでECRビルドエラーから得た4つの知見
はじめに
ECRをただビルドしたかった...はじめて使うといろいろハマりポイントが多くてたくさん調べる羽目に
自分自身が次ハマらないようにまとめておく。TL;DR
- 1.
aws/codebuild/standard:2.0を使用するときはruntime-versionsを指定する必要がある- 2.ビルドを実行するロールにECRを操作するポリシーを追加する必要がある
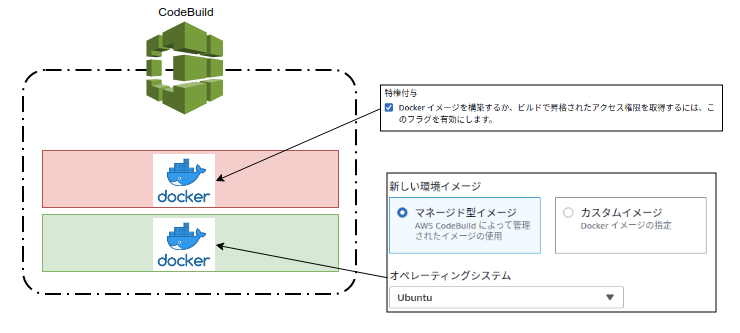
- 3.Dockerの特権付与チェックを入れる必要がある
- 4.ECRの「プッシュコマンドの表示」をよく見て環境変数を設定する
4つのエラー詳細と対応方法
1.
aws/codebuild/standard:2.0を使用するときはruntime-versionsを指定する必要があるYAML_FILE_ERROR: This build image requires selecting at least one runtime version.
- 今回はDockerを利用していたため以下の設定を
buildspec.ymlに追記する必要があった。buildspec.ymlphases: install: runtime-versions: docker: 182.ビルドを実行するロールにECRを操作するポリシーを追加する必要がある
COMMAND_EXECUTION_ERROR: Error while executing command: $(aws ecr get-login --no-include-email --region $AWS_DEFAULT_REGION). Reason: exit status 255
- デフォルトではECRのポリシーは設定されていない。
- 自分で設定を追加する必要がある
- IAMでロールにAmazonEC2ContainerRegistryPowerUser(ECRの操作を許可する)ポリシーをアタッチ
3.Dockerの特権付与チェックを入れる必要がある
[Container] 2019/09/07 17:00:26 Running command docker build -t $IMAGE_REPO_NAME:$IMAGE_TAG . Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
- Dockerデーモンが起動していないようなエラーが発生
- CodeBuildは実行自体がDocker(Ubuntuなど選択)だが、その中でDockerを使うため、チェックが必要になる
- Docker in Dockerのような実行Docker(Ubuntu)の上でECRをBuildするためのDockerが動作しているイメージ
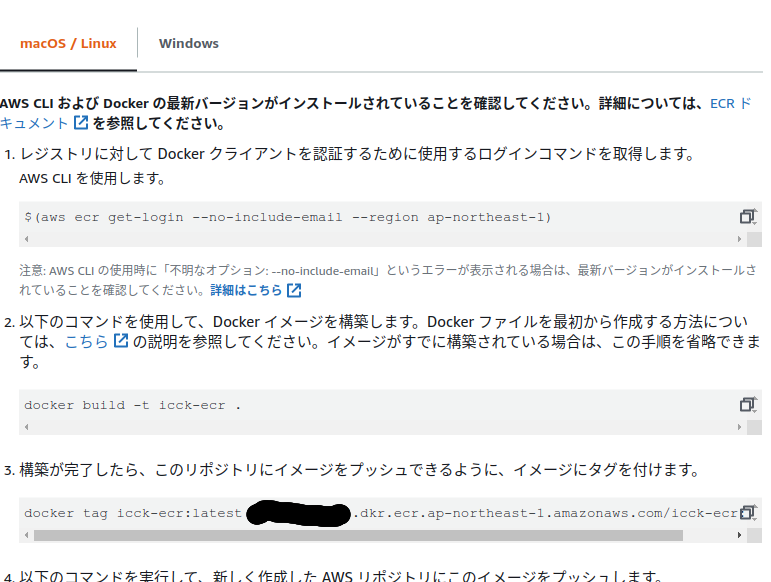
4.ECRの「プッシュコマンドの表示」をよく見て環境変数を設定する
[Container] 2019/09/07 17:32:13 Phase context status code: COMMAND_EXECUTION_ERROR Message: Error while executing command: docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$IMAGE_TAG. Reason: exit status 1
- アカウントIDの環境変数にずっとIAMユーザー名を入れるミスをしていた。
- ECRの「プッシュコマンドの表示」にプッシュに必要な環境変数の設定サンプルがあるので確認する
- 隠した部分をよく見れば、アカウントIDだと気がつくことができた
- ちなみにbuildにつかった
buildspec.ymlはこちら。- 原始的だが、
echoでログを出していく事もミス発見に繋がった。buildspec.ymlversion: 0.2 phases: install: runtime-versions: docker: 18 pre_build: commands: - echo Logging in to Amazon ECR... - $(aws ecr get-login --no-include-email --region $AWS_DEFAULT_REGION) build: commands: - echo Build started on `date` - echo Building the Docker image... - echo $IMAGE_REPO_NAME - docker build -t $IMAGE_REPO_NAME:$IMAGE_TAG . - echo docker tag $IMAGE_REPO_NAME:$IMAGE_TAG $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$IMAGE_TAG - docker tag $IMAGE_REPO_NAME:$IMAGE_TAG $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$IMAGE_TAG post_build: commands: - echo Build completed on `date` - echo Pushing the Docker image... - docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$IMAGE_TAG - printf '[{"name":"<container-definition>","imageUri":"%s"}]' $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME:$IMAGE_TAG > artifacts.json artifacts: files: artifacts.jsonさいごに
- ECRのbuild&pushを行うときのハマりポイントは理解さえすれば二度とハマらない内容でした。
- 手動より楽なことを実感できたのでパイプライン等と組み合わせてどんどん最適化していきたいです。
- こちらのブログにもAWS関連いくつか記事を書き始めました。

- 投稿日:2019-09-09T03:10:18+09:00
awscliでメモリ使用率80%以上になったらアラートを上げる設定を入れる
準備
awscliで実行
カスタムメトリクスなので、
--namespace System/Linuxになります。注意aws cloudwatch put-metric-alarm --alarm-name "MemoryUtilization80%" --namespace System/Linux \ --metric-name MemoryUtilization --dimensions "Name=InstanceId,Value=i-0219028c30d71bee2" --period 300 \ --statistic Average --threshold 80 --comparison-operator GreaterThanOrEqualToThreshold \ --evaluation-periods 1 --alarm-actions arn:aws:sns:ap-northeast-1:697333814928:Default_CloudWatch_Alarms_Topic \ --ok-actions arn:aws:sns:ap-northeast-1:697333814928:Default_CloudWatch_Alarms_Topic
- 投稿日:2019-09-09T01:03:36+09:00
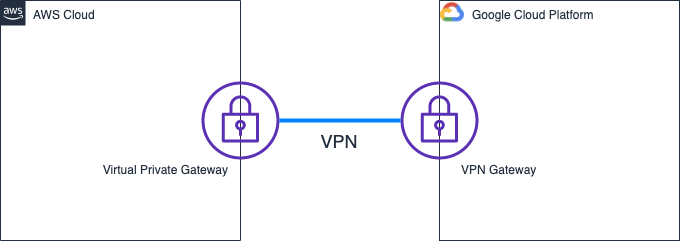
AWSーGCP間をVPNでつないでみた
AWSとGCPの間をIPSec VPNでつないでみました。
構成
AWS側にVirtual Private Gateways、GCP側にVPN Gatewayを用意して、両者をIPsec VPNで接続します。
GCPのドキュメントにはAWSと接続可能との記述があります。(英語版)
https://cloud.google.com/vpn/docs/concepts/overviewA gateway that is connected to a Cloud VPN gateway. A peer VPN gateway can be one of the following:
- Another Cloud VPN gateway
- A VPN gateway hosted by another cloud provider such as AWS or Azure
- An on-premises VPN device or VPN service
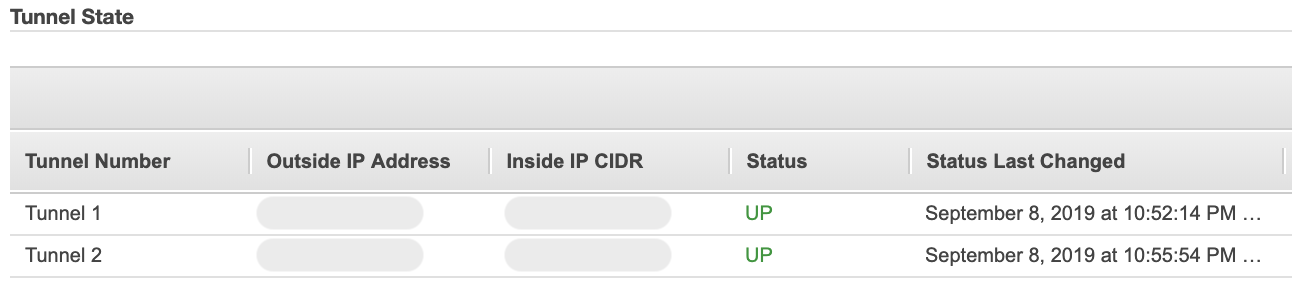
接続結果
AWS側
GCP側
必要なもの
- GCPのアカウント
- AWSのアカウント
構築手順
Pre shared keyとIP以外はデフォルト値で接続できました。
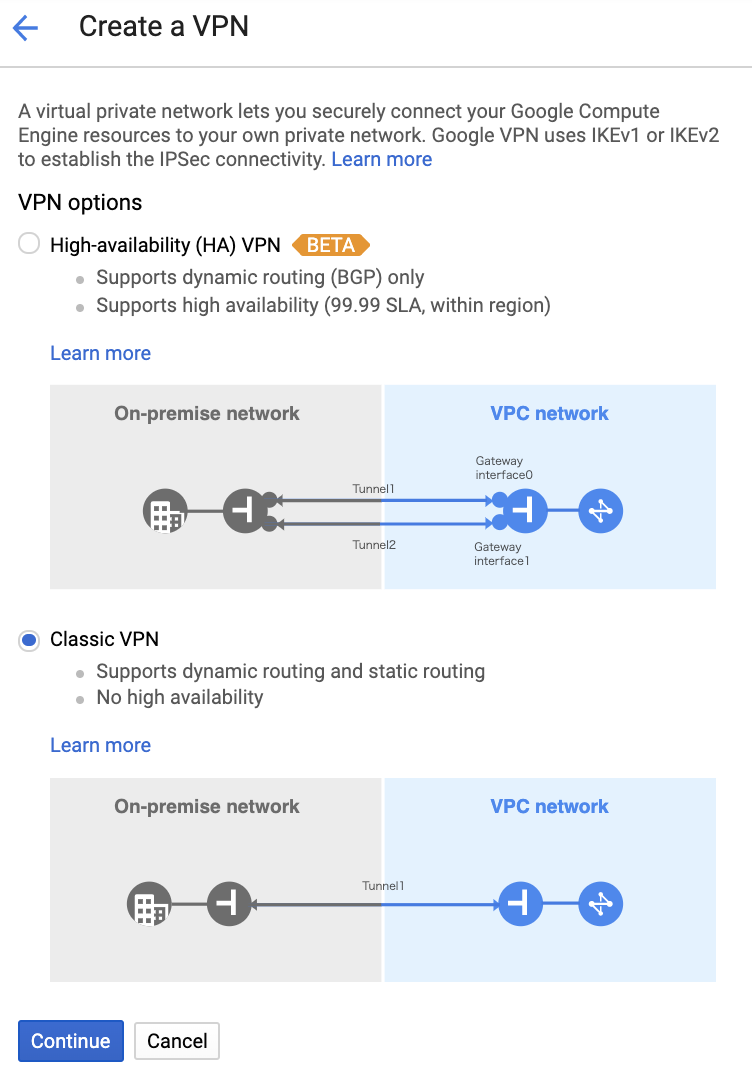
1. GCP: VPN connectionの作成開始
Classic VPNを選択します。
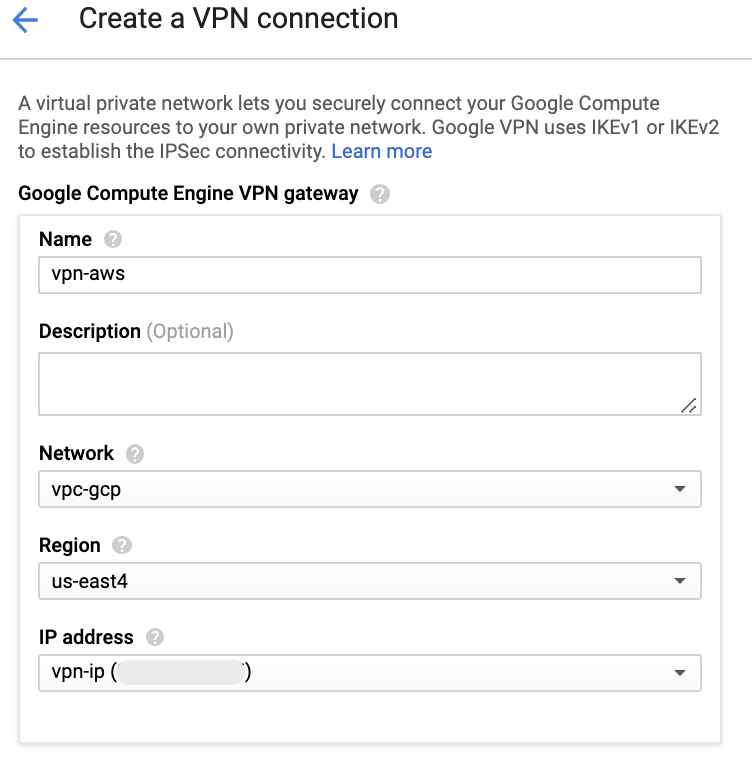
名前等指定します。IP addressはこの画面から新規に作成します。
2. AWS: Virtual Private GatewayとCustomer Gatewayの作成
Virtual Private GatewayとCustomer Gatewayを作成します。
Customer Gateway作成時に、1.で作成したIPを指定します。3. AWS: VPN Connectionの作成
VPN Connection作成時に、2.で作成したVirtual Private GatewayとCustomer Gatewayを指定します。
また今回はルーティングはStaticにしたので、GCP側のCIDRを指定します。
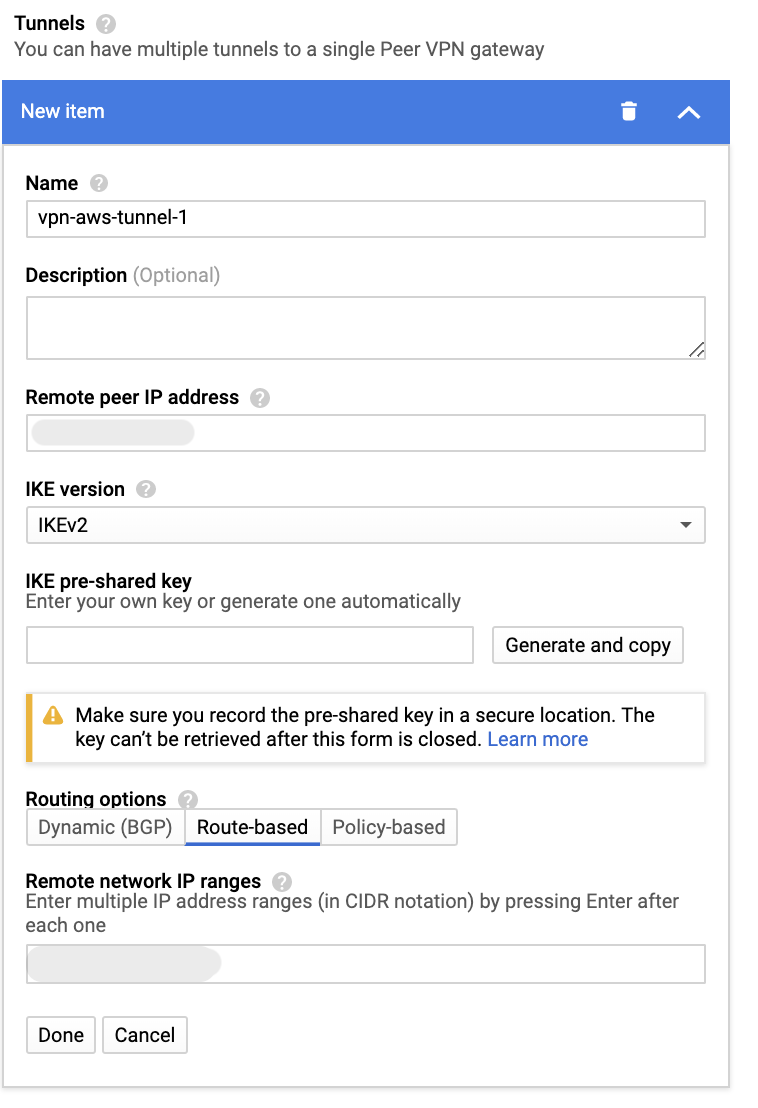
Pre-Shared Keyは指定しないまま、作成します。4. GCP: Tunnelの指定
Remote peer IP addressに3.で作成したtunnelのOutside IP Addressを指定します。
Remote network IP rangesには、AWSのVPCのCIDRを指定します。
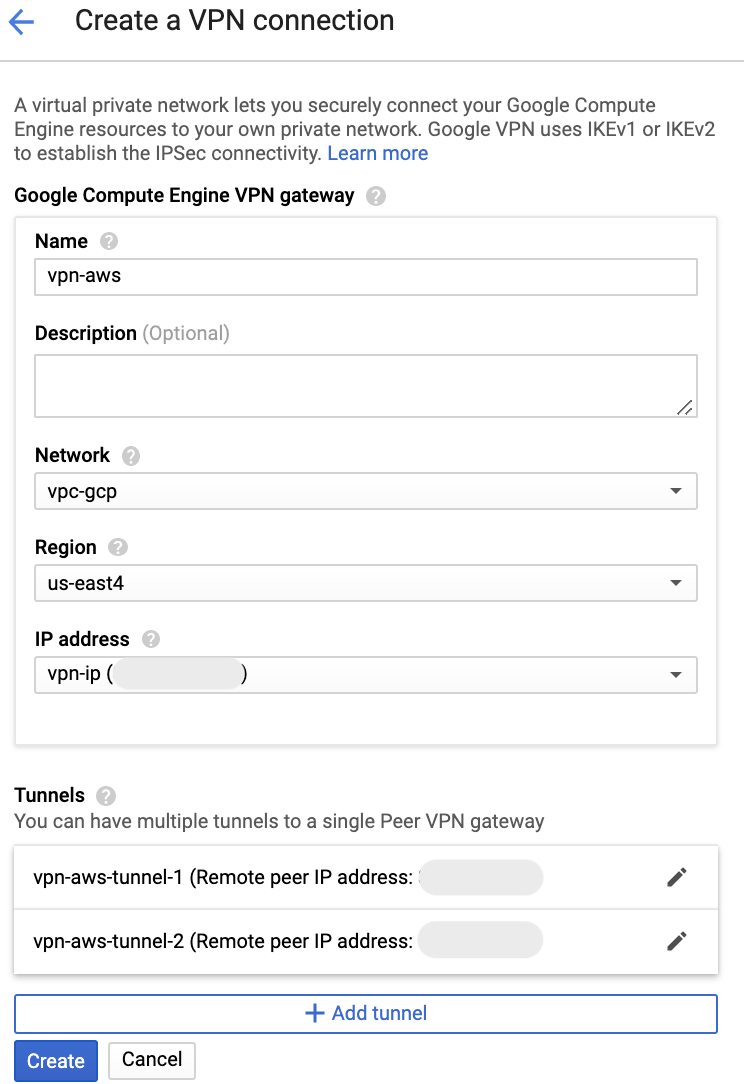
IKE pre-shared keyを作成して、Doneをクリックします。tunnelは2個必要なので、上記手順をもう1回繰り返します。
tunnelを2個指定したらCreateをクリックしてVPN connectionを作成します。
5. AWS: VPN ConnectionにPre-Shared Keyを設定
4.で作成したIKE pre-shared keyを、VPN Connectionの各tunnelのPre-Shared Keyに設定します。
tunnelは1個づつしか変更できないため、少し時間がかかります。6. 完成