- 投稿日:2019-08-16T23:29:57+09:00
Python3ではじめるシステムトレード:Jupyter notebookのインストール
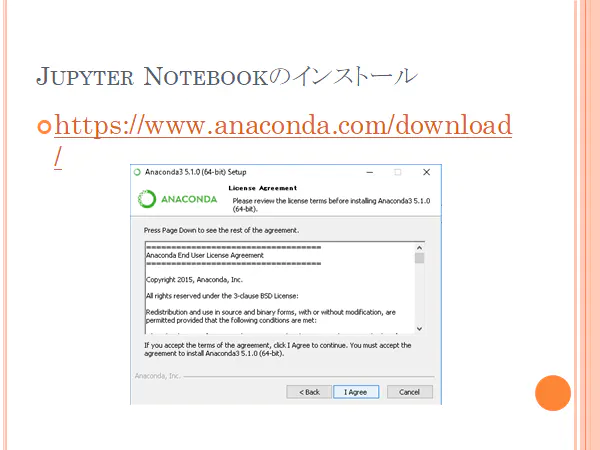
最新版のダウンロードとインストール
最新版はつぎのURLからダウンロード可能です。
https://www.anaconda.com/distribution/ダウンロードファイルはダウンロードホルダーに保存されます。
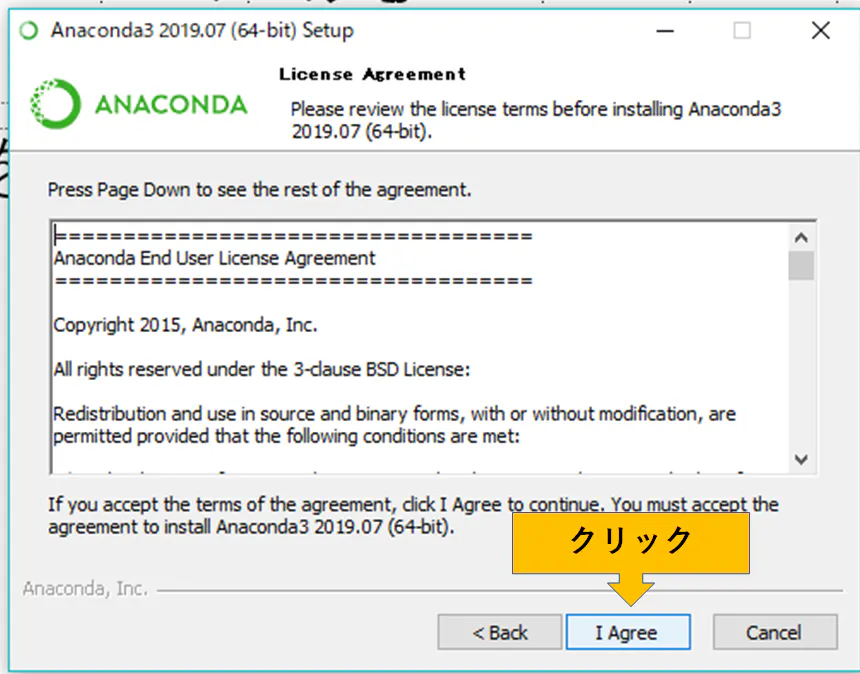
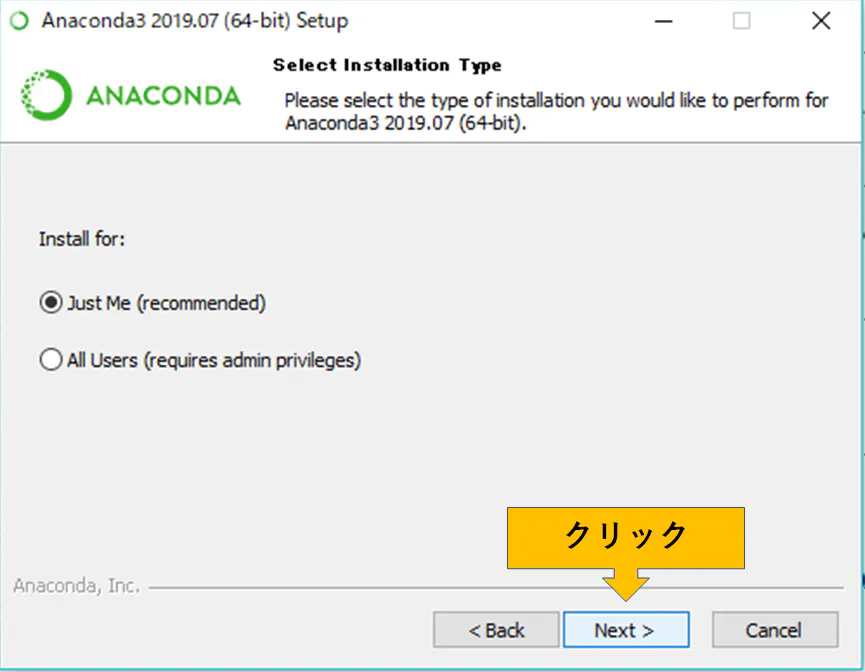
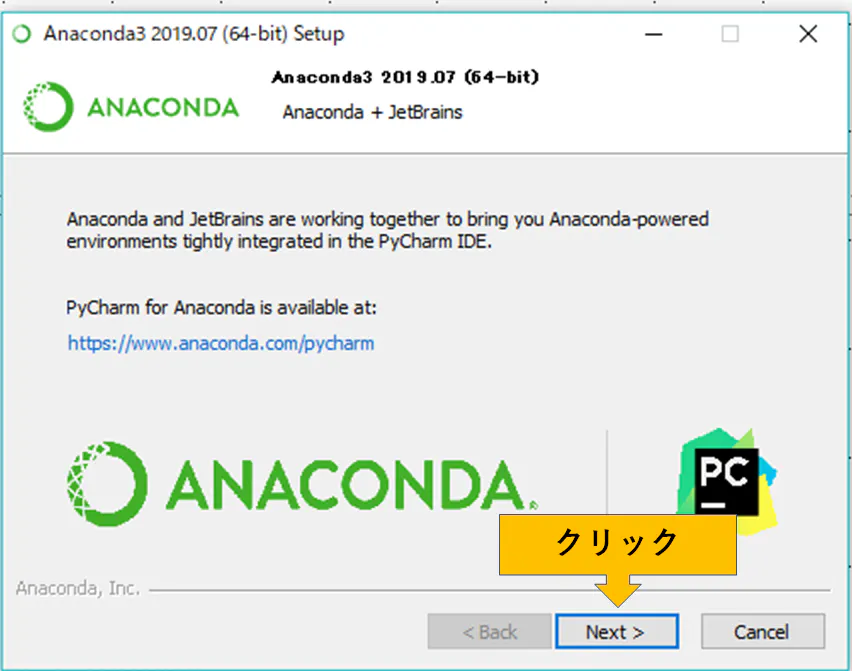
それをクリックするとインストールが始まります。
追加のインストール
$ pip install pandas-datareader
%matplotlib inline import matplotlib.pyplot as plt #描画ライブラリ import pandas_datareader.data as web #データのダウンロードライブラリ tsd = web.DataReader("NIKKEI225","FRED").plot()
;./
Juypter notebookで何ができるのか?
yahoo finance us から多くのデータがダウンロードできます。
Yahoo Finance USから株価をダウンロードしてみた。(https://qiita.com/innovation1005/items/5be026cf7e1d459e9562)
システムトレードってなに?
https://qiita.com/innovation1005/items/2b5a291b98ebf39dfd8b
リスクマネジメントって何?
https://qiita.com/innovation1005/items/8419cda5d57f9f7b1a85
予測について
https://qiita.com/innovation1005/items/76d8a93c261e7d357ab8
トレンドについて
https://qiita.com/innovation1005/items/e8490ed173e268f3ba1e
参考文献・サイト
「Python3ではじめるシステムトレード」(パンローリング)
ひとつ前のバージョンのダウンロードとインストール。














- 投稿日:2019-08-16T23:27:23+09:00
湯婆婆は参照で落ちるから名前を書かない方がいい
千と千尋の神隠し
2019/08/16の金曜ロードショーでノーカットの『千と千尋の神隠し』が放送されました
いや〜よかった!
いつ見てもあれはいいですね!「契約書だよ。そこに名前を書きな。働かせてやる。 その代わり嫌だとか、帰りたいとか言ったらすぐ子豚にしてやるからね。 あの、名前ってここですか? そうだよもぅぐずぐずしないでさっさと書きな! まったく……つまらない誓いをたてちまったもんだよ。 働きたい者には仕事をやるだなんて…… 書いたかい? はい……あっ。 フン。千尋というのかい? はい。 贅沢な名だねぇ。 今からおまえの名前は千だ。 いいかい、千だよ。分かったら返事をするんだ、千!!」というシーンを知っていますか?
Twitterを見つつ鑑賞していたら
https://twitter.com/SabanikiTofu/status/1162323952309424134?s=20
というツイートを目にしました
「これは面白い。たぶん湯婆婆は文字列の一文字目だけにしてるんだろう」と考えました湯婆婆を作る
じゃあとりあえず湯婆婆を作ります
hot_water_old_lady.pyprint("契約書だよ。そこに名前を書きな。働かせてやる。\nその代わり嫌だとか、帰りたいとか言ったらすぐ子豚にしてやるからね。\nそうだよもぅぐずぐずしないでさっさと書きな!\n\nまったく……つまらない誓いをたてちまったもんだよ。働きたい者には仕事をやるだなんて…… 書いたかい?") name = input() short_name = name[0] print("はい…あっ。 \n\nフン。%sというのかい? \n\nはい。 \n\n贅沢な名だねぇ。 今からおまえの名前は%sだ。\nいいかい、%sだよ。分かったら返事をするんだ、%s!!"% (name, short_name, short_name, short_name))はい終わり
$ python hot_water_old_lady.py 契約書だよ。そこに名前を書きな。働かせてやる。 その代わり嫌だとか、帰りたいとか言ったらすぐ子豚にしてやるからね。 そうだよもぅぐずぐずしないでさっさと書きな! まったく……つまらない誓いをたてちまったもんだよ。働きたい者には仕事をやるだなんて…… 書いたかい? 千尋 はい…あっ。 フン。千尋というのかい? はい。 贅沢な名だねぇ。 今からおまえの名前は千だ。 いいかい、千だよ。分かったら返事をするんだ、千!!はい、ちゃんと湯婆婆してますね
じゃあ名前を書かないでいきましょうpython hot_water_old_lady.py 契約書だよ。そこに名前を書きな。働かせてやる。 その代わり嫌だとか、帰りたいとか言ったらすぐ子豚にしてやるからね。 そうだよもぅぐずぐずしないでさっさと書きな! まったく……つまらない誓いをたてちまったもんだよ。働きたい者には仕事をやるだなんて…… 書いたかい? Traceback (most recent call last): File "hot_water_old_lady.py", line 3, in <module> short_name = name[0] IndexError: string index out of rangeはい、湯婆婆が落ちましたね
文字列の""の0番目を参照したからですね結論
湯婆婆は落ちる
cでやった人もいるらしいのでみなさんも湯婆婆作りましょう〜
https://twitter.com/cmpl_error/status/1162330445683412992?s=20追記
2019/08/17 プログラム内のミスをご指摘いただき少し修正しました

- 投稿日:2019-08-16T23:18:01+09:00
圧倒的非プログラマーがDeep Learningを学ぶ
プロフィール
機械メーカにて電気回路エンジニア(2018年入社)
大学院では洋上風力発電の電力制御について従事。
プログラム経験としてはCを用いてマイコンを制御したくらい。
業務では全くソフトウェアには触れない。なぜ今からDeep Learningを学ぶのか
入社してから世の中がAIブームであることを知った。
経済誌などで情報を集めると
AI/IoT技術などを活用したインダストリー4.0であったり、
VUCA社会という、正解への道筋が見えにくい社会に突入しているらしい。シンギュラリティが仮にきたとして、
環境の変化に対応する力を培っておこうと思った。
そんなノンプログラマの争うところを記事としてみようと決意。目標
最終的には簡単な機械学習モデルを組み、
構造の理解ができればいいと思っている。(2019年内)まずは「ゼロから作るDeep Learning: Pythonで学ぶディープラーニングの理論と実装」を読み、理解できるようにしたいと思う。
ほかに具体的な達成目標が思いつかないのがちょっと悩みである。
- 投稿日:2019-08-16T23:13:09+09:00
Pythonを使ってシミュレーションしながら学ぶ母平均の検定
目次
- 1.はじめに
- 2.母平均の検定の目的
- 3.母平均の検定あれこれ
- 3.1 母平均の検定統計量t値の性質
- 3.2 母平均の検定における判定ロジック
- 3.3 有意水準に基づく棄却が出来ない場合何が判断出来るか
1.はじめに
統計学を学びはじめて仮説検定につまづくというのは良くある話かとおもいます。かく言う私もそうです。
特に、確率変数を論理的に扱って帰無仮説を棄却する云々の仮説検定のロジックが腹落ちしませんでした。
本記事では、母平均の検定を題材に仮説検定の自分なりの理解を説明します。Pythonの実行環境例:Anaconda3、Jupyter
2.母平均の検定の目的
母平均の検定は、品質管理などで良く使われます。例えば、1ロットで10000本の芯を製造する生産ラインがあったとします(あくまで例です)。ある検査工程では、同一ロットで製造した芯の平均(簡略化のために分散は考慮しません)が60mm以外ならば不合格とする場合、どのように判定するのが合理的でしょうか?全数調査では時間やコスト的に難しい場合、標本調査により合否を判定したいことがあると思います。
ここで活躍するのが母平均の検定です。母平均では、標本を基に母平均が期待している値か否かを判定することを目的としています。3.母平均の検定あれこれ
母平均の検定にあたっては下記の検定統計量(以降、t値)を使用します。
$$t=\dfrac{(\hat{\mu}-\mu_0)}{\hat{\sigma}/N}$$
ここで$\hat{\mu}$は標本平均、$\hat{\sigma}$は標本分散、$N$は標本数であり、$\mu_0$が期待する母平均です。ではなぜ、わざわざ検定統計量を算出するのでしょうか?それは、「①標本が互いに独立で正規分布に従っている」と仮定する場合、t値が面白い性質を示すからです。3.1 母平均の検定統計量t値の性質
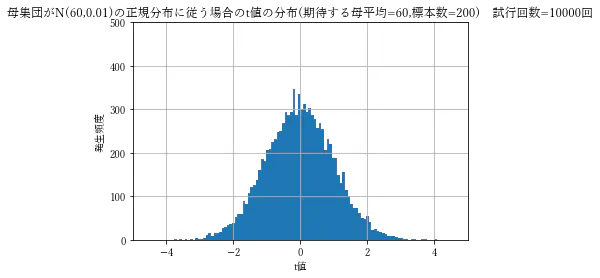
例えば、母集団が平均(以降、真の母平均)=60、分散=0.01の正規分布に従っていると仮定する場合、期待する母平均が60のt値の発生頻度は下記グラフのようになります。
グラフ出力の実行コードは下記を参照。t値の分布出力import matplotlib from scipy.stats import norm import numpy as np import matplotlib.pyplot as plt #日本語表記に使用 matplotlib.rcParams['font.family']='Yu Mincho' #母集団が正規分布に従うと仮定 mu=60 sigma2=0.01 #サンプル数 N=200 #期待する母平均 mu0=60 #試行回数 simu=10000 t_hist=[] for i in range(simu): #標本平均・標本分散を算出する samples=norm.rvs(loc=mu, scale=sigma2, size=N) # 標本平均⇒t検定の検定統計量算出に使用 m=np.average(samples) # 標本分散⇒t検定の検定統計量算出に使 s=np.std(samples,ddof=1) #t検定の検定統計量 t=(m-mu0)/(s/np.sqrt(N)) t_hist=np.append(t_hist, t) plt.hist(t_hist,bins=int(simu/100)) plt.title('母集団がN('+str(mu)+','+str(sigma2)+')の正規分布に従う場合のt値の分布(期待する母平均='+str(mu0)+','+'標本数='+str(N)+') 試行回数='+str(simu)+'回') plt.xlabel('t値') plt.ylabel('発生頻度') plt.xlim(-5,5) plt.ylim(0,500) plt.grid()ご覧の通り正規分布のような形を示します。実はt値は、①の仮定の下では自由度がN-1のt分布(裾野の広い正規分布で自由度を上げると正規分布に近づく)に従います。検定統計量が知られた確率分布に従うので、標本データから算出した検定統計量の発生確率を算出することが出来ます。
t値への理解を更に深めるために真の母平均を少し変化($\pm 0.001$)させたときにt値の分布がどのように変わるかを見てみましょう。
このように、"真の母平均"="期待する母平均"の場合、t値の分布はt値=0を中心に左右対称になりますが、"真の母平均"<"期待する母平均"の場合は山のトップが負になり、"期待する母平均"<"真の母平均"の場合は山のトップが正になります。
見やすくするためにt分布の出力結果を表示します。"真の母平均"="期待する母平均"の場合(青)と"期待する母平均"<"真の母平均"の場合(オレンジ)のt分布です。例えば、t値が2だったとします。この時、青の分布よりもオレンジの分布の方がt値が2になる確率が高いことが読み取れます。このことから直観的にですが、期待する母平均よりも真の母平均の方が大きい可能性が高いと解ります。
グラフ出力の実行コードは下記を参照。t分布出力import numpy as np import matplotlib.pyplot as plt from scipy import stats import matplotlib matplotlib.rcParams['font.family']='Yu Mincho' #自由度 Dof=200 #プロット数 plots=1000 tMatrix=np.zeros(NumberOfSamples) tMatrix2=np.zeros(NumberOfSamples) pMatrix=np.zeros(NumberOfSamples) for i in range(plots): tMatrix[i]=stats.t.ppf(1-i/plots,Dof-1) tMatrix2[i]=talpMatrix[i]+1.5 pMatrix[i]=stats.t.pdf(tMatrix[i],Dof-1) plt.plot(tMatrix,pMatrix) plt.plot(tMatrix2,pMatrix) plt.title('自由度='+str(Dof)+'-1のt分布') plt.ylabel('確率') plt.xlabel('t値') plt.ylim(0,0.5) plt.xlim(-5,5) plt.grid()3.2 母平均の検定における判定ロジック
母平均の検定の目的は、"真の母平均"="期待する母平均"と判定できるかどうかでした。
例えば、200件の標本データを元に算出したt値が2の場合、どうすれば"真の母平均"="期待する母平均"がロジカルに判定できるでしょうか?論理学ではこのような場合、背理法を用いるかと思います。背理法では、ある仮定のもとで矛盾を導くことで仮定が成り立たないことを証明します。つまり、「"真の母平均"="期待する母平均"」という仮定のもとで矛盾を導くことが出来れば「"真の母平均"="期待する母平均"」が成り立たないことが言えます。仮説検定ではこの考え方を応用するために有意水準を導入します。有意水準以下の場合、発生確率が十分小さく仮定が否定(統計の用語で棄却)出来ることを前提条件として設定します。
母平均の検定における判定ロジックは以下のようになります。
- 有意水準を設定
- 判定したい仮定(帰無仮説)を設定
- 帰無仮説のもと検定統計量を算出
- 3で算出した検定統計量から確率を算出
- 4で算出した確率が1で設定した有意水準以下の場合、2で設定した帰無仮説を棄却⇒判定成功
- 4で算出した確率が1で設定した有意水準より大きい場合、新たな帰無仮説を設定する
先述の例の場合、「"真の母平均"="期待する母平均"」という帰無仮説のもと$t\geq2$となる確率は約0.03(3%)です。有意水準として5%を設定した場合、帰無仮説が棄却できます。つまり、"真の母平均"$\neq$"期待する母平均"と判定できます。ここで、$t\geq2$としたのはt値の計算式よりt値が0から離れれば離れるほ真の母平均と期待する母平均が乖離する可能性が高いからです。
3.3 有意水準に基づく棄却が出来ない場合何が判断出来るか
有意水準に基づく棄却が出来ない場合をもう少し説明します。これは、t分布のグラフをみただけではイメージが難しいです。t値が1の場合を考えます。このとき次のグラフが役立ちます。真の母平均を変化させたとき$1\leq t\leq 5$となる確率をシミュレーションしたグラフです。ここで$t\leq5$という条件を追加したのは自由度199のt分布は$\pm2$に多くが分布するからです。
t値が1の場合、帰無仮説(グラフのx軸の0.000)における発生確率は約19%であるため有意水準5%と比較して大きく棄却できません。しかし、帰無仮説が棄却できないからといって帰無仮説が正しいとは言えません。グラフの通り、$1\leq t\leq 5$となりうる真の母平均は多く存在します。従って、帰無仮説が棄却出来ない場合は何も判断出来ません
グラフ出力の実行コードは下記を参照。
真の母平均を変化させたときの確率import matplotlib from scipy.stats import norm import numpy as np import matplotlib.pyplot as plt #進捗表示用 import sys import time def progress(p, l): sys.stdout.write("\r%d / 100" %(int(p * 100 / (l - 1)))) sys.stdout.flush() #日本語表記に使用 matplotlib.rcParams['font.family']='Yu Mincho' #母集団が正規分布に従うと仮定 _mu=60 sigma2=0.01 #サンプル数 N=200 #期待する母平均 mu0=60 #試行回数 simu=1000 t_hist=[] # 母平均の変更 mu_sim =100 delta=sigma2/mu_sim mu_start=_mu-sigma2/2 mu_hist =np.zeros(mu_sim) t_hist_geq2=np.zeros(mu_sim) _t=1 _t2=5 cntAll=0 for j in range(mu_sim): progress(j, mu_sim) mu=mu_start+j*delta mu_hist[j]=mu-mu0 cnt=0 for i in range(simu): #標本平均・標本分散を算出する samples=norm.rvs(loc=mu, scale=sigma2, size=N) # 標本平均⇒t検定の検定統計量算出に使用 m=np.average(samples) # 標本分散⇒t検定の検定統計量算出に使 s=np.std(samples,ddof=1) #t検定の検定統計量 t=(m-mu0)/(s/np.sqrt(N)) if(t>=_t and t<=_t2): cnt=cnt+1 t_hist_geq2[j]=cnt plt.plot(mu_hist,t_hist_geq2/simu) plt.title('真の母平均を変化させたときの'+str(_t)+'<=t<='+str(_t2)+'となる確率(期待する母平均='+str(mu0)+',真の母分散='+str(sigma2)+') 試行回数='+str(simu)+'回') plt.xlabel('真の母平均-期待する母平均') plt.ylabel(str(_t)+'<=t<='+str(_t2)+'となる確率') plt.xlim(-sigma2/2,sigma2/2) plt.grid()





- 投稿日:2019-08-16T23:09:03+09:00
どうしても池の面積を調べたい時のモンテカルロ法 ~計算物理学I (朝倉書店)を参考にpythonを使って~
モンテカルロ積分の説明から簡単なものの実装まで
モンテカルロ積分とその他の積分法の違い
普通、積分というと微小面積や微小体積を足し合わせて計算するイメージがあるかと思いますが、モンテカルロ積分はそれらとは大きく概念が異なる積分の手法です。モンテカルロ積分を簡潔に言えば「乱数を使用する」積分と言えるでしょう。
「乱数を使用する」とは
あなたは牧場の中の柵で囲われた領域の面積($S_{Fence}$)を求めたいと考えました。しかし、あなたの手元には物差しもスケールも巻き尺もありません。ただ、あなたは牧場全体の面積($S_{Ranch}$)を知っています。さてこのような状況で、どのようにして柵の中の面積を求めることができるでしょうか。
答えは「牧場内に適当に(一様にランダムに)たくさんの石を投げる」です。
ランダムに投げられた石は牧場内の柵の内外のいずれかに落ちますが、投げ方が一様でかつ投げた石の数が十分なほど多ければ、柵の中に落ちる数($N_{in}$)と柵の外側に落ちる数($N_{out}$)は、それぞれの領域の面積に比例すると考えられます。
すると、柵の中の面積($S_{Fence}$)は以下のように表すことができるでしょう。
S_{Fence} = S_{Ranch} \times \frac{N_{in}}{N_{in}+N_{out}}
このような面積や体積の求め方をモンテカルロ積分といいます。プログラムの中で「投石」は乱数生成によって実施することとなります。したがって、モンテカルロ積分は乱数を使用した積分方法と言えます。モンテカルロ積分の利点
多次元積分において、その他の積分よりも高速かつ誤差が少ない結果を得ることができます。今回は1次元のみですが、次回は簡単な10次元積分を実装したいと思います。
モンテカルロ積分の簡単なものの実装
さてモンテカルロ法について簡単に学習したところで、pythonを用いて簡単なモンテカルロ積分のプログラミングを作っていきます。
具体的には計算物理学I(朝倉書店)のP.101からP.102の課題を私なりに作成しました。課題の内容は以下です。1.一辺が2の正方形で囲まれた円形の池(r=1)を考える.
2. 池の面積の厳密な値は$\iint dA = \pi$という既知の値である.
3. $-1 \le r_i \le 1$ の乱数列を発生する
4. $i = 1$から$N$について$(x_i,y_i) = (r_{2i-1},r_{2i})$とする。
5. $x_i^2 + y_i^2 <1$なら$N_{pond}=N_{pond}+1$, その他は$N_{box}=N_{box}+1$とする.
6. (5.76)を用いて面積を計算し, そこから$\pi$を求める.(5.76)とは先ほど示した$S_{Fence}$を求める式と同様のものです。
さて、上記問題を解決するためのコードを作成してみましたが、かなりシンプルなものになりました。montecarlo.pyimport numpy as np import random #投げる石の個数(size)を与えることで池の面積を返す式を定義 def MonteCarlo_circle(size): Npond = Nbox = 0. list_r = np.zeros(2*size) #石の落ちた座標を記録するための配列を作成 list_xin = list_yin = list_xout = list_yout = np.array([]) #-1≦r_i≦1の範囲の乱数列を生成 for i0 in range(2*size): ran_Num = random.uniform(-1, 1) list_r[i0] = ran_Num #石の落ちた場所と個数を数える。 for i1 in range(0,size): length = list_r[2*i1]**2 + list_r[2*i1+1]**2 if length < 1: Npond += 1 list_xin = np.append(list_xin, list_r[2*i1]) list_yin = np.append(list_yin, list_r[2*i1+1]) else : Nbox += 1 list_xout = np.append(list_xout, list_r[2*i1]) list_yout = np.append(list_yout, list_r[2*i1+1]) #それぞれの石の数によって面積を計算する。4は池を囲む正方形の面積 Apond = 4*Npond/(Npond + Nbox) #石の落ちた場所と面積の計算結果を返す。 return list_xin, list_yin, list_xout, list_yout, Apond使用したパッケージはnumpyとrandomです。
numpyは必ず必要というわけではありませんが行列やベクトルの計算に便利なので、今後の応用のために導入しました。(最初はnumpyのnumpy.random.rand()で乱数列を作成しようと考えていたのですが、生成される乱数rが0≦r<1の範囲であり、問題の条件を厳密には満たさなかったのでやめたという裏話もあります……。参考1)
randomは乱数列を生成するために使用しました。random.uniform(a, b)がa <= b であればa≦N≦bであるようなの浮動小数点数Nを返してくれるためです。参考2)その他は問題の通りの挙動としていますが、今回は池に落ちた時とそれ以外の時の石の座標を記録してプロットしてみることとします。
実行結果
投げる石の数を5000個としたときの実行結果をプロットすると以下のようになりました。(赤い線が池の外周で、池の中に落ちた石を水色、外に落ちた石を緑色にしました。)
ちゃんと、池の中に落ちたものとそうでないものを分類できていることが分かりますね。また、これはたまたまですが池の面積も厳密解の$\pi$とかなり近い値になりました。(実際は新たに乱数列を生成するたびに結果は変わります。石の数をより増やすことや、同じ投石数での計算結果を平均化することなどで結果の変動は小さくできると考えられます。)
これで安心して池の面積が分かりますね。よかったよかった。また、何か間違いや勘違い等がありましたら教えていただければ幸いです。
参考書籍
R.H.Landau・他 (2018)『実践Pythonライブラリー 計算物理学I -数値計算の基礎/HPC/フーリエウェーブレット解析』 (小柳義夫・他訳) 朝倉書店

- 投稿日:2019-08-16T22:49:07+09:00
Google Cloud Function + Cloud Scheduler + Python で定期的に Twitter 投稿する
概要
- Google Cloud Platform + Twitter API だけで完結するシステム構成とする
- Cloud Functions 上で Python のプログラムを定期実行して Twitter へ投稿する
- プログラミング言語には Python 3.7 を使用する
- Twitter へ投稿する Python のライブラリとして python-twitter を使用する
- 定期実行には Cloud Scheduler + Cloud Pub/Sub を使用する
- 動作環境や料金情報などは2019年8月16日現在の情報
Cloud Functions とは
Google Cloud Functions に関するドキュメント | Cloud Functions | Google Cloud
Google Cloud Functions は軽量なコンピューティング ソリューションで、デベロッパーはサーバーやランタイム環境を管理することなく、Cloud イベントに応答する単一目的のスタンドアロン関数を作成することができます。
Cloud Scheduler とは
Cloud Scheduler | Cloud Scheduler | Google Cloud
Cloud Scheduler は、エンタープライズ クラスのフルマネージド cron ジョブ スケジューラです。
Unix cron 形式でスケジュールを定義して、1 日に複数回ジョブを実行したり、1 年のうちの特定の日や月にジョブを実行したりできます。
python-twitter とは
Twitter API を Python から使えるようにしたライブラリ。
Cloud Functions で関数を作成する
Google Cloud Platform にてプロジェクトを作成したら、左上のメニューから Cloud Functions を選択する。
関数を作成する。
トリガーには「Cloud Pub/Cub」を指定する。
新しいトピックを作成して、名前をつける。Cloud Scheduler で使うため、わかりやすい命名をしたほうが良い。
ソースコードをインラインエディタで入力する。
ランタイムには Python 3.7 を指定する。
main.py には以下の内容を入力する。
import os import sys import time import twitter def get_twitter_api(credentials): return twitter.Api( consumer_key=credentials['consumer_key'], consumer_secret=credentials['consumer_secret'], access_token_key=credentials['access_token_key'], access_token_secret=credentials['access_token_secret']) def hello_pubsub(event, context): try: api = get_twitter_api(os.environ) status = api.PostUpdate(f'Hello, world. {time.time()}') print(str(status)) except: print(str(sys.exc_info()))requirements.txt には以下の内容を入力する。
# Function dependencies, for example: # package>=version python-twitter「環境変数、ネットワーキング、タイムアウトなど」をクリックすると、詳細オプションが表示される。
ここでは環境変数を追加する。
Twitter API をコールするのに必要なパラメータをセットする。
「作成」ボタンを押すとプログラムがデプロイされる。
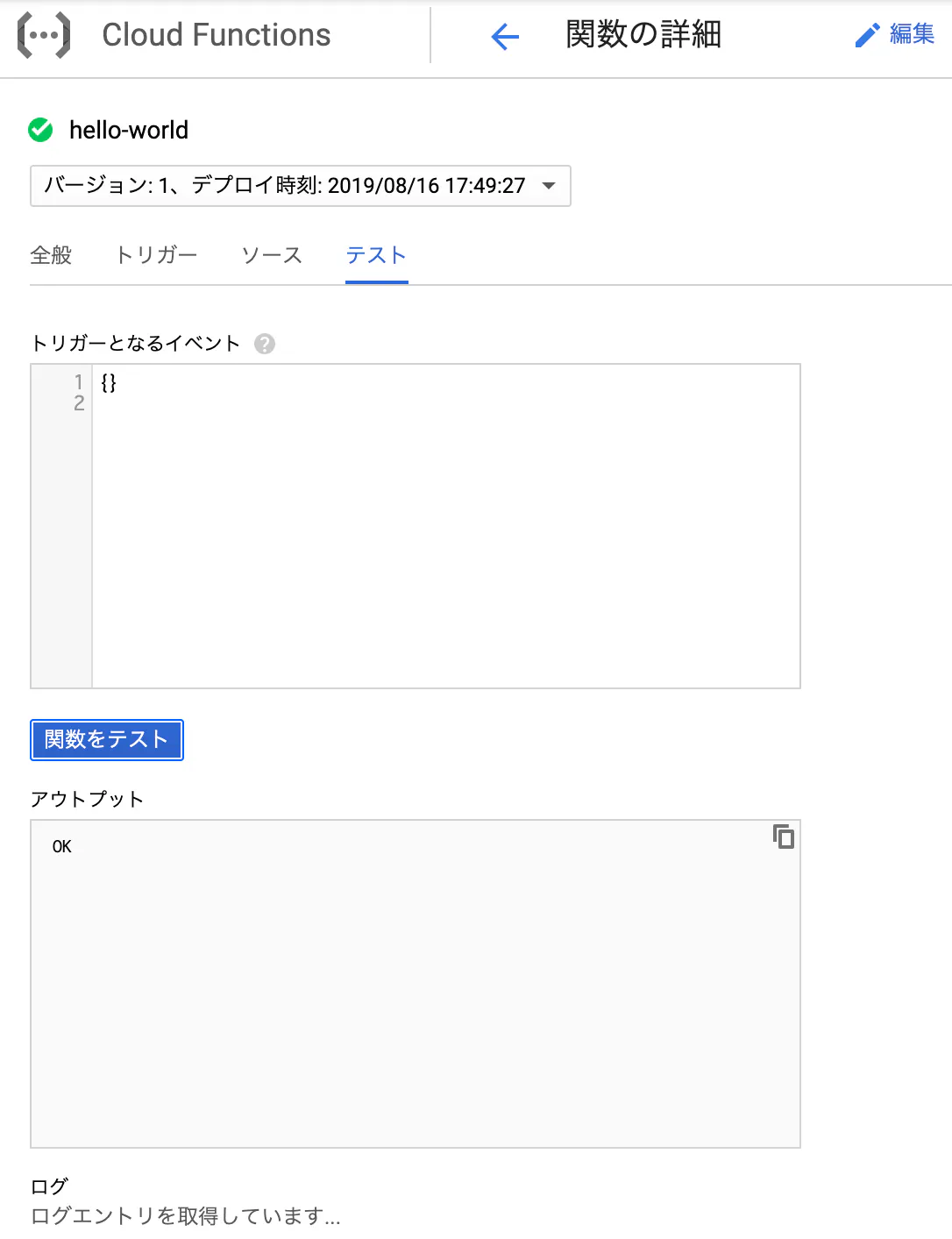
右のメニューなどから関数のテスト画面へ移動する。
「関数をテスト」をクリックしてプログラムを実行できる。
エラーなどのメッセージは、「アウトプット」の項目ではなく、ログに出力される。
Cloud Scheduler で定期実行を設定する
左上のメニューから Cloud Scheduler を選択する。
プロジェクトで最初のジョブを作成するときは、リージョンの選択が必要となる。
リージョンによっては使えないプロダクトがあるので注意。
参考: ロケーション - リージョンとゾーン | Google Cloud
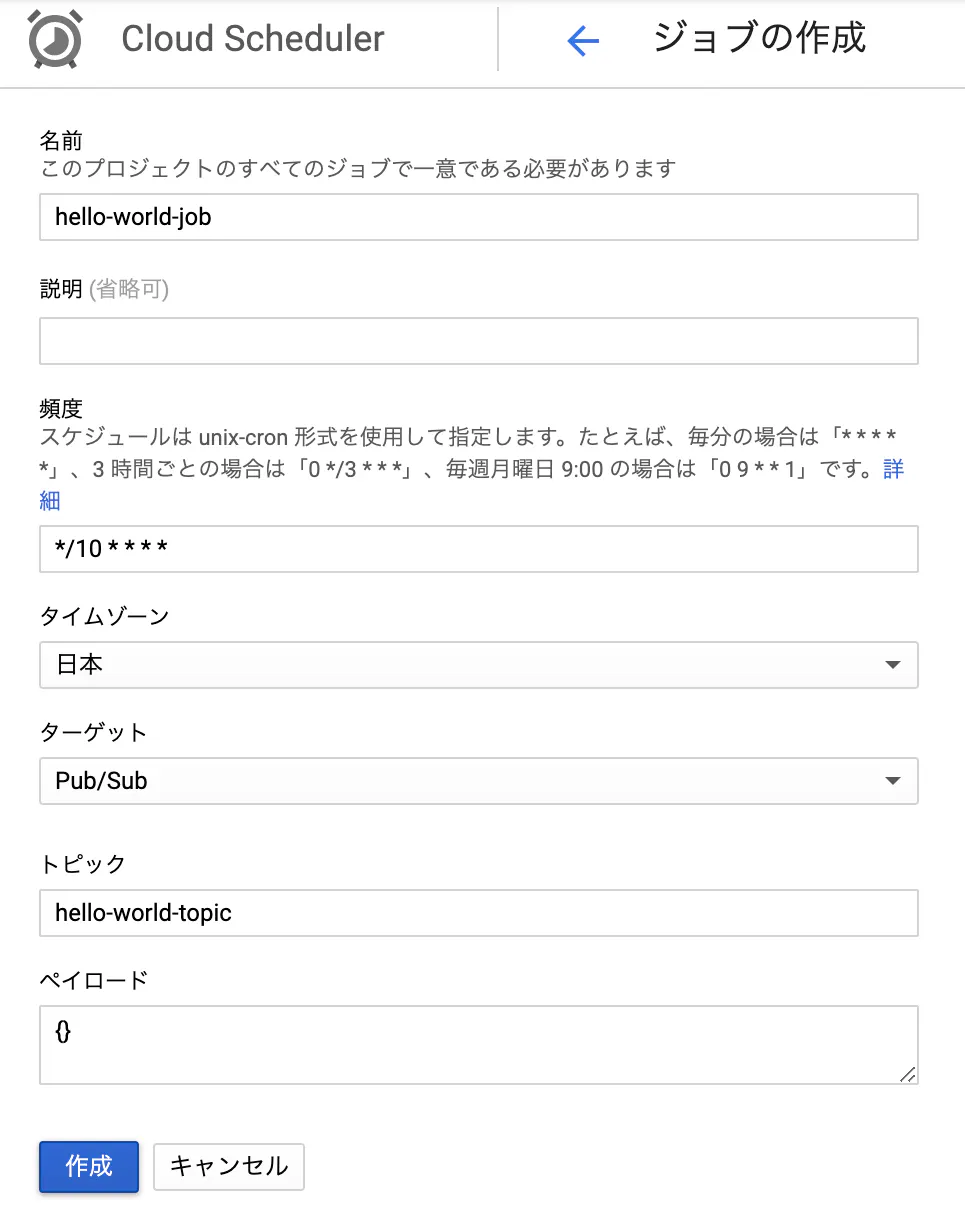
ジョブを作成する。
頻度には、今回は10分おきに実行する設定「*/10 * * * *」を入力する。
ターゲットには Pub/Sub を指定する。
トピックには Cloud Functions で作成したトピック名を入力する。
ペイロードには関数に渡すデータを入力する。ここでは「{}」を入力する。
作成したジョブは「今すぐ実行」することも可能だし、設定した頻度でも実行される。
ジョブを実行すると、ターゲットを介して紐付けてある Cloud Functions の関数が実行される。
10分おきの実行は頻繁なので、試し終わったらジョブを削除しておいたほうが良い。
料金について
料金 | Cloud Functions のドキュメント | Google Cloud
呼び出し料金は 1 回あたり \$0.0000004 の単価制で、関数の結果や使用期間に関係なく請求されます。ただし、毎月最初の 200 万回までは無料です。
Cloud Functions にはコンピューティング時間リソースを永久的に無料で使える階層があり、GB 秒と GHz 秒の両方の割り当てが含まれています。無料階層には 200 万回の呼び出しのほかに、400,000 GB 秒、200,000 GHz 秒のコンピューティング時間と、1 か月あたり 5 GB のインターネット下りトラフィックも含まれています。無料階層を使用する場合でも、有効な請求先アカウントが必要です。
料金 | Cloud Scheduler のドキュメント | Google Cloud
Cloud Scheduler の料金は「ジョブ」を基準に計算されます。Cloud Scheduler のジョブは、定義された頻度で行うようにスケジュールした 1 つのアクティビティのことを指します。
実際にジョブを行うことを「実行」と呼びます。ジョブは個々の実行単位で課金されることはありません。たとえば、1 つのジョブを「1 か月間毎日」行うように定義しても、そのジョブの 30 回の実行について月額 \$3 が課金されるのではなく、全体として月額 \$0.10 が課金されます。
Google アカウントごとに、毎月 3 つのジョブを無料で利用できます。この無料枠は、プロジェクト レベルではなくアカウント レベルで集計されるので注意してください。たとえば、アカウントに 5 つのプロジェクトがあり、各プロジェクトに 2 つのジョブがある場合、無料のジョブは 3 つ、有料のジョブは 7 つになります。
料金 | Cloud Pub/Sub ドキュメント | Google Cloud
メッセージのパブリッシュまたは配信の料金は TiB あたり \$40 で、階層はありません。また、リージョン内の下りデータに対する料金が導入されました。インターネットの下り料金と GCP リージョン間でのインターネット配信の料金は、ゾーンの下りと Google サービスへの下りを除き、Compute Engine のネットワーク料金と同様です。Cloud Pub/Sub の使用に対するゾーンの下り料金は発生しません。Google サービスへの下りは下り料金の対象となります。たとえば、1 MiB のメッセージを us-west1 にパブリッシュし、europe-west1 のサブスクライバーに配信すると、2 つの SKU 間で合計 3 MiB の料金が課金されます。基本的なメッセージ配信で 2 MiB(パブリッシュと配信に 1 MiB ずつ)とアメリカ大陸から EMEA へのリージョン間のデータ配信で 1 MiB が課金対象になります。
参考資料







- 投稿日:2019-08-16T22:01:54+09:00
Pythonでaws-sam-cliをローカル実行するまで
AWSコンソールでポチポチしてみたのですが
ローカル環境での実行をしてみたいなとおもい、その備忘録です。環境:
macOS High Sierra 10.13.6
AWS SAM CLI
pip 19.2.2
Python 3.7.2
Docker for macOS
目次
- AWS SAM CLIをインストールする
- sam init
- テストを実行
- ローカルでLambda関数を呼び出す
1. AWS SAM CLIをインストールする
pip を使用して AWS SAM CLI をインストール
$ pip install aws-sam-cliバージョンの確認
$ sam --version SAM CLI, version 0.19.02. sam init
sam init コマンドで python3.7のサンプルアプリケーションを作成
$ sam init --runtime python3.7 [+] Initializing project structure... Project generated: ./sam-app Steps you can take next within the project folder =================================================== [*] Invoke Function: sam local invoke HelloWorldFunction --event event.json [*] Start API Gateway locally: sam local start-api Read sam-app/README.md for further instructions [*] Project initialization is now completeReadとのこと => https://github.com/yoshiyoshifujii/sam-app/blob/master/README.md
ツリーで見てみる
$ tree sam-app/ sam-app/ ├── README.md ├── event.json ├── hello_world │ ├── __init__.py │ ├── __pycache__ │ │ ├── __init__.cpython-37.pyc │ │ └── app.cpython-37.pyc │ ├── app.py │ └── requirements.txt ├── template.yaml └── tests └── unit ├── __init__.py ├── __pycache__ │ ├── __init__.cpython-37.pyc │ └── test_handler.cpython-37.pyc └── test_handler.py 5 directories, 12 files3. テストを実行
テストを実行してみる
$ cd sam-app$ python -m pytest tests/ -v ========================================== test session starts ========================================== platform darwin -- Python 3.7.2, pytest-5.1.0, py-1.8.0, pluggy-0.12.0 -- /Library/Frameworks/Python.framework/Versions/3.7/bin/python3 cachedir: .pytest_cache rootdir: /Users/suwa/sam-app plugins: mock-1.10.4 collected 1 item tests/unit/test_handler.py::test_lambda_handler PASSED [100%] =========================================== 1 passed in 0.07s ===========================================ビルドします
$ sam build4. ローカルでLambda関数を呼び出す
まずDockerを起動する
ローカルで API Gateway 経由で Lambda 関数を呼び出す$ sam local start-apiブラウザで下記URLにアクセスするとコンテナイメージがダウンロードされ、コードが実行されてブラウザに出力が表示されます。
http://127.0.0.1:3000/hello
{"message": "hello world”}他のblogではLocationが表示されていたのですが
$ vi ./hello_world/app.pyで、下にある
# "location": ip.text.replace("\n", "")の、コメントアウトを外せばLocationも表示されます。
- 投稿日:2019-08-16T21:26:44+09:00
【解説付き】Django チュートリアル その2 -前編-
はじめに
これは、【解説付き】Django チュートリアル その1に続き、
はじめての Django アプリ作成、その2に解説をつけて初学者にわかりやすく学んでいただきたいというためのものです。その2は、ボリュームがあるため前編/後編とさせていただいております。
対象
- pythonはなんとなくわかってるけど、djangoを覚えたい
- 業務でdjango触ってたけど、きちんと理解したい
上記の方々を対象としています。
環境は、Macを使用して進めていきますので、Windowsユーザーの方は、Windows環境に読み替えてついてきていただければと思います。settings.py
mysite/settings.pyを見ていきましょう
これは、 Django の設定を管理するための Pythonファイルです。INSTALLED_APPSの設定
INSTALLED_APPSは、Djangoインスタンスの中で有効化したいDjangoアプリケーションの名前を記載します。
pip installなどで、個別に追加するアプリケーションもここに追加していくことになります。mysite/settings.py... # Application definition INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ] ...デフォルトでは、 よく利用される下記のアプリケーションが、
INSTALLED_APPSに指定されています。
- django.contrib.admin - 管理(admin)サイト。後ほど説明します。
- django.contrib.auth - 認証システム
- django.contrib.contenttypes - コンテンツタイプフレームワーク
- django.contrib.sessions - セッションフレームワーク
- django.contrib.messages - メッセージフレームワーク
- django.contrib.staticfiles - 静的ファイルの管理フレームワーク
これらのアプリケーションはデータベースを使用するため、事前にデータベース内にテーブルを作る必要があります。
こちらは後ほど説明します。Databaseの設定
デフォルトの設定では
SQLiteが指定されています。
データベースに詳しくなかったり、Django を試してみたいだけなら、SQLiteのままで進めましょう。
SQLiteはPythonに標準で組み込まれているため、接続するために何もインストールする必要がありません。
本番環境で使う場合には、AWSやGCPでも提供されているPostgreSQLやMySQLなどのデータベースが良いでしょう。公式のチュートリアルでは、
PostgreSQLを使用しています。mysite/settings.py... # Database # https://docs.djangoproject.com/en/2.2/ref/settings/#databases # デフォルトのままの、SQLiteの例 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } } ...他のデータベースを使いたい場合、データベースと接続するモジュール(mysql client等)をインストールして、
settings.py内にある、DATABASESのdefault項目内の以下のキーをデータベースの接続設定に合うように変更してください。
ENGINE
'django.db.backends.sqlite3'、'django.db.backends.postgresql'、'django.db.backends.mysql'または'django.db.backends.oracle'のいずれかにします。
※その他のバックエンド も利用可能です。NAME
データベースの名前です。SQLiteを使用している場合、データベースはコンピュータ上のファイルになります。
その場合、NAME には、そのファイルのファイル名を含んだ絶対パスを指定する必要があります。
デフォルト値はos.path.join(BASE_DIR, 'db.sqlite3')で、ファイルはプロジェクトのディレクトリに保存されます。
SQLite以外を使う場合、 データベースに接続するための、USERやPASSWORDそしてHOSTなどの追加設定を加える必要があります。
※詳細については DATABASES のリファレンスドキュメントを参照してください。TIME_ZONE の設定
mysite/settings.pyで、 タイムゾーンを指定する事ができます。mysite/settings.pyTIME_ZONE = 'UTC' USE_TZ = True
- TIME_ZONE: TIME_ZONEの指定により、テンプレートで出力される日時情報が変換して出力されます
- USE_TZ: フォームの日付入力欄で、入力した日付が変換されます
※タイムゾーン関連は複雑なため、別途記事にまとめるのでここで詳細は割愛します。
migrateコマンドを実行する
ここまで設定した内容だけでは、
INSTALLED_APPSの機能を使うことはできません。
前述した通り、データベースにテーブルが必要です。マイグレーションファイルから、テーブルを自動的に作成してくれる
migrateコマンドを実行してみましょう
※マイグレーションファイルについては、この先で触れていきます。$ python manage.py migrate
migrateコマンドはINSTALLED_APPSに記載されている情報を元に、必要なテーブルを作成します。※マイグレーションファイルはアプリケーション内に内包されています。
Djangoが作成したテーブルを、確認したい場合は、データベース毎のコマンドで確認できます。
データベースのクライアント上で、
\dt(PostgreSQL)SHOW TABLES;(MySQL).schema(SQLite)SELECT TABLE_NAME FROM USER_TABLES;(Oracle)と入力してみましょう。
Model
Modelとは
Modelには、データベースの定義と、それに付随するMETAデータをクラスとして記述します。
Modelの作成
これから開発する
pollsアプリケーションでは、投票項目 (Question)と選択肢 (Choice)の二つのモデルを作成します。
Questionには「質問事項 (question)」と「公開日 (publication date)」 の情報があります。
Choiceには「選択肢のテキスト」と「投票数 (vote)」 という二つのフィールドがあります。
Choiceデータは、Questionに関連づけられるone to manyとなります。Django では、こうした概念を簡単な Python クラスで表現できます。
polls/models.pyファイルを以下のように編集してください。polls/models.pyfrom django.db import models class Question(models.Model): question_text = models.CharField(max_length=200) pub_date = models.DateTimeField('date published') class Choice(models.Model): # Questionに対してリレーションを貼る question = models.ForeignKey(Question, on_delete=models.CASCADE) choice_text = models.CharField(max_length=200) votes = models.IntegerField(default=0)Model(テーブル)は
django.db.models.Modelを継承して、クラスを作ります。
クラスは、テーブルの定義、
クラス変数は、テーブルのカラムの定義となります。Modelフィールド
各フィールドは
Fieldクラスのインスタンスとして表現されています。
例えば、CharFieldは文字のフィールド(カラム)で、DateTimeFieldは日時のフィールド(カラム)です。フィールド名(verbose)
Field の最初の引数には、フィールド名を指定できます。(省略可能)
question_text = models.CharField("question's text", max_length=200)指定しない場合は、
question_textのアンダースコアをスペースに置き換えたquestion textとなります。上の例の、
Question.pub_dateの'date published'もフィールド名となります。フィールドのパラメータ(引数)
Field クラスの中には必須の引数を持つものがあります。
例えばCharFieldにはmax_lengthを指定する必要があります。
この引数はデータベースの定義で使われる他、バリデーションでも使われます。(後ほど説明)Field には、オプションの引数もあります。
上記の場合、Choice.votesの default の値を0に設定しました。
これは、Choiceデータを作成する際に、Choice.votesの値が指定されていなければ、「0を設定する」という意味です。ForeignKey(リレーション)
polls/models.pyclass Question(models.Model): ... class Choice(models.Model): question = models.ForeignKey(Question, on_delete=models.CASCADE) ...ForeignKeyを使用して、リレーションを定義することができます。
これは、ChoiceがQuestionに関連付けられること意味します。
Django では多対一(many to one)、多対多(many to many)、そして一対一(one to one)のようなデータベースリレーションシップすべてをサポートします。今回の構造だと下記のようなテーブルとなります。
Questionテーブル
id question_text pub_date 1 好きな食べものは何ですか? 2019-08-16 00:00:00 Choiceテーブル
id question_id choice_text votes 1 1 和食 0 2 1 洋食 0 3 1 イタリアン 0 プロジェクトにアプリケーション(パッケージ)を追加する
この段階では、プロジェクトが
pollsアプリケーションを認識できていません。
pollsをプロジェクトに追加させることで、
前述したModelファイルを使って、アプリケーションのデータベーススキーマ(migrateファイル)を作成 (CREATE TABLE 文を実行) できます。アプリケーションを認識させるには、
settings.pyのINSTALLED_APPSに追加する必要があります。
PollsConfigクラスは、polls/apps.pyにあるので、指定する記述は'polls.apps.PollsConfig'となります。下記のように
mysite/settings.pyを編集し、INSTALLED_APPSに上記のパスを追加します。mysite/settings.py... INSTALLED_APPS = [ # pollsパッケージの追加 'polls.apps.PollsConfig', 'django.contrib.admin', ... ] ...これで Django は、
pollsアプリケーションを認識することができます。migrate
※チュートリアル通した後に見返すくらいでも良いかもしれません。軽く読み進めたい人はmigrateのポイントに進めてもらって大丈夫です。
makemigrationsコマンドを使って、マイグレーションファイルを作成します。マイグレーションファイル ・・・データベースを作成・変更するためのスキーマの定義情報
$ python manage.py makemigrations pollsコマンドが成功すると、下記のようなメッセージが出力されます
(選択しているデータベースにより若干メッセージは変わります)Migrations for 'polls': polls/migrations/0001_initial.py: - Create model Choice - Create model Question - Add field question to choice
makemigrationsを実行すると、Modelの変更内容(この場合、新しいものを作成しました)を、マイグレーションファイルとして生成されます。マイグレーションはモデル(と、データベーススキーマ情報)の変更をファイルとして保存する方法です。
生成されたマイグレーションをファイルpolls/migrations/0001_initial.pyは、ファイルを開いて確認することもできます。
マイグレーションのファイルを作成するたびに、毎回読む必要はありません。
ですが、マイグレーションの変更内容を微調整したいという時は、修正も可能です。Django には、マイグレーションを自動的に実行し、データベーススキーマを更新・管理するためのコマンドがあります。これは
migrateと呼ばれるコマンドで、この後すぐに見ていきます。
その前に、マイグレーションがどんなSQLを実行するのか見てみましょう。
sqlmigrateコマンドはマイグレーションの名前を指定し、実行されるSQLを出力します。$ python manage.py sqlmigrate polls 0001次のような結果が表示されます。
チュートリアルのPostgreSQLの出力BEGIN; -- -- Create model Choice -- CREATE TABLE "polls_choice" ( "id" serial NOT NULL PRIMARY KEY, "choice_text" varchar(200) NOT NULL, "votes" integer NOT NULL ); -- -- Create model Question -- CREATE TABLE "polls_question" ( "id" serial NOT NULL PRIMARY KEY, "question_text" varchar(200) NOT NULL, "pub_date" timestamp with time zone NOT NULL ); -- -- Add field question to choice -- ALTER TABLE "polls_choice" ADD COLUMN "question_id" integer NOT NULL; ALTER TABLE "polls_choice" ALTER COLUMN "question_id" DROP DEFAULT; CREATE INDEX "polls_choice_7aa0f6ee" ON "polls_choice" ("question_id"); ALTER TABLE "polls_choice" ADD CONSTRAINT "polls_choice_question_id_246c99a640fbbd72_fk_polls_question_id" FOREIGN KEY ("question_id") REFERENCES "polls_question" ("id") DEFERRABLE INITIALLY DEFERRED; COMMIT;SQLiteの出力BEGIN; -- -- Create model Question -- CREATE TABLE "polls_question" ( "id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "question_text" varchar(200) NOT NULL, "pub_date" datetime NOT NULL ); -- -- Create model Choice -- CREATE TABLE "polls_choice" ( "id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "choice_text" varchar(200) NOT NULL, "votes" integer NOT NULL, "question_id" integer NOT NULL REFERENCES "polls_question" ("id") DEFERRABLE INITIALLY DEFERRED ); CREATE INDEX "polls_choice_question_id_c5b4b260" ON "polls_choice" ("question_id"); COMMIT;以下のポイントを覚えておいてください
sqlmigrateの出力は、使用しているデータベースによって異なります。- テーブル名はアプリケーションの名前 (
polls) とモデルの小文字表記 のquestionとchoiceを組み合わせて、polls_questionやpolls_choiceのように自動的に生成されます。 (指定することも可能です)- 主キー (primary key, ID) は自動的に追加されます (この挙動もオーバライド可能です)。
- Django は外部キーのフィールド名に "_id"(今回は
question_id) を追加します。(指定することも可能です)- 外部キーリレーションシップは FOREIGN KEY 制約で明確化されます。 DEFERRABLE の部分については心配しないでください。 PostgreSQLに外部キーをトランザクション終了まで強制しないようにするためのものです。
- 使用するデータベースに合わせて、
auto_increment (MySQL)、serial (PostgreSQL)もしくはinteger primary key autoincrement (SQLite)のようなデータベース固有の型が自動的に選択され生成されます。フィールド名のクォーティング (例えば、ダブルクォートにするか、シングルクォートにするか) も同様です。sqlmigrateコマンドはデータベースにマイグレーションは実行されません。実行されるSQLが何であるかをスクリーンに表示するだけです。これはDjangoが何をしようとしているかを確認したり、データベース管理者に変更のためのSQLスクリプトを要求されているときに役に立ちます。もし興味があれば
python manage.py checkを実行することもできます。 これはマイグレーションを作成したりデータベースに影響なく、プロジェクトに何か問題がないか確認します 。
migrateを再度実行し、 Modelで定義したテーブルを作成しましょう。$ python manage.py migrate Operations to perform: Apply all migrations: admin, auth, contenttypes, polls, sessions Running migrations: Rendering model states... DONE Applying polls.0001_initial... OK
migrateコマンドは、未適応のマイグレーションファイルを探索し、データベースに対して実行していきます。
重要なのは、モデルに対して行った変更はデータベースのスキーマに同期するということです。(Djangoはデータベース内の django_migrations テーブルを利用して、マイグレーションの変更履歴を管理しています。)
migrateのポイント
今の段階では、Modelの変更を実施するための3ステップガイドを覚えておいてください
(最低限、ここだけ押さえておけば、問題ないと思います)
- Modelを変更する (models.py のクラスを修正)
- 変更状態のマイグレーションファイルを作成するために
python manage.py makemigrationsを実行します。- データベースに変更を適用するために
python manage.py migrateを実行します。マイグレーションの作成と適用のコマンドが分割されている理由は、マイグレーションをバージョン管理システムにコミットし、アプリとともに配布するためです。これによって、あなたの開発が容易になるだけでなく、他の開発者や本番環境にとって使いやすいものになります。
次回予告
ここまでがdjango チュートリアルのその2 -前篇- でした。
既にdjangoに触れてる人や、多言語に詳しい人ならわかるけど、初めての人にはわかりにくい部分が多いと思います。
本家のチュートリアルに補足情報を盛り込んだ形で記載しているので理解の手助けになれれば幸いです。次回は、はじめての Django アプリ作成、その2の後編について書いていこうと思います。
- 投稿日:2019-08-16T21:08:03+09:00
SymPyでラプラス変換
先駆者様
Qiitaでは
という記事がありました。しかしインターネット上を調べてみるとSymPyなる便利なモジュールがあるようなので、それでラプラス変換をしてみましょう。
ラプラス変換
SymPyのラプラス変換機能を用いるためにはlaplace_transform関数を用います。>>> import sympy as sp >>> s, t = sp.symbols('s, t') >>> w = sp.symbols('w', real=True) >>> sp.laplace_transform(sp.cos(w*t), t, s) (s/(s**2 + w**2), 0, Eq(Abs(periodic_argument(polar_lift(w)**2, oo)), 0))上述の最終行の先頭がラプラス変換結果です。ここでは$\cos (wt)$を変数$t$から変数$s$の関数に変換しています。
ラプラス逆変換
$\frac{s}{s^2+w^2}$が逆変換によって$\cos$関数に戻ることも確認してみましょう。そのためには
inverse_laplace_transform関数を用います。変数$s$から変数$t$への変換であることに留意しましょう。>>> expression = sp.laplace_transform(sp.cos(w*t), t, s) >>> print(expression) (s/(s**2 + w**2), 0, Eq(Abs(periodic_argument(polar_lift(w)**2, oo)), 0)) >>> sp.inverse_laplace_transform(expression[0], s, t) cos(t*w)*Heaviside(t)となり、無事に$\cos$関数に戻ってくることができました。
結言
なんとなく我が家にラプラス変換の本が転がっていたので、「これをPythonで行うにはどうすればよいのか?」という暇つぶし程度に考えていましたが、結果
SymPyの威力を思い知らされた、そんな記事の仕上がりになりました。
- 投稿日:2019-08-16T21:04:43+09:00
Flask で後始末関数が呼ばれる順序
(この記事は私の blog の http://umezawa.dyndns.info/wordpress/?p=7337 の転載です)
概要
Flask で、後始末関数である
teardown_appcontextteardown_requestafter_requestが呼ばれる順序。ググってもそのものズバリがヒットしなかったので。from flask import Flask app = Flask(__name__) @app.after_request def after_request(x): print("after_request") return x @app.teardown_request def teardown_request(x): print("teardown_request") @app.teardown_appcontext def teardown_appcontext(x): print("teardown_appcontext") @app.route("/") def view(): return "" app.run(debug=True, host="0.0.0.0")結果
[umezawa@devubuntu:pts/0 ~]$ python3 flask_teardown_order.py * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 702-370-689 after_request teardown_request teardown_appcontext 192.168.0.4 - - [16/Aug/2019 20:31:53] "GET / HTTP/1.1" 200 -環境
- Ubuntu 18.04 LTS
- Flask 0.12.2
- 投稿日:2019-08-16T21:04:43+09:00
Flask で後始末メソッドが呼ばれる順序
(この記事は私の blog の http://umezawa.dyndns.info/wordpress/?p=7337 の転載です)
概要
Flask で、後始末メソッドである
teardown_appcontextteardown_requestafter_requestが呼ばれる順序。ググってもそのものズバリがヒットしなかったので。from flask import Flask app = Flask(__name__) @app.after_request def after_request(x): print("after_request") return x @app.teardown_request def teardown_request(x): print("teardown_request") @app.teardown_appcontext def teardown_appcontext(x): print("teardown_appcontext") @app.route("/") def view(): return "" app.run(debug=True, host="0.0.0.0")結果
[umezawa@devubuntu:pts/0 ~]$ python3 flask_teardown_order.py * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 702-370-689 after_request teardown_request teardown_appcontext 192.168.0.4 - - [16/Aug/2019 20:31:53] "GET / HTTP/1.1" 200 -環境
- Ubuntu 18.04 LTS
- Flask 0.12.2
- 投稿日:2019-08-16T20:41:40+09:00
ComposerからAIプラットフォームのジョブを起動する
これは何?
前回でつくったカスタムコードトレーニングを、パッケージ化してCloud ComposerのDAGから起動する手順。
準備
Cloud Storageのバケットを作成する。現在、ML Engineの学習処理は東京リージョンにはないので、台湾リージョンで実行する。バケットも台湾リージョンに作成する。
$ PROJECT_ID=<プロジェクトID> $ BUCKET_NAME=${PROJECT_ID}-mlengine $ REGION=asia-east1 $ gsutil mb -l $REGION gs://$BUCKET_NAMEソースコード
ML Engine
前回と同様にアヤメデータの学習をAI Platformのジョブとして登録するが、フォルダ構成を[公式]に準拠したものにする。Githubにアップ済み。
. └── iris ├── setup.py # パッケージ化の設定 └── trainer ├── __init__.py └── task.py # 学習処理本体
scikit-learnのインストール設定をする。setup.pyfrom setuptools import find_packages from setuptools import setup REQUIRED_PACKAGES = ['scikit-learn'] setup( name='iris', version='0.1', install_requires=REQUIRED_PACKAGES, packages=find_packages(), include_package_data=True, )ML EngineはPython2.7系でしか実行できないので、それに合わせる。
task.py# coding:utf-8 import logging from sklearn.svm import SVC from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split def run(): # データの読込 iris = load_iris() # X_train: 特徴量の学習データ # X_test: 特徴量のテストデータ # y_train: ラベルの学習データ # y_test: ラベルのテストデータ X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, train_size=0.8, random_state=0) # 学習 model = SVC() model.fit(X_train, y_train) # テスト print("accuracy:{}".format(model.score(X_test, y_test))) if __name__ == '__main__': logging.info("iris task") run()プロジェクトフォルダでパッケージングする
iris $ python setup.py sdist
distフォルダにiris-0.1.tar.gzがつくられるので、作成したバケットにアップロードする。Cloud Composer
以前の記事を参考に、環境をつくる。
今回はcomposer上で学習処理を実行せずに、ML Engineのジョブを起動するのでMLEngineTrainingOperatorを使ってDAGを作成する。
パラメータのpackage_urisに先程アップロードしたファイルを指定する。iris.pyfrom airflow import DAG from airflow.contrib.operators.mlengine_operator import MLEngineTrainingOperator import datetime default_args = { 'start_date': datetime.datetime(2018, 1, 1), } with DAG( "iris", schedule_interval=None, default_args=default_args) as dag: task = MLEngineTrainingOperator( project_id="<プロジェクトID>", job_id="iris_" + datetime.datetime.now().strftime('%Y%m%d%H%M%S'), package_uris="gs://<ストレージのパス>/iris-0.1.tar.gz", training_args="", region="asia-east1", training_python_module="trainer.task", task_id="iris", python_version=2.7 ) task作成したDAGファイルをcomposerのDAGフォルダにアップロードする。
DAGが作成されたら実行し状態を確認する。
ML Enginieにもジョブが登録されているか確認する。
Cloud Composerはお値段高めなので終わったら削除する。


- 投稿日:2019-08-16T19:40:55+09:00
Watsonで巡回セールスマン問題を解く
はじめに
Watsonで数独を解く! Decision Optimizerを使ってみたに引き続きDecision Optimizerシリーズ第二段です。
今回はあまりにも有名な問題「巡回セールスマン問題」にチャレンジしてみます。巡回セールスマン問題とは
一人のセールスマンが、N箇所の場所を一筆書きで回りたい。この場合に最短時間で回れるコースをどうやってみつけるか?
という問題です。
数学的には「NP困難」と呼ばれる領域の問題で、少しNが大きくなると、調べるべき組み合わせの数が爆発的に増大し、完全解を求められないことがわかっています。より詳しい話は、下記のWikipediaの記事を参照してください。CPLEXの2つのライブラリ
これから、この問題をCPLEXを使って解いていくのですが、その前にCPLEXの2種類のライブラリについて説明しておきます。
Mathematical Programming Modeling (MP) と呼ばれるライブラリと、Constraint Programming Modeling (CP) と呼ばれるライブラリがその2つです。
前回紹介した「数独」は、CPで解く種類の問題です。
前回の記事の最後に紹介した「原油のブレンド問題」は、MPで解く問題となります。違いは、MPの場合は目的関数と呼ばれる関数があり、この関数の値を最大にする組み合わせをみつける問題である点となります。今回解く、巡回セールスマン問題も、移動距離合計という目的関数が存在するのでMPで解くべき問題ということになります。数学的原理
CPLEXで問題を解く場合、制約や目的関数など、数学的な原理を事前に明確にしておく必要があります。
前回紹介した数独では、この原理はほぼ自明なものだったのですが、今回は結構数式としての記述が難しい問題になります。
この点に関しては、下記リンク先の情報を参考にさせてもらいました。http://satemochi.blog.fc2.com/blog-entry-24.html
ただ、条件式に関しては、コードで表現しやすいように、一部同値な式で書き直しています。
($x_{ii} = 0$という制約を付け加えることで、条件式を簡略化した)最終的な数式を書き直すと、次のようになります。
この式の中で$x_{ij}とu_{i}$がどういう意味を持つかについては、下のPythonコードのコメントのところに書いておきましたので、そちらを参照して下さい。
なんとなく$u_iはいらなくてx_{ij}$だけでいいのではという気がするのですが、この変数は、2個以上の小さなループの集合になる解を排除して、全体で一つの大きなループにするために必要な変数です。このことを記述しているのが、制約式の一番最後にある謎の式で、どうしてこれでいいかについては、上のリンク先記事を参照して下さい。$ x_{ii} = 0 $ $(i = 0, 1, .. N-1)$
$ 0 \leqq x_{ij} \leqq 1$ $i\ne j$ $(i, j = 0, 1, .., N-1)$$\displaystyle\sum_{i=0}^{N-1} x_{ij} = 1$ $(j = 0, 1, .. N-1)$
$\displaystyle\sum_{j=0}^{N-1} x_{ij} = 1$ $(i = 0, 1, .. N-1)$$ u_0 = 0$
$ 1 \leqq u_i \leqq N-1$ $(i = 1, 2, .., N-1)$$u_i - u_j + N \cdot x_{ij} \leqq N-1$ $(i, j = 0, 1, .., N-1)$
また、目的関数は次の式になります。
$ cost = \displaystyle\sum_{i=0}^{N-1}\displaystyle\sum_{j=0}^{N-1}
c_{ij}x_{ij}
$Jupyter Notebookコード
ここまでの準備ができれば、後は上の数式をPython APIで表現するだけです。
実装コードの全体は、
https://github.com/makaishi2/sample-data/blob/master/notebooks/TSP.ipynb
にアップしてあります。また、前の記事のようにURL指定でWatson StudioのJupyter Notebookにロードする場合は、次のURLを指定して下さい。
https://raw.githubusercontent.com/makaishi2/sample-data/master/notebooks/TSP.ipynb
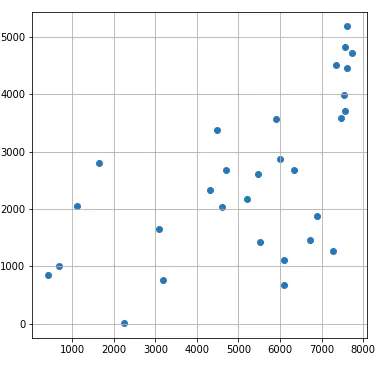
結果概要
オリジナルデータは48件分あります。
Notebookのコードでは、変数Nの設定で、このうち何件分のデータで最適化を行うか、指定できるようになっています。
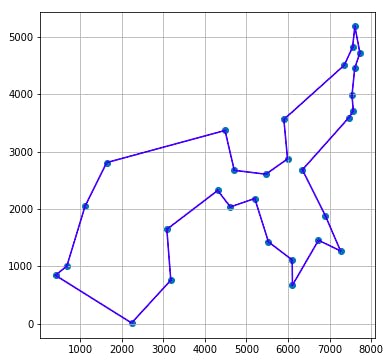
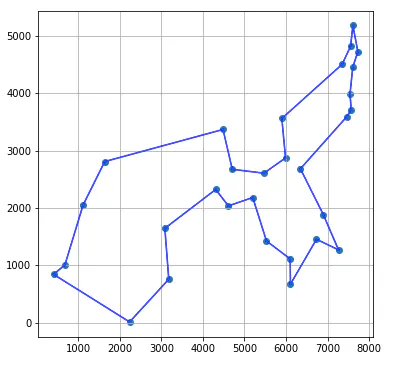
かかった時間は25件の場合で約10秒、30件の場合で約4分弱でした。30件の場合の元データ散布図と、それに対してCPLEXが示した解によるルート図を以下に示します。
コード解説
いつものようにコードの簡単な解説を以下に示します。
問題データのロード
ライブラリロード
# ライブラリのロード import numpy as np import pandas as pd import matplotlib.pyplot as plt from IPython.display import displayデータのロード
オリジナル問題の48件分のデータを、githubからロードする作りにしました。
# データのロード # 48件は巡回セールスマン問題のオリジナルデータです url = 'https://raw.githubusercontent.com/makaishi2/sample-data/master/data/att48.csv' df = pd.read_csv(url) display(df.head()) print('size = ', df.values.shape)下の図のような結果が返ってくるはずです。
対象項目絞り込み
Nの変数設定で、分析対象項目の絞り込みを行います。絞り込んだ結果に関しては散布図表示しています。
# 対象項目数 # N = 25 は10秒程度で解決 # N = 25 # N=30 は4分弱かかる N = 30 # これ以上の値での結果は未確認 # 絞り込んだデータを使って、初期化と散布図表示 data = df[:N] data_np = np.array(data) plt.figure(figsize=(6,6)) plt.scatter(data_np[:,0], data_np[:,1]) plt.grid() plt.show()コスト配列の作成
任意のノード間のコストの配列(c)を座標値から計算します。
下の例では便宜上ユークリッド距離にしていますが、この距離の値をGoogle APIなど利用して2点間の実距離に差し替えれば、そのままリアルな最適化問題として使えるかと思います。# 距離関数の定義 # 便宜上ユークリッド距離にしています def distance(i, j): return np.sqrt(np.sum((data_np[i,:] - data_np[j,:])** 2)) # コスト配列の定義 c = np.zeros((N,N)) for i in range(N): for j in range(N): c[i, j] = distance(i, j)CPLEX APIによる問題定義
ここから先は、CPLEX APIを利用した、問題定義となります。
環境の確認
最初に次のAPI呼出しで、環境を確認してみます。
# CPLEX環境の確認 from docplex.mp.environment import Environment env = Environment() env.print_information()手元の環境では、次のような結果になりました。
* system is: Linux 64bit * Python version 3.6.8, located at: /opt/conda/envs/Python36/bin/python * docplex is present, version is (2, 10, 150) * CPLEX library is present, version is 12.9.0.1, located at: /opt/conda/envs/Python36/lib/python3.6/site-packages * pandas is present, version is 0.24.1モデルの定義
最初にモデルインスタンスの定義を行います。TSPは「Traveling Salesman Problem」の略です。
# モデルの宣言 from docplex.mp.model import Model mdl = Model(name="TSP")モデルパラメータの設定
モデルに対しては必要に応じてパラメータ設定ができるようです。下記のサンプルではスレッド数(MAXは2のようです)と最大時間数を設定しています。
(他にどんなことができるかは現在調査中)# モデルのパラメータ定義 # スレッド数: 2 mdl.parameters.threads = 2 # 最大時間数: 600秒 mdl.parameters.timelimit = 600決定変数の宣言
次は決定変数の宣言です。
決定変数が行列型のxと配列型のuの二種類を宣言します。それぞれの意味・目的はコメントに記載しておきました。# 決定変数の宣言 # x : 移動matrix # i番目のノードからj番目のノードに移動する時 x_ij = 1 # それ以外の場合 x_ij = 0 x = mdl.integer_var_matrix(N, N) # u: 順序変数 # 0番目のノードの次に移動するノードがiの場合 # u[i] = 1 # その次に移動するノードがiの場合 # u[j] = 2 # .. のように定義する u = mdl.integer_var_list(N)制約の定義
次に制約の定義を行います。
元になる数式は、前の節に記載しておきましたので、そちらを参照して下さい。# u(順序変数)の制約 # 最初のノードは0番目 : u[0] = 0 # それ以外の順序変数は1以上 N-1以下 mdl.add_constraint(u[0] == 0) for i in range(1, N): mdl.add_constraint(u[i] >= 1) mdl.add_constraint(u[i] <= N-1) # x(移動matrix)の制約 # 自分から自分への移動はないので、u_ii = 0 # それ以外の場合は u_ij は0か1 for i in range(N): for j in range(N): if i == j: mdl.add_constraint(x[i, j] == 0) else: mdl.add_constraint(x[i, j] >= 0) mdl.add_constraint(x[i, j] <= 1) # x(移動matirx)に関する縦の制約 for i in range(N): mdl.add_constraint(mdl.sum(x[i, j] for j in range(N)) == 1) # x(移動matirx)に関する横の制約 for j in range(N): mdl.add_constraint(mdl.sum(x[i, j] for i in range(N)) == 1) # 部分路制約 # ループが全体で1つであるための条件 # 参考リンク http://satemochi.blog.fc2.com/blog-entry-24.html for i in range(1, N): for j in range(1, N): mdl.add_constraint(u[i] - u[j] + N * x[i,j] <= N -1)最適化関数の定義
最後に最適化関数の定義を行います。
# 総移動コスト total_cost = mdl.sum(c[i, j] * x[i, j] for i in range(N) for j in range(N)) # 最適化の定義 mdl.minimize(total_cost)設定の確認
これでモデルの記述は全部終わりました。
最後にprint_information関数で、記述のサマリーを確認します。# 制約設定の確認 mdl.print_information()下記のような結果が返ってくるはずです。
Model: TSP - number of variables: 930 - binary=0, integer=930, continuous=0 - number of constraints: 2730 - linear=2730 - parameters: defaults - problem type is: MILP元のノード数が30個の場合で、決定変数の数が930個、制約の数は2730個になっています。
これはとても人間の力では解けないので、ツールにお任せするしかなさそうです。問題を解く
いよいよ
solve関数を呼び出して、問題を解きます。
今回は、log_outputのオプションも付けて、途中経過の表示も行ってみましょう。# 問題を解く # ログ出力をONにして、詳細情報も表示します mdl.solve(log_output = True) mdl.report()下記のような結果が返ってくるはずです。
WARNING: Number of workers has been reduced to 2 to comply with platform limitations. CPXPARAM_Read_DataCheck 1 CPXPARAM_Threads 2 Tried aggregator 1 time. MIP Presolve eliminated 1858 rows and 31 columns. MIP Presolve modified 1624 coefficients. Reduced MIP has 872 rows, 899 columns, and 4176 nonzeros. Reduced MIP has 870 binaries, 29 generals, 0 SOSs, and 0 indicators. Presolve time = 0.01 sec. (3.03 ticks) Probing time = 0.01 sec. (2.90 ticks) Tried aggregator 1 time. Reduced MIP has 872 rows, 899 columns, and 4176 nonzeros. Reduced MIP has 870 binaries, 29 generals, 0 SOSs, and 0 indicators. Presolve time = 0.01 sec. (3.18 ticks) Probing time = 0.01 sec. (2.89 ticks) Clique table members: 466. MIP emphasis: balance optimality and feasibility. MIP search method: dynamic search. Parallel mode: deterministic, using up to 2 threads. Root relaxation solution time = 0.00 sec. (1.41 ticks) Nodes Cuts/ Node Left Objective IInf Best Integer Best Bound ItCnt Gap * 0+ 0 86255.7609 0.0000 100.00% 0 0 18184.3571 62 86255.7609 18184.3571 51 78.92% 0 0 20769.9760 72 86255.7609 Cuts: 93 94 75.92% 0 0 20848.4887 72 86255.7609 Cuts: 45 126 75.83% 0 0 20848.4887 72 86255.7609 Cuts: 43 141 75.83% 0 0 20848.4887 71 86255.7609 Cuts: 15 152 75.83% * 0+ 0 41843.4590 20848.4887 50.18% 0 2 20848.4887 71 41843.4590 20848.4887 152 50.18% Elapsed time = 0.18 sec. (85.35 ticks, tree = 0.02 MB, solutions = 2) * 141 109 integral 0 32550.0557 20852.8478 1158 35.94% * 239+ 162 32483.1076 20859.3823 35.78% * 246 187 integral 0 32154.2342 20859.3823 1971 35.13% (途中略) 325448 20165 cutoff 25354.1056 25157.6747 2674217 0.77% 334254 15022 cutoff 25354.1056 25192.3348 2742881 0.64% 343461 8762 cutoff 25354.1056 25244.3208 2809424 0.43% Elapsed time = 221.50 sec. (173320.15 ticks, tree = 7.03 MB, solutions = 19) GUB cover cuts applied: 22 Clique cuts applied: 12 Cover cuts applied: 22 Implied bound cuts applied: 15 Flow cuts applied: 1 Mixed integer rounding cuts applied: 102 Zero-half cuts applied: 41 Multi commodity flow cuts applied: 1 Lift and project cuts applied: 21 Gomory fractional cuts applied: 22 Root node processing (before b&c): Real time = 0.19 sec. (85.04 ticks) Parallel b&c, 2 threads: Real time = 225.75 sec. (176705.75 ticks) Sync time (average) = 3.91 sec. Wait time (average) = 0.12 sec. ------------ Total (root+branch&cut) = 225.94 sec. (176790.79 ticks) * model TSP solved with objective = 25354.106詳細の確認
get_solve_details関数で、解の詳細を確認してみます。# 詳細情報の表示 print(mdl.get_solve_details())こんな結果が返ってくるはずです。
status = integer optimal, tolerance time = 225.95 s. problem = MILP gap = 0.00996211%結果のグラフ表示
最後に見つかった解を散布図上に表示してみましょう。
# 結果の取得 indexes = [u[i].solution_value for i in range(N)] matrix = [[x[i, j].solution_value for j in range(N)] for i in range(N)] ar = np.array(matrix) # 結果の散布図上での表示 data_np = np.array(data) plt.figure(figsize=(6,6)) plt.scatter(data_np[:,0], data_np[:,1]) for i in range(N): for j in range(N): if ar[i, j] == 1: plt.plot(data_np[[i,j],0], data_np[[i,j],1], c='b') plt.grid() plt.show()下記のようなグラフが表示されれば成功です。お疲れ様でした。

- 投稿日:2019-08-16T19:28:43+09:00
IPアドレスからAS番号を調べる方法
IPアドレスからAS番号(ASN:Autonomous System number)を調べる方法のメモ。
・whoisを使う方法
・GeoIP2のISPデータベース(有料)を使う方法
・ipinfo.ioを使う方法(参考: IPからAS番号を簡単に調べる方法)whois
まずはwhoisのインストール。
Ubuntuの場合$ sudo apt install whois下記のコマンドでAS番号を含むIPアドレスの情報を取得できる。
$ whois -h whois.radb.net IP_ADDRESS # IP_ADDRESSを任意のIPアドレスに置換このままだと、AS番号以外の情報も含まれてしまうので、出力を整形する。
awkがインストールされてない場合は、$ sudo apt-get install gawkでインストール。$ whois -h whois.radb.net IP_ADDRESS | grep 'origin:' | head -1 | awk '{print $2}'実行例(8.8.8.8)$ whois -h whois.radb.net 8.8.8.8 | grep 'origin:' | head -1 | awk '{print $2}' AS15169GeoIP2 ISP Database
有料版のGeoIP2 ISP DatabaseでもAS情報を取得できます。
ローカルにデータベースファイル(.mmdb)を保存して読み込む形式なので、whoisに問い合わせるよりも高速です。
ただ、定期的にデータベースファイルをアップデートする必要があります。ここでは、Python3からGeoIP2データベースファイルを読み込んでAS情報を取得するサンプルスクリプトを紹介します。
sample.py#!/usr/bin/python3 import geoip2.database DB_PATH = "/xxx/GeoIP2-ISP.mmdb" # GeoIP2-ISP.mmdbのパスを指定 # 引数: IPアドレス # 戻り値: AS番号, ASの組織名 def get_asn_geoip2(ip:str) -> tuple: reader = geoip2.database.Reader(DB_PATH) response = reader.isp(ip) asn = "AS" + str(response.autonomous_system_number) as_org = response.autonomous_system_organization return asn, as_orgipinfo.io
参考: IPからAS番号を簡単に調べる方法
ipinfo.ioからAS番号を調べる方法もあるようです。
無料の場合、投げられるクエリ数に制限があります。$ curl ipinfo.io/8.8.8.8/org AS15169 Google LLC
- 投稿日:2019-08-16T19:11:33+09:00
Python 棒の切り分け
問題
長さn[cm]の1本の棒を1[cm]単位に切り分けることを考えます。
ただし1本の棒を一度に切ることができるのは1人だけです。
切り分けられた棒が3本あれば、同時に3人できることができます。
最大m人の人がいるとき、最短何回で切り分けられるかを求めてください。
例えば、n = 8, m = 3の時は下図のようになり、
4回で切り分けることができます。n=8、m=3の場合.1回目 |1|2|3|4||5|6|7|8| 2回目 |1|2||3|4| |5|6||7|8| 3回目 |1||2| |3||4| |5||6| |7|8| <= 3人しかいないので1ヶ所残る 4回目 |1| |2| |3| |4| |5| |6| |7||8| |1| |2| |3| |4| |5| |6| |7| |8|問題1
n = 20, m = 3の時の回数を求めてください。
問題2
n = 100, m = 5の時の回数を求めてください。引用「プログラマ脳を鍛える数学パズル 著者 長井 敏克」
回答
answer_1.pydef cutbar(m, n, current, count): if current >= n: print("Count:", count) elif current < m: count += 1 current = current * 2 cutbar(m, n, current, count) else: count += 1 current += m cutbar(m, n, current, count) count = 0 cutbar(3, 20, 1, count) # Count: 8 cutbar(5, 100, 1, count) # Count: 22answer_2.pydef cutbar(m, n): count = 0 current = 1 while n > current: current += current if current < m else m count = count + 1 print(count) cutbar(3, 20) # Count: 8 cutbar(5, 100) # Count: 22つまづいたところ
ずばり
current += mや
current += current if current < m else mのような、
なぜcurrent(棒の本数)にm(人数)などを足すのかということですね。
最後は無理やりおちつかせた形になりました・・・原因としては、
問題を読んだはじめの印象が「どんどん棒の本数を倍にしていくんだな」というもので、
それに最後まで引っ張られてしまいました。確かに
answer_1.pyでは、途中まで棒の本数を倍にし続けます。
しかし、棒の本数が人数を超えたあとは、
棒の本数がn(cm)を超えるまでm(人数)をひたすら足し続けるような処理内容でした。
answer_2.pyに至っては、棒の本数を倍するなど全くせず、
本数か人数を足していくような処理内容です。
結局、「こういうものなんだな」に近いような感じで自分を納得させました。
再帰や三項演算子を使う機会となったのは、いい経験になりました。
今後自然に書けるようになって行きたいです。以上、ご拝読ありがとうございました。
- 投稿日:2019-08-16T18:06:19+09:00
anacondaをインストールしたのにcondaコマンドがなかった
とっくのとうにAnacondaはインストールされていたが...
いかんせん私のMacは大昔に環境構築をし、そこにさらに増築に増築を重ねて、とっ散らかった状態でした。
とりあえずターミナルでcondaとタイプだ
zsh: command not found: condaおやおや、穏やかではありませんねぇ...
.zshrcを確認
...結論からいうと、condaに関する記述がありませんでした。素直にPATHを通しましょう。
具体的な記述
% echo "source ~/anaconda3/etc/profile.d/conda.sh" >> ~/.zshrcこの後
% source .zshrcで.zshrcの内容を反映させましょう。
確認
% conda --version conda 4.5.4これでcondaコマンドがターミナルから使用できるようになりました。
- 投稿日:2019-08-16T17:56:28+09:00
LeetCode / Single Number
(ブログ記事からの転載)
昨夜実家の富山から帰ってきました。
台風さんがフェーン現象を巻き起こしたせいで、北陸は地獄のような気候になってます。
私が兼ねてから主張している国民総打ち水法の制定を真摯に考えるべきかと思います![https://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A7%E3%83%BC%E3%83%B3%E7%8F%BE%E8%B1%A1:embed:cite]
さて、今日の問題。
[https://leetcode.com/problems/single-number/]
Given a non-empty array of integers, every element appears twice except for one. Find that single one.
Note:
Your algorithm should have a linear runtime complexity. Could you implement it without using extra memory?
Example 1:
Input: [2,2,1]
Output: 1Example 2:
Input: [4,1,2,1,2]
Output: 4からでは内intのlistに対して、1つだけ存在する1度しか登場しない要素を返す問題です。
事実上、NoteのYour algorithm should have a linear runtime complexity. Could you implement it without using extra memory?に対して回答できるかどうかの問題と読み替えて良いと思います。解答・解説
自力ではextra memoryを使う解法しか思いつかなかったので、まずは2つ示します。
解法1
誰でも思いつく(けどこれじゃ問題の意味がないと気づいて書かない)コードを、一応載せておきます。
class Solution: def singleNumber(self, nums: List[int]) -> int: ans = [] for n in nums: if n in ans: ans.remove(n) else: ans.append(n) return ans[0]解法2
こちらの解法は少し難易度が上がるでしょうか。
まずはsetで集合をとり、重複した要素を排除します。この集合の合計値の2倍と、元のlistの差分が答えになります。class Solution: def singleNumber(self, nums: List[int]) -> int: return sum(set(nums))*2 - sum(nums)しかし、set(nums)によって空間計算量が$O(n)$に達するのは変わりません。
解法3
さて、extra memoryを使わない解法ですが、ビット演算子のXOR(排他的論理和)を使います。
XORは、2つの入力のどちらか片方が真でもう片方が偽の時には結果が真となり、両方とも真あるいは両方とも偽の時は偽となる演算のことです。
例えば、以下のように計算されます。>>> 1 ^ 3 2 # 3は2進数で11、1は2進数で01。これのXORは10で、10進数にすると2このXORを利用して、以下のような解法が成立します。
class Solution: def singleNumber(self, nums: List[int]) -> int: for i in range(1,len(nums)): nums[0] ^= nums[i] return nums[0]これは何をしているかというと、全要素についてXORをとっています。
nums = [2,1,4,5,2,4,1]であれば 2 ^ 1 ^ 4 ^ 5 ^ 2 ^ 4 ^ 1 を計算するわけですが、このとき、
- a = bのとき、 a ^ b = 0
- a ^ b = b ^ a
の性質を利用すると、以下のように計算され、解が得られます。
-> 2 ^ 1 ^ 4 ^ 5 ^ 2 ^ 4 ^ 1 => 2 ^ 2 ^ 1 ^ 1 ^ 4 ^ 4 ^ 5 => 0 ^ 0 ^ 0 ^ 0 ^ 5 => 0 ^ 5 => 5
- 投稿日:2019-08-16T17:55:47+09:00
[Python] 文字列の"True"/"False"をboolとして判別する
True/False
Python で文字列の
"True"と"False"を bool 型として判定したいときに、どうすればいいか考えていました1。要件としてはこんな感じで:
- 型が文字列だったら、文字列の内容で
True/Falseを判定する- それ以外の型だったら、組み込み関数
bool()に渡して判定してもらういちおう書けたのですが、もっといい方法がありそうな気も……。
def is_true(bexp): if type(bexp) == str: return bexp.lower() in ('true', 'yes', 'on', 'enable') return bool(bexp)これはこれで、コンパクトにまとまっているので、まあいいかな。どの文字列を
True扱いにするのかも分かりやすいですし。追補
渡すものが文字列と決まっていて(
Noneもないなら)、かつTrueに絞るなら、もっとずっとシンプルになりますね。result = bool_string.lower() == 'true'ちょっと分かりにくい??
ふと思いついて試してみた
bool('False')はTrueになったのでした。 ↩
- 投稿日:2019-08-16T17:55:47+09:00
Pythonで文字列の"True"/"False"をboolとして判別する
True/False
Python で文字列の
"True"と"False"を bool 型として判定したいときに、どうすればいいか考えていました1。要件としてはこんな感じで:
- 型が文字列だったら、文字列の内容で
True/Falseを判定する- それ以外の型だったら、組み込み関数
bool()に渡して判定してもらういちおう書けたのですが、もっといい方法がありそうな気も……。
def is_true(bexp): if type(bexp) == str: return bexp.lower() in ('true', 'yes', 'on', 'enable') return bool(bexp)これはこれで、コンパクトにまとまっているので、まあいいかな。どの文字列を
True扱いにするのかも分かりやすいですし。追補
渡すものが文字列と決まっていて(
Noneもないなら)、かつTrueに絞るなら、もっとずっとシンプルになりますね。result = bool_string.lower() == 'true'ちょっと分かりにくい??
追補2
コメントで、速くて見やすいコードをいただきました!
ありがとうございます! @shiracamusdef is_true(value): return False if value == 'False' else bool(value)今は修正されて見られなくなっていますが、
evalを使うのは盲点でした。eval('True')変な値が入ると落ちますが、渡す値が確実に
"True"/"False"の2値なら、スマートで素敵です。>>> eval('True') True >>> eval('true') Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<string>", line 1, in <module> NameError: name 'true' is not defined
ふと思いついて試してみた
bool('False')はTrueになったのでした。 ↩
- 投稿日:2019-08-16T17:46:55+09:00
pythonでWebサイトに自動ログイン
はじめに
pythonを使用してWebサイトに自動ログインするプログラムを作ってみました。
seleniumを使用。
geckodriverを使用してFireFoxを制御します。複数のサイトにログインすることを想定して作成してます。
1サイト目は、ログイン後にボタン押下が必要なサイトを想定。対象の検索してクリック。
2サイト目は新規タブで開いてログイン。なお、投稿者は、pythonを勉強して日が浅いです。
Qiitaの投稿も初です。技術レベルは低いです。環境
OS 言語 ブラウザ windows10 python3.7 FireFox 事前準備
driverの入手
ドライバーを下記から入手する。
https://github.com/mozilla/geckodriver/releases入手したdriver(geckodriver.exe)をpathが通っている場所に配置
PCの環境設定とかする。省略。
seleniumuのインストール
pip install selenium
コーディング
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import TimeoutException browser = webdriver.Firefox() type(browser) #Webサイト1 ユーザー名・パスワード入力欄はtextBoxでid有り browser.get('Webサイト1') usr_name_el = browser.find_element_by_id('対象のID') usr_name_el.send_keys('ユーザー名') usr_pass_el = browser.find_element_by_id('対象のID') usr_pass_el.send_keys('パスワード') usr_pass_el.submit() #ログイン後、あるボタンを押してトップページ遷移させたいサイトのため下記コード。 aタグでクラス名有り WebDriverWait(browser, 30).until(EC.presence_of_element_located((By.CLASS_NAME, "対象のクラス名"))) link_el = browser.find_element_by_class_name("対象のクラス名") type(link_el) link_el.click() #Webサイト2 #ユーザー名入力欄はtextBoxでid有り、パスワードはidとclassが無いのでxpathで検索 browser.execute_script( 'window.open()' ) #新規タブ開く browser.switch_to.window(browser.window_handles[-1]) #新規タブに移動 browser.get('Webサイト2') usr_name_el = browser.find_element_by_id('対象のID') usr_name_el.send_keys('ユーザー名') usr_pass_el = browser.find_element_by_xpath('対象のパス。開発者ツールからコピーするのが楽') usr_pass_el.send_keys('パスワード') usr_pass_el.submit()参考にしたもの
要素の見つけ方
https://selenium-python.readthedocs.io/locating-elements.htmlおわりに
プログラムでブラウザの制御が思ったより簡単に出来たので、
仕事で毎日ログインするようなサイトの自動化をしてみようと思います。
- 投稿日:2019-08-16T17:07:36+09:00
Python プログラミング ワークショップ - 超々入門編 Vol.1
本題の前に
位置付け・前提
本記事は、社内ワークショップ のために用意したものです。そのため、次の前提で進めることをご理解ください。
本ワークショップの目的
参加者が必要に併せて自学できる入口に立つ ことを目的とします。
- 実用的なプログラミングを ハンズオン形式 で実行して、理解を深めます。
- 本ワークショップだけで、あらゆるプログラムがすいすい組めるようになるわけではありません。
- 後日にプログラミングで何かを作ろうとしたときに、自分で調べて製作できるようになることを目指します。
- なんかこういうもんだ、という感じで軽く頭に残れば大丈夫と考えましょう。
ワークショップの進め方
ワークショップは、基本的にハンズオンを中心に進めます。(一部解説は入れます)
- ご自分の業務用途のパソコンを利用してください。
- 基本的には「写経」を原則とします。
- 写経 = 自分でキー入力して写すこと ≠ コピペ
- 書き方を頭の中に入力する/刷り込むつもりで、時間がかかっても全て手でキー入力してください。
- IMEの入力補完はOK。
- 入力間違いによるトライ・アンド・エラーも、学習の中での重要な要素とご理解ください。
- 紹介する内容は、基本的には分からないものです。一度すべて動作させてから「あー、あんな感じか」とニュアンスを掴んでください。
- 深く悩んではいけません。
注意
本ワークショップは 60〜120分 を想定しています。そのため、本格的な学習には時間が圧倒的に足りないので、体系的な学習は行いません。
本格的に0から思い通りのプログラムが組めるようになるには、自学習もしくは何らかの講座を受講する必要があります。
ターゲット
本ワークショップでは、主に下記の参加者を対象とします。
- プログラミングを本業としない人
- プログラミングが苦手、あるいは実用的なプログラムを組んだことが無い人
- プログラミングの基礎的なことを知らない初心者
中上級者はまったく相手にしていないため、敢えて言及しない事項が沢山あることについてはご了承ください。
プログラミング環境の準備
次のどちらかをインストールしてください。時間的な余裕がある方は、Anaconda をインストールしてください。
注意:両方インストールする必要はありません
Python 3.7
- 「Download Python 3.7.4」リンクからインストールしてください。
- 執筆時点では、3.7.4 が最新
- こちらはシンプルです。
- エディタとコマンドプロンプトでプログラミングする必要があります。
- 慣れたエディタを使い方は、こちらが良いです。
Anaconda
- 「Download」リンクからインストールしてください。
- 執筆時点では、3.7 が最新
- Python + 色々詰め込んだパッケージソフトウェア集
- こちらは少しデータが大きいです。
- プログラミング専用の総合環境(IDE)やパッケージ管理ツールが付属します。
- こちらを選んだ方は、同梱される Spyder という統合を使用することを推奨します。
- 細かい使い方は説明しません。上記のリンクに加え、コチラが参考になります。
本日のゴール
インターネットから特定のページをダウンロードして、ファイルに保存するプログラムを作れるようになること。
可能であれば、書いた内容については後から正しく理解してください。ただし、完璧に覚える必要はありません。
ハンズオン開始
ハンズオン1
ハンズオン1-1. 文字を表示するスクリプトを作る
c:\scriptフォルダを作成し、次のスクリプトを exp01.py という名前で保存しなさい。
exp01.pyprint("Hello World!")
ハンズオン1-2. 文字を表示するスクリプトを実行する
コマンドプロンプトで、下記のようにスクリプト exp01.py を実行しなさい。(Spyder なら「ファイル実行」ボタン もしくは「F5」キー)
cd c:\script python exp01.py実行結果が下記ならOK。
Hello World!
解説1
プログラミングのおやくそく1
- 基本的に 上から一行ずつ実行 します。
- プログラミングとは、「プログラムを書く → 実行する → 誤ったところを修正する → 再実行する」を繰り返すのが基本です。
- なるべく読みやすく、短く書ければ書けるほど良いです。
- 最初はルールを暗記しないこと。慣れるまでは、後でググれるように練習していくのが近道です。
今回は「Python(パイソン)」というプログラミング言語(プログラミングの書き方)を扱いますが、大抵のプログラミングの学習に共通します。
ハンズオン1-1 解説
文字を表示するために、下記の命令をプログラムとして保存しました。
print("{表示したい内容}")また、プログラムを書いた時点では、まだ内容が誤っていても分かりません。
ハンズオン1-2 解説
今回扱うプログラミング言語「Python」で書いたプログラムをコマンドプロンプトで実行しました。
python {実行したいスクリプトファイルのパス}今回は画面上に表示して終わりです。ファイルなどには保存されません。
ハンズオン2
ハンズオン2-1. 文章を使い回して表示する
c:\scriptフォルダに、次のスクリプトを exp2-1.py という名前で保存しなさい。
exp2-1.pyTEXT = "Hello World!" print(TEXT) print(TEXT)大文字小文字に注意してください。
次にコマンドプロンプトで、下記のようにスクリプト exp2-1.py を実行しなさい。(Spyder なら「ファイル実行」ボタン もしくは「F5」キー)
cd c:\script python exp2-1.py実行結果が下記ならOK。
Hello World! Hello World!
ハンズオン2-2. 文章をファイルに保存する
c:\scriptフォルダに、次のスクリプトを exp2-2.py という名前で保存しなさい。
exp2-2.pyTEXT = "Hello World!" file = open("hello.txt", "w") file.write(TEXT) file.close大文字小文字に注意してください。
次にコマンドプロンプトで、下記のようにスクリプト exp2-2.py を実行しなさい。(Spyder なら「ファイル実行」ボタン もしくは「F5」キー)
cd c:\script python exp2-2.py実行結果が下記ならOK。
何も表示されない、というのが正常です。
もし何か表示されたら誤っています。
解説2
プログラムのおやくそく2
ここでは「変数」と「ファイルの扱い方」を実演しました。
「変数」は、プログラミングの基本中の基本です。書き方は違っても、プログラミングなら必ず出てきます。
「変数」は、今回は「何かに付けた別名」と覚えてください。
また、「ファイルの扱い方」もプログラミング言語によって違いが多少ありますが、考え方はほとんど同じです。
以降の解説で詳しく説明します。
ハンズオン2-1 解説
今回は、"Hello World"というテキスト(文章)に「TEXT」という別名をつけました。
これをプログラムで現すとこうなります。
(抜粋)exp2-1.pyTEXT = "Hello World!"これを「変数に入れる」と言ったりします。とてもとてもよく出てきます。
この「変数」のメリットは沢山ありますが、ここでは「長い文章を毎回書かずに、短い別名で使いまわせる」ことがメリットになります。
ハンズオン2-2 解説
プログラミングの変わったルールとして、ファイルは一度必ず変数に入れないと扱えない というルールがあります。
そのため、ハンズオン2-2では一度ファイルを変数 file に入れています。
(抜粋)exp2-2.pyfile = open("hello.txt", "w")これはファイルへ書き込む時の定型的な書き方です。
(書き方)open.py{変数} = open("{ファイルパス}", "w")こういうもんだ、と理解してください。
次に、ファイルに書き込みます
(抜粋)exp2-2.pyfile.write(TEXT)こうすると、ファイルの変数 file に対して、変数 TEXT の中身を書き込むという処理になります。
(書き方)write.py{ファイルの変数}.write({書き込みたいこと})
最後に、ファイルを閉じます。
(抜粋)exp2-2.pyfile.closeこのように書き込んだら閉じないと、正常に書き込まれなかったり、実行したパソコンのメモリ上にゴミが残ってしまって不具合の元になったりします。
(書き方)close.py{ファイルの変数}.close
ファイルの書き込みは、開く → 書く → 閉じるの順に処理します。
パソコンのアプリケーションで、ファイルを編集するのと同じですね。
ハンズオン3
ハンズオン3-0 準備
簡単にインターネットからダウンロードするモジュールをインストールします。
コマンドプロントから、下記のコマンドを実行してください。
pip install requestsPythonの便利ツール(モジュールやライブラリと呼ぶ)を、新たに追加する手順です。
今回はプログラムを簡単にするために使用します。
ハンズオン3-1. インターネットのデータを表示する
c:\scriptフォルダに、次のスクリプトを exp3-1.py という名前で保存しなさい。
exp3-1.pyimport requests URL = "https://example.com/" RESULT = requests.get(URL) print(RESULT.text)大文字小文字に注意してください。
次にコマンドプロンプトで、下記のようにスクリプト exp3-1.py を実行しなさい。(Spyder なら「ファイル実行」ボタン もしくは「F5」キー)
cd c:\script python exp3-1.py実行結果が下記ならOK。
3-1.html<!doctype html> <html> <head> <title>Example Domain</title> <meta charset="utf-8" /> <meta http-equiv="Content-type" content="text/html; charset=utf-8" /> <meta name="viewport" content="width=device-width, initial-scale=1" /> <style type="text/css"> body { background-color: #f0f0f2; margin: 0; padding: 0; font-family: "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif; } div { width: 600px; margin: 5em auto; padding: 50px; background-color: #fff; border-radius: 1em; } a:link, a:visited { color: #38488f; text-decoration: none; } @media (max-width: 700px) { body { background-color: #fff; } div { width: auto; margin: 0 auto; border-radius: 0; padding: 1em; } } </style> </head> <body> <div> <h1>Example Domain</h1> <p>This domain is established to be used for illustrative examples in documents. You may use this domain in examples without prior coordination or asking for permission.</p> <p><a href="http://www.iana.org/domains/example">More information...</a></p> </div> </body> </html>取得したWEBページのデータ(HTML)が表示されました。
ハンズオン3-2 ダウンロードして保存する
c:\scriptフォルダに、次のスクリプトを exp3-2.py という名前で保存しなさい。
exp3-2.pyimport requests URL = "https://example.com/" RESULT = requests.get(URL) file = open('exp.html', 'w'); file.write(RESULT.text) file.close()大文字小文字に注意してください。
次にコマンドプロンプトで、下記のようにスクリプト exp3-2.py を実行しなさい。(Spyder なら「ファイル実行」ボタン もしくは「F5」キー)
cd c:\script python exp3-2.py実行結果が下記ならOK。
何も表示されないのが正解です。何か表示されると誤りです。修正してください。
あとは保存した exp.html を開いて、正常に表示されるかを確認してください。
解説3
ハンズオン3-1 解説
こちらでは、インターネットからファイルをダウンロードする方法を紹介しています。
あらかじめインストールした、requestsモジュールを使えるようにした箇所がこちらです。
(抜粋)exp3-1.pyimport requests
そして、そのrequestsモジュールを使って、ダウンロード(GET)する処理がこちらです。
(抜粋)exp3-1.pyURL = "https://example.com/" RESULT = requests.get(URL)あらかじめ変数 URL に対して、実際に接続するURLを入れました。そのURLに対してダウンロードを仕掛けています。
そして、そのダウンロードした結果は、変数 RESULT に入れています。
通常は、このような書き方をします。
(書き方)requests_get.py{結果を入れる変数} = requests.get({URLのテキスト})
そして、ダウンロードできた内容(テキスト)を表示する処理がこちらになります。
(抜粋)exp3-1.pyprint(RESULT.text)変数RESULT には、ダウンロードした結果データが沢山入っています。その中から内容(テキスト)だけを表示します。
RESULT ではなく、RESULT.text とするところがポイントです。
ちなみに、RESULT.status_code とすると、HTTPステータスコードが表示できます。(正常なら 200 が表示される)
ハンズオン3-2 解説
最後は、これまでのハンズオンの総まとめになります。
ハンズオン3-1 と違って、ダウンロードした内容(HTML)をファイルに保存します。
(抜粋)exp3-2.pyfile = open('exp.html', 'w'); file.write(RESULT.text) file.close()この内容は ハンズオン2-2 とほぼ同じです。
保存する対象が RESULT.text、つまりはダウンロードしたテキストデータになっている点だけです。
ハンズオン3-2 は実用的
ハンズオン3-2 のスクリプトは、URLとファイルパスを変更すれば実用的に使えます。
- ワンクリックで、どこか社内外のサイトからファイルをダウンロードする運用に使う。
- タスクスケジューラに登録して、定期的にダウンロードさせる。など…
沢山のファイルを一括ダウンロードしたい場合は、同じスクリプトの中で何回も処理を書けば良いのです。
簡単でしょ?
終わりに
プログラミングの基礎的なエッセンスを、いくつも詰め込んだワークショップにしてみました。
説明を端折っている部分が沢山あります。
また、繰り返し処理 や 関数、テキストの整形など、さらに実用的に使える内容は含められていません。
そのため、今後も学習したい方はリクエストをいただければと思います。
参考となる情報源
公式
- Python チュートリアル
- Python 言語リファレンス — Python 3.7.4 ドキュメント
- Python 標準ライブラリ — Python 3.7.4 ドキュメント
- Python 3.7.4 ドキュメント
- Pythonモジュール索引
Python リファレンスサイト
- Python入門 ~Pythonのインストール方法やPythonを使ったプログラミングの方法について解説します~ | PythonWeb
- やりたいこと別の逆引きなので参照しやすい。
- Pythonに関する情報 | note.nkmk.me
- やりたいこと別の逆引きなので参照しやすい。
- Python入門 - とほほのWWW入門
- 読みやすいけど、少し古いので注意。Python2ベース。
- Python - Qiita
- ここで検索すれば大抵の前例は出てくる。
Python関連書籍
- 退屈なことはPythonにやらせよう ―ノンプログラマーにもできる自動化処理プログラミング
- 筆者が Python を学ぶキッカケになった書籍。ただし、タイトルは釣り。
- いちばんやさしい Python 入門教室
- 初学者向けに学びやすいと評判。
- スラスラ読める Pythonふりがなプログラミング
- 同上。
Python 学習サービス
手軽にやれるWebサービス/オンラインスクールを集めました。
* [Python 3入門 (全31回) - プログラミング
(補足)ハンズオン3-0 準備
簡単にインターネットからダウンロードするモジュールをインストールします。
コマンドプロントから、下記のコマンドを実行してください。
pip install requestsPythonの便利ツール(モジュールやライブラリと呼ぶ)を、新たに追加する手順です。
今回はプログラムを簡単にするために使用します。
ならドットインストール](https://dotinstall.com/lessons/basic_python_v3)
* 無料で少しは学習できて良い。
* CheckiO - coding games and programming challenges for beginner and advanced
* ゲーム形式で学べて良いと評判。ただし、英語。
おわりに
今後、ワークショップで取り扱いたい題材や困りごとがあれば、本記事のコメントもしくは直接ご連絡ください。(社内外問わず)


- 投稿日:2019-08-16T16:47:37+09:00
[Python] AtCoderで使えるPythonのversionは3.4.3
はじめに
皆さんはAtCoderで使用できる言語のversionは意識したことがあるでしょうか?
AtCoderに慣れるために過去問を解いていたところ、思わぬ落とし穴に落ちました。
今回は、version違いによるミスを書いていきます。問題
今回の問題を以下に載せます。
C - Anti-Division考え方
問題内容はシンプルで、整数$A~D$のうち、$A$以上$B$以下で、$C$でも$D$でも割り切れないものの個数を求めるという問題。
$A$以上$B$以下で、$C$でも$D$でも割り切れないものの個数を直接求めるよりは、$C$または$D$で割り切れる個数を、$A$以上$B$以下の個数から引くほうが簡単そうなのでその方法で行きます。
$C$または$D$で割り切れる個数は、$C$で割り切れる個数と$D$で割り切れる個数の合計から、$C$かつ$D$で割り切れる個数を引けば求められます。そのため、$C$と$D$の最小公倍数を求める必要があります。
実際に書いたコード
最小公倍数を求めるには、最大公約数を求める必要があります。調べてみると、Pythonには便利なことにmathモジュールにあるgcd()関数で最大公約数を求めることが出来ます。
書いたコードが以下になります。C_Anti_Divisionfrom sys import stdin import math def lcm(x, y): return (x * y) // math.gcd(x, y) def main(): A, B, C, D = [int(x) for x in stdin.readline().rstrip().split()] C_D_lcm = lcm(C, D) z = B//C_D_lcm - A//C_D_lcm if A % C == 0: x = (B//C) + 1 - (A//C) else: x = (B//C) - A//C y = B//D - A//D print((B-A+1)-(x+y-z)) if __name__ == "__main__": main()結果
実際に提出してみると結果はRE。
おかしい。自分の環境では確かに動いたはず。
もう一度自分の環境で動かしてみると、$ python3 C_Anti_Division.py 314159265358979323 846264338327950288 419716939 937510582 532105071133627368正しく動きました。
REの原因はversion違い!
リファレンスで調べてみると、math.gcd()はversion3.5に追加されたみたいです。AtCoderのPythonはversion3.4.3なので、使用できないのです。
さらに調べていくと、version3.4以前はmathモジュールではなくfractionsモジュールにgcd()関数があるみたいです。
mathモジュールではなくfractionsモジュールに変更したところ、無事に通りました。ちなみに、fractionsモジュールのgcd()はversion3.5から非推奨らしく、version3.7.3で使用するとmath.gcd()を薦めてきます。
$ python3 -V Python 3.7.3 $ python3 C_Anti_Division.py 314159265358979323 846264338327950288 419716939 937510582 C_Anti_Division.py:6: DeprecationWarning: fractions.gcd() is deprecated. Use math.gcd() instead. return (x * y) // fractions.gcd(x, y) 532105071133627368AtCoderで使用できる言語のversion
AtCoderで使用できる言語のversionはコンテストごとのルールに記載されています。
言語によっては使用できるライブラリ(Python3ではnumpy,scipy,scipy,C++ではBoostなど)があります。
また、コンテストによっては使えないものもあるので、参加する前にルールを確認したほうがいいかもしれません。今回のコンテストで使用できる言語のversion一覧は以下になります。
https://atcoder.jp/contests/abc131/rulesまとめ
AtCoderと自分の環境を同じversionにしましょう。そうすればこのようなミスは起きません。
もし、今までversionを気にしずに解いていたのなら、このようなことが起こりえることを意識していただきたいです。
- 投稿日:2019-08-16T13:39:33+09:00
Macでpythonのarucoライブラリを動かす
目的
Macでpythonのaruroライブラリを動かした際の備忘録です。
準備
関連ライブラリのインストール
$ pip install opencv-python $ pip install opencv-contrib-python $ pip install pyzbar $ pip install pillow $ brew install zbar (windowsの場合はyum install zbar)コード
下記記事のコードを使わせて頂きます。
テスト
▪️ARマーカー
python sample.py
▪️QRコード
python qr.py b'http://icon-qr.quel.jp/00000071298450'
ARマーカ/QRコード共に読み取れました。
CodingError対策
$ python sample2.py Traceback (most recent call last): File "sample2.py", line 2, in <module> aruco = cv2.aruco AttributeError: module 'cv2.cv2' has no attribute 'aruco'arucoライブラリインストールが必要
$ pip install opencv-contrib-python--
$ python sample.py Reader Traceback (most recent call last): File "sample.py", line 51, in <module> arReader() File "sample.py", line 32, in arReader imghalf = cv2.resize(frame,(halfWidth,halfHeight)) TypeError: integer argument expected, got floatresizeの引数はintegerである必要がある。round()関数で四捨五入する。
sample.pyhalfWidth = round( halfWidth ) halfHeight = round( halfHeight )--
$ python qr.py Traceback (most recent call last): File "qr.py", line 3, in <module> from pyzbar.pyzbar import decode ModuleNotFoundError: No module named 'pyzbar'pyzbarをインストールする必要があります
pip install pyzbar pip install pillow brew install zbar (windowsの場合はyum install zbar)参考
【Pythonでプログラミング】arucoライブラリを使ってARマーカを認識してみた
ArUco マーカーの検出
Pythonで画像ファイルからQRコードを読み込む (MacOS)
Pythonでバーコードを読み込む
Python3でQRコードを読み込みたかった


- 投稿日:2019-08-16T13:36:21+09:00
WebスクレイピングしたデータをGrafana で可視化する ②構築編
前回の記事で
Python(スクレイピング) + Influxdb + Grafanaで作る、データの可視化について本記事で詳しく解説します。なお、本記事は解説を目的とします。
"手順に"興味がある方はリポジトリのREADMEをご参照ください。おさらい
前回記事の再掲。
- できあがった構成こんな感じ

※だいたいの構成検討とかは通勤中に(頭の中だけで)練っていたので、手を動かし始めたら1日で作れました。
各コンテナの役割
- app: 30秒間隔でWebサイトをスクレイピングする。取得したデータを加工し、時系列DB(Influxdb)に格納する
- influxdb: OSSの時系列データベース(time series database)
- grafana: グラフ表示を担当
そもそも何を可視化するの?
Amazonギフト券を割安で買い付けられるサービスが存在します。
ギフト券を現金化したい売り手と、安く購入したい買い手とのマッチングサービスで、一種の市場を形成しているわけです。
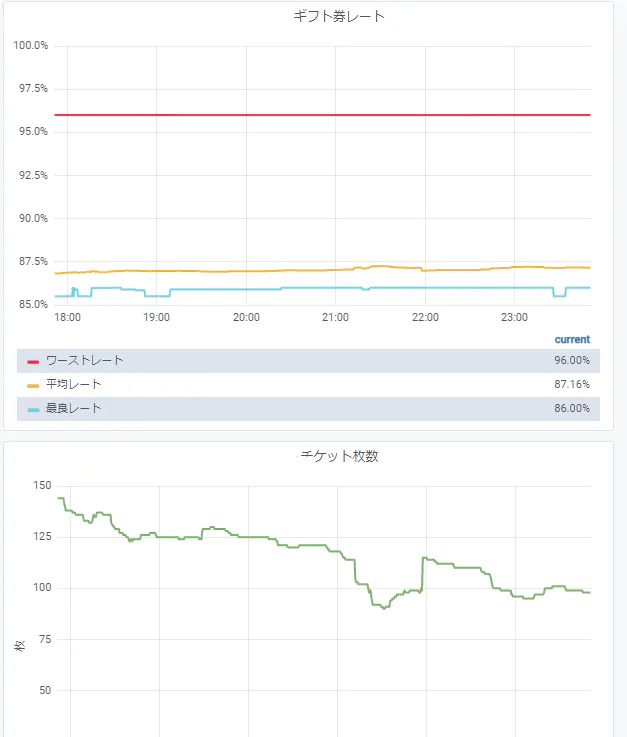
この市場を、株式市場や為替市場と同じようにチャート表示してみたい というのがモチベーションです。実際に作ったのは以下のようなチャート描画です(グラフ表示はGrafana ですが)。
スクレイピング
前置き
こんな記事書いといてアレですが、スクレイピングという手法はあまり胸を張って良いものではないと考えてます(※個人の意見です)。
数十秒~数分間隔のスクレイピングならまだしも、ミリ秒レベルの間隔でなんか実行してしまうと「それDoSじゃん」と思ってしまいます。したがって、本記事および成果物(Github)では 私が実際に実装したスクレイピングツールの宛先URLおよびサービスは晒しませんのでご理解お願いします。
スクレイピング実装
Pythonの
urllib3とBeautifulSoup4を利用。これらを利用したスクレイピング自体については詳しく解説しませんのでググってください。
ここでは、本ケースで取得したいデータの前提を記載します。まず、Webページ内に以下のような表(テーブル)があるとします。
そして、このページ要素から以下のデータを集めることを考えます
- 最も安い販売レート(最良レート): best_rate
- レートの平均値: avg
- ワーストレート: worst_rate
- 総枚数: amount_sum
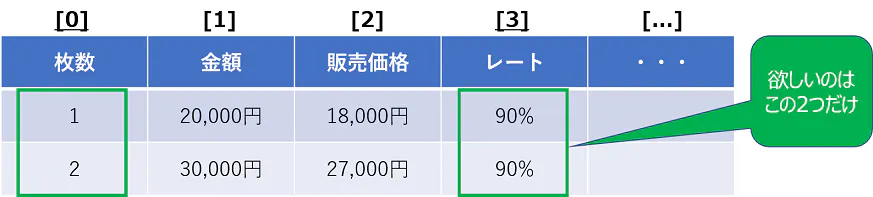
さて、htmlのテーブル要素の場合大抵以下のような構成になっていると思います。
ここでポイントとなるのは、HTMLにはタグとその階層構造があるということです。
表の行要素(黄色の部分)とセル要素(緑の部分)がそれぞれtrタグとtdタグにあたり、セル要素をforループで取得していきます。
今回取得したいのはギフト券のレートと枚数なので、for ループで全ての要素をした後 必要なデータを抜き出していく流れです。
以下がコードの抜粋です。app/main.py(抜粋)import urllib3 import certifi from bs4 import BeautifulSoup def scrape(url): # HTTPリクエストを生成 http = urllib3.PoolManager( cert_reqs='CERT_REQUIRED', ca_certs=certifi.where() ) # 対象URLをHTTP GETして保持 res = http.request('GET', url) soup = BeautifulSoup(res.data, 'html.parser') table_body = soup.select_one('#tbody1') amounts = [] rates = [] for tr in table_body.find_all('tr'): temp_list = [] for td in tr.find_all('td'): temp_list.append(td.string) amounts.append(int(temp_list[0].replace('枚', ''))) # "チケット枚数"リストに追加 rates.append(float(temp_list[3].replace('%', ''))) # "レート"リストに追加 # 最良レート、ワーストレート best_rate = min(rates) ; worst_rate = max(rates) # レート平均(重みつき) avg = ... return {'best_rate': best_rate, 'worst_rate': worst_rate, 'avg': avg, 'amount_sum': sum(amounts)} # チケット枚数の総量: sum(amounts)
「全ての要素をした後 必要なデータを抜き出して」いるのが以下の部分です。
amounts.append(int(temp_list[0].replace('枚', ''))) # "チケット枚数"リストに追加 rates.append(float(temp_list[3].replace('%', ''))) # "レート"リストに追加取得データの書き込み
ここまででスクレイピングの実行およびデータ加工が完了しました。
続いて取得データをInfluxdbに書き込みすれば良いのですが、Pythonのライブラリが準備されています。
したがって何も難しいことなく実装できます。なお、ここで書き込みを行う際にJSON形式のリクエストボディを生成するため、上述のスクレイピングの関数では辞書型オブジェクトを返すようにしています。
return {'best_rate': best_rate, 'worst_rate': worst_rate, 'avg': avg, 'amount_sum': sum(amounts)} # チケット枚数の総量: sum(amounts)app/main.py(抜粋)impoert os from influxdb import InfluxDBClient # influxdbへ書き込み処理を行う def insert(measurement, values): client = InfluxDBClient( host=os.environ['INFLUXDB_HOST'], port=os.environ['INFLUXDB_PORT'], database=os.environ['INFLUXDB_DATABASE'] ) json_payload = [ { "measurement": measurement, "fields": values } ] client.write_points(json_payload)書き込み先DBの情報は環境変数から取得します。
pythonが実行されるDocker コンテナの起動時に環境変数を定義するようDockerfile に記述します。app/DockerfileFROM docker.io/python:3.7.4-alpine3.10 RUN apk add --no-cache bash && \ pip3 --no-cache-dir install influxdb urllib3 beautifulsoup4 certifi COPY ./main.py /app/main.py ENV INFLUXDB_HOST="scraping_and_grafana_influxdb_1" \ INFLUXDB_PORT="8086" \ INFLUXDB_DATABASE="mydb"コンテナ名や起動ポート番号を変更する場合は適宜変更してください。あとデータベース名("mydb")も同様。
Influxdbのススメ
Influxdbは時系列データベースです。
簡単なクエリ実行を例に動きを見てみましょう。コンテナデータベース起動~データベース作成まで。
$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE docker.io/influxdb 1.7 d1e103e42e17 4 weeks ago 258 MB $ docker run -d --rm --name influxdb -p 8086:8086 docker.io/influxdb:1.7 7a554*** $ docker exec -it influxdb influx -precision rfc3339 Connected to http://localhost:8086 version 1.7.7 InfluxDB shell version: 1.7.7 > show databases name: databases name ---- _internal > CREATE DATABASE sample_db > SHOW DATABASES name: databases name ---- _internal sample_db > USE sample_db Using database sample_dbテーブル作成~レコード挿入
ここで、Influxdbの用法について。
Influxdb では一般のRDBMSでいう所のTABLEをMEASUREMENTと呼称します。正にメトリクスと位置付けているんですね。そして、挿入クエリの書式は以下。
(引用元: Influxdb and time series data - Slideshare)面白いのは、レコードにおいてタグと値を分けています(「値」はVALUEと言うべきか、measurement と言うべきか...)。
タグは省略可能です。テーブル名とタグはカンマ区切り、VALUEはスペースの後記述します。
また、InfluxdbではCREATE TABLE文も省略可能です(正しくはCREATE MEASUREMENTですが)> SHOW MEASUREMENTS > > INSERT cpu,host=A,region=tokyo usage=0.6,LA=0.3 > > SHOW MEASUREMENTS # "CREATE MEASUREMENT"文は不要 name: measurements name ---- cpu > SELECT * FROM cpu name: cpu time LA host region usage ---- -- ---- ------ ----- 2019-08-13T16:05:25.964591986Z 0.3 A tokyo 0.6INSERT文で指定したVALUEは
usage=0.6,LA=0.3のみでしたが、自動的にタイムスタンプが付与されているのが分かります。
Influxdbでは、基本的にこのtimeカラムをがキーの1つとなるように設計するとGoodだと思います。データが取得出来たらGrafanaで可視化
割愛します。
プラグインを選択して進んでいくだけです。まとめ
とりあえず今回は自宅の仮想サーバで実現しました。
今後の展望としては、お勉強として以下のことにも少しずつ挑戦できたら楽しいなと思ってます。
- 自動テストを組み込んでみる
- DBに書き込みしたデータの信頼性担保(EFSを利用?)
- コンテナオーケストレーションツールを組み合わせてみる



- 投稿日:2019-08-16T13:22:19+09:00
ROSを始めよう その9
前回の内容
今回の内容
今回はArduinoなどによる自作ロボットの動かし方を見ていきましょう。
マイコンをROSを動かすrosserial
Arduinoとrosserialの準備
$ sudo apt-get install ros-kinetic-rosserial ros-kinetic-rosserial-arduinoでインストールします。
また、$ sudo apt-get install arduinoでArduinoをインストールして$ arduinoで立ち上げます。
そして、以下のようにインストールをしたら準備完了です。$ cd ~/sketchbook/libraries $ rosrun rosserial_arduino make_libraries.py .プログラムでLチカさせる
まずは以下のプログラムをArduinoに書き込みます。
arduino_blink.ino#include <ros.h> #include <std_msgs/Bool.h> #include <std_msgs/String.h> ros::NodeHandle node; std_msgs::String chat; ros::Publisher pub("arduino", &chat); void ledCallback(const std_msgs::Bool &is_led_on){ if (is_led_on.data) { digitalWrite(13, HIGH); chat.data = "led on!"; } else { digitalWrite(13, LOW); chat.data = "led off!"; } pub.publish(&chat); } ros::Subscriber<std_msgs::Bool> sub("led", &ledCallback); void setup() { pinMode(13, OUTPUT); node.initNode(); node.subscribe(sub); node.advertise(pub); } void loop() { node.spinOnce(); delay(1); }次に
$ roscoreを立ち上げ、$ rosrun rosserial_python serial_node.py _port:=/dev/ttyUSB0と実行します。(Arduinoが認識されているのが、/dev/ttyACM0ならそのように書きましょう。)もし書き込み権限がなければ、
$ sudo chmod 777 /dev/ttyUSB0と権限を与えましょう。
$ rostopic echo /arduinoでArduinoから送られてくるMessageを確認できます。
$ rostopic pub /led std_msgs/Bool trueや$ rostopic pub /led std_msgs/Bool falseでTopic /ledを発行して、LED変化とMessageを確認できます。サーボモーターの利用
$ sudo apt-get install ros-kinetic-dynamixel-motorでDynamixelというサーボモーターをROSで制御できるようになります。まとめ
今回はArduinoなどによる自作ロボットの動かし方を見ていきました。
これにてROSの勉強はひとまず終わりです。あとは実践あるのみ!色々作っていきましょう。
- 投稿日:2019-08-16T13:21:41+09:00
ROSを始めよう その8
前回の内容
今回の内容
今回は座標変換ツールtfなどを見ていきましょう。
参考:http://wiki.ros.org/ja/tf/Tutorials
http://wiki.ros.org/ja/urdf/Tutorials/Create%20your%20own%20urdf%20file
http://wiki.ros.org/ja/pcl/Tutorials座標変換ツールtf
ロボットアームなどを動かす時には、関節角度から手先の位置を求める順運動学の問題などを解く必要があります。tfはこれを手助けしてくれるツールです。
PR2を動かしてみる
$roslaunch pr2_gazebo pr2_empty_world.launchでシミュレーターを立ち上げる。
次に動かす際に便利なライブラリを取ってきます。(まだリリースされていないソフトです。)$ cd ~/catkin_ws/src $ git clone https://github.com/OTL/ez_utils.git $ cd ~/catkin_ws $ catkin_makeそして
$ rosrun rviz rvizとrvizを立ち上げて、Robot Modelを表示します。(表示されない場合、画面左のGlobal Optionsをbase_linkにセットしましょう。)
さらに、TFをAddして表示しましょう。(画面左のTFのFramesのAll Enabledをクリックして表示を外して見やすくしましょう。)
TFのhead_plate_frameとl_gripper_led_frameにチェックを入れると、PR2の頭と左手先のフレームが表示されます。
$ rosrun tf tf_echo /head_plate_frame /l_gripper_led_frameと打つと、/head_plate_frameから見た/l_gripper_led_frameの座標系、すなわち相対位置を得られます。常に頭が左手先を見続けるプログラムを作ってみる
look_hand.py#!/usr/bin/env python import rospy import tf2_ros from ez_utils.ez_joints import JointsServer if __name__ == '__main__': rospy.init_node('pr2_look_left_hand') # TFのデータを蓄えるバッファを作成 tf_buffer = tf2_ros.Buffer() # TransformListenerを作成 tf_listener = tf2_ros.TransformListener(tf_buffer) # 頭と左腕をTopicで動かせる状態にする head = JointsServer('/head_traj_controller') left_arm = JointsServer('/l_arm_controller') # 首の角度の初期化 yaw_angle = 0.0 pitch_angle = 0.0 rate = rospy.Rate(10.0) while not rospy.is_shutdown(): try: # frame間の相対関係を取得 trans = tf_buffer.lookup_transform('head_plate_frame', 'l_gripper_led_frame', rospy.Time()) # 首の角度を決定 yaw_angle = trans.transform.translation.y / 1.0 pitch_angle = -trans.transform.translation.z / 1.0 print trans.transform.translation # 角度をロボットに送信 head.set_positions([yaw_angle, pitch_angle]) except (tf2_ros.LookupException, tf2_ros.ConnectivityException, tf2_ros.ExtrapolationException): rospy.logwarn('tf not found') rate.sleep()chmodで実行可能にし、
$ rosrun ros_beginner look_hand.pyで実行しましょう。
rosrun rqt_ez_publisher rqt_ez_publisherでrqt_ez_publisherを立ち上げ、左手先を動かしてみましょう。
Topicとして/l_arm_controller/follow_positionを選択して追加し、スライダーで動かすことができます。その他の基本的なライブラリ
ロボット定義フォーマットURDF
ROSで自作ロボットを使う場合などに、ロボットの見た目やモーターの配置、センサーの配置を定義するファイルが必要になります。これがURDFです。
参考:http://wiki.ros.org/urdf3次元点群処理PointCloud Library
3次元点群を扱った認識プログラムを書く際に縁なライブラリとしてpcl_rosがあります。
参考:http://wiki.ros.org/pcl_rosInteractiveMarkers
rvizを使って入力をするためのツールです。
参考:http://wiki.ros.org/interactive_markersまとめ
今回は座標変換ツールtfなどを見ていきました。
次回は、Arduinoなどによる自作ロボットの動かし方を見ていきましょう。
- 投稿日:2019-08-16T13:20:39+09:00
ROSを始めよう その7
前回の内容
今回の内容
今回はROSの分散機能について見ていきましょう。
参考:http://wiki.ros.org/ja/ROS/Tutorials/MultipleMachines
http://wiki.ros.org/ja/ROS/Tutorials/Recording%20and%20playing%20back%20dataROSでの通信
今まで見てきたROSの通信ですが、簡単に仕組みを説明します。
例えば、Topic通信の場合です。
ROSのすべてのNodeはMasterのIPやポート番号などが記録された環境変数ROS_MASTER_URIを参照してMasterと通信できるので、以下のようになります。
1. PublisherのNodeとMasterが通信をして、NodeのIPやポート番号をMasterが内部情報として記録する
2. SubscriberのNodeとMasterが通信をして、NodeのIPやポート番号をMasterが内部情報として記録する
3. TopicにPublishやSubscribeがなされると、Topicの情報とそれに対するPublisher、SubscriberがどれなのかをMasterが内部情報として記録する
4. TopicのPublisherとSubscriberのペアができたら、MasterはそれぞれのNodeにお互いのIPやポート番号を伝える
5. PublisherとSubscriberは与えられた情報を使って、Masterを介さずに通信を始めるこの仕組みによってROSでは複数のコンピューターを利用することができます。
192.168.0.1のコンピューターと192.168.0.2のコンピューターでTopic通信する場合、
(192.168.0.1側)$ roscore $ export ROS_JP=192.168.0.1 $ rosrun ros_beginner talker.py(192.168.0.2側)
$ export ROS_MASTER_URI=http://192.168.0.1:11311 $ export ROS_JP=192.168.0.2 $ rosrun ros_beginner listener.pyとすれば良いです。
画像処理
先ほど説明したROSの分散機能を用いて、画像処理をしてみましょう。
カメラの準備
PCの場合、
$ ls /dev/video*などで標準装備されているカメラを探せます。
USBカメラを使う場合、
sudo apt-get install ros-kinetic-usb-camでROSドライバをインストールし、
rosrun usb_cam usb_cam_nodeを実行すると、カメラの情報が/usb_cam/camera_infoに、画像が/usb_cam/image_rawにPublishされます。これは$ rostopic listで確認できます。
$ rosrun image_view image_view image:/usb_cam/image_rawとすれば画像が表示できます。青色抽出プログラム
color.py#!/usr/bin/env python import rospy import cv2 import numpy as np from sensor_msgs.msg import Image from cv_bridge import CvBridge, CvBridgeError class ColorExtract(object): def __init__(self): # 青色抽出してマスクされた画像をPublishする self._image_pub = rospy.Publisher('masked_image', Image, queue_size=1) # 入力される画像をSubscribeする self._image_sub = rospy.Subscriber('/usb_cam/image_raw', Image, self.callback) # OpenCVのデータ形式cv::MatとROSのMessage形式sensor_msgs/Imageを変換する self._bridge = CvBridge() def callback(self, data): # OpenCVの形式に変換 try: cv_image = self._bridge.imgmsg_to_cv2(data, 'bgr8') except CvBridgeError, e: print e hsv = cv2.cvtColor(cv_image, cv2.COLOR_BGR2HSV) lower_blue = np.array([110,50,50]) upper_blue = np.array([130,255,255]) # 青を抽出してマスク画像とする color_mask = cv2.inRange(hsv, lower_blue, upper_blue) res = cv2.bitwise_and(cv_image, cv_image, mask=color_mask) # ROSの形式に変換 try: self._image_pub.publish(self._bridge.cv2_to_imgmsg(res, 'bgr8')) except CvBridgeError, e: print e if __name__ == '__main__': rospy.init_node('color_extract') color = ColorExtract() try: rospy.spin() except KeyboardInterrupt: pass青色認識で前進、赤色認識で後退させるプログラム
color_vel.py#!/usr/bin/env python import rospy import cv2 import numpy as np from sensor_msgs.msg import Image from geometry_msgs.msg import Twist from cv_bridge import CvBridge, CvBridgeError class ColorExtract(object): def __init__(self): self._vel_pub = rospy.Publisher('cmd_vel', Twist, queue_size=1) # デバッグ用 self._blue_pub = rospy.Publisher('blue_image', Image, queue_size=1) # デバッグ用 self._red_pub = rospy.Publisher('red_image', Image, queue_size=1) self._image_sub = rospy.Subscriber('/usb_cam/image_raw', Image, self.callback) self._bridge = CvBridge() # ロボットの速度 self._vel = Twist() def get_colored_area(self, cv_image, lower, upper): hsv_image = cv2.cvtColor(cv_image, cv2.COLOR_BGR2HSV) mask_image = cv2.inRange(hsv_image, lower, upper) extracted_image = cv2.bitwise_and(cv_image, cv_image, mask=mask_image) # 色抽出した部分の画素数をカウント area = cv2.countNonZero(mask_image) return (area, extracted_image) def callback(self, data): try: cv_image = self._bridge.imgmsg_to_cv2(data, 'bgr8') except CvBridgeError, e: print e blue_area, blue_image = self.get_colored_area( cv_image, np.array([50,100,100]), np.array([150,255,255])) red_area, red_image = self.get_colored_area( cv_image, np.array([150,100,150]), np.array([180,255,255])) try: self._blue_pub.publish(self._bridge.cv2_to_imgmsg(blue_image, 'bgr8')) self._red_pub.publish(self._bridge.cv2_to_imgmsg(red_image, 'bgr8')) except CvBridgeError, e: print e rospy.loginfo('blue=%d, red=%d' % (blue_area, red_area)) # 1000画素以上で速度指令を出す if blue_area > 1000: self._vel.linear.x = 0.5 self._vel_pub.publish(self._vel) if red_area > 1000: self._vel.linear.x = -0.5 self._vel_pub.publish(self._vel) if __name__ == '__main__': rospy.init_node('color_extract') color = ColorExtract() try: rospy.spin() except KeyboardInterrupt: pass
$ roslaunch kabuki_gazebo kabuki_playground.launchでシミュレーターを実行
$ rosrun usb_cam usb_cam_nodeでカメラを準備
$ rosrun ros_beginner color_vel.py cmd_vel:=/mobile_base/commands/velocityで実行
デバッグ用に画像表示もしましょう。(&をつけるとバックグラウンドで実行できます、$ fgで戻せます)
$ rosrun image_view image_view image:=/blue_image &
$ rosrun image_view image_view image:=/red_image &
$ rosrun image_view image_view image:=/usb_cam/image_raw &rosbagによる実験データの記録
rosbagというツールでTopicとして出力されたデータを記録・保存することができます。
記録
まずは
$ rosrun usb_cam usb_cam_nodeでカメラを立ち上げ、$ rosrun image_view image_view image:=/usb_cam/image_rawで画像を確認しましょう。
$ rosbag record /usb_cam/camera_info /usb_cam/image_raw -O images.bagとすると、/usb_cam/camera_infoと/usb_cam/image_rawをimages.bagという名前で保存します。color_vel.pyなどを実行して実験を開始し、終了したらCtrl+cで終了しましょう。
$ rosbag record -aとすれば、全Topicを記録できます。再生
$ rosbag play images.bagで記録したデータを再生できます。
$ rosbag play -l images.bagとすると、再生終了後、先頭に戻ります。
$ rosbag info images.bagとすると、中身を確認できます。
$ rqt_bag images.bagで中身を可視化できます。
画面の上の方に色々ボタンが並んでいますが、一番右の画像表示ボタンを押せば、画像が表示されます。また、各TopicをPublishしたい時には、発行したいTopicの行を右クリックしてPublishを選択して、上の方の再生ボタンを押せば良いです。まとめ
今回はROSの分散機能について見ていきました。
次回は座標変換ツールtfなどについて見ていきましょう。
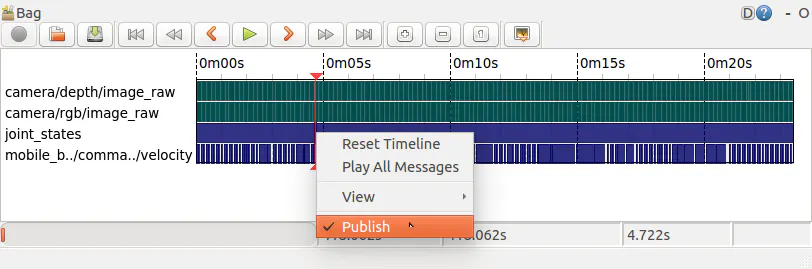
- 投稿日:2019-08-16T13:19:43+09:00
ROSを始めよう その6
前回の内容
今回の内容
今回はROSのGUIについて見ていきましょう。
参考:http://wiki.ros.org/ja/visualization/Tutorials可視化ツールrviz
rvizというツールを使うと、ロボットの内部情報やセンサの可視化ができます。
立ち上げ方
roscoeを立ち上げた後、
$ rosrun rviz rvizで立ち上げます。Turtlebotシミュレーターで使ってみる
シミュレーターのインストール $ sudo apt-get install ros-kinetic-turtlebot-gazebo $ source ~/.bashrc 立ち上げる $ roslaunch turtlebot_gazebo turtlebot_world.launch 別のターミナルで自律移動プログラムも立ち上げる $ roslaunch turtlebot_gazebo amcl_demo.launch 別のターミナルでrvizを立ち上げる $ rosrun rviz rviz最初は何も表示されていないのですが、画面左下のAddボタンから表示するものを追加できます。
画面左に並んでいるのは表示中のものです。
例えば、
By display typeからRobotModelを選ぶと、ロボットのモデルが表示されます。
By topicから/mapのMapを選ぶと、あらかじめ作成された地図が表示されます。
/camera/depth/pointsのPointCloud2を選ぶと、Kinectのセンサ情報が表示されます。
/odomのOdometryを選ぶと、ロボットの現在位置が表示されます。
/move_base/NavfnROS/planのPathを選ぶと、ロボットの行きたい経路が表示されます。
これらはPublishされているTopicを3次元的に表示させているのです。また、画面上方の2D Navi Goalボタンを押して、ロボット近くの地面をドラッグすると、ロボットを自律移動させることができます。表示される緑の矢印の根元がゴール位置、向きがロボットのゴール姿勢となります。
rqt
これまでもrqt_graphやrqt_consoleなどを使ってきましたが、その仲間を紹介します。
rqt_plot
PublishされているTopicの値をグラフにできます。
$ rqt_plotで立ち上がります。
上の欄に/turtle1/cmd_vel/linear/xなどと書いて+ボタンを押すか、$ rqt_plot /turtle1/cmd_vel/linear/xとして立ち上げれば良い。rqt_ez_publisher
スライダーなどでTopicにPublishできます。
インストール $ sudo apt-get install ros-kinetic-rqt-ez-publisher $ roscore $ rosrun turtles turtles_node $ rosrun rqt_ez_publisher rqt_ez_publisherこれで立ち上がります。画面上でTopicを選択すると、/turtle1/cmd_velをPublishするGUIなどにできます。
rqt
今まで出てきた複数のrqtのモジュールを同じWindowにまとめてみましょう。
$ rqtで立ち上げて、画面上のPluginsからVisualizationのPlotやEasy Message Publisherを選択すると、同じWindowにまとまります。
ジョイスティックで操縦する
ジョイスティックでロボットを操縦したい時もあると思いますので、簡単に方法を紹介します。
ls -l /dev/input/js*みたいにすると認識されているジョイスティックがわかります。
まず、$ rosrun joy joy_node(/dev/input/js0以外で認識されているジョイスティックを使うなら$ rosrun joy joy_node _dev:=/dev/input/js1)を実行すると、sensor_msgs/Joy型の/joyというTopicをPublishします。それを使って、0番ボタンを押しながら移動操作ができるプログラムを実行してみましょう。
joy_twist.pyimport rospy from sensor_msgs.msg import Joy from geometry_msgs.msg import Twist class JoyTwist(object): def __init__(self): self._joy_sub = rospy.Subscriber('joy', Joy, self.joy_callback, queue_size=1) self._twist_pub = rospy.Publisher('cmd_vel', Twist, queue_size=1) def joy_callback(self, joy_msg): if joy_msg.buttons[0] == 1: twist = Twist() twist.linear.x = joy_msg.axes[1] * 0.5 twist.angular.z = joy_msg.axes[0] * 1.0 self._twist_pub.publish(twist) if __name__ == '__main__': rospy.init_node('joy_twist') joy_twist = JoyTwist() rospy.spin()
$ roslaunch kabuki_gazebo kabuki_playground.launchでシミュレーターを実行し、
$ rosrun ros_beginner joy_twist.py cmd_vel:=/mobile_base/commands/velocityで実行します。
ちなみに$ sudo apt-get install ros-kinetic-teleop-twist-joyで機能が色々使えるようになります。C++だと、
joy_twist.cpp#include <ros/ros.h> #include <sensor_msgs/Joy.h> #include <geometry_msgs/Twist.h> class JoyTwist { public: JoyTwist() { ros::NodeHandle node; joy_sub_ = node.subscribe("joy", 1, &JoyTwist::joyCallback, this); twist_pub_ = node.advertise<geometry_msgs::Twist>("cmd_vel", 1); } void joyCallback(const sensor_msgs::Joy &joy_msg) { if (joy_msg.buttons[0] == 1) { geometry_msgs::Twist twist; twist.linear.x = joy_msg.axes[1] * 0.5; twist.angular.z = joy_msg.axes[0] * 1.0; twist_pub_.publish(twist); } } private: ros::Subscriber joy_sub_; ros::Publisher twist_pub_; }; int main(int argc, char **argv) { ros::init(argc, argv, "joy_twist"); JoyTwist joy_twist; ros::spin(); }と書けますので、CMakeLists.txtを編集してcatkin_makeでビルドして、
rosrun ros_beginner joy_twistで実行しましょう。まとめ
今回はROSのGUIについて見ていきました。
次回はROSの分散機能について見ていきましょう。

- 投稿日:2019-08-16T13:17:08+09:00
ROSを始めよう その5
前回の内容
今回の内容
今回はActionについてみていきましょう。
参考:http://wiki.ros.org/ja/actionlib_tutorials/TutorialsAction
actionlib
ここまでTopicやServiceを見てきましたが、ロボットの自律移動の指令など、「長時間かかるのでTopicのように非同期通信にしたいけど、Serviceのように成否は知りたい」というときもあると思います。そんなときactionlibというライブラリを用いれば、これが可能となります。仕組みとしては、指令を出すTopicと結果を返すTopicを扱いやすくまとめてくれています。
Action Messageの作成
ActionをするにはAction Messageというものを定義する必要があります。
まず、ros_beginnerの下にactionというディレクトリを作成し、その中に以下のようなファイルを作成しましょう。GoUntilBumper.actiongeometry_msgs/Twist target_vel int32 timeout_sec --- bool bumper_hit --- geometry_msgs/Twist current_vel一番上がGoalと呼ばれる引数のようなもので、目的の値を表します。
真ん中がResultと呼ばれ、その成否を主に返します。
一番下がFeedbackと呼ばれ、途中経過として返したい情報を発行します。次に、CMakeLists.txtを変更しましょう。
find_packageの中に、geometry_msgsとactionlib_msgsを足します。
60行目あたりのadd_action_filesをコメントアウトし、actionファイルはGoUntilBumper.actionに変更します。
その下のgenerate_messagesの中に、geometry_msgsとactionlib_msgsを追加します。最後に~/catkin_wsで
$ catkin_makeをしてビルドしましょう。
$ ls devel/share/ros_beginner/msg/とすると、msgファイルがたくさんできているはずです。
これで準備完了です。ActionServerの作成
bumper_action.py#!/usr/bin/env python import rospy from geometry_msgs.msg import Twist from kobuki_msgs.msg import BumperEvent import actionlib from ros_beginner.msg import GoUntilBumperAction from ros_beginner.msg import GoUntilBumperResult from ros_beginner.msg import GoUntilBumperFeedback class BumperAction(object): def __init__(self): self._pub = rospy.Publisher('/mobile_base/commands/velocity', Twist, queue_size=10) self._sub = rospy.Subscriber('/mobile_base/events/bumper', BumperEvent, self.bumper_callback, queue_size=1) # Parameterから最大速度を取得 self._max_vel = rospy.get_param('~max_vel', 0.5) # bumper_actionという名前でGoUntilBumperAction型のActionを作成(self.go_until_bumperが実際の動作) self._action_server = actionlib.SimpleActionServer( 'bumper_action', GoUntilBumperAction, execute_cb=self.go_until_bumper, auto_start=False) # バンパーが当たったかどうか self._hit_bumper = False # ActionServerをスタートさせる self._action_server.start() # バンパーに当たった時の処理、Subscriberに呼ばれる def bumper_callback(self, bumper): self._hit_bumper = True # ActionServerの実体 def go_until_bumper(self, goal): print(goal.target_vel) r = rospy.Rate(10.0) zero_vel = Twist() for i in range(10 * goal.timeout_sec): # 外部から停止指令が来ているかどうか if self._action_server.is_preempt_requested(): self._action_server.set_preempted() break # バンパーにぶつかっているかどうか if self._hit_bumper: self._pub.publish(zero_vel) break else: # 目標の速度でロボットを動かす if goal.target_vel.linear.x > self._max_vel: goal.target_vel.linear.x = self._max_vel self._pub.publish(goal.target_vel) # 現在の速度を途中経過としてFeedbackで返す feedback = GoUntilBumperFeedback(current_vel=goal.target_vel) self._action_server.publish_feedback(feedback) r.sleep() # 実行結果を返す result = GoUntilBumperResult(bumper_hit=self._hit_bumper) self._action_server.set_succeeded(result) if __name__ == '__main__': rospy.init_node('bumper_action') bumper_action = BumperAction() # 無限ループでActionServerが呼ばれるのを待つ rospy.spin()ActionClientの作成
bumper_client.py#!/usr/bin/env python import rospy import actionlib from ros_beginner.msg import GoUntilBumperAction from ros_beginner.msg import GoUntilBumperGoal def go_until_bumper(): # bumper_actionという名前でGoUntilBumperAction型のActionClientを作成 action_client = actionlib.SimpleActionClient('bumper_action', GoUntilBumperAction) # ActionServerの準備を待つ action_client.wait_for_server() # 目標の値をセットする goal = GoUntilBumperGoal() goal.target_vel.linear.x = 0.8 goal.timeout_sec = 10 # ゴールを送る action_client.send_goal(goal) # 結果を待つ action_client.wait_for_result() # 結果を取得 result = action_client.get_result() if result.bumper_hit: rospy.loginfo('bumper hit!!') else: rospy.loginfo('failed') if __name__ == '__main__': try: rospy.init_node('bumper_client') go_until_bumper() except rospy.ROSInterruptException: pass実行
$ roslaunch kobuki_gazebo kobuki_playground.launchでシミュレーターを立ち上げ、
いつものようにchmodで実行可能にした後、
$ rosrun ros_beginner bumper_action.py
$ rosrun ros_beginner bumper_client.pyを実行しましょう。
ロボットの移動が完了すると、client側に結果が表示されるはずです。Pythonライブラリにする
今の機能をライブラリにしてみましょう。
そのためにはまず、以下の手順で、~/catkin_ws/src/ros_beginner/src/ros_beginner/を作る必要があります。$ cd ~/catkin_ws/src/ros_beginner $ mkdir -p src/ros_beginner スクリプトをディレクトリ内にコピー $ cp scripts/bumper_action.py src/ros_beginner/ $ cp scripts/bumper_client.py src/ros_beginner/ 空のファイル__init.pyを作成(ライブラリとして認識されるために必要) $ touch src/ros_beginner/__init__.py次に、以下の~/catkin_ws/src/ros_beginner/setup.pyを作成します。
setup.pyfrom distutils.core import setup from catkin_pkg.python_setup import generate_distutils_setup setup_args = generate_distutils_setup( packages=['ros_beginner'], package_dir={'': 'src'}, ) setup(**setup_args)次にCMakeList.txtの23行目あたりの
catkin_python_setup()をコメントアウトしてください。最後に~/catkin_wsで
catkin_makeをすれば準備完了です。ライブラリを使ってActionServerプログラムを書くと、
bumper_action_use_lib.py#!/usr/bin/env python import rospy from ros_beginner.bumper_action import BumperAction if __name__ == '__main__': rospy.init_node('bumper_action_use_lib') bumper_action = BumperAction() rospy.spin()ActionClientプログラムを書くと、
bumper_client_use_lib.py#!/usr/bin/env python import rospy from ros_beginner.bumper_client import go_until_bumper rospy.init_node('bumper_client_use_lib') go_until_bumper()こんなに分かりやすくなりましたね。
まとめ
今回はActionをみていきました。
次回はROSのGUIについてみていきましょう。
- 投稿日:2019-08-16T13:15:54+09:00
ROSを始めよう その4
前回の内容
今回の内容
今回はROSのプログラムをシミュレーターも交えて練習していきましょう。
参考:http://wiki.ros.org/ja/ROS/Tutorials/CreatingMsgAndSrvシミュレーターgazeboを使ってみる
インストールと実行
$ sudo apt-get install ros-kinetic-kobuki-gazeboでkobukiというロボットのシミュレーターをインストールします。
注:ラズパイでgazeboを動かすのはかなりキツイと思います。
それから、このインストールがうまくいかない場合はその6で紹介するturtlebotの方を使ってみましょう。
$ roslaunch kobuki_gazebo kobuki_playground.launchと打つと、シミュレーターgazeboが立ち上がります。Publisherでロボットを動かす
vel_bumper.py#! /usr/bin/env python import rospy from geometry_msgs.msg import Twist from kobuki_msgs.msg import BumperEvent rospy.init_node('vel_bumper') # Parameter(プライベートパラメータ)を取得する vel_x = rospy.get_param('~vel_x', 0.5) vel_ros = rospy.get_param('~vel_rot', 1.0) # Twist型のTopicに書き出すPublisherの作成 pub = rospy.Publisher('/mobile_base/commands/velocity', Twist, queue_size=10) def callback(bumper): # ぶつかるとbumperが反応してバックする back_vel = Twist() back_vel.linear.x = -vel_x rate = rospy.Rate(10.0) # 0.5秒Publishを続ける for i in range(5): pub.publish(vel) rate.sleep() # BumperEvent型のTopicを購読して、callbackを呼ぶSubscriberの作成 sub = rospy.Subscriber('/mobile_base/events/bumper', BumperEvent, callback) while not rospy.is_shutdown(): vel = Twist() # キーボード入力を受け付ける direction = raw_input('f: forward, b: backward, l: left, r:right > ') # 入力に応じて並進速度や回転速度を変更する if 'f' in direction: vel.linear.x = vel_x if 'b' in direction: vel.linear.x = -vel_x if 'l' in direction: vel.angular.z = vel_rot if 'r' in direction: vel.angular.z = -vel_rot if 'q' in direction: break print vel rate = rospy.Rate(10.0) # 1秒Publishを続ける for i in range(10): pub.publish(vel) rate.sleep()新しいターミナルでこのプログラムを実行してみましょう。
いつものように、chmod 755で実行可能にしてrosrunで実行します。
ちなみに、ロボットの座標系は基本的に前がx軸(赤)、左がy軸(緑)、上がz軸(青)となっています。
キーボードの入力に合わせてロボットが動き、壁にぶつかるとバックします。また、速度についてはParameterでセットすることができます。
$ rosparam set /vel_bumper/vel_x 1.0のようにコマンドを使うか、実行時に$ rosrun ros_beginner vel_bumper.py _vel_x:=1.0のように引数として与えるかすればよいです。
また、roslaunchにまとめるのであれば、以下のようにすればよいです。<roslaunch> <node pkg="ros_beginner" name="vel_bumper" type="vel_bumper.py"> <param name="vel_x" value="1.0"> </node> </roslaunch>他のロボットを動かす
ROSのメリットとして、同じプログラムで異なるロボットが動かせたりします。
例えば、以下のようにturtlebotを動かせます。
引数で、PublishするTopicを変更していますが、これは型が同じだからできることです。$ rosrun turtlesim turtlesim_node $ rosrun ros_beginner vel_bumper.py /mobile_base/commands/velocity:=/turtle1/cmd_vel _vel_x:=1.5また、以下のようにPR2というロボットを動かせます。
$ sudo apt-get install ros-kinetic-pr2-simulator $ roslaunch pr2_gazebo pr2_empty_world.launch $ rosrun ros_beginner vel_bumper.py /mobile_base/commands/velocity:=/base_controller/command独自のTopicやServiceを作る
自分でTopicやServiceを作りたい場合も出てくると思います。その作り方を見ていきましょう。
コマンドrosmsg
まず、ROSでやりとりするデータであるMessageを調べるコマンドを紹介します。型を調べるときに便利なので、覚えておきましょう。
$ rosmsg show geometry_msgs/TwistのようにやりとりするMessageの型を調べることができます。
$ rosmsg listで利用可能な全Messageが表示できます。独自のTopic
ROSのMessageはmsgファイルというもので定義されています。
例えば、先ほどのgeometry_msgs/Twistについてみてみましょう。$ roscd geometer_msgs` $ cat msg/Twist.msgで定義を見ることができます。
Twist.msg# comment Vector3 linear Vector3 angularどうやらVector3型のlinear、angularというデータを持つようですね。
このように、msgファイルを書くことで独自の型のMessageが定義でき、Topic通信ができます。$ roscd ros_beginner $ mkdir msg $ cd msgmsgと名付けたディレクトリの中に、自作のmsgファイルは作りましょう。自作のものを使うためには、いろいろ設定が必要なのですが、次の独自のServiceのところでまとめて説明します。
独自のService
独自のServiceを作るには、srvファイルで定義する必要があります。
$ roscd ros_beginner $ mkdir srv $ cd srvsrvと名付けたディレクトリの中に、以下のようなファイルを作ってみましょう。
SetVelocity.srvfloat64 linear_velocity float64 angular_velocity --- bool success並進速度と回転速度を入力として成否を出力するように定義しました。
これを使うためにいろいろな設定をしていきます。
まず、ros_beginnerの下にあるpackage.xmlを編集します。
35行目massage_generationと
39行目message_runtimeをコメントアウトして有効化します。次に、CMakeLists.txtの7行目からのfind_package内にmessage_genrationを追加します。
53行目からのadd_service_filesをコメントアウトし、srvファイルをSetVelocity.srvに変更します。(今回はありませんが、独自のTopicがある場合、add_message_filesをコメントアウトし、msgファイルを自作のものに変更します。)
67行目からのgenerate_messagesをコメントアウトします。これで、
$ rossrv show ros_beginner/SetVelocityで定義が参照できるようになるはずです。最後に~catkin_wsで
$ catkin_makeすれば、使用可能になります。独自のServiceを使ってみる
先ほど作ったServiceを利用すると、「外部から指定できる速度の範囲があり、それによって速度がセットされたか無視されたかを返す」ようなことができます。
velocity_server.py#!/usr/bin/env python import rospy from geometry_msgs.msg import Twist from ros_start.srv import SetVelocity from ros_start.srv import SetVelocityResponse MAX_LINEAR_VELOCITY = 1.0 MIN_LINEAR_VELOCITY = -1.0 MAX_ANGULAR_VELOCITY = 2.0 MIN_ANGULAR_VELOCITY = -2.0 def velocity_handler(req): vel = Twist() is_set_success = True if req.linear_velocity <= MAX_LINEAR_VELOCITY and ( req.linear_velocity >= MIN_LINEAR_VELOCITY): vel.linear.x = req.linear_velocity else: is_set_success = False if req.angular_velocity <= MAX_ANGULAR_VELOCITY and ( req.angular_velocity >= MIN_ANGULAR_VELOCITY): vel.angular.z = req.angular_velocity else: is_set_success = False print vel if is_set_success: pub.publish(vel) return SetVelocityResponse(success=is_set_success) if __name__ == '__main__': rospy.init_node('velocity_server') pub = rospy.Publisher('/mobile_base/commands/velocity', Twist, queue_size=10) service_server = rospy.Service('set_velocity', SetVelocity, velocity_handler) rospy.spin()velocity_client.py#!/usr/bin/env python import rospy from ros_start.srv import SetVelocity import sys if __name__ == '__main__': rospy.init_node('velocity_client') set_velocity = rospy.ServiceProxy('set_velocity', SetVelocity) linear_vel = float(sys.argv[1]) angular_vel = float(sys.argv[2]) response = set_velocity(linear_vel, angular_vel) if response.success: rospy.loginfo('set [%f, %f] success' % (linear_vel, angular_vel)) else: rospy.logerr('set [%f, %f] failed' % (linear_vel, angular_vel))では実行してみましょう。
$ roslaunch kobuki_gazebo kobuki_playground.launchを実行
chmodで実行可能にして、$ rosrun ros_beginner velocity_server.py
chmodで実行可能にして、$ rosrun ros_beginner velocity_client.py 0.5 0.0まとめ
今回はROSのプログラムをシミュレーターも交えて練習していきました。
次回はActionという通信を見ていきたいと思います。