- 投稿日:2019-08-16T23:24:10+09:00
Alexaランキングの上位1,000,000件を取得する
AlexaランキングはAmazonが運営しているWebサイトのアクセス数のランク付けのサービスです。
ここでは、無料でアクセス数上位1mのリストを取得する方法を紹介します。
参考: https://gist.github.com/chilts/7229605ダウンロード
対象の1mのリストはAWSのS3にアップロードされています。
http://s3.amazonaws.com/alexa-static/top-1m.csv.zip
タイムスタンプを見る限り、一応毎日更新はされているようですが、中身がちゃんと更新されているかは分からないです。
* 内容が3ヶ月くらい古いと言っている人もいるようです: https://gist.github.com/chilts/7229605#gistcomment-2880207ブラウザ経由でもダウンロードできますが、ここではCUIでのダウンロードの例を書きます。
$ wget http://s3.amazonaws.com/alexa-static/top-1m.csv.zip $ unzip top-1m.csv.zipこれでファイルが解凍され、csv形式でアクセス数上位1mのサイトのリスト(
top-1m.csv)を取得できます。$ cat top-1m.csv | head -n 10 # 上位10件を表示 1,google.com 2,youtube.com 3,tmall.com 4,baidu.com 5,qq.com 6,sohu.com 7,facebook.com 8,login.tmall.com 9,taobao.com 10,wikipedia.org
- 投稿日:2019-08-16T22:23:26+09:00
BigQuery Cloud SQL federated queryでRDSのデータにクエリを実行してみる
BigQueryからCloudSQLに直接クエリが実行できるようになったということですが、サービスの基盤はAWSを利用しているためDBはもちろんRDS。。。
そこでどうにかしてRDSに溜まっているデータに対してBigQueryから直接クエリを実行したいと思いやってみました。
正確には、RDSをCloudSQLでレプリケーションしてCloud SQL federated queryでBigQueryからクエリを実行してみました。構成
既にソースDBに対して3台のリードレプリカが作成されている状態だったので、こんな感じの構成にしていきたいと思います。CloudSQLレプリケーション設定
外部サーバーからCloudSQLレプリカに複製する場合いくつか要件があるのでそれを満たしているか確認します。
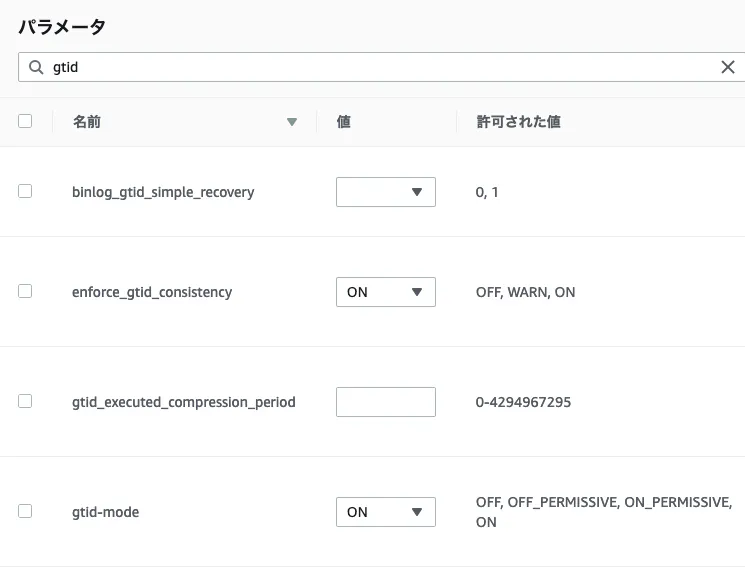
- GTID が有効にされていて、GTID 整合性が強制されること。
問題はここでした。
AWSのドキュメントを見るとDB インスタンスまたはリードレプリカで RDS MySQL バージョン 5.7.22 以下を使用している場合は、DB インスタンスまたはリードレプリカをアップグレードします。RDS MySQL バージョン 5.7.23 以降の MySQL 5.7 バージョンにアップグレードします。
稼働中DBのバージョンを勝手にあげる訳にはいかないので、一先ずやりたいことが出来るか検証用の環境を作って試してみます。RDS設定
まずパラメータグループの作成を行います。
名前 値 enforce_gtid_consistency ON gtid-mode ON GTIDを使用したレプリケーションを構成するために、このように変更します。
ついでに、パブリックアクセシビリティを【はい】に変更しCloudSQLから接続できる状態にします。
ソースDBにmysqldumpを実行しても良いのですが、後に本番環境でやることを考えてリードレプリカの一台にmysqldumpを実行したいと思います。
念の為リードレプリカのレプリケーションを停止しておきます。mysql> CALL mysql.rds_stop_replication;GCPのドキュメントにコマンドが記載されているのですが、そのままだとエラーになるので
--master-data=1は省きます。
一つのコマンドでGCSにアップロードをしても良いのですが、今回は一度サーバー上に保存します。$ mysqldump \ -h [MASTER_IP] -P [MASTER_PORT] -u [USERNAME] -p \ --databases [DBS] \ --hex-blob --skip-triggers \ --order-by-primary --no-autocommit \ --ignore-table [VIEW] \ --single-transaction --set-gtid-purged=on > ./dump.sqlmysqldumpが終了したらGCSにアップロードします。
$ gsutil cp ./dump.sql gs://[BUCKET]/[PATH_TO_DUMP]CloudSQL設定
ここからやっとGCPをいじり始めます。
CloudSQLからデータ移行を選択します。
移行を開始を選択して入力が必要な部分を埋めていきます。
ソースのパブリックIPアドレスについては、nslookupでホストを指定して調べました。
レプリケーションユーザーですが、今回はCloudSQLのIPからのみ接続を許可したいのでRDS側には後ほどユーザーを作成したいと思います。
証明証ですが、こちらにダウンロードリンクが記載されているので入手します。
ダウンロードした証明書を指定し、【次へ】を選択。
そしてBigQueryのデータロケーションと同じゾーン・任意のマシンタイプを選択、先ほどGCSにアップロードしたダンプファイルを指定しリードレプリカの作成をします。CloudSQLからRDSへの接続設定
GCPドキュメントにもある通り、この作業はCloudSQLでリードレプリカの作成をしてから30分以内に行わないとリードレプリカの作成が停止します。
ということで、CloudSQLのリードレプリカ作成オペレーションの終了を待たずに並行して作業を進めていきます。
まずCloudSQLリードレプリカのIPアドレスを調べます。$ gcloud sql instances describe [REPLICA_NAME] --format="default(ipAddresses)" ipAddresses: - ipAddress: xxx.xxx.xxx.xxx type: PRIMARY - ipAddress: xxx.xxx.xxx.xxx type: OUTGOINGIPアドレスを取得できるようになるまで数分かかります。
CloudSQL(OUTGOINGのIP)からソースデータベースに接続できるようにRDS側でセキュリティグループ等を設定します。
次にレプリケーションユーザーを作成します。
既に作成している場合は飛ばしてください。mysql> CREATE USER 'cloudsql_rep'@'OUTGOINGのIP' IDENTIFIED BY 'パスワード'; mysql> GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'cloudsql_rep'@'OUTGOINGのIP';ここまで設定したらCloudSQLにダンプファイルが復元されるまで待ちます。
CloudSQLでリードレプリカの作成が終了したら一応確認します。
mysql> SHOW SLAVE STATUS ¥G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: xxx.xxx.xxx.xxx Master_User: cloudsql_rep Master_Port: 3306 Connect_Retry: 60 ...無事レプリケーションができているようです。
mysqldumpを実行するためにレプリケーションを停止したリードレプリカも忘れずに再開しておきます。mysql> CALL mysql.rds_start_replicartion;BigQuery 接続を作成
いよいよ大詰めです。
BigQueryのコンソールから接続の作成を選択し、
必要な情報を入力していきます。
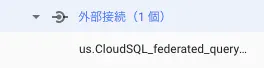
接続を作成を選択すると・・・
外部接続が現れました!
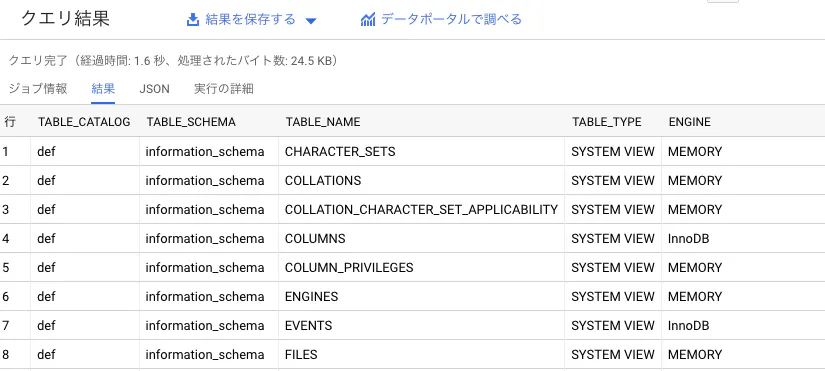
取り敢えずクエリを実行してみます。SELECT * FROM EXTERNAL_QUERY("プロジェクトID.ゾーン.CloudSQL_federated_query_RDS", "SELECT * FROM INFORMATION_SCHEMA.TABLES;");
結果が返ってきました!さいごに
残念なことに本番環境のRDSはMySQLのバージョンが要件を満たせていなかったため検証用に環境を作って試してみましたが、やりたいことはできそうなので気づかれないように本番環境のバージョンを上げておきたいと思います。
Cloud SQL federated queryについてですが、CloudSQLに対してクエリを実行しているのでBigQueryほどのスピードにはなりません。
また、クエリ結果もキャッシュされないようなのであまり調子に乗りすぎると気づかぬうちにスキャン量が積み重なってしまうかもしれません。。。
ただ、いろいろな可能性を感じられるのでいじり倒してみたいと思います。







- 投稿日:2019-08-16T22:01:54+09:00
Pythonでaws-sam-cliをローカル実行するまで
AWSコンソールでポチポチしてみたのですが
ローカル環境での実行をしてみたいなとおもい、その備忘録です。環境:
macOS High Sierra 10.13.6
AWS SAM CLI
pip 19.2.2
Python 3.7.2
Docker for macOS
目次
- AWS SAM CLIをインストールする
- sam init
- テストを実行
- ローカルでLambda関数を呼び出す
1. AWS SAM CLIをインストールする
pip を使用して AWS SAM CLI をインストール
$ pip install aws-sam-cliバージョンの確認
$ sam --version SAM CLI, version 0.19.02. sam init
sam init コマンドで python3.7のサンプルアプリケーションを作成
$ sam init --runtime python3.7 [+] Initializing project structure... Project generated: ./sam-app Steps you can take next within the project folder =================================================== [*] Invoke Function: sam local invoke HelloWorldFunction --event event.json [*] Start API Gateway locally: sam local start-api Read sam-app/README.md for further instructions [*] Project initialization is now completeReadとのこと => https://github.com/yoshiyoshifujii/sam-app/blob/master/README.md
ツリーで見てみる
$ tree sam-app/ sam-app/ ├── README.md ├── event.json ├── hello_world │ ├── __init__.py │ ├── __pycache__ │ │ ├── __init__.cpython-37.pyc │ │ └── app.cpython-37.pyc │ ├── app.py │ └── requirements.txt ├── template.yaml └── tests └── unit ├── __init__.py ├── __pycache__ │ ├── __init__.cpython-37.pyc │ └── test_handler.cpython-37.pyc └── test_handler.py 5 directories, 12 files3. テストを実行
テストを実行してみる
$ cd sam-app$ python -m pytest tests/ -v ========================================== test session starts ========================================== platform darwin -- Python 3.7.2, pytest-5.1.0, py-1.8.0, pluggy-0.12.0 -- /Library/Frameworks/Python.framework/Versions/3.7/bin/python3 cachedir: .pytest_cache rootdir: /Users/suwa/sam-app plugins: mock-1.10.4 collected 1 item tests/unit/test_handler.py::test_lambda_handler PASSED [100%] =========================================== 1 passed in 0.07s ===========================================ビルドします
$ sam build4. ローカルでLambda関数を呼び出す
まずDockerを起動する
ローカルで API Gateway 経由で Lambda 関数を呼び出す$ sam local start-apiブラウザで下記URLにアクセスするとコンテナイメージがダウンロードされ、コードが実行されてブラウザに出力が表示されます。
http://127.0.0.1:3000/hello
{"message": "hello world”}他のblogではLocationが表示されていたのですが
$ vi ./hello_world/app.pyで、下にある
# "location": ip.text.replace("\n", "")の、コメントアウトを外せばLocationも表示されます。
- 投稿日:2019-08-16T21:42:41+09:00
[JAWS-UG 磐田] コンテナハンズオン
【ハンズオン演習】コンテナ(Docker)に触ってみよう
◆概要
コンテナについて解説を交えて触ってみましょう。
◆ハンズオンを始める前に
・パソコンの準備をお願いします。
※パソコンでのハンズオンを実施いたします。
・会場設置のWi-Fiへ接続願います。
※インターネットへの接続を前提としています。
・AWSアカウントの準備はお済みですか?
※ハンズオン開始前までに準備願います。
作成手順:https://aws.amazon.com/jp/register-flow/・ターミナルソフトウェアの準備
※EC2(サーバ)の操作時に使用します。
Windowsクライアントの方は、Tera TermやPuTTYなどをご用意ください。・ハンズオン終了後の操作について
※使用したEC2・ECS・ECR・ALBは、AWSの課金対象になります。必要ない場合は、削除してください。
[ECS(クラスター)削除方法]
[ECS(タスク定義)登録解除方法]
[ECRイメージ削除方法]
[Cloudformation削除方法]
※下記順番で削除願います。
1.jawsug-iwata-20190821-alb
2.jawsug-iwata-20190821-ec2
3.jawsug-iwata-20190821-vpc
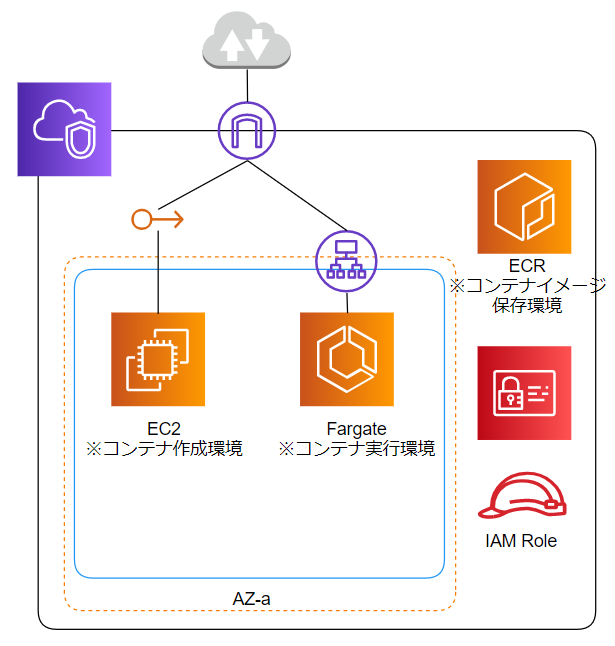
◆今回の演習環境について

【演習内容】
①演習環境準備
②EC2を使用してコンテナイメージ作成&リポジトリ登録
③Fargateでアプリケーション実行&プログラム更新
◆ハンズオンを始める前に・・・
・AWSマネジメントコンソールにログインして、東京リージョンが選択されている事を確認してください。
・画面上にIAM・EC2・S3の文字が表示されている事を確認してください。
※表示されていない場合は、画面左上のサービスをクリックして各サービスを選択してください。
①演習環境の準備
1.ハンズオンのVPC環境構築用のCloudFormationの実行
上のリンクより、ハンズオン用のVPC環境を構築するためのCloudFormationを実行します。
※環境構築完了後、次の手順に進んでください。
2.EC2用のキーペアー作成
2-1.[作成手順]
※作成済みの場合は、次へ進んでください。
3.ハンズオンのEC2環境構築用のCloudFormationの実行
上のリンクより、ハンズオン用のEC2環境を構築するためのCloudFormationを実行します。
※環境構築完了後、次の手順に進んでください。
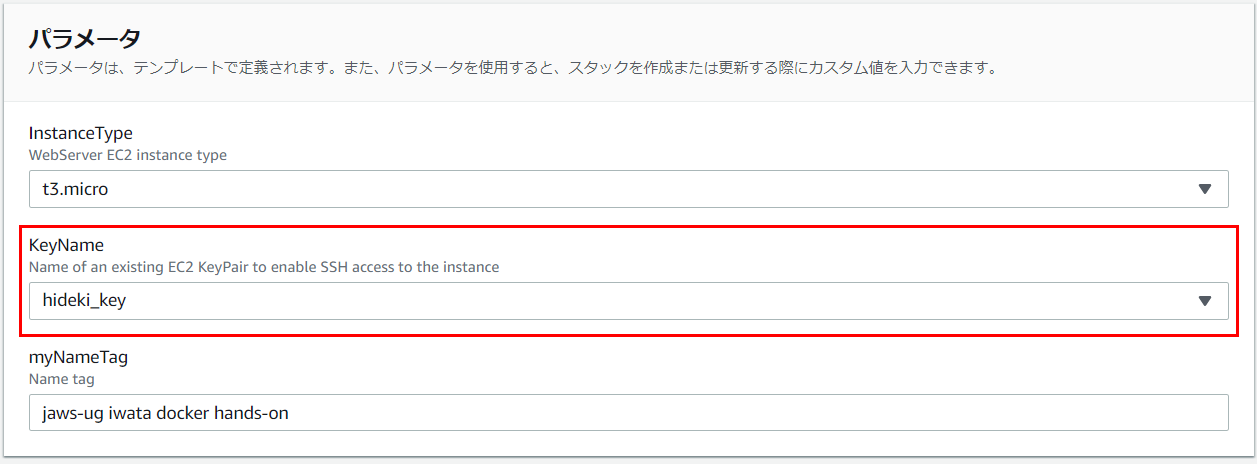
3-1.KeyNameの選択
※2.で作成したキーペアーまたは作成済みキーペアーを選択
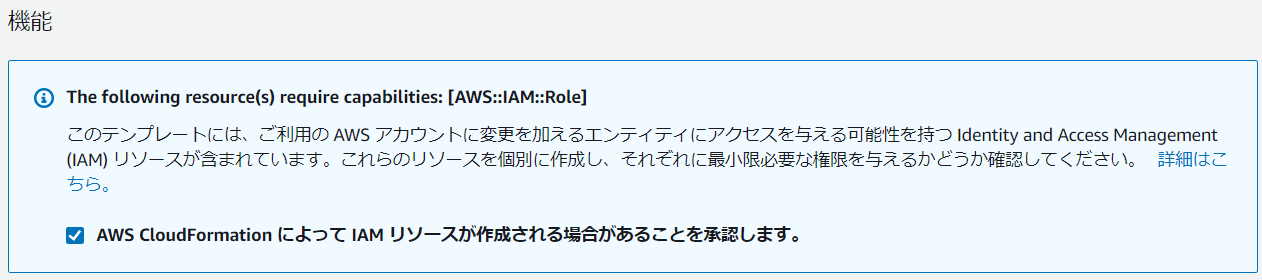
3-2.機能の項目で、承認欄をチェック
※チェック後、スタックの作成をクリックしてください。
4.EC2への接続
4-1.Amazon EC2コンソールを開きます。
※リンク先をクリックすると、東京リージョンのコンソールに接続します。
4-2.作成したEC2サーバを選択し、[接続]をクリックします。
4-3.パブリックDNSの文字列をコピー、ターミナルソフトでssh接続します。
ログインユーザー ec2-user 5.ハンズオンのALB環境構築用のCloudFormationの実行
上のリンクより、ハンズオン用のALB環境を構築するためのCloudFormationを実行します。
※環境構築完了後、次の手順に進んでください。
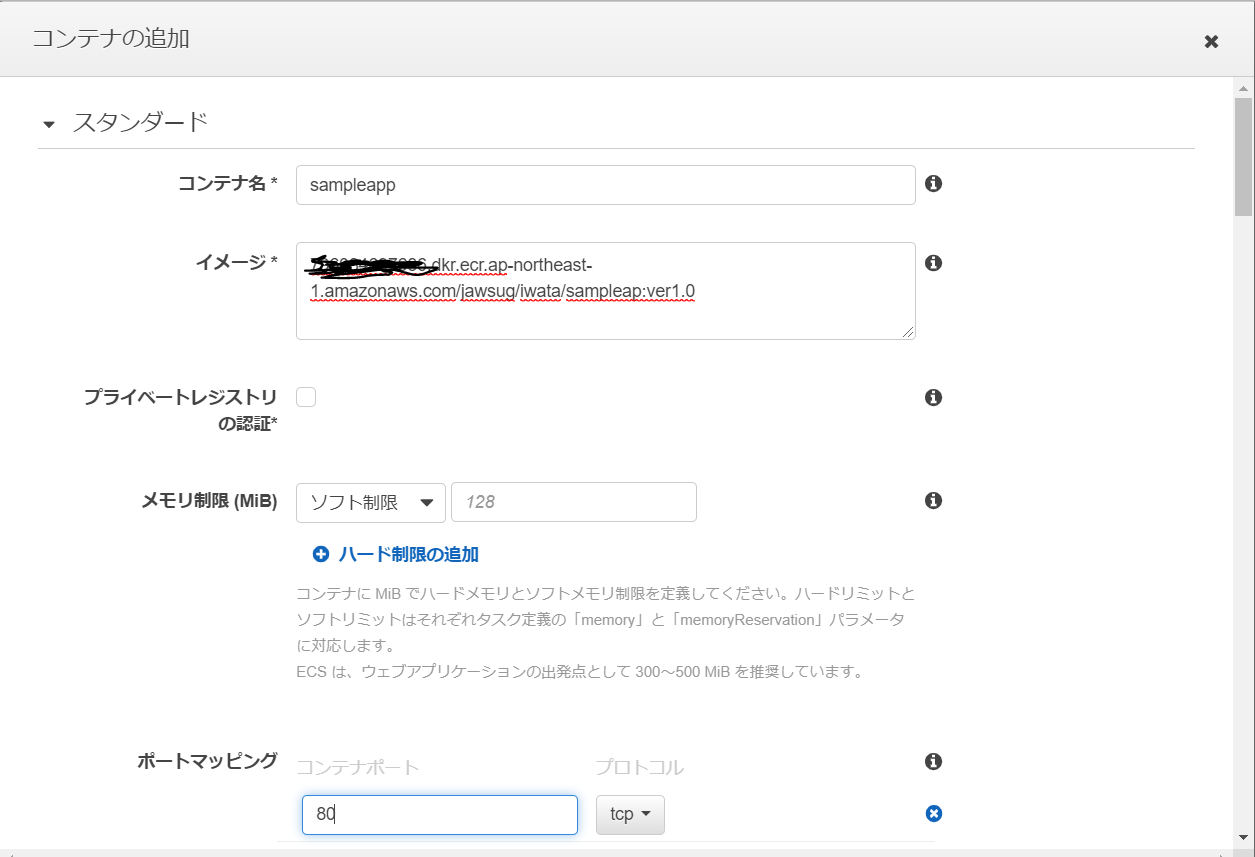
②EC2を使用してコンテナイメージ作成&リポジトリ登録
1.ターミナルソフトからコマンド入力
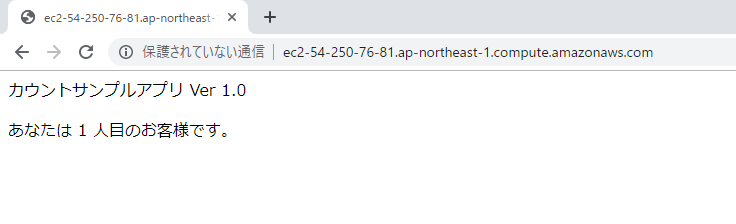
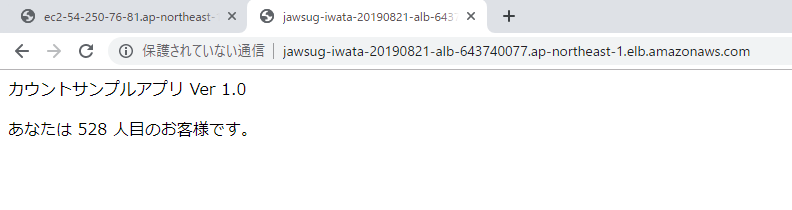
# ハンズオンフォルダーに移動 cd docker-hands-on # コンテナイメージの作成 docker build -t jawsug/iwata/sampleap:ver1.0 ./ # コンテナイメージの確認 docker images # コンテナの実行 docker run -d -p 80:80 --rm --name sampleap jawsug/iwata/sampleap:ver1.02.ブラウザーで接続
パブリックDNSアドレスを入力し、接続します。
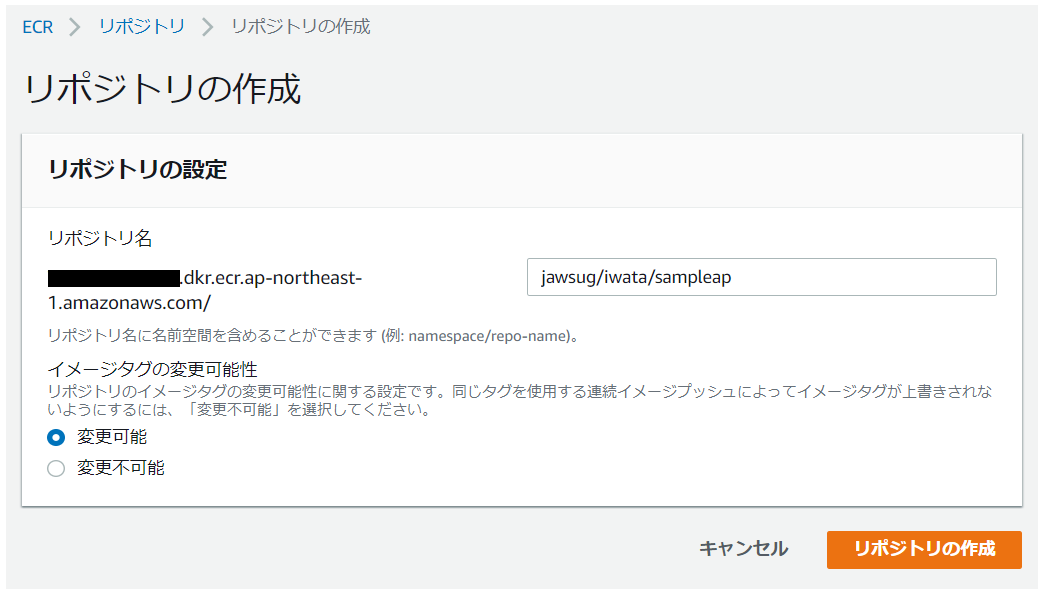
3.リポジトリ登録
3-1.[リポジトリ作成手順]
リポジトリ名 jawsug/iwata/sampleap
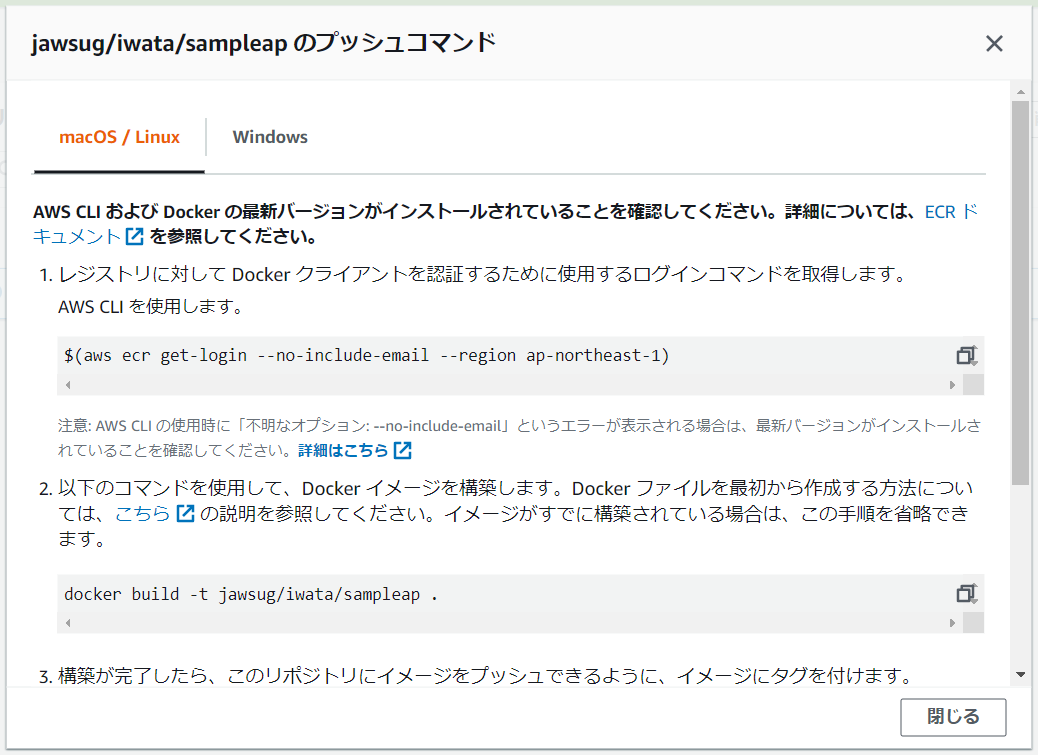
3-2.リポジトリへのコンテナイメージプッシュ手順
リポジトリを選択し、プッシュコマンドの表示をクリック
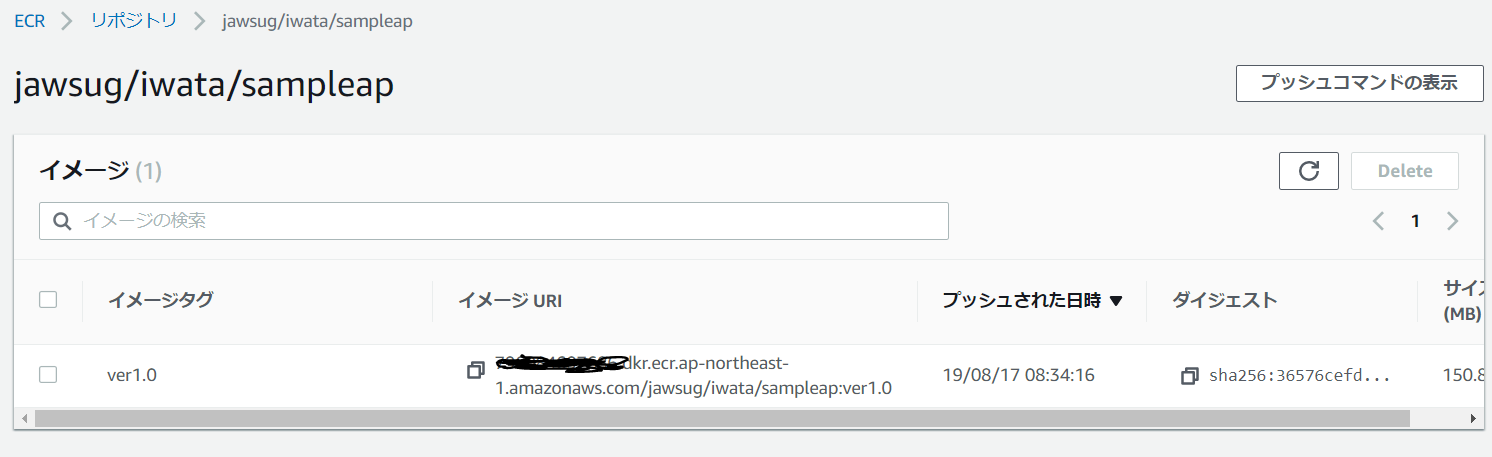
# ECRリポジトリへの接続 $(aws ecr get-login --no-include-email --region ap-northeast-1) # コンテナイメージのタグ名変更 docker tag jawsug/iwata/sampleap:ver1.0 XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/jawsug/iwata/sampleap:latest ※XXXXXXXXXXXXは、プッシュコマンドの表示で確認してください。 # コンテナイメージのレジストリ登録 docker push XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/jawsug/iwata/sampleap:latest ※XXXXXXXXXXXXは、プッシュコマンドの表示で確認してください。登録が成功すると、下記のようになります。
③Fargateでアプリケーション実行&プログラム更新
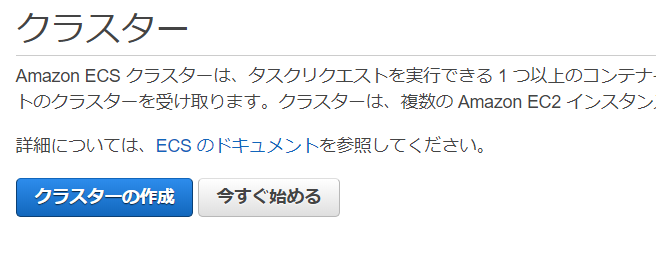
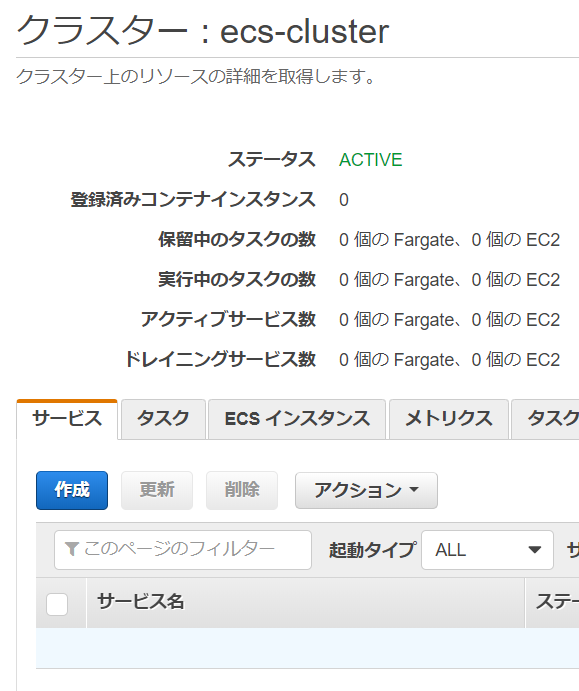
1.ECSでクラスター作成
1-1.[ECSクラスター作成手順]
クラスター名 ecs-cluster
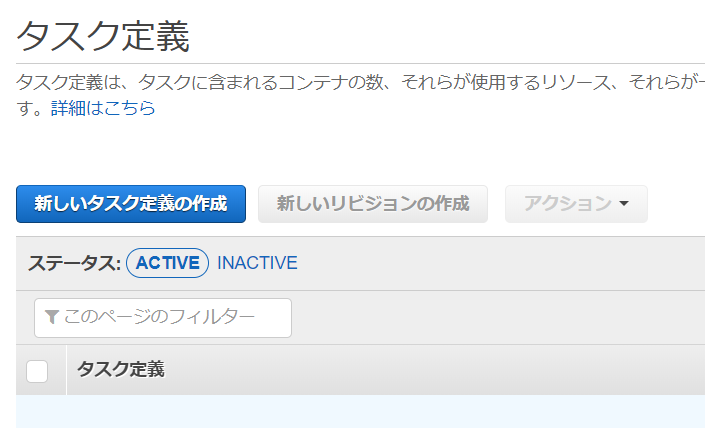
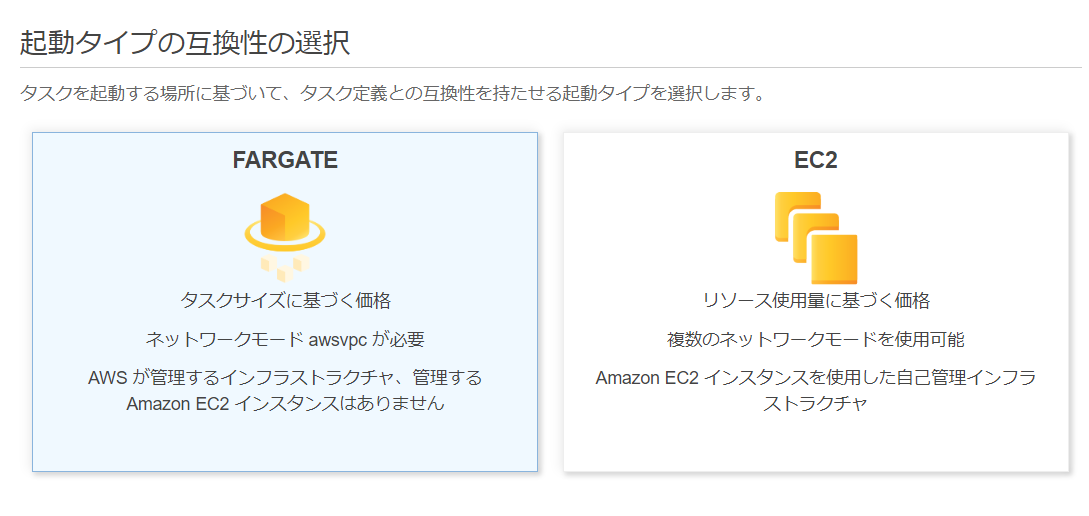
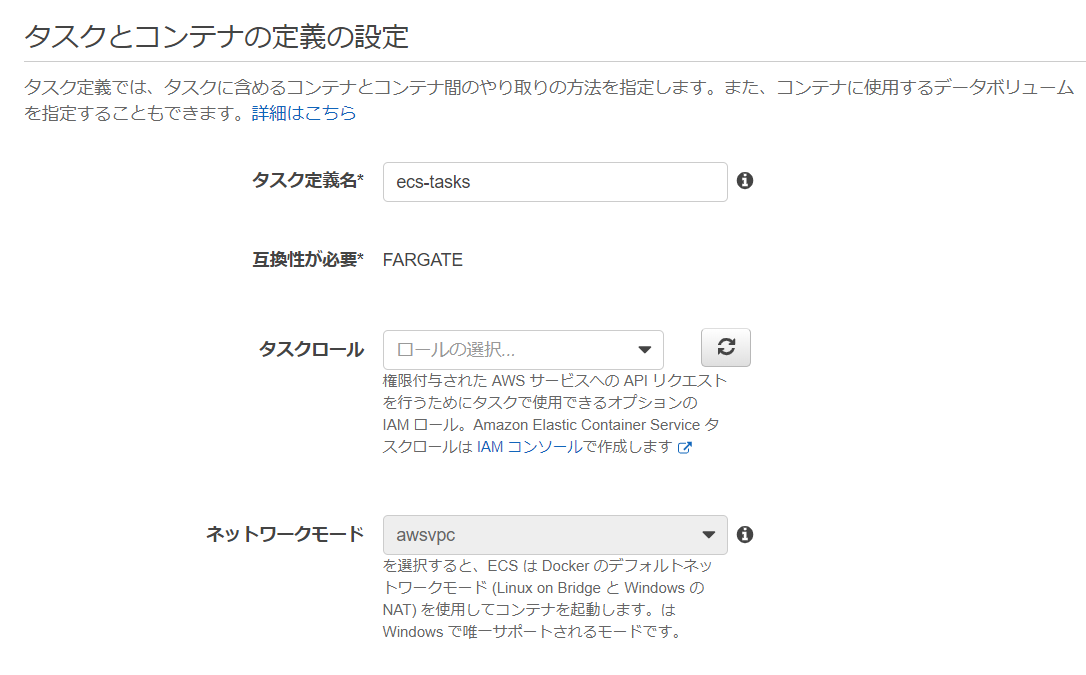
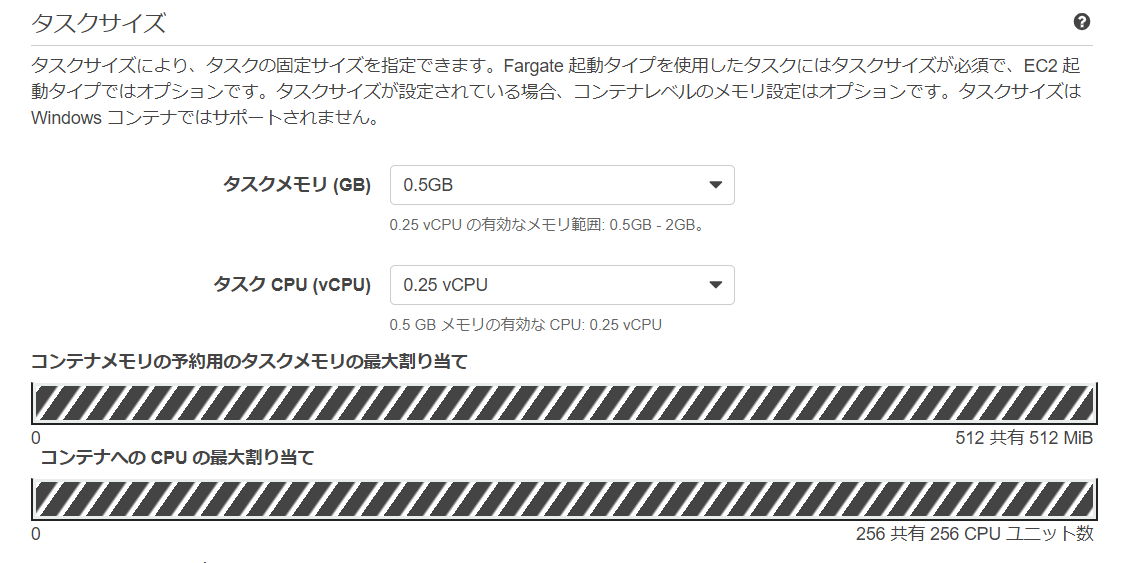
2.ECSでタスク定義作成
2-1.[ECSタスク定義作成手順]
タスク定義名 ecs-tasks
タスクメモリ タスクCPU 0.5GB 0.25vCPU
コンテナ名 イメージ ポートマッピング sampleap XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/jawsug/iwata/sampleap:latest 80
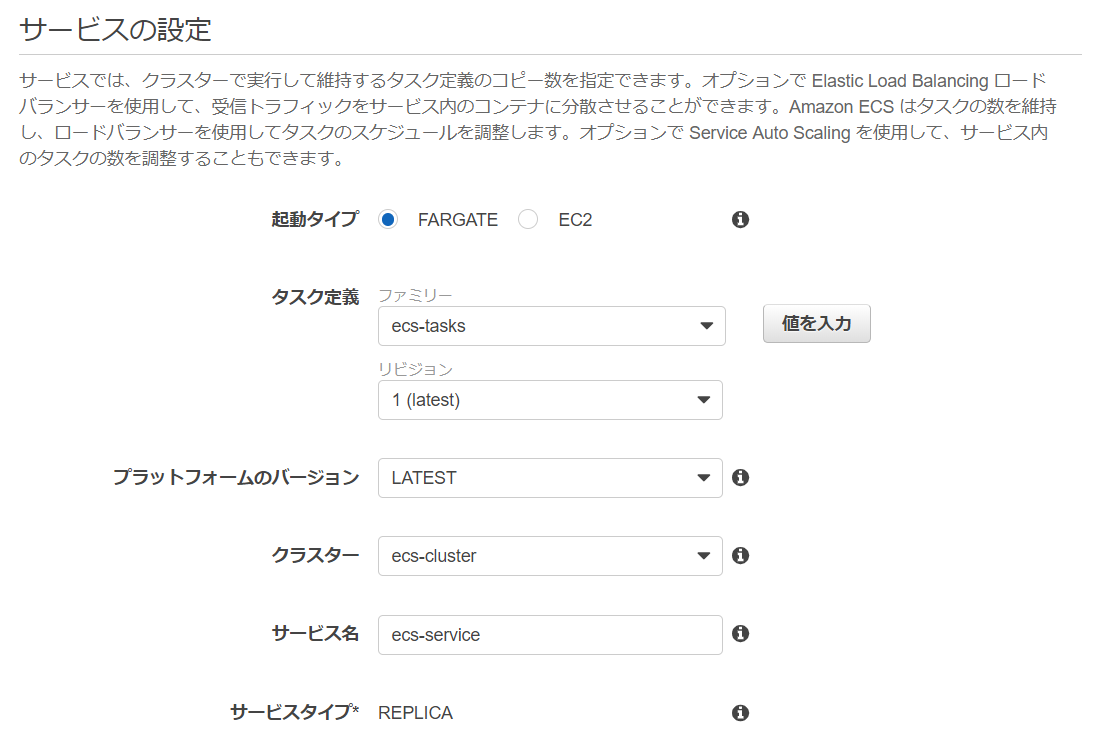
3.ECSでサービス作成
3-1.[ECSサービス作成手順]
サービス名 ecs-service
タスクの数 1
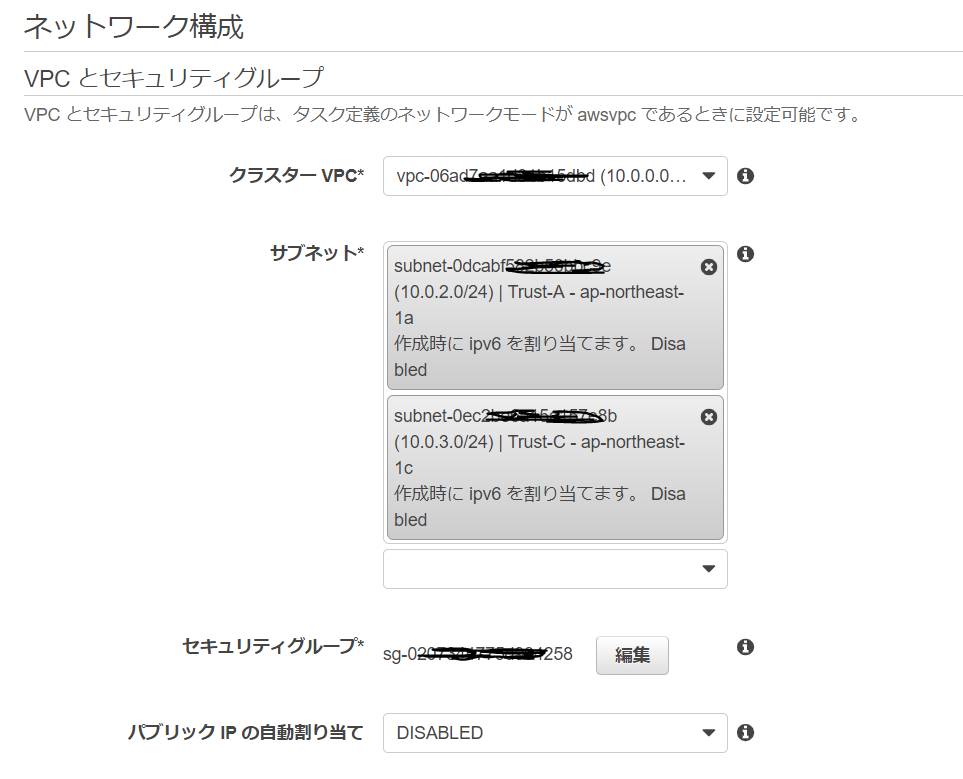
クラスターVPC JAWS-UG IWATA VPC_Tokyo01
サブネット Trust-A Trust-C
セキュリティグループ fargate-sg
パブリック IP の自動割り当て DISABLED
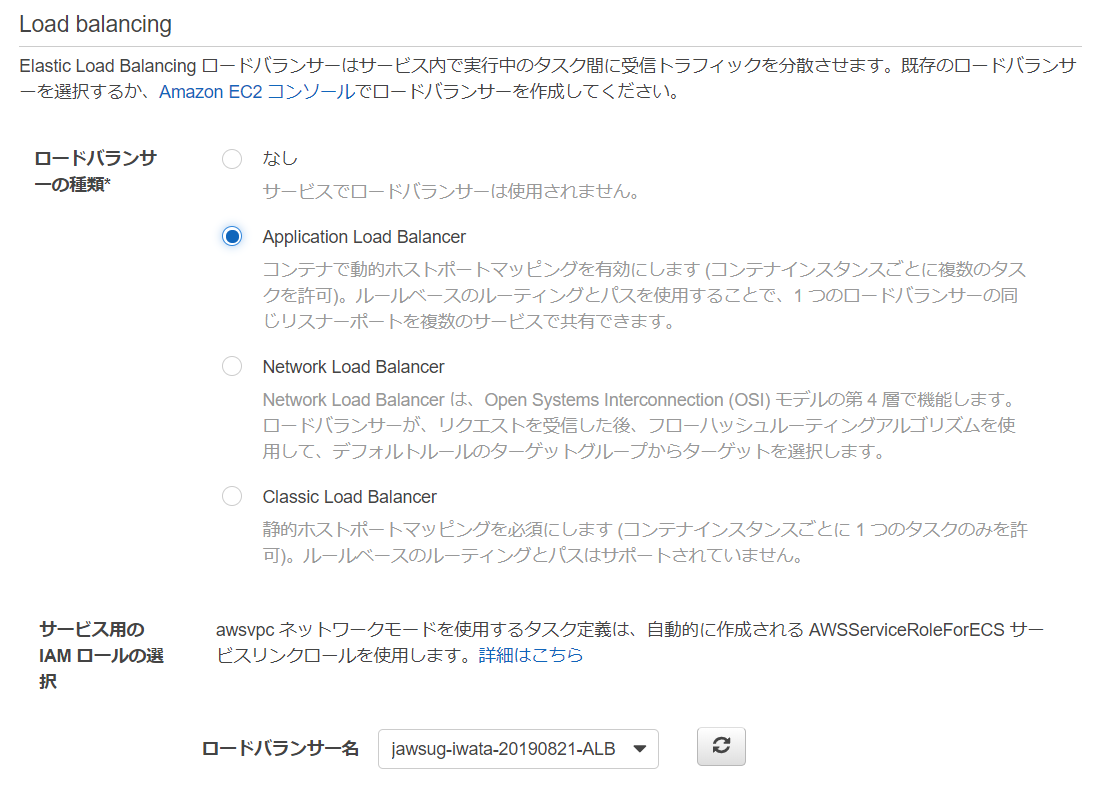
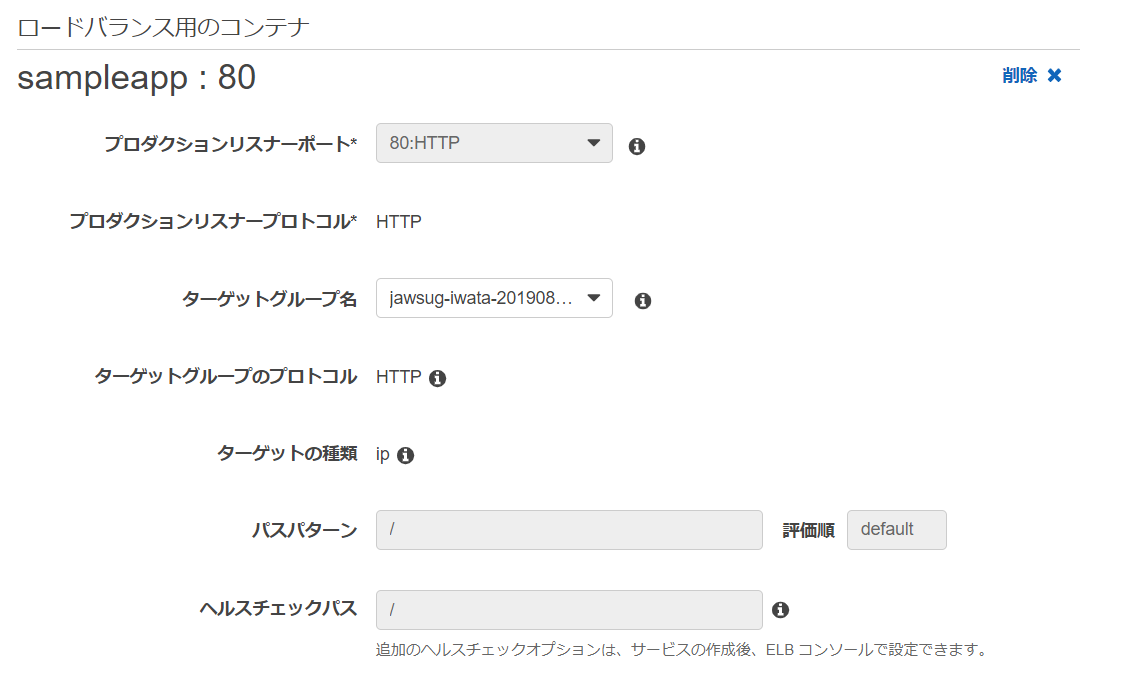
ロードバランサー名 プロダクションリスナーポート ターゲットグループ名 jawsug-iwata-20190821-ALB 80 : HTTP jawsug-iwata-20190821-TG
4.ALBにブラウザーで接続
4-1.ALBのDNSアドレスを入力し、接続します。
5.プログラムの更新
5-1.ターミナルソフトからコマンド入力
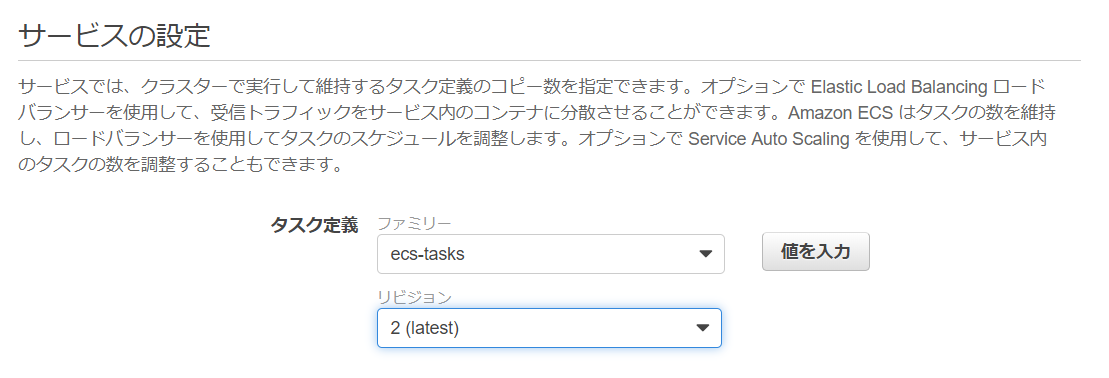
cd docker-hands-on cp -p src/index_ver2.0.php src/index.php docker build -t jawsug/iwata/sampleap:ver2.0 ./ docker tag jawsug/iwata/sampleap:ver2.0 XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/jawsug/iwata/sampleap:latest docker push XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/jawsug/iwata/sampleap:latest ※XXXXXXXXXXXXは、プッシュコマンドの表示で確認してください。5-1.[タスク定義の更新]
5-2.[サービスの更新]:タスク定義のリビジョンを最新の番号に更新する。
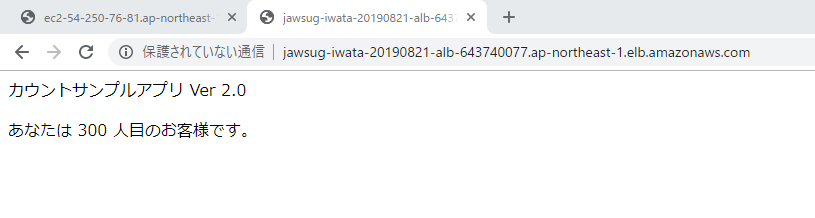
6.ALBにブラウザーで接続
6-1.ALBのDNSアドレスを入力し、接続します。






- 投稿日:2019-08-16T21:24:15+09:00
EC2でdigdagを動かすチュートリアル
記事の目的
- EC2へdigdagを導入して、GUIを表示するまでの方法について説明
- digdagはインメモリで実行する前提
EC2へのdigdag導入
前提
- パブリックアクセス可能なEC2(Amazon Linux 2)にssh接続できること
digdagのDL
- EC2へssh接続後、下記コマンドを実行
- 適宜sudoで実行する必要
# digdagのDL $ curl -o /usr/local/bin/digdag -L "https://dl.digdag.io/digdag-latest" # digdagの権限を変更 $ chmod +x /usr/local/bin/digdag # digdagのインストール成功を確認 $ digdag —version(javaをインストールしていない場合のみ、下記を実行)
$ sudo yum install java-1.8.0-openjdk-src.x86_64 #1.8を選択 $ sudo alternatives —config java #インストール成功を確認 $ java -versiondigdag serverのサービス化(Unitファイルの作成)
# サービスを新規作成 $ vi /etc/systemd/system/digdag.service #以下を記載する [Unit] Description=digdag [Service] Restart=always ExecStart=/bin/sh -c "/usr/local/bin/digdag server -b 0.0.0.0 --memory" [Install] WantedBy=multi-user.targetdigdag起動&自動起動設定
# 設定ファイルの再読み込み $ systemctl daemon-reload # サービス自動起動設定 $ systemctl enable digdag # サービス起動 $ systemctl start digdag動作確認
- 上記にアクセスし、digdagのGUI画面が表示されていれば成功
※GUI画面が表示されない場合、AWSのセキュリティグループで65432番のポートのインバウンドが開放されていることを確認してください。
参考
- 投稿日:2019-08-16T20:11:28+09:00
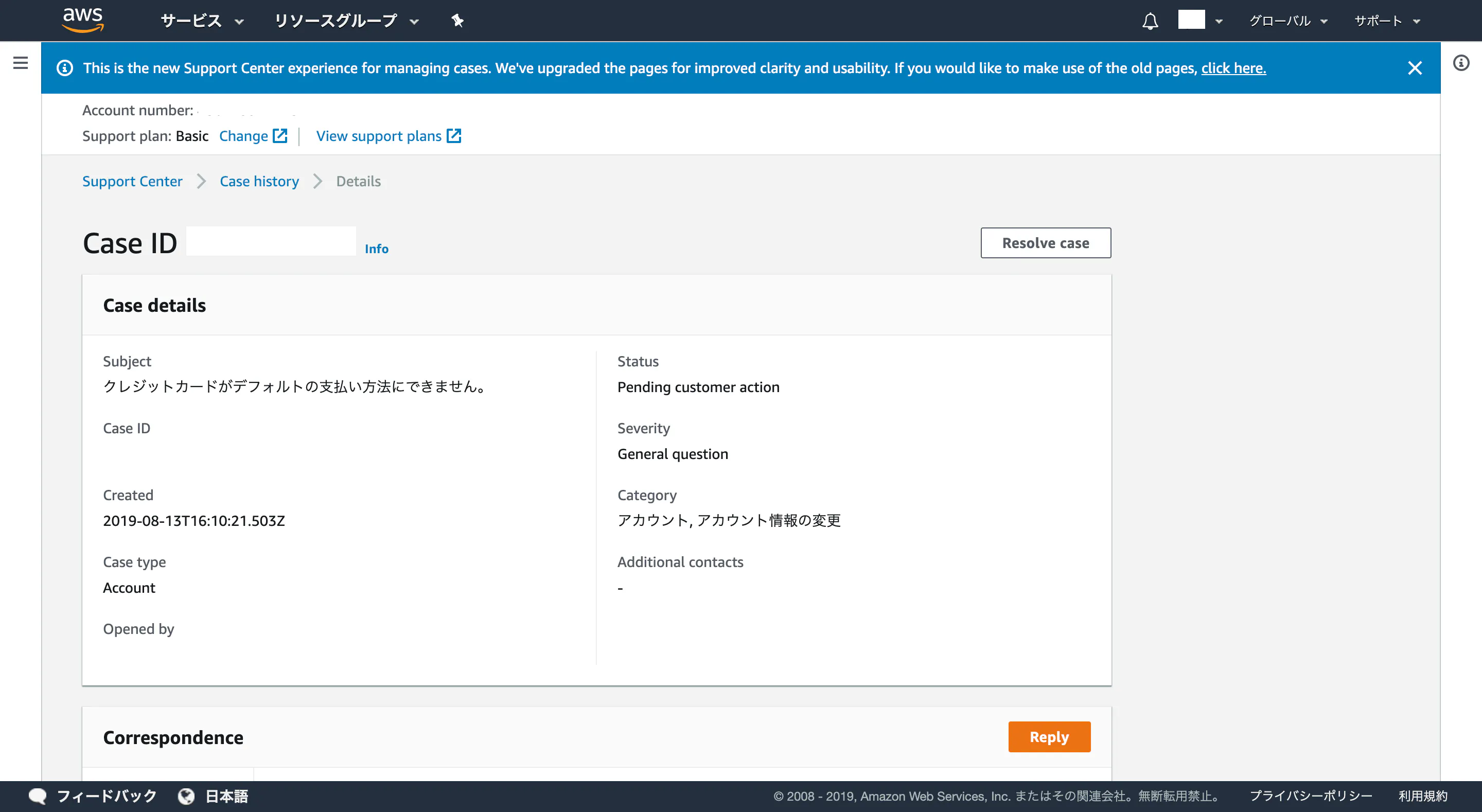
AWSのクレジットカード登録ができない時(ボクの場合)の解決策
AWSを半年ぶりに開いて個人開発しようとしたら、AWSのクレジットカードの登録ができない問題が起こりました
クレジットカードが登録できないとEC2に入れないのです。。。
ボクは過去にホームレスになった時があって、クレジットカードの滞納を3ヶ月以上してしまったので、ブラックリストに名前が乗っています。
(みなさん気をつけましょう)
そのクレジットカード以外のカードに登録を変更しようとしたら今回の問題が起きました。
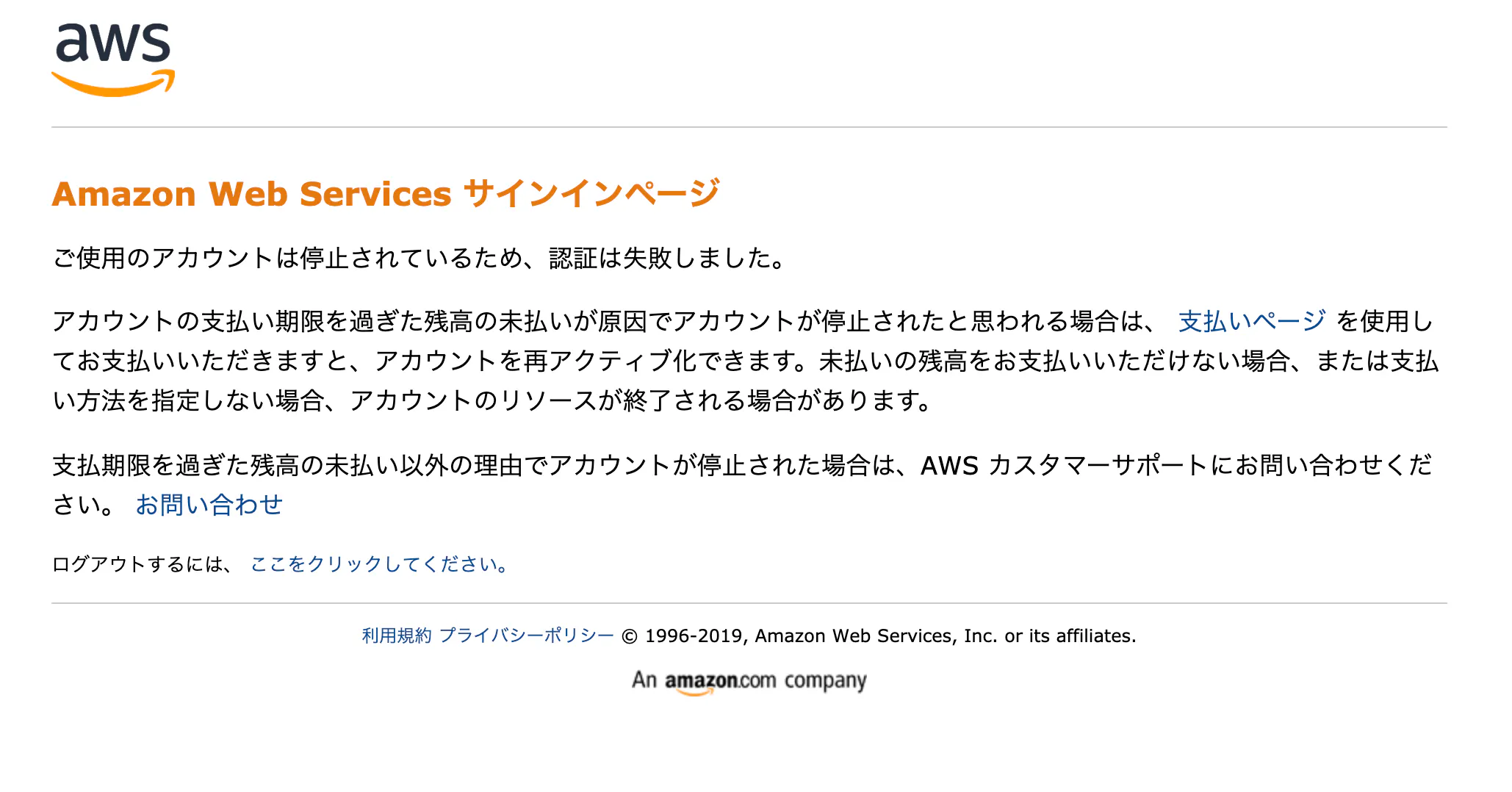
何回も何回も何回も、新しいクレジットカード(デビットカード)をデフォルトに編集・登録しようと試みましたが、一向に反映されませんでした。
下の画像のエラーです。もう見飽きました。。。
何回もトライアンドエラーする事にいい加減飽きたので、AWSカスタマーサービスにお問い合わせする事にしました。
(はじめからやれよ)問い合わせ詳細は下の画像です。
解決策
すると翌日、AWSカスタマーサービスから返信(下の画像)がきました。
新規アカウントを作ればいいだけでした。
初めから問い合わせすればよかった〜〜〜〜〜〜
(永久凍結になると思っていたので本当にホッとしました)告知
今、
進撃のITコミュニティで一緒に活動してくれる方を募集しています。
参加は無料です。
下に参加URLを貼ってます。
管理者はブロックチェーン実務経験あります。
参加資格はプログラマーからマーケター、AIやブロックチェーン、動画編集者やディレクター、youtuber、インスタグラマーも対象です。
進撃のIT Facebook
https://www.facebook.com/groups/612023275874253/
進撃のIT Slack
https://attack-on-it.herokuapp.com/
進撃のIT Twitter
https://twitter.com/IT13389135
進撃のIT Qiita記事
https://qiita.com/f___juntaro_/items/81136c85a8002cc442ac




- 投稿日:2019-08-16T17:13:00+09:00
AWSのUbuntu-18.04にsshできない
こんなエラーが出るとき
$ ssh -i key.pem ec2-user@ip-address Connection closed by ip-address port 22原因は単純で,デフォルトのユーザー名が
ec2-userじゃなくてubuntu.
なので,$ ssh -i key.pem ubuntu@ip-addressでつながる.
- 投稿日:2019-08-16T17:04:26+09:00
AmazonSQSAsyncの呼び出し方
AmazonSQSAsync の呼び出し方です。
AmazonSQSAsync sqs = SQS.getAsyncClient(); try { CreateQueueResult queue = sqs.createQueue( new CreateQueueRequest().withQueueName(QUEUE_NAME)); HashMap<String, MessageAttributeValue> map = new HashMap<String, MessageAttributeValue>(); map.put( "foo", new MessageAttributeValue().withDataType("String").withStringValue( "aaa")); Future<SendMessageResult> result = sqs.sendMessageAsync( new SendMessageRequest(queue.getQueueUrl(), "Message") .withMessageAttributes(map)); while (!result.isDone()) { Thread.sleep(10); } } catch (Exception e) { logger.error(e); } finally { sqs.shutdown(); }sqs.sendMessageAsync の返り値として Future が返ってきます。 isDone() メソッドが呼ばれるとSQSの送信が完了した判定になるので、それまでループで待って最後shutdownするのがお作法のようです。
- 投稿日:2019-08-16T16:59:57+09:00
AWS S3 のJava SDKで転送完了時にshutdownNowを呼ばないとスレッドが残り続ける
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/HLuploadFileJava.html
にS3へのファイルアップの方法が記載されています。ただここの処理の最後で shutdownNow を呼ばないと、s3Clientのスレッドが残り続けてしまうことがあるようです。(SDKのバージョンによるかも知れません。)
AmazonS3 s3Client = AmazonS3ClientBuilder.standard() .withRegion(clientRegion) .withCredentials(new ProfileCredentialsProvider()) .build(); TransferManager tm = TransferManagerBuilder.standard() .withS3Client(s3Client) .build(); // TransferManager processes all transfers asynchronously, // so this call returns immediately. Upload upload = tm.upload(bucketName, keyName, new File(filePath)); System.out.println("Object upload started"); // Optionally, wait for the upload to finish before continuing. upload.waitForCompletion(); System.out.println("Object upload complete"); // 以下のようにして転送マネージャーを終了させる必要があります。 tm.shutdownNow();参考
- 投稿日:2019-08-16T16:11:03+09:00
【AWS】開発環境では動くが本番だと�動かない事例集
Qiita初投稿になります。
何か不備や誤りがあったらご指摘をいただけるととてもありがたいです!経緯
スクールでの課題や個人アプリの開発でAWSを使っており、デプロイも双方担当をさせていただいておりました。
その中で、苦戦をした大きな比率を占めるのが、開発環境だと動くのに何故か本番環境だと動かない事例です。
本番で動かないと実際のサービスだと何も意味がないにも関わらず、このパターンが結構ありましたので、これから対処をする方がどういう方法や考え方で解いていけばいいのかをまとめます。
デプロイで苦戦をすると本当にイライラしてしまうので、イライラを少しでも沈めるのに貢献をできたらなと思います。開発環境(個人アプリもスクールの課題も同一です)
言語:Ruby 2.5.1
フレームワーク:Rails 5.2.3
データベース:MySQL5.6
ライブラリ:JQuery
自動デプロイ:capistrano
Webサーバー(本番):nginx
APサーバー(本番):unicorn
Web・APサーバー(開発):puma
今回は双方ともにEC2、S3を用いております。前提とエラーの基本の見方
EC2インスタンスの再起動が1番今まで救われたケースが多いです。まずは試してみましょう。(MySQLとnginxの再起動も必要です)
そして、エラーを解決をする基本はエラーログを見て忠実に動くことです。これは本番環境でも開発環境でも一緒です。
エラーが出る場合、開発環境だとターミナルやビューに出てきます。ただ、本番環境だと出てこないため、本番環境だと別でコマンドで見ていきます。
エラーログの本番環境の場所はlinuxコマンドでログインをして確認をします。注意をするのは自動デプロイの前後でエラーが吐き出される場所が異なることです。自動デプロイをしたにも関わらず元のままの位置でファイルを開いても意味がないです。#手動デプロイ後 /var/www/アプリ名/log/production.log #capistranoでの自動デプロイ後 /var/www/アプリ名/current/log/production.loglogにまで移動をしたらcat等のコマンドでエラーログを見ることができます。
①pumaとの性能の違いで、拡張子がついていなかった時
ActionView::Template::Error (The asset "bannar_image" is not present in the asset pipeline.):
※本番環境のエラーログです。
これが一番はじめのエラーでした。こちらに関しては上記のエラー文を見ると、bannar_imageが間違っているのが何となく分かると思います。
このbannar_imageという記述があったのが、image_tagになるので、image_tagに関して調べてみました。index.erb#エラーが起きたコードのイメージ <%= image_tag 'bannar_image' %> #他のサイトで見た見本のコード <%= image_tag 'flower.png' %>実際にビューファイルを比べてみると何か違和感が、、、上のコードは実は拡張子がなかったのです。
そのため、本番環境では動かなかったのです。ちなみにこの時はそれまで自動デプロイが初めてできた瞬間に出たエラーだったため、自動デプロイのcapistranoのエラーだと勘違いをしてしまっておりました。
自動デプロイのエラーばかり見ていたので、何もエラーログがないのに原因不明のエラーが起こっていると勘違いして、だいぶハマりました。
デプロイがどういう流れになっていてどういう仕組みになっているのかを理解をしていないとこういうところで非常に苦戦をします。というかpumaは何故拡張子がないのに動くのか、、、
②application.jsにJQueryが2つあった時
こちらはそこまで難しくないエラーです。お互いに干渉してしまうため、エラーになるようです。
今出せないのですが、エラーログも出ていて、そんなに複雑なエラーログではありませんでした。application.js=require rails-ujs =require jquery-ujs下のコードはヴァージョンが古い時に使っていたようでして、Rails5.1以降は上のコードを使うみたいです。
これはスクールの発表で先輩グループの発表の際に触れていたので、すぐに分かりました。
①もだけどそもそもpumaの時点でエラー起きてくれないのかな。。。③データベース関連で開発環境とmigrationの状況が異なってしまった時
ActionView::Template::Error (Unknown database 'freemarket_sample_54c_production'):
チーム開発でmearge済みのmigrationファイルを変更をしてその後に再度meargeをしたり、
rake db:reset等を繰り返しているといつか起きてしまうかと思います。
私たちのチームではどうしようもなくなってしまい、結局一から本番環境のデータベースを構築をし直したのですが、これは本来あまりやっていいことではないかと思っています。
もちろん開発の初期段階ですので正直困りはしなかったのですが、実際のサービスだと既に重要な顧客データが多数入っているためです。
こちらは他に何かやり方あれば教えていただけると非常に嬉しいです。ちなみにcapistrano導入後はデータベースをcreateしたり、dropをさせるときもエラーを見るのと同じくcurrent上でコマンドは打ちます。
rake:db:seedも同様で、capistrano導入後はディレクトリの位置が変更をされるためです。④credentials.yml関連
ActiveSupport::MessageEncryptor::InvalidMessage
このエラーは序盤結構多かったです。こちらに関しては他に詳しい記事も多数あるかと思いますので割愛します。
credentials.ymlに関しては最初は結構苦戦をしましたが、慣れるとAPIkeyの管理がすごく簡単でした。
怖がるものではないかと思います。⑤データベース内に数値が入っていなかった時
ActionView::Template::Error (undefined method `id' for nil:NilClass):
すごく単純なようで起きがちなエラーです。
特にテーブルを増やしてカラムに新しく外部キーを増やすと起こりがちです。
私はデータベースをSQLで直接いじっていましたが、Sequelpro等で本番でも見れるようにすることができるので、入れたら楽に設定をできると思います。
※ベーシック認証をしてからだと思うのですが、途中からSequelproは使えなくなりました。おそらく弾かれてしまったのだと思います。もしかするとベーシック認証を使っていてもできるのかもしれませんが、私は調べきれませんでした。⑥JQueryで発火をしなかった※データが入っていない時
エラーログは出ません。
インクリメンタルサーチをしようとしたのですが、本番環境のデータで名前を検索をする際に、そもそも該当の名前のデータが入っていませんでした。。。これは完全に単なる勘違いです。即解決できましたが、全くエラーログが出てこないので原因が不明になるので少しの時間、不安になりました。
これも上記の⑤と一緒でSequelproとか入れたらわかりやすそうです。まとめ
基本はエラーログをしっかりと見ていけば何とかなりました。ただ、データベース関連は視覚化ができていなかったので、苦労をしました。
これに関してはエラーログの構造等を理解しだしてから、格段に理解が深まったので、細かいWebアプリの仕組みに関しては理解をしといたほうがいいなと感じました。
今回挙げた事例に関しては正直かなり簡単なほうだと思っています。これから先も出てくる事例は多いと思うので、また何かあれば記事に挙げていきます。参考記事
https://www.javadrive.jp/rails/template/index11.html
https://www.bokukoko.info/entry/2017/10/27/231129
https://qiita.com/scivola/items/cc06ddbfd94d3118f693
- 投稿日:2019-08-16T16:11:03+09:00
【AWS】開発環境では動くが本番だと動かない事例集
Qiita初投稿になります。
何か不備や誤りがあったらご指摘をいただけるととてもありがたいです!経緯
スクールでの課題や個人アプリの開発でAWSを使っており、デプロイも双方担当をさせていただいておりました。
その中で、苦戦をした大きな比率を占めるのが、開発環境だと動くのに何故か本番環境だと動かない事例です。
本番で動かないと実際のサービスだと何も意味がないにも関わらず、このパターンが結構ありましたので、これから対処をする方がどういう方法や考え方で解いていけばいいのかをまとめます。
デプロイで苦戦をすると本当にイライラしてしまうので、イライラを少しでも沈めるのに貢献をできたらなと思います。開発環境(個人アプリもスクールの課題も同一です)
言語:Ruby 2.5.1
フレームワーク:Rails 5.2.3
データベース:MySQL5.6
ライブラリ:JQuery
自動デプロイ:capistrano
Webサーバー(本番):nginx
APサーバー(本番):unicorn
Web・APサーバー(開発):puma
今回は双方ともにEC2、S3を用いております。前提とエラーの基本の見方
EC2インスタンスの再起動が1番今まで救われたケースが多いです。まずは試してみましょう。(MySQLとnginxの再起動も必要です)
そして、エラーを解決をする基本はエラーログを見て忠実に動くことです。これは本番環境でも開発環境でも一緒です。
エラーが出る場合、開発環境だとターミナルやビューに出てきます。ただ、本番環境だと出てこないため、本番環境だと別でコマンドで見ていきます。
エラーログの本番環境の場所はlinuxコマンドでログインをして確認をします。注意をするのは自動デプロイの前後でエラーが吐き出される場所が異なることです。自動デプロイをしたにも関わらず元のままの位置でファイルを開いても意味がないです。#手動デプロイ後 /var/www/アプリ名/log/production.log #capistranoでの自動デプロイ後 /var/www/アプリ名/current/log/production.loglogにまで移動をしたらcat等のコマンドでエラーログを見ることができます。
①pumaとの性能の違いで、拡張子がついていなかった時
ActionView::Template::Error (The asset "bannar_image" is not present in the asset pipeline.):
※本番環境のエラーログです。
これが一番はじめのエラーでした。こちらに関しては上記のエラー文を見ると、bannar_imageが間違っているのが何となく分かると思います。
このbannar_imageという記述があったのが、image_tagになるので、image_tagに関して調べてみました。index.erb#エラーが起きたコードのイメージ <%= image_tag 'bannar_image' %> #他のサイトで見た見本のコード <%= image_tag 'flower.png' %>実際にビューファイルを比べてみると何か違和感が、、、上のコードは実は拡張子がなかったのです。
そのため、本番環境では動かなかったのです。ちなみにこの時はそれまで自動デプロイが初めてできた瞬間に出たエラーだったため、自動デプロイのcapistranoのエラーだと勘違いをしてしまっておりました。
自動デプロイのエラーばかり見ていたので、何もエラーログがないのに原因不明のエラーが起こっていると勘違いして、だいぶハマりました。
デプロイがどういう流れになっていてどういう仕組みになっているのかを理解をしていないとこういうところで非常に苦戦をします。というかpumaは何故拡張子がないのに動くのか、、、
②application.jsにJQueryが2つあった時
こちらはそこまで難しくないエラーです。お互いに干渉してしまうため、エラーになるようです。
今出せないのですが、エラーログも出ていて、そんなに複雑なエラーログではありませんでした。application.js=require rails-ujs =require jquery-ujs下のコードはヴァージョンが古い時に使っていたようでして、Rails5.1以降は上のコードを使うみたいです。
これはスクールの発表で先輩グループの発表の際に触れていたので、すぐに分かりました。
①もだけどそもそもpumaの時点でエラー起きてくれないのかな。。。③データベース関連で開発環境とmigrationの状況が異なってしまった時
ActionView::Template::Error (Unknown database 'freemarket_sample_54c_production'):
チーム開発でmearge済みのmigrationファイルを変更をしてその後に再度meargeをしたり、
rake db:reset等を繰り返しているといつか起きてしまうかと思います。
私たちのチームではどうしようもなくなってしまい、結局一から本番環境のデータベースを構築をし直したのですが、これは本来あまりやっていいことではないかと思っています。
もちろん開発の初期段階ですので正直困りはしなかったのですが、実際のサービスだと既に重要な顧客データが多数入っているためです。
こちらは他に何かやり方あれば教えていただけると非常に嬉しいです。ちなみにcapistrano導入後はデータベースをcreateしたり、dropをさせるときもエラーを見るのと同じくcurrent上でコマンドは打ちます。
rake:db:seedも同様で、capistrano導入後はディレクトリの位置が変更をされるためです。④credentials.yml関連
ActiveSupport::MessageEncryptor::InvalidMessage
このエラーは序盤結構多かったです。こちらに関しては他に詳しい記事も多数あるかと思いますので割愛します。
credentials.ymlに関しては最初は結構苦戦をしましたが、慣れるとAPIkeyの管理がすごく簡単でした。
怖がるものではないかと思います。⑤データベース内に数値が入っていなかった時
ActionView::Template::Error (undefined method `id' for nil:NilClass):
すごく単純なようで起きがちなエラーです。
特にテーブルを増やしてカラムに新しく外部キーを増やすと起こりがちです。
私はデータベースをSQLで直接いじっていましたが、Sequelpro等で本番でも見れるようにすることができるので、入れたら楽に設定をできると思います。
※ベーシック認証をしてからだと思うのですが、途中からSequelproは使えなくなりました。おそらく弾かれてしまったのだと思います。もしかするとベーシック認証を使っていてもできるのかもしれませんが、私は調べきれませんでした。⑥JQueryで発火をしなかった※データが入っていない時
エラーログは出ません。
インクリメンタルサーチをしようとしたのですが、本番環境のデータで名前を検索をする際に、そもそも該当の名前のデータが入っていませんでした。。。これは完全に単なる勘違いです。即解決できましたが、全くエラーログが出てこないので原因が不明になるので少しの時間、不安になりました。
これも上記の⑤と一緒でSequelproとか入れたらわかりやすそうです。まとめ
基本はエラーログをしっかりと見ていけば何とかなりました。ただ、データベース関連は視覚化ができていなかったので、苦労をしました。
これに関してはエラーログの構造等を理解しだしてから、格段に理解が深まったので、細かいWebアプリの仕組みに関しては理解をしといたほうがいいなと感じました。
今回挙げた事例に関しては正直かなり簡単なほうだと思っています。これから先も出てくる事例は多いと思うので、また何かあれば記事に挙げていきます。参考記事
https://www.javadrive.jp/rails/template/index11.html
https://www.bokukoko.info/entry/2017/10/27/231129
https://qiita.com/scivola/items/cc06ddbfd94d3118f693
- 投稿日:2019-08-16T16:07:08+09:00
AWS LambdaのCustom RuntimeでサーバーレスDartしてみた
最近Dartに興味を持ってきたので今回はDartの話をします。
今までDartはkotlinやscalaと比べてイケてないという評判を聞いて食わず嫌いしていたのですが、Flutterに採用されてから盛り返してるっぽいのを見てお盆休みで時間もあるし
ロゴもかっこいいしちょっと触って見ようかなと思ったのでLambdaで動くようにしてみました。最終的な成果物はこちらにおいてあります。
デプロイしてみる
ではとりあえずこの自作ランタイムを使うときの流れを見ていきます。
デプロイに必要な物は以下の通りです。
- Dart
- Serverless Framework
- docker
まず
serverless.ymlです。serverless.ymlservice: serverless-dart-sls custom: defaultStage: dev api_version: v0 provider: name: aws runtime: provided region: ap-northeast-1 stage: ${opt:stage, self:custom.defaultStage} functions: hello: handler: hello events: - http: path: hello method: get integration: lambda world: handler: world events: - http: path: world method: post integration: lambdaServerless Frameworkがわかる方にはほとんど説明不要だとは思います。
使ったことが無い方へ説明をするとfunctionsがLambdaを定義している箇所で、それぞれhelloをハンドラーとしてgetリクエストを<url>/helloで受け付けるLambdaファンクションhelloとworldをハンドラーとしてpostリクエストを<url>/worldで受け付けるLambdaファンクションworldが定義されています。次にここでハンドラーとして指定されている
helloとworldを見ていきます。
src/handlerの中にそれぞれhello.dartとworld.dartというファイルを用意しています。hello.dartimport '../../runtime.dart'; dynamic hello(dynamic event) { return {'msg': '新たな光に会いに行こう。'}; } void main() { lambdaHandler(hello); }getに対して適当なメッセージを返却するコードです。
lambdaHandlerが今回自作したランタイムでlambdが呼び出されたときにhelloを実行するようにしています。world.dartimport '../../runtime.dart'; dynamic world(dynamic event) { final body = event['body']; return body; } void main() { lambdaHandler(world); }こちらもほぼ同じです。
postで入ってきたbodyをそのまま返しています。それではこれらをデプロイするための簡単なスクリプトを用意してあるので実行してみましょう。
問題無くデプロイされれば以下のような画面が出てくるはずです。$ ./deploy.sh Password: # 一部コマンドのためにsudoが必要 Resolving dependencies... Got dependencies! (略) Serverless: Stack update finished... Service Information service: serverless-dart-sls stage: dev region: ap-northeast-1 stack: serverless-dart-sls-dev resources: 16 api keys: None endpoints: GET - https://hoge.execute-api.ap-northeast-1.amazonaws.com/dev/hello POST - https://hoge.execute-api.ap-northeast-1.amazonaws.com/dev/world functions: hello: serverless-dart-sls-dev-hello world: serverless-dart-sls-dev-world layers: None (略)それぞれ正しくデプロイできていれば以下のようなレスポンスが帰ってくるはずです。
$ curl https://hoge.execute-api.ap-northeast-1.amazonaws.com/dev/hello {"msg":"新たな光に会いに行こう。"} $ curl -X POST -H "Content-Type: application/json" -d '[{"name": "島村卯月"}, {"name": "渋谷凛"}, {"name": "本田未央"}]' \ https://hoge.execute-api.ap-northeast-1.amazonaws.com/dev/world [{"name":"島村卯月"},{"name":"渋谷凛"},{"name":"本田未央"}]中身を見てみよう
Lambdaで動かすためのランタイムの中身をもう少し詳しく見ていきましょう。
まずcustom runtimeで任意のLambdaを動かすのに必要なことは大きく2つです。
- 所定のapiから必要な情報を取得し得た情報を利用して何かをした後また別のapiに対して結果を送りつける無限ループの実装
- custom runtimeに設定したときに起動時に最初に実行されるファイル
bootstrapの用意まず無限ループの方から見ていきます。
今回はルートディレクトリにruntime.dartというファイルを用意しています。runtime.dartimport 'package:http/http.dart' as http; import 'dart:convert'; import 'dart:io' show Platform; void lambdaHandler(Function callback) async { final api = Platform.environment['AWS_LAMBDA_RUNTIME_API']; while (true) { final response = await http.get('http://${api}/2018-06-01/runtime/invocation/next'); final event_data = json.decode(utf8.decode(response.bodyBytes)); final request_id = response.headers['lambda-runtime-aws-request-id']; final result = await callback(event_data); http.post( 'http://${api}/2018-06-01/runtime/invocation/${request_id}/response', body: json.encode(result)); } }あまり難しいことはしていませんが一通り見ていきます。
http://${Platform.environment['AWS_LAMBDA_RUNTIME_API']}/2018-06-01/runtime/invocation/nextを叩くことでLambdaへのリクエストの各種情報とリクエストIDが取得できます。
これをこの関数の引数のcallbackに処理をさせ、その結果をそのままhttp://${Platform.environment['AWS_LAMBDA_RUNTIME_API']}/2018-06-01/runtime/invocation/${request_id}/responseに引き渡すことで結果を返却することができます。次に
bootstrapです。もし先程デプロイしたままであればルートディレクトリにこのようなファイルがあるはずです。bootstrap#!/bin/sh bin_dir="$LAMBDA_TASK_ROOT/./.aot" $bin_dir/dartaotruntime $bin_dir/$_HANDLER.dart.aot
.aotというディレクトリにaotのランタイムとコンパイルした結果を設置してありlambdaが起動したときにそれをそのまま実行するようになっています。
このbootstrapや.aotの中身を用意しているので先程使用したdeploy.shなのですが、この中身はこんな感じになってます。deploy.sh#!/bin/bash stg=$1 [ "$stg" = "" ] && stg="dev" handler_dir="./src/handler" bin_dir="./.aot" rm -rf ./bootstrap $bin_dir mkdir $bin_dir cat <<EOF > ./bootstrap #!/bin/sh bin_dir="\$LAMBDA_TASK_ROOT/$bin_dir" \$bin_dir/dartaotruntime \$bin_dir/\$_HANDLER.dart.aot EOF chmod +x ./bootstrap || exit 1 docker run --rm -v $(pwd):/work -w /work google/dart cp /usr/lib/dart/bin/dartaotruntime ./.aot sudo chmod +x $bin_dir/dartaotruntime || exit 1 pub get || exit 1 cat ./serverless.yml | grep 'handler' | awk '{print $2}' | while read line; do dart2aot $handler_dir/$line.dart $bin_dir/$line.dart.aot || exit 1 done && sls deploy -s $stg一つずつ見ていきましょう。
handler_dir="./src/handler" bin_dir="./.aot" rm -rf ./bootstrap $bin_dir mkdir $bin_dirまずコンパイル結果を置く場所や元のハンドラー場所を設定し、前回のデプロイ時作ったファイル類を掃除してます。
cat <<EOF > ./bootstrap #!/bin/sh bin_dir="\$LAMBDA_TASK_ROOT/$bin_dir" \$bin_dir/dartaotruntime \$bin_dir/\$_HANDLER.dart.aot EOF chmod +x ./bootstrap || exit 1実行に必要な
bootstrapを生成しています。
別にbootstrapはわざわざ毎回生成する必要は本来無いのですが、既存のプロジェクトへの組み込みやすさ等を考えて今回はここで生成するようにしてしまいました。docker run --rm -v $(pwd):/work -w /work google/dart cp /usr/lib/dart/bin/dartaotruntime ./.aot sudo chmod +x $bin_dir/dartaotruntime || exit 1 pub get || exit 1ここでdart側の事前準備をしています。
dartのdokcerイメージからlinux向けのaotの実行ランタイムをとって来ていますがこれはmacを考慮してそうしているだけでlinuxな環境ならローカルにある物をそのまま持ってきても問題無く動作します。
正直ここはもっと色々な物を一緒に詰めてやる必要があるかな?っと思ってたのですがlayerとかで頑張って用意する必要もなくあっさり動いてしまいました。cat ./serverless.yml | grep 'handler' | awk '{print $2}' | while read line; do dart2aot $handler_dir/$line.dart $bin_dir/$line.dart.aot || exit 1 done && sls deploy -s $stg最後に各ハンドラーをコンパイルしてデプロイしています。
grepやawkでガチャガチャやってますがこれでハンドラーに指定している名前を引っ張りだしてコンパイルしています。$ cat ./serverless.yml | grep 'handler' | awk '{print $2}' hello worldまたデプロイ時にステージを選択するオプションに引数を渡していますがこれはこのスクリプトに渡す引数をそのまま横流し、無いなら
devになるようにしています。stg=$1 [ "$stg" = "" ] && stg="dev"Q.仕組みとかよくわかんねぇけどとりあえず既存のプロジェクトに組み込みてぇんだけどどうすればいいのさ?
そういった声にお答えしてこんな感じにやればいいんじゃねって感じの手順を用意しました。
ただし筆者はFlutter等の実践的なフロントやアプリのDartの経験があるわけでは無く、動作は保証しかねるのであしからず。1. pubspec.yamlにhttp追記
pubspec.yamldependencies: http: ^0.12.0+22. pubspec.yaml同じ階層にserverless.ymlとdeploy.shを設置
おそらく同じ階層にあればいけるはず
3. お好きなところにruntime.dartとハンドラーを置いておくディレクトリを用意
runtime.dartはハンドラーから読めれば良いのでそれぞれのプロジェクトにとって適切な場所に置いておいてください。
ハンドラーを置くディレクトリもデフォルトではsrc/handlerとしていますが簡単に変更出来るのでこれも適切な場所に用意してください。
ただしこのデプロイスクリプトではハンドラーのディレクトリに更を階層分けるような構造には対応していないので注意してください。4. deploy.shの修正
もし3でハンドラー置き場等を変更していたりする場合にはここの変数を修正します。
handler_dir="./src/handler" bin_dir="./.aot"
handler_dirがハンドラー置き場なので好きに変更しましょう。
またコンパイル結果を置く場所もここで変更できます。5. デプロイ実行
これで実行すればデプロイされるはずです。
$ ./deploy.sh完走した感想
ということでDart on Lambdaでした。
Dartはシングルバイナリを吐くタイプの言語では無いのでCrystalなどに比べて正直もっと苦戦すると思ってたのですが思いの外あっさり動きましたね。
あと今回始めてDartを触ってみて思ったのですが、vscodeの拡張の出来がいいのか思ってたより開発しやすかったです。
ロゴが好きなので触っただけだったので実績だけ作って終わりでもいいかなって感じで始めたけどこれならしばらくは個人で開発するLambdaはDartにしてもいいかもしれないですね。

- 投稿日:2019-08-16T15:52:15+09:00
【API作るよ】Serverless FrameworkとSAMを比較してみる
AWSでAPIを作りましょう(唐突)
面倒なことはフレームワークに丸投げしましょう。TL;DR
- AWSでサーバレスアーキテクチャ構築するときに代表的なフレームワークであるServerless FrameworkとSAMを比較してみたよ
- 筆者の判定だとServerless Frameworkに軍配かな
- SAMはプラグインがやや少ないのと癖が強いから今後に期待!
導入
サーバサイドエンジニアをやっているとAWSでAPI構築しましょうっていう案件に参画することがあるかもしれません。
そんなときに、ゼロから作ろうって話になることも……あるかもしれません。で、だいたいそのときにAWSで
- Lambda
- DynamoDB
- API Gateway
とかそれぞれの知識が必要になってくるわけですが、一つ一つ個別に作ってるとかなり大変です。
Serverless FrameworkやSAMのようなフレームワークを使えば、そこらへんを設定ファイル一枚、コマンド一発で構築まで全部やってくれます。Serverless Frameworkについて
この手のフレームワークのデファクトスタンダード……とまで言うと言いすぎかもしれませんが、この手のフレームワークにしては非常に「枯れて」いて、機能も充実しています。
APIを構築する場合……というかサーバレス環境を構築する場合、
「あるURIにPOST投げるとDynamoDBに要素がPUTされる」
みたいな機能を作ることになると思いますが、いちいち試すためにデプロイするのも面倒ですから、ローカルでDynamoDBを動かして機能を試してみたいところですよね。そんなときローカルでサクッと動かせるというのは結構重要です。
詳細はこちらを参照してください(丸投げ)
Serverless アプリケーションをローカルで開発する
このとおりに作れば大丈夫です。……丸投げが酷すぎるので、少し補足します。
Serverless FrameworkはNode.js系のプラグインが非常に充実していて、上記の記事にもあるように
serverless-dynamodb-localのようなプラグインを導入するとかなり気軽にローカルでDynamoDBの環境を構築することができます。
後述しますが、SAMを使う場合だともう少し複雑になります。【以下余談】
S3との連携プラグインも存在していますが……
https://www.npmjs.com/package/serverless-s3-localLambdaをPythonで構築する場合、ちょっと微妙です。
ローカルでの構築例がgithubにありますが……
https://github.com/ar90n/serverless-s3-local/blob/master/example/simple_event_python/handler.py読んで頂くとわかるように、「ファイル書き込むだけ」的なコードになっており、ローカルでの動作確認という用途としては……少々残念です。
【余談ここまで】SAMについて
真打ち、AWS公式のフレームワークです。
みんな大好きVisual Studio Code向けに公式提供されているAWS Toolkitと連携してます。
Pycharm版もあるぞ。Serverless Frameworkがコマンド一発でデプロイできるのと比較して、少しステップは多いですがVisual Studio CodeのGUIからポチポチとクリックでデプロイができ、これはこれで便利です。
しかもローカル実行やデバッグもできるスグレモノ。
(画像は公式のREADMEより)これはもうSAMを選ぶしか無いのでは?
と言いたいところですが……実際の構築をざっとお読みください。
こちらの記事が非常にわかりやすいです(再度丸投げ)
Serverless アプリケーションをローカルで開発するServerless Frameworkとの違いは色々あるのですが、開発したAPIをローカルで実行する場合の最大の違いは……
- リクエストをローカルで受け取る
- Dockerプロセスが立ち上がる
- Lambdaが実行される
という三段階にあると考えています。
特に2番が曲者で、上記の記事では
- DynamoDBをDockerでローカルに構築する
- DynamoDBが起動するネットワークを作成
- Lambda実行のDockerプロセスが機動するネットワークを指定
という流れで、LambdaがDynamoDBにアクセスできるようにしています。
……これ、デバッグが難しいです……
DynamoDBが動いているネットワークが指定されちゃってるので、逆にローカル実行した際にネックになっちゃってるみたいでアクセスが上手くできなかったです。一応"Configure"から色々設定してデバッグの引数などは設定できるようですが、一方VSCodeでリモートデバッグ的な設定をして、Dockerプロセスの生成後にステップ実行……みたいな方法は厳しそうでした。
そこまでやるなら普通にServerless Frameworkで構築して、引数:eventのモックみたいなものを作成してそのままデバッグしてしまったほうが楽なのでは?……という感が否めませんでした。
やってみると実際そっちのほうが楽でした。それと、AWS Toolkitが出て間もないので情報がやや少ないというのも大きいです。
SAM自体はAWS Toolkit以前からあったのでそれなりに情報があるのですが、AWS Toolkitを使わない場合「Serverless Frameworkよりも多少複雑で、プラグインが少ない」フレームワークという印象で、正直あまり良い印象はありません。結論
Serverless FrameworkとSAMの最大の差は、要するに
「プラグインの豊富さ」
だと考えています。
例えばSAMで例に出した記事の場合はDynamoDB localを自前で構築していますが、自前で構築する要素が多くなればなるほどそれは負債になる可能性が高いわけで……
これがプラグインひとつ定義すればOKということであれば非常に楽です。そんなこんなで今回私が関わった案件ではServerless Frameworkを選定しましたが、今後SAM・AWS Toolkitのプラグインや知見が増えた場合、SAMのほうが楽に構築できるようになるかもしれません。
その他フレームワークについて
Serverless Framework、SAMに限らずこの手のフレームワークにはPython系のフレーム枠であるZappaなども存在しています。
……が。情報が明らかに少ないです。
システム立ち上げにおいて「みんな使ってるのを使う」はある程度の正義です。また、Lambdaを用いたAPI構築の場合、真打ちの真打ちと言ってもいいでしょう、AWS Cloud9が存在しています。
こちらはフレームワークではなくIDEです。
そのままの状態でデバッグしたり、そのままデプロイしたり、かなり機能が豊富で
「アレ? これがベストなのでは?」
と思い、色々検証しましたが……
- ステップ実行がうまく動いてくれない
- 何故かデバッグ時の「停止」ボタンがない
ことで心が折れました。
1に関しては自分の設定ミスの可能性もありますので、もう少し調査したら変わっていたかもしれません。が、2に関してはもう完全に心が折れました。
「そこ!?」と言われてしまうかもしれませんが、「当然のように大抵のIDEで備えているものがパッと分かる位置に置いていない」IDEの使用を今後の参画者に強いるのは、自分には無理だなぁと。
これはいくらなんでも学習コストや開発者に対する制約が多すぎるなという感想です。結論の結論
Serverless Frameworkはとてもいいぞ。
SAMとAWS Toolkitは今後に期待ですね。


- 投稿日:2019-08-16T15:26:08+09:00
KubeEdge環境を構築してみた by AWS EC2
TL;DR
KubeEdgeの公式手順に従ってKubeEdge環境をEC2インスタンス上に構築してみた
基本的には参考サイトに載っている手順に準じて構築している
構築までしかしていないので悪しからず!そもそもKubeEdgeとは?
CNCF(Cloud Native Computing Foundation)の配下で最近GAされたエッジコンピューティングフレイムワークのOSS
→ 詳しくはこちら
Kubernetes(以下、k8s)もCNCFによりGAされており、いわば本家お墨付きのようなエッジ用k8s
似たようなので、Rancherのk3sがある → GitHubはじめに
KubeEdge環境の構築には主に3通りの方法がある(詳しくはGHのUsage参照)
- 用意されたバイナリを実行し、k8s環境から全て自動構築する
- k8sの環境を自前で構築し、 リリースパッケージを使って構築する
- k8s環境を自前で構築し、ソースからビルドして構築する
今回は2つ目の方法で構築している、なぜか?
答え単純、1つ目の方法で上手くいかなかったからである!
※筆者は3回やって挫折
3度目に失敗してから「もう自分でやったほうが早いな」と思い至り2番目の方法で構築したらすんなりできた環境
今回は構築方法までなのでエッジ側もAWSのEC2インスタンスでお手軽に構築してみた
本来ならエッジ側はラズパイなどのデバイスになるはずである
以下、環境情報バージョン
全て最新版を使用した(2019年8月時点)
- Docker: 19.03.1
- Kubernetes: 1.15.2
- kubeedge: 1.0.0
マシンスペック
マスタを大きく設定したけど、こんなにいらなかった
これならローカルのVMでも動かせそうである
- master
- OS: Ubuntu 18.04 LTS
- CPU: 8
- Memory: 32GB
- Storage: 30GiB
稼働状況
Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 850m (21%) 100m (2%) memory 190Mi (1%) 390Mi (2%) ephemeral-storage 0 (0%) 0 (0%)
- worker
- OS: Ubuntu 18.04 LTS
- CPU: 2
- Memory: 4GB
- Storage: 15GiB
構築手順
本題である構築手順!
EC2インスタンスの立て方については書かないので悪しからず
公式に従い「kubeadm」でk8sクラスタを構築する共通
まずは必須であるDockerとk8s関連のパッケージをそれぞれにインストールする
sudo apt update sudo apt upgrade -y # アップグレードは筆者の好み、正直しない方がいいかもしれない # docker sudo su - apt-get update && apt-get install apt-transport-https ca-certificates curl software-properties-common curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add - add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable" apt-get update && apt-get install docker-ce cat > /etc/docker/daemon.json <<EOF { "exec-opts": ["native.cgroupdriver=systemd"], "log-driver": "json-file", "log-opts": { "max-size": "100m" }, "storage-driver": "overlay2" } EOF mkdir -p /etc/systemd/system/docker.service.d systemctl daemon-reload systemctl restart docker systemctl status docker # k8s関連 apt-get update && apt-get install -y apt-transport-https curl curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF apt-get update apt-get install -y kubelet kubeadm kubectl apt-mark hold kubelet kubeadm kubectl echo 'KUBELET_EXTRA_ARGS=--cgroup-driver=systemd' > /etc/default/kubelet systemctl daemon-reload systemctl restart kubelet systemctl status kubelet # まだkubeletは動かないが問題ないマスタ
共通の構築ができたらまずはマスタを構築する
今回はCNIにArmでも動く「flannel」を使うsudo su - # for flannel kubeadm init --pod-network-cidr=10.244.0.0/16 sysctl -w net.bridge.bridge-nf-call-iptables=1 # KubeEdge用に編集する vim /etc/kubernetes/manifests/kube-apiserver.yaml - - --insecure-port=0 + - --insecure-port=8080 + - --insecure-bind-address=0.0.0.0 # flannelのPodをデプロイする kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml kubectl label nodes ip-172-31-38-225 type=master kubectl get nodes -L type # StatusがReadyになっているはず # KubeEdgeで使うCRDをデプロイする wget -L https://github.com/kubeedge/kubeedge/blob/master/build/crds/devices/devices_v1alpha1_devicemodel.yaml kubectl create -f devices_v1alpha1_devicemodel.yaml wget -L https://github.com/kubeedge/kubeedge/blob/master/build/crds/devices/devices_v1alpha1_device.yaml kubectl create -f devices_v1alpha1_device.yaml # KubeEdgeのリリースパッケージをダウンロード curl -LO https://github.com/kubeedge/kubeedge/releases/download/v1.0.0/kubeedge-v1.0.0-linux-amd64.tar.gz tar -xf kubeedge-v1.0.0-linux-amd64.tar.gz -C /etc # KubeEdgeで使う証明書を発行 wget -L https://github.com/kubeedge/kubeedge/blob/master/build/tools/certgen.sh chmod +x certgen.sh bash -x ./certgen.sh genCertAndKey edge # マスタ側のKubeEdgeを起動する cd /etc/kubeedge/cloud nohup ./edgecontroller > edgecontroller.log 2>&1 & tail edgecontroller.log # エッジ側に同じものを送るためにコピーしておく cp -r /etc/kubeedge /home/ubuntu chown ubuntu:ubuntu /home/ubuntu/kubeedge -Rローカル
今回はマスタ側で発行した証明書などをエッジ側にも置くためにローカルからSCPでコピーして送った
※マスタとエッジが直接SSHできるならこれはいらないscp -r -i ~/.ssh/aws/admin.pem ubuntu@<master-ip>:/home/ubuntu/kubeedge ~/ scp -r -i ~/.ssh/aws/admin.pem /home/ubuntu/kubeedge ubuntu@<edge-ip>:/home/ubuntu/エッジ
さて、マスタが構築できたらエッジを構築したk8sクラスタに参加させる
※「kubectl」をマスタ側で叩いているが、エッジでも叩けるようにすればどちらでも問題ない
→ 詳しくはこちらsudo su - # 送っておいたファイルを適切な場所に置いておく cp -r /home/ubuntu/kubeedge /etc chown root:root /etc/kubeedge -R # 構築したクラスタに参加させる ※適宜置き換える kubeadm join 172.31.38.225:6443 --token <token> \ --discovery-token-ca-cert-hash sha256:<ca-cert-hash> # in master # nodeの名前は適宜置き換える kubectl get nodes # 新しくnodeが追加されているはず kubectl lobel nodes ip-172-31-39-8 type=worker wget -L https://github.com/kubeedge/kubeedge/blob/release-1.0/build/node.json vim node.json - name: "fb4ebb70-2783-42b8-b3ef-63e2fd6d242e", + name: "ip-172-31-39-8", kubectl apply -f node.json # エッジ側のKubeEdgeを起動する cd /etc/kubeedge/edge vim conf/edge.yaml # nodeの名前を適切に修正する - url: wss://172.31.38.225:10000/e632aba927ea4ac2b575ec1603d56f10/fb4ebb70-2783-42b8-b3ef-63e2fd6d242e/events + url: wss://172.31.38.225:10000/e632aba927ea4ac2b575ec1603d56f10/ip-172-31-39-8/events - node-id: fb4ebb70-2783-42b8-b3ef-63e2fd6d242e + node-id: ip-172-31-39-8 - hostname-override: fb4ebb70-2783-42b8-b3ef-63e2fd6d242e + hostname-override: ip-172-31-39-8 nohup ./edge_core > edge_core.log 2>&1 & tail edge_core.logテスト
最後にちゃんと動いてるか、簡単に確認する
kubectl apply -f https://raw.githubusercontent.com/kubeedge/kubeedge/release-1.0/build/deployment.yaml kubectl get pods kubectl get deployおわりに
とりあえず動くものを構築してみた
最初の方にも書いたが、参考サイトに従って構築したので不明な点は参考サイトを参照してほしい
正直KubeEdge自体が正しく動いているか、確信が持ててない...
故に次は、KubeEdgeのExampleを試してみたいと思う
→ https://github.com/kubeedge/examples/tree/master/led-raspberrypi参考
- docker
- kubeadm(+flannel)
- KubeEdge
- 投稿日:2019-08-16T14:16:13+09:00
時間のかかるPythonスクリプトを定期実行させる
環境
macOS version 10.14.6
Ubuntu 16.04 in AWS
Python 3.5.2前提
AWSのEC2インスタンスを使って、自動的にスクリプトを起動するcron jobを作りました。
本来は、
・AWS Lambda
・ECS Scheduled Tasks
等を使うのが得策だとは思いますが、①今回実行するスクリプトが丸一日くらいかかる(Lambdaは15分が限界との噂)
②手っ取り早く、安く済ませたいとの考えがあり、少しレガシーかもしれないですが、シンプルなcrontabを使用することにしました。
本当はDocker環境とかを構築したかったのですが、初心者で且つ時間の都合上、EC2に収まってしまいました。
より良い方法等あれば、ぜひ教えて頂ければと思っております。
cronの選定に関しては、下記などを参考にしました。
https://medium.com/better-programming/cron-job-patterns-in-aws-126fbf54a2761, EC2インスタンスに接続
インスタンスは作成済みとの前提で進めていきます。今回は上記の環境で動かしていきます。
ターミナルで、$ ssh -i ~/directory/directory/sample.pem ubuntu@IPv4 パブリックIPssh接続でサーバーにログインします。
ubuntuの部分は、AMI(サーバーの種類?)によって変わるので、気をつけてください。
余談ですが、ファイル・フォルダのパスがわからない場合は、そのファイル・フォルダをターミナルにドラッグ&ドロップするとフルパスが表示されるみたいです。当たり前すぎるかもしれないですが、初心者の私は割と重宝しています・・・2, Pythonをインストール
サーバーにPythonをインストールしていきます。Ubuntu環境なので、aptコマンドを使っていきます。
念の為、$ sudo apt update $ sudo apt upgradeを実行しておきます。
以下でPythonをインストールしていきます。$ sudo apt install python3 python3-pip python3-dev最低限ここまではどの人も共通してインストールするのかなと思っております。
あとは、使うモジュール等によって必要なものがあると思うので、その都度インストールすればいいかと思いました。
今回私は後述するモジュールを使うために、以下のものもインストールしました。$ sudo apt install libmysqlclient-dev libffi-dev libssl-dev build-essentialもしかしたら、いらないものも含まれてるかもしれません。
3, モジュールをインストール
今回のスクリプトで使ったのは以下のモジュールだったので、サーバーで使えるようにインストールします。
$ pip3 install requests sqlalchemy selenium lxml paramiko eventlet mysqlclient4,crontabを編集する
EC2にはcron jobのための機能がもともと入ってるみたいなので、以下のコマンドを入力すると、cronに関する記述ができる編集画面に移行します。
$ crontab -e気をつけないといけないのが、
$ crontab -rとすると、全てのcrontabのデータが消えるみたいなので、設定してからは、気をつけないと苦労が水の泡になるそうです。私は毎回指差し確認しながら実行しています・・・。余談ですが、初心者の私がビビったのは、編集画面をVimにしてしまったこと。泣きそうになりました。
nanoがなんだかんだわかりやすかったので、怖い方はnanoを使ったほうがいいとは思います。
editorは以下で後からでも変えれます。$ select-editor
それではcrontabに記述していきますが、書き方はいろいろあるので、要件にあった内容を調べたほうがいいと思います。今回私は以下のようにしました。
0 20 * * * python3 /insert-fullpath/sample.py >> /insert-fullpath/cron_log.txt 2>&1
上記は「毎日20時にsample.pyを起動する。出力されたもの、さらにエラーが出た場合は予め作っておいたcron_log.txtに書き込んでください」という指示です。
とにかく、起動しているかわからず怖かったので実行結果がわかるように上記のようにしました。
ちなみに、保存した上記crontabのファイルは、ターミナルの指示に従って、何も操作せずに保存すると/var/spool/cron/crontabs/bitnami/に存在していました。5, タイムゾーンの設定
デフォルトだとサーバーはロンドン時間になってると思うので、タイムゾーンも確認しておきます。
$ timedatectl上記で現行のタイムゾーンを確認
$ sudo timedatectl set-timezone America/Vancouverこれで、バンクーバー時間になると思います。
おわりに
社内でブラウザテストのスクリプトを起動させるために、今回初心者ながらいろいろ試してみました。本当はLambdaやDockerなどの技術を使いたかったのですが、力及ばず。
よりよい方法やお気づきの点がありましたら、お声がけ頂けると大変嬉しいです。今働かしていただいている会社のサービスも、ぜひ御覧ください!
サッカー順位表 FootyStats
- 投稿日:2019-08-16T13:25:26+09:00
【PHP】Amazon SESを使った添付ファイル付きメールを送信する
はじめに
この記事ではAmazon SESを利用してPHPでメール送信する方法について説明します。
またAWSやSESについての説明や導入方法については様々な記事がありますので、本記事では省きます。簡易メールの送信(SendEmail)
最も簡単なメール送信で、送信元アドレス・送信先アドレス(複数可)・件名・本文を設定することでメール送信できます。
Request Parameters
Destination
・ 送信先のメールアドレス(配列)
Message
・ メール本文
・ メール件名
Source
・ 送信元のメールアドレスその他にもBCC送信などもあるようなので必要な方は公式サイトの確認をお願いします。
実装:テキストメールの場合
Textメールuse Aws\Ses\SesClient; class MailUtil { public static function sendMail() { // Amazon SES クライアントのインスタンス生成 $client = new SesClient([ 'region' => env("AWS_SES_REGION"), // SESのリージョン 'version' => 'latest', 'credentials' => [ 'key' => env("AWS_KEY"), 'secret'=> env("AWS_SECRET")] ]); $fromAddress = "testFrom@test.com"; $toAddressList[] = "testTo@test.com"; $subject = "SESメールの送信"; $text = "SESメールの実装方法について"; // 送信元アドレス・送信先アドレス(Array)、件名、本文をリクエストパラメータに代入 $request = []; $request['Source'] = $fromAddress; $request['Destination']['ToAddresses'] = $toAddressList; $request['Message']['Subject']['Data'] = $subject; $request['Message']['Body']['Text']['Data'] = $text; // 送信する $client->sendEmail($request); } }実装:HTMLメールの場合
リクエストパラメータを下記のように設定するだけで可能となります。
HTMLメール$request = []; $request['Source'] = $fromAddress; $request['Destination']['ToAddresses'] = $toAddressList; $request['Message']['Subject']['Data'] = $subject; $request['Message']['Body']['Html']['Data'] = $text; $request['Message']['Body']['Html']['Charset'] = 'iso-2022-jp';AWS SDK for PHP を使用して E メールを送信する
添付ファイル付きメールの送信(SendRawEmail)
SendEmailに対してSendRawEmailは高度なメールカスタマイズをすることができます。
最終的なソースコード
use Aws\Ses\SesClient; use Carbon; class MailUtil { public static function sendAttachedMail($toAddrList, $fromAddr, $subject, $body, $data) { // sendEmailと同様 $client = new SesClient([ 'region' => env("AWS_SES_REGION"), 'version' => 'latest', 'credentials' => [ 'key' => env("AWS_KEY"), 'secret' => env("AWS_SECRET") ] ]); # 添付ファイル(今回はwindowsをメインで想定していたのでSJIS-winにエンコードしてます) $attachFileData['data'] = mb_convert_encoding($data, 'SJIS-win', 'UTF-8'); $attachFileData['filename'] = Carbon::now()->format('Ymd') . '.csv'; $attachFileData['mimetype'] = 'text/csv'; // RawMessageの作成 $msg = self::createRawMessage($toAddrList, $fromAddr, $subject, $body, $attachFileData); $client->sendRawEmail([ 'Source' => $fromAddress, 'Destinations' => [$toAddressList], 'RawMessage' => [ 'Data' => $msg, ], ]); } /** * 添付ファイル付きメール用のRawMessageを作成する */ private static function createRawMessage($to, $from, $subject, $body, $filedata) { if (isset($filedata['filename']) && isset($filedata['data']) && isset($filedata['mimetype'])) { $boundaryStr = uniqid(rand()); $message = "To: " . $to . "\n"; $message .= "From: " . $from . "\n"; $message .= "Subject: " . $subject = str_replace("\r", "", $subject) . "\n"; $message .= "MIME-Version: 1.0\n"; $message .= 'Content-Type: multipart/mixed; boundary="' . $boundaryStr . '"'; $message .= "\n\n"; $message .= "--" . $boundaryStr . "\n"; $message .= "Content-Type: text/html; charset=iso-2022-jp"; $message .= "\n"; $message .= "Content-Transfer-Encoding: 7bit\n"; $message .= "Content-Disposition: inline\n"; $message .= "\n"; $message .= $body; $message .= "\n"; $message .= "\n"; $message .= "--" . $boundaryStr . "\n"; $message .= 'Content-Type: ' . $filedata['mimetype'] . '; name="' . $filedata['filename'] . '"'; $message .= "\n"; $message .= "Content-Transfer-Encoding: base64\n"; $message .= 'Content-Disposition: attachment; filename="' . $filedata['filename'] . '"'; $message .= "\n\n"; $message .= base64_encode($filedata['data']); $message .= "\n"; } else { Log::warning('添付ファイルデータが設定されていません'); } } }https://github.com/aws/aws-sdk-php/issues/1295#issuecomment-307517135
解説
boundary
メッセージヘッダやコンテンツといったメールの各パートは、boundary で分離されます。
boundary は、各パートの開始と終了を示す文字列で、これらを使ってメッセージ本文、または今回のような添付ファイルを分けて、設定を行なっていきます。ヘッダー
ヘッダーには送信先、送信元、件名、MIME-Ver、コンテンツタイプを設定します。
今回はヘッダー・本文・添付ファイルを設定するため、メッセージのコンテンツタイプにmultipart/mixedを設定します。これを設定することで各パートを別々に扱う必要があることがわかります。$message = "To: " . $to . "\n"; $message .= "From: " . $from . "\n"; $message .= "Subject: " . $subject = str_replace("\r", "", $subject) . "\n"; $message .= "MIME-Version: 1.0\n"; $message .= 'Content-Type: multipart/mixed; boundary="' . $boundaryStr . '"'; $message .= "\n\n";メッセージ本文
文字コードに関しては、古いメーラーを使用したユーザーが想定されるためUTF-8ではなく
iso-2022-jpを選択しましたが、最近はUTF-8でも問題ないかと思います。$message .= "Content-Type: text/html; charset=iso-2022-jp"; $message .= "\n"; $message .= "Content-Transfer-Encoding: 7bit\n"; $message .= "Content-Disposition: inline\n"; $message .= "\n"; $message .= $body;Content-Disposition
・ inline
メール本文のようなWebページの一部またはWebページとして表示可能である場合はinlineを設定します。・ attachment
ダウンロード可能な添付ファイルの場合に、Content-Disposition: attachment; filename="hoge.xxx"といった形式で記述します。添付ファイル
// mimetype:'text/csv' $message .= "--" . $boundaryStr . "\n"; $message .= 'Content-Type: ' . $filedata['mimetype'] . '; name="' . $filedata['filename'] . '"'; $message .= "\n"; $message .= "Content-Transfer-Encoding: base64\n"; $message .= 'Content-Disposition: attachment; filename="' . $filedata['filename'] . '"'; $message .= "\n\n"; $message .= base64_encode($filedata['data']);
- Content-Type
添付ファイルの種類で今回はCSVファイルを指定- Content-Disposition
添付ファイルのためattachmentをセットし、添付ファイル名を指定- Content-Transfer-Encoding
添付ファイルのエンコードに使用されるスキーム。添付ファイルでは、ほとんどの場合この値は base64指定補足説明
送信結果の判別
AWS SESではメール送信結果を受け取ることができます。
しかし受け取り可能なのは送信失敗(バウンス処理、迷惑メール)となった場合のみで成功通知は受け取ることができません。
種別 結果判別可否 送信成功 △ バウンス処理 ◯ 迷惑メール ◯ そのため送信後はしばらく待って失敗通知が来ていなければ、おそらく送信成功したのだと判断する必要があり注意が必要となります。
参考
- 投稿日:2019-08-16T10:53:05+09:00
aws Lambdaのカスタムランタイムを利用してaws-cliを実行する
awsのリソースを自動展開するシステムを開発しています。リソース内部の設定が複雑でありPython SDKで実装するとコマンドの検証に不便が出てきそうな雰囲気だったためaws-cliをLambdaで実行しようと考えました。
AWSのチュートリアルを見ればファイルの構3成は把握できると思います。bootstrapがイベントを
while trueで待ち受け、検知するとそれをパースしてイベントハンドラ(ここではfunction.shの関数)に投げます。その出力を以ってレスポンスとして返します。コード
チュートリアルのコードに一部インストール用の設定を加えています。インストールを含むためテスト実行時にTimeoutエラーが出るかもしれませんが焦らずにタイムアウト時間を伸ばしましよう。
bootstrap#!/bin/sh set -euo pipefail # tmpフォルダ内にawscliを配置するためHOMEとPATHを設定 export HOME="/tmp" export PATH="$HOME/.local/bin:$PATH" # pipをインストール cd /tmp curl -sSL https://bootstrap.pypa.io/get-pip.py -o get-pip.py python get-pip.py --user # pipを用いてawscliをインストール pip install awscli --user # Handler format: <script_name>.<function_name> # # The script file <script_name>.sh must be located at the root of your # function's deployment package, alongside this bootstrap executable. source $(dirname "$0")/"$(echo $_HANDLER | cut -d. -f1).sh" while true do # Request the next event from the Lambda runtime HEADERS="$(mktemp)" EVENT_DATA=$(curl -v -sS -LD "$HEADERS" -X GET "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/next") INVOCATION_ID=$(grep -Fi Lambda-Runtime-Aws-Request-Id "$HEADERS" | tr -d '[:space:]' | cut -d: -f2) # Execute the handler function from the script RESPONSE=$($(echo "$_HANDLER" | cut -d. -f2) "$EVENT_DATA") # Send the response to Lambda runtime curl -v -sS -X POST "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/$INVOCATION_ID/response" -d "$RESPONSE" donehandlerでaws-cliの動作を確認する。標準エラー出力へaws-cliのバージョンが出力されるか確認します。
function.shfunction handler () { EVENT_DATA=$1 # このhandlerの標準出力(1)がそのままbootstrapでRESPONSEになる # よってデバッグ用echoは標準エラー出力へ逃がす必要がある echo "$EVENT_DATA" 1>&2; echo $(aws --version 1>&2); RESPONSE="Echoing request: '$EVENT_DATA'" echo $RESPONSE }無事に出力されれば動作しています。今回のコードではtestにデフォルトのものをそのまま利用しているため
$EVENT_DATAはデフォルトのものです。output{"key1":"value1","key2":"value2","key3":"value3"} aws-cli/1.16.219 Python/2.7.16 Linux/4.14.123-95.109.amzn2.x86_64 botocore/1.12.209to do
- aws-cliを利用した自動展開の検証
- リソース立ち上げ時間とタイムアウトの格闘
- 投稿日:2019-08-16T09:07:34+09:00
AWS CDKの'aws-s3-deployment'を使ってクライアントサイドも一緒にデプロイする
動機
SPAでアプリケーション作ってS3+CloudFrontで公開することってよくありますよね?
どうせならSPA側のリソースとCloudFormationのスタックを別々に管理するのではなく、例えばスタックをdeployしたらSPA側(つまりS3の中身)も同時に更新したいものです。
今までそれをやろうと思うと例えば...
- SPA側の最新のビルドを(CodePipelineなどを使って)どこかのバケット(ビルドバケットと呼ぶ)に常に置いておく
- CloudFormation側にCustom Resourceを定義して、ビルドバケットからデプロイ用のバケットにsyncする
- しかもLambda側からは普通にaws s3 syncが呼べないためawsclidriverのwrapperとか用意しなきゃいけない...
ということで、面倒で仕方無いわけです。
そんなことを思いながら、先日(もう古い?)GAになったAWS-CDKのリファレンスを眺めていると...
aws-s3-deployment
...ん?何これ?
しかもサンプルソースを見ると、
const websiteBucket = new s3.Bucket(this, 'WebsiteBucket', { websiteIndexDocument: 'index.html', publicReadAccess: true }); new s3deploy.BucketDeployment(this, 'DeployWebsite', { source: s3deploy.Source.asset('./website-dist'), destinationBucket: websiteBucket, destinationKeyPrefix: 'web/static' // optional prefix in destination bucket });./website-distにあるソースをWebsiteBucketにデプロイしてくれるっていうのかい!?
これは試すしか無いってことでやってみました。
環境周り
awscliのセットアップ
もう色々な方が書いているので省略。公式を見て頑張ってください。
当然、ACCESS KEY IDとSECRET KEYを発行するユーザーにはS3やCloudFrontなどを作ることができるポリシーやCloudFormationをいじることができるポリシーが当たっていないとダメです。私はAdminロールが当たってるユーザーでやりました。
node.js,npmのインストール
これもよしなに頑張ってください。グーグル先生に訊いた方が早いです。
aws-cdkのインストール
$ npm install -g aws-cdk $ cdk --version 1.4.0 (build 175471f)cdk bootstrap
aws-cdkを動作させるために必要な環境(zipしたソースを置くためのバケットなど)をよしなに作ってくれるみたいです。
$ cdk bootstrapこれがエラーになるようであればawscliのprofileに紐づいているIAMの権限周りを見直してみてください。
やりたいこと
フォルダ構成
こんな感じで、web以外はcdk initで自動的に作成される構成。
webディレクトリにデプロイしたいリソースを入れて置いて、cdk buildで一気にデプロイしたい。ちなみに今回はvue-cliを使ってtypescript + vueをcreateした際の初期のサンプルを入れています。
詳しく知りたい方はこちらなど参考にされるといいんじゃないでしょうか。
やってみた
aws cdkプロジェクトの作成
$ mkdir s3-deployment-inspection $ cd s3-deployment-inspection $ cdk init --language typescriptうまく行けば上記フォルダ構成の"web"以外ができるはず。
なお、今回はフォルダ名を"s3-deployment-inspection"としているため、作成されるテンプレートはlib/s3-deployment-inspection-stack.tsimport cdk = require('@aws-cdk/core'); export class S3DeploymentInspectionStack extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props); // The code that defines your stack goes here } }と行った命名になっている。設定より規約。素晴らしい。
vueプロジェクトの作成
$ vue create web # 色々質問されるので答える。今回はtypescriptのプロジェクトを選びました。vueプロジェクトのビルド
今回はvue createした際に出来るサンプルをそのままビルドしました。
$ cd web $ npm run build #./distにindex.htmlを含むリソースがデプロイされる(/tsconfig.jsonの修正)
さて、Vue側のビルドが終わったのでプロジェクトルートに戻って、
$ cd ../ $ pwd # ${your root}/s3-deployment-inspectionまだ何も書いてないけれどcdkの方もビルドしてみようかとしたところ、
$ npm run build #実質$ tsc 叩いてるのと一緒ビルドエラーが発生。
よくよく考えると、webの中にも*.tsがあって、別のnode_modulesに依存しているにも関わらずそれも一緒にビルドしようとするのでエラーが発生してしまう。ということで、ルート側のtsconfig.jsonを修正。excludeに"web/*"を追加。
tsconfig.json{ "compilerOptions": { "target":"ES2018", "module": "commonjs", "lib": ["es2016", "es2017.object", "es2017.string"], "declaration": true, "strict": true, "noImplicitAny": true, "strictNullChecks": true, "noImplicitThis": true, "alwaysStrict": true, "noUnusedLocals": false, "noUnusedParameters": false, "noImplicitReturns": true, "noFallthroughCasesInSwitch": false, "inlineSourceMap": true, "inlineSources": true, "experimentalDecorators": true, "strictPropertyInitialization":false }, "exclude": ["cdk.out","web/*"] }必要なライブラリをnpm install
cdk initしただけでは@aws-cdk/coreしかインストールされていません。
例えば、スタックの中でs3バケットを作りたいのであれば@aws-cdk/aws-s3などそれぞれのリソースに応じたライブラリが必要です。$ pwd # ${your root}/s3-deployment-inspection # 間違えてweb下でやらないように!! $ npm install --save @aws-cdk/aws-s3 @aws-cdk/aws-s3-deployment @aws-cdk/aws-cloudfront @aws-cdk/aws-iam2019/08/15時点 最新版(1.4.0)の@aws-cdk/aws-s3-deploymentが動かない問題
みなさんが見られる頃には解消しているといいのですが。。。
こちらの通りうまく動かないみたいです。解消しない場合は、前バージョン(@1.3.0)をnpm installしましょう。
$ npm install --save @aws-cdk/aws-s3-deployment@1.3.0スタックの定義
ということでここから本番。CDKを使ってスタックを定義していく。
lib/s3-deployment-inspection-stack.tsimport cdk = require('@aws-cdk/core'); import * as s3 from '@aws-cdk/aws-s3'; import * as iam from '@aws-cdk/aws-iam'; import * as s3Deploy from '@aws-cdk/aws-s3-deployment'; import * as cf from '@aws-cdk/aws-cloudfront'; export class S3DeploymentInspectionStack extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props); // Vueをデプロイする先のS3バケット const websiteBucket = new s3.Bucket(this, `WebsiteBucket-${this.stackName}`); // 今回のメイン // ./web/distに先ほどビルドしたビルド結果をwebsiteBucketにデプロイする // たった4行で済むなんて。。。 new s3Deploy.BucketDeployment(this, 'DeployWebsite',{ source: s3Deploy.Source.asset('./web/dist'), destinationBucket: websiteBucket }); // CloudFrontからwebsiteBucketにアクセスする際のOriginAccessIdentity const OAI = new cf.CfnCloudFrontOriginAccessIdentity(this, `identity-${this.stackName}`,{ cloudFrontOriginAccessIdentityConfig:{ comment: `WebsiteBucket-${this.stackName}` } }); // webSiteBucketのBucketPolicyのStatement // 先ほど作ったOAIにs3:GetObjectを許可する // websiteBucketはpublic access出来ない設定(デフォルト)になっているので // こうしておかないとCloudFrontからアクセス出来ない const webSiteBucketPolicyStatement = new iam.PolicyStatement({effect: iam.Effect.ALLOW}); webSiteBucketPolicyStatement.addCanonicalUserPrincipal(OAI.attrS3CanonicalUserId); webSiteBucketPolicyStatement.addActions("s3:GetObject"); webSiteBucketPolicyStatement.addResources(`${websiteBucket.bucketArn}/*`); websiteBucket.addToResourcePolicy(webSiteBucketPolicyStatement); // CloudFrontのdistribution // 先ほど作ったOAIを指定しておくのがポイント const distribution = new cf.CloudFrontWebDistribution(this, `Distribution-${this.stackName}`, { originConfigs:[ { s3OriginSource: { s3BucketSource: websiteBucket, originAccessIdentityId: OAI.ref }, behaviors: [{ isDefaultBehavior: true}] } ] }); // CloudFrontのドメインを調べるのにいちいちAWS Consoleに入りたく無いので // URLに整形して出力しておく new cdk.CfnOutput(this, 'CFTopURL', {value: `https://${distribution.domainName}/`}) } }ビルド & デプロイ
$ npm run build #tsに構文エラー等がなければ何も出力されないはず $ cdk build # CloudFrontのdistribution作ってるだけあって、やや待たされるのはやむなしか # なんやかんやあって最後は以下が出力されるはず ✅ S3DeploymentInspectionStack Outputs: S3DeploymentInspectionStack.CFTopURL = https://xxxxxxxxx.cloudfront.net/ Stack ARN: arn:aws:cloudformation:ap-northeast-1:xxxxxxxxxxx:stack/S3DeploymentInspectionStack/15c9fc40-bef3-11e9-a934-06ce06e5203e確認
ということで、Outputsに出力されているURLをブラウザで叩いてみると...
ちゃんとVueのサンプルページが表示される。
追加確認 webだけ編集しても変更検知してくれるだろうか?
スタックの定義を変更したら変更検知して差分をデプロイしてくれそうだが、webのソースだけ変更したら検知して再デプロイしてくれるだろうか?
ということで実験。
Vueのサンプルソースを編集
web/src/App.vue<template> <div id="app"> <img alt="Vue logo" src="./assets/logo.png"> <!--CHANGE: msgの末尾に!!を追加--> <HelloWorld msg="Welcome to Your Vue.js + TypeScript App!!"/> </div> </template> <script lang="ts"> import { Component, Vue } from 'vue-property-decorator'; import HelloWorld from './components/HelloWorld.vue'; @Component({ components: { HelloWorld, }, }) export default class App extends Vue {} </script> <style> #app { font-family: 'Avenir', Helvetica, Arial, sans-serif; -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale; text-align: center; color: #2c3e50; margin-top: 60px; } </style>webを再ビルドしてcdk deploy
$ cd web $ npm run build $ cd ../ $ cdk deploy S3DeploymentInspectionStack: deploying... S3DeploymentInspectionStack: creating CloudFormation changeset... 0/2 | 6:51:44 | UPDATE_IN_PROGRESS | Custom::CDKBucketDeployment | DeployWebsite/CustomResource/Default (DeployWebsiteCustomResourceD116527B) 1/2 | 6:52:08 | UPDATE_COMPLETE | Custom::CDKBucketDeployment | DeployWebsite/CustomResource/Default (DeployWebsiteCustomResourceD116527B) ✅ S3DeploymentInspectionStack Outputs: S3DeploymentInspectionStack.CFTopURL = https://xxxxxxxxxxx.cloudfront.net/ Stack ARN: arn:aws:cloudformation:ap-northeast-1:xxxxxxxxxx:stack/S3DeploymentInspectionStack/75086bf0-bf17-11e9-a934-06ce06e5203eお、変更検知されたっぽい。
確認
ブラウザをリロードしてみたが、変更されておらず。。。そうか、よく考えたらCloudFrontはデフォルトでキャッシュが効くな。。。TTLを0にしておくべきだった。
というわけでinvalidate。
$ aws cloudfront list-distributions # 長いので出力は貼らないがdistributionの一覧がjsonで出てくるので先ほど作ったdistributionを探してIDを取得する $ aws cloudfront create-invalidation --distribution-id ${YOUR DISTRIBUTION ID} --paths '/*'再確認
ちゃんとTypeScript App!!になっている。
追加確認 具体的にどうやってwebのソースをデプロイしてるんだろう?
記事の冒頭に書いた通り、自分でやるときはCustom Resourceを作っていたが果たして...
ということで、CloudFormationのコンソールに入って、作成されたスタックをデザイナで見てみる。
やはりCustom Resource作ってるか。そうだよな、それしか無いよな。
でも自分で作らなければいけないより一億倍楽!!
後片付け
cdk destroyでスタックごと消してくれる。
$ cdk destroy Are you sure you want to delete: S3DeploymentInspectionStack (y/n)? y所感
AWS CDKの魅力はカプセル化だと思う
一見、CloudFormationをTypeScriptやPythonで書けるだけのサービスに見えるけどさもあらず。今回検証したようなCustom Resourceを使ってS3にファイル群を転送するような動きはネイティブなCloudFormationでも出来るが、そこを内部実装を隠匿してs3-deploymentというサービスに仕立て上げられているのが素晴らしい。
私は興味があったので中身をみてCustom Resourceがあることを知りましたが、別にCustom Resourceという存在すら知らなくてもこの動きを実現出来るわけなので。
今回検証した以外にもそうやって上手くカプセル化されているAPIが色々ありそうなので、興味ある方はリファレンス読んでみてください。
OAI周りが不満...まだまだ発展途上
せっかくファイルのデプロイまでカプセル化してるのに、CloudFrontのOriginAccessIdentityを作ったりBucketPolicyと紐付けたりといった工程はカプセル化出来んもんかね。。。
と思ったら、やっぱりIssueに上がってた。
aws-cloudfront: easily support Origin Access Identity for S3 buckets
これからどんどん進化していくフレームワークだってことですね。楽しみ。
相当強力だが、学習コストはまだまた高そう
そもそもネイティブなCloudFormationの書き方を知らないと、世界観が把握しづらくてリファレンスとか読み解くのに苦労しそうな気がしてるのですがどうなんでしょう??私は個人的にCloudFormation
地獄に片足を突っ込んでいたのでリファレンスもCDKのメリットも割とすんなり入ってきましたが。。。もっとカプセル化が進めば、ネイティブなCfnを知らない人でもスッとInfrastructure As Codeが出来るようなフレームワークになるかも知れませんね。
このフレームワークのおかげで、Infrastructure as Codeに対するハードルが少しでも下がることを願っています。




- 投稿日:2019-08-16T08:14:16+09:00
AWS ソリューションアーキテクト合格までの対策 (2019年5月時点の情報)
はじめに
AWS 認定ソリューションアーキテクト – アソシエイトに合格したので、やってきたことをまとめました。
なるべく時間を掛けずに合格したかったので、仕事しながら資格取得を目指している方にはオススメかもしれません。筆者スペック
- 社内SE
- AWS若干触ったことがある(個人アカウントにて検証利用)
- 2019年5月にクラウドプラクティショナー取得
- 知識があるうちにさらに上位資格を目指した。
試験結果
- [合格] 739点 / 1000点
対策(その1)
試験に向けての対策を書き残しておきます。
- 書籍で対策
- AWS認定 ソリューションアーキテクト アソシエイト 教科書
- 1周斜め読み(5日間)、1周章末問題解きながら読み込み(2日間)、以下に記載の模擬テスト受講したところ、以下の通りダメダメな結果に。
- 絶望的過ぎて別の書籍を書い直す羽目に。
模擬試験(その1)
- ダメ過ぎ・・。
総合スコア: 56% トピックレベルスコア: 1.0 Design Resilient Architectures: 66% 2.0 Define Performant Architectures: 57% 3.0 Specify Secure Applications and Architectures: 33% 4.0 Design Cost-Optimized Architectures: 50% 5.0 Define Operationally-Excellent Architectures: 100%対策(その2)

- AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト アソシエイト
- 1周斜め読み(3日間)、1周章末問題解きながら読み込み(3日間)、以下に記載の模擬テスト受講後に再度読み込み(2日間)
模擬試験(その2)
- 今度はマシな結果になった!これなら本番はイケる!
総合スコア: 88% トピックレベルスコア: 1.0 Design Resilient Architectures: 100% 2.0 Define Performant Architectures: 71% 3.0 Specify Secure Applications and Architectures: 83% 4.0 Design Cost-Optimized Architectures: 100% 5.0 Define Operationally-Excellent Architectures: 100%本試験
ピアソンVueにて試験申し込み。
で!模擬試験は簡単過ぎるから本試験は覚悟しろ!って他サイトにも書かれていましたが、模擬試験と同等の内容でした。
アンケートが終わると、すぐその場で合否が出ます。
まとめ
- まとめると、難易度は 上記の黒色の書籍 < 模擬試験 ≒ 本試験 <<< 上記のオレンジ色の書籍
- なので、上記、オレンジ色の書籍で対策しておけば、問題なし!!!!
- と、思いたいのですが、黒色の本は概要を抑える為には悪くない。オレンジ色で詳細まで把握。
- なので、二冊を我慢してやり切るのが合格への確かな道のりかと思います!

- 投稿日:2019-08-16T02:48:20+09:00
AWS 認定ソリューションアーキテクト – アソシエイト(SAA-C01)に合格しました
SAA-C01に合格出来たので、感想や使用教材をレポートとして纏めようと思います。
私のスペック
関連しそうな資格だと、応用情報技術者や情報セキュリティスペシャリスト 1とCCNAに合格しています。
英語は苦手です。(英語ドキュメントは時間をかけて翻訳を駆使すれば読める程度)
1年程度AWSを用いたインフラ構築,運用保守業務に携わっています。試験対策教材
- 合格対策 AWS認定ソリューションアーキテクト - アソシエイト
- 合格対策本は2015年頃出版時点の情報で古く、更新が必要な個所も多々散見される為、AWS公式ドキュメント等で補完が必要ではあります。ですが、現在でも通用する箇所の方が多く、試験対策やAWSについて学ぶ為のとっかかりとしては分かり易く良い教材であったと思います。
- AWS ホワイトペーパー内のアマゾン ウェブ サービスの概要
- ホワイトペーパーはAWSが展開している全サービスの概要が記載されていますので、1回は目を通しておく事をお勧めします。
- AWS WEB問題集で学習しよう
- 有料ですが豊富な問題量と回答後即解説形式による確認が出来る点でお勧めです。無料でもサンプル問題が27問購読できます。
模擬試験について
CertMetricsよりPSIのAWS Certified Solutions Architect - Associate - Practice(SAA-P01)を選択し、受験料を支払うとすぐに実施できました。
制限時間30分の設問数は30問です。
完了するか制限時間に達すると問題が終了し、戻れなくなります。模擬試験終了後に問題内容や自身の回答を見直す事はできません。
問題内容は本試験より簡単でしたが、形式が本試験と同じなので慣れておく為にも実施しておいた方が良いと思いました。
試験官とのチャットはありませんが、フラグ機能や言語切り替えが可能です。結果
受験完了後すぐに模擬試験の総合スコアとトピックレベルスコアがメールで届きました。私のスコアは以下のような感じです。
セクション スコア 1.0 Design Resilient Architectures 66% 2.0 Define Performant Architectures 28% 3.0 Specify Secure Applications and Architectures 66% 4.0 Design Cost-Optimized Architectures 100% 5.0 Define Operationally-Excellent Architectures 100% 総合スコア 60% パフォーマンスに優れたアーキテクチャを定義する分野が弱いようでした・・・
業務で取り扱っていないAuto Scalingに関する設問に全く歯が立たず悔しい思いを味わう事が出来ました。2
合格ラインに届いてはいませんでしたが、引きずっているといつまで経っても受験出来ないと思ったので、思い切って約2週間後に本試験を予約し、受験料も支払いました。3PSI試験について
あまり試験の内容と深くは関係が無いですがAWSの PSI 試験が初めてだったので少し触れようと思います。
試験は PSI と ピアソンVUE から選択出来ますが、どちらも基本は同じなようです。4
CCNAを監督付きの ピアソンVUE 公認テストセンターで受験した事はあります。試験時間は平日の10:00 AM もしくは 2:00 PMから選択できました。朝弱いので昼から受験可能なのは助かります...
試験は2:00~4:10迄の制限時間130分で設問数は65問でした。
会場へは持ち物として以下を持参しました。試験開始の15分前から入室可能で、その後は自身のタイミングで試験を開始できます。
入室時には荷物を入れるロッカーの鍵、上記身分証明書2つ以外の持ち込みは禁止で、紙とボールペンは受付に言えば貰えます。(紙とペンは試験終了後即回収)
初めにメールアドレスと名前での認証とカメラで顔の撮影、スキャナでの運転免許証(表のみ)の撮影、クレカをカメラで裏表見せてPASSしました。
130分の間にトイレに行きたくなったらどうしようと思っていましたが、チャット上でLive monitorさん(試験官)に申告すれば20分以内の退室は認められるそうです。
最初は暑かったので上着を脱いで試験を開始したのですが、長い間冷房の効いた室内でじっとしていたので寒くなってきて上着を着ようとしたらLive monitorさん(試験官)に「両手は机の上に!!」と怒られてしまいました。ちゃんと監視されてるみたいです。
マウスしか使わないのに130分程度両手を机の上に置いておくのは伸びたり体勢変えたりが難しいので地味に辛かったです。
試験終了後、即時合否が出ます。嬉しくなって小さくガッツポーズを取ったら、暫く沈黙していたLive monitorさんが「おめでとうございます!」と祝ってくれました。(ちょっと嬉しかったです。)試験結果
受験者スコア: 804
※合格に必要な最低スコア: 720
結果詳細のスコアと評価では、全セクションで「十分な知識を有する」判定でした。
先達の受験者達はセクション毎の取得スコアが見れるようなのですが、人によって記載されていた合格ラインのパーセンテージが違っていたりするので方式が変わったのだと考えています。感想
ひとまず1発合格出来たので安心できました。
AWSに認められた事で私の設計に自信が持てるようになりました。PJ内での発言にも箔が付いたような気がします。以下のような業務で取り扱っておらず、勉強でも実際には触れていないサービスからの出題が多く、試験中は内心不安でいっぱいでした。
- Auto Scaling
- DynamoDB
- Redshift
また、恐らくハズレ選択肢の一つですが、Snowballのような合格対策で範囲外のサービスを見かけました。
なので、ホワイトペーパーに一通り目を通して各サービスで凡そどのような事が出来るのか等の概要を知っておいて良かったと思いました。当然ながらコンピューティング, ストレージ, データベース, VPCネットワークに於ける疎通やセキュリティ, IAMについてもしっかりと勉強しておいた方が良いと思います。
- 投稿日:2019-08-16T02:07:57+09:00
EC2インスタンス停止による料金の発生について
EC2インスタンスを停止中にしたら料金が発生していた
勉強不足で私は知りませんでした。
停止中のEC2インスタンスに関連づけられているElasticIPは、課金対象だということを。標題の件、私の失敗談をご紹介します。
先日、クレジットカードの明細を見たときに
「Amazon web services ¥48」
という記載がありました。おやおや?と思い、AWSの「請求」を確認すると
請求の内訳.AWS Service Charges $0.44 ▼ Elastic Compute Cloud ▼ Asia Pacific (Tokyo) Elastic IP Addresses $0.41 $0.005 per Elastic IP address not attached to a running instance per hour (prorated)82.600 Hrs $0.41 徴収される消費税(日本) $0.03どうやらElasticIPで料金が発生している様子です。
こちらについて公式サイトで調べてみます。
Elastic IP の料金を理解する - Amazon Web Services次の条件が満たされている限り、Elastic IP アドレスに料金は発生しません。
- Elastic IP アドレスが EC2 インスタンスに関連付けられている。
- Elastic IP アドレスに関連付けられているインスタンスが実行中である。
- インスタンスに 1 つの Elastic IP アドレスしか添付されていない。
これらの条件を満たしていない Elastic IP アドレスについては、1 時間単位で請求されます。
私は、7月の終わりにEC2インスタンスを停止中にしていました。
今回の料金発生は、2つ目の「ElasticIPアドレスに関連付けられているインスタンスが実行中である。」という条件を満たしていないことが原因でした。これを回避するには、EC2インスタンスを実行中にする、もしくはElasticIPを解放する必要があります。
停止中にした経緯
「AWS Free Tier limit alert」
というタイトルのメールが届きました。メール本文抜粋.AWS Free Tier usage limit alerting via AWS Budgets 07/28/2019 Dear AWS Customer, Your AWS account xxxxxxxxxxxx has exceeded 85% of the usage limit for one or more AWS Free Tier-eligible services for the month of July. AWS Free Tier Usage as of 07/28/2019 AWS Free Tier Usage Limit 642 Hrs 750 hours of Amazon EC2 Linux t2.micro instance usage「t2.microインスタンスは、月に750時間まで無料で使えるけど、あなたの利用時間は既に85%を超えているから念の為お知らせしとくね」
ということだと思われます。31日 × 24時間 = 744時間
t2.microインスタンスを一つだけ使う分には、750時間は超えません。
ということは、そのままで大丈夫!しかし、このメールを初めて見た当時の自分はこう思いました。
「アラートが来てドキッとするくらいなら、停止中にしておいて必要なときにまた実行中にすればいいや」と・・・。
(EC2インスタンスを複数使うときだけElasticIPを解放すれば良いのだと思ってた)終わりに
今回は、しなくてもいいことをして料金発生という失敗でした・・・。
ただ、今回の失敗を経て、利用するサービスの仕組みはよく調べて理解しておくべきだと実感できました。もし、料金について気になる方はAWSのマネジメントコンソールから「請求」と検索してご確認ください
ご覧いただきましてありがとうございました。
内容に不備がございましたら、ご指摘いただけますと幸いです。