- 投稿日:2019-07-30T23:01:33+09:00
RailsのMVCをまとめてみる
はじめに
RailsはMVCアーキテクチャを採用しています。
MVCアーキテクチャに基づき、Railsはどのような流れで処理を行っているのかを確認していこうと思います。注意すること
調べていて分かったことなのですが、どうやら
RailsはMVCではない
のだそうです。正しくは
RailsはMVC2である
そうです。
(Model2MVCやModel2など、他にも呼び方があるみたいです)「Rails MVC」と「MVC」で検索して理解を深めようとした結果、
分かったような分かっていないような
というモヤモヤした気持ちになった方もいるのではないでしょうか。今回はMVCとMVC2の違いについてはまとめませんが、
MVC?あぁRailsのやつだよね?
という理解は厳密には間違っているそうですので、先に記述しておきます。RailsのMVC
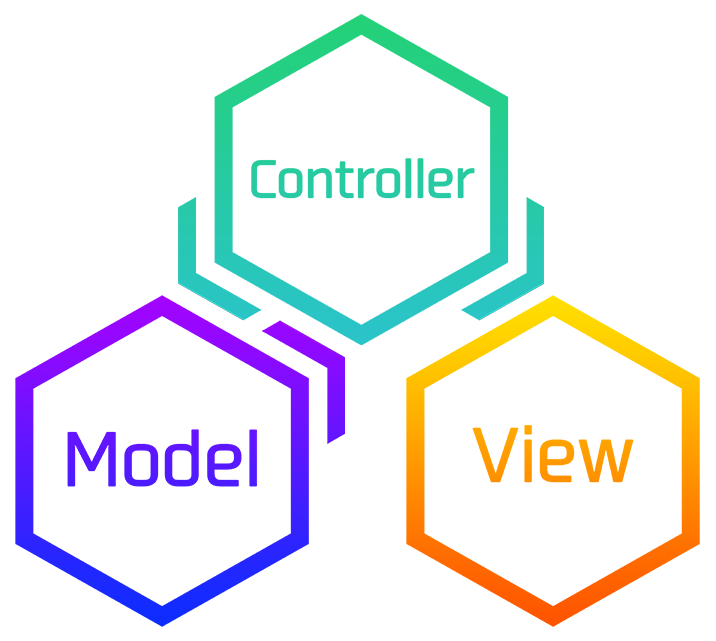
MVCは次の3つの要素を指します。
- Model(モデル)
- View(ビュー)
- Controller(コントローラー)
それぞれの役割は次のようになります。
Model
データベースを管理し、検索・挿入・更新・削除などを行います。
View
Webページ上でどのように表示するかが定義されています。
Controller
ModelとViewに指示を出します。
Modelから必要な情報を取得し、それらをもとにViewにWebページを構築させます。また、RailsではControllerでの処理をアクションと呼び、
複数定義することができます。処理の流れ
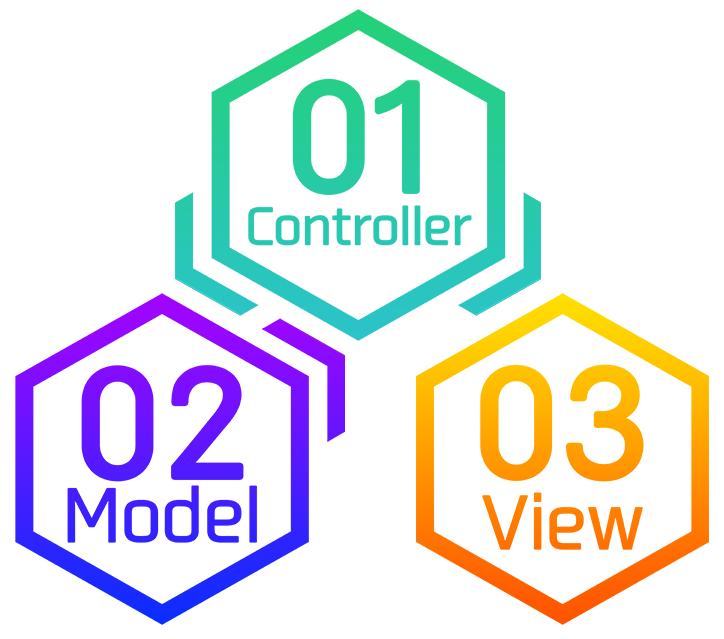
Model・Controller・Viewは次の順番で処理されます。
もう少し具体的に処理を書きだすと
- 指定されたControllerの、指定されたアクションが起動
- ControllerはModelを通してデータベースとやりとりする
- データベースから取得したデータを元に、ControllerはViewにWebページを構築させる
- Viewの内容をレスポンスとして返す
といった流れとなります。
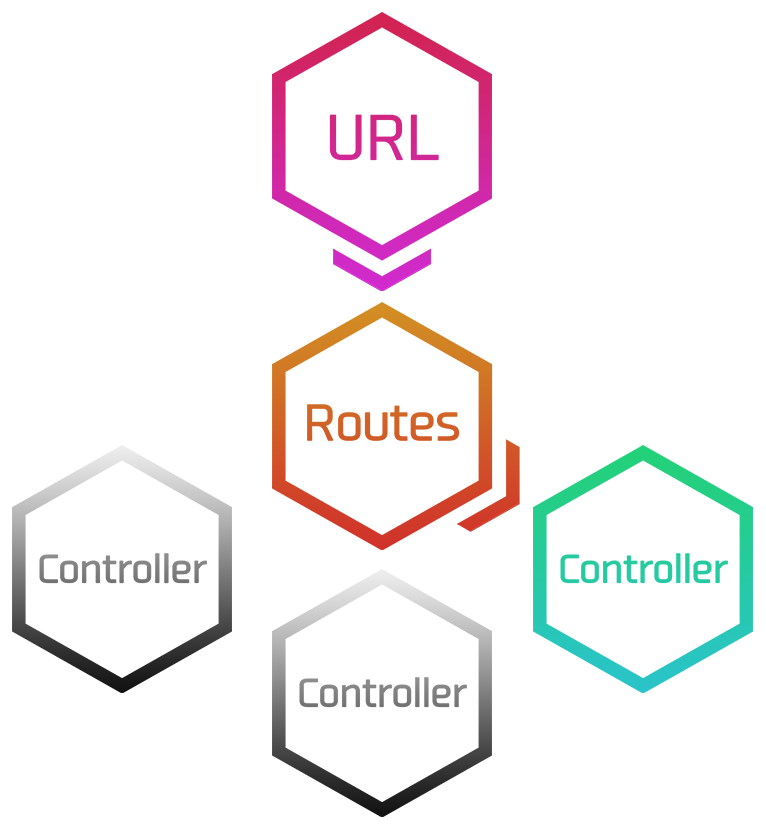
ルーティングについて
routes.rbファイルに定義された通り、
リクエストされたURLとControllerのアクションを結びつけます。
地図みたいなものですね。
おわりに
各ファイルの役割や処理の流れが整理できていなかったのですが、
投稿するためにまとめることで多少理解できたかなと思います。
コーディングしているときに迷わないよう、常に処理を意識しながら作業していこうと思います。
- 投稿日:2019-07-30T22:58:12+09:00
例外処理の設計について
例外処理とは
多くのプログラミング言語には例外処理という機能があります。
例外処理とは、本来ならばプログラム中で起こってはいけないことが起こってしまった時 (例外) でもプログラムが異常な動作をしないよう、 しっかりと処理を行う事です。この
例外処理を適切に実装していれば、もし例外が起こってしまっても、素早く原因の特定や復旧の対応ができ、さらに大きな例外を引き起こす可能性を少なくする事が出来ます。逆に例外処理が不適切だと原因の特定に時間がかかってしまったり、異常なデータを増やしてしまい、大きなエラーを引き起こす可能性があります。
上記のような事態を招かず、また壊れてしまっても復旧のしやすいアプリケーションを作成する為にも適切な例外処理の設計を考える必要があります。ここからは、Railsアプリケーションの例外処理をどのように考えていくのかについて説明していきたいと思います。
例外(エラー)を分類する
例外(エラー)は、
業務エラーとシステムエラーの2つに分類する事が出来ます。
それぞれのエラーについて説明していきたいと思います。業務エラー
業務エラーとは、
アプリケーション側で想定される範囲内で、プログラムの実行が中断され正常終了出来なかった場合のエラーです。業務エラーとして扱われるのは以下のような場合です。
- メールアドレスのフォーマットがおかしい
- 電話番号の桁数がおかしい
- 数字のみ入力可能なのに日本語が入力されている
上記のような、不適切な入力値の場合、以下のような場合も業務エラーとして扱います。
- ユーザーが権限のないページにアクセスしようとした場合
- すでに登録済みのユーザーIDでアカウント登録しようとした場合
業務エラーはHTTPステータスコードとしては、「400 Bad Request」などの400番台のHTTPステータスコードの場合です。
このように、業務エラーはプログラム自体に問題があるというわけではなく、ユーザーが操作をやり直せば正常に処理する事ができるエラーです。システムエラー
システムエラーとは、
アプリケーション側で想定外の異常事態が発生し、処理を正常に終了出来なくなった場合のエラーです。システムエラーとして扱われるのは以下のような場合です。
- データベースがダウンしている
- プログラムに何かしらのバグがある場合
システムエラーはHTTPステータスコードとしては、「500 Internal Server Error」などの500番台のHTTPステータスコードの場合です。
このように、システムエラーはデータベースのダウンやプログラムのバグなど操作しているユーザー側ではどうにも出来ないエラーです。システムエラーが起きた場合はシステムの運用者が責任を持って復旧させる必要があります。次は、2つに分類されたエラーは画面上にどのように出すのか考えていきたいと思います。
例外(エラー)時の画面設計
ここでは、ここまで説明してきた2つのエラーが起こった場合の画面表示を説明していきたいと思います。
業務エラー発生時の画面表示
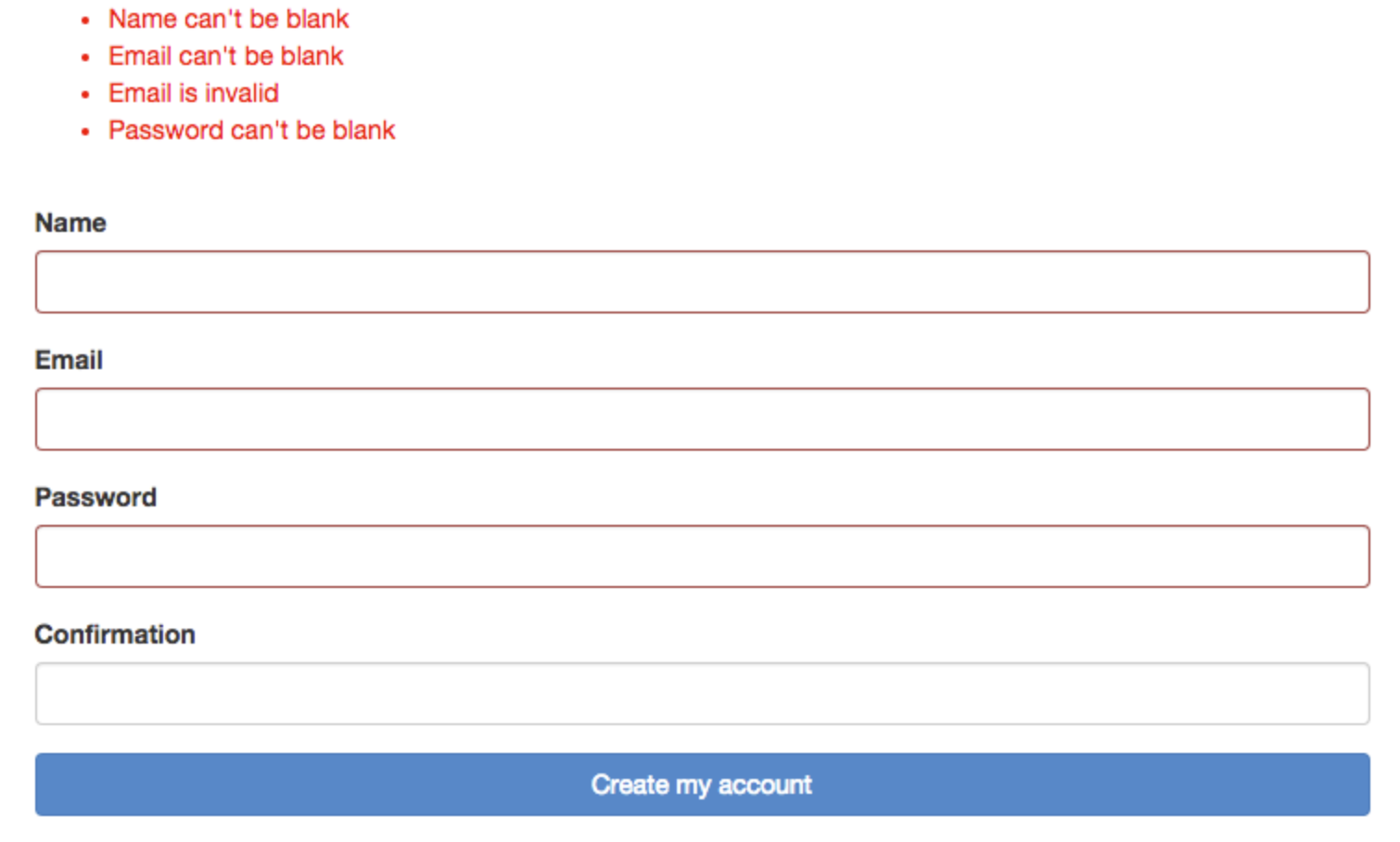
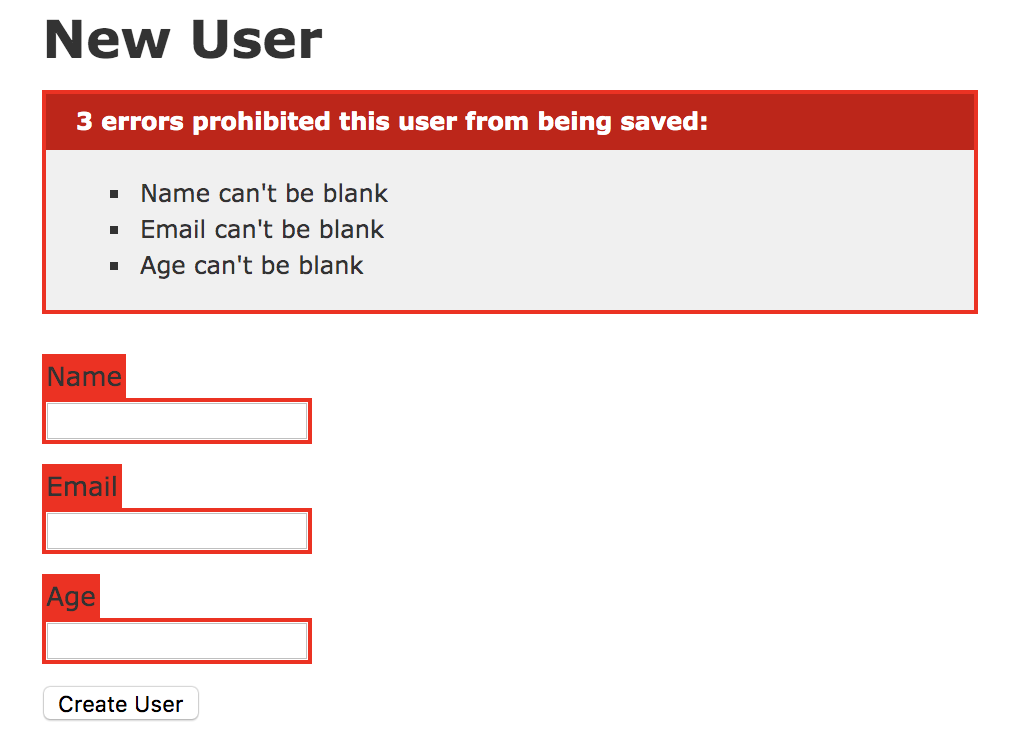
まずは、業務エラー時の画面表示について説明します。下記はRailsアプリケーションでユーザー登録時にバリデーションエラーが発生した場合です。
画面を見ると、不適切な入力値により、バリデーションエラーが発生している事がわかります。
このように、
業務エラーの場合はユーザーの不適切な操作によるエラーなので、エラーの原因とユーザーが次に行うべき操作を表示してあげましょう。システムエラー発生時の画面表示
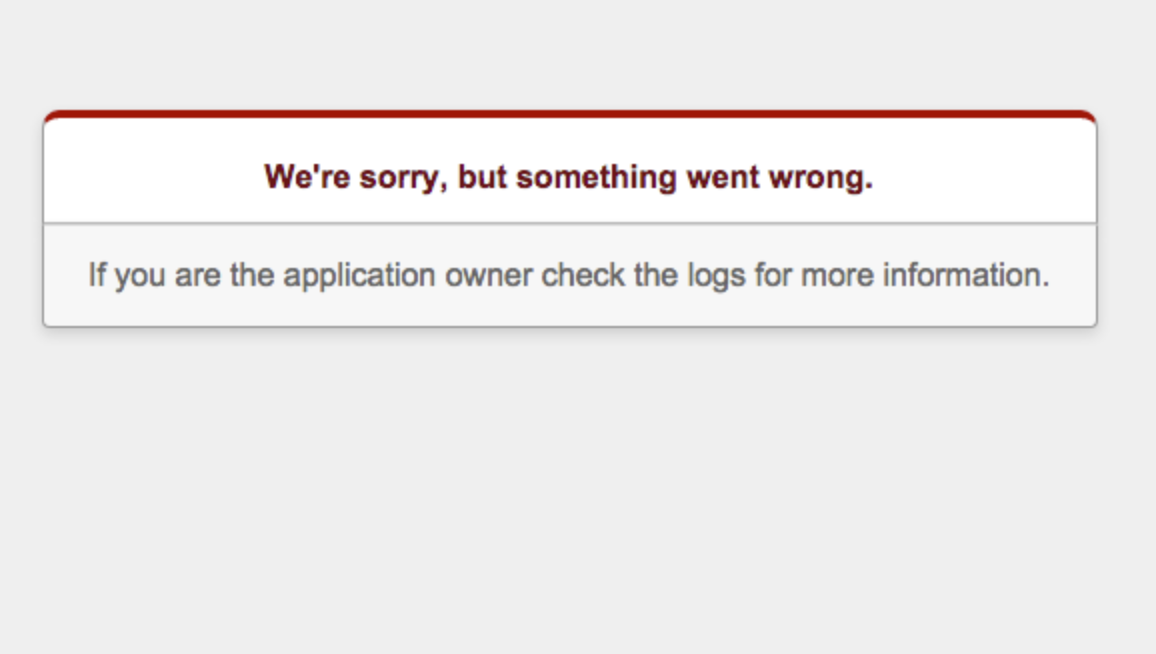
下記は、システムエラー時の画面表示です。
これは、Railsの500エラー画面ですが、このように
システムエラーの場合は、ユーザー側ではどうにも出来ないので 「申し訳ございません。不具合が発生しました。こちら側で対応します。」 のような画面を表示してあげましょう。Railsアプリケーションの例外処理の実装方法
ここからは、Railsアプリケーションの例外処理の実装方法について見ていきましょう。
下記は、ユーザーを登録する際に例外処理を実装した場合のコードです。
def create @user = User.new(user_params) if @user.save # 戻り値のtrue/falseで分岐 # trueの場合 redirect_to users_path, notice: 'ユーザー登録が完了しました' else # 戻り値がfalse ユーザー登録失敗時 # 失敗時は@user.errorsにエラーの原因が格納される # render :new end end/users/new.html.erb<% @user.errors.full_messages.each do |message| %> <li><%= message %></li> <% end %>上記コードを順番に見ていきましょう。
if @user.saveまず、こちらのコードにてsaveメソッドの戻り値で分岐しています。
戻り値は、問題なく保存が成功した場合はtrue、バリデーションでなどで保存が失敗した場合はfalseが返ります。
もし失敗した時には、@user.errorsにエラーの原因が格納されます。そして、newページをレンダリングしている事がわかります。newページでは、先ほど@user.errorsに格納されたメッセージが表示されます。下記は登録失敗時のユーザー登録画面です。ユーザーは、なぜエラーになったのか、次はどう行うべきかがわかります。
さて、次は先ほどのコードで、saveメソッドの戻り値(true/false)を無視した場合はどうなるのか見ていきたいと思います。
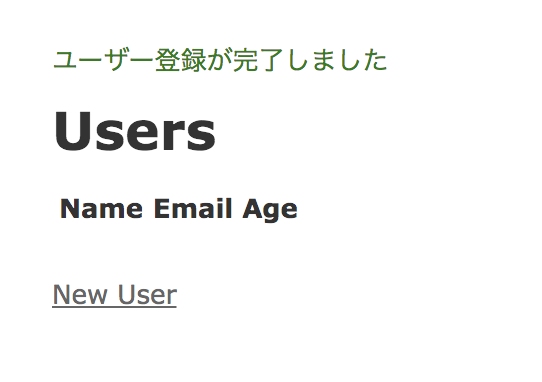
def create @user = User.new(user_params) @user.save redirect_to users_path, notice: 'ユーザー登録が完了しました' endこちらのコードではsaveメソッドの戻り値を無視しています。バリデーションでなどで保存が失敗した場合はどうなるでしょうか。下記は失敗時の画面表示です。
保存には失敗しているにも関わらず、
ユーザー登録が完了しました。という文字が表示されているのがわかります。このままですとユーザー側は登録が完了したと思うでしょう。Rubyには破壊的メソッドの
save!があります。
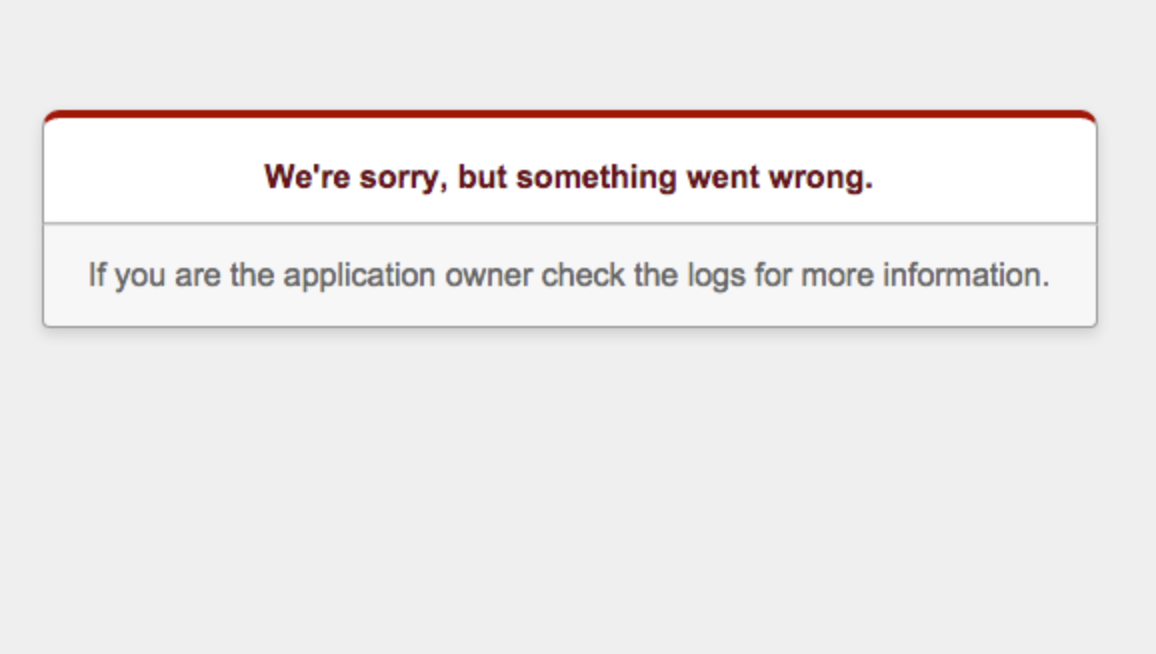
先程のコードをsave!メソッドで書くとこうなります。def create @user = User.new(user_params) @user.save! redirect_to users_path, notice: 'ユーザー登録が完了しました' end
save!メソッドを使った時の画面の表示は下記のようになります。
このように、業務エラーが想定される場合は戻り値を受け取り、成功時、失敗時の処理を書きましょう。もし「通常、業務エラーは起こりえない。もし業務エラーが発生すれば、それは何らかの異常事態」という場合は、破壊的メソッドのsave!メソッドを使いましょう。まとめ
というわけで、ここまで例外処理の考え方について説明してきました。
例外は、
アプリケーション側で想定される範囲内の業務エラーとアプリケーション側で想定外の異常事態が発生した場合のシステムエラーの2つに分類されます。2つに分類できると言っても、「これは業務エラーなのか? システムエラーなのか?このエラー処理は適切なんだろうか?」と正直僕は悩む事が多々あります。そのようなときは、開発チームの方に相談して結論を出すのがいいと思います。
そうする事で、的外れな例外処理を実装する事がなくなり、知識も増えていくでしょう。
- 投稿日:2019-07-30T22:42:22+09:00
rubocopの設定
Gem の導入
Gemfilegroup :development, :test do # Call 'byebug' anywhere in the code to stop execution and get a debugger console gem "byebug", platforms: [:mri, :mingw, :x64_mingw] gem "pry-byebug" gem "pry-doc" gem "pry-rails" gem "rubocop-performance" gem "rubocop-rails" gem "rubocop-rspec" end ----中略----- group :test do gem "factory_bot_rails" gem "faker" gem "rspec-rails" gem "rspec_junit_formatter" end必要ファイルの作成
rubocop.ymlrequire: - rubocop-rails inherit_from: - config/rubocop/rubocop.yml - config/rubocop/rails.yml - config/rubocop/rspec.yml AllCops: TargetRubyVersion: 2.6config/rubocop/rails.ymlRails: Enabled: true # ActiveRecord で association を安易に delegate すると # N+1 を起こしまくるので、なるべく delegate 的なメソッドを使わずに # コストが掛かっていることを自覚できるようにしておきたい。 # メソッドでも危ういが、DSL だと更に意識から抜けるので無効に。 Rails/Delegate: Enabled: false # 意図せずに exit を書くこと無いでしょ? # 毎回 Exclude / rubocop:disable する方が手間。 Rails/Exit: Enabled: false # -File.join(Rails.root, "app", "models") # +Rails.root.join("app", "models") # はともかく # -Rails.root.join("app/models") # +Rails.root.join("app", "models") # は Pathname#plus が行っているので意味無いのでは? Rails/FilePath: Enabled: false # 桁が揃わなくて気持ち悪い # create(:user, logged_in_at: 1.day.ago) # create(:user, logged_in_at: 2.days.ago) Rails/PluralizationGrammar: Enabled: false # unless 文を使ってでも「空」を条件にした方が # 「存在する」よりも「空」の方が状態として特別なので # 脳内モデルと合致しやすい。 Rails/Present: Enabled: false # method_missing を隠したい場合は respond_to? を使うべき Rails/SafeNavigation: ConvertTry: true # valid? チェックし忘れを防ぎたい Rails/SaveBang: Enabled: true # staging 環境を使っているので追加 Rails/UnknownEnv: Environments: - development # rubocop default.yml - test # rubocop default.yml - production # rubocop default.yml - stagingconfig/rubocop/rspec.ymlrequire: "rubocop-rspec" # 日本語だと「〜の場合」になるので suffix でないと対応できない RSpec/ContextWording: Enabled: false # subject はコピペ可搬性よりもそのまま USAGE であって欲しい RSpec/DescribedClass: EnforcedStyle: explicit # it が一つしか無いような context では空行を開ける方が読みづらい # context "when foo is bar" do # let(:foo) { bar } # it { is_expected.to do_something } # end RSpec/EmptyLineAfterFinalLet: Enabled: false # each で回したり aggregate_failures 使ってたりすると厳しい。 # feature spec は exclude でも良いかもしれない。 # ヒアドキュメント使うと一瞬で超えるので disable も検討。 RSpec/ExampleLength: Max: 8 # block の方がテスト対象が # * `{}` の前後のスペースと相まって目立つ # * 普段書く形と同じなので自然に脳内に入ってくる RSpec/ExpectChange: EnforcedStyle: block # one-liner の should は書きやすいし意味が通りやすいし副作用も無いので撥ねる必要がない。 # ただ expect 派に対して強制するほどでもないので統一はしない。 RSpec/ImplicitExpect: Enabled: false # let を使うのは context 間で条件が違うものが存在する時だけにしたい。 # before の方が事前条件を整えていることが分かりやすい。 RSpec/InstanceVariable: Enabled: false # spec_helper で meta[:aggregate_failures] を設定することで # aggregate_failures が全ての spec で有効になる。 # # ほぼ MultipleExpectations についてはチェックされなくなる設定なので注意。 # パフォーマンスの問題さえ無ければ 1 example 1 assertion にしておく方が # 読みやすいテストになりやすいので、そこはレビューで担保していく必要がある。 RSpec/MultipleExpectations: AggregateFailuresByDefault: true # 変に名前つけて呼ぶ方が分かりづらい。 # テスト対象メソッドを呼ぶだけの subject 以外を書かないようにする方が効く。 RSpec/NamedSubject: Enabled: false # Model # `- #method # |- 頻出ケースのテスト 1 # |- 頻出ケースのテスト 2 # `- レアケース # |- レアケースのテスト 1 # `- レアケースのテスト 2 # のように括り出すと、レアケースのテストを読み飛ばせるようになり # テストを読む人にやさしくなる。 # デフォルトの 3 より少し緩めてもヨサソウ。 RSpec/NestedGroups: Max: 4 # ブロックは初見だと返り値を書いていると気づけないので and_return にしたいが、 # ブロックの方が見た目がスッキリして見やすいので、どちらでもお好きにどうぞ。 RSpec/ReturnFromStub: Enabled: falseconfig/rubocop/rubocop.yml# 自動生成されるものはチェック対象から除外する AllCops: Exclude: - "node_modules/**/*" # rubocop config/default.yml - "vendor/**/*" # rubocop config/default.yml - "db/schema.rb" #################### Layout ################################ # メソッドをグループ分けして書き順を揃えておくと読みやすくなる。 # 多少のツラミはあるかもしれない。 # TODO: Categories を調整することで # https://github.com/pocke/rubocop-rails-order_model_declarative_methods # を再現できそう。 Layout/ClassStructure: Enabled: true # メソッドチェーンの改行は末尾に . を入れる # * REPL に貼り付けた際の暴発を防ぐため # * 途中にコメントをはさむことができて実用上圧倒的に便利 Layout/DotPosition: EnforcedStyle: trailing # 桁揃えが綺麗にならないことが多いので migration は除外 Layout/ExtraSpacing: Exclude: - "db/migrate/*.rb" # special_inside_parentheses (default) と比べて # * 横に長くなりづらい # * メソッド名の長さが変わったときに diff が少ない Layout/IndentFirstArrayElement: EnforcedStyle: consistent # ({ と hash を開始した場合に ( の位置にインデントさせる # そもそも {} が必要ない可能性が高いが Style/BracesAroundHashParameters はチェックしないことにしたので Layout/IndentFirstHashElement: EnforcedStyle: consistent # private/protected は一段深くインデントする Layout/IndentationConsistency: EnforcedStyle: indented_internal_methods # メソッドチェーン感がより感じられるインデントにする Layout/MultilineMethodCallIndentation: EnforcedStyle: indented_relative_to_receiver # {} は 1 行で書くときに主に使われるので、スペースよりも # 横に長くならない方が嬉しさが多い。 # そもそも {| のスタイルの方が一般的だったと認識している。 Layout/SpaceInsideBlockBraces: SpaceBeforeBlockParameters: false #################### Lint ################################## # spec 内では # expect { subject }.to change { foo } # という書き方をよく行うので () を省略したい。 # { foo } は明らかに change に紐付く。 Lint/AmbiguousBlockAssociation: Exclude: - "spec/**/*_spec.rb" # Style/EmptyCaseCondition と同じく網羅の表現力が empty when を認めた方が高いし、 # 頻出する対象を最初の when で撥ねるのはパフォーマンス向上で頻出する。 # また、 # case foo # when 42 # # nop # when 1..100 # ... # end # と、下の when がキャッチしてしまう場合等に対応していない。 # See. http://tech.sideci.com/entry/2016/11/01/105900 Lint/EmptyWhen: Enabled: false # RuntimeError は「特定の Error を定義できない場合」なので、 # 定義できるエラーは RuntimeError ではなく StandardError を継承する。 Lint/InheritException: EnforcedStyle: standard_error # * 同名のメソッドがある場合にローカル変数に `_` を付ける # * 一時変数として `_` を付ける # というテクニックは頻出する Lint/UnderscorePrefixedVariableName: Enabled: false # 子クラスで実装させるつもりで中身が # raise NotImplementedError # のみのメソッドが引っかかるので。 # (raise せずに中身が空だと IgnoreEmptyMethods でセーフ) Lint/UnusedMethodArgument: Enabled: false # select 以外では引っかからないと思うので # mutating_methods のチェックを有効に。 # TODO: select は引数が無い (ブロックのみ) の場合にだけチェックする # ようにすると誤検知がほぼ無くなる? Lint/Void: CheckForMethodsWithNoSideEffects: true #################### Metrics ############################### # 30 まではギリギリ許せる範囲だったけど # リリースごとに 3 ずつぐらい下げていきます。20 まで下げたい。 Metrics/AbcSize: Max: 24 # Gemfile, Guardfile は DSL 的で基本的に複雑にはならないので除外 # rake, rspec, environments, routes は巨大な block 不可避なので除外 # TODO: ExcludedMethods の精査 Metrics/BlockLength: Exclude: - "Rakefile" - "**/*.rake" - "spec/**/*.rb" - "Gemfile" - "Guardfile" - "config/environments/*.rb" - "config/routes.rb" - "config/routes/**/*.rb" - "*.gemspec" # 6 は強すぎるので緩める Metrics/CyclomaticComplexity: Max: 10 # * 警告 120文字 # * 禁止 160文字 # のイメージ Metrics/LineLength: Max: 160 Exclude: - "db/migrate/*.rb" # 20 行超えるのは migration ファイル以外滅多に無い Metrics/MethodLength: Max: 20 Exclude: - "db/migrate/*.rb" # 分岐の数。ガード句を多用しているとデフォルト 7 だと厳しい Metrics/PerceivedComplexity: Max: 8 #################### Naming ################################ # has_ から始まるメソッドは許可する Naming/PredicateName: NamePrefixBlacklist: - "is_" - "have_" NamePrefix: - "is_" - "have_" # 3 文字未満だと指摘されるが、未使用を示す _ や e(rror), b(lock), # n(umber) といった 1 文字変数は頻出するし、前置詞(by, to, ...)や # よく知られた省略語 (op: operator とか pk: primary key とか) も妥当。 # 変数 s にどんな文字列かを形容したい場合と、不要な場合とがある=無効 Naming/UncommunicativeMethodParamName: Enabled: false #################### Security ############################## # 毎回 YAML.safe_load(yaml_str, [Date, Time]) するのは面倒で。。 Security/YAMLLoad: Enabled: false #################### Style ################################# # レキシカルスコープの扱いが alias_method の方が自然。 # https://ernie.io/2014/10/23/in-defense-of-alias/ のように # 問題になる場合は自分で緩める。 Style/Alias: EnforcedStyle: prefer_alias_method # redirect_to xxx and return のイディオムを維持したい Style/AndOr: EnforcedStyle: conditionals # 日本語のコメントを許可する Style/AsciiComments: Enabled: false # do .. end から更にメソッドチェーンすると見づらいので # auto-correct せず、自分で修正する # spec 内は見た目が綺麗になるので許可 Style/BlockDelimiters: AutoCorrect: false Exclude: - "spec/**/*_spec.rb" # option 等、明示的にハッシュにした方が分かりやすい場合もある Style/BracesAroundHashParameters: Enabled: false # scope が違うとか親 module の存在確認が必要とかデメリットはあるが、 # namespace 付きのクラスはかなり頻繁に作るので簡単に書きたい。 Style/ClassAndModuleChildren: Enabled: false # Style/CollectionMethods 自体は無効になっているのだが、 # https://github.com/bbatsov/rubocop/issues/1084 # https://github.com/bbatsov/rubocop/issues/1334 # Performance/Detect がこの設定値を見るので PreferredMethods だけ変更しておく。 # # デフォルト値から変えたのは # find -> detect # ActiveRecord の find と間違えやすいため # reduce -> inject # detect, reject, select と並べたときに韻を踏んでいるため。 # collect -> map を維持しているのは文字数が圧倒的に少ないため。 Style/CollectionMethods: PreferredMethods: detect: "detect" find: "detect" inject: "inject" reduce: "inject" # ドキュメントの無い public class を許可する Style/Documentation: Enabled: false # !! のイディオムは積極的に使う Style/DoubleNegation: Enabled: false # case # when ios? # when android? # end # のようなものは case の方が網羅の表現力が高い Style/EmptyCaseCondition: Enabled: false # 明示的に else で nil を返すのは分かりやすいので許可する Style/EmptyElse: EnforcedStyle: empty # 空メソッドの場合だけ1行で書かなければいけない理由が無い # 「セミコロンは使わない」に寄せた方がルールがシンプル Style/EmptyMethod: EnforcedStyle: expanded # いずれかに揃えるのならば `sprintf` や `format` より String#% が好きです Style/FormatString: EnforcedStyle: percent # まだ対応するには早い Style/FrozenStringLiteralComment: Enabled: false # if 文の中に 3 行程度のブロックを書くぐらいは許容した方が現実的 # NOTE: https://github.com/bbatsov/rubocop/commit/29945958034db13af9e8ff385ec58cb9eb464596 # の影響で、if 文の中身が 1 行の場合に警告されるようになっている。 # Style/IfUnlessModifier の設定見てくれないかなぁ? (v0.36.0) Style/GuardClause: MinBodyLength: 5 # rake タスクの順序の hash は rocket を許可する Style/HashSyntax: Exclude: - "**/*.rake" - "Rakefile" # 平たくしてしまうと条件のグルーピングが脳内モデルとズレやすい Style/IfInsideElse: Enabled: false # 条件式の方を意識させたい場合には後置の if/unless を使わない方が分かりやすい Style/IfUnlessModifier: Enabled: false # scope 等は複数行でも lambda ではなく ->{} で揃えた方が見た目が綺麗 Style/Lambda: EnforcedStyle: literal # end.some_method とチェインするのはダサい # Style/BlockDelimiters と相性が悪いけど、頑張ってコードを修正してください Style/MethodCalledOnDoEndBlock: Enabled: true # この 2 つは単発で動かすのが分かっているので Object を汚染しても問題ない。 # spec/dummy は Rails Engine を開発するときに絶対に引っかかるので入れておく。 Style/MixinUsage: Exclude: - "bin/setup" - "bin/update" - "spec/dummy/bin/setup" - "spec/dummy/bin/update" # 1_000_000 と区切り文字が 2 個以上必要になる場合のみ _ 区切りを必須にする # 10_000_00 は許可しない。(これは例えば 10000 ドルをセント単位にする時に便利だが # 頻出しないので foolproof に振る Style/NumericLiterals: MinDigits: 7 Strict: true # foo.positive? は foo > 0 に比べて意味が曖昧になる # foo.zero? は許可したいけどメソッドごとに指定できないので一括で disable に Style/NumericPredicate: Enabled: false # falsy な場合という条件式の方を意識させたい場合がある。 # Style/IfUnlessModifier と同じ雰囲気。 Style/OrAssignment: Enabled: false # 正規表現にマッチさせた時の特殊変数の置き換えは Regex.last_match ではなく # 名前付きキャプチャを使って参照したいので auto-correct しない Style/PerlBackrefs: AutoCorrect: false # Hash#has_key? の方が key? よりも意味が通る Style/PreferredHashMethods: EnforcedStyle: verbose # 受け取り側で multiple assignment しろというのを明示 Style/RedundantReturn: AllowMultipleReturnValues: true # 特に model 内において、ローカル変数とメソッド呼び出しの区別をつけた方が分かりやすい場合が多い Style/RedundantSelf: Enabled: false # 無指定だと StandardError を rescue するのは常識の範疇なので。 Style/RescueStandardError: EnforcedStyle: implicit # user&.admin? が、[nil, true, false] の 3 値を返すことに一瞬で気づけず # boolean を返すっぽく見えてしまうので無効に。 # user && user.admin? なら短絡評価で nil が返ってくるのが一目で分かるので。 # (boolean を返すメソッド以外なら積極的に使いたいんだけどねぇ # # 他に auto-correct してはいけないパターンとして # if hoge && hoge.count > 1 # がある。 Style/SafeNavigation: Enabled: false # spec 内は見た目が綺麗になるので許可 Style/Semicolon: Exclude: - "spec/**/*_spec.rb" # * 式展開したい場合に書き換えるのが面倒 # * 文章ではダブルクォートよりもシングルクォートの方が頻出する # ことから EnforcedStyle: double_quotes 推奨 Style/StringLiterals: EnforcedStyle: double_quotes # 式展開中でもダブルクォートを使う # 普段の文字列リテラルがダブルクォートなので使い分けるのが面倒 Style/StringLiteralsInInterpolation: EnforcedStyle: double_quotes # String#intern は ruby の内部表現すぎるので String#to_sym を使う Style/StringMethods: Enabled: true # %w() と %i() が見分けづらいので Style/WordArray と合わせて無効に。 # 書き手に委ねるという意味で、Enabled: false にしています。使っても良い。 Style/SymbolArray: Enabled: false # 三項演算子は分かりやすく使いたい。 # () を外さない方が条件式が何なのか読み取りやすいと感じる。 Style/TernaryParentheses: EnforcedStyle: require_parentheses_when_complex # 複数行の場合はケツカンマを入れる(引数) # Ruby は関数の引数もカンマを許容しているので # * 単行は常にケツカンマ無し # * 複数行は常にケツカンマ有り # に統一したい。 # 見た目がアレだが、ES2017 でも関数引数のケツカンマが許容されるので # 世界はそちらに向かっている。 Style/TrailingCommaInArguments: EnforcedStyleForMultiline: comma # 複数行の場合はケツカンマを入れる(Arrayリテラル) # JSON がケツカンマを許していないという反対意見もあるが、 # 古い JScript の仕様に縛られる必要は無い。 # IE9 以降はリテラルでケツカンマ OK なので正しい差分行の検出に寄せる。 # 2 insertions(+), 1 deletion(-) ではなく、1 insertions Style/TrailingCommaInArrayLiteral: EnforcedStyleForMultiline: comma # 複数行の場合はケツカンマを入れる(Hashリテラル) Style/TrailingCommaInHashLiteral: EnforcedStyleForMultiline: comma # %w() と %i() が見分けづらいので Style/SymbolArray と合わせて無効に。 # 書き手に委ねるという意味で、Enabled: false にしています。使っても良い。 Style/WordArray: Enabled: false # 0 <= foo && foo < 5 のように数直線上に並べるのは # コードを読みやすくするテクニックなので equality_operators_only に。 # Style/YodaCondition: # # TODO: rubocop 0.63.0以降はforbid_for_equality_operators_onlyなので依存を引き上げれば有効にできる # EnforcedStyle: forbid_for_equality_operators_only # 条件式で arr.size > 0 が使われた時に # if !arr.empty? # else # end # に修正されるのが嫌。 # 中身を入れ替えて否定外しても良いんだけど、どちらが例外的な処理なのかが分かりづらくなる。 Style/ZeroLengthPredicate: Enabled: false整形を実行させるコマンド
$ be rubocop -a
- 投稿日:2019-07-30T22:26:34+09:00
Railsチュートリアル(第1章、第2章)
はじめに
Railsチュートリアルの第1章と第2章を終わらせました。
ポイントだけまとめます。環境構築
環境構築は昨日記事を書きました。
DockerでRailsの環境構築Herokuへのデプロイ
まず、Herokuのアカウントを作成します。
https://signup.heroku.com/
上記のページで必要事項を入力して、アカウントを作成します。次にHerokuのインストールをします。
以下のサイトに書いてあるコマンドを実行し、Homebrewを使用してHerokuをインストールします。
https://devcenter.heroku.com/articles/heroku-clibrew tap heroku/brew && brew install heroku以下のコマンドでバージョンが表示されたら成功です。
heroku --version次に以下のコマンドを実行して、herokuのログインとssh鍵の登録を行います。
herokuに登録したメールアドレスとパスワードを聞かれます。heroku login --interactive heroku keys:add次に、Heroku上のアプリケーションを作成します。
heroku create最後にHerokuにリポジトリをプッシュしてデプロイ完了です。
gitでバージョン管理している必要があります。git push heroku masterscaffold
scaffoldはモデルとそれの作成/取得/更新/削除といった画面をまとめて作成してくれるものらしいです。
※私はDocker上で動かしているので、先頭にdocker-compose run webをつけています。rails generate scaffold "モデル名" "カラム名":"型"その後、マイグレーションファイルを元にDB上のテーブルを作成します。
以下のコマンドで、まだマイグレーションされていないファイルをmigrateします。rails db:migrateこれで
"ルート"/usersというパスにアクセスでき、追加などを行うことができます。validate
追加や編集時に入力内容のチェックを記述できます。
/app/models/配下の各モデルファイルに以下のように記述します。
チェックはカンマ区切りで追加できます。validates "カラムのシンボル", "チェック内容" # チェック例:最大値140文字 # length: {maximum: 140}モデル同士の関連
あるモデルが複数のモデルを持っている場合は、
has_many、ひとつのモデルに紐づく場合はbelongs_toをモデルファイル内に記述します。has_many: "モデルのシンボルの複数形" belong_to: "モデルのシンボルの単数形"Herokuでのmigrate
Herokuにデプロイする場合は、プッシュ後に、migrateを実行しておきます。
heroku rails db:migrate
- 投稿日:2019-07-30T21:41:22+09:00
【初心者向け・動画付き】Railsで日時をフォーマットするときはstrftimeよりも、lメソッドを使おう
はじめに:日時の表示に関してよくある問題
何も考えずにViewに
created_atのような日付を出力すると、「あれっ?」と思うような表示になることがあります。app/views/users/index.html.erb<% @users.each do |user| %> <tr> <td><%= user.name %></td> <!-- 作成日時を表示する --> <td><%= user.created_at %></td> <td><%= link_to 'Show', user %></td> <td><%= link_to 'Edit', edit_user_path(user) %></td> <td><%= link_to 'Destroy', user, method: :delete, data: { confirm: 'Are you sure?' } %></td> </tr> <% end %>
具体的には以下の2つのポイントが「あれっ?」と思う点だと思います。
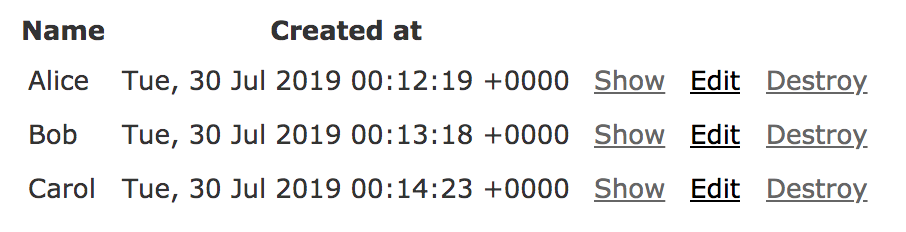
- 日本時間(JST)ではなく、世界標準時(UTC)で表示されてしまう
- "Tue, 30 Jul 2019 00:12:19 +0000"のようなフォーマットは日本人にとって馴染みがない
この記事ではこの問題を解決する方法を紹介します。
タイムゾーンを日本時間に変更する
最初にタイムゾーンを日本時間にしましょう。
config/application.rbに以下の設定を追加し、サーバーを再起動してください。config/application.rbmodule TimeFormatSandbox class Application < Rails::Application # ... # タイムゾーンを日本時間に設定 config.time_zone = 'Asia/Tokyo' end endこれで画面に表示された日時が日本時間になります。
日本人が読みやすい日時フォーマットにする
続いて、日時の表示形式を日本人が読みやすいフォーマットに変更しましょう。
strftimeでも変更できるが、あまりオススメできない
ネットを検索すると以下のように
strftimeメソッドを使って検索する方法がよく出てきます。<%= user.created_at.strftime('%Y/%m/%d %H:%M:%S') %>もちろんこれでも目的は達成できるのですが、他にも日時を表示するViewがあると、
'%Y/%m/%d %H:%M:%S'のような書式文字列を繰り返し書かないといけないため、コードがDRYになりません。DRYでないコードは変更に弱いコードになります。
変更に弱いコードは良くないコードです。lメソッドでDRYに書式を指定する(オススメ)
Railsには
lメソッドという便利なメソッドがあるので、これを活用しましょう。以下は
lメソッドの使用例です。<!-- lメソッドを使って書式を指定する --> <td><%= l user.created_at %></td>ただし、
lメソッドを使うだけでは何も変化がありません。
lメソッドを活用するには、もう少し作業が必要です。次に行うのはロケールの設定です。
今回は日本人が読みやすい書式にするのが目的なので、アプリケーションのロケールを:jaに設定します。
config/application.rbに以下の設定を追加してください。config/application.rbmodule TimeFormatSandbox class Application < Rails::Application # ... # デフォルトのロケールを日本(ja)に設定 config.i18n.default_locale = :ja end end続いて、
config/locales/ja.ymlというファイルを作成し、以下のような設定を記述します。config/locales/ja.ymlja: time: formats: default: "%Y/%m/%d %H:%M:%S"上の設定は日時(time)のデフォルトの書式を
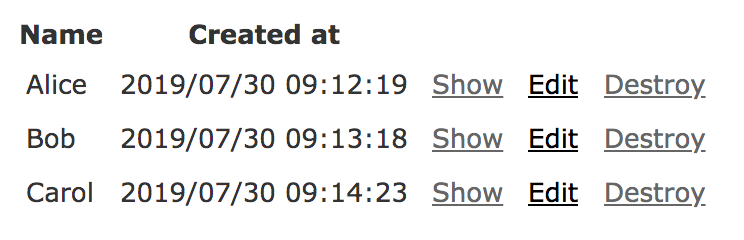
%Y/%m/%d %H:%M:%Sにするための設定です。これでサーバーを再起動すると、日本人向けの書式で日時が表示されます。
strftimeメソッドとは異なり、l foo.created_atのような記述でどのViewでも同じ書式が得られるため、コードもDRYになります。Tips: i18n_generatorsでja.ymlを自動生成する
上で作成した
config/locales/ja.ymlは、i18n_generators gemを使って自動生成すると便利です。
このgemの使い方は以下のとおりです。まず、Gemfileにi18n_generatorsを追加し、
bundle installを実行します。Gemfilegroup :development do # ... gem 'i18n_generators' end次にターミナルから以下のコマンドを実行します。
rails g i18n_locale ja
config/locales/ja.ymlが生成されるので、このファイルを開いてja > time > formats > defaultの書式文字列を編集します。
デフォルトの書式文字列は"%Y年%m月%d日(%a) %H時%M分%S秒 %z"になっているので、これを要件に合わせて変更してください。なお、i18n_generatorsが生成した
ja.ymlには他にも日本語ロケール向けの設定がたくさん定義されています。
i18n_generatorsに関する詳しい情報はREADMEを参照してください。https://github.com/amatsuda/i18n_generators
Tips: View以外ではI18n.lを使う
Viewでは
lと書くだけでOKですが、lメソッドがヘルパーメソッドとして提供されていない場所(Modelなど)では、lだけではNoMethodErrorになります。
その場合は、lの代わりにI18n.lと書けば、日時をフォーマットすることができます。ちなみに
lはlocalizeのエイリアスメソッドなので、localizeと書いても構いません。以下の記述はどれも同じ結果になります。
= l user.created_at = I18n.l user.created_at = localize user.created_at = I18n.localize user.created_at追記:Time::DATE_FORMATS[:default]を変更するのもオススメしない
日時のフォーマットを変更する方法としてもうひとつ、
Time::DATE_FORMATS[:default]の設定を変えるという方法もあるようです。config/initializers/time_formats.rbTime::DATE_FORMATS[:default] = '%Y/%m/%d %H:%M:%S'こうすると、
lメソッドもstrftimeも使わずに書式を統一することができます。<!-- 何もしなくても書式が'%Y/%m/%d %H:%M:%S'になる --> <td><%= user.created_at %></td>これだけ見ると「すごく便利じゃん!」と思うかもしれません。
ですが、アプリケーション全体のデフォルト設定が変わってしまうため、予期しない問題を引き起こすかもしれません。
実際に問題が発生する事例は以下の記事で紹介されています。RailsのTime::DATE_FORMATS[:default]は変更しないほうがいい - Qiita
ですので、この方法もあまりオススメできません。
動画はこちら
この記事の内容はYouTube動画としてアップしています。
動画を見たい方は以下のリンクから視聴してください。参考文献

- 投稿日:2019-07-30T21:01:30+09:00
PostgreSQLのインストールからRailsアプリ作成まで
Qiita初投稿になる初学者です。
プログラミングスクールのカリキュラムではmysqlを使ってRailsアプリを作成していましたが、Herokuというクラウド・アプリケーション・プラットフォームへのデプロイを見据えて、新しくPostgreSQLをインストールしてRailsアプリの作成しましたので、その過程を備忘録として投稿します。
間違い等あれば御指摘の程、宜しくお願い致します。
参考にさせて頂いた記事
https://qiita.com/longtime1116/items/9045717ff8607bed07fe
https://qiita.com/taKassi/items/8e43171aeda300b67213
https://qiita.com/torini/items/9952d91c4a7087b23481HomebrewでPostgreSQLをインストール
$ brew update $ brew install postgresqlpostgresql を brew で install したときに、/usr/local/var/postgresが作成されている。
これを環境変数にセットしておく。
~/.bashrc に以下を追加。$ export PGDATA='/usr/local/var/postgres' $ source ~/.bashrcPostgreSQL Accountを作成
$ sudo -u postgres psqlパスワード入力を求められるので入力(macログインのパスワード)
postgres=# create role ユーザー名 with created login password 'パスワード'; postgres=# \qRails newでアプリ作成
$ rails new アプリ名 -d postgresql $ cd アプリ名config/database.ymlの編集
config/database.ymldefault: &default adapter: postgresql encoding: unicode pool: 5 # 以下、3行を追加 username: ユーザー名 # さっき作ったPostgreSQL Accountと同一のもの password: パスワード # さっき作ったPostgreSQL Accountと同一のもの host: localhostデータベース作成
$ rails db:create $ psql -l # 作ったデータベースを確認できる。
- 投稿日:2019-07-30T20:28:39+09:00
Rails mail develop tips
Railsでメール周りの開発をやることが多いので、ノウハウってわけじゃないが雑に書き残しておく。
思いつきで書いてるので、後で思い出したら追記予定アジェンダ
- preview
- CSS
- HTMLメールの作り方
- 確認
- バウンス
- unsubscribe
preview
開発時にHTMLの見た目を確認する方法
実際にメール送って、 https://github.com/ryanb/letter_opener を使って確認することが多いが、preview機能を使ったほうが圧倒的に早い
Rails Guides - Action Mailer の基礎 にpreviewのリンクがあるのでこちらを参考にCSS
HTMLメールにCSSを当てて装飾したい場合があるが、CSSは埋め込み方式 + tableレイアウトで作るのがほとんど。
CSSをせめて外のファイルで管理して他のメールに使いまわしたいので、
その場合は https://github.com/fphilipe/premailer-rails を使うapp/mailers/application_mailer.rbclass ApplicationMailer < ActionMailer::Base layout 'mailer' endapp/views/layouts/mailer.html.slimhtml head = stylesheet_link_tag 'email', media: 'all' body = yieldapp/assets/stylesheets/email.scss.main { background: #f3f3f3; }あとはテーブルレイアウトでいい感じに
HTMLメールの作り方
1からHTMLメールを作るのはすごく大変なので、HTMLメールを作ってそれをHTMLに落とし込めるようにする
以前は https://mailchimp.com/ でGUIでポチポチしていい感じに作ったあとHTMLに吐き出し、それをslimやhamlに置き換えていたhttps://beefree.io/ は使ったことないけど、これでもいいかも
確認
実際にメールを飛ばすが、本当のユーザーに飛ばすのはよくないので、メールは飛ばないけど実際の画面を見れるサービスを使う。
letter_openerやpreviewでは見つからないバグを見つけるのに便利(cssで画像を埋め込んだパターンで本番だと見えないとか)https://mailcatcher.me/ or https://mailtrap.io/
mailtrapはLaravelで使ったことあるけど、こっちのほうがセットアップ楽かも?(mailcatcherは自身でセットアップしたことない)
バウンス
メールのバウンス管理は本当にだるい。今までメールの開発について書いてきたが、めんどくさいので https://sendgrid.kke.co.jp/ 等外部のメール配信サービスに金払って使うほうがいい。
バウンス管理や開封率のレポートとか全部やってくれるし、send gridのgemもあるAWSのSESでやっていた時は、以下のような対応をした
- SESが失敗したバウンスの結果をSQSに流し込む
- https://github.com/phstc/shoryuken でSQSのデータを取り出す
- 取り出した結果をngリストみたいなテーブルに保存し、アプリケーションからメールを飛ばさないように対応
※確かAWSさんからバウンスレート10%超えたから2週間で改善しないとメールをスパム認定するから改善してねーって言われて速攻で対応して0.2%ぐらいにしたような記憶。ダブルオプトインじゃなくて、シングルオプトインだったからバウンスレートがやばかった
unsubscribe(配信停止)
メルマガ等送られてくる場合、たまに非購読にするリンクがないメールが送られてくるが、特定電子メール法により禁止されているので、つける必要がある
(法律周りはそこまで詳しいわけじゃないのでご了承ください)よくあるのが、ログイン後にこの画面にいってメルマガ配信停止してくださいみたいなのあるけど、そもそもパスワード覚えてねぇよみたいなことになりがちで結果的に迷惑メール設定してみたいなパターンが多すぎる。
ちなみにsendgridを使えばメール本文に1クリックで配信停止にできるリンクを仕込めます。
結論
自分で開発するのはやめて、sendgridを使おう
- 投稿日:2019-07-30T19:57:27+09:00
cannot load such file -- bcrypt というエラー
passwordを暗号化したいために
gem bcryptをbundle installした後、
ブラウザを再起動したときに出たエラー原因はよくわからないですが、rails serverを再起動することで直りました。
定期的にrails serverは再起動した方がいいんですかねぇ、他にもこれを再起動することで直ったエラーがあったような参考URL↓
http://tusukuru.hatenablog.com/entry/2016/08/24/160059
- 投稿日:2019-07-30T15:42:57+09:00
ArgumentError: Missing required arguments: aws_access_key_id, aws_secret_access_key
awsのs3を導入して、capistranoを使っていた時エラーが出ました。
(unicorn,nginx使用)
どうやら、keyが見当たりませんと出たので、確認しに行った。でも、環境変数はちゃんと登録されていたし、なぜだろうと思った。
原因は、unicornの設定fileのpathが間違っていた。
working_directoryあたり。
ちゃんと、pathがcurrentになっていますか?pathがcapi使った時にcurrentになるので、ちゃんとcurrent指定をしてあげましょう。
また、working_directoryが二重になっていないかなども確認するといいかもです。
- 投稿日:2019-07-30T14:31:03+09:00
Raspberry Pi上でbundle installをして無理だった話
なぜRaspberry Piでrails?
家のPCがSurface Proなのだが、Surface ProはVirtual Boxが入らないので仮想環境でLinuxを動かせず、デュアルブートをするほどストレージに空き領域もないため仕方なくRaspberry Piで環境を構築したのである。
発生したエラー
Gemfileに「gem install bcrypt」を追加し、
>> bundle install
を実行したとき
Fetching bcrypt 3.1.13
Installing bcrypt 3.1.13 with native extensions
Gem::Ext::BuildError: ERROR: Failed to build gem native extension.
・
・
・
・
An error occurred while installing bcrypt (3.1.13), and Bundler cannot continue.
Make sure that `gem install bcrypt -v '3.1.13' --source 'https://rubygems.org/'` succeeds before
bundling.
となった。
エラーメッセージの通りに
>> gem install bcrypt -v '3.1.13' --source 'https://rubygems.org/'
を実行する
すると、、、
Building native extensions. This could take a while...
ERROR: Error installing bcrypt:
ERROR: Failed to build gem native extension.
・
・
・
・
make "DESTDIR="
compiling bcrypt_ext.c
compiling crypt_blowfish.c
gcc -D__SKIP_GNU -I/home/pi/.rbenv/versions/2.5.3/include -D_FILE_OFFSET_BITS=64 -c -o x86.o x86.S
x86.S: Assembler messages:
x86.S:202: Error: junk at end of line, first unrecognized character is `,'
<builtin>: recipe for target 'x86.o' failed
make: *** [x86.o] Error 1
原因
エラーを見てわかる人もいるかと思うが、どうやらgem installで落としてくるパッケージにはrubyで書かれておらずx86用のCPUのマシンで動作するc言語で書かれたネイティブコードがあるらしい。
今回は「bcrypt」がそれに該当、、、さすがにこれをRaspberry PiのARM用にクロスコンパイルするパワーが無く断念
解決策
本来はRaspberry Piの上で開発などする人がいないかと思うが、、、同じような人がいたら
解決策としては
①自分でRaspberry PiのARM用にクロスコンパイルする
②別の環境でinstallする(他のx86が載っているPC環境かクラウド環境)組み込みエンジニアの見解としては断然②のほうが楽だと思われます笑
①でできた人がいたらそのファイルくださいね笑
- 投稿日:2019-07-30T13:02:50+09:00
【Rails】郵便番号をDBに保存 → 月毎にCSVの差分から更新する
はじめに
全国の郵便番号から住所テーブルに一括で保存し、月毎に更新するタスクを作ってみました。
しかし、郵便番号は約12万行ほどあり、更新する際にこれを総舐めするのは負荷がでかくて無駄が多いです。
これを解決すべく、月ごとの差分から更新するタスクも作ってみたので参考までに公開してみようと思います。やること
1. 郵便番号一覧のDBを作成
2. 郵便番号をダウンロード
3. CSVからDBに保存
4. CSVの差分から更新1. 郵便番号一覧のDBを作成
- 郵便番号(
zip_code)
- 都道府県(state)
- 市区町村(city)
- 番地(street)db.rbclass CreateAddresses < ActiveRecord::Migration[5.0] def change create_table :addresses do |t| t.column :zip_code, "CHAR(7)", null: false t.string :state, null: false t.string :city, null: false t.string :street t.timestamps end add_index :addresses, :zip_code, unique: true, name: "add_unique_index_zip_code" end end2. 郵便番号をダウンロード
郵便番号をダウンロードするタスクを作成します。
郵便番号はこちらからダウンロードが可能。
保存と更新の両方で使うのでモジュール化しておくと楽でしょう。lib/address_download.rbmodule JapanPost module AddressDownload def download_zipcode_file @download_url = "https://www.post.japanpost.jp/zipcode/dl/roman/ken_all_rome.zip" @download_path = Rails.root.join("lib", "tasks", "data", "tmp") download_zip_file unzip end def download_zip_file zip_file = open(@download_url) @zip_name = File.basename @download_url File.open(@download_path + @zip_name, "w") do |file| file.write zip_file.read.force_encoding("UTF-8") end end def unzip Zip::File.open(@download_path + @zip_name) do |zip| zip.each do |entry| @csv_name = "KEN_ALL_#{entry.time.strftime('%Y%m')}.CSV" zip.extract(entry, @download_path + @csv_name) { true } end end File.delete @download_path + @zip_name end end endざっくりと処理の流れ↓
1. zipファイルをダウンロード
2. 解凍してlib/tasks/data/tmp/配下に今月分のKEN_ALL.CSVを作る
3. zipファイルだけ削除解凍の参考記事: https://qiita.com/ogontaro/items/e11d10a460e127ad29d0
3. 郵便番号をDBに保存
lib/tasks/tmp/import_address.rakenamespace :tmp do desc "郵便番号をインポート" task import_address: :environment do include JapanPost::AddressDownload download_zipcode_file import_zipcode end private def import_zipcode addresses = [] CSV.open(@download_path + @csv_name, encoding: "Shift_JIS:UTF-8").each do |row| addresses << Address.new( zip_code: row[0], state: row[1], city: row[2], street: row[3].sub(/(.*|以下に掲載がない場合/, ""), ) end Address.import addresses end endCSVを読み込んでデータを流し込みます。
大通西(1~19丁目) → 大通西
以下に掲載がない場合 → ""
となるように、(より後ろ、以下に掲載がない場合は削除するようにしてます。このタスクを走らせると、
lib/tasks/data/tmp/配下に今月分のKEN_ALL.CSVが残ってるはずです。$ ls lib/tasks/data/tmp/ KEN_ALL_201906.CSV月毎の更新で、先月分の
KEN_ALL.CSVから差分を抽出する際必要になるので消さないようにしましょう。あとは更新するだけなので、このタスクは不要です。
tmpにしたのはこれが理由で、走らせたらは削除してもOK。4. CSVの差分からDBを更新する
lib/tasks/update_address.rakerequire "diff-lcs" namespace :address do desc "郵便番号を更新" task update: :environment do include JapanPost::AddressDownload download_zipcode_file update_zipcodes end private def update_zipcodes last_month_csv = CSV.read(@download_path + "KEN_ALL_#{Time.current.ago(1.month).strftime('%Y%m')}.CSV", encoding: "Shift_JIS:UTF-8") this_month_csv = CSV.read(@download_path + @csv_name, encoding: "Shift_JIS:UTF-8") diffs = Diff::LCS.diff(last_month_csv, this_month_csv) File.delete @download_path + "KEN_ALL_#{Time.current.ago(1.month).strftime('%Y%m')}.CSV" return if diffs.blank? addresses = [] diffs.flatten.select(&:adding?).each do |diff| row = diff.element address = Address.find_or_initialize_by(zip_code: row[0]) address.state = row[1] address.city = row[2] address.street = row[3].sub(/(.*|以下に掲載がない場合/, "") addresses << address end Address.import addresses, on_duplicate_key_update: [:state, :city, :street] end end先月分のCSV(
last_month_csv)と, 今月分のCSV(this_month_csvの差分を抽出して更新しています。
CSVの差分はこんな感じで求めることが可能。diffs = Diff::LCS.diff(変更前のCSV, 変更後のCSV)差分の中身はこんな感じです。
> diffs.flatten => [ ["-", 0, ["0600000", "hoge北海道", "札幌市 中央区", "以下に掲載がない場合", "HOKKAIDO", "SAPPORO SHI CHUO KU", "IKANIKEISAIGANAIBAAI"]], ["-", 1, ["0640941", "fuga北海道", "札幌市 中央区", "旭ケ丘", "HOKKAIDO", "SAPPORO SHI CHUO KU", "ASAHIGAOKA"]], ["+", 0, ["0600000", "北海道", "札幌市 中央区", "以下に掲載がない場合", "HOKKAIDO", "SAPPORO SHI CHUO KU", "IKANIKEISAIGANAIBAAI"]], ["+", 1, ["0640941", "北海道", "札幌市 中央区", "旭ケ丘", "HOKKAIDO", "SAPPORO SHI CHUO KU", "ASAHIGAOKA"]] ]そこから
adding?を使い、変更後のものに絞ればいいわけです。> diffs.flatten.select(&:adding?) => [ ["+", 0, ["0600000", "北海道", "札幌市 中央区", "以下に掲載がない場合", "HOKKAIDO", "SAPPORO SHI CHUO KU", "IKANIKEISAIGANAIBAAI"]], ["+", 1, ["0640941", "北海道", "札幌市 中央区", "旭ケ丘", "HOKKAIDO", "SAPPORO SHI CHUO KU", "ASAHIGAOKA"]] ]
diffの中身はelementで取り出します。> diff => ["+", 0, ["0600000", "北海道", "札幌市 中央区", "以下に掲載がない場合", "HOKKAIDO", "SAPPORO SHI CHUO KU", "IKANIKEISAIGANAIBAAI"]] > diff.element => ["0600000", "北海道", "札幌市 中央区", "以下に掲載がない場合", "HOKKAIDO", "SAPPORO SHI CHUO KU", "IKANIKEISAIGANAIBAAI"]adding?・・・変更後を取り出す
element・・・変更のシーケンスを取り出す参考: https://www.rubydoc.info/gems/diff-lcs/1.2.5/Diff/LCS/Change#adding%3F-instance_method
※[補足]
ここではじめて先月分のCSVを削除しますが、File.delete @download_path + "KEN_ALL_#{Time.current.ago(1.month).strftime('%Y%m')}.CSV"今月分のCSVは残すことを忘れてはいけません。
これはimportしたときと同様、来月更新するときに必要になるからです。$ ls lib/tasks/data/tmp/ KEN_ALL_201906.CSV ← 削除 KEN_ALL_201907.CSV ← 残す月毎走らせる
あとは更新タスクを毎月走らせてあげればOK。
config/schedule.rb# 郵便番号に変更があれば更新 # DL先: https://www.post.japanpost.jp/zipcode/dl/roman/ken_all_rome.zip every 1.month, at: "3:00pm" do rake "address:update" end注意点としては、先に
importを済ませてから走らせることです。そうでないと、先月分のCSVがなくて差分を抽出できないためです。文字化け対策とか(おまけ)
Encoding::UndefinedConversionError: "\xEC" from ASCII-8BIT to UTF-8
Zipファイルを読み込む際にこのようなエラーが出た場合、
force_encoding("UTF-8")をしてすれば解決しました。# 変更前 zip_file.read # 変更後 zip_file.read.force_encoding("UTF-8")参考: https://blog.tanebox.com/archives/452/
ArgumentError: invalid byte sequence in UTF-8
CSVを開くときにこのエラーが出た場合、以下のように修正しましょう。
#変更前 CSV.open("KEN_ALL.CSV") #変更後 CSV.open("KEN_ALL.CSV", encoding: 'Shift_JIS:UTF-8')CSVは
JISで読みこもうとするため、UTF-8に変換してあげる必要があります。
- 投稿日:2019-07-30T12:28:25+09:00
Image Failed to manipulate with MiniMagick, maybe it is not an image? Original Error: You must have ImageMagick or GraphicsMagick installed
railsで画像アプリを作成中にエラー
バリデーション
Image Failed to manipulate with MiniMagick, maybe it is not an image? Original Error: You must have ImageMagick or GraphicsMagick installed
ターミナル
解決策
$ brew install imagemagick
imagemagickがインストールされていなかったみたいです。インストール
できました〜〜〜
参考
https://qiita.com/Tommydevelop/items/756a7e3d7dd55d0a62a9告知
今、
進撃のITコミュニティで一緒に活動してくれる方を募集しています。
参加は無料です。
下に参加URLを貼ってます。
管理者はブロックチェーン実務経験あります。
参加資格はプログラマーからマーケター、AIやブロックチェーン、動画編集者やディレクター、youtuber、インスタグラマーも対象です。
進撃のIT Facebook
https://www.facebook.com/groups/612023275874253/
進撃のIT Slack
https://attack-on-it.herokuapp.com/
進撃のIT Twitter
https://twitter.com/IT13389135
進撃のIT Qiita記事
https://qiita.com/f___juntaro_/items/81136c85a8002cc442ac





- 投稿日:2019-07-30T11:57:33+09:00
Net::SMTPAuthenticationError: 451 Authentication failed: Could not authenticate
sendgrid - 451 Authentication failed: Could not authenticate - Stack Overflow
451
配信に失敗しました。多くの場合、送信側の問題ではなく、受信側のサーバエラーが原因で発生します。
例)
- 451 mta1012.mail.gq1.yahoo.com Resources temporarily unavailable. Please try again later [#4.16.1].
- 451 Temporary local problem – please try later
- 投稿日:2019-07-30T09:11:06+09:00
railsでの新規アプリケーション作成手順
rails 5.0
例:新規投稿と一覧表示ができる簡単なアプリ開発。1. アプリケーション作成 rails new
ターミナルrails new アプリケーション名 -d データベースの指定 $ rails new mini-app -d mysql $ bundle install gemの更新2. DB作成 rake db:create
ターミナルディレクトリに注意 $ rake db:create3. modelを作成
ターミナルpost model作成 $ rails g model post4. マイグレーションファイルにカラムを設定
qiita.rbclass CreatePosts < ActiveRecord::Migration[5.2] def change create_table :posts do |t| t.text :text end end end5. マイグレーションファイルの内容をテーブルに反映
ターミナル$ rake db:migrate作成したテーブルのカラムに仮データを入力
6. コントローラーを作成
ターミナル$ rails g controller posts7. コントローラーにアクションを指定
qiita.rb#一覧表示 def index @posts = Post.all end #新規投稿 def new @post = Post.new end #新規投稿の保存 def create @post = Post.create(text: post_params[:text]) redirect_to root_path controller: :posts, action: :index #保存後、一覧に戻る end private def post_params params.require(:post).permit(:text) end end8. コントローラーのアクションに対応するviewを作成
- view/posts/index.html.erb
- view/posts/new.html.erb
9. ルーティングファイルにコントローラーのアクションパスを指定
qiita.rbRails.application.routes.draw do resources :posts,only: [:index,:new,:create] end10. rails s でサーバー立ち上げ
ターミナル$ rails s localhost:にアクセス
- 投稿日:2019-07-30T07:47:53+09:00
【Rails】form_for 練習用に超簡単なミニアプリを作成する
はじめに
form_for系の練習のため、最小構成で登録系のアプリを作成。
後は個人で適当にカスタマイズ。仕様
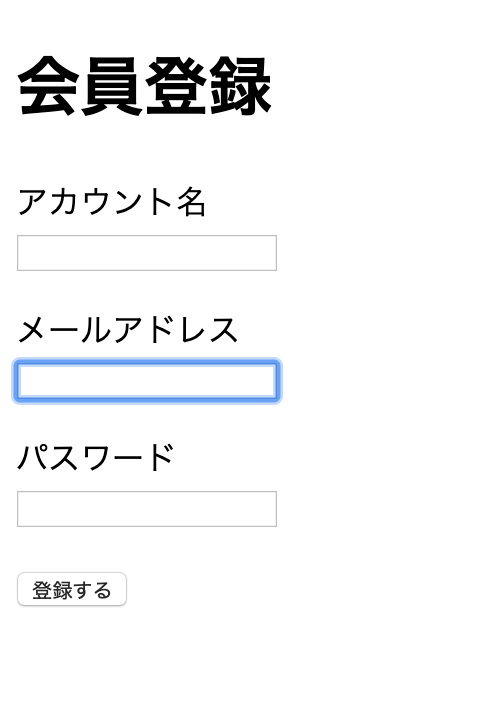
- viewは情報登録画面(/view/user/new.html.erb)のみを定義。
- アカウント名、メールアドレス、パスワードのみをuserTBLに登録するフォームを設置。
- 情報登録後は情報登録画面(/view/user/new.html.erb)にリダイレクトさせる。
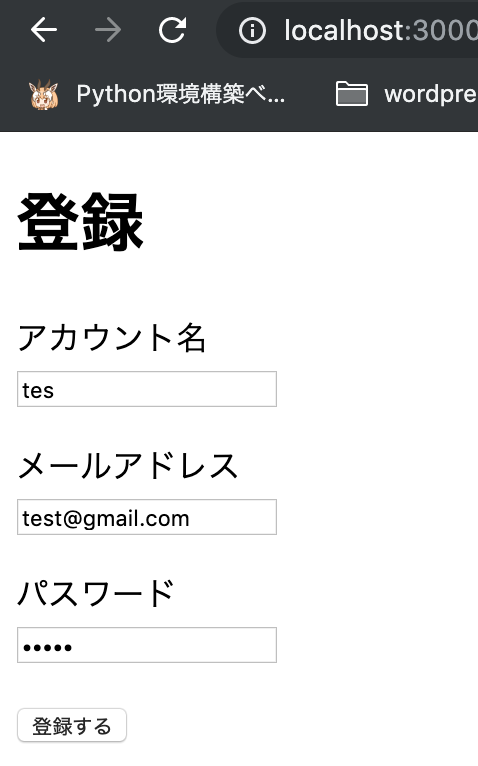
画面イメージ
ルーティングは以下のみ定義。
routes.rbRails.application.routes.draw do root 'users#new' resources :users, only: [:new, :create] enduserTBL
column 型 name string string password string 構築手順
アプリケーションをmysqlで作成
$ rails new rails_practice -d mysql -Tアプリケーションのディレクトリへ移動
$ cd rails_practiceDB作成
$ rake db:createusersコントローラ作成
$ rails g controller users以下の通り編集
users_controller.rbclass UsersController < ApplicationController class UsersController < ApplicationController def new @user = User.new end def create @user = User.new(user_params) @user.save redirect_to :root end private def user_params params.require(:user).permit(:name, :email, :password) end enduserモデル作成
$ rails g model userrails g model user コマンドで生成されたマイグレーションファイルを以下の通り編集
20190729115345_create_users.rbclass CreateUsers < ActiveRecord::Migration[5.2] def change create_table :users do |t| t.string :name t.string :email t.string :password t.timestamps end end endマイグレートコマンドを実行
$ rails db:migrate以下の通りなればOK
ビュー作成
view/users/new.html.erb<head> <meta charset="utf-8"> </head> <h1> 会員登録 </h1> <body> <%= form_for(@user, url: users_path, method: :post) do |f| %> <p> <%= f.label :name, "アカウント名" %><br> <%= f.text_field :name %> </p> <p> <%= f.label :email, "メールアドレス" %><br> <%= f.email_field :email %> </p> <p> <%= f.label :password, "パスワード" %><br> <%= f.password_field :password %> </p> <%= f.submit "登録する"%> <% end %> </body>ルーティング設定
routes.rbRails.application.routes.draw do root 'users#new' resources :users, only: [:new, :create] end動作確認
入力
DBへの登録を確認
DBへの登録後、リダイレクト
以上

- 投稿日:2019-07-30T04:24:55+09:00
rails カラムの値 一斉変更
1日1回回答できるクイズの残回答数を24時にリセットするバッチにて用いた
app/models/quiz.rbclass Quiz < ActiveRecord::Base def self.reset_quota QuizUserStatus.all.update_all(quota: 1) end endなお、条件次第で残1以上になるため今回はこのような実装にした
以上。
- 投稿日:2019-07-30T04:07:45+09:00
ruby match 正規表現、大文字小文字区別しない
以下AndroidであればPlayStore、iosであればAppStoreにリダイレクトさせるロジックの一部
if ua.match(/android/i) != nil redirect_to "https://play.google.com/store/apps/details?id=hoge" elsif ua.match(/ios/i) != nil || ua.match(/iphone/i) != nil || ua.match(/ipad/i) != nil redirect_to "https://itunes.apple.com/th/app/fuga" end
- 投稿日:2019-07-30T03:54:34+09:00
mysql 重複なし 結合して出現回数でソート
SELECT message, COUNT(*) AS COUNT FROM chats GROUP BY message ORDER BY COUNT DESC条件指定する場合
SELECT message, COUNT(*) AS COUNT FROM chats where created_at BETWEEN ('2018-12-01 00:00:00') AND ('2018-12-31 00:00:00') GROUP BY message ORDER BY COUNT DESC余談:RailsのActiveRecordでやる場合
# ActiveRecord Chat.select(:message,:created_at) .where(created_at: '2018-12-01'..'2018-12-31') .order('count_message desc') .group(:message) .count(:message)結合して重複なしソート
SELECT user_status_id,SUM(score),facebook_id,fullname,phone,address FROM results INNER JOIN user_vote_product_profiles ON results.user_status_id = user_vote_product_profiles.id GROUP BY user_status_id ORDER BY SUM(score) DESC;そっからランダム抽出
SELECT user_status_id,SUM(score),facebook_id,fullname,phone,address FROM results INNER JOIN user_vote_product_profiles ON results.user_status_id = user_vote_product_profiles.id GROUP BY user_status_id HAVING SUM(score) >= 100 ORDER BY RAND() LIMIT 9;今回はクイズアプリの成績上位者からランダムで景品の当選者を選抜するのにこれらSQLを使った
以上。
- 投稿日:2019-07-30T03:54:34+09:00
mysql 重複なし 出現回数でソート
SELECT message, COUNT(*) AS COUNT FROM chats GROUP BY message ORDER BY COUNT DESC条件指定する場合
SELECT message, COUNT(*) AS COUNT FROM chats where created_at BETWEEN ('2018-12-01 00:00:00') AND ('2018-12-31 00:00:00') GROUP BY message ORDER BY COUNT DESC余談:RailsのActiveRecordでやる場合
# ActiveRecord Chat.select(:message,:created_at) .where(created_at: '2018-12-01'..'2018-12-31') .order('count_message desc') .group(:message) .count(:message)結合して重複なしソート
SELECT user_status_id,SUM(score),facebook_id,fullname,phone,address FROM results INNER JOIN user_vote_product_profiles ON results.user_status_id = user_vote_product_profiles.id GROUP BY user_status_id ORDER BY SUM(score) DESC;そっからランダム抽出
SELECT user_status_id,SUM(score),facebook_id,fullname,phone,address FROM results INNER JOIN user_vote_product_profiles ON results.user_status_id = user_vote_product_profiles.id GROUP BY user_status_id HAVING SUM(score) >= 100 ORDER BY RAND() LIMIT 9;今回はクイズアプリの成績上位者からランダムで景品の当選者を取得するのにこれらSQLを使った
以上。
- 投稿日:2019-07-30T01:27:43+09:00
railsでパーシャルに引数が渡らないときはcocoonが関係しているかも
パーシャルに引数が渡らない
※ cocoonを使用している場合しか以下は参考になりません。
例えば以下のような構成だとします。
必要最低限しか書いていません。
- パーシャル呼び出し側
.cocoon-container = f.fields_for :form_items do |form_item| = render 'partial', f: form_item, partial_arg: 'パーシャルに渡す引数' .add_button = link_to_add_association '追加ボタン', f, :form_items,
- パーシャル
.nested-fields .field = link_to_remove_association '削除ボタン', f / ここら辺で partial_arg を参照するとなぜか undefined local value になるなぜかパーシャルで
partial_argを参照するとundefinedになります。解決方法
パーシャル呼び出し側の追加ボタンにオプションを足してあげるといけます!
.cocoon-container = f.fields_for :form_items do |form_item| = render 'partial', f: form_item .add_button = link_to_add_association '追加ボタン', f, :form_items, render_options: {locals: { partial_arg: 'パーシャルに渡す引数' }}
render_options: {locals: { partial_arg: 'パーシャルに渡す引数' }}のところです!
もちろん、partial_argは好きな名前で大丈夫です!以上!
- 投稿日:2019-07-30T00:50:46+09:00
Capistranoで、EC2+S3への自動デプロイで起きたエラー集と基礎用語
はじめに
メルカリクローンアプリの作成でグループ開発でデプロイを担当しました。
今回はほぼ前提知識ない中、疑問に思った用語とエラーの解決へのプロセス、そして今回意識した事を備忘録とチームメンバーとの共有資料として記載しておきます。環境
Ruby → 2.5.1
Rails → 5.2.3
Capistrano → 3.11.0
carrierwave用語
用語の説明ですが、100%正しい知識ではないかも知れないです。と言うのも、もっと深い知識を知るともっと差別化しないと状況がごちゃごちゃになると思いますが、今回は小規模での開発だったので最低限の知識で乗り切りました。
私は今後必要になったら、詳細について調べていくつもりです。もっと詳細に知りたい人は随時調べてみてください。●ssh
EC2に入るとき使っている下記のコマンド
$ ssh -i キーの名前.pem ec2-user@00.000.0.00Secure Shellの略。リモートコンピュータと通信するためのプロトコルです。
ざっくり鍵を使って暗号化と復号で認証作業をしています。
さらっとやったchomd600は読み込み、書き込み権限の付与をしています。●sudo
スーパーユーザーでdoする。スーパーユーザーとはrootの事です。
rootユーザーは権限が強過ぎるのでコマンド単位だけその力を使おうと言うコマンド。●mysqld
dはデーモンの略です。mysqldはmysqlからデータを持ってきたりしてくれるものと言う認識です。
デーモンは常に待機状態でいるプログラムです。●nginx
webサーバーの一つ。webサーバーとはリクエストを受け取り、レスポンスを返す役割を請け負っています。
nginxの特徴が気になる人は別途調べてみてください。●tail
logを見るときに使用。最後の10行が表示される。-fのオプションを使用する事でログを垂れ流しに出来る。
個人的には、あまり使いませんでした。●cat
ファイルの中身を見る事が出来る。logやエラーが起きた箇所の本番環境での記述を見るために使った。-nオプションで行数を表示出来るので見やすい.
●RAILS_ENV
動作環境を指定したい時に使用。環境がどうこうのエラーが出た時に確認したり、場合によっては環境を指定してあげないとエラーが出る事があったので使った。
エラーへの対処
まず最初に特に何もしていない部分のエラーが起きた時は、EC2インスタンスの停止→起動をするのが得策です。
無料枠を使っているせいなのか、期待通りの動きをしてくれない事があるらしいです。(真偽は確認していませんが、何日か空けて自動デプロイしようとすると大体エラーが出ていました。仕様と諦めていたので、わかる方教えてください)
なので、心辺りのないエラーや自動デプロイが止まる時は再起動をしてみて、それでも起こるならエラーに対処をしてくのが時間効率がいいと思います。
では、私がハマったり頻度の高かったエラーを書いていきます。Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)
(2)の場合はsocketがないので
$ touch mysql.sockで、解決出来ると思います。ないなら作ってやる、それだけです。ここから発展して(38)に変わる事があるようですが、それは私は出会わなかったので、割愛します。
Can't connect to local MySQL server through socket '/tmp/mysql.sock' (111)
検索してみると、権限がない事に起因するエラーの様ですが、私の場合には当てはまりませんでした。mysqlにアクセス出来ない旨のエラーなのでひとまず
$ mysql -u root -pでひとまずルートに入る事が出来るが確認してみる→出来なかったら検索
入れたらsocketの指定をしているファイル(database.yml)の設定を見る
それも合っていたら、環境変数を指定してみる$ rake db:migrate RAILS_ENV=production私はこれで解決しました。
他にも、mysql.sockが消えていない為、新しいmysql.sockが生成出来ず起動できないみたいな事もある様です。
この辺の解決策は他の方の記事を参考に出来ると思うのでそちらを見てみてください。credentials.yml.enc
ここは一番苦労しました。ただ参考資料が沢山のあるので、状況を整理しながらやっていけば問題なく出来ると思います。
チーム開発で起こっていたミスとしては。
・master→rails newした人とデプロイ担当が違う為、master.keyが複数ある環境で開発を進めていた
・APIkeyを書く人が、自分のmaster.keyで新しいcredentials.ymlを作ってしまったファイルをmargeして本番環境で開けなくなった
などです。
暗号化されている為コンフリクトが起きた時にわかりにくいので、一度丁寧に確認するのが良いと思います。
今回のチーム開発では初期段階でmaster.keyの共有をして、使わないkeyは消してしまうのが得策と思います。以下、大変参考になった記事です。
https://qiita.com/NaokiIshimura/items/2a179f2ab910992c4d39
https://qiita.com/yuuuking/items/53a37a2e998972be32b8まとめ
チーム共有がメインの記事なので、分かりにくいところもあると思いますが、デプロイ担当で思ったことは、どの環境で、どのコマンドを、何に対してやったのかをわかった上で作業を進めるのが大切だと思いました(当たり前ですが)。
自分でも良くわからない状況で、適当にコマンドを叩いていると周りもフォローしにくくなりますし、泥沼にハマる確率が高くなります(体験談)。
頑張れ!デプロイ担当!
※口頭説明しながら前提で作ったのと、知識不足で憶測や間違った解釈を書いている可能性が高いので後日書き足すか、限定公開にする予定です。
- 投稿日:2019-07-30T00:07:55+09:00
VimmerがRuby on Railsを書くときに使えるVimプラグイン集 2019
vimでRuby on Railsを書くときに重宝するプラグインを紹介します。
- NERDTree ファイルツリー
- vim-rails ファイル移動、Railsコマンド実行
- fzf.vim インクリメンタル検索
- vim-endwise
ifやdefなどのend補完- coc.nvim 補完
- ale 静的解析
設定例として、自分の
.vimrcに書いている設定を載せてます。NERDTree
scrooloose/nerdtree
ファイルツリー機能が使えます。ド定番です。
参考
vim-plugin NERDTree で開発効率をアップする! @zwirkyvim-rails
tpope/vim-rails
railsプロジェクト内のシームレスな移動や、vimからのrailsコマンドの実行が出来るようになります。
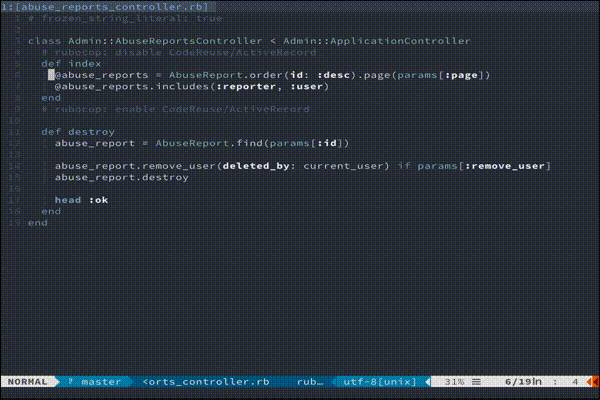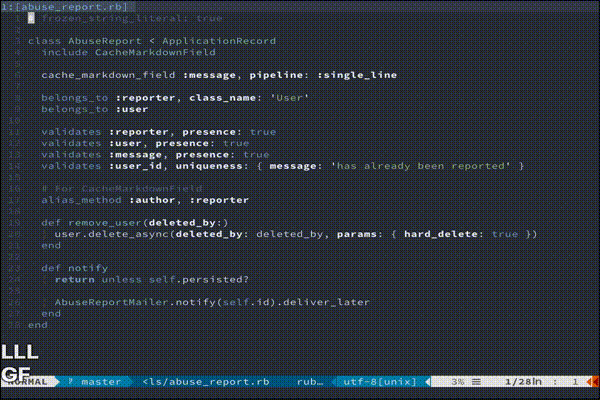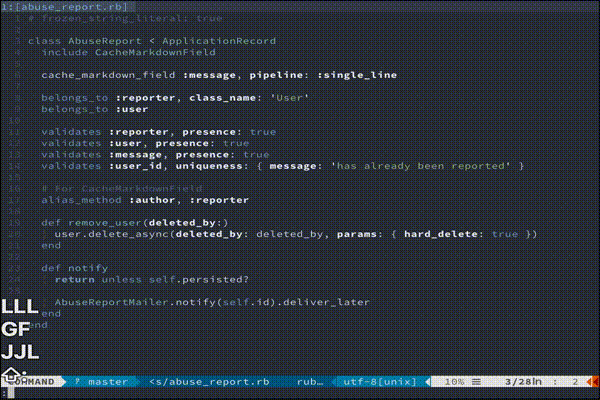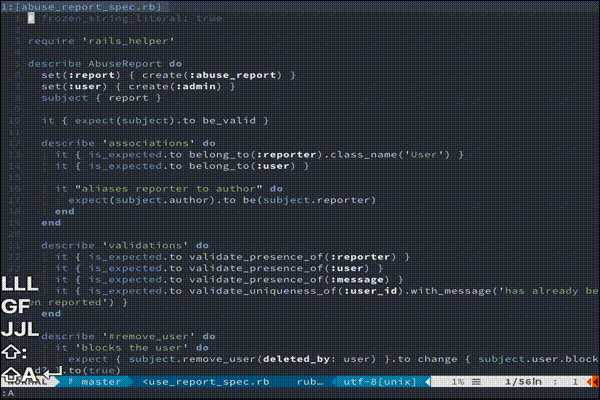
GIFでは例として、
gfでカーソル下の文字列から該当するファイルを開き、:Aで対応するspecファイルを開いています。参考
vim-rails よく使いそうなやつ @bibiofzf.vim
junegunn/fzf.vim
Go言語製の fzf と呼ばれるコマンドラインツールを使用したプラグインで、プロジェクト内のファイル名や、ソースコードの文字列あいまい検索ができます。
.vimrclet g:fzf_action = { \ 'ctrl-s': 'split' } nnoremap <C-p> :FZFFileList<CR> command! FZFFileList call fzf#run(fzf#wrap({ \ 'source': 'find . -type d -name .git -prune -o ! -name .DS_Store', \ 'down': '40%'})) nnoremap <C-b> :Buffers<CR> nnoremap <C-g> :Ag<CR> nnoremap <silent> <C-]> :call fzf#vim#tags(expand('<cword>'))<CR> let g:fzf_buffers_jump = 1 command! -bang -nargs=? -complete=dir Files \ call fzf#vim#files(<q-args>, fzf#vim#with_preview(), <bang>0)
GIFでは
ctrl+pでファイル名検索、ctrl+bでバッファー検索をしています。
ctagsとの連携なんかもできちゃいます。
fzf.vimはプラグイン本体に加えてfzfそのもののインストールも必要になりますが、
fzfはvim抜きにしてもコマンドラインツールとしてとても優秀なのでオススメです。参考
fzfとvimで少ない労力で作業効率を引き上げた話 @Sa2Knight
さいつよのターミナル環境を構築しよう @b4b4r07ファイル検索プラグインの別の選択肢としてdenite.nvim(unite.vimのつよいやつ)というプラグインがあります。
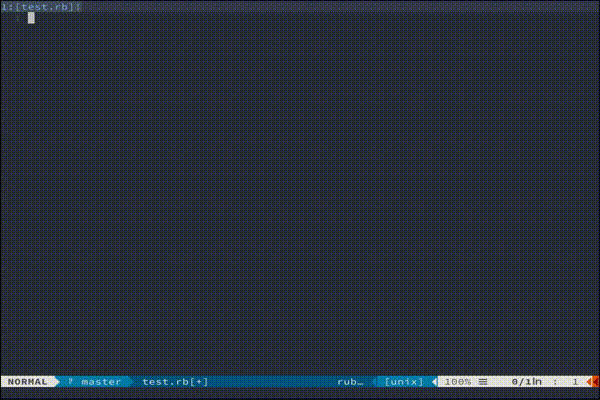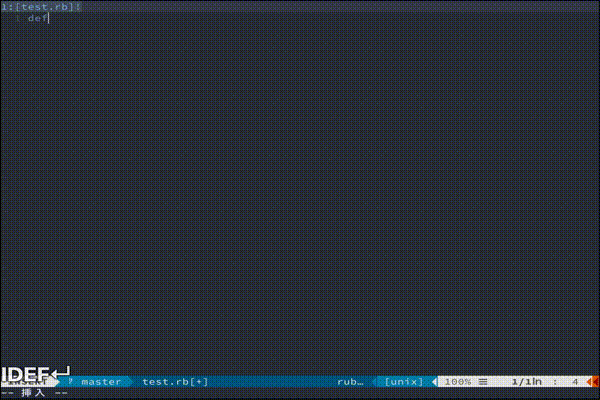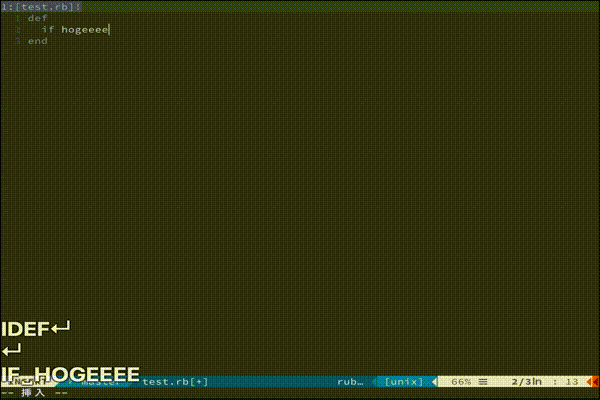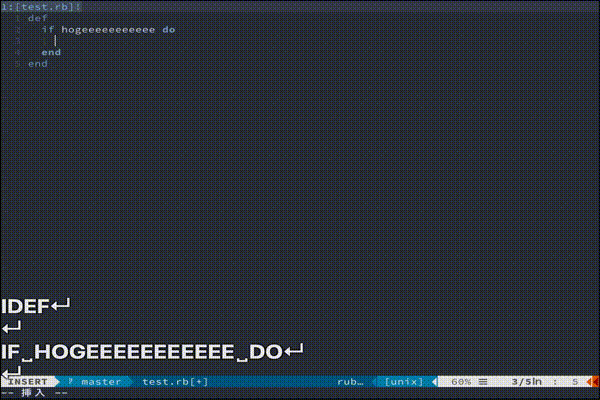
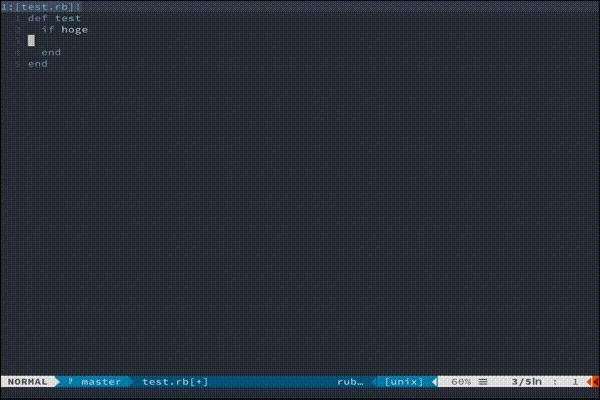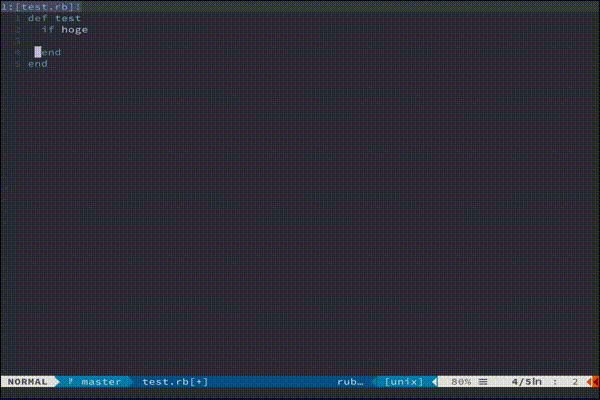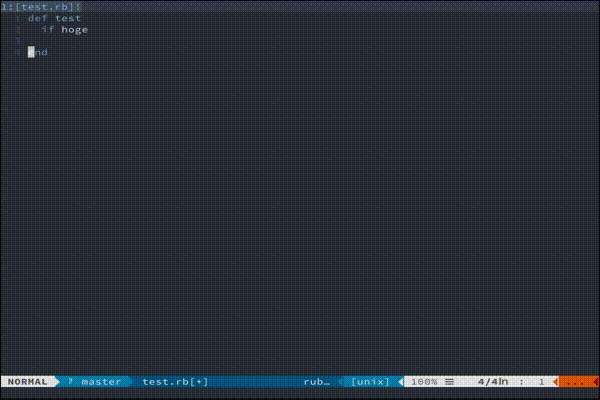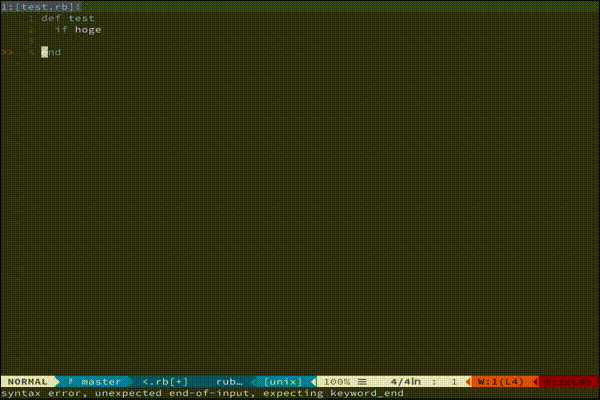
もっと複雑な処理を走らせたい方におすすめです。(あんまりわかってない)vim-endwise
tpope/vim-endwise
def...endや、if...endなどの対応するキーワードを自動補完してくれます。
地味にきいてくる便利さです。
coc.nvim
neoclide/coc.nvim
coc.nvimはTypeScript製の補間プラグインです。LanguageServerProtocol(以下LSP)と呼ばれる、コーディング支援用のプロトコルが使用可能で、強力な補完機能が使えます。
rubyの場合、 solargraphと呼ばれるLSPのgemを使用します。
coc.nvimは、 独自の設定ファイルとして.vim/coc-settings.jsonを使用します。coc-settings.json{ "suggest.enablePreselect": true, "solargraph.commandPath": "solargraphの絶対パス" }.vimrclet g:coc_global_extensions = ['coc-solargraph'] inoremap <silent><expr> <TAB> \ pumvisible() ? "\<C-n>" : \ <SID>check_back_space() ? "\<TAB>" : \ coc#refresh() inoremap <expr><S-TAB> pumvisible() ? "\<C-p>" : "\<C-h>" function! s:check_back_space() abort let col = col('.') - 1 return !col || getline('.')[col - 1] =~# '\s' endfunction
右に[LS]と表記されている単語が、LSPによる補完候補です。
めっちゃ出ます。参考
LanguageServerProtocol(LSP)のススメ @himanoa
neovim + coc.nvim で LSP 藻ログ
coc.nvimの他にも、asyncomplete + vim-lsp や、 deoplete + LanguageClient-neovim の組み合わせでもLSPの補完が使えます。ale
w0rp/ale
gemのrubocop構文エラーを自動で非同期静的解析してくれるツールです。.vimrclet g:ale_fixers = { \ 'ruby': ['rubocop'], \ }
if...endのendを消すと構文エラーを指摘してくれます。言語ごとにfix, lintツールを指定すると
ruby以外でも大活躍してくれます。参考
neovim + ?ale + ?rubocop hoshinotsuyoshi.comまとめ
他にも良いプラグインがあれば教えてください
それではよい vim, rails ライフを…