- 投稿日:2019-07-30T23:50:41+09:00
AmplifyでAuthしてみるときに詰まったこと
概要
基本的には このサイト を参考にさせていただいてほとんど完結しました。
しかし、詰まるところもあったので、その部分について書きます。詰まったこと
aws-amplify-reactが読み込めない
エラー発生箇所
import { Authenticator } from 'aws-amplify-react'発生したエラー
Could not find a declaration file for module 'aws-amplify-react'. '<path>' implicitly has an 'any' type. Try `npm install @types/aws-amplify-react` if it exists or add a new declaration (.d.ts) file containing `declare module 'aws-amplify-react';`ts(7016)参考にさせていただいたサイトでも同様のエラーが出たことが報告されていて、その解決法が書かれていたのですが、その解決法では解決しませんでした。
そこで、ググりました。
この GitHubのページ によると
aws-amplify-reactの型が定義されていないために起こるエラーであるそうです。.d.tsファイルに
declare module 'aws-amplify-react'を追加するとエラーが消えました。ググってから気づきましたが、解決方法がエラーメッセージに出てましたね。
エラーメッセージをちゃんと読まずにGoogle検索しがちなのは良くない癖ですね。まとめ
このエラーは型が定義されていないときに起こるエラーであり、型の定義が見つからない時は、エラーメッセージに出てる通り
npm install @type/hogeで型の定義を追加できればそれでよく、できない場合は今回のように自分で追加すれば解決できるようです。
- 投稿日:2019-07-30T20:27:50+09:00
ホスティングサービスを比較してみた
はじめに
ウェブサイト・ウェブサービスを公開するには、自分でサーバーを用意するかホスティングサービスを利用しなくてはいけません。
よほどの理由がない限り自分でサーバーを用意するのではなくホスティングサービスを利用する人が多いと思います。
しかし近年ではホスティングサービスの特徴が多種多様になっており選定基準も複雑になりました。
そこで本記事では、有名どころのサービスを比較して紹介することで皆様の選定の助けになればと思います。なるべく主観的にならないように気をつけていますが
一部は、筆者の実体験に基づくものもあるのでご承知ください。GitHub Pages
無料で使える静的サイトのホスティングサービスです。
要件を満たすならば第一に検討してもよいかもしれません。メリット
- 無料で独自ドメインを設定できる。
- ブランチへのプッシュするだけで公開される。
デメリット
- 動的なサイトには対応してない。
Netlify
少ないステップで静的サイトを公開できるホスティングサービスです。
GitHub Pagesでは要件を満たせない場合に検討してみるとよさそうです。メリット
- 無料で使える機能が多い。独自ドメインも無料です。
- 継続的インテグレーションに標準で対応している。
- フォーム機能など、部分的に動的な機能を使える。
- サーバーレス関数を使える。(AWS Lambdaのようなもの)
デメリット
- Netlify固有機能を使わないと動的なサイトは構築できない。
Heroku
多くのプログラミング言語に対応したPaaSです。
動的なウェブサービスを立ち上げたいときに手軽です。類似サービスとして、AppHarborという.NETに特化したサービスもあります。
メリット
- VCSとの連携機能が豊富。
- 拡張機能が豊富。
デメリット
- 東京リージョン(2019/07/30時点)に対応していない。
- 無料だと550時間/月までしか使えない。超えるとスリープされる。
AWS
Amazonが提供するクラウドサービスです。
メリット
- プライベートクラウドやネットワークの設定レベルで多様な構成をカスタマイズできる。
デメリット
- 多様な種類を揃えているため、サービスの選定及び設計ノウハウが必要。
Microsoft Azure
Microsoftが提供するクラウドサービスです。
メリット
- Visual Studioとの親和性が高い。
- サポートも充実
デメリット
- AWSと比較すると料金が高くなりやすい。
GCP
Googleが提供するクラウドサービスです。
メリット
- Googleが提供する幅広いサービスと同等のインフラを活用したクラウドサービスを利用できる。
- 膨大なビッグデータを高速で処理できる。
- 機械学習の技術において、リードしている。
デメリット
- リージョンや日本語情報が少ない。
- 日本語訳が準備されていない。
Vultr
コストパフォーマンスに優れたVPSです。
メリット
- UIがシンプルで使いやすい。
- 日本ロケーションのサーバーも選択できる。
デメリット
- 日本語に対応していない。
さくらのVPS
日本での知名度が高くコストパフォーマンスに優れたVPSです。
英語に抵抗がなければ、さくらのVPSより、前述のVultrがおすすめです。メリット
- ディスクをSSD、HDDから選べる点や、目的に合わせて選ぶことができる。
- 機能面と料金でコストパフォーマンスに優れている。
- 日本リージョンが多い。
デメリット
- 料金が安いが、サーバースペックが他社より劣っている。
- CPUやメモリ容量を見ると、若干スペックが低い。
- 障害が多い。
まとめ
なるべく上から順番に、要件に照らしあわせて選定できるように並べました。
クラウドサービス系は、大規模なウェブサービスや学習には向いていますが、
小規模であればクラウドサービスを使う必要はないかもしれません。またGMO系サービス(ロリポップ、お名前サーバー etc)は、本記事では紹介しませんでしたが、
全体的におすすめしません。初年度の見せかけの安さにつられて使う人が多いと思いますが
使い勝手が悪くサポートも異常に悪いです。ほとんどサポートがBOTで運用されているのではないかと疑うレベルです。
- 投稿日:2019-07-30T19:31:06+09:00
AWS上でphpをrpmでインストールする時のrequireメッセージに注意
Error: Package: php-mysql-5.3.3-49.el6.x86_64 (/php-mysql-5.3.3-49.el6.x86_64) Requires: php-common(x86-64) = 5.3.3-49.el6 Removing: php-common-5.3.3-49.el6.x86_64 (installed)とか言ってるくせに、本当にいるのはphp-pdoと言うこの詐欺メッセージ。だって、既にこのcommonは入れてるから。
php-pdoとは
php-data-objectのことで、データベースの文字列をphpの扱うオブジェクトデータに変換するものです。これを引っ張ってきてください。
- 投稿日:2019-07-30T16:13:21+09:00
Lambdaでsoxを使用して音声を左右のチャンネルに分割する
AmazonConnectの録音ファイルが顧客とエージェントで左右のチャンネルに分割されている為、それを分割しようとした時のメモです。
Q: エージェントと顧客の音声は別々のステレオ音声チャネルに保存されるのですか?
はい。エージェントの音声は右チャネルに保存されます。エンドカスタマーやカンファレンスに参加した人など、すべての着信音声は左チャネルに保存されます。
AWSより引用ハマった事
lambdaのランタイムを
nodejs10.xで検証していたのですが、soxが動作しませんでした。解決策
lambdaでsoxを動作させたい場合は、
nodejs8.10をランタイムに設定しましょう。分割していく
AmazonConnectからS3に通話音声ファイル(.wav)が格納された際にLambdaが実行される前提となっています。
soxを使うために
lambda-audioをインストール。npm i lambda-audiotypescriptで書いてます。
import {Handler} from 'aws-lambda'; import {S3} from "aws-sdk"; class S3Service { constructor(private s3: S3) { } async get(bucketName, key) { const params = { Bucket: bucketName, Key: key }; return await this.s3.getObject(params).promise(); } async put(bucketName, key, body) { const params = { Bucket: bucketName, Key: key, Body: body, }; return await this.s3.putObject(params).promise(); } } export const handler: Handler = async (event: any) => { const s3 = new S3Service(new S3()); const fs = require('fs'); const lambdaAudio = require('lambda-audio'); const nowTime = (new Date()).getTime(); const wavPath = '/tmp/' + nowTime + '.wav'; // S3に格納された.wavの情報を取得する for (let record of event.Records) { const key = record.s3.object.key; const bucketName = record.s3.bucket.name; const object = await s3.get(bucketName, decodeURIComponent(key)); await fs.writeFile(wavPath, object.Body, 'binary', err => { if (err) { console.error(err); return; } }); } // ここで左のチャンネルを抽出している const leftOutput = `/tmp/${nowTime}_output_l.wav`; await lambdaAudio.sox([wavPath, leftOutput, 'remix', '1']) .then(response => { console.log(`soxLeft: ${response}`); }) .catch(errorResponse => { console.log('Error from the sox command:', errorResponse) }); // ここで右のチャンネルを抽出している const rightOutput = `/tmp/${nowTime}_output_r.wav`; await lambdaAudio.sox([wavPath, rightOutput, 'remix', '2']) .then(response => { console.log(`soxRight: ${response}`); }) .catch(errorResponse => { console.log('Error from the sox command:', errorResponse) }); // S3へ格納(※1) await s3.put('BUCKET_NAME', `${nowTime}/l.wav`, fs.readFileSync(leftOutput)); await s3.put('BUCKET_NAME', `${nowTime}/r.wav`, fs.readFileSync(rightOutput)); return {} };※1
'BUCKET_NAME'に保存先となるS3を指定まとめ
顧客、エージェントの音声を分割することにより、文字起こし等に使用する際に便利になると思います。
ファイルサイズが2倍になるため、利用料金は2倍になりますが、、、
- 投稿日:2019-07-30T16:04:44+09:00
Amazon Workspace(Linux)から、RemminaでWindowsにリモートデスクトップ接続(RDP)
AWSのWorkspaces(Linux)から、WindowsにRDP接続したいと相談した所、Remminaがイケテルという事だったので、試して見ました。
以下、Remminaのインストール手順です(yum repoよく分かってないので、冗長かも知れませんが、覚書的にメモメモ)
環境
- AWS Workspaces(Amazon Linux2)
- Remmina(+RDPプラグイン)
接続先は、EC2(Windows Server 2016)で試しました。
インストール
まず、EPELを入れます。
wget https://dl.fedoraproject.org/pub/epel/7/x86_64/Packages/e/epel-release-7-11.noarch.rpm sudo rpm -ivh epel-release-7-11.noarch.rpmNUX REPOをインストールします。
sudo rpm --import http://li.nux.ro/download/nux/RPM-GPG-KEY-nux.ro sudo yum -y install epel-release sudo rpm -Uvh http://li.nux.ro/download/nux/dextop/el7/x86_64/nux-dextop-release-0-5.el7.nux.noarch.rpmEPELとNUXがリポとして追加されている事を確認します。
$ yum repolist .. .. .. epel/x86_64 Extra Packages for Enterprise L 13,040+288 nux-dextop/x86_64 Nux.Ro RPMs for general desktop 2,658+44で、remmina(とRDPプラグイン)を、yumでインストール。
sudo yum --enablerepo=nux-dextop install remmina remmina-plugins-rdp使い方
メニューのどこかに「Remmina Remote Desktop Client」があるので、それで起動。
接続名、接続先情報(SERVER, USER, PASSWORD)を入れて、接続出来ればOK。
参考URL
- EPELの設定方法
- NUX REPOの設定方法
- remminaのインストール手順の説明
- 投稿日:2019-07-30T15:42:57+09:00
ArgumentError: Missing required arguments: aws_access_key_id, aws_secret_access_key
awsのs3を導入して、capistranoを使っていた時エラーが出ました。
(unicorn,nginx使用)
どうやら、keyが見当たりませんと出たので、確認しに行った。でも、環境変数はちゃんと登録されていたし、なぜだろうと思った。
原因は、unicornの設定fileのpathが間違っていた。
working_directoryあたり。
ちゃんと、pathがcurrentになっていますか?pathがcapi使った時にcurrentになるので、ちゃんとcurrent指定をしてあげましょう。
また、working_directoryが二重になっていないかなども確認するといいかもです。
- 投稿日:2019-07-30T15:34:01+09:00
Hyperledger Iroha v1.0 環境構築
概要
AWS EC2 (Amazon Linux AMI) にHyperledger Irohaの環境構築を行う
環境
- AWS EC2 (Amazon Linux AMI)
- Git
Docs
Hyperledger Irohaドキュメンテーション
https://iroha.readthedocs.io/ja/latest/index.html環境構築手順
Docker インストール & 起動
# インストール $ sudo yum install -y docker # 起動 $ sudo service docker start # dockerグループにec2-userを追加 $ sudo usermod -a -G docker ec2-user $ cat /etc/group | grep docker # 一度リモートからログアウトして、再度ログイン $ exit # dockerが追加されていることを確認 $ docker info | grep dockerDocker Compose インストール
# docker-compose インストール $ sudo curl -L "https://github.com/docker/compose/releases/download/1.23.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose # 権限設定 $ sudo chmod +x /usr/local/bin/docker-composeDocker 操作
# Docker ネットワークを作成 $ docker network create iroha-network # PostgreSQLのコンテナを起動 $ docker run --name some-postgres \ -e POSTGRES_USER=postgres \ -e POSTGRES_PASSWORD=mysecretpassword \ -p 500:500 \ --network=iroha-network \ -d postgres:9.5 # Blockstoreを作成 $ docker volume create blockstore # 設定ファイルの準備 $ git clone -b develop https://github.com/hyperledger/iroha --depth=1 # Irohaコンテナを起動 & ログイン $ docker run -it --name iroha \ -p 50051:50051 \ -v $(pwd)/iroha/example:/opt/iroha_data \ -v blockstore:/tmp/block_store \ --network=iroha-network \ --entrypoint=/bin/bash \ hyperledger/iroha:developIroha 起動(コンテナ内で操作)
# Irohaデーモン(バックグラウンドで動作するプロセス)起動 $ irohad --config config.docker --genesis_block genesis.block --keypair_name node0これでIrohaが起動されます。
- 投稿日:2019-07-30T13:28:56+09:00
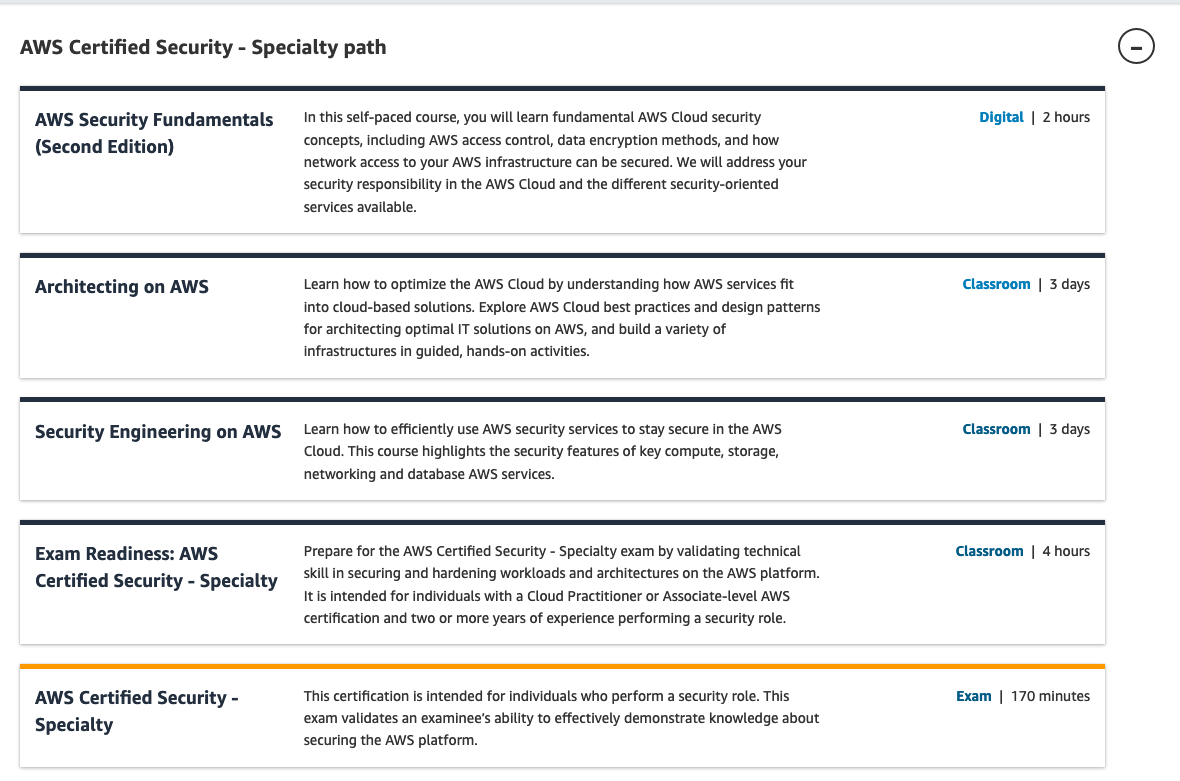
AWSのセキュリティエンジニアの認定試験
AWS認定セキュリティ専門知識の試験を受けようと思うので、その概要メモ
概要
AWS プラットフォームのセキュリティ強化における技術的な専門知識を認定します。経験豊かなセキュリティ担当者が対象です。
オフィシャルな情報は下記にまとまっている。
AWS 認定セキュリティ – 専門知識 | AWS
Learning Path - Specialty
AWS Security Documentation
AWS Security Blog必要知識
- AWS ワークロードの保護に関する最低 2 年間の実践経験
- AWS でのワークロードのセキュリティコントロール
- IT セキュリティ分野でセキュリティソリューションの設計と実装に従事した最低 5 年間の経験
試験の注意点
- 選択式(択一回答・複数回答)
- 未回答の問題は不正解扱い
- 統計調査用の問題が混じっている(採点されないし、試験の合否に影響しない)
- 750/1000点で合格
試験内容
- インシデント対応
- アクセスキー漏洩、インスタンス乗っ取りなど
- インシデント対応計画に必要なAWSサービス
- 自動アラートなど
- ログと監視
- 設計、実装、トラブルシューティング
- おそらくCloudTrail/CloudWatch/WAF/Configなどのログが出る
- S3でのログの保管の仕方、分析の仕方なども出そう?
- インフラストラクチャのセキュリティ
- AWSのエッジセキュリティ(よくわからない)
- セキュアなネットワークインフラストラクチャ
- VPCのアクセス制御など
- ホストベースのセキュリティ
- IDおよびアクセス管理
- IAM全般
- データ保護
- キーの管理
- KMS全般
- その他S3,HSMなども出るか?
出そうなサービス
- CloudWatch
- CloudTrail
- Config
- Cognito
- KMS
- Lambda
- APIGateway
- IAM
- VPC全般
- WAF
下記は比較的新しいサービスなので出題されるかどうか不明なもの
- GuardDuty
- Macie
- SecurityHub
- ControllTower
気をつけること
- 各サービス間の連携を図で描けるように勉強する
- サーバレスのセキュリティを重点的に
- S3でコンテンツを配信していて、サーバレスでどうやって認証するか?
- ”コストを考慮する”と言う条件が出てきそうなので、各サービスの料金も見ておく
- Blogを眺め読みする

- 投稿日:2019-07-30T12:44:39+09:00
AWS Lambdaのランタイムサポート
AWS LambdaのランタイムサポートはランタイムのEOLと同時に新規作成ができなくなり、その後1~2ヵ月で更新もできなくなる。
Node.jsはメジャーバージョンアップが1年ごとで、EOLもリリースから2年半と短いため、頻繁なEOL対応が必要となる。(Pythonはリリースから5年間サポートされる。)
ランタイム LTS開始 EOL 廃止 (作成) 廃止 (更新) Python 2.7 2010/07/03 2020/01/01 (未定) (未定) Python 3.5 2015/09/13 2020/09/13 (サポート対象外) (サポート対象外) Python 3.6 2016/12/23 2021/12/23 (未定) (未定) Python 3.7 2018/06/27 2023/06/27 (未定) (未定) Node.js 0.10 2013/03/11 2016/10/31 2016/10/31 2016/10/31 Node.js 4.3 2015/10/01 2018/04/30 2018/12/15 2019/4/30 Node.js 6.10 2016/10/18 2019/04/30 2019/04/30 2019/6/30 Node.js 8.10 2017/10/31 2019/12 (予定) ※ (未定) (未定) Node.js 10.x 2018/10/30 2021/04 (予定) (未定) (未定) Node.js 12.x 2019/10/22 2022/04 (予定) (未定) (未定) ※ OpenSSL-1.0.2と同時のEOLとするため、通常よりも早く設定されている。
参考
- 投稿日:2019-07-30T09:45:36+09:00
nuxt generate + S3 + CloudFront + Lambda Edge で静的サイト構築&ハマりポイントと解決法
Repsona LLCの代表兼エンジニア(ひとり)の、ガッシーです。ひとりで、「理想のタスク管理ツール」Repsona(レプソナ)を作っています。
前回の記事(Nuxt + Sails + TypeScript + Fargateでタスク管理ツールを作ったら快適だった話)でRepsona本体側の全体像をざっくりと書きました。今回はウェブサイトのについてです。
Nuxt は静的ウェブサイト制作にも断然おすすめ
https://repsona.com
Repsona では本体のアプリケーションに Nuxt を採用していますが、ウェブサイトにも Nuxt を使っています。小規模なサイトをサクッと作りたい人にとってもおすすめです。
- 公式ドキュメントのままやれば簡単に始められる
- SPC のおかげで HTML を書いている感覚でコンポーネント化できる
- おかげで パーツの使い回しがきく
- おかげで CSS を多少ムチャしても破綻しにくい
- 「JavaScriptでやりたーい」的な見せ方はライブラリでだいたいできる
- jQuery も組み込んじゃえば使える
- webpack とかJavaScript界の色々を考えなくていい(組み込まれてる)
- ビルドは
nuxt generateだけでいいそして快適に作ったサイトを、S3 + CloudFront でデプロイしたい!と思う方もいるでしょう。今回はその手順と、ハマったところと解決法を共有したいと思います。
前提
- ドメイン取得済み、Route 53 設定済み、ACM設定済み
- Nuxt環境構築済み、サイト作成済み、
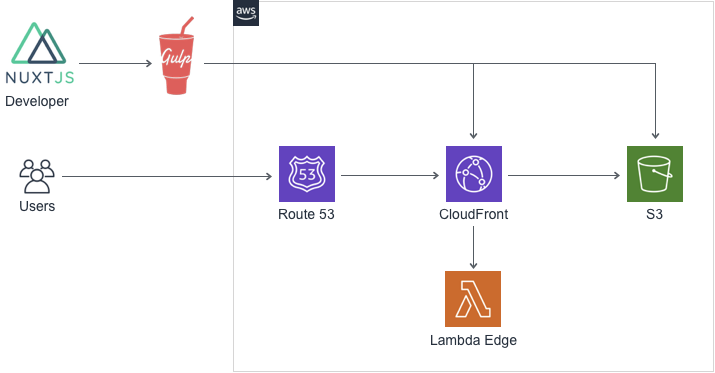
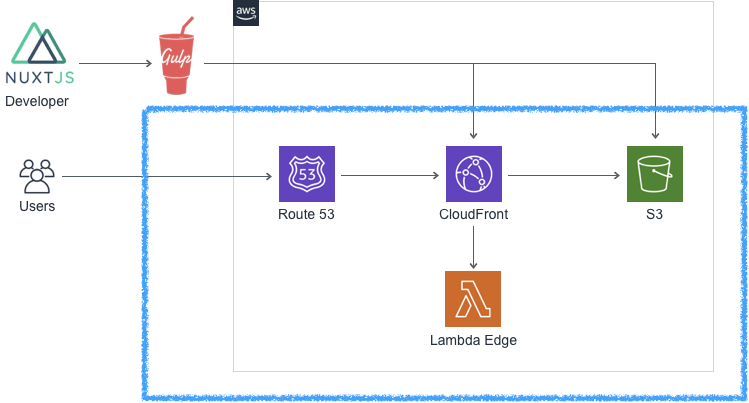
nuxt generateできるアーキテクチャ
nuxt generateで静的ファイル生成- gulpでS3にデプロイ & CloudFront invalidate
- Lambda Edge でオリジンパスをハンドリング
構築手順
公式ドキュメント通りやればよし!なんですが、公式が「シークレットキーを記載したdeploy.shを作って.gitignoreする」というなんだか微妙なかんじなので、ちょっとアレンジした手元の手順を紹介します。
- S3 バケットを作成する
- CloudFront distribution を作成する
- Route 53 を設定する
- Lambda Edge でオリジンパスのハンドリングを設定する
- セキュリティアクセスを設定する
- ビルドスクリプトを作成する
- CloudFront invalidate のスクリプトを修正する
- デプロイして確認する
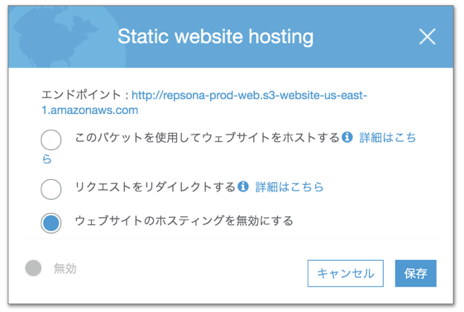
S3 バケットを作成する
バケットを作ります。全部デフォルト設定のままでよかったはず。CloudFront経由のアクセスのみ許可するので、
静的ウェブホスティングも無効でOKです。
CloudFront distribution を作成する
- Create Distribution > Web - Get Started
- Origin Domain Name > さっき作ったバケットを選択 (プルダウンにでてくる)
- Origin Path > (空白)
- Origin ID > (勝手に入る値)
- Restrict Bucket Access > Yes
- Origin Access Identity > 初めてなら Create a New Identity
- Grant Read Permissions on Bucket > Yes, Update Bucket Policy
- Alternate Domain Names > ドメイン名
Repsonaの場合repsona.com www.repsona.com
- SSL Certificate > Custom SSL Certificate (example.com): (プルダウンにでてくる)
- まだ作ってなければ Learn more about using ACM.
- 他項目は各自の都合に合わせてください(デフォルトでもよかったはず)。
Route 53 を設定する
管理下にあるドメインに「レコードセットの作成」から下記の設定を入れて、CloudFront distribution にまわしてやります。
Repsonaの場合repsona.com. タイプ: A エイリアス先: さっき作った CloudFront distribution (プルダウンにでてくる)Repsonaの場合www.repsona.com. タイプ: A エイリアス先: さっき作った CloudFront distribution (プルダウンにでてくる)アクセスできるか確認する
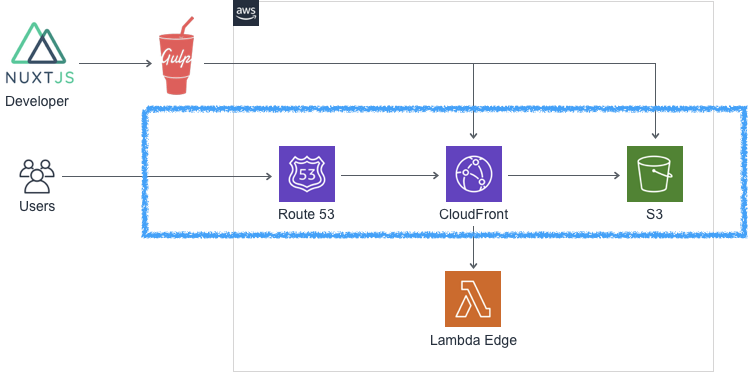
ここまでで、青で囲んだ部分が通っているはずです。
S3バケット直下に
index.htmlを置いて、https://ドメイン名/index.htmlでアクセスできるか確認しておきましょう。Lambda Edge でオリジンパスのハンドリングを設定する
CloudFront には S3 でいうところのインデックスドキュメントにあたるものがありません。
Default Root Objectを設定すれば、以下のindex.htmlナシはいけますが◯: https://ドメイン名/index.html ◯: https://ドメイン名/ ◯: https://ドメイン名以下の
index.htmlナシはいけません。◯: https://ドメイン名/foo/index.html ×: https://ドメイン名/foo/ ×: https://ドメイン名/fooそこで、Lambda Edge を、
イベントタイプ: origin-requestに仕掛けます。index-handler/index.js// arranged: https://github.com/CloudUnder/lambda-edge-nice-urls const config = { suffix: '/index.html', appendToDirs: 'index.html', } const regexSuffixless = /\/[^/.]+$/ // e.g. "/some/page" but not "/", "/some/" or "/some.jpg" const regexTrailingSlash = /.+\/$/ // e.g. "/some/" or "/some/page/" but not root "/" exports.handler = function handler (event, context, callback) { const {request} = event.Records[0].cf const {uri} = request const {suffix, appendToDirs} = config if (suffix && uri.match(regexSuffixless)) { request.uri = uri + suffix callback(null, request) return } if (appendToDirs && uri.match(regexTrailingSlash)) { request.uri = uri + appendToDirs callback(null, request) return } callback(null, request) }Lambda Function のARN(
arn:aws:lambda:us-east-1:000000000000:function:index-handller:1みないなの)をコピっておいて、CloudFront > Behaviors の下の方にある、 Lambda Function Associations の Lambda Function ARN にセットします。$LATESTは使えません。アクセスできるか確認する
ここまでで、青枠全部いけました。
S3バケットにfoo/index.htmlを置いて、スラありスラなしなど含めて、アクセス確認をしてみます。セキュリティアクセスを設定する
デプロイ用のユーザーに「バケットへのファイル配置」と「CloudFrontのキャッシュ削除」の権限を与えます。以下のポリシーを作成し、デプロイを実行するユーザーにアタッチしてください。ユーザーがない場合はここで作成し、アクセスキーとシークレットキーを取得してください。
※ 公式ママだとうまくいかず、すこし変更しています。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObjectAcl", "s3:GetObject", "s3:AbortMultipartUpload", "s3:ListBucket", "s3:DeleteObject", "s3:PutObjectAcl", "s3:ListMultipartUploadParts" ], "Resource": [ "arn:aws:s3:::さっき作ったS3バケット名/*", "arn:aws:s3:::さっき作ったS3バケット名" ] }, { "Effect": "Allow", "Action": [ "cloudfront:ListInvalidations", "cloudfront:GetInvalidation", "cloudfront:CreateInvalidation" ], "Resource": "*" } ] }ビルドスクリプトを作成する
Gulp をインストールする
npmの場合npm install --save-dev gulp gulp-awspublish gulp-cloudfront-invalidate-aws-publish concurrent-transform npm install -g gulpyarnの場合yarn add -D gulp gulp-awspublish gulp-cloudfront-invalidate-aws-publish concurrent-transform yarn global add gulp
gulpfile.jsを作成する※ 公式ママだとうまくいかず、すこし変更しています。
const gulp = require('gulp') const awspublish = require('gulp-awspublish') const cloudfront = require('./modules/gulp-cloudfront-invalidate-aws-publish') const parallelize = require('concurrent-transform') // https://docs.aws.amazon.com/cli/latest/userguide/cli-environment.html const config = { // 必須 params: {Bucket: process.env.AWS_BUCKET_NAME}, accessKeyId: process.env.AWS_ACCESS_KEY_ID, secretAccessKey: process.env.AWS_SECRET_ACCESS_KEY, // 任意 deleteOldVersions: false, // PRODUCTION で使用しない distribution: process.env.AWS_CLOUDFRONT, // CloudFront distribution ID region: process.env.AWS_DEFAULT_REGION, headers: {'x-amz-acl': 'private' /*'Cache-Control': 'max-age=315360000, no-transform, public',*/}, // 適切なデフォルト値 - これらのファイル及びディレクトリは gitignore されている distDir: 'dist', indexRootPath: true, cacheFileName: '.awspublish.' + environment, concurrentUploads: 10, wait: true, // CloudFront のキャッシュ削除が完了するまでの時間(約30〜60秒) } gulp.task('deploy', function () { // S3 オプションを使用して新しい publisher を作成する // http://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/S3.html#constructor-property const publisher = awspublish.create(config, config) // console.log(publisher) let g = gulp.src('./' + config.distDir + '/**') // publisher は、上記で指定した Content-Length、Content-Type、および他のヘッダーを追加する // 指定しない場合、はデフォルトで x-amz-acl が public-read に設定される g = g.pipe(parallelize(publisher.publish(config.headers), config.concurrentUploads)) // CDN のキャッシュを削除する if (config.distribution) { console.log('Configured with CloudFront distribution') g = g.pipe(cloudfront(config)) } else { console.log('No CloudFront distribution configured - skipping CDN invalidation') } // 削除したファイルを同期する if (config.deleteOldVersions) { g = g.pipe(publisher.sync()) } // 連続したアップロードを高速化するためにキャッシュファイルを作成する g = g.pipe(publisher.cache()) // アップロードの更新をコンソールに出力する g = g.pipe(awspublish.reporter()) return g })
package.jsonに追記する
yarn run deployでproductionデプロイできるようにscriptsを追加する。{ "scripts": { "deploy": "rm -r ./dist; cross-env NODE_ENV=production nuxt generate; cross-env NODE_ENV=production gulp deploy", },環境変数を設定する
.env等AWS_BUCKET_NAME = バケット名 AWS_CLOUDFRONT = 14文字の大文字のID AWS_ACCESS_KEY_ID = アクセスキー AWS_SECRET_ACCESS_KEY = シークレットキー AWS_DEFAULT_REGION = リージョン(us-east-1みたいなの)CloudFront invalidate のスクリプトを修正する
Lambda Edge でオリジンパスのハンドリングをするおかげで、スラありスラなしでアクセス可能ですが、全て別々のリソースとしてCloudFrontにキャッシュされてしまいます。デプロイ時に同時にinvalidateしたいところですが、ここで使っているライブラリ
gulp-cloudfront-invalidate-aws-publishのindexRootPaths: trueは、スラなしinvalidateをリクエストしてくれないので、本家に手を加えて利用しています(プルリク)。modules/gulp-cloudfront-invalidate-aws-publish/index.js// https://github.com/lpender/gulp-cloudfront-invalidate-aws-publish/blob/master/index.js var PluginError = require('plugin-error') , log = require('fancy-log') , through = require('through2') , aws = require('aws-sdk') module.exports = function (options) { options.wait = !!options.wait options.indexRootPath = !!options.indexRootPath var cloudfront = new aws.CloudFront() if ('credentials' in options) { cloudfront.config.update({ credentials: options.credentials }) } else { cloudfront.config.update({ accessKeyId: options.accessKeyId || process.env.AWS_ACCESS_KEY_ID, secretAccessKey: options.secretAccessKey || process.env.AWS_SECRET_ACCESS_KEY, sessionToken: options.sessionToken || process.env.AWS_SESSION_TOKEN }) } var files = [] var complain = function (err, msg, callback) { callback(false) throw new PluginError('gulp-cloudfront-invalidate', msg + ': ' + err) } var check = function (id, callback) { cloudfront.getInvalidation({ DistributionId: options.distribution, Id: id }, function (err, res) { if (err) { return complain(err, 'Could not check on invalidation', callback) } if (res.Invalidation.Status === 'Completed') { return callback() } else { setTimeout(function () { check(id, callback) }, 1000) } }) } var processFile = function (file, encoding, callback) { // https://github.com/pgherveou/gulp-awspublish/blob/master/lib/log-reporter.js // var state if (!file.s3) { return callback(null, file) } if (!file.s3.state) { return callback(null, file) } if (options.states && options.states.indexOf(file.s3.state) === -1) { return callback(null, file) } switch (file.s3.state) { case 'update': case 'create': case 'delete': { let path = file.s3.path if (options.originPath) { const originRegex = new RegExp(options.originPath.replace(/^\//, '') + '/?') path = path.replace(originRegex, '') } files.push(path) if (options.indexRootPath && /index\.html$/.test(path)) { files.push(path.replace(/index\.html$/, '')) files.push(path.replace(/\/index\.html$/, '')) // スラなしも invalidate してほしい } break } case 'cache': case 'skip': break default: log('Unknown state: ' + file.s3.state) break } return callback(null, file) } var invalidate = function (callback) { if (files.length == 0) { return callback() } files = files.map(function (file) { return '/' + file }) cloudfront.createInvalidation({ DistributionId: options.distribution, InvalidationBatch: { CallerReference: Date.now().toString(), Paths: { Quantity: files.length, Items: files } } }, function (err, res) { if (err) { return complain(err, 'Could not invalidate cloudfront', callback) } log('Cloudfront invalidation created: ' + res.Invalidation.Id) if (!options.wait) { return callback() } check(res.Invalidation.Id, callback) }) } return through.obj(processFile, invalidate) }デプロイして確認する
それではいってみます!
yarn run deployおめでとう!デプロイがうまくいけば、指定したドメインで、成果物にアクセスできるようになっているはずです。うまく動作したかどうかは、公式によると、下記らしいです。
NOTE: CloudFront invalidation created:XXXX は CloudFront invalidation を行う npm パッケージからの唯一の出力です。それが表示されない場合は、動作していません。
ハマりポイントと解決法
ポリシーがうまく適用されない
公式通りのポリシーをあてているはずなのにうまく行かず、VisualEditorでいろいろといじりながらなんとかうまくいく設定にたどり着きました。
"cloudfront:UnknownOperation"がダメだったのかな。現状動いていますが、s3:ListBucketはほんとはリソースわけなきゃいかんかも。デプロイ実行したらでたエラー
[12:32:01] Using gulpfile ~/xxxxxx/repsona-website/gulpfile.js [12:32:01] Starting 'deploy'... Configured with CloudFront distribution [12:32:02] 'deploy' errored after 1.51 s [12:32:02] AccessDenied: Access Denied at Request.extractError (/Users/xxxxxx/xxxxxx/repsona-website/node_modules/aws-sdk/lib/services/s3.js:585:35) at Request.callListeners (/Users/xxxxxx/xxxxxx/repsona-website/node_modules/aws-sdk/lib/sequential_executor.js:106:20) at Request.emit (/Users/xxxxxx/xxxxxx/repsona-website/node_modules/aws-sdk/lib/sequential_executor.js:78:10) at Request.emit (/Users/xxxxxx/xxxxxx/repsona-website/node_modules/aws-sdk/lib/request.js:683:14) at Request.transition (/Users/xxxxxx/xxxxxx/repsona-website/node_modules/aws-sdk/lib/request.js:22:10) at AcceptorStateMachine.runTo (/Users/xxxxxx/xxxxxx/repsona-website/node_modules/aws-sdk/lib/state_machine.js:14:12) at /Users/xxxxxx/xxxxxx/repsona-website/node_modules/aws-sdk/lib/state_machine.js:26:10 at Request.<anonymous> (/Users/xxxxxx/xxxxxx/repsona-website/node_modules/aws-sdk/lib/request.js:38:9) at Request.<anonymous> (/Users/xxxxxx/xxxxxx/repsona-website/node_modules/aws-sdk/lib/request.js:685:12) at Request.callListeners (/Users/xxxxxx/xxxxxx/repsona-website/node_modules/aws-sdk/lib/sequential_executor.js:116:18) error Command failed with exit code 1. info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command.Access が Denied であること以外なんもわからん!ポリシーも無事適用できて
put objectもできていただけにかなりハマりました。どうやらS3のアクセス権限設定で、いつからか、ブロックパブリックアクセスがすべてブロックがデフォルトになったようで、そうすると、publicなファイルは配置できません。それで、gulpfile.jsにheaders: {'x-amz-acl': 'private'}の記述を追加して、privateとしてputするようにしました。https://ホスト名/index.html じゃないと AccessDenied
上述の通り、Lambda Edgeで回避しました。
まとめ
- どこでコケてるかわかりにくいので、確認できるポイント毎に確認すべし
- 構築は結構手間だけど、一度通ってしまえばすごく楽
nuxt generateで静的ウェブサイトにもコンポーネントの概念を・・すごくイイ- 静的サイト生成なので当たり前だけど、ものすごくはやい
という感じで快適に開発しています。ぜひお試しください。
そして、Repsonaもぜひお試しください。ベータ期間中、制限なく無料で使えます。
チームのための理想のタスク管理ツール | Repsona
- 投稿日:2019-07-30T08:21:08+09:00
AWS EC2上でNode.jsを管理者ユーザーから実行した際のError: listen EACCES: permission denied 0.0.0.0:XXXXについて
はじめに
よく理解しないまま続けてしまい、ハマってしまったので書き残しておきます。
問題
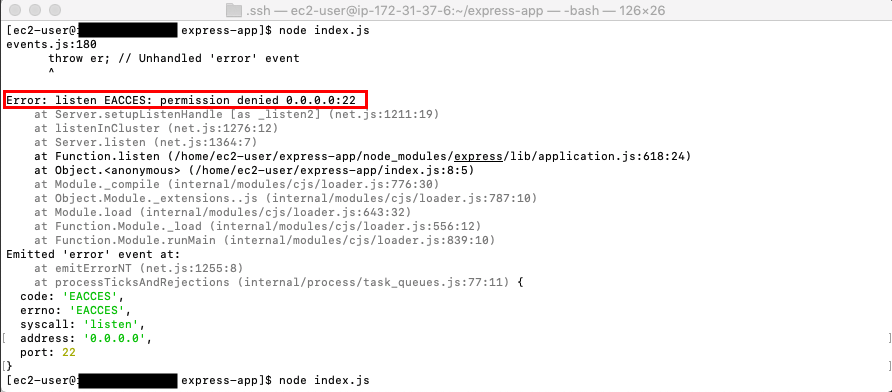
前回まででローカル(VScode)からリモートサーバー(AWS EC2)の編集ができるようになりましたが、いざindex.jsファイルを追加し、実行しようとすると以下のようなエラーが出ます。
前回の記事:https://qiita.com/kobyta/items/510e638ba6693de12871
permission deniedとなっているので、安直にsudo権限からアクセスしたら、「sudo : node : コマンドが見つかりません」と出てくきます。
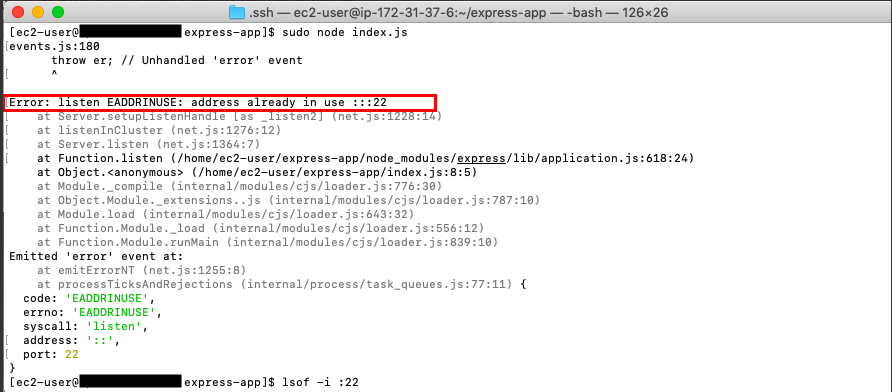
同じような問題にぶつかっていた人がいたので、自分もそれに習い下のようにシンボリックリンクを作成しましたが、下記画像のようにaddress already in useと出てきて断念、、(既に22番ポートをローカルとリモートサーバーのやりとりに使っていたせいか、、。そもそもシンボリックリンクを作る理由がわかっていない。管理者ユーザーとrootユーザーでPATHが同じならばエラーが解決するのか、、。)terminal$ sudo ln -s /home/ec2-user/.nvm/versions/node/v12.6.0/bin/node /usr/bin/node $ sudo ln -s /home/ec2-user/.nvm/versions/node/v12.6.0/bin/npm /usr/bin/npm $ sudo ln -s /usr/local/bin/node-waf /usr/bin/node-waf
- 一言メモ 「管理者ユーザーとrootユーザーと一般ユーザー」
ここまで「管理者」=「root」と思ってきましたが、そうでは無いようです。「root」は管理者より上位にいる神みたいな存在で、「管理者」だけが「sudo」コマンドを使って一時的に神の力を得るということらしいです。「一般」ユーザーはそもそも「sudo」コマンドが使えません。解決策
別のやり方を模索。以下の参考記事①で1024番以下のポート番号は管理者権限を持たないユーザーには実行できないことを知る。また参考記事②でnode.jeを管理者ユーザーから実行する際にポート番号3000を使っている人がいたので自分も同じようにやってみる。
参考記事①:http://dotnsf.blog.jp/archives/1066514800.html
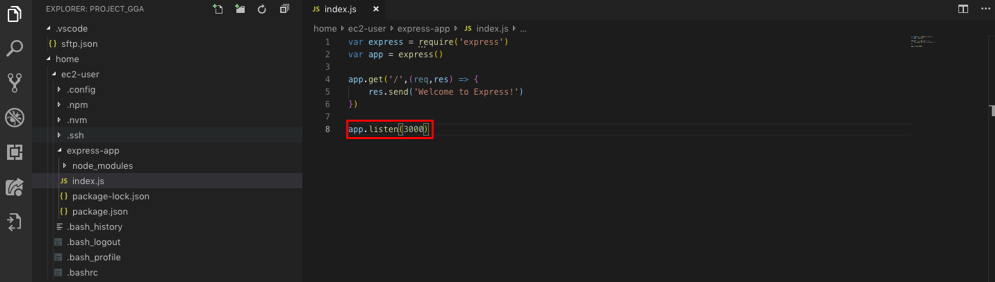
参考記事②:https://qiita.com/oishihiroaki/items/bc663eb1282d87c46e97AWS EC2のセキュリティグループで以下のようにインバウンドに3000番のポートを増やす。
実行しようとしていた「index.js」のポート番号を3000に変更。ローカルからリモートサーバーに変更を送信。
「管理者」ユーザーで実行した後、「 http://パブリックIPアドレス:3000/ 」にアクセスすると実行できていました。
- 一言メモ「ブラウザのアクセス先について」
httpやhttpsなどではポート番号のデフォルトが80、443と決まっており「 http://パブリックIPアドレス/ 」とすればアクセスできる。今回のように別のポートを使いたい場合、「 http://パブリックIPアドレス:ポート番号/ 」というように指定しなければならない。なんとか実行できる環境まで行けたので、nodeでのアプリ制作を進めたいと思います。

- 投稿日:2019-07-30T08:16:23+09:00
【AWS】いろいろなサービスをいじってみた
■サービス一覧
■AWSとは
・AWSについて
https://qiita.com/modokkin/items/fc1280eda4356816a3f9・AWSアカウントの作成
https://aws.amazon.com/jp/register-flow/■IAM(Identity and Access Management)
AWSのユーザとアクセスの管理
・セキュリティの初期設定
https://qiita.com/tmknom/items/303db2d1d928db720888
①ルートアカウントの MFA を有効化
※多要素認証(MFA)
E メールアドレスとパスワードの他に、MFA デバイスからの認証コードを求められます。
https://aws.amazon.com/jp/iam/details/mfa/②個々の IAM ユーザーの作成
ルートアカウント
└ユーザアカウント ←普段こちらを使うようにする
③グループを使用したアクセス許可の割り当て
④IAM パスワードポリシーの適用
⑤アクセスキーのローテーション・ロールの設定
例)
Lambda関数A
└ロールA
└ポリシーA
└ポリシーB■EC2(Amazon Elastic Compute Cloud)
仮想サーバー機能を提供するクラウドサービス。
初期費用は不要。スペックと稼働時間に応じて課金される。
オートスケール機能を利用することで、インスタンスの処理能力を自由に拡張または縮小できる。・EC2を使ったWebサーバー構築
https://qiita.com/tseno/items/47ae835933fd919772e6・teratermでログイン
https://dev.classmethod.jp/cloud/aws/aws-beginner-ec2-ssh/・WinScpでログイン、アップロード
https://torutsume.net/aws-ec2_fileupload/・Python3環境構築
https://qiita.com/tisk_jdb/items/01bd6ef9209acc3a275f・EC2でFlaskアプリを立ち上げる
https://qiita.com/2355/items/7b4074afa5e0f16656f1※Python用Webアプリケーションフレームワーク「Flask」について
https://qiita.com/t-iguchi/items/f7847729631022a5041f
http://python.zombie-hunting-club.com/entry/2017/11/03/223503#■API Gateway
データ、ビジネスロジック、機能にアクセスするための「玄関」として機能する
REST API および WebSocket API を作成できます。https://aws.amazon.com/jp/api-gateway/
https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/welcome.html※APIとは
http://e-words.jp/w/API.html※RESTとは
https://qiita.com/TakahiRoyte/items/949f4e88caecb02119aa・LambdaとDynamoDBを使ったAPI開発
https://qiita.com/miutex/items/d80c9ff0290966eb0cf8・ajaxでメッセージを送る
https://www.tantan-biyori.info/blog/2019/01/amazon-api-gatewayapi.html■DynamoDB
サーバレスで高速で柔軟なNoSQLデータベースサービス
https://aws.amazon.com/jp/dynamodb/・DynamoDBとRDBとの違い
http://blog.serverworks.co.jp/tech/2017/04/12/what_is_different_dynamodb_and_rds/・DynamoDBにテーブルを作成する
https://dev.classmethod.jp/cloud/aws/serverless-first-dynamodb/■Lambda
サーバレスを実現するためのサービス
https://aws.amazon.com/jp/lambda/
https://www.bit-drive.ne.jp/managed-cloud/column/column_14.html・S3のファイルをコピーする関数を作る
https://dev.classmethod.jp/cloud/aws/lambda-my-first-step/■S3(Amazon Simple Storage Service)
スケーラビリティ、データ可用性、セキュリティ、およびパフォーマンスを提供するオブジェクトストレージサービスです。https://aws.amazon.com/jp/s3/
S3料金表
https://service.plan-b.co.jp/blog/creative/4981/
S3の料金 = ストレージに保存している容量 + S3に対するリクエスト(GET、PUTなど)数 + データ転送料金アップロード&ダウンロード
https://dev.classmethod.jp/cloud/aws/amazon-s3-file-up-down/※S3のバケットのトリガー設定は一つだけらしい
https://qiita.com/cobot00/items/140835a759055522c523■IoT Core
AWS IoT Core は、インターネットに接続されたデバイスから、クラウドアプリケーションやその他のデバイスに簡単かつ安全に通信するためのマネージド型クラウドサービスです。
https://aws.amazon.com/jp/iot-core/・pythonでPubSub
https://symfoware.blog.fc2.com/blog-entry-2224.html
- 投稿日:2019-07-30T04:36:53+09:00
AWS Chatbot 雑感
思い立ったが吉日、Qiita初投稿です。
業務でAWSリソース監視基盤のSlack通知をLambdaで作ろうとしていたタイミングで、
まだベータ版ではありますがSlack通知が簡単に出来る「AWS Chatbot」の話を聞いたので試してみました。
https://aws.amazon.com/jp/chatbot/利用可能なサービス
- Amazon CloudWatch
- AWS Health
- AWS Budgets
- AWS Security Hub
- Amazon GuardDuty
- AWS CloudFormation
https://aws.amazon.com/jp/blogs/devops/introducing-aws-chatbot-chatops-for-aws/
最初、公式ドキュメント読まずに適当にS3バケットのイベント通知で試して、「あれ? Slack反応しないぞ???」とかやってました。
現段階ではまだこれだけの様ですが、ここに無いサービス(Configとか)も、CloudWatch側で引っかければ一応通知出来ますね。事前準備
通知対象のSlackワークスペースにブラウザでログインしておく
(Chatbot作成時にSlackワークスペースへのアプリインストール確認があります)SNSトピックを作成しておく
(今回作成する「Chatbot」は、SNSトピックのサブスクリプションの位置付けになります)これだけ。
いちいちLambda準備しなくてもいい。素敵。使ってみた感想
既に公式のハンズオン手順を紹介して下さっているQiita記事があるので、
手順の詳細は是非そちらを参考にしましょう(しました)
前述のリンクからChatbotの作成画面に行き、通知対象のチャンネル名や
使用するSNSトピック名をポチポチするだけです。今回はGuardDutyの通知を試したので、以下の様な感じでやりました。
全リージョンにStackSetsでGuardDuty有効化
(GuardDuty通知用のSNSトピックも併せて各リージョン毎に作成)マネコンより、AdministratorレベルのユーザでChatbotリソース作成
(この際に、1.で作成した各リージョンのSNSトピックを一度に指定)素敵だったのは2.の部分で、各リージョンのSNSトピックを一度にまとめて指定出来るという点。
Chatbotリソース作成後、ちゃんと全リージョンのSNSトピックのサブスクリプションとして、
Chatbotサービスのエンドポイント(global.sns-api.chatbot.amazonaws.com)が設定されていました。ただ、1つのChatbotで指定できる通知先のSlackチャンネルは一つだけなので、
リージョン毎に別チャンネルに通知したい、とかであれば大人しくその分だけChatbotを作成しましょう。Slack側の通知内容
Slackにはこんな感じでメッセージが飛んできます。
(GuardDutyの結果サンプルを生成してみた結果)
おわりに
「別にリッチな内容じゃなくていいから、とにかく監視メッセージをSlack通知したい!」
といった状況において、自前でコードを書かなくて良くなったのは朗報かと。まだベータ版という事もあり、SNSトピックを使った任意のテキストメッセージや、
未対応サービスからのメッセージは送れない、CLIやCloudformationテンプレートも未実装、
といった部分もありますが、かなり需要のあるサービスだと思うので、
今後更に使い勝手が良くなって行ってほしいですね。参考

- 投稿日:2019-07-30T00:50:46+09:00
Capistranoで、EC2+S3への自動デプロイで起きたエラー集と基礎用語
はじめに
メルカリクローンアプリの作成でグループ開発でデプロイを担当しました。
今回はほぼ前提知識ない中、疑問に思った用語とエラーの解決へのプロセス、そして今回意識した事を備忘録とチームメンバーとの共有資料として記載しておきます。環境
Ruby → 2.5.1
Rails → 5.2.3
Capistrano → 3.11.0
carrierwave用語
用語の説明ですが、100%正しい知識ではないかも知れないです。と言うのも、もっと深い知識を知るともっと差別化しないと状況がごちゃごちゃになると思いますが、今回は小規模での開発だったので最低限の知識で乗り切りました。
私は今後必要になったら、詳細について調べていくつもりです。もっと詳細に知りたい人は随時調べてみてください。●ssh
EC2に入るとき使っている下記のコマンド
$ ssh -i キーの名前.pem ec2-user@00.000.0.00Secure Shellの略。リモートコンピュータと通信するためのプロトコルです。
ざっくり鍵を使って暗号化と復号で認証作業をしています。
さらっとやったchomd600は読み込み、書き込み権限の付与をしています。●sudo
スーパーユーザーでdoする。スーパーユーザーとはrootの事です。
rootユーザーは権限が強過ぎるのでコマンド単位だけその力を使おうと言うコマンド。●mysqld
dはデーモンの略です。mysqldはmysqlからデータを持ってきたりしてくれるものと言う認識です。
デーモンは常に待機状態でいるプログラムです。●nginx
webサーバーの一つ。webサーバーとはリクエストを受け取り、レスポンスを返す役割を請け負っています。
nginxの特徴が気になる人は別途調べてみてください。●tail
logを見るときに使用。最後の10行が表示される。-fのオプションを使用する事でログを垂れ流しに出来る。
個人的には、あまり使いませんでした。●cat
ファイルの中身を見る事が出来る。logやエラーが起きた箇所の本番環境での記述を見るために使った。-nオプションで行数を表示出来るので見やすい.
●RAILS_ENV
動作環境を指定したい時に使用。環境がどうこうのエラーが出た時に確認したり、場合によっては環境を指定してあげないとエラーが出る事があったので使った。
エラーへの対処
まず最初に特に何もしていない部分のエラーが起きた時は、EC2インスタンスの停止→起動をするのが得策です。
無料枠を使っているせいなのか、期待通りの動きをしてくれない事があるらしいです。(真偽は確認していませんが、何日か空けて自動デプロイしようとすると大体エラーが出ていました。仕様と諦めていたので、わかる方教えてください)
なので、心辺りのないエラーや自動デプロイが止まる時は再起動をしてみて、それでも起こるならエラーに対処をしてくのが時間効率がいいと思います。
では、私がハマったり頻度の高かったエラーを書いていきます。Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)
(2)の場合はsocketがないので
$ touch mysql.sockで、解決出来ると思います。ないなら作ってやる、それだけです。ここから発展して(38)に変わる事があるようですが、それは私は出会わなかったので、割愛します。
Can't connect to local MySQL server through socket '/tmp/mysql.sock' (111)
検索してみると、権限がない事に起因するエラーの様ですが、私の場合には当てはまりませんでした。mysqlにアクセス出来ない旨のエラーなのでひとまず
$ mysql -u root -pでひとまずルートに入る事が出来るが確認してみる→出来なかったら検索
入れたらsocketの指定をしているファイル(database.yml)の設定を見る
それも合っていたら、環境変数を指定してみる$ rake db:migrate RAILS_ENV=production私はこれで解決しました。
他にも、mysql.sockが消えていない為、新しいmysql.sockが生成出来ず起動できないみたいな事もある様です。
この辺の解決策は他の方の記事を参考に出来ると思うのでそちらを見てみてください。credentials.yml.enc
ここは一番苦労しました。ただ参考資料が沢山のあるので、状況を整理しながらやっていけば問題なく出来ると思います。
チーム開発で起こっていたミスとしては。
・master→rails newした人とデプロイ担当が違う為、master.keyが複数ある環境で開発を進めていた
・APIkeyを書く人が、自分のmaster.keyで新しいcredentials.ymlを作ってしまったファイルをmargeして本番環境で開けなくなった
などです。
暗号化されている為コンフリクトが起きた時にわかりにくいので、一度丁寧に確認するのが良いと思います。
今回のチーム開発では初期段階でmaster.keyの共有をして、使わないkeyは消してしまうのが得策と思います。以下、大変参考になった記事です。
https://qiita.com/NaokiIshimura/items/2a179f2ab910992c4d39
https://qiita.com/yuuuking/items/53a37a2e998972be32b8まとめ
チーム共有がメインの記事なので、分かりにくいところもあると思いますが、デプロイ担当で思ったことは、どの環境で、どのコマンドを、何に対してやったのかをわかった上で作業を進めるのが大切だと思いました(当たり前ですが)。
自分でも良くわからない状況で、適当にコマンドを叩いていると周りもフォローしにくくなりますし、泥沼にハマる確率が高くなります(体験談)。
頑張れ!デプロイ担当!
※口頭説明しながら前提で作ったのと、知識不足で憶測や間違った解釈を書いている可能性が高いので後日書き足すか、限定公開にする予定です。