- 投稿日:2019-07-30T23:45:39+09:00
Python+Windowsタスクスケジューラで暑さ指数をLINE通知
こんばんは、@0yanです。
先日、実家に暮らしている妹から「お母さんが『うちは風通し良くて涼しいからエアコンつけなくて大丈夫』とか言ってエアコンつけないんだけど!熱中症になっちゃうよ!何とか言って!!」とヘルプ連絡が来たため、環境省の暑さ指数(WBGT)を家族のグループLINEに定期通知するようにしました。前提条件
Windowsのタスクスケジューラ使っていますので自宅でPC起動しっ放しです(知識不足でHerokuやAWSにデプロイできていません)。
申し訳ございませんが、予めご承知おきくださいませ。流れ
1.LINE Notifyからアクセストークンget
2.コーディング
3.LINE Notifyをトークルームに招待
4.batファイル作成&タスクスケジューラの設定LINE Notifyからアクセストークンget
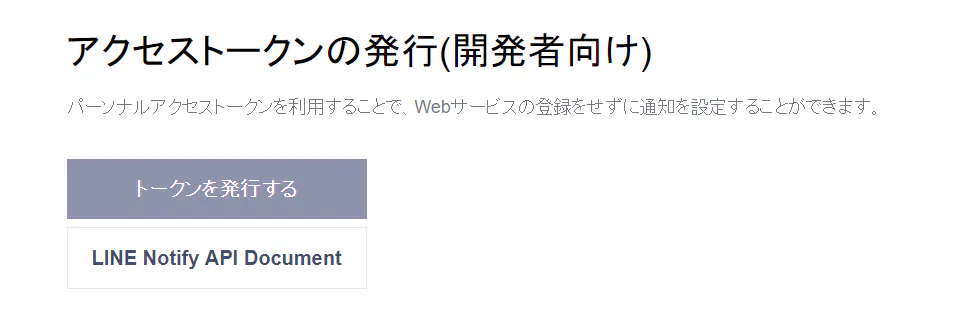
①LINE Notifyにログイン後、右上の自分の名前をクリックし、マイページに飛びます。
②次ページ下部の「トークンを発行する」ボタンを押下します。
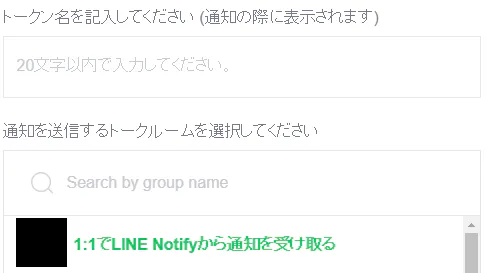
③トークン名の記入、通知するトークルームを選択(ご自身向けの場合は「1:1でLINE Notifyから通知を受け取る」を選択)して「発行する」ボタンを押下します。
④発行されたトークンをコピー、メモしておきます。ページ遷移するとトークンは二度と表示されないそうなのでご注意ください。
コーディング
BeautifulSoupで環境省の熱中症予防情報サイトから暑さ指数の情報を取得、LINE Notifyのエンドポイントにポストしております。
詳しくはコメントをご参照くださいませ。wbgt.py# coding:utf-8 import bs4 import urllib import requests def main(): # LINEの通知系API(POST)のエンドポイント(アクセストークンに関連付けられたユーザまたはグループに通知を送信) END_POINT_URL = "https://notify-api.line.me/api/notify" # LINE Notifyのアクセストークン TOKEN = "LINE Notifyのページで発行・コピーしたトークンをここにペースト" # リクエストヘッダ(付与してアクセスすることで認証できる) header = { "Content-Type": "application/x-www-form-urlencoded", "Authorization": "Bearer " + TOKEN } try: # 環境省 熱中症予防情報サイト(スマホ版)のページ情報取得 WBGT_URL = "定期通知したい市区町村のページURLをコピペ" html = urllib.request.urlopen(WBGT_URL).read() # BeautifulSoupオブジェクトの生成 soup = bs4.BeautifulSoup(html, 'html5lib') # spanタグすべて取得 spans = soup.find_all('span') # メッセージの初期化 message = "" # spanタグの中身(テキスト)を取得し、改行で区切ったうえでメッセージに追加 for span in spans: message += span.text message += '\n' # メッセージの最後にURLも追加 message += "→ 変数「WBGT_URL」と同じ文字列をコピペ" # リクエストパラメータ(通知オフでないとき、ユーザーに通知する) parameter = { "message": message, "notificationDisabled": False } # エンドポイントにPOST requests.post(END_POINT_URL, headers=header, params=parameter) # 例外処理 except Exception as ex: print(ex) if __name__ == '__main__': main()LINE Notifyをトークルームに招待
トークルームにLINE Notifyを招待しないと通知飛ばないので招待します。
batファイル作成&タスクスケジューラの設定
こちら(↓)をご覧ください。
さいごに
関東も昨日梅雨明けしたので、これからが夏本番です。
皆様も是非、ご活用くださいませ!


- 投稿日:2019-07-30T23:39:42+09:00
QuizKnockの名詞抜きクイズをpythonで再現してみた。クイズもあるよ^^
名詞抜きクイズとは
東大生クイズ王 伊沢拓司さんを編集長とするWEBメディアQuizKnock。1
YouTubeでも活動をされており、その中の企画で名詞抜きクイズというものがあります。詳しくはこちらの動画をご覧ください。
業務で形態素解析をやる機会があり、その日の帰宅後に観た動画がちょうどこれで「あ、形態素解析」。
ということでpythonでクイズを再現してみました。準備
必要なライブラリは形態素解析するためのjanomeのみ。
pip installで簡単に入れられるのでjanomeを使ったけど、MeCabでもなんでもいいです。pip install janome時事問題などに対応するために、新語や固有語辞書を追加したほうが良い気もします。
やること
クイズの問題文を形態素解析。→名詞を文字数分の空白に置き換え。
これだけ。実装
from janome.tokenizer import Tokenizer def filter_noun(text): tokenizer = Tokenizer() tokens = tokenizer.tokenize(text) quiz = [] for token in tokens: if token.part_of_speech.startswith('名詞'): quiz.append(' ' * len(token.surface)) else: quiz.append(token.surface) return ''.join(quiz)やってみた
動画内で出題されたクイズで試してみます。
第1問filter_noun('マラソンなどで一気に何人もの選手を追い抜くことを、ある野菜を使って何というでしょう?')結果がこちら。
などで一気に もの を追い抜く を、ある を使って というでしょう?動画内で出題された状態と同じになりました^^
正解は「ごぼう抜き」です。
ちなみにQuizKnockメンバーの山本さんは「などで一気に」が読み上げられた時点で正解していましたもう一問やってみた。
第2問filter_noun('「入り江」という意味のスペイン語に由来する、日本では志摩半島や三陸海岸に見られる複雑に入り組んだ海岸を何というでしょう?')結果がこちら。
「 」という の に する、 では や に見られる に入り組んだ を何というでしょう?それっぽいかんじになった。
正解は「リアス式海岸」。さあ問題。
エンジニアのみなさんに名詞抜きクイズ〜
第1問に を置く、 、 、 、 の4つの の を取って する は というでしょう?第2問を することで の と協働して をレビューしたり、 を管理しつつ を ができる、最も な は何でしょう?第3問で に 、 から に向け、 が する を何というでしょう?いかがでしょうか。わかったかたはコメントお待ちしてます。
(ちょうどいい難度の問題を作ることが難しかったので、ちょっと調整しました、ごめんなさい笑)
- 投稿日:2019-07-30T23:20:57+09:00
[RaspberryPi3/4用] QEMU4.0.0 + Debian Buster armhf, RAM 4GB, CPU 8 core 仮想環境での OpenCV 4.1.1 のビルド (TBB・VFPV3・NEON有効)
1.Introduction
そもそも自力でチューニングする必要が無い方は、コチラのOpenVINO を導入することをオススメします。 OpenCV 4.1.1 が10分ほどで導入可能です。
いつも参考にさせていただいている @mt08 さんの [メモ] ラズパイ OpenCV 4.1.1 ビルド時の__atomic_~~エラー対処 のノウハウをもとに、TBBのビルドとVFPV3/NEONを有効化した状態で、RaspberryPi3/4用 の OpenCV4.1.1 をビルドしました。 仮想環境を使用するため、実機でビルドするよりも格段に遅いと思います。 なお、TBBを組み込むことで若干OpenCVのパフォーマンスが上がるそうです。
このビルド環境は、過去の私の記事 QEMU4.0.0 のハードウェアエミュレーションモードで Debian Buster armhf のOSイメージをゼロから作成する方法 (Kernel 4.19.0-5-armmp-lpae, Tensorflow armhfビルド用) で構築した Raspbian 相当の環境を CPU 8 core 設定で使用します。 cmake時のワーニングをなるべく表示させないような手順を心がけました。
cmakeのログ
cmake_log-- The CXX compiler identification is GNU 8.3.0 -- The C compiler identification is GNU 8.3.0 -- Check for working CXX compiler: /usr/bin/c++ -- Check for working CXX compiler: /usr/bin/c++ -- works -- Detecting CXX compiler ABI info -- Detecting CXX compiler ABI info - done -- Detecting CXX compile features -- Detecting CXX compile features - done -- Check for working C compiler: /usr/bin/cc -- Check for working C compiler: /usr/bin/cc -- works -- Detecting C compiler ABI info -- Detecting C compiler ABI info - done -- Detecting C compile features -- Detecting C compile features - done -- Detected processor: armv7l -- sizeof(void) = 4 on 64 bit processor. Assume 32-bit compilation mode -- Found PythonInterp: /usr/bin/python2.7 (found suitable version "2.7.16", minimum required is "2.7") -- Found PythonLibs: /usr/lib/arm-linux-gnueabihf/libpython2.7.so (found suitable exact version "2.7.16") Traceback (most recent call last): File "<string>", line 1, in <module> ImportError: No module named numpy.distutils -- Found PythonInterp: /usr/bin/python3 (found suitable version "3.7.3", minimum required is "3.2") -- Found PythonLibs: /usr/lib/arm-linux-gnueabihf/libpython3.7m.so (found suitable exact version "3.7.3") -- Looking for ccache - found (/usr/bin/ccache) -- Performing Test HAVE_CXX_FSIGNED_CHAR -- Performing Test HAVE_CXX_FSIGNED_CHAR - Success -- Performing Test HAVE_C_FSIGNED_CHAR -- Performing Test HAVE_C_FSIGNED_CHAR - Success -- Performing Test HAVE_CXX_W -- Performing Test HAVE_CXX_W - Success -- Performing Test HAVE_C_W -- Performing Test HAVE_C_W - Success -- Performing Test HAVE_CXX_WALL -- Performing Test HAVE_CXX_WALL - Success -- Performing Test HAVE_C_WALL -- Performing Test HAVE_C_WALL - Success -- Performing Test HAVE_CXX_WERROR_RETURN_TYPE -- Performing Test HAVE_CXX_WERROR_RETURN_TYPE - Success -- Performing Test HAVE_C_WERROR_RETURN_TYPE -- Performing Test HAVE_C_WERROR_RETURN_TYPE - Success -- Performing Test HAVE_CXX_WERROR_NON_VIRTUAL_DTOR -- Performing Test HAVE_CXX_WERROR_NON_VIRTUAL_DTOR - Success -- Performing Test HAVE_C_WERROR_NON_VIRTUAL_DTOR -- Performing Test HAVE_C_WERROR_NON_VIRTUAL_DTOR - Success -- Performing Test HAVE_CXX_WERROR_ADDRESS -- Performing Test HAVE_CXX_WERROR_ADDRESS - Success -- Performing Test HAVE_C_WERROR_ADDRESS -- Performing Test HAVE_C_WERROR_ADDRESS - Success -- Performing Test HAVE_CXX_WERROR_SEQUENCE_POINT -- Performing Test HAVE_CXX_WERROR_SEQUENCE_POINT - Success -- Performing Test HAVE_C_WERROR_SEQUENCE_POINT -- Performing Test HAVE_C_WERROR_SEQUENCE_POINT - Success -- Performing Test HAVE_CXX_WFORMAT -- Performing Test HAVE_CXX_WFORMAT - Success -- Performing Test HAVE_C_WFORMAT -- Performing Test HAVE_C_WFORMAT - Success -- Performing Test HAVE_CXX_WERROR_FORMAT_SECURITY -- Performing Test HAVE_CXX_WERROR_FORMAT_SECURITY - Success -- Performing Test HAVE_C_WERROR_FORMAT_SECURITY -- Performing Test HAVE_C_WERROR_FORMAT_SECURITY - Success -- Performing Test HAVE_CXX_WMISSING_DECLARATIONS -- Performing Test HAVE_CXX_WMISSING_DECLARATIONS - Success -- Performing Test HAVE_C_WMISSING_DECLARATIONS -- Performing Test HAVE_C_WMISSING_DECLARATIONS - Success -- Performing Test HAVE_CXX_WMISSING_PROTOTYPES -- Performing Test HAVE_CXX_WMISSING_PROTOTYPES - Failed -- Performing Test HAVE_C_WMISSING_PROTOTYPES -- Performing Test HAVE_C_WMISSING_PROTOTYPES - Success -- Performing Test HAVE_CXX_WSTRICT_PROTOTYPES -- Performing Test HAVE_CXX_WSTRICT_PROTOTYPES - Failed -- Performing Test HAVE_C_WSTRICT_PROTOTYPES -- Performing Test HAVE_C_WSTRICT_PROTOTYPES - Success -- Performing Test HAVE_CXX_WUNDEF -- Performing Test HAVE_CXX_WUNDEF - Success -- Performing Test HAVE_C_WUNDEF -- Performing Test HAVE_C_WUNDEF - Success -- Performing Test HAVE_CXX_WINIT_SELF -- Performing Test HAVE_CXX_WINIT_SELF - Success -- Performing Test HAVE_C_WINIT_SELF -- Performing Test HAVE_C_WINIT_SELF - Success -- Performing Test HAVE_CXX_WPOINTER_ARITH -- Performing Test HAVE_CXX_WPOINTER_ARITH - Success -- Performing Test HAVE_C_WPOINTER_ARITH -- Performing Test HAVE_C_WPOINTER_ARITH - Success -- Performing Test HAVE_CXX_WSHADOW -- Performing Test HAVE_CXX_WSHADOW - Success -- Performing Test HAVE_C_WSHADOW -- Performing Test HAVE_C_WSHADOW - Success -- Performing Test HAVE_CXX_WSIGN_PROMO -- Performing Test HAVE_CXX_WSIGN_PROMO - Success -- Performing Test HAVE_C_WSIGN_PROMO -- Performing Test HAVE_C_WSIGN_PROMO - Failed -- Performing Test HAVE_CXX_WUNINITIALIZED -- Performing Test HAVE_CXX_WUNINITIALIZED - Success -- Performing Test HAVE_C_WUNINITIALIZED -- Performing Test HAVE_C_WUNINITIALIZED - Success -- Performing Test HAVE_CXX_WSUGGEST_OVERRIDE -- Performing Test HAVE_CXX_WSUGGEST_OVERRIDE - Success -- Performing Test HAVE_C_WSUGGEST_OVERRIDE -- Performing Test HAVE_C_WSUGGEST_OVERRIDE - Failed -- Performing Test HAVE_CXX_WNO_DELETE_NON_VIRTUAL_DTOR -- Performing Test HAVE_CXX_WNO_DELETE_NON_VIRTUAL_DTOR - Success -- Performing Test HAVE_C_WNO_DELETE_NON_VIRTUAL_DTOR -- Performing Test HAVE_C_WNO_DELETE_NON_VIRTUAL_DTOR - Failed -- Performing Test HAVE_CXX_WNO_UNNAMED_TYPE_TEMPLATE_ARGS -- Performing Test HAVE_CXX_WNO_UNNAMED_TYPE_TEMPLATE_ARGS - Failed -- Performing Test HAVE_C_WNO_UNNAMED_TYPE_TEMPLATE_ARGS -- Performing Test HAVE_C_WNO_UNNAMED_TYPE_TEMPLATE_ARGS - Failed -- Performing Test HAVE_CXX_WNO_COMMENT -- Performing Test HAVE_CXX_WNO_COMMENT - Success -- Performing Test HAVE_C_WNO_COMMENT -- Performing Test HAVE_C_WNO_COMMENT - Success -- Performing Test HAVE_CXX_WIMPLICIT_FALLTHROUGH_3 -- Performing Test HAVE_CXX_WIMPLICIT_FALLTHROUGH_3 - Success -- Performing Test HAVE_C_WIMPLICIT_FALLTHROUGH_3 -- Performing Test HAVE_C_WIMPLICIT_FALLTHROUGH_3 - Success -- Performing Test HAVE_CXX_WNO_STRICT_OVERFLOW -- Performing Test HAVE_CXX_WNO_STRICT_OVERFLOW - Success -- Performing Test HAVE_C_WNO_STRICT_OVERFLOW -- Performing Test HAVE_C_WNO_STRICT_OVERFLOW - Success -- Performing Test HAVE_CXX_FDIAGNOSTICS_SHOW_OPTION -- Performing Test HAVE_CXX_FDIAGNOSTICS_SHOW_OPTION - Success -- Performing Test HAVE_C_FDIAGNOSTICS_SHOW_OPTION -- Performing Test HAVE_C_FDIAGNOSTICS_SHOW_OPTION - Success -- Performing Test HAVE_CXX_PTHREAD -- Performing Test HAVE_CXX_PTHREAD - Success -- Performing Test HAVE_C_PTHREAD -- Performing Test HAVE_C_PTHREAD - Success -- Performing Test HAVE_CXX_FOMIT_FRAME_POINTER -- Performing Test HAVE_CXX_FOMIT_FRAME_POINTER - Success -- Performing Test HAVE_C_FOMIT_FRAME_POINTER -- Performing Test HAVE_C_FOMIT_FRAME_POINTER - Success -- Performing Test HAVE_CXX_FFUNCTION_SECTIONS -- Performing Test HAVE_CXX_FFUNCTION_SECTIONS - Success -- Performing Test HAVE_C_FFUNCTION_SECTIONS -- Performing Test HAVE_C_FFUNCTION_SECTIONS - Success -- Performing Test HAVE_CXX_FDATA_SECTIONS -- Performing Test HAVE_CXX_FDATA_SECTIONS - Success -- Performing Test HAVE_C_FDATA_SECTIONS -- Performing Test HAVE_C_FDATA_SECTIONS - Success -- Performing Test HAVE_CXX_MFPU_VFPV3 -- Performing Test HAVE_CXX_MFPU_VFPV3 - Success -- Performing Test HAVE_CPU_NEON_SUPPORT (check file: cmake/checks/cpu_neon.cpp) -- Performing Test HAVE_CPU_NEON_SUPPORT - Failed -- Performing Test HAVE_CXX_MFPU_NEON (check file: cmake/checks/cpu_neon.cpp) -- Performing Test HAVE_CXX_MFPU_NEON - Success -- Performing Test HAVE_CPU_FP16_SUPPORT (check file: cmake/checks/cpu_fp16.cpp) -- Performing Test HAVE_CPU_FP16_SUPPORT - Failed -- Performing Test HAVE_CXX_MFPU_NEON_FP16_MFP16_FORMAT_IEEE (check file: cmake/checks/cpu_fp16.cpp) -- Performing Test HAVE_CXX_MFPU_NEON_FP16_MFP16_FORMAT_IEEE - Success -- Performing Test HAVE_CPU_BASELINE_FLAGS -- Performing Test HAVE_CPU_BASELINE_FLAGS - Success -- Performing Test HAVE_CXX_FVISIBILITY_HIDDEN -- Performing Test HAVE_CXX_FVISIBILITY_HIDDEN - Success -- Performing Test HAVE_C_FVISIBILITY_HIDDEN -- Performing Test HAVE_C_FVISIBILITY_HIDDEN - Success -- Performing Test HAVE_CXX_FVISIBILITY_INLINES_HIDDEN -- Performing Test HAVE_CXX_FVISIBILITY_INLINES_HIDDEN - Success -- Performing Test HAVE_C_FVISIBILITY_INLINES_HIDDEN -- Performing Test HAVE_C_FVISIBILITY_INLINES_HIDDEN - Failed -- Looking for pthread.h -- Looking for pthread.h - found -- Looking for posix_memalign -- Looking for posix_memalign - found -- Looking for malloc.h -- Looking for malloc.h - found -- Looking for memalign -- Looking for memalign - found -- Check if the system is big endian -- Searching 16 bit integer -- Looking for sys/types.h -- Looking for sys/types.h - found -- Looking for stdint.h -- Looking for stdint.h - found -- Looking for stddef.h -- Looking for stddef.h - found -- Check size of unsigned short -- Check size of unsigned short - done -- Using unsigned short -- Check if the system is big endian - little endian -- Found ZLIB: /usr/lib/arm-linux-gnueabihf/libz.so (found suitable version "1.2.11", minimum required is "1.2.3") -- Found JPEG: /usr/lib/arm-linux-gnueabihf/libjpeg.so (found version "62") -- Found TIFF: /usr/lib/arm-linux-gnueabihf/libtiff.so (found version "4.0.10") -- Found WebP: /usr/lib/arm-linux-gnueabihf/libwebp.so -- Could NOT find Jasper (missing: JASPER_LIBRARIES JASPER_INCLUDE_DIR) -- Performing Test HAVE_C_WNO_IMPLICIT_FUNCTION_DECLARATION -- Performing Test HAVE_C_WNO_IMPLICIT_FUNCTION_DECLARATION - Success -- Performing Test HAVE_C_WNO_UNINITIALIZED -- Performing Test HAVE_C_WNO_UNINITIALIZED - Success -- Performing Test HAVE_C_WNO_MISSING_PROTOTYPES -- Performing Test HAVE_C_WNO_MISSING_PROTOTYPES - Success -- Performing Test HAVE_C_WNO_UNUSED_BUT_SET_PARAMETER -- Performing Test HAVE_C_WNO_UNUSED_BUT_SET_PARAMETER - Success -- Performing Test HAVE_C_WNO_MISSING_DECLARATIONS -- Performing Test HAVE_C_WNO_MISSING_DECLARATIONS - Success -- Performing Test HAVE_C_WNO_UNUSED -- Performing Test HAVE_C_WNO_UNUSED - Success -- Performing Test HAVE_C_WNO_SHADOW -- Performing Test HAVE_C_WNO_SHADOW - Success -- Performing Test HAVE_C_WNO_SIGN_COMPARE -- Performing Test HAVE_C_WNO_SIGN_COMPARE - Success -- Performing Test HAVE_C_WNO_POINTER_COMPARE -- Performing Test HAVE_C_WNO_POINTER_COMPARE - Success -- Performing Test HAVE_C_WNO_ABSOLUTE_VALUE -- Performing Test HAVE_C_WNO_ABSOLUTE_VALUE - Failed -- Performing Test HAVE_C_WNO_IMPLICIT_FALLTHROUGH -- Performing Test HAVE_C_WNO_IMPLICIT_FALLTHROUGH - Success -- Performing Test HAVE_C_WNO_UNUSED_PARAMETER -- Performing Test HAVE_C_WNO_UNUSED_PARAMETER - Success -- Performing Test HAVE_C_WNO_STRICT_PROTOTYPES -- Performing Test HAVE_C_WNO_STRICT_PROTOTYPES - Success -- Found ZLIB: /usr/lib/arm-linux-gnueabihf/libz.so (found version "1.2.11") -- Found PNG: /usr/lib/arm-linux-gnueabihf/libpng.so (found version "1.6.36") -- Looking for /usr/include/libpng/png.h -- Looking for /usr/include/libpng/png.h - found -- Looking for semaphore.h -- Looking for semaphore.h - found -- Performing Test HAVE_CXX_WNO_SHADOW -- Performing Test HAVE_CXX_WNO_SHADOW - Success -- Performing Test HAVE_CXX_WNO_UNUSED -- Performing Test HAVE_CXX_WNO_UNUSED - Success -- Performing Test HAVE_CXX_WNO_SIGN_COMPARE -- Performing Test HAVE_CXX_WNO_SIGN_COMPARE - Success -- Performing Test HAVE_CXX_WNO_UNDEF -- Performing Test HAVE_CXX_WNO_UNDEF - Success -- Performing Test HAVE_CXX_WNO_MISSING_DECLARATIONS -- Performing Test HAVE_CXX_WNO_MISSING_DECLARATIONS - Success -- Performing Test HAVE_CXX_WNO_UNINITIALIZED -- Performing Test HAVE_CXX_WNO_UNINITIALIZED - Success -- Performing Test HAVE_CXX_WNO_SWITCH -- Performing Test HAVE_CXX_WNO_SWITCH - Success -- Performing Test HAVE_CXX_WNO_PARENTHESES -- Performing Test HAVE_CXX_WNO_PARENTHESES - Success -- Performing Test HAVE_CXX_WNO_ARRAY_BOUNDS -- Performing Test HAVE_CXX_WNO_ARRAY_BOUNDS - Success -- Performing Test HAVE_CXX_WNO_EXTRA -- Performing Test HAVE_CXX_WNO_EXTRA - Success -- Performing Test HAVE_CXX_WNO_DEPRECATED_DECLARATIONS -- Performing Test HAVE_CXX_WNO_DEPRECATED_DECLARATIONS - Success -- Performing Test HAVE_CXX_WNO_MISLEADING_INDENTATION -- Performing Test HAVE_CXX_WNO_MISLEADING_INDENTATION - Success -- Performing Test HAVE_CXX_WNO_DEPRECATED -- Performing Test HAVE_CXX_WNO_DEPRECATED - Success -- Performing Test HAVE_CXX_WNO_SUGGEST_OVERRIDE -- Performing Test HAVE_CXX_WNO_SUGGEST_OVERRIDE - Success -- Performing Test HAVE_CXX_WNO_INCONSISTENT_MISSING_OVERRIDE -- Performing Test HAVE_CXX_WNO_INCONSISTENT_MISSING_OVERRIDE - Failed -- Performing Test HAVE_CXX_WNO_IMPLICIT_FALLTHROUGH -- Performing Test HAVE_CXX_WNO_IMPLICIT_FALLTHROUGH - Success -- Performing Test HAVE_CXX_WNO_TAUTOLOGICAL_COMPARE -- Performing Test HAVE_CXX_WNO_TAUTOLOGICAL_COMPARE - Success -- Performing Test HAVE_CXX_WNO_MISSING_PROTOTYPES -- Performing Test HAVE_CXX_WNO_MISSING_PROTOTYPES - Failed -- Performing Test HAVE_CXX_WNO_REORDER -- Performing Test HAVE_CXX_WNO_REORDER - Success -- Performing Test HAVE_CXX_WNO_UNUSED_RESULT -- Performing Test HAVE_CXX_WNO_UNUSED_RESULT - Success -- Performing Test HAVE_CXX_WNO_CLASS_MEMACCESS -- Performing Test HAVE_CXX_WNO_CLASS_MEMACCESS - Success -- Checking for module 'gtk+-3.0' -- Found gtk+-3.0, version 3.24.5 -- Checking for module 'gthread-2.0' -- Found gthread-2.0, version 2.58.3 -- TBB: Download: 2019_U8.tar.gz -- Performing Test HAVE_CXX_WNO_UNUSED_PARAMETER -- Performing Test HAVE_CXX_WNO_UNUSED_PARAMETER - Success -- Could not find OpenBLAS include. Turning OpenBLAS_FOUND off -- Could not find OpenBLAS lib. Turning OpenBLAS_FOUND off -- Found Atlas: /usr/include/arm-linux-gnueabihf -- Found Atlas (include: /usr/include/arm-linux-gnueabihf, library: /usr/lib/arm-linux-gnueabihf/libatlas.so) -- LAPACK(Atlas): LAPACK_LIBRARIES: /usr/lib/arm-linux-gnueabihf/liblapack.so;/usr/lib/arm-linux-gnueabihf/libcblas.so;/usr/lib/arm-linux-gnueabihf/libatlas.so -- LAPACK(Atlas): Support is enabled. -- Performing Test HAVE_CXX_WNO_UNUSED_LOCAL_TYPEDEFS -- Performing Test HAVE_CXX_WNO_UNUSED_LOCAL_TYPEDEFS - Success -- Performing Test HAVE_CXX_WNO_SIGN_PROMO -- Performing Test HAVE_CXX_WNO_SIGN_PROMO - Success -- Performing Test HAVE_CXX_WNO_TAUTOLOGICAL_UNDEFINED_COMPARE -- Performing Test HAVE_CXX_WNO_TAUTOLOGICAL_UNDEFINED_COMPARE - Failed -- Performing Test HAVE_CXX_WNO_IGNORED_QUALIFIERS -- Performing Test HAVE_CXX_WNO_IGNORED_QUALIFIERS - Success -- Performing Test HAVE_CXX_WNO_UNUSED_FUNCTION -- Performing Test HAVE_CXX_WNO_UNUSED_FUNCTION - Success -- Performing Test HAVE_CXX_WNO_UNUSED_CONST_VARIABLE -- Performing Test HAVE_CXX_WNO_UNUSED_CONST_VARIABLE - Success -- Performing Test HAVE_CXX_WNO_SHORTEN_64_TO_32 -- Performing Test HAVE_CXX_WNO_SHORTEN_64_TO_32 - Failed -- Performing Test HAVE_CXX_WNO_INVALID_OFFSETOF -- Performing Test HAVE_CXX_WNO_INVALID_OFFSETOF - Success -- Performing Test HAVE_CXX_WNO_ENUM_COMPARE_SWITCH -- Performing Test HAVE_CXX_WNO_ENUM_COMPARE_SWITCH - Failed -- Could NOT find JNI (missing: JAVA_AWT_LIBRARY JAVA_JVM_LIBRARY JAVA_INCLUDE_PATH JAVA_INCLUDE_PATH2 JAVA_AWT_INCLUDE_PATH) -- The imported target "vtkRenderingPythonTkWidgets" references the file "/usr/lib/arm-linux-gnueabihf/libvtkRenderingPythonTkWidgets.so" but this file does not exist. Possible reasons include: * The file was deleted, renamed, or moved to another location. * An install or uninstall procedure did not complete successfully. * The installation package was faulty and contained "/usr/lib/cmake/vtk-6.3/VTKTargets.cmake" but not all the files it references. -- The imported target "vtk" references the file "/usr/bin/vtk" but this file does not exist. Possible reasons include: * The file was deleted, renamed, or moved to another location. * An install or uninstall procedure did not complete successfully. * The installation package was faulty and contained "/usr/lib/cmake/vtk-6.3/VTKTargets.cmake" but not all the files it references. -- Found VTK 6.3.0 (/usr/lib/cmake/vtk-6.3/UseVTK.cmake) -- Performing Test HAVE_C_WNO_UNUSED_VARIABLE -- Performing Test HAVE_C_WNO_UNUSED_VARIABLE - Success -- Performing Test CXX_HAS_MFPU_NEON -- Performing Test CXX_HAS_MFPU_NEON - Success -- Performing Test C_HAS_MFPU_NEON -- Performing Test C_HAS_MFPU_NEON - Success -- Looking for dlerror in dl -- Looking for dlerror in dl - found -- Performing Test HAVE_C_WNO_UNDEF -- Performing Test HAVE_C_WNO_UNDEF - Success -- ADE: Download: v0.1.1d.zip -- OpenCV Python: during development append to PYTHONPATH: /home/debian/opencv/opencv-4.1.1/build/python_loader -- Checking for modules 'libavcodec;libavformat;libavutil;libswscale' -- Found libavcodec, version 58.35.100 -- Found libavformat, version 58.20.100 -- Found libavutil, version 56.22.100 -- Found libswscale, version 5.3.100 -- Checking for module 'libavresample' -- Found libavresample, version 4.0.0 -- Checking for module 'gstreamer-base-1.0' -- Found gstreamer-base-1.0, version 1.14.4 -- Checking for module 'gstreamer-app-1.0' -- Found gstreamer-app-1.0, version 1.14.4 -- Checking for module 'gstreamer-riff-1.0' -- Found gstreamer-riff-1.0, version 1.14.4 -- Checking for module 'gstreamer-pbutils-1.0' -- Found gstreamer-pbutils-1.0, version 1.14.4 -- Checking for module 'libdc1394-2' -- Found libdc1394-2, version 2.2.5 -- Caffe: NO -- Protobuf: NO -- Glog: YES -- Checking for module 'freetype2' -- Found freetype2, version 22.1.16 -- Checking for module 'harfbuzz' -- Found harfbuzz, version 2.3.1 -- freetype2: YES (ver 22.1.16) -- harfbuzz: YES (ver 2.3.1) -- HDF5: Using hdf5 compiler wrapper to determine C configuration -- Found HDF5: /usr/lib/arm-linux-gnueabihf/hdf5/serial/libhdf5.so;/usr/lib/arm-linux-gnueabihf/libpthread.so;/usr/lib/arm-linux-gnueabihf/libsz.so;/usr/lib/arm-linux-gnueabihf/libz.so;/usr/lib/arm-linux-gnueabihf/libdl.so;/usr/lib/arm-linux-gnueabihf/libm.so (found version "1.10.4") -- Module opencv_ovis disabled because OGRE3D was not found -- No preference for use of exported gflags CMake configuration set, and no hints for include/library directories provided. Defaulting to preferring an installed/exported gflags CMake configuration if available. -- Found installed version of gflags: /usr/lib/arm-linux-gnueabihf/cmake/gflags -- Detected gflags version: 2.2.2 -- Found installed version of Eigen: /usr/lib/cmake/eigen3 -- Found required Ceres dependency: Eigen version 3.3.7 in /usr/include/eigen3 -- Found required Ceres dependency: glog -- Found installed version of gflags: /usr/lib/arm-linux-gnueabihf/cmake/gflags -- Detected gflags version: 2.2.2 -- Found required Ceres dependency: gflags -- Found Ceres version: 1.14.0 installed in: /usr with components: [EigenSparse, SparseLinearAlgebraLibrary, LAPACK, SuiteSparse, CXSparse, SchurSpecializations, OpenMP, Multithreading] -- Checking SFM deps... TRUE -- HDF5: Using hdf5 compiler wrapper to determine C configuration -- Excluding from source files list: modules/imgproc/src/corner.avx.cpp -- Excluding from source files list: modules/imgproc/src/imgwarp.avx2.cpp -- Excluding from source files list: modules/imgproc/src/imgwarp.sse4_1.cpp -- Excluding from source files list: modules/imgproc/src/resize.avx2.cpp -- Excluding from source files list: modules/imgproc/src/resize.sse4_1.cpp -- Excluding from source files list: modules/imgproc/src/sumpixels.avx512_skx.cpp -- Registering hook 'INIT_MODULE_SOURCES_opencv_dnn': /home/debian/opencv/opencv-4.1.1/modules/dnn/cmake/hooks/INIT_MODULE_SOURCES_opencv_dnn.cmake -- opencv_dnn: filter out ocl4dnn source code -- opencv_dnn: filter out cuda4dnn source code -- Excluding from source files list: <BUILD>/modules/dnn/layers/layers_common.avx.cpp -- Excluding from source files list: <BUILD>/modules/dnn/layers/layers_common.avx2.cpp -- Excluding from source files list: <BUILD>/modules/dnn/layers/layers_common.avx512_skx.cpp -- Excluding from source files list: modules/features2d/src/fast.avx2.cpp -- Performing Test HAVE_CXX_WNO_OVERLOADED_VIRTUAL -- Performing Test HAVE_CXX_WNO_OVERLOADED_VIRTUAL - Success -- Checking for module 'tesseract' -- Found tesseract, version 4.0.0 -- Tesseract: YES (ver 4.0.0) -- xfeatures2d/boostdesc: Download: boostdesc_bgm.i -- xfeatures2d/boostdesc: Download: boostdesc_bgm_bi.i -- xfeatures2d/boostdesc: Download: boostdesc_bgm_hd.i -- xfeatures2d/boostdesc: Download: boostdesc_binboost_064.i -- xfeatures2d/boostdesc: Download: boostdesc_binboost_128.i -- xfeatures2d/boostdesc: Download: boostdesc_binboost_256.i -- xfeatures2d/boostdesc: Download: boostdesc_lbgm.i -- xfeatures2d/vgg: Download: vgg_generated_48.i -- xfeatures2d/vgg: Download: vgg_generated_64.i -- xfeatures2d/vgg: Download: vgg_generated_80.i -- xfeatures2d/vgg: Download: vgg_generated_120.i -- data: Download: face_landmark_model.dat -- No preference for use of exported gflags CMake configuration set, and no hints for include/library directories provided. Defaulting to preferring an installed/exported gflags CMake configuration if available. -- Found installed version of gflags: /usr/lib/arm-linux-gnueabihf/cmake/gflags -- Detected gflags version: 2.2.2 -- Found installed version of Eigen: /usr/lib/cmake/eigen3 -- Found required Ceres dependency: Eigen version 3.3.7 in /usr/include/eigen3 -- Found required Ceres dependency: glog -- Found installed version of gflags: /usr/lib/arm-linux-gnueabihf/cmake/gflags -- Detected gflags version: 2.2.2 -- Found required Ceres dependency: gflags -- Found Ceres version: 1.14.0 installed in: /usr with components: [EigenSparse, SparseLinearAlgebraLibrary, LAPACK, SuiteSparse, CXSparse, SchurSpecializations, OpenMP, Multithreading] -- Checking SFM deps... TRUE -- Performing Test HAVE_CXX_WNO_UNUSED_BUT_SET_VARIABLE -- Performing Test HAVE_CXX_WNO_UNUSED_BUT_SET_VARIABLE - Success -- Performing Test HAVE_CXX_WNO_UNUSED_PRIVATE_FIELD -- Performing Test HAVE_CXX_WNO_UNUSED_PRIVATE_FIELD - Failed -- -- General configuration for OpenCV 4.1.1 ===================================== -- Version control: unknown -- -- Extra modules: -- Location (extra): /home/debian/opencv/opencv_contrib-4.1.1/modules -- Version control (extra): unknown -- -- Platform: -- Timestamp: 2019-07-30T13:27:22Z -- Host: Linux 4.19.0-5-armmp-lpae armv7l -- CMake: 3.13.4 -- CMake generator: Unix Makefiles -- CMake build tool: /usr/bin/make -- Configuration: Release -- -- CPU/HW features: -- Baseline: VFPV3 NEON -- requested: DETECT -- required: VFPV3 NEON -- -- C/C++: -- Built as dynamic libs?: YES -- C++ Compiler: /usr/bin/c++ (ver 8.3.0) -- C++ flags (Release): -DTBB_USE_GCC_BUILTINS=1 -D__TBB_64BIT_ATOMICS=0 -fsigned-char -W -Wall -Werror=return-type -Werror=non-virtual-dtor -Werror=address -Werror=sequence-point -Wformat -Werror=format-security -Wmissing-declarations -Wundef -Winit-self -Wpointer-arith -Wshadow -Wsign-promo -Wuninitialized -Winit-self -Wsuggest-override -Wno-delete-non-virtual-dtor -Wno-comment -Wimplicit-fallthrough=3 -Wno-strict-overflow -fdiagnostics-show-option -pthread -fomit-frame-pointer -ffunction-sections -fdata-sections -mfpu=neon -fvisibility=hidden -fvisibility-inlines-hidden -O3 -DNDEBUG -DNDEBUG -- C++ flags (Debug): -DTBB_USE_GCC_BUILTINS=1 -D__TBB_64BIT_ATOMICS=0 -fsigned-char -W -Wall -Werror=return-type -Werror=non-virtual-dtor -Werror=address -Werror=sequence-point -Wformat -Werror=format-security -Wmissing-declarations -Wundef -Winit-self -Wpointer-arith -Wshadow -Wsign-promo -Wuninitialized -Winit-self -Wsuggest-override -Wno-delete-non-virtual-dtor -Wno-comment -Wimplicit-fallthrough=3 -Wno-strict-overflow -fdiagnostics-show-option -pthread -fomit-frame-pointer -ffunction-sections -fdata-sections -mfpu=neon -fvisibility=hidden -fvisibility-inlines-hidden -g -O0 -DDEBUG -D_DEBUG -- C Compiler: /usr/bin/cc -- C flags (Release): -fsigned-char -W -Wall -Werror=return-type -Werror=non-virtual-dtor -Werror=address -Werror=sequence-point -Wformat -Werror=format-security -Wmissing-declarations -Wmissing-prototypes -Wstrict-prototypes -Wundef -Winit-self -Wpointer-arith -Wshadow -Wuninitialized -Winit-self -Wno-comment -Wimplicit-fallthrough=3 -Wno-strict-overflow -fdiagnostics-show-option -pthread -fomit-frame-pointer -ffunction-sections -fdata-sections -mfpu=neon -fvisibility=hidden -O3 -DNDEBUG -DNDEBUG -- C flags (Debug): -fsigned-char -W -Wall -Werror=return-type -Werror=non-virtual-dtor -Werror=address -Werror=sequence-point -Wformat -Werror=format-security -Wmissing-declarations -Wmissing-prototypes -Wstrict-prototypes -Wundef -Winit-self -Wpointer-arith -Wshadow -Wuninitialized -Winit-self -Wno-comment -Wimplicit-fallthrough=3 -Wno-strict-overflow -fdiagnostics-show-option -pthread -fomit-frame-pointer -ffunction-sections -fdata-sections -mfpu=neon -fvisibility=hidden -g -O0 -DDEBUG -D_DEBUG -- Linker flags (Release): -latomic -Wl,--gc-sections -- Linker flags (Debug): -latomic -Wl,--gc-sections -- ccache: YES -- Precompiled headers: NO -- Extra dependencies: dl m pthread rt -- 3rdparty dependencies: -- -- OpenCV modules: -- To be built: aruco bgsegm bioinspired calib3d ccalib core datasets dnn dnn_objdetect dpm face features2d flann freetype fuzzy gapi hdf hfs highgui img_hash imgcodecs imgproc line_descriptor ml objdetect optflow phase_unwrapping photo plot python3 quality reg rgbd saliency sfm shape stereo stitching structured_light superres surface_matching text tracking ts video videoio videostab viz xfeatures2d ximgproc xobjdetect xphoto -- Disabled: world -- Disabled by dependency: - -- Unavailable: cnn_3dobj cudaarithm cudabgsegm cudacodec cudafeatures2d cudafilters cudaimgproc cudalegacy cudaobjdetect cudaoptflow cudastereo cudawarping cudev cvv java js matlab ovis python2 -- Applications: perf_tests apps -- Documentation: NO -- Non-free algorithms: NO -- -- GUI: -- GTK+: YES (ver 3.24.5) -- GThread : YES (ver 2.58.3) -- GtkGlExt: NO -- VTK support: YES (ver 6.3.0) -- -- Media I/O: -- ZLib: /usr/lib/arm-linux-gnueabihf/libz.so (ver 1.2.11) -- JPEG: /usr/lib/arm-linux-gnueabihf/libjpeg.so (ver 62) -- WEBP: /usr/lib/arm-linux-gnueabihf/libwebp.so (ver encoder: 0x020e) -- PNG: /usr/lib/arm-linux-gnueabihf/libpng.so (ver 1.6.36) -- TIFF: /usr/lib/arm-linux-gnueabihf/libtiff.so (ver 42 / 4.0.10) -- JPEG 2000: build (ver 1.900.1) -- OpenEXR: build (ver 2.3.0) -- HDR: YES -- SUNRASTER: YES -- PXM: YES -- PFM: YES -- -- Video I/O: -- DC1394: YES (2.2.5) -- FFMPEG: YES -- avcodec: YES (58.35.100) -- avformat: YES (58.20.100) -- avutil: YES (56.22.100) -- swscale: YES (5.3.100) -- avresample: YES (4.0.0) -- GStreamer: YES (1.14.4) -- v4l/v4l2: YES (linux/videodev2.h) -- -- Parallel framework: TBB (ver 2019.0 interface 11008) -- -- Trace: YES (with Intel ITT) -- -- Other third-party libraries: -- Lapack: YES (/usr/lib/arm-linux-gnueabihf/liblapack.so /usr/lib/arm-linux-gnueabihf/libcblas.so /usr/lib/arm-linux-gnueabihf/libatlas.so) -- Eigen: YES (ver 3.3.7) -- Custom HAL: YES (carotene (ver 0.0.1)) -- Protobuf: build (3.5.1) -- -- Python 3: -- Interpreter: /usr/bin/python3 (ver 3.7.3) -- Libraries: /usr/lib/arm-linux-gnueabihf/libpython3.7m.so (ver 3.7.3) -- numpy: /usr/local/lib/python3.7/dist-packages/numpy/core/include (ver 1.16.4) -- install path: lib/python3.7/dist-packages/cv2/python-3.7 -- -- Python (for build): /usr/bin/python3 -- -- Java: -- ant: NO -- JNI: NO -- Java wrappers: NO -- Java tests: NO -- -- Install to: /usr/local -- ----------------------------------------------------------------- -- -- Configuring done -- Generating done -- Build files have been written to: /home/debian/opencv/opencv-4.1.1/buildちなみに私は RaspberryPi4 を所持していません。 仮想環境で作業することのメリットと言えば、RaspberryPiと同等の環境をあちこちの端末上に量産できることです。 ビルド好きな方は、いろいろなビルドパラメータで同時並行で試行することができますね。 はい、承知しております。 Docker や chroot でいいじゃん、とか冷たいこと言わないでください。
2.Environment
- Ubuntu 16.04 x86_64
- QEMU 4.0.0
- Debian Buster armhf (RAM 4GB, CPU 8 core)
3.Procedure
まず、 QEMU4.0.0 のハードウェアエミュレーションモードで Debian Buster armhf のOSイメージをゼロから作成する方法 (Kernel 4.19.0-5-armmp-lpae, Tensorflow armhfビルド用) でQEMUの仮想環境を構築します。そのうえで下記のコマンドにより、 CPU 8core かつ RAM 4GB の Debian Buster armhf を起動します。
Start_Debian_Buster$ qemu-system-arm -M virt -m 4096 -smp 8 \ -kernel vmlinuz-4.19.0-5-armmp-lpae \ -initrd initrd.img-4.19.0-5-armmp-lpae \ -append 'root=/dev/vda2' \ -drive if=none,file=hda.qcow2,format=qcow2,id=hd \ -device virtio-blk-device,drive=hd \ -netdev user,id=mynet \ -device virtio-net-device,netdev=mynet \ -nographic次に、下記の手順で OpenCV 4.1.1 をビルドします。
Download_and_build_OpenCV# Install required tools $ sudo apt-get install -y \ libjpeg62-turbo-dev libtiff5-dev libpng16-16 libceres-dev \ libatlas3-base liblapack3 libv4l-0 libxvidcore4 liblept5 \ libopenblas-dev libatlas-base-dev libavcodec-dev libblas-dev \ libavformat-dev libavutil-dev libswscale-dev libpng-dev \ libtiff-dev ccache libeigen3-dev liblapacke-dev libavresample-dev \ libtesseract-dev libgoogle-glog-dev libgflags-dev libvtk6-dev \ libharfbuzz-dev libdc1394-22-dev libtesseract-dev \ libgstreamer-opencv1.0-0 libgstreamer-plugins-base1.0-dev \ libgstreamer-ocaml-dev libgstreamer1.0-dev libgstreamermm-1.0-dev \ libgtk2.0-dev libgtk-3-dev libcanberra-gtk-dev libcanberra-gtk3-dev # Download OpenCV 4.1.1 $ curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=1LrhoBQcYEz-zFCDY-_lNMJ1OZpay9PhP" > /dev/null $ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)" $ curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=1LrhoBQcYEz-zFCDY-_lNMJ1OZpay9PhP" -o opencv.zip # Download OpenCV_contrib 4.1.1 $ curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=1GxzSbwwhk1rlq8lH8yQUFgqXATNm0Z8l" > /dev/null $ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)" $ curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=1GxzSbwwhk1rlq8lH8yQUFgqXATNm0Z8l" -o opencv_contrib.zip $ unzip opencv.zip $ unzip opencv_contrib.zip $ rm opencv.zip opencv_contrib.zip $ cd opencv-4.1.1 $ mkdir build;cd build $ nano ../modules/core/include/opencv2/core/private.hpp # include <Eigen/Core> ↓ # include <eigen3/Eigen/Core> $ cmake -D CMAKE_CXX_FLAGS="-DTBB_USE_GCC_BUILTINS=1 -D__TBB_64BIT_ATOMICS=0" \ -D CMAKE_BUILD_TYPE=Release \ -D CMAKE_INSTALL_PREFIX=/usr/local \ -D INSTALL_PYTHON_EXAMPLES=OFF \ -D OPENCV_EXTRA_MODULES_PATH=${PWD}/../../opencv_contrib-4.1.1/modules \ -D BUILD_EXAMPLES=OFF \ -D BUILD_TESTS=OFF \ -D PYTHON_DEFAULT_EXECUTABLE=$(which python3) \ -D BUILD_opencv_python2=OFF \ -D BUILD_opencv_python3=ON \ -D WITH_OPENCL=OFF \ -D WITH_OPENGL=OFF \ -D WITH_TBB=ON \ -D BUILD_TBB=ON \ -D WITH_CUDA=OFF \ -D WITH_QT=OFF \ -D ENABLE_VFPV3=ON \ -D ENABLE_NEON=ON \ -D OPENCV_GENERATE_PKGCONFIG=ON \ -DCMAKE_SHARED_LINKER_FLAGS='-latomic' .. $ make -j $(($(nproc) + 1)) $ sudo make install $ sudo ldconfig以上でビルドとインストールが完了です。 インストーラの生成方法は後日追記します。
そもそも、どんなビルドオプションがあるかなんか分からへんやん。という方へ。
ccmakeという便利なツールがあります。buildフォルダへ移動したあとにccmake ..を実行すると。。。Install_ccmake$ sudo apt-get install cmake-curses-gui $ cd opencv-4.1.1/build $ ccmake ..下図のように表示されますので、 C を押すと。。。
このような表示に変わりますのでしばらく待ちます。
下図のように表示されたら、 E を押します。
すると、下図のような表示に切り替わります。 Enter キーを押すとパラメータが変更できます。 この画面のイメージでは12ページ分の設定があることになっていますね。 OpenCVの設定、多すぎてカオスです。
4.Reference articles
[メモ] ラズパイ OpenCV 4.1.1 ビルド時の__atomic_~~エラー対処 - Qiita - mt08さん
5.Finally
@mt08さんのおかげで、Tensorflow のフルビルドに比べて1000倍楽でした。




- 投稿日:2019-07-30T23:19:36+09:00
2019年のPython仮想環境はvenvで
Python3のvenvがお手軽かつ便利ということで試してみた。
環境: macOS Mojave
前提: brewはインストール済みデフォルトの確認
$ which python /usr/local/bin/python $ python --version Python 2.7.16Python3のインストール
$ brew install python3PATHとバージョンの確認
$ which python /usr/local/bin/python $ python --version Python 2.7.16 $ which python3 /usr/local/bin/python3 $ python3 --version Python 3.7.4Python3での仮想環境の作成(適当なディレクトリで)
$ mkdir py37 $ cd py37 $ python3 -m venv env # envは仮想環境名仮想環境の有効化
$ source env/bin/activate (env) $ which python /private/tmp/py37/env/bin/python (env) $ python --version Python 3.7.4仮想環境の無効化
(env) $ deactivate $ python --version Python 2.7.16
- 2.7系はpyenv使うしかないかな

- 投稿日:2019-07-30T23:07:34+09:00
ラズパイ電子工作~PWM制御を用いた簡易扇風機~
この記事はリンク情報システムの「2019 Tech Connect Summer」のリレー記事です。
engineer.hanzomonのグループメンバーによってリレーされます。(リンク情報システムのFacebookはコチラ)
今日で5日目………筆者は私@t_slash_kです。
ふぇぇ………暑い……けど…………頑張る………………!
………ということで本日はそんな暑い夏を少しでも快適に過ごせるように、
「Raspberry Pi 3」と「PWM制御」を用いてモーターを制御する扇風機を製作してみました。記事の内容も割と箸休め的部分が大きいので、読みながら涼んでいってください。くれぐれも体調は壊さないように。1.扇風機の仕様
仕様
「ラズパイで扇風機を作ろう!」といっても、「ただスイッチを入れたら扇風機の羽が回る」だけのものならわざわざラズパイを使わなくてもモーターとスイッチと電源と配線材があればすぐに出来上がります。それではラズパイを使う意味がないので、以下の仕様を追加しました。
・4段階の風量調節(後述のPWM制御を用いる)
・1つの押ボタンスイッチを押す度に「扇風機の回転/停止」及び
「4段階の風量調節」をおこなう(市販のハンディ扇風機によくある仕様)
・現在の扇風機の状態をコンソールで表示PWM制御とは
ラズパイの出力はデジタル方式なので、オン/オフの2通りしか出力できません。そこで、PWM(Pulse Width Modulation:パルス変調)という出力方式を用いることで、擬似的にアナログ方式の出力を行います。
PWMの仕組みとしては、出力のオン/オフの切り替えを高速で行い、1周期のうちの「オンの時間の長さ」に比例した任意の電圧を出力することで擬似的なアナログ出力を得るといった感じです。
本記事ではこのPWMを用いて、扇風機の羽を回すモーターの回転数を制御していきます。2.用意/準備したもの
- Raspberry Pi 3 Model B(ラズパイ)及びラズパイ用の電源
- FA‐130モーター(FA-130RAでも可)
- 3枚プロペラ(小)
- 単3電池2本用電池ボックス×2(単3×4電池ボックスでも可)
- 単3電池×4
- コンデンサ 0.1μF
- 抵抗 5.1kΩ
- タクトスイッチ(押ボタンスイッチ)
- モータードライバー TA7291P
- ブレッドボード
- ジャンパワイヤ(オス~オス)(オス~メス)
- はんだごて&はんだ
- 両面テープ
- カップ焼きそばの容器
3.ラズパイ側の準備
初期設定
ラズパイを動かすにはまず初期設定として「Raspbian」をインストールする必要がありますが、この方法についてはラズパイ関連の書籍には必ずと言っていいほど記載されていますし、ネットの海にごろごろ転がっているためここでは割愛します。
なんなら、最近は秋葉原に行けば「OS書き込み済Raspberry Piスターターセット」なるお得セットが店頭に陳列されています。便利な世の中になったなぁ…インターフェースの準備
ラズパイで電子回路を制御するには、 GPIO (General Purpose Input/Output)とよばれる
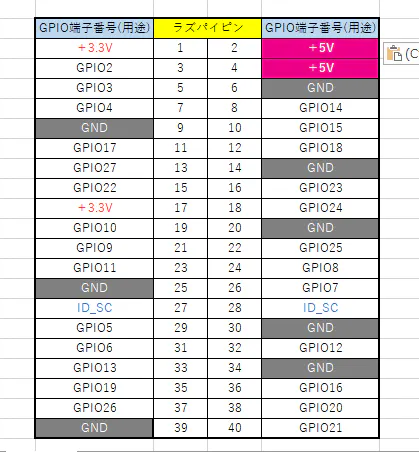
インターフェースを利用します。このGPIOをプログラムで操作するには、関連するライブラリが必要となります。そのライブラリとしてraspberry-gpio-python(RPi.GPIO)がラズパイには標準でインストールされているされていますが、今回は「WiringPi」と呼ばれるライブラリを用いているため、以下のコマンドを実行してWiringPiをインストールしておきます。$ sudo pip3 install wiringpiGPIOピンとラズパイピンの対応図
ラズパイピンの端子番号とGPIOの番号は違うため、以下に対応図を示します。
4.扇風機の製作
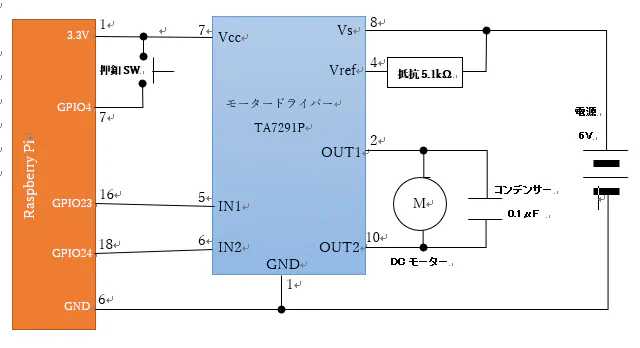
回路について
今回製作する扇風機の回路図を以下に示します。
まずは前提として、モーターの動作には数百mA~数十Aの大電流を消費します。そんな大電流を流したらラズパイ自体が停止するか、最悪壊れるリスクがあります。つまり何が言いたいかと言うと、モーターはラズパイで直接制御できません。
そこで今回はTA7291Pというモータードライバーを介して、ラズパイでのモーター制御を行うようにしました。データシートはこちらから。
また、モーターにはノイズ軽減用のコンデンサーを、モータードライバーのVrefには電流制限用の抵抗をつけておきます。実際に組み立て
1.ノイズ軽減用のコンデンサーをモーターの端子にはんだ付けします。
2.回路図の通りに、ブレッドボードに回路を組んでいきます。ここでポイントを1点。
・モータードライバー「TA7291P」は1列に10本のピンが並んだ形状となっていますが、金属の角の部分の切り欠きが大きいほうの端のピンが1番ピンとなります。以降はのピン配置は単純に順送りとなっています。データシート見れば何言いたいかは大体わかるはず
3.配線が終わったら、モーター、電池ボックス、ブレッドボードをカップ焼きそばの容器に両面テープで固定します。この際、モーターの軸にプロペラも取り付けてしまいます。
5.ソースコードの説明
ソースコード及びソースコードの説明について、以下に記述します。
なお、ソースコードはpythonを使って書きました。# ライブラリのインポート import RPi.GPIO as GPIO import wiringpi as pi import time # スイッチを接続したGPIOピンの定義 POWER_SW_PIN = 4 # モータードライバーを接続したGPIOピンの定義 IN1_MOTOR_PIN = 23 IN2_MOTOR_PIN = 24 # 各種設定 pi.wiringPiSetupGpio() pi.pinMode( POWER_SW_PIN, pi.INPUT ) pi.pinMode( IN1_MOTOR_PIN, pi.OUTPUT ) pi.pinMode( IN2_MOTOR_PIN, pi.OUTPUT ) pi.pullUpDnControl( POWER_SW_PIN, pi.PUD_DOWN ) # モータードライバを接続したGPIOをPWM出力できるようにする pi.softPwmCreate( IN1_MOTOR_PIN, 0, 100 ) pi.softPwmCreate( IN2_MOTOR_PIN, 0, 100 ) # モーターを停止した状態にする pi.softPwmWrite( IN1_MOTOR_PIN, 0 ) pi.softPwmWrite( IN2_MOTOR_PIN, 0 ) # ボタンが押された回数を初期化 countPower = 0 # 正常処理 try: while True: # ボタンが押されたらif文内の処理を実行 if ( pi.digitalRead( POWER_SW_PIN ) == pi.HIGH ): time.sleep( 0.5 ) # ボタンが押された回数のカウントを1つ上げる countPower = countPower + 1 # ボタンが押された回数によってモーターの制御を分岐 if countPower % 5 == 1: pi.softPwmWrite( IN1_MOTOR_PIN, 0 ) pi.softPwmWrite( IN2_MOTOR_PIN, 25 ) print("微風") elif countPower % 5 == 2: pi.softPwmWrite( IN1_MOTOR_PIN, 0 ) pi.softPwmWrite( IN2_MOTOR_PIN, 50 ) print("弱風") elif countPower % 5 == 3: pi.softPwmWrite( IN1_MOTOR_PIN, 0 ) pi.softPwmWrite( IN2_MOTOR_PIN, 75 ) print("強風") elif countPower % 5 == 4: pi.softPwmWrite( IN1_MOTOR_PIN, 0 ) pi.softPwmWrite( IN2_MOTOR_PIN, 100 ) print("最大") else: pi.softPwmWrite( IN1_MOTOR_PIN, 100 ) pi.softPwmWrite( IN2_MOTOR_PIN, 100 ) print("停止\n") # スイッチのチャタリング防止 while ( pi.digitalRead( POWER_SW_PIN ) == pi.LOW ): time.sleep( 0.1 ) time.sleep( 0.1 ) # プログラム強制終了時にモーターを止める except KeyboardInterrupt: pi.softPwmWrite( IN1_MOTOR_PIN, 0 ) pi.softPwmWrite( IN2_MOTOR_PIN, 0 ) print("Stop")
ソースコードのコメント文で説明しきれなかった特筆すべき点として、
・「#各種設定」の処理は上から順に
・「GPIOの初期化」
・「スイッチを接続したGPIOピンを入力モードに指定」
・「モータードライバのIN1に接続した端子を出力モードに指定」
・「モータードライバのIN2に接続した端子を出力モードに指定」
・「スイッチを接続したGPIOピンのプルダウン抵抗を有効化」
となっております。
・「# ボタンが押された回数によってモーターの制御を分岐」について、現在のソースコードではプロペラは左回転します。右回転にしたい場合は、「pi.softPwmWrite()」内の第2引数の数字をIN1とIN2で逆にすることで実現できます。6.実行~涼んでみよう~
回路の組み立て及びソースコードの準備が完了したらさっそくプログラムを実行してみましょう。
実行しただけだとモーターは停止状態のままになっています。その状態で、押ボタンスイッチを1回押します。すると……
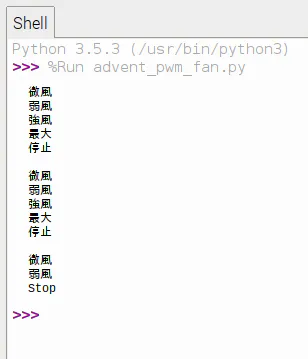
モーターが回り始め、プロペラから風が出てきます。押ボタンスイッチを押すたびに、「微風→弱風→強風→最大風→停止→微風・・・」と、風量の状態が切り替わります。プログラムを終了すると扇風機も止まります。これらの状態はコンソール上でも確認できます(下図)。
………………とにかく、めっちゃ涼しい!
7.おわりに
筆者は小~中学生の頃から趣味でちょくちょく電子工作をしていました(
最近はあまりしていなかったのですが)。
今回の記事執筆を通して「Raspberry Piを用いての電子工作」というものに触れて、「電子工作の形態の多様化」と「自分もしかしたらこんなものも作れるかもしれない」という自分への新たな可能性を改めて感じました。ぶっちゃけ楽しかったです。今後も続けていきたいです。最後に、夏休みの宿題の「自由研究」のネタに悩んでいるであろう小中学生の皆さん。電子工作やロボット工作などの「ものづくり」を通して童心に帰りたい大人の皆さん。
筆者と同じように「手軽に楽しく技術スキルを上げたい」と考えている皆さん。この機会にラズパイ電子工作に触れてみるのはいかがでしょうか。
特に小学生の皆さんは2020年度には小学校でプログラミング教育が必修化されるみたいだし………(P.S.)明日は@taisuke3さんが記事執筆を担当します。



- 投稿日:2019-07-30T22:50:01+09:00
Joblibの様々な便利機能を把握する
Joblibとは
Joblibは、並列処理などいろんな便利機能を寄せ集めたようなPythonライブラリです。
Joblibを使うことで
- 並列化
- メモ化
- 直列化〔シリアライズ〕
などを簡単に実装でき、特にPythonコードの高速化に役立ちます。
Joblibは一般に並列化に使われることが多いようですが、ドキュメントを覗いてみると他にも便利な機能が色々とまとめられていたので、本記事ではその辺を整理してみました。
なお、Joblibはpipでインストールできます。
pip install joblib並列化
下記の例では平方根を返す関数(
math.sqrt)を並列化しています。from joblib import Parallel, delayed from math import sqrt out = Parallel(n_jobs=2)(delayed(sqrt)(i) for i in range(100)) print(out) # [0.0, 1.0, 1.4142135623730951, 1.7320508075688772, 2.0, 2.23606797749979, ...ポイントは、
n_jobs=2でコア数を指定しているところです。
n_jobs=1でコア数が1、n_jobs=2でコア数が2になります。
もちろん、コア数が多ければ多いほど高速になります。
またコア数の上限は環境に依りますが、n_jobs=-1とすることで自動的に上限のコア数がセットされます。メモ化
下記の例では平方根を返す関数(
math.sqrt)をメモ化(Wikipedia)しています。from joblib import Memory import math cachedir = "./memory_cache" memory = Memory(cachedir, verbose=0) @memory.cache def calc(x): print("RUNNING......") return math.sqrt(x) print(calc(2)) print(calc(2)) print(calc(5)) # RUNNING...... # 1.41421356237 # 1.41421356237 # RUNNING...... # 1.73205080757ポイントは、関数を
@memory.cacheでデコレートしているところです。
デコレートした関数の出力結果に注目してみましょう。1回目の実行では、引数
2を与えて通常通り計算が行われています。しかし、同じ引数(
2)を与えた2回目の実行では、関数の中で計算は行われず計算結果だけが返ってきていることがわかります。そして、1回目や2回目と異なる引数(
5)を与えた3回目の実行では、今度は関数の中で計算が行われた上で計算結果が返ってきています。このような挙動を特定の関数に与えるテクニックをメモ化と言います。
重複する引数による関数の再計算を防ぐことで、特に同じ引数が頻出する場面(フィボナッチ数列など)で高速化が期待できます。直列化 〔シリアライズ〕
※ここでの直列化はオブジェクトのバイナリ列への変換を指します。
下記の例では平方根を返す関数(
numpy.sqrt)が返したリストを直列化(Wikipedia)しています。import joblib import numpy as np out = np.sqrt(np.arange(1024)) filename = "./pydata" with open(filename, "wb") as f: joblib.dump(out, f, compress=3) with open(filename, "rb") as f: loaded = joblib.load(f) print(loaded) # [ 0. 1. 1.41421356 ..., 31.95309062 31.96873473 31.98437118]流れとしては、
- 関数(
numpy.sqrt)がリストを出力する(もちろん関数は何でもよい)joblib.dumpを使ってリストを圧縮して./pydataに保存する(compressで圧縮率の変更が可能)joblib.loadを使って圧縮データから元のリストを復元するということを行なっています。
まとめ
項目 利用 備考 並列化 joblib.Parallel同時に複数の演算処理を実行する メモ化 joblib.Memory計算結果を一時保存し、重複する引数による関数の再計算を防ぐ 直列化 joblib.dump,joblib.load大容量の計算結果を圧縮して保存する(取り出す) Joblibで素敵なPythonライフを!
参考
- 投稿日:2019-07-30T22:44:08+09:00
話題の粛清ソートアルゴリズム「スターリンソート」をPythonで実装した
スターリンソートとは
ソートされていない要素を粛清することでO(N)でソートできるスターリンソートとかいうのを見て爆笑してる
— やんぎん (@4116You) July 28, 2019今話題の計算量が $O(n)$ で済む驚異のソートアルゴリズム、スターリンソートをご存知でしょうか。
中身はいたってシンプルで、ソートされていない要素を削除(粛清)して、強引に昇順リストを生成します。
例えば、[1, 2, 1, 1, 4, 3, 9]というリストをスターリンソートすると[1, 2, 4, 9]になります。(1, 1, 3が粛清されました)粛清というパワーワードがポイントですね。
既に先人達が色々な言語で実装しておりますが、知らない言語しかなかったのでこの度Pythonで実装してみました。
先行研究
計算量O(n)の画期的なソートアルゴリズムであるスターリンソートをHaskell で実装してみた #Haskell
計算量O(n)で噂のスターリンソートを実装してみた
[Rust] スターリンソートと PartialOrd
rubyでスターリンソートをやってみた(ブロック渡しも可能)Pythonで実装
コード
src = [1, 2, 1, 1, 4, 3, 9] purge = [] #purge : [動詞]〜を粛清する # 粛清すべき要素のインデックスを探す tmp = src[0] - 1 for i, e in enumerate(src): if e < tmp: purge.append(i) else: tmp = e # Let's 粛清!! for i, e in enumerate(purge): src.pop(e - i) print(src)標準出力
[1, 2, 4, 9]
1 1 3が粛清され、見事に昇順ソートされましたね。
ルールに従わない要素は消す、なんとも強引なアルゴリズムです。よいこのみなさんは他の正しいソートアルゴリズムを使いましょう。
追記
pop()は粛清感が出るけど計算量が $O(n)$ じゃなくなる、とのコメント多数頂いたのでpop()を使わない実装を考えました。data = [1, 2, 1, 1, 4, 3, 9] purged_data = [] #purge : [動詞]〜を粛清する tmp = data[0] - 1 for i, e in enumerate(data): if tmp <= e: purged_data.append(e) tmp = e print(purged_data)[1, 2, 4, 9]粛清感が薄れますが、このほうがすっきりしますね。
計算量も減りますし。(ていうか粛清感ってなんだよ)
- 投稿日:2019-07-30T22:31:26+09:00
Mementoパターンで戦国シミュレーション
Mementoパターンで戦国シミュレーション
某社内の勉強会で発表する資料づくりの一環でコードを書きました。
数学ガールの著者でもある結城浩さんの増補改訂版 Java言語で学ぶデザインパターン入門に基づき、
Pythonでプログラムを作成しました。nobunaga.pyimport random import time class Nobunaga: Busho = ['みつひで', 'らんまる', 'ひでよし', 'かついえ'] def __init__(self, strength, resource): self.strength = strength self.resource = resource self.busho = [] def get_strength(self): return self.strength def get_resource(self): return self.resource def get_busho(self): prefix = '' if bool(random.randint(0,1)): prefix = '強い' return prefix + random.choice(Nobunaga.Busho) def __str__(self): return '[兵力 = {}, 資源 = {}, 武将 = {}]'.format(self.strength, self.resource, self.busho) def battle(self): dice = random.randint(1, 6) if dice == 1: self.strength += 100 print('兵士を鍛錬し兵力が100上がった!') elif dice == 2 and self.resource > 99: self.resource *= 1.5 print('戦を行って勝ち、資源が1.5倍になった!') elif dice == 3 and self.resource > 99: self.strength -= 100 self.resource //= 2 print('戦を行って負け、資源が半分になった!') print('兵力が100下がった!') elif dice == 4: b = self.get_busho() print('武将の{}が仲間になった!'.format(b)) self.busho.append(b) elif dice == 5: if len(self.busho) > 0: b = random.choice(self.busho) print('武将{}が裏切った!'.format(b)) self.busho.remove(b) else: print('何も起こらなかった') elif dice == 6: self.resource += 100 print('農地を手に入れ、資源を100手に入れた!') else: print('資源が不足して何もできなかった...') def create_memento(self): m = Memento(self.strength,self.resource) for b in self.busho: if b.startswith('強い'): m.add_busho(b) return m def restore_memento(self, memento): self.strength = memento.get_strength() self.busho = memento.get_busho() class Memento: def __init__(self,strength,resource): self.strength = strength self.resource = 0 self.busho = [] def get_strength(self): return self.strength def add_busho(self, busho): self.busho.append(busho) def get_busho(self): return self.busho def main(): #クラスNobunagaのインスタンスnobuを生成 nobu = Nobunaga(100,100) memento = nobu.create_memento() for i in range(10): print(str(i+1)+'年目') print('ステータス:{}'.format(nobu)) #メソッド名はもう少し考えればよかった...。battle以外もするのになぁ。 nobu.battle() print('兵力は{}に、資源は{}になった!'.format(nobu.get_strength(), nobu.get_resource())) if nobu.get_strength() > memento.get_strength(): print(' (だいぶ強くなったから、現在の状態を巻物に記しておこう)') memento = nobu.create_memento() elif nobu.get_strength() < memento.get_strength() / 2: print(' (だいぶ弱くなったから、以前の状態まで時間を遡ろう)') nobu.restore_memento(memento) time.sleep(1) print() if __name__ == '__main__': main()実行結果1年目 ステータス:[兵力 = 100, 資源 = 100, 武将 = []] 兵士を鍛錬し兵力が100上がった! 兵力は200に、資源は100になった! (だいぶ強くなったから、現在の状態を巻物に記しておこう) 2年目 ステータス:[兵力 = 200, 資源 = 100, 武将 = []] 何も起こらなかった 兵力は200に、資源は100になった! 3年目 ステータス:[兵力 = 200, 資源 = 100, 武将 = []] 何も起こらなかった 兵力は200に、資源は100になった! 4年目 ステータス:[兵力 = 200, 資源 = 100, 武将 = []] 戦を行って勝ち、資源が1.5倍になった! 兵力は200に、資源は150.0になった! 5年目 ステータス:[兵力 = 200, 資源 = 150.0, 武将 = []] 農地を手に入れ、資源を100手に入れた! 兵力は200に、資源は250.0になった! 6年目 ステータス:[兵力 = 200, 資源 = 250.0, 武将 = []] 武将の強いみつひでが仲間になった! 兵力は200に、資源は250.0になった! 7年目 ステータス:[兵力 = 200, 資源 = 250.0, 武将 = ['強いみつひで']] 戦を行って勝ち、資源が1.5倍になった! 兵力は200に、資源は375.0になった! 8年目 ステータス:[兵力 = 200, 資源 = 375.0, 武将 = ['強いみつひで']] 戦を行って勝ち、資源が1.5倍になった! 兵力は200に、資源は562.5になった! 9年目 ステータス:[兵力 = 200, 資源 = 562.5, 武将 = ['強いみつひで']] 戦を行って負け、資源が半分になった! 兵力が100下がった! 兵力は100に、資源は281.0になった! 10年目 ステータス:[兵力 = 100, 資源 = 281.0, 武将 = ['強いみつひで']] 戦を行って負け、資源が半分になった! 兵力が100下がった! 兵力は0に、資源は140.0になった! (だいぶ弱くなったから、以前の状態まで時間を遡ろう)ところで、強いってどうやって決めるのでしょうか?資源が多くても強いですし、武将が多くいても強い気がします
Strategyパターンと組み合わせてnobuの戦略を考えるのも面白いかもしれません!それではまた!
- 投稿日:2019-07-30T22:21:48+09:00
LeetCode / Convert Sorted Array to Binary Search Tree
(ブログ記事からの転載)
[https://leetcode.com/problems/convert-sorted-array-to-binary-search-tree/]
Given an array where elements are sorted in ascending order, convert it to a height balanced BST.
For this problem, a height-balanced binary tree is defined as a binary tree in which the depth of the two subtrees of every node never differ by more than 1.
Example:
a height-balanced binary tree is defined as a binary tree in which the depth of the two subtrees of every node never differ by more than 1ということで、
2つのsubtree間の深さに2以上の違いがないtree」を作れと言われています。解答・解説
解法1
2つのsubtree間の深さも1より大きな違いがないようなtreeは色々考えられるわけですが、問題文にもあった下図のように、
(binarytreeライブラリで作ってみましたがイマイチですね。。。)大元のrootから左右に2本subtreeが出て、あとは1本しかsubtreeがないようなtreeを考え、2つのsubtreeの深さに2以上の違いがないtree
を作るのがシンプルなアルゴリズムになります。より具体的には、
[-10, -3, 0, 5, 9] -> left: [-10, -3], root: 0, right: [5, 9]
のように、中央値をrootとし、中央値より前の値のリストをroot.leftに、中央値より後の値のリストをroot.rightとします。
そして、root.leftとroot.rightに対して同じ処理をする再帰的な構造にします。# Definition for a binary tree node. # class TreeNode: # def __init__(self, x): # self.val = x # self.left = None # self.right = None class Solution: def sortedArrayToBST(self, nums: List[int]) -> TreeNode: if not nums: return None mid = len(nums) // 2 root = TreeNode(nums[mid]) root.left = self.sortedArrayToBST(nums[:mid]) root.right = self.sortedArrayToBST(nums[mid+1:]) return root解法2
Discussionを眺めていたら、リストのスライスはコストが高いということで、修正案がありました。
class Solution: def sortedArrayToBST(self, nums: List[int]) -> TreeNode: def convert(left, right): if left > right: return None mid = (left + right) // 2 node = TreeNode(nums[mid]) node.left = convert(left, mid - 1) node.right = convert(mid + 1, right) return node return convert(0, len(nums) - 1)Python操作に関するコストは以下のページにまとまっています。

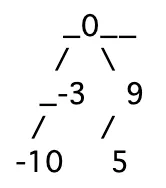
- 投稿日:2019-07-30T21:34:16+09:00
e-Stat API機能のバージョン3.0を使って統計表情報のCSVを取得してみる
e-Stat API機能のバージョン3.0を使って統計表情報のCSVを取得してみる
2019年7月26日、e-Stat API機能のバージョン3.0の提供が開始された。
統計表情報をCSV形式で取得できるようになったので、やってみる。
https://www.e-stat.go.jp/api/node/172
import os import io import requests import pandas as pdurl = "http://api.e-stat.go.jp/rest/3.0/app/getSimpleStatsList" app_id = os.getenv("E_STAT_API_APP_ID") limit = 10 params = {"appId": app_id, "limit": limit}response = requests.get(url, params=params)csv_text = response.text[response.text.find('"TABLE_INF",') :]df = pd.read_csv(io.StringIO(csv_text))df
TABLE_INF STAT_CODE STAT_NAME GOV_ORG_CODE GOV_ORG_NAME TABULATION_CATEGORY TABULATION_SUB_CATEGORY1 TABULATION_SUB_CATEGORY2 TABULATION_SUB_CATEGORY3 TABULATION_SUB_CATEGORY4 ... SURVEY_DATE OPEN_DATE SMALL_AREA COLLECT_AREA OVERALL_TOTAL_NUMBER UPDATED_DATE MAIN_CATEGORY_CODE MAIN_CATEGORY SUB_CATEGORY_CODE SUB_CATEGORY 0 3288322 20111 民間企業の勤務条件制度等調査 20 人事院 民間企業の勤務条件制度等調査(民間企業退職給付調査) 統計表 1 定年制と定年退職者の継続雇用の状況 NaN NaN ... 201601-201612 2019-03-20 0 該当なし 25 2019-03-30 3 労働・賃金 2 賃金・労働条件 1 3288323 20111 民間企業の勤務条件制度等調査 20 人事院 民間企業の勤務条件制度等調査(民間企業退職給付調査) 統計表 1 定年制と定年退職者の継続雇用の状況 NaN NaN ... 201601-201612 2019-03-20 0 該当なし 35 2019-03-30 3 労働・賃金 2 賃金・労働条件 2 3288324 20111 民間企業の勤務条件制度等調査 20 人事院 民間企業の勤務条件制度等調査(民間企業退職給付調査) 統計表 1 定年制と定年退職者の継続雇用の状況 NaN NaN ... 201601-201612 2019-03-20 0 該当なし 50 2019-03-30 3 労働・賃金 2 賃金・労働条件 3 3293683 20111 民間企業の勤務条件制度等調査 20 人事院 民間企業の勤務条件制度等調査(民間企業退職給付調査) 統計表 1 定年制と定年退職者の継続雇用の状況 NaN NaN ... 201601-201612 2019-03-20 0 該当なし 45 2019-03-30 3 労働・賃金 2 賃金・労働条件 4 3293681 20111 民間企業の勤務条件制度等調査 20 人事院 民間企業の勤務条件制度等調査(民間企業退職給付調査) 統計表 1 定年制と定年退職者の継続雇用の状況 NaN NaN ... 201601-201612 2019-03-20 0 該当なし 90 2019-03-30 3 労働・賃金 2 賃金・労働条件 5 3293682 20111 民間企業の勤務条件制度等調査 20 人事院 民間企業の勤務条件制度等調査(民間企業退職給付調査) 統計表 1 定年制と定年退職者の継続雇用の状況 NaN NaN ... 201601-201612 2019-03-20 0 該当なし 20 2019-03-30 3 労働・賃金 2 賃金・労働条件 6 3288404 20111 民間企業の勤務条件制度等調査 20 人事院 民間企業の勤務条件制度等調査(民間企業退職給付調査) 統計表 2 退職一時金・企業年金制度の状況 NaN NaN ... 201601-201612 2019-03-20 0 該当なし 25 2019-03-30 3 労働・賃金 2 賃金・労働条件 7 3293661 20111 民間企業の勤務条件制度等調査 20 人事院 民間企業の勤務条件制度等調査(民間企業退職給付調査) 統計表 2 退職一時金・企業年金制度の状況 NaN NaN ... 201601-201612 2019-03-20 0 該当なし 75 2019-03-30 3 労働・賃金 2 賃金・労働条件 8 3293684 20111 民間企業の勤務条件制度等調査 20 人事院 民間企業の勤務条件制度等調査(民間企業退職給付調査) 統計表 2 退職一時金・企業年金制度の状況 NaN NaN ... 201601-201612 2019-03-20 0 該当なし 72 2019-03-30 3 労働・賃金 2 賃金・労働条件 9 3293685 20111 民間企業の勤務条件制度等調査 20 人事院 民間企業の勤務条件制度等調査(民間企業退職給付調査) 統計表 2 退職一時金・企業年金制度の状況 NaN NaN ... 201601-201612 2019-03-20 0 該当なし 15 2019-03-30 3 労働・賃金 2 賃金・労働条件 10 rows × 35 columns
- 投稿日:2019-07-30T20:53:43+09:00
【Python】WordCloudでテキスト内のよく使われる単語を可視化しよう!【Mecab無し】
☁ WordCloudとは
文章中で出現頻度の高い単語を複数選び出し、その頻度に応じた大きさで図示する手法。
上記は実際に『レディー・ガガ』の『Born This Way』の歌詞で作成してみました。
この様にテキスト内の出現頻度の高い単語が大きく表示されビジュアル化出来ます。
そして比較的に簡単なコードで実践出来ます!
? 今回やりたいこと
1、WordCloudを作成してみる。
2、猫の形などユニークなWordCloudに挑戦
3、日本語文章でMecab(形態素解析エンジン)を使用せずに実現する(思い付き)
・準備
・Python3
・WordCloudMacはpipでインストール出来ます。
pip install wordcloudオープンソースなので本家GitHubのURL載せておきます。
【GitHub】word_cloud - amueller
☁ WordCloudの実践
1、同じフォルダに、
analyze.txtを作成して分析したい文章を入れて保存する。
2、Pythonコードを書きます。visualwords.py# coding: utf-8 from wordcloud import WordCloud # 作成したテキストの読み込み with open('analyze.txt', 'r') as f: text = f.read() # 除外したい単語 stop_text = ["ぴよぴよ", "ぽよぽよ"] # wordcloudの設定 wordcloud = WordCloud(background_color="white", font_path="/system/Library/Fonts/ヒラギノ角ゴシック W4.ttc", collocations = False, stopwords = stop_text, width=800,height=600).generate(text) # worcloudの作成 wordcloud.to_file("./wordcloud.png")・設定の補足
font_path=""にはPCのフォントパスを指定します。(上記はMac)
collocations = False同じ単語が2つ表示されるのを防ぐ
無事、レディー・ガガの『Born This Way』の歌詞で作成出来ました。
手軽に使ってみるだけならとても簡単ですね!
?? 日本語でWordCloud
では次に私のTwitter(@aocattleya)の過去全ツイートで作成してみます。
Twitterにて、[設定とプライバシー] → [Twitterデータ] → [データをリクエスト]
自分の全てのツイートがDL出来ます。(分析するテキストは何でもOK)
上手く出来ませんね...。
スペースで区切られてる英語文章と違い日本語はWordCloudに対応していません。
なので、Mecabという形態素解析エンジンを使うのが一般的です。
※今回は使いません。・Mecabとは
オープンソースの形態素解析エンジン。
現GoogleソフトウェアエンジニアでGoogle 日本語入力開発者の一人である工藤拓によって開発されている。簡単に説明すると、名詞や助詞などを判別してくれます。
Mecabの名称は開発者の好物メカブ
↓
Mecab の 名称 は 開発者 の 好物 メカブ
今回、簡単にWordCloudを試すのにインストールの面倒なMecabを入れるほどかな...。
と考えていると、自分でスペース区切りにすれば?と思いついたのでやってみました。試行錯誤の結果、見栄えを良くする為に以下を削除します。(自由に変更可)
・a〜Z 全て
・カタカナ 3文字以下
・ひらがな 4文字以下
・漢字 2文字以下a〜Zを削除
'''--------- a-Zを全て削除 ---------''' romaji = re.compile("[a-zA-Z]+") text = romaji.sub("", text)
re.compile("[a-zA-Z]+")
正規表現でa〜z、A〜Zを指定します。そして分析するテキスト内から見つけ出し → 空文字へ置換
(正規表現の置換の場合は、replaceではなくsub)テキスト内からa-z,A-Zが削除されました。
3文字以下のカタカナを削除
'''--------------------- 3文字以下の カタカナ を削除 ---------------------''' found_katanaka_list = [] four_text_list = [] pos = 0 katanaka_pattern = re.compile('[ァ-ヴ]+') while True: match1 = katanaka_pattern.search( text, pos ) if match1 == None: break # 見つかったカタカナの後からループ開始 pos = match1.end( 0 ) found_katanaka_list.append(match1[0]) for katakana_words in found_katanaka_list: # 文字数指定 if len(katakana_words) >= 4: four_text_list.append(katakana_words) text = katanaka_pattern.sub(" ", text) for katakana in four_text_list: text += " " + katakana + " "内容は、
1、正規表現でテキスト内からカタカナを見つけ出しリスト1へ追加(While文1つ目)
2、リスト1内から4文字以上のカタカナを見つけ出しリスト2へ追加(for文1つ目)
3、テキスト内のカタカナ全てを削除(下から4行目)
4、テキスト内にリスト2を前後にスペースを付けて追加(for文2つ目)これで、分析するテキストファイルから3文字以下のカタカナが消え、
4文字以上のカタカナの前後に、スペースが付いた状態で追加出来ました。4文字以下の ひらがな を削除
'''--------------------- 4文字以下の ひらがな を削除 ---------------------''' found_hiragana_list = [] five_text_list = [] pos = 0 hiragana_pattern = re.compile('[ぁ-ん]+') while True: match2 = hiragana_pattern.search( text, pos ) if match2 == None: break pos = match2.end( 0 ) found_hiragana_list.append(match2[0]) for hiragana_words in found_hiragana_list: # 文字数指定 if len(hiragana_words) >= 5: five_text_list.append(hiragana_words) text = hiragana_pattern.sub(" ", text) for hiragana in five_text_list: text += " " + hiragana + " "2文字以下の漢字を削除
visualwords.py'''---------------- 2文字以下の 漢字 を削除 ----------------''' found_kanzi_list = [] three_text_list = [] pos = 0 kanzi_pattern = re.compile('[一-龥]+') while True: match3 = kanzi_pattern.search( text, pos ) if match3 == None: break pos = match3.end( 0 ) found_kanzi_list.append(match3[0]) for kanzi_words in found_kanzi_list: # 文字数指定 if len(kanzi_words) >= 3: three_text_list.append(kanzi_words) text = kanzi_pattern.sub(" ", text) for kanzi in three_text_list: text += " " + kanzi + " "処理はほぼ同じ
完成した繋がったコードはこちら → default_visualwords.py(GitHub)実行してみます↓↓↓
いい感じになりました。
これだけではありきたりな見た目なので猫の形で作成してみましょう。? WordCloud 猫ver.
背景透過した猫のpng画像を用意してmaskとして設定します。
猫以外も、もちろん可能で画像は黒でなくても大丈夫です。from PIL import Image import numpy as np mask = np.array(Image.open('cat.png')) mask = np.where(mask == 0, 0, 255)'''----------- WordCloudの設定 -----------''' wordcloud = WordCloud(mask = mask, stopwords = stop, font_path="/system/Library/Fonts/ヒラギノ角ゴシック W4.ttc", colormap = 'copper_r', width=800, height=600).generate(text)画像を読み込んで、WordCloudの設定でmaskの指定と文字色をオレンジに変更。
完成したコード → visualwords.py(GitHub)
実行してみます↓↓↓
なかなかいい感じではないでしょうか!
ひとまず満足です。
似た方法で、分析するワードを絞り作成してみるのも良いかもと思いました。
テキスト内から指定した
プログラミング言語だけを見つけて他は全て削除
→ プログラミング言語だけの人気順WordCloudテキスト内から指定した
ポケモンの名前だけを見つけて他は全て削除
→ ポケモンの名前だけの人気順WordCloud今回は、カタカナや漢字などを指定しましたが面白そうです。
コードはリポジトリにまとめています。
【GitHub】WordCloud - aocattleya苦戦したこと
例えばテキスト内から、ひらがな4文字以下を削除しようとした場合に、
初めは4文字以下の単語を単純に見つけ出して削除していたのですが、
ひらがな全てが消えてしまう現象が起きました。
ありがとうならばあ,り,が,と,うで分解されて消えていた模様
なので上記のコードの、
1、テキスト内から5文字以上の、ひらがなを見つけてリストに追加
2、テキスト内からひらがな全て削除
3、後からテキスト内にリストを追加
というように修正した。
・問題点
・
君の名は。のような混ざった単語が出ない、個別に取得すれば可能だけど想定し辛い..。
・ カタカナ,ひらがな,漢字の処理が似てるので関数に出来そう?あと変数名見ずらい気がする。
..もうちっと力を付けるまで待っておくれ(๑•́‧̫•̀๑)
・終わりに
最初は簡単に実践できれば良いと思っていたのですが、
思い付きから色々やってみて、自己流ながら納得出来るように作れて楽しく嬉しかった。
正規表現は全く使ったことが無かったので使えたのも良かったです。WordCloud自体は結構有名な物なので、ぜひ色々試してみて下さい!
・参考
・ Pythonでテキストマイニング ②Word Cloudで可視化
・ Word Cloudで同じ単語が2回出てきて困る
~ リンク ~
https://twitter.com/aocattleya
GitHub
https://github.com/aocattleya
? Qiita
https://qiita.com/aocattleya




- 投稿日:2019-07-30T19:37:39+09:00
リッジ回帰の実装
はじめに
この記事は古川研究室 Workout_calendar 15日目の記事です。
線形回帰の勉強をしたら自ずとリッジ回帰も出てくると思います。線形回帰と何が違うんだろうと思ったので記事にしてみました!リッジ回帰とは
リッジ回帰とは過学習を防ぐため線形回帰に正則化項(ペナルティ項)としてL2ノルムを導入したモデルです。ざっくり説明すると過学習を抑える手法の一つとも言えます。
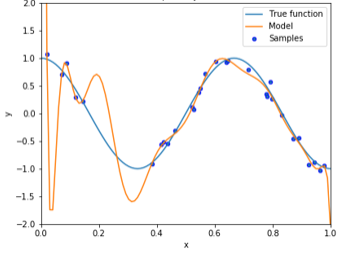
線形回帰での過学習
真の関数を$\cos$関数としノイズを乗せてプロットした点に多項式でフィッティングすると以下の図のように過学習してしまいます。これでは新しい入力に対して正確な予想ができません。ここで過学習を起こしているモデルのパラメーター$\theta$を確認してみます。パラメータ値が大きくなっていることがわかります。このように、過学習の特徴として学習したパラメータ値が大きくなる性質があります。そこでリッジ回帰ではこのパラメータ値が大きくならないように正則化項を用います。正則化項は様々ありますが、リッジ回帰ではL2ノルムを正則化項で用います。L1ノルムを用いるとラッソ回帰になります。
線形回帰により$cos$関数を14次多項式(下記)でフィッティングした様子(上図)
$y=θ_{14}x^{14}+θ_{13}x^{13}+θ_{12}x^{12}...+θ_{1}x+θ_{0}$リッジ回帰における正則化項の働き
先ほど述べた通り、線形回帰で過学習を起こすとパラメータの絶対値が増加します。
よってここではL2ノルムによりどのようにパラメータ値の増加化を防ぐのかを具体的にみていきます。まずは線形回帰から説明します。線形回帰では主に最小二乗法で誤差を求め、勾配降下法(他の手法もあります)で誤差を最小にするパラメータを求めます。(勾配降下法の説明は省きます)最小二乗誤差$J_{LS}(\theta)$は以下の式で示します。
$J_{LS}(\theta)=\displaystyle{\frac{1}{2}\sum_{i=1}^{N}(f_{\theta}(x_{i})-y_{i})^2}$
リッジ回帰ではこの二乗誤差に正則化項(L2ノルム)を加えます。
$J_{LS}(\theta)=\underset{\Large二乗誤差}{\underline{\displaystyle{\frac{1}{2}\sum_{i=1}^{N}(f_{\theta}(x_{i})-y_{i})^2}}}+\displaystyle\underset{\Large正則化項}{\underline{\frac{1}{2}\lambda\sum_{j=1}^{M}(\theta_{j})^2}}$正則化項をよくみるとパラメータ $\theta_{j}$ の2乗があるのが分かります。高次多項式において二乗誤差だけを最小化しようとするとパラメータ値が増大し(過学習)、プラスされている正則化項の値が大きくなってしまいます。
リッジ回帰ではこの正則化項を加えた状態での最小誤差を求めているので、$\theta_{j}$が大きくなるようなパラメータ値は選択しません。よって過学習を防ぐことができます。次に、正則化項には $\lambda$ を含んでいるのが分かります。これは正則化項の影響の強さを示しています。$\lambda$ はハイパーパラメータなので、事前に値を決めておく必要があります。$\lambda$を小さくすると正則化項の影響が小さくなり $\lambda=0$ にすると正則化項が消滅します(線形回帰)。逆に$\lambda$を大きくすると正則化項の影響が強くなります。以下の図は$\lambda$の値を大きくした場合のリッジ回帰を実装したものです。($\lambda=1$ 、14次多項式でフィッティング)
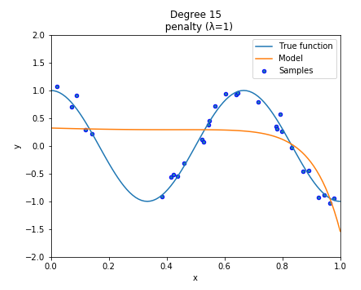
右側のパラメータ値が0に近い値になっているのが分かります。これはこれ以上正則化項の値を大きくしないように$\theta$の値を0に近づけるように学習していると言えます。このように$\lambda$は適切な値に設定しないと不適切なモデルになることがあります。モデルによって様子を見ながら適切な $\lambda$ を選択する必要があります。
なんだか罰が強すぎて何もできねぇって感じですね。リッジ回帰でのノルムのイメージ
次にノルムについて解説します。
イメージしやすいように1次関数による二乗誤差を考えます。y=θ_{1}x+θ_{0}この関数をリッジ回帰式にあてはめると以下のようになります。
J_{LS}(\theta)=\displaystyle\frac{1}{2} \sum_{i=1}^{n}(y_{i}-(θ_{1}x_{i}+θ_{0}))^2 +\frac{λ}{2}((θ_{1})^2+(θ_{0})^2) \lambda>0ここで正則化項の中身である$(θ_{1})^2+(θ_{0})^2$に注目します。これがL2ノルムなのですが、円の方程式になっていることが分かります。
L2ノルムのイメージとしてはxyz軸にそれぞれ{$\theta_{0},\theta_{1},$二乗誤差}をとります。するとxyz空間に各パラメータ値 $\theta_{0},\theta_{1}$における二乗誤差値からなる曲面を構成します。
正則化項がないとこの平面の全ての範囲から二乗誤差を最小にする$\theta_{0},\theta_{1}$を選択します。正則化項を導入すると下図のように、円の範囲内から二乗誤差を最小にする$\theta_{0},\theta_{1}$を選択します。高次関数でも同様に二乗誤差を最小にするパラメータ値の範囲を制限することで過学習を防いでいるのです。
$\theta_{0},\theta_{1}$の選択範囲である円の半径は正則化項の$\lambda$を調整することで可能です。$\lambda$ を小さくすると正則化項の値が小さくなり$\theta_{0},\theta_{1}$を選ぶ範囲が大きくなります。
実際にpythonで二乗誤差の平面を描写したものが以下になります(1次関数です)。先ほど述べた通り、L2ノルムを導入すると赤い円の範囲から二乗誤差を最小にするパラメータを選択します。実際、円の半径は$\lambda$によって変化するので下図はあくまでもイメージです。
L2ノルムは円形ですが $θ_{0},θ_{1}$の選択範囲の形状はノルムによって変化します。
ノルムによる範囲形状の変化は下図のようになります。特定のパラメータ値を0にしたい場合はL1ノルムを使うなど、必要に応じてどのノルムを使うのか検討するのが良いと思います。$|\theta_{0}|^p+|\theta_{1}|^p$
リッジ回帰の実装(Python)
実際にpythonでリッジ回帰を実装してみましょう。
真の関数は$\cos$関数で、データ点は$\cos$関数にノイズを加えたものを用意しました。
また、比較対象として $λ=0$ の場合(ペナルティ項を0にしたもの)を用意しました。
フィッティングモデルは14次の多項式です。
上図がpythonでの実行結果です。左側がリッジ回帰、右側はペナルティ項を0(線形回帰)にしたものです。リッジ回帰では過学習が抑制されているのが分かります。ハイパーパラメータである $\lambda$ はうまくフィッティングできるように $\lambda=0.0001$ としました。
以下にプログラムを載せています。
import numpy as np import matplotlib.pyplot as plt from sklearn.pipeline import Pipeline from sklearn.preprocessing import PolynomialFeatures from sklearn.linear_model import LinearRegression from sklearn.model_selection import cross_val_score from sklearn.linear_model import Ridge from sklearn import linear_model def true_fun(X): return np.cos( 3*np.pi * X) np.random.seed(0) n_samples = 30 #30個の点を用意 degrees = [15] #14次 X = np.sort(np.random.rand(n_samples)) y = true_fun(X) + np.random.randn(n_samples) * 0.1 #真の関数にノイズを乗せる。 plt.figure(figsize=(14, 5)) for i in range(len(degrees)): ax = plt.subplot(1, len(degrees), i + 1) plt.setp(ax, xticks=(), yticks=()) polynomial_features = PolynomialFeatures(degree=degrees[i], include_bias=False) #多項式の定義 linear_regression = linear_model.Ridge(alpha=0.0001) #リッジ回帰の定義 pipeline = Pipeline([("polynomial_features", polynomial_features), ("linear_regression", linear_regression)]) pipeline.fit(X[:, np.newaxis], y) # 評価 scores = cross_val_score(pipeline, X[:, np.newaxis], y, scoring="neg_mean_squared_error", cv=10) reg=linear_regression reg.coef_ print(reg.coef_) linear_regression2 = linear_model.Ridge(alpha=0.0) pipeline2 = Pipeline([("polynomial_features", polynomial_features), ("linear_regression", linear_regression2)]) pipeline2.fit(X[:, np.newaxis], y) # 評価 scores2 = cross_val_score(pipeline2, X[:, np.newaxis], y, scoring="neg_mean_squared_error", cv=10) reg=linear_regression2 reg.coef_ print(reg.coef_) #plt.figure(figsize=(3, 3)) plt.subplot(1,2,1) X_test = np.linspace(0, 1, 100) #0から1の間に100個の等差数列を作る。 #学習した関数 plt.plot(X_test, true_fun(X_test), label="True function") plt.plot(X_test, pipeline.predict(X_test[:, np.newaxis]), label="Model") plt.scatter(X, y, edgecolor='b', s=20, label="Samples") plt.xlabel("x") plt.ylabel("y") plt.xlim((0, 1)) plt.ylim((-2, 2)) plt.legend(loc="best") plt.title("Degree {}\n penalty (λ=0.0001)".format( degrees[i], -scores.mean(), scores.std())) plt.subplot(1,2,2) plt.plot(X_test, true_fun(X_test), label="True function") plt.plot(X_test, pipeline2.predict(X_test[:, np.newaxis]), label="Model") plt.scatter(X, y, edgecolor='b', s=20, label="Samples") plt.xlabel("x") plt.ylabel("y") plt.xlim((0, 1)) plt.ylim((-2, 2)) plt.legend(loc="best") plt.title("Degree {}\n No penalty (λ=0)".format( degrees[i], -scores.mean(), scores.std())) plt.show()最後に
本記事を記述するにあたり、以下の参考文献を大いに活用させて頂きました。
参考文献
書籍
イラストで学ぶ機械学習webサイト
http://aidiary.hatenablog.com/entry/20140401/1396362757https://scikit-learn.org/stable/auto_examples/model_selection/plot_underfitting_overfitting.html








- 投稿日:2019-07-30T19:32:02+09:00
タンパク質3Dモデリングでかっこいい画像を作る Pymol+Blender
個人的に大仕事をしたので、メモを兼ねてはじめてQiitaに書きます。
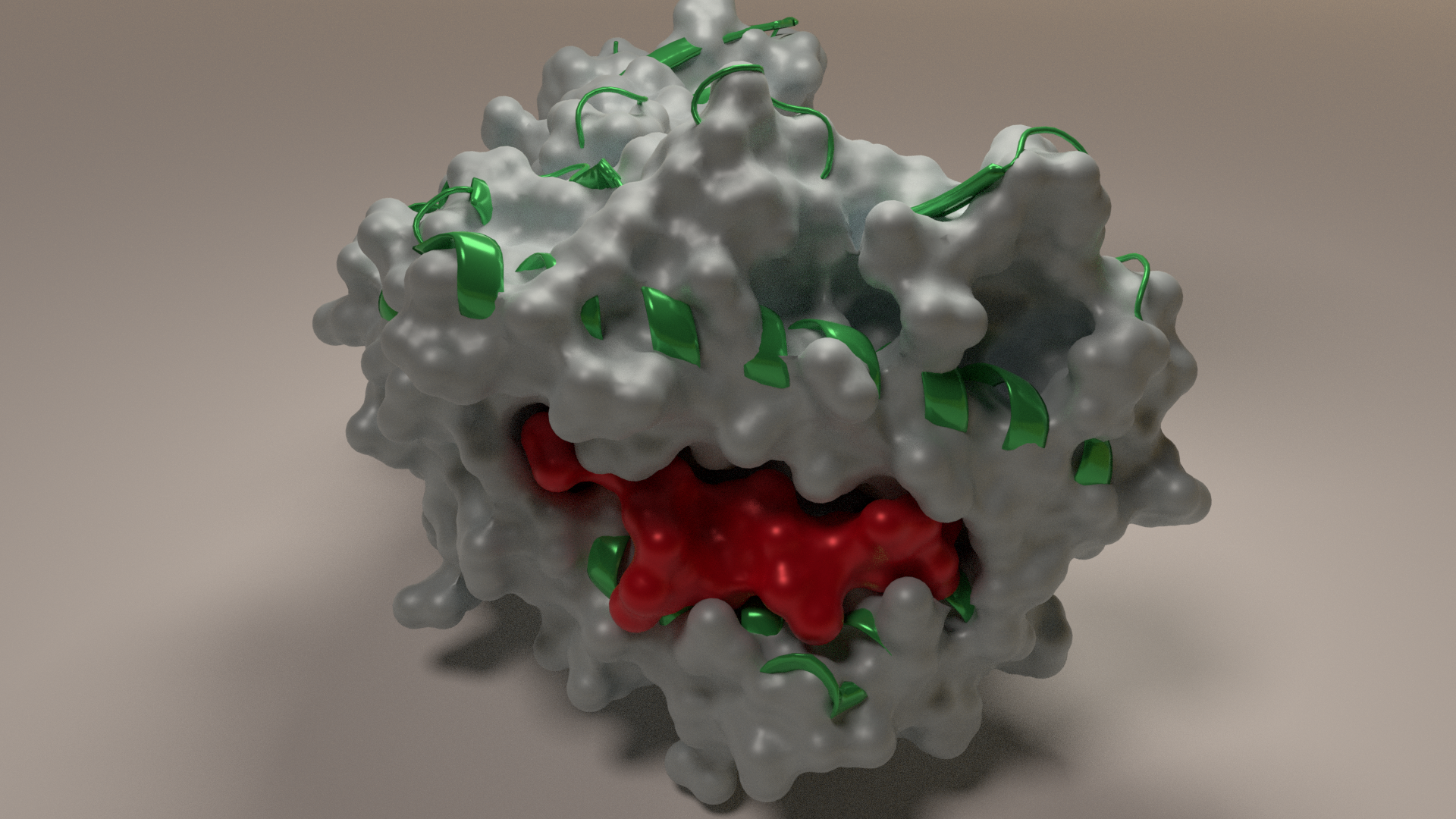
Blenderを使い始めて3週間ほどのペーペーです。こういうかっこいい画像を作りたい
(画像はリンク先より引用)http://dmnfarrell.github.io/bioinformatics/proteins-blender環境
- Windows10 64bit
- メモリ8GB, グラボなし
やること
- Anacondaのインストール
- Pymolのインストール
- Blenderのインストール
- PDBから必要なタンパク質モデルをダウンロード
- Pymolでプレ加工してwrlファイルでエクスポート
- Blenderでかっこよく加工
必要なもののインストール
AnacondaとPymolに関してはこちら
https://qiita.com/tonets/items/1927058e4297fc1c060d
Pymolはcp36mなどバージョンを確認しないとインストール時エラーが出ます。
https://qiita.com/hnishi/items/5e5e1fd4902fbe809e73私の会社用Windows10はどうしてもAnacondaをインストールできず(OSをクリーンインストールしてもダメ)
VirtualBoxにUbuntuを入れてやるという力業で進めました。
自宅のWin機では問題なくできたので、以下の話はubuntu環境に限りません。Blenderのバージョンで罠にはまる
Blenderは無料で利用できる高機能3Dモデリングソフトです。
https://www.blender.org/
Blenderはちょうど大きなバージョンアップの最中で、もうすぐ2.80が正式リリースされます。ここで注意していただきたいこととして、
Pymolで表示する "stick" をBlenderに取り込むには、旧バージョン2.79である必要があります。
私は2.80で操作を覚えてきたため、2.79で取り込んだ後2.80で編集するという方法で進めました。PDBファイルのPymol描画
流行りのPD-1のデータをダウンロードしてみます。(http://www.rcsb.org/structure/6RPG)
検索して一番最近アップされたものを適当に選びました。
Pymolを開き、file → open でダウンロードしたPDBファイルを開きます。
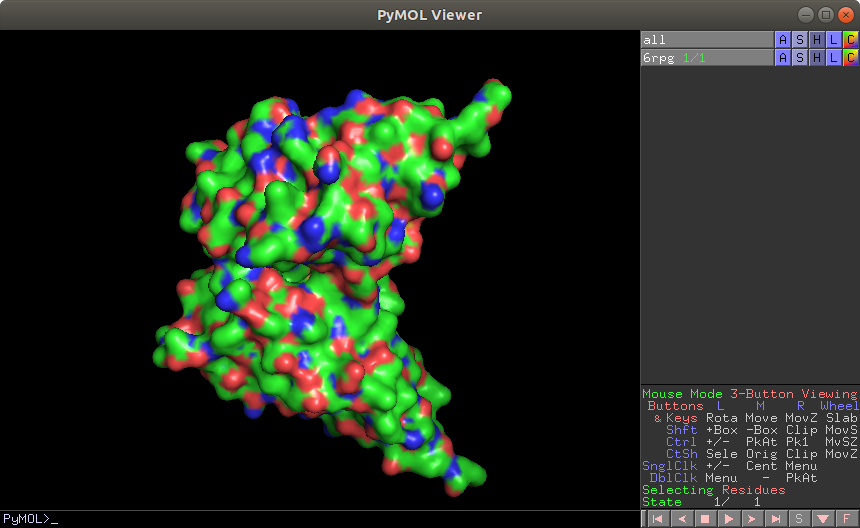
allのH - Everuthing で全て消した後、6rpgのS - Surface を表示します。
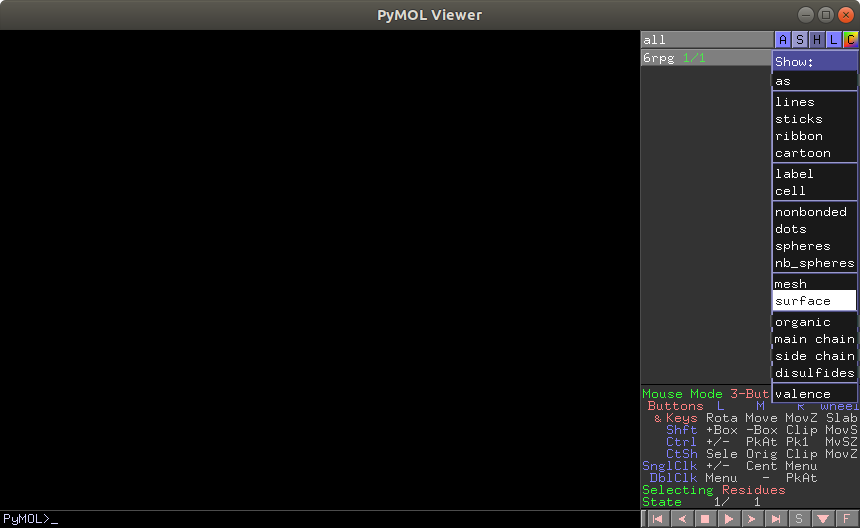
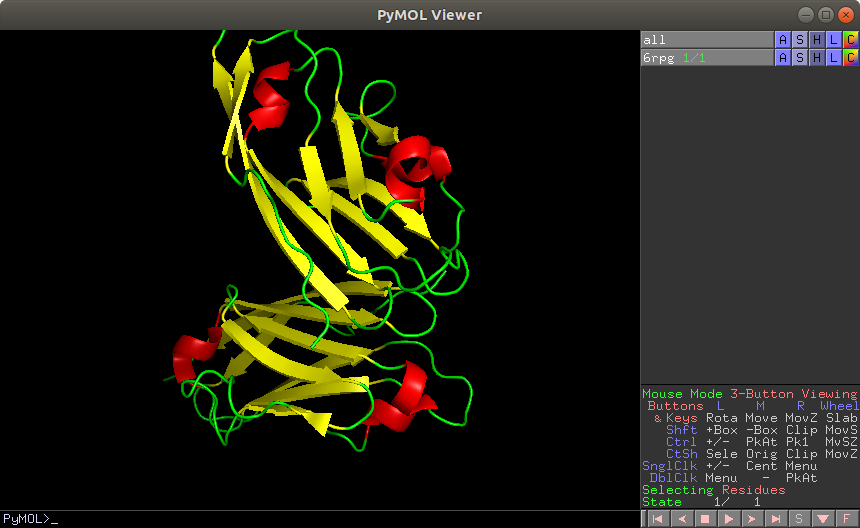
かっこいい・・・。 同様に H - EverythingのあとS - cartoon, C - ssでこのようになります。
今回はsurfaceのみ表示させたあと、コマンドラインに set surface_quality,1 として画質の調整をします。
file → save image as VRML2 で wrlファイルを作成します。
前述のとおり、ここで S - stick として表示させたあとwrlファイルを作成しても
Blender 2.80ではインポート時にエラーとなります。stickで取り込みたい場合は2.79を使用してください。
(これに気づくのに3日かかった)
surface, cartoonについては2.80でも直接いけました。それと私の場合はPymolで追加のペプチドを作りました。作成にはbuilderを使っています。
参考 https://pymolwiki.org/index.php/Builder
作成しただけのペプチドからエクスポートしたwrlファイルは、PDBからダウンロードしたファイルと違い
3D位置情報を含みません。例えば酵素に基質が結合するような形状を作りたい場合は、
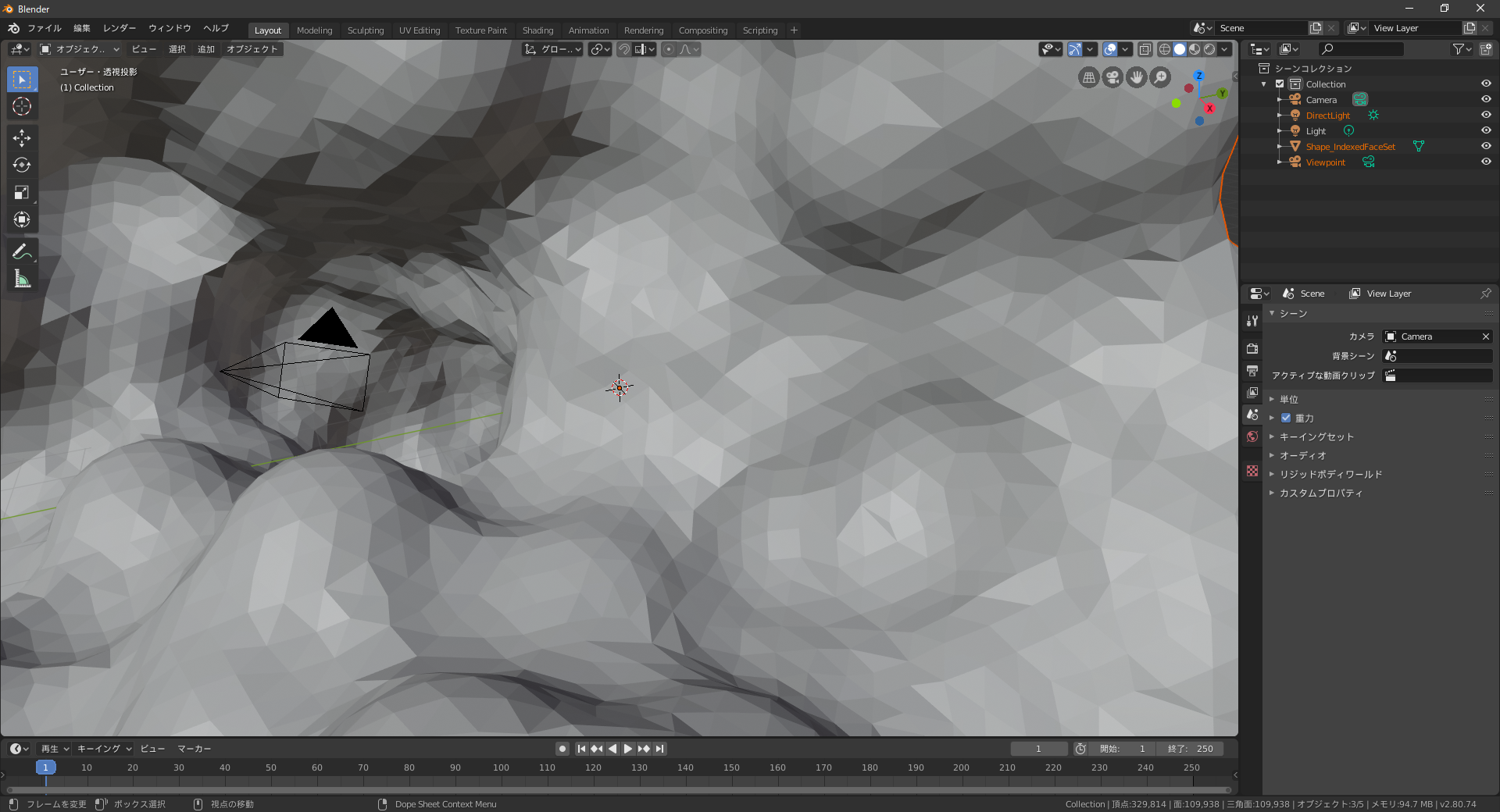
別途位置情報のシミュレーション等をする必要があると思われます。Blenderにインポートして加工
Blender 2.80を開いて、x で最初のオブジェクトを削除。
ファイル → インポート → X3D extensible 3D で先ほどのwrlファイルをインポート。
巨大なメッシュオブジェクトが開かれるので s で適当なサイズに縮小して位置を調整。
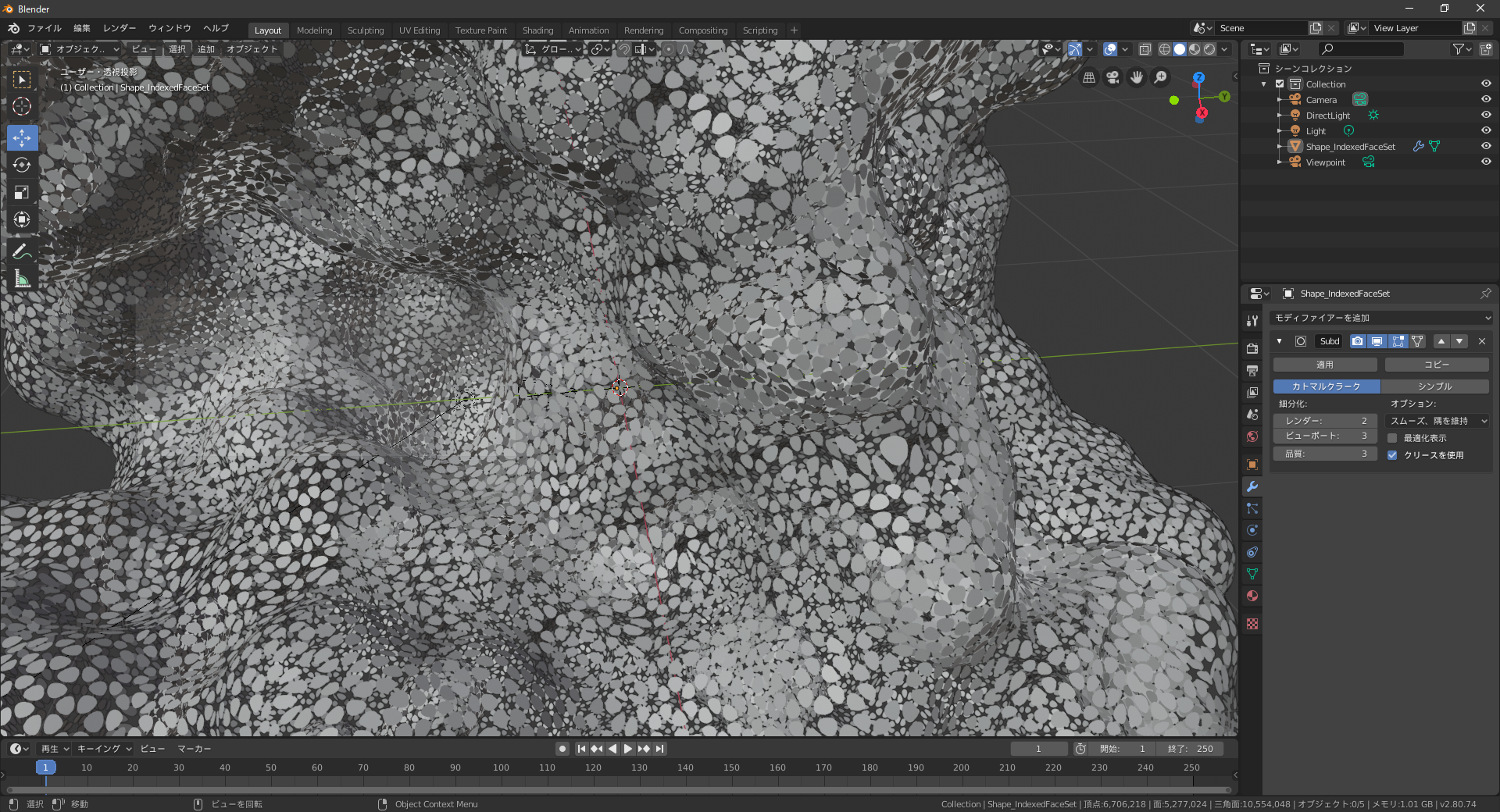
見てのとおりまだカクカクです。通常メッシュをなめらかにするにはモディファイヤーでサブディビジョンサーフェスを使いますが、
PDBから落としてきたファイルには通用しません。謎の斑点になります。あと重い。。
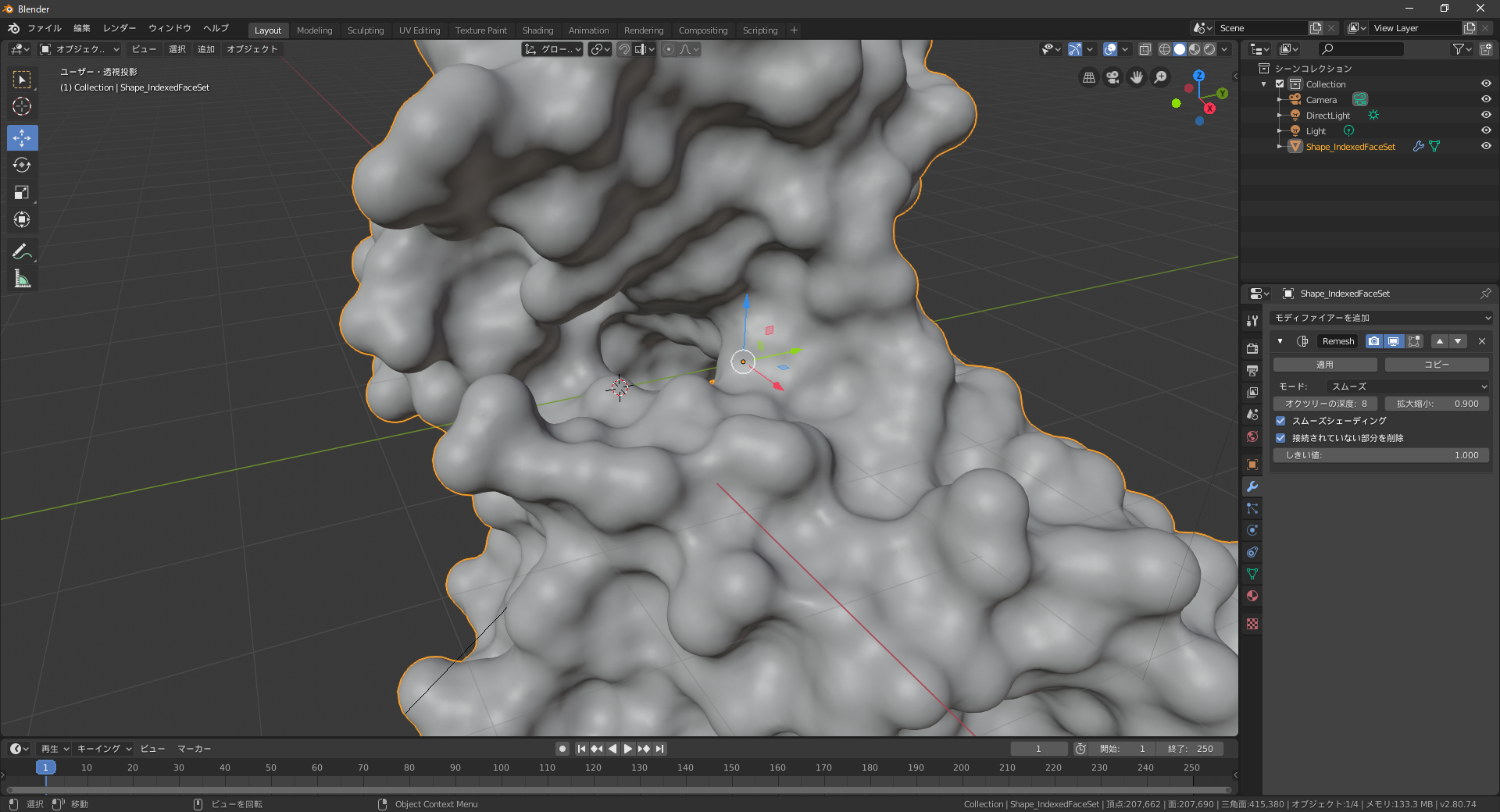
どうすればいいのか色々といじくりまわした結果、モディファイヤーからリメッシュで解決しました。
深度8、モード:スムーズ、スムーズシェーディングにチェック、とするとご覧の通り。
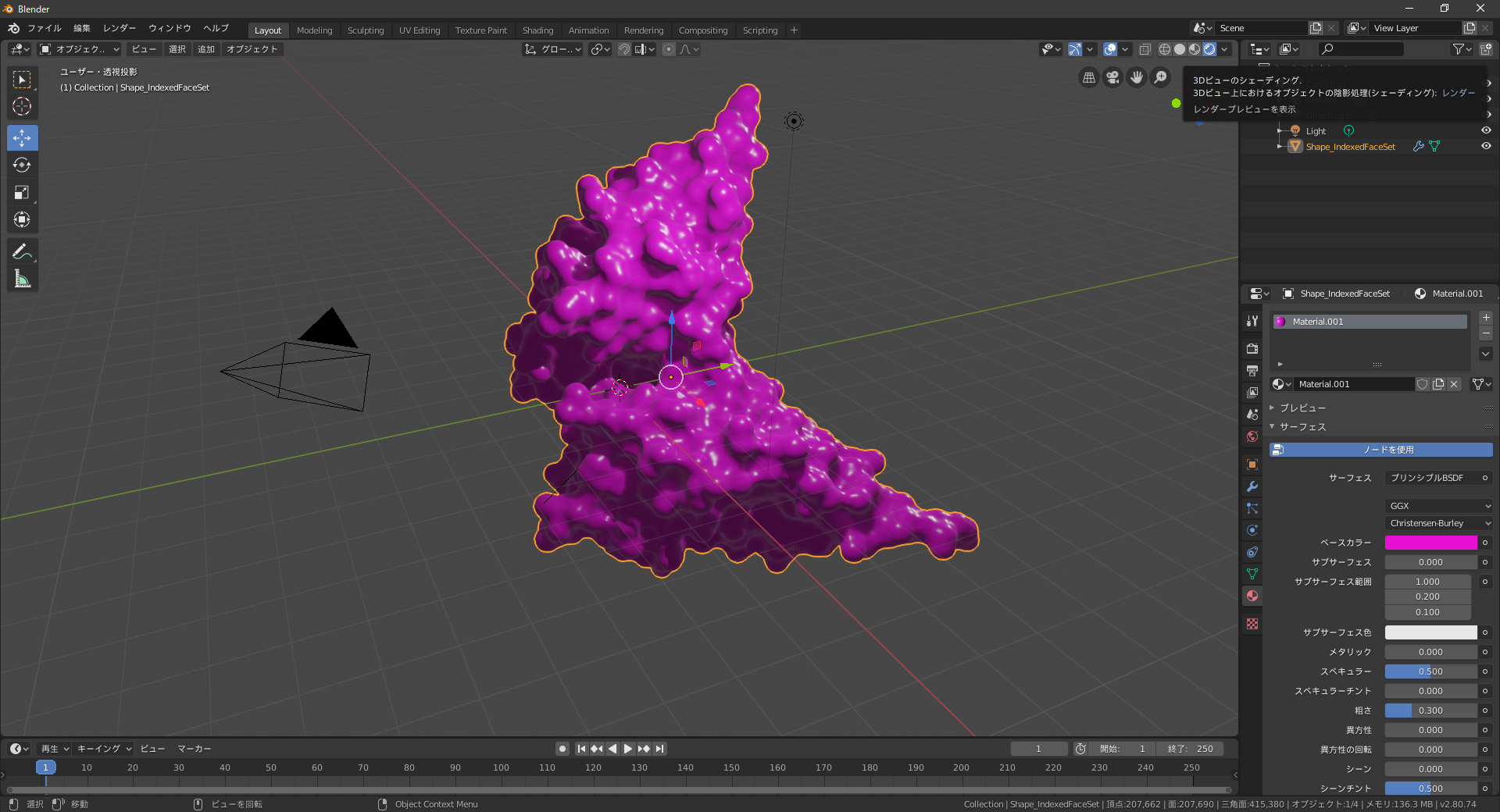
あとは好みの加工をしていくことになります。
メッシュをクリックしてマテリアルを新規追加。ベースカラーを紫、粗さを0.3。
3dビューのシェーディングをオンにすればあっというまに生々しい(グロテスクな?)モデルができます。
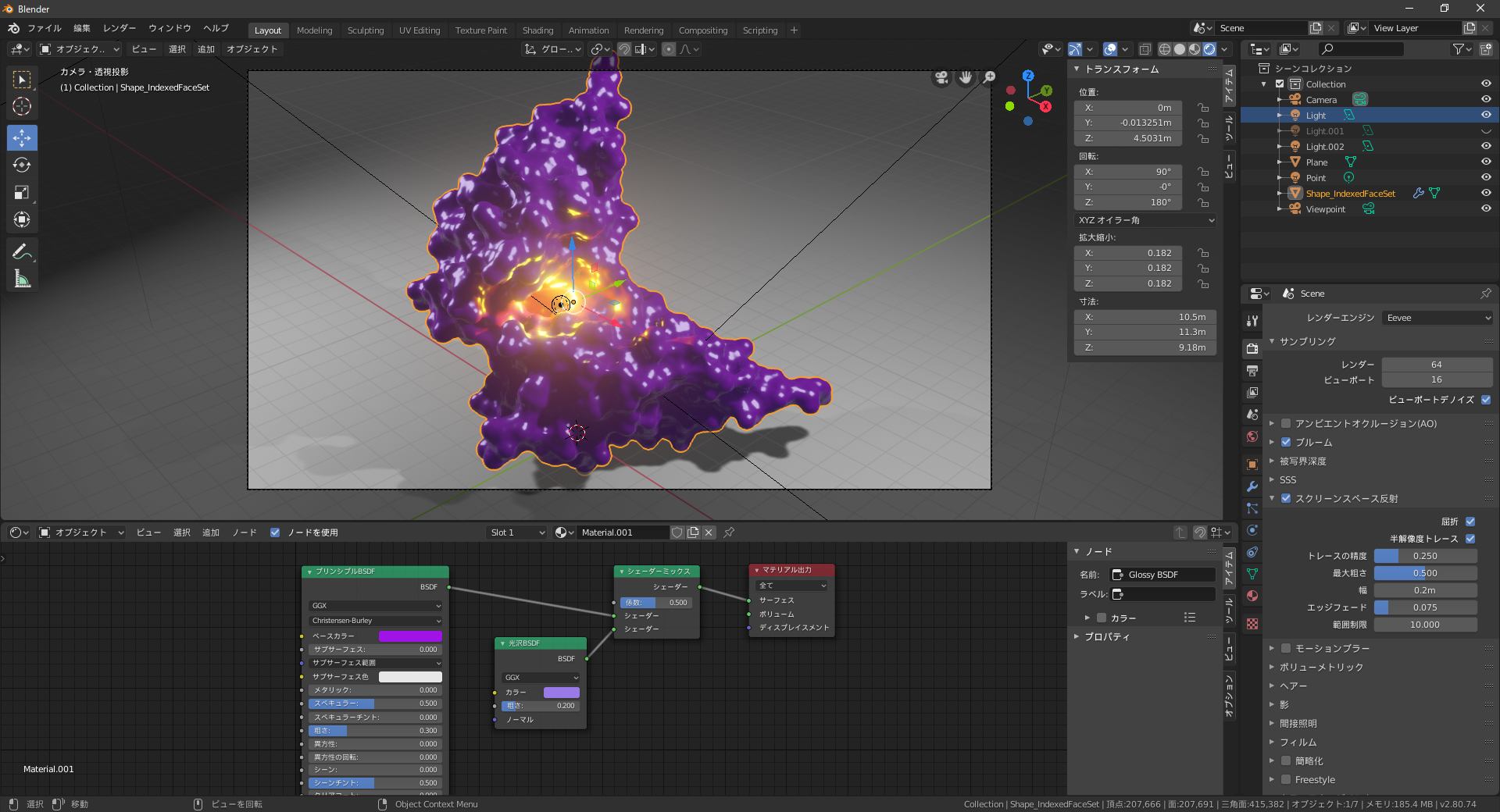
今回は以下に並べるような加工を施してみました。
- 位置を上にずらして、平面メッシュを追加(床の作成)
- エリアのライトを3つほど設置して明るさの調整
- ポイントのライトをオブジェクトの中心付近に置いて色と明るさの調整
- レンダー → 「プルーム」、「スクリーンスペース反射」とその中の「屈折」にチェック
- カメラ位置を調整してレンダリング(F12)
完成したものがこちら!
まとめ
Blenderのバージョン違いと、リメッシュに気づかなかったことでだいぶ時間がかかりました。
インストール系を除けば、これらの加工は20分程度でできます。
冒頭に挙げたような画像もほとんどこの流れで作れるはずです。
あとは位置情報を含むPDBファイルをシミュレートで作るところが難しそう。
サイエンスイラストレーション楽しい!参考
http://www.protein.osaka-u.ac.jp/rcsfp/supracryst/suzuki/jpxtal/Katsutani/index.php
https://pymolwiki.org/index.php/2._Translucent_Surfaces


- 投稿日:2019-07-30T17:34:08+09:00
PwC's Analytics Hackathon
概要
PwC's Analytics Hackathonは、スキルや創造性を活かして、社会の課題解決に取組むイベントです。
皆さんとPwCの若手コンサルタントでチームをつくり、企業や組織が抱える課題を解決するために「どのようなデータ分析手法が最適であるか」を考えて頂きます。実際に検討した手法を用いてデータ分析を行い、その結果から解決策を検討し、発表を行っていただくプログラムとなります。
ハッカソン後は、PwCのコンサルタントとフランクにお話いただく懇親会も予定しています。
こんな人にぜひ!
- コンサルタントの仕事を体験してみたい人
- データサイエンティストに興味がある人
- データ分析を用いた研究をしている人
- テクノロジーを用いたビジネスを考えることが好きな人
- 新しいアイデアを考えることが好きな人
- ご自身の分析スキル・プログラミングスキルを試してみたい人
- Hackathonに参加してみたい人
推奨スキル
プログラミングスキル
下記のいずれかの対象言語でのプログラミング経験
- Python
- Ruby
- Perl
- R
- MATLAB
- C
- C++分析スキル
下記のいずれかの分析アルゴリズムの使用経験
- 回帰:ロジスティック回帰、SVMなど
- ツリー:決定木、ランダムフォレストなど
- ベイズ:単純ベイズ(ナイーブベイズ)など
- アンサンブル学習 : ブースティング、バギングなど
- 時系列:AR、MA、(S)ARIMAモデルなど
- 商品分析:アソシエーション分析、ABC分析、バスケット分析など
- 顧客分析:デシル分析、RFM分析など
- 自然言語解析:テキスト解析、共起ネットワーク、感情分析、Word 2 Vectorなど
- クラスタリング:k近傍法(KNN)、階層型クラスタリング、非階層型クラスタリング(K-Means)、トピックモデルなど
- 異常検知(外れ値検知):教師なし異常検知、教師あり異常検知、半教師あり異常検知など
- ニューラルネットワーク:CNN、RNN、LSTM、自己組織化マップ(SOM)など開催概要
- 開催日:2019年9月7日(土)10:00-21:00
- 実施場所:PwCコンサルティング合同会社 丸の内パークビルディング21F
- 服装:自由
- 募集人数:約50名(※)
- 参加資格:2021年3月卒業/修了見込みかつ2021年4月/10月入社が可能な方
- 交通費:遠方から新幹線もしくは飛行機で参加される方には、弊社規定に従い、交通費をお支払いいたします。※国内のみ
- 持ち物:Windows PCやMac、タブレットなどハックするためにご自身が必要と判断するもの
- 応募方法:当社採用ウェブサイトのマイページに登録後、イベントにエントリー
- 当社採用ウェブサイトURL:http://bit.ly/2YAAJTi
- 応募締切:2019年8月30日(金)23:59
(※)応募者多数の場合、抽選となります、予めご了承ください。
- 投稿日:2019-07-30T16:45:32+09:00
Windows環境下のPythonのprintで豆腐文字が出る問題への対策
はじめに
Windowsでbash + python の環境を作っていた時に、標準出力のprintで、日本語が豆腐に文字化けする現象が発生したので、その対応策に関するメモです。
この記事に書いてあること
- Windows上のPythonで標準入出力が文字化けする OR エラーを吐く 時の対処方法
- Windows上のPythonでファイル読み書きが文字化けする OR エラーを吐く 時の対処方法
環境
- OS: Windows10
- 環境
- 裏: git-for-windowsのbash および Msys2のzsh
- 表: Cmder
- python: anaconda python 3.7
何が問題か?
Python上で標準出力をしたとき、日本語が□(いわゆる豆腐)として表示されます。
よくある文字エンコーディング問題の一種で、matplotlibとかでよく見るやつです。普段MacとLinuxしか使わないため、標準出力でこんな現象が発生すること自体知りませんでした。
対策
一昔前にデフォルトエンコーディングを設定したようなノリで、
sitecustomize.pyを以下のように書き加えておきます。import io, sys # sys.stdin = io.TextIOWrapper(sys.stdin.buffer, encoding='utf-8') sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8') sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')これは標準出力と標準エラー出力をutf-8で吐き出せという命令です。これでutf-8で標準出力されるようになります。
※ sys.stdinは標準入力用。標準入力でも同じような問題が起きるため、ついでに追加しておくことをお勧めします。
余談:openのwirteでも似た問題が
fo = open('out.txt', 'w') fo.write('正しく書き出せない')ファイルオブジェクトにwriteしたときにも同様の問題が発生します。
標準出力の問題と同じように
sitecustomize.pyをいじるとなんとかなるかもしれないが、最近はファイルオブジェクトを開くときに文字エンコードを指定してやるのがスタンダードらしいので、私もそれに従うことにしました。fo = open('out.txt', 'w', encoding='utf-8') fo.write('正しく書き出せる')
- 投稿日:2019-07-30T16:42:27+09:00
PythonでGoogleスプレッドシートに色付きシートを作成する方法
Motive
python
gspreadを使って色付きのシートを作成する方法をまとめてみました。Method
PythonでGoogleスプレッドシートに結合cellを作成する方法と同様に
batch_updateメソッドを使ってjsonから直接書き込む手法を取ります。value.json{ "requests": [ { "addSheet": { "properties": { "title": "開発環境", "gridProperties": { "rowCount": 3, "columnCount": 3 }, "tabColor": { "red": 1.0, "green": 0.3, "blue": 0.4 } } } } ] }setting.ini[googleSpreadSheet] book_id = {{ スプレッドシートのID }} keyfile_name = {{認証に必要なjsonファイル}}.jsonimport configparser import json import os import json from oauth2client.service_account import ServiceAccountCredentials import gspread def main(): config = configparser.ConfigParser() ini_file = os.path.join("./", 'setting.ini') config.read(ini_file) scope = ["https://spreadsheets.google.com/feeds", "https://www.googleapis.com/auth/drive"] book_id = config.get("googleSpreadSheet", "book_id") path = os.path.join("./", config.get("googleSpreadSheet", "keyfile_name")) credentials = ServiceAccountCredentials.from_json_keyfile_name(path, scope) client = gspread.authorize(credentials) gfile = client.open_by_key(book_id) dst = {} with open("value.json", encoding='utf-8') as fin: dst = json.load(fin) gfile.batch_update(dst) if __name__ == "__main__": main()これで完成です。
Future
gspreadにあるadd_worksheetメソッドにcolorの引数があると可能なのですが、現在はタイトルとシートの範囲指定くらいしかできません。 github には下記の通りになっています。def add_worksheet(self, title, rows, cols): """Adds a new worksheet to a spreadsheet. :param title: A title of a new worksheet. :type title: str :param rows: Number of rows. :type rows: int :param cols: Number of columns. :type cols: int :returns: a newly created :class:`worksheets <gsperad.models.Worksheet>`. """ body = { 'requests': [{ 'addSheet': { 'properties': { 'title': title, 'sheetType': 'GRID', 'gridProperties': { 'rowCount': rows, 'columnCount': cols } } } }] } data = self.batch_update(body) properties = data['replies'][0]['addSheet']['properties'] worksheet = Worksheet(self, properties) return worksheetもし引数を追加することになった時は
def add_worksheet(self, title, rows, cols, red=255, green=128, blue=0):とRGBを別々に設定する方法があるのですが、htmlのカラーコードが馴染みがありそうなので下記とおりにした方がいいのかもしれません。def add_worksheet(self, title, rows, cols, color=None): red = 0.8 green = 0.8 blue = 0.8 if color is not None: red = int("0x{}".format(color[1:3]),16) green = int("0x{}".format(color[3:5]),16) blue = int("0x{}".format(color[5:]),16) body = { 'requests': [{ 'addSheet': { 'properties': { 'title': title, 'sheetType': 'GRID', 'gridProperties': { 'rowCount': rows, 'columnCount': cols } } } }] } if color is not None: body["requests"][0]["addSheet"]["properties"]["tabColor"] = {"red": red,"green": green,"blue": blue} data = self.batch_update(body) properties = data['replies'][0]['addSheet']['properties'] worksheet = Worksheet(self, properties) return worksheetissuesにでもリクエストするか。
Reference
- 投稿日:2019-07-30T16:42:04+09:00
2.Flaskチュートリアルをやってみた(2019/7/30)
flaskチュートリアルをやってみた
タイトルにもある通りFlaskのチュートリアルを進めたのですが、日本語版チュートリアルは情報が古くうまく動かない部分などがあったため、それらの点を解説しつつブログアプリflaskrを作成していきます。
step0
チュートリアルではディレクトリ構成を解説しています。
この点は問題はありません。manage.py requirements.txt flaskr/ |- __init__.py |- config.py |- views.py |- models.py |- static/ |- style.css |- templates/ |- layout.html |- show_entries.html特筆するまでもないですが、flaskはtemplates以下のhtmlファイルを参照するようにできているのでそれ以外のフォルダ名だと動きません。
requirements.txt
ここも問題はありません。
Flask Flask-SQLAlchemy以下のコマンドでインストールしてください。
pip install -r requirements.txtmanage.py
このファイルを実行することでflaskrというブログアプリを動かします。
from flaskr import app app.run(host='127.0.0.1', port=5000, debug=True)flaskr/init.py
ここでは1つ注意する点があります。
チュートリアル通りに作成すると実行した際に以下のようなエラーが起きます。ModuleNotFoundError: No module named 'flask.ext'flask.ext.sqlalchemyの使用はあまり推奨されていないようです。
そのため、2行目を以下のように変更することでこのエラーは解消されます。from flask import Flask from flask_sqlalchemy import SQLAlchemy app = Flask(__name__) app.config.from_object('flaskr.config') db = SQLAlchemy(app) import flaskr.viewsflaskr/config.py
データベースの設定とセッション情報を暗号化するための情報などまとめてconfigfileで管理することができます。
SQLALCHEMY_DATABASE_URI = 'sqlite:///flaskr.db' SECRET_KEY = 'secret key'step1
ここからデータベースを作成していくみたいです。
flaskr/models.py
from flaskr import db class Entry(db.Model): __tablename__ = 'entries' id = db.Column(db.Integer, primary_key=True) title = db.Column(db.Text) text = db.Column(db.Text) def __repr__(self): return '<Entry id={id} title={title!r}>'.format( id=self.id, title=self.title) def init(): db.create_all()注意点として、上記のコードを書いた段階ではまだデータベースはできていません。
その状態でアプリを起動すると以下のようなエラーが表示されます。sqlalchemy.exc.OperationalError: (sqlite3.OperationalError) no such table: entries忘れずにターミナルで以下のように打ち込んでデータベースファイルの作成を行なってください。
$ python >>> from flaskr.models import init >>> init()チュートリアルではここで動作の確認を行なっていますが、これはやってもやらなくても問題ありません。
step2
ここではブログの一覧と投稿画面を作ります。
flaskr/views.py
ここも特に問題はありません。チュートリアルの通り進めてください。
from flask import request, redirect, url_for, render_template, flash from flaskr import app, db from flaskr.models import Entry @app.route('/') def show_entries(): entries = Entry.query.order_by(Entry.id.desc()).all() return render_template('show_entries.html', entries=entries) @app.route('/add', methods=['POST']) def add_entry(): entry = Entry( title=request.form['title'], text=request.form['text'] ) db.session.add(entry) db.session.commit() flash('New entry was successfully posted') return redirect(url_for('show_entries'))step3
htmlとcss、ブログの機能ではなくて表側をいじっていきます。
flaskr/template/layout.html
<!doctype html> <title>Flaskr</title> <link rel=stylesheet type=text/css href="{{ url_for('static', filename='style.css') }}"> <div class=page> <h1>Flaskr</h1> {% for message in get_flashed_messages() %} <div class=flash>{{ message }}</div> {% endfor %} {% block body %}{% endblock %} </div>flaskr/templates/show_entries.html
{% extends "layout.html" %} {% block body %} <form action="{{ url_for('add_entry') }}" method=post class=add-entry> <dl> <dt>Title: <dd><input type=text size=20 name=title> <dt>Text: <dd><textarea name=text rows=5 cols=20></textarea> <dd><input type=submit value=Share> </dl> </form> <ul class=entries> {% for entry in entries %} <li><h2>{{ entry.title }}</h2>{{ entry.text|safe }} {% else %} <li><em>Unbelievable. No entries here so far</em> {% endfor %} </ul> {% endblock %}flaskr/static/style.css
body { font-family: sans-serif; background: #eee; } a, h1, h2 { color: #377ba8; } h1, h2 { font-family: 'Georgia', serif; margin: 0; } h1 { border-bottom: 2px solid #eee; } h2 { font-size: 1.2em; } .page { margin: 2em auto; width: 35em; border: 5px solid #ccc; padding: 0.8em; background: white; } .entries { list-style: none; margin: 0; padding: 0; } .entries li { margin: 0.8em 1.2em; } .entries li h2 { margin-left: -1em; } .add-entry { font-size: 0.9em; border-bottom: 1px solid #ccc; } .add-entry dl { font-weight: bold; } .metanav { text-align: right; font-size: 0.8em; padding: 0.3em; margin-bottom: 1em; background: #fafafa; } .flash { background: #cee5F5; padding: 0.5em; border: 1px solid #aacbe2; } .error { background: #f0d6d6; padding: 0.5em; }あとはチュートリアルの最後にあるように以下のように打ち込むことで問題なく動くと思われます。
python manage.py自分がつまづいた点
その1
No module named flask上記のようにエラーが出た場合はpythonのバージョンが混在している等の問題がある可能性があります。
非常に基本的な部分なのですがmacだと初期状態でpythonが2.7なのでpython3をデフォルトにする必要がありました。(必須ではないのですがpython3で統一している方が何かと便利なので)
基本的に上のリンクに従って進めて、もしもエラーが出てしまった場合は下のリンクで解決できると思います。
https://qiita.com/sebeckawamura/items/4bc5945245877f250d2e
https://qiita.com/1152v/items/68bb8d1edf10af36bd0d
その2
OSError: [Errno 48] Address already in use上記のエラーはアプリを前回起動した時のプロセス(なんか邪魔なものくらいの認識で大丈夫です)が残っている状態です。アプリを起動している状態でコードをいじったりしてまうとこのようになる可能性があります。
$ lsof -i:5000そのためこのようにターミナルで打ち込んで使用中のプロセスを切ってあげましょう。
python3.7 23820 kinouchiyuta 3u IPv4 0xa9d666bd1529b1a1 0t0 TCP localhost:commplex-main (LISTEN) python3.7 23836 kinouchiyuta 3u IPv4 0xa9d666bd1529b1a1 0t0 TCP localhost:commplex-main (LISTEN) python3.7 23836 kinouchiyuta 4u IPv4 0xa9d666bd1529b1a1 0t0 TCP localhost:commplex-main (LISTEN)このように使用中のプロセスが出てきたら
$ kill -9 [該当のID]今回だと以下のように打ち込めば問題ないですね。
$ kill -9 23820 $ kill -9 23836
- 投稿日:2019-07-30T16:35:39+09:00
【競馬新聞の読み方】レース結果を読む♬
※これ書いていたら、大種牡馬ディープインパクトが本日亡くなったとのこと、ご冥福と子供たちのますますの発展を祈ります
前回はOCRを駆使して読もうと試みたが、Pyocr+TessaractOCRの組み合わせだと、精度いまいちで完敗感いっぱいだったので、今回はいわゆる「スクレイピング技術+正規表現で読む」をやってみた。
【参考】
・分かりやすいpythonの正規表現の例
ところで、JRAサイトのレース結果サイトをスクレイピングしようとしたが、このページDBに情報をためておいて、小出しに出力するように作成されていて、こんなのなかなか持ってこれない。。。ということで、ソースを読み込むこととしました。
基本は、おまけに掲載したような構造になっています。
まずは、以下のページをJRAのページからデータを取得して、再現することを目標にします。
やったこと
・正規表現で読む
・一つずつ解釈する
・得られたデータを保存する
・データから画面を作成する・正規表現で読む
最初の一歩として参考のコードを動かします。
最初のコードは動きましたが、特に使わないので以下から話を進めます。import re html = '''<div id="songs-list"> <h2 class="title">songs</h2> <p class="introduction"> classic songs </p> <ul id="list" class="list-group"> <li data-view="4" class="active"> <a href="/again.mp3" singer="Yui">again</a> </li> <li data-view="6"><a href="/Darling.mp3" singer="西野カナ">Darling</a></li> <li data-view="5"><a href="/手をつなぐ理由.mp3" singer="西野カナ">手をつなぐ理由</a></li> </ul> </div>''' pattern = '<li.*?singer="(.*?)">(.*?)</a>' # findall results = re.findall(pattern, html, re.S) # Type:list print(type(results)) # 抽出 for result in results: print(result[0], result[1])肝心なところは、(参考のコメントから引用を#⃣で表します)
①htmlは'''でくくる
②pattern = '<li.*?singer="(.*?)">(.*?)</a>'として
results = re.findall(pattern, html, re.S)
で抽出する
③resultはlist
ってところで、肝心なのは②のpatternをどのように定義する(見る)かです。
④抽出したい部分を(.*?)と()でくくる#⃣()で取りたい文字を
⑤#⃣.*?でなるべく少ない文字をマッチするため
⑥#⃣ re.Sをしていたため、.*は改行を識別できる
以上の情報と参考の正規表現の表をたよりにおまけに記載したようなhtmlから情報取得します・一つずつ解釈する
一番簡単そうな例として、
<td class="f_time">39.2</td>を取得します。
これは以下のコードで取得できます。#<td class="f_time">37.9</td> pattern='<td class="f_time">(.*?)(.*?)</td>' # findall results = re.findall(pattern, html, re.S) # Type:list print(type(results)) # 抽出 for result in results: print(result[1])上記で以下が取得できました。
<class 'list'> 37.0 37.6 ... 39.2理由はわかりませんが、
pattern='<td class="f_time">(.*?)</td>'と一個で取得しようとするとうまくいきません。また、数値だということでpattern='<td class="f_time">(.\d+)(.\d+)</td>'では、37と.6がresult[0]とresult[1]に分離してしまいます。ということで、上記のコードにたどり着きました。つぎに、馬名を取得したいと思います。いろいろ情報が付加していますが、肝心な馬名は以下の部分です。
<a href="#" onclick="return doAction('/JRADB/accessU.html','pw01dud002014100977/D1');">ディープスピリッツ</a>
これに対応するのは以下です。
pattern='<a href="#" onclick="return doAction(.*?);">(.*?)</a>'
実際やってみると、以下のように騎手も調教師も出てきてしまいます。
これでもいいかと思いますが、騎手のところに特別な減量などの情報が入っています。これを取り除きたいが。。。リフトトゥヘヴン C.ルメール 加藤 征弘 ... ホルンカズマ <span title="1kg減量">☆</span>横山 武史 栗田 徹ということで、まずは馬名のために以下のパターンに変更します。
pattern='<td class="horse">.*?<a href="#" onclick="return doAction(.*?);">(.*?)</a>.*?</td>'
これでうまく取得できました。このコードは以下のhtml見るとわかるように、馬名の前のより広い範囲で指定してその必要ない部分も含めて取得することにより馬名を取得することにしました。<div class="horse"> <span class="horse_icon"><img src="/JRADB/img/kigo/maru-chi.png" alt="マルチ"></span><a href="#" onclick="return doAction('/JRADB/accessU.html','pw01dud002014100977/D1');">ディープスピリッツ</a> <div class="icon blinker"><img src="/JRADB/img/kigo/icon_blinker.png" alt="ブリンカー"></div> </div>ここで、取得したいのは馬名なのでdoActionの後の()は不要な気がします。しかしこれを外すと馬名の全体が取得できませんでした。
ということで上記のコードで取得して書き出しは以下のようにします。
つまり、最初の文字列を捨てます。for result in results: print(result[1])こうして、以下のように取得できました。
リフトトゥヘヴン ライジングドラゴン ... ディープスピリッツ調教師や騎手も同様ですが、騎手はあの特別減量の記載があるのであれをどうにかしたいと思います。
これには参考の以下のものを使いました。# subでaを除き html = re.sub('<a.*?>|</a>', '', html)今回は、騎手減量の部分のhtmlが以下のとおりなのでspanを取り除くとあとは馬名と同じコードで行けそうです。
<td class="jockey"><a href="#" onclick="return doAction('/JRADB/accessK.html','pw04kmk001180/D0');"><span title="3kg減量">▲</span>団野 大成</a></td>
ということで以下としました。html = re.sub('<span.*?>|</span>', '', html) pattern='<td class="jockey"><a href="#" onclick="return doAction(.*?);">(.*?)</a></td>'実は一番難儀をしたのが、増減付き馬体重です。htmlは以下のようになっています。
つまり、隙間だらけなんですね。。。<td class="h_weight"> 458<span>(-2)</span> </td>これは以下のpatternで取得できました。
pattern='<td class="h_weight">(.*?\s)(.*?(\d+))<span>((.*?))</span>(.*?)</td>'486 (+2) 446 (+20) ... 458 (-2)※しかし二着馬+20だったんだね。。。
最後に謎の(.*?)をくっつけて、無事に人気順位<td class="pop">6</td>まで取得できました。pattern='<td class="pop">(.*?)(.*?)</td>' # findall results = re.findall(pattern, html, re.S) # Type:list print(type(results)) # 抽出 for result in results: print(result[1])・得られたデータを保存する
m(_)m
今回はここさぼって以下のようにだらだら書きました。
list使えば、もう少し簡単に書けるはずですが、。。。最後の`writer.writerow(map(lambda x: x, result1))`のイメージもわかないので。。
ということで、コード。。。for result in results: print(result[1]) Result.append(result[1]) print(Result, len(Result)) i=0 result_0=[] for j in range(12): re=Result[j+i*12] result_0.append(re) i=1 result_1=[] for j in range(12): re=Result[j+i*12] result_1.append(re) ... with open('./Keiba/keiba_results_.csv', 'w+', newline='') as f: writer = csv.writer(f) writer.writerow(map(lambda x: x, result_0)) writer.writerow(map(lambda x: x, result_1)) ... writer.writerow(map(lambda x: x, result_9))・データから画面を作成する
ということで、以下のような絵が描けました。これならもとのリザルトでいいのではという問題でなく、一応上記によりデータ取得できたので今後予測に役立てよう。。
コードは以下に置きました
ほとんどhtmlで埋め尽くされていますが、。。
・read_keiba_paper/find_sentence.pyまとめ
・JRAサイトのレース結果のデータを読み取ってcsvファイルに保存できた
・htmlをコード埋め込みから読込みに変更しようと思う
・コードがやっつけなので整理する
・同じように競馬新聞データを読んで予測に利用しようと思うおまけ
<class 'list'> リフトトゥヘヴン ライジングドラゴン オウケンスターダム キングスクロス フクノワイルド ボルンカズマ インナーハート ロードソリスト カリブメーカー ウォーターファラオ スプリングフット ディープスピリッツ <class 'list'> 486 (+2) 446 (+20) 478 (-4) 472 (-4) 480 (-2) 488 (-6) 522 (+16) 456 (+4) 510 (0) 446 (+4) 490 (+10) 458 (-2) <class 'list'> 1:44.5 1:45.4 1:45.8 1:45.9 1:46.3 1:46.6 1:46.6 1:46.7 1:46.8 1:46.9 1:47.3 1:47.3 <class 'list'> 37.0 37.6 37.8 37.9 40.3 39.0 39.1 38.9 38.9 38.6 37.9 39.2 <class 'list'> C.ルメール 武 豊 三浦 皇成 藤岡 康太 加藤 祥太 ☆横山 武史 岩田 康誠 ▲団野 大成 吉田 隼人 菱田 裕二 原田 和真 丹内 祐次 <class 'list'> 牡5 57.0 牡4 57.0 牡5 57.0 牡4 57.0 牡3 54.0 牡3 53.0 牡3 54.0 牡5 54.0 牝4 55.0 牡3 54.0 牡5 57.0 牡5 57.0 <class 'list'> 加藤 征弘 吉田 直弘 国枝 栄 大久保 龍志 杉山 晴紀 栗田 徹 吉村 圭司 和田 勇介 河内 洋 岡田 稲男 小桧山 悟 羽月 友彦 <class 'list'> 1 5 9 7 2 3 4 11 10 12 8 6欲しい情報がある、肝心な部分は以下の繰り返しになっています。
<tr> <td class="place">12</td> <td class="waku"><img src="/JRADB/img/waku/6.png" alt="枠6緑"></td> <td class="num">8</td> <td class="horse"> <div class="horse"> <span class="horse_icon"><img src="/JRADB/img/kigo/maru-chi.png" alt="マルチ"></span><a href="#" onclick="return doAction('/JRADB/accessU.html','pw01dud002014100977/D1');">ディープスピリッツ</a> <div class="icon blinker"><img src="/JRADB/img/kigo/icon_blinker.png" alt="ブリンカー"></div> </div> </td> <td class="age">牡5</td> <td class="weight">57.0</td> <td class="jockey"><a href="#" onclick="return doAction('/JRADB/accessK.html','pw04kmk001091/7D');">丹内 祐次</a></td> <td class="time">1:47.3</td> <td class="margin">クビ</td> <td class="corner"> <div class="corner_list"> <ul> <li title="1コーナー通過順位">8</li> <li title="2コーナー通過順位">8</li> <li title="3コーナー通過順位">10</li> <li title="4コーナー通過順位">10</li> </ul> </div> </td> <td class="f_time">39.2</td> <td class="h_weight"> 458<span>(-2)</span> </td> <td class="trainer"><a href="#" onclick="return doAction('/JRADB/accessC.html','pw05cmk001091/C0');">羽月 友彦</a></td> <td class="pop">6</td> </tr>
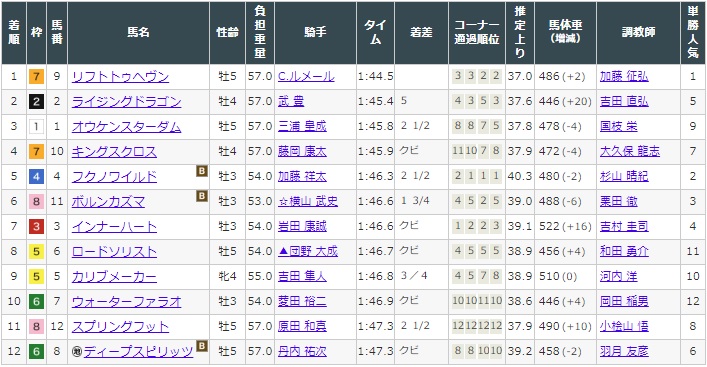
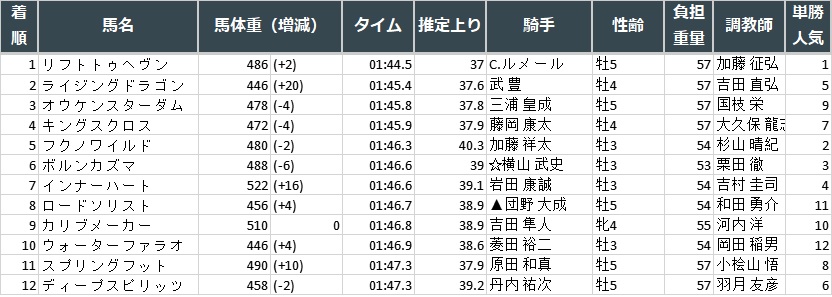
- 投稿日:2019-07-30T16:00:00+09:00
Microsoft Cognitive Toolkit : Image Classification Part1 Understanding COCO dataset
目標
Microsoft Cognitive Toolkit (CNTK) を用いて画像分類をやってみたのでその内容を記事にまとめました。
Part1 では、Microsoft Cognitive Toolkit を使って画像分類するための準備を行います。
画像分類を行うための訓練データセットとして、Microsoft が提供する Microsoft Common Objects in Context (COCO) を用います。以下の順で紹介します。
- COCO データセットのダウンロード
- COCO データセットの解析
- 訓練するための画像の準備
- CNTK が提供するビルトインリーダーが読み込むファイルの作成
導入
COCO データセットのダウンロード
Microsoft COCO は数万の一般的な画像と、その画像に対するカテゴリー、バウンディングボックス、セグメンテーション、キャプションの情報が付与されたデータセットです。[1]
Microsoft COCO Common Objects in Context
上記のページにアクセスしてページ上部の Dataset の Download へ移動すると、Tools, Images, Annotations という項目があるページに辿りつきます。
まずは、Images から画像をダウンロードします。2014, 2015, 2017 がありますが、今回は 2014 Train images を選びます。13GB もあるのでダウンロードにかなり時間がかかります。
次に、Annotations から画像に関する情報が含まれているファイルをダウンロードします。画像と同じく 2014 Train/Val annotations を選びます。こちらのダウンロードはすぐに終わります。
ダウンロードが終わって各々を解凍すると、82,783枚の JEPG 画像と、captions, instances, person key points の train/validation の JSON ファイルが手に入りますので、任意のディレクトリに移動します。今回のディレクトリの構成は以下のようにしました。
COCO
|―train2014
|―COCO_train2014_000000000009.jpg
|―...
|―annotations
|―captions_train2014.json
|―...
coco_categories.pyCOCO データセットの解析
画像に対するカテゴリーは、80 カテゴリー(人、車、本、猫、など)と 12 のスーパーカテゴリー(outdoor, food, indoor, appliance, sports, person, animal, vehicle, furniture, accessory, electronic, kitchen)があります。今回は 80 カテゴリー分類を目指します。
Microsoft は COCO データセットを扱うための API である pycocotools を提供してます。ですが、ここでは理解を深めるために自分で情報を取得することにしました。
Python 標準ライブラリの json を使って instances_train2014.json を読み込んでみます。
import json with open("./annotations/instances_train2014.json", "rb") as file: dataset = json.load(file) print(dataset.keys())読み込んだデータは辞書形式で、info, images, licenses, categories, annotations の情報が含まれています。
今回この記事で用いるのは annotations です。annotations の内容は辞書型になっており、以下のような情報が含まれています。{'info': 'images': 'licenses': 'categories': 'annotations': {'segmentation': # iscrowd=1 のとき RLE(Run-Length Encoding) 'area' : # セグメンテーションの面積 'iscrowd' : # 0 or 1 'image_id' : # 画像のID 'bbox' : # [x座標, y座標, 幅, 高さ] 'category_id' : # カテゴリーのID 'id' : # 識別番号 } }'iscrowd' が 0 であれば認識物体が1つだけ存在することを、1 のときは 1枚の画像に複数の認識物体が存在することを表します。
'iscrowd' が 1 のときの複数の認識物体のバウンディングボックスの情報は 'segmentation' に Run-Length Encoding で圧縮されているようですが、解読できなかったため、今回は 'iscrowd' が 0 のものだけを使いました。今回は画像をトリミングするための 'bbox' とラベル付けするための 'category_id' を主に用います。
訓練するための画像の準備
画像分類のモデルには畳み込みニューラルネットワーク (CNN) を用います。入力画像は RGB カラー画像でサイズは 224x224 とします。
COCO データセットには様々なサイズの画像が存在するので、'bbox' の情報を使って分類する対象をトリミングをしました。但し、トリミング後の画像サイズは 256x256 にしました。これは訓練時に画像データに対してスケール変換などの処理を行うための余白を確保するためです。
また、CNN は回転、反転、輝度変化を吸収する機構をもたない [2] ので、ここではトリミングした画像に回転を加えて向きに対する頑健性を考慮しました。但し、回転角は 45度のみ採用しました。反転と輝度変化は訓練時に CNTK のビルトインリーダーを用いて行います。
CNTK が提供するビルトインリーダーが読み込むファイルの作成
CNTK で画像分類を行う場合には、画像分類タスクに特化した効率的なビルトインリーダーの1つである ImageDeserializer が用意されています。今回はこの ImageDeserializer を用いるためのテキストファイルを作成します。また、入力画像を正規化するための平均画像を xml ファイルで保存します。
画像分類のための準備を行うプログラムの大まかな処理の流れは以下のようになります。
- アノテーション情報の読み取り
- バウンディングボックスに基づいて画像をトリミング
- 画像のトリミング、回転
- 画像の保存と保存した画像の PATH とカテゴリーラベルの書き込み
実装
実行環境
ハードウェア
・CPU Intel(R) Core(TM) i7-7700K 3.60GHz
ソフトウェア
・Windows 10 Pro 1903
・Python 3.6.6
・numpy 1.16.4
・opencv-contrib-python 3.4.2.17実行するプログラム
coco_categories.pyimport cv2 import json import numpy as np import os import random import xml.dom.minidom import xml.etree.cElementTree as et categories = {"1": [0, "person"], "2": [1, "bicycle"], "3": [2, "car"], "4": [3, "motorcycle"], "5": [4, "airplane"], "6": [5, "bus"], "7": [6, "train"], "8": [7, "truck"], "9": [8, "boat"], "10": [9, "traffic light"], "11": [10, "fire hydrant"], "13": [11, "stop sign"], "14": [12, "parking meter"], "15": [13, "bench"], "16": [14, "bird"], "17": [15, "cat"], "18": [16, "dog"], "19": [17, "horse"], "20": [18, "sheep"], "21": [19, "cow"], "22": [20, "elephant"], "23": [21, "bear"], "24": [22, "zebra"], "25": [23, "giraffe"], "27": [24, "backpack"], "28": [25, "umbrella"], "31": [26, "handbag"], "32": [27, "tie"], "33": [28, "suitcase"], "34": [29, "frisbee"], "35": [30, "skis"], "36": [31, "snowboard"], "37": [32, "sports ball"], "38": [33, "kite"], "39": [34, "baseball bat"], "40": [35, "baseball glove"], "41": [36, "skateboard"], "42": [37, "surfboard"], "43": [38, "tennis racket"], "44": [39, "bottle"], "46": [40, "wine glass"], "47": [41, "cup"], "48": [42, "fork"], "49": [43, "knife"], "50": [44, "spoon"], "51": [45, "bowl"], "52": [46, "banana"], "53": [47, "apple"], "54": [48, "sandwich"], "55": [49, "orange"], "56": [50, "broccoli"], "57": [51, "carrot"], "58": [52, "hot dog"], "59": [53, "pizza"], "60": [54, "donut"], "61": [55, "cake"], "62": [56, "chair"], "63": [57, "couch"], "64": [58, "potted plant"], "65": [59, "bed"], "67": [60, "dining table"], "70": [61, "toilet"], "72": [62, "tv"], "73": [63, "laptop"], "74": [64, "mouse"], "75": [65, "remote"], "76": [66, "keyboard"], "77": [67, "cell phone"], "78": [68, "microwave"], "79": [69, "oven"], "80": [70, "toaster"], "81": [71, "sink"], "82": [72, "refrigerator"], "84": [73, "book"], "85": [74, "clock"], "86": [75, "vase"], "87": [76, "scissors"], "88": [77, "teddy bear"], "89": [78, "hair drier"], "90": [79, "toothbrush"]} img_channel = 3 img_height = 256 img_width = 256 def coco256x256(dir_file, data_file, train=True): """ Trimming 256x256 image from COCO dataset """ instance_file = "%s/annotations/instances_%s.json" % (dir_file, data_file) dir_file256 = dir_file + "/coco256x256/" # Make a directory to save trimming images if not os.path.exists(dir_file256 + data_file): os.makedirs(dir_file256 + data_file) # Read instances json file with open(instance_file, "rb") as file: dataset = json.load(file) annotations = dataset["annotations"] set_filenames = set() num_samples = 0 img_mean = np.zeros((3, 224, 224), dtype="float32") # (RGB, height, width) with open("./" + data_file + "_coco256x256_map.txt", "w") as mapfile: for ann in annotations: """ segmentation : iscrowd=1 RLE(Run-length encoding) area : segmentation area iscrowd : 0 or 1 image_id : image ID bbox : [x-coordinate, y-coordinate, width, height] category_id : 80 categories id : ID """ # # Get annotation keys # if ann["iscrowd"] == 1: continue image_id = ann["image_id"] category_id = ann["category_id"] bbox_id = ann["bbox"] filename = "{:s}/{:s}/COCO_{:s}_{:0>12s}.jpg".format(dir_file, data_file, data_file, str(image_id)) class_id = categories[str(category_id)][0] x, y, w, h = bbox_id # # Trimming 256x256 image # img = cv2.imread(filename) try: if w < img_width / 4 or h < img_height / 4: # Remove very small bbox continue elif h >= img_height and w >= img_width: # width and height large bbox img256 = cv2.resize(img[int(y): int(y + h), int(x): int(x + w), :], (img_width, img_height)) elif w >= img_width and h < img_height: # large width yc = y + h / 2 - img_height / 2 if int(yc + img_height) >= img.shape[0]: # out of height img256 = img[img.shape[0] - img_height:, int(x): int(x + w), :] else: img256 = img[int(yc): int(yc) + img_height, int(x): int(x + w), :] elif w < img_width and h >= img_height: # large height xc = x + w / 2 - img_width / 2 if int(xc + img_width) >= img.shape[1]: # out of width img256 = img[int(y): int(y + h), img.shape[1] - img_width:, :] else: img256 = img[int(y): int(y + h), int(xc): int(xc) + img_width, :] else: yc = y + h / 2 - img_height / 2 xc = x + w / 2 - img_width / 2 if int(yc + img_height) >= img.shape[0] and int(xc + img_width) >= img.shape[1]: # out of image img256 = img[img.shape[0] - img_height:, img.shape[1] - img_width:, :] elif int(yc + img_height) >= img.shape[0]: # out of height img256 = img[img.shape[0] - img_height:, int(x): int(x + w), :] elif int(xc + img_width) >= img.shape[1]: # out of width img256 = img[int(y): int(y + h), img.shape[1] - img_width:, :] else: img256 = img[int(yc): int(yc) + img_height, int(xc): int(xc) + img_width, :] # # Resize image and map file # img256 = cv2.resize(img256, (img_width, img_height)) filename256 = "{:s}/{:s}/COCO_{:s}_{:0>12s}.jpg".format(dir_file256, data_file, data_file, str(image_id)) while filename256 in set_filenames: filename256 = filename256[:-4] + str(random.randint(0, 9)) + ".jpg" # No Overwrite set_filenames.add(filename256) except cv2.error: continue # # Rotation # if train: images = [img256] filenames = [filename256] # Rotation Ml = cv2.getRotationMatrix2D((img256.shape[1] // 2, img256.shape[0] // 2), angle=45, scale=1.0) Mr = cv2.getRotationMatrix2D((img256.shape[1] // 2, img256.shape[0] // 2), angle=-45, scale=1.0) channel_mean = img256.mean(axis=(0, 1)) channel_value = int(channel_mean[0]), int(channel_mean[1]), int(channel_mean[2]) images.append(cv2.warpAffine(img256, Ml, (img_width, img_height), borderValue=channel_value)) images.append(cv2.warpAffine(img256, Mr, (img_width, img_height), borderValue=channel_value)) filenames.append(filename256[:-4] + "_rtl.jpg") filenames.append(filename256[:-4] + "_rtr.jpg") for savename, saveimg in zip(filenames, images): mapfile.write("%s\t%d\n" % (savename, class_id)) cv2.imwrite(savename, saveimg) else: mapfile.write("%s\t%d\n" % (filename256, class_id)) cv2.imwrite(filename256, img256) # # Compute mean image # img_mean += img256[16:240, 16:240, ::-1].transpose(2, 0, 1) # # Count samples # num_samples += 1 if num_samples % 10000 == 0: print("Now %d samples..." % num_samples) # # Save mean image as xml # if train: save_mean_xml(data_file + "_coco256x256_mean.xml", img_mean / num_samples) # # Finish trimming image # print("\nNumber of samples:", num_samples) def save_mean_xml(mean_file, data): root = et.Element("opencv_storage") et.SubElement(root, "Channel").text = "3" et.SubElement(root, "Row").text = "224" et.SubElement(root, "Col").text = "224" img_mean = et.SubElement(root, "MeanImg", type_id="opencv-matrix") et.SubElement(img_mean, "rows").text = "1" et.SubElement(img_mean, "cols").text = str(3 * 224 * 224) et.SubElement(img_mean, "dt").text = "f" et.SubElement(img_mean, "data").text = " ".join( ["%e\n" % n if (i + 1) % 4 == 0 else "%e" % n for i, n in enumerate(np.reshape(data, (3 * 224 * 224)))]) tree = et.ElementTree(root) tree.write(mean_file) x = xml.dom.minidom.parse(mean_file) with open(mean_file, "w") as f: f.write(x.toprettyxml(indent=" ")) if __name__ == "__main__": dir_file = "./COCO" data_file = "train2014" coco256x256(dir_file, data_file)
結果
プログラムを実行すると、以下のような 256x256 にトリミングされた画像が作成されていきます。
Now 10000 samples... Now 20000 samples... ... Now 180000 samples... Number of samples: 182816トリミングできた画像は 182,816枚、作成された画像ファイルは合計で 548,448 枚でした。
解説
実行するプログラムのいくつかの箇所を抜き出して補足しておきます。
最初に JSON ファイルを辞書型で読み込んで、アノテーション情報が含まれている 'annotations' を抜き出しています。
coco256x256instance_file = "%s/annotations/instances_%s.json" % (dir_file, data_file) ... # Read instances json file with open(instance_file, "rb") as file: dataset = json.load(file) annotations = dataset["annotations"]次に、バウンディングボックスの情報に基づいて画像をトリミングします。但し、iscrowd = 1 のとき、つまり1つの画像に複数の認識物体が存在する場合は除外しています。また、バウンディングボックスで囲まれた認識物体が小さすぎる場合も除いています。
coco256x256# # Get annotation keys # if ann["iscrowd"] == 1: continue ... if w < img_width / 4 or h < img_height / 4: # Remove very small bbox continue画像のトリミングを行う部分ですが、元々の画像が小さかった場合やバウンディングボックスの大きさによって処理を変えています。
というのも、COCO データセットにはいくつかミステイクと思われるようなアノテーションがされているものもあり、試行錯誤した結果このような見栄えの良くない分岐処理になりましたが、そこは目を瞑ってください。また、アノテーションの情報は1つの画像に関して複数の認識物体を指定しているものがあり、それらの名前が重複しないようにしています。
coco256x256# # Resize image and map file # img256 = cv2.resize(img256, (img_width, img_height)) filename256 = "{:s}/{:s}/COCO_{:s}_{:0>12s}.jpg".format(dir_file256, data_file, data_file, str(image_id)) while filename256 in set_filenames: filename256 = filename256[:-4] + str(random.randint(0, 9)) + ".jpg" # No Overwrite set_filenames.add(filename256)訓練用のデータを作成する際はトリミングと 45度回転の 3種類の画像が作成されます。回転した際に生じる余白部分は各画像のチャネル毎の平均値で埋めています。引数 train を False にすればトリミング画像のみを作成します。
CNTK のビルトインリーダーの1つである ImageDeserializer が読み込むテキストファイルの作成は以下のように行います。
coco256x256mapfile.write("%s\t%d\n" % (filename256, class_id))ビルトインリーダー用のテキストファイルは非常に大きくなるため開くのが難しいかもしれませんが、内容は以下のようになっています。
各行がデータの単位になっており、画像の PATH とその画像のカテゴリー番号がタブで区切られています。train2014_coco256x256_map.txt./COCO/coco224x224//train2014/COCO_train2014_0000002180962.jpg 56 ./COCO/coco224x224//train2014/COCO_train2014_0000005366494.jpg 56 ...最後にトリミングから求めた平均画像を xml ファイルとして保存しています。
coco256x256# # Save mean image as xml # if train: save_mean_xml(data_file + "_coco256x256_mean.xml", img_mean / num_samples)画像の保存とビルトインリーダーで読み込むファイルの作成が完了すれば、ようやく訓練を行う準備が整ったので、Part2 では CNTK を使って画像分類のための畳み込みニューラルネットワークの訓練を行います。
参考
Microsoft COCO Common Objects in Context
Python API for CNTK 2.6 CNTK 201: Part A - CIFAR-10 Data Loader
- Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. "Microsoft COCO: Common Objects in Context", European Conference on Computer Vision. 2014, pp 740-755.
- 原田達也、『機械学習プロフェッショナルシリーズ 画像認識』、講談社、2017


- 投稿日:2019-07-30T12:53:11+09:00
Pythonで「中心極限定理」を確かめてみる
中心極限定理
統計において正規分布は重要な役割を果たしていますが、それは以下のような中心極限定理が成り立つからです。これにより、nを十分大きい数字として、n個の標本を取り出してその平均を調べる時、正規分布の特性を適用して調べることができます。
\begin{align} \\ &平均値\mu、分散\sigma^2 の分布に従う独立したn個の確率変数X_1、X_2、...、X_n について、\\ &次のように\bar{X}を定義する。\\ \\ &\bar{X} = \frac{X_1 + X_2 + ... + X_n}{n}\\ &nが大きいとき、この確率変数\bar{X}は平均値\mu、分散\frac{\sigma^2}{n}の正規分布に従う。\\ &\qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \\ \end{align}例:一様分布の平均を正規分布で近似する
Juliaで学ぶ確率変数(5) - 正規分布(連続型)
Juliaで学ぶ確率変数(6) - 一様分布(連続型)中心極限定理によって、次のことが言える
- n個の確率変数を取ってその平均を求める
- それを何回も繰り返せば、平均値(X)とその確率(Y)のグラフは正規分布で近似できる
以上のことを確かめるためにPythonプログラムを作ります。
プログラムの概要は以下の通りです。
- もととなる確率変数として、区間[0, 10]の一様分布を考えます。 n=10個の一様分布の平均を求めます。
- それを1000回繰り返し、同じ平均値の頻度(何回出現するか)をカウントします。
- 頻度を確率に変換して(1000で割って)、プロットします。
import numpy as np import matplotlib.pyplot as plt from decimal import Decimal d={} for i in range(1000): a=np.random.uniform(low=0.0,high=10, size=10) b=np.mean(a) c=np.around(b, decimals=0) if c in d: d[c]=d[c]+1 else: d[c]=1 ds = sorted(d.items(), key=lambda x:x[0]) print(ds) n = len(ds) xs=[x for (x,y) in ds] ys=[y/1000 for (x,y) in ds] print(xs) print(ys) plt.bar(xs, ys, 0.35, linewidth=0)一応、プロットする数字を出力しました。
[(2.0, 3), (3.0, 52), (4.0, 227), (5.0, 422), (6.0, 245), (7.0, 48), (8.0, 3)] [2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0] [0.003, 0.052, 0.227, 0.422, 0.245, 0.048, 0.003]なるほど、プロットしたグラフは正規分布に近いようです。
実際に正規分布で近似できているかを確認します。
中心極限定理の定理を使って、もとの一様分布の平均値と分散から、正規分布の平均値と分散を求めます。
- 平均値は一様分布と同じで5です。
- 分散は(10*10/12)/10です。
前のプログラムの最後尾に、以下のプログラムを追加して、再実行しプロットします。
from scipy.stats import norm X = np.arange(0,10,1) Y = norm.pdf(X, loc=5, scale=np.sqrt(10*10/12/10)) plt.plot(X,Y,color='r')なるほど、確かに正規分布で近似できているようです。中心極限定理は魔法のような定理ですね!
今回は以上です。
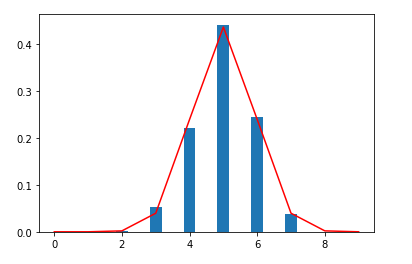
- 投稿日:2019-07-30T12:44:39+09:00
AWS Lambdaのランタイムサポート
AWS LambdaのランタイムサポートはランタイムのEOLと同時に新規作成ができなくなり、その後1~2ヵ月で更新もできなくなる。
Node.jsはメジャーバージョンアップが1年ごとで、EOLもリリースから2年半と短いため、頻繁なEOL対応が必要となる。(Pythonはリリースから5年間サポートされる。)
ランタイム LTS開始 EOL 廃止 (作成) 廃止 (更新) Python 2.7 2010/07/03 2020/01/01 (未定) (未定) Python 3.5 2015/09/13 2020/09/13 (サポート対象外) (サポート対象外) Python 3.6 2016/12/23 2021/12/23 (未定) (未定) Python 3.7 2018/06/27 2023/06/27 (未定) (未定) Node.js 0.10 2013/03/11 2016/10/31 2016/10/31 2016/10/31 Node.js 4.3 2015/10/01 2018/04/30 2018/12/15 2019/4/30 Node.js 6.10 2016/10/18 2019/04/30 2019/04/30 2019/6/30 Node.js 8.10 2017/10/31 2019/12 (予定) ※ (未定) (未定) Node.js 10.x 2018/10/30 2021/04 (予定) (未定) (未定) Node.js 12.x 2019/10/22 2022/04 (予定) (未定) (未定) ※ OpenSSL-1.0.2と同時のEOLとするため、通常よりも早く設定されている。
参考
- 投稿日:2019-07-30T11:17:54+09:00
自動生成
Pythonでツイートを生成したい! -マルコフ連鎖編-
https://qiita.com/h_tashiro/items/9d1c3dfece86b1848625LSTM-RNNを使って芥川龍之介っぽい文章を自動生成させてみた
https://qiita.com/odrum428/items/8864a5476027b910b9b5短歌
pythonでpoemから俳句、短歌を自動生成する
https://qiita.com/tyonekura@github/items/b26577e1cff55f11a319深層学習とマルコフ連鎖による短歌自動生成Ver.0.10
https://qiita.com/aokikenichi/items/13d9b327581f9ddc3c57短歌を自動で生成
http://sasakiarara.com/sizzle/Pythonによる文章自動生成入門
Pythonによる文章自動生成入門!Python ✖︎ 自然言語処理 ✖︎ ディープラーニング
https://pycon.jp/2017/en/schedule/presentation/21/Slide
https://www.slideshare.net/otanet/pycon-jp2017-20170908ota-79578217Pythonによる文章自動生成入門!Python ✖︎ 自然言語処理 ✖︎ ディープラーニング (Hiromitsu Ota) - PyCon JP 2017
https://www.youtube.com/watch?v=2nChvKvqJ1Y英語
【Python】機械学習で文章を自動生成する方法
https://sleepless-se.net/2018/08/20/python-machine-learning/【Python】BidirectionalRNNを使って文章を自動生成
https://sleepless-se.net/2019/03/21/【python】bidirectionalrnn-create-sentence/Typoglycemiaの自動生成をPythonでやってみよう(英語版)
https://note.mu/mybrain_record/n/nb2ba57ca5c02日本語
Typoglycemiaの自動生成をPythonでやってみよう(日本語版)
https://note.mu/mybrain_record/n/nfda99c12e1beディープラーニングで文章を自動生成したい!
https://blog.aidemy.net/entry/2018/10/05/195404マルコフ連鎖による日本語文章自動生成プログラムの覚書【Python】
https://chishiki-motomeru.com/post/20190329/マルコフ連鎖を使って〇〇っぽい文章を自動生成してみた
https://www.pc-koubou.jp/magazine/4238コードが書けない猫でもできるDeepLearningの文章自動生成(+ColaboratoryのTipsとSnippet)
https://medium.com/eureka-engineering/colaboratory-e8634e7836fa自動文章生成AI(LSTM)に架空の歴史を作成させた方法とアルゴリズム
https://spjai.com/ai-history/pythonで自動文章生成
https://www.blue-weblog.com/entry/2017/07/17/0818192016-01-27 マルコフ連鎖を使ってブログの記事を自動生成してみた
https://karaage.hatenadiary.jp/entry/2016/01/27/073000
- 投稿日:2019-07-30T09:38:59+09:00
「頑張れ宗谷本線」のモザイクアートを作る
ディープラーニングを申し訳程度に入れてモザイクアートの自動生成を行います。「頑張れ宗谷本線」のモザイクアートに触発されて作ったものです。
※この記事は趣味全開な内容です。過度なテクノロジーは期待しないでください。
宗谷本線
せっかくなので宗谷本線について簡単な解説をしましょう。宗谷本線とは北海道を走る「日本最北端」の鉄道路線です。
地図([*1]より)の赤で囲った部分が宗谷本線です。拡大してみましょう([*1]より)。
旭山動物園で有名な旭川駅から、日本最北端の駅である稚内駅までを結ぶのが宗谷本線です。ひとまず日本最北端の駅=稚内であるというのを知っておいてください。沿線情報は書き出すと長くなってしまうので省略しますが、ほかには音威子府(おといねっぷ)というなんだかかっこいい名前の場所があるなぐらいに認識しておけばさらに良いです。
この地図を見ると「最果てに向かうなんだか寂しい路線だな」というイメージを持つかもしれません。しかし、つい35年ほど前まではもっと賑やかな路線でした。これは1983年の時刻表から([*2])です。
つい35年ほど前は、道北には今は亡き鉄道網が網の目のように張り巡らされていました。宗谷本線の音威子府や名寄(なよろ)は交通の要衝であったのがわかります。これは道北に限った話ではなく、北海道全体でそうでした。1983年の北海道の路線図は次のとおりです。ぜひ最初の2019年の路線図と見比べてみてください。
もはや同じ北海道と思えないぐらい、現在では消えた路線が大量にありました1。
宗谷本線は、道北の大動脈ともいえる路線で、寝台列車が毎日運行されていたこともありました。1983年の時刻表([*2])からです。
一方で2019年現在の時刻表([*1]より)は以下のとおりです。
旭川~名寄は若干今のほうが便利な感はありますが、名寄~稚内間は随分寂しくなりましたね。かつての急行列車はほとんど消滅しましたし、普通列車もかなりが姿を消しました。こんなに時刻表がスカスカで寂しい路線ではなかったのです。逆に言えば、現在の宗谷本線はかつて豪華な大動脈の面影が残っている路線、とも言うことができます。
そんな宗谷本線ですがついに存続を問われる路線となりました。JR北海道の資料からです
日本最北の路線も、残念ながらいつまでもあり続ける保証はありません。
頑張れ宗谷本線
そんな宗谷本線ですが、今年に入って景気のいい話があります。「風っこそうや」というトロッコ列車が走るのです。(画像はJR北海道のホームページより)
以前から北海道ではノロッコなど、トロッコ列車の運行はありましたが、この「風っこそうや」の場合は、JR東日本から車両を借りて運行するという非常に珍しい試みなのです。
沿線の有志の方が行っている応援プロジェクトでは、クラウドファンディングで目標額80万円のところを、11日間で103万円を達成したとのことです。それだけ注目度が高いことであるのがわかります。(画像はクラウドファンディングのサイトからです)
今回はこの「頑張れ宗谷本線」のようなイラスト(モザイクアートと言うそうです)を自分も作ってみることにしました。地元の方が愛を込めて作ったものには遠くは及びませんが、それっぽいものを作ることができました。
モザイクアートの理論
ここから技術的な話に入ります。モザイクアートは実は機械的に作ることができます。モザイクアートのベースの画像を$B$とし、実際に貼り付ける参照画像を$R_k (k=1,\cdots,M)$とします。
モザイクアートの理論とは、ベース画像をいくつかのパッチ(四角形)に分割し、それに対して「どの参照画像を配置すればいいか」という問題を解くことです。これを定式化しましょう。
ベース画像を$(N_x, N_y)$というパッチに分割するとします。すると、ベース画像のパッチは、$B_{i, j} (i=1,\cdots,N_x, \quad j=1,\cdots,N_y)$という表記で表されます。$B_{i, j}$に対する最適な参照画像$R_{k^*}$の求め方は、
\newcommand{\argmin}{\mathop{\rm arg~min}\limits} k^*_{i,j}=\argmin_{k=1\to M}\mathcal{L}(\mathcal{M}(B_{i,j}), \mathcal{M}(R_k)) \tag{1}を解くことです。ここで、$\mathcal{L}(\cdot)$は損失関数、$\mathcal{M}(\cdot)$は画像同士の近さを測る何らかの指標です。
損失関数$\mathcal{L}(\cdot)$は平均二乗誤差(L2ノルム)や、平均絶対値誤差(L1ノルム)などを使います。今回のケースでは、平均絶対値誤差を使います。
$\mathcal{M}(\cdot)$が直感的にわかりづらいですが、最も単純なのがピクセル同士の値を比較するということです。この場合は、ディープラーニングのMean absolute errorで最小化するのと同じです。
もう少し発展させたケースでは、$\mathcal{M}(\cdot)$に訓練済みモデルの特徴量を使うということです。つまり、例えば、訓練済みVGG16の中間層の値を取って、その値が近いもの同士を配置するという、スタイル変換におけるPerceptual lossと同じになります。ここらへんの発想はReframe Visualizationにかなり近いです。
実装
ベース画像は、自分が名寄駅で撮ったキハ54を使います。参照画像は、画像処理で頻繁に使われるImageNetのValidationデータセット(5万枚)を使います。ベース画像は以下のとおりです。
この(元)画像の解像度は3968×2976ですが、縦93pixel×横124pixelを1つのパッチとし、32×32の合計1024枚のパッチに分割します。1024枚のパッチに対して、参照画像の最適な割り当てを計算します。
そして$\mathcal{M}(\cdot)$は以下の4ケースを使いました。
- ピクセル同士の差(Identity)
- 訓練済みVGG16のblock1_poolの値
- 訓練済みVGG16のblock2_poolの値
- 訓練済みVGG16のblock3_poolの値
VGG16は、ディープラーニングの伝統的なモデルですが、スタイル変換では未だに優位性があることが確認されています。VGG16は以下のような構成です(VGGの論文より)。
結果
$\mathcal{M}(\cdot)$を変えてモザイクアートを作ると次のようになりました。ただし、block1_poolのケースではメモリ(RAM)の制約で参照画像の枚数を25000枚に減らしています。
ピクセル差の場合は、全体的にのっぺりとした印象(まだ写真っぽい)、block1_poolは適度にゴツゴツしていて良さそう(人間が作ったような感じ)受けます。モザイクアートの印象は、画像の拡大率によってかなり変わるので、いろいろなスケールで見てみるのをおすすめします。
残りの2ケース、特にblock3_poolは元の列車の形を認識するのが難しくなってしまいましたね。これは情報を落としすぎです。
最初の2ケースを拡大してみましょう。
ピクセル差で最適化(Identity)
VGGのblock1_poolで最適化
いずれのケースでも「普通」や「ワンマン」のような、文字や輪郭の部分が潰れてしまうのは致し方ないです。そこを入れたいのなら手動で再挿入するのが手っ取り早いかと思います。
なぜこうなるのか
$\mathcal{M}(\cdot)$について、ピクセル差を取る場合は発想がわかりやすいのですが、なぜVGGの特徴量を取るのかということに補足しておきましょう。
この記事においてニューラルネットワーク(VGG16)の特徴量を取った理由とは、再構成後の画像の粗さのコントロールです。訓練済みVGG16のやっていることは、画像を入力して、どういう画像が映っているかという意味的な情報を出力します。したがって、深い層(例:block3_poolなど)を取るほど、元のピクセル情報は削ぎ落とされて、全体のぼんやりした情報を参照するようになります。block3_poolなどで最適化したときに、元の列車の形を認識しづらくなった理由の1つはこれです。
別の言い方をすれば、ニューラルネットワークの特徴量を使う、ディープラーニングのアプローチを使うことで、自動的に生成するモザイクアートの表現に幅を持たせることができます。
問題点
浅い層の特徴マップを取る場合、メモリをひたすら食いがちなので、そこでのargminの計算が時間がかかりました。何らかの次元削減か、昨日ツイッター上で見つけた近似最近傍探索の最前線などの手法を使うと計算時間を短縮できそうです。
感想
多分こんな感じでできるだろうと思って実装したら、そこそこ形になりました。ひとまず形になってよかったです。以前、ディープラーニングのモザイク除去の薄くない薄い本を書いたのですが、このアート手法も「モザイクアート」ということで、何かと自分はモザイクに縁があるみたいです。
宗谷本線は非常に面白く楽しい場所なので、ぜひ遊びに行ってみてください。自分も近いうちに(この記事を書いた7/30時点)に風っこそうやに乗りに行くので楽しみです。
コード
https://github.com/koshian2/DeepMosaicArt
おおよそKerasの実装です。Pythonで100行も行きません。
引用元
[*1]:JTB小さな時刻表 春号, JTBパブリッシング, 2019年2月
[*2]:国鉄監修時刻表, 日本交通公社 ,1983年8月
これらの路線が消えてしまった原因はいろいろありますが、大きな要因としては、戦後国の政策により、国鉄が引き揚げ者や満鉄社員を引き受けたことで人件費が圧迫したこと23、その余波でローカル線の廃止が進められたこと、モータリゼーションの普及、北海道の成長を下支えした石炭産業が高度経済成長期に失速したこと、北海道全体の人口が日本全体よりもいち早く減少傾向になったこと4などが挙げられます。これら以外にもあるでしょうが、複合的かつ根が深い問題となっているのが実情です。 ↩
中湧別にある名寄本線の資料にそのような記載あり https://twitter.com/koshian2/status/1105462262959992839/photo/1 ↩
国土交通省の白書より。国鉄の損益状況の推移の資料あり。それによると、支出高騰の大部分が人件費と物価の高騰で、これが大きく収益を悪化させていたのがわかります https://www.mlit.go.jp/hakusyo/transport/shouwa57/ind020101/001.html ↩
北海道全体で人口減少が始まるのはおおよそ平成以降ですが、支庁単位で見れば石狩支庁(札幌近郊)以外は、1960~1980年代から人口減少が始まっていた点には留意すべきです。 https://pucchi.net/hokkaido/geo/population02.php ↩
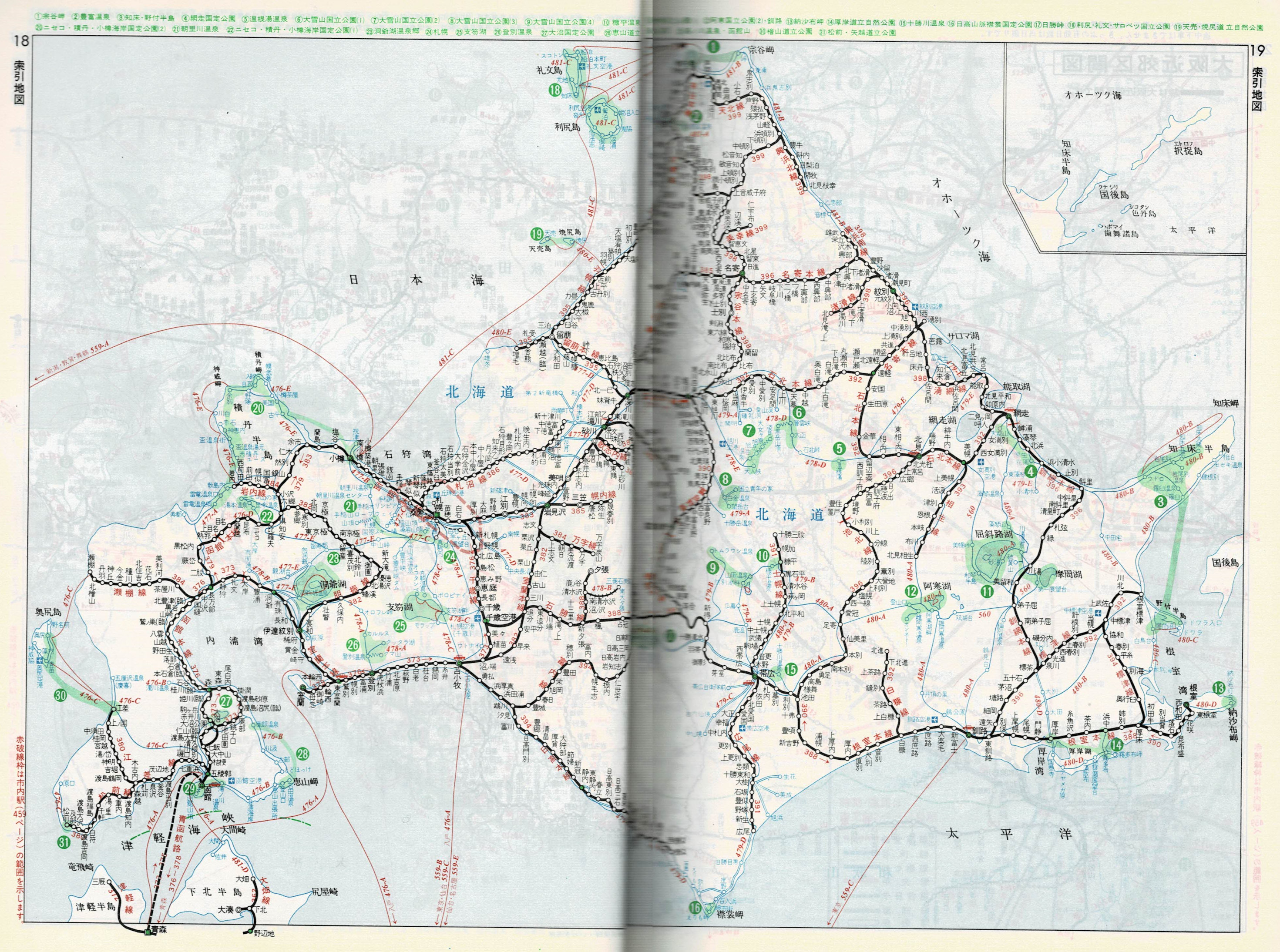

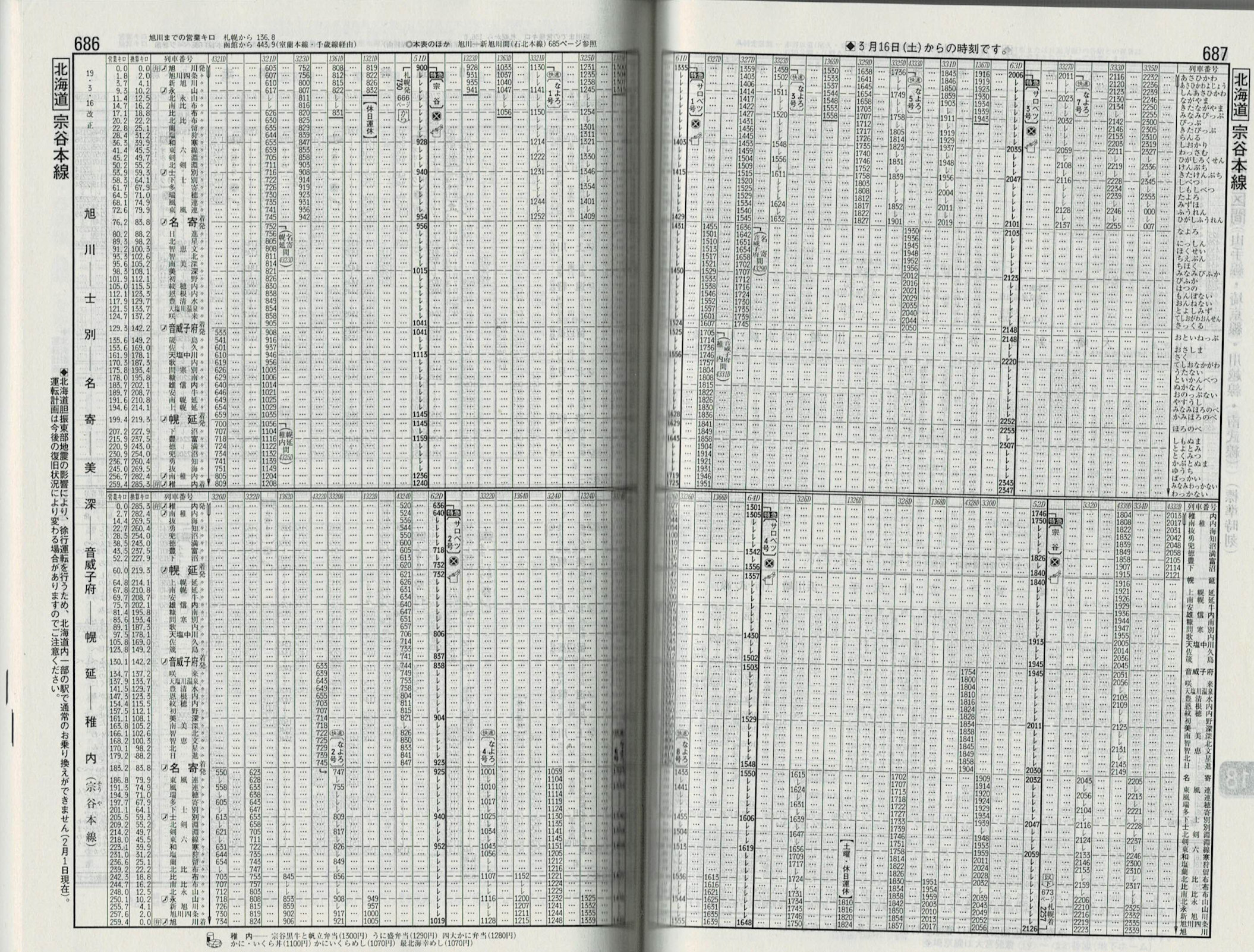
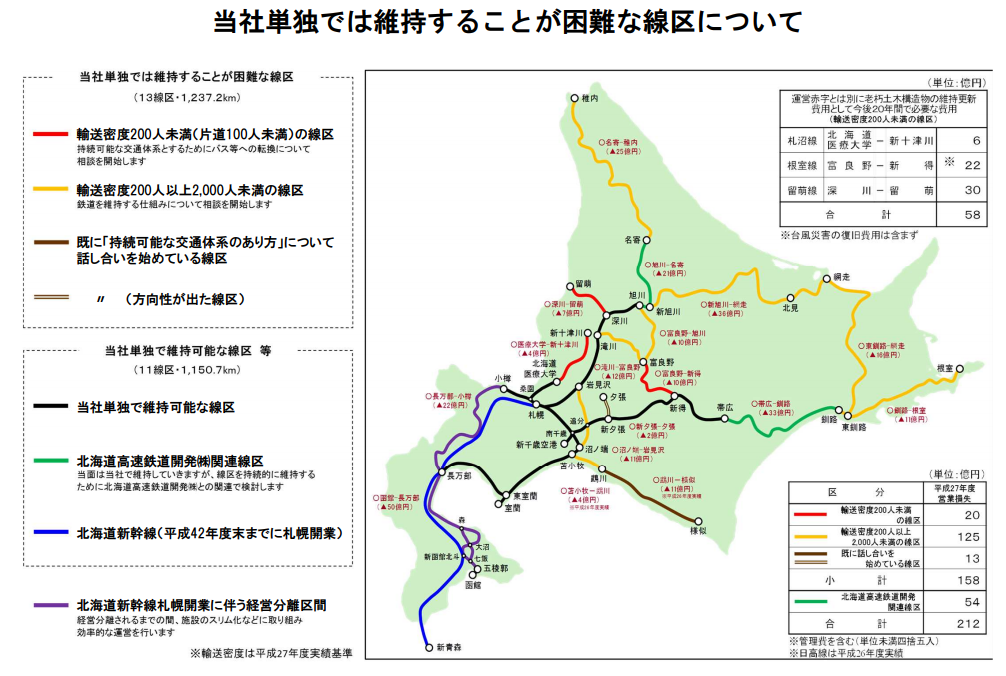





- 投稿日:2019-07-30T08:58:55+09:00
【Programming News】Qiitaまとめ記事 July 29, 2019 Vol.15
筆者が2019/7/29(月)に気になったQiitaの記事をまとめました。昨日のまとめ記事はこちら。
2019/7/21(日)~2019/7/27(土)のWeeklyのまとめのまとめ記事もこちらで公開しております。
Java
Python
- Tips
- Apps
Rails
- Tips
Vue.js
Android
- Tips
Swift
- Beginner
- Tips
Kotlin
- Beginner
- Tips
Flutter
JavaScript
- Beginner
- Tips
Node.js
React
Laravel
Keras
- Beginner
PowerShel
Spark
R言語
MySQL
Azure
AWS
- EC2
- AWS Lambda
- Tips
- AWS CodeStar
Docker
- Tips
- DockerコンテナのロギングにGrafana+Lokiを試してみた
- 最短2文でLibraのテストネットを立ち上げるDockerイメージ作りました
- もっと簡単にDockerでNuxt.jsを始めてみる(続Dockerでローカル環境を汚さずにNuxt.jsを始めてみる)
- Hugo を Docker 上で動作させる
- Nginx版:mkcertを使ってローカル環境でもDockerでも楽々SSL
- Vagrant環境のDockerでJenkinsサーバを構築し、スレーブのWindowsマシンを接続する(前半)
- Vagrant環境のDockerでJenkinsサーバを構築し、スレーブのWindowsマシンを接続する(後半)
- DockerでNuxt.js on TypeScriptを始めてみよう
- DockerでRailsの環境構築
TypeScript
Google Apps Script
機械学習
- Beginner
Raspberry
- Tips
Develop
- Tips
- Meetup
Intellij IDEA
更新情報
Kotlin
- Kotlin入門
Android
Java
IDE
- 投稿日:2019-07-30T08:05:30+09:00
【3分で分かる】回帰問題と分類問題の違い
これから機械学習を勉強してみたい!と思っている方に向けて書きました。今回は回帰問題と分類問題について説明します。難しい言葉や数式は全く出てこないので安心してください。また、記事の最後にクイズも用意したので、ぜひチャレンジしてみてください。
機械学習の種類
機械学習は大きく分けて3つの種類があります。教師あり学習、教師なし学習、強化学習です。この記事では機械学習の中で最も一般的である教師あり学習について取り扱います。
教師あり学習とは?
例えば動物の画像データを大量に用意します。これらの画像データにはそれぞれ動物の種類の名前が正解として紐づけられています(この画像のはイヌ、この画像はネコといったように)。
大量の画像を機械に何度も何度も見せることによって、だんだんとそれぞれの動物の特徴が分かってきます。
そしてまだ見せていないイヌの画像データを見せたときに、機械は「しっぽがあって、ギザギザの歯があって・・・」と分析して、「これはイヌです。」と答えるようになるのです。
このようにあらかじめ正解が分かっているデータを分析させて、未知のデータを予測させる手法を教師あり学習と呼びます。さて、この記事の本題に移りますが、実は教師あり学習には回帰問題と分類問題といった2つのアルゴリズムがあります。さっそく見ていきましょう。
回帰問題とは?
例えば次のようなグラフがあったとしましょう。このグラフは、ある土地における温度と湿度の関係を表しています。
もし温度が23℃のとき、湿度はどれくらいになるでしょうか。残念ながら23℃はこのグラフ上にプロットされていないので自分で予想を立てなければいけません。
図1のように直線を引いた場合は湿度35%、図2のように曲線を引いた場合は湿度37%です。わずかな違いではありますが、湿度の値が線の引き方によって変わりました。
しかしながらどちらも共通していることは、温度が決まれば湿度も必ず決まるということです。線を引いたことによって、温度が17℃のときや34℃のときも湿度を求めることができますよね。これは引いた線がずっと続いていて途切れていないからです(これを連続しているといいます)。
回帰問題とは連続した数値における予測を行う問題です。分類問題とは?
柴犬の特徴って何でしょうか?体の高さよりも体の長さの方がやや長く、小さな立ち耳で巻き尾、短毛でダブルコート。毛の色は茶色や黒色で腹は白色です。
大量のイヌの画像で学習した機械に、正解が「柴犬」の画像(機会にとっては未知のデータ)を機械に見せます。最初に機械が「体の大きさ」で判別したとしましょう。大型犬である「ハスキー」や「ゴールデンレトリバー」の可能性が消えます。続いて「しっぽの立ち具合」で判別します。ここで、しっぽが垂れている「ダルメシアン」などの可能性が消えます。・・・。
というように機械は「このイヌはこういった特徴がある」ということを学習していて、それに基づいて正解を出します。
分類問題とは、データがどのグループに属するのか予測する問題です。確認クイズ
次の例は回帰問題、分類問題のどちらかに当てはまるか答えてください。
去年発売されたパソコンが欲しい。今から数えて3か月後にお金が貯まるので買いたいと思っている。いくらくらいの値段で買えるか予想したい。
↓
↓
↓
↓
↓
↓
↓クイズの答え
回帰問題
参考
『ゼロから作るDeep Learning pythonで学ぶディープラーニングの理論と実装』
『Coursera Machine Learning』


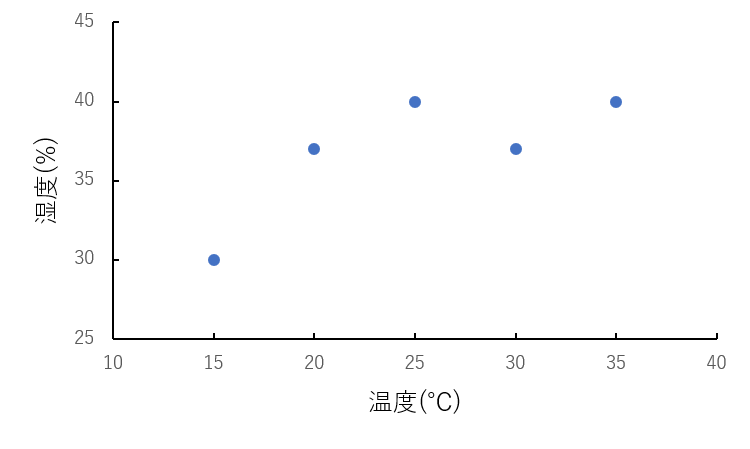
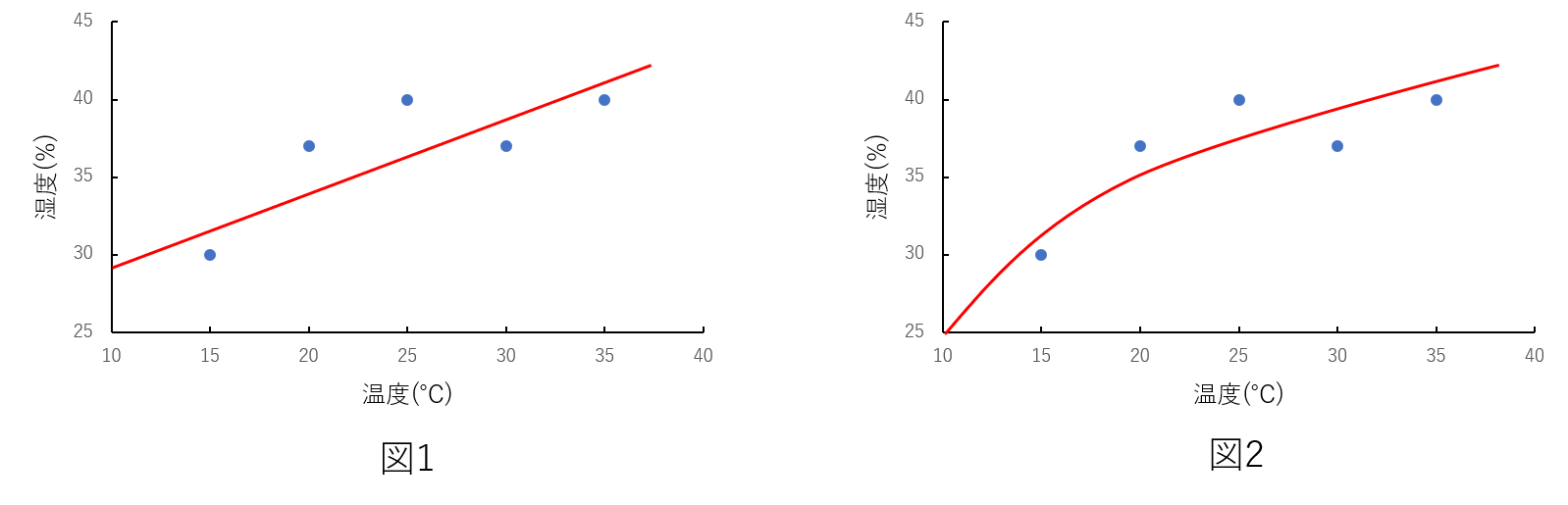

- 投稿日:2019-07-30T07:33:03+09:00
ラズパイでYubikeyを光らせてみる
はじめに
ラズパイにFIDO2セキュリティキーを接続してCTAPコマンドでお話してみました。
- FIDOとかCTAPって何?
- CTAP
環境
- ラズパイ:Raspberry Pi 3 Model b+
- ラズパイのOS:raspbian stretch (2019-04-08)
- 光らせるFIDO2セキュリティキー:Security Key by Yubico
- 言語:Python 3.5.3
補足
2019/7/30時点でRaspbinはBusterというバージョンなんですが、これ新しすぎてちょっとアレなんで一つ前のStrechというバージョンを使います。Strechをインストールする方法については以下を参考にしました。
→参考:Raspbian Busterリリース!Stretchとの違いとStretchの入手方法
ここまでセットアップした状態から始めます
- ラズビアンstrechはセットアップ完了して、ラズパイ起動できる状態
- Wifi接続済み
- 日本語入力システムインストール済み
- VNC・SSH接続できる状態
サンプルプロラム実行までの手順
pythonのバージョン確認
pythonの2と3が最初から入っています。今回はpython3でやります。
pythonのバージョン確認pi@raspberrypi:~ $ python --version Python 2.7.13 pi@raspberrypi:~ $ python3 --version Python 3.5.3openssl 1.0.2のインストール
まず、OpenSSLをいれます。
pipでインストールできませんでした。どうやらラズパイ用のOpenSSLはないらしく、仕方がないので、ソースを落としてきてビルドします。openssl_1.0.2のインストールwget https://www.openssl.org/source/openssl-1.0.2.tar.gz tar xvf openssl-1.0.2.tar.gz cd openssl-1.0.2 ./config zlib shared no-ssl2 make && sudo make install // makeには30分くらいかかります参考:Raspberry Piに最新版の各種ツール・言語・ライブラリをインストールする
サンプルソースのダウンロード
YubicoのサンプルをGitHubから落とします。
どこか作業のフォルダを作ってその中で実行しましょう。
注意:Python3なのでpip3ですサンプルソースのダウンロード// gitでソースを落とす git clone https://github.com/Yubico/python-fido2.git // fido2をインストールする pip3 install fido2 // インストールに成功すると // Successfully installed asn1crypto-0.24.0 cffi-1.12.3 cryptography-2.7 fido2-0.7.0 pycparser-2.19 six-1.12.0 // と出る // ちゃんとfido2がインストールされたかどうか確認 pip3 list | grep fido2 // fido2 (0.7.0)とか出ればOKサンプルソースの実行
落としてきたサンプルソースのexamplesディレクトリにpyが今回実行するサンプルです。
get_info.py
FIDO2キーの情報をGETして出力するサンプルです。
ラズパイのUSBにYubikeyを刺して、get_info.pyを実行します。
Yubikeyがビカビカ光って、結果が表示されたらOK。キーにGetInfoコマンドを送ってGETしたキーの情報を出力したあと、Winkコマンドを送ってキーを光らせているようです。
注意:pyの実行はpython3
get_info.pypi@raspberrypi:~/work/python-fido2-master/examples $ python3 get_info.py // ここからが実行結果(適当に改行いれてます) CONNECT: CtapHidDevice(/dev/hidraw1) CTAPHID protocol version: 2 DEVICE INFO: Info( versions: ['U2F_V2', 'FIDO_2_0'], extensions: ['hmac-secret'], aaguid: h'fa2b99dc9e3942578f924a30d23c4118', options: {'clientPin': True, 'up': True, 'rk': True, 'plat': False}, max_message_size: 1200, pin_protocols: [1] ) WINK sent!credential.py
キーにクレデンシャルを登録して、認証を行うサンプルです。
CTAPの以下のコマンドが使われています。
- authenticatorMakeCredential
- authenticatorGetAssertion
- authenticatorGetNextAssertion
- authenticatorClientPIN
credential.pypi@raspberrypi:~/work/python-fido2/examples $ python3 credential.py Use USB HID channel. Please enter PIN: // ◆ここでPINを入力してENTERします Touch your authenticator device now... // ◆ここでキーをタッチします // キーにクレデンシャルを登録して成功すると以下のログが出る New credential created! CLIENT DATA: { "origin": "https://example.com", "clientExtensions": {}, "challenge": "Y2hhbGxlbmdl", "type": "webauthn.create" } ATTESTATION OBJECT: AttestationObject( fmt: 'packed', auth_data: AuthenticatorData( rp_id_hash: h'a379a6f6...2fa13d2125586ce1947', flags: 0x45, counter: 66, credential_data: AttestedCredentialData( aaguid: h'fa2b99dc9e3942578f924a30d23c4118', credential_id: h'9b26...f262d2bfbb3525cf8b', public_key: { 1: 2, 3: -7, -1: 1, -2: b'\x00\x...84\x99`\x9f/\xda', -3: b'\x98\x...x9f\x90J\xe5\xda' } ), att_statement: { 'alg': -7, 'sig': b'0F\x02!\...xd3+\xaap\xa7|\x1bBKA\xd9X', 'x5c': [ b'0\x82\x02\xbc9...9\xff\xbc\x93\x8c\xa0\xb47' ] } ) CREDENTIAL DATA: AttestedCredentialData( aaguid: h'fa2b99dc9e3942578f924a30d23c4118', credential_id: h'9b262e9c0fe5fa34d7a687b5cc1b81abd9ecebee055de2f9c04985b0b691c41f059f4ab3e043bec57426863ba1f05288de1f27d36b8e935762d2bfbb3525cf8b', public_key: { 1: 2, 3: -7, -1: 1, -2: b'\x00\xbdm\xce\xc2\xc2\xb0!#u\xc18\xb9Z\xd5R[A\x14\xea\xfe\xc6F\xe1T\xcc\x84\x99`\x9f/\xda', -3: b'\x98\x89,\xa9\xacv\x92\xa9q7\xee;\xa3\xf1\x7f\x1f-%\xb0[\x80\xeeR\xf0\xb8|\xee\x9f\x90J\xe5\xda' } Attestation signature verified! // 登録完了した、という意味。 // 認証のテスト Touch your authenticator device now... // ◆もう一度キーにタッチします。 Credential authenticated! CLIENT DATA: { "origin": "https://example.com", "clientExtensions": {}, "challenge": "Q0hBTExFTkdF", "type": "webauthn.get" } ASSERTION DATA: AssertionResponse( credential: { 'id': b"\x9b&.\x9c\xd2\xbf\xb\xcf\x8b...", 'type': 'public-key' }, auth_data: AuthenticatorData( rp_id_hash: h'a379ad30ab13d21255ce1947...', flags: 0x05, counter: 67 ), signature: h'3044022016c0224af4814eaa6cb...' ) Assertion signature verified! // 認証も完了した、という意味ラズパイでVSCODEでpyをデバック実行してみる
さて、次はこのサンプルプログラムをデバック実行してみたくなります。
ラズパイに開発環境を導入します。
開発環境は今最もモダンなVSCODEにします。
(VSCODEはラズパイではcode-ossっていう名前です)このcode-ossですが、セットアップにトラップが2つあります。(2019/7/30時点)
トラップ1
あちこちのサイトで以下の2発のコマンドでインストールしていますが、私の環境ではエラーになりました。このやり方はNGです。
code-ossのインストール→失敗sudo -s . <( wget -O - https://code.headmelted.com/installers/apt.sh ) // 色々処理が走って、最後に以下のエラーメッセージが出てインストール失敗する // E: 認証されていないパッケージがあり、-y オプションが --allow-unauthenticated な しで使用されました // Visual Studio Code install failed.トラップ2
code-ossをインストールできても、起動したら真っ黒なウィンドウがでてくるだけでなんもできません。最新バージョンのモジュールはダメみたいです。
参考:RaspberryPiにVSCodeをインストールして起動してもウィンドウに何も表示されない問題
というわけで、上記トラップを回避してcode-ossをセットアップする手順は以下の通り
- guiを使うので、SSHではなくVNC接続するか、ラズパイにモニタキーボードつないで直でやりましょう。
- どっか作業ディレクトリを作成して、その中でやりましょう。
1)apt.shを落としてくる
wget https://code.headmelted.com/installers/apt.sh2)テキストエディタでapt.shを開いて以下の行を変更する
変更前apt-get install -t ${repo_name} -y ${code_executable_name}; #apt-get install -t ${repo_name} -y --allow-unauthenticated ${code_executable_name};変更後#apt-get install -t ${repo_name} -y ${code_executable_name}; apt-get install -t ${repo_name} -y --allow-unauthenticated ${code_executable_name};3)apt.shを実行して再起動する
apt.shを実行して再起動するsudo -s . apt.sh // こんなコメントが出たらOK Installation complete! You can start code at any time by calling "code-oss" within a terminal. A shortcut should also now be available in your desktop menus (depending on your distribution). // rebootしましょう reboot4)code-ossをダウングレードする
code-ossをダウングレードするsudo apt-get install code-oss=1.29.0-1539702286 // コマンドが成功したら、更新しないマークを付けてreboot sudo apt-mark hold code-oss reboot5)code-oss起動!
code-oss起動!code-oss
あとは適当にoss-codeを操作していくと、勝手にインストールがリコメンドされるので入れていきます。
- japanese
- Python
- Linter Pylint
ラズパイなのでさくさくはいかないですが、デバック実行もOK。
おつかれさまでした
いがいと簡単!



- 投稿日:2019-07-30T06:39:07+09:00
python-cgiモジュールのFieldStorage型について
はじめに
pythonでwebページ間でデータをやりとりする為に
cgiモジュールを使った際に
調べたcgi.FieldStorage型について整理しました。Pythonの公式ドキュメントはこちら
https://docs.python.org/3/library/cgi.htmlpython-cgiについての記事はこちら
https://qiita.com/r_i_qita/items/82fb537688e0f2be4915cgi.FieldStorage
cgiモジュールで使用されているクラス。
FieldStorageクラスをインスタンス化することで、
クライアントから送られるフォームの内容を取得できるようになる。主な使い方
pythonファイルが実行された
<form></form>に紐付くhtmlタグを取得する。例えば、以下のような記述を html と python に書いた場合、変数formの中身は次のようになる。
変数form(FieldStorage型)
(None, None, [MiniFieldStorage('hdn_name', 'hdn_value1'), MiniFieldStorage('hdn_name', 'hdn_value2'), MiniFieldStorage('text_name', 'text_value'), MiniFieldStorage('button', 'submit!!')])# Python form = cgi.FieldStorage()<!-- HTML --> <form name="formSubmit" action="cgibin.py"> <input type="hidden" name="hdn_name" value="hdn_value1"> <input type="hidden" name="hdn_name" value="hdn_value2"> <input type="text" name="text_name" value="text_value"> <input type="submit" name="button" value="submit!!"> </form>データの取り出し方
上記のhtml, cgi.FiledStorageインスタンスを例に
フォームのデータを取り出す方法を以下に記載します。注釈
以降の説明では例の
name="hogename"に当たる部分をhtml_name,
value="hogevalue"に当たる部分をhtml_value と表現します。<!-- (例) --> <input type="hidden" name="hogename" value="hogevalue">form.getvalue(name)
指定したhtml_nameに紐付く、全てのhtml_valueを返す。
紐付くhtml_nameが
1つの場合はString型、複数ある場合はlist型で返す。# 例1) # 変数名:格納されるデータ:型 # ret:'text_value':<class str> ret = form.getvalue('text_name')# 例2) # 変数名:格納されるデータ:型 # ret:['hdn_value1', 'hdn_value2']:<class list> ret = form.getvalue('hdn_name')上記の通り、
html_nameの数によって、返ってくる型が異なるので、バグ懸念があります。
個人的には、後述のform.getlist()を使った方が良いと思います。form.getlist(name)
指定したhtml_nameに紐付く、全てのhtml_valueを返す。
紐付くhtml_nameの数に関わらず、list型で返す。# 例1) # 変数名:格納されるデータ:型 # ret:['text_value']:<class list> ret = form.getlist('text_name')# 例2) # 変数名:格納されるデータ:型 # ret:['hdn_value1', 'hdn_value2']:<class list> ret = form.getlist('hdn_name')form.list
pythonファイルが実行された
<form>タグに紐付く、html_nameとhtml_valueをlistで返す。
listの要素はMiniFieldStorage型。
MiniFieldStorage型は、辞書型のように(key, value)形式でデータを持つ。# 例) # 変数名:格納されるデータ:型 # ret:[MiniFieldStorage('hdn_name', 'hdn_value1'), MiniFieldStorage('hdn_name', 'hdn_value2'), MiniFieldStorage('text_name', 'text_value'), MiniFieldStorage('button', 'submit!!')]:<class list> ret = form.listhtmlタグを全部取ってきて
XXXというhtml_valueがあれば処理1、
YYYというhtml_valueがあれば処理2 というような分岐処理に使える。form[name]
指定したhtml_nameとそれに紐付くhtml_valueをMiniFieldStorage型で返す。
紐付くhtml_nameが複数ある場合、list型 of MiniFieldStorage型で返す。# 例1) # 変数名:格納されるデータ:型 # ret:MiniFieldStorage('text_name', 'text_value'):<class MiniFieldStorage> ret = form['text_name']# 例2) # 変数名:格納されるデータ:型 # ret:[MiniFieldStorage('hdn_name', 'hdn_value1'), MiniFieldStorage('hdn_name', 'hdn_value2')]:<class list> ret = form['hdn_name']form[name].value
指定したhtml_nameに紐付く、html_valueをString型で返す。
ただし、紐付くhtml_nameが複数ある場合、
form[name]がlist型で返ってくる為、AttributeErrorが発生する。# 例1) # 変数名:格納されるデータ:型 # ret:'text_value':<class str> ret = form['text_name'].value# 例2) # raise AttributeError ret = form['hdn_name'].valueまとめ
以上のようにcgi.FieldStorageを使ってフォームの情報を取り出す事で
Webページ間のデータの受け渡しや動的なhtml処理などを簡単に行えます。
とても便利。
- 投稿日:2019-07-30T03:01:36+09:00
mecab ipadic-NEologd を Google Colaboratory で使う
これはなに?
形態素解析のデファクトスタンダードであるMeCabと、その追加辞書mecab-ipadic-NEologdをGoogle Colaboratoryで動かすためのコードです。
8割方自分用の備忘録です。
MeCabのインストール
!apt install aptitude swig !aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y !pip install mecab-python3mecab-ipadic-NEologdのインストール
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git !echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n -a2つ合わせて実行すれば、形態素解析の環境構築は修了です。インストール完了まで2~3分程度かかります。
pythonからの呼び出し
MeCab.Tagger()を呼び出す際に、引数にmecab-ipadic-NEologdのパスを指定する必要があります。辞書のパスはecho `mecab-config --dicdir`"/mecab-ipadic-neologd"で取得できます。mecab.pyimport MeCab import subprocess cmd='echo `mecab-config --dicdir`"/mecab-ipadic-neologd"' path = (subprocess.Popen(cmd, stdout=subprocess.PIPE, shell=True).communicate()[0]).decode('utf-8') m=MeCab.Tagger("-d {0}".format(path))これで呼び出し完了です。あとは使うだけ。
mecab.pyprint(m.parse("彼女はペンパイナッポーアッポーペンと恋ダンスを踊った。")) #>> #彼女 名詞,代名詞,一般,*,*,*,彼女,カノジョ,カノジョ #は 助詞,係助詞,*,*,*,*,は,ハ,ワ #ペンパイナッポーアッポーペン 名詞,固有名詞,一般,*,*,*,Pen-Pineapple-Apple-Pen,ペンパイナッポーアッポーペン,ペンパイナッポーアッポーペン #と 助詞,並立助詞,*,*,*,*,と,ト,ト #恋ダンス 名詞,固有名詞,一般,*,*,*,恋ダンス,コイダンス,コイダンス #を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ #踊っ 動詞,自立,*,*,五段・ラ行,連用タ接続,踊る,オドッ,オドッ #た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ #。 記号,句点,*,*,*,*,。,。,。 #EOSお疲れさまでした。
参考文献
https://github.com/neologd/mecab-ipadic-neologd/blob/master/README.ja.md
https://qiita.com/inatatsu_csg/items/40b11701d256a84a0510
https://engineering.linecorp.com/ja/blog/mecab-ipadic-neologd-new-words-and-expressions/
- 投稿日:2019-07-30T00:06:00+09:00
hackerrack Loop処理
hackerrankのLOOPのところで躓いたので、その解決方法を残しておこうと思います。
2 x 1 = 2
2 x 2 = 4
2 x 3 = 6
2 x 4 = 8
2 x 5 = 10このように式全体を出したいとき
n=int(input()) i=int(input()) n × i = niこのように定義しても、8や10といった=の後の数字しか出ませんでした。
ではどのようにすれば式全体が出せるでしょうか?
n= int(input().strip()) for i in range(1,6): print("{} x {} = {}".format(n, i, (n*i)))このように書くことでできます。
詳しく説明すると、
strip()で文字列の前後の空白を取り除きます。
2行目のrange関数では()の中で、変数の初めと終わりの値を定義できます。
そして、{}を使うことで、変数は変えつつ、文字列として出すことができます。
.formatの()の中の引数の順番と{}の中の変数は一致するので、
この場合だと1つ目にはn、2つ目にはi、3つ目にはn*iがが入ります。以上になります。
何か間違いや指摘があればお願いします。
- 投稿日:2019-07-30T00:00:17+09:00
pytestのテスト関数にパラメータつけてみる(parametrize, pytest_generate_tests)
単体テスト書いてますか?
めんどくさくてサボりがちになってしまいますが。ていうか、サボってますが。今後もコードを触る可能性があるなら、単体テストを書く作業は必ずペイします。低リスク、利益率数百パーセントという夢のような投資です。
これ読みに来てる人は、そんなの分かってると信じて。
テストコードをコピペする作業に飽きた人のために、pytestのテスト関数にパラメータ付けをしてみます。今回は、私が開発している量子コンピュータ用ライブラリBlueqatで実際に使われているテストコードから、実際の例を抜き出してみます。
pytest.mark.parametrizeを使う見た方が早いので、いきなり実例です。
parametrizeを使う@pytest.mark.parametrize('arg, expect', [ ("01011", (0, 1, 0, 1, 1)), ({"00011": 2, "10100": 3}, {(0, 0, 0, 1, 1): 2, (1, 0, 1, 0, 0): 3}), (Counter({"00011": 2, "10100": 3}), Counter({(0, 0, 0, 1, 1): 2, (1, 0, 1, 0, 0): 3})) ]) def test_to_inttuple(arg, expect): assert to_inttuple(arg) == expect
parametrizeを使わなければ、恐らくこうなったでしょう。parametrizeを使わなかった場合def test_to_inttuple1(): assert to_inttuple("01011") == (0, 1, 0, 1, 1) def test_to_inttuple2(): assert to_inttuple({"00011": 2, "10100": 3}) == {(0, 0, 0, 1, 1): 2, (1, 0, 1, 0, 0): 3} def test_to_inttuple3(): assert to_inttuple(Counter({"00011": 2, "10100": 3})) == Counter({(0, 0, 0, 1, 1): 2, (1, 0, 1, 0, 0): 3})テスト関数は、なにもなければ引数なしで作りますが、既に見たように
parametrizeの使い方@pytest.mark.parametrize('引数1, 引数2, ...', [ (テストケース1の引数1, テストケース1の引数2, ...), (テストケース2の引数1, テストケース2の引数2, ...), ... ]) def test_hogehoge(引数1, 引数2): assert hogehoge(引数1, 引数2)のようにできます。引数が1つの場合、
parametrizeの使い方(1引数)@pytest.mark.parametrize('引数', [テストケース1の引数, テストケース2の引数, ...]) def test_hogehoge(引数): assert hogehoge(引数)でも構いません。
便利ですね。
テストケースをコマンドラインオプションに応じて、動的に作る
parametrizeで十分便利なんですが。最近、開発しているBlueqatに、NVIDIA GPUでしか動かないオプション機能が追加されました。
CIツールとしてCircle CIを使っていますが、GPUのコードは動かないので、そっちは自分の開発環境でテストして、Circle CIではGPUなしで動くコードを動かしたいという需要ができました。(ほんとはGPUもCircle CIでやりたいが。GPUインスタンス立てる金ないから許して)また、同時期に類似のオプション機能の追加があったので、それも含めてテストしたい、となりました。
Blueqatでは、以下のようにして、裏で使うプログラム(backendと呼んでいます)を選べます。
backendの指定c = Circuit() c.run() # => デフォルトのbackendで動く c.run(backend='numpy') # => 'numpy'という名前のbackendで動く今まで、デフォルトの'numpy' backendしかテストしてなかったのですが、新たに'numba' backendとGPU必須の'qgate' backendが加わりました。
テストコードの再利用と、テストするbackendを選ぶ(Circle CIではGPU必須のコードを外す)需要が出たので、コマンドラインオプションからテストするbackendを選べるようにしました。
pytest_addoptionでコマンドラインオプションを追加するテストのあるディレクトリに
conftest.pyというファイルを作り、そこにpytest_addoptionという関数を定義し、その中でparser.addoptionを呼んでオプションを追加します。conftest.py(コマンドラインオプションの追加)def pytest_addoption(parser): parser.addoption('--add-backend', default=['numpy'], action='append')
parser.addoptionの引数は、ドキュメントには、標準ライブラリのargparse.add_optionと同じだと書いてありますが、argparse.add_argumentだと思われます。上に書いたコードでは、
--add-backendオプションを定義し、デフォルト値を['numpy']としています。--add-backend numbaとコマンドラインオプションを指定すると、その値が追加(append)され['numpy', 'numba']となります。
pytest_generate_testsでパラメータ化するこれも
conftest.pyに書きます。conftest.py(コマンドラインオプションからテストを作る)def pytest_generate_tests(metafunc): if 'backend' in metafunc.fixturenames: metafunc.parametrize('backend', metafunc.config.getoption('--add-backend'))テストの引数に
backendが含まれていたら、backendに、--add-backendオプションで指定されたリストでparametrizeします。続いて、他のテストファイルで、backendパラメータを使ったテストを書きます。
test_*.pydef test_hgate1(backend): assert is_vec_same(Circuit().h[1].h[0].run(backend=backend), np.array([0.5, 0.5, 0.5, 0.5])) def test_hgate2(backend): assert is_vec_same(Circuit().x[0].h[0].run(backend=backend), np.array([1 / np.sqrt(2), -1 / np.sqrt(2)]))これらは
python -m pytest .
のように動かした場合はtest_*.py(pytest_generate_testsを使わずparametrizeで書く・その1)@pytest.mark.parametrize('backend', ['numpy']) def test_hgate1(backend): assert is_vec_same(Circuit().h[1].h[0].run(backend=backend), np.array([0.5, 0.5, 0.5, 0.5])) @pytest.mark.parametrize('backend', ['numpy']) def test_hgate2(backend): assert is_vec_same(Circuit().x[0].h[0].run(backend=backend), np.array([1 / np.sqrt(2), -1 / np.sqrt(2)]))と同じになります。また、
python -m pytest . --add-backend numba --add-backend qgate
のように動かした場合はtest_*.py(pytest_generate_testsを使わずparametrizeで書く・その2)@pytest.mark.parametrize('backend', ['numpy', 'numba', 'qgate']) def test_hgate1(backend): assert is_vec_same(Circuit().h[1].h[0].run(backend=backend), np.array([0.5, 0.5, 0.5, 0.5])) @pytest.mark.parametrize('backend', ['numpy', 'numba', 'qgate']) def test_hgate2(backend): assert is_vec_same(Circuit().x[0].h[0].run(backend=backend), np.array([1 / np.sqrt(2), -1 / np.sqrt(2)]))と同じになります。
ややハードルが上がりますが、一度がんばってしまえば楽で、メリットは大きいかと思います。
参考文献