- 投稿日:2019-07-11T23:30:31+09:00
言語処理100本ノックをNLP屋がやってみる: 第3章 20~29
はじめに
だいぶ間が空いてしまいました。お久しぶりです。
言語処理100本ノックの続き、今回は第3章をやっていきます。過去分はこちら↓
第1章 00~09 - 第2章 10~19Wikipediaの記事を以下のフォーマットで書き出したファイルjawiki-country.json.gzがある.
1行に1記事の情報がJSON形式で格納される
各行には記事名が"title"キーに,記事本文が"text"キーの辞書オブジェクトに格納され,そのオブジェクトがJSON形式で書き出される
ファイル全体はgzipで圧縮される
以下の処理を行うプログラムを作成せよ.ということで、人類が手にした最強兵器、正規表現に入門する章です。
あと、gzipファイルを読み込んだりjsonを読み込んだりすることに慣れていきます。
題材のgzファイルは本家から落とせますので手元にご用意を。20. JSONデータの読み込み
Wikipedia記事のJSONファイルを読み込み,「イギリス」に関する記事本文を表示せよ.問題21-29では,ここで抽出した記事本文に対して実行せよ.
この章は doctest がちょっと書きづらいので、ターミナルで確認する形にしておきます。
読み込むフォーマットは上にも引用したとおり、{"title": "タイトル", "text": "本文"}という感じです。各行がこのフォーマットのjsonになっているファイルが、gzipで圧縮されているファイルです。これを読み込むコードはこんな感じ。nlp20.pyimport gzip import json import re # あとで使うのでimportしておきます def load_json_gz(filename): """ 指定されたファイルを読み込みます。 """ with gzip.open(filename, 'rt', encoding='utf-8') as f: return {item['title']: item['text'] for item in [json.loads(line) for line in f]} articles = load_json_gz('jawiki-country.json.gz') england = articles['イギリス'] print(england)
gzip.openを使うと、普通にファイルをopenするのと同じインターフェースで gz ファイルを読み込むことができます。楽ちん楽ちん。
各行をjsonとしてパースするのはjson.loadsメソッドを使います。
リスト内包表記で辞書にしてロード結果を返して、その結果から「イギリス」に関する内容を
実行結果がこちら。確認$ python nlp20.py {{redirect|UK}} {{基礎情報 国 |略名 = イギリス |日本語国名 = グレートブリテン及び北アイルランド連合王国 ...(略)うん、イギリスの情報が取れていそうですね。
21. カテゴリ名を含む行を抽出
記事中でカテゴリ名を宣言している行を抽出せよ.
カテゴリ名の書き方については、 https://ja.wikipedia.org/wiki/Help:カテゴリ によると以下の通りだそうです。
同じカテゴリに属すページをまとめるには、[[Category:カテゴリ名]]あるいは、[[Category:カテゴリ名|ソートキー]]と記述します。
というわけで、「[[Category:」を含む行を探してあげれば良さそうです。
先程のコードの続きでカテゴリ名がある行を抽出してみましょう。nlp20.py-つづきcategory_lines = [line for line in england.split('\n') if '[[Category:' in line] print(category_lines)
englandの中には先程取り出した「イギリス」の記事本文が入っています。
リスト内包表記内ではこれを改行コードで分割し、if 文で「[[Category:」を含む行だけを取り出しています。
実行結果がこちら。確認$ python nlp20.py ['[[Category:イギリス|*]]', '[[Category:英連邦王国|*]]', '[[Category:G8加盟国]]', '[[Category:欧州連合加盟国]]', '[[Category:海洋国家]]', '[[Category:君主国]]', '[[Category:島国|くれいとふりてん]]', '[[Category:1801年に設立された州・地域]]']こちらも正しく取れていそうです。
22. カテゴリ名の抽出
記事のカテゴリ名を(行単位ではなく名前で)抽出せよ.
いよいよ真面目に正規表現を使います。
先程引用したとおり、カテゴリ名のフォーマットは「[[Category:カテゴリ名]]あるいは、[[Category:カテゴリ名|ソートキー]]」です。
これをどちらもまとめて引っ掛けられる正規表現は\[\[Category:(.*?)(\|.*?)\]\]という感じでしょうか。
一個目のカッコ内が求めるカテゴリ名に当たります。
二個目のカッコはソートキーが指定されている場合にそれをカテゴリ名に含めないための指定です。では、これで抽出できるか試してみましょうか。
今度も先程のコードの続きに書きます。nlp20.py-さらにつづきcategories = [t[0] for t in re.findall(r'\[\[Category:(.*?)(\|.*?)?\]\]', england)] print(categories)
re.findallを使って、指定した正規表現に適合する箇所をすべて取得しています。
t[0]には一個目のカッコの内容、t[1]には二個目のカッコの内容が入ってきます。
結果がこちら。確認$ python nlp20.py ['イギリス', '英連邦王国', 'G8加盟国', '欧州連合加盟国', '海洋国家', '君主国', '島国', '1801年に設立された州・地域']さきほどの 21 で抽出された各行のカテゴリ名が取れていますね。
23. セクション構造
記事中に含まれるセクション名とそのレベル(例えば"== セクション名 =="なら1)を表示せよ.
nlp20.py-さらにつづきfor section in re.findall(r'(=+)([^=]+)\1\n', england): print('{}\t{}'.format(section[1].strip(), len(section[0])-1))ここでは正規表現内でカッコに括った範囲を「\1」を利用して参照しています。
# 正規表現 意味 ===外交と軍事===\nでマッチする部分 1 (=+)「=」1文字以上が続くだけ全部マッチ 最初の "===" 2 ([^=]+)「=」以外の文字(i.e. [^=])が1文字以上続くだけ全部マッチ 外交と軍事 3 \1#1の内容と同じものがここでマッチする。 二回目の "===" 4 \n改行 \n
re.findallが返してくれる各マッチ箇所のデータには、[0]に1つ目のカッコ内の内容、つまり '=' の連続が、[1]には 2つ目のカッコ内の内容すなわちセクション名が入っています。
なお、セクションのレベルは「=」の数-1になるので、len(section[0])-1としてレベルを算出しています。確認国名 1 歴史 1 地理 1 気候 2 政治 1 外交と軍事 1 地方行政区分 1 主要都市 2 科学技術 1 経済 1 鉱業 2 農業 2 貿易 2 通貨 2 企業 2 交通 1 道路 2 鉄道 2 海運 2 航空 2 通信 1 国民 1 言語 2 宗教 2 婚姻 2 教育 2 文化 1 食文化 2 文学 2 哲学 2 音楽 2 イギリスのポピュラー音楽 3 映画 2 コメディ 2 国花 2 世界遺産 2 祝祭日 2 スポーツ 1 サッカー 2 競馬 2 モータースポーツ 2 脚注 1 関連項目 1 外部リンク 124. ファイル参照の抽出
記事から参照されているメディアファイルをすべて抜き出せ.
メディアファイルの書き方ですが、
[[File:ファイル名]]あるいは[[ファイル:ファイル名]]が基本のようです。[[File:ファイル名|オプション]]の形式でファイル名の後にパイプ(|)区切りでオプション情報を付与することも出来ます。詳細はこちらを。nlp20.py-つづきfor file in re.findall(r'\[\[(ファイル|File):([^]|]+?)(\|.*?)+\]\]', england): print(file[1])そこで、こんな感じに正規表現を書いてあげれば、前項と同様に2つ目のカッコの中を取り出すことでファイル名だけを取り出すことが出来ます。
結果Royal Coat of Arms of the United Kingdom.svg Battle of Waterloo 1815.PNG The British Empire.png Uk topo en.jpg BenNevis2005.jpg Elizabeth II greets NASA GSFC employees, May 8, 2007 edit.jpg Palace of Westminster, London - Feb 2007.jpg David Cameron and Barack Obama at the G20 Summit in Toronto.jpg Soldiers Trooping the Colour, 16th June 2007.jpg Scotland Parliament Holyrood.jpg London.bankofengland.arp.jpg City of London skyline from London City Hall - Oct 2008.jpg Oil platform in the North SeaPros.jpg Eurostar at St Pancras Jan 2008.jpg Heathrow T5.jpg Anglospeak.svg CHANDOS3.jpg The Fabs.JPG Wembley Stadium, illuminated.jpg25. テンプレートの抽出
記事中に含まれる「基礎情報」テンプレートのフィールド名と値を抽出し,辞書オブジェクトとして格納せよ.
テンプレートについてはこちらを見ていただければと思いますが、書式はさきほどのファイルの場合と似ていて、
{{テンプレート名|オプション|オプション...}}といった書式です。
ただ実際のデータを見てみると、これまでとちがって{{から}}までの間に改行が入っていたりするようですね。
あと、前の24でも本当は気にすべきだったのですが、「オプション」の位置で更に{{テンプレート名}}の形式でテンプレートが入っていたりするようです。つまり、{{~}}のカッコが入れ子になってしまっているんですね。これは難題です。
というのも、正規表現は基本的に入れ子構造が苦手なんですね。事実上入れ子は標準的な正規表現では扱えません1。
そこで、簡易的なパーサーを作って、ちゃんと入れ子構造も考慮した形にしてみました。
説明は・・・長くなるので省きます。nlp20.py-つづきdef parse_article(article): """ 渡されたarticleの内容をパースします。 基本的には文字列のリストになって帰ってきますが、 テンプレート、内部リンクの場合はリストが一段深くネストされて帰ってきます。 下の doctest を見たほうがわかりやすいかと。 >>> parse_article('foo{{bar|opt1=value1|opt2={{template|opt1=value100|opt2=value101}}hoge[[link|printed]]|opt3=huga}}') ['foo', ['{{', 'bar', '|', 'opt1', '=', 'value1', '|', 'opt2', '=', ['{{', 'template', '|', 'opt1', '=', 'value100', '|', 'opt2', '=', 'value101', '}}'], 'hoge', ['[[', 'link', '|', 'printed', ']]'], '|', 'opt3', '=', 'huga', '}}']] """ parsed = [[]] for s in re.findall(r'{{|}}|\[\[|\]\]|\||=|[^{}\[\]|=]+', article): if s in ('{{', '[['): parsed[-1].append([s]) parsed.append(parsed[-1][-1]) elif s in ('}}', ']]'): parsed[-1].append(s) parsed.remove(parsed[-1]) else: parsed[-1].append(s) return parsed[0] def join_all(nested_list): """ リストを文字列として連結します。 リスト内の要素にリストが有った場合、再帰的に連結を行います。 >>> join_all(['a', ['b', ['c', 'd'], 'e'], 'f']) 'abcdef' """ return ''.join([join_all(i) if type(i) is list else i for i in nested_list]) result = {} for item in parse_article(england): # 基礎情報〜という名前のテンプレートを探す if type(item) is list and item[0] == '{{' and item[1].startswith('基礎情報'): # テンプレート内の '|' のインデックスを全部見つける。 option_indices = [i for i, s in enumerate(item) if s == '|'] for i in option_indices: # '|' の次の要素がオプション名 key = item[i+1] # オプションの値は、'|' の3つ先以降、'|' か '}}' が出てくるまで。 value = itertools.takewhile(lambda s: s not in ('|', '}}'), item[i+3:]) # 辞書に突っ込む。 result[key.strip()] = join_all(value).strip() pprint.pprint(result)doctestは出力が長いときに改行が入れられないのが若干イマイチですね。
(doctestでそこまで頑張ったテストを書くなということかも)これを実行すると、しっかりパースできたことがわかります。
結果{'GDP/人': '36,727<ref name="imf-statistics-gdp" />', 'GDP値': '2兆3162億<ref name="imf-statistics-gdp" />', 'GDP値MER': '2兆4337億<ref name="imf-statistics-gdp" />', 'GDP値元': '1兆5478億<ref ' 'name="imf-statistics-gdp">http://www.imf.org/external/pubs/ft/weo/2012/02/weodata/weorept.aspx?pr.x=70&pr.y=13&sy=2010&ey=2012&scsm=1&ssd=1&sort=country&ds=.&br=1&c=112&s=NGDP%2CNGDPD%2CPPPGDP%2CPPPPC&grp=0&a= ' 'IMF>Data and Statistics>World Economic Outlook Databases>By ' 'Countrise>United Kingdom</ref>', 'GDP統計年': '2012', 'GDP統計年MER': '2012', 'GDP統計年元': '2012', 'GDP順位': '6', 'GDP順位MER': '5', 'ISO 3166-1': 'GB / GBR', 'ccTLD': '[[.uk]] / [[.gb]]<ref>使用は.ukに比べ圧倒的少数。</ref>', '人口値': '63,181,775<ref>http://esa.un.org/unpd/wpp/Excel-Data/population.htm ' 'United Nations Department of Economic and Social Affairs>Population ' 'Division>Data>Population>Total Population</ref>', '人口大きさ': '1 E7', '人口密度値': '246', '人口統計年': '2011', '人口順位': '22', '位置画像': 'Location_UK_EU_Europe_001.svg', '元首等氏名': '[[エリザベス2世]]', '元首等肩書': '[[イギリスの君主|女王]]', '公式国名': '{{lang|en|United Kingdom of Great Britain and Northern ' 'Ireland}}<ref>英語以外での正式国名:<br/>\n' '*{{lang|gd|An Rìoghachd Aonaichte na Breatainn Mhòr agus Eirinn mu ' 'Thuath}}([[スコットランド・ゲール語]])<br/>\n' '*{{lang|cy|Teyrnas Gyfunol Prydain Fawr a Gogledd ' 'Iwerddon}}([[ウェールズ語]])<br/>\n' '*{{lang|ga|Ríocht Aontaithe na Breataine Móire agus Tuaisceart na ' 'hÉireann}}([[アイルランド語]])<br/>\n' '*{{lang|kw|An Rywvaneth Unys a Vreten Veur hag Iwerdhon ' 'Glédh}}([[コーンウォール語]])<br/>\n' '*{{lang|sco|Unitit Kinrick o Great Breetain an Northren ' 'Ireland}}([[スコットランド語]])<br/>\n' '**{{lang|sco|Claught Kängrick o Docht Brätain an Norlin ' 'Airlann}}、{{lang|sco|Unitet Kängdom o Great Brittain an Norlin ' 'Airlann}}(アルスター・スコットランド語)</ref>', '公用語': '[[英語]](事実上)', '国旗画像': 'Flag of the United Kingdom.svg', '国歌': '[[女王陛下万歳|神よ女王陛下を守り給え]]', '国章リンク': '([[イギリスの国章|国章]])', '国章画像': '[[ファイル:Royal Coat of Arms of the United Kingdom.svg|85px|イギリスの国章]]', '国際電話番号': '44', '夏時間': '+1', '建国形態': '建国', '日本語国名': 'グレートブリテン及び北アイルランド連合王国', '時間帯': '±0', '最大都市': 'ロンドン', '標語': '{{lang|fr|Dieu et mon droit}}<br/>([[フランス語]]:神と私の権利)', '水面積率': '1.3%', '注記': '<references />', '略名': 'イギリス', '確立年月日1': '[[927年]]/[[843年]]', '確立年月日2': '[[1707年]]', '確立年月日3': '[[1801年]]', '確立年月日4': '[[1927年]]', '確立形態1': '[[イングランド王国]]/[[スコットランド王国]]<br />(両国とも[[連合法 (1707年)|1707年連合法]]まで)', '確立形態2': '[[グレートブリテン王国]]建国<br />([[連合法 (1707年)|1707年連合法]])', '確立形態3': '[[グレートブリテン及びアイルランド連合王国]]建国<br />([[連合法 (1800年)|1800年連合法]])', '確立形態4': "現在の国号「'''グレートブリテン及び北アイルランド連合王国'''」に変更", '通貨': '[[スターリング・ポンド|UKポンド]] (£)', '通貨コード': 'GBP', '面積値': '244,820', '面積大きさ': '1 E11', '面積順位': '76', '首相等氏名': '[[デーヴィッド・キャメロン]]', '首相等肩書': '[[イギリスの首相|首相]]', '首都': '[[ロンドン]]'}26. 強調マークアップの除去
25の処理時に,テンプレートの値からMediaWikiの強調マークアップ(弱い強調,強調,強い強調のすべて)を除去してテキストに変換せよ(参考: マークアップ早見表).
ここで言う「弱い強調」「強調」「強い強調」は、現在のリンク先では「他との区別」「強調」「車体と強調」と名前が変わっているようです。
''他との区別'''''強調''''''''斜体と強調'''''と、シングルクォート 2 / 3 / 5個連続している場合に、除去してしまえばいいわけですね。25がめんどかったのに、急に簡単。辞書に突っ込むところで、これらをリプレースしてしまいましょう。
nlp20.py-途中を差し替えresult = {} for item in parse_article(england): # 基礎情報〜という名前のテンプレートを探す if type(item) is list and item[0] == '{{' and item[1].startswith('基礎情報'): # テンプレート内の '|' のインデックスを全部見つける。 option_indices = [i for i, s in enumerate(item) if s == '|'] for i in option_indices: # '|' の次の要素がオプション名 key = item[i+1] # オプションの値は、'|' の3つ先以降、'|' か '}}' が出てくるまで。 value = itertools.takewhile(lambda s: s not in ('|', '}}'), item[i+3:]) # '' / ''' / ''''' を除去する。 value_str = re.sub(r"'{2,3}|'{5}", '', join_all(list(value))) # 辞書に突っ込む。 result[key] = value_str pprint.pprint(result)これで実行すると、強調が消えます。実際のデータでは
'''しかない気がしますが。結果{'GDP/人': '36,727<ref name="imf-statistics-gdp" />', 'GDP値': '2兆3162億<ref name="imf-statistics-gdp" />', 'GDP値MER': '2兆4337億<ref name="imf-statistics-gdp" />', 'GDP値元': '1兆5478億<ref ' 'name="imf-statistics-gdp">http://www.imf.org/external/pubs/ft/weo/2012/02/weodata/weorept.aspx?pr.x=70&pr.y=13&sy=2010&ey=2012&scsm=1&ssd=1&sort=country&ds=.&br=1&c=112&s=NGDP%2CNGDPD%2CPPPGDP%2CPPPPC&grp=0&a= ' 'IMF>Data and Statistics>World Economic Outlook Databases>By ' 'Countrise>United Kingdom</ref>', 'GDP統計年': '2012', 'GDP統計年MER': '2012', 'GDP統計年元': '2012', 'GDP順位': '6', 'GDP順位MER': '5', 'ISO 3166-1': 'GB / GBR', 'ccTLD': '[[.uk]] / [[.gb]]<ref>使用は.ukに比べ圧倒的少数。</ref>', '人口値': '63,181,775<ref>http://esa.un.org/unpd/wpp/Excel-Data/population.htm ' 'United Nations Department of Economic and Social Affairs>Population ' 'Division>Data>Population>Total Population</ref>', '人口大きさ': '1 E7', '人口密度値': '246', '人口統計年': '2011', '人口順位': '22', '位置画像': 'Location_UK_EU_Europe_001.svg', '元首等氏名': '[[エリザベス2世]]', '元首等肩書': '[[イギリスの君主|女王]]', '公式国名': '{{lang|en|United Kingdom of Great Britain and Northern ' 'Ireland}}<ref>英語以外での正式国名:<br/>\n' '*{{lang|gd|An Rìoghachd Aonaichte na Breatainn Mhòr agus Eirinn mu ' 'Thuath}}([[スコットランド・ゲール語]])<br/>\n' '*{{lang|cy|Teyrnas Gyfunol Prydain Fawr a Gogledd ' 'Iwerddon}}([[ウェールズ語]])<br/>\n' '*{{lang|ga|Ríocht Aontaithe na Breataine Móire agus Tuaisceart na ' 'hÉireann}}([[アイルランド語]])<br/>\n' '*{{lang|kw|An Rywvaneth Unys a Vreten Veur hag Iwerdhon ' 'Glédh}}([[コーンウォール語]])<br/>\n' '*{{lang|sco|Unitit Kinrick o Great Breetain an Northren ' 'Ireland}}([[スコットランド語]])<br/>\n' '**{{lang|sco|Claught Kängrick o Docht Brätain an Norlin ' 'Airlann}}、{{lang|sco|Unitet Kängdom o Great Brittain an Norlin ' 'Airlann}}(アルスター・スコットランド語)</ref>', '公用語': '[[英語]](事実上)', '国旗画像': 'Flag of the United Kingdom.svg', '国歌': '[[女王陛下万歳|神よ女王陛下を守り給え]]', '国章リンク': '([[イギリスの国章|国章]])', '国章画像': '[[ファイル:Royal Coat of Arms of the United Kingdom.svg|85px|イギリスの国章]]', '国際電話番号': '44', '夏時間': '+1', '建国形態': '建国', '日本語国名': 'グレートブリテン及び北アイルランド連合王国', '時間帯': '±0', '最大都市': 'ロンドン', '標語': '{{lang|fr|Dieu et mon droit}}<br/>([[フランス語]]:神と私の権利)', '水面積率': '1.3%', '注記': '<references />', '略名': 'イギリス', '確立年月日1': '[[927年]]/[[843年]]', '確立年月日2': '[[1707年]]', '確立年月日3': '[[1801年]]', '確立年月日4': '[[1927年]]', '確立形態1': '[[イングランド王国]]/[[スコットランド王国]]<br />(両国とも[[連合法 (1707年)|1707年連合法]]まで)', '確立形態2': '[[グレートブリテン王国]]建国<br />([[連合法 (1707年)|1707年連合法]])', '確立形態3': '[[グレートブリテン及びアイルランド連合王国]]建国<br />([[連合法 (1800年)|1800年連合法]])', '確立形態4': '現在の国号「グレートブリテン及び北アイルランド連合王国」に変更', '通貨': '[[スターリング・ポンド|UKポンド]] (£)', '通貨コード': 'GBP', '面積値': '244,820', '面積大きさ': '1 E11', '面積順位': '76', '首相等氏名': '[[デーヴィッド・キャメロン]]', '首相等肩書': '[[イギリスの首相|首相]]', '首都': '[[ロンドン]]'}27. 内部リンクの除去
26の処理に加えて,テンプレートの値からMediaWikiの内部リンクマークアップを除去し,テキストに変換せよ(参考: マークアップ早見表).
さっきよりは若干面倒な問題。
内部リンクには大きく二種類の書き方があるようで、[[記事名]]と記事に対してリンクしつつ、表示される文字も記事名そのものの場合と、[[記事名|表示文字]]と記事名と表示される文字が異なるパターン。
また、先に出てきた画像の場合は、[[画像ファイル名|オプション...|代替文]]というフォーマットになるため2、結局パイプ区切りの最後を取ればいいという結論になります。
[[Category:...]]という形式のカテゴリ表記に関してはここでは無視します。なぜならちょっと疲れてきたから。nlp20.py-差し替えresult = {} for item in parse_article(england): # 基礎情報〜という名前のテンプレートを探す if type(item) is list and item[0] == '{{' and item[1].startswith('基礎情報'): # テンプレート内の '|' のインデックスを全部見つける。 option_indices = [i for i, s in enumerate(item) if s == '|'] for i in option_indices: # '|' の次の要素がオプション名 key = item[i+1] # オプションの値は、'|' の3つ先以降、'|' か '}}' が出てくるまで。 value = itertools.takewhile(lambda s: s not in ('|', '}}'), item[i+3:]) # '' / ''' / ''''' を除去する value_str = re.sub(r"'{2,3}|'{5}", '', join_all(value).strip()) # 内部リンク(画像等も含む)を除去する。代替文があればそれを採用する。(つまりパイプ区切りの最後) value_str = re.sub(r"\[\[([^|\]]+\|)*(.*?)\]\]", "\\2", value_str) # 辞書に突っ込む。 result[key.strip()] = value_str pprint.pprint(result)実行すると内部リンクが処理されていることがわかります。
結果{'GDP/人': '36,727<ref name="imf-statistics-gdp" />', 'GDP値': '2兆3162億<ref name="imf-statistics-gdp" />', 'GDP値MER': '2兆4337億<ref name="imf-statistics-gdp" />', 'GDP値元': '1兆5478億<ref ' 'name="imf-statistics-gdp">http://www.imf.org/external/pubs/ft/weo/2012/02/weodata/weorept.aspx?pr.x=70&pr.y=13&sy=2010&ey=2012&scsm=1&ssd=1&sort=country&ds=.&br=1&c=112&s=NGDP%2CNGDPD%2CPPPGDP%2CPPPPC&grp=0&a= ' 'IMF>Data and Statistics>World Economic Outlook Databases>By ' 'Countrise>United Kingdom</ref>', 'GDP統計年': '2012', 'GDP統計年MER': '2012', 'GDP統計年元': '2012', 'GDP順位': '6', 'GDP順位MER': '5', 'ISO 3166-1': 'GB / GBR', 'ccTLD': '.uk / .gb<ref>使用は.ukに比べ圧倒的少数。</ref>', '人口値': '63,181,775<ref>http://esa.un.org/unpd/wpp/Excel-Data/population.htm ' 'United Nations Department of Economic and Social Affairs>Population ' 'Division>Data>Population>Total Population</ref>', '人口大きさ': '1 E7', '人口密度値': '246', '人口統計年': '2011', '人口順位': '22', '位置画像': 'Location_UK_EU_Europe_001.svg', '元首等氏名': 'エリザベス2世', '元首等肩書': '女王', '公式国名': '{{lang|en|United Kingdom of Great Britain and Northern ' 'Ireland}}<ref>英語以外での正式国名:<br/>\n' '*{{lang|gd|An Rìoghachd Aonaichte na Breatainn Mhòr agus Eirinn mu ' 'Thuath}}(スコットランド・ゲール語)<br/>\n' '*{{lang|cy|Teyrnas Gyfunol Prydain Fawr a Gogledd ' 'Iwerddon}}(ウェールズ語)<br/>\n' '*{{lang|ga|Ríocht Aontaithe na Breataine Móire agus Tuaisceart na ' 'hÉireann}}(アイルランド語)<br/>\n' '*{{lang|kw|An Rywvaneth Unys a Vreten Veur hag Iwerdhon ' 'Glédh}}(コーンウォール語)<br/>\n' '*{{lang|sco|Unitit Kinrick o Great Breetain an Northren ' 'Ireland}}(スコットランド語)<br/>\n' '**{{lang|sco|Claught Kängrick o Docht Brätain an Norlin ' 'Airlann}}、{{lang|sco|Unitet Kängdom o Great Brittain an Norlin ' 'Airlann}}(アルスター・スコットランド語)</ref>', '公用語': '英語(事実上)', '国旗画像': 'Flag of the United Kingdom.svg', '国歌': '神よ女王陛下を守り給え', '国章リンク': '(国章)', '国章画像': 'イギリスの国章', '国際電話番号': '44', '夏時間': '+1', '建国形態': '建国', '日本語国名': 'グレートブリテン及び北アイルランド連合王国', '時間帯': '±0', '最大都市': 'ロンドン', '標語': '{{lang|fr|Dieu et mon droit}}<br/>(フランス語:神と私の権利)', '水面積率': '1.3%', '注記': '<references />', '略名': 'イギリス', '確立年月日1': '927年/843年', '確立年月日2': '1707年', '確立年月日3': '1801年', '確立年月日4': '1927年', '確立形態1': 'イングランド王国/スコットランド王国<br />(両国とも1707年連合法まで)', '確立形態2': 'グレートブリテン王国建国<br />(1707年連合法)', '確立形態3': 'グレートブリテン及びアイルランド連合王国建国<br />(1800年連合法)', '確立形態4': '現在の国号「グレートブリテン及び北アイルランド連合王国」に変更', '通貨': 'UKポンド (£)', '通貨コード': 'GBP', '面積値': '244,820', '面積大きさ': '1 E11', '面積順位': '76', '首相等氏名': 'デーヴィッド・キャメロン', '首相等肩書': '首相', '首都': 'ロンドン'}28. MediaWikiマークアップの除去
27の処理に加えて,テンプレートの値からMediaWikiマークアップを可能な限り除去し,国の基本情報を整形せよ.
まあ、可能な限りきれいにしろってことですね。
ここでは、以下の3つを追加でやってみました。
- タグの除去
- {{lang}}テンプレート を文字列部分だけに
- <br> タグを改行に
というわけで再度差し替え版。
nlp20.py-差し替えresult = {} for item in parse_article(england): # 基礎情報〜という名前のテンプレートを探す if type(item) is list and item[0] == '{{' and item[1].startswith('基礎情報'): # テンプレート内の '|' のインデックスを全部見つける。 option_indices = [i for i, s in enumerate(item) if s == '|'] for i in option_indices: # '|' の次の要素がオプション名 key = item[i+1] # オプションの値は、'|' の3つ先以降、'|' か '}}' が出てくるまで。 value = itertools.takewhile(lambda s: s not in ('|', '}}'), item[i+3:]) # '' / ''' / ''''' を除去する value_str = re.sub(r"'{2,3}|'{5}", '', join_all(value).strip()) # 内部リンク(画像等も含む)を除去する。代替文があればそれを採用する。(つまりパイプ区切りの最後) value_str = re.sub(r"\[\[([^|\]]+\|)*(.*?)\]\]", "\\2", value_str) # <ref> タグを除去。<ref ... /> の書き方と <ref ...>...</ref> の書き方がある。 # (?s) は . を改行文字にもヒットさせるためのフラグ。 value_str = re.sub(r"(?s)<ref[^>]*?/>|<ref[^>]*?>.*?</ref>", '', value_str) # {{lang|言語タグ|文字列}} を文字列部分だけにする value_str = re.sub(r"{{lang\|[^|]+\|(.*?)}}", '\\1', value_str) # <br> タグを \n に置換 value_str = re.sub(r"<br\s*?/>", '\n', value_str) # 辞書に突っ込む。 result[key.strip()] = value_str pprint.pprint(result)結果はこちら。
結果{'GDP/人': '36,727', 'GDP値': '2兆3162億', 'GDP値MER': '2兆4337億', 'GDP値元': '1兆5478億', 'GDP統計年': '2012', 'GDP統計年MER': '2012', 'GDP統計年元': '2012', 'GDP順位': '6', 'GDP順位MER': '5', 'ISO 3166-1': 'GB / GBR', 'ccTLD': '.uk / .gb', '人口値': '63,181,775', '人口大きさ': '1 E7', '人口密度値': '246', '人口統計年': '2011', '人口順位': '22', '位置画像': 'Location_UK_EU_Europe_001.svg', '元首等氏名': 'エリザベス2世', '元首等肩書': '女王', '公式国名': 'United Kingdom of Great Britain and Northern Ireland', '公用語': '英語(事実上)', '国旗画像': 'Flag of the United Kingdom.svg', '国歌': '神よ女王陛下を守り給え', '国章リンク': '(国章)', '国章画像': 'イギリスの国章', '国際電話番号': '44', '夏時間': '+1', '建国形態': '建国', '日本語国名': 'グレートブリテン及び北アイルランド連合王国', '時間帯': '±0', '最大都市': 'ロンドン', '標語': 'Dieu et mon droit\n(フランス語:神と私の権利)', '水面積率': '1.3%', '注記': '', '略名': 'イギリス', '確立年月日1': '927年/843年', '確立年月日2': '1707年', '確立年月日3': '1801年', '確立年月日4': '1927年', '確立形態1': 'イングランド王国/スコットランド王国\n(両国とも1707年連合法まで)', '確立形態2': 'グレートブリテン王国建国\n(1707年連合法)', '確立形態3': 'グレートブリテン及びアイルランド連合王国建国\n(1800年連合法)', '確立形態4': '現在の国号「グレートブリテン及び北アイルランド連合王国」に変更', '通貨': 'UKポンド (£)', '通貨コード': 'GBP', '面積値': '244,820', '面積大きさ': '1 E11', '面積順位': '76', '首相等氏名': 'デーヴィッド・キャメロン', '首相等肩書': '首相', '首都': 'ロンドン'}だいぶ読みやすくなりましたね。
29. 国旗画像のURLを取得する
テンプレートの内容を利用し,国旗画像のURLを取得せよ.(ヒント: MediaWiki APIのimageinfoを呼び出して,ファイル参照をURLに変換すればよい)
最後は急にAPI呼び出し。
上記のページを読むと、以下のようなリクエストを送ればAPIでURLが取得できるようです。GET https://ja.wikipedia.org/w/api.php?action=query&format=json&prop=imageinfo&titles=File:Flag%20of%20the%20United%20Kingdom.svg&iiprop=url実際これを vscode の REST client で流してみた結果がこちら。
{ "continue": { "iistart": "2007-09-03T09:51:34Z", "continue": "||" }, "query": { "normalized": [ { "from": "File:Flag of the United Kingdom.svg", "to": "\u30d5\u30a1\u30a4\u30eb:Flag of the United Kingdom.svg" } ], "pages": { "-1": { "ns": 6, "title": "\u30d5\u30a1\u30a4\u30eb:Flag of the United Kingdom.svg", "missing": "", "known": "", "imagerepository": "shared", "imageinfo": [ { "url": "https://upload.wikimedia.org/wikipedia/commons/a/ae/Flag_of_the_United_Kingdom.svg", "descriptionurl": "https://commons.wikimedia.org/wiki/File:Flag_of_the_United_Kingdom.svg", "descriptionshorturl": "https://commons.wikimedia.org/w/index.php?curid=347935" } ] } } } }結果の query > pages > * > imageinfo[0] > url を取ればいいっぽいですね。
実際、pythonで呼び出してみましょう。
コードはさっきまでの続きです。resultに記事「イギリス」の基礎情報テンプレートの内容のパース結果が入っています。nlp20.py-つづきapi_url = 'https://ja.wikipedia.org/w/api.php?{}' params = { 'action': 'query', 'format': 'json', 'prop': 'imageinfo', 'titles': 'File:{}'.format(result['国旗画像']), 'iiprop': 'url' } req = urllib.request.Request(api_url.format(urllib.parse.urlencode(params))) with urllib.request.urlopen(req) as res: j = json.loads(res.read()) print(list(j['query']['pages'].values())[0]['imageinfo'][0]['url'])これでURLが表示されます。
結果https://upload.wikimedia.org/wikipedia/commons/a/ae/Flag_of_the_United_Kingdom.svgというわけで無事URLが表示されました。
第3章はこれでおしまい。25が難関でしたね。最初から真面目にパースしようとするのが結局一番早かった。
次回はいつになるかわかりませんが、また気が向いたら。
- 投稿日:2019-07-11T23:26:52+09:00
Flask appの名前付けにまつわる謎を解明したので解説
実行環境
OS: Ubuntu 18.04.2 LTS
python: 3.6.8
Flask: 1.1.1本文
以下のFlaskアプリケーションを起動させるファイルを実行してみた時に事件は起こった。
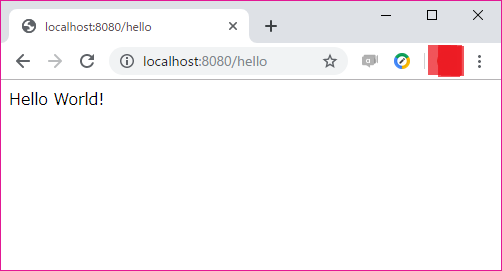
study_flask.pyfrom flask import Flask app = Flask(__name__) @app.route('/') def hello(): return "Hello World!" app.run()実行してみた結果は以下。
$ python study_flask.py * Serving Flask app "study_flask" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: off * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)ふむふむちゃんとFlaskのサーバーが動いてくれてるなあ。
ん?
* Serving Flask app "study_flask" (lazy loading)んん?
Flask app "study_flask"んんんん???
お気付きであろうか。
直接実行したファイル内で__name__を名称としたFlask appを作成しているのに、
Flask app名が__main__ではなく、ファイル名になっていることに!一応解説しておくと、
__name__には基本的にファイル名が拡張子なしで保存される。
__name__が記述されたファイルが直接実行された時のみ"__main__"という文字列が入る。今回の場合は直接実行しているので、
__main__という名称のFlask appが出来上がると思っていたが違った。私はこのことに非常にもやもやし、
この理由を業務時間内に調べた。(あかん)いろんなサイトを見てみたが、
解説が載っているサイトを見つけられなかったため、
直接Flaskのソースコードを読むことにした。flask/app.pyclass Flask(_PackageBoundObject): """The flask object implements a WSGI application and acts as the central object. It is passed the name of the module or package of the application. Once it is created it will act as a central registry for the view functions, the URL rules, template configuration and much more. The name of the package is used to resolve resources from inside the package or the folder the module is contained in depending on if the package parameter resolves to an actual python package (a folder with an :file:`__init__.py` file inside) or a standard module (just a ``.py`` file). ~~省略〜〜 """ def __init__( self, import_name, static_url_path=None, static_folder="static", static_host=None, host_matching=False, subdomain_matching=False, template_folder="templates", instance_path=None, instance_relative_config=False, root_path=None, ):ふむふむ。
__name__は直接flaskの名称になるのではなく、
import_nameの引数として渡されている様だ。このimport_nameはself.import_nameに代入されていた。
さらに読み進めていくと以下のような関数を発見。
flask/app.pydef name(self): """The name of the application. This is usually the import name with the difference that it's guessed from the run file if the import name is main. This name is used as a display name when Flask needs the name of the application. It can be set and overridden to change the value. .. versionadded:: 0.8 """ if self.import_name == "__main__": fn = getattr(sys.modules["__main__"], "__file__", None) if fn is None: return "__main__" return os.path.splitext(os.path.basename(fn))[0] return self.import_name色々やってるけど、重要なのはここ↓
if self.import_name == "__main__": fn = getattr(sys.modules["__main__"], "__file__", None) "~~省略~~" return os.path.splitext(os.path.basename(fn))[0]もしself.import_nameが"main"だったら、
最初に実行したファイルの名称を取ってくるという処理が書かれていた!!なるほど。
結構単純だった。。実はここにたどり着くまでに時間かなり使っちゃった。
わかってみると単純なんだけどわからないうちは複雑。プログラミングなんて全部単純だよって言える人になりたいな。
- 投稿日:2019-07-11T23:26:52+09:00
【マニアック】Flaskにまつわる謎を一つ解明したので解説
実行環境
OS: Ubuntu 18.04.2 LTS
python: 3.6.8
Flask: 1.1.1本文
以下のFlaskアプリケーションを起動させるファイルを実行してみた時に事件は起こった。
study_flask.pyfrom flask import Flask app = Flask(__name__) @app.route('/') def hello(): return "Hello World!" app.run()実行してみた結果は以下。
$ python study_flask.py * Serving Flask app "study_flask" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: off * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)ふむふむちゃんとFlaskのサーバーが動いてくれてるなあ。
ん?
* Serving Flask app "study_flask" (lazy loading)んん?
Flask app "study_flask"んんんん???
お気付きであろうか。
直接実行したファイル内で__name__を名称としたFlask appを作成しているのに、
Flask app名が__main__ではなく、ファイル名になっていることに!一応解説しておくと、
__name__には基本的にファイル名が拡張子なしで保存される。
__name__が記述されたファイルが直接実行された時のみ"__main__"という文字列が入る。今回の場合は直接実行しているので、
__main__という名称のFlask appが出来上がると思っていたが違った。私はこのことに非常にもやもやし、
この理由を業務時間内に調べた。(あかん)いろんなサイトを見てみたが、
解説が載っているサイトを見つけられなかったため、
直接Flaskのソースコードを読むことにした。flask/app.pyclass Flask(_PackageBoundObject): """The flask object implements a WSGI application and acts as the central object. It is passed the name of the module or package of the application. Once it is created it will act as a central registry for the view functions, the URL rules, template configuration and much more. The name of the package is used to resolve resources from inside the package or the folder the module is contained in depending on if the package parameter resolves to an actual python package (a folder with an :file:`__init__.py` file inside) or a standard module (just a ``.py`` file). ~~省略〜〜 """ def __init__( self, import_name, static_url_path=None, static_folder="static", static_host=None, host_matching=False, subdomain_matching=False, template_folder="templates", instance_path=None, instance_relative_config=False, root_path=None, ):ふむふむ。
__name__は直接flaskの名称になるのではなく、
import_nameの引数として渡されている様だ。このimport_nameはself.import_nameに代入されていた。
さらに読み進めていくと以下のような関数を発見。
flask/app.pydef name(self): """The name of the application. This is usually the import name with the difference that it's guessed from the run file if the import name is main. This name is used as a display name when Flask needs the name of the application. It can be set and overridden to change the value. .. versionadded:: 0.8 """ if self.import_name == "__main__": fn = getattr(sys.modules["__main__"], "__file__", None) if fn is None: return "__main__" return os.path.splitext(os.path.basename(fn))[0] return self.import_name色々やってるけど、重要なのはここ↓
if self.import_name == "__main__": fn = getattr(sys.modules["__main__"], "__file__", None) "~~省略~~" return os.path.splitext(os.path.basename(fn))[0]もしself.import_nameが"main"だったら、
最初に実行したファイルの名称を取ってくるという処理が書かれていた!!なるほど。
結構単純だった。。実はここにたどり着くまでに時間かなり使っちゃった。
わかってみると単純なんだけどわからないうちは複雑。プログラミングなんて全部単純だよって言える人になりたいな。
- 投稿日:2019-07-11T21:23:24+09:00
typing.Union[A,B]からAに変換するには
結論を1行で言うと
typing.cast(A, Union[A,B]のオブジェクト)せよ。発生した問題
コレクションオブジェクト(リストを保持するクラス)を実装しているときに遭遇した問題。
# 財布クラス(説明用に今考えた) from typing import List, Union class Wallet: def __init__(self, coins: List[Coin]) -> None: self._wallet = coins def __getitem__(self, key: Union[int, slice]) -> Union[Coin, List[Coin]]: return self._wallet[key] # 硬貨クラス class Coin: def __init__(self, value: int) -> None: self.value = value @staticmethod def exchange(value) -> List[Coin]: # 複数の硬貨でお金を表現する。ロジックは割愛上のようなクラスがあったとする。利用するとしたらこんな感じ。
coins = Coin.exchange(1000) # Coin(100)が10個のリストができるイメージ wallet = Wallet(coins) coin = wallet[0] # mypyに怒られる何が起きているの?
最後の行では
mypyにincompatible type "Union[List[Coin], Coin]"; expected "Coin"と怒られる。
__getitem__側はintとsliceの両方に対応して、Union[Coin, List[Coin]]になっている。それに対し、
coin = wallet[0]の左辺ではCoinしか想定してないため、List[Coin]返ってきたらどうするの?責任取れるの?と聞いているわけ。解決策
コーディングする側からすると、「察してくださいよ。まあ慌てるなよ」と言いたいところだが、そうしたことが通用する相手ではない。
from typing import cast coin = cast(Coin, wallet[0])と型のキャストをしてあげればよい。もちろん、値には変更はない。
参考
- 投稿日:2019-07-11T19:45:36+09:00
【Python】画像の比率を維持して長辺を指定した長さに
コマンドで変更後の長辺の長さと画像を格納したディレクトリを指定します。
ファイル拡張子チェックは割愛。
python2.7で動作確認してますが、print関数だけ直せば3でも動くでしょう。コード
resize_max_side.py#!/usr/bin/python # -*- coding: UTF-8 -*- """feature detection.""" import sys import os import cv2 def resize(image, max_side_size): ori_height, ori_width = image.shape[:2] modi_height = max_side_size modi_width = max_side_size if ori_height > ori_width: modi_width = ori_width * modi_height / ori_height else: modi_height = ori_height * modi_width / ori_width size = (modi_height, modi_width) print str(size) resized_image = cv2.resize(image, size) return resized_image if __name__ == '__main__': args = sys.argv dir_path = args[1] max_side_size = int(args[2]) file_names = os.listdir(dir_path) for file_name in file_names: file_path = dir_path + file_name image = cv2.imread(file_path) resized_image = resize(image, max_side_size) cv2.imwrite(file_path, resized_image)実行
# python resize_max_side.py images/ 100
- 投稿日:2019-07-11T18:02:48+09:00
PythonのNaNに関する注意事項
- 投稿日:2019-07-11T18:00:42+09:00
pythonのはじめ方
python何から手をつけたらいいですか?とかIDEはなにを入れたらいいですか?と質問してくれた積極的な方がいたので説明用にメモを残します。
はじめに
対象
- pythonをやったことないけど、何から始めたらいいのか思いつかない人。
環境はWindowsを想定しています
私がWindowsもしくはLinuxを使っていてMacは使っていないので、
Windowsユーザ向けの情報です。流れ
- pythonインストール
- エディタインストール
- Hello World実行
- WebでHello World(bottle利用)
- おすすめの技術紹介
pythonインストール
Python公式ページでpython本体をダウンロードしましょう。
バージョンは3系を選択しましょう
pythonのバージョンには2系と3系があります。メジャーバージョンの違いのことですね。
python2.7.16とかpython3.7.4とかですね。ライブラリの対応バージョンにももちろん関連しますが、かなり3系に対応されて来ていますし構文も改善されているのでバージョンは3系を選択しましょう。python2とpython3の違いについては以下のページを参考にしてみてください。
- Python2からPython3.0での変更点(わかりやすい)
- 2系と3系の違い(わかりやすい)
- 【公式ページ】Python 2 から Python 3 への移植
- Supporting Python 3: An in-depth guide
32bit or 64bit
Downloadのボタンを押すとPCが64bitでも32bit版がダウンロードされます。
学習レベルでは64bitにこだわる必要はないと思いますが、必要であれば64bit版のinstallerを使いましょう。64bit版のダウンロードは以前投稿の最後"注意"という部分に書いてあります。
エディタをインストール
IDEについて
Java言語ならEclipse、C#はVisualStudioというように、pythonではJetBrains社のPyCharmというIDEを使うことが多いようです。(JetBrainsのIntelliJ IDEAもJava開発でシェアをEclipseと同等もしくはそれ以上に伸ばしている模様)
PyCharmを使うとvirtualenvとかcondaとか環境使えるしコード補完もあるから便利だと思います。
ただ、学習のため基礎もやっておくといいと思います。
また公式サイトの手順はIDEを使っていない前提で説明が書かれているので一通りやってみるにはコマンドプロンプトとエディタで取り組んでみることをおすすめします。エディタおすすめ
Hello Worldなどサクッとコード書いてみるにはちょっとしたエディタで十分だと思います。
個人的なおすすめは以下です。
pythonコードも見やすし、多少の補完もしてくれます。その気になればエディタ上から実行も可能です。
また、IDLEを使うのも学習用としてはいいと思います。
↓こちらに画面イメージとか載せておきました。
https://qiita.com/HyunwookPark/items/c7eef970c7d7c05b09adHello World実行
ソースコード書く
任意の場所にディレクトリを作成して.pyファイルを新規作成しましょう。
ソースコードの内容はまずはHelloWorldで。この内容だけならimport文も不要です。test.py
print('Hello World!!')実行
コマンドプロンプトもしくはWindows PowerShellで以下のようにコマンド実行してみましょう。
> python test.py Hello World!!WebでHello World(bottle利用)
ライブラリをインストール
ライブラリをインストール方法は色々ありますが、もっとも基本的なのはpipを使う方法でしょう。
コマンドプロンプトもしくはWindows PowerShellで以下のようにコマンド実行してみましょう。
> pip install bottle Collecting bottle Downloading https://files.pythonhosted.org/packages/69/d1/efdd0a5584169cdf791d726264089ce5d96846a8978c44ac6e13ae234327/bottle-0.12.17-py3-none-any.whl (89kB) |████████████████████████████████| 92kB 1.5MB/s Installing collected packages: bottle Successfully installed bottle-0.12.17ソースコードを書く
hellobottle.py
from bottle import route, run @route('/hello') def hello(): return "Hello World!" run(host='localhost', port=8080, debug=True)実行
> python hellobottle.py Bottle v0.12.17 server starting up (using WSGIRefServer())... Listening on http://localhost:8080/ Hit Ctrl-C to quit.ブラウザでアクセス
ブラウザで上記にアクセスするとサーバからの応答が確認できる。
おすすめの技術紹介
pythonに興味が湧いたら以下のようなライブラリで好きなものを作ってみましょう。
ライブラリ 概要 tkinter WindowアプリなどGUI画面を作るためのライブラリ(python標準搭載なのでインストール不要) NumPy 数学計算が得意なライブラリでCythonで記述されていて高速 pandas データ解析のためのライブラリでCSVの読み込みやデータ操作などができる matplotlib グラフ描画のライブラリでNumPyやpandasと組み合わせて使うことが多い scikit-learn 最近のお流行り"機械学習"のライブラリ Django Ruby on RailsっぽいWeb用フレームワークでログイン機能や画面を作るtemplate機能、O/Rマッパー機能などが含まれる bottle pとても軽量なWeb用フレームワークでURIからのルーティング機能が主な機能 Flask とても軽量なWeb用フレームワークでbottleよりシェアが多いように見える(使ったことないので語れません) pygame pythonでゲームを作るためのライブラリ Pyxel pythonでレトロゲームを作るためのライブラリ(個人的にやってみたいだけ) 参考
公式ドキュメント
おまけ
virtualenv
プロジェクトによって利用するpythonのバージョンが違っていたりLinuxではデフォルトでpython2がインストールされていてpython3がどうも使いづらかったりするときのために仮想環境を使うことが多いようです。
virtualenvというものです。
pycharmを使う場合はプロジェクトを作るときにvirtualenvの利用を聞かれたりします。
知っておくといいかも
技術名 概要 CPython 公式Pythonのこと Cython PythonのようなコーディングでコンパイルするとC言語のコードでPython拡張モジュールを作ることができる pyenv virtualenvのお友達 pypy pythonを高速実行できるとうわさのもの Anaconda pythonのディストリビューションでデータサイエンスおよび機械学習関連のライブラリが含まれる Jupyter Notebook Anacondaに含まれるツールで、デバッグのような実行方法ができるエディタのようなものグラフとか画像とかすぐ表示できる pip pythonのパッケージ管理ツール
- 投稿日:2019-07-11T17:58:01+09:00
Python+XPATH+Selenium(headless)で色々なサイトのランキング情報のスクレーピング
やりたいこと
Amazonやニュースサイトのランキングをタブで一括表示できるアプリがあると便利だな、と考えました。
けれど探しても見当たらないので、自分で作りました。
以下からダウンロードできますので是非使ってみてください(Androidのみ)
https://play.google.com/store/apps/details?id=atellieryotta.unsmart_newsサーバ側はPython+Selenium(headless)で一時間ごとに各サイトをスクレーピングし、サーバ上に保存、モバイルアプリ側は今はやりのflutterで構築し、そのデータを読み込んでいます。
今回はサーバ側の内容をご紹介します。基本の手順(Amazonの本ランキング取得)
あらかじめ取得するサイトの構造が分かっているなら、XPATHによるスクレーピングが便利です。
XPATHを調べるにはChromeを使うのが簡単です。
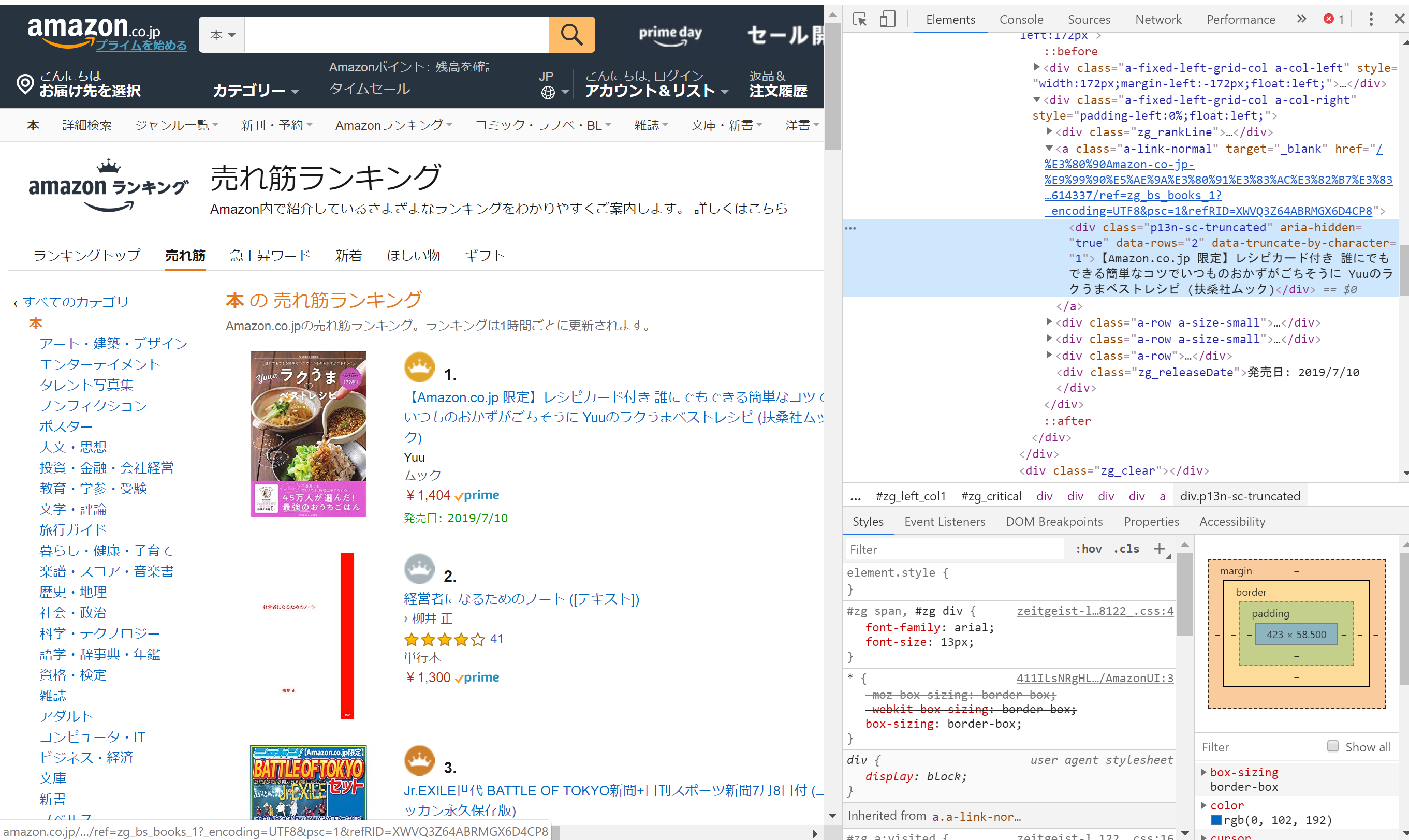
今回はAmazonの本のランキングページを開き、本のタイトルのところで右クリック→「検証」を選択すると、
右側に開発者用のメニューが表示されるので、右クリックから→「Copy」→「Copy XPATH」を選択すると、クリップボートにXPATHがコピーされます。
一位と二位について取得するとそれぞれ以下の通りであることがわかります。
//[@id="zg_critical"]/div[1]/div[1]/div/div[2]/a/div
//[@id="zg_critical"]/div[2]/div[1]/div/div[2]/a/div一つ目のdivの[]内を1~10に変えてやればよさそうです。
ただここにトラップがあり、ランキング1~3位と4位以降では@id以降が変わっています。
4位以降は以下のXPATHを取る必要があります。(iは可変)//*[@id="zg_nonCritical"]/div[{i}]/div[1]/div/div[2]/a/div
サイトによって仕様は異なるので何度かトライアンドエラーしながらXPATHを突き詰めていく必要があります。
タイトルに加えて、リンク先のURLやサムネイル画像のURLについても同様の手順でXPATHを確認できます。
最終的には以下のプログラムでランキングをスクレーピングできました。
(スクレーピングの際はサーバに過負荷をかけないようにご注意ください)amazon_book.pyimport sys,os import requests import bs4 import lxml.html import shutil fpath = "/tmp/hoge.tsv" url = 'https://www.amazon.co.jp/gp/bestsellers/books' url_base = 'https://www.amazon.co.jp/' response = requests.get(url) html = lxml.html.fromstring(response.content) f = open(fpath, mode="w"); for i in range(1,4): # rank 1~3 xpath1 = f'//*[@id="zg_critical"]/div[{i}]/div[1]/div/div[2]/a/div' # text, xpath2 = f'//*[@id="zg_critical"]/div[{i}]/div[1]/div/div[2]/a' # link xpath3 = f'//*[@id="zg_critical"]/div[{i}]/div[1]/div/div[1]/a/img' # image link1 = html.xpath(xpath1) link2 = html.xpath(xpath2) link3 = html.xpath(xpath3) text = link1[0].text.strip() href = link2[0].get("href").strip() # 空白が入り込むのでstrip image = link3[0].get("src").strip() f.write(f'{i} {url_base}{href} {text} {image}\n') for i in range(1,8): # rank 4~10 xpath1 = f'//*[@id="zg_nonCritical"]/div[{i}]/div[1]/div/div[2]/a/div' # text, xpath2 = f'//*[@id="zg_nonCritical"]/div[{i}]/div[1]/div/div[2]/a' # link xpath3 = f'//*[@id="zg_nonCritical"]/div[{i}]/div[1]/div/div[1]/a/img' # image link1 = html.xpath(xpath1) link2 = html.xpath(xpath2) link3 = html.xpath(xpath3) text = link1[0].text.strip() href = link2[0].get("href").strip() image = link3[0].get("src").strip() j = i+3 f.write(f'{j} {url_base}{href} {text} {image}\n') f.close()これを実行することで以下のような出力が得られます。
タブ区切りで、ランキング、リンク先URL、タイトル、サムネイルURLをダンプしています。hoge.tsv1 https://www.amazon.co.jp//%E3%80%90Amazon-co-jp-%E9%99%90%E5%AE%9A%E3%80%91%E3%83%AC%E3%82%B7%E3%83%94%E3%82%AB%E3%83%BC%E3%83%89%E4%BB%98%E3%81%8D-%E8%AA%B0%E3%81%AB%E3%81%A7%E3%82%82%E3%81%A7%E3%81%8D%E3%82%8B%E7%B0%A1%E5%8D%98%E3%81%AA%E3%82%B3%E3%83%84%E3%81%A7%E3%81%84%E3%81%A4%E3%82%82%E3%81%AE%E3%81%8A%E3%81%8B%E3%81%9A%E3%81%8C%E3%81%94%E3%81%A1%E3%81%9D%E3%81%86%E3%81%AB-Yuu%E3%81%AE%E3%83%A9%E3%82%AF%E3%81%86%E3%81%BE%E3%83%99%E3%82%B9%E3%83%88%E3%83%AC%E3%82%B7%E3%83%94-%E6%89%B6%E6%A1%91%E7%A4%BE%E3%83%A0%E3%83%83%E3%82%AF/dp/4594614337?_encoding=UTF8&psc=1 【Amazon.co.jp 限定】レシピカード付き 誰にでもできる簡単なコツでいつものおかずがご ちそうに Yuuのラクうまベストレシピ (扶桑社ムック) https://images-na.ssl-images-amazon.com/images/I/81sIUM7QXoL._AC_UL160_SR160,160_.jpg 2 https://www.amazon.co.jp//%E7%B5%8C%E5%96%B6%E8%80%85%E3%81%AB%E3%81%AA%E3%82%8B%E3%81%9F%E3%82%81%E3%81%AE%E3%83%8E%E3%83%BC%E3%83%88-%E3%83%86%E3%82%AD%E3%82%B9%E3%83%88-%E6%9F%B3%E4%BA%95-%E6%AD%A3/dp/4569826954?_encoding=UTF8&psc=1 経営者になるためのノ ート ([テキスト]) https://images-na.ssl-images-amazon.com/images/I/61aHoJlmwoL._AC_UL160_SR160,160_.jpg 3 https://www.amazon.co.jp//Jr-EXILE%E4%B8%96%E4%BB%A3-BATTLE-TOKYO%E6%96%B0%E8%81%9E-%E6%97%A5%E5%88%8A%E3%82%B9%E3%83%9D%E3%83%BC%E3%83%84%E6%96%B0%E8%81%9E7%E6%9C%888%E6%97%A5%E4%BB%98-%E3%83%8B%E3%83%83%E3%82%AB%E3%83%B3%E6%B0%B8%E4%B9%85%E4%BF%9D%E5%AD%98%E7%89%88/dp/B07TNVXLZH?_encoding=UTF8&psc=1 Jr.EXILE世代 BATTLE OF TOKYO新聞+日刊スポーツ新聞7月8日付 (ニッカン永久保存版) https://images-na.ssl-images-amazon.com/images/I/911FzCntefL._AC_UL160_SR160,160_.jpg 4 https://www.amazon.co.jp//%E5%A4%8F%E3%81%AE%E9%A8%8E%E5%A3%AB-%E7%99%BE%E7%94%B0-%E5%B0%9A%E6%A8%B9/dp/4103364149?_encoding=UTF8&psc=1 夏の騎士 https://images-na.ssl-images-amazon.com/images/I/81JqVie4p8L._AC_UL160_SR160,160_.jpg 5 https://www.amazon.co.jp//%E3%81%8F%E3%81%B3%E3%82%8C%E6%AF%8D%E3%81%A1%E3%82%83%E3%82%93%E3%81%AE%E3%82%86%E3%82%8B%E3%82%81%E3%82%8B%E3%82%AB%E3%83%A9%E3%83%80-DVD%E4%BB%98%E3%81%8D-%E6%89%B6%E6%A1%91%E7%A4%BE%E3%83%A0%E3%83%83%E3%82%AF-%E6%9D%91%E7%94%B0-%E5%8F%8B%E7%BE%8E%E5%AD%90/dp/4594614248?_encoding=UTF8&psc=1 くびれ母ちゃんのゆるめるカラダ DVD付き (扶桑社ムック) https://images-na.ssl-images-amazon.com/images/I/81kx4Dcvo4L._AC_UL160_SR160,160_.jpg 6 https://www.amazon.co.jp//OAD%E4%BB%98%E3%81%8D-%E8%BB%A2%E7%94%9F%E3%81%97%E3%81%9F%E3%82%89%E3%82%B9%E3%83%A9%E3%82%A4%E3%83%A0%E3%81%A0%E3%81%A3%E3%81%9F%E4%BB%B6-12-%E9%99%90%E5%AE%9A%E7%89%88-%E8%AC%9B%E8%AB%87%E7%A4%BE%E3%82%AD%E3%83%A3%E3%83%A9%E3%82%AF%E3%82%BF%E3%83%BC%E3%82%BA%E3%83%A9%E3%82%A4%E3%83%84/dp/406513935X?_encoding=UTF8&psc=1 OAD付き 転生したらスライムだった件(12)限 定版 (講談社キャラクターズライツ) https://images-na.ssl-images-amazon.com/images/I/51xlRxe7ykL._AC_UL160_SR160,160_.jpg 7 https://www.amazon.co.jp//1%E6%97%A53%E5%88%86%E8%A6%8B%E3%82%8B%E3%81%A0%E3%81%91%E3%81%A7%E3%81%90%E3%82%93%E3%81%90%E3%82%93%E7%9B%AE%E3%81%8C%E3%82%88%E3%81%8F%E3%81%AA%E3%82%8B-%E3%82%AC%E3%83%9C%E3%83%BC%E3%83%AB%E3%83%BB%E3%82%A2%E3%82%A4-%E5%B9%B3%E6%9D%BE-%E9%A1%9E/dp/4797399694?_encoding=UTF8&psc=1 1日3分見るだけでぐんぐん目がよくなる! ガボール・アイ https://images-na.ssl-images-amazon.com/images/I/71k2FysEGIL._AC_UL160_SR160,160_.jpg 8 https://www.amazon.co.jp//%E6%97%A5%E5%90%91%E5%9D%8246-1st%E3%82%B0%E3%83%AB%E3%83%BC%E3%83%97%E5%86%99%E7%9C%9F%E9%9B%86%E3%80%8E%E3%82%BF%E3%82%A4%E3%83%88%E3%83%AB%E6%9C%AA%E5%AE%9A%E3%80%8F/dp/4103527811?_encoding=UTF8&psc=1 日向坂46 1stグループ写真集 『タイトル未定』 https://images-na.ssl-images-amazon.com/images/I/911IeCcqO8L._AC_UL160_SR160,107_.jpg 9 https://www.amazon.co.jp//%E6%98%9F%E9%87%8E%E6%BA%90-%E3%81%B5%E3%81%9F%E3%82%8A%E3%81%8D%E3%82%8A%E3%81%A7%E8%A9%B1%E3%81%9D%E3%81%86-AERA%E3%83%A0%E3%83%83%E3%82%AF/dp/4022792337?_encoding=UTF8&psc=1 星野源 ふたりきりで話そう (AERAムック) https://images-na.ssl-images-amazon.com/images/I/61RXvslphbL._AC_UL160_SR160,160_.jpg 10 https://www.amazon.co.jp//%E3%83%8B%E3%83%A5%E3%83%BC%E3%82%BF%E3%82%A4%E3%83%97%E3%81%AE%E6%99%82%E4%BB%A3-%E6%96%B0%E6%99%82%E4%BB%A3%E3%82%92%E7%94%9F%E3%81%8D%E6%8A%9C%E3%81%8F24%E3%81%AE%E6%80%9D%E8%80%83%E3%83%BB%E8%A1%8C%E5%8B%95%E6%A7%98%E5%BC%8F-%E5%B1%B1%E5%8F%A3-%E5%91%A8/dp/447810834X?_encoding=UTF8&psc=1 ニュータイプの時代 新時代を生き抜く24の思考・行動様式 https://images-na.ssl-images-amazon.com/images/I/81bUaj2cn%2BL._AC_UL160_SR160,160_.jpg動的生成されるコンテンツへの対応(日刊スポーツ)
だいたいのサイトは上記のやり方でスクレーピングできますが、動的に生成されるコンテンツがあるサイトはSeleniumのheadlessブラウザを利用することで、動的に生成されたコンテンツを取得することができます。
以下のような、ただURLをダンプするだけのプログラムを作っておくと便利です(ここだけrubyですが、訳は聞かないでください。。。)
※あらかじめLinux版のgoogle-chromeとchromedriverの準備が必要となります。chrome_helper.rbrequire 'selenium-webdriver' url = ARGV[0] out = ARGV[1] ua = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36" caps = Selenium::WebDriver::Remote::Capabilities.chrome("chromeOptions" => {binary: '/usr/bin/google-chrome', args: ["--headless", "--disable-gpu", "--user-agent=#{ua}", "window-size=1280x800"]}) $driver = Selenium::WebDriver.for :chrome, desired_capabilities: caps $driver.manage.timeouts.implicit_wait = 30 $driver.get url html = $driver.page_source File.open(out, "w") do |text| text.puts(html) end日刊スポーツのサイトを例にとると以下のようになります。
nikkan.pyimport sys,os import requests import bs4 import lxml.html import shutil fpath = /tmp/hoge.tsv url = 'https://www.nikkansports.com/ranking/#total' url_base = '' ### use chromedriver tmp = "nikkan.tmp" os.system(f"ruby chrome_helper.rb {url} {tmp}") f = open(tmp) content = f.read() html = lxml.html.fromstring(content) ## あとはいつもの f = open(fpath, mode="w"); for i in range(1,11): xpath = f'//*[@id="sougou"]/ul/li[{i}]/a' xpath2 = f'//*[@id="sougou"]/ul/li[{i}]/a/text()' xpath3 = f'//*[@id="sougou"]/ul/li[{i}]/a/img' link = html.xpath(xpath) link2 = html.xpath(xpath2) link3 = html.xpath(xpath3) href = link[0].get("href") text = link2[0] image = link3[0].get("style") image = image.replace("background-image: url(", "").replace(");", "") # 余計なスタイルシート指定を削除 f.write(f'{i} {url_base}{href} {text} {image}\n') f.close()ログインが必要なコンテンツへの対応
Seleniumを使うことによりログインが必要なコンテンツへのアクセスも容易に行えます。
以下の記事が参考になります。
Seleniumでログインを含めてWebスクレイピングしてみたhttps://qiita.com/cheekykorkind/items/efec86759073bf3f72e9
Python + Selenium + Chrome で自動ログインいくつかhttps://qiita.com/memakura/items/dbe7f6edadd456da1c5d
- 投稿日:2019-07-11T16:08:05+09:00
【日記】pythonでせっかくテストコードを書いたのでカバレッジも計測してみる
私が現在開発しているプロジェクトでは、かなりしっかりとテストコードを書いています。
ここまでしっかりとしたテストコードを書いたんなら、カバレッジとやらもかなりイイ感じになってんじゃね?と思い、今まで計測したことのないカバレッジを見てみることにしました。私はテストコードを書くために
unittestを使用しています。
unittest --- ユニットテストフレームワークしかし、これだけではカバレッジを計測することはできません。
カバレッジを計測するためには別のパッケージが必要です。
今回はその名もずばりcoverageというパッケージを使いました。
Coverage.pyこちらは、私が理解できた範囲では、
python3 hoge.pyのようにcoverage hoge.pyと実行すると、そのとき通ったコードの割合を記録してくれるという使い方をするカバレッジ測定ツールのようです。開発しているプロジェクトを普通に
py main.pyと実行しただけでは当然全てのコードを通ることはありません。
従って、ユニットテストを実行するときにこのcoverageを利用してみましょう。
すなわち、いつもはこんな感じでテストをしていたところを↓ターミナル.> py -m unittest discover code.unit_tests次のように変更するのです↓
ターミナル.> coverage run -m unittest discover code.unit_testsこのようにして実行し、記録して、そのあともう一度コマンドを実行して結果を表示します。
ターミナル.> coverage report -m実際に下記のようにカバレッジを測定することができました。
やった~!カバレッジの計測できたよ~! pic.twitter.com/L2Tz6n03Hj
— ヒト?♀️速バラ撒きおじさん/あつし (@Anaakikutsushit) July 11, 2019割と注意深くテストを書いていたつもりだったんですが、一か所だけカバレッジが6割弱のモジュールがありますね。発見出来てよかった。
今日はこんなところで。
- 投稿日:2019-07-11T15:53:52+09:00
ロジスティック回帰を多クラス分類に
はじめに
これは筆者の勉強まとめページですので、指摘しまくってい頂けると幸いです
ロジスティック回帰を多クラス分類に持ち込む
https://qiita.com/raso0527/items/266714c5661e8376c04a
ロジスティック回帰は上記のページでTensorFlowを用いて実装しました
これを多クラス分類に使用してみます損失関数自体は変化しませんが、正解データの構造が少しだけ変化します
1クラス分類では、setosaとversicolorに対して1というデータ、virginicaには0というデータを与え、Sigmoid関数の出力の値がこの値に近づくようにパラメータを学習しました
今回は、[setosa] = [1, 0, 0], [versicolor] = [0, 1, 0], [virginica] = [0, 0, 1] とワンホットベクトルと呼ばれるものに正解データを変換します
以下がコードになります
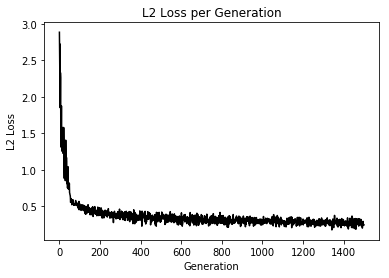
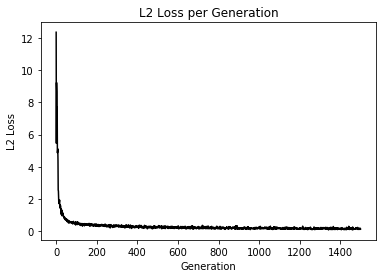
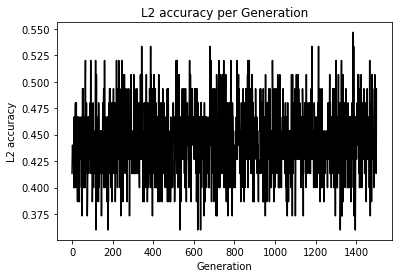
import matplotlib.pyplot as plt import tensorflow as tf import numpy as np from sklearn import datasets # シード値を固定して実行の度に同じ乱数が発生するようにしている tf.set_random_seed(1000) np.random.seed(1000) sess = tf.Session() # setosa, versicolor, virginicaの分類を行う iris = datasets.load_iris() x_vals = iris.data target = iris.target # ワンホットベクトルの作成 y1 = [[1, 0, 0] for i in target if i == 0] y2 = [[0, 1, 0] for i in target if i == 1] y3 = [[0, 0, 1] for i in target if i == 2] y_vals = np.array(y1+y2+y3) learning_rate = 0.05 batch_size = 25 x_data = tf.placeholder(shape = [None, 4], dtype = tf.float32) y_target = tf.placeholder(shape = [None, 3], dtype = tf.float32) A = tf.Variable(tf.random_normal(shape = [4, 3])) b = tf.Variable(tf.random_normal(shape = [3])) model_output = tf.add(tf.matmul(x_data, A), b) loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits = model_output, labels = y_target)) # loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = model_output, labels = y_target)) init = tf.global_variables_initializer() sess.run(init) optimizer = tf.train.GradientDescentOptimizer(learning_rate) train = optimizer.minimize(loss) prediction = tf.round(tf.sigmoid(model_output)) prediction_correct = tf.cast(tf.equal(prediction, y_target), tf.float32) accuracy = tf.reduce_mean(prediction_correct) loss_vec = [] accuracy_vec = [] for i in range(1500): rand_index = np.random.choice(len(x_vals), size = batch_size) rand_x = x_vals[rand_index] rand_y = y_vals[rand_index] sess.run(train, feed_dict = {x_data: rand_x, y_target: rand_y}) tmp_accuracy, temp_loss = sess.run([accuracy, loss], feed_dict = {x_data: rand_x, y_target: rand_y}) loss_vec.append(temp_loss) accuracy_vec.append(tmp_accuracy) if (i + 1) % 25 == 0: print("Step #" + str(i + 1) + " A = " + str(sess.run(A)) + " b = " + str(sess.run(b))) print("Loss = " + str(temp_loss)) print("Acc = " + str(tmp_accuracy)) plt.plot(loss_vec, "k-") plt.title("Loss per Generation") plt.xlabel("Generation") plt.ylabel("Loss") plt.show() plt.plot(accuracy_vec, "k-") plt.title("Accuracy per Generation") plt.xlabel("Generation") plt.ylabel("Accuracy") plt.show()Loss値とAccuracyの変化
うん、学習はしているけど今回もテスト検証めんどくちゃかったのでしてません、ごめんなちゃい
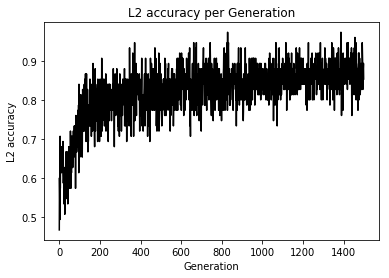
てか、これってSoftmaxCrossEntropyとどっちが評価として良いのかなあと思い損失関数を変化させ実験
Loss値とAccuracyの変化
え、めっちゃ差が出てるんだけど...
追加学習して変化をもう一度みてみよう
やはり変化なしでした
初期値やデータにも依存するのかな?
こんなに顕著に変化に現れると思いませんでしたってのが今回の感想です


- 投稿日:2019-07-11T15:34:02+09:00
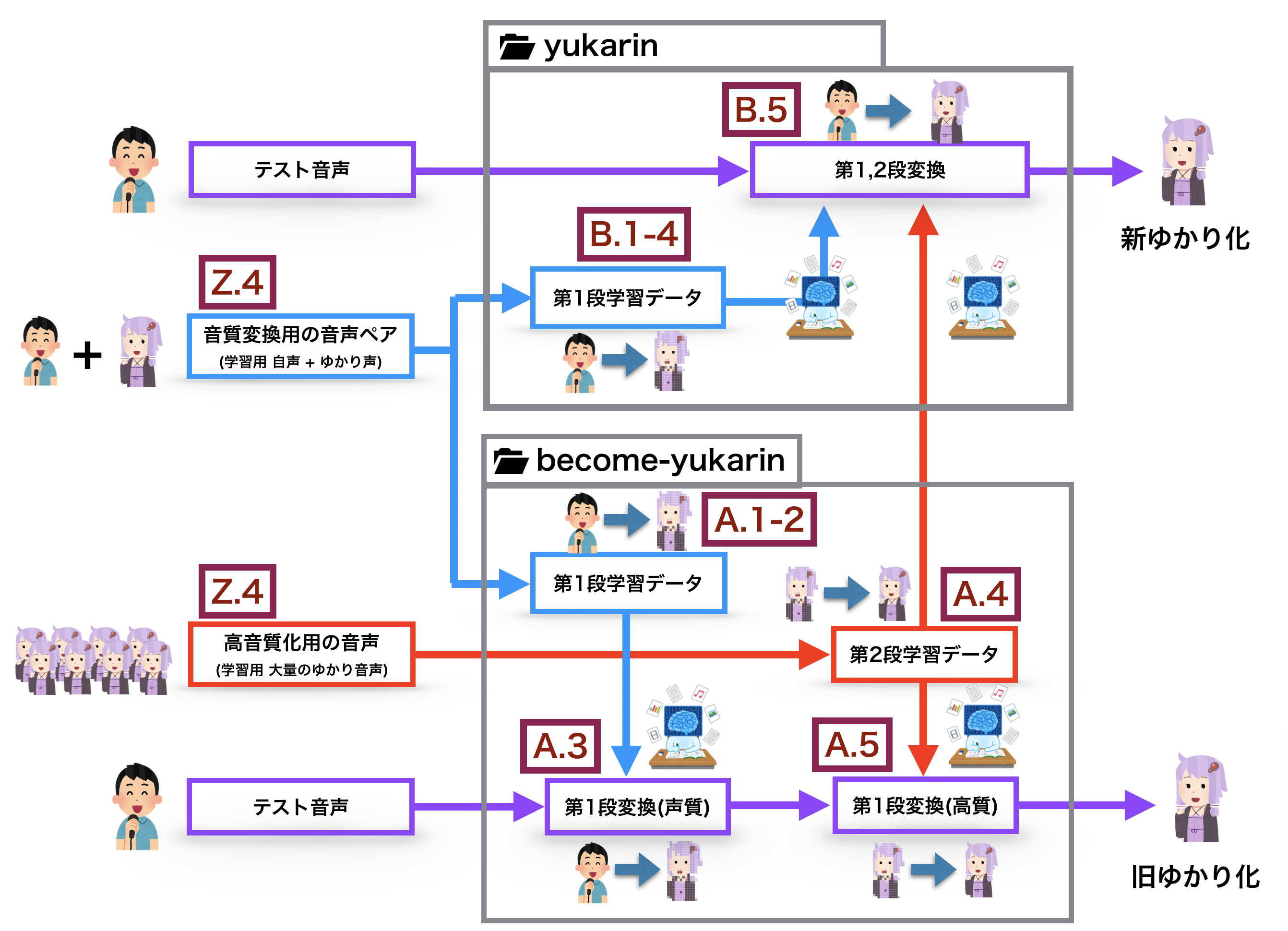
『Yukarinライブラリ』become-yukarin, yukarin コマンド解説(我流ノウハウ付)
概要
『Yukarinライブラリ』yukarin, become-yukarin リポジトリで、自分の音声をターゲット音声に変換する手順を紹介する。
yukarin は become-yukarin の改良版リポジトリであるが、2019/06/24 現在、become-yukarin での学習データを必要が必要になる。
よって、冗長となるが、 become-yukarin, yukarin 両方のコマンド解説を行う。前提として『Yukarinライブラリ』 yukarin, become-yukarin 概要・リポジトリ関係を整理してみたを把握しているものとします。
◾️ Yukarinライブラリとは?
『自分の声(自声)』を 『好きな音声(ターゲットボイス)』に 1対1 対応で音質変換をする OSS です。
yukarin, become-yukarin ではオフラインでの音声変換しかできませんが、学習データを realtime-yukain で実行することで、リアルタイム変換することもできます。詳細は下記を参照ください。
- 製作者のヒホ様の動画 : ディープラーニングの力で結月ゆかりの声になってみた
- 製作者のヒホ様のブログ: ディープラーニングの力で結月ゆかりの声になってみた
- まとめ情報記事 : ディープラーニング声質変換OSS「誰でも好きなキャラの声になれる」レポジトリ become-yukarinなどの関連記事等一覧◾️ 用語
Yukarinライブラリ
『yukarin』 と 『become-yukarin』の 2つをひっくるめて『Yukarinライブラリ』と命名されています。
- Hiroshiba/yukarin : 誰でも好きなキャラの声になれるリポジトリ』
- Hiroshiba/become-yukarin : 旧名は『ディープラーニングの力で誰でも結月ゆかりになれるリポジトリ』
"ゆかり音声"
ターゲット音声は任意ですが、イメージしやすいように 『ターゲット音声 = 結月ゆかり』と仮定します。
よって、"ターゲット音声"を"ゆかり音声"と表現します。◾️ GPU は何がいいの?
- realtime-yukarin を使う: GTX 1060(6G) 以上(readmeより)
- ただ変換するだけ: GTX 970(4G) 以上(become-yukarinの第2段では GPUメモリが 4G必要)
- 個人的なおすすめ : GTX 1070(8G) 中古(安くて・そこそこ早くて、GPUメモリが 8Gある)
◾️ 環境構築方法
・ Ubuntu v19.04 (RTX対応)
・ Ubuntu v18.10 LTS : @sakamotothogo 様◾️ 知っていると便利な知識
- git : リポジトリの更新を簡単に反映されるので強く推奨
- PyCharm コミュニティ版(無料) : Python・機械学習を勉強するなら強く推奨
◾️ エラーなどで困った時は?
- 気軽にコメントに書いてください!
- 『Yukarinライブラリ』 become-yukarin, yukarin のトラブルシューティング を見てみる
- yukarinコマンドジェネレーター! も参考になります
◾️ 目次
Z. become-yukarin, yukarin共通の事前作業
- Z.0 念のためのソフトインストール
- Z.1 ディレクトリ作成
- Z.2 各種リポジトリの取得
- Z.3 念のためのソフトインストール
- Z.4 音声データの収録
- Z.5 音声データの配置とリサンプリング
- Z.6 うっかり削除対策・バックアップ
- Z.7 環境変数の設定
- Z.8 ライブラリのインストール
A. become-yukarin
- A.1 音声変換のための特徴量抽出
- A.2 第1段の学習
- A.3 第1段を使った音声変換
- A.4 第2段の学習
- A.5 第2段を使った音質向上
B. yukarin
- B.1 音声変換のための特徴量抽出
- B.2 音響特徴量のアライメント
- B.3 周波数の統計量を求める
- B.4 第1段学習
- B.5 yukarin での音声変換
Z. become-yukarin, yukarin共通の事前作業
Z.0 念のためのソフトインストール
念のため ffmpeg, sox をインストールコマンドを実行してください。
コマンド(Ubuntu)
sudo apt install tree sudo apt install ffmpeg sudo apt install soxZ.1 ディレクトリ作成
作業ディレクトリを決定する
任意で構いませんが、後でディレクトリ移動させると環境変数の書き換えが必要となるので、気をつけてください。
この記事では HOME 直下の deep_yukarin ディレクトリで作業をすると仮定します。
以下で説明する各種コマンドはdeep_yukarin直下で、実行すると想定しています。mkdir ~/deep_yukarin cd deep_yukarinディレクトリ作成
本記事では以下のディレクトリ構造を前提にコマンド解説します。
リポジトリの相関や音声データの依存関係を考慮して、独断と偏見で決めてました。
作業ディレクトリに移動したあと、下記コマンドをコピペで実行してください。コマンド
mkdir dat mkdir dat/1st_models_by mkdir dat/2nd_models_by mkdir dat/1st_models_y mkdir dat/1st_models_by/yukari mkdir dat/1st_models_by/yukari/npy_pair mkdir dat/2nd_models_by/yukari mkdir dat/1st_models_y/yukari mkdir dat/1st_models_y/yukari/aligned_indexes mkdir dat/1st_models_y/yukari/aligned_wav mkdir dat/1st_models_y/yukari/statistics mkdir dat/1st_models_y/yukari/npy_pair mkdir dat/input mkdir dat/output mkdir dat/voice_src mkdir dat/voice_src/voice_24000 mkdir dat/voice_src/voice_44100 mkdir dat/voice_src/voice_24000/yukari_pair mkdir dat/voice_src/voice_24000/yukari_pair/own mkdir dat/voice_src/voice_24000/yukari_pair/target mkdir dat/voice_src/voice_24000/yukari_single mkdir dat/voice_src/voice_44100/yukari_pair mkdir dat/voice_src/voice_44100/yukari_pair/own mkdir dat/voice_src/voice_44100/yukari_pair/target mkdir dat/voice_src/voice_44100/yukari_singleチェック
tree コマンドで下記のようになっているか確認してください。tree dat dat ├── 1st_models_by │ └── yukari ├── 1st_models_y │ └── yukari ├── 2nd_models_by │ └── yukari ├── input ├── output └── voice_src ├── voice_24000 │ ├── yukari_pair │ │ ├── own │ │ └── target │ └── yukari_single └── voice_44100 ├── yukari_pair │ ├── own │ └── target └── yukari_singleZ.2 各種リポジトリの取得
- yukarin
- become-yukarin
- 筆者自作のチェックツール
- 日本声優統計学会の音素バランス文 を git で取得します。
* git を使わずサイトからダウンロードでもいいが、更新があった場合修正が面倒です。
* 筆者のチェックツールは必須ではありませんが、あること前提で解説します。コマンド
git clone https://github.com/Hiroshiba/become-yukarin git clone https://github.com/Hiroshiba/yukarin git clone git@bitbucket.org:YoshikazuOota/yukarin-tools.git git clone git@github.com:YoshikazuOota/balance_sentences.gitチェック
tree -L 1 . ├── balance_sentences ├── become-yukarin ├── dat ├── yukarin └── yukarin-tools補足: 各種リポジトリを最新版を反映する場合
yukarin, become-yukarin 等の各種のディレクトリに移動して、git pullを実行するcd ~/deep_yukarin cd [yukarin, become-yukarin] git pullさらに yukarin-tools 用に下記コマンドを実行してください。
sudo apt install node sudo apt install lm-sensors cd yukarin-tools npm install cd ~/deep_yukarinZ.4 音声データの収録
Z.4.1 音声データ作成におすすめする"音素バランス文"
CC BY-SA 4.0で公開されている、日本声優統計学会の音素バランス文がおすすめです。
balance_sentences/balance_sentences.txtに読み上げ文がありますので、必要に応じて利用してください。利用の際には 日本声優統計学会 から継承されている CC BY-SA 4.0 にしたがってください。
Z.4.2 第1段のゆかり・自声の収録
下記動画を参照してください。
これは一例であってベストってわけではありませんYukarinライブラリ用の音声収録方法の紹介
収録は 44100Hz / 16bit で行なっていますが、学習時には 24000Hz / 16bit にリサンプリングします。
(後々、高いサンプリングで学習したい場合があるかもしれないので、収録時は高サンプリングでいいと思います)ごめんなさい!
以前の記事では、『voiceroid2 などは 44100Hzがデフォルトなので、44100Hz で音声変換すればいい』と、書きましたがあまり適切では無いようです。
人間の音声はほぼ 10000Hz 以下に収まるそうなので、 学習音声のサンプリングはデフォルトの 24000Hzで良さそうです。
(シャノンのサンプリング定義より、24000Hz でサンプリングすれば 12000Hz 以下の音声解析ができます)Z.4.3 第2段のゆかりボイスの生成
自分は第1段で使ったゆかりボイス + 自分の動画で使った調教済み音声を使用しました(約2時間)。
ヒホ様の issueによると『私はJNASを読ませたものを用いました。』とのことです(約60時間)。
経験則的では、大量にボイスを用意すれば、内容は適当で良さそうです(違ったらごめんなさい)。Z.5 音声データの配置とリサンプリング
Z.5.1 音声データの配置
Z.4 で収録した音声データをそれぞれ下記のディレクトリに配置してください
- dat/voice_src/voice_44100/yukari_pair/own : Z.4 で収録した第1段の自声
- dat/voice_src/voice_44100/yukari_pair/target : Z.4 で生成した第1段のゆかり音声
- dat/voice_src/voice_44100/yukari_single : Z.4 で生成した第2段のゆかり音声
Z.5.2 ファイル数チェック(チェックサム)
下記の2ディレクトリには、同じ名前で同数のファイルを設置する必要があります。
- dat/voice_src/voice_44100/yukari_pair/own : Z.4 で収録した第1段の自声
- dat/voice_src/voice_44100/yukari_pair/target : Z.4 で生成した第1段のゆかり音声
手戻りが無いように下記コマンドで、ファイル数をチェックします。
./yukarin-tools/count_checker.js -b dat/voice_src/voice_44100/yukari_pair/own -d dat/voice_src/voice_44100/yukari_pair/targetZ.5.3 フォーマットチェック
自作ツールで、wav ファイルのフォーマットをチェックします。
-sでチェックするサンプリングレートを指定します./yukarin-tools/format_checker.js dat/voice_src/voice_44100/yukari_pair/own -s 44100 ./yukarin-tools/format_checker.js dat/voice_src/voice_44100/yukari_pair/target -s 44100 ./yukarin-tools/format_checker.js dat/voice_src/voice_44100/yukari_single -s 44100問題がなければ下記のようなメッセージが表示されます。
./yukarin-tools/format_checker.js dat/voice_src/voice_44100/yukari_single -s 44100 debug : {"src":"dat/voice_src/voice_44100/yukari_pair/own","sampling":44100} all files format : > channels : 1 > bits per sample : 16 > encoding : Signed Integer PCM > sampling : 44100 result : OKZ.5.4 リサンプリング
収録音声を Yukarinライブラリのデフォルトフォーマット 24000Hz /16 bit に変換します。
-bサンプリングする元データディレクトリ-dサンプリングしたデータを入れるディレクトリ(念の為、上書きできないようにしています)-sでチェックするサンプリングレートを指定します./yukarin-tools/resampling.js -b dat/voice_src/voice_44100/yukari_pair/own -d dat/voice_src/voice_24000/yukari_pair/own -s 24000 ./yukarin-tools/resampling.js -b dat/voice_src/voice_44100/yukari_pair/target -d dat/voice_src/voice_24000/yukari_pair/target -s 24000 ./yukarin-tools/resampling.js -b dat/voice_src/voice_44100/yukari_single -d dat/voice_src/voice_24000/yukari_single -s 24000自声(own)のリサンプリングで下記のような Warnが出るかもしれません。
これは、『ボリュームMAX超えているのがあるけどええんか?』的な、注意です。
アラートで、5 samplesの部分が100 samplesとか大きな数字になっていなければ、大丈夫です。sox WARN rate: rate clipped 5 samples; decrease volume? sox WARN dither: dither clipped 5 samples; decrease volume?Z.5.5 リサンプリングのチェック
しつこいですが、リサンプリング結果をチェックします。
./yukarin-tools/format_checker.js dat/voice_src/voice_24000/yukari_pair/own -s 24000 ./yukarin-tools/format_checker.js dat/voice_src/voice_24000/yukari_pair/target -s 24000 ./yukarin-tools/format_checker.js dat/voice_src/voice_24000/yukari_single -s 24000Z.6 うっかり削除対策・バックアップ
収録音声など、せっかく作った音声データを削除してしまわないように、データをリードオンリーにします。
念の為、別ストレージへバックアップもおすすめします。chmod -R 555 dat/voice_src書き込みできるように戻す場合は下記コマンドを実行してください
chmod -R 755 dat/voice_srcZ.7 環境変数の設定
emacs, vim 等で
~/.bashrcを開き、下記の一行を付け加えてください。
[user_name]の箇所は、アカウントに応じて適宜変更してください。export PYTHONPATH=/home/[user_name]/deep_yukarin/become-yukarin:/home/[user_name]/deep_yukarin/yukarin修正後、下記コマンドを実行してください。
このコマンドを実行しないと上記修正が反映されません。source ~/.bashrc下記コマンドで、先ほどの設定が表示されるか確認してください。
echo $PYTHONPATH > /home/[user_name]/deep_yukarin/become-yukarin:/home/[user_name]/deep_yukarin/yukarinZ.8 ライブラリのインストール
yukarin, become-yukarin に必要なライブラリをインストールします。
pip install -r become-yukarin/requirements.txt pip install world4py pip install -r yukarin/requiremets.txt* yukarin のライブラリインストールで、CUDA周りの再インストールされます。
A become-yukarin
A.1 音声変換のための特徴量抽出
become-yukarin の第1段の学習モデル作成は主に
dat/1st_models_by/yukarinで作業をします。
第1段の音声ファイルは少ないので、コピーして使うことにします。cp -r dat/voice_src/voice_24000/yukari_pair dat/1st_models_by/yukari/voice_pairコピーした音声ファイルから、音声の特徴量を抽出します。
(オプションの解説はしません。各種コマンドオプションは-hを付けて確認してください。 (expython become-yukarin/scripts/extract_acoustic_feature_arg -h)python become-yukarin/scripts/extract_acoustic_feature.py \ -i1 dat/1st_models_by/yukari/voice_pair/own \ -i2 dat/1st_models_by/yukari/voice_pair/target \ -o1 dat/1st_models_by/yukari/npy_pair/own \ -o2 dat/1st_models_by/yukari/npy_pair/target念の為、生成した npyファイルのチェックサムをとる。
./tools/count_checker.js -b dat/1st_models_by/yukari/voice_pair/target -d dat/1st_models_by/yukari/npy_pair/targetA.2 第1段の学習(become-yukarin)
学習前に設定ファイルをコピーして書き換えます。
cp become-yukarin/recipe/config.json dat/1st_models_by/yukari/エディタで config.json を開き
emacs dat/1st_models_by/yukari/config.json下記の6行を、書き換えてください。
その際、input_glob,target_glob音声収録をした時のプリフィックス "v-" などを忘れずにしてください。"input_glob": "dat/1st_models_by/yukari/npy_pair/own/v-*.npy", "input_mean_path": "dat/1st_models_by/yukari/npy_pair/own/mean.npy", "input_var_path": "dat/1st_models_by/yukari/npy_pair/own/var.npy", "target_glob": "dat/1st_models_by/yukari/npy_pair/target/v_*.npy", "target_mean_path": "ddat/1st_models_by/yukari/npy_pair/target/mean.npy", "target_var_path": "dat/1st_models_by/yukari/npy_pair/target/var.npy",さらに、GPUを使いための下記の設定をしてください。(cpu -1, gpu 0)
"gpu": 0,設定が終わったら、下記コマンドで学習を行います。
python become-yukarin/train.py dat/1st_models_by/yukari/config.json dat/1st_models_by/yukari/1st_yukari_model_byエラーがなければ、predictor_XXXX.npz と言う学習済みファイルが生成されます。
predictor_250000.npz 程度が出力されるのを待ちます(GTX 1070で 7時間ぐらい)。進捗チェックコマンド
watch -n 60 ls -latr dat/1st_models_by/yukari/1st_yukari_model_by蛇足
CPU,GPUの温度は以下でチェックできます。
熱暴走にはお気をつけて! (筆者は2回、熱保護でPCをクラッシュさせました)./yukarin-tools/watch_temperature.shA.3 第1段を使った音声変換
音声変換に使う入力・出力ファイルを格納するディレクトリを作成します。
test_dataには Z.4.2 で作った学習データとは、違う自声の音声データ(24000Hz / 16bit)を配置します。mkdir ./test_data mkdir ./output mkdir ./output/1st_yukari_model_by次に、上手く学習できていそうなデータの目星を付けます。
ヒホ様は train.pyの学習数について #10 のように選んでいるそうです。以下の選び方は我流です。参考までの一例です!
下記で、 5000ステップごとのdiscriminator/accuracyとdiscriminator/lossを出力します./yukarin-tools/log2accuracy.js dat/1st_models_by/yukari/1st_yukari_model_by/logここで着目するのは
acc(discriminator/accuracy)とloss(discriminator/loss)です。
accは問題なければ、90% 〜 97% ぐらいまで上がります。
これが 80% 程度から上がっていなければ、学習用音声の質が悪いか、手順にミスがあるかと思います。経験則では下記のデータが変換精度が高かったです。
- イテレーションが少ない
-accが大きい
-lossが小さい下記の結果から、選ぶなら下記 3つほどが候補になります。
(学習回数のイテレーションは大きければ大きいほどいいと言うことはありません。過学習と言う精度が下がる現象が起こります。)
- 145000 :: train > acc : 0.95, loss 0.283 :: test > acc 0.53 ( 4:13:21)
- 180000 :: train > acc : 0.95, loss 0.273 :: test > acc 0.63 ( 5:14:42)
- 220000 :: train > acc : 0.96, loss 0.227 :: test > acc 0.52 ( 6:24:50)
{ acc: 0.85, skip: 5000, full: false, src: 'dat/1st_models_by/yukari/1st_yukari_model_by/log' } - 15000 :: train > acc : 0.86, loss 0.654 :: test > acc 0.53 ( 0:26:06) - 25000 :: train > acc : 0.87, loss 0.627 :: test > acc 0.67 ( 0:43:32) - 30000 :: train > acc : 0.88, loss 0.552 :: test > acc 0.48 ( 0:52:15) - 35000 :: train > acc : 0.89, loss 0.538 :: test > acc 0.66 ( 1:00:58) - 40000 :: train > acc : 0.89, loss 0.521 :: test > acc 0.55 ( 1:09:41) - 45000 :: train > acc : 0.90, loss 0.489 :: test > acc 0.58 ( 1:18:25) - 50000 :: train > acc : 0.90, loss 0.511 :: test > acc 0.56 ( 1:27:08) - 55000 :: train > acc : 0.89, loss 0.499 :: test > acc 0.53 ( 1:35:52) - 60000 :: train > acc : 0.91, loss 0.472 :: test > acc 0.70 ( 1:44:35) - 65000 :: train > acc : 0.90, loss 0.483 :: test > acc 0.66 ( 1:53:19) - 70000 :: train > acc : 0.89, loss 0.513 :: test > acc 0.63 ( 2:02:03) - 75000 :: train > acc : 0.90, loss 0.485 :: test > acc 0.58 ( 2:10:47) - 80000 :: train > acc : 0.91, loss 0.457 :: test > acc 0.55 ( 2:19:31) - 85000 :: train > acc : 0.90, loss 0.472 :: test > acc 0.52 ( 2:28:15) - 90000 :: train > acc : 0.91, loss 0.450 :: test > acc 0.59 ( 2:37:00) - 95000 :: train > acc : 0.89, loss 0.510 :: test > acc 0.50 ( 2:45:44) - 100000 :: train > acc : 0.91, loss 0.437 :: test > acc 0.70 ( 2:54:30) - 105000 :: train > acc : 0.90, loss 0.483 :: test > acc 0.61 ( 3:03:14) - 110000 :: train > acc : 0.91, loss 0.422 :: test > acc 0.63 ( 3:12:03) - 115000 :: train > acc : 0.92, loss 0.383 :: test > acc 0.64 ( 3:20:48) - 120000 :: train > acc : 0.91, loss 0.418 :: test > acc 0.58 ( 3:29:33) - 125000 :: train > acc : 0.92, loss 0.385 :: test > acc 0.41 ( 3:38:19) - 130000 :: train > acc : 0.93, loss 0.354 :: test > acc 0.39 ( 3:47:04) - 135000 :: train > acc : 0.94, loss 0.327 :: test > acc 0.58 ( 3:55:50) - 140000 :: train > acc : 0.92, loss 0.391 :: test > acc 0.61 ( 4:04:35) - 145000 :: train > acc : 0.95, loss 0.283 :: test > acc 0.53 ( 4:13:21) - 150000 :: train > acc : 0.93, loss 0.379 :: test > acc 0.45 ( 4:22:06) - 155000 :: train > acc : 0.94, loss 0.326 :: test > acc 0.41 ( 4:30:52) - 160000 :: train > acc : 0.94, loss 0.330 :: test > acc 0.58 ( 4:39:38) - 165000 :: train > acc : 0.93, loss 0.360 :: test > acc 0.50 ( 4:48:24) - 170000 :: train > acc : 0.93, loss 0.348 :: test > acc 0.64 ( 4:57:10) - 175000 :: train > acc : 0.94, loss 0.321 :: test > acc 0.58 ( 5:05:56) - 180000 :: train > acc : 0.95, loss 0.273 :: test > acc 0.63 ( 5:14:42) - 185000 :: train > acc : 0.94, loss 0.278 :: test > acc 0.72 ( 5:23:28) - 190000 :: train > acc : 0.94, loss 0.295 :: test > acc 0.64 ( 5:32:14) - 195000 :: train > acc : 0.94, loss 0.279 :: test > acc 0.66 ( 5:41:00) - 200000 :: train > acc : 0.94, loss 0.308 :: test > acc 0.50 ( 5:49:46) - 205000 :: train > acc : 0.95, loss 0.268 :: test > acc 0.69 ( 5:58:32) - 210000 :: train > acc : 0.93, loss 0.326 :: test > acc 0.56 ( 6:07:18) - 215000 :: train > acc : 0.94, loss 0.290 :: test > acc 0.64 ( 6:16:04) - 220000 :: train > acc : 0.96, loss 0.227 :: test > acc 0.52 ( 6:24:50) - 225000 :: train > acc : 0.95, loss 0.251 :: test > acc 0.59 ( 6:33:37) - 230000 :: train > acc : 0.96, loss 0.238 :: test > acc 0.72 ( 6:42:23) - 235000 :: train > acc : 0.96, loss 0.216 :: test > acc 0.53 ( 6:51:09) - 240000 :: train > acc : 0.95, loss 0.259 :: test > acc 0.55 ( 6:59:56) - 245000 :: train > acc : 0.96, loss 0.228 :: test > acc 0.70 ( 7:08:43) - 250000 :: train > acc : 0.95, loss 0.253 :: test > acc 0.67 ( 7:17:29)変換の実行は下記コマンドで実行します。
[イテレーション数] には 変換したい数字を入れてください。python become-yukarin/scripts/voice_conversion_test.py 1st_yukari_model_by \ -iwd dat/1st_models_by/yukari/voice_pair/own \ -md dat/1st_models_by/yukari \ -it [イテレーション数]変換結果は
output/1st_yukari_model_byに保存されます。
成功した場合
inputディレクトリの音声変換結果dat/1st_models_by/yukari/voice_pair/ownからランダムに選ばれた音声変換結果が入っています。
筆者の変換結果(葵音声)
個人的には predictor_145000.npz が一番いい様に思います。
ちなみに、ヒホ様のデモでは 19万 イテレーションの学習データを使用したそうです(train.pyの学習数について)。
あと、理屈はわかりませんが、音声の後半にノイズ入ります。変換前データの後方の無音時間をカットすれば問題ないと思います。
- predictor_95000.npz
- predictor_145000.npz
- predictor_180000.npz
- predictor_220000.npz
- predictor_235000.npz
A.4 第2段学習
voice ソース から直接参照して(データ数が多いのでコピーしません)、音声特徴量を抽出します。
python become-yukarin/scripts/extract_spectrogram_pair.py \ -i dat/voice_src/voice_24000/yukari_single \ -o dat/2nd_models_by/yukari/npy_single
LLVM ERROR: out of memory等で、出てハングアップすることがあります。
その時はctrl + cで処理を中断して、、2回、3回と繰り返すことで、全ての音声を変換できると思います。変換後、下記コマンドで全ファイルが変換されているかチェックします。
数が合わなければ、上記処理を繰り返しましょう。./yukarin-tools/count_checker.js -b dat/2nd_models_by/yukari/npy_single -d dat/voice_src/voice_24000/yukari_singlecp become-yukarin/recipe/config_sr.json dat/2nd_models_by/yukari/A.2 同様に、config_sr.py をコピーして、データ置き、三行修正をします。
batchsizeは GPU Mem 4G なら 1, GPU Mem 8G なら 2"input_glob": "dat/2nd_models_by/yukari/npy_single/*.npy", "batchsize": 1 "gpu": 0,設定が終われば、下記コマンドで学習します。
こちらは、第1段に比べてかなりの時間がかかります。
自分は 100,000イテレーションほどのデータを使用していますが、どの程度が適切なのかはわかりません。python become-yukarin/train_sr.py \ dat/2nd_models_by/yukari/config_sr.json \ dat/2nd_models_by/yukari/2nd_yukari_model_by進捗チェックコマンド
watch -n 60 ls -latr dat/1st_models_by/yukari/2nd_yukari_model_byA.5 第2段を使った音質向上
A.3 で変換したデータを
test_data_srにコピーします。mkdir test_data_sr cp output/1st_yukari_model_by/* test_data_sr./yukarin-tools/format_checker.js dat/2nd_models_by/yukari/npy_single dat/voice_src/voice_24000/yukari_single
python become-yukarin/scripts/super_resolution_test.py 2nd_yukari_model_by/ \ -md dat/2nd_models_by/yukari \ -iwd dat/voice_src/voice_24000/yukari_single第2段のプレディクターは 2nd_yukari_model_by 内で一番、イテレーションが大きいものが使われます。
筆者の変換結果(葵音声)
predictor_145000.npz の第1段音声が割と綺麗に取れているので、差がわかりにくいですが、多少音質がよくなっていると思います。predictor_145000.npz の第1段に第2段を適用した音声
B. yukarin
yukarinって何が違うの?
現状では、基本リファクタリングがメインで、新規点は 声のピッチを調整が簡単になった とのことです。
また、音声変換の精度も少し変わるようです。B.1 音声変換のための特徴量抽出
ざっくり言うと、B.1, B.2 の処理は、A.1 を分割しているだけで処理内容はほとんど同じっぽいです。
A.1 同様音声ファイルはコピーして使います。
cp -r dat/voice_src/voice_24000/yukari_pair dat/1st_models_y/yukari/voice_pair自声の特徴量抽出
python yukarin/scripts/extract_acoustic_feature.py \ -i './dat/1st_models_y/yukari/voice_pair/own/*.wav' \ -o './dat/1st_models_y/yukari/npy_pair/own'注: readmeの * -> *.wav に変更しているのは安全のため
ゆかりの特徴量抽出
python yukarin/scripts/extract_acoustic_feature.py \ -i './dat/1st_models_y/yukari/voice_pair/target/*.wav' \ -o './dat/1st_models_y/yukari/npy_pair/target'npyのチェックサム
./yukarin-tools/count_checker.js -b dat/1st_models_y/yukari/npy_pair/own -d dat/1st_models_y/yukari/npy_pair/targetB.2 音響特徴量のアライメント
自声とゆかり音声の微妙なずれを補償する。
python yukarin/scripts/extract_align_indexes.py \ -i1 './dat/1st_models_y/yukari/npy_pair/own/*.npy' \ -i2 './dat/1st_models_y/yukari/npy_pair/target/*.npy' \ -o './dat/1st_models_y/yukari/aligned_indexes/'B.3 周波数の統計量を求める
声の高さの平均、分散を求める。
この平均値をいじることで、変換後の音声のピッチを調整できるようです。python yukarin/scripts/extract_f0_statistics.py\ -i './dat/1st_models_y/yukari/npy_pair/own/*.npy' \ -o './dat/1st_models_y/yukari/statistics/own.npy'python yukarin/scripts/extract_f0_statistics.py\ -i './dat/1st_models_y/yukari/npy_pair/target/*.npy' \ -o './dat/1st_models_y/yukari/statistics/target.npy'B.4 第1段学習(yukarin)
cp yukarin/sample_config.json ./dat/1st_models_y/yukari/config.jsonemacs dat/1st_models/config.json で編集
L15-17"input_glob": "./dat/1st_models_y/yukari/npy_pair/own/*.npy", "target_glob": "./dat/1st_models_y/yukari/npy_pair/target/*.npy", "indexes_glob": "./dat/1st_models_y/yukari/aligned_indexes/*.npy",python yukarin/train.py \ ./dat/1st_models_y/yukari/config.json \ ./dat/1st_models_y/yukari/1st_yukari_model_y学習進行チェックコマンド
watch -n 60 "pwd; ls -ltr dat/1st_models_y/yukari/1st_yukari_model_y"B.5 yukarin での音声変換(第1,2段)
become-yukarin で使用したテストデータを移動させます。
cp test_data/*.wav dat/input/A.3 同様に音質が良さそうな学習データをピックアップします。
./yukarin-tools/log2accuracy.js dat/1st_models_y/yukari/1st_yukari_model_y/logyukarinは become-yuakrin に比べて、
accが高めになりました。
- 120000 :: train > acc : 0.98, loss 0.121 :: test > acc 0.57 ( 3:36:31)
- 160000 :: train > acc : 0.98, loss 0.116 :: test > acc 0.57 ( 4:48:56)
- 210000 :: train > acc : 0.98, loss 0.107 :: test > acc 0.65 ( 6:19:33)
{ acc: 0.85, skip: 5000, full: false, src: 'dat/1st_models_y/yukari/1st_yukari_model_y/log' } - 5000 :: train > acc : 0.95, loss 0.379 :: test > acc 0.51 ( 0:09:00) - 10000 :: train > acc : 0.97, loss 0.232 :: test > acc 0.59 ( 0:18:01) - 15000 :: train > acc : 0.97, loss 0.200 :: test > acc 0.52 ( 0:27:03) - 20000 :: train > acc : 0.97, loss 0.199 :: test > acc 0.56 ( 0:36:03) - 25000 :: train > acc : 0.98, loss 0.170 :: test > acc 0.57 ( 0:45:04) - 30000 :: train > acc : 0.98, loss 0.164 :: test > acc 0.57 ( 0:54:05) - 35000 :: train > acc : 0.98, loss 0.155 :: test > acc 0.63 ( 1:03:07) - 40000 :: train > acc : 0.98, loss 0.157 :: test > acc 0.59 ( 1:12:09) - 45000 :: train > acc : 0.98, loss 0.158 :: test > acc 0.56 ( 1:21:09) - 50000 :: train > acc : 0.98, loss 0.152 :: test > acc 0.57 ( 1:30:09) - 55000 :: train > acc : 0.98, loss 0.146 :: test > acc 0.52 ( 1:39:10) - 60000 :: train > acc : 0.98, loss 0.153 :: test > acc 0.66 ( 1:48:11) - 65000 :: train > acc : 0.98, loss 0.143 :: test > acc 0.54 ( 1:57:11) - 70000 :: train > acc : 0.98, loss 0.147 :: test > acc 0.57 ( 2:06:13) - 75000 :: train > acc : 0.98, loss 0.137 :: test > acc 0.62 ( 2:15:15) - 80000 :: train > acc : 0.98, loss 0.140 :: test > acc 0.57 ( 2:24:16) - 85000 :: train > acc : 0.98, loss 0.142 :: test > acc 0.61 ( 2:33:18) - 90000 :: train > acc : 0.98, loss 0.137 :: test > acc 0.50 ( 2:42:20) - 95000 :: train > acc : 0.98, loss 0.133 :: test > acc 0.68 ( 2:51:22) - 100000 :: train > acc : 0.98, loss 0.138 :: test > acc 0.56 ( 3:00:23) - 105000 :: train > acc : 0.98, loss 0.145 :: test > acc 0.68 ( 3:09:25) - 110000 :: train > acc : 0.98, loss 0.132 :: test > acc 0.71 ( 3:18:27) - 115000 :: train > acc : 0.98, loss 0.152 :: test > acc 0.64 ( 3:27:29) - 120000 :: train > acc : 0.98, loss 0.121 :: test > acc 0.57 ( 3:36:31) - 125000 :: train > acc : 0.98, loss 0.113 :: test > acc 0.58 ( 3:45:35) - 130000 :: train > acc : 0.98, loss 0.136 :: test > acc 0.59 ( 3:54:38) - 135000 :: train > acc : 0.98, loss 0.130 :: test > acc 0.63 ( 4:03:41) - 140000 :: train > acc : 0.98, loss 0.123 :: test > acc 0.63 ( 4:12:45) - 145000 :: train > acc : 0.98, loss 0.123 :: test > acc 0.60 ( 4:21:48) - 150000 :: train > acc : 0.98, loss 0.131 :: test > acc 0.60 ( 4:30:51) - 155000 :: train > acc : 0.98, loss 0.110 :: test > acc 0.63 ( 4:39:53) - 160000 :: train > acc : 0.98, loss 0.116 :: test > acc 0.57 ( 4:48:56) - 165000 :: train > acc : 0.98, loss 0.139 :: test > acc 0.56 ( 4:57:59) - 170000 :: train > acc : 0.98, loss 0.121 :: test > acc 0.59 ( 5:07:01) - 175000 :: train > acc : 0.97, loss 0.205 :: test > acc 0.61 ( 5:16:05) - 180000 :: train > acc : 0.98, loss 0.112 :: test > acc 0.62 ( 5:25:08) - 185000 :: train > acc : 0.98, loss 0.119 :: test > acc 0.64 ( 5:34:12) - 190000 :: train > acc : 0.98, loss 0.136 :: test > acc 0.64 ( 5:43:15) - 195000 :: train > acc : 0.98, loss 0.116 :: test > acc 0.73 ( 5:52:19) - 200000 :: train > acc : 0.98, loss 0.109 :: test > acc 0.59 ( 6:01:23) - 205000 :: train > acc : 0.99, loss 0.104 :: test > acc 0.61 ( 6:10:28) - 210000 :: train > acc : 0.98, loss 0.107 :: test > acc 0.65 ( 6:19:33) - 215000 :: train > acc : 0.98, loss 0.110 :: test > acc 0.66 ( 6:28:38) - 220000 :: train > acc : 0.98, loss 0.114 :: test > acc 0.65 ( 6:37:42) - 225000 :: train > acc : 0.99, loss 0.107 :: test > acc 0.68 ( 6:46:46) - 230000 :: train > acc : 0.98, loss 0.108 :: test > acc 0.60 ( 6:55:51) - 235000 :: train > acc : 0.98, loss 0.108 :: test > acc 0.70 ( 7:04:54) - 240000 :: train > acc : 0.99, loss 0.110 :: test > acc 0.74 ( 7:13:58) - 245000 :: train > acc : 0.98, loss 0.107 :: test > acc 0.63 ( 7:23:03) - 250000 :: train > acc : 0.98, loss 0.108 :: test > acc変換候補イテレーション
- 120000 :: train > acc : 0.98, loss 0.121 :: test > acc 0.57 ( 3:36:31)
- 160000 :: train > acc : 0.98, loss 0.116 :: test > acc 0.57 ( 4:48:56)
- 210000 :: train > acc : 0.98, loss 0.107 :: test > acc 0.65 ( 6:19:33)
音声変換実行コマンド
コマンドが長くてわかりにくいですが,
[イテレーション数]は書き換えてくださいpython yukarin/scripts/voice_change.py \ --voice_changer_model_dir './dat/1st_models_y/yukari/1st_yukari_model_y' \ --voice_changer_config './dat/1st_models_y/yukari/1st_yukari_model_y/config.json' \ --voice_changer_model_iteration [イテレーション数] \ --super_resolution_model './dat/2nd_models_by/yukari/2nd_yukari_model_by/predictor_100000.npz' \ --super_resolution_config './dat/2nd_models_by/yukari/2nd_yukari_model_by/config.json' \ --input_statistics './dat/1st_models_y/yukari/statistics/own.npy' \ --target_statistics './dat/1st_models_y/yukari/statistics/target.npy' \ --out_sampling_rate 24000 \ --dataset_input_wave_dir './dat/1st_models_y/yukari/voice_pair/own' \ --dataset_target_wave_dir './dat/1st_models_y/yukari/voice_pair/target' \ --test_wave_dir './dat/input' \ --output_dir './dat/output' \ --gpu 0出力結果
第2段の学習モデルは A.5 と同じものを使用しています。
@AI_Kiritan 様の場合は、変換精度が向上しているようですが、自分はノイズが増えてしまいました。
手順は同じはずなので、学習用音声が yukarin のアルゴリズムにあっていないのかと思います(調査したいところです)。どんぐりの背比べですが、イテレーション 120000が一番良いかと思います。
自分の場合 サ行、タ行 の発話でノイズになりやすい様です。これは発話の癖なのでしょうか・・・?サ行の音は「歯擦音(しさつおん)」と呼ばれて、この音はプロのミキサーも、綺麗に聞こえる用に調整するのが難しいそうです。
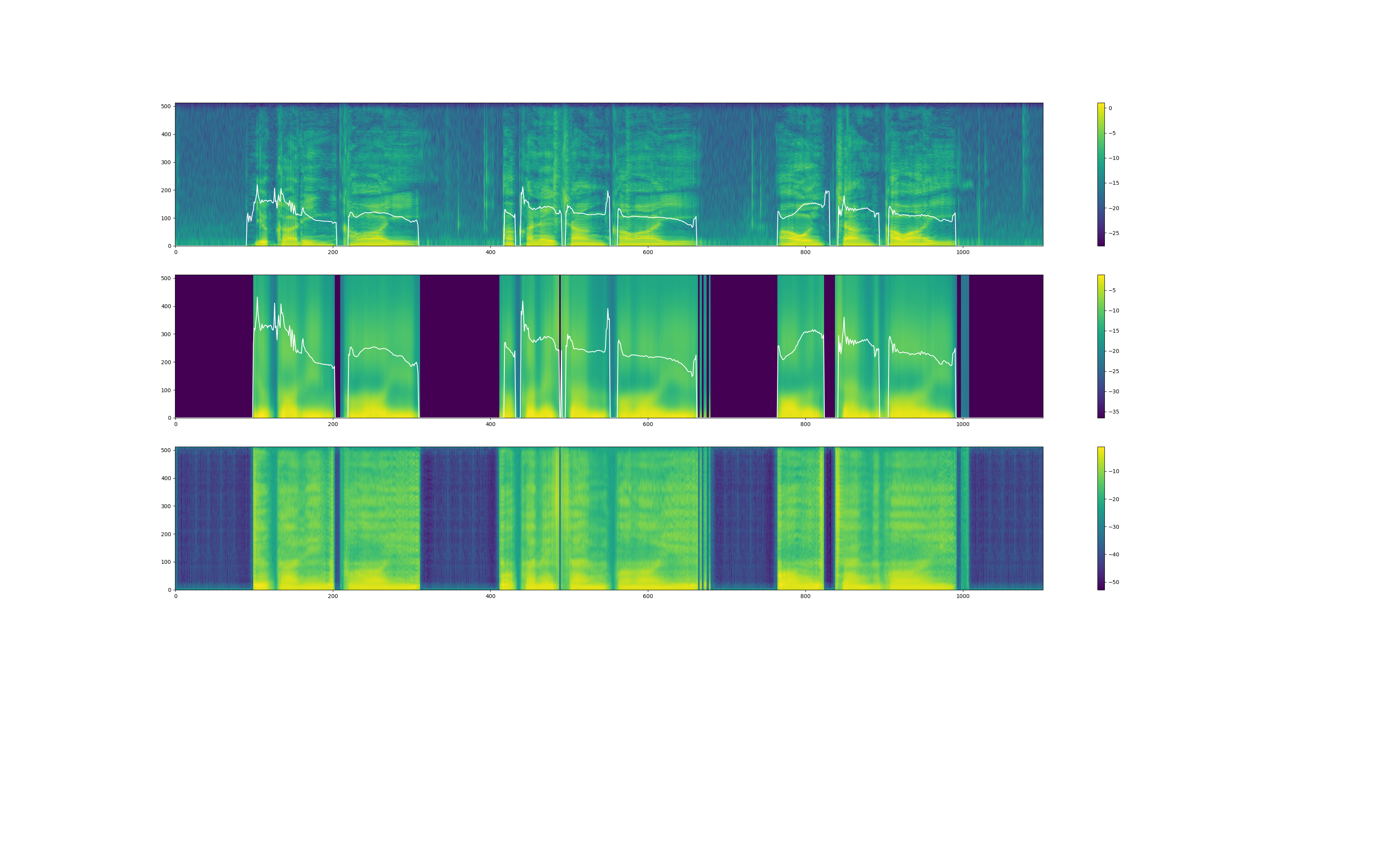
もしかして、音声変換もしにくい音なのかもしれません。また、yukarin の音声出力時には、変換音声の"スペクトラム" & "f0(基本周波数)" のプロットらしきものが出力されます(まだ詳しく見てないです)。
プロット図(yukarin_120000)
test01.png
test02.png
test03.png
終わりに
realtime-yukarin は B.5 のコマンドと同じ要領で実行できます。(readmeを見るだけで済むと思うので、記事にしないと思います)
はやり、リアルタイムで音声変換するのは夢ですよね!よくわからないところが、あればコメントよろしくお願いします!
それでは、良い音声変換ライフを!


- 投稿日:2019-07-11T15:34:02+09:00
『Yukarinライブラリ』become-yukarin, yukarin コマンド解説
概要
『Yukarinライブラリ』yukarin, become-yukarin リポジトリで、自分の音声をターゲット音声に変換する手順を紹介する。
yukarin は become-yukarin の改良版リポジトリであるが、2019/06/24 現在、become-yukarin での学習データを必要が必要になる。
よって、冗長となるが、 become-yukarin, yukarin 両方のコマンド解説を行う。前提として『Yukarinライブラリ』 yukarin, become-yukarin 概要・リポジトリ関係を整理してみたを把握しているものとします。
◾️ Yukarinライブラリとは?
『自分の声(自声)』を 『好きな音声(ターゲットボイス)』に 1対1 対応で音質変換をする OSS です。
yukarin, become-yukarin ではオフラインでの音声変換しかできませんが、学習データを realtime-yukain で実行することで、リアルタイム変換することもできます。詳細は下記を参照ください。
- 製作者のヒホ様の動画 : ディープラーニングの力で結月ゆかりの声になってみた
- 製作者のヒホ様のブログ: ディープラーニングの力で結月ゆかりの声になってみた
- まとめ情報記事 : ディープラーニング声質変換OSS「誰でも好きなキャラの声になれる」レポジトリ become-yukarinなどの関連記事等一覧◾️ 用語
Yukarinライブラリ
『yukarin』 と 『become-yukarin』の 2つをひっくるめて『Yukarinライブラリ』と命名されています。
- Hiroshiba/yukarin : 誰でも好きなキャラの声になれるリポジトリ』
- Hiroshiba/become-yukarin : 旧名は『ディープラーニングの力で誰でも結月ゆかりになれるリポジトリ』
"ゆかり音声"
ターゲット音声は任意ですが、イメージしやすいように 『ターゲット音声 = 結月ゆかり』と仮定します。
よって、"ターゲット音声"を"ゆかり音声"と表現します。◾️ GPU は何がいいの?
- realtime-yukarin を使う: GTX 1060(6G) 以上(readmeより)
- ただ変換するだけ: GTX 970(4G) 以上(become-yukarinの第2段では GPUメモリが 4G必要)
- 個人的なおすすめ : GTX 1070(8G) 中古(安くて・そこそこ早くて、GPUメモリが 8Gある)
◾️ 環境構築方法
・ Ubuntu v19.04 (RTX対応)
・ Ubuntu v18.10 LTS : @sakamotothogo 様◾️ 知っていると便利な知識
- git : 簡単に最新リポジトリに更新できる
- PyCharm コミュニティ版(無料) : Python・機械学習を勉強するなら強く推奨
◾️ エラーなどで困った時は?
- 気軽にコメントに書いてください!
- 『Yukarinライブラリ』 become-yukarin, yukarin のトラブルシューティング を見てみる
- yukarinコマンドジェネレーター! も参考になります
◾️ 目次
Z. become-yukarin, yukarin共通の事前作業
- Z.0 念のためのソフトインストール
- Z.1 ディレクトリ作成
- Z.2 各種リポジトリの取得
- Z.3 念のためのソフトインストール
- Z.4 音声データの収録
- Z.5 音声データの配置とリサンプリング
- Z.6 うっかり削除対策・バックアップ
- Z.7 環境変数の設定
- Z.8 ライブラリのインストール
A. become-yukarin
- A.1 音声変換のための特徴量抽出
- A.2 第1段の学習
- A.3 第1段を使った音声変換
- A.4 第2段の学習
- A.5 第2段を使った音質向上
B. yukarin
- B.1 音声変換のための特徴量抽出
- B.2 音響特徴量のアライメント
- B.3 周波数の統計量を求める
- B.4 第1段学習
- B.5 yukarin での音声変換
Z. become-yukarin, yukarin共通の事前作業
Z.0 念のためのソフトインストール
ffmpeg, sox, tree をインストールコマンドを実行してください。
コマンド(Ubuntu)
sudo apt install tree sudo apt install ffmpeg sudo apt install soxZ.1 ディレクトリ作成
作業ディレクトリを決定する
任意で構いませんが、後でディレクトリ移動させると環境変数の書き換えが必要となるので、気をつけてください。
この記事では HOME 直下の deep_yukarin ディレクトリで作業をすると仮定します。
以下で説明する各種コマンドはdeep_yukarin直下で、実行すると想定しています。mkdir ~/deep_yukarin cd deep_yukarinディレクトリ作成
本記事では以下のディレクトリ構造を前提にコマンド解説します。
リポジトリの相関や音声データの依存関係を考慮して、独断と偏見で決めてました。
作業ディレクトリに移動したあと、下記コマンドをコピペで実行してください。コマンド
mkdir dat mkdir dat/1st_models_by mkdir dat/2nd_models_by mkdir dat/1st_models_y mkdir dat/1st_models_by/yukari mkdir dat/1st_models_by/yukari/npy_pair mkdir dat/2nd_models_by/yukari mkdir dat/1st_models_y/yukari mkdir dat/1st_models_y/yukari/aligned_indexes mkdir dat/1st_models_y/yukari/aligned_wav mkdir dat/1st_models_y/yukari/statistics mkdir dat/1st_models_y/yukari/npy_pair mkdir dat/input mkdir dat/output mkdir dat/voice_src mkdir dat/voice_src/voice_24000 mkdir dat/voice_src/voice_44100 mkdir dat/voice_src/voice_24000/yukari_pair mkdir dat/voice_src/voice_24000/yukari_pair/own mkdir dat/voice_src/voice_24000/yukari_pair/target mkdir dat/voice_src/voice_24000/yukari_single mkdir dat/voice_src/voice_44100/yukari_pair mkdir dat/voice_src/voice_44100/yukari_pair/own mkdir dat/voice_src/voice_44100/yukari_pair/target mkdir dat/voice_src/voice_44100/yukari_singleチェック
tree コマンドで下記のようになっているか確認してください。tree dat dat ├── 1st_models_by │ └── yukari ├── 1st_models_y │ └── yukari ├── 2nd_models_by │ └── yukari ├── input ├── output └── voice_src ├── voice_24000 │ ├── yukari_pair │ │ ├── own │ │ └── target │ └── yukari_single └── voice_44100 ├── yukari_pair │ ├── own │ └── target └── yukari_singleZ.2 各種リポジトリの取得
- yukarin
- become-yukarin
- 筆者自作のチェックツール
- 日本声優統計学会の音素バランス文 を git で取得します。
* git を使わずサイトからダウンロードでもいいが、更新があった場合修正が面倒です。
* 筆者のチェックツールは必須ではありませんが、あること前提で解説します。コマンド
git clone https://github.com/Hiroshiba/become-yukarin git clone https://github.com/Hiroshiba/yukarin git clone git@bitbucket.org:YoshikazuOota/yukarin-tools.git git clone git@github.com:YoshikazuOota/balance_sentences.gitチェック
tree -L 1 . ├── balance_sentences ├── become-yukarin ├── dat ├── yukarin └── yukarin-tools補足: 各種リポジトリを最新版を反映する場合
yukarin, become-yukarin 等の各種のディレクトリに移動して、git pullを実行するcd ~/deep_yukarin cd [yukarin, become-yukarin] git pullさらに yukarin-tools 用に下記コマンドを実行してください。
sudo apt install node sudo apt install lm-sensors cd yukarin-tools npm install cd ~/deep_yukarinZ.4 音声データの収録
Z.4.1 音声データ作成におすすめする"音素バランス文"
CC BY-SA 4.0で公開されている、日本声優統計学会の音素バランス文がおすすめです。
balance_sentences/balance_sentences.txtに読み上げ文がありますので、必要に応じて利用してください。利用の際には 日本声優統計学会 から継承されている CC BY-SA 4.0 にしたがってください。
Z.4.2 第1段のゆかり・自声の収録
下記動画を参照してください。
これは一例であってベストってわけではありませんYukarinライブラリ用の音声収録方法の紹介
収録は 44100Hz / 16bit で行なっていますが、学習時には 24000Hz / 16bit にリサンプリングします。
(後々、高いサンプリングで学習したい場合があるかもしれないので、収録時は高サンプリングでいいと思います)ごめんなさい!
以前の記事では、『voiceroid2 などは 44100Hzがデフォルトなので、44100Hz で音声変換すればいい』と、書きましたがあまり適切では無いようです。
人間の音声はほぼ 10000Hz 以下に収まるそうなので、 学習音声のサンプリングはデフォルトの 24000Hzで良さそうです。
(シャノンのサンプリング定義より、24000Hz でサンプリングすれば 12000Hz 以下の音声解析ができます)Z.4.3 第2段のゆかりボイスの生成
自分は第1段で使ったゆかりボイス + 自分の動画で使った調教済み音声を使用しました(約2時間)。
ヒホ様の issueによると『私はJNASを読ませたものを用いました。』とのことです(約60時間)。
経験則的では、大量にボイスを用意すれば、内容は適当で良さそうです(違ったらごめんなさい)。Z.5 音声データの配置とリサンプリング
Z.5.1 音声データの配置
Z.4 で収録した音声データをそれぞれ下記のディレクトリに配置してください
- dat/voice_src/voice_44100/yukari_pair/own : Z.4 で収録した第1段の自声
- dat/voice_src/voice_44100/yukari_pair/target : Z.4 で生成した第1段のゆかり音声
- dat/voice_src/voice_44100/yukari_single : Z.4 で生成した第2段のゆかり音声
Z.5.2 ファイル数チェック(チェックサム)
下記の2ディレクトリには、同じ名前で同数のファイルを設置する必要があります。
- dat/voice_src/voice_44100/yukari_pair/own : Z.4 で収録した第1段の自声
- dat/voice_src/voice_44100/yukari_pair/target : Z.4 で生成した第1段のゆかり音声
手戻りが無いように下記コマンドで、ファイル数をチェックします。
./yukarin-tools/count_checker.js -b dat/voice_src/voice_44100/yukari_pair/own -d dat/voice_src/voice_44100/yukari_pair/targetZ.5.3 フォーマットチェック
自作ツールで、wav ファイルのフォーマットをチェックします。
-sでチェックするサンプリングレートを指定します./yukarin-tools/format_checker.js dat/voice_src/voice_44100/yukari_pair/own -s 44100 ./yukarin-tools/format_checker.js dat/voice_src/voice_44100/yukari_pair/target -s 44100 ./yukarin-tools/format_checker.js dat/voice_src/voice_44100/yukari_single -s 44100問題がなければ下記のようなメッセージが表示されます。
./yukarin-tools/format_checker.js dat/voice_src/voice_44100/yukari_single -s 44100 debug : {"src":"dat/voice_src/voice_44100/yukari_pair/own","sampling":44100} all files format : > channels : 1 > bits per sample : 16 > encoding : Signed Integer PCM > sampling : 44100 result : OKZ.5.4 リサンプリング
収録音声を Yukarinライブラリのデフォルトフォーマット 24000Hz /16 bit に変換します。
-bサンプリングする元データディレクトリ-dサンプリングしたデータを入れるディレクトリ(念の為、上書きできないようにしています)-sでチェックするサンプリングレートを指定します./yukarin-tools/resampling.js -b dat/voice_src/voice_44100/yukari_pair/own -d dat/voice_src/voice_24000/yukari_pair/own -s 24000 ./yukarin-tools/resampling.js -b dat/voice_src/voice_44100/yukari_pair/target -d dat/voice_src/voice_24000/yukari_pair/target -s 24000 ./yukarin-tools/resampling.js -b dat/voice_src/voice_44100/yukari_single -d dat/voice_src/voice_24000/yukari_single -s 24000自声(own)のリサンプリングで下記のような Warnが出るかもしれません。
これは、『ボリュームMAX超えているのがあるけどええんか?』的な、注意です。
アラートで、5 samplesの部分が100 samplesとか大きな数字になっていなければ、大丈夫です。sox WARN rate: rate clipped 5 samples; decrease volume? sox WARN dither: dither clipped 5 samples; decrease volume?Z.5.5 リサンプリングのチェック
しつこいですが、リサンプリング結果をチェックします。
./yukarin-tools/format_checker.js dat/voice_src/voice_24000/yukari_pair/own -s 24000 ./yukarin-tools/format_checker.js dat/voice_src/voice_24000/yukari_pair/target -s 24000 ./yukarin-tools/format_checker.js dat/voice_src/voice_24000/yukari_single -s 24000Z.6 うっかり削除対策・バックアップ
収録音声など、せっかく作った音声データを削除してしまわないように、データをリードオンリーにします。
念の為、別ストレージへバックアップもおすすめします。chmod -R 555 dat/voice_src書き込みできるように戻す場合は下記コマンドを実行してください
chmod -R 755 dat/voice_srcZ.7 環境変数の設定
emacs, vim 等で
~/.bashrcを開き、下記の一行を付け加えてください。
[user_name]の箇所は、アカウントに応じて適宜変更してください。export PYTHONPATH=/home/[user_name]/deep_yukarin/become-yukarin:/home/[user_name]/deep_yukarin/yukarin修正後、下記コマンドを実行してください。
このコマンドを実行しないと上記修正が反映されません。source ~/.bashrc下記コマンドで、先ほどの設定が表示されるか確認してください。
echo $PYTHONPATH > /home/[user_name]/deep_yukarin/become-yukarin:/home/[user_name]/deep_yukarin/yukarinZ.8 ライブラリのインストール
yukarin, become-yukarin に必要なライブラリをインストールします。
pip install -r become-yukarin/requirements.txt pip install world4py pip install -r yukarin/requiremets.txt* yukarin のライブラリインストールで、CUDA周りの再インストールされます。
A become-yukarin
A.1 音声変換のための特徴量抽出
become-yukarin の第1段の学習モデル作成は主に
dat/1st_models_by/yukarinで作業をします。
第1段の音声ファイルは少ないので、コピーして使うことにします。cp -r dat/voice_src/voice_24000/yukari_pair dat/1st_models_by/yukari/voice_pairコピーした音声ファイルから、音声の特徴量を抽出します。
(オプションの解説はしません。各種コマンドオプションは-hを付けて確認してください。 (expython become-yukarin/scripts/extract_acoustic_feature_arg -h)python become-yukarin/scripts/extract_acoustic_feature.py \ -i1 dat/1st_models_by/yukari/voice_pair/own \ -i2 dat/1st_models_by/yukari/voice_pair/target \ -o1 dat/1st_models_by/yukari/npy_pair/own \ -o2 dat/1st_models_by/yukari/npy_pair/target念の為、生成した npyファイルのチェックサムをとる。
./tools/count_checker.js -b dat/1st_models_by/yukari/voice_pair/target -d dat/1st_models_by/yukari/npy_pair/targetA.2 第1段の学習(become-yukarin)
学習前に設定ファイルをコピーして書き換えます。
cp become-yukarin/recipe/config.json dat/1st_models_by/yukari/エディタで config.json を開き
emacs dat/1st_models_by/yukari/config.json下記の6行を、書き換えてください。
その際、input_glob,target_glob音声収録をした時のプリフィックス "v-" などを忘れずにしてください。"input_glob": "dat/1st_models_by/yukari/npy_pair/own/v-*.npy", "input_mean_path": "dat/1st_models_by/yukari/npy_pair/own/mean.npy", "input_var_path": "dat/1st_models_by/yukari/npy_pair/own/var.npy", "target_glob": "dat/1st_models_by/yukari/npy_pair/target/v_*.npy", "target_mean_path": "ddat/1st_models_by/yukari/npy_pair/target/mean.npy", "target_var_path": "dat/1st_models_by/yukari/npy_pair/target/var.npy",さらに、GPUを使いための下記の設定をしてください。(cpu -1, gpu 0)
"gpu": 0,設定が終わったら、下記コマンドで学習を行います。
python become-yukarin/train.py dat/1st_models_by/yukari/config.json dat/1st_models_by/yukari/1st_yukari_model_byエラーがなければ、predictor_XXXX.npz と言う学習済みファイルが生成されます。
predictor_250000.npz 程度が出力されるのを待ちます(GTX 1070で 7時間ぐらい)。進捗チェックコマンド
watch -n 60 ls -latr dat/1st_models_by/yukari/1st_yukari_model_by蛇足
CPU,GPUの温度は以下でチェックできます。
熱暴走にはお気をつけて! (筆者は2回、熱保護でPCをクラッシュさせました)./yukarin-tools/watch_temperature.shA.3 第1段を使った音声変換
音声変換に使う入力・出力ファイルを格納するディレクトリを作成します。
test_dataには Z.4.2 で作った学習データとは、違う自声の音声データ(24000Hz / 16bit)を配置します。mkdir ./test_data mkdir ./output mkdir ./output/1st_yukari_model_by次に、上手く学習できていそうなデータの目星を付けます。
ヒホ様は train.pyの学習数について #10 のように選んでいるそうです。以下の選び方は我流です。参考までの一例です!
下記で、 5000ステップごとのdiscriminator/accuracyとdiscriminator/lossを出力します./yukarin-tools/log2accuracy.js dat/1st_models_by/yukari/1st_yukari_model_by/logここで着目するのは
acc(discriminator/accuracy)とloss(discriminator/loss)です。
accは問題なければ、90% 〜 97% ぐらいまで上がります。
これが 80% 程度から上がっていなければ、学習用音声の質が悪いか、手順にミスがあるかと思います。経験則では下記のデータが変換精度が高かったです。
- イテレーションが少ない
-accが大きい
-lossが小さい下記の結果から、選ぶなら下記 3つほどが候補になります。
(学習回数のイテレーションは大きければ大きいほどいいと言うことはありません。過学習と言う精度が下がる現象が起こります。)
- 145000 :: train > acc : 0.95, loss 0.283 :: test > acc 0.53 ( 4:13:21)
- 180000 :: train > acc : 0.95, loss 0.273 :: test > acc 0.63 ( 5:14:42)
- 220000 :: train > acc : 0.96, loss 0.227 :: test > acc 0.52 ( 6:24:50)
{ acc: 0.85, skip: 5000, full: false, src: 'dat/1st_models_by/yukari/1st_yukari_model_by/log' } - 15000 :: train > acc : 0.86, loss 0.654 :: test > acc 0.53 ( 0:26:06) - 25000 :: train > acc : 0.87, loss 0.627 :: test > acc 0.67 ( 0:43:32) - 30000 :: train > acc : 0.88, loss 0.552 :: test > acc 0.48 ( 0:52:15) - 35000 :: train > acc : 0.89, loss 0.538 :: test > acc 0.66 ( 1:00:58) - 40000 :: train > acc : 0.89, loss 0.521 :: test > acc 0.55 ( 1:09:41) - 45000 :: train > acc : 0.90, loss 0.489 :: test > acc 0.58 ( 1:18:25) - 50000 :: train > acc : 0.90, loss 0.511 :: test > acc 0.56 ( 1:27:08) - 55000 :: train > acc : 0.89, loss 0.499 :: test > acc 0.53 ( 1:35:52) - 60000 :: train > acc : 0.91, loss 0.472 :: test > acc 0.70 ( 1:44:35) - 65000 :: train > acc : 0.90, loss 0.483 :: test > acc 0.66 ( 1:53:19) - 70000 :: train > acc : 0.89, loss 0.513 :: test > acc 0.63 ( 2:02:03) - 75000 :: train > acc : 0.90, loss 0.485 :: test > acc 0.58 ( 2:10:47) - 80000 :: train > acc : 0.91, loss 0.457 :: test > acc 0.55 ( 2:19:31) - 85000 :: train > acc : 0.90, loss 0.472 :: test > acc 0.52 ( 2:28:15) - 90000 :: train > acc : 0.91, loss 0.450 :: test > acc 0.59 ( 2:37:00) - 95000 :: train > acc : 0.89, loss 0.510 :: test > acc 0.50 ( 2:45:44) - 100000 :: train > acc : 0.91, loss 0.437 :: test > acc 0.70 ( 2:54:30) - 105000 :: train > acc : 0.90, loss 0.483 :: test > acc 0.61 ( 3:03:14) - 110000 :: train > acc : 0.91, loss 0.422 :: test > acc 0.63 ( 3:12:03) - 115000 :: train > acc : 0.92, loss 0.383 :: test > acc 0.64 ( 3:20:48) - 120000 :: train > acc : 0.91, loss 0.418 :: test > acc 0.58 ( 3:29:33) - 125000 :: train > acc : 0.92, loss 0.385 :: test > acc 0.41 ( 3:38:19) - 130000 :: train > acc : 0.93, loss 0.354 :: test > acc 0.39 ( 3:47:04) - 135000 :: train > acc : 0.94, loss 0.327 :: test > acc 0.58 ( 3:55:50) - 140000 :: train > acc : 0.92, loss 0.391 :: test > acc 0.61 ( 4:04:35) - 145000 :: train > acc : 0.95, loss 0.283 :: test > acc 0.53 ( 4:13:21) - 150000 :: train > acc : 0.93, loss 0.379 :: test > acc 0.45 ( 4:22:06) - 155000 :: train > acc : 0.94, loss 0.326 :: test > acc 0.41 ( 4:30:52) - 160000 :: train > acc : 0.94, loss 0.330 :: test > acc 0.58 ( 4:39:38) - 165000 :: train > acc : 0.93, loss 0.360 :: test > acc 0.50 ( 4:48:24) - 170000 :: train > acc : 0.93, loss 0.348 :: test > acc 0.64 ( 4:57:10) - 175000 :: train > acc : 0.94, loss 0.321 :: test > acc 0.58 ( 5:05:56) - 180000 :: train > acc : 0.95, loss 0.273 :: test > acc 0.63 ( 5:14:42) - 185000 :: train > acc : 0.94, loss 0.278 :: test > acc 0.72 ( 5:23:28) - 190000 :: train > acc : 0.94, loss 0.295 :: test > acc 0.64 ( 5:32:14) - 195000 :: train > acc : 0.94, loss 0.279 :: test > acc 0.66 ( 5:41:00) - 200000 :: train > acc : 0.94, loss 0.308 :: test > acc 0.50 ( 5:49:46) - 205000 :: train > acc : 0.95, loss 0.268 :: test > acc 0.69 ( 5:58:32) - 210000 :: train > acc : 0.93, loss 0.326 :: test > acc 0.56 ( 6:07:18) - 215000 :: train > acc : 0.94, loss 0.290 :: test > acc 0.64 ( 6:16:04) - 220000 :: train > acc : 0.96, loss 0.227 :: test > acc 0.52 ( 6:24:50) - 225000 :: train > acc : 0.95, loss 0.251 :: test > acc 0.59 ( 6:33:37) - 230000 :: train > acc : 0.96, loss 0.238 :: test > acc 0.72 ( 6:42:23) - 235000 :: train > acc : 0.96, loss 0.216 :: test > acc 0.53 ( 6:51:09) - 240000 :: train > acc : 0.95, loss 0.259 :: test > acc 0.55 ( 6:59:56) - 245000 :: train > acc : 0.96, loss 0.228 :: test > acc 0.70 ( 7:08:43) - 250000 :: train > acc : 0.95, loss 0.253 :: test > acc 0.67 ( 7:17:29)変換の実行は下記コマンドで実行します。
[イテレーション数] には 変換したい数字を入れてください。python become-yukarin/scripts/voice_conversion_test.py 1st_yukari_model_by \ -iwd dat/1st_models_by/yukari/voice_pair/own \ -md dat/1st_models_by/yukari \ -it [イテレーション数]変換結果は
output/1st_yukari_model_byに保存されます。
成功した場合
inputディレクトリの音声変換結果dat/1st_models_by/yukari/voice_pair/ownからランダムに選ばれた音声変換結果が入っています。
筆者の変換結果(葵音声)
個人的には predictor_145000.npz が一番いい様に思います。
ちなみに、ヒホ様のデモでは 19万 イテレーションの学習データを使用したそうです(train.pyの学習数について)。
あと、理屈はわかりませんが、音声の後半にノイズ入ります。変換前データの後方の無音時間をカットすれば問題ないと思います。
- predictor_95000.npz
- predictor_145000.npz
- predictor_180000.npz
- predictor_220000.npz
- predictor_235000.npz
A.4 第2段学習
voice ソース から直接参照して(データ数が多いのでコピーしません)、音声特徴量を抽出します。
python become-yukarin/scripts/extract_spectrogram_pair.py \ -i dat/voice_src/voice_24000/yukari_single \ -o dat/2nd_models_by/yukari/npy_single
LLVM ERROR: out of memory等で、出てハングアップすることがあります。
その時はctrl + cで処理を中断して、、2回、3回と繰り返すことで、全ての音声を変換できると思います。変換後、下記コマンドで全ファイルが変換されているかチェックします。
数が合わなければ、上記処理を繰り返しましょう。./yukarin-tools/count_checker.js -b dat/2nd_models_by/yukari/npy_single -d dat/voice_src/voice_24000/yukari_singlecp become-yukarin/recipe/config_sr.json dat/2nd_models_by/yukari/A.2 同様に、config_sr.py をコピーして、データ置き、三行修正をします。
batchsizeは GPU Mem 4G なら 1, GPU Mem 8G なら 2"input_glob": "dat/2nd_models_by/yukari/npy_single/*.npy", "batchsize": 1 "gpu": 0,設定が終われば、下記コマンドで学習します。
こちらは、第1段に比べてかなりの時間がかかります。
自分は 100,000イテレーションほどのデータを使用していますが、どの程度が適切なのかはわかりません。python become-yukarin/train_sr.py \ dat/2nd_models_by/yukari/config_sr.json \ dat/2nd_models_by/yukari/2nd_yukari_model_by進捗チェックコマンド
watch -n 60 ls -latr dat/1st_models_by/yukari/2nd_yukari_model_byA.5 第2段を使った音質向上
A.3 で変換したデータを
test_data_srにコピーします。mkdir test_data_sr cp output/1st_yukari_model_by/* test_data_sr./yukarin-tools/format_checker.js dat/2nd_models_by/yukari/npy_single dat/voice_src/voice_24000/yukari_single
python become-yukarin/scripts/super_resolution_test.py 2nd_yukari_model_by/ \ -md dat/2nd_models_by/yukari \ -iwd dat/voice_src/voice_24000/yukari_single第2段のプレディクターは 2nd_yukari_model_by 内で一番、イテレーションが大きいものが使われます。
筆者の変換結果(葵音声)
predictor_145000.npz の第1段音声が割と綺麗に取れているので、差がわかりにくいですが、多少音質がよくなっていると思います。predictor_145000.npz の第1段に第2段を適用した音声
B. yukarin
yukarinって何が違うの?
現状では、基本リファクタリングがメインで、新規点は 声のピッチを調整が簡単になった とのことです。
また、音声変換の精度も少し変わるようです。B.1 音声変換のための特徴量抽出
ざっくり言うと、B.1, B.2 の処理は、A.1 を分割しているだけで処理内容はほとんど同じっぽいです。
A.1 同様音声ファイルはコピーして使います。
cp -r dat/voice_src/voice_24000/yukari_pair dat/1st_models_y/yukari/voice_pair自声の特徴量抽出
python yukarin/scripts/extract_acoustic_feature.py \ -i './dat/1st_models_y/yukari/voice_pair/own/*.wav' \ -o './dat/1st_models_y/yukari/npy_pair/own'注: readmeの * -> *.wav に変更しているのは安全のため
ゆかりの特徴量抽出
python yukarin/scripts/extract_acoustic_feature.py \ -i './dat/1st_models_y/yukari/voice_pair/target/*.wav' \ -o './dat/1st_models_y/yukari/npy_pair/target'npyのチェックサム
./yukarin-tools/count_checker.js -b dat/1st_models_y/yukari/npy_pair/own -d dat/1st_models_y/yukari/npy_pair/targetB.2 音響特徴量のアライメント
自声とゆかり音声の微妙なずれを補償する。
python yukarin/scripts/extract_align_indexes.py \ -i1 './dat/1st_models_y/yukari/npy_pair/own/*.npy' \ -i2 './dat/1st_models_y/yukari/npy_pair/target/*.npy' \ -o './dat/1st_models_y/yukari/aligned_indexes/'B.3 周波数の統計量を求める
声の高さの平均、分散を求める。
この平均値をいじることで、変換後の音声のピッチを調整できるようです。python yukarin/scripts/extract_f0_statistics.py\ -i './dat/1st_models_y/yukari/npy_pair/own/*.npy' \ -o './dat/1st_models_y/yukari/statistics/own.npy'python yukarin/scripts/extract_f0_statistics.py\ -i './dat/1st_models_y/yukari/npy_pair/target/*.npy' \ -o './dat/1st_models_y/yukari/statistics/target.npy'B.4 第1段学習(yukarin)
cp yukarin/sample_config.json ./dat/1st_models_y/yukari/config.jsonemacs dat/1st_models/config.json で編集
L15-17"input_glob": "./dat/1st_models_y/yukari/npy_pair/own/*.npy", "target_glob": "./dat/1st_models_y/yukari/npy_pair/target/*.npy", "indexes_glob": "./dat/1st_models_y/yukari/aligned_indexes/*.npy",python yukarin/train.py \ ./dat/1st_models_y/yukari/config.json \ ./dat/1st_models_y/yukari/1st_yukari_model_y学習進行チェックコマンド
watch -n 60 "pwd; ls -ltr dat/1st_models_y/yukari/1st_yukari_model_y"B.5 yukarin での音声変換(第1,2段)
become-yukarin で使用したテストデータを移動させます。
cp test_data/*.wav dat/input/A.3 同様に音質が良さそうな学習データをピックアップします。
./yukarin-tools/log2accuracy.js dat/1st_models_y/yukari/1st_yukari_model_y/logyukarinは become-yuakrin に比べて、
accが高めになりました。
- 120000 :: train > acc : 0.98, loss 0.121 :: test > acc 0.57 ( 3:36:31)
- 160000 :: train > acc : 0.98, loss 0.116 :: test > acc 0.57 ( 4:48:56)
- 210000 :: train > acc : 0.98, loss 0.107 :: test > acc 0.65 ( 6:19:33)
{ acc: 0.85, skip: 5000, full: false, src: 'dat/1st_models_y/yukari/1st_yukari_model_y/log' } - 5000 :: train > acc : 0.95, loss 0.379 :: test > acc 0.51 ( 0:09:00) - 10000 :: train > acc : 0.97, loss 0.232 :: test > acc 0.59 ( 0:18:01) - 15000 :: train > acc : 0.97, loss 0.200 :: test > acc 0.52 ( 0:27:03) - 20000 :: train > acc : 0.97, loss 0.199 :: test > acc 0.56 ( 0:36:03) - 25000 :: train > acc : 0.98, loss 0.170 :: test > acc 0.57 ( 0:45:04) - 30000 :: train > acc : 0.98, loss 0.164 :: test > acc 0.57 ( 0:54:05) - 35000 :: train > acc : 0.98, loss 0.155 :: test > acc 0.63 ( 1:03:07) - 40000 :: train > acc : 0.98, loss 0.157 :: test > acc 0.59 ( 1:12:09) - 45000 :: train > acc : 0.98, loss 0.158 :: test > acc 0.56 ( 1:21:09) - 50000 :: train > acc : 0.98, loss 0.152 :: test > acc 0.57 ( 1:30:09) - 55000 :: train > acc : 0.98, loss 0.146 :: test > acc 0.52 ( 1:39:10) - 60000 :: train > acc : 0.98, loss 0.153 :: test > acc 0.66 ( 1:48:11) - 65000 :: train > acc : 0.98, loss 0.143 :: test > acc 0.54 ( 1:57:11) - 70000 :: train > acc : 0.98, loss 0.147 :: test > acc 0.57 ( 2:06:13) - 75000 :: train > acc : 0.98, loss 0.137 :: test > acc 0.62 ( 2:15:15) - 80000 :: train > acc : 0.98, loss 0.140 :: test > acc 0.57 ( 2:24:16) - 85000 :: train > acc : 0.98, loss 0.142 :: test > acc 0.61 ( 2:33:18) - 90000 :: train > acc : 0.98, loss 0.137 :: test > acc 0.50 ( 2:42:20) - 95000 :: train > acc : 0.98, loss 0.133 :: test > acc 0.68 ( 2:51:22) - 100000 :: train > acc : 0.98, loss 0.138 :: test > acc 0.56 ( 3:00:23) - 105000 :: train > acc : 0.98, loss 0.145 :: test > acc 0.68 ( 3:09:25) - 110000 :: train > acc : 0.98, loss 0.132 :: test > acc 0.71 ( 3:18:27) - 115000 :: train > acc : 0.98, loss 0.152 :: test > acc 0.64 ( 3:27:29) - 120000 :: train > acc : 0.98, loss 0.121 :: test > acc 0.57 ( 3:36:31) - 125000 :: train > acc : 0.98, loss 0.113 :: test > acc 0.58 ( 3:45:35) - 130000 :: train > acc : 0.98, loss 0.136 :: test > acc 0.59 ( 3:54:38) - 135000 :: train > acc : 0.98, loss 0.130 :: test > acc 0.63 ( 4:03:41) - 140000 :: train > acc : 0.98, loss 0.123 :: test > acc 0.63 ( 4:12:45) - 145000 :: train > acc : 0.98, loss 0.123 :: test > acc 0.60 ( 4:21:48) - 150000 :: train > acc : 0.98, loss 0.131 :: test > acc 0.60 ( 4:30:51) - 155000 :: train > acc : 0.98, loss 0.110 :: test > acc 0.63 ( 4:39:53) - 160000 :: train > acc : 0.98, loss 0.116 :: test > acc 0.57 ( 4:48:56) - 165000 :: train > acc : 0.98, loss 0.139 :: test > acc 0.56 ( 4:57:59) - 170000 :: train > acc : 0.98, loss 0.121 :: test > acc 0.59 ( 5:07:01) - 175000 :: train > acc : 0.97, loss 0.205 :: test > acc 0.61 ( 5:16:05) - 180000 :: train > acc : 0.98, loss 0.112 :: test > acc 0.62 ( 5:25:08) - 185000 :: train > acc : 0.98, loss 0.119 :: test > acc 0.64 ( 5:34:12) - 190000 :: train > acc : 0.98, loss 0.136 :: test > acc 0.64 ( 5:43:15) - 195000 :: train > acc : 0.98, loss 0.116 :: test > acc 0.73 ( 5:52:19) - 200000 :: train > acc : 0.98, loss 0.109 :: test > acc 0.59 ( 6:01:23) - 205000 :: train > acc : 0.99, loss 0.104 :: test > acc 0.61 ( 6:10:28) - 210000 :: train > acc : 0.98, loss 0.107 :: test > acc 0.65 ( 6:19:33) - 215000 :: train > acc : 0.98, loss 0.110 :: test > acc 0.66 ( 6:28:38) - 220000 :: train > acc : 0.98, loss 0.114 :: test > acc 0.65 ( 6:37:42) - 225000 :: train > acc : 0.99, loss 0.107 :: test > acc 0.68 ( 6:46:46) - 230000 :: train > acc : 0.98, loss 0.108 :: test > acc 0.60 ( 6:55:51) - 235000 :: train > acc : 0.98, loss 0.108 :: test > acc 0.70 ( 7:04:54) - 240000 :: train > acc : 0.99, loss 0.110 :: test > acc 0.74 ( 7:13:58) - 245000 :: train > acc : 0.98, loss 0.107 :: test > acc 0.63 ( 7:23:03) - 250000 :: train > acc : 0.98, loss 0.108 :: test > acc変換候補イテレーション
- 120000 :: train > acc : 0.98, loss 0.121 :: test > acc 0.57 ( 3:36:31)
- 160000 :: train > acc : 0.98, loss 0.116 :: test > acc 0.57 ( 4:48:56)
- 210000 :: train > acc : 0.98, loss 0.107 :: test > acc 0.65 ( 6:19:33)
音声変換実行コマンド
コマンドが長くてわかりにくいですが,
[イテレーション数]は書き換えてくださいpython yukarin/scripts/voice_change.py \ --voice_changer_model_dir './dat/1st_models_y/yukari/1st_yukari_model_y' \ --voice_changer_config './dat/1st_models_y/yukari/1st_yukari_model_y/config.json' \ --voice_changer_model_iteration [イテレーション数] \ --super_resolution_model './dat/2nd_models_by/yukari/2nd_yukari_model_by/predictor_100000.npz' \ --super_resolution_config './dat/2nd_models_by/yukari/2nd_yukari_model_by/config.json' \ --input_statistics './dat/1st_models_y/yukari/statistics/own.npy' \ --target_statistics './dat/1st_models_y/yukari/statistics/target.npy' \ --out_sampling_rate 24000 \ --dataset_input_wave_dir './dat/1st_models_y/yukari/voice_pair/own' \ --dataset_target_wave_dir './dat/1st_models_y/yukari/voice_pair/target' \ --test_wave_dir './dat/input' \ --output_dir './dat/output' \ --gpu 0出力結果
第2段の学習モデルは A.5 と同じものを使用しています。
@AI_Kiritan 様の場合は、変換精度が向上しているようですが、自分はノイズが増えてしまいました。
手順は同じはずなので、学習用音声が yukarin のアルゴリズムにあっていないのかと思います(調査したいところです)。どんぐりの背比べですが、イテレーション 120000が一番良いかと思います。
自分の場合 サ行、タ行 の発話でノイズになりやすい様です。これは発話の癖なのでしょうか・・・?サ行の音は「歯擦音(しさつおん)」と呼ばれて、この音はプロのミキサーも、綺麗に聞こえる用に調整するのが難しいそうです。
もしかして、音声変換もしにくい音なのかもしれません。また、yukarin の音声出力時には、変換音声の"スペクトラム" & "f0(基本周波数)" のプロットらしきものが出力されます(まだ詳しく見てないです)。
プロット図(yukarin_120000)
test01.png
test02.png
test03.png
終わりに
realtime-yukarin は B.5 のコマンドと同じ要領で実行できます。(readmeを見るだけで済むと思うので、記事にしないと思います)
はやり、リアルタイムで音声変換するのは夢ですよね!よくわからないところが、あればコメントよろしくお願いします!
それでは、良い音声変換ライフを!
- 投稿日:2019-07-11T14:32:10+09:00
色を決めるのが面倒くさいので自動で決めたい
色を決めるのが面倒くさいとき、ありますよね。そのとき用の小ネタです。matplotlib で何かプロットを作ります。
%matplotlib inline import matplotlib.pyplot as plt import pandas as pdimport numpy as np from sklearn.datasets.samples_generator import make_blobs n_labels = 3 X, label = make_blobs(n_samples=100, centers=n_labels, n_features=2, cluster_std=np.random.rand(n_labels)*3) df = pd.DataFrame(dict(x1=X[:,0], x2=X[:,1], label=label))色を決めるときは、たとえばこのようにします。
colors = {0:'red', 1:'blue', 2:'green'}fig, ax = plt.subplots() grouped = df.groupby('label') for key, group in grouped: group.plot(ax=ax, kind='scatter', x='x1', y='x2', label=key, color=colors[key]) plt.legend(loc = 'right', bbox_to_anchor = (0.7, 0.5, 0.5, 0.1), borderaxespad = 0.0) plt.grid() plt.show()
色の数が3つくらいなら、以上のようにすればいいんですが、色が10個とかもっとあると面倒臭いじゃないですか。ならばランダムに決めてしまいましょう。
import matplotlib import random colors = [cname for cname in matplotlib.colors.cnames.keys()] random.shuffle(colors)このようにすると、matplotlib で定義されている(名前のある)色が全列挙されます。(順番はランダムにシャッフルされています)
colors['darkkhaki', 'black', 'blue', 'burlywood', 'gainsboro', 'mintcream', 'lightslategray', 'brown', 'cyan', 'mediumseagreen', 'darkolivegreen', 'darkmagenta', 'lightblue', 'mediumspringgreen', 'slategrey', 'mediumorchid', 'navajowhite', 'red', 'plum', 'mediumblue', 'indianred', 'hotpink', 'darkorange', 'coral', 'teal', 'sandybrown', 'lavender', 'khaki', 'lightsalmon', 'lightslategrey', 'azure', 'palegoldenrod', 'aliceblue', 'darkblue', 'lightsteelblue', 'chartreuse', 'silver', 'magenta', 'yellowgreen', 'crimson', 'aqua', 'linen', 'lightyellow', 'forestgreen', 'grey', 'darkorchid', 'floralwhite', 'lightgreen', 'lime', 'antiquewhite', 'dimgrey', 'ivory', 'gray', 'aquamarine', 'darkgrey', 'honeydew', 'powderblue', 'darkgreen', 'lightgrey', 'darkseagreen', 'darkgray', 'chocolate', 'beige', 'slateblue', 'cadetblue', 'seashell', 'olive', 'yellow', 'salmon', 'dodgerblue', 'peru', 'maroon', 'wheat', 'lightcyan', 'peachpuff', 'lightseagreen', 'royalblue', 'goldenrod', 'paleturquoise', 'purple', 'indigo', 'tan', 'lightgoldenrodyellow', 'lemonchiffon', 'darkturquoise', 'orange', 'orchid', 'lightskyblue', 'saddlebrown', 'lightgray', 'darksalmon', 'ghostwhite', 'limegreen', 'turquoise', 'navy', 'rosybrown', 'moccasin', 'papayawhip', 'green', 'greenyellow', 'cornflowerblue', 'darkcyan', 'blanchedalmond', 'deepskyblue', 'darkslateblue', 'midnightblue', 'snow', 'lightpink', 'darkslategrey', 'whitesmoke', 'oldlace', 'pink', 'mediumvioletred', 'mistyrose', 'sienna', 'blueviolet', 'fuchsia', 'tomato', 'dimgray', 'palevioletred', 'mediumpurple', 'rebeccapurple', 'lavenderblush', 'thistle', 'firebrick', 'springgreen', 'slategray', 'violet', 'skyblue', 'darkgoldenrod', 'darkviolet', 'deeppink', 'darkslategray', 'mediumturquoise', 'cornsilk', 'mediumaquamarine', 'steelblue', 'lightcoral', 'bisque', 'olivedrab', 'darkred', 'gold', 'white', 'palegreen', 'mediumslateblue', 'seagreen', 'lawngreen', 'orangered']そうすれば、色の数が数十個に増えても怖くありません。
import numpy as np from sklearn.datasets.samples_generator import make_blobs n_labels = 10 X, label = make_blobs(n_samples=100, centers=n_labels, n_features=2, cluster_std=np.random.rand(n_labels)*3) df = pd.DataFrame(dict(x1=X[:,0], x2=X[:,1], label=label))fig, ax = plt.subplots() grouped = df.groupby('label') for key, group in grouped: group.plot(ax=ax, kind='scatter', x='x1', y='x2', label=key, color=colors[key]) plt.legend(loc = 'right', bbox_to_anchor = (0.7, 0.5, 0.5, 0.1), borderaxespad = 0.0) plt.grid() plt.show()
色合いが気に入らなければ、
random.shuffle(colors)で色を並び替えて、納得いくまで繰り返せばいいです。気に入った配色になれば、colors の中身を確認してそれを再利用すればいいです。
fig, ax = plt.subplots() grouped = df.groupby('label') for key, group in grouped: group.plot(ax=ax, kind='scatter', x='x1', y='x2', label=key, color=colors[key]) plt.legend(loc = 'right', bbox_to_anchor = (0.7, 0.5, 0.5, 0.1), borderaxespad = 0.0) plt.grid() plt.show()
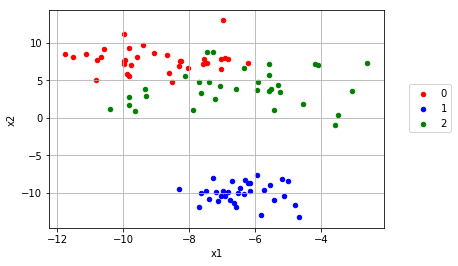

- 投稿日:2019-07-11T14:01:17+09:00
"Qiita への記事更新を API 経由で行ってみる"
- 新規記事は POST、既存記事の更新は PATCH
- 投稿日:2019-07-11T14:01:17+09:00
Qiita への記事更新を API 経由で行ってみる
- API v2 Document
- 新規記事は
POST、既存記事の更新はPATCH。title,body,tagsヘッダが無いと、400 Bad Request が返ってくる。- 「下書き」に関する項目は見つけられていない。 ヘッダ
privateは限定公開に関するものの様子。サンプルコード
- API Token は、環境変数
QIITA_TOKENに保管してとってくる。# -*- coding: utf-8 -*- # # Update an article via Qiita API # import sys import os import logging import json import requests QIITA_URL = 'https://qiita.com/api/v2/items' TAGS = ["qiita_id", "title", "tags"] def parse(filepath, max_header_lines=10): u'''Parse original article (Cryogen format)''' title = None qiita_id = None tags = [{"name": "update_via_api", "version": []}] body = '' line_count = 0 with open(filepath) as f: for line in f: line_count += 1 if line.find(':qiita_id ') > 0: try: qiita_id = line.strip().split()[1] except IndexError: qiita_id = '' if line.find(':title ') > 0: title = line.strip().split(' ', 1)[1] if line.find(':tags ') > 0: keys = line.strip().split(' ', 1)[1] for k in json.loads(keys): tags.append({"name": k, "version": []}) if line.rstrip().endswith('}') or line_count > max_header_lines: break if qiita_id is None: return None for line in f: body += line return { 'title': title, 'qiita_id': qiita_id, 'tags': tags, 'body': body, 'tweet': False, 'private': False, } def submit(item, token, url=QIITA_URL, article_id=None): u'''Submit to Qiita v2 API''' headers = { 'Content-Type': 'application/json', 'Authorization': 'Bearer {}'.format(token) } if article_id is None or article_id == '': res = requests.post(url, headers=headers, json=item) else: url = "{}/{}".format(url, article_id) res = requests.patch(url, headers=headers, json=item) if res.status_code >= 400: logging.error(res.json()) res.raise_for_status() logging.info(json.dumps(res.json(), indent=2)) return res def execute(filepath, token): item = parse(filepath) if item is None: logging.warning("SKIP. No qiita_id tag found.") return logging.debug(json.dumps(item, indent=2)) res = submit(item, token=token, article_id=item['qiita_id']) if __name__ == "__main__": token = os.environ['QIITA_TOKEN'] for arg in sys.argv[1:]: execute(arg, token)
- 投稿日:2019-07-11T13:41:37+09:00
主双対アルゴリズムを用いた LASSO 回帰
主双対アルゴリズム1を使用して LASSO (least absolute shrinkage and selection operator) 回帰を実装してみた.
扱う問題
\min_{w}{\frac1n\|Xw-y\|_1 + \alpha\|w\|_1}ここで $X\in\mathbb{R}^{n\times m},\ y\in\mathbb{R}^n$ は入力データセット,$w\in\mathbb{R}^m$ は決定変数,$\alpha$ は正則化パラメータである.
\|w\|_1 = \max_{-1\leq p\leq1}\left<w, p\right>より,先の最適化問題は,
\min_w{\max_{-1 \leq (p, q) \leq 1}{\frac1n\left<Xw-y, q\right> + \alpha\left<w, p\right>}}とかける.
主双対アルゴリズム
近接点法を用いて交互に最小化・最大化問題を解く.
\left\{ \begin{align} &w^{k+1} = \mathop{\mathrm{arg~min}}\limits_{w}{\left\{\frac1n\left<Xw-y, q^k\right> + \alpha\left<w, p^k\right> + \frac12\|w - w^k\|_X^2\right\}}\\ &\bar{w}^{k+1} = 2w^{k+1} - w^k\\ &(p^{k+1}, q^{k+1}) = \mathop{\mathrm{arg~max}}\limits_{-1 \leq (p, q) \leq 1}{\left\{\frac1n\left<X\bar{w}^{k+1}-y, q\right> + \alpha\left<\bar{w}^{k+1}, p\right> - \frac12\|(p, q) - (p^k, q^k)\|_Y^2\right\}} \end{align} \right.ここで,
K = \left(\frac1nX^\top\hspace{-1pt}, \alpha I\right)^\top\hspace{-1pt}\\ \|x\|_X^2 = \left<x, T^{-1}x\right>\\ T = \mathrm{diag}(\tau)\quad \mathrm{where}\quad \tau_j=\frac{1}{\sum_{i}|K_{i,j}|^{2-\beta}}\\ \|y\|_Y^2 = \left<y, \Sigma^{-1}y\right>\\ \Sigma = \mathrm{diag}(\sigma)\quad \mathrm{where}\quad \sigma_i=\frac{1}{\sum_{j}|K_{i,j}|^{\beta}}である.これより,更新式は
\left\{ \begin{align} &w^{k+1} = w^k - T\left(\frac1nX^\top\hspace{-1pt}q^k + \alpha p^k\right)\\ &\bar{w}^{k+1} = 2w^{k+1} - w^k\\ &(p^{k+1}, q^{k+1}) = \mathrm{proj}_{[-1, 1]}\left((p^k, q^k) + \Sigma\left(\alpha\bar{w}^{k+1}, \frac1n(X\bar{w}^{k+1} - y)\right)\right) \end{align} \right.となる.
ソースコード
Python で実装.
- MacOS Mojave : 10.14.3
- Python : 3.7.3
- numpy : 1.16.4
ソースコードや実行した notebook は Github に.
from typing import Tuple, List import numpy as np from tqdm import trange class Lasso: """ Lasso regression model using the preconditioned primal dual algorithm """ def __init__(self, alpha: float = 1.0, beta: float = 0.5, max_iter: int = 1000, extended_output: bool = False): """ Parameters ---------- alpha : float A regularization parameter. beta : float in [0.0, 2.0] A parameter used in step size. max_iter : int The maximum number of iterations. extended_output : bool If True, return the value of the objective function of each iteration. """ np.random.seed(0) self.alpha = alpha self.beta = beta self.max_iter = max_iter self.extended_output = extended_output self.coef_ = None self.objective_function = list() def _step_size(self, X: np.ndarray) -> Tuple[np.ndarray, np.ndarray]: n_samples, n_features = X.shape abs_X = np.abs(X) tau = np.sum(abs_X ** self.beta, axis=0) tau += self.alpha ** self.beta tau = 1 / tau sigma = np.empty(n_samples + n_features, dtype=X.dtype) sigma[:n_samples] = np.sum(abs_X ** (2 - self.beta), axis=1) sigma[n_samples:] = self.alpha ** (2 - self.beta) sigma = 1. / sigma return tau, sigma def fit(self, X: np.ndarray, y: np.ndarray) -> None: """ Parameters ---------- X : array, shape = (n_samples, n_features) y : array, shape = (n_samples, ) """ n_samples, n_features = X.shape n_samples_inv = 1 / n_samples bar_X = X * n_samples_inv bar_y = y * n_samples_inv tau, sigma = self._step_size(bar_X) # initialize res = np.zeros(n_features, dtype=X.dtype) dual = np.zeros(n_samples + n_features, dtype=X.dtype) dual[:n_samples] = np.clip(-sigma[:n_samples] * y * n_samples_inv, -1, 1) # objective function if self.extended_output: self.objective_function.append( np.sum(np.abs(bar_y)) + self.alpha * np.sum(np.abs(res)) ) # main loop for _ in trange(self.max_iter): w = res - tau * (bar_X.T.dot(dual[:n_samples]) + self.alpha * dual[n_samples:]) bar_w = 2 * w - res dual[:n_samples] = dual[:n_samples] + sigma[:n_samples] * (bar_X.dot(bar_w) - bar_y) dual[n_samples:] = dual[n_samples:] + sigma[n_samples:] * bar_w * self.alpha dual = np.clip(dual, -1, 1) res = w if self.extended_output: self.objective_function.append( np.sum(np.abs(bar_X.dot(w) - bar_y)) + self.alpha * np.sum(np.abs(res)) ) self.coef_ = res実行結果.
$X,\ w$ を乱数で与え,$w$ の復元を見ている.復元誤差 (error) は $\alpha$ に依存するが,実装した Lasso は収束が遅く scikit-learn のが良さそう.
Thomas Pock and Antonin Chambolle 2012 "Diagonal preconditioning for first order primal-dual algorithms in convex optimization" 2011 International Conference on Computer Vision https://ieeexplore.ieee.org/abstract/document/6126441 ↩
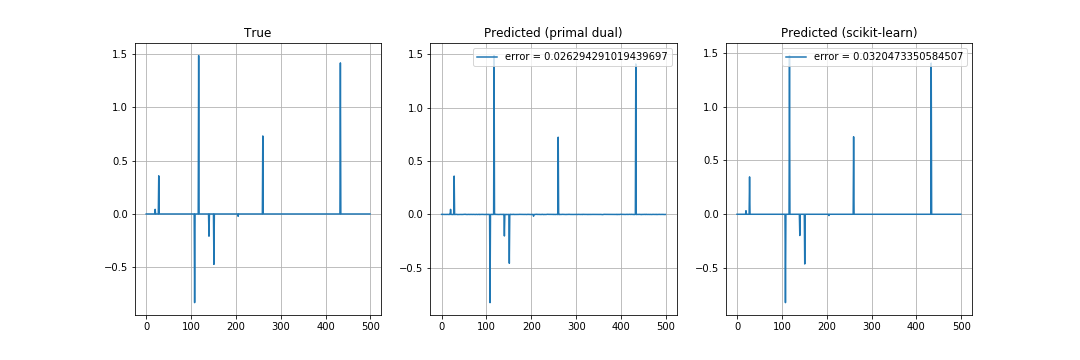
- 投稿日:2019-07-11T13:34:58+09:00
5000円以下でAI, IoT, RISC-Vが全部試せるガジェット
今回は、最近の技術要素がお手軽なコスト(※1)で凝縮されているシングルボードコンピュータ(SBC)キットである、「Sipeed Maixduino Kit」を紹介します。
※1: 2019年7月11現在、国内では3,500〜3,888円で販売されています。
主な国内販売店
※ なお、M5StickVという超小型な無線なしのバッテリー内蔵のものもあります。
キットの構成
まず、キットの構成は次の通りです。
- SBC(Maixduino)本体
- サイズ:Arduino UNOとほぼ同じピン配置、ボード形状
- USBコネクタ:Type-C
- カメラ
- 最大解像度:1600x1200
- 液晶
- 画面サイズ:2.4インチ
- 解像度:QVGA(320x240)
ボード本体の機能
- メインMPUモジュール
- Sipeed M1 module w/o WiFi(SOM)
- Kendryte K210(SoC)
- RISC-V(64bit/デュアルコア/FPU付)
- 各種ハードウェアアクセラレータ
- KPU(汎用ニューラルネットワーク処理)
- APU(音声)
- FFT(周波数)
- AES/SHA256(セキュリティ)
- 無線モジュール(サブMPU)
- ESP32(ESP-WROOM-32)
- Wi-Fi(2.4GHz, 802.11.b/g/n)
- Bluetooth 4.2(BLE/Classic)
- マイク
- モノラル
- スピーカーアンプ(3W)
- スピーカー自体はついてないので外付けする必要有
- microSD(TF)スロット
- microSDをさすことができる
- Arduino互換ピン
なにができるのか?
このキットとPCを使ってできることは次のようなことです。
- プログラミング
- Python
- MicroPythonベースのMaixPyがプレインストール済
- PCとUSBでシリアル通信でPythonコードを書き込める
- Arduino
- Arduino IDE上で開発可能
- 深層学習
- 動画・静止画
- 音声
- IoT
- ロボットカー
- 投稿日:2019-07-11T11:10:31+09:00
Python で "in list" の処理はめちゃくちゃ遅い
リストの中に特定の要素があるか探す処理
とある競技プログラミングで、「大量の要素群の中に特定の要素が入っているかチェックする」といった処理を実装する必要がありました。
私は何も考えずに List 型で実装しました。
概ね同じ事をしているのが以下のコードになります。
list.pyimport time from random import randint a = list() for _ in range(100000): a.append(randint(1, 10000000)) # 1 ~ 10000000 の間の数値をランダムに 100000 個リストに append for _ in range(10): # 今回は実験のため、10回実行 result = 0 start_time = time.time() for _ in range(100000): num = randint(1, 10000000) # 改めて1 ~ 10000000 の間の数値をランダムに 100000 個選び、リスト中にあれば result を + 1 する if num in a: # 要素がリスト中に存在するかチェック result += 1 # print(result) print("elapsed_time:{time} sec".format(time=time.time() - start_time))実行結果elapsed_time:240.42141199111938 sec elapsed_time:227.7156150341034 sec elapsed_time:220.98236417770386 sec elapsed_time:216.4878408908844 sec elapsed_time:213.12895107269287 sec elapsed_time:214.8469820022583 sec elapsed_time:218.6278579235077 sec elapsed_time:215.24347305297852 sec elapsed_time:223.3752110004425 sec elapsed_time:218.8238799571991 sec平均3分半かかります。
これでは遅くてどうやっても規定の秒数以内で終わりませんでした。
その旨を Twitter で愚痴ったところ、「List じゃなくて Set でやれば高速化できますよ」という天の声を頂きました。
本当に?と思い、試しに実装してみました。同じ処理を Set で書いてみる
では、同じ処理を Set 型を使ってやってみましょう。
set.pyimport time from random import randint a = set() for _ in range(100000): a.add(randint(1, 10000000)) # 1 ~ 10000000 の間の数値をランダムに 100000 個を集合に add for _ in range(10): # 今回は実験のため、10回実行 result = 0 start_time = time.time() for _ in range(100000): num = randint(1, 10000000) # 改めて1 ~ 10000000 の間の数値をランダムに 100000 個選び、集合中にあれば result を + 1 する if num in a: # 要素が集合中に存在するかチェック result += 1 # print(result) print("elapsed_time:{time} sec".format(time=time.time() - start_time))実行結果elapsed_time:0.23300909996032715 sec elapsed_time:0.22655510902404785 sec elapsed_time:0.20099782943725586 sec elapsed_time:0.23000216484069824 sec elapsed_time:0.25554895401000977 sec elapsed_time:0.2030048370361328 sec elapsed_time:0.22499608993530273 sec elapsed_time:0.24254608154296875 sec elapsed_time:0.24500298500061035 sec elapsed_time:0.21805286407470703 sec速っ!リストの時のおよそ 100 倍のスピードで処理が完了しています。
どうしてこんなに差が出るのか
Python における List の実装
Python では list() は 「リスト構造」で実装されています。
つまり、リストaに入っている各要素は.appendが呼ばれた順番に入っているだけで、要素を探す時のヒントはありません。
if num in a:の処理を行うためには、リストの要素を全探索する必要があります。
上記を延々繰り返す…そのため、100000回100000個の要素の全探索が走った list 版は非常に実行に時間がかかったのです。
Python における Set の実装
Python では set() は「ハッシュテーブル」で実装されています。(今回調べて知りました…!)
つまり、実際の数値以外にインデックスが貼られた探索しやすい整数とのペアで値が入っています。
そのお陰で、例えば「集合中に120という値があるか」という探索は、ハッシュ値を元に要素を探すことができるため、探索は非常に少ない回数で済みます。(CPythonのコードまでは読めませんでしたが、きっと凄い人達が凄い方法で実装しているのです…)
これが、探索時間に圧倒的な差が出た理由です。
ちなみに、dict() のキーも同じハッシュテーブルのため、辞書型のキーの探索はとても高速に行われます。
Set は単純に重複を許さないことや、和集合・差集合を計算できるだけでなく、こんなメリットがあったんですね。
Python を業務で3年触って、大分分かっているつもりでしたが、まだまだでした。参考
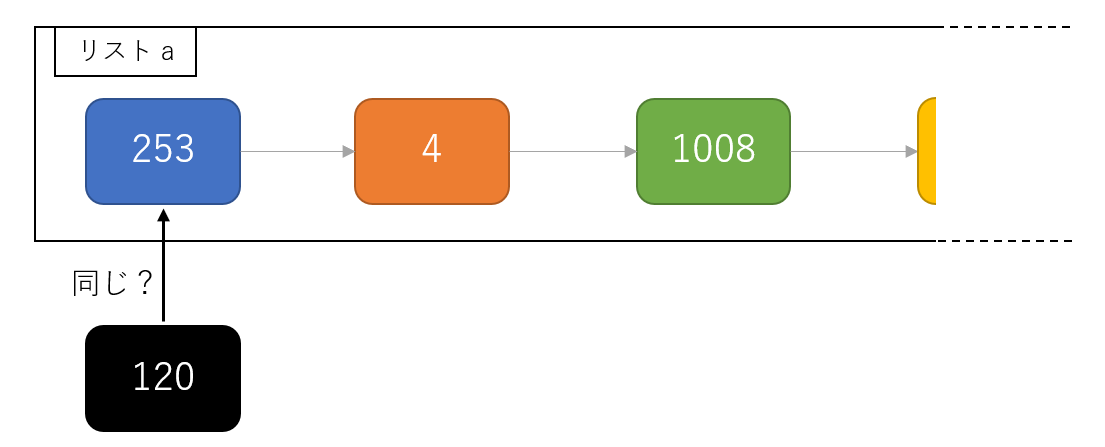
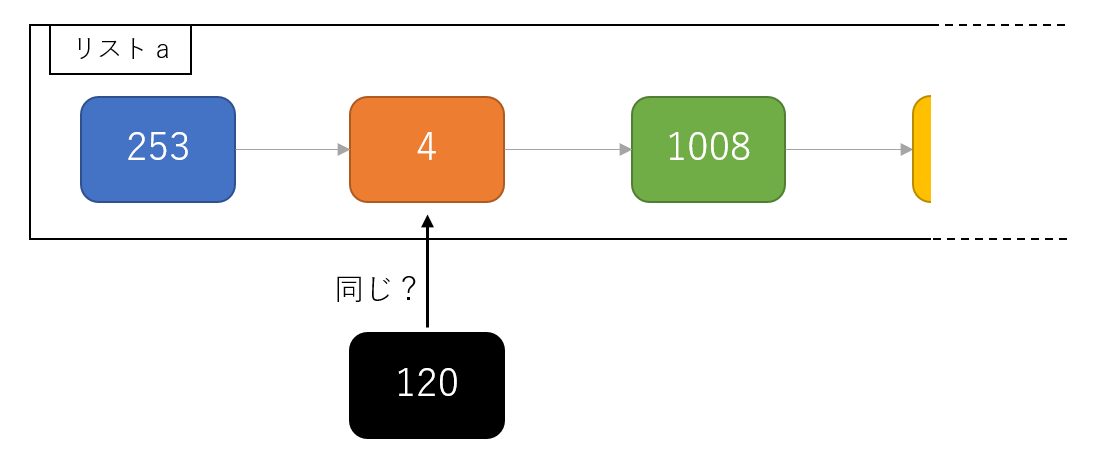
- 投稿日:2019-07-11T11:10:00+09:00
2枚の画像から中間画像を生成する
はじめに
2枚の画像から中間画像をさくっと生成したかったので opencv を使って書いてみました。
メモ程度の内容ですが誰かの参考になればと思います。ソースコード
generator.py#coding:utf-8 import numpy import cv2 split = 10 imgStart = cv2.imread("start.jpg") imgEnd = cv2.imread("end.jpg") # 0.0~1.0 imgStart = (imgStart / 255) imgEnd = (imgEnd / 255) calc = split - 1 for i in range(split): imgTmp = (imgStart / calc * (calc - i)) + (imgEnd / calc * i) imgRes = cv2.resize(imgTmp,(640, 480)) cv2.imshow("color", imgRes) cv2.imwrite(str(i) + ".jpg", imgTmp * 255) cv2.waitKey(10) cv2.waitKey(0) cv2.destroyAllWindows()実行結果
実行前
generator.py / start.jpg / end.jpg の3ファイルがある状態で実行します。
コマンド
python generator.py実行後
0.jpg ~ 9.jpg の計10枚の画像が出力されました。
終わりに
よければ ブログ「Unity+AssetStoreおすすめ情報」の方にも色々記載しているのでぜひご参照いただければと思います。
- 投稿日:2019-07-11T10:54:23+09:00
八村塁(Rui Hachimura)の NBA初年度成績を予測する
八村塁(Rui Hachimura)の NBA初年度成績を予測する
いやー、日本人初の NBAドラフト指名、震えましたね。
指名されるだけならまだしも、1巡目9位指名って!
世界で 4億5千万人がプレイすると言われるバスケットボールという競技において、その中でトップリーグに日本人がドラフトされることは驚くべきことです。
ちなみにかの Kobe Bryant でさえ1巡目13位です。
https://en.wikipedia.org/wiki/Kobe_Bryantまぁチーム事情とか色々あるので一概に順位が高いほどすごいというわけではないんですが、それでも驚愕です。
さて、今回はそのような知識を "あまり" 入れずに、純粋に科学(特に計算機科学)の力だけをもって、八村選手がどのような成績を残せるのかを予測してみたいと思います。
"あまり" と書いているのは、ちょっとデータが与えられていなくてどうしようもなくて、、、とか色々な事情を考慮してです。以下、文体が敬体から常体に変わります。
基本的なアイディア
大学時代に八村選手と同じようなスタッツを残した選手を見つけ出し、その選手が NBA 初年度に残した成績を参照することで、八村選手の活躍もある程度推測できるのではないか?
データ
Google BigQuery に
bigquery-public-data/ncaa_basketballという公開データがあるのでこれを使用する。
もともと kaggle で使用された課題用のデータだが、実際の NCAA のスタッツが実名で得られる。SELECT * FROM `bigquery-public-data.ncaa_basketball.mbb_teams` WHERE market="Gonzaga" LIMIT 1;として、チームID を取得したあとで、
SELECT * FROM `bigquery-public-data.ncaa_basketball.mbb_players_games_sr` WHERE team_id="2f4d21f8-6d5f-48a5-abca-52a30583871a" AND first_name="Rui" AND tournament = "NCAA" LIMIT 1000;とすると八村選手の登録されている試合の結果が取得できる。
BigQuery上で集計まで行っても良いが、できる限り python側に raw に近い状態で持ってきた方が扱いが楽なため、試合ごとのデータをダウンロードする。
なお、クエリ結果は 1GB までであればそのまま直接 json で Google Drive上に保存できる。そして、まずは八村選手と身長、体重、ポジションの近いプレイヤーを抜き出す。
SELECT * FROM `bigquery-public-data.ncaa_basketball.mbb_players_games_sr` WHERE height BETWEEN 75 AND 85 AND weight BETWEEN 205 AND 245 AND position="F" AND season BETWEEN 2011 AND 2015 AND tournament = "NCAA" LIMIT 100000;BigQuery上では 2003年のデータから取得できるが、あまり昔のデータを引っ張ってきてもルールや文化が変わってしまっているので 2011年から 2015年に大学でプレーしていた選手に限定する。
また、身長は ±5-inch、体重は ±20-pounds とし、ポジションはフォワード(F)のプレイヤーだけを取得する。ただ、BigQuery上にあるデータが 2017年までのものなので、八村選手がメインでプレーした 2018年のデータはない。
そこで、 ESPN から 2018年のデータを取得する。
https://www.espn.com/mens-college-basketball/team/stats/_/id/2250実はこの ESPN から取得したデータは kaggle で用いられたものよりも粒度が荒く(とはいえバスケットボールで通常用いられる指標である)、このまま結合しようとすると色々と不都合があるのであとで再整形する。
データ読み込み
BigQuery から取得したデータは jsonl形式(一行ずつが独立した jsonフォーマットになっているテキスト形式)なので、これを python で読み込んで pandas.DataFrame の形に変換する。
import pandas as pd DATA_PATH_RUI = './data/bq-results-20190710-040500-jn11labq5atn.json' DATA_PATH_SIM = './data/bq-results-20190711-072404-txneu5c4yv68.json' # jsonl を読み込んで pandas.DataFrame に変換する関数 def read_jsonl(path): with open(path, 'r') as f: data = f.readlines() data = map(lambda x: x.rstrip(), data) data_json_str = "[" + ','.join(data) + "]" return pd.read_json(data_json_str) # 八村選手のデータを読み込む df_rui = read_jsonl(DATA_PATH_RUI) # 他の選手のデータを読み込む df_sim = read_jsonl(DATA_PATH_SIM)ちなみにこの時点で何人くらいの候補プレイヤーがいるかというと、
names = df_sim.abbr_name.unique() print(f'The number of similar players to Rui Hachimura = {len(names)}') # => The number of similar players to Rui Hachimura = 1300ということで 1,300人が該当した。
八村選手の身長は 2m を超え、体重は 100kg 近いが、5年間で同じような体格の選手がこれだけいるということである。
アメリカの大学バスケ市場の凄まじさがこれだけで伝わってくる。前処理(preprocess)
さて、BigQuery から取得したデータは各試合ごとのスコア(ボックススコアと呼ばれる)なので、これを各年で集計する必要がある。
基本的にバスケットボールの世界では統計値には平均値のみを使用し、分散その他統計値はあまり用いられない。
ESPN のデータも例外ではなく平均値のみなので、平均を計算する関数で簡単に済ませられる。さて、
DataFrame.mean()メソッドを使用したいのだが、ここで注意しなければならない点がいくつかある。
- 文字列は
mean()によって無視される- 割合の平均は全体の割合に等しくない
- 欠損値の扱い
- (カラム毎のスケール)
今回使用するデータは非常に綺麗なフォーマットである。
綺麗とはどういうことかというと、文字列はちゃんと文字列として格納してあるし、数値は数値として格納してある、...ということである。
「何を当たり前のことを...?」と思う人もいるかもしれない。
それが、こと日本国内においてはこの当たり前でないデータが数多くある。原理的に仕方ないものとしては、元号が一つの例として挙げられる。
元号は知っての通り、令和元年などと表記される。
この元年とは1st yearのことであり、当然2nd yearと連続する値である。
しかし、多くのソフトウェア、ミドルウェアでは令和元年と令和2年は連続する整数ではなく、ただの文字列として扱われる。
そこで、年次毎の売上推移を見たければ元号から西暦に変換する必要がある。原理的に仕方無くないものに関しては、ここでは言及しない。
"ネ申エクセル" と揶揄されるものは大方これを含む。話はそれたが、綺麗なフォーマットにおいては、
mean()は正しく機能する。
何も考えずにDataFrame.groupby(...).mean()とすれば、groupby()した中での平均値を求めてくれる。
今回の例で言えば、player_id、season、full_nameが固有なデータ行について集計してくれ、というものである。
多くの場合、player_idとfull_nameは一致するので、どちらか一方を指定すればよいのだが、あとでデータを見るときにどちらもあった方が便利なため残しておく。ここまでで、綺麗なフォーマットであれば
mean()で機械的に平均が計算できるとのべたが、割合の平均は全体の割合に等しくない という点に注意する必要がある。例えば、一試合目で 2本打って 1本入り 50%、二試合目で 3本打って 2本入り 66.6..% とする。
このとき、割合の平均をとると、(50 + 66.6...) / 2 = 116.6... / 2= 58.3...となる。
一方、全体では 5本打って 3本入ったのだから、3 / 5 = 0.6 = 60%である。
このように、割合の平均を取ると、全体の割合から歪んでしまうことに注意しなければならない。最後に、欠損値について考えなければならない。
欠損値とはその名の通り、記録できていないデータである。
例えば、出場機会がなく得点が 0点のとき、そのまま 0 としてしまうとあとで困る(特に平均や除算を行う場合)ので、
NA や NaN といった疑似的な数値を入れることがある。
この欠損値をそのままにしても上手くいくアルゴリズムはいくつかある(How to deal with Missing Value - xgboostのだが、大抵はそうでない。
かといって、前述のようにただ 0 としてしまうのはあまり良くない。そこで、「何もしない」、「平均値または中央値で埋める」、「最頻値で埋める」などといったヒューリスティックが使われている(6 Different Ways to Compensate for Missing Values In a Dataset (Data Imputation with examples))。
しかし、これをすれば良いというものはなく、データセットや問題に応じてどの方法で欠損値を扱うかを毎回検討せねばならず、このことがデータサイエンティストが当たる最初の壁となる。
さらにもう一つ、処理するアルゴリズムによっては、カラムごとの値のスケールを調整しなければならない場合もある。
例えば、平均得点が 5点違うのと、平均ブロック数が 5つ違うのとでは、意味合いが全く異なる。
選手の類似性という点に着目すると決めている以上、この差異が十分よく反映されるように変換を施すべきである。さて、前置きが長くなったが、今回の場合に照らすと
- パーセンテージの平均は使わない(ちゃんと計算する)
- 欠損値を埋める必要がある
- 値を正規化、標準化する必要がある
となる。以下に具体的な処理を示す。
使用するカラムを指定する
DataFrame を扱う際、カラムを指定して処理を行いたい場合が多いので、あらかじめ処理対象のカラムを記憶しておくと良い。
ここでは、num_labelsという変数に数値型の値を格納している。str_labels = [ # プレイヤーID 'player_id', # プレイヤー名 'full_name', # シーズン 'season', ] num_labels = [ # アシスト数 'assists', # ブロック数 'blocks', # ディフェンスリバウンド数 'defensive_rebounds', # フィールドゴール試投数 'field_goals_att', # フィールドゴール成功数 'field_goals_made', # フリースロー試投数 'free_throws_att', # フリースロー成功数 'free_throws_made', # 身長 'height', # 出場時間 'minutes', # オフェンスリバウンド数 'offensive_rebounds', # 得点数 'points', # リバウンド数 'rebounds', # スティール数 'steals', # 3P試投数 'three_points_att', # 3P成功数 'three_points_made', # ターンオーバー数 'turnovers', # 2P試投数 'two_points_att', # 2P成功数 'two_points_made', # 体重 'weight', ]欠損値処理
今回は、欠損値はそのカラムの平均値で埋めるという処理を施す。
# 値が数値か否かを判定するメソッド def is_number(x): return (type(x) is int or type(x) is float) and not np.isnan(x)# 「値が数値ならそのままの値を、そうでなければ平均値を返すメソッド」を返すメソッド def value_or_mean(df, label): mean = df[label].dropna().mean() def f(row): v = None if is_number(row[label]): v = row[label] else: v = mean return v return f # 欠損値を埋める処理 def fillna(df): _df = df.copy() neighbors = [] for label in num_labels: _df[label] = df.apply(value_or_mean(df, label), axis=1) return _df df_sim = fillna(df_sim)統計処理
ここまで来て、やっと統計処理を行うことができる。
# 八村選手のスタッツをシーズンごとに計算 df_rui_stats = df_rui.groupby(['player_id', 'season', 'full_name']).mean() # 他のプレイヤーのスタッツをシーズンごとに計算 df_sim_stats = df_sim.groupby(['player_id', 'season', 'full_name']).mean()標準化
今回のケースでは、平均を引いて標準偏差で割る標準化を行う。
なぜ閉区間[0, 1]へのフラットな射影ではなく標準化をするかというと、今回重要なのは平均に比べてどのくらい異質なスコアを各プレイヤーが示しているかという点だからである。
例えば、平均得点が 30点のプレイヤーがいたとしよう。このとき、他のプレイヤーも同様に 30点近くを記録しているのであれば、そのプレイヤーは平均的な得点力、と見れるかも知れない。一方、他のプレイヤーの平均得点が高々10点近くなのであれば、そのプレイヤーの得点力は並外れていると評価できる。
このように、平均からどのくらい離れているか、異常であるかを示す変換として標準化を使用できる。def standardize(df, labels): _df = df.copy() for label in labels: # 平均と標準偏差を計算 mean = df[label].mean() std = df[label].std() values = [] for val in df[label].values: # 標準偏差が 0 でなければ標準化する if std > 0: values.append((val - mean) / std) # 標準偏差が 0 の場合は、どのプレイヤーも同じ値をとるということなので、 # とりあえず 0 を入れておけば問題ない(厳密には平均を入れるが、類似度計算にはあまり関係ない) else: values.append(0.0) # ラベルに示されるカラムを更新 _df[label] = values return _df df = standardize(df, num_labels)さて、ここまでが前処理である。
次節では、いよいよ類似度計算に移る。類似度計算(Cosine類似度)
ある 2つのベクトルが類似しているとはどういうことだろうか?
例えば各ベクトルの大きさをとって、それぞれが近い値なら類似しているといえるかもしれない。
2つのベクトルを超平面上にプロットして、その距離が近くても類似しているといえるかもしれない。
さて、ここでの類似とは、「2人のプレイヤーが似たタイプのプレイを得意とする選手である」と定義する。
すなわち、似たプレイスタイルであれば、その強弱は考えない、ということである。
なぜこのように定義するかというと、NBA にドラフトされるような選手はその時点である程度プレイスタイルが完成されており、リーグに入ってもそれほど大きくプレイスタイルを変えないだろう、という知見による。
プレイスタイルが変わらないのであれば、異なるのはその洗練度であり、その選手がどう成長していくかも含めて参考になるだろう。これらを踏まえ、類似度には Cosine類似度を採用する。
Cosine類似度は、ベクトルの内積をそれぞれの大きさの積で割ったものとして定義される。
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.pairwise.cosine_similarity.html幾何学的には、2つのベクトルの角度が小さいほど、値が大きくなる指標である。
Cosine類似度は自分で実装しても良いのだが、python ではscikit-learnに実装されているため、それを使用する。
このような指標(metric)は意外とハマるので極力ありものを使ったほうが良い。
ハマりどころは境界値(0 や inf)が多い。from sklearn.metrics.pairwise import cosine_similarity def calc_cos(row, df): cosines = [] for _, x in df.iterrows(): X = row.values.reshape(1, -1) Y = x.values.reshape(1, -1) cosines.append(cosine_similarity(X, Y)[0][0]) return cosines # iloc[0] は八村選手のデータ cos = calc_cos(df.iloc[0], df) df['cosine'] = cosCosine類似度が計算できたら、後はソートするだけである。
df_similar = df.sort_values('cosine', ascending=False)この結果は、公開した jupyter notebook に載せているので興味があればご覧いただきたい。
結果
さて、以上より、Cosine類似度において類似していると思しき選手のリストを手に入れた。
そこで、類似度の高い選手について、NBA でどんな成績を残しているか見ていく。ここで注意すべきなのは、Cosine類似度を用いているため、類似性はあくまでプレイスタイルに関してであり、実際にはそれほど活躍していない選手も載っているということだ。
そのような選手と、八村選手のようにリーグから注目されている選手とを区別するために、ドラフトされているか否かを指標に入れる。
ただし、このデータは配布されていないため、名前を Google検索して目でドラフト順位を記載したものである。
また、ドラフト外の選手は上述の理由で取り上げないこととする。1st pick of Rui-like draft, Montrezl Harrell(Houston Rockets, 32nd)
まずは最もプレイスタイルが近いと判定された選手、Montrezl Harrell。
https://www.basketball-reference.com/players/h/harremo01.html現在は LA Clippers に所属しており、カンファレンス・ファーストラウンドで昨季の王者である Golden State Warriors を苦しめた。
初年度成績はまずまずといったところ。
全体32位での指名なので、八村選手はこれよりも良いスタッツが期待できる。エースとまではいかないが、若いチームで安定した数字を残しており、4年目でこのくらいの数字であれば NBA に残り続けることができるだろう、という成績だ。
ちなみに契約金は 600万ドル(およそ7億円)と報じられている。
https://www.espn.com/nba/team/roster/_/name/lac/la-clippersただし今シーズンは大型選手補強が行われており、プレイタイムは減るかも知れない。
初年度成績(Houston Rockets)
- 39ゲーム出場(1ゲーム先発)
- 平均9.7分プレイ
- 平均3.6得点
- 平均1.7リバウンド
- 平均0.3スティール
- 平均0.3ブロック
- 平均0.4ターンオーバー
- 平均1.2パーソナルファウル
最新シーズン成績(4年目:LA Clippers)
- 82ゲーム出場(5ゲーム先発)
- 平均26.3分プレイ
- 平均16.6得点
- 平均6.5リバウンド
- 平均0.9スティール
- 平均1.3ブロック
- 平均1.6ターンオーバー
- 平均3.1パーソナルファウル
2nd pick of Rui-like draft, T.J. Leaf(Indiana Pacers, 18th)
イスラエル出身のプレイヤー T.J. Leaf。
https://www.basketball-reference.com/players/l/leaftj01.html八村選手と同じく 1ラウンドでの指名(18位)であるが、正直なところ、それほど目立つ活躍はできていない。
趣旨が変わってしまうのであまり詳しくは調査していないが、もしかするとコミュニケーションの問題があったのかもしれない。初年度成績(Indiana Pacers)
- 53ゲーム出場(0ゲーム先発)
- 平均8.7分プレイ
- 平均2.9得点
- 平均1.5リバウンド
- 平均0.1スティール
- 平均0.1ブロック
- 平均0.2ターンオーバー
- 平均0.8パーソナルファウル
最新シーズン成績(2年目:Indiana Pacers)
- 58ゲーム出場(1ゲーム先発)
- 平均9.0分プレイ
- 平均3.9得点
- 平均2.2リバウンド
- 平均0.2スティール
- 平均0.3ブロック
- 平均0.2ターンオーバー
- 平均0.6パーソナルファウル
3rd pick of Rui-like draft, Marquese Chriss(Sacramento Kings, 8th)
全体8位指名で、今回最も八村選手と指名順が近い Marquese Chriss選手。
https://www.basketball-reference.com/players/c/chrisma01.html初年度はなんと全ゲームに出場、内75ゲームで先発するという期待のされ方。
また、スタッツも初年度にしては非常に良く、上々のスタートだったが、現在はトレードされて出場機会もぐっと減ってしまっている。初年度成績(Sacramento Kings)
- 82ゲーム出場(75ゲーム先発)
- 平均21.3分プレイ
- 平均9.2得点
- 平均4.2リバウンド
- 平均0.8スティール
- 平均0.9ブロック
- 平均1.3ターンオーバー
- 平均3.2パーソナルファウル
最新シーズン成績(5年目:Cleveland Cavaliers)
- 27ゲーム出場(2ゲーム先発)
- 平均14.6分プレイ
- 平均5.7得点
- 平均4.2リバウンド
- 平均0.6スティール
- 平均0.3ブロック
- 平均0.9ターンオーバー
- 平均2.4パーソナルファウル
考察
チームの育成、起用方針に大きく左右されるので一概には言えないが、実力や期待度的には Marquese Chriss と同じくらいのプレイタイムが与えられ、成績を残してもおかしくない。
一方で、やはりそれほど甘くない世界、成績が伸び悩めばトレード、最悪解雇されることもありうる。
八村選手は渡邊選手とともに日本の期待を大きく背負っているが、直近の成績を重視せず、 Montrezl Harrell のように成長を続けて欲しい。結論(予想)
Washinton Wizards の事情も考えて、だいたい Marquese Chriss の上位互換となるような成績を残すのではないだろうか。
- 70ゲーム出場(56ゲーム先発)
- 平均25.0分プレイ
- 平均14.0得点
- 平均6.0リバウンド
- 平均0.8スティール
- 平均2.0ブロック
- 平均1.3ターンオーバー
- 平均3.2パーソナルファウル
おまけ
使用した jupyter notebook は github で公開中
https://github.com/chase0213/rui8_prediction
- 投稿日:2019-07-11T10:23:33+09:00
数の集合を受け取って、正規分布を仮定して、その正規分布に従う乱数を返す
難しい話ではないんですが、
ある数字の集合があったときに、それが正規分布に従うと仮定して、その正規分布に従う乱数をたくさん得たい。
これを実行する関数を作ってみました。
import numpy as np def random_gauss(numbers, size=10): return np.random.normal(loc = np.mean(numbers), scale = np.std(numbers), size = size)これで、たとえば得られた数字が [5, 4, 5, 6, 5, 4, 5] で、それが正規分布に従うと仮定して、その正規分布に従う乱数を 10 個得たいとします。
obtained = [5, 4, 5, 6, 5, 4, 5] random_gauss(obtained, 10)array([4.77977069, 4.6853802 , 5.26933192, 4.53865225, 5.24104428, 3.92201318, 4.31394991, 5.11750001, 5.14838062, 3.23263734])10x10 の配列にしたければ、このように使えます。
obtained = [5, 4, 5, 6, 5, 4, 5] random_gauss(obtained, (10, 10))array([[4.29329647, 5.2471627 , 4.71340084, 5.85465204, 5.89516407, 4.55110482, 6.25525269, 4.64901171, 5.42536685, 5.58770788], [5.67861129, 4.94102328, 6.77790586, 3.8582164 , 5.36784665, 5.43751184, 5.14030784, 4.78585029, 4.7084496 , 4.25353288], [4.26591012, 4.24099113, 5.46428238, 5.27744576, 4.41300475, 6.07647302, 5.05453331, 5.97655124, 4.98670422, 5.17337313], [4.40873499, 4.5629429 , 3.73268542, 4.82958227, 4.40850147, 6.28637949, 4.65911079, 4.15151204, 4.89566688, 5.28266135], [4.7034054 , 5.17026093, 4.4403553 , 4.62355895, 4.7855689 , 4.67839428, 6.01478859, 5.74358323, 5.11884483, 5.11134914], [4.0797462 , 3.95483888, 4.51260295, 5.84880821, 2.84667954, 5.31916493, 4.73691626, 4.75109749, 4.58356682, 4.55128143], [5.84606006, 4.38274727, 5.324277 , 5.12168242, 3.60557967, 4.92809603, 4.78279947, 5.85618519, 4.4952449 , 4.61218377], [4.06391996, 5.49536423, 3.91027041, 5.23696996, 4.64761352, 3.98023659, 4.73758287, 5.12500023, 5.6862004 , 5.72124111], [4.8539152 , 5.50043533, 5.88674704, 4.3603309 , 4.56167419, 4.94060109, 5.64930582, 4.28465173, 4.79660025, 4.69518196], [4.59096486, 5.24698098, 4.95728241, 5.00961799, 4.35292064, 4.02801381, 5.58337414, 5.71661697, 4.38613982, 5.57674788]])簡単、簡単。
- 投稿日:2019-07-11T05:43:52+09:00
pipenvによるpythonアプリケーション実行環境をDockerとVirtualBox(Vagrant)で作る
前置き
pythonでバッチやWebアプリケーション(Django/Flask等)の環境を作るときのベースイメージとなるものをDockerとVagrantで作ったのでその記録です。(DockerもVagrant(VirtualBox)もベースはCentOS(7.6)です)
本当は、nginxやuWSGIなどとの連携や簡単なアプリケーションまで作って載せよう思いましたが、長くなったので、気が向いたら書くことにします。
Dockerコンテナ版
前提
sshで接続できるpipenvで作るpython実行環境のDockerコンテナのサンプルです。
これをこのまま利用するというよりはこれでビルドしたイメージをベースにDjangoやuWSGIをインストールした派生イメージを作ったり、pythonのバッチアプリケーションを実行するコンテナを作ったりする想定で作ったものです。試したDockerのバージョンは以下の通りです。
Client: Docker Engine - Community Version: 18.09.2 API version: 1.39 Go version: go1.10.8 Git commit: 6247962 Built: Sun Feb 10 04:12:39 2019 OS/Arch: darwin/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 18.09.2 API version: 1.39 (minimum version 1.12) Go version: go1.10.6 Git commit: 6247962 Built: Sun Feb 10 04:13:06 2019 OS/Arch: linux/amd64 Experimental: falseDockerfileの中身
FROM centos:7 ARG APP_USR_PWD ARG BASE_GROUP=apps ARG APP_USER=app ARG APP_HOME=/home/app # only python3.x.y ARG PYTHON_VERSION=3.7.4 RUN test -n "${APP_USR_PWD}" && \ groupadd ${BASE_GROUP} && \ useradd -d ${APP_HOME} -G ${BASE_GROUP} -s /bin/bash ${APP_USER} && \ yum install -y epel-release && \ yum install -y https://centos7.iuscommunity.org/ius-release.rpm && \ yum install -y sudo python-pip openssh openssh-server passwd logrotate sudo wget vim jq \ gcc git libffi-devel zlib-devel bzip2 bzip2-devel readline readline-devel sqlite sqlite-devel openssl openssl-devel && \ yum -y update && yum -y clean all && rm -rf /var/cache/yum/ && \ echo "${APP_USER}:${APP_USR_PWD}" | chpasswd && \ echo "${APP_USER} ALL=(ALL) ALL" > /etc/sudoers.d/${APP_USER} && \ pip install pip --upgrade && pip install pipenv # install pyenv RUN git clone https://github.com/pyenv/pyenv.git ${APP_HOME}/.pyenv && \ chown -R ${APP_USER}:${BASE_GROUP} ${APP_HOME}/ && \ echo '' >> ${APP_HOME}/.bash_profile && \ echo 'export PYENV_ROOT="${HOME}/.pyenv"' >> ${APP_HOME}/.bash_profile && \ echo 'export PATH="${PYENV_ROOT}/bin:${PATH}"' >> ${APP_HOME}/.bash_profile && \ echo 'if command -v pyenv 1>/dev/null 2>&1; then' >> ${APP_HOME}/.bash_profile && \ echo ' eval "$(pyenv init -)"' >> ${APP_HOME}/.bash_profile && \ echo 'fi' >> ${APP_HOME}/.bash_profile && \ echo "export PIPENV_DEFAULT_PYTHON_VERSION=${PYTHON_VERSION}" >> ${APP_HOME}/.bash_profile && \ echo 'export PIPENV_VENV_IN_PROJECT=true' >> ${APP_HOME}/.bash_profile # install python. RUN su - ${APP_USER} -c "pyenv install ${PYTHON_VERSION} && pyenv global ${PYTHON_VERSION} && pyenv rehash && pip install --upgrade pip && pip install pipenv" # setup ssh. RUN ssh-keygen -q -f /etc/ssh/ssh_host_rsa_key -N '' -t rsa && \ ssh-keygen -q -f /etc/ssh/ssh_host_ecdsa_key -N '' -t ecdsa && \ ssh-keygen -q -f /etc/ssh/ssh_host_ed25519_key -N '' -t ed25519 && \ mkdir -p ${APP_HOME}/.ssh && chmod 700 ${APP_HOME}/.ssh # Add public key to container. ADD id_rsa.pub ${APP_HOME}/.ssh/authorized_keys RUN chown -R ${APP_USER}:${BASE_GROUP} ${APP_HOME}/.ssh/ EXPOSE 22 ENTRYPOINT ["/usr/sbin/sshd", "-D"]事前作業
- Dockerfileと同じディレクトリにSSHログインする秘密鍵に対応する公開鍵を
id_rsa.pubというファイル名で配置すること!!- 社内のプロキシ環境下の場合は、DockerfileのFROMの直後当たりに環境変数の設定を追加する。
例)
FROM centos:7 ENV http_proxy=http://proxy.xx.yy:9999 \ https_proxy=http://proxy.xx.yy:9999 # 以下省略・・・ビルド方法
docker build -t {イメージ名}[:{タグ}] --build-arg APP_USR_PWD={SSHログインユーザがsudoするときに必要なパスワード}上記以外に以下の値が
--build-argで上書き可能である。
- BASE_GROUP:アプリケーションの実行(=SSH接続)ユーザの所属グループ(デフォルト
apps)- APP_USER:アプリケーションの実行(=SSH接続)ユーザ名(デフォルト
app)- APP_HOME:アプリケーションの実行(=SSH接続)ユーザのホームディレクトリ(デフォルト
/home/app)- PYTHON_VERSION:pipenvでインストールするアプリケーションの実行(=SSH接続)ユーザのグローバルのpythonバージョン(デフォルト3.7.4)
PYTHON_VERSIONはすべてのバージョンを確認しているわけではないので、指定するものによってはインストールするパッケージが不足している可能性もあります。
起動方法
docker run -d -p ホスト側のポート番号:22 --name {任意のコンテナ名} {イメージ名}[:{タグ}]dockerホストからのアクセス
- root
docker exec -it {任意のコンテナ名} bash- app
docker exec -it --user app {任意のコンテナ名}Dockerホスト外からSSH接続方法
DockerホストOS側のファイアーウォール設定などで起動方法に記載した「ホスト側のポート番号」でアクセス可能であること。
(この点についてはDockerホスト環境に依存するので割愛)接続情報は以下の通りです。適宜、利用するSSHクライアントツールに以下の情報を指定してください。
- ホスト:接続元から見たDockerホストのホスト名 or IPアドレス
- ポート番号:起動方法に記載した「ホスト側のポート番号」
- ユーザ:app(
--build-arg APP_USER=xxxとした場合はxxx)- 秘密鍵:Dockerfileと同じディレクトリに配置した公開鍵の秘密鍵
Vagrant+VirtualBox版
前提
VagrantのproviderはVirtualBoxを前提としていますが、VagrantfileのVirtualBox依存部分を他のプロバイダーに書き換えれば、問題なく動くと思います。
Vagrant版を作ったのはDockerが動かない(正確には動かすのにいろいろな作業が必要になりそう)環境の人がいたので、急遽つくったのものなので、
DockerfileのRUNでいろいろインストールしているところを外だしのprovistion.shに移したものです。
個人的には、実稼働環境の構築も考慮して、Ansible-Playbookで書きたいところなので、そのうち気が向いたら書き直します。試したVagrantとVirutualBOXのバージョンは以下の通りです。
$ VBoxManage --version 6.0.8r130520 $ vagrant version Installed Version: 2.2.5 Latest Version: 2.2.5 You're running an up-to-date version of Vagrant!事前作業
- Vagarnt sshでログインできるのでSSHの設定は特別には行っていません。
- 社内のプロキシ環境下の場合は、以下の作業を実施しておくこと。
- vagrant-proxyconfをインストールする。
vagrant plugin install vagrant-proxyconf- 環境変数に
http_proxy/https_proxy/no_proxyを登録する。)Vagrantfileとprovision.sh
Vagrantfileのprovision設定をinlineで書くとみづらい&書きづらいのでprovision.shに外だししました。
forwarded_portのホスト側のポート番号、private_networkのIPアドレス、sync_folderのパス部分は各自の環境に合わせて変更してください。Vagranfile# -*- mode: ruby -*- # vi: set ft=ruby : Vagrant.configure("2") do |config| # 利用するプラグイン定義 config.vagrant.plugins = ["vagrant-vbguest", "vagrant-winnfsd"] # boxイメージ指定 config.vm.box = "centos/7" config.vm.box_version = "1902.01" config.vm.box_check_update = false # GuestAdditionsを更新しない config.vbguest.auto_update = false # プロキシ設定 if Vagrant.has_plugin?("vagrant-proxyconf") if ENV['http_proxy'] config.proxy.http = ENV['http_proxy'] end if ENV['https_proxy'] config.proxy.https = ENV['https_proxy'] end if ENV['no_proxy'] config.proxy.no_proxy = ENV['no_proxy'] end end # ポートフォワード設定(外部PCからのSSHアクセス用) config.vm.network "forwarded_port", id: "ssh", guest: 22, host: 2222 # NFSに必要なprivate(host only)ネットワーク # ipの代わりに`type: "dhcp"`でも可。 config.vm.network :private_network, id: "default-network", ip: "192.168.132.101" # ホスト名 config.vm.hostname = "app.python.localohost" # ローカルでコーディングしたものをNFSマウントでゲスト側に認識させるためのディレクトリ # ⇒アプリを置く場所の想定です。 config.vm.synced_folder ".", "/home/vagrant/apps", type: "nfs", nfs_export: true, nfs_version: 3 # ゲストOSのリソースは適宜変更してください。 config.vm.provider :virtualbox do |vb| vb.name = "python-app" # VirtualBox上のゲストOS名 vb.gui = false vb.memory = 2048 vb.cpus = 2 vb.check_guest_additions = false vb.functional_vboxsf = false end # python3に必要なパッケージやpipenv(pyenv)のインストールなど。 config.vm.provision :shell do |shell| shell.name = 'provision' shell.env = { :PYTHON_VERSION => "3.7.4", } shell.path = "provision.sh" end endprovision.sh#!/bin/bash set -eo pipefail echo "Start provision!!" # パラメータ定義 # pythonのバージョン定義(環境変数で上書き可能) PYTHON_VERSION=${PYTHON_VERSION:-"3.7.4"} # めんどくさいのでvagrantをそのまま使う。 APP_GROUP="vagrant" APP_USER="vagrant" APP_HOME="/home/${APP_USER}" # rootのssh接続を不可/パスなし接続不可(公開鍵認証のみ) sed -i -e 's/#PermitRootLogin yes/PermitRootLogin no/' \ -e 's/#PermitEmptyPasswords no/PermitEmptyPasswords no/' /etc/ssh/sshd_config # パッケージのインストール等 # epelとiusの追加 yum install -y epel-release https://centos7.iuscommunity.org/ius-release.rpm # update yum update -y # 必要なパッケージの追加(pythonに特化すれば全部ではなく、一部はサーバー上に必要そうなコマンド群も含む) yum install -y wget jq git openssl \ gcc python-pip python-devel \ zlib-devel libffi-devel bzip2-devel \ openssl-devel ncurses-devel sqlite-devel \ readline-devel tk-devel gdbm-devel \ libuuid-devel xz-devel systemd-devel # お掃除 yum -y clean all && rm -rf /var/cache/yum/ # pyenvをインストールする git clone https://github.com/pyenv/pyenv.git ${APP_HOME}/.pyenv # アプリユーザで利用できるようにインストール cat << EOS >> ${APP_HOME}/.bash_profile # Add pyenv setting export PYENV_ROOT="\$HOME/.pyenv" export PATH="\$PYENV_ROOT/bin:\$PATH" if command -v pyenv 1>/dev/null 2>&1; then eval "\$(pyenv init -)" fi export PIPENV_DEFAULT_PYTHON_VERSION=${PYTHON_VERSION} export PIPENV_VENV_IN_PROJECT=true EOS chown -R ${APP_USER}:${APP_GROUP} ${APP_HOME}/.pyenv # アプリケーションユーザ用のpythonはpyenvでglobalにセット su - ${APP_USER} -c "pyenv install ${PYTHON_VERSION} && pyenv global ${PYTHON_VERSION} && pyenv rehash && pip install --upgrade pip && pip install pipenv" echo "Fisnish provision!!"起動方法
Vagrantfile/provision.shを同じディレクトリにおいて、そのディレクトリをカレントにした状態で
vagrant upホストからのアクセス
vagrant sshVirtualBoxホスト外からSSH接続方法
ホストOS側のファイアーウォール設定などで起動方法に記載した「ホスト側のポート番号」でアクセス可能であること。
接続情報は以下の通りです。適宜、利用するSSHクライアントツールに以下の情報を指定してください。
- ホスト:接続元から見たVirtualBoxホストのホスト名 or IPアドレス
- ポート番号:2222
- ユーザ:vagrant
- 秘密鍵:
vagrant ssh-configで実行した``に秘密鍵のパスが記載されています。例)
Host default HostName 127.0.0.1 User vagrant Port 2222 UserKnownHostsFile /dev/null StrictHostKeyChecking no PasswordAuthentication no IdentityFile {カレントディレクトリ}/.vagrant/machines/default/virtualbox/private_key IdentitiesOnly yes LogLevel FATALなお、これはUnix/Linux/Macなどの${HOME}/.ssh/configに記載する内容となります。ただ、上の設定はlocalhostを前提にしているので
HostNameに指定する値は接続元から見たVirtualBOXホストのホスト名 or IPアドレスにしてください。
また、先頭のdefaultはVagrantの識別名なのでここも任意変更可能で、例えばHost pythonのように指定した場合、ssh pythonのように打つことでログインすることができます。(Vagrantの仕様とは直接関係ないので細かいことは割愛)SSH接続後の利用例(共通)
pipenvのことが書きたいわけではないので、ほんの触りだけ。。。
# プロジェクトディレクトリ作る。 mkdir test cd test # pipenv(pyenv)による仮想環境を作る pipenv --python 3.7.4 # =>これでPipfileが作られる # PyPIパッケージモジュールをインストールする(上位人気のPyPIパッケージ) pipenv install simplejson setuptools requests python-dateutil PyYAML # => Pipfileに追記され、Piplockファイルにインストールされたバージョン情報とか諸々書き込まれる # あとは作るものに依存するので割愛します。追記
↑のVagrantfileの
config.vm.synced_folder ".", "/home/vagrant/apps", type: "nfs"の部分についてですが、VPN接続時にマウントエラーが発生するという事象にぶち当たりました。
回避方法は別記事にしましたので、ご参照ください。
- 投稿日:2019-07-11T03:15:26+09:00
Selenium for Python Elementにフォーカスを当てる
はじめに
Seleniumで要素をクリックするとフォーカスが移るものだと思っていました。
挙動を監視していると、どうもそうではないように思える事が多々あります。
そこで確実にフォーカスを移す方法を考えてみました。実装
JavaScriptとPythonを使って実現します。
JavaScript
実際にファーカスを移す処理はJavaScriptで行います。
ここでは、以下のような記述にしてみました。javascriptarguments[0].focus()Python
上記のJavaScriptをSeleniumから呼び出します。
pythondef focusToElement(driver, by, value): JavaScriptFocusToElement = "arguments[0].focus()" element = driver.find_element(by, value) driver.execute_script(JavaScriptFocusToElement, element)実際に使う場合は、以下のようになります。
pythonfocusToElement(driver, By.XPATH, "//input[@name='cat']")最後に
フォーカスを移す処理を入れてみたら既存のプログラムの安定性が上がりました。
また、スクロールの挙動がおかしかったのが治りました。
明示的にフォーカスを当てるのも考えて方が良いかもしれません。
- 投稿日:2019-07-11T03:15:13+09:00
python×Cloud Functions×FirestoreでAPIを簡単に作ってみる Pt2 テスト編(要約)
概要
Cloud Functionsは2019/7時点でpythonのエミュレータがありません。それで最初に躓いたのが、関数へのパラメータの受渡をローカルでどうテストするかです。結果的に、Cloud Functions同様にFlaskのrequestオブジェクトを使うのが楽だったので、やり方をまとめます。
また、折角なのでFirestoreも含めて、ローカルでテストしてみます。開発環境
- 開発環境
- MacOS
- python3.7
- pycharm
要約
やることは以下の通りです。
- テストしたい関数のソースを作る
- Flaskを使ってローカルにAPIを作る
- 2を実行して、localhostにリクエストを投げる
テストしたい関数
functions/getFilteredUser.pyimport json from google.cloud import firestore # ソースはPt1と同じ def get_filtered_user(request): request_json = request.get_json() if request.args and 'name' in request.args: request_name = request.args.get('name') elif request_json and 'name' in request_json: request_name = request_json['name'] else: request_name = '' db = firestore.Client() query = db.collection('user').where('name', '==', request_name) docs = query.get() users_list = [] for doc in docs: users_list.append(doc.to_dict()) return_json = json.dumps({"users": users_list}, ensure_ascii=False) return return_jsonFlaskでローカルにAPI作成
localServer.pyfrom flask import Flask, request, abort, render_template, send_from_directory # テストしたい関数を外部ソースからimport from functions.getFilteredUser import get_filtered_user app = Flask(__name__) # methodにPOST等も指定(FlaskではデフォルトGETのみのため) # '/~'がテストするときのパス @app.route('/get-filtered-user'', methods=['GET', 'POST']) def local_api(): return get_filtered_user(request) if __name__ == '__main__': app.run()Firestoreへのアクセス方法として、実行時に環境変数で秘密鍵ファイルを読み込ませています。localServer.pyを実行するとAPIが作られます。
POSTでリクエスト
$ curl -X POST -H "Content-Type: application/json" -d '{"name": "Alice"}' http://127.0.0.1:5000/get-filtered-user {"users": [{"age": 19, "name": "Alice", "gender": "female"}]}これで、Cloud Functionsにデプロイせずともテストできるようになりました。デプロイすると2分ほど待ちますが、この方法だとすぐにテストできます。
詳細版を後日書く予定
長くなりそうなので一旦要約だけ記載しましたが、だいぶ端折って説明しています。Firestoreにローカルからアクセスする手順とかも含め、もう少し解説を加えた詳細版を後日書こうと思います。
参考文献
- 投稿日:2019-07-11T03:01:15+09:00
pythonの基礎文法
pythonの基礎文法
pythonの基礎文法を例を挙げながら説明します。
コーディング規約
pythonのコーディング規約は、PEP8というものがほぼオフィシャルと言えるものがある。
(世の中らのライブラリにはこれに従っていないものも少ならからず存在するが。。。)PEP8では基本的なことしから記載されていないため、このルールをベースとしてプロジェクト独自のコーディングルールを作っていくとよい。
主なルール
- インデントはスペースで4文字(タブは使わない)
- 1行の長さは最大79文字(エディタのルーラや整形ツールとかではみ出さないにする)
※docstring やコメントは72文字- 余計な空白は使わない
- 関数や変数名は小文字のスネークケース
- 定数は大文字のスネークケース(後述するが、pythonに定数という概念はない)
- クラス名はCapWords(先頭大文字のキャメルケース)
全体イメージ
細かい例を挙げる前にソースファイルの全体イメージ例を記載する。
コマンドラインなどがから実行されるスクリプトの例
#!/usr/bin/env python import sys # 関数の定義 def func(param): print(param) return param * 2 # メイン if __name__ == '__main__': print(sys.argv) # コマンドライン引数 func(sys.argv[1])共通モジュールのスクリプト例
# クラスの定義 class SampleClass(object): CONST_VALUE = 10 class_field = 'abcde' def __init__(self, param): self.__param = param def instance_method(self, param): pass @classmehtod def class_method(cls, param): pass @staticmethod def static_method(param): pass # グローバルな関数 def common_func(param): passモジュールのインポート
python標準やpipで提供されたモジュールの取り込み例
# パッケージ全体のロード import os # パッケージの中から特定のモジュールをロード from datetime import date # エイリアスを付ける from datetime import datetime dt自作モジュールの取り込み例
自作モジュールは、javaでjarでまとめるライブラリのようにsetting.pyというファイルを作成してその実行環境下で利用できるモジュールとして登録する方法と自プロジェクト配下のサブディレクトリ配下に共通モジュールを置くケースがあるが、ここでは後者のみについて例を挙げる。
ディレクトリ構成
MY_PROJECT │ main.py │ └─sub_modules │ test_lib.py │ __init__.pymain.py#!usr/bin/env python # test_lib.pyをlibという名前で取り込む import sub_modules.test_lib as lib # test_lib.py内のcommon_funcを取り込む from sub_modules.test_lib import common_func if __name__ == '__main__': lib.common_func() common_func()sub_modules/test_lib.pydef common_func(): pass
__init__.pyについてロードされるモジュールの所属するサブディレクトリには、
__init__.pyというファイルを作る必要がある。
中身は空でOKだが、ここに配下のモジュールのインポート処理などを記載することもできる。コメントの書き方
- 行コメントは
## これはコメントです print('hoge') # この形もOK
- ブロックコメントは
"""or'''で括る"""コメント開始 あいうえお かきくえこ """
- pydocについては以下のリンク集を参照
- docstringというjavadocコメント的なものがある。
docstringのコメントの書き方はドキュメント生成ツールとの組み合わせで決まるので クラスや関数の定義をどのようなコメントで書くかはツールの仕様次第。
pydoc/docstringに関するリンク集
標準出力
python2系はprintはステートメントで、python3系ではprintは組み込み関数である。
# 普通に print('abcde') # 複数を同時に a = 'A' b = 'B' c = 'C' print(a, b, c) # A B C print(a, b, c, sep='|') # A|B|C # 改行を除きたい print('abcdef', end='')データ型の基本
# 文字列 # python2系は`u'abcde'`みたいにしないとunicodeにならなかったが、 # python3は全部unicode str = 'abcde' # 文字列はダブルクォートでもシングルクォートでもOK。 # 真偽値 ok = True ng = False # 整数(python3からはintとlongの差はなくなった。(メモリが許す限りの桁数が入る)) int_num = 10 # 浮動小数点(floatとdoubleみたいな違いはない) float_num = 1.234 # 小数を含む演算するときはDecimalを使う(浮動小数点問題があるから) from decimal import Decimal print(0.1*0.2) # => 0.020000000000000004 val1 = Decimal("0.1") # なんでか引数は文字列でなければいけない val2 = Decimal("0.2") result = val1 * val2 print(float(result)) # => 0.02 # リスト(配列) list = [1,2,3,4,5] list.append(6) print(list) # 辞書(dict) dic = { "str": "string", "num": 10, "arr": [1,2,3,4,5] } dic['add_prop'] = 'Additional' print(dic) # タプル(一言でいえば、イミュータブル(変更不可能)なリスト) arr1 = (1, 2, 3) # arr1.append(4) => エラーになる print(arr1) # 要素が1つしかない場合はカンマで終わる arr2 = (1,) print(arr2) arr3 = (1) print(arr3) # => 数字の1とみなされる。 # 日時 from datetime import datetime, date today = date.today() now = datetime.now() # 書式変換 today.strftime('%Y/%m/%d') now.strftime('%Y/%m/%d %H:%M:%S.%f')四則演算
概ね、一般的なプログラム言語と違いはないが、インクリメント・デクリメント演算子は無いので
i += 1のようにする記述する必要がある点は注意。a = 5 b = 3 # 和 print(a + b) # 8 # 差 print(a - b) # 2 # 積 print(a * b) # 15 # 商 print(a / b) # 1.6666666666666667 # 商の整数部のみ print(a // b) # 1 # 商の整数部分 print(a % b) # 2 # タブルでまとめて取得 q, r = divmod(a, b) # q=1, r=2 # a += bは可能だが、`++`などのインクリメント演算子は無し a += b print(a) # 8制御系
if-elif-else
import random random_val = random.randint(1,10) remainder = random_val % 3 if remainder == 0: print(f'0:{random_val}') elif remainder == 1: print(f'1:{random_val}') else: print(f'2:{random_val}')ループ
# forループ for i in range(10): # => 0-9 print(i) # 辞書(dict)のループ sample_dict = {'a': 'A', 'b': 'B', 'c': 'C'} # keyのみ for key in sample_dict: # sample_dict.keys()でも可 value = sample_dict[key] print(f'{key}={value}') # valueのみ for value in sample_dict.values(): print(value) # keyとvalueのセット for key, value in sample_dict.items(): print(f'{key}={value}') # while i = 10 while True: print(i) if i < 1: break i += -1 # continueもあるけど割愛例外処理
書き方こそ違えどほぼjavaと一緒です。
try: val = 1 / 0 except: print('!!!Exception!!!') # 例外を指定(ちなみにJavaのように複数の例外を並べて発生する例外毎に処理を定義可) try: val = 1 / 0 except ZeroDivisionError as e: print(e) finally: print('finally') # スタックトレースを得る import sys import traceback try: val = 1 / 0 except Exception as e: exception_type, message, _trace = sys.exc_info() print(f'exception_type={exception_type.__name__}, message={message}') print(traceback.format_tb(_trace)) print('================================') # 通常表示されるトレースを文字列にするなら以下の方法 except_str = traceback.format_exc() print(except_str)関数の定義
関数定義例
def func(param1, param2='default', *args, **kwargs): # pythonはIndentでブロック管理する。(スペース4が標準) print(f'param1={param1}, param2={param2}') print(f'可変長引数={args}') print(f'名前付き引数={kwargs}') return 'result'引数について
上述の関数を以下で実行した場合の結果例を示す。
ret = func(1, 'abcde', True, foo='FOO', bar='BAR') print(ret) """ param1=1, param2=abcde 可変長引数=(True,) 名前付き引数={'foo': 'FOO', 'bar': 'BAR'} result """クラスの定義
クラス定義例
def SampleClass(): """クラス定義の例です。 pythonは1ファイル1クラスとしない方がよく見ますが、 Java出身者が規約を決めたせいでそうなっているプロジェクトはあったりする。 """ # クラス変数(インスタンス化しなくてもアクセス可) class_variable = 10 # コンストラクタ def __init__(self, param): """コンストラクタ。 selfはインスタンス化された自身を指す 第一引数がそうなるだけで"self"という名前でないといけないわけではないが、 慣例的に"self"とする。 """ # インスタンス変数 self.param = param # 疑似プライベートなインスタンス変数 self.__pseudo_private = 'aaa' """↑が何で疑似というかというと、`インスタンス.__pseudo_private`では アクセスできないけど、`インスタンス._SampleClass__param`と書くと アクセスできるため。 pythonにはアクセス修飾子は無いのでこんな使い分けをするのが慣例。 (アンスコ1つをprivate的に扱われていることもあるが、アンスコ1つだと 普通にアクセスできるのでアンスコ2つが原則) """ # __init__の他にも__new__とか__call__というのも存在する。 # https://qiita.com/FGtatsuro/items/49f907a809e53b874b18 def method(self, param): """インスタンスメソッド """ pass @classmethod def class_method(cls, param): """クラスメソッド 第一引数がクラス自身の参照となる。 """ print('class method') @staticmethod def static_method(param): """スタティックメソッド """ print('static method') # クラスメソッドとスタティックメソッドの使い分けは正直わからん。 # (クラスメソッドの必要性を感じることがあまりない) def __str__(self): """javaのtoString()みたいなもの 人が見たときにわかりやすい内容で返す。 str(object) と組み込み関数 format(), print() によって呼ばれる """ return self.param def __repr__(self): """こっちも似たようなものだが、こちらは 再び元のオブジェクトに戻せる文字列で返す. 組み込み関数`repr(オブジェクト)`の実行で呼ばれる __repr__しか定義していないと、str(オブジェクト)でもreprが呼ばれる """ return self.__class__.__name__ + "(" + self.param + ")"継承について
pythonでは多重継承が可能である。
良し悪しは宗教論争になるので割愛するが、個人的にはケースバイケースで使ってもよいとは考える。def Parent1(object): def __init__(self): print('Parent1') def Parent2(object): def __init__(self): print('Parent2') def Child(Parent1, Parent2): """pythonではこんな感じに多重継承ができる。 """ def __init__(self): print('Child')文字列加工の基本
文字列は配列なので配列の部分抽出の書き方を利用する。
str = 'abcde' # left print(str[:3]) # => abc # mid print(str[2:4]) # => cd # mid(末尾まで) print(str[3:]) # => de # right print(str[-3:]) # => cde # split print(str.split('c')) # => ['ab', 'de'] # join(listのメソッドじゃなくて、strのメソッドなので注意) print('@'.join(['abc', 'def', 'ghi'])) # => abc@def@ghi文字列の書式変換
C言語のprintf的なやつ
# 左詰め/右詰め print('|%5s|%-5s|' % ('A', 'B')) # 整数 print('|%d|%05d|' % (123, 456)) # 浮動小数点 print('|%f|%5.3f|' % (123.456, 456.78)) # 他にもhex(16進数)とか8進数とかもあるが割愛format関数
# format関数 print('{}={}'.format('key', 'value')) # => key=value # 位置Index付き print('{1}={0}'.format('key', 'value')) # => `value=key`と出力される # python3.6からこんなことができるようになった(便利) key = 'key' value = 'value' print(f'{key}={value}') # => key=valluewithステートメント
javaでいうtry-with-resourcesに近いもので自動でクローズしてくれる。
基本的にクローズが必要なものはwithで書く。with open('memo.txt', 'r', encoding='utf-8') as f: for s_line in f: # print関数は末尾に改行が自動ではいる # またこの読み込み方法だと各行にも改行が入るので print(s_line, end='') # もしくは、末尾の改行をとる。 # この書き方は改行コードがlfである前提でcrlfの場合は気を付ける) print(s_line[:-1])内包表記
内包表記とは以下の例にあげるような書き方。
あるオブジェクトリストを特定条件で絞るとかをするときに1行で書けたりする。# 内包表記 list1 = [i for i in range(10)] print(list1) # list(range(10))でも同じ。 # 条件付き内包表記(偶数だけ) # リストから特定要素だけ抜くのを1行で書ける!! list2 = [i for i in range(10) if i % 2 == 0] print(list2)ラムダ(lambda)式
pythonもラムダ式使えます。
ラムダ式とは無名関数を定義できる式みたい。(言葉の表現は怪しい…)# 偶数/奇数の判定 get_odd_even = lambda x: 'even' if x % 2 == 0 else 'odd'これは以下の関数定義と同等です。
# ↑は以下と同等です。 def get_odd_even(x): if x % 2 == 0: return 'even' else: return 'odd'上の例では、lambda式を
get_odd_evenに代入しているので無名というとちょっと違う気もするけど。。。どんな時に使うというと、よく見るのはlistやdictを特定の条件でフィルタしたり、ソートしたりする場合。
具体的には組み込み関数のfilterとsortはフィルタ条件やソートルールの定義として引数に関数をとることができるが、そのときにわざわざ関数として定義する必要なないような場合にlambda式で定義したりする。int_list = [9, 3, 2, 7, 1, 6, 4, 5, 8] # filter関数はpython3からイテレータを返すのでlist関数を適用する必要がある。 print(list(filter(lambda x:x % 2 == 0, int_list))) # [2, 4, 6, 8]コマンドライン引数
sys.argvを利用した例。
test.py#!/usr/bin/env python import sys if __name__ == "__main__": for arg in sys.argv: print(arg)./test.py A B C`と実行すると
/home/xxxx/python/studies/args.py A B Cのようになる。(先頭はスクリプトのパス)
ただ、これだと引数の意味が分かりづらくなるので、実践的利用する場合は
argparseを利用した方が望ましい。argparseの使い方。
スクリプトのコマンドライン引数を以下のように定義することで、自動的にチェックやヘルプなどを出力してくれる便利なパッケージモジュール。(標準pythonについてます)
args.py#!/usr/bin/env python import argparse class DataSizeAction(argparse.Action): """ fooオプションが指定された場合のアクション定義クラス """ def __init__(self, option_strings, dest, nargs=None, **kwargs): """ 独自チェックコンストラクタ Actionの使い方があってるかを実装するらしいが、例が思いつかないので割愛。。 """ super(DataSizeAction, self).__init__(option_strings, dest, **kwargs) def __call__(self, parser, namespace, values, option_string=None): """ ここには当該オプションを受けた処理を記載する。 例1)指定されたオプション値のバリデーションチェック 例2)指定されたオプション値を加工する [参考]https://qiita.com/ronin_gw/items/af07ab62ea9e7213293d """ try: if values.endswith('K'): data_size = int(values[:-1]) * 1024 elif values.endswith('M'): data_size = int(values[:-1]) * 1024 * 1024 elif values.endswith('G'): data_size = int(values[:-1]) * 1024 * 1024 * 1024 else: data_size = int(values) except ValueError: parser.error(f'Invalid argument ({values})') setattr(namespace, self.dest, data_size) # パーサーの生成 parser = argparse.ArgumentParser(description='このスクリプトの概要.') # 必須の引数の追加(第一引数にハイフンを付けない) parser.add_argument('required_param_1', help='必須パラメータ1') parser.add_argument('required_param_2', help='必須パラメータ2') # 任意の型定義付きパラメータ(名前にハイフン1つか2つで始まるようにつける。どちらか一方でも可) parser.add_argument('-i', '--int_value', default=1, type=int, help='整数を指定') parser.add_argument('-f', '--float_value', default=2.3, type=float, help='小数を指定') parser.add_argument('-s', '--string_value', default='DEFAULT', type=str, help='文字列') # Bool(True/False)が欲しい場合は、オプションの有無で以下のようにした方がよい。 parser.add_argument('-b', '--bool_value', action='store_true', help='このオプションを指定するとTrue') # 複数指定 parser.add_argument('-l', '--list', nargs='*', type=int, help='選択肢') # 選択肢 parser.add_argument('-c', '--color', choices=['red', 'blue', 'yellow'], help='信号の色') # 独自のアクション定義 parser.add_argument('-d', '--data_size', action=DataSizeAction, help='指定された単位付きの値') if __name__ == "__main__": # Namespaceというオブジェクトで返される。 args = parser.parse_args() print(args) # Namespaceというオブジェクトで返される。 print(f'args={args}') # こんな感じで各プロパティにアクセスできる print('====================================================') print(f'required_param_1={args.required_param_1}') print(f'required_param_2={args.required_param_2}') print(f'int_value={args.int_value}') print(f'float_value={args.float_value}') print(f'string_value={args.string_value}') print(f'bool_value={args.bool_value}') print(f'list={args.list}') print(f'color={args.color}') print('====================================================') # あんまり用途ないけど全パラメータを確認する方法として辞書化できる。 args_dict = vars(args) print('====================================================') for key, value in args_dict.items(): print(f'{key}={value}') print('====================================================')1つ1つ説明すると長くなるので、これを
./args.py -i 1 -f 1.2 -s '!STRING!' -l 1 2 3 -c "red" -d 512M required_value_1 required_value_2
or
./args.py --int_value 1 --float_value 1.2 --string_value '!STRING!' --list_value 1 2 3 --color "red" --data_size 512M required_value_1 required_value_2
で実行した結果Namespace(bool_value=False, color='red', data_size=536870912, float_value=1.2, int_value=1, list_value=[1, 2, 3], required_param_1='required_value_1', required_param_2='required_value_2', string_value='!STRING!') args=Namespace(bool_value=False, color='red', data_size=536870912, float_value=1.2, int_value=1, list_value=[1, 2, 3], required_param_1='required_value_1', required_param_2='required_value_2', string_value='!STRING!') ==================================================== required_param_1=required_value_1 required_param_2=required_value_2 int_value=1 float_value=1.2 string_value=!STRING! bool_value=False list=[1, 2, 3] color=red ==================================================== ==================================================== required_param_1=required_value_1 required_param_2=required_value_2 int_value=1 float_value=1.2 string_value=!STRING! bool_value=False list_value=[1, 2, 3] color=red data_size=536870912 ====================================================あとは、以下のリンクを参照してください。
* 16.4. argparse — コマンドラインオプション、引数、サブコマンドのパーサー
* Argparse チュートリアル
- 投稿日:2019-07-11T02:53:21+09:00
pythonのことはじめ
pythonのことはじめ
このページはpythonとはなんぞやといった基礎的な情報を、Javaとの違いを交えてまとめます。
Contents
pythonとは
- pythonとはインタプリタ型のプログラム言語である。
- pythonのバージョンは現在は、2系と3系が主流でそこそそこの違いがある。
新しく作るものは、3系を採用するのが主流だと思われるが、用の中の多くのアプリケーションやツールなどではまだまだ2系であるものも少なくない。- 科学計算や統計処理などのライブラリが豊富に提供されているため、昨今の人工知能とかのバズワードに乗って、シェアを拡大している。
pythonの特徴
- シンプルなコードで読みやすい
- 他の言語に比べて比較的に記述量が少なく済むことが多い。
- インデントでブロックを識別する(オフサイドルール)
- すべての変数はオブジェクトである。(Javaのようなプリミティブ型は無い)
- 動的型付けである。(変数に型宣言などはなく、最初に代入されて時に決まる(実行時))
- クラスを使ったオブジェクト指向型の実装もできるが、javaのように全部クラスで書かないといけないわけではなく、関数型プログラミング的な特徴も持っている。
また、1ファイル1クラスのような縛りもない。(コーディングルールで縛ることも私の経験上では少ない)その他、いろいろあるが、弊社で主流のみんな知っているであろうjavaとの比較記事を参照。
javaとの比較
pythonの実行環境
pythonの実行環境は、公式サイトからそれぞれのOSにあったものをインストールすることで実行可能となる。
Unix/Linux系の各ディストリビューションについては、概ねデフォルトでインストールされている。
(大半はv2.7当たりが入っているが、最新のものだと3系がデフォルトになっているものとちらほら出てきた)Anacondaのように中にpythonを含まれるプロダクトとかもある。
Anacodaについては以下を参照。
Anaconda を利用した Python のインストールパッケージ(ライブラリ)の管理
javaのmaven/gradle、NodeJSのnpm/yarn、PHPのcomposerなどのようにパッケージ(ライブラリ)を管理するためのpipというものを利用する。
公式のpythonをインストールするとで一緒にインストールされるので、実質的にこれがスタンダート。実行例)
* httpのクライアントライブラリをインストールする。
pip install requests
* インストールされているパッケージ一覧を表示
pip freeze実行仮想環境について
1つの端末(OS)で複数のバージョンなどを実行する仮想環境を構築する仕組みがいくつかの方法で用意されている。
この仮想環境を利用する理由は、以下のようなもの。
- 複数のプロジェクトで異なるバージョンを利用していたりするケース
- 多くのLinuxのディストリビューションの各モジュールはpythonで実行されているものがあり、前述の通り、大抵はOS標準でインストールされているバージョンを前提とした実装となっているため、標準をアンインストールして異なるバージョンをインストールするとOSのモジュールが動かなくなってしまう可能性があるため
仮想環境の構築方法には、いくつかの仕組みが提供されいてるが、詳細は以下のリンク集を参照。
私的な見解では、pythonのオフィシャルがvenvを取り込んだこと、パッケージも含めた仮想環境を簡単に作れることから、Pipenv(venvとpipのセットで全体を管理)が主流になっていくのではないかと思われる。
※Pipenvはnodeのnpmのpackage.jsonに似た感じでPipfile/Pipfile.lockでプロジェクトで利用する仮想環境、パッケージ(ライブラリ)のバージョン全体を管理できる。実際にpythonで実装したアプリケーションを実行する場合でもDockerようなコンテナでそのアプリケーションプロセス以外を動かさないなどのケースを除いては、この仮想環境でアプリケーションを実行することが多い。(私的見解)
仮想環境関連のリンク集
- 投稿日:2019-07-11T02:35:06+09:00
【練習】pythonでbaseball-labをスクレイピングする
はじめに
【世界で5万人が受講】実践 Python データサイエンス
を受講して野球のデータを触ってみたくなったので
スクレイピングしてみることにした。
著者のプログラミング歴は2週間ほどやってみたこと
- ベースボールラボから2018年のベイスターズの野手データを抜き出す
- 抜き出したデータをdataframe化
参考
ベースボールラボ
【世界で5万人が受講】実践 Python データサイエンスコード
from bs4 import BeautifulSoup import requests import pandas as pd from pandas import Series, DataFrame #2018年のベイスターズの野手データ url = 'http://www.baseball-lab.jp/player/batter/3/2018/' #この辺は講座の情報通りおこなった result = requests.get(url) c = result.content soup = BeautifulSoup(c) summary = soup.find('div', {'class': 'content-holder'}) tables = summary.find_all('table') data = [] rows = tables[0].find_all('tr') for tr in rows: cols = tr.find_all('td') th_sort = tr.find_all('th') for td in cols: players = td.find(text=True) data.append(players) #numpyをimportして、リストをアレイ化して26個ずつにreshapeする import numpy as np arr1 = np.array(data).reshape(-1,26)ここまででdataframe化するアレイは用意できたのでcolumnsに設定する項目を作っておく(thタグから取り出そうとしたが、改行のせいか中身がないデータが返ってきたため)
:index_batter.txt 背番号 選手名 試合 打席 打数 得点 安打 二塁打 三塁打 本塁打 塁打 打点 三振 四球 敬遠 死球 犠打 犠飛 盗塁 盗塁刺 併殺打 失策 打率 長打率 出塁率 OPS#columnsに名前を付ける f = open('index_batter.txt') index_batter = f.read().split() print(index_batter) f.close() df = DataFrame(arr1) df.columns = index_batter #実行 df
今後の課題
- 選手名に改行やスペースがあり、扱いづらいので修正したい
- columnsの名前をhtmlから直接引っ張ってきたい
- 年度別や他チームとの比較したい
- データの可視化
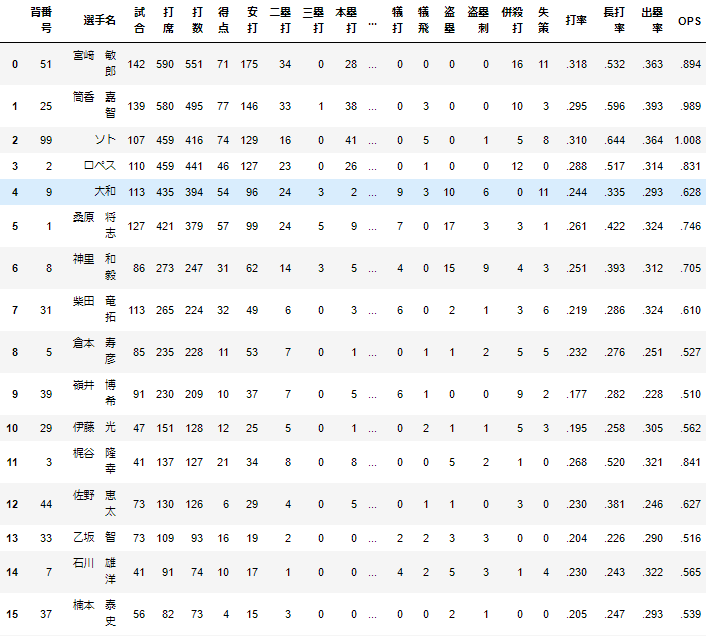
- 投稿日:2019-07-11T00:27:34+09:00
outgoing webhooksから画像情報が取れないことを知る。
outgoing webhooksから画像情報が取れない
本体がlambdaに乗っかるslackbotを作ってるときにoutgoing webhooksから画像情報が取れないことに気づきました。
試行錯誤の末、何とか小細工して解決できたので共有します。outgoing webhooksのpostdata
token=XXXXXXXXXXXXXXXXXX team_id=T0001 team_domain=example channel_id=C2147483705 channel_name=test thread_ts=1504640714.003543 timestamp=1504640775.000005 user_id=U2147483697 user_name=Steve text=googlebot: What is the air-speed velocity of an unladen swallow? trigger_word=googlebot:textがあるならimageも欲しかったなぁ
files.listを呼ぶという二度手間で解決しました。
てな訳で画像を投稿→slackのfile.list呼ぶ→レスポンス.filesをtimestampの降順にソート→一番先頭の要素を取得という方法で画像情報の取得に成功しました。。。
(画像を投稿してから30秒ほど待たないとfile.listには反映されないのでご注意を)def sort_data(file_data): """ timestampが一番新しいファイルを返す。 Parameters ---------- file_data : str ファイルデータ """ try: print("sort_data start") files = file_data["files"] timestamp = "" # timestampが一番新しいファイル latest_file = "" for i,file in enumerate(files): if i == 0: timestamp = files[i]["timestamp"] latest_file = files[i] else: if int(files[i]["timestamp"]) > int(timestamp): latest_file = files[i] timestamp = files[i]["timestamp"] print("sort_data end") return latest_file except Exception: raiseもっとスマートなやり方をご存知の方いらっしゃいましたら教えてください。。。
参考URL
・slack api
https://api.slack.com/methods/files.list
・slcak outgoingwebhooks
https://api.slack.com/custom-integrations/outgoing-webhooks
- 投稿日:2019-07-11T00:12:03+09:00
ウィナー・ホッフ方程式をPythonで解いてみた,その4
ウィナーフィルタをアフィン射影法(APA1)で解く
数式2は
\begin{align} & \min_{\boldsymbol w_k} \|\boldsymbol w_k - \boldsymbol w_{k-1}\|^2 \\ & \text{subject to } \boldsymbol w_k^H \boldsymbol U_k = \boldsymbol d_k \\ \\ {\boldsymbol d}_k &= [d_{k-L_s+1}, \cdots, d_{k}] \\ {\boldsymbol U}_k &= [ {\boldsymbol u}_{k-L_s+1}, \cdots, {\boldsymbol u} _ {k} ] \\ {\boldsymbol u}_k &= [ u_k, \cdots, u_{k-K+1} ] \\ \end{align}を解いてこう。
\begin{align} \boldsymbol \xi_k &= \boldsymbol d_k - \boldsymbol w^H_{k-1} \boldsymbol U_k \\ \Delta \boldsymbol w &= \boldsymbol U_k ( \boldsymbol U_k^H \boldsymbol U_k )^{-1} \boldsymbol \xi^H_k\\ \boldsymbol w_k &= \boldsymbol w_{k-1} + \mu \boldsymbol U_k ( \boldsymbol U_k^H \boldsymbol U_k )^{-1} \boldsymbol \xi^H_k\\ \end{align}ただし,逆行列部分の安定性を確保するため,下記のようにする。
\begin{align} \boldsymbol w_k &= \boldsymbol w_{k-1} + \mu \boldsymbol U_k ( \alpha \boldsymbol I + \boldsymbol U_k^H \boldsymbol U_k )^{-1} \boldsymbol \xi^H_k\\ \end{align}Python で書くとこう。なお,計算が重いので$n = shift \times i$として,下記のように$shift$ずつ計算するようにしている。
\begin{align} \boldsymbol w_{last} = \boldsymbol 0 \\ \text{For } i = 0, 1, \cdots & \\ n &= L_s - shift \times i \\ \boldsymbol dk &= [d_{n-L_s}, \cdots, d_{n-1}] \\ \boldsymbol Uk &= \begin{bmatrix} u_{n-L_s} & u_{n-L_s+1} & \cdots & u_{n-L_s+K-1} & \cdots & u_{n-1} & u_{n} \\ u_{n-L_s-1} & u_{n-L_s} & \cdots & u_{n-L_s+K-2} & \cdots & u_{n-2} & u_{n-1} \\ \vdots & & \ddots & \vdots & & \vdots & \vdots \\ u_{n-L_s-K+1} & u_{n-L_s+1-K+1} & \cdots & u_{n-L_s} & \cdots & u_{n-K} & u_{n-K+1} \\ \end{bmatrix} \\ \\ \boldsymbol\xi k[i] &= \boldsymbol dk - {\boldsymbol w_{last}}^H \, \boldsymbol Uk \\ \boldsymbol w k[i] &= \boldsymbol w_{last} + \mu \, \boldsymbol Uk \, ( \alpha \boldsymbol I + {\boldsymbol Uk}^H \boldsymbol Uk )^{-1} \, {\boldsymbol \xi k[i]}^H\\ {\boldsymbol w_{last}} &= \boldsymbol w k[i] \\ \end{align}# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt import scipy.signal as sg from mpl_toolkits.mplot3d import Axes3D z = np.arange(0, 512) h0 = 1 / (1 + np.exp(0.0001 * (z - 128) ** 2)) #h0=1/(1+np.exp(0.03*z)) Wref = h0 / np.sum(h0) * 2 plt.plot(Wref) plt.title("$w_{ref}$") plt.show() #x = np.linspace(0, 1, 4096) x = np.linspace(0, 2, 8192) #y1 = np.sin(2 * np.pi * x) + 0.2 * np.sin(np.pi * 20 * (x + 0.1)) y1 = np.sin(2 * np.pi * x) + 0.2*np.sin(np.pi * 20 * x + 0.1 * np.pi) y2 = sg.lfilter(Wref, [1], y1) μ = 0.5 α = 0.00001 Ls = 512 K = 512 shift = 128 N = np.append(np.arange(Ls, len(x), shift), len(x)) yk = np.zeros(len(x)) last_wk = np.zeros(K) wk = np.zeros((len(N), K)) ξk = np.zeros((len(N), Ls)) for i, n in enumerate(N): dk = y2[n-Ls:n] #Uk = np.array([[ y1[n - k - l + 1] if n - k - l + 1 >= 0 else 0 for l in range(Ls, 0, -1)] for k in range(0, K)]) Uk = np.zeros((K, Ls)) for k in range(K): s1 = 0 s2 = n-Ls-k if s2 < 0: s1 = -s2 s2 = 0 if n-k > 0: Uk[k, s1:Ls] = y1[s2:n-k] ξk[i] = dk - last_wk.T @ Uk wk[i] = last_wk + μ * Uk @ np.linalg.inv(α * np.eye(Ls) + Uk.T @ Uk) @ np.conj(ξk[i].T) yk[n-Ls:n] = np.conj(wk[i].T) @ Uk last_wk = wk[i] plt.plot(N, np.sqrt(np.sum(ξk ** 2, axis=1))) plt.xlim(0) plt.legend(["$\|ξ_k\|$"]) plt.show() plt.plot(y2) plt.plot(yk) plt.xlim(0) plt.legend(["$y2$", "$yk$"]) plt.show() plt.plot(yk-y2) plt.xlim(0) plt.legend(["$yk-y2$"]) plt.show() err = np.sum(np.abs(wk - np.ones((wk.shape[0],1)) * Wref), axis=1) / np.sum(np.abs(Wref)) plt.plot(N, err) plt.xlim(0) plt.legend(['$\\frac{ \| w_k-w_{ref} \| }{ \| w_{ref} \| }$']) plt.show() XX, YY = np.meshgrid(np.arange(wk.shape[1]), N) plt.figure().add_subplot(111, projection='3d').plot_wireframe(XX, YY, wk) plt.title("$wk$") plt.show()