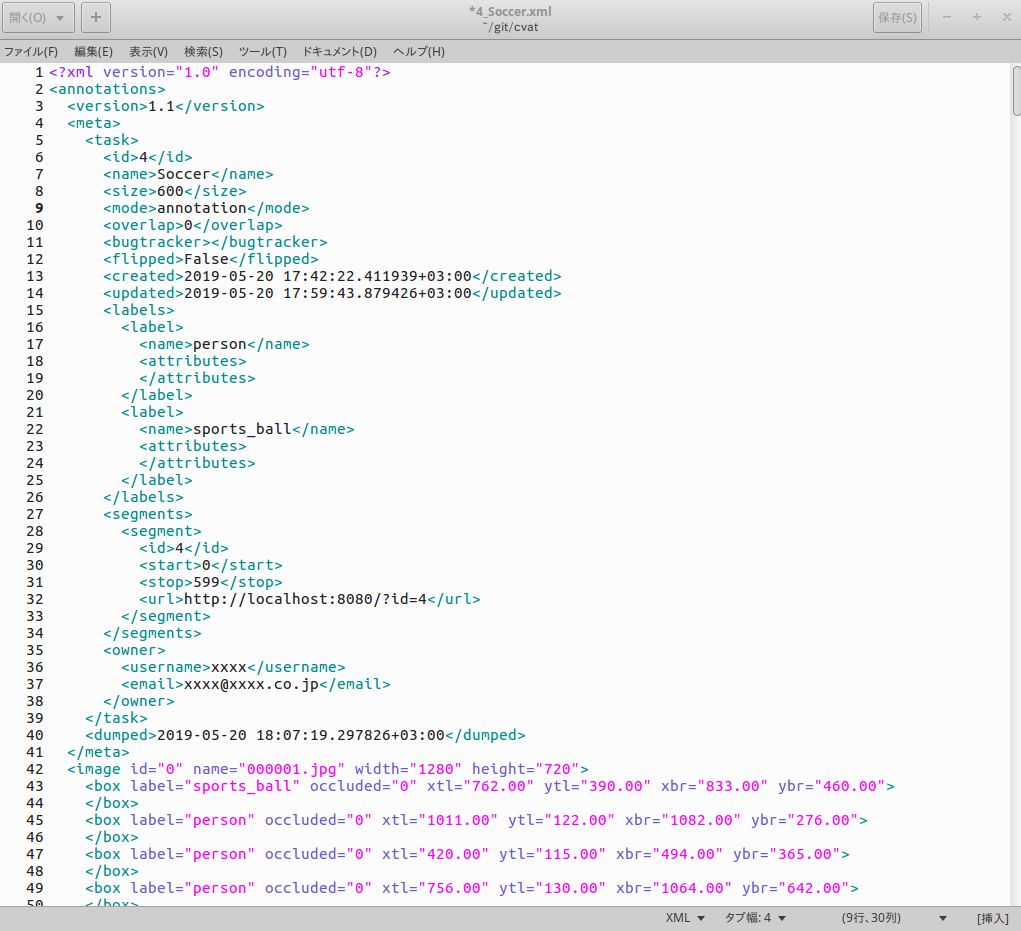
- 投稿日:2019-05-21T23:59:54+09:00
【備忘録】pythonとkivyで開発したアプリをiPhoneに実機転送する方法
注意
筆者自身が勉強中である為、この記事で説明はあまりできていません。
誤りがありましたらコメント頂けるとありがたいです。
やりたいこと
pythonを勉強したい!
なんか適当にアプリを作りたい!
できるならスマホアプリを作りたい!
(外出先でいろいろ遊べるので。)ひとまず、
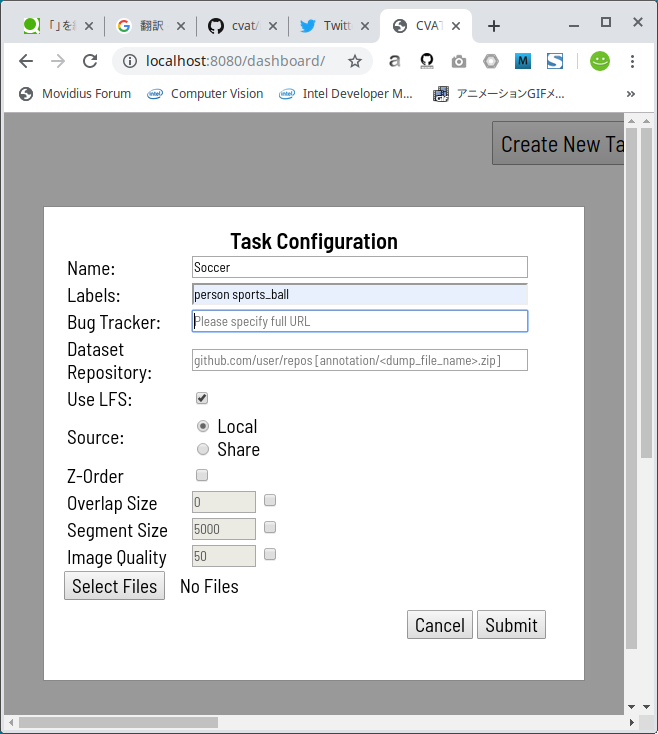
kivyのtutorialとして提供されているPong GameをiPhone実機で実行することを目標にする。実行環境
python3.6.5(Kivy3.appを入れたらこのバージョンのpythonがインストールされた)
kivy1.10.1
Cython0.28.1
MacmacOS Mojave 10.14.4
Xcode10.2.1
iPhoneiOS 12.2手順
基本的にはここに書いてあるコマンドを実行していけばよいが、一部補足して記載する。
https://github.com/kivy/kivy-ios1
git clonegit clone https://github.com/kivy/kivy-ios.gitここにある
toolchain.pyをあとで実行するので、git cloneしておく。
kivy-iosディレクトリが作成されるので、cd kivy-iosしておく。2 権限(?)の設定
2-1
kivyのpythonバージョンの確認
kivyとタイプするとpythonプロンプトが起動する。このとき、上図のようにpythonのバージョンを確認できる。
※筆者はbrewによりpython 3.7.3を元々インストールしていたが、Kivy3.appによりkivyをインストールしたところ、kivyにはpython 3.6.5が関連付いた。
パスも異なる為共存しても問題ないが、pythonを実行する際はどの場所にあるどのバージョンのpythonを実行しているかを気にする必要がある。2-2
pipのpythonバージョンの確認head -1 $(which pip)
pipコマンド(実態はpythonスクリプト)のシバンに書いてあるpythonのバージョンを確認する。
シバンだけで確認できない場合は、シンボリックリンクを追ったりpython --versionしてみる。
2つのバージョンが一致していれば、2-4へ移動。2つのバージョンが一致していない場合、一致させる必要がある。
おそらく、kivyのpythonバージョンに合わせる方が楽。2-3
pipを作成し、バージョンを一致させる適当なディレクトリに
cdして下記を実行する。
※実行するpythonは2-1で確認したkivyのpythonで実行する。
上図で言うpython 3.6.5がどこかにあるのでそのpythonで実行する。wget https://bootstrap.pypa.io/get-pip.py python get-pip.pyこのときに使用する
pythonがポイントで、pythonのパス・バージョンに応じたpipが生成される。
また、実行したpythonが存在するディレクトリにpipが作成される為、/usr/local/bin/pythonなどで実行するとpipが上書きされる可能性がある為注意。
なお、後続の処理で実行するtoolchain.pyの中でwhich pipを行いpipのパスを取得しているようなので、pipを作成した場合はwhich pipでどのpipが参照されているかを確認した方がよい。2-4
pip実行pip install -r requirements.txtこの権限(?)の設定は
python毎に実行が必要らしく、kivyに関連付いているpythonのバージョンを変更した場合、再度実行が必要になる。
ちなみにrequirements.txtの内容は下記である。
バージョンの設定か何かをしているようだが、よく分からない。。requirements.txtpbxproj==2.5.1 requests>=2.133 Xcodeのコマンドラインツールのインストール
xcode-select --install1つ注意点として、電源を繋いでいないとインストールできなかった。
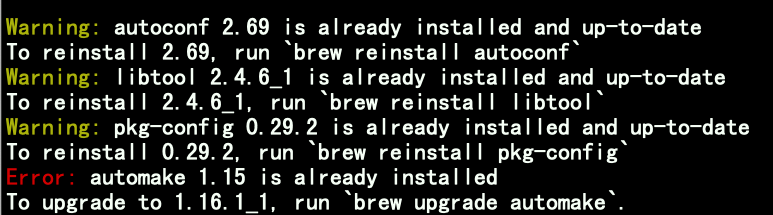
4 なんかインストール
brew install autoconf automake libtool pkg-config英文を読む限り必須作業なのか微妙だが、やれるものはやっておこう。
インストール時に下図のように警告やエラーが出ることがある。
警告は、「それ最新入ってるよ」なのでOK。
エラーは、「それ入ってるけどちょい古いから更新かけてね」なので、更新をかける。4-1 最新バージョンへ更新
brew upgrade automake4-2 リンクの設定
brew link libtool
上図のように警告が出ることがある。
これも「既にリンクあるよ」なのでOK。5 Cythonのインストール
pip install cython==0.28.12019-05-20現在、こちらのkivyのインストール手順ではCython=0.23を指定している。
上記は有志の方による翻訳のhtml版だが、翻訳時のバージョンが単に0.23だっただけだと推察。
※有志の方、翻訳ありがとうございます!大変助かっています!6 一旦確認
./toolchain.py recipesここで上記コマンドが正常に実行できれば、ここまでの手順はOKと判断できる。
出力結果はrecipeと呼ばれるものの一覧であり、よく分からないがこれらが何なのかは重要なことだと思うので後で調べる。7 ビルド
./toolchain.py build python3 kivyビルドが1回以上必要らしいが、時間がかかることがある。
初回は40分ほどかかった。
なお標準出力にログが大量に出力されるが、ほとんどがDEBUGログである為toolchain.pyのどこかをいじればログの出力を抑制できそうな気がする。
また、作成したアプリに応じてビルド対象を増減する必要がある。8 Xcode Projectの作成
./toolchain.py create <title> <app_directory>上記の書式で
toolchain.pyを実行する。
第2引数の「<title>」は作成するアプリの名前なので慎重に決定する。
※<app_directory>にはmain.pyが存在していないといけない。9 Xcodeでプロジェクトを開く
open <title>-ios/<title>.xcodeproj上記コマンドを実行すると、Xcodeで使用するファイルをまとめたディレクトリ(
<title>-ios)が作成される。
<title>.xcodeprojがその名の通りXcodeのプロジェクトファイルなのでopenする。
※作成された<title>-iosの中身を勝手にいじってはいけない。10 まずはSimulatorで実行
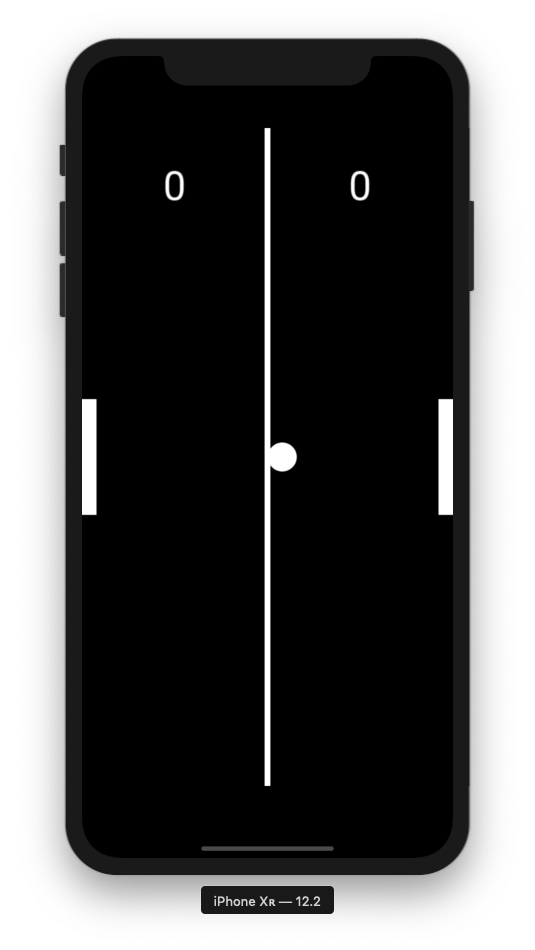
実機で動かす前にSimulatorで実行ができないと話にならないので、Simulatorで実行してみる。
再生ボタンを押下後、下図のようにSimulatorが起動する(一旦iOSのバージョンは適当でよい)。
※初回実行時は少し時間がかかる。
リンゴのマークとプログレスバーが表示される。
左にスライドすると下図のようにpongのアプリがあるのでクリックする。
すると下図のようにpongがSimulator上で実行できていることが確認できる。
11 iPhone実機転送の準備
11-1 iPhoneをMacに接続する。
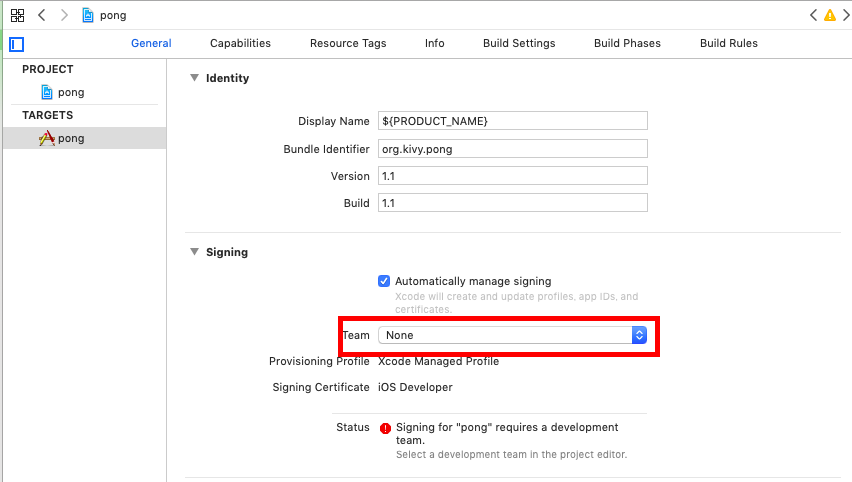
11-2 下図の「Team」を選択する。
※個人開発でも個人アカウントが出てくるのでそれを選択。
※場合によってはapple IDにログインが求められる。
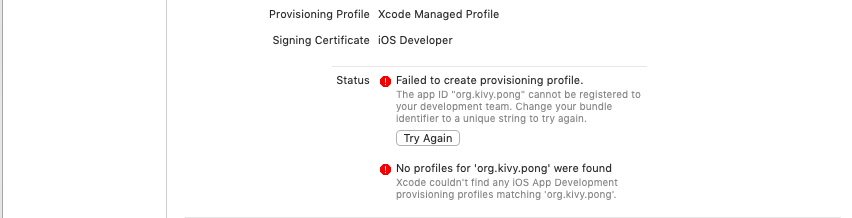
11-3 下図のようなエラーが発生した場合は、こちらのサイト様を参考に解消する。
11-4 下図のように出力先を実機にする。
12 iPhone実機転送
12-1 再生ボタンを押下!
12-2 iPhone側でアプリの実行を許可する。
アプリ単位ではなくdeveloper単位の様子。
以上。






- 投稿日:2019-05-21T23:28:17+09:00
Google Colaboratory を始めて使うときの注意点
はじめに
Google Colaboratoryは設定不要で無料で使えるjupyter notebook環境で、GPU、TPUを無料で使えるのが強みです。
Colaboratory へようこそ - Colaboratory
初めて使ってみて引っかかったところを備忘録としてまとめます。
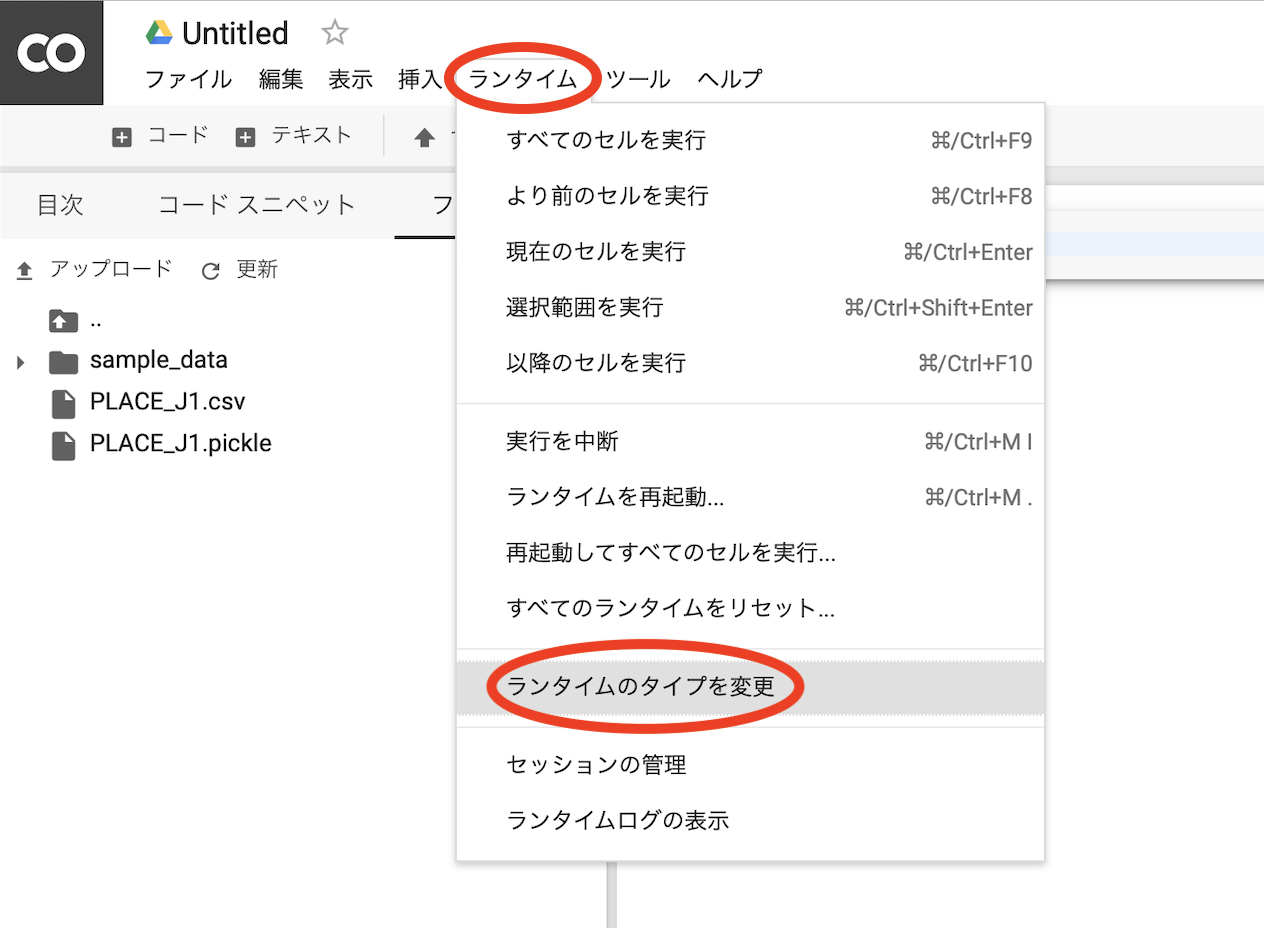
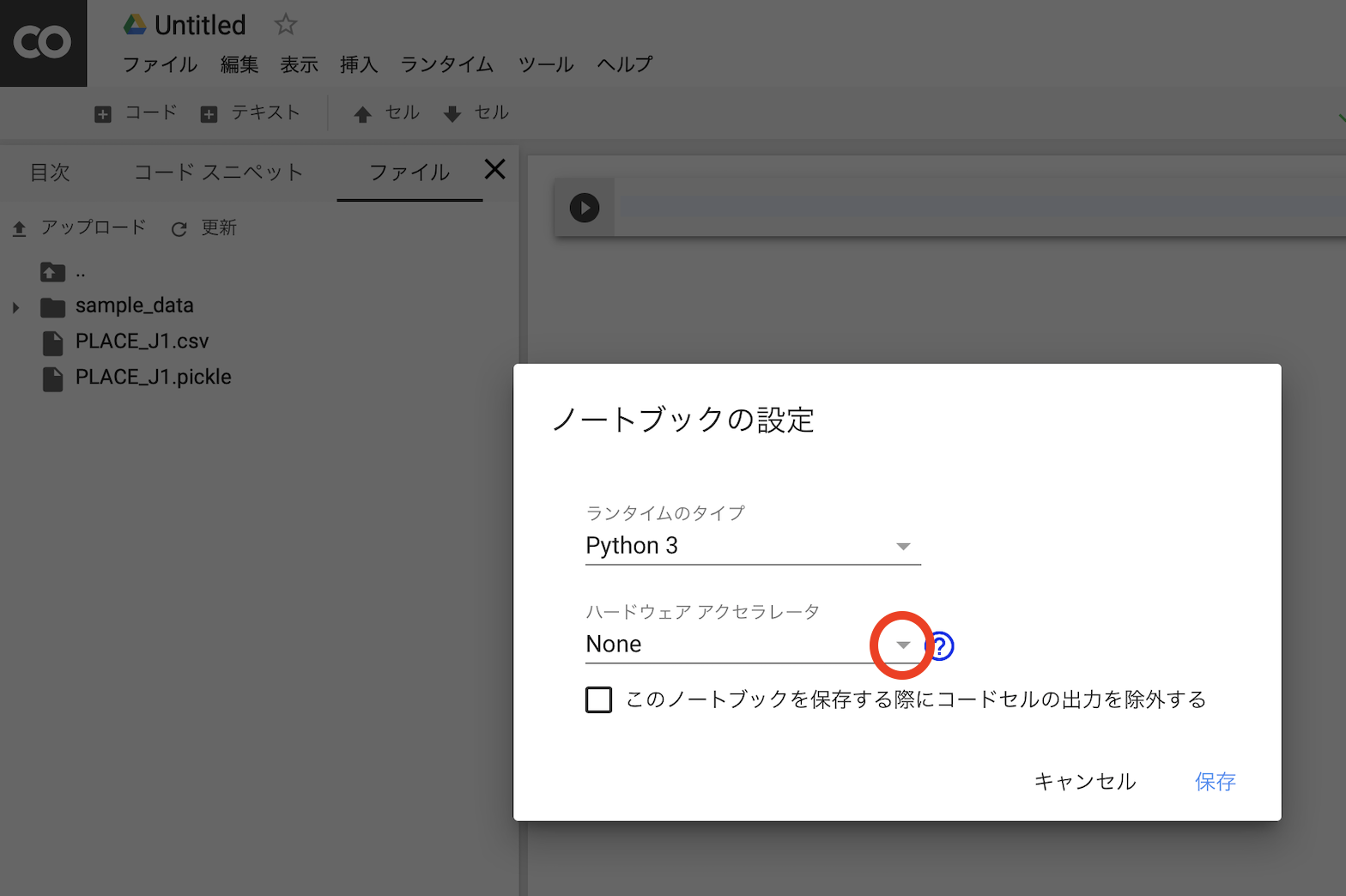
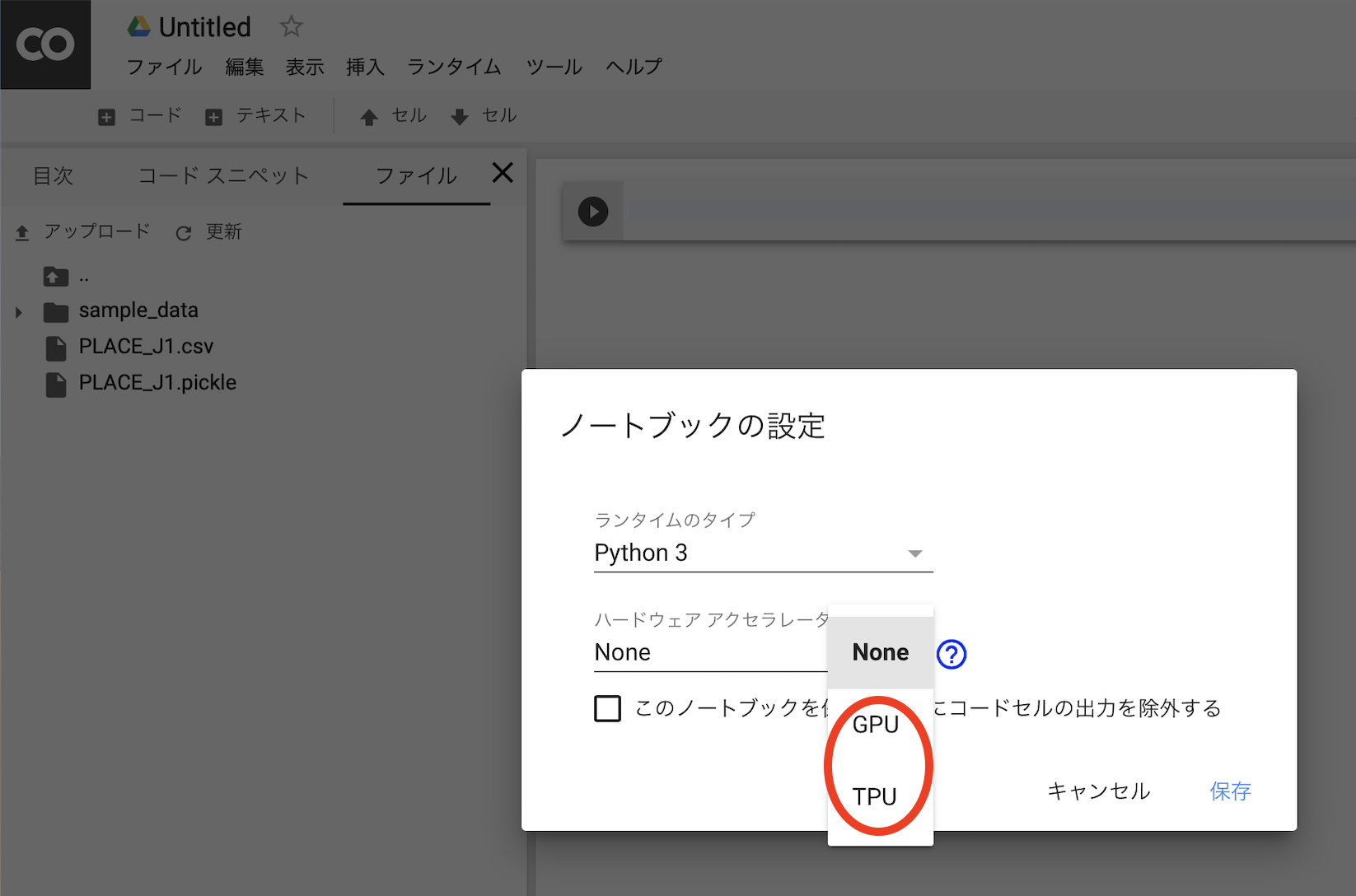
GPU、TPUを使えるようにする
デフォルトではGPUでもTPUでもないので注意が必要です。
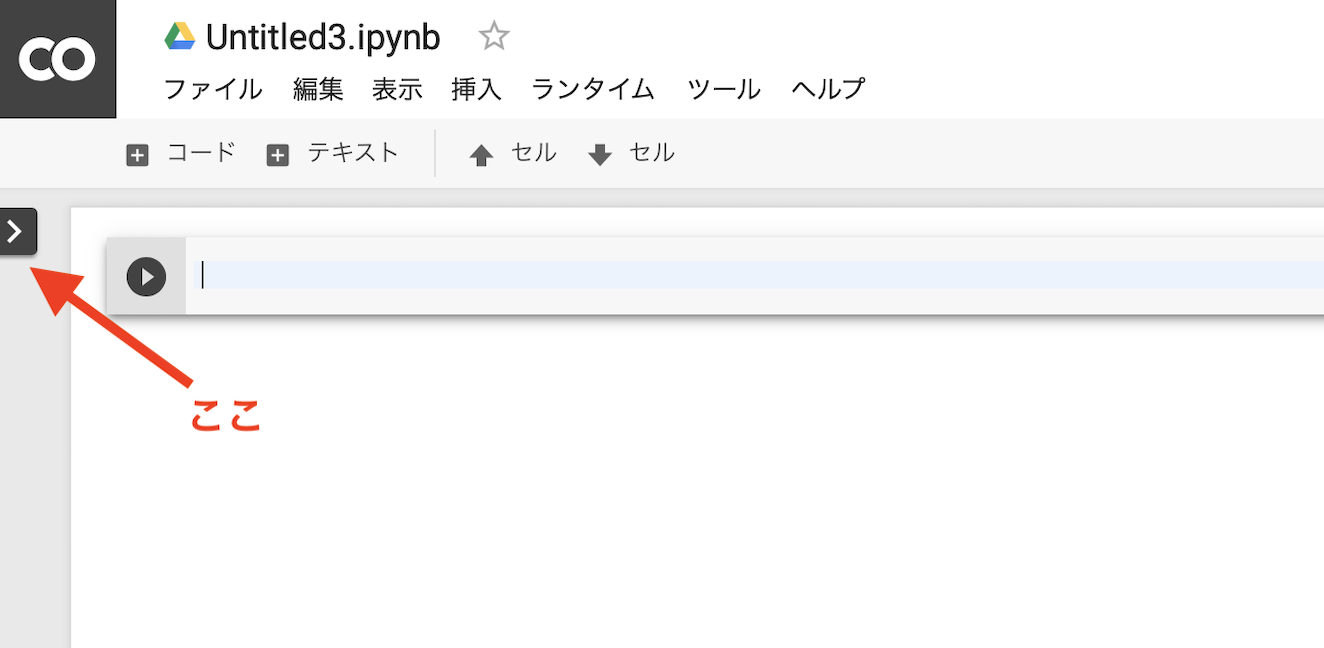
ファイルの入出力
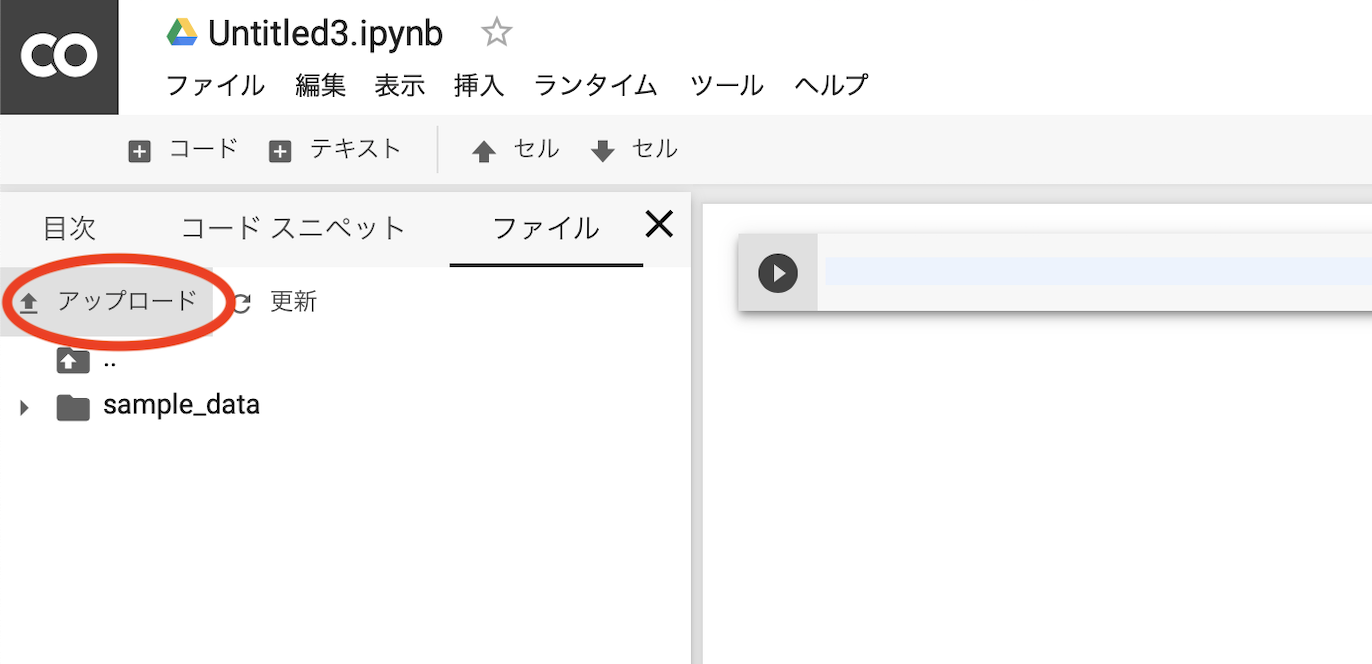
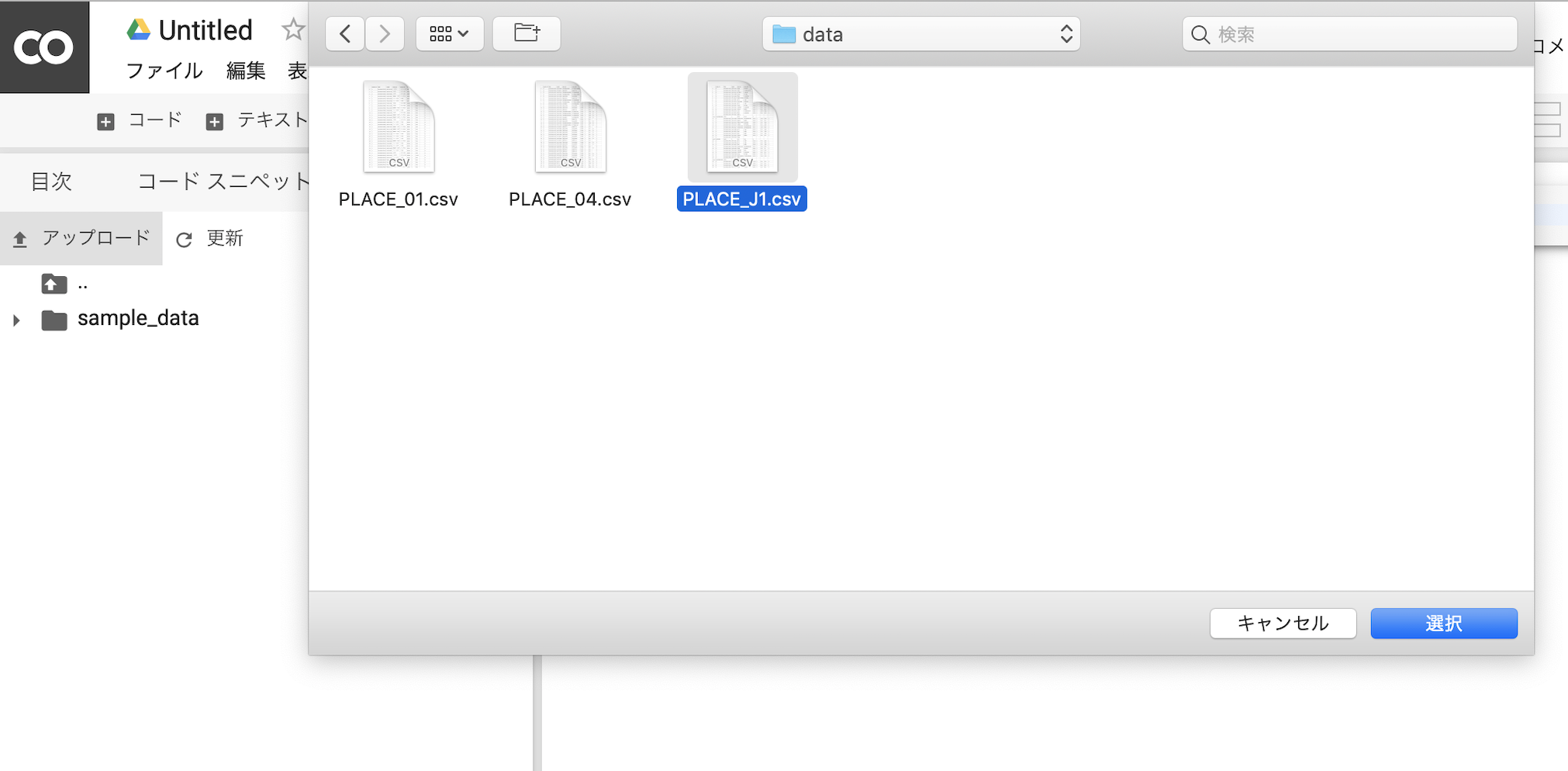
ファイルのアップロードも簡単です。
アップロード
ここで、この方法は簡単ですがアップロードが驚異的に遅い点にも注意が必要です。
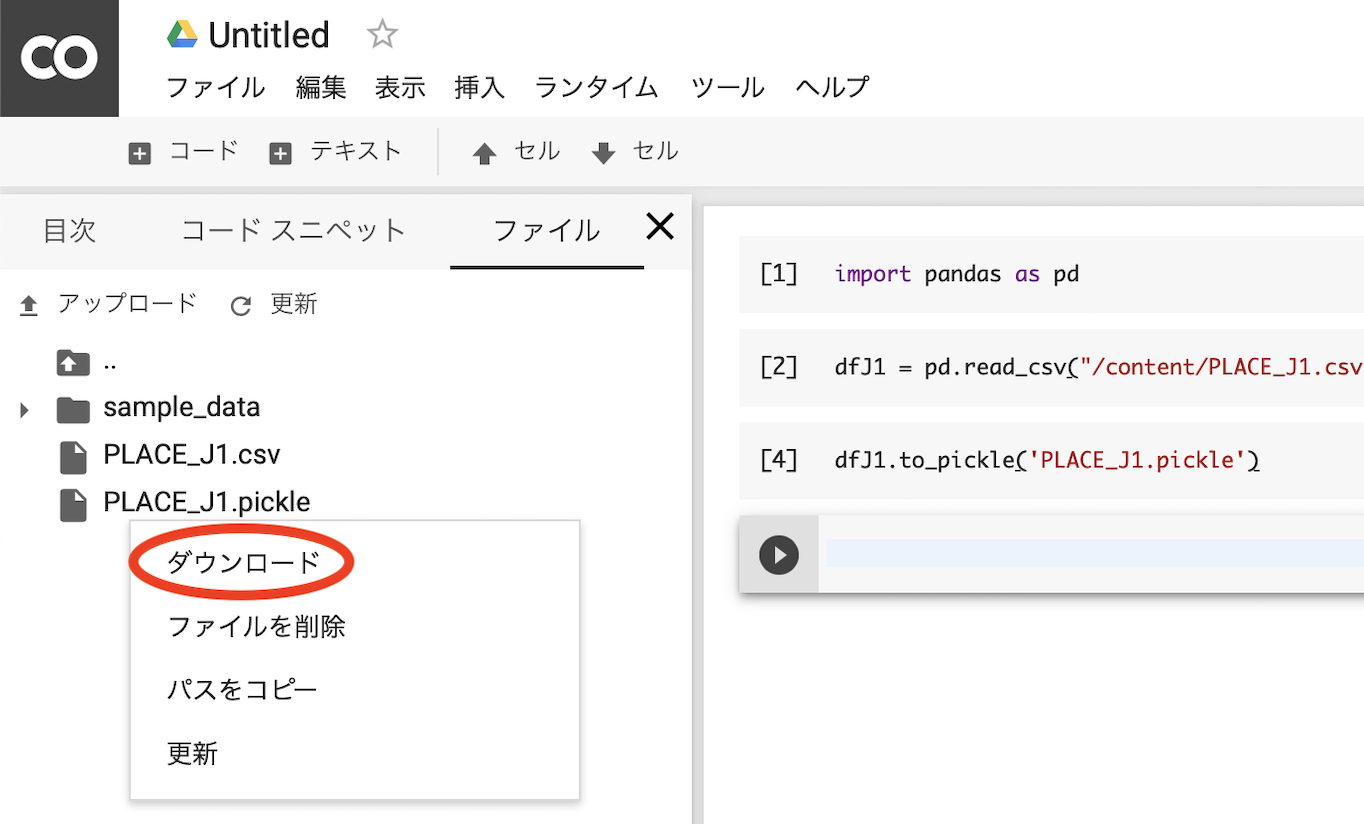
Google Driveから読み込むのが速いです。ダウンロード
こちらは思いのほか簡単にできるようです。
- 投稿日:2019-05-21T23:28:03+09:00
pandasのseriesにインデックスのリストを渡してまとめて処理する
seriesにリストを渡せることを知ったので具体例を書いておきます。
まず適当にseriesを生成して、
import pandas as pd labels = ["a","b","c","d","e"] series = pd.Series(index=labels)a NaN
b NaN
c NaN
d NaN
e NaNseries[["a","b","e"]] = [1,2,3]a 1.0
b 2.0
c NaN
d NaN
e 3.0まとめて処理できて便利そうです。
- 投稿日:2019-05-21T23:27:46+09:00
csvをpickleで保存して読み取りを速くする
はじめに
データ読み込みに毎回何十秒もかかっていたらデータ分析どころではありません。
pickleで保存したら速いようなのでその方法と欠点をまとめます。csvをpickleで保存する
import pandas as pd df = pd.read_csv("/Users/data/alldata.csv")csvを読み込んで
df.to_pickle('alldata.pickle')これでpickleが出力されます。
pickleを読み込む
df = pd.read_pickle('/Users/data/alldata.pickle')適切なパスを指定して読み込みます。
ちなみに各々かかる時間を計測すると、
%time df1 = pd.read_pickle('/Users/data/alldata.pickle') %time df2 = pd.read_csv('/Users/data/alldata.csv')CPU times: user 3.36 s, sys: 2.86 s, total: 6.22 s
Wall time: 6.82 s
CPU times: user 29.2 s, sys: 8.65 s, total: 37.8 s
Wall time: 42 s6倍ほどの差があるようです。
利点と欠点
pickle速いから全部それでいいや、という訳ではなく、csvはデータが破損してもまだ救いようがありますがpickleは厳しいです。
大事なデータはcsvとpickle両方とも出力しておくのが良いでしょう。
- 投稿日:2019-05-21T23:07:25+09:00
CentOS+Python+Selenium+Chromeで画面キャプチャ取得
Python、pipがインストールされていることを確認
python3 --version pip --versionSeleniumをインストール
# Seleniumのインストール pip install selenium # Seleniumがインストールされたことを確認 pip freezeGoogleChromeをインストール
Chrome用リポジトリの作成 vi /etc/yum.repos.d/google-chrome.repo # インストール yum -y install google-chrome-stable libOSMesa # バージョン確認 google-chrome --versiongoogle-chrome.repo[google-chrome] name=google-chrome baseurl=http://dl.google.com/linux/chrome/rpm/stable/x86_64 enabled=1 gpgcheck=1 gpgkey=https://dl.google.com/linux/linux_signing_key.pubChromeDriverをインストール
最新バージョンは↓から確認すること。
https://sites.google.com/a/chromium.org/chromedriver/downloads# 事前準備 yum -y install libX11 GConf2 fontconfig # ChromeDriverインストール wget https://chromedriver.storage.googleapis.com/74.0.3729.6/chromedriver_linux64.zip unzip chromedriver_linux64.zip mv chromedriver /usr/local/bin/日本語フォント(IPAフォント)をインストール
# インストール yum -y install ipa-gothic-fonts ipa-mincho-fonts ipa-pgothic-fonts ipa-pmincho-fonts # フォントキャッシュを更新 fc-cache -fv画面キャプチャ例
test.pyfrom selenium import webdriver from selenium.webdriver.chrome.options import Options url1 = "https://www.google.com/" url2 = "https://www.google.com/search?q=python" # Chromeのヘッドレスモードを有効にする options = Options() options.add_argument('--headless') options.add_argument('--no-sandbox') options.add_argument('--disable-gpu') options.add_argument('--window-size=1280,1024') # Chromeを起動 driver = webdriver.Chrome(options=options) # Googleトップページの画面キャプチャを保存 driver.get(url1) driver.save_screenshot("google1.png") # キーワード検索結果の画面キャプチャを保存 driver.get(url2) driver.save_screenshot("google2.png") # Chromeを終了 driver.quit()
ワーニングメッセージが表示された場合の対処方法
# 変更前 webdriver.Chrome(chrome_options=options) # 変更後 webdriver.Chrome(options=options)バージョン不一致によるエラーが表示された場合
ChromeDriverとChromeのバージョン不一致によりエラーが表示される。
利用しているChromeのバージョンにあったChromeDriverを入れ直すことで解消可能。#エラーが発生した際に確認した情報 google-chrome --version Google Chrome 74.0.3729.157 chromedriver --version ChromeDriver 2.45.615279 (12b89733300bd268cff3b78fc76cb8f3a7cc44e5)ChromeDriver2.45はChrome70-72がサポート範囲だったためエラー





- 投稿日:2019-05-21T22:55:01+09:00
PythonでSambaサーバーにあるExcelファイルを編集する
概要
PythonからSambaファイルサーバーに接続し、xlsxファイルを開き、編集、保存する。
なお、一時ファイルを作らずに作業を行う。環境
- Ubuntu Server 18.04.2 LTS
- Python 3.6.7
追加パッケージ
- openpyxl
- pysmb
コード
import io import platform import openpyxl import smb from smb.SMBConnection import SMBConnection conn = SMBConnection( "username", "password", platform.uname().node, "remote_name", use_ntlm_v2=True, ) # ファイルサーバーに接続する conn.connect("hostname", 139) root = "/" filepath = "/hoge.xlsx" # 開く with io.BytesIO() as inputfile: conn.retrieveFile(root, filepath, inputfile) workbook = openpyxl.load_workbook(inputfile) # ここで編集操作など # 保存 with io.BytesIO() as outputfile: workbook.save(outputfile) outputfile.seek(0) conn.storeFile(root, filepath, outputfile)
- 投稿日:2019-05-21T22:08:31+09:00
GAN, DCGAN, ConditionalGANを実装してみたった
GAN, DCGAN, ConditionalGANを Pytorch, Chainer, Kerasで実装してみました!(今更だけど)
実装の仕方は我流かもしれないです?
cifar10、MNISTで試してだいたい成功?してます
https://github.com/yoyoyo-yo/DeepLearningMugenKnock
の「画像生成編」に入れてます。
試してみてください!!
ConditionalGANはDCGANで生成したい画像のラベルをこちら側が指定できるようにしたものです!(それぞれの詳しい説明は「画像生成編」のREADMEに書いてます)
これから他のGANとTensorFlow実装をやります(やるとは言ってない
- 投稿日:2019-05-21T21:48:00+09:00
PythonでSambaサーバーにあるWordファイルを編集する
概要
PythonからSambaファイルサーバーに接続し、docxファイルを開き、編集、保存する。
なお、一時ファイルを作らずに作業を行う。環境
- Ubuntu Server 18.04.2 LTS
- Python 3.6.7
追加パッケージ
- python-docx
- pysmb
コード
import io import platform import docx import smb from smb.SMBConnection import SMBConnection conn = SMBConnection( "username", "password", platform.uname().node, "remote_name", use_ntlm_v2=True, ) # ファイルサーバーに接続する conn.connect("hostname", 139) root = "/" filepath = "/hoge.docx" # 開く with io.BytesIO() as inputfile: conn.retrieveFile(root, filepath, inputfile) doc = docx.Document(inputfile) # ここで編集操作など # 保存 with io.BytesIO() as outputfile: doc.save(outputfile) outputfile.seek(0) conn.storeFile(root, filepath, outputfile)
- 投稿日:2019-05-21T21:47:24+09:00
30分で始めるDjangoでwebアプリ(hello worldまで)
Djangoを触る機会があったので、ver2.1の公式ドキュメントのチュートリアル通りにお試ししてみた作業ログ。
タイトルは盛り過ぎました。
pipのインストールとアクセス制限のところで時間喰って45分くらいかかりましたUbuntuサーバを用意
Vagrantのubuntu/bionic64を使って構築しました。
vagrant@django-serv:~$ cat /etc/lsb-release DISTRIB_ID=Ubuntu DISTRIB_RELEASE=18.04 DISTRIB_CODENAME=bionic DISTRIB_DESCRIPTION="Ubuntu 18.04.2 LTS" vagrant@django-serv:~$Python環境は
vagrant@django-serv:~$ python3 --version Python 3.6.7 vagrant@django-serv:~$ python3 Python 3.6.7 (default, Oct 22 2018, 11:32:17) [GCC 8.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import django Traceback (most recent call last): File "<stdin>", line 1, in <module> ModuleNotFoundError: No module named 'django' >>> vagrant@django-serv:~$Djangoはまだ入っていない。
さっそく始めましょう。
Django ドキュメント | Django ドキュメント | Django以下、VMのIPアドレスは
192.168.244.201とします。Djangoのインストール
クイックインストールガイド | Django ドキュメント | Django
ここからInstall the Django codeを参照。
vagrant@django-serv:~$ pip install Django==2.1 Command 'pip' not found, but can be installed with: apt install python-pip Please ask your administrator. vagrant@django-serv:~$oh...
pipのインストール
vagrant@django-serv:~$ sudo apt install python-pip Reading package lists... Done Building dependency tree Reading state information... Done : :大量にパッケージインストールされるけどこれは2.7版だった。
正解はpython3-pipだった。vagrant@django-serv:~$ sudo apt install python3-pip Reading package lists... Done Building dependency tree Reading state information... Done The following additional packages will be installed: dh-python libpython3-dev libpython3.6-dev python3-crypto python3-dev python3-distutils python3-keyring python3-keyrings.alt python3-lib2to3 python3-secretstorage python3-setuptools python3-wheel python3-xdg python3.6-dev Suggested packages: python-crypto-doc gnome-keyring libkf5wallet-bin gir1.2-gnomekeyring-1.0 python-secretstorage-doc python-setuptools-doc The following NEW packages will be installed: dh-python libpython3-dev libpython3.6-dev python3-crypto python3-dev python3-distutils python3-keyring python3-keyrings.alt python3-lib2to3 python3-pip python3-secretstorage python3-setuptools python3-wheel python3-xdg python3.6-devvagrant@django-serv:~$ ll /usr/bin/pip* -rwxr-xr-x 1 root root 292 May 16 2018 /usr/bin/pip* -rwxr-xr-x 1 root root 292 May 16 2018 /usr/bin/pip2* -rwxr-xr-x 1 root root 293 May 16 2018 /usr/bin/pip3*んー。。
Djangoインストール
vagrant@django-serv:~$ pip3 install Django==2.1 Collecting Django==2.1 Downloading https://files.pythonhosted.org/packages/51/1a/e0ac7886c7123a03814178d7517dc822af0fe51a72e1a6bff26153103322/Django-2.1-py3-none-any.whl (7.3MB) 100% |████████████████████████████████| 512kB 1.8MB/s Installing collected packages: pytz, Django Successfully installed Django-2.1 pytz-2019.1vagrant@django-serv:~$ python3 Python 3.6.7 (default, Oct 22 2018, 11:32:17) [GCC 8.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import django >>> print(django.get_version()) 2.1 >>>vagrant@django-serv:~$ python -m django --version /usr/bin/python: No module named django vagrant@django-serv:~$ python3 -m django --version 2.1 vagrant@django-serv:~$ python --version Python 2.7.15rc1 vagrant@django-serv:~$あぁ、python2が入ったばかりに面倒なことに。
あとでやりなおそう。アプリケーションの作成
https://docs.djangoproject.com/ja/2.1/intro/tutorial01/
プロジェクト作成
vagrant@django-serv:~src$ which django-admin vagrant@django-serv:~src$ん?
vagrant@django-serv:~src$ django-admin startproject mysite Command 'django-admin' not found, but can be installed with: apt install python-django-common Please ask your administrator. vagrant@django-serv:~src$あれ?
探してみたら、こんなところにあった
vagrant@django-serv:~src$ ls ~/.local/bin/ __pycache__ django-admin django-admin.pyvagrant@django-serv:~src$ export PATH=$PATH:~/.local/bin vagrant@django-serv:~src$ which django-admin /home/vagrant/.local/bin/django-admin vagrant@django-serv:~src$vagrant@django-serv:~src$ django-admin startproject mysite vagrant@django-serv:~src$ ls mysite vagrant@django-serv:~src$ vagrant@django-serv:~/src$ tree . └── mysite ├── manage.py └── mysite ├── __init__.py ├── settings.py ├── urls.py └── wsgi.py 2 directories, 5 files vagrant@django-serv:~/src$開発用サーバ起動
プロジェクトに移動して
python3 manage.py runserverを実行vagrant@django-serv:~/src$ cd mysite/ vagrant@django-serv:~/src/mysite$ python3 manage.py runserver Performing system checks... System check identified no issues (0 silenced). You have 15 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them. May 21, 2019 - 11:58:13 Django version 2.1, using settings 'mysite.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CONTROL-C.これでlocalhostからのみアクセスするサーバが起動する。
VMで動かしてるのでlocalhostからcurlするしかないね。もう一つシェルを起動し、
curlすると以下のようにアクセスログが表示される。May 21, 2019 - 11:58:13 Django version 2.1, using settings 'mysite.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CONTROL-C. [21/May/2019 12:00:38] "GET / HTTP/1.1" 200 16348これだとわかりづらいので、一度
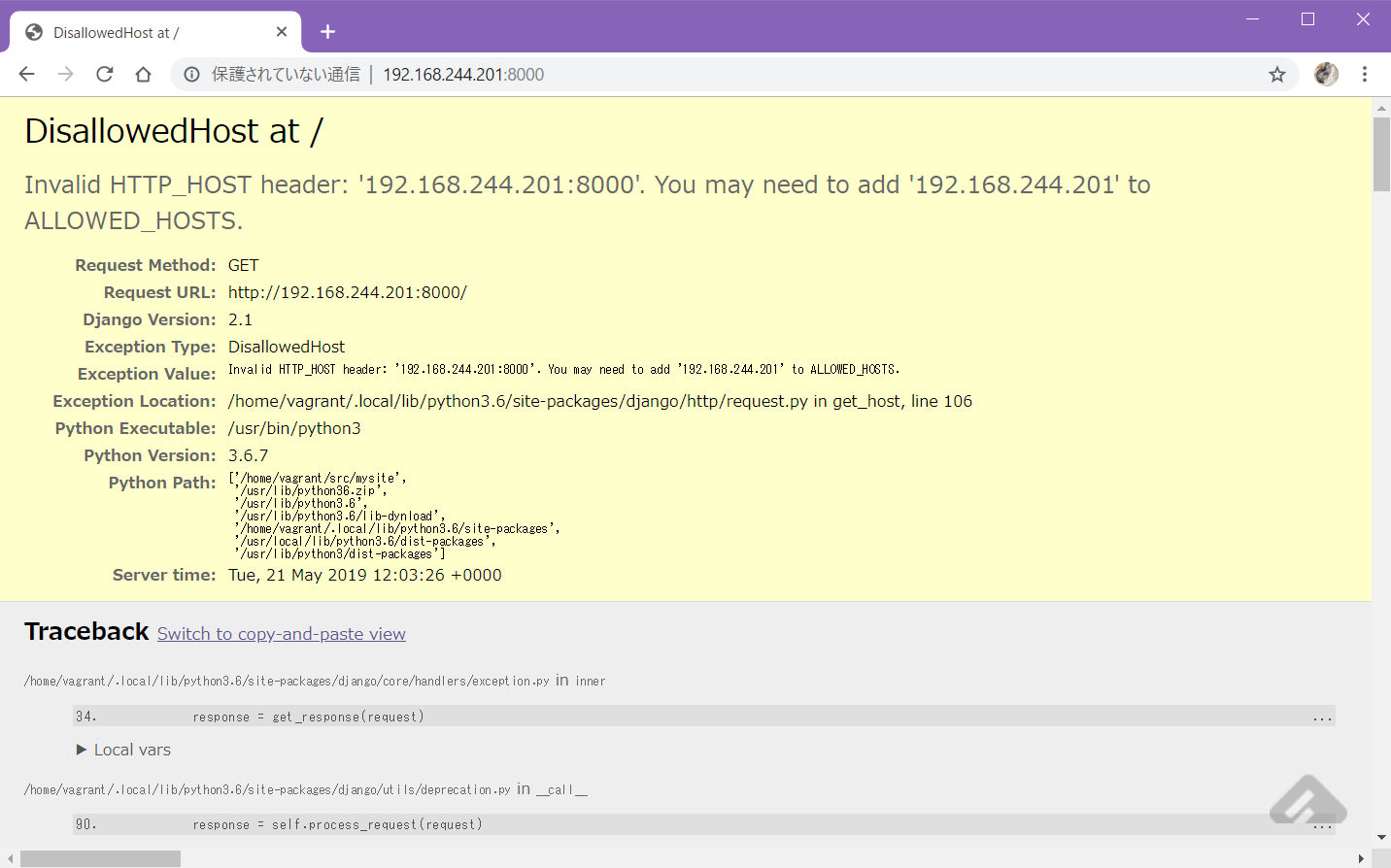
Ctrl-cで停止し、0.0.0.0でlistenするように起動しなおす。vagrant@django-serv:~/src/mysite$ python3 manage.py runserver 0:8000 Performing system checks... System check identified no issues (0 silenced). You have 15 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them. May 21, 2019 - 12:03:09 Django version 2.1, using settings 'mysite.settings' Starting development server at http://0:8000/ Quit the server with CONTROL-C.ブラウザからアクセス。
ぐぬぬ…
デフォルトでアクセス制限してるのか。Django version 2.1, using settings 'mysite.settings' Starting development server at http://0:8000/ Quit the server with CONTROL-C. Invalid HTTP_HOST header: '192.168.244.201:8000'. You may need to add '192.168.244.201' to ALLOWED_HOSTS. Bad Request: / [21/May/2019 12:03:26] "GET / HTTP/1.1" 400 59658 Invalid HTTP_HOST header: '192.168.244.201:8000'. You may need to add '192.168.244.201' to ALLOWED_HOSTS. Bad Request: /favicon.ico [21/May/2019 12:03:27] "GET /favicon.ico HTTP/1.1" 400 59574--- mysite/settings.py.org 2019-05-21 11:53:40.067134637 +0000 +++ mysite/settings.py 2019-05-21 12:12:18.185914636 +0000 @@ -27,3 +27,3 @@ -ALLOWED_HOSTS = [] +ALLOWED_HOSTS = ["192.168.244.201"]
ALLOWED_HOSTSの内容はローカルのVMなどで外部アクセス制御を考えなくてもよければ["*"]でも良い。Django 1.5以降ではALLOWED_HOSTSの設定が必要 – ymyzk’s blog
気を取り直して再実行。
vagrant@django-serv:~/src/mysite$ python3 manage.py runserver 0:8000 Performing system checks... System check identified no issues (0 silenced). You have 15 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them. May 21, 2019 - 12:12:48 Django version 2.1, using settings 'mysite.settings' Starting development server at http://0:8000/ Quit the server with CONTROL-C. [21/May/2019 12:12:49] "GET / HTTP/1.1" 200 16348 [21/May/2019 12:12:49] "GET /static/admin/css/fonts.css HTTP/1.1" 200 423 [21/May/2019 12:12:49] "GET /static/admin/fonts/Roboto-Bold-webfont.woff HTTP/1.1" 200 82564 [21/May/2019 12:12:49] "GET /static/admin/fonts/Roboto-Regular-webfont.woff HTTP/1.1" 200 80304 [21/May/2019 12:12:49] "GET /static/admin/fonts/Roboto-Light-webfont.woff HTTP/1.1" 200 81348アプリケーションの作成
チュートリアル通り、「Pollsアプリ」を作成する。
実行するコマンドはpython3 manage.py startapp polls
mysite配下じゃないのねーと思いつつ、チュートリアル通りmanage.pyと同じ階層に作成vagrant@django-serv:~/src/mysite$ ls db.sqlite3 manage.py mysite vagrant@django-serv:~/src/mysite$ ls mysite/ __init__.py __pycache__ settings.py settings.py.org urls.py wsgi.py vagrant@django-serv:~/src/mysite$ python3 manage.py startapp polls vagrant@django-serv:~/src/mysite$ ls db.sqlite3 manage.py mysite polls vagrant@django-serv:~/src/mysite$ tree . ├── db.sqlite3 ├── manage.py ├── mysite │ ├── __init__.py │ ├── __pycache__ │ │ ├── __init__.cpython-36.pyc │ │ ├── settings.cpython-36.pyc │ │ ├── urls.cpython-36.pyc │ │ └── wsgi.cpython-36.pyc │ ├── settings.py │ ├── settings.py.org │ ├── urls.py │ └── wsgi.py └── polls ├── __init__.py ├── admin.py ├── apps.py ├── migrations │ └── __init__.py ├── models.py ├── tests.py └── views.py 4 directories, 18 files vagrant@django-serv:~/src/mysite$Viewの作成
polls/views.pyを開く。中身は何もないので、チュートリアル通りのコードを実装する。
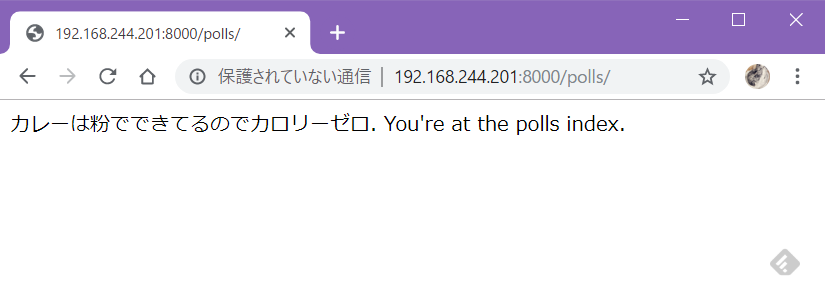
テンプレートとして作成された最初の状態とimportが変わってるので注意。polls/views.pyfrom django.http import HttpResponse # Create your views here. def index(request): return HttpResponse("カレーは粉でできてるのでカロリーゼロ. You're at the polls index.")URLconfの作成
唐突に
URLconfという単語が出てきたけど、作成したViewを呼び出すためのURLを設定するもの、という感じかな?
polls/urls.pyを作成する。polls/urls.pyfrom django.urls import path from . import views urlpatterns = [ path('', views.index, name='index'), ]
path()の引数については、チュートリアル1ページ目の末尾に載っているのでご参考。次に
mysite/urls.pyに、上記polls/urls.pyの内容を取り込む。--- mysite/urls.py.org 2019-05-21 11:53:40.067134637 +0000 +++ mysite/urls.py 2019-05-21 12:26:52.223474670 +0000 @@ -16,5 +16,6 @@ from django.contrib import admin -from django.urls import path +from django.urls import include, path urlpatterns = [ + path('polls/', include('polls.urls')), path('admin/', admin.site.urls),これで再度
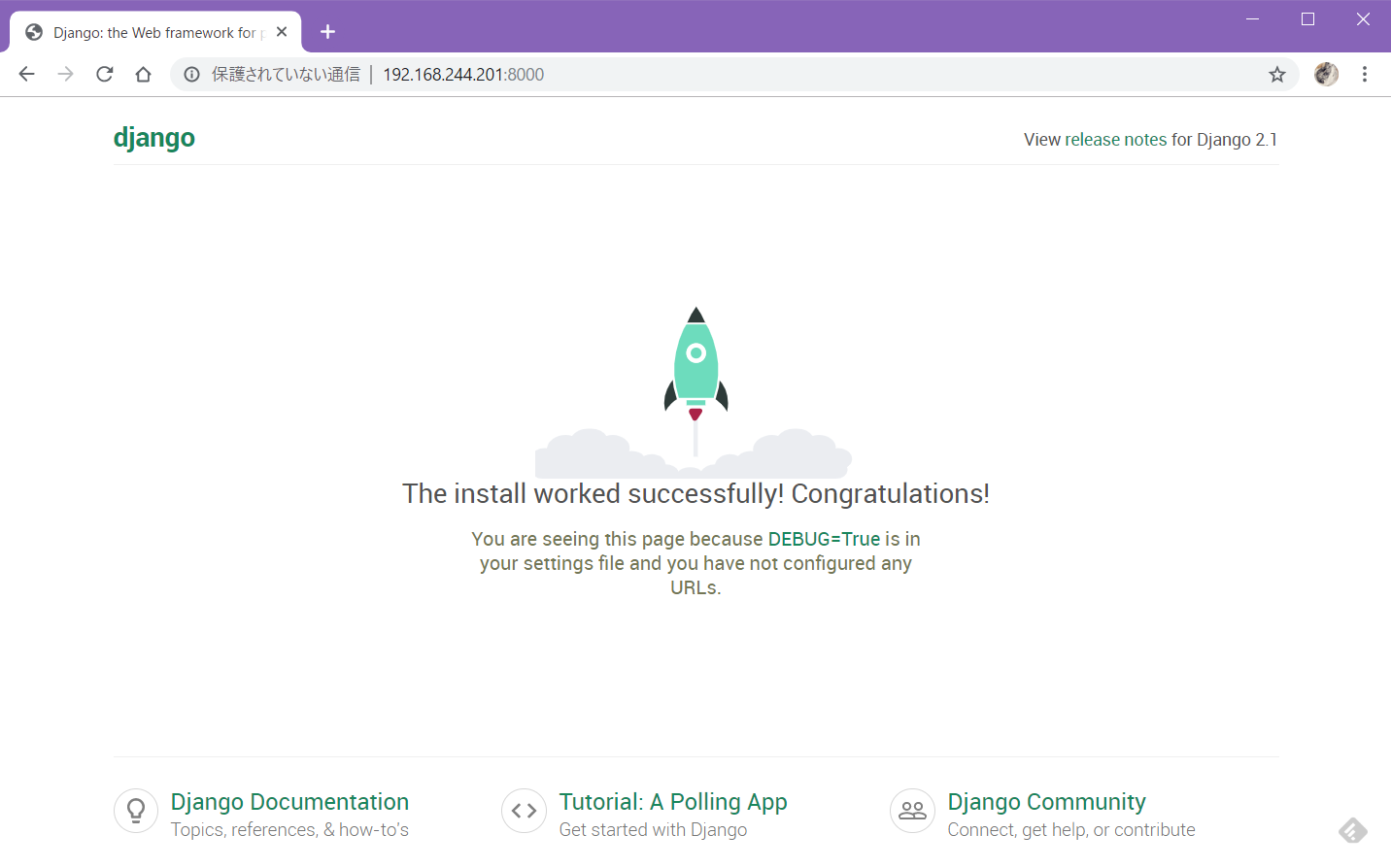
python3 manage.py runserver 0:8000でテスト実行し、ブラウザで/polls/へアクセス。
うごいた(・∀・)
- 投稿日:2019-05-21T21:06:35+09:00
APIGatewayとLambdaについてまとめる
API GatewayとAWS Lambda
はじめに
基本的な設定方法は以下のサイトを参考にしてください。
【API Gateway】AWS Lambda統合のPythonでHello, world1.1. やろうとしていること
このパートでは、クライアントからの要求をAPI gatewayを通してLambdaで処理して何らかの反応を返すというもの
1.2. サービスの説明
1. API gatewayについて[1]
API gateway : APIの作成と管理が簡単にできるサービス
◯APIの作成:AWS Lambda、EC2、もしくはAWS外でパブリックとして公開されているアプリケーションをAPIとして公開することができます。
◯APIの管理:Amazon API Gatewayは、APIの管理に必要な以下のような事項をお客様側での実施が必要なく、AWS側で提供しています。2. AWS Lambdaについて[2]
Lambda : AWSに関するなにかしらのイベントによって処理を実行する環境
関数として処理を定義する。
3. bottleについて
bottle : Pythonで一番軽量なWEBフレームワーク
lambda関数内の処理や、htmlの"form"から送られたpostの処理に利用する。特に考えるのはrequestオブジェクト。各サブクラスについて
BaseRequestが親クラスとなって様々なサブクラスが作成される。
1. query
2. forms
3. files
4. params
5. json特に送信データが写真のときはmultipart/form-dataになる。その場合用いるのは"files"クラス
filesクラス
メソッド
+ .get("KEY") : KEYに対応するVALUEのオブジェクトが取得できる
+ .filename : ファイル名が取得できる
+ .name : html内の"form"のnameが取得できる
+ .file : fileObject(BytesIO buffer or temporary file)を開くことができる1.3. サービスの設定方法
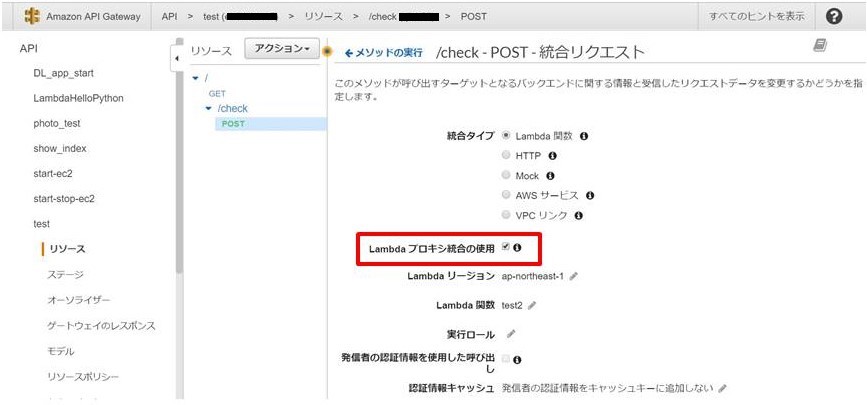
1. API gatewayの設定
- RESTfum APIの設定
- メソッドの設定
/(GET) ┗/check(POST)
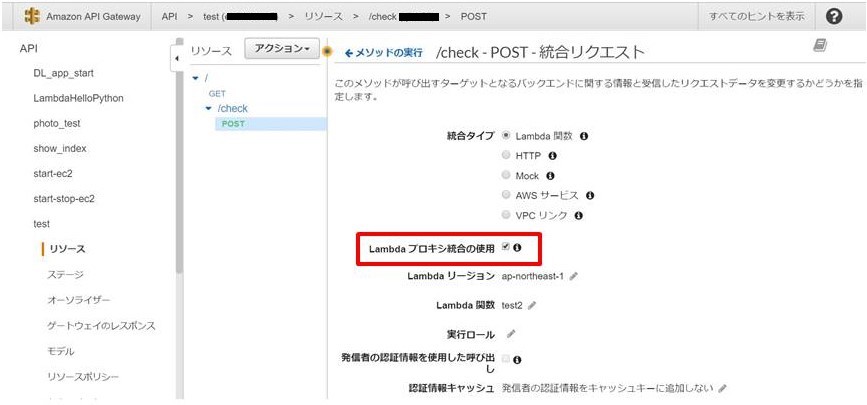
- 「Lambdaプロキシ統合の使用」にチェック
- これによってレスポンスの種類ごとにテンプレートを変更しなくて済む
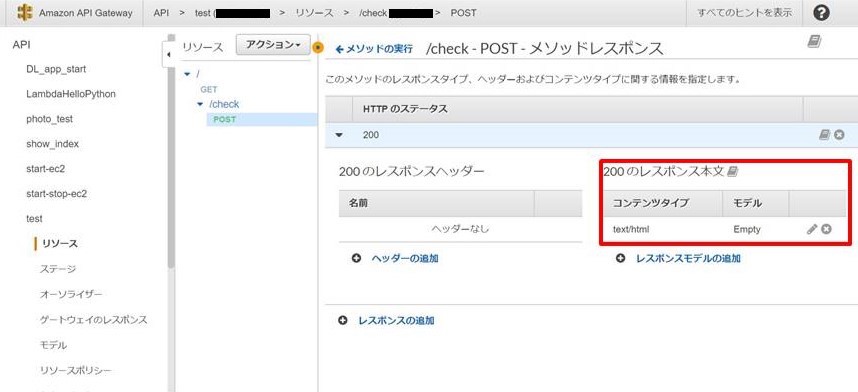
- 「メソッドレスポンス」の設定変更
- 「200のレスポンス本文」を”text/html”に変更 →htmlファイルを表示させるため

- それぞれのメソッドのテスト
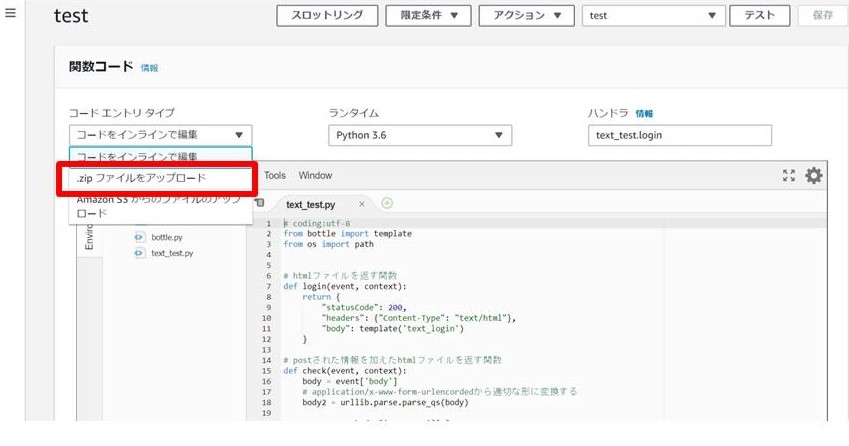
2. Lambdaの設定
手順
- 利用するファイルをまとめて圧縮
- AWS Lambdaの設定
1. 利用するファイルをまとめて圧縮
今回使用したファイル集 ・sample/ ├ bottle.py # webフレームワーク ├ text_test.py # text送信の場合 ├ photo_test.py # 画像送信の場合 └ views/ # htmlファイル ├ text_login.html ├ text_check.html └ photo_login.html各コードサンプル
1. テキストを送信する場合
text_test.py
text_test.py# coding:utf-8 from bottle import template import urllib # htmlファイルを返す関数 def login(event, context): return { "statusCode": 200, "headers": {"Content-Type": "text/html"}, "body": template('text_login') } # postされた情報を加えたhtmlファイルを返す関数 def check(event, context): body = event['body'] # application/x-www-form-urlencordedから適切な形に変換する body2 = urllib.parse.parse_qs(body) username = body2['username'][0] email = body2['email'][0] return { "statusCode": 200, "headers": {"Content-Type": "text/html"}, "body": template('text_check', username=username, email=email) }text_login.html
text_login.html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> </head> <body> <h1>メールアドレスと名前を送信してください</h1> <form method="post" enctype="application/x-www-form-urlencoded" action="/check"> <input placeholder="名前" name="username" type="text"/> <input placeholder="メール" name="email" type="text"/> <input value="送信" type="submit"/> </form> </body> </html>text_check.html
text_check.html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> </head> <body> <h1>確認</h1> <h2>名前</h2> <p>{{ username }}</p> <h2>メールアドレス</h2> <p>{{ email }}</p> </body> </html>2. 画像を送信する場合
photo_test.py
photo_test.py# coding:utf-8 from bottle import template # htmlファイルを返す関数 def show_page(event, context): return { "statusCode": 200, "headers": {"Content-Type": "text/html"}, "body": template('photo_login') } # postされた画像の生データを表示 def check(event, context): photo_data = event['body'] return { "statusCode": 200, "headers": {"Content-Type": "application/json"}, "body": {"message": photo_data} }photo_login.html
photi_login.html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>PhotoTest</title> </head> <body> <h1>Test</h1> <h2>画像を挿入してください</h2> <form method="post" enctype="multipart/form-data" action="/photo"> <input placeholder="画像" name="photo" type="file" /> <input placeholder="送信" type="submit" /> </form> </body> </html>
- 注意:htmlファイルのformタグの”action”はAPI gatewayでの「APIのデプロイ」が完了してから追加記入すること。宛先が異なると正しく動作しない。
2. AWS Lambdaの設定
- 使うファイルをzipで圧縮
- AWS Lambdaサイト内の「関数の作成」にて関数を設定後、zipファイルを転送

- AWS Lambda関数のトリガー作成
- 今回はAPI gatewayをトリガーとする。各種設定を行い、二つの機能を接続する
- サイト内の「テスト」にて正常に動くか試す。
1.4. 注意すべき部分
IAMロールについて
AWSのサービス(API gateway, Lambdaなど)を利用する際、権限を設定する必要がある。
一般には標準的なもので間に合うが、S3を用いたりEC2と通信したい場合は適切なIAMロールに変更する必要がある。proxyと本文マッピングテンプレートについて
API gatewayではレスポンスの形を適切に変更することが可能である。主に2つの整形方法がある。
1. プロキシ統合
2. マッピングテンプレートの利用今回は1.のプロキシ統合を用いた。これにより、レスポンスの形が統一されるためLambdaで処理する方法が統一されるからである。
ただ、2.であればレスポンスを適切な形に整形してLambdaに送れるため処理が用意になるというメリットもある。[3]
以下はformでpostしたデータを整形するためのマッピングテンプレートである。[4]"queryParameters" : { #set( $tmpstr = $input.body ) #foreach( $keyandvaluestr in $tmpstr.split( '&' ) ) #set( $keyandvaluearray = $keyandvaluestr.split( '=' ) ) "$keyandvaluearray[0]" : "$keyandvaluearray[1]"#if( $foreach.hasNext ),#end #end }参考サイト
[1] 5分でわかるAmazon API Gateway
[2] AWS Lambda超入門
[3] API Gatewayの本文マッピングテンプレートを理解する
[4] API Gateway + Lambda にFormからPOSTする時のマッピングテンプレートを作成しました
- 投稿日:2019-05-21T17:35:25+09:00
復活の呪文を実装してみた
復活の呪文とは
データを64種類のひらがなから成る文字列に変換し、紙などに記録する保存方式である。主に記録用電子媒体が存在しない環境で用いられた。
使用する文字
ぴったり64種類1なので、6ビットの情報を表現できる。
あいうえお まみむめも やゆ
かきくけこ らりるれろ よわ
さしすせそ がぎぐげご
たちつてと ざじずぜぞ
なにぬねの ばびぶべぼ
はひふへほ ぱぴぷぺぽ変換形式
- 元データを6ビットずつに分割(6ビットに満たない分は0を追加して6ビットにする)
- 変換表を使って各6ビットの値を変換
↓これが
abc↓こうなって
01100001 01100010 01100011 011000 010110 001001 100011↓こうなる
のぬこらって、これまんまBase64じゃん
Base64は、データを64種類の印字可能な英数字のみを用いて、それ以外の文字を扱うことの出来ない通信環境にてマルチバイト文字やバイナリデータを扱うためのエンコード方式である。
単なる偶然ではなさそうですね?2
実装してみる
使用する文字
理解も兼ねてクラス化してみた。復活エンコーダー。
fukkatsu.pyclass FukkatsuEncoder: __USABLE_CHARS = \ 'あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほ' \ 'まみむめもらりるれろがぎぐげござじずぜぞばびぶべぼぱぴぷぺぽ' \ 'やゆよわ'復活の呪文に変換する
内部で2進数を表現する「文字列」に変換しているので、わかりやすい代わりに効率は悪い。
fukkatsu.pydef encode(self, raw: bytes) -> str: b = ''.join(map(lambda c: format(c, '08b'), raw)) # 6の倍数になるようゼロ埋めする b += '00000' b = b[0:-(len(b)%6)] # 連番が偶数となる要素は空文字なので除外する encoded = ''.join(map(lambda c: self.__USABLE_CHARS[int(c, 2)], \ re.split('(.{6})', b)[1::2] \ )) return encoded復活の呪文から元データを復元する
なんか動かない
fukkatsu.pydef decode(self, encoded: str) -> bytes: b = ''.join(map(lambda c: format(self.__USABLE_CHARS.find(c), '06b'), \ encoded)) # 8の倍数に満たない場合、末尾は捨てられてしまうので問題なし raw = ''.join(map(lambda i: chr(int(i, 2)), \ re.split('(.{8})', b)[1::2])) return raw
decode()の引数に「あいう」を渡すと以下のエラー。UnicodeEncodeError: 'cp932' codec can't encode character '\xe3' in position 0: illegal multibyte sequence
文字列とバイト列は別物
バイトを文字に変換
chr()してから結合join()しているので、マルチバイト文字の場合がダメでした。ここはバイト列bytes()を作ってから、必要に応じて文字列に変換するのが正解。fukkatsu.pyraw = bytes(map(lambda i: int(i, 2), \ re.split('(.{8})', b)[1::2]))ソースコード
Gistに置いておきました。
decode()のバグっていたリビジョンも残してあります。
https://gist.github.com/cress-cc/985dc5923686e21f19ee14a57129ade4これは何の役に立つのか
何の役にも立ちません。
一般人には伝わらない感覚 ↩
- 投稿日:2019-05-21T17:01:26+09:00
非線形モデル予測制御におけるニュートン法をpythonで実装する(強化学習との関係をそえて)
はじめに
非線形モデル予測制御におけるCGMRES法をpythoで実装するの記事の関連記事です。
入力制約付き非線形最適制御問題を解いてます。
ハミルトニアンの微分等はまだ必要ですが、C/GMRESのような計算手法を用いず、数値微分を用いたニュートン法を実装しているため前回の記事よりも簡易になっています。
また、すこーしだけ強化学習と最適制御について述べています。
強化学習好きな方にも興味を持っていただけることを勝手に期待しています。
ただ、双方にそれなりに知っている方からすると、当たり前のことを言うな!となるかと思いますので、すっと読み飛ばしていただけると嬉しいです。本記事のコードは、
https://github.com/Shunichi09/linear_nonlinear_control
に上がっています。おしながき
- 前提とすこーしだけ無駄話
- 問題の定式化とその具体例
- 予備知識
- 問題設定(前回記事の引用)
- オイラーラグランジュ方程式の導出(前回記事の引用)
- 結果
- 具体的なプログラムについて
- 最後に
前提とすこーしだけ無駄話
このパートは無駄話を含みます。NMPCにだけ興味があるんだ!という人は飛ばしてください。
以前から最適制御に興味があって、いろいろと勉強していると、多くの点で強化学習との共通点が存在することに気づき、今では、強化学習と最適制御の両輪で勉強しています。実は最適制御系の研究が多い、計測と制御の2019年の3月号にもダイナミクスと機械学習の融合に挑むというタイトルで、特集が組まれています。この中の記事、制御工学者のための強化学習入門で、強化学習の手法の1つが適応最適制御の1つであることが述べられています。興味のある方はぜひ読んでみてください。
足立先生の制御工学の人工知能の近くて遠い関係の記事も面白いかと思います。なお、僕はこの記事に感銘を受けて、適応制御も少しずつですが、勉強中です。参考記事です。(僕の)ここでは、それらの記事にinspireされたこともあり、すこーしだけ、強化学習と最適制御の関係について述べてみようと思います。
強化学習と最適制御の目標
そもそも強化学習と最適制御の目標って何なのでしょうか?
強化学習の目標は、
報酬の和の期待値を最大化する方策を求めることです
\text{maximize} \ J = E_{\tau \sim \pi_\theta(\tau)} \left[ \sum_t r(x_t, u_t) \right]$r$はreward、$x$はstate、$u$はactionです(あえて、$x$と$u$を使ってます。制御側からの記事なので。)
さらに、$\pi$は方策(あるstate、$x$のもとでinput、$u$を吐き出すもの)で、$\theta$はパラメータになります。
なお、$\tau$は軌道です。stateとactionの時系列です。$\tau=(x_1, u_1, ... x_T, u_T)$となります。では、有限(無限)時間最適制御の目的はなんでしょうか?(2次形式の一般的な形で述べています。)
時間ステップT間(無限時間)のコストを最小にする入力を求めることです
\text{minimize} \ J = \sum_t x[k]Qx[k] + u[k]Ru[k](正確に書くと)
\text{minimize} \ J = \sum_{k=0}^{N-1} \left [x[k]Qx[k] + u[k]Ru[k] \right ] + x[N] S_f x[N](Nは予測ステップ数)
(ですが、強化学習によせて書いてます)ここで、$ - r(x_t, u_t) = x[k]Qx[k] + u[k]Ru[k]$にしてしまいましょう。
最大をとるか、最小をとるかは、報酬で考えるか、コストで考えるかだけの違いなので、強化学習には期待値を取るということが残ることを除けば、これらが同じように見えることは確かではあります。ベルマン(最適)方程式
2つの分野が近いことをベルマン方程式からも感じることができます。
ベルマン(最適)方程式は、強化学習側からの人からすると、V^{\pi}(x_t) = \max [E_{\pi} [r_{t+1} + \gamma V^{\pi}(x_{t+1})] ]ここで、$r$はreward(即時報酬)、$V$は状態価値、$\gamma$は割引率、$\pi$は方策(あるstate、$x$のもとでinput、$u$を吐き出すもの)です。
となることは、多くの本や記事が述べてくれています。この式はモデルがあり、かつテーブル型つまり、stateとactionの数が有限であれば、もともと仮定している状態価値$V$を使って、反復的に解くことができることは知られているわけです。sergey levineはbootstrap updateと言っていますね。もちろん、モデルがない場合でもデータ・ドリブンに価値を推定していくQ学習等が提案されていますね。では続いて最適制御です。一般的な最適制御は決定論的なモデルを持っている(あくまで一般的です。)と仮定しています。
モデルは以下の離散モデルを想定しましょう。\boldsymbol{x}[k]= \boldsymbol{Ax} [k]+ \boldsymbol{Bu}[k]ここで最適制御のベルマン方程式は、
V(x, k) = \min \left (L(x[k], u[k]) + x[N] S_f x[N] +\sum_{l=k+1}^{N-1} L(x(l), u(l)) \right ) \\ L(x[k], u[k]) = x[k]Qx[k] + u[k]Ru[k]になります。そして、この式をとけばいいわけです!(解析的に解くことができるのは限定されたケースのみです。)
目標と同じように、最大最小を考慮し、期待値を取ることを除けば強化学習と同じですね。
そしてなんとこのベルマン方程式から簡単に下記の離散リカッチ方程式が導出することができます。S(k) = Q + A^TS(k+1)A - A^TS(k+1)B(R+B^TS(K+1)B)^{-1}B^TS(k+1)A詳しい証明をしてもいいのですが、ここでは、省略します。
興味がある人は、大塚先生の非線形最適制御入門(コロナ社)を見てみてください。(連続系での導出ももちろんできます。)
強化学習の勉強したうえでこの本を読むとそのつながりが鮮明に見えてきます。長い前提のまとめ
さて、なんとなく2つのつながりが見えてきたところで。
強化学習は確率的な要素を含んだ、最適制御と言えそうだなーというのは分かっていただけたかと思います。
最適制御は、action(入力)は連続にする代わりに、評価関数を二次系(凸)にかつモデルを決定論的なものを用意しています。
強化学習は、モデルがない代わりにデータ・ドリブンにしたり、確率的な方策を扱うためにactionを有限にしたりしているわけですね!なので、一般的な最適制御は強化学習の中の1つで、特に決定論的なモデルがあり、評価関数も入力に関して凸のケースであると言えそうです。 (もちろん確率的最適制御なども提案されていますが、そこら辺まで行くと同じになりそうなのであくまで一般的な話です。)
今述べたのは基本的な2つの分野の考え方であって、それぞれ拡張する手法はもちろん、昔から提案されているとは思いますが、実はここ最近?、強化学習の中でもモデルベース強化学習(モデル(報酬と状態遷移)を使用する(または獲得して使用する)強化学習のことです。)の内容の論文を多く見かけます。
この前開かれた、ICLR2019のトレンドでも、モデルベース強化学習の内容の発表が多かったことが知られています。
(参考:piqcyさんのブログや元の記事)モデル使うならほぼ、最適制御じゃないか!と思われる方も多いかと思いますが
強化学習でいうモデルベースは\boldsymbol{x}[k+1]= \boldsymbol{Ax}[k] + \boldsymbol{Bu}[k] \\ \boldsymbol{\dot{x}}= \boldsymbol{Ax} + \boldsymbol{Bu}や
\boldsymbol{\dot{x}}= f(\boldsymbol{x}, \boldsymbol{u})を特定で指しているわけではなく、今のstate(ここでいうs)とaction(ここでいうu)から、次の状態遷移と貰える報酬がわかりそれを使うことを指しているわけなので、いわゆる数式的に述べることのできる、この形だけではありません。モンテカルロツリーサーチはその例ですし、さらに言えば、Dynaのようなモデルを獲得しながら、制御する手法も多く提案されています。
2つの分野を結ぶ研究は結構hotであるというわけです!
さて、大まかな関係がわかったところで、通常のDQNなどの、データ・ドリブンの強化学習と比較して、モデルを使うことのメリットはどこにあるのでしょうか?
モデルベースにすることのメリットはサンプル効率が非常に良くなることであると言われています。(piqcyさんのpythonで学ぶ強化学習)
これは直感的にもわかりますね。
モデルによって次の状態が決まるので、データを集めずに(自分自身が実際に動かなくても)自分の方策を更新することができるからです。さらに言うと、モデルがあることで、方策の勾配を解析的に算出、または、方策を算出できるケースがあります。最適制御はまさに後者の例の1つですね。
解析的に求まれば、なんとなく学習が安定しそうなことは自明かと思います。かなり前置きが長くなってしまいましたが、モデルベースにするメリットが大まかにわかったところで、この記事の本題に入りましょう。
この記事は、その最適制御の中でも、非線形モデル予測制御(上記の有限時間最適制御問題を繰り返し解法する手法)のプログラムの解き方と書き方について述べています。
高校数学がある方であれば、そこまで難しくなく、理解ができると思います。
勝手ながら、少しでも多くの最適制御、または強化学習好きな方が、異なる分野に興味を持ってくれたならいいなという思いです。予備知識
Newton法とは
後で使うのでここで補足しておきます。
ここでいう、Newton法は$[f_1(x, y), f_2(x, y)]^T = \boldsymbol{0}$といった連立方程式を近似的に解く手法のことを指します。もちろん高次でも使えます。
たくさん記事があるとは思いますので導出はそちらにお任せして、ここでは式の形だけ述べておきます。
参考は、この辺でしょうか?Newton法はヤコビ行列を用いますので、
F = \begin{bmatrix} \frac{\partial f_1(x, y)}{\partial x} \ \frac{\partial f_1(x, y)}{\partial x} \\ \frac{\partial f_1(x, y)}{\partial x} \ \frac{\partial f_1(x, y)}{\partial x} \end{bmatrix}Newton法の更新式は、
\begin{pmatrix} x_{k+1} \\ y_{k+1} \end{pmatrix} = \begin{pmatrix} x_{k}\\ y_{k} \end{pmatrix} - F^{-1} \begin{pmatrix} f_1(x_{k}, y_{k}) \\ f_2(x_{k}, y_{k}) \end{pmatrix}で差分が小さくなるまで$(x, k)$を更新していけば、近似的に解を求められることになります。
オイラーラグランジュ方程式とベルマン方程式の関係
このあとで使う、最適制御問題を解法するのに必要なオイラーラグランジュ方程式ですが、
さっきのベルマン方程式から導出ができることは知られています。
詳しい証明は他の本にお任せしますが、ここで言いたいのは、今回実装するオイラーラグランジュ方程式を使った解法は、
ベルマン方程式を解いていることになるということです。最適制御的な目線でいうなら、オイラーラグランジュ方程式の導出には変分法を用いるのに対して、ハミルトニアン・ヤコビ・ベルマン方程式(さっきのベルマン方程式)には、動的計画法を用います。そして、それらの2つはもちろん同じ最適制御問題を解いていますので繋がるというわけです。
問題設定
前回と同様に、教科書(コロナ社)と同じにしましょう。
前回の記事からの引用です。
評価関数の入力に対する係数を少しだけ変えていますが、結果が綺麗になるように調整しただけです。では,問題の定式化を行います.
ここでは非線形最適制御入門における教科書(コロナ社)の例題と同様にするために,以下とします.
状態方程式は\begin{bmatrix} \dot{x_1} \\ \dot{x_2} \\ \end{bmatrix} = \begin{bmatrix} x_2 \\ (1-x_1^2-x_2^2)x_2-x_1+u \\ \end{bmatrix}, |u| \leq 0.5とし,評価関数
J = \frac{1}{2}(x_1^2(t+T)+x_2^2(t+T))+\int_{t}^{t+T}\frac{1}{2}(x_1^2+x_2^2+0.5 u^2)d\tauとします.
ここで,入力に対する不等式制約を考慮するために,ダミー入力$v$を用いて,u^2+v^2-0.5^2=0という等式制約を導入して,さらに評価関数を補正します.
J = \frac{1}{2}(x_1^2(t+T)+x_2^2(t+T))+\int_{t}^{t+T}\frac{1}{2}(x_1^2+x_2^2+0.5u^2)-0.01vd\tauまた,等式制約や状態方程式の制約を含めたハミルトニアン$H$は以下のように計算することができます。
H = \frac{1}{2}(x_1^2+x_2^2+0.5u^2)-0.01v+\lambda_1x_2+\lambda_2((1-x_1^2-x_2^2)x_2-x_1+u)+\rho(u^2+v^2-0.5^2)オイラーラグランジュ方程式の導出
かなりサボりで申し訳ないのですが、ここも前回の記事からの引用です。
オイラーラグランジュ方程式は、最適化問題におけるKKT条件を示したものになります。
また、先ほども述べたようにこれはベルマン方程式から導出できます。まず,必要になるのは,以下の3つです
すべてハミルトニアンを偏微分したものになります\frac{\partial H}{\partial \boldsymbol{x}}, \frac{\partial \varphi}{\partial \boldsymbol{x}}, \frac{\partial H}{\partial \boldsymbol{u}}ここで,$\varphi$は終端状態$(t+T)$へのペナルティ関数,つまり,積分項の外,$\frac{1}{2}(x_1^2(t+T)+x_2^2(t+T))$になります.
実際計算してみると(ただの計算問題です)
なお,これからの入力はダミー入力を含んでいますので注意してください(ベクトル表記になっているのはそのためです)
算出する際もダミー入力は一生くっついてきます
ベクトルによる微分は検索していただくとたくさん説明がでてきますので,それにのっとると,\frac{\partial H}{\partial \boldsymbol{x}} = \begin{bmatrix} x_1 - 2 x_1 x_2 \lambda_2 - \lambda_2 \\ x_2 + \lambda_1 + (-3x_2^2-x_1^2+1)\lambda_2 \\ \end{bmatrix}\\ \frac{\partial \varphi}{\partial \boldsymbol{x}} = \begin{bmatrix} x_1 \\ x_2 \\ \end{bmatrix} \\ \frac{\partial H}{\partial \boldsymbol{u}} = \begin{bmatrix} u + \lambda_2 + 2\rho u \\ -0.01+2\rho v \\ \end{bmatrix} \\これを計算したことで,最適性条件である以下の式たちを
\dot{\boldsymbol{x}} = f(\boldsymbol{x}, \boldsymbol{u}, t) , \boldsymbol{x}(t_0) = x_0 \\ \dot{\boldsymbol{\lambda}} = - \frac{\partial H}{\partial \boldsymbol{u}}, \boldsymbol{\lambda}(t+T)=\frac{\partial \varphi}{\partial \boldsymbol{x}}(\boldsymbol{x}(t+T)) \\ \frac{\partial H}{\partial \boldsymbol{u}} = 0 \\ C(\boldsymbol{x}, \boldsymbol{u}) = 0すべて求めることができました.ここで$C$は等式拘束条件です.ここではダミー入力を含んだ,$u^2+v^2-0.5^2=0$の式になります.
また,上2つは,状態方程式,随伴方程式
になります.
つまり,評価関数$J$を最小化する問題は,二点境界値問題に落とすことができたわけです.しかし,これどのようにすれば解けるのでしょうか
解析的に解くのは難しいので,反復法で解きます.
基本的なアルゴリズムは以下の通りです.
- まず,初期状態$\boldsymbol{x}$を取得する
- 初期推定解$\boldsymbol{u}(t)$を適当に決定する
- 1,推定解$\boldsymbol{u}(t)$を用いて,未来の状態と随伴状態を状態方程式,随伴方程式から求める
- 最適性条件を満たすか確認
- 推定解$\boldsymbol{u}(t)$を何らかの指針で改善
- 3-を繰り返す
ここでいう最適性条件は,
\frac{\partial H}{\partial \boldsymbol{u}} = 0 \\ C(\boldsymbol{x}, \boldsymbol{u}) = 0の2つになります.
このやり方で,最適性条件を満たす推定解を得ることができれば,良いのですが...何らかの指針
これが非常に難しいです.基本的な形であれば,評価関数の勾配を求めて更新する勾配法等で求めることができますが,ダミー入力,等式制約その他もろもろが入ってくるともはや単純な勾配法では困難です.
しかも,解析的に出すことははなからあきらめているのでここで,
一旦,制御量を離散化しますつまり,すべて差分方程式にするということです.状態方程式,随伴方程式,最適性条件等,すべてを離散化して差分方程式化します.
そうすることで,より簡便に近似解を得ることができるようになります.
例えば,10ステップとした場合は,10この入力(この場合,ダミー入力を入れると20個ですね)を求める問題になるわけです.すべてを離散化した結果,こんな形で最適性行列を算出できます
もちろんこれらの変数はすべて,随伴方程式と状態方程式を満たした上での話です。\boldsymbol{F} = \begin{bmatrix} \frac{\partial H}{\partial u}(\boldsymbol{x}^*[0], \boldsymbol{u}^*[0], \boldsymbol{\lambda}^*[1]) \\ C(\boldsymbol{x}^*[0], \boldsymbol{u}^*[0], \boldsymbol{\lambda}^*[1]) \\ ... \\ \frac{\partial H}{\partial u}(\boldsymbol{x}^*[N-1], \boldsymbol{u}^*[N-1], \boldsymbol{\lambda}^*[N]) \\ C(\boldsymbol{x}^*[N-1], \boldsymbol{u}^*[N-1], \boldsymbol{\lambda}^*[N]) \end{bmatrix}さらに,$\boldsymbol{U}$を導入して,
\boldsymbol{U} = \begin{bmatrix} \boldsymbol{u}^*[0] \\ \rho^*[0] \\ ... \\ \boldsymbol{u}^*[N-1] \\ \rho^*[N-1] \\ \end{bmatrix}とします.ここで注意点は,繰り返しになりますが,入力はダミー入力を含んでいるということと,
等式拘束条件の数に応じて,$\rho$のみとしているものは数が増えるということです例えば,仮に離散化したステップを10とした場合今回でいうと
- 入力が1つ
- ダミー入力が1つ
- 等式制約条件が1つ(それに対応するラグランジュ乗数は1つ)
になりますので,この行列は30×1になります
さて、ここからが今回は異なります。ここで求めたいのは、
\boldsymbol{F}(\boldsymbol{U}) = \boldsymbol{0}この最適性行列の連立方程式を満たす入力の時系列$\boldsymbol{U}$です。前回は、この入力の時系列$\boldsymbol{U}$を算出するために、CGMRES法を用いて最適性行列の勾配$\frac{\partial \boldsymbol{F}}{\partial \boldsymbol{U}}$を計算することなく、追跡していましたが、今回はこれをNewton法で求めていきます。
なので、さっきのNewton法の式を使うと、
\boldsymbol{F}_n = \boldsymbol{F}(\boldsymbol{U}_{n}) \\ \boldsymbol{U_{n+1}} = \boldsymbol{U_{n}} - (\frac{\partial \boldsymbol{F}}{\partial \boldsymbol{U}}(\boldsymbol{U}_{n}))^{-1}\boldsymbol{F}_nここでの$n$は反復回数を示すものです。
ただ、ここで一点問題なのは$\frac{\partial \boldsymbol{F}}{\partial \boldsymbol{U}}$です。
解析的に計算して求めてもいいのですが、ここでは数値微分をしてしまいしょう。
$\boldsymbol{U}$を変化させて、後は、それを変化分で割ればよいですね。ここだと30個の変数があるので、30回数値微分をするので少し時間がかかります。詳しくはプログラムを見てください。では最後にアルゴリズムをまとめておきましょう
- まず,初期状態$\boldsymbol{x}$を取得する
- 初期推定解$\boldsymbol{u}(t)$を適当に決定する
- 1,推定解$\boldsymbol{u}(t)$を用いて,未来の状態と随伴状態を状態方程式,随伴方程式から求める
- 最適性条件を満たすか確認
- 推定解$\boldsymbol{u}(t)$($\boldsymbol{U}$)をニュートン法を用いて更新、算出
- 3-を繰り返す
結果
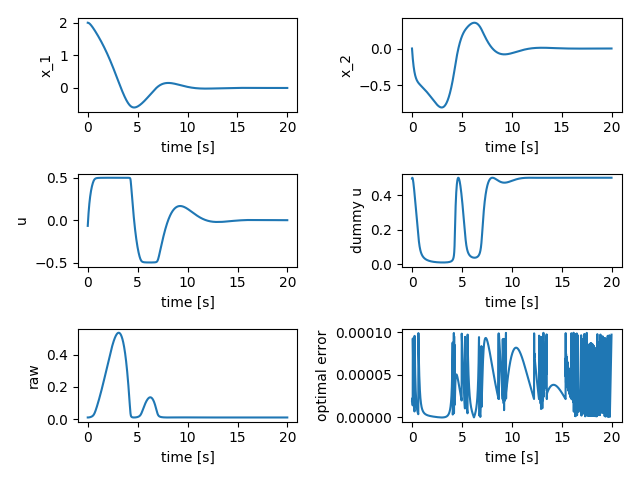
forkか、cloneしてもらって、
$ python main_example.pyを実行してもらうと
が出てきます。制約条件を考慮できていますね!
具体的なプログラムについて
詳しいコードは
https://github.com/Shunichi09/linear_nonlinear_control/tree/master/nmpc/newton
にのっていますがプログラムの書き方の概要を少しだけ。
- SampleSystemClass
シミュレータ(環境)です。
入力を入れると、状態を更新してくれます。
- NMPCSimulatorSystemClass
これはNMPC内で保持しておくシミュレータです。
状態の予測と随伴方程式の計算をしてくれます。
通常、制御対象と、そのNMPCで予測を行うモデルは異なることが多いため、ここは分けています。
(このプログラム内では、モデル化誤差等はのせてないので式は同じになってます。)
- NMPCControllerWithNewtonClass
NMPCのシミュレータを使用し、最適入力を計算します。
最後に
制御工学の最適制御分野の中手法の1つ、非線形モデル予測制御について強化学習との関連をまとめながら、述べさせていただきました。
最適制御の欠点は、モデルがなければなにもできないことです。この安定解析などがしっかりと行えるこの美しい理論もモデルがなければ使えません。
強化学習の欠点は、確率的なモデルを扱ったり、そもそもモデルがないものを扱ったり、するので基本的にはデータ・ドリブンになります。そのため、学習が安定しなかったり、そもそも学習し終わっても、システムの安定性(絶対にゴールにたどり着くことや最適性など)が言える例は少ないです。それぞれ改善する手法は多く提案されていますが、ここで言いたいのは、強化学習も最適制御の1つですし、最適制御もまた、強化学習の1つであるように僕は感じています。
そこで、互いの手法の欠点を指摘しあうことも重要ではあると思いますが、互いにその欠点を補いながら、新しい革新的な手法が生まれることを期待しています。
僕自身も最適制御と強化学習、双方のアプローチを深く理解して、その2つの研究の間を埋められるようになれればなと勝手に思っています。最後まで読んでくださった方ありがとうございました。
一応内容については精査したつもりではありますが、一個人が校閲などなしで書いていますのでもし間違い等あれば、コメントをいただけると嬉しいです。
- 投稿日:2019-05-21T16:49:28+09:00
qiita api python
この記事はまだエラー修正中です。
mac OS
Qiita APIをPythonから使ってみる
https://qiita.com/sotoiwa/items/e2254893f5b0b92bb06e$ python Python 3.6.0 |Anaconda custom (64-bit)| (default, Dec 23 2016, 13:19:00) [GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)] on darwin >>> ^D $ pip install prettytable Collecting prettytable Downloading https://files.pythonhosted.org/packages/ef/30/4b0746848746ed5941f052479e7c23d2b56d174b82f4fd34a25e389831f5/prettytable-0.7.2.tar.bz2 Building wheels for collected packages: prettytable Building wheel for prettytable (setup.py) ... done Stored in directory: /Users/ogawakiyoshi/Library/Caches/pip/wheels/80/34/1c/3967380d9676d162cb59513bd9dc862d0584e045a162095606 Successfully built prettytable Installing collected packages: prettytable Successfully installed prettytable-0.7.2 $ python qiitacheck.py Traceback (most recent call last): File "qiitacheck.py", line 273, in <module> main() File "qiitacheck.py", line 232, in main token = os.environ['QIITA_TOKEN'] File "/Users/ogawakiyoshi/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/os.py", line 669, in __getitem__ raise KeyError(key) from None KeyError: 'QIITA_TOKEN'設定してなかった。
$ export QIITA_TOKEN= 16進数 $ python qiitacheck.py Traceback (most recent call last): File "qiitacheck.py", line 273, in <module> main() File "qiitacheck.py", line 232, in main token = os.environ[''] File "/Users/ogawakiyoshi/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/os.py", line 669, in __getitem__ raise KeyError(key) from None KeyError: ''$ ./qiitacheck.py Traceback (most recent call last): File "./qiitacheck.py", line 273, in <module> main() File "./qiitacheck.py", line 233, in main items = get_items(token) File "./qiitacheck.py", line 81, in get_items response.raise_for_status() File "/Users/ogawakiyoshi/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/requests/models.py", line 893, in raise_for_status raise HTTPError(http_error_msg, response=self) requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://qiita.com/api/v2/items/8da100d945da8dc09600/stockersえ、エラーなの。20分くらい処理したのに。
原因調査中。GASでQiita APIを使ってView・いいね・ストック数の一覧を取得する
https://qiita.com/tksnino/items/7e6a587ff6e1817490ad【Qiita API】いいね!閲覧数の自動集計
https://qiita.com/Naoto9282/items/252c4b386aeafc0052ba$curl -H 'Authorization: Bearer [アクセストークン]' https://qiita.com/api/v2/authenticated_user/items {"message":"Unauthorized","type":"unauthorized"}そりゃそうでしょう
[アクセストークン]
のところは、
ユーザの管理画面
https://qiita.com/settings/applications
に接続して、取得しないといけない。
アクセストークンの説明
のところには、
アクセストークンの説明
と書いて、「発行する」を押した。長い16進数らしきものが出るので、ありがたくコピーして、curlコマンドの [アクセストークン]
のところにペーストする。すごい大量のデータがでてきた。
qiita.py#!/usr/bin/env python # coding: utf-8 # @Naoto9282 2019年02月07日 02時02分 (JST) # @kaizen_nagoya 2019 05 21 import requests import json url = 'https://qiita.com/api/v2/authenticated_user/items' headers = {"content-type": "application/json", "Authorization": "Bearer [アクセストークン]"} res = requests.get(url, headers=headers) list = res.json() for item in list: item_id = item['id'] title = item['title'] likes_count = item['likes_count'] url = 'https://qiita.com/api/v2/items/' + item_id res = requests.get(url, headers=headers) json = res.json() page_views_count = json['page_views_count'] print(title, page_views_count, likes_count)$ ./qiita.py Traceback (most recent call last): File "./qiita.py", line 6, in <module> import requests ImportError: No module named requests $ python quita.py正常出力。
プログラムちょい替え(5)pyhon中央値 114 1 人の間違いを繰り返せない系設計を 49 1 Line Driven Design 39 0 VPN Gate 29 0 「best practice」が「一番良い方法」ではない三つの理由 30 0 ISO, IEC, ITUの国際規格を読むには 24 0 テレビ会議システムを設営する 110 1 今年度の目標的な何か 103 1 docker(12)dockerでX11を動かすいくつかの方法 149 1 docker(11)docker file作ってみた 134 1 「小学生だった僕がプログラミングを覚えるまでにやったこと」をdockerで 170 3 中小企業庁用語集の書き直し案 49 1 請負契約でないと機敏(agile)にはできない 52 0 Maker Fairに出展するとよさげなもの(だしたもの)集め 42 1 音響技術におけるソフトウェアの役割 43 2 IT業界における長期計画、中期計画、単年度計画、短期計画 35 0 Qiita(31)Qiitaでfollowしている人をTwitterでfollowする 327 1 論文でRFC参照 42 1 不具合対処報告(案) 41 1 Qiita(30) 丸1日Qiitaが新規編集させてくれなかった時にやった事 80 1なして20件しか出力しない?
['プログラムちょい替え(5)pyhon中央値', 115, 1] ['人の間違いを繰り返せない系設計を', 50, 1] ['Line Driven Design', 39, 0] ['VPN Gate', 29, 0] ['「best practice」が「一番良い方法」ではない三つの理由', 30, 0] ['ISO, IEC, ITUの国際規格を読むには', 24, 0] ['テレビ会議システムを設営する', 110, 1] ['今年度の目標的な何か', 103, 1] ['docker(12)dockerでX11を動かすいくつかの方法', 149, 1] ['docker(11)docker file作ってみた', 134, 1] ['「小学生だった僕がプログラミングを覚えるまでにやったこと」をdockerで', 170, 3] ['中小企業庁用語集の書き直し案', 49, 1] ['請負契約でないと機敏(agile)にはできない', 52, 0] ['Maker Fairに出展するとよさげなもの(だしたもの)集め', 42, 1] ['音響技術におけるソフトウェアの役割', 43, 2] ['IT業界における長期計画、中期計画、単年度計画、短期計画', 35, 0] ['Qiita(31)Qiitaでfollowしている人をTwitterでfollowする', 327, 1] ['論文でRFC参照', 42, 1] ['不具合対処報告(案)', 41, 1] ['Qiita(30) 丸1日Qiitaが新規編集させてくれなかった時にやった事', 80, 1]やっぱ20件。
参考資料
Qiita API で公開情報の記事一覧を取得する、アクセストークンなどの認証必要なしのスクリプト例
https://qiita.com/YumaInaura/items/8004559925f40059abceQiitaの投稿記事からデータセット作った
https://qiita.com/dcm_chida/items/687654685dc434bdc9d4Qiita(11)「Qiitaいいな〜自分のいいね分析」自分版
https://qiita.com/kaizen_nagoya/items/11955909b0302d9ba999
- 投稿日:2019-05-21T16:38:11+09:00
QuantXでBlack-Litterman ModelとBollinger Bandsを組み合わせてみた
はじめに
株式会社Smart Tradeが提供している投資アルゴリズム開発プラットフォームQuantX Factoryで,ポートフォリオ選択についての数理モデルであるBlack-Litterman Modelとテクニカル指標であるBollinger Bandsを用いた取引アルゴリズムを実装しました.
Black-Litterman Modelとは
前回の記事で紹介しているので,以下を参照してください.
QuantXでBlack-Litterman Modelを実装してみたBollinger Bandsとは
Bollinger Bandsとは,Bollinger Capital Management創立者のJohn Bollingerが1980年代前半に考案した,移動平均線と標準偏差であるσバンドから価格の幅を見ることのできるテクニカル指標で,価格の変動範囲やトレンドにおける過熱のサイン,トレンドの反転を判断する目安になります.1
以下が参考になります.
ボリンジャーバンドの使い方・見方 順張りと逆張り両方で使えるテクニカル分析実装
コードの全体像
import pandas as pd import talib as ta import numpy as np def judge_expand(upperband, lowerband, n, m): volatility = upperband - lowerband vol = volatility.tolist() status = [0] * len(vol) for i in range(m, len(vol)): if m < n: if vol[i] > 3 * min(vol[i-n:i-1]): status[i] = 1 else: if vol[i] > 3 * min(vol[i-m:i-1]): status[i] = 1 return np.array(status) def judge_plus_two_sigma(upperband, price): pts = np.greater_equal(price, upperband) return pts.astype(int) def judge_minus_two_sigma(lowerband, price): mts = np.less_equal(price, lowerband) return mts.astype(int) def initialize(ctx): ctx.configure( channels={ "jp.stock": { "symbols": [ "jp.stock.2914", #日本たばこ産業 "jp.stock.3382", #セブン&アイ・ホールディングス "jp.stock.4063", #信越化学工業 "jp.stock.4452", #花王 "jp.stock.4502", #武田薬品工業 "jp.stock.4503", #アステラス製薬 "jp.stock.6098", #リクルートホールディングス "jp.stock.6501", #日立製作所 "jp.stock.6752", #パナソニック "jp.stock.6758", #ソニー "jp.stock.6861", #キーエンス "jp.stock.6954", #ファナック "jp.stock.6981", #村田製作所 "jp.stock.7203", #トヨタ自動車 "jp.stock.7267", #本田技研工業 "jp.stock.7751", #キヤノン "jp.stock.7974", #任天堂 "jp.stock.8031", #三井物産 "jp.stock.8058", #三菱商事 "jp.stock.8306", #三菱UFJフィナンシャル・グループ "jp.stock.8316", #三井住友フィナンシャルグループ "jp.stock.8411", #みずほフィナンシャルグループ "jp.stock.8766", #東京海上ホールディングス "jp.stock.8802", #三菱地所 "jp.stock.9020", #東日本旅客鉄道 "jp.stock.9022", #東海旅客鉄道 "jp.stock.9432", #日本電信電話 "jp.stock.9433", #KDDI "jp.stock.9437", #NTTドコモ "jp.stock.9984", #ソフトバンクグループ ], "columns": [ #"open_price_adj", # 始値(株式分割調整後) #"high_price_adj", # 高値(株式分割調整後) #"low_price_adj", # 安値(株式分割調整後) #"volume_adj", # 出来高 #"txn_volume", # 売買代金 "close_price_adj", # 終値(株式分割調整後) ] } } ) issued = { "jp.stock.2914": 2000000000, #日本たばこ産業 "jp.stock.3382": 886441983, #セブン&アイ・ホールディングス "jp.stock.4063": 427606693, #信越化学工業 "jp.stock.4452": 488700000, #花王 "jp.stock.4502": 1565005908, #武田薬品工業 "jp.stock.4503": 1979823175, #アステラス製薬 "jp.stock.6098": 1695960030, #リクルートホールディングス "jp.stock.6501": 966692677, #日立製作所 "jp.stock.6752": 2453053497, #パナソニック "jp.stock.6758": 1271230341, #ソニー "jp.stock.6861": 121603842, #キーエンス "jp.stock.6954": 204040771, #ファナック "jp.stock.6981": 675814281, #村田製作所 "jp.stock.7203": 3262997492, #トヨタ自動車 "jp.stock.7267": 1811428430, #本田技研工業 "jp.stock.7751": 1333763464, #キヤノン "jp.stock.7974": 131669000, #任天堂 "jp.stock.8031": 1742345627, #三井物産 "jp.stock.8058": 1590076851, #三菱商事 "jp.stock.8306": 13667770520,#三菱UFJフィナンシャル・グループ "jp.stock.8316": 1399401420, #三井住友フィナンシャルグループ "jp.stock.8411": 25392498945,#みずほフィナンシャルグループ "jp.stock.8766": 710000000, #東京海上ホールディングス "jp.stock.8802": 1391038170, #三菱地所 "jp.stock.9020": 381822200, #東日本旅客鉄道 "jp.stock.9022": 206000000, #東海旅客鉄道 "jp.stock.9432": 1950394470, #日本電信電話 "jp.stock.9433": 2532004445, #KDDI "jp.stock.9437": 3335231094, #NTTドコモ "jp.stock.9984": 1100660365, #ソフトバンクグループ } def _my_signal(data): cp = data["close_price_adj"].fillna(method="ffill") upperband = {} middleband = {} lowerband = {} buy_sig = pd.DataFrame(data=0,columns=[], index=cp.index) sell_sig = pd.DataFrame(data=0,columns=[], index=cp.index) df_uband = pd.DataFrame(data=0,columns=[], index=cp.index) df_lband = pd.DataFrame(data=0,columns=[], index=cp.index) expand = pd.DataFrame(data=0,columns=[], index=cp.index) minus_two_sigma = pd.DataFrame(data=0,columns=[], index=cp.index) plus_two_sigma = pd.DataFrame(data=0,columns=[], index=cp.index) for (sym, val) in cp.items(): upperband[sym], middleband[sym], lowerband[sym] = ta.BBANDS( cp[sym].values.astype(np.double), timeperiod=24, nbdevup=2.3, nbdevdn=2.3, matype=0 ) expand[sym] = judge_expand(upperband[sym],lowerband[sym],24,48) df_lband[sym] = lowerband[sym] df_uband[sym] = upperband[sym] minus_two_sigma[sym] = judge_minus_two_sigma(df_lband[sym],cp[sym]) plus_two_sigma[sym] = judge_plus_two_sigma(df_uband[sym],cp[sym]) buy_sig[sym] = minus_two_sigma[sym] + 2*plus_two_sigma[sym]*expand[sym] - minus_two_sigma[sym]*expand[sym] sell_sig[sym] = plus_two_sigma[sym] + 2*minus_two_sigma[sym]*expand[sym] - plus_two_sigma[sym]*expand[sym] sum_mkt_cap = pd.Series(data=0, index=cp.index) mkt_cap = pd.DataFrame(data=0, index=cp.index, columns=[]) weight = pd.DataFrame(data=0, index=cp.index, columns=[]) daily = pd.DataFrame(data=0, index=cp.index, columns=cp.columns) df_w_posterior = pd.DataFrame(data=0, index=cp.index[245:], columns=cp.columns) for sym, val in cp.items(): mkt_cap[sym] = val * issued[sym] sum_mkt_cap += mkt_cap[sym] for sym, val in cp.items(): weight[sym] = mkt_cap[sym] / sum_mkt_cap # 2x30 (投資家のビュー) P = np.array( [ [-0.5,-0.25,0,0,0,0,0,-0.25,-0.75,0,0,0,0,0,-0.75,0,0,0,0,0,-0.25,0,0.25,0.25,0.5,0.75,0,0,0,1], [-0.25,-0.5,0,0,0,0,0,0,0,0,1,0,-0.75,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,-0.75,1] ] ) # 2×1(投資家のビュー) Q = np.array([[0.05], [0.07]]) # 2×1(投資家のビューへの確信度) omega = np.array( [ [0.001065383, 0], [0, 0.001851738] ] ) for i in daily.columns: daily[i] = cp[i].pct_change() sigma = daily[:245].cov().as_matrix() delta = 25 tau = 0.05 ganma = 0.3 count = 0 w_matrix =[] for index, row in weight[245:].iterrows(): row_list = list(row) count += 1 w_out = [] for num, i in enumerate(row_list): w_in = [] w_in.append(row_list[num]) w_out.append(w_in) w = np.array(w_out) r_eq = delta * np.dot(sigma, w) r_posterior = r_eq + np.dot(np.dot(tau*np.dot(sigma, P.T), np.linalg.inv(tau*np.dot(np.dot(P, sigma), P.T) + omega)), (Q - np.dot(P, r_eq))) sigma_posterior = sigma + tau * sigma - tau * np.dot(np.dot(np.dot(sigma, P.T), np.linalg.inv(tau*np.dot(np.dot(P, sigma), P.T)+omega)), tau*np.dot(P, sigma)) w_posterior = np.dot(np.linalg.inv(delta * sigma_posterior), r_posterior).T w_matrix = np.append(w_matrix, w_posterior) w_matrix_rt = w_matrix.reshape(count, 30).T for sym, val in zip(weight[245:].keys(), w_matrix_rt): post = pd.Series(val, index=cp[245:], name = sym) df_w_posterior[sym] = post.values return { "upperband:price": df_uband, "lowerband:price": df_lband, "buy:sig": buy_sig, "sell:sig": sell_sig, "weight:g2": weight, "weight_post:g2": df_w_posterior, "weight_comp:g2": (1 - ganma) * weight + ganma * df_w_posterior, "weight_diff:g2": weight - df_w_posterior, } ctx.regist_signal("my_signal", _my_signal) def handle_signals(ctx, date, current): df = current.copy() df_buy = df["buy:sig"] df_sell = df["sell:sig"] for (sym, val) in df_buy.items(): if df_buy[sym] == 1: sec = ctx.getSecurity(sym) sec.order_target_percent(df["weight_comp:g2"][sym]) elif df_buy[sym] == 2: sec = ctx.getSecurity(sym) sec.order_target_percent(df["weight_comp:g2"][sym]) for (sym, val) in df_sell.items(): if df_sell[sym] == 1: sec = ctx.getSecurity(sym) sec.order_target_percent(0) elif df_sell[sym] == 2: sec = ctx.getSecurity(sym) sec.order_target_percent(0)
def judge_expand(upperband, lowerband, n, m): volatility = upperband - lowerband vol = volatility.tolist() status = [0] * len(vol) for i in range(m, len(vol)): if m < n: if vol[i] > 3 * min(vol[i-n:i-1]): status[i] = 1 else: if vol[i] > 3 * min(vol[i-m:i-1]): status[i] = 1 return np.array(status) def judge_plus_two_sigma(upperband, price): pts = np.greater_equal(price, upperband) return pts.astype(int) def judge_minus_two_sigma(lowerband, price): mts = np.less_equal(price, lowerband) return mts.astype(int)以下の記事にアルゴリズムの説明があります.
QuantXでボリンジャーバンドのアルゴリズムを改良してみるdef handle_signals(ctx, date, current): df = current.copy() df_buy = df["buy:sig"] df_sell = df["sell:sig"] for (sym, val) in df_buy.items(): if df_buy[sym] == 1: sec = ctx.getSecurity(sym) sec.order_target_percent(df["weight_comp:g2"][sym]) elif df_buy[sym] == 2: sec = ctx.getSecurity(sym) sec.order_target_percent(df["weight_comp:g2"][sym]) for (sym, val) in df_sell.items(): if df_sell[sym] == 1: sec = ctx.getSecurity(sym) sec.order_target_percent(0) elif df_sell[sym] == 2: sec = ctx.getSecurity(sym) sec.order_target_percent(0)買いシグナルが出ているときは,その銘柄にBlack-Litterman Modelによる割合で注文を行います.
また,売りシグナルが出ているときは,その銘柄の保有する割合を0%にします.実験
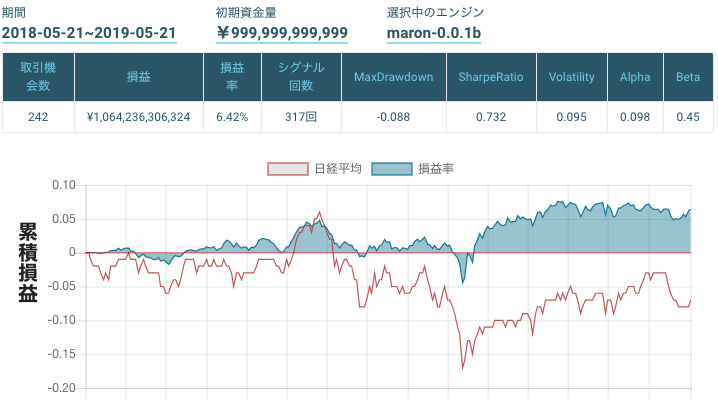
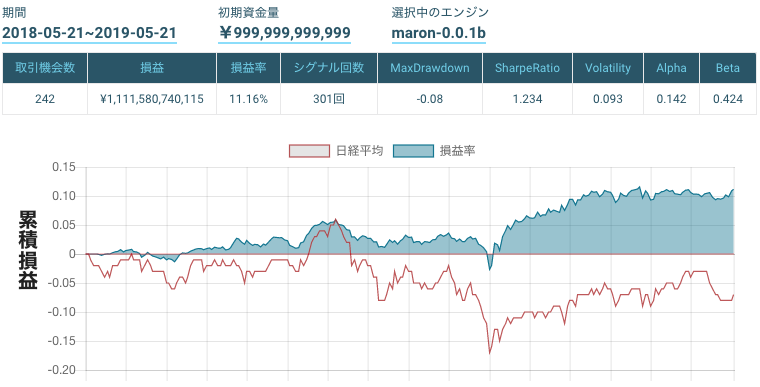
期間 2018-05-21 ~ 2019-05-21
銘柄 TOPIX Core30結果
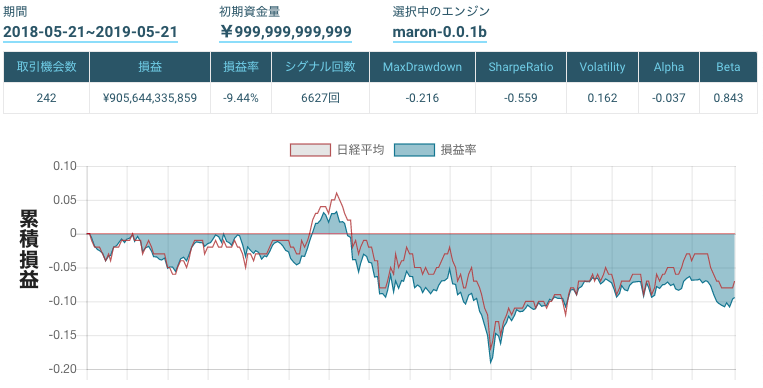
時価総額による単純な重みづけのみ
https://factory.quantx.io/developer/c1d66abce4f9474981f2cf57e021e46e
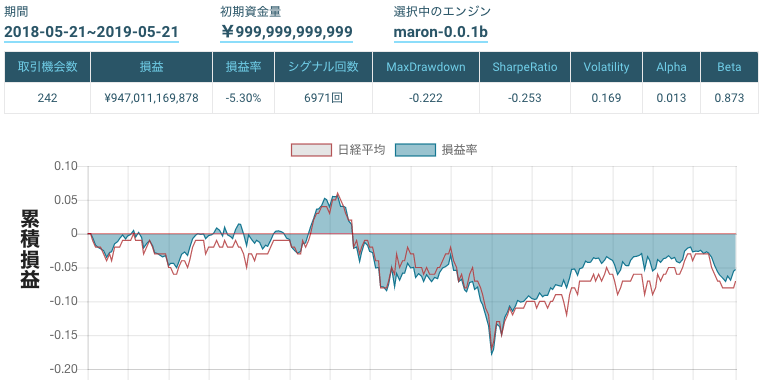
Black-Litterman Modelのみ
https://factory.quantx.io/developer/1939fbe747c94440a9cb1cfa8ea88129
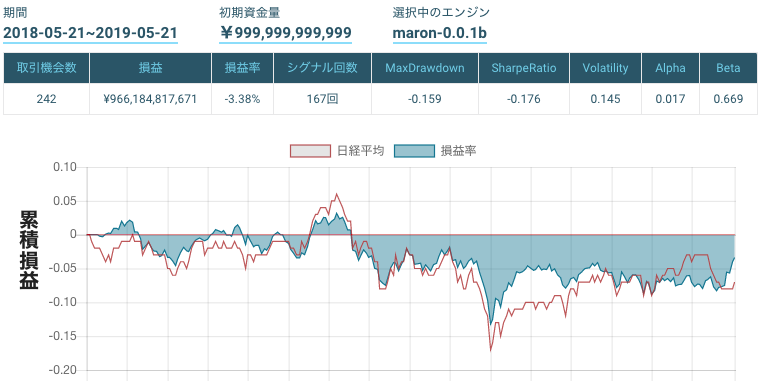
Bollinger Bandsのみ
https://factory.quantx.io/developer/1b500ec0ddc34cc3a4505fc54e8b5adb
時価総額による単純な重みづけとBollinger Bandsの組み合わせ
https://factory.quantx.io/developer/e0409ea7328148cd8574b2278594d4ba
Black-Litterman ModelとBollinger Bandsの組み合わせ
https://factory.quantx.io/developer/7e3ab5c28dbf404ea20fa5a7bb8181aa
おわりに
Black-Litterman Modelとテクニカル分析の組み合わせの可能性を感じました.また,投資家のビューをそれなりに適当なものにできると,効果を発揮することが実感できました.
下記のURLからQuantX Factory上で今回紹介したコードのバックテストを行うことが出来ます.
https://factory.quantx.io/developer/7e3ab5c28dbf404ea20fa5a7bb8181aa参考文献
以下の記事を参考にしています.
ブラック・リッターマンモデルによる資産配分を解説してみる(Pythonによる実行例つき)免責注意事項
この記事のコードや知識を使った実際の取引で生じた損益に関しては一切の責任を負いかねますので御了承下さい.
- 投稿日:2019-05-21T15:49:27+09:00
【python】メンドクサイを自動にさせてみた2【seleniumで自動登録】
解析したメールをseleniumで処理
前回の記事で届いたメールから特定のメールを一時的にデスクトップのmailcheck.txtに出力させる方法を書きました。
次はこのmailcheck.txtの中身を使ってseleniumに自動で記入してもらいます。
ひとまず全体を載せます。mail.py#selenium処理 def def_selenium(): with open(UserPath,'r') as rf: read_text = rf.readlines() find_str1 = "特定文字1" find_str2 = "特定文字2" if find_str1 in read_text == True: return elif find_str2 in read_text == True: return read_text_strip = [line.strip() for line in read_text] l_XXX_both = [(i, read_text) for i, read_text in enumerate(read_text_strip) if '項目1' in read_text] i1 = l_XXX_both[0] l_XXX_both = [(i, read_text) for i, read_text in enumerate(read_text_strip) if '項目2' in read_text] Koumoku_Day = read_text[i1[0]] #項目1 Koumoku_Name = read_text[i2[0]] #項目2 #フォーマット処理 pKoumoku_Day = datetime.strptime(Koumoku_Day, '%Y年%m月%d日') fKoumoku_Day = datetime.strftime(pKoumoku_Day, '%Y/%m/%d') fKoumoku_Name = Koumoku_Name.split(':')[1] #ネットに接続 driver = webdriver.Chrome("C:/driver/chromedriver.exe") time.sleep(1) driver.get("予約管理のログインURL") time.sleep(4) #ログイン elem_search_word = driver.find_element_by_id("uid") elem_search_word.send_keys("ユーザーネーム") elem_search_word = driver.find_element_by_id("passwd") elem_search_word.send_keys("パスワード") elem_search_btn = driver.find_element_by_css_selector(".login-button") elem_search_btn.click() time.sleep(3) #予約管理ページに移行 driver.get("予約管理のURL") time.sleep(3) #日付をKoumoku_Dayの日に elem_search_word = driver.find_element_by_id("currentDate") elem_search_word.clear() elem_search_word.send_keys(fKoumoku_Day) time.sleep(3) #ラジオボタンの選択 elem_search = driver.find_element_by_id("equip_radio_9") driver.execute_script("arguments[0].click();", elem_search) #ラジオボタンを選択するためのJS time.sleep(3) #上から順に空欄を見つけるを押下 elem_search_tr = driver.find_elements_by_xpath( "//div[@class='ui-selectee']" ) for i in range(0,100,2): text_elem = elem_search_tr[i].text if text_elem.find("×") == -1: #空きを発見したので、ループを抜けて入力処理 elem_search_tr[i].click() break else: continue time.sleep(3) driver.find_element_by_link_text(u"ページ2").click() time.sleep(3) #氏名 elem_search_word = driver.find_element_by_id("client_name") elem_search_word.send_keys(fKoumoku_Name) time.sleep(3) #登録ボタン elem_search_btn = driver.find_element_by_id("submit") elem_search_btn.click() time.sleep(3) Alert(driver).accept() time.sleep(3) driver.quit()seleniumに関してはもっと詳しくわかりやすい記事がいくらでもあるので、使った技術をピックアップしていきます。
mail.py#selenium処理 def def_selenium(): with open(UserPath,'r') as rf: read_text = rf.readlines() find_str1 = "特定文字1" find_str2 = "特定文字2" if find_str1 in read_text == True: return elif find_str2 in read_text == True: return最初にデスクトップに作成したファイルを読み取ります。
readlines()で一行ずつ区切って格納できます。
文章がきれいに並んでいてくれるおかげで、こうすることで文字の切り取りがやりやすくなりました。
特定の文字が含まれていた場合、処理を行わずに次のメールを見に行きます。mail.pyread_text_strip = [line.strip() for line in read_text] l_XXX_both = [(i, read_text) for i, read_text in enumerate(read_text_strip) if '項目1' in read_text] i1 = l_XXX_both[0] l_XXX_both = [(i, read_text) for i, read_text in enumerate(read_text_strip) if '項目2' in read_text] Koumoku_Day = read_text[i1[0]] #項目1 Koumoku_Name = read_text[i2[0]] #項目2 #フォーマット処理 pKoumoku_Day = datetime.strptime(Koumoku_Day, '%Y年%m月%d日') fKoumoku_Day = datetime.strftime(pKoumoku_Day, '%Y/%m/%d') fKoumoku_Name = Koumoku_Name.split(':')[1]最初の一文でread_text_stripにリスト形式でテキストを格納します。
.strip()は、文字列型のメソッドで特定の文字列や空白文字を削除するためのメソッドです。
それからさらに「項目1」という文字を検索し、ヒットした行をl_XXX_bothに入れています。
こうすることで、文章の変更などにより、メール文の長さが変わってしまっても、定型部分は拾えるとしたわけです。フォーマット処理で自分の扱いたい日付の形に変更しました。
mail.py#ネットに接続 driver = webdriver.Chrome("C:/driver/chromedriver.exe") time.sleep(1) driver.get("予約管理のログインURL") time.sleep(4) #ログイン elem_search_word = driver.find_element_by_id("uid") elem_search_word.send_keys("ユーザーネーム") elem_search_word = driver.find_element_by_id("passwd") elem_search_word.send_keys("パスワード") elem_search_btn = driver.find_element_by_css_selector(".login-button") elem_search_btn.click() time.sleep(3) #予約管理ページに移行 driver.get("予約管理のURL") time.sleep(3)やっとseleniumの出番です。seleniumがchromeのWEBドライバーという自動処理専用のソフトを起動します。
chromedriverは検索すればすぐ出てきます。getで行きたいURLのページに飛びます。
ちょくちょくtime.sleepを挟むのは、処理が早すぎるとうまく動作しないためです。
sleepの時間は自分のPCのスペックや回線の速さを見て調整するといいです。find_element_by_〇〇でそのページの必要な要素をターゲットします。
この要素を上手く見つけられるかがselenium成功の鍵と言って過言ではないと思っています。
idなのか、css_selectorなのか、xpathなのか、自分のやりやすい方法を探すのがいいです。
個人的にはidから探し、うまくいかなければxpathを使うようにしてます。
css_selectorも便利なんですけど、なぜか好きになれません。elem_search_btn.click()のようにボタンの要素を見つければクリックもできます。
mail.py#ラジオボタンの選択 elem_search = driver.find_element_by_id("equip_radio_9") driver.execute_script("arguments[0].click();", elem_search) #ラジオボタンを選択するためのJS time.sleep(3)ラジオボタンには少し苦労しました。
終わってみればなんてことはない、javascriptでクリックするだけなんですが、JSに疎い私はなんとかfind_elementで済ませようとしました。
ですがどーにもうまくいきません。
要素だけ探して、JSでのクリックが一番いいとたどり着きました。
driver.execute_scriptは今後もお世話になる技術として覚えておきました。#上から順に空欄を見つけるを押下 elem_search_tr = driver.find_elements_by_xpath( "//div[@class='ui-selectee']" ) for i in range(0,100,2): text_elem = elem_search_tr[i].text if text_elem.find("×") == -1: #空きを発見したので、ループを抜けて入力処理 elem_search_tr[i].click() break else: continueこの予約管理のシステムはエクセルを思い描いていただくとわかりやすいのですが、
予約が埋まっていると「x」が記入されているため、find("x")で-1以外の数値が返ってきます。
-1が返ってくるとそこは空白とわかるので、空白を見つけたらクリックしてループを抜けます。Alert(driver).accept() time.sleep(3)画面に出てくる確認のポップアップをaccept()でOKします。
これで一通りの処理を終了し、再度メールに特定のアドレスがないかを確認します。まとめ
文章に起こしてみるとそんなに難しいことはしてませんが、あれやこれや探しながらエラーに一つずつ対応してとしてるとまぁまぁ時間がかかりました。
でも実際に思ったように動いた時の達成感、やったった感は何とも言えないですね。
この記事が初学者の方、うまく動かなくて困ってる方の力に少しでもなれれば幸いです。ここまでご覧いただきまして、ありがとうございました。
- 投稿日:2019-05-21T15:31:09+09:00
[自分用メモ]Djangoで初Webアプリ開発に挑戦 Part6
前回
[自分用メモ]Djangoで初Webアプリ開発に挑戦 Part5
簡単なフォームの作成
テンプレートの編集
"polls/detail.html"を更新してHTMLの
<form>要素を入れます。
"detail.html"を以下のように編集します。polls/templates/polls/detail.html<h1>{{ question.question_text }}</h1> {% if error_message %}<p><strong>{{ error_message }}</strong></p>{% endif %} <form action="{% url 'polls:vote' question.id %}" method="post"> {% csrf_token %} {% for choice in question.choice_set.all %} <input type="radio" name="choice" id="choice{{ forloop.counter }}" value="{{ choice.id }}"> <label for="choice{{ forloop.counter }}">{{ choice.choice_text }}</label><br> {% endfor %} <input type="submit" value="Vote"> </form>テンプレートはいい感じなので、ここに情報を送る"view.py"のvoteメソッドを編集します。
ビューの編集
投票ページ
polls/views.pyfrom django.http import HttpResponse, HttpResponseRedirect from django.shortcuts import get_object_or_404, render from django.urls import reverse from .models import Choice, Question # ... def vote(request, question_id): question = get_object_or_404(Question, pk=question_id) try: selected_choice = question.choice_set.get(pk=request.POST['choice']) except (KeyError, Choice.DoesNotExist): return render(request, 'polls/detail.html', { 'question': question, 'error_message': "You didn't select a choice.", }) else: selected_choice.votes += 1 selected_choice.save() return HttpResponseRedirect(reverse('polls:results', args=(question.id,)))わかりやすいように、"polls/view.py"からリクエストとともに飛ばされてきた変数をまとめておくと、
view.py内 detail.html内 question(Question class)のインスタンスもしくは404 question.(~~) error_message="You didn't select a choice." error_message となります。
{{ forloop.counter }}はこのテンプレートファイル内での、forイテレーション数をカウントしていることみたいです。voteメソッドが長いので、一度解体してみます。
- 引数:リクエストと、URLに入力された整数question_id。
- 例外処理
- (try)"detail.html"内のname属性"choice"である、inputタグの値{{ choice.id }}をpkとするchoice_setオブジェクト(これはquestion_idをpkとするQuestionオブジェクトの中のオブジェクト)を、Choiceクラスのインスタンスである変数
selected_choiceに格納。- (except)もし、"detail.html"でchoiceが未選択の場合、"detail.html"をエラーメッセージ付きで再表示します。
- つまり"detail.html"のif文は、この「エラーメッセージ」がある場合の処理を記述しています。
- (else)何も問題なければselected_choiceのプライベート変数vote(default=0)に1を足して、データベースにセーブします。
- 最後にHttpResponseRedirectコンストラクタによって、リクエストの送り先を'polls:results'に、URLパターンを与える位置引数をquestion_idとしたreverse()関数を送ります。
結果ページ
上にある通り、voteのフローが終わると'polls:results'へリクエストが送られますので、resultページのビューを完成させます。
polls/views.pyfrom django.shortcuts import get_object_or_404, render def results(request, question_id): question = get_object_or_404(Question, pk=question_id) return render(request, 'polls/results.html', {'question': question})ビューが完成したので、それを我々がブラウザで確認できるようテンプレートファイルを作ります。
polls/templates/polls/results.html<h1>{{ question.question_text }}</h1> <ul> {% for choice in question.choice_set.all %} <li>{{ choice.choice_text }} -- {{ choice.votes }} vote{{ choice.votes|pluralize }}</li> {% endfor %} </ul> <a href="{% url 'polls:detail' question.id %}">Vote again?</a>次は汎用ビュー(クラスベースビュー)についてまとめようと思うので、今回は短いですがここで切っておきます。
- 投稿日:2019-05-21T14:06:24+09:00
Atcoderで使うコードの保管庫(python)[随時更新]
頻出するコードを書き留めておく(お手製)
バグやより最適なコードなどありましたらコメントください.
随時更新します
Union Find
u = Union(N) #ノード数Nで初期化
u.union(a,b) # a,bを結合(0-indexed)
u.count(a) # aを含む連結成分の個数をカウントUnionFind.pyclass Union(): def __init__(me,N): me.N = N me.up = [-1]*N me.down = [ [] for i in range(N) ] def union(me,a,b): ua = me.up[a] if me.up[a]!=-1 else a ub = me.up[b] if me.up[b]!=-1 else b if (ua == ub): return if ( len(me.down[ua]) < len(me.down[ub]) ): ub,ua = ua,ub for v in me.down[ub]: me.up[v] = ua me.down[ua].extend( me.down[ub] ) me.down[ub] = [] me.up[ub] = ua me.down[ua].append( ub ) def count(me,a): ua = me.up[a] if me.up[a]!=-1 else a return len(me.down[ua])+1
- 投稿日:2019-05-21T13:54:46+09:00
Ricty を神フォントだと崇める僕が、ライセンスフリーなプログラミングフォント「白源」を作った話
誰もが知る(?)プログラミングフォントこと Ricty にインスパイアされ、Ricty のように英文フォントと和文フォントを合成したプログラミングフォントを作りました。
その名も、プログラミングフォント「白源 (はくげん/HackGen)」です!
白源 (はくげん/HackGen) 生成元にはプログラミング向け英文フォント Hack と、Adobe 製作の源ノ角ゴシックに丸みを付けた派生フォント 源柔ゴシック を使用させていただきました。
白源の生成元である Hack、及び源柔ゴシックには、いずれも SIL Open Font License Version 1.1 という大らかなライセンスが適用されているため、改変及び配布が自由となっています。したがって、白源の生成済みフォントファイル (ttf ファイル) は GitHub からダウンロードして、すぐにご利用いただけます。
「白源 (はくげん/HackGen)」の特徴
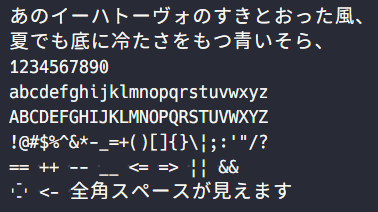
プログラミングフォント「白源 (はくげん/HackGen)」には以下のような特徴があります。
- 文字幅 半角1:全角2 の正統派な等幅フォント
- Hack 由来の読みやすく、しっとりとした印象の英字
- 源柔ゴシック由来の引き締まりつつ、丸ゴシックの風合いのあるカナ文字・漢字
- 全角スペースの可視化、パイプ記号
|の破断線化 (Ricty インスパイア)- Windows 上の VSCode など、Electron 製のエディターでもしっかりとアンチエイリアスが掛かる (Ricty だと綺麗にアンチエイリアスが掛からず、ガビガビした表示になる)
ダウンロード
この後の章は退屈だと思うので、ひとまずこのあたりでダウンロードリンクを貼っておきます。ぜひお試しください!
※ページ内の「HackGen_v<バージョン>.zip」という名称の ZIP ファイルをダウンロードしてご使用ください。
謝辞
Hack を提供してくださっている作者様、源柔ゴシックを提供してくださっている作者様、並びに源柔ゴシックの生成元である源ノ角ゴシックと M+ OUTLINE FONTS の作者様へ、この場を借りて深くお礼申し上げます。
「白源」作成までの経緯
Ricty は美しい
プログラミングフォントについて調べると、必ずと言っていいほど出てくるのが 「Ricty」という和文対応のプログラミングフォントです。
和文対応のプログラミングフォントはいくつか公開されていますが、その中でも Ricty は抜きん出て視認性に優れ、さらに英文と和文の字体のバランスがとても良く、合成されたフォント同士が高度に調和されている印象を受けました。
それに魅了された僕は、いくつかのプログラミングフォントを試しては結局 Ricty に戻る…を繰り返していたのでした。
以下は普段使用している、Ricty の視認性向上版となる Ricty Discord です。
Ricty Discord ちなみに Ricty は、英文のラテン文字には Consolas を意識して作られたという Inconsolata、和文の文字には視認性の良い Migu 1M というフォントが表示されるように合成されたフォントですが、Migu 1M のライセンスの影響で合成後のフォントファイルの配布は行われておらず、合成スクリプトのみを公開する形が取られています。 (合成スクリプトの使い方は割愛します)
Ricty のデメリット
とにかく美しい Ricty ですが、フォント比較系のブログ記事で否定的な意見を見かけることもあります。否定意見では以下が多い気がします。
- Inconsolata の字体が細すぎて見づらい、表示がかすれる
- Migu 1M (M+ OUTLINE FONTS) の丸みを帯びた字体が好みではない
- フォント生成がめんどくさい
そこで Ricty と同等の視認性を持ち、字体はもっと太く、そして和文は M+ 系のフォント以外で、さらにライセンス問題もクリアしてそのまま配布できるフォントは作れないだろうかと考えました。
M+ 系フォントはなぜか Electron 製エディターの DirectWrite との相性が悪い
もう一つ、Windows ユーザーの自分には許し難いデメリットがあったのでした。それは、Windows 上の Electron 製のテキストエディターではアンチエイリアスがうまく掛かってくれないことです。(きっと Mac なら綺麗なんだろうな…使ったことないですけど。)
Ricty Discord 白源 (はくげん/HackGen) 普段僕は、VSCode や Inkdrop といった、エディター部が Electron 製のアプリを利用しています。
もちろんそれらのアプリ上での表示は、上記のようにガタガタなものになるのでした。悲しみ。
フォント選定
フォントの選定は、前述の通り Hack と源柔ゴシックにしました。以下、簡単にご紹介です。
しっかりとした太さを持った「Hack」
Hack は SIL ライセンスで提供されている素敵フォントです。太めで見やすい字体を見た瞬間、「これだ!!」と思って選定しました。
このフォントは、プログラミングフォント「Cica」の元になっているのを知っている方もいるのではないでしょうか。
ライセンスフリーな和文フォントの定番「源ノ角ゴシック」の派生フォント「源柔ゴシック」
ライセンスフリーで和文フォント、と考えた時点で源ノ角ゴシック系だと決めていました。
いくつか試した中で、丸ゴシック風の源柔ゴシックの L タイプ(丸みが少ない版)が Hack の雰囲気に合っていると感じたため、採用させていただきました。
ちなみに源ノ角ゴシックの派生フォントでは最も有名なのではなかろうかという源真ゴシックは、前述の DirectWrite 問題が発生していました。源柔ゴシックと同じ作者の方のフォントなので、ちょっと不思議です。
いざ、「白源」を生成
詳細な生成手順やノウハウは、また別の記事にまとめたいと思いますが、流れとしては以下のような感じです。
- Hack の高さを源柔ゴシックに合わせ、さらに幅を狭める (X 幅:87%, Y 幅:91%)
- 破断線 (brokenbar) をパイプ記号 (verticalbar) にコピーして Y 幅:114% に変形
- 源柔ゴシックの幅を Hack に合わせて広げる
- 編集した Hack と源柔ゴシックを合成
- フォントの高さ等のメタデータが保存されている OS/2 テーブル、post テーブルを修正 (これをしないと等幅フォントとして OS に認識されなかったり、斜体や太字としてフォント登録がされなかったりする)
今後の課題
今回は Ricty の生成スクリプトをかなり踏襲しているため、その範囲で対応できない部分 (主に Hack の修正) を手動で行っています。将来的には、そのあたりも全てスクリプトで自動生成できるようにしたいところです。
その際にはおそらく、シェルスクリプトではなく Python で実装する必要が出てくるだろうと思っています。
参考
フォント作成にあたり、以下の記事が大いに参考になりました。
ありがとうございました。
- 投稿日:2019-05-21T13:29:25+09:00
AtomとPython3でAtCoderを始めるまで
AtCoderを始めたので、AtomとPython3でコードを素早くテストする環境を作りたい!と思ってやったことをまとめています。
※パッケージのインストール方法とかは調べればたくさん出てくるので割愛します。atom-runner
atomで編集したコードをショートカットで実行するパッケージです。
しかしデフォルトではPython2系で実行される(環境による?)のでPython3を実行するように変更します。
Atom>個人設定からconfig.csonを開きrunner: scopes: python: "Python3"と追記。あとはpythonファイルを開いて
Ctrl+R(Mac)で実行できます!標準input()を実行するためのセッティング
Python3系を動かせるようになりましたが、このままではAtCoderでよく使う
N = input()が使えません。「どっから入力したらええねん!?」みたいに怒られてしまうのです。
そこで、input.txtというファイルを作成し、下記のコードをプログラムの先頭に付けることで標準入力先をこのinput.txtに繋ぎます。import sys import os f = open('input.txt', 'r') sys.stdin = fこれで、入力を
input.txtに記述することでinput()が使えるようになりました!スニペットの設定
よく使うコードは
snipets.csonに書いておくことですぐに呼び出すことができるようになります。時短です。
例えば上のinput.txtを標準入力に繋ぐコードは、ファイル作るごとに先頭に書かなければならない、メンドくさいですよね?
Atom>スニペットからsnipets.csonを開き、下のコードを貼り付けることで'.source.python': 'atcoder_input': 'prefix':'atcoder' 'body':''' import sys import os f = open('input.txt', 'r') sys.stdin = f '''
'atcoder'と入力すればエンターキーで上のコードが記述されます。まとめ
設定は以上です。まだ始めたばかりなのでコンテストに参加したら使用感を書いてみようと思います。
参考にしたサイト
- 投稿日:2019-05-21T13:28:38+09:00
WSGIを使ってDjangoをターミナルから叩いてみた
概要
Djangoで開発しててWSGI(Web Server Gateway Interface)ってたまに聞くけどよくわかってなかったんで調べてみたら、(あれ、これってひょっとしてpythonで直接叩ける?)とふと思ったんで、検証してみました。
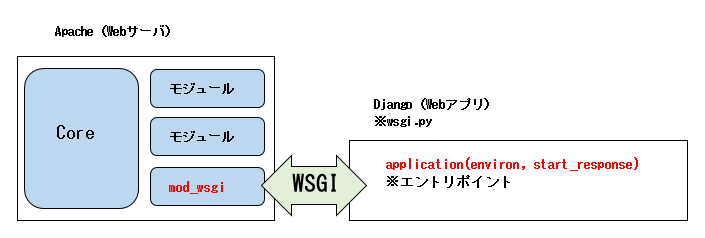
まずWSGIの概要
WSGIの詳細な仕様は各々調べてもらうとして、apache+djangoをWSGIで動かしたとして、大まかに以下の図のような関係になっています。
図にあるようにapacheとdjangoがやり取りするインターフェースの規格がWSGIです。
django側の入り口となるのはwsgi.pyファイルで、そのファイル内に記述されているcallableなエントリポイント(ここではapplication)をapacheが呼び出すことでやり取りします。と書くと分かりづらいかもしれまんせんが、要は、apacheからapplication関数を呼び出して、その結果をブラウザとかに返すというような感じです。
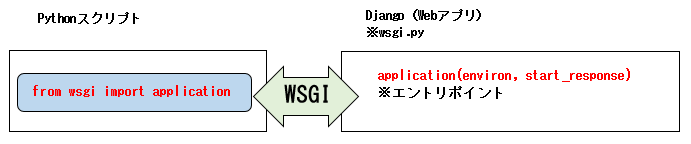
冒頭の疑問
WSGIの利点として、WSGIの仕様に対応していれば、呼び出し側(apacheとか)やWebアプリ側(djangoとか)が何であっても正常に動作する、というのがあります。
では、以下の場合でも動作するのでは?と考えました。
WSGIの仕様さえ守っていれば何でもいいんだから、呼び出し側はpythonスクリプトにしてimportしてやってもいけるのでは?
というわけで検証してみました。
検証環境
- Centos : 7
- Python : 3.7.1
- Django : 2.1.7
上記の環境で、こちらのチュートリアルに沿ってPollsのviewを作って、そのviewをPythonスクリプトからWSGIを通して呼び出してみました。
Pythonスクリプトの内容
以下が、applicationを呼び出す
kick_wsgi.pyスクリプトです。kick_wsgi.py# wsgi.pyファイルのapplicationエントリポイントのimport from mysite.wsgi import application # applicationに渡すメソッド # 検証だけなので適当、表示のみ def start_response(status, response_headers): print('status => %s' % status) print('response_headers => %s' % response_headers) # applicationでGETメソッドを動作させる為に必要な最低限のパラメータ environ = {} environ['PATH_INFO'] = '/polls/' environ['REQUEST_URI'] = '/polls/' environ['REQUEST_METHOD'] = 'GET' environ['SERVER_NAME'] = 'localhost.localdomain' environ['SERVER_PORT'] = '80' environ['wsgi.input'] = '' # これは謎、無いと怒られる # application呼び出し response = application(environ, start_response) # HTMLのコンテンツ表示 print('content => %s' % response.content)applicationの第2引数:start_responseはdjangoの結果を受け取るだけなんでここでは適当です。重要なのは第1引数:environで、上記のスクリプトを見るとenvironで渡すパラメータには見覚えのあるパラメータ名が並んでいると思います。とりあえずdjangoを騙くらかして動かせればいいんで、最低限必要そうなのをセットしてます。
スクリプトの実行結果
[guest@localhost hoge]$ PYTHONPATH=. python kick_wsgi.py status => 200 OK response_headers => [('Content-Type', 'text/html; charset=utf-8'), ('X-Frame-Options', 'SAMEORIGIN'), ('Content-Length', '40')] content => b"Hello, world. You're at the polls index."想定通りの結果が返ってきました!
まとめ
djangoをWSGIを使ってキックするのは思いのほかシンプルで簡単でした。シンプルだからこそ、WSGIに対応しているWebサーバやWebアプリであれば部品のように交換して動作させられるんでしょう。
あと私のようなターミナル大好き人間にとってはフレームワークやらなんやらをターミナルから直接叩ける方法があると嬉しかったりするのでこの記事は備忘録用でもあります。(ターミナルから直接叩けて何が嬉しいのか・・それはターミナル好きにしかわからない・・)
- 投稿日:2019-05-21T13:04:23+09:00
和暦西暦変換を如何に完全に処理するか
text値の日付と思われる値を、date型の日付値に変換処理を作る事になり
あーでもないこーでもないと頭を悩ませた結果が以下の処理です。
最大の懸案は、「2桁の数値のみ」の年を如何に正しく変換するか、なのですが
今のところ正解がわかりません(´・ω・`)
19[63]と昭和[63]とかどうしたもんですかね?想定するtextは
「2015年1月1日」「15年1月1日」「2015年01月01日」
「2015/1/1」「2015/01/01」「15/1/1」「15/01/01」
「2015-1-1」「2015-01-01」「15-1-1」「15-01-01」
「2015.1.1」「2015.01.01」「15.1.1」「15.01.01」
「平成27年1月1日」「平成27年01月01日」「H27年1月1日」「H27年01月01日」
「H27/1/1」「H27/01/01」
「H27-1-1」「H27-01-01」
「H27.1.1」「H27.01.01」
ざっとこんな感じです。とりあえず作った処理は↓な感じ。
datetextToDate.pydef datetextToDate(self, date): #渡された日付を日付型にして返す #和暦対応 list_wareki = ["昭和", 1925], ["平成", 1988], ["令和", 2018], ["S", 1925], ["H", 1988], ["R", 2018] # #引数を取得 date_text = date # #和暦判定 for nengou, nensuu in list_wareki: result_find_date_text_type = date_text.find(nengou) if result_find_date_text_type != -1: year_add = nensuu break # # #日付区切り毎に処理を行う #区切りが「年月日」 if (date_text.find("年") != -1): search_date_regular = "((?<![0-9])[0-9]{1,4})年([0-9]{1,2})月([0-9]{1,2})日" #区切りが「/」 elif (date_text.find("/") != -1): search_date_regular = "((?<![0-9])[0-9]{1,4})/([0-9]{1,2})/([0-9]{1,2})" #区切りが「-」 elif (date_text.find("-") != -1): search_date_regular = "((?<![0-9])[0-9]{1,4})-([0-9]{1,2})-([0-9]{1,2})" #区切りが「.」 elif (date_text.find(".") != -1): search_date_regular = "((?<![0-9])[0-9]{1,4})\.([0-9]{1,2})\.([0-9]{1,2})" #区切りが見つからなかった場合 else: return "日付の区切り記号が判定出来ませんでした。:" + date, False # #日付を各要素に分解する search_result_date = re.search(search_date_regular, date_text) # #日付が入っていない場合は処理を抜ける if search_result_date == None: return "年月日の3つが取得出来ませんでした:" + date, False # y = int(search_result_date.group(1)) m = int(search_result_date.group(2)) d = int(search_result_date.group(3)) # #和暦の場合 if result_find_date_text_type != -1: y = y + year_add else: #西暦だが2桁の場合 if len(str(y)) == 2: y = y + 2000 # #日付チェック try: newDataStr="%04d/%02d/%02d"%(y,m,d) newDate=datetime.datetime.strptime(newDataStr,"%Y/%m/%d") #return True except ValueError: return "日付が正しい値ではありませんでした:" + date, False # #日付に変換する date_dt = str(datetime.date(y, m, d)) date_dt = datetime.datetime.strptime(date_dt, "%Y-%m-%d") # #変換後の値を返す return date_dt, True
- 投稿日:2019-05-21T12:42:05+09:00
最尤法(method of maximum likelihood)を用いた画像分類
はじめに
最尤推定(maximum likelihood estimation)や最尤法(method of maximum likelihood)とは,統計学において,与えられたデータからそれが従う確率分布の母数を点推定する方法のことをさします.
尤とは非常に優れているという意味で,直訳すれば最も非常に優れている推定方法,となりますね(笑)今回やること
画像の特定の5箇所を5クラスに設定して,該当するクラスごとに10点のr,g,b値を教師データとして格納し, 入力画像の各画素がどのクラスに該当するかを最尤法を用いて算出する.
アルゴリズム
今回のプログラムでは,入力した画像の特徴的な部分を任意に5クラス選出し,
画像の各画素がどのクラスに属するかを最尤法を用いて推定していきます.
使用する言語はPython3です.以下の画像のように,入力画像の一部を1~5のクラス番号を振り,各クラスから教師データ用に10点を選出し,座標ごとのr,g,bの格納します.
その後,
・各クラスの平均画素値
$$m=[Rmean,Gmean,Bmean]$$
・各クラスの共分散行列
$$cV$$
・共分散行列の逆行列
$$cV^{-1}$$
・共分散行列の行列式
$$|cV|$$
を計算します.
そして上記を用いて尤度の計算をおこないます.
尤度の計算式は、以下の式を用います。$$ J(x,c) = log|cV|+d^2(x,c)$$
$$ d^2(x,c) = (x-m)cV^{-1}(x-m)^t$$ここで,入力画像の各座標の画素値(r,g,b)がxとなります.
5種類のクラス分の計算を行い,J(x,c)が最小のクラスに分類していきます.実際に数値を適当に設定して出力した画像はこちらになります.
ソースコード
雑ですが,サンプルコードはこちらにあげてあります.
https://github.com/legion98/Maximum-Likelihood-Method-exampleコード中に記載されている教師データの座標は,適当に仮置きしたものなので,
画像編集ソフト等を用いて,自分で選出して使ってください.


- 投稿日:2019-05-21T12:24:38+09:00
リモートURLを指定すると #Twitter #API を叩いて画像付きツイートをする #python スクリプトの例
config.py
CONSUMER_KEY='' CONSUMER_SECRET='' ACCESS_TOKEN='' ACCESS_TOKEN_SECRET=''twitterauth.py
#!/usr/bin/env python3 import os, config from requests_oauthlib import OAuth1Session if os.environ.get('TWITTER_CONSUMER_KEY'): CONSUMER_KEY = os.environ.get('TWITTER_CONSUMER_KEY') CONSUMER_SECRET = os.environ.get('TWITTER_CONSUMER_SECRET') ACCESS_TOKEN = os.environ.get('TWITTER_ACCESS_TOKEN') ACCESS_TOKEN_SECRET = os.environ.get('TWITTER_ACCESS_TOKEN_SECRET') else: CONSUMER_KEY = config.CONSUMER_KEY CONSUMER_SECRET = config.CONSUMER_SECRET ACCESS_TOKEN = config.ACCESS_TOKEN ACCESS_TOKEN_SECRET = config.ACCESS_TOKEN_SECRET def twitter(): return OAuth1Session(CONSUMER_KEY, CONSUMER_SECRET, ACCESS_TOKEN, ACCESS_TOKEN_SECRET)script.py
#!/usr/bin/env python3 import json, config, os, twitterauth, sys, base64 url = 'https://dummyimage.com/600x400/000/fff' twitter = twitterauth.twitter() image_bytes = base64.b64encode(requests.get(url).content) image_base64_str = image_bytes.decode('utf-8') media_api_params = { "media_data": image_base64_str } media_api_url = 'https://upload.twitter.com/1.1/media/upload.json' media_api_res = twitter.post(media_api_url, params = media_api_params) media_id_string = media_api_res.json().get('media_id_string') update_api_params = { "status" : "test message", "media_ids" : media_id_string, } update_api_url = 'https://api.twitter.com/1.1/statuses/update.json' update_api_res = twitter.post(update_api_url, params = update_api_params) print(json.dumps(media_api_res.json()))# result
Original by Github issue

- 投稿日:2019-05-21T12:05:38+09:00
Python
公式サイト
データ型
データ型
区分 型名 説明 例 基本 int 整数 123 基本 float 実数 12.3 基本 bool 真偽値 True 基本 str 文字列。「"」「'」どちらでもよい "Pythonとは" 基本 tuple タプル(データのまとまり) ('A', 1) 基本 list リスト(データのまとまり) [100, 200, 300] 基本 dict 辞書(データのまとまり) {'score': 100, 'name': 'ts'} 基本 bytes ASCII(英数字と一部の記号)のみの特殊な文字列 b'Japan' 基本 bytearray ASCII文字のまとまり bytearray(200) 基本 range 数のシーケンス range(10) 特殊 NoneType 値が存在しないことを表す None 特殊 NotImplementedType ある型に対して演算が実装されていないことを表す NotImplemented 特殊 Ellipsis 一部の構文で使われる特殊な値 ... 特殊 complex 複素数 3j 特殊 builtin_function_or_method 組み込み関数・メソッド その他 function 関数 自分で定義した関数 その他 type 型(クラス) int 型の調査方法
ターミナルでは下記のみでよいが、スクリプトで利用する場合はprintと組み合わせて表示させる。
type(値)int型
整数の値を利用する。
「0x」を頭に付けることで16進数、「0b」を付けることで8進数を扱うことが可能。float型
整数以外の数値全般に利用する。
桁数の大きな値は「E」記号を付けて10の○○乗という表現も可能。str型
「"」「'」どちらでも利用可能。
エスケープシーケンス
表現 説明 ¥newline バックスラッシュと改行を無視 ¥¥ バックスラッシュ(¥) ¥' シングルクォート ¥" ダブルクォート ¥a ASCII端末ベル ¥b ASCIIバックスペース ¥f ASCIIフォームフィード ¥n ASCIIラインフィード ¥r ASCIIキャリッジリターン ¥t ASCII水平タブ ¥v ASCII垂直タブ ¥ooo 8進数のoooを持つ文字(oooは任意の8進数) ¥xhh 16進数のhhを持つ文字(hhは任意の16進数) ¥N{name} ユニコードでnameという名前の文字 ¥uxxxx 16bitの16進数xxxxを持つ文字 ¥Uxxxxxxxx 32bitの16進数xxxxxxxxを持つ文字 変数宣言
変数名に利用できるのは半角英数字、およびアンダースコアで大文字・小文字を区別する。
全て大文字は定数扱いとなる。変数名 = 値演算
算術演算
表記 説明 A + B AとBを足す A - B AからBを引く A * B AにBをかける A ** B AのB乗 A / B AをBで割る(割り切れるまで) A // B AをBで割る(小数点以下は切り捨て) A % B AをBで割った余り 文字列の演算
表記 説明 "文字列" + "文字列" 文字列を結合 "文字列" * ○ 文字列を○回繰り返す キャスト(型変換)
表記 説明 int(値) 値をint型に変換 float(値) 値をfloat型に変換 str(値) 値をstr型に変換 bool(値) 値をbool型に変換 比較演算
表記 説明 A == B AとBは等しい A != B AとBは等しくない A < B AはBより小さい A <= B AはB以下 A > B AはBより大きい A >= B AはB以上 代入演算
表記 説明 変数 += 値 変数に値を加算する 変数 -= 値 変数から値を減算する 変数 *= 値 変数に値を乗算する 変数 /= 値 変数を値で割り切れるまで除算する 変数 //= 値 変数を値で除算する 変数 %= 値 変数を値で除算した余りを代入する 論理演算
種類 表記 説明 論理積 A and B AとBが両方TrueならTrue、そうでないならばFalse 論理和 A or B AとBいずれかがTrueならTrue、両方FalseならFalse 否定 not A AがTrueならFalse、FalseならTrue プログラムの書き方
改行
改行したい場所に¥記号を入れることで、次の行も1文として扱われる
msg = "Hello! I'm " + name + ", " ¥ + age + "."三重クォートによるテキストの記述
テキストを三重クォートで囲むことにより、複数行のテキストと改行などの
エスケープシーケンスを自動で変数へ格納する。str1 = """テキスト テキスト テキスト """ str2 = '''テキスト テキスト テキスト '''文字列のフォーマット
事前に定義した変数を{}内に展開して文字列を設定する。
+演算子による複雑な文字列結合を簡潔に記載することが可能。msg = f"Hello! I'm {name}, {age}."コメント
# 1行コメント ''' 複数行コメント 複数行コメント 複数行コメント '''データ構造
データ構造 説明 リスト 多数の値をまとめて扱う。変更可能 タプル 多数の値をまとめて扱う。変更不可 レンジ 指定範囲の整数をまとめて扱う セット 値のみ保管(インデックスはない)。値は重複できない 辞書 キーと値をセットで保管する リスト
リストの宣言
変数名 = [値, 値, 値, …] 変数名 = list(値, 値, 値, …)リストの取得、設定
変数名[添字] 変数名[添字] = ○リストの演算
表記 説明 利用例 リスト + リスト リストを結合する [1,2,3] + [4,5] ⇒ [1,2,3,4,5] リスト * ○ リストを○回分結合する [1,2,3] * 3 ⇒ [1,2,3,1,2,3,1,2,3] 値 in リスト 値がリストに含まれているか調べる arr = [10,20,30]
10 in arr ⇒ True値 not in リスト 値がリストに含まれていないか調べる arr = [10,20,30]
20 not in arr ⇒ Falseリスト[開始位置:終了位置] 一定範囲の要素をまとめて取り出す arr = [10,20,30,40,50]
arr[1:4] ⇒ [20,30,40]len(リスト) リストの要素数を取得 arr = [10,30,20,50,40]
len(arr) ⇒ 5max(リスト) リストの最大値を取得 arr = [10,30,20,50,40]
max(arr) ⇒ 50min(リスト) リストの最小値を取得 arr = [10,30,20,50,40]
min(arr) ⇒ 10リスト.append(値) リストの最後尾に要素を追加 arr = [10,20,30]
arr.append(100) ⇒ [10,20,30,100]リスト.insert(インデックス,値) 指定位置に値を挿入 arr = [10,20,30]
arr.insert(1,100) ⇒ [10,100,20,30]リスト.remove(値) リストから値を削除。同じ値が複数ある場合は1番最初の要素を削除 arr = [10,20,30,20]
arr.remove(20)del リスト(インデックス) 指定位置の要素を削除。インデックスを忘れるとリスト自体が削除されるので注意 arr = [10,20,30]
del arr(1) ⇒ [10,30]リスト.index(値) 値の位置を調べる。複数ある場合は最初の位置を返す arr = [10,20,30,20]
arr.index(20) ⇒ 1リスト.pop() 最後の要素を削除 arr = [10,20,30]
arr.pop() ⇒ [10,20]リスト.clear() リストの要素を全て削除 arr = [10,20,30]
arr.clear() ⇒ []リスト.reverse() 並び順を反転する arr = [10,30,20]
arr.reverse()
arr ⇒ [20,30,10]リスト.sort 昇順に並べ替え arr = [10,30,20]
arr.sort()
arr ⇒ [10,20,30]リスト.sort(reverse=True) 降順に並べ替え arr = [10,30,20]
arr.sort(reverse=True)
arr ⇒ [30,20,10]タプル
タプルの宣言
変数名 = (値, 値, 値, …)タプルの取得
変数名[添字]タプルの演算
表記 説明 利用例 タプル + タプル タプルを結合する (1,2,3) + (4,5) ⇒ (1,2,3,4,5) タプル * ○ タプルを○回分結合する (1,2,3) * 3 ⇒ (1,2,3,1,2,3,1,2,3) 値 in タプル 値がタプルに含まれているか調べる tp = (10,20,30)
10 in tp ⇒ True値 not in タプル 値がタプルに含まれていないか調べる tp = (10,20,30)
20 not in tp ⇒ Falseタプル[開始位置:終了位置] 一定範囲の要素をまとめて取り出す tp= (10,20,30,40,50)
tp[1:4] ⇒ [20,30,40]len(タプル) タプルの要素数を取得 tp = (10,30,20,50,40)
len(tp) ⇒ 5max(タプル) タプルの最大値を取得 tp = (10,30,20,50,40)
max(tp) ⇒ 50min(タプル) タプルの最小値を取得 tp = (10,30,20,50,40)
min(tp) ⇒ 10レンジ
レンジの宣言
#ゼロから指定の値まで 変数名 = range(終了値) #指定した範囲 変数名 = range(開始値, 終了値) #一定間隔 変数名 = range(開始値, 終了値, ステップ)レンジの取得
変数名[添字]レンジの演算
表記 説明 利用例 値 in レンジ 値がレンジに含まれているか調べる rg = range(10)
5 in rg ⇒ True値 not in レンジ 値がレンジに含まれていないか調べる rg = range(10)
5 not in rg ⇒ Falseレンジ[開始位置:終了位置] 一定範囲の要素をまとめて取り出す rg = range(10)
rg[1:4] ⇒ [1,2,3]len(レンジ) レンジの要素数を取得 rg = range(10)
len(rg) ⇒ 10max(レンジ) レンジの最大値を取得 rg = range(10)
max(rg) ⇒ 9min(レンジ) レンジの最小値を取得 rg = range(10)
min(rg) ⇒ 0シーケンス間の変換
表記 説明 list(値) リストに変換する tuple(値) タプルに変換する range(値) レンジに変換する セット
セットの宣言
変数名 = {値, 値, 値, …} 変数名 = set([値, 値, 値, …])セットの演算
表記 説明 利用例 値 in セット 値がセットに含まれているか調べる st = {1,2,3,4,5}
3 in st ⇒ True値 not in セット 値がセットに含まれていないか調べる st = {1,2,3,4,5}
3 not in st ⇒ Falseセット.add(値) セットに値を追加 st = {1,2,3,4,5}
st.add(6) ⇒ {1,2,3,4,5,6}セット.remove(値) セットから値を削除 st = {1,2,3,4,5}
st.remove(3) ⇒ {1,2,4,5}len(セット) セットの要素数を取得 st = {1,2,3,4,5}
len(st) ⇒ 5max(セット) セットの最大値を取得 st = {1,2,3,4,5}
max(st) ⇒ 5min(セット) セットの最小値を取得 st = {1,2,3,4,5}
min(st) ⇒ 1セットの比較演算
表記 説明 A == B AとBは同じ(含まれる値が全く同じ) A != B AとBは異なる(含まれる値が違っている) A < B AはBに含まれる(Aの値は全てBに含まれる) A <= B AはBと同じか、Bに含まれる A > B BはAに含まれる(Bの値は全てAに含まれる) A >= B BはAと同じか、Aに含まれる セットの論理演算
表記 説明 A & B AとBの両方に含まれる値をセットとして取り出す A | B AまたはBどちらか一方、または両方に含まれる値をセットとして取り出す A ^ B AとBのどちらか一方にだけ含まれる値をセットとして取り出す A - B AからBに含まれる値を取り除いたセットを取り出す 辞書
辞書の宣言
変数名 = {キー1: 値1, キー2: 値2, …} 変数名 = dict([キー1 = 値1, キー2 = 値2, …])辞書の取得、設定
変数名[キー] 変数名[キー] = 値辞書の演算
表記 説明 利用例 del 辞書[キー] 辞書の値の削除 dc = {'a':100, 'b':200, 'c':300}
del dc['b'] ⇒ {'a':100, 'c':300}キー in 辞書 キーが辞書に含まれているか調べる dc = {'a':100, 'b':200, 'c':300}
'b' in st ⇒ Trueキー not in 辞書 キーが辞書に含まれていないか調べる dc = {'a':100, 'b':200, 'c':300}
'b' not in st ⇒ Falselen(辞書) 辞書の要素数を取得 dc = {'a':100, 'b':200, 'c':300}
len(dc) ⇒ 3max(辞書) キーの最大値を取得 dc = {'a':100, 'b':200, 'c':300}
max(dc) ⇒ 'c'min(辞書) キーの最小値を取得 dc = {'a':100, 'b':200, 'c':300}
min(dc) ⇒ 'a'辞書.keys() 全てのキーワードを取得 dc = {'a':100, 'b':200, 'c':300}
dc.keys() ⇒ ['a', 'b', 'c']辞書.values() 全ての値を取得 dc = {'a':100, 'b':200, 'c':300}
dc.values() ⇒ ['100', '200', '300']辞書.items() 全ての要素(キー、値) dc = {'a':100, 'b':200, 'c':300}
dc.items() ⇒ [('a':100), ('b':200), ('c':300)]制御構文
条件分岐(if)
単一項目との比較
if 条件1: 条件1がTrueの場合の処理 elif 条件2: 条件2がTrueの場合の処理 else: 全ての条件がFalseの場合の処理複数項目との比較
if 値 in コンテナ: 条件1がTrueの場合の処理 elif 値 in コンテナ: 条件2がTrueの場合の処理 else: 全ての条件がFalseの場合の処理繰り返し(for)
コンテナ内の要素の繰り返し
for 変数 in コンテナ: 繰り返す処理 else: 全データ取得後の処理レンジを利用した繰り返し
for 変数 in レンジ: 繰り返す処理 else: 全データ取得後の処理 #レンジの指定 range(終了値) range(開始値, 終了値) range(開始値, 終了値, ステップ)辞書を利用した繰り返し
for 変数 in 辞書: #変数に取り出されるのはキーのため、辞書[キー]の形で値を取り出すこと! 繰り返す処理 else: 全データ取得後の処理繰り返し(while)
条件がTrueの間、処理を繰り返し続ける
while 条件: 繰り返す処理 else: 繰り返し終了時の処理繰り返しの制御
#次の繰り返しに進む continue #繰り返しを中断 breakリスト内包表記
forによるリスト内包表記
○ for ○ in コンテナ条件がTrueとなった要素のみリストに格納
○ for ○ in コンテナ if 条件組み込み関数
print:値を出力
print(出力する値, end="\n", file=sys.stdout, flush=False) #end #出力された値の最後につける値。デフォルトは\n(改行) #file #出力先のファイル。デフォルトは標準出力 #flush #バッファするか、強制的にフラッシュするかを指定input:値を入力
input(値)その他
関数 説明 int 整数の値を生成 float 実数の値を生成 bool 真偽値を生成 str 文字列を生成 list リストを生成 tuple タプルを生成 range レンジを生成 set セットを生成 dict 辞書を生成 abs(数値) 絶対値を得る any(コンテナ) 任意の要素を得る(ランダム) hex(整数) 16進数を得る oct(整数) 8進数を得る bin(整数) 2進数を得る eval(文字列) 文字列を評価する sum(コンテナ) 合計を得る pow(整数1, 整数2) 累乗を得る round(実数) 少数を丸める ユーザー定義関数
基本形
def 関数名(引数1, 引数2, …): 実行する処理 return 戻り値キーワード引数、デフォルト値
def 関数名(キー1 = デフォルト値, キー2 = デフォルト値, …): 実効する処理 return 戻り値可変長引数
可変長の値を受け取る変数にアスタリスクを付ける。呼び出す際にアスタリスクは不要(タプルとして渡される)。
通常の引数、可変長引数を混在させる場合は、通常の引数を先に記載する。def 関数名(*変数): 実行する処理 return 戻り値キーワード引数を可変長として渡す場合は、アスタリスクを2つ記載する。
def 関数名(**変数):ラムダ式
ラムダ式はその場で定義できる1行だけの関数のこと。
最後に実行した処理の結果が戻り値となるため、returnは不要。lambda 引数 : 実行文クラス
基本形
クラスに何も用意しない場合は「pass」を記載する。
class クラス名: クラス変数 = 値 #クラスメソッド @classmethod def クラスメソッド名(cls, 引数): 処理 #初期化処理 def __init__(self, 引数): インスタンス変数 = 値 処理 #インスタンスメソッド def インスタンスメソッド名(self, 引数): インスタンス変数 = 値 処理 オブジェクト変数 = クラス名()変数のアクセス範囲
#パブリック変数 変数 = 値 #プライベート変数 __変数 = 値演算子の処理を実装
ユーザー定義クラスは演算に対応していない。
そのため各演算子に対応した処理を実装する場合は下記演算を利用する。
演算子 メソッド + __add__(self,other) += __iadd__(self,other) - __sub__(self,other) -= __isub__(self,other) * __mul__(self,other) *= __imul__(self,other) / __truediv__(self,other) /= __itruediv__(self,other) // __floordiv__(self,other) //= __ifloordiv__(self,other) % __mod__(self,other) %= __imod__(self,other) 文字列表記(クラスの出力)
「print(オブジェクト変数)」で出力する内容を定義する。
def __str__(self): return 文字列プロパティ
#プロパティの取得 @property def プロパティ名(self): return 値 #プロパティの設定 @プロパティ名.setter def プロパティ名(self, 値): 値を設定する処理継承、オーバーライド
スーパークラスと同名のメソッドを定義することにより、処理をオーバーライド(上書き)することが可能。
class クラス名(継承するクラス, …): def インスタンスメソッド名(self, 引数): インスタンス変数 = 値 処理例外処理
基本形
try: 通常の処理 except 例外クラス1 as 例外変数: 例外クラス1発生時の処理 except 例外クラス2 as 例外変数: 例外クラス2発生時の処理 except (例外クラス3, 例外クラス4) as 例外変数: 例外クラス3、例外クラス4発生時の処理 except Exception as 例外変数: 上記までで記載していない全ての例外発生時の処理 finally: 構文を抜ける際の処理例外の送信
raiseを記載することにより、一度キャッチした例外の再送信、指定した例外インスタンスの送信が可能。
try: 通常の処理 except 例外クラス as 例外変数: 例外発生時の処理 #例外クラスの送信 raise 例外クラスユーザー定義の例外インスタンスを作成した場合も、raiseで例外の送信を行う。
class エラークラス(): エラークラスの処理 try: 通常の処理 except 例外クラス as 例外変数: 例外発生時の処理 #例外クラスの送信 raise 例外クラスファイル操作
ファイルアクセスの開始
open(ファイルパス, mode=モード)
モード 役割 r 読み込み許可 w 書き出し許可(既にファイルがある場合は上書き) x 排他的生成(既にファイルがあると失敗する) a 追記許可(既にファイルがある場合は最後に追加) w+ 読み書き可能 テキストの一括読み込み
サイズを省略するとファイル全文を読み込む。
ファイルオブジェクト.read(サイズ)withによるclose処理の省略
with open(ファイルパス, mode=モード) as 変数: 処理を記述1行ずつ読み込む
for 変数 in ファイルオブジェクト: 処理を記述マルチバイト文字の読み込み
#codecsモジュールの読み込み import codecs #エンコードを指定してファイルを開く with codecs.open(ファイルパス, mode=モード, encode=エンコード): 処理を記述ファイルへの書き込み
ファイルオブジェクト.write(書き出す文字列)ファイルアクセス利用時の主な例外
エラー名 内容 ValueError 既にファイルがcloseされていた場合 FileNotFoundError 読み込みモード(r)で開いた際に、ファイルがなかった場合 FileExistsError 排他的生成モード(x)で開いた際に、既に同名のファイルがあった場合 PermissionError アクセスするファイルが、OSによりパーミッションが与えられていなかった場合 io.UnsupportedOperation 読み込みモードで開いているファイルに書き込みを行うなど、サポートされていない操作を行った場合 アクセス位置の移動(seek)
ファイルオブジェクト.seek(数値, 位置) #ファイルの基準位置 # os.SEEK_SET:ファイルの先頭位置 # os.SEEK_END:ファイルの終端位置 # os.SEEK_CUR:現在位置モジュール
モジュールの読み込み、利用
#読み込み import モジュール #モジュールの要素の利用 モジュール.変数 モジュール.関数(引数) モジュール.クラス(引数)標準ライブラリ
下記ドキュメントを参照。
https://docs.python.org/ja/3/library/index.htmlmath(算術計算)
from math import * #絶対値の取得 fabs(数値) #四捨五入 round(float型の値) #切り上げ ceil(float型の値) #切り捨て floor(float型の値) #剰余を求める fmod(引数1, 引数2) #リストの合計を求める fsum(リスト)random(乱数)
from random import * #0〜1未満のランダムな実数 random() #0〜上限までの整数の乱数 randrange(上限) #下限〜上限までの整数の乱数 randrange(下限, 上限) #リストをランダムに並べ替える shuffle(リスト) #ランダムな項目を得る choice(リスト) #ランダムに指定個数を得る sample(リスト, 個数)datetime(日時)
from datetime import * #現在日時を取得 datetime.today() #指定日時の取得 datetime(年, 月, 日, 時, 分, 秒, マイクロ秒) #西暦を取得 日時変数.year #月を取得 日時変数.month #日を取得 日時変数.day #時を取得 日時変数.hour #分を取得 日時変数.minute #秒を取得 日時変数.second #マイクロ秒を取得 日時変数.microseconddate(日付)
from datetime import * #現在日付を取得 date.today() #指定日付を取得 date(年, 月, 日) #datetimeからdateを取得 datetime.date() #年を取得 日付変数.year #月を取得 日付変数.month #日を取得 日付変数.daytime(時刻)
from datetime import * #現在時刻を取得(現在時刻を直接得る関数はないため、日時インスタンスから時刻を取り出す) 日時インスタンス = datetime.today() 日時インスタンス.time #指定時刻を取得 time(時, 分, 秒, マイクロ秒)timedelta(日時の加算・減算)
#日時の減算 <datetime/date/time> - <datetime/date/time> #日時の加算 <datetime/date/time> + <timedelta> #timedelta(経過日数を表す) timedelta(days=0,seconds=0,microseconds=0,minutes=0,hours=0,weeks=0)csv(CSVファイル)
#CSVファイル読み込みオブジェクト生成 変数 = reader( ファイルオブジェクト, delimiter=',', #データの区切り文字 doublequote=True, #データ内のクォート二重化 escapechar=None, #エスケープ文字 lineterminator='\r\n', #行の区切り文字 quotechar='"', #クォート記号の文字 skipinitialspace=False #データ冒頭のスペース除去 ) #CSVファイル書き込みオブジェクト生成 変数 = writer( ファイルオブジェクト, delimiter=',', #データの区切り文字 doublequote=True, #データ内のクォート二重化 escapechar=None, #エスケープ文字 lineterminator='\r\n', #行の区切り文字 quotechar='"', #クォート記号の文字 skipinitialspace=False #データ冒頭のスペース除去 )re(正規表現)
主な関数
from re import * #文字列の先頭とマッチするか調べる match(パターン, テキスト) #最初にマッチしたものを調べる search(パターン, テキスト) #マッチした文字列すべてを取得する findall(パターン, テキスト) #マッチした文字列を分割する split(パターン, テキスト) #正規表現による置換 sub(パターン, 置換文字列, 検索文字列)パターン
パターン 説明 . 改行以外の任意の文字 ^ 先頭 $ 末尾 * 0回以上の繰り返し + 1回以上の繰り返し {} 直前の文字を指定回数繰り返し [] いくつかの文字の集合 () 正規表現のグループ \ - 文字の範囲 エスケープ文字
エスケープ文字 説明 ¥A 文字列の先頭 ¥d 数字。[0-9]と同じ ¥D 数字以外。[^0-9]と同じ ¥s 空白文字(スペース、タブ、改行文字など) ¥S 空白文字以外 ¥w 単語文字。[a-zA-Z0-9]と同じ ¥W 単語文字以外 ¥z 文字列の末尾 外部パッケージ
pip操作
#pipをアップデート python3 -m pip install -U pip #パッケージのインストール python3 -m pip install パッケージ #パッケージのアップデート python3 -m pip install -U パッケージ #パッケージのアンインストール python3 -m pip uninstall パッケージPython Package Index(PyPI)
外部パッケージの検索に利用する
https://pypi.org/Requests(Web情報の取得)
#Requestsのインストール pip install requests #Requestsのインポート import requests #GETリクエスト requests.get(アドレス, パラメータ) #POSTリクエスト requests.post(アドレス, パラメータ) #PUTリクエスト requests.put(アドレス, パラメータ) #DELETEリクエスト requests.delete(アドレス, パラメータ)PEP8(Pythonの慣習)
インデントに関する規約
- タブ、スペースどちらを使ってもよいが、混在は避ける
- スペースは4つが基本
文の改行に関する規約
- 長い文は改行する。半角80文字程度を目安とする
- 演算は演算子の前で改行
- ()、[]はながければ改行
命名規則
- 一時的に利用する変数は1文字の名前
- パッケージ、モジュールは短い小文字の名前
- 関数名はアンダースコア気泡
- クラスはキャメル記法
- メソッドは小文字で始まるキャメル記法
- ローカル変数は短く
- 定数は大文字のアンダースコア記法 キーワードと重複する名前は最後にアンダースコア
- 投稿日:2019-05-21T11:16:35+09:00
Neo4jをJupyter notebookで実行する
はじめに
グラフネットワーク分析用ツールNeo4jをJupyterから実行し、
結果をJupyter notebook上に可視化させる。実行には、Neo4jboltドライバーを利用する。
本内容のNotebookはこちら。
実行環境
CentOS
openJDK 8
python 3.6.6
Jupyter notebook 4.3.0Neo4j CommunityEdition 3.5.5
Neo4jboltドライバー
準備
インストール
Neo4j
Neo4j をインストール
DLとインストール方法はこちらPython ライブラリ
Neo4jboltドライバー をインストール$ pip install neo4j
Neo4j パラメータ変更
- ホストOSからアクセス可能にするため、以下のパラメータをコメントアウト
$ vi $NEO4J_HOME/conf/neo4j.conf # With default configuration Neo4j only accepts local connections. # To accept non-local connections, uncomment this line: dbms.connectors.default_listen_address=0.0.0.0
- bolt ドライバーを利用可能にするために、以下のパラメータをコメントアウト
$ vi $NEO4J_HOME/conf/neo4j.conf # Bolt connector dbms.connector.bolt.enabled=true dbms.connector.bolt.tls_level=OPTIONAL dbms.connector.bolt.listen_address=:7687Neo4jを起動
$ $NEO4J_HOME/bin/neo4j start*初回起動後、以下にアクセスし必要に応じてパスワードを変更
http://localhost:7474
データ
データはmovieのデータを利用
実行
Jupyter notebookから以下の内容を実行
ライブラリのインポート、ドライバーに接続
import pandas as pd from neo4j import GraphDatabase, basic_auth import matplotlib.pyplot as plt %matplotlib inline driver = GraphDatabase.driver("bolt://localhost:7687", auth=basic_auth("neo4j", "Welcome1"))
グラフデータの分析、取得
Query = '''CALL algo.betweenness.stream('','',{direction:'both'}) YIELD nodeId, centrality MATCH (person:Person) WHERE id(person) = nodeId RETURN person.name, centrality ORDER BY centrality DESC LIMIT 10''' session = driver.session() res = session.run(Query) col = ['name', 'centrality'] df = pd.DataFrame([r.values() for r in res], columns=col) session.close() del session
棒グラフの作成
plt.figure(figsize=(15, 6)) plt.bar(list(range(len(df))), df['centrality']) plt.xticks(list(range(len(df))), df['name'])
結果
- 投稿日:2019-05-21T10:49:14+09:00
プログラムちょい替え(5)pyhon中央値
数学オンチのプログラマが数学を学習し直すらしいです【統計その1】
https://qiita.com/manzyun/items/833ae7fba582d899c618median.pydata = [100, 300, 423, 328, 516, 412] data.sort() # **超大事** if len(data) % 2 == 0: # リストの要素の数の奇数・偶数判定 # 偶数でした m1 = len(data) / 2 m2 = (len(data) / 2) + 1 # 整数に変換して位置合わせ m1 = int(m1) - 1 m2 = int(m2) - 1 print(data[m1] + data[m2]) / 2 else: # 奇数でした m = (len(data) + 1) / 2 m = int(m) - 1 print(data[m])pythn3で実行
$ python Python 3.6.0 |Anaconda custom (64-bit)| (default, Dec 23 2016, 13:19:00) [GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)] on darwin Type "help", "copyright", "credits" or "license" for more information. $ python median.py 740 Traceback (most recent call last): File "median.py", line 12, in <module> print(data[m1] + data[m2]) / 2 TypeError: unsupported operand type(s) for /: 'NoneType' and 'int'変更してみた。
median2.py#!/usr/bin/env python # coding: utf-8 # @imanzyun 2018年10月30日 11時31分 (JST) # @kaizen_nagoya 2019 05 21 data = [100, 300, 423, 328, 516, 412] data.sort() # **超大事** if len(data) % 2 == 0: # リストの要素の数の奇数・偶数判定 # 偶数でした m1 = int(len(data) / 2)-1 print((data[m1] + data[m1+1]) / 2) else: # 奇数でした m = int((len(data) + 1) / 2)-1 print(data[m])ついでに、おまじない、処理の変更も。
直したところと付け加えたこと
1 print の()
print文の後ろに/2があった。/2も括弧でくくった。
2 #!/usr/bin/env python
chmod +x median2.pyとすれば、./median2.py
で実行できる。3 # coding: utf-8
ファイルがutf-8であれば不要なのかもしれないが、Webで公開すると、どういう文字コードで保存するシステムがあるかわからないため、おまじないとして書いておく。
4 m2
m1-1で済むので途中の計算はしない。
5 mの計算
2つの式を1つに。
みにくくなるかもしれない。
好みかも。
- 投稿日:2019-05-21T02:07:31+09:00
外貨を全角の日本円にして返すコードを書いた
グーグル検索でよくない?
いちいち新しいタグを開いて入力するのがめんどくさい。また、39億6487万ドルとかごちゃごちゃした数字になると、「変換」の文字を含めないと円換算してくれないのが忙しい業務中はリズムが崩れて腹立たしいことこの上ありません。
出来たもの
日本語だけでなく、外国語も対応(グーグル翻訳)です。日本語で書かれた元の通貨とその額、円換算した額、換算レートを参照した時間を返します。ただし、1万ないし1千以下の数値は普段必要ないため、細かい金額が重要な場合は使えません。また、対応通貨はとりあえずよく遭遇するドル、ユーロ、元、ルーブル、ポンドです。コードは最下部ないしGithubにあります。
例$500 million ('5億ドル', '約549億7526万1132円', ['05月21日 00:00 更新']) 350,9 миллиарда рублей ('3509億ルーブル', '約5982億9599万274円', ['05月21日 00:00 更新'])必要なモジュール
インストールpip install mojimoji pip install googletransコード全文
コード全文import requests import lxml.html import re import mojimoji from googletrans import Translator def fcur(currency, tril=0, bil=0, mil=0, thous=0): """ Convert forreign currency to full_width japanese yen """ translator = Translator() currency = translator.translate(currency, dest='ja').text # translate to ja translated = mojimoji.han_to_zen(currency) currency = re.sub(r'ドル', ' USD', currency) # replace with currency code currency = re.sub(r'ルーブル', ' RUB', currency) currency = re.sub(r'元', ' CNY', currency) currency = re.sub(r'ポンド', ' GBP', currency) currency = re.sub(r'ユーロ', ' EUR', currency) currency = re.sub(r',', '', currency) # get rid of commma cur_name = currency.split()[-1] # get currency name if '兆' in currency: # convert to number, multiplying by powers of 10 tril = int(re.findall(r'\d{1,4}(?=兆)', currency)[0]) * (10 ** 12) if '億' in currency: bil = int(re.findall(r'\d{1,4}(?=億)', currency)[0]) * (10 ** 8) if '万' in currency: mil = int(re.findall(r'\d{1,4}(?=万)', currency)[0]) * (10 ** 4) if '千' in currency: thous = int(re.findall(r'\d(?=千)', currency)[0]) * (10 ** 3) ammount = tril + bil + mil + thous url = 'https://keisanki.me/calculator/index/{}/{}'.format(cur_name, ammount) response = requests.get(url) content = lxml.html.fromstring(response.content) yen = content.xpath('/html/body/section[1]/div/div/div[1]/h1/span/text()')[0] date = content.xpath('/html/body/section[1]/div/div/div[1]/h3/text()') # retrieve date to check whether currency data are actuall table = str.maketrans('','',',') # get rid of comma yen = yen.translate(table) yen_fullwidth = mojimoji.han_to_zen(yen) # convert to fullwidth return translated, yen_fullwidth, date fcur(input())
- 投稿日:2019-05-21T02:01:09+09:00
docker imageを直接pullしてみた
https://github.com/cielavenir/pulldockerimage
背景
userlandの仮想化基盤としてだけでなく、ソフトウェアの直接導入にもdockerは使われてきている。dockerはimageという単位で取り扱うことが多いが、このimageをリモートリポジトリからpullしたり、リモートリポジトリにpushしたりすることが可能である。これによりimageを共有することができるのである。
ところが一部、このpullを直接はできない環境があり得る。当該マシンが直接インターネットに繋がっていないことや、イントラネットにすら繋がっていないこともあるだろう。そのような場合、docker loadにより標準入出力を介してimageをやり取りすることになる。この場合に使われるのはpullしてきたファイル群をTarで固めたものである。これは手元のdocker daemonからdocker saveすることで作成することができるが、一旦手元にdocker pullしなければ、docker saveは実行できない。バッチ処理に組み込む場合等、不便なことがあるかもしれない。
今回は、リモートからダウンロードしたdocker imageのTarを直接標準出力に生成することを試みる。[1]はそうした試みの先駆けであるが、単体ではログイン機構を有しておらず、docker.ioで使うには力不足である。これをBashからRuby/Pythonで書き直し、再利用をしやすくしたい。方法
docker pullはHTTPSを用いており、認証 -> マニフェストダウンロード -> レイヤーダウンロード -> メタファイル生成という順序で行われる。
まずはマニフェストをダウンロードする。ここで401になったら、WWW-Authenticateヘッダの情報を用いて認証を行う。この認証はBasic認証であり、docker loginが済んでいれば、認証文字列は.docker/config.jsonから直接得ることができる。ここで帰ってきたtokenをBearer認証に用いる。レイヤーはマニフェストに書いてある順番で重ねれば良い。レイヤーのIDは[1]にならいSHA256(parentId+"\n"+layerDigest+"\n")とした。結果
モジュール
Pythonは標準ライブラリで完結させることができた。Rubyはminitarとmechanizeについて外部ライブラリを利用する。minitarはTarライブラリで、mechanizeはプログラムベースブラウザとも言うべきウェブ操作ライブラリである。
WWW-Authenticateヘッダの取扱い
Pythonはurllib内にparse_keqv_listやparse_http_listといった関数群があり、これでparseすることができる。Rubyは標準ライブラリでは処理できないため、mechanizeを使用する。ただし、mechanizeはsavonというSOAPライブラリが導入されている環境に導入しようとするとruby-ntlm関係でエラーが発生することが知られているため、今回はMechanize::HTTP::WWWAuthenticateParserの中身を埋め込むこととした。
30xステータスコードの取扱い
mechanizeであれば30xステータスコードが来たら自動でLocationを読みに行ってくれるが、HTTPを直接触る限りそういうわけにも行かない。30xが来たら、今のレスポンスを捨てたあと、locationを読みに行き30xが来る限りレスポンスを捨てることを繰り返せば良い。この繰り返しはブロック(Pythonの場合はcontextmanagerを使う)を用いて行い、HTTP bodyはyieldで渡すようにすると、後処理が楽である。
Tarの取扱い
Tar(に限らずアーカイブファイル一般)はヘッダにメンバサイズを書かなければならない(またはアーカイブに追加したあとでシークが必要であるが、標準出力を扱うため認められない)。HTTPヘッダのContent-Lengthをこのメンバサイズとして書き込めば良い。Rubyの場合は、tar.add_fileではなくtar.add_file_simpleを使う必要があった。add_fileはメンバ内に書き込んだサイズを自動判別(しシーク)するバージョンだからである。
結論
今回はRuby/Pythonを用いてdocker imageをtarとしてpullすることができた。
https://github.com/cielavenir/pulldockerimage にて利用可能である。参考
[1] https://raw.githubusercontent.com/moby/moby/master/contrib/download-frozen-image-v2.sh
余談
(英語で書いたとしても)Linux Journalとかに載せるレベルじゃないですよねー肝心な場所のアルゴリズムは既存の技術ですしorz
7bgzfは違う領域だからある程度の価値があるけども。
- 投稿日:2019-05-21T01:36:08+09:00
独習Python入門 -1日でプログラミングに強くなる-(技術評論社)学習メモ
はじめに
独習Python入門 ―1日でプログラミングに強くなる!
https://gihyo.jp/book/2016/978-4-7741-8329-9
- 上記の書籍(以下、本書)を学習した記録をまとめたものです。
- 基本的には一度解釈した内容を自分の言葉で置き換えて書いています。
- 誤った記載があった場合は、私のミスです。
- なるべくオリジナリティがある部分の引用は避けていますが、本書の記載内容やコードをそのまま転記する際にはその旨明記します。
1.はじめてのプログラミング
- プログラムとは何か
- Pythonのインストール
- 四則演算を試す
>>>対話モード時のプロンプト- データ型
- 数値型
- 整数
- 浮動小数点数
- …
- 文字列
- 真偽型
- 演算子
- 算術演算子
- 比較演算子
- 代入演算子
- 文字コード
- 変数
2.条件で分ける方法(分岐の基礎文法)
- 開発環境のセットアップ
- ディレクトリの概念
- 絶対パス
- 相対パス
- 条件分岐
if文の書式if <判断条件>: <条件に合致した場合の実行内容>
:が付く次の行での実行内容をブロックと呼ぶ。
ブロックであることはインデントして表現する。
インデントを正しく行っていないと以下のエラーが表示される。
SyntaxError: expected an indented blockelseを伴う場合if <判断条件>: <条件に合致した場合の実行内容> else: <条件に合致しなかった場合の実行内容>elifを伴う場合if <判断条件>: <条件に合致した場合の実行内容> elif <条件に合致しなかった場合の追加の判断条件>: <追加の判断条件に合致した場合の実行内容> else: <追加の判断条件に合致しなかった場合の実行内容>
- 条件の組み合わせ
- and
- or
- not
- 予約語
- print関数
- input関数
input('aaa')
- aaaを標準出力に書き出したのち、入力を文字列に変換して返す
- int関数
int(bbb)
- bbbを数値型に変換する
- float関数
float(ccc)
- 浮動小数点数に変換する
3.繰り返しさせる方法(反復の基礎文法)
- 配列
- インデックス
[ ]で括る配列の指定<配列型の変数名> = [値1,値2,…]配列に存在しないインデックスを指定した場合のエラー。
IndexError: list index out of rangefor文は、配列と、そこから取り出した値を入れる変数とセットで使う。
for文for <変数> in <配列>: <実行する内容>if文のサンプルhairetu = ["a","b","c"] for hennsuu in hairetu: print(hennsuu)上記の実行結果a b c
- Don't Repeat Yourselfの精神
- break
- 条件に合致した場合に以降の繰り返し処理を中断
- continue
- 条件に合致した場合、該当箇所のみ処理をスキップ
whileは条件に合致しなくなるかbreakするまで処理を繰り返す。
while文while <条件>: <実行する内容>
- #でコメントを入れる
4.関数を使ってみよう!
組み込み関数
- 引数と戻り値の考え方
- 組み込み関数
- len関数
- 文字列の長さや配列の要素数を返す
- pow関数
- 引数が2つの場合は累乗した値を、3つの場合は前者2つの掛けた値を3つ目で割った場合の余りを返す
- max関数
- min関数
- range関数
引数のデータ型を混在させた場合に出るエラー例。
TypeError: '<' not supported between instances of 'str' and 'int'公式リファレンス
https://docs.python.org/ja/3/library/functions.html自作の関数
関数の定義の仕方def <関数名>(<引数>): return <戻り値>引数として与えられた文字列に
dayo!を結合したものを返す関数「kannsuu」サンプルdef kannsuu(aaa): return aaa + 'dayo' + '!' xxx = kannsuu('Kojima') print(xxx)実行結果Kojimadayo!
- ネストしてif文を含む関数の例
- 戻り値の定義は必須ではない
- 関数の定義の思想
- 汎用性を意識する
- 引数は少なめにする
- 戻り値はシンプルにする
ほかの関数(import)
組み込み関数以外の関数は
importしてからでないと使用できない。
コードは本書から抜粋。importを用いる例>>> import platform >>> x = platform.system() >>> print(x) Windows5.いろいろな型を学ぼう
辞書型
- 数値
- 文字列
- 真偽
- 配列
- 辞書型
{ }で括る辞書型の作り方1<変数名> = { '<キーワード1>': '要素1', '<キーワード2>': '要素2', '<キーワード3>': '要素3', }辞書型の作り方2(dict関数)<変数名> = dict( <キーワード1>='要素1', <キーワード2>='要素2', <キーワード3>='要素3', )辞書型もfor文による繰り返しに対応している。
for <変数> in <辞書型>キーワード可変長引数
関数の引数に辞書型を指定する場合、
**を付与しておけば任意数の引数を渡せる。キーワード可変引数を受け付ける関数def kannsuu(**aaa): return len(aaa) xxx = kannsuu(Inu='Wann',Neko='Nyann') print(xxx)実行結果2引数aaaに
**を付与していない場合は以下のエラーが出る。
TypeError: kannsuu() got an unexpected keyword argument 'Inu'タプル
- 変更ができない配列のようなもの
( )で括って,で区切る( )が無くてもいいタプル型の要素を変更しようとするとエラーが出る。
タプル型の要素を変更しようとした場合>>> tuphenn = ('a','b','C') >>> tuphenn[1] = 'B' Traceback (most recent call last): File "<pyshell#2>", line 1, in <module> tuphenn[1] = 'B' TypeError: 'tuple' object does not support item assignmentキーワード可変長引数の時は
**だったが、*を付与することでタプルを任意の数、引数として渡すことができる。集合
- 要素の重複が排除された配列のこと
set()関数を使うset関数>>> set([1,2,3,4,5,5,5,6,7,7,8,9]) {1, 2, 3, 4, 5, 6, 7, 8, 9}
- 和集合
A | B- 差集合
A - B- 積集合
A & B- 排他集合
A ^ BNone
ナン。
6.エラーと例外を使いこなす
- 正常系/異常系
- エラー
- 構文エラー
- 実行する前に文法でこけている
SyntaxError:- 例外
- 構文としては問題ないけど実行しようとしてエラー
IndexError:ZeroDivisionError:FileNotFoundError:
open(<開くファイル>,<開くモード>)- …
- 例外処理
- プログラムの実行環境に問題がある
- 事前条件が満たされていない
try~except文try: <処理内容> except <例外の種別> as <例外内容を格納する変数名>: #asとそのあとの変数名は省略可能 <例外処理> finally: #省略可 <例外が発生してもしなくても実行したい内容>
- open関数などと組み合わせて使うwith構文
- finallyでのcloseを指定しなくてもよくなる
7.オブジェクトとクラスとは何か?
オブジェクトとは
公式リファレンスより抜粋。
https://docs.python.org/ja/3.7/reference/datamodel.htmlPython における オブジェクト (object) とは、データを抽象的に表したものです。Python プログラムにおけるデータは全て、オブジェクトまたはオブジェクト間の関係として表されます。(ある意味では、プログラムコードもまたオブジェクトとして表されます。これはフォン・ノイマン: Von Neumann の "プログラム記憶方式コンピュータ: stored program computer" のモデルに適合します。)
すべての属性は、同一性 (identity)、型、値をもっています。 同一性 は生成されたあとは変更されません。これはオブジェクトのアドレスのようなものだと考えられるかもしれません。
- オブジェクトの要素
- ID
- 型
- 値
Hennsuオブジェクト>>> Hennsuu = 'Hoge' #変数を定義 >>> id(Hennsuu) 54274624 #ID >>> type(Hennsuu) <class 'str'> #型(文字列型)#ここでのclassは「オブジェクトとクラス」におけるクラスとは別物 >>> print(Hennsuu) Hoge #値Hairetsuオブジェクト>>> Hairetsu = [1,2,3] #配列を定義 >>> id(Hairetsu) 54324280 #ID >>> type(Hairetsu) <class 'list'> #型(配列型) >>> print(Hairetsu) [1, 2, 3] #値オブジェクトの後に
.をつけることで「オブジェクトが保有している関数を呼び出すことができる」と本書では表現している。str.upper>>> Hennsuu = 'hOge' >>> Hennsuu.upper() 'HOGE'このあたりは完全に理解が追い付いていないが、関数のうち、オブジェクトの後ろに
.を付与して記載する方式のものをメソッドと呼ぶのかと捉えている。上記の例のうち、「Hennsuuが保有している関数」というのは違和感があるので、「オブジェクトHennsuuの型である文字列型が保有する関数(メソッド)を、オブジェクトの後に.を付与する書き方をすることで呼び出すことができる」という解釈の仕方をした。文字列メソッドの一つstr.upper
https://docs.python.org/ja/3/library/stdtypes.html#str.upperクラスとは
- オブジェクトの情報や振る舞いを定義したテンプレートがクラス
- クラスから生成されたオブジェクトがインスタンス
- オブジェクトやクラスを定義すると拡張性が高くなるのでうれしい
クラスの定義class <クラス名>: <クラスの変数の定義>クラスの定義および変数の代入例class Seito: Kokugo = 0 Suugaku = 0 Eigo = 0 Kato = Seito() Kato.Kokugo = 80 Kato.Suugaku = 70 Kato.Eigo = 50 Takahashi = Seito() Takahashi.Kokugo = 90 Takahashi.Suugaku = 60 Takahashi.Eigo = 0 print(Kato.Suugaku) print(Takahashi.Kokugo)実行結果70 90クラスで関数を定義する
class内でインデント下げてdefする際は、第一引数としてselfを用いる。classでdefするclass Seito: Kokugo = 0 Suugaku = 0 Eigo = 0 def Heikinn(self): return (self.Kokugo + self.Suugaku + self.Eigo) / 3 Kato = Seito() Kato.Kokugo = 80 Kato.Suugaku = 70 Kato.Eigo = 50 print(Kato.Heikinn())実行結果66.66666666666667クラスの継承
クラスの継承class <クラス名>(<継承元のクラス名>): <クラスの定義>継承元のクラスをスーパークラスという。
クラスの継承例class Seito: Kokugo = 0 Suugaku = 0 Eigo = 0 class Jidou(Seito): pass #何も定義しない Suzuki = Jidou() Suzuki.Kokugo = 70 #クラスJidouで定義していない変数を使用できる print(Suzuki.Kokugo)実行結果70継承先のクラスでクラスの定義を上書きすることが可能。
関数の上書きclass Seito: Kokugo = 0 Suugaku = 0 Eigo = 0 def Heikinn(self): return (self.Kokugo + self.Suugaku + self.Eigo) / 3 class Jidou(Seito): Sannsuu = 0 def Heikinn(self): return (self.Kokugo + self.Sannsuu + self.Eigo) / 3 Suzuki = Jidou() Suzuki.Kokugo = 70 Suzuki.Sannsuu = 50 Suzuki.Eigo = 60 print(Suzuki.Heikinn())実行結果60.08.自分が書いたプログラムをテストする
- テストするプログラムを作ってテストさせるとよい
- プログラムの要件が明確になる
- 再利用できる
- プログラムが洗練される
- デグレを防げる
unittestモジュールを使ったテストの例。
関数やクラスの名称以外は本書の内容を転記したもの。unittestのテストimport unittest def tashizann(a,b): return a + b class tashizann_kakuninn(unittest.TestCase): #1 def test_tashizann(self): #2 self.assertEqual(10,tashizann(2,8)) #3 if __name__ == "__main__": #4 unittest.main()実行結果. ---------------------------------------------------------------------- Ran 1 test in 0.008s OK
ちなみに上記のファイルの名称を
unittest.pyにして動かしたら以下のエラーが出た。
AttributeError: module 'unittest' has no attribute 'TestCase'理由を自分の言葉で表現できるほどは理解が追い付かなかったので、調べた際のサイトのリンクを貼っておく。(
unittestモジュールが、最初にimportしたものでなく、ファイル名で指定されたものだと認識されて、unittest.pyの中にはTestCaceという属性は定義されていないよ、というエラーなのだろうか。)
上記のコードでやっていることのメインとしては、
#3のところの部分でtashizann関数に2と8を引数として与えた場合の戻り値と、期待する値10を比較させて、一致していればOKが返ってくるというもの。それを行う上で注意点がいくつかある。
-#1unittestモジュールのTestCaseクラスを継承すること
-#2テストを実行する関数にはtest_から始まる名称をつけること
-#4おまじない。おまじないについては、以下のサイトを参照し、「他のプログラムからimportされた時に実行されないようにするため」という位置づけのものだと捉えた。
Pythonのif name == "main" とは何ですか?への回答
テストでエラーが発生した場合は以下のような結果に。
unittestでエラーが出る場合import unittest def tashizann(a,b): return a + b class tashizann_kakuninn(unittest.TestCase): def test_tashizann(self): self.assertEqual(20,tashizann(4,13)) #ここの値を変更 if __name__ == "__main__": unittest.main()実行結果F ====================================================================== FAIL: test_tashizann (__main__.tashizann_kakuninn) ---------------------------------------------------------------------- Traceback (most recent call last): File "<実行したプログラムのファイルパス>", line 8, in test_tashizann self.assertEqual(20,tashizann(4,13)) AssertionError: 20 != 17 ---------------------------------------------------------------------- Ran 1 test in 0.000s FAILED (failures=1)assertEqual以外にも様々なメソッドがある。
[アサートメソッド一覧]
https://docs.python.org/ja/3/library/unittest.html#assert-methods9.明日から使えるWebプログラミング
- スクレイピング
- HTML
- タグ
- CSS
- セレクタ
スクレイピングに便利なBeautifulSoupという外部ライブラリのインストール。
>pip3 install beautifulsoup4 Collecting beautifulsoup4 Downloading https://files.pythonhosted.org/packages/1d/5d/3260694a59df0ec52f8b4883f5d23b130bc237602a1411fa670eae12351e/beautifulsoup4-4.7.1-py3-none-any.whl (94kB) 100% |████████████████████████████████| 102kB 1.1MB/s Collecting soupsieve>=1.2 (from beautifulsoup4) Downloading https://files.pythonhosted.org/packages/b9/a5/7ea40d0f8676bde6e464a6435a48bc5db09b1a8f4f06d41dd997b8f3c616/soupsieve-1.9.1-py2.py3-none-any.whl Installing collected packages: soupsieve, beautifulsoup4 Successfully installed beautifulsoup4-4.7.1 soupsieve-1.9.1 You are using pip version 9.0.1, however version 19.1.1 is available. You should consider upgrading via the 'python -m pip install --upgrade pip' command.スクレイピングの実行例。(変数名とアクセス先以外は本書の内容を借用。)
yahooニュースのページからh1タグに設定されている文字をとってくるimport urllib.request from bs4 import BeautifulSoup Syutokusaki = urllib.request.urlopen('https://news.yahoo.co.jp') Kaiseki = BeautifulSoup(Syutokusaki,"html.parser") print(Kaiseki.find('h1').text)実行結果Yahoo!ニュース10.Webアプリケーションことはじめ
- HTML
- CSS
- JavaScript
- HTTP
- プロトコル
- Webサーバ
- 動的
- 静的
- データベース
- SQL
- セキュリティ
- プログラム
pythonで
http.serverというモジュールを利用してWebサーバを動かすことができる。
以下のコードは本書から引用。pythonでwebサーバを動かすimport http.server http.server.test(HandlerClass=http.server.CGIHTTPRequestHandler)上記のプログラムを実行すると、そのプログラムの格納パスをドキュメントルートとしてwebサーバが実行される。index.htmlなどを作成して格納しておけば、ブラウザで
http://locallhost:8000でアクセスすることでその内容が参照できる。実行結果Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ... 127.0.0.1 - - [21/May/2019 00:11:17] "GET / HTTP/1.1" 200 - 127.0.0.1 - - [21/May/2019 00:11:42] "GET / HTTP/1.1" 200 -アクセスがあった場合、その内容が上記のように記録される。
cgi.FieldStorage()関数を使用したユーザの入力を受け付けるページの作成11.今後の学習に向けて
- 振り返り
- #1.
- 変数
- #2,#3.
- Don't Repeat Yoursekf
- 入れ子を避ける
- 配列に慣れる
- #4,#5
- 関数
- 辞書型
- #6.
- エラーを制すものはプログラムを制す
- #7.
- オブジェクト
- データ
- 処理
- 要件を主語と述語でシンプルに表現する
- #8.
- 自分の書いたプログラムをテストするプログラムを書く
- #9、#10
- スクレイピング
- Webアプリケーション
- 次に何を学ぶか
- 動くプログラムを読み書きすることが最短ルート
- データベース
- HTMLとCSS
- 学習曲線
- 潜伏期間がある
- プログラミングによって何をしたいか
終わりに
まさに初心者向けの入門書という感じでとっつきやすく書かれているので、初めから順番に手を動かしながら読んでいけば大まかにpythonの基礎が理解できると思います。似たような初心者向けの書籍を並行して読んでいると、なんとなく勘所が分かってきて面白いです。この記事の一番の想定読者は「一度本書を読んだ自分」なので、この記事だけを読んでも内容は入ってこないかと思いますが、どこかしらが学習のとっかかりになれば幸いです。
- 投稿日:2019-05-21T00:59:11+09:00
OpenCVのツール"CVAT"による動画ファイルからのオートアノテーション実行とTFRecord形式データセットの生成
1.Introduction
みなさん、アノテーション祭り、楽しんでますか? 私は吐き気がするほど嫌いです。
今回はオートアノテーションにチャレンジします。 動画を静止画に変換する手間は必要ですが、大量の画像を一気に投入することで、自動的にアノテーションが完了する、という夢のようなツールの検証です。 どうも、 前回記事 のVATICというツールが、OpenCVの公式ツールとして取り込まれたうえに、大幅な機能強化と改善が行われているようです。
2.Environment
- Ubuntu 16.04 (公式の推奨環境は Ubuntu 18.04)
- CUDA 9.0
- cuDNN 7.2
- Docker
- Client:
- Version: 18.09.6
- API version: 1.39
- Go version: go1.10.8
- Git commit: 481bc77
- Built: Sat May 4 02:35:27 2019
- OS/Arch: linux/amd64
- Experimental: false
- Server: Docker Engine - Community
- Engine:
- Version: 18.09.6
- API version: 1.39 (minimum version 1.12)
- Go version: go1.10.8
- Git commit: 481bc77
- Built: Sat May 4 01:59:36 2019
- OS/Arch: linux/amd64
- Experimental: false
- NVIDIA Docker 2.0.3
- Google Chrome
3.Procedure
3−1.Convert video file to still image
まず、動画ファイルをffmpegというツールを使用して静止画に変換します。 CVATへは動画を直接投入することもできますが、最終的にアノテーションデータをTFRecord形式へ変換することが目的の場合は、現時点では静止画へあらかじめ変換しておく必要があります。 以降の作業はホームディレクトリを基点として作業を進めていく前提とします。
ホームディレクトリの直下に
Videosというフォルダが有り、その中にFreestyleFootball.mp4という動画ファイルがある想定でコマンドを記載します。 おちゃカメラ。 - ffmpegの使い方やコマンド一覧をまとめました。動画リサイズ・静止画変換・フレーム補間について を参考にさせていただきました。 ありがとうございます。.mp4_convert_to_.jpegcd ~ sudo apt install -y ffmpeg mkdir -p Videos/img ffmpeg \ -i Videos/FreestyleFootball.mp4 \ -ss 0 \ -t 30 \ -f image2 \ -vcodec mjpeg \ -qscale 1 -qmin 1 -qmax 1 \ -r 20 \ Videos/img/%06d.jpg
オプション 概要 -i 入力ファイルの指定 -ss 静止画に変換したい動画の再生開始位置(秒) -t 静止画に変換したい動画の長さ(秒) -f 変換フォーマットの指定 -vcodec コーデックの指定 Motion JPEG=mjpeg, PNG=png -qscale JPEG画像の品質 -r 切り出したい画像の1秒あたりの枚数(フレームレート) %06d.jpg 書き出すファイル名の指定。%06d.jpgと指定すると6桁の連番画像ファイルが生成される Execution_logffmpeg version 2.8.15-0ubuntu0.16.04.1 Copyright (c) 2000-2018 the FFmpeg developers built with gcc 5.4.0 (Ubuntu 5.4.0-6ubuntu1~16.04.10) 20160609 configuration: --prefix=/usr --extra-version=0ubuntu0.16.04.1 --build-suffix=-ffmpeg --toolchain=hardened --libdir=/usr/lib/x86_64-linux-gnu --incdir=/usr/include/x86_64-linux-gnu --cc=cc --cxx=g++ --enable-gpl --enable-shared --disable-stripping --disable-decoder=libopenjpeg --disable-decoder=libschroedinger --enable-avresample --enable-avisynth --enable-gnutls --enable-ladspa --enable-libass --enable-libbluray --enable-libbs2b --enable-libcaca --enable-libcdio --enable-libflite --enable-libfontconfig --enable-libfreetype --enable-libfribidi --enable-libgme --enable-libgsm --enable-libmodplug --enable-libmp3lame --enable-libopenjpeg --enable-libopus --enable-libpulse --enable-librtmp --enable-libschroedinger --enable-libshine --enable-libsnappy --enable-libsoxr --enable-libspeex --enable-libssh --enable-libtheora --enable-libtwolame --enable-libvorbis --enable-libvpx --enable-libwavpack --enable-libwebp --enable-libx265 --enable-libxvid --enable-libzvbi --enable-openal --enable-opengl --enable-x11grab --enable-libdc1394 --enable-libiec61883 --enable-libzmq --enable-frei0r --enable-libx264 --enable-libopencv libavutil 54. 31.100 / 54. 31.100 libavcodec 56. 60.100 / 56. 60.100 libavformat 56. 40.101 / 56. 40.101 libavdevice 56. 4.100 / 56. 4.100 libavfilter 5. 40.101 / 5. 40.101 libavresample 2. 1. 0 / 2. 1. 0 libswscale 3. 1.101 / 3. 1.101 libswresample 1. 2.101 / 1. 2.101 libpostproc 53. 3.100 / 53. 3.100 Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'git/Videos/FreestyleFootball.mp4': Metadata: major_brand : mp42 minor_version : 0 compatible_brands: isommp42 creation_time : 2016-08-14 07:51:03 Duration: 00:03:49.41, start: 0.000000, bitrate: 2179 kb/s Stream #0:0(und): Video: h264 (Main) (avc1 / 0x31637661), yuv420p, 1280x720 [SAR 1:1 DAR 16:9], 2050 kb/s, 25 fps, 25 tbr, 90k tbn, 50 tbc (default) Metadata: creation_time : 2016-08-14 07:51:03 handler_name : ISO Media file produced by Google Inc. Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 44100 Hz, stereo, fltp, 125 kb/s (default) Metadata: creation_time : 2016-08-14 07:51:03 handler_name : ISO Media file produced by Google Inc. Please use -q:a or -q:v, -qscale is ambiguous [swscaler @ 0x126f0e0] deprecated pixel format used, make sure you did set range correctly Output #0, image2, to 'git/Videos/img/%06d.jpg': Metadata: major_brand : mp42 minor_version : 0 compatible_brands: isommp42 encoder : Lavf56.40.101 Stream #0:0(und): Video: mjpeg, yuvj420p(pc), 1280x720 [SAR 1:1 DAR 16:9], q=1-1, 200 kb/s, 20 fps, 20 tbn, 20 tbc (default) Metadata: creation_time : 2016-08-14 07:51:03 handler_name : ISO Media file produced by Google Inc. encoder : Lavc56.60.100 mjpeg Stream mapping: Stream #0:0 -> #0:0 (h264 (native) -> mjpeg (native)) Press [q] to stop, [?] for help Past duration 0.799995 too large Past duration 0.999992 too large frame= 600 fps=325 q=1.0 Lsize=N/A time=00:00:30.00 bitrate=N/A dup=0 drop=148 video:122679kB audio:0kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: unknown
imgフォルダ配下に 600枚 の jpeg画像が生成されました。 30秒 x 20フレーム = 600画像
3−2.Constructing a CVAT execution environment
公式リポジトリの今後のアップデートにより手順が動作しなくなることを避けるため、私自身のリポジトリへForkしたものを使用します。 私のTwitterをフォローいただいている方は、下記のコマンドを実行した後の顛末をご存知かと思いますが、私のラップトップPCとの相性が良くなかったのか、一時的に、シャットダウンも、再起動も、ハードリセットも、全てが操作不能になりました。 ただ、ラップトップPCのバッテリ残量をゼロにして再度電源をONにしたところ正常に復帰しました。
公式の推奨環境は、Ubuntu 18.04 (x86_64/amd64)ですが、私のラップトップPCはUbuntu 16.04 (x86_64)でしたので、もしかしたらOSとの相性の問題もあるかもしれません。 いずれにせよ特別な処置はしていませんが、現在は異常をきたすことなく正常に利用できています。Clone_CVAT_repositorygit clone https://github.com/PINTO0309/cvat.git cd cvat sudo apt-get update sudo apt-get install -y \ apt-transport-https ca-certificates curl gnupg-agent software-properties-common curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) stable" sudo apt-get update sudo apt-get install -y docker-ce docker-ce-cli containerd.io sudo groupadd docker sudo usermod -aG docker $USER sudo apt-get install -y python3-pip sudo -H pip3 install docker-compose docker-compose \ -f docker-compose.yml \ -f components/cuda/docker-compose.cuda.yml \ -f components/openvino/docker-compose.openvino.yml \ -f components/tf_annotation/docker-compose.tf_annotation.yml up -d --build docker exec -it cvat bash -ic 'python3 ~/manage.py createsuperuser'3−3.Execution of automatic annotation
ブラウザを起動し、アドレスバーに
http://localhost:8080を入力してアクセスします。
そうすると、下図のようにアッサリ塩味なポータルが起動します。
Create New Taskボタンをクリックすると、下図のようにダイアログが表示されますので、最低限必要な情報を入力します。
私がアノテーションしたいのは、人とボールですので、personとsports_ballを半角空白区切りで Labels欄 に入力します。 なお、Tensorflow によるオートアノテーションを行う場合に Labels欄 へ入力可能なラベル名は下記のいずれかです。 Tensorflow によるオートアノテーションを行わない場合は下記に限らず、自由入力で複数のラベルを指定可能です。Label_name_that_can_be_specified_when_performing_auto_annotation'surfboard', 'car', 'skateboard', 'boat', 'clock', 'cat', 'cow', 'knife', 'apple', 'cup', 'tv', 'baseball_bat', 'book', 'suitcase', 'tennis_racket', 'stop_sign', 'couch', 'cell_phone', 'keyboard', 'cake', 'tie', 'frisbee', 'truck', 'fire_hydrant', 'snowboard', 'bed', 'vase', 'teddy_bear', 'toaster', 'wine_glass', 'traffic_light', 'broccoli', 'backpack', 'carrot', 'potted_plant', 'donut', 'umbrella', 'parking_meter', 'bottle', 'sandwich', 'motorcycle', 'bear', 'banana', 'person', 'scissors', 'elephant', 'dining_table', 'toothbrush', 'toilet', 'skis', 'bowl', 'sheep', 'refrigerator', 'oven', 'microwave', 'train', 'orange', 'mouse', 'laptop', 'bench', 'bicycle', 'fork', 'kite', 'zebra', 'baseball_glove', 'bus', 'spoon', 'horse', 'handbag', 'pizza', 'sports_ball', 'airplane', 'hair_drier', 'hot_dog', 'remote', 'sink', 'dog', 'bird', 'giraffe', 'chair'.
Select Filesボタンをクリックして、3−1.Convert video file to still imageで作成した静止画を全て指定します。 私の場合は、 600枚 のJPEG静止画を生成しましたので、600枚全てを選択して開きました。
Submitボタンをクリックします。
下図のRun TF Annotationボタンをクリックすると、
警告メッセージが表示されますので、Okをクリックします。
しばらく待つとボタンの表示がCancel TF Annotation [0%]という表示に変わり、リアルタイムに進捗率が更新されていきます。 精度の高いモデルを使用しているためか、かなり時間が掛かりますので気長に待ちましょう。
ちなみに、4分間5734フレームの動画をアノテーションするのに、私の環境では2時間掛かりました。
さて、変換が終わったらhttp://localhost:8080/?id=xのリンクをクリックすると、アノテーション結果を確認することができます。 さて、どうなっているでしょうか。。。
機械任せの自動アノテーションにもかかわらず、精度が高すぎますねw
衝撃的です。では、ブラウザの戻る矢印をクリックしてポータルに戻ります。
アノテーション済みの CVAT形式XMLファイル を出力するため、Dump Annotationボタンをクリックします。n_xxxx.xmlという名前のXMLファイルがダウンロードされてくるはずです。nの部分はタスクID、xxxxの部分はTask Nameです。
アノテーション済みCVAT形式XMLファイルの中身は下図のイメージです。<mode>がannotationとなっていることがポイントです。 もしannotationとなっていない場合は動画ファイルを変換してしまっています。 その場合、TFRecord形式への変換はできませんので、オートアノテーションの最初の手順からやり直してください。
このあとの TFRecord形式 への変換作業に使用するため、n_xxxx.xmlファイルをcvatフォルダの直下にコピーしておきます。Copy_XML_file_to_working_foldercp ~/Downloads/n_xxxx.xml ~/cvat3−4.Annotation data conversion from CVAT format to TFRecord format
さて、ここまでできたら Tensorflow Object Detection API の力を借りて、 CVAT形式 から TFRecord形式 へコンバージョンします。 やってみると分かりますが、ココから先はCVAT Dockerコンテナ内で実施するととても面倒なことになります。(sudoコマンドが通らなかったり、Permissionが通っていなかったり、その他モロモロと、本質的ではない部分でつまづきます)
好き嫌いの問題ではありますが、HostPC上での作業をオススメします。まずは、 Tensorflow Object Detection API を導入します。 私は 前回記事 - 今更ですが、VATICによる動画の自動追尾アノテーションを使用してTFRecord形式への変換まで実施してみました[Docker編] あるいは 過去の記事 - Edge TPU Accelaratorの動作を少しでも高速化したかったのでMobileNetv2-SSD/MobileNetv1-SSD+MS-COCOをPascal VOCで転移学習して.tfliteを生成した_Docker編_その2 あるいは 過去の記事 - Edge TPU Accelaratorの動作を少しでも高速化したかったのでMS-COCOをPascal VOCで転移学習して.tfliteを生成した_GoogleColaboratory[GPU]編_その3 で3種類の環境を構築済みですので改めての作業は不要ですが、念の為 公式に記載されている手順 に少しだけ味付けをして下記に転記しておきます。 一応、実環境で動作は確認済みです。
Installation_procedure_of_"Tensorflow_Object_Detection_API"sudo apt-get update sudo apt-get install -y --no-install-recommends python3-pip python3-dev sudo -H pip3 install -r requirements.txt git clone https://github.com/tensorflow/models.git cd models sudo -H pip3 install --user Cython contextlib2 pillow lxml jupyter matplotlib git clone https://github.com/cocodataset/cocoapi.git cd cocoapi/PythonAPI make cd ../../research cp -r ../cocoapi/PythonAPI/pycocotools . protoc object_detection/protos/*.proto --python_out=. export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slimでは、ようやくCVATフォーマットからTFRecordフォーマット(.tfrecord)へ変換してみます。
下記のコマンドを実行します。 (cd ../..でcvatフォルダへ戻ってから実行します。)
</path/to/cvat/xml>と</path/to/images>と</path/to/output/directory>を自身の環境に合わせて変更してから実行します。Convert_CVAT_format_to_TFRecord_formatcd ../.. mkdir outputs sed -i "s%os.path.join(output_dir.absolute(),%os.path.join(str(output_dir.absolute()),%g" "utils/tfrecords/converter.py" sed -i "s%os.path.join(output_dir,%os.path.join(str(output_dir),%g" "utils/tfrecords/converter.py" python3 utils/tfrecords/converter.py \ --cvat-xml </path/to/cvat/xml> \ --image-dir </path/to/images> \ --output-dir </path/to/output/directory>Convert_CVAT_format_to_TFRecord_format_samplecd ../.. mkdir outputs sed -i "s%os.path.join(output_dir.absolute(),%os.path.join(str(output_dir.absolute()),%g" "utils/tfrecords/converter.py" sed -i "s%os.path.join(output_dir,%os.path.join(str(output_dir),%g" "utils/tfrecords/converter.py" python3 utils/tfrecords/converter.py \ --cvat-xml n_xxxx.xml \ --image-dir ${HOME}/Videos/img \ --output-dir ./outputsHow_to_use_converter.pyusage: converter.py [-h] --cvat-xml FILE --image-dir DIRECTORY --output-dir DIRECTORY [--train-percentage PERCENTAGE] [--min-train NUM] [--attribute NAME] Convert CVAT XML annotations to tfrecords format optional arguments: -h, --help show this help message and exit --cvat-xml FILE input file with CVAT annotation in xml format --image-dir DIRECTORY directory which contains original images --output-dir DIRECTORY directory for output annotations in tfrecords format --train-percentage PERCENTAGE the percentage of training data to total data (default: 90) --min-train NUM The minimum number of images above which the label is considered (default: 10) --attribute NAME The attribute name based on which the object can identified無事にトレーニングデータの
train.tfrecordファイルと、 検証用データのeval.tfrecordファイルが生成されました。 これで Tensorflow Lite のpipelineなどを使用して独自の超大量なデータセットで学習が簡単にできるようになりましたね。
label_map.pbtxtの中身は下図のようにちゃんと生成されています。
4.Finally
オートアノテーションを使用して TFRecord形式 のデータ・セット作成まで成功しました。
これで大量の動画データから超大量のデータ・セットを独自生成することがあまり手間ではなくなりました。
オートアノテーション最高!!単に高精度のFaster R-CNNでオブジェクトディテクションをしているだけですので、ふ〜ん、という感じの方々が多いとは思います。
まぁ、いいんですよ。 楽しければ。5.Reference articles
https://github.com/opencv/cvat/blob/develop/cvat/apps/documentation/installation.md
https://github.com/opencv/cvat/blob/develop/utils/tfrecords/converter.md
https://photo-tea.com/p/17/ffmpeg-command-list/