- 投稿日:2019-01-26T23:41:07+09:00
Postgre SQL なんと外部キーでJOINできない状況に遭遇!!
中規模な学習塾でデータ分析などをしています。塾で授業を受けている科目のテスト結果を抽出したい。ということが多々あります。
しかし、なんと、塾で授業を受けている科目のテスト結果を抽出する際に、外部キーでJOINできないという不思議な現象に出会いました。テーブル
テーブルの中身はこんな感じになっています。
科目マスタ
科目ID 科目名 1 英語 2 算数 3 国語 ... 10 英語 11 数学 12 国語 授業テーブル
授業ID 生徒ID 生徒区分 講師ID 科目ID ... 1 123 中学生 987 1 2 456 中学生 654 1 3 789 中学生 321 1 4 135 中学生 975 2 5 791 中学生 864 2 6 246 中学生 310 2 テスト結果テーブル
テスト結果ID 生徒ID 科目ID 点数 ... 1 123 10 50 2 456 10 60 3 789 10 60 4 123 11 70 5 123 12 80 6 456 12 30 生徒が、何の授業を取っていて担当講師が誰なのかは「授業テーブル」にしかありません。
もちろんテスト結果は「テスト結果テーブル」にあります。
「テスト結果テーブル」と「授業テーブル」をJOINすれば、塾で授業を受けている科目のテスト結果を抽出できます。問題発生
生徒IDと科目IDをKEYにしてJOINするんですが、「授業テーブル」の科目IDはつねに1桁のID、「テスト結果テーブル」の科目IDは常に2桁のIDになってます。
なぜかはわかりませんが、「授業テーブル」では中学生でも高校生でも小学生の科目IDが入るようになっています。「テスト結果テーブル」では中学生は中学生用の科目IDがふられています。
なぜこんな仕様になっているのか、作った人に小一時間問い詰めたい。(笑)
理由が分かる方は、ぜひ教えてください。解決編
中学生は「国・数・理・社・英・音・体・美・技家」の9科目あります。どうも、「授業テーブル」の科目IDに+9をすると「テスト結果テーブル」の科目IDになるようです。
ということで、こんなSQLを書いてみました。subject.sqlSELECT * FROM 授業テーブル INNER JOIN テスト結果テーブル ON 授業テーブル.生徒ID = テスト結果テーブル.生徒ID AND 授業テーブル.科目ID+9 = テスト結果テーブル.科目IDこれで、無事にテーブルをJOINできました。ON句の中で演算できるとは。
いやいや、きちんとシステム設計できていればこんな危ない解決策を取らなくてもいいのだけれど。
というか、普通はもっときちんとしたシステムだよね?「もっと良い解決策あるよ。」という方、「間違いあるよ。」と指摘してくださる親切な方、ぜひコメントください。
よろしくお願いいたします。
- 投稿日:2019-01-26T21:47:51+09:00
BigQueryとPython(pandas)を連携させてみた
概要
- PythonからBigQueryのテーブルを読み込みます。
- Pythonで作成したdataframeをBigQueryに書き込みます。
- これにより、GCSにエクスポートしてからダウンロードみたいなことをしなくてすむようになります。
環境
- Mac OS High Sierra
- Google Cloud Platform
- BigQuery
- Python 3.6.2
- Jupyter Notebook
- pandas 0.22.0
- pandas-gbq 0.9.0
- 今回の肝です。後ほどインストールします
準備①:BigQueryにテーブルを作成する
- BigQueryの公式ドキュメントで配布されているデータをロードしてみます。
# データセット作成(bq ロケーション mk データセット名) $ bq --location=asia-northeast1 mk test # ローカル上のデータをロードして、テーブルを作成(bq load データセット名.テーブル名 パス オプション) $ bq load test.yob2017 ロードしたいデータのパス name:string,gender:string,count:integer # テーブルが作成されているか確認 $ bq ls test
- テーブルが作成されました!

準備②:pandas-gbqをインストールする
# インストール $ pip install pandas-gbq -U # 確認 $ pip list | grep pandas
- インストールできました。

- これで準備が整ったので、Jupyterを起動して、pandasでBigQueryのテーブルを読み込んでみます。
テーブルの読み込み
# pandasをインポートします import pandas as pd # GCPのプロジェクトIDとテーブルを読み込む際のクエリを変数に入れておきます projectid = 'プロジェクト名' query = 'SELECT * FROM test.yob2017' # pandasのread_gqbにて読み込みます。 # クエリとプロジェクトidを引数に設定する。 # dialect='standard'とすることで標準SQLを使用(default='legacy') df = pd.read_gbq(query, projectid, dialect='standard')
- ここまで実行すると、「Please visit this URL~」のような文章がリンクとなって表示されるので、それを押してください。
- ※pandas-gbqをインストールしていないとここでエラーが出ます。
- リンクをそのまま進んでいくと、認証コードが表示されるのでコピーし、Jupyterに戻り、下記のボックスに貼り付けし、Enterを押します。

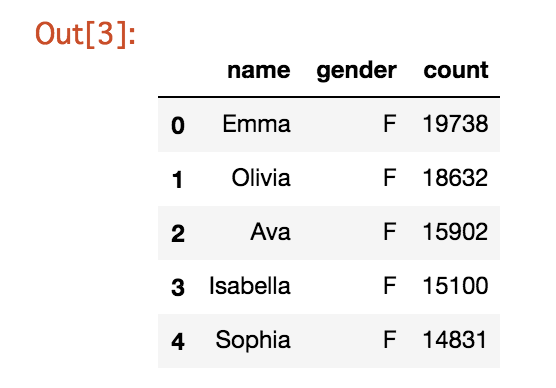
- データフレームを確認してみます。
df.head()
- これでBigQueryのテーブルをデータフレームに読み込むことができました。
- 次は読み込んだデータフレームを少し加工して、BigQueryのテーブルとしてアップロードしてみましょう。
データフレームの書き込み
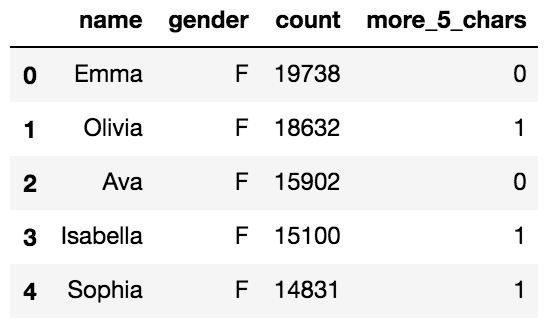
- まず「name」の列が5文字以上かどうかのフラグを新たな列に追加します。
# データフレームのコピー df1 = df.copy() # フラグ付与 df1['more_5_chars'] = (df1['name'].apply( lambda x: len(x)) >= 5).astype(int)
- このデータフレームをアップしてみます。
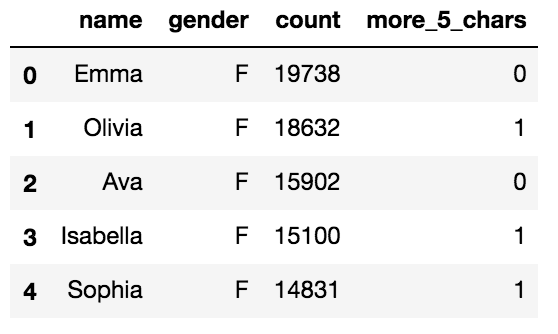 # to_gbqを利用します。 # 引数には'データセット名.データセット名'とプロジェクトIDを指定します。 # if_existsという引数があり、ここを'append'にするとデータがinsertされ、'replace'にするとテーブルが置き換えられる。(default='fail') df1.to_gbq('test.new_yob2017', projectid)# テーブルが作成されているか確認してみます。 $ bq ls test
# to_gbqを利用します。 # 引数には'データセット名.データセット名'とプロジェクトIDを指定します。 # if_existsという引数があり、ここを'append'にするとデータがinsertされ、'replace'にするとテーブルが置き換えられる。(default='fail') df1.to_gbq('test.new_yob2017', projectid)# テーブルが作成されているか確認してみます。 $ bq ls test
新しいテーブル(new_yob2017)が作成されていますね。
このようにpandas-gbqをインストールしJupyter上で認証するだけで、簡単にBigQueryとPythonでデータのやり取りが可能となります。是非参考にしてみてください。
参考