- 投稿日:2019-01-26T19:32:49+09:00
論文まとめ:Shake-Shake regularization
はじめに
ICLR2017から正則化関連の以下の論文
[1] X. Gastaldi, "Shake-Shake regularization"
のまとめ。arXiv:
https://arxiv.org/abs/1705.07485著者のGithubコード:
https://github.com/xgastaldi/shake-shake
torchを使ってる。概要
- 正則化の1つ
- ResNetのredisual block における 2 つの経路に対して順伝播時はランダムな掛け率 $\alpha$と$1 - \alpha$ で足し合わせる。
- 逆伝播時は $\alpha$ とは異なる $\beta$ を用いて計算する
しくみ
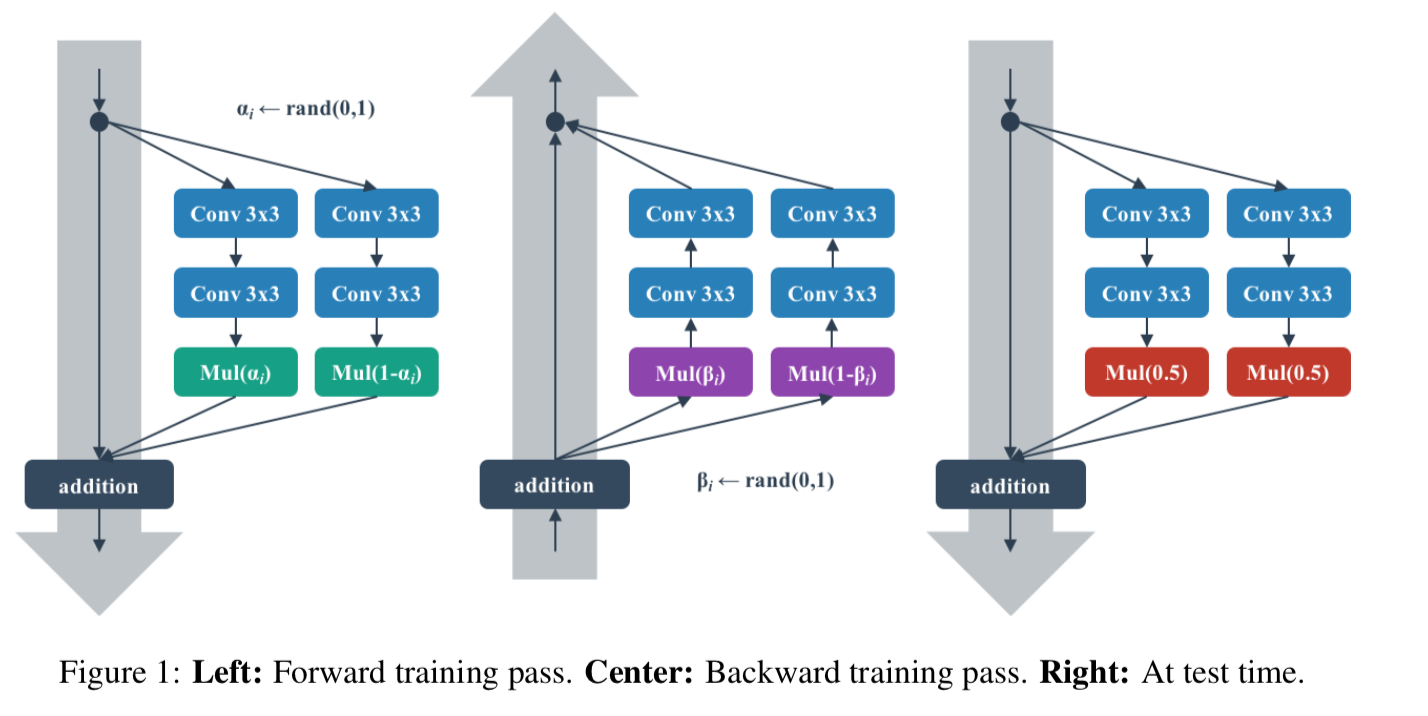
以下の[1]Figure 1 で説明する。
図のような residualなstreamが2つある場合を考える。単純なresidual blockだと
x_{i + 1} = x_i + \mathcal{F}(x_i, \mathcal{W}_i^{(1)}) + \mathcal{F}(x_i, \mathcal{W}_i^{(2)})と3つを足す。
shake-shakeでは乱数 $\alpha_i \in [0,1]$ を発生させて
x_{i + 1} = x_i + \alpha_i \mathcal{F}(x_i, \mathcal{W}_i^{(1)}) + (1-\alpha_i)\mathcal{F}(x_i, \mathcal{W}_i^{(2)})とする。(Figure 1 の左)
通常の勾配降下法で誤差逆伝播させると勾配はそれぞれ $\alpha$ 、 $1-\alpha$ で伝わるが、ここは別の乱数 $\beta \in [0,1]$ を発生させて、それぞれ $\beta_i$ 、 $1 - \beta_i$ とする。(Figure 1 の中央)
推論時はそれぞれ $0.5$ の掛け率で足し合わせる。(Figure 1 の右)
実験と結果
書きかけ
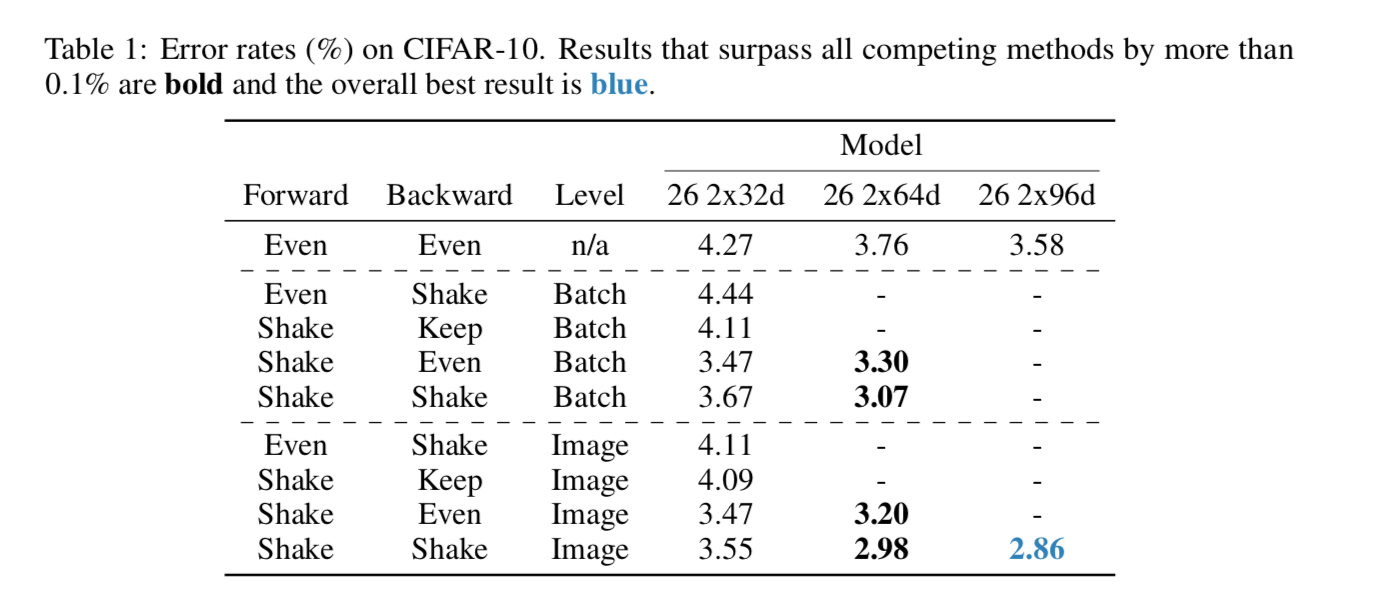
shake, even, keep の比較
- shake:shake-shakeをする
- keep:forwardでshakeした掛け率をbackwardでも使う
- even:0.5、0.5の掛け率を使用
としてそれをmini-batchレベルとimageレベルで行い、性能を比較した。使用したモデルはresnet系。用いたデータはCifar-10
imageレベルでforwardもbackwardもshake-shakeしたものが一番性能がいい。
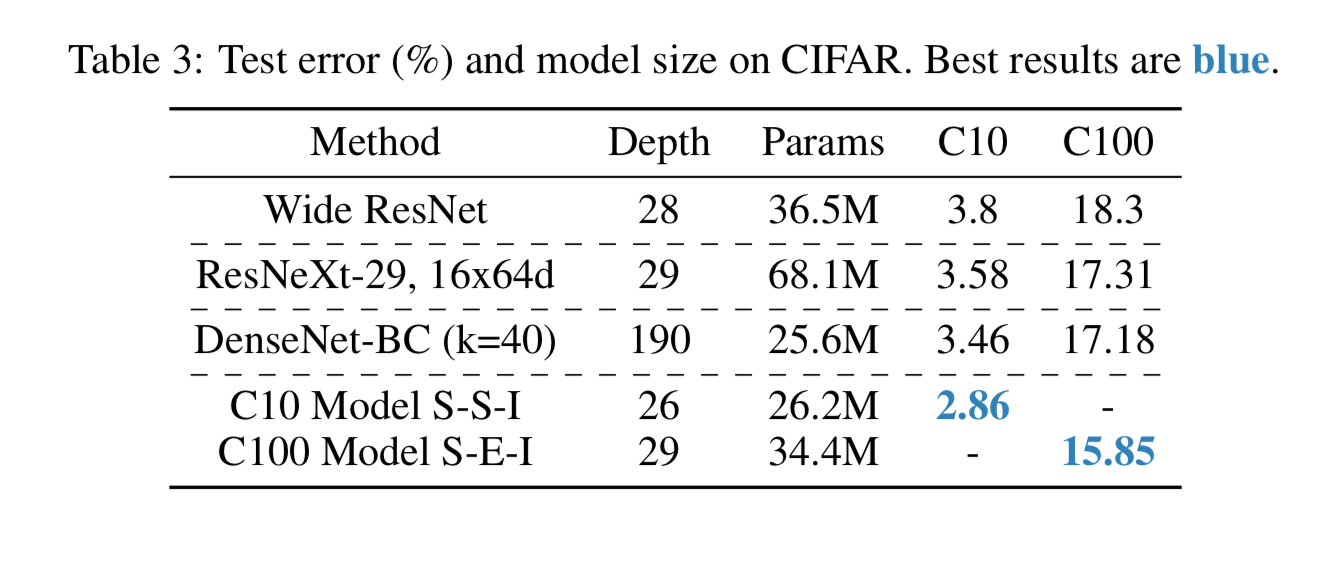
他の有名モデルとの比較
Cifar-10で他の有名モデルとtest errorを比較したものが以下。
DenseNetやResNeXtに勝ってる。
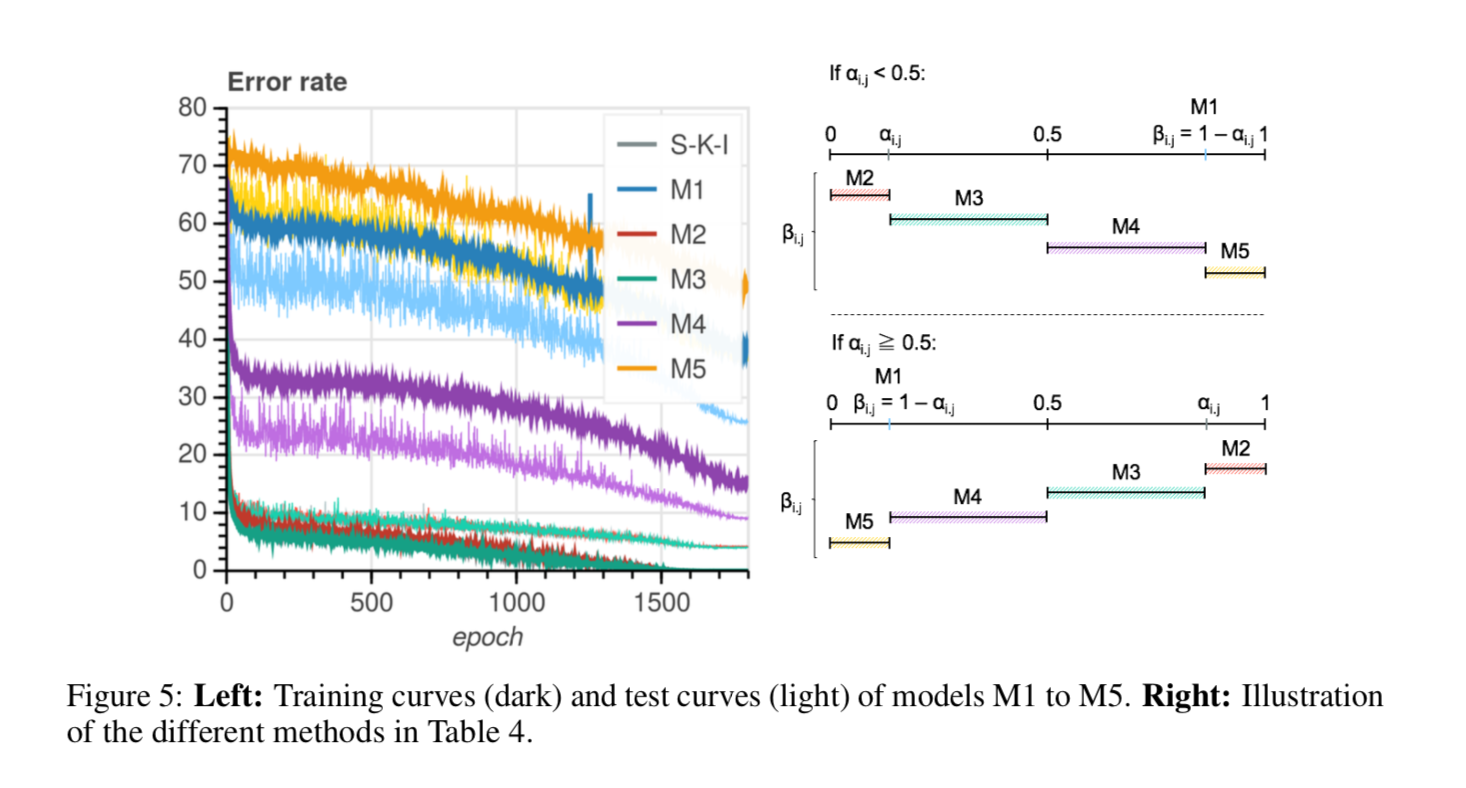
backwardの掛け率を変化させた時の性能の変化

- 投稿日:2019-01-26T13:37:58+09:00
TensorFlowを使ってBitcoinの価格を予想してみた
詳細ディープラーニングの本を読んだので、勉強の題材としてBitcoinの予測を行ってみました。
https://www.amazon.co.jp/dp/B072JC21DH/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1利用した技術や手法
- TensorFlow
- リカレントニューラルネットワーク
- LSTM
- Adam
TensorFlowとは
Googleが作成した機械学習用ライブラリ
機械学習の様々なアルゴリズムをライブラリ化してくれているので、アルゴリズムを理解していなくても機械学習のモデルを作成できる。リカレントニューラルネットワークとは
時系列のデータの扱う時に利用する手法
今回の場合だと、過去のビットコインの価格から、未来の価格を予測するので、この手法が当てはまってそうLSTMとは
長期の過去時間から学習を進めていくと、勾配が消失してしまい学習が進まなくなるから、その対処法となる手法
Adamとは
学習率の調整の手法
最初は大きく学習率をとって、学習が進めるにつれて学習率を小さくしてくれるこれらを使って作成したソースコードはこちら
https://github.com/unamu1229/deep_larning_bitcoin/blob/master/bitcoin.py学習データは
https://www.blockchain.com/ja/charts/market-price
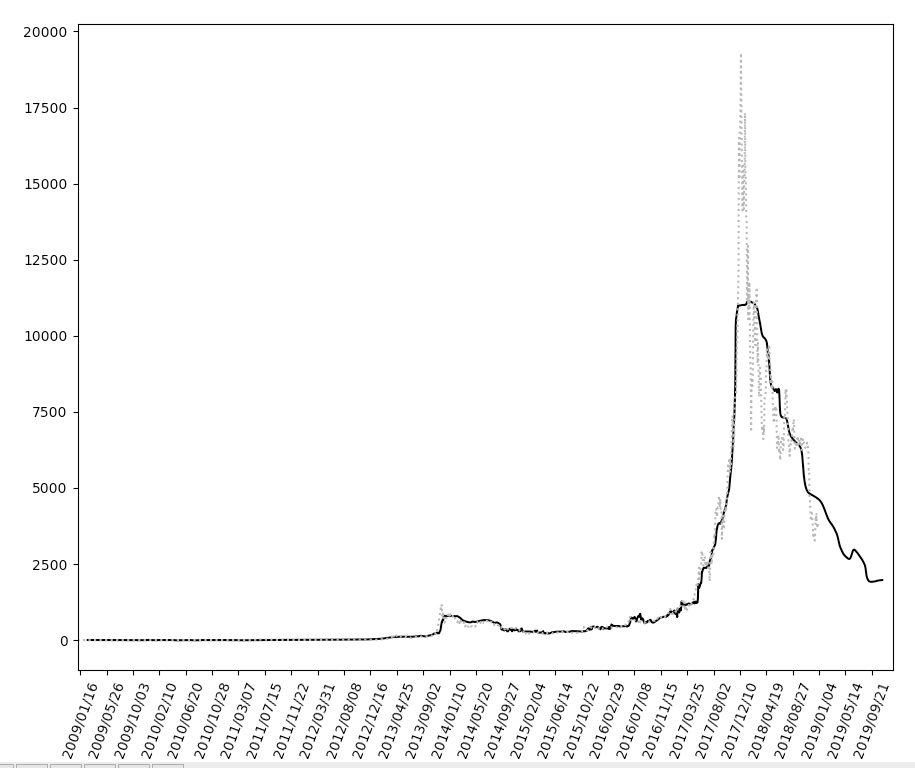
からダウンロードした、2009-01-03から2019-01-01までのビットコインの市場価格予想結果のグラフこのような具合、y軸はドルになり、x軸は日付。
点線は学習のデータになり、実線は学習したモデルが予測したビットコインの市場価格になります。
ビットコインの価格が高騰した時の予測の市場価格と実際の市場価格に大きくズレがあります。
もっと学習の回数(epochs)を増やすことで、この辺りのズレも少なくなりそうです。
- 投稿日:2019-01-26T00:18:39+09:00
BERTの学習済みモデルを利用して日本語文章の尤度を測る
概要
BERTの本家には文章の尤度を測るサンプルがなかった。
尤度を測れるまでの作業メモ
- 本家 GitHub google-research/bert
- 言語モデル拡張 GitHub xu-song/bert-as-language-model
- 日本語モデル BERT with SentencePiece を日本語 Wikipedia で学習してモデルを公開しました
- 日本語モデルコード GitHub yoheikikuta/bert-japanese
謝辞
google-researchチーム、xu-songさん、yoheikikutaさんに感謝いたします。
フォークしたソース
GitHub KTaskn/bert-as-language-model
手順
- 言語モデル拡張をgit cloneする
- 日本語モデルコードからtokenization_sentencepiece.pyをダウンロードする
- クローンしたディレクトリにmodelsディレクトリを作成する
- 日本語モデルから "内容" => "google drive"から日本語モデルをダウンロードしmodelsディレクトリに保存する
- run_lm_predict.pyのコードを修正する
- 日本語モデルのconfig.iniを参考にからbert_config.jsonを作成する
bash.$ git clone https://github.com/xu-song/bert-as-language-model.git $ mkdir models $ wget --no-check-certificate https://raw.githubusercontent.com/yoheikikuta/bert-japanese/master/src/tokenization_sentencepiece.py # modelsにモデルをダウンロード # bert_configを作成する $ export BERT_BASE_DIR=models $ export INPUT_FILE=data/lm/test.ja.tsv $ python run_lm_predict.py \ --input_file=$INPUT_FILE \ --vocab_file=$BERT_BASE_DIR/wiki-ja.vocab \ --bert_config_file=$BERT_BASE_DIR/bert_config.json \ --init_checkpoint=$BERT_BASE_DIR/model.ckpt-1400000 \ --max_seq_length=128 \ --output_dir=/tmp/lm_output/ \ --jp_tokenizer=Truerun_lm_predict.py# 21行目〜 import os import json import modeling import tokenization # 追加 import tokenization_sentencepiece as tokenization_jp import numpy as np import tensorflow as tf # ~~ # 93行目〜 flags.DEFINE_integer( "num_tpu_cores", 8, "Only used if `use_tpu` is True. Total number of TPU cores to use.") # 追加 flags.DEFINE_bool("jp_tokenizer", False, "Use JP Tokenizer") class InputExample(object): def __init__(self, unique_id, text): self.unique_id = unique_id self.text = text # 310行目〜 # 変更 if FLAGS.jp_tokenizer: tokenizer = tokenization_jp.FullTokenizer( model_file="./models/jp_model/wiki-ja.model", vocab_file="./models/jp_model/wiki-ja.vocab", do_lower_case=True) else: tokenizer = tokenization.FullTokenizer( vocab_file=FLAGS.vocab_file, do_lower_case=FLAGS.do_lower_case)bert_config.json{ "attention_probs_dropout_prob" : 0.1, "hidden_act" : "gelu", "hidden_dropout_prob" : 0.1, "hidden_size" : 768, "initializer_range" : 0.02, "intermediate_size" : 3072, "max_position_embeddings" : 512, "num_attention_heads" : 12, "num_hidden_layers" : 12, "type_vocab_size" : 2, "vocab_size" : 32000 }実行結果
data/lm/test.ja.tsv私は本を読む 私は日本を読む 本の国土は広い 日本の国土は広い/tmp/lm_output/test_results.json[ { "tokens": [ { "token": "▁", "prob": 0.9849837422370911 }, { "token": "私は", "prob": 0.01772877760231495 }, { "token": "本", "prob": 0.38430821895599365 }, { "token": "を読む", "prob": 0.14501915872097015 } ], "ppl": 5.6616988500880625 }, { "tokens": [ { "token": "▁", "prob": 0.9833461046218872 }, { "token": "私は", "prob": 0.019558683037757874 }, { "token": "日本", "prob": 0.00026242720196023583 }, { "token": "を読む", "prob": 0.0007271786453202367 } ], "ppl": 128.47718205285057 }, { "tokens": [ { "token": "▁", "prob": 0.011469533666968346 }, { "token": "本の", "prob": 2.954236833829782e-06 }, { "token": "国土", "prob": 5.874089401913807e-05 }, { "token": "は", "prob": 0.514896810054779 }, { "token": "広い", "prob": 3.2568786991760135e-05 } ], "ppl": 1973.8280517535734 }, { "tokens": [ { "token": "▁日本の", "prob": 0.001967047341167927 }, { "token": "国土", "prob": 0.07699552178382874 }, { "token": "は", "prob": 0.11561550199985504 }, { "token": "広い", "prob": 2.0818872144445777e-05 } ], "ppl": 228.85563777870746 } ]summary.* 私は本を読む => 5.6616988500880625 * 私は日本を読む => 128.47718205285057 * 本の国土は広い => 1973.8280517535734 * 日本の国土は広い => 228.85563777870746うまくいったかな?
以上