- 投稿日:2019-01-27T05:16:49+09:00
AWSでDjangoのWEBサーバーを作る(Amazon Linux 2、HTTPS化)
Djangoのウェブサーバーを作ります。ハッカソンとかで良く使うのでメモです。
インスタンスの作成
EC2のダッシュボードを開き、インスタンスを作成します。
イメージはAmazon Linux 2 AMI (HVM), SSD Volume Type - ami-0d7ed3ddb85b521a6を選択しました。インスタンスタイプは
t2.microです。
セキュリティグループの設定で、SSH(22)、HTTP(80)、HTTPS(443)、TCP(8000)用のポートを開放します。キーペアを任意の名前で作成し、できた
.pemファイルをPuTTY genで.ppkファイルに変換します。インスタンスの作成が完了したら、Elastic IPを開き、新しいアドレスを割り当てます。作成したインスタンスにそのIPアドレスを関連付けます。
ドメインを取得
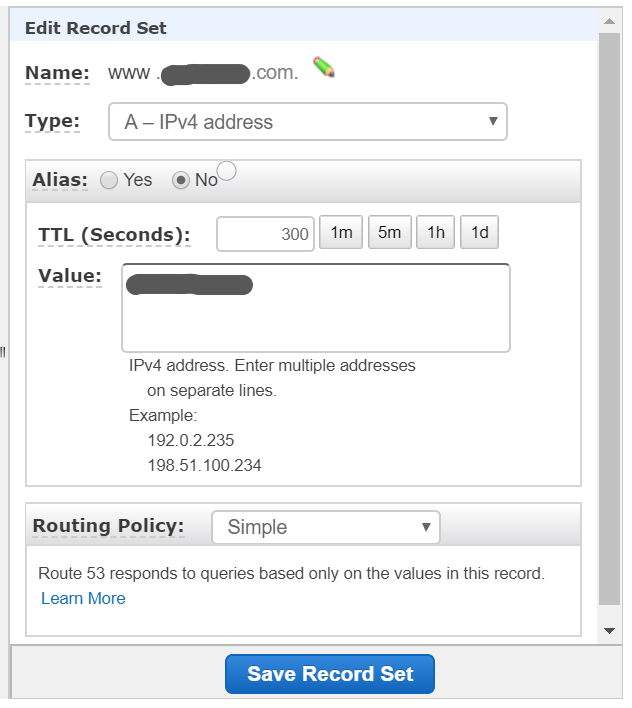
Route53でdomainを作ってください。
www.{name}.com のValueのところにElastic IPを設定します。
チュートリアル: Amazon Linux 2 に LAMP ウェブサーバーをインストールする
PuTTYでパブリックIPもしくは、DNS名(www.{name}.com)でSSH接続します。ここで.ppkファイルを使います。ユーザー名は
ec2-userです。sudo yum update -y sudo amazon-linux-extras install -y lamp-mariadb10.2-php7.2 php7.2 sudo yum install -y httpd mariadb-server sudo systemctl start httpd sudo systemctl enable httpd sudo systemctl is-enabled httpdTest Pageを表示( http://www.{name}.com )します。
sudo usermod -a -G apache ec2-user exitもう一回ログインします。
groups sudo chown -R ec2-user:apache /var/www sudo chmod 2775 /var/www && find /var/www -type d -exec sudo chmod 2775 {} \; find /var/www -type f -exec sudo chmod 0664 {} \;HTTPSに対応させます。(Google Home MiniでWebAPIを使ったアプリ作るときとかに必要だったので)
sudo systemctl is-enabled httpd sudo systemctl start httpd && sudo systemctl enable httpd sudo yum update -y sudo yum install -y mod_sslインスタンスを再起動します。
sudo systemctl restart httpdHTTPSで接続(https://www.{name}.com )します。
プライバシーエラーになりますが、下の詳細設定からアクセスできます。
保護されていないアクセスとなります。CA 署名証明書の取得
付録: Amazon Linux 2 での Let's Encrypt と Certbot の使用を参考にします。
sudo wget -r --no-parent -A 'epel-release-*.rpm' http://dl.fedoraproject.org/pub/epel/7/x86_64/Packages/e/ sudo rpm -Uvh dl.fedoraproject.org/pub/epel/7/x86_64/Packages/e/epel-release-*.rpm sudo yum-config-manager --enable epel* sudo yum repolist all
/etc/httpd/conf/httpd.confのListen 80の下に追記します。sudo vi /etc/httpd/conf/httpd.conf <VirtualHost *:80> DocumentRoot "/var/www/html" ServerName "{name}.com" ServerAlias "www.{name}.com" </VirtualHost>Cerbotを実行します。
sudo systemctl restart httpd sudo yum install -y certbot python2-certbot-apache sudo certbot1."Enter email address (used for urgent renewal and security notices)" というプロンプトが表示されたら、
メールアドレスを入力し、Enter2.Let's Encrypt のサービス利用規約に同意するため、
Aを入力し、Enter3.EFF のメーリングリストに登録するための承認のため、
Yを入力し、Enter4.共通名およびサブジェクト代替名 (SAN) が表示され、
2を入力し、Enter1: {name}.com 2: www.{name}.com5.HTTP クエリを HTTPS にリダイレクトするどうかの確認で、HTTPS 経由の暗号化接続のみ受け入れる場合、
2を入力し、EnterHTTPS( https://www.{name}.com )に安全に接続できることを確かめます。
Certbot を自動化
sudo vi /etc/crontab 39 1,13 * * * root certbot renew --no-self-upgrade sudo systemctl restart crondDjangoやーる
ここからは、LAMP環境作ったのに、Djangoやーるっていう内容です。
Amazon Linux 2にAnacondaをインストールします。wget https://repo.continuum.io/archive/Anaconda3-2018.12-Linux-x86_64.sh bash Anaconda3-2018.12-Linux-x86_64.shyesを入力してインストール、最後にyesを入力して.bashrcを生成します。
/home/ec2-user/anaconda3にインストールされました。
Django用にPython3.6環境を作ります。conda create -n django python=3.6condaのコマンドがないと言われたら、
source /home/ec2-user/anaconda3/etc/profile.d/conda.shPATHが通ってないので、
cat /home/ec2-user/.bashrcで確認しましょう。# .bashrc # Source global definitions if [ -f /etc/bashrc ]; then . /etc/bashrc fi # Uncomment the following line if you don't like systemctl's auto-paging feature: # export SYSTEMD_PAGER= # User specific aliases and functions # added by Anaconda3 2018.12 installer # >>> conda init >>> # !! Contents within this block are managed by 'conda init' !! __conda_setup="$(CONDA_REPORT_ERRORS=false '/home/ec2-user/anaconda3/bin/conda' shell.bash hook 2> /dev/null)" if [ $? -eq 0 ]; then \eval "$__conda_setup" else if [ -f "/home/ec2-user/anaconda3/etc/profile.d/conda.sh" ]; then . "/home/ec2-user/anaconda3/etc/profile.d/conda.sh" CONDA_CHANGEPS1=false conda activate base else \export PATH="/home/ec2-user/anaconda3/bin:$PATH" fi fi unset __conda_setup # <<< conda init <<<
cat /home/ec2-user/.bashrc-anaconda3.bakも確認しましょう。# .bashrc # Source global definitions if [ -f /etc/bashrc ]; then . /etc/bashrc fi # Uncomment the following line if you don't like systemctl's auto-paging feature: # export SYSTEMD_PAGER= # User specific aliases and functionsAnacondaでdjango環境に入り、Djangoをインストールします。
source activate django (django) pip install django (django) django-admin startproject project_name (django) cd helloworld (django) python manage.py migrate (django) python manage.py runserverもし、activateがないと言われたら、
source /home/ec2-user/anaconda3/bin/activate django次にHTTPSに対応させます。
pip install django-sslserver cd helloworld sudo vi settings.pyDEBUG = False ALLOWED_HOSTS = ['www.{name}.com'] # Application definition INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'sslserver', ] SECURE_PROXY_SSL_HEADER = ('HTTP_X_FORWARDED_PROTO', 'https') SECURE_SSL_REDIRECT = True SESSION_COOKIE_SECURE = True CSRF_COOKIE_SECURE = True
python manage.py runsslserver 0.0.0.0:8000の後に、.crtと.keyを指定する必要があります。/etc/letsencrypt/live/www.{name}.com/以下にあるのですが、.pemファイルになっているので、拡張子を変えてコピペします。sudo cp /etc/letsencrypt/live/www.{name}.com/fullchain.pem /etc/letsencrypt/live/www.{name}.com/fullchain.crt sudo cp /etc/letsencrypt/live/www.{name}.com/privkey.pem /etc/letsencrypt/live/www.{name}.com/privkey.key sudo chmod 755 /etc/letsencrypt/live/ sudo chmod 755 /etc/letsencrypt/live/www.{name}.com/fullchain.crt sudo chmod 755 /etc/letsencrypt/live/www.{name}.com/privkey.key実行してみましょう。
python manage.py runsslserver 0.0.0.0:8000 --certificate /etc/letsencrypt/live/www.{name}.com/fullchain.crt --key /etc/letsencrypt/live/www.{name}.com/privkey.key( https://www.{name}.com:8000/ )に接続します。
Not Found The requested resource was not found on this server.( https://www.{name}.com:8000/admin/ )に接続します。
adminユーザーを作るには、下記のようにします。
(django) [ec2-user@ip-xxx-xx-xx-xx helloworld]$ python manage.py createsuperuser Username (leave blank to use 'ec2-user'): admin Email address: gachi.kumamcn@gmail.com Password: Password (again): Superuser created successfully.HelloWorld
HelloWorldコンテンツを作成します。
views.pyを作成します。
from django.http import HttpResponse def helloworld(req): return HttpResponse('Hello, World !!')settings.pyにhelloworldを追加します。
INSTALLED_APPS = [ .... 'helloworld', ]urls.pyにもhelloworldを追加します。
import helloworld.views urlpatterns = [ path('helloworld/', helloworld.views.helloworld), path('admin/', admin.site.urls), ]実行して、( https://www.{name}.com:8000/helloworld/ )に接続します。
バックグラウンドで実行
バックグラウンドでサーバーを起動します。
末尾に&をつけるだけだと、標準出力されてしまいますので、nohupと&で囲みましょう。nohup python manage.py runsslserver 0.0.0.0:8000 --certificate /etc/letsencrypt/live/www.{name}.com/fullchain.crt --key /etc/letsencrypt/live/www.{name}.com/privkey.key > /dev/null 2>&1 < /dev/null &バックグラウンドのサーバーを停止します。
ps -ef|awk 'BEGIN{}{if(match($8, /python/))system("kill -9 " $2)}END{}'

- 投稿日:2019-01-27T02:14:12+09:00
Pycharm + Tensorflow + Virtualenv/pyenvの環境構築
Tensorflowの環境を作ろうとして、ハマったのでメモ。 ポイントだけ書いておく。
用語
さらっとおさらい
統合開発環境PyCharm
PythonのIDE。有名なので使います。今回はCE版
https://qiita.com/yamionp/items/f88d50da8d6b548fc44cpyenv
Pythonのバージョン切り替えに使用
基本的にPythonのバージョンごとに管理
同一バージョンで複数のPython環境を管理不可能(パッケージが混在する)
数値計算用のpython2.7.10と自然言語処理用のpython2.7.10にはならずpython2.7.10として数値計算ようのパッケージと自然言語処理用のパッケージが混在virtualenv
仮想環境の構築に使用
基本的にディレクトリ単位でpythonのバージョン,パッケージを管理
数値計算用のpython2.7.10と自然言語処理用のpython2.7.10分けて使用可能
https://qiita.com/niwak2/items/5490607be32202ce1314インストール
brew cask
GUIまでインストールできちゃうhomebrew。便利なので入れておくことをおすすめします。
brew install caskroom/cask/brew-caskなお、Pycharmはこんな感じでインストールできちゃいます。
https://qiita.com/ryurock/items/1432578d364985f6cb06brew cask install pycharm-cepyenvとpyenv-virtualenvをインストール
https://qiita.com/KazaKago/items/587ac1224afc2c9350f1
pyenv-virtualenvのインストール$ brew install pyenv-virtualenvPythonをインストール
例は3.5.2。TensorflowではPythonのバージョンは「Requires Python 3.4, 3.5, or 3.6」と指定があった
https://www.tensorflow.org/install/pipインストールできる一覧を表示するにはpyenv install -lと打ち込んで下さい
$ pyenv install 3.5.2 $ pyenv rehashxcode-select --installがうまくいかない場合(ここでハマった!!)
Pythonがインストールできない場合、xcode-select --installを打てというサイトが多いので、
やってみたがうまくいかない。
https://qiita.com/zreactor/items/c3fd04417e0d61af0afexcode-selectの最新バージョン(2354)にMojave用のmacOS SDK headerがデフォルトで入っていないのが原因のようです。マニュアルで以下をインストールする必要あるとのこと。
以下で解決しました
sudo installer -pkg /Library/Developer/CommandLineTools/Packages/macOS_SDK_headers_for_macOS_10.14.pkg -target /TensorFlowの実行環境を作る
こうすることでローカルを汚さずに環境が作れます(例は環境名が"TensorFlow"。適宜変更)
$ pyenv virtualenv 3.5.2 TensorFlow $ pyenv rehash作成したTensorFlow用の環境へ切り替え
pyenv globalを使って、作成したTensorFlow環境へ変更
$ pyenv global TensorFlow $ python -V Python 3.5.2うまくPythonのバージョンが切り替わらない場合は、bash_profileに追記
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile反映するのを忘れずにね。
$ source ~/.bash_profile元に戻したいと時
$ pyenv global system環境の指定は後述するPyCharmで行うので、ここでTenserFlow環境になっている必要はない
pipのインストール
次にPython向けのプラグイン管理ツールであるpipをインストール
$ sudo easy_install pip $ sudo pip install --upgrade pipTensorFlowのインストール
TensorFlowのインストール。適宜公式を参考に。
https://www.tensorflow.org/install/$ pip install tensorflowPycharmにて指定。
ここの説明があまり書いていないものが多くハマりました。
preference>Project Interpreter>設定ボタンから、先ほど作ったTensorflow環境を「Add」すると、
以下のように追加される。追加されたら、New Projectで新規プロジェクト作成時に、環境として選べるようになる。

- 投稿日:2019-01-27T01:40:53+09:00
fishでvirtualenvを起動する
virtualenv activeteをfishで
python3 -m venv myvenv
source myvenv/bin/activateとすると仮想環境が立ち上がり、シェル上にもカレントディレクトリ左に環境名(ここではmyvenv)が表示されるfishで実行したが立ち上がっていない感じ
myvenv/bin/の中身を確認してみると
activate.fishというfish用のファイルがある。
したがって以下で起動できる。
source myvenv/bin/activate.fish環境
virtualenv v16
Virtualenv — virtualenv 16.3.0 documentation
- 投稿日:2019-01-27T01:19:48+09:00
AI研究用「打ち出の小槌」サービス(デモ)
こ、これは、、いったい何よ?
- ひと振りするだけで、コインがザックザク出てくる 、というサービス(デモ版)を作ってみた、というお話です。
http://35.237.23.189/jcoin_generator.html- → まずは、[ Shake it ! ] ボタンを押してみてください。
(URLは変更または廃止することがあります)- 以前、コインをバラまいた画像から合計金額を推定するAI という記事を投稿しましたが、それに用いた学習データ生成エンジンを切り出し、 サービス化したものです。
そ、それで、、何をしたいのよ?
- いまどきのAI(人工知能)といえば、機械学習とその応用を指すことが多いように思います。
- 機械学習は一般に、たっくさんのデータが必要となります。
- 機械学習の中ではポピュラーな「教師あり学習」については、個々の学習用データに「教師データ」(=正解ラベル)を付与する必要があります。
- たとえば、画像につけるタイトルが教師データとなります。
(下記では、ねこ、いぬ、さる)
= ねこ
= いぬ
= さる
- ところが、これ(教師データを付与すること=ラべリンク)は、死ぬほど手間がかかります。
- きょうびの機械学習では、何千個、何万個、・・のラべリングが必要になることがありますが、これらは通常、人間が作業せざるを得ません。
そんなわけで、フリー?なデータがネット上で用意していただいていたりするわけですが、
http://www.cs.toronto.edu/~kriz/cifar.html
http://yann.lecun.com/exdb/mnist/おっと! まとめてくれてる人がいました。。すばらしい!
https://www.codexa.net/ml-dataset-list/しかし当然ながら、独自のデータを用意したいときは大変!
もっとも、ある程度のデータがたまれば、元データを機械的に加工する「水増し」とよばるデータ拡張が可能な場合はあるにはありますが・・。
=ねこ
=ねこ
=ねこ
もちろん、水増しだけではやっていけません。
ところが、逆に教師データから学習用データを自動生成が可能な機械学習の分野があるのではないか、と考えました。
本件のコインバラまきネタ、などがそういう例です。
=16円
=28円
=12円
=9円
=21円・・・・・
(他にも自動生成ネタがあるのですが、それは別の機会に紹介しようかと・・)実際には、金額そのものが教師データではなく、各種類それぞれのコインの枚数を教師データとしました。データ生成手順は次の通りです。
- 乱数で各コインの枚数を決める。(この時点で金額が確定)
- その後、各コインの枚数に応じたバラまき画像を生成。
これで学習したモデルが、現時点で実用に使えるわけではありません。
しかし、「多くのデータで学習する機械学習のモデルの振る舞い」を研究する材料となり得る、と考えました。
打ち出の小槌サービスの画面を、もう一度参照して下さい。生成するデータの属性や数をパラメータで制御できる、のは自動生成ならでは、です。
こ、このサービスって、今どう使えるのよ?
- と言われると、これは「こんなことができるよー」という単なるデモでして、
- しいて言えば、生成されたページを右クリックとかして「名前を付けて保存」(ウェブページ、完全、=chromeブラウザの場合)とかすると、教師データがHTMLに記載された画像データのセットが得られます。
- しかし、このサービスそのものは、ショボくて安い IAAS の仮想マシンを使っており、大量のデータ生成を想定していません。(酷使するとたぶん死にます。)
- 本当に大量のデータを作りたい場合は、コインバラまきネタのソースコード をとってきて、各自の環境に移植してください。
- 億万長者になれるかも。先は長いですが。
【まとめ】本件に限らず、機械学習用のデータを最初から自動生成する仕組みを「打ち出の小槌(うちでのこづち)」と呼ぶことにします。









- 投稿日:2019-01-27T01:16:37+09:00
Pythonで株価情報を取得して、MySQLに格納する
やりたいこと
データ分析用に永続データとして日本の株価情報を取得して、MySQLに格納します。
MySQLの環境は、MetabaseとMySQL環境をDockerで作るで作成したMySQLに格納します。データソース
データソースはQuandlというサイトを利用します。
有料データもありますが、無料でも使えます。
今回はQuandlで収集されているデータの中から、東京証券取引所が提供しているデータを利用します。環境
- Mac OS X 10.14.2
- Python 3.7.1
- Quandl 3.4.5
手順
アカウント登録
APIキーを取得するためにQuandlのアカウント登録を行います。
登録は無料です。APIキーの確認
アカウントを作成したら、右上のメニューから[ACCOUNT SETTINGS]を選択します。
プロフィール画面に遷移すると、[YOUR API KEY]にAPIが記載されているのでメモします。データの取得
実際にデータを取得してみます
※必要なライブラリは適宜インストールしてください。#!/usr/local/bin/python3 # -*- coding: utf-8 -*- import datetime import quandl import pandas as pd # 各種設定 ## 取得したい日付レンジの指定 start = datetime.datetime(2007, 1, 1) end = datetime.datetime(2019, 1, 19) # 取得したい会社のティックシンボルを記載します。 ## 例えばの武田薬品工業の場合 TSE/4502 となります。 ## https://www.quandl.com/data/TSE/4502-Takeda-Pharmaceutical-Co-Ltd-4502 company_id = 'TSE/4502' # APIキーの設定 quandl.ApiConfig.api_key = '前の手順で確認したAPIキーをここに記載' # データ取得 df = quandl.get(company_id ,start_date=start,end_date=end)データが以下のように取得できていることを確認します。
>>> df.head() Open High Low Close Volume Date 2007-01-04 8180.0 8210.0 8170.0 8180.0 1401400.0 2007-01-05 8180.0 8180.0 7970.0 8010.0 3020100.0 2007-01-09 8000.0 8010.0 7940.0 7950.0 2696200.0 2007-01-10 7950.0 7960.0 7760.0 7760.0 3807700.0 2007-01-11 7820.0 7890.0 7710.0 7760.0 3286800.0MySQLにデータを格納する。
取得したデータをMySQLに格納します。
上の続きと思ってください。import sqlalchemy as sa ## Indexが日付なので行に取り込んで、データ型を変更する。 df = df.reset_index() df['Date'] = pd.to_datetime(df['Date']) ## 表名の指定 table_name = 'TAKEDA' ## 接続情報設定 engine = sa.create_engine('mysql+mysqlconnector://stock:stock@127.0.0.1/stock', echo=True) # MySQLにデータを格納 df.to_sql(table_name, engine , index=False, if_exists='replace')データの確認
MySQLにアクセスして、データを確認します。
$ mysql --host=127.0.0.1 --user=stock --password mysql> use stock Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> show tables; +-----------------+ | Tables_in_stock | +-----------------+ | AAPL | | TAKEDA | +-----------------+ mysql> desc TAKEDA; +--------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+----------+------+-----+---------+-------+ | Date | datetime | YES | | NULL | | | Open | double | YES | | NULL | | | High | double | YES | | NULL | | | Low | double | YES | | NULL | | | Close | double | YES | | NULL | | | Volume | double | YES | | NULL | | +--------+----------+------+-----+---------+-------+ 6 rows in set (0.00 sec)
- 投稿日:2019-01-26T23:58:24+09:00
プログラミング未経験者がPython覚えて子ども用計算ドリルを作る
まえがき
35歳までプログラミングを一切やったことはなかったのですが、いろいろ作りたいものが出てきたのでUdemyでプログラミングを覚えることにしました。なんとなく覚えやすそうで最近流行っているらしいPythonを勉強しました。
Pythonの勉強をするために使ったUdemyのコース
プログラミング言語 Python 3 入門
https://www.udemy.com/intro-to-python3/learn/v4/contentみんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習
https://www.udemy.com/learning-ai/learn/v4/overview今回作りたいもの
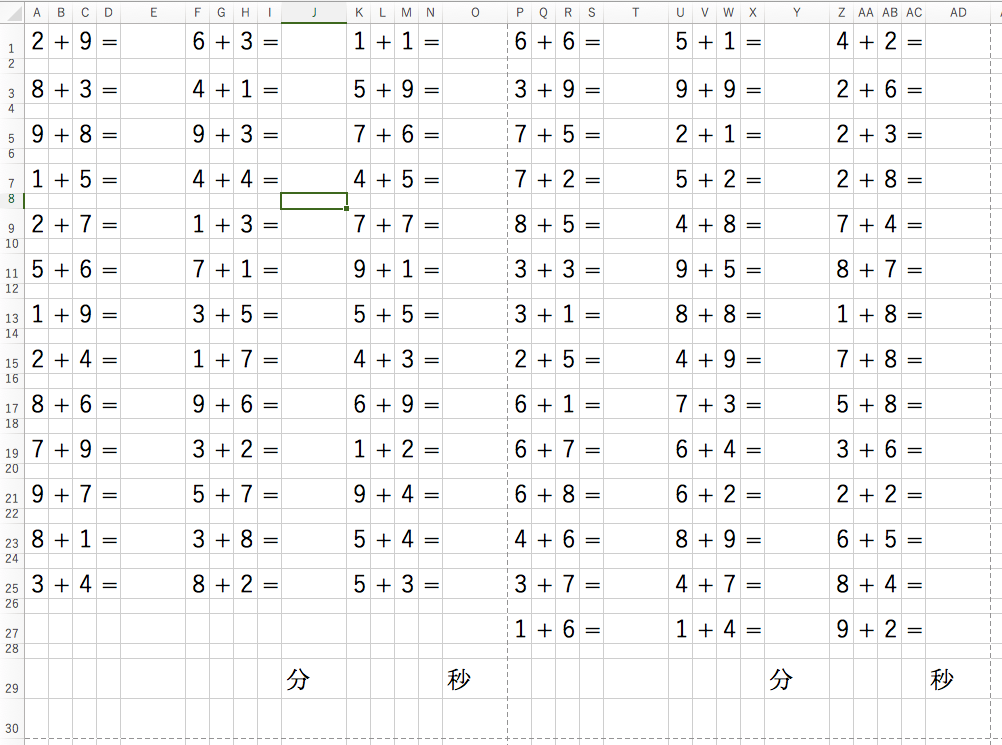
四則演算の計算ドリルを作ります。まずは足し算で繰り上がりがあるものと無いものがまじった計算ドリルです。
↓こういうの
なんでこれを作りたいかというと、うちには小学生の子どもがいて、毎日足し算のドリルをやらせたいのですが、こういう計算ドリルって市販のものだと数枚しかついていないのです。仮に自分で作ってコピーしても、子どもは並びを覚えているので計算せずに、記憶だけで解こうとしてしまうので、並びが変わると応用がききません。
今回は、足し算がA4用紙で印刷できるかたちで出力されて、かつ毎回計算の並びが異なるものを作ろうと思います。
ちなみに分とか秒と書いてあるのは毎回タイムを測っておいて、どれぐらいのスピードでできたかを毎回記録していくために入れています。まだ足し算が完全にできないときには結構時間がかかるのですが、だんだん早くなってくるのが可視化されるので、褒めるポイントが増えるしモチベーションにもつながるのです(タイムが伸びなかったり遅くなるとモチベーションが落ちるのですが)。
ちなみに自分で作った問題でやってみたのですが、30秒でした。あと1、2秒は縮められると思いますが鉛筆のスピード的にそれが限界かなあと。このプログラムで計算ドリルを作って皆さんもやってみてください。要件
- 繰り上がりありと繰り上がりなしの足し算が並んでいる。
- 6+7と7+6は別の足し算とする。(小さい子はこれを同じものだという認識がまだない)
- プログラムを実行する毎回並びが変わる。
- Excelで出力できる、A4で印刷できる。
Udemyで勉強したコース
プログラミング言語 Python 3 入門
https://www.udemy.com/intro-to-python3/learn/v4/contentみんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習
https://www.udemy.com/learning-ai/learn/v4/overview開発したプログラム
まず完成品です。多分スーパーな人から見たらきれいじゃないプログラムだってわかるんですけど、今はこれで精一杯です。
increase.pyimport openpyxl import random def insert(under, c, x, y, line): for r in range(1, line, 2): if x < under: number = list[x][y] sheet.cell(row=r, column=c, value=number) x += 1 book = openpyxl.load_workbook('足し算.xlsx') sheet =book['Sheet1'] list = [] for a in range(1, 10): for b in range(1, 10): list.append([a, b]) random.shuffle(list) under = 13 c = 1 x = 0 y = 0 line = 26 while under < len(list)/2 : if y == 0: insert(under, c, x, y, line) c += 2 y = 1 else: insert(under, c, x, y, line) under += 13 c += 3 x += 13 y = 0 under +=1 line +=2 while under <= len(list) : if y == 0: insert(under, c, x, y, line) c += 2 y = 1 else: insert(under, c, x, y, line) under += 14 c += 3 x += 14 y = 0 book.save('足し算.xlsx')あと今回はExcelに数字を埋め込む形でやりました。スペースを作るために、一段とばしで数字を入れていくやり方にしたのですが、別にこんなことしなくても文字と幅をうまく調整すればよかったんじゃないかと作ってから思いました。
A列からO列を1枚目、P列からAD列を2枚目として印刷できるように幅や高さを調整しています。
+とか=とか分とか秒という文字は予め入れておいて、今回のプログラムで挿入することはしません。あくまで数字だけです。
一個ずつ解説していきます。
足し算のリストを作る。
list = [] for a in range(1, 10): for b in range(1, 10): list.append([a, b]) random.shuffle(list)aが+の右側、bが左側です。for a in range(1, 10)で変数aに1〜9の数字を入れ、合わせてbにも同様に1〜9を入れます。これによって、listには[[1,1],[1,2],[1,3],〜[9,8],[9,9]]と値が入っていってくれます。
listができたらrandomを使って配列の並びをバラバラにします。
randomは
import random
で使えるようにしています。
randomについての簡単な解説はこちらから。
pythonでrandomを使ってみる。
https://qiita.com/ajitama/items/cacf4d68b26333143fd8Excelのファイルを開く
Excelのファイルを開いたり書き換えたりするときにはopenpyxlというモジュールを使います。
pythonのopenpyxlの使い方メモ
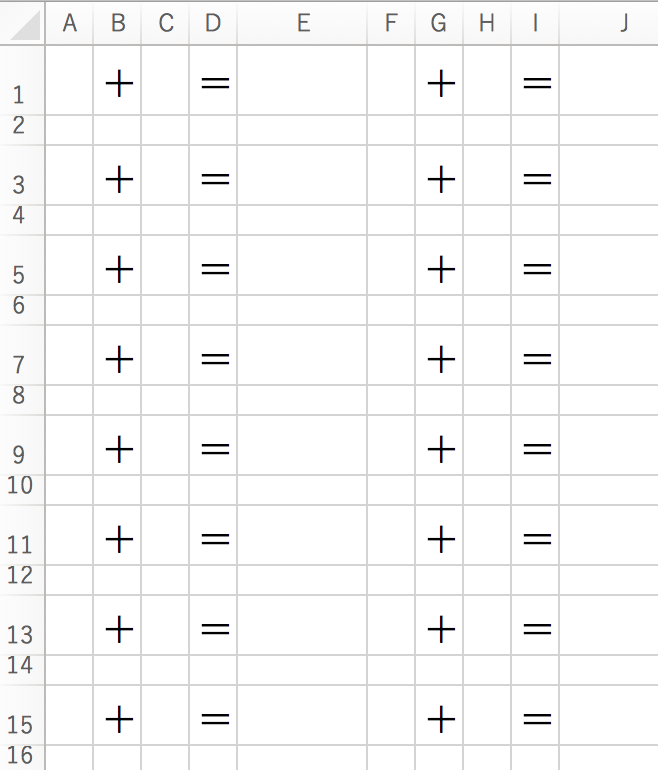
https://qiita.com/sky_jokerxx/items/dc9d8827d946b467ba4bbook = openpyxl.load_workbook('足し算.xlsx') sheet =book['Sheet1']pythonのファイルが置いてあるところに足し算というエクセルファイルをおいておきます。それをopenpyxl.load_workbook('足し算.xlsx')で指定して開きます。bookという名前は適当に決めました。book['Sheet1']でシートを指定します。
今回作ったExcelファイルのシートは画像のようなフォーマットにしています。+と=は予め入れておいて、AとCのところに配列の値を挿入していきます。
配列の値をExcelに挿入する。
こういう関数を作りました。
def insert(under, c, x, y, line): for r in range(1, line, 2): if x < under: number = list[x][y] sheet.cell(row=r, column=c, value=number) x += 1やりたいこととしては、まずA列にリストのaの値を挿入していくということです。
まず、
number = list[x][y]
について、プログラミングを知っている人なら説明を省略していいですが、そうじゃない人向けに書きます。
はさっき作った足し算のリストのx番目の配列のy番目の値をnumberに入れるという意味です。[[1,1],[1,2],[1,3],〜[9,8],[9,9]]というリストでnumber = list[1][0]なら[1,2]の1をnumberに入れますし、list[1][1]は2をnumberに入れいます。さっきのリストでいうaは0で、bは1ですね。次に
sheet.cell(row=r, column=c, value=number)
について説明します。openpyxlのモジュールの機能でcellを使うと指定の場所に値を入れる事ができます。普通はA1とかA3とかで指定しますが、今回は繰り返し処理をしたいので行列表記でいれます。
rowで行(1行目、2行目などですね)、columnは列(A列やB列のことで、A列は1、B列は2です)で、valueで挿入する値をしていします。
たとえばsheet.cell(row=1, column=1, value=3)とするとA1に3という数字を入れてくれます。そして、
for r in range(1, line, 2): if x < under:ですが、rは先のsheet.cellでrowに入る値を指します。for r in range(1, line, 2)で1、3、5、7という順でrに値を入れるのを繰り返します。値を入れてほしいのは26行目までなので、lineには26をいれておきます。
if x < underではリストの配列の順番を制御しているものがunderをいう基準より下かどうかを判定します。
後述しますが、1列目ではこういう値が入れます。
insert(13, 1, 0, 0, 26):
するとそれ以降の関数はこのようになります。for r in range(1, 26, 2): if x < 13: number = list[x][0] sheet.cell(row=r, column=1, value=number) x += 1xは最初0からスタートしてリストの0番目のaの値を取ってきます。その後にA1のセルに値を挿入したあとに、xに1がプラスされます。
このあとfor文に戻ってrが3になったあとにリストの1番目をとってきて、A3のセルにaの値を挿入して、xに1がプラスされて2になって、ということをxが13になるまで繰り返されます。こうやってA列の下まで値が入っていきます。C列以降に値を挿入する
C列以降に値を入れようと思ったら、先程のfor文はこういう値になります。xは0に戻る必要があります。
for r in range(1, 26, 2): if x < 13: number = list[x][1] sheet.cell(row=r, column=3, value=number) x += 1先程のとの違いは3列目numberのところの数式の[0]が[1]になってリストのbの値をとってこようとしてるところと、4列目のcolumnが3になっています。ここが3になるとC列に値を入れようとしているということです。先程A列に入れていたことと同じことをやっていきます。
この動きを数式にしようとすると、under = 13 c = 1 x = 0 y = 0 line = 26 while under < len(list)/2 : if y == 0: insert(under, c, x, y, line) c += 2 y = 1 else: insert(under, c, x, y, line) under += 13 c += 3 x += 13 y = 0となります。まず、if文のところから説明するのですが、yが0だった場合は、aの値を挿入する処理を行っていきます。
そしてinsert関数が完了するとcに2を足して、yを1にします。
ここはwhileによってループするのですが、yが1なので下の段の計算に入って、またinsert関数を適用させてbの値をExcelに挿入していきます。
そしてbの値の挿入を完了するとunderとxに13を足します。これは、先のリストで0番目〜12番目まで値の取得が完了したため、次のF列に入れる値は、13番目〜26番目の値であるためです。
cに3を加えているのはD列で=、E列に回答用のスペースを作っているので、3列分ずれるひつようがあるためです。またyは0に戻して、リストのaの値をとってこれるようにします。
whileでループさせないようにするとこんな頭の悪いプログラムになります。
insert(13, 1, 0, 0, 26)←A列
insert(13, 3, 0, 1, 26)←C列
insert(26, 6, 13, 0, 26)←F列
insert(26, 8, 13, 1, 26)←H列
insert(39, 11, 26, 0, 26)←K列
insert(39, 13, 26, 1, 26)←M列
最初どうしていいかわかんなくてこんなのをまず書いてから、ロジック考えていましたけど。それで、whileがwhile under < len(list)/2ってなっている理由なのですが、1枚目と2枚目で計算ドリルの問題数が違うためなのです。
2枚目の計算ドリルに値を挿入する。
1+1から9+9までの組み合わせは81個あります。これを2枚にきっちり分けようとすると、39問と42問の分け方になってしまいます。40問と41問という分け方もできるでしょうかど、プログラムのロジックがよくわからなくなるのでそこは妥協しました。2枚目の方が問題数多いのです。
under +=1 line +=2 while under <= len(list) : if y == 0: insert(under, c, x, y, line) c += 2 y = 1 else: insert(under, c, x, y, line) under += 14 c += 3 x += 14 y = 01列あたりの問題数が13問から14問に増えるので、underに1を、lineに2を足して、14問分のループができるようにしました。
これでM列に値を挿入するのにどのようなinsert関数にどのような値が入っているかというと、以下のとおりです。xは39からスタートです。for r in range(1, 28, 2): if x < 53: number = list[x][0] sheet.cell(row=r, column=16, value=number) x += 1whileを使わないとこんなinsert関数の処理が行われます。
insert(53, 16, 39, 0, 28)←P列
insert(53, 18, 39, 1, 28)←R列
insert(67, 21, 53, 0, 28)←U列
insert(67, 23, 53, 1, 28)←W列
insert(67, 26, 67, 0, 28)←Z列
insert(67, 28, 67, 1, 28)←AB列Excelを保存する。
ようやく値を入れ終わりました。openpyxlモジュールのsaveを使うとファイル保存ができます。今回は上書き保存でいいので開いたファイルと同じ名前で保存しました。
book.save('足し算.xlsx')以上です。これでPythonを実行するたびに、問題の並びが変わる計算ドリルを作る事ができました。
足し算以外の計算の作り方
引き算
2-1から18-9までのパターンです。引く側が一桁でかつ答えが0を除く1桁になる引き算の混ざったリストは以下のかたちでできます。Excelの+は-に変えておいてください。
list = [] for a in range(2, 19): for b in range(1, 10): if a - b < 10 and a - b > 0 : list.append([a, b]) random.shuffle(list)掛け算
これは九九の問題ですね。足し算と一緒です。Excel側で+を×に変えておいてください。
list = [] for a in range(1, 10): for b in range(1, 10): list.append([a, b]) random.shuffle(list)割り算
これは1÷1とかやっても仕方ないので2スタートです。
list = [] for a in range(2, 10): for b in range(2, 10): list.append([a * b, b]) random.shuffle(list)ただ、これだと問題数が64問になるので、1ページ32問になってしまいます。ただ、それだと1枚11行、11行、10行の組み合わせで、数式が複雑になってしまいます。まあ、1枚目10行、10行、11行で2枚目は全部11行とかにすればいいと思うのですが、なんかそれは納得いかない。ここは全体的に解決方法見つけたら改めてプログラムを書こうと思います。
余談1
最初は「みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習」からやっていたのですが、途中からついていけなくなるところがあって、Pythonに特化した学習コースがあるのがいいなと思って「プログラミング言語 Python 3 入門」をやっていました。
開発環境は「プログラミング言語 Python 3 入門」はターミナルを使って進めているのですが、プログラムの保存の仕方などの説明はなく、書いては消しという使い方しかできなかったので、「みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習」で使っていたPyCharmの方がプログラムの保存もできるしインタフェースがとっつきやすいのでこっちを使っています。なんとなくですが、「知識ゼロから○○を作る」みたいなタイプの学習プログラムって、初学者にはわからない専門用語を多用していたり、なぜそうなるのか、という説明をすっ飛ばしていたりすることが多いので、プログラミングを本当に一から勉強するなら、その説明に特化したもののほうがいいのかなという気がします。


- 投稿日:2019-01-26T22:58:39+09:00
(macOS) Vagrant + CentOS + pyenv + anaconda でホストOSから jupyter notebookを使う
macOSをクリーンインストールする度に再設定するのでメモ
環境
以下の環境で動作確認済み
ホスト
- macOS 10.14.3
- VirtualBox 6.0.2
- Vagrant 2.2.3
ゲスト
- CentOS 7.6 (1810)
- pyenv 1.2.9
- anaconda 3-5.3.1
- Python 3.7.2
VirtualBoxのインストール
- 公式サイト(https://www.virtualbox.org/wiki/Downloads) からmaxOS用のインストーラをダウンロード
- ダウンロードしたdmgファイルをダブルクリックし、インストール実行
- terminalに以下のコマンドを入力し、バージョン確認
$ VBoxManage -v 6.0.2r128162Vagrantのインストール
- 公式サイト(https://www.vagrantup.com/downloads.html) からmaxOS用のインストーラをダウンロード
- ダウンロードしたdmgファイルをダブルクリックし、インストール実行
- terminalに以下のコマンドを入力し、バージョン確認
$ vagrant --version Vagrant 2.2.3Vagrantの設定
Vagrant用ディレクトリを作成し、ボックスの作成・初期化 (box addは不要)
# ホームディレクトリから開始 $ cd ~ # Vagrantディレクトリを作成 $ mkdir Vagrant # Vagrantに移動 $ cd Vagrant # Vagrantの下にcentOSディレクトリを作成 $ mkdir centOS # centOSに移動 $ cd centOS # vagrant init 実行 $ vagrant init centos/7Vagrantfileの編集
vagrant initを実行すると、カレントディレクトリ(ここではcentOSディレクトリ)にVagrantfileができているのでテキストエディタで開き、以下の2行をアンコメント('#'を削除してコメントアウトを取り消し)# config.vm.network "forwarded_port", guest: 80, host: 8080 <中略> # config.vm.network "private_network", ip: "192.168.33.10"↓
config.vm.network "forwarded_port", guest: 80, host: 8080 <中略> config.vm.network "private_network", ip: "192.168.33.10"ゲストOSの立ち上げ
以下のコマンドでCentOS7を起動
$ vagrant upCentOSにssh接続
起動に成功したらsshでログイン
$ vagrant sshpyenvとAnacondaのインストール
ログインしたら最初にyumの更新とgitインストール
$ sudo yum -y update $ sudo yum -y install gitpyenvをgitから取得
$ git clone https://github.com/yyuu/pyenv.git ~/.pyenvpyenvの環境変数を設定
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "(pyenv init -)"' >> ~/.bash_profile $ source ~/.bash_profilememo
環境変数を.bashrcに書き込むと、bashが正常に動かなく(コマンドが全てcommand not foundに)なったので
.bash_profileに書き込んだところ正常に動作したanacondaのインストール
# anacondaのバージョン一覧確認 $ pyenv install -l | grep ana # 最新版インストール(少し時間がかかる) $ pyenv install anaconda3-5.3.1 $ pyenv rehash # anacondaのPythonをデフォルトに設定 $ pyenv global anaconda3-5.3.1 # anacondaの環境変数を設定 $ echo 'export PATH="$PYENV_ROOT/versions/anaconda3-5.3.1/bin/:$PATH"' >> ~/.bash_profile $ source ~/.bash_profile # Pythonのバージョン確認 $ pyenv versions system * anaconda3-5.3.1 (set by /home/vagrant/.pyenv/version) # condaのアップデート $ conda update conda # 下記が表示されたら'y'を入力してEnter Proceed ([y]/n)?jupyter notebookの起動
jupyter notebookはanacondaに同梱されているので、ここではそのまま使う
(anacondaで仮想環境を作る場合は別途設定)# jupyter notebookを起動 $ jupyter notebook --no-browser --ip=0.0.0.0 # 下記が表示されたらtoken(xxxxxxxxxxxxxxxxxxxxxxxxxの部分)をコピーしておく Copy/paste this URL into your browser when you connect for the first time, to login with a token: http://(localhost.localdomain or 127.0.0.1):8080/?token=xxxxxxxxxxxxxxxxxxxxxxxxxjupyter notebookへアクセス
ホストOSに戻り、ブラウザで以下のURLを開く
初回アクセス時にtokenの入力とパスワード設定を聞かれるので、コピーしておいたtokenを入力し、
パスワードを設定する
500 : Internal Server Errorが表示された場合は、ゲストOSのterminalに戻り
[⌃C]でjupyter notebookを一旦終了し、再度起動する
以下の記事、サイトを参考にさせて頂きました
https://qiita.com/sk427/items/9f215931c8249ada75cd
https://qiita.com/1000ch/items/93841f76ea52551b6a97
https://qiita.com/N-K-Kota/items/a36902d43c48d054bb6f
https://qiita.com/supersaiakujin/items/50def6f33b79f9a61b18
https://mashi-prog.hatenablog.com/entry/2018/06/09/105911
- 投稿日:2019-01-26T21:50:31+09:00
Numpy 基礎からよく使うものまで
機械学習を行うに当たって、Numpyの基本的な操作と個人的によく使う機能をまとめました。
Numpy基本機能
0.ライブラリのインポート
import numpy as np1.配列の作成
- 1次元配列
np.array([1, 2, 3]) >>> array([1, 2, 3])
- 2次元配列
np.array([[1, 2, 3], [4, 5, 6]]) >>> array([1, 2, 3], [4, 5, 6]])
- print関数で配列をすっきり表示
a = np.array([[1, 2, 3], [4, 5, 6]]) print(a) >>> [[1 2 3] [4 5 6]]
- 全ての要素が0である行列を返す np.zeros()
np.zeros((2, 4)) #引数に配列の形態を入力 >>> array([0, 0, 0, 0], [0, 0, 0, 0]])
- 全ての要素が1である行列を返す np.ones()
np.ones((3, 3)) #引数に配列の形態を入力 >>> array([[1., 1., 1.], [1., 1., 1.], [1., 1., 1.]])
- range関数のような連続する1次元の行列を作る(Numpy版 range関数) np.arange()
np.arange(11) #0から1までの連続値 >>> array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) np.arange(0, 16, 3) #0から15までの3ずつ大きくなる連続値 >>> array([0, 3, 6, 9, 12, 15])
- 指定した範囲内で等間隔に分割された値の行列を作る np.linspace()
np.linspace(0, 5, 9) #0から5までの範囲を9つに均等に分割 (9つの分割点を返す) >>> array([0., 0.625, 1.25, 1.875, 2.5, 3.125, 3.75, 4.375, 5.])
- 単位行列の生成 np.eye()
np.eye(3, 3) >>> array([[1., 0., 0.], [0., 1., 0.], [0., 0., 1.]])
- 全て指定の数値の配列の生成 np.full()
np.full((4, 2), 123) >>> array([[123, 123], [123, 123], [123, 123], [123, 123]])2.配列の情報を確認
- .ndim : 行列の次元を表します。最初に何個 "[" が続いているかに対応します。
- .shape : 各次元の要素数を表示。
- .size : 行列の要素の全個数です。
- .dtype : 要素のデータ型を表します。
a = np.array([[1, 2, 3], [4, 5, 6]]) a.shape #各次元の要素数を確認 >>> (2, 3)3.配列の参照・変形など
- インデックス・スライス操作
a = np.array([[1, 2, 3], [4, 5, 6]]) print(a) >>> [[1 2 3] [4 5 6]] a[0, 2] #1行目の3列目の値を表示 >>> 3 a[-1, 1] #後ろから1行目(この場合は2列目)の2列目の値を表示 >>> 5 print(a[:, 2]) #全行の3列目を表示(:は全てを意味する) >>> [3 6]a = np.array([0, 1, 2, 3, 4, 5]) a >>> [0 1 2 3 4 5] print(a[:4]) #4つ目まで表示 >>> [0 1 2 3] print(a[2:5]) #3つ目から5つ目まで表示 >>> [2 3 4]
- 配列の変形 .reshape()
a = np.array([0, 1, 2, 3, 4, 5]) a >>> [0 1 2 3 4 5] a.reshape(3, 2) #3×2に変形 >>> array([[0, 1], [2, 3], [4, 5]]) #指定した配列の要素数が合わない場合はエラーになる
その他
- .ravel() : 行列を1次元に変換する
- .flatten() : 行列を1次元に変換する
- .T : 行列を転置させる
- .diagonal() : 対角要素を表示
4.乱数
Python標準のrandomモジュールとは別に、Numpyにも乱数発生機能がある。
- 0以上1未満の乱数を生成 np.random.random()
np.random.random(10) >>> array([0.03554718, 0.74723843, 0.27291435, 0.26284813, 0.79078377, 0.00814339, 0.41940143, 0.81117724, 0.98409866, 0.38093226])
- 乱数の固定 np.random.seed()
np.random.seed(0) #同じ乱数が生成される
- 0以上1未満の高次元の乱数配列生成 np.random.rand()
np.random.rand(3, 4) >>> array([[0.85371393, 0.87247222, 0.09849451, 0.84980366], [0.17332104, 0.84787819, 0.98709454, 0.99205639], [0.78306371, 0.8567189 , 0.75677948, 0.60070442]])
- 指定範囲内の乱数を生成 np.random.randint() / np.random.uniform()
np.random.randint(1, 10, (2, 3)) #1次元の場合はタプルでなく数値を入力 #1から10までの整数をランダム生成 <10は出ない> >>> array([[3, 1, 4], [8, 9, 2]]) np.random.uniform(1, 10, (2, 3)) #1から10までの小数値をランダム生成 >>> array([[6.04938728, 8.58981204, 2.71022283], [5.7859627 , 7.2292891 , 9.7463006 ]])
- 平均0、標準偏差1の標準正規分布に従う乱数の出力 np.random.randn()
np.random.randn(3, 2) >>> array([[ 0.48735179, 1.70962469], [-0.1878482 , -0.22249371], [-0.71046488, -1.26965019]])
- 任意の平均、標準偏差の正規分布に従う乱数の出力 np.random.normal()
np.random.normal(0, 1, (3, 2)) #平均0、標準偏差1、3行2列 で指定 >>> array([[ 0.44271636, 0.0011947 ], [-0.11190774, 0.88837843], [-0.32281972, 0.62059076]])5.ユニバーサル関数
Numpyの関数はメソッド呼び出し可能
- .sum() : 合計
- .max() : 最大値
- .min() : 最小値
- .mean() : 平均値
- .var() : 分散
- .std() : 標準偏差
- .abs() : 絶対値
- .floor() : 四捨五入
axisで行<0>と列<1>を指定可能
- .min(axis=0) 最小の行を表示
- .min(axis=1) 最小の列を表示
6.その他機能
- 内積の計算 np.dot()
vector_a = np.array([1, 2, 3]) vector_b = np.array([4, 5, 6]) np.dot(vector_a, vector_b) >>> 32
- 配列に対して自作の関数を適用したい場合 np.vectorize()
np.vectorizeは、関数を配列に適用できるように変換する関数
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # ラムダ式で1000を足す関数を作成 add_1000 = lambda x: x + 1000 # np.vectorize()に関数を読み込む vectorized_add_1000 = np.vectorize(add_1000) # 配列aに適用 vectorized_add_1000(a) >>> array([[1001, 1002, 1003], [1004, 1005, 1006], [1007, 1008, 1009]])
- 投稿日:2019-01-26T21:47:51+09:00
BigQueryとPython(pandas)を連携させてみた
概要
- PythonからBigQueryのテーブルを読み込みます。
- Pythonで作成したdataframeをBigQueryに書き込みます。
- これにより、GCSにエクスポートしてからダウンロードみたいなことをしなくてすむようになります。
環境
- Mac OS High Sierra
- Google Cloud Platform
- BigQuery
- Python 3.6.2
- Jupyter Notebook
- pandas 0.22.0
- pandas-gbq 0.9.0
- 今回の肝です。後ほどインストールします
準備①:BigQueryにテーブルを作成する
- BigQueryの公式ドキュメントで配布されているデータをロードしてみます。
# データセット作成(bq ロケーション mk データセット名) $ bq --location=asia-northeast1 mk test # ローカル上のデータをロードして、テーブルを作成(bq load データセット名.テーブル名 パス オプション) $ bq load test.yob2017 ロードしたいデータのパス name:string,gender:string,count:integer # テーブルが作成されているか確認 $ bq ls test
- テーブルが作成されました!

準備②:pandas-gbqをインストールする
# インストール $ pip install pandas-gbq -U # 確認 $ pip list | grep pandas
- インストールできました。

- これで準備が整ったので、Jupyterを起動して、pandasでBigQueryのテーブルを読み込んでみます。
テーブルの読み込み
# pandasをインポートします import pandas as pd # GCPのプロジェクトIDとテーブルを読み込む際のクエリを変数に入れておきます projectid = 'プロジェクト名' query = 'SELECT * FROM test.yob2017' # pandasのread_gqbにて読み込みます。 # クエリとプロジェクトidを引数に設定する。 # dialect='standard'とすることで標準SQLを使用(default='legacy') df = pd.read_gbq(query, projectid, dialect='standard')
- ここまで実行すると、「Please visit this URL~」のような文章がリンクとなって表示されるので、それを押してください。
- ※pandas-gbqをインストールしていないとここでエラーが出ます。
- リンクをそのまま進んでいくと、認証コードが表示されるのでコピーし、Jupyterに戻り、下記のボックスに貼り付けし、Enterを押します。

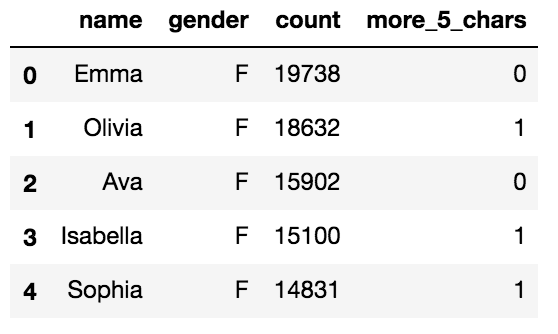
- データフレームを確認してみます。
df.head()
- これでBigQueryのテーブルをデータフレームに読み込むことができました。
- 次は読み込んだデータフレームを少し加工して、BigQueryのテーブルとしてアップロードしてみましょう。
データフレームの書き込み
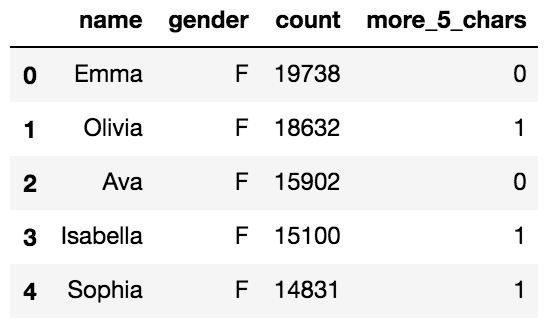
- まず「name」の列が5文字以上かどうかのフラグを新たな列に追加します。
# データフレームのコピー df1 = df.copy() # フラグ付与 df1['more_5_chars'] = (df1['name'].apply( lambda x: len(x)) >= 5).astype(int)
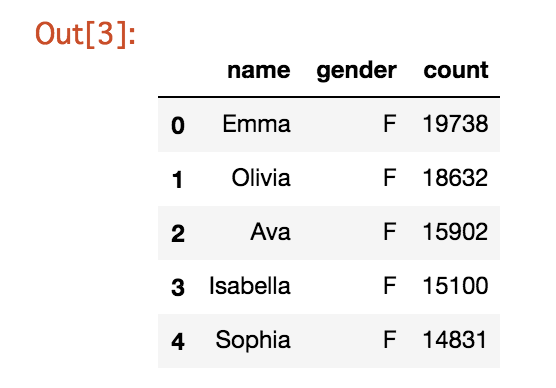
- このデータフレームをアップしてみます。
 # to_gbqを利用します。 # 引数には'データセット名.データセット名'とプロジェクトIDを指定します。 # if_existsという引数があり、ここを'append'にするとデータがinsertされ、'replace'にするとテーブルが置き換えられる。(default='fail') df1.to_gbq('test.new_yob2017', projectid)# テーブルが作成されているか確認してみます。 $ bq ls test
# to_gbqを利用します。 # 引数には'データセット名.データセット名'とプロジェクトIDを指定します。 # if_existsという引数があり、ここを'append'にするとデータがinsertされ、'replace'にするとテーブルが置き換えられる。(default='fail') df1.to_gbq('test.new_yob2017', projectid)# テーブルが作成されているか確認してみます。 $ bq ls test
新しいテーブル(new_yob2017)が作成されていますね。
このようにpandas-gbqをインストールしJupyter上で認証するだけで、簡単にBigQueryとPythonでデータのやり取りが可能となります。是非参考にしてみてください。
参考




- 投稿日:2019-01-26T19:32:00+09:00
Azure VMでOpen3Dやーる(Data Science Virtual Machine - Windows Server 2016、NV6)
AzureのWindowsマシンでOpen3Dを実行するまでのメモです。
NVシリーズ以外はOpenGLのバージョンが1.1と古いため、表示ができません。NVシリーズのVMを作成
Azure Portalを開きます。
リソースの作成から、Data Science Virtual Machine - Windows Server 2016を検索し、新規作成します。
インスタンスの詳細の地域を
米国中南部、サイズをNV6とします。
作成できたら、RDPで接続します。NVIDIA GPU ドライバーの設定
「Windows を実行している N シリーズ VM に NVIDIA GPU ドライバーをインストールする」を参考に、下記ドライバーをインストールします。
インストールしたら、再起動します。
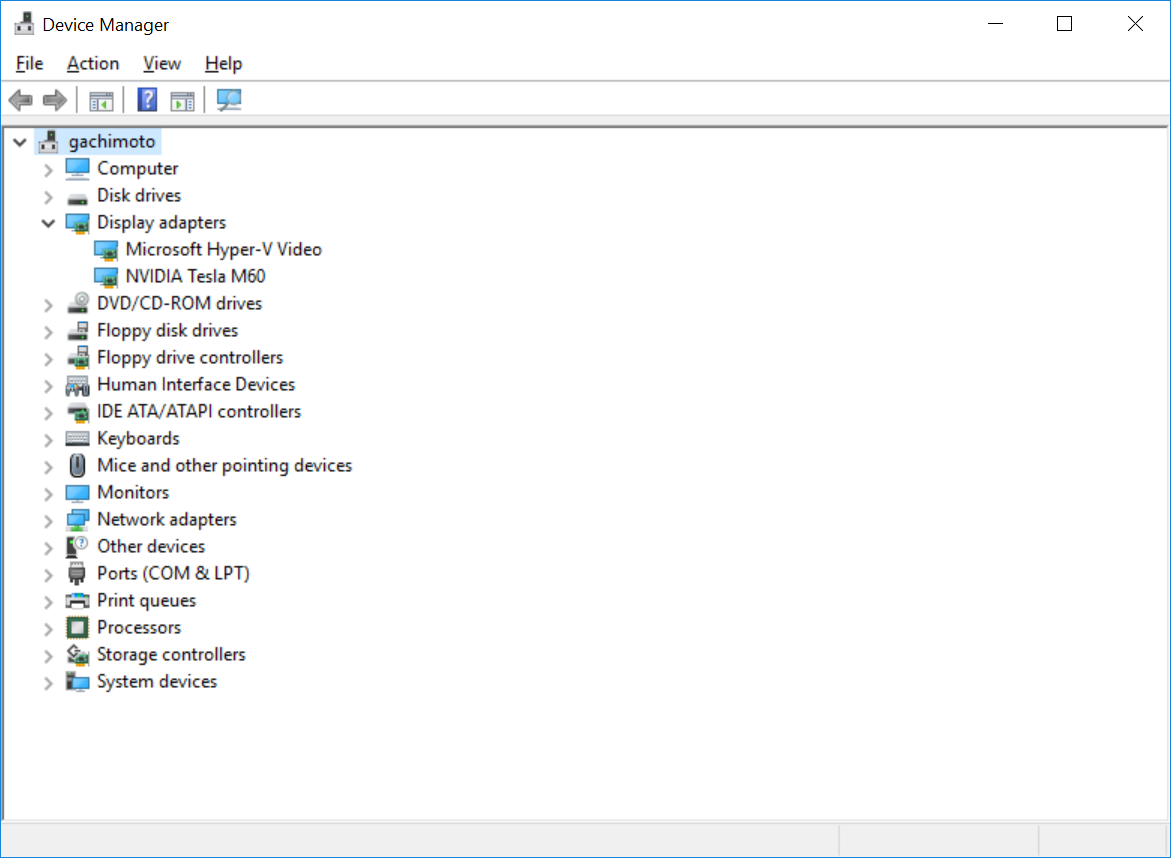
デバイスマネージャーからDisplay adaptersに
NVIDIA Tesla M60があることを確認します。
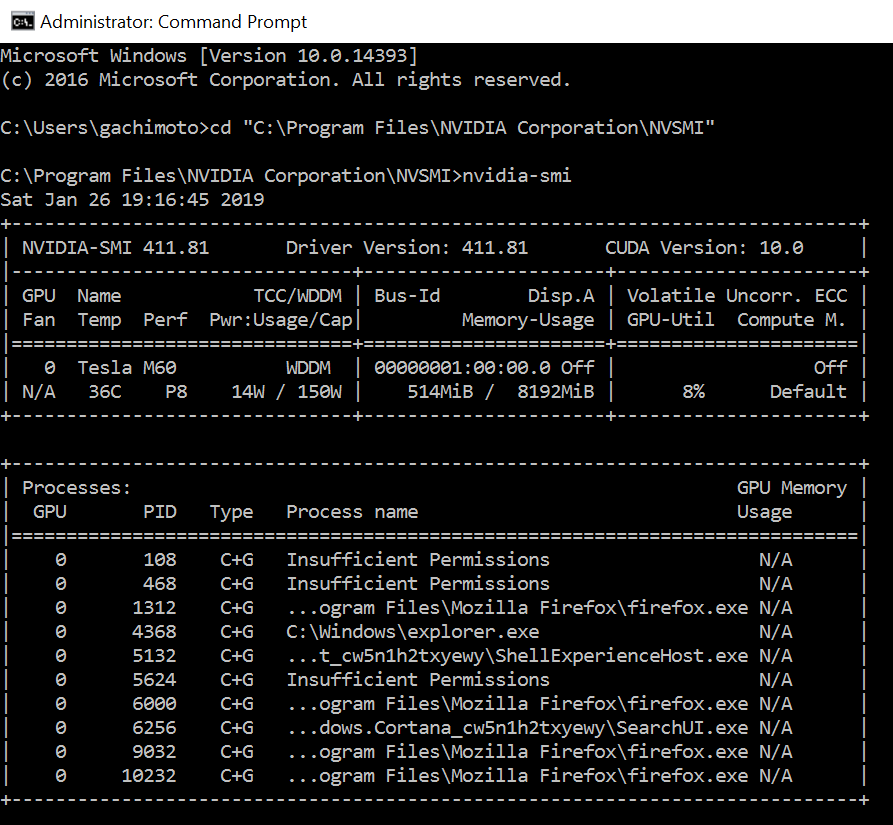
nvidia-smiを実行し、GPUが動作していることを確認します。
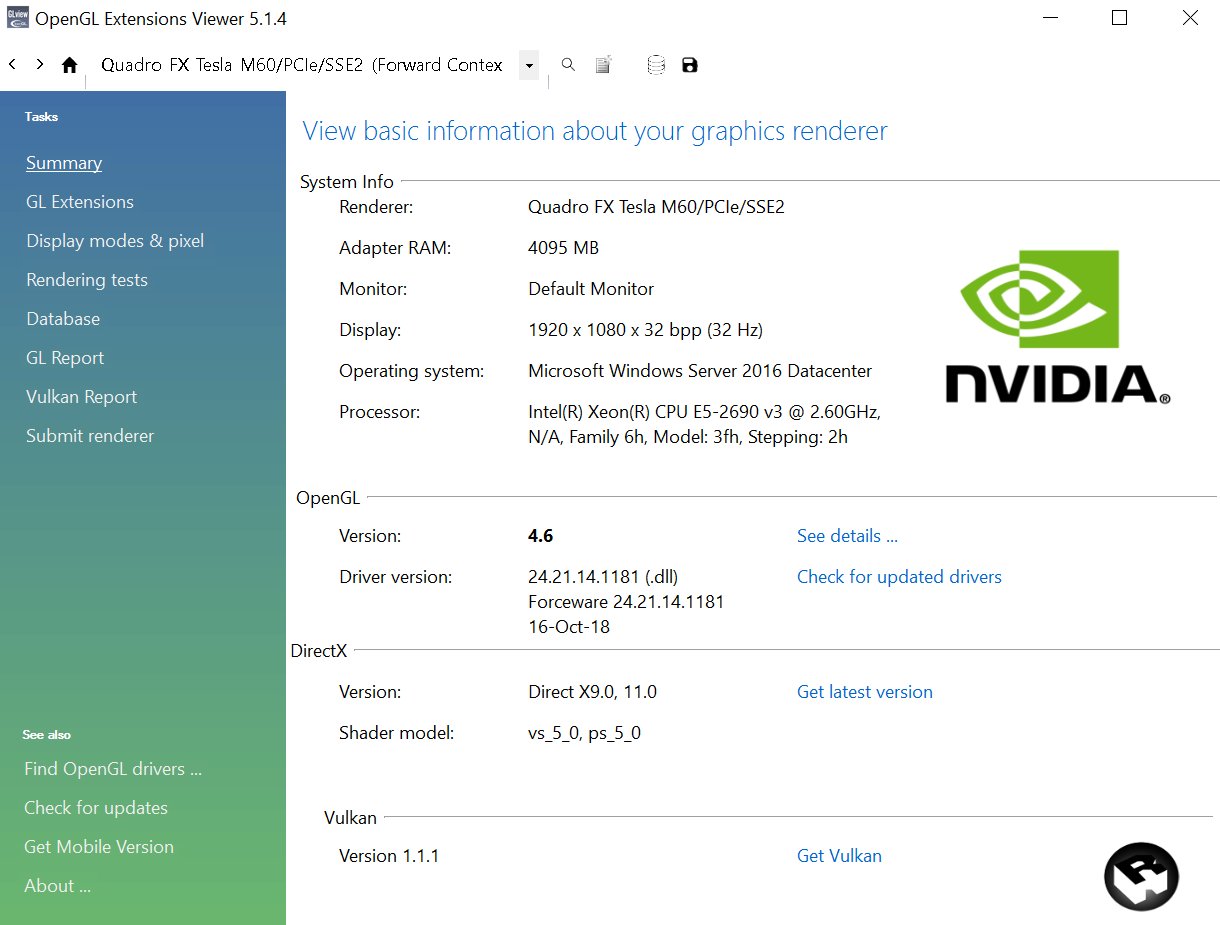
OpenGL Extensions Viewerをここからインストールします。
OpenGL Extensions Viewerを起動しOpenGLのバージョンが
4.6になっていればOKです。
Open3Dやーる
Anaconda Promptを開き、Python3.6環境を作成します。
conda create -n py36 python=3.6py36環境に入ります。
activate py36必要なライブラリをインストールします。
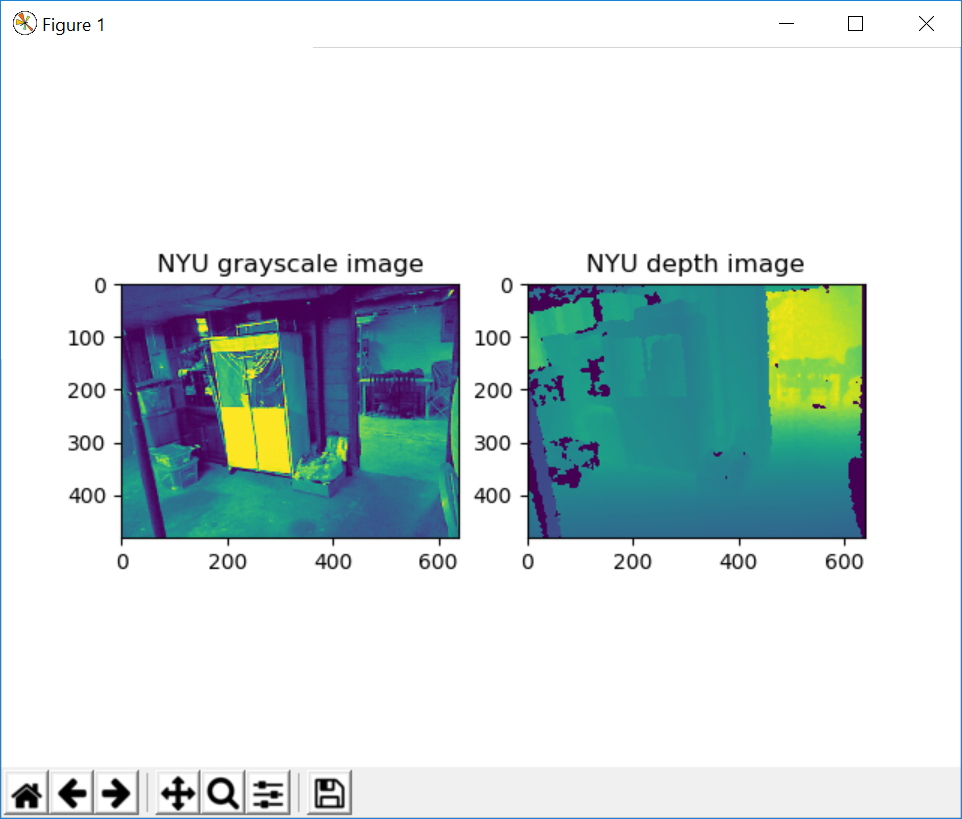
pip install opencv-python pip install opencv-contrib-python pip install open3d-python pip install matplotlib pip install pillowOpen3D v0.5.0をダウンロードします。rgbd_nyu.pyを実行してみましょう。
cd Downloads\Open3D-0.5.0\examples\Python\Basic python rgbd_nyu.py
このように表示されればOKです。OpenGLのバージョンが1.1だと失敗します。

- 投稿日:2019-01-26T17:28:30+09:00
pirkaというAIを公開した感想
はじめに
「pirka」というAIを1月26日正午に公開したのでまとめてみた。どういうものかも含めてうだうだ書いていく。うだうだ。
僕は誰?
いとっぴー
・13歳。
・Pythonとモッツァレラチーズのピザが好き。
・デバッグの進み具合で一喜一憂する単細胞生物。
・ECoder'sや学生LTに参加している。pirkaとは?
僕がいつからか[いつ?]開発している、「人と楽しく会話することを目的とした」AI。ニューラルネットワークやらディープラーニングやらもやってみたいけど、メインPCがラズパイなので現時点では簡単な機械学習でガマン。だから知性は低い。MacBook Proほしいな。
機能
・今の感情を4つの数値で表し、ユーザの発言によって変化させる。
・「こんにちは」「かわいいね」などの幾つかの決まった発言に対しては、今の感情に応じてそれぞれ決まった応答を返す。
・それ以外の発言は、テンプレートを使って返す。
・テンプレートはユーザの発言から学習する。
・「猫は可愛いね」「虹は七色」などの発言を「常識」と判定し、{ "猫" : ["可愛い"], "虹" : ["七色"] }というように学習する。
・学習した常識から三段論法を使って新たな常識を導き出す。名前の由来
「pirka」というアイヌ語の言葉が可愛いなと思ったのでつけた。「美しい」という意味。
大変だったこと
いろいろある。
MeCabがWindowsで使うのがクソめんどい
コンピュータに辞書を引かせてる処理「形態素解析」を行うmecab-pythonの、Windowsでのインストールが面倒らしい。ということで、セットアップ用のコマンドをOSごとに用意することにした。1月中にやりたい。公開直後、ダウンロードしてくださった方が教えてくださった。
PyQt5の日本語資料が少ない
GUIモジュールPyQt5の日本語資料が少なすぎたので、自分で英語の資料を和訳する羽目になった。
開発スピードにムラがある
バグ発生
↓
取り敢えずデバッグしてみる
↓
解決しない
↓
脳がフランス革命起こして開発意欲をギロチンに処すこんなことを2、3日に一度繰り返してました。モチベの維持は難しい…。
補足
(1月27日記)
この記事が10評価、GitHubのレポジトリが7評価いきました。ありがとうございます。まとめ
こちらからダウンロードしてみてください。
- 投稿日:2019-01-26T16:16:37+09:00
Pythonで自然指数関数を自作してみる
数学ライブラリのあの関数,どんな計算してるの?
現代の大抵のプロセッサというのは四則演算を行う命令しか用意されていない.あってもそれらを組み合わせた積和演算ぐらい.下手すると乗算命令と除算命令が省かれていたりもする.だけど,$\sin$ とか $\log$ とか $\exp$ とか計算できてしまう.なぜか?
四則演算だけで計算する
とりあえず今は自然指数関数を作りたい.指数は実数としよう.
値を求めるための手法はいくつかあると思うが,ここではマクローリン展開を使うこととしよう.大体,こういうのはWikipediaを見れば分かるようになってる.e^x = \sum_{n=0}^{\infty} \frac{x^n}{n!} \qquad \text{for all } x無限級数の形になってはいるが,$n$ を大きくしていけば, $\frac{x^n}{n!}$ は多分 $0$ に近づいていくので,適当なところで計算をやめて大丈夫そう.$n$は自然数なので,$x^n$も$n!$も普通に乗算だけで計算できる.あとは除算して,加算するだけなので,四則演算だけで計算できている.これで完璧だね!
・・・・・・
・・・・
嘘つけ.これ,$x=0$ だと $n=0$ で $0^0$ が出てきて計算できないじゃん.そこだけ場合分けが必要.
e^x = \begin{cases} 1 & (x = 0)\\ \sum_{n=0}^{\infty} \frac{x^n}{n!} & (\text{otherwise}) \end{cases}四則演算だけで自然指数関数の計算ができそうなことが分かった.しかも,意外と簡単そうな計算だ.これならすぐ作れそう!
昔見た何かのライブラリも,アセンブリを追っていくと,やはりマクローリン展開を使って計算しているような雰囲気だった.
Wikipediaを見れば分かるように,$\sin$ も $\ln$ も,マクローリン展開が既に知られているので,同様に実装することができそうだ(今回はやらないけど).
pythonで実装
今回はpythonで自作の自然指数関数
my_expを実装してみる.もちろん,ライブラリは使わない.ついでなので,最近覚えたunittestも使ってみる.まずは作ってみる
とりあえず作ってみた.
dがMY_PREC以下になったら,計算結果が十分収束したと判断して,ループを終了する.importは省略してるわけではなく,importする必要が無かったので本当に何も書いていない.mymath.pyMY_PREC = 0.00000000000001 def my_exp(x): if x == 0: return 1.0 sum = 1.0 d = 1.0 n = 1 while d > MY_PREC: d = d * x / n sum += d n += 1 return sumね,簡単でしょ?
ユニットテストで
my_expの出来具合を確認する.比較する値は,mathライブラリを使って求める.求まった2つの値の差の絶対値が十分小さければ,同じ値とみなして,my_expは正しく計算できているものとする.さすがに,まったく同じ計算精度で計算ができるとは期待していないため,このようにした.x=0の場合は厳密に1であるべきなので,差の絶対値ではなく,assertEqualを使って,1.0と比較した.test_mymath.pyimport unittest from mymath import my_exp import math TEST_PREC = .0000000000001 class TestMyExp(unittest.TestCase): def test_my_exp(self): self.assertEqual(1.0, my_exp(0)) self.assertLess(self.__cmp(1/2), TEST_PREC) self.assertLess(self.__cmp(1), TEST_PREC) self.assertLess(self.__cmp(-1), TEST_PREC) def __cmp(self, x): t = math.exp(x) myexp = my_exp(x) d = t - myexp return d if d > 0 else -d if __name__ == "__main__": unittest.main()このユニットテストを走らせると,次のような結果を得る.
> python .\test_mymath.py F ====================================================================== FAIL: test_my_exp (__main__.TestMyExp) ---------------------------------------------------------------------- Traceback (most recent call last): File ".\test_mymath.py", line 11, in test_my_exp self.assertLess(self.__cmp(-1), TEST_PREC) AssertionError: 0.36787944117144233 not less than 1e-13 ---------------------------------------------------------------------- Ran 1 test in 0.001s FAILED (failures=1)
x=0のときに問題ないのはソースを見れば明らかなので,わざわざテストしなくて良いような気がしてしまうが,そうではない.バグというのはテストしなかった部分に存在するということを忘れてはならない.全ての値でテストするのは現実的でない以上,何をテストデータとして選択するかは,よく考えて選ばなければならない.1
x=1はネイピア数そのものが求まるわけだが,ちゃんと計算できているようだ.しかし,
x=-1で値が大きくずれているようだ.xが負の場合
よく考えると,
xが負の場合,dも負の値を取り得る.しかしながら,whileの条件はdが負の場合を想定していない.n=1でいきなりdは負の値になるので,ループがすぐに終了してしまうことが分かる.$e^x=\frac{1}{e^{-x}}$だから,$x$が負の場合は$e^{-x}$を計算して,後で逆数にしてやることにする.
xが負の場合に対応したmy_expは次のようになる.mymath.pydef my_exp(x): if x == 0: return 1.0 sig = 0 if x < 0: sig = 1 x = -x d = 1.0 sum = d n = 1 while d > MY_PREC: d = d * x / n sum += d n += 1 return sum if sig == 0 else 1 / sumついでなので,ユニットテストのデータも少し追加してみる.
test_mymath.pyself.assertLess(self.__cmp(2), TEST_PREC) self.assertLess(self.__cmp(-2), TEST_PREC) self.assertLess(self.__cmp(100), TEST_PREC)実行結果は次のとおり.
F ====================================================================== FAIL: test_my_exp (__main__.TestMyExp) ---------------------------------------------------------------------- Traceback (most recent call last): File ".\test_mymath.py", line 14, in test_my_exp self.assertLess(self.__cmp(100), TEST_PREC) AssertionError: 1.9807040628566084e+28 not less than 1e-13 ---------------------------------------------------------------------- Ran 1 test in 0.003s FAILED (failures=1)
x=100で非常に大きく値が違っていることが分かる.指数関数の計算を間違えたのだろうか?ユニットテストの改良
計算結果を見てみると,次のようになっていた.
>>> mymath.my_exp(100) 2.6881171418161336e+43 >>> math.exp(100) 2.6881171418161356e+43似たような結果が得られている.しかし,指数部が43なので,単純に差の絶対値を計算すれば,それはもう非常に大きな値になってしまう.
ここではユニットテストの比較のやり方を改良する.mathライブラリで得られた結果に対して,差がどれくらいの比になるかを計算する.この比が十分小さければ,
my_exp関数は正しく実装できているものとする.これであれば,計算結果の大小にかかわらず,定量的な評価ができそうだ.test_mymath.pydef __cmp(self, x): t = math.exp(x) myexp = my_exp(x) d = t - myexp d = d if d > 0 else -d res = d / t return res実行してみる.
. ---------------------------------------------------------------------- Ran 1 test in 0.000s OKこれで完成だ!
・・・・・・本当に?
もっとユニットテスト
ユニットテストに
x=708の場合を追加してみる.test_mymath.pyself.assertLess(self.__cmp(708), TEST_PREC)実行すると,次の通り・・・
やばい,結果が返ってこないだと!?pythonの対話モードで確認してみる.
>>> math.exp(708) 3.023383144276055e+307 >>> mymath.my_exp(708)mathライブラリはちゃんと計算できているが,
my_expは結果が返ってこない.これの原因は,dの値が大きくなりすぎるから.$n$が小さい間は$n!$に比べて,$x^n$の増加が非常に大きく,dが収束する前に無限大になってしまう.そうなると,dは収束しなくなるのでループを抜けられなくなってしまう.実際に確認すると,n=681でdは無限大になっていた.ここでは改良のために,$e^{a+b}={e^a}{e^b}$という性質を使う.指数を整数+小数に分けて,整数部は普通に乗算のループで,小数部をマクローリン級数で求めて,最後にこの2つの値を乗算する.あと,ネイピア数は数値計算だけで求められるといっても,さすがにこれは定数として定義しておくことにする.
mymath.pyMY_PREC = 0.00000000000001 my_e = 2.718281828459045 def my_exp(x): if x == 0: return 1.0 sig = 0 if x < 0: sig = 1 x = -x x1 = int(x) x2 = x - x1 res = 1.0 for i in range(x1): res *= my_e if x2 > 0: d = 1.0 sum = d n = 1 while d > MY_PREC: d = d * x2 / n sum += d n += 1 res *= sum return res if sig == 0 else 1 / resこの場合,
xを整数にすると,マクローリン級数の計算が全くなされないことになるので,ユニットテストでは必ず小数点以下が0でない値で確認しなければならない.テストをさらに追加する.test_mymath.pyself.assertLess(self.__cmp(708.1), TEST_PREC) self.assertLess(self.__cmp(708.5), TEST_PREC) self.assertLess(self.__cmp(708.7), TEST_PREC)このユニットテストは成功した.
今度こそ完成だね!さらにユニットテスト
次のテストを追加してみる.
test_mymath.pyself.assertLess(self.__cmp(710), TEST_PREC)実行結果は次の通り.
E ====================================================================== ERROR: test_my_exp (__main__.TestMyExp) ---------------------------------------------------------------------- Traceback (most recent call last): File ".\test_mymath.py", line 19, in test_my_exp self.assertLess(self.__cmp(710), TEST_PREC) File ".\test_mymath.py", line 22, in __cmp t = math.exp(x) OverflowError: math range error ---------------------------------------------------------------------- Ran 1 test in 0.001s FAILED (errors=1)今度はmathライブラリの方でオーバフロー例外が発生している.ということは,おそらく,
my_expの方もオーバフローが発生する.my_expにも例外出力が必要だし,ユニットテストもオーバフローの例外処理が必要そうだ.
my_exp関数は,整数部の計算の後と,最終的な結果を求めた後の2カ所で,無限大の判定をし,そうであるなら例外が発生するようにした.まあ,最後の1カ所だけでも良いのだが,ムダにループ回す必要も無いかと思って2カ所にした.mymath.pydef my_exp(x): if x == 0: return 1.0 sig = 0 if x < 0: sig = 1 x = -x x1 = int(x) x2 = x - x1 res = 1.0 for i in range(x1): res *= my_e if res == float('inf'): raise OverflowError if x2 > 0: d = 1.0 sum = d n = 1 while d > MY_PREC: d = d * x2 / n sum += d n += 1 res *= sum if res == float('inf'): raise OverflowError return res if sig == 0 else 1 / resユニットテストは例外処理を追加した.mathライブラリも
my_expもオーバフローが発生したなら,値は一致したものとする.どちらか一方がオーバフローならば,一応,不一致としておく.両方ともオーバフローが発生しなければ,今まで通り.$e^x$は全域で正の値を取ることが分かっているので,オーバフロー時は結果を-1とすることで,容易に判別できる.test_mymath.pydef __cmp(self, x): try: t = math.exp(x) except OverflowError: t = -1 try: myexp = my_exp(x) except OverflowError: myexp = -1 if t < 0: if myexp < 0: res = 0 print('inf x={0}:math.exp my_exp'.format(x)) else: res = 1 print('inf x={0}:math.exp'.format(x)) else: if myexp < 0: res = 1 print('inf x={0}:my_exp'.format(x)) else: d = t - myexp d = d if d > 0 else -d res = d / t return res最終的に,次のようなテストを行った.
test_mymath.pydef test_my_exp(self): self.assertEqual(1.0, my_exp(0)) self.assertLess(self.__cmp(1/16), TEST_PREC) self.assertLess(self.__cmp(1/8), TEST_PREC) self.assertLess(self.__cmp(1/4), TEST_PREC) self.assertLess(self.__cmp(1/2), TEST_PREC) self.assertLess(self.__cmp(1), TEST_PREC) self.assertLess(self.__cmp(-1), TEST_PREC) self.assertLess(self.__cmp(2), TEST_PREC) self.assertLess(self.__cmp(-2), TEST_PREC) self.assertLess(self.__cmp(3.1415), TEST_PREC) self.assertLess(self.__cmp(10), TEST_PREC) self.assertLess(self.__cmp(100), TEST_PREC) self.assertLess(self.__cmp(707), TEST_PREC) self.assertLess(self.__cmp(708), TEST_PREC) self.assertLess(self.__cmp(709), TEST_PREC) self.assertLess(self.__cmp(-709), TEST_PREC) self.assertLess(self.__cmp(709.5), TEST_PREC) self.assertLess(self.__cmp(709.8), TEST_PREC) self.assertLess(self.__cmp(709.9), TEST_PREC) self.assertLess(self.__cmp(710), TEST_PREC)結果は次の通り.
inf x=709.8:math.exp my_exp inf x=709.9:math.exp my_exp inf x=710:math.exp my_exp . ---------------------------------------------------------------------- Ran 1 test in 0.001s OK
x=709.8, 709.9, 710で両方ともオーバフローが発生していることが分かる.片方だけオーバフローというのは,少なくともこのテストデータの中には無かったようだ.本当にそういう場合があるのかどうかまでは検証しない.単にめんどすぎるので.まとめ
Pythonを使って,mathライブラリを使わず,四則演算だけで自然指数関数
my_expを実装した.計算結果はmathライブラリのexpと比較して,計算精度の細かな違いはあるものの,ほぼ同じものができたと考えられる.ついでなので,最近覚えた,unittestを使って検証を行った.ユニットテストのおかげで,かなり楽に検証が行えるようになったし,デバッグにも十分役に立ってくれた.元の数式は単純に見えても,それを実際にプログラムを組んでテストを重ねていくと,元の数式だけでは見えてこなかった問題点をいくつも発見することができた.
my_exp関数の完成し具合としてはまあこんなもんだろう.細かい改良点はあるだろうが,別にこれで何をするってわけでもなし,これで実装完了としたい.
このプログラムの場合,最初のif文を削除するとバグに・・・と思ったが,実は正しい結果が得られる.$x\ne0$ なら,$n=0$ のとき,必ず $\frac{x^n}{n!}=1$ になるため,最初から
sum=1.0(=d)となるようにハードコーディングしてある.したがって,この後のループでは $n\geq1$ のときのみを計算していることになる.ところが,$x=0$ の場合,ハードコーティング部は特に条件が無いので $x\ne0$ のときとまったく同じ処理が進み,ループへ到達する.このループでdはすぐに0となり,sum(=1.0)に加算しても結果は変わらず,明らかにd < MY_PRECなので,すぐにループを抜けてしまう.当然,$n\geq2$ で $\frac{x^n}{n!}=0$ なのは明らかなので,計算しなくても特に支障は無い.したがって,sum=1.0のまま結果を返すことになるが,これはx=0のときに欲しい値と厳密に一致することになる. ↩
- 投稿日:2019-01-26T15:04:40+09:00
【Python】mac で matplotlib 使用時に ImportError: Python is not installed as a framework. が出る場合の対処法
事象
macOS で
matplotlibを使用したプログラムを実行したところ次のようなエラーが発生しました。$ python main.py Traceback (most recent call last): File "main.py", line 3, in <module> import matplotlib.pyplot as plt File "/Users/RM/Documents/deep-learning-practice/.venv/lib/python3.7/site-packages/matplotlib/pyplot.py", line 2374, in <module> switch_backend(rcParams["backend"]) File "/Users/RM/Documents/deep-learning-practice/.venv/lib/python3.7/site-packages/matplotlib/pyplot.py", line 207, in switch_backend backend_mod = importlib.import_module(backend_name) File "/Users/RM/Documents/deep-learning-practice/.venv/lib/python3.7/importlib/__init__.py", line 127, in import_module return _bootstrap._gcd_import(name[level:], package, level) File "/Users/RM/Documents/deep-learning-practice/.venv/lib/python3.7/site-packages/matplotlib/backends/backend_macosx.py", line 14, in <module> from matplotlib.backends import _macosx ImportError: Python is not installed as a framework. The Mac OS X backend will not be able to function correctly if Python is not installed as a framework. See the Python documentation for more information on installing Python as a framework on Mac OS X. Please either reinstall Python as a framework, or try one of the other backends. If you are using (Ana)Conda please install python.app and replace the use of 'python' with 'pythonw'. See 'Working with Matplotlib on OSX' in the Matplotlib FAQ for more information.対処法
ターミナルで次のコマンドを実行します。
sed -i -e 's/backend: TkAgg/backend: Agg/' $(python -c "import matplotlib;print(matplotlib.matplotlib_fname())")参照
こちらの記事で解決しました。
Pythonでmatplotlibをimportするとエラーが出る場合の対処策(Mac)補足
python -c <<コマンド>>はコマンドラインで Python を実行します。
$()はコマンド内でコマンドを実行します。
sed -e "s/置換前/置換後/" 対象ファイルは対象ファイルの対象文字列を置換して文字列を返却します。
sed -iで破壊的にコマンドを実行します。要するに対象を直接編集します。
- 投稿日:2019-01-26T14:04:29+09:00
Annictから今期アニメ情報を取得し、視聴者数上位10のアニメ情報のみをSlackに通知する
TL;DR
- 以下の二つを組み合わせ、Annictで視聴者上位10までのアニメの一覧をSlackに通知するスクリプトを作成しました。
- Annict GraphQL API
- Slack incomming hook
はじめに
社会人1年目、エンジニア見習いのtsunekohです。
社会人になってからアニメを見る本数が圧倒的に減少したことを実感しています。ただ、仕事で忙しいとはいえ、話題になっているアニメについては確認しておきたいものです。
その悩みを解消すべく、Annictというサービスで今期比較的視聴されているアニメの一覧を列挙してSlackに通知するスクリプトを作成しました。
Annictについて
Annictとは視聴したアニメを記録するためのサービスです。SNS的要素も持ち合わせていて、同じサービスを利用している人がどういったアニメを過去に視聴したのか、現在放映中のアニメのうち何を見ているのかを閲覧することも可能となっています。また、APIを用いることにより、これらの情報を取得することも可能となっています。
APIとしてはREST APIとGraphQL APIの二つが用意されています。取得できる情報として何があるのかは、Annict Developers を、使い方については、Annict開発者によるQiitaの記事を参照ください。
今回はGraphQL APIを使って、Annictに登録されているアニメのデータを取得しました。
メイキング
Gistに挙げています。(雑なつくりなのはご容赦ください。)
https://gist.github.com/kohnakagawa/463e0336c5bdf2941a37232ba394dea0まず、現在時刻から年とシーズン名を取得します。
# 月からシーズン名へ変換する関数 def month_to_season(month): if 1 <= month < 4: return "winter" elif 4 <= month < 7: return "spring" elif 7 <= month < 10: return "summer" else: return "autumn" def get_current_qr(): current_time = datetime.datetime.now() year = str(current_time.year) month = current_time.month return "-".join([year, month_to_season(month)])この情報を基にして、GraphQLのクエリを作成します。
Annict GraphQL APIではWATCHERS_COUNTという変数に各作品の視聴数が保存されています。今回は視聴者数が多い順に上位10のアニメを取り出したいので、GraphQL のクエリにorderBy: { field: WATCHERS_COUNT, direction: DESC}, first: 10を入れておきます。クエリの全体は以下のようになります。
GRAPH_QL_QUERY = """ query { searchWorks( seasons: ["%s"], orderBy: { field: WATCHERS_COUNT, direction: DESC}, first: 10 ) { edges { node { title officialSiteUrl watchersCount reviewsCount image { recommendedImageUrl } reviews( first: 2 orderBy: {field: LIKES_COUNT, direction: DESC}, ) { edges { node { body impressionsCount } } } } } } } """ % get_current_qr()作成したクエリをrequestsライブラリを使ってPOSTします。 (
params["annict_url"]にはhttps://api.annict.com/graphqlが入ります。)qb_req = requests.post( params["annict_url"], headers={ "Accept": "application/json", "Authorization": "Bearer {}".format(params["annict_key"]) }, data=QUERY )レスポンスからJSONを取り出した後、Slack投稿用メッセージを作成します。この際、投稿されたメッセージが見やすくなるようにattachmentsをつけます。
def make_attachments(json_data_raw): return [ { "color": "#36a64f", "pretext": "視聴者数 第{}位".format(idx + 1), "title": item["node"]["title"], "title_link": item["node"]["officialSiteUrl"], "image_url": item["node"]["image"]["recommendedImageUrl"], "thumb_url": item["node"]["image"]["recommendedImageUrl"], "text": "Annict 視聴者数: {}, レビュワー数: {}".format(item["node"]["watchersCount"], item["node"]["reviewsCount"]), "fields": [ { "title": "コメント (影響度: {})".format(comment["node"]["impressionsCount"]), "value": comment["node"]["body"], "short": "true" } for comment in item["node"]["reviews"]["edges"] ] } for idx, item in enumerate(json_data_raw["searchWorks"]["edges"]) ]attachmentsを作成した後は、incomming webhooksを使って、チャンネルへ投稿を行います。incomming webhooksの使い方についてはこのページを参考にしました。
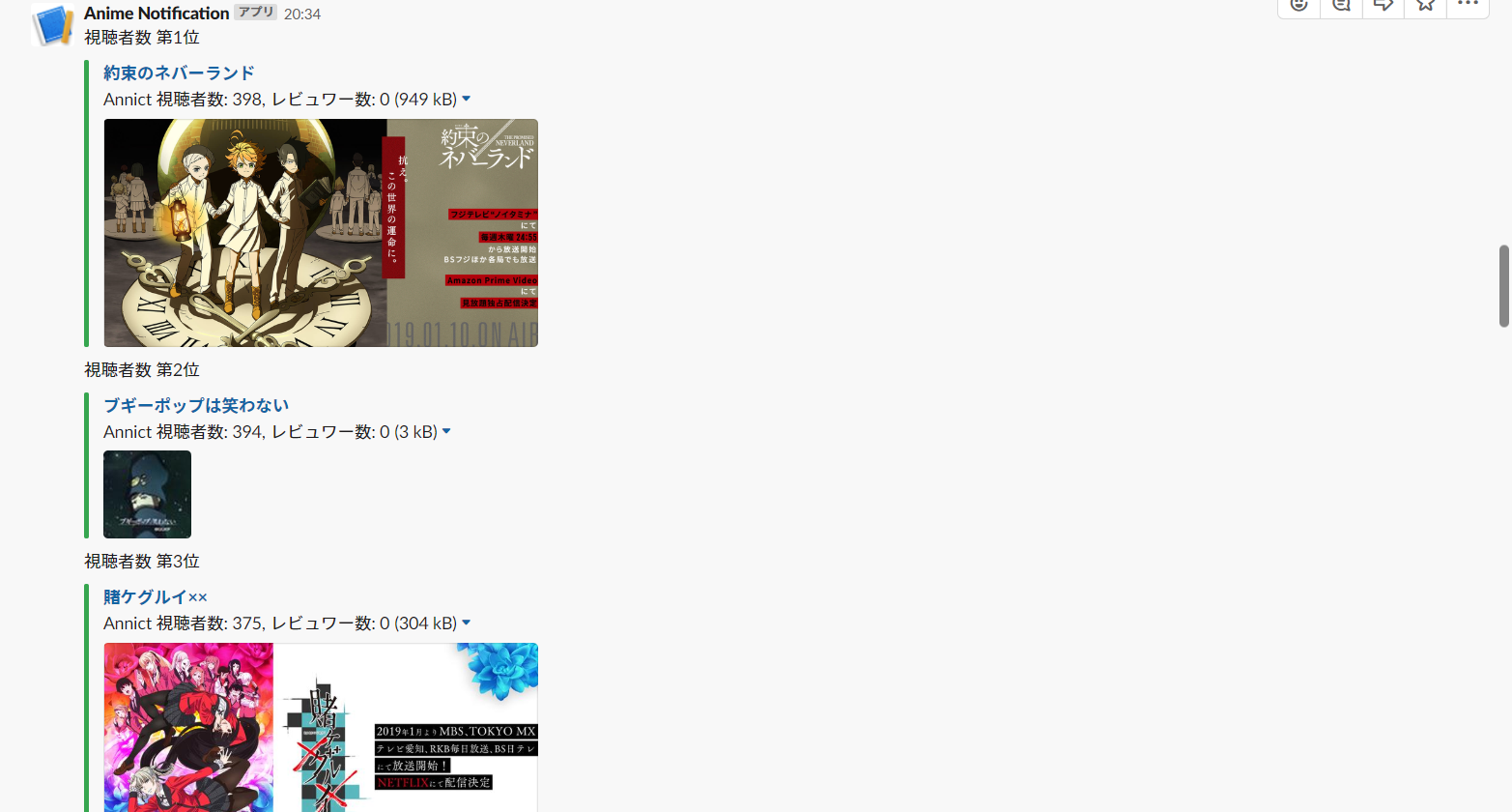
attachments = make_attachments(json_raw) slack.notify(attachments=attachments)スクリプトを実行すると、チャンネルに下記画像に示したようなアニメの情報がチャンネルに通知されます。
「約束のネバーランド」と「賭ケグルイ」は見ていいるけども、「ブギーポップは笑わない」は見ていない。これは見ないといけないな。。
おわりに
視聴したアニメの記録だけでなく、視聴するアニメの選定にもAnnictは使えるなと感じました。素晴らしいサービスAnnictを運営されているshimbaco様に感謝です。
- 投稿日:2019-01-26T12:24:59+09:00
Pythonで何ができる?
- 前回:
- 次回:https://qiita.com/New_enpitsu_15/items/ee95bde0858e9f77acf0
- 目次:https://qiita.com/New_enpitsu_15/private/479c69897780cabd01f4
Python?
Pythonとはインプリンタ型のプログラム言語…
すなわち、さっと書いてさっと動かせる初心者には持って来いの言語です。
言語使用も綺麗で、
プログラムなんてしたことない!って人から
本職プログラマまで。万人にお勧めできる素敵な言語です。Pythonに向いていること
Pythonはよく"機械学習"の分野での活躍が取り上げられます。
が、Pythonで出来ることは機械学習だけではありません。
かの有名な"Minecraft"のModだって作ろうと思えば作れますし、
まさかの展開で有名になった"ドキドキ文芸部"だってPythonで書かれています。
DropboxなんかもPythonなんですって!Pythonは"C"などと比べると実行速度は遅い(速くする方法もなくはない)
のですが、その分文法がシンプルで簡単な処理をさっと書くこともできます。なによりわかりやすい!拡張機能も豊富にあるので、できないことはほぼないでしょうが、向いていることといえば
- 機械学習
- Webアプリケーション
- 中小規模の開発
だと思っています。
私的に初心者にはPythonがおすすめですが、ほかにも素敵な言語がたくさんあるので
「プログラム言語」とでも調べてみてください。
どの言語を学ぶべきかなど、いろいろ参考になると思いますよ。参考
https://www.sejuku.net/blog/9017
https://dividable.net/python/how-python-is-useful/
- 投稿日:2019-01-26T11:55:31+09:00
data2textで特徴量から言語生成しよう
data2text1とは、あるデータを説明するためのテキスト等を生成するタスクです。今回は、「感情」「行動」を入力すると、それに対する反応を生成する、というモデルを考えます。
簡単な仕組み
入力する特徴量に対して出力したいテンプレートをラベル付します。あとは、ニューラルネットを使うにしろ使わないにしろ、通常の機械学習のプロセスとして学習させるだけです。
入力と出力の説明
単純化のために、入力する感情は1つ、行動は1つと考え、さらに行動は「スポーツ」「勉強」「その他のイベント」のいずれかであるとします。
出力は、その入力に対しての反応です。以下は出力のテンプレートを定義したファイルです:
0 n,sports お疲れ様です。{}これからも頑張ってください。 1 p,sports いいね!{}はエキサイティング! 2 n,study がんばりましたね。休憩も必要ですよ。 3 p,study いいね!{}って簡単? 4 n,event それは大変でしたね。||大変でしたね。||大丈夫ですか? 5 p,event いいね!||やったね!||グッジョブ!これを、templates.txtという名前で保存しておきます。
事前準備
gensimによるword2vecをjawikiのダンプファイルで訓練しておきます。
訓練データ
訓練データを手作業で作成します。以下のリンクで訓練データを公開しています。
https://pastebin.com/B73Ykydcこのファイルを、train.txtという名前で保存します。
コード
データのロード、訓練、サンプルデータに対する予測を行うコードが以下です:
import numpy as np import MeCab from gensim.models import KeyedVectors from scipy import spatial from sklearn.linear_model import LogisticRegression def load_data(datafile="./train.txt", vecfile="./model.wv", mecabopts="-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd"): data = [] with open("train.txt") as f: for i,line in enumerate(f): if i==0: continue a = line.strip().split("\t") a = [x for x in a if x != ''] print(a) emo,tags,label = a tags = tags.split(",") label = int(label) data.append((emo, tags, label)) tpos = ["名詞", "動詞", "形容詞"] tagger = MeCab.Tagger(mecabopts) wv = KeyedVectors.load(vecfile, mmap='r') return {"wv": wv, "tagger":tagger,"data":data, "tpos": tpos} def data2vec(wv, emo, tags, tagger, tpos, dim): evec = tags2vecs(wv, [emo], tagger, tpos, dim) tvec = tags2vecs(wv, tags, tagger, tpos, dim) return {"evec":evec, "tvec": tvec} def fix_data(data, dim=200): X = [] y = [] for e,tags,l in data["data"]: tmp = data2vec(data["wv"], e,tags, data["tagger"], data["tpos"], dim) tmp = np.hstack((tmp["evec"], tmp["tvec"])) X.append(tmp) y.append(l) return X, y def train(X, y): from sklearn.linear_model import LogisticRegression clf = LogisticRegression() clf.fit(X, y) return clf def test(clf, emo, tags, data, dim=200): tmp = data2vec(data["wv"], emo, tags, data["tagger"], data["tpos"], dim) vec = [np.hstack((tmp["evec"],tmp["tvec"]))] return clf.predict(vec) def execute(emo, tags): import random data = load_data() X, y = fix_data(data) clf = train(X, y) label = test(clf, emo, tags, data, dim=200)[0] ts = {} with open("./templates.txt") as f: for line in f: tmp = line.strip().split("\t") tmp = [x for x in tmp if '' != x] idx, _, sentence = tmp idx = int(idx) sentence = sentence.split("||") if isinstance(sentence, str): sentence = [sentence] ts[idx] = sentence sent = random.choice(ts[label]).format(tags[0]) return sent def tags2vecs(wv, tags, tagger, tpos, dim): vecs = [] if isinstance(tags, str): tags = [tags] for tag in tags: for ts in tagger.parse(tag).strip().split('\n'): if isinstance(ts, str): ts = [ts] for t in ts: if "\t" not in t: continue flag = sum([p in t for p in tpos]) if flag < 1: continue t = t.split("\t")[0] if len(t) < 2: continue try: vecs.append(wv[t]) except KeyError: continue if vecs: return np.mean(vecs, axis=0) else: return np.zeros(dim) if __name__ == "__main__": emo = "楽しい" tags = ["心理学"] print(execute(emo, tags))入力: emo=楽しい, tags=["心理学"]
出力:
いいね!心理学って簡単?
- 投稿日:2019-01-26T11:47:25+09:00
【個人メモ】pyenv
pyenvのインストール
brew install pyenv
注)ファイルの作成場所は~/.pyenvインストール可能なバージョンを確認
pyenv install --list2系のインストール(なくても良いけど)
pyenv install 2.7.153系のインストール
pyenv install 3.7.2システム内で切り替え可能なバージョンの確認
pyenv versionsバージョンの切り替え(システム全体とカレントディレクトリのみに分けて設定できる)
pyenv global 3.7.2
pyenv local 2.7.15
- 投稿日:2019-01-26T11:15:11+09:00
【個人メモ】pythonのパッケージとライブラリ依存関係のエラー対処法
作業環境のパッケージ情報を収集
pip freeze > pip.txt
pyenv version
pyenv uninstall [実行環境のバージョン]ライブラリのインストール
sudo apt install hogehoge続いてpythonを再インストール
pyenv instrall [先ほど削除したバージョン]パッケージの再インストール
pip install -r pip.txt(matplotlibでtkinterについてのエラーが起きた際にpython-tkとtk-devのライブラリをインストールした)
- 投稿日:2019-01-26T10:48:38+09:00
Raspberryで wifi Spycam
ラズパイでスパイカムを作成する
下ごしらえ
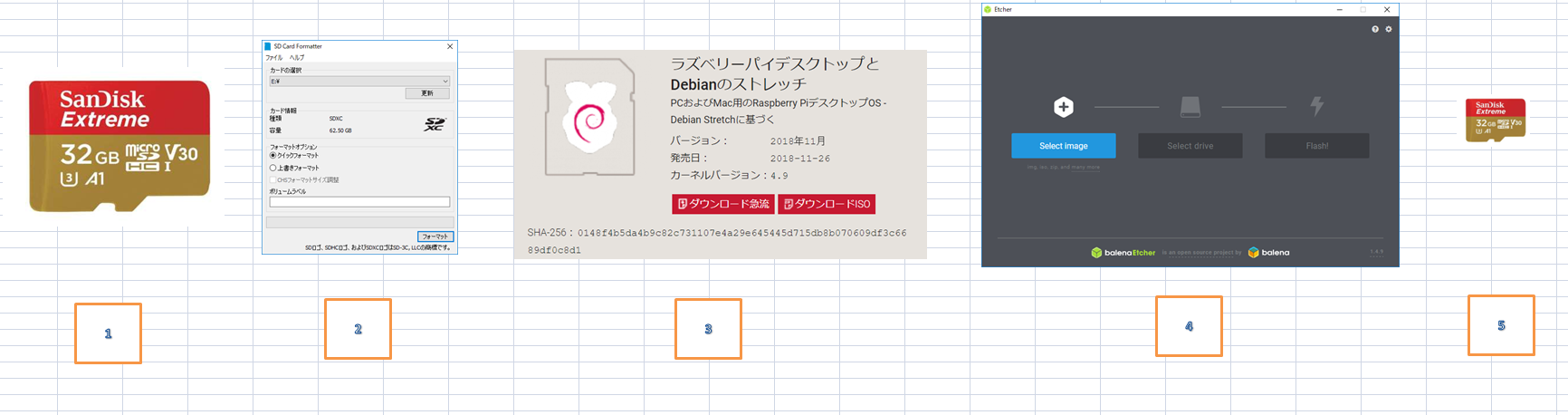
1.MicroSD カードを用意する
2.Fat32でフォーマットする。
https://www.raspberrypi.org/documentation/installation/sdxc_formatting.md
FAT32でないとダメダメ ハマるよ!!!!
- Raspbianのダウンロード https://www.raspberrypi.org/downloads/
- イメージをMicro SDに展開 https://www.techspot.com/downloads/6931-etcher.html
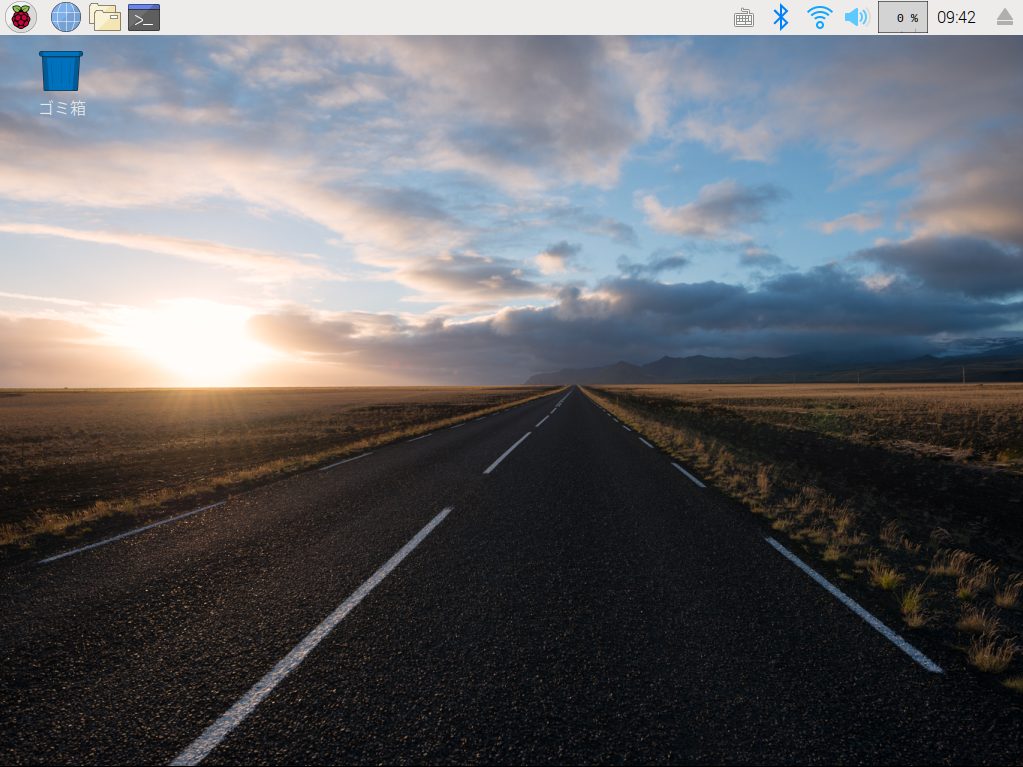
- ラズパイに挿入 成功すると
早速SSHを使えるようにする。
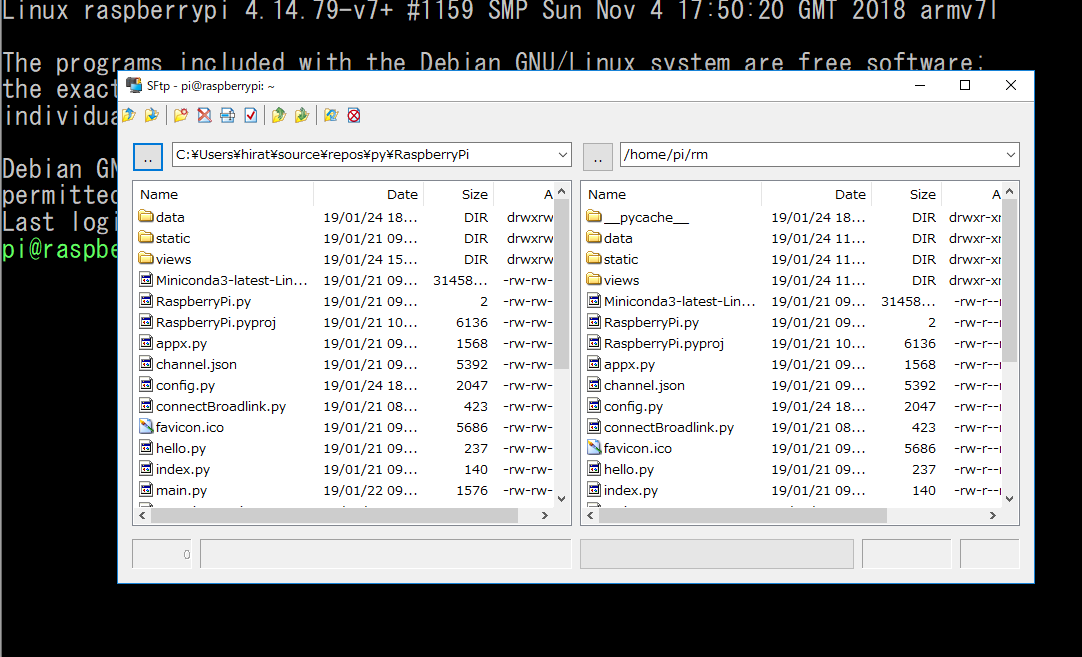
https://qiita.com/Halhira/items/1da2ae543217be26988a手間がかかりますです。
ラズパイやっているとラズベリーケークが食べたくなりました。
ついでに手作りです。ラズパイ夜食で~す
手作りケーキの作り方お教えします。
いいよね くださいね!
open CVを導入します。
https://qiita.com/mt08/items/e8e8e728cf106ac83218
を参照に導入
sudo apt autoremove -y libopencv{3,4}、は、以前にインストールしたものを取り除くものなので、インストールされてなければ、エラーを無視してすすめてください。
bottleをインストール
sudo pip3 install bottle
プログラムを転送 Rlogin のSSHを使っています。
11.raspberry pi
2.余っているWeb Camera
3.Python Program
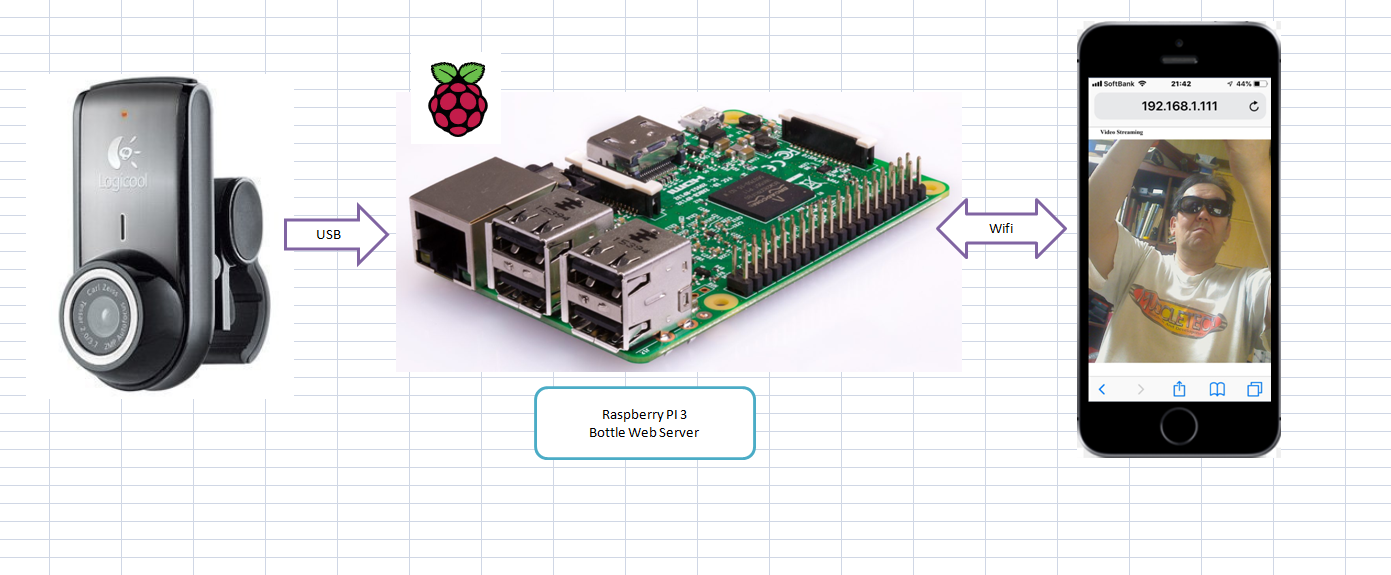
システムポンチ絵(システム概要図みたいなもの)
簡単なプログラムspycam.pyfrom bottle import * import cv2 class VideoCamera(object): def __init__(self): self.video = cv2.VideoCapture(0) def __del__(self): self.video.release() def get_frame(self): return cv2.imencode('.jpg', self.video.read()[1])[1].tobytes() def gen(camera): while True: yield (b'--frame\r\nContent-Type: image/jpeg\r\n\r\n' + camera.get_frame() + b'\r\n\r\n') @route('/video_feed') def video_feed(): response.content_type = 'multipart/x-mixed-replace; boundary=frame' return gen(VideoCamera()) @route('/') def index(): return '<div align="center"><h1>Video Streaming</h1><img src="/video_feed"></div>' run(host='0.0.0.0', port=8081)wifiを確認(アドレス 例は、192168.1.111)する。
1.下記のプログラムをRaspberry PIに入れる。
2.実行する解説
return cv2.imencode('.jpg', self.video.read()[1])[1].tobytes()tupleで返される値を一行に書いた。
一般的な御作法で書くと・・・success, image = self.video.read() ret, jpeg = cv2.imencode('.jpg', image) return jpeg.tobytes()yieldを用いてmotion jpegを作成
yield (b'--frame\r\nContent-Type: image/jpeg\r\n\r\n' + camera.get_frame() + b'\r\n\r\n')「Stupid Phone」から http://192.168.1.111:8081 アクセスする。


- 投稿日:2019-01-26T10:44:43+09:00
モンティ・ホール問題が納得いかなかったので、モンテカルロシミュレーションしてみた(2)
続き
モンティ・ホール問題が納得いかなかったので、モンテカルロシミュレーションしてみた
シミュレーションの結果、参加者はドアを変更すると賞品を得られる確率が2倍になるのは明らか。
しかし、やはり納得がいかない。
直感的にわからない。
じゃあ、montyさんが賞品のあるドアの位置を知らなかったらどうなる?早速、コードを修正してみました。
変更箇所
使用前
if monty_select != select and doors[monty_select] == 0:#賞品が無く、参加者が選ばなかったドアを選ぶ break使用後
もしmontyが賞品のあるドアを開けてしまったら、その回はなかったことに。
raiseで例外を投げます。
(あまり綺麗なコードではないですが。)if monty_select != select:#参加者が選ばなかったドアを選ぶ if doors[monty_select] != 0:#もしmontyが選んだドアに賞品があったら。その回はなかったことにする。 raise breakfor i in range(n):#指定回数を繰り返す try: change += monty(change = True) except: change_invalid += 1 #montyが賞品のあるドアを開けてしまった。 try: nochange += monty(change = False) except: nochange_invalid += 1 #montyが賞品のあるドアを開けてしまった。修正済みコード
import random import sys #引数 n = int(sys.argv[1]) #賞を得るのに、成功すると1、失敗すると0を返す #change ドアを変更するか #True:変更する #False:変更しない def monty(change): #3枚のドア doors = [0,0,0] #乱数でどのドアに賞品があるかを決める prize = random.randint(0,2) doors[prize] = 1 #参加者がドアを選ぶ select = random.randint(0,2) #続いてmontyがドアを選ぶ while True: monty_select = random.randint(0,2) if monty_select != select:#参加者が選ばなかったドアを選ぶ if doors[monty_select] != 0:#もしmontyが選んだドアに賞品があったら。その回はなかったことにする。 raise break if change:#ドアを変更する場合 while True: select_change = random.randint(0,2) if monty_select != select_change and select != select_change:#montyも参加者も選ばないドア select = select_change break if doors[select] == 1:#賞を得られたら1を返す return 1 return 0#賞が得られなければ0を返す change = 0 change_invalid = 0 nochange = 0 nochange_invalid= 0 for i in range(n):#指定回数を繰り返す try: change += monty(change = True) except: change_invalid += 1 #montyが賞品のあるドアを開けてしまった。 try: nochange += monty(change = False) except: nochange_invalid += 1 #montyが賞品のあるドアを開けてしまった。 #結果の表示 print("turn",n) print("change ",change,"invalid",change_invalid) print("nochange", nochange, "invalid" ,nochange_invalid)実行結果
今度は、ドアを変えても変えなくてもほぼ同じになりました。
invalidがmontyが賞品のあるドアを開けてしまって無効となった回数です。
このinvalidの数分に何か原因があるんでしょうけど。
やっぱり直感的には良くわからないですね。。。turn 1000 change 341 invalid 344 nochange 344 invalid 323 turn 1000 change 325 invalid 346 nochange 382 invalid 313 turn 1000 change 334 invalid 352 nochange 344 invalid 331
- 投稿日:2019-01-26T09:46:16+09:00
【個人メモ】pythonでgmailを受信する(書きかけ)
Googleの開発者コンソールにログインしてGmailAPIを有効にする
https://console.developers.google.com/flows/enableapi?apiid=gmail
からclient_id.jsonをダウンロードユーザ認証を実行
1. google-api-python-clientをインストール
pip3 install --upgrade google-api-python-clientgmail-auth.pyを実行
メール操作の確認画面が表示されるのでOK
credentials-gmail.jsonがローカルフォルダに作成されるrecvmail.pyの様なメールアクセス用のプログラムを実行
- 投稿日:2019-01-26T09:41:52+09:00
k8s=Kubernetesについて本気で調べてみた。ついでにi18n
背景
最近、k8s という単語をよく目にするようになりました。
k8s とは、Kubernetesのことだそうです。
k ~8文字~ s なので、k8sと書くそうです。Kubernetesとは何か?は、
他の多数の素晴らしい入門記事様を見ていただくとして、
興味を持ったのは、
k8s = Kubernetes って一意に決まるの?
ということです。もし、他の単語でもk8sがいるなら、
「k8sの座」を、Kubernetesだけに奪われてよいのか、
いや、良いハズがないっ!(反語表現)そこで、
まさにタイトル通り「k8s=Kubernetes」が成立するのか調べます。
「Kubernetes」について本気で調べてみた、
というわけではないのであしからずご了承ください。※正確には「k」が大文字じゃね?とかあるかもしれませんが、
「Kubernetes」の時は、大文字の方が多くても、
「k8s」の時は、小文字の書き方を多く見かける気がするので、
この調査では大文字小文字は区別せずに(基本小文字で)扱うことにします。さっそく調査に乗り出すことに
まず、英辞郎のテキストデータを用意します。
以前、このサイトで購入していました。(500円)
https://booth.pm/ja/items/777563およそ、200万単語含まれています。スゴイ。
このデータを、pythonで、
{"見出し語":"意味"} の形の辞書形式に加工します。
ここは本題では無いのでコードは省略します。
調査対象の単語リストの準備ができました!中身を見ると、
「k」で始まる単語は約2万1千語ありました!
(他のアルファベットに比べかなり少ないほうです)k8sチェッカーの作成
正規表現で、k8sの条件を満たすかチェックする
チェック関数を作成します。^k[A-Za-z]{8}s$の形を基本として、少し一般的に作りました。
import re #kNs_checker("k",8,"s", target_word)が条件にハマるかチェックするよ def kNs_checker(head_char, num, tail_char, target_word): #k8s (k + 8 文字 + s) #target_word = r'kubernetes' #pattern = r'^k[A-Za-z]{8}s$' pattern = r'^' + head_char + '[A-Za-z]{' + str(num) + '}' + tail_char + '$' result = re.match(pattern, target_word) if result: #none以外の場合 #print(result.group()) return 1 else: return 0 return 0 print(kNs_checker("k",8,"s", "kubernetes") )k2sを求めてみよう!
まずは、k2sから求めてみましょう。
さきほどの「k8sチェッカー」を用いて、辞書を検索します。
「k8sチェッカー」が「1」を返す=条件を満たす、ので、
その単語を列挙します。k2sを求める#「k」で始まる単語の辞書の読み込み {"見出し語":"意味"} dict = load_dict("k") def pickup_word(head_char, num, tail_char): for key,val in dict.items(): if kNs_checker(head_char, num, tail_char, key) > 0: print(key + ": " +val) pickup_word("k",2,"s")k2sの結果kiss: キスする kris: クリース◆マレー人が用いる短剣 kvas: クヴァス◆ロシアの発酵飲料 # ※結果の意味の所は、加工しています。k2sの時点でも3つと意外と少ないですね。
これはKubernetesが一意の座を得ることが出来るかも!?※他に、kids、などが思いつきますが、
辞書上、原型しか登録されていない場合もあり、
複数形や活用は無視します。k3s~k7sの結果
「2」を3~7に変えて上記のプログラムを動かします。
k3sの結果kecks: 〈英俗〉ズボン kudos: 〔功績などに対する〕称賛、賛辞 kumis: <→koumiss> クミス、乳酒◆中央アジアの伝統食品。 kurus: クルーシュ◆トルコの貨幣単位ほうほう。
k4sの結果kairos: 〈ギリシャ語〉実行[決断]の時、潮時 kermes: ケルメス◆カイガラムシの雌の羽を乾燥させた赤紫色の染料の原料 killas: 《地学》粘板岩 knives: knifeの複数形 kouros: クーロス◆古代ギリシャの青年の裸体像 kyphos: 《病理》〔脊柱の〕後彎(症)日本語でも知らんがな、って単語が多いですね。
k5sの結果kalends: 〔古代ローマ暦の〕月の最初の日 kenosis: 神性放棄 ketosis: 《病理》ケトーシス、ケトン症 keyless: キー[鍵]のない[不要の] kickass: <→kick-ass>〈卑俗〉エネルギー、力 kinesis: キネシス◆生物の動き kinless: 親類[親族]のない kissass: <→kick-ass>〈卑俗〉エネルギー、力 klipdas: 《動物》ケープハイラックス koumiss: クミス、乳酒◆中央アジアの伝統食品。 kylikes: kylixの複数形だんだん増えているし。数字の少ない方が多いと思ってた。
k6sの結果keenness: 鋭さ、熱心さ keftedes: ケフテデス◆ギリシャ料理の肉だんご kehillos: kehillahの複数形 kindless: 不親切な kindness: 親切(であること)、思いやり(があること) kinesics: 動作学 kinetics: 《物理》動力学 kingless: 国王の存在しない kneesies: 〈米俗〉〔恋人同士などが愛情の表現として〕膝と膝を触れ合わせること knickers: 〔女性用の〕ブルマー knockers: 〈卑〉おっぱい kouskous:〈アラビア語〉クスクス◆パスタの一種。世界最小のパスタ kurtosis: カートシス、尖度 kyphoses: kyphosisの複数形 kyphosis: 《病理》〔脊柱の〕後彎症おっぱい!?
k7sの結果kaluresis: =<→kaliuresis>カリウム利尿 kantharos: カンタロス◆上方に伸びた取っ手(2個)が付いている大きな杯 katabases: katabasisの複数形 katabasis: 《軍事》退却 katharsis: <→catharsis>カタルシス、〔精神の〕浄化 keratitis: 《病理》角膜炎 keratorus: 《医》角膜膨隆 keratoses: keratosisの複数形 keratosis: 《病理》角化症◆【略】K ketolides: ケトライド系薬◆【略】KLs ketolyses: ketolysisの複数形 ketolysis: 《化学》ケトン分解 kibbutzes: kibbutzの複数形 kidstakes: ごまかし、見せ掛け kilobucks: 千ドル、大金 kilogauss: 《電気》キロガウス◆【略】kG kinetoses: kinetosisの複数形 kinetosis: 《医》乗り物酔い knismesis: 《生理》軽いくすぐり刺激◆羽根が触れたり虫がはったときなど knotgrass: 《植物》ニワヤナギ、ミチヤナギ kookiness: 〈俗〉変人ぶり、異様なこと kraurosis: 《病理》萎縮症もっと増えてる。これはk8sも厳しいか・・・?
おまちかね、k8sの発表です★
k8sの結果kaliuresis: カリウム利尿 karyolysis: 《生物》核溶解 katholikos: =<→catholicos>〔東方教会の〕総主教 keloidosis: ケロイド症 keratinous: ケラチン[角質]の[から成る・に似た] kindliness: 親切(な行為)、温情、温和 kinematics: 《物理》運動学 klinotaxis: 《生物》屈曲走性 knockknees: <→knock-knees>《医》X脚、外反膝 kohlrabies: kohlrabi(《植物》コールラビ、カブカンラン)の複数形なんと、10件のk8sが見つかりました!!
残念Kubernetesよ、k8sはお前だけのものではないのだ!
さあ、これからは、k8sについて語るときは、
「え、それって、ケロイド症について話しているの?」
「k8s入門って、X脚に入門するってこと?」
「絵本で分かるk8sって、キリンが核溶解する絵本?」
って確認することで、話している対象を間違えずにすみますね。さらに、K8sの結果
Kubernetes一意性信者の野望を完全に打ち砕くため、
念を入れて、「K」が大文字の場合も、
同様のプログラムで求めてみました。K8sの結果Kannapolis: {地名} : カナポリス◆米国 Karagatsis: {人名} : カラガーチス Karamanlis: {人名} : カラマンリス Kariotakis: {人名} : カリオタキス Kastanakis: {人名} : カスタナキス Katsuwonus: 《魚》カツオ属 Kilcommons: {人名} : キルコモンズ Kolkasrags: {地名} : コルカ岬 Kompaneets: {人名} : カンパニェーツ Korolkovas: {人名} : コロルコワス Korostvets: {人名} : コロストベッツ「K8s」だろうが、「k8s」だろうが、
世界はKubernetesを中心に回っているわけではありません。
もしかしたら、あなたの見つけた「K8s入門」は、
「カツオ(Katsuwonus)」に入門することになるかもしれない。
https://ja.wikipedia.org/wiki/カツオ提言:これからは、キリンとかクジラ以外に、
「カツオ」も登場させてあげるのが
元祖K8sに対する礼儀ではなかろうか?こうなると、最大値が知りたくなる
最大のkNsはなにか? を知りたくなるのが人情です。
pythonの正規表現のところを以下のように変更します。pattern = r'^' + head_char + '[A-Za-z]*' + tail_char + '$'上記を実行して調べた結果、
k18s が最大だと分かりました!keratoconjunctivitis: 《眼科》角結膜炎
なんと、k8sを2倍以上うわまわっています。
これは、k8sを語る上でほぼ必須のムダ知識ですね。
k18sを知っていれば、k8sより2倍強いです。i18n は一意なのか?
同様の問題として、
i18n = internationalization なのか調べてみます。Internationalization(国際化対応)とは、文化、地域、言語によって異なるターゲットオーディエンスに合わせて容易にローカライズできる製品、アプリケーション、または文書内容の設計と開発のことです。~W3Cの定義~
コードはk8sのものと全く同様です。
i18nを求めるdef pickup_word(head_char, num, tail_char): for key,val in dict.items(): if kNs_checker(head_char, num, tail_char, key) > 0: print(key + ": " +val) pickup_word("i",18,"n")i18nの結果immunophotodetection: 免疫光学的検出 institutionalisation: =<→institutionalization>制度化、慣行化 institutionalization: 制度化、慣行化 internationalisation: <→internationalization>国際化、国際管理下に置くこと、国際管理化 internationalization: 国際化、国際管理下に置くこと、国際管理化 iodochlorhydroxyquin: 《薬学》ヨードクロルヒドロキシキンKubernetesは、英辞郎には存在しなかったのですが、
internationalizationは、本人が英辞郎にも居ました。
そして、残念internationalizationよ、i18nはお前だけのものではないのだ!
kNsは18が最高値で、18で一意だったので、
i18nならもう少し頑張ってくれるかと思ったのですが、
いやー、おしかったですね。これからは、i18nについて語る時は、
ヨードクロルヒドロキシキンについての話しじゃないよね?
と確認していく必要があります。まとめ
こうしてこの世界にまた一つ新たなトリビアが生まれた
- k8sは、Kubernetesのみの一意に定まらない
- 最大はk18s = keratoconjunctivitis = 角結膜炎
- i18nは、必ずしも国際化対応のことではない
この記事によって、
k8s や、i18n について語る時に生じる誤解を
0.00001%くらい軽減できたと思います!
エンジニアが良く使う言葉について、
とても役に立つ有用な知識を得ることができました。コンテナとかdockerとか、ムズカシイ言葉を一切使わず、
ここまでk8sについて詳細に解説している記事は
他に類を見ないのではないでしょうか。k8sとは何か? と聞かれた場合には、
この記事を紹介してあげると、とてもkindlinessですね。または、「カツオ(Katsuwonus)の略だよ!」 と教えてあげると、
魚類まで網羅したあなたの博識ぶりに驚くこと間違いなしです。現場からは以上です。
- 投稿日:2019-01-26T09:39:09+09:00
No.021【Python】 Counterについて②
今回は引き続き、「Counterメソッド」について書いていきます。
I'll write about "Counter method in python" on this page.■ Counterメソッドによる演算ついて
Calculation by Counter method・ Setメソッド同様、Counterメソッドにて演算することが可能である。
You can calculate by a counter method instead of a set one.
>>> from collections import Counter >>> >>> a = Counter("aaaabbbc") >>> b = Counter("abbbcc") >>> >>> a Counter({'a': 4, 'b': 3, 'c': 1}) >>> >>> b Counter({'b': 3, 'c': 2, 'a': 1}) >>> >>> a + b Counter({'b': 6, 'a': 5, 'c': 3}) >>> >>> a - b Counter({'a': 3}) >>> >>> b - a Counter({'c': 1}) >>> a & b Counter({'b': 3, 'a': 1, 'c': 1}) >>> >>> a | b Counter({'a': 4, 'b': 3, 'c': 2})■ most_common()メソッドについて
・ タプル(要素, 出現回数)を出現回数順に並べたリストを返すことができる。You can return a tuple(element, the number of occurences)
>>> from collections import Counter >>> >>> a = Counter("aaaabbbc") >>> >>> b = Counter("abbbcc") >>> >>> print(b.most_common()) [('b', 3), ('c', 2), ('a', 1)] >>> >>> # 出現回数の少ない順の場合は、増分を-1としたスライスを利用する >>> >>> print(b.most_common()[::-1]) [('a', 1), ('c', 2), ('b', 3)] >>> >>> # 出現回数順に並べた要素・出現回数のリストを個別に欲しい場合 >>> >>> values, counts = zip(*a.most_common()) >>> >>> print(values) ('a', 'b', 'c') >>> >>> print(counts) (4, 3, 1)・条件を満たす要素の個数をカウント
リストやタプルに特定の条件を満たす要素がいくつあるのかをカウントする場合、条件を満たす要素のリストを「リスト内包表記」にて生成し、その個数をlen( )で取得する。
When you count elements, which are satisfied with specific conditions, in a list or a tuple, you create the list of elements by List comprehension and acquire the numbers by len functions.>>> l = list(range(-5, 6 )) >>> >>> print(l) [-5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5] >>> >>> print([i for i in l if i < 0]) [-5, -4, -3, -2, -1] >>> >>> print([i for i in l if i % 2 == 1]) [-5, -3, -1, 1, 3, 5] >>> >>> print(len([i for i in l if i % 2 == 1])) 6 >>> >>> # 例_文字列のリストに対する条件 >>> >>> l = ['egg', 'salt and pepper', 'mayonnaise'] >>> >>> print([s for s in l if s.endswith('e')]) ['mayonnaise'] >>> >>> print(len([s for s in l if s.endswith('e')])) 1・出現回数が条件を満たす要素をカウントする場合
When you count elements satisfied with condition for the number of occurrences...
>>> l = ['a', 'a', 'a', 'b', 'b', 'b', 'c'] >>> >>> print([i for i in l if l.count(i) >= 2]) ['a', 'a', 'a', 'b', 'b', 'b'] >>> >>> print(len([i for i in l if l.count(i) >= 2])) 6 >>> >>> c = Counter(l) >>> >>> print([i[0] for i in c.items() if i[1] >=2]) ['a', 'b'] >>> >>> print(len([i[0] for i in c.items() if i[1] >= 2])) 2・文字列の単語の出現個数をカウントする場合
When you count the number of occurrences for the string of words...
>>> s = 'you must eat this sandwich,which uses the egg comes from organic chicken, and you would know what the real sandwich is.' >>> >>> s_remove = s.replace(',', ' ').replace('.', ' ') >>> >>> print(s_remove) you must eat this sandwich which uses the egg comes from organic chicken and you would know what the real sandwich is >>> >>> word_list = s_remove.split() >>> >>> print(word_list) ['you', 'must', 'eat', 'this', 'sandwich', 'which', 'uses', 'the', 'egg', 'comes', 'from', 'organic', 'chicken', 'and', 'you', 'would', 'know', 'what', 'the', 'real', 'sandwich', 'is'] >>> >>> # リスト化により、各単語の出現回数や単語の種類の取得、最も出現回数の多い単語を取得したりできることが可能である >>> >>> print(word_list.count('egg')) 1 >>> >>> print(len(set(word_list))) 19 >>> >>> c = Counter(word_list) >>> >>> print(c) Counter({'you': 2, 'sandwich': 2, 'the': 2, 'must': 1, 'eat': 1, 'this': 1, 'which': 1, 'uses': 1, 'egg': 1, 'comes': 1, 'from': 1, 'organic': 1, 'chicken': 1, 'and': 1, 'would': 1, 'know': 1, 'what': 1, 'real': 1, 'is': 1}) >>> >>> print(c.most_common()[0][0]) you・文字列の文字の出現個数をカウント
Count the number of occurrences for the string of characters.
>>> s = 'iloveeggsandwichesbecauseireallylilkeeggandmayonnaise' >>> >>> print(s.count('s')) 4 >>> print(s.count('e')) 9 >>> >>> c = Counter(s) >>> >>> print(c) Counter({'e': 9, 'a': 6, 'i': 5, 'l': 5, 'g': 4, 's': 4, 'n': 4, 'o': 2, 'd': 2, 'c': 2, 'y': 2, 'v': 1, 'w': 1, 'h': 1, 'b': 1, 'u': 1, 'r': 1, 'k': 1, 'm': 1})いかがでしたでしょうか。
How was my post?本ブログは、随時に更新していきますので、
定期的な購読をよろしくお願いします。
I'll update my blogs at all times.
So, please subscribe my blogs from now on.本ブログについて、
何か要望等ありましたら、気軽にメッセージをください!
If you have some requests, please leave some messages! by You-Tarinまた、「Qiita」へ投稿した内容は、随時ブログへ移動して行きたいと思いますので、
よろしくお願いします。
