- 投稿日:2021-03-05T23:22:45+09:00
関数からされているグローバル変数の名前を取得する
CPythonの関数が参照している名前(ローカル変数と自由変数を除く)は、その関数のコードオブジェクトの
co_namesに保存されていることは以前書きました。co_namesは、グローバル変数名だけでなく、例えば次の例ではyも含んでいます。def foo(): return x.y foo.__code__.co_names # => ('x', 'y')ではグローバル変数の名前だけを取り出したい場合はどうするかについてです。
結論から言うと、dis標準ライブラリで、その関数をディスアセンブリし、LOAD_GLOABLインストラクションの引数を取り出す、という方法があるようです。def global_names(func): insts = list(dis.get_instructions(func.__code__)) names = [] for inst in insts: if inst.opname == "LOAD_GLOBAL" and inst.argval not in names: names.append(inst.argval) return tuple(names)ただこの方法だと、ネストした関数内で参照されているグローバル変数名は取得できないようです。
def foo(): def bar(): return x return bar() global_names(foo) # => ()
- 投稿日:2021-03-05T23:14:05+09:00
可変長ループを書こう!
はじめに
突然ですが、あなたは多重ループは書けますか?
???:「書けますー!」
test.pycnt = 0 for i0 in range(3): for i1 in range(3): for i2 in range(3): for i3 in range(3): ##### ここに処理を書く ##### cnt += 1 ##### print(cnt) # 81これは $4$ 重ループになってますが、これの可変なやつ(詳細は後述)をうまく処理しようというのがこの記事の趣旨です。言語は Python 、特に PyPy での実行を想定しています。
ループを書くことが目的なので「処理」のところは何でもよいのですが、ここではループした回数をカウントしています。実際の問題では、
ans += calc(i0, i1, i2, i3)のような数え上げを計算したり、ans = max(ans, calc(i0, i1, i2, i3))のような更新をしたり、あるいは DP テーブルを更新したりするイメージです。可変長ループとは
だいたいこんなのができるものを可変長ループと呼んでいます 1。
- 可変個($K$ 個とします)の変数 $i_0,\ \cdots, i_{K-1}$ でループをする
- $i_k$ は $[l_k,\ r_k)$ の範囲の整数をループする。 $l_k,\ r_k$ は $i_0,\ \cdots,\ i_{k-1}$ に依存してもよい
- 変数間に満たすべき条件 $P(i_{k_0},\ \cdots,\ i_{k_{s-1}}) $ がいくつかある
- 非再帰かつ 空間 計算量 $O(K)$
- $i_0,\ \cdots,\ i_{k-1}$ が満たすべき条件を満足していない場合は $i_k$ 以降のループは回さない 2
いくつか例を挙げてみます。まずは愚直ループで書いてみるので、可変長にするにはどうすれば良いか考えながら見てみてください。
例1(愚直)
変数 $i_0,\ i_1,\ i_2,\ i_3$ が $0\le i_k < 2k+1$ を満たす整数を動くループを書いてください。
愚直に書くとこんな感じ。test.pycnt = 0 for i0 in range(1): for i1 in range(3): for i2 in range(5): for i3 in range(7): ##### ここに処理を書く ##### cnt += 1 ##### print(cnt) # 105これぐらいなら Python の itertools を使うなどいろんな書き方があると思います3。
例2(愚直)
さっきのに加えて、「隣り合う変数の合計が $3$ の倍数になるものは除く」という条件を入れたらどうなるでしょうか。
test.pycnt = 0 for i0 in range(1): for i1 in range(3): if (i0 + i1) % 3 == 0: continue for i2 in range(5): if (i1 + i2) % 3 == 0: continue for i3 in range(7): if (i2 + i3) % 3 == 0: continue ##### ここに処理を書く ##### cnt += 1 ##### print(cnt) # 31これも itertools などでできそうですが、普通にループして全てのループ変数の組に対して条件を判定するやり方だと無駄なループができて計算量が大きくなってしまう可能性があります。具体的には、上の例だと
(i0 + i1) % 3 == 0の時点でその後のi2やi3を見る必要はないにも関わらず、ループを回してしまうことになりそうです。
なので上のcontinueのように、条件を満たさなくなった時点でそれ以降の変数のループを回さないようにしたいです。例3(愚直)
次はループ範囲がそれより前の変数に依存する場合を考えてみましょう。
例えば $i_k$ のループ範囲が $[0,\ i_0+\cdots +i_{k-1}+2)$ のように表される場合です。この例では右側だけ動かしていますが、左側が前の変数に依存することもありえます。test.pycnt = 0 for i0 in range(1): for i1 in range(i0 + 2): if (i0 + i1) % 3 == 0: continue for i2 in range(i0 + i1 + 2): if (i1 + i2) % 3 == 0: continue for i3 in range(i0 + i1 + i2 + 2): if (i2 + i3) % 3 == 0: continue ##### ここに処理を書く ##### cnt += 1 ##### print(cnt) # 5これのループ変数の個数を増やすと(例えば $K=10$ など)結構大変そうですね。
まあ書けなくはないんですけど。test.pycnt = 0 for i0 in range(1): for i1 in range(i0 + 2): if (i0 + i1) % 3 == 0: continue for i2 in range(i0 + i1 + 2): if (i1 + i2) % 3 == 0: continue for i3 in range(i0 + i1 + i2 + 2): if (i2 + i3) % 3 == 0: continue for i4 in range(i0 + i1 + i2 + i3 + 2): if (i3 + i4) % 3 == 0: continue for i5 in range(i0 + i1 + i2 + i3 + i4 + 2): if (i4 + i5) % 3 == 0: continue for i6 in range(i0 + i1 + i2 + i3 + i4 + i5 + 2): if (i5 + i6) % 3 == 0: continue for i7 in range(i0 + i1 + i2 + i3 + i4 + i5 + i6 + 2): if (i6 + i7) % 3 == 0: continue for i8 in range(i0 + i1 + i2 + i3 + i4 + i5 + i6 + i7 + 2): if (i7 + i8) % 3 == 0: continue for i9 in range(i0 + i1 + i2 + i3 + i4 + i5 + i6 + i7 + i8 + 2): if (i8 + i9) % 3 == 0: continue ##### ここに処理を書く ##### cnt += 1 ##### print(cnt) # 5964602これをきれいに書くのを目標にしましょう 4。
他の方法
本記事で示す方法以外にもいくつか方法があります。これらが使えることもあるでしょう。
愚直にループを書く
上の例で書いたようなやつです。ただこれだとループの深さなどが可変の問題には対応しづらいですね。itertools
不要なところもループしてしまうので場合によっては計算量が増えてしまう可能性があります。再帰 DFS
再帰は言語によっては遅くなるので使いたくなかったりします。BFS
メモリが $O(K)$ では収まらないです。本記事の方法
可変長対応、不要なループをしない 5 、非再帰、メモリは $O(K)$ 、のすべてを満足する方法です。アイデア
アイデアというほどでもないですが、本記事の実装方法です。
- 各ループ変数に対して、「初期値」「終了値」を持つ。具体的には $i$ 番目のループ変数の初期値・終了値をそれぞれ
L[i]およびR[i]で表す- while 文をでループする
これだけです。
実装
さっきの例1
さっきの例で実装してみます。
chk関数で満たすべき条件を設定しています。この例では特に NG 条件がないので必ず $0$ を返すようにしています。test.pydef chk(i): if not i: return 0 # i 番目の変数の条件(OK なら 0 を、NG なら 1 を返す) # i-1 番目までの変数に依存しても良い return 0 K = 4 # ループ変数の個数 Z = [0] * K L = [0] * K R = [0] * K L[0], R[0] = 0, 1 # 半開区間 [L, R) をループする i = 0 cnt = 0 while i >= 0: while i < K - 1: i += 1 ##### 初期値・終了値の設定 ##### L[i] = 0 R[i] = 2 * i + 1 ##### Z[i] = L[i] if chk(i): break else: ##### ここに処理を書く ##### cnt += 1 ##### Z[i] += 1 while Z[i] >= R[i] or chk(i): if Z[i] < R[i]: Z[i] += 1 while Z[i] >= R[i]: i -= 1 if i < 0: break Z[i] += 1 if i < 0: break print(cnt) # 105さっきの例2
ループ変数間に条件がある場合です。
chk関数に条件を入れています。 $i$ 番目のループ変数の条件のところでは $i$ 番目までの変数に依存して決めて良いです。言い換えると、いくつかのループ変数に関係する条件については、その中で最も大きな番号のループ変数のところで判定をして、 NG ならすぐ次に移るようにしています。test.pydef chk(i): if not i: return 0 # i 番目の変数の条件(OK なら 0 を、NG なら 1 を返す) # i-1 番目までの変数に依存しても良い return 1 if (Z[i-1] + Z[i]) % 3 == 0 else 0 K = 4 # ループ変数の個数 Z = [0] * K L = [0] * K R = [0] * K L[0], R[0] = 0, 1 # 半開区間 [L, R) をループする i = 0 cnt = 0 while i >= 0: while i < K - 1: i += 1 ##### 初期値・終了値の設定 ##### L[i] = 0 R[i] = 2 * i + 1 ##### Z[i] = L[i] if chk(i): break else: ##### ここに処理を書く ##### cnt += 1 ##### Z[i] += 1 while Z[i] >= R[i] or chk(i): if Z[i] < R[i]: Z[i] += 1 while Z[i] >= R[i]: i -= 1 if i < 0: break Z[i] += 1 if i < 0: break print(cnt) # 31さっきの例3
$i$ 番目のループ変数の範囲が $i-1$ 番目までのループ変数に依存する場合です。
R[i] = sum(Z[:i]) + 2のところで設定しています 6 。test.pydef chk(i): if not i: return 0 # i 番目の変数の条件(OK なら 0 を、NG なら 1 を返す) # i-1 番目までの変数に依存しても良い return 1 if (Z[i-1] + Z[i]) % 3 == 0 else 0 K = 4 # ループ変数の個数 Z = [0] * K L = [0] * K R = [0] * K L[0], R[0] = 0, 1 # 半開区間 [L, R) をループする i = 0 cnt = 0 while i >= 0: while i < K - 1: i += 1 ##### 初期値・終了値の設定 ##### L[i] = 0 R[i] = sum(Z[:i]) + 2 ##### Z[i] = L[i] if chk(i): break else: ##### ここに処理を書く ##### cnt += 1 ##### Z[i] += 1 while Z[i] >= R[i] or chk(i): if Z[i] < R[i]: Z[i] += 1 while Z[i] >= R[i]: i -= 1 if i < 0: break Z[i] += 1 if i < 0: break print(cnt) # 5さっきみたいに $K=10$ にしてみましょう。
test.pydef chk(i): if not i: return 0 # i 番目の変数の条件(OK なら 0 を、NG なら 1 を返す) # i-1 番目までの変数に依存しても良い return 1 if (Z[i-1] + Z[i]) % 3 == 0 else 0 K = 10 # ループ変数の個数 Z = [0] * K L = [0] * K R = [0] * K L[0], R[0] = 0, 1 # 半開区間 [L, R) をループする i = 0 cnt = 0 while i >= 0: while i < K - 1: i += 1 ##### 初期値・終了値の設定 ##### L[i] = 0 R[i] = sum(Z[:i]) + 2 ##### Z[i] = L[i] if chk(i): break else: ##### ここに処理を書く ##### cnt += 1 ##### Z[i] += 1 while Z[i] >= R[i] or chk(i): if Z[i] < R[i]: Z[i] += 1 while Z[i] >= R[i]: i -= 1 if i < 0: break Z[i] += 1 if i < 0: break print(cnt) # 5964602ちゃんと同じ結果になりました。
問題(ネタバレ注意)
ABC 161 - D
問題
ループするだけですね。ACコード
愚直ループ でもできるけど本番では書きたくないです。ARC 095 - E
問題
想定解じゃないけど、自然に可変長ループすると枝刈りになって通ります 7 8。想定解の方法でも可変長ループが使えます。
ACコードARC 104 - E
問題
まあこれぐらいなら可変長ループいらないけど。
ACコード (古い書き方してたときのやつなのでこの記事の書き方とは違う)Q&A
Q. これ需要あるの?
A. あんまりない気がしています。でも私は結構使ってます。直感的に書ける 9 ので気に入っています。書いても需要ない記事ばかり書く人というのが存在していてほしい
— えびちゃん (@rsk0315_h4x) March 3, 2021Q. 再帰じゃダメなの?
A. PyPy だと再帰遅いので 10 。もちろん計算時間に十分余裕があるなら大丈夫です。Q. BFS じゃだめなの?
A. これは全然だめじゃないです。本記事の方法だとメモリが $O(K)$ で良いというメリットがありますが、メモリがネックになることはあまりない気がします。Q. そもそも PyPy だと JIT コンパイルでめちゃくちゃメモリ食うから、メモリ $O(K)$ って意味なくない?
A. それを言われるととてもつらい気持ちになります。Q. もっときれいに書けない?
A. 書けそう。教えてください。Q. Step は設定できないの?(ループ変数を $2$ ずつ増やすとか)
A. ちょっといじればできます。
- 投稿日:2021-03-05T23:04:03+09:00
IOとダックタイピング
はじめに
今日、以下のようなプログラムを書いていました(一部わざとコメントを抜いています)
app.pyfrom flask import Flask, render_template, send_file from great_algorithm import GreatAlgorithm app = Flask(__name__) # 実際にはセッションごとにインスタンスを作ってるが割愛 algo = GreatAlgorithm() @app.route('/', methods=['GET']) def start(): return render_template('index.html', algo=algo) # パスパラメータ使って「何番目の画像」とかしてるわけだが割愛 @app.route('/image') def image(): return send_file(algo.get_image('jpg'), mimetype='image/jpeg') @app.route('/', methods=['POST']) def update(): # フォーム値をupdateメソッドに渡すわけだが割愛 algo.update() return render_template('index.html', algo=algo) if __name__ == '__main__': app.run(debug=True)great_algorithm.pyimport io import numpy as np import matplotlib.pyplot as plt class GreatAlgorithm: def __init__(self): # 本題じゃないので適当 img = np.random.random((400, 400)) img = img * 255 img = img.astype('uint8') self._img = img def update(self): # 本題じゃないので割愛 pass def get_image(self, format): f = io.BytesIO() plt.imsave(f, self._img, format=format) f.seek(0) return f何をしているのか
某エッチな絵を作るあれではないですが1、「画像を提示」→「評価」→「評価に基づいて画像を更新」ということをしています。ただしその部分は今回の萌えポイントとは関係ないので割愛です。
元々Webインタフェースを作る気はなかったのですが、評価値を手入力するのがめんどくさいのでWeb化するかと思って「あれ?ここどうやればいいんだろう」と思って調べたところが今回の本題(萌えポイント)です。
画像は上記のようにNumPy配列です。ターミナル(と言っても別ウインドウは開きますが)でmatplotlib使ってimshowするだけならそれでまったく問題ありません。しかし、Web化するとなると「画像ファイル」を作る必要があります。萌えポイント
flask.send_file
先にflask側から。今までflaskで「動的に画像作って返す」ということをしたことがなかったので「flask return jpg」でググり以下の記事を見つけ、send_file使えばいけそうということはわかりました。
https://stackoverflow.com/questions/8637153/how-to-return-images-in-flask-responseただ、「ファイルに書き出したくないな(一時ファイル作りたくないな)」という気持ちがありドキュメントを確認したところ、
send_file(filename_or_fp, mimetype=None, as_attachment=False, attachment_filename=None, add_etags=True, cache_timeout=None, conditional=False, last_modified=None)
filename_or_fp – the filename of the file to send. This is relative to the root_path if a relative path is specified. Alternatively a file object might be provided in which case X-Sendfile might not work and fall back to the traditional method. Make sure that the file pointer is positioned at the start of data to send before calling send_file().
「ファイル名ではなく、ファイルオブジェクトを渡せる」ことが確認できました。
matplotlib.pyplot.imsave
次に画像を作る側のmatplotlibです。imsaveを使えば画像ファイルとして書き出せるわけですが、
imsave(fname, arr, **kwargs)
fname : str or path-like or file-likeおぉ!こっちもファイルオブジェクトを渡せる!これで勝てる!
io.BytesIO
「ファイルオブジェクト」と言っても、「本物のファイルを開いて(ファイルに対応するオブジェクトを作成して)」上記のsend_fileやimsaveに渡すわけではありません。
「ファイルのような挙動をする」オブジェクトを渡してreadさせたりwriteさせたりすればいいわけです。そう、みんな大好きダックタイピングですね。readやwriteの呼び出しに応じてくれれば別に本物のファイルである必要はないわけです。Pythonにはそのような「ファイルのような挙動をする」クラスがあらかじめ用意されています。io.BytesIOです。
というわけで一番の萌えポイントを今度はコメント付きで見てみましょう。great_algorithm.py抜粋def get_image(self, format): # ファイルに出力するのではなくメモリに出力させる f = io.BytesIO() plt.imsave(f, self._img, format=format) # 読み込み側が便利なようにoffsetを先頭にしておく f.seek(0) return fapp.py抜粋@app.route('/image') def image(): return send_file(algo.get_image('jpg'), mimetype='image/jpeg')BytesIOオブジェクトに「画像ファイルの内容」を出力させ、それをそのままsend_fileに渡して最終的にブラウザまで届くようになっています。
一時ファイルなど作らないで済みます!
ちなみに、matplotlib側のformat引数、flask側のmimetype引数は普通なら指定しませんが今回は「ファイル名から決定」ができないので指定する必要があります(指定しないとエラーになります)まとめ
- 保持している情報を画像ファイルにして返したいが一時ファイルは作りたくない
- flaskのsend_fileは「ファイルオブジェクト」を受け付けてくれる
- matplotlibのimsaveも「ファイルオブジェクト」を受け付けてくれる
- よしBytesIOの出番だ
「ファイルパスでもファイルオブジェクトでもよい」というのは使う側にとってはとてもありがたい仕様です。
作る側は大変ですが。特にPythonみたいな言語的にオーバーロードのない言語だと・・・オチ
その後に考えた結果、「世代ごとの画像」はログ的に残す必要あるなということで結局「ファイル出力」しないといけないかという考えに至りました。
一応私、「遺伝的アルゴリズムチョットワカル」な人間なのですが、あらためて考えてみるとあれ提示される画像が2枚だけだけど、多様性考えると母集団が2個体だけなんてことはないよな、どう管理されてるんだろう(一定数保持して評価の低い古い世代から消していく?)と思いました。 ↩
- 投稿日:2021-03-05T22:48:15+09:00
OpenCVで画像を不定形の座標で切り出し背景を透明にする
Open CVで作業をするとき毎回忘れてそのたびに解決策を探す小ネタの一つに上のものがある。
結構面倒なので毎回ゲンナリしてしばらくやる気を失いがちなのでこれ以上繰り返さないために書く。
pythonです。結論はこれ
import cv2 import numpy as np def cutByPoints(src_img,poly): mask = np.zeros_like(src_img) # (y, x, c) mytest=cv2.cvtColor(mask,cv2.COLOR_BGR2BGRA)#アルファ追加 全画素黒 mytest[:] = (0, 0, 0,0)#全画素透過 mytest = cv2.fillConvexPoly(mytest, np.array(poly), color=(255, 255, 255,255))#図=白 背景=透明 src_img2=cv2.cvtColor(src_img,cv2.COLOR_BGR2BGRA) masked_src_img00 = np.where(mytest==255, src_img2, mytest)#図=元画像 背景=透明 minx =-1 miny=-1 maxx=-1 maxy=-1 leng=len(poly) for i in range(leng): if i==0: minx=poly[i][0] maxx=poly[i][0] miny=poly[i][1] maxy=poly[i][1] else : if minx>poly[i][0]: minx=poly[i][0] if maxx<poly[i][0]: maxx=poly[i][0] if miny>poly[i][1]: miny=poly[i][1] if maxy<poly[i][1]: maxy=poly[i][1] resimg=masked_src_img00[miny : maxy, minx : maxx] return resimgこれ以上googleしないために書いた
使い方はこんな感じ
src_img = cv2.imread("/home/kokawa2003/ピクチャ/kyBXv.png")#元画像 #座標(星の右半分) poly= [ [200, 0], [260, 160], [400, 160], [300, 240], [400, 400], [200, 320], ] img_bool=cutByPoints(src_img,poly) cv2.imwrite("./masked_crop.png", img_bool)
- 投稿日:2021-03-05T22:28:23+09:00
標準入力で渡された高さと長さが分かる図形を二次元配列にする
今回、例に出す図形
今回、例として出す入力は、
例1(文字列の場合) 4 7 O O O X O O O O O X X X O O O X X X X X O X X X X X X X 例2(数字列の場合) 4 7 0 0 0 1 0 0 0 0 0 1 1 1 0 0 0 1 1 1 1 1 0 1 1 1 1 1 1 1文字列の場合
h ,w = [int(x) for x in input().split()] l = [input().split() for _ in range(h)] print(l)数字列の場合
h ,w = [int(x) for x in input().split()] l = [[int(x) for x in input().split()] for _ in range(h)] print(l)全ての結果
#結果(文字列の結果) [['O', 'O', 'O', 'X', 'O', 'O', 'O'], ['O', 'O', 'X', 'X', 'X', 'O', 'O'], ['O', 'X', 'X', 'X', 'X', 'X', 'O'], ['X', 'X', 'X', 'X', 'X', 'X', 'X']] #結果(数字列の場合) [[0, 0, 0, 1, 0, 0, 0], [0, 0, 1, 1, 1, 0, 0], [0, 1, 1, 1, 1, 1, 0], [1, 1, 1, 1, 1, 1, 1]]終わりに
初めてQiitaで記事を試しに書いてみました。まだPython3の経験が3ヶ月なので、これから暇つぶしに書いていこうと思います。
- 投稿日:2021-03-05T22:28:23+09:00
標準入力で入力された高さと長さが分かる図形を二次元配列にする
今回、例に出す図形
今回、例として出す入力は、
例1(文字列の場合) 4 7 O O O X O O O O O X X X O O O X X X X X O X X X X X X X 例2(数字列の場合) 4 7 0 0 0 1 0 0 0 0 0 1 1 1 0 0 0 1 1 1 1 1 0 1 1 1 1 1 1 1文字列の場合
h ,w = [int(x) for x in input().split()] l = [input().split() for _ in range(h)] print(l)数字列の場合
h ,w = [int(x) for x in input().split()] l = [[int(x) for x in input().split()] for _ in range(h)] print(l)全ての結果
#結果(文字列の結果) [['O', 'O', 'O', 'X', 'O', 'O', 'O'], ['O', 'O', 'X', 'X', 'X', 'O', 'O'], ['O', 'X', 'X', 'X', 'X', 'X', 'O'], ['X', 'X', 'X', 'X', 'X', 'X', 'X']] #結果(数字列の場合) [[0, 0, 0, 1, 0, 0, 0], [0, 0, 1, 1, 1, 0, 0], [0, 1, 1, 1, 1, 1, 0], [1, 1, 1, 1, 1, 1, 1]]終わりに
初めてQiitaで記事を試しに書いてみました。まだPython3の経験が3ヶ月なので、これから暇つぶしに書いていこうと思います。
- 投稿日:2021-03-05T21:28:41+09:00
python で関数合成的な何か
関数合成的な何か
$ python -V Python 3.8.6a.pyimport functools class F: @staticmethod def __cmp(f1, f2): def __i1(*args1, **kwargs1): def __i2(*args2, **kwargs2): return f1(*args2, **kwargs2) return f2(__i2(*args1, **kwargs1)) return __i1 @classmethod def composite(cls, *fs): return functools.reduce(cls.__cmp, fs)test
a_test.pyimport pytest import functools from a import F def test_args1(): """1引数の関数合成""" def d1(a): r = a * 2 print(f"d1: {a} * 2 = {r}") return r def d2(a): r = a + 1 print(f"d2: {a} + 1 = {r}") return r def d3(a): r = a // 3 print(f"d3: {a} / 3 = {r}") return r f = F.composite(d1, d2, d3, d1, d2) assert f(123) == 165 def test_args2(): """2引数以上はできないので適当にカリー化するとよい""" def d1(a, b): r = a * b print(f"d1: {a} * {b} = {r}") return r def d2(a, b): r = a + b print(f"d2: {a} + {b} = {r}") return r d3 = functools.partial(d1, b=2) d4 = functools.partial(d2, b=1) d5 = functools.partial(d1, b=3) d6 = functools.partial(d2, b=4) f = F.composite(d3, d4, d5, d6) assert f(123) == 745 def test_args3(): """2引数以上は(ry""" def d1(a, b, c): r = a // b - c print(f"d1: {a} // {b} - {c} = {r}") return r def d2(a, b, c): r = (a + b) ** c print(f"d2: ({a} + {b}) ** {c} = {r}") return r d3 = functools.partial(d1, b=5, c=5) d4 = functools.partial(d2, b=3, c=2) d5 = functools.partial(d1, b=345, c=3) d6 = functools.partial(d2, b=4, c=8) f = F.composite(d3, d4, d5, d6) assert f(123) == 256run test
bash$ pytest -V pytest 6.1.2 $ pytest -s -v a_test.py =============================================== test session starts =============================================== platform darwin -- Python 3.8.6, pytest-6.1.2, py-1.9.0, pluggy-0.13.1 -- /Users/kuryu/.pyenv/versions/3.8.6/bin/python3.8 cachedir: .pytest_cache rootdir: /Users/kuryu/workspace/work plugins: Faker-4.16.0 collected 3 items a_test.py::test_args1 d1: 123 * 2 = 246 d2: 246 + 1 = 247 d3: 247 / 3 = 82 d1: 82 * 2 = 164 d2: 164 + 1 = 165 PASSED a_test.py::test_args2 d1: 123 * 2 = 246 d2: 246 + 1 = 247 d1: 247 * 3 = 741 d2: 741 + 4 = 745 PASSED a_test.py::test_args3 d1: 123 // 5 - 5 = 19 d2: (19 + 3) ** 2 = 484 d1: 484 // 345 - 3 = -2 d2: (-2 + 4) ** 8 = 256 PASSED ================================================ 3 passed in 0.06s ================================================カレー食べたい。
- 投稿日:2021-03-05T20:54:34+09:00
python で関数合成的な何か
a.pyimport functools class F: @staticmethod def __cmp(f1, f2): def __i1(*args1, **kwargs1): def __i2(*args2, **kwargs2): return f1(*args2, **kwargs2) return f2(__i2(*args1, **kwargs1)) return __i1 @classmethod def composite(cls, *fs): return functools.reduce(cls.__cmp, fs) def d1(a): r = a * 2 print("called d1", a, r) return r def d2(a): r = a + 1 print("called d2", a, r) return r def d3(a): r = a / 3 print("called d3", a, r) return r if __name__ == '__main__': f = F.composite(d1, d2, d3, d1, d2) print(f(123))bash$ python a.py called d1 123 246 called d2 246 247 called d3 247 82.33333333333333 called d1 82.33333333333333 164.66666666666666 called d2 164.66666666666666 165.66666666666666 165.66666666666666検算
In [1]: a = 123 In [2]: a = a * 2 In [3]: a = a + 1 In [4]: a = a / 3 In [5]: a = a * 2 In [6]: a = a - 1 In [7]: a Out[7]: 163.66666666666666
- 投稿日:2021-03-05T19:07:05+09:00
関数結果をキャッシュして使う(functools.lru_cached)(Python)
概要
関数結果をキャッシュしたい時に、functools.lru_cachedを使えば良い。
自前で作らなくても大丈夫かもしれない。
内容
環境
macOS Catalina
Python 3.7.0全体像
fibo.pyimport functools @functools.lru_cache(maxsize=None) def factorial(n): print('in', n) return n * factorial(n-1) if n else 1 print('fac 5', factorial(5)) print('fac 3', factorial(3)) print('fac 12', factorial(12))outputin 5 in 4 in 3 in 2 in 1 in 0 fac 5 120 fac 3 6 in 12 in 11 in 10 in 9 in 8 in 7 in 6 fac 12 479001600同じ引数は2度評価されていないことが分かる。
解説
lru: least recently used
最近使ったものだけを
maxsizeまでキャッシュする。
maxsize=Noneとすると、全てキャッシュされる。蛇足
wrapにより、以下のメソッド・属性が追加される。
-factorial.cache_info():maxsizeやcache済数などを示す
-factorial.__wrapped__:wrap前の関数。cache回避や別のwrapに有用。
-factorial.cache_clear():cacheを削除する
-factorial.cache_parameters():3.9以降で使用可能。dictで返す。参考にさせていただいた本・頁
- https://docs.python.org/3/library/functools.html#functools.lru_cache
- https://docs.python.org/ja/3/library/functools.html
感想
便利!使えそう。
今後
使っていきたい。
- 投稿日:2021-03-05T18:53:55+09:00
Google ColabでYOLOv5を使って物体検出してみた
はじめに
Google Colaboratory上でYOLOv5を使用して、物体検出(object detection)する方法についてまとめました。
目次
YOLOv5とは
※上図は、YOLOv5のGitHubページからの引用
物体検出モデルとしては、SSDやYOLOが有名です。
YOLOのversion3であるYOLOv3は、その精度と処理の速さから広く使用されています。
YOLOv5はそのYOLOのversion5にあたり、2020年にリリースされました。
現在でも精力的に開発が進められています。YOLO v3については、以下の記事をご参照下さい。
実装
※言語はPython、環境はGoogle Colaboratoryを使用しています。ご自身の環境に合わせて適宜読み替えて下さい。
※以下の実装は、YOLOv5のGitHubページの、「Train Custom Data」のチュートリアルの内容を一部改変したものです。YOLOv5の準備
まず事前準備として作業ディレクトリを作成しておき、以降その配下で作業を進めていきます。
WORKING_DIR = '/content/tmp' !mkdir $WORKING_DIR %cd $WORKING_DIRYOLOv5をインストールします。
!git clone https://github.com/ultralytics/yolov5無事インストールが完了したら、yolov5配下に移動して依存ライブラリをインストールします。
%cd yolov5/ !pip install -qr requirements.txt学習データの準備
それでは早速学習してモデルを作成したいのですが、そのためには学習データが必要になります。
物体検出における学習データは、画像とそのラベルになります。ラベルは、物体のクラス(その物体が何かを表す)と座標(その物体が画像内のどこに写っているか)になります。
学習データについては、画像を多数用意し、それぞれの画像にラベル付け(何が、どこに、写っているか。アノテーションとも言う)を行って正解データを作成する必要があります。
しかし、この作業にはかなりの時間と労力を要するので、今回はすでに用意されている公開データである、COCOデータセットを使用することにします。それでは、COCOデータセットをダウンロードしてきます。
!wget https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip !unzip coco128.zipCOCOデータセットの中身を確認してみましょう。
上記でダウンロードして展開したcoco128のディレクトリ構成は以下のようになっています。coco128 |_images | |_train2017 | |_000000000009.jpg | |_000000000025.jpg | |_000000000030.jpg | ︙ |_labels |_train2017 |_000000000009.txt |_000000000025.txt |_000000000030.txt ︙imagesディレクトリにはjpgファイルが、labelsディレクトリにはtxtファイルが入っています。
また、それぞれ(拡張子を除いて)ファイル名が一致するものが対応しており、画像とそのラベルになっています。
例えば、000000000009.jpgと000000000009.txtは、以下のようになっています。
000000000009.txt45 0.479492 0.688771 0.955609 0.5955 45 0.736516 0.247188 0.498875 0.476417 50 0.637063 0.732938 0.494125 0.510583 45 0.339438 0.418896 0.678875 0.7815 49 0.646836 0.132552 0.118047 0.096937 49 0.773148 0.129802 0.090734 0.097229 49 0.668297 0.226906 0.131281 0.146896 49 0.642859 0.079219 0.148063 0.148062この写真には、検出対象となる物体が8つあり、それぞれのクラス(45, 49, 50)および座標が
クラス、$x$座標、$y$座標、幅、高さ
の順に記載されています(注釈)。これら2つのファイルは、以下のラベル付きデータを表しています(以下のアノテーションはRoboflowを使用)。
今回は、公開データであるCOCOデータセットを使用しますが、オリジナルのデータの場合にも上記と同様のディレクトリ構成、同様のフォーマットのtxtデータを用意してあげることでモデルを作成することができます。
学習
学習データが用意できたので、学習を行います。
学習は、非常に大きな処理を必要とするため、通常GPUを使用します。
今回はGoogle Colaboratoryを使用していますので、無料でGPUを使うことができます。
「ランタイム>ランタイムのタイプを変更」から「ハードウェア アクセラレータ」を「GPU」
に設定しておきます。GPUに設定できたら、以下のコマンドを実行して学習を行います。
!python train.py --img 640 --batch 16 --epochs 300 --data coco128.yaml --weights yolov5x.ptここでは、yolov5xというモデルを使用して、300エポックの学習を行っています。
学習にはしばらく時間がかかるのでご注意下さい。
5xは最も大きなモデルのため、精度が出やすい分学習には時間がかかります。
試しに学習してみたいという場合には、最も軽量な5sのモデルでかつ少ないエポック数で学習してみることをオススメします。学習中には、以下のように表示されるので、どれぐらい学習が進んでいるかを確認することができます。
Epoch gpu_mem box obj cls total targets img_size 0/299 3.29G 0.04357 0.06778 0.01869 0.13 207 640: 100% 8/8 [00:05<00:00, 1.58it/s] Class Images Targets P R mAP@.5 mAP@.5:.95: 100% 4/4 [00:04<00:00, 1.22s/it] all 128 929 0.647 0.626 0.659 0.432 Epoch gpu_mem box obj cls total targets img_size 1/299 6.66G 0.04307 0.06652 0.02082 0.1304 227 640: 100% 8/8 [00:02<00:00, 2.69it/s] Class Images Targets P R mAP@.5 mAP@.5:.95: 100% 4/4 [00:02<00:00, 1.45it/s] all 128 929 0.68 0.607 0.664 0.434 Epoch gpu_mem box obj cls total targets img_size 2/299 6.66G 0.04457 0.06889 0.01857 0.132 191 640: 100% 8/8 [00:02<00:00, 2.69it/s] Class Images Targets P R mAP@.5 mAP@.5:.95: 100% 4/4 [00:02<00:00, 1.44it/s] all 128 929 0.647 0.63 0.666 0.436 ︙ Epoch gpu_mem box obj cls total targets img_size 299/299 6.66G 0.02718 0.03315 0.004541 0.06487 235 640: 100% 8/8 [00:02<00:00, 2.88it/s] Class Images Targets P R mAP@.5 mAP@.5:.95: 100% 4/4 [00:05<00:00, 1.35s/it] all 128 929 0.953 0.911 0.966 0.795 Optimizer stripped from runs/train/exp/weights/last.pt, 14.8MB Optimizer stripped from runs/train/exp/weights/best.pt, 14.8MB 300 epochs completed in 0.574 hours.無事学習が完了したら、TensorBoardを使用して学習の様子をグラフで確認してみましょう。
# tensorboardの表示 %load_ext tensorboard %tensorboard --logdir runs以下のように、学習の推移が確認できます。
※オレンジがyolov5s, 青がyolov5xのグラフです
推論
それでは、上記でつくったモデル(学習済みモデル)を使用して、推論を行ってみましょう。
!python detect.py --source data/images --weights yolov5x.pt --conf 0.50ここでは、data/images配下の画像に対して推論を行い、確信度が0.50以上のものについてオーバーレイ(検出した物体のクラスと座標を枠で囲んで表示)しています。
まとめ
今回、YOLOv5を使用してGoogle Colaboratory上で物体検出をしてみました。
今回の流れをおさらいすると、以下になります。
- YOLOv5の準備
- 学習データの準備
- 学習
- 推論
また、学習に際しては、最も大きなモデルである5xを300エポック学習させてみました。
これらの選定については、
- どれぐらいの精度が欲しいか
- 学習にかけられる時間はどれぐらいか
が判断材料になるかと思います。
注釈
- 実際には、画像全体の大きさで割ったもの(規格化したもの)になります。画像全体の幅を$W$、高さを$H$としたとき、それぞれ$x\rightarrow x/W, y\rightarrow y/H, w\rightarrow w/W,h\rightarrow h/H$となります。詳しくは、YOLOv5公式ページを参照下さい。
参考文献






- 投稿日:2021-03-05T18:15:58+09:00
Pythonで学ぶ制御工学 第12弾:極・零点と振る舞い
#Pythonで学ぶ制御工学< 極・零点と振る舞い >
はじめに
基本的な制御工学をPythonで実装し,復習も兼ねて制御工学への理解をより深めることが目的である.
その第12弾として「極・零点と振る舞い」を扱う.極と振る舞い
前回(https://qiita.com/Yuya-Shimizu/items/2c9acdb6fdc2ef7440e5 )で,システムの安定性について学び,伝達関数において,極の実部が負であるとき安定となると知った.今回は,もう少し詳細に極とシステムの振る舞いについて知る.また,零点と振る舞いについても後述する.
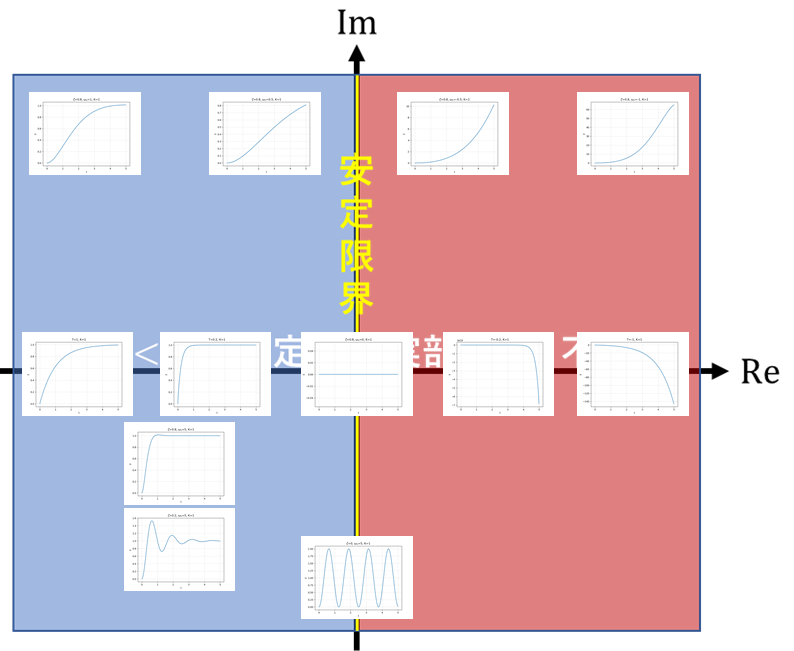
まず,極と振る舞いついて,図を使っての説明を以下に示す.
式から考えると,おおむねこんな感じである.続いて,前回示した安定領域を複素数平面で表現したものに実際に条件別に出力させた応答信号を配置した.以下にその図を示す.
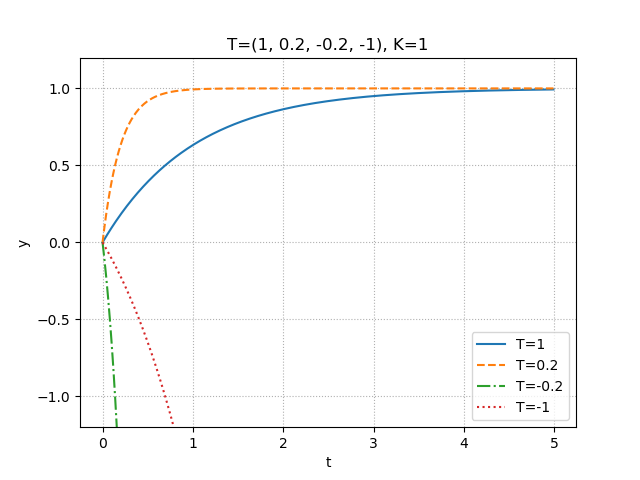
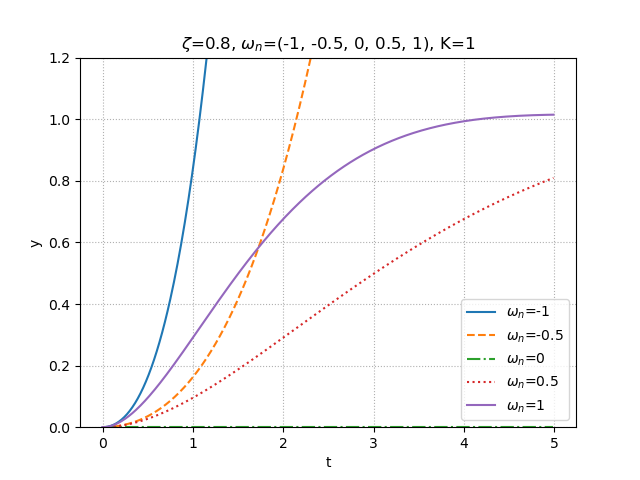
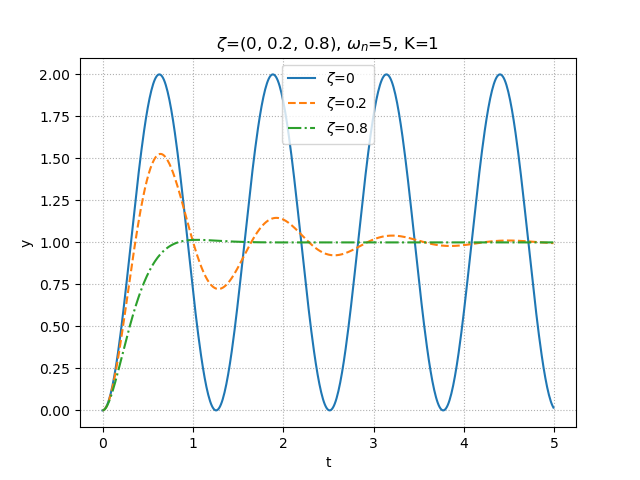
少し見づらいが,先ほどの式から得られた特徴から見ていくと分かりやすい.まず,1次遅れ系のものは,すべて実軸上にあることが分かる.また,2次遅れ系において,$\zeta$を固定させて$\omega_n$を変化させたものが図の上方4つになるが,1次遅れ系も2次遅れ系も実部の大きさによって,応答速度が変化していることが分かる.残るは,図の下方3つだが,これらは2次遅れ系において,$\omega_n$を固定させて$\zeta$を変化させたものである.これらも先ほどの説明どおり,$\zeta=0$,すなわち虚軸上にあるものは,持続振動になっており,また$\zeta$が小さいほど,虚部は大きくなり,より振動的になっていることが分かる.また,虚部が大きいほど振動周期も短くなる.以下にそれぞれの条件に合わせた比較図を3つ示しておく.1つ目は1次遅れ系の時定数変化による振る舞いの違い.2つ目は2次遅れ系の固有角振動数の変化による振る舞いの違い.3つ目は2次遅れ系の減衰係数の変化による振る舞いの違いである.
図 1次遅れ系の時定数変化による振る舞いの違い
図 2次遅れ系の固有角振動数の変化による振る舞いの違い
図 2次遅れ系の減衰係数の変化による振る舞いの違いなお,ここで示した応答信号を出力するプログラムのソースコードは最後に示す.
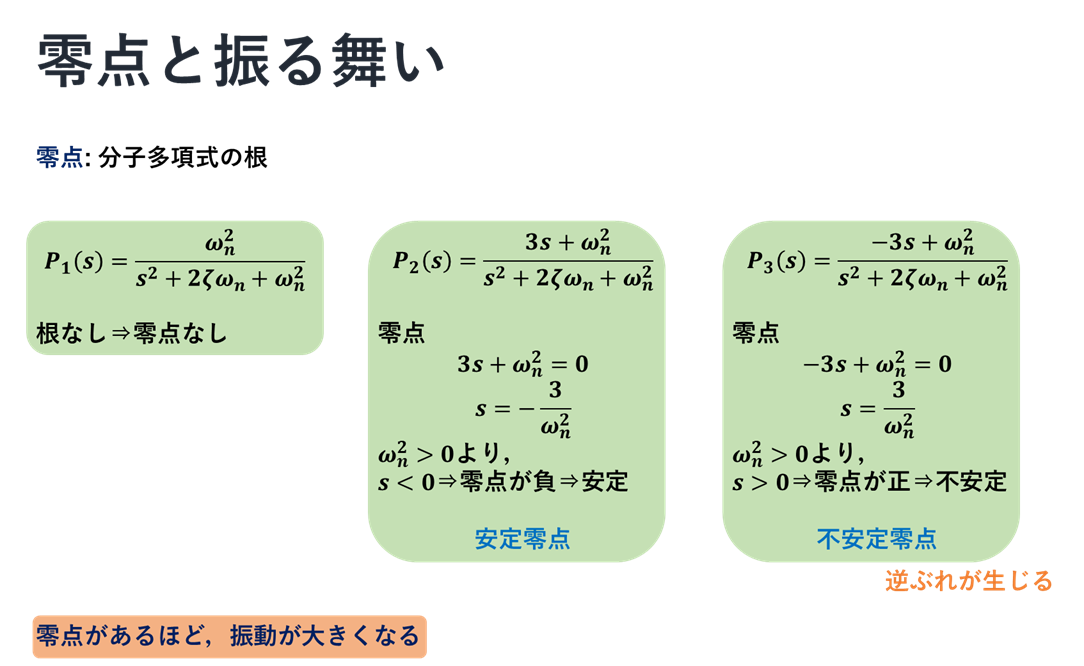
零点と振る舞い
続いて,零点と振る舞いついて,図を使っての説明を以下に示す.
式でいうと,おおむねこんな感じである.続いて,それらの応答信号の振る舞いを次に示す.
$P_1$と$P_2$の応答を比べることで,説明にあったとおり,零点があるときの方が振動が大きくなっていることが分かる.また,$P_3$に注目すると,はじめに少し外れたところへ応答している.このことから,不安定零点であるとき,逆ぶれが生じていることが分かる.
ソースコード
最後に,今回の図を作成するときに作ったプログラムのソースコードを示しておく.
ソースコード①:極と振る舞い(1次遅れ系)
step1.py""" 2021/03/05 @Yuya Shimizu 極と振る舞い(1次遅れ系) """ from control.matlab import * import matplotlib.pyplot as plt import numpy as np from for_plot import * #自分で定義した関数をインポート #定義した関数について (https://qiita.com/Yuya-Shimizu/items/f811317d733ee3f45623) ##1次遅れ系のステップ応答 K = 1 #ゲインの設定 T = (1, 0.2, -0.2, -1) #時定数の設定 y=[] t=[] for i in range(len(T)): P = tf([0, K], [T[i], 1]) #1次遅れ系 yy, tt = step(P, np.arange(0, 5, 0.01)) #ステップ応答(0~5秒で,0.01刻み) y.append(yy) t.append(tt) for i in range(len(T)): fig, ax = plt.subplots() ax.plot(t[i], y[i]) plot_set(ax, 't', 'y') #グリッドやラベルを与える関数(自作のfor_plotライブラリより) plt.title(f"T={T[i]}, K={K}") plt.show() #1つの図にまとめる fig, ax = plt.subplots() LS = linestyle_generator() #線種を与える関数(自作のfor_plotライブラリより) for i in range(len(T)): ax.plot(t[i], y[i], ls=next(LS), label=f"T={T[i]}") plot_set(ax, 't', 'y', 'best') ax.set_ylim(-1.2, 1.2) plt.title(f"T={T}, K={K}") plt.show()ソースコード②:極と振る舞い(2次遅れ系)
step2.py""" 2021/03/05 @Yuya Shimizu 極と振る舞い(2次遅れ系) """ from control.matlab import * import matplotlib.pyplot as plt import numpy as np from for_plot import * #自分で定義した関数をインポート #定義した関数について (https://qiita.com/Yuya-Shimizu/items/f811317d733ee3f45623) ##2次遅れ系のステップ応答(固有角振動数omega_nを変化させる) zeta = 0.8 omega_n = (-1, -0.5, 0, 0.5, 1) #3種類の固有角振動数を用意 K = 1 y=[] t=[] for i in range(len(omega_n)): P = tf([0, K*omega_n[i]**2], [1, 2*zeta*omega_n[i], omega_n[i]**2]) #2次遅れ系 yy, tt = step(P, np.arange(0, 5, 0.01)) #ステップ応答(0~5秒で,0.01刻み) y.append(yy) t.append(tt) #図示 for i in range(len(omega_n)): fig, ax = plt.subplots() ax.plot(t[i], y[i]) plot_set(ax, 't', 'y') #グリッドやラベルを与える関数(自作のfor_plotライブラリより) plt.title(f"$\zeta$={zeta}, $\omega_n$={omega_n[i]}, K={K}") plt.show() #図示の準備 fig, ax = plt.subplots() LS = linestyle_generator() #線種を与える関数(自作のfor_plotライブラリより) for i in range(len(omega_n)): ax.plot(t[i], y[i], ls=next(LS), label=f"$\omega_n$={omega_n[i]}") plot_set(ax, 't', 'y', 'best') ax.set_ylim(0, 1.2) plt.title(f"$\zeta$={zeta}, $\omega_n$={omega_n}, K={K}") plt.show() ##2次遅れ系のステップ応答(減衰係数zetaを変化させる) zeta = (0, 0.2, 0.8) #5種類の減衰係数を用意 omega_n = 5 K = 1 y=[] t=[] for i in range(len(zeta)): P = tf([0, K*omega_n**2], [1, 2*zeta[i]*omega_n, omega_n**2]) #2次遅れ系 yy, tt = step(P, np.arange(0, 5, 0.01)) #ステップ応答(0~5秒で,0.01刻み) y.append(yy) t.append(tt) #図示 for i in range(len(zeta)): fig, ax = plt.subplots() ax.plot(t[i], y[i]) plot_set(ax, 't', 'y') #グリッドやラベルを与える関数(自作のfor_plotライブラリより) plt.title(f"$\zeta$={zeta[i]}, $\omega_n$={omega_n}, K={K}") plt.show() #図示の準備 fig, ax = plt.subplots() LS = linestyle_generator() #線種を与える関数(自作のfor_plotライブラリより) for i in range(len(zeta)): ax.plot(t[i], y[i], ls=next(LS), label=f"$\zeta$={zeta[i]}") plot_set(ax, 't', 'y', 'best') plt.title(f"$\zeta$={zeta}, $\omega_n$={omega_n}, K={K}") plt.show()ソースコード③:零点と振る舞い
step3.py""" 2021/03/05 @Yuya Shimizu 零点と振る舞い """ from control.matlab import * import matplotlib.pyplot as plt import numpy as np from for_plot import * #自分で定義した関数をインポート #定義した関数について (https://qiita.com/Yuya-Shimizu/items/f811317d733ee3f45623) ##零点による振る舞いの変化 zeta = 0.3 #減衰係数 omega_n = 5 #固有角振動数 K = 1 #ゲイン Np = [[0, K*omega_n**2], #P1 : 零点なし [3, K*omega_n**2], #P2 : 安定零点 [-3, K*omega_n**2]] #P3 : 不安定零点 #図示の準備 fig, ax = plt.subplots() LS = linestyle_generator() #線種を与える関数(自作のfor_plotライブラリより) for i in range(len(Np)): P = tf(Np[i], [1, 2*zeta*omega_n, omega_n**2]) y, t = step(P, np.arange(0, 5, 0.01)) #ステップ応答(0~5秒で,0.01刻み) ax.plot(t, y, ls=next(LS), label=f"$P_{i+1}$") plot_set(ax, 't', 'y', 'best') plt.title(f"$\zeta$={zeta}, $\omega_n$={omega_n}, K={K}") plt.show()感想
今回は,式からと図から極・零点と振る舞いについて学んだ.これらは,システムの振る舞いを理解するのに非常に重要な部分であると思う.
参考文献
Pyhtonによる制御工学入門 南 祐樹 著 オーム社


- 投稿日:2021-03-05T17:32:32+09:00
Wikipediaの情報をCSVに保存し、Railsで活用
野球選手のデータをRailsで扱いたかったんですが、活用できるAPIがなかったので自力で集めてみました。
PythonはGoogleColaboratoryを使用してます。0.流れ
Wikipediaの情報をGoogleColaboratoryからスクレイピング
↓
データを整え、CSVに保存
↓
Railsのデータベースに保存
↓
表示する1.スクレイピング
準備
import requests import pandas as pd from bs4 import BeautifulSoup # 広島東洋カープの選手一覧 url = "https://ja.wikipedia.org/wiki/%E5%BA%83%E5%B3%B6%E6%9D%B1%E6%B4%8B%E3%82%AB%E3%83%BC%E3%83%97%E3%81%AE%E9%81%B8%E6%89%8B%E4%B8%80%E8%A6%A7"データの取得
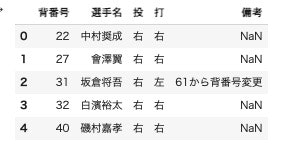
df = pd.read_html(url) df[5].head()
df[4]には投手の情報が入っています。
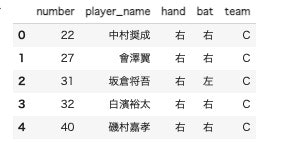
df[5],[6],[7]に捕手、内野手、外野手の情報が入っているので、野手として1つにまとめます。df_before_fielder = pd.concat([df[5], df[6], df[7]], ignore_index=True) #新たに行番号の割り当てのオプションカラム名を英語表記に変更
df_before_fielder.rename(columns={"背番号":"number", "選手名":"player_name", "投":"hand", "打":"bat", "備考":"remark"}, inplace=True) df_fielder=df_before_fielder.drop("remark", axis=1) #備考蘭がいらなかったため削除 df_fielder["team"]="C" #チーム名として、カープ(Carp)の省略英表記のCを追加 df_fielder.head()
2.CSV保存
from google.colab import files import datetime # ファイル名に日時を挿入 dt_now = datetime.datetime.now() dt = dt_now.strftime('%Y%m%d%H%M%S') file_name = "c_pitcher_"+ dt + ".csv" # CSVに変換 df_fielder.to_csv(file_name, index=False) # CSVファイルのダウンロード files.download(file_name)3.Rails
モデルの作成
$ rails g model Player number:integer player_name:string hand:string bat:string team:stringCSVの情報をデータベースに保存
require 'csv' CSV.foreach("c_fielder_20210304124010.csv", headers: true) do |row| #「headers: true」先頭行をヘッダーとするので、rowには入らない Player.create!( # rowには、["22", "中村奨成", "右", "右", "C"]と各選手の情報が入っている。 number: row[0].to_i, #ファイル内で文字列になっていたため数値へ変換 player_name: row[1], hand: row[2], bat: row[3], team: row[4] ) end puts "Finish!"コントローラの作成
$ rails g controller Players indexコントローラからDBの情報を取得
class PlayersController < ApplicationController def index @players = Player.all end endビューで表示
<% @players.each do |player| %> <li style="list-style: none"> <%= player.number %> <%= player.player_name %> <%= player.hand %> <%= player.bat %> <%= player.team %> </li> <% end %>4.結果
こんな感じに表示することができました。

- 投稿日:2021-03-05T17:20:32+09:00
FizzBuzzをPythonで作成
背景
手習いでFizzBuzzをやってみようと思う。
FizzBuzzの仕様
1から100までの数をプリントするプログラムを書け。ただし3の倍数のときは数の代わりに「Fizz」と、5の倍数のときは「Buzz」とプリントし、3と5両方の倍数の場合には「FizzBuzz」とプリントすること。
コード
for cnt in range(1, 101): if cnt % 15 == 0: print("FizzBuzz") elif cnt % 3 == 0: print("Fizz") elif cnt % 5 == 0: print("Buzz") else: print(cnt)感想
この後、やさしい本でよく確認しようと思います。
- 投稿日:2021-03-05T17:07:53+09:00
動的クラス継承とかいう黒魔術
はじめに
最初に断っておきますが、Pythonでは公式で動的クラス継承をサポートしていません。ということは推奨されないということですので、基本的に使わないでください。というか使わなくてもなんとかなるでしょう。
本記事の方法では一応普通のクラス継承と見た目変わらなさそうな動作をしますが、もしかしたら意図しない動作をする可能性も大いにあります。
その辺りの詳しい検証はしていませんので、使う場合は自分だけとか、ごく小規模なグループ内程度に留めておいてください。もちろん自己責任でよろしくお願いします。
また、そういった詳細についてご存知の方いらっしゃればご教授よろしくお願いします!概要
動的クラス継承できたらなんか便利じゃね?ということが研究中にありましたので、できないかな〜といろいろ調べたところ、残念ながら求める記事には辿り着けず...しかしいろいろなサイトを参考にそれっぽいことを実現しましたので覚書しておきます。
多重継承とはまた違いますのでご注意ください。(Pythonの多重継承もなかなか闇が深いみたいですね〜)目次
クラスの継承
まずはクラスの継承について簡単に触れておきます。
クラスの継承はオブジェクト指向プログラミングにおける最大のメリットの一つで、使えるとコードがスッキリして見やすくなることが多いです。
図で例えると、「動物」がインターフェイス/抽象クラス、「猫」「犬」が親クラス、それ以外が子クラスといった感じで名前がつけられています。インターフェイス/抽象クラス
インターフェイスや抽象クラスの違いについてはこちらなどをご覧ください。
Pythonではabcというパッケージを利用すれば生成することができます。
正直インターフェイスと抽象クラスの違いについてはイマイチ理解できていない感が否めませんが、まあこれらを継承したクラスに対して特定のメソッドなどを強制的に実装させる、というのがキーポイントのようです。
実装の設計図みたいな理解でいいのではないでしょうか。先の図では「動物」がその役割を担っています。
例えば「鳴く」というメソッドを定義しておけば、子クラスで鳴き方の詳細を実装するように強制できます。親クラス
インターフェイスや抽象クラスとは違い、子クラスにメソッドの実装を強制したりはできません。(
NotImplementedErrorを投げておけば似たようなことはできます)
子クラス群に共通した処理を実装しておけば、子クラスでそのメソッドを実装する必要がなくなります。
例えば「猫」クラスに「グルーミング」というメソッドを実装しておけば、子クラスである「ペルシャ」などでいちいち「グルーミング」を実装する必要がなくなります。子クラス
子クラスはインターフェイスや抽象クラス、親クラスを継承したクラスのことを言います。
図では「猫」「犬」「ペルシャ」「ジャーマンシェパード」などにあたります。
それぞれに固有のメソッドなどを実装することを目的としており、まあ詳細の実装をするためのクラスって感じです。動的クラス継承
さて、本題である動的クラス継承の実装詳細について見ていきましょう。
とりあえずコード全文を載せます。
動的クラス継承コード全体
dynamic_class_inheritance.pyfrom dataclasses import dataclass import numpy as np @dataclass class Survive(): heart_beat: int = 150 def meow(self): print("ミャー") @dataclass class Dead(): heart_bead: int = 0 year_of_enjoyment: int = 5 @dataclass class SchrodingerCat(): threshold: float = 0.5 def __post_init__(self, *args, **kwds): if np.random.rand() > self.threshold: obj = Survive() else: obj = Dead() # Add attributes to myself for k, v in obj.__dict__.items(): if k not in self.__dict__: self.__dict__[k] = v # Keep them under the control of dataclass and rename my class name. my_fields = [] for k, v in self.__dict__.items(): if isinstance(v, (dict, list, set)): my_fields.append((k, type(v), field(default_factory=v))) else: my_fields.append((k, type(v), v)) self.__class__ = make_dataclass(f"{obj.__class__.__name__}SchrodingerCat", my_fields, bases=(SchrodingerCat, obj.__class__)) # Add funcgtions and properties to myself. for k in dir(obj): if k not in dir(self): setattr(self, k, getattr(obj, k)) def hello(self): print("吾輩は猫である。名前はまだない。") cat = SchrodingerCat() print(cat.__class__) print(f"{isinstance(cat, SchrodingerCat)=}") print(f"{isinstance(cat, Survive)=}") print(f"{isinstance(cat, Dead)=}") print(cat) pprint(fields(cat)) for x in dir(cat): if x[0] != "_": print(x) cat.hello() if isinstance(cat, Survive): cat.meow()
みんな大好きシュレーディンガーの猫に登場してもらいました。
(画像はwikipediaより)
__post_init__にて確率で猫の生死が決まり、それを元にアトリビュートや関数の継承が行われます。
詳しく見ていきます。アトリビュートの継承
まずアトリビュートの継承から見ていきます。
アトリビュートの継承コード
dynamic_class_inheritance.py# Add attributes to myself for k, v in obj.__dict__.items(): if k not in self.__dict__: self.__dict__[k] = v # Keep them under the control of dataclass and rename my class name. my_fields = [] for k, v in self.__dict__.items(): if isinstance(v, (dict, list, set)): my_fields.append((k, type(v), field(default_factory=v))) else: my_fields.append((k, type(v), v)) self.__class__ = make_dataclass(f"{obj.__class__.__name__}SchrodingerCat", my_fields, bases=(SchrodingerCat, obj.__class__))
オブジェクトのアトリビュートを取得するにはobj.__dict__を利用します。この__dict__にはオブジェクトが持つ全てのアトリビュートが含まれており、objにあってselfにないアトリビュートのみselfに追加するようにしてあります。
もし双方が同じアトリビュートを持つ場合にobjの値へ上書きしたい場合は、if文を消してしまえばOKなはずです。後半部分は
dataclassを使用している場合にのみ必要な処理で、追加したアトリビュートを含めた全てのアトリビュートを持つdataclassクラスを生成してself.__class__に上書きしています。
リスト型や辞書型、集合型はfieldを利用した時の宣言方法が異なるため場合分けしてあります。
また、make_dataclassのbasesキーワードは親クラスの設定をしてくれるクラスです。
つまるところ、この部分での処理をまとめると、
- フィールドを生成
SchrodingerCatとobj.__class__を継承した新しいクラスを生成self.__class__に上書きといったことをしています。
メソッド・プロパティの継承
メソッド・プロパティの継承コード
dynamic_class_inheritance.py# Add funcgtions and properties to myself. for k in dir(obj): if k not in dir(self): setattr(self, k, getattr(obj, k))
メソッドやプロパティの一覧を取得するにはdir関数を利用します。(ちなみに実はアトリビュートも取得されますが、コードの読みやすさのためにわざと分けています)
ここでもobjにあってselfにないメソッド・プロパティのみselfに追加しています。
もし上書きしたい場合はやはりif文を削除すればOKのはずです。ただ__init__などの特殊メソッドも上書きされてしまうので注意/工夫が必要です。おわりに
シュレーディンガーの猫って、それ自体は超有名ですが、実際きちんと知ってる人ってどのくらいいるんでしょうか?
ぼく自身も「猫かわいそう」くらいにしか思ってませんでしたが、実は結構奥が深い、面白い思考実験だと知って驚きました。量子力学の世界は摩訶不思議ですね〜参考


- 投稿日:2021-03-05T16:39:02+09:00
「0から作るDeepLearning」の6章を写経した時のエラー原因2
こんにちは!
今日のエラー原因を書きます。
使用した本:「0から作るDeepLearning」
リポジトリしたプログラム → deep-learning-from-scratch
「hyperparameter.optimization.py」の写経について
・9割方写し間違いで文法的な間違いはなかった。
エラー対策
移し直すのみ
所感
3日連続で写経していると段々と移すスピードが早くなってきている感覚があります。
後は詳細なプログラムの内容を理解していきたいと思います。
- 投稿日:2021-03-05T16:33:33+09:00
Dashで作成したアプリをGitHubと連携させてHerokuに自動デプロイ
はじめに
Dashで作成したアプリをHerokuにデプロイでアプリを Heroku にデプロイした。GitHub と連携させることができるようなので試してみた。私の GitHub アカウントはこれ。
GitHub にコードをプッシュ
自身の GitHub にて whc-app という名前のリモートレポジトリを作成。Dashで作成したアプリをHerokuにデプロイにて、すでにローカルレポジトリが存在するため、リモートレポジトリにプッシュする。
$ git remote add origin https://github.com/bemac-honda/whc-app.git $ git branch -M main $ git push -u origin mainGitHub と連携
Heroku Dashboardにて、[ whc-app ] → [ Deploy タブ ] → [ Deployment method ] から "GitHub" を選択。[ Connect to GitHub ] で自身のレポジトリを検索して [ Connect ]。
連携がうまくできれば Automatic deploys と Manual deploy の 2 通りのデプロイができるようになるので、順に試す。Manual deploy
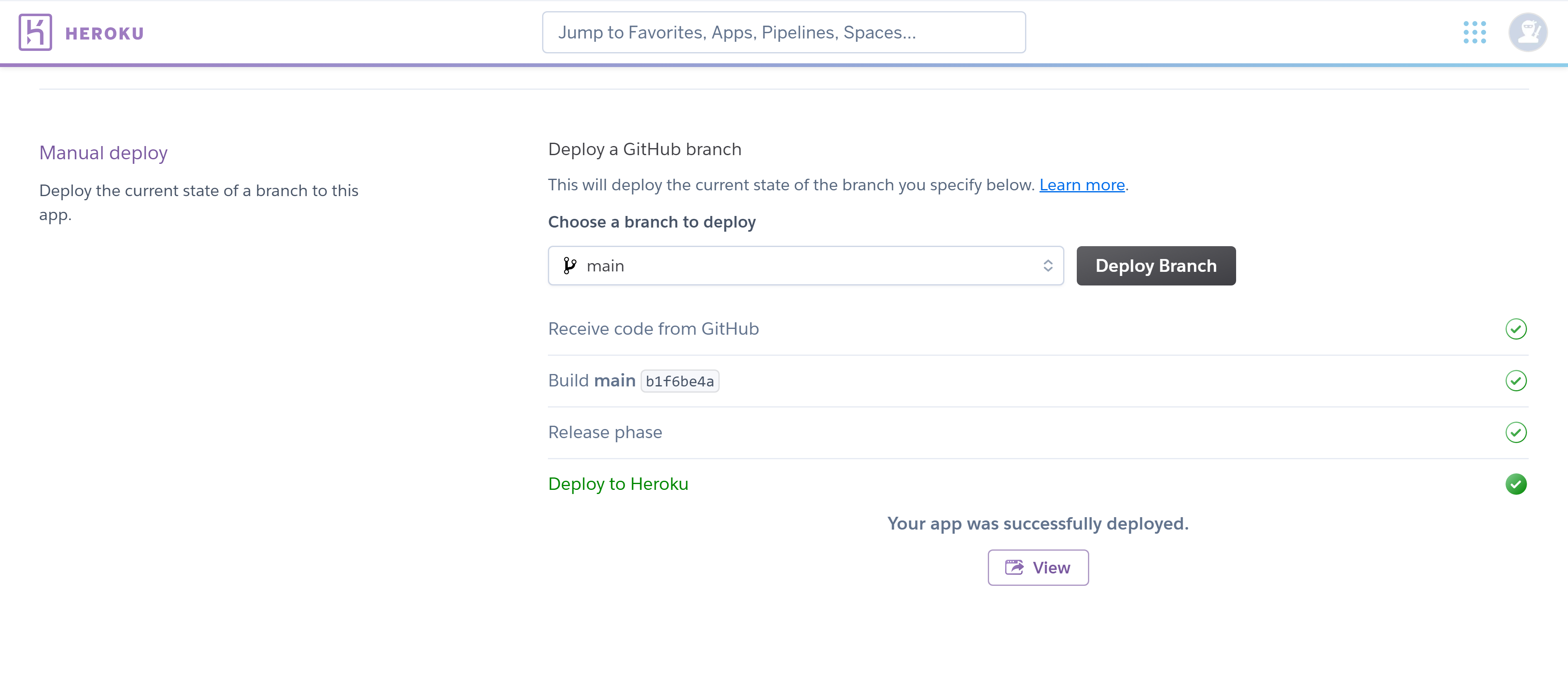
文字とおり手動でデプロイを行う。
[ Manual deploy ] にて、ブランチを選択して [ Deploy Branch ] を押すだけ。なにもなければ main ブランチでよいと思う。問題なくデプロイできれば [ View ] からそのままアプリを見ることができる。Automatic deploys
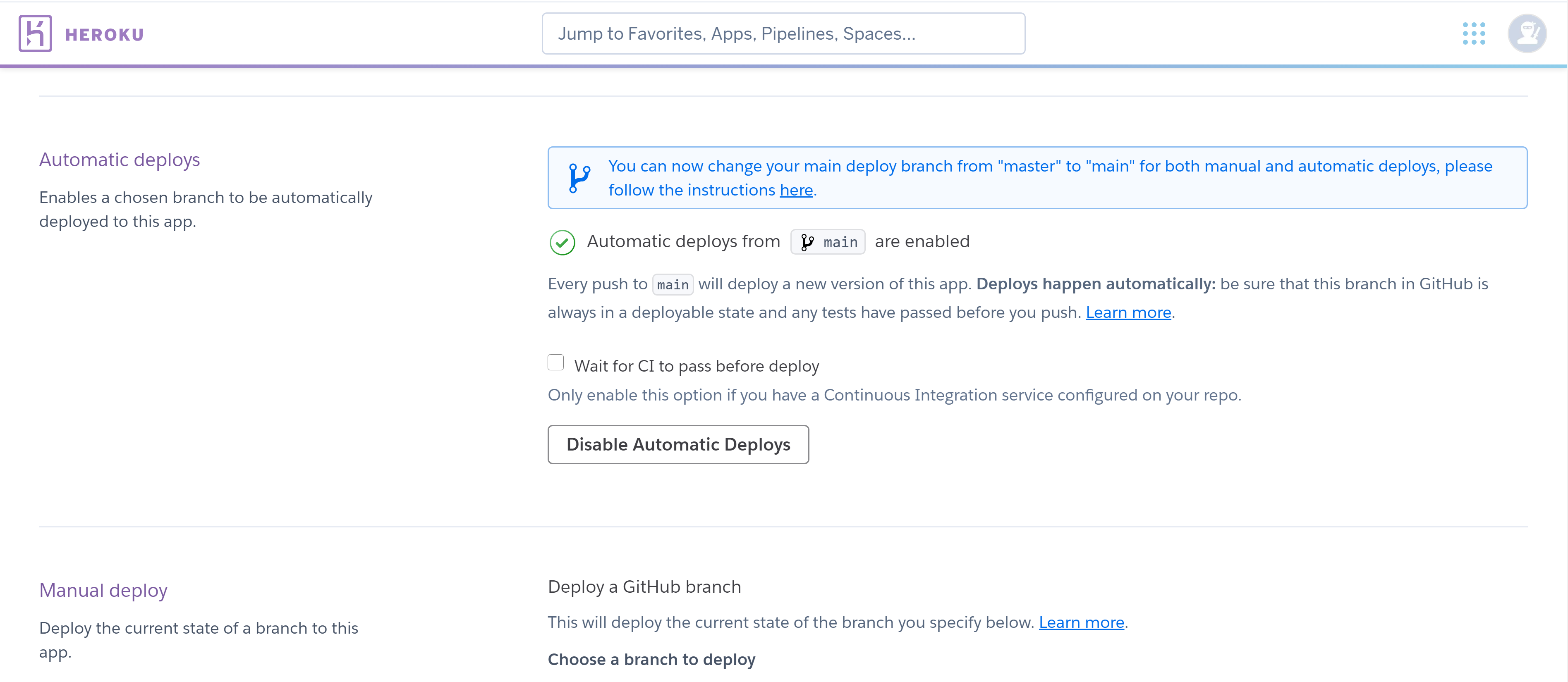
GitHub にプッシュするとソースコードの変更を検知して、自動で Heroku のビルドを実行し、デプロイしてくれる。
[ Automatic deploys ] にて、ブランチを選択して [ Enable Automatic Deploys ] をクリック。これで今後コードを変更した際は GitHub にさえプッシュしておけば自動でデプロイされる。
- 投稿日:2021-03-05T16:12:47+09:00
WaniCTF simple をGhidraで静的解析してみた
Ghidraを勉強した記録として残しておく。
基本的な stack strings の問題なのでsimpleと名付けられたのだと思う。表層解析で得られる文字列 incorrect を検索
普通にmain関数内main関数のデコンパイル結果(当初)
undefined8 main(void) { size_t sVar1; undefined8 uVar2; char local_78 [48]; char local_48 [60]; uint local_c; printf("input flag : "); __isoc99_scanf(&DAT_00100922,local_48); sVar1 = strlen(local_48); if (sVar1 == 0x24) { local_78[0] = 'F'; local_78[1] = 0x4c; local_78[2] = 0x41; (中略) local_78[33] = 0x67; local_78[34] = 0x73; local_78[35] = 0x7d; local_c = 0; while (local_c < 0x24) { if (local_48[(int)local_c] != local_78[(int)local_c]) { puts("Incorrect"); return 1; } local_c = local_c + 1; } printf("Correct! Flag is %s\n",local_48); uVar2 = 0; } else { puts("incorrect"); uVar2 = 1; } return uVar2; }変数の型を変更してデコンパイル結果の誤りを正し,わかりやすい変数名に変更
undefined8 main(void) { size_t size; undefined8 uVar1; char flag [48]; char input_value [60]; int i; printf("input flag : "); __isoc99_scanf(&DAT_00100922,input_value); size = strlen(input_value); if (size == 0x24) { flag[0] = 'F'; flag[1] = 0x4c; flag[2] = 0x41; (中略) flag[33] = 0x67; flag[34] = 0x73; flag[35] = 0x7d; i = 0; while ((uint)i < 0x24) { if (input_value[i] != flag[i]) { puts("Incorrect"); return 1; } i = i + 1; } printf("Correct! Flag is %s\n",input_value); uVar1 = 0; } else { puts("incorrect"); uVar1 = 1; } return uVar1; }ソルバー ( Ghidra Script )
ans=[] inst = getInstructionAt(toAddr(0x00100793)) i = 0 while i < 0x24: ans.append(inst.getOpObjects(1)[0].getValue()) inst = inst.getNext() i = i + 1 print(ans) print(''.join(map(chr,ans)))
- 投稿日:2021-03-05T16:12:31+09:00
体験して学ぶ! ~ロジスティック回帰~
こんにちは、N高人工知能研究会のまさきです
AIの大衆化をモットーに誰もがAIに興味を持てる教材(記事)を作っていきます!2回目である今回は ロジスティック回帰 というアルゴリズムを体験してもらいます
よろしくお願いします開発環境や前提知識について
こちらの前回の記事と全く同じです。
GoogleColabでのノートブック作成方法も前回を参考に進めてください。分類アルゴリズムと回帰アルゴリズムの違い
まずは分類アルゴリズムと回帰アルゴリズムの違いから説明していきます。
例えば前回の記事で紹介した 線形回帰 は
このような連続値を表現しました。
具体的には
- 過去の気象データを使用して明日の天気を予想する
- 今までの動画視聴履歴からおすすめの動画を導き出す
などなど大雑把にいうと過去のデータから未来の何かを予測するものです
そしてもう一つの分類アルゴリズムは
- 花弁の長さや幅を元に数種類の花を分類する
- 映画のレビューを元にそれが好意的なレビューなのか批判的なレビューなのかを予測する
などなど分類は受け取ったデータが何に属するのかを予測するものです
今回紹介するロジスティック回帰は後者の分類アルゴリズムです。
名前に「回帰」とついていますが分類アルゴリズムなので注意してくださいねロジスティック回帰を体験する
今回は「LogisticRegression.ipynb」という名前でファイルを作成しました
今回の課題
こちらのコードを実行してみてください
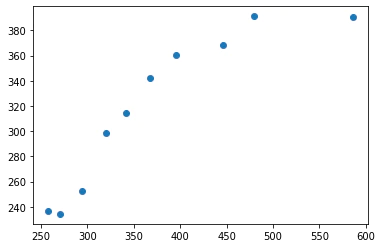
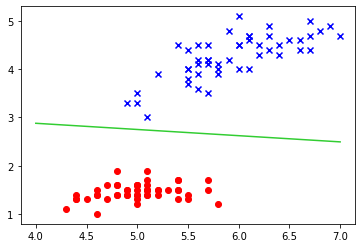
from sklearn import datasets import matplotlib.pyplot as plt # Irisデータセット(後述)をロード iris = datasets.load_iris() # (cm単位の花びらの長さ),(がく片の長さ)の二つの特徴量を抽出 X = iris.data[:100, [0, 2]] # クラスラベルを取得 y = iris.target[:100] plt.scatter(X[:50, 0], X[:50, 1], c='red') plt.scatter(X[50:, 0], X[50:, 1], c='blue', marker='x')すると
こんなグラフが表示されるはずです。
今回はこの赤と青のクラスを分ける下の画像のような線をコンピュータに見つけてもらうのが目的です!
irisデータセットについて
コードのコメントに書いてあったirisデータセットというのはネット上に公開されていて誰でも利用できるデータセットのことです。
他にも色々なデータセットが存在しています。
今回利用するirisはアヤメという花の花弁とがくに関する4つの特徴量を元に3種類のアヤメをクラス分けするというものです。上のコードではわかりやすさを優先し花の種類を二種類に、特徴量も同じく二種類に限定しています
ロジスティック回帰で学習する
次に学習させます!
と言っても学習データもすでに作成しているので少しコードを書くだけです!from sklearn import linear_model # ロジスティック回帰の識別器を用意 lr = linear_model.LogisticRegression() # 識別器を学習させる lr.fit(X, y)これだけ。
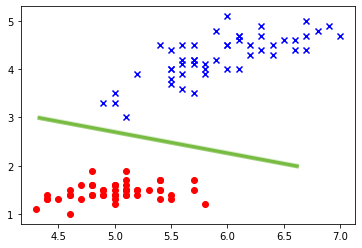
ではどんな感じに線を引いてくれてるかみてみましょう
w_0 = lr.intercept_[0] w_1 = lr.coef_[0,0] w_2 = lr.coef_[0,1] # 元データをプロット plt.scatter(X[:50, 0], X[:50, 1], c='red') plt.scatter(X[50:, 0], X[50:, 1], c='blue', marker='x') # 境界線 プロット plt.plot([4,7], list(map(lambda x: (-w_1 * x - w_0)/w_2, [4,7])), color='limegreen')
バッチリ分けられていますね!次の課題:3つのクラスを分ける
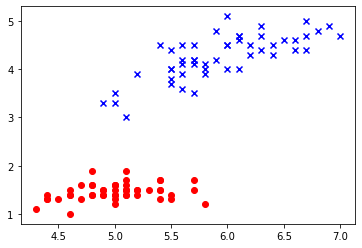
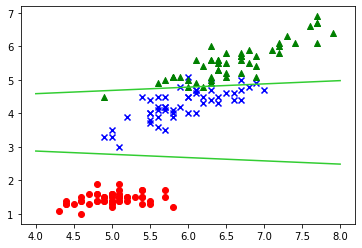
学習データを定義しなおした下のコードを実行してみてください
X = iris.data[:, [0, 2]] y = iris.target plt.scatter(X[:50, 0], X[:50, 1], c='red') plt.scatter(X[50:100, 0], X[50:100, 1], c='blue', marker='x') plt.scatter(X[100:150, 0], X[100:150, 1], c='green', marker='^')
先程の二つのクラスに新しく緑の三角のクラスが加わっていますね!
同じようにロジスティック回帰で分類してみましょう# ロジスティック回帰の識別器を用意 lr = linear_model.LogisticRegression(multi_class='ovr') # 識別器を学習させる lr.fit(X, y)multi_classというパラメータを新しく設定します
次に可視化してみましょう# 元データをプロット plt.scatter(X[:50, 0], X[:50, 1], c='red') plt.scatter(X[50:100, 0], X[50:100, 1], c='blue', marker='x') plt.scatter(X[100:150, 0], X[100:150, 1], c='green', marker='^') # 赤と青の境界線 w_0 = lr.intercept_[0] w_1 = lr.coef_[0,0] w_2 = lr.coef_[0,1] # 境界線 プロット plt.plot([4,8], list(map(lambda x: (-w_1 * x - w_0)/w_2, [4,7])), color='limegreen') # 青と緑の境界線 w_0 = lr.intercept_[2] w_1 = lr.coef_[2,0] w_2 = lr.coef_[2, 1] plt.plot([4,8], list(map(lambda x: (-w_1 * x - w_0)/w_2, [4,7])), color='limegreen')
直線しか引けないので緑と青の境界線が完璧ではありませんが、いい感じに引けましたね実践問題
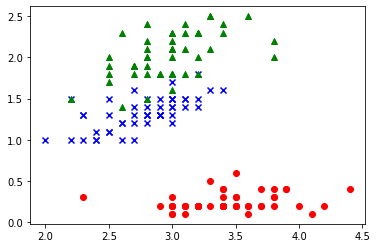
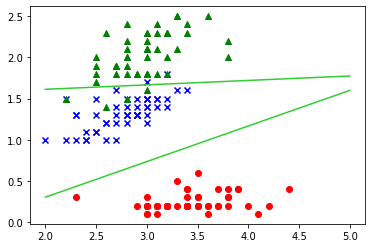
X = iris.data[:, [1, 3]] y = iris.target plt.scatter(X[:50, 0], X[:50, 1], c='red') plt.scatter(X[50:100, 0], X[50:100, 1], c='blue', marker='x') plt.scatter(X[100:150, 0], X[100:150, 1], c='green', marker='^')
こちらのグラフを同じように3つのクラスに分けてみてください!
うまくできるとこんなふうになるはずです
参考書籍
終わりに
この記事を最後まで読んでいただいてありがとうございます
これからもAI初心者なりに頑張ってわかりやすい教材(記事)をたくさん作っていくのでよろしくお願いします!N高生の方であればぜひslackの「人工知能研究会」チャンネルに参加してみてくださいね


- 投稿日:2021-03-05T15:57:29+09:00
Dashで作成したアプリをHerokuにデプロイ
はじめに
Dashで世界遺産を世界地図にプロットでアプリを作成してみたので、Heroku を使ってデプロイしてみる。準備はGetting Started on Heroku with Pythonを、Dash アプリのデプロイはDeploying Dash Appsを参考に進める。実行環境は以下の通り。
- Windows10 Pro
- Python 3.7.6
- Anaconda 4.9.2コマンドライン上で行うものはすべて Anaconda Prompt で実行している。
準備
Heroku にデプロイするにあたり、以下が必要となる。
- Git
- Heroku Command Line Interface (CLI)Git はすでにインストールしてあるため、Heroku CLI をインストール。Getting Started on Heroku with Pythonにインストーラがあるので、該当するものをダウンロードし、インストールする。インストールはデフォルトのまま行った。
Anaconda Prompt 上で
$ heroku loginコマンドを実行すると、ウェブブラウザが立ち上がるのでログイン(アカウントがない場合は作成)する。ログインが完了したらこのブラウザは消しても問題ない。Dash アプリのデプロイ
Deploying Dash Appsに従って進める。なお、仮想環境は venv ではなく Anaconda を用いている。
1. プロジェクトディレクトリの作成
$ mkdir world-heritage-cite $ cd world-heritage-cite2. Git によるディレクトリの初期化
test はもともと使用していた仮想環境。デプロイには gunicorn が必要となるため、インストールする。
$ git init $ conda activate test $ pip install gunicorn3. app.py, .gitignore, requirements.txt, and Procfile の作成
app.py
app.py はDashで世界遺産を世界地図にプロットで作成したものを data とともにそのまま置く。名前は必ず app.py である必要があるようなので、名前を変更しておく。また
import osとserver = app.serverの二文をプログラムに追記しておく。.gitignore
参考記事とは違いがあるので、いくつか削除して作成。正直理解していないので、詳しい方いたらコメントください。
# venv # venv は使用していない *.pyc # .DS_Store # Mac OS 特有のもの(?) .env # 正直よくわかっていないので残しとくProcfile
以下内容で作成。
web: gunicorn app:serverrequirements.txt
$ pip freeze > requirements.txtで自動で生成されるとのことだったが、以降で行う 4 のプッシュ時にエラーを吐いたので、自分で書く。(Anaconda を使っているので、pip freeze がうまく機能しないのかも。)dash dash-core-components dash-html-components gunicorn numpy pandas plotly4. Heroku の初期化、Git へのプッシュ、デプロイ
以下コマンドを実行。(余談ですが Windows は ' ' だとエラーを吐くようなので、" " を使う必要があるらしい。)
$ heroku create whc-app $ git add . $ git commit -m "Initial commit" $ git push heroku master $ heroku ps:scale web=1https://whc-app.herokuapp.comに接続するもエラー。
heroku logs --tailでエラーログを見てみると、app.py での単純なプログラムのミス(データの読み込みをローカルにおける絶対パスにしていた)ためだった。修正後はうまく動いた。次は Heroku でのデプロイができたので、AWS におけるデプロイなども試したい。
- 投稿日:2021-03-05T15:17:44+09:00
[Django][RESTframework]追加、更新、取得の簡単な動的APIを作成する 備忘録
前書き
すごく遠回りしながらなんとか作成できたAPIについて備忘録を残す。
今回作ったAPIは以下のようになる
# ユーザーの登録 http://127.0.0.1:8000/v1/user/ # pk=1 のユーザー情報を更新 http://127.0.0.1:8000/v1/user/1/ # pk=2 のユーザー情報を取得 http://127.0.0.1:8000/v1/user/2/affinity準備
プロジェクト名:project
アプリ名 :api構成
└─project ├─api │ ├─migrations │ │ └─.. │ ├─__init__.py │ ├─apps.py │ ├─models.py │ ├─serializer.py │ ├─urls.py │ └─views.py ├─project │ ├─__init__.py │ ├─asgi.py │ ├─settings.py │ ├─urls.py │ └─wsgi.py ├─db.sqlite3 └─manage.pyプロジェクト作成
$ django-admin startproject project $ cd project $ python manage.py startapp api $ brew install mysql $ pip install pymysql $ pip install djangorestframework $ pip install django-filter $ mysql.server start # mysql.server stop でサーバー停止 #MySQLに入る $ mysql -u rootMySQLの操作
mysql> show databases; mysql> create database sample; mysql> show databases; mysql> exitmanage.py
manage.pyimport pymysql #追加 pymysql.install_as_MySQLdb() #追加$ python manage.py migrate $ mysql -u root mysql> use sample; mysql> show tables; mysql> exitsettings.py
settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'api', #追加 'rest_framework', #追加 'django_filters', #追加 ] DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'sample', # 作成したデータベース名 'USER': 'root', # ログインユーザー名 'HOST': '', 'PORT': '', } } # ペジネーション REST_FRAMEWORK = { 'DEFAULT_FILTER_BACKENDS': ['django_filters.rest_framework.DjangoFilterBackend'], 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.LimitOffsetPagination', 'PAGE_SIZE': 5 } LANGUAGE_CODE = 'ja' TIME_ZONE = 'Asia/Tokyo'models.py
最初にモデルを作成する
データベースに保存する内容を記述models.pyfrom django.db import models """ CharField (文字列が入る)文字数制限必要 TextField(文章が入る) ImageField(写真ファイルが入る) FileField(不特定のファイルが入る) IntegerField(数値が入る)オーバーフロー注意 BooleanField(True/False)が入る *いわゆるフラッグ DateField(日付が入る) DateTimeField(日時が入る) ForeignKey(外部キー) *一対多のリレーションになる。(言葉だけでも覚えておきましょう!) ManyToManyField(複数の外部キーが入る) *多対多のリレーションになる OneToOneField(外部キー) *一対一のリレーションになる """ class BaseAPI(models.Model): first_name = models.CharField(max_length=32) last_name = models.CharField(max_length=32) class Meta: verbose_name_plural = "ベースAPI"serializer.py
Modelに対してデータを適切な形にして入力、出力するもの
-[参考サイト6]serializer.py# coding: utf-8 from .models import BaseAPI from rest_framework import serializers class BaseAPISerializer(serializers.ModelSerializer): class Meta: model = BaseAPI fields = ( 'first_name', 'last_name' )views.py
Viewの設定についてはここを参照
クラス 操作 CreateAPIView 登録(POST) ListAPIView 一覧取得(GET) RetrieveAPIView 取得(GET) UpdateAPIView 更新(PUT、PATCH) DestroyAPIView 削除(DELETE) -[参考サイト3]
views.py# coding: utf-8 from .models import BaseAPI from .serializer import BaseAPISerializer from rest_framework import generics class BaseAPIViewSet_POST(generics.CreateAPIView): queryset = BaseAPI.objects.all() serializer_class = BaseAPISerializer class BaseAPIViewSet_PUT(generics.UpdateAPIView): queryset = BaseAPI.objects.all() serializer_class = BaseAPISerializer class BaseAPIViewSet_GET(generics.RetrieveAPIView): queryset = BaseAPI.objects.all() serializer_class = BaseAPISerializerproject/urls.py
v1は慣習でAPIのバージョンを表すそう Ver 1.0.1みたいな
urls.py"""プロジェクト名 URL Configuration 'urlpatterns'リストはURLをビューにルーティングします。 詳細は以下を参照してください。 https://docs.djangoproject.com/en/3.1/topics/http/urls/ 例を紹介します。 関数ビュー 1. インポートの追加: from アプリ名 import views 2. urlpatternsにURLを追加する: path('', views.home, name='home') クラスベースのビュー 1. インポートの追加: from 他のアプリ名.views import Home 2. urlpatternsにURLを追加する: path('', Home.as_view(), name='home') 別の URLconf を含む 1. include() 関数をインポートします: from django.urls import include, path 2. urlpatternsにURLを追加する: path('blog/', include('blog.urls') """ from django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('v1/', include('api.urls')), ]api/urls.py
動的なルーティングを行いたい場合
< str:pk > と記述するapp/urls.py# coding: utf-8 from django.urls import path from .views import BaseAPIViewSet_POST, BaseAPIViewSet_PUT, BaseAPIViewSet_GET app_name = 'api' urlpatterns = [ path('user/', BaseAPIViewSet_POST.as_view(), name='POST'), path('user/<str:pk>/', BaseAPIViewSet_PUT.as_view(), name='PUT'), path('user/<str:pk>/affinity', BaseAPIViewSet_GET.as_view(), name='GET'), ]$ python manage.py runserver# ユーザーの登録 http://127.0.0.1:8000/v1/user/
# pk=1 のユーザー情報を更新 # (存在しないpkを指定するとサイトにアクセスできないと表示される) http://127.0.0.1:8000/v1/user/1/ # pk=2 のユーザー情報を取得 # (存在しないpkを指定するとサイトにアクセスできないと表示される) http://127.0.0.1:8000/v1/user/2/affinityこれで完成
参考サイト
1, Django REST Framework の使い方メモ
2, Django REST Frameworkを使って爆速でAPIを実装する
3, DRFのGeneric viewの使い方
4, Django REST framework カスタマイズ方法 - チュートリアルの補足
5, Django 開発者への道① ~ Modelsを理解する ~
6, Django REST frameworkで学んだことをまとめてみた

- 投稿日:2021-03-05T15:13:46+09:00
PipenvでFlaskアプリをHerokuにデプロイする手順
はじめに
Flaskで作ったWebアプリをPipenvでHerokuに公開する手順を書いた。
requirements.txtを使わずにPipenvを使っている手順でまとまっているものが無さそうだったので。前提条件
- pythonがインストールされていること
- pipがインストールされていること
- pipenvがインストールされていること(
pip install pipenv)- GitのCLIが使えること(Macなら最初から入っている)
- GitHubのアカウントがあること
- Herokuのアカウントがあること(Heroku CLIは不要)
手順
作業ディレクトリ作成
ターミナルmkdir myapp cd myapp依存関係を追加
Pipenvで必要なライブラリの依存関係を定義する。
Pythonは3系を使う。
今回はFlaskアプリを作るので、flaskとgunicornの2つを入れる。ターミナルpipenv --python 3 pipenv install flask pipenv install gunicornこの時点で
PipfileとPipfile.lockの2ファイルができているはず。Flaskアプリ作成
アプリケーションの本体を書き、
app.pyという名前で保存する。
ここでは簡単のため、以下の内容にする。app.py# -*- coding: utf-8 -*- from flask import Flask app = Flask(__name__) @app.route('/') def index(): return 'Hello, World' if __name__ == '__main__': app.run()ローカルで動くことを確認
ローカルで動作確認をするには以下のようにする。
pipenv run python app.py(普通に
python app.pyとするとグローバルに定義されたPythonを使ってしまうので注意)
以下のように表示されればOK。* Serving Flask app "app" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: off * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)ブラウザでhttp://localhost:5000 にアクセスして、期待通りの内容になっているか確認。
上の例だと、「Hello, World」という文字列が表示されていればOK。
Procfileを作成公開したときに実行する処理の内容を記載した
Procfileを作成する。
(必ずプロジェクトのルートに置く)Procfileweb: gunicorn app:appGitに登録
公開する準備として、ここまでの内容をGitに登録する。
ターミナルgit init git add . git commit -m "first commit"GitHubに登録
ブラウザからGitHubにログイン。
新しいリポジトリを作る。(privateでもOK)
指示にしたがってプッシュするターミナルgit remote add origin git@github.com:以下略 git branch -M main git push -u origin mainHerokuと連携して公開
ブラウザからHerokuにログイン。
Create new app。
- App nameに適当なアプリ名を入力。(これが公開するときのURLに含まれることになる。早いもの勝ちなので
myappとかはすでに取られている)- Deployment methodにGitHubを指定。
- Connect to GitHubで先ほど作ったGitHubリポジトリを指定。(初めてやるときは認証が入るはず。指示に従っていればOK)
- Automatic DeploysでEnable Automatic Deploysを押す(これでGitHubリポジトリの特定のブランチ(例えば
main)にプッシュされたことを検知して、自動でデプロイを行うようになる)- 最初のデプロイをしたいので、Manual DeployでDeploy Branchを押す。
ブラウザでhttp://<アプリ名>.herokuapp.comにアクセスして、想定通りの内容になっているか確認。
これで公開ができた。
- 投稿日:2021-03-05T15:11:06+09:00
IMAPでメールを取得するときのフラグの話
(Pythonタグついてるけど、Pythonに関係ないIMAPに関することなんですけどね。試したのがPythonだったので)
IMAPのフラグについて
メッセージフラグ
IMAP4 では、各メッセージに対して、6個の標準フラグがあります。
\recent
最近届いたメッセージ(新着メール)
\seen
読まれたメッセージ(既読メール *1)
\deleted
削除フラグが設定されたメッセージ
\draft
下書きフラグが設定されたメッセージ
\flaged
特別なメッセージを示すフラグIMAPにAppend1で付加できないフラグ
答えは
\recent理由はRFC3501参照ですが 抜粋すると
\Recent Message is "recently" arrived in this mailbox. This session is the first session to have been notified about this message; if the session is read-write, subsequent sessions will not see \Recent set for this message. This flag can not be altered by the client._人人人人人人人人人人人人人人人人人人人人人_
> This flag can not be altered by the client. <
 ̄Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y ̄_人人人人人人人人人人人人人人人人人人人人人人人人人人人人_
> このフラグはクライアントが変更することはできません。 <
 ̄Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y ̄AサーバからBサーバにメールをコピーする処理を作っていたときに発見。
既読のものは既読・未読の未読でコピーしたい!
と思ってフラグを全部コピーしてましたがエラーが出てしまいましたとさ。
今回の記事で出てくる関数的なものは Pythonでお話しますが、ほかの言語でも同じだと思います。 ↩
- 投稿日:2021-03-05T14:31:42+09:00
Kaggle Courses 学習メモ(機械学習イントロダクション編 2/2)
前回の続きです.
2分木の基礎を学び,データを切り出し,モデルを作ることには成功しました.
しかし,MAEを用いてモデルを評価した所,バリデーションデータに対する分類精度が?になってしまいましたね.
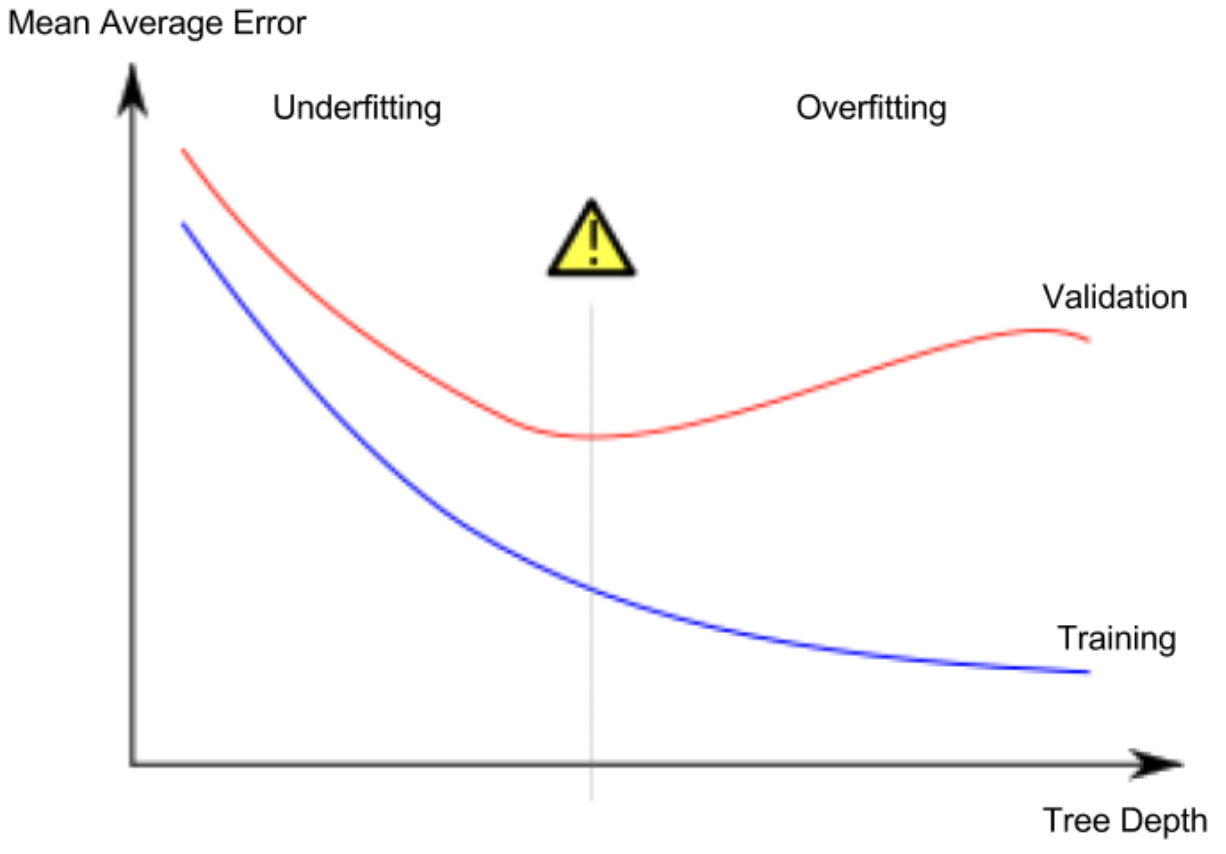
この原因について考察していきます.未学習と過学習
やはり2分木で考える.
葉にたどり着くまでに分岐をn回行うと,葉の数は$2^n$のオーダーになる.歯の数が増えれば増えるほど,各葉に分類される家の数は少なくなる.
この場合,たしかにデータセットに対してはいい感じの予測をするが,新規データに対しては信頼性の低い予測をする可能性がある(過学習,Overfitting)
逆に木を小さく(shallow)しすぎると分割が足りなすぎて精度が上がらない(未学習,Underfitting)
scikit-learnでは
max_leaf_nodes引数で葉の深さを設定することで木のサイズ全体を調整することが出来る.
木を大きくすればするほど,モデルはUnderfittingしてる領域からOverfittingしてる領域に移るわけだが,今回Coursesで取り扱う例では,どれくらいの深さが良いのか?検証してみよう.def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y): model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0) model.fit(train_X, train_y) preds_val = model.predict(val_X) mae = mean_absolute_error(val_y, preds_val) return(mae) # 木の深さを変えながらMAEでモデルを評価 for max_leaf_nodes in [5, 50, 500, 5000]: my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y) print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae)) #Max leaf nodes: 5 Mean Absolute Error: 347380 #Max leaf nodes: 50 Mean Absolute Error: 258171 #Max leaf nodes: 500 Mean Absolute Error: 243495 #Max leaf nodes: 5000 Mean Absolute Error: 254983
[5,50,500,5000]の中だと,500くらいの分割が一番いい感じ.
続きはまた余裕がある時に.
- 投稿日:2021-03-05T14:29:51+09:00
IQ Bot:明細の抽出が意図した行で止まらなかったら
はじめに
IQ Botで明細の取得をしてみると、行の抽出が意図した場所で止まらず、余計な行まで拾ってきてしまうケースがあります。
だめじゃん! と思うかもしれませんが、明細の構造を自動で取得する、準定型対応OCRの宿命ともいえる事象です。
(参考:非定型OCRを正しく知って、上手に付き合おう ~定型OCRにはない、非定型OCR固有の課題~)そしてIQ Botの場合、このケースにはちゃんと対応方法があります。
この記事では、そんな場合の対処方法を説明します。
基本:ストッパーとなる文字列を指定する方法
基本となるのは、ストッパーとなる文字列を指定する方法です。
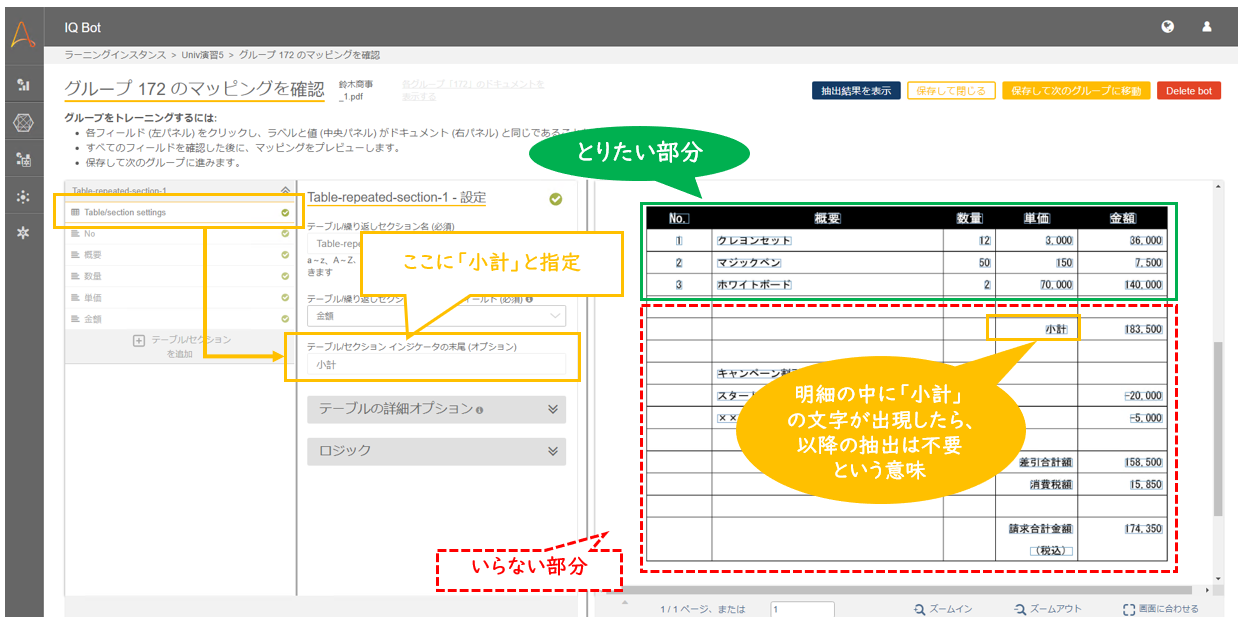
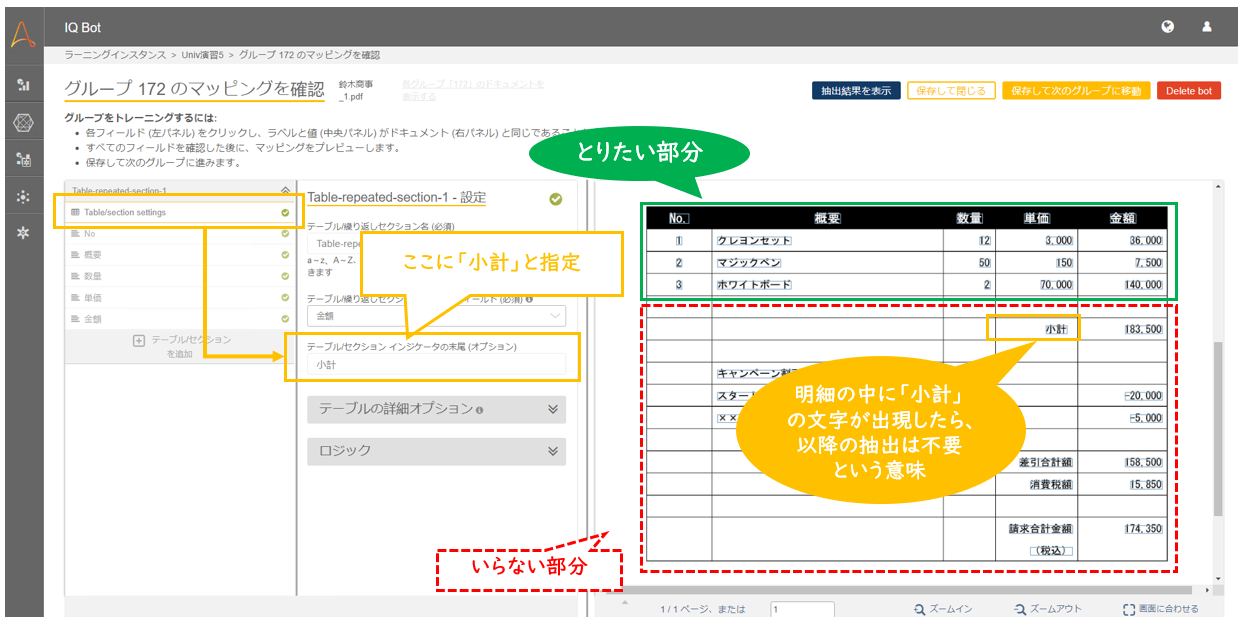
上記の帳票を見てみると、「小計」という文字が出現する前後で、明細の必要な部分と不要な部分が分かれています。
そこで、「Table/section settings」配下の「テーブル/セクション インジケータの末尾」に「小計」と指定します。
これは、明細の中に「小計」という文字列が現れたら、以降の抽出は不要ですよ、という指定になります。
文字列指定でテーブルを止める際の注意点
上記で説明した「テーブル/セクション インジケータの末尾」に指定できるのは、固定の文字列のみです。
正規表現などで複数のパターンを指定することはできません。したがって、この方法でテーブルの抽出を止められるのは、以下の条件をすべて満たす場合に限られます。
文字列指定でテーブル抽出を止められる条件
a.テーブル(明細)の抽出したい部分が終わった直後に、いつも必ず決まった文字列が出現する
上記の例でいえば、抽出したいテーブルの直後にいつも必ず「小計」という文字列が出現する必要があります。
「小計」の他にも「消費税」や「送料」など、ストッパーとなる文字列に複数の可能性がある場合などは、次に説明するカスタムロジックで対応する必要があります。b.上記a.の文字を、OCRが安定して読み取ることができる(誤読の可能性が低い)
例えば帳票上の「小計」をOCRが誤って「小言十」と読んでしまった場合、「小言十」はストッパーとして定義されていないのでテーブルの抽出を止めることができません。
したがって、OCRが安定して読み取れる項目をストッパーとして選ぶ必要があります。「計」を「言十」として読むケースはOCRでは時々見られるのですが、このような可能性があらかじめ予測できる場合も、次に説明するカスタムロジックで対応する必要があります。
c.上記a.の文字が必要な明細の途中で出現しない
上記の例では「小計」をストッパーとして使っていますが、もしも抽出したい明細の途中に「小計」という文字列が現れてしまうと、IQ Botはそこで抽出をやめてしまいます。
文字列指定でテーブルを止める方法のまとめ
文字列指定でテーブルを止める方法は、最も簡単なやりかたです。
ですが、上に挙げた注意点などを鑑みると、文字列指定でテーブル抽出を止める方法が適用できるケースが限られているのも事実です。文字列指定では対応できない条件でテーブル抽出を止めたい場合は、カスタムロジックを使って対応する必要があります。
応用:カスタムロジックを使う
カスタムロジックを使用して抽出行を止める方法は、明細の構造により千差万別です。
帳票自体のデータの構造に多種多様なパターンが想定されるため、「このロジックを使えば、あらゆるパターンに対応できます!」という万能なロジックは残念ながらありません。
ここではあくまでも参考として、最も基本的なパターンのロジックを載せておきます。
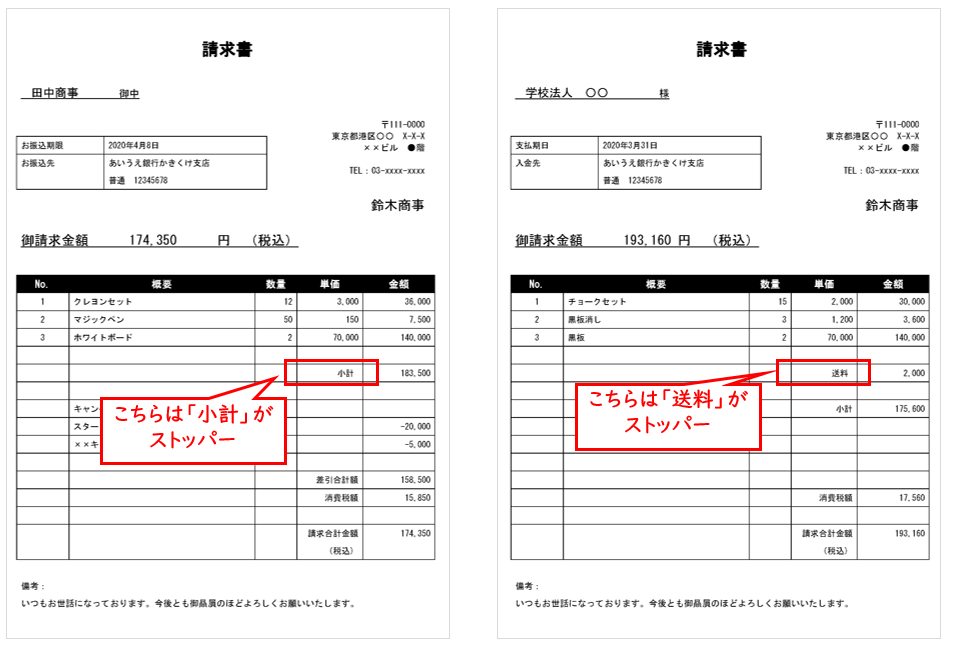
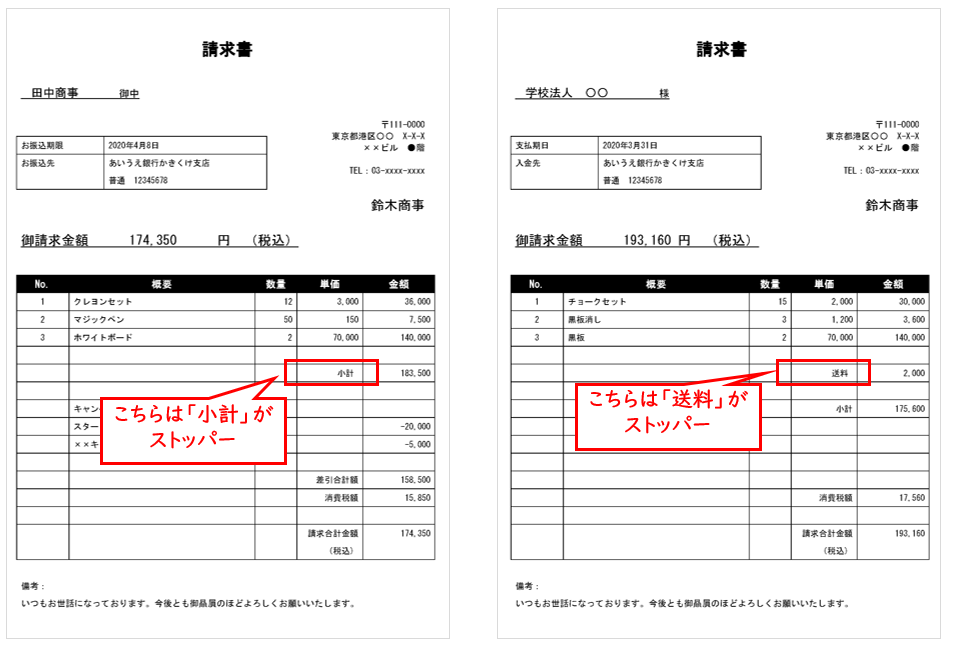
このロジックでは、以下のような明細を扱います。
ストッパーの候補は「小計」と「送料」があって、いずれも単価欄に出現するというパターンです。
単価欄に出現する「小計」と「送料」を根拠に表の抽出を止める場合# 値を保存する変数: table_values import pandas as pd df = pd.DataFrame(table_values) #削除対象の文字列が出現する列名 #(IQ Botの列名に合わせる) col = "単価" #「この文字列が出現したら、それ以降の行を削除」という文字列を定義 flagList = ("小計","送料") #抽出対象かどうかを設定するフラグ isTaisho = True #明細行を上から順番にループする for i in range(len(df)): #フラグ判定(単価欄の内容(df.at[str(i),col])がflagListの要素(j)と一致したらフラグを立てる) for j in flagList: if df.at[str(i),col] == j: isTaisho = False #フラグがFalseなら、対象列に固有の文字列を代入 if isTaisho == False: df.at[str(i),col] = "この行は削除対象です" #固有の文字列を代入した列を削除する df = df[df[col] != "この行は削除対象です"] #表の操作をするときに必ず入れるコード(最後) table_values = df.to_dict()簡単に補足
解説はほぼコードの中のコメントに書いていますが、少しだけ補足しておきます。
(初心者向けです。コードの意味がわかった人は読み飛ばして大丈夫です。)フラグ判定と全体の構造
このロジックの最大のポイントは、フラグ判定の部分です。
ループの手前でフラグにTrueを立てておき、条件に該当したらFalseにします。
この条件を定義するロジックを対象の帳票に合わせて書き換えることで、それなりに色々な帳票に対応できるようになります。ループの中でFalse→Trueに戻す箇所はないため、一度Falseになったらそれ以降はずっとFalseです。
この構造により、「ひとたび条件を満たす行が見つかったら、以降の明細は不要ですよ」という処理ができあがります。
不要な行の削除
また、不要な行の削除の削除のしかたもちょっと特徴的です。
これは IQ Bot というより、pandasに特有の実装方法のようですが、「フラグが立っていたら、それ以降の行を1行1行消していく」という処理構造にはなっていません。
かわりに、
- フラグが立っていたら、削除対象だとわかる固有の値を特定の列に入れる
- 特定の列に固有の値が入っている行を最後にまとめて削除する
という2段階の構造をとります。
今回のケースでは、単価欄に「"この行は削除対象です"」という固有の値を入れて、最後にそれを条件に削除しています。
固有の値は、その値を根拠に削除対象の判別がつけば何でも良いです。
なお、不要な行の削除については以下の記事に若干詳しく書きましたので、あわせて参照してみてください。
https://qiita.com/IQ_Bocchi/items/e714b15225f425a582c5このケースは、先ほどから何度も言っている「固有の値」を特定の列に入れることで「不要な行」を意図的に作り出し、最後に除外しているという仕組みです。
以上!
今回の記事は以上です。
ご不明な点や今後の記事のリクエストなどあれば、お気軽にコメントください。
TwitterでからんでいただいてもOKです。それでは!

- 投稿日:2021-03-05T14:29:51+09:00
【IQ Bot】明細の抽出が意図した行で止まらなかったら
はじめに
IQ Botで明細の取得をしてみると、行の抽出が意図した場所で止まらず、余計な行まで拾ってきてしまうケースがあります。
だめじゃん! と思うかもしれませんが、明細の構造を自動で取得する、準定型対応OCRの宿命ともいえる事象です。
(参考:非定型OCRを正しく知って、上手に付き合おう ~定型OCRにはない、非定型OCR固有の課題~)そしてIQ Botの場合、このケースにはちゃんと対応方法があります。
この記事では、そんな場合の対処方法を説明します。
基本:ストッパーとなる文字列を指定する方法
基本となるのは、ストッパーとなる文字列を指定する方法です。
上記の帳票を見てみると、「小計」という文字が出現する前後で、明細の必要な部分と不要な部分が分かれています。
そこで、「Table/section settings」配下の「テーブル/セクション インジケータの末尾」に「小計」と指定します。
これは、明細の中に「小計」という文字列が現れたら、以降の抽出は不要ですよ、という指定になります。
文字列指定でテーブルを止める際の注意点
上記で説明した「テーブル/セクション インジケータの末尾」に指定できるのは、固定の文字列のみです。
正規表現などで複数のパターンを指定することはできません。したがって、この方法でテーブルの抽出を止められるのは、以下の条件をすべて満たす場合に限られます。
文字列指定でテーブル抽出を止められる条件
a.テーブル(明細)の抽出したい部分が終わった直後に、いつも必ず決まった文字列が出現する
上記の例でいえば、抽出したいテーブルの直後にいつも必ず「小計」という文字列が出現する必要があります。
「小計」の他にも「消費税」や「送料」など、ストッパーとなる文字列に複数の可能性がある場合などは、次に説明するカスタムロジックで対応する必要があります。b.上記a.の文字を、OCRが安定して読み取ることができる(誤読の可能性が低い)
例えば帳票上の「小計」をOCRが誤って「小言十」と読んでしまった場合、「小言十」はストッパーとして定義されていないのでテーブルの抽出を止めることができません。
したがって、OCRが安定して読み取れる項目をストッパーとして選ぶ必要があります。「計」を「言十」として読むケースはOCRでは時々見られるのですが、このような可能性があらかじめ予測できる場合も、次に説明するカスタムロジックで対応する必要があります。
c.上記a.の文字が必要な明細の途中で出現しない
上記の例では「小計」をストッパーとして使っていますが、もしも抽出したい明細の途中に「小計」という文字列が現れてしまうと、IQ Botはそこで抽出をやめてしまいます。
文字列指定でテーブルを止める方法のまとめ
文字列指定でテーブルを止める方法は、最も簡単なやりかたです。
ですが、上に挙げた注意点などを鑑みると、文字列指定でテーブル抽出を止める方法が適用できるケースが限られているのも事実です。文字列指定では対応できない条件でテーブル抽出を止めたい場合は、カスタムロジックを使って対応する必要があります。
応用:カスタムロジックを使う
カスタムロジックを使用して抽出行を止める方法は、明細の構造により千差万別です。
帳票自体のデータの構造に多種多様なパターンが想定されるため、「このロジックを使えば、あらゆるパターンに対応できます!」という万能なロジックは残念ながらありません。
ここではあくまでも参考として、最も基本的なパターンのロジックを載せておきます。
このロジックでは、以下のような明細を扱います。
ストッパーの候補は「小計」と「送料」があって、いずれも単価欄に出現するというパターンです。
ロジック例
単価欄に出現する「小計」と「送料」を根拠に表の抽出を止める場合# 値を保存する変数: table_values import pandas as pd df = pd.DataFrame(table_values) #削除対象の文字列が出現する列名 #(IQ Botの列名に合わせる) col = "単価" #「この文字列が出現したら、それ以降の行を削除」という文字列を定義 flagList = ("小計","送料") #抽出対象かどうかを設定するフラグ isTaisho = True #明細行を上から順番にループする for i in range(len(df)): #フラグ判定(単価欄の内容(df.at[str(i),col])がflagListの要素(j)と一致したらフラグを立てる) for j in flagList: if df.at[str(i),col] == j: isTaisho = False #フラグがFalseなら、対象列に固有の文字列を代入 if isTaisho == False: df.at[str(i),col] = "この行は削除対象です" #固有の文字列を代入した列を削除する df = df[df[col] != "この行は削除対象です"] #表の操作をするときに必ず入れるコード(最後) table_values = df.to_dict()簡単に補足
解説はほぼコードの中のコメントに書いていますが、少しだけ補足しておきます。
(初心者向けです。コードの意味がわかった人は読み飛ばして大丈夫です。)フラグ判定と全体の構造
このロジックの最大のポイントは、フラグ判定の部分です。
ループの手前でフラグにTrueを立てておき、条件に該当したらFalseにします。
この条件を定義するロジックを対象の帳票に合わせて書き換えることで、それなりに色々な帳票に対応できるようになります。ループの中でFalse→Trueに戻す箇所はないため、一度Falseになったらそれ以降はずっとFalseです。
この構造により、「ひとたび条件を満たす行が見つかったら、以降の明細は不要ですよ」という処理ができあがります。
不要な行の削除
また、不要な行の削除の削除のしかたもちょっと特徴的です。
これは IQ Bot というより、pandasに特有の実装方法のようですが、「フラグが立っていたら、それ以降の行を1行1行消していく」という処理構造にはなっていません。
かわりに、
- フラグが立っていたら、削除対象だとわかる固有の値を特定の列に入れる
- 特定の列に固有の値が入っている行を最後にまとめて削除する
という2段階の構造をとります。
今回のケースでは、単価欄に「"この行は削除対象です"」という固有の値を入れて、最後にそれを条件に削除しています。
固有の値は、その値を根拠に削除対象の判別がつけば何でも良いです。
なお、不要な行の削除については以下の記事に若干詳しく書きましたので、あわせて参照してみてください。
https://qiita.com/IQ_Bocchi/items/e714b15225f425a582c5このケースは、先ほどから何度も言っている「固有の値」を特定の列に入れることで「不要な行」を意図的に作り出し、最後に除外しているという仕組みです。
以上!
今回の記事は以上です。
ご不明な点や今後の記事のリクエストなどあれば、お気軽にコメントください。
TwitterでからんでいただいてもOKです。それでは!

- 投稿日:2021-03-05T14:20:51+09:00
RocketChatでChatbotによりJenkinsJOBを起動したいのだが(前編)
RocketChatからチャットボットでJenkinsJOBを起動したい
開発環境にさまざまツールが入ってくると
その使い方を覚えるのに拒否をしてくる方々が一定数発生します。といってその方がに理解を求めるために対面で時間をとって話をしても状況は改善することはあまりないです。そしてその流れに便乗して学ぶことを止める方々が増幅する状況になります。よくないですね。
チャットボットでいいんじゃないの
RocketChat導入スミなので学びたくないんだったらチャットボットでいいんでないの?ということでチャットボット利用に向けて対応します。ま、RocketChat自体も使いたくないという人が一定数居るのですが、もはや道にもならんので切り捨てます。チャットツール利用ですら抵抗受けるってのは予想してなかったけど。
RocketChatなのでHubotを使いたいが
チャットボットもいろいろあったり、自前で作ったりとさまざまな模様。RocketChatだとどうやらHubotが事実上のスタンダードの模様。んじゃ、利用したいんだけどDevOps環境に既に入っているしそれいい?
→ 不安だからダメ〜(管理者)
→ 別インスタンスで作るならいいけど(管理者)
は?別インスタンスってそれは管理者が巻き込まれたくないって理由から?
全体観点からかんがえてもらえないものなのか///
が、そんな話をやっていると永遠に事が進まない。んじゃ、別インスタンスでHubotを立てるには
「どうぞそちらの予算で」(管理者)
「ーーーオイ」じゃ、いくらなのさ
「見積もり出してください」
そして何度も催促するが1か月経過しても見積もりは出てこない。
「結局、理由をつけて拒否したかっただけかい?」ラチ明かないのでChatbotを自前で作ることにした
もういいや、自分で作ることにした。
Webの先人さまたちに教えを請うとどうやら何とかなりそうな予感
- RocketChatのwebhool outgoingとのインターフェースを利用
- サーバサイドのAPIアプリを作れば良い(GUIはいらない→RocketChat様が担う)
- サーバサイドのAPIアプリからJenkinsを起動する処理を呼び出す(実は既にPython部品として作ってある)
なるほど、3番目で作った部品をそのまま使えそうなのでサーバサイドAPIアプリはPythonってことで。スクラッチで書くのも大変そうなのでライブラリを使用する。なにがいいか。
- Flask :よく使われているようだが
- FastAPI:こちらの方が早くて、Swaggerも持っているのでお勧めが多い
というこで
FastAPIを使って書くことにします(あまり考えずぎず、とっとと決断)まずはRocketChatからのJenkinsJOB起動だけにしぼる
RocketChatからは
jenkins?jobname=aaaa¶m1=p1¶m2=p2でチャットを飛ばすと指定したJenkinsJOB(=aaaa)をデフォルトでもっているパラメータ(param:p1,param:p2、、、、可変)で上書きして実行するようになればOK。RocketChatインストール/設定やFastAPIやuvicornインストール/起動などは先人たちが解説してますので省略します。
リクエストボディから欲しい情報
rid
チャットボットからJOB起動リクエストを投げたときにそのリクエストが投入されたチャンネルに結果を返したいので
ridが必要になります。作ったJenkinnsJOB側でも結果を投入するチャンネルを指定するパラメータを持っている実装をしていますので。リクエストパラメータ
jenkins?jobname=aaaaa¶m1=p1¶m2=p2の部分が必要になります(当然)。実験してみて
リクエストパラメータを取得するコードは容易に書けます。だけど本来持っている
ridが何故か取れない。たぶん実装の方法が良くないのだろう。もう一度FastAPIのガイドを見て再考する。これではだめだ〜
ちゃんとFastAPIの良いところ使って再度実装し直す
適当に実装すれば適当な結果にしかならない。。。ので
FastAPIが提供している機能を使って再実装します。FastAPIのBaseModelを継承して受け取ったリクエストボディをきっちり型にはめて処理します。
BaseModelを継承して実装するところも事例がたくさんありますので先人たちに聞いてみてください。さて実行すると422エラー(型が一致していないよー)と。
INFO: 192.168.10.110:43184 - "POST /jenkins HTTP/1.1" 422 Unprocessable Entity INFO: 192.168.10.110:43186 - "POST /jenkins HTTP/1.1" 422 Unprocessable Entity INFO: 192.168.10.110:43196 - "POST /jenkins HTTP/1.1" 422 Unprocessable Entity INFO: 192.168.10.110:43278 - "POST /jenkins HTTP/1.1" 422 Unprocessable Entity INFO: 192.168.10.110:43304 - "POST /jenkins HTTP/1.1" 422 Unprocessable EntityリクエストBodyを1行の文字列とみなして受け取りClassを定義してみたけどどうやらNG。じゃ、リクエストボディの構造ってどうなってるのか。。。わからん(RocketChatのガイドには当然のうように書いてない)。
う〜ん?
F12でブラウザ側のNetworkタブから中身を推察してみるが
はい、飛ばしているのはおぼろげに見えますね。
これが渡ってくることを前提に受け取るClassを定義してみますが状況変わらず422連呼。デバッグコードを書いてみる
FastAPIはこの辺スマートにやれるはずだが。。。
仕方ないのでrequestを使ってベタでリクエストの中身を除くデバッグコードを使います(このコードのまま運用では絶対使わないことを誓って)
1 ######################################################### 0 # 調査用コード 1 ######################################################### 2 @app.post("/jenkins") 3 async def read_requestbody(request: Request): 4 pprint(f'request body test') 5 print('==== request 構造 ====') 6 pprint(f'{list(request)}') 7 print('==== request headers ====') 8 pprint(f'{request.headers}') 9 byte_1 = await request.body() 10 print('==== request body ====') 11 print(type(byte_1)) 12 print(byte_1) 13 str_my_json = byte_1.decode('utf-8') 14 print('==== request body json ====') 15 print(type(str_my_json)) 16 print(str_my_json) 17 print('==== request body json(整形) ====') 18 data = json.loads(str_my_json) 19 pprint(data) 20 print('-'*80)そして結果を眺めてみる。
==== request body json(整形) ==== {'bot': False, 'channel_id': 'GENERAL', 'channel_name': 'general', 'message_id': 'yj6WFMPNnBP39bJkA', 'siteUrl': 'http://localhost:3000', 'text': 'jenkins?jobname=test¶m1=p1¶m2=p2', 'timestamp': '2021-03-05T03:29:50.829Z', 'token': 'e9q968t9jyw', 'trigger_word': 'jenkins', 'user_id': 'fr8prGxt3YakXtZDz', 'user_name': 'admin'}おう。。。ブラウザF12で見えている情報と全然違う
BaseModelによる定義を再考
得られたデバッグコードからリクエストボディを受け取る入れ物定義を再度記述。
0 class Item(BaseModel): 1 bot: str 2 channel_id: str 3 channel_name: str 4 siteUrl: str 5 text: str 6 timestamp: str 7 token: str 8 trigger_word: str 9 user_id: str 10 user_name: str再実行
0 ######################################################### 1 # 振る舞い定義 2 ######################################################### 3 @app.post("/jenkins") 4 async def read_requestbody(item: Item): 5 pprint(item) 6 print('-'*80) 7 pprint(f'channel_id: {item.channel_id}') 8 pprint(f'channel_name: {item.channel_name}') 9 pprint(f'token: {item.token}') 10 pprint(f'param_string: {item.text}') 11 return {}結果は上々
Item(bot='False', channel_id='GENERAL', channel_name='general', siteUrl='http://localhost:3000', text='jenkins?jobname=test¶m1=p1¶m2=p2', timestamp='2021-03-05T03:34:05.242Z', token='e9q968t9jyw', trigger_word='jenkins', user_id='fr8prGxt3YakXtZDz', user_name='admin') -------------------------------------------------------------------------------- 'channel_id: GENERAL' 'channel_name: general' 'token: e9q968t9jyw' 'param_string: jenkins?jobname=test¶m1=p1¶m2=p2' INFO: 192.168.10.110:55934 - "POST /jenkins HTTP/1.1" 200 OKまとめ
- FastAPI、簡単にアプリAPIを書くにはとてもやりやすい。
- データの型規約もきっちりできるので運用目的のコードも品質を保つことが出来そう
- 今後も使おう!(GUIのないサーバアプリ)
ということで、ざくっと断片知識を持ち寄って作ってみたのですがちょっと罠があったものの効率良く実装が出来そう。
ちゃんと体系的に理解するためにも
FastAPIチュートリアルを一通りやっておくことにする。お試しコード全量
エラーハンドリングはまだ全く入ってないけど。
from fastapi import FastAPI from fastapi import Query from fastapi import Path from fastapi import Request from typing import Optional from typing import List from pydantic import BaseModel from pydantic import Field from pprint import pprint import json ######################################################### # リクエストボディインターフェース定義 ######################################################### class Item(BaseModel): bot: str channel_id: str channel_name: str siteUrl: str text: str timestamp: str token: str trigger_word: str user_id: str user_name: str ######################################################### # インスタンス生成 ######################################################### app = FastAPI() ######################################################### # 振る舞い定義 ######################################################### @app.post("/jenkins") async def read_requestbody(item: Item): pprint(item) print('-'*80) pprint(f'channel_id: {item.channel_id}') pprint(f'channel_name: {item.channel_name}') pprint(f'token: {item.token}') pprint(f'param_string: {item.text}') return {} ######################################################### # 調査用コード ######################################################### @app.post("/jenkins") async def read_requestbody(request: Request): pprint(f'request body test') print('==== request 構造 ====') pprint(f'{list(request)}') print('==== request headers ====') pprint(f'{request.headers}') byte_1 = await request.body() print('==== request body ====') print(type(byte_1)) print(byte_1) str_my_json = byte_1.decode('utf-8') print('==== request body json ====') print(type(str_my_json)) print(str_my_json) print('==== request body json(整形) ====') data = json.loads(str_my_json) pprint(data) print('-'*80)
- 投稿日:2021-03-05T13:50:21+09:00
【Python演算処理】「N次球概念導入による円/球関係の数理の統合」?
子供の頃から「円周や円の面積や球の表面積や体積を求める式」と半径(Radius)と直径(Diameter)が裏側でどう繋がっているか気になって仕方がありませんでした。そして、とうとう…
微積分概念導入による部分的解決
【Python演算処理】半径・直径・円周長・円の面積・球の表面積・球の体積の計算上の往復
やがて微積分概念を知り、以下を連続的に考えられる様になりました。まぁ面倒な計算は全てコンピューターにやらせてしまえばいいのです。
半径rの円の面積πr^2 ⇄ 円周長2πr
import sympy as sp r,f,g,h = sp.symbols('r,f,g,h') #元関数 f=sp.pi*r**2 #半径rの円の面積(pi*r^2)をrで微分すると #円周の長さ(2*pi*r)となる。 g=sp.diff(f,r,1) #逆に円周の長さ(2*pi*r)をrで積分すると #半径rの円の面積(pi*r^2)になる。 h=sp.integrate(g,r) #画面表示 sp.init_printing() display(f) print(sp.latex(f)) display(g) print(sp.latex(g)) display(h) print(sp.latex(h))元関数
\pi r^{2}微分結果
2 \pi r積分結果
\pi r^{2}半径rの球の体積(4/3*pi*r^3) ⇄ 球の表面積(4*pi*r^2)
import sympy as sp r,f,g,h = sp.symbols('r,f,g,h') #元関数 f=sp.Rational(4,3)*sp.pi*r**3 #半径rの球の体積(4/3*pi*r^3)をrで微分すると #球の表面積(4*pi*r^2)となる。 g=sp.diff(f,r,1) #逆に球の表面積(4*pi*r^2)をrで積分すると #半径rの球の体積(4/3*pi*r^3)となる。 h=sp.integrate(g,r) #画面表示 sp.init_printing() display(f) print(sp.latex(f)) display(g) print(sp.latex(g)) display(h) print(sp.latex(h))元関数
\frac{4 \pi r^{3}}{3}微分結果
4 \pi r^{2}積分結果
\frac{4 \pi r^{3}}{3}ちなみに引数の変遷は所謂「微積分における冪乗算の不定積分公式」通り。
\int x^b dx=\frac{1}{β+1} x^{β+1}ただしこの計算式にはβ=-1の時に分母が0になる問題があり、実際には別の計算方法で代用されています。
【数理考古学】冪乗算(Exponentiation)の微積分import sympy as sp a,x,f,g,h = sp.symbols('a,x,f,g,h,i,j') #元関数 f=a**x #f'(x)一階微分 g=sp.diff(f,r,1) #f''(x)二階微分 h=sp.diff(f,r,2) #f'(x)一階積分 i=sp.integrate(g,r) #f''(x)二階積分 j=sp.integrate(i,r) #画面表示 sp.init_printing() display(f) print(sp.latex(f)) display(g) print(sp.latex(g)) display(h) print(sp.latex(h)) display(i) print(sp.latex(i)) display(j) print(sp.latex(j))元関数
a^{x}一階微分
a^{x} \log{\left(a \right)}二階微分
a^{x} \log{\left(a \right)}^{2}一階積分
\begin{cases} \frac{a^{x}}{\log{\left(a \right)}} & \text{for}\: \log{\left(a \right)} \neq 0 \\x & \text{otherwise} \end{cases}二階積分
\begin{cases} \begin{cases} \frac{a^{x}}{\log{\left(a \right)}^{2}} & \text{for}\: \log{\left(a \right)}^{2} \neq 0 \\\frac{x}{\log{\left(a \right)}} & \text{otherwise} \end{cases} & \text{for}\: \left(a \geq 0 \wedge a < 1\right) \vee a > 1 \\\frac{x^{2}}{2} & \text{otherwise} \end{cases}さらには球の表面積4πr^2をもう1回微分すると得られる8πrなる式に邂逅して困惑が広がります。え、どういう事、それ…
面積の微分はどこの長さ? - Biglobe
球の体積を微分すると、球の表面積になりますが…N次元球概念導入による完全解決
そしてとうとう今月になって辿り着いたのがこの概念。
【Python演算処理】半径・直径・円周長・円の面積・球の表面積・球の体積の計算上の往復
①以下の式に従って、半径rのn次元球の体積は $c_n r^n$、表面積は$n c_nr^{n−1}$と規定される。
c_n = \frac{\pi^{\frac{n}{2}}}{\Gamma(\frac{n}{2}+1)}②$n=1$ のとき$C_n=\frac{\pi^{\frac{1}{2}}}{\Gamma(\frac{1}{2}+1)}=2$なので、1次元球の体積(直径)は2rと規定される。
import math as m def f0(n): return m.pi**(n/2)/m.gamma(n/2+1) print(f0(1)) #出力結果 1.9999999999999998③$n=2$ のとき$C_n=\frac{\pi^{\frac{2}{2}}}{\Gamma(\frac{2}{2}+1)}=\pi$なので、2次元球の体積(面積)は$\pi r^2$、表面積(円周長)は$2 \pi r$と規定される。
import math as m def f0(n): return m.pi**(n/2)/m.gamma(n/2+1) print(f0(2)) print(m.pi) #出力結果 3.141592653589793 3.141592653589793④$n=3$ のとき$C_n=\frac{\pi^{\frac{3}{2}}}{\Gamma(\frac{3}{2}+1)}=\frac{3}{4} \pi$なので、3次元球の体積は$\frac{3}{4} \pi r^3$、表面積は$4 \pi r^2$と規定される。
import math as m def f0(n): return m.pi**(n/2)/m.gamma(n/2+1) print(f0(3)) print(4/3*m.pi) #出力結果 4.1887902047863905 4.1887902047863905⑤$n=4$ のとき$C_n=\frac{\pi^{\frac{4}{2}}}{\Gamma(\frac{4}{2}+1)}=\frac{1}{2} \pi^2$なので、4次元球の体積は$\frac{1}{2} r^4$、表面積は$2 \pi^2 r^3$と規定される。
import math as m def f0(n): return m.pi**(n/2)/m.gamma(n/2+1) print(f0(4)) print(1/2*m.pi**2) #出力結果 4.934802200544679 4.934802200544679確かに、こう考えれば何もかもスッキリしますね(棒読み)。
ガンマ関数 - Wikipedia互いに同値となるいくつかの定義が存在するが、1729年、数学者レオンハルト・オイラーが無限乗積の形で、最初に導入した。
なんとこの概念にまでオイラーが先鞭をつけていたとは。そんな感じで以下続報…
- 投稿日:2021-03-05T11:42:20+09:00
機械学習アルゴリズムメモ 決定木編
決定木とは
決定木とは分類や回帰に用いられる機械学習手法である。
データの特徴量に対して閾値処理を行い、これを繰り返すことで木のようにデータを分析する。【アルゴリズム】
決定木にはCARTやC4.5などのアルゴリズムがある。
本記事ではCARTの概要を説明する。
データの分割を行う際、適切に分割する閾値が必要となるが、以下の式(不純度)が最小となるように決定する。
nはノード内の総データ数、niはクラスi番目のデータ数。Gini = 1 - \sum_{i=1}^{classes}(\frac{n_i}{n})^2木の深さが深くなるにつれ、過学習しやすくなるので事前に深さを決めておくこともできる。
【回帰】
このようにして得られた木に対して予測したいデータを同じ閾値を用いて分類する。
分類されたノードに属する学習データの平均値を予測値とする。【分類】
同じく得られた木に対して予測したいデータを同じ閾値を用いて分類する。
分類されたノードに属する学習データの多数決を取り、予測クラスとする。scikit-learnでの使い方
【回帰】
from sklearn.tree import DecisionTreeRegressor tree = DecisionTreeRegressor() tree.fit(X_train, y_train) tree.score(X_test, y_test)【分類】
from sklearn.tree import DecisionTreeClassifier tree = DecisionTreeClassifier() tree.fit(X_train, y_train) tree.score(X_test, y_test)パラメータ
scikit-learnでのパラメータ名 概要 初期値 特性 max_depth 木の深さ None 木の深さを指定。Noneの場合、純粋になるまで深くなる。 max_leaf_nodes 葉の最大数 None 葉の最大数を指定。Noneの場合、純粋になるまで増える。 min_samples_leaf 最小分割サンプル数 2 分割する最小のサンプル数を指定。 メリット
人間の考え方に近いアルゴリズムであるため、判断基準が明確となりやすい。
データのスケーリングが必要ない。デメリット
枝刈りを行ったとしても過剰に適合しやすい。
未知データに対しては非常に弱い。
- 投稿日:2021-03-05T11:24:32+09:00
OpenCVで画像を回転+保存
概要
PythonのOpenCVで画像を回転させ,保存するプログラムを作ってみました.
CNNの学習で,データ拡張に使いました.開発環境
- Windows10
- Python ver3.7.7
- OpenCV ver3.4.1
コード
import cv2 import os import glob def main(): img_files = glob.glob('*.jpg') for f in img_files: img = cv2.imread(f) fname, fext = os.path.splitext(f) height, width, channels = img.shape center = (int(width/2), int(height/2)) #回転のテンプレ #trans = cv2.getRotationMatrix2D(center, angle , scale) #90度回転 trans1 = cv2.getRotationMatrix2D(center, 90 , 1.0) #アフィン変換 image_1 = cv2.warpAffine(img, trans1, (width,height)) cv2.imwrite(fname+"_90.jpg", image_1) #180度回転 trans2 = cv2.getRotationMatrix2D(center, 180 , 1.0) #アフィン変換 image_2 = cv2.warpAffine(img, trans2, (width,height)) cv2.imwrite(fname+"_180.jpg", image_2) #270度回転 trans3 = cv2.getRotationMatrix2D(center, 270 , 1.0) #アフィン変換 image_3 = cv2.warpAffine(img, trans3, (width,height)) cv2.imwrite(fname+"_270.jpg", image_3) if __name__ == "__main__": main()10行目あたり(for f ~のところ)のコードは,同じフォルダー内の画像(このコードではjpg)を全部読み込むものです.
transは画像の回転です.image_は,回転を画像に反映させて,cv2.imwriteで画像の保存をします.
このコードでは,画像を90度,180度,270度回転させてます.
最後の2行のif文は,画像の読み込みでforがエラーした時のものらしいです(自分はあんまりわかってません).出力される画像
入力した画像はこちらです.
出力された画像はこちらです.


画像が正方形ではない場合は,黒い部分が発生してしまうので,縦横の大きさが等しいものにしか使えないです.
おまけ
読み込ませる画像のファイル名に全角の文字が含まれているとエラーが出ます.
(OpenCVは全角文字を含むファイルは読み込めないんですかね?)


- 投稿日:2021-03-05T11:10:56+09:00
Google Cloud Functions × Cloud FirestoreをPythonで実装する
Cloud Functions × Cloud Firestore 連携
Firebaseプロジェクト > 「プロジェクトを設定」を選択
サービスアカウントを選択
新しい秘密鍵の生成をクリック
Cloud Firestore データ生成
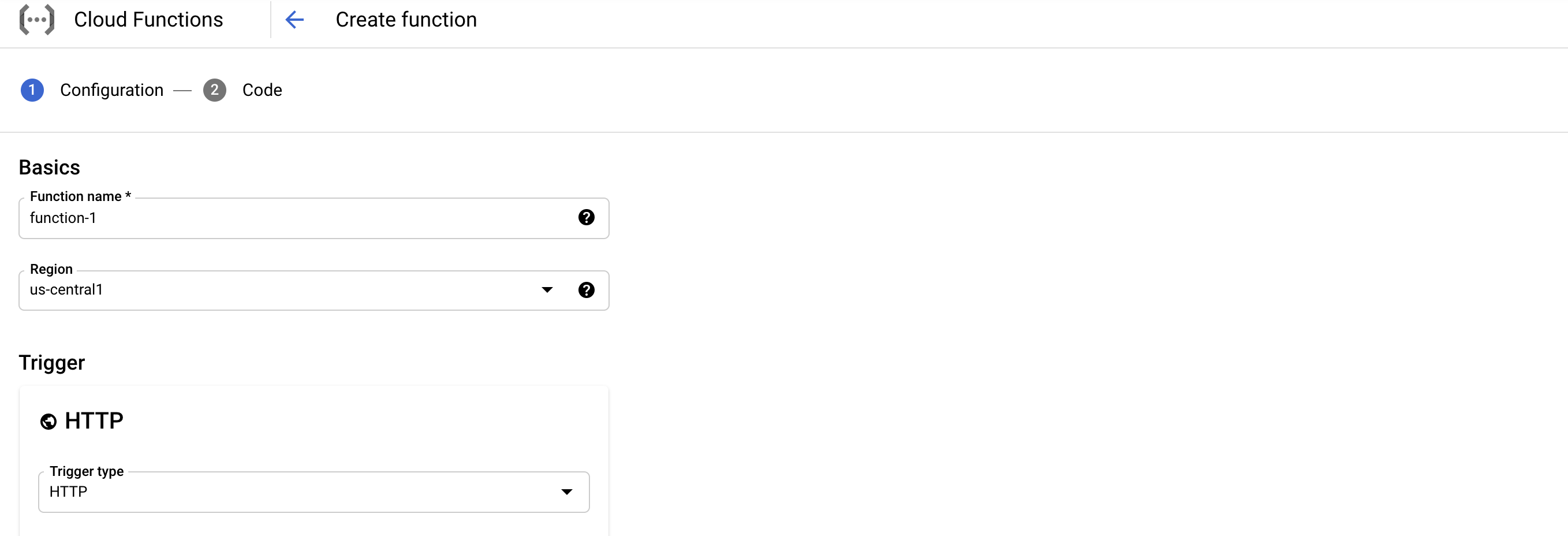
GCPコンソール > Cloud Functions > 「Create function」 選択
Cloud Functions 実装 ※HTTPトリガー
Cloud Firestore 秘密鍵インポート
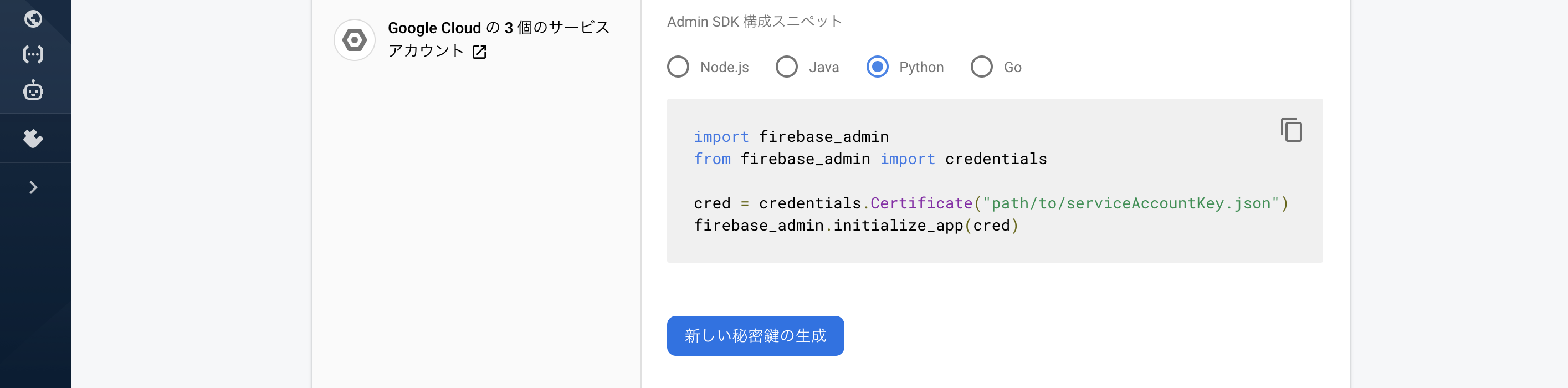
main.pyimport firebase_admin from firebase_admin import firestore from firebase_admin import credentials def sample_functions(request): cred = credentials.Certificate("path/to/serviceAccountKey.json") # 秘密鍵 firebase_admin.initialize_app(cred)Cloud Firestore データやり取り
main.pyimport firebase_admin from firebase_admin import firestore from firebase_admin import credentials def sample_functions(request): cred = credentials.Certificate("path/to/serviceAccountKey.json") # 秘密鍵 firebase_admin.initialize_app(cred) ## Firestore アクセス db = firestore.client() ## document指定 doc_ref = db.collection('users').document('user') ## データ取得 doc = doc_ref.get() sample = json.dumps(doc.to_dict()) return sampleパッケージ指定
requirements.txt# Function dependencies, for example: # package>=version firebase-admin google-cloud-firestoreデプロイ実施
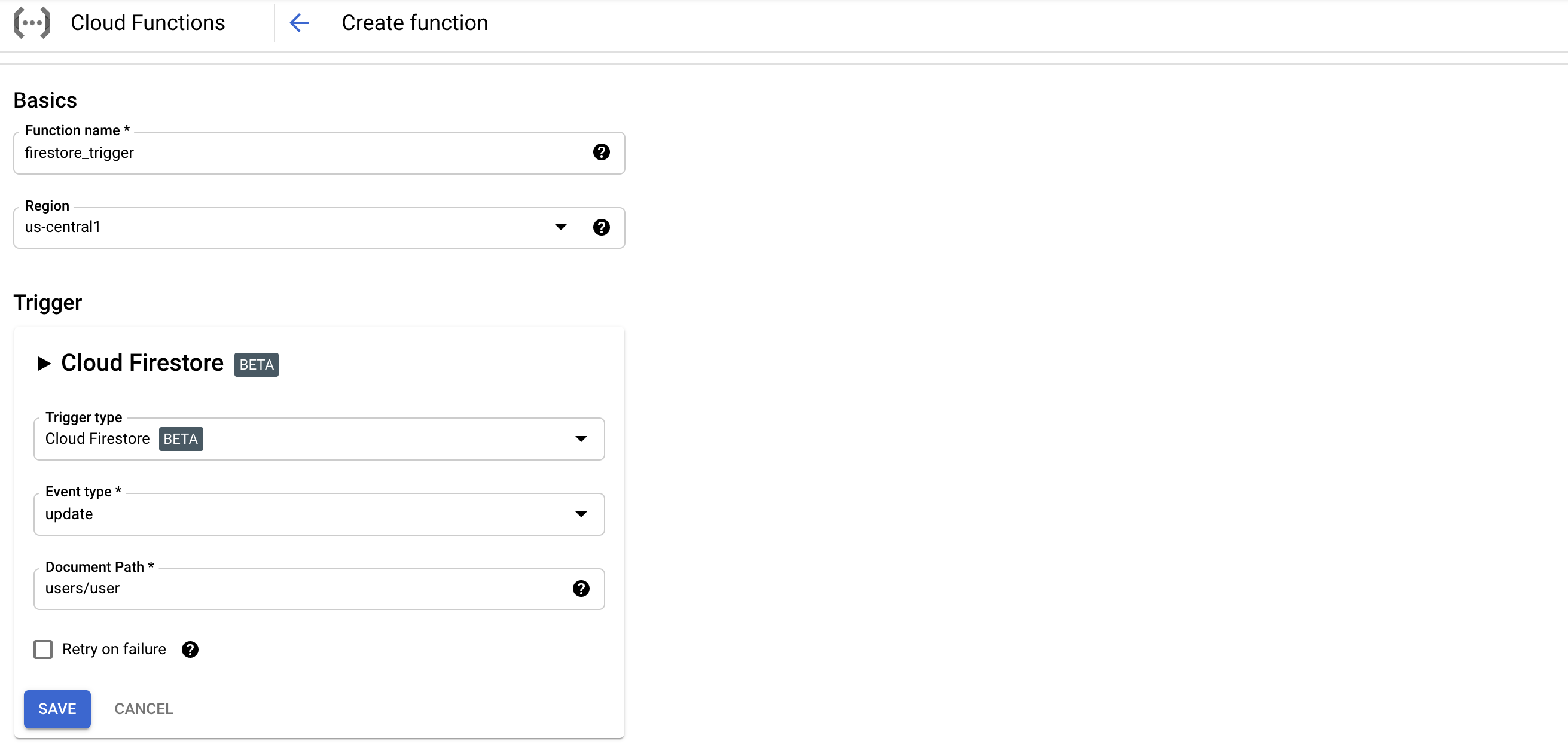
Cloud Firestore トリガーの場合
トリガー設定
Function 設定
main.pyimport firebase_admin from firebase_admin import firestore from firebase_admin import credentials def sample_functions(data, context): cred = credentials.Certificate("path/to/serviceAccountKey.json") # 秘密鍵 firebase_admin.initialize_app(cred) ## トリガー呼び出し trigger_resource = context.resource ## Firestore アクセス db = firestore.client() ## document指定 doc_ref = db.collection('users').document('user') ## データ取得 doc = doc_ref.get() sample = json.dumps(doc.to_dict()) return sampleデプロイ実施
参考文献