- 投稿日:2021-03-05T23:32:29+09:00
Amazon SNS で送られる CloudWatch Events ルールの通知内容をカスタマイズする
はじめに
CloudWatchアラームでSNS通知を行う際、デフォルト通知内容は以下のようになります。(Eメール通知の場合。)
この内容はLambdaを利用することでカスタマイズすることができます。
構成
カスタマイズ通知を送ることが目的なので構成は以下のようにシンプルです。
準備は、
- SNSの設定
- IAMロールの用意
- Lambda関数の作成
- CloudWatchイベントの設定
の順番に行います。
設定
今回は aws-cli を利用して作成します。
① SNSの設定
検知した際の通知先設定を行います。
まず、トピックの作成です。トピックの作成$ aws sns create-topic --name customNotification { "TopicArn": "arn:aws:sns:ap-northeast-1:123456789012:customNotification" }次は通知先となるサブスクリプションの登録です。
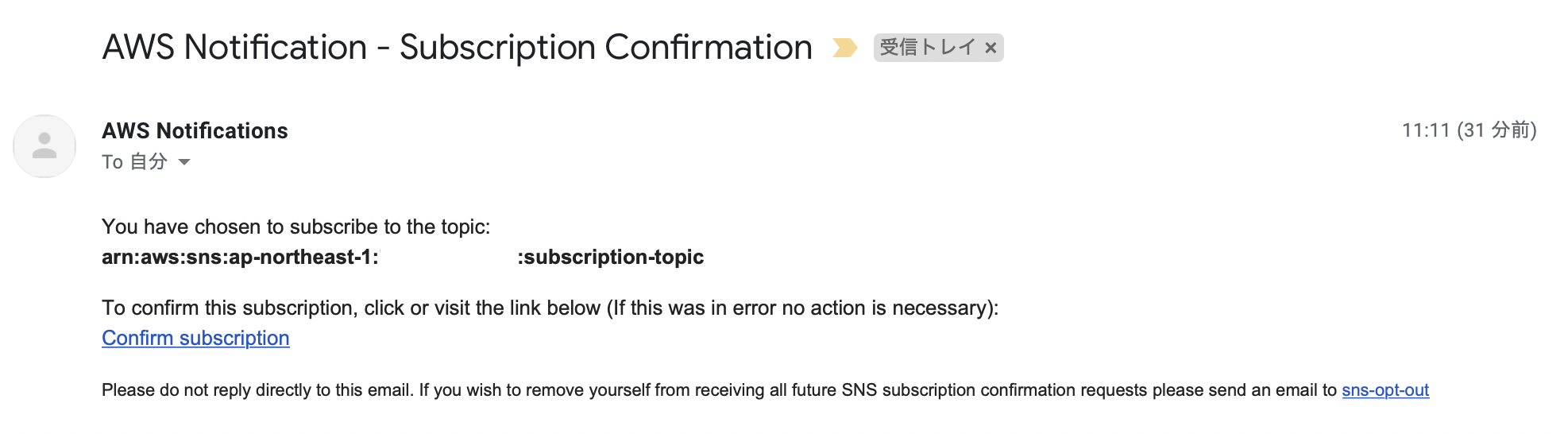
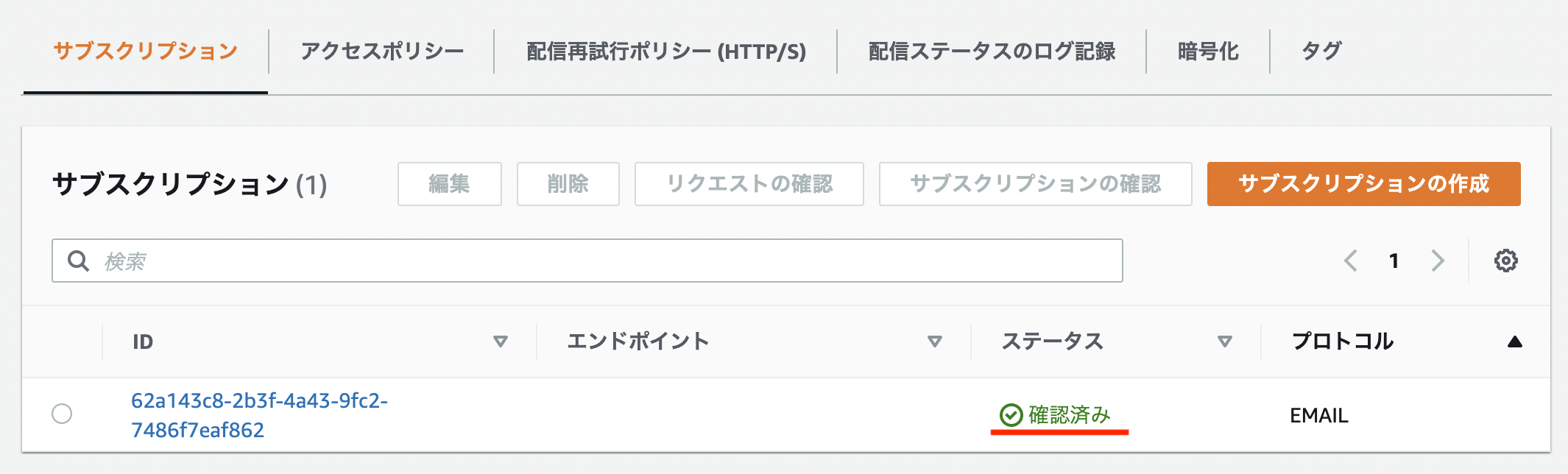
サブスクリプションの登録$ aws sns subscribe --topic-arn arn:aws:sns:ap-northeast-1:123456789012:customNotification --protocol email --notification-endpoint test@hogehoge.jp { "SubscriptionArn": "pending confirmation" }登録先が Email の場合、以下のような確認メールが届きます。
また、このままだとステータスが 「PendingConfirmation」 となっていて送れる状態になっていません。サブスクリプションステータスの確認$ aws sns list-subscriptions-by-topic --topic-arn arn:aws:sns:ap-northeast-1:123456789012:customNotification { "Subscriptions": [ { "SubscriptionArn": "PendingConfirmation", "Owner": "123456789012", "Protocol": "email", "Endpoint": "test@hogehoge.jp", "TopicArn": "arn:aws:sns:ap-northeast-1:123456789012:customNotification" } ] }
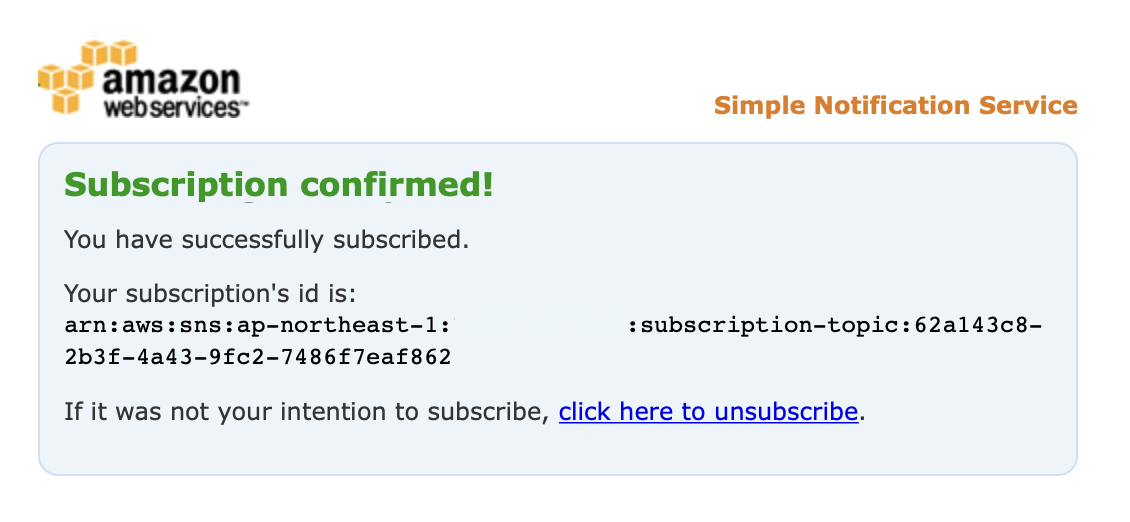
届いたメールの 「Confirm subscription」 のリンクをクリックして承認します。
すると、先ほど 「PendingConfirmation」 となっていた SubscriptionArn がサブスクリプションのARNに置き換わっているのが確認できます。サブスクリプションステータスの確認$ aws sns list-subscriptions-by-topic --topic-arn arn:aws:sns:ap-northeast-1:123456789012:customNotification { "Subscriptions": [ { "SubscriptionArn": "arn:aws:sns:ap-northeast-1:123456789012:subscription-topic:62a143c8-2b3f-4a43-9fc2-7486f7eaf862", "Owner": "123456789012", "Protocol": "email", "Endpoint": "test@hogehoge.jp", "TopicArn": "arn:aws:sns:ap-northeast-1:123456789012:customNotification" } ] }
これで送信可能な状態となりました。
② IAMロール の用意
ここでは Lambda が SNS を利用するために必要な権限を持つ IAMロール を作成します。
IAMロール を作成するには 信頼ポリシー という定義が必要になります。信頼ポリシーの作成$ vim trust-policy.jsonjsonファイルに以下の定義をします。
trust-policy.json{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "lambda.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }ロール の作成を行います。
$ aws iam create-role --role-name customNotification --assume-role-policy-document file://trust-policy.json { "Role": { "Path": "/", "RoleName": "customNotification", "RoleId": "AROA2Z62YJE3UEXRGMVTO", "Arn": "arn:aws:iam::123456789012:role/customNotification", "CreateDate": "2021-02-20T05:50:54+00:00", "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "lambda.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } } }次に ポリシー を ロール ヘアタッチします。
ここではAWSLambdaExecuteとAmazonSNSFullAccessをアタッチします。attach-role-policy(AWSLambdaBasicExecutionRole)$ aws iam attach-role-policy --role-name customNotification --policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRoleattach-role-policy(AmazonSNSFullAccess)$ aws iam attach-role-policy --role-name customNotification --policy-arn arn:aws:iam::aws:policy/AmazonSNSFullAccess以上で IAMロール の準備は完了です。
③ Lambda関数の作成
メインとなる Lambda関数 を作成です。
関数の作成$ vim customNotification.py以下のコードを用意します。
customNotification.pyimport boto3 import json import os sns_arn = os.environ['SNS_TOPIC_ARN'] custom_subject = os.environ['CUSTOM_SUBJECT'] def lambda_handler(event, context): print(sns_arn) client = boto3.client("sns") resp = client.publish(TargetArn=sns_arn, Message=json.dumps(event), Subject=custom_subject)用意したファイルを zipファイル化 します。
zip$ zip customNotification.zip customNotification.pyそれではこの zipファイル と、先ほど用意した IAMロール で Lambda関数 を作成します。
create-function$ aws lambda create-function --function-name customNotification --role arn:aws:iam::123456789012:role/customNotification --runtime python3.8 --handler customNotification.lambda_handler --zip-file fileb://customNotification.zip { "FunctionName": "customNotification", "FunctionArn": "arn:aws:lambda:ap-northeast-1:123456789012:function:customNotification", "Runtime": "python3.8", "Role": "arn:aws:iam::123456789012:role/customNotification", "Handler": "customNotification.lambda_handler", "CodeSize": 403, "Description": "", "Timeout": 3, "MemorySize": 128, "LastModified": "2021-02-20T06:04:08.989+0000", "CodeSha256": "X26yWax91NNEr09NDQVU8PDZBNUIuWmWOlTJr3sfilA=", "Version": "$LATEST", "TracingConfig": { "Mode": "PassThrough" }, "RevisionId": "792f557a-454c-4dd1-a854-e612e4e7997d", "State": "Active", "LastUpdateStatus": "Successful" }作成したら 環境変数 の設定を行います。
update-function-configuration$ aws lambda update-function-configuration --function-name customNotification --environment Variables='{SNS_TOPIC_ARN="arn:aws:sns:ap-northeast-1:123456789012:customNotification",CUSTOM_SUBJECT="TEST通知"}' { "FunctionName": "customNotification", "FunctionArn": "arn:aws:lambda:ap-northeast-1:123456789012:function:customNotification", "Runtime": "python3.8", "Role": "arn:aws:iam::123456789012:role/customNotification", "Handler": "customNotification.lambda_handler", "CodeSize": 403, "Description": "", "Timeout": 3, "MemorySize": 128, "LastModified": "2021-02-20T06:06:45.523+0000", "CodeSha256": "X26yWax91NNEr09NDQVU8PDZBNUIuWmWOlTJr3sfilA=", "Version": "$LATEST", "Environment": { "Variables": { "SNS_TOPIC_ARN": "arn:aws:sns:ap-northeast-1:123456789012:customNotification", "CUSTOM_SUBJECT": "TEST通知" } }, "TracingConfig": { "Mode": "PassThrough" }, "RevisionId": "0dd3494e-72af-4e5b-8586-8d464b4b739e", "State": "Active", "LastUpdateStatus": "Successful" }ここではメール件名が
TEST通知となるように設定しています。④ CloudWatchイベント の設定
今回は簡単なテストを行うために S3バケット が
作成/削除された場合に通知される設定を行います。イベントパターンの作成$ vim event-pattern.jsonevent-pattern.json{ "source": [ "aws.s3" ], "detail-type": [ "AWS API Call via CloudTrail" ], "detail": { "eventSource": [ "s3.amazonaws.com" ], "eventName": [ "CreateBucket", "DeleteBucket" ] } }put-rule$ aws events put-rule --name customNotification --event-pattern file://event-pattern.json { "RuleArn": "arn:aws:events:ap-northeast-1:123456789012:rule/customNotification" }aws-cli で設定する際は
add-permissionで権限追加を忘れずに行いましょう。add-permission% aws lambda add-permission --function-name customNotification --statement-id 1 --principal events.amazonaws.com --action 'lambda:InvokeFunction' --source-arn arn:aws:events:ap-northeast-1:123456789012:rule/customNotification { "Statement": "{\"Sid\":\"1\",\"Effect\":\"Allow\",\"Principal\":{\"Service\":\"events.amazonaws.com\"},\"Action\":\"lambda:InvokeFunction\",\"Resource\":\"arn:aws:lambda:ap-northeast-1:123456789012:function:customNotification\",\"Condition\":{\"ArnLike\":{\"AWS:SourceArn\":\"arn:aws:events:ap-northeast-1:123456789012:rule/customNotification\"}}}" }それではターゲットに Lambda を指定します。
put-targets% aws events put-targets --rule customNotification --targets "Id"="Target1","Arn"="arn:aws:lambda:ap-northeast-1:123456789012:function:customNotification" { "FailedEntryCount": 0, "FailedEntries": [] }これでテスト準備完了です。
テスト
S3バケット を作成し通知されるかテストします。
% aws s3 mb s3://customnotification-test make_bucket: customnotification-testちゃんと設定ができていると以下のような通知が届きます。
おわりに
今回はメール件名のカスタマイズのみを行いましたが、メッセージ部分をカスタマイズしたい場合は
event部分をカスタマイズすることで可能です。参考
CloudWatch Events ルールのデフォルトの Amazon SNS メールの件名「AWS 通知メッセージ」を変更するにはどうすればよいですか?
チュートリアル: CloudWatch イベント を使用して AWS Lambda 関数をスケジュールする
イベントパターン
AWS CLI での高レベル (S3) コマンドの使用



- 投稿日:2021-03-05T22:10:45+09:00
パイロットライトってなんだろ?
パイロットライトってなんだろ?
AWSの勉強中に出てきた単語、パイロットライトについて調べてみました!
響きがかっこいい!こんなかんじ?↓
パイロットライトとは
DR リージョンでシステムの最も重要なコア要素を常に実行している環境の最小バージョンを維持します。復旧の必要が生じたときに、重要なコアを中心として完全な本番環境をすばやくプロビジョンすることができます。
災害対策 (DR) はどのように計画するのですか? - AWS Well-Architected フレームワークよりホットスタンバイみたいに常に別の場所でサブのシステムを動かしておくんじゃなくて、最小限の核となる部分だけをスタンバイしておくってことみたいです。
Black Beltでも出てきていたようです。
AWS Black Belt Online Seminar AWSで実現するDisaster Recoveryよりなるほど!
AMIやらCloudFormationを使ったり、EC2インスタンス自体を停止させておいて、普段は余計なコストをかけないけど、障害が起きたらいつでも立ちあげられるように準備しておくと。
コスパのいい準備ってところかな!他にもいろんな記事がありました。
パイロットライト:停止した状態のサーバーを別のリージョンに用意しておき、障害発生時に立ち上げる。
AWS 耐障害性と高可用性よりDR 用にスペックの低い DB を起動しておいて、通常時はデータの同期のみを行います。障害発生時には、 DR 用のリージョンでアプリケーションを起動し、 DB のスペックを上げて対応します。そして元のリージョンの復旧作業を行います。
AWS 上でのディザスタリカバリ (DR) 構成 4 パターンより言ってることは大体同じようなかんじですね。
AWS以外で検索がヒットしなかったので、AWS独自用語的な単語なのかも??まとめ
今回はAWSにおけるDR対応で出てきたパイロットライトについて調べてみました。
響きがかっこよかったけど、やってることもかっこいいと思うのは僕だけでしょうか?
コスパのいい準備なんてすばらしい考え方だと思います!
日常生活でのパイロットライトも考えてみようかな?(災害対策とか)


- 投稿日:2021-03-05T20:44:44+09:00
みんな 300US$分のAWS無料クレジット申請したよね?
はじめに:
この投稿は、AWSへ適当な内容で申請することを促してAWSを困らせようとかいう意図はありません(^0^;) あくまでもAWSの活用に少しでも興味ある人へのAWS有料機能の「お試し」利用を促進する意図でのご紹介ですwみんなお金ないよね?ね?
2020年の4月にフリーランスから再就職して以来、本業が多忙で全然個人的なプログラム開発をする体力と気力がなくて、AWSの無料枠期間ローテーションでDiscordのBGMボットのトラフィック課金をたまに支払っている程度なのですが、、、
2/28にAWSから随分昔にも一度見たことあるような美味しいキャンペーン?のメールが届きました。
AWS契約しているみなさんのところにも同様のメールが届いているはず。正式には「AWS PoC ( Proof of Concept) プログラム」という名称みたいです。
『300 USD分のAWS無料クレジットを申請できます』
なんて素敵な響きでしょう。こんな素敵な日本語があったのか!(ハイスクールDxD風)
お客様のビジネスに有効な PoC (概念実証) の構築も支援したいと考えています。
ここで、「趣味でAWS使ってるだけなので、PoCとか大層なことやらないし、個人だし・・・」
なんて思ってメールを読んだ瞬間に削除しちゃったあなた! そうあなたですよ!モッタイナイ!! そう、モッタイナイ なのです!
メーラーからサルベージしてでも取り戻して申請しましょうww
趣味でAWS使っているだけの個人だけど大丈夫?
実際に届いたメールのリンクを踏むと以下のような申請画面に飛びます。
この申請項目で、「プロジェクトの目的」というメニューの選択肢は以下からの選択です。
・開発およびテスト
・スキルの学習と構築
・移行
・本番環境でのワークロード
・PoC (概念実証)そう、PoC限定なんかじゃないんですよ。
「開発およびテスト」や「スキルの学習と構築」という興味のある普段使いの内容で全然OKなんです!他の項目で悩ましいのは、あたかも企業でないと申請できないようないくつかの項目ですが、今流行りの?副業の一環も含めてフリーランスを自称すればあなたは個人事業主!立派なお一人様組織ですww
以下のように、ちゃんと選択肢を乗り越えられます。
・従業員数 → 社員は俺様1人で十分 (1~19人)
・想定予算 → 無料枠期間利用で課金ゼロでもOK (月額 50 USD未満)
・構築内容 → 以下から適当にどうぞ
・AIと機械学習
・バッチ処理
・ビッグデータ、分析、ビジネスインテリジェンス
・ビジネスアプリケーション – Microsoft
・ビジネスアプリケーション – Oracle
・ビジネスアプリケーション – その他
・ビジネスアプリケーション – SAP
・コンテンツ配信
・ゲーム
・IoT
・トレーニングと認定
・メディアサービス
・移行
・モバイルアプリケーション
・その他
・ストレージ&バックアップ
・ウェブサイトとウェブアプリ
※途中に「その他」がある時点でAWS側もここはどうでもいい気がしますw
・御社名 → 屋号の登録していなくても、自分で「この屋号でやってます」と言えば自称フリーランスなら通るので適当に迷惑がかからない実存しない名称でもOK(笑)ポチっとな
フォームを埋めたら申請ボタンを「ポチっ」。
審査の結果は、私の場合1週間弱で審査通過でクレジット適用のメールが届きました\(^O^)/
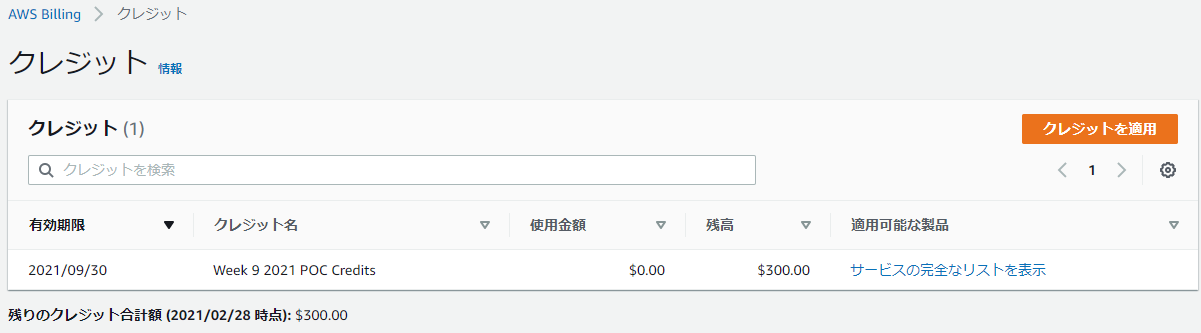
AWSコンソールのBilling画面でクレジットを確認すると、9/30期限まででちゃんと300 US$のクレジットが追加されています!
無課金勢が約3萬円分のクレジットを手に入れた!
「約3万円分のAWSクレジットがある」というだけで、急にプログラム開発のモチベーションがあがりますww
週末に疲れて引き籠もるのが常のフルリモート社畜でもなんか作ってみようと立ち上がるってものです(苦笑)あとは、強化学習系のスポット課金にでも、SageMakerの従量課金でも、各種サービスの無料枠超過分にでも充当しましょう♪
なお、支給されたクレジットは、課金発生後に自動で充当されますので、ときどきBilling画面でクレジット残額を確認しながら使いましょう。調子に乗って、300 US$使い切って高額請求が来ても当局は一切責任を負いませんよ!



- 投稿日:2021-03-05T20:35:13+09:00
EC2でWebRTC Ayameサーバー立ち上げ
環境構築
アプリ
Windows 10
AWSアカウント
Unity 2019.4.xWebRTC Signalling Server Ayame
Ayame YAMLファイル - WebRTCが繋がりにくい時、このファイルが重要です。設定
まず新しいEC2インスタンスを作成してください。AWSダッシュボードの左のタブウインドウで、インスタンスを開けます。
インスタンスを起動します。今回は、Windowsインスタンスを選びました。
無料版を選びまして、「確認と作成ボタン」と残りの設定はAWSに任せます。
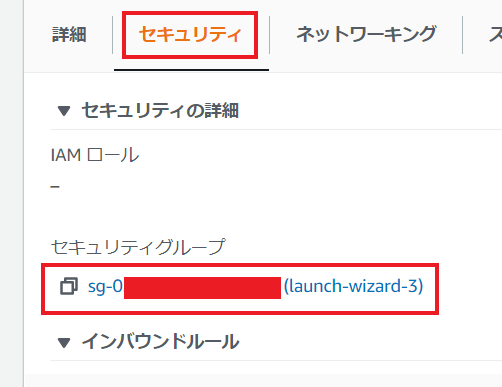
作成したインスタンスを開けて、セキュリティタブを選んで、設定します。
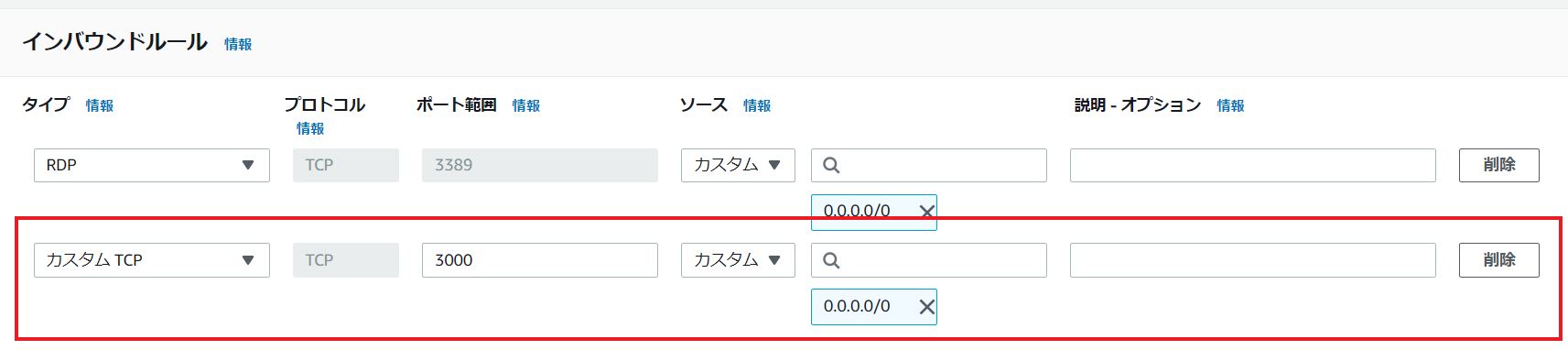
インバウンドルールを編集します。カスタムTCPポート3000を追加します。保存します。
インスタンスと接続して、RDPを選んでください。
サーバー立ち上げ
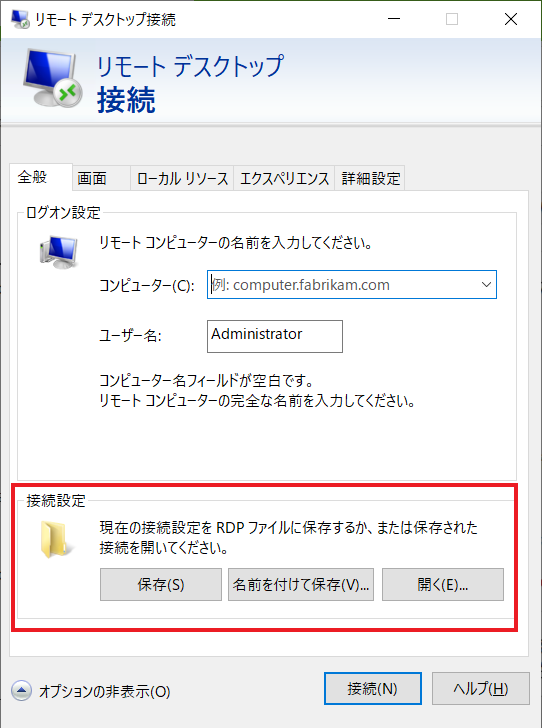
Windows 10でリモートデスクトップ接続アプリを開いてください。
オプションの表示を開いてください。接続設定はRDPファイルから開いてください。
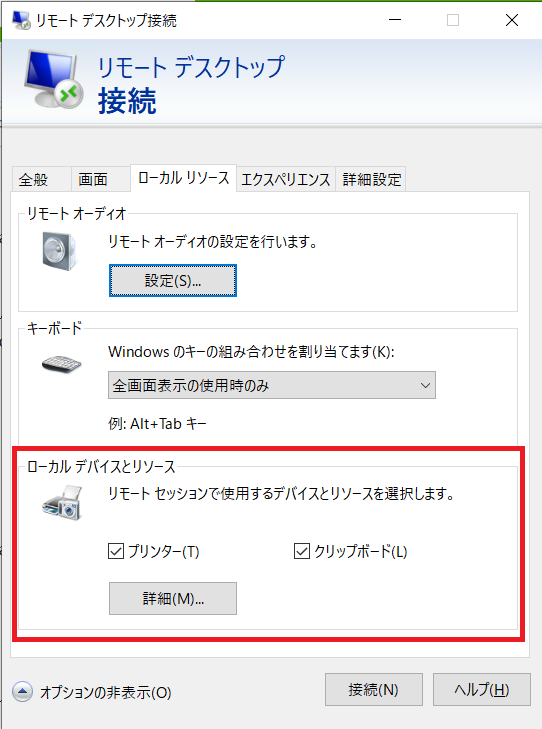
接続前に、ファイル転送をできるためローカルソースを開いてください。
ローカルデバイスとリソースで詳細を開いてください。後、ドライブでチェック入れてください。
終わったら、接続してください。
Ayameサーバーをダウンロードしてください。EC2のOSを対応できる、一つ選択してください。今回の記事はWindows OSを使いましたので、ayame_windows_amd64.exe.gzをダウンロードしました。
exeファイルを引き抜くして、YAMLファイルと一緒のフォルダーで入れました。
EC2でエクスプローラーのNetworkを開いて、tsclientでダウンロードしたAyameサーバーのフォルダーをEC2へコピーしてください。今回の記事でAyameサーバーのフォルダーはデスクトップへコピーしました。
Command Prompt (CMD)を開いて、Ayameフォルダーへ移動して、ayame_windows_amd64.exeを発生します。
繋がりにくい時、EC2のFirewallを消してください。まだ繋がりにくい場合は、yamlファイルでwebhook_request_timeoutをちょっと上げてください。
UNITYプロジェクトの設定
編集中





- 投稿日:2021-03-05T18:18:30+09:00
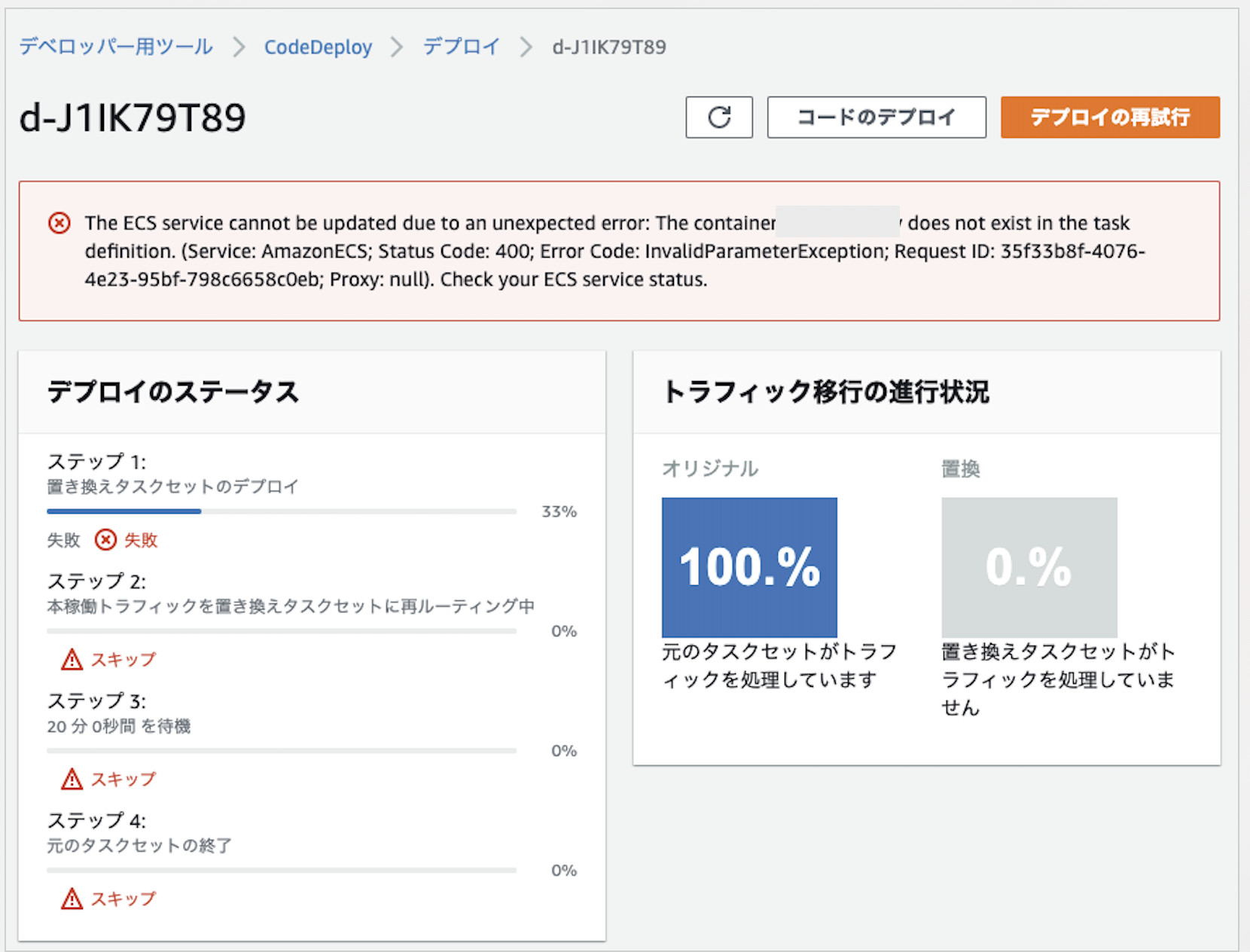
【CodePipeline】エラー対処法: unexpected error: The container <container-name> does not exist in the task definition.
CodePipelineで以下のようなエラーがでた場合の対処法について。
The ECS service cannot be updated due to an unexpected error: The container does not exist in the task definition.
エラー内容
問題が発生してECSをアップデートできない。taskdefinitionの中に指定されたコンテナ名がないとの指摘。
原因
appspec.ymlファイルで指定したcontainer nameが間違っている(stgのコンテナ名を指していた。)
対処法
appspec.ymlのcontainer nameを修正して完了。
下記の
ContainerName: "sample-website"の部分。appspec.ymlversion: 0.0 Resources: - TargetService: Type: AWS::ECS::Service Properties: TaskDefinition: <TASK_DEFINITION> LoadBalancerInfo: ContainerName: "sample-website" ContainerPort: 80
- 投稿日:2021-03-05T18:14:13+09:00
Let's encryptでAmazon Linux2でDNS-01で証明書を手動で作る
概要
- AWS上でやんごとなき事情で限定公開しかできないインスタンスで証明書が欲しいよ
- Route53も使えないけど、外部でDNS登録はできるからDNS-01方式だったらやれそうだよ
って方向けの内容です
ちょくちょくやるけど忘れちゃうのでメモ
(きっと探せば類似記事がいっぱいあるだろうなぁ)やりかた
certbotをインストール
# 聞かれたらよしなに'y'か'-y'オプションつけてね sudo amazon-linux-extras install epel sudo yum install certbot証明書発行
オプションで指定できるけど今回は手入力
sudo certbot certonly --manual --preferred-challenges dns色々聞かれる
コマンド実行の中で証明書発行のためにアカウント作成周りのことが聞かれる
[ec2-user@ip-10-210-15-44 ~]$ sudo certbot certonly --manual --preferred-challenges dns Saving debug log to /var/log/letsencrypt/letsencrypt.log Plugins selected: Authenticator manual, Installer None Enter email address (used for urgent renewal and security notices) (Enter 'c' to cancel): xxx@xxx.com書いてある通り、緊急通知とかの連絡先のメールアドレスを入れる
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Please read the Terms of Service at https://letsencrypt.org/documents/LE-SA-v1.2-November-15-2017.pdf. You must agree in order to register with the ACME server. Do you agree? - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - (Y)es/(N)o: Y利用許諾に同意してね
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Would you be willing, once your first certificate is successfully issued, to share your email address with the Electronic Frontier Foundation, a founding partner of the Let's Encrypt project and the non-profit organization that develops Certbot? We'd like to send you email about our work encrypting the web, EFF news, campaigns, and ways to support digital freedom. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - (Y)es/(N)o: Y Account registered.管理している団体をサポートするために何かしらメール送ってもいいかい?(的な意訳)
YでもNでもどちらでもお好きな方を
ここまででアカウント登録証明書発行周り
Please enter in your domain name(s) (comma and/or space separated) (Enter 'c' to cancel): xxx.xxx.com証明書を発行したいFQDNが聞かれるので入力する
入力したらDNS登録が待っているので待機DNS登録確認
Requesting a certificate for xxx.xxx.com Performing the following challenges: dns-01 challenge for xxx.xxx.com - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Please deploy a DNS TXT record under the name _acme-challenge.xxx.xxx.com with the following value: xxxxxxxxxxxx Before continuing, verify the record is deployed. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Press Enter to Continue上記のように表示されたらDNS登録
_acme-challenge.xxx.xxx.comと書かれたFQDNを、
TXTレコードでxxxxxxxxxxxxと書かれている所の値で指定して登録別ウィンドウや別EC2等で正常に目的のレコードが登録されているかを確認
(社内とかより外側のDNSを叩きに行った方が正確なものが取れそうなので、EC2がおすすめ)[ec2-user@ip-10-210-15-95 ~]$ dig _acme-challenge.xxx.xxx.com txt ; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.amzn2.2 <<>> _acme-challenge.xxx.xxx.com txt ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 65226 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;_acme-challenge.xxx.xxx.com. IN TXT ;; ANSWER SECTION: _acme-challenge.xxx.xxx.com. 60 IN TXT "xxxxxxxxxxxx" ;; Query time: 9 msec ;; SERVER: 10.210.15.2#53(10.210.15.2) ;; WHEN: 金 3月 05 17:58:31 JST 2021 ;; MSG SIZE rcvd: 117上記のように登録されていることが確認できたら、Enter
Waiting for verification... Cleaning up challenges IMPORTANT NOTES: - Congratulations! Your certificate and chain have been saved at: /etc/letsencrypt/live/xxx.xxx.com/fullchain.pem Your key file has been saved at: /etc/letsencrypt/live/xxx.xxx.com/privkey.pem Your certificate will expire on 2021-06-03. To obtain a new or tweaked version of this certificate in the future, simply run certbot again. To non-interactively renew *all* of your certificates, run "certbot renew" - If you like Certbot, please consider supporting our work by: Donating to ISRG / Let's Encrypt: https://letsencrypt.org/donate Donating to EFF: https://eff.org/donate-leこれで
/etc/letsencrypt/live/xxx.xxx.com/配下に証明書が発行されたので、
よしなに使いたいアプリに食わせて使いましょうおまけ
Nginxならこんな感じで上記ファイルを指定して使う
(デフォルトConfigからいじる場合)server { listen 443 ssl http2; listen [::]:443 ssl http2; server_name _; root /usr/share/nginx/html; ssl_certificate "/etc/letsencrypt/live/xxx.xxx.com/fullchain.pem"; ssl_certificate_key "/etc/letsencrypt/live/xxx.xxx.com/privkey.pem"; ssl_prefer_server_ciphers on; # Load configuration files for the default server block. include /etc/nginx/default.d/*.conf; error_page 404 /404.html; location = /40x.html { } error_page 500 502 503 504 /50x.html; location = /50x.html { } }
- 投稿日:2021-03-05T17:59:57+09:00
AmazonBraketで学ぶ量子コンピュータ⑤
この記事について
量子コンピュータの勉強をはじめて最近一通りAmazonBraketを触り終えました。
最近登場したサービスであることもあり、少し丁寧なドキュメントを残しておくと後続の方が勉強しやすくなったり、参照してわからないところを調べる際に便利かなと思ったので
自分自身の理解向上も兼ねて記事にまとめていっています。なお、量子コンピュータ関係の他の記事は、こちらのページで一覧にしています
※本記事は2021年2月に更新している記事です。更新などにより内容が変わっている可能性もあるのでご注意ください。
概要
本記事では量子コンピュータの導入部分に関して解説をしていこうと思います。
参照するのはこちらの4_Superdense_coding.ipynbというサンプルです。
こちらでは量子超高密度化という量子コンピュータで良く扱われる回路に触れた後、実際にAmazon Braket内でその回路を実装するというサンプルになっています。
なので今回は量子高密度符号化の説明をした後、実際のサンプルの説明に入っていこうかと思います。Braketを使わずに、マウスで簡単に確認してみたい方は、下記も参照ください。
マウスだけ!で作る超高密度符号化実験前提知識
こちらの4_Superdense_coding.ipynbというサンプルでは主に量子高密度符号化というものを扱っています。
量子高密度符号化というものは「1つのqubitだけを送信することで2つの古典的なビットを送信する方法」です。
送信者(アリス)は量子ゲートを適用した後の量子を受信者(ボブ)に送信することで受信者は2ビットの古典ビットのメッセージを復号できます。量子高密度符号化
概要
量子高密度符号化というものは「1つのqubitだけを送信することで2つの古典的なビットを送信する方法」です。
まず最初のプロセスとしてアリスとボブは、もつれ状態のqubitのペア(つまり、ベル状態のペア)を共有する必要があります。
次に、アリスは、2つの古典ビットで送信する可能性のある4つのメッセージのうち、1つを選択します。
00, 01, 10, 11のうちの1つを選択するという意味です。
どの2ビット文字列を送信したいかに応じて、アリスは対応する量子ゲートを適用して、希望するメッセージを符号化します。
メッセージに対応する量子ゲートを適用した後、アリスはゲート適用後の自分の量子ビットをボブに送信し、ボブは最初のエンタングル処理を元に戻すことでメッセージを復号します。流れ
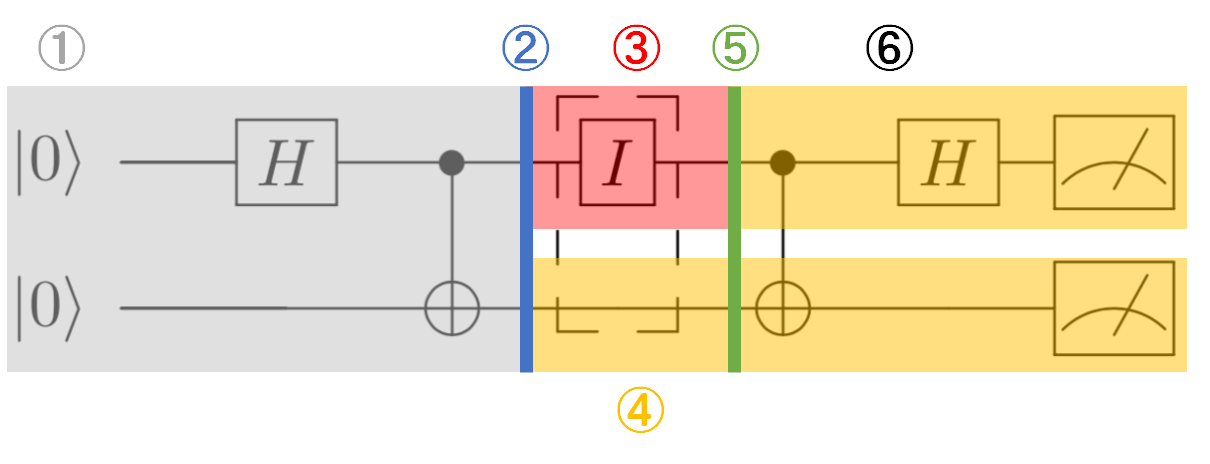
量子高密度符号化の流れを回路図とともに説明していきます。
まず流れをざっと示すと①.ベルペア(もつれ状態にある2量子ビット)を用意します。ベルペアを用意するのは誰であっても構いません。アリスであってもボブであっても別の第三者であっても。今回は別の第三者が用意してくれたと仮定しましょう。
②.第三者が用意してくれたベルペアを何らかの方法でアリスとボブは共有します。つまり、片方をアリスがもう片方をボブが受け取ります。
③.アリスは受け取ったベル状態にある片方の量子ビットに対し、何らかの送りたいメッセージに対応する量子ゲート操作を行います。
④.ボブは量子ビットを受け取ったすぐのタイミングでは何もしません。
⑤.アリスはゲート操作を行った量子ビットを何らかの方法でボブに送信します。
⑥.アリスから送られてきた量子ビットをコントロールビットとして、自分の量子ビットをターゲットビットとしてCNOTゲートを適用し、アリスから送られてきた量子ビットにハダマードゲートを適用することによって、アリスの2ビットのメッセージをデコードします。回路図で示すとそれぞれのプルセスに対応する図は以下のように示されます。
番号と対応づけて読んでいただけるとわかりやすくて良いかと思います。
では
③.アリスは受け取ったベル状態にある片方の量子ビットに対し、何らかの送りたいメッセージに対応する量子ゲート操作を行います。
ではどういった量子ゲート操作を行うのでしょうか?
実際に計算してみてアリスがどんなゲート操作を行うかを解き明かしていきましょう。アリスの量子ゲート
まず結論から申し上げるとアリスは送りたいメッセージに対して以下のゲート操作を行います。
Message Alice's encoding 00 ? 01 ? 10 ? 11 ?? これらの操作で本当に送りたいメッセージを送れるのかどうか解き明かしていきます。
00 を送る。
00 を送る場合を考えます。
上記 ② の時点でベル状態(もつれ状態)をアリスとボブは共有するのでこの時点での量子状態は| 00 \rangle + | 11 \rangleとなります。(面倒なので規格化は無視して考えています。)
次に $I$ を適用するので
| 00 \rangle + | 11 \rangle \xrightarrow{I} | 00 \rangle + | 11 \rangleとなります。恒等変換なので何も変化なしですね。
この後CNOTを適用する。つまり、0量子ビット側(アリスビット側)が1の時、もう片方のビットを反転させます。
| 00 \rangle + | 11 \rangle \xrightarrow{I} | 00 \rangle + | 11 \rangle \xrightarrow{CNOT} | 00 \rangle + | 10 \rangleそして最後にアリス側のビットにアダマールゲートを適用すると
| 00 \rangle + | 10 \rangle \xrightarrow{H} (| 0 \rangle + | 1 \rangle) | 0 \rangle + (| 0 \rangle - | 1 \rangle) | 0 \rangle = | 00 \rangleとなり、$| 00 \rangle$となることがわかります。
01 を送る。
01 を送る場合を考えます。
上記 ② の時点でベル状態(もつれ状態)をアリスとボブは共有するのでこの時点での量子状態は| 00 \rangle + | 11 \rangleとなります。(今回も面倒なので規格化は無視して考えています。)
次に $X$ を適用するので
| 00 \rangle + | 11 \rangle \xrightarrow{X} | 10 \rangle + | 01 \rangleとなります。
この後CNOTを適用する。つまり、0量子ビット側(アリスビット側)が1の時、もう片方のビットを反転させます。
| 00 \rangle + | 11 \rangle \xrightarrow{X} | 10 \rangle + | 01 \rangle \xrightarrow{CNOT} | 11 \rangle + | 01 \rangleそして最後にアリス側のビットにアダマールゲートを適用すると
| 11 \rangle + | 01 \rangle \xrightarrow{H} (| 0 \rangle - | 1 \rangle) | 1 \rangle + (| 0 \rangle + | 1 \rangle) | 1 \rangle = | 01 \rangleとなり、$| 01 \rangle$となることがわかります。
10 を送る。
そろそろ手を抜きますね笑
ベル状態を共有して$Z$を適用後、CNOTを適用するので以下の通りになります。| 00 \rangle + | 11 \rangle \xrightarrow{Z} | 00 \rangle - | 11 \rangle \xrightarrow{CNOT} | 00 \rangle - | 10 \rangleそして最後にアリス側のビットにアダマールゲートを適用すると
| 00 \rangle - | 10 \rangle \xrightarrow{H} | 10 \rangleとなり、$| 10 \rangle$となることがわかります。
11 を送る。
ベル状態を共有して$ZX$を適用後、CNOTを適用するので以下の通りになります。
| 00 \rangle + | 11 \rangle \xrightarrow{ZX} | 01 \rangle - | 10 \rangle \xrightarrow{CNOT} | 01 \rangle - | 11 \rangleそして最後にアリス側のビットにアダマールゲートを適用すると
| 01 \rangle - | 11 \rangle \xrightarrow{H} | 11 \rangleとなり、$| 11 \rangle$となることがわかります。
アリスの量子ゲートまとめ
結果的にアリスの量子ゲートによって以下のようにまとめられることがわかるかと思います。
Message Alice's encoding State Bob receives
(non-normalized)After ?? gate
(non-normalized)After ? gate 00 ? |00⟩ + |11⟩ |00⟩ + |10⟩ |00⟩ 01 ? |10⟩ + |01⟩ |11⟩ + |01⟩ |01⟩ 10 ? |00⟩ - |11⟩ |00⟩ - |10⟩ |10⟩ 11 ?? |01⟩ - |10⟩ |01⟩ - |11⟩ |11⟩ AmazonBraket
ここから実際にAmazonBraketを使って説明していきます。
環境を用意されていない方は、まずはこちらの記事やドキュメントなどを参考に環境を用意してください。環境を用意すると以下のようにデフォルトでサンプルコードがGitHubからインポートされています。
今回はこの配下にある
getting_started/4_Superdense_coding.ipynb
を見ていきます。事前準備
事前準備として必要なものをいくつか解説していこうと思いましたが、特に特別なこともなさそうなのでここは割愛していきます。
Amazon Braketのサンプル上では1.必要なモジュールをインポートしてきて、
2.S3バケットの登録
3.結果取得の関数定義(get_result)を行っているのでそちらを見てみてください。
この記事のシリーズを読んでいただければそこまで難しい内容ではないかと思います。本体
準備を終えたところで本体の方に入っていきます。
以下の図も意識しつつ、説明を見ていただける理解しやすいかと思います。
ベル状態の準備
まずはベル状態を準備します。(①)
circ = Circuit(); circ.h([0]); circ.cnot(0,1);アリスの量子ゲート
アリスは任意の量子ゲートを適用します。(③)
Amazon Braketのサンプルではアリスが適用できる量子ゲートを以下の通り、辞書型で用意しています。# Four possible messages and their corresponding gates message = {"00": Circuit().i(0), "01": Circuit().x(0), "10": Circuit().z(0), "11": Circuit().x(0).z(0) }今回はまずは01を選んでそれを
circ回路に追加していきます。# Select message to send. Let's start with '01' for now m = "01" # Encode the message circ.add_circuit(message[m]);復号
最後に復号します(⑥)
circ.cnot(0,1); circ.h([0]);回路図を見てみましょう。
print(circ)出力結果
T : |0|1|2|3|4| q0 : -H-C-X-C-H- | | q1 : ---X---X--- T : |0|1|2|3|4|01を送る回路ができたと思います。
実行
実行してみます。
counts = get_result(device, circ, s3_folder) print(counts)キューにたまるのでしばらくは結果が返ってきませんが、
結果が返ってくると以下のような出力結果を得ることができます。
すべてのメッセージの送信
以下の通りループを組んであげることですべてのメッセージに対する検証を行うことができます。
for m in message: # Reproduce the full circuit above by concatenating all of the gates: newcirc = Circuit().h([0]).cnot(0,1).add_circuit(message[m]).cnot(0,1).h([0]); # Run the circuit: counts = get_result(device, newcirc, s3_folder) print("Message: " + m + ". Results:") print(counts)実行してあげるとすべてのメッセージの結果を取得することができるので是非実行してみてください。
最後に
以上で「AmazonBraketで学ぶ量子コンピュータ⑤」を終わります。
今回は量子高密度符号化を行ってみることでサンプルを動かしてみました。
Braketを使わずに、マウスで簡単に確認してみたい方は、下記も参照ください。
マウスだけ!で作る超高密度符号化実験
また別記事で他のBraketサンプルの解説を行ないながら量子コンピュータを学んでいける記事を書いていくので是非見てみてください。


- 投稿日:2021-03-05T17:33:41+09:00
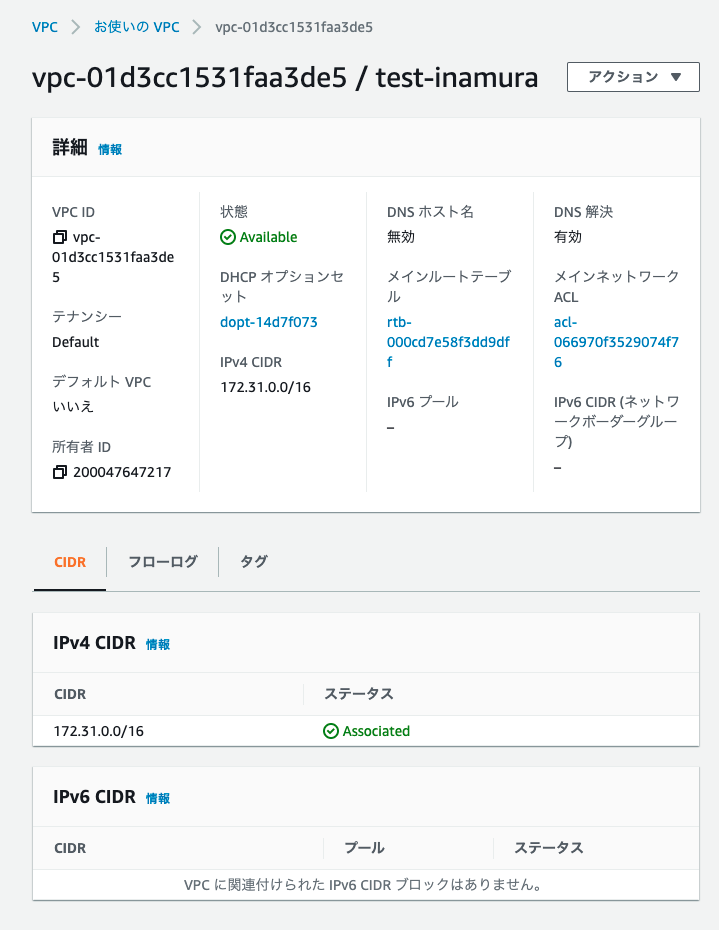
VPCの全体像⓶(AWS)
ルートテーブル
ルートテーブルとは、
・サブネット1つにつき1個
・サブネットから外に出る通信をどこに向けて発信するかを決めるルール
・ルートと呼ばれるルールで構成されている
・最も明確なルートが優先されて適用
(狭いIPアドレスに範囲にマッチしたルールほど、優先的に適応される)ルートと呼ばれる1つのルールの集合体を、ルートテーブルといいます。
ローカルルート(local route)
ローカルルートの特徴は、
・VPCの内部を示しており、VPC内の全てのリソースの通信を可能にする
・最初はlocalルートのみ格納されている
・localルートは削除できないインターネットゲートウェイ
続いては、VPCをインターネットと接続するためにインターネットゲートウェイを設定していきます。
インターネットゲートウェイとは、
・VPC内のAWSリソースとインターネットを繋げるもの
・自動でスケールし、可用性が高い
(アクセスが集まりすぎても、AWSが自動で分散処理をしてくれる)
・サブネットのルートテーブルで設定して使用するパブリックサブネット(Public subnet)
・ルートテーブルに、インターネットゲートウェイへのルーティング有
(EC2インスタンスからインターネットゲートウェイに直接アクセスできる)・外部公開しても大丈夫なAWSリソースを置く。
プライベートサブネット(Private subnet)
・ルートテーブルに、インターネットゲートウェイへのルーティング無
(EC2インスタンスからインターネットゲートウェイに直接アクセスできない)・ルートテーブルに、(パブリックサブネットにある)NAT gatewayへのルーティング有
・セキュリティレベルが高いデータベースなどを置く。
NAT
NAT gatewayとは、
・プライベートサブネットからインターネット接続を可能にする
・アウトバウンド(発信)はできるが、インバウンド(受信)はできない
(セキュリティレベルがだいぶ高まる)NAT gatewayはインターネットゲートウェイと同様に、負荷が高まるとAWS側で自動でスケールしてくれるので、可用性が高まる。
まとめ
パブリックサブネットのEC2インスタンスは、EC2→インターネットゲートウェイに接続。
プライベートサブネットのEC2インスタンスは、EC2→(パブリックサブネット内の)NAT→インターネットゲートウェイに接続。
*ちなみにプライベートサブネットのEC2にログインするには、一旦パブリックサブネットのEC2にログインしてから再度プライベートサブネットのEC2にログインする2段階の踏み台の形をとっています。
- 投稿日:2021-03-05T17:17:52+09:00
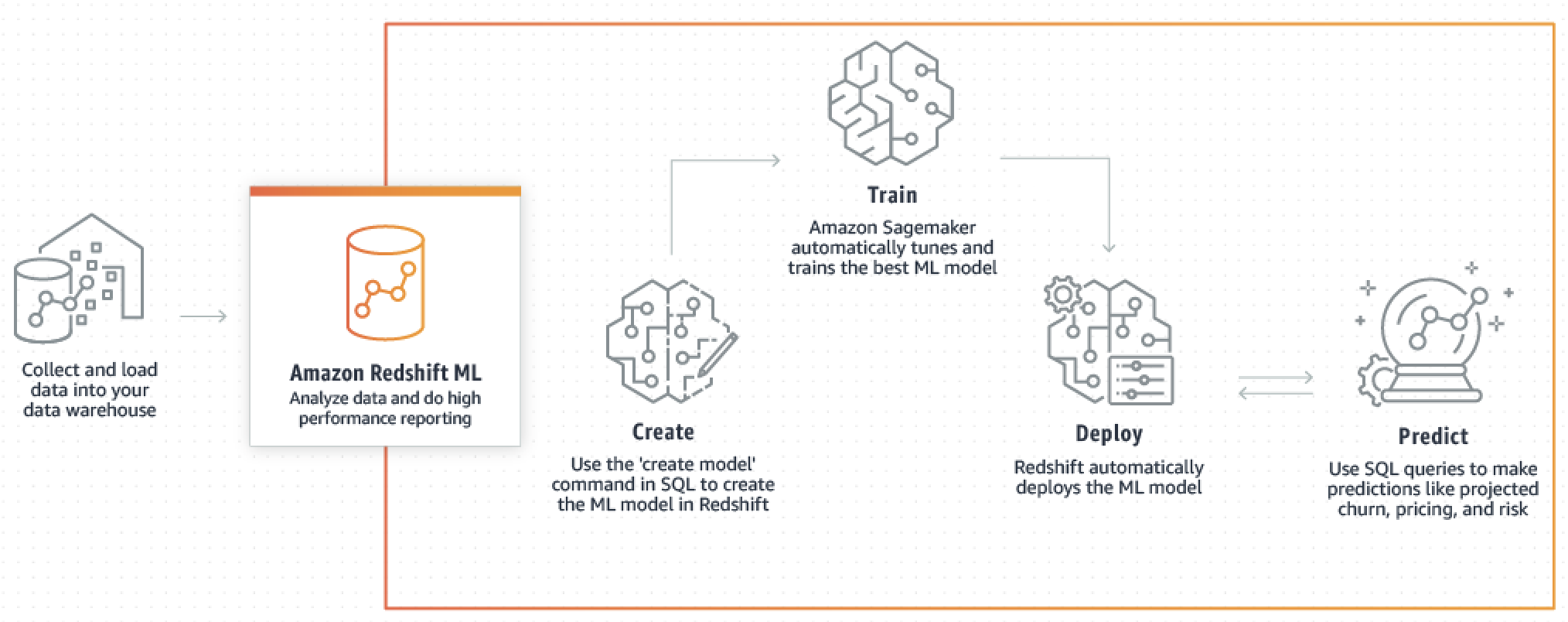
Amazon Redshift ML で機械学習モデル構築 + 周辺AWSサービス設定手順まとめ
はじめに
サンプルデータを AWS Redshift にインポートし、Amazon Redshift ML で機械学習モデルを構築するまでの流れです。作成したばかりの AWS アカウントを想定しているので、周辺環境の設定内容で引っかかった方はご参照ください。
ターゲット
- SQL をメインで利用するデータエンジニア/アナリスト
- Amazon Redshift を利用
利用サービス
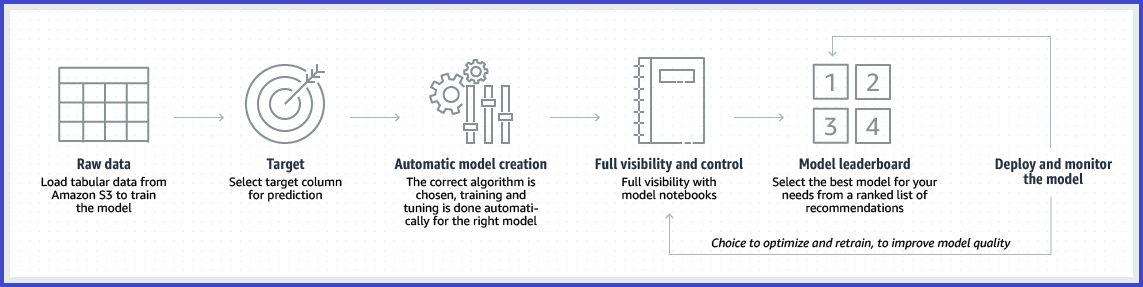
Amazon SageMaker Autopilot
- 自動機械学習 (AutoML) プロセスの主要なタスクを自動化
- 最適なアルゴリズムを選択し、モデルのトレーニングとチューニングが容易
- 最低料金や初期費用なし
- 回帰、二項分類、複数クラスの分類をサポート
Amazon Redshift ML
- SQL を利用して Redshift のデータから機械学習モデルをデプロイ
- 予測結果も Redshift から SQL で取得可能
- バックエンドでは Amazon SageMaker Autopilot が動作
利用データ概要
本記事ではこちらのウェブサイトの情報とデータを利用します。
イーコマースのログデータ元に組み上げられた単一の CSV データです。
背景
- 顧客をランダムに3つに分け、販促キャンペーンのメールを配信
- メンズ商品のキャンペーン
- レディース商品のキャンペーン
- 配信なし
- ウェブサイトの訪問履歴や購入金額をトラッキング
- トラッキングの期間はキャンペーンメール配信から2週間
目的
無作為にキャンペーンを打つのでは販促費の無駄になります。よって、
- 普段は購入する意欲は高くない
- 施策を打てば購入する可能性が大幅に上がる
といったユーザーに絞って販促費を投入できれば ROI が最大化できるはずです。
その手法の一つに Uplift Modeling があります。
本記事では Uplift Modeling のロジックへの組み込みを想定し、特定のキャンペーンを打つべきユーザーを予測する機械学習モデルを作成します。なお、モデル作成には2020年12月にパブリックプレビューになった Amazon Redshift ML を用います。
データセット
- 過去12か月以内に物品を購入した64,000人の顧客情報
- ダウンロードURL
- Windows であれば、リンクを右クリック > リンク先を保存
スキーマ
カラム名 データ型 概要 Recency int4 前回の購入から経過した月数 History_Segment varchar(256) 過去1年間の購入金額の区分 History float (8) 過去1年間の購入金額 Mens boolean 過去に男性向け製品を購入したかどうか Womens boolean 過去に女性向け製品を購入したかどうか Zip_Code varchar(256) 顧客の居住カテゴリ。Urban, Sunurban, Rural Newbie boolean 過去1年で新規顧客になったかどうか Channel varchar(256) 過去に顧客が購買した経路 Segment varchar(256) 受け取ったキャンペーンメールの種類。Mens E-mail, Womens E-mail, No E-mail Visit boolean 過去2週間にウェブサイトを訪問したかどうか Conversion boolean 過去2週間に購買に至ったかどうか Spend float (8) 過去2週間の購入金額 AWS 環境構築
IAM role
Redshift ML 経由で SageMaker Autopilot を操作できるようにするため、対応する権限を設定します。
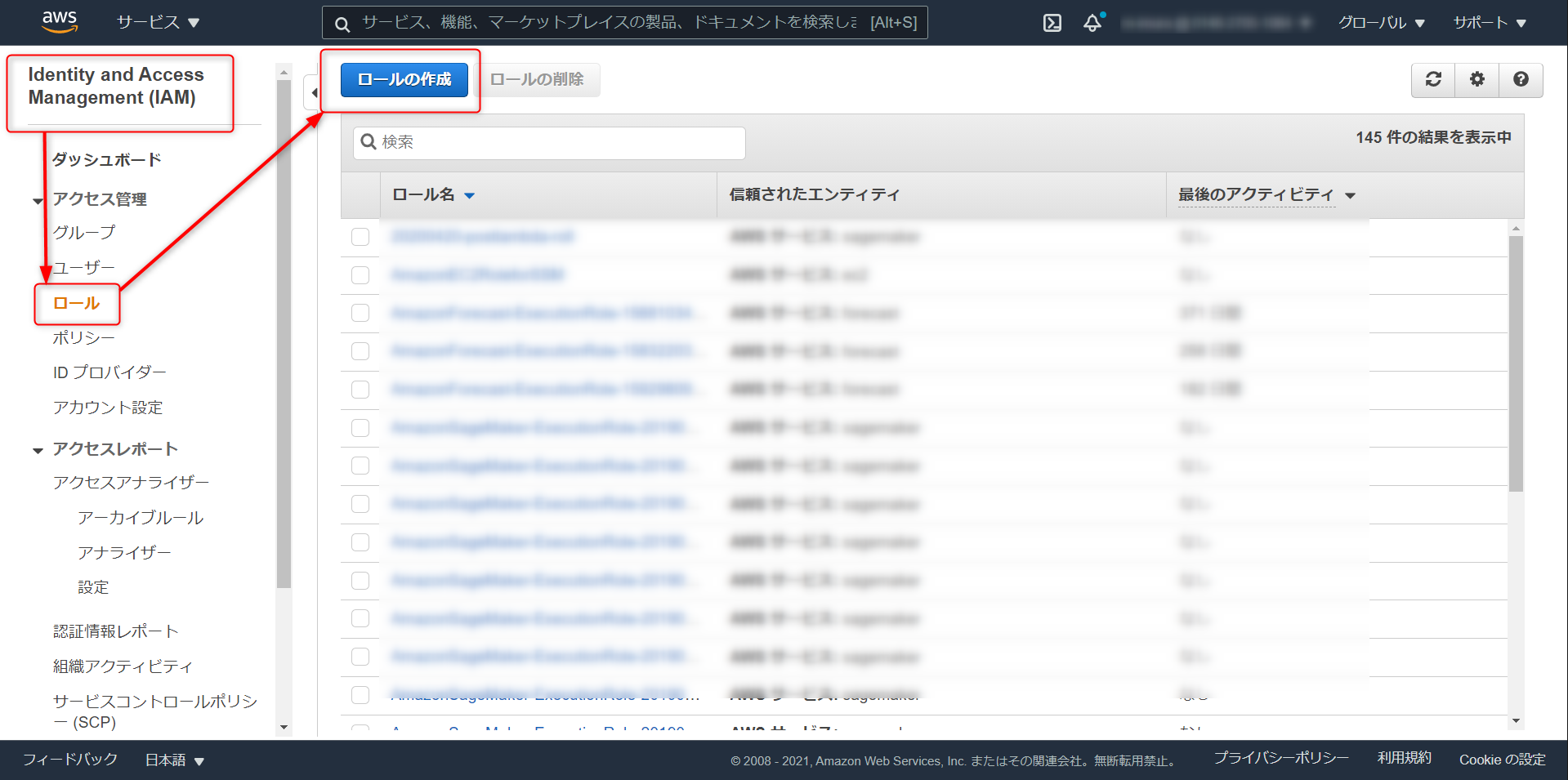
IAM > ロール > ロールの作成
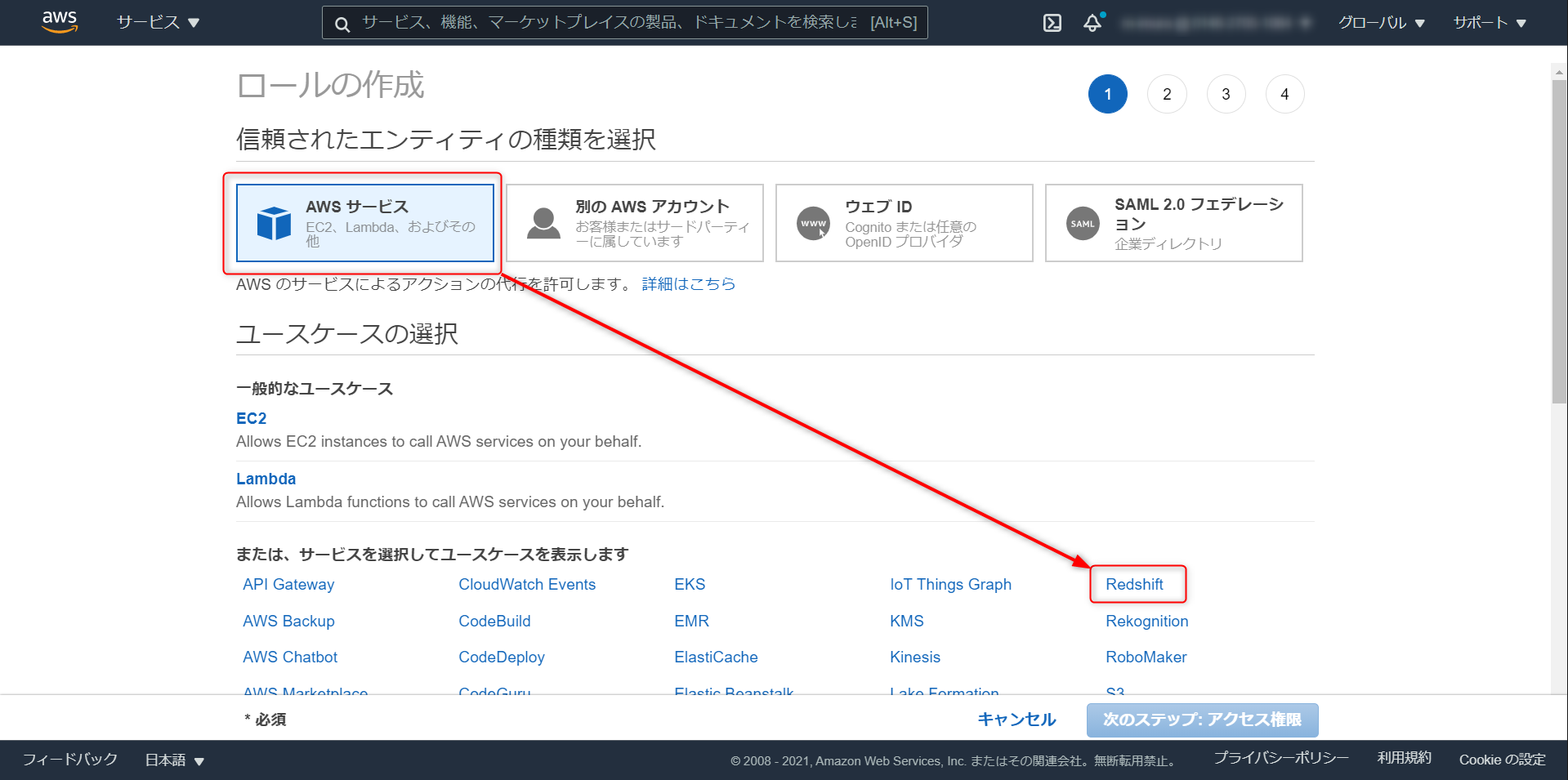
AWS サービス > Redshift と進み、
画面下部の Reedshift - Customiable を選択
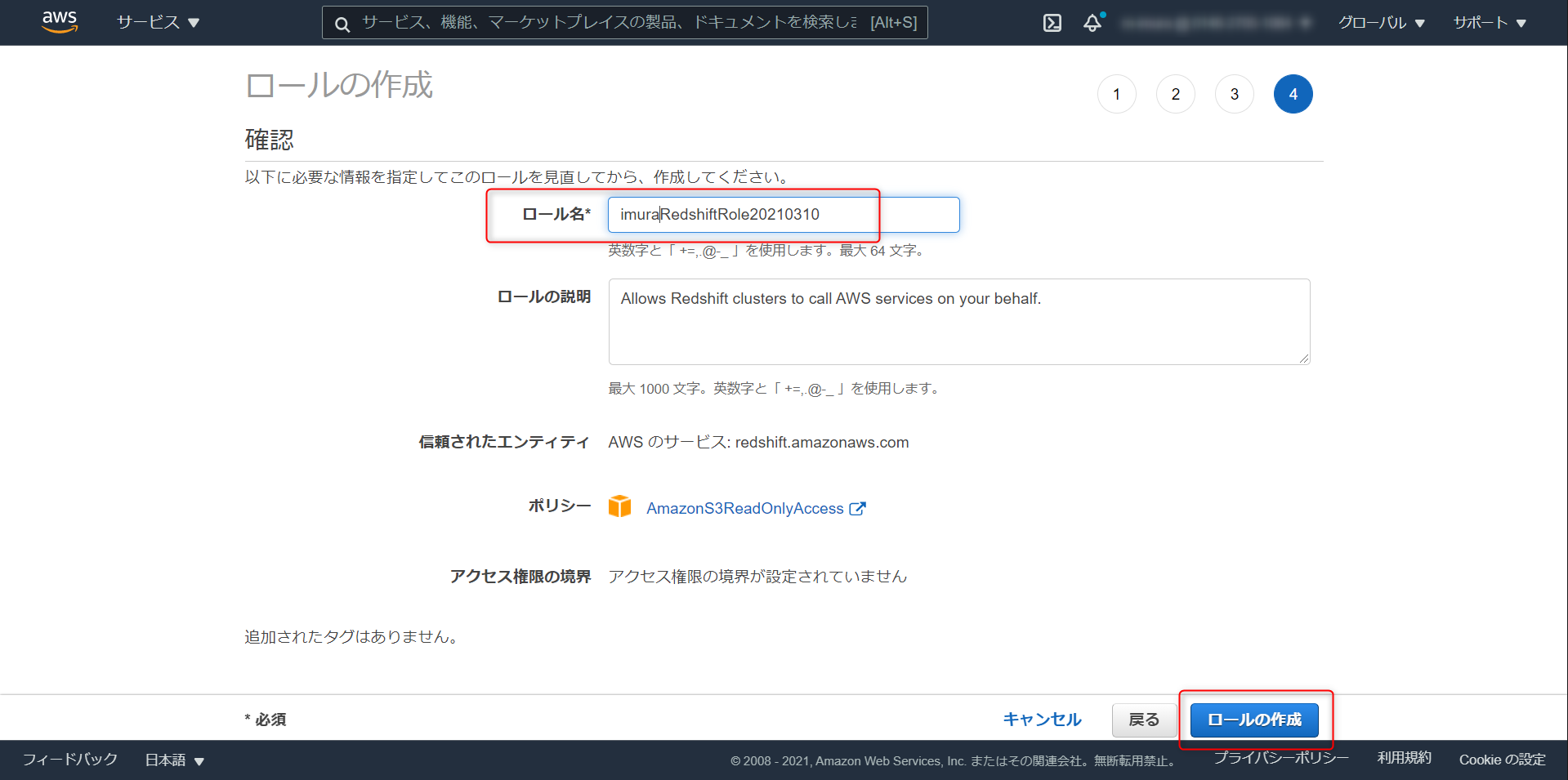
ロール名を任意で設定、ロールの作成をクリック
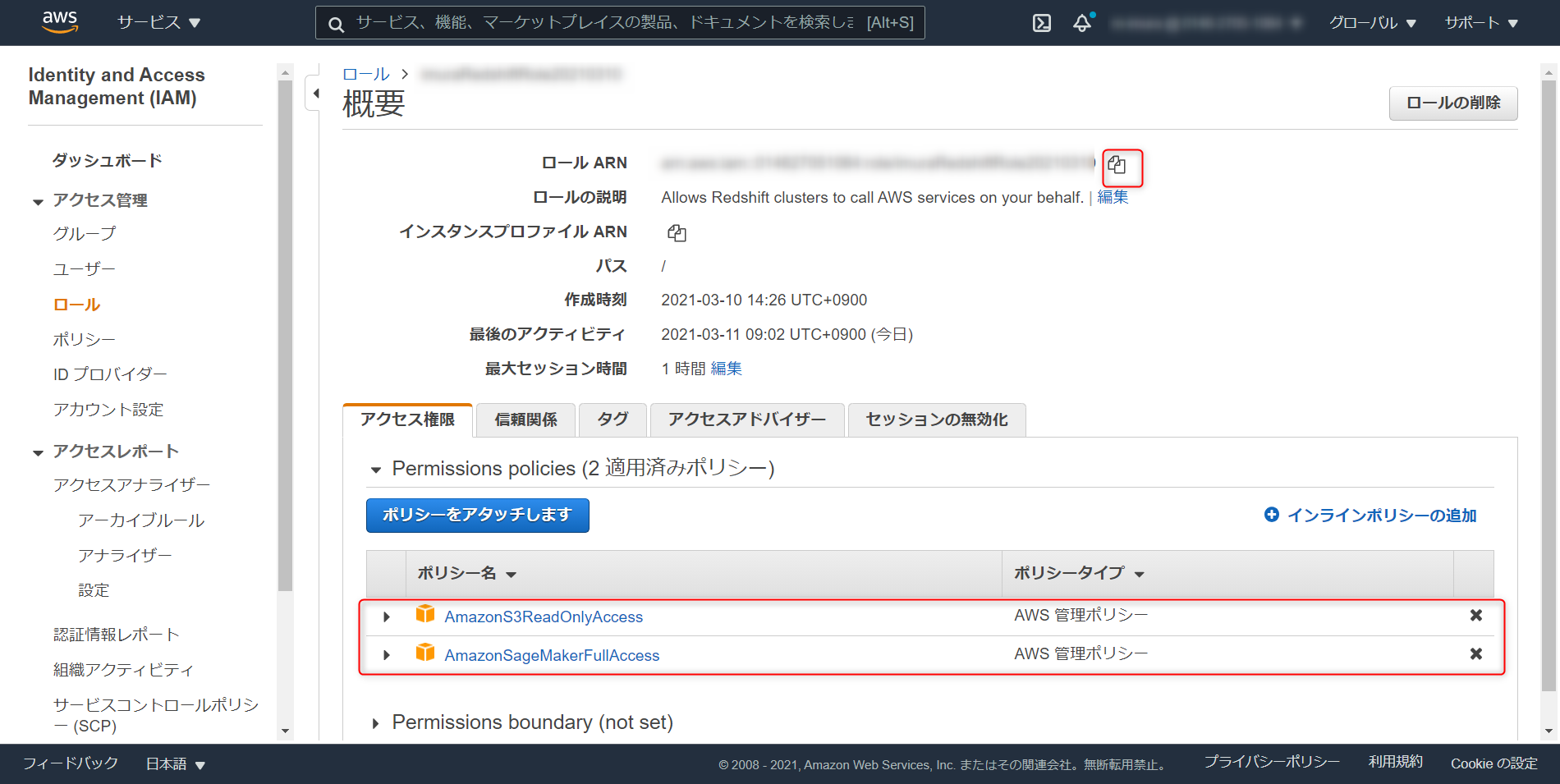
作成したロールを開き、アクセス権限のタブで AmazonS3ReadOnlyAccess と AmazonSageMakerFullAccess のポリシーアタッチ (ベストプラクティスに則って最小権限で実装する場合は本記事の下部のURL参照)
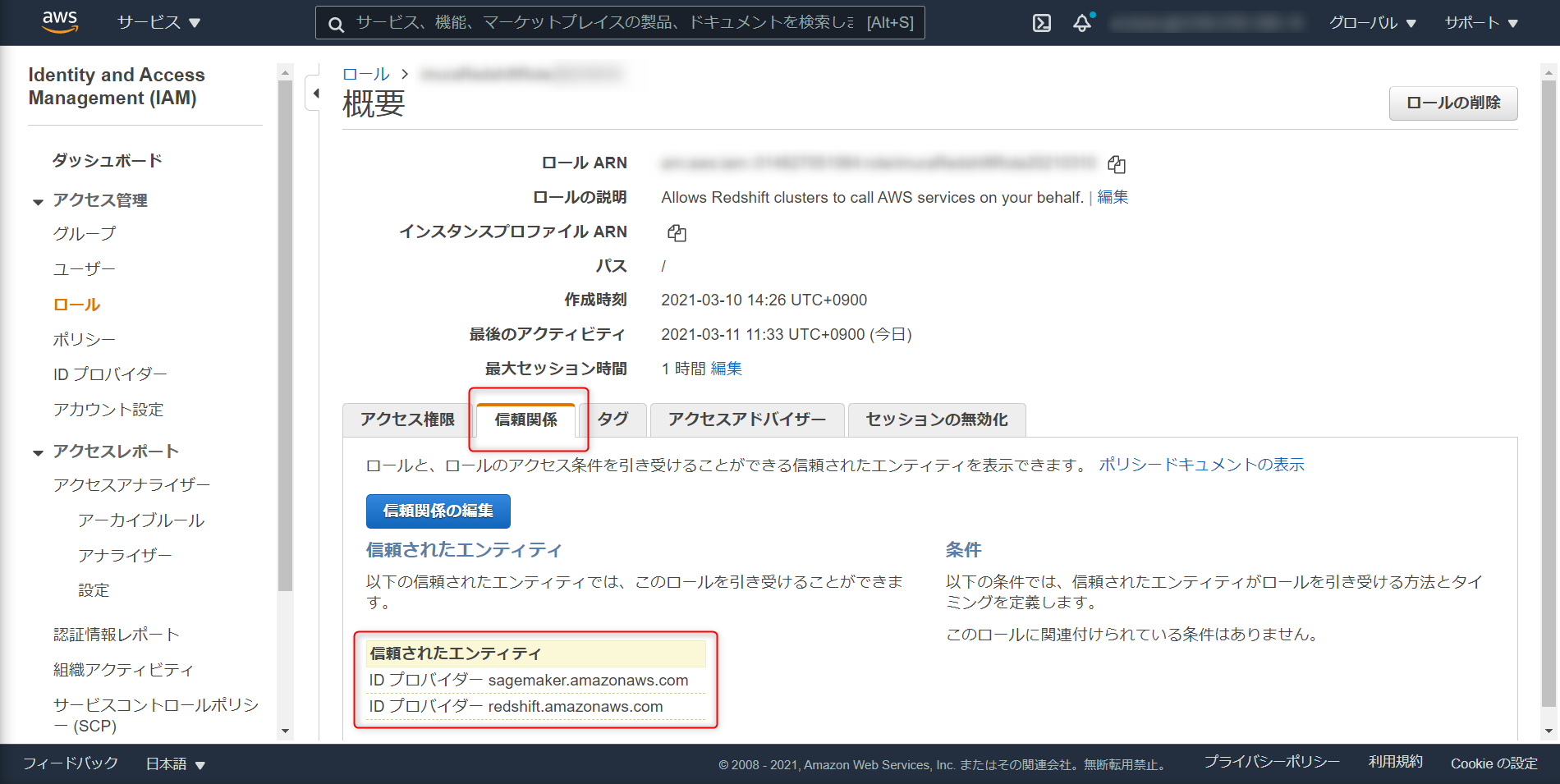
信頼関係のタブで、redshift と sagemaker を追加
TrustedEntity
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "redshift.amazonaws.com", "sagemaker.amazonaws.com" ] }, "Action": "sts:AssumeRole" } ] }最後に
iam role arnをコピー
S3
今回はシンプルにするため、以下の用途をカバーする単一S3バケットを構築します。
- Redshift テーブル用データの保存
- Redshiftml Amazon S3 からデータを読み込むための Amazon ML アクセス許可の取得
- Amazon S3 に予測を出力するために Amazon ML のアクセス許可を得る
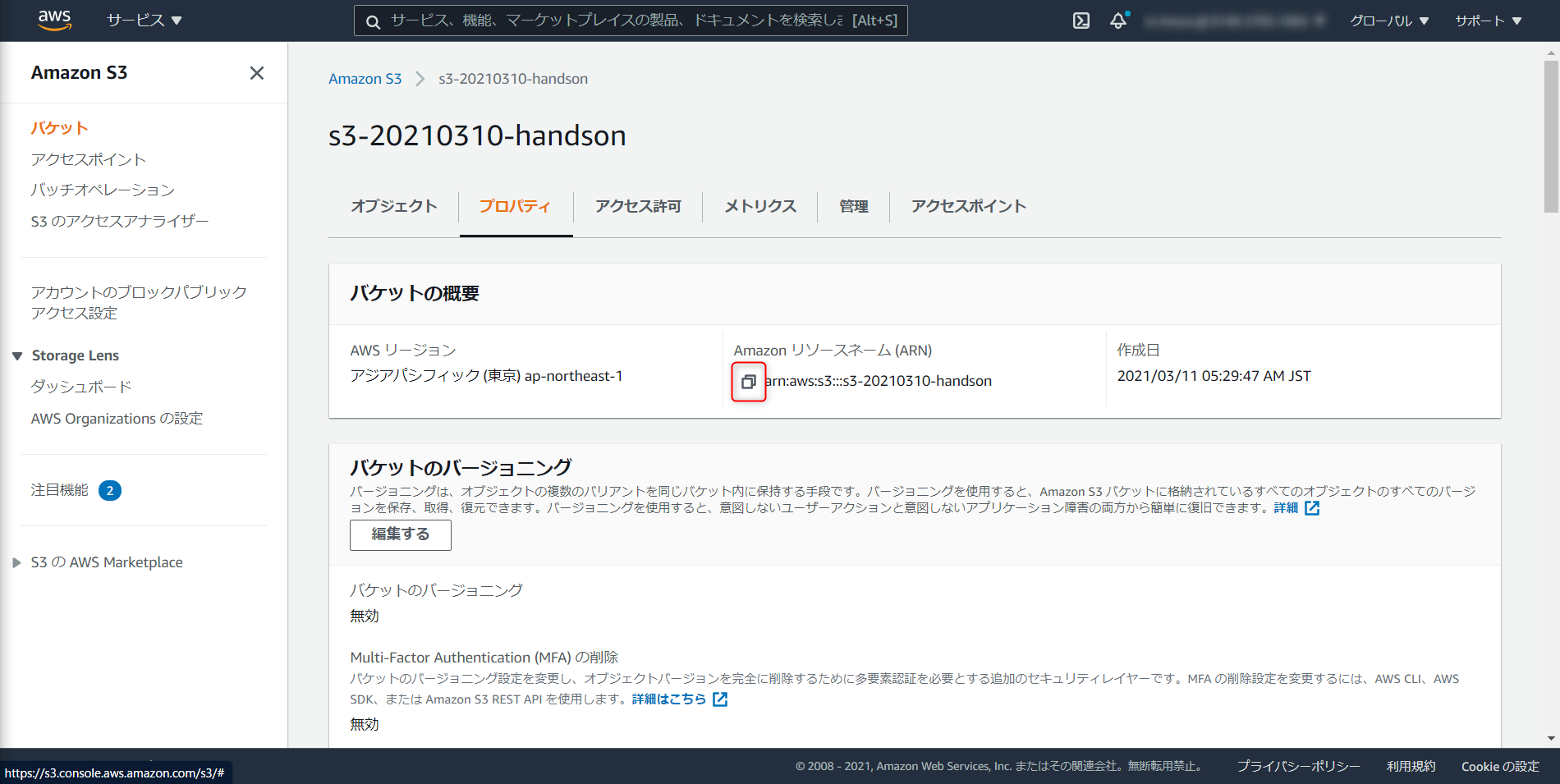
S3バケットをデフォルト値で構築、
S3 ARNをコピー
アクセス許可 > バケットポリシーと進み、Amazon Redshift と SageMaker Autopilot が利用できるように以下の通りバケットポリシーを変更。先ほど作成したロールをプリンシパルに設定
{ "Version": "2008-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "{iam-role-arn}" }, "Action": [ "s3:GetObject", "s3:PutObject", "s3:PutObjectAcl" ], "Resource": "{s3-arn}/*" }, { "Effect": "Allow", "Principal": { "AWS": "{iam-role-arn}" }, "Action": "s3:ListBucket", "Resource": "{s3-arn}" } ] }実行権限が大きいので本番デプロイ時は以下を参照、権限を絞ることをお勧めします。
Redshift クラスタ
構築に
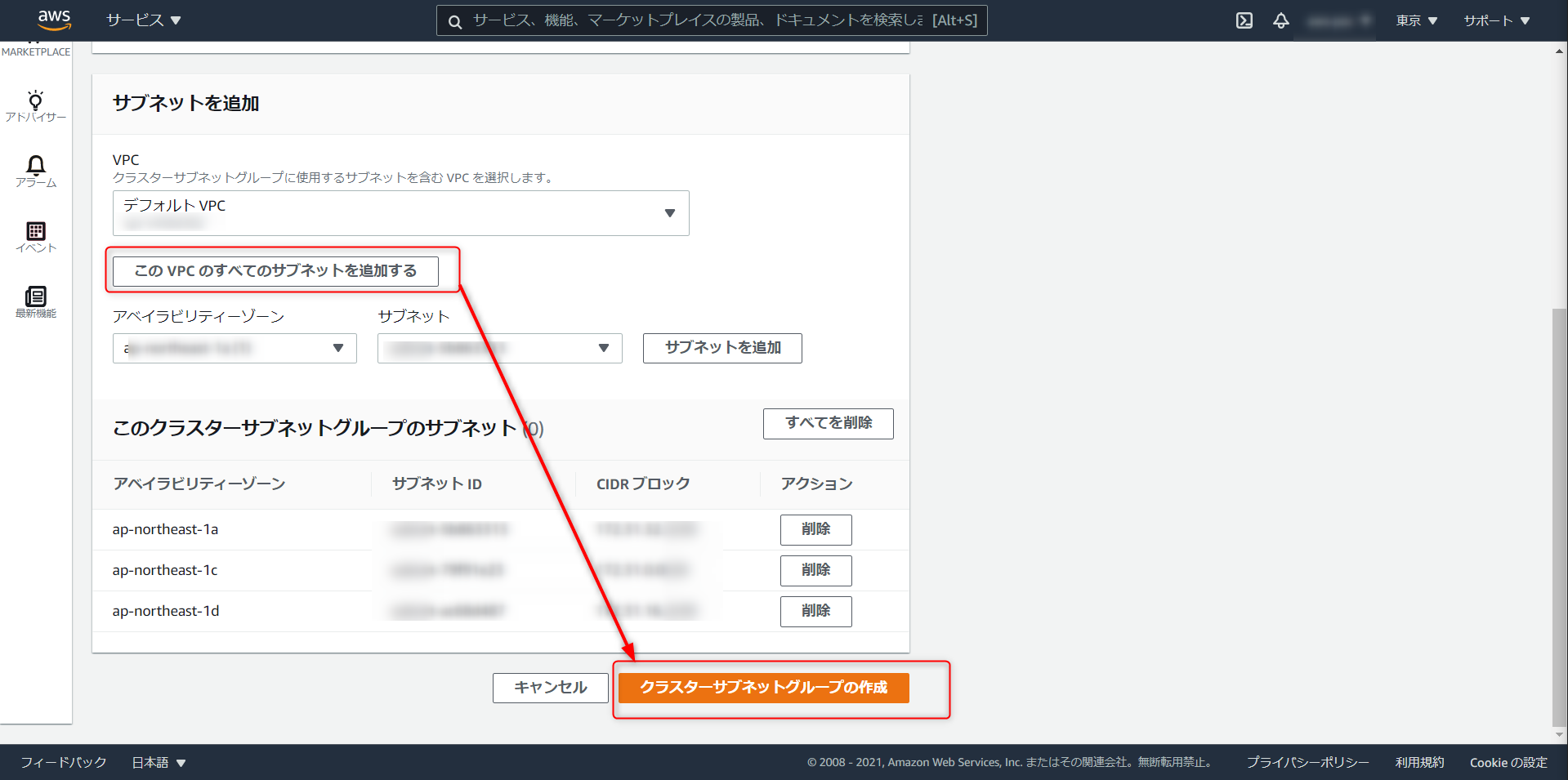
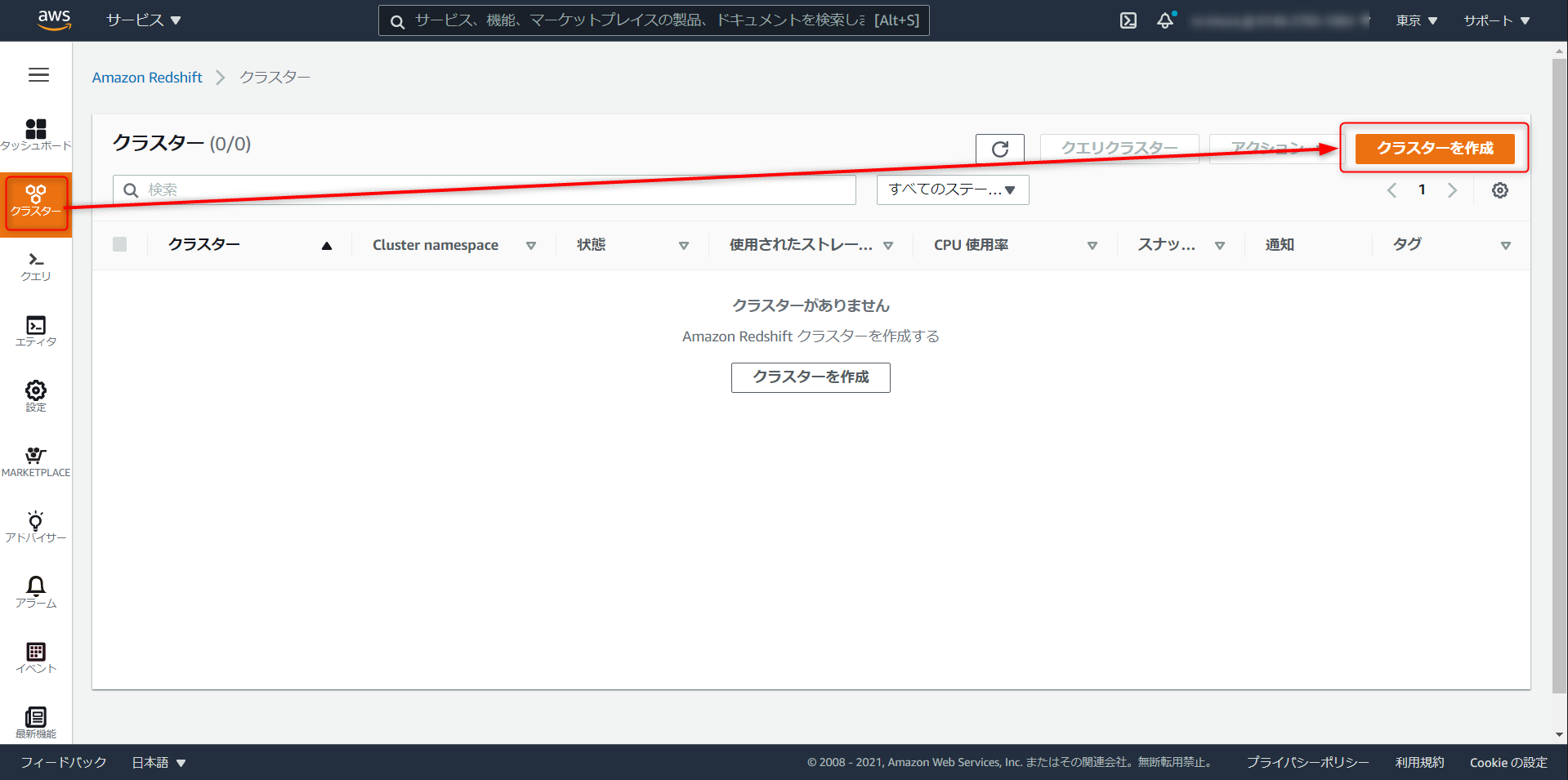
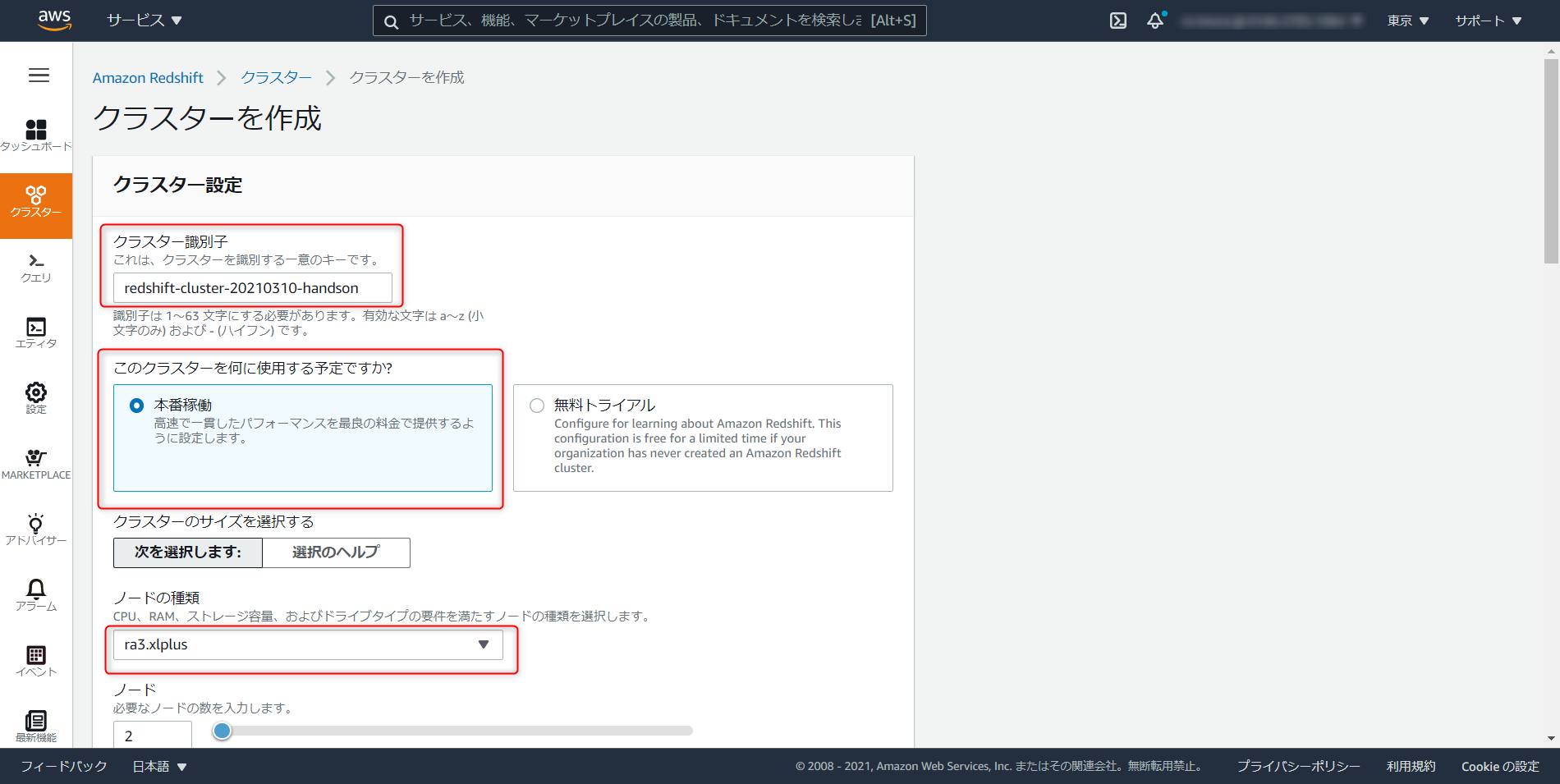
iam role arnとS3 ARNが必要です。設定 > サブネットグループと進み、任意で名称を設定、VPC のすべてのサブネットを追加、クラスターサブネットグループの作成をクリック
クラスタ > クラスタの作成
クラスタ識別子を任意で入力。dc2.large が最も安価なクラスタだが Redshift ML は対応していないので注意 (2021年3月12日時点)
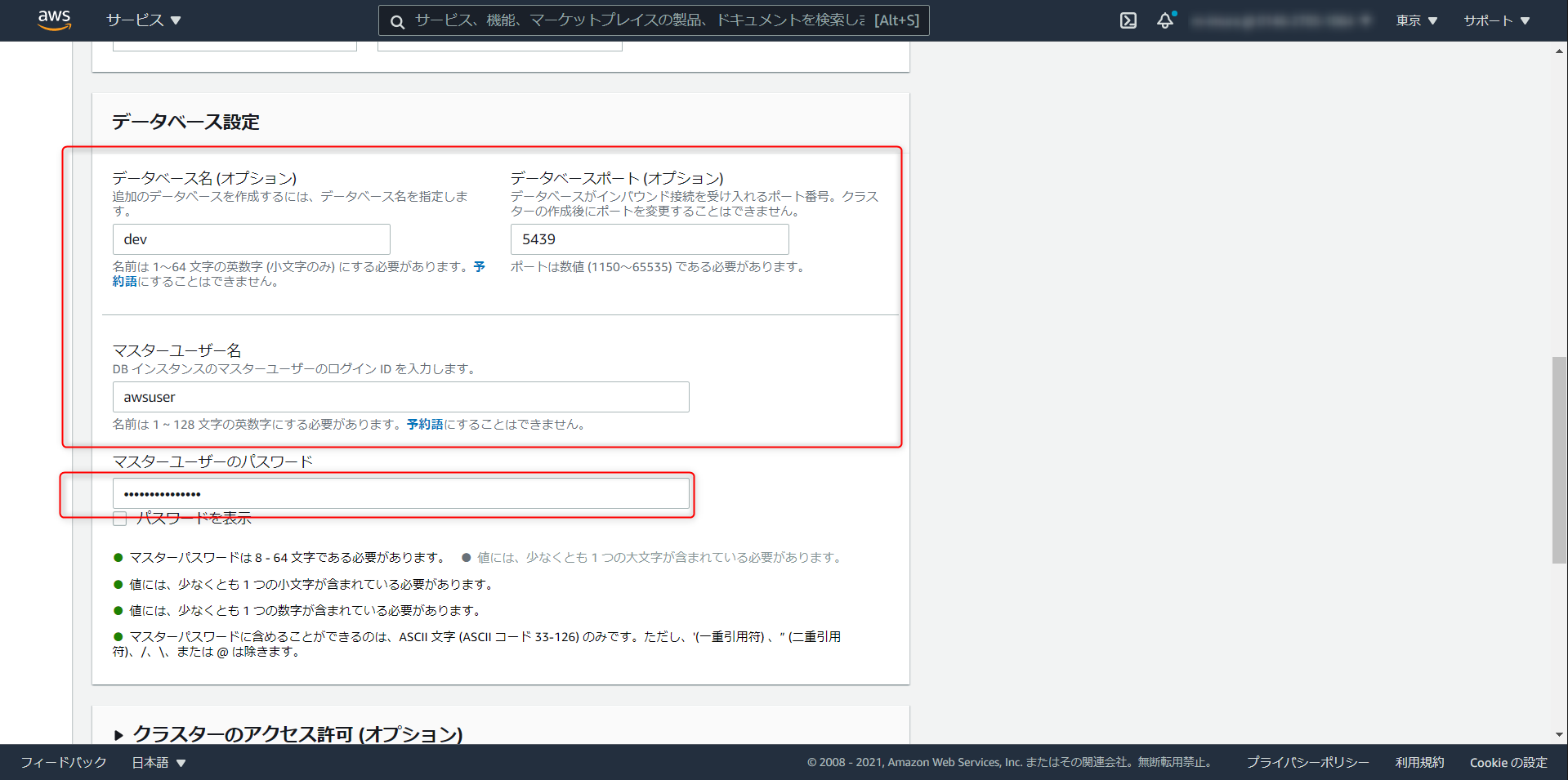
Database Name、Port、Master User Name はデフォルト値でOK。Password を任意で入力。
Master USer NameとPasswordを控えておく。
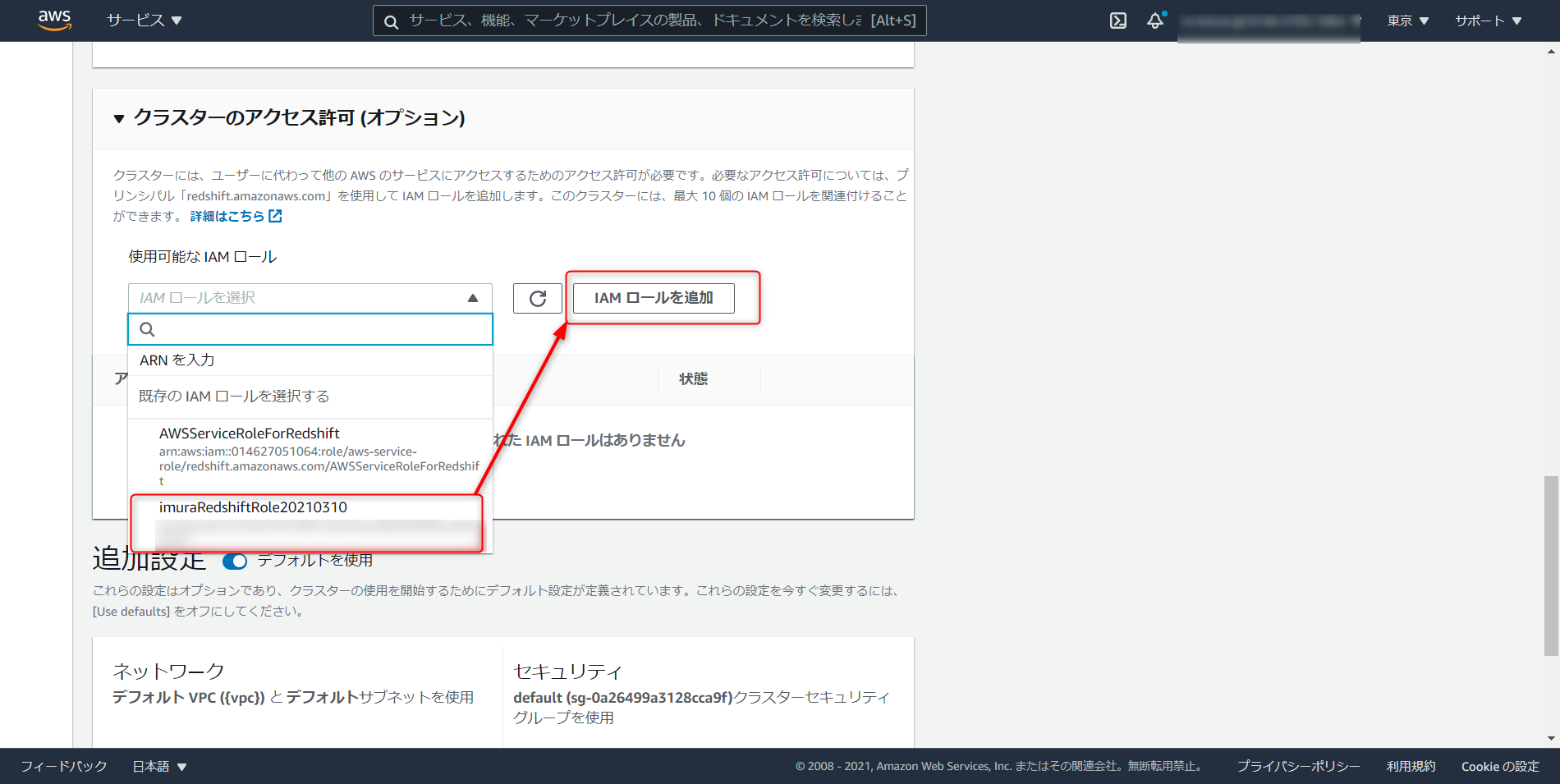
クラスタのアクセス許可から先ほど作成した IAM ロールの
iam role arnを選択、「IAM ロールを追加」を選択
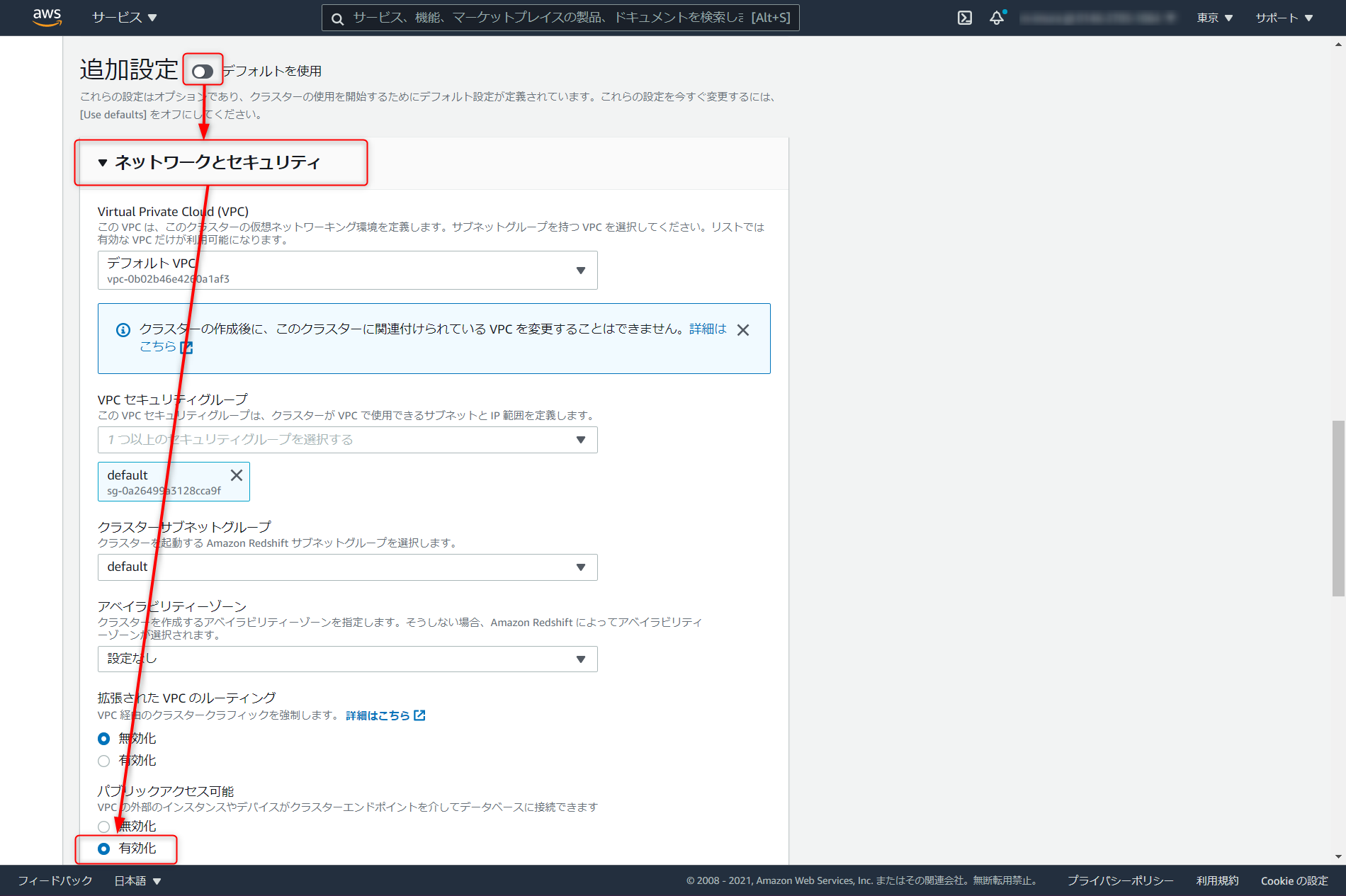
今回ローカルの SQL クライアントからクエリをたたく。追加設定のデフォルトを使用を解除し、ネットワークとセキュリティの項目で、パブリックアクセスの有効化にチェックを入れる
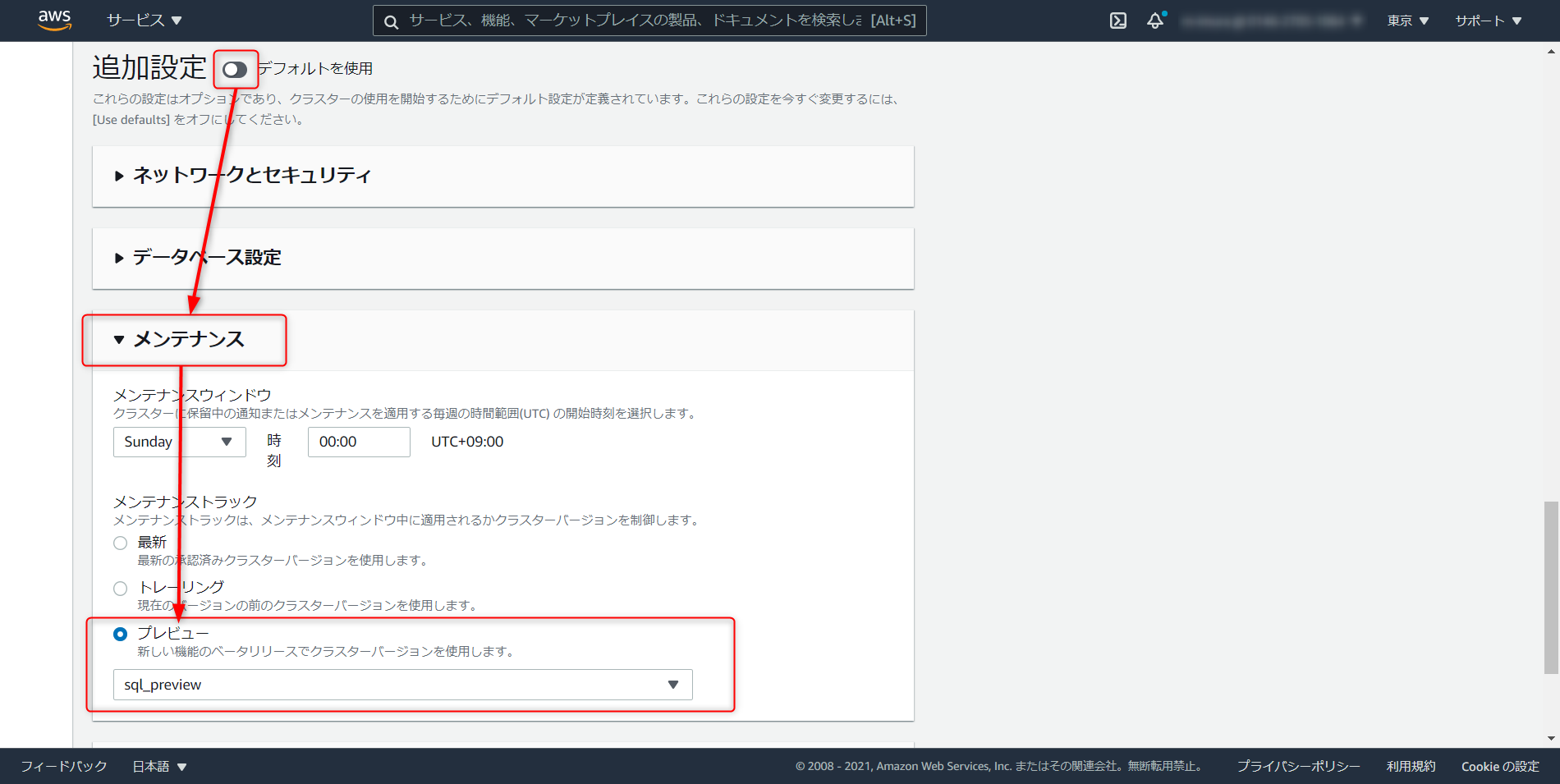
メンテナンスタブ > メンテナンストラックでプレビューの sql_preview を選択。ここまで設定が完了したらクラスタの作成へと進む
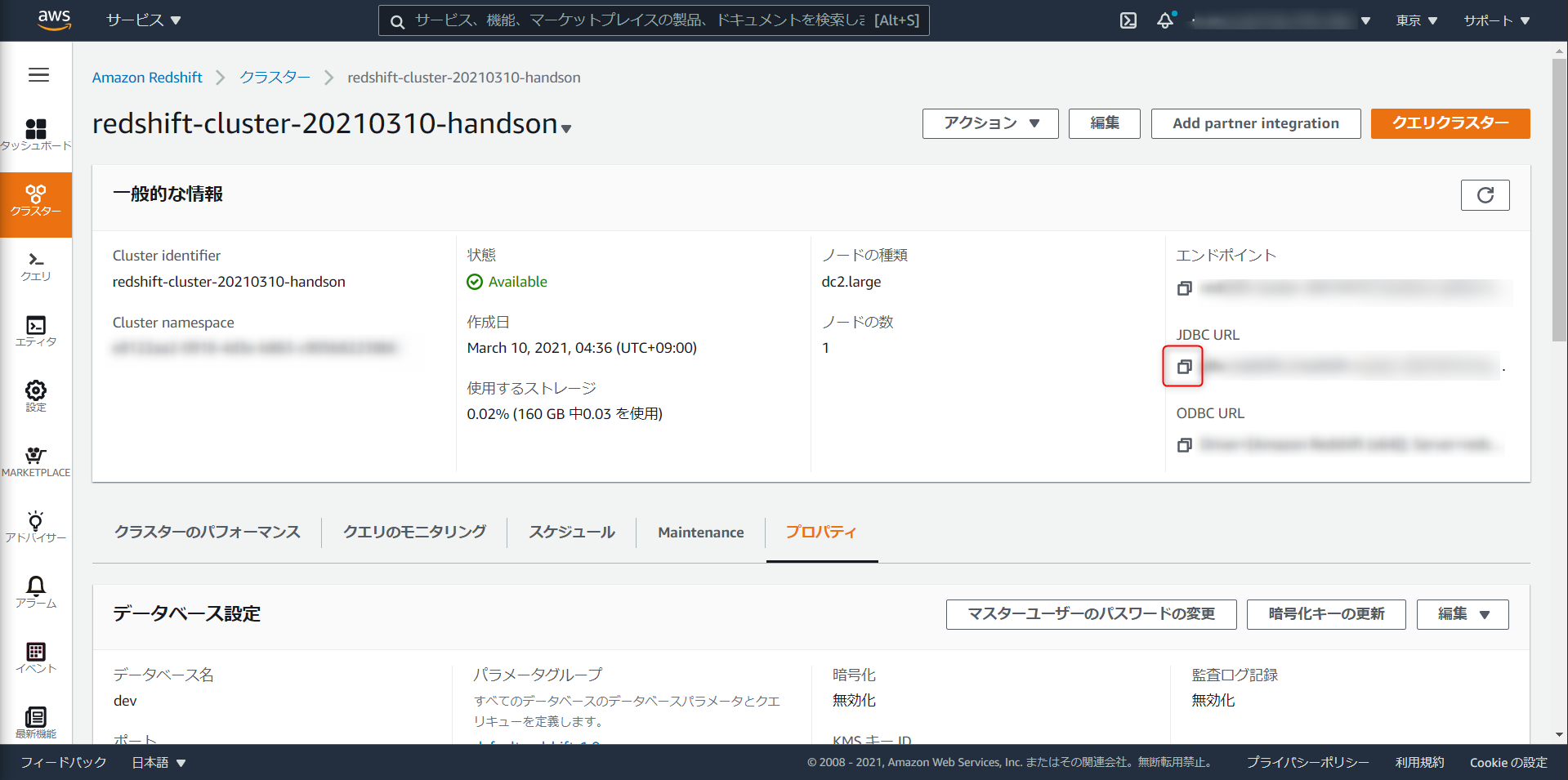
デプロイが完了したら、
JDBC URLを控えておく
VPC
Redshift クラスタをインターネット経由で操作できるよう、ネットワークを構成します。
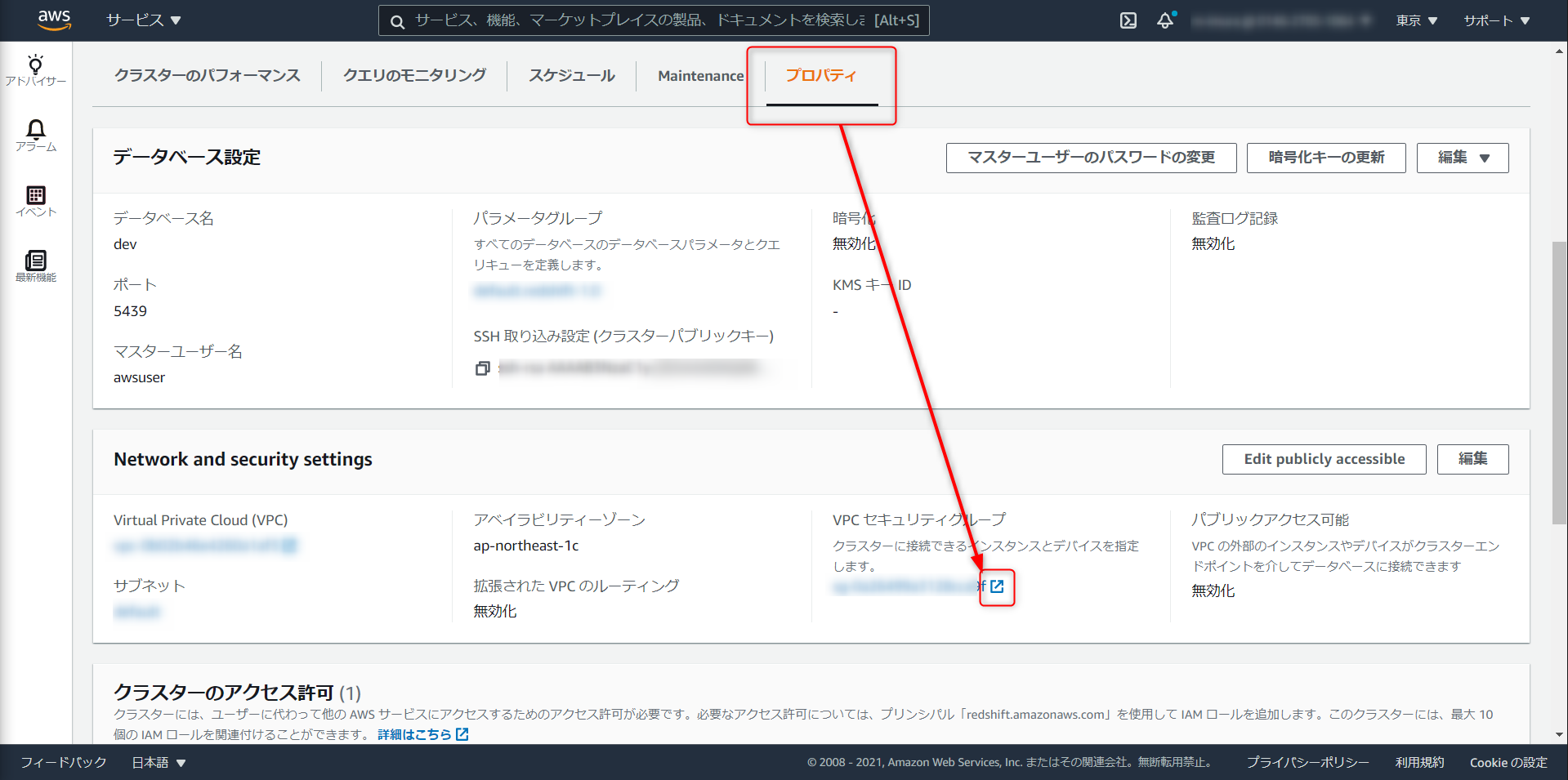
先ほど作成したクラスタのプロパティから、VPC セキュリティグループと進む
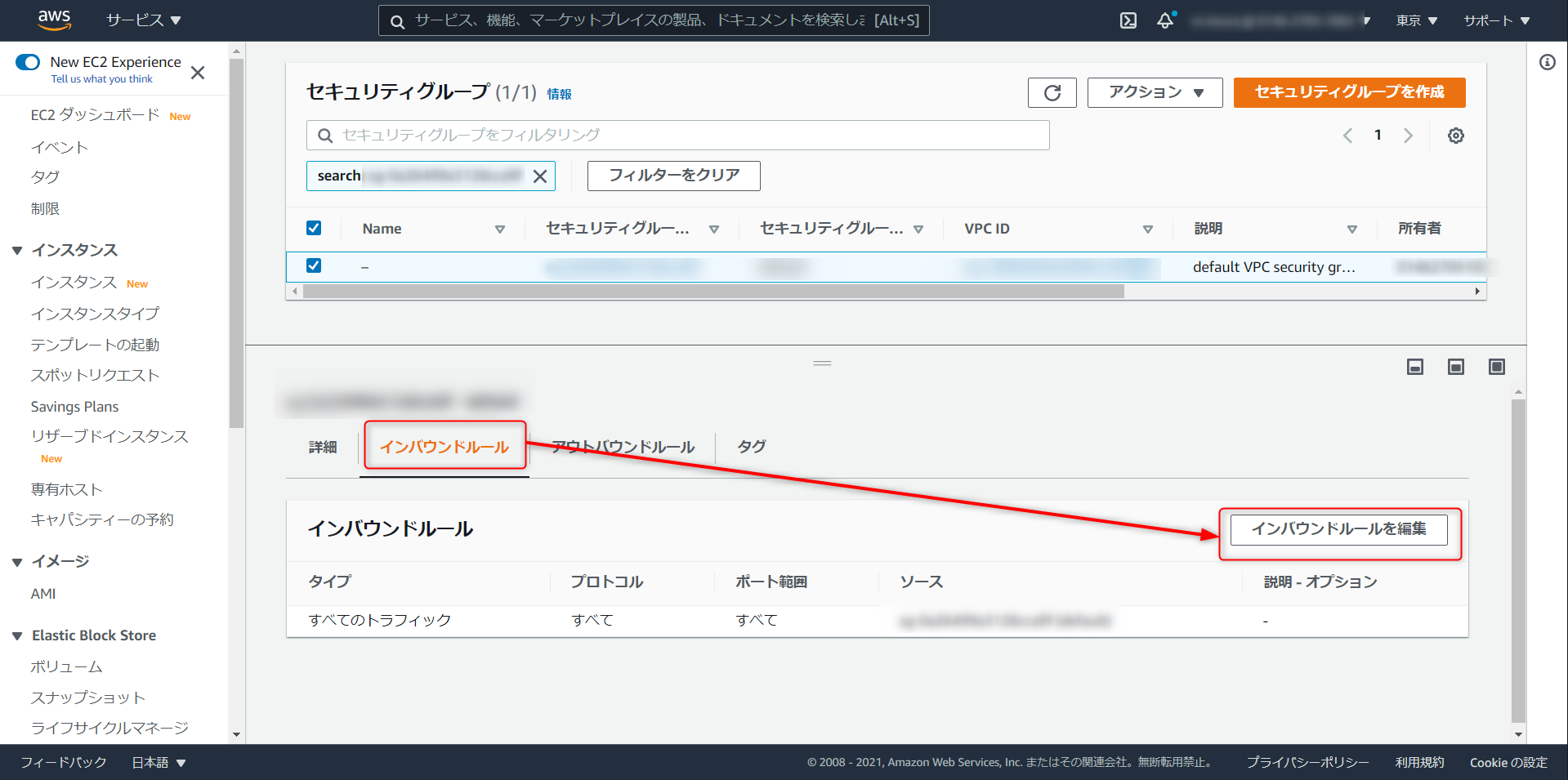
デフォルトだと下記の状態。インバウンドルール > インバウンドルールを編集
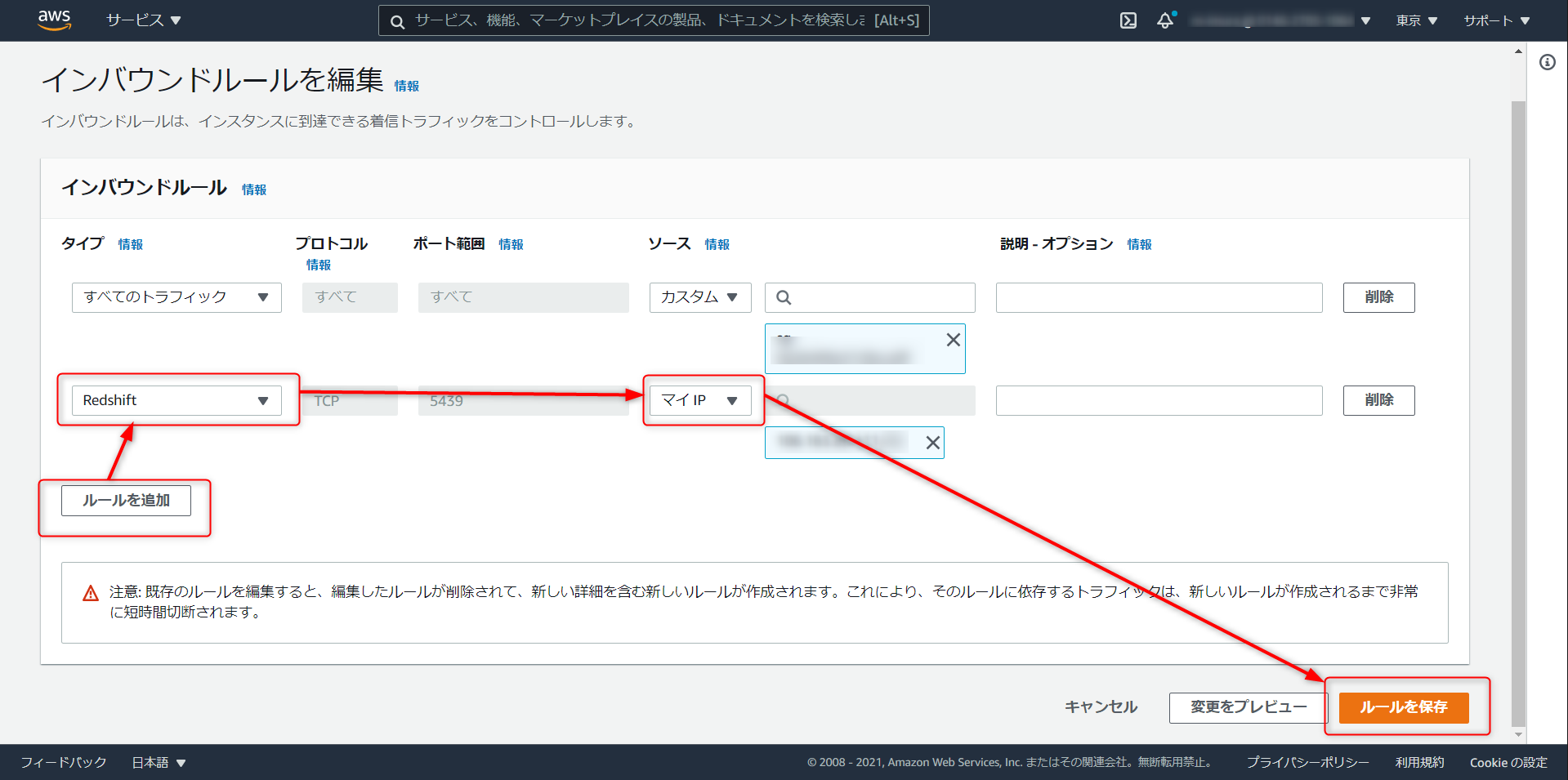
ルールの追加 > タイプを Redshift に選択 > マイIP と進み、ルールを保存をクリック。この作業でローカル環境から Redshift への接続が通るようになる。
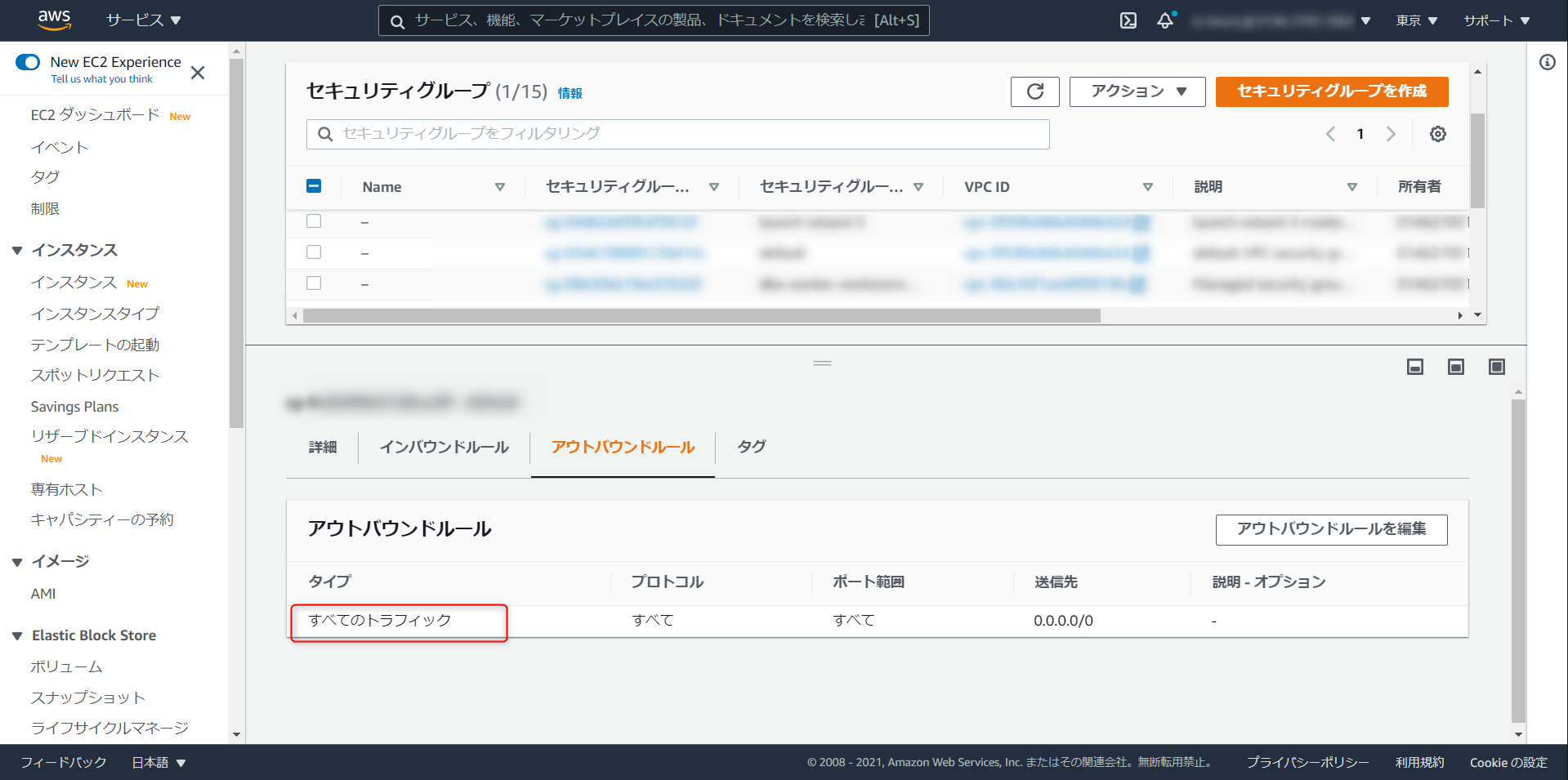
アウトバウンドルールが以下の状態になっていることを確認
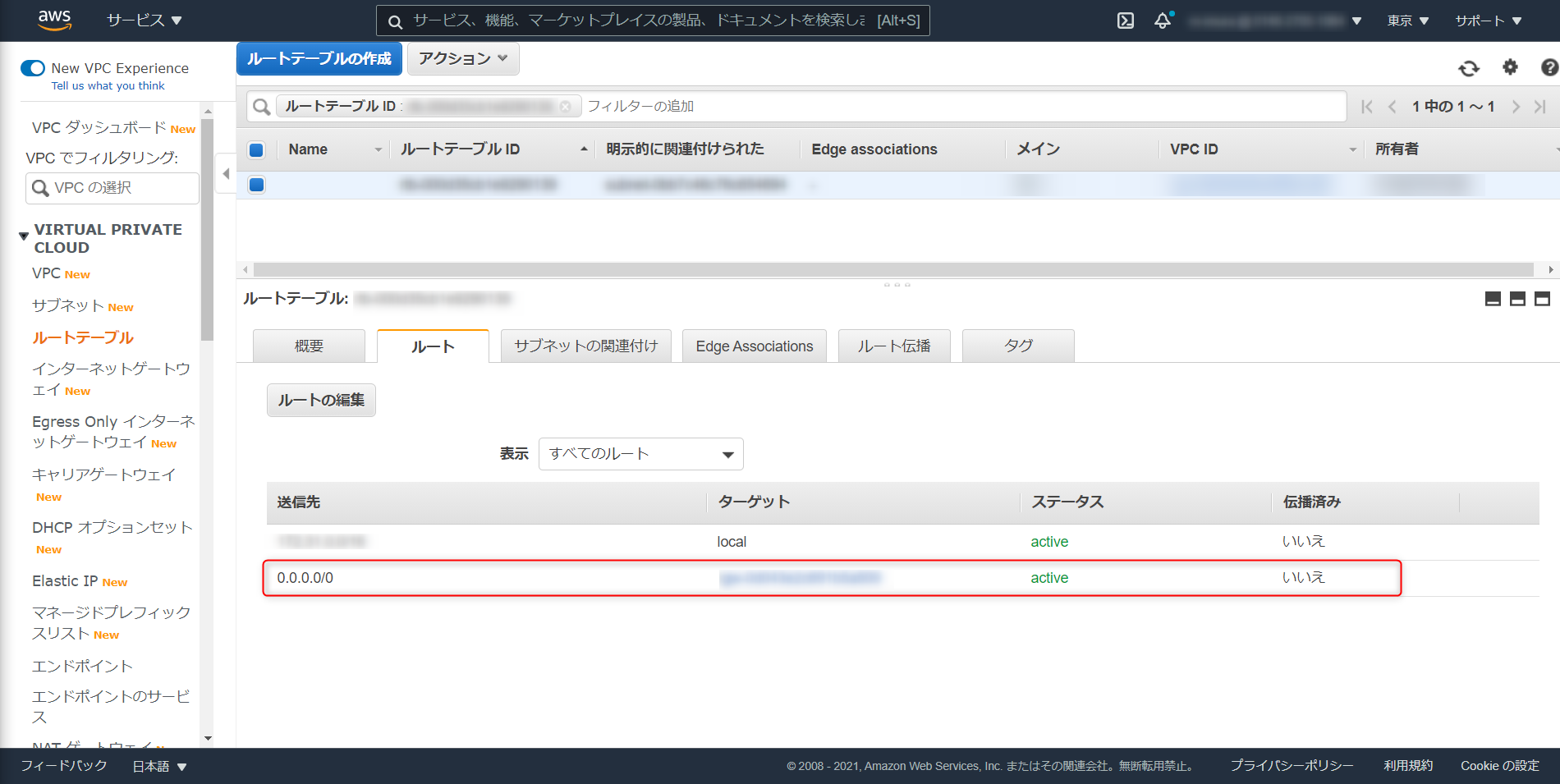
備考:Redshift クラスタの VPC サブネットのルートテーブルで、送信先 0.0.0.0/0 が blackhole になっている場合、SQL クライアントから接続する際、Connection Timeout が発生する。ルートの編集と進み、該当設定を再設定する
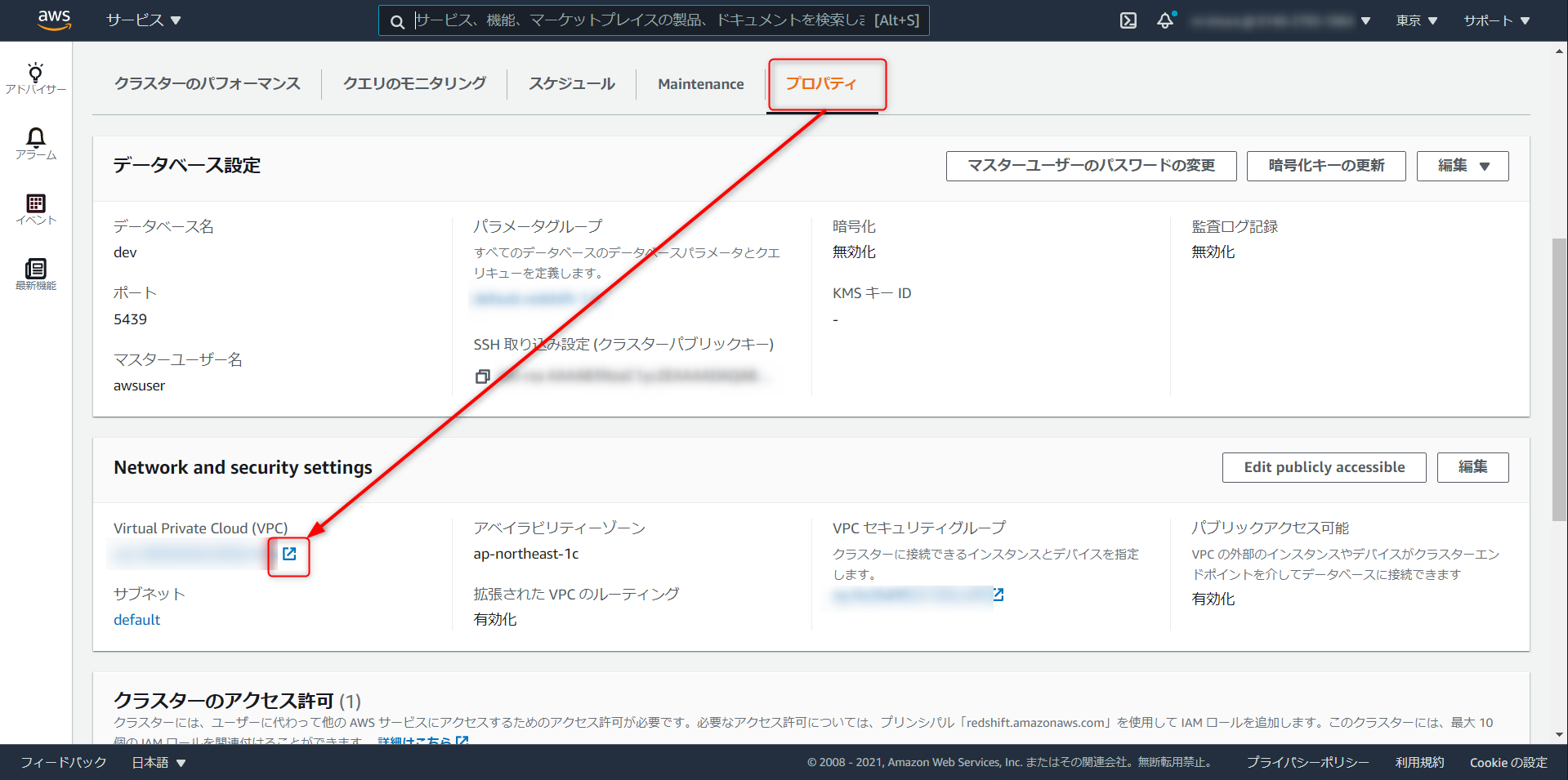
インターネットゲートウェイ
インターネットに接続するためのゲートウェイがない場合は以下手順で構築します。
Redshift クラスタのプロパティから VPC と進み、別タブで開いておく
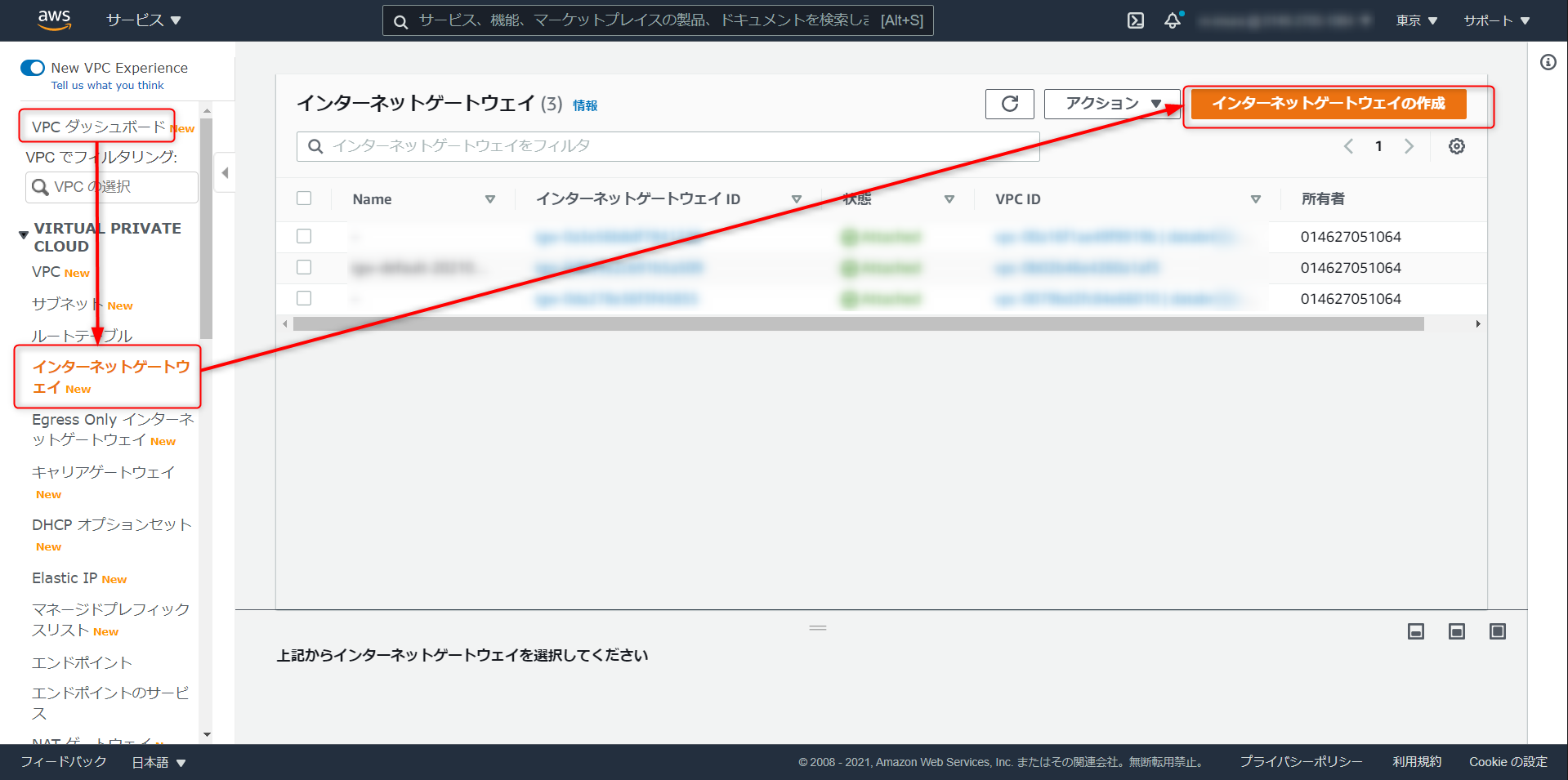
VPC ダッシュボード > インターネットゲートウェイ > インターネットゲートウェイの作成
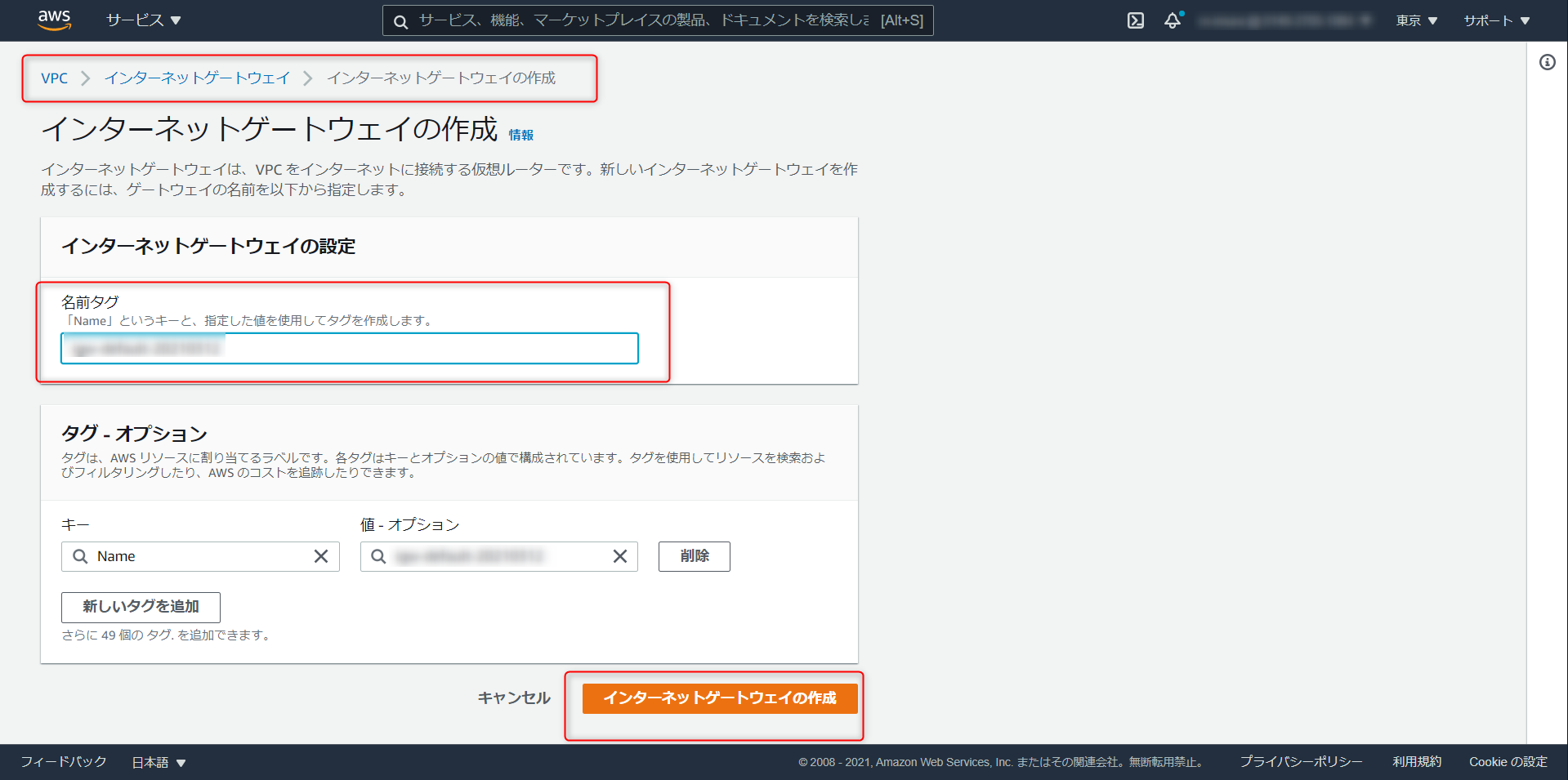
任意でゲートウェイの名称を入力、作成をクリック
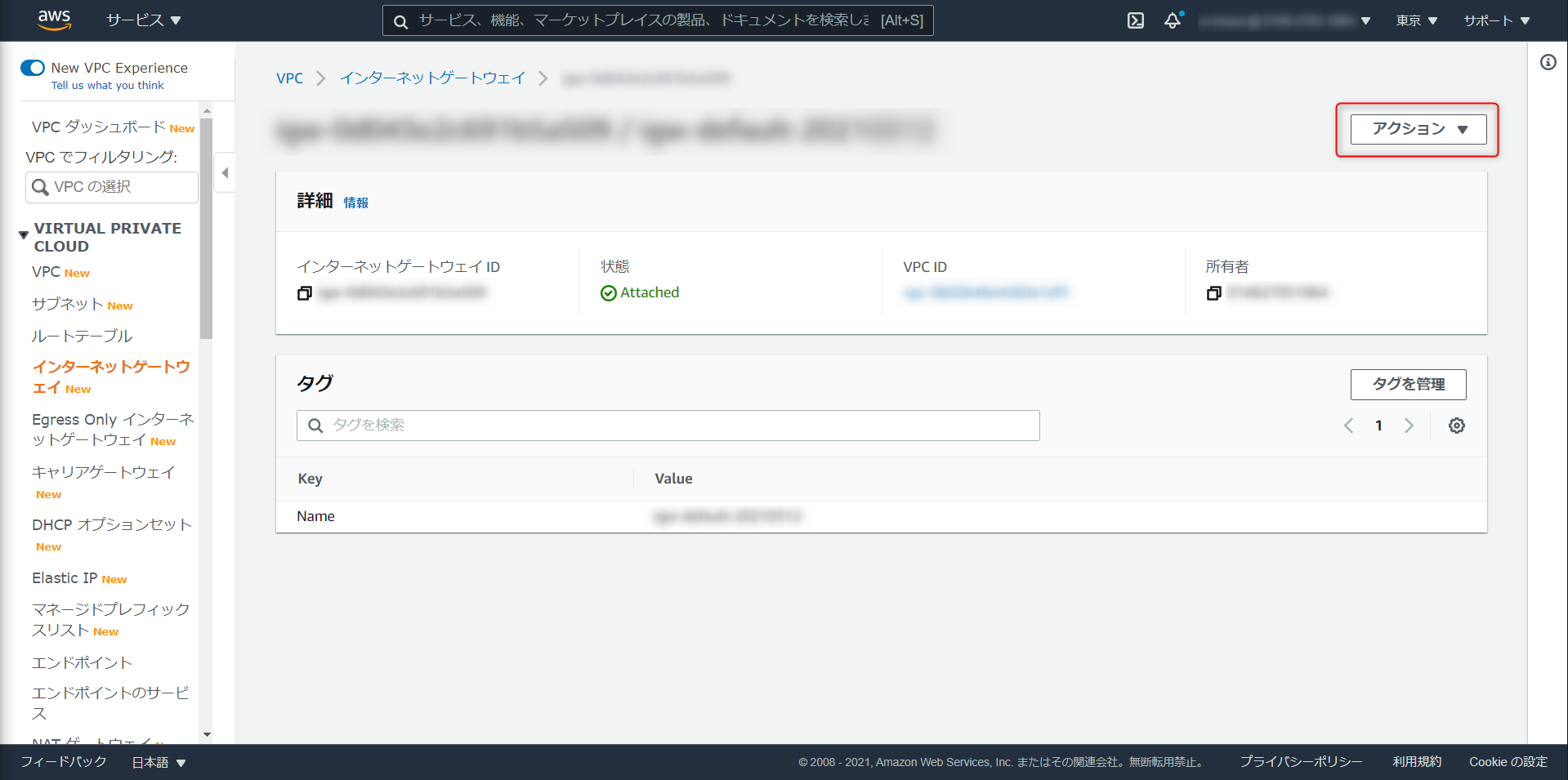
作成したインターネットゲートウェイを Redshift クラスタが稼働しているのVPCにアタッチ
データのアップロード
ダウンロードした CSV データを S3 にアップロード、
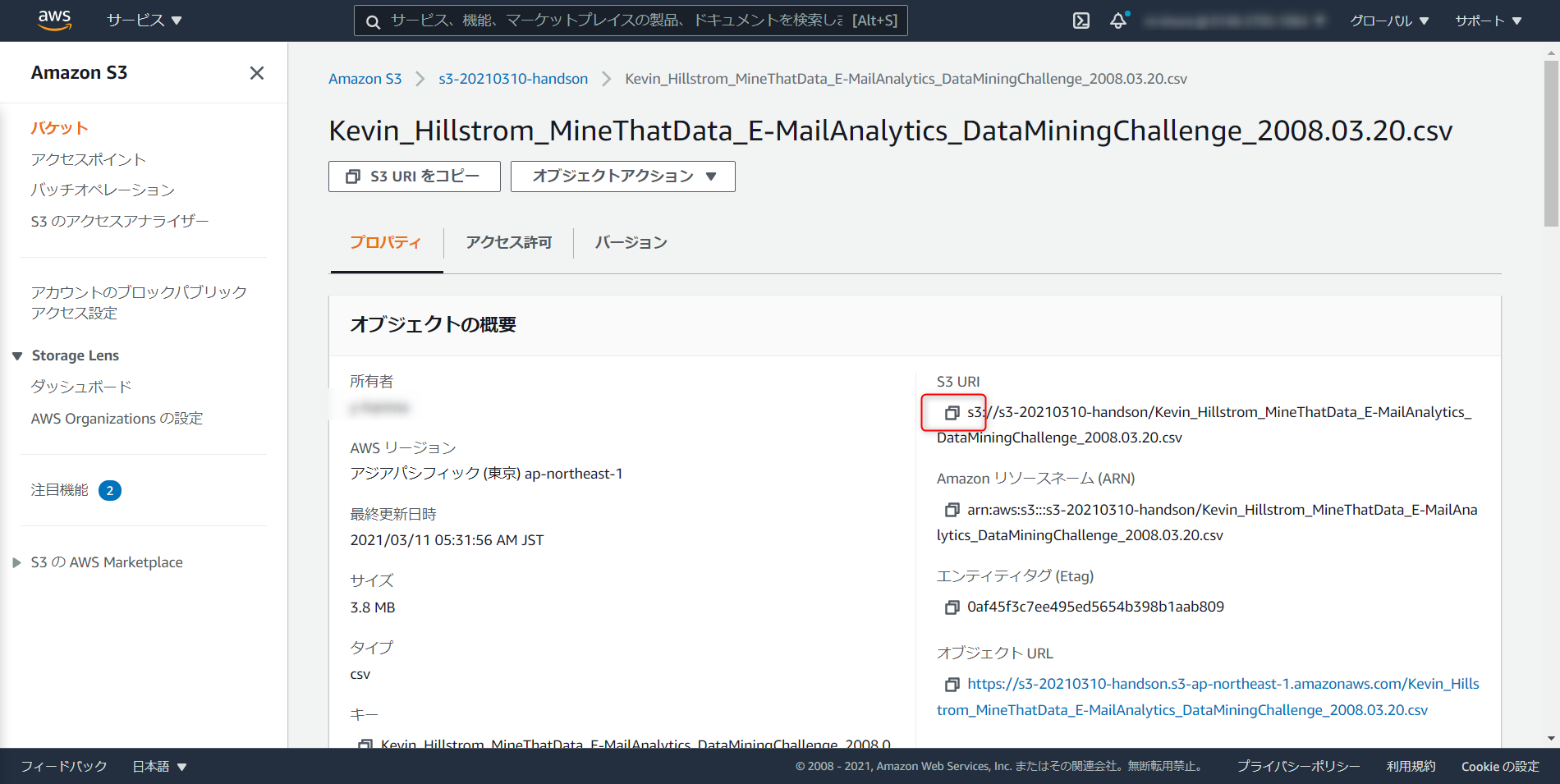
S3 URIをコピーしておく
今回は SQL クライアントに DBeaver を用いる。
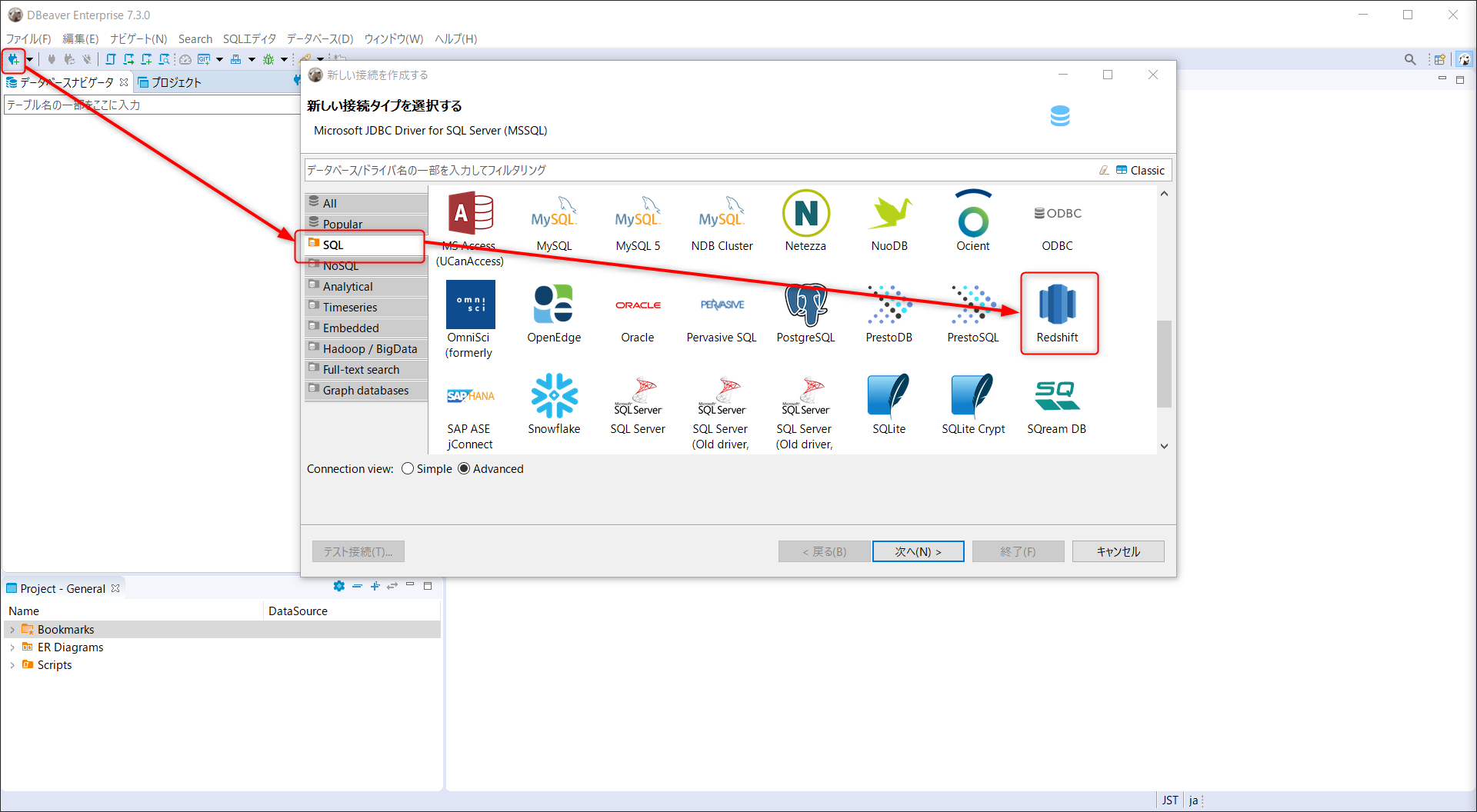
DBeaber をインストールしたら、新しい接続を選択、Redshift へと進む
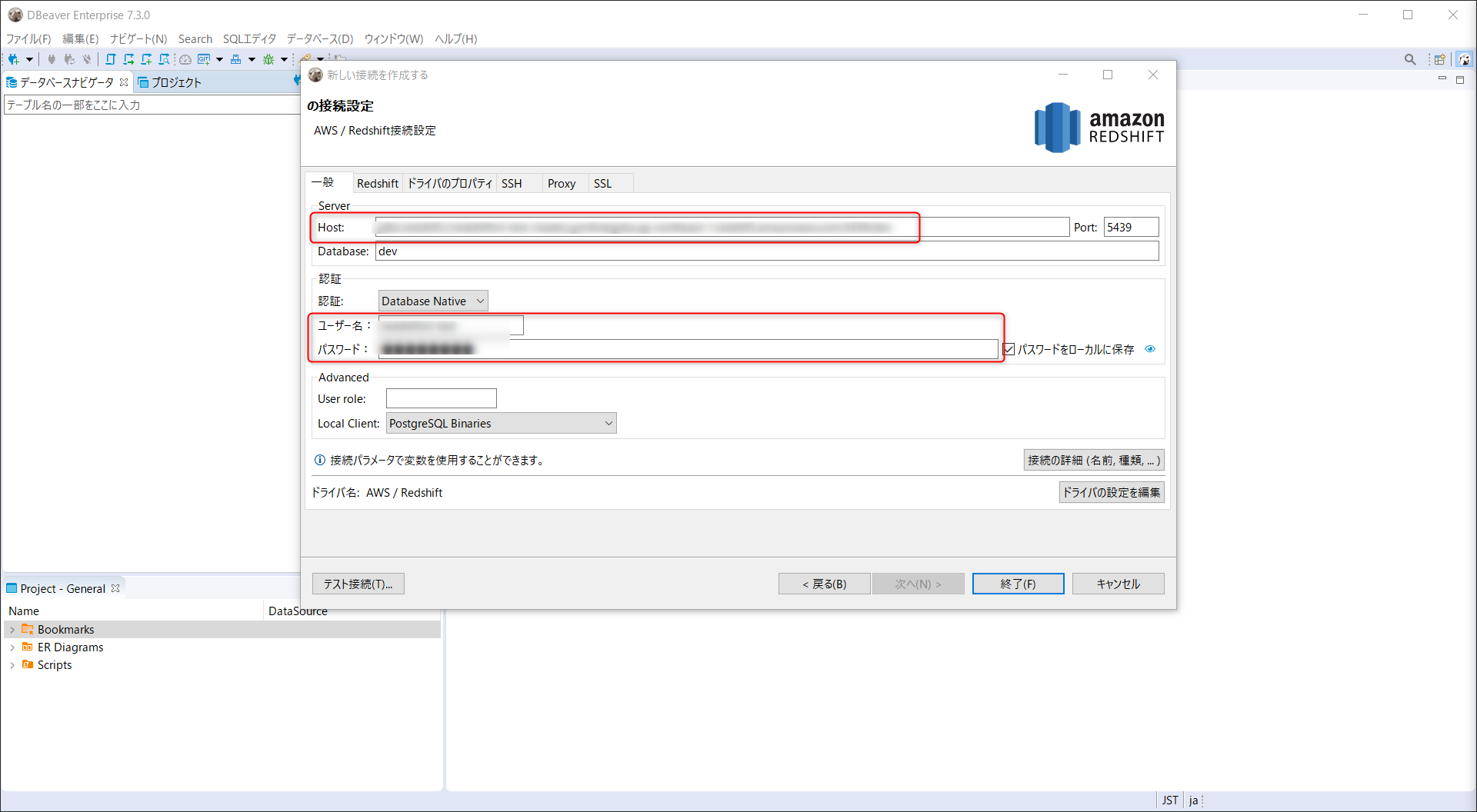
JDBC ホスト、
Master USer Name、Passwordを入力し、終了をクリック
JDBC ホスト名は、JDBC URLからdbc:redshift://と:5439/devを除いた文字列となるので注意
RedshiftMLモデル構築
ローデータテーブル作成
モデル作成の権限をユーザーに付与します。
1GRANT CREATE MODEL TO awsuser;作成するデータベースやモデルを保持するスキーマを作成します。
2CREATE SCHEMA redshiftml_test;ローデータ用のテーブルを作成します。
3create table redshiftml_test.minethatdata_orig( recency int4, history_segment varchar(256), history float (8), mens boolean, womens boolean, zip_code varchar(256), newbie boolean, channel varchar(256), segment varchar(256), visit boolean, conversion boolean, spend float (8) );S3 から CSV データをインポートします。
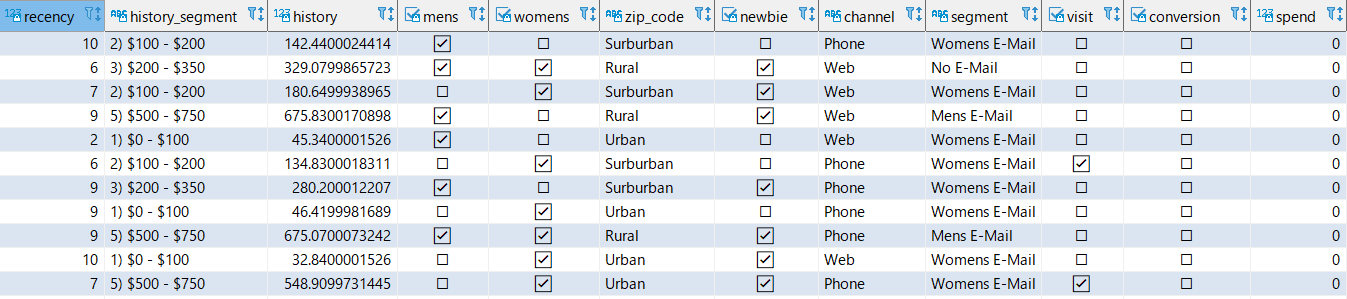
CSV data S3 URIとiam-role-arnはリソース作成時に拾ったパラメータです。4copy redshiftml_test.minethatdata_orig from '{CSV data S3 URI}' iam_role '{iam-role-arn}' csv IGNOREHEADER 1 ;ローデータテーブルのプレビュー
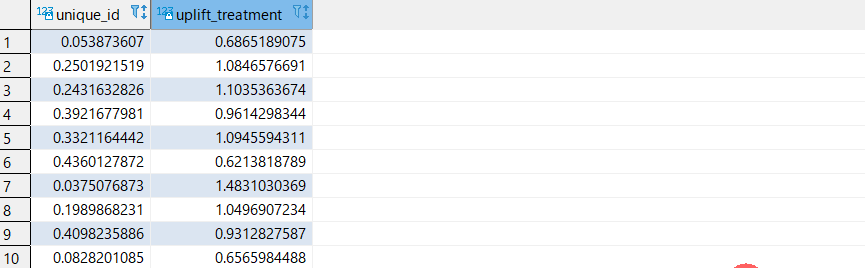
5select * from redshiftml_test.minethatdata_orig limit 10;out
学習用テーブル作成
以降のクエリを別のユーザーが行う場合は、スキーマの変更権限を付与します。
6GRANT CREATE, USAGE ON SCHEMA redshiftml_test TO awsuser;モデル学習しやすいようにテーブルを作成します。
- segment (受け取ったキャンペーンメールの種類。Mens E-mail, Womens E-mail, No E-mail) を 1/0 で表現 (w 列)
- Spend (過去2週間の購入金額) を目的変数として利用 (y 列)
- 通し番号を unique_id として付与
- unique_id ベースで TRAIN データと TEST データに分割 (assigm 列)
7CREATE TABLE redshiftml_test.MineThatData AS SELECT *, CASE WHEN unique_id >= 0.50 THEN 'TRAIN' ELSE 'TEST' END AS assign FROM ( SELECT *, RANDOM() AS unique_id, CASE segment WHEN 'Mens E-Mail' THEN 1 WHEN 'No E-Mail' THEN 0 END AS w, spend AS y FROM redshiftml_test.minethatdata_orig WHERE segment IN ('Mens E-Mail', 'No E-Mail') )学習用テーブルのプレビュー
8select * from redshiftml_test.MineThatData limit 10;out
モデル構築
TRAIN データに割り振ったユーザーから (assign = 'TRAIN')、男性向けメールを送るを送ったユーザーを抽出し (w = 1) 、指標値を MSE とした回帰モデルを作成します。
- MSE (平均二乗誤差)
- 成果位地と予測値の差を事情し、平均値をとったもの
- 実際と予測値の誤差が大きいほどモデルの精度が悪いと判断
- 外れ値にも過剰適合(=過学習)してしまう可能性も
9CREATE MODEL redshiftml_test.uplist_treatment FROM ( SELECT recency, history, mens, womens, zip_code, newbie, channel, y FROM redshiftml_test.MineThatData WHERE w = 1 AND assign = 'TRAIN' ) TARGET y FUNCTION uplift_treatment IAM_ROLE '{iam-role-arn}' AUTO ON PROBLEM_TYPE REGRESSION OBJECTIVE 'MSE' SETTINGS ( S3_BUCKET '{s3 bucket name}' );以下クエリでモデルの概要を取得できます。
10SHOW MODEL redshiftml_test.uplist_treatment今回のデータセットではモデル構築の完了に一時間ほど要しました。
SageMaker > ハイパーパラメータの調整ジョブ から進捗を確認できます。
未完了の状態で推論するクエリを投げてもモデルの準備ができていないと怒られます。のんびり待ちましょう。
推論実行
推論結果の参照を Redshift の別ユーザーが行う場合は、権限を付与します
11GRANT EXECUTE ON MODEL redshiftml_test.uplist_treatment TO awsuser;以下で Redshift 経由で推論結果を取得できます。uplift_treatment の数値が高いユーザーに対して優先的に販促キャンペーンを打てそうです。
12SELECT unique_id, redshiftml_test.uplift_treatment(RECENCY, HISTORY, MENS, WOMENS, ZIP_CODE, NEWBIE, CHANNEL) FROM ( SELECT * FROM redshiftml_test.MineThatData WHERE w = 1 AND assign = 'TEST' )out
参考クエリ
0-- アクセス可能なモデル一覧取得 SHOW MODEL ALL; -- Redshift データベースからのモデルの削除 drop model redshiftml_test.uplist_treatment; -- テーブル名一覧取得 SELECT DISTINCT pg_table_def.tablename FROM pg_table_def WHERE schemaname = 'public' AND tablename NOT LIKE'%_pkey' ORDER BY tablename; -- インポートでエラーが出る場合にはこちらからログを参照 select query, substring(filename,22,25) as filename,line_number as line, substring(colname,0,12) as column, type, position as pos, substring(raw_line,0,30) as line_text, substring(raw_field_value,0,15) as field_text, substring(err_reason,0,45) as reason from stl_load_errors order by query desc limit 10;まとめ
SQL だけで機械学習モデルのデプロイ、Redshift 経由で推論結果の取得までできるのは便利ですね。
バックエンドでは SageMaker Autopilot が動作しているので、SageMaker のコンソールからモデルをデプロイすればエンドポイント経由での推論も可能です。
そうなればドリフト値を SageMaker Model Monitor でトラッキング出来るので MLOPS 環境の構築のハードルも下がるのではないでしょうか?
Redshift ユーザーは是非触ってみてください。参考リンク
大半のSQLスクリプトはこちらの記事からお借りしました。
Amazon Redshift ML の紹介記事です。
公式ドキュメント


- 投稿日:2021-03-05T16:42:02+09:00
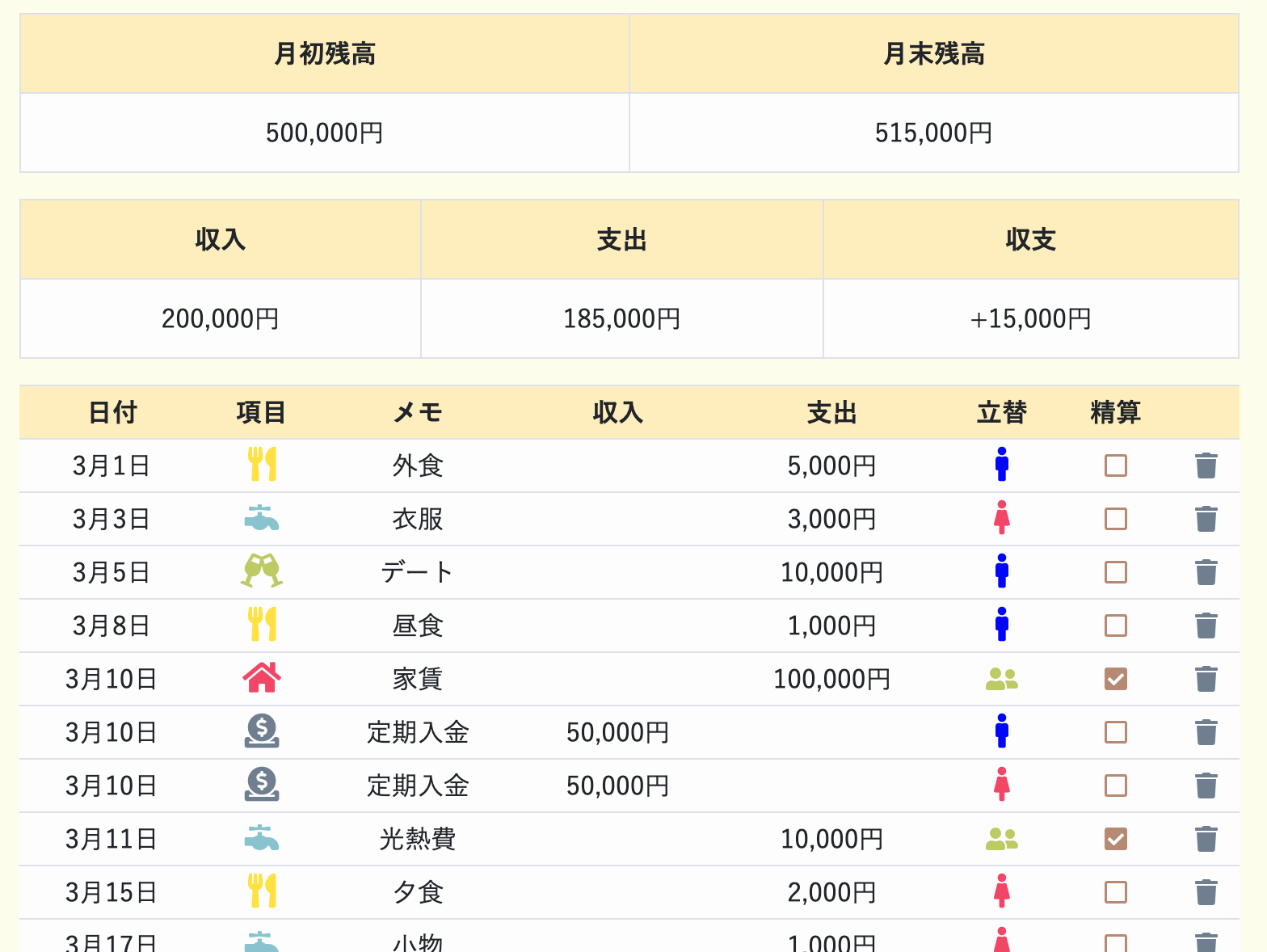
"共働き夫婦特化型"の家計簿作りました!〜Common Wallet(コモンウォレット)〜
はじめに
※「はじめに」では私の家計簿への愛が無駄に長く語られます。
面倒な人は次章までお飛ばし下さい。・共働き夫婦の家庭に質問です。
「どのように家計を管理してますか?」
A)一部または全部のお金を渡し、片方が管理(いわゆる「お小遣い制」)
B)それぞれ自分の財布で管理して、家賃は旦那、食費は嫁など項目ごとに分担する
C)共通財布を用意し、毎月お金をお互い入れて、そこで生活費をやりくりする。
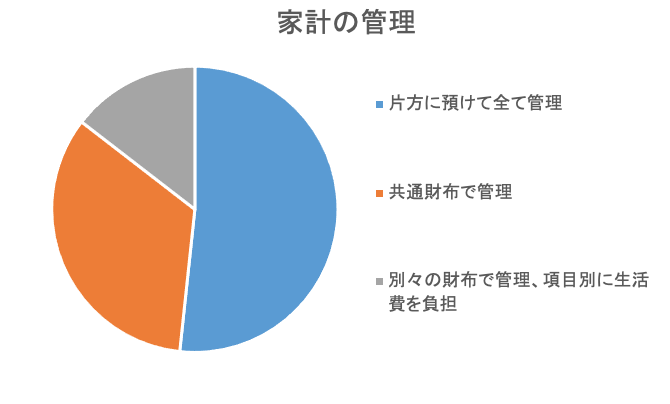
だいたいこの3つでしょうか?ちなみにリクルートブライダル総研が行った「新婚生活実態調査」によると、
共働き家庭では、Aが50.5%、Cが33.0%、最後にBが14.2%と、
Aが半数以上を締めているらしいです。(ちなみにうちの両親もAです。)
※上記調査を基に筆者作成しかもAの中でも「妻が管理」が46.8%、「夫が管理」はわずか3.7%と、妻が殆ど、、、
つまり世の中の財布は大半を妻が握っているのです!!私は世の旦那に問いかけたい、、、
「それで良いんですか?」
と。
自分の稼いだお金がいつのまにか搾取されていることも気づかず、
いつまでも妻に尻に敷かれてて良いんですか!!(世のお小遣い制の男性陣どうか叩かないで・・・)そういう意味で私はBも良いなと思ってます。完全に個人管理ですし、何より楽ですし。
ただ、生活費の負担額は極力平等に、そして公開されている方がお金に対する不満はなくなるかな、とも思い、
うちではCの共通財布制を採用しています。
不満があれば家計簿を見れば一発で原因がわかります。
実際うちではお金の喧嘩は一度もしたことないから、共通財布の家計簿管理は夫婦仲的にもおすすめです!笑ただ、
共通財布って管理がものすごく面倒なんです。というのも、家計簿って逐一入力するのさえ面倒ですよね?
共通財布だとそれに加えて、たまに個人の財布から立替えたりすることもあるので、その立替処理も記録してるともうぐっちゃぐちゃになるんです。
それに、毎月の入金額も給料から色々計算したい場合、それも別途で管理しているともう何がなんだかわからなくなります。私も色んな家計簿を試してみましたが、上記の悩みを解決する家計簿が見つからず、
仕方なく、自作のエクセルで管理してました。しかし!今や私も半人前ながらプログラミングを勉強している身!
プログラマーならそのアプリを作ってしまおう、ということで作りました!!
スマホでも操作しやすいようにしたかったですし。名付けて「Common Wallet(コモンウォレット)」共通財布専用家計簿アプリです。
共通財布家計簿「Common Wallet(コモンウォレット)」
以下が私が今回作ったアプリです。
Common Wallet
いくつか機能をご紹介したいと思います。①基本的な家計簿機能
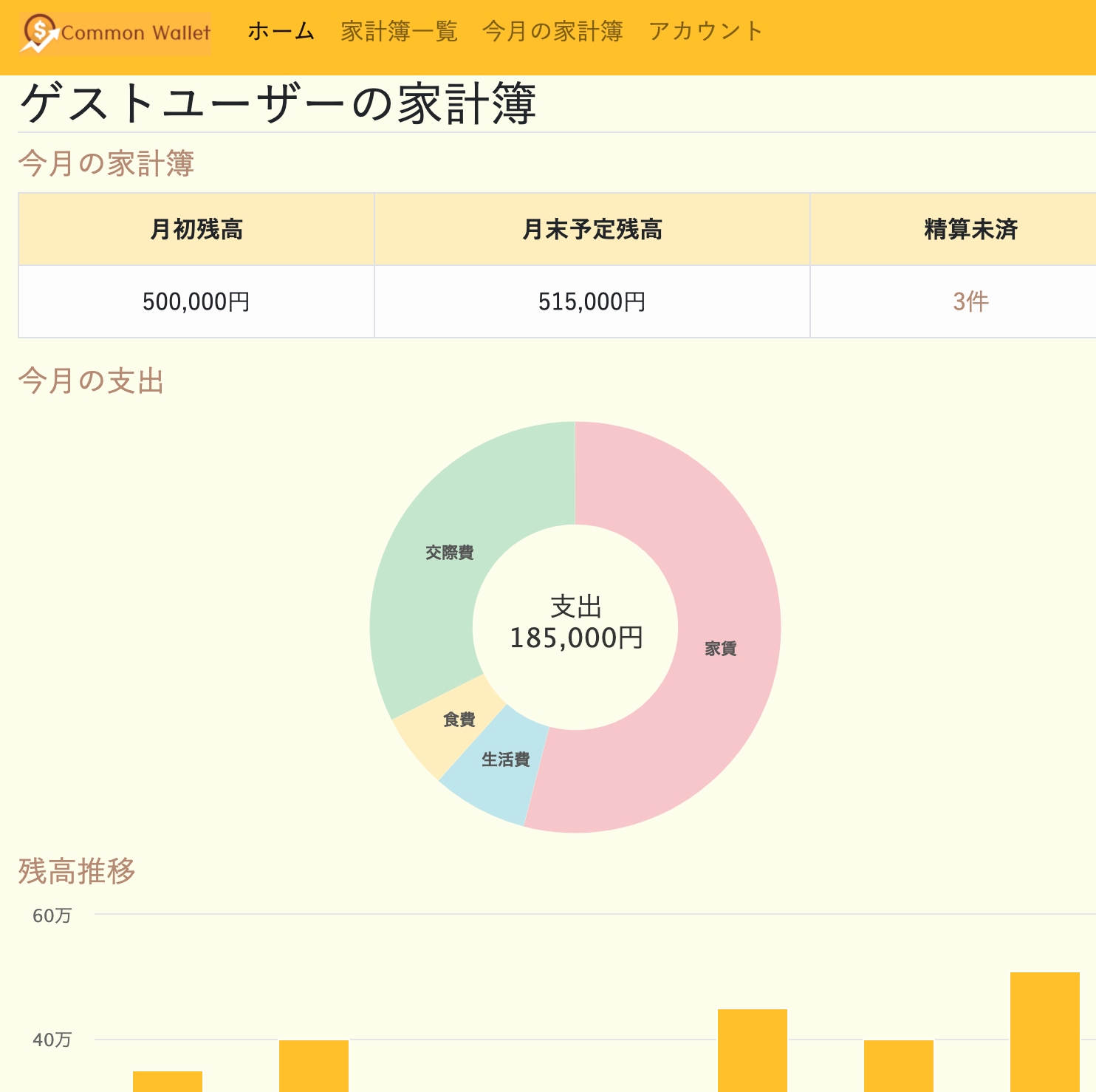
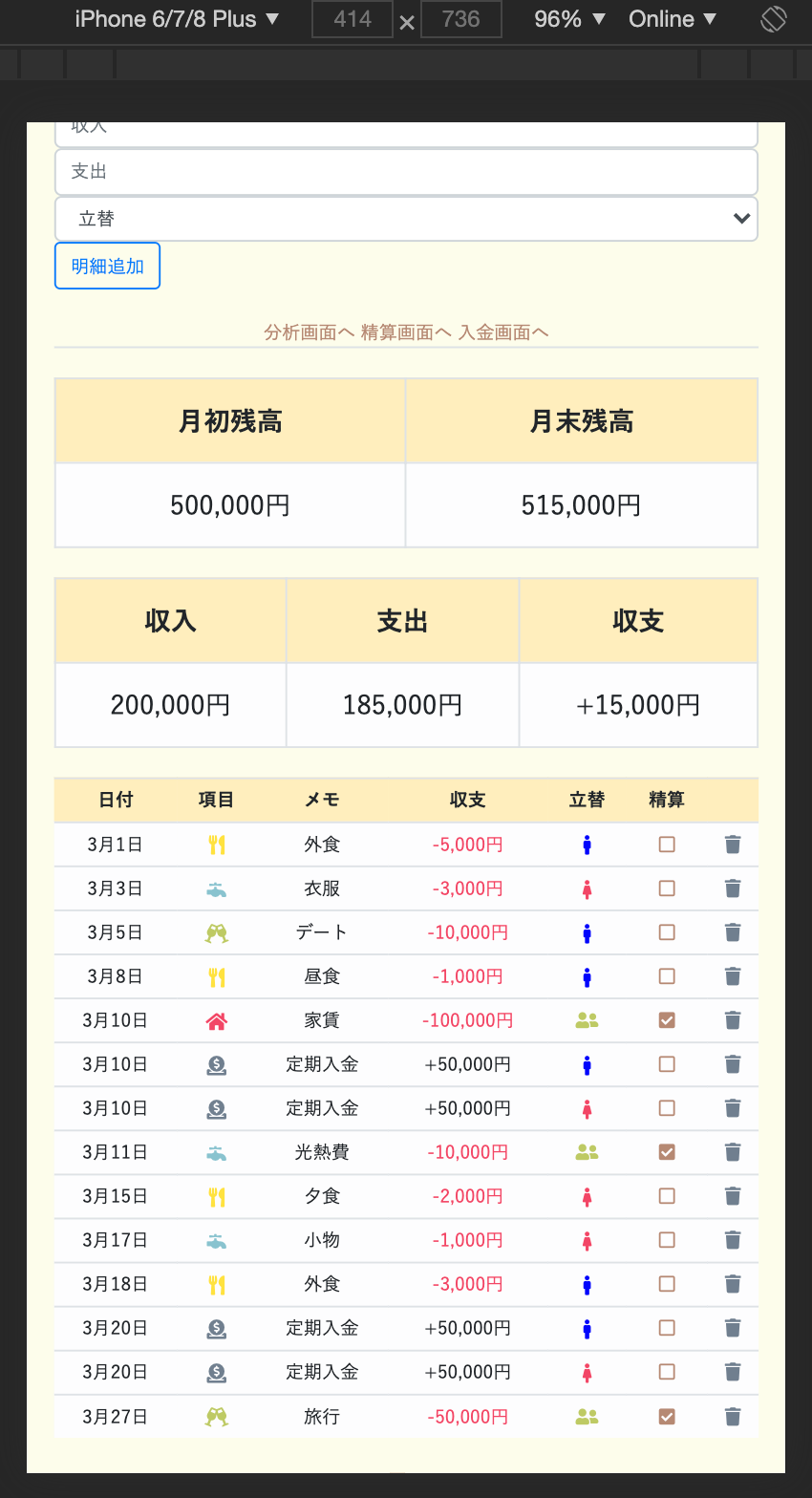
通常の家計簿アプリにある機能
「明細入力」「残高管理」「予算管理」等は実装してあるので、
共通財布ではなく個人の家計簿として利用することもできます。
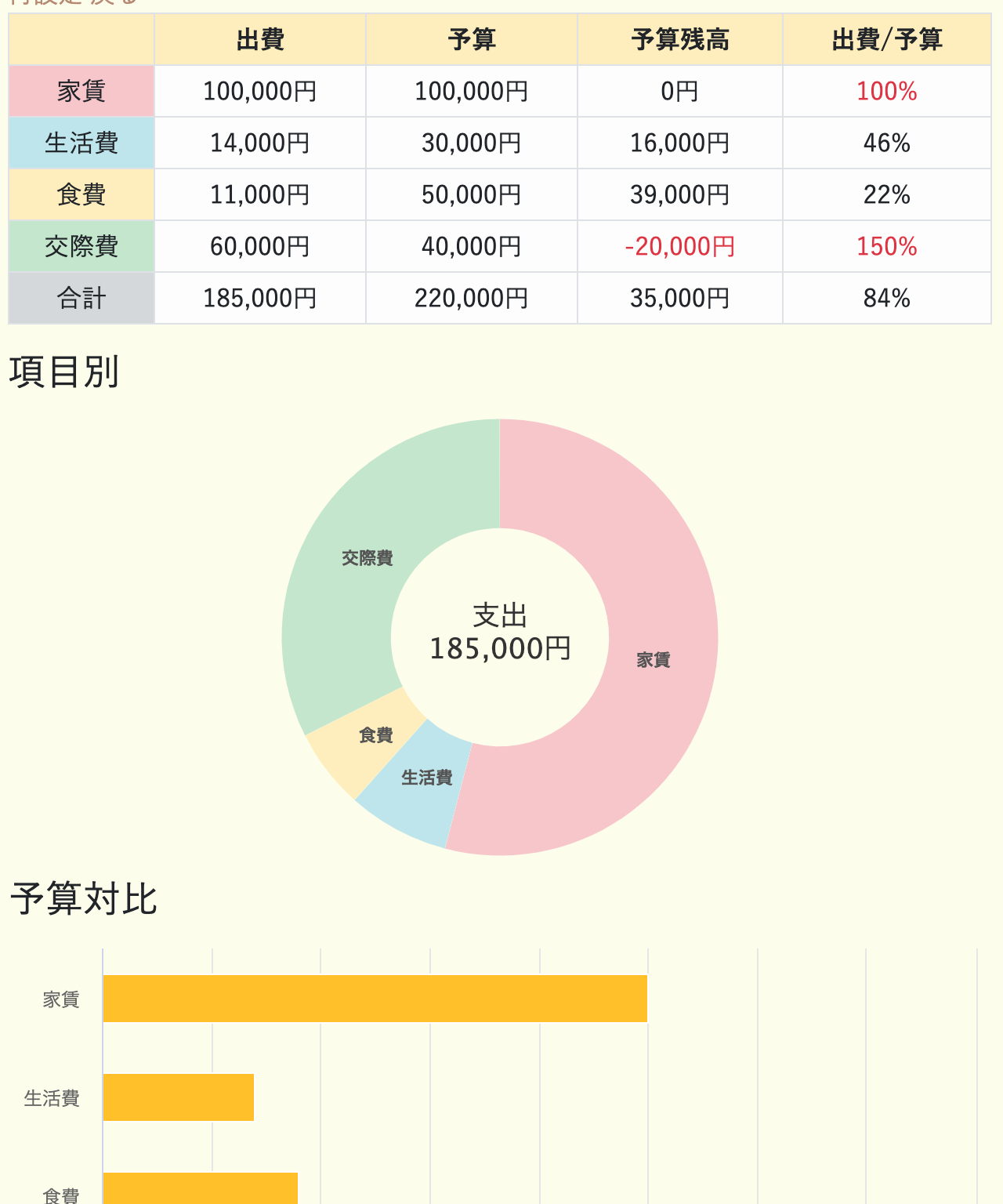
②データ分析
支出と予算を入力すると、
分析画面から「項目別支出」や「予算対比」など各種データを閲覧できます。
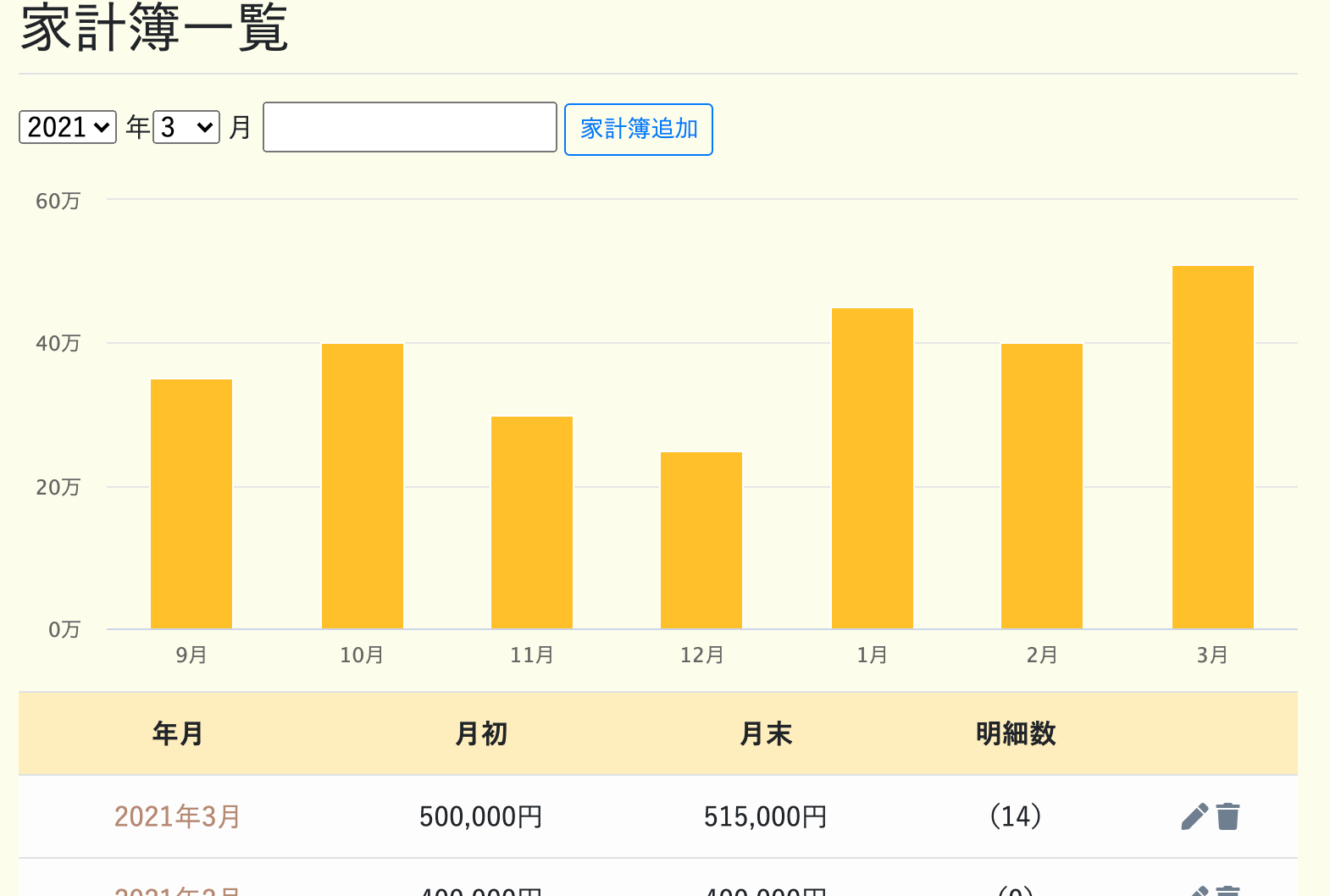
また家計簿一覧ページでは、
月次の残高推移もグラフで確認できます。
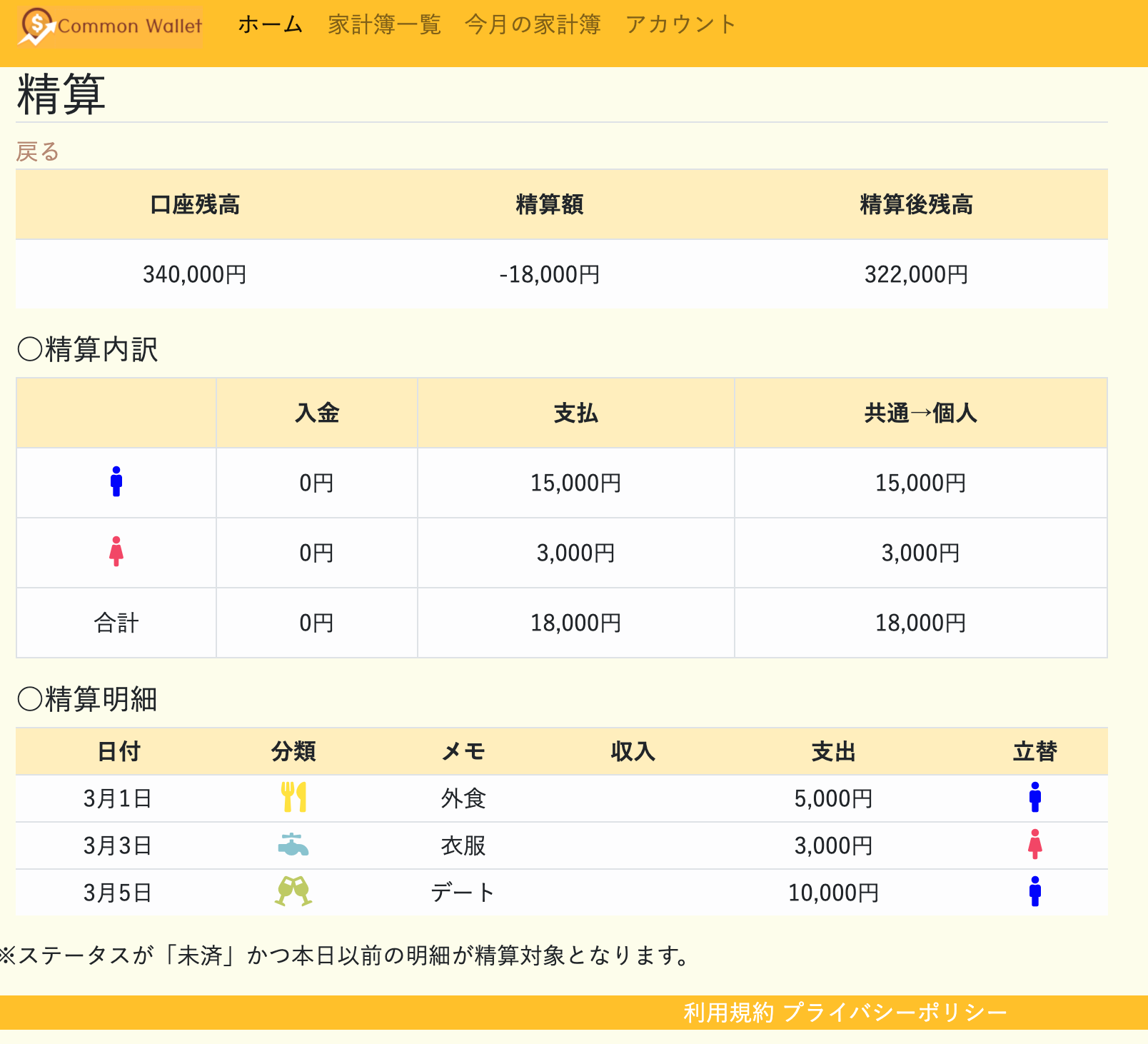
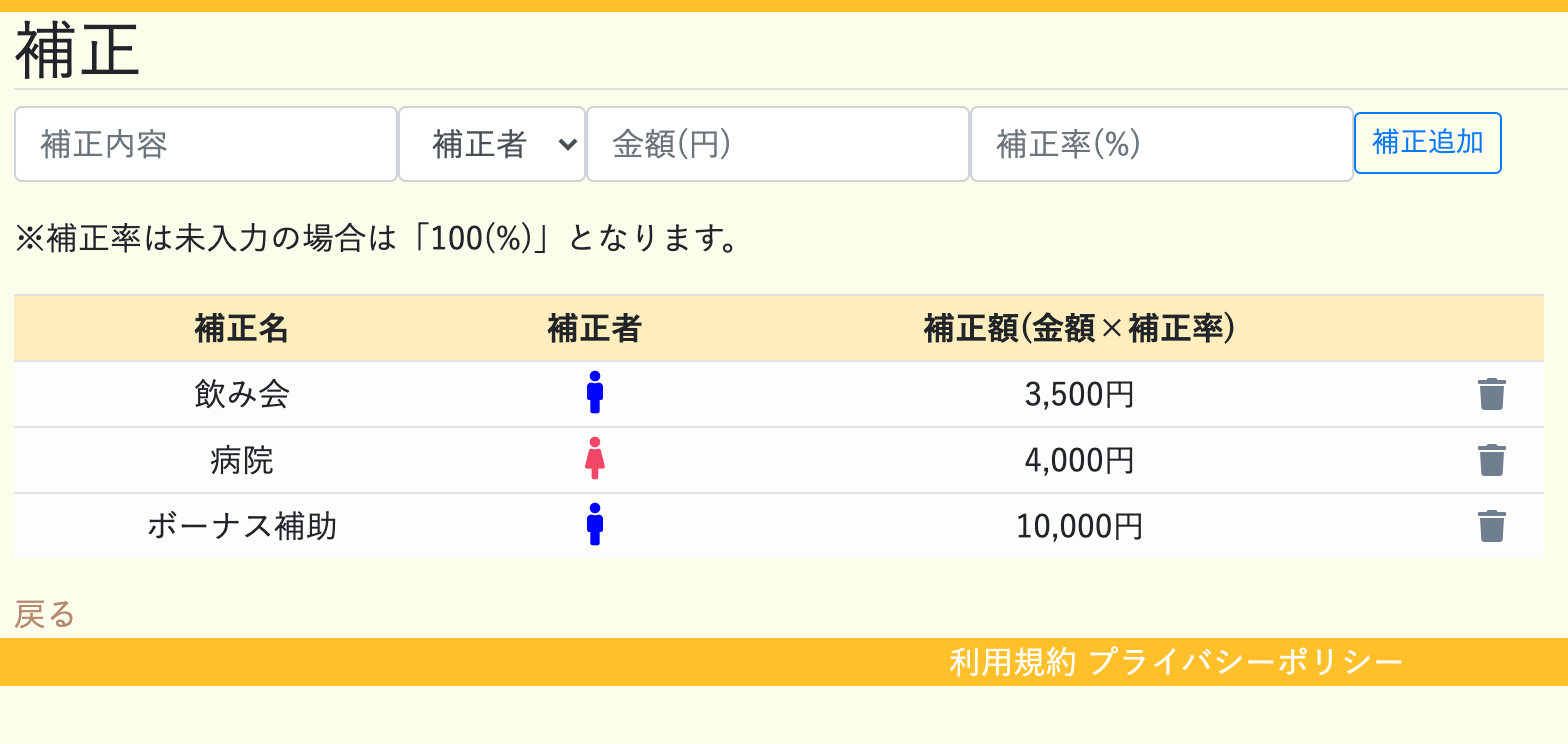
③精算機能
精算画面で精算未済の明細について
自動的に集計して精算額を算出してくれます。
精算対象はステータスが「未済」かつ今日以前の日付のものになります。
また、精算画面については、
ホーム画面の精算未済欄からも飛ぶことができます。
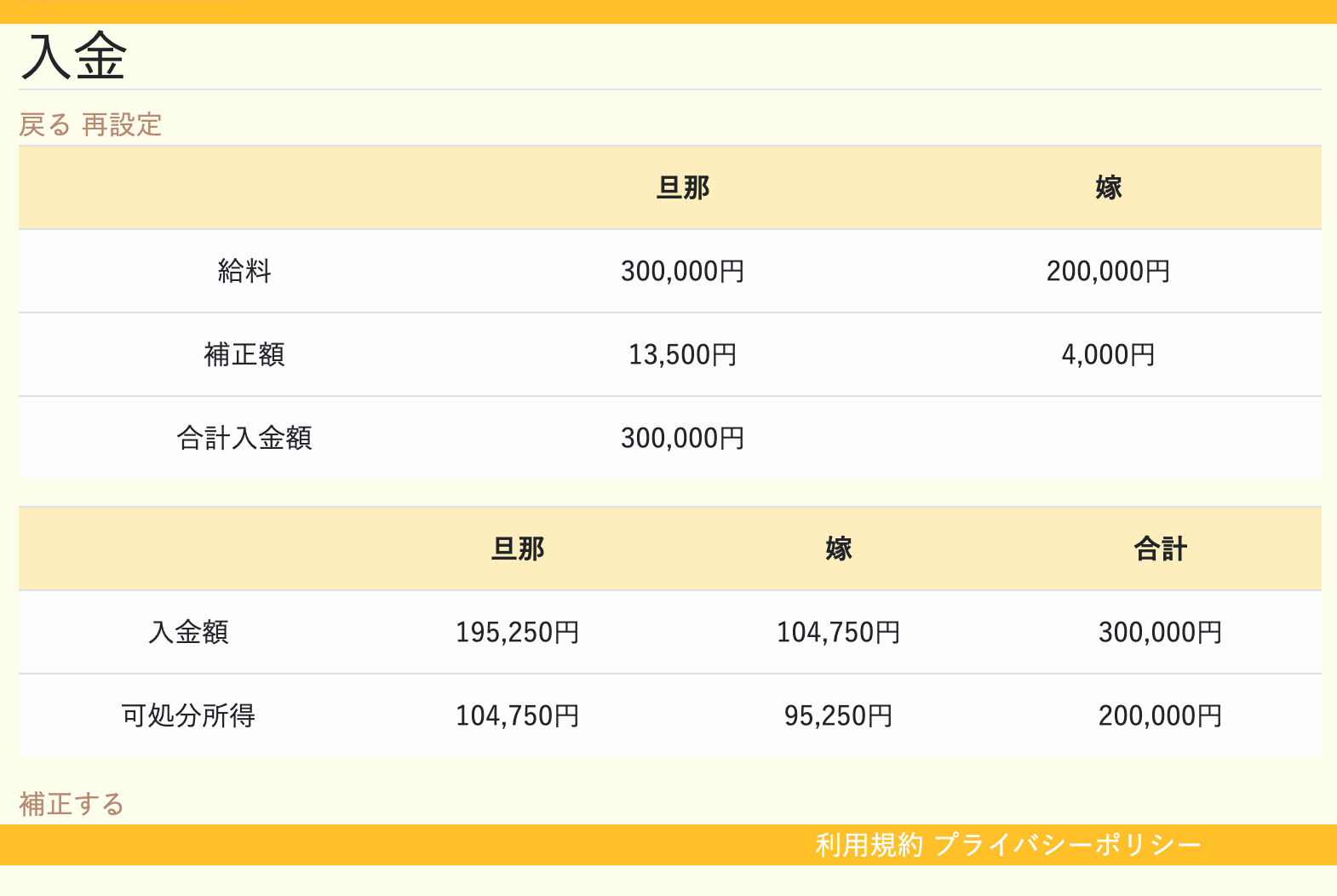
④入金計算
毎月の入金金額を算出してくれます。
算出方法は「可処分所得均等法(私が勝手に命名笑)」を採用しており、
生活費を差し引いた残りの手取りが夫婦同額になるような入金額を計算してくれます。
ただしこの場合、給料を多くもらっている方が、かなり多く負担するケースがあるので、補正項目を追加しています。
補正基準については各家庭で決めてもらっていいと思います。
技術面
僕は未熟者なので大した技術は使えていないですが、
苦労した箇所の参考記事は勉強中の方にも参考になると思うのでご紹介します。
rails使ってます。Highcharts
本サービスで使っているグラフはchartkickの「Highcharts」を使っています。
chartkickでは他にも、chart-js、 Google Chartsが使えますが、
Highchartsが微調整も利きやすく、そしてきれいな印象です。
この記事にすごくわかりやすい作成例があったので、参考にしました。
chartkick × Highchartsでドーナツグラフを作るAjax処理
初めて実践でAjax処理をしたのでだいぶ苦労しました。。。
そもそもjsの書き方とか知らないし。。。
でも何度も追加や削除を行う画面ではAjax化しないとかなりUX的にマイナスだと思うので、
使うべきだなと感じました。
以下の記事を読んでAjaxの理解が進みました。
Ruby on RailsのAjax処理のおさらい
RailsにおけるAjaxの実装(JavaScriptとjQueryのコード比較)AWSデプロイ
初めて作った(クソ)アプリ「笑うぎんこうまん」はherokuが全部勝手にデプロイしてくれたので、超絶楽チンでした。
でも、「まともなサービスなら独自ドメインもしっかり取りたいし、しっかり勉強もしたい!」とか意気込んでAWSに挑戦してみましたが、しっかり爆死。。。
用語全てが意味不明でだいぶしんどかったですが、構築知識は身についたなと思います。
ちなみにAWSデプロイは以下の記事がすごく丁寧でわかりやすいです。
世界一丁寧なAWS解説レスポンシブデザイン
今回は「スマホでも操作しやすい」を目的としていたので、
レスポンシブデザインにもところどころこだわりました。
例えば明細一覧画面。大きい画面では収入・支出が別々に記載されていますが、
スマホサイズでは「収支」とまとめて書かれています。○パソコンサイズ
○スマホサイズ
これはCSSでサイズごとに文字を「display:none;」して非表示にしています。
以下の記事を参考にしました。
【レスポンシブデザイン】不要な要素をCSSだけで非表示にする方法
ただし記事にもある通り、
「display:none;」はSEO的にリスクがあるそうなのでご利用は計画的に笑おわりに
以上が今回私の作ったアプリの説明です。
正直ここまで細かく家計簿を作る人もそうそういないと思うので、かなりニッチなサービスですが、、、笑良ければ使って下さい。

- 投稿日:2021-03-05T16:25:20+09:00
VPCの全体像⓵(AWS)
VPCとは
VPCとは、仮想ネットワークサービスのことです。
これはAWSで作った様々なものを繋ぎ合わせる大変重要なサービスです。なぜなら全てのサービスを関連するものであり、エラーの原因にもVPCの知識が必要になることが多いからです。
VPCは、AWS内部のネットワーク環境で自分専用のAWSの領域です。その領域をどのようなセキュリティルールで守るのか、どの通信を入ってくるのを許可、拒否するのか。VPCは、セキュリティ面の設定も含まれるサービスです。
AWSアカウントを作成した後にデフォルトでVPCが1つ作成されていますが、このデフォルトVPCは使わずに個別に作成していくケースが多いです。
サーバーの拠点
VPCの説明に入る前に、大切な用語である
・アベーラビリティゾーン
・リージョン
・エッジロケーションについて抑えていきます。
*以下は、AWSの公式サイト(Gloval Infrastructure)の内容です。
アベーラビリティゾーン(AZ)
アベーラビリティゾーン(AZ)とは、データセンタのことです。
各データセンターには、数万台のサーバーが収容されていると言われています。このデータセンターの単位(青点)のことをアベーラビリティゾーン(AZ)と呼ばれています。
日本にも、東京に4つ、大阪に3つのAZがあります。
大きなデータセンターを持つよりも、小さなデータセンターに分割する方が安全です。リージョン
AZを束ねた地域(オレンジ点)を、リージョンといいます。
エッジロケーション
クラウドフロントが情報をキャッシュして送る拠点を、エッジロケーション(ピンク点)といいます。キャッシュすることでネットワークの通信速度の遅延を防ぐことができます。しかし、AWSを利用する際は、こちらを意識する必要はありません。
*キャッシュ:一度使ったものを保存しておき次回以降の速度アップに役立てる方法
これからは、基本的には東京リージョンを使うという前提で説明していきます。
複数のVPCを使うとき
個人で使う分には、VPCが1つあれば十分です。
しかし、企業では複数のVPCを使うことが多いです。Ex)ショッピングサイトのVPC、動画サイトのVPC、ゲームサイトのVPC
なおVPCを作成できる数には制限があります。
1アカウントにつき、最大5つまでのVPCを作成できます。マルチVPC
1つのアカウントで複数のVPCを設定するパターンを、マルチVPCといいます。
1つのアカウントを使用するので、中規模企業向きとなります。マルチアカウント
AWSでは、クレジットカードを登録した管理アカウントから複数のアカウントを作ることができます。この作成した複数のアカウントぞれぞれにVPCを作成していくというやり方があります。これをマルチアカウントといいます。
チームが明確に分かれているような会社なら、マルチアカウントのようにアカウントを分けた方が権限管理がしやすくなります。複数のアカウントを使用するので、大規模企業向きとなります。
サブネット
大きなネットワークを複数の小さなネットワークに分けてセキュリティレベルを高めようという考え方があります。その小さなネットワークをサブネットといいます。
サブネットは、データセンター(AZ)をまたいで作成することはできません。なので1つのAZを利用して作成していきます。
VPCやサブネットには、IPアドレスの範囲を割り当てて使用していきます。
パブリックサブネット(Public subnet)
・インターネット接続可
ルートテーブルにインターネットゲートウェイのルーティング有
プライベートナブネット(Private subnet)
・インターネット接続不可
ルートテーブルにインターネットゲートウェイのルーティング無
- 投稿日:2021-03-05T14:36:34+09:00
40 代おっさん EC2 に EBS をアタッチする
本記事について
本記事は AWS 初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
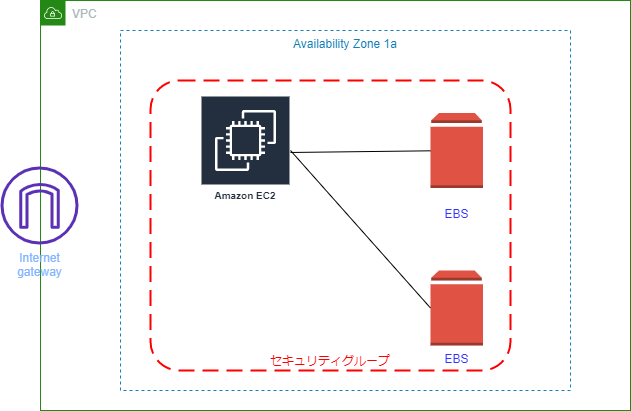
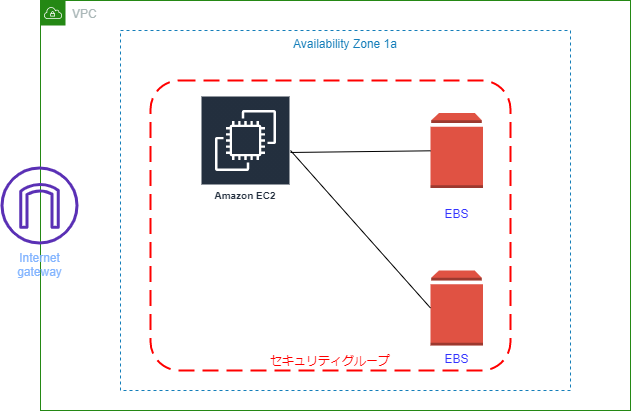
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。AWS 最終作成図
作成図構築手順
❶ EC2 インスタンス作成と同時に Apache インストール
こちらの記事は ↓
https://qiita.com/drafts/738c8f1905428e20e426/edit
❷ EBS を作成してアタッチする
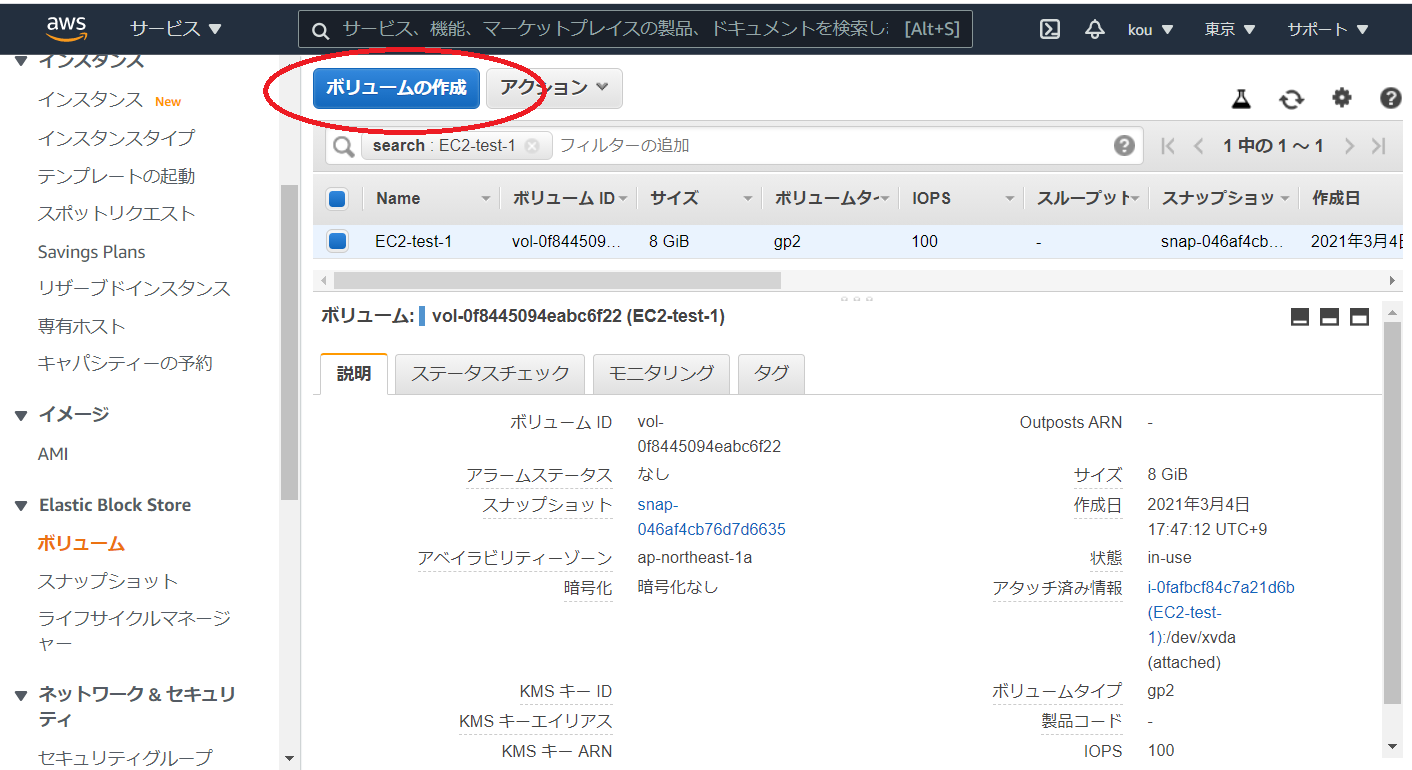
❸ アタッチしたあとマウントして使える状態にする2. EBS を作成してアタッチする
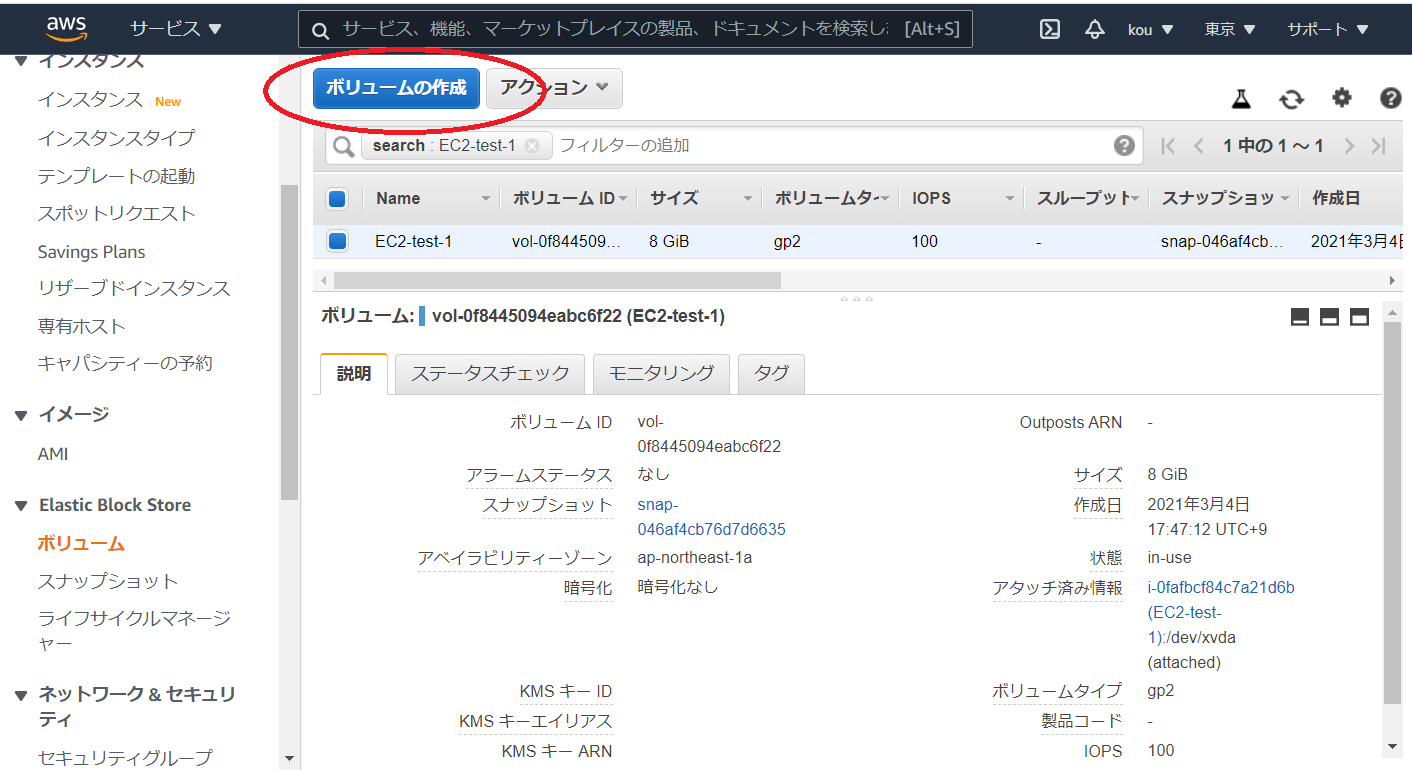
サービスから EC2 を選んでください
そして左ペインからボリュームを選択
ボリュームの作成をクリック
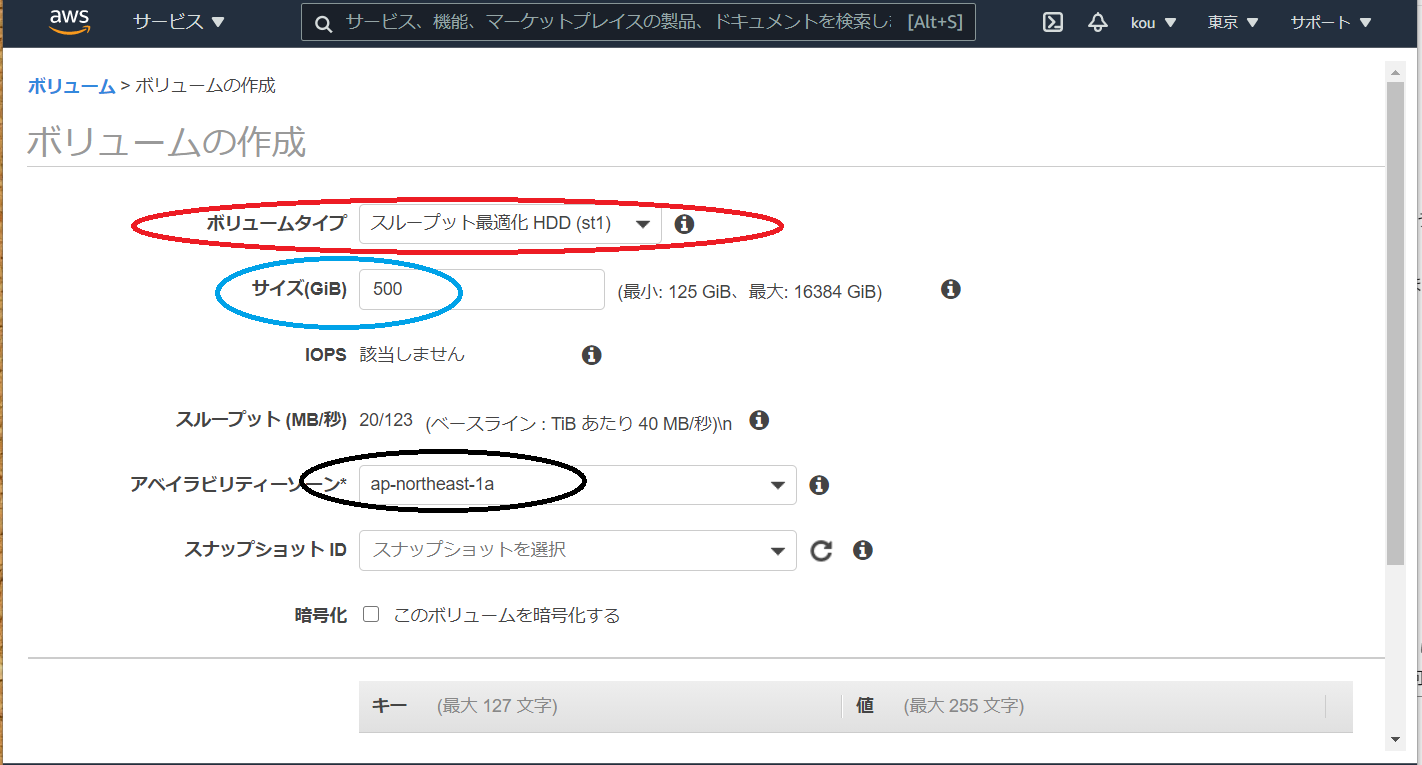
(赤枠)ボリュームタイプは色々ありますが今回はスループット最適化 HDD で
(青枠)今回は500で
(黒枠)ここで注意してほしいのはインスタンスと同じところにあるアベイラビリティーゾーンでないといけないと言うことを覚えておいてください
終わりましたら右下のほうにあるボリュームの作成をクリック
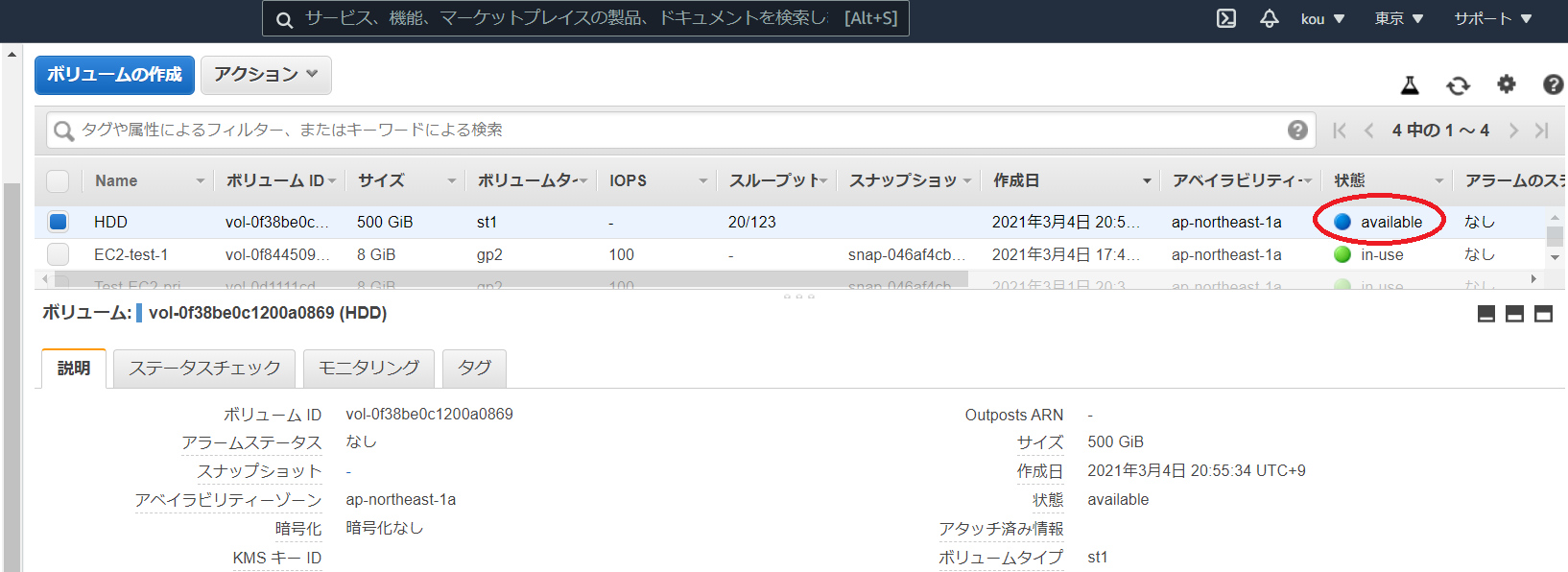
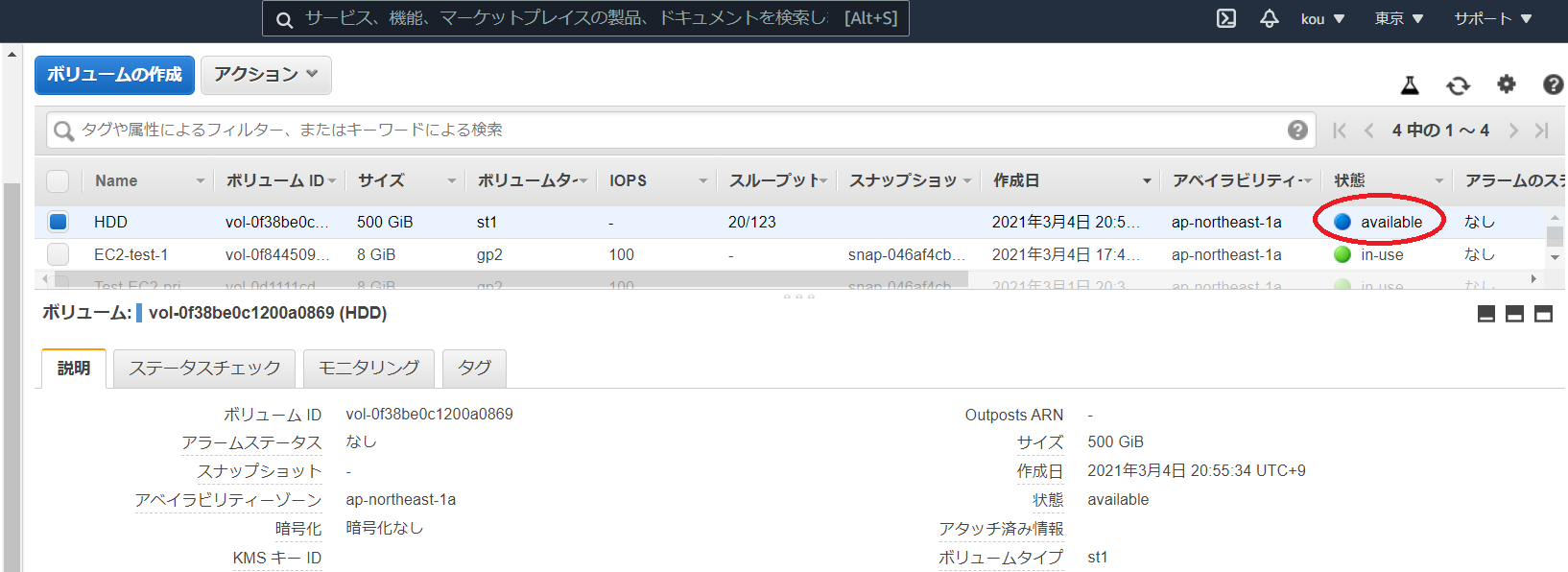
確認すると EBS ができています.
今は available(赤枠)でありどこにもアタッチされていません
ではアタッチします
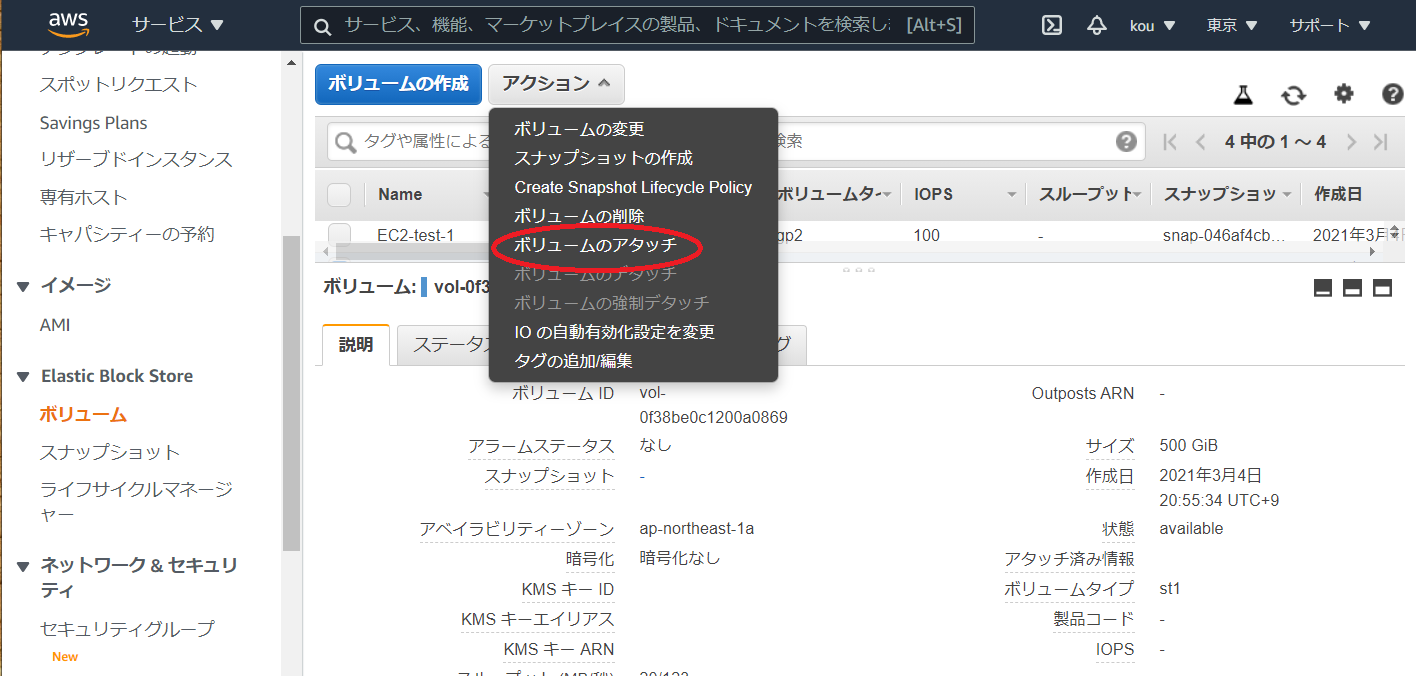
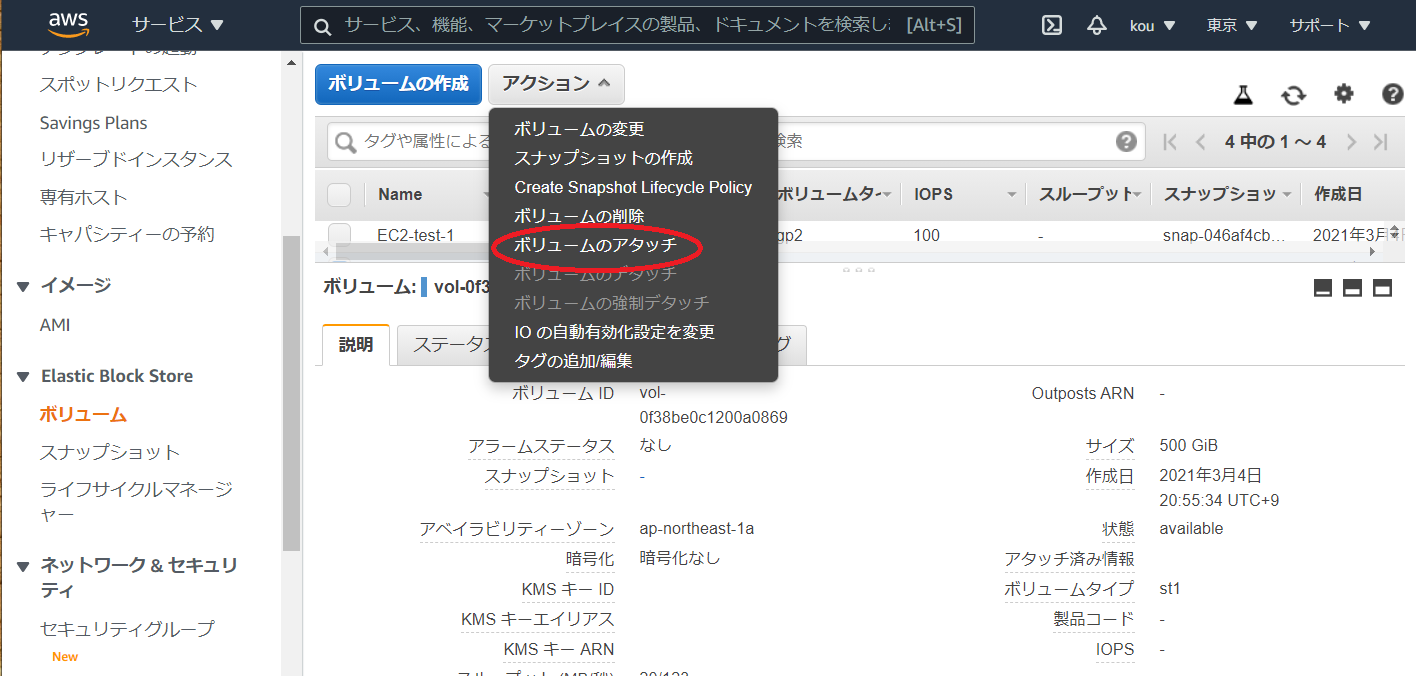
写真上のアクションをクリックするとボリュームのアタッチ(赤枠)があるのでそれをクリック
そうすると ↓ のようになります
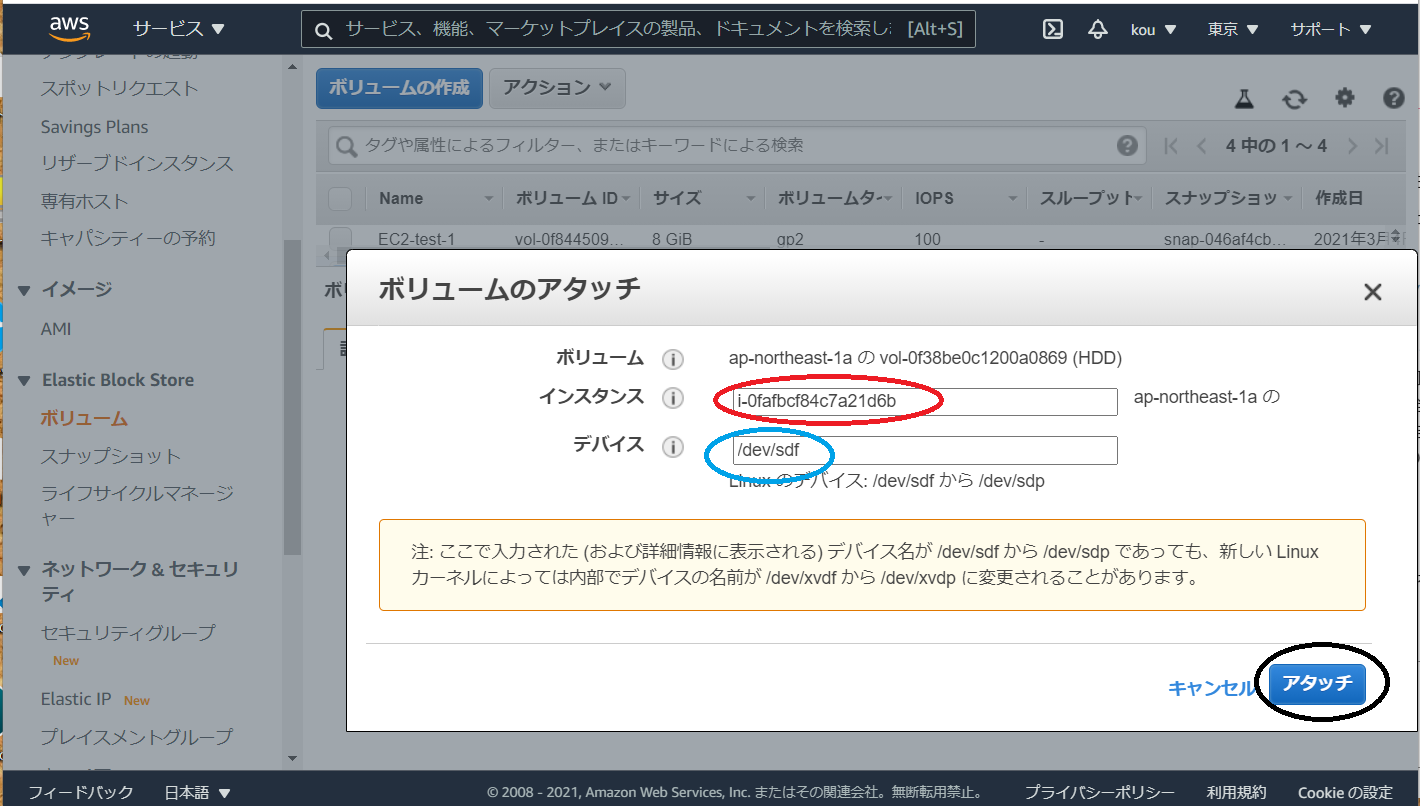
(赤枠)作ったインスタンスを選択
(青枠)デフォルトで入っていますが名前を覚えるかコピーしておいてください
(黒枠)すべて終わったらアタッチをクリック
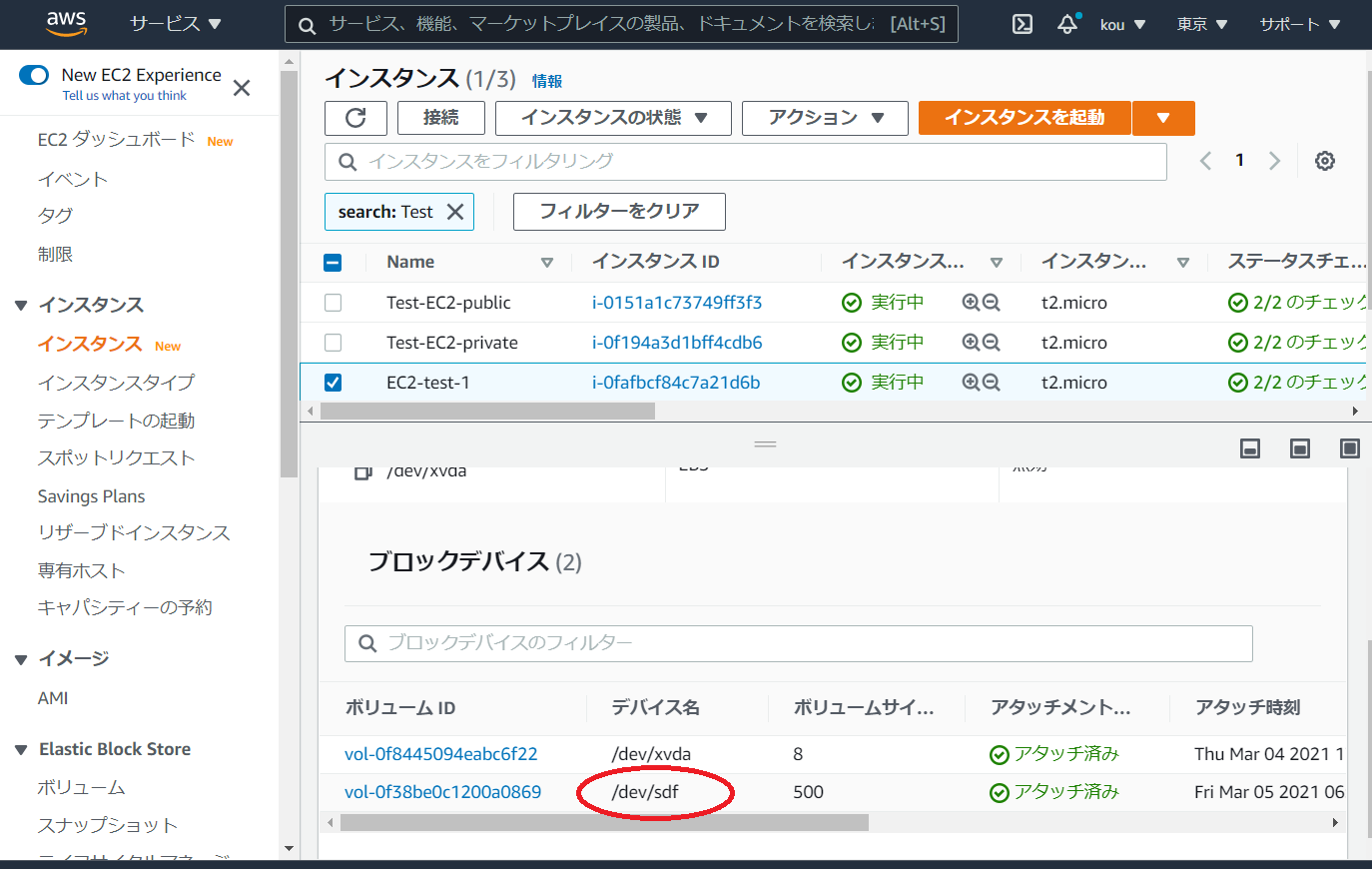
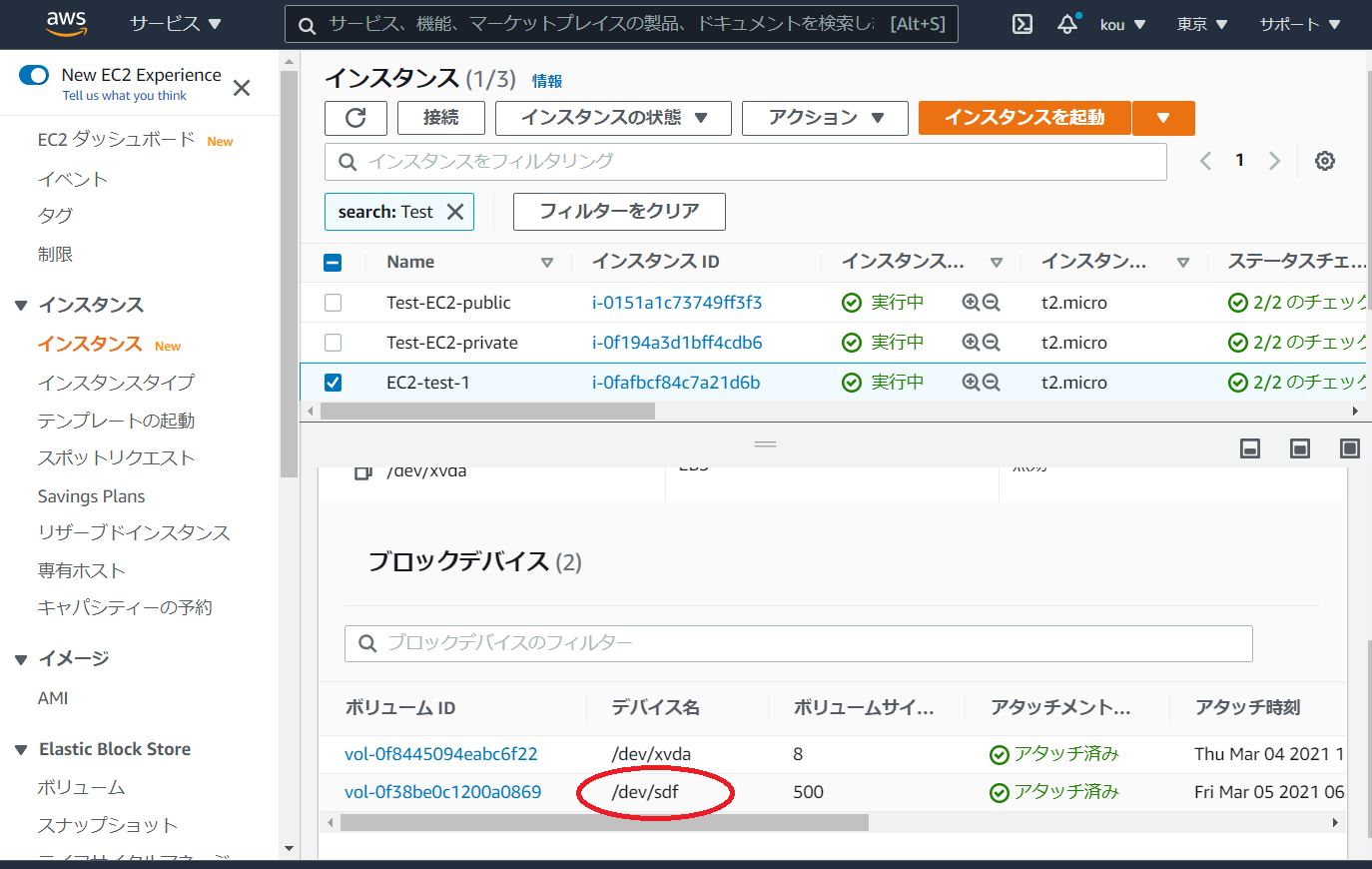
EC2 のストレージを確認してみると/dev/sdf がアタッチされています(赤枠)
最後に
実はアタッチしただけだと使えないとのこと
つらいっすね~~
でも勉強のため頑張りますまたこの記事は AWS 初学者を導く体系的な動画学習サービス「AWS CloudTech」の課題カリキュラムで作成しました。
https://aws-cloud-tech.com/
- 投稿日:2021-03-05T14:36:34+09:00
40 代おっさん EC2 に EBS をアタッチしてみた
本記事について
本記事は AWS 初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。AWS 最終作成図
作成図構築手順
❶ EC2 インスタンス作成と同時に Apache インストール
こちらの記事は ↓
https://qiita.com/drafts/738c8f1905428e20e426/edit
❷ EBS を作成してアタッチする
❸ アタッチしたあとマウントして使える状態にする2. EBS を作成してアタッチする
サービスから EC2 を選んでください
そして左ペインからボリュームを選択
ボリュームの作成をクリック
(赤枠)ボリュームタイプは色々ありますが今回はスループット最適化 HDD で
(青枠)今回は500で
(黒枠)ここで注意してほしいのはインスタンスと同じところにあるアベイラビリティーゾーンでないといけないと言うことを覚えておいてください
終わりましたら右下のほうにあるボリュームの作成をクリック
確認すると EBS ができています.
今は available(赤枠)でありどこにもアタッチされていません
ではアタッチします
写真上のアクションをクリックするとボリュームのアタッチ(赤枠)があるのでそれをクリック
そうすると ↓ のようになります
(赤枠)作ったインスタンスを選択
(青枠)デフォルトで入っていますが名前を覚えるかコピーしておいてください
(黒枠)すべて終わったらアタッチをクリック
EC2 のストレージを確認してみると/dev/sdf がアタッチされています(赤枠)
最後に
実はアタッチしただけだと使えないとのこと
つらいっすね~~
でも勉強のため頑張りますまたこの記事は AWS 初学者を導く体系的な動画学習サービス「AWS CloudTech」の課題カリキュラムで作成しました。
https://aws-cloud-tech.com/


- 投稿日:2021-03-05T14:34:14+09:00
【AWS】CodePipelineでコード変更後のデプロイを自動化する手順(セキュリティの高いプロジェクトのCI/CD化)
AWSのCodePipelineでコード変更後のデプロイを自動化する手順(プロジェクトのCI/CD化)
セキュリティを高めるために、すべてのデータをgithubで管理するのではなく、.envファイルやCodePipelineのタスク定義ファイルなど重要なデータはAWS上のCodeCommitに置くプロジェクトでCodePipelineを実行する方法について。
目次
- CodePipelineとは?
- CodePipelineのメリットは?
- CodePipelineの料金イメージ
- CI/CDとは何か?
- CodePipelineのルール
- 作成するCodePipelineの概要
- CodePipelineの作成
CodePipelineとは?
AWSのサービスの一つで、簡単にいうと本番化の自動化。
AWS上で運用しているサービスで、コード改修など変更があった場合に、変更を自動検知してサービスを自動デプロイ(本番化)することができる。
自動更新を開始するトリガーは自分で設定できる。例えば、githubでコード変更があった場合や、ECRに新しいイメージがプッシュされた場合など。
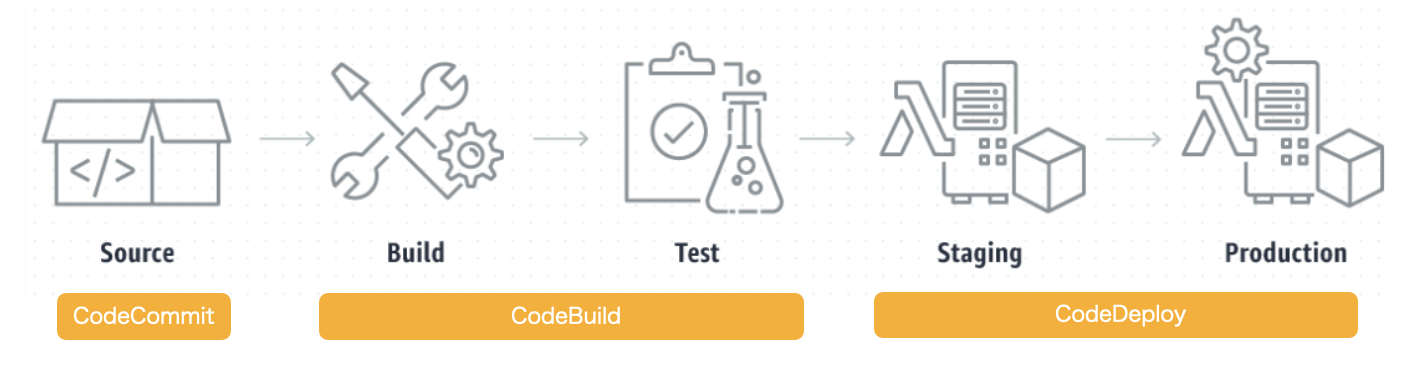
▼CodePipelineの処理の流れ
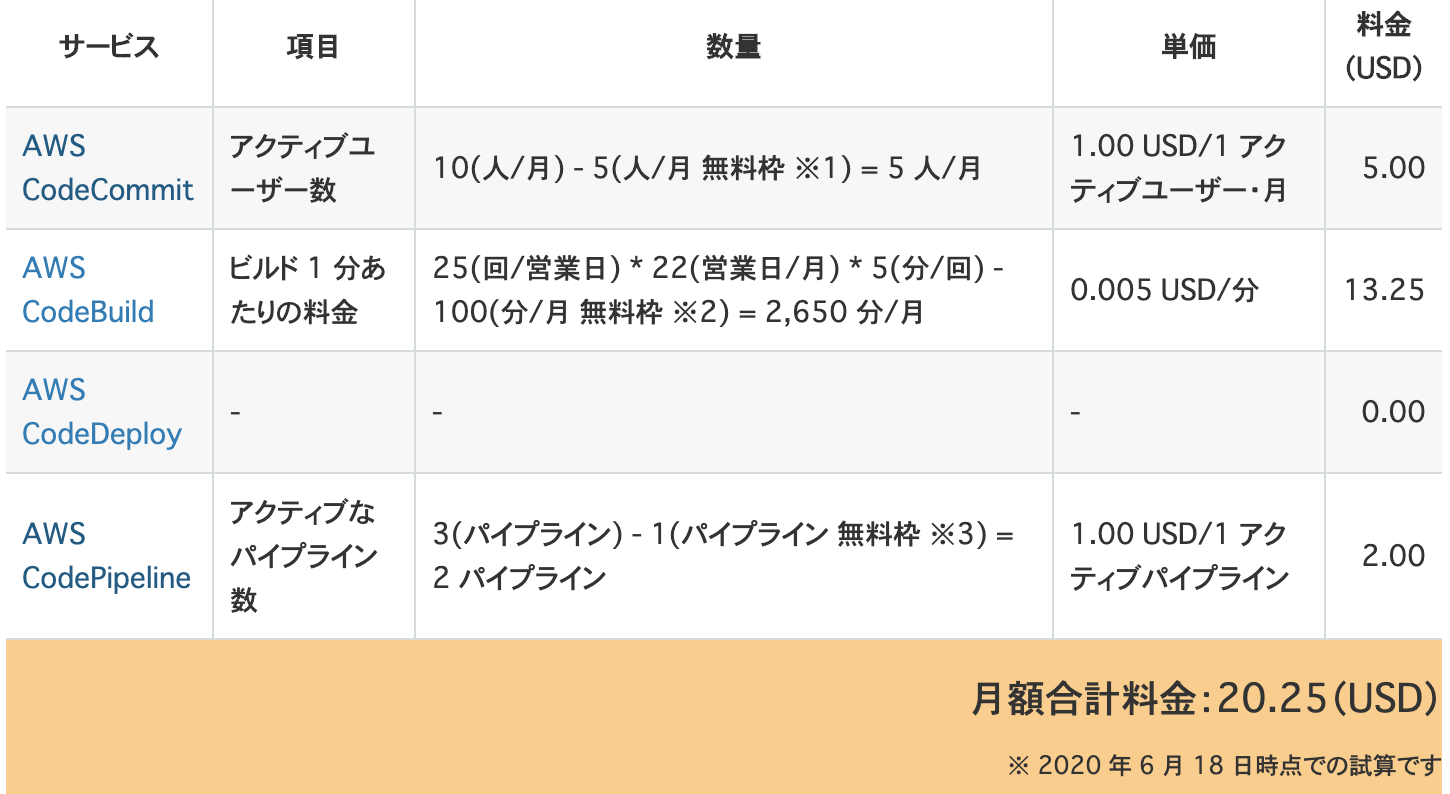
▼AWSの各種サービスとCodePipelineの関係
CodePipelineのメリットは?
CodePipelineがない場合の本番化を知っておくとCodePipelineのメリットがわかりやすい。
手動の場合(やること)コード変更(ローカル) ↓ コードをレポジトリにプッシュ(github, CodeCommit,,,) ↓ イメージのビルド(ローカル) ↓ イメージをプッシュ(ECR) ↓ タスク定義の更新(ECS) ↓ サービスの更新(ECS) 上記をステージとプロダクションのそれぞれで実施。特にイメージが変更になる度に、タスク定義とサービスの更新作業が発生するのが手間。
これをCodePiplineで自動化すると以下のようになる。▼githubの変更をトリガーにする
自動化の例1(やること)コード変更(ローカル) ↓ コードをレポジトリにプッシュ(github, CodeCommit,,,)残りのイメージの作成、タスク定義やサービスの更新、イメージからコンテナを作成しテスト、本番公開を自動でやってくれる。
▼CodeCommitとECRの変更をトリガーにする自動化の例2(やること)コード変更(ローカル) ↓ コードをレポジトリにプッシュ(CodeCommit,,,) ※トリガー1 ↓ イメージのビルド(ローカル) ※トリガー2 ↓ イメージをプッシュ(ECR) 上記をステージとプロダクションのそれぞれで実施。残りのタスク定義やサービスの更新、イメージからコンテナを作成しテスト、本番公開を自動でやってくれる。
>(参考)【AWS】更新後のDockerコンテナを手動でデプロイする手順(ECRとECSの操作方法)
CodePipelineの料金イメージ
CodePipelineで何を監視&動かすかによって料金が変わる。
▼CodeCommit, CodeBuild, CodeDeployを使う場合
コストを安くする方法
CodeBuildでイメージのビルドとテストを実行するが、この作業はローカルでも十分に実行可能。
AWSでCodeBuildを使ってビルド&テストするよりもローカルで実行した方が早いこともあり、ビルドをCodePipelineに組み込まなければその分コストを抑えられる。
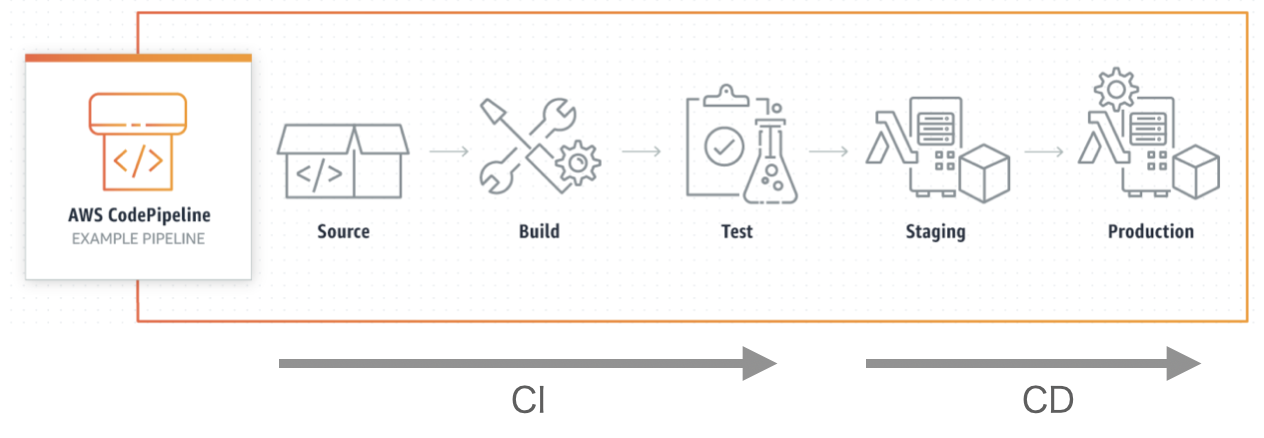
CI/CDとは何か?
CodePipelineを調べているとよく直面する用語。
簡単にいうと本番化を自動するという概念。
CI/CD(本番化の自動化)ができるサービスの一つにCodePipelineがあるというイメージ。他にもCircleCiという他社サービスもある。
CIがデプロイまでの処理の自動化で、CDがデプロイ後の処理の自動化。
CIとは?
Continuous Integrationの略で日本語では、継続的インテグレーションという。
プロジェクトの運用では、本番環境のコードを直接いじることは基本的になく、ブランチを切ってmasterに統合(インテグレーション)していく。
Dockerの場合は、更新後のイメージをビルドし、レポジトリに統合(インテグレーション)する。
このインテグレーションの作業を自動的(継続的)にすることをCIという。
CDとは?
Continuous Deploymentの略で日本語では、継続的デプロイメントという。
運用中のアプリケーションのコードを変更した場合は、その変更内容を反映(デプロイ)する必要がある。
このデプロイの作業を自動的(継続的)にすることをCDという。
CodePipelineのルール
- ステージは2つ以上
- 最初はソースステージから始まる
- ビルドかデプロイのステージが1つ以上必要
ステージとは?
CodePipelineでは監視やデプロイなど個々のアクションをステージと呼ぶ。ステージは全部で6種類ある。
ステージ名 処理内容 主な対象 source 監視対象を選ぶ S3, ECR, CodeCommit, Github build イメージをビルドする CodeBuild, Jenkins test イメージのテストを行う CodeBuild, Jenkins deploy 新しいサービスを始動する CodeDeploy, S3, ECS approval 手動で承認をすると次のステージに進める 手動 invoke 呼び出し Lambda, Step Functions ソースステージとは?
監視対象を選択するステージをソースステージと呼ぶ。上記のsourceにあたる。
例えばCodeCommitを選択すれば、指定のレポジトリのブランチで変更を検知した場合に、設定してある自動化プロセスが発火する。
最少構成
CodePipelineの最少構成は以下となる。
ソースステージ(固定) ↓ デプロイステージ
CodePipelineの作成
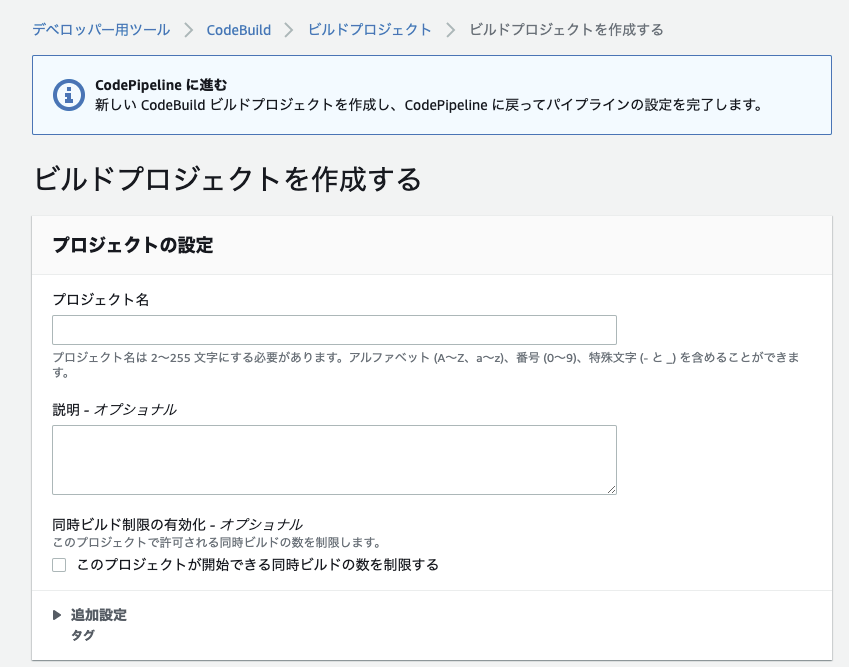
作成するCodePipelineの概要
1. CodeCommitとECRの変更をトリガーにする 2. イメージの作成はローカルで実施(CodeBuildは使わない) 3. 完全自動デプロイはStagingまで 4. Productionデプロイの前に承認作業を入れる 5. 承認されたらProductionを自動デプロイ▼作成後のイメージ
1. パイプラインの設定
CodePipelineに入り作成ボタンをクリクする。
↓
1-1. パイプラインの作成
・パイプライン名
任意(わかりやすいようにプロジェクトに沿った名前をつける)。なお、指定した名前が、ロール名の末尾に自動で追加される。(変更可能)
・サービスロール
CodePipelineは様々なAWSサービスにアクセスするため、専用のIAMを作成する必要がある。「新しいサービスロール」を選べば、入力内容に沿って専用のIAMを自動作成してくれる。
既存のIAMを選択することも可能。選択できるのはCodePipeline用のIAMのみ。
基本的には、新規作成する。
・ロール名
新しいサービスロールを作成する場合は名前をつける必要がある。
パイプライン名を入力すれば自動で専用の名前が入る。(変更も可能)ロール名AWSCodePipelineServiceRole-ap-<リージョン>-<パイプライン名>
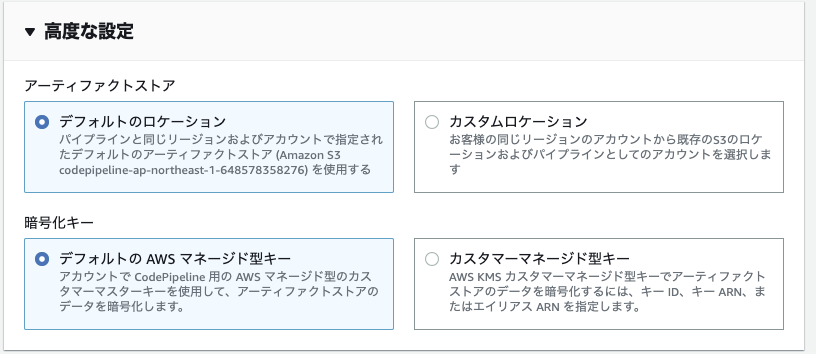
1-2. 高度な設定
アーティファクトとは?
CodePipelneを設定する中で頻繁に出てくるワードに「アーティファクト」がある。
アーティファクトとはひとまとまりのデータのこと。(オブジェクトに似たイメージ)
コードやイメージなど①受け取ったデータを、必要に応じて処理を施し、②次のステージに渡していくときに、これらのデータにそれぞれアーティファクト名をつけて、どのアーティファクトを渡すか指定する。
各ステージからみて、
①受け取ったアーティファクトを「入力アーティファクト」
②渡すアーティファクトを「出力アーティファクト」
と呼ぶ。ステージ1 ↓ ステージ1の出力アーティファクト ↓ ステージ2の入力アーティファクト ステージ2 ↓ ステージ2の出力アーティファクト
▼参考例
CodeCommitにプッシュされた変更後のソースコードが一つのアーティファクトになる。(仮に名前を アーティファクトA とする)また、更新後のイメージをECRにプッシュした場合はイメージがアーティファクトとなる。(仮に名前を アーティファクトB とする)
次のデプロイステージに2つのアーティファクトを渡す。その中で、コンテナの起動に使うためのイメージを指定するタブでは、アーティファクトBを入力する。
・アーティファクトストアとは?
アーティファクト(入出力データ)の保存場所のこと。
デフォルトはパイプラインと同じリージョンおよびアカウントのS3。自分で選ぶことも可能。
基本的にはデフォルトでOK。
・暗号化キー
パイプラインのアーティファクトの暗号化方法を選択する。基本的にはデフォルトのAWSマネージド型キー(CMK)でOK。
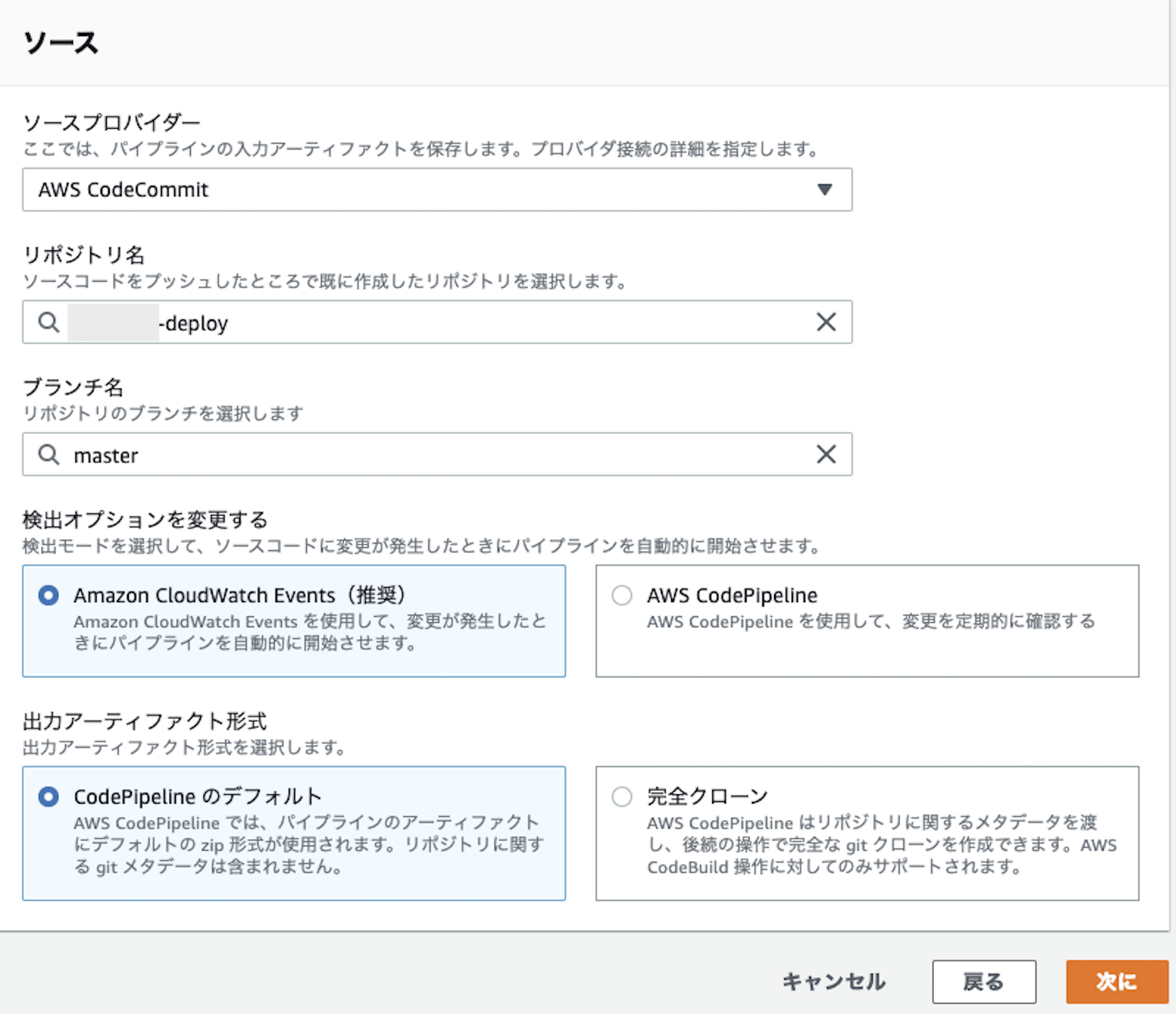
2. ソースステージの追加
CodeCommitの変更をトリガーとしてCodePipelineを作動させるため、CodePipelineを選択。(後から変更・追加も可能)
選択すると、CodeCommitに登録されているレポジトリとブランチがプルダウンで選択できるようになる。
変更を検知する、リポジトリとブランチ名を選択。
2-1. 検出オプションの選択
変更をどのように検知するか。CloudWatchEventsかCodePipelineを選択できる。
CloudWatchEventsで変更を検知する方法が推奨。
2-2. 出力アーティファクトの選択
アーティファクトをどのように出力するか。デフォルトと完全クローンが選択できる。
デフォルトのZip形式で出力を選択する。
完全なクローンを作成する場合は、CodeBuildにクローンで生成されたレポジトリにアクセスするための権限を付与する必要がある。
3. ビルドステージの追加
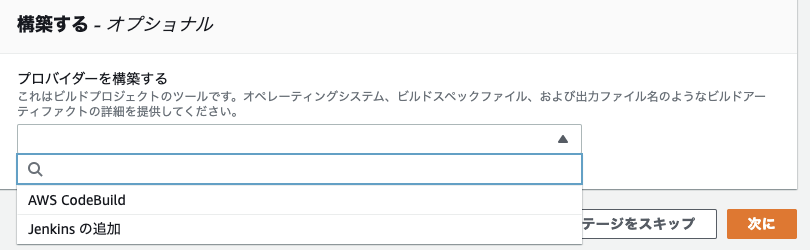
*今回、ビルドはローカルで行うため、スキップする。
▼参考として、内容だけサラッと確認ビルドプロジェクトの作り方
イメージ作成とテストをするサービスを選択する。CodeBuildとJankinsが選択できる。
CodeBuildとは?
受け取ったソースコードからイメージを作成し、作成したイメージをECRにプッシュするサービス。
▼CodeBuildでビルドプロジェクトを作成する場合
中段の「プロジェクトを作成する」から、CodeBuildに飛び、プロジェクトを作成することができる。
↓ CodeBuild
(参考)CodeBuildとは?
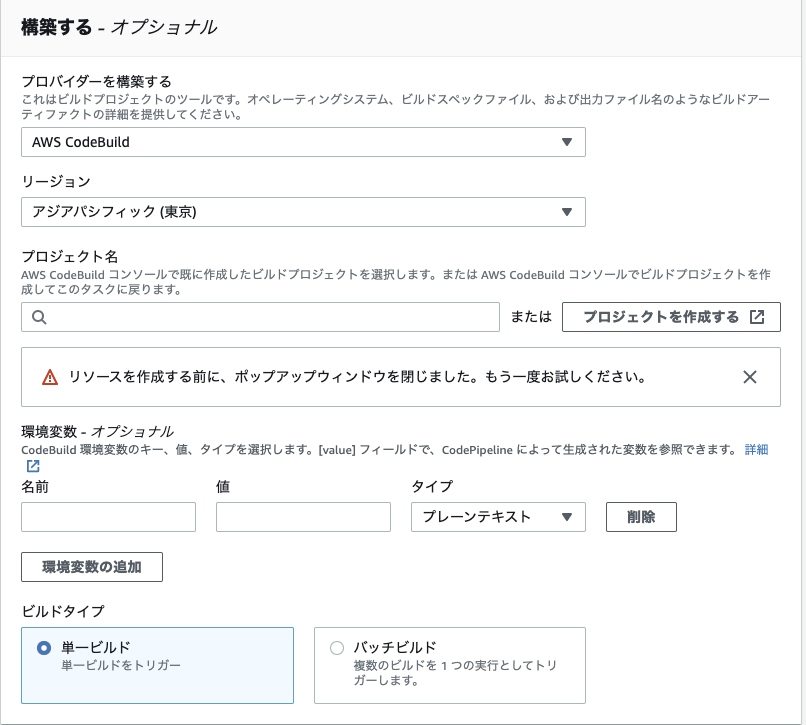
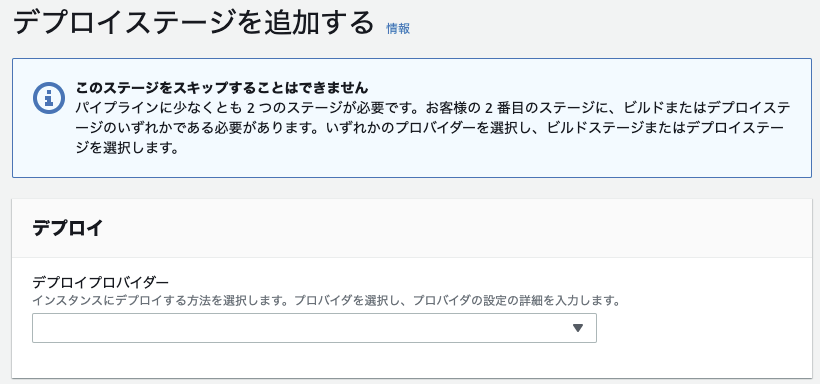
4. デプロイステージの追加
デプロイで使用するCodeDeployの設定を行っていく。
4-1. プロバイダーの選択
↓ デプロイの方法を選択する。
今回は、デプロイにBlue/Greenを選択。
4-2. CodeDeployのアプリケーションを選択
既存から選択するか、新規作成することができる。
CodeDeployのプラットフォームはEC2, Lamba, ECSから選択することができる。
ECSでクラスターを作成した場合のCodeDeploy
ECSでクラスターを作成した場合、そのサービス名で自動でCodeDeployのアプリケーションとデプロイグループも自動で作成される。
今回はECSで作成したアプリケーションを使うため、冒頭に
AppECS-がついている。
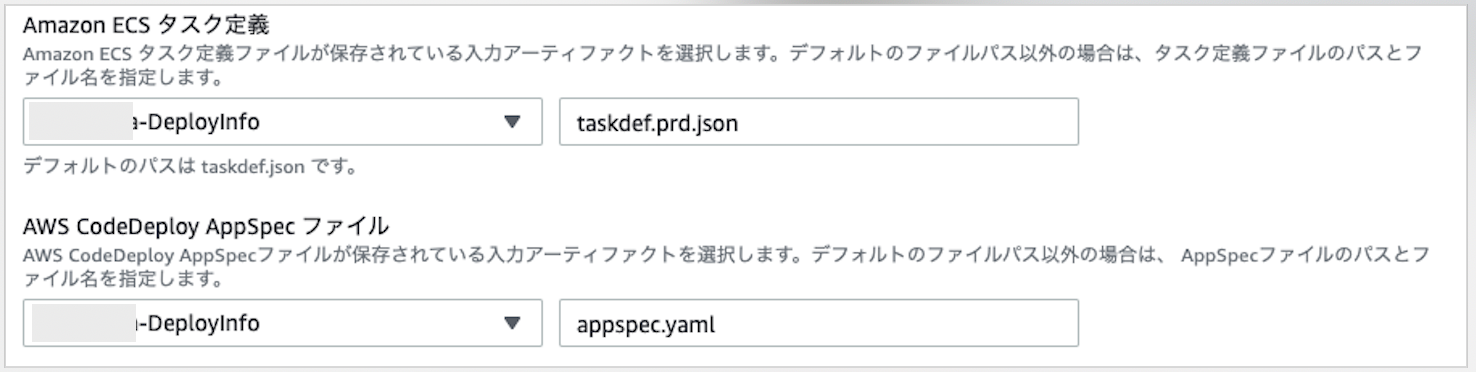
4-3. タスク定義ファイルの指定
コンテナ定義が書かれた、タスク定義ファイルを指定する。
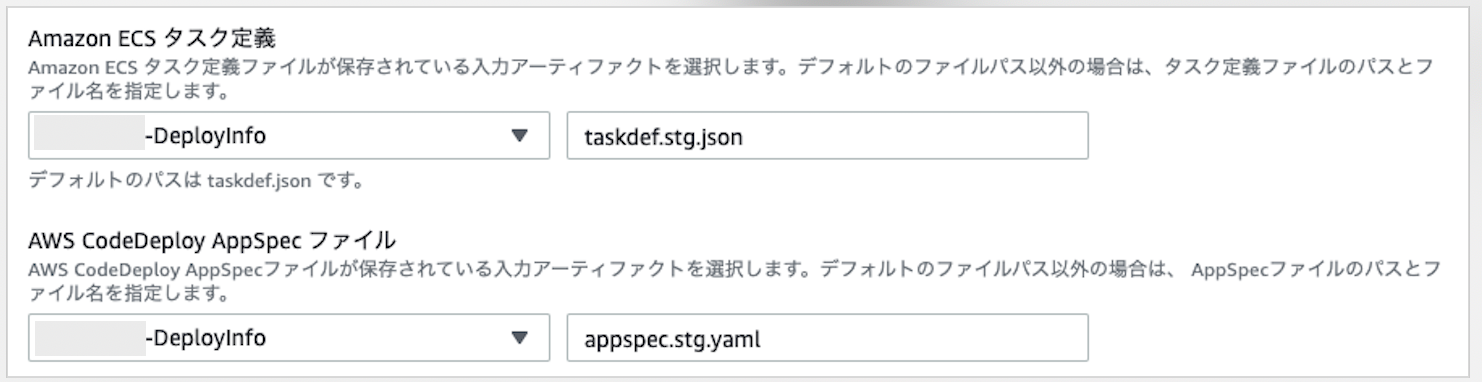
デフォルトではtaskdef.jsonを使う。任意の名前をつけたい場合は入力する。(今回はtaskdef.stg.jsonを指定)
タスク定義ファイルとは?
コンテナ起動のための詳細情報が書かれたjson形式のファイル。デフォルトは
taskdef.json。コンテナ名、ポート番号、環境変数などが記載されている。ECSでタスク定義をした際に作成される。
SourceArtifactとは?
前の処理から、CodeDeployに渡されたひとまとまりのデータ。
ここでは、CodeCommitのソースコードが渡されている。つまりここでは、CodeCommitにプッシュされたディレクトリの
taskdef.stg.jsonファイルをコンテナ起動のためのタスク定義ファイルとして使うことを指示している。タスク定義ファイルの例{ "executionRoleArn": "arn:aws:iam::account_ID:role/ecsTaskExecutionRole", "containerDefinitions": [ { "name": "sample-website", "image": "<IMAGE>", "essential": true, "portMappings": [ { "hostPort": 80, "protocol": "tcp", "containerPort": 80 } ] } ], "requiresCompatibilities": [ "FARGATE" ], "networkMode": "awsvpc", "cpu": "256", "memory": "512", "family": "ecs-demo" }イメージ名をプレースホルダー
"image": "<IMAGE>"で指定してあることに注目。
4-4. appspecファイルの指定
デプロイ時に使用するappsepcファイルを指定する。
ファイル名拡張子は
.ymlでも問題ない。CodeCommitにプッシュしたファイル名と合わせる。appspecファイルとは?
各デプロイメントでライフサイクルイベントフックを定義したファイル。
ECSで作成したCodeDeployの場合は、以下を定義する。
- ECSサービスの名前
- コンテナー名とポート番号(トラフィックを新しいタスクセットに転送する)
- 検証テストとして使用される関数(任意)
appspecファイルの例version: 0.0 Resources: - TargetService: Type: AWS::ECS::Service Properties: TaskDefinition: <TASK_DEFINITION> LoadBalancerInfo: ContainerName: "sample-website" ContainerPort: 80タスク定義名をプレースホルダー
TaskDefinition: <TASK_DEFINITION>で指定してあることに注目。
動的更新のためのIMAGE名を指定
前の処理から渡された、入力アーティファクトでイメージ名を動的に取得するため
"image": "<IMAGE>",としてある。このイメージ名を使うため、プレースホルダーはIMAGEを選択。
次へをクリック。
5. レビュー
設定した内容を確認して、問題なければパイプラインを作成する。
6. タスク定義ファイルの作成
タスク定義ファイル
taskdef.json(今回はtaskdef.stg.json)を作成し、そこにJSON形式のタスクデータを貼り付ける。6-1. デプロイグループで対象のECSサービス名確認する
デベロッパー用ツール > CodeDeploy > アプリケーション > AppECS(ECSクラスター名) → DgpECS(ECSデプロイグループ名)で、CodeDeployで設計した内容が表示される。
その中の、「環境設定」で、「クラスター名」と「サービス名」を確認する。
6-2. 貼り付けるデータの取得
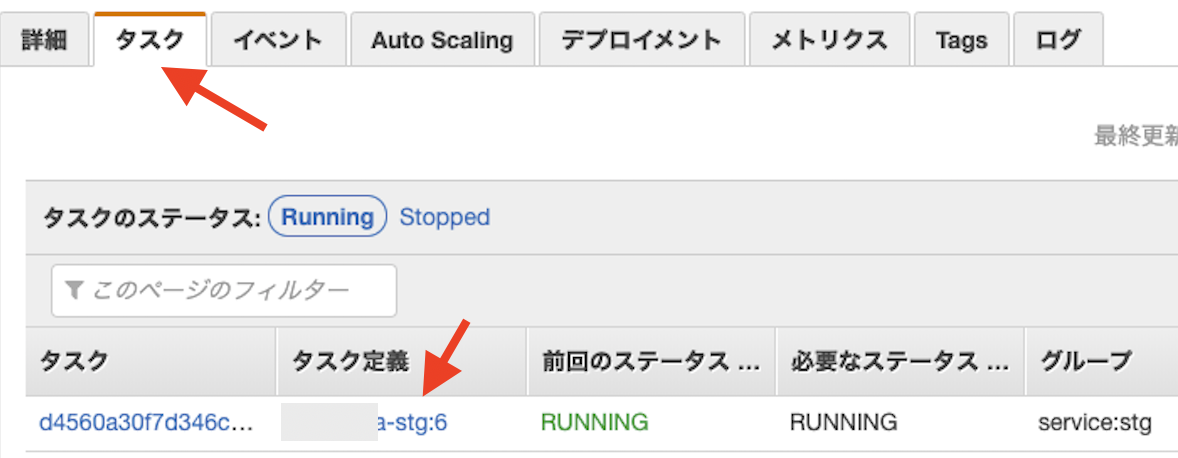
・CodeDeployで対象としたECSサービスに移動する。(リンクをクリックすれば飛ぶ)
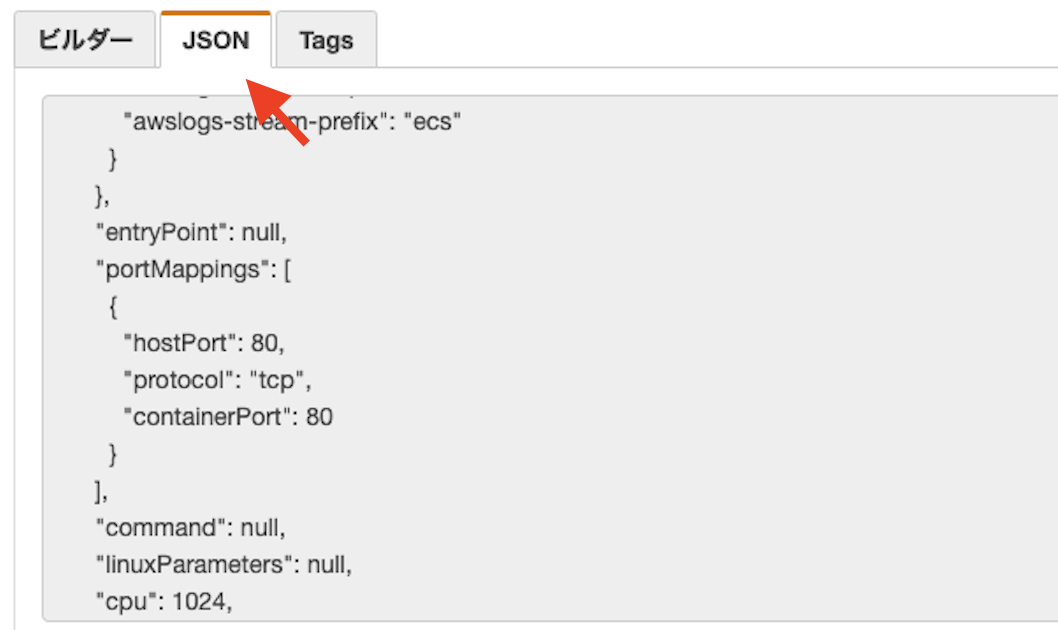
・タスクタブを選択して、タスク定義をクリックする。
・JSONタブで表示されるデータをすべてコピーする。
6-3. ファイルの作成とデータの貼り付け
ローカルでCodeCommitと同期しているルートディレクトリに
taskdef.stg.jsonを作成し、先ほどコピーしたタスク定義を貼り付ける。
6-4. imageプロパティの編集
デフォルトで指定されている更新用のイメージは、ビルドした時点でのイメージを指している。(タグがlatestであっても)
このためimageをプレースホルダーで、更新されたデータ(入力アーティファクトから受け取ったデータ)が入るようにする。
変更前"image": "111111111111.dkr.ecr.ap-northeast-1.amazonaws.com/reposirory-name:latest"↓
変更後"image": "<IMAGE>",他はそのままでOK。
このタスク定義ファイルは環境変数が含まれているため取り扱いに注意が必要。(なので、githubではなく、ここだけCodeCommit上に置いている)
7. apspecファイルの作成
7-1. ファイルの作成
ローカルでCodeCommitと同期しているルートディレクトリに
appspec.ymlを作成する。7-2. データの貼り付け
appspec.ymlversion: 0.0 Resources: - TargetService: Type: AWS::ECS::Service Properties: TaskDefinition: <TASK_DEFINITION> LoadBalancerInfo: ContainerName: "sample-website" ContainerPort: 80ContainerNameには、対象のコンテナ名をいれる。
7-3. CodeCommitにプッシュ
apspecとtaskdefファイルが作成できたら、git add と git commit し、masterにプッシュする。
このCodeCommitと連携している部分を、サブモジュールとして管理している場合は、親のプロジェクトでも、git add と git commitする。(参照するコミットを変更するため)
コミットメッセージは任意。[update]submoduleなど。7-4. CodePipelineで確認する
プッシュした内容がパイプラインに反映されているか確認する。
デベロッパー用ツール > CodePipeline > パイプライン > パイプライン名
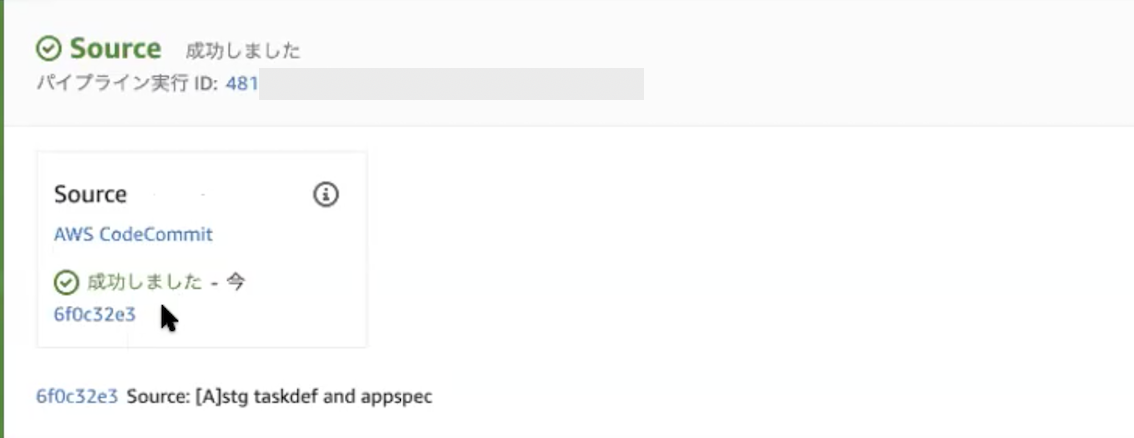
8. Source名を変更
Sourceの中にECRなど他にも追加するアクションがあるため、CodeCommitのアクション名をわかりやすい名前に変更する。
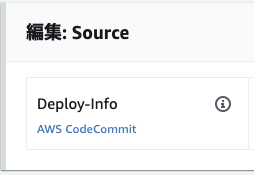
環境変数やtaskdefやappsepcなどデプロイに必要な情報が入っているため、今回は「Deploy-info」にする。
↓ Deploy-info
9. Sourceにステージを追加
対象のパイプラインで「編集」ボタンをクリックする。
↓
↓ ステージを編集をクリック
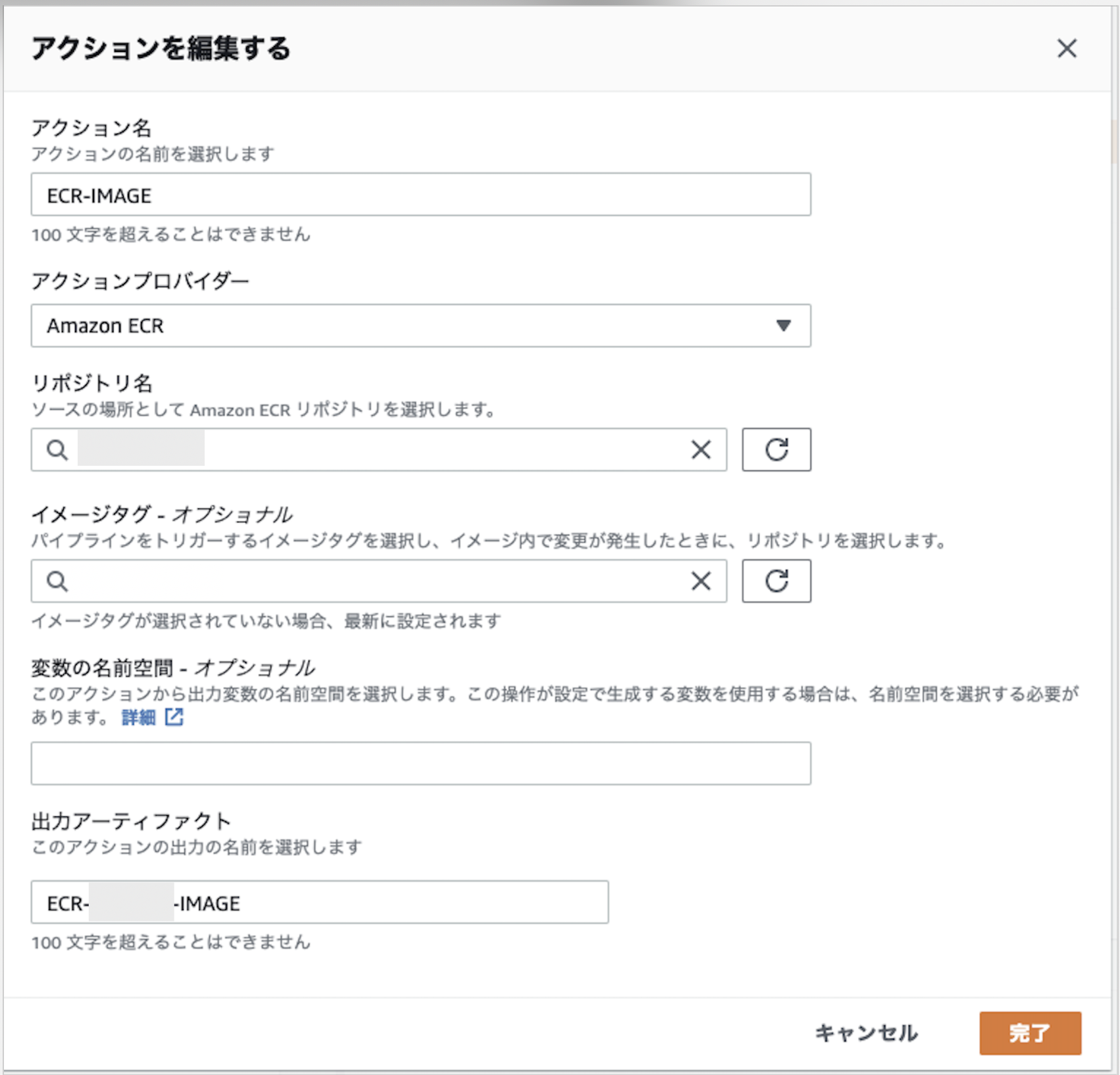
↓ アクションを追加をクリック
・アクション名
パイプラインに表示される名前(任意)・アクションプロバイダー
ECR (プルダウンの Sourceから選択)・リポジトリ名
プルダウンから選択・イメージタグ
デフォルトはlatest。今回はそのままでOK・出力アーティファクト
次のステージに渡すデータ名(任意)
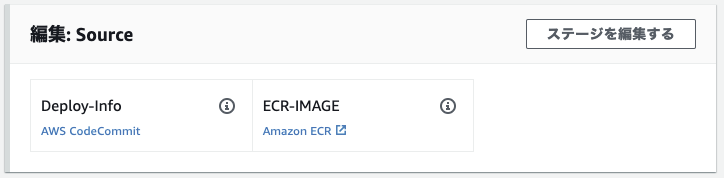
完了をクリックして追加完了。
SourceにECRのイメージが追加された。
10. ステージング用のデプロイアクションの編集
10-1. デプロイアクション名の編集
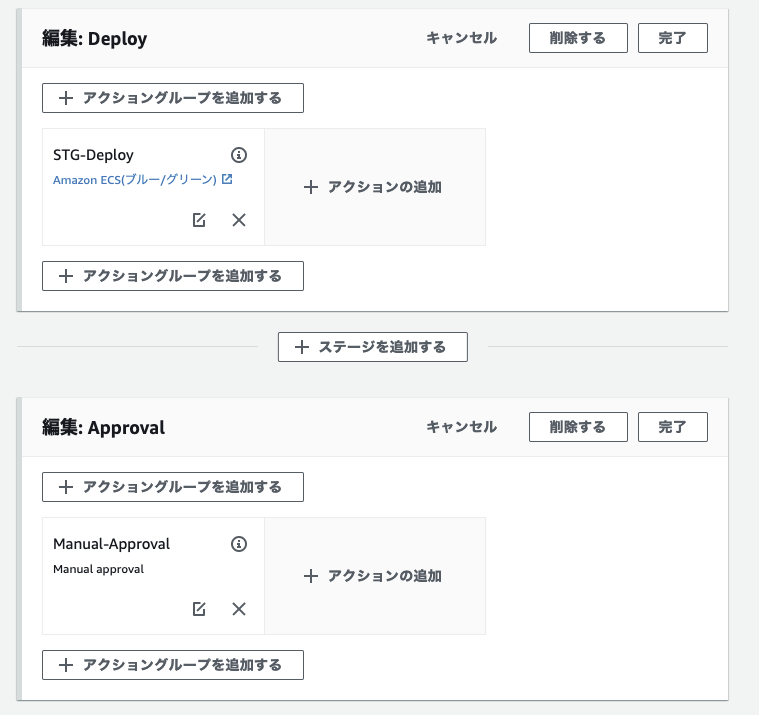
今回作成しようとしているCodePipelineは、まず、ステージングのデプロイがあり、次にプロダクションのデプロイがくる2本立てになっている。
わかりやすいように、ステージングのデプロイのアクション名を変更する。
↓ STG-Deployに変更
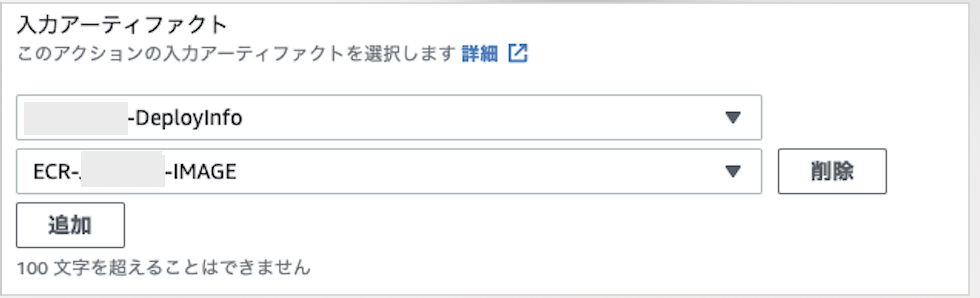
10-2. 入力アーティファクトの追加
2つのSourceから渡された出力アーティファクトを受け取る設定をする。
▼アクション名と出力アーティファクト名
・Deploy-Info: -DeployInfo
・ECR-IMAGE: ECR--IMAGE▼プルダウンから選択
10-3. タスク定義ファイルとappspecファイルを指定
taskdef.jsonとappspec.ymlが入っている入力アーティファクトを選び、ファイル名を指定する。
10-4. デプロイ用のイメージの指定
コンテナ起動の元となるイメージが入っている、入力アーティファクト名とイメージ名を指定する。
(補足)変数の名前空間
変数の名前空間はデフォルトのままでOK。今回は使用しない。
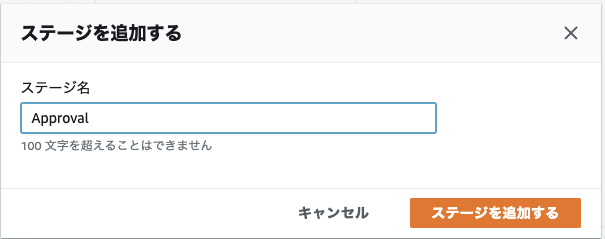
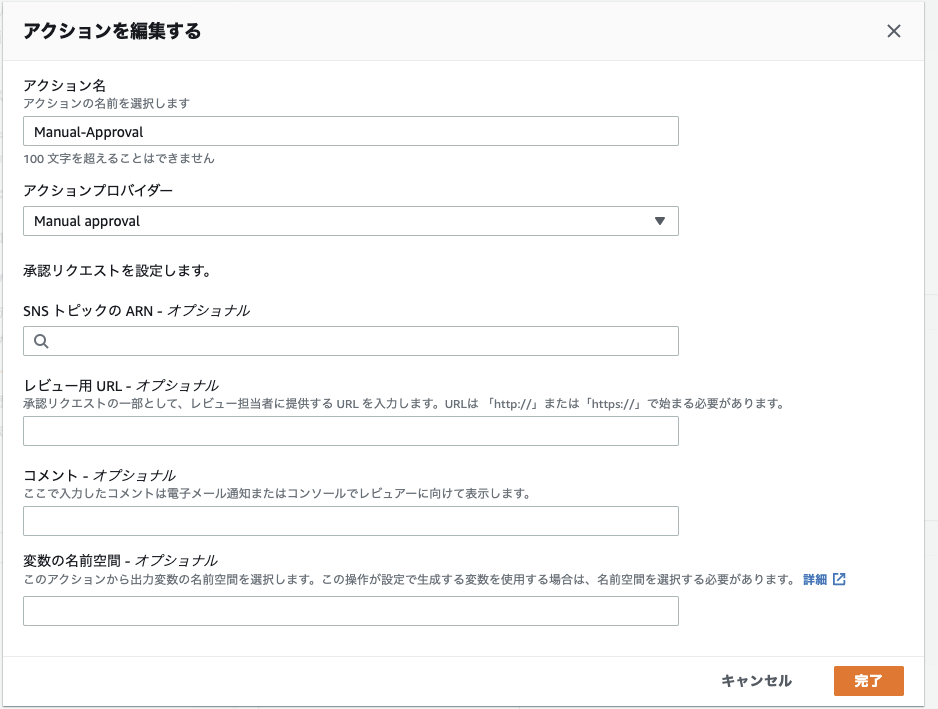
11. 認証ステージの追加
ステージから本番環境をデプロイする前に、手動の承認を追加する。
ステージを追加するを選択。
↓ アクション名を入力(任意)
↓ アクションプロバーダーで
Manual Approvalを選択
承認ステージに入ったときに、承認者が内容の確認をしやすいように、URLやコメントを入れることもできる。
STG-Deployの後に、承認ステージの追加が完了。
12. 本番環境のデプロイステージを追加
手動承認が完了したら、本番環境にデプロイが進むようにする。
ステージングと本番環境の違い
今回は、ステージングと本番環境の切り分けをコンテナに渡す環境変数で設定している。
ステージングの場合は、ステージング用のサイト
(https://stg~)にステージング環境用のAPIトークンで入ってデータを取得する。本番環境の場合は、本番用のサイト
(https://~)に本番環境用のAPIトークンで入ってデータを取得する。環境変数はタスク定義ファイルに記述されているため、本番環境用の
taskdef.prd.jsonを作成し、入力アーティファクトからそのファイルを選択する。ここがステージングとの違い。逆にいうとここだけしか違わない。
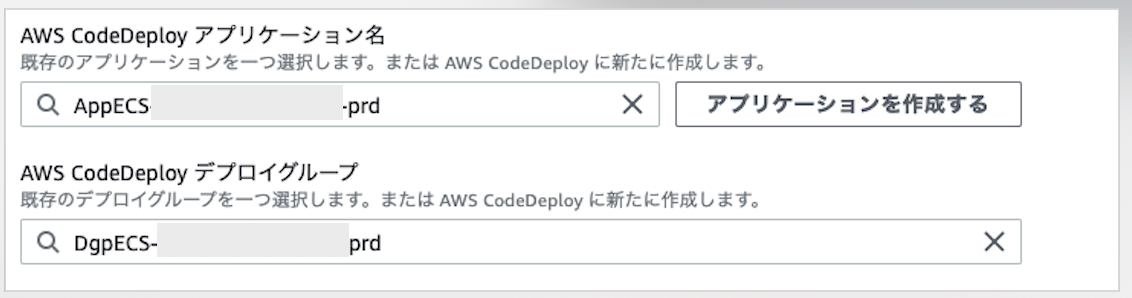
12-1. CodeDeoloyのアプリケーション名とデプロイグループを指定
12-2. 入力アーティファクトを選択
taskdef、appspec, イメージが入ったアーティファクトを指定する。
▼アクション名と出力アーティファクト名
・Deploy-Info: -DeployInfo
・ECR-IMAGE: ECR--IMAGE▼プルダウンから選択
12-3. タスク定義ファイルとappspecファイルを指定
taskdef.jsonとappspec.ymlが入っている入力アーティファクトを選び、ファイル名を指定する。
12-4. デプロイ用のイメージの指定
コンテナ起動の元となるイメージが入っている、入力アーティファクト名とイメージ名を指定する。
(補足)変数の名前空間
変数の名前空間はデフォルトのままでOK。今回は使用しない。
12-5. 保存と変更
ステージを追加したら必ず保存すること。これを忘れるともう一度入力し直しになる。。
12-6. CodePipelineの変更をリリースする
最後に、変更をリリースして、CodePipelineの設定は完了。
次に、taskdef.prd.jsonファイルを作成していく。
12-7. 貼り付けるデータの取得
対象のクラスターのサービスに移動する。ECRに入り以下ページに移動。
クラスター > クラスター名 > サービス: サービス名・タスクタブを選択して、タスク定義をクリックする。(先ほどはstgだったが、今回はprdを選択)
・JSONタブで表示されるデータをすべてコピーする。
12-8. ファイルの作成とデータの貼り付け
ローカルでCodeCommitと同期しているルートディレクトリに
taskdef.prd.jsonを作成し、先ほどコピーしたタスク定義を貼り付ける。
12-9. imageプロパティの編集
デフォルトで指定されている更新用のイメージは、ビルドした時点でのイメージを指している。(タグがlatestであっても)
このためimageをプレースホルダーで、更新されたデータ(入力アーティファクトから受け取ったデータ)が入るようにする。
変更前"image": "111111111111.dkr.ecr.ap-northeast-1.amazonaws.com/reposirory-name:latest"↓
変更後"image": "<IMAGE>",他はそのままでOK。
12-10. CodeCommitにプッシュ
作成したtaskdef.prd.jsonファイルを、git add と git commit し、masterにプッシュする。
このCodeCommitと連携している部分を、サブモジュールとして管理している場合は、親のプロジェクトでも、git add と git commitする。(参照するコミットを変更するため)
コミットメッセージは任意。[update]submoduleなど。
13. CodePipelineで進行状況の確認
プッシュされたことで、CodeCommitの変更内容を検知して、CodePipelineが動き出したか確認する。
デベロッパー用ツール > CodePipeline > パイプライン > パイプライン名
Sourceが進行中になる。↓ Sourceが完了するとステージングのデプロイに進む
↓ 詳細リンクをクリック
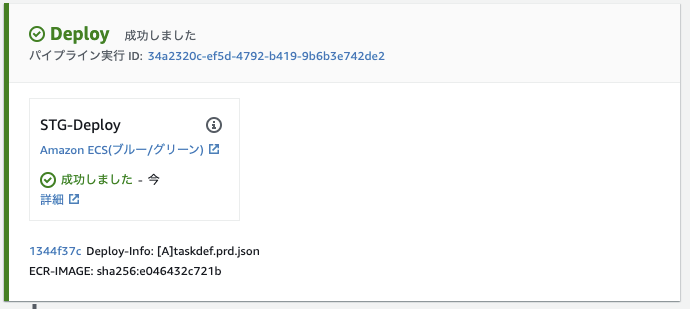
デベロッパー用ツール > CodeDeploy > デプロイ > デプロイIDページに移動し、進行状況が確認できる。
↓ デプロイ完了
↓ CodePipelineに戻る
「ステータスが成功しました」になる。
↓ 承認ステージに進む
↓ 手動承認
↓
14. 元の環境の保持時間の変更
Blue/Greenは、新しい開発環境(Green)を構築したときに、古い環境(Blue)も一定時間残す仕様になっている。
デフォルトでは、Greenに切り替えて1時間問題がなければBlueを削除する。
この削除までの時間は自由に設定することができる。
今回、1時間も待機していないといけないのは長いため、ステージング環境は0分(新しいサーバーが切り替わったら即切り替え完了)、プロダクション環境は30分に設定する。
14-1. 元の環境の保持時間の変更方法
▼ステージングの元のリビジョンの保持時間を変更
CodeDeployのアプリケーションで、ステージングのアプリケーションの中のアプリケーショングループを選択する。
デベロッパー用ツール > CodeDeploy > アプリケーション > AppECS(ECSクラスター名) → DgpECS(ECSデプロイグループ名)一番下の「デプロイ設定」の「元のリビジョンの終了」を0時間0分に設定する。
変更が完了したら、「変更の保存」をクリックして完了。
同様に、プロダクションのアプリケーションを選択肢、「元のリビジョンの終了」を0時間30分に設定する。
変更が完了したら、「変更の保存」をクリックして完了。
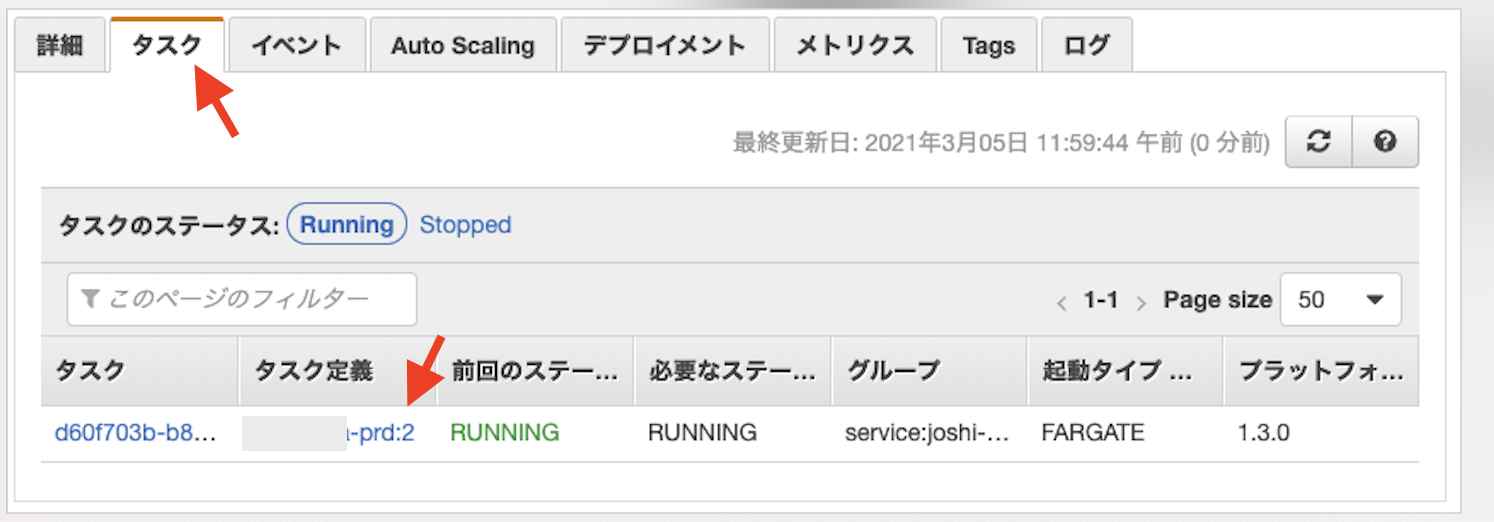
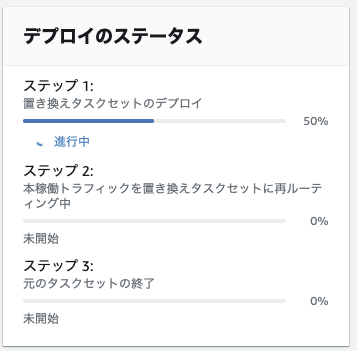
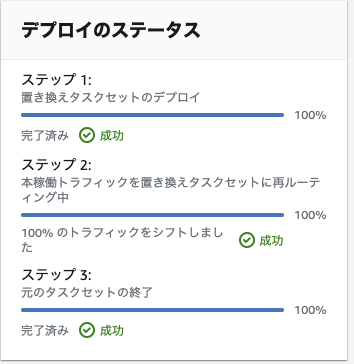
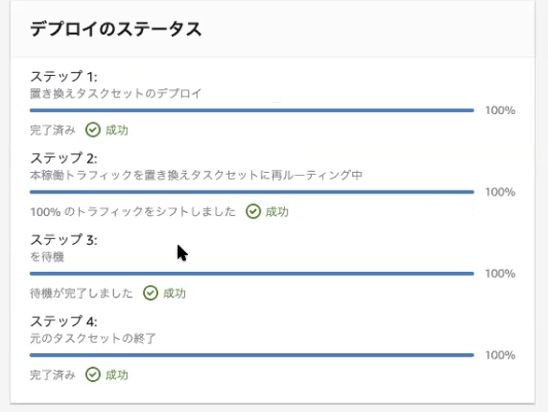
14-2. 待機中のタスクの強制終了
ステップ1とステップ2が終わっていれば、更新後の環境構築と再ルーティングは終わっている。
ステップ3で指定時間待機中だが、これをスキップしたい場合は、右上の「元のタスクセットの終了」をクリックする。
↓
ステップ3とステップ4も完了となり、このステージが完了し、次のステージに進めるようになる。
参考リンク
CodePipeline
CodeDeploy



























- 投稿日:2021-03-05T14:29:49+09:00
AWS EKSとは?
勉強前イメージ
Kubernetesのための何かって感じ。。。
調査
AWS EKSとは?
kubernetesのマネージドサービスで、AWS上で簡単に実行できるようなりました。
そもそもKubernetesとは?
コンテナの運用管理・自動化を目的に作られた、オープンソースのシステムで
Kとsの間にあるuberneteの8文字であるため、K8sと表記されることもあります。
- Kubernetesは何をするのか?
コンテナの運用管理・自動化をします。
よって、Kubernetesの管理対象はコンテナになります。
以下図のように、Kubernetesを管理します
また、自動化や複数のコンテナ管理を
コンテナオーケストレーションと呼ばれます
- Dockerと何が違うの?
Dockerは1台のサーバ上でコンテナを作成し、その管理をしています。
しかし、複数台のサーバで稼働するコンテナを横断的に管理することが出来ないので、
複数台のサーバにまたがったコンテナを増やさないといけない場合に対処出来ません。
それを解決するのがKubernetesで、複数台のサーバのコンテナ管理を1台の実行環境のように扱うことが出来ます。
- Docker : 1台のサーバ上でしかコンテナを管理できない
- Kubernetes : 複数台のサーバにまたがったコンテナ管理ができる
AWS EKSの特徴
そんなKubernetesを簡単に実行できるのがEKSですが、特徴としては以下です。
- 高可用性
複数のAZにまたがって管理されているので、1つのAZに障害が発生してもサービスを維持することが出来ます。
- セキュリティの強化
AWS Fargateを使用してサーバの管理をせずともコンテナを稼働させることができ、
アプリケーションごとにリソースの指定ができるので設計時にアプリケーションを分離させることが出来ます。
- オンプレのコンテナ管理も可能
AWS Outpostsというサービスを使用することでオンプレで稼働しているコンテナもEKSで管理を行うことが出来ます。
- 他のAWSサービスとの統合が簡単
ALBなど他のAWSサービスと統合をすることで負荷分散を行うことが出来ます。
勉強後イメージ
正直DockerとKubernetes、似たようなもんやろって思ってたところからちょっとわかった気がする。
そんな便利なやつがAWSのフルマネージドサービスで使えて、しかもほかサービスと統合するとオンプレのコンテナ管理もできる!参考

- 投稿日:2021-03-05T12:49:30+09:00
AWS環境で分析基盤構築のちょっとした話
はじめに
エキサイトのL&C事業部ではオンプレ環境からクラウド環境に順次に移行しております。その中にオンプレOracleのデータベース移行は最も難易度が高いです。ここで2つの選択肢があります
- ①オンプレOracle → AWS Oracle
- ②オンプレOracle → AWS PosgreSQL表題通り分析基盤についてお話ししたいので、AWS環境のRDS(Oracle/PostgreSQL)からどうやって分析基盤を構築するのか紹介したいと思います。
実現したいモデル
ゴールは、RDSからRedshiftにデータ転送の際に、個人情報が含まれるデータをハッシュ化したり、不要なデータを削除したりします。また、面倒なバッチを書きたくないので、フルマネージド型のETLサービスのGlueを選択しました。
実際に検証してみる
AWS PostgreSQL → Redshiftへデータ転送
結論から話せれば、Glueで結構簡単に実現できまました。場合によって若干Glueジョブのスクリプトに手を加えることもありますが、以下のようにほぼほぼいけます。
- STEP1:AWS PostgreSQL上に分析用のユーザーとViewを作成します。
- STEP2:AWS Glue上にCrawlerがPostgreSQLのViewを参照して、Data Catalogテーブルを作成できます。
- STEP3:AWS Glue上にジョブを作成して、データソースにPostgreSQLのData Catalogテーブルを指定、ターゲットにRedshiftを指定すれば、自動でRedshift側にテーブルが作成され、データが転送されます。
AWS Oracle → Redshiftへデータ転送
このケースの大きな問題は、AWS Glue上にCrawlerがOracleのViewを参照できないのです。公式ドキュメント上にはっきりとできないと書いていないが、AWS担当者に問い合わせしたところ、実現ができないと回答していただきました。ここで2つの選択肢があります。
- AWS Glueのジョブから直接にOracleのViewを参照するように実装
- OracleのViewを経由せずに、直接にOracleのテーブルを参照する。不要なデータ削除や個人情報のハッシュ化などは、Glueのジョブで実装します。
結論
AWS Oracle → Redshiftへデータ転送のケースは、OracleのViewを経由せずに直接にGlueジョブのスクリプトに手を加えた方が幸せだと考えます。

- 投稿日:2021-03-05T11:27:27+09:00
Bitwarden on AWS 環境構築
概要 Outline(TL;DR)
パスワード管理ツール
Bitwardenのサーバー機能をCloudFormationでAWS上に構築する。目的 Purpose
- いつも利用しているパスワード管理ツール
Bitwardenの機能理解のため。- 現在勉強中のAWSの各種サービス群の中でも、個人的に重要視している
CloudFormationのサービス理解のため。前提条件 Requirements
- 利用者は自分自身のみの想定。
- どのAWSアカウントにおいても再現性高く環境再構築が出来るようにIaC化する。
- 何かあった場合を考慮してすぐに環境を破棄できるようにする。
- Githubに成果物を登録する。
- コンテナ型仮想化技術を取り入れる。
- スクラム開発の手法を取り入れて進める。
- AWS請求料金を低額に抑える。1000円/月までを目安とする。
- セキュリティ対策のWAF導入は別途。
環境 Environments
- AWS
- AWSアカウント
- Amazon Virtual Private Cloud
- AWS Identity and Access Management
- AWS CloudFormation
- Amazon Elastic Container Service
- Amazon Simple Storage Service
- Amazon CloudWatch
- AWS Auto Scaling
段取り Steps
- 計画
- Trelloサインアップ
- Trelloボード新規作成
- スクラム開発用のリスト構成
- プロダクトバックログ作成
- スプリントバックログ選定
- 実施
- AWS構成要素の洗い出し
- AWS構成図作成
- CloudFormationのAWS公式ページにて開始手順の確認
- CloudFormationテンプレート(ECS, YAML形式)の検索
- GitHubにテンプレートYAMLファイルコミット
- AWSアカウントにてテンプレートからスタック作成できるかプレビュー(IAM権限確認)
- BitwardenのDockerコンテナが無いか検索
- YAMLテンプレートを構成図に合わせて改修
- Work In Progress
参考 Reference
- 投稿日:2021-03-05T11:12:24+09:00
AWSのS3に画像やstaticファイルをアップロードする方法
AWSコンソールでS3を作成
- AWSのコンソールにログイン
- S3にアクセス
バケットを作成をクリックバケット名を入れて、後はデフォルトの設定でバケットの作成をします。- 作成されたバケットをクリックして詳細画面へ
- アクセス許可のタブを開きます
- Cross-Origin Resource Sharing (CORS)の中身を以下に編集します。
[ { "AllowedHeaders": [ "*" ], "AllowedMethods": [ "POST", "GET", "PUT" ], "AllowedOrigins": [ "*" ] } ]AWSコンソールでIAMユーザーの作成
次にS3を操作できる権限を持ったユーザーを作るためにIAMを使います。
ユーザー名とアクセスの種類の両方に✔して次のステップへ行きます。
既存のポリシーを直接アタッチから
S3と検索してAmazonS3FulAccessにチェックを入れます。
後は、次のステップに進み続けてユーザーを作成します。その際に
ACCESS_IDとSECRET_KEY(重要)が出てくるのでそれを控えておいてください。
控えておかないと新しいユーザーを作成しなおさなければなりません。必要なパッケージをインストール
$ pip install django-storages $ pip install boto3settings.pyの設定
INSTALLED_APPSに
storagesを追加します。settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', # My apps 'blog', 'searches', # aws 'storages', #追加します。 ]
settings.pyの一番下で作成したS3バケットの設定を書きます。settings.py#S3 BUCKETS CONFIG """ AWS_ACCESS_KEY_ID = '***********' # Iamのuserid AWS_SECRET_ACCESS_KEY = '**********' # Iamのuser key AWS_STORAGE_BUCKET_NAME = 'renren-django-blog' #S3バケットの名前 AWS_S3_FILE_OVERWRITE = False #同じ名前のファイルを上書きするか? AWS_DEFAULT_ACL = None # DEFAULT_FILE_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage' STATICFILES_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage' """より細かい設定についてみたい方は公式ドキュメントをみてください。
実際にS3にアップロード
表示されない場合はinspectモードを起動(windowsならF12)し、ファイルのパスを調べる
python manage.py collectstaticで自動でAmazonに上げてくれる
AWS_ACCESS_KEY_IDやAWS_SECRET_ACCESS_KEY等は機密情報として.envファイルに書きそれを参照するのが推奨されます。以下のサイトを参考にして設定してください。
参考サイト:【Django】環境変数を効率的に管理する「django-environ」の使い方結論だけ言うとsettings.pyファイルが以下のようになります。
setting.pyAWS_ACCESS_KEY_ID = env('AWS_ACCESS_KEY_ID') AWS_SECRET_ACCESS_KEY = env('AWS_SECRET_ACCESS_KEY') AWS_STORAGE_BUCKET_NAME = env('AWS_STORAGE_BUCKET_NAME') AWS_S3_FILE_OVERWRITE = False AWS_DEFAULT_ACL = None DEFAULT_FILE_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage' STATICFILES_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'.envAWS_ACCESS_KEY_ID=*********** AWS_SECRET_ACCESS_KEY=********** AWS_STORAGE_BUCKET_NAME=**************S3バケットへのアップロード
python manage.py collectstaticを実行することで、今現在ローカルのstaticフォルダにあるファイルが全てS3上にアップロードされます。
mediaフォルダに画像がある場合は最初だけ手動でアップロードする必要があります。参考
公式ドキュメント
File Storage with AWS S3 Buckets Upload | Django (3.0) Crash Course Tutorials (pt 22)
- 投稿日:2021-03-05T09:15:29+09:00
AirflowのSecrets Backendsを読み解く
- 個人的に調べたのでメモ
Airflow Secrets Backendsとは
Airflowが利用する設定周り、Config、Variables、ConnectionsをAirflow外部で管理するための機能
管理画面からは見れない、実行時に毎回取りにいく形になるAWSをSecrets Backendsとして調べてみた
AWSの外部接続サービスとして、SSMとSecretsManagerが用意されている。
利用可能バージョンは、SSMは
1.10.10、SecretsManagerは1.10.11から可能となります。利点
- 管理画面、Airflow CLIなどで毎回設定を追加しなくて良くなる
- 一つのリポジトリを複数人で開発する場合、追加、変更を意識する必要がなくなる
欠点
- Secretの管理費、取得回数による費用が増える
- AWS料金表
- 一ヶ月使った例
- Connection 10 個 (シークレット 10 × 0.40/month = 4$)
- 一日1000回 API (コール 1000 × 30 × 0.40/10000コール = 1.2$)
- 合計 5.2$
設定方法
airflow.cfgの設定(Airflow1.10.10以降の場合)
SecretsManager(1.10.11)を利用する場合は以下のように設定
[secrets] backend = airflow.contrib.secrets.aws_secrets_manager.SecretsManagerBackend backend_kwargs = {"connections_prefix": "airflow/connections", "profile_name": "default"}
- connections_prefix
- default:
airflow/connections- SecretsManagerのシークレット名のprefixを設定する
- SecretsManager側では、
airflow/connections/{connection name}として設定する- 呼び出し側では、aws_hook(などのhook)の引数としてaws_conn_idに
{connection name}を設定してと実行する- 実行時に、
airflow/connections/{connection name}でprofile_nameのアカウントから値を取得して利用することができる- profile_name
- default: None
- SecretsManagerで値を取りに行くアカウント情報
- なければ環境変数、インスタンスロールとか見に行くはず
- variables_prefix
- default:
airflow/variables- 試してないのでコード参照
airflow.cfgの設定(Airflow2系の場合)(試してはいない)
Airflow SecretsManagerを利用する場合は以下のように設定
[secrets] backend = airflow.providers.amazon.aws.secrets.secrets_manager.SecretsManagerBackend #ここのproviderのパッケージの位置が2.0から変更されている backend_kwargs = {"connections_prefix": "airflow/connections", "profile_name": "default"}SecretsManager側の設定
- airflow.cfgの
[secrets]で設定されたアカウントのSecretsManagerにairflow/connections/{connection name}のシークレット名でSecretsValueを登録する- SecretsValue
- プレーンテキストで、URI形式で記述する必要がある(キー、バリューでは設定できない)
- Connection-TypeがAWSの場合(
アクセスキーとシークレットキーの場合、最後@を忘れずに)
aws://AKIAIRI1111111111:xxxxxsxadgfasdgsdfgofdsgfa@- Connection-TypeがAWSの場合(
AssumeRoleを利用する場合(Extraの使い方))
aws://?role_arn=arn%3Aaws%3Aiam%3A%3A240057002457%3Arole%2FWebIdentity-Role最後に
- 思ったほど参考となる資料がなかった
- 設定をみるとわかるようにConnectionsしか確認していない
- Configを状況に応じて変更する運用などが見えてきていない
- 個人メモなので間違いあれば指摘ください
参考資料
コード
SecretsManagerのSecret Backendsの仕組み
Connection-TypeAWSの仕組み設定
- 投稿日:2021-03-05T07:35:55+09:00
【初学者】AWSハンズオン①VPC構築
【初学者】AWSハンズオン①VPC構築
はじめに
前回のQiitaの記事知識0から175時間で合格したAWS認定ソリューションアーキテクト-アソシエイト-がキッカケとなりまして、駆け出しエンジニアにランクアップとなりました。3月入社なので5日目エンジニアということになります。AWSに関して今年1月からの2ヶ月目、未経験からのよわよわエンジニアですが、誰かの役にたちますように。
今回は入社してから構築しています、VPCについてのハンズオン記事を書いていきます。
ほぼ同じ内容ですが弊社技術ブログリンクも貼らせてください
【初学者向け】AWSハンズオン①VPC構築前提
・すでにAWSのアカウントを取得しているものとします、サインアップへのリンクはココから
概要
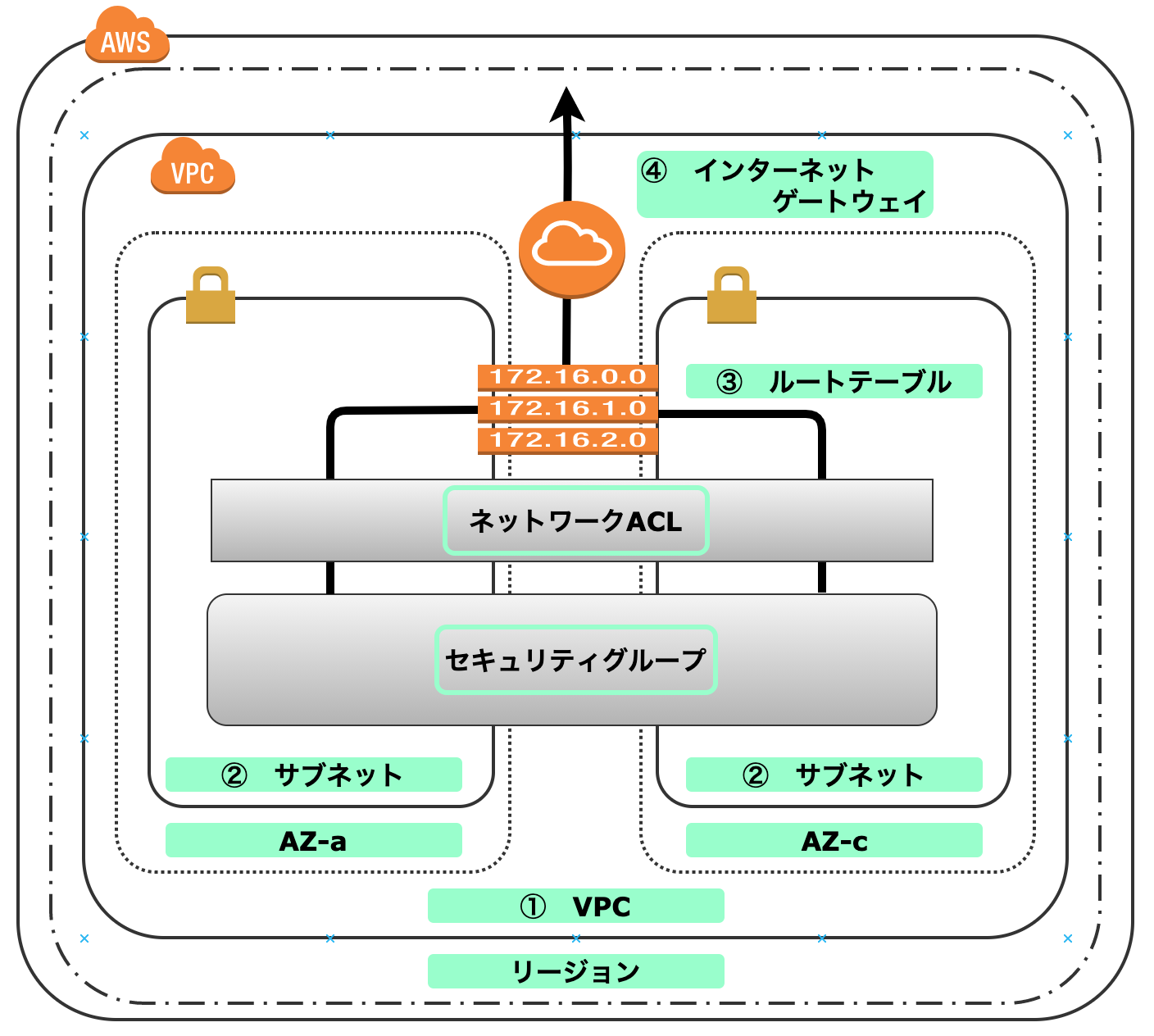
AWSの環境(①VPC〜②サブネット〜③ルートテーブル〜④インターネットゲートウェイ)までを構築していく手順をハンズオン形式で公開していきます。
最後まで読めば、下記図の構築ができることを目指します(制作目安:15分)
①VPC
リージョンの選択
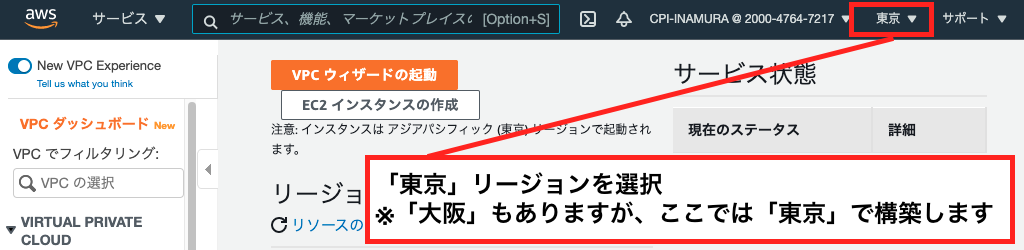
1:「東京」リージョンを選択する
VPCネットワークの作成
2:VPCを選択
3:どんどん選択して作成を進めます(クリックだけ)
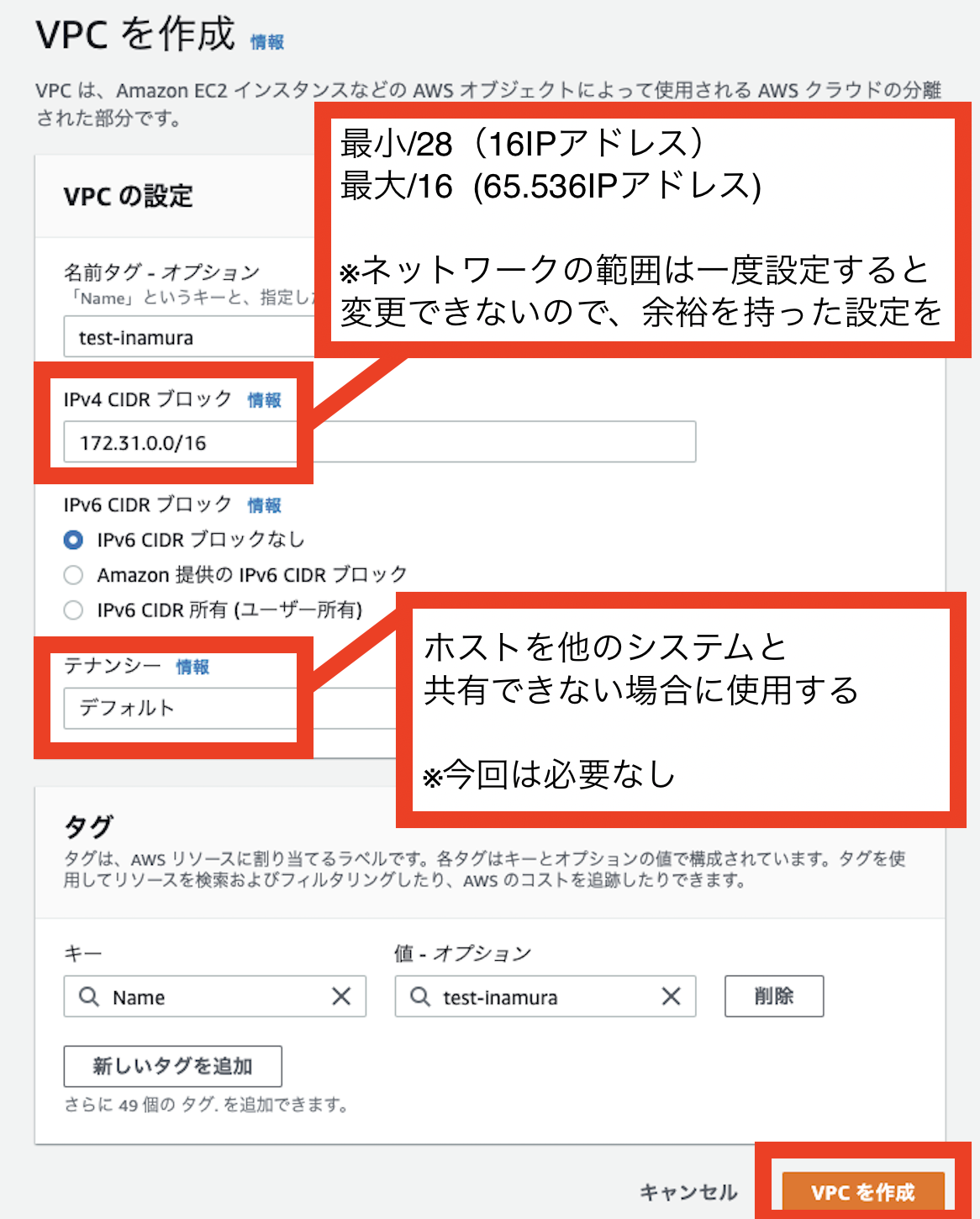
4:VPCの作成
ここでのCIDR(サイダー)は案件などによって変更されてくると思いますが、今は構築出来ればいいので同じCIDRの値でもOKです。
5:完成詳細画面
ただ作る”だけ”なら5分もかからない。だからこそ手を動かして構築してみよう。次はサブネットを作ってみるよ。
②サブネット
1:サブネットの選択
複数の小さなネットワークに分割して管理していく際の、管理単位のネットワークのことです
2:どんどん選択して作成を進めます(このショットいる?)
3:サブネットにおける設定の部分
VPC(172.31.0.0/16)の中に、サブネットAZ-a(172.31.1.0/24)とサブネットAZーc(172.31.2.0/24)を構築します。同じ値には出来ないのです。
4:完了
ただ作る”だけ”なら5分もかからない(2回目)。だからこそ手を動かして構築してみよう。次はルートテーブルです
③ルートテーブル
ルートテーブルの作成
1:ルートテーブル選択
サブネットの中で稼働するEC2インスタンス(今回未作成)のルートを制御するためのものです。インターネットを利用して通信する場合はインターネットゲートウェイ(次の項目)をルーティング先に指定したりします。
2:ルートテーブルの作成
3:ルートテーブルの完成
あっという間!!
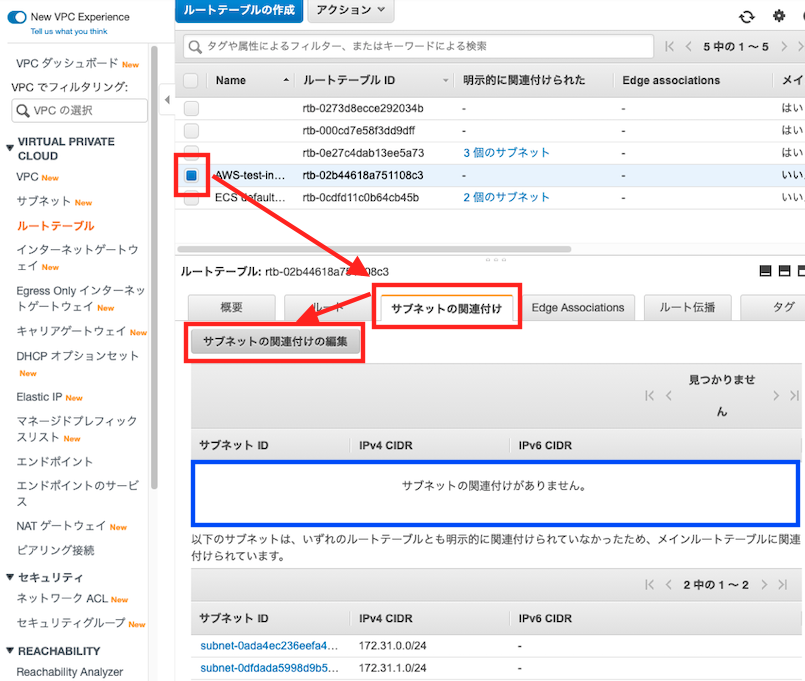
ルートテーブルとサブネットの関連付け
ですがルートテーブルが出来ただけなので、サブネットと関連づけていきます
4:ルートテーブル選択
5:関連付け
6:完了
こうやってみると関連づけられているのがわかります。最後のインターネットゲートウェイにいきましょう
④インターネットゲートウェイ(IGW)
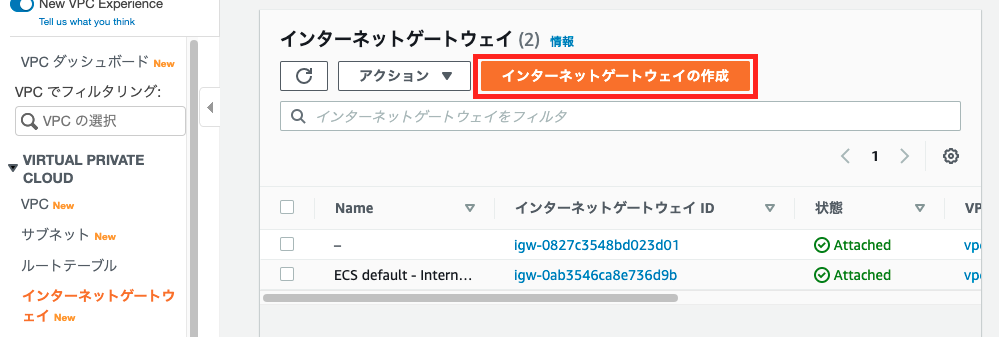
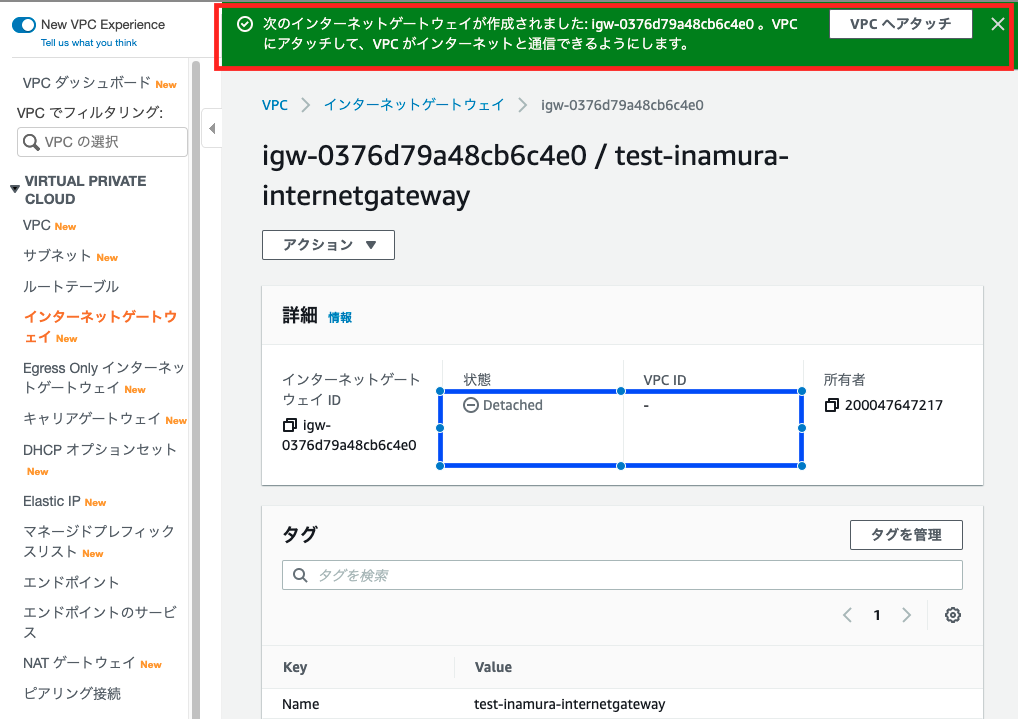
インターネットゲートウェイの作成
1:インターネットゲートウェイ選択
VPC内のEC2インスタンスがインターネットを通じて通信するさに必要になるものです
2:インターネットゲートウェイ作成
3:インターネットゲートウェイ完成
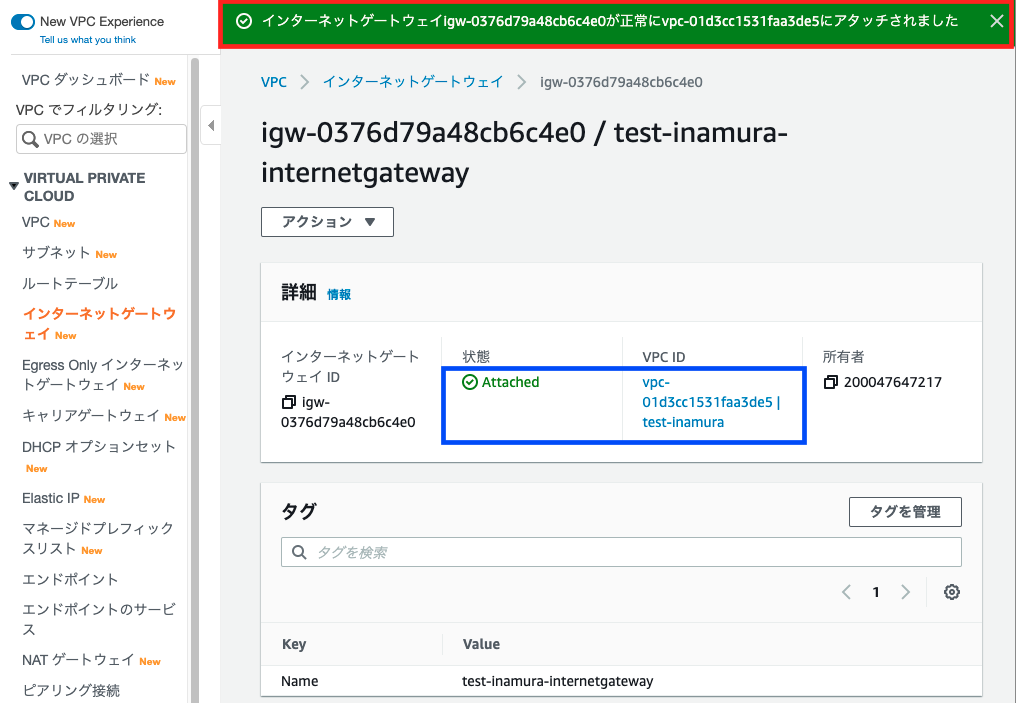
インターネットゲートウェイとVPCへのアタッチ
4:VPCにアタッチ
5:VPCにアタッチ完成
先ほどの『detached』状態から、『attached』になっていることがわかります
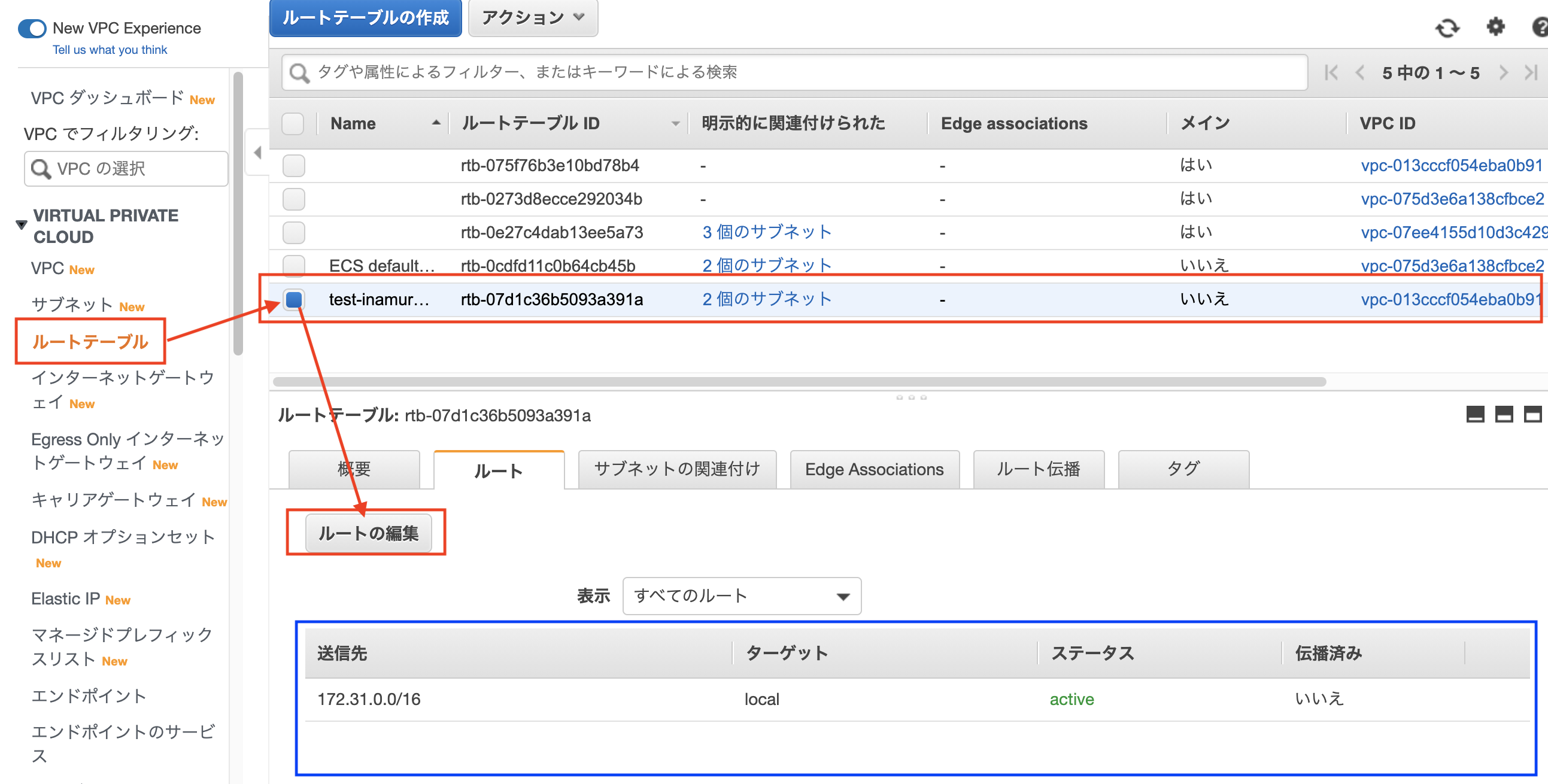
インターネットゲートウェイとルートテーブルの設定
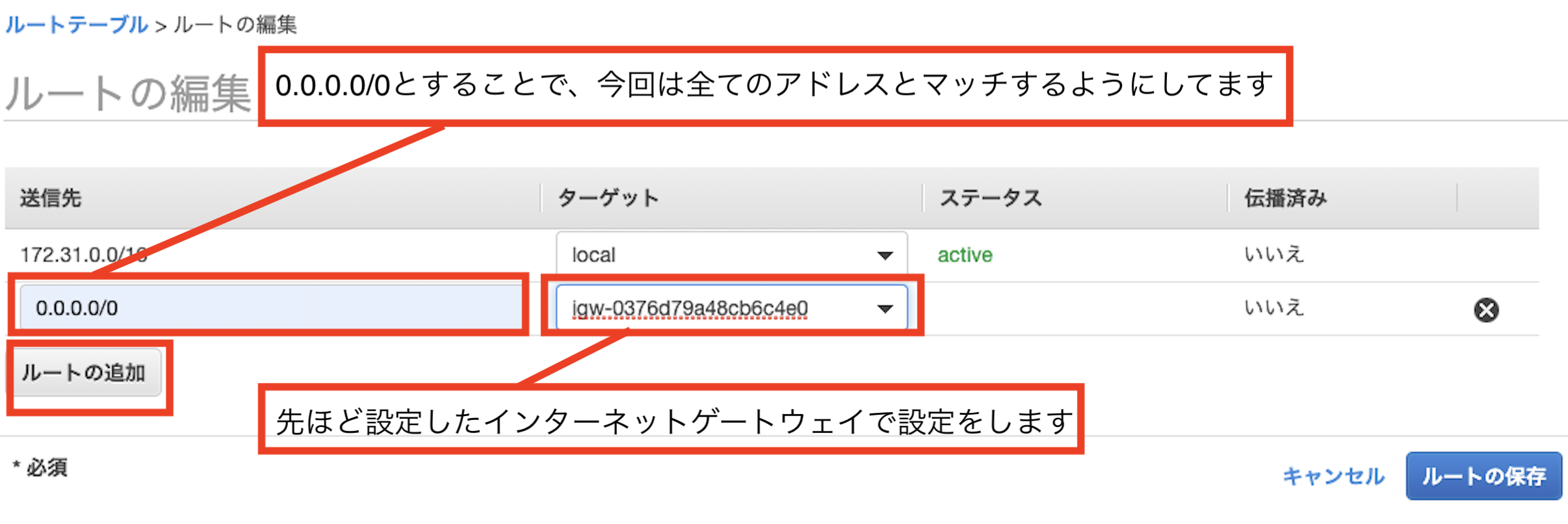
VPCにアタッチしたことにより、ルートテーブルとインターネットゲートウェイを設定することができるようになりました、さっそく設定しましょう。
6:ルートテーブル選択する
7:ルートを編集する
8:インターネットゲートウェイとルートテーブルの設定完了
お疲れ様でした、これでインターネットからの接続も出来るようになりました。
が、これだとセキュリティがガバガバです。構成図にもある『セキュリティグループ』『ネットワークACL』のセキュリティ項目がありますが、こちらは次回に記述します。
まとめ
スクショ祭りになってしまいましたが、何かをしたいけど何をしたらヨクワカラナイなんて方の、少しでも手を動かすための力になれたら幸いです。
間違い等ございましたら、お手数ですがご気軽にご教授いただけると幸いです。
ここまで読んでいただき、誠にありがとうございます。※スクショのタイミングで写っているVPCのIDが異なる部分があり、ご迷惑をおかけします。内容的にはハンズオンに問題ないとしたものを選び利用しています。
参考書籍・記事
こちらの記事を参考にさせていただております。
【参考書籍】
Amazon Web Services パターン別構築・運用ガイド 改
Amazon Web Services 業務システム設計・移行ガイド
【サイト】
0から始めるAWS入門①:VPC編
【初心者向け】初めて VPC 環境作成してみた