- 投稿日:2021-03-03T23:58:49+09:00
機械学習アルゴリズムメモ ロジスティック回帰編
ロジスティック回帰とは
ロジスティック回帰とは名前によらず分類に用いられるアルゴリズムである。
線形回帰を分類に拡張させたモデルである。【アルゴリズム】
データの重み付き和にロジスティック関数(シグモイド関数)を適用させ、データがターゲットに分類している確率を出力する。さらに確率が0.5を境界として、y=1(属している),y=0(属していない)を決定する。
Sigmoid(t) = \frac{1}{1 + exp(-t)} \\ \hat{p} = Sigmoid (\sum_{i=1}^{p} w_ix + b) \\ \hat{y} = \left\{ \begin{array}{ll} 0 & (\hat{p} \lt 0.5) \\ 1 & (\hat{p} \geq 0.5) \end{array} \right.以下の損失関数が最小となるように係数wと切片bの値を調整する。
yが1の場合、確率が1に近くなければならなく、yが0の場合、確率が0にならなければならないという直感に沿っている。E(w, b) = - \frac{1}{n} \sum_{i=1}^{n} [y^{(i)}log({\hat p^{(i)}}) + (1 - y^{(i)})log(1 - {\hat p^{(i)}})]scikit-learnでの使い方
from sklearn.linear_model import LogisticRegression logreg = LogisticRegression() logreg.fit(X_train, y_train) logreg.score(X_test, y_test)パラメータ
scikit-learnでのパラメータ名 概要 初期値 特性 C 正則化パラメータ 1.0 値を小さくすると、強く正則化する。 penalty 正則化手法 "l2" 正則化について選択できる。solverには"l1"が対応していないものもあるので注意。 solver 最適化手法 "lbfgs" 大きなデータセットの場合、"sag"や"saga"を選ぶ。 メリット
ほかの機械学習手法と比べて単純なモデルであり、訓練及び予測についても高速で行うことができる。
単純なモデルであるので理解しやすい。デメリット
低次元空間ではサンプル数が特徴量の数よりも多くなってしまうため、良い精度が得られない。
- 投稿日:2021-03-03T23:38:08+09:00
M1mac Pyaudioインストール時エラー対応
Pyaudioのインストール
Pyaudioのインストール時にエラーとなったので、自分用メモ
実行環境
Homebrew 3.0.2
Python 3.9.2インストール
Pyaudioにはportaudioというライブラリが必要とのことなのでHomebrewでインストール
$ brew install portaudio $ pip3 install pyaudioPyaudioインストール時に
fatal error: 'portaudio.h' file not foundというエラーが発生エラー対応
下記オプションを指定し再インストール
pip3 install --global-option='build_ext' --global-option='-I/opt/homebrew/include' --global-option='-L/opt/homebrew/lib' pyaudio確認
$ pip3 freeze PyAudio==0.2.11インストール成功!
- 投稿日:2021-03-03T23:23:03+09:00
[python]約数を列挙するプログラム
約数を列挙するプログラム
Pythonを利用して自然数の約数を取得する
プログラムの何通りか約数とは
数学において、整数 N の約数(やくすう、英: divisor)とは、N を割り切る整数またはそれらの集合のことである。
割り切るかどうかということにおいて、符号は本質的な問題ではないため、N を正の整数(自然数)に、約数は正の数に限定して考えることも多い。
自然数や整数の範囲でなく文字式や抽象代数学における整域などで「約数」と同様の意味を用いる場合は、「因数」(いんすう)、「因子」(いんし、英: factor)が使われることが多い。
整数 a が整数 N の約数であることを、記号 | を用いて a | N と表す。listの内包表記
一番簡潔にかける書き方
list.pynum = 30 answer = [i for i in range(1, num+1) if num % i ==0] print(answer) #結果:[1, 2, 3, 5, 6, 10, 15, 30]While
約数を大きい順に出力
while.pyn = 30 x = n while n > 0: if x % n ==0: print(n) n -= 1 #結果:30, 15, 10, 6, 5, 3, 2, 1約数を小さい順に出力
while.pyn = 1 x = 30 while n <= 30: if x % n ==0: print(n) n += 1 #結果:1, 2, 3, 5, 6, 10, 15, 30関数
nに数字を与えることで結果を返す
while.pydef divisor(n): i = 1 table = [] while i * i <= n: if n%i == 0: table.append(i) table.append(n//i) i += 1 table =sorted(list(set(table))) return table #結果:[1, 2, 3, 4, 6, 12, 37, 74, 111, 148, 222, 444]最後に
もっといい方法があれば知りたいです
- 投稿日:2021-03-03T22:45:51+09:00
Lチカで始めるテスト自動化(14)sleepの時間をランダムに設定する
1. はじめに
sleepの時間をランダムに設定できるようにします。
2. 新規コマンド
最小値~最大値の範囲内でランダムな時間sleepするコマンドを作成します。
コマンド 引数 機能 rusleep スリープ時間(最小値), スリープ時間(最大値) 最小値~最大値の範囲内でランダムな時間sleepする。単位は秒。 3. テストランナーの改修
random.uniform()でランダムな値を生成しsleep()に渡します。
test-runner.pyimport random (略) def main(): (略) fval = 0.0 (略) elif cmd[0] == "rusleep": fval = random.uniform(float(cmd[1]), float(cmd[2])) cmd.append(str(fval)) sleep(fval) (略)4. 実行結果
以下のコマンドで実行します。
> python test-runner.py rusleep4.1 テストスクリプト
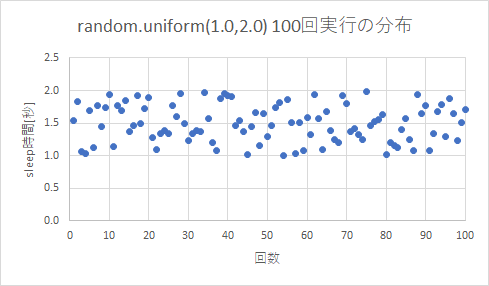
最小値を1.0、最大値を2.0とし、100回実行するテストスクリプトです。
rusleep.csvrusleep,1.0,2.0 (以下、同一内容を100行)4.2 テスト実行結果
平均値は1.497でした。
rusleep_result.csv2021/03/03 21:40:28,rusleep,1.0,2.0,1.5323377896008619,OK 2021/03/03 21:40:30,rusleep,1.0,2.0,1.8266354990565334,OK (略) 2021/03/03 21:42:56,rusleep,1.0,2.0,1.5044505776491246,OK 2021/03/03 21:42:57,rusleep,1.0,2.0,1.7092165168215359,OK
5. おわりに
- randomモジュールのおかげで数行程度のコーディングでsleepの時間をランダムに設定できるようになりました。
- 正規分布にしたいといったカスタマイズも容易にできます。
- ヒストグラムを見ると多少凸凹してはいますが、十分ランダムと思います。
付録A. test-runner.pyのソース
test-runner.py#!/usr/bin/python3 # # This software includes the work that is distributed # in the Apache License 2.0 # from time import sleep import random import sys import codecs import csv import datetime import serial import pyvisa as visa import cv2 from PIL import Image import pyocr import pyocr.builders import platform import subprocess from subprocess import PIPE UNINITIALIZED = 0xdeadbeef NUM_OF_SERVO = 6 def serial_write(h, string): if h != UNINITIALIZED: string = string + '\n' string = str.encode(string) h.write(string) return True else: print("UART Not Initialized.") return False def close_uart(h): if h != UNINITIALIZED: h.close() else: #print("UART Not Initialized.") pass def open_dso(): rm = visa.ResourceManager() resources = rm.list_resources() #print(resources) for resource in resources: #print(resource) try: dso = rm.open_resource(resource) except: print(resource, "Not Found.") else: print(resource, "Detected.") return dso #Throw an error to caller if none succeed. return dso def open_cam(camera_number, width, height): h = cv2.VideoCapture(camera_number) h.set(cv2.CAP_PROP_FRAME_WIDTH, width) h.set(cv2.CAP_PROP_FRAME_HEIGHT, height) return h def close_cam(cam): if cam != UNINITIALIZED: cam.release() def capture_cam(cam, filename): if cam != UNINITIALIZED: _, img = cam.read() cv2.imwrite(filename, img) return True else: print("CAM Not Ready.") return False def crop_img(filename_in, v, h, filename_out): img = cv2.imread(filename_in, cv2.IMREAD_COLOR) v0 = int(v.split(':')[0]) v1 = int(v.split(':')[1]) h0 = int(h.split(':')[0]) h1 = int(h.split(':')[1]) img2 = img[v0:v1, h0:h1] cv2.imwrite(filename_out, img2) return True def open_ocr(): ocr = pyocr.get_available_tools() if len(ocr) != 0: ocr = ocr[0] else: ocr = UNINITIALIZED print("OCR Not Ready.") return ocr def exec_ocr(ocr, filename): try: txt = ocr.image_to_string( Image.open(filename), lang = "eng", builder = pyocr.builders.TextBuilder() ) except: print("OCR Fail.") else: return txt def exec_labelimg(filename, label_string): if platform.system() == "Windows" : python = "python" grep = "findstr" else: python = "python3" grep = "grep" cmd = python + \ " label_image.py \ --graph=c:\\tmp\\output_graph.pb \ --labels=c:\\tmp\\output_labels.txt \ --input_layer=Placeholder \ --output_layer=final_result \ --image=" + filename \ + "|" + grep + " " + label_string print(cmd) log = subprocess.run(cmd, stdout=subprocess.PIPE, shell=True) ret = log.stdout.strip().decode("utf-8").split(" ")[1] return ret def set_servo(uart, servo_id, servo_pos): if servo_id < 0 or servo_id >= NUM_OF_SERVO: print("Invalid Servo ID") return False if servo_pos < 0 or servo_pos > 180: print("Invalid Servo Position") return False if uart != UNINITIALIZED: serial_write(uart, "servoread") servo_position = uart.readline().strip().decode('utf-8') print(servo_position) # discard "OK" devnull = uart.readline().strip().decode('utf-8') current_pos = int(servo_position.split(' ')[servo_id]) #print(servo_id, current_pos) if current_pos < servo_pos: start = current_pos +1 stop = servo_pos +1 step = 1 else: start = current_pos -1 stop = servo_pos -1 step = -1 for i in range(start, stop, step): command = "servo " + str(servo_id) + " " + str(i) print(command) serial_write(uart, command) # discard "OK" devnull = uart.readline().strip().decode('utf-8') sleep(0.2) # sec. return True else: print("UART Not Initialized.") return False def main(): is_passed = True val = str(UNINITIALIZED) fval = 0.0 uart = UNINITIALIZED dso = UNINITIALIZED cam = UNINITIALIZED ocr = UNINITIALIZED if len(sys.argv) == 2: script_file_name = sys.argv[1] + ".csv" result_file_name = sys.argv[1] + "_result.csv" else: script_file_name = "script.csv" result_file_name = "result.csv" with codecs.open(script_file_name, 'r', 'utf-8') as file: script = csv.reader(file, delimiter=',', lineterminator='\r\n', quotechar='"') with codecs.open(result_file_name, 'w', 'utf-8') as file: result = csv.writer(file, delimiter=',', lineterminator='\r\n', quotechar='"') for cmd in script: timestamp = datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") print(cmd) if "#" in cmd[0]: pass elif cmd[0] == "sleep": sleep(float(cmd[1])) elif cmd[0] == "rusleep": fval = random.uniform(float(cmd[1]), float(cmd[2])) cmd.append(str(fval)) sleep(fval) elif cmd[0] == "open_uart": if len(cmd) == 2: dsrdtr_val = 1 else: dsrdtr_val = int(cmd[2]) try: uart = serial.Serial(cmd[1], 115200, timeout=1.0, dsrdtr=dsrdtr_val) except: is_passed = False elif cmd[0] == "send": ret = serial_write(uart, cmd[1]) if ret == False: is_passed = False elif cmd[0] == "rcvd": try: val = uart.readline().strip().decode('utf-8') cmd.append(val) except: is_passed = False elif cmd[0] == "open_dso": try: dso = open_dso() except: is_passed = False elif cmd[0] == "dso": try: if "?" in cmd[1]: val = dso.query(cmd[1]).rstrip().replace(",", "-") cmd.append(val) else: dso.write(cmd[1]) except: is_passed = False elif cmd[0] == "open_cam": if len(cmd) == 2: cam = open_cam(int(cmd[1]), 640, 480) else: cam = open_cam(int(cmd[1]), int(cmd[2]), int(cmd[3])) elif cmd[0] == "close_cam": close_cam(cam) cam = UNINITIALIZED elif cmd[0] == "capture_cam": ret = capture_cam(cam, cmd[1]) if ret == False: is_passed = False elif cmd[0] == "crop_img": crop_img(cmd[1], cmd[2], cmd[3], cmd[4]) elif cmd[0] == "open_ocr": ocr = open_ocr() if ocr == UNINITIALIZED: is_passed = False elif cmd[0] == "exec_ocr": try: val = exec_ocr(ocr, cmd[1]) except: is_passed = False else: cmd.append(str(val)) elif cmd[0] == "exec_labelimg": try: val = exec_labelimg(cmd[1], cmd[2]) except: is_passed = False else: cmd.append(str(val)) elif cmd[0] == "set_servo": ret = set_servo(uart, int(cmd[1]), int(cmd[2])) if ret == False: is_passed = False elif cmd[0] == "run": ret = subprocess.run(cmd[1], shell=True, stdout=PIPE, stderr=PIPE, universal_newlines=True) val = ret.stdout.strip() print(ret) if ret.returncode != 0: is_passed = False elif cmd[0] == "eval_str_eq": if str(val) != str(cmd[1]): is_passed = False elif cmd[0] == "eval_int_eq": if int(val) != int(cmd[1]): is_passed = False elif cmd[0] == "eval_int_gt": if int(val) < int(cmd[1]): is_passed = False elif cmd[0] == "eval_int_lt": if int(val) > int(cmd[1]): is_passed = False elif cmd[0] == "eval_dbl_eq": if float(val) != float(cmd[1]): is_passed = False elif cmd[0] == "eval_dbl_gt": if float(val) < float(cmd[1]): is_passed = False elif cmd[0] == "eval_dbl_lt": if float(val) > float(cmd[1]): is_passed = False else: cmd.append("#") if is_passed == True: cmd.append("OK") cmd.insert(0,timestamp) print(cmd) result.writerow(cmd) else: cmd.append("NG") cmd.insert(0,timestamp) print(cmd) result.writerow(cmd) close_uart(uart) close_cam(cam) print("FAIL") sys.exit(1) if is_passed == True: close_uart(uart) close_cam(cam) print("PASS") sys.exit(0) main()付録B. Lチカで始めるテスト自動化・記事一覧
- Lチカで始めるテスト自動化
- Lチカで始めるテスト自動化(2)テストスクリプトの保守性向上
- Lチカで始めるテスト自動化(3)オシロスコープの組込み
- Lチカで始めるテスト自動化(4)テストスクリプトの保守性向上(2)
- Lチカで始めるテスト自動化(5)WebカメラおよびOCRの組込み
- Lチカで始めるテスト自動化(6)AI(機械学習)を用いたPass/Fail判定
- Lチカで始めるテスト自動化(7)タイムスタンプの保存
- Lチカで始めるテスト自動化(8)HDMIビデオキャプチャデバイスの組込み
- Lチカで始めるテスト自動化(9)6DoFロボットアームの組込み
- Lチカで始めるテスト自動化(10)6DoFロボットアームの制御スクリプトの保守性向上
- Lチカで始めるテスト自動化(11)ロボットアームのコントローラ製作
- Lチカで始めるテスト自動化(12)書籍化の作業メモ
- Lチカで始めるテスト自動化(13)外部プログラムの呼出し
電子書籍化したものを技術書典で頒布しています。

- 投稿日:2021-03-03T22:20:42+09:00
【Numpy】BGR画像をRGB画像へ変換
目的
画像データのNumpy配列をBGRからRGBに可逆変換する。
Opencvで画像を取り込み、Numpy配列としてデータをコネコネした後、
matplotlibで表示して色がおかしい...となることが多いのでメモ。事前準備
インポート
必要なライブラリをインポート
import os import numpy as np import cv2 import matplotlib.pyplot as plt画像の読み込み
今回は画像3枚を読み込む。
ちなみに読み込む画像はこんな感じ
# 3枚の256x256xRGB画像を読み込むための行列 imgs = np.ndarray((3, 256, 256, 3)) for i, img in enumerate(os.listdir()): # .pngファイルのみリードする。 if os.path.splitext(img)[1] == '.png': imgs[i] = cv2.imread(img)表示してみる
画像の準備ができたので表示する。
for i in range(len(imgs)): plt.subplot(1, 3, i+1) plt.title(img_names[i]) plt.imshow(imgs[i]) plt.show()opencvで読み込んでいるので表示されるのはRBGの画像ではなく、BGRの画像。
BGRに変換して表示する
変換
rgb_imgs = imgs[:,:,:,::-1] rgb_imgs.shape # -> (3, 256, 256, 3)表示してみる
for i in range(len(rbg_imgs)): plt.subplot(1, 3, i+1) plt.title(img_names[i]) plt.imshow(rbg_imgs[i]) plt.show()ちゃんと元のRGB画像にもどせました。
なにしてる?
「:, :, :, 」は行列のshape、つまりここでは3枚の256x256の部分に該当し、
「::-1」の部分で3チャンネル逆順で取り出している。rgb_imgs = imgs[:,:,:,::-1] x = np.array((1,2,3)) x # -> array([1, 2, 3]) x[::-1] # -> array([3, 2, 1])



- 投稿日:2021-03-03T22:06:39+09:00
Pythonを使ってPDFを目標ファイルサイズ以下に分割する
はじめに
ある日、巨大なPDFファイルを作成したところ、先方からクラウドストレージが使えないのでメールで送ってくれと言われました。7zipで圧縮して分割して送ったらセキュリティポリシー違反で届きませんでした。
そんな時に30分くらいで作ったコードです。どんぴしゃのものが見つからなかったのでやり方をメモしておきます。いろいろ雑なのはご愛敬。
コード
実行環境:
- ubuntu 20.04 on WSL1
- Python 3.8.2
- PyPDF2 1.26.0
- pathlib 1.0.1
split_pdf.pyimport PyPDF2 from pathlib import Path import os def split_file(pfin): # 目標サイズに応じて変更 MAX_SIZE = 9000000 if os.path.getsize(pfin) > MAX_SIZE: # PDF読み込み r = PyPDF2.PdfFileReader(str(pfin), strict=False) lastpage = r.numPages # 1ページに達したら終了 if lastpage == 1: return # 真ん中で分割するためのページ split = lastpage // 2 # ファイル名生成 suffixはお好みで f1 = Path(f'{pfin.stem}_1.pdf') f2 = Path(f'{pfin.stem}_2.pdf') w = PyPDF2.PdfFileWriter() # 1ページづつwriterに追加 for i in range(lastpage): w.addPage(r.getPage(i)) # splitに達したらファイル名f1として保存 if i == split: with open(f1, 'wb') as f: w.write(f) del w w = PyPDF2.PdfFileWriter() # 最後まで追加したらファイル名f2として保存 with open(f2, 'wb') as f: w.write(f) del w # f1が目標ファイルサイズを超えていたら再帰的に渡す if os.path.getsize(f1) > MAX_SIZE: split_file(f1) # f2が目標ファイルサイズを超えていたら再帰的に渡す if os.path.getsize(f2) > MAX_SIZE: split_file(f2) # 処理が終わったら元ファイルを削除(残したかったらコメントアウト) pfin.unlink() if __name__ == "__main__": # 例としてhoge.pdfを分割したいとする split_file(Path('hoge.pdf'))補足
- このプログラムを実行すると
input: hoge.pdf output: hoge_1_1.pdf hoge_1_2.pdf hoge_2.pdfのように出力されます。最後にお好みでリネームしてください。
- 巨大すぎるファイルを細かく分割するとファイル名が長くなります。ほどほどの深さになるように適切にパラメータを設定してください
- あくまで
MAX_SIZEを超えない程度に分割したいという思想で作ったプログラムです。MAX_SIZEギリギリに作りたいときは別のやり方をお勧めします- このやり方は1ページのサイズが
MAX_SIZEを超えた場合はMAX_SIZE以下にできません最後に
最初に受け渡し方法を相談しておきましょう
- 投稿日:2021-03-03T21:21:51+09:00
SQLiteでファイルを使用してテーブル作成する方法(ターミナル/Python)
Pythonの標準ライブラリにはSQLiteと呼ばれるデータベースが付属しており、別途データベースを用意しなくとも簡単にプロトタイプなどを作成することができます。
環境
- Mac OS Big Sur 11.2.1
- Python 3.9.1
- SQLite 3.32.3
使い方
SQLiteはPythonの標準ライブラリに含まれているため、Pythonが使用できる状態であればすぐに使用することができます。
$ sqlite3 <DATABASE_FILE> sqlite>ターミナルでファイルを使用する
仮に単語カードのデータを保存するようなテーブルを考えます。必要なのはIDと質問、答えだと思いますので以下のようなSQLを用意します。
schema.sqlDROP TABLE IF EXISTS card; CREATE TABLE card ( id INTEGER PRIMARY KEY AUTOINCREMENT, question TEXT, answer TEXT );これを直接実行する場合、sqliteに接続した上で
.readコマンドを実行します。sqlite> .read schema.sqlPythonでファイルを使用する
上記ターミナルと同じファイルを使用する場合、以下のようにファイルを読み込んだ上で
executescriptを実行します。import sqlite3 conn = sqlite3.connect('<DATABASE_FILE>') cursor = conn.cursor() with open('./schema.sql') as f: cursor.executescript(f.read())テーブル確認
テーブルの情報は
sqlite_masterテーブルに保存されています。よって正常に実行できていれば、以下の通り先ほどのテーブル情報が表示されるはずです。$ sqlite3 <DATABASE_FILE> sqlite> select * from sqlite_master; table|card|card|2|CREATE TABLE card ( id INTEGER PRIMARY KEY AUTOINCREMENT, question TEXT, answer TEXT ) table|sqlite_sequence|sqlite_sequence|3|CREATE TABLE sqlite_sequence(name,seq)
- 投稿日:2021-03-03T21:16:48+09:00
APIからのライン通知を改行する方法【Python/LINE Notify】
キノコードさんの動画↓を見ながらLINE Notifyを使ってみました。
・【仕事の自動化】PythonでLINEを操作。メッセージや画像を自分へ送信しよう!【初心者の方もわかりやすいように解説】
https://youtu.be/FuCJd0ftVsU動画内では「通知を改行する方法」には触れられていなかったので、自分用にメモ。
Lineで通知する文章を改行したい場合、「\n」を入れると改行できます。
つまり、通常のpythonと同じように書けば大丈夫みたいです。例
通知したい文章に対して…
line_notify_test.pysend_contents = f'今日は{strftime}({day_of_the_week[weekday]})です。'改行したい部分に「\n」を入れる。
line_notify_test.pysend_contents = f'\n今日は\n{strftime}({day_of_the_week[weekday]})です。'結果
(念のために…上のコードだけで自動でLINEに通知は来ません。
APIを使ってLINEに通知を送る方法を知りたい方は、冒頭紹介した動画を見てください。)ちなみに…
f文字列(フォーマット文字列)…つまり、f''で囲うやつじゃなくて、普通(?)に書く場合。
「シングルクォーテーションではなく、ダブルクォーテーションで囲まないと改行してくれない」みたいな記事を見ました。
ただ、やってみると僕はどちらでもできました。line_notify_test.pysend_contents = "\n今日は\n" + str(strftime) + "(" + str(day_of_the_week[weekday]) + ")です。"line_notify_test.pysend_contents = '\n今日は\n' + str(strftime) + '(' + str(day_of_the_week[weekday]) + ')です。'昔はできなかったのかもしれません。
- 投稿日:2021-03-03T20:55:51+09:00
Python, Dataframeをcsvに変更する方法
- 投稿日:2021-03-03T20:51:04+09:00
DockerでAnaconda環境構築+jupyterを起動させる
0.はじめに
SIGNATEで「日本取引所グループ ファンダメンタルズ分析チャレンジ」というコンペが開催されています。私も参加していますが、その中で出てくる知識に関して基礎部分をまとめよう!という動機の記事第3弾(最終回)です。
本コンペのチュートリアルではDocker環境でサンプルコード(.ipynb )が動くようになっていて、結構運営への質問も多かったようである。私事ですが最近実務でもクラウド/コンテナを勉強しなければならなくなったので、本記事はその備忘録も多少兼ねています。
- 動作環境
- OS : Windows10 pro (Ver.2004)
- Docker : 20.10.2
1.Dockerって何なのか?
これに関しても溢れるほど解説記事がありますが、本記事は自分自身の備忘録を兼ねる為、理解に必要な周辺知識含めて
なるべく平易な用語を使って私なりの理解を改めて書いておこうと思います。
※なおサーバやインフラ系の知識については自分自身もまだ勉強中な身ですので、悪しからず。・仮想環境(PC)とは?
「1つの物理的なPC(OS)の中で別の仮想的なPC(OS)を動かす」こと。
pythonをやっている方の場合「conda」等の仮想環境を思い浮かべてもらえるとわかりやすいかも。
あれは「この検証にはpython3.6を使いたいけど、あの検証にはpython3.8が使いたい!」という時に実行環境を分けることができますよね? これをpythonだけではなくて別の言語、はたまたOSまで使い分けたい!という場合にこの仮想環境が必要なのである。・Dockerとは?
↑で説明した仮想化環境を提供するソフトウェア(Docker社が公開しているOSS)の1つ。仮想化環境の実現に「コンテナ型」という技術を使っている。
なお、Dockerを動かすためのOSにはlinuxが必要である。
よってWindowsの場合はWSL(Windows Subsystem for Linux)というものを使用することでDockerを使えるようになる。・で、そのコンテナって何?
データとかプログラムとかOS(正確にはOSっぽいもの)とかを細かい部屋に分ける「仕切り(物置)」のこと。その物置を別のPC(環境)にそのまま移設することも出来るので、貿易船で積み荷として輸送されるコンテナみたいだね!っていうことで「コンテナ」と名付けられているらしい。
Dockerの場合、Dockerエンジンを使うことでこのコンテナが使えるようになる。
・(Docker)コンテナイメージとは?
貿易コンテナの中には当然「荷物」が入っているはずである。その積み荷を「コンテナイメージ」と呼んでいる。
CD-Rを例にすると、CD-Rの中に入っているデータがまさにここでいうイメージである。(CD-Rは持ち運んで色々なPCにインストールできるのでコンテナとも言えるかも・・)通常は
OS(linuxとかWindowsとか)+アプリ(pythonとかTensorflowとか)がインストール済の環境をまとめたものが積み荷(イメージ)として存在する。
コンテナイメージ自体は、一般的に企業や有志が誰でも使えるように配布していて、我々はそのイメージをコンテナに格納することで全く同じ環境を簡単に構築できるというわけである。
Docker Hubというサイトでこの配布されているイメージを確認可能。また、当然逆に自作コンテナからイメージを作ることもできる。
配布されているイメージで足らない分を自分で改造すれば、その改造コンテナを新イメージとして作ることもできる。・2台の物理PCにそれぞれ環境を作るのと何が違うの?
物理的な環境が違っていたり、PC構成が微妙に違っていても「意識せずに同じ環境が用意できる」ことが強み。
1台目のPCで苦労して環境構築し、同じ環境を2台目にも。。という場合に「あれ?うまくいかない」という場面はみんな経験したことがあるのではないだろうか?Qiitaを見てみても「環境構築」の記事がたくさん見受けられるということは、みんなそれだけ微妙な構成違いで苦しんでいるということの裏返しなのである。つまり、
どんな環境でも絶対に動いてほしい場合にこのコンテナ(Docker)という技術はとても重宝するのである・でなんで、色々な仮想化手法がある中でDockerがいいの?
とにかく動作が軽い。
詳細は記載しないが、「OSの一部機能をホストPC(物理PC)に託している」ことが軽量につながっているらしい。※これが「OSっぽいもの」と呼んでいる正体。実際には完全なOSではないのである。2.Dockerの導入
過去に素晴らしい解説記事があったので、この記事を参照して環境構築してください。
なお、私のPCはwindows10 proですが今はWindows10 Homeでもproでも↓の方法で構築すればOKなはずです。(この手の記事でよく出てくるHyper-VはWSL2になってからは不要です)参考記事:WindowsでDockerを始める手順
※もしかしたらWin10のバージョンが古いと失敗するかもですが、その場合は現時点(2021/2時点)最新のVer.2004にアップデートしてください。
3.Dockerでpython(Anaconda)環境を構築
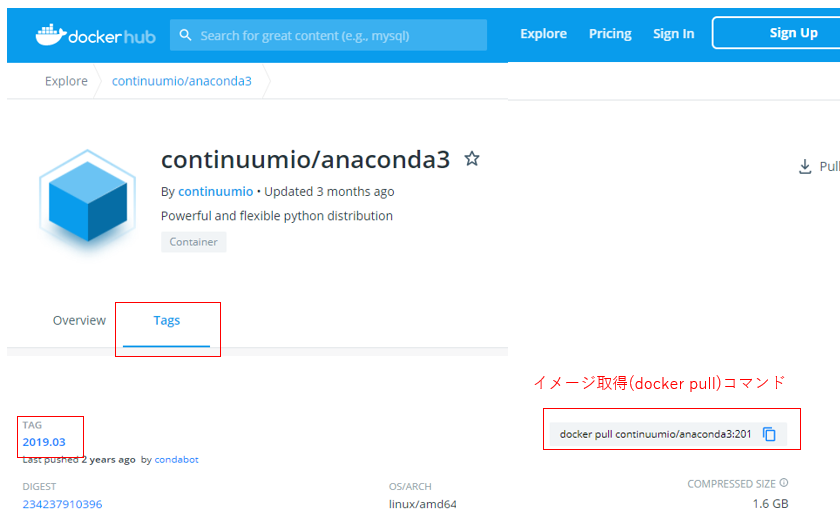
Anacondaの公式がDockerイメージをDocker hubで公開しているのでこれを使うだけ。
・continuumio/anaconda3 – Docker Hub
↑がAnacondaの配布イメージのページである。もしAnacondaの古いバージョンで作成したい場合は「Tags」の中に入っている。コンペの中では「Anaconda3 2019.03」のコンテナイメージ(以下参考図)を使っているので、今回はそれを例として進める。まずはコンテナイメージから取得する。
※コマンドプロンプトにて docker pull continuumio/anaconda3:2019.03これでAnacondaイメージを取得できた。ちなみにこの時「このAnacondaイメージってなんのOSっぽいものが一緒に使われてるんだ??」って疑問に思ったのでそれも調べてみる。
※コマンドプロンプトにて docker inspect --format="{{ .Os}}" continuumio/anaconda3:2019.03実行結果linuxつまりこのAnacondaイメージで一緒になっているOSはlinuxということがわかった。
JupyterはこのAnacondaの中に入っているので、これを使う。4.コンテナ経由でjupyter notebookを起動
落としてきたイメージをコンテナに乗せて起動し、jupyterをそこから起動させていく。
その際に「マウント」といって、自分のPCのローカルフォルダとDockerの中のディレクトリ(フォルダ)を同期させるようなことを今回はしていく。
このマウントをすることで、コンテナから外部(自分の指定したフォルダ)を操作することができるようになる。4-1.まずは落としてきたイメージの確認
docker images実行結果REPOSITORY TAG IMAGE ID CREATED SIZE continuumio/anaconda3 2019.03 (略) (略) (略)先程
docker pullで落としてきたanaconda3のイメージがあることが確認できた。4-2.コンテナの作成、コンテナ内のディレクトリ構造確認
下のコマンドでイメージからコンテナを作成し、rootディレクトリに入ることが出来る
docker run -it continuumio/anaconda3:2019.03実行結果(base) root@*****:/#このままlinuxの直下ファイル確認コマンド(ls)を押せばroot直下のコンテナ内ディレクトリ等が確認可能
ls ※(base) root@*****:/#の中で実行している実行結果bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var今回は「マウント」を行うので、コンテナ内のどのディレクトリにマウントするか?を考える上でディレクトリ構造の把握をしておくといい。
ちなみに、(base) root@*****:/#(コンテナ)の中から抜け出すには「exit」コマンドを入力すればいい4-3.マウント設定等を反映させてコンテナを起動する
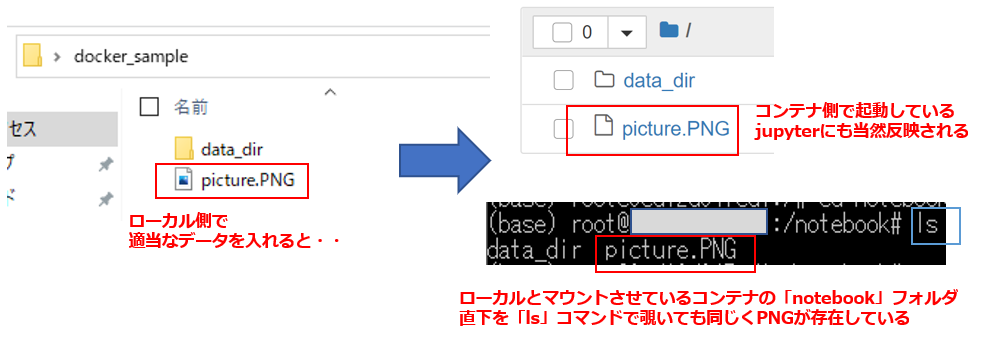
まずは、Windows側でコンテナ側とマウントさせたいフォルダ(コンテナ側のjupyterから直接参照させるフォルダ)を作成しておく
# Windows側のディレクトリ構成 #「docker_sample 」の直下にIPython(jupyterのプログラム)を配置させる ※ここをマウント対象にする #「data_dir」の中にjupyterで読み込むようなデータを入れる想定 ''' Windows側ディレクトリ Desktop -- docker_sample -- data_dir -- 共有するファイル(csvとか画像とか) '''Windows側の準備が終わったならば、まずはjupyterプログラムを配置させるディレクトリへ移動しておく。
cd C:\Users\***\Desktop\docker_sample ※ディレクトリをjupyterを起動させたい場所にしておく次にマウント設定等をした上でのコンテナ起動コマンドを実行する
""" 【docker run + オプション(下記) + イメージ】 --name → コンテナ名を指定(なくてもいい) -v → マウント指定(コロンの左側がローカル側、右側がコンテナ側のpath) -p → ポート接続(コロンの左側がローカル側、右側がコンテナ側※jupyterは8888) --rm → コンテナ終了時にコンテナ自動的に削除 --it → ホスト側のターミナルからコンテナ内部の操作 ※^ は長いコマンドの場合に改行の意味を示すコマンド(キャレット) ※-v "%cd%":/notebook の意味は「ローカル側が未記載≒今のpath(docker_sample)」、 「コンテナ側はnotebookフォルダ」をマウントさせるという意味。 notebookフォルダはデフォルトでは存在しないのでコンテナ側で作成される """ docker run --name docker_practice ^ -v "%cd%":/notebook ^ -p 8888:8888 --rm -it continuumio/anaconda3:2019.03実行結果(base) root@****:/#これでローカル側をマウントした上でコンテナを起動できた!
後は、この起動したコンテナの中でjupyterを起動するだけである""" jupyter notebook以下は起動オプション。ここでの説明は省略する。 最後の「/notebook」はなくてもいいが、つけておくと最初のjupyter起動ディレクトリがマウントさせているnotebookになる ※この時点ですでに「コンテナ」に入っているのでlinux環境。改行が^ではなく、バックスラッシュになる """ jupyter notebook --ip 0.0.0.0 --allow-root --no-browser \ --NotebookApp.disable_check_xsrf=True --NotebookApp.token='' \ --NotebookApp.password='' /notebook実行結果・・・略・・・ [I **:**:** NotebookApp] The Jupyter Notebook is running at: [I **:**:** NotebookApp] http://*****:8888/後は、ブラウザから
http://localhost:8888/でjupyterを起動すれば、docker_sampleをマウントした「notebook」ディレクトリでスタートする。
そしてローカル側でマウントさせたフォルダ直下であれば、適当にファイルを入れればjupyter側(コンテナ側)でも同様に確認できるはず。
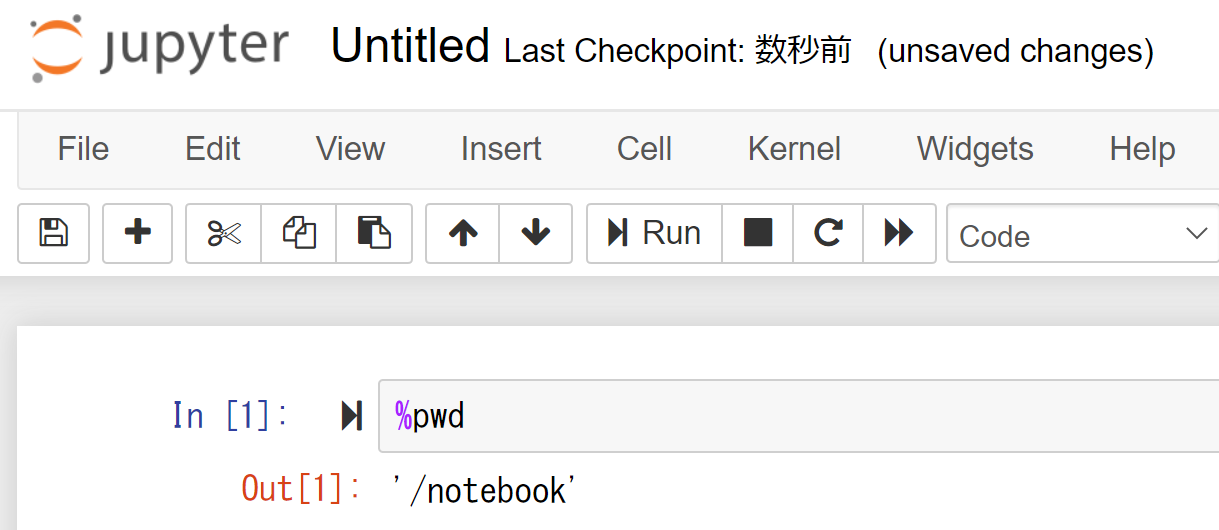
そして、適当にプログラムを作成して下のようなコマンドを入れれば、今このjupyterがいるディレクトリがコンテナ側のマウントディレクトリ「/notebook」であることがわかる。
これで後は好きに分析をやっていけばいい。
※jupyterでは、%を入れることでlinuxコマンドを扱える。%pwdで今自分がいるpathを表示できる
5.おわりに
どうだったであろうか?
ちなみに今回長々と記事にしたものは、本来Dockerでは1命令で全て完結できる。
(イメージのダウンロードも実は不要。無ければ勝手にダウンロードする仕組み)
しかし↓の命令をいきなり見ても、慣れていない人にはアレルギーが出るので、細かく分けて説明してきた。
本記事はDockerのほんの取っ掛かりにすぎず、まだまだ色々知ることはあると思うが、この記事をとっかかりにDockerで色々作業をしていってくれると私も報われます。一緒に勉強していきましょう""" Windows側のフォルダ準備やチェンジディレクトリ(cd)さえしておけば、 本記事の解説内容は実はこの1命令で済んでしまう(実際のコンペチュートリアルはこれだけが書かれていた) """ docker run --name docker_practice -v "%cd%":/notebook ^ -p 8888:8888 --rm -it continuumio/anaconda3:2019.03 ^ jupyter notebook --ip 0.0.0.0 --allow-root --no-browser ^ --NotebookApp.disable_check_xsrf=True --NotebookApp.token='' ^ --NotebookApp.password='' /notebook

- 投稿日:2021-03-03T19:58:00+09:00
Numpyにおけるデータの取得と格納、及び関数呼び出し
ndarrayにおける色んな参照方法をやってみた
import numpy as np print(np.__version__) data = np.array([[1,2,3,4,5], [10,20,30,40,50], [100,200,300,400,500]]) print(data)1.19.2 [[ 1 2 3 4 5] [ 10 20 30 40 50] [100 200 300 400 500]]取得
d = data[1] print(d)[10 20 30 40 50]d = data[[1]] print(d)[[10 20 30 40 50]]d = data[:,2] print(d)[ 3 30 300]d = data[:,2:3] print(d)[[ 3] [ 30] [300]]d = data[1,2:4] print(d)[30 40]d = data[1:2,2:4] print(d)[[30 40]]d = data[1,2] print(d)30d = data[1,2:3] print(d)[30]d = data[1:2,2:3] print(d)[[30]]d = data[[0,1,2],1] print(d)[ 2 20 200]d = data[1,[1,2,3]] print(d)[20 30 40]d = data[[1,2],[2,4]] print(d)[ 30 500]d = data[[0,1],[1,2,3]] print(d) --------------------------------------------------------------------------- IndexError Traceback (most recent call last) <ipython-input-14-d9878e643f58> in <module> ----> 1 d = data[[0,1],[1,2,3]] 2 print(d) IndexError: shape mismatch: indexing arrays could not be broadcast together with shapes (2,) (3,)d = data[np.ix_([0, 1], [1,2,3])] print(d)[[ 2 3 4] [20 30 40]]代入
data1 = data.copy() data1[1] = 1000 print(data1)[[ 1 2 3 4 5] [1000 1000 1000 1000 1000] [ 100 200 300 400 500]]data1 = data.copy() data1[[1]] = 1000 print(data1)[[ 1 2 3 4 5] [1000 1000 1000 1000 1000] [ 100 200 300 400 500]]data1 = data.copy() data1[:,2] = 1000 print(data1)[[ 1 2 1000 4 5] [ 10 20 1000 40 50] [ 100 200 1000 400 500]]data1 = data.copy() data1[:,2:3] = 1000 print(data1)[[ 1 2 1000 4 5] [ 10 20 1000 40 50] [ 100 200 1000 400 500]]data1 = data.copy() data1[1,2:4] = 1000 print(data1)[[ 1 2 3 4 5] [ 10 20 1000 1000 50] [ 100 200 300 400 500]]data1 = data.copy() data1[1:2,2:4] = 1000 print(data1)[[ 1 2 3 4 5] [ 10 20 1000 1000 50] [ 100 200 300 400 500]]data1 = data.copy() data1[1,2] = 1000 print(data1)[[ 1 2 3 4 5] [ 10 20 1000 40 50] [ 100 200 300 400 500]]data1 = data.copy() data1[1,2:3] = 1000 print(data1)[[ 1 2 3 4 5] [ 10 20 1000 40 50] [ 100 200 300 400 500]]data1 = data.copy() data1[1:2,2:3] = 1000 print(data1)[[ 1 2 3 4 5] [ 10 20 1000 40 50] [ 100 200 300 400 500]]data1 = data.copy() data1[[0,1,2],1] = 1000 print(data1)[[ 1 1000 3 4 5] [ 10 1000 30 40 50] [ 100 1000 300 400 500]]data1 = data.copy() data1[1,[1,2,3]] = 1000 print(data1)[[ 1 2 3 4 5] [ 10 1000 1000 1000 50] [ 100 200 300 400 500]]data1 = data.copy() data1[np.ix_([0, 1], [1,2,3])] = 1000 print(data1)[[ 1 1000 1000 1000 5] [ 10 1000 1000 1000 50] [ 100 200 300 400 500]]関数呼び出し
def hoge(d): print(d) d[0] = 2000 print(d)data1 = data.copy() hoge(data1[1]) print(data1)[10 20 30 40 50] [2000 20 30 40 50] [[ 1 2 3 4 5] [2000 20 30 40 50] [ 100 200 300 400 500]]data1 = data.copy() hoge(data1[[1]]) print(data1)[[10 20 30 40 50]] [[2000 2000 2000 2000 2000]] [[ 1 2 3 4 5] [ 10 20 30 40 50] [100 200 300 400 500]]data1 = data.copy() hoge(data1[:,2]) print(data1)[ 3 30 300] [2000 30 300] [[ 1 2 2000 4 5] [ 10 20 30 40 50] [ 100 200 300 400 500]]data1 = data.copy() hoge(data1[:,2:3]) print(data1)[[ 3] [ 30] [300]] [[2000] [ 30] [ 300]] [[ 1 2 2000 4 5] [ 10 20 30 40 50] [ 100 200 300 400 500]]data1 = data.copy() hoge(data1[1,2:4]) print(data1)[30 40] [2000 40] [[ 1 2 3 4 5] [ 10 20 2000 40 50] [ 100 200 300 400 500]]data1 = data.copy() hoge(data1[1:2,2:4]) print(data1)[[30 40]] [[2000 2000]] [[ 1 2 3 4 5] [ 10 20 2000 2000 50] [ 100 200 300 400 500]]data1 = data.copy() hoge(data1[1,2]) print(data1) 30 --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-65-07c98b5a0381> in <module> 1 data1 = data.copy() ----> 2 hoge(data1[1,2]) 3 print(data1) <ipython-input-58-7cd04c1a5a75> in hoge(d) 1 def hoge(d): 2 print(d) ----> 3 d[0] = 2000 4 print(d) TypeError: 'numpy.int32' object does not support item assignmentdata1 = data.copy() hoge(data1[1,2:3]) print(data1)[30] [2000] [[ 1 2 3 4 5] [ 10 20 2000 40 50] [ 100 200 300 400 500]]data1 = data.copy() hoge(data1[1:2,2:3]) print(data1)[[30]] [[2000]] [[ 1 2 3 4 5] [ 10 20 2000 40 50] [ 100 200 300 400 500]]data1 = data.copy() hoge(data1[[0,1,2],1]) print(data1)[ 2 20 200] [2000 20 200] [[ 1 2 3 4 5] [ 10 20 30 40 50] [100 200 300 400 500]]data1 = data.copy() hoge(data1[1,[1,2,3]]) print(data1)[20 30 40] [2000 30 40] [[ 1 2 3 4 5] [ 10 20 30 40 50] [100 200 300 400 500]]data1 = data.copy() hoge(data1[np.ix_([0, 1], [1,2,3])]) print(data1)[[ 2 3 4] [20 30 40]] [[2000 2000 2000] [ 20 30 40]] [[ 1 2 3 4 5] [ 10 20 30 40 50] [100 200 300 400 500]]
- 投稿日:2021-03-03T18:58:04+09:00
Wayback Machineを使ったwebページのアーカイブの保存を自動化した話
はじめに
webサイトが消えてしまって、保存しておいたらよかった、ということありますよね。
pythonを使用してurlの一覧から自動でwebアーカイブサービスに登録するスクリプトを作りました。使用するアーカイブサービスの候補
ウェブ魚拓
ウェブ魚拓
https://megalodon.jp/
これは国産のサービスでおそらく一番有名なものではないでしょうか。
しかしウェブ魚拓は1日、1IP、20アクセスまでらしいです。
ソース:高校メロン部http://shimarisu.webcrow.jp/gyotaku.html
なので却下archive.today
海外のサイトでは。
archive.today
http://archive.vn/
というサイトも有名ではないでしょうか。
試してみましたが、待ち時間のqueueが#1500になっていました。
さらに自動化しようとしましたが、CAPTCHAが出てしまいだめでした。また有志が作ったapiを使用してみたが、動かず。
https://github.com/pastpages/archiveisimport archiveis archive_url = archiveis.capture("https://ncode.syosetu.com/n9669bk/1/") print (archive_url)429 Client Error: Too Many Requests for url: https://archive.md/queueが長いのが原因かな
Laravelで429 (Too Many Requests)が出た時の対策
初めてなのにどうしてだろうWayback Machine
今回のメインであるWayback Machine
https://archive.org/web/
どうやら世界最大級のアーカイブサービスみたいですね
今回はこのサイトに登録していこうと思います。
なお同じページをアーカイブするときは最後に保存されてから30分たっていないとできません。概要はこちら
https://warp.da.ndl.go.jp/contents/reccommend/world_wa/world_wa02.htmlどうやら1分あたり15urlという制限しかないらしい。
https://gist.github.com/eggplants/414bab0230f14358642faf364bc1f7ecやること
今回はSeleniumを使用して自動化しようと思います。
PythonでSeleniumを利用してWebサイトのログインを自動化する方法を現役エンジニアが解説【初心者向け】
https://qiita.com/Chanmoro/items/9a3c86bb465c1cce738a1.chromeが必要なので、ダウンロードしてください。
2.seleniumをダウンロードしてください
pip install seleniumseleniumとは、pythonでchromeを動かすライブラリです。
Python + Selenium で Chrome の自動操作を一通り
こちらを参考にしてください。3.chromedriver.exeをダウンロードしてください。
chromedriver.exeはseleniumでchromeを動かすために必要なものです。
検索するとバイナリでダウンロードする方法などがあるそうですが、
今回はホームページから直接zipをダウンロードします。https://chromedriver.chromium.org/downloads
ここからchromeのバージョンとosにあったものをダウンロード、
そして解凍バージョンについては
https://qiita.com/iHacat/items/9c5c186f0d146bc98784
こちらを参考に4.スクリプト
weyback_registrater.pyfrom time import sleep from selenium import webdriver def url_registrater(url): driver.get('https://web.archive.org/save') submit_url_form = driver.find_element_by_xpath('//*[@id="web-save-url-input"]') submit_url_form.send_keys(url) save_button = driver.find_element_by_xpath('//*[@id="web-save-form"]/input[2]') save_button.click() #Wayback Machineは1分に15urlまで sleep(4.1) def login(mail, password): #ログイン処理 driver.get('https://archive.org/account/login') email_input_form = driver.find_element_by_xpath('//*[@id="maincontent"]/div/div/div[2]/section[3]/form/label[1]/input') email_input_form.send_keys(mail) password_input_form = driver.find_element_by_xpath('/html/body/div/main/div/div/div[2]/section[3]/form/label[2]/div/input') password_input_form.send_keys(password) login_button = driver.find_element_by_xpath('//*[@id="maincontent"]/div/div/div[2]/section[3]/form/input[3]') login_button.click() sleep(1) #Trueはチェックボックスにチェックを入れている状態 def url_registrater_logined(url, outlink=True, error_page=True, screen_shot=True, in_my_web=True, email_result=True): driver.get('https://web.archive.org/save') submit_url_form = driver.find_element_by_xpath('//*[@id="web-save-url-input"]') submit_url_form.send_keys(url) #チェックボックス #ページ内のurlの先も保存するか if outlink==True: save_outlinks_button =driver.find_element_by_xpath('//*[@id="capture_outlinks"]') save_outlinks_button.click() #ページがerrorでも保存するか #このチェックボックスだけ最初からチェックが入っているので挙動を逆に if error_page==False: error_page_button =driver.find_element_by_xpath('//*[@id="capture_all"]') error_page_button.click() #スクリーンショットを保存するか if screen_shot==True: screen_shot_button =driver.find_element_by_xpath('//*[@id="capture_screenshot"]') screen_shot_button.click() #ログインアカウントに追加するか if in_my_web==True: in_my_web_button =driver.find_element_by_xpath('//*[@id="wm-save-mywebarchive"]') in_my_web_button.click() #結果をメールアドレスに追加するか if email_result==True: email_result_button =driver.find_element_by_xpath('//*[@id="email_result"]') email_result_button.click() #これがないとチェックボックスを押す前ににページが遷移してしまう sleep(1) save_button = driver.find_element_by_xpath('//*[@id="web-save-form"]/input[2]') save_button.click() #Wayback Machineは1分に15urlまで sleep(3.1) #使い方 #chromedriver.exeのパスをかく driver = webdriver.Chrome("path") #ダウンロードしたいurlのリスト urllist=["https://www.google.com/?hl=ja", "https://www.yahoo.co.jp/"] #1.ログインなし for url in urllist: url_registrater(url) """ #2.ログインした状態で使いとき(できることが増える) login('mail', 'password') for url in urllist: url_registrater_logined(url) """5.使い方
1.ダウンロードしたchromedriver.exeのパスを書く
2.アーカイブしたいurlの一覧をリストで作る
(外部のファイルを読み込むなどはご自由に)
3.ログインしたいときはメールアドレスとパスワードを書く
なおこのサイトは10 minute mailのような捨てメールアドレスでも登録できます。
ログインするとスクリーンショットを保存したり、ページのリンク先も保存できるなどできることが増える(スクリプトのチェックボックスの説明を参照)
4.実行するうまくいくとchromeが開いてどんどん登録していきます。
問題点
・ずっと動かしていると、sleepを挟んでいるのにたまに1分15urlに引っかかってしまう。
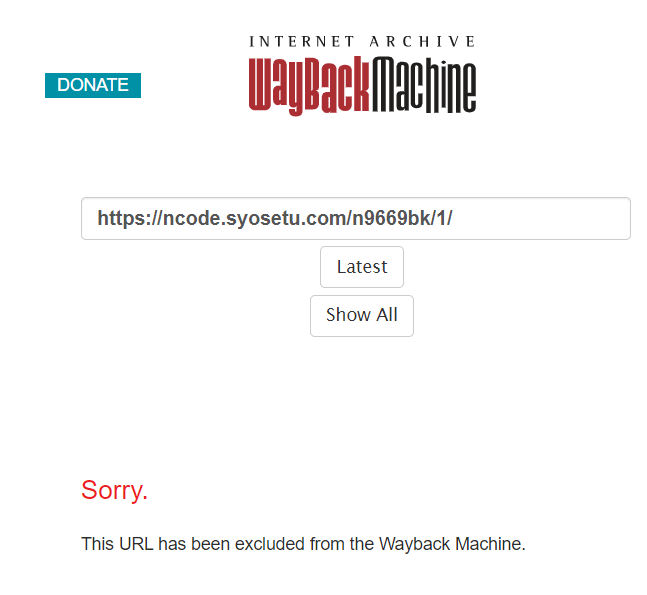
・一部のサイトは
このようにダウンロードできないサイトがある。
どうも著作権の関係で昔ごたついたらしい
https://it.srad.jp/story/18/12/04/0637201/
小説家になろうの作品をどんどん登録しようと思ったのに…まとめ
自動でwebアーカイブサービスに登録するスクリプトを作りました。
seleniumを使った強引(?)な手でしたが、
もっとrequestとか使ったスマートな方法があれば教えてください。
これでクリック1つでいろいろ登録できそうです。
- 投稿日:2021-03-03T18:52:38+09:00
Detectron2で小銭を数える
はじめに
この記事ではDetectron2というFacebook AIが開発している物体検出ライブラリを利用して,自作のデータセットに対して物体検出をしてみます.実際にやってみるとDetectron2に関する日本語・英語の情報があまり見つからず少し苦労したので,私と同じようにDetectron2で物体検出をしようとしている人の助けになれば幸いです.
データセットとして日本硬貨4種類(1円,5円,10円,100円)が含まれた画像を用意し,PretrainedのFaster R-CNNを訓練しています.結果として次のように硬貨を検知できました.
※データセットに50円,500円硬貨が含まれていないのは,たまたま財布に入っていなかったためです.
※今気づきましたがhundredをスペルミスしてますね.恥ずかしいですが直すのが面倒なのでこのままで行きます.僕は深層学習に関して全く詳しくないため,訓練時のパラメータや設定などは公式チュートリアルそのままか,あるいは適当に決めています.なのでその辺りに関しては説明しません(できません).データセットの準備や訓練の手順を説明し,上の画像のようなそこそこ使えそうな結果を得ることを目指しています.
作成した硬貨のデータセットはGitHubに上げています.
訓練時のコードはGoogle Colabにあります.
公式チュートリアルでは,独自のデータセット(風船の画像)のInstance Segmentationを通して基本的な使い方を学ぶことができます.
データセット作成
画像を用意する
iPhoneで硬貨の画像を30枚程度撮りました.30枚という枚数は適当です.
各画像には硬貨が1~5枚写っています.iPhoneで撮った画像はサイズがとても大きく,訓練に時間がかかってしまいそうだったので大幅に縮小しました.
Annotationをつける
撮影した画像の硬貨に対してBounding Boxを付けていきます.
Bounding Boxのデータを保存する形式にはいろいろな種類がありますが,その中でもDetectron2はCOCOフォーマットという形式をサポートしています.もちろんそれ以外の形式でも使えますが,COCOフォーマットで作っておくとデータセットの読み込みがとても楽です.
そのためにCOCO Annotatorというツールを利用しました.
使い方については以下のリンクを参考にしました.初めて使うと少し戸惑う部分があるので公式のGetting Startedに沿って進めていくのがおすすめです.Detectron2
ここから実際にDetectron2を使っていきます.コードはGoogle Colabにあります.
セットアップ
基本的に公式のチュートリアルそのままです.Detectron2をインストールしたあとに「ランタイムの再起動」を行う必要があるので注意してください.
データセット登録
GitHubから硬貨データセットをダウンロードし展開します.
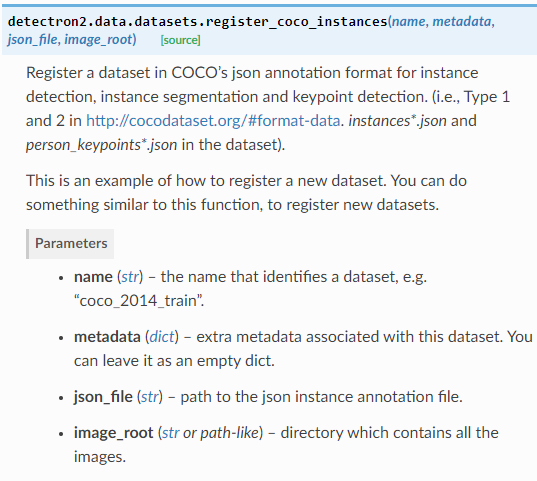
!wget https://github.com/Be4rR/JapaneseCoins/blob/main/coins.zip?raw=true -q -O coins.zip !unzip coins.zip > /dev/nullダウンロードしたデータセットを
register_coco_instancesで登録します.register_coco_instances("coins", {}, "./coins/coco-1612779490.2197058.json", "./coins")
nameは重複しなければなんでも良いみたいです.後でデータセットを指定するときに使います.
json_fileはAnnotationファイルのパスを指定します.
image_rootは画像を含むフォルダのパスを指定します.データセットが正しく登録できているか確認します.
データセットの中からランダムに3枚選び,画像とAnnotationを表示します.coins_metadata = MetadataCatalog.get("coins") dataset_dicts = DatasetCatalog.get("coins") for d in random.sample(dataset_dicts, 3): img = cv2.imread(d["file_name"]) visualizer = Visualizer(img[:, :, ::-1], metadata=coins_metadata, scale=1.0) vis = visualizer.draw_dataset_dict(d) cv2_imshow(vis.get_image()[:, :, ::-1])
hundredをスペルミスしてますがデータセットの登録は問題なさそうです.ちなみに
img[:, :, ::-1]は画像のRGB形式⇔BGR形式を変換しています.
画像を読み込むときcv2.imreadはBGR形式で画像を読み込むのに対して,VisualizerはRGB形式で画像を受け取るため変換が必要になります.
参考:Python, OpenCVでBGRとRGBを変換するcvtColor訓練
Faster RCNNをModel Zooからダウンロードして訓練(Fine Tune)します.
いろんなパラメータがありますが,とりあえず変えないといけないのは分類のクラス数
cfg.MODEL.ROI_HEADS.NUM_CLASSESです.今回は1円,5円,10円,100円を分類するので4にします.学習率など他にも大事なパラメータがありますが,決め方をよく知らないのでスルーします.
cfg = get_cfg() cfg.merge_from_file(model_zoo.get_config_file("COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml")) cfg.DATASETS.TRAIN = ("coins",) cfg.DATASETS.TEST = () cfg.DATALOADER.NUM_WORKERS = 2 cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml") cfg.SOLVER.IMS_PER_BATCH = 2 cfg.SOLVER.BASE_LR = 0.0004 cfg.SOLVER.MAX_ITER = ( 500 ) cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = ( 128 ) cfg.MODEL.ROI_HEADS.NUM_CLASSES = 4 os.makedirs(cfg.OUTPUT_DIR, exist_ok=True) trainer = DefaultTrainer(cfg) trainer.resume_or_load(resume=False) trainer.train()タスクごとに様々なモデルが使えます.どんなモデルがあるのかについては次のリンクを参考にしてください.
硬貨を検出させてみる
訓練したモデルを読み込みます.
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TESTは検出の閾値です.cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "model_final.pth") cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.6 predictor = DefaultPredictor(cfg)Annotationが付いていない
IMG_4693.jpg~IMG_4695.jpgを使って硬貨を検出させてみます.for num in [4693, 4694, 4695]: im = cv2.imread(f"./coins/IMG_{num}.jpg") outputs = predictor(im) v = Visualizer(im[:, :, ::-1], metadata=coins_metadata, scale=1.0 ) v = v.draw_instance_predictions(outputs["instances"].to("cpu")) cv2_imshow(v.get_image()[:, :, ::-1])
たまに重複して検出してしまったりしていますが,概ねうまく検出できています.
おわりに
荒削りですがデータセット作成から訓練,簡単なテストまでできました.
モデルの評価まではできませんでしたが,気になる方は公式のチュートリアルに説明があるので見てみてください.

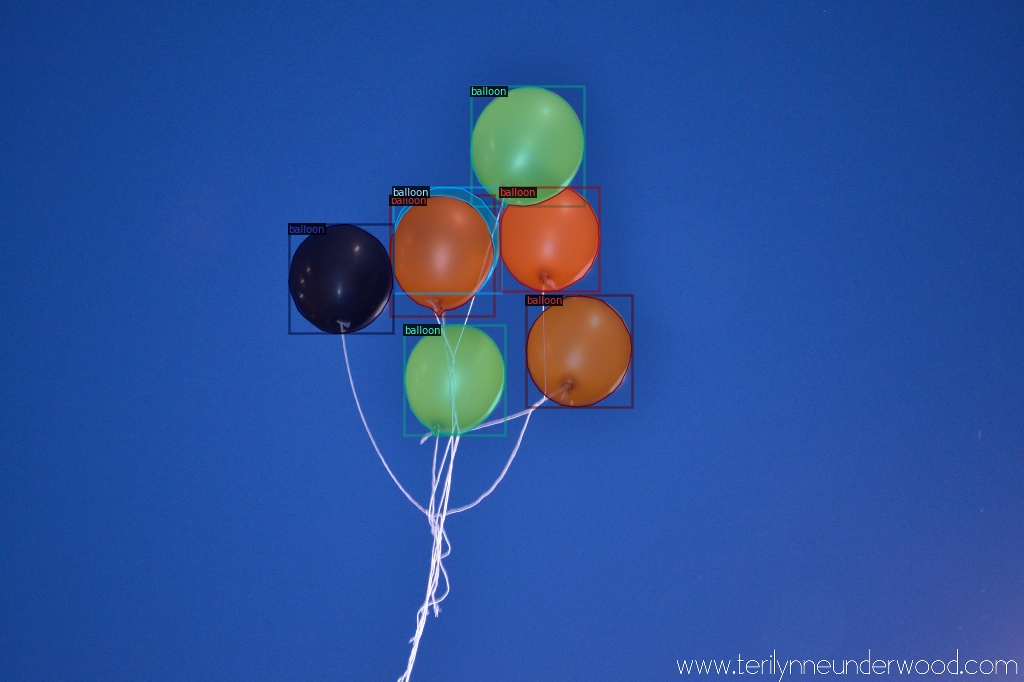



- 投稿日:2021-03-03T17:16:45+09:00
Dashで作る機械学習アプリ
はじめに
default of credit card clients Data Setデータを使って、基礎分析や簡単な分類モデルの構築などを行ってきた。せっかくなので動かせるものを作ろうと思い、Dashを用いたウェブアプリの作成を行った。機械学習アプリと名乗るにはおこがましい出来だが、どうぞご容赦を・・・。
アプリのイメージ
上記データには債権者がデフォルトするかしないかを示すフラグ "default payment next month" という項目があるので、デフォルトの分類モデルを作る。アプリのイメージは以下。
1. ロジスティック回帰、決定木、サポートベクターマシンの3種類からモデルを選択
2. 説明変数(量的変数、質的変数)を複数選択
3. 上記2項目を設定後、決定ボタンを押すことで学習開始
4. 学習結果を表示とりあえず動くものができればいいので、機械学習の精度とデザインは一旦置いておく。
コールバック関数の引数State
今回のアプリを作成するにあたり、Dashでウェブアプリ作成①、Dashでウェブアプリ作成②、Dashで世界遺産を世界地図にプロットあたりで学習したこと以外で、dash.dependenciesライブラリのStateが便利だったので書いておく。
もともとコールバック関数の引数としては Input(と Output )しか知らなかったため、上記1および2にて項目を選択する度にコールバック関数が呼び出されてしまっていた。これはイメージしたものと違うなと感じ調査したところ、State なるものを見つけた。Input と使い方はほぼ同様だが、State はコールバック関数を呼び出すトリガーにはならないらしい。上記1と2で選択した情報は State としてコールバック関数に渡して、3の決定ボタンをトリガーに State の情報をもとに学習するようにすれば、イメージ通りのものが作れるはず。上記を踏まえたコードは以下に示す。(①CSV形式に直したデータセット、②標準化およびダミー変数化などの前処理後データが必要。過去記事ありきのコードとなってしまっているため、このままでは実行できない。。。)
app.py# Run this app with `python app.py` and # visit http://127.0.0.1:8050/ in your web browser. import dash import dash_html_components as html import dash_core_components as dcc from dash.dependencies import Input, Output, State import plotly.express as px import pandas as pd # For models import numpy as np from sklearn.model_selection import train_test_split from sklearn.metrics import roc_curve, roc_auc_score from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC # from sklearn.preprocessing import StandardScaler df = pd.read_csv( "c:/***/data/default_of_credit_card_clients.csv", header=1, index_col=0) col = df.columns.values quantity_col = col[[0, 4, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22]] quality_col = col[[1, 2, 3, 5, 6, 7, 8, 9, 10]] df_p = pd.read_csv( "c:/***/preprocessed_data.csv", header=0, index_col=0) col_p = df_p.columns.values # quantity_col_p = df_p.iloc[:, :14] quality_col_p = df_p.iloc[:, 14:-1] external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css'] app = dash.Dash(__name__, external_stylesheets=external_stylesheets) app.layout = html.Div([ html.H4(children='default of credit card clients Data Set'), html.Div([ html.Label('Training model'), dcc.Dropdown(id='model', options=[ {'label': 'Logistic Regression', 'value': 'Logistic Regression'}, {'label': 'Decision Tree', 'value': 'Decision Tree'}, {'label': 'SVM', 'value': 'SVM'} ], value='Logistic Regression' ), html.Label(children='Quantity column'), dcc.Dropdown(id='quantity-col', options=[{'label': i, 'value': i} for i in quantity_col], value=[i for i in quantity_col], multi=True ), html.Label(children='Quality column'), dcc.Dropdown(id='quality-col', options=[{'label': i, 'value': i} for i in quality_col], value=[i for i in quality_col], multi=True ), html.Button('Enter', id='enter-button', n_clicks=0) ]), html.H5('Result'), html.Div(id='result') ]) def make_dummycol(column): # ダミー変数を含む列名のリストを作成 dummycol = [] for c in column: dummycol += [c + "_{}".format(i) for i in range(-1, 9)] l = [cp for cp in quality_col_p if cp in dummycol] return l def train(model, quantity_col, quality_col): # 選択モデルとデータを使用して学習、AUCスコアを返す col_list = list(quantity_col) + make_dummycol(quality_col) X = df_p[col_list] Y = df["default payment next month"] X_train, X_test, Y_train, Y_test = train_test_split( X, Y, test_size=0.2, random_state=0) if model == 'Logistic Regression': lr = LogisticRegression(max_iter=2000) lr.fit(X_train, Y_train) THRESHOLD = 0.30 Y_pred = np.where(lr.predict_proba(X_test)[:, 1] > THRESHOLD, 1, 0) elif model == 'Decision Tree': dt = DecisionTreeClassifier(max_depth=4) dt = dt.fit(X_train, Y_train) Y_pred = dt.predict(X_test) elif model == 'SVM': svm = SVC(kernel="rbf", gamma="scale") svm.fit(X_train, Y_train) Y_pred = svm.predict(X_test) return html.Div([model, ": AUC Score:", round(roc_auc_score(Y_test, Y_pred), 3)]) @app.callback( Output('result', 'children'), Input('enter-button', 'n_clicks'), State('model', 'value'), State('quantity-col', 'value'), State('quality-col', 'value')) def show_result(enter, model, quantity_col, quality_col): return train(model, quantity_col, quality_col) # print("Coefficients:", lr.coef_[0]) # print("Intercept:", lr.intercept_[0]) if __name__ == '__main__': app.run_server(debug=True)実行結果は以下のようになる。(以下GIFでは為井していないが、SVMは他2つと比べ実行時間が長い。)
おわりに
各モデルごとのパラメータ修正やその他結果の表示など修正すべき点は多々あるが、一旦ここまで。動くものを作るのはおもしろい。

- 投稿日:2021-03-03T17:11:51+09:00
「0から作るDeepLearning」の5章を写経した時のエラー原因
こんにちは!
今日のエラー原因を書きます。
使用した本:「0から作るDeepLearning」
1「two_layer_net.py」の写経について
・5行目の[「common.layers」がなぜか
「ModuleNotFoundError: No module named 'common'」
とエラー表示された。2「train_neuralnet.py」の写経について
・6行目の「dataset.mnist」がなぜか
「ModuleNotFoundError: No module named 'dataset'」
とエラー表示された。エラー対策
1,2共に練習用に作ったpracticeディレクトリの中にcommonとdatesetをコピペしたら無事に直りました。
所感
今回はネットで調べたエラー対策方法で直って安心しました。
後写しているときに目がいかれそう。
- 投稿日:2021-03-03T16:39:00+09:00
Pandas.DataFrameに対する取得位置と取得タイプの違い
Pandas.DataFrameに対する取得位置と取得タイプの違い
Pandas.DataFrame.ilocを使って、データの取得と代入、関数呼び出しを行って、添字の違いによるデータの型の違いなどを、Jupyter上で調べてみました。
iloc
取得
# データフレームを作る import pandas as pd df = pd.DataFrame( [[1,2,3,4,5],[10,20,30,40,50],[100,200,300,400,500]] ) print(df) print(type(df)) print(hex(id(df)))0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 <class 'pandas.core.frame.DataFrame'> 0x1e72b0426c8#ilocは関数じゃない d = df.iloc(0) print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.indexing._iLocIndexer'> <pandas.core.indexing._iLocIndexer object at 0x000001E72B3F4458> 0x1e72b3f4458列指定
# ilocによる取り出し # 列指定(範囲) d = df.iloc[:,2] print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.series.Series'> 0 3 1 30 2 300 Name: 2, dtype: int64 0x1e72a91e048# ilocによる取り出し # 列指定(範囲) d = df.iloc[:,2:3] #終端は含まないので注意 print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 2 0 3 1 30 2 300 0x1e72a8a8a08# ilocによる取り出し # 列指定(範囲) d = df.iloc[:, [True, False, True, False, True]] # 列の数分のTrue/False指定が無いとエラーになる print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 2 4 0 1 3 5 1 10 30 50 2 100 300 500 0x1e72a959608# ilocによる取り出し # 列指定(範囲) d = df.iloc[:, [0,2]] print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 2 0 1 3 1 10 30 2 100 300 0x1e72a941348# ilocによる取り出し # 列指定(範囲) # [:,]が無いと行指定になる d = df.iloc[[0,2]] print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 2 100 200 300 400 500 0x1e72b02e348# ilocによる取り出し # 列指定(範囲) d = df.iloc[:, [2]] print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 2 0 3 1 30 2 300 0x1e72a931c08行指定
# ilocによる取り出し # 行指定 d = df.iloc[0] print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.series.Series'> 0 1 1 2 2 3 3 4 4 5 Name: 0, dtype: int64 0x1e72a909948# ilocによる取り出し # 行指定 d = df.iloc[[0]] print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 0x1e72a921648# ilocによる取り出し # 行指定(個別指定) d = df.iloc[[0,2]] print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 2 100 200 300 400 500 0x1e72a91dc88# ilocによる取り出し # 行指定(範囲指定) d = df.iloc[0:2] # ここは[[]] でない事に注意 print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 0x1e72a921208# ilocによる取り出し
# 行指定(範囲指定)
d = df.iloc[[0:2]] \# [[]]にするとエラーになる
print(type(d))
print(d)
File "", line 3
d = df.iloc[[0:2]] # [[]]にするとエラーになる
^
SyntaxError: invalid syntax行と列の指定
# ilocによる取り出し # 行指定(指定した行と列範囲) d = df.iloc[0,2:4] print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.series.Series'> 2 3 3 4 Name: 0, dtype: int64 0x1e72a909888# ilocによる取り出し # 行指定(指定した行と列範囲) d = df.iloc[0,[2,4]] print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.series.Series'> 2 3 4 5 Name: 0, dtype: int64 0x1e72a941ac8# ilocによる取り出し # 行指定(指定した列と行範囲) d = df.iloc[0:2,2] print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.series.Series'> 0 3 1 30 Name: 2, dtype: int64 0x1e72a97f148# ilocによる取り出し # 行指定(指定した列と行範囲) d = df.iloc[[0,2],2] print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.series.Series'> 0 3 2 300 Name: 2, dtype: int64 0x1e72a8a8348# ilocによる取り出し # 行指定(指定した行範囲と列範囲) d = df.iloc[0:2,2:4] print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 2 3 0 3 4 1 30 40 0x1e72a95b848# ilocによる取り出し # 行指定(指定した行と列) d = df.iloc[0,2] print(type(d)) print(d) print(hex(id(d)))<class 'numpy.int64'> 3 0x1e72ad9af50# ilocによる取り出し # 行指定(指定した行と列) d = df.iloc[[0],2] print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.series.Series'> 0 3 Name: 2, dtype: int64 0x1e72a942c48# ilocによる取り出し # 行指定(指定した行と列) d = df.iloc[0,[2]] print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.series.Series'> 2 3 Name: 0, dtype: int64 0x1e72a930b48# ilocによる取り出し # 行指定(指定した行と列) d = df.iloc[[0],[2]] print(type(d)) print(d) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 2 0 3 0x1e72b037c48代入
列指定
# ilocによる代入 # 列指定(範囲) df1 = df.copy() df1.iloc[:,2] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 4 5 1 10 20 1000 40 50 2 100 200 1000 400 500 0x1e72b037c48# ilocによる代入 # 列指定(範囲) df1 = df.copy() df1.iloc[:,2:3] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 4 5 1 10 20 1000 40 50 2 100 200 1000 400 500 0x1e72b037c48# ilocによる代入 # 列指定(範囲) df1 = df.copy() df1.iloc[:, [True, False, True, False, True]] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1000 2 1000 4 1000 1 1000 20 1000 40 1000 2 1000 200 1000 400 1000 0x1e72b037c48# ilocによる代入 # 列指定(範囲) df1 = df.copy() df1.iloc[:, [0,2]] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1000 2 1000 4 5 1 1000 20 1000 40 50 2 1000 200 1000 400 500 0x1e72b037c48# ilocによる代入 # 列指定(範囲) df1 = df.copy() df1.iloc[:, [2]] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 4 5 1 10 20 1000 40 50 2 100 200 1000 400 500 0x1e72b037c48行指定
# ilocによる代入 # 行指定 df1 = df.copy() df1.iloc[0] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1000 1000 1000 1000 1000 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72b037c48# ilocによる代入 # 行指定 df1 = df.copy() df1.iloc[[0]] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1000 1000 1000 1000 1000 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72b037c48# ilocによる代入 # 行指定(個別指定) df1 = df.copy() df1.iloc[[0,2]] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1000 1000 1000 1000 1000 1 10 20 30 40 50 2 1000 1000 1000 1000 1000 0x1e72b037c48# ilocによる代入 # 行指定(範囲指定) df1 = df.copy() df1.iloc[0:2] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1000 1000 1000 1000 1000 1 1000 1000 1000 1000 1000 2 100 200 300 400 500 0x1e72b037c48行と列の指定
# ilocによる代入 # 行指定(指定した行と列範囲) df1 = df.copy() df1.iloc[0,2:4] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 1000 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72b037c48# ilocによる代入 # 行指定(指定した行と列範囲) df1 = df.copy() df1.iloc[0,[2,4]] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 4 1000 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72b037c48# ilocによる代入 # 行指定(指定した行と列範囲) df1 = df.copy() df1.iloc[0:2,2] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 4 5 1 10 20 1000 40 50 2 100 200 300 400 500 0x1e72b037c48# ilocによる代入 # 行指定(指定した列と行範囲) df1 = df.copy() df1.iloc[[0,2],2] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 4 5 1 10 20 30 40 50 2 100 200 1000 400 500 0x1e72b037c48# ilocによる代入 # 行指定(指定した行範囲と列範囲) df1 = df.copy() df1.iloc[0:2,2:4] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 1000 5 1 10 20 1000 1000 50 2 100 200 300 400 500 0x1e72b037c48# ilocによる代入 # 行指定(指定した行と列) df1 = df.copy() df1.iloc[0,2] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72b037c48# ilocによる代入 # 行指定(指定した行と列) df1 = df.copy() df1.iloc[[0],2] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72b037c48# ilocによる代入 # 行指定(指定した行と列) df1 = df.copy() df1.iloc[0,[2]] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72b037c48# ilocによる代入 # 行指定(指定した行と列) df1 = df.copy() df1.iloc[[0],[2]] = 1000 print(type(df1)) print(df1) print(hex(id(d)))<class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72b037c48関数への引数
def for_Int(d): print("----for_Int--") print(type(d)) print(hex(id(d))) d = 1000 print(d) print("----for_Int--") def for_Series(d): print("----for_Series--") print(type(d)) print(hex(id(d))) d[0] = 1000 print(d) print("----for_Series--") def for_DataFrameIat(d): print("----for_DataFrameIat--") print(type(d)) print(hex(id(d))) d.iat[0,0] = 1000 print(d) print("----for_DataFrameIat--") def for_DataFrameIloc(d): print("----for_DataFrameIloc--") print(type(d)) print(hex(id(d))) d.iloc[0,0] = 1000 print(d) print("----for_DataFrameIloc--")列指定
# 列指定 df1 = df.copy() for_Series(df1.iloc[:,2]) print(type(df1)) print(df1) print(hex(id(d)))----for_Series-- <class 'pandas.core.series.Series'> 0 1000 1 30 2 300 Name: 2, dtype: int64 ----for_Series-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72b037c48# 列指定(範囲) df1 = df.copy() for_DataFrameIat(df1.iloc[:,2:3]) print(type(df1)) print(df1) print(hex(id(df1))) df2 = df.copy() for_DataFrameIloc(df2.iloc[:,2:3]) print(type(df1)) print(df1) print(hex(id(df1)))----for_DataFrame-- <class 'pandas.core.frame.DataFrame'> 2 0 1000 1 30 2 300 ----for_DataFrame-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a95b288 ----for_DataFrame-- <class 'pandas.core.frame.DataFrame'> 2 0 1000 1 30 2 300 ----for_DataFrame-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a95b288 C:\Users\akira\Anaconda3\lib\site-packages\pandas\core\indexing.py:671: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy self._setitem_with_indexer(indexer, value) C:\Users\akira\Anaconda3\lib\site-packages\ipykernel_launcher.py:19: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy関数内においてilocで代入すると警告が表示される
# 列指定(範囲) df1 = df.copy() for_DataFrameIat(df1.iloc[:, [True, False, True, False, True]]) print(type(df1)) print(df1) print(hex(id(df1))) df1 = df.copy() for_DataFrameIloc(df1.iloc[:, [True, False, True, False, True]]) print(type(df1)) print(df1) print(hex(id(df1)))----for_DataFrame-- <class 'pandas.core.frame.DataFrame'> 0 2 4 0 1000 3 5 1 10 30 50 2 100 300 500 ----for_DataFrame-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a909188 ----for_DataFrame-- <class 'pandas.core.frame.DataFrame'> 0 2 4 0 1000 3 5 1 10 30 50 2 100 300 500 ----for_DataFrame-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a91d948 C:\Users\akira\Anaconda3\lib\site-packages\pandas\core\indexing.py:671: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy self._setitem_with_indexer(indexer, value) C:\Users\akira\Anaconda3\lib\site-packages\ipykernel_launcher.py:19: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy# 列指定(範囲) df1 = df.copy() for_DataFrameIat(df1.iloc[:, [0,2]]) print(type(df1)) print(df1) print(hex(id(df1))) df1 = df.copy() for_DataFrameIloc(df1.iloc[:, [0,2]]) print(type(df1)) print(df1) print(hex(id(df1)))----for_DataFrameIat-- <class 'pandas.core.frame.DataFrame'> 0x1e72b216248 0 2 0 1000 3 1 10 30 2 100 300 ----for_DataFrameIat-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a911848 ----for_DataFrameIloc-- <class 'pandas.core.frame.DataFrame'> 0x1e72b216348 0 2 0 1000 3 1 10 30 2 100 300 ----for_DataFrameIloc-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72b216848 C:\Users\akira\Anaconda3\lib\site-packages\pandas\core\indexing.py:671: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy self._setitem_with_indexer(indexer, value) C:\Users\akira\Anaconda3\lib\site-packages\ipykernel_launcher.py:22: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy# 列指定(範囲) df1 = df.copy() for_DataFrameIat(df1.iloc[:, [2]]) print(type(df1)) print(df1) print(hex(id(df1))) df1 = df.copy() for_DataFrameIloc(df1.iloc[:, [2]]) print(type(df1)) print(df1) print(hex(id(df1)))----for_DataFrameIat-- <class 'pandas.core.frame.DataFrame'> 2 0 1000 1 30 2 300 ----for_DataFrameIat-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72b02ef48 ----for_DataFrameIloc-- <class 'pandas.core.frame.DataFrame'> 2 0 1000 1 30 2 300 ----for_DataFrameIloc-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a8a6448 C:\Users\akira\Anaconda3\lib\site-packages\pandas\core\indexing.py:671: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy self._setitem_with_indexer(indexer, value) C:\Users\akira\Anaconda3\lib\site-packages\ipykernel_launcher.py:19: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy行指定
df1 = df.copy() for_Series(df1.iloc[0]) print(type(df1)) print(df1) print(hex(id(df1)))----for_Series-- <class 'pandas.core.series.Series'> 0 1000 1 2 2 3 3 4 4 5 Name: 0, dtype: int64 ----for_Series-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1000 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72b042608df1 = df.copy() for_DataFrameIat(df1.iloc[[0]] ) print(type(df1)) print(df1) print(hex(id(df1))) df1 = df.copy() for_DataFrameIloc(df1.iloc[[0]] ) print(type(df1)) print(df1) print(hex(id(df1)))----for_DataFrameIat-- <class 'pandas.core.frame.DataFrame'> 0x1e72a91e4c8 0 1 2 3 4 0 1000 2 3 4 5 ----for_DataFrameIat-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72b042b08 ----for_DataFrameIloc-- <class 'pandas.core.frame.DataFrame'> 0x1e72a909c88 0 1 2 3 4 0 1000 2 3 4 5 ----for_DataFrameIloc-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a95b0c8 C:\Users\akira\Anaconda3\lib\site-packages\pandas\core\indexing.py:671: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy self._setitem_with_indexer(indexer, value) C:\Users\akira\Anaconda3\lib\site-packages\ipykernel_launcher.py:22: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy# 行指定(個別指定) df1 = df.copy() for_DataFrameIat(df1.iloc[[0,2]] ) print(type(df1)) print(df1) print(hex(id(df1))) df1 = df.copy() for_DataFrameIloc(df1.iloc[[0,2]] ) print(type(df1)) print(df1) print(hex(id(df1)))----for_DataFrameIat-- <class 'pandas.core.frame.DataFrame'> 0x1e72b042f48 0 1 2 3 4 0 1000 2 3 4 5 2 100 200 300 400 500 ----for_DataFrameIat-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a959a08 ----for_DataFrameIloc-- <class 'pandas.core.frame.DataFrame'> 0x1e72a941788 0 1 2 3 4 0 1000 2 3 4 5 2 100 200 300 400 500 ----for_DataFrameIloc-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72b0421c8 C:\Users\akira\Anaconda3\lib\site-packages\pandas\core\indexing.py:671: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy self._setitem_with_indexer(indexer, value) C:\Users\akira\Anaconda3\lib\site-packages\ipykernel_launcher.py:22: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy# 列指定(範囲) df1 = df.copy() for_DataFrameIat(df1.iloc[0:2]) print(type(df1)) print(df1) print(hex(id(df1))) df1 = df.copy() for_DataFrameIloc(df1.iloc[0:2]) print(type(df1)) print(df1) print(hex(id(df1)))----for_DataFrameIat-- <class 'pandas.core.frame.DataFrame'> 0x1e72a942c48 0 1 2 3 4 0 1000 2 3 4 5 1 10 20 30 40 50 ----for_DataFrameIat-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1000 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a942d08 ----for_DataFrameIloc-- <class 'pandas.core.frame.DataFrame'> 0x1e72a93cd48 0 1 2 3 4 0 1000 2 3 4 5 1 10 20 30 40 50 ----for_DataFrameIloc-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1000 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a8b1fc8 C:\Users\akira\Anaconda3\lib\site-packages\pandas\core\indexing.py:671: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy self._setitem_with_indexer(indexer, value) C:\Users\akira\Anaconda3\lib\site-packages\ipykernel_launcher.py:22: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy行と列の指定
# 行指定(指定した行と列範囲) df1 = df.copy() for_Series(df1.iloc[0,2:4]) print(type(df1)) print(df1) print(hex(id(df1)))----for_Series-- <class 'pandas.core.series.Series'> 0x1e72b216348 2 3 3 4 0 1000 Name: 0, dtype: int64 ----for_Series-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72b2169c8# 行指定(指定した行と列範囲) df1 = df.copy() for_Series(df1.iloc[0,[2,4]]) print(type(df1)) print(df1) print(hex(id(df1)))----for_Series-- <class 'pandas.core.series.Series'> 0x1e72b216208 2 3 4 5 0 1000 Name: 0, dtype: int64 ----for_Series-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a92edc8# 行指定(指定した行と列範囲) df1 = df.copy() for_Series(df1.iloc[0:2,2]) print(type(df1)) print(df1) print(hex(id(df1)))----for_Series-- <class 'pandas.core.series.Series'> 0x1e72a955708 0 1000 1 30 Name: 2, dtype: int64 ----for_Series-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72b2164c8# 行指定(指定した列と行範囲) df1 = df.copy() for_Series(df1.iloc[[0,2],2]) print(type(df1)) print(df1) print(hex(id(df1)))----for_Series-- <class 'pandas.core.series.Series'> 0x1e72adfe188 0 1000 2 300 Name: 2, dtype: int64 ----for_Series-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a930d08# 行指定(指定した行範囲と列範囲) df1 = df.copy() for_DataFrameIat(df1.iloc[0:2,2:4]) print(type(df1)) print(df1) print(hex(id(df1))) df1 = df.copy() for_DataFrameIloc(df1.iloc[0:2,2:4]) print(type(df1)) print(df1) print(hex(id(df1)))----for_DataFrameIat-- <class 'pandas.core.frame.DataFrame'> 0x1e72a929c08 2 3 0 1000 4 1 30 40 ----for_DataFrameIat-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a929388 ----for_DataFrameIloc-- <class 'pandas.core.frame.DataFrame'> 0x1e72a91b1c8 2 3 0 1000 4 1 30 40 ----for_DataFrameIloc-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 1000 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a8e6e48# 行指定(指定した行と列) df1 = df.copy() for_Int(df1.iloc[0,2]) print(type(df1)) print(df1) print(hex(id(df1)))----for_Int-- <class 'numpy.int64'> 0x1e72b3f0d10 1000 ----for_Int-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a8bedc8# 行指定(指定した行と列) df1 = df.copy() for_Series(df1.iloc[[0],2]) print(type(df1)) print(df1) print(hex(id(df1)))----for_Series-- <class 'pandas.core.series.Series'> 0x1e72b08c108 0 1000 Name: 2, dtype: int64 ----for_Series-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a8c4188# 行指定(指定した行と列) df1 = df.copy() for_Series(df1.iloc[0,[2]] ) print(type(df1)) print(df1) print(hex(id(df1)))----for_Series-- <class 'pandas.core.series.Series'> 0x1e72a91d648 2 3 0 1000 Name: 0, dtype: int64 ----for_Series-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a97f5c8# 行指定(指定した行と列) df1 = df.copy() for_DataFrameIat(df1.iloc[[0],[2]]) print(type(df1)) print(df1) print(hex(id(df1))) df1 = df.copy() for_DataFrameIloc(df1.iloc[[0],[2]]) print(type(df1)) print(df1) print(hex(id(df1)))----for_DataFrameIat-- <class 'pandas.core.frame.DataFrame'> 0x1e72a921248 2 0 1000 ----for_DataFrameIat-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a942d08 ----for_DataFrameIloc-- <class 'pandas.core.frame.DataFrame'> 0x1e72a8ed708 2 0 1000 ----for_DataFrameIloc-- <class 'pandas.core.frame.DataFrame'> 0 1 2 3 4 0 1 2 3 4 5 1 10 20 30 40 50 2 100 200 300 400 500 0x1e72a9410c8
- 投稿日:2021-03-03T15:04:23+09:00
Python, tsvファイルの読み取り方
- 投稿日:2021-03-03T14:48:39+09:00
pandasのplotを用いたカテゴリカル値と連続値の可視化
pandasのplotを用いたカテゴリカル値と連続値の可視化
kaggleとかでcsvファイルのデータ分析をする際に,keyごとの特徴量を可視化して比較したくなったりするので.
カテゴリカル値の場合はバーの上に数を表示.Content
- カテゴリカル値の可視化
- 連続値の可視化
- 2DataFrame 間のカテゴリカル値の比較
- 2DataFrame 間の連続値の比較
必要なライブラリのimport
python3import pandas as pd import numpy as np import matplotlib import matplotlib.pyplot as plt np.random.seed(seed=0)jupyter notebookなら以下も追加
python3%matplotlib inlineDataFrameの準備
python3length=500 train_df = pd.DataFrame(np.random.normal(loc=0, scale=1, size=(length)),columns=["cont"]) eval_df = pd.DataFrame(np.random.normal(loc=1, scale=0.5, size=(length)),columns=["cont"]) train_df = train_df.assign(cat=np.random.randint(0,5,length)) eval_df = eval_df.assign(cat=np.random.randint(0,6,length))カテゴリカル値の可視化
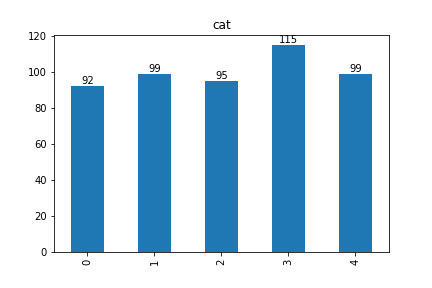
python3def categorical_plot(df, key): data = df[key].value_counts(sort=False) ax = df[key].value_counts(sort=False).plot(kind="bar", title=key) for i, d in enumerate(data): ax.text(i, d, d, horizontalalignment="center", verticalalignment="bottom") return axpython3categorical_plot(train_df, "cat")
連続値の可視化
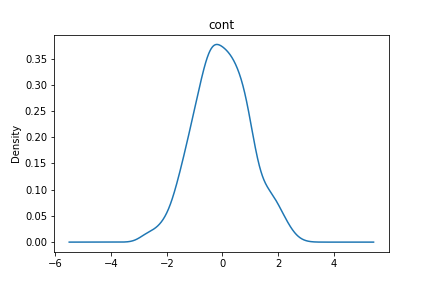
python3def continuous_plot(df, key): ax = df[key].plot(kind="density", title=key) return axpython3continuous_plot(train_df, "cont")
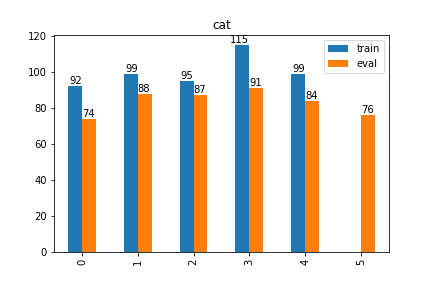
2DataFrame間のカテゴリカル値の比較
python3def compare_cat(trdf, evdf, key): tr_df = trdf.rename(columns={key: "train"}) ev_df = evdf.rename(columns={key: "eval"}) tr_df = tr_df["train"].value_counts(sort=False) ev_df = ev_df["eval"].value_counts(sort=False) plot_df = pd.concat([tr_df, ev_df], axis=1) ax = plot_df.plot(kind="bar", title=key) for i, d in enumerate(tr_df): ax.text(i, d, d, horizontalalignment="right", verticalalignment="bottom") for i, d in enumerate(ev_df): ax.text(i, d, d, horizontalalignment="left", verticalalignment="bottom") return axpython3compare_cat(train_df, eval_df, "cat")
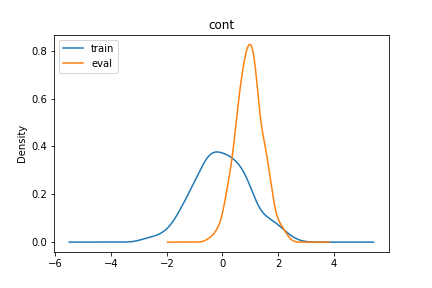
2DataFrame間の連続値の比較
python3def compare_cont(trdf, evdf, key): tr_df = trdf.rename(columns={key: "train"})["train"] ev_df = evdf.rename(columns={key: "eval"})["eval"] plot_df = pd.concat([tr_df, ev_df], axis=1) ax = plot_df.plot(kind="density", title=key).legend(loc="upper left") return axpython3compare_cont(train_df, eval_df, "cont")
- 投稿日:2021-03-03T14:48:39+09:00
pandasのplotを用いたカテゴリカル値と連続値の分布の可視化
pandasのplotを用いたカテゴリカル値と連続値の分布の可視化
kaggleとかでcsvファイルのデータ分析をする際に,keyごとの特徴量の分布を可視化して比較したくなる.
カテゴリカル値の場合はバーの上に数を表示.Content
- カテゴリカル値の可視化
- 連続値の可視化
- 2DataFrame 間のカテゴリカル値の比較
- 2DataFrame 間の連続値の比較
必要なライブラリのimport
python3import pandas as pd import numpy as np import matplotlib import matplotlib.pyplot as plt np.random.seed(seed=0)jupyter notebookなら以下も追加
python3%matplotlib inlineDataFrameの準備
python3length=500 train_df = pd.DataFrame(np.random.normal(loc=0, scale=1, size=(length)),columns=["cont"]) eval_df = pd.DataFrame(np.random.normal(loc=1, scale=0.5, size=(length)),columns=["cont"]) train_df = train_df.assign(cat=np.random.randint(0,5,length)) eval_df = eval_df.assign(cat=np.random.randint(0,6,length))カテゴリカル値の可視化
python3def categorical_plot(df, key): data = df[key].value_counts(sort=False) ax = df[key].value_counts(sort=False).plot(kind="bar", title=key) for i, d in enumerate(data): ax.text(i, d, d, horizontalalignment="center", verticalalignment="bottom") return axpython3categorical_plot(train_df, "cat")
連続値の可視化
python3def continuous_plot(df, key): ax = df[key].plot(kind="density", title=key) return axpython3continuous_plot(train_df, "cont")
2DataFrame間のカテゴリカル値の比較
python3def compare_cat(trdf, evdf, key): tr_df = trdf.rename(columns={key: "train"}) ev_df = evdf.rename(columns={key: "eval"}) tr_df = tr_df["train"].value_counts(sort=False) ev_df = ev_df["eval"].value_counts(sort=False) plot_df = pd.concat([tr_df, ev_df], axis=1) ax = plot_df.plot(kind="bar", title=key) for i, d in enumerate(tr_df): ax.text(i, d, d, horizontalalignment="right", verticalalignment="bottom") for i, d in enumerate(ev_df): ax.text(i, d, d, horizontalalignment="left", verticalalignment="bottom") return axpython3compare_cat(train_df, eval_df, "cat")
2DataFrame間の連続値の比較
python3def compare_cont(trdf, evdf, key): tr_df = trdf.rename(columns={key: "train"})["train"] ev_df = evdf.rename(columns={key: "eval"})["eval"] plot_df = pd.concat([tr_df, ev_df], axis=1) ax = plot_df.plot(kind="density", title=key).legend(loc="upper left") return axpython3compare_cont(train_df, eval_df, "cont")
- 投稿日:2021-03-03T14:02:30+09:00
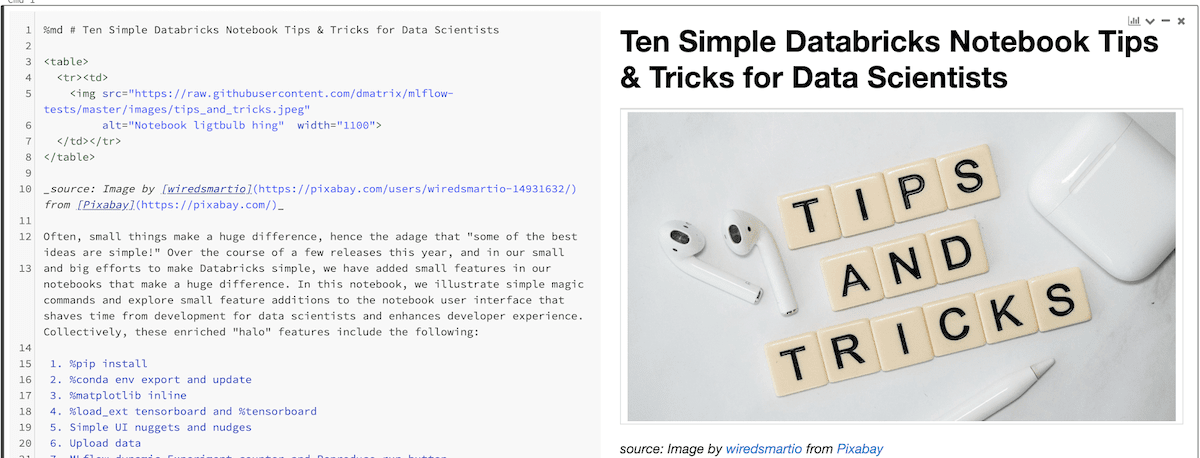
データサイエンスのためのDatabricksの10のtips & tricks
Ten Simple Databricks Notebook Tips & Tricks for Data Scientists - The Databricks Blogの翻訳です。
"ベストなアイデアのいくつかはシンプルなものである!(some of the best ideas are simple!)"と言う格言が示す通り、小さな物事の積み重ねが大きな違いに繋がると言うことはよくあることです。2020年を通じて何回かのリリースを通じて、Databricksをよりシンプルするために、大きな違いに繋がる小さな機能追加を行いました。
本記事および関連ノートブックにおいては、データサイエンティストの開発経験を改善し、開発時間を短縮するために追加した、シンプルなマジックコマンドおよびノートブックにおけるユーザーインタフェースをご紹介します。
これらの機能は以下の通りとなります:
- %pip install
- %conda env export および update
- %matplotlib inline
- %load_ext tensorboard および %tensorboard
- コードをモジュール化するために %run による外部ノートブックの実行
- データのアップロード
- MLflow: Experimentの動的カウンター および Reproduce run ボタン
- UIに関するちょっとしたノウハウ
- SQLコードのフォーマット
- クラスターにログインするためのWebターミナル
シンプルにするために、個々の機能の使い方をこちらにまとめています。しかし、ノートブックをダウンロードすることをお勧めします。もし、Databricksの統合データ分析プラットフォームを利用したことが無いのでしたら、こちらから利用できます。ノートブックをDatabricks統合分析プラットフォームにインポートして実行するだけです。
1. %pipマジックコマンド: Pythonパッケージのインストール及びPython環境の管理
Databricks Runtime(DBR)あるいはDatabricks Runtime for Machine Learning(MLR)には一連のPython及び機械学習(ML)ライブラリがインストールされています。しかし、実行したいタスクに適合したライブラリやバージョンが存在しないケースがあります。この場合、%pipや%condaを使用することで簡単にクラスター上のPythonパッケージをカスタマイズすることができます。
この機能がリリースされる前は、データサイエンティストはinit scriptを作成し、wheelファイルをローカルで構築し、dbfs上にアップロードし、パッケージをインストールするためにinit scriptを実行する必要がありました。これは脆弱なプロセスです。今では、プライベートあるいはパブリックなリポジトリに対して
%pip install <package>を実行するだけで済みます。あるいは、複数のパッケージをインストールする必要がある場合には、
%pip install -r <path>/requirements.txtを実行することができます。pipとcondaを用いて、どの様にnotebookスコープのPython環境を管理するのかに関して理解を深めるのでしたら、こちらのブログを参考にしてください。
2. %condaおよび%pipマジックコマンド: Notebook環境の共有
クラスター環境がセットアップされると、いくつかのことが実行できる様になります。
a) 以降のセッションで再インストールできる様にファイルを保存する
b) 他の人に保存したファイルを共有するクラスターは揮発性なものですので、クラスターがシャットダウンされるとインストールされたライブラリは削除されます。インストールされたパッケージのリストを保存することは良いプラクティスです。これにより、再現性を確保できるとともに、データチームのメンバーが検証開発のために環境を再構築できる様になります。%condaマジックコマンドは2020年にリリースされた新機能の一部となっています。これにより作業がシンプルになります。インストールされたPythonパッケージのリストをエクスポートして保存するだけです。
%conda env export -f /jsd_conda_env.yml or %pip freeze > /jsd_pip_env.txt共通のシャードあるいはパブリックdbfsから、別のデータサイエンティストが
%conda env update -f <yaml_file_path>を実行することでPythonパッケージを再現することができます。3. %matplotlibマジックコマンド: 画像をインラインに表示
探索的データ分析(EDA)においては、データの可視化は重要なステップとなります。データのクレンジング後に限らず、特徴量エンジニアリング、モデルトレーニングに至るまで、データにおけるパターン、関係性を見出すために可視化を行いたくなるでしょう。
数多くのデータ可視化のためのPythonライブラリのなかで、
matplotlibが共通して用いられています。DBRやMLRにおいてはいくつかのPythonライブラリがインストールされていますが、現状matplotlib inline機能のみがノートブックセルでサポートされています。DBR 6.5以降でビルトインされているマジックコマンドにより、
display(figure)やdisplay(figure.show())の明示的な呼び出しや、spark.databricks.workspace.matplotlibInline.enabled = trueの設定なしにノートブックセルのインラインでグラフを表示することができます。4. PyTorch、TensorFlowにおける%tensorboardマジックコマンド
最近発表した通り、Databricks Runtime(DBR)の一部としてリリースされたこのマジックコマンドは、ノートブックにTensorBoardから得られるトレーニングメトリクスを表示するものです。この新機能はこれまで提供していた
dbutils.tensorboard.start()を置き換えるものになります。旧機能は別のタブでTensorBoardのメトリクスを参照する必要があり、データ分析者がノートブックから離れることでフローを切断するものでした。もはや、データ分析者はノートブックを離れて別のタブでTensorBoardを参照する必要はありません。インラインでの可視化は開発者の体験とシンプルさを改善するものです。
DBRやMLRにインストールされているTensorFlowやPyTorchライブラリを利用することができますが、この記事ではPyTorch(ノートブックを参照ください)を使用しています。
%load_ext tensorboard %tensorboard --logdir=./runs5. 外部ノートブックを実行するための%runマジックコマンド
ソフトウェアエンジニアリングにおける一般的なデザインパターンおよびプラクティスを参考にして、データサイエンティストはクラス、変数、ユーティリティメソッドを外部のノートブックを定義できます。すなわち、データサイエンティストは、IDEでPythonモジュールをimportする様に、これらのクラスを"インポート"することができます。厳密に言うと、ノートブックの場合は、
%run auxiliary_notebookコマンドを通じて、外部ノートブックで定義されたクラスが、現在実行しているノートブックのスコープに読み込まれる形になります。これまで述べてきた新機能と異なり、これは新しいものではありませんが、この機能を利用することで、全体をまとまりあるものにし、driver(メイン)ノートブックの可読性を高めます。何人かの開発者は、データ処理を別のノートブックに分割するために外部ノートブックを活用しています。個々のノートブックがデータ処理、探索のためのデータ分析を行い、結果を呼び出し元のノートブックに返却します。
外部ノートブックの他の使い道としては、クラス、変数、ユーティリティ関数の再利用が挙げられます。例えば、
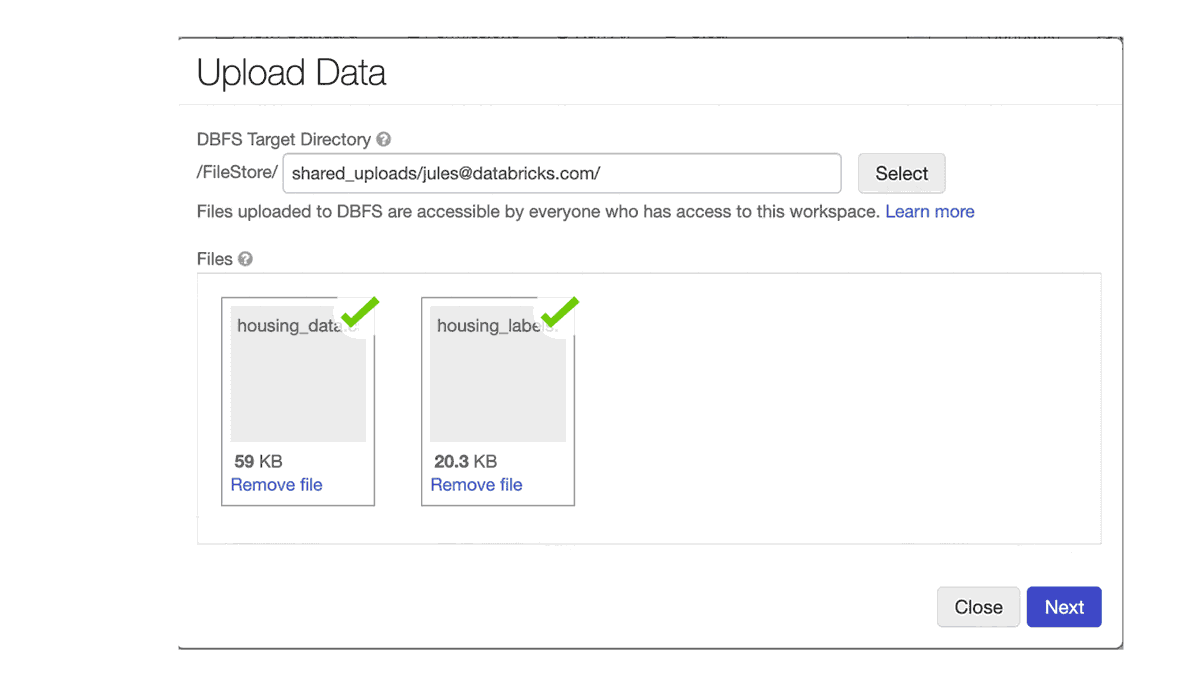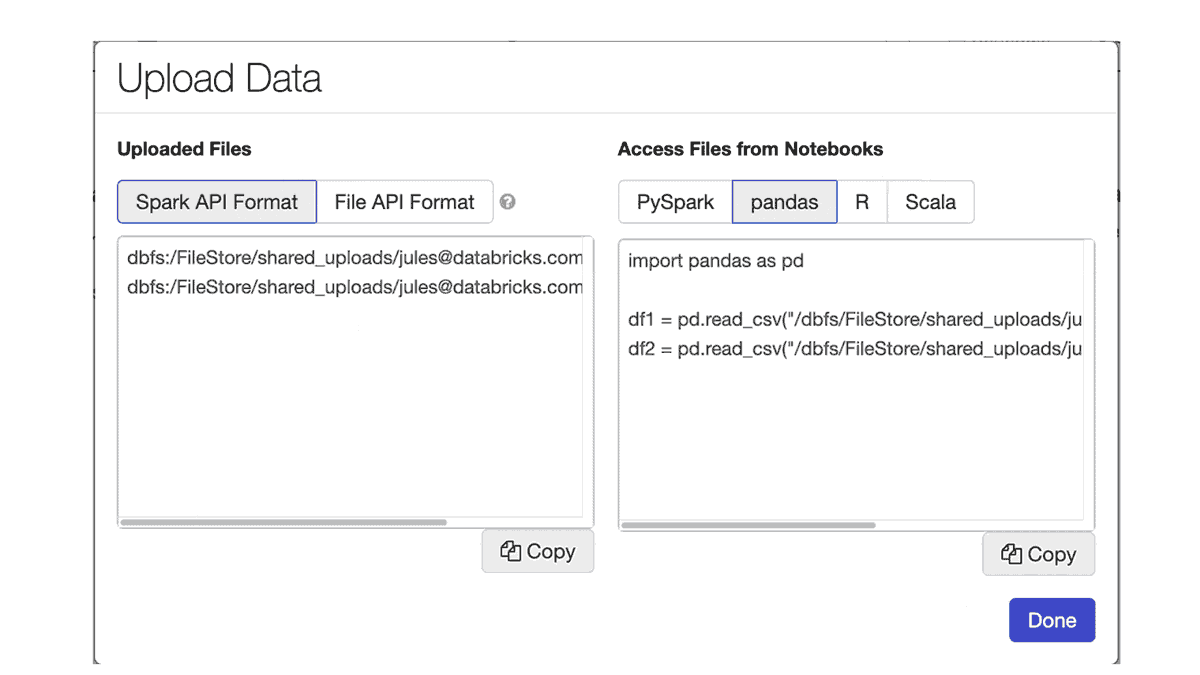
UtilsやRFRModelなどのクラスが外部ノートブックcls/import_classesで定義されます。%run ./cls/import_classesを実行することで、呼び出し元のノートブックのスコープにこれら全てのクラスが読み込まれます。このシンプルな手順で、ノートブックが散在することが無くなります。クラスを定義し、コードをモジュール化し、再利用するだけです!6. データのアップロード
ラップトップにあるローカルのデータをDatabricksで分析したくなるケースがあるかと思います。ノートブックのFileメニューにある新たなデータアップロード機能でローカルデータをワークスペースにアップロードできます。デフォルトのアップロード先は /shared_uploads/your-email-address となりますが、アップロード先を選択できますし、Upload Fileダイアログからファイルを読み込むためのコードを取得することができます。今回のケースでは、CSVファイルを読み込むためのpandasのコードを選択しています。
7.1 MLflow Experimentの動的カウンター
MLflowのUIはDatabricksと密に連携しています。MLflow APIを用いてモデルをトレーニングする都度、データサイエンティストにビジュアルなフィードバックを提供するために
Experimentラベルのカウンターが動的に増加します。
Experimentをクリックすることで、画面横に個々のRunのMLflowエンティティであるrun、パラメーター、メトリクス、モデルなどを含むサマリーを一覧で表示します。7.2 MLflow Reproduce Runボタン
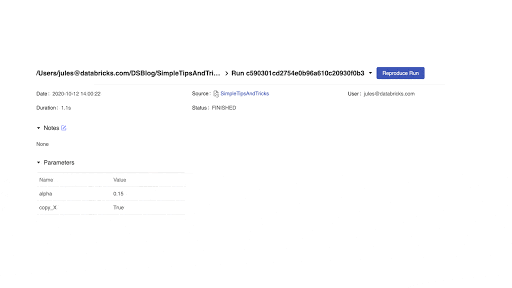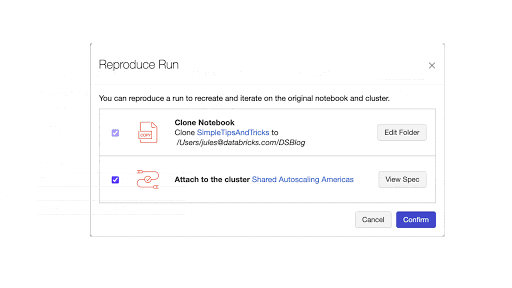
他の改善点として、Experimentを再現するためのノートブックを再作成する機能があります。MLflowのrunページからReproduce Runボタンをクリックすることでノートブックを生成し現在のクラスターにアタッチされます。
8. UIに関するちょっとしたノウハウ
データサイエンティストが自身のタスクを効率的にこなすために、データの中身を確認する、セル削除のアンドゥ、分割スクリーンの表示などを含め、ノートブックにおいては以下の改善がなされています:
より高速な処理実行のための電球ヒント(light bulb hint): ノートブック上のセルが実行される都度、Databricks runtimeは目の前のタスクを効率的にするためのヒントを提示することがあります。例えば、モデルのトレーニングを行なっている際には、MLflowによるパラメーター、メトリクスのトラッキングを提案します。
あるいは、SQLテーブルとしてParquet形式のデータフレームをSQLテーブルとして永続化しようとした際に、より効率的、信頼性のあるDelta Lakeのテーブルをお勧めします。また、バックエンドのエンジンが、最適化の余地がある複雑なSpark処理、あるいは、不均一なデータフレーム(一方が非常に大きく、一方が非常に小さい)のJOINを実行しようとしていることを検知した場合には、より良いパフォーマンスのためにApache Spark 3.0の適合クエリ実行を提案します。
これらの小さなノウハウによって、データサイエンティストやデータエンジニアが、最適化されたSparkの機能や、トレーニングを容易に管理できるMLflowの様なツールを活用できる様になります。
セル削除のアンドゥ: 重要なコードを開発する過程で、不可逆的にセルを削除してしまい、取り返しのつかない状態になって初めてそれに気づくと言うことを何度経験したことがありますでしょうか。今となっては、ノートブックが削除されたセルを追跡していますので、簡単にセル削除をアンドゥできます。
ここまでを全て実行(Run All Above): いくつかのシナリオにおいては、現在のセルの上までのセルにあったバグを修正し、上にあるセル全てを実行したいと言うケースがあるかと思います。この作業を簡単に実行できます。
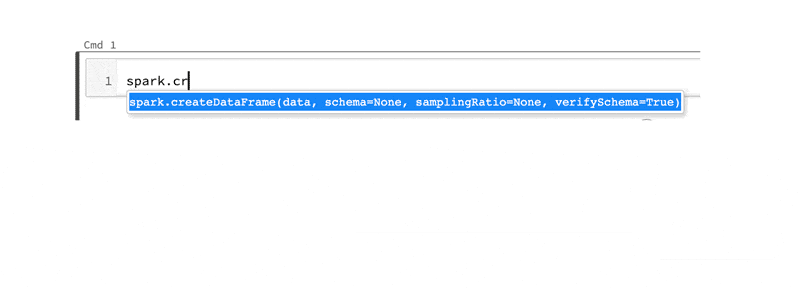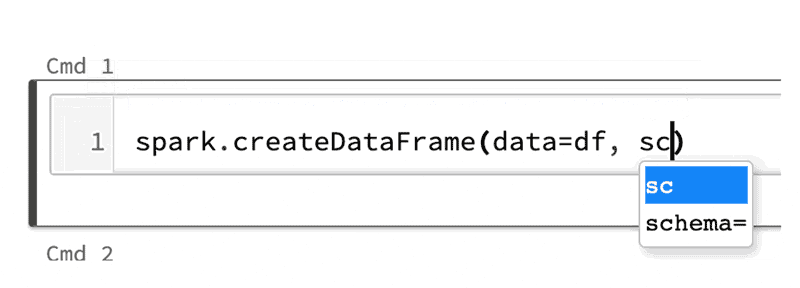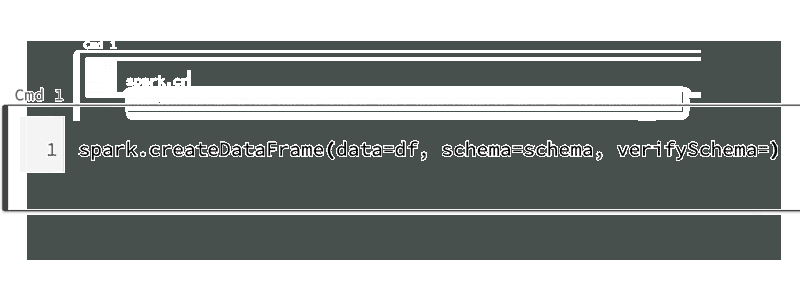
コードコンプリーションのためのタブキー: 一般的なPython3の関数、Spark 3.0のメソッド両方に対して、メソッド名の後でタブキーを押すと、メソッド、プロパティがドロップダウンリストが表示されます。
Side-by-Sideビュー: PyCharmの様なPython IDE同様、ノートブック上でマークダウンの内容とレンダリング結果を横並びで表示することができます。メニューのView->Side-by-Sideを選択することでビューを切り替えることができます。
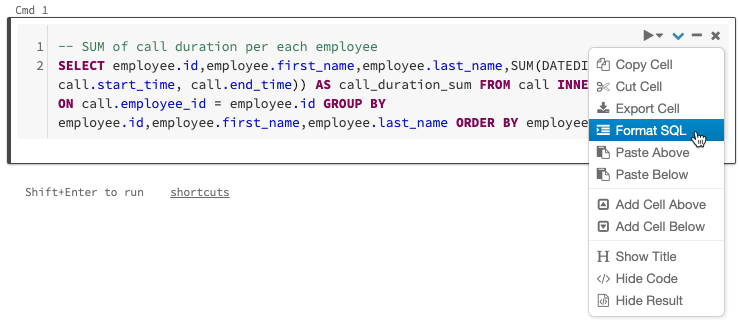
9. SQLコードのフォーマット
新たな機能ではないですが、このノウハウによって、フリーフォーマットで書かれたSQLを簡単にフォーマットできます。
10. クラスターにログインするためのWebターミナル
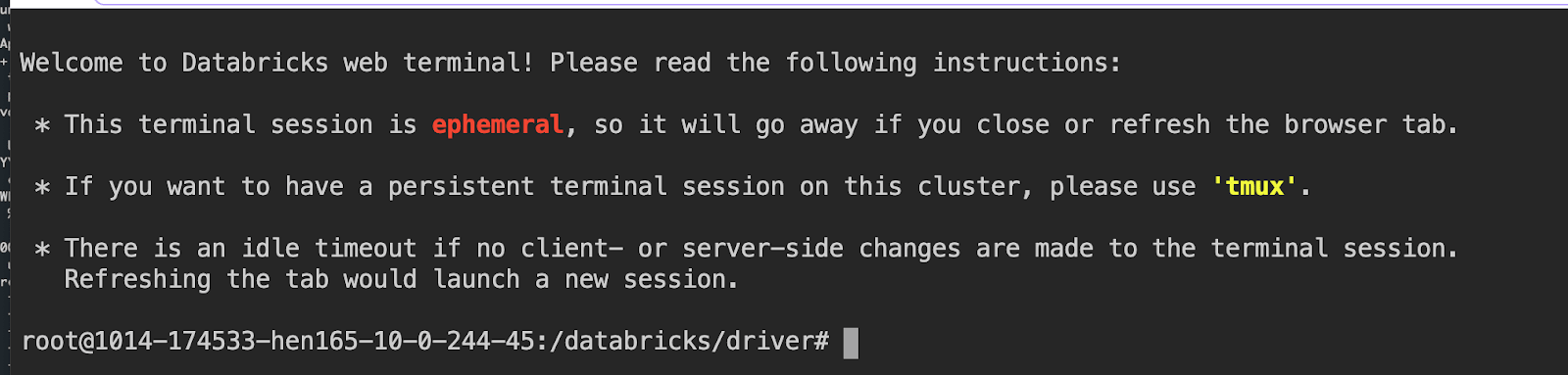
データサイエンティストを含むデータチームの方々は、ノートブックから直接ドライバーノードにログインできます。面倒なsshの設定が必要となるsshマジックコマンドの%shは不要です。さらに、システム管理者、セキュリティ担当は仮想プライベートネットワークにsshポートを開けることを嫌がります。ユーザー視点からしても、ドライバーノードにアクセスするためにSSHキーのセットアップが不要です。お使いのワークスペースの管理者が、クラスターに対して"Can Attach To"権限を付与していれば、すぐにWebターミナルを利用できます。
こちらの記事で発表されている様に、完全にインタラクティブなシェルとドライバーノードに対して制御されたアクセスを提供します。Webターミナルを使うためには、ドロップダウンメニューからTerminalを選択します。
これらの機能は小さいながらも、実験、プレゼンテーション、データ探索に至るプロセスにおける摩擦を軽減し、コードフローを円滑にします。次回は、これらのシンプルなアイデアをDatabricksノートブック上で実現してみてください。サンプルノートブックをダウンロードいただき、Databricks統合データ分析プラットフォーム(DBR 7.2以降あるいはMLR 7.2以降)でインポートの上、活用してみてください。
データチームがどのように困難な課題を解決するのかを知りたいのでしたら、是非Data + AI Summit Europeを見てください。



- 投稿日:2021-03-03T14:02:30+09:00
データサイエンティスト向けの10個のシンプルなDatabricksノートブック tips & tricks
Ten Simple Databricks Notebook Tips & Tricks for Data Scientists - The Databricks Blogの翻訳です。
"ベストなアイデアのいくつかはシンプルなものである!(some of the best ideas are simple!)"と言う格言が示す通り、小さな物事の積み重ねが大きな違いに繋がると言うことはよくあることです。2020年を通じて何回かのリリースを通じて、Databricksをよりシンプルするために、大きな違いに繋がる小さな機能追加を行いました。
本記事および関連ノートブックにおいては、データサイエンティストの開発経験を改善し、開発時間を短縮するために追加した、シンプルなマジックコマンドおよびノートブックにおけるユーザーインタフェースをご紹介します。
これらの機能は以下の通りとなります:
- %pip install
- %conda env export および update
- %matplotlib inline
- %load_ext tensorboard および %tensorboard
- コードをモジュール化するために %run による外部ノートブックの実行
- データのアップロード
- MLflow: Experimentの動的カウンター および Reproduce run ボタン
- UIに関するちょっとしたノウハウ
- SQLコードのフォーマット
- クラスターにログインするためのWebターミナル
シンプルにするために、個々の機能の使い方をこちらにまとめています。しかし、ノートブックをダウンロードすることをお勧めします。もし、Databricksの統合データ分析プラットフォームを利用したことが無いのでしたら、こちらから利用できます。ノートブックをDatabricks統合分析プラットフォームにインポートして実行するだけです。
1. %pipマジックコマンド: Pythonパッケージのインストール及びPython環境の管理
Databricks Runtime(DBR)あるいはDatabricks Runtime for Machine Learning(MLR)には一連のPython及び機械学習(ML)ライブラリがインストールされています。しかし、実行したいタスクに適合したライブラリやバージョンが存在しないケースがあります。この場合、%pipや%condaを使用することで簡単にクラスター上のPythonパッケージをカスタマイズすることができます。
この機能がリリースされる前は、データサイエンティストはinit scriptを作成し、wheelファイルをローカルで構築し、dbfs上にアップロードし、パッケージをインストールするためにinit scriptを実行する必要がありました。これは脆弱なプロセスです。今では、プライベートあるいはパブリックなリポジトリに対して
%pip install <package>を実行するだけで済みます。あるいは、複数のパッケージをインストールする必要がある場合には、
%pip install -r <path>/requirements.txtを実行することができます。pipとcondaを用いて、どの様にnotebookスコープのPython環境を管理するのかに関して理解を深めるのでしたら、こちらのブログを参考にしてください。
2. %condaおよび%pipマジックコマンド: Notebook環境の共有
クラスター環境がセットアップされると、いくつかのことが実行できる様になります。
a) 以降のセッションで再インストールできる様にファイルを保存する
b) 他の人に保存したファイルを共有するクラスターは揮発性なものですので、クラスターがシャットダウンされるとインストールされたライブラリは削除されます。インストールされたパッケージのリストを保存することは良いプラクティスです。これにより、再現性を確保できるとともに、データチームのメンバーが検証開発のために環境を再構築できる様になります。%condaマジックコマンドは2020年にリリースされた新機能の一部となっています。これにより作業がシンプルになります。インストールされたPythonパッケージのリストをエクスポートして保存するだけです。
%conda env export -f /jsd_conda_env.yml or %pip freeze > /jsd_pip_env.txt共通のシャードあるいはパブリックdbfsから、別のデータサイエンティストが
%conda env update -f <yaml_file_path>を実行することでPythonパッケージを再現することができます。3. %matplotlibマジックコマンド: 画像をインラインに表示
探索的データ分析(EDA)においては、データの可視化は重要なステップとなります。データのクレンジング後に限らず、特徴量エンジニアリング、モデルトレーニングに至るまで、データにおけるパターン、関係性を見出すために可視化を行いたくなるでしょう。
数多くのデータ可視化のためのPythonライブラリのなかで、
matplotlibが共通して用いられています。DBRやMLRにおいてはいくつかのPythonライブラリがインストールされていますが、現状matplotlib inline機能のみがノートブックセルでサポートされています。DBR 6.5以降でビルトインされているマジックコマンドにより、
display(figure)やdisplay(figure.show())の明示的な呼び出しや、spark.databricks.workspace.matplotlibInline.enabled = trueの設定なしにノートブックセルのインラインでグラフを表示することができます。4. PyTorch、TensorFlowにおける%tensorboardマジックコマンド
最近発表した通り、Databricks Runtime(DBR)の一部としてリリースされたこのマジックコマンドは、ノートブックにTensorBoardから得られるトレーニングメトリクスを表示するものです。この新機能はこれまで提供していた
dbutils.tensorboard.start()を置き換えるものになります。旧機能は別のタブでTensorBoardのメトリクスを参照する必要があり、データ分析者がノートブックから離れることでフローを切断するものでした。もはや、データ分析者はノートブックを離れて別のタブでTensorBoardを参照する必要はありません。インラインでの可視化は開発者の体験とシンプルさを改善するものです。
DBRやMLRにインストールされているTensorFlowやPyTorchライブラリを利用することができますが、この記事ではPyTorch(ノートブックを参照ください)を使用しています。
%load_ext tensorboard %tensorboard --logdir=./runs5. 外部ノートブックを実行するための%runマジックコマンド
ソフトウェアエンジニアリングにおける一般的なデザインパターンおよびプラクティスを参考にして、データサイエンティストはクラス、変数、ユーティリティメソッドを外部のノートブックを定義できます。すなわち、データサイエンティストは、IDEでPythonモジュールをimportする様に、これらのクラスを"インポート"することができます。厳密に言うと、ノートブックの場合は、
%run auxiliary_notebookコマンドを通じて、外部ノートブックで定義されたクラスが、現在実行しているノートブックのスコープに読み込まれる形になります。これまで述べてきた新機能と異なり、これは新しいものではありませんが、この機能を利用することで、全体をまとまりあるものにし、driver(メイン)ノートブックの可読性を高めます。何人かの開発者は、データ処理を別のノートブックに分割するために外部ノートブックを活用しています。個々のノートブックがデータ処理、探索のためのデータ分析を行い、結果を呼び出し元のノートブックに返却します。
外部ノートブックの他の使い道としては、クラス、変数、ユーティリティ関数の再利用が挙げられます。例えば、
UtilsやRFRModelなどのクラスが外部ノートブックcls/import_classesで定義されます。%run ./cls/import_classesを実行することで、呼び出し元のノートブックのスコープにこれら全てのクラスが読み込まれます。このシンプルな手順で、ノートブックが散在することが無くなります。クラスを定義し、コードをモジュール化し、再利用するだけです!6. データのアップロード
ラップトップにあるローカルのデータをDatabricksで分析したくなるケースがあるかと思います。ノートブックのFileメニューにある新たなデータアップロード機能でローカルデータをワークスペースにアップロードできます。デフォルトのアップロード先は /shared_uploads/your-email-address となりますが、アップロード先を選択できますし、Upload Fileダイアログからファイルを読み込むためのコードを取得することができます。今回のケースでは、CSVファイルを読み込むためのpandasのコードを選択しています。
7.1 MLflow Experimentの動的カウンター
MLflowのUIはDatabricksと密に連携しています。MLflow APIを用いてモデルをトレーニングする都度、データサイエンティストにビジュアルなフィードバックを提供するために
Experimentラベルのカウンターが動的に増加します。
Experimentをクリックすることで、画面横に個々のRunのMLflowエンティティであるrun、パラメーター、メトリクス、モデルなどを含むサマリーを一覧で表示します。7.2 MLflow Reproduce Runボタン
他の改善点として、Experimentを再現するためのノートブックを再作成する機能があります。MLflowのrunページからReproduce Runボタンをクリックすることでノートブックを生成し現在のクラスターにアタッチされます。
8. UIに関するちょっとしたノウハウ
データサイエンティストが自身のタスクを効率的にこなすために、データの中身を確認する、セル削除のアンドゥ、分割スクリーンの表示などを含め、ノートブックにおいては以下の改善がなされています:
より高速な処理実行のための電球ヒント(light bulb hint): ノートブック上のセルが実行される都度、Databricks runtimeは目の前のタスクを効率的にするためのヒントを提示することがあります。例えば、モデルのトレーニングを行なっている際には、MLflowによるパラメーター、メトリクスのトラッキングを提案します。
あるいは、SQLテーブルとしてParquet形式のデータフレームをSQLテーブルとして永続化しようとした際に、より効率的、信頼性のあるDelta Lakeのテーブルをお勧めします。また、バックエンドのエンジンが、最適化の余地がある複雑なSpark処理、あるいは、不均一なデータフレーム(一方が非常に大きく、一方が非常に小さい)のJOINを実行しようとしていることを検知した場合には、より良いパフォーマンスのためにApache Spark 3.0の適合クエリ実行を提案します。
これらの小さなノウハウによって、データサイエンティストやデータエンジニアが、最適化されたSparkの機能や、トレーニングを容易に管理できるMLflowの様なツールを活用できる様になります。
セル削除のアンドゥ: 重要なコードを開発する過程で、不可逆的にセルを削除してしまい、取り返しのつかない状態になって初めてそれに気づくと言うことを何度経験したことがありますでしょうか。今となっては、ノートブックが削除されたセルを追跡していますので、簡単にセル削除をアンドゥできます。
ここまでを全て実行(Run All Above): いくつかのシナリオにおいては、現在のセルの上までのセルにあったバグを修正し、上にあるセル全てを実行したいと言うケースがあるかと思います。この作業を簡単に実行できます。
コードコンプリーションのためのタブキー: 一般的なPython3の関数、Spark 3.0のメソッド両方に対して、メソッド名の後でタブキーを押すと、メソッド、プロパティがドロップダウンリストが表示されます。
Side-by-Sideビュー: PyCharmの様なPython IDE同様、ノートブック上でマークダウンの内容とレンダリング結果を横並びで表示することができます。メニューのView->Side-by-Sideを選択することでビューを切り替えることができます。
9. SQLコードのフォーマット
新たな機能ではないですが、このノウハウによって、フリーフォーマットで書かれたSQLを簡単にフォーマットできます。
10. クラスターにログインするためのWebターミナル
データサイエンティストを含むデータチームの方々は、ノートブックから直接ドライバーノードにログインできます。面倒なsshの設定が必要となるsshマジックコマンドの%shは不要です。さらに、システム管理者、セキュリティ担当は仮想プライベートネットワークにsshポートを開けることを嫌がります。ユーザー視点からしても、ドライバーノードにアクセスするためにSSHキーのセットアップが不要です。お使いのワークスペースの管理者が、クラスターに対して"Can Attach To"権限を付与していれば、すぐにWebターミナルを利用できます。
こちらの記事で発表されている様に、完全にインタラクティブなシェルとドライバーノードに対して制御されたアクセスを提供します。Webターミナルを使うためには、ドロップダウンメニューからTerminalを選択します。
これらの機能は小さいながらも、実験、プレゼンテーション、データ探索に至るプロセスにおける摩擦を軽減し、コードフローを円滑にします。次回は、これらのシンプルなアイデアをDatabricksノートブック上で実現してみてください。サンプルノートブックをダウンロードいただき、Databricks統合データ分析プラットフォーム(DBR 7.2以降あるいはMLR 7.2以降)でインポートの上、活用してみてください。
データチームがどのように困難な課題を解決するのかを知りたいのでしたら、是非Data + AI Summit Europeを見てください。
- 投稿日:2021-03-03T13:40:40+09:00
tensorflow1系を入れずにmellotronを動かす方法
Texarを以下の手順でインストール
git clone https://github.com/asyml/texar-pytorch.git cd texar-pytorch pip install -e .公式ドキュメントより引用
hparams.pyを以下のように書き換える。(ファイルのパスは自分で設定をしてください)
from text.symbols import symbols from texar.torch import HParams # main.py def create_hparams(hparams_string=None, verbose=False): """Create model hyperparameters. Parse nondefault from given string.""" hparams = { ################################ # Experiment Parameters # ################################ "epochs": 50000, "iters_per_checkpoint": 500, "seed": 1234, "dynamic_loss_scaling": True, "fp16_run": False, "distributed_run": False, "dist_backend": "nccl", "dist_url": "tcp://localhost:54321", "cudnn_enabled": True, "cudnn_benchmark": False, "ignore_layers": ['speaker_embedding.weight'], ################################ # Data Parameters # ################################ "training_files": $YOUR_PATH, "validation_files": $YOUR_PATH, "text_cleaners": ['basic_cleaners'], "p_arpabet": 1.0, "cmudict_path": "data/cmu_dictionary", ################################ # Audio Parameters # ################################ "max_wav_value": 32768.0, "sampling_rate": 22050, "filter_length": 1024, "hop_length": 256, "win_length": 1024, "n_mel_channels": 80, "mel_fmin": 0.0, "mel_fmax": 8000.0, "f0_min": 80, "f0_max": 880, "harm_thresh": 0.25, ################################ # Model Parameters # ################################ "n_symbols": len(symbols), "symbols_embedding_dim": 512, # Encoder parameters "encoder_kernel_size": 5, "encoder_n_convolutions": 3, "encoder_embedding_dim": 512, # Decoder parameters "n_frames_per_step": 1, # currently only 1 is supported "decoder_rnn_dim": 1024, "prenet_dim": 256, "prenet_f0_n_layers": 1, "prenet_f0_dim": 1, "prenet_f0_kernel_size": 1, "prenet_rms_dim": 0, "prenet_rms_kernel_size": 1, "max_decoder_steps": 1000, "gate_threshold": 0.5, "p_attention_dropout": 0.1, "p_decoder_dropout": 0.1, "p_teacher_forcing": 1.0, # Attention parameters "attention_rnn_dim": 1024, "attention_dim": 128, # Location Layer parameters "attention_location_n_filters": 32, "attention_location_kernel_size": 31, # Mel-post processing network parameters "postnet_embedding_dim": 512, "postnet_kernel_size": 5, "postnet_n_convolutions": 5, # Speaker embedding "n_speakers": 123, "speaker_embedding_dim": 128, # Reference encoder "with_gst": True, "ref_enc_filters": [32, 32, 64, 64, 128, 128], "ref_enc_size": [3, 3], "ref_enc_strides": [2, 2], "ref_enc_pad": [1, 1], "ref_enc_gru_size": 128, # Style Token Layer "token_embedding_size": 256, "token_num": 10, "num_heads": 8, ################################ # Optimization Hyperparameters # ################################ "use_saved_learning_rate": False, "learning_rate": 1e-3, "learning_rate_min": 1e-5, "learning_rate_anneal": 50000, "weight_decay": 1e-6, "grad_clip_thresh": 1.0, "batch_size": 32, "mask_padding": True, # set model's padded outputs to padded values } """ if hparams_string: tf.compat.v1.logging.info( 'Parsing command line hparams: %s', hparams_string) hparams.parse(hparams_string) if verbose: tf.compat.v1.logging.info('Final parsed hparams: %s', hparams.values()) """ hparams = HParams(hparams, hparams) return hparams
- 投稿日:2021-03-03T13:23:11+09:00
『Django API× React 』でSNSアプリ作成 ~React徹底解剖・デプロイ編~
背景
話題のPython/Djangoに興味を持ったので勉強をはじめました。
ruby on railsを独学で勉強したので、ある程度の動的言語の仕組みは理解しています。
今回はフロントにreact.jsを使ったので、djangoとあまり関係ないですが徹底的に解剖して理解します。以前rails×vueでSPA開発したので、モダンなjavascriptフレームワークはある程度理解しているつもりです。本記事の目標
前回作成したDjango restframeworkのapiを利用してSPAを作成する。フロントはreactを使うが、トレンドのtypescript, react hooks, redux toolkitを理解して使用する。かつDjango APIはAWSを使ってデプロイ、フロントはFirebaseを使ってデプロイしてそれぞれを連携させる。
【使用技術】
■バックエンド
Django restframework, Anaconda-Navigater, PyCharm
■フロントエンド
React Hooks, Redux Tool kit, TypeScript
■インフラ
firebase, AWS(EC2,VPC,ACM,ROUTE53)
【参考】
本記事はudemyの下記講座で学んだ内容のアウトプットです。なのでコード等は講座の内容がベースとなっております。コードは一部省略して、特に自分が引っかかったところを抜粋しています。pythonの基礎文法はprogateとpyqで学びました。
- 『最速で学ぶTypeScript』
- 『[基礎編]React Hooks + Django REST Framework API でフルスタックWeb開発』
- 『[Redux編] Redux Tool KitとReact HooksによるモダンReact フロントエンド開発』
- 『[Instagramクローン編] React Hooks + Django Restframework』
【前回までの関連記事】
Railsしか触ったことないけどPython・Djangoに挑戦してみた 〜環境構築・hello world編〜
Railsしか触ったことないけどPython・Djangoに挑戦してみた 〜簡易SNSアプリ作成編〜
『Django API× React 』でSNSアプリ作成 ~Django APIを徹底解剖編~またaxiosなどに関してはrails×vueの記事で書いてあるのでそちらも参照してください。
【その他参考記事】
目次
- SNSアプリのフロントプロジェクト構造
- Typescriptについて
- react hooksについて
- redux toolkitについて
- AWSとFirebaseでデプロイ
では早速いきましょう。
1. SNSアプリのフロントプロジェクト構造
一部省略しますが大事なところだけ抜粋します。
sns_app
├ api_sns(django側)
└ manage.py
└ api(アプリケーション)/
└ views.py
└ urls.py
└ models.py
└ api_sns(プロジェクト)/
└ settings.py
├ react_sns(react側)
└ public/
└ src/
└ app/
└ features/
└ auth/
└Auth.tsx
└authSlice.tsx
└Auth.module.css
└ core/
└ post/
└ types.ts
└ features/
└ index.tsx/基本的にはreact側はcreate-react-appをしたファイル構造、django側はdjango-admin startprojectをしたファイル構造になっています。今回はreact側のファイル構造を主に説明します。基本的にはsrc/features以下を使います。srcには機能ごと(auth,postなど)ごとにフォルダが存在し、その中にredux定義用のsliceファイル、表示のためのコンポーネントファイルとcssファイルがあります。これらをapp/フォルダのなかにある、sotre.tsで一つにしています。
2.Typescriptとは
■Typescriptについて
javascriptの代替言語です。javascriptと何が違うと、Typescriptは型を定義してプログラミングをします。型を定義できると何が良いかというと綺麗なコードを効率的に書けることです。例えばTypescriptでは関数の引数や返り値の型を指定し、それ以外の指定されていない型を排除使えなくします。開発が大規模になればなるほどコードがごっちゃになりますが、型を定義しておくことで可読性が高まるとのことです。またTypescriptはmicrosoftが開発言語なので,visual studio codeをエディタで使用しているならその補完機能の恩恵を授かることができます。
まだ個人開発程度しかやっていないので思いっきりTypescriptの恩恵を受けれてはいないですが、visual studio codeを使用して返り値や引数として渡される値を確認しながらコードを打つことができたのは良いと思いました。■コード例
今回はreactでプロジェクトを作成していますが、Typescriptを使う際は生成時に下記のようにします。
ターミナルnpx create-react-app . --template redux-typescriptまた関数宣言時にその都度、型宣言するのも間違いではないですが、別途型宣言用のファイルを作成するのが良いです。そうすることで型の管理が楽になりますし、必要なときはその型ファイルからimportするだけで使用可能です。今回はreactプロジェクトのなかのsrc/features以下にtypes.tsを作成しました。
types.tsexport interface File extends Blob { readonly lastModified: number; readonly name: string; } export interface PROPS_AUTHEN { email: string; password: string; } export interface PROPS_PROFILE { id: number; nickName: string; img: File | null; } export interface PROPS_NICKNAME { nickName: string; } . . /*一部省略*/exportは出力、interfaceは型の定義をまとめるという意味です。そのあとのPROPS_AUTHENなどが型の名前です。また中身は、PROPS_AUTHENでいうとemailとpasswordがあり、それぞれの型を指定しています。またPROPS_PROFILEのimgのように「File | null」のように複数の型を指定することができます。
また使うときは下記のようにします。
auth/authSlice. . . import { PROPS_AUTHEN, PROPS_PROFILE, PROPS_NICKNAME } from "../types"; export const fetchAsyncLogin = createAsyncThunk( "auth/post", async (authen: PROPS_AUTHEN) => { const res = await axios.post(`${apiUrl}authen/jwt/create`, authen, { headers: { "Content-Type": "application/json", }, }); return res.data; } ); . .async (authen: PROPS_AUTHEN)のところでさきほどtypes.tsで定義した型をimportしています。
■その他参考記事
3. react hooksについて
■react hooksの概要について
react hooksとは関数コンポーネントだけでデータの受け渡しを可能にしたAPIです。
reactには従来からclassコンポーネントと関数コンポーネントがあり、classコンポーネントはstateを保持することができますが記述が複雑になりがちというのが特徴で、関数コンポーネントはstateは保持できないものの記述は比較的簡単というのが特徴でした。つまりreact hooksとは関数コンポーネントの弱点を克服し、stateを保持できるようにしたものです。これによって簡単なものであればreduxを使わずに、またはreduxを最小限に抑えることを可能にし、より簡素に素早くアプリケーションの構築ができるようになります。■useStateの使い方
今回のアプリケーションではuseStateとpropsくらいしか使っていないです。ただuseStateが一番大事かなと思っているのでそれを紹介します。その他のuseEffectやuseReducerは使い方だと意味だけ記述します。
EditProfileimport React, { useState } from "react"; const [image, setImage] = useState<File | null>(null); <input type="file" id="imageInput" hidden={true} onChange={(e) => setImage(e.target.files![0])} />まずはuseStateをimportします。constの行でimageとsetImageを定義していますが、imageはstateの状態、setImageはstateの状態に変更を加えるアクションです。image,setImageをuseStateで定義しており、inputで画像が挿入されたときにuseStateの値が変動するというイメージです。useStateでは数値や文字列はもちろん、配列やオブジェクトを持つことも可能です。
■その他のHooksの概要
- 『useEffect』:effectは副作用というニュアンスらしいです。つまりコンポーネントが呼ばれたとき、もしくは指定したアクションが起こったとき、特定に処理をするというものです。
- 『useReducer』:redux、vueでいうとvuexと似た機能です。newState=reducer(currentState, action)、[state, dispatch] = useReducer(reducer, initialState)のように定義、usereducerの引数で特定のアクションとデフォルトの値を設定するという感じです。useStateと似ています。
- 『useContext』:コンポーネントが複数層存在する際に、1つ1つ辿らなくてもデータの引き渡しができるようにするアクションです。
- その他にもuseContext,useCallback,useMemoなどがあります。参考記事をみればだいたいわかると思います。
■その他参考記事
4. redux toolkitについて
■redux・redux toolkitについて
reduxはvueでいうvuexのことであり、つまり状態管理するためのものです。そしてredux toolkitはそのreduxを簡単に記述するためのツールです。2019年あたりに使われた技術なので、比較的新しいですが、最近良く使われているそうです。reduxの構造を理解すれば簡単ですが、vuexとか触ったことないと中々難解です。下記記事がすごいわかりやすかったので載せておきます。
Redux入門【ダイジェスト版】10分で理解するReduxの基礎
ざっくりとした流れは、viewからアクションを呼び出し→Reducerを呼び出す→stateの変更という流れです。reduxはsotreという大きなくくりがあり、各stateはslicerという単位で管理されています。今回はuser認証のreduxファイルをみていきます。
■コード例
authSlice.ts// ①importの説明 import { createSlice, createAsyncThunk } from "@reduxjs/toolkit"; import { RootState } from "../../app/store"; import axios from "axios"; import { PROPS_AUTHEN, PROPS_PROFILE, PROPS_NICKNAME } from "../types"; // ②urlの設定 const apiUrl = process.env.REACT_APP_DEV_API_URL; // ③tokenの取得 export const fetchAsyncLogin = createAsyncThunk( "auth/post", async (authen: PROPS_AUTHEN) => { const res = await axios.post(`${apiUrl}authen/jwt/create`, authen, { headers: { "Content-Type": "application/json", }, }); return res.data; } ); // ④ユーザー登録 export const fetchAsyncRegister = createAsyncThunk( "auth/register", async (auth: PROPS_AUTHEN) => { const res = await axios.post(`${apiUrl}api/register/`, auth, { headers: { "Content-Type": "application/json", }, }); return res.data; } ); // ⑤プロフィールの作成 export const fetchAsyncCreateProf = createAsyncThunk( "profile/post", async (nickName: PROPS_NICKNAME) => { const res = await axios.post(`${apiUrl}api/profile/`, nickName, { headers: { "Content-Type": "application/json", Authorization: `JWT ${localStorage.localJWT}`, }, }); return res.data; } ); // ⑥プロフィールの更新 export const fetchAsyncUpdateProf = createAsyncThunk( "profile/put", async (profile: PROPS_PROFILE) => { const uploadData = new FormData(); uploadData.append("nickName", profile.nickName); profile.img && uploadData.append("img", profile.img, profile.img.name); const res = await axios.put( `${apiUrl}api/profile/${profile.id}/`, uploadData, { headers: { "Content-Type": "application/json", Authorization: `JWT ${localStorage.localJWT}`, }, } ); return res.data; } ); // ⑦マイプロフィールの取得 export const fetchAsyncGetMyProf = createAsyncThunk("profile/get", async () => { const res = await axios.get(`${apiUrl}api/myprofile/`, { headers: { Authorization: `JWT ${localStorage.localJWT}`, }, }); return res.data[0]; }); // ⑧プロフィールの取得 export const fetchAsyncGetProfs = createAsyncThunk("profiles/get", async () => { const res = await axios.get(`${apiUrl}api/profile/`, { headers: { Authorization: `JWT ${localStorage.localJWT}`, }, }); return res.data; }); // ⑨その他のアクションの設定 export const authSlice = createSlice({ name: "auth", initialState: { openSignIn: true, openSignUp: false, openProfile: false, isLoadingAuth: false, myprofile: { id: 0, nickName: "", userProfile: 0, created_on: "", img: "", }, profiles: [ { id: 0, nickName: "", userProfile: 0, created_on: "", img: "", }, ], }, reducers: { fetchCredStart(state) { state.isLoadingAuth = true; }, fetchCredEnd(state) { state.isLoadingAuth = false; }, setOpenSignIn(state) { state.openSignIn = true; }, resetOpenSignIn(state) { state.openSignIn = false; }, setOpenSignUp(state) { state.openSignUp = true; }, resetOpenSignUp(state) { state.openSignUp = false; }, setOpenProfile(state) { state.openProfile = true; }, resetOpenProfile(state) { state.openProfile = false; }, editNickname(state, action) { state.myprofile.nickName = action.payload; }, }, //⑩extrareducerの設定 extraReducers: (builder) => { builder.addCase(fetchAsyncLogin.fulfilled, (state, action) => { localStorage.setItem("localJWT", action.payload.access); }); builder.addCase(fetchAsyncCreateProf.fulfilled, (state, action) => { state.myprofile = action.payload; }); builder.addCase(fetchAsyncGetMyProf.fulfilled, (state, action) => { state.myprofile = action.payload; }); builder.addCase(fetchAsyncGetProfs.fulfilled, (state, action) => { state.profiles = action.payload; }); builder.addCase(fetchAsyncUpdateProf.fulfilled, (state, action) => { state.myprofile = action.payload; state.profiles = state.profiles.map((prof) => prof.id === action.payload.id ? action.payload : prof ); }); }, }); //⑪アクションの出力 export const { fetchCredStart, fetchCredEnd, setOpenSignIn, resetOpenSignIn, setOpenSignUp, resetOpenSignUp, setOpenProfile, resetOpenProfile, editNickname, } = authSlice.actions; //⑫userSelectorの定義 export const selectIsLoadingAuth = (state: RootState) => state.auth.isLoadingAuth; export const selectOpenSignIn = (state: RootState) => state.auth.openSignIn; export const selectOpenSignUp = (state: RootState) => state.auth.openSignUp; export const selectOpenProfile = (state: RootState) => state.auth.openProfile; export const selectProfile = (state: RootState) => state.auth.myprofile; export const selectProfiles = (state: RootState) => state.auth.profiles; export default authSlice.reducer;
- ①「createslice」とはstate,action,reducerをまとめて作成できるものです。今回は⑨のところででてきます。「createAsyncThunk」も同じですが、こちらは非同期のアクションの生成になります。その次の「Rootstate」とはreduxを管理している大元のことです。app/storeで管理していて、各slicerファイルはapp/storeで読み込むことで使えるようになります。あとはAPI通信用のaxios,typescriptの型を定義したファイルをimportしています。
- ②はAPI通信用のURLの設定です。「.env」ファイルに環境変数REACT_APP_DEV_API_URLを登録します。REACT_APP_DEV_API_URLの変数の中身は、DjangoのURLです。「.env」の環境変数を呼び出すときはprocess.env.〜で呼び出します。
- ③〜⑧は非同期通信のアクションを定義しています。呼び出すデータは違えど構造はほとんど同じです。「axios.{post or get}(パス名)」でAPIにアクセスします。第2引数にparamsの中身、第3引数にheader情報を指定しています。ログインしてないとできないアクションは第3引数でjwtの情報が必要です(今回はローカルストレージに保存しています。ログインでJWT取得時にローカルストレージにJWTが保存されます)。またasyncのあとに型をしています。⑥だけは画像の送信のためformDataを使っています。formDataはjavascriptの内容なので説明は割愛します。
- ⑨は「createslice」でアクションを定義しています。ここは大きくinitial state, reducer, extrareducerに分かれています。initial stateはその名の通り初期値です。今回はmodalを使っているので、そのmodalを開くか開かないかをtrue,falseで決めています。reducerはそのstateの値を動かすアクションです。
- ⑩は先程③~⑧で設定した非同期関数に追加して、行う処理を記載しています。ちなみにbuilderはjavascriptのデザインパターンです。最初の1つは「fetchAsyncLogin.fulfilled」でfetchAsyncLoginの処理が終わったあとに実行するという意味です。それ以下の「localStorage.setItem("localJWT", action.payload.access);」では取得したJWTをlocalに保存しています。「action.payload.access」は「return res.data;」の中身を取得しています。2つ目以降は取得したデータをstateに保存しています。
- ⑪はアクションを他のコンポーネントで使えるようにexportしています。
- ⑫はstateのデータ・値をコンポーネントから取得できるようにするための設定です。
Auth.tsx//①importの説明 import React from "react"; import { AppDispatch } from "../../app/store"; import { useSelector, useDispatch } from "react-redux"; import styles from "./Auth.module.css"; import Modal from "react-modal"; import { Formik } from "formik"; import * as Yup from "yup"; import { TextField, Button, CircularProgress } from "@material-ui/core"; import { fetchAsyncGetPosts, fetchAsyncGetComments } from "../post/postSlice"; //②アクションのimport import { selectIsLoadingAuth, selectOpenSignIn, selectOpenSignUp, setOpenSignIn, resetOpenSignIn, setOpenSignUp, resetOpenSignUp, fetchCredStart, fetchCredEnd, fetchAsyncLogin, fetchAsyncRegister, fetchAsyncGetMyProf, fetchAsyncGetProfs, fetchAsyncCreateProf, } from "./authSlice"; const customStyles = { overlay: { backgroundColor: "#777777", }, content: { top: "55%", left: "50%", width: 280, height: 350, padding: "50px", transform: "translate(-50%, -50%)", }, }; //③stateの定義 const Auth: React.FC = () => { Modal.setAppElement("#root"); const openSignIn = useSelector(selectOpenSignIn); const openSignUp = useSelector(selectOpenSignUp); const isLoadingAuth = useSelector(selectIsLoadingAuth); const dispatch: AppDispatch = useDispatch(); //④サインアップ用のモーダル return ( <> <Modal isOpen={openSignUp} onRequestClose={async () => { await dispatch(resetOpenSignUp()); }} style={customStyles} > <Formik initialErrors={{ email: "required" }} initialValues={{ email: "", password: "" }} onSubmit={async (values) => { await dispatch(fetchCredStart()); const resultReg = await dispatch(fetchAsyncRegister(values)); if (fetchAsyncRegister.fulfilled.match(resultReg)) { await dispatch(fetchAsyncLogin(values)); await dispatch(fetchAsyncCreateProf({ nickName: "anonymous" })); await dispatch(fetchAsyncGetProfs()); await dispatch(fetchAsyncGetPosts()); await dispatch(fetchAsyncGetComments()); await dispatch(fetchAsyncGetMyProf()); } await dispatch(fetchCredEnd()); await dispatch(resetOpenSignUp()); }} validationSchema={Yup.object().shape({ email: Yup.string() .email("email format is wrong") .required("email is must"), password: Yup.string().required("password is must").min(4), })} > {({ handleSubmit, handleChange, handleBlur, values, errors, touched, isValid, }) => ( <div> <form onSubmit={handleSubmit}> <div className={styles.auth_signUp}> <h1 className={styles.auth_title}>SNS clone</h1> <br /> <div className={styles.auth_progress}> {isLoadingAuth && <CircularProgress />} </div> <br /> <TextField placeholder="email" type="input" name="email" onChange={handleChange} onBlur={handleBlur} value={values.email} /> <br /> {touched.email && errors.email ? ( <div className={styles.auth_error}>{errors.email}</div> ) : null} <TextField placeholder="password" type="password" name="password" onChange={handleChange} onBlur={handleBlur} value={values.password} /> {touched.password && errors.password ? ( <div className={styles.auth_error}>{errors.password}</div> ) : null} <br /> <br /> <Button variant="contained" color="primary" disabled={!isValid} type="submit" > Register </Button> <br /> <br /> <span className={styles.auth_text} onClick={async () => { await dispatch(setOpenSignIn()); await dispatch(resetOpenSignUp()); }} > You already have a account ? </span> </div> </form> </div> )} </Formik> </Modal> . . . //一部省略 </> ); }; export default Auth;
- ①AppDispatchはapp/storeの内容をimportし、authslicerなどの内容を使えるようにしています。useSelectorはreduxからstateを参照するもの、useDispatchはreduxからdispatchを使うために必要です。Modalはログインやサインインなどに使うフォームみたいなものです。Formikはフォームの管理に使えるライブラリで、Yupがバリデーションに使えるライブラリです。@material-ui/coreでマテリアルUIをimportすると簡単におしゃれなコンポーネントが使えるようになります。
- ②authSliceでexportしたアクションをimportして使えるようにしています。
- ③authSliceで定義しているstateの状態を定義・管理しています。
- ④がサインアップ用のモーダルの記述です。基本的にはdispatchと呼ばれている箇所は、authSliceで定義したアクションを呼び出しています。dispatchで呼び出されたreducerをauthSliceで追い、どのstateが動かされているかを確認するという流れでコードが理解できるようになります。
以上で終わりです。ちなみにchromeの拡張機能を使えば、ブラウザでreduxのstateなどが確認できるので非常に便利です。
5. AWSとFirebaseでデプロイ
フロントのreactプロジェクトはfirebase hostingでデプロイし、バックエンドのDjangoAPIはAWSのEC2でデプロイして、それを結合します。
■firebase hostingでのデプロイ
10分で終わります。本記事では省略しますが、下記記事で簡単にデプロイできるかと思います。
(初心者向け)Firebase HostingへReactプロジェクトを公開する手順
デプロイで来たら一旦完了です。■AWSでのデプロイ
こちらも本記事で省略します。以前railsでのAWSに関する記事を書いたのでそちらを参照ください。ただ1点注意があります。それはfirebaseとAPI通信するためにはSSL証明を取って、HTTPS化する必要があります。そのためROUTE53,ACMの設定が必要です。
【前書いた記事】
【0からAWSに挑戦】EC2とVPCを使ってRailsアプリをAWSにデプロイする part1
【0からAWSに挑戦】ROUTE53を使ってドメイン設定 && ACMによるSSL化EC2内でDjangoに必要なパッケージ等のインストールが必要ですが、下記記事が役に立ちました。djangoではwebサーバーにnginx,アプリケーション・サーバーにgunicornを使うのがスタンダードらしいです。
【20分でデプロイ】AWS EC2にDjango+PostgreSQL+Nginx環境を構築してササッと公開■APIとフロントを連携させる
あとはそれぞれのファイルのURL設定をデプロイしたURLに変えるだけです。
(EC2上)setting.py. . CORS_ORIGIN_WHITELIST = [ "firebase側のURLを設定する" ] . .(firebase側).envREACT_APP_DEV_API_URL="APIのURL"ここでAWSのEC2をHTTPSにしていないとエラーが起こります。firebase側はもう一度deployコマンドを打つと反映されます。
以上で完成!!! firebase側のurlにアクセスして完了!!!
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
まとめ
vue.jsを学習済みだったのでreact.jsを比較的すんなり理解できました。一応これでもバックエンド・インフラ系の志望なので、APIでどう連携して、どういう仕組で動いているかは意識していたいです。おそらく今後の開発に役立つと信じて、、、
あとはrailsでも思いましががjwtあたりの認証がすごい大事だなと感じたので、改めて別途記事を書きたいなと思います。参考
下記udemy講座を参考にしています。
- 投稿日:2021-03-03T12:59:38+09:00
aws samでlambda layerを使いこなす
背景
aws-samがどうやら使いにくいという噂がちらちら聞こえたのでどういうことか調べてみました。
一番の悩みは共通処理を書きにくいのでどうしても各ハンドラーにコピペの嵐をしてしまっているとのことです。(え!調査
これはlambda-layerを使えば一瞬で解決。はい終了。
かと思ったら、そうでもなくてパス体系がローカルとlambda上でだいぶ変わってしまうことでうまくlambda-layerを使えないとのこと。例えば、以下のようなフォルダ構成の場合。
├── handlers(lambda-function) │ └── create_user │ ├── app.py │ └── requirements.txt ├── layers(lambda-layer) │ ├── db_layer │ │ ├── models │ │ │ └── user.py │ │ ├── setting.py │ └── lib_layer │ ├── lambda_common.py │ ├── log_config.py │ ├── requirements.txt │ └── setup.pyローカルで
handlers.create_user.appからdb_layer.models.userをimportする場合。from layers.db_layer.models import userとなると思います。ただ、これをlambdaにのっけたときとか
sam local start-apiで実行するとインポートエラーがおきます。
理由としては、lambda-layerは実行環境の/opt/python/以下に配置されるためです。この場合のインポート方法はpip installしたパッケージを使うのと似ています
。。ということは、解決の方法としてはローカルでlayersをそれぞれパッケージとしてインストールすればいいと仮説を立てました。
仮説検証
1. layersのインストール
setup.pyを用意して(割愛)
pipenv install -d -e layers/db_layer layers/lib_layerを実行すると
Pipfileが以下のようになり、他の人がpipenv sync -dとかをやってくれれば環境が整うようになりました。[dev-packages] (略) db-layer = {editable = true, path = "./layers/db_layer"} lib-layer = {editable = true, path = "./layers/lib_layer"} [requires] python_version = "3.8"2. import方法の変更
先ほどのローカルでのインストール方法を
from layers.db_layer.models import user以下のように変更
from models import user以下の二つを確認。
- unittestを実行してimport失敗しないこと
sam local start-apiを実行して、正常に動くこと結論
pythonのlambda-layerはローカルでインストールすればうまくパス周りの整合性がとれて、開発は捗ります。
デバッグもテストもしやすいし、samとはうまく付き合っていけそうだなという所感です。
それ踏まえてのレポジトリを貼っておきます。pythonで裏側作る際に参考程度に使っていただけると報われます。
※なにか不具合あっても補償はできませんが、質問やお問い合わせ、改善要望はお待ちしております。
- 投稿日:2021-03-03T12:59:38+09:00
aws samでlambda layerを使う
背景
aws-samがどうやら使いにくいという噂がちらちら聞こえたのでどういうことか調べてみました。
一番の悩みは共通処理を書きにくいのでどうしても各ハンドラーにコピペの嵐をしてしまっているとのことです。(え!調査
これはlambda-layerを使えば一瞬で解決。はい終了。
かと思ったら、そうでもなくてパス体系がローカルとlambda上でだいぶ変わってしまうことでうまくlambda-layerを使えないとのこと。例えば、以下のようなフォルダ構成の場合。
├── handlers(lambda-function) │ └── create_user │ ├── app.py │ └── requirements.txt ├── layers(lambda-layer) │ ├── db_layer │ │ ├── models │ │ │ └── user.py │ │ ├── setting.py │ └── lib_layer │ ├── lambda_common.py │ ├── log_config.py │ ├── requirements.txt │ └── setup.pyローカルで
handlers.create_user.appからdb_layer.models.userをimportする場合。from layers.db_layer.models import userとなると思います。ただ、これをlambdaにのっけたときとか
sam local start-apiで実行するとインポートエラーがおきます。
理由としては、lambda-layerは実行環境の/opt/python/以下に配置されるためです。この場合のインポート方法はpip installしたパッケージを使うのと似ています
。。ということは、解決の方法としてはローカルでlayersをそれぞれパッケージとしてインストールすればいいと仮説を立てました。
仮説検証
1. layersのインストール
setup.pyを用意して(割愛)
pipenv install -d -e layers/db_layer layers/lib_layerを実行すると
Pipfileが以下のようになり、他の人がpipenv sync -dとかをやってくれれば環境が整うようになりました。[dev-packages] (略) db-layer = {editable = true, path = "./layers/db_layer"} lib-layer = {editable = true, path = "./layers/lib_layer"} [requires] python_version = "3.8"2. import方法の変更
先ほどのローカルでのインストール方法を
from layers.db_layer.models import user以下のように変更
from models import user以下の二つを確認。
- unittestを実行してimport失敗しないこと
sam local start-apiを実行して、正常に動くこと結論
pythonのlambda-layerはローカルでインストールすればうまくパス周りの整合性がとれて、開発は捗ります。
デバッグもテストもしやすいし、samとはうまく付き合っていけそうだなという所感です。
それ踏まえてのレポジトリを貼っておきます。pythonで裏側作る際に参考程度に使っていただけると報われます。
※なにか不具合あっても補償はできませんが、質問やお問い合わせ、改善要望はお待ちしております。
- 投稿日:2021-03-03T12:57:07+09:00
rdkitでSMILESから構造式を返すdiscord botを作りたいという願望(1)
0. は?願望?
確かに動いてるんですよ、だから書いてるんです。しかしながら、どうも無理やり感が半端なく、問題をたくさんはらんでいるので、ひとまずこんな名前になってるわけです。後の期待を込めて(1)とか書いてますが、後続があるかさえわかりません。ひとまず動きました。そういうことです。
要するに、
あんまり再現性とか期待しないでね!
ということです。
いや、この記事意味あるんか...1. で、何がしたいの?
タイトルのままです。discordでSMILESを投げたらpngで構造式返してくれるアレがやりたいわけです。私は手書きで綺麗なベンゼン環が書けないので、CPUにやらせてサボりたいわけです。でも同時に、いちいちノーパソ開いて無料なのがとてもありがたい某ソフトを起動させたりするのもまためんどくさいわけです。どうにかして「スマートフォンの画面にsmiles打ち込むだけで...あら不思議!」をやりたいわけです!!!
ここで一つ疑問がわいてきます。
「そういうbotとかサービスって、既にあるよね...?」
確かにあります。ありますとも。でも私には自分で作らなばならないやんごとなき理由があったのです。それは、
どうしても自分でやってみたかった
ということです。これなら仕方ないですね。以上、モチベでした。
2 じゃあ、どうやるの?
そういえば、rdkitっていう、便利なやつがありましたね。あれ、使いましょう。discord botのdiscord側の設定に関しては、ネットで調べればたくさん出てくると思うので、割愛します。まずは適当にdiscord.pyを入れておきます。Windowsならば、以下を叩きます(他のOSの場合は、リンクに飛んで確認してください)。
discord.pyを入れるpy -3 -m pip install -U discord.pyよし、できました。次はrdkitを使いたいわけですが、悲報があるそうです。
RDKIT IS NOT AVAILABLE ON PYPI!!!
これは、辛いですね。で、見てみると、Anacondaを使えと書いてあります。では有難く使わせてもらいましょう。conda入ってない人はここから適当に入れて下さい。おそらくスムーズに入ると思います。
次に、下のコマンドを打てって言っているので、素直に打ちます。rdkitを入れるconda create -c rdkit -n my-rdkit-env rdkit入りました。はい。
これで実行時に以下のコマンドを叩けば、rdkitがimportできるはずです。
仮想環境のactivateconda activate my-rdkit-envまたは以下でもいいと思います。
仮想環境のactivatecall activate.batのパス call activate my-rdkit-envやったね!下準備完了です。さぁコードを書いていきましょう。discord.pyの公式ページ等を参考にしました。
ChemConverter.py#必要なライブラリ import discord from rdkit import Chem from rdkit.Chem import Draw client = discord.Client() @client.event async def on_ready(): print('Successfully Connected') @client.event async def on_message(message): if message.author == client.user: return if botとして機能する何らかの条件(あるチャンネルに発言があった、など): str=message.content mol=Chem.MolFromSmiles(str) if mol is None: await message.channel.send('Oops! There is something wrong with SMILES!') else: Draw.MolToFile(mol, 'mol.png') await message.channel.send(file=discord.File('mol.png')) client.run('ここにAccessTokenを入れます。Secretじゃないので注意!')これで動きます。いやぁ、めでたしめでたし。
ただこれ、少しめんどくささが残ります。というのも、いちいち仮想環境をactivateして実行までしなきゃいけないのです。これ嫌ですね。なぜならそのためにノーパソを開かなきゃいけないからです!(だったら例のソフトでいいやん...)
そこで、下のようなbatを書いておきます。callにしないとactivateしたときにそのまま次のコマンドを実行してくれないっぽいです。
ChemConverter.batcall activate.batのパス call activate my-rdkit-env cd ChemConverter.pyのあるディレクトリのパス python ChemConverter.pyこれでChemConverter.batを動かすだけで一発でbotが起動するようになりました。最後に、このbatをタイムスケジューラでスタートアップ時に実行するようにしておけば、勝手にバックグラウンドで立ち上がってくれます。便利ですね。よかった、よかった。
3. ん?問題なんてあった?
そんなものはなかった、と言いたいところですが、お気づきの通り、山ほどあります。
まず、
1. でかい化合物だと構造式がつぶれます。
見るのが早いです。これです。
つぎに、
2.ノーパソを起動していないと動きません。
だって、ノーパソ上で動いてるんだもん。そりゃそうだ。いや、一応打開しようとはしましたよ?herokuとかPythonAnywhereとかで動かせないかな~と思っていろいろやってみました。というか、どちらにせよ、condaがないとrdkitが入れにくすぎるんじゃー!!!いやー、世の中でこういうbotつくってるひとはすごいなー(遠い目)
4. え、これで終わり?
はい、終わりです。
ということで、こんな感じにやれれば、ダサいうえにPCを私たちが起きている時間ずっと稼働させておくための電気代という犠牲を伴いますが、何とか動かせました。
進展があったら書こうかと思います。
次があったときは、またよろしくお願いします。
ここまで読んでいただいた方、ありがとうございました。
何かのお役に立てれば光栄です。環境とか
Windows 10
Python 3.6.2
- 投稿日:2021-03-03T12:40:11+09:00
ValueError: Only one class present in y_true. ROC AUC score is not defined in that case.
- 投稿日:2021-03-03T12:12:24+09:00
herokuでのProcfileの書き方
要約
herokuでProcfileに
web: python run.pyと書くと動かなかったが、
web: gunicorn -k uvicorn.workers.UvicornWorker run:apiと書くと動いた。以下詳細
responderで簡単なアプリを作った。run.pyimport responder import os api = responder.API() @api.route("/") def index(req, resp): resp.text = req.method if __name__ == "__main__": port = int(os.environ.get("PORT", 5042)) api.run(port=port)ルートに来たリクエストのメソッド(GET,POST...)を表示するだけの簡単なアプリである。
これをherokuに上げるため、次のような
Procfileを書いた。Procfileweb: python run.pyこの状態でアプリケーションをherokuにアップロードしたとき、エラーが発生した。
log2021-03-03T02:25:34.944654+00:00 heroku[web.1]: Starting process with command `python run.py` 2021-03-03T02:25:40.000000+00:00 app[api]: Build succeeded 2021-03-03T02:25:43.750097+00:00 heroku[web.1]: Process exited with status 1 2021-03-03T02:25:43.829241+00:00 heroku[web.1]: State changed from starting to crashed 2021-03-03T02:25:43.836710+00:00 heroku[web.1]: State changed from crashed to starting 2021-03-03T02:25:43.533551+00:00 app[web.1]: WARNING: You must pass the application as an import string to enable 'reload' or 'workers'. 2021-03-03T02:25:49.229908+00:00 heroku[web.1]: Starting process with command `python run.py` 2021-03-03T02:25:53.558366+00:00 heroku[web.1]: Process exited with status 1 2021-03-03T02:25:53.636099+00:00 heroku[web.1]: State changed from starting to crashed 2021-03-03T02:25:53.451857+00:00 app[web.1]: WARNING: You must pass the appli cation as an import string to enable 'reload' or 'workers'.
Process exited with status 1って言ってるが手元でpython run.pyをすると問題なく動く。原理はよくわかっていないが、Procfileをgunicornを使う形式に変えたところ、動作した。
Procfileweb: gunicorn -k uvicorn.workers.UvicornWorker run:apiflaskだと単に
gunicorn run:appとかで行けると思われる。
- 投稿日:2021-03-03T11:36:48+09:00
numpy.ndarrayの連結
以下記事を参考にしています。
http://tanukigraph.hatenablog.com/entry/2017/08/23/195756忘れやすいのでメモ。
import numpy as np a = np.array([[1,2],[3,4]]) b = np.array([[5,6],[7,8]]) c = np.array([[1,2],[3,4],[5,6]])1. (2,2)×2 -> (4,2)
np.concatenate([a,b],axis=0) # output array([[1, 2], [3, 4], [5, 6], [7, 8]])※concatnateで次元を上げることはできない
2. (2,2)×2 -> (2,2,2)
パターン1
np.stack([a,b],axis=0) # output array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])パターン2
np.stack([a,b],axis=1) array([[[1, 2], [5, 6]], [[3, 4], [7, 8]]])
- 投稿日:2021-03-03T10:12:14+09:00
Blackpinkのメンバーを判別する判別器
きっかけ
Aidemyのプレミアムプランを受講しましたので、そこで学んだことを記録として残そうと思います。
参考にしたもの
この判別機を作成するにあたり、下記の記事を参考にさせていただきました。
https://qiita.com/mczkzk/items/fda37ac4f9ddab2d7f45
https://qiita.com/Taka_input/items/04a23bd8e9101788e583
https://qiita.com/bohemian916/items/9630661cd5292240f8c7
https://nine-num-98.blogspot.com/2019/12/ai-lovelive-01.html
https://github.com/tatsuyah/CNN-Image-Classifier.gitまた、画像収集はgithubを参照し、ネットから画像を収集しています。
この記事は画像収集を行った後の作業から書いてあります。
画像は一人当たり200枚集めました。
https://github.com/hardikvasa/google-images-download.git使用したカスケード:
https://github.com/opencv/opencv/tree/master/data/haarcascadesディレクトリ構成
├face_detection.py
├face_inlation.py
├count.py
├face_training.py
├result.py
│
├haarcascade_frontalface_default.xml
│
├model/
├final_model.h5
│
├data
├01_org/
├02_face/
├03_face_inflation/
├04_validation/
├05_test/
├06_rec/使用したライブラリ
opencv-python 4.5.1.48
numpy 1.18.5
glob2 0.7
scipy 1.4.1
tensorflow 2.3.0
matplotlib 3.2.2画像から顔部分を切り取り
まずは集めた画像から顔部分を抜き出します。
macのパソコンでフォルダを作成すると「.DS_Store」が勝手に作成されてしまいます。
メンバーの名前リストにこれが含まれないように「.」から始まるフォルダ名は除外しています。face_detection.pyimport cv2 import os import shutil org_dir = "dataset/01_org/" face_dir = "dataset/02_face/" cascade_xml = "haarcascade_frontalface_default.xml" def main(): name_list = [filename for filename in os.listdir(org_dir) if not filename.startswith(".")] print(name_list) for name in name_list: name.replace(" ", "_") org_char_dir = org_dir + name + "/" print(org_char_dir) face_char_dir = face_dir + name + "/" os.makedirs(face_char_dir, exist_ok=True) print(len(face_char_dir)) detect_face(org_char_dir, face_char_dir) def detect_face(org_char_dir, face_char_dir): image_list = os.listdir(org_char_dir) for image_file in image_list: org_image = cv2.imread(org_char_dir + image_file) if org_image is None: print("Not open:", image_file) continue #convert gray_scale img_gs = cv2.cvtColor(org_image, cv2.COLOR_BGR2GRAY) #detect_face cascade = cv2.CascadeClassifier(cascade_xml) for i_mn in range(1, 7, 1): face_list = cascade.detectMultiScale(img_gs, scaleFactor=1.1, minNeighbors=i_mn, minSize=(200, 200)) #if more than one_face detected, get image (64*64) if len(face_list ) > 0: for rect in face_list: image = org_image[rect[1]:rect[1]+rect[3], rect[0]:rect[0]+rect[2]] if image.shape[0] < 64 or image.shape[1] < 64: continue face_image = cv2.resize(image, (64, 64)) else: continue #save face_image face_file_name = os.path.join(face_char_dir, "face-" + image_file) cv2.imwrite(str(face_file_name), face_image) if __name__ == "__main__": main()顔以外の画像を削除します。
画像の水増し
画像を水増しして増やしていきます。
face_inflation.py#画像の水増し import os import cv2 import glob from scipy import ndimage import numpy as np SearchName = ["jenny", "jisoo", "rose", "lisa"] ImgSize = (250, 250) for name in SearchName: print("{}の写真を増やします".format(name)) in_dir = "./data/02_face/" + name + "_face/*" out_dir = "./data/03_face_inflation/" + name os.makedirs(out_dir, exist_ok=True) in_jpg=glob.glob(in_dir) img_file_name_list = os.listdir("./data/02_face/"+name+"_face/") for i in range(len(in_jpg)): img = cv2.imread(str(in_jpg[i])) #rotate for ang in [-10, 0, 10]: img_rot = ndimage.rotate(img, ang) img_rot = cv2.resize(img_rot, ImgSize) fileName = os.path.join(out_dir, str(i)+"_"+str(ang)+".jpg") cv2.imwrite(str(fileName), img_rot) #thureshold img_thr = cv2.threshold(img_rot, 100, 255, cv2.THRESH_TOZERO)[1] fileName = os.path.join(out_dir, str(i)+"_"+str(ang)+"thr.jpg") cv2.imwrite(str(fileName), img_thr) #filter img_filter = cv2.GaussianBlur(img_rot,(5, 5), 0) fileName = os.path.join(out_dir, str(i)+"_"+str(ang)+"filter.jpg") cv2.imwrite(str(fileName), img_filter) #contrast min_table = 50 max_table = 205 diff_table = max_table - min_table LUT_HC = np.arange(256, dtype = 'uint8' ) LUT_LC = np.arange(256, dtype = 'uint8' ) for i in range(0, min_table): LUT_HC[i] = 0 for i in range(min_table, max_table): LUT_HC[i] = 255 * (i - min_table) / diff_table for i in range(max_table, 255): LUT_HC[i] = 255 for i in range(256): LUT_LC[i] = min_table + i * (diff_table) / 255 low_cont_img = cv2.LUT(img_rot, LUT_LC) fileName = os.path.join(out_dir, str(i)+"_"+str(ang)+"low_lut.jpg") cv2.imwrite(str(fileName), low_cont_img) high_cont_img = cv2.LUT(img_rot, LUT_HC) fileName = os.path.join(out_dir, str(i)+"_"+str(ang)+"high_lut.jpg") cv2.imwrite(str(fileName), high_cont_img) row,col,ch = img_rot.shape s_vs_p = 0.5 amount = 0.004 sp_img = img_rot.copy() #noise1 num_salt = np.ceil(amount * img_rot.size * s_vs_p) coords = [np.random.randint(0, i-1 , int(num_salt)) for i in img_rot.shape] sp_img[coords[:-1]] = (255,255,255) fileName = os.path.join(out_dir, str(i)+"_"+str(ang)+"salt.jpg") cv2.imwrite(str(fileName), sp_img) #noise2 num_pepper = np.ceil(amount* img_rot.size * (1. - s_vs_p)) coords = [np.random.randint(0, i-1 , int(num_pepper)) for i in img_rot.shape] sp_img[coords[:-1]] = (0,0,0) fileName = os.path.join(out_dir, str(i)+"_"+str(ang)+"pepper.jpg") cv2.imwrite(str(fileName), sp_img) #rotate hflip_img = cv2.flip(img_rot, 1) fileName = os.path.join(out_dir, str(i)+"_"+str(ang)+"hflip.jpg") cv2.imwrite(str(fileName), hflip_img) vflip_img = cv2.flip(img_rot, 0) fileName = os.path.join(out_dir, str(i)+"_"+str(ang)+"vflip.jpg") cv2.imwrite(str(fileName), vflip_img) print("画像の水増し完了!")一枚の画像に対して3方向の画像を作成した後にそれぞれの画像にコントラストの変化(2種)、ノイズ処理(2種)、閾値、フィルター処理,回転処理(2種)を行うので1枚の画像が27枚になります。
次に水増しした画像をtraining用とvalidation用に振り分けます。
count.pyimport os import shutil import glob import random face_dir = "dataset/03_face_inflated/" name_list = [filename for filename in os.listdir(face_dir) if not filename.startswith(".")] print(name_list) for name in name_list: in_dir = face_dir + name + "/*" in_jpg = glob.glob(in_dir) img_file_name_list = os.listdir(face_dir + name + "/") random.shuffle(in_jpg) os.makedirs("dataset/04_validation/" + name, exist_ok=True) for t in range(len(in_jpg)//5): shutil.move(str(in_jpg[t]), "dataset/04_validation/" + name)学習
face_training.py#python 04_cnn_face_train.py model/final_model.h5 import os import tensorflow.keras from tensorflow.keras.models import Sequential,Model from tensorflow.keras.layers import Input, Dense, Dropout, Flatten, Conv2D, MaxPooling2D, Activation from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.optimizers import RMSprop import numpy as np import matplotlib import matplotlib.pyplot as plt import time import sys img_width, img_height = 64, 64 batch_size = 32 validation_steps = 300 nb_filters1 = 32 nb_filters2 = 64 nb_patience = 10 nb_filter2 = 64 conv1_size = 3 conv2_size = 2 pool_size = 2 classes_num = 4 lr = 0.0004 epochs = 200 train_data_dir = "dataset/03_face_inflated/" validation_data_dir = "dataset/04_validation/" model = Sequential() model.add(Conv2D(nb_filters1, conv1_size, conv1_size, padding ="same", input_shape=(img_width, img_height, 3))) model.add(Activation("relu")) model.add(MaxPooling2D(pool_size=(pool_size, pool_size))) model.add(Conv2D(nb_filters2, conv2_size, conv2_size, padding ="same")) model.add(Activation("relu")) model.add(MaxPooling2D(pool_size=(pool_size, pool_size))) model.add(Flatten()) model.add(Dense(256)) model.add(Activation("relu")) model.add(Dropout(0.5)) model.add(Dense(classes_num, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer="sgd", metrics=['accuracy']) train_datagen = ImageDataGenerator( rescale=1. / 255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True) test_datagen = ImageDataGenerator(rescale=1. / 255) train_generator = train_datagen.flow_from_directory( train_data_dir, target_size=(img_height, img_width), batch_size=batch_size, class_mode='categorical') validation_generator = test_datagen.flow_from_directory( validation_data_dir, target_size=(img_height, img_width), batch_size=batch_size, class_mode='categorical') model.fit_generator( train_generator, epochs=epochs, validation_data=validation_generator, validation_steps=validation_steps) target_dir = 'model/' if not os.path.exists(target_dir): os.makedirs(target_dir) model.save('model/final_model.h5') model.save_weights('model/weights.h5') plt.xlabel("time step") plt.ylabel("accuracy") plt.ylim(0, max(history.history["accuracy"])) accuracy, = plt.plot(history.history["accuracy"], c="#56B4E9") plt.legend([accuracy], ["accuracy"]) plt.show() plt.savefig("cnn_face_train_figure.png")学習した結果はこのようになりました。
Epoch 197/200 239/239 [==============================] - 8s 35ms/step - loss: 0.2494 - accuracy: 0.9116 Epoch 198/200 239/239 [==============================] - 8s 35ms/step - loss: 0.2399 - accuracy: 0.9140 Epoch 199/200 239/239 [==============================] - 8s 35ms/step - loss: 0.2329 - accuracy: 0.9174 Epoch 200/200 239/239 [==============================] - 8s 35ms/step - loss: 0.2446 - accuracy: 0.9137学習結果
result.py#python 05_cnn_face_recognition.py model/final_model.h5 import tensorflow.keras import numpy as np import cv2 import os, sys cv_width, cv_height = 64, 64 minN = 15 #difinition image size img_width, img_height = 64, 64 #directory for train_data_set train_data_dir = "dataset/03_face_inflation" #directory for test_dataset test_data_dir = "dataset/04_test" #directory for face_detection rec_data_dir = "dataset/05_rec" classes = os.listdir(train_data_dir) cascade_xml = "haarcascade_frontalface_default.xml" def detect_face (image, model): #convert gray scale image_gs = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) cascade = cv2.CascadeClassifier(cascade_xml) #detect face face_list = cascade.detectMultiScale(image_gs, scaleFactor=1.1, minNeighbors=2, minSize=(30, 30)) if len(face_list) > 0: for rect in face_list: print(face_list) face_img = image[rect[1]:rect[1]+rect[3], rect[0]:rect[0]+rect[2]] if face_img.shape[0] < 10 or face_img.shape[1] < 10: print("too small") continue #definision of face_img and size face_img = cv2.resize(face_img, (img_width, img_height)) #conversion BGR->RGB, float_type for keras face_img = cv2.cvtColor(face_img, cv2.COLOR_BGR2RGB).astype(np.float32) #recognition face_img name = predict_who(face_img, model) cv2.rectangle(image, tuple(rect[0:2]), tuple(rect[0:2]+rect[2:4]), (0, 0, 255), thickness = 3) x, y, width, height = rect cv2.putText(image, name, (x, y + height+60), cv2.FONT_HERSHEY_DUPLEX, 0.5, (0, 0, 255), 2) else: print("No face") return image def predict_who(x, model): #tensor surgery x = np.expand_dims(x, axis=0) #normalization x = x/255 pred = model.predict(x)[0] top = 2 top_indices = pred.argsort()[-top:][::-1] result = [(classes[i], pred[i]) for i in top_indices] print(result) print('=======================================') return result[0][0] def main(): savefile = "model/final_model.h5" model = tensorflow.keras.models.load_model(savefile) test_imagelist = os.listdir(test_data_dir) for test_image in test_imagelist: file_name = os.path.join(test_data_dir, test_image) print(file_name) image = cv2.imread(file_name) if image is None: print("Not open:", file_name) continue rec_image = detect_face(image, model) rec_file_name = os.path.join(rec_data_dir, "rec-" + test_image) cv2.imwrite(rec_file_name, rec_image) if __name__ == "__main__": main()結果
05_dataset/にいれたテスト用画像の顔を認識し、メンバーを判別してくれます。
======================================= dataset/05_test/ダウンロード.jpg [[ 34 133 66 66]] [(' blackpink rose', 0.9970631), (' blackpink jenny', 0.0029275673)] ======================================= dataset/05_test/ダウンロード (4).jpg [[40 36 73 73]] [(' blackpink lisa', 0.9999974), (' blackpink jisoo', 2.6306848e-06)] =======================================
まとめ
githubにもコードを公開しました。
https://github.com/priekosukeyauchi/face_classification.git

