- 投稿日:2021-03-03T23:12:28+09:00
【AWS】Lambdaを利用したスクレイピング【Container Support】
はじめに
re:Invent 2020において、Lambdaでコンテナイメージがサポートされました。
一番の注目ポイントは、従来のZip形式では依存パッケージ等も含め250MBまでだった容量制限が10GBまで増えた点です。
これにより、多様なモジュールを利用する機械学習系の処理が可能になったり、seleniumで利用するHeadless BrowserをLambda Layerでデプロイする必要が無くなったのではないかと思います。
(ただし、最大実行時間は変わらず15分であることに注意してください)コンテナイメージの実現方法として以下の2つがあります。
1. AWSが提供するベースイメージを利用する
2. Lambda Runtime APIを実装したカスタムイメージを作成する本記事では、AWS提供のベースイメージを利用して、下図のようにAWSのサービスステータス画面をスクレイピングして(※)、(AWS側に障害が発生していないときに限り)AWSサービス一覧を取得するLambdaを作成してみようと思います。
なお、LambdaのランタイムはPython3.8、IaCはterraformを利用します。
※ status.aws.amazon.comでは、以下のとおりスクレイピングが許可されています。
curl https://status.aws.amazon.com/robots.txt User-agent: * Allow: /動作環境
$ aws --version aws-cli/2.1.27 Python/3.7.4 Darwin/19.4.0 exe/x86_64 prompt/off $ terraform -v Terraform v0.13.6スクレイピング処理用のコンテナ作成
まずは、スクレイピングを行い、S3にスクレイピング結果のCSVを出力する処理をPythonで記載していきます。
事前準備
Mockを用意するのが面倒なので、CSVのアップロード先S3バケットとコンテナのPush先リポジトリを作成しておきます。
main.tfresource "aws_s3_bucket" "upload_bucket" { bucket = "test-upload-bucket-20210302" acl = "private" force_destroy = true } resource "aws_ecr_repository" "scraping" { name = "aws_status_scraping" image_tag_mutability = "MUTABLE" image_scanning_configuration { scan_on_push = true } }コーティング
以下のようなコードを記載しました。
app.pyimport requests import lxml import re import csv import os import boto3 from bs4 import BeautifulSoup s3 = boto3.resource('s3') output_bucket = s3.Bucket(os.environ.get("OUTPUT_BUCKET_NAME")) URL = "https://status.aws.amazon.com/" TMP_FILE_PATH = "/tmp/tmp.csv" UPLOAD_FILE_NAME = os.environ.get("UPLOAD_FILE_NAME") def handler(event, context): try: print({"message": f"start scraping {URL}"}) res = requests.get(URL) soup = BeautifulSoup(res.content, "lxml", from_encoding='utf-8') service_name_rows = soup.select('.bb.top.pad8') service_names = {re.sub('\s\(.*\)', '', service_name.text) for service_name in service_name_rows if service_name.text != "No recent events."} write_csv(service_names) output_bucket.upload_file(TMP_FILE_PATH, UPLOAD_FILE_NAME) print({"message": f"end scraping {URL}"}) return "Succeeded!!!" except: return "Failed..." def write_csv(target_set): with open(TMP_FILE_PATH, 'w') as f: writer = csv.writer(f) for service in list(target_set): writer.writerow([service])requirements.txtrequests beautifulsoup4 lxmlprintでログ出力を行っている理由は、後述のローカル実行時でログを出力させたい場合、dict形式で出力しないとdocker logsに表示されなかったためです。(loggingモジュールでのログ出力方法は分かりませんでした。)
(参考)
実際にLambda上で動作させる場合は、stringであってもCloudWatchLogsに出力されるのでご安心ください。コンテナ作成
AWSの公式Dockerイメージをベースに、前手順で作成したPythonのコードと依存パッケージがインストールされた状態のイメージを作成します。
以下のDockerFileを作成し、buildを行います。DockerfileFROM public.ecr.aws/lambda/python:3.8 COPY requirements.txt ${LAMBDA_TASK_ROOT} RUN pip install -r requirements.txt COPY app.py ${LAMBDA_TASK_ROOT} CMD [ "app.handler" ]$ docker build -t aws_serivce_scraping . #DockerfileがあるDirで実行 $ docker images REPOSITORY TAG IMAGE ID CREATED SIZE aws_serivce_scraping latest e8d983af1fb9 5 seconds ago 619MBローカルでの検証
先ほどの手順で作成したDockerイメージを利用して、ローカル上で検証を行います。
docker runコマンドでコンテナを起動するとLambda Runtime Interface Emulatorが立ち上がり、curlを利用してランタイムAPIを呼び出すことでPythonのコードを実行することができます。# Lambdaコンテナ起動 $ docker run --rm -p 9000:8080 \ -e AWS_ACCESS_KEY_ID=xxxxx \ # 自身のアクセスキーIDを指定 -e AWS_SECRET_ACCESS_KEY=xxxxx \ # 自身のアクセスキーを指定 -e AWS_DEFAULT_REGION=ap-northeast-1 \ -e OUTPUT_BUCKET_NAME=test-upload-bucket-20210302 \ -e UPLOAD_FILE_NAME=aws_services.csv \ aws_serivce_scraping # LambdaのランタイムAPIを呼び出して実行 $ curl -d '{}' http://localhost:9000/2015-03-31/functions/function/invocations "Succeeded!!!" # DockerLogsには以下のようなログが出力されている # time="2021-03-02T13:37:41.022" level=info msg="exec '/var/runtime/bootstrap' (cwd=/var/task, handler=)" # time="2021-03-02T13:37:54.458" level=info ?msg="extensionsDisabledByLayer(/opt/disable-extensions-jwigqn8j) -> stat /opt/disable-extensions-jwigqn8j: no such file or directory" # time="2021-03-02T13:37:54.458" level=warning msg="Cannot list external agents" error="open /opt/extensions: no such file or directory" # START RequestId: a74e925e-6425-4a06-a517-a58ea1608e83 Version: $LATEST # {'message': 'start scraping https://status.aws.amazon.com/'} # {'message': 'end scraping https://status.aws.amazon.com/'} # END RequestId: a74e925e-6425-4a06-a517-a58ea1608e83 # REPORT RequestId: a74e925e-6425-4a06-a517-a58ea1608e83 Init Duration: 1.05 ms Duration: 7667.90 ms Billed Duration: 7700 ms Memory Size: 3008 MB Max Memory Used: 3008 MB # アップロードされたファイルを確認 $ aws s3 ls s3://test-upload-bucket-20210302 2021-03-02 22:38:02 3883 aws_services.csv # ファイルをS3からローカルにコピー $ aws s3 cp s3://test-upload-bucket-20210302/aws_services.csv /tmp/ download: s3://test-upload-bucket-20210302/aws_services.csv to ../../tmp/aws_services.csv # ファイルの中身を確認 $ head -n 10 /tmp/aws_services.csv AWS IoT Device Management AWS Firewall Manager AWS DeepComposer AWS CloudTrail Amazon Braket Amazon WorkMail Amazon AppStream 2.0 AWS IoT 1-Click Amazon Neptune Amazon Cognito # ファイル削除 $ aws s3 rm s3://test-upload-bucket-20210302/aws_services.csv delete: s3://test-upload-bucket-20210302/aws_services.csvイメージのPush
ローカル環境での検証が完了したので、ECRへイメージをPushし、Lambdaが利用できる状態にします。
ecr_repo=<AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin ${ecr_repo} docker tag aws_serivce_scraping:latest ${ecr_repo}/aws_status_scraping:latest docker push ${ecr_repo}/aws_status_scraping:latestLambda作成
Dockerイメージの検証・Pushが完了したので、以下のリソースを作成していきます。
- Lambda関数
- 今回作成したコンテナを稼働させる関数
- IAM Role
- LambdaへS3を操作する権限を与えるロール
terraformのコードを以下のように修正し、applyを行ってください。
main.tflocals { function_name = "aws_status_scraping" tag_name = "latest" upload_file_name = "aws_services.csv" } resource "aws_s3_bucket" "upload_bucket" { bucket = "test-upload-bucket-20210302" acl = "private" force_destroy = true } resource "aws_ecr_repository" "scraping" { name = "aws_status_scraping" image_tag_mutability = "MUTABLE" image_scanning_configuration { scan_on_push = true } } // Dockerイメージの変更を検出するためにイメージの情報を読み込む data "aws_ecr_image" "scraping" { repository_name = aws_ecr_repository.scraping.name image_tag = local.tag_name } resource "aws_lambda_function" "aws_status_scraping" { function_name = local.function_name role = aws_iam_role.lambda_iam_role.arn package_type = "Image" image_uri = "${aws_ecr_repository.scraping.repository_url}:${local.tag_name}" memory_size = 256 timeout = 60 source_code_hash = trimprefix(data.aws_ecr_image.scraping.id, "sha256:") //Dockerイメージに変更があった場合の更新処理 environment { variables = { OUTPUT_BUCKET_NAME = aws_s3_bucket.upload_bucket.id UPLOAD_FILE_NAME = local.upload_file_name } } } // LambdaがAssumeするロールを作成 resource "aws_iam_role" "lambda_iam_role" { name = "lambda_${local.function_name}" assume_role_policy = data.aws_iam_policy_document.lambda_assume_role_policy.json } // LambdaにAssumeする権限を与えるポリシー data "aws_iam_policy_document" "lambda_assume_role_policy" { statement { actions = ["sts:AssumeRole"] principals { identifiers = ["lambda.amazonaws.com"] type = "Service" } effect = "Allow" } } // 「LambdaにAssumeする権限を与えるポリシー」をロールにアタッチ resource "aws_iam_role_policy_attachment" "basic_execution" { role = aws_iam_role.lambda_iam_role.name policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole" } // S3へファイルアップロードが行えるようフルアクセス権限をロールにアタッチ // Note: プロダクション環境等では必ず対象バケットや許可するアクションを絞ってください resource "aws_iam_role_policy_attachment" "s3_full_access" { role = aws_iam_role.lambda_iam_role.name policy_arn = "arn:aws:iam::aws:policy/AmazonS3FullAccess" }Lambdaの動作確認
CLI経由もしくはAWS管理コンソールから
aws_status_scraping関数を実行します。$ aws lambda invoke --function-name aws_status_scraping \ --payload '{}' \ --cli-binary-format raw-in-base64-out \ response.json { "StatusCode": 200, "ExecutedVersion": "$LATEST" } $ cat response.json "Succeeded!!!" # アップロードされたファイルを確認(結果は割愛) $ aws s3 ls s3://test-upload-bucket-20210302 $ aws s3 cp s3://test-upload-bucket-20210302/aws_services.csv /tmp/ $ head -n 10 /tmp/aws_services.csvDrift検出
最後に、コンテナに変更を加えた際にDriftが検出されることを確認します。
Lambdaリソースに記載した以下により、DockerイメージのHashの違いで差分を検出することができます。source_code_hash = trimprefix(data.aws_ecr_image.scraping.id, "sha256:") //Dockerイメージに変更があった場合の更新処理成功時のメッセージを変更してbuild & pushします。
app.py- return "Succeeded!!!" + return "Succeeded..."terraformのplan結果として差分が出力されればOKです。
# aws_lambda_function.aws_status_scraping will be updated in-place ~ resource "aws_lambda_function" "aws_status_scraping" { arn = "arn:aws:lambda:ap-northeast-1:321498468606:function:aws_status_scraping" function_name = "aws_status_scraping" id = "aws_status_scraping" image_uri = "321498468606.dkr.ecr.ap-northeast-1.amazonaws.com/aws_status_scraping:latest" invoke_arn = "arn:aws:apigateway:ap-northeast-1:lambda:path/2015-03-31/functions/arn:aws:lambda:ap-northeast-1:321498468606:function:aws_status_scraping/invocations" ~ last_modified = "2021-03-02T13:54:32.064+0000" -> (known after apply) layers = [] memory_size = 256 package_type = "Image" publish = false qualified_arn = "arn:aws:lambda:ap-northeast-1:321498468606:function:aws_status_scraping:$LATEST" reserved_concurrent_executions = -1 role = "arn:aws:iam::321498468606:role/lambda_aws_status_scraping" ~ source_code_hash = "07b6ae0e9c3f3c8cbc265dc16d012d079aedb5bbae8b35c777c502e3cb1d9d98" -> "79c095fd303af7739e343689e540763995e32cff99704e10e4c67a8d2f2113eb" source_code_size = 0 tags = {} timeout = 60 version = "$LATEST" environment { variables = { "OUTPUT_BUCKET_NAME" = "test-upload-bucket-20210302" "UPLOAD_FILE_NAME" = "aws_services.csv" } } tracing_config { mode = "PassThrough" } } Plan: 0 to add, 1 to change, 0 to destroy.applyをしてあげることで、変更後のDockerイメージを利用することができます。
$ aws lambda invoke --function-name aws_status_scraping \ --payload '{}' \ --cli-binary-format raw-in-base64-out \ response.json $ cat response.json "Succeeded..."⏎さいごに
- 全体的に簡単に利用し易い機能であると感じました。(カスタムイメージは触ったことが無いので何とも言えないですが)
- CI/CD周り、特にECR側のDockerイメージを更新した際には、たとえタグが変わらなくてもLambda側の更新処理(update-function-cod)が必要である点は気を付ける必要がありそうです。イメージのpushをしてリリースをした気にならないようにしましょう。
- また、terraformのnull_resourceを利用してコンテナのビルド、プッシュ機構を用意することも可能ですが、planのタイミングでコンテナイメージのビルドが行われず、差分が検出できないので注意してください。

- 投稿日:2021-03-03T23:11:10+09:00
[AWS] Lambda + API Gateway でサーバーレスWeb APIを作る ①Lambdaファンクション篇
2021/03時点での情報です。AWSのコンソール画面や仕様は頻繁に変更されるので注意してください。
AWSのサービスであるLambdaとAPI Gatewayを使ってサーバーレスのWeb APIを作成したので備忘録として手順をまとめておきます。
間違えていたら教えていただけるとありがたいです。ゴール
AWS LambdaとAmazon API Gatewayを利用してHTTPプロトコルのGET/POSTで呼び出せる単純なWeb APIを作成すること。
やらないこと
- AWS自体や他のサービスの説明
- 最低限のコード以外の実装
APIの仕様
パラメーターの値を簡単に加工して返すだけのシンプルなAPIです。
GET/POST共通
パラメーター名 値 name 名前を入力します age 年齢を入力します。 レスポンス
// nameとageにはパラメーターで渡した値が代入されます。 { "answer": "My name is ${name}, I am ${age} years old." }AWS Lambdaとは
AWS Lambda はサーバーレスコンピューティングサービスで、サーバーのプロビジョニングや管理、ワークロード対応のクラスタースケーリングロジックの作成、イベント統合の維持、ランタイムの管理を行わずにコードを実行できます。Lambda を使用すれば、実質どのようなタイプのアプリケーションやバックエンドサービスでも管理を必要とせずに実行できます。コードを ZIP ファイルまたはコンテナイメージとしてアップロードするだけで、Lambda はあらゆる規模のトラフィックに対して、自動的かつ正確にコンピューティング実行能力を割り当て、受信リクエストやイベントに基づいてコードを実行します。コードは、140 の AWS のサービスから自動的にトリガーするよう設定することも、ウェブやモバイルアプリケーションから直接呼び出すよう設定することもできます。Lambda 関数をお気に入りの言語 (Node.js、Python、Go、Java など) で記述し、サーバーレスツールと AWS SAM や Docker CLI などのコンテナツールの両方を使用して、関数をビルド、テスト、デプロイできます。(公式より)
だいたいこんな感じ
- サーバーを建てないでコード(関数)を実行できるよ
- コードはいろんな言語で書けるよ
- 勝手に適切なCPUリソースを割り当ててくれるよ
- アプリケーションや他のAWSのサービスから作成した関数を呼び出せるよ
単一の関数をアップロードして独立して実行できるサービスです。
Amazon API Gatewayとは
フルマネージド型サービスの Amazon API Gateway を利用すれば、開発者は規模にかかわらず簡単に API の作成、公開、保守、モニタリング、保護を行えます。API は、アプリケーションがバックエンドサービスからのデータ、ビジネスロジック、機能にアクセスするための「フロントドア」として機能します。API Gateway を使用すれば、リアルタイム双方向通信アプリケーションを実現する RESTful API および WebSocket API を作成することができます。API Gateway は、コンテナ化されたサーバーレスのワークロードやウェブアプリケーションをサポートします。
だいたいこんな感じ
- 外部からHTTPプロトコルを通じてサービスを呼び出せるURLを作成してくれるよ
- 受け取ったリクエストを他のサービスに渡してくれるよ
- バージョン管理やモニタリングとか色々できるよ
今回の実装部分
Lambdaファンクションの作成・コードの実装
Lambdaで作成する関数の単位はファンクションです。
ファンクションを作成してコードを実装(もしくはアップロード)します。ファンクション作成
Lambdaサービスのページから
Functions>Create Functionをクリック
Author from scratchを選択Function nameにファンクション名を作成Runtimeでコードを書く言語を指定(今回はNode.jsで書きます)Create Functionをクリック
これでファンクションが作成できたので中身を実装していきます。
ファンクションのコード実装
今回はコンソールで直接コードを書きます。
Designerでファンクション名を選択してください。
すると下に
Function codeエリアが現れるのでここにコードを書いていきます。
GETの(クエリパラメーターを受け取る)場合の実装
HTTPリクエストをGETで受け取った場合、API Gatewayから渡される
event変数のqueryStringParametersにクエリパラメーターが格納されています。
なのでまずはGETリクエストを受け取った際のコードを実装してみます。exports.handler = async (event) => { const name = event.queryStringParameters.name const age = event.queryStringParameters.age return { "statusCode": 200, "headers": { "Access-Control-Allow-Origin": "*", "Access-Control-Allow-Methods": "GET" }, "body": `{ "answer": "My name is ${name}, I am ${age} years old." }`, "isBase64Encoded": false } }ポイントは先程言ったとおり
event.queryStringParametersからパラメーターが取得できるというところと、レスポンスの形式です。後ほど紹介しますが、API GatewayとLambdaの連携方法として
Lambdaプロキシ統合という方法を使用します。
この方法で連携する場合にはレスポンスは以下の形式で返す必要があります。{ "isBase64Encoded" : "boolean", "statusCode": "number", "headers": { ... }, "body": "JSON string" }デプロイ・テスト
コードを実装したら
Deployを押してください。
コードがデプロイされて実行可能になります。それではテストパラメーターを設定してテストを行います。
Testボタンを押します。
Configure test eventが開きます。
Create new test eventを選択してイベント名を指定、パラメーターを入力します。(スクショではすでに作成済みなのでEdit saved test eventsが選択されています。)
プロキシ統合の形式に合わせてパラメーターを指定します。success{ "queryStringParameters": { "name": "Akumachan", "age": "100030" } }
Createを押してポップアップが閉じたら再度Testを押してテストを実行します。
実行結果が表示されました。イージー!
POSTの(リクエストボディを受け取る)場合の実装
HTTPリクエストをPOSTで受け取った場合、API Gatewayから渡される
event変数のbodyにクエリパラメーターが格納されています。
event.bodyは文字列形式で格納されているようなのでJSONでリクエストボディを送信している場合はJSON.parseしてパラメーターにアクセスします。と、その前にメソッドによって処理を変えるコードを挿入します。
メソッドの種類はevent.httpMethodに格納されているのでメソッドごとに分岐します。index.jsexports.handler = async (event) => { let name, age if (event.httpMethod == "GET") { name = event.queryStringParameters.name age = event.queryStringParameters.age } else if (event.httpMethod == "POST") { // Return response for POST request } else { // Return error. } return { statusCode: 200, body: `{ "answer": "My name is ${name}, I am ${age} years old." }`, } }それではPOSTリクエストボディからパラメーターを取り出して
nameとageに代入します。index.jsexports.handler = async (event) => { let name, age if (event.httpMethod == "GET") { name = event.queryStringParameters.name age = event.queryStringParameters.age } else if (event.httpMethod == "POST") { const body = JSON.parse(event.body) name = body.name age = body.age } else { // Return error. } return { statusCode: 200, body: `{ "answer": "My name is ${name}, I am ${age} years old." }`, } }レスポンスの形式は共通のコードなので、これでテストを実行してみましょう。
Deployを押してデプロイを完了してください。テスト
Testの横の▼をクリックしてConfigure test eventをクリック、Create new test eventからパラメーターを指定します。successPOST{ "httpMethod": "POST", "body": "{\"name\": \"AkumachanPOST\",\"age\": \"100032\"}" }
Createボタンを押してポップアップが閉じたらTestをクリックして実行します。
これでPOSTリクエストからのリクエストも処理できるようになりました。
次回に続く。







- 投稿日:2021-03-03T21:53:21+09:00
CircleCIでAWS ECR/ECS へのデプロイする方法
RailsアプリをAWSへデプロイしたいと考え、CiecleCIを利用したCI/CDパイプライン構築について学んでいます。
公式AWS ECR/ECS へのデプロイ - CircleCIにとても詳しく記載があるのですが、完全な設定ファイルをコピペしても、エラーになってしまいます。
発生するエラー
#!/bin/sh -eo pipefail # Error calling workflow: 'build-and-deploy' # Error calling job: 'aws-ecr/build_and_push_image' # Type error for argument region: expected type: env_var_name, actual value: \"${AWS_DEFAULT_REGION}\" (type string) # Type error for argument account-url: expected type: env_var_name, actual value: \"${AWS_ACCOUNT_ID}.dkr.ecr.${AWS_DEFAULT_REGION}.amazonaws.com\" (type string) # # ------- # Warning: This configuration was auto-generated to show you the message above. # Don't rerun this job. Rerunning will have no effect. falseエラー文章を読むと、
account-urlとrepoの Value の記述で Type error が発生しているようです。# 中略 account-url: "${AWS_ACCOUNT_ID}.dkr.ecr.${AWS_DEFAULT_REGION}.amazonaws.com" repo: "${AWS_RESOURCE_NAME_PREFIX}"解決策
Issueが上がっていました。
Type check error when try to build using ecr version above 0.0.4 · Issue #47 · CircleCI-Public/aws-ecr-orb · GitHubAPIのバージョンアップによって、記法が変わったようです。Issueを参考に
account-urlとregitonを書き換えて無事デプロイ出来ました。下記が私の設定ファイルです。
備忘録をかねてコメントを追加しています。circleci/config.ymlversion: 2.1 orbs: aws-ecr: circleci/aws-ecr@0.0.10 aws-ecs: circleci/aws-ecs@0.0.8 workflows: build-and-deploy: jobs: - aws-ecr/build_and_push_image: # ECRのURL XXX.dkr.ecr.ap-northeast-1.amazonaws.com account-url: AWS_ECR_ACCOUNT_URL # ERCのリポジトリ名 repo: AWS_ECR_REPO_NAME region: AWS_DEFAULT_REGION tag: "${CIRCLE_SHA1}" - aws-ecs/deploy-service-update: requires: - aws-ecr/build_and_push_image aws-region: AWS_DEFAULT_REGION # ECSのタスク定義名 family: AWS_ECS_TASK_FAMILY_NAME # ECSのサービス名 service-name: AWS_ECS_SERVICE_NAME # ECSのクラスタ名 cluster-name: AWS_ECS_CLUSTER_NAME # ECSのタスク定義で指定したコンテナ名 container-image-name-updates: "container=${AWS_ECR_REPO_NAME},tag=${CIRCLE_SHA1}"ちなみに、設定した環境変数は下記です。
AWS_DEFAULT_REGION AWS_ECR_REPO_NAME AWS_ECS_TASK_FAMILY_NAME AWS_ECS_SERVICE_NAME AWS_ECS_CLUSTER_NAME
- 投稿日:2021-03-03T21:53:21+09:00
CircleCIでAWS ECR/ECSへデプロイする方法
RailsアプリをAWSへデプロイしたいと考え、CiecleCIを利用したCI/CDパイプライン構築について学んでいます。
公式AWS ECR/ECS へのデプロイ - CircleCIにとても詳しく記載があるのですが、完全な設定ファイルをコピペしても、エラーになってしまいます。
発生するエラー
#!/bin/sh -eo pipefail # Error calling workflow: 'build-and-deploy' # Error calling job: 'aws-ecr/build_and_push_image' # Type error for argument region: expected type: env_var_name, actual value: \"${AWS_DEFAULT_REGION}\" (type string) # Type error for argument account-url: expected type: env_var_name, actual value: \"${AWS_ACCOUNT_ID}.dkr.ecr.${AWS_DEFAULT_REGION}.amazonaws.com\" (type string) # # ------- # Warning: This configuration was auto-generated to show you the message above. # Don't rerun this job. Rerunning will have no effect. falseエラー文章を読むと、
account-urlとrepoの Value の記述で Type error が発生しているようです。# 中略 account-url: "${AWS_ACCOUNT_ID}.dkr.ecr.${AWS_DEFAULT_REGION}.amazonaws.com" repo: "${AWS_RESOURCE_NAME_PREFIX}"解決策
Issueが上がっていました。
Type check error when try to build using ecr version above 0.0.4 · Issue #47 · CircleCI-Public/aws-ecr-orb · GitHubAPIのバージョンアップによって、記法が変わったようです。Issueを参考に
account-urlとregitonを書き換えて無事デプロイ出来ました。下記が私の設定ファイルです。
備忘録をかねてコメントを追加しています。circleci/config.ymlversion: 2.1 orbs: aws-ecr: circleci/aws-ecr@0.0.10 aws-ecs: circleci/aws-ecs@0.0.8 workflows: build-and-deploy: jobs: - aws-ecr/build_and_push_image: # ECRのURL XXX.dkr.ecr.ap-northeast-1.amazonaws.com account-url: AWS_ECR_ACCOUNT_URL # ERCのリポジトリ名 repo: AWS_ECR_REPO_NAME region: AWS_DEFAULT_REGION tag: "${CIRCLE_SHA1}" - aws-ecs/deploy-service-update: requires: - aws-ecr/build_and_push_image aws-region: AWS_DEFAULT_REGION # ECSのタスク定義名 family: AWS_ECS_TASK_FAMILY_NAME # ECSのサービス名 service-name: AWS_ECS_SERVICE_NAME # ECSのクラスタ名 cluster-name: AWS_ECS_CLUSTER_NAME # ECSのタスク定義で指定したコンテナ名 container-image-name-updates: "container=${AWS_ECR_REPO_NAME},tag=${CIRCLE_SHA1}"ちなみに、設定した環境変数は下記です。
AWS_DEFAULT_REGION AWS_ECR_REPO_NAME AWS_ECS_TASK_FAMILY_NAME AWS_ECS_SERVICE_NAME AWS_ECS_CLUSTER_NAME
- 投稿日:2021-03-03T21:44:57+09:00
Amazon Lookout for Visionで青森認証やってみた
不良品検出のAIサービス「Amazon Lookout for Vision」が先週25日(木)に東京リージョンでの提供開始が発表されましたが、27日(土)には早くも「AWSの基礎を学ぼう」コミュニティのハンズオンが開催され、実際に体験してみることができました。
AI、機械学習系のハンズオンということで待ち時間なんかもあるわけですが、そこにソラコムの @ma2shita さんの「Amazon Lookout for Vision 向いてるコト、使いどころと注意点」とかJAWS-UG名古屋の @nori2takanori さんの「画像ベース異常検知Amazon Lookout for Visionを使ってみよう」とかLTが入って、退屈する暇のない2時間でした。その中で出てきたスライドの一枚がこちら。
Lookout for Visionは不良品見地にしか使えないサービスじゃないぞ、と。アイデア次第だぞ、と。じゃあ安直ですが、あれやってみようと思いました。あれです、青森認証です。
「青森版『私はロボットではありません』画像選択」とのことですが、「“Apple”の認証画面」なる呼び名もあるようです。しかしここは独断により青森認証と呼ぶことにします。
千里の道もリンゴより
ハンズオンでは手順は決して複雑ではなかったけど、とにかく「正常な布地写真」と穴が開いてたり異物混入してたりする「異常な布地写真」を使ってたのが印象に残ってます。Lookout for Visionはこれらを学習して、「これ正常」「これ異常」と見分けられるようになってくれるサービスなのです。
ということはフジの画像とフジじゃないリンゴの画像を学習させて、「これ正常(フジ)」「これ異常(フジじゃない)」と見分けられる教え込めばいいわけです。青森脳育成プロジェクトです。青森脳育成の第一歩は、リンゴ画像から、なのです。そういうわけで、フジとフジじゃないリンゴ画像をかき集めたのがこちら。
……疲れました。しかしこれさえ済めば勝ったも同然です。
青森脳の誕生(Lookout for Visionのモデル作成まで)
AWSにサインインし、Lookout for Visionsの「プロジェクト」を開きます。初回セットアップとしてS3バケットを作りたいと言われるので、許可します。
適当な名前でプロジェクトを作ります。
ここで作成されるデータセットに「画像を追加」として、まずフジの画像をまとめてアップロードします。20枚集まってました。
アップロードされた画像に「正常」「異常」のラベルを付けます。今回はフジの画像をアップロードしたので、すべて「正常」としたいです。「このページのすべてのイメージを選択」→「正常として分類」→次のページへ移動→「このページのすべてのイメージを選択」→…を繰り返して、すべてに「正常(Normal)」のマークを付けます。済んだら「変更(20)を保存」で保存します。
同様に、フジ以外のリンゴ画像もアップロードし、すべて「異常」として登録します。アップロード後、「フィルター」で「ラベルなし」を指定すると、あとからアップロードした画像だけが表示されるので、同じ手順で全部「異常(Anomaly)」ラベルを付けて保存します。
正常画像が20枚以上、異常画像が10枚以上になると、学習が可能になります。具体的には、「モデルをトレーニング」というボタンが押せるようになるので、やっちゃいます。モデルのトレーニングには30分ぐらいかかる(かかった)ので、しばらく待ちます。
一点、ポイントを。画像サイズがすべて同じじゃないと、以下のエラーメッセージで失敗します。学習開始直後すぐに出るようなので、少しの間見守っているといいかもしれません。
Images in the dataset must have the same dimensions.モデルのステータスが「トレーニングが完了」になれば、準備完了です。言い換えれば、青森脳の誕生です。ここまでノーコード、ノーコマンド、ノーAI/ML知識で来れてしまいました。素晴らしいですね。
対決、青森認証 vs 青森脳(Lookout for Visionによる異常判別)
いよいよ青森脳を青森認証に挑ませます。そのためには、青森認証のリンゴ画像を一つ一つ、青森脳に見せてやれるようにします。そう、また個別ファイルを作成するわけです。こんな感じです。
これさえ済めば、勝ったも同然です。青森脳(Lookout for Visionで作成したモデル)による異常判別は、残念ながらAWS CLIを使った実行になりますが、コマンドはほぼコピペでOKです。モデルの画面で「モデルを使用」タブを開くと、必要なコマンドが表示されます。
一つ目のコマンドをそのまま実行すると、青森脳が起動されます。起動完了までに少し時間がかかり、それを待たずに二つ目の異常識別コマンドを実行しようとすると「状態がHOSTEDになるまで実行できないよ」的なエラーメッセージが返ってきます。起動状況はパフォーマンスメトリクスタブで確認できるので、完了を待ってください。
起動が完了したら、二つ目の異常識別コマンドを実行します。これもほぼこのまま実行すればいいのですが、最後の
/path/ti/image.jpg部分を識別したい画像ファイルのパスに変更します。相対パスでも、Windows環境ではパス区切り文字が\でも大丈夫でした。実行例はこんな感じです。
実行結果で先ず見るのは
IsNomalous。これがtrueのときは「異常発見」ということになります。今回の場合はtrue=異常=フジじゃない、ということです。この例ではフジの写真画像を指定して判別させていて、falseつまり正常、フジだと判別されていますね。もう一つ見ておくのがConfidence。これは判定結果の信頼度を表しています。56%ぐらい……自信なさげですね。大丈夫、合ってますよ。ここでまた引っ掛かったところをいくつか。
- AWS CLIが古いと
aws lookoutbisionができません。Changelog見る限りそんなことはなさそうなのですが、私の環境は2.0.0版で実行できませんでした。saisinnnoMSIfairu (2.1.27版でした)に更新しました。- 識別対象画像も学習用画像と同じサイズにしておくことが必要です。サイズが異なると
Image failed to pass validation.というエラーになります。こんなあたりに気を付けながら、9つのリンゴ画像を一つ一つ判別していけば、青森認証に回答できます……できるはずです……!あ、判別が終わったら三つ目のコマンドを実行して、青森脳を停止してやってください。青森脳(モデル)の稼働時間中は、利用料金が発生し続けます。本当に止めるのだけは忘れないでください。
そしてこうなった
ということで、やってみた結果をまとめておきます。正解も公開されているので、それも並べておきましょう。
残念ながら、あと一歩でした。上段中央のフジを「フジじゃない」と認識してしまいました。信頼度も(もっと低信頼度の異常判定もあるとはいえ)52%とそこそこ低めに出ています。本当にもうちょっとという感じで残念です。実用にする場合はここで、もう少しトレーニングを重ねていくことになりますが、今回はここまでです。
さいごに少し、ハンズオンおよびその間のLT2本で学んだことを思い出しながら、Lookout for Visionについて振り返ってみたいと思います。
- Lookout for Visionが得意なのは正常/異常の2値分類。今回は「フジ=正常」「フジじゃない=異常」というキメをしたので、Lookout for Visionの対象にできました。これがフジと紅玉と北斗と…を区別する、といった3種類以上の分類になるときは、他サービスを使います。
- 学習時と異常判別時の画像サイズは全部統一。しないとトレーニング実行時とか、異常判別時とかにエラーになる。
- 画像ファイルの品質も併せておいた方がいい。今回、枝についたまま緑の背景の画像がいくつも学習用画像に入ってました。青森認証での表示に合わせ、この背景をきれいに削除してやったら精度が上がったのではと思います。
- 学習用画像の収集が容易になる工夫をする。画像合成で作っちゃうとか、数を用意し異常バリエーションを作りやすいお菓子を対象にやってみるとか。
- 用途はアイデア次第。正常/異常の二値分類しかできませんが、例えば「家電の運転ランプを撮影して正常(消灯)/異常(点灯)判別で切り忘れを調べる」とか「ドアのカギを撮影して正常(横になってる)/異常(縦になってる)判別で締め忘れを調べる」とか、不良品検出以外にもいろいろな使い道がありそうです。
以上、青森認証は青森脳で解けるのか、でした(違いました)。
参照
- Amazon Lookout for Vision (コンピュータービジョンを使用して視覚表現の欠陥や異常を発見) | AWS
- Amazon Lookout for Vision 東京リージョンで一般提供開始のお知らせとオンデマンドウェビナーのご紹介 | Amazon Web Services ブログ
- AWSの基礎を学ぼう 特別編 最新サービスをみんなで触ってみる はじめての画像ベース異常検知 - connpass
- Amazon Lookout for Vision 向いてるコト、使いどころと注意点/what-amazon-lookout-for-vision-can-be-used-for-and-how-to-use-it - Speaker Deck
- 画像ベース異常検知Amazon Lookout for Visionを使ってみよう
実施中はエラー解決に以下も参考にさせていただきました。













- 投稿日:2021-03-03T21:26:02+09:00
AWS Step Functions とは
勉強前イメージ
全然イメージつかん・・
そういうサービスがあるってことだけは知ってる調査
AWS Step Functions とは
分散アプリケーションやマイクロサービスをステートマシンと呼ばれる仕組みで設定や管理の自動化ができます。
AWSコンソール上では各サービスをコンポーネントとしてワークフローという形式で可視化することが出来ます。
また、各種実行履歴などもログから追うことも出来ます。
Step Functionsを使用することで、タスクで構成される複雑なワークフローを簡単に定義できますステートマシンのイメージ
例えば自販機だと3つのプロセスに分割できます。
- 入金待ち
- ユーザが購入に十分な金額を投入するまで待機。
- 入金され次第、次のプロセスに進む
- ジュースの選択
- ユーザがジュースの選択を行うまで待機。
- 選択され次第、次のプロセスに進む。
- おつり・ジュースの出力
このフローをStep Functionsでは
ステートマシンと呼び、
人間による操作を必要とするような長時間実行されたり・半自動化されたワークフローを作成することもできます。AWS Step Functions の費用
Step Functionsは状態の遷移ごとに課金が発生。
毎月4000回までは無料だが、4000回を超えると課金が発生。
リージョンごとに費用は異なります。コンソール上で確認
- ステートマシンの作成
- ステートマシンを定義する
試しに作るだけなので、標準のタイプで進めます。
ワークフローを定義して、それを可視化(右の図)することが出来ます。
- 詳細を指定
ステートマシン名やアクセス制御など、デフォルトで進め、記載できるとステートマシンの作成を行います。
- 作成されました
- ステートマシンを実行する
- 実行
デフォルト値で実行します
- 結果を確認
グラフインスペクター で、各ステップごとの実行結果も確認することが出来ます。
勉強後イメージ
今まで全部自動で・・・みたいなのはよくAWSのサービスでもあったけど、
途中で人間が入力しないといけないという場合も使うことができるのか!参考








- 投稿日:2021-03-03T17:54:41+09:00
MySQLの文字コード関連設定を1つ1つ説明する
提供しているサービスで絵文字を利用できるようにした際の記録です。
「MySQL 絵文字」のようなクエリで検索をかけると、色々な記事にヒットします。
文字コードをutf8mb4にすれば良い、というのはすぐに分かるのですが
- どうしてこの設定を変更するのか?
の解説記事が少なかったので、調べた内容をまとめておきます。
前提条件&環境
- AWSのRDSでデータベースを管理している
- MySQL 5.6.x
- 変更前の文字コードはUTF-8
RDSで文字コードを確認する方法
RDSのコンソールで
character_で検索かけると確認できます。
6つの項目がヒットすると思います。(画像は一部抜粋)
それぞれ「utf8」が設定されていました。
MySQLの文字コード関連の設定値の意味
概要
英文はRDSまま、翻訳は筆者訳です。
項目 意味(英) 意味(日) character_set_client The character set for statements that arrive from the client クライアント側から受け取った命令文の文字コード character_set_connection The character set used for literals that do not have a character set introducer and for number-to-string conversion イントロデューサー(※1)なしの文字列や数値から文字列への変換に利用される文字コード character_set_database The character set used by the default database. デフォルトデータベースで使う文字コード character_set_filesystem The file system character set. ファイルシステムで使う文字コード。csvやtsvなどを読み込むときに、ファイル名の解釈(ファイル名を参照する文字列リテラル)に使う文字コード。 character_set_results The character set used for returning query results to the client. SQLの実行結果(クエリ)をクライアントに返すときに利用する文字コード character_set_server The server's default character set. MySQLサーバーのデフォルトの文字コード また、下記も変更が必要です(正確には変更したほうがベター)
項目 意味(英) 意味(日) collation_server - 文字列の照合順序 詳細
概要だけだとわかりにくいので、詳細も調べました。(概要のままのもあります。すいません。)
character_set_client
クライアント(mysql)から送られてきた文字コードをどのように解釈するか、です。
character_set_connection
イントロデューサーなしの文字列や数値から文字列への変換に利用される文字コードです。
イントロデューサーとは?
文字列(正確には文字列リテラル)の前に記載されている文字コードのことです。
例では、_latin1の部分です。
イントロデューサーが、SQLパーサーに、後続する文字列リテラルが●●文字セットですよ、と教えています。例:
SELECT _latin1'string';character_set_database
MySQLのドキュメントから引用します。
* charecter_set_databaseデフォルトデータベースで使用される文字セット。 デフォルトのデータベースが変更されるたびに、サーバーはこの変数を設定します。 デフォルトデータベースが存在しない場合、変数は character_set_server と同じ値になります。デフォルトデータベースとは?
use文を使って選択したデータベースのことです。
# これで指定したデータベース use database_namecharacter_set_filesystem
SQLの
LOAD_FILE()関数などで、ファイル名を参照するときに、どの文字コードで読み取るかのオプションです。
(あくまで、ファイル名の解釈であり中身ではない)私の環境では、この値は空でした。
デフォルト値はbinaryです。Amazon RDS for MySQL のパラメーターを設定するためのベストプラクティス。パート 3: セキュリティ、操作管理性、および接続タイムアウトに関連するパラメーター
character_set_results
SQLの実行結果(クエリ)をクライアントに返すときに利用する文字コード
character_set_server
MySQLサーバーのデフォルトの文字コード
collation_server
collationは照合する、という意味です。
SQLのWHERE等で、文字列比較を行う際に設定します。詳しいことは参考文献を読んでいただくと良いのですが、このパラメータの設定次第では、
寿司の絵文字とビールの絵文字が同一になってしまう問題が発生してしまいます。
(? = ?:寿司ビール問題というそうです。天才的なネーミングですね。)設定例
最後にクラウドフォーメーションの設定例です。
ポイントは下記の通り
* しれっとMySQLのversionを上げている
* パラメータグループ名が衝突して更新できないので、名前を変えている
* MySQL関連の文字コードを変えている
* 照合順序も変えているtemplate.yml- RdsParameterGroup + RdsParameterGroup57: Type: "AWS::RDS::DBParameterGroup Properties: - Family: mysql5.6 + Family: mysql5.7 Description: "MySQLのパラメータグループの設定です。実環境では適切な名前を設定してください。" Parameters: slow_query_log: 1 query_cache_type: 1 query_cache_size: 10485760 query_cache_limit: 1048576 innodb_buffer_pool_dump_at_shutdown: 1 - character_set_client: utf8 - character_set_connection: utf8 - character_set_database: utf8 - character_set_results: utf8 - character_set_server: utf8 - collation_server: utf8_general_ci + character_set_client: utf8mb4 + character_set_connection: utf8mb4 + character_set_database: utf8mb4 + character_set_results: utf8mb4 + character_set_server: utf8mb4 + collation_server: utf8mb4_bin skip-character-set-client-handshake: 1 Tags: - Key: Name参考文献
charecter_set_database
Amazon RDS for MySQL のパラメーターを設定するためのベストプラクティス。パート 3: セキュリティ、操作管理性、および接続タイムアウトに関連するパラメーター
寿司とビールについて話し合いをしてきました
- https://labs.gree.jp/blog/2017/04/16406/
- 絵文字の「? = ?」の問題を説明してくれています。
- collationの例がわかりやすかったです

- 投稿日:2021-03-03T17:54:38+09:00
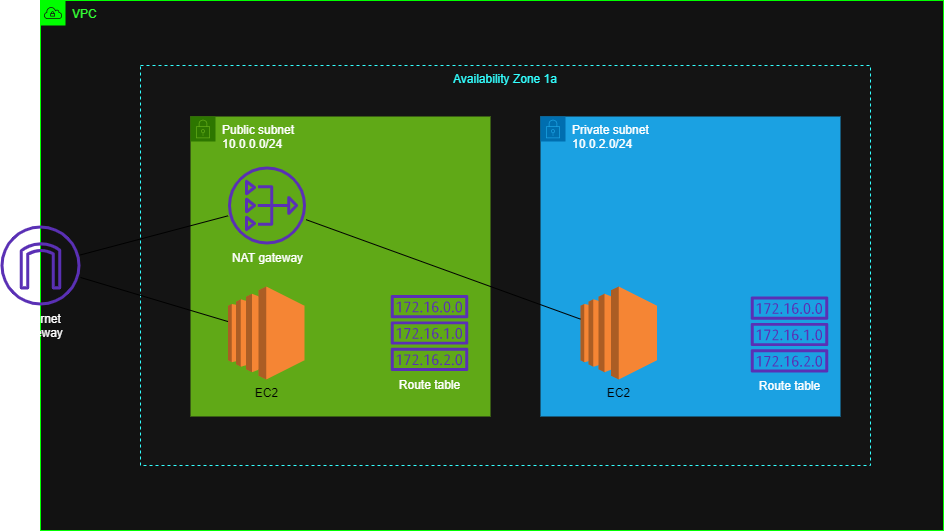
40 代おっさん NAT gateway 経由して EC2 に繋げてみた ③
本記事について
本記事は AWS 初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。AWS 作成図
VPC 部分については
https://qiita.com/kou551121/items/2535fe3de57a5c813687
EC2 部分については
https://qiita.com/kou551121/items/56f2e075d33fbf345787構築手順
❶ private subnet に EC2 インスタンスを設置
https://qiita.com/kou551121/items/3869db7c1e4bc72b2ab9
を参照してくださいまたこの記事は AWS 初学者を導く体系的な動画学習サービス「AWS CloudTech」の課題カリキュラムで作成しました。
https://aws-cloud-tech.com/
❷ public subnet にある EC2 インスタンスを踏み台にして private subnet の EC2 にログインする。
https://qiita.com/kou551121/items/6b1b237c8822861d334d
を参照してください❸ NAT gateway を作成して NAT gateway を経由して private subnet の EC2 インスタンスにログイン
3. NAT gateway を作成して NAT gateway を経由して private subnet の EC2 インスタンスにログイン
VPC のサービスに画面遷移してください
そこから左ウィンドウの NAT ゲートウェイをクリック
その画面より NAT ゲートウェイを作成をクリック
赤枠 NAT ゲートウェイの名前を入れてください
青枠 配置するサブネット、今回は Test-subnet-public に配置
黒枠 Elastic IP の割り当てをクリック
緑枠 新しい Elastic IP が割り当てられましたあとは右下にある NAT ゲートウェイを作成をクリック
このようになったら大丈夫です
今現在は 「private subnet」 「public subnet」 ともに同じルートテーブルが同じになっています
次 AT ゲートウェイを経由して private subnet の EC2 にログインするようにルートテーブルを作成します左ウィンドウより、ルートテーブルをクリック、そして上のほうにあるルートテーブルの作成をクリック
赤枠 名前(自分は routetable-private)
青枠 作った VPC(自分は Test-VPC)
終わったら作成(黒枠)をクリック
routetable-private にチャック(赤枠)
ルートを選択して(青枠)
ルートの編集をクリック(黒枠)
ルートの追加をクリック(赤枠)
送信先を 0.0.0.0/0(青枠)
ターゲットをクリックすると色々でてきますが NAT Gateway を選択、そして自分の作った NAT Gateway を選択(自分は Test-natgw)(黒枠)
終わったらルートの保存をクリック(緑枠)
これで大丈夫です
つぎにサブネットの関連付けをします。
左ウィンドウよりサブネットをクリック
Test-subnet-private(赤枠)をチャック
アクションからルートテーブルの関連付けを編集をクリック(青枠)
赤枠にルートテーブル ID に自分の作ったルートテーブル(routetable-private)を選択
保存をクリック(青枠)
ルートテーブルがこのようになっていれば大丈夫です
では本当に NAT gateway を経由して private subnet の EC2 インスタンスにログインか確かめたいと思います。Tera Term を起動して private subnet に入ってください
curl httpbin.org/ipを入れてください
これは・・・
↓ を見てください
と NAT ゲートウェイの Elastic IP と同じなのがわかりますね
これで NAT ゲートウェイ経由して通信しているとわかります最後に
やっと作成図をすべてクリアしました!!
長かった・・・
でもでも AWS はこれから始まったばかり、がんばるぞ~~またこの記事は AWS 初学者を導く体系的な動画学習サービス「AWS CloudTech」の課題カリキュラムで作成しました。
https://aws-cloud-tech.com/












- 投稿日:2021-03-03T16:34:57+09:00
[AWS] [tomcat]インスタンスタイプによってsetenv.shを置き換える
AWSのEC2のインスタンスタイプによって CATALINA_OPTSに記載されているヒープサイズを変えたいということはよくあることだと思います。
ここではお手軽に、インスタンスタイプごとのsetenv.shをS3に用意しておいて、それを起動時シェルで置き換えるという方法を紹介します。
複数のsetenv.shを用意する
まず、利用する可能性があるインスタンスタイプごとのsenenv.shを用意します。
今回はt3.mediumとt5.largeの2パターンを用意します。
ファイル名は{インスタンスタイプ}.setenv.shとつけて下さい。今回ですと、t3.medium.setenv.shとr5.large.setenv.shとなります。
t3.medium.setenv.sh
t3.mediumはメモリ4GBなので、以下のように2048MBをtomcatに割り当ててみました。
t3.medium.setenv.shexport CATALINA_OPTS="\ ${CATALINA_OPTS} \ -Xms2048m \ -Xmx2048m \ ... "r5.large.setenv.sh
r5.largeはメモリ16GBなので、以下のように8192MBをtomcatに割り当ててみました。
r5.large.setenv.shexport CATALINA_OPTS="\ ${CATALINA_OPTS} \ -Xms8192m \ -Xmx8192m \ ... "S3にアップロード
以下のように、上記で作成したファイルをS3の任意のバケットに保存します。
setenv.shを置き換える
それでは、EC2のユーザーデータなどの起動時スクリプトに以下を記述しておきます。
S3からsetenv.shをダウンロード
S3から用意したインスタンスタイプのsetenv.shを全部落としてきます。IAMロールなどのパーミッションをセットするのを忘れずに。配置場所はtomcatディレクトリのbinフォルダの中です。
$ aws s3 sync s3://your-bucket/middleware/tomcat/setenv/ /path-to-tomcat/bin/インスタンスタイプに合わせて置き換える
以下のコマンドで自身のインスタンスタイプを取得して、{インスタンスタイプ}.setenv.shをsetenv.shに置き換えます(コピーします)。
$ ec2-metadata -t | cut -d":" -f2 | xargs echo | xargs -I{} ls {}.setenv.sh | xargs -I{} cp {} setenv.sh以上になります。
このやり方なら、インスタンスタイプに合わせて自由にsetenv.shを用意することができ、利用するインスタンスタイプが増えたとしてもS3上のファイルを増やせば対応できますので、ソースコードの修正は不要になります。
setenv.shたちをGit管理しておくのもおすすめです。オートスケーリングで複数のインスタンスタイプを利用しながら、スケールアウトしていく場合などに利用する想定で作成しました。
以上ご参考になればと。

- 投稿日:2021-03-03T15:58:40+09:00
[日本語訳] AWS Amazon Polly 開発者ガイド APIリファレンス_其の2: DataTypes
これは・・・
AWS > ドキュメント > Amazon Polly > 開発者ガイド
のAPIリファレンスより下層(Action,DataTypes)が日本語になってなくて読みにくいのでgoogle翻訳にコピペして日本語化したものをテキストエディタにコピペする代わりにココに書いたものです。
※場合によっては英単語のままにしてるヶ所もあります
※各章の最後にある"See Also" は省略
※「パターン」は(正規表現による)使える文字列
※「〜を参照してください」みたいなヶ所のリンクは無し
※文章の整形としてインデント(字下げ)代わりにMarkdownの"引用"を使用
※この色の文章は補足メモなどの追加で、元記事や翻訳後にあるものではないです
関連項目メニュー代わり
- APIリファレンス > Action 以下
- APIリファレンス > DataTypes 以下 ←※いまココ
APIリファレンス - Data Types
次のデータ型がサポートされています:
ここではメニュー代わりにページ内リンクです
- Lexicon
- LexiconAttributes
- LexiconDescription
- SynthesisTask
- Voicehttps://docs.aws.amazon.com/ja_jp/polly/latest/dg/API_Types.html
Lexicon
https://docs.aws.amazon.com/ja_jp/polly/latest/dg/API_Lexicon.html
レキシコン名とレキシコンコンテンツを文字列形式で提供します。 詳細については、"Pronunciation Lexicon Specification (PLS) Version 1.0"を参照してください。
Contents
Content
文字列形式のレキシコンコンテンツ。 レキシコンの内容はPLS形式である必要があります。
type:文字列
必須かどうか:必須ではない
Name
レキシコンの名前。
type:文字列
パターン:
[0-9A-Za-z]{1,20}必須かどうか:必須ではない
LexiconAttributes
https://docs.aws.amazon.com/ja_jp/polly/latest/dg/API_LexiconAttributes.html
語彙素の数、言語コードなど、レキシコンを説明するメタデータが含まれています。 詳細については、レキシコンの管理を参照してください。
Contents
Alphabet
レキシコンで使用されるフォネティックコード。 有効な値は
ipaとx-sampaです。type:文字列
必須かどうか:必須ではない
LanguageCode
レキシコンが適用される言語コード。 「en」などの言語コードを持つレキシコンは、すべての英語言語(en-GB、en-US、en-AUS、en-WLSなど)に適用されます。
type:文字列
有効な値:
arb | cmn-CN | cy-GB | da-DK | de-DE | en-AU | en-GB | en-GB-WLS | en-IN | en-US | es-ES | es-MX | es-US | fr-CA | fr-FR | is-IS | it-IT | ja-JP | hi-IN | ko-KR | nb-NO | nl-NL | pl-PL | pt-BR | pt-PT | ro-RO | ru-RU | sv-SE | tr-TR必須かどうか:必須ではない
LastModified
レキシコンが最後に変更された日付(タイムスタンプ値)。
type:タイムスタンプ
必須かどうか:必須ではない
LexemesCount
レキシコン内の語彙素の数。
type:整数
必須かどうか:必須ではない
LexiconArn
レキシコンのAmazonリソース名(ARN)。
type:文字列
必須かどうか:必須ではない
Size
レキシコンの合計サイズ(文字数)。
type:整数
必須かどうか:必須ではない
LexiconDescription
https://docs.aws.amazon.com/ja_jp/polly/latest/dg/API_LexiconDescription.html
レキシコンの内容について説明します。
Contents
Attributes
レキシコンメタデータを提供します。
type:LexiconAttributesオブジェクト
必須かどうか:必須ではない
Name
レキシコンの名前。
type:文字列
パターン:
[0-9A-Za-z]{1,20}必須かどうか:必須ではない
SynthesisTask
https://docs.aws.amazon.com/ja_jp/polly/latest/dg/API_SynthesisTask.html
音声合成タスクに関する情報を提供するSynthesisTaskオブジェクト。
Contents
CreationTime
合成タスクが開始された時刻のタイムスタンプ。
type:タイムスタンプ
必須かどうか:必須ではない
Engine
音声合成の入力テキストを処理するときに使用するAmazonPollyのエンジン(標準またはニューラル)を指定します。選択したエンジンでサポートされていない音声を使用すると、エラーが発生します。
type:文字列
有効な値:
standard | neural必須かどうか:必須ではない
LanguageCode
合成タスク用のオプションの言語コード。これは、インド英語(en-IN)またはヒンディー語(hi-IN)のいずれかに使用できるAditiなどのバイリンガル音声を使用する場合にのみ必要です。
バイリンガル音声が使用され、言語コードが指定されていない場合、AmazonPollyはバイリンガル音声のデフォルト言語を使用します。音声のデフォルト言語は、LanguageCodeパラメーターのDescribeVoices操作によって返される言語です。たとえば、言語コードが指定されていない場合、Aditiはヒンディー語ではなくインド英語を使用します。
type:文字列
有効な値:
arb | cmn-CN | cy-GB | da-DK | de-DE | en-AU | en-GB | en-GB-WLS | en-IN | en-US | es-ES | es-MX | es-US | fr-CA | fr-FR | is-IS | it-IT | ja-JP | hi-IN | ko-KR | nb-NO | nl-NL | pl-PL | pt-BR | pt-PT | ro-RO | ru-RU | sv-SE | tr-TR
必須かどうか:必須ではない
LexiconNames
合成中にサービスに適用する1つ以上の発音レキシコン名のリスト。レキシコンは、レキシコンの言語が音声の言語と同じである場合にのみ適用されます。
type:文字列の配列
配列メンバー:最大5アイテム。
パターン:
[0-9A-Za-z]{1,20}必須かどうか:必須ではない
OutputFormat
返される出力がエンコードされる形式。 オーディオストリームの場合、これはmp3、ogg_vorbis、またはpcmになります。 スピーチマークの場合、これはjsonになります。
type:文字列
必須かどうか:必須ではない
OutputUri
出力音声ファイルの経路。
type:文字列
必須かどうか:必須ではない
RequestCharacters
合成された請求可能な文字の数。
type:整数
必須かどうか:必須ではない
SampleRate
Hzで指定された可聴周波数。
mp3とogg_vorbisの有効な値は、「8000」、「16000」、「22050」、および「24000」です。標準音声のデフォルト値は「22050」です。ニューラルボイスのデフォルト値は「24000」です。
pcmの有効な値は「8000」と「16000」。デフォルト値は「16000」。
type:文字列
必須かどうか:必須ではない
SnsTopicArn
音声合成タスクのステータス通知を提供するためにオプションで使用されるSNSトピックのARN。
type:文字列
パターン:
^arn:aws(-(cn|iso(-b)?|us-gov))?:sns:[a-z0-9_-]{1,50}:\d{12}:[a-zA-Z0-9_-]{1,256}$必須かどうか:必須ではない
SpeechMarkTypes
入力テキストに対して返されるスピーチマークのタイプ。
type:文字列の配列
配列メンバー:最大4アイテム。
有効な値:
sentence | ssml | viseme | word必須かどうか:必須ではない
TaskId
Amazon Pollyは、音声合成タスクの識別子を生成しました。
type:文字列
パターン:
^[a-zA-Z0-9_-]{1,100}$必須かどうか:必須ではない
TaskStatusReason
タスクが失敗した場合のエラーを含む、特定の音声合成タスクの現在のステータスの理由。
type:文字列
必須かどうか:必須ではない
TextType
入力テキストがプレーンテキストかSSMLかを指定します。デフォルト値はプレーンテキストです。
type:文字列
有効な値:
ssml | text必須かどうか:必須ではない
VoiceId
合成に使用する音声ID。
type:文字列
有効な値:
Aditi | Amy | Astrid | Bianca | Brian | Camila | Carla | Carmen | Celine | Chantal | Conchita | Cristiano | Dora | Emma | Enrique | Ewa | Filiz | Geraint | Giorgio | Gwyneth | Hans | Ines | Ivy | Jacek | Jan | Joanna | Joey | Justin | Karl | Kendra | Kevin | Kimberly | Lea | Liv | Lotte | Lucia | Lupe | Mads | Maja | Marlene | Mathieu | Matthew | Maxim | Mia | Miguel | Mizuki | Naja | Nicole | Penelope | Raveena | Ricardo | Ruben | Russell | Salli | Seoyeon | Takumi | Tatyana | Vicki | Vitoria | Zeina | Zhiyu
必須かどうか:必須ではない
Voice
Contents
AdditionalLanguageCodes
デフォルトの言語に加えて、指定された音声で使用可能な言語の追加コード。
たとえば、Aditiのデフォルト言語は、その言語で最初に使用されたため、インド英語(en-IN)です。 Aditiはインド英語とヒンディー語の両方でバイリンガルで流暢であるため、このパラメーターはコードhi-INを表示します。
type:文字列の配列
有効な値:
arb | cmn-CN | cy-GB | da-DK | de-DE | en-AU | en-GB | en-GB-WLS | en-IN | en-US | es-ES | es-MX | es-US | fr-CA | fr-FR | is-IS | it-IT | ja-JP | hi-IN | ko-KR | nb-NO | nl-NL | pl-PL | pt-BR | pt-PT | ro-RO | ru-RU | sv-SE | tr-TR必須かどうか:必須ではない
Gender
声の性別。
type:文字列
有効な値:
Female | Mal必須かどうか:必須ではない
Id
AmazonPollyが割り当てる音声ID。これは、SynthesizeSpeech操作を呼び出すときに指定するIDです。
type:文字列
有効な値:
Aditi | Amy | Astrid | Bianca | Brian | Camila | Carla | Carmen | Celine | Chantal | Conchita | Cristiano | Dora | Emma | Enrique | Ewa | Filiz | Geraint | Giorgio | Gwyneth | Hans | Ines | Ivy | Jacek | Jan | Joanna | Joey | Justin | Karl | Kendra | Kevin | Kimberly | Lea | Liv | Lotte | Lucia | Lupe | Mads | Maja | Marlene | Mathieu | Matthew | Maxim | Mia | Miguel | Mizuki | Naja | Nicole | Penelope | Raveena | Ricardo | Ruben | Russell | Salli | Seoyeon | Takumi | Tatyana | Vicki | Vitoria | Zeina | Zhiyu必須かどうか:必須ではない
LanguageCode
声の言語コード。
type:文字列
有効な値:
arb | cmn-CN | cy-GB | da-DK | de-DE | en-AU | en-GB | en-GB-WLS | en-IN | en-US | es-ES | es-MX | es-US | fr-CA | fr-FR | is-IS | it-IT | ja-JP | hi-IN | ko-KR | nb-NO | nl-NL | pl-PL | pt-BR | pt-PT | ro-RO | ru-RU | sv-SE | tr-TR必須かどうか:必須ではない
LanguageName
英語で人間が読める言語の名前。
type:文字列
必須かどうか:必須ではない
__Name_
声の名前(たとえば、Salli、Kendraなど)。これにより、アプリケーションに表示される可能性のある人間が読める音声名が提供されます。
type:文字列
必須かどうか:必須ではない
SupportedEngines
特定の音声でサポートされるエンジン(標準またはニューラル)を指定します。
type:文字列の配列
有効な値:
standard | neural必須かどうか:必須ではない


- 投稿日:2021-03-03T15:55:39+09:00
[日本語訳] AWS Amazon Polly 開発者ガイド APIリファレンス _其の1: Action
これは・・・
AWS > ドキュメント > Amazon Polly > 開発者ガイド
のAPIリファレンスより下層(Action,DataTypes)が日本語になってなくて読みにくいのでgoogle翻訳にコピペして日本語化したものをテキストエディタにコピペする代わりにココに書いたものです。
※場合によっては英単語のままにしてるヶ所もあります
※各章の最後にある"See Also" は省略
※「パターン」は(正規表現による)使える文字列
※「〜を参照してください」みたいなヶ所のリンクは無し
※文章の整形としてインデント(字下げ)代わりにMarkdownの"引用"を使用
※この色の文章は補足メモなどの追加で、元記事や翻訳後にあるものではないです
関連項目メニュー代わり
- APIリファレンス > Action 以下 ←※いまココ
- APIリファレンス > DataTypes 以下
APIリファレンス - Actions
次のアクションがサポートされています:
ここではメニュー代わりにページ内リンクです
- DeleteLexicon
- DescribeVoices
- GetLexicon
- GetSpeechSynthesisTask
- ListLexicons
- ListSpeechSynthesisTasks
- PutLexicon
- StartSpeechSynthesisTask
- SynthesizeSpeechhttps://docs.aws.amazon.com/ja_jp/polly/latest/dg/API_Operations.html
DeleteLexicon
https://docs.aws.amazon.com/ja_jp/polly/latest/dg/API_DeleteLexicon.html
AWSリージョンに保存されている指定された発音レキシコンを削除します。 削除されたレキシコンは音声合成に使用できません。また、GetLexiconまたはListLexiconAPIを使用してレキシコンを取得することもできません。
詳細については、レキシコンの管理を参照してください。
Request構文
DELETE /v1/lexicons/LexiconName HTTP/1.1
URIリクエストパラメータ
リクエストは次のURIパラメータを使用します。
LexiconName
削除するレキシコンの名前。 リージョン内の既存のレキシコンである必要があります。
パターン:[0-9A-Za-z] {1,20}
必須かどうか:必須
Request本文
リクエストにはリクエスト本文がありません。
Response構文
HTTP/1.1 200=
Response要素
アクションが成功すると、サービスは空のHTTPボディを含むHTTP200応答を送り返します。
エラー
LexiconNotFoundException
AmazonPollyは指定されたレキシコンを見つけることができません。これは、レキシコンが欠落しているか、名前のスペルが間違っているか、別のリージョンにあるレキシコンを指定していることが原因である可能性があります。レキシコンが存在し、リージョン内にあり(ListLexiconsを参照)、名前のスペルが正しいことを確認します。その後、再試行してください。
HTTPステータスコード:404
ServiceFailureException
不明な状態が原因でサービス障害が発生しました。HTTPステータスコード:500
DescribeVoices
https://docs.aws.amazon.com/ja_jp/polly/latest/dg/API_DescribeVoices.html
音声合成を要求するときに使用できる音声のリストを返します。 各音声は指定された言語を話し、男性または女性のいずれかであり、音声名のASCIIバージョンであるIDによって識別されます。
音声を合成する場合(
SynthesizeSpeech)、DescribeVoicesによって返される音声のリストから必要な音声の音声IDを指定します。たとえば、ニュースリーダーアプリケーションで特定の言語のニュースを読みたいが、ユーザーに音声を選択するオプションを提供したいとします。
DescribeVoices操作を使用すると、選択可能な音声のリストをユーザーに提供できます。オプションで言語コードを指定して、使用可能な音声をフィルタリングできます。 たとえば、
en-USを指定すると、操作は使用可能なすべての米国英語の音声のリストを返します。この操作には、
polly:DescribeVoicesアクションを実行するためのアクセス許可が必要です。
Request構文
GET /v1/voices?Engine=Engine&IncludeAdditionalLanguageCodes=IncludeAdditionalLanguageCodes&LanguageCode=LanguageCode&NextToken=NextToken HTTP/1.1
URIリクエストパラメータ
リクエストは次のURIパラメータを使用します。
Engine
音声合成用の入力テキストを処理するときにAmazonPollyが使用するエンジン(標準またはニューラル)を指定します。
有効な値:standard | neuralIncludeAdditionalLanguageCodes
指定された言語を追加言語として使用するバイリンガル音声を返すかどうかを示すブール値。たとえば、米国英語(es-US)を使用するすべての言語を要求し、イタリア語(it-IT)と米国英語の両方を話すイタリア語の音声がある場合、
yesを指定するとその音声が含まれますが、noを指定します。LanguageCode
返された音声のリストをフィルタリングするための言語識別タグ(言語名のISO639コード-ISO3166国コード)。このオプションのパラメーターを指定しない場合、使用可能なすべてのボイスが返されます。
有効な値:
arb | cmn-CN | cy-GB | da-DK | de-DE | en-AU | en-GB | en-GB-WLS | en-IN | en-US | es-ES | es-MX | es-US | fr-CA | fr-FR | is-IS | it-IT | ja-JP | hi-IN | ko-KR | nb-NO | nl-NL | pl-PL | pt-BR | pt-PT | ro-RO | ru-RU | sv-SE | tr-TRNextToken
前の
DescribeVoices操作から返された不透明なページネーショントークン。存在する場合、これはリストを続行する場所を示します。長さの制約:最小長は0。最大長は4096。
Request本文
リクエストにはリクエスト本文がありません。
Response構文
HTTP/1.1 200 Content-type: application/json { "NextToken": "string", "Voices": [ { "AdditionalLanguageCodes": [ "string" ], "Gender": "string", "Id": "string", "LanguageCode": "string", "LanguageName": "string", "Name": "string", "SupportedEngines": [ "string" ] } ] }Σ( ꒪﹃ ꒪)ハイライトが思ったようにいかん…、"string" が以下で出る「type:文字列」の文字列ってことで、比較的任意の値のことです
Response要素
アクションが成功すると、サービスはHTTP200応答を送り返します。
次のデータは、サービスによってJSON形式で返されます。
NextToken
音声のリストを続行するために次のリクエストで使用するページネーショントークン。 NextTokenは、応答が切り捨てられた場合にのみ返されます。
type:文字列
長さの制約:最小長は0。最大長は4096。
Voices
ボイスとそのプロパティのリスト。
type:音声オブジェクトの配列
エラー
InvalidNextTokenException
NextTokenが無効です。 スペルが正しいことを確認してから、再試行してください。
HTTPステータスコード:400ServiceFailureException
不明な状態が原因でサービス障害が発生しました。
HTTPステータスコード:500
GetLexicon
https://docs.aws.amazon.com/ja_jp/polly/latest/dg/API_GetLexicon.html
AWSリージョンに保存されている指定された発音レキシコンのコンテンツを返します。 詳細については、レキシコンの管理を参照してください。
Request構文
GET /v1/lexicons/LexiconName HTTP/1.1URIリクエストパラメータ
リクエストは次のURIパラメータを使用します。
LexiconName
レキシコンの名前。
パターン:[0-9A-Za-z]{1,20}
必須かどうか: 必須
Request本文
リクエストにはリクエスト本文がありません。
Response 構文
HTTP/1.1 200 Content-type: application/json { "Lexicon": { "Content": "string", "Name": "string" }, "LexiconAttributes": { "Alphabet": "string", "LanguageCode": "string", "LastModified": number, "LexemesCount": number, "LexiconArn": "string", "Size": number } }Σ( ꒪﹃ ꒪)ハイライトが思ったようにいかん…、"string" が以下で出る「type:文字列」の文字列ってことで、比較的任意の値のことです
Response要素
アクションが成功すると、サービスはHTTP200応答を送り返します。
次のデータは、サービスによってJSON形式で返されます。
Lexicon
レキシコンの名前と文字列の内容を提供するレキシコンオブジェクト。
type:レキシコンオブジェクト
LexiconAttributes
使用されている音声アルファベット、言語コード、レキシコンARN、レキシコンで定義されている語彙素の数、バイト単位のレキシコンのサイズなど、レキシコンのメタデータ。
Type:LexiconAttributesオブジェクト
エラー
LexiconNotFoundException
AmazonPollyは指定されたレキシコンを見つけることができません。 これは、レキシコンが欠落しているか、名前のスペルが間違っているか、別のリージョンにあるレキシコンを指定していることが原因である可能性があります。
レキシコンが存在し、リージョン内にあり(ListLexiconsを参照)、名前のスペルが正しいことを確認します。 その後、再試行してください。
HTTPステータスコード:404
ServiceFailureException
不明な状態が原因でサービス障害が発生しました。
HTTPステータスコード:500
GetSpeechSynthesisTask
https://docs.aws.amazon.com/ja_jp/polly/latest/dg/API_GetSpeechSynthesisTask.html
TaskIDに基づいて特定のSpeechSynthesisTaskオブジェクトを取得します。 このオブジェクトには、タスクのステータスなど、特定の音声合成タスクに関する情報と、タスクの出力を含むS3バケットへのリンクが含まれています。
Request構文
GET /v1/synthesisTasks/TaskId HTTP/1.1
URIリクエストパラメータ
リクエストは次のURIパラメータを使用します。
TaskId
Amazon Pollyは、音声合成タスクの識別子を生成しました。パターン:
^[a-zA-Z0-9_-]{1,100}$必須かどうか:必須
Request本文
リクエストにはリクエスト本文がありません。
Response構文
HTTP/1.1 200 Content-type: application/json { "SynthesisTask": { "CreationTime": number, "Engine": "string", "LanguageCode": "string", "LexiconNames": [ "string" ], "OutputFormat": "string", "OutputUri": "string", "RequestCharacters": number, "SampleRate": "string", "SnsTopicArn": "string", "SpeechMarkTypes": [ "string" ], "TaskId": "string", "TaskStatus": "string", "TaskStatusReason": "string", "TextType": "string", "VoiceId": "string" } }Σ( ꒪﹃ ꒪)ハイライトが思ったようにいかん…、"string" が以下で出る「type:文字列」の文字列ってことで、比較的任意の値のことです
Response要素
アクションが成功すると、サービスはHTTP200応答を送り返します。
次のデータは、サービスによってJSON形式で返されます。
SynthesisTask
出力形式、作成時間、タスクステータスなど、要求されたタスクからの情報を提供するSynthesisTaskオブジェクト。
Type:SynthesisTaskオブジェクト
エラー
InvalidTaskIdException
指定されたタスクIDは無効です。 有効なタスクIDを入力して、再試行してください。
HTTPステータスコード:400ServiceFailureException
不明な状態が原因でサービス障害が発生しました。
HTTPステータスコード:500SynthesisTaskNotFoundException
要求されたタスクIDを持つ音声合成タスクが見つかりません。
HTTPステータスコード:400
ListLexicons
https://docs.aws.amazon.com/ja_jp/polly/latest/dg/API_ListLexicons.html
AWSリージョンに保存されている発音レキシコンのリストを返します。 詳細については、レキシコンの管理を参照してください。
Request構文
GET /v1/lexicons?NextToken=NextToken HTTP/1.1
URIリクエストパラメータ
リクエストは次のURIパラメータを使用します。
NextToken
以前の
ListLexicons操作から返された不透明なページネーショントークン。 存在する場合は、レキシコンのリストを続行する場所を示します。長さの制約:最小長は0。最大長は4096。
Request本文
リクエストにはリクエスト本文がありません。
Response構文
HTTP/1.1 200 Content-type: application/json { "Lexicons": [ { "Attributes": { "Alphabet": "string", "LanguageCode": "string", "LastModified": number, "LexemesCount": number, "LexiconArn": "string", "Size": number }, "Name": "string" } ], "NextToken": "string" }Σ( ꒪﹃ ꒪)ハイライトが思ったようにいかん…、"string" が以下で出る「type:文字列」の文字列ってことで、比較的任意の値のことです
Response要素
アクションが成功すると、サービスはHTTP200応答を送り返します。
次のデータは、サービスによってJSON形式で返されます。
Lexicons
レキシコンの名前と属性のリスト。
type:LexiconDescriptionオブジェクトの配列NextToken
レキシコンのリストを続行するために次のリクエストで使用するページネーショントークン。 NextTokenは、応答が切り捨てられた場合にのみ返されます。
type:文字列
長さの制約:最小長は0。最大長は4096。
エラー
InvalidNextTokenException
NextTokenが無効です。 スペルが正しいことを確認してから、再試行してください。
HTTPステータスコード:400ServiceFailureException
不明な状態が原因でサービス障害が発生しました。
HTTPステータスコード:500
ListSpeechSynthesisTasks
https://docs.aws.amazon.com/ja_jp/polly/latest/dg/API_ListSpeechSynthesisTasks.html
作成日順に並べられたSpeechSynthesisTaskオブジェクトのリストを返します。 この操作では、タスクをステータスでフィルタリングできます。たとえば、ユーザーは完了したタスクのみを一覧表示できます。
Request構文
GET /v1/synthesisTasks?MaxResults=MaxResults&NextToken=NextToken&Status=Status HTTP/1.1URI リクエストパラメータ
リクエストは次のURIパラメータを使用します。
MaxResults
リスト操作で返される音声合成タスクの最大数。
有効範囲:最小値1。最大値100。
NextToken
音声合成タスクのリストを続行するために、次のリクエストで使用するページネーショントークン。
長さの制約:最小長は0。最大長は4096。
Status
リスト操作で返された音声合成タスクのステータス
有効な値:
scheduled | inProgress | completed | failed「有効な値」は左から スケジュール済み| 進行中 | 完了| 失敗
Request本文
リクエストにはリクエスト本文がありません。
Response構文
HTTP/1.1 200 Content-type: application/json { "NextToken": "string", "SynthesisTasks": [ { "CreationTime": number, "Engine": "string", "LanguageCode": "string", "LexiconNames": [ "string" ], "OutputFormat": "string", "OutputUri": "string", "RequestCharacters": number, "SampleRate": "string", "SnsTopicArn": "string", "SpeechMarkTypes": [ "string" ], "TaskId": "string", "TaskStatus": "string", "TaskStatusReason": "string", "TextType": "string", "VoiceId": "string" } ] }Σ( ꒪﹃ ꒪)ハイライトが思ったようにいかん…、"string" が以下で出る「type:文字列」の文字列ってことで、比較的任意の値のことです
Response要素
アクションが成功すると、サービスはHTTP200応答を送り返します。
次のデータは、サービスによってJSON形式で返されます。
NextToken
このリクエストの前のリスト操作から返された不透明なページネーショントークン。 存在する場合、これはリストを続行する場所を示します。
type: 文字列
長さの制約:最小長は0。最大長は4096。
SynthesisTasks
出力形式、作成時間、タスクステータスなど、リスト要求で指定されたタスクからの情報を提供するSynthesisTaskオブジェクトのリスト。
type: SynthesisTaskオブジェクトの配列
エラー
InvalidNextTokenException
NextTokenが無効です。 スペルが正しいことを確認してから、再試行してください。
HTTPステータスコード:400ServiceFailureException
不明な状態が原因でサービス障害が発生しました。
HTTPステータスコード:500
PutLexicon
https://docs.aws.amazon.com/ja_jp/polly/latest/dg/API_PutLexicon.html
AWSリージョンに発音レキシコンを保存します。 同じ名前のレキシコンがすでにリージョンに存在する場合は、新しいレキシコンによって上書きされます。 レキシコン操作には結果整合性があるため、レキシコンがSynthesizeSpeech操作で使用できるようになるまでに時間がかかる場合があります。
詳細については、レキシコンの管理を参照してください。
Request構文
PUT /v1/lexicons/LexiconName HTTP/1.1 Content-type: application/json { "Content": "string" }
URIリクエストパラメータ
リクエストは次のURIパラメータを使用します。
LexiconName
レキシコンの名前。 名前は、正規表現形式[0-9A-Za-z] {1,20}に従う必要があります。 つまり、名前は最大20文字の大文字と小文字を区別する英数字の文字列です。
パターン:
[0-9A-Za-z]{1,20}必須かどうか:必須
リクエスト本文
リクエストは、JSON形式で次のデータを受け入れます。
Content
文字列データとしてのPLSレキシコンのコンテンツ。
type:文字列必須かどうか:必須
Response 構文
HTTP/1.1 200
Response要素
アクションが成功すると、サービスは空のHTTPボディを含むHTTP200応答を送り返します。
エラー
InvalidLexiconException
AmazonPollyは指定されたレキシコンを見つけることができません。レキシコンの名前のスペルが正しいことを確認してから、再試行してください。
HTTPステータスコード:400
LexiconSizeExceededException
この操作では、指定されたレキシコンの最大サイズを超えます。
HTTPステータスコード:400
MaxLexemeLengthExceededException
この操作では、語彙素の最大サイズを超えます。
HTTPステータスコード:400
MaxLexiconsNumberExceededException
この操作では、レキシコンの最大数を超えます。
HTTPステータスコード:400
ServiceFailureException
不明な状態が原因でサービス障害が発生しました。
HTTPステータスコード:500
UnsupportedPlsAlphabetException
レキシコンで指定されたアルファベットは、サポートされているアルファベットではありません。有効な値はx-sampaとipaです。
HTTPステータスコード:400
UnsupportedPlsLanguageException
レキシコンで指定されている言語はサポートされていません。サポートされている言語のリストについては、レキシコン属性を参照してください。
HTTPステータスコード:400
StartSpeechSynthesisTask
https://docs.aws.amazon.com/ja_jp/polly/latest/dg/API_StartSpeechSynthesisTask.html
新しい
SpeechSynthesisTaskを開始することにより、非同期合成タスクの作成を許可します。 この操作には、音声合成に必要なすべての標準情報に加えて、合成タスクの出力を保存するサービスのAmazon S3バケットの名前と2つのオプションのパラメーター(OutputS3KeyPrefixとSnsTopicArn)が必要です。 合成タスクが作成されると、この操作はSpeechSynthesisTaskオブジェクトを返します。このオブジェクトには、このタスクの識別子と現在のステータスが含まれます。「Amazon S3」はAWSのストレージサービス
Request構文
POST /v1/synthesisTasks HTTP/1.1 Content-type: application/json { "Engine": "string", "LanguageCode": "string", "LexiconNames": [ "string" ], "OutputFormat": "string", "OutputS3BucketName": "string", "OutputS3KeyPrefix": "string", "SampleRate": "string", "SnsTopicArn": "string", "SpeechMarkTypes": [ "string" ], "Text": "string", "TextType": "string", "VoiceId": "string" }Σ( ꒪﹃ ꒪)ハイライトが思ったようにいかん…、"string" が以下で出る「type:文字列」の文字列ってことで、比較的任意の値のことです
必須の分(4つ)を含めていくつか指定した例(必須じゃないのはなくても構わない)
{ "Engine": "standard ", "OutputFormat": "mp3", "OutputS3BucketName": "kimigaomoideninaruameni", "SampleRate": "24000", "Text": "君が思い出になる前に", "VoiceId": "Takumi" }※下記表は、全部じゃなくてとりあえずいくつか抜粋したもの
項目名 説明 例 Engine 標準またはニューラルを指定 standard / neural OutputFormat 出力のサウンド形式(スピーチマークの場合json) *必須
json / mp3 / ogg_vorbis / pcmOutputS3BucketName 出力ファイルが保存されるAmazonS3バケット名 *必須 SampleRate サンプリングレート (デフォルト値)
スタンダード:22,050Hz
ニューラル:24,000HzTextType 入力テキストがプレーンテキストかSSMLかを指定 ssml / text Text 再生するテキスト
(TextTypeとしてssmlを指定する場合は、入力テキストのSSML形式)*必須 VoiceId 使用する音声ID *必須
URIリクエストパラメータ
リクエストはURIパラメータを使用しません。
Request本文
リクエストは、JSON形式で次のデータを受け入れます。
Engine
音声合成の入力テキストを処理するときに使用するAmazonPollyのエンジン(標準またはニューラル)を指定します。選択したエンジンでサポートされていない音声を使用すると、エラーが発生します。
type:文字列
有効な値:
standard | neural必須かどうか:必須ではない
LanguageCode
音声合成リクエストのオプションの言語コード。これは、インド英語(en-IN)またはヒンディー語(hi-IN)のいずれかに使用できるAditiなどのバイリンガル音声を使用する場合にのみ必要です。
バイリンガル音声が使用され、言語コードが指定されていない場合、AmazonPollyはバイリンガル音声のデフォルト言語を使用します。音声のデフォルト言語は、
LanguageCodeパラメーターのDescribeVoices操作によって返される言語です。たとえば、言語コードが指定されていない場合、Aditiはヒンディー語ではなくインド英語を使用します。type:文字列
有効な値:
arb | cmn-CN | cy-GB | da-DK | de-DE | en-AU | en-GB | en-GB-WLS | en-IN | en-US | es-ES | es-MX | es-US | fr-CA | fr-FR | is-IS | it-IT | ja-JP | hi-IN | ko-KR | nb-NO | nl-NL | pl-PL | pt-BR | pt-PT | ro-RO | ru-RU | sv-SE | tr-TR必須かどうか:必須ではない
LexiconNames
合成中にサービスに適用する1つ以上の発音レキシコン名のリスト。レキシコンは、レキシコンの言語が音声の言語と同じである場合にのみ適用されます。
type:文字列の配列
配列メンバー:最大5アイテム。
パターン:
[0-9A-Za-z]{1,20}必須かどうか:必須ではない
OutputFormat
返される出力がエンコードされる形式。オーディオストリームの場合、これはmp3、ogg_vorbis、またはpcmになります。スピーチマークの場合、これはjsonになります。
type:文字列
有効な値:
json | mp3 | ogg_vorbis | pcm必須かどうか:必須
OutputS3BucketName
出力ファイルが保存されるAmazonS3バケット名。
type:文字列
パターン:
^[a-z0-9][\.\-a-z0-9]{1,61}[a-z0-9]$必須かどうか:必須
OutputS3KeyPrefix
出力音声ファイルのAmazonS3キープレフィックス。
type:文字列
パターン:
^[0-9a-zA-Z\/\!\-_\.\*\'\(\):;\$@=+\,\?&]{0,800}$必須かどうか:必須ではない
SampleRate
Hzで指定された可聴周波数。
mp3とogg_vorbisの有効な値は、「8000」、「16000」、「22050」、および「24000」です。標準音声のデフォルト値は「22050」です。ニューラルボイスのデフォルト値は「24000」です。
pcmの有効な値は「8000」と「16000」。デフォルト値は「16000」。
type:文字列
必須かどうか:必須ではない
SnsTopicArn
音声合成タスクのステータス通知を提供するためにオプションで使用されるSNSトピックのARN。
type:文字列
パターン:
^arn:aws(-(cn|iso(-b)?|us-gov))?:sns:[a-z0-9_-]{1,50}:\d{12}:[a-zA-Z0-9_-]{1,256}$必須かどうか:必須ではない
SpeechMarkTypes
入力テキストに対して返されるスピーチマークのタイプ。
type:文字列の配列
配列メンバー:最大4アイテム。
有効な値:
sentence | ssml | viseme | word必須かどうか:必須ではない
Text
合成する入力テキスト。 TextTypeとしてssmlを指定する場合は、入力テキストのSSML形式に従います。
type:文字列
必須かどうか:必須
TextType
入力テキストがプレーンテキストかSSMLかを指定します。デフォルト値はプレーンテキストです。
type:文字列
有効な値:
ssml | text必須かどうか:必須ではない
VoiceId
合成に使用する音声ID。
type:文字列
有効な値:
Aditi | Amy | Astrid | Bianca | Brian | Camila | Carla | Carmen | Celine | Chantal | Conchita | Cristiano | Dora | Emma | Enrique | Ewa | Filiz | Geraint | Giorgio | Gwyneth | Hans | Ines | Ivy | Jacek | Jan | Joanna | Joey | Justin | Karl | Kendra | Kevin | Kimberly | Lea | Liv | Lotte | Lucia | Lupe | Mads | Maja | Marlene | Mathieu | Matthew | Maxim | Mia | Miguel | Mizuki | Naja | Nicole | Penelope | Raveena | Ricardo | Ruben | Russell | Salli | Seoyeon | Takumi | Tatyana | Vicki | Vitoria | Zeina | Zhiyu必須かどうか:必須
Response構文
HTTP/1.1 200 Content-type: application/json { "SynthesisTask": { "CreationTime": number, "Engine": "string", "LanguageCode": "string", "LexiconNames": [ "string" ], "OutputFormat": "string", "OutputUri": "string", "RequestCharacters": number, "SampleRate": "string", "SnsTopicArn": "string", "SpeechMarkTypes": [ "string" ], "TaskId": "string", "TaskStatus": "string", "TaskStatusReason": "string", "TextType": "string", "VoiceId": "string" } }
Response要素
アクションが成功すると、サービスはHTTP200応答を送り返します。
次のデータは、サービスによってJSON形式で返されます。
SynthesisTask
新しく送信された音声合成タスクに関する情報と属性を提供するSynthesisTaskオブジェクト。
type:SynthesisTaskオブジェクト
エラー
EngineNotSupportedException
このエンジンは、指定した音声と互換性がありません。エンジンと互換性のある新しいボイスを選択するか、エンジンを変更して操作を再開してください。
HTTPステータスコード:400
InvalidS3BucketException
指定されたAmazonS3バケット名が無効です。 S3バケットの命名要件で入力を確認して、再試行してください。
HTTPステータスコード:400
InvalidS3KeyException
指定されたAmazonS3キープレフィックスが無効です。有効なS3オブジェクトキー名を入力してください。
HTTPステータスコード:400
InvalidSampleRateException
指定されたサンプルレートは無効です。
HTTPステータスコード:400
InvalidSnsTopicArnException
指定されたSNSトピックARNが無効です。有効なSNSトピックARNを入力して、再試行してください。
HTTPステータスコード:400
InvalidSsmlException
指定したSSMLが無効です。 SSML構文、タグと値のスペルを確認してから、再試行してください。
HTTPステータスコード:400
LanguageNotSupportedException
指定された言語は、現在この機能でAmazonPollyによってサポートされていません。
HTTPステータスコード:400
LexiconNotFoundException
AmazonPollyは指定されたレキシコンを見つけることができません。これは、レキシコンが欠落しているか、名前のスペルが間違っているか、別のリージョンにあるレキシコンを指定していることが原因である可能性があります。
レキシコンが存在し、リージョン内にあり(ListLexiconsを参照)、名前のスペルが正しいことを確認します。その後、再試行してください。
HTTPステータスコード:404
MarksNotSupportedForFormatException
選択したOutputFormatでは、スピーチマークはサポートされていません。スピーチマークは、json形式のコンテンツでのみ使用できます。
HTTPステータスコード:400
ServiceFailureException
不明な状態が原因でサービス障害が発生しました。
HTTPステータスコード:500
SsmlMarksNotSupportedForTextTypeException
SSMLスピーチマークは、プレーンテキストタイプの入力ではサポートされていません。
HTTPステータスコード:400
TextLengthExceededException
「テキスト」パラメータの値が、許容される制限を超えています。
SynthesizeSpeechAPIの場合、入力テキストの制限は合計で最大6000文字であり、そのうち3000文字を超えて請求できる文字はありません。StartSpeechSynthesisTask APIの場合、最大は200,000文字で、そのうち100,000文字を超えて請求することはできません。 SSMLタグは請求文字としてカウントされません。HTTPステータスコード:400
SynthesizeSpeech
https://docs.aws.amazon.com/ja_jp/polly/latest/dg/API_SynthesizeSpeech.html
UTF-8入力、プレーンテキストまたはSSMLをバイトストリームに合成します。 SSML入力は、有効で整形式のSSMLである必要があります。 一部のアルファベットは、音素マッピングを使用しない限り、すべての音声で使用できない場合があります(たとえば、キリル文字が英語の音声でまったく読み取られない場合があります)。 詳細については、「 How it Works」を参照してください。
Request構文
POST /v1/speech HTTP/1.1 Content-type: application/json { "Engine": "string", "LanguageCode": "string", "LexiconNames": [ "string" ], "OutputFormat": "string", "SampleRate": "string", "SpeechMarkTypes": [ "string" ], "Text": "string", "TextType": "string", "VoiceId": "string" }Σ( ꒪﹃ ꒪)ハイライトが思ったようにいかん…、"string" が以下で出る「type:文字列」の文字列ってことで、比較的任意の値のことです
必須の分(4つ)を含めていくつか指定した例(必須じゃないのはなくても構わない){ "Engine": "standard ", "OutputFormat": "mp3", "SampleRate": "24000", "Text": "君が思い出になる前に", "VoiceId": "Takumi" }※下記表は、全部じゃなくてとりあえずいくつか抜粋したもの
項目名 説明 例 Engine 標準またはニューラルを指定 standard / neural OutputFormat 出力のサウンド形式(スピーチマークの場合json) *必須
json / mp3 / ogg_vorbis / pcmSampleRate サンプリングレート (デフォルト値)
スタンダード:22,050Hz
ニューラル:24,000HzTextType 入力テキストがプレーンテキストかSSMLかを指定 ssml / text Text 再生するテキスト
(TextTypeとしてssmlを指定する場合は、入力テキストのSSML形式)*必須 VoiceId 使用する音声ID *必須
URIリクエストパラメータ
リクエストはURIパラメータを使用しません。
Request本文
リクエストは、JSON形式で次のデータを受け入れます。
Engine
音声合成の入力テキストを処理するときに使用するAmazonPollyのエンジン(標準またはニューラル)を指定します。 Amazon Pollyの音声と、標準のみ、NTTSのみ、および標準形式とNTTS形式の両方で使用できる音声については、「Available Voices」を参照してください。
NTTS-only voices
Kevin(en-US)などのNTTSのみの音声を使用する場合、このパラメータは必須であり、neuralに設定する必要があります。エンジンが指定されていない場合、または標準に設定されている場合、エラーが発生します。
type:文字列
有効な値:
standard | neural必須かどうか:必須
Standard voices
標準の音声の場合、これは必須ではありません。エンジンパラメータのデフォルトは標準です。エンジンが指定されていない場合、または標準に設定されていて、NTTSのみの音声が選択されている場合、エラーが発生します。type:文字列
有効な値:
standard | neural必須かどうか:必須ではない
LanguageCode
SynthesizeSpeechリクエストのオプションの言語コード。これは、インド英語(en-IN)またはヒンディー語(hi-IN)のいずれかに使用できるAditiなどのバイリンガル音声を使用する場合にのみ必要です。
バイリンガル音声が使用され、言語コードが指定されていない場合、AmazonPollyはバイリンガル音声のデフォルト言語を使用します。音声のデフォルト言語は、LanguageCodeパラメーターのDescribeVoices操作によって返される言語です。たとえば、言語コードが指定されていない場合、Aditiはヒンディー語ではなくインド英語を使用します。
type:文字列
有効な値:
: arb | cmn-CN | cy-GB | da-DK | de-DE | en-AU | en-GB | en-GB-WLS | en-IN | en-US | es-ES | es-MX | es-US | fr-CA | fr-FR | is-IS | it-IT | ja-JP | hi-IN | ko-KR | nb-NO | nl-NL | pl-PL | pt-BR | pt-PT | ro-RO | ru-RU | sv-SE | tr-TR必須かどうか:必須ではない
LexiconNames
合成中にサービスに適用する1つ以上の発音レキシコン名のリスト。レキシコンは、レキシコンの言語が音声の言語と同じである場合にのみ適用されます。レキシコンの保存については、PutLexiconを参照してください。
type:文字列の配列
配列メンバー:最大5アイテム。
パターン:
[0-9A-Za-z]{1,20}必須かどうか:必須ではない
OutputFormat
返される出力がエンコードされる形式。オーディオストリームの場合、これはmp3、ogg_vorbis、またはpcmになります。スピーチマークの場合、これはjsonになります。
pcmを使用する場合、返されるコンテンツは、署名付き16ビット、1チャネル(モノラル)、リトルエンディアン形式のaudio / pcmです。
type:文字列
有効な値:
json | mp3 | ogg_vorbis | pcm必須かどうか:必須
SampleRate
Hzで指定された可聴周波数。
mp3とogg_vorbisの有効な値は、「8000」、「16000」、「22050」、および「24000」です。標準音声のデフォルト値は「22050」です。ニューラルボイスのデフォルト値は「24000」です。
pcmの有効な値は「8000」と「16000」です。デフォルト値は「16000」です。
type:文字列
必須かどうか:必須ではない
SpeechMarkTypes
入力テキストに対して返されるスピーチマークのタイプ。
タイプ:文字列の配列
配列メンバー:最大4アイテム。
有効な値:
sentence | ssml | viseme | word必須かどうか:必須ではない
Text_
合成するテキストを入力します。 TextTypeとしてssmlを指定する場合は、入力テキストのSSML形式に従います。
type:文字列
必須かどうか:必須
TextType
入力テキストがプレーンテキストかSSMLかを指定します。デフォルト値はプレーンテキストです。詳細については、「SSMLの使用」を参照してください。
type:文字列
有効な値:
ssml | text必須かどうか:必須ではない
VoiceId
合成に使用する音声ID。 DescribeVoices操作を呼び出すことにより、使用可能な音声IDのリストを取得できます。
type:文字列
有効な値:
Aditi | Amy | Astrid | Bianca | Brian | Camila | Carla | Carmen | Celine | Chantal | Conchita | Cristiano | Dora | Emma | Enrique | Ewa | Filiz | Geraint | Giorgio | Gwyneth | Hans | Ines | Ivy | Jacek | Jan | Joanna | Joey | Justin | Karl | Kendra | Kevin | Kimberly | Lea | Liv | Lotte | Lucia | Lupe | Mads | Maja | Marlene | Mathieu | Matthew | Maxim | Mia | Miguel | Mizuki | Naja | Nicole | Penelope | Raveena | Ricardo | Ruben | Russell | Salli | Seoyeon | Takumi | Tatyana | Vicki | Vitoria | Zeina | Zhiyu必須かどうか:必須
Response構文
HTTP/1.1 200 Content-Type: ContentType x-amzn-RequestCharacters: RequestCharacters AudioStream
Response要素
アクションが成功すると、サービスはHTTP200応答を送り返します。
応答は次のHTTPヘッダーを返します。
ContentType
タイプオーディオストリームを指定します。 これは、リクエストのOutputFormatパラメータを反映している必要があります。
OutputFormatとしてmp3を要求した場合、返されるContentTypeはaudio / mpegです。
OutputFormatとしてogg_vorbisをリクエストした場合、返されるContentTypeはaudio / oggです。
OutputFormatとしてpcmを要求した場合、返されるContentTypeは、符号付き16ビット、1チャネル(モノラル)、リトルエンディアン形式のaudio / pcmです。
OutputFormatとしてjsonをリクエストした場合、返されるContentTypeはaudio / jsonです。
RequestCharacters
合成された文字の数。
応答は、HTTPボディとして次を返します。
AudioStream
合成音声を含むストリーム。
エラー
EngineNotSupportedException
このエンジンは、指定した音声と互換性がありません。エンジンと互換性のある新しいボイスを選択するか、エンジンを変更して操作を再開してください。
HTTPステータスコード:400
InvalidSampleRateException
指定されたサンプルレートは無効です。
HTTPステータスコード:400
InvalidSsmlException
指定したSSMLが無効です。 SSML構文、タグと値のスペルを確認してから、再試行してください。
HTTPステータスコード:400
LanguageNotSupportedException
指定された言語は、現在この機能でAmazonPollyによってサポートされていません。
HTTPステータスコード:400
LexiconNotFoundException
AmazonPollyは指定されたレキシコンを見つけることができません。これは、レキシコンが欠落しているか、名前のスペルが間違っているか、別のリージョンにあるレキシコンを指定していることが原因である可能性があります。
レキシコンが存在し、リージョン内にあり(ListLexiconsを参照)、名前のスペルが正しいことを確認します。その後、再試行してください。
HTTPステータスコード:404
MarksNotSupportedForFormatException
選択したOutputFormatでは、スピーチマークはサポートされていません。スピーチマークは、json形式のコンテンツでのみ使用できます。
HTTPステータスコード:400
ServiceFailureException
不明な状態が原因でサービス障害が発生しました。
HTTPステータスコード:500
SsmlMarksNotSupportedForTextTypeException
SSMLスピーチマークは、プレーンテキストタイプの入力ではサポートされていません。
HTTPステータスコード:400
TextLengthExceededException
"text"パラメータの値が、許容される制限を超えています。
SynthesizeSpeechAPIの場合、入力テキストの制限は合計で最大6000文字であり、そのうち3000文字を超えて請求できる文字はありません。StartSpeechSynthesisTask APIの場合、最大は200,000文字で、そのうち100,000文字を超えて請求することはできません。 SSMLタグは請求文字としてカウントされません。HTTPステータスコード:400
- 投稿日:2021-03-03T14:43:15+09:00
スクール生のAWSクラウドプラクティショナー(CLF)合格体験記
私は、
・プログラミング未経験
・プログラミングスクール生
・AWSの知識(VPC、EC2、RDSハンズオン経験のみ)です。
毎日勉強3~4時間を1週間続けて、無事合格できました。
具体的に勉強に使ったサイトや書籍を紹介したいと思います。やったこと
①まずは問題を1回分解いてみる
とにもかくにも、どんな問題が出るか把握することが第1ステップだと思います。②udemyや本で、浅く全体を理解
正直、意味不明ですが、あまり気にせずに進みました。使った教材
書籍
・AWS認定資格試験テキスト AWS認定ソリューションアーキテクト - アソシエイト 改訂第2版
udemy
・AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得]③問題集をたくさん解いて、反復する
正解率30%とかでしたが、あまり気にせずやりました。
正直回答も意味不明なものが多かったです。
意味不明にも2種類ありました。
・反復するうちに理解できたもの
・何度やっても理解不能何度やっても理解不能は、
・Amazon Web Services Japan 公式YOUTUBEを観ました。ストレージやデータベースの説明がめちゃくちゃ分かりやすいです。
・AWS系YOUTUBER動画を観ました。再生回数が少なくても分かりやすい動画はたくさんありました。使った問題集
udemy
この問題だけで合格可能!AWS 認定クラウドプラクティショナー 模擬試験問題集(7回分455問)
web問題集
・https://learn-aws.cafe/clf
・https://aws-exam.net/clf/clf_question.php試験当日の状態(※この程度でも受かりました。)
udemyの基礎問題 正解率80%(3回反復してるにも関わらず)
udemyの応用問題 正解率48%(初見)
ゴリ押しの暗記(例. ”ストリーミング”で書いてたら、脳筋で"Kinesis"を選ぶ。)
さいごに
クラウドプラクティショナーに関しては、"質"より"量"が良いと思いました。
とにかく、過去問を解きまくるのが良かったのかもしれません。
ソリューションアーキテクトの合格体験記も書ければいいなと思います。
少しでも参考になれば幸いです。
- 投稿日:2021-03-03T13:07:00+09:00
Discord botをAWS APIGateway+Lambdaで動かしたい
- 本記事は記載途中です *
- 現時点ではdiscord.pyがAPI GatewayのWebSocket I/Fの動きと連動させられないので、この手のラッパーを使わず、スクラッチで書く必要があるなーと考えています。 *
Discordとは
テキスト+音声会話用コミュニケーションツールの一種。
競合としてはテキスト+音声両方ではTeamsとLINE、テキストのみであればSlack、音声会話ではZoom、WebEx、Skype辺りが競合する。特徴としてはゲーム用途に特化させた設計になっていて、その方面に向けた機能が多い。
但し現在はゲーム用途以外でも使用するケースが増えているらしい。Discord BOTについて
その他のツールと同様に、特定イベントに対しテキスト応答を行う。(例えばユーザがチャンネルにJoinしたらいらっしゃいませ、とか)
そういったメジャーな処理に加えて、他ツールではAPI等が存在しない音声系の調整が可能なのが特徴。(全員ミュートなど)
(少なくともLINE、Teamsはいずれも2021/2月時点で各公式Docsには存在しない。またTeamsは不明だがLINEは2年以上APIの構成が変わってないので今後の更新は期待できそうにないと思う)BOT作成者がBOTを公開状態にすると、原則自由に使用可能になる。
Discord自体の利用は無料であるが、BOTの処理を行うサーバは別途必要で、そのサーバ利用/維持費はBOT作成者が負担する。
My BOTサーバインフラ方面設計
今回のポイントは「サーバ利用/維持費用」である。
費用やセキュリティ面を度外視するなら、グローバルIP+適当なドメイン付けたWebサーバを用意し、Discordからの処理を受け付ければ良いが
当然相応の維持費も要るし、セキュリティ対応も手間である。というわけで調べても情報があまりなかったAWS API Gateway + Lambda(Python)でDiscord BOT作成を試みた。
(保険としてherokuやAWS EC2もあるが、ここは折角なのでServerlessで)ラフのアーキテクチャは以下の通り。
HTTPのフロント部分のリクエスト受付はAPI Gatewayが対応し、その後の処理はLambdaのPythonが対応する。
API GatewayはAWSフルマネージドであり脆弱性対応はAWSが実施する。
多分時折中のEC2インスタンスが入れ替わったりするが、冗長化された上で実施されるため無停止である。
(たまたま運悪くリクエスト中にインスタンスシャットダウンを食らう可能性はあるが、確率はかなり低い上リトライすればOKである)使用料は
100万リクエストあたり1.29USDである。LambdaはAWS上でスクリプト実行を行うプラットフォームで、所定のコードを置いておき各イベントに応じて起動が行われるマネージドサービスである。
Lamdba画面上から操作して実行したり、Lambda自体のcronで定期実行も可能であるが、今回はAPI Gatewayのリクエスト受信と連動させる。使用料は
リクエスト10万件あたり 0.20USDと処理のCPU時間とメモリ量&利用時間に応じた費用が発生する。API GatewayとLambda現時点で想定月額利用料は
5.00USD/月である。
別途通信料はあるが、テキストのみであるため一旦考慮しない。この構成における最も大きなメリットは「処理を行わないIdle状態時には費用や手間が掛からない」点にある。
また相当量の処理を継続して実行しつづけるような状態でなければ、維持費はサーバ1台を起動しつづけるより安価になる想定である。
特に頻繁に処理を行うわけではなく、1日10回未満の処理を想定しているため、このメリットを最大に享受する構成になっている。もし今後BOTを公開したり、Discordのチャンネル内のユーザが増えた場合は使用量に応じたAWS利用料が発生する見込みであるが
現時点でBOTを公開する予定はなく、ユーザもせいぜい2桁人数のため、1日10回未満程度の処理想定としている。設計を詰めてみた結果(2021/3/2時点)
これら設計のアプリケーション部分はdiscord.pyを使用する想定だったが、
インフラ部分とdiscord.pyが噛み合わないことが判明している。discord.pyは起動後、自身のプロセスが常駐しWebSocketを対応するが、
API Gateway+Lambdaでは以下のように、リクエストごとにLambda Functionを呼び出す形になるため噛み合わない。以下URLより図を抜粋
https://qiita.com/G-awa/items/472bc1a9d46178f3d7a4
今後の進め方(2021/3/2時点)
API Gateway + lambdaを維持し、lambda functionにDiscordの生APIで実装する。
大人しくEC2上でdiscord.pyを使う。
BOT自体は3月下旬に使用したいため、現時点では実装の早い2案を採用する予定である。


- 投稿日:2021-03-03T11:52:52+09:00
Cognitoを使ってAPI Gatewayのアクセス認証をしてみた
はじめに
これまでS3のバケットポリシーとAPI Gatewayのリソースポリシーでアクセス元のIP制限をかけていたため、許可されているIPアドレスからでないと、アクセスし、APIをたたけないようになっていました。しかし、今回訳あってIP制限を外すことになってしまい、APIを誰でも叩き放題になってしまったので、解決策を考えました。
方法検討
API Gatewayで使えるアクセスを認証
APIのアクセスを認証する方法を調べたところ以下の3つが出てきました。
- Cognito
- Lambdaオーソライザー
- IAM認証
Cognito
Cognitoユーザープールで認証時にユーザープールトークンが発行され、そのトークンを使用して認証する方法です。
わたしが思うユースケース
- ユーザー認証にCognitoを使用しているとき
Lambdaオーソライザー
API Gatewayを叩いた時に、認証用のLambda関数を呼び、認証が通れば、実行したいAPI(今回だとLambda関数)が実行されるようになるという方法です。
わたしが思うユースケース
- Auth0などのCognito外の認証プラットフォームを使っているとき
参考
- https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/apigateway-use-lambda-authorizer.html
- https://dev.classmethod.jp/articles/lambda-authorizer/
IAM認証
APIの実行権限を付与したIAMユーザーを作成し、IAMユーザーのアクセスキー、シークレットキーを使ってAWS Signature V4 署名を作成し認証する方法です。
ユーザーにIAMロールが付与されていれば、それも使用することができます。わたしが思うユースケース
- サーバーからAPIをたたくとき(EC2などIAMロールが使えるときはIAMロールを利用)
- CognitoのグループでIAMロールを付与しているとき
参考
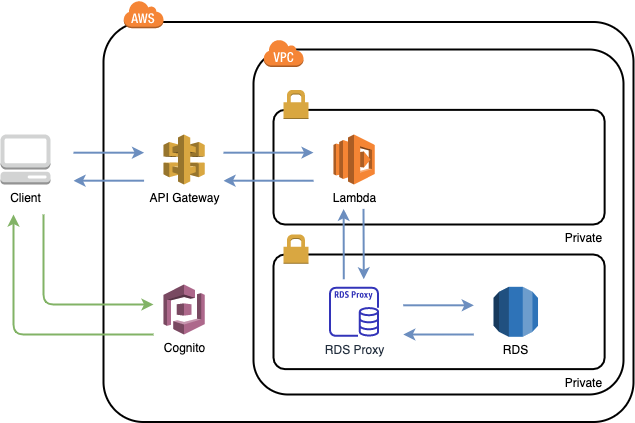
現在の構成図
アプリケーション部分の構成図は下記の通りです。
ユーザー認証部分はCognito + Amplifyフレームワークで構築しています。構築の基本部分については「【React】ユーザー認証をCognito + Amplifyで構築してみた」の構築準備編と構築完成編をご覧ください。
そして、アプリケーション部分はLambda + RDS Proxy + RDSで実装しています。この構築方法については「祝GA‼︎【Go】Lambda + RDS 接続にRDS Proxyを使ってみた」をご覧ください。結論
現状、Cognitoユーザープールを使ってユーザー認証をしているので、API Gatewayのアクセス認証にもCognitoを使うことにしました!
手順
既存の構成にAPIのアクセス認証をつけていくので、Cognitoユーザープールを使ってのユーザー認証、API Gatewayを使ってLambdaを実行する部分については既に構築できていることを前提として、下記の流れで進めていきます。ただ、今回はDB操作は行わず、メッセージを送り、メッセージをそのまま返すLambda関数を実行するようにしています。
- API Gatewayの設定
- フロントの実装
やってみる
1. API Gatewayの設定
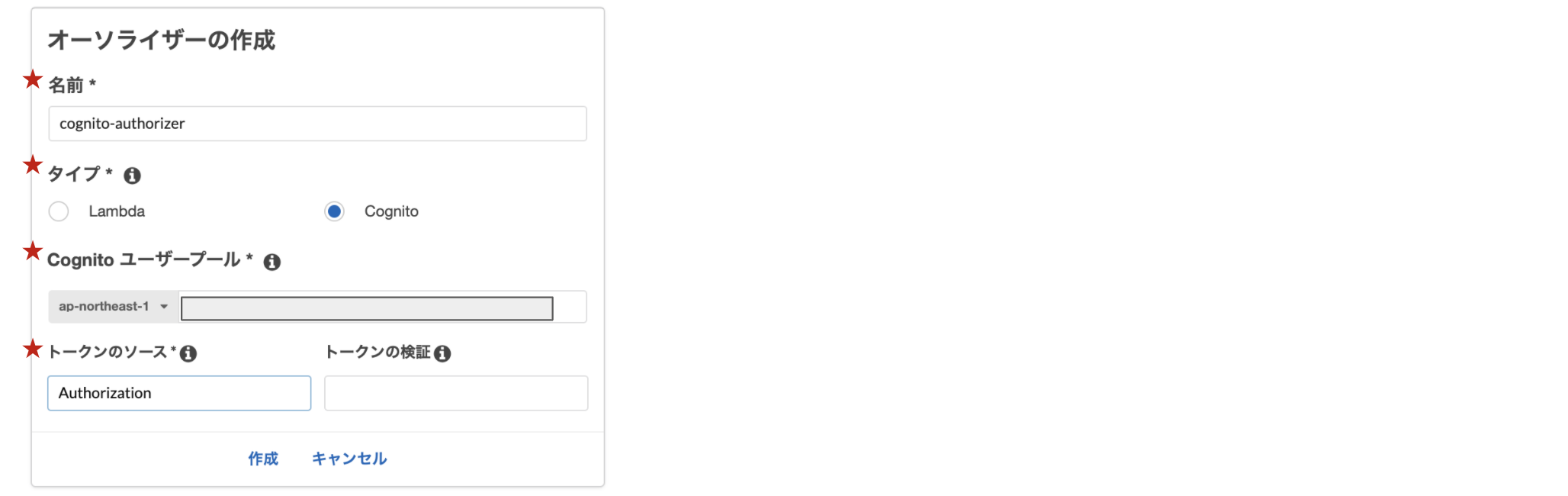
まず、API Gatewayのオーソライザーを作成していきます。
API Gatewayのコンソールから、[オーソライザー]を開きます。
新規でオーソライザーを作成します。
名前、タイプ、Cognitoユーザープール、トークンのソースを入力し、作成ボタンをクリックします。トークンのソースAuthorizationはリクエストのヘッダーとしてトークンを送るときに使います。
次に、作成したオーソライザーはメソッド単位で設定していきます。つまり、複数メソッドがある場合はそれぞれに設定しないとトークンなしでAPI Gatewayを叩けてしまうので注意です。
次のように、[リソース]→[オーソライザーを設定したいメソッド]→[メソッドリクエスト]を開きます。
許可の部分に先ほど作った
cognito-authorizerを設定します。選択肢に出てこない場合はリロードなどすると選択肢に出てきます!
そして最後にデプロイします!
これでオーソライザーの設定は完了です。2. フロントの実装
取得したユーザープールトークンをヘッダーにつけてAPI Gatewayをたたく処理を実装します。
axiosのインストール
API Gatewayを叩くのにaxiosを使うために、プロジェクトにaxiosを追加します。
$ yarn add axiosソースコード
認証時に必要なトークンは下記の方法で取得可能です。
const user = Auth.currentAuthenticatedUser() const idToken = user.signInUserSession.idToken.jwtTokenこの
idTokenをAuthorizationキーのバリューとしてヘッダーに持たせることで、リクエストが可能になります。App.jsimport React from "react"; import Amplify, {Auth} from 'aws-amplify'; import awsconfig from './aws-exports'; import {withAuthenticator} from "@aws-amplify/ui-react"; import axios from "axios"; import "./App.css" Amplify.configure(awsconfig); function App() { const API_URL = "<API Gatewayで取得したURL>" const [message, setMessage] = React.useState(""); const [response, setResponse] = React.useState(""); const handleChange = event => { setMessage(event.target.value); }; const handleSubmit = async(event) => { const user = await Auth.currentAuthenticatedUser() const idToken = user.signInUserSession.idToken.jwtToken const headers = {headers: {"Authorization": idToken}}; axios.post(API_URL, {message: message}, headers) .then((response) => { if(response.data.message === message){ setResponse(response.data.message); } else { throw Error(response.data.errorMessage) } }).catch((response) => { alert("登録に失敗しました。もう一度送信してください。"); console.log(response); }); event.preventDefault(); } return ( <fieldset> <form onSubmit={handleSubmit}> <label > <input type="text" value={message} onChange={handleChange} /> </label> <input type="submit" value="送信" /> </form> <div>{response}</div> </fieldset> ); } export default withAuthenticator(App);実行結果
ヘッダーあり
入力欄の下に、Lambdaから返ってきたメッセージが表示されるようになっています。入力した値がLambdaを介して返ってきています!
ヘッダーなし
ちなみに、ヘッダーにidトークンを付けずに実行してみました。
※ API Gatewayをたたくところのみ抜粋
App.jsaxios.post(API_ADD_URL, {message: message}) .then((response) => { if(response.data.message === message){ setResponse(response.data.message); } else { throw Error(response.data.errorMessage) } }).catch((response) => { alert("送信に失敗しました。もう一度送信してください。"); console.log(response); });ソースを上記のように変更し、実行すると・・
エラーが出て、Lambdaが実行できないことがわかりました!
おわりに
無事に、API Gatewayにアクセス認証をつけることができました!今回はもともとCognitoユーザープールを使ってユーザー認証をやっていたので、Cognitoのオーソライザーを使って簡単に設定することができました。既存のシステムの構成によってこれでIP制限を外しても、セキュリティを担保することができたのではないかと思います!めでたし!
参考





- 投稿日:2021-03-03T11:38:40+09:00
AWS EC2インスタンス内からRDSのMySQLにログインする
- 投稿日:2021-03-03T09:36:16+09:00
サーバーサイドの全体像
サーバーとは
サーバーとは、情報やデータをいつでも提供してくれる、提供専用のコンピューターのこと。
個人用のPCと比較した時に、大きく異なる部分は2つ
・IPアドレスが固定されている
・レスポンスを返すようにOSとアプリケーションが設定されているIPアドレスが固定されている
普段私たちが使っているPCは、IPアドレスが固定されていません。
なぜなら、・情報を取得する側であり、提供する側でないから
・セキュリティの観点から同じIPアドレスだと外部からの攻撃を受けやすいから※AWSのEC2もデフォルトではIPアドレスが変わってしまう設定になっています。そこでElastic IP addressをEC2にアタッチさせることで、IPアドレスを固定させます。IPアドレスを固定化した後は、Route53(DNSサーバー)でドメインとIPアドレスを対応させます。こうすることで、クライアント側(個人用のPC)からサーバーへリクエストを送ることができます。
しかし、これだけではダメです。
サーバーがリクエストを返すには、OSを設定する必要があります。サーバーのOSの設定
OSとは、スマホやパソコンに搭載された基本ソフトウエアのことです。スマホでアプリケーションが使えたり、パソコンで基本的な操作ができるのは、全てOSがあるおけげです。またWebサービスやアプリケーションを動かすには、必ずOSが必要です。そのためサーバーにもOSを入れないと動かすことができません。
では、サーバーでは具体的にどのようなOSを使うかというとLinux(RedHat, CentOS, Amazon Linux 2など)が一般的です。Linuxは、サーバーの用途にあったOSとなります。
サーバーの管理と操作
サーバーは通常、温度管理やセキュリティが行き届いた専用施設であるデータセンターに置かれています。
※EC2もAWSが管理するデータセンタに置かれています。サーバーは離れた場所にあるので、遠隔で通信してログインして操作する必要があります。
操作の設定には、
・CUI : コマンドを使って操作する
・GUI : マウスや指を使って直感的に画面を操作するの2種類が存在します。
サーバーでは、CUIを使うのが一般的です。
理由は、コマンドを打って作業した方が作業効率が良いからです。サーバーのアプリケーションの設定
サーバーにOSを設定しただけでは、サイトを見ることはできません。具体的なアプリケーションを設定してサーバーにアップロードし、それをOSを連携させることが必要になります。
HTML,CSSの仕組みとデメリット
HTML,CSSのファイルをアップロードすると、シンプルなWebページだけのサービスが提供することが可能です。クライアント(あなたのPC)が、「Webページの情報ください」というシンプルなリクエストを出して、サーバーがHTML, CSSで作られたファイルをレスポンスとして返す。これだけでもシンプルなWebページを世界中に公開することができます。
しかし何度アップデートしても同じページが表示されるだけで、ユーザごとのプロフィールページ、データなどは扱うことができません。
データベース、サーバーサイド言語の存在意義
クライアントからリクエストを受け取ったサーバーは、クライアントにリスポンスを返す前に処理を行っています。
SNSのプロフィールを更新したり、いいねを押したり、世界中の人に最新のWebページを更新するためには、2つの仕組みが必要です。
それは、データを保存と作成する仕組みです。
データの保存(データベース)
例えば、SNSのユーザのプロフィール情報、サイトの更新情報、獲得したいいね数などの膨大の情報はWebページ運用するために管理する必要があります。
このデータを保存する場所をデータベースと言います。
そのデータベースに保存されているデータを取り扱う言語があります。
それが、SQLです。ここでの注意点は、
データベースはあくまで情報の保管庫であり、データベースのデータをSQLで取り出すことはできます。しかし、そのデータを加工したり表示したりするには別の仕組みが必要になります。データの作成(サーバーサイド言語)
そこで必要になるのが、サーバサイド言語です。
サーバサイド言語は、
・取り出したデータをどのように加工するか
・どのように表示するか処理する言語です。
Ex) python, Ruby, PHP, Java
SNSの例だと、
⓵あなたがSNSを見たいと、サーバーにリクエストを送ります。
⓶サーバーがあなたのプロフィールの情報(データ)を、サーバーサイド言語を用いてデータベースから取り出す
⓷取り出したデータをHTMLの中に組み込んで、あなたのプロフィールが入ったWebページを生成する
⓸その生成したWebページをリスポンスとして返すという流れになります。
※AWSでは、EC2(サーバー)の中にデータベースやサーバサイド言語もインストールして、EC2一台でWebサービスを構築することも可能です。しかし通常はセキュリティの観点からデータベースだけ別のサーバーに分けて配置します。そこでRDS(データベースのサービス)を用いて、その中のEC2のデータベースにソフトウエアをインストールして、AWS上で使いやすくアレンジしています。
- 投稿日:2021-03-03T09:11:14+09:00
AWS ECRでAccessDeniedExceptionが発生したときの解決法
概要
自作RailsアプリをECSにデプロイするために、ECRにログイン時に発生しました。
$ aws ecr get-login-password --region ap-northeast-1 An error occurred (AccessDeniedException) when calling the GetAuthorizationToken operation: User: arn:aws:iam::125724222608:user/ecr_replication is not authorized to perform: ecr:GetAuthorizationToken on resource: *環境
$ aws --version aws-cli/2.1.26 Python/3.9.1 Darwin/20.2.0 source/x86_64 prompt/off解決策(IAMを作成して、ECR用のポリシーをアタッチする)
Amazon ECR エラーメッセージのトラブルシューティングに詳細は記載されていますが、
AccessDeniedExceptionが発生した場合は下記のどちらか加賀下人
- ECRを使用するアクセス権限がユーザーに付与されていない
- アクセス権限が正しく設定されていない
そこで、「アクセス権限が正しく設定されていない」に対しては、適切なポリシー(下記)を作成し、ECRへのデプロイ用IAMロールにアタッチしました。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ecr:GetAuthorizationToken", "ecr:BatchCheckLayerAvailability", "ecr:GetDownloadUrlForLayer", "ecr:GetRepositoryPolicy", "ecr:DescribeRepositories", "ecr:ListImages", "ecr:DescribeImages", "ecr:BatchGetImage", "ecr:InitiateLayerUpload", "ecr:UploadLayerPart", "ecr:CompleteLayerUpload", "ecr:PutImage" ], "Resource": "*" } ] }次に、「アクセス権限が正しく設定されていない」に対しては、ターミナル上で
aws configureと入力し、作成したIAMの設定を入力しました。
作成後、aws configure listと入力し、IAMの情報が記載されていることを確認しました。結果、無事ログインに成功し、ECRへのイメージのPushもすることができました?
参考
- 投稿日:2021-03-03T06:19:46+09:00
40 代おっさん NAT gateway 経由して EC2 に繋げてみた ②
本記事について
本記事は AWS 初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。AWS 作成図
VPC 部分については
https://qiita.com/kou551121/items/2535fe3de57a5c813687
EC2 部分については
https://qiita.com/kou551121/items/56f2e075d33fbf345787構築手順
❶ private subnet に EC2 インスタンスを設置
https://qiita.com/kou551121/items/3869db7c1e4bc72b2ab9
を参照してください❷ public subnet にある EC2 インスタンスを踏み台にして private subnet の EC2 にログインする。
❸ NAT gateway を作成して NAT gateway を経由して private subnet の EC2 インスタンスにログイン
2. public subnet にある EC2 インスタンスを踏み台にして private subnet の EC2 にログインする
今回も Tera Term を使用したいと思います。
流れ
- public subnet の EC2 にログインする。
- public subnet の EC2 にキーペアを送る。
- public subnet の EC2 を踏み台にして private subnet の EC2 にログインする。
流れを実際にやってみる
1. public subnet の EC2 にログインする
■windows で EC2 にログインする手順(Tera Term を使用)
参考
Amazon EC2 に SSH 接続する【Windows、Macintosh】
https://dev.classmethod.jp/articles/aws-beginner-ec2-ssh/ログインした画面 ↓
2. public subnet の EC2 にキーペアを送る
作ったキーペア(自分は Test-key.pem)を Tera Term にドラック&ドロップ
このような画面になるので OK を押してください
OK 押すと何も変わらないので確認のため ls コマンド(linux コマンド わからない人は調べてみてください)
linux 参考教科書
https://linuc.org/textbooks/linux/
https://www.amazon.co.jp/%E6%96%B0%E3%81%97%E3%81%84Linux%E3%81%AE%E6%95%99%E7%A7%91%E6%9B%B8-%E4%B8%89%E5%AE%85-%E8%8B%B1%E6%98%8E/dp/4797380942?ref_=Oct_s9_apbd_otopr_hd_bw_b26ma&pf_rd_r=198P1EBCTY9X7Z1NZ6PE&pf_rd_p=4745f390-fc6a-5e7d-a99c-ffafed320525&pf_rd_s=merchandised-search-10&pf_rd_t=BROWSE&pf_rd_i=502732
他にもいろいろあるみたいですが、進めている方がいらっしゃったので載せてみます!!
自分も頑張って勉強します!ls コマンド入れたのが ↓
キーペアが送られているのが確認できています
3. public subnet の EC2 を踏み台にして private subnet の EC2 にログインする
ssh -i Test-Key.pem ec2-user@10.0.2.19上のコマンドを打ってください。
説明すると ssh -i が ssh で通信することを指定して
Test-Key.pem が秘密鍵を指定してます
ec2-user ユーザー名を指定
@10.0.2.19 が Test-EC2-private のプライベート IPv4 アドレスになります。
(↓ 赤枠)
ちなみにこのままコマンドを打つと
おっと何かエラーでた!!
実は AWS CloudTech のもくもく会、諸先輩方からパーミッション変えるの忘れないでねと事前にアドバイスがありましたのですぐにわかり、以下のコマンド打ちました!!chmod 400 Test-Key.pem
もう一回ログイン!!
赤枠と青枠を見比べると変化していることがわかります。
つまり public subnet の EC2 を踏み台にして private subnet の EC2 にログインできたことになります。最後に
ふ~~なんとか public subnet の EC2 を踏み台にして private subnet の EC2 にログインできましたね・・・
つぎは NAT gateway を作成して NAT gateway を経由して private subnet の EC2 インスタンスにログインしたいと思います。長くなったので次回で行きたいと思います。またこの記事は AWS 初学者を導く体系的な動画学習サービス「AWS CloudTech」の課題カリキュラムで作成しました。
https://aws-cloud-tech.com/







- 投稿日:2021-03-03T05:08:15+09:00
AWS Data Migration Serviceでは同一構成のDBを複製できない
AWS Data Migration Serviceとは
データベースを短期間で安全に移行できるAWSのサービスで、移行中でもソースデータベースは完全に利用可能な状態に保たれ、データベースを利用するアプリケーションのダウンタイムを最小限に抑えられるのが特長。一般に普及している商用またはオープンソースのデータベース間の移行が可能で、Microsoft SQL から Amazon Aurora といった異なるデータベースプラットフォーム間の移行もサポートしている。さらにAmazon Redshift と Amazon S3 にデータをストリーミングすることで、データベースをペタバイト規模のデータウェアハウスに統合することもできる。
レプリケーション(複製)元となるDBやスキーマ、テーブルを「ソース」、レプリケーション先のことをターゲットと呼ぶ。
AWS DMSではできないこと
大規模な移行プロジェクトでも使用可能だが、比較的日常のユースケースだと、既存のテスト環境で再現が困難かつ複雑なバグの調査等の為に本番スキーマを同一構成で複製したいというのがある。
しかし実際使ってみると、原理はともかく下記の制約があり使い勝手がいまいちという感が否めなかったりする。
1. DMSで作成されるオブジェクトはテーブルと主キー等の一部の制約のみ
2. インデックスやプロシージャ、ビューは(レプリケーション後に)ターゲット側で手動で反映する必要がある
3. DR(ディザスタリカバリ)のような同一構成を維持する必要がある場合、ソース、ターゲット両方のDBにオブジェクトを作成する必要がある特に手動とはいえインデックスを作成するのに地味に手間と時間がかかる為、自動化して欲しかったところ。
その他惜しい点
移行タスクというのは、基本的に一時的なものでサービスのように常時行う必要はない。
一方でレプリケーションインスタンスは起動中ずっと料金が発生してしまう点に注意して欲しい。
タスクの実行中のみ課金される親切設計なら尚良かったが流石に求め過ぎか。参考
AWS Database Migration Service
AWS Database Migration Service のベストプラクティス
【AWS Black Belt Online Seminar】AWS Database Migration Service


- 投稿日:2021-03-03T00:05:48+09:00
AWS大阪リージョンの注意事項
待望のAWS大阪リージョン(ap-northeast-3)が登場
これまでローカルリージョンとして限定利用のみたっだ大阪リージョンが正規リージョンとしてリリースされました。正規リリースに伴い誰でも利用できます。しかし、ローカルリージョンから昇格したためか、通常のリージョンとは少し違う特徴があります。全部調べられたわけではありませんが、気がついた範囲で紹介します。
リージョンはデフォルト有効でGuardDutyがない
2019年3月20日以降にリリースされたリージョンは、デフォルトでは利用できず明示的にリージョンを有効化する必要があります。ところが大阪リージョンはデフォルトで有効化されているため、有効化作業は不要です。ローカルリージョンとして大阪リージョンが登場したのが2018年で、この仕様になる前だったからかとみられます。設定不要で使えて便利ですが、使わないリージョンが有効化されることで、攻撃者が知らないうちに不正なインスタンスを起動して仮想通貨マイニングなどを行うリスクが発生します。大阪リージョンでもGuardDutyを忘れずに設定、といいたいところですが大阪リージョンにはGuardDutyがありません。ないものはしょうがないので、AWS OrganizationsのService Control Policyを検討するなどしましょう。AWS Configは利用できるので、全リージョンで有効化している場合は大阪リージョンにも忘れずに追加設定しておきましょう。
サービスが微妙に少ない(特にセキュリティ系のサービスは少ない)
先述のGuardDutyがないこともありますが、サービスが微妙に少ないです。さすがにEC2とかRDSとかはあるのですが、利用している人も多いであろうCodeBuildやCloud9, GuardDuty, EFS, WAF, Detectiveなども実装されていません。大阪リージョンでサービスを動かそうとする前に、一度必要なサービスがリリースされているか確認した方がよいです。セキュリティ、監査系のサービスが少ない印象があるので要注意。
AMDインスタンス, Gravitonインスタンスの設定がない
大阪リージョンはIntelCPUインスタンスのみで、EPYCやGravitonを使ったインスタンスタイプは今のところありません。そのうち追加されるかと思われますが、現状ではあきらめる必要があります。
インスタンスタイプによってはマルチAZ構成を取れない
これが大阪リージョン最大の特徴だと思います。大阪リージョンは一部のインスタンスタイプが1AZのみの提供になっています。具体的にはt2, c4, d2, m4, r4, x1, x1eが1AZ(apne3-az3)のみの提供です。(このゾーンがa, b, cのどのゾーンになるのかはアカウントによって異なるため、利用されるアカウントでご確認ください)このため、これらのインスタンスタイプを使ってしまうとAZ間冗長構成を取れないので注意してください。今から使うならt3, m5など次の世代のインスタンスを使う方がよいですが、古いシステムを移設したいなど旧世代インスタンスを必要とする場合には意識する必要があります。
大阪リージョンの利用戦略
リリース経緯もあって若干特殊な仕様になっていたり、現時点では機能も控えめな大阪リージョンなので、今の時点では(少なくとも自分自身が担当しているシステムにおいて)大阪リージョン単体で使うのは若干厳しい気がしています。利用を検討するときは、使おうとしている機能が大阪に展開されているか、使い始める前にチェックしておく必要があるでしょう。幸いにしてVPC Peeringは利用できるので、足りない機能を東京リージョンで補いながら大阪リージョンでシステムを展開していくのがよいんじゃないかと思います。