- 投稿日:2021-03-01T23:43:35+09:00
DockerでサーバーをPumaからNginx+unicornに切り替える
はじめに
PumaでAWSにデプロイしていましたが、今回Nginx+Unicornに環境を切り替えましたので、その忘備録を作りました。dockerでPumaからサーバーを切り替えたい方の参考になればと思います。
ファイル構成
コンテナはrailsアプリ用、Mysql用、nginx用の3つを作成
.(railsプロジェクト) ├── Dockerfile ├── docker-compose.yml ├── Gemfile ├── Gemfile.lock ├── config | └──datebase.yml | └──unicorn.conf.rb └── nginx ├──Dockerfile └──nginx.conf1. Dockerfile(rails)
# 19.01.20現在最新安定版のイメージを取得 FROM ruby:2.5.3 # dockerizeパッケージダウンロード用環境変数 ENV DOCKERIZE_VERSION v0.6.1 # 必要なパッケージのインストール RUN apt-get update && \ apt-get install -y --no-install-recommends\ mariadb-client \ build-essential \ wget \ vim \ && wget https://github.com/jwilder/dockerize/releases/download/$DOCKERIZE_VERSION/dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz \ && tar -C /usr/local/bin -xzvf dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz \ && rm dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* RUN curl -sL https://deb.nodesource.com/setup_10.x | bash - \ && apt-get install -y nodejs RUN mkdir /app_name ENV APP_ROOT /app_name WORKDIR $APP_ROOT ADD ./Gemfile $APP_ROOT/Gemfile ADD ./Gemfile.lock $APP_ROOT/Gemfile.lock # エラー回避の為、bundlerのバージョン下げる RUN gem install bundler:1.17.3 RUN bundle install ADD . $APP_ROOT今回 bundlerがないよ!とのエラーが発生した為、RUN gem install bundler で取得しました。最初は最新版をダウンロードしてしまった為、もともとプロジェクトで使用していたbundlerと変わってしまい整合性が取れなくなってしまい、バージョンを指定することにしました。
2. Dockerfile(Nginx) 作成
FROM nginx:stable COPY nginx.conf /etc/nginx/conf.d/myapp.conf CMD /usr/sbin/nginx -g 'daemon off;' -c /etc/nginx/nginx.conf3. nginx.conf 作成
upstream unicorn { server unix:/app_name/tmp/sockets/.unicorn.sock fail_timeout=0; } server { listen 80 default; server_name localhost; access_log /var/log/nginx/access.log; error_log /var/log/nginx/error.log; root /app_name/public; client_max_body_size 100m; error_page 404 /404.html; error_page 505 502 503 504 /500.html; try_files $uri/index.html $uri @unicorn; keepalive_timeout 5; location @unicorn { proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_pass http://unicorn; } }4. Gemfile追加
gem 'unicorn'5. config/unicorn.conf.rb 作成
$worker = 2 $timeout = 30 # 自分のアプリケーションまでのpath $app_dir = "/app_name" $listen = File.expand_path 'tmp/sockets/.unicorn.sock', $app_dir $pid = File.expand_path 'tmp/pids/unicorn.pid', $app_dir $std_log = File.expand_path 'log/unicorn.log', $app_dir # set config worker_processes $worker working_directory $app_dir stderr_path $std_log stdout_path $std_log timeout $timeout listen $listen pid $pid # loading booster preload_app true # before starting processes before_fork do |server, worker| defined?(ActiveRecord::Base) and ActiveRecord::Base.connection.disconnect! old_pid = "#{server.config[:pid]}.oldbin" if old_pid != server.pid begin Process.kill "QUIT", File.read(old_pid).to_i rescue Errno::ENOENT, Errno::ESRCH end end end # after finishing processes after_fork do |server, worker| defined?(ActiveRecord::Base) and ActiveRecord::Base.establish_connection endここでは自分のアプリケーションまでのpathを間違えないこと。今回は $app_dir = "/app_name"で指定
6. 3.docker-compose.yml
version: '3' services: # データベースのサービス定義 db: image: mysql:5.7 command: mysqld --character-set-server=utf8 --collation-server=utf8_unicode_ci volumes: - db-volume:/var/lib/mysql environment: MYSQL_ROOT_PASSWORD: password MYSQL_DATABASE: root ports: - '3306:3306' # アプリケーションサーバーのサービス定義 web: build: . # unicorn.pidを事前に削除 command: /bin/sh -c "rm -f tmp/pids/unicorn.pid && dockerize -wait tcp://db:3306 -timeout 20s bundle exec unicorn -p 3000 -c /app_name/config/unicorn.conf.rb" volumes: - .:/app_name - bundle:/usr/local/bundle:delegated - tmp-data:/app_name/tmp/sockets - public-data:/app_name/public - /app/vendor - /app/tmp - /app/log - /app/.git ports: - "3000:3000" tty: true stdin_open: true links: - db environment: - "SELENIUM_DRIVER_URL=http://selenium_chrome:4444/wd/hub" # WEBサーバーのサービス定義 nginx: build: context: ./nginx dockerfile: Dockerfile ports: - 80:80 restart: always volumes: - tmp-data:/app_name/tmp/sockets - public-data:/app_name/public links: - web selenium_chrome: image: selenium/standalone-chrome-debug logging: driver: none volumes: public-data: tmp-data: mysql-data: db-volume: bundle:pidファイルが残ってしまいエラー発生していた為、事前に rm -f tmp/pids/unicorn.pid でpidファイル削除。Pumaだとserver.pidファイルだけど、今回はUnicornなのでunicorn.pidを削除します。
ここでコンテナはrailsアプリ用、Mysql用、nginx用の3つを作成します。自分はrailsアプリ用のコンテナが直ぐに落ちてしまい数日ハマりました。
さいごに
今回最も苦戦したことはrailsアプリ用のコンテナをどうしても立ち上げることができなかったことです。
またdockerの仕組みの理解がまだまだ曖昧なので、一つひとつ調べながら、それでも何度もdockerコンテナを削除しては作り直しました。その際余計なコンテナやイメージが残ってしまい時間を多く費やしてしまいました。その時にお世話になった記事も記載しておきます。ここまで読んで頂きありがとうございました。今回主に参考にさせていただいた記事
docker-compose build/upがエラーで上手くいかなかった時に参考にした主な記事
- 投稿日:2021-03-01T20:42:41+09:00
Docker コンテナ構築の第一歩
こんにちは。
Dockerについて学習したので、アウトプットも兼ねて初学者ならではの視点で記事を書いてみようと思います。私が初めてDockerについて記事を読んで学習した際、「で、結局何ができるんだ?」という疑問が残ってしまいましたが、実際にコマンドを叩いてコンテナ構築をしてみると、何が便利なのかイメージができたので実践してみることをお勧めします。
概要はわかるけど、コンテナ構築の部分だけ知りたいという方は、ローカル環境にコンテナを構築の項まで飛ばしてください。
なお、仕組み等の詳細説明は割愛します。
Docker, コンテナとは何かをイメージしていただくための記事になっています。間違った部分等ありましたらご指摘いただけると幸いです。
Dockerとは

Dockerは、コンテナ型仮想環境を管理するプラットフォームのことです。
環境の構築・実行だけでなく、配布することもできます。
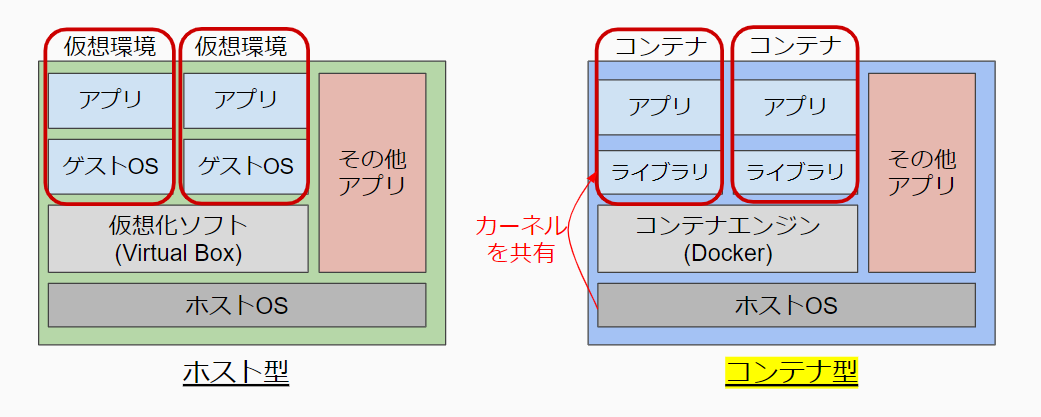
自分はDocker = コンテナと勘違いしていました。コンテナ型仮想環境
コンテナ型仮想環境は、仮想化技術の一種です。
私は以前にOracle社のVirtualBoxを利用した経験があったため、VirtualBoxが該当するホスト型仮想環境と比較して説明します。
ホスト型は、仮想環境ごとにゲストOSを立ち上げるのに対し、コンテナ型はホストOSのカーネルを共有して動作しています。
そのため、他の仮想化技術と比べ起動が速く、軽量に動作するといったメリットがあります。
Dockerの特徴
コンテナは、Dockerfileというソースコードから構築します。(このようにコードベースでインフラ構築を定義する考え方をInfrastructure as Codeといいます。)
これによって、開発したアプリケーションが別環境だと動かないといった環境差異を防ぐことができます。他にも、
- Dockerfileを(Github等で)共有することで、どこでも誰でも同じ環境が作れる。
- 環境を壊してしまった場合などに、環境の再構築が容易。
などといった特徴があります。
コンテナ構築の流れ
Dockerfileからイメージを作り、イメージからコンテナを立ち上げるという流れです。
イメージとは ... コンテナの構成をまとめたもので、コンテナを構築するベースのようなものです。DockerHubには、wordpress, mysql, pythonなどがイメージファイルとして公開されており、それらを自分で組み合わせたイメージを作成します。Docker Hub 概要 — Docker-docs-ja 19.03 ドキュメント
なお、Dockerではコンテナ1つにアプリケーション1つが推奨されているので、例えば
MySQL+nginx+flaskなど、複数のアプリケーションを組み合わせているサービスををDockerで動かす場合は、利用するアプリケーション分コンテナを構築し、docker-composeやKubernatesなどのコンテナオーケストレーションサービスを利用する必要があります。ローカル環境にコンテナを構築
今回は、コンテナ環境でPythonのwebフレームワークである、flaskを動かしてみようと思います。
ローカル環境にDockerがインストールされていることが前提です。Get Docker | Docker Documentation
前提ファイルの準備
Dockerfileとpythonファイルのmain.pyを同じディレクトリに用意します。
./
├ main.py
└ Dockerfilemain.pyfrom flask import Flask app = Flask(__name__) @app.route('/') def hello_world(): return 'Hello from Docker!' if __name__ == '__main__': app.debug = True app.run(host='0.0.0.0')pythonファイルの内容は、ルートにアクセスがあったらHello from Dockerと表示する単純なflaskプログラムです。
DockerfileFROM python:latest RUN mkdir /src && \ pip install flask COPY main.py /src CMD ["python", "/src/main.py"] # "python /src/main.py"と同じ
FROM... 作成するDockerイメージのベースイメージを指定。DockerHubからダウンロードされる。pythonの最新バージョンを指定。RUN... イメージのビルド時に実行されるコマンド。srcというディレクトリを作成するコマンドと、pipを使ってflaskをインストールするコマンドを指定。COPY... ホストマシンのファイルやディレクトリをコンテナ内にコピーする。先程用意したmain.pyをコンテナ内のsrcディレクトリにコピーする。CMD... コンテナ起動時に実行されるコマンドを指定。スペース区切りで配列化した形式。python /src/main.pyでpythonファイルを実行している。イメージのビルド
$ docker image build -t tutorial/docker-flask:latest .
-t以降は、<account name>/<image name>:<tag>の形式で指定します。
account name... 名前衝突を避けるための名前空間image name... イメージ名tag... バージョンやラベル末尾にDockerfileのあるディレクトリを指定します。(今回はカレントを指定)
このように表示されればビルドが完了です。
Successfully built 03bb880c97ac Successfully tagged tutorial/docker-flask:latest
docker image lsコマンドで、イメージのリストが確認できます。$ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE tutorial/docker-flask latest 03bb880c97ac 7 minutes ago 895MBコンテナ起動
最後に、作成したイメージからコンテナを起動します。
$ docker container run -d -p 8080:5000 tutorial/docker-flask:latest
-dはバックグラウンドで実行するオプションです。ここで重要なのが、
-p 8080:5000の部分です。
これはポートフォワーディングという設定で、ホストのポートとコンテナ内のポートを接続する設定です。
flaskでは、デフォルトで5000番ポートを使用しているため、この記述で8080番ポートへのアクセスを、5000番ポートへ転送しています。アクセスしてみる
localhostの8080番ポートにアクセスすると、無事
Hello from Docker!と表示され、コンテナ内でpythonが動いていることが確認できます。後片付け
コンテナの停止
$ docker ps -aで起動しているコンテナを確認します。
-aを指定することで、停止中のコンテナも表示されます。$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8b15d95aa3b2 tutorial/docker-flask:latest "python /src/main.py" 10 minutes ago Up 10 minutes 0.0.0.0:8080->5000/tcp sad_blackwell
$ docker stop <CONTAINER ID or NAMES>でコンテナが停止します。$ docker stop 8b15d95aa3b2もしくは
$ docker stop sad_blackwell
$ docker ps -aで、STATUSがExitedとなっており、停止されているのが確認できます。$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8b15d95aa3b2 tutorial/docker-flask:latest "python /src/main.py" 15 minutes ago Exited (0) 3 minutes ago sad_blackwellコンテナを再度起動する際も、同様に
$ docker start <CONTAINER ID もしくは NAMES>でコンテナを起動することができます。コンテナ削除(任意)
停止のやり方と同様に、
$ docker ps -aでCONTAINER IDもしくはNAMESの欄を確認します。$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8b15d95aa3b2 tutorial/docker-flask:latest "python /src/main.py" 23 minutes ago Up 6 minutes 0.0.0.0:8080->5000/tcp sad_blackwell
$ docker rm <CONTAINER ID or NAMES>でコンテナの削除ができます。$ docker rm 8b15d95aa3b2もしくは
$ docker rm sad_blackwell
$ docker ps -aで削除できたか確認する$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES無事消えていることが確認できました。
イメージ削除(任意)
$ docker imagesで保存されているのイメージの確認をします。$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE tutorial/docker-flask latest 03bb880c97ac 39 minutes ago 895MBイメージの削除は、
$ docker rmi <REPOSITORY or IMAGE ID>で行います。$ docker rmi tutorial/docker-flaskもしくは
$ docker rmi 03bb880c97ac
$ docker imagesで削除の確認$ docker images REPOSITORY TAG IMAGE ID CREATED SIZEイメージが削除されていることが確認できました。


- 投稿日:2021-03-01T20:42:41+09:00
Docker 簡単な説明とコンテナ構築
こんにちは。
Dockerについて学習したので、アウトプットも兼ねて初学者ならではの視点で記事を書いてみようと思います。私が初めてDockerについて記事を読んで学習した際、「で、結局何ができるんだ?」という疑問が残ってしまいましたが、実際にコマンドを叩いてコンテナ構築をしてみると、何が便利なのかイメージができたので実践してみることをお勧めします。
概要はわかるけど、コンテナ構築の部分だけ知りたいという方は、ローカル環境にコンテナを構築の項まで飛ばしてください。
なお、仕組み等の詳細説明は割愛します。
Docker, コンテナとは何かをイメージしていただくための記事になっています。間違った部分等ありましたらご指摘いただけると幸いです。
Dockerとは
Dockerは、コンテナ型仮想環境を管理するプラットフォームのことです。
環境の構築・実行だけでなく、配布することもできます。
自分はDocker = コンテナと勘違いしていました。コンテナ型仮想環境
コンテナ型仮想環境は、仮想化技術の一種です。
私は以前にOracle社のVirtualBoxを利用した経験があったため、VirtualBoxが該当するホスト型仮想環境と比較して説明します。
ホスト型は、仮想環境ごとにゲストOSを立ち上げるのに対し、コンテナ型はホストOSのカーネルを共有して動作しています。
そのため、他の仮想化技術と比べ起動が速く、軽量に動作するといったメリットがあります。
Dockerの特徴
コンテナは、Dockerfileというソースコードから構築します。(このようにコードベースでインフラ構築を定義する考え方をInfrastructure as Codeといいます。)
これによって、開発したアプリケーションが別環境だと動かないといった環境差異を防ぐことができます。他にも、
- Dockerfileを(Github等で)共有することで、どこでも誰でも同じ環境が作れる。
- 環境を壊してしまった場合などに、環境の再構築が容易。
などといった特徴があります。
コンテナ構築の流れ
Dockerfileからイメージを作り、イメージからコンテナを立ち上げるという流れです。
イメージとは ... コンテナの構成をまとめたもので、コンテナを構築するベースのようなものです。DockerHubには、wordpress, mysql, pythonなどがイメージファイルとして公開されており、それらを自分で組み合わせたイメージを作成します。Docker Hub 概要 — Docker-docs-ja 19.03 ドキュメント
なお、Dockerではコンテナ1つにアプリケーション1つが推奨されているので、例えば
MySQL+nginx+flaskなど、複数のアプリケーションを組み合わせているサービスををDockerで動かす場合は、利用するアプリケーション分コンテナを構築し、docker-composeやKubernatesなどのコンテナオーケストレーションサービスを利用する必要があります。ローカル環境にコンテナを構築
今回は、コンテナ環境でPythonのwebフレームワークである、flaskを動かしてみようと思います。
ローカル環境にDockerがインストールされていることが前提です。Get Docker | Docker Documentation
前提ファイルの準備
Dockerfileとpythonファイルのmain.pyを同じディレクトリに用意します。
./
├ main.py
└ Dockerfilemain.pyfrom flask import Flask app = Flask(__name__) @app.route('/') def hello_world(): return 'Hello from Docker!' if __name__ == '__main__': app.debug = True app.run(host='0.0.0.0')pythonファイルの内容は、ルートにアクセスがあったらHello from Dockerと表示する単純なflaskプログラムです。
DockerfileFROM python:latest RUN mkdir /src && \ pip install flask COPY main.py /src CMD ["python", "/src/main.py"] # "python /src/main.py"と同じ
FROM... 作成するDockerイメージのベースイメージを指定。DockerHubからダウンロードされる。pythonの最新バージョンを指定。RUN... イメージのビルド時に実行されるコマンド。srcというディレクトリを作成するコマンドと、pipを使ってflaskをインストールするコマンドを指定。COPY... ホストマシンのファイルやディレクトリをコンテナ内にコピーする。先程用意したmain.pyをコンテナ内のsrcディレクトリにコピーする。CMD... コンテナ起動時に実行されるコマンドを指定。スペース区切りで配列化した形式。python /src/main.pyでpythonファイルを実行している。イメージのビルド
$ docker image build -t tutorial/docker-flask:latest .
-t以降は、<account name>/<image name>:<tag>の形式で指定します。
account name... 名前衝突を避けるための名前空間image name... イメージ名tag... バージョンやラベル末尾にDockerfileのあるディレクトリを指定します。(今回はカレントを指定)
このように表示されればビルドが完了です。
Successfully built 03bb880c97ac Successfully tagged tutorial/docker-flask:latest
docker image lsコマンドで、イメージのリストが確認できます。$ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE tutorial/docker-flask latest 03bb880c97ac 7 minutes ago 895MBコンテナ起動
最後に、作成したイメージからコンテナを起動します。
$ docker container run -d -p 8080:5000 tutorial/docker-flask:latest
-dはバックグラウンドで実行するオプションです。ここで重要なのが、
-p 8080:5000の部分です。
これはポートフォワーディングという設定で、ホストのポートとコンテナ内のポートを接続する設定です。
flaskでは、デフォルトで5000番ポートを使用しているため、この記述で8080番ポートへのアクセスを、5000番ポートへ転送しています。アクセスしてみる
localhostの8080番ポートにアクセスすると、無事
Hello from Docker!と表示され、コンテナ内でpythonが動いていることが確認できます。後片付け
コンテナの停止
$ docker ps -aで起動しているコンテナを確認します。
-aを指定することで、停止中のコンテナも表示されます。$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8b15d95aa3b2 tutorial/docker-flask:latest "python /src/main.py" 10 minutes ago Up 10 minutes 0.0.0.0:8080->5000/tcp sad_blackwell
$ docker stop <CONTAINER ID or NAMES>でコンテナが停止します。$ docker stop 8b15d95aa3b2もしくは
$ docker stop sad_blackwell
$ docker ps -aで、STATUSがExitedとなっており、停止されているのが確認できます。$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8b15d95aa3b2 tutorial/docker-flask:latest "python /src/main.py" 15 minutes ago Exited (0) 3 minutes ago sad_blackwellコンテナを再度起動する際も、同様に
$ docker start <CONTAINER ID もしくは NAMES>でコンテナを起動することができます。コンテナ削除(任意)
停止のやり方と同様に、
$ docker ps -aでCONTAINER IDもしくはNAMESの欄を確認します。$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8b15d95aa3b2 tutorial/docker-flask:latest "python /src/main.py" 23 minutes ago Up 6 minutes 0.0.0.0:8080->5000/tcp sad_blackwell
$ docker rm <CONTAINER ID or NAMES>でコンテナの削除ができます。$ docker rm 8b15d95aa3b2もしくは
$ docker rm sad_blackwell
$ docker ps -aで削除できたか確認する$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES無事消えていることが確認できました。
イメージ削除(任意)
$ docker imagesで保存されているのイメージの確認をします。$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE tutorial/docker-flask latest 03bb880c97ac 39 minutes ago 895MBイメージの削除は、
$ docker rmi <REPOSITORY or IMAGE ID>で行います。$ docker rmi tutorial/docker-flaskもしくは
$ docker rmi 03bb880c97ac
$ docker imagesで削除の確認$ docker images REPOSITORY TAG IMAGE ID CREATED SIZEイメージが削除されていることが確認できました。
- 投稿日:2021-03-01T20:42:41+09:00
Docker コンテナ構築入門
こんにちは。
Dockerについて学習したので、アウトプットも兼ねて初学者ならではの視点で記事を書いてみようと思います。筆者が初めてDockerについて記事を読んで学習した際、「で、結局何ができるんだ?」という疑問が残ってしまいましたが、実際にコマンドを叩いてコンテナ構築をしてみると、何が便利なのかイメージができたので実践してみることをお勧めします。
なお、仕組み等の詳細説明は割愛します。
間違った部分等ありましたらご指摘いただけると幸いです。
Dockerの特徴
コンテナは、Dockerfileというソースコードから構築します。(このようにコードベースでインフラ構築を定義する考え方をInfrastructure as Codeといいます。)
これによって、開発したアプリケーションが別環境だと動かないといった環境差異を防ぐことができます。他にも、
- Dockerfileを(Github等で)共有することで、どこでも誰でも同じ環境が作れる。
- 環境を壊してしまった場合などに、環境の再構築が容易。
などといった特徴があります。
コンテナ構築の流れ
Dockerfileからイメージを作り、イメージからコンテナを立ち上げるという流れです。
イメージとは ... コンテナの構成をまとめたもので、コンテナを構築するベースのようなものです。DockerHubには、wordpress, mysql, pythonなどがイメージファイルとして公開されており、それらを自分で組み合わせたイメージを作成します。Docker Hub 概要 — Docker-docs-ja 19.03 ドキュメント
なお、Dockerではコンテナ1つにアプリケーション1つが推奨されているので、例えば
MySQL+nginx+flaskなど、複数のアプリケーションを組み合わせているサービスををDockerで動かす場合は、利用するアプリケーション分コンテナを構築し、docker-composeやKubernatesなどのコンテナオーケストレーションサービスを利用する必要があります。ローカル環境にコンテナを構築
今回は、コンテナ環境でPythonのwebフレームワークである、flaskを動かしてみようと思います。
なお、ホスト環境にPythonやFlaskをインストールする必要はありません。ローカル環境にDockerがインストールされていることが前提です。
Get Docker | Docker Documentation
前提ファイルの準備
Dockerfileとpythonファイルのmain.pyを同じディレクトリに用意します。
./
├ main.py
└ Dockerfilemain.pyfrom flask import Flask app = Flask(__name__) @app.route('/') def hello_world(): return 'Hello from Docker!' if __name__ == '__main__': app.debug = True app.run(host='0.0.0.0')pythonファイルの内容は、ルートにアクセスがあったらHello from Dockerと表示する単純なflaskプログラムです。
DockerfileFROM python:latest RUN mkdir /src && \ pip install flask COPY main.py /src CMD ["python", "/src/main.py"] # "python /src/main.py"と同じ
FROM... 作成するDockerイメージのベースイメージを指定。DockerHubからダウンロードされる。pythonの最新バージョンを指定。RUN... イメージのビルド時に実行されるコマンド。srcというディレクトリを作成するコマンドと、pipを使ってflaskをインストールするコマンドを指定。COPY... ホストマシンのファイルやディレクトリをコンテナ内にコピーする。先程用意したmain.pyをコンテナ内のsrcディレクトリにコピーする。CMD... コンテナ起動時に実行されるコマンドを指定。スペース区切りで配列化した形式。python /src/main.pyでpythonファイルを実行している。イメージのビルド
$ docker image build -t tutorial/docker-flask:latest .
-t以降は、<account name>/<image name>:<tag>の形式で指定します。
account name... 名前衝突を避けるための名前空間image name... イメージ名tag... バージョンやラベル末尾にDockerfileのあるディレクトリを指定します。(今回はカレントを指定)
このように表示されればビルドが完了です。
Successfully built 03bb880c97ac Successfully tagged tutorial/docker-flask:latest
docker image lsコマンドで、イメージのリストが確認できます。$ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE tutorial/docker-flask latest 03bb880c97ac 7 minutes ago 895MBコンテナ起動
最後に、作成したイメージからコンテナを起動します。
$ docker container run -d -p 8080:5000 tutorial/docker-flask:latest
-dはバックグラウンドで実行するオプションです。ここで重要なのが、
-p 8080:5000の部分です。
これはポートフォワーディングという設定で、ホストのポートとコンテナ内のポートを接続する設定です。
flaskでは、デフォルトで5000番ポートを使用しているため、この記述で8080番ポートへのアクセスを、5000番ポートへ転送しています。アクセスしてみる
localhostの8080番ポートにアクセスすると、無事
Hello from Docker!と表示され、コンテナ内でpythonが動いていることが確認できます。後片付け
コンテナの停止
$ docker ps -aで起動しているコンテナを確認します。
-aを指定することで、停止中のコンテナも表示されます。$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8b15d95aa3b2 tutorial/docker-flask:latest "python /src/main.py" 10 minutes ago Up 10 minutes 0.0.0.0:8080->5000/tcp sad_blackwell
$ docker stop <CONTAINER ID or NAMES>でコンテナが停止します。$ docker stop 8b15d95aa3b2もしくは
$ docker stop sad_blackwell
$ docker ps -aで、STATUSがExitedとなっており、停止されているのが確認できます。$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8b15d95aa3b2 tutorial/docker-flask:latest "python /src/main.py" 15 minutes ago Exited (0) 3 minutes ago sad_blackwellコンテナを再度起動する際も、同様に
$ docker start <CONTAINER ID もしくは NAMES>でコンテナを起動することができます。コンテナ削除(任意)
停止のやり方と同様に、
$ docker ps -aでCONTAINER IDもしくはNAMESの欄を確認します。$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8b15d95aa3b2 tutorial/docker-flask:latest "python /src/main.py" 23 minutes ago Up 6 minutes 0.0.0.0:8080->5000/tcp sad_blackwell
$ docker rm <CONTAINER ID or NAMES>でコンテナの削除ができます。$ docker rm 8b15d95aa3b2もしくは
$ docker rm sad_blackwell
$ docker ps -aで削除できたか確認する$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES無事消えていることが確認できました。
イメージ削除(任意)
$ docker imagesで保存されているのイメージの確認をします。$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE tutorial/docker-flask latest 03bb880c97ac 39 minutes ago 895MBイメージの削除は、
$ docker rmi <REPOSITORY or IMAGE ID>で行います。$ docker rmi tutorial/docker-flaskもしくは
$ docker rmi 03bb880c97ac
$ docker imagesで削除の確認$ docker images REPOSITORY TAG IMAGE ID CREATED SIZEイメージが削除されていることが確認できました。
- 投稿日:2021-03-01T18:12:39+09:00
VSCode + Docker で C++ 使って WASM の開発環境構築
ことの発端
VSCode + Docker で C++ の開発環境が簡単に構築できたので、そのまま、WASMの開発環境も作ってしまえということで、メモ書きです。
手順
1. コンテナ作成〜CMakeLists.txt作成
前に投稿させていただいた「C++の開発環境をDockerで構築してVSCodeでリモート開発 」の手順で進めますが、
Dockerファイルを下記のファイルに差し替えてください。1DockerfileFROM ubuntu:18.04 RUN apt-get update \ && apt-get install -y build-essential gdb cmake git python3 \ && git clone https://github.com/emscripten-core/emsdk.git \ && cd emsdk \ && ./emsdk install latest \ && ./emsdk activate latest \ && echo 'source "/emsdk/emsdk_env.sh"' >> $HOME/.bashrcコンテナのビルドやっちゃった人は、
Dockerfileを上のように書き換えて [F1] でコマンドパレットを表示させてRemote-Containers: Revuild Containerを実行すれば、コンテナをリビルドしてくれます。(便利だ〜)
2. CMakeLists.txt に追加
CMakeLists.txtに下記の行を追加します。CMakeLists.txtset(CMAKE_EXECUTABLE_SUFFIX ".html")こいつを指定しないと html を自分で書くことになります。
3. emscripten 用のビルドフォルダを作成してビルド
下記の順にコマンドを実行
mkdir build.em cd build.em emcmake cmake .. make4. 実行
ブラウザのセキュリティ設定によりますが、大概はローカルファイルだとwasmのロードでエラーして動かないと思います。
なので、VSCodeの拡張機能 Live Server : ritwickdey.liveserver をインストールします。インストールすると、右下にGo Liveが表示されるので、こいつを押下します。
ブラウザにファイル一覧が表示されると思うので、
build.emフォルダをクリックして、htmlファイルをクリックします。
こんな感じで表示されれば完成です。
本家の手順では
.bash_profileに環境設定を追加していますが、.bashrcに追加する変更を加えてます。(参照記事: https://teratail.com/questions/45915 ) ↩



- 投稿日:2021-03-01T17:18:07+09:00
[WIP] kotlin> 単体テスト時にdockerイメージを使う > gradle-docker-compose-plugin
単体テスト時にdockerイメージを起動できる、GraldeのPluginである
gradle-docker-compose-pluginを使いました。サンプルプロジェクトとして、
dockerで起動したMockサーバーを使ってAPIアクセスの単体テストを作ってみます。今回の目的は、
HTTP経由でデータを取得するHTTP Clientの単体テストを行いたいを解決することです。成果物
sugasaki/gradle-docker-compose-test
使うもの
- IntelliJ Idea
- avast/gradle-docker-compose-plugin Gradleプラグインに追加することで単体テスト時にDockerを実行
- Fuel Kotlin用 HTTP Client
- MockServer APIテストのためのMock Server
概要
HTTPからデータを取得する機能を単体テストする
- Gracleにgradle-docker-compose-pluginを追加
- Docker Composeファイルを設置(作成)
- 単体テストする
gradle-docker-compose-pluginのメモ
公式サイトを訳したものをメモとして残します。
Gradle環境でのローカル開発と統合テストのためのDocker Composeの使用を簡素化します。
composeUpタスクはアプリケーションを起動し、すべてのコンテナが健全になり、公開されているTCPポートがすべて開くまで(アプリケーションの準備が整うまで)待ちます。特定のコンテナの割り当てられたホストとポートを読み込み、dockerCompose.servicesInfosプロパティに格納します。
composeDownタスクは、'stopContainers' が 'true' (デフォルト値) に設定されている場合にのみ、アプリケーションを停止し、コンテナを削除します。
composeDownForcedタスクはアプリケーションを停止し、コンテナを削除します。
composePullタスクは、アプリケーションが必要とする画像をプルし、オプションでビルドします。これは例えば、ビルド時間を短縮するためにdockerイメージをキャッシュするCIプラットフォームで有用です。
composeBuildタスクはアプリケーションのサービスをビルドします。
composePushタスクはサービスのイメージをそれぞれのレジストリ/リポジトリにプッシュします。
composeLogsタスクはすべてのコンテナのログを containerLogToDir ディレクトリのファイルに保存します。Quick start
依存関係に追加
buildscript { repositories { jcenter() } dependencies { classpath "com.avast.gradle:gradle-docker-compose-plugin:$versionHere" } } apply plugin: 'docker-compose' dockerCompose.isRequiredBy(test)プラグイン指定
Gradle Portal プラグインを使用します (上記のように依存関係を追加する必要はありません)
plugins { id 'com.avast.gradle.docker-compose' version "$versionHere" }
- docker-compose upはプロジェクトディレクトリで実行されるので、docker-compose.ymlファイルを使用します。
- 提供されたタスク(上の例ではテスト)が新規プロセスを実行する場合、環境変数とJavaシステムのプロパティが提供されます。
- 環境変数の名前は${serviceName}HOSTと${serviceName}_TCP${exposedPort}です。(例: WEB_HOST, WEB_TCP_80)。
- Javaシステムプロパティの名前は${serviceName}.hostと${serviceName}.tcp.${exposedPort}です。(例: web.host と web.tcp.80)
- サービスがスケーリングされている場合、サービス名のサフィックスは 1, 2... です (例: WEB1_HOST と WEB1_TCP_80, web_1.host と web_1.tcp.80)
Why to use Docker Compose?
自分のコンピュータ上でアプリケーションを実行できるようにしたいし、同僚にも動作するようにしなければなりません。
docker-compose upを実行するだけで完了します - 例えば、動作中のデータベース。自分のコンピュータ上でアプリケーションをテストできるようにしたい - 自分のアプリケーションが開発/テスト環境にデプロイされ、受入れ/エンドツーエンドテストが実行されるまでは待ちたくありません。コンピュータ上でこれらのテストを実行したい - これらのテストの前に docker-compose up を実行することを意味します。
Why this plugin?
テストの前に
docker-compose upが呼ばれるようにするのは簡単ですが、このプラグインで解決できる問題がいくつかあります。
docker-compose up -d(detached) を実行した場合、このコマンドはすぐに戻ります。このプラグインは、すべてのコンテナが健全な状態になり、すべてのサービスのエクスポートされた TCP ポートがオープンするまで待機します。健全な状態になるまで待ったり、TCP ポートが開いている状態でタイムアウトした場合 (デフォルトは 15 分です)、関連するサービスのログを表示します。
docker-compose.yml で公開されているポートの固定値 (例: 8888:80) を指定しないことをお勧めします。ポートを公開する際に固定値を指定しない (80だけを使用する) と、ポートはランダムなフリーポートとして公開されます。このプラグインは、割り当てられたポート (コンテナの IP アドレスも) を読み込み、
dockerCompose.servicesInfoマップに格納します。Linux、Windows、MacでLinuxコンテナを使用している場合と、Windowsコンテナを使用している場合では、細かな違いがあります。このプラグインはこれらの違いを処理してくれるので、 どの環境でも同じ経験をすることができます。
Tips
dockerCompose.isRequiredBy(anyTask)を任意のタスク、例えばカスタムのintegrationTestタスクに対して呼び出すことができます。
あるDockerfileがGradleによって生成されたアーティファクトを必要としている場合は、
composeUp.dependOn project(':my-app').distTarのように、標準的な方法でこの依存関係を宣言することができます。
dockerComposeのすべてのプロパティは意味のあるデフォルト値を持っているので、触る必要はありません。興味のある方はComposeSettings.groovyを参考にしてみてください。
dockerCompose.servicesInfosには実行中のコンテナに関する情報が含まれているので、composeUpタスクが終了した後にこのプロパティにアクセスする必要があります。そのため、テストタスクのdoFirstはこのプロパティにアクセスするのに最適な場所です。プラグインは
docker-compose.override.ymlファイルを尊重しますが、useComposeFilesでファイルが指定されていない場合に限ります(コマンドラインの動作に準拠します)。
ContainerInfo.groovyをチェックして、コンテナの実行について知ることができます。GradleのビルドでDockerホストを決定し(つまりdocker-machine起動)、composeで使用する環境変数DOCKER_HOSTを設定することができます:
dockerCompose { environment.put 'DOCKER_HOST', '192.168.64.9'}
docker-composeで実行されるサービスが特定のホスト(CirceCI 2.0のようにDockerとは異なる)で実行されている場合は、環境変数services_hostを使用することができます。この値は、サービスが待ち受けていると予想されるホスト名として使用されます。Fuel
割愛します
MockServer
- 投稿日:2021-03-01T15:24:29+09:00
C++の開発環境をDockerで構築してVSCodeでリモート開発
ことの発端
VSCode でC++の開発環境構築(Windows / MacOS) の記事を書いていて「何故にdocker使わない?」ということに気付き、やってみたら、更に簡単だったのでメモ。
Docker 未経験の方でも、Dockerさえインストールできれば1、この手順で進めれば大丈夫です。
これをキッカケに Docker って何者なのかを調べてみると良いかと思います。手順
1. DockerFile を作成
ここで開発用のフォルダを作成し、まずは Dockerileを作成します。
DockerfileFROM ubuntu:18.04 RUN apt-get update && apt-get install -y build-essential gdb cmake今回は docker-compose は使用しません。2
2. VSCodeからコンテナ内へリモート接続する
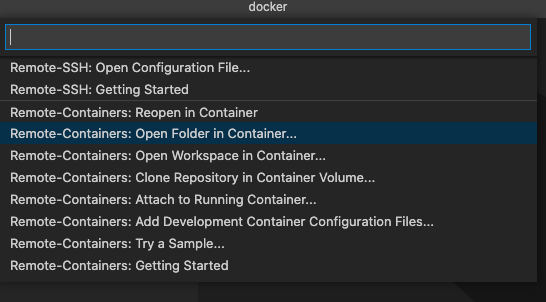
拡張機能 Remote - Containers : ms-vscode-remote.remote-containers をインストールします。
インストールすると、左下の緑色のボタンが表示されるので、クリックします。
コマンドパレットが表示されるので今回は
Remote-Containers: Open Folder in Containers...を選びます。
フォルダ選択画面が表示されるので、Dockerファイルが存在するフォルダを選択します。
コマンドパレットが表示されるので
From 'Dockerfile'を選択します。
この手順で、コンテナビルド→設定→起動→ログインが行われます。
3. 開発用の拡張機能をインストール
拡張機能 C/C++ : ms-vscode.cpptools をインストールします。
拡張機能CMake Tools : ms-vscode.cmake-tools をインストールします。
VSCodeはリモート環境毎に拡張機能をインストールするという素晴らしい仕様なので、既にローカルで拡張機能をインストールしていても、再度インストールがされているか確認をしてください。
4. 開発開始
[F1] でコマンドパレットを表示しして、
Cmake: Configureを選択します。
Kit の選択が要求されるので
GCC 7.5.0を選択します。
右下に
CMakeLists.txtを作るか聞いてくるのでCreateを押下します。
プロジェクト名を入力してと言われるので、適切な名前を入力します。
実行ファイル(Executable)からライブラリファイル(Library)かと聞かれるので、
Executableを選択します。
この手順で、
CMakeLists.txtとmain.cppが生成されます。5. ビルドとデバッグ実行
- [F7] でビルドが行われます。
- [CTRL] + [F5] でデバッグ実行が開始されます。
ブレイクポイントやら、スタックトレース、変数のウォッチなどは、一般的な開発環境と同じなので、ここでは割愛します。
その他
- VSCode を閉じれば、コンテナは自動的に停止します。
- 次回からは VSCode を起動して Recent からフォルダを選択すれば、自動的にコンテナを起動してくれます。
- VSCodeでgitの操作を行いたいなら、
Dockerfileにgitを追加しましょう。- gitを使う場合
.gitignoreにbuildと.devcontainerを追加しましょう。Remote-Container使えば、C++以外でもDockerを使って開発環境構築するのは良いかも。
VT-xを使っているミドルウエア(VMWareやVirtualBoxなど)をインストールしている場合はホスト環境にDockerを入れると、ネットワークドライバがコンフリクトしてアンインストールに苦労するかもなので、注意してください。 ↩
docker-compose.ymlを書いても良いのですが、MS謹製のRemote-Containersがvolumeのbindとか面倒見てくれるので今回はこの子に甘えます。外部からのネットワークかインバウンドを想定したプログラムならVSCodeのターミナルで起動したプロセスがTCPをリスニングした場合、自動的にポートフォワードしてくれるので特に設定不要です。 ↩docker-compose.ymlを記述する必要がありますが、ここでは割愛します。






- 投稿日:2021-03-01T11:33:51+09:00
【入門】SQLWorkbench/Jを用いたJDBC経由のGridDB接続とデータベース操作
GridDBは、NoSQLとSQLのデュアルインタフェースを備えているデータベースです。リアルタイム性の高い登録や参照にはNoSQLインタフェース、大規模なデータ集約・加工にはSQLインタフェースというようにうまく使い分けることができるようです。
今回、Docker DesktopのCentOSコンテナで、JDBC (Java Database Connectivity) ドライバ経由で動作するオープンソースの SQL クライアントツール SQLWorkbench/Jをインストールして、JDBC経由でのGridDBデータベースに接続する方法についてステップバイステップで紹介します。また、典型的なGridDBのデータモデルの具体例を用いて、SQL構文を解説しながら、SQLWorkbench/JでのGridDBデータベースのSQL操作についても紹介します。
- 前提条件
- 事前準備
- GridDB 構築済みの CentOS コンテナ のビルド・起動
- GridDBサーバの起動
- GridDB JDBCドライバーの構築
- SQL Workbench/J の入手とインストール
- SQL Workbench/J でのJDBC経由によるGridDBとの接続確認
- データベース操作をしてみる
前提条件
今回は、すでに Docker Desktop で CentOS コンテナの環境が構築され その上にGridDB Community Edition のセットアップされ動作確認されていることを前提としています。これらを環境を用意する場合は、次の記事を参照していただければと思います。
【入門】はじめての Docker Desktop の CentOS コンテナでの GridDB Community Edition のセットアップ
以降、ここでは、GridDB Community Edition のセットアップ・動作確認された CentOS のイメージの名前をcentos:gahoh とします。
事前準備
GridDB 構築済みの CentOS コンテナ のビルド・起動
GridDB Community Edition のセットアップ・動作確認された CentOS のイメージ centos:gahoh からCentOS コンテナをビルドして起動します。
$ docker run -it --name="centos" centos:gahoh /bin/bash #GridDB サーバの起動
# su - gsadm Last login: Mon Jan 18 09:44:28 UTC 2021 on pts/0 $ cd $ pwd /var/lib/gridstore $ gs_startnode -u admin/admin -w . Started node. $ gs_joincluster -c myCluster -u admin/admin -w .. Joined node $ gs_stat -u admin/admin | egrep Status "clusterStatus": "MASTER", "nodeStatus": "ACTIVE", "partitionStatus": "NORMAL",設定内容
「【入門】はじめての Docker Desktop の CentOS コンテナでの GridDB Community Edition のセットアップ」による GridDB サーバの設定内容は、クラスタ名以外は、デフォルト値の設定のままになっています。次に主な設定項目を示します。
設定項目 値 クラスタ名 myCluster マルチキャストアドレス 239.0.0.1 (デフォルト値) マルチキャストポート番号 31999 (デフォルト値) ユーザ名 admin (デフォルト値) ユーザパスワード admin (デフォルト値) SQLマルチキャストアドレス 239.0.0.1 (デフォルト値) SQLマルチキャストポート番号 41999 (デフォルト値) もし、これらの設定内容を変更している場合は、必要に応じてパラメータなどの修正が必要となりますので注意願いまます。
GridDB JDBCドライバーの構築
git clone コマンドを用いて、Gitのリポジトリ https://github.com/griddb/jdbc をディレクトリ griddb_jdbc に複製します。
$ git clone https://github.com/griddb/jdbc.git griddb_jdbc Cloning into 'griddb_jdbc'... remote: Enumerating objects: 208, done. remote: Total 208 (delta 0), reused 0 (delta 0), pack-reused 208 Receiving objects: 100% (208/208), 403.07 KiB | 365.00 KiB/s, done. Resolving deltas: 100% (43/43), done. $ビルド
Javaのビルドツール Apache Antを用いて GridDB JDBCドライバをビルドします。
$ cd griddb_jdbc/ $ ant Buildfile: /var/lib/gridstore/griddb_jdbc/build.xml compile: [mkdir] Created dir: /var/lib/gridstore/griddb_jdbc/obj/main [javac] Compiling 65 source files to /var/lib/gridstore/griddb_jdbc/obj/main [javac] warning: [options] bootstrap class path not set in conjunction with -source 1.6 [javac] Note: Some input files use or override a deprecated API. [javac] Note: Recompile with -Xlint:deprecation for details. [javac] Note: Some input files use unchecked or unsafe operations. [javac] Note: Recompile with -Xlint:unchecked for details. [javac] 1 warning mainJar: [mkdir] Created dir: /var/lib/gridstore/griddb_jdbc/bin [jar] Building jar: /var/lib/gridstore/griddb_jdbc/bin/gridstore-jdbc.jar callLoggingCompile: [mkdir] Created dir: /var/lib/gridstore/griddb_jdbc/obj/call_logging [javac] Compiling 3 source files to /var/lib/gridstore/griddb_jdbc/obj/call_logging [javac] warning: [options] bootstrap class path not set in conjunction with -source 1.6 [javac] 1 warning callLoggingJar: [jar] Building jar: /var/lib/gridstore/griddb_jdbc/bin/gridstore-jdbc-call-logging.jar jar: BUILD SUCCESSFUL Total time: 5 seconds $これで、bin/ フォルダの下に次のファイルが作成されます。
JDBCドライバー gridstore-jdbc.jar
JDBCログイングドライバー gridstore-jdbc-call-logging.jar$ ls bin gridstore-jdbc-call-logging.jar gridstore-jdbc.jar次に、JDBCドライバファイル gridstore-jdbc.jar を /usr/share/java/ の下にコピーしておきます。
$ sudo cp bin/gridstore-jdbc.jar /usr/share/java/ We trust you have received the usual lecture from the local System Administrator. It usually boils down to these three things: #1) Respect the privacy of others. #2) Think before you type. #3) With great power comes great responsibility. [sudo] password for gsadm: $サンプルプログラムの実行
JDBCドライバーがちゃんと構築されているか確かめるため、サンプルプログラムを実行してみます。
import java.net.URLEncoder; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.Statement; import java.util.Properties; public class JDBCSelect { public static void main(String[] args){ try { //=============================================== // クラスタに接続する //=============================================== // JDBCの接続情報 String jdbcAddress = "239.0.0.1"; String jdbcPort = "41999"; String clusterName = "myCluster"; String databaseName = "public"; String username = "admin"; String password = "admin"; String applicationName = "SampleJDBC"; // クラスタ名とデータベース名はエンコードする String encodeClusterName = URLEncoder.encode(clusterName, "UTF-8"); String encodeDatabaseName = URLEncoder.encode(databaseName, "UTF-8"); // URLを組み立てる (マルチキャスト方式) String jdbcUrl = "jdbc:gs://"+jdbcAddress+":"+jdbcPort+"/"+encodeClusterName+"/"+encodeDatabaseName; Properties prop = new Properties(); prop.setProperty("user", username); prop.setProperty("password", password); prop.setProperty("applicationName", applicationName); // 接続する Connection con = DriverManager.getConnection(jdbcUrl, prop); //=============================================== // コンテナ作成とデータ登録 //=============================================== { Statement stmt = con.createStatement(); // (存在した場合は削除する) stmt.executeUpdate("DROP TABLE IF EXISTS SampleJDBC_Select"); // コンテナ作成 stmt.executeUpdate("CREATE TABLE IF NOT EXISTS SampleJDBC_Select ( id integer PRIMARY KEY, value string )"); System.out.println("SQL Create Table name=SampleJDBC_Select"); // ロウ登録 int ret1 = stmt.executeUpdate("INSERT INTO SampleJDBC_Select values "+ "(0, 'test0'),(1, 'test1'),(2, 'test2'),(3, 'test3'),(4, 'test4')"); System.out.println("SQL Insert count=" + ret1); stmt.close(); } //=============================================== // 検索の実行 //=============================================== // (1)ステートメント作成 Statement stmt = con.createStatement(); // (2)SQL実行 ResultSet rs = stmt.executeQuery("SELECT * from SampleJDBC_Select where ID > 2"); // (3)結果の取得 while( rs.next() ){ int id = rs.getInt(1); String value = rs.getString(2); System.out.println("SQL row(id=" + id + ", value=" + value + ")"); } //=============================================== // 終了処理 //=============================================== stmt.close(); con.close(); System.out.println("success!"); } catch ( Exception e ){ e.printStackTrace(); } } }なお、起動した GridDB サーバのクラスタ名、ユーザ名、パスワードなどの設定内容を変更している場合は、ソースコード JDBCSelect.javaを編集して、クラスタ名、ユーザ名、パスワードなどの設定パラメータを修正する必要があります。
$ cd sample/ja/jdbc $ javac -encoding UTF-8 JDBCSelect.java $ export CLASSPATH=:/usr/share/java/gridstore-jdbc.jar $ java JDBCSelect SQL Create Table name=SampleJDBC_Select SQL Insert count=5 SQL row(id=3, value=test3) SQL row(id=4, value=test4) success! $これでJDBCドライバーがちゃんと構築されていることが確認できました。次は、SQL Workbench/J のインストールです。
SQL Workbench/J のインストール
SQL Workbench/J は、 Thomas Kellerer により開発・提供されている JDBC ドライバ経由で動作するオープンソースの SQL クライアントツールです。
Javaランタイム上で動くOS非依存のJavaアプリケーションで、ライセンスの利用規約としては一部(特定の国の政府機関など)利用を制限しています。日本での利用では特に問題はありません。
SQL Workbench/Jの入手方法とインストール方法
SQL Workbench/Jは、専用ホームページのダウンロード画面より入手してください。
ダウンロード画面には、数種類のダウンロードリンクがありますが「Generic package for all systems including all optional libraries (sha1) https://www.sql-workbench.eu/Workbench-Build127-with-optional-libs.zip が、現在の安定版であり、jarファイル、マニュアル(HTMLおよびPDF)、アプリケーションを起動するためのLinux / Unixベースのシステム(MacOSを含む)のシェルスクリプト、 およびWindows®ランチャーとサンプルXSLTスクリプトが含まれています。
ダウンロードしたファイルは、ZIP形式で圧縮されていますので、任意の場所に解凍してください。これで、SQL Workbench/Jのインストールは終了です。具体的なインストールの大まかな流れは次の通りです。
# wget https://www.sql-workbench.eu/Workbench-Build127-with-optional-libs.zip # mkdir sqlworkbench # cd sqlworkbench # unzip ../Workbench-Build127-with-optional-libs.zip # chmod +x *.sh # ./sqlwbconsole.shでは、詳細を見ていきましょう。
ダウンロード
wgetコマンドで、URLを指定してダウンロードします。
$ exit # # wget https://www.sql-workbench.eu/Workbench-Build127-with-optional-libs.zip --2021-01-18 06:23:01-- https://www.sql-workbench.eu/Workbench-Build127-with-optional-libs.zip Resolving www.sql-workbench.eu (www.sql-workbench.eu)... 217.160.0.56, 2001:8d8:100f:f000::20b Connecting to www.sql-workbench.eu (www.sql-workbench.eu)|217.160.0.56|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 28852920 (28M) [application/zip] Saving to: 'Workbench-Build127-with-optional-libs.zip' 100%[==============================================================================>] 28,852,920 2.53MB/s in 12s 2021-01-18 06:23:14 (2.26 MB/s) - 'Workbench-Build127-with-optional-libs.zip' saved [28852920/28852920] #解凍
# mkdir sqlworkbench # cd sqlworkbench # unzip ../Workbench-Build127-with-optional-libs.zip Archive: ../Workbench-Build127-with-optional-libs.zip inflating: sqlworkbench.jar creating: ext/ inflating: ext/commons-codec.jar (途中省略) inflating: workbench32.png creating: manual/ inflating: manual/SQLWorkbench-Manual.pdf (途中省略) inflating: manual/workspace-usage.html creating: xslt/ inflating: xslt/jdbctypes2oracle.xslt (途中省略) inflating: xslt/wbreport2proc.xslt #これで、SQL Workbench/Jのインストールは完了です。これでコマンドライン SQLWorkbench/Jを実行できるようになりました。
SQL Workbench/J でのJDBC経由によるGridDBとの接続確認
起動
コマンドライン SQLWorkbench/J を起動します。
su - gsadm Last login: Mon Jan 25 05:36:08 UTC 2021 on pts/0 $ cd /sqlworkbench/ $ ./sqlwbconsole.sh SQL Workbench/J (127) console interface started. Enter exit to quit. Enter WbHelp for a list of SQL Workbench/J specific commands Config directory: /var/lib/gridstore/.sqlworkbench SQL>GridDBへの接続
WbConnectコマンドでGridDBに接続します。
WbConnect -driver=com.toshiba.mwcloud.gs.sql.Driver -driverJar=/usr/share/java/gridstore-jdbc.jar -url=jdbc:gs://239.0.0.1:41999/myCluster/public -username=admin -password=admin;
パラメータとして、JDBCドライバのクラス名、jarファイル、JDBCの接続URL、DBMSのユーザ名、そのパスワードを指定します。
パラメータ 説明 値 -driver JDBCドライバーの完全なクラス名を指定します com.toshiba.mwcloud.gs.sql.Driver -driverJar JDBCドライバーを含む.jarファイルへのフルパス名を指定します /usr/share/java/gridstore-jdbc.jar -url JDBC接続時の URL 形式 jdbc:gs ://239.0.0.1:41999/myCluster/public -username DBMSのユーザ名を指定します admin (デフォルト値) -password ユーザパスワードを指定します admin (デフォルト値) 補足 パラメータ -url
接続方法によって、パラメータ -urlの形式が異なります。デフォルトのマルチキャスト方式でクラスタ内のノードに自動接続の場合は、次のようになります。
jdbc:gs://(multicastAddress):(portNo)/(clusterName)/(databaseName)
- multicastAddress:GridDBクラスタとの接続に使うマルチキャストアドレス。(デフォルト: 239.0.0.1)
- portNo:GridDBクラスタとの接続に使うポート番号。(デフォルト: 41999)
- clusterName:GridDBクラスタのクラスタ名
- databaseName:データベース名。省略した場合はデフォルトデータベース(public)に接続します。
固定リスト方式、プロバイダ方式などで接続する場合は、「GridDB SQLリファレンス」を参照願います。
SQL> WbConnect -driver=com.toshiba.mwcloud.gs.sql.Driver -driverJar=/usr/share/java/gridstore-jdbc.jar -url=jdbc:gs://239.0.0.1:41999/myCluster/public -username=admin -password=admin; Connection to "User=admin, URL=jdbc:gs://239.0.0.1:41999/myCluster/public" successfulデータの読み込み
先のサンプルプログラムで作成したデータを読み込みます。
SELECT * FROM SampleJDBC_Select;
SQL> SELECT * FROM SampleJDBC_Select; id | value ---+------ 0 | test0 1 | test1 2 | test2 3 | test3 4 | test4 (5 Rows) SELECT executed successfullyこれで動作確認は終わりです。
データベース操作をしてみる
今回のSQL Workbench/J を用いたデータベース操作の大まかな流れは、次の通りとなります。
- テーブルの作成
- データの登録(格納)
- データの取得(検索)
- テーブルの削除
実際にSQL Workbench/J を用いてデータベースを操作する前に、今回の操作するデータベース (例)の内容とGridDBでサポートされているSQLについて紹介します。
データベース (例)の内容
GridDBにデータを登録し検索するには、データを格納するコンテナ (テーブル) を作成する必要があります。なお、NoSQLインタフェースで操作する場合はコンテナ、NewSQLインタフェース (SQLインタフェース) で操作する場合はテーブルと呼ぶようです。今回、SQLで操作するので、以降、テーブルと呼びます。
テーブルには、一般的なさまざまなデータを管理するためのコレクションテーブルと時系列データを管理するのに適した時系列テーブルの2つのタイプがあります。今回、ある施設で、各階の各部屋に装置が置かれ、その装置がアラートを検知すると、その検知時刻とアラートレベル、アラート詳細情報をデータベースに登録するような例を用います。それには次のデータソースが存在することとします。
装置管理情報
装置毎の定義情報を表現するものであり、装置毎に割り当てられた装置ID、装置タイプおよびその装置が設置されている階数とその設置されている部屋番号で構成されます。
装置ID:id 装置タイプ:type 設置階数:floor 設置部屋番号:room 装置管理情報は、一般のロウとカラムから構成されるコレクションテーブルである装置管理情報テーブル(テーブル名:equipTable)に格納します。
アラート履歴情報
検知されたアラート情報を表現するものであり、発生したアラートの日付時刻、アラートのレベル、およびアラート詳細情報で構成されます。
検知時刻:date 装置ID:id アラートレベル:level アラート詳細情報:detail アラート履歴情報は、発生するデータを発生した時刻とともに管理するのに適したタイプの時系列テーブルであるアラート履歴情報テーブル(テーブル名:alertTable)に格納します。
GridDBでサポートされている SQL
GridDBでサポートされるSQL文は、次の通りです。
コマンド 概要 CREATE DATABASE データベースを作成する。 CREATE TABLE テーブルを作成する。 CREATE INDEX 索引を作成する。 CREATE VIEW ビューを作成する。 CREATE USER 一般ユーザを作成する。 DROP DATABASE データベースを削除する。 DROP TABLE テーブルを削除する。 DROP INDEX 索引を削除する。 DROP VIEW ビューを削除する。 DROP USER 一般ユーザを削除する。 ALTER TABLE テーブルの構造を変更します。 GRANT 一般ユーザにデータベースへのアクセス権を設定する。 REVOKE 一般ユーザからデータベースへのアクセス権を削除する。 SET PASSWORD 一般ユーザのパスワードを変更する。 SELECT データを取得する。 INSERT テーブルに行を挿入する。 DELETE テーブルから行を削除する。 UPDATE テーブルにある行を更新する。 コメント コメントを表記する。 ヒント 実行計画を制御する。 GridDBのSQLは基本的にSQL-92がベースになっているようです。
SQL文としては、SELECT文、INSERT文、UPDATE文、DELETE文などのデータ操作言語 (DML)、CREATE文やDROP文などのデータ定義言語(DDL) や GRANT文、REVOKE文などのデータ制御言語 (DCL) をサポートしています。
句としては、FROM句、GROUP BY句、HAVING句、ORDER BY句、WHERE句、LIMIT句/OFFSET句、JOIN句、UNION/INTERSECT/EXCEPT句、OVER句をサポートしてます。特にJOIN については、内部結合 [NATURAL] [INNER] JOIN、左外部結合 [NATURAL] LEFT [OUTER] JOIN、クロス結合 [NATURAL] CROSS JOINに対応しているよう複数のテーブルを跨いだJOINが可能なようです。
また、もちろん、演算子、関数、CASEなどもサポートしています。
詳細は「GridDB SQLリファレンス」を参照してください。テーブル作成 (CREATE TABLE)
では、装置を管理するコレクションテーブルである装置管理情報のテーブル (テーブル名:equipTable) とアラート履歴を管理する時系列テーブルであるアラート履歴情報のテーブル (テーブル名:alertTable ) を作成します。
装置管理情報テーブル (テーブル名:equipTable) の作成
コレクションテーブルのタイプの装置管理情報テーブル (テーブル名:equipTable) は次の通りです。
装置ID:id 装置タイプ:type 設置階数:floor 設置部屋番号:room テーブル equipTable のカラムは、装置ID:id、装置タイプ:type、設置階:floor、設置部屋番号:room とします。また、テーブルのロウの一貫性を保証するために、主キー (プライマリキー) を装置ID:idに設定します。なお、プライマリキーを設定したカラム 装置ID:id には、NULL値を許容しません。
SQL文は次の通りです。
CREATE TABLE equipTable (
id INTEGER PRIMARY KEY,
type STRING,
floor INTEGER,
room INTEGER
);では、実際に SQLWorkbench/Jで、テーブル equipTable を作成します。
SQL> CREATE TABLE equipTable ( ..> id INTEGER PRIMARY KEY, ..> type STRING, ..> floor INTEGER, ..> room INTEGER ..> ); Table equipTable createdテーブル equipTable が作成されました。
アラート履歴情報テーブル (テーブル名:alertTable) の作成
時系列テーブルのタイプのアラート履歴情報テーブル (テーブル名:alertTable)は次の通りです。
検知時刻:date 装置ID:id アラートレベル:level アラート詳細情報:detail テーブル alertTable のカラムは、検知時刻:date、装置ID:id、アラートレベル:alertLebel、詳細メッセージ:detail とします。時系列テーブルの場合は、プライマリキーは先頭カラムに設定しなければなりません。なお、GridDBでは、カラムを0番から数えるため、カラム番号0に設定することになります。プライマリーキーは、TIMESTAMP型で、指定は必須です。プライマリーキーに設定したカラムには、カラムの型に応じてあらかじめ既定された、デフォルトの索引が設定されるようです。
GridDBのアプリケーションを高速化するには、処理するデータをできるだけメモリに配置することが重要とのことです。 テーブルパーティショニングを用いると、テーブルのデータを分割して配置することで、CPUやメモリリソースを効率的に活用した処理が可能のようです。分割したデータは、データパーティションという複数の内部コンテナに格納します。データをどのデータパーティションに格納するかは、テーブル作成時に指定されたパーティショニングキーのカラムの値を基に決定されるようです。
テーブルパーティショニングの方法として、ハッシュパーティショニング、インターバルパーティショニング、インターバル-ハッシュパーティショニングの3種類があります。ここでは、指定された一定の値間隔(今回は分割幅値:1日)でデータを分割して、データパーティションに格納するインターバルパーティショニングテーブルとして作成します。ある一定の範囲の値を持つデータを同じデータパーティション上に格納するので、登録するデータが連続値の場合や、特定期間の範囲の検索を行う場合などに、より少ないメモリで処理できます。
また、期限解放を使用します。パーティション期限解放として、今回は保持期間:2日としています。ロウの保持期限は、データパーティションのロウ格納期間の最終日時に保持期間を足した日時です。同じデータパーティションに格納されているロウは、全て同じ保持期限になります。
SQL文は次の通りです。
CREATE TABLE alertTable (
date TIMESTAMP PRIMARY KEY,
id INTEGER,
level INTEGER,
detail STRING
) USING TIMESERIES WITH (
expiration_type='PARTITION',
expiration_time=2,
expiration_time_unit='DAY'
) PARTITION BY RANGE (date) EVERY (1, DAY);では、実際に SQLWorkbench/Jで、テーブル alertTable を作成します。
SQL> CREATE TABLE alertTable ( ..> date TIMESTAMP PRIMARY KEY, ..> id INTEGER, ..> level INTEGER, ..> detail STRING ..> ) USING TIMESERIES WITH ( ..> expiration_type='PARTITION', ..> expiration_time=2, ..> expiration_time_unit='DAY' ..> ) PARTITION BY RANGE (date) EVERY (1, DAY); Table alertTable createdこれで、テーブル alertTable を作成されました。
データ登録 (INSERT)
では、データ登録をします。
装置管理情報テーブル (テーブル名:equipTable) へのデータ登録
装置管理情報テーブルに次のデータを登録します。
装置ID:id 装置タイプ:type 設置階数:floor 設置部屋番号:room 1 CAMERA 1 1 2 THERMO 1 1 3 THERMO 4 3 4 THERMO 6 2 5 WATT 1 1 6 WATT 6 1 そのためのSQL文は次の通りです。
INSERT INTO equipTable VALUES(1, 'CAMERA', 1, 1);
INSERT INTO equipTable VALUES(2, 'THERMO', 1, 1);
INSERT INTO equipTable VALUES(3, 'THERMO', 4, 3);
INSERT INTO equipTable VALUES(4, 'THERMO', 6, 2);
INSERT INTO equipTable VALUES(5, 'WATT', 1, 1);
INSERT INTO equipTable VALUES(6, 'WATT', 6, 1);では、実際に SQLWorkbench/Jで、テーブル equipTable にデータ登録します。
SQL> INSERT INTO equipTable VALUES(1, 'CAMERA', 1, 1); INSERT INTO equipTable successful 1 row affected SQL> INSERT INTO equipTable VALUES(2, 'THERMO', 1, 1); INSERT INTO equipTable successful 1 row affected SQL> INSERT INTO equipTable VALUES(3, 'THERMO', 4, 3); INSERT INTO equipTable successful 1 row affected SQL> INSERT INTO equipTable VALUES(4, 'THERMO', 6, 2); INSERT INTO equipTable successful 1 row affected SQL> INSERT INTO equipTable VALUES(5, 'WATT', 1, 1); INSERT INTO equipTable successful 1 row affected SQL> INSERT INTO equipTable VALUES(6, 'WATT', 6, 1); INSERT INTO equipTable successful 1 row affectedアラート履歴情報テーブル (テーブル名:alertTable) へのデータ登録
アラート履歴情報テーブルに現在の時間を起点に次のようなデータを登録してみます。
検知時刻:date 装置ID:id アラートレベル:
levelアラート詳細情報:
detail96時間前の年-月-日 時:分:秒 2 1 96 hours ago 72時間前の年-月-日 時:分:秒 1 2 72 hours ago 48時間前の年-月-日 時:分:秒 6 3 48 hours ago 24時間前の年-月-日 時:分:秒 5 4 24 hours ago 18時間前の年-月-日 時:分:秒 4 1 18 hours ago 12時間前の年-月-日 時:分:秒 3 2 12 hours ago 9時間前の年-月-日 時:分:秒 2 3 9 hours ago 6時間前の年-月-日 時:分:秒 2 4 6 hours ago 3時間前の年-月-日 時:分:秒 2 3 3 hours ago 現在の年-月-日 時:分:秒 1 4 SQL文は次の通りです。
SELECT NOW();
INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -96), 2, 1, '96 hours ago' );
INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -72), 1, 2, '72 hours ago' );
INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -48), 6, 3, '48 hours ago' );
INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -24), 5, 4, '24 hours ago');
INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -18), 4, 1, '18 hours ago');
INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -12), 3, 2, '12 hours ago');
INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -9), 2, 3, '9 hours ago');
INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -6), 2, 4, '6 hours ago');
INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -3), 2, 3, '3 hours ago');
INSERT INTO alertTable VALUES(NOW(), 1, 4, '');ここで、注意をしておきたいことは、NOW関数で、現在の日時(タイムスタンプ)を取得しておきます。
なぜならば、デーブル alertTable は期限解放(パーティション期限解放として、今回は保持期間:2日)を指定しているので、検索する日時で、データの検索結果(数)が異なるからです。(すなわち、以降の検索での結果では、本記事の例と実際が異なる場合があります)では、実際に SQLWorkbench/Jで、デーブル alertTable にデータの登録をします。
SQL> SELECT NOW(); Col1 ------------------- 2021-02-26 16:32:50 (1 Row) SELECT executed successfully SQL> INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -96), 2, 1, '96 hours ago' ); INSERT INTO alertTable successful 1 row affected SQL> INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -72), 1, 2, '72 hours ago' ); INSERT INTO alertTable successful 1 row affected SQL> INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -48), 6, 3, '48 hours ago' ); INSERT INTO alertTable successful 1 row affected SQL> INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -24), 5, 4, '24 hours ago'); INSERT INTO alertTable successful 1 row affected SQL> INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -18), 4, 1, '18 hours ago'); INSERT INTO alertTable successful 1 row affected SQL> INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -12), 3, 2, '12 hours ago'); INSERT INTO alertTable successful 1 row affected SQL> INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -9), 2, 3, '9 hours ago'); INSERT INTO alertTable successful 1 row affected SQL> INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -6), 2, 4, '6 hours ago'); INSERT INTO alertTable successful 1 row affected SQL> INSERT INTO alertTable VALUES(TIMESTAMP_ADD(HOUR, NOW(), -3), 2, 3, '3 hours ago'); INSERT INTO alertTable successful 1 row affected SQL> INSERT INTO alertTable VALUES(NOW(), 1, 4, ''); INSERT INTO alertTable successful 1 row affectedデータ検索
全件データ検索
SELECT * FROM table_name;
ロウおよびカラムの全件データ検索のSQL文は次の通りです。
SELECT * FROM equipTable;
SELECT * FROM alertTable;では、実際に SQLWorkbench/Jで、全件データ検索します。
SQL> SELECT * FROM equipTable; id | type | floor | room_no ---+--------+-------+-------- 1 | CAMERA | 1 | 1 2 | THERMO | 1 | 1 3 | THERMO | 4 | 3 4 | THERMO | 6 | 2 5 | WATT | 1 | 1 6 | WATT | 6 | 1 (6 Rows) SELECT executed successfullySQL> SELECT * FROM alertTable; date | id | level | detail --------------------+----+-------+------------- 2021-02-24 16:32:49 | 6 | 3 | 48 hours ago 2021-02-26 04:32:50 | 3 | 2 | 12 hours ago 2021-02-26 07:32:50 | 2 | 3 | 9 hours ago 2021-02-26 10:32:50 | 2 | 4 | 6 hours ago 2021-02-26 13:32:50 | 2 | 3 | 3 hours ago 2021-02-26 16:32:51 | 1 | 4 | 2021-02-25 16:32:50 | 5 | 4 | 24 hours ago 2021-02-25 22:32:50 | 4 | 1 | 18 hours ago (8 Rows) SELECT executed successfully検索されるロウの順序はタイミングによって異なります。
ところで、10ロウを登録したはずなのに8ロウしか検索されません。理由は、テーブル alertTableに、作成時に設定した保持期間:2日間を超えたロウデータを、検索や削除などの操作対象から外して参照不可とした後、データベースから物理的に削除する期限解放機能が指定されているからです。 これにより、データベースサイズ肥大化によるパフォーマンス低下を防ぐことができます。取得するデータをソート:ORDER BY句
ORDER BY column_name_1 [{ASC|DESC}] [, column_name_2 [{ASC|DESC}] ...]
ORDER BY句を用いて、テーブル alertTableの検知時刻:dateの値に応じて、昇順 (ASC)で ロウを並べ替えます。
具体的なSQL文は次の通りです。
SELECT * FROM alertTable order by date ASC;
ASCは省略することができます。
では、実際に SQLWorkbench/Jで、並べ替えて見ます。SQL> SELECT * FROM alertTable order by date ASC; date | id | level | detail --------------------+----+-------+------------- 2021-02-24 16:32:49 | 6 | 3 | 48 hours ago 2021-02-25 16:32:50 | 5 | 4 | 24 hours ago 2021-02-25 22:32:50 | 4 | 1 | 18 hours ago 2021-02-26 04:32:50 | 3 | 2 | 12 hours ago 2021-02-26 07:32:50 | 2 | 3 | 9 hours ago 2021-02-26 10:32:50 | 2 | 4 | 6 hours ago 2021-02-26 13:32:50 | 2 | 3 | 3 hours ago 2021-02-26 16:32:51 | 1 | 4 | (8 Rows) SELECT executed successfully取得するデータの条件を設定:WHERE句
WHERE search_conditions
WHERE句を用いて、データを登録した日(今回の例では、2021-02-26)に絞って検索してみます。SQL文は次の通りです。
SELECT * FROM alertTable WHERE date >= TIMESTAMP('2021-02-26T00:00:00Z') AND date < TIMESTAMP('2021-02-27T00:00:00Z') ;
では、実際に SQLWorkbench/Jで、期間:2021-01-26に絞って検索してみます。
SQL> SELECT * FROM alertTable WHERE date >= TIMESTAMP('2021-02-26T00:00:00Z') AND date < TIMESTAMP('2021-02-27T00:00:00Z') ; date | id | level | detail --------------------+----+-------+------------- 2021-02-26 04:32:50 | 3 | 2 | 12 hours ago 2021-02-26 07:32:50 | 2 | 3 | 9 hours ago 2021-02-26 10:32:50 | 2 | 4 | 6 hours ago 2021-02-26 13:32:50 | 2 | 3 | 3 hours ago 2021-02-26 16:32:51 | 1 | 4 | (5 Rows) SELECT executed successfullyデータの最大値を求める:MAX関数
テーブル alertTableのアラート値:levelの最大値を求める場合は、 MAX関数を用いて、次のようにSQLを書きます。
SELECT MAX(level) AS max FROM alertTable WHERE date >= TIMESTAMP('2021-02-26T00:00:00Z') AND date < TIMESTAMP('2021-02-27T00:00:00Z') ;
なお、このサンプルは分かりやすいようにAS句を使用して列に別名をつけています。
では、実際に SQLWorkbench/Jで、テーブル alertTableのアラート値:levelの最大値を求めてみます。SQL> SELECT MAX(level) AS max FROM alertTable WHERE date >= TIMESTAMP('2021-02-26T00:00:00Z') AND date < TIMESTAMP('2021-02-27T00:00:00Z') ; max --- 4 (1 Row) SELECT executed successfullyデータをグループ化する:GROUP BY句
GROUP BY column_name_1 [, column_name_2 ...]
GROUP BY句を用いてグループ毎に集計してみます。
SEGROUP BY句で装置ID:id 毎にアラートレベル:level の最大を求めて表示するSQL文は次のようになります。SELECT id, MAX(level) AS max FROM alertTable GROUP BY id;
SQL> SELECT id, MAX(level) AS max FROM alertTable GROUP BY id; id | max ---+---- 1 | 4 2 | 4 3 | 2 4 | 1 5 | 4 6 | 3 (6 Rows) SELECT executed successfullywhere句でデータを登録した日(今回の例では、2021-02-08)で範囲を絞り、GROUP BY句で装置ID:id 毎にアラートレベル:level の最大を求めて表示するSQL文は次のようになります。
SELECT id, MAX(level) AS max FROM alertTable
WHERE date >= TIMESTAMP('2021-02-26T00:00:00Z') AND date < TIMESTAMP('2021-02-27T00:00:00Z') GROUP BY id;SQL> SELECT id, MAX(level) AS max FROM alertTable ..> WHERE date >= TIMESTAMP('2021-02-26T00:00:00Z') AND date < TIMESTAMP('2021-02-27T00:00:00Z') GROUP BY id; id | max ---+---- 1 | 4 2 | 4 3 | 2 (3 Rows) SELECT executed successfully異なるテーブル同士を結合:JOIN句
table_name1 [INNER] JOIN table_name2 ON table_name1.row_name = table_name2.row_name
テーブル alertTableをGROUP BY句で装置ID:id 毎にアラートレベル:levelの最大値を集計した結果を テーブル equipTable と 装置ID:idをキーにしてJOIN句を用いて結合し、装置ID:id、装置タイプ:type、設置階:floor、設置部屋番号:room、それとアラートレベル:levelの最大値を表示します。
SELECT equipTable.id, type, floor, room, max FROM equipTable JOIN
(SELECT id, MAX(level) AS max FROM alertTable GROUP BY id) t ON equipTable.id = t.id;SQL> SELECT equipTable.id, type, floor, room, max FROM equipTable JOIN ..> (SELECT id, MAX(level) AS max FROM alertTable GROUP BY id) t ON equipTable.id = t.id; id | type | floor | room | max ---+--------+-------+------+---- 1 | CAMERA | 1 | 1 | 4 2 | THERMO | 1 | 1 | 4 3 | THERMO | 4 | 3 | 2 4 | THERMO | 6 | 2 | 1 5 | WATT | 1 | 1 | 4 6 | WATT | 6 | 1 | 3 (6 Rows) SELECT executed successfullyテーブル alertTableをwhere句で範囲付けして、さらにGROUP BY句で装置ID:id 毎にアラートレベル:levelの最大値を集計した結果を テーブル equipTable と 装置ID:idをキーにしてJOIN句を用いて結合し、装置ID:id、装置タイプ:type、設置階:floor、設置部屋番号:room、それとアラートレベル:levelの最大値を表示します。
SELECT equipTable.id, type, floor, room, max FROM equipTable JOIN
(SELECT id, MAX(Level) AS max FROM alertTable
WHERE date >= TIMESTAMP('2021-02-26T00:00:00Z') AND date < TIMESTAMP('2021-02-27T00:00:00Z') GROUP BY id) t
ON equipTable.id = t.id;SQL> SELECT equipTable.id, type, floor, room, max FROM equipTable JOIN ..> (SELECT id, MAX(Level) AS max FROM alertTable ..> WHERE date >= TIMESTAMP('2021-02-26T00:00:00Z') AND date < TIMESTAMP('2021-02-27T00:00:00Z') GROUP BY id) t ..> ON equipTable.id = t.id; id | type | floor | room | max ---+--------+-------+------+---- 1 | CAMERA | 1 | 1 | 4 2 | THERMO | 1 | 1 | 4 3 | THERMO | 4 | 3 | 2 (3 Rows) SELECT executed successfully任意の順でソートする:ORDER BY句 CASE式
テーブル equipTable で3階以上で、CAMERA(1)→THERMO(2)→WATT(3)→AMP(4)の順にソートされた結果が返します。
SELECT * FROM equipTable WHERE floor >= 3 ORDER BY CASE type
WHEN 'CAMERA' THEN 1
WHEN 'THERMO' THEN 2
WHEN 'WATT' THEN 3
WHEN 'AMP' THEN 4
ELSE 5
END;CAMERA(1)→THERMO(2)→WATT(3)→AMP(4)の順にソートされた結果が返ってきます。
SQL> SELECT * FROM equipTable WHERE floor >= 3 ORDER BY CASE type ..> WHEN 'CAMERA' THEN 1 ..> WHEN 'THERMO' THEN 2 ..> WHEN 'WATT' THEN 3 ..> WHEN 'AMP' THEN 4 ..> ELSE 5 ..> END; id | type | floor | room ---+--------+-------+----- 3 | THERMO | 4 | 3 4 | THERMO | 6 | 2 6 | WATT | 6 | 1 (3 Rows) SELECT executed successfullyテーブルの削除
テーブル equipTable、alertTableを削除します。
DROP TABLE equipTable;
DROP TABLE alertTable;SQL> DROP TABLE equipTable; Table equipTable dropped SQL> DROP TABLE alertTable; Table alertTable droppedさいごに
今回、Docker DesktopのCentOSコンテナで、JDBCドライバ経由で動作する SQLWorkbench/Jをインストールして、JDBC経由でのGridDBへと方法についてステップバイステップで紹介し、また、具体的なGridbDBのデータモデルの例を用いて、SQLWorkbench/JによるGridDBデータベースのSQL操作についても記述したつもりです。
記述について誤りがあったり、気になることがあれば、編集リクエストやコメントでフィードバックしていただけると助かります。
- 投稿日:2021-03-01T02:58:02+09:00
Wordpressの環境構築をDockerで行った結果出た[ERROR] --initialize specified but the data directory has files in it. Aborting.[ERROR] Aborting
前提
- Docker Desktopでいろいろ操作してます
- Windows10 homeを使ってます
参考にした記事A
※自分はプログラミング始めて4日目の超初心者です、落書きだと思って見てください
経緯
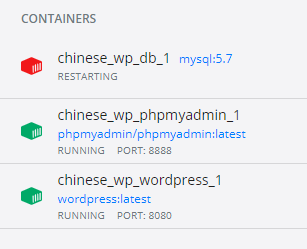
記事Aの通りに環境構築をして(パスワードなどは個人用に変えた)みたが結果はDockerコンテナのうち「phpmyadmin」「Wordpress」は正常に「runnning」と表示され緑色になったが「MySQL」だけは「restarting」と赤いままだった。
以下はこの赤色を緑色にする方法を書きます。
※この状態でlocalhost:[ポート番号]にアクセスすると以下のようになります
方法
docker-compose.ymlのdbの
volumes:
- ./db/mysql:/var/lib/mysql
という部分をいじります。/var/lib/mysql → /var/lib/「mysql以外のなにか」にしましょう
例:/var/lib/mysql_mymy
いじり終わったらコンテナを止めてから削除し、MySQLのイメージも削除します
(■が止める、ゴミ箱マークで削除)そして「docker-compose up -d」で再度コンテナを起動します
そのときには全部緑の「runnning」になっているはずです原理
わかりません、Stack Overflowにそう書いてありました。。。
だれか教えて下さい。。。参考:https://stackoverflow.com/questions/37644118/initializing-mysql-directory-error
Qiitaの書き方わからないので多分めっちゃ見にくいです
ごめんなさい



- 投稿日:2021-03-01T00:42:53+09:00
DockerでRails開発時に,画像の保存先をAWS S3にする
先日,Rails, Dockerでの開発時に画像の保存先をローカルからS3に変更した際の手順を記録した.
開発環境
WSL2 (ubuntu 18.04 LTS)
Docker
- Ruby (2.7.1)
- Rails (6.0.3)画像をS3に保存する手順
Active Storageがインストールされており,S3バケット作成まで完了していることを想定
Active Storageのインストールは以下のコマンドでできる
terminaldocker-compose run コンテナ名 rails active_storage:install docker-compose run コンテナ名 rails db:migrate用意するもの
S3バケット情報
- バケット名
- リージョン
IAMユーザー情報
- アクセスキー
- シークレットアクセスキー
手順
1. root dirにて以下のコマンドを実行
terminaldocker exec -it コンテナID sh /app # EDITOR=vi rails credentials:editコンテナIDは以下のコマンドで確認できる
terminaldocker ps2. credentialsを編集
credentialsをターミナル上で編集する
awsは最初コメントアウトされているので外す (それに気付かずハマってしまいました)
aws: access_key_id: 取得したアクセスキー secret_access_key: 取得したシークレットアクセスキー入力し保存する.
Esc→:wqでセーブして保存する.
:wq3. config/storage.ymlの編集
regionとbucketを作成したものに書き換える.
config/storage.ymlamazon: service: S3 access_key_id: <%= Rails.application.credentials.dig(:aws, :access_key_id) %> secret_access_key: <%= Rails.application.credentials.dig(:aws, :secret_access_key) %> region: "リージョン" bucket: "bucket名"4. aws-sdk-s3というgemをインストールする
Gemfileを編集
Gemfilegem 'aws-sdk-s3', require: falseGemfileを書き換えたので,コンテナをbuildし直す.
terminaldocker-compose build コンテナ名5. config/environments/development.rbでActive Storageの参照先を:localから:amazonへと変更
config/environments/development.rbconfig.active_storage.service = :amazon以上で,S3のバケットに画像が保存された.