- 投稿日:2021-03-01T23:11:40+09:00
【学習メモ】 AWS Aurora
Aurora
高性能、低コストのDB。
特徴:
・高並列処理によるストレージアクセスのクエリを高速処理することできる。
・大量の書き込みor読み込みを同時に扱うことができる。
・DBの集約やスループット向上が見込まれる。
・MySQL/PostgreSQLと互換性がある。
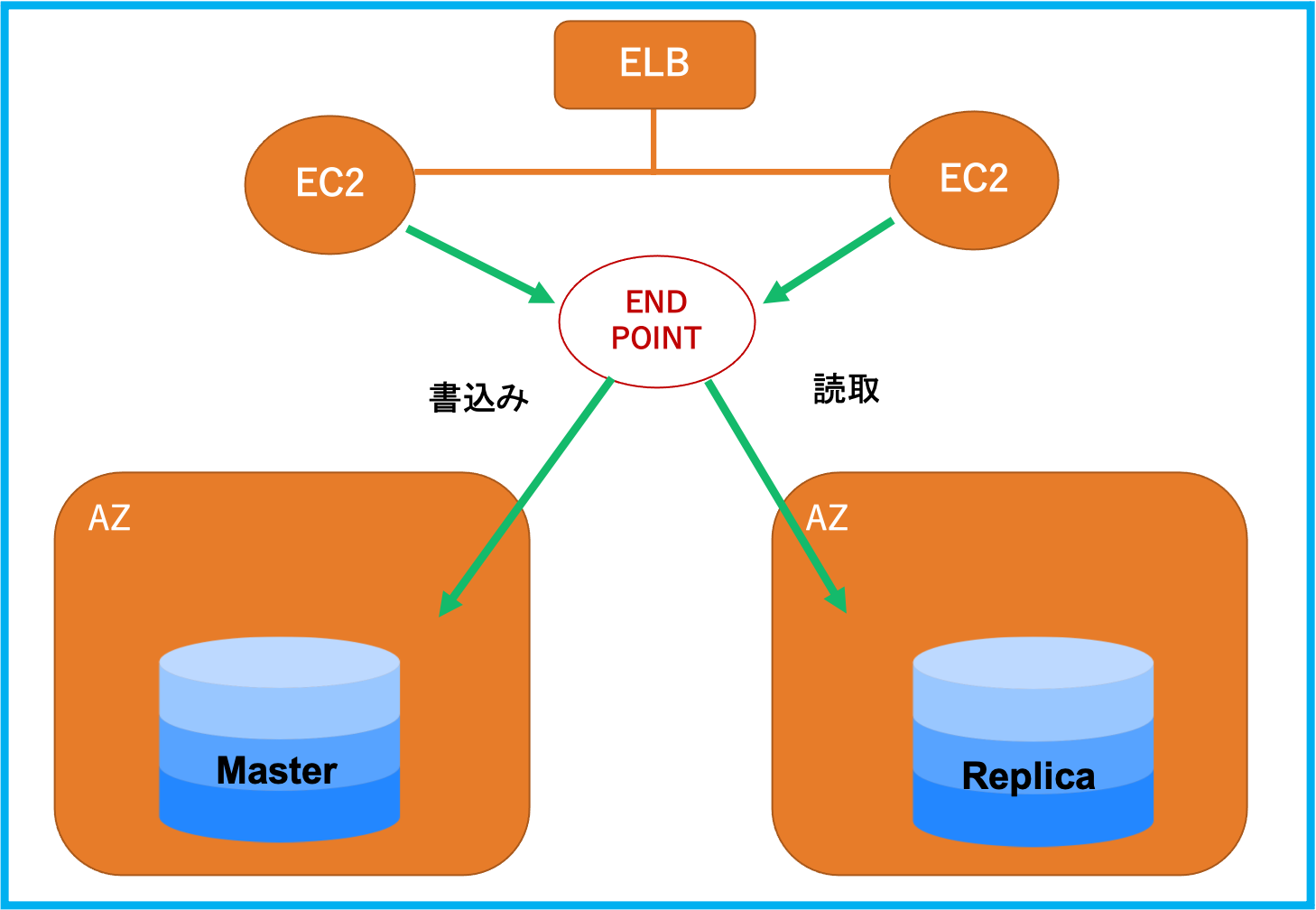
・分散型なので、耐障害性&自己回復性、スケーラビリティがある。特徴:耐障害性&自己回復性
・3つのAZに2つのコピーを設置可能
・過去のデータをそのままS3に継続的に増分バックアップ
・リストア:差分適用がなく、どのタイミングでも安定リストアできる。Auroraの仕組み
エンドポイントより接続し、書込みの場合はマスタに接続、読取の場合はレプリカに接続する。
また、マスタは障害が起きた時、レプリカにフェイルオーバーする。MySQLやPostgreSQLのスナップショットからをAuroraに移行することできる。
- 投稿日:2021-03-01T22:43:02+09:00
未経験からweb系自社開発企業内定までの過程の築き方と今後のキャリア形成
この記事を書くにあたり
今私は契約社員ではあるが、
ベンチャー企業にて開発部門にて戦力になるべく奮闘中。
少し客観的な視点でここまでの道のりと今後の目標などを踏まえ、
反省点なども含め時系列で整理していこうと思う。
また、未経験スキルでの転職のリアル感が伝わればどんな感じで転職の道が進んでいくのか、
よりわかりやすいと思うのでその辺も書いていきたいと思う。簡単な経歴
高校を卒業してインフラ系の会社に入社。
- 数年間、機械や装置を扱うオペレーターを担当、簡単なシーケンスなども作成。
1社目のインフラ系の会社を辞める半年前にプログラミングスクールに入校。
- 選択した言語はJavaとSwift。
空白期間を経て、コールセンターへ入社。
- 担当はテクニカルサポート。
SES会社へ入社。
- 緊急事態宣言の影響でどこへもアサインできず社内待機を過ごす。
コールセンターへ入社。
- 経験を生かしてテクニカルサポートを担当。
テスター求人を見てベンチャー企業へ入社。
- 現在に至る。
全くの未経験期間
プログラミングスクールを探すまで
今でこそ、転職のノウハウは良い意味でも悪い意味でも慣れた物だが、まず、10年もいた会社から転職するということが未知の世界であったため、何をして良いか分からない状態であった。
電車の中吊りで転職サイトの広告を見て気になるなと思う程度でその先はどうなっているのかすらわからないって感じ。
なので、転職について色々とググってみたりYouTubeを見たりしたものだった。この状態では正しい情報を見つけ出すのって相当難しい。
少し端折るが、そんなこともありパソコンのスキルが相当落ちていたと実感し、先ずはスクールを探した。
結局は実際に校舎がある老舗のスクールへ入校した。
結果的には、当時の自分にとっては問題ない入校だった。
なぜなら、当時は分からなかったがパソコンのスペックもエンジニアが持つ物ではなかったので結果的によかったと思う。
その程度の知識であったのだった。入校後の受講プログラム
当時受講したのが、JavaとSwift。
正確に言えばAndroidとiPhoneアプリ作成コース。
なぜこのコースを選んだかといえば、単純にアプリを作ってみたかったからということと、
メジャーな言語であるJavaも習うことができるということ。
結果的にこのコースを選んだのは少し遠回りだった気もした。
Web制作コースやPHP、JSなどの言語を選んでおけばとも後々思ったりもしたが、
今の仕事をしている段階では全く役に立たないとも思ってはいない。
幅広い視点を持つことは全然問題ないことでもあるし、
情報系などの大学も出ていない私にとってJavaは言語の基礎を教えてくれたと言っても過言ではないだろう。
その後で、自分で調べて学べば良いという思考になったので、あとは何も問題ない。
話を戻すと、Javaを中心に受講させてもらい、オマケ程度にアプリ作成といった感じで半年ほどで受講を修了した。
コンパイルとは何か。
2進数、16進数、、、
機械語とは。
などなど
少しアカデミックなことを触れてコーディングに入っていき、
演習問題の繰り返しだった。初めての転職フェア
そんなこんなで1社目はさっさと辞めてしまわないと辞めづらく、精神的にももたないので、
転職ができなくても辞めるつもりでいた。
とはいえのんびり転職を待つのもよくないので、
先ずは転職フェアに参加してみることにした。
知っている人なら知っている転職フェア。
あれはいわゆるSESフェア。
まあ、わかるとは思うが行かない方が良い。
分からない人にとってはIT業界ってああいうところなんだと洗脳されかける。面接を受けてみたり、エントリーをしてみるがが上手くいかない。
コールセンター(テクサポ)へ
そんなこんなで仕事をしないのもよくないので、
コールセンターへ流れ着く。
転職後はほとんどをコールセンターで過ごすことになる。朝活でPHP
コールセンターにずっといるわけにもいかないので、
朝の喫茶店で毎日就業前にPHPの勉強をすることにした。緊急事態宣言を抜けてのベンチャーへ
色々あってコールセンターを行き来するのだが、
ようやくベンチャーでテスター業務から携わることになるわけだった。
それができたのも、
結局はReactでFirebaseにデプロイまで行けた知識を持てたということ。
コードを書いているだけでは話が薄っぺらくなってしまう。
そして、入社して思うのは実務経験に勝るものはないということ。
お金を貰いながらその業務に専念することでのスキルアップは格段に違う。
ようやく、ポジションに来れたのだから、
コーディングだけでなく、テストケースの作成、サーバー、インフラ側の知識、RDBやAPIのことなど、
いままで自分だけでは時間を割くことができなかったことにもやっていくことができるのではないだろうか。
周囲の優秀なエンジニアに囲まれて仕事ができることがいかに幸せなことか、
昨今の転職の大変さを聞いてよく身に染みる。今も少しずつコーディングをしているが、
EC2ぐらいを使って繋げられたらと思っている。JenkinsやCircleciを使って自動テストの知識についても増やしていきたい。
AWSを学ぶのならDockerもやりたいわけだ。学ぶことは多い。
フロントの勉強をしていると、
限界を感じることが多く、
向上心があればどうしてもインフラ周りにいきたくなる。
なるほど、フロント側にフルスタックが多いのも納得と思った今日この頃。
- 投稿日:2021-03-01T22:36:24+09:00
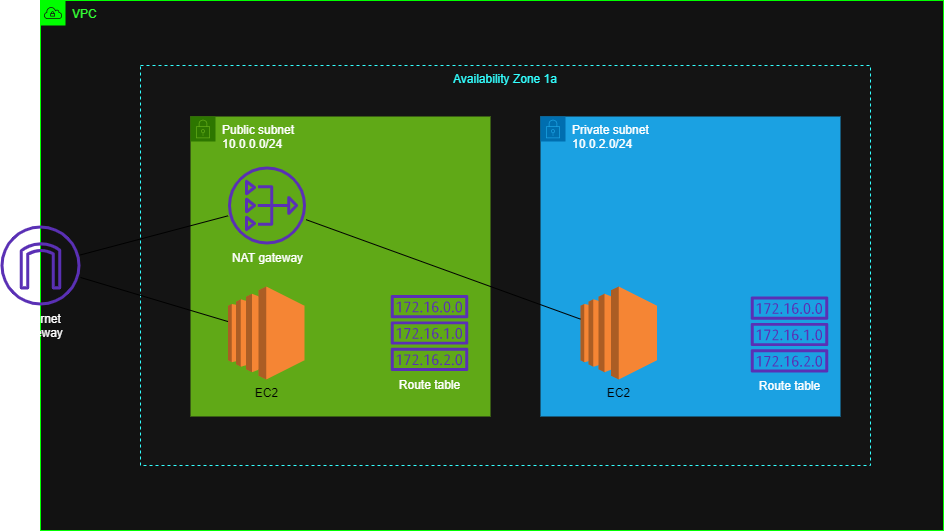
40代おっさんNAT gateway 経由してEC2に繋げてみた
本記事について
本記事はAWS初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。AWS作成図
VPC部分については
https://qiita.com/kou551121/items/2535fe3de57a5c813687
EC2部分については
https://qiita.com/kou551121/items/56f2e075d33fbf345787構築手順
❶ private subnet にEC2インスタンスを設置
❷ public subnetにあるEC2インスタンスを踏み台にしてprivate subnetのEC2にログインする。
❸ NAT gateway を作成してNAT gatewayを経由してprivate subnetのEC2インスタンスにログイン
1. private subnet にEC2インスタンスを設置
ではまずEC2ダッシュボードに画面遷移してください
インスタンスを起動をクリック(赤枠)
Amazon Linux 2 AMI (HVM), SSD Volume Type を選択(赤枠)
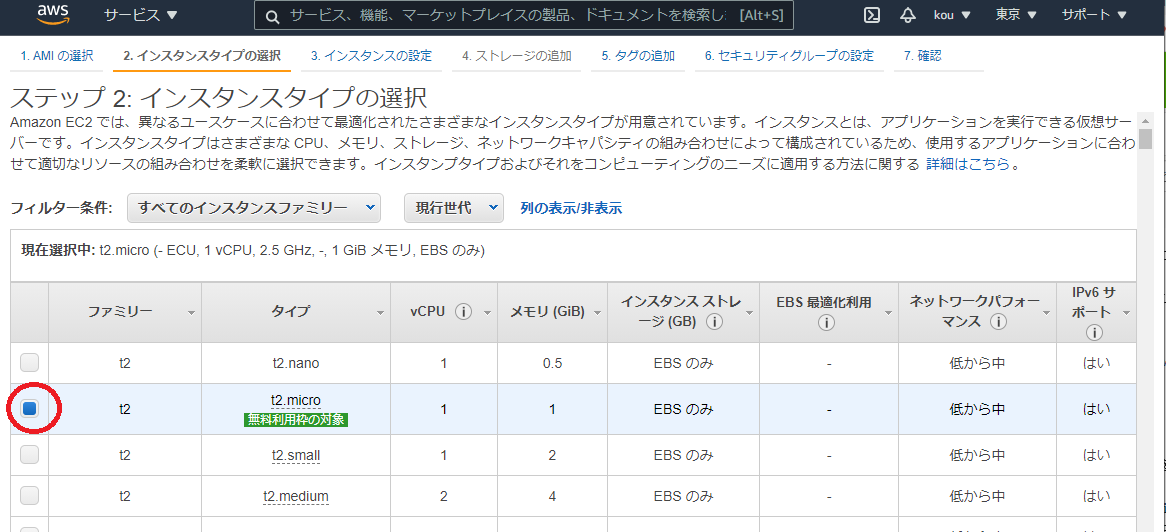
t2.micro を選択(赤枠)
右下にある 「次のステップ:ストレージの追加をクリック」
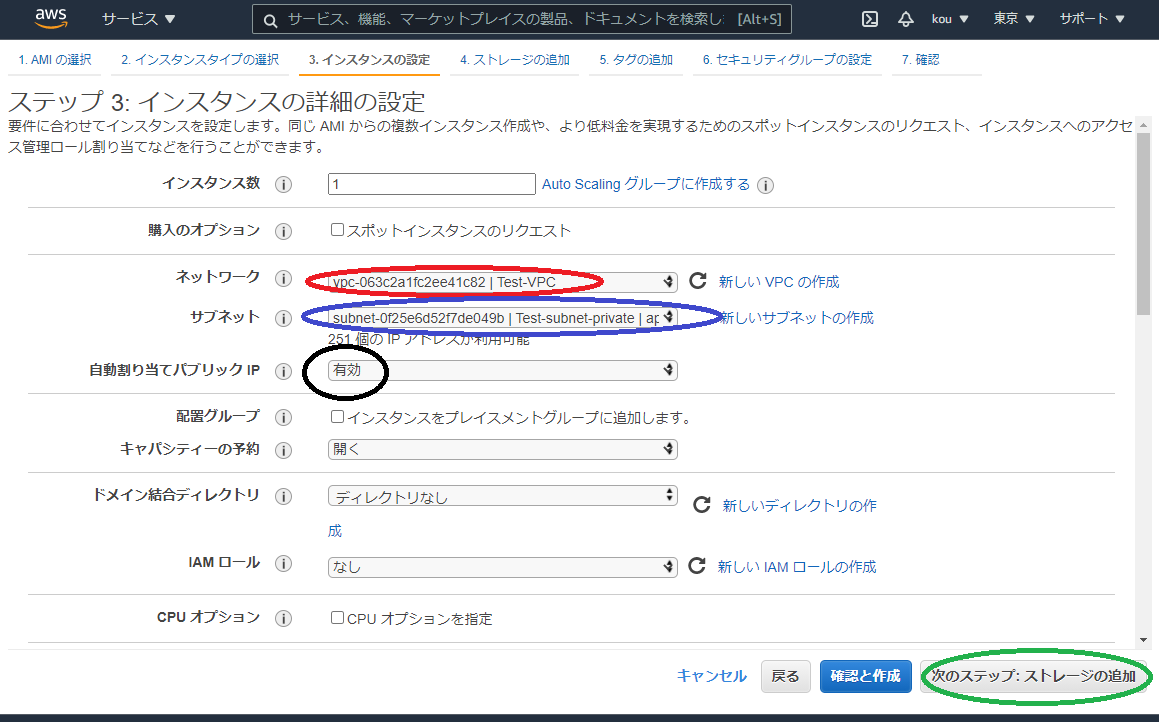
赤枠に自分の作ったVPC(自分はTest-VPC)を選択
青枠は自分の作ったサブネット(今回はTest-subnet-private)を選択
黒枠は有効にしてください
終わったら「次のステップ:ストレージの追加」(緑枠)をクリック
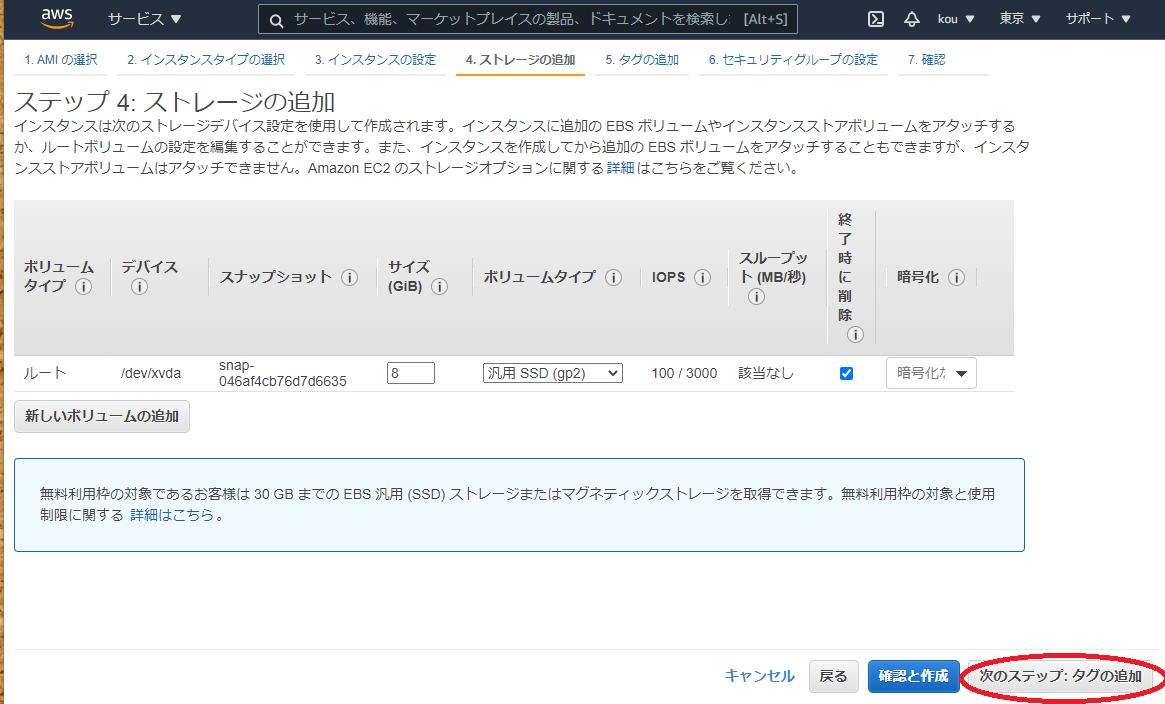
ここは何もせずそのままで(必要あれば変えてください)「次のステップ:タグの追加」(赤枠)をクリック
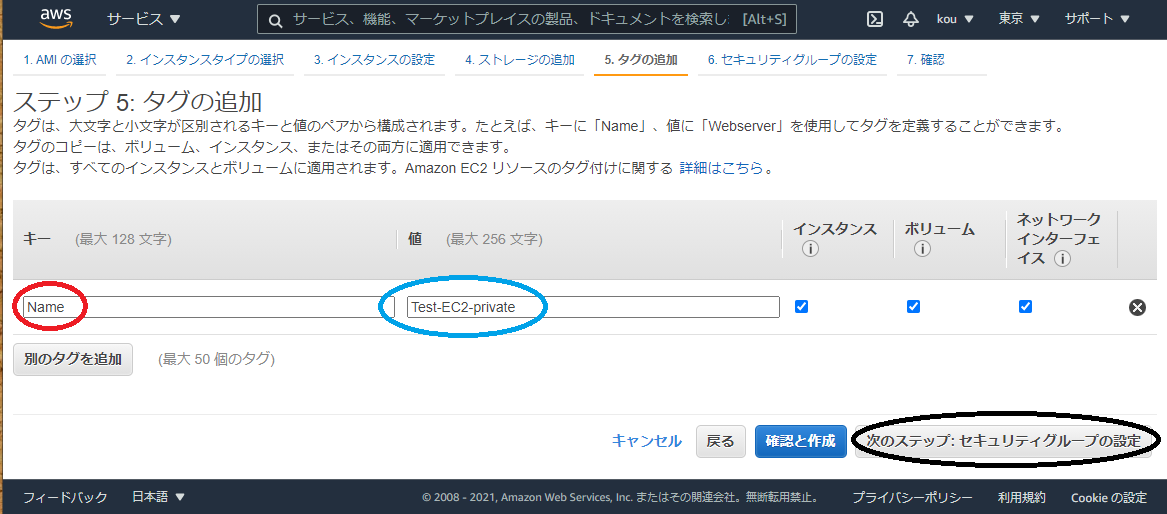
赤枠にはNameを入れてください
青枠にはTest-EC2-privateを入れてください
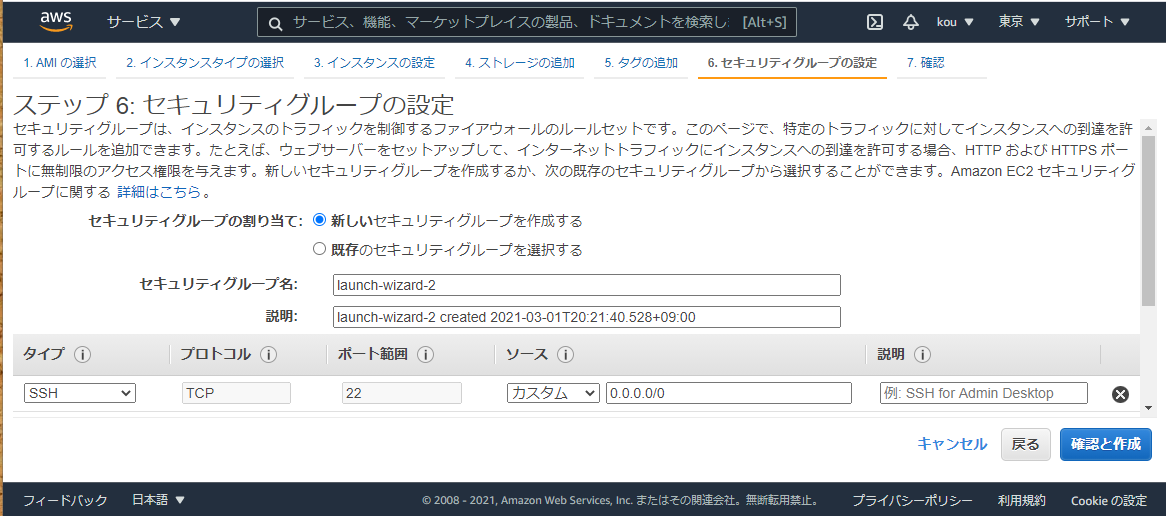
黒枠「次のステップ:セキュリティグループの設定」をクリック
こちらは今回は何もせず右下の確認と作成をクリック
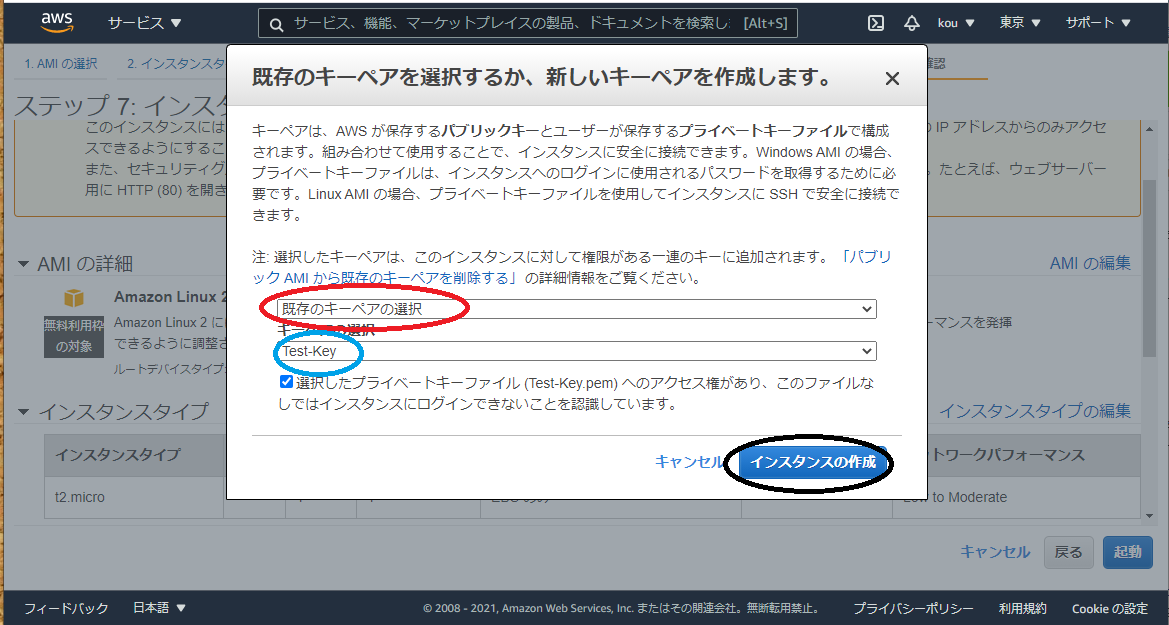
(必要であれば変えてください)次の画面で確認を行い、問題がなければ右下の起動をクリック
今回はキーペアを作らず既存のキーペア(赤枠)を使用します。
Test-Key(青枠)を選択
終わったらインスタンスの作成(黒枠)をクリック
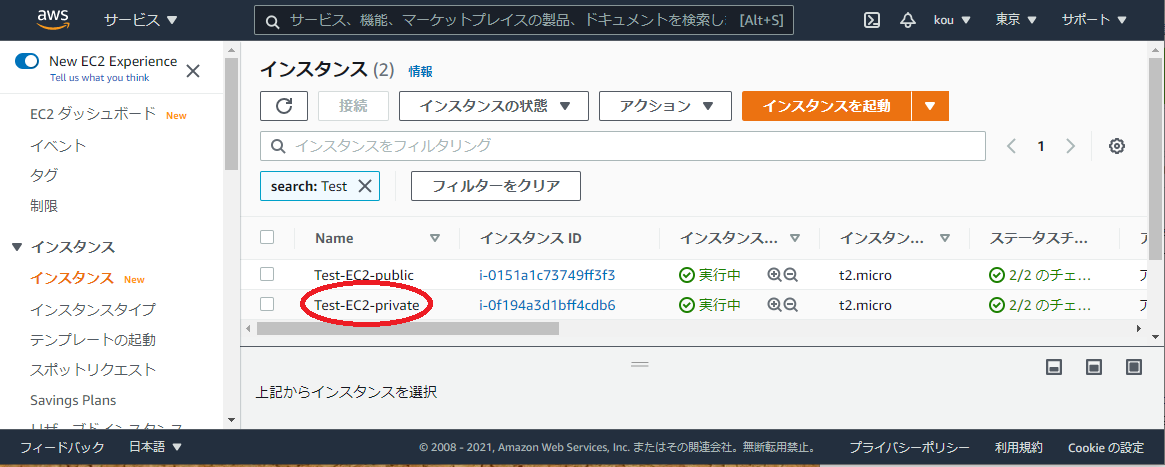
このようにインスタンス(赤枠)ができていることを確認できます
最後に
このまま続けると長くなるため、構築手順❷から今度にしたいと思います。
今回はインスタンス作成の復習みたくなっています。
もしインスタンス作成をしっかり見たい方は
https://qiita.com/kou551121/items/56f2e075d33fbf345787
こちらを確認してくださいまたこの記事は AWS 初学者を導く体系的な動画学習サービス「AWS CloudTech」の課題カリキュラムで作成しました。
https://aws-cloud-tech.com/
- 投稿日:2021-03-01T22:21:30+09:00
Cloudfrontの 署名付きCookie 署名付きURL とは?
勉強前イメージ
署名付き・・・って?
SSL的な話?調査
基本的にはどちらも同じ機能で、コンテンツにアクセスできる
ユーザを制御します署名付きCookie のユースケース
- 複数の制限されたファイル(HLS形式の動画やウェブサイトの購読者の領域にあるすべてのファイルなど)へのアクセスを提供する場合
- 現在のURLを変更したくない場合
署名付きURL のユースケース
- 個別のファイル (アプリケーションのインストールダウンロード) へのアクセスを制限する場合
- ユーザーがCookieをサポートしていないクライアント(カスタムHTTPクライアント等)を使用している場合
そもそもcloudfrontとは?
AWSのCDN(負荷分散をするためのコンテンツを配信するためだけのネットワーク)のサービスです。
詳細は こちら をご確認くださいcloudfrontでの設定箇所
こちら日本語翻訳かけてます
勉強後イメージ
確かにURLを変えたくない時とかは、署名付きCookieを使えばいいのねー
参考
- 投稿日:2021-03-01T21:12:52+09:00
CloudFrontで公開したSPAでページ遷移を行う時に、403エラーが返ってくる時の対処法
CloudFrontにてVue.jsで作成したSPAを公開して
window.loactionなどでページ遷移を行うと以下のようなエラーが起きました。<Error> <Code>AccessDenied</Code> <Message>Access Denied</Message> <RequestId>xxx</RequestId> <HostId>xxx</HostId> </Error>S3やCloudFrontでおなじみのエラーです。
ただ、今回のエラーはホーム画面は表示されるのにページ移動したら急にこのようなエラーが起きました。
また、
this.$routerなどでページ遷移を行う時にはしっかりとページが表示されました。
this.$routerではページが表示される当たり、恐らくページを再描画するとどこか違うファイルを参照してしまうためこのようなエラーが起きているんだと思います。何はともあれ、CloudFrontで次のように設定をしてあげるとこのエラーは解消されます。
「CloudFront」→「Error Pages」のタブを開いて「Create Custom Error Pages」をクリックしてください。
HTTP Error Code 403: Forbidden Error Caching Minimum TTL 0 Customize Error Response Yes Response Page Path / HTTP Response Code 200: OK 無事ページを再描画してもページが表示されるようになりました!
以上、「CloudFrontで公開したSPAでページ遷移を行う時に、403エラーが返ってくる時の対処法」でした!
また、何か間違っていることがあればご指摘頂けると幸いです。
他にも初心者さん向けに記事を投稿しているので、時間があれば他の記事も見て下さい!!
あと、最近「ココナラ」で環境構築のお手伝いをするサービスを始めました。
気になる方はぜひ一度ご相談ください!
Thank you for reading
- 投稿日:2021-03-01T20:25:37+09:00
初心者がAWSとJavaでHello Worldレベルの何かがしたい
背景
会社の査定目標でJavaとAWSで何か作成します!と記入したものの先延ばしにしている内に結局
何も作れず査定日に近づいてしまったので、もうHello Worldレベルでもいいので何か
しなくてはということで取り組みました(実は提出義務はないので正直に作る必要も
本当はないのですが)。
作るの簡単だけど何か頑張ってそうに見えるAWS×Javaの成果物アイデアが別に何かあればぜひ
お教えください。非常に喜びます!概要
AWSコンソールのLambda上から、maven projectをpackage化したJarファイルを起動します。
①Mavenプロジェクトの作成
Eclipse上で適当にMaven Projectを作成します。
②Lambdaの実行対象であるJavaクラスを作成
これもシンプルに作成します。argはLambdaから渡される引数です。
package qiitaLambda; public class Qiita { public static String handleRequest(String arg) { return arg + "20210301"; } }③Jarファイルを作成する
プロジェクト名を右クリック→実行(R)→Mavenビルドで設定画面を開き、設定画面上でゴール(G)にpackageと入力し実行します。
④AWS Lambdaコンソール上で関数を作成する。
⑤Jarファイルをアップロードする
⑥ランタイム設定を行う
ハンドラを{package名}.{クラス名}::{メソッド名}に変更します。
⑦テスト設定をする
画面右上のテストを押下すると設定画面が出るのでイベント名とその内容を書きます。ここではシンプルに文字列のHelloを記載し、これが②の関数のargに渡されます。
⑧テストをする
もう一度画面右上のテストを押下するとLambda関数が実行されます。実行結果を見ると⑦のようにLambdaで記述したHelloとあらかじめ②のJavaクラスで記述していた日付を結合して表示しているのでJarファイルを呼べていることが確認できます。
感想
背景でも述べさせていただきましたが、作るのは簡単だけど何か頑張ってそうに見えるAWS×Javaの成果物アイデアが別に何かあればぜひぜひお教え下さい!









- 投稿日:2021-03-01T18:58:50+09:00
【AWS】Route53にエイリアスレコードを追加する手順。
個人用メモです。
既存のドメインに、新しいサービスを追加する、エイリアスレコードの作成方法について。
目次
Route53のエイリアスレコードとは?
AWSの既存リソースにルーティングするために設定する別名のこと。
追加するレコードがAタイプ(または、AAAA、CNAMEの場合)で作成することができる。
そのURLで入力があった場合に、CloudFrontやS3、ロードバランサーなどに振り分けることができる。
どんな時に使うか?
大元となる既存リソースの機能を複数のサービスで共有する場合など。(例えば記事エディタを複数のサービスで作成するなど)
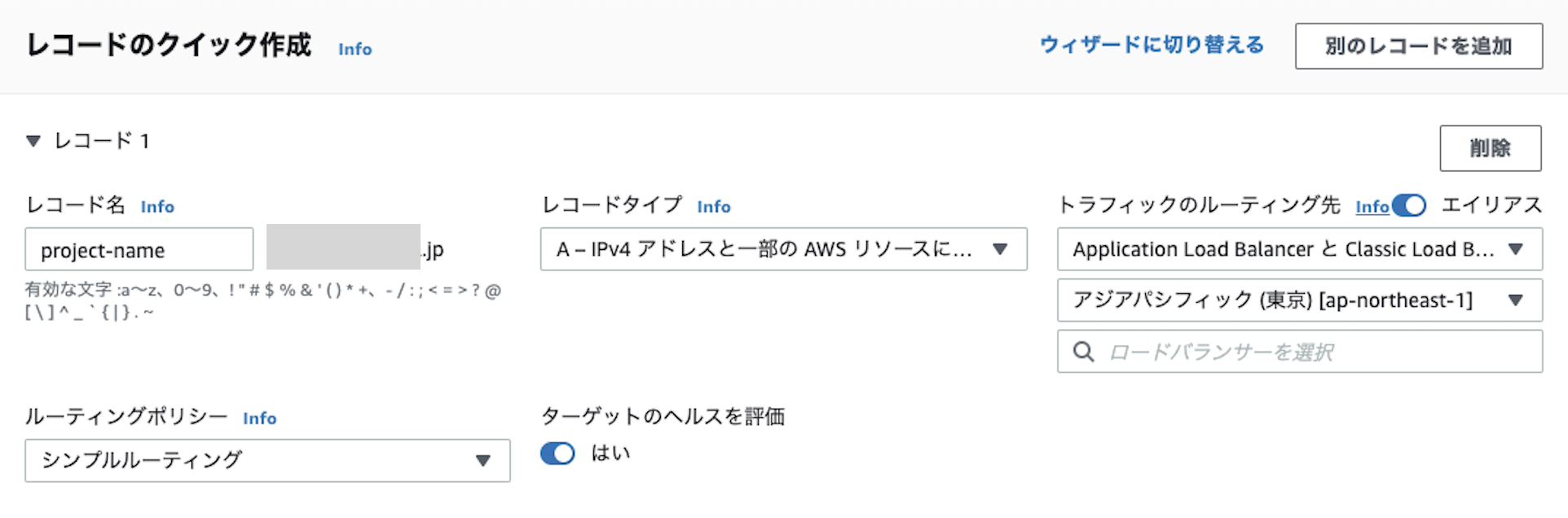
レコードタイプAとは?
Addressの冒頭大文字。ドメインに対するIPv4アドレスを登録している。
・AAAAタイプとは?
ドメイン名に対して、IPv6(IPv4の進化版)を指定するレコード。基本的な考え方はIPアドレスに対するドメイン名ということでIPv4と同じ。(IPアドレスの仕様が異なるだけ)
・CNAMEタイプとは?
ドメイン名の別名(Canonical NAME)を指定するレコード。IPアドレスは共有となる。
example.comのCNAMEとして、www.example.comを用意するなど。Aレコードでも作成できるが、IPアドレスに変更があった場合にAレコードは大元とAレコードの二つのIPアドレスを変更しなければいけない。CANEMであれば、大元のみ変更すればOK。
Route53にエイリアスレコード作成手順
エイリアス(別名)レコードなので、既に存在しているドメインを選択して作成していく。
1. 対象のドメインを選択する
Route53 > ホストゾーン からエイリアスの追加対象となるドメインを選択する。
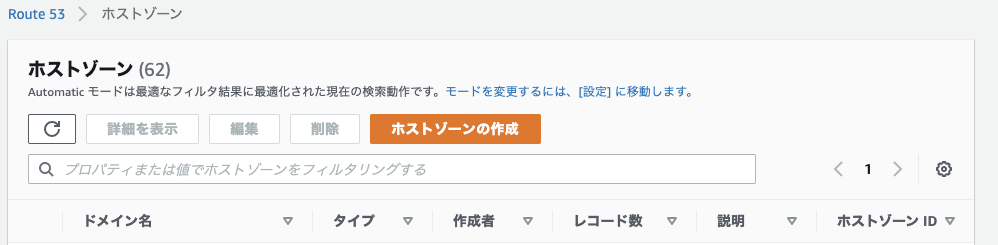
2. レコードの作成
↓レコード作成画面
2-1. レコード名
指定したドメインのサブドメになる形で入力する。わかりやすい名前をつける。
2-2. レコードタイプ
A(IPv4)を選択。
レコードのタイプは様々あるが、エイリアスをONにする場合はAWSリソースにルーティングできるタイプのみになる。
選択するルーティング先によって、IPv4のみであったりと選択肢が変わる。
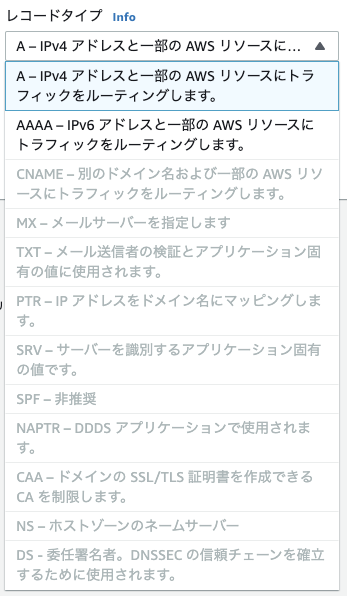
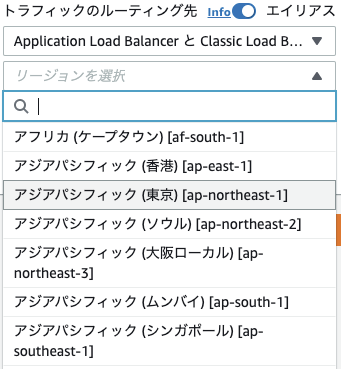
2-3. エイリアスとトラフィックのルーティング先
AWSのリソースにルーティングするためエイリアスをONにし、ルーティング先を選ぶ。
(ここではロードバランサを選択)
リージョンの選択
次に、ルーティング先のサービスのリージョンを選択する。
(ここでは東京を選択)
サービスの選択
登録してあるサービスからルティングしたいものを選ぶ。
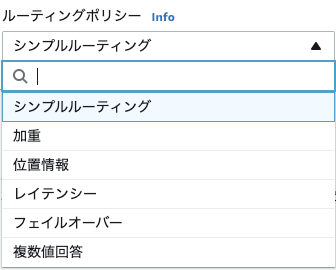
2-4. ルティーングポリシー
Route53がクエリに対してどう応答するかの、ルーティングポリシーを選択する。
ルーティングポリシー 内容 シンプルルーティング ドメインで特定の機能を実行する単一のリソースがある場合 加重 指定した比率で複数のリソースにトラフィックをルーティングする場合 位置情報 ユーザーの位置に基づいてトラフィックをルーティングする場合 レイテンシー 複数の AWS リージョンにリソースがあり、レイテンシーの最も小さいリージョンにトラフィックをルーティングする場合 フェイルオーバー アクティブ/パッシブフェイルオーバーを構成する場合 複数値回答 ランダムに選ばれた最大 8 つの正常なレコードを使用して Route 53 が DNS クエリに応答する場合
2-5. ターゲットのヘルスを評価
「はい」にすると、作成したエイリアスレコードのヘルスチェック(正常に動作しているかの確認)を行う。
2-6. レコードの作成
設定が完了したら、「レコードの作成」をクリック
以上でエイリアスレコードの作成が完了。
3. Route53の注意点
Route53は本番公開中のサービスとも直結しているため、作業時は注意すること。
間違って、他のレコードを削除したり、ゾーンを削除したりしてしまうと、そのサービスが稼働しなくなってしまう。(500系エラーになる)
参考リンク
▼AWS エイリアスレコード
▼AWS ルーティングポリシー
▼AWS ヘルスチェック




- 投稿日:2021-03-01T18:54:52+09:00
AWS EC2でuserdataの実行結果Logの確認
- 投稿日:2021-03-01T18:54:46+09:00
#40 代おっさん EC2 を作成してみた ③
本記事について
本記事は AWS 初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。AWS 作成図
VPC 部分については
https://qiita.com/kou551121/items/2535fe3de57a5c813687
今回は EC2 を作成することをメインにしております。
EC2 詳しく知りたい方は
https://qiita.com/kou551121/items/54acbecd4fa147bc4d51構築手順
❶EC2 を作成する。
https://qiita.com/kou551121/items/56f2e075d33fbf345787
(❶ の部分を知りたい方はこちらを)
❷ セキュリティーグループの作成
https://qiita.com/kou551121/items/b86ea1dafb04501e741d>
❸EC2 インスタンスに接続3.EC2 インスタンスに接続
インスタンスに接続するためには ssh でログインするためのツールが必要となります。
自分は wiWindows なので下に参考資料あげておきます!!
Tera Term(今回はこれがあれば十分だと思います!!)
https://dev.classmethod.jp/articles/aws-beginner-ec2-ssh/VSCode で Remote Development 仕様の場合(これからを考えるとこれができるとうれしいと思います)
https://qiita.com/HoriThe3rd/items/b2f6c440f096106cf89eちなみに VSCode を使用する場合こちらも使うかもしれませんので(WSL)
https://qiita.com/matarillo/items/61a9ead4bfe2868a0b86今回はとりあえず Tera Term のほうで行きたいと思います!
下がインスタンスにログインした様子です。このようになっていたらログインできたことになります。
とりあえずインスタンスに接続しましたが、
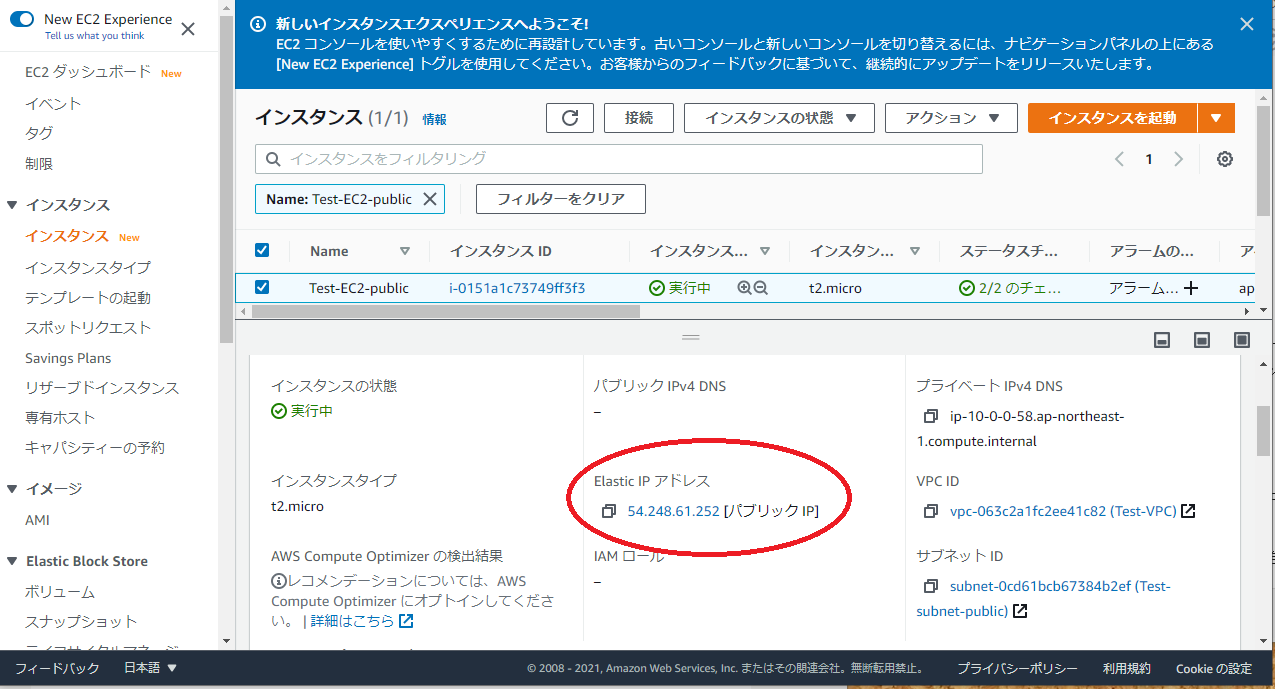
Public IP アドレスだとインスタンスを停止、再起動するたびに変わるので不便です。
Elastic IP アドレスに変えたいと思います。
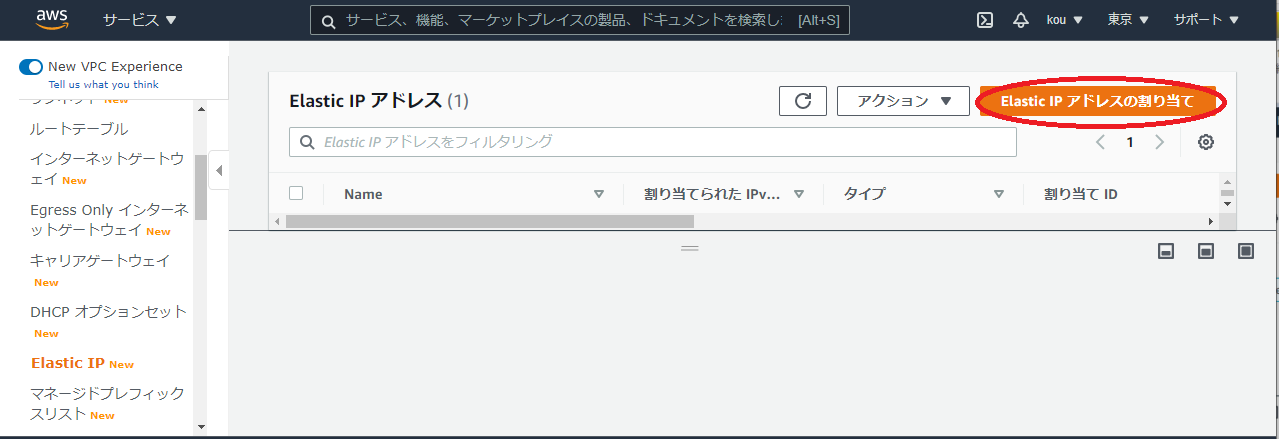
まずは VPC の画面に行き Elastic IP をクリック(赤枠)
下の画面に画面遷移
Elastic IP アドレスの割り当て(赤枠)をクリック
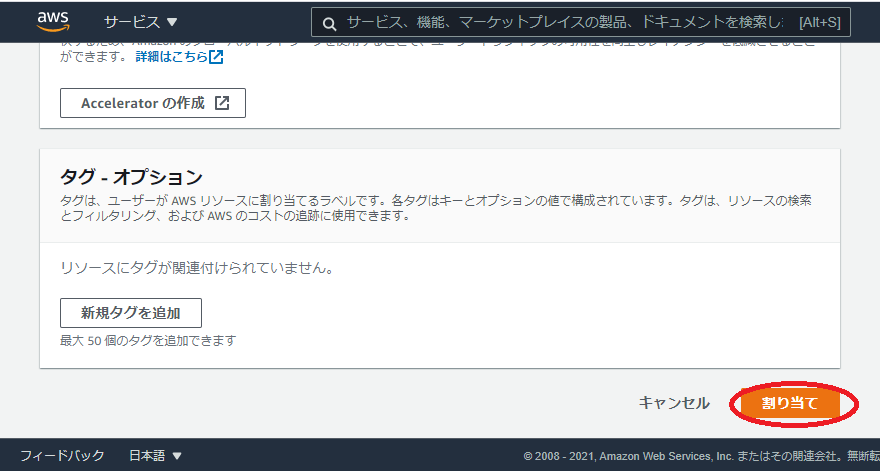
今回は何もせず下のほうにある割り当て(赤枠)をクリック
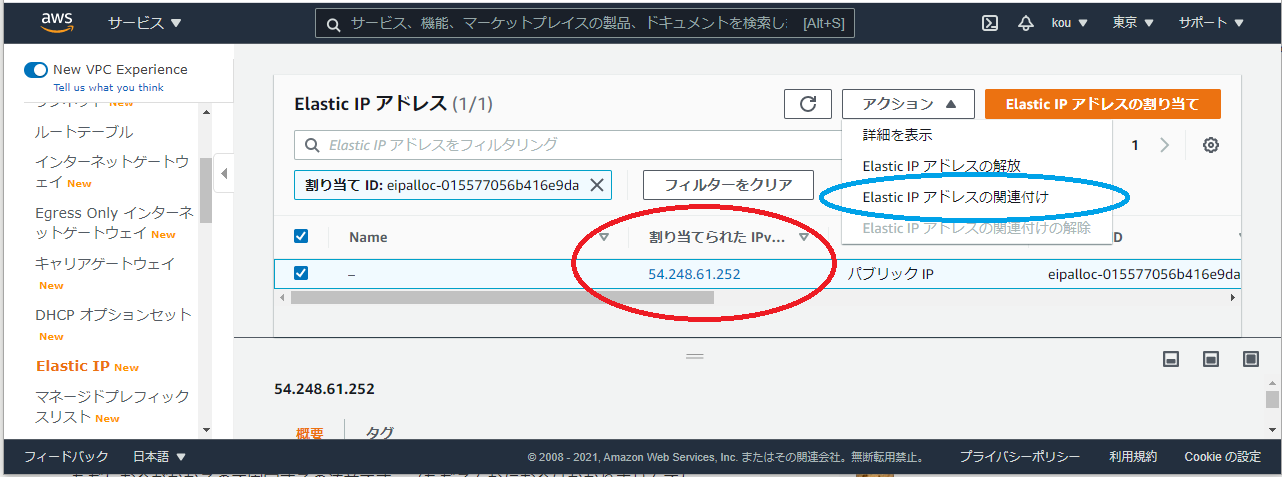
赤枠を見ると割り当てられていますね。それだけでは終わらずつぎはアクションから Elastic IP アドレスの関連付けをクリックしてください。
そうすると下のように画面遷移します
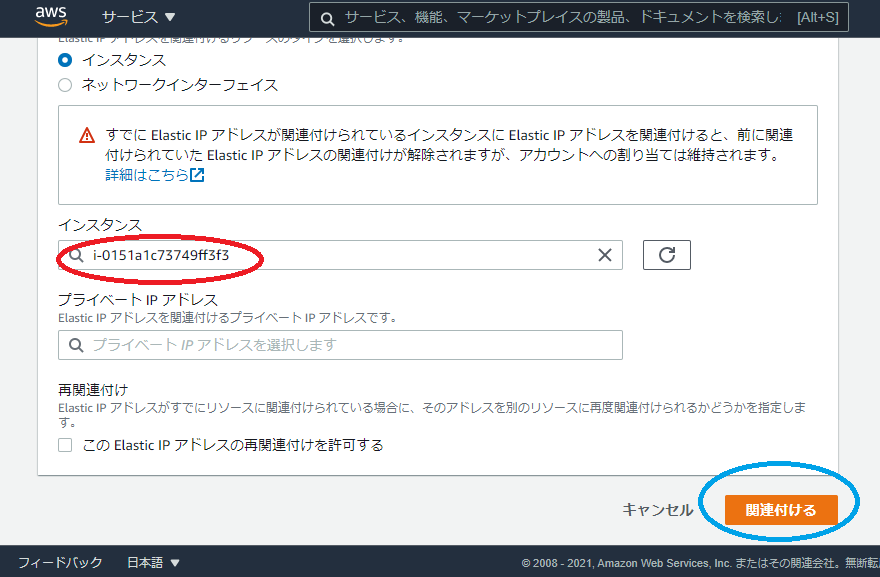
赤枠に自分の作ったインスタンス(自分は Test-EC2-public)を選んでください
選んだら関連付け(青枠)クリック
関連付けられたか確認したいのでサービスから EC2 を選んで自分が選んだインスタンスの詳細を確認してください
このように変わっていると思います。最後に
これでいつでも EC2 インスタンスに入れると思います。これで EC2 インスタンス作成は終わりたいと思います。
でも実は構成図にはまだ終わっていないところがあります。
そうです、NAT gateway から Private subnet の EC2 に繋げていない・・・・
次回はそれをやりたいと思います!!
頑張ります!またこの記事は AWS 初学者を導く体系的な動画学習サービス「AWS CloudTech」の課題カリキュラムで作成しました。
https://aws-cloud-tech.com/
- 投稿日:2021-03-01T17:10:10+09:00
【AWS】ECSのタスク定義とは何か?コンテナ要件を定めたタスク定義の作成方法。
ECRにイメージを保存したら、そのイメージからコンテナを作成するためのタスク定義(task definition)を行う。
タスク定義(task definition)はAWSのECS(Elastic Container Service)のサービスの一つ。
ECSはDockerのこと。ローカルではなくAWS上でDockerを使う(運用する)ためのサービス。
開発環境ではなく、本番環境(またはステージング環境)を作成する場合に使う。
目次
- AWSのタスク定義はDockerでいう何のこと?
- タスク定義の手順
- 起動タイプの互換性の選択
- タスクとコンテナ定義の設定
- コンテナの定義
- 設定後のコンテナ設定後の例
- ボリュームの設定
- タグの設定
- タスク定義の作成
- タスク定義の修正
- タスクの設定事例
AWSのタスク定義はDockerでいう何のこと?
タスク定義はDcokerでいうところ、
- Dockerのインストールサーバーの設定
- コンテナ起動のためのイメージの取得
- コンテナ起動のための要件定義
になる。
なので、docker-compose.ymlがタスク定義にあたる。
docker-composeで複数のコンテナを定義できるのと同様に、ECSでも1つのタスクの中に複数のコンテナを定義できる。
▼docker-compose.ymlの例
コンテナを起動するためのイメージを指定し、起動要件を定義している。例services: web: build: . image: test:latest container_name: web_app ports: - "8000:80" env_file: - .env.local environment: - APP_ENV=local - APP_DEBUG=true volumes: - .:/code networks: - front-tier - back-tierこれを、ECSのタスク定義で行う。
タスク定義の手順
まずは、AWSにログインしてECSのサービスからタスク定義を行う。
「新しいタスク定義の作成」をクリック。
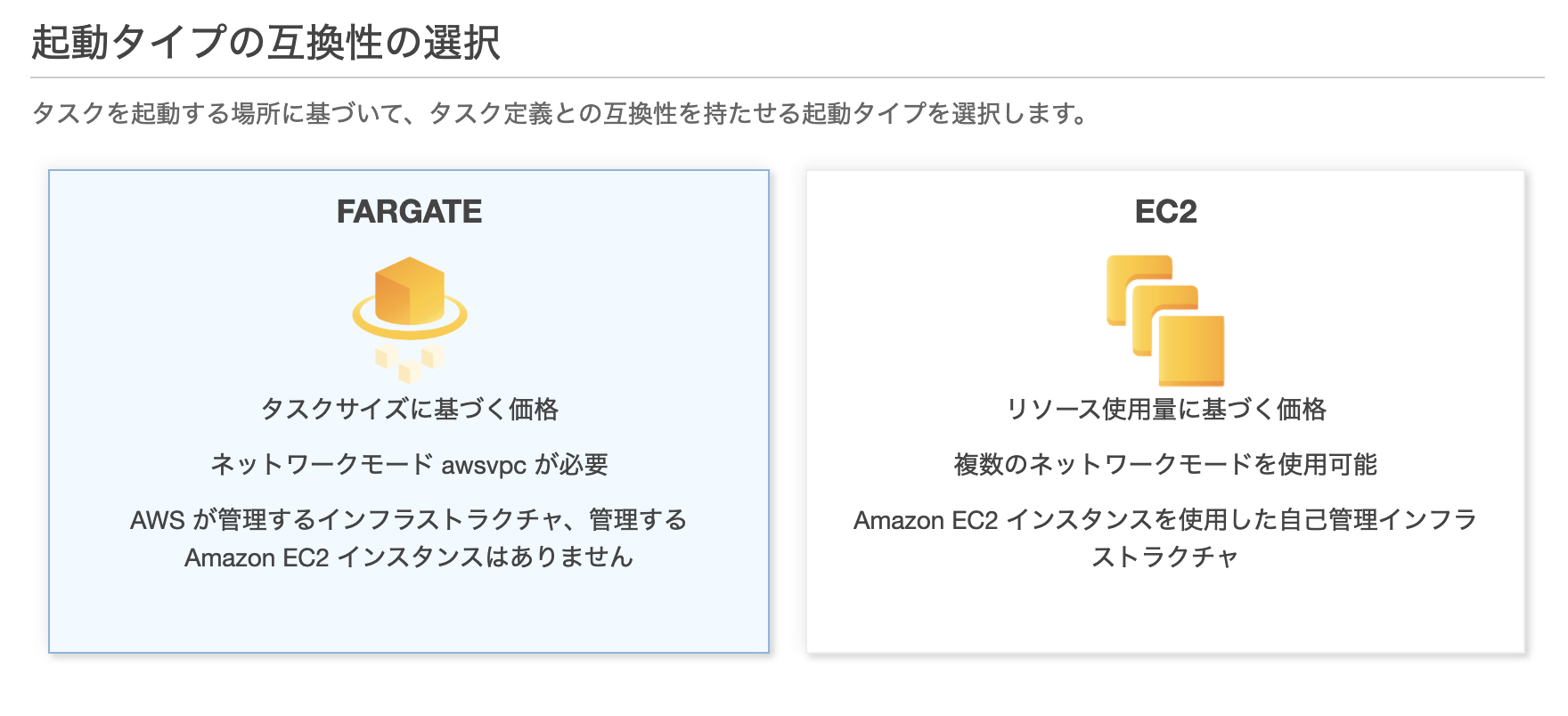
1. 起動タイプの互換性の選択
起動タイプは、Dockerを展開するためのインフラとなる仮想サーバーのこと。
基本的にはFargateを選ぶ。選択したら右下の「次へ」をクリック。
FargateはECS専用のサーバーで、AWSが保守管理をしてくれる手間いらずなサーバー。
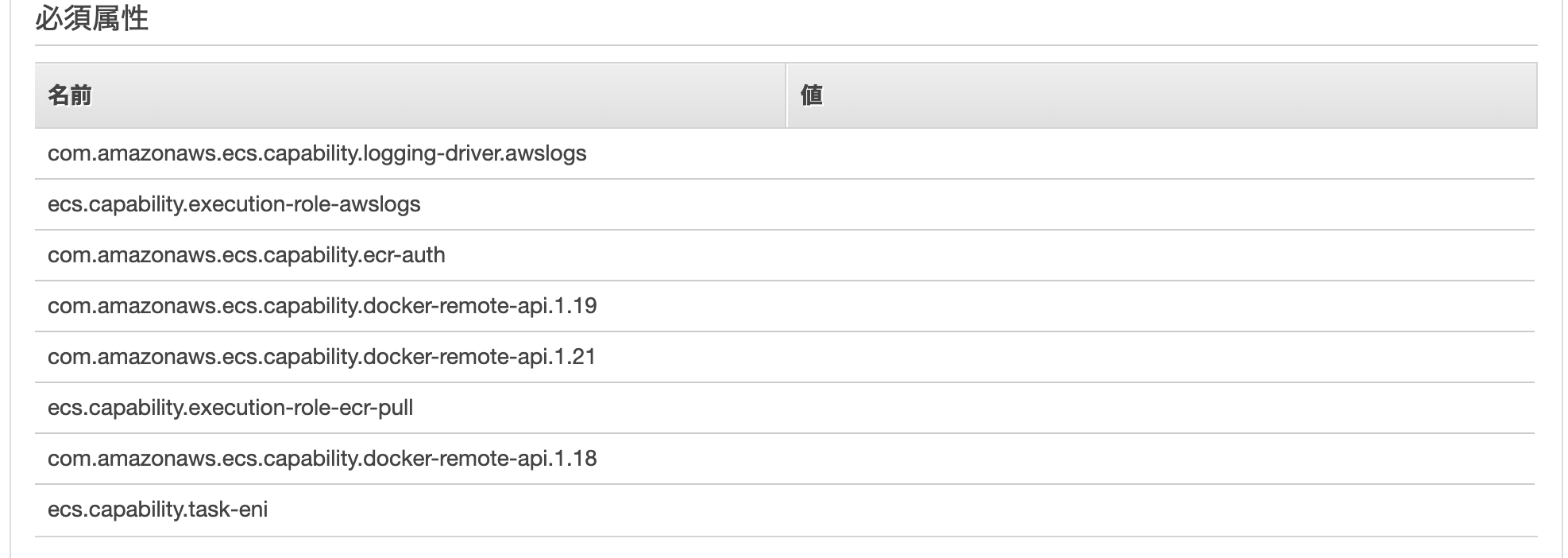
(参考)FargateとEC2の違い。タスク定義ではどちらを選べばいいのか?
2. タスクとコンテナ定義の設定
次にタスクとコンテナの定義の設定を行う。やることは、
- タスク定義名とタスクロールの選択
- タスク実行のロールの選択
- タスクサイズの選択
- コンテナの定義
となる。他にも設定できるオプションはあるが、ここでは主要どころのみ設定。
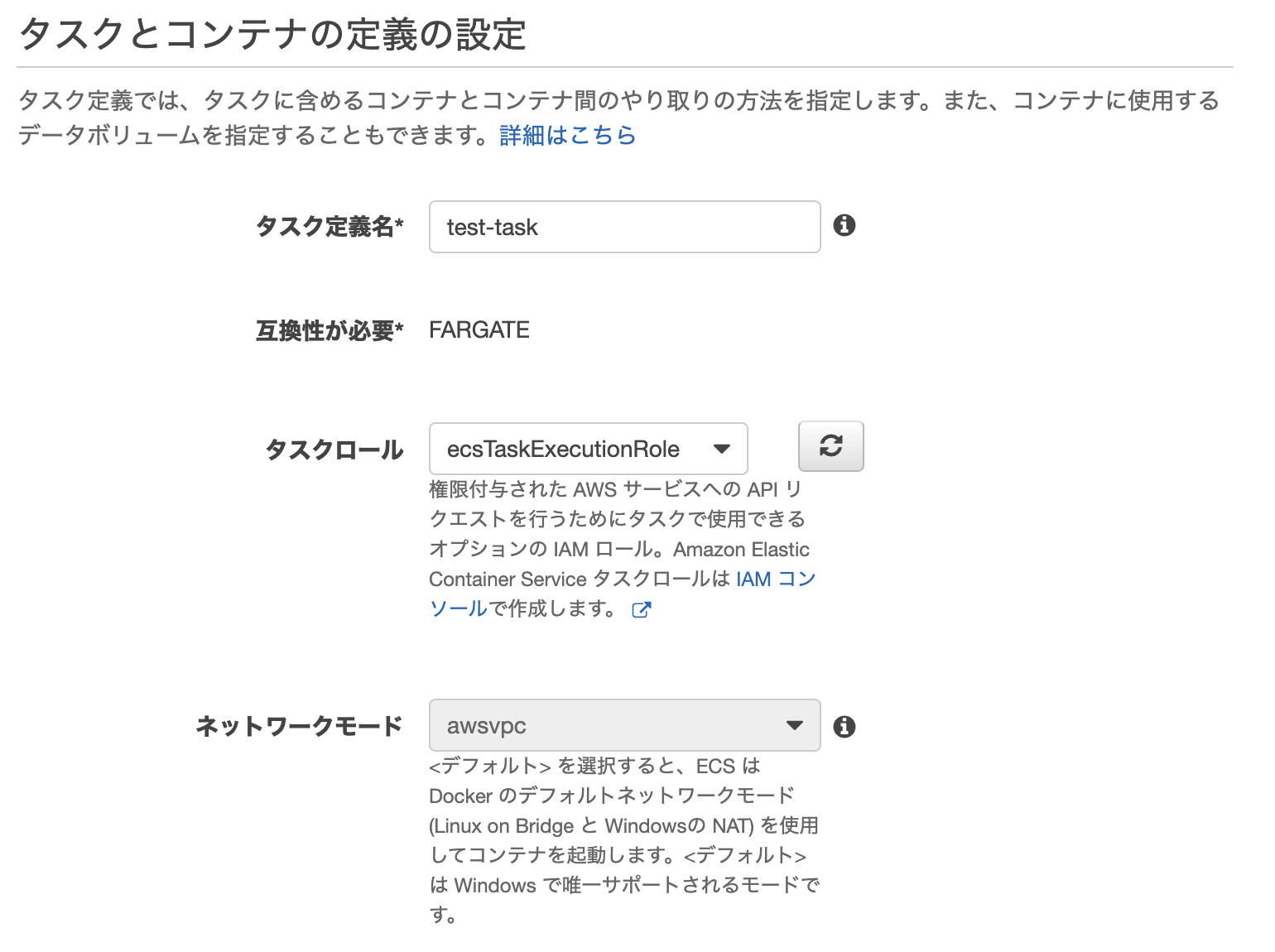
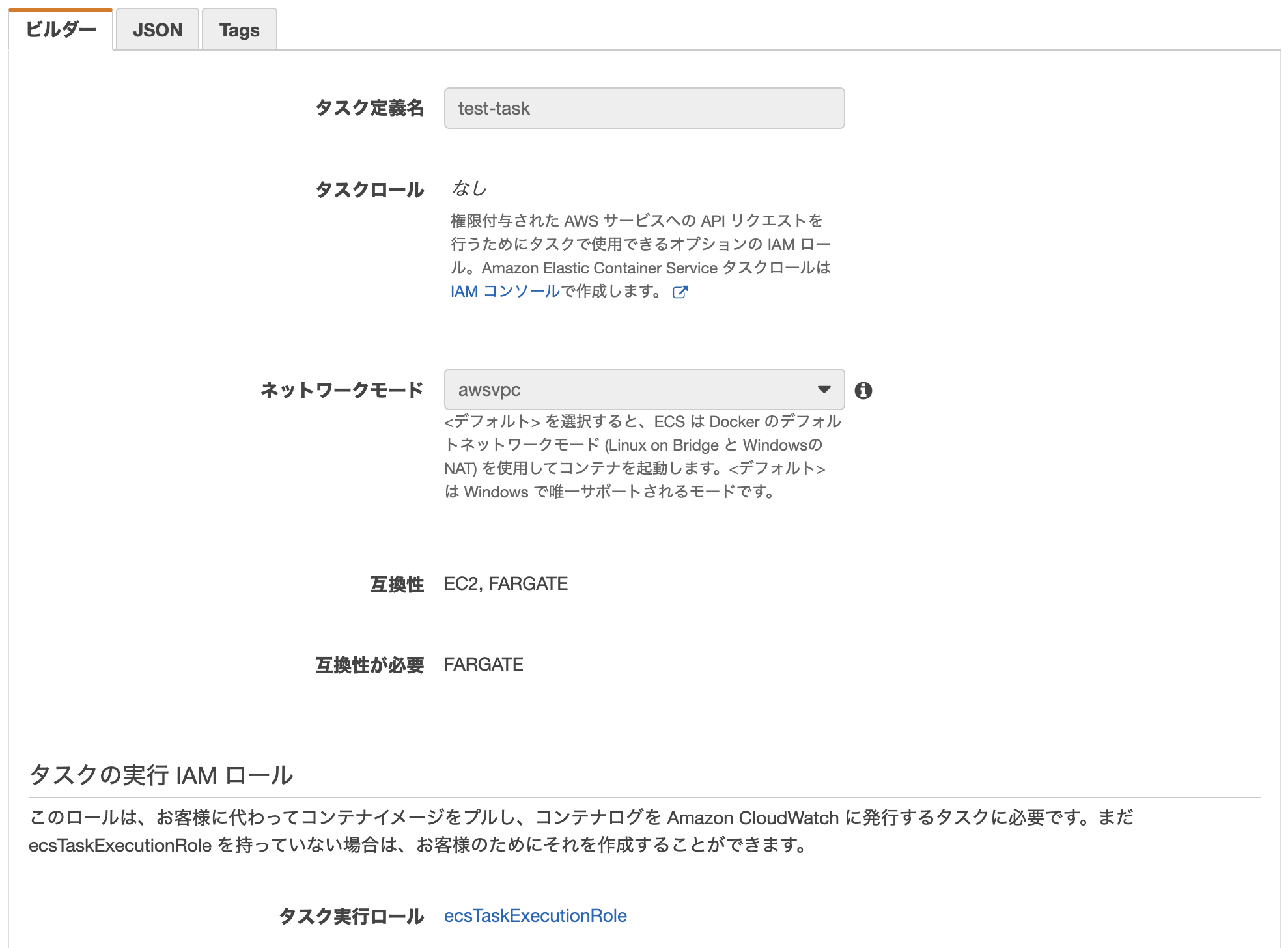
2-1. タスク定義名とタスクロールの選択
・タスク定義名の設定
任意で好きなタスク名を設定可能。
後ほどクラスターを作成するときに必要になるので、わかりやすい名前にしておく。
・タスクロールの選択
コンテナを起動したときに、コンテナからAWSのサービスに接続したい場合に設定する。
どのAWSサービスへの接続を許可するかは、AWSのIAM(Identity and Access Management)で設定する。
IAMのロール名を作成し、そこにAWSのサービスを付与する。
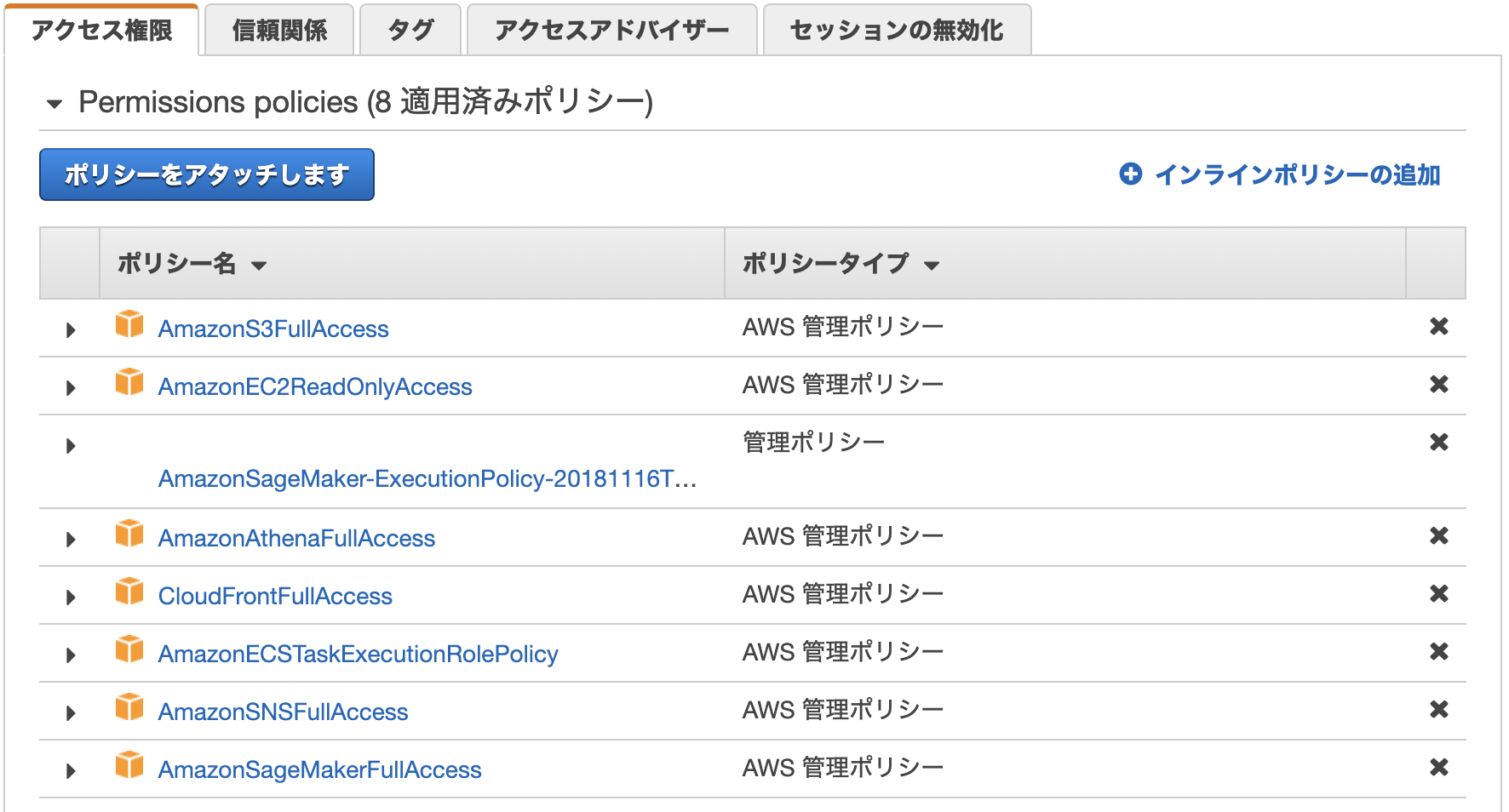
▼ECS用のタスクロール
ECSでの選択はプルダウンから行う。ここで表示されるのは、「AWS サービス: ecs-tasks」となっているロールのみ。
ECS専用のロールとして、デフォルトでecsTaskExecutionRoleが用意されている。
▼IAMのタスクロールの例S3やEC2、CouldFontへのアクセスを許可している。
・ネットワークモード awsvpc
Fargateではawsvpcとなる。
awsvpcはAWS VPCのことで、Amazon Virtual Private Cloudの略。
AWS上のサービスを一つのまとまり(ネットワーク)として定義できる。
一つのvpcの中に定義したサービス同士はもちろん接続される。他のaws vpcとも接続することができる。
今回タスク定義する Fargate用に専用のAWS vpcが作成される。
2-2. タスク実行のロールの選択
コンテナ起動時にECR(Elastic Container Registry)からイメージの取得を許可するIAMロールを設定する。
ecsTaskExecutionRoleを選択すればOK。
ecsTaskExecutionRoleはAWSがデフォルトで用意しているタスクロール。
このAmazonECSTaskExecutionRolePolicyがメインで、この中で、①ECRの読み込み許可と②CloudWatch Logs(AWSのログ管理機能)へのデータ送信を許可している。
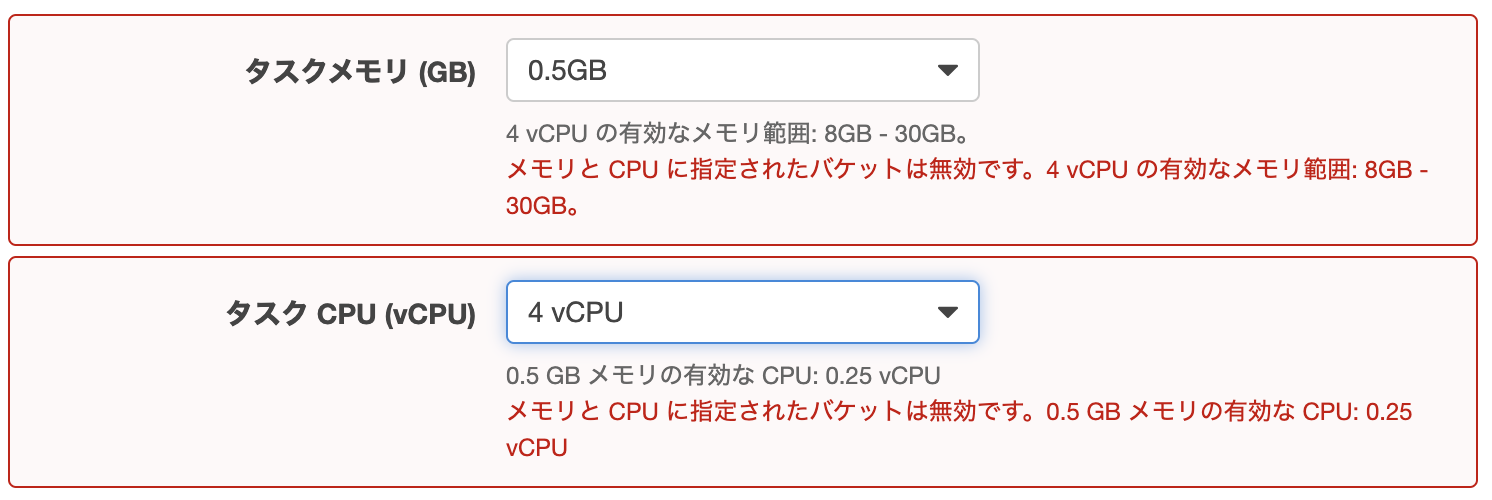
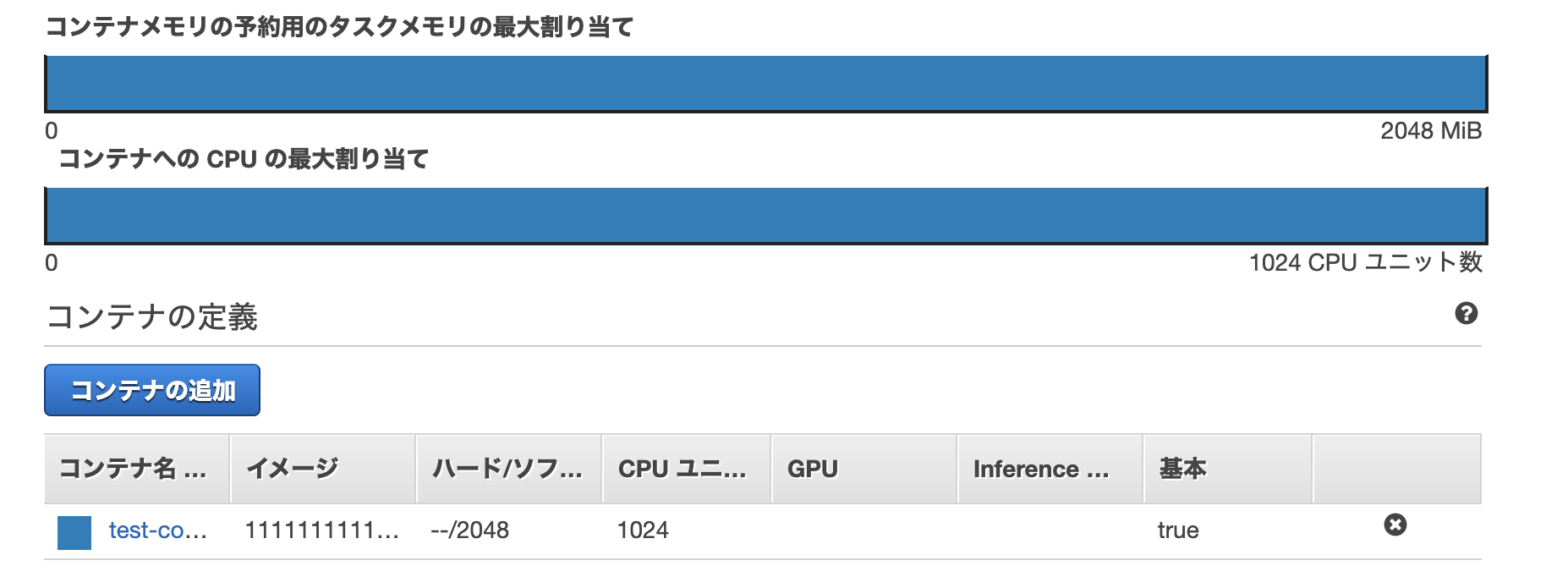
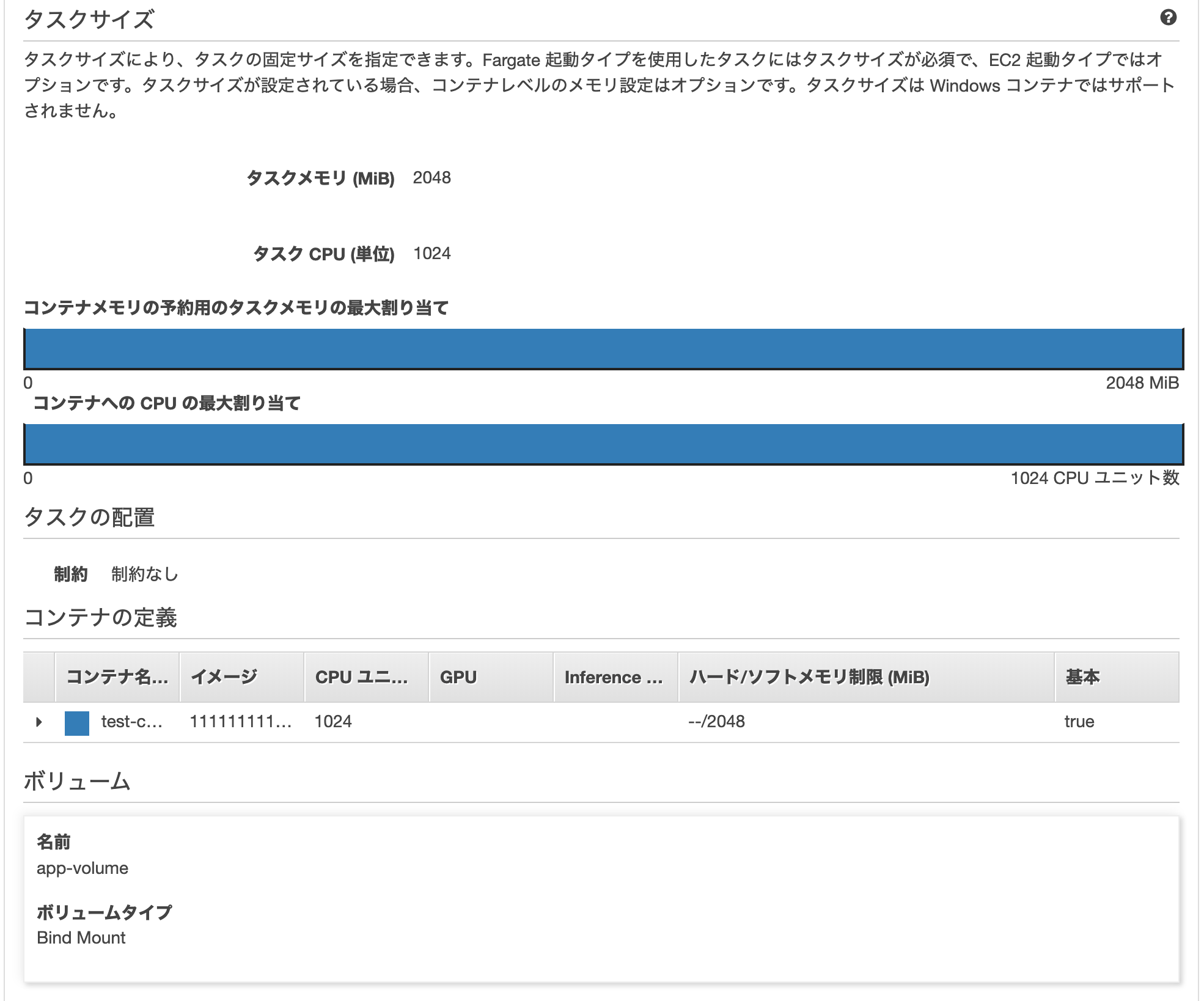
2-3. タスクサイズの選択
1つのタスクに割り当てるCPUとメモリのサイズを設定する。
1つのタスクの中には複数のコンテナが設定できるが、各コンテナに毎に設定するCPUとメモリの合計は、ここで指定したタスクサイズ以内となる。
FargateはCPUとメモリの使用上限の設定が必須。AWSがその決められた範囲内で各コンテナにいい感じに割り振ってくれる。(コンテナ毎のメモリとCPUユニットを定義しない場合)
EC2の場合はタスクサイズの設定はオプションなので設定しなくてもいい。必要な量に応じて自動的に調整される。
・タスクメモリ[GB]
0.5GB ~ 30GB・タスクCPU[vCPU]
0.25, 0.5, 1, 2, 4vCPU・vCPUとは?
Virtual CPUの略で、仮想サーバー毎に割り当てられたCPUのサイズを表す。
・CPUのサイズ
AWSのCPU > 仮想サーバーのCPU >= コンテナのCPU適用可能なCPUとメモリサイズ
タスクCPUとメモリサイズには適用可能な組み合わせがある。範囲外は設定できない。
タスクCPU CPUユニット数 タスクメモリ 0.25vCPU 256 512MB, 1 ~ 2GB 0.5vCPU 512 1 ~ 4GB 2vCPU 2048 4 ~ 16GB 4vCPU 4096 8 ~ 30GB 適用するタスクCPUやタスクメモリのサイズが大きいほど、ヘビーな処理もできるようになるが、その分料金も増す。
▼適用範囲外の例
今回は、1つのコンテナしか使用しないため、タスクメモリ:2GB(2MiB)、タスクCPU:1024(1vCPU)を選択する。
コンテナの数が増える場合は、CPUやメモリを増やす。
3. コンテナの定義
「コンテナの追加」をクリックして、タスクの中に起動するコンテナを定義していく。
3-1. コンテナ名
任意のコンテナ名を設定。
docker-compose.ymlのcontainer_nameディレクティブ。3-2. イメージ
コンテナの起動に使用するイメージを記載する。
・
<ホスト名>/<レポジトリ名>ECRのイメージを使用する場合は以下のようになる。
111111111111.dkr.ecr.ap-northeast-1.amazonaws.com/test-appプライベートレジストリの認証
ECR以外のイメージを使用する場合に設定する。
3-3. メモリ制限
メモリ制限にはソフト制限とハード制限がある。
Fargateの場合はAWSが自動で割り振るため設定しなくてもいい。設定した場合は各コンテナのメモリ使用上限値となる。(EC2の場合は必須)
ソフト制限とハード制限の違い
ハード制限は
memory、ソフト制限はmemoryReservationという。・ハード制限の場合
設定したメモリを超えるとコンテナを強制終了する。・ソフト制限の場合
設定したメモリを維持しようとする。ただし、一時的に設定したメモリを超える場合などは余っているメモリを自動で割り当てる。ソフト制限とハード制限の併用する場合
ソフト制限で維持して欲しいメモリを割り当て、仮にそのメモリをオーバーしたとき、ここのメモリを超えたら強制終了したい!という場合に、ハード制限も設定することができる。
このため、ハード制限はソフト制限よりも大きくする必要がある。
例えば、ソフト制限128MiBに対してハード制限256MiBを設定すると、一時的に128MiBを超えても256MiB以内であればコンテナは処理を続行する。
256MiBを超えてしまった場合はコンテナを強制終了する。
▼タスク定義の設定今回は使用するコンテナは1つのため、タスクに割り当てたメモリをソフト制限としてコンテナにも割り当てる。(Fagateなので設定しなくてもいい)
3-4. ポートマッピング
コンテナ側で開放するポートを設定する。
例えば、docker-composeやターミナル起動中のコンテナを確認したときに、
portに表示される右側のポート番号が入る。docker-compose.ymlports: - "8000:80"terminalの例$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES dc84c2ca4e97 test-app:latest "/docker/local/webse…" 3 weeks ago Up 12 days 9000/tcp, 0.0.0.0:8000->80/tcp test-app▼タスク定義の設定
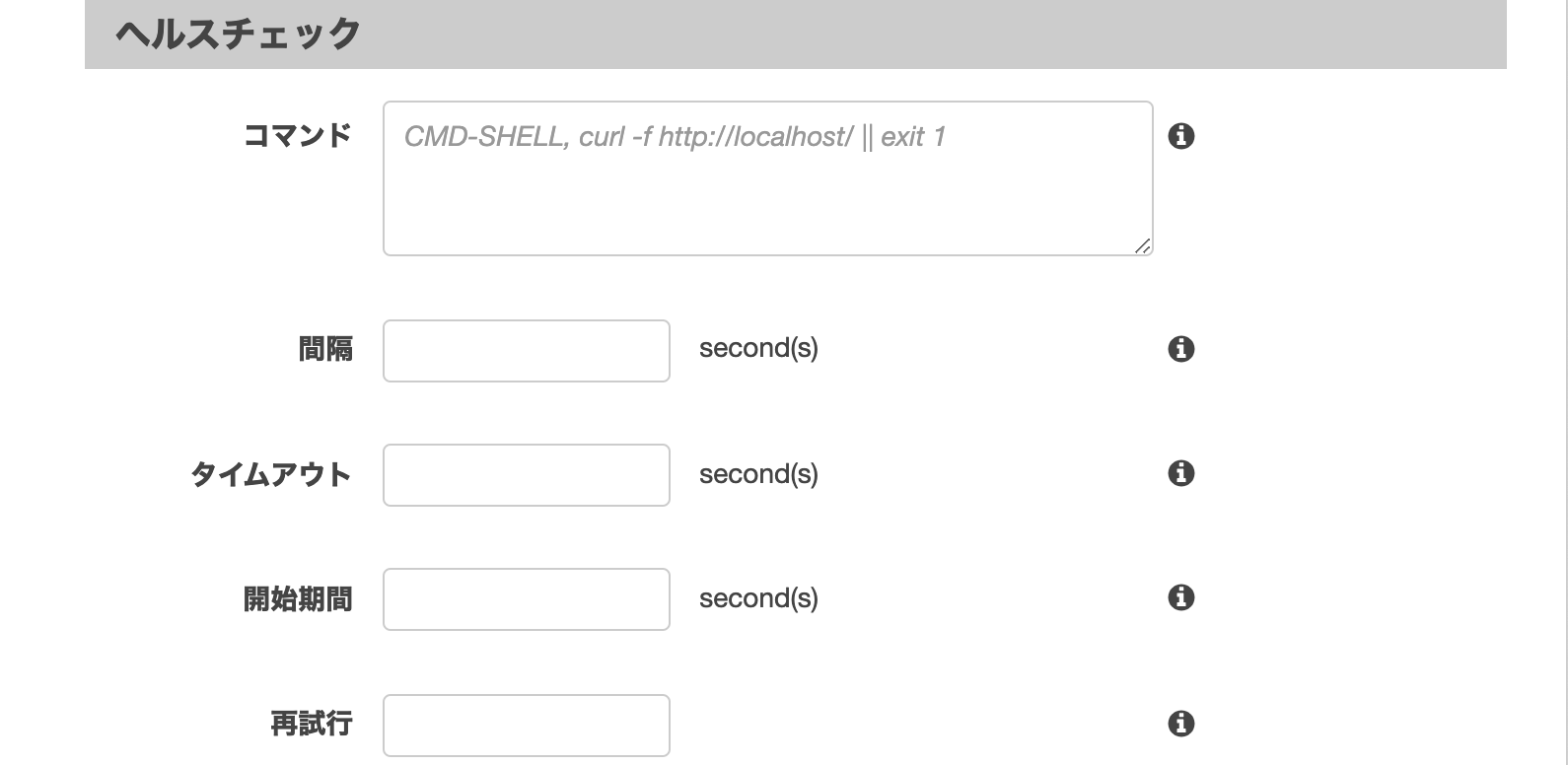
3-5. ヘルスチェック
サービスが問題なく運用しているかを確認するためのチェック項目。
確認として実行するコマンドを作成し登録しておく。最終的にコンテナが異常と判定してアラートを出すまでに実行するヘルスチェックの回数などを設定できる。
- interval(間隔): ヘルスチェックの実行間隔
- timeout: ヘルスチェックでfalseと判断するまでに待機する時間
- startPeriod(開始期間): 再試行でfalseと判断するまでに待機する猶予期間
- retries(再試行): コンテナ異常と判断するまでに実行するヘルスチェックの回数
▼タスク定義の設定
今回は設定しない。
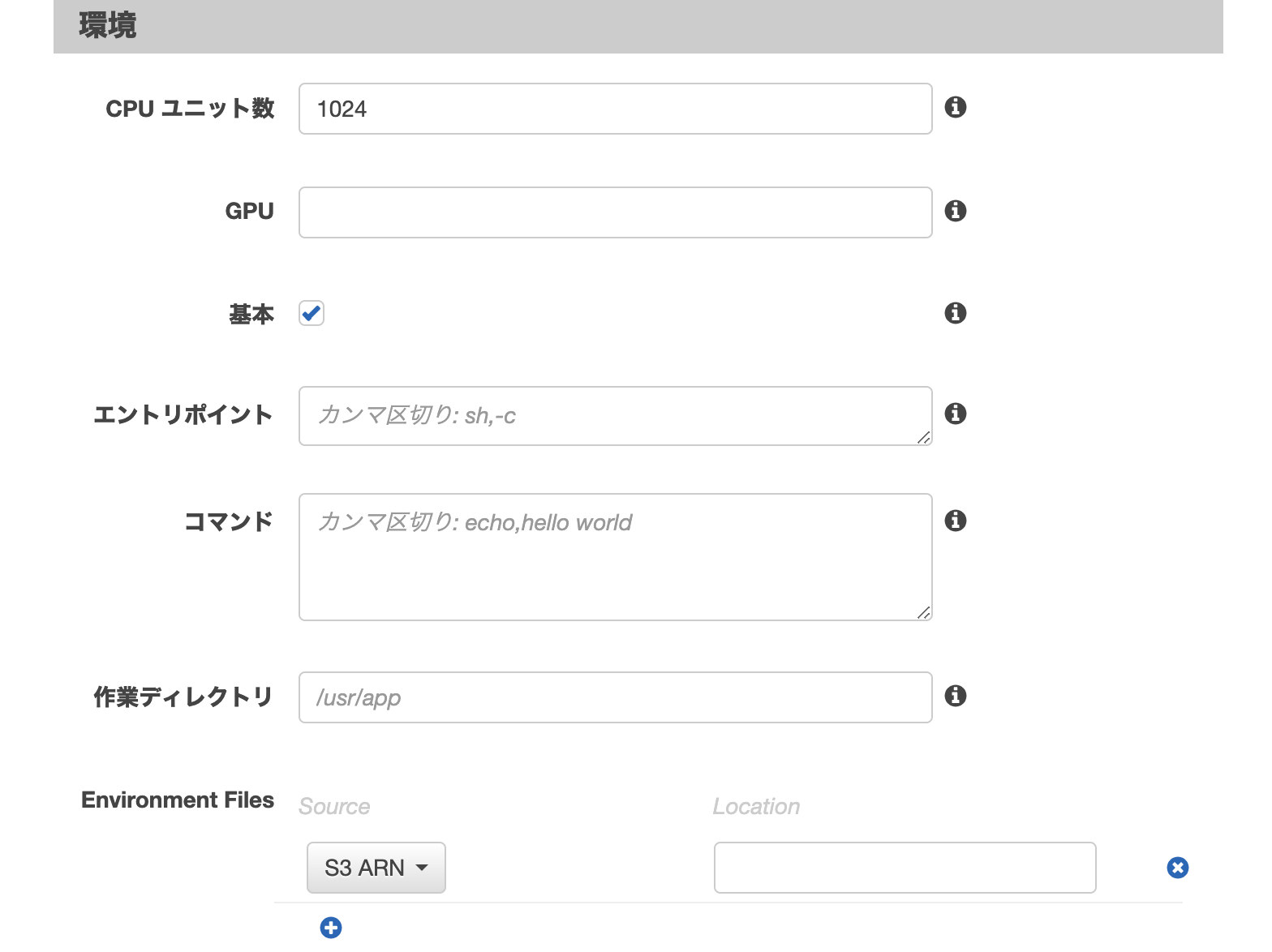
3-6. 環境設定
コンテナ起動時の環境を設定する。
・CPUユニット数
タスクに割り当てたCPU数の中から、割り当てたい量を指定する。(タスクCPU以下であること)今回は、このコンテナのみのため、すべてのCPUである1024を割り当て。
・GPUユニット数
GPUを使用する場合に割り当てる。
Fargateの場合は割り当てられない。・エントリポイント
コンテナに渡すエントリポイント。指定したshファイル(またはコマンド)を実行する。Dockerfileかdocker-composeの中に定義してあれば不要。
・コマンド
コンテナに渡すコマンド。指定したコマンドを実行する。Dockerfileかdocker-composeの中にCMDまたは、entrypointが定義してあれば不要。
・作業ディレクトリ
コンテナ起動したときの作業ディレクトリ。WORKDIRディレクティブと対応。Dockerfileかdocker-composeに記述してあれば不要。
・Environment Files
環境変数を記述したファイルがS3にある場合は読み込むことができる。
ない場合は、次の環境変数で個別に設定していく。
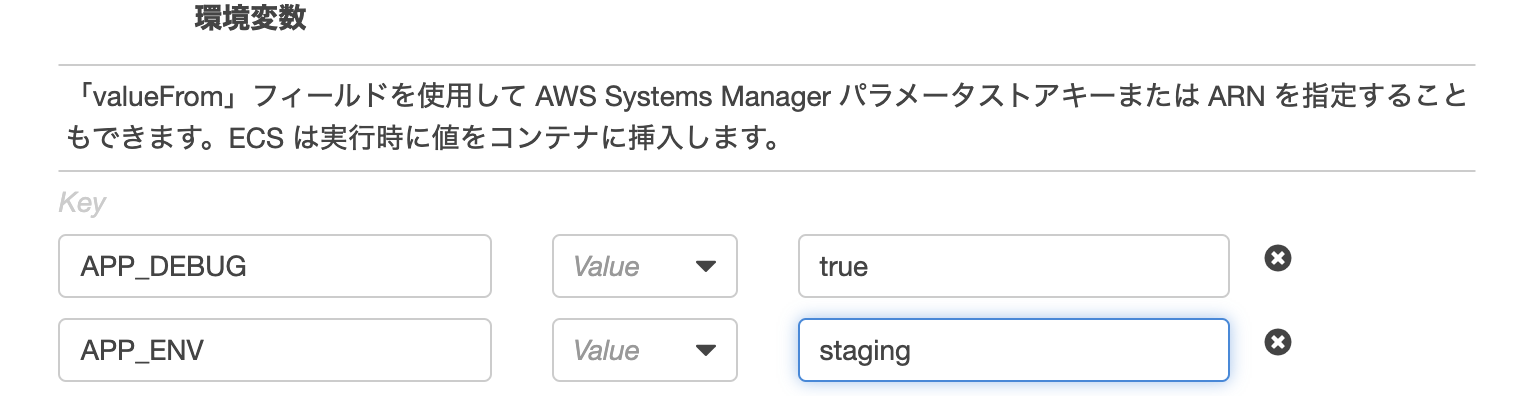
3-7. 環境変数
環境変数がある場合は、一つづつ記述していく。
3-8. コンテナタイムアウト
・タイムアウト開始
依存関係にあるコンテナが上手く立ち上がらない場合に適用される。依存関係にあるコンテナが起動するまでの再試行を行う待機時間。
Fargateで値を設定しない場合は、デフォルトで3分が適用される。
・停止タイムアウト
コンテナが正常終了しなかった場合に強制終了するまでの待機時間。Fargateで値を設定しない場合は、デフォルトで30秒が適用される。
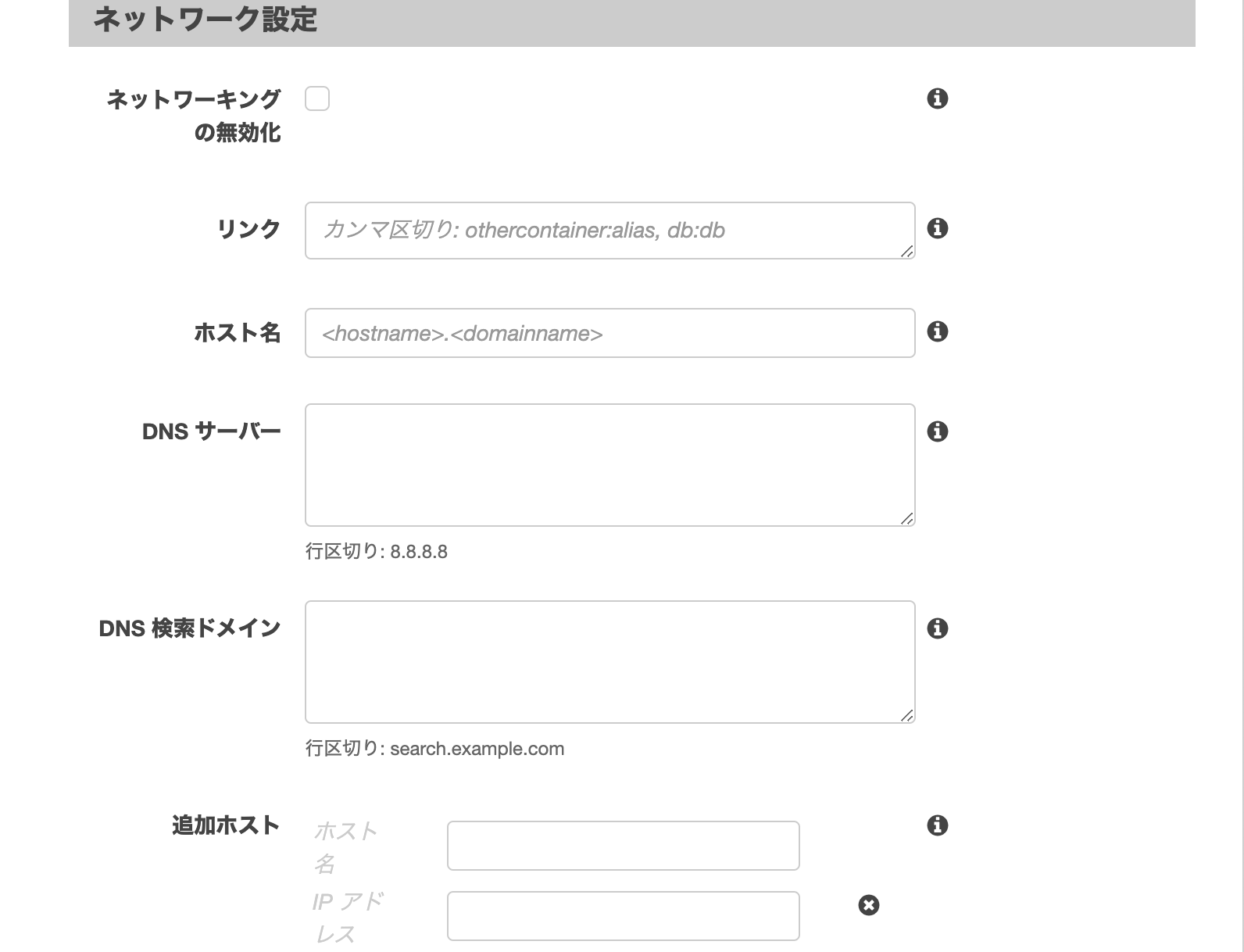
3-9. ネットワーク設定
docker-composeはコンテナを起動した場合に、複数コンテナがある場合は自動でネットワークで繋ぐ。
このネットワークをfalseにしたり、依存関係の設定やDNSサーバーの設定ができる。
対応するディレクティブは、networks, links, dnsなど。
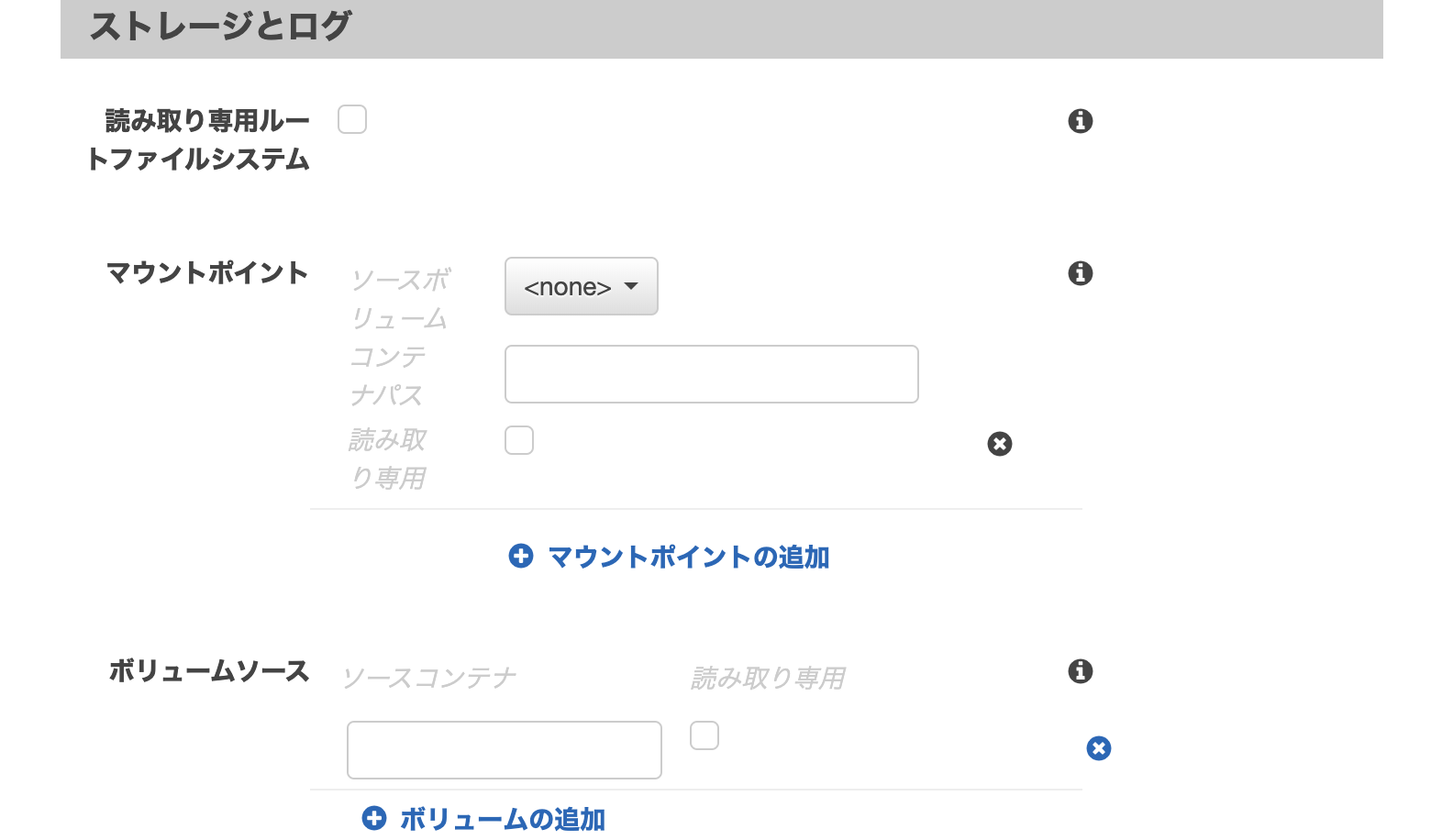
3-10. ストレージとログ
ここではサービス毎のボリュームの設定とログの設定ができる。
デフォルトではコンテナを停止するとデータは削除される。データを残したい場合はボリュームを設定する。
▼マウントポイントとボリュームソースの違い
マウントポイント
各コンテナに設定するボリューム。
volumeディレクティブに相当。ホスト側と同期させたいディレクトリや、同期させたくないディレクトリを記述する。
ボリュームソース
他のサービスやコンテナのボリュームを使う場合に使用。
volumes_fromディレクティブに相当。読み込み専用(ro)や書き込み(rw)を指定できる。
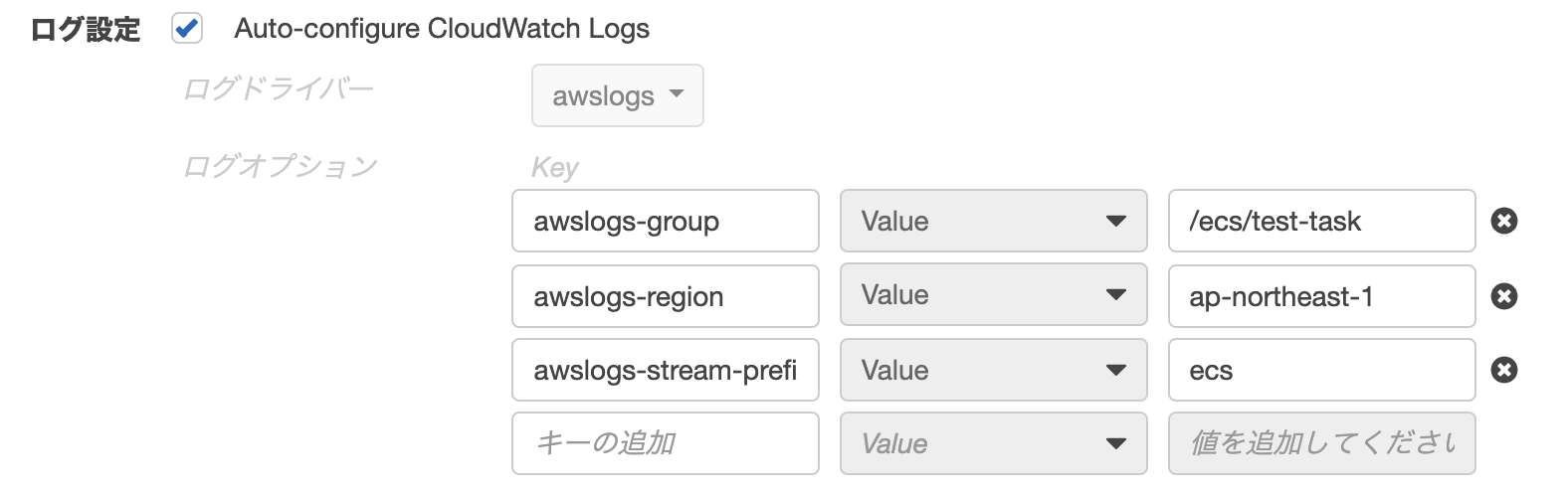
volumes_from: - service_name - service_name:ro - container:container_name - container:container_name:rwログ設定
Cloud Watchにログを出力する場合に使用する。
3-11. リソースの制限
コンテナのデフォルトのulimitsを上書きする。ulimitsディレクティブに相当。
コンテナが使用できるオープンファイルの数を制限する。デフォルトのソフト制限は1024。ハード制限は4096(Fagateの場合)
使用できるタスク数をもっと増やしたい/減らしたい場合に設定する。
3-12. Dockerのラベル
dockerの
--labelオプションに該当。コンテナにキー/値のラベル(メタデータ)を設定する。
4. 設定後のコンテナ設定後の例
ECRのイメージ、CPUユニット数、ソフト制限を設定したあとは次のようになる。
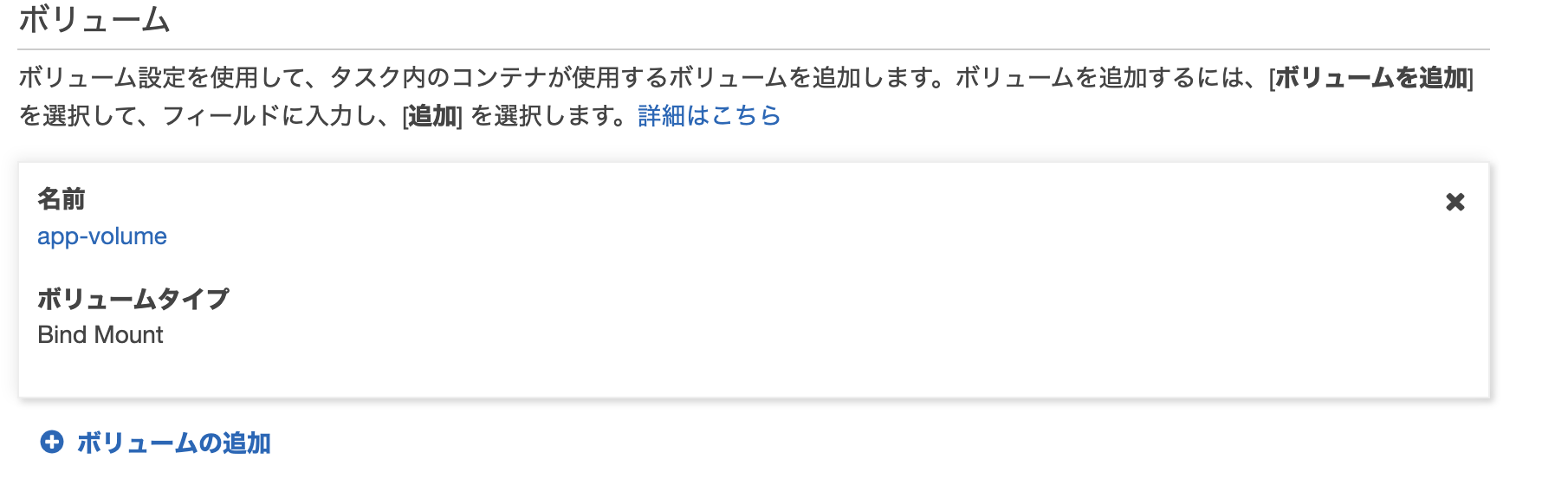
5. ボリュームの設定
サービス間で共有するボリュームがある場合はここで設定する。
docker-composeでサービス内ではなく、サービス外に定義したボリュームがここにあたる。
docker-composeの例version: "3.7" volumes: app-volume: app-db-volume: app-node_modules2: app-bundle2: services: db: container_name: db image: mdillon/postgis:10-alpine ports: - 5435:5432 volumes: - app-db-volume:/data
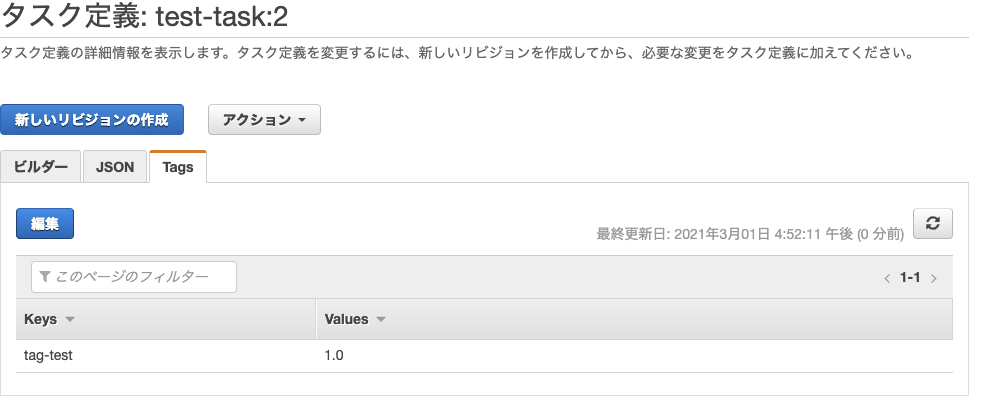
6. タグの設定
タスクを管理しやすくするために、タグを設定することができる。
コンテナとは直接的に関係ないが、このタスク定義が何を指すのかを記述する。
タスク定義内の「Tags」タブから確認できる。
7. タスク定義の作成
最後に右下の「作成」ボタンを押せば、タスク定義が完了する。
8. タスク定義の修正
「新しいリビジョンの作成」をクリックすることで、既存のタスク定義を編集し、新たなタスクを作成することができる。
編集後はタスク新しいタスクが追加されていく。過去のタスク設定もログとして残っていく。
タスク定義のステータスは「Active」にしておくこと。後ほどクラスターを作成するときに、どのタスク定義を使うかを選択するが、その際Activeになっているタスクしか選択できない。
タスク定義は以上。
9. タスクの設定事例
参考リンク
▼AWS タスク定義
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/task_definitions.html▼AWS コンテナの設定パラメータ
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/task_definition_parameters.html










- 投稿日:2021-03-01T12:35:56+09:00
【AWS】ECSの起動タイプの互換性とは?FARGATEって何やねん!?EC2との違いは何?
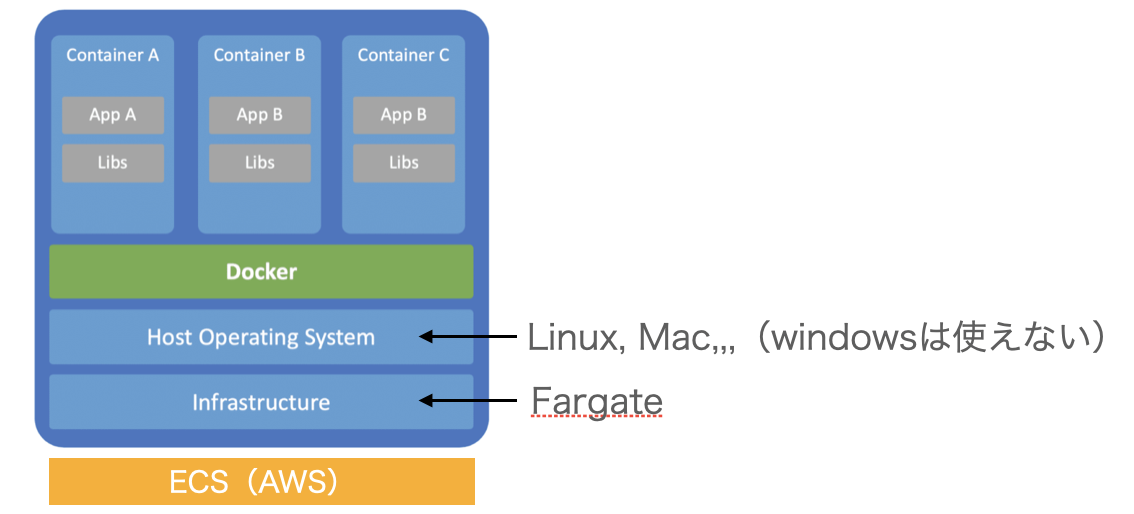
ローカルのDockerプロジェクトを、本番用としてAWS上に展開するサービスとして、ECS(Elastic Container Service)がある。
このECSでタスク定義など設定を行っていく際に必ず直面するのが、「起動タイプの互換性」や「FARGATEとEC2」といった用語。しかも、結構しょっぱなから出てくる、、
この、「起動タイプの互換性」や「FARGATEとEC2」を理解する。
目次
起動タイプの互換性とは?
AWSでコンテナを起動させるためには、そもそもコンテナを起動するためのGuest OS(Linuxなど)をインストールするサーバー(コンピュータ)を用意する必要がある。
この大元のインフラとなるサーバーが、ここでいう起動タイプとなる。
ECSでDockerサービスを展開するために使えるサーバーは(1)Fargateと(2)EC2の二つ。
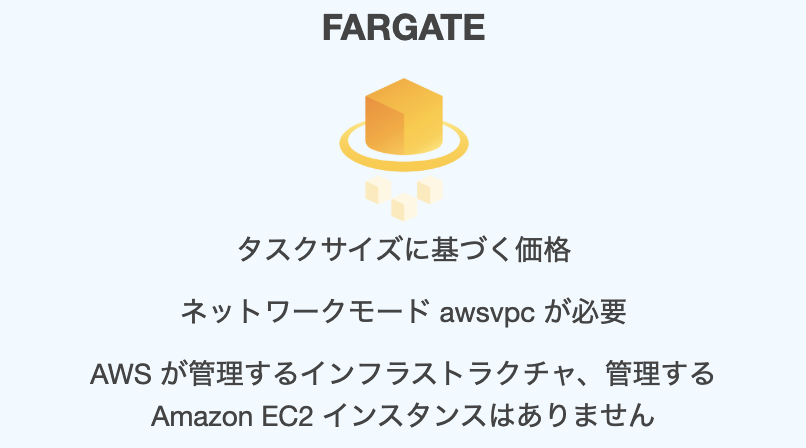
Fargateとは?
Fargateはファーゲートと読み、AWSが作ったサービス名で英語辞典にその意味は載っていない。
FargateはECS(AWS上)でコンテナを実行するためのサーバーの種類の一つ。保守管理が要らないのが最大の特徴。
AWSによると「コンテナ向けサーバーレスコンピューティングエンジン」とのこと。(これまたわかりにくい、、)
コンテナ向けサーバーレスコンピューティングエンジンって何?
保守管理のいらないコンテナ専用のサーバーという意味。
保守管理をAWSがやってくれるので、バージョンアップやセキュリティ対策など気にしなくていい超手間いらずなサーバー。
・サーバーレスとは?
サーバーがない(レス)という意味ではなく、保守管理のいらない(レス)サーバーということ。・コンピューティングエンジンとは?
プログラムの処理システムのこと。英語だとCompute Engineと書く。馴染みのある用語だと「仮想マシン」1台のコンピュータで複数のコンピュータを作動させる技術のこと。Dockerのコンテナの説明で、仮想マシンの上にコンテンがのっかているイメージをよく目にするが、まさにあれのこと。
Fargateを選択すると、GuestOSにwindowsは使えない。
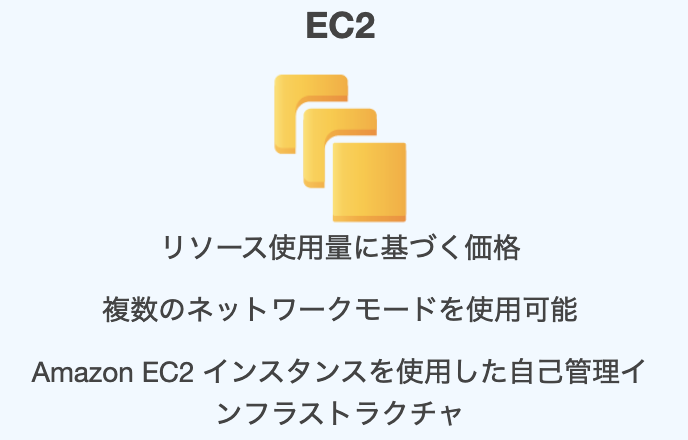
EC2とは?
ユーザーがAWSクラウドの中に自由に設計できるサーバーのこと。
Elastic Compute Cloudの略。Cから始まる単語二つを略してEC2と呼ばれる。
AWSによると「インスタンスと呼ばれる仮想コンピューティング環境」や「安全でサイズ変更可能なコンピューティング性能をクラウド内で提供するウェブサービス」とのこと。
・仮想コンピューティング環境とは?
仮想コンピューティング環境 = 仮想サーバーのこと。サーバーとしてはAWSの持つものが本体で、その中に更にサーバーを作るため、本体じゃないよという意味で「仮想」がつく。・インスタンスとは?
インスタンスは実態のこと。EC2を作る前は、AWSのクラウドがあるのみで、その中にサーバーは存在していない。サーバー(EC2)を自分で設計することで新しい仮想サーバーが生み出される。これを一つの実態と捉えて、一つの一つのEC2のことをインスタンスと呼ぶ。
インスタンスは一つ一つで起動・停止、またはコピー、削除もできる。
タスク定義の中のEC2とは?
タスク定義の最初に選択するEC2は、Dockerを展開するためのインフラとして、EC2サーバーを選択するという意味。
自由に設計できるサーバーなので、容量やセキュリティーの状況など自己管理する必要がある。
FargateとEC2の違いは?
FargateもEC2もどちらもAWS上の仮想サーバー。
ECSのタスク定義では、Dockerやコンテナを作成するための大元のインフラ環境となる。
どちらを選んでもいいが、FargateはAWSが運用保守管理をしてくれる手間要らずのサーバー。
EC2は自己管理ができるサーバーとなる。
FargateとEC2どっちを選べばいいの?
基本的にはFargateを選べばOK。
FargateはECSのサービスをより使いやすくするためにAWSが作成した専用のサーバー。
EC2でいちいちサーバー構築して保守管理するのめんどくさいというユーザーの悩みを解決してくれている。
もちろん、自分で保守管理したいといったニーズがあればEC2を選択してコンテナを作成していくことも可能。
- 投稿日:2021-03-01T12:17:24+09:00
Fargate PV 1.4.0 では空文字のコマンド引数が無視されるから気を付けた方がいい
tl; dr
- Fargate プラットフォームバージョン 1.4.0 では、コンテナで実行するコマンドの引数に空文字を渡すと無視される。
- Fargate プラットフォームバージョン 1.4.0 を使用する限り、この挙動は回避できない模様。
- 現時点で引数に空文字を使うには Fargate プラットフォームバージョン 1.3.0 を利用するしかない模様。
検証
Dockerfile
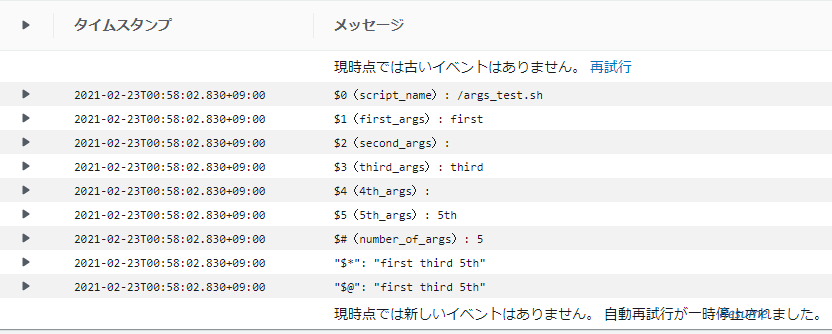
FROM alpine:3.13.2 RUN echo 'echo "\$0(script_name): $0"; \ echo "\$1(first_args): $1"; \ echo "\$2(second_args): $2"; \ echo "\$3(third_args): $3"; \ echo "\$4(4th_args): $4"; \ echo "\$5(5th_args): $5"; \ echo "\$#(number_of_args): $#"; \ echo "\"\$*\": \"$*\""; \ echo "\"\$@\": \"$@\""' > /args_test.sh CMD ["/bin/sh", "/args_test.sh", "first", "", "third", "", "5th"]Fargate PV 1.3.0 での実行結果
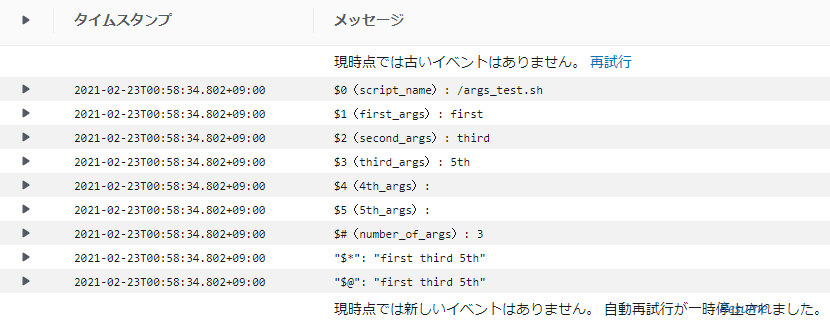
Fargate PV 1.4.0 での実行結果
どうすべきか
- LATEST が 1.4.0 に変更されるにあたって、検証を行う際はネットワーク周りの確認だけでなく、コンテナの最終的な実行結果まで確認を行った方が良さそう。
- その確認が難しいようであれば、現時点では 1.3.0 に固定するのが無難そう。
- また、タスク定義やタスク実行時の CMD 上書きでも再現するため、動的に引数を設定している様なタスクでは、さらに検証で注意が必要である。
- 投稿日:2021-03-01T11:46:30+09:00
AWSの基本的なサービスと機能を整理したで
はじめに
- AWSのサービスと機能は共通点が複雑なところもあるので、自分用にまとめてたものがありました。
- 僕がAWSクラウドプラクティショナーを受験した時の内容なので変わってるかもしれません。(2021/2/14現在)
- AWS認定資格クラウドプラクティショナーの一発合格体験記 の続きになります。よければこちらも参考にしてください。
サービスごとの整理
EC2
- アウト通信に転送料金が発生する。
- EC2からS3にアクセスするにはEC2インスタンスにIAMロールを指定する。
- 数ヶ月利用しない場合、AMIを作成してから削除する。
- EC2だけを停止してもEBSボリュームが残るため。
- AMIにはEC2のほか、EBS、管理情報も含まれる。
- AutoScalling
- 起動設定は「AutoScallingグループ」「AutoScallingポリシー」「インスタンスタイプ(=性能)」を指定する。
- 水平スケーリングが行いやすい。
- 水平スケーリングのうちサーバーを増やすのがスケールアウト。=停止不要。
- 垂直スケーリングのうち性能を上げるのがスケールアップ。=停止必要。
- インスタンスタイプ
- オンデマンドインスタンス=定価料金。
- リザーブドインスタンス通常=1-3年の利用で割引が適用できる。
- リザーブドインスタンスコンバーチブル=インスタンスファミリー変更可。
- 最安値はリザーブド&3年契約&前払い&スタンダード。
- スポットインスタンス=検証、動画編集で利用。止まっても大丈夫な時に利用。
- EC2インスタンス作成時にプロビジョニングできる機能はユーザーデータ。
- EC2インスタンスにSSH接続するときは、キーペアを使用する。
- EC2インスタンスにSSH接続できない場合は、プライベートIPアドレスを指定してる。
- デフォルトでは冗長化されない。
- サーバーレスではない、典型的なアンマネージドサービス。
- そのため、定期的なパッチあてがユーザー側に求められる。
- ログファイルを取得する時には、CloudWatchログを使用する。
- インスタンスに関連づけられてないElasticIPは課金対象になる。
- 停止しているインスタンスに関連づけている場合もElasticIPは課金対象になる。
EBS
- EC2にネットワーク越しでアタッチする。
- 同一AZ内のインスタンスにのみアタッチできる。
- 複数のEBSが1つのEC2にアタッチできるが、複数のEC2にアタッチできない。
- 複数のEC2にアタッチする場合には、EFSを使用する必要がある。
- AZ内の複数サーバーに自動レプリケートされる。
- あとからストレージタイプを変更できる。
- あとからストレージ容量を増やすことができる。
- デフォルトで暗号化される。
- 永続的なストレージ。
- 一時的なストレージにはインスタンスストア(EC2に物理的に接続)を利用する。
- バックアップはS3のスナップショットを使用する。
- ボリュームタイプ
- プロビジョンド IPOS SSD=16,000を超えるIOPSが必要な場合に使用。
- 汎用SSD=最大で16,000IOPSが必要な場合に使用。一定の性能を約束しない。
- スループット最適化SSD=コスト節約する必要、SSDほど性能が不要な時。
- スナップショットは非同期のㅤため書き込みとタイミングがかぶると誤差が生じる。
- EBSには絶えず変化するようなデータの保存が向いてる。
- 高性能で高可用性だが、高速処理ができない。
- ボリュームの暗号化には、KMSを使用する。
- リージョンを跨いで、スナップショットによる復元ができる。
セキュリティグループ
- EC2インスタンスに紐づけられ、デフォルトでインバウンドアクセス拒否されている。
- 許可するものを指定していくホワイトリスト作成方式。
- ステートフルのため、通信の復路は動的に許可する。
- ルールは全て適用される。
ネットワークACL
- VPCのサブネットに紐づけられ、デフォルトでインバウンドアクセス許可されている。
- ステートレスのため、通信の復路も検査する。
- ルールは番号の低い順に適用される。
- 特定のIPアドレスから不正アクセスを受けた場合、このアドレスからのアクセスを拒否できる。
S3
- オブジェクトは複数のAZに自動的に冗長化される。
- リージョンに配置される。
- S3に保存したデータの暗号化には、「S3で管理されたキー」「KMSで管理されたキー」を使用する。
- アウト通信に転送料金が発生する。
- デフォルトでフォールトトレランスを考慮した設計になっている。
- ストレージタイプ(可用性、耐久性を備えている)
- 標準タイプ
- 標準IA定頻度アクセス
- 1ゾーンIA=アクセス頻度が少なく、冗長化される可用性を必要としない。
- Glacier=単独で利用できる、アーカイブ用。
- アクセス権限は「アクセスコントロールリスト(ACL)」「バケットポリシー」「IAMポリシー」で設定する。
- アクセスログはELBに保存する。
- S3 Transger Acceleration
- エッジロケーションを利用する。
- クライアントとS3バケットの長距離間でファイルを高速&簡単&安全に転送できる。
- Strage Gatewayにより、オンプレ用の長期的なデータバックアップに使用できる。
- 静的ウェブホスティングやCloud Front向けのメディアデータ保存に向いている。
ELB
- ALB
- レイヤー7でHTTP/HTTPSをサポート。
- NLB
- レイヤー4でTCPをサポート。
- アクセスログはS3に保存される。
- サーバー毎ロードバランシングするにはALBでパスルーティングする。
Global Accelerator
- 地理的に近いエンドポイントにトラフィックをルーティングする。
- 世界中のユーザーに対して提供する。
CloudWatch
- 標準メトリクスは、CPU使用率、バイト数、トラフィックを取得。
- カスタムメトリクスは、メモリ使用率などを取得できる。
- 有料サービス。
Route53
- 正常なエンドポイントのみトラフィックをルーティングさせ、ヘルスチェックを行う。
- DNSサービスとドメイン登録を提供する。
- エンドユーザーの最も近いデータセンターにルーティングする。
- レイテンシーベースのルーティングは1つのドメインに対して複数のDNSレコードを用意することで、低レイテンシーを実現している。
Cloud Front
- 世界中のユーザーがAPIリクエストとレスポンスのレイテンシーを抑えるために利用。
- API Gatewayと連携すべきサービス。
- WAFとも連携すべきサービス。
Sage Maker
- 機械学習モデルを構築&トレーニングするフルマネージドサービス。
Dynamo DB
- リージョンに設置する。
- デフォルトでフォールトトレランス設計になっている。
- 複数のAZに自動保存される。
- セッションデータを高速に処理することができる。
- フルマネージドのNoSQL型データベース。
- ゲームの行動記録処理、IoTデータの蓄積、銀行の入出金記録の蓄積。
- DynamoDB Stream を使用すると、クロスリージョンレプリケーションが有効になる。
- DAXを使用するとリクエストのレイテンシーをミリ秒→マイクロ秒に短縮できる。
- 利用負荷があらかじめ予測できる場合は、プロビジョンドスループット選択する。
Managed Apache Cassandra
- OSSと互換性のあるNoSQL型データベース。
- スケーラブルで可用性が高いマネージドデータベース。
RDS
- デフォルトで自動バックアップされる。
- バックアップはリージョンのS3に保存される=RDSと同じAZに保存されない。
- スナップショットを定期的に保存するためにTransfer Accelerationを利用する。
- リードレプリカが備わっている。
- 可用性の担保ができ、データの冗長化ができるので災害復旧対応ができる。
- 読み取り速度の負荷分散ができるので、読み込みの軽減が実現できる。
- 同AZでも別AZでも機能する。
- マルチAZ構成がとられているので信頼性が担保される。
- プライマリDBが応答しない場合自動でフェイルオーバーを行う。(=ホットスタンバイ)
- 銀行の振り込み処理に利用できる。
- 暗号化の対象は「インスタンス」「自動バックアップ」「スナップショット」。
- ストレージサイズは増やすことだけ可能。
- インスタンスタイプは減らすことができる。
ElastiCache
- デフォルトで自動バックアップ。
- インメモリ型のNoSQL型キャッシュデータベース。
- アプリのレスポンスが高速に処理できるよう頻繁にアクセスするデータを保存。
- IoTアプリのデータレイヤーなどミリ秒未満のレイテンシーを必要とするサービスに利用。
Redshift
- 数ペタバイト規模のデータウェアハウス。
- フルマネージドのリレーショナルデータベース。
- BIツールとして利用可能。
- セッションデータの解析に利用できる。
Snowball edge
- 数ペタバイトのデータ転送に利用。
- 1エクサバイトのデータ転送にはSnowmobileを使用。
- 機械学習の実行に利用可能。
- オフラインでも使用できる。
- オンプレミスからAWSクラウドへ移行のための安全で大量データの転送を実現可能。
EMR (Elastic Map Reduce)
- ビッグデータのセット分析や処理を行うために使用する。
- 大規模環境でHadoopを使った大量データ処理など。
- ストリーム分析やETL(抽出、変換、読み込み)に利用できる。
- HadoopやSparkなどビッグデータフレームワークとして使用。
- マネージド型クラスターデータプラットフォーム。
- IoTの大量データセット分析・処理にも役立つ。
NATゲートウェイ
- マネージドサービスでパブリックサブネットに指定する。
- NATインスタンス
- マネージドでないため冗長化しておらず単一障害点になりやすい。
- パブリックサブネットに指定する。
Lambda
- サーバーレスサービス。
- リクエストの受信回数に合わせて自動スケールするため、ユーザーがAutoScallingを設定する必要なし。
- 料金は時間単位ではなく、ミリ秒単位で発生する。
- 主要なプログラミング言語がサポートされている。
- 呼びだされた時だけコンピュートリソースを確保してコード実行する。
Fargate
- サーバーレスサービス。
- ECSとEKSの両方で動くコンテナ向けサーバーレスコンピューティングエンジン。
ECS (Elastic Container Service)
- EC2インスタンスのクラスタでコンテナ化されたアプリを実行できる。
EKS (Elastic Kubernates Service)
ECR (Elastic Container Registry)
- DockerコンテナイメージをAWSに保存するサービス。
- フルマネージドサービス。
Guard Duty
- 不審な疑わしいアクティビティを検知する。
- VPCフローログを解析するほか、IPドレスやドメインリストも解析する。
OpsWork
- ChefやPuppetを使用してEC2インスタンスの構成方法を自動化する、構成管理サービス。
Elastic BeanStalk
- アプリケーションを素早くデプロイし管理を自動化する。
- .NETやPython、Go、Node.jsなどをサポート。
- アプリのプロビジョニング、負荷分散、AutoScalling、モニタリングなどを提供する。
CloudFormation
- テンプレートに記載したコードに基づいてインフラを展開できる。
- 無料で利用できる。
- AWS環境セットアップの自動化ツール。
- インフラストラクチャをコード化するための管理サービス。
StepFunction
- コードを記述することなく(ノーコード)、アプリケーションにワークフローオートメーションを数分で追加できる。
AWS Config
- AWSリソース設定を評価、審査できる。
- リソース設定をモニタリングし、評価を自動化する。
System Manager
- 統一されたユーザーインターフェースを介して複数のAWSサービスからの運用データを可視化する。
- 運用タスク(メンテナンス、デプロイタスク自動化、スケジューリング)を自動化する。
- インフラストラクチャを可視化し制御する、一元的に運用作業項目を表示、調査、解決する。
- 選択した目的やアクティビティごとにAWSリソースをグループ化する。
Cloud HSM
- クラウドで暗号化キーを管理するためのハードウェアセキュリティモジュール。
- グローバルの業界スタンダードの暗号化対応を保証する。
Cognito
- モバイルアプリからAWSリソースにアクセスできるサービス。
STS(Security Token Service)
- AWSリソースに対して一時的な認証情報を提供する。
Inspector
- セキュリティの自動化評価を行いデプロイしたアプリのセキュリティとコンプライアンスを向上できる。
- 事前に定義したセキュリティテンプレートに対してEC2インスタンスを分析し脆弱性を診断する。
Trusted Advisor
- 以下5項目の向上を支援。
- コスト最適化(インスタンスタイプの見直し、使用率の高いEC2、ElasticIP状態など)
- パフォーマンス(セキュリティグループの増大など)
- セキュリティ(S3バケットアクセス、MFA、セキュリティグループの開ポートなど)
- フォールトトレランス耐障害性(EBSスナップショット、RDSマルチAZ構成など)
- サービス制限(意図しないアクションを避ける)※この項目利用は事前申請が必要。
- 全ての項目を利用できるのはビジネスプランとエンタープライズプランのみ。
機能ごとの整理
MFAを有効にするために使用するサービス
- CLI
- IAM
コンプライアンスと脆弱性のリアルタイムモニタリング
- Config
- Inspector
- Trusted Advisor
VPCのマネジメントコンソールから操作可能なサービス
- セキュリティグループ
- インターネットゲートウェイ
ルートユーザーアカウントがある場合の保護するための方法
- アクセスキーを作成しない。
- すでにある場合は削除する。
- 保持しなければならない場合は定期的に回転(変更)する必要あり。
99%稼動が要件のサービス、99.9999999999%稼動が要件のサービスで利用する方法
- マルチAZ展開(前者)
- マルチリージョン展開(後者)
はじめからデフォルトでマルチAZ構成設計になっているサービス
- DynamoDB
- S3
AWS環境セットアップ自動化に使用するツール
- CloudFormation
- Elastic BeanStalk
サーバーレスサービス
- Lambda
- Fargate
デフォルトで自動バックアップするサービス
- RDS
- ElasticCache
- Redshift
DDoS攻撃を緩和できるサービス
- Cloud Front
- WAF
- Shield
EBSの価格に影響をあたえるもの
- GBサイズのデータ容量
- アウトバウンドのデータ転送量
- スナップショット
自動でスケーリングするサービス
- Lambda
- S3
AZ間でデータを自動的にレプリケートするサービス
- S3
- DynamoDB
最後に
何か質問や訂正箇所あればコメントまで!
みなさまが一発で合格できますように?ではでは?
- 投稿日:2021-03-01T11:24:58+09:00
マルチクラウド下でのTerraformのディレクトリを改めて考える
概要
TerraformはAWSやGCPなどのクラウドを管理するための構成管理ツールですが、
自分でtfファイルやディレクトリ構成の粒度を決めれます。
Terraformでマルチクラウドを扱う時にどのような粒度でディレクトリを分ければいいのかを考えていきます。前提条件
Terraformを使う場面は様々ですが、今回はGCPとAWS2つのクラウドをTerraformで管理することを前提とします。
またAWSはステージングアカウントと本番アカウント2つある前提で話します。※様々な流派がTerraformにあるのですが、今回はシンプルにしたいのでworkplaceやmoduleは使わないです
以下が今回例として扱うGCPとAWSの状態です。
AWSアカウント: - prodアカウント ・・・ 本番環境用 - stgアカウント ・・・ ステージング環境用/開発環境用 GCPアカウント: - anlytics folder ・・・ 分析環境用のfolder |- prod project ・・・ 本番分析環境用のプロジェクト |- stg project ・・・ ステージング分析環境用のプロジェクト |_ dev project ・・・ 開発分析環境用のプロジェクト - corporate folder ・・・ 社内ツール用のfolder |- prod project ・・・ 本番社内ツール環境用のプロジェクト |- stg project ・・・ ステージング社内ツール環境用のプロジェクト |_ dev project ・・・ 開発社内ツール環境用のプロジェクト各クラウドの特徴
AWSとGCPの特徴は色々あるのですが、Terraformで扱う上で一番の違うはnamespaceの違いだと思います。
AWS: 1アカウントでnamespaceを分けて複数の環境を管理しづらい
GCP: 1アカウントでFolder/Projectごとに環境を分けて管理できるAWSは1アカウントで役割ごとにVPCをなどのAWSサービスを分けても強権のIAMを持っていれば、
アカウント内にあるどのAWSサービスでも触ることができます。
ですが、GCPはこのProjectでは強権を持っているが、別のProjectでは強権を持たせない等の振り分けができます。Terraformのディレクトリ案
上記を踏まえた上で以下の案があります。
案1: 環境ごとで分ける
- メリット
- 階層が深くないのでどのような環境があるかがパッと見でわかる
- デメリット
- どのクラウドでどのアカウントを扱っているのかがわからない
main/common ・・・ 環境共通用tfファイル郡 /prod ・・・ 本番環境用tfファイル郡 /stg ・・・ ステージング環境用tfファイル郡 /dev ・・・ 開発環境用tfファイル郡案2: サービスごとに分ける
- メリット
- GCPとAWSが密接に関わっているアプリケーションがあると表現がしやすい
- デメリット
- どのクラウドでどのアカウントをあつかっているかが分かりづらい
main/common ・・・ サービス共通用tfファイル郡 /frontend ・・・ フロントエンドサービス用のディレクトリ /prod ・・・ 本番フロントエンド環境用tfファイル郡 /stg ・・・ ステージングフロントエンド環境用tfファイル郡 /dev ・・・ 開発フロントエンド環境用tfファイル郡 /backend ・・・ バックエンドサービス用のディレクトリ /prod ・・・ 本番バックエンド環境用tfファイル郡 /stg ・・・ ステージングバックエンド環境用tfファイル郡 /dev ・・・ 開発バックエンド環境用tfファイル郡 /corporate ・・・ 社内ツール環境用のディレクトリ /prod ・・・ 本番社内ツール環境用tfファイル郡 /stg ・・・ ステージング社内ツール環境用tfファイル郡 /dev ・・・ 開発社内ツール環境用tfファイル郡 /analytics ・・・ 分析サービス用のディレクトリ /prod ・・・ 本番分析環境用tfファイル郡 /stg ・・・ ステージング分析環境用tfファイル郡 /dev ・・・ 開発分析環境用tfファイル郡案3: クラウドごとアカウント(folder)ごと環境ごとで分ける
- メリット
- どのクラウドでどのアカウント(folder)があり、どんな環境があるかわかる
- デメリット
- ディレクトリ階層が深いので、ディレクトリ構造が分かってないと分かり辛い
main/aws ・・・ aws用のディレクトリ /prod ・・・ 本番AWSアカウント用のディレクトリ /common ・・・ 本番AWSアカウントで共通に使うもののtfファイル群 /prod ・・・ 本番環境用tfファイル郡 /stg ・・・ ステージングAWSアカウント用のディレクトリ /common ・・・ ステージングAWSアカウントで共通に使うもののtfファイル群 /stg ・・・ ステージング環境用tfファイル郡 /dev ・・・ 開発環境用tfファイル郡 /gcp ・・・ gcp用のディレクトリ /anlytics ・・・ gcp分析環境folder用のディレクトリ /prod ・・・ 本番分析環境用tfファイル郡 /stg ・・・ ステージング分析環境用tfファイル郡 /dev ・・・ 開発分析環境用tfファイル郡 /corporate ・・・ gcp社内ツール環境用のディレクトリ /prod ・・・ 本番社内ツール環境用tfファイル郡 /stg ・・・ ステージング社内ツール環境用tfファイル郡 /dev ・・・ 開発社内ツール環境用tfファイル郡結論
今回の例であれば、ディレクトリでクラウド、アカウントを表現している
案3か、サービスごとに分ける案2が運用しやすいと思います。もしAWSとGCPが疎結合であれば、
案3を採用するとどのクラウドのどのアカウントにどういうリソースがあるのかがパッとわかるので事故を防止できて運用しやすいと思いますし、AWSとGCPが密結合であれば、
案2を採用し、サービスという単位で管理すると各クラウドの環境ごとにTerraformを適用し、それぞれで整合性をとる必要がないので運用がしやすいと思います。
案1の場合は、AWSだけでTerraformを使って管理する場合、もしくはマルチクラウド 間、マルチサービス間(上記の例だとAWSとGCP、フロントエンドサービスとバックエンドサービス)が密結合である場合に採用することをお勧めします。
- 投稿日:2021-03-01T10:47:24+09:00
Route53を用いてCloudFrontに独自ドメインを設定する
1 はじめに
皆さんはRoute53を用いてCloudFrontに独自ドメインを設定したいと思ったことはありますか?
私はあります。
CloudFrontのURLを見かけるたびに独自ドメインを設定したくてウズウズしてしまいます。
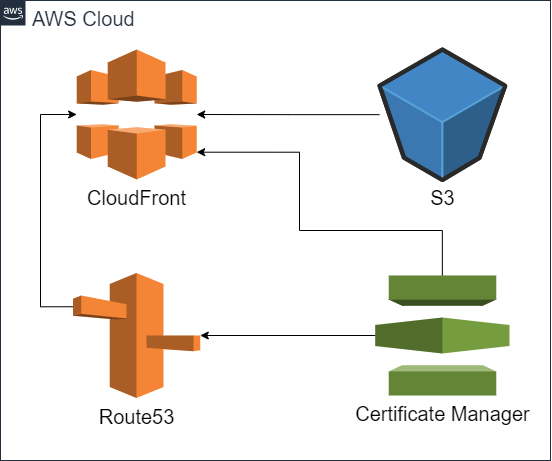
さすがに見知らぬURLに独自ドメインを設定することはできないため、この記事にて勘弁してください。2 全体イメージ
このようなイメージで作成します。
ACMでサーバー証明書を作成し、それをCloudFrontとRoute53に紐づけます。
Route53をCloudFrontに紐づければ完了です。
3 実施手順
以下の手順で実施します。
1 ドメイン取得可否確認
2 Route53のホストゾーン作成
3 ドメイン取得・Nameservers登録
4 Certificate Managerでのサーバー証明書作成
5 S3バケット作成
6 CloudFrontディストリビューション作成
7 Route53レコード作成1 ドメイン取得可否確認
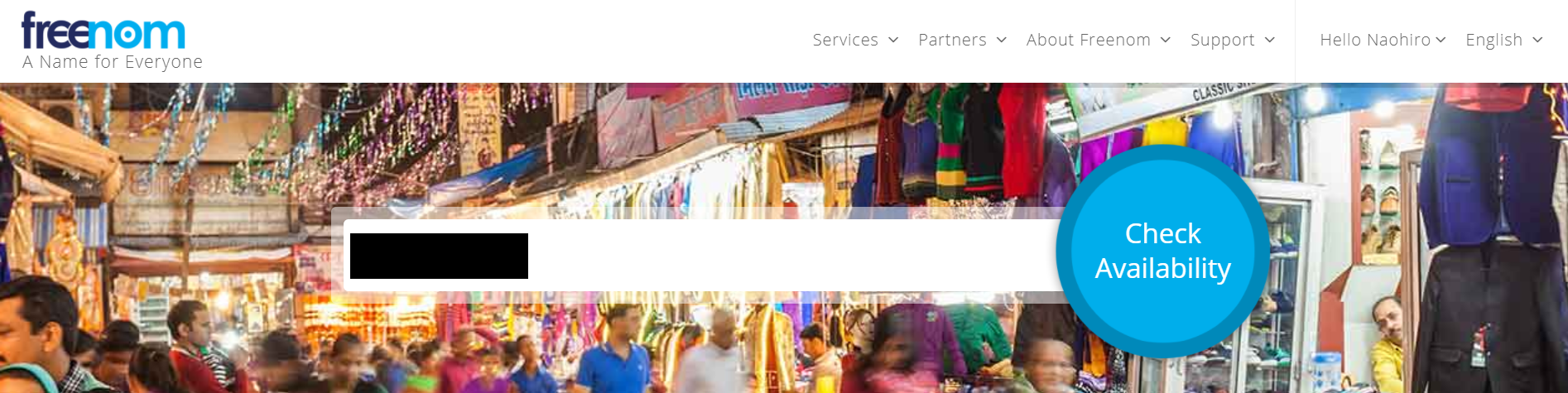
私は以下サイトにて無料ドメインを取得します。
https://my.freenom.com/clientarea.phpすでにドメインを取得している方はそちらを、そうでない方は私と一緒にこちらのサイトで作成しましょう。
まずは、アカウントを作成してください。アカウント作成後、以下のような画面になるのでドメインが取得可能かチェックしておきましょう。
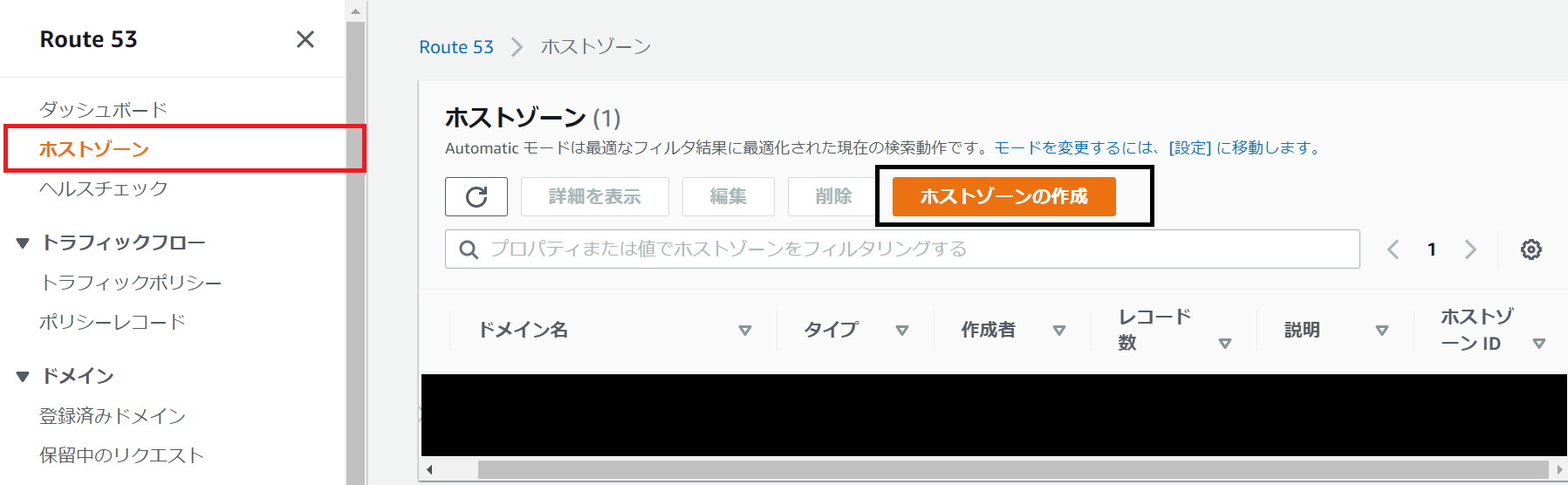
2 Route53のホストゾーン作成・NameServers登録
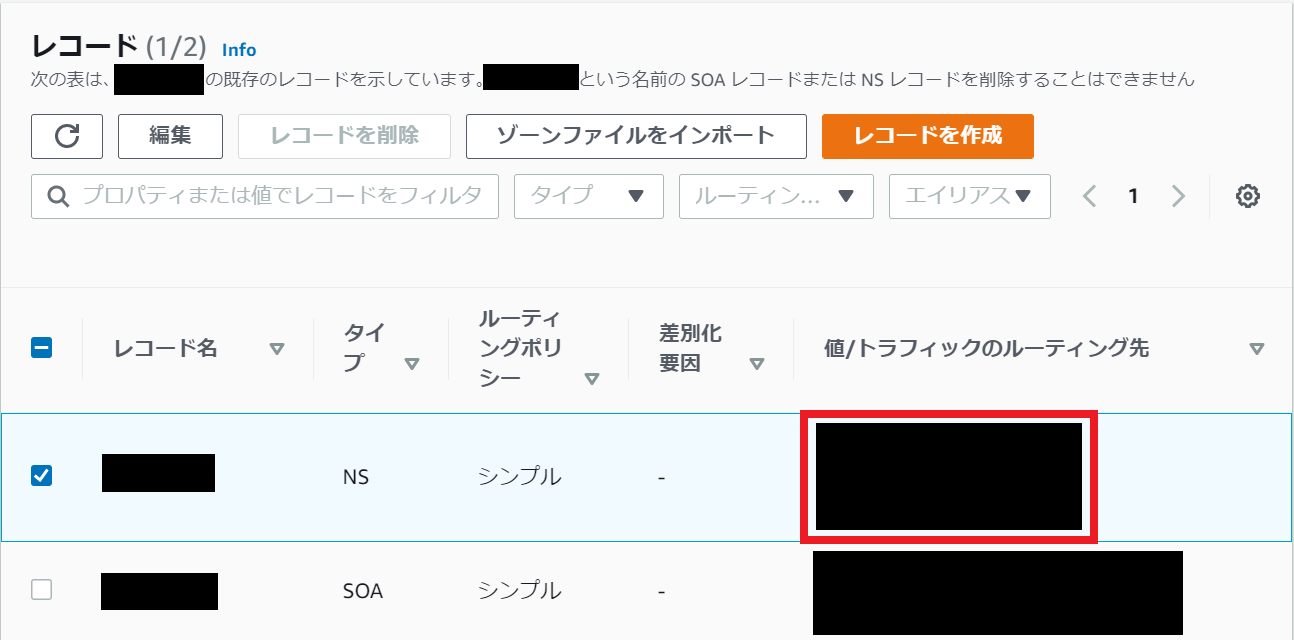
Route53にてホストゾーンの作成を行います。ドメイン名は先ほどの取得可能なものを使用します。
ホストゾーン作成後、NSレコードが4つ作成されるため、これらを控えましょう。
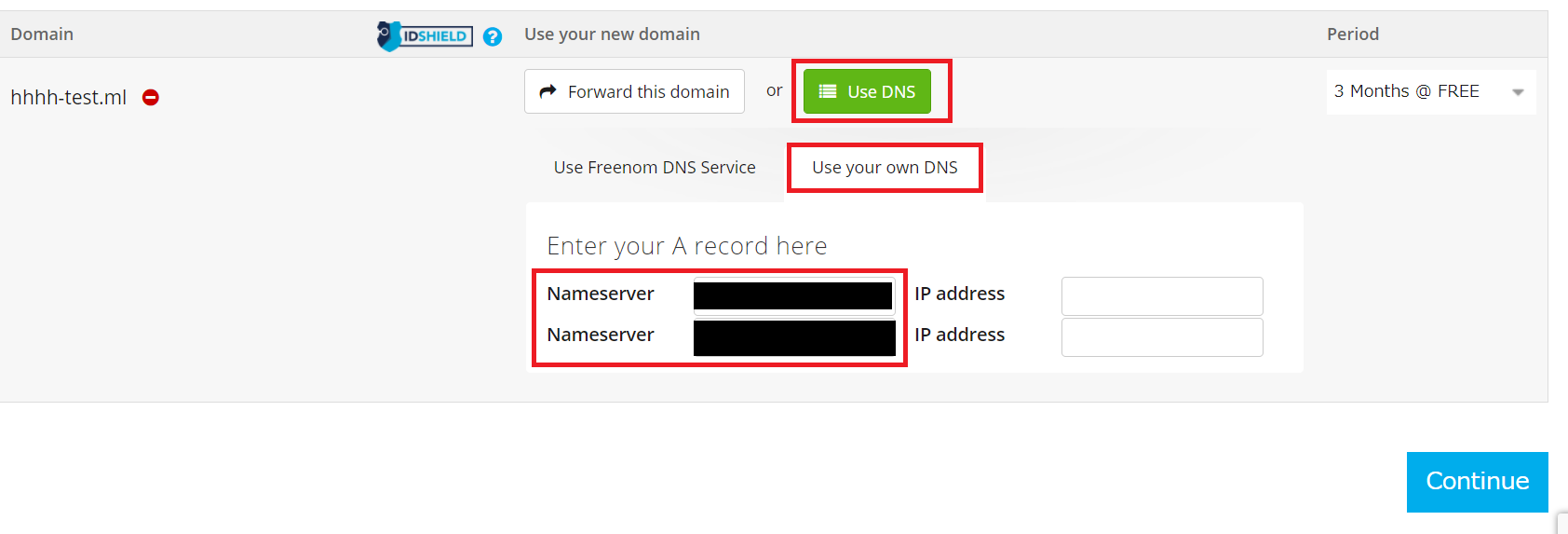
3 ドメイン取得・Nameservers登録
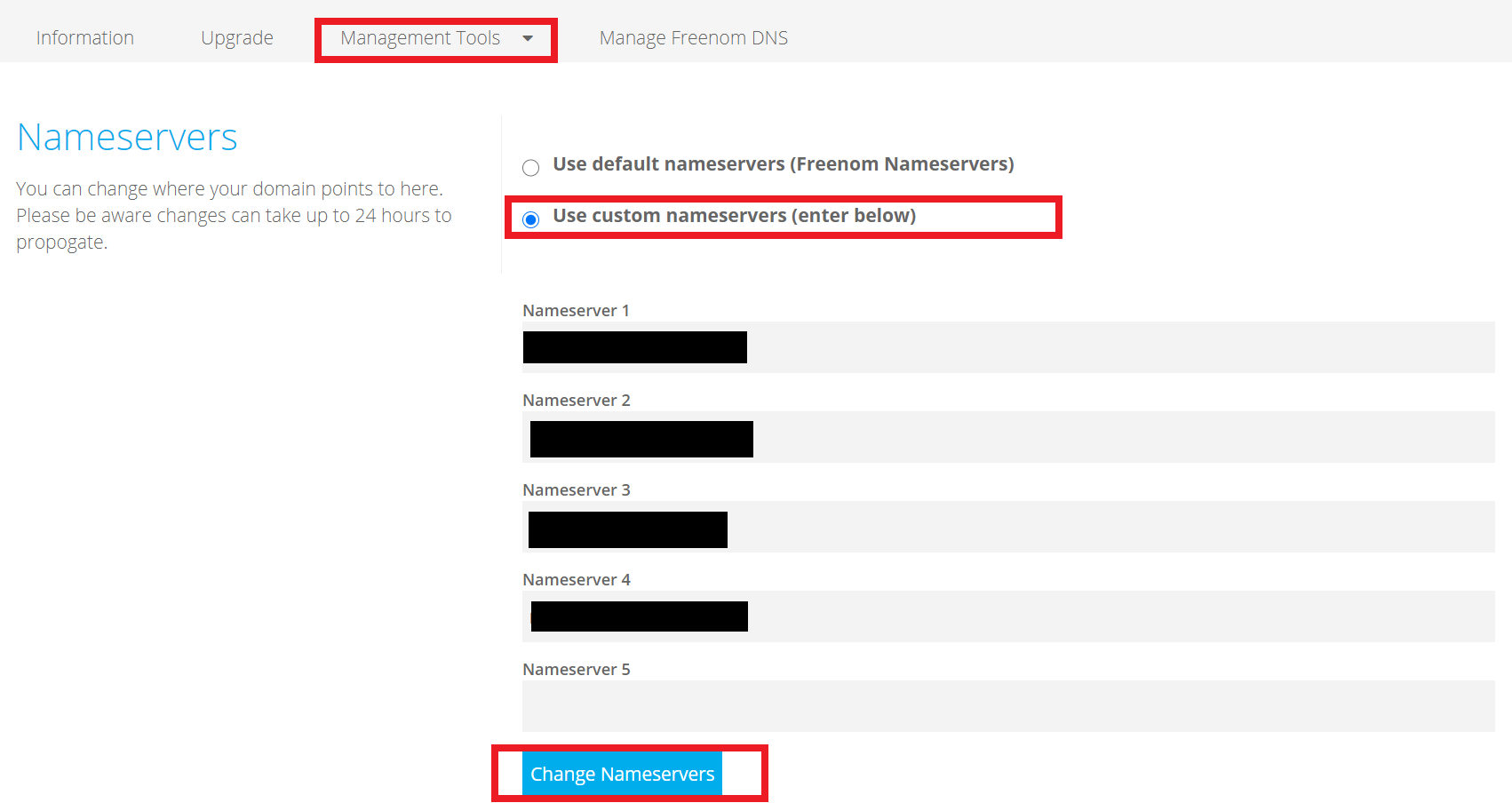
freenumに戻って作業します。先ほど確認したドメインをCheckOutし、「Use DNS」→「Use Your own DNS」→「Nameserver」に、先ほどのNSレコードを二つ入力します。(末尾の「.」は不要ですので消してください。)
その後、My Domainにてドメインを選択し、「Management Tools」→「Nameservers」を選択します。こちらに残りのNSレコードを記入し、登録します。
(末尾の「.」は不要ですので消してください)
Nameserversの登録はfreenumでは最大で24時間かかります。以下コマンドを用いれば ANSWER SECTION: に登録完了したNameserverが表示されます。$ dig NS <ドメイン名>4 Certificate Managerでのサーバー証明書作成
AWS Certificate Manager(ACM)を利用し、SSL/TLS通信(HTTPS)に必要なサーバ証明書を発行します。CloudFrontでACMを利用するにはリージョンをバージニア(us-east-1)に設定します。
大事なことなのでもう一度言いますが、リージョンをバージニア(us-east-1)に設定します。
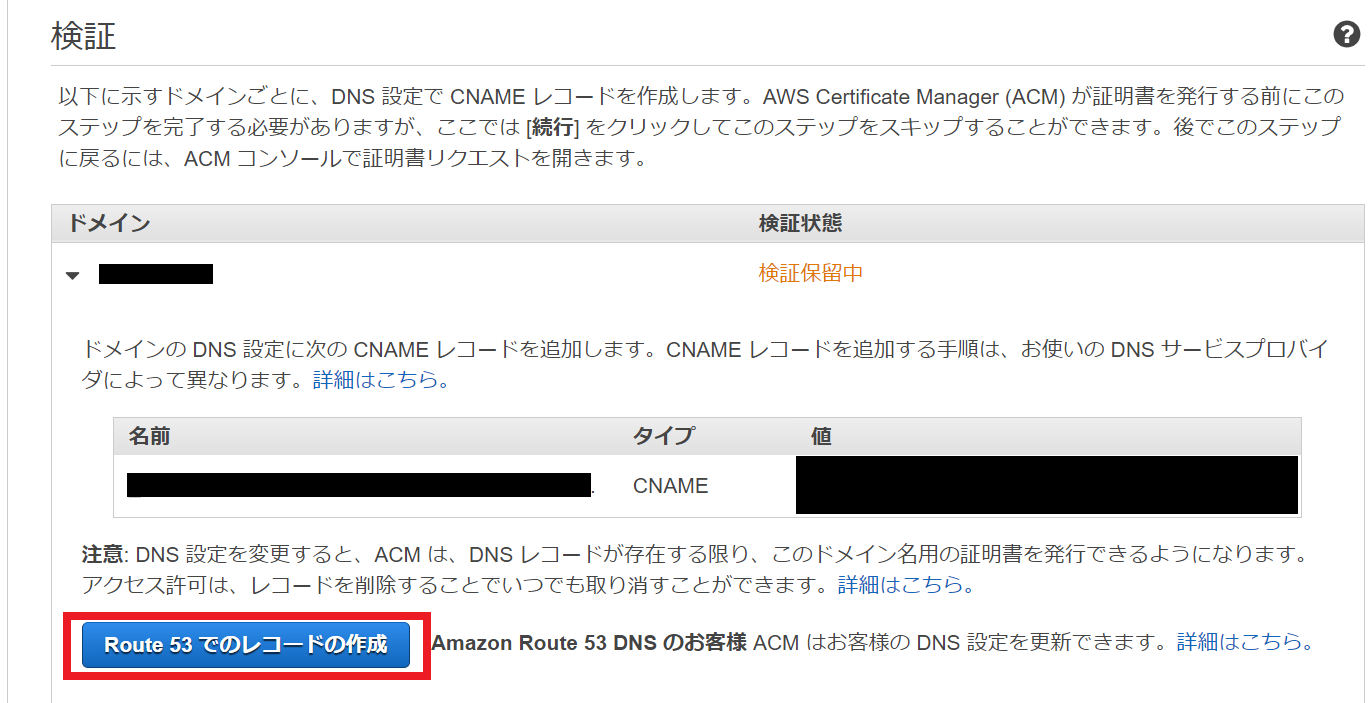
まず、「証明書のリクエスト」をクリックします。証明書のタイプは「パブリック証明書のリクエスト」を選択しましょう。ドメイン名は今回利用するドメインを指定し、「DNS の検証」を選択します。
「確定とリクエスト」をクリックしたら検証について表示されます。「Route53でのレコードの作成」を選択し、レコードを作成しましょう。
なお、手順2のNameserver登録完了していなければ証明書の検証は終わりません。焦らずに待ちましょう。
5 S3バケット作成
S3バケットの作成を行います。バケットの作成をクリックし任意のバケット名で作成します。(私はドメイン名で作成するのをお勧めします。)パブリックアクセスはブロックするようにしましょう。
6 CloudFrontディストリビューション作成
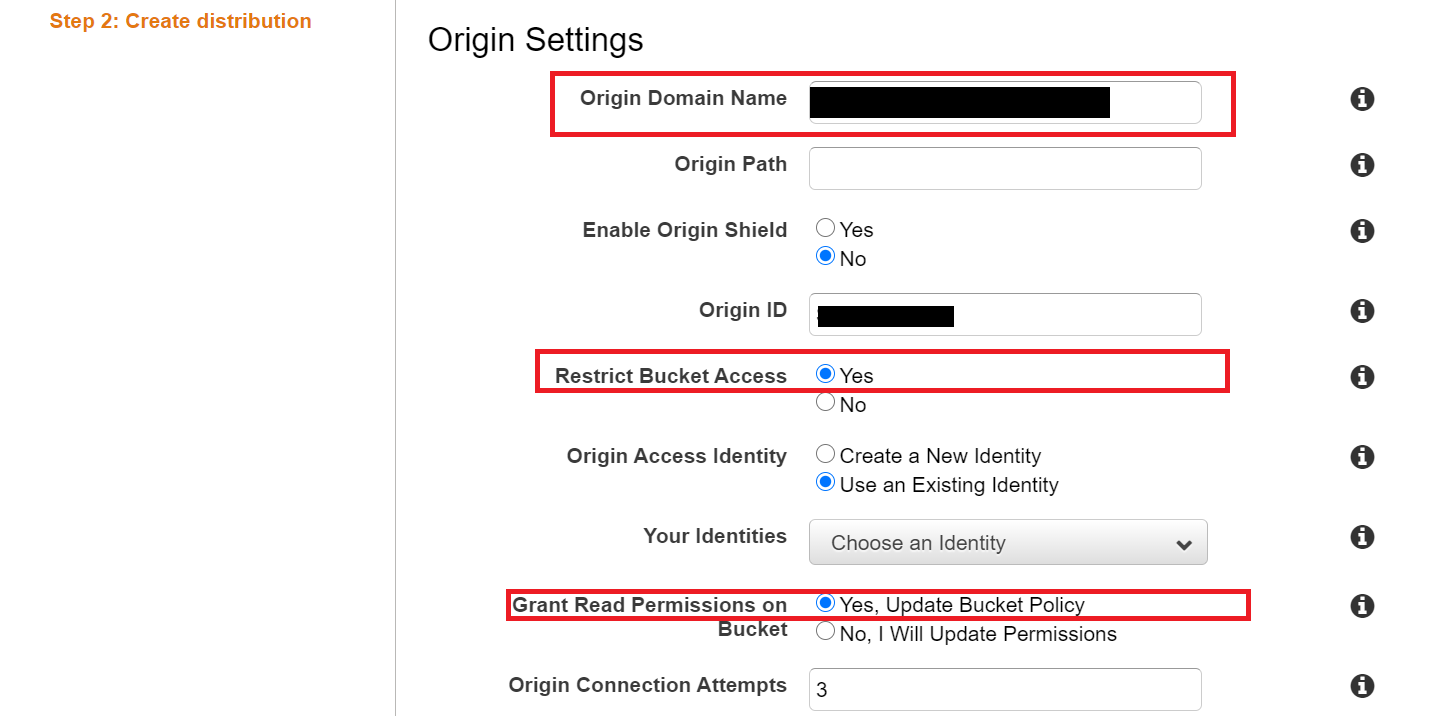
Create Distributionでディストリビューションを作成します。
Origin Settingsに関しては、Origin Domain NameでS3のバケットを指名し、Restrict Bucket AccessをYesにします。Origin Access Identityは必要に応じ選択してください。Grant Read Permissions on Bucket を「Yes, Update Bucket Policy」にします。
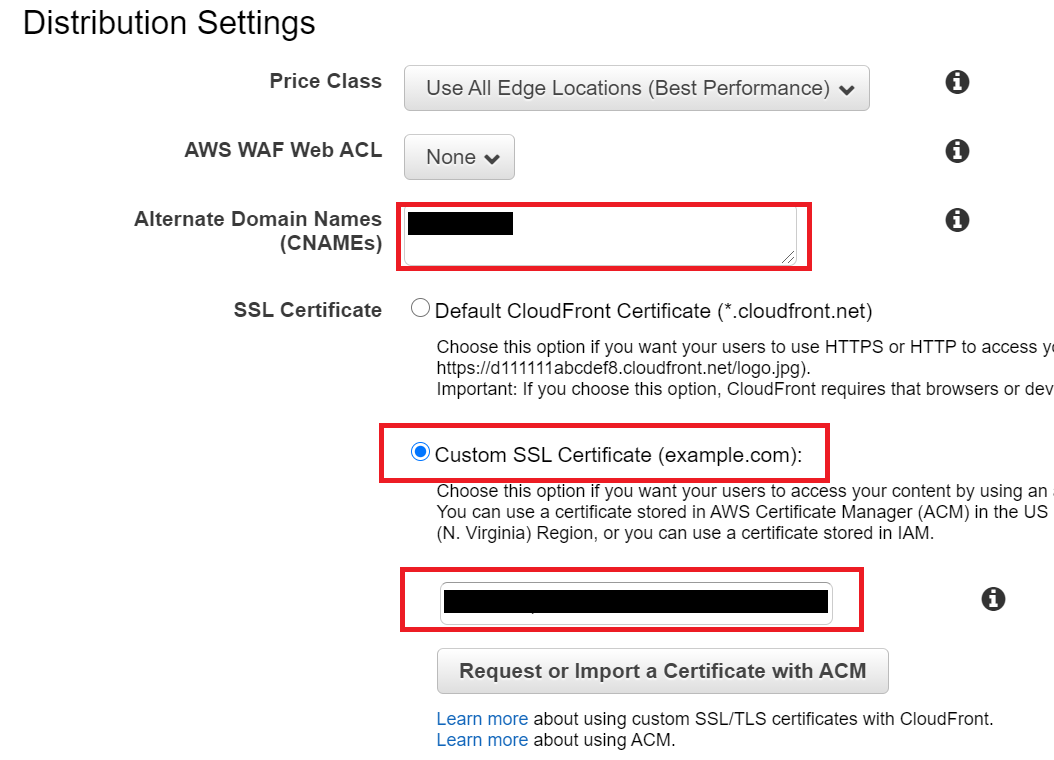
Default Cache Behavior Settings の Viewer Protocol Policyは「Redirect HTTP to HTTPS」にしましょう。
Distribution SettingsではAlternate Domain Names(CNAMEs)に取得したドメインを入力します。SSL Certificateは「Custom SSL Certificate (example.com):」を選択し、先ほどACMで作成した証明書を選択します。Custom SSL Client Supportは「SNI」とすると、追加費用発生を回避できます。DistributionのStateがEnabledになるまで待ちます。
7 Route53レコード作成
最後にROute53に作成したホストゾーンにCloudFrontを指定したレコードを作成しましょう。「レコードの作成」を選択し、エイリアスをオンにします。「CloudFrontディストリビューションへのエイリアス」→「米国東部(バージニア北部)」「作成したディストリビューション」を選びレコードを作成します。
これで、独自ドメインをCloudFrontに設定することができました!4 参考
以下サイトを参考にされて頂きました。ありがとうございます。
・無料ドメイン(.tk)とRoute53を利用して0円でHTTPS環境を設定してみた
https://dev.classmethod.jp/articles/mesoko-r53-cdn/・ACM証明書発行をDNS検証で行う【エンジニアブログより】
https://www.wantedly.com/companies/serverworks/post_articles/101309・CloudFront で S3 静的ウェブサイトホスティングを SSL/TLS に対応させる
https://dev.classmethod.jp/articles/tls-for-s3-web-hosting-with-cloudfront/5 終わりに
これにてすべての手順は完了です。
皆さんもCloudFront・Route53・ACMを用いて、素敵な独自ドメインライフを楽しんでください。
- 投稿日:2021-03-01T09:21:17+09:00
AWS認定ソリューションアーキテクトプロフェッショナルに920点で合格するために使用した教材とおすすめ度
先日、AWS認定ソリューションアーキテクトプロフェッショナル(以下、AWS SAP)に920点で合格しました。
というと、すごく聞こえますが、1度の不合格を経て、2度目の受験でなんとか合格することができました。
AWS SAPは、試験範囲がとても広いことからAWS認定試験の中で一番難しいと言われています。私自身、何度も心が折れそうになりました。そんなときに励まされたのが色々な方のブログや記事でしたので、私が勉強で使用した教材とおすすめ度をまとめてみました。
経歴
- AWS利用歴は2年
- サーバー、インフラを主に担当しています
- オンプレ、ハイブリッドの経験はありません
- 1年前にAWS認定ソリューションアーキテクトアソシエイト取得済
実績
- 2020年12月
- コロナの影響で年末年始の予定がなくなったので受験を決意
- 2020年1月
- 1回目の受験。727点で不合格。
- 2020年2月
- 2回目の受験。920点で合格!
正確には数えていないのですが、100時間以上は勉強したと思います。
使用した教材とおすすめ度
私が使用した教材とおすすめ度を記載します。
一通り紹介した後に私なりのおすすめの勉強法も紹介します。おすすめ度:◎ (とても効果的だった教材)
AWS認定ソリューションアーキテクト-プロフェッショナル ~試験特性から導き出した演習問題と詳細解説
本記事執筆時点では唯一の日本語対策本です。
まずはこちらの書籍でSAPの試験で問われるシナリオの特性を把握することをおすすめします。
私の場合、下記が弱点であることが把握できました。
- マルチアカウントの管理方法
- ディザスタリカバリの種類と実現方法
- オンプレミスとVPCの接続方法
- オンプレミスからクラウドへの移行
AWS WEB問題集で学習しよう
有料のWEB問題集です。
本試験でも似た問題点が多く出題されましたので、おすすめです。
また、後述するUdemyの問題集と異なり、1問毎に答え合わせができるので学習が進めやすかったです。Black Belt
AWS公式のオンラインセミナーです。
勉強を進めていく中で知らないサービスがあればまずはBlackbeltをみて概要を掴みましょう。おすすめ度:〇(効果的だった教材)
AWS デジタルトレーニング
無料のAWS公式のデジタルトレーニングです。
試験の概要を掴むことができました。ホワイトペーパー
重要だとわかっていてもなかなか読めないですよね。私もそうでした。(そして1度落ちました)
私は2度目の受験前にAWS デジタルトレーニングで紹介されている下記のペーパーにを斜め読みしつつ、同じような内容が取り上げられているBlack Beltを探して読みました。
問題を解くだとどうしても断片的な知識になってしまうと感じていたのですが、ホワイトペーパーを読むことで知識を体系的に整理できました。おすすめ度:△(あまり効果が感じられなかった教材 ※私個人の見解です)
Udemy AWS 認定ソリューションアーキテクト プロフェッショナル模擬試験問題集
1度目の受験前に本講座を受講して臨んだのですが、本試験の問題とはすこし違ったような印象を受けました。
模擬試験1回分を受講してからでないと答え合わせができないのも私の勉強法には合いませんでした。AWS公式模擬試験
受験していないため分からないというのが正確です。
問題の答えが分からないということだったので、受験しませんでした。おすすめ学習方法
以上をふまえたおすすめの勉強法は以下になります。
- 対策本+デジタルトレーニングで試験の概要を把握する
- WEB問題集を解き進めて、間違えた問題を復習する
- ホワイトペーパーで知識を体系的に整理する
上記を実施しつつ、弱いなと感じたサービスや機能があれば随時Black Belt、公式マニュアルで補強する
自宅受験での注意点
コロナ禍で自宅受験される方も多いと思うので、注意点を記載しておきます。
- 試験の途中でお手洗いにはいけません 。3時間の長丁場なので事前にしっかりと済ませておきましょう。
- ティッシュは持ち込めません。花粉症の方は薬などで対応しておきましょう。
まとめ
AWS SAPに合格するために私が使用した教材とおすすめ度をまとめました。
AWS SAPはとても難しく、何度も心が折れそうになりましたが、なんとか合格することができました。
この記事がこれからAWS SAPを受験する方の役に立てば嬉しく思います。
P.S. 3年後の更新が今から怖いです。。
- 投稿日:2021-03-01T09:05:53+09:00
新型コロナ陽性者数をQuickSightで予測してみた
はじめに
AWSのBIツールQuickSightにて、ノーコードで機械学習を用いた予測ができるとのことで
最近よく目にする新型コロナ陽性者数で試してみました。
また、データの自動更新についても試してみました。データソース
新型コロナ陽性者数のデータはオープンデータとして厚生労働省のサイトで公開されています。
https://www.mhlw.go.jp/stf/covid-19/open-data.htmlこの中から陽性者数をダウンロードして使います。
方針
ダウンロードしたファイルpcr_positive_daily.csvを直接QuickSight(SPICE)に取り込みでもいいのですが、
ここではS3に保存してそれをQuickSightのSPICEに取り込むようにします。
理由:
このデータは日々更新されていくので、この出来上がったグラフも最新データに追随していかせたいのです。
データソースがS3だと自動更新させて追随させることができるのですが、
ファイルのアップロードだと自動更新できないのでこうします。
自動更新の方法については後述。S3にアップロード
手動でダウンロードしたファイルをS3にアップロードします。
今回は以下の場所にアップロードしたとします。
s3://dummy_bucket/hogehoge/pcr_positive_daily.csvマニフェストファイルの準備
pcr_positive_daily.csvを開くと、以下のようなデータであることがわかります。
pcr_positive_daily.csv日付,PCR 検査陽性者数(単日) 2020/1/16,1 2020/1/17,0 2020/1/18,0 以下略ですので以下のような記述のマニフェストファイルを用意します。
pcr_positive_daily.json{ "fileLocations": [ {"URIs": ["s3://dummy_bucket/hogehoge/pcr_positive_daily.csv"]} ], "globalUploadSettings": { "format": "CSV", "delimiter": ",", "containsHeader": "true" } }それぞれの項目の意味などはこちらを参照してください。
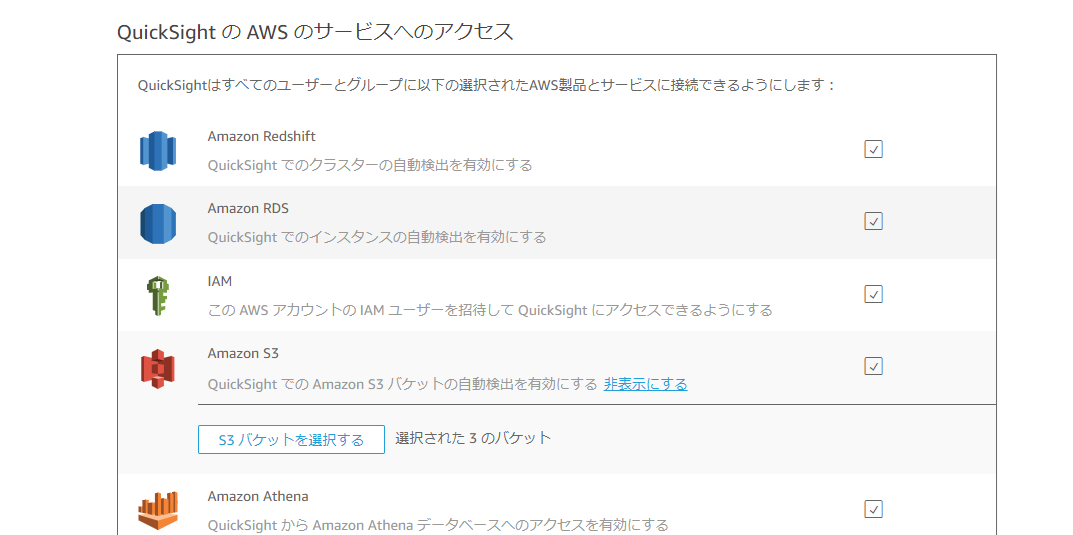
QuickSight > ユーザーガイド > Amazon S3 のマニフェストファイルでサポートされている形式QuickSightのバケット許可
QuickSightにS3のバケットdummy_bucketにアクセスできるよう許可を与えます。
QuickSight右上のアイコン > QuickSightの管理 > セキュリティとアクセス権限
QuickSightのAWSサービスへのアクセス の 追加または削除する をクリック
Amazon S3の説明文にある 詳細 のリンクをクリック
S3バケットを選択する
目的のバケットであるdummy_bucketにチェックを入れて 完了 します。
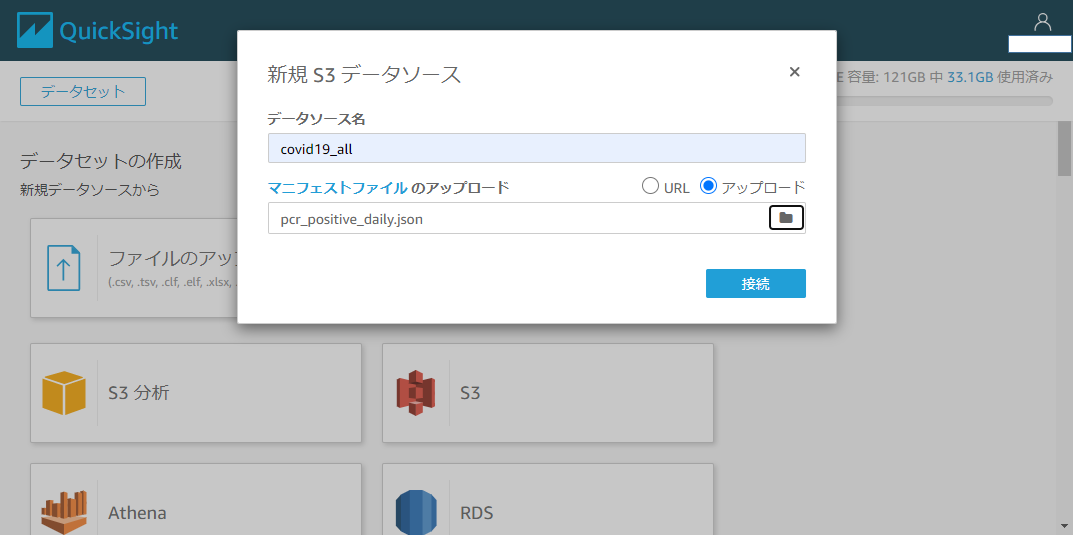
取り込み
QuickSightの左のサイドバーのデータセット > 新しいデータセット > S3
データソース名は適当に(ここではcovid19_allにしています)。
マニフェストファイルのアップロードでは先ほど作成したマニフェストファイルを指定します。
接続ができたら確認してみましょう。
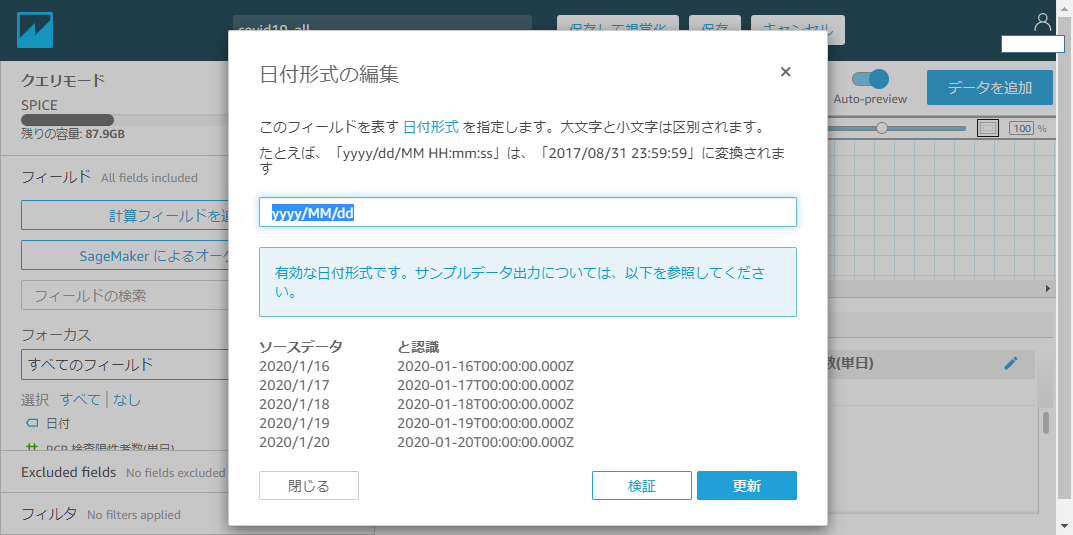
、、、日付カラムが文字列型として認識されてしまってますね。
データ型を指定してあげましょう。
分析
先ほど作ったデータソースをもとに分析を作り、そこに今回の目的である予測を追加します。
グラフ化
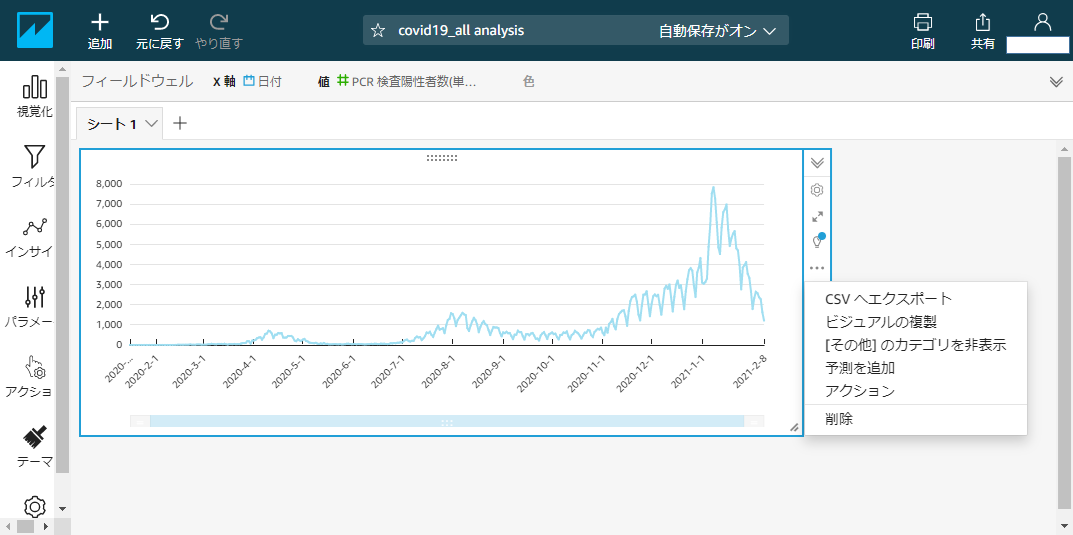
X軸に日付、値にPCR検査陽性者数を指定して折れ線グラフを描画します。
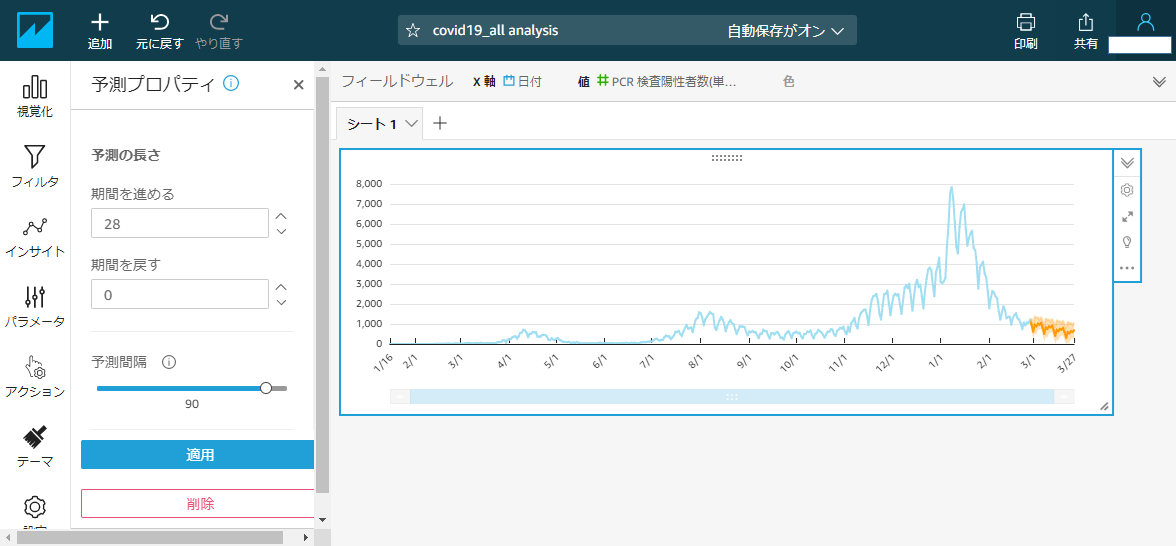
ラベルのフォーマットなどをいい感じに整えましょう。予測を追加
グラフ右上の折り畳みメニュー>・・・>予測を追加
こんな感じで予測が表示されます
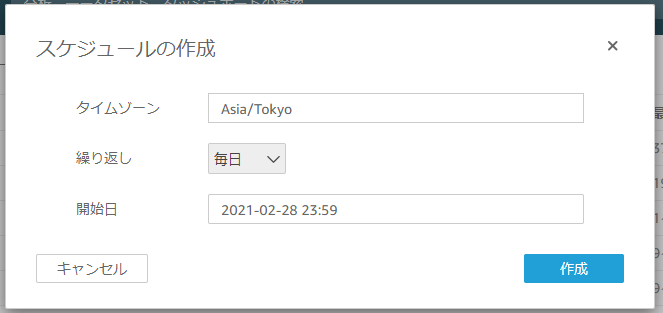
自動化
元のデータが更新に追随してQuickSightも更新されるよう、自動化します。
Lambdaでデータを取得して、データセットを更新するように設定します。Lambda
Lambdaで厚生労働省のサイトからデータをダウンロードしてS3に保存するように記載します。
保存先は先ほどマニフェストファイルで指定した
s3://dummy_bucket/hogehoge/pcr_positive_daily.csv
になるようにします。
詳細は割愛。
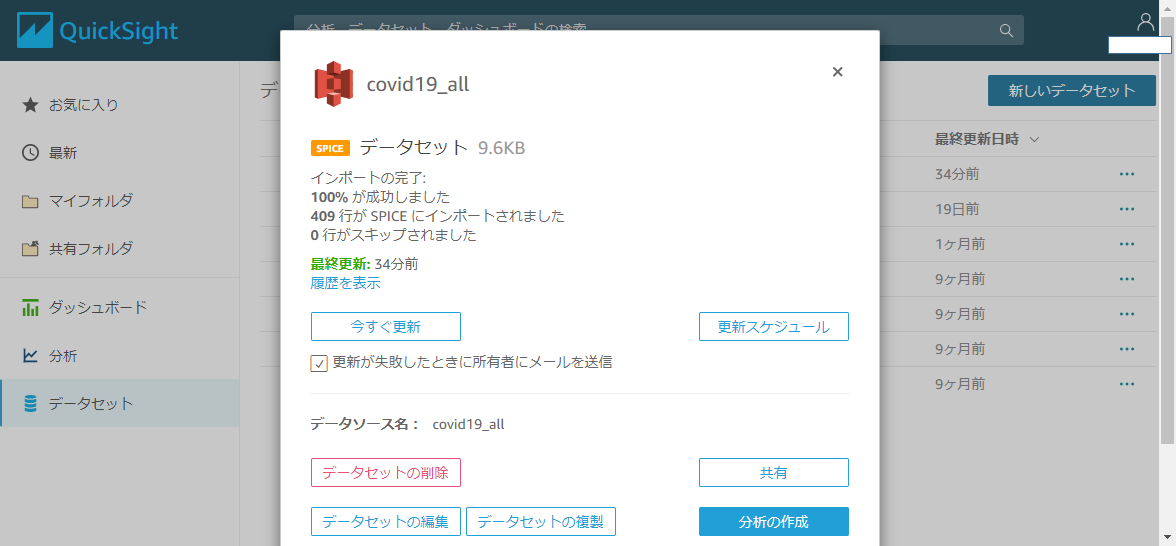
トリガーで日次バッチとして動くように設定します。データセット
QuickSightのTopからデータセットを開き、
先ほど作ったcovid19_allのデータセットを開きます。
更新スケジュール から日次で動くようにスケジュールを設定します。
おわりに
以上、機械学習に関する知識なしに簡単に予測のグラフを描画できました。
長々と書きましたが、グラフさえ描画できてしまえば、
メニューから予測を追加するだけと非常に簡単なので利用機会が出てきそうです。

- 投稿日:2021-03-01T08:52:45+09:00
Amazon Cognitoを使ってシンプルなログイン画面を作ってみる
AWS資格取得に向けて実際にAWSを利用してみたシリーズの投稿です。
今回はAWSを使って素早く簡単にユーザーのサインアップ/サインインおよびアクセスコントロールの機能を追加できるAmazon Cognitoを利用してみる編です。1時間程度でCognitoを利用したログイン機能が作成できます。
資格勉強的にはCognitoのユーザープール、IDプールの違いを確認しつつ、手っ取り早くログイン画面の作成するための手順になっています。
興味がある方は読んでみて下さい。資格試験の勉強法は記事は以下を参照。
AWS初心者がAWS 認定ソリューションアーキテクト – アソシエイト資格試験に合格した時の勉強法
AWS初心者がAWS 認定ソリューションアーキテクト – プロフェッショナル資格試験に合格した時の勉強法想定読者
- AWSでログイン機能(認証・認可)ができるCognitoを使ってサクッとログイン画面を作りたい人
- Cognitoのユーザープール、IDプールをAWSコンソールで確認して理解を深めたい人
料金
無料利用枠が、Cognito ユーザープールに直接サインインするユーザーの場合は 50,000 MAU、SAML 2.0 ベースの ID プロバイダーを介してフェデレーションされるユーザーの場合は 50 MAU 分あるため、サクッと作って個人で試すだけなら無料で出来るようです。
公式ページ
作業時間
約1時間
完成画面
こんなログイン画面ができます。
※今回は、Cognitoを試すことに目的にしているためデザインは一切ありません^^;
可能な限りシンプルなHTMLとJavaScriptで実現しています。以下のページを参考にしていますが、さらにシンプルにしてみました。
https://www.tdi.co.jp/miso/amazon-cognito-activation-sign-inメールアドレスをIDとして使用しており、AuthenticateUserは使用しているライブラリでログインするときに使うメソッド名になります。
加えて、ユーザ(メールアドレスとパスワード)登録画面、メールアドレスの確認(メールアドレス認証)画面も作るので全部で3画面を作成します。
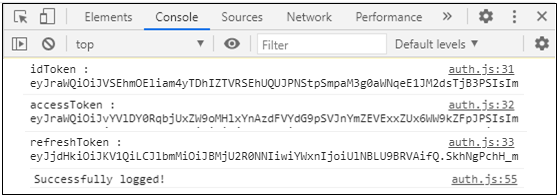
ログインに成功するとこんな感じ。
ログイン後に各種AWSサービスにアクセスするために必要な認証情報(IDトークン/アクセストークン/リフレッシュトークン)をブラウザのコンソールに表示させています。では、実際に手順に従ってやってみましょう。
作業手順
作業手順は以下の5つの手順になります。
1、2はAWSコンソールで作成、3~5はHTML/JavaScript実装になります。1.AWSコンソール Cognitoからユーザプールの作成
2.AWSコンソール CognitoからIDプールの作成
3.画面実装 ユーザ登録画面(サインアップ画面)作成
4.画面実装 ユーザID(メールアドレス)認証画面作成
5.画面実装 ログイン画面作成事前準備
AWSアカウントは前提条件として割愛すると、以下を準備すれば事前準備完了です。簡単ですね。
- テキストエディタ/ブラウザ
今回はEclipseのようなIDEは不要なためテキストエディタで実装して、そのままブラウザで動かします。
- CognitoSDKダウンロード
Cognitoとのやり取りにはJavaScriptの以下のSDK(amazon-cognito-identity-js)を使用します。
以下の3つのユースケースをそのまま使っているところがあるのでこちらも参考にしてみてください。
Use case 1. Registering a user with the application. One needs to create a CognitoUserPool object by providing a UserPoolId and a ClientId and signing up by using a username, password, attribute list, and validation data.
Use case 2. Confirming a registered, unauthenticated user using a confirmation code received via SMS.
Use case 4. Authenticating a user and establishing a user session with the Amazon Cognito Identity service.
その他、2つのAWS SDKが必要になるので全部で3つダウンロードしておきましょう。
ダウンロードできたら次から手順に従って作業開始です。
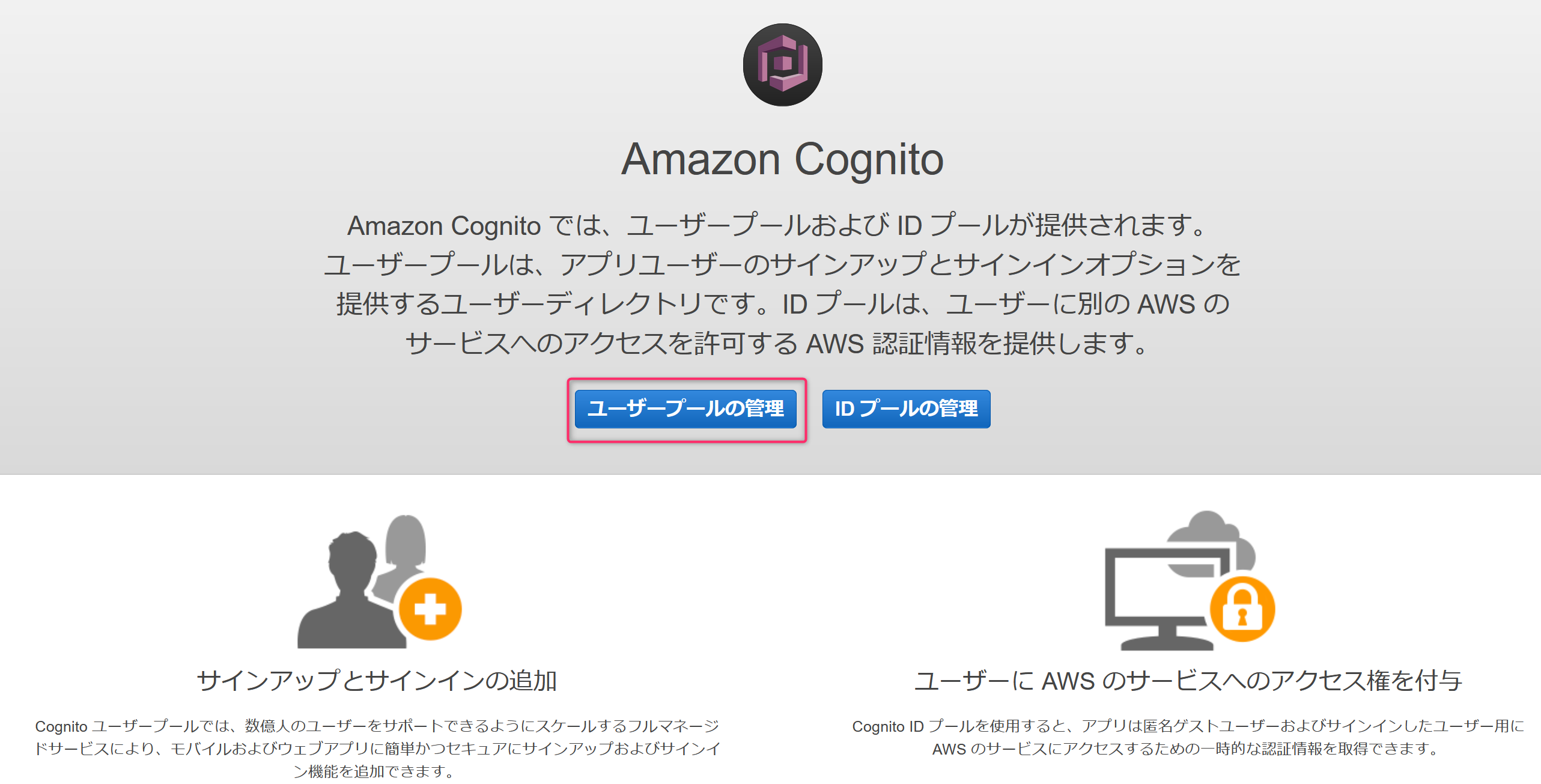
1.AWSコンソール Cognitoからユーザプールの作成
まずはAWSコンソールのCognitoのサービス画面からユーザープールの作成です。
基本的には画面の指示に従っていけば簡単にできます。
まずは、ユーザープールの管理をクリック。
ユーザープールを作成するをクリック。
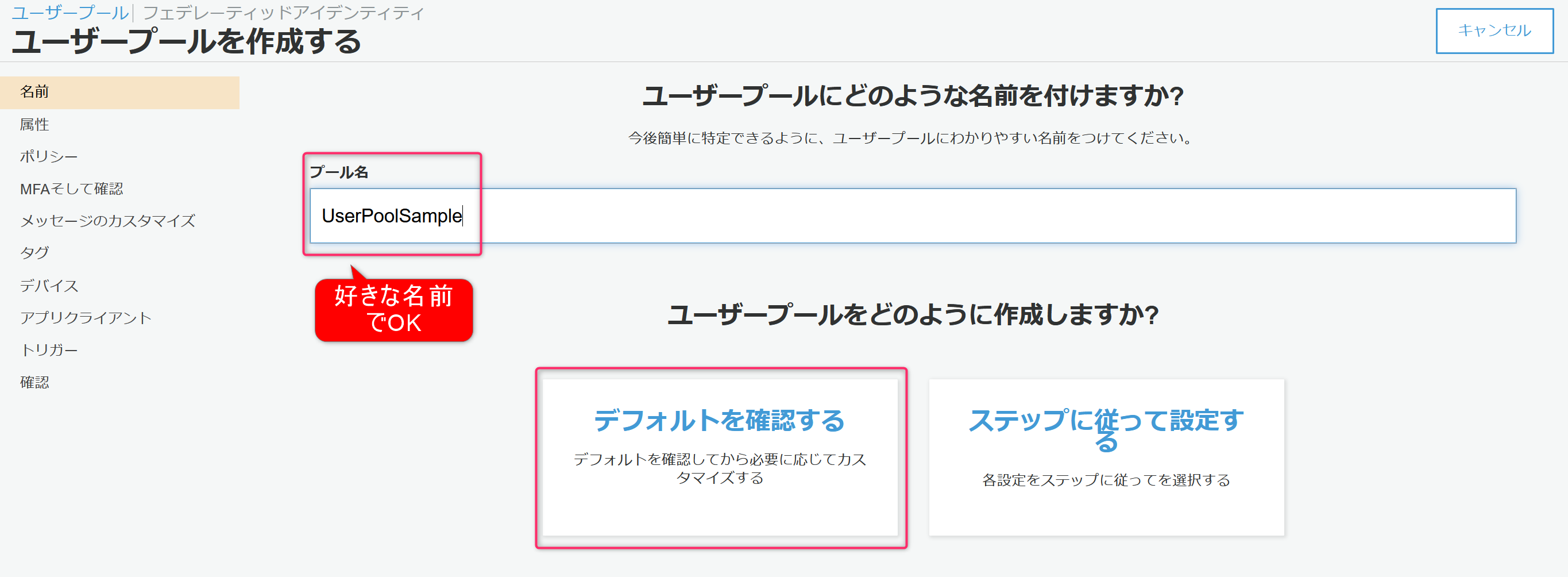
好きなプール名を入力。
入力したらデフォルトを確認するをクリック。
デフォルト値で登録された設定内容の一覧が表示されます。
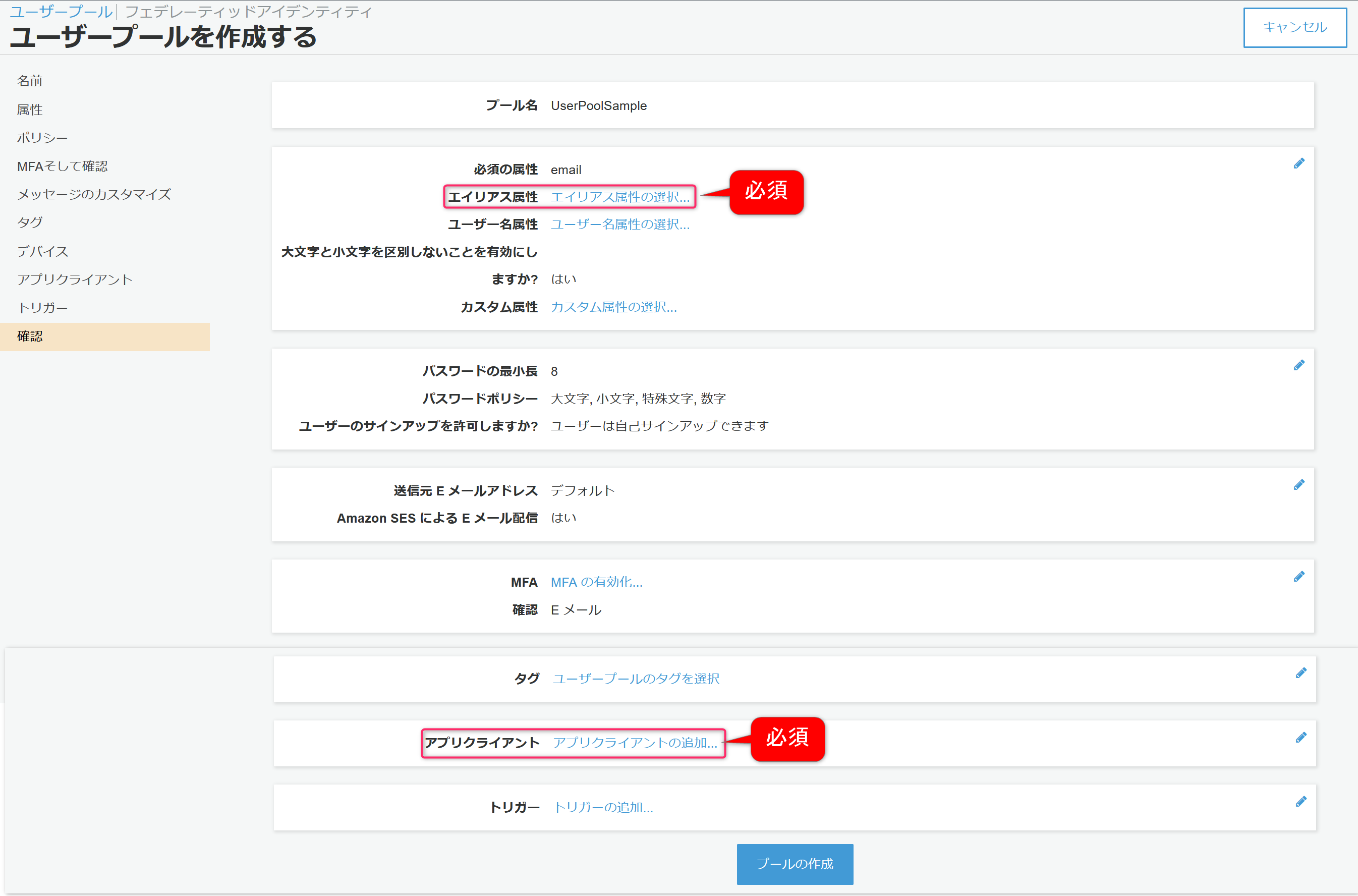
今回やりたいことを実現するために最低限、エイリアス属性、アプリクライアントの2つは変更する必要があります。
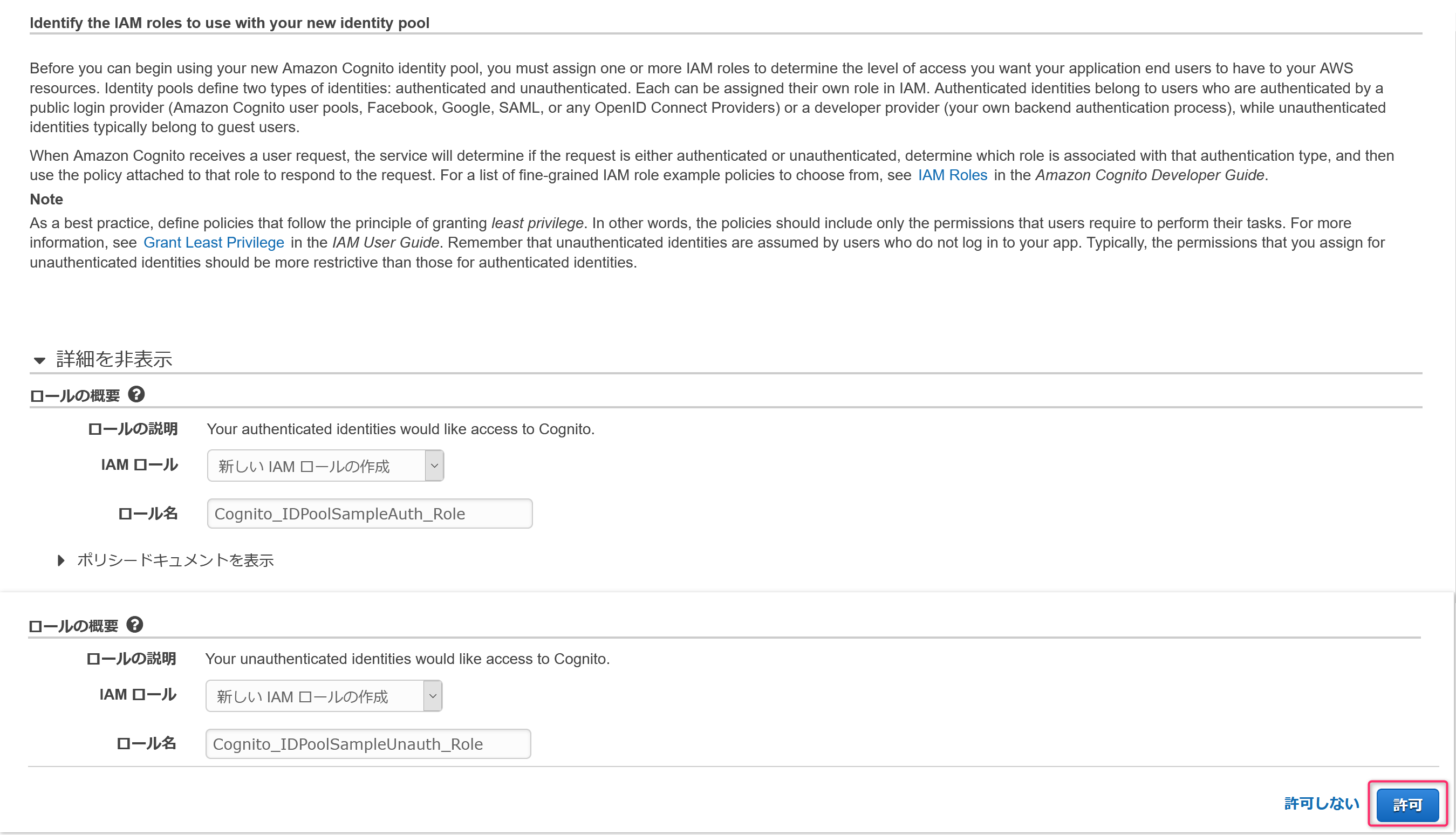
この後、画面が出てくればわかりますが、エイリアス属性は今回登録するユーザの属性設定、アプリクライアントはログイン画面を作成するプログラムを特定する設定になります。
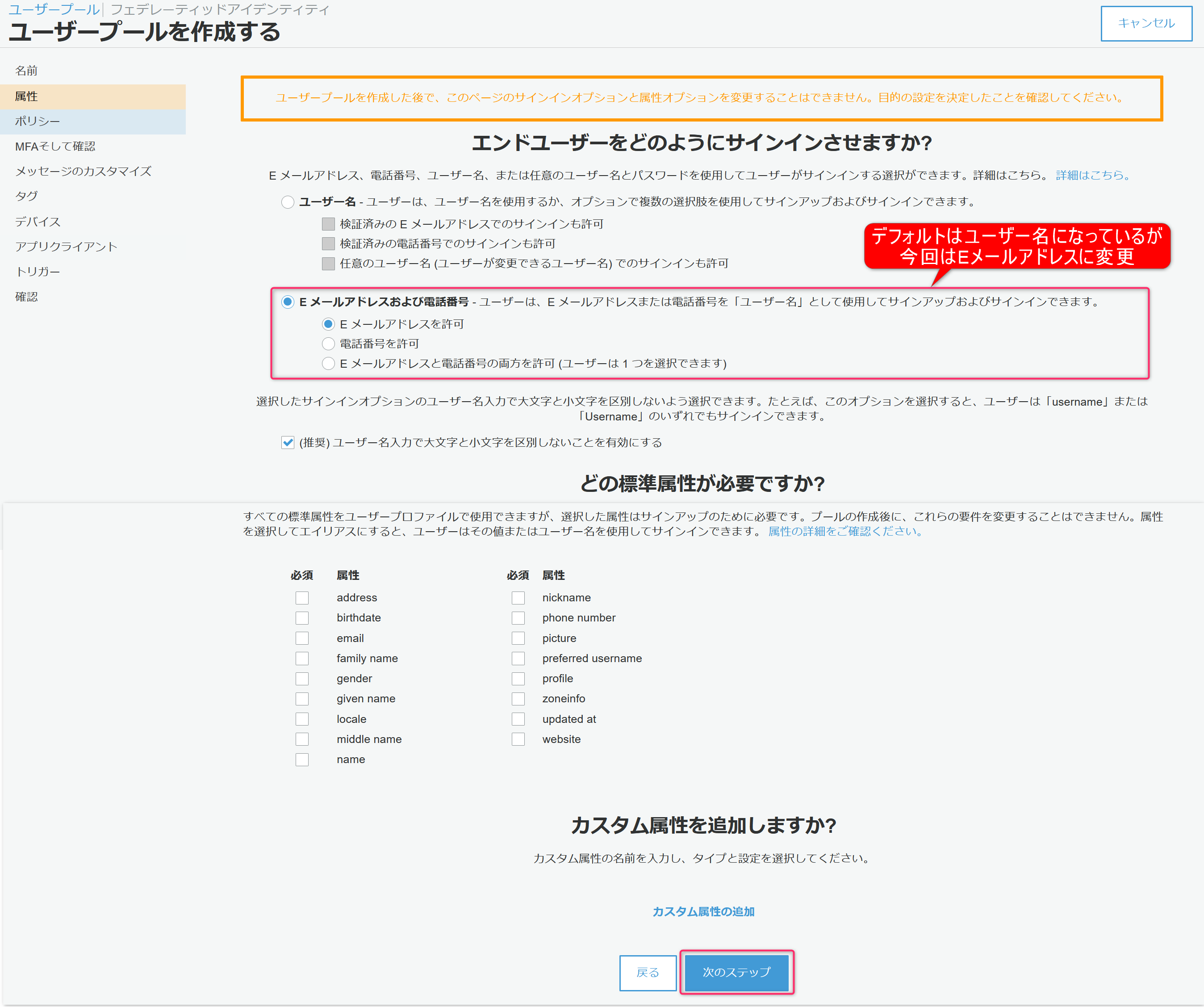
では、まずエイリアス属性の選択をクリックし設定を行います。
今回はメールアドレスを使用するので、Eメールアドレスおよび電話番号を選択。
メールアドレスしか使用しないため他の属性はチェックせず、そのまま次のステップをクリック。
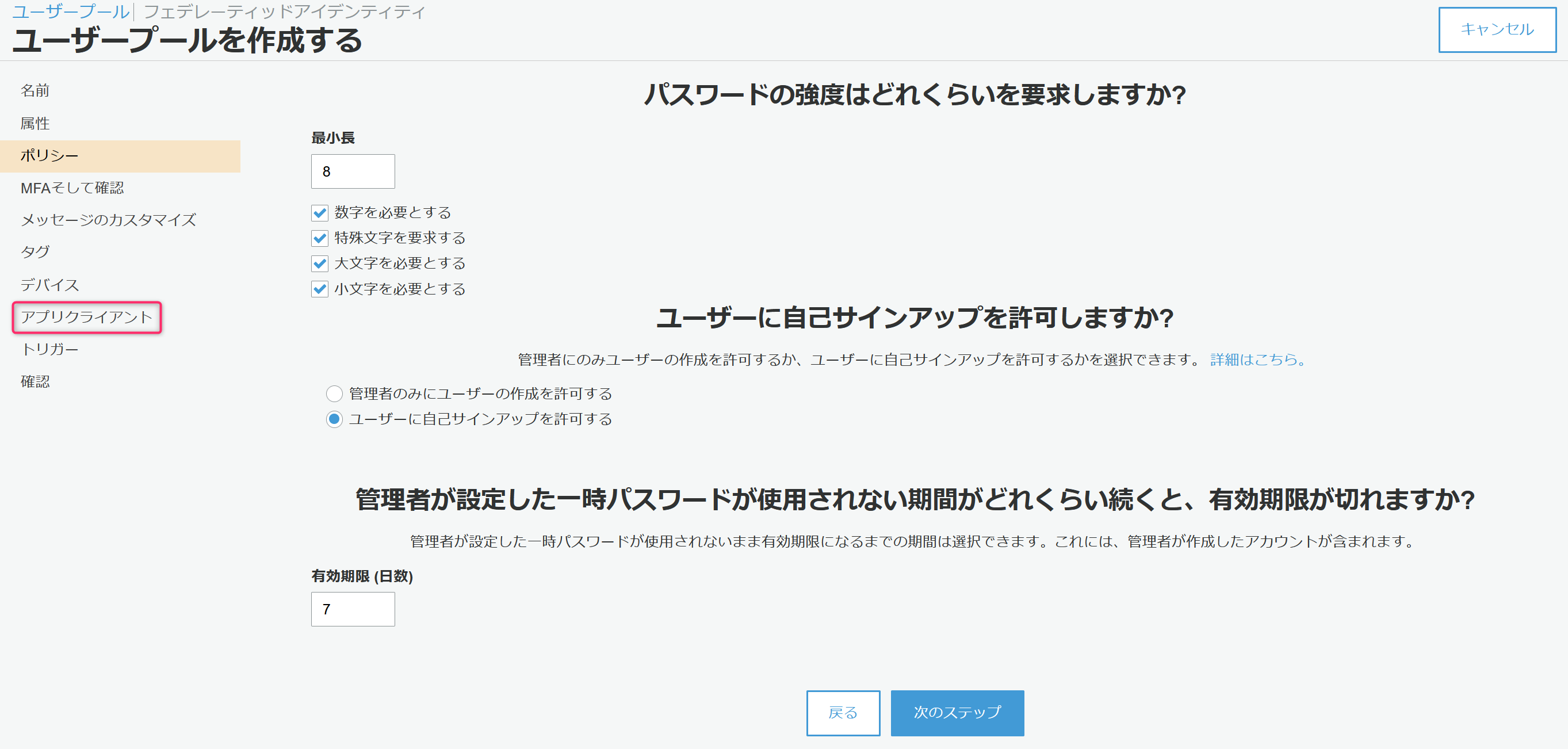
次に必須の設定となるアプリクライアントをクリック。
表示された画面でアプリクライアントの追加をクリック。
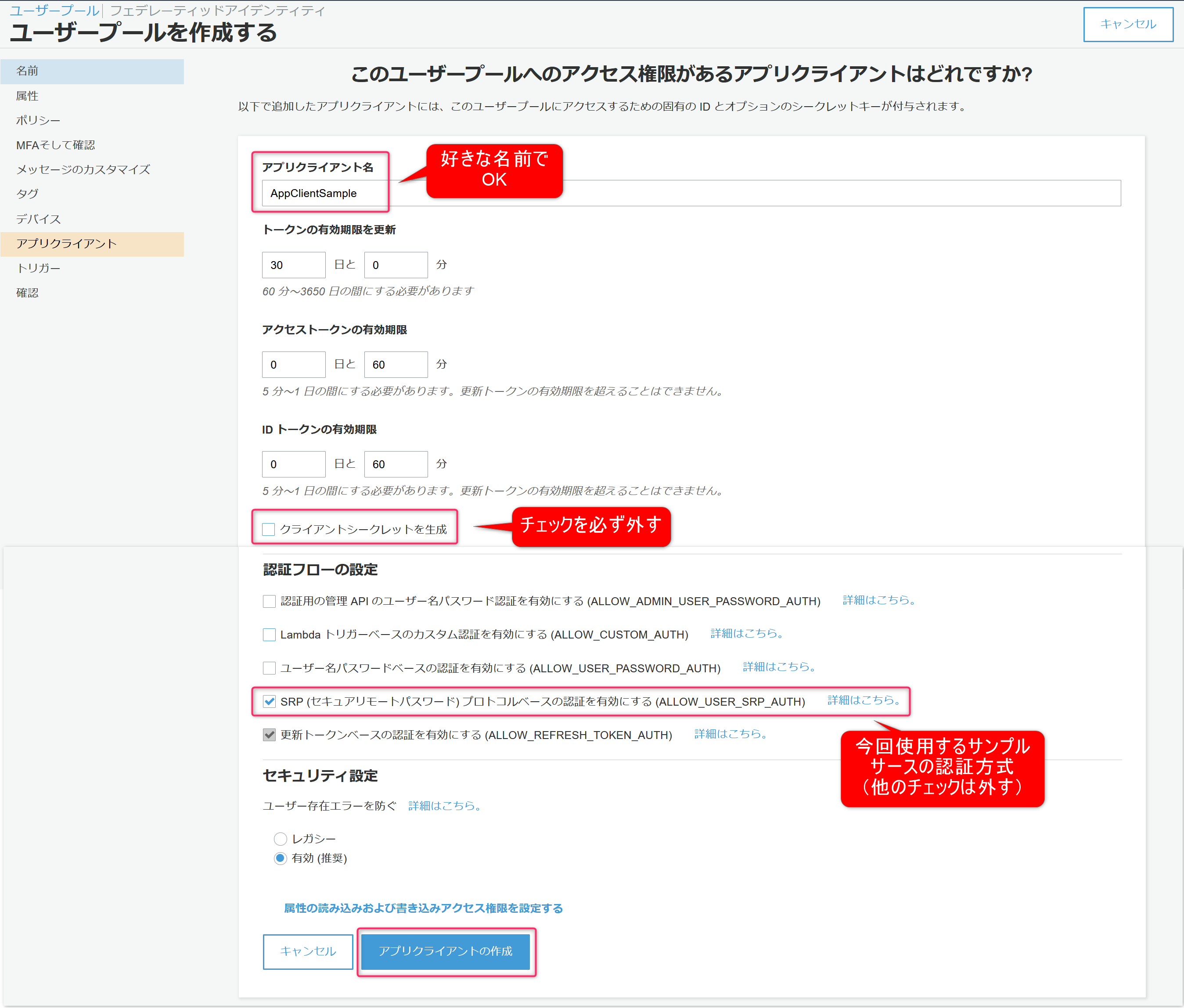
アプリクライアント名は好きな名前でOK。
今回、アプリクライアントの認証は実施しないためクライアントシークレットを生成のチェックを外します。
また、使用するSDKのライブラリはSRPプロトコルで認証しているためSRP (セキュアリモートパスワード) プロトコルベースの認証を有効にする (ALLOW_USER_SRP_AUTH)のチェックのみ残し後はチェックを外します。(「更新トークンベースの認証を有効にする」のチェックは外せません)
最後にアプリクライアントの作成をクリック。
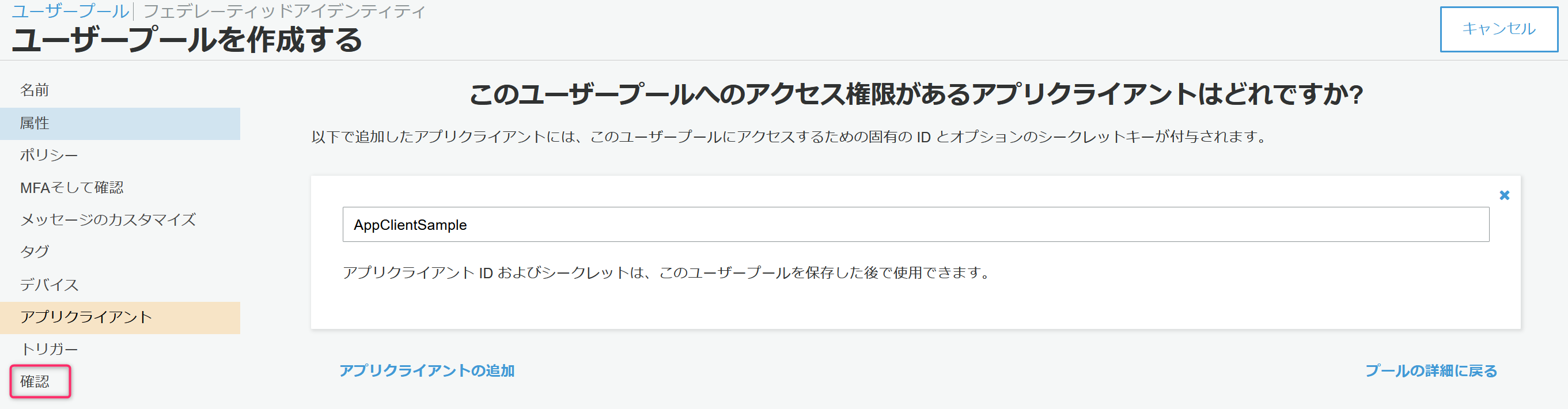
必須登録が完了したので確認をクリック。
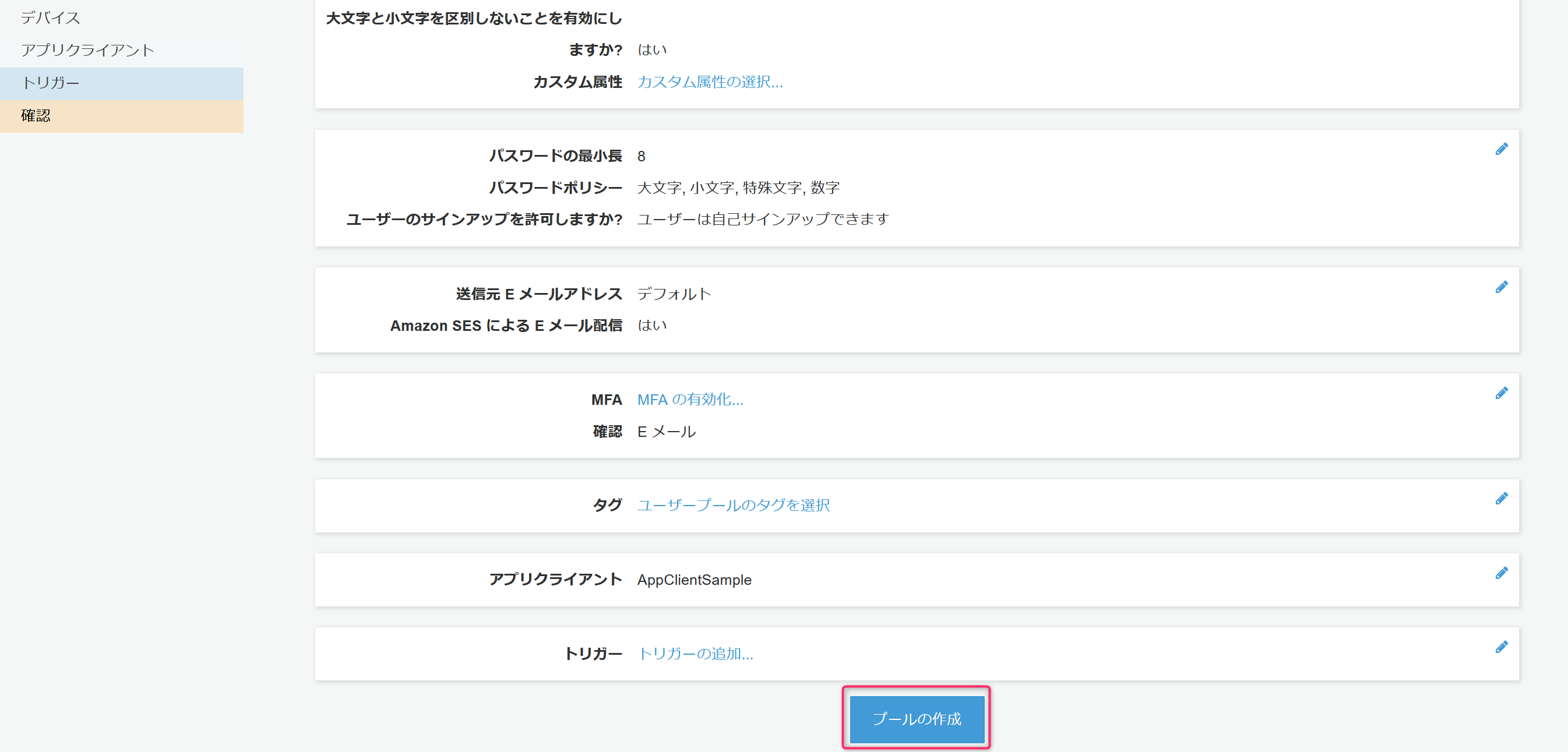
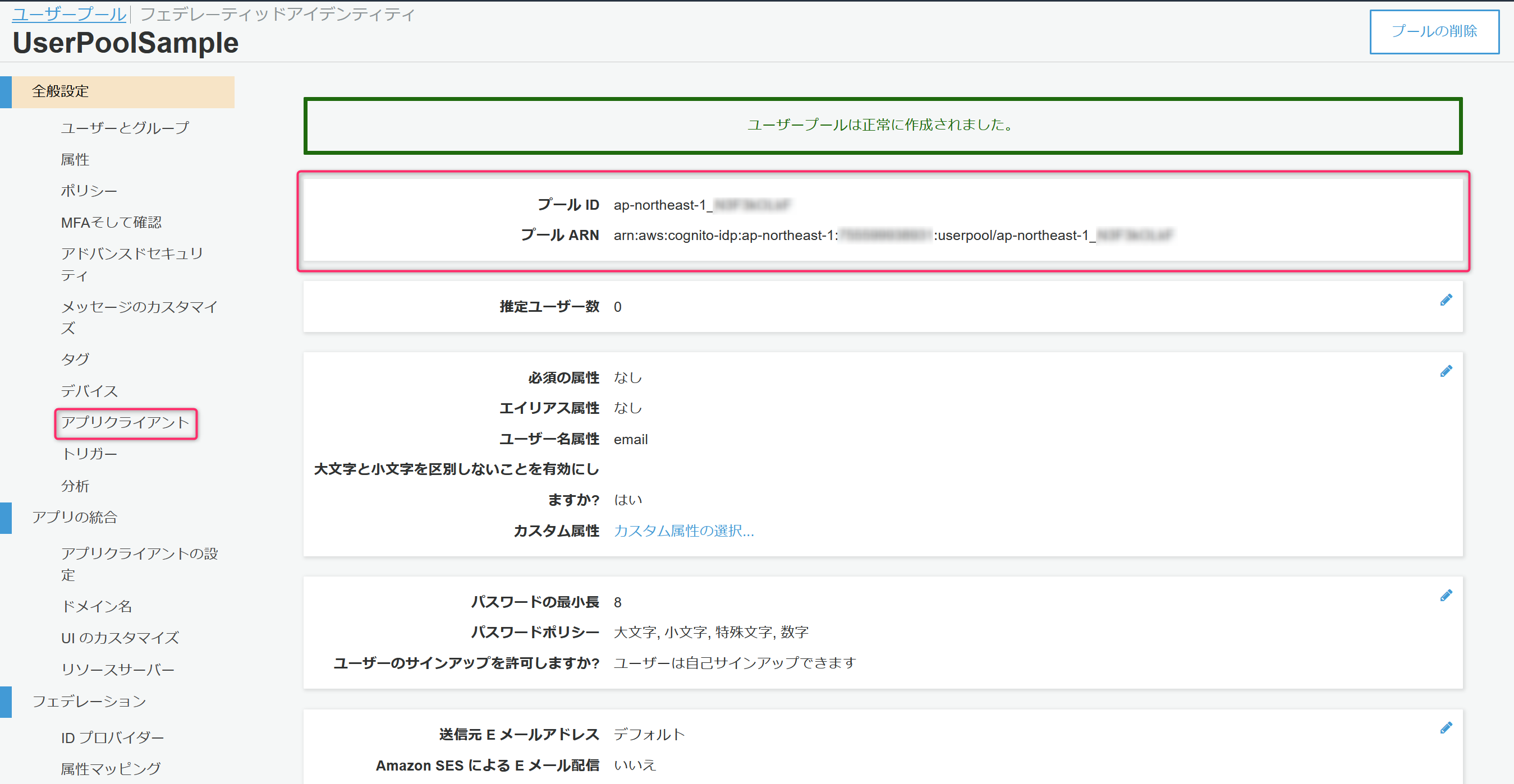
プールの作成をクリックすると、ユーザープールが作成されます。
問題がなれけば作成された旨のメッセージと作成されたユーザープールの固有情報(プールIDとプールARN)が表示されます。
プールIDは次の手順のIDプール/実装するJavaScriptの中で指定する必要があるためメモしておきます。
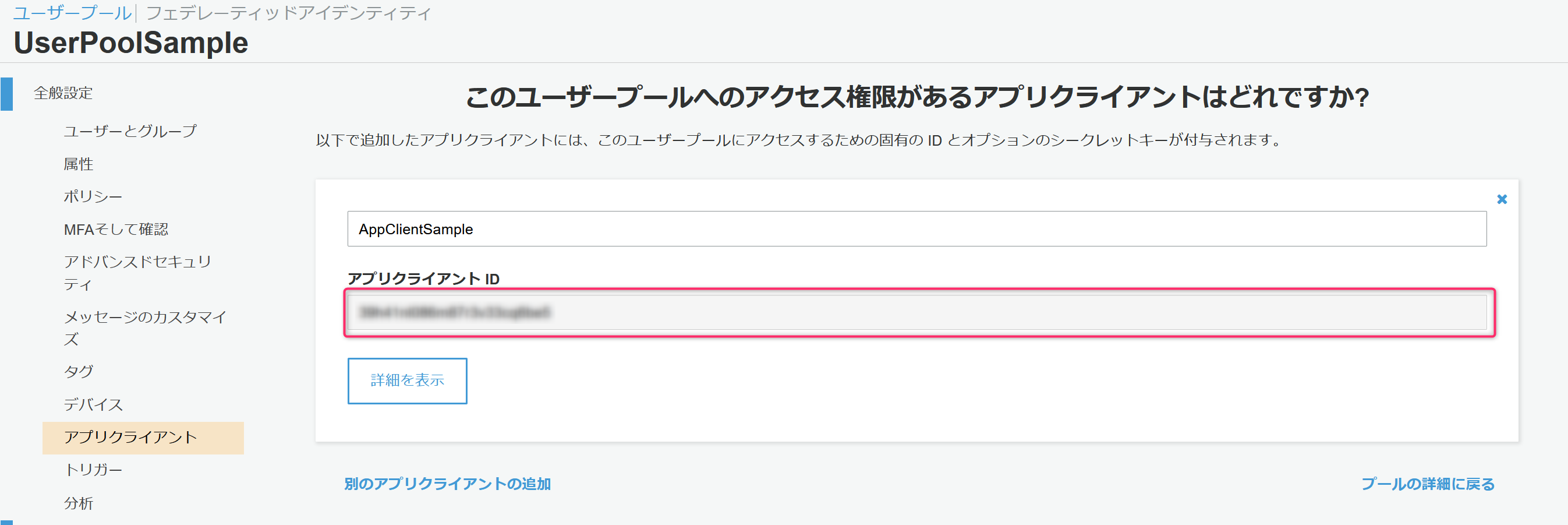
加えて、アプリクライアントの情報も必要になるためアプリクライアントをクリック。
アプリクライアントIDが次の手順のIDプール/実装するJavaScriptの中で指定する必要があるためこちらもメモしておきます。
ここまででユーザープールの作成が完了です。
2.AWSコンソール CognitoからIDプールの作成
そのまま続けてAWSコンソールでIDプールを作成します。
ユーザープールに比べるとサクッとできます。
まずはIDプールの管理をクリック。
新しいIDプールの作成をクリック。
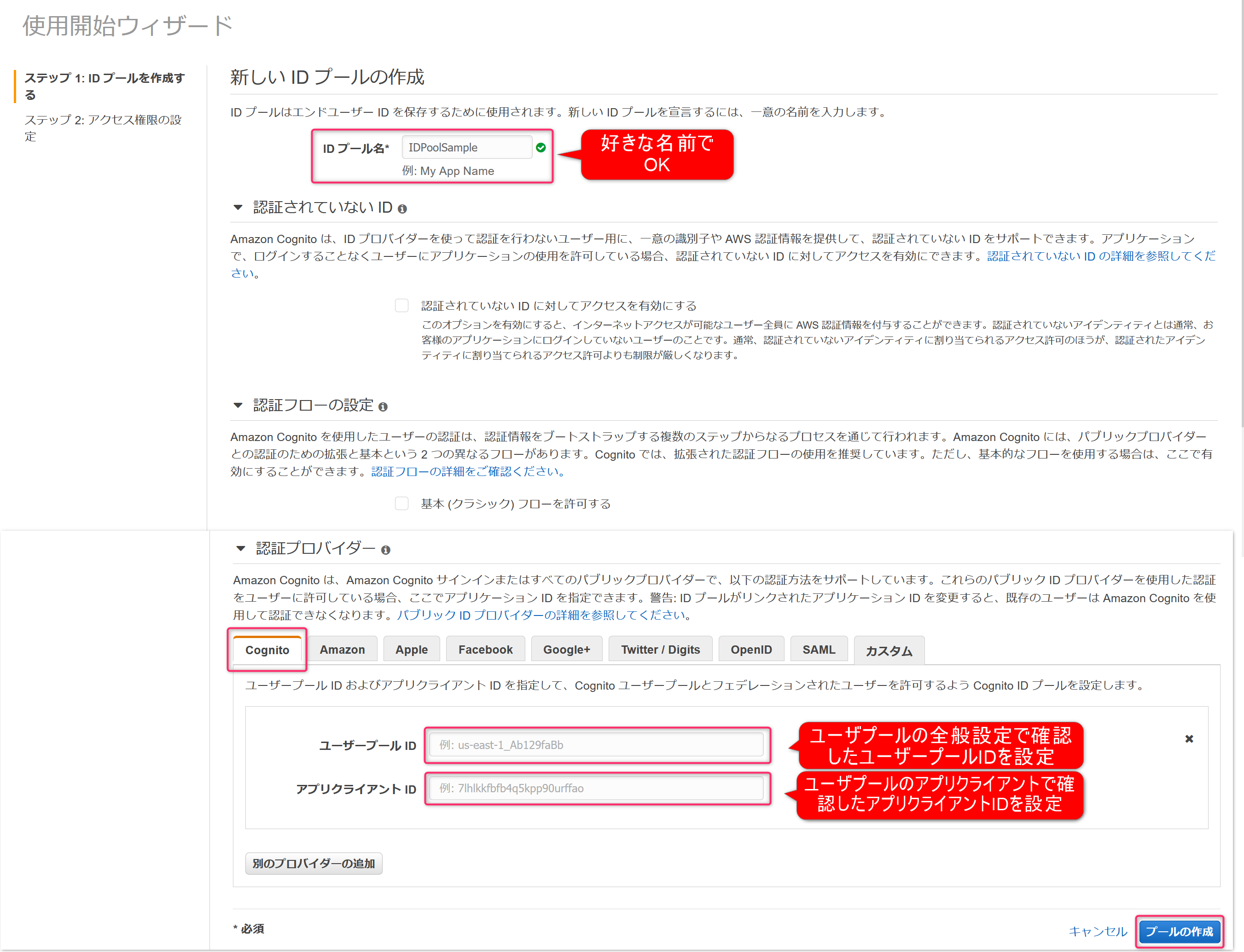
IDプール名は好きな名前でOK。
今回、認証プロバイダーには前の手順で作成したユーザープールを使用するため、Cognitoをクリック。
前の手順でメモしたユーザープールIDとアプリクライアントIDを入力します。
最後にプールの作成をクリック。
IDプールで使用するIAMが自動的に作成されるため、許可をクリック。
以上でIDプールの作成完了です。
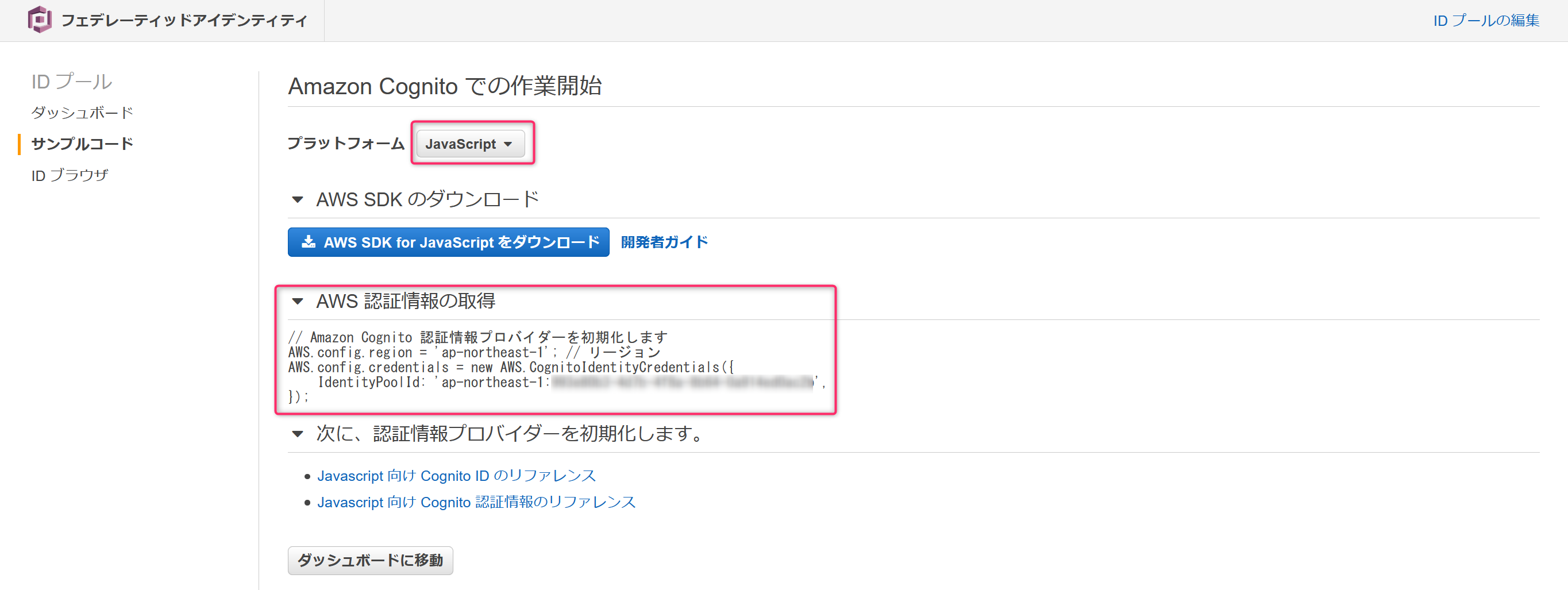
今回はJavaScriptでクライアントを実装するため、表示された画面でJavaScriptを選択し表示された認証情報からIDプールのIDをメモしておきます。
3.画面実装 ユーザ登録画面(サインアップ画面)作成
ここからはHTML/JavaScriptで画面の作成を行います。
3画面を3つのHTML、3つのJavaScriptで作成します。
事前準備でダウンロードした3つのSDKを含め、JavaScriptはjsフォルダに格納するのため完成後のフォルダ構成は以下になります。WORK_FOLDER\signup.html WORK_FOLDER\confirm.html WORK_FOLDER\auth.html WORK_FOLDER\js WORK_FOLDER\js\signup.js WORK_FOLDER\js\confirm.js WORK_FOLDER\js\auth.js WORK_FOLDER\js\aws-sdk.min.js WORK_FOLDER\js\aws-cognito-sdk.min.js WORK_FOLDER\js\amazon-cognito-identity.min.js(WORK_FOLDERはどこでも大丈夫です)
では、画面作成に移りましょう。
ユーザ登録画面はこんな感じの画面を作成します。
最初にHTMLです。以下をコピペしてテキストエディタで保存すればOKです。
signup.html<!DOCTYPE html> <html> <head> <meta charset="UTF-8"></meta> <title>CognitoSignUp</title> <script src="js/aws-cognito-sdk.min.js"></script> <script src="js/amazon-cognito-identity.min.js"></script> <script src="js/signup.js"></script> </head> <body> <h1>CognitoSignUp</h1> <span style="display: inline-block; width: 100px;">Email</span> <input type="text" id="email" placeholder="Email Address"> <br/> <span style="display: inline-block; width: 100px;">Password</span> <input type="password" id="password" placeholder="Password"> <br/><br/> <input type="button" value="CognitoSignUp" onclick="OnCognitoSignUp();"> </body> </html>次はJavaScriptです。
このJavaScriptサンプルは事前準備のところでリンクを貼り付けたamazon-cognito-identity-jsのUse case 1になります。
XXX部(ユーザープールIDとクライアントIDの2か所)、手順1.AWSコンソール Cognitoからユーザプールの作成でメモったIDに変えてください。signup.jsfunction OnCognitoSignUp() { var poolData = { UserPoolId: 'ap-northeast-1_XXXXXXXXX', // Your user pool id here ClientId: 'XXXXXXXXXXXXXXXXXX', // Your client id here }; var userPool = new AmazonCognitoIdentity.CognitoUserPool(poolData); var username = document.getElementById("email").value; var password = document.getElementById("password").value; userPool.signUp(username, password, null, null, function( err, result ) { if (err) { alert(err.message || JSON.stringify(err)); return; } var cognitoUser = result.user; console.log('user name is ' + cognitoUser.getUsername()); }); }完成です!
では、signup.htmlにブラウザからアクセスしてみましょう。
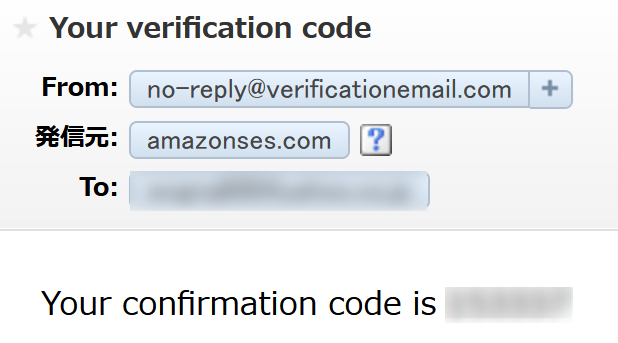
うまく表示されたら有効なメールアドレスとパスワードを入力してCognitoSignUpボタンを押します。
ブラウザのコンソールに以下が表示されれば成功です。
成功していれば入力したメールアドレスに以下のメールが届くので認証コードを控えます。(この認証コードを次の画面で使います)
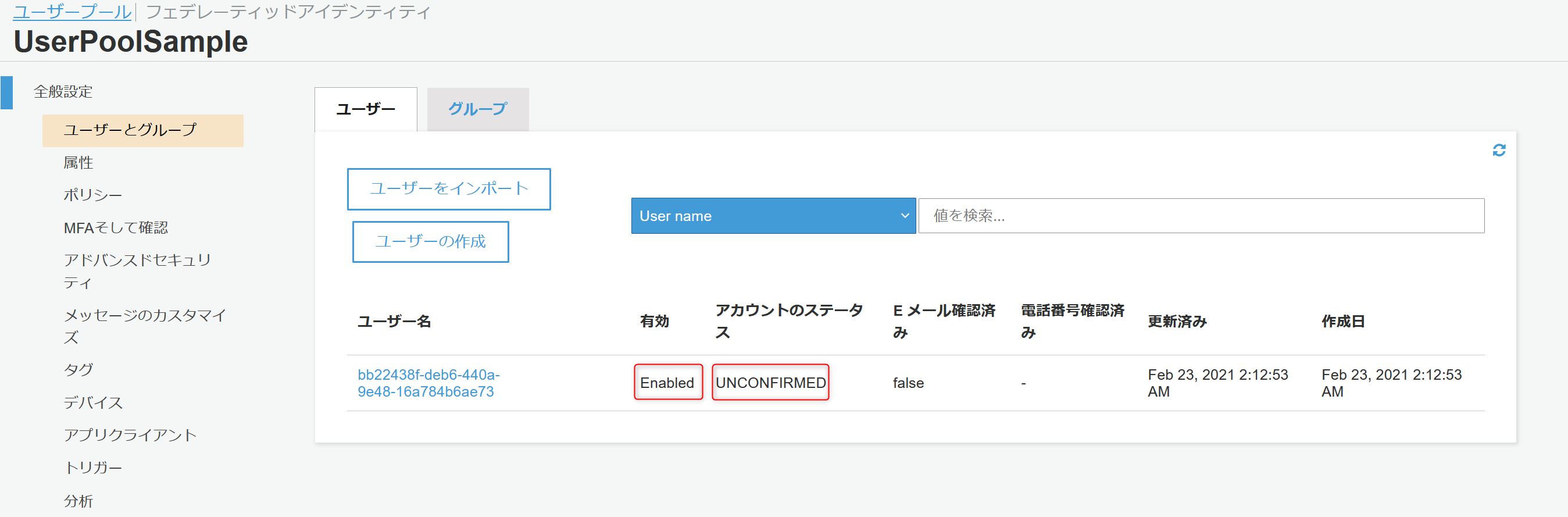
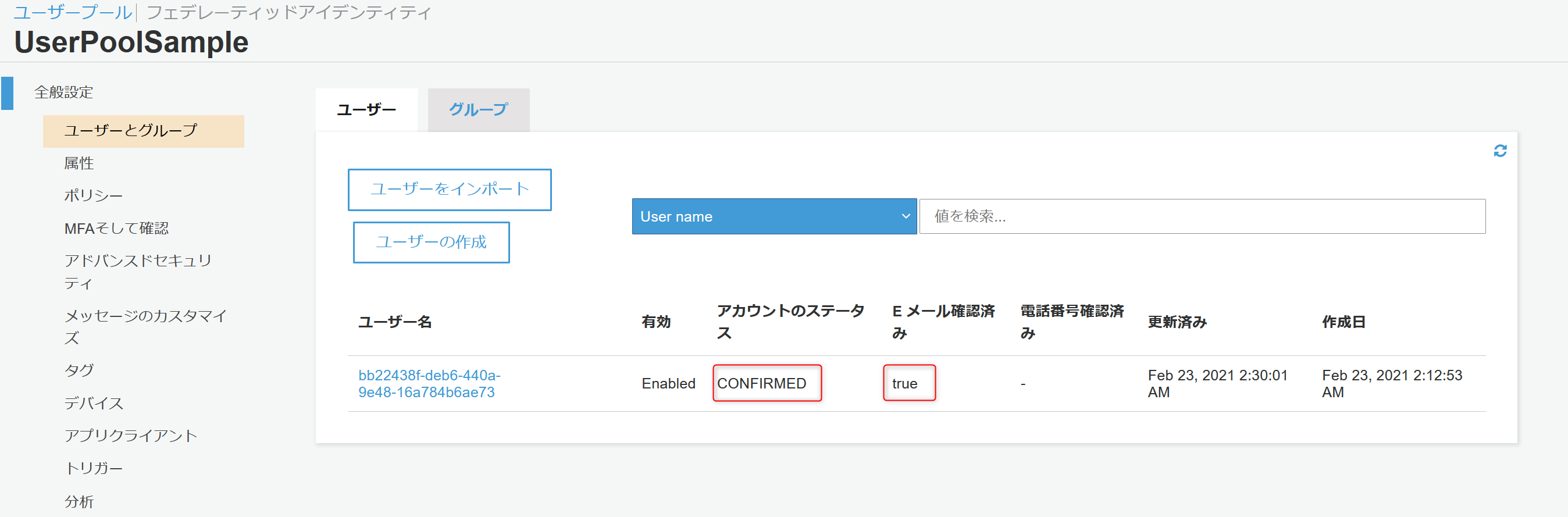
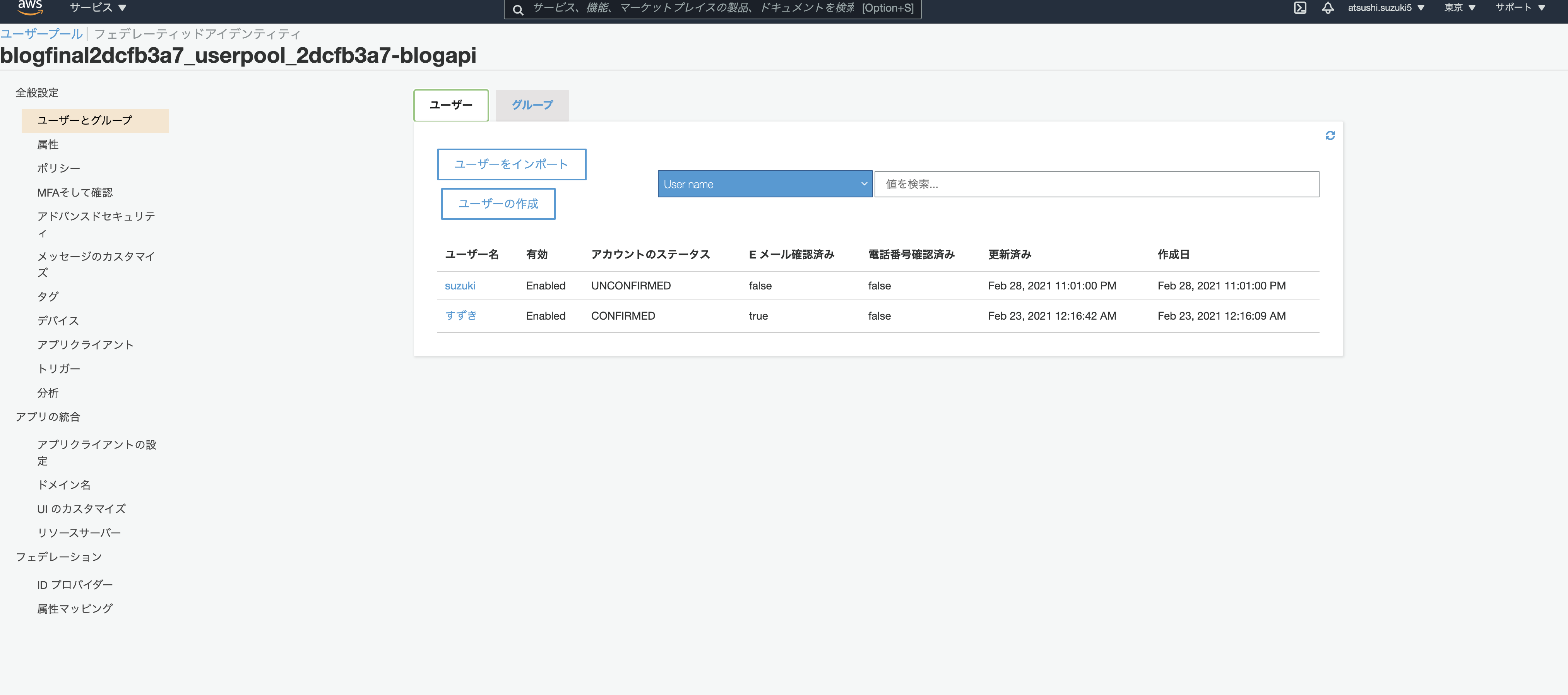
この状態になるとAWSコンソールからユーザープールにユーザが登録されたのが確認できます。
有効状態ではありますが、メールアドレスの認証が済んでいないのでUNCONFIRMED状態であることが確認できます。
確認できたら次の画面作成に進みましょう。
4.画面実装 ユーザID(メールアドレス)認証画面作成
引き続き、認証画面を作成します。完成後画面はこんな感じ。
まずはHTMLです。以下をコピペすればOKです。
confirm.html<!DOCTYPE html> <html> <head> <meta charset="UTF-8"></meta> <title>CognitoConfirmRegistration</title> <script src="js/aws-cognito-sdk.min.js"></script> <script src="js/amazon-cognito-identity.min.js"></script> <script src="js/confirm.js"></script> </head> <body> <h1>CognitoConfirmRegistration</h1> <span style="display: inline-block; width: 100px;">Email</span> <input type="text" id="email" placeholder="Email Address"> <br/> <span style="display: inline-block; width: 100px;">ConfirmCode</span> <input type="text" id="ConfirmCode" placeholder="Confirm Code"> <br/><br/> <input type="button" value="CognitoConfirmRegistration" onclick="OnCognitoConfirmRegistration();"> </body> </html>JavaScriptです。
このサンプルはamazon-cognito-identity-jsのUse case 2になります。
最初の画面と同じでXXX部(ユーザープールIDとクライアントIDの2か所)、手順1.AWSコンソール Cognitoからユーザプールの作成でメモったIDに変えてください。confirm.jsfunction OnCognitoConfirmRegistration() { var poolData = { UserPoolId: 'ap-northeast-1_XXXXXXXXX', // Your user pool id here ClientId: 'XXXXXXXXXXXXXXXXXX', // Your client id here }; var userPool = new AmazonCognitoIdentity.CognitoUserPool(poolData); var username = document.getElementById("email").value; var code = document.getElementById("ConfirmCode").value; var userData = { Username: username, Pool: userPool, }; var cognitoUser = new AmazonCognitoIdentity.CognitoUser(userData); cognitoUser.confirmRegistration(code, true, function(err, result) { if (err) { alert(err.message || JSON.stringify(err)); return; } console.log('call result: ' + result); }); }完成です!!
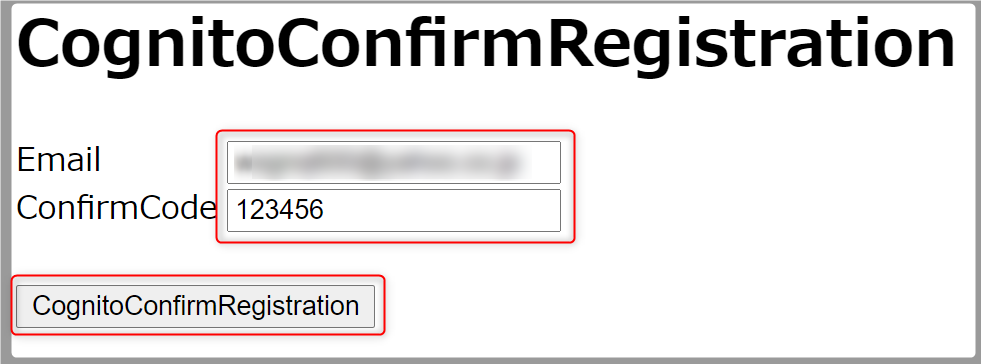
confirm.htmlをブラウザで開き、メールアドレスとメールで届いた認証コードを入力、
CognitoConfirmRegistrationボタンを押します。
ブラウザのコンソールに以下が表示されれば成功です。
AWSコンソールでも状態を確認してみましょう。
CONFIRMED状態であること、Eメールアドレスが確認済みであることが確認できます。
確認できたら最後の画面作成に進みましょう。
5.画面実装 ログイン画面作成
最後にログイン画面を作成します。完成後画面はこんな感じ。
HTMLです。前の手順のように以下をコピペすればOKですが、SDK(aws-sdk.min.js)が増えていることに注意しましょう。
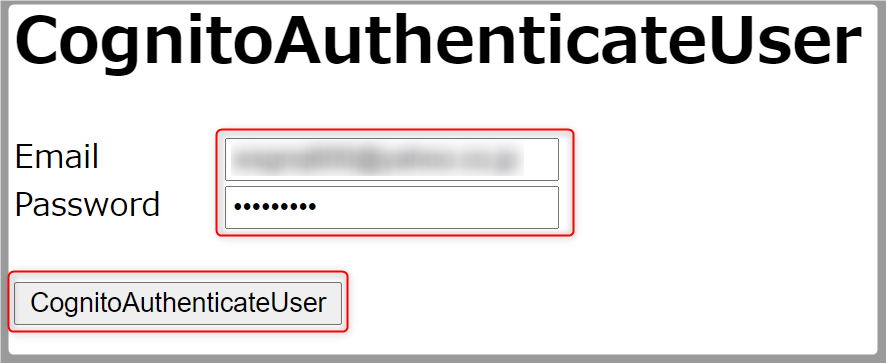
auth.html<!DOCTYPE html> <html> <head> <meta charset="UTF-8"></meta> <title>CognitoAuthenticateUser</title> <script src="js/aws-sdk.min.js"></script> <script src="js/aws-cognito-sdk.min.js"></script> <script src="js/amazon-cognito-identity.min.js"></script> <script src="js/auth.js"></script> </head> <body> <h1>CognitoAuthenticateUser</h1> <span style="display: inline-block; width: 100px;">Email</span> <input type="text" id="email" placeholder="Email Address"> <br/> <span style="display: inline-block; width: 100px;">Password</span> <input type="password" id="password" placeholder="Password"> <br/><br/> <input type="button" value="CognitoAuthenticateUser" onclick="OnCognitoAuthenticateUser();"> </body> </html>次にJavaScriptです。
このサンプルはamazon-cognito-identity-jsのUse case 4になります。
今ままでと同じでXXX部(ユーザープールIDとクライアントIDの2か所)がありますが、それに加えてファイル中ほどに、IDプールのIDとユーザープールID(似てますが、ユーザープールARNではないです)を設定する箇所があり、合計4か所の変更点があるので注意してください。
初登場のIDプールのIDは、手順2.AWSコンソール CognitoからIDプールの作成でメモったIDになります。auth.jsfunction OnCognitoAuthenticateUser() { var username = document.getElementById("email").value; var password = document.getElementById("password").value; var authenticationData = { Username: username, Password: password, }; var authenticationDetails = new AmazonCognitoIdentity.AuthenticationDetails( authenticationData ); var poolData = { UserPoolId: 'ap-northeast-1_XXXXXXXXX', // Your user pool id here ClientId: 'XXXXXXXXXXXXXXXXXX', // Your client id here }; var userPool = new AmazonCognitoIdentity.CognitoUserPool(poolData); var userData = { Username: username, Pool: userPool, }; var cognitoUser = new AmazonCognitoIdentity.CognitoUser(userData); cognitoUser.authenticateUser(authenticationDetails, { onSuccess: function(result) { var idToken = result.getIdToken().getJwtToken(); // IDトークン var accessToken = result.getAccessToken().getJwtToken(); // アクセストークン var refreshToken = result.getRefreshToken().getToken(); // 更新トークン console.log("idToken : " + idToken); console.log("accessToken : " + accessToken); console.log("refreshToken : " + refreshToken); //POTENTIAL: Region needs to be set if not already set previously elsewhere. AWS.config.region = 'ap-northeast-1'; AWS.config.credentials = new AWS.CognitoIdentityCredentials({ IdentityPoolId: 'ap-northeast-1:XXXXXXXXXXXXXXXXXX', // your identity pool id here Logins: { // Change the key below according to the specific region your user pool is in. 'cognito-idp.ap-northeast-1.amazonaws.com/ap-northeast-1_XXXXXXXXX': result .getIdToken() .getJwtToken(), }, }); //refreshes credentials using AWS.CognitoIdentity.getCredentialsForIdentity() AWS.config.credentials.refresh(error => { if (error) { console.error(error); } else { // Instantiate aws sdk service objects now that the credentials have been updated. // example: var s3 = new AWS.S3(); console.log('Successfully logged!'); } }); }, onFailure: function(err) { alert(err.message || JSON.stringify(err)); }, }); }完成です!!!
auth.htmlをブラウザで開き、メールアドレスとユーザー登録画面で入力したパスワードを入力、
CognitoAuthenticateUserボタンを押します。
ブラウザのコンソールに以下が表示されれば成功です。
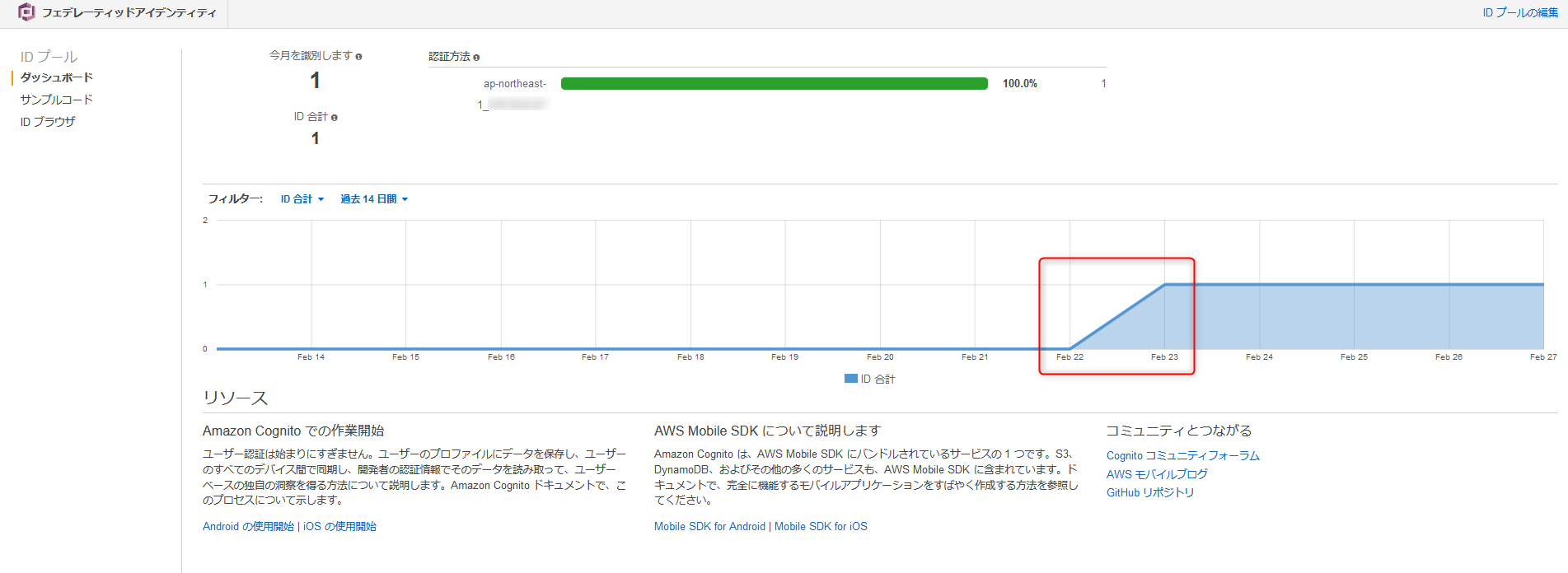
こちらもAWSコンソールで確認します。ただし、今回の確認先はIDプールになります。
ログインするとアクティブなユーザーが1になっていることが確認できます。
今回は以上です!お疲れ様でした!!
まとめ
AWSコンソールの操作と簡単なHTML/JavaScriptでログイン画面を作ることができました。
予想より簡単だったのではないでしょうか?
認証情報が払い出されたので、ここからは認証情報を使って様々なAWSリソースにアクセスができるようになります。(認証情報に対しIAMで適切な権限付与は必要です)
これはCognitoのほんの一部の機能なのでまだまだできることはたくさんあるようです。
それも機をみてできる限り投稿していこうと思います。ここまで読んで頂き、ありがとうございました!






- 投稿日:2021-03-01T08:45:27+09:00
AWS認定ソリューションアーキテクトプロフェッショナルに920点で合格した勉強法
先日、AWS認定ソリューションアーキテクトプロフェッショナル(以下、AWS SAP)に920点で合格しました。
というと、すごく聞こえますが、1度の不合格を経て、2度目の受験でなんとか合格することができました。
AWS SAPは、試験範囲がとても広いことからAWS認定試験の中で一番難しいと言われています。私自身、何度も心が折れそうになりました。そんなときに励まされたのが色々な方のブログや記事でしたので、私の勉強法もまとめてみました。
経歴
- AWS利用歴は2年
- サーバー、インフラを主に担当しています
- オンプレ、ハイブリッドの経験はありません
- 1年前にAWS認定ソリューションアーキテクトアソシエイト取得済
実績
- 2020年12月
- コロナの影響で年末年始の予定がなくなったので受験を決意
- 2020年1月
- 1回目の受験。727点で不合格。
- 2020年2月
- 2回目の受験。920点で合格!
正確には数えていないのですが、100時間以上は勉強したと思います。
使用した教材とおすすめ度
私が使用した教材とおすすめ度を記載します。
一通り紹介した後に私なりのおすすめの勉強法も紹介します。おすすめ度:◎ (とても効果的だった教材)
AWS認定ソリューションアーキテクト-プロフェッショナル ~試験特性から導き出した演習問題と詳細解説
本記事執筆時点では唯一の日本語対策本です。
まずはこちらの書籍でSAPの試験で問われるシナリオの特性を把握することをおすすめします。
私の場合、下記が弱点であることが把握できました。
- マルチアカウントの管理方法
- ディザスタリカバリの種類と実現方法
- オンプレミスとVPCの接続方法
- オンプレミスからクラウドへの移行
AWS WEB問題集で学習しよう
有料のWEB問題集です。
本試験でも似た問題点が多く出題されましたので、おすすめです。
また、後述するUdemyの問題集と異なり、1問毎に答え合わせができるので学習が進めやすかったです。Black Belt
AWS公式のオンラインセミナーです。
勉強を進めていく中で知らないサービスがあればまずはBlackbeltをみて概要を掴みましょう。おすすめ度:〇(効果的だった教材)
AWS デジタルトレーニング
無料のAWS公式のデジタルトレーニングです。
試験の概要を掴むことができました。ホワイトペーパー
重要だとわかっていてもなかなか読めないですよね。私もそうでした。(そして1度落ちました)
私は2度目の受験前にAWS デジタルトレーニングで紹介されている下記のペーパーにを斜め読みしつつ、同じような内容が取り上げられているBlack Beltを探して読みました。
問題を解くだとどうしても断片的な知識になってしまうと感じていたのですが、ホワイトペーパーを読むことで知識を体系的に整理できました。おすすめ度:△(あまり効果が感じられなかった教材 ※私個人の見解です)
Udemy AWS 認定ソリューションアーキテクト プロフェッショナル模擬試験問題集
1度目の受験前に本講座を受講して臨んだのですが、本試験の問題とはすこし違ったような印象を受けました。
模擬試験1回分を受講してからでないと答え合わせができないのも私の勉強法には合いませんでした。AWS公式模擬試験
受験していないため分からないというのが正確です。
問題の答えが分からないということだったので、受験しませんでした。おすすめ学習方法
以上をふまえたおすすめの勉強法は以下になります。
- 対策本+デジタルトレーニングで試験の概要を把握する
- WEB問題集を解き進めて、間違えた問題を復習する
- ホワイトペーパーで知識を体系的に整理する
上記を実施しつつ、弱いなと感じたサービスや機能があれば随時Black Belt、公式マニュアルで補強する
自宅受験での注意点
コロナ禍で自宅受験される方も多いと思うので、注意点を記載しておきます。
- 試験の途中でお手洗いにはいけません 。3時間の長丁場なので事前にしっかりと済ませておきましょう。
- ティッシュは持ち込めません。花粉症の方は薬などで対応しておきましょう。
まとめ
AWS SAPに合格した私の勉強法をまとめました。
AWS SAPはとても難しく、何度も心が折れそうになりましたが、なんとか合格することができました。
この記事がこれからAWS SAPを受験する方の役に立てば嬉しく思います。
P.S. 3年後の更新が今から怖いです。。
- 投稿日:2021-03-01T08:14:10+09:00
AWS Amplifyでリソース(API, Auth)構築からフロントエンド(React)へ導入するまでの手順をまとめました
はじめに
AWS Amplifyを使うとサーバレスのバックエンドを簡単につくれるという話をききました。個人でアプリ開発をやってみたいなーという気持ちがあったのですが、バックエンド構築の手間がネックでなかなか手をつけられずにいたので、この機会にAmplifyを学習してみることにしました。
以下はAPIとAuthリソースを構築してフロント側に実装するまでのまとめです。AWS Amplify とは
CLIでコマンドをポチポチするだけでクラウドにバックエンドリソース(S3やAPI GatewayなどのAWSサービス)を設定することができ、サーバレスバックエンドを簡単に構築できるサービスです。このサービスを使うことで、アプリ開発を超高速に行うことができます。
コマンドで作成できるリソースとしては以下のようなものがあります。
- Auth: Amazon Cognito(SignIn/SignUp機能を追加)
- Analytics: Amazon Pinpoint(ユーザのセッションやイベントを記録)
- Storage: Amazon S3
- Caching: Amazon Cloudfront
- API: API Gateway+Lambda(REST)やAppSync(GraphQL)
Black Beltの資料にもっと詳しい内容が載っています。
Amplify CLI の導入
バックエンドリソースをポチポチするだけで作成するには、Amplify CLIの導入と自分のAWSアカウントとの紐付けが必要になります。
導入方法は公式Docsに書いてあるので割愛しますが、簡単にまとめると以下のことを行っています。
- Amplify CLIのインストール(Node.jsとnpmの事前導入が必要)
- Amplifyの設定でAWSリソースを作成するためのIAMユーザを新規作成
- アクセスキーIDとシークレットアクセスキーを入力してAmplify CLIとIAMユーザを紐付け
アプリ構築
AmplifyでGraphQLやAuthなどのバックエンドリソースを構築し、Reactで作成したアプリでこれらを利用するところまでをまとめました。
最初にnpx create-react-app <app名>でプロジェクトを作成してください。バックエンド構築
まずはプロジェクトにamplifyを導入します。以下のコマンドをうつと、デフォルトのエディタや使用フレームワークに関する質問がでてくるのでそれに答えます。
amplify init ? Enter a name for the project chatapp ? Enter a name for the environment dev ? Choose your default editor: Visual Studio Code ? Choose the type of app that you're building javascript Please tell us about your project ? What javascript framework are you using react ? Source Directory Path: src ? Distribution Directory Path: build ? Build Command: npm run-script build ? Start Command: npm run-script start Using default provider awscloudformation ? Select the authentication method you want to use: (Use arrow keys) ? Select the authentication method you want to use: AWS profile For more information on AWS Profiles, see: https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-profiles.html ? Please choose the profile you want to use defaultAPI(GraphQL)リソースの構築
以下のコマンドで質問に答えていくと、
amplify/backendの直下にapiフォルダが作成されます。amplify add api ? Please select from one of the below mentioned services: GraphQL ? Provide API name: chatapp ? Choose the default authorization type for the API API key ? Enter a description for the API key: ? After how many days from now the API key should expire (1-365): 365 ? Do you want to configure advanced settings for the GraphQL API No, I am done. ? Do you have an annotated GraphQL schema? No ? Choose a schema template: Single object with fields (e.g., “Todo” with ID, name, description)schema.graphqlでスキーマを定義します。
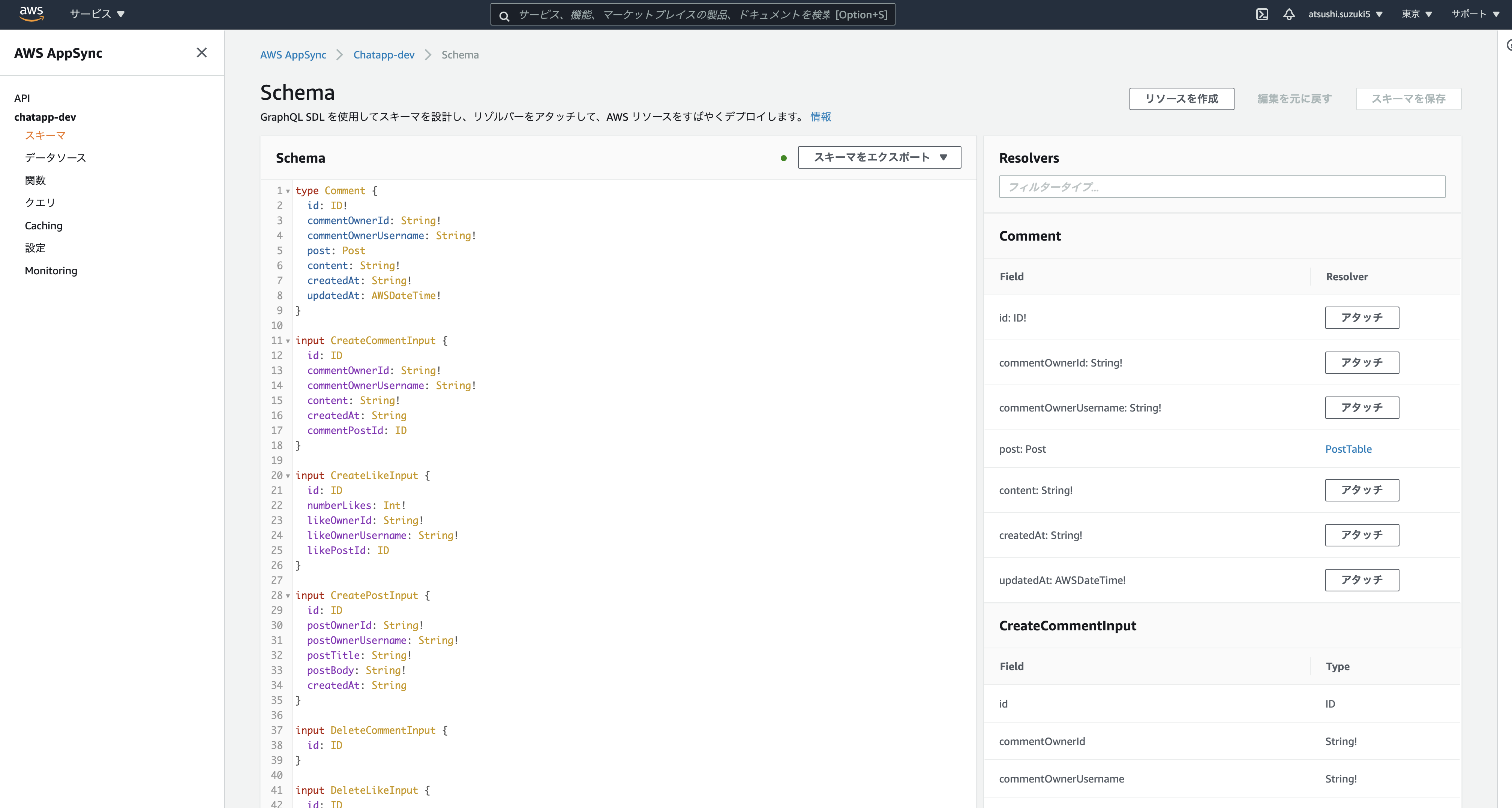
type Post @model { id: ID! postOwnerId: String! postOwnerUsername: String! postTitle: String! postBody: String! createdAt: String comments: [Comment] @connection(name: "PostComments") #relationship likes: [Like] @connection(name: "PostLikes") } type Comment @model { id: ID! commentOwnerId: String! commentOwnerUsername: String! post: Post @connection(name: "PostComments") content: String! createdAt: String! } type Like @model { id: ID! numberLikes: Int! likeOwnerId: String! likeOwnerUsername: String! post: Post @connection(name: "PostLikes") }typeに@modelというディレクティブをつけると、データソース(DynamoDB)との連携やresolverを自動で生成してくれます。
また、amplify codegenでsrc/graphqlにクライアントソースコード側でもアクセスできるライブラリも自動で生成してくれます。ディレクティブについては、こちらのサイトが参考になりました。
amplify pushを実行して以下の質問に答えると、AWSのリソース(AppSync)が構築されます。amplify push | Category | Resource name | Operation | Provider plugin | | -------- | ------------- | --------- | ----------------- | | Api | chatapp | Create | awscloudformation | ? Are you sure you want to continue? Yes ? Do you want to generate code for your newly created GraphQL API Yes ? Choose the code generation language target javascript ? Enter the file name pattern of graphql queries, mutations and subscriptions src/graphql/**/*.js ? Do you want to generate/update all possible GraphQL operations - queries, mutations and subscriptions Yes ? Enter maximum statement depth [increase from default if your schema is deeply nested] 2
amplify console apiでAppSyncの画面を開くと、作成したSchemaを確認することができます。
Authリソースの構築
amplify add authを実行した後にamplify pushでAWSのリソース(Cognito)が構築されます。amplify add auth Using service: Cognito, provided by: awscloudformation The current configured provider is Amazon Cognito. Do you want to use the default authentication and security configuration? Default configuration Warning: you will not be able to edit these selections. How do you want users to be able to sign in? Username Do you want to configure advanced settings? No, I am done.フロントエンドの設定
構築したAWSリソースをフロントエンド(React)で使う方法をまとめました。
API(GraphQL)
作成したQueryとMutationの読み込み方をまとめました。
Query
npm install aws-amplify aws-amplify-reactで必要なライブラリを導入し、作成したクエリを読み込んでAPI.graphql(graphqlOperation(listPosts))のようにするとクエリが実行されます。このとき、データを取得した後に表示を行いたいので、非同期処理(async~await)を行っています。import { listPosts } from '../graphql/queries'; import { API, graphqlOperation } from 'aws-amplify'; const getPosts = async () => { const result = await API.graphql(graphqlOperation(listPosts)); };Mutation
こちらもクエリと同様でgraphqlフォルダから読み込んで実行します。
以下はdeletePostの例です。削除するpostの指定のために、postIdを引数としてとっています。const handleDeletePost = async (postId) => { const input = { id: postId, }; await API.graphql(graphqlOperation(deletePost, { input }));Auth
withAuthentificatorをインポートしてAppをラッピングしてあげます。import './App.css'; import { DisplayPosts } from './components/DisplayPosts'; import { CreatePost } from './components/CreatePost'; import { withAuthenticator } from 'aws-amplify-react'; function App() { return ( <div className="App"> <CreatePost /> <DisplayPosts /> </div> ); } export default withAuthenticator(App, { includeGreetings: true });すると以下のようなログイン画面が自動で作られます。
作成したアカウントはCognitoのユーザプールで管理されます。
おわりに
React Native+Amplifyでお腹弱い人向けのサービスでもつくろうかなと思っています。
- 投稿日:2021-03-01T00:44:45+09:00
[aws-cdk]S3 + CloudFrontで静的コンテンツ配信する
S3 + CloudFrontの構成で静的コンテンツ配信する構成をCDKで作ってみた。
YAMLから開放されて非常に良い・・・CDKはいいぞ!
前提
- aws-cdkの実行環境は構築済み
- 今回は TypeScript で構築してます
- Route53の設定済み
- ACMで証明書を発行済み
準備
不足しているパッケージを追加します。
$ npm i -D @aws-cdk/aws-s3 @aws-cdk/aws-cloudfront @aws-cdk/aws-route53-targetsコード
ディレクトリ構成
今回は以下の構成で動かすことを想定しています。l
./ ├ bin/ │ └ cdk.ts └ lib/ └ sample/ └ index.tsbin/cdk.ts
sample/index.tsのpropsに値を渡してあげるだけです。import * as cdk from '@aws-cdk/core'; import { SampleStack } from '../lib/sample'; const app = new cdk.App(); new SampleStack(app, "sample-stack", { // 公開したいドメイン名を指定(バケット名にもなる) domain: "sample.xxxxxxx.com", // 設定済みのRoute53の情報 route53HostedZoneId: "xxxxxxxxx", route53HostedZoneName: "xxxxxxxxxxx", // 作成済みの証明書のARN acmCertificateArn: "arn:aws:acm:us-east-1:xxxxxxxxxxxx:certificate/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", // CloudFrontに設定するTTL cfTtl: cdk.Duration.minutes(5), });Stack
import * as core from "@aws-cdk/core"; import * as s3 from "@aws-cdk/aws-s3"; import * as cf from "@aws-cdk/aws-cloudfront"; import * as route53 from "@aws-cdk/aws-route53"; import * as targets from "@aws-cdk/aws-route53-targets"; export interface SampleStackProps extends core.StackProps { readonly domain: string; readonly route53HostedZoneId: string; readonly route53HostedZoneName: string; readonly acmCertificateArn: string; readonly cfTtl: core.Duration; } export class SampleStack extends core.Stack { constructor(scope: core.Construct, id: string, props: SampleStackProps) { super(scope, id, props); const bucket = new s3.Bucket(this, "S3Bucket", { bucketName: props.domain, accessControl: s3.BucketAccessControl.PRIVATE, removalPolicy: core.RemovalPolicy.DESTROY, }); const identity = new cf.OriginAccessIdentity(this, "OriginAccessIdentity", { comment: `${bucket.bucketName} access identity`, }); const distribution = new cf.CloudFrontWebDistribution(this, "Distribution", { enableIpV6: true, httpVersion: cf.HttpVersion.HTTP2, viewerProtocolPolicy: cf.ViewerProtocolPolicy.REDIRECT_TO_HTTPS, viewerCertificate: { aliases: [props.domain], props: { acmCertificateArn: props.acmCertificateArn, sslSupportMethod: cf.SSLMethod.SNI, minimumProtocolVersion: "TLSv1.2_2019", }, }, originConfigs: [ { s3OriginSource: { s3BucketSource: bucket, originAccessIdentity: identity, }, behaviors: [ { isDefaultBehavior: true, allowedMethods: cf.CloudFrontAllowedMethods.GET_HEAD, cachedMethods: cf.CloudFrontAllowedCachedMethods.GET_HEAD, defaultTtl: props.cfTtl, maxTtl: props.cfTtl, minTtl: props.cfTtl, forwardedValues: { queryString: false, }, }, ], }, ], }); new route53.ARecord(this, "Route53ARecordSet", { zone: route53.HostedZone.fromHostedZoneAttributes(this, "Route53HostedZone", { hostedZoneId: props.route53HostedZoneId, zoneName: props.route53HostedZoneName, }), recordName: props.domain, target: route53.RecordTarget.fromAlias(new targets.CloudFrontTarget(distribution)), }); } }うごかす
しばらく待ちます・・・
 $ cdk deploy sample-stack sample-stack: deploying... sample-stack: creating CloudFormation changeset... [██████████████████████████████████████████████████████████] (7/7) ✅ sample-stack Stack ARN: arn:aws:cloudformation:ap-northeast-1:xxxxxxxxxxxx:stack/sample-stack/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
$ cdk deploy sample-stack sample-stack: deploying... sample-stack: creating CloudFormation changeset... [██████████████████████████████████████████████████████████] (7/7) ✅ sample-stack Stack ARN: arn:aws:cloudformation:ap-northeast-1:xxxxxxxxxxxx:stack/sample-stack/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx確認
とりあえず試したいだけなので、S3にはコンソールから適当なファイルをアップロード済みです
bin/cdk.tsでSampleStackに渡したドメインを開くと、ページが表示されるかと思います!$ open sample.xxxxxxx.com
破棄
今回作った構成は不要なので消しておきます

バケットの中身は事前に空にしておきます$ cdk destroy sample-stack Are you sure you want to delete: sample-stack (y/n)? y sample-stack: destroying... ✅ sample-stack: destroyed
- 投稿日:2021-03-01T00:42:53+09:00
DockerでRails開発時に,画像の保存先をAWS S3にする
先日,Rails, Dockerでの開発時に画像の保存先をローカルからS3に変更した際の手順を記録した.
開発環境
WSL2 (ubuntu 18.04 LTS)
Docker
- Ruby (2.7.1)
- Rails (6.0.3)画像をS3に保存する手順
Active Storageがインストールされており,S3バケット作成まで完了していることを想定
Active Storageのインストールは以下のコマンドでできる
terminaldocker-compose run コンテナ名 rails active_storage:install docker-compose run コンテナ名 rails db:migrate用意するもの
S3バケット情報
- バケット名
- リージョン
IAMユーザー情報
- アクセスキー
- シークレットアクセスキー
手順
1. root dirにて以下のコマンドを実行
terminaldocker exec -it コンテナID sh /app # EDITOR=vi rails credentials:editコンテナIDは以下のコマンドで確認できる
terminaldocker ps2. credentialsを編集
credentialsをターミナル上で編集する
awsは最初コメントアウトされているので外す (それに気付かずハマってしまいました)
aws: access_key_id: 取得したアクセスキー secret_access_key: 取得したシークレットアクセスキー入力し保存する.
Esc→:wqでセーブして保存する.
:wq3. config/storage.ymlの編集
regionとbucketを作成したものに書き換える.
config/storage.ymlamazon: service: S3 access_key_id: <%= Rails.application.credentials.dig(:aws, :access_key_id) %> secret_access_key: <%= Rails.application.credentials.dig(:aws, :secret_access_key) %> region: "リージョン" bucket: "bucket名"4. aws-sdk-s3というgemをインストールする
Gemfileを編集
Gemfilegem 'aws-sdk-s3', require: falseGemfileを書き換えたので,コンテナをbuildし直す.
terminaldocker-compose build コンテナ名5. config/environments/development.rbでActive Storageの参照先を:localから:amazonへと変更
config/environments/development.rbconfig.active_storage.service = :amazon以上で,S3のバケットに画像が保存された.
- 投稿日:2021-03-01T00:31:34+09:00
AWSの環境をTerraformを使って構築してみた
AWSで使い捨ての環境を構築する際は、AWS CloudFormationを利用することが多いと思います。
検証環境をテンプレートとして残しておいたり、マネジメントコンソールやAWS CLIから簡単に構築/削除を行うことができます。AWS公式のツール以外だと、Terraformが選択肢の1つとして挙げられます。
Terraformって何?
HashiCorp社が提供するTerraformは、インフラ構築や設定などをコード(テンプレートファイル)を使って自動化するツールです。(Infrastructure as Code)
AWS以外にも数多くのプロバイダ(クラウドサービスやツール)に対応しています。この記事の載時点では最新バージョン0.14.5までリリースされています。(2021年 1月時点)
Terraformの開発は非常に活発であり、最新バージョンのリリースもかなり頻度が高いです。
今後、Infrastructure as Codeの分野でますます注目を浴びそうです。
https://www.terraform.io/構築内容
今回はシンプルな環境を構築します。作成するawsリソースは以下の通りです。
- VPC
- Internet Gateway
- Subnetインストール
Mac環境でのインストールはHomebrewを利用します。
$ brew install terraform
$ terraform versionテンプレートファイルの作成
Terraformのインストールを終えたら、AWSの環境構築を行っていきます。
はじめにワークディレクトリを作成して、その中にTerraformのテンプレートファイルを作成します。
下記のようなディレクトリ構成にします。terraform
├ env
├ main.tf
├ modules
└ variables.tf基本的にはmain.tfにコードを書いて行きます。
変数の宣言
terraformでは変数が使用できます。使用方法は何通りかありますが、ここではファイルから値を渡す方法を用います。
envディレクトリの配下に、<任意の名前>.tfvarsというファイルを作成し以下のように記述します。env
└ dev.tfvars# プロジェクト名 name = "Example" # 環境名 env = "dev" # profile profile = "default" # vpc vpc_cidr_block = "10.100.0.0/16"awsのアクセスキーやシークレットキーを直接記述するのは危険なので、代わりにawsのクレデンシャルを参照させます。
変数:profileには使用するクレデンシャルの名前をセットします。プロバイダーの設定
テンプレートを書く際にまず必要となるのはプロバイダーの設定です。
Terraformは複数のプロバイダーに対応しているため、「どのプロバイダーを使用するか?」を始めに宣言する必要があります。
main.tfに記述します。terraform
└ main.tf##################################### # 初期設定 ##################################### terraform { required_version = ">= 0.12.0" required_providers { aws = "~> 3.0" } backend "s3"{} } provider "aws" { profile = var.profile region = "ap-northeast-1" } locals { az_names = slice(data.aws_availability_zones.available.names, 0, var.az_cnt) name = "project-${var.env}" } ##################################### # Availability Zones ##################################### data "aws_availability_zones" "available" { state = "available" }providerブロックの中でvar.profileという値が使用されています。
localsブロックの中でもvar.envという値が使用されています。
これは、.tfvarsで宣言した変数になります。var.<変数名>という感じです。
main.tfでこのような変数を使用する場合は、variables.tfの中で型の宣言をする必要があります。terraform
└ variables.tfvariable "env" { type = string description = "Current state of project:dev, stage, prod..." } variable "profile" { type = string description = "The aws profile name." }moduleの使い方
terraformでコードを書いていくと、コードがとても長くなっていくので、
モジュールとして分けてしまいます。
使用する意味合いとしては、VPCの部分、EC2の部分などとリソースごとに分けることで可読性を高めることができます。moduleを使用する際は、main.tfにmoduleブロックを記述し、moduleのなかで使用する変数を宣言します。
terraform
└ main.tf##################################### # VPC ##################################### module "vpc" { source = "./modules/vpc" name = local.name vpc_cidr_block = var.vpc_cidr_block az_names = local.az_names }ourceにはmoduleとして使用する.tfファイルのパスを指定します。(後ほどファイルを作成します。)
local.<変数名>はlocalsブロック内で宣言した変数を示しています。次に、modulesディレクトリの下にvpcディレクトリを作成し、その中にmain.tfとvariables.tfを作成します。
modules
└ vpc
├ main.tf
└ variables.tf先ほどのmoduleブロック内で宣言した変数の型を、modules/vpc/variables.tfにて宣言します。
variable "name" { type = string description = "The cidr_block." } variable "vpc_cidr_block" { type = string description = "The VPC's CIDR block." } variable "az_names" { type = list(string) description = "The AZ names" }次にmodules/vpc/main.tfにコードを書いていきます。ここではproviderの宣言は必要ありません。
locals { az_cnt = length(var.az_names) } ##################################### # VPC ##################################### resource "aws_vpc" "this" { cidr_block = var.vpc_cidr_block enable_dns_support = true enable_dns_hostnames = true tags = { Name = "${var.name}-vpc" } } ##################################### # Internet Gateway ##################################### resource "aws_internet_gateway" "this" { vpc_id = aws_vpc.this.id tags = { Name = "${var.name}-igw" } } ##################################### # Publiuc Subnet ##################################### resource "aws_subnet" "public" { count = local.az_cnt vpc_id = aws_vpc.this.id cidr_block = cidrsubnet(var.vpc_cidr_block, 8, count.index) availability_zone = var.az_names[count.index] tags = { Name = "${var.name}-subnet-public-${var.az_names[count.index]}" } }dry runの使用方法
実際に記述したterraformコードをデプロイする前にdry runを行うことで、
作成されるリソースや現時点との差分を確認することができます。
dry runする場合はターミナルで以下のコマンドを実行します。terraform plan -var-file=./env/dev.tfvars An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: + create Terraform will perform the following actions: # module.vpc.aws_internet_gateway.this will be created + resource "aws_internet_gateway" "this" { + arn = (known after apply) + id = (known after apply) + owner_id = (known after apply) + tags = { + "Name" = "project-dev-igw" } + vpc_id = (known after apply) } # module.vpc.aws_subnet.public[0] will be created + resource "aws_subnet" "public" { + arn = (known after apply) + assign_ipv6_address_on_creation = false + availability_zone = "ap-northeast-1a" + availability_zone_id = (known after apply) + cidr_block = "10.100.0.0/24" + id = (known after apply) + ipv6_cidr_block_association_id = (known after apply) + map_public_ip_on_launch = false + owner_id = (known after apply) + tags = { + "Name" = "project-dev-subnet-public-ap-northeast-1a" } + vpc_id = (known after apply) } # module.vpc.aws_subnet.public[1] will be created + resource "aws_subnet" "public" { + arn = (known after apply) + assign_ipv6_address_on_creation = false + availability_zone = "ap-northeast-1c" + availability_zone_id = (known after apply) + cidr_block = "10.100.1.0/24" + id = (known after apply) + ipv6_cidr_block_association_id = (known after apply) + map_public_ip_on_launch = false + owner_id = (known after apply) + tags = { + "Name" = "project-dev-subnet-public-ap-northeast-1c" } + vpc_id = (known after apply) } # module.vpc.aws_vpc.this will be created + resource "aws_vpc" "this" { + arn = (known after apply) + assign_generated_ipv6_cidr_block = false + cidr_block = "10.100.0.0/16" + default_network_acl_id = (known after apply) + default_route_table_id = (known after apply) + default_security_group_id = (known after apply) + dhcp_options_id = (known after apply) + enable_classiclink = (known after apply) + enable_classiclink_dns_support = (known after apply) + enable_dns_hostnames = true + enable_dns_support = true + id = (known after apply) + instance_tenancy = "default" + ipv6_association_id = (known after apply) + ipv6_cidr_block = (known after apply) + main_route_table_id = (known after apply) + owner_id = (known after apply) + tags = { + "Name" = "project-dev-vpc" } } Plan: 4 to add, 0 to change, 0 to destroy. ------------------------------------------------------------------------ Note: You didn't specify an "-out" parameter to save this plan, so Terraform can't guarantee that exactly these actions will be performed if "terraform apply" is subsequently run.デプロイ
dry runを実行して何も問題がなければいよいよデプロイをします。
デプロイするにはターミナルで下記コマンドを実行します。terraform apply -var-file=./env/dev.tfvars #出力された内容でデプロイするか聞かれるので'yes'と入力する Do you want to perform these actions? Terraform will perform the actions described above. Only 'yes' will be accepted to approve. Enter a value: yes # 実行ログが下に出力される環境削除
デプロイした環境を削除する場合は、ターミナルで下記コマンドを実行します。
terraform destroy -var-file=./env/dev.tfvars #出力された内容を削除するか聞かれるので'yes'と入力する Do you really want to destroy all resources? Terraform will destroy all your managed infrastructure, as shown above. There is no undo. Only 'yes' will be accepted to confirm. Enter a value: yes # 実行ログが下に出力される使ってみた感想
コマンド叩くだけでインフラの構築が簡単にできてしまうことに驚きました。
テンプレートを用意してしまえば、使い捨ての検証環境をバンバン立てられちゃいますね!
構築するリソースをモジュールに分けることで、インフラの全体像が把握しやすくなると感じました!
コードだからバージョン管理もしやすそうです。ドキュメントにはとてもお世話になりました。不明点があったらとりあえずドキュメントを見ましょう。
https://registry.terraform.io/providers/hashicorp/aws/latest/docs