- 投稿日:2021-02-28T18:04:29+09:00
TensorFlow2 + Keras で画像分類に挑戦 CNN編2 ~畳み込み処理を視覚的に理解する~
はじめに
TensorFlow2 + Keras による画像分類の勉強メモ(CNN編の第2弾)です。MLP編(多層パーセプトロンモデル編)については、こちら をご覧ください。
前回は「とりあえず動かす」ということで、MNIST を対象に TF/Keras でシンプルなCNN(畳み込みニューラルネットワークモデル)を定義し、学習と評価を行ないました。
CNNモデルの定義(TF/Keras)model = tf.keras.models.Sequential() model.add( tf.keras.layers.Reshape((28, 28, 1), input_shape=(28, 28)) ) model.add( tf.keras.layers.Conv2D(32, kernel_size=(3,3), activation='relu') ) # 畳み込み層 model.add( tf.keras.layers.MaxPooling2D(pool_size=(2,2)) ) model.add( tf.keras.layers.Flatten() ) model.add( tf.keras.layers.Dense(128, activation='relu') ) model.add( tf.keras.layers.Dropout(0.2) ) model.add( tf.keras.layers.Dense(10, activation='softmax') )今回は、畳み込み処理(Convolution)とは、何なのか?どんなことをしているのか?について、図とコードと使ってできるだけ分かりやすく解説していきたいと思います。
畳み込み処理(Convolution)
CNNの最大の特徴は、畳み込み層が存在することです。TF/Keras で定義するモデル的には
tf.keras.layers.Conv2D(32, kernel_size=(3,3), activation='relu')のような「畳み込み層」が含まれていると、CNNモデルと言えます。この畳み込み層では「畳み込みフィルタの適用(フィルタの畳み込み処理)」が行なわれています。この「フィルタの適用」とは gimp や フォトショップ などの画像処理ソフトでのフィルタ処理(ぼかし処理、モザイク処理、シャープ化など)と同じことです。
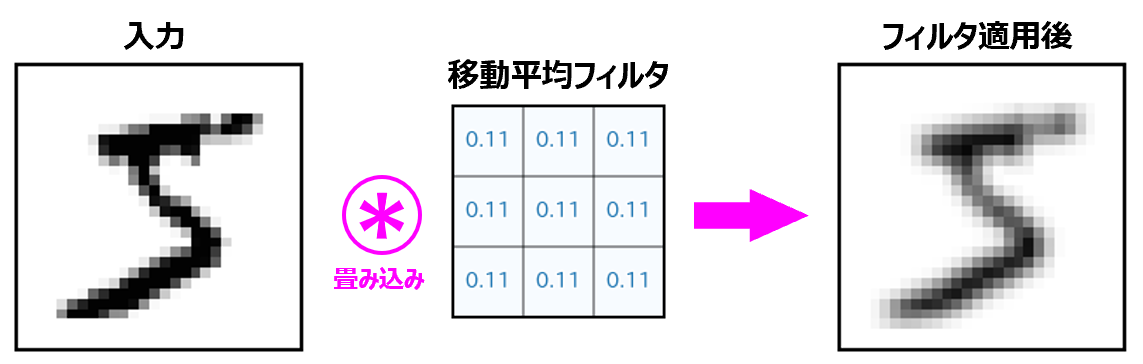
(やや正確性を欠きますが)言葉で表現すれば畳み込みフィルタの適用とは「入力画像を構成している各ピクセルについて、適当な重みを付けて周囲のピクセル情報を取り込んで出力画像を作成すること」なります。
具体的には、
Conv2D層の通過によって、次のようにデータが変化します。
上記の例では、フィルタの要素値(=重み)を「すべて $0.11$ 」のように、こちら側で用意して与えています。しかし、CNNではフィルタの要素値(=重み)は学習を通じて最適化・決定していきます。
Conv2D(...) で任意フィルタで畳み込む
単にフィルタを畳み込むだけなら OpenCV でやったほうが早いのですが、ここでは TF/Keras で CNNモデルを作成するときに使用する
tf.keras.layers.Conv2D(...)で実行してみたいと思います。例として、ここでは MNIST の手書き文字画像に、3種のフィルタを畳み込んでみたいと思います。
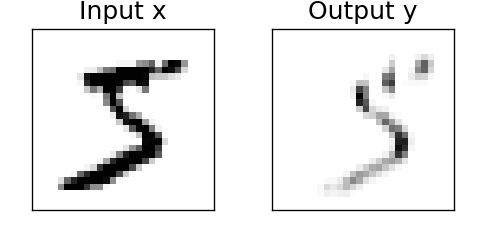
tf.keras.layers.Conv2D(...)の単層で構成されるモデルを作成し、model.set_weights(...)でフィルタ(=重み)をセットして、y=model(x)で結果を取得します。任意のフィルタを畳み込む%tensorflow_version 2.x import numpy as np import tensorflow as tf import matplotlib.pyplot as plt # (0)準備:画像表示関数 def show_image(img,title=None): plt.figure(figsize=(2,2),dpi=120) plt.gcf().patch.set_facecolor('white') plt.xticks([]) plt.yticks([]) plt.title(title,fontsize=15) plt.imshow(img,cmap='Greys') plt.show() plt.close() # (1) 入力データ x の準備 mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train/255.0, x_test/255.0 x = x_train[0] # 訓練用データの0番目の画像を使用 show_image(x,title='Input x') # (2) モデルに入力できる形に整形 x_size = x.shape x = x.reshape([1,x_size[0],x_size[1],1]) # shape:(28, 28)=>(1,28,28,1) x = x.astype(np.float32) # (3) サイズ 3x3 のフィルタ w を作成 a = np.array([[1,1,1],[1,1,1],[1,1,1]])/9 # 移動平均フィルタ #a = np.array([[1,2,1],[0,0,0],[-1,-2,-1]]) # ソーベルフィルタ(横方向検出) #a = np.array([[1,0,-1],[2,0,-2],[1,0,-1]]) # ソーベルフィルタ(縦方向検出) a = a.astype(np.float32) a = a.reshape([3,3,1,1]) # shape:(3, 3) => (3,3,1,1) w = [a] # (4) フィルタを畳み込むモデルを構築 model = tf.keras.models.Sequential() model.add( tf.keras.layers.Conv2D(filters=1, kernel_size=(3,3), use_bias=False, padding='same', activation='relu', input_shape=(28,28,1))) # (5) フィルタ w をモデルにセット model.set_weights(w) # (6) 畳み込み処理の実行 y = model(x) y = y.numpy().reshape(y.numpy().shape[1:3]) # shape:(1,28,28,1)=>(28,28) show_image(y,title='Output y')フィルタに関する部分のコメントアウトを切り替えながら実行すると、次のような結果が得られます。
平均化フィルタ
ソーベルフィルタ(横方向検出)
ソーベルフィルタ(縦方向検出)
カーネルサイズ
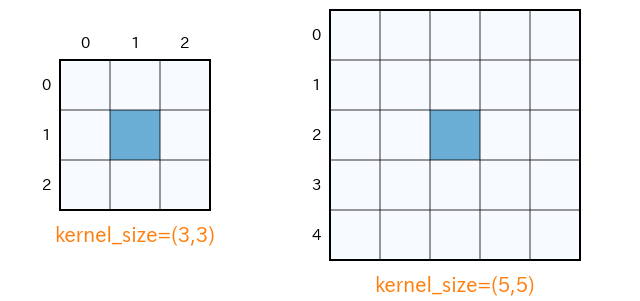
フィルタが、どのぐらい周辺のピクセル情報までを取り込むかという縦横の範囲をカーネルサイズ(フィルタサイズ)といいます。一般には「$3\times 3$」や「$5\times 5$」のような奇数値が使われます。
tf.keras.layers.Conv2D(32, kernel_size=(3,3), activation='relu')の(3, 3)がカーネルサイズの指定になります。カーネルサイズが $3\times 3$ ということは、自身を含め周囲 $9$ マスの情報の重み付き和をフィルタ適用後の値とすることを意味します。カーネルサイズ $5\times 5$ では自身を含めて周囲 $25$ マスの情報の重み付き和で適用後の値が決まります。
カーネル値
このカーネル(行列)の各要素には、畳み込み処理のための「重み」が格納されます。どのような値を入れるかによって、そのフィルタが、ぼかし効果を与えるものになったり、エッジ強調をするものになったり変化します。


- 投稿日:2021-02-28T17:18:17+09:00
KerasでGANの実装 (サンプルコード有り)
はじめに
以前投稿した記事「kerasでGAN(mnist)動かしてみた」で扱っていたGANのコードを今更ながらGithubで公開しました。
これからGANを勉強したい方などの参考になればと思っています。
データは全てMnist、ライブライはKerasを使っています。Github: https://github.com/ozora-ogino/keras-gan-example
コードの説明
GithubリポジトリにはGAN, DCGAN, CGANが実装されています。
それぞれ以下のようなクラスで実装しています。gan.pyclass GAN(): def __init__(self): self.img_rows = 28 self.img_cols = 28 self.channels = 1 self.img_shape = (self.img_rows, self.img_cols, self.channels) self.latent_dim = 100 optimizer = Adam(0.0002, 0.5) # 識別モデルのビルドとコンパイル self.discriminator = self.build_discriminator() self.discriminator.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy']) # 生成モデルのビルド self.generator = self.build_generator() # ノイズ z = Input(shape=(self.latent_dim,)) img = self.generator(z) # 画像生成時の識別モデルの学習をOFF self.discriminator.trainable = False # 識別モデルは画像(Fake or Real)を入力として、それがFakeかどうかを判定します。 validity = self.discriminator(img) # モデルを結合 self.combined = Model(z, validity) self.combined.compile(loss='binary_crossentropy', optimizer=optimizer) def build_generator(self): model = Sequential() model.add(Dense(256, input_dim=self.latent_dim)) model.add(LeakyReLU(alpha=0.2)) model.add(BatchNormalization(momentum=0.8)) model.add(Dense(512)) model.add(LeakyReLU(alpha=0.2)) model.add(BatchNormalization(momentum=0.8)) model.add(Dense(1024)) model.add(LeakyReLU(alpha=0.2)) model.add(BatchNormalization(momentum=0.8)) model.add(Dense(np.prod(self.img_shape), activation='tanh')) model.add(Reshape(self.img_shape)) model.summary() noise = Input(shape=(self.latent_dim,)) img = model(noise) return Model(noise, img) def build_discriminator(self): model = Sequential() model.add(Flatten(input_shape=self.img_shape)) model.add(Dense(512)) model.add(LeakyReLU(alpha=0.2)) model.add(Dense(256)) model.add(LeakyReLU(alpha=0.2)) model.add(Dense(1, activation='sigmoid')) model.summary() img = Input(shape=self.img_shape) validity = model(img) return Model(img, validity) def train(self, epochs, batch_size=128, sample_interval=50): (X_train, _), (_, _) = mnist.load_data() # 前処理のスケーリング X_train = X_train / 127.5 - 1. X_train = np.expand_dims(X_train, axis=3) # Adversarial ground truths valid = np.ones((batch_size, 1)) fake = np.zeros((batch_size, 1)) for epoch in range(epochs): # *** 識別モデルの学習 *** # ランダムにバッチを抽出させる idx = np.random.randint(0, X_train.shape[0], batch_size) imgs = X_train[idx] noise = np.random.normal(0, 1, (batch_size, self.latent_dim)) # 生成画像のバッチ gen_imgs = self.generator.predict(noise) # 学習 d_loss_real = self.discriminator.train_on_batch(imgs, valid) d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake) d_loss = 0.5 * np.add(d_loss_real, d_loss_fake) # *** 生成モデルの学習 *** noise = np.random.normal(0, 1, (batch_size, self.latent_dim)) # ノイズと画像を入力として学習 g_loss = self.combined.train_on_batch(noise, valid) # 進捗 print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss)) # 画像の保存 if epoch % sample_interval == 0: self.sample_images(epoch) def sample_images(self, epoch): r, c = 5, 5 noise = np.random.normal(0, 1, (r * c, self.latent_dim)) gen_imgs = self.generator.predict(noise) # スケーリング gen_imgs = 0.5 * gen_imgs + 0.5 fig, axs = plt.subplots(r, c) cnt = 0 for i in range(r): for j in range(c): axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray') axs[i,j].axis('off') cnt += 1 fig.savefig("images/%d.png" % epoch) plt.close()どなたかこれから学ぶ方のためになれば幸いです!
参考
実践GAN 敵対的生成ネットワークによる深層学習
Keras-GAN: https://github.com/eriklindernoren/Keras-GAN
- 投稿日:2021-02-28T16:36:58+09:00
Tensorflow2.4 Install 備忘録
概要
年末に組んだ自作PCでもTensorflow(TF)が使えるようにセットアップしたのでその備忘録
前回のCuda10のインストールよりも格段に簡単になっていた
TFオフィシャルの手順だけではうまくいかない箇所があったので書き残す
- 実施時期: 2021年2月
- OS: Ubuntu18.04LTS
- CPU: Ryzen 5600X
- GPU: GeForce RTX3070
- Python: AnacondaのPython3.7
経緯
RTX2000シリーズと比べ格段に性能が向上したとされるRTX3000をどうしてもトレーニングに使ってみたい。
購入前から何気に知ってはいたが、最新TF2.4はcuda11+cuDnn8が要件となっている。
購入後に知ったのは、RTX3000シリーズのnvidia driverは450以降しかなく、しかしこれはcuda10のサポート外であること。
つまりpipインストールでは、RTX3000シリーズで使用できるTFはTF2.4以降となる。
TF2.4で実装された新機能も試したいので、cuda11へのアップグレードは必須となる。
condaインストールではTF2.3までだが、これでは性能が向上したcuda11のパワーが使えない。本当はcudaなどインストールせずにcondaでTF2.4 with cuda11を入れたいところだが、下記のようにcondaの最新版はTF2.3まで
二月ほど待ったけど、condaからリリースされる様子がないので、仕方なくcuda+cuDnnを入れることにした。
TF2.4はコンパイルせずにcondaの仮想環境にpipでインストールする。吉報!
2021/3/9にconda-forgeを確認したらTF2.4.1がリリースされていた。
前準備
CUDA対応NVIDIAボードが刺さっていることを確認する。
$ lspci | grep -i nvidia 07:00.0 VGA compatible controller: NVIDIA Corporation Device 2484 (rev a1) 07:00.1 Audio device: NVIDIA Corporation Device 228b (rev a1)Nvidia Driverのインストール
ディスプレイドライバが標準のnouveauでなくてもよければ、これは入れておく必要がある。
cudaをインストールする、しないは関係ない。
このPCの構成でインストール可能なドライバを探す。$ sudo ubuntu-drivers devices == /sys/devices/pci0000:00/0000:00:03.1/0000:07:00.0 == modalias : pci:v000010DEd00002484sv00001462sd00003909bc03sc00i00 vendor : NVIDIA Corporation driver : nvidia-driver-460 - distro non-free recommended driver : xserver-xorg-video-nouveau - distro free builtinrecommended表示のバージョンをインストールする。
これは環境によるが少なくとも450以降でなければならない。これもTF2.4の要件のひとつ$ sudo apt install --no-install-recommends nvidia-driver-460インストールされたか確認する。
$ sudo nvidia-smi +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.39 Driver Version: 460.39 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 GeForce RTX 3070 Off | 00000000:07:00.0 On | N/A | | 0% 48C P8 17W / 220W | 180MiB / 7979MiB | 1% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 1189 G /usr/lib/xorg/Xorg 115MiB | | 0 N/A N/A 1496 G /usr/bin/gnome-shell 27MiB | | 0 N/A N/A 2113 G ...gAAAAAAAAA --shared-files 34MiB | +-----------------------------------------------------------------------------+ここで、"CUDA Version: 11.2"と表示される。
しかし、driverのインストールだけでCUDAは入らないので、11.2が何なのかは知らない。cuda, cuDnnのインストール
下記のTFオフィシャルの手順をそのまま実行する。
オフィシャルにはdriver 450のインストール手順も含まれていたが、すでに行っているので削除した。
またスクリプト中のコメントにも書かれてあるとおり、インストールするのはruntimeである。
cudaで開発したい人はdeveloper向けcudaをインストールしなければならない。cudaやcuDnnのバージョンはTFの指定があるので、スクリプト中のバージョン番号は変えてはならない。
nvidia driverは450.X以降であればOK$ sudo apt install --no-install-recommends nvidia-driver-460 # Add NVIDIA package repositories wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600 sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/ /" sudo apt-get update wget http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb sudo apt install ./nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb sudo apt-get update wget https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/libnvinfer7_7.1.3-1+cuda11.0_amd64.deb sudo apt install ./libnvinfer7_7.1.3-1+cuda11.0_amd64.deb sudo apt-get update # Install development and runtime libraries (~4GB) sudo apt-get install --no-install-recommends \ cuda-11-0 \ libcudnn8=8.0.4.30-1+cuda11.0 \ libcudnn8-dev=8.0.4.30-1+cuda11.0 # Install TensorRT. Requires that libcudnn8 is installed above. sudo apt-get install -y --no-install-recommends libnvinfer7=7.1.3-1+cuda11.0 \ libnvinfer-dev=7.1.3-1+cuda11.0 \ libnvinfer-plugin7=7.1.3-1+cuda11.0TFのオフィシャル手順に記載はなかったが、.bashrcに下記の2行を追加する。
export PATH=/usr/local/cuda-11.0/bin${PATH:+:${PATH}} export LD_LIBRARY_PATH=/usr/local/cuda-11.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}もちろん下記のフォルダが作成されていることは少なくとも確認する。
/usr/local/cuda-11.0/binTensorflowのインストール
コンパイルせずに、簡単なpipでインストールする。
これもTFのオフィシャルを一読しておく。
書かれているインストール要件は下記なので、"-V"で確認しておく
対応Python: 3.5, 3.6, 3.7 ,3.8
pip: 19.0以降現時点でpython3.8に対応していないパケージも多いのでPython3.7で作成することをお勧めする。
インストールする仮想環境を作成する。
別の用途でOpenCVも使うためPython3.7で仮想環境"hoge"を作る。$ conda create -n hoge python=3.7 $ conda activate hogepipでここにTFをインストールする。動作確認用にjupyterとnumpyなど諸々もインストールしておくこと。
(hoge)$ pip install tensorflow (hoge)$ conda install jupyterjupyter notebookを起動し、セルで下記を確認する。
import tensorflow as tf print(tf.__version__) print(len(tf.config.list_physical_devices('GPU'))>0)インストールされたTFのバージョン(バージョン未指定だったので最新がインストールされているはず)と、GPUボードを認識している'true'が表示されること。
試しにオイラの昔使ったモデルを実行したが、fit()の箇所で下記のエラーが発生した。
Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
下記を参考にTF_FORCE_GPU_ALLOW_GROWTHをTrueにすることでエラーは出なくなった。
GPUのメモリを際限なく使用する設定がデフォルトであり、これに制限をかけるときに使うコマンドらしい。
これは環境によるので必ずしも必要ではないが、いつも制限をかけてよいのであれば.bashrcに書いておけば良い。
詳細は下記を参考
以上