- 投稿日:2021-01-25T23:54:03+09:00
Pythonで学ぶアルゴリズム 第21弾:並べ替え(クイックソート)
#Pythonで学ぶアルゴリズム< クイックソート >
はじめに
基本的なアルゴリズムをPythonで実装し,アルゴリズムの理解を深める.
その第21弾としてクイックソートを扱う.クイックソート
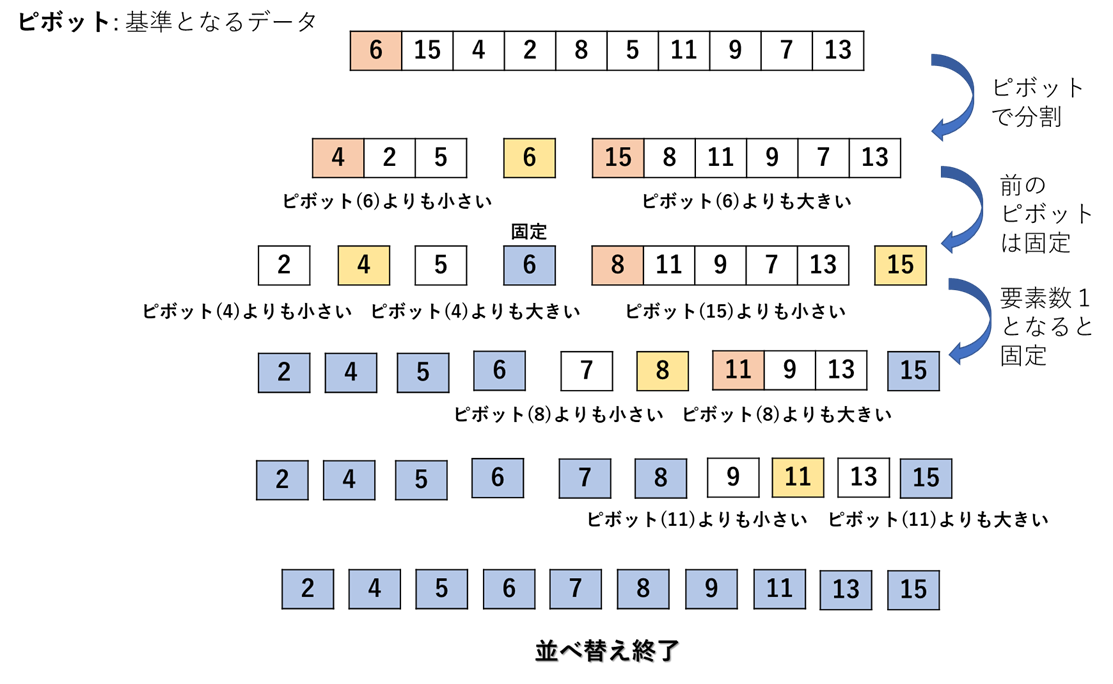
・クイックソート:リストから任意にデータを選択し,これを基準として小さい要素と大きい要素に
$\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ $分割し,それぞれのリストでまた同じような処理を繰り返してソートする方法.
・ピボット(pivot):クイックソートで基準となるデータ.選び方は様々であるが,ここではリストの
$\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ $先頭としている.以上のことを踏まえて,次にクイックソートの一連の流れ図を示す.
実装
先ほどの手順に従ったプログラムのコードとそのときの出力を以下に示す.
今回は再帰を用いた方が非常に簡単にかけることが分かる.コード
quick_sort.py""" 2021/01/25 @Yuya Shimizu クイックソート """ def quick_sort(data): #分割できなくなる(リスト要素が1以下)であれば,そのままデータを返す(並べ替えの必要なし) if len(data) <= 1: return data pivot = data.pop(0) #リストの先頭をピボットとして取り出す # ピボットより小さいものでリストを作る left = [i for i in data if i <= pivot] # ピボットより大きいものでリストを作る right = [i for i in data if i > pivot] left = quick_sort(left) #入力に対する左側リストを形成する right = quick_sort(right) #入力に対する右側リストを形成する #########再帰しきった結果のみ,quick_sort関数の出力として返される #########それ以外のreturnは上のleft = quick_sort(right), left = quick_sort(right) return left + [pivot] + right if __name__ == '__main__': DATA = [6, 15, 4, 2, 8, 5, 11, 9, 7, 13] print(f"{DATA} → {quick_sort(DATA)}")出力
[6, 15, 4, 2, 8, 5, 11, 9, 7, 13] → [2, 4, 5, 6, 7, 8, 9, 11, 13, 15]計算量
ピボットの選択が重要!うまく半分に分割できるようなピボットを選ぶことができると,マージソートと同様に$O(nlogn)$となる.ただし,ピボットをうまく選ぶことができないと,最悪な場合,$O(n^2)$となる.実用上は問題ないほど高速だが,多くのライブラリでは他のソートアルゴリズムと組み合わせるなど,高速化が図られているらしい.
感想
とりあえず,基本的な並べ替えのアルゴリズムはある程度,学ぶことができたのではないかと思う.この並べ替えに関するアルゴリズムについてはあと2つ残っている.【処理速度の比較】と【ビンソート】である.どんどん進めていきたい.
参考文献
Pythonで始めるアルゴリズム入門 伝統的なアルゴリズムで学ぶ定石と計算量
増井 敏克 著 翔泳社
- 投稿日:2021-01-25T23:27:23+09:00
Windowsアプリケーションの自動化-Python編②-
Pythonで
win32guiと、win32conを使ってWindowsアプリケーションのメニューバーを操作する
今回はフリーソフトの「サクラエディタ」を操作してみる参考URL
- サクラエディタ
- Pythonで外部プログラムのメニューバーを操作する(WM_COMMAND)
- Section6.3 メニューバー 応用編
- (C++)外部アプリケーションのメニューバー操作作業環境
- Windows10
- Anaconda3 2020.11
- Python3.8.5
- サクラエディタ v2.2.0.1 ←ちょっと古い
メニューバーを操作して日付を挿入するイメージ
編集(E)メニューから挿入(I)→日付挿入(D)を選択するとPCの現在時刻が出力される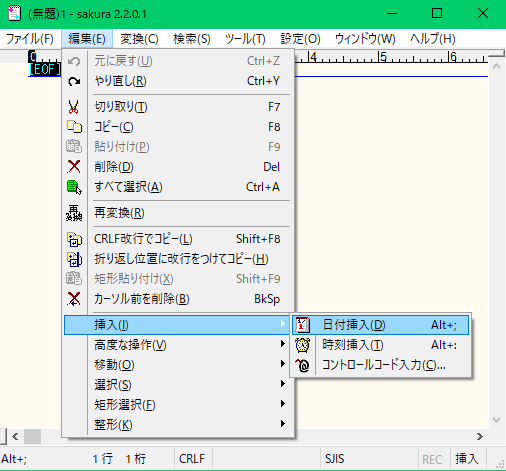
上記のメニューバー操作を、Pythonで自動化する
メニューバー(タブメニュー)とそのサブメニューのハンドルを取得
メニューバーのハンドルは、子ウィンドウハンドルではなく
win32gui.GetMenu()で取得できる
サブメニューや、サブメニューのサブメニューはwin32gui.GetSubMenu()winapi.pyimport win32gui import win32con def run(): p_hWnd = win32gui.FindWindow(None,"(無題)1 - sakura 2.2.0.1 ") # 親ウィンドウハンドル(識別番号)を取得 win32gui.SetForegroundWindow(p_hWnd) # アプリケーションをデスクトップの前面に表示 p_menu_hWnd = win32gui.GetMenu(p_hWnd) # メニューバーのハンドルを取得 p_menu_count = win32gui.GetMenuItemCount(p_menu_hWnd) # メニューバー内のサブメニューの個数を取得 # 各サブメニューのハンドルを取得 s_menu_dict = {} for i in range(p_menu_count): s_menu_dict["s_menu_pos{}".format(i)] = win32gui.GetSubMenu(p_menu_hWnd, i) [print(k,v) for k,v in s_menu_dict.items()] # サブメニュー辞書確認 if __name__ == '__main__': run()
- サブメニューのハンドルの例
メニューバー 位置 SubMenu hWnd ファイル(F) 0 15402645 編集(E) 1 459021 変換(C) 2 67635661 検索(S) 3 18022831 ツール(T) 4 31787639 設定(O) 5 5573367 ウィンドウ(W) 6 93652277 ヘルプ(H) 7 62851833 それぞれのメニューのタブにハンドルが割り振られていることが確認できる
サブメニューのサブメニューを取得する
winapi.pyimport win32gui import win32con def run(): p_hWnd = win32gui.FindWindow(None,"(無題)1 - sakura 2.2.0.1 ") # 親ウィンドウハンドル(識別番号)を取得 win32gui.SetForegroundWindow(p_hWnd) # アプリケーションをデスクトップの前面に表示 p_menu_hWnd = win32gui.GetMenu(p_hWnd) # メニューバーのハンドルを取得 p_menu_count = win32gui.GetMenuItemCount(p_menu_hWnd) # メニューバー内のサブメニューの個数を取得 # 各サブメニューのハンドルを取得 s_menu_dict = {} for i in range(p_menu_count): s_menu_dict["s_menu_pos{}".format(i)] = win32gui.GetSubMenu(p_menu_hWnd, i) [print(k,v) for k,v in s_menu_dict.items()] # サブメニュー辞書確認 # 編集(E)メニューのサブメニューのIDを取得 edit_menu = s_menu_dict["s_menu_pos1"] # 編集(E)はpos1 edit_menu_count = win32gui.GetMenuItemCount(edit_menu) # 編集メニュー内のサブメニューの個数を取得 edit_menu_dict = {} for i in range(edit_menu_count): s_menu_list = [win32gui.GetMenuItemID(edit_menu, i), win32gui.GetSubMenu(edit_menu, i)] edit_menu_dict["edit_menu_pos{}".format(i)] = s_menu_list [print(k,v) for k,v in edit_menu_dict.items()] if __name__ == '__main__': run()
- 編集メニューのIDとサブメニューの例(存在しない場合は0)
編集メニュー 位置 ID SubMenu hWnd 元に戻す(U) 0 30210 0 やり直し(R) 1 30211 0 (セパレーター) 2 0 0 切り取り(T) 3 30601 0 コピー(C) 4 30602 0 貼り付け(P) 5 30604 0 削除(D) 6 30221 0 すべて選択(A) 7 30401 0 (セパレーター) 8 0 0 再変換(R) 9 30285 0 (セパレーター) 10 0 0 CRLF改行でコピー(L) 11 30603 0 折り返し位置に改行をつけてコピー(H) 12 30608 0 矩形貼り付け(X) 13 30605 0 カーソル前を削除(B) 14 30222 0 (セパレーター) 15 0 0 挿入(I) 16 -1 1903099 高度な操作(V) 17 -1 57936345 移動(O) 18 -1 120392207 選択(S) 19 -1 56298477 矩形選択(F) 20 -1 290589067 整形(K) 21 -1 162268843 このIDに対して
win32com.SendMessage()が実行できる
ここでIDの取得に失敗して-1が返されているメニューはサブメニューが存在する
今回は日付挿入がしたいので、挿入(I)メニューのサブメニューからIDを取得する日付挿入メニューを実行する
winapi.pyimport win32gui import win32con def run(): p_hWnd = win32gui.FindWindow(None,"(無題)1 - sakura 2.2.0.1 ") # 親ウィンドウハンドル(識別番号)を取得 win32gui.SetForegroundWindow(p_hWnd) # アプリケーションをデスクトップの前面に表示 p_menu_hWnd = win32gui.GetMenu(p_hWnd) # メニューバーのハンドルを取得 p_menu_count = win32gui.GetMenuItemCount(p_menu_hWnd) # メニューバー内のサブメニューの個数を取得 # 各サブメニューのハンドルを取得 s_menu_dict = {} for i in range(p_menu_count): s_menu_dict["s_menu_pos{}".format(i)] = win32gui.GetSubMenu(p_menu_hWnd, i) [print(k,v) for k,v in s_menu_dict.items()] # サブメニュー辞書確認 # 編集(E)メニューのサブメニューのIDを取得 edit_menu = s_menu_dict["s_menu_pos1"] # 編集(E)はpos1 edit_menu_count = win32gui.GetMenuItemCount(edit_menu) # 編集メニュー内のサブメニューの個数を取得 edit_menu_dict = {} for i in range(edit_menu_count): s_menu_list = [win32gui.GetMenuItemID(edit_menu, i), win32gui.GetSubMenu(edit_menu, i)] edit_menu_dict["edit_menu_pos{}".format(i)] = s_menu_list [print(k,v) for k,v in edit_menu_dict.items()] # 挿入(I)メニューのサブメニューのIDを取得する ins_menu = edit_menu_dict["edit_menu_pos16"][1] # 挿入(I)はpos16 ins_menu_count = win32gui.GetMenuItemCount(ins_menu) # 挿入メニュー内のサブメニューの個数を取得 ins_menu_dict = {} for i in range(ins_menu_count): ins_menu_dict["ins_menu_pos{}".format(i)] = win32gui.GetMenuItemID(ins_menu,i) [print(k,v) for k,v in ins_menu_dict.items()] # 日付挿入を実行 win32gui.SendMessage(p_hWnd, win32con.WM_COMMAND, ins_menu_dict["ins_menu_pos0"], p_menu_hWnd) # 日付挿入(D)はpos0 if __name__ == '__main__': run()
- 挿入メニューのIDの例
挿入メニュー 位置 ID 日付挿入(D) 0 30790 時刻挿入(T) 1 30791 コントロールコード入力(C) 2 30792 ようやく目的のメニューIDを確認できた
- SendMessageの引数は下記のようにする
win32gui.SendMessage([親ウィンドウハンドル],[win32con.WM_COMMAND],[対象メニューのID],[メニューバーのハンドル])とまあ、今回はこのくらいで終わり
まとめ
メニューバーのハンドル値やIDをprint文で確認しながらなんとかサブメニューのサブメニューまで操作する方法は確認できましたが、メニューのテキストを直接参照できたらもう少し読み易くなると思いますね
前回の記事 | [次回の記事]
- 投稿日:2021-01-25T22:50:49+09:00
Matplotlib時系列プロット
時系列データのプロット
実世界のデータの多くは時系列で整理されています。可視化は時系列データのパターンを見出すための優れた方法です。 Matplotlibを使用した時系列データのプロットを試みます。
サンプルデータとして以下を使用します。date列は時系列、value01とvalue02は時系列で変化する計測値列です。
date,value01,value02 2021-01-01,1,100 2021-01-02,3,500 2021-01-03,2,200 2021-01-04,4,600 2021-01-05,3,300 2021-01-06,5,700 2021-01-07,4,400 2021-01-08,6,800 2021-01-09,5,500 2021-01-10,7,900 2021-01-11,6,600 2021-01-12,8,1000 2021-01-13,7,700 2021-01-14,9,1100 2021-01-15,8,800 2021-01-16,10,1200まずはサンプルデータをインポートします。(日付をインデックスとして)pandas.read_csv
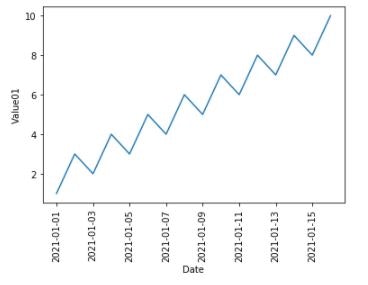
import pandas as pd df = pd.read_csv('df.csv', parse_dates=['date'], index_col='date')時系列データの全体をプロットします。
import matplotlib.pyplot as plt fig, ax = plt.subplots() plt.xticks(rotation=90) ax.plot(df.index, df['value01']) ax.set_xlabel('Date') ax.set_ylabel('Value01') plt.show()
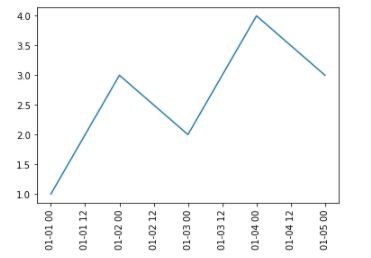
時系列データのズームインをし、プロットします。ズームインした期間の拡大図が得られます。
import matplotlib.pyplot as plt fig, ax = plt.subplots() plt.xticks(rotation=90) # ズームイン df_zoom_in = df['2021-01-01':'2021-01-05'] ax.plot(df_zoom_in.index, df_zoom_in["value01"]) plt.show()
複数変数の時系列プロット
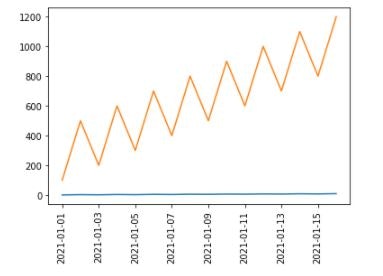
2つの変数value01とvalue02を同時にプロットしてみると、下記のようにvalue01の特徴を見出すことができなくなります。
理由はvalue01の測定値スケールが1~10まで、value02の100~1200よりずっと小さいから。import matplotlib.pyplot as plt fig, ax = plt.subplots() plt.xticks(rotation=90) ax.plot(df.index, df['value01']) ax.plot(df.index, df['value02']) plt.show()
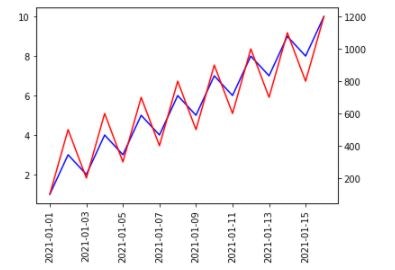
この場合、双軸を使用します。2つの異なるy軸スケールを使用して、同じサブプロットにプロットします。
import matplotlib.pyplot as plt fig, ax = plt.subplots() plt.xticks(rotation=90) ax.plot(df.index, df['value01'], color='b') # X軸を共有する双軸 ax2 = ax.twinx() ax2.plot(df.index, df['value02'], color='r') plt.show()
時系列データを多数プロットする場合、プロット用関数を定義してみます。
matplotlib.axes.Axes.tick_paramsdef plot_timeseries(axes, x, y, color, xlabel, ylabel): axes.plot(x, y, color=color) axes.set_xlabel(xlabel) axes.set_ylabel(ylabel, color=color) axes.tick_params('y', colors=color)定義した関数を使ってみます。
fig, ax = plt.subplots() plt.xticks(rotation=90) plot_timeseries(ax, df.index, df['value01'], 'blue', 'Date', 'Value01') ax2 = ax.twinx() plot_timeseries(ax2, df.index, df['value02'], 'red', 'Date', 'Value02') plt.show()
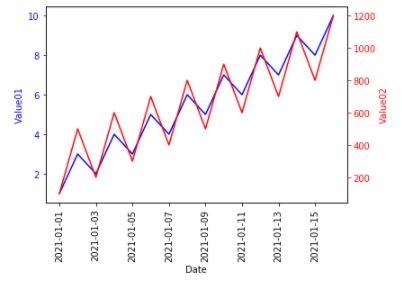
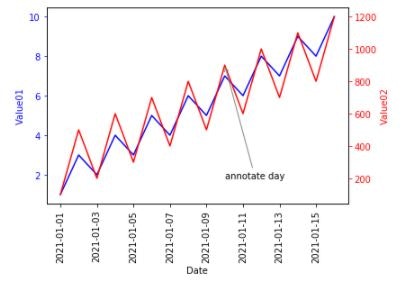
時系列データの注釈
注釈を付けることは、可視化を強化する重要な方法です。特定の部分を参照するテキストでデータのいくつかの特徴を強調でき、その特徴を説明します。
fig, ax = plt.subplots() plt.xticks(rotation=90) plot_timeseries(ax, df.index, df['value01'], 'blue', 'Date', 'Value01') ax2 = ax.twinx() plot_timeseries(ax2, df.index, df['value02'], 'red', 'Date', 'Value02') ax2.annotate('annotate day', xy=(pd.Timestamp('2021-01-10'), 900), xytext=(pd.Timestamp('2021-01-10'), 200), arrowprops={'arrowstyle': '->', 'color': 'gray'}) plt.show()
- 投稿日:2021-01-25T22:45:25+09:00
Unscented Transformation(アンセンテッド変換,U変換):非線形変換後の確率変数の推定
はじめに
Unscented Transformation(アンセンテッド変換,U変換)は,Unscented Kalman Filterの中で出てくるけど,U変換単体での説明がなくて困ってるので今の理解をまとめました.
間違ってる所など教えていただけるととてもありがたいです.Unscented Transformationの概要
U変換は,標準正規分布に従う確率変数$x$の平均$\bar{x}$と分散共分散行列$P_x$が既知であるとき,$x$の非線形変換$y=f(x)$で変換される確率変数$y$の$\bar{y}$と$P_y$を推定する方法である.
まず,この場合,モンテカロ的に
\bar{y}\simeq\frac{1}{N}\sum_{i=1}^Nf(x_i)P_y \simeq \frac{1}{N}\sum_{i=1}^N(f(x_i)-\bar{y})(f(x_i)-\bar{y})^Tのように計算することが思いつくが,精度をよく計算するにはNを大きくする必要があり,実用上問題がある.
線形近似をすることなく,モンテカロ法のよいところを利用できるように,できるだけ少ないサンプル点を用いて,変換後の確率変数の統計的性質を推定する方法がU変換である.
まず,確率変数$x$からサンプルする値(シグマ点)を決め,シグマ点を非線形変換し,変換した値から$y$の$\bar{y}$と$P_y$を求める.
参考1:UKF (Unscented Kalman Filter)っ て何 ?
import matplotlib.pyplot as plt import numpy as np import random import math import scipy.linalg入力には$X=(X_1,X_2)$を用いる.
平均ベクトルは,
\mu=(E[X_1],E[X_2])=(\bar{x}_1,\bar{x}_2)分散共分散ベクトルは,
P_x = [ \begin{array}{cc} var[X_1] & cov[X_1,X_2] \\ cov[X_2,X_1] & var[X_2] \end{array} ] = [ \begin{array}{cc} \sigma_1^2 & \sigma_1\sigma_2 \\ \sigma_1\sigma_2 & \sigma_2^2 \end{array} ]で表すことができる.
よって, $X_1,X_2$にそれぞれ平均0分散1,平均1分散2の標準正規分布を用いると考えると,\bar{x}=[0, 1]P_x = [ \begin{array}{cc} 1 & 2 \\ 2 & 4 \end{array} ]となる.
これを入力として用いる.出力は1次元とし$f(x)=x[0]*x[1]$の非線形変換を考える.
# xの次元数 n = 2 # yの次元数 m = 1 # xの平均と分散 x_mean = np.array([0, 1]) x_P = np.array([[1,2],[2,4]]) print("xの平均",x_mean) print("xの分散共分散行列",x_P) # xの非線形変換 def f(x): return [x[0]*x[1]]xの平均 [0 1]
xの分散共分散行列 [[1 2]
[2 4]]シグマ点を計算する
\sigma_0 = \bar{x} \tag{1}\sigma_i = \bar{x}+(\sqrt{(n+\lambda)}P_x) \tag{2}\sigma_i = \bar{x}-(\sqrt{(n+\lambda)}P_x) \tag{3}ここで,$\lambda$は以下のように計算される.
\lambda = \alpha^2*(n+\kappa)-n \tag{4}ここで,$\alpha$と$\kappa$はハイパーパラメータである.
$\alpha$:平均の状態値の周りのシグマ ポイントの広がりを決定します。0-1のスカラー値として指定します.これは通常、小さい正の数値です.シグマポイントの広がりは$\alpha$に比例します.値が小さいほど、シグマポイントは平均の状態に近くなります.
$\kappa$:通常は0に設定されます.値が小さいほど,シグマポイントは平均の状態に近くなります.広がりは$\kappa$の平方根に比例します。
参考1:Unscented Kalman Filter, MathWorks
参考2:Unscentedカルマンフィルタを使用した自己位置推定MATLAB, Pythonサンプルプログラム# パラメータ alpha = 0.5 kappa = 0 # 式4 lambd=alpha**2*(n+kappa)-n print("ラムダ", lambd) # シグマ点をサンプリング sigma = np.zeros((n, 2*n+1)) # 式1 sigma[:,0] = x_mean gamma=math.sqrt(n+lamda) # 式2 for i in range(n): sigma[:,i+1] = x_mean + gamma * x_P[:,i] # 式3 for i in range(n): sigma[:,i+n+1] =x_mean - gamma * x_P[:,i] print("選択されたシグマ点") for i in range(2*n+1): print(sigma[:,i])ラムダ -1.5
選択されたシグマ点
[0. 1.]
[0.00141421 1.00282843]
[0.00282843 1.00565685]
[-0.00141421 0.99717157]
[-0.00282843 0.99434315]変換
非線形変換により$y_{\sigma}$をもとめる.
y_{\sigma}=f(\sigma) \tag{5}重み関数$w_i$を求める.
w_0=\frac{\lambda}{n+\lambda} \tag{6}w_i=\frac{1}{2(n+\lambda)} \tag{7}$y$の平均と分散は以下のように計算できる.
\bar{y} \simeq \sum_{i=0}^{2n}w_iy_{\sigma i} \tag{8}P_y \simeq \sum_{i=0}^{2n} w_i (y_{\sigma i}-\bar{y})*(y_{\sigma i}-\bar{y})^T \tag{9}sigma_y = np.zeros((m, 2*n+1)) # 非線形変換 式5 for i in range(len(sigma)): sigma_y[:,i] = f(sigma[:,i]) w = np.zeros((1, 2*n+1)) # 重み関数計算 式6,7 w[:,0] = lambd/(n+lambd) for i in range(2*n): w[:,i+1] = 1/(2*(n+lambd)) print("重み関数", w) y_mean=0 # yの平均計算 式8 for i in range(2*n+1): y_mean += w[:,i]*sigma_y[:,i] y_P = 0 # yの分散共分散計算 式9 for i in range(2*n+1): y_P += w[:,i]*(sigma_y[:,i]-y_mean)*(sigma_y[:,i]-y_mean).T print("yの平均",y_mean) print("yの分散共分散行列",y_P)重み関数 [[-3. 1. 1. 1. 1.]]
yの平均 [0.00141821]
yの分散共分散行列 [-8.47032947e-22]
- 投稿日:2021-01-25T22:42:29+09:00
【RaspberryPi】起動確認用LEDをpython、systemctlを使って制御
概要
RaspberryPiの起動が完了するとLEDが点灯する機能を追加
※LEDは11ピン(GPIO17)に接続実行環境
MCU:Raspberry Pi Zero W
OS:Raspberry Pi OS Buster回路
回路図省略
電流制限抵抗は明るさを抑えるために2.2kΩを使用実装
pythonプログラム
LEDの点灯制御をするためのpythonプログラム
$ sudo nano /home/pi/PowerLED.py最終行にsleep()を入れるとpythonプログラムが終了してもLEDが点灯しっぱなしになる
綺麗な方法ではないが、バックグラウンドで動くプログラムを節約したいので暫定的にこれで実施PowerLED.py#!/usr/bin/python3 import RPi.GPIO as GPIO import time LED_PIN = 17 GPIO.setmode(GPIO.BCM) GPIO.setup(LED_PIN, GPIO.OUT) GPIO.output(LED_PIN, GPIO.HIGH) time.sleep(3)serviceファイル
systemctlで制御するためのserviceファイルを作成
パラメータは最低限にしているので、これより減らすと色々問題が起こるかも$ sudo nano /lib/systemd/system/PowerLED.service他サイトではshebangを使用・serviceファイルのExecStart行ではファイル名のみを記載する方法も紹介されていたが、上手くいかなかったのでserviceファイル上でpython3を指定(フルパスで指定しないとエラーになる)
その他のパラメータについては別記事に記載PowerLED.service[Unit] Description = Power LED of Startup After=multi-user.target [Service] ExecStart=/usr/bin/python3 /home/pi/App/PowerLED.py Restart=on-failure Type=simple [Install] WantedBy=multi-user.targetserviceの設定
動作確認
$ sudo systemctl daemon-reload $ sudo systemctl start PowerLED ~LEDが点灯したらOK~RaspberryPi起動時に自動起動するよう設定
$ sudo systemctl enable PowerLED
- 投稿日:2021-01-25T22:41:04+09:00
社会人2年目終盤になってやっとQiitaを始めてみる
- 投稿日:2021-01-25T22:08:51+09:00
データ前処理編~衛星画像データと深層学習による湖水のクロロフィル濃度推定~
概要
衛星画像データと深層学習による湖水のクロロフィル濃度推定の研究を行っております。
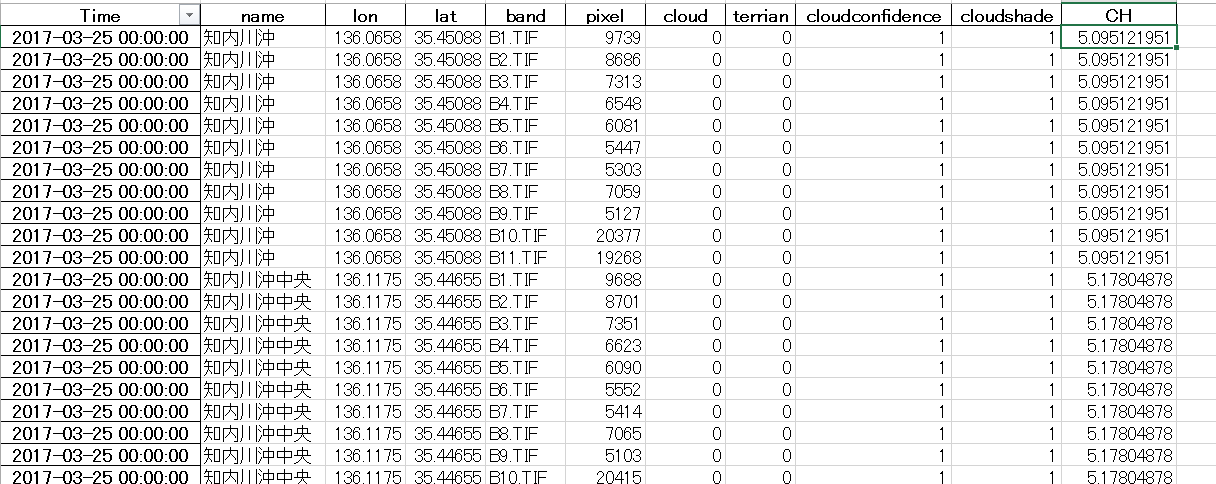
衛星画像データを取得し、衛星画像データから該当する水質拠点の緯度経度を指定して抽出したピクセル値(DN値)や、雲の情報を元に表を作成しました。これからまたディープニューラルネットに学習させるために、データの前処理・成形したいと思います。その時役に立ったPythonプログラミングモジュールやメソッド等について今回は記述していきたいと思います。元になるデータ表
こんな感じのデータを作成しています。
左から、衛星画像データ取得日、水質拠点、水質拠点の緯度経度、衛星画像データのバンドタイプ、抽出したピクセル値(DN値)、cloud 雲情報(0 or 1 雲だったら1、じゃなかったら0)、terrian(陸かどうか),
cloudconfidence(雲である確率。00 不確定 01 雲の可能性低い 10 雲の可能性中 11 雲の可能性大)、cloudshade(雲影の確率)、正解用データのCH(クロロフィル濃度)
これからディープニューラルネットに入力するための形状に変換します。pandasで条件抽出してから表をArray型に変換
ディープニューラルネットに入力するためには、データをArray型に変換する必要があります。
変換した際のプログラミングはこちら↓import numpy as np import pandas as pd all_data = pd.read_excel("表のPath") time = [] time = all_data["Time"].unique() kyoten = [] kyoten = all_data["name"].unique() list = [] list2 = [] pixel = [] CH = [] Cloud = [] terrian = [] CC = [] CS = [] for t in time: for n in kyoten: pixel = all_data["pixel"][(all_data["Time"] == t) & (all_data["name"] == n)].values CH = all_data["CH"][(all_data["Time"] == t) & (all_data["name"] == n)].values Cloud = all_data["cloud"][(all_data["Time"] == t) & (all_data["name"] == n)].values CC = all_data["cloudconfidence"][(all_data["Time"] == t) & (all_data["name"] == n)].values CS = all_data["cloudshade"][(all_data["Time"] == t) & (all_data["name"] == n)].values if len(CH2) != 0: list += [[pixel2, Cloud[0], CC[0], CS[0]]] list2 += [[CH[0]]] data_array = np.array(list) CH_array = np.array(list2)ここで使用したモジュールはpandasとnumpy
機械学習には必要不可欠な二つですよね。
ここでポイントになるのはpandasの条件を指定して表から値を抽出する方法と、リストからnp.array("list)でarray型に変換してるところぐらいですね。
しかし、こんな感じで3次元以上の不規則なarrayになっています。
多次元リストを一次元に平坦化し、リストをサブリストに変換する方法
まず多次元リストを一次元に平坦化します。
参考にしたサイトはこちら→多次元リストを一次元に平坦化する方法for el in l: if isinstance(el, collections.Iterable) and not isinstance(el, (str, bytes)): yield from flatten(el) else: yield el list1 = [] for x in data_array: list1 += flatten(x)これだけだと全データが平坦化されているので、日付ごとのピクセル値~クロロフィル値のサブセットに分けます。リストをn個のサブリストに分割する方法
def split_list(l, n): """ リストをサブリストに分割する :param l: リスト :param n: サブリストの要素数 :return: """ for idx in range(0, len(l), n): yield l[idx:idx + n] #14個の要素でリストを分割 inputs = np.array(list(split_list(list1, 14)))これで完成です!これからデータを正規化して、学習用データとテストデータに分けます。
データの正規化と学習用データ・テストデータに分割する方法
学習用データ・テストデータに分割する方法
0~1に正規化する前に、対数をとってますが、これはデータの分布をより正規分布に近づけ機械学習に効果的にするためです。必要なモジュールのインポート
from sklearn.model_selection import train_test_split from sklearn import preprocessingデータの対数をとったものを、さらに0~1に正規化
scaler = preprocessing.MinMaxScaler() pixel_log = scaler.fit_transform(np.log(inputs[:, 0:11])) cloud = scaler.fit_transform(inputs[:, 11:]) CH_log = scaler.fit_transform(np.log(CH_array))ピクセル値と雲情報などの結合しさらに衛星データとクロロフィルデータの結合(いったん全部シャッフルするため
input_log = np.concatenate((pixel_log, cloud), axis=1) 衛星データとクロロフィルデータの結合(いったん全部シャッフルするため) zenbu = np.concatenate((input_log,CH_log),axis=1)学習用データとテストデータに分割してから衛星データと正解クロロフィル濃度データに分割
zenbu_train, zenbu_test = train_test_split(zenbu, shuffle=True) inputs_train = zenbu_train[:,0:14] CH_train = zenbu_train[:,14:] inputs_test = zenbu_test[:,0:14] CH_test = zenbu_test[:,14:]終わり
以上長くなりましたが、データの前処理はこれでおわりです!
次回はいよいよディープニューラルネット構築です!
お読みいただきありがとうございました。
- 投稿日:2021-01-25T20:26:24+09:00
クロージャはlogを計算する関数を作ることで理解できる
対数計算をする関数>>> import math >>> def log(底): # エンクロージャ。関数「log底」を返す関数 ... def log底(真数): # クロージャ。返される関数 ... return math.log(真数, 底) # エンクロージャ内の変数「底」を、クロージャ内で利用する。 ... return log底 ... >>> log(2)(8) 3.0
log(2)(8) == 3の解説1.
log(2)の呼び出しまず
log(2)が評価された時点で、エンクロージャlog(底)が呼び出される。1-1.
def log底(真数): return math.log(真数, 2)が実行されるエンクロージャ内で、クロージャの定義が実行される。この時、クロージャ内の変数はエンクロージャ内と共通であるため、
底==2が成立する。1-2.
return log底が実行されるエンクロージャ呼び出し
log(2)の評価値は、math.log(真数, 2)を返却する関数そのものである2.
log(2)(8)の呼び出し1-2節より、
log(2)は「math.log(真数, 2)を返却する関数」として評価されるのだった。
故に、log(2)は(lambda 真数: math.log(真数, 2))と同じようなことをを意味するのだ。
log(2)(8)つまり(lambda 真数: math.log(真数, 2))(8)が呼び出されることで、真数=8が代入され、
math.log(8, 2)が実行されるのである。
- 投稿日:2021-01-25T20:17:09+09:00
複数のファイル名の頭を指定した文字数分だけ一括削除する
すんごい大量のファイルの、名前を、頭から指定した文字数だけ削除したい
たいしたことない特徴
・大量のファイルが入っている親のフォルダを.py内で指定
・ターミナルで実行
・何ファイルあっても大丈夫注意!!必ず守ってください
変更したいファイルでやる前に、どうでもいいファイルでテストしてみるか、ファイルを複製しておいてくださいね。消しちゃいけない文字まで消した時にもし後戻りできないと悲惨なのと、責任は負えません。
ファイルの場所
'/Users/hogehoge/test_folder/'
この「folder」の下に以下のような名前の大量のファイルがあると仮定します消したい文字fileA.txt
消したい文字fileB.txt
消したい文字fileC.txt
消したい文字fileD.txt
(以下大量)期待する結果
fileA.txt
fileB.txt
fileC.txt
fileD.txt
(以下大量)変えるところ
以下のコードの
path1と、new_nameの中身ですコード
test.pyimport glob import os path1 = '/Users/hogehoge/test_folder/' path2 = path1 + '*' flist = glob.glob(path2) i = 1 # ファイル名を一括で変更する for file in flist: print('ファイル名:',file) onlyfile = os.path.split(file)[1] #以下の[0:]の数字を消したい文字数に変更してください new_name = onlyfile[0:] os.rename(file, path1 + new_name) i+=1
- 投稿日:2021-01-25T20:07:45+09:00
__init__.py を作るのが地味に面倒なのでショートカット作った
小ネタです。
Python でパッケージ切るのに毎回
__init__.pyを touch するわけですが、__init__.pyって微妙にタイプしづらくて面倒くさくないですか?面倒くさいですよね...?まれにtouch __init.pyってタイプしてしまって「ああ、もう」みたいな気持ちになった人、私だけじゃないはず。。。ということでシェルから叩けるようにしてみました。ソースはこちら。
https://gist.github.com/hassaku63/956daea19d7542dbd82246ffdeaac2d1
# # 引用: https://gist.github.com/hassaku63/956daea19d7542dbd82246ffdeaac2d1 # function make-pypkg-dir () { curdir=$(pwd); created_dir=$(dirname $1)/$(basename $1); mkdir $1 \ && touch ${created_dir}/__init__.py \ && echo "${created_dir}/__init__.py is created." }.bashrc もしくは .zshrc に入れて使っています。
make-pypkg-dir path/to/package/dir/
のように使用します。function はシェルの補完が効くので、多少タイプは楽になりました。でもPython公式でなんかしら対応するツールがあるならそっちに乗り換えたい。
シェルに明るくないため、エラーハンドリングは現状適当です。シェルの rc に置いとくのも正解なのかどうかよくわかってない。 コマンドとしてきちんとしたものが作れたなら
/usr/local/binなど、ユーザー空間でパスが通ってる場所に置いとくとかの方が正解のような気もしますが、あくまでちょっとしたショートカットでしかないので現状の rc で定義ベタ書きで使うのでもええかな、、という気もします。シェル芸人の先生から more better なアプローチがあればフィードバックいただけたら嬉しいです
- 投稿日:2021-01-25T19:28:05+09:00
BERTで行う文章分類 PART1(環境構築編)
実行環境
OS:macOS 10.15.7
開発環境:Nova(Python対応テキストエディタならOK)
パッケージのinstall:Anaconda 4.9.2
Python:3.8.3必要なパッケージ
Pytorchやnltkなどはインストールが必要なので、pipやcondaなどで適宜インストールしてください。
ここでは、以下のライブラリがインストールされているとして話を進めていきます。import torch import torch.utils.data import torch.nn as nn import numpy as np import random import torch.nn.functional as F from sklearn.model_selection import train_test_split import pickle import math import transformers from transformers import AutoTokenizer, AutoModel, AutoModelForMaskedLM, BertJapaneseTokenizer import re import requests import unicodedata import nltk from nltk.corpus import wordnet from bs4 import BeautifulSoupお問い合わせ
内容に関する質問は
mailto:deepblack.inc@gmail.com
までお願いします。
- 投稿日:2021-01-25T19:21:28+09:00
いざとなれば会社に通える田舎を探す(その1駅情報取得)
背景
コロナで在宅勤務が続いているため、都会で手狭な家に住んでいるのが苦しくなってきました。週に数日や月に数日しか出社しないなら、通勤に片道2時間ぐらいかかる田舎で暮らすことも現実的かも。(定期代がフルに支給されない)新幹線通勤までも視野に入れれば結構遠くに住めるかも?
でもどの地域を狙うのといいのか?
しばらく前に「東工大の一限に間に合う範囲の地図を作ってみました」というのが話題になってました。
同じような地図を作ってみたいと思い、会社の最寄り駅に平日朝9時に到着するための乗車時間を地図にマッピングしてみました。
手順
- 日本全国の駅名と緯度経度を取得
- 各駅から最寄り駅までの経路を検索し所要時間を取得
- 各駅の位置と所要時間を地図にプロット
これらをできるだけオープンソースのツールか、フリーミアムのサービスの無料枠でなんとかしたい。
今回は駅情報取得について。
経路検索サービスの検討
今回一番ネックになりそうなのが経路検索のところ。hideki@鉄分多め さんの「Google Directions APIで乗り換え案内情報を取ろうとしたが。。。?」ノートを参考に検討。
Google Mapsの路線検索が使えないのは残念。有料路線検索サービス提供業者の中で、駅すぱあと、ジョルダン、Navitimeは無料枠や無料APIの用意があるようです。
今回はユーザー登録後すぐにアクセスキーを送ってきてくれた「駅すぱあとWebサービス フリープラン」を利用することにします。
駅情報取得
Pythonを利用。外部ライブラリとしてrequestとpandasを使います。
ekispert-get-all-stations.pyimport requests import pandas as pd # security tokens are defined in secret.py file # ekispert_token = "" from secret import ekispert_token ekispert_endpoint = 'http://api.ekispert.jp' eki = '/v1/json/station' from collections import MutableMapping def flatten(d, parent_key='', sep='_'): """ flatten dictionary https://stackoverflow.com/questions/6027558/flatten-nested-dictionaries-compressing-keys """ items = [] for k, v in d.items(): new_key = parent_key + sep + k if parent_key else k if isinstance(v, MutableMapping): items.extend(flatten(v, new_key, sep=sep).items()) else: items.append((new_key, v)) return dict(items) offset = 1 #print("offset: {}".format(offset)) payload = {'key': ekispert_token, 'offset': offset, 'limit': 100, 'gcs': 'wgs84'} r = requests.get(ekispert_endpoint+eki, params=payload) result_all = r.json() offset += 100 n_max = int(result_all['ResultSet']['max']) #print("Max: {}".format(n_max)) while offset <= n_max: #print("offset: {}".format(offset)) payload = {'key': ekispert_token, 'offset': offset, 'limit': 100, 'gcs': 'wgs84'} r = requests.get(ekispert_endpoint+eki, params=payload) result_all['ResultSet']['Point'].extend(r.json()['ResultSet']['Point']) offset += 100 stations_flat = [flatten(result) for result in result_all['ResultSet']['Point']] df = pd.DataFrame(stations_flat) df['GeoPoint_longi_d'] = df['GeoPoint_longi_d'].apply(float) df['GeoPoint_lati_d'] = df['GeoPoint_lati_d'].apply(float) fname = "ekispert_stations_" + result_all['ResultSet']['engineVersion'] + ".pkl" df.to_pickle(fname)一部補足説明
offset = 1 #print("offset: {}".format(offset)) payload = {'key': ekispert_token, 'offset': offset, 'limit': 100, 'gcs': 'wgs84'} r = requests.get(ekispert_endpoint+eki, params=payload) result_all = r.json() offset += 100 n_max = int(result_all['ResultSet']['max']) #print("Max: {}".format(n_max))とりあえず一度駅情報を100件分取得。'gcs'を'wgs84'としているのは、地図へのプロットをmapboxのサービスを利用するつもりなので。
2020年1月11日時点では全部で9,274件分のデータが存在するらしい。while offset <= n_max: #print("offset: {}".format(offset)) payload = {'key': ekispert_token, 'offset': offset, 'limit': 100, 'gcs': 'wgs84'} r = requests.get(ekispert_endpoint+eki, params=payload) result_all['ResultSet']['Point'].extend(r.json()['ResultSet']['Point']) offset += 100残りデータをオフセットしながら取得。駅の情報はr.json()['ResultSet']['Point']にリスト形式で存在するので、最初に取得したresult_all['ResultSet']['Point']のリストに追加(extend)していく。
stations_flat = [flatten(result) for result in result_all['ResultSet']['Point']]駅情報は入れ子構造の辞書形式になっている。扱いづらいので、flatten関数にかけて単純な辞書形式に変換しておく。
flatten前
{'Station': {'code': '26242', 'Name': '相生(兵庫県)', 'Type': 'train', 'Yomi': 'あいおい'}, 'Prefecture': {'code': '28', 'Name': '兵庫県'}, 'GeoPoint': {'longi': '134.28.26.46', 'lati': '34.49.5.91', 'longi_d': '134.474019', 'lati_d': '34.818309', 'gcs': 'wgs84'}}flatten後
{'Station_code': '26242', 'Station_Name': '相生(兵庫県)', 'Station_Type': 'train', 'Station_Yomi': 'あいおい', 'Prefecture_code': '28', 'Prefecture_Name': '兵庫県', 'GeoPoint_longi': '134.28.26.46', 'GeoPoint_lati': '34.49.5.91', 'GeoPoint_longi_d': '134.474019', 'GeoPoint_lati_d': '34.818309', 'GeoPoint_gcs': 'wgs84'}df = pd.DataFrame(stations_flat) df['GeoPoint_longi_d'] = df['GeoPoint_longi_d'].apply(float) df['GeoPoint_lati_d'] = df['GeoPoint_lati_d'].apply(float)Pandas.DataFrameオブジェクトを作成し、緯度経度情報を文字列からfloatに変換。
fname = "ekispert_stations_" + result_all['ResultSet']['engineVersion'] + ".pkl" df.to_pickle(fname)バージョン名をつけてpickle形式で保存。
分析
せっかくなので全国の駅情報をちょっと覗いてみる。
df = pd.read_pickle("ekispert_stations_202101_02a.pkl")先程保存したファイルからpandas.DataFrameを読み戻す。
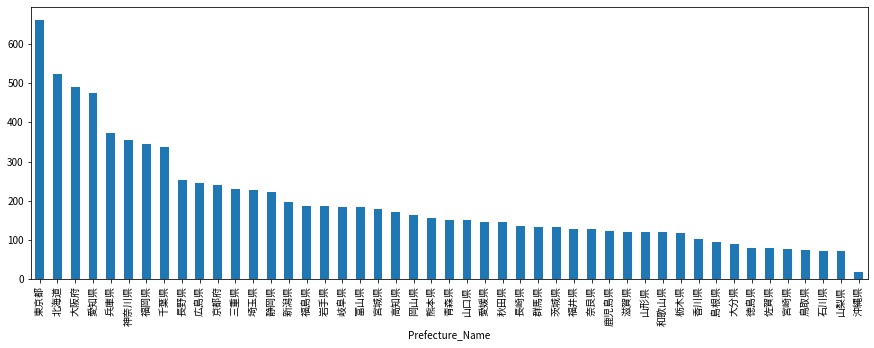
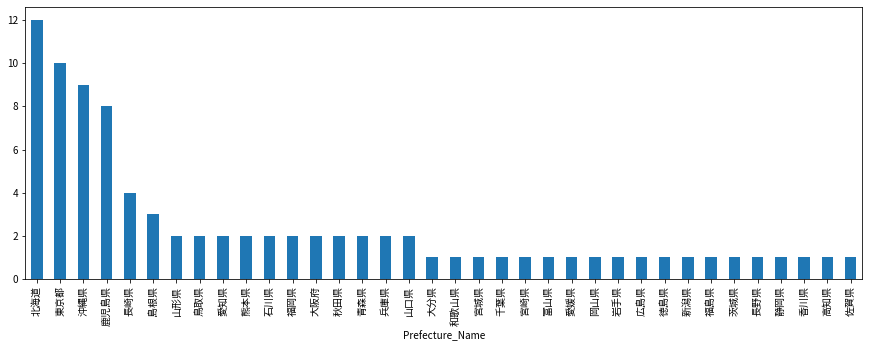
df[df['Station_Type']=='train'].groupby('Prefecture_Name').count()['Station_code'].sort_values(ascending=False).plot(kind='bar', figsize=(15,5))
鉄道の駅の数を都道府県別に並べてみた。当然東京・大阪・愛知の大都市圏が多いですね。そんな中北海道も面積が大きいからか駅数が多い。(でも人は少ないだろうから経営は大変だろうなぁ)
df[df['Station_Type']=='plane'].groupby('Prefecture_Name').count()['Station_code'].sort_values(ascending=False).plot(kind='bar', figsize=(15,5))
空港の数でみると、北海道が多いのは納得。東京が10個もあるのかと一瞬驚きますが、大島や三宅島なども東京都だからですね。
pt = df.groupby(['Prefecture_Name', 'Station_Type']).count()['Station_code'].unstack(fill_value=0).stack() pt[pt==0].index逆に空港がゼロの県はこれら。
MultiIndex([( '三重県', 'plane'), ( '京都府', 'plane'), ( '埼玉県', 'plane'), ( '奈良県', 'plane'), ( '山梨県', 'plane'), ( '岐阜県', 'plane'), ( '栃木県', 'plane'), ( '滋賀県', 'plane'), ('神奈川県', 'plane'), ( '福井県', 'plane'), ( '群馬県', 'plane')], names=['Prefecture_Name', 'Station_Type'])全駅をmapboxを使って地図上にプロットしてみる。
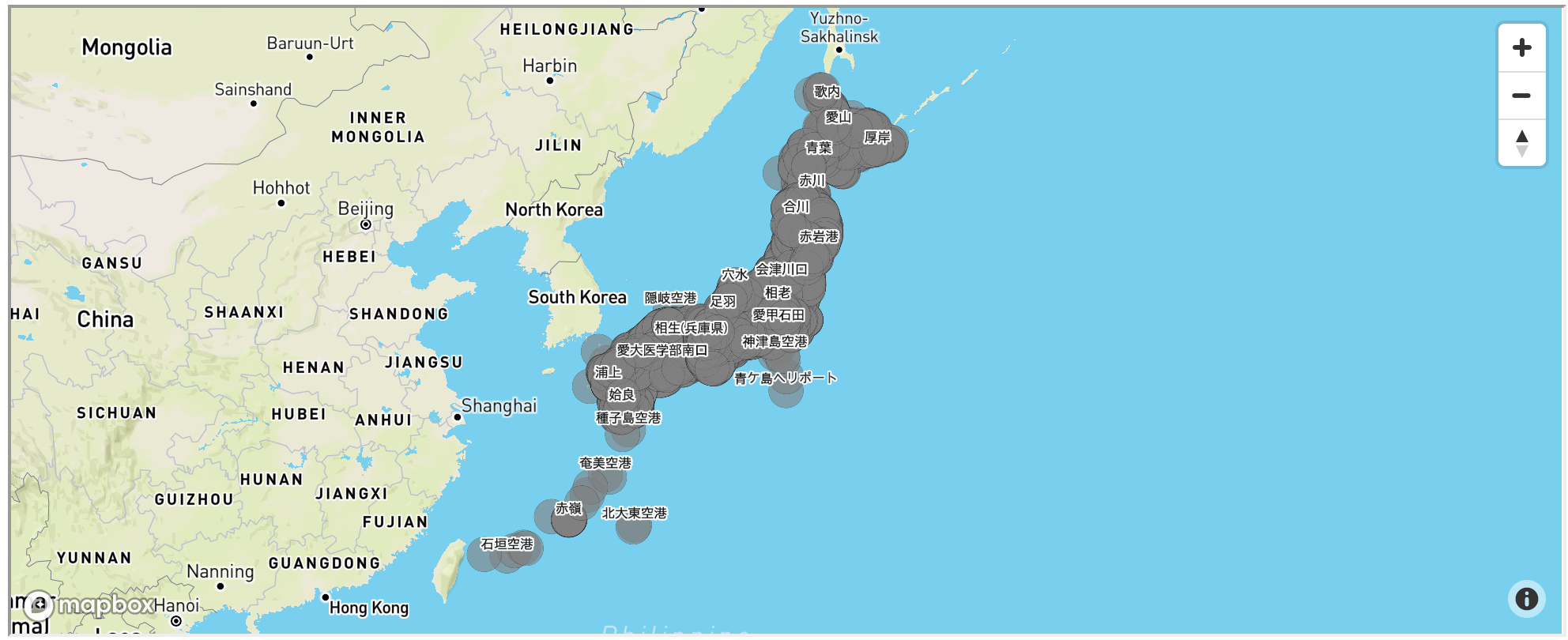
from mapboxgl.utils import df_to_geojson, create_color_stops from mapboxgl.viz import CircleViz # security tokens are defined in secret.py file # mapbox_token = "" from secret import mapbox_token points = df_to_geojson(df, properties=['Station_code', 'Station_Name', 'Station_Type', 'Station_Yomi', 'Prefecture_code', 'Prefecture_Name'], lat='GeoPoint_lati_d', lon='GeoPoint_longi_d', precision=6) map_center = df[df['Station_Name']=='日本橋(東京都)'].to_dict('records')[0] viz = CircleViz(points, access_token=mapbox_token, height='400px', radius=10, stroke_color='black', opacity=0.6, label_property='Station_Name', center=(map_center['GeoPoint_longi_d'],map_center['GeoPoint_lati_d']), style='mapbox://styles/mapbox/outdoors-v11', zoom=3, ) viz.create_html("all_stations.html") viz.show()mapboxgl-jupyterを使うとたったこれだけのコードでぐりぐりできるマップが作れちゃいます。
こちらにHTML置いておいたのでぐりぐりしてみてください。
Powered by 駅すぱあとWebサービス
- 投稿日:2021-01-25T19:04:34+09:00
Elastic Beanstalk で python の Django アプリケーションをデプロイする方法
はじめに
以下に公式の開発者ガイドがありますが、こちらはEB CLIを使用した方法です。
Elastic Beanstalk の管理画面からアプリケーションをアップロードしたかったのですが、何点かハマりどころがあったので、まとめて記録として残します。公式の開発者ガイド
Elastic Beanstalk への Django アプリケーションのデプロイBeanstalk 管理画面からアプリケーションを作成
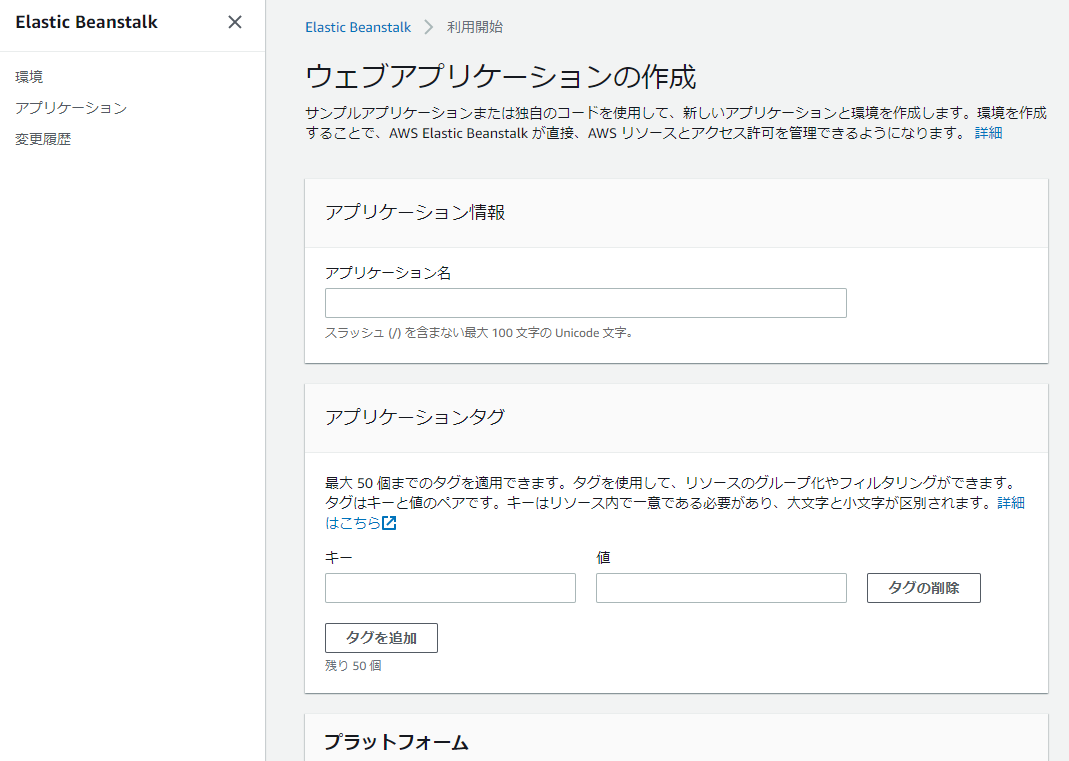
管理画面からアプリケーションを作成します。
アプリケーション名を入力します。
プラットフォームにpythonを選択します。
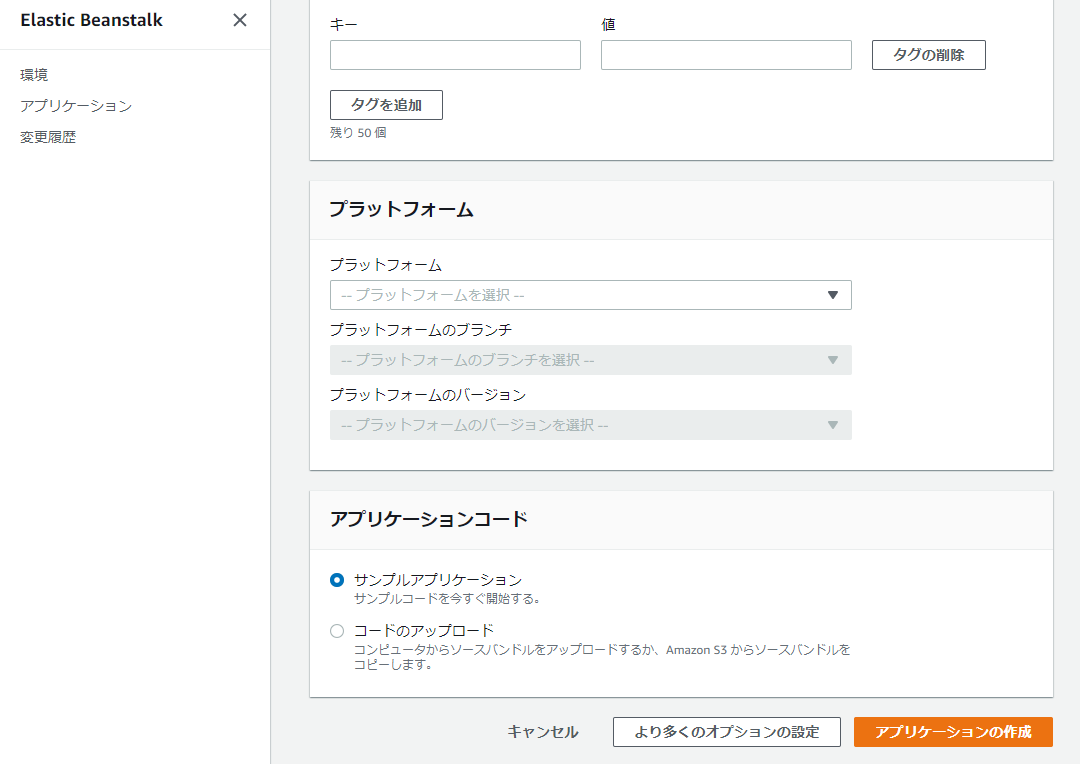
アプリケーションコードの部分は、ここでは一旦サンプルアプリケーションを選んで進みます。
作成されました。
サンプルアプリケーションが確認できます。
アプリケーションの準備
Djangoのアプリケーションに以下のファイルの追加が必要です。
django.configの追加
プロジェクトフォルダの直下に.ebextensions/django.config を作成します。
option_settings: aws:elasticbeanstalk:container:python: WSGIPath: testpj.wsgi:applicationtestpjの部分はプロジェクトの名前に適宜変更します。
requirements.txt の追加
下記コマンドを実行して、requirements.txtを作成します。
$ pip freeze
プログラムのアップロード
プログラムをアップロードする時はzipファイルをアップロードします。
ここで注意が必要ですが、親ディレクトリは含めてはいけません。
下記ように最上位のディレクトリを除き、zipファイルを作成してアップロードします。またvenvディレクトリは不要なので削除します。
親ディレクトリも含めてアップロードした場合、ヘルスの部分に「Following services are not running: web.」というエラーがでていましたが、原因がわからずハマりました。
まとめ
ハマりどころがいくつかありましたが、一度わかってしまえば簡単です。
どなたかの参考になりますように。

- 投稿日:2021-01-25T18:45:00+09:00
PythonでMatplotlibを利用したグラフの描画サンプル
生成したランダムな時系列データをプロットするサンプル。
実行すると以下のようにウィンドウが立ち上がり、グラフが描画されます。>>> import random >>> import matplotlib.pyplot as plt >>> >>> y = [ random.random() * 100 for i in range(100) ] >>> t = [ i in range(100) ] >>> >>> plt.plot(t, y) [<matplotlib.lines.Line2D object at 0x14b096730>] >>> plt.show()
- 投稿日:2021-01-25T17:09:27+09:00
CuteRでかわいい女の子仕様のQRコードを作ってみた。
目的
お客様との関係性を深めたい!
そのために、オンライン・オフラインの融合でのデータ活用が必要だと思う。
オンライン・オフラインの橋渡しのツールの一つであるQRコードについて調べてみたところ、
どうやら変わったQRコードを作れるらしい。例えば、このようなQRコードが作成できる。
かわいい。
お客様が、かわいいと感じるから読み込むとは思っていないが、マーケの施策の一手段として何かできないかとは思った。Cute Rのインストール
mkdir CuteR cd CuteR pip install CuteR git clone https://github.com/chinuno-usami/CuteR.gitQRコードを作成してみる
一番上のディレクトリで、コマンドをうつ。
CuteR -c 10 -e H -o sample_output.png -v 10 sample_input.png http://www.chinuno.com自分でもやってみる。
任意の画像(今回であれば女の子)のファイル格納。
そのファイル名と、sample_input.pngと置き換える。
作成後のファイル名を決めて、sample_output.pngと置き換える。
QRコードにしたいURLは、http://~~ と置き換える。その他のコマンドはこちら。
CuteR.py [-h] [-o OUTPUT] [-v VERSION] [-e {Q,H,M,L}] [-b BRIGHTNESS] [-c CONTRAST] [-C] [-r R G B A] [-p] image text Combine your QR code with custom picture positional arguments: image text QRcode Text. optional arguments: -h, --help show this help message and exit -o OUTPUT, --output OUTPUT Name of output file. -v VERSION, --version VERSION QR version.In range of [1-40] -e {Q,H,M,L}, --errorcorrect {Q,H,M,L} Error correct -b BRIGHTNESS, --brightness BRIGHTNESS Brightness enhance -c CONTRAST, --contrast CONTRAST Contrast enhance -C, --colourful colourful mode -r R G B A, --rgba R G B A color to replace black -p, --pixelate pixelate精度
カラフルモードだと、別のURLに飛ぶことがあった。
(株)デンソーウェーブのQRに関する特許について
1994年特許出願で、20年で失効(5年延長可)であるため、問題なさそう。

- 投稿日:2021-01-25T17:07:34+09:00
分子生物学研究室の一般人がPythonで研究する話①環境構築編
蛍光顕微鏡画像の解析でImageJ(フリーの画像解析ソフト)を使っているのが当研究室。
先輩方は手作業でやってて大変そうだな~~と勝手に思っていたら自分でも使うことになってしまった!ってのがM1になった2020年5月くらいの出来事。
この時点では多少Pythonに触れたことはあった(それこそみんなのPythonとかで)が、全くもって使えない状態だったのにもかかわらず。画像解析ってプログラミングでオートメーション化できたら楽じゃない?っていう素人思考に乗っ取られてPythonでの画像解析を開発することに。
https://satoshithermophilus.hatenablog.com/
とか参考にしながらある程度の画像解析を見よう見まねで作ったは良い物の、自分の思い通りの開発なんてモノは一切出来ないので、改めてPythonを勉強しようとなったのが2021年1月(現在)というわけだ。
さぁみんなのPythonで勉強するぞ!ってツイートしたら著者に補足されて後に引けなくなった人がpythonで研究できるように色々頑張った話。(みんなのPythonの話は今回はほとんど出てこない)(柴田さんはご丁寧にリツイートまでしてくれた)
※独自の解釈を多分に含む
※こうやると良いよ!ではなくやったことの議事録
○Pythonの導入
Python自体はプログラム言語の一つであるが、加えて数理計算やデータサイエンス、機械学習でよく使う機能をパッケージングしたのがAnacondaである。ざっくり言うとPythonより強い奴、Anacondaだしね。このAnaconda、結構癖が強くて苦しむことになるが、数理計算(グラフ描写等も含めて)は必要な機能なのでAnacondaでの導入をすることにした。
AnacondaのWebサイトでwindows用Anacondaをインストールし、説明の英語はよくわからんので推奨設定のままインストール。○Pathを通す
ここら辺からプログラムとかパソコンに疎い(研究室の中では強い方)自分には意味がわからないことになってくる。このpathは顔パスのパスと同義(多分)、pathを通すとpythonを開いて!ってコマンドプロンプトで命令するときにC:Users/ユーザー名/Anaconda3/Python.exe 的なことを書かずにPythonって書けば良くなるらしい。何言ってるかわからないと思うが、windowsなら「環境変数を編集」って左下から検索して、ユーザー環境変数のpathをクリックして編集をクリック。新規→参照かPython.exeが保存されているフォルダを選択して環境変数に追加してあげればパスが通ることになるらしい。他にもいろいろPathを通さなければならないらしいが、環境変数の設定についてちゃんと書かれているwebサイトを適宜調べてやるのが良いと思う。
ちなみにAnacondaのインストール時に推奨設定通りではなく一回チェックするとこのpathを通しておいてくれる、言っといてくれよ。○VScodeの導入
Virtual Studio Codeはプログラムを書くためのツール。
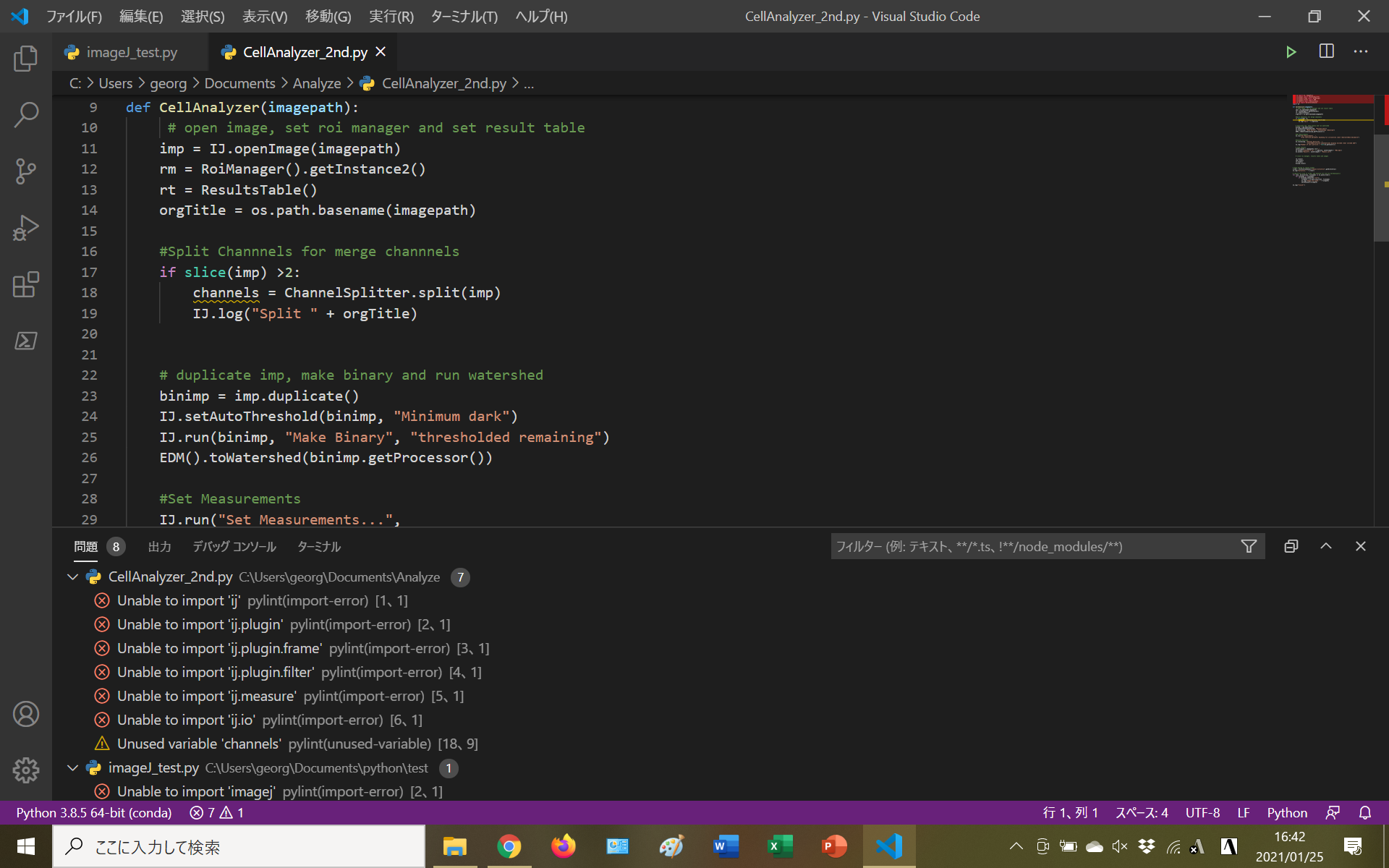
いろいろ色がついて格好いい・・・のではなく、編集に便利。(下にエラー出まくってるのは気にしないで)
導入もサイトからインストールするだけ、Pythonの実行環境をAnaconda環境やそうじゃない環境で選べるようなのでどこかしらで便利になるだろう。みんなのPython中で使用しているJupyter Notebookが便利なので、VScodeでも使えるようにしておいた(Jupyterの説明は適宜検索)○ImageJをVScodeで動かせるのか
ImageJでpythonを使っていたときはImageJがJavaで出来ているため、ImageJ内のツールでJython(Java+Python)を使って書いてImageJ内で動かしていた。これを外部のソフト(VScode)から動かせないか、と言う疑問が湧いた(動かせるのであればVScodeの仕様でやった方が楽そう)。外部のPythonからImageJを動かすにはpyImageJというモジュールが必要のようだった。これをcondaを使ってインストール・・・というところでプロキシの問題があって断念(ラボでやったから大学のプロキシに引っかかったくさい)。もう最後のこの文章なんの解説もしてないけどいいや。
体感としてはImageJをVScodeで外から動かすことは出来そうだけど自分の能力的な問題も込みでまだ難しそう。☆要はどういう環境構築したの
・Python(Anaconda)をインストールしpathを通した。
・VScodeで編集できるようにした
・ついでにJupyterNotebookをVScodeで使えるようにしたとりあえずはこんな感じ。研究に即利用できる感じではないが、勉強するには十分だと思う。
というわけで明日から本当にみんなのPythonを勉強する(はず)。
- 投稿日:2021-01-25T16:55:55+09:00
MacOS CatalinaでVisualStudioCodeの環境設定【Python3】
はじめに
Python3の開発環境構築の忘却録。
pyenvのインストール
cd ~/ git clone https://github.com/pyenv/pyenv.git ~/.pyenvPythonのバージョンを複数切り替えて使いたいので、GitHubからDownload。
.zshrcに設定追加
export PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init -)"Terminal立ち上げ直すか、
sourceで読み込み直しする。該当のPythonをインストール
pyenv install --list // Versionリスト表示 pyenv install 3.9.0 // 現時点で最新版 pyenv global 3.9.0 // globalで使用許可 python --version仮想環境の構築
mkdir python-app cd python-app python3 -m venv venv
python3 -m venv [任意名]で環境作成出来る。VSCodeダウンロード
Downloadはこちらから
https://azure.microsoft.com/ja-jp/products/visual-studio-code/プラグインのインストール
こちらをインストールする。setting.jsonの用意
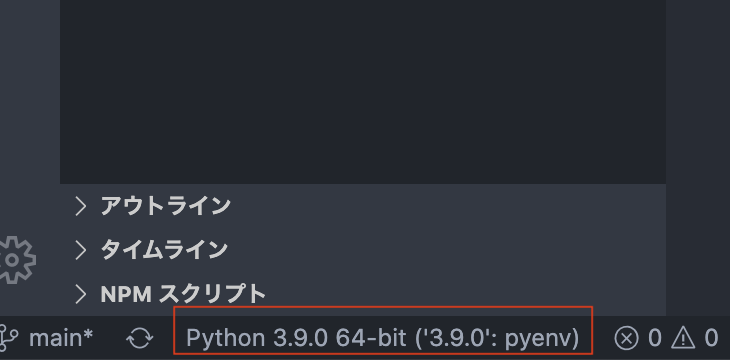
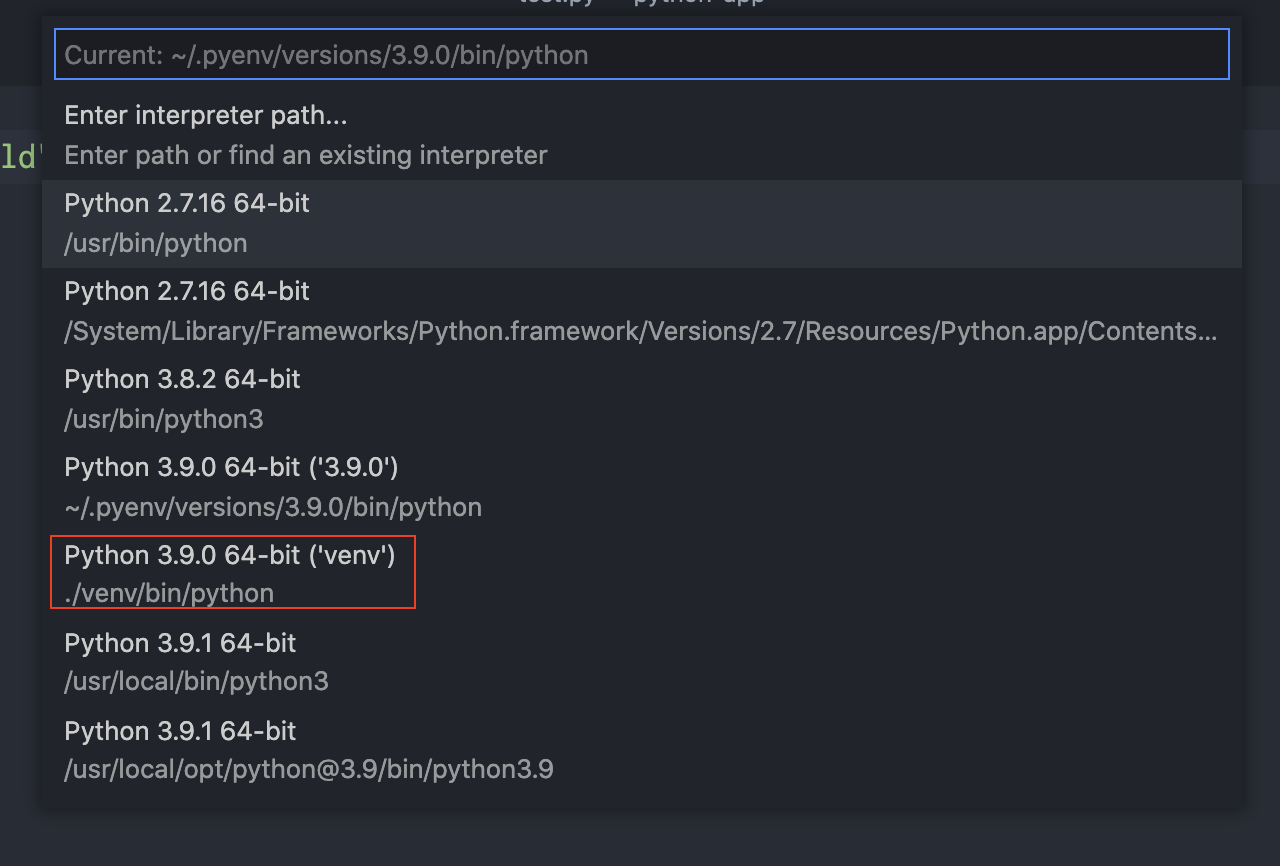
左下の赤丸部分を押下するとPython選択画面が出てくる。
該当のPythonを選択すると.vscodeディレクトリとsetting.jsonが作られる。Hello World
hellow.pyprint("Hello World")該当ディレクトリに
hello.py作成し、右上の「▷」で挙動確認。
Terminalが立ち上がりHello Worldが表示される。
- 投稿日:2021-01-25T16:26:35+09:00
Python で環境変数を読むときのいろいろ
Python で環境変数を読み込む際の Tips
Python で環境変数を読むときの書き方をメモっておきます。
環境変数の取得方法
- 取得方法は 3 あります。
os.getenv(name: str) -> Optional[str]os.environ[name: str] -> str # or raise KeyErroros.environ.get(name: str) -> Optional[str]- いずれも値を取得できた場合、必ず str 型で返却します。
os.getenvとos.environ.getに違いはありません。個人的には文字数の少ない前者(os.getenv)を推奨します。import os # 以降、省略します # 値がない場合に None を返す os.environ.get('HOME') # '/home/user' os.getenv('UNKNOWN_ENV') # None # 値がない場合に KeyError 発生 os.environ['UNKNOWN_ENV'] # => KeyError: 'UNKNOWN_ENV'基本
初期値
os.getenv(name: str, default: str)で初期値をセットすることができます。- 初期値には str 型以外の値もセットできますが、os.getenv() の結果は必ず str 型 ですので、通常は合わせるべきです。os.getenv() の外で型を変換します。
os.getenv('MESSAGE', 'hello') # 'hello' num = int(os.getenv('NUMBER_ENV', '5')) print(num, type(num) # 5, <class 'int'>フラグ
- bool 型の値を扱う際は、以下のようにするとスマートです。
- True に該当しなければ False (もしくは、 False に該当しなければ True)という設計がよいかと思います。
- 必要に応じて、True/False/それ以外は例外 という設計にします。
- 様々なケースに対応した書き方をのせているので、必要なパターンをお使いください。
# 以下、環境変数 'FLAG' をフラグとする。 # True とみなす文字以外は False とする os.getenv('FLAG', 'False') == 'True' # 'True' のみ True os.getenv('FLAG', 'F') == 'T' # 'T' のみ True # 大小問わず true 以外は False とする os.getenv('FLAG', 'False').lower() == 'true' # True : 'true', 'TRUE', 'True', ... # False : 他。セットしていない場合も含む。 # true/false/エラー os.environ['FLAG'] == 'true' # True : 'true' # False : 'false' # 他は KeyError # 初期値あり {'true': True, 'false': False}[os.getenv('FLAG', 'false')] # True となる値: 'true' # Falseとなる値: 'false', セットしていない # 他は KeyError # 初期値あり、エラーなし os.getenv('FLAG', 'false') == 'true' # True : 'true' # False : 他。セットしていない場合も含む。 # 1, 0 をフラグとする bool(int(os.getenv('FLAG'))) # True : '1' # False : '0' # 他は ValueError (int に変換できないため) # 1, 0 をフラグとして初期値は False bool(int(os.getenv('FLAG'), '0')) # True : '1' # False : '0', セットしていない # 他は ValueError (int に変換できないため) # いろんなパターンに対応した True os.getenv('FLAG', 'False')).lower() in ['t', 'true', '1'] # True : '1', 't', 'T', 'true', 'True', 'TRUE', ... # False : 他 # いろんなパターンに対応しつつ、不明な値で例外 bool({'t': 1, 'true': 1, 'f': 0, 'false': 0}[os.getenv('FLAG')]) # True : 't', 'T', 'true', 'True', 'TRUE', ... # False : 'f', 'F', 'false', 'False', 'FALSE', ... # 他は KeyErrorファイルパスからファイル読み込み
- 1 行で書けます。
# 文字列として読み込む content: str = open(os.getenv('FILE_PATH'), 'r', encoding='UTF-8').read() # 初期値あり content: str = open(os.getenv('FILE_PATH', 'file.txt'), 'r', encoding='UTF-8').read() # JSON ファイルを dict として読み込み import json config: dict = json.load(open(os.getenv('CONFIG_PATH', 'config.json'), 'r', encoding='UTF-8')) # CSV ファイルを list[list[str]] で読み込み import csv [r for r in csv.reader(open(os.getenv('CSV_DATA', 'data.csv'), 'r', encoding='UTF-8'))] # CSV ファイルを 1 行ずつ list[str] で読み込み for row in csv.reader(open(os.getenv('CONFIG_PATH', 'test.csv'), 'r', encoding='UTF-8'): print(row)
- 投稿日:2021-01-25T16:22:37+09:00
kivyMDチュートリアルに入門する
kivyMDとは
kivyMDとは以下マニュアルにある通りで、クロスプラットフォームで開発できて
マテリアルデザインなフレームワークとなっています。以下参照の原文とgoogle翻訳した文を冒頭だけ載せておきます。
kivyMD Is a collection of Material Design compliant widgets for use with, Kivy cross-platform graphical framework a framework for cross-platform, touch-enabled graphical applications. The project’s goal is to approximate Google’s Material Design spec as close as possible without sacrificing ease of use or application performance. kivyMDは、Kivyクロスプラットフォームグラフィカルフレームワークで使用する マテリアルデザイン準拠のウィジェットのコレクションであり、クロスプラット フォームのタッチ対応グラフィカルアプリケーション用のフレームワークです。 プロジェクトの目標は、使いやすさやアプリケーションのパフォーマンスを犠牲 にすることなく、Googleのマテリアルデザインの仕様を可能な限り近似することです。てかお前誰よ
初めての投稿なのに手慣れてる感出してしまいました、すみません。
virtyと言い、都内でITエンジニアをしている者です。
言うまでもなく、好きな言語はpythonです。
あとは、他に気になっている技術は次のようなものがあります。
- docker/kubernetes
- Kotlin
- Flutter
- AWS/GCP
どうしてまたkivyMDなの?
誰も聞いてないよ!みたいな声が出てきそうですが、勝手に喋らせてもらいます。
もともとkivyであるアプリを作りたいなぁと考えていました(ちなみに今更ながら
GUIアプリ)。で、UIがなんか昔っぽいなぁ(コントリビューターの方すみません!)
と感じていてこれだと他のものにしようかなと考えていたところ、kivyMDに出会って
しまいました(確か、stackoverflowで見たのかな)。おほーいいですねぇと思い
即決して、そこからは色々と情報を漁っていたりしていました。ですが、
これを見た方もご存知ですが、情報がありませんね。びっくりしました。これはQiitaに
投稿し始めた理由にもなるのですが、情報が無さすぎるのとせっかくチュートリアルを見るので
あれば忘備録として世の中に共有しようと考えたのです(余計なお節介)。今までネットの情報
に助けてもらった恩返しを!というのは大げさですが、そろそろコピペして読み取り専用となる
のを脱却するためにも良い機会でした。これからの展望
これからはというと、参照マニュアルの方で色々と書かれているものを実際に動かしてみて
あれやこれや調査していこうと思います。changelogとかまで調べていくのは大変なので、
下記項目にフォーカスしようかと思っています。
- Getting Started
- Themes
- Components
- Behaviors
- API(余力あれば)
なお、ここではkivyの使い方などは基本触れていかないでいこうと思います(というか
自分も完全にはわかっていない)。ですので、そちらを知りたい!という方は以下の情報
を見るとなるほどそうだったのか!となるかもしれませんしならないかもしれません。Kivyによるアプリケーション開発のすすめ (Jun okazaki) - PyCon JP 2017
https://www.youtube.com/watch?v=iVOVpIXzbYY&feature=youtu.be
Kivyプログラミング ―Pythonでつくるマルチタッチアプリ―(書籍)
https://www.asakura.co.jp/books/isbn/978-4-254-12896-3/
あとは、自分以外にも色々書かれている方いらっしゃいますのでそちらを参照してもらえればと。
おわりに
というまぁ、なんか終始ふわふわしてますがこんな感じで進めていこうかと思います。
基本休日とかにやるので、週1くらいが目安で進めていくかなと。あとは気になっている
技術に浮気して、先にそちらを取り掛かるかもです。よろしくお願いします。ごきげんよう(謎の上品感を出す)。
- 投稿日:2021-01-25T16:10:08+09:00
pytestでデバッグする際の個人的頻出オプション
はじめに
個人的に頻繁に使うオプションの紹介です。
こちらで紹介しているのは最低限ですので気になった方はご自身で調べてみてください。
オプション 結果 -k 特定のテストケースを実行する -s printを出力する --pdb テスト失敗時にデバッグモードにする 環境
$ pytest -V pytest 6.0.1オプション
特定のテストケースを実行する
test.pydef test_success(): assert(1+2) == 3 def test_success2(): assert(2+3) == 5 def test_failed(): assert(1+2) == 4テストを実行します。今回は成功ケースのみを対象にします。
pytest -k test_success3件のテストケース中、2件が実行されました。
部分一致になるのでこのメソッド名だとtest_success1件だけを実行できない点に注意が必要です。collected 3 items / 1 deselected / 2 selected tests\test_app.py .. [100%] =================== 2 passed, 1 deselected in 3.02s===================printの中身を出力する
テストがpassするとテストケースの中に記述したprint文はコンソール上に出ないので、意図的に出したい時に利用します。
test.pydef test_success(): sample = 1+2 print("変数sampleの中身:",sample) assert(sample) == 3pytest -s成功ケースですが
collected 1 item tests\test_app.py 変数sampleの中身: 3 tests\test_app.py . [100%] =================== 1 passed in 0.25s===================テスト失敗時にデバッグモードになるようにする
pytest --pdbtests\test_app.py:183: AssertionError >>>>>>>>>>>>>>>>>>>>>>>>> entering PDB>>>>>>>>>>>>>>>>>>>>>>>>> >>>>>>>>>>>PDB post_mortem (IO-capturing turned off)>>>>>>>>>>> (Pdb) print(sample) 3 (Pdb)終了時は
qを入力してエンター
pdbはpythonの対話型デバッガーです。
https://docs.python.org/ja/3/library/pdb.html
- 投稿日:2021-01-25T15:50:26+09:00
Pythonによるデータ分析の教科書3
4-4 scikit-learn
scikit-learn:公式HP
前処理
前処理・欠損値への対応 ・カテゴリ変数のエンコーディング・・・何らかの方法で数値に変換する符号化() ・特徴量の正規化前処理-欠損値への対応・欠損値を除去する・・・残念ながらsckit learnに「除去」機能なし!!pandas使って!! ・欠損値を補完する*注意)「欠損値の補完」は、pandas と scikit learn の両方にあるので注意!!
前処理-カテゴリ変数のエンコーディング・[次元を増やさない方法]カテゴリ変数の数値置換エンコーディング・・・label encoding ・[次元を増やす方法]カテゴリ変数のOne-hot(ダミー変数化)エンコーディング前処理-カテゴリ変数のエンコーディング-カテゴリ変数のOne-hot(ダミー変数化)エンコーディング# scikit-learn使用=preprocessingモジュール OneHotEncorderクラス # pandas使用=get_dummies関数*注意)preprocessingモジュール・・・まさに和訳通りで「前処理」モジュール!!
前処理-特徴量の正規化
AIで取り扱う変数についてデータの値の持つ意味合い、尺度を考えると次の4つに分類できる 大別すると「定性的データ」「定量的データ」になる ### 定性的データ(質的データ、カテゴリーデータ、カテゴリカルデータ) # 名義尺度 ・電話番号、血液型 ・数として意味はない ・この数を用いて計算できない。計算できるのは出現頻度だけ。 # 順序尺度 ・スポーツの順位 ・数の順序・大きさに意味がある。間隔に意味はない。 ・大小比較ができる。間隔や平均は意味がない。 ### 定量的データ(量的データ) # 間隔尺度 ・温度、西暦 ・数値として間隔に意味がある。 ・和差の計算はできる。比率は意味がない。 # 比例尺度 ・長さ、重さ ・数値として間隔/比率に意味がある。 ・和/差/比率が計算できる。学習
教師あり学習の概要
教師あり学習・分類(classification):離散値・・・サポートベクタマシーン、決定木、ランダムフォレスト、K近傍法 ・回帰(regression):連続値教師なし学習の概要
教師なし学習・次元削減 ・クラスタリング(cluster):離散値[グループ分類]分類グループ数を分析者が決めるアルゴリズムと決めないアルゴリズム ## 分類グループ数を分析者が決めるアルゴリズム(非階層的クラスタリング) k-means(k平均法) ## 分類グループ数を分析者が決めないアルゴリズム(階層的クラスタリング) ### 凝集型 ### 分割型 ### 非階層的クラスタリング ・クラスタリング(cluster):離散値・・・k-means、階層的クラスタリング、DBSCANアンサンブル学習の概要
アンサンブル学習・普通は高精度のモデルを1つ作る<=>低精度のモデルを複数作る∴アンサンブル学習 ・「モデルを複数作る」ということは、「訓練データ+テストデータを複数つくる」ということ ・「全データを母集団」 => 「標本を複数抽出」 => 「モデルを複数作成」 ##アンサンブル学習の手法 ・バギング(bagging)・・・ブートストラップ法(重複可能な復元抽出のこと) ・ブースティング(boosting)・・・ ##結果の予測方法・・・モデル複数なので結果複数 ・多数決 ・平均 ・加重平均教師あり学習-分類(classification)
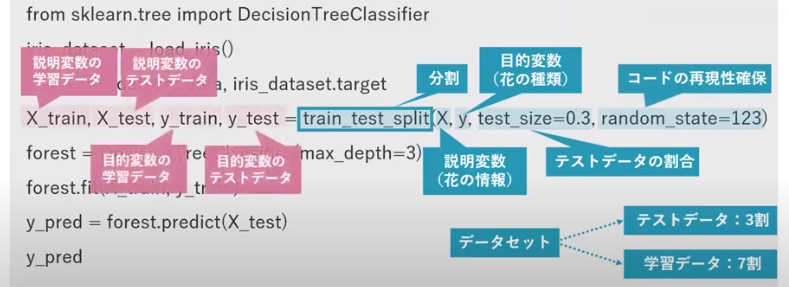
分類モデルの構築#i.データセットの分割・・・学習/テストデータに分割 #ii.学習(モデルの構築)・・・既知データ学習データを用いてモデル構築 #iii.予測・・・ #iv.モデルの評価・・・未知データへの汎化性能評価 from sklearn.datasets import load_iris #[irisデータセット]datasetモジュールload_iris関数 from sklearn.model_selection import train_test_split #[データ分割]modelモジュールtrain_test_split関数 from sklearn.tree import DecisionTreeClassifier #[アルゴリズム:決定木]treeモジュールDecisionTreeClassifier関数 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)# 学習データとテストデータに分割 iris = load_iris() #irisデータセットを読み込む X, y = iris.data, iris.target #iris情報(説明変数:長さ・幅)、iris種類(目的変数) tree = DecisionTreeClassifier(max_depth=3) #決定木をインスタンス化する (木の最大深さ=3) forest.fit(X_train, y_train) #学習(分類モデルの構築) y_pred = forest.predict(X_test) #予測:説明変数のテストデータを与える y_pred #予測値の表示 from sklearn.metrics import classification_report #評価指標:適合率、再現率 print(classification_report(y_test,y_pred)) *内容:決定木のパラメータ・・・決定木の深さ(補足)
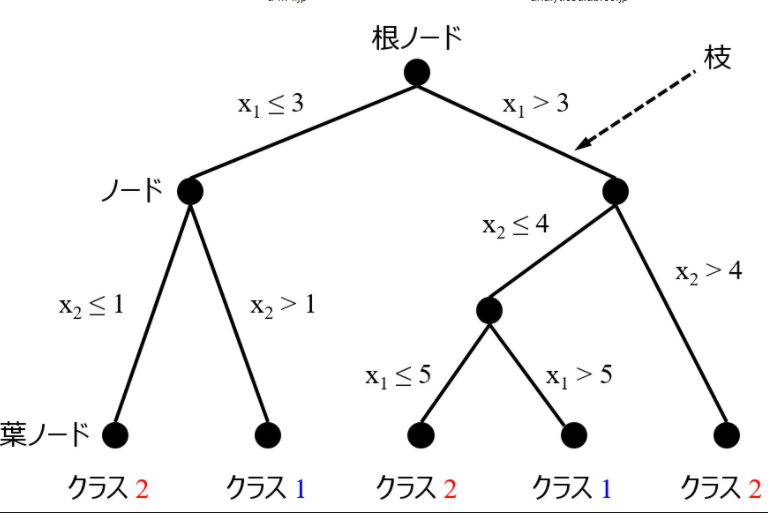
決定木## 決定木ですること ・どの特徴量のどの値で分割するかを決めること ・クラスをきれいに決めること ## 評価指標 [不純度]・・・「クラスをきれいに分けられず、どれだけ混在しているか」 [情報利得]・・・「クラス分けしてどれだけ不純度が下がったか(良くなったか)」 「」 ## 不純度の評価指標 [エントロピー] [分類誤差] [ジニ不純度]・・・確率に注目する ・ノード(頂点)とエッジ(線)からなる ・最上位ノード=根ノード(root node)、最下位ノード=葉ノード(leaf node) from sklearn.tree import DecisionTreeClassifier # ## ハイパーパラメータ 決定木の深さ・・・深くしすぎる(細かく分類しすぎる)と「過学習」を起こす 細かく分類すればいいというものでもない *注)決定木の可視化ツール・・・pydotplus、
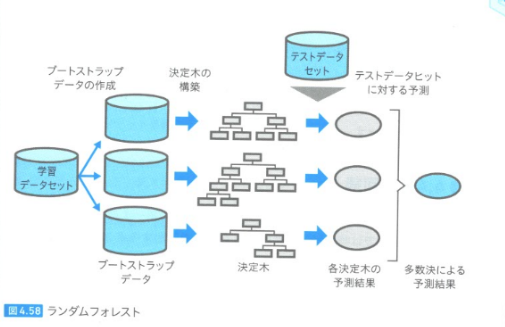
ランダムフォレスト## 概要 ・決定木の発展版。 ・決定木の深さによる過学習を回避するための方法がランダムフォレスト ・学習データから複数の学習データ(ブートストラップデータ)を作って、複数の決定木を作る。=>モデルを複数作る!! ・決定木+バギング=>ランダムフォレスト from sklearn.ensemble import RandomForestClassifier #アンサンブルモジュールのRandomForest使う=>アンサンブル学習だから!!
ランダムフォレストの周辺技術・ブートストラップ:データをランダムにサンプルする手法の1つ ・ブートストラップサンプリング:学習データから複数の学習データを復元抽出で作る方法 ・ブートストラップデータ:ブートストラップサンプリングで作った複数の学習データの集合 ・バギング:アンサンブル学習の1種。複数モデルを作り平均の多数決を取って予測結果とする。 ・アンサンブル(仏:ensemble):ランダムフォレストの周辺技術:詳細はここ
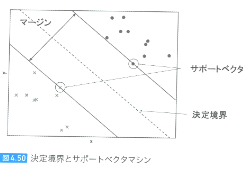
サポートベクタマシン・分類、回帰、外れ値検出・・・どれでもOK!! ・線形分離できないデータも次元拡張することで線形分離可能 ・線形分離する直線とそれに最も近い各クラスのデータ間の距離が最も大きくなる直線を引く=>マージンを最大化 ## 評価指数 ・[マージン]・・・2つのクラスの直線間距離 ・[サポートベクタ]・・・各クラスの直線に乗っているデータ ・[決定境界]・・・2つのクラスの直線間のど真ん中 ## ハイパーパラメータ [パラメータC]・・・マージンの広さと狭さを設定 マージン大・・・サポートベクタの個数増加 マージン小・・・サポートベクタの個数減少 ## 特徴 特徴量間のオーダーに影響を受けやすい 正則化をかならず行う
教師あり学習-回帰(regression)
##正則化法 損失関数に正則化項(ペナルティー関数)を付ける 目的関数に ・ラッソ回帰(L1正則化,マンハッタンノルム)・・・least absolute shrinkage and selection operator, Lasso, LASSO ・リッジ回帰(L2正則化,ユークリッドノルム)・・・歴史的には1970年にHoerlとKennardによってリッジ回帰は提案された。 行列の対角成分について畝(ウネ/ridge)を作る意味でリッジ回帰と呼ばれる。 短縮形ではなさそうです。ラッソとリッジのイメージ:詳細はここ
ラッソとリッジのイメージ:詳細はここ教師なし学習
教師なし学習・次元削減・・・主成分分析 ・クラスタリング・・・[グループ分類] 階層的クラスタリング、非階層的クラスタリング次元削減
主成分分析
主成分分析(次元圧縮手法)・高次元のデータに対して分散が大きくなる方向を探す ・元の次元 or 低い次元にデータを変換する=>次元圧縮 from sklearn.decomposition import PCA pca=PCA(n_components=2) # 新たな2つの特徴量に変換 X_pca = pca.fit_transform() #*注意)decomposition 分解、PCA principal Component Analysis 主 成分 分析
クラスタリング
概要クラスタリングには2つの手法がある ・非階層的クラスタリング:k-means法(k平均法) ・階層的クラスタリング: 一言でいうと「グループに分類」 ##k-means法 ・全データに適当にラベリングする(最終的にこのラベリングを適正にしてクラスタリングする) ・各々のラベル毎に重心を求める ・ラベルの貼り直し(一番近い重心のラベルに変更) ・改めてラベル毎の重心を求める ##階層的クラスタリング ・凝集型、分割型の2つ手法がある ・モデルの評価
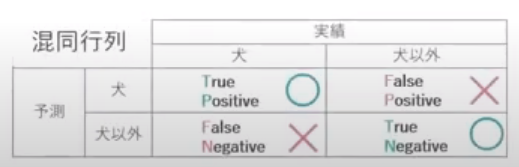
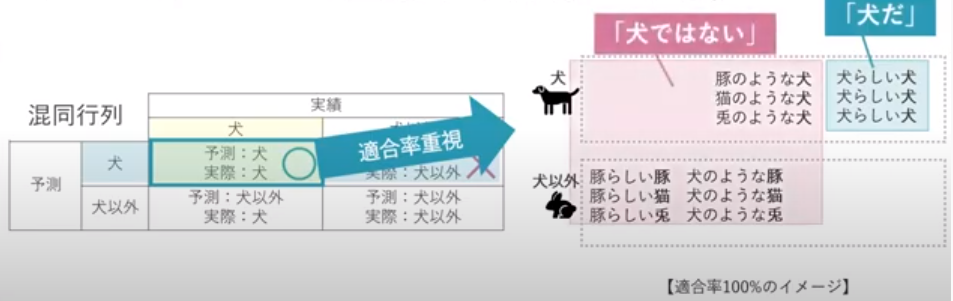
精度分類と回帰で精度の評価指標が異なる # 「分類」の4評価指標 混合行列を作りデータを抜き出して4つの評価指標を求める 適合率と再現率はトレードオフの関係にある # 使うクラス scikit-learnのmetricsモジュールのclassification_report関数 ### 正解率 ### 再現率・・・取りこぼしたくない時に重視する指標(最大公約数、ルーズにする) ・グレイなデータ(答えが確実でないデータ)の教師ラベル(答え)をTrueにしてしまえば適合率はアップする ### 適合率・・・なるべく間違えないようにしたい時に重視する指標(最小公倍数、シビアにする) ・グレイなデータ(答えが確実でないデータ)の教師ラベル(答え)をFalseにしてしまえば適合率はアップする ### F値 ・・・バランス(再現率と適合率)の調和平均 # 「回帰」の3評価指標 ### R 決定係数 ### RMSE 平方平均二乗誤差 ### MAE 平均絶対誤差
ハイパーパラメータの最適化
パラメータは学習時に決定されない 学習とは別にユーザーが値を指定する 決定木の深さ ランダムフォレストに含まれる決定木の個数 ・グリッドリサーチ・・・ ・ランダムリサーチまとめ
使うクラスと関数from sklearn.preprocessing import Imputer # from sklearn.preprocessing import LabelEncoder # ラベルエンコーディング from sklearn.preprocessing import OneHotEncoder # One-hotエンコーディング from sklearn.preprocessing import StandardScalar # 分散正規化 from sklearn.model_selection import train_test_split # [関数]学習データとテストデータに分割 from sklearn.svn import SVC #[クラス]サポートベクタマシン from sklearn.tree import DecisionTreeClassifier #[クラス]決定木 from sklearn.ensemble import RandomForestClassifier #[クラス]ランダムフォレスト from sklearn.linear_model import LinearRegression #[クラス]線形回帰 from sklearn.decomposition import PCA #[クラス]主成分分析 from sklearn.metrics import classification_report #[関数]分類器の定量化指標(適合率、再現率、F値、正解率) from sklearn.model_selection import cross_val_score #[関数]交差検証(cross validation) from sklearn.svn import SVC from sklearn.svn import SVC*注)classfier 分類



- 投稿日:2021-01-25T15:33:38+09:00
動画ファイルからサイズ情報やサムネイルをPythonのOpenCVで取得
OpenCVというライブラリがあり、これで動画ファイルを扱えるようです。OpenCVを使って、動画ファイルからサイズ情報やサムネイルを取得してみました。
OpenCVをインストール
この記事の内容を試すには以下のコマンドのみで十分でした。Python環境整備済みのLinuxの前提です。
$ pip install opencv-python私の環境で
pipenvでインストールしたら、バージョンは以下のようになりました。$ pipenv install opencv-python $ pipenv run pip list Package Version ------------- -------- numpy 1.19.5 opencv-python 4.5.1.48 pip 20.3.3 setuptools 51.0.0 wheel 0.36.2動画サイズや長さなどの情報を取得
動画ファイルから縦横サイズ、再生時間、コーデックの情報を取得します。
# OpenCVをインポート import cv2 # サンプル動画ファイル videoPath = "./sample.mp4" cap = cv2.VideoCapture(videoPath) # 横幅 print(f"width: {cap.get(cv2.CAP_PROP_FRAME_WIDTH)}") # width: 600.0 # 高さ print(f"height: {cap.get(cv2.CAP_PROP_FRAME_HEIGHT)}") # height: 360.0 # フレームレート print(f"fps: {cap.get(cv2.CAP_PROP_FPS)}") # fps: 30.0 # フレーム数 print(f"frame_count: {cap.get(cv2.CAP_PROP_FRAME_COUNT)}") # frame_count: 639.0 # 再生時間 print(f"length: {cap.get(cv2.CAP_PROP_FRAME_COUNT) / cap.get(cv2.CAP_PROP_FPS)} s") # length: 21.3 s print("fourcc: " + int(cap.get(cv2.CAP_PROP_FOURCC)).to_bytes(4, "little").decode("utf-8")) # fourcc: avc1 # コーデックの種類を4文字で表すコードコーデックの種類を表すコードはfourccという4文字のコードです。
最初のフレームから画像ファイルを作成
動画ファイルの最初のフレームをNumpy配列で取得し、それを画像ファイルで書き出します。
import cv2 def buildVideoCaptures(videoPath, outputPath): cap = cv2.VideoCapture(videoPath) if not cap.isOpened(): return # 最初のフレームを読み込む _, img = cap.read() # imgは読み込んだフレームのNumpy配列でのピクセル情報(BGR) # imgのshapeは (高さ, 横幅, 3) # 画像ファイルで書き出す # 書き出すときの画像フォーマットはファイル名から自動で決定 cv2.imwrite(outputPath, img) buildVideoCaptures("./sample.mp4", "./thumbnail.jpg") # PNG出力もOK #buildVideoCaptures("./sample.mp4", "./thumbnail.png")最初のフレームからサムネイルを作成
次は画像をリサイズして、サムネイルとして画像ファイルを作成します。
cv2.resizeというメソッドでリサイズできます。import cv2 def buildVideoCaptures(videoPath, outputPath): cap = cv2.VideoCapture(videoPath) if not cap.isOpened(): return _, img = cap.read() # imgは読み込んだフレームのNumpy配列でのピクセル情報(BGR) # imgのshapeは (高さ, 横幅, 3) # 画像サイズを取得 width = img.shape[1] height = img.shape[0] # 縮小後のサイズを決定 newWidth = 100 newHeight = int(height * newWidth / width) # リサイズ img = cv2.resize(img, (newWidth, newHeight)) # 画像ファイルで書き出す cv2.imwrite(outputPath, img) buildVideoCaptures("./sample.mp4", "./thumbnail.jpg")動画の途中からもサムネイルを作成
最初のフレームだけではなく、途中のフレームからも画像を取得します。再生時間を10分割して、10個のサムネイルを作成します。
import cv2 def buildVideoCaptures(videoPath, outputPath): cap = cv2.VideoCapture(videoPath) if not cap.isOpened(): return # フレーム数を取得 frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) for i in range(10): # フレーム位置を設定 cap.set(cv2.CAP_PROP_POS_FRAMES, i * frame_count / 10) _, img = cap.read() # imgは読み込んだフレームのNumpy配列でのピクセル情報(BGR) # imgのshapeは (高さ, 横幅, 3) # 画像サイズを取得 width = img.shape[1] height = img.shape[0] # 縮小後のサイズを決定 newWidth = 100 newHeight = int(height * newWidth / width) # リサイズ img = cv2.resize(img, (newWidth, newHeight)) # 画像ファイルで書き出す # ファイル名には連番を付ける cv2.imwrite(outputPath % i, img) buildVideoCaptures("./sample.mp4", "./thumbnail%d.jpg") # 出力ファイル名には連番を付ける
- 投稿日:2021-01-25T15:15:14+09:00
色々めんどくさいので作りながら学ぶ事ぶCNN概要から実装まで
概要
・CNNとは
・畳み込みとプーリング実装
・im2col / col2im
・畳み込みとプーリングの実装
・CNN実装
・データ拡張
~~~~~~~~~~~~~
こんな感じで緩く進めていきたいと思います。1.CNNの概要
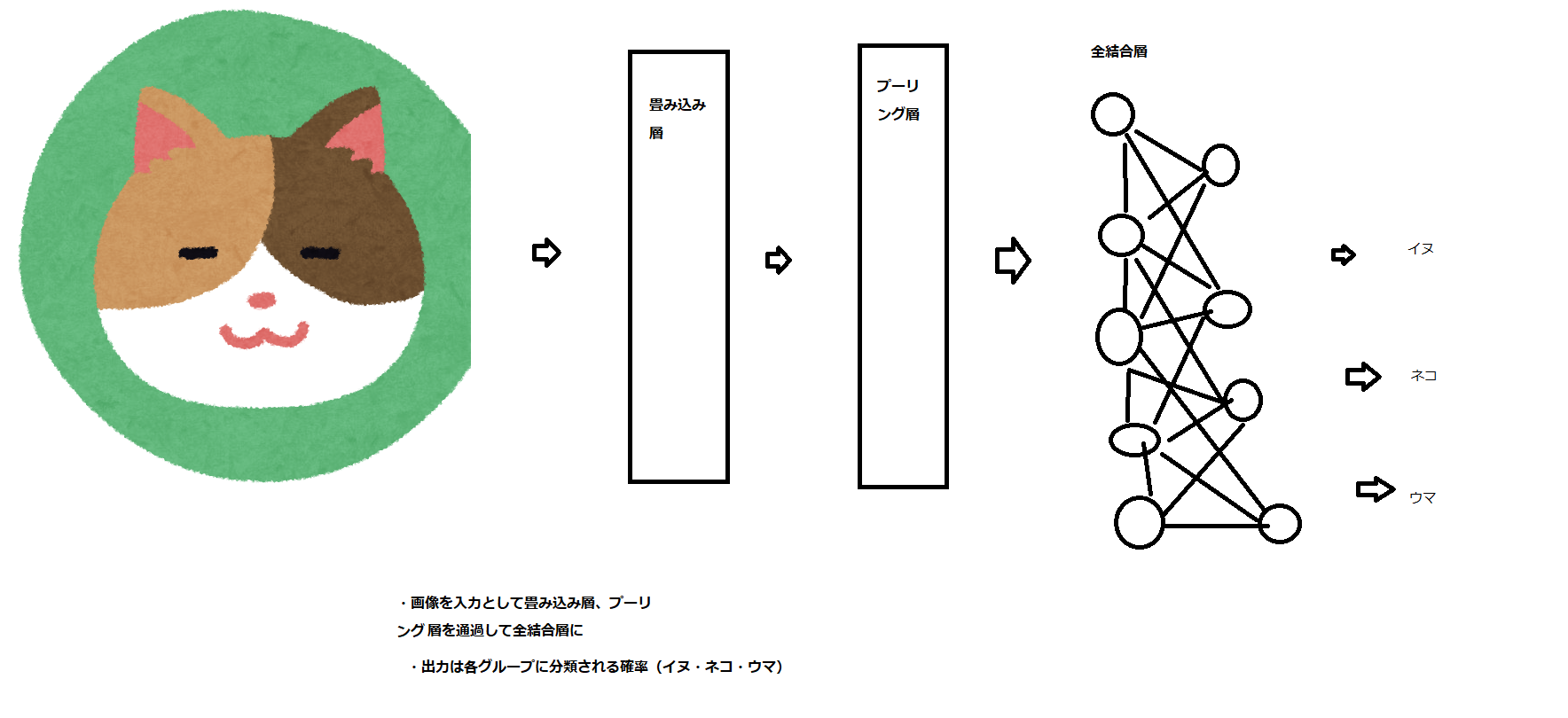
*図の全結合層の一一層目はお互いには干渉しません。適当に線を引きすぎました。
・画像を入力として、畳み込み、プーリング層を経て全結合層へ
・出力は各グループに分類される確率となる畳み込み層では、出力が入力の一部の影響しか受けない局所性の強い処理が行われます。
プーリング層では、認識する対象の位置に柔軟に対応できる仕組みが備わる
*畳み込みで何度か繰り返し処理をさ、組み込み+プーリング層で繰り返し処理をされ、全結合層でも繰り返し処理を行い出力します。
ここで、行われる作業一覧
・畳み込みでは、フィルター処理の結果入力画像は画像の特徴を表す複数の画像に変換されます
・プーリング層では、画像の特徴を損なわないように画像のサイズが縮小されます
・全結合層ではこれまで扱ってきたニューラルネットワークの相当を同じように層間のすべてのニューロンが接続されます2.畳み込みとプーリング実装
Markdown: [Qiita]
畳み込みネットワークの「基礎の基礎」を理解する ~ディープラーニング入門
https://www.imagazine.co.jp/%E7%95%B3%E3%81%BF%E8%BE%BC%E3%81%BF%E3%83%8D%E3%83%83%E3%83%88%E3%83%AF%E3%83%BC%E3%82%AF%E3%81%AE%E3%80%8C%E5%9F%BA%E7%A4%8E%E3%81%AE%E5%9F%BA%E7%A4%8E%E3%80%8D%E3%82%92%E7%90%86%E8%A7%A3%E3%81%99/上記参照していただければわかると思います。
3.im2col / col2im
im2col / col2imとは?
im2col = 複数バッチ、複数チャンネルの画像を1つの行列に変換
畳み込み層の順伝播col2im = 1つの行列を複数バッチ、複数チャンネルの画像
畳み込み層の逆伝播で使用詳しくわかりやすくしてる記事
https://qiita.com/kuroitu/items/7877c002e192955c78574.畳み込みとプーリングの実装
●im2colの実装
import numpy as np def im2col(img, flt_h, flt_w): # 入力画像、フィルタの高さ、幅 img_h, img_w = img.shape # 入力画像の高さ、幅 out_h = img_h - flt_h + 1 # 出力画像の高さ(パディング無し、ストライド1) out_w = img_w - flt_w + 1 # 出力画像の幅(パディング無し、ストライド1) cols = np.zeros((flt_h*flt_w, out_h*out_w)) # 生成される行列のサイズ for h in range(out_h): h_lim = h + flt_h # h:フィルタがかかる領域の上端、h_lim:フィルタがかかる領域の下端 for w in range(out_w): w_lim = w + flt_w # w:フィルタがかかる領域の左端、w_lim:フィルタがかかる領域の右端 cols[:, h*out_w+w] = img[h:h_lim, w:w_lim].reshape(-1) return cols↓行列に変換
img = np.array([[1, 2, 3, 4], # 入力画像 [5, 6, 7, 8], [9, 10,11,12], [13,14,15,16]]) cols = im2col(img, 2, 2) # 入力画像と、フィルタの高さ、幅を渡す print(cols)[[1, 2, 3, 4]
[5, 6, 7, 8]
[9, 10,11,12]
[13,14,15,16]
各値が各pxに値します。したがってこの値が4x4の画像になります。[[ 1. 2. 3. 5. 6. 7. 9. 10. 11.] [ 2. 3. 4. 6. 7. 8. 10. 11. 12.] [ 5. 6. 7. 9. 10. 11. 13. 14. 15.] [ 6. 7. 8. 10. 11. 12. 14. 15. 16.]]1.2.5.6/2.3.6.7/と出力されていると確認ができましたので行列になっています。
def im2col(images, flt_h, flt_w, stride, pad): n_bt, n_ch, img_h, img_w = images.shape out_h = (img_h - flt_h + 2*pad) // stride + 1 # 出力画像の高さ out_w = (img_w - flt_w + 2*pad) // stride + 1 # 出力画像の幅 img_pad = np.pad(images, [(0,0), (0,0), (pad, pad), (pad, pad)], "constant") cols = np.zeros((n_bt, n_ch, flt_h, flt_w, out_h, out_w)) for h in range(flt_h): h_lim = h + stride*out_h for w in range(flt_w): w_lim = w + stride*out_w cols[:, :, h, w, :, :] = img_pad[:, :, h:h_lim:stride, w:w_lim:stride] cols = cols.transpose(1, 2, 3, 0, 4, 5).reshape(n_ch*flt_h*flt_w, n_bt*out_h*out_w) return cols様々なバッチサイズ、チャンネル数、パディング幅、ストライドに対応し、forによる繰り返しを最小化したim2colのコード例です。
●畳み込みの実装
import matplotlib.pyplot as plt from sklearn import datasets digits = datasets.load_digits() print(digits.data.shape) image = digits.data[0].reshape(8, 8) plt.imshow(image, cmap="gray") plt.show()(1797, 64)
1797のデータセットが入っていて、64pxからなっていることがわかります。
def im2col(img, flt_h, flt_w, out_h, out_w): # 入力画像、フィルタの高さ、幅、出力画像の高さ、幅 cols = np.zeros((flt_h*flt_w, out_h*out_w)) # 生成される行列のサイズ for h in range(out_h): h_lim = h + flt_h # h:フィルタがかかる領域の上端、h_lim:フィルタがかかる領域の下端 for w in range(out_w): w_lim = w + flt_w # w:フィルタがかかる領域の左端、w_lim:フィルタがかかる領域の右端 cols[:, h*out_w+w] = img[h:h_lim, w:w_lim].reshape(-1) return colsシンプルなim2colの関数を使います
flt = np.array([[-1, 1, -1,], # 縦の線を強調するフィルタ [-1, 1, -1,], [-1, 1, -1,]]) flt_h, flt_w = flt.shape flt = flt.reshape(-1) # 行数が1の行列 img_h, img_w = image.shape # 入力画像の高さ、幅 out_h = img_h - flt_h + 1 # 出力画像の高さ(パディング無し、ストライド1) out_w = img_w - flt_w + 1 # 出力画像の幅(パディング無し、ストライド1) cols = im2col(image, flt_h, flt_w, out_h, out_w) image_out = np.dot(flt, cols) # 畳み込み image_out = image_out.reshape(out_h, out_w) plt.imshow(image_out, cmap="gray") plt.show()im2colで画像を行列に変換し、フィルタとの行列積により畳み込みを行います。
画像から縦の行が協調され、画像サイズが小さくなりました。(8*8→6*6へ)
●プーリングの実装
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets digits = datasets.load_digits() print(digits.data.shape) image = digits.data[0].reshape(8, 8) plt.imshow(image, cmap="gray") plt.show()(1797, 64)
上の画像に対してプーリングを行うdef im2col(img, flt_h, flt_w, out_h, out_w, stride): # 入力画像、プーリング領域の高さ、幅、出力画像の高さ、幅、ストライド cols = np.zeros((flt_h*flt_w, out_h*out_w)) # 生成される行列のサイズ for h in range(out_h): h_lim = stride*h + flt_h # h:プーリング領域の上端、h_lim:プーリング領域の下端 for w in range(out_w): w_lim = stride*w + flt_w # w:プーリング領域の左端、w_lim:プーリング領域の右端 cols[:, h*out_w+w] = img[stride*h:h_lim, stride*w:w_lim].reshape(-1) return colsimg_h, img_w = image.shape # 入力画像の高さ、幅 pool = 2 # プーリング領域のサイズ out_h = img_h//pool # 出力画像の高さ out_w = img_w//pool # 出力画像の幅 cols = im2col(image, pool, pool, out_h, out_w, pool) image_out = np.max(cols, axis=0) # Maxプーリング image_out = image_out.reshape(out_h, out_w) plt.imshow(image_out, cmap="gray") plt.show()
各2x2の領域の最大値が抽出され、新たな画像となりました。
8x8の画像が、4x4の画像に変換されたことになります5.CNNの実装
CIFAR-10を読み込み、ランダムな25枚の画像を表示します
import numpy as np import matplotlib.pyplot as plt import keras from keras.datasets import cifar10 (x_train, t_train), (x_test, t_test) = cifar10.load_data() print("Image size:", x_train[0].shape) cifar10_labels = np.array(["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]) n_image = 25 rand_idx = np.random.randint(0, len(x_train), n_image) plt.figure(figsize=(10,10)) # 画像の表示サイズ for i in range(n_image): cifar_img=plt.subplot(5,5,i+1) plt.imshow(x_train[rand_idx[i]]) label = cifar10_labels[t_train[rand_idx[i]]] plt.title(label) plt.tick_params(labelbottom=False, labelleft=False, bottom=False, left=False) # ラベルとメモリを非表示に plt.show()
CNNの各設定を行います。わかりやすいように0・1で表現してもらうように指示します。
正解の値は1ですbatch_size = 32 epochs = 20 n_class = 10 # 10のクラスに分類 # one-hot表現に変換 t_train = keras.utils.to_categorical(t_train, n_class) t_test = keras.utils.to_categorical(t_test, n_class) print(t_train[:10])[[0. 0. 0. 0. 0. 0. 1. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.] [0. 0. 0. 0. 1. 0. 0. 0. 0. 0.] [0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 1. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 1. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 1. 0.] [0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]]上記 1 の表現が正解のクラスを表現しています。
●モデルの構築
複数の層を書いていきます。
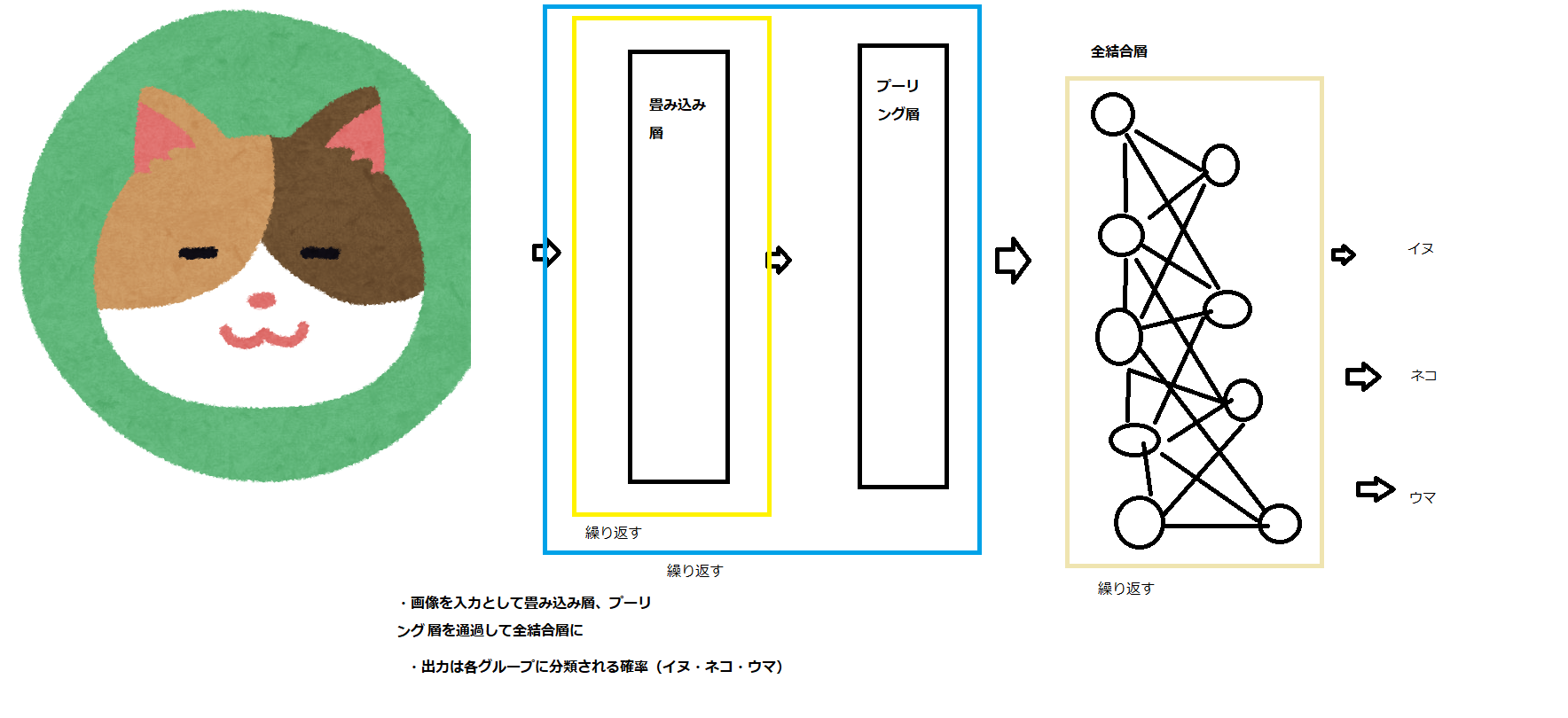
順番は畳み込み層
畳み込み層
Maxプーリング層
畳み込み層
畳み込み層
Maxプーリング層
全結合層
全結合層全結合層の直後にドロップアウトを含みモデルの汎化性能が向上させます。
from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Conv2D, MaxPooling2D from keras.optimizers import Adam model = Sequential() model.add(Conv2D(32, (3, 3), padding='same', input_shape=x_train.shape[1:])) # ゼロパディング、バッチサイズ以外の画像の形状を指定 model.add(Activation('relu')) model.add(Conv2D(32, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(64, (3, 3), padding='same')) model.add(Activation('relu')) model.add(Conv2D(64, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) # 一次元の配列に変換 model.add(Dense(256)) model.add(Activation('relu')) model.add(Dropout(0.5)) # ドロップアウト model.add(Dense(n_class)) model.add(Activation('softmax')) model.compile(optimizer=Adam(), loss='categorical_crossentropy', metrics=['accuracy']) model.summary()Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 32, 32, 32) 896 _________________________________________________________________ activation (Activation) (None, 32, 32, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 30, 30, 32) 9248 _________________________________________________________________ activation_1 (Activation) (None, 30, 30, 32) 0 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 15, 15, 32) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 15, 15, 64) 18496 _________________________________________________________________ activation_2 (Activation) (None, 15, 15, 64) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 13, 13, 64) 36928 _________________________________________________________________ activation_3 (Activation) (None, 13, 13, 64) 0 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 6, 6, 64) 0 _________________________________________________________________ flatten (Flatten) (None, 2304) 0 _________________________________________________________________ dense (Dense) (None, 256) 590080 _________________________________________________________________ activation_4 (Activation) (None, 256) 0 _________________________________________________________________ dropout (Dropout) (None, 256) 0 _________________________________________________________________ dense_1 (Dense) (None, 10) 2570 _________________________________________________________________ activation_5 (Activation) (None, 10) 0 ================================================================= Total params: 658,218 Trainable params: 658,218 Non-trainable params: 0 _________________________________________________________________できました。
続いてモデルを訓練していきます。x_train = X_train x_test = x_test history = model.fit(x_train, t_train, epochs=epochs, batch_size=batch_size, validation_data=(x_test, t_test))出力まで5分ほど時間がかかります。
出力.
Epoch 1/20
1563/1563 [==============================] - 14s 5ms/step - loss: 1.8161 - accuracy: 0.3263 - val_loss: 1.1969 - val_accuracy: 0.5715
Epoch 2/20
1563/1563 [==============================] - 7s 4ms/step - loss: 1.1615 - accuracy: 0.5884 - val_loss: 0.9519 - val_accuracy: 0.6721
Epoch 3/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.9493 - accuracy: 0.6640 - val_loss: 0.8289 - val_accuracy: 0.7106
Epoch 4/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.8288 - accuracy: 0.7098 - val_loss: 0.8436 - val_accuracy: 0.7126
Epoch 5/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.7578 - accuracy: 0.7354 - val_loss: 0.7730 - val_accuracy: 0.7355
Epoch 6/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.6848 - accuracy: 0.7592 - val_loss: 0.7858 - val_accuracy: 0.7310
Epoch 7/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.6173 - accuracy: 0.7811 - val_loss: 0.7767 - val_accuracy: 0.7414
Epoch 8/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.5755 - accuracy: 0.7971 - val_loss: 0.7518 - val_accuracy: 0.7475
Epoch 9/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.5185 - accuracy: 0.8170 - val_loss: 0.7397 - val_accuracy: 0.7585
Epoch 10/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.4857 - accuracy: 0.8260 - val_loss: 0.7376 - val_accuracy: 0.7642
Epoch 11/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.4600 - accuracy: 0.8368 - val_loss: 0.7776 - val_accuracy: 0.7592
Epoch 12/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.4231 - accuracy: 0.8492 - val_loss: 0.8102 - val_accuracy: 0.7567
Epoch 13/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.4029 - accuracy: 0.8557 - val_loss: 0.8251 - val_accuracy: 0.7574
Epoch 14/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.3732 - accuracy: 0.8647 - val_loss: 0.8881 - val_accuracy: 0.7568
Epoch 15/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.3579 - accuracy: 0.8730 - val_loss: 0.8452 - val_accuracy: 0.7597
Epoch 16/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.3246 - accuracy: 0.8822 - val_loss: 0.8970 - val_accuracy: 0.7572
Epoch 17/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.3204 - accuracy: 0.8832 - val_loss: 0.9088 - val_accuracy: 0.7615
Epoch 18/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.3271 - accuracy: 0.8808 - val_loss: 0.8909 - val_accuracy: 0.7621
Epoch 19/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.3012 - accuracy: 0.8909 - val_loss: 0.9523 - val_accuracy: 0.7518
Epoch 20/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.2893 - accuracy: 0.8939 - val_loss: 1.0589 - val_accuracy: 0.7469
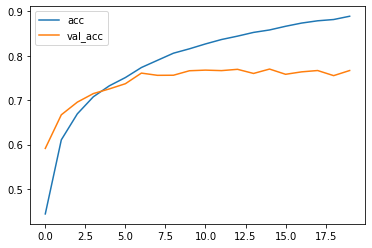
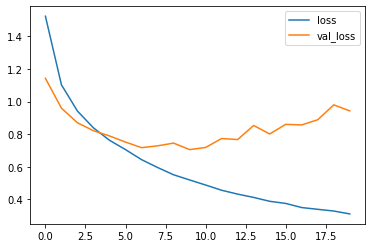
●学習の推移
import matplotlib.pyplot as plt train_loss = history.history['loss'] # 訓練用データの誤差 train_acc = history.history['accuracy'] # 訓練用データの精度 val_loss = history.history['val_loss'] # 検証用データの誤差 val_acc = history.history['val_accuracy'] # 検証用データの精度 plt.plot(np.arange(len(train_loss)), train_loss, label='loss') plt.plot(np.arange(len(val_loss)), val_loss, label='val_loss') plt.legend() plt.show() plt.plot(np.arange(len(train_acc)), train_acc, label='acc') plt.plot(np.arange(len(val_acc)), val_acc, label='val_acc') plt.legend() plt.show()
良いデータが確認できました。
●評価
モデルの評価を行っていきます。
loss, accuracy = model.evaluate(x_test, t_test) print(loss, accuracy)出力.313/313 [==============================] - 1s 3ms/step - loss: 0.9427 - accuracy: 0.7668 0.9427096843719482 0.76679998636245730.9427096843719482 0.7667999863624573
良い感じで判断ができていると確認ができたので
再度モデルを使い予想を行いますn_image = 25 rand_idx = np.random.randint(0, len(x_test), n_image) y_rand = model.predict(x_test[rand_idx]) predicted_class = np.argmax(y_rand, axis=1) plt.figure(figsize=(10, 10)) # 画像の表示サイズ for i in range(n_image): cifar_img=plt.subplot(5, 5, i+1) plt.imshow(x_test[rand_idx[i]]) label = cifar10_labels[predicted_class[i]] plt.title(label) plt.tick_params(labelbottom=False, labelleft=False, bottom=False, left=False) plt.show()
実際の精度は微妙な感じですがモデルを作成し判定を行うことができました。
次回もっと精度を上げる
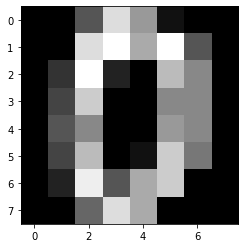
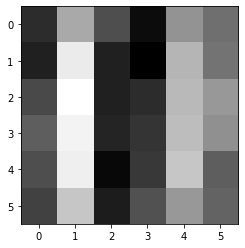
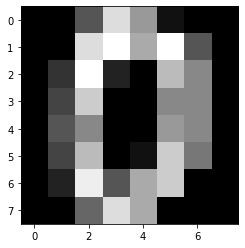



- 投稿日:2021-01-25T15:15:14+09:00
色々めんどくさいので作りながら学ぶCNN概要から実装まで
概要
・CNNとは
・畳み込みとプーリング実装
・im2col / col2im
・畳み込みとプーリングの実装
・CNN実装
・データ拡張
~~~~~~~~~~~~~
こんな感じで緩く進めていきたいと思います。1.CNNの概要
*図の全結合層の一一層目はお互いには干渉しません。適当に線を引きすぎました。
・画像を入力として、畳み込み、プーリング層を経て全結合層へ
・出力は各グループに分類される確率となる畳み込み層では、出力が入力の一部の影響しか受けない局所性の強い処理が行われます。
プーリング層では、認識する対象の位置に柔軟に対応できる仕組みが備わる
*畳み込みで何度か繰り返し処理をさ、組み込み+プーリング層で繰り返し処理をされ、全結合層でも繰り返し処理を行い出力します。
ここで、行われる作業一覧
・畳み込みでは、フィルター処理の結果入力画像は画像の特徴を表す複数の画像に変換されます
・プーリング層では、画像の特徴を損なわないように画像のサイズが縮小されます
・全結合層ではこれまで扱ってきたニューラルネットワークの相当を同じように層間のすべてのニューロンが接続されます2.畳み込みとプーリング実装
Markdown: [Qiita]
畳み込みネットワークの「基礎の基礎」を理解する ~ディープラーニング入門
https://www.imagazine.co.jp/%E7%95%B3%E3%81%BF%E8%BE%BC%E3%81%BF%E3%83%8D%E3%83%83%E3%83%88%E3%83%AF%E3%83%BC%E3%82%AF%E3%81%AE%E3%80%8C%E5%9F%BA%E7%A4%8E%E3%81%AE%E5%9F%BA%E7%A4%8E%E3%80%8D%E3%82%92%E7%90%86%E8%A7%A3%E3%81%99/上記参照していただければわかると思います。
3.im2col / col2im
im2col / col2imとは?
im2col = 複数バッチ、複数チャンネルの画像を1つの行列に変換
畳み込み層の順伝播col2im = 1つの行列を複数バッチ、複数チャンネルの画像
畳み込み層の逆伝播で使用詳しくわかりやすくしてる記事
https://qiita.com/kuroitu/items/7877c002e192955c78574.畳み込みとプーリングの実装
●im2colの実装
Sequential: モデルを生成するためのモジュール
Conv2d: 2次元畳み込み層のモジュール
MaxPool2D: 2次元最大プーリング層のモジュール
Adam: 最適化には,Adamを用いる
Dense: 全結合層のレイヤモジュール
Activation: 活性化関数モジュール
Dropout: ドロップアウトモジュール
Flatten: 入力を平滑化するモジュール
plot_model: 構築したモデルを図として出力する
Tensorboard: 学習過程をTensorboardに保存
cifar10: CIFAR-10データセットを扱う為のモジュール
to_categorical: One-Hot表現をするために使用import numpy as np def im2col(img, flt_h, flt_w): # 入力画像、フィルタの高さ、幅 img_h, img_w = img.shape # 入力画像の高さ、幅 out_h = img_h - flt_h + 1 # 出力画像の高さ(パディング無し、ストライド1) out_w = img_w - flt_w + 1 # 出力画像の幅(パディング無し、ストライド1) cols = np.zeros((flt_h*flt_w, out_h*out_w)) # 生成される行列のサイズ for h in range(out_h): h_lim = h + flt_h # h:フィルタがかかる領域の上端、h_lim:フィルタがかかる領域の下端 for w in range(out_w): w_lim = w + flt_w # w:フィルタがかかる領域の左端、w_lim:フィルタがかかる領域の右端 cols[:, h*out_w+w] = img[h:h_lim, w:w_lim].reshape(-1) return cols↓行列に変換
img = np.array([[1, 2, 3, 4], # 入力画像 [5, 6, 7, 8], [9, 10,11,12], [13,14,15,16]]) cols = im2col(img, 2, 2) # 入力画像と、フィルタの高さ、幅を渡す print(cols)[[1, 2, 3, 4]
[5, 6, 7, 8]
[9, 10,11,12]
[13,14,15,16]
各値が各pxに値します。したがってこの値が4x4の画像になります。[[ 1. 2. 3. 5. 6. 7. 9. 10. 11.] [ 2. 3. 4. 6. 7. 8. 10. 11. 12.] [ 5. 6. 7. 9. 10. 11. 13. 14. 15.] [ 6. 7. 8. 10. 11. 12. 14. 15. 16.]]1.2.5.6/2.3.6.7/と出力されていると確認ができましたので行列になっています。
def im2col(images, flt_h, flt_w, stride, pad): n_bt, n_ch, img_h, img_w = images.shape out_h = (img_h - flt_h + 2*pad) // stride + 1 # 出力画像の高さ out_w = (img_w - flt_w + 2*pad) // stride + 1 # 出力画像の幅 img_pad = np.pad(images, [(0,0), (0,0), (pad, pad), (pad, pad)], "constant") cols = np.zeros((n_bt, n_ch, flt_h, flt_w, out_h, out_w)) for h in range(flt_h): h_lim = h + stride*out_h for w in range(flt_w): w_lim = w + stride*out_w cols[:, :, h, w, :, :] = img_pad[:, :, h:h_lim:stride, w:w_lim:stride] cols = cols.transpose(1, 2, 3, 0, 4, 5).reshape(n_ch*flt_h*flt_w, n_bt*out_h*out_w) return cols様々なバッチサイズ、チャンネル数、パディング幅、ストライドに対応し、forによる繰り返しを最小化したim2colのコード例です。
●畳み込みの実装
import matplotlib.pyplot as plt from sklearn import datasets digits = datasets.load_digits() print(digits.data.shape) image = digits.data[0].reshape(8, 8) plt.imshow(image, cmap="gray") plt.show()(1797, 64)
1797のデータセットが入っていて、64pxからなっていることがわかります。
def im2col(img, flt_h, flt_w, out_h, out_w): # 入力画像、フィルタの高さ、幅、出力画像の高さ、幅 cols = np.zeros((flt_h*flt_w, out_h*out_w)) # 生成される行列のサイズ for h in range(out_h): h_lim = h + flt_h # h:フィルタがかかる領域の上端、h_lim:フィルタがかかる領域の下端 for w in range(out_w): w_lim = w + flt_w # w:フィルタがかかる領域の左端、w_lim:フィルタがかかる領域の右端 cols[:, h*out_w+w] = img[h:h_lim, w:w_lim].reshape(-1) return colsシンプルなim2colの関数を使います
flt = np.array([[-1, 1, -1,], # 縦の線を強調するフィルタ [-1, 1, -1,], [-1, 1, -1,]]) flt_h, flt_w = flt.shape flt = flt.reshape(-1) # 行数が1の行列 img_h, img_w = image.shape # 入力画像の高さ、幅 out_h = img_h - flt_h + 1 # 出力画像の高さ(パディング無し、ストライド1) out_w = img_w - flt_w + 1 # 出力画像の幅(パディング無し、ストライド1) cols = im2col(image, flt_h, flt_w, out_h, out_w) image_out = np.dot(flt, cols) # 畳み込み image_out = image_out.reshape(out_h, out_w) plt.imshow(image_out, cmap="gray") plt.show()im2colで画像を行列に変換し、フィルタとの行列積により畳み込みを行います。
画像から縦の行が協調され、画像サイズが小さくなりました。(8*8→6*6へ)
●プーリングの実装
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets digits = datasets.load_digits() print(digits.data.shape) image = digits.data[0].reshape(8, 8) plt.imshow(image, cmap="gray") plt.show()(1797, 64)
上の画像に対してプーリングを行うdef im2col(img, flt_h, flt_w, out_h, out_w, stride): # 入力画像、プーリング領域の高さ、幅、出力画像の高さ、幅、ストライド cols = np.zeros((flt_h*flt_w, out_h*out_w)) # 生成される行列のサイズ for h in range(out_h): h_lim = stride*h + flt_h # h:プーリング領域の上端、h_lim:プーリング領域の下端 for w in range(out_w): w_lim = stride*w + flt_w # w:プーリング領域の左端、w_lim:プーリング領域の右端 cols[:, h*out_w+w] = img[stride*h:h_lim, stride*w:w_lim].reshape(-1) return colsimg_h, img_w = image.shape # 入力画像の高さ、幅 pool = 2 # プーリング領域のサイズ out_h = img_h//pool # 出力画像の高さ out_w = img_w//pool # 出力画像の幅 cols = im2col(image, pool, pool, out_h, out_w, pool) image_out = np.max(cols, axis=0) # Maxプーリング image_out = image_out.reshape(out_h, out_w) plt.imshow(image_out, cmap="gray") plt.show()
各2x2の領域の最大値が抽出され、新たな画像となりました。
8x8の画像が、4x4の画像に変換されたことになります5.CNNの実装
CIFAR-10を読み込み、ランダムな25枚の画像を表示します
import numpy as np import matplotlib.pyplot as plt import keras from keras.datasets import cifar10 (x_train, t_train), (x_test, t_test) = cifar10.load_data() print("Image size:", x_train[0].shape) cifar10_labels = np.array(["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]) n_image = 25 rand_idx = np.random.randint(0, len(x_train), n_image) plt.figure(figsize=(10,10)) # 画像の表示サイズ for i in range(n_image): cifar_img=plt.subplot(5,5,i+1) plt.imshow(x_train[rand_idx[i]]) label = cifar10_labels[t_train[rand_idx[i]]] plt.title(label) plt.tick_params(labelbottom=False, labelleft=False, bottom=False, left=False) # ラベルとメモリを非表示に plt.show()
CNNの各設定を行います。わかりやすいように0・1で表現してもらうように指示します。
正解の値は1ですbatch_size = 32 epochs = 20 n_class = 10 # 10のクラスに分類 # one-hot表現に変換 t_train = keras.utils.to_categorical(t_train, n_class) t_test = keras.utils.to_categorical(t_test, n_class) print(t_train[:10])[[0. 0. 0. 0. 0. 0. 1. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.] [0. 0. 0. 0. 1. 0. 0. 0. 0. 0.] [0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 1. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 1. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 1. 0.] [0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]]上記 1 の表現が正解のクラスを表現しています。
●モデルの構築
複数の層を書いていきます。
順番は畳み込み層
畳み込み層
Maxプーリング層
畳み込み層
畳み込み層
Maxプーリング層
全結合層
全結合層全結合層の直後にドロップアウトを含みモデルの汎化性能が向上させます。
from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Conv2D, MaxPooling2D from keras.optimizers import Adam model = Sequential() model.add(Conv2D(32, (3, 3), padding='same', input_shape=x_train.shape[1:])) # ゼロパディング、バッチサイズ以外の画像の形状を指定 model.add(Activation('relu')) model.add(Conv2D(32, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(64, (3, 3), padding='same')) model.add(Activation('relu')) model.add(Conv2D(64, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) # 一次元の配列に変換 model.add(Dense(256)) model.add(Activation('relu')) model.add(Dropout(0.5)) # ドロップアウト model.add(Dense(n_class)) model.add(Activation('softmax')) model.compile(optimizer=Adam(), loss='categorical_crossentropy', metrics=['accuracy']) model.summary()Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 32, 32, 32) 896 _________________________________________________________________ activation (Activation) (None, 32, 32, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 30, 30, 32) 9248 _________________________________________________________________ activation_1 (Activation) (None, 30, 30, 32) 0 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 15, 15, 32) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 15, 15, 64) 18496 _________________________________________________________________ activation_2 (Activation) (None, 15, 15, 64) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 13, 13, 64) 36928 _________________________________________________________________ activation_3 (Activation) (None, 13, 13, 64) 0 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 6, 6, 64) 0 _________________________________________________________________ flatten (Flatten) (None, 2304) 0 _________________________________________________________________ dense (Dense) (None, 256) 590080 _________________________________________________________________ activation_4 (Activation) (None, 256) 0 _________________________________________________________________ dropout (Dropout) (None, 256) 0 _________________________________________________________________ dense_1 (Dense) (None, 10) 2570 _________________________________________________________________ activation_5 (Activation) (None, 10) 0 ================================================================= Total params: 658,218 Trainable params: 658,218 Non-trainable params: 0 _________________________________________________________________できました。
続いてモデルを訓練していきます。x_train = X_train x_test = x_test history = model.fit(x_train, t_train, epochs=epochs, batch_size=batch_size, validation_data=(x_test, t_test))出力まで5分ほど時間がかかります。
出力.
Epoch 1/20
1563/1563 [==============================] - 14s 5ms/step - loss: 1.8161 - accuracy: 0.3263 - val_loss: 1.1969 - val_accuracy: 0.5715
Epoch 2/20
1563/1563 [==============================] - 7s 4ms/step - loss: 1.1615 - accuracy: 0.5884 - val_loss: 0.9519 - val_accuracy: 0.6721
Epoch 3/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.9493 - accuracy: 0.6640 - val_loss: 0.8289 - val_accuracy: 0.7106
Epoch 4/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.8288 - accuracy: 0.7098 - val_loss: 0.8436 - val_accuracy: 0.7126
Epoch 5/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.7578 - accuracy: 0.7354 - val_loss: 0.7730 - val_accuracy: 0.7355
Epoch 6/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.6848 - accuracy: 0.7592 - val_loss: 0.7858 - val_accuracy: 0.7310
Epoch 7/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.6173 - accuracy: 0.7811 - val_loss: 0.7767 - val_accuracy: 0.7414
Epoch 8/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.5755 - accuracy: 0.7971 - val_loss: 0.7518 - val_accuracy: 0.7475
Epoch 9/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.5185 - accuracy: 0.8170 - val_loss: 0.7397 - val_accuracy: 0.7585
Epoch 10/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.4857 - accuracy: 0.8260 - val_loss: 0.7376 - val_accuracy: 0.7642
Epoch 11/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.4600 - accuracy: 0.8368 - val_loss: 0.7776 - val_accuracy: 0.7592
Epoch 12/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.4231 - accuracy: 0.8492 - val_loss: 0.8102 - val_accuracy: 0.7567
Epoch 13/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.4029 - accuracy: 0.8557 - val_loss: 0.8251 - val_accuracy: 0.7574
Epoch 14/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.3732 - accuracy: 0.8647 - val_loss: 0.8881 - val_accuracy: 0.7568
Epoch 15/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.3579 - accuracy: 0.8730 - val_loss: 0.8452 - val_accuracy: 0.7597
Epoch 16/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.3246 - accuracy: 0.8822 - val_loss: 0.8970 - val_accuracy: 0.7572
Epoch 17/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.3204 - accuracy: 0.8832 - val_loss: 0.9088 - val_accuracy: 0.7615
Epoch 18/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.3271 - accuracy: 0.8808 - val_loss: 0.8909 - val_accuracy: 0.7621
Epoch 19/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.3012 - accuracy: 0.8909 - val_loss: 0.9523 - val_accuracy: 0.7518
Epoch 20/20
1563/1563 [==============================] - 7s 4ms/step - loss: 0.2893 - accuracy: 0.8939 - val_loss: 1.0589 - val_accuracy: 0.7469
●学習の推移
import matplotlib.pyplot as plt train_loss = history.history['loss'] # 訓練用データの誤差 train_acc = history.history['accuracy'] # 訓練用データの精度 val_loss = history.history['val_loss'] # 検証用データの誤差 val_acc = history.history['val_accuracy'] # 検証用データの精度 plt.plot(np.arange(len(train_loss)), train_loss, label='loss') plt.plot(np.arange(len(val_loss)), val_loss, label='val_loss') plt.legend() plt.show() plt.plot(np.arange(len(train_acc)), train_acc, label='acc') plt.plot(np.arange(len(val_acc)), val_acc, label='val_acc') plt.legend() plt.show()
良いデータが確認できました。
●評価
モデルの評価を行っていきます。
loss, accuracy = model.evaluate(x_test, t_test) print(loss, accuracy)出力.313/313 [==============================] - 1s 3ms/step - loss: 0.9427 - accuracy: 0.7668 0.9427096843719482 0.76679998636245730.9427096843719482 0.7667999863624573
良い感じで判断ができていると確認ができたので
再度モデルを使い予想を行いますn_image = 25 rand_idx = np.random.randint(0, len(x_test), n_image) y_rand = model.predict(x_test[rand_idx]) predicted_class = np.argmax(y_rand, axis=1) plt.figure(figsize=(10, 10)) # 画像の表示サイズ for i in range(n_image): cifar_img=plt.subplot(5, 5, i+1) plt.imshow(x_test[rand_idx[i]]) label = cifar10_labels[predicted_class[i]] plt.title(label) plt.tick_params(labelbottom=False, labelleft=False, bottom=False, left=False) plt.show()
実際の精度は微妙な感じですがモデルを作成し判定を行うことができました。
次回もっと精度を上げる
- 投稿日:2021-01-25T15:09:04+09:00
【Python】Pandasを使って売上分析【xlsxを読み込む】
目的
某サイトの売上分析を行う。
売上増減の要因を把握するために、商品ごとに売上を確認。
増減への貢献度(が高い商品についてさらに詳しく分析。いつもやっている流れは
1.週間レポート(全トランザクションデータ)を商品名ごとに集計
2.増減に関与している商品を見つける
3.そこからリファラルなど詳細を調べて、解決策を探る。特に統計的なことはなく、単純にEXCELで毎週しているデータ整理などの作業を自動化し、分析自体にもっと時間を費やしたいと思い、初心者ながらやってみることに。
Pythonにやってもらうこと
1.EXCELファイル(.xlsx)を読み込んで、データフレームに落とし込む
2.いらない行を削除
3.商品名やその他必要な項目ごとに集計
4.シートに書き出して、保存xlsxファイルを読み込む
pandasはインストール済みなので、
import pandas as pd df = pd.read_excal('ファイルパス')すると次のエラーが発生。
ImportError: Missing optional dependency 'xlrd'. Install xlrd >= 1.0.0 for Excel support Use pip or conda to install xlrd.調べてみると、EXCELファイルを読み込むにはxlrdをインストールしないといけないらしい。
ということで、Terminalで以下を実行。pip3 install xlrd次に出たエラーがこちら。
raise XLRDError(FILE_FORMAT_DESCRIPTIONS[file_format]+'; not supported') xlrd.biffh.XLRDError: Excel xlsx file; not supported調べてみると、xlrd(2.01)はxlsファイル以外のサポートを終了したとのこと。
解決方法は
1. xlrdのふるい古いバージョンをインストールする(セキュリティ上の問題があるかも)pip install xlrd==1.2.0
- openpyxlを用いてxlsxファイルを開く
import openpyxl pandas.read_excel(‘ファイル名(ファイルパス)’, engine=’openpyxl’)セキュリティの観点からこちらを採用。
xlsxファイルの最終的な読み込み+データフレームへの落とし込みコードはこちら。import pandas as pd import openpyxl df = pd.read_excel('ファイル名', engine='openpyxl')参照
https://obgynai.com/python-pandas-excel-read/
https://stackoverflow.com/questions/65254535/xlrd-biffh-xlrderror-excel-xlsx-file-not-supported
https://exerror.com/xlrd-biffh-xlrderror-excel-xlsx-file-not-supported/ピボットテーブルの要領で商品ごとに集計
EXCELのピボットテーブルの機能は、pivot_tableで実行できます。
基本の型はこちら。
pd.pivot_table(df, index='行データ', columns='列データ', values='数値', aggfunc='sum')indexとcolumns,valuesには、表のデーブルヘッダー名に置き換える。
aggfuncは集計方法です(sumは合計)。
今回は'商品名'ごとの売上'数量'の'合計'を見たいだけなので、columnsは削除。実行結果はこんな感じになります。
商品名 数量 A 12 B 55 C 8ひとまずここまで。
- 投稿日:2021-01-25T14:53:29+09:00
C++とPythonで画像の色々な位置合わせをしてみる
概要
位置合わせというといまいちピンとこないですが、画像内のある部分の座標を合わせちゃおう!と言えばイメージがつくかもしれません。
この記事は、その位置合わせをC++で実装してみたよ、というものです。
やはりかなり多くの人がPythonでやっていて、C++ではそのままのコードがあまりなかったので情報共有がてら執筆します。最終的には、Pythonでも同様の位置合わせを行っていき、速度や精度を観察していきたいと思います。
皆様の位置合わせの引き出しが少しでも増えたら幸いです。
位置合わせって?
こんな大々的に言っているのですが、こーゆージャンルが存在するのかはわかりません。
私も半年くらい前に知りました(笑)それでは、代表的な位置合わせ手法を1つ紹介しますので雰囲気をつかんでください。
環境
windows10
Python
Python 3.7.4
OpenCV 3.4.2
C++
C++14
OpenCV 4.5.1テンプレートマッチング
はい、とても有名ですね。
OpenCVで関数化しちゃってます。なにをしているかを軽く説明すると、テンプレートマッチングは画像を左上から探索していき、輝度情報の差の二乗などを使って類似度を計算しています。
しかし、この方法では物体が回転したり、物体のサイズが違ったりすると全く違う座標として計算されてしまいます。初耳で「確かに!」とはならないと思うので百聞は一見に如かず。実際に見てみましょう!
実験
まず今回使用する画像です。
適当にお金を並べたものと1円玉をトリミングしたものです。
マークダウンのプレビューだと1円玉単品の画像が大きくなっちゃってますが、実際は同じサイズです。さっそくこれを1円玉でテンプレートマッチングしてみましょう!
はい。1円玉のところは特に中心が白くなっています。
一番類似度が高かった場所をプログラムで囲ってみます。
左上らしいです。ちなみにトリミングした1円玉は左上のだったのでそれもわかったんですかね(笑)
それでは、実際にこの左上の1円玉を回転させたり大きくさせたりしてみます。
同様にテンプレートマッチングをすると、
[回転]
[拡大]
今回は確実に例が悪かったので回転による影響を受ける様子があまり見られませんでしたが、拡大の影響は一目瞭然です。
最も類似度が高かった座標も他の1円玉の座標になっています。
一応ソースです
template_match.py# 画像読み込み ref_img = cv2.imread("./ref_coin.png") tgt_img = cv2.imread("./tgt_coin.png") # テンプレートマッチング match_result = cv2.matchTemplate(ref_img, tgt_img, cv2.TM_CCOEFF_NORMED) min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(match_result) # 四角形を描画 h, w = tgt_img.shape[:2] top_left = max_loc bottom_right = (top_left[0] + h, top_left[1] + w) cv2.rectangle(result,top_left, bottom_right, (0,0,255), 3)template_match.cpp// 画像読み込み Mat ref_img = imread("./ref_coin.png"); Mat tgt_img = imread("./tgt_coin.png"); // 出力先変数定義 Mat match_result; Point pos; // テンプレートマッチング matchTemplate(ref_img, tgt_img, match_result, CV_TM_CCOEFF_NORMED); minMaxLoc(match_result, NULL, NULL, NULL, &pos); // 四角形を描画 rectangle(ref_img, Rect(pos.x, pos.y, tgt_img.cols, tgt_img.rows), Scalar(0, 0, 255), 3);これでテンプレートマッチングの元画像への依存度の高さがわかったのではないのでしょうか。
長ったらしい前置きはここまでとして本題に入っていきます!
アプローチ1
Phase Only Correlation (POC)、日本語で位相限定相関法というものがあります。
どんな手法かというと、それぞれの画像をフーリエ変換して、パワースペクトル画像を生成します。それらの相関をとった新たなパワースペクトル画像を生成し、最後に逆フーリエ変換することで相関の強かった座標のみがハイライトされたような画像が生成されます。
そのピーク値の座標を求めることで一番相関の強い座標を得ることができるという手法です。このようにフーリエ変換することで、現画像は振幅(輝度)と位相(像の輪郭)に分解されます。こうすることで輝度情報のみを扱っているテンプレートマッチングよりも判断材料が1つ増え、外乱の影響を受けにくくなったことがわかります。
このサイトで可視化もしながらとても丁寧に説明してくれているので、ぜひ参考にしてください。
そして!長々と原理を説明したから1から実装するのかと思いきや、OpenCVで関数化されています。(https://docs.opencv.org/master/d7/df3/group__imgproc__motion.html)
ですので、それを使って楽に実装していきましょう!
実装
今回使用する画像です。
ランドルト環を位置合わせしていきましょう!
2枚目のように右に100ピクセル、下に100ピクセル平行移動させた画像を用意しました。
また、平行移動させる前に左に90度回転させた画像も用意しました (以降、平行移動画像、回転画像と呼ぶ)。
仕様上、OpenCVのPOCはグレースケール画像を渡さないと動いてくれません。
IMREAD_GRAYSCALEをそっと添えてあげましょう。
また、画像の要素も小数である必要があります。そっとどうにかしてあげましょう。それではコードを書いていきます!
poc.py# グレースケールとして画像読み込み ref_img = cv2.imread("./Landolt.png", cv2.IMREAD_GRAYSCALE) tgt_img = cv2.imread("./ShiftLandolt.png", cv2.IMREAD_GRAYSCALE) # 位相限定相関法 (x, y), response = cv2.phaseCorrelate(ref_img .astype(np.float32), tgt_img .astype(np.float32)) # affine変換による平行移動 M = np.float32([[1, 0, -x], [0, 1, -y]]) aligned_img= cv2.warpAffine(tgt_img, M, (w, h)) print(f'Shift X: {x}\nShift Y: {y}') >>Shift X: 99.99693842207353 Shift Y: 99.99310716347935poc.cpp// グレースケールとして画像読み込み Mat ref_img = imread("./Landolt.png", IMREAD_GRAYSCALE); Mat tgt_img = imread("./ShiftLandolt.png", IMREAD_GRAYSCALE); // 出力先変数定義 Mat aligned_img; double response; // Float型に変換したため、matの範囲は[0:1]となり、255で割る必要がある。 ref_img.convertTo(ref_img, CV_64FC1, 1.0 / 255.0); tgt_img.convertTo(tgt_img, CV_64FC1, 1.0 / 255.0); // 位相限定相関法 Point2d shift = phaseCorrelate(ref_img, tgt_img); // affine変換による平行移動 Mat M = (Mat_<double>(2, 3) << 1.0, 0.0, -shift.x, 0.0, 1.0, -shift.y); warpAffine(tgt_img, aligned_img, M, aligned_img.size()); printf("Shift X: %g\nShift Y: %g\n", shift.x, shift.y); >>Shift X: 99.997 Shift Y: 99.9932
aligned_imgを出力したらこんな感じ
回転画像に対してPOCを適用したらこんな感じ
意外と位置合いましたね(笑)アプローチ2
Rotation Invariant Phase Only Correlation (RIPOC)、日本語で回転不変位相限定相関法というものがあります。
字面からわかるように先ほどのPOCを改良した手法です。
これもかなりかいつまんで説明すると、フーリエ変換した後に、その画像を対数極座標に変換します。(対数極座標について)
こうすることで2次元座標(x, y)が対数極座標(ρ, θ) (ρ:ある点と原点との距離の対数、θ:x軸とのなす角)に変換されます。ですので、この極座標系では角度と大きさを対数座標で表現できるようになります。
そこに先ほどのPOCを使って画像の移動量を取得することで、角度と大きさを補正するという手法です。目からうろこですね?角度と大きさを補正できたら、後はまた平行移動の位置合わせを行って無事完了です。
それでは確実に簡単であろうPythonから実装していきます(笑)
実装(Python)
対象画像を回転画像として実装していきます。
それでは段階に分けて見ていきましょう!
まずはフーリエ変換までripoc.py# 画像読み込み ref_img = cv2.imread("./Landolt.png", cv2.IMREAD_GRAYSCALE) tgt_img = cv2.imread("./RotateLandolt.png", cv2.IMREAD_GRAYSCALE) # Numpy配列に変換 ref_img_gray = np.array(ref_img,dtype=np.float64) tgt_img_gray = np.array(tgt_img,dtype=np.float64) # 画像サイズ定義 h, w = ref_img_gray.shape center = (w/2, h/2) # 窓関数定義 hunning_y = np.hanning(h) hunning_x = np.hanning(h) hunning_w = hunning_y.reshape(h, 1)*hunning_x # フーリエ変換 ref_img_fft = np.fft.fftshift(np.log(np.abs(np.fft.fft2(ref_img_gray*hunning_w)))) tgt_img_fft = np.fft.fftshift(np.log(np.abs(np.fft.fft2(tgt_img_gray*hunning_w))))
tgt_img_fftを出力してみると、
真っ白です。原因は、フーリエ変換後の画像はMat形式のFloat64なんて無視して普通に1以上の値を返してきたからです。
正規化して確認すると、
美しい画像が出力されました!
この画像の中心を削ると低周波数成分がカットされるハイパスフィルタの挙動になったりします。
興味がある方はこのサイトで詳細に説明されてたので、見てみてください。では、対数極座標変換して、回転とスケールを導出してみます!
ripoc.py# 対数極座標変換 (lanczos法補間) l = np.sqrt(w*w + h*h) m = l/np.log(l) flags = cv2.INTER_LANCZOS4 + cv2.WARP_POLAR_LOG ref_img_pol = cv2.warpPolar(ref_img_fft, (w, h), center, m, flags) tgt_img_pol = cv2.warpPolar(tgt_img_fft, (w, h), center, m, flags) # 位相限定相関法 (x, y), response = cv2.phaseCorrelate(ref_img_pol, tgt_img_pol, hunning_w) # 角度と大きさを導出 angle = y*360/h scale = (np.e)**(x/m) print(f'angle: {angle}\nscale:{scale}') >>angle: 0.017308490013098775 scale:0.9986876396874065
tgt_img_polを出力してみると、
人間にはもうなにがなんだかわからないですが、printの出力結果から、角度と大きさが取れているのは確認できます。
求められた角度と大きさからaffine変換行列を求めて、変換させると、
後はまたPOCとかして位置合わせをすれば合いそう!
それではこのコードを平行移動画像と回転画像に対して実行していきます!
一応コード全文
template_match.py# 画像読み込み ref_img = cv2.imread("./Landolt.png", cv2.IMREAD_GRAYSCALE) tgt_img = cv2.imread("./RotateLandolt.png", cv2.IMREAD_GRAYSCALE) # Numpy配列に変換 ref_img_gray = np.array(ref_img,dtype=np.float64) tgt_img_gray = np.array(tgt_img,dtype=np.float64) # 画像サイズ定義 h, w = ref_img_gray.shape center = (w/2, h/2) # 窓関数定義 hunning_y = np.hanning(h) hunning_x = np.hanning(h) hunning_w = hunning_y.reshape(h, 1)*hunning_x # フーリエ変換 ref_img_fft = np.fft.fftshift(np.log(np.abs(np.fft.fft2(ref_img_gray*hunning_w)))) tgt_img_fft = np.fft.fftshift(np.log(np.abs(np.fft.fft2(tgt_img_gray*hunning_w)))) # 対数極座標変換 (lanczos法補間) l = np.sqrt(w*w + h*h) m = l/np.log(l) flags = cv2.INTER_LANCZOS4 + cv2.WARP_POLAR_LOG ref_img_pol = cv2.warpPolar(ref_img_fft, (w, h), center, m, flags) tgt_img_pol = cv2.warpPolar(tgt_img_fft, (w, h), center, m, flags) # 位相限定相関法 (x, y), response = cv2.phaseCorrelate(ref_img_pol, tgt_img_pol, hunning_w) # affine変換による平行移動 angle = y*360/h scale = (np.e)**(x/m) M = cv2.getRotationMatrix2D(center, angle, scale) tgt_img_affine = cv2.warpAffine((tgt_img_gray), M, (w, h)) # 位相限定相関法 (x, y), response = cv2.phaseCorrelate(ref_img_gray, tgt_img_affine) #位相限定相関法の返り値から画像を生成 M[0][2] -= x M[1][2] -= y dst = cv2.warpAffine(tgt_img, M, (w, h))平行移動画像の出力結果
ripoc.pyprint(f'Shift X: {x}\nShift Y: {y}\nangle: {angle}\nscale:{scale}') >>Shift X: 99.93655082583143 Shift Y: 99.88039360791896 angle: 0.017308490013098775 scale:0.9986876396874065回転画像の出力結果
ripoc.pyprint(f'Shift X: {x}\nShift Y: {y}\nangle: {angle}\nscale:{scale}') >>Shift X: -98.93914068317139 Shift Y: 100.10505647091378 angle: -89.94978000131137 scale:1.0002553379376475両画像ともにかなりの精度で合っています(主観)。回転量もいい具合に補正できていますね。
これでみんなの視力が良くなるはずです。また、この主観をカバーするために、ある座標の輝度値の差分をとったりして精度を評価するといった手段など、様々なものがあります。
実装(C++)
上記のPythonコードを参考に、C++で実装していきます。
まず、準備としてフーリエ変換をする関数を用意します。
フーリエ変換は、このサイトを参考に実装しました。fft.cppMat fft(Mat src) { // 変数定義 Mat padded; int m = getOptimalDFTSize(src.rows); int n = getOptimalDFTSize(src.cols); // 入力画像を中央に配置。周囲は0でパディングする。 copyMakeBorder(src, padded, 0, m - src.rows, 0, n - src.cols, BORDER_CONSTANT, Scalar::all(0)); // フーリエ変換画像の入れ子定義 Mat planes[] = { Mat_<double>(padded), Mat::zeros(padded.size(), CV_64F) }; Mat complexI; merge(planes, 2, complexI); // フーリエ変換 dft(complexI, complexI); // 対数に変換 split(complexI, planes); magnitude(planes[0], planes[1], planes[0]); Mat magI = planes[0]; log(magI, magI); // 行・列が奇数の時に、偶数に変換するためトリミングする magI = magI(Rect(0, 0, magI.cols & -2, magI.rows & -2)); // 以下で象限の入れ替え int cx = magI.cols / 2; int cy = magI.rows / 2; Mat q0(magI, Rect(0, 0, cx, cy)); // 左上(第二象限) Mat q1(magI, Rect(cx, 0, cx, cy)); // 右上(第一象限) Mat q2(magI, Rect(0, cy, cx, cy)); // 左下(第三象限) Mat q3(magI, Rect(cx, cy, cx, cy)); // 右下(第四象限) Mat tmp; q0.copyTo(tmp); q3.copyTo(q0); tmp.copyTo(q3); q1.copyTo(tmp); q2.copyTo(q1); tmp.copyTo(q2); // 正規化 normalize(magI, magI, 0, 1, NORM_MINMAX, -1); return magI; }大体のやっていることはコメントに書いておきました。
さて、フーリエ変換された画像を返す関数が作成できたのでRIPOCを実装していきます!ripoc.cpp// 変数定義 const int height = ref_img.rows; const int width = ref_img.cols; Point center = Point(width / 2, height / 2); const Size window_size(height, height); Mat aligned_img = Mat::zeros(tgt_img.size(), CV_64FC1); // グレースケールに変換+Folat型に変換 ref_img.convertTo(ref_img, CV_64FC1, 1.0 / 255.0); tgt_img.convertTo(tgt_img, CV_64FC1, 1.0 / 255.0); // フーリエ変換 Mat ref_img_fft = fft(ref_img); Mat tgt_img_fft = fft(tgt_img); // 対数極座標変換された画像の入れ子 Mat bg_ref = Mat::zeros(ref_img.size(), CV_64FC1); Mat bg_tgt = Mat::zeros(tgt_img.size(), CV_64FC1); // 窓関数定義 Mat matHann; cv::createHanningWindow(matHann, window_size, CV_64FC1); // 対数極座標変換 (lanczos法補間) double l = sqrt(height * height + width * width); double m = l / log(l); int flags = INTER_LANCZOS4 + WARP_POLAR_LOG; warpPolar(ref_img_fft, bg_ref, window_size, center, m, flags); warpPolar(tgt_img_fft, bg_tgt, window_size, center, m, flags); // 位相限定相関法 Point2d pt = phaseCorrelate(bg_ref, bg_tgt); // 角度と大きさを導出 float rotate = pt.y * 360 / width; float scale = exp(pt.x / m); // アフィン変換係数行列取得 Mat M = getRotationMatrix2D(center, rotate, scale); Mat rotated_img = Mat::zeros(tgt_img.size(), CV_64FC1); // 角度と大きさを補正 warpAffine(tgt_img, rotated_img, M, tgt_img.size()); rotated_img.convertTo(rotated_img, CV_64FC1, 1.0 / 255.0); // 位相限定相関法 pt = phaseCorrelate(ref_img, rotated_img); // affine変換行列を調整してaffine変換 M.at<double>(0, 2) -= pt.x; M.at<double>(1, 2) -= pt.y; warpAffine(tgt_img, aligned_img, M, tgt_img.size());これで完成です!
aligned_imgの出力を見てみましょう!平行移動画像の出力結果
ripoc.cpp// ripoc.cpp内 printf("Rotation: %g\nScale: %g\n", rotate, scale); // poc.cpp内 printf("Shift X: %g\nShift Y: %g\n", shift.x, shift.y); >>Rotation: 0.011399 Scale: 1.00014 Shift X: 98.1662 Shift Y: 100.914回転画像の出力結果
ripoc.cpp// ripoc.cpp内 printf("Rotation: %g\nScale: %g\n", rotate, scale); // poc.cpp内 printf("Shift X: %g\nShift Y: %g\n", shift.x, shift.y); >>Rotation: -89.9924 Scale: 1.00039 Shift X: -99.0014 Shift Y: 100.003C++でも両画像ともにかなりの精度で合っています。
それでは、どうせなので速度比較を行っていきたいと思います!!
C++とPythonの速度比較
今回使用した画像サイズ:(800[px], 800[px], 3[ch])
PCスペック:メモリ:16[GB]
CPU:i5-9300H
ベースクロック:2.4[GHz]計算時間はfor文で100回実行してその平均としました。
C++計算時間[ms] Python計算時間[ms] POC(位相限定相関法) 34.036662 18.470275 RIPOC(回転不変位相限定相関法) 135.769934 133.652456 これは意外です。
差が顕著だったPOCをステップ実行して計算時間を調査したところ、C++では
cv::phaseCorrelate関数の計算に30[ms]前後かかっていました。この時点でPythonを下回っています。私の実装ではRIPOCで2回
cv::phaseCorrelate関数を使っているので、それ以外の計算はC++の方が早いと単純には考えられます。まぁ最大のボトルネックは私の書き方にあると思いますが←
さいごに
テンプレートマッチング以外にもこんなマッチングの手法があるよという紹介でした
他にもcv::findtransformECCという関数とかもありますので、気になる方はそちらもチェック!今回は同じサイズのランドルト環に対して実行しましたが、RIPOCは回転以外にもスケール変化に対応しているので、精度が気になる方は是非実験してみてください
Pythonの方がOpenCV関数の実行速度が速いという意外な結果になりました
これからは脳死でC++の方が早いよというのはやめようと思いますそれでは、楽しい位相限定相関法・回転不変位相限定相関法ライフをenjoyしてください!
参考資料
画像のフーリエ変換
POC
RIPOC





















- 投稿日:2021-01-25T14:48:25+09:00
cronでpythonプログラムの実行をスケジューリングする
1時間おきにpythonプログラムを実行させたいとする。
例として1時間おきに更新される情報をスクレイピングしたい場合などである。
その様な場合、例えばfor文で回して処理の最後にtime.sleepすることで対応できる。
ただ、これは処理を実行させ続けるという意味でリソースの無駄遣いである。
この様な場合はtime-based schedulerでプログラムの実行管理ができる。このtime-based schedulerとしてUNIX系ではcronが使える。
その際には以下が必要になる。
- 実行するプログラム(pythonプログラム)
- いつそのプログラムが実行されるかを指示するファイル(crontab)
本記事に含まれる内容
- crontabの書式
- cronの実行手順
crontabの書式
cronではまずcrontabを用意する必要があり、cronを管理するconfigファイルの様なものである。書式は以下の通りである。以下を見ても明らかな通り、最短の実行間隔は1分である。
# +------------ minute (0 - 59) # | +---------- hour (0 - 23) # | | +-------- day of the month (1 - 31) # | | | +------ month (1 - 12) # | | | | +---- day of the week (0 - 6) (Sunday=0) # | | | | | # * * * * * command to execute毎日、0時0分に実行したい場合は以下となる
0 0 * * *30分おきに実行したい場合は以下となる
0,30 * * * *オフセットが違うだけで以下も30分おきの実行となる
15,45 * * * *月曜日の午前6時40分のみ実行したいとする
40 6 * * 1午前9時から午後6時まで30分おきの実行をしたい場合は以下である
0, 30 9-18 * * *毎時10分おきの実行をしたい場合は以下である
0-59/10 * * *予め用意されている定義もある
以下は1月1日の24時に実行される(= 0 0 1 1 *)@yearly command以下はrebootされる度に実行したい場合
@rebootcronの実行手順
実行するpythonプログラムとして以下を用意する。
実行内容としてはtimeスタンプ結果を名前とするディレクトリの作成である。mkdir.pyimport os import time print('Now : ', time.time()) os.mkdir(str(int(time.time())))上記のファイルを毎分実行したいとする。
ここでcronを使うため、crontabを編集モードで開く。$ crontab -e内容を確認する場合は以下の引数となる。
$ crontab -l実行ファイルを毎分実行したい場合は以下の通り。
* * * * * cd {実行ファイルの保存先} && python mkdir.pycronはsh shellを使っており低レベルのエイリアスがわからない場合がある。
例えばファイル実行時にpython3を用いる場合はpython3の場所を絶対pathで示す必要がある。
以下でpython3の場所を取得し、$ whereis python3取得したpathは以下の様に記載する。
* * * * * cd {実行ファイルの保存先} && {python3の絶対パス} mkdir.py一方、cronはback ground processなのでmkdir.py内のprint関数の出力は目視で確認できない。以下とすることで、print関数の出力をlogファイルに出力できる。
* * * * * cd {実行ファイルの保存先} && python mkdir.py >> mkdir.out以上までで、crontabの編集は終了しており、毎分の書き込まれるlogファイルの内容は以下のコマンドで確認できる
$ tail -f mkdir.out
- 投稿日:2021-01-25T14:44:02+09:00
pythonプログラムをbackground processで使用する方法
procesには2種類あり、forward processとbackground processである。
forward processはファイルの実行が終了するまで他の実行ができない。
その様な場合にはbackground processが有効である。本記事に含まれる内容
- background process化と終了方法
- 実行結果をファイルに出力する方法
- ターミナルウィンドウを閉じてもプロセスを終了させない方法
background process化と終了方法
数字を毎秒足し上げていくsum.pyを実行したいファイルとする。
sum.pyimport time x = 0 while True: time.sleep(1) x += 1 print(x)下記実行後、毎秒加算の結果が出力される
$ python sum.py以下とすることで、プロセスIDが出力されbackgroundで実行され続ける
$ python sum.py &このプロセスを終了する場合は以下の通り
$ kill -9 {プロセスID}実行結果をファイルに出力する方法
上記のまでの方法ではterminalに実行結果が出力され続ける。
他の作業を行なっている場合にこれは煩わしいので、新規にファイルを作成し、実行結果をファイルに出力することを考える。以下でoutという名前のファイルを作成した。
$ python sum.py > out &作成したoutというファイルに出力があるか確認するため、outの最終行を確認する。
$ tail -f out上記を実行しても出力はない。
また、以下を実行してもファイルは空であることが確認される。$ cat outこれは実行されたPythonプログラムの出力はバッファメモリに保存されるためである。つまり実行したPythonプログラムの処理が終了するまでoutには書き込みされない。
以下とすることで、逐次的にファイルに保存される。
$ python -u sum.py > out &作成したoutというファイルに出力があることが確認できる。
$ tail -f outターミナルウィンドウを閉じてもプロセスを終了させない方法
上記までの方法ではファイル実行中のターミナルウィンドウを閉じると処理が停止する。以下を実行することで処理が終了されない。
$ nohup python -u add.py &(nohupはno hung upの略)
以下を省略した理由は、nohupを使用した場合出力先を指定しなくても自動的にログファイルが生成されるからである。
> out以下の様にプロセスを終了したい場合、
まず実行中のプロセスのうち、add.pyに関わるものをマッチングで検索する。$ ps ax | grep add.py取得したプロセスIDを終了する。
$ kill -9 {プロセスID}
- 投稿日:2021-01-25T13:55:49+09:00
python のクラス
python クラス
参考
https://rinatz.github.io/python-book/ch03-02-scopes/
クラス定義
test.pyclass Rectangle: def __init__(self, width, height): self.width = width self.height = height def area(self): return self.width * self.height def main(): rectagle = Rectangle(10, 20) print(f'The value of width is {rectangle.width}') print(f'The value of height is {rectangle.height}') if __name__ '__main__': main()__init__
コンストラクタ。
1. インスタンス化するときに最初に呼び出される
2. クラスのメンバ変数を定義して初期化する
第1引数は必ずselfである。
selfはクラスインスタンスそのものの変数。関数
クラスのメンバとして定義された関数はメソッドとも呼ばれる。クラスに関数を定義するとき、第1引数が
selfである必要がある。実際にはRectangle.area(rectangle)にように呼び出される。継承
test2.pyclass Square(Rectangle): def __init__(self, size): super().__init__(size, size) def main(): square = Square(10) area = square.area() print(f'The area is {area}') if __name__ == '__main__': main()
SquareクラスはRectangleクラスのメンバをすべて引き継いでいる。これをクラスの継承という。Rectangleが長方形を扱うのに対してSquareは正方形を扱う。Rectangleが持つすべてのメンバsquare.width, square.height, square.area()を参照できる。インターフェース
クラスとそのクラス関数の定義を行い、外部関数の引数にクラスを渡すことで、関数にクラスを継承させる。下の
callはインターフェース的な役割をしている。test3.pyclass A: def __init__(self): pass def greet(self): print('This is class A') class B: def __init__(self): pass def greet(self): print('This is class B') def call(x): x.greet() def main(): call(A()) call(B()) if __name__ == '__main__': main()インターフェースのメリットは、引数と使用関数が明示できることである。また、仕様変更に強い。
スコープ
Pythonではすべてのメンバが
Publicとして扱われるが、習慣として下記のようにスコープを区別するようになっている。
スコープ 命名規則 public method() protected _method() private __method() 特殊属性
__doc__
Print.__doc__には"""..."""で囲まれた改行を含む複数行の文字列を定義できる。"""この文字列は 1つの文字列として 扱われます。"""__init__
クラスインスタンスを作成する。
__getattribute__
クラスのメンバやメソッドを参照したときに呼び出される。
test4.pypoint = Point(10, 20) point.x # point.__getattribute__('x') point.distance() # point.__getattribute__('distance')()__getattr__
__getattributrre__()でのメンバ参照に失敗した場合に呼び出される。定義されていないものにアクセスすると起こる。test5.pypoint.x2 # point.__getattribute__('x2')__getitem__
クラスインスタンスに対して
[]を使用したときに呼び出される。test6.pypoint = Point(10, 20) point['x'] # point.__getitem__('x')__setattr__
メンバの代入をしたときに呼び出される。
test7.pypoint = Point(10, 20) point.x = 30 # point.__setattr__('x', 30)比較
特殊属性 意味 ne point1 != point2 le point1 <= point2 lt point1 < point2 ge point1 >= point2 gt point1 > point2 __str__
文字列へのキャストを行うときに呼び出される。
test8.pypoint = Point(10, 20) print(point) # print(point.__str__())
- 投稿日:2021-01-25T13:30:15+09:00
Djangoの環境構築
はじめに
Linux(Ubuntu)でのDjangoの環境構築までをまとめました。
Djangoを勉強し始めたのはつい先日で、使ったコマンドからアウトプットとして記録していきたいなぁと思います。
また、今回の記事は以下の参考サイトに書かれていることを簡易的にまとめたものですので、詳しく知りたい方はそちらの方をご覧ください。あくまで自分用です。参考
仮想環境(virtual environment)の作成
ディレクトリの作成
command-line$ mkdir (作成するディレクトリの名前) $ cd (作成したディレクトリの名前)仮想環境の作成
command-line$ python -m venv myvenvmyvenvは仮想環境の名前は以下の条件を守ればどんな名前でも作成可能
* 必ず小文字で表記する
* スペースは入れないこと
ここで作成した名前は今後多く使うことになるからわかりやすいものにしといたほうがいいかも?仮想環境を起動
bommand-line$ source myvenv/bin/activate
sourceでできない場合もあるからその時は以下のコマンドを実行command-line$ . myvenv/bin/activate行頭に(myvenv)がついたら成功!
Djangoのインストール
Djangoのインストールに使うソフトウェアpipの確認
command-line(myvenv) ~$ python -m pip install --upgrade pipパッケージのインストール
requirementsファイルでパッケージをインストールする。
requirementsはpip installでインストールする依存関係の一覧が記載されているファイル
requirements.txtを(作成したディレクトリ)の中に作成する
requirements.txt中に以下のテキストを記述requirements.txtDjango~=2.2.4Djangoのインストール
以下のコマンドを実行してDjangoをインストールする
command-line(myvenv) ~$ pip install -r requirements.txtこれでDjangoの環境構築が完了!
さいごに
自分は最近勉強を始めたばかりの初心者なので間違えている所があったらご指摘していただけたらこちらも勉強になるのでありがたいです。
また、はじめの方にも書きましたがあくまで自分用ですので、
これからDjangoを勉強しようとしている方は参考サイトをご覧ください。
今回はご覧いただきありがとうございました。