- 投稿日:2021-01-13T23:30:14+09:00
ターミナルからCloudWatch logsをTailする方法
はじめに
めちゃめちゃ便利なツールを教えていただいたので、共有したいと思います。
検証用にECSのコンテナから吐き出されたログをCloudWatch logsに出力し確認することがあると思います。
その時、CloudWatch logsにStream出力されたログを、itermなどのターミナルから確認したいという方におすすめのツールを紹介します。AWSlogs
awslogsというツールを使用することで、この願いが叶います。
インストール
- pipで入れたい人
pip install awslogs
- brewで入れたい人
brew install awslogsawslogsのサブコマンド
サブコマンド 説明 groups CloudWatch Logsのロググループ名を表示 streams CloudWatch Logsのストリーム名を表示 get CloudWatch Logsのストリームに発生したイベントを表示 オプション
-w オプション
このオプションは、ログを表示し続けます。-G オプション
ロググループ名を省略して表示させます。-S オプション
ストリーム名を省略して表示させます。--timestamp オプション
ストリームにイベントが発生した時間を表示します。-s オプション
ストリームにイベントが発生した時間以降のログを表示させます。上記を踏まえ、tailする時のコマンドはこれ
awslogs get [log_group_name] -w -s 10m -G -S --timestamp
意味は、10分前以降の指定したロググループのイベントをtailし、ストリーム名、ロググループ名を省略し、ストリームにイベントが発生した時間は表示するという意味です。awslogs get ??? -w -s 10m -G -S --timestamp
- 投稿日:2021-01-13T23:28:24+09:00
Rubyでスプレッドシートからデータを取得するAPIを作成してみた(with サービスアカウント)
概要
スプレッドシートからデータを取得してjsonに整形するみたいなAPIを作成してみました。
意外とサービスアカウントを使っている記事が少なかったので少しでも参考になればと思います。環境
Ruby: 2.5.7
Ruby on Jets: 2.3.18
(Railsライクなフレームワークなので、Railsでもできます)サービスアカウントについて
ユーザではなくアプリケーションレベルで使用するアカウント。ユーザで認証する場合はそのユーザがアプリケーションの管理からはずれた場合などに認証情報を変えなければならなくなるため不便。
サービスアカウントはユーザに依存しないのでユーザなど関係なくアプリケーションからAPIを叩く場合にはこちらが便利。
ちなみに今回はバックエンドからユーザなど関係なくAPIを叩くために使うのでサービスアカウントを利用しました。
サービスアカウントの作成
作成していない場合は以下を参考に作成してください。ここでは省きます
https://support.google.com/a/answer/7378726?hl=ja
サービスアカウントからcredentialファイルをjsonファイルで取得
認証情報 > サービスアカウントを管理 > 作成したアカウントの操作 > 鍵を作成
json形式で鍵を作成して、
ダウンロードしたらアプリのトップディレクトリにgoogle-sa-credential.jsonという名前で保存APIを有効にする
https://console.developers.google.com/apis/dashboard
GCPコンソールの「APIとサービス」から
- Google Drive API
- Google Sheets API
を検索してそれぞれ有効にする。
サービスアカウントでフォルダ、スプレッドシートを作成する
サービスアカウントでスプレッドシートを操作する際には、以下のいずれかの必要がある。
- サービスアカウントによって作成されている
- サービスアカウントが編集者として共有されている
- 公開されている
スプレッドシートの「共有」でサービスアカウントを許可できるならば、共有した時点でこのタスクを必要としないので飛ばしてもOKです。
以下に2つのrakeタスクを記述しました
- 指定したフォルダID配下にフォルダを作成する(指定しなければ最上階にフォルダを作成する)
- 指定したフォルダID配下にスプレッドシートを作成する
# lib/tasks/google_drive.rake namespace :google_drive do desc 'Create folder with Service account' task :create_folder, [:title, :email_address, :collection_id] => :environment do |_, args| session = create_session folder = if args[:collection_id] session.file_by_id(args[:collection_id]).create_subcollection(args[:title]) else session.root_collection.create_subcollection(args[:title]) end folder.acl.push(type: 'user', email_address: args[:email_address], role: 'writer') p "Created folder: #{folder.human_url}" end desc 'Create sheet with Service account' task :create_sheet, [:title, :email_address, :collection_id] => :environment do |_, args| session = create_session sheet = session.file_by_id(args[:collection_id]).create_spreadsheet(args[:title]) sheet.acl.push(type: 'user', email_address: args[:email_address], role: 'writer') p "Created sheet: #{sheet.human_url}" end def create_session ::GoogleDrive::Session.from_service_account_key('google-sa-credential.json') end end$ bundle exec rake 'google_drive:create_folder[<フォルダタイトル>,<共有したいユーザのメールアドレス>]' $ bundle exec rake 'google_drive:create_sheet[<シートタイトル>,<共有したいユーザのメールアドレス>]'補足
collection: folderの意味
ACL: アクセス制御リスト。IAMと似て非なるもの。バケットやオブジェクトに柔軟に権限を与えるっぽい。
その後の実装方針
- gem google_driveを使用する
- spreadsheet → worksheet → json
- gem google_api_clientを使用する
- 柔軟性がない(jsonで出力できてもどちらにせよしたい形に変換しなければならない)
json構造を柔軟に変更できるように1の方針で実装しました。
所々moduleに切り分けていますが必須ではないです
また、routingは省略しますGemfile
gem 'google_drive'controller
# controller session = GoogleDriveSession.create_session service = SpreadSheetToHashService.new(session) service.run! render json: JSON.dump(service.records)session作成module
# google_drive_session.rb module GoogleDriveSession CREDENTIAL_PATH = 'google-sa-credential.json' def self.create_session return ::GoogleDrive::Session.from_service_account_key(CREDENTIAL_PATH) end endちなみに自分の場合は開発環境以外ではSecrets Managerから取得する(gem 'aws-sdk-secretsmanager'を使用)
# google_drive_session.rb module GoogleDriveSession CREDENTIAL_PATH = 'google-sa-credential.json' def self.create_session return ::GoogleDrive::Session.from_service_account_key(CREDENTIAL_PATH) if Jets.env.development? credential_json = RequestSecretsManager.request('/<project_name>/google-sa-credential') credential_hash = JSON.parse(credential_json) File.open("/tmp/#{CREDENTIAL_PATH}", 'w') do |f| JSON.dump(credential_hash, f) end ::GoogleDrive::Session.from_service_account_key("/tmp/#{CREDENTIAL_PATH}") end end # request_secrets_manager.rb require 'aws-sdk-secretsmanager' module RequestSecretsManager def self.request(secret_name) client = Aws::SecretsManager::Client.new(region: Jets.aws.region) get_secret_value_response = client.get_secret_value(secret_id: secret_name) get_secret_value_response.secret_string end endservice
# spread_sheet_to_hash_service.rb class SpreadSheetToHashService attr_reader :records SPREADSHEET_ID = '<スプレッドシートのID>' WORKSHEET_ID = '<ワークシートのID(1ページ目は0)>' HEADER_COUNT = 1 def initialize(session) @session = session end def run! worksheet = SpreadSheet.identify_worksheet_by_id(@session, SPREADSHEET_ID, WORKSHEET_ID) convert_worksheet_to_hash(worksheet) end private def convert_worksheet_to_hash(worksheet) # ヘッダをスキップする @records = worksheet.rows(HEADER_COUNT).map { |row| # ここでセル単位で好きな形にする # rowは行のこと、一行ずつのイテレータ # row[0]: 1列目の値 # row[1]: 2列目の値 } end endspread sheet操作用module
# spread_sheet.rb module SpreadSheet def self.identify_worksheet_by_id(session, spread_sheet_id, work_sheet_id) spreadsheet = session.file_by_id(spread_sheet_id) spreadsheet.worksheet_by_sheet_id(work_sheet_id) end endまとめ
これでスプレッドシートの内容を柔軟にjsonへ変更してレスポンスとして返すことができます!
参考

- 投稿日:2021-01-13T23:20:16+09:00
【初心者向け】Cloud9の容量不足をEBSストレージを追加して解決する
はじめに
勉強用にCloud9を使っているときに容量不足を解決した手順の備忘録として。
Cloud9が動いているインスタンスのストレージを拡張します。
EC2を自分で構築しない/Linuxをあまり触らない人向け。筆者も同じくらいなので理論の部分はあやふやです。注意事項
AWSの無料枠(1年間)を過ぎると、ボリュームの使用量に合わせて課金されるので、拡張の際はご注意ください。
記事を書いてる2021年1月時点で、だいたい1GBにつき0.08~0.1USD/月くらいっぽいです。
https://aws.amazon.com/jp/ebs/pricing/手順
- 心当たりがある人は、いらないファイルを消す
- EC2のボリューム(EBS)を拡張する
- 拡張したボリュームをファイルシステムに適用する
1.心当たりがある人は、いらないファイルを消す
Dockerとかの容量食うものを使っている人は、ですね。
Railsチュートリアルとかの勉強にCloud9を使ってる人は特に消せるものもないかと思います。2.EC2のボリュームを拡張する
Cloud9のEC2にくっついているボリュームを拡張します。
EC2・ボリュームとはなんぞや?という方は、かみ砕いていえば、
・EC2:仮想サーバ。Cloud9(開発環境)もここの中で動いてます。
・ボリューム(EBS):サーバの保存領域・仮想ディスク。
です。手順はこちらが詳しく、そっくりそのまま実行で大丈夫です。
AWS Cloud9 で利用している EBS ボリューム領域を拡張する
ボリューム拡張・EC2の再起動まで終わったら次へ。3.拡張したボリュームをファイルシステムに適用する
公式ガイドの通りです。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/recognize-expanded-volume-linux.htmlが、ちょっと技術文書的な書き方なので簡単に補足します。これ以降すべてターミナル上での操作です。
①ディスク空き容量を
sudo df -hTコマンドで確認するこんな感じの結果が出てくると思います。
Filesystem Type Size Used Avail Use% Mounted on udev devtmpfs 476M 0 476M 0% /dev tmpfs tmpfs 98M 11M 88M 11% /run /dev/xxxx1 ext4 9.7G 9.7G 0 100% / 以下略Mounted on列が
/、つまりルートディレクトリに割り当てられているファイルシステムのディスク使用率Use%が100%ないしカツカツであれば、2.で拡張したボリュームが割り当たっていない可能性があります。
この時点でボリュームが割り当たってるケースもあるんですかね? その場合はここで作業完了です。②ボリュームに拡張が必要なパーティションがあるかを
lsblkコマンドで確認するざっくりですが、パーティション=ボリュームをさらに、(論理ないし物理的ななにがしかで)区切ったもの とのことです。
ディスクを増やしても、ディスクに割り当てたパーティションが増えなければ、インスタンスとして使える空き容量が増えないので、状況を確認します。
ボリュームを10GB→20GBに増やした場合、こんな感じの結果が出てくると思います。NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT loop0 7:0 0 55.4M 1 loop /snap/core18/1932 loop1 7:1 0 32.3M 1 loop /snap/amazon-ssm-agent/2996 loop2 7:2 0 55.4M 1 loop /snap/core18/1944 loop3 7:3 0 97.9M 1 loop /snap/core/10577 loop4 7:4 0 97.9M 1 loop /snap/core/10583 loop5 7:5 0 12.7M 1 loop /snap/amazon-ssm-agent/495 xxxx 202:0 0 20G 0 disk └─xxxx1 202:1 0 10G 0 part /ルートディレクトリ
/に割り当たっているパーティションxxxx1の容量が10GBしかありません。
一方でディスク本体であるxxxxには、2でボリュームに割り当てた通りの20GBの容量があるので、ディスク容量増がパーティションに反映できていない状況です。③容量を
sudo growpart /dev/xxxx 1コマンドでパーティションに割り当てるxxxx にはファイルシステム上のディスクの名前を割り当てます。
①のFilesystem列の名称から、末尾1(パーティションの番号)を省いたものがディスク名称です。
コマンド引数3つめの1はパーティション番号を示しています。④上記の
growpartコマンドでFAILED: failed to make temp dirエラーが出たら…ディスクを本当に100%のカツカツまで使い切ると発生するみたいです。
この場合の手順はこちら。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/ebs-volume-size-increase/tmpfs(メモリに格納されている一時ファイルシステム)を/tmpにマウントします。
sudo mount -o size=10M,rw,nodev,nosuid -t tmpfs tmpfs /tmpコマンドの詳細はちょっとわからず、すみません…
(/と異なるディスクが割り当たっている/tmpにtmpfsを移すことで、一時的にメモリ上のtmpfsを使えるようにするってことだろうか。)
ともあれこれで、sizeオプションで指定した10Mの空き容量ができるので、growpartコマンドを再実行してください。⑤パーティションの容量をファイルシステムに反映する
③が終わったら、再び
dh -hTコマンドを実行します。Filesystem Type Size Used Avail Use% Mounted on udev devtmpfs 476M 0 476M 0% /dev tmpfs tmpfs 98M 11M 88M 11% /run /dev/xxxx1 ext4 9.7G 9.7G 0 100% / 以下略まだ/dev/xxxx1が20GBになっていません。
③でディスク側の準備はパーティション含め完了したものの、OS(Linux)側でそれを認識できてない状態みたいです。
なので次に、ディスク側へ増やした容量をファイルシステムへ反映させます。ここはファイルシステムのタイプによってコマンドが異なります。
Type列がext4の場合、sudo resize2fs /dev/xxxx1xfsの場合、(※筆者はこっちは実行してません。ドキュメントによればこうみたいです)
sudo xfs_growfs -d /これで容量拡張完了です。確認のために
dh -hTコマンドを実行します。Filesystem Type Size Used Avail Use% Mounted on udev devtmpfs 476M 0 476M 0% /dev tmpfs tmpfs 98M 2.0M 96M 2% /run /dev/xxxx1 ext4 20G 9.7G 9.7G 50% /無事ルートディレクトリ
/の容量が20GBになり、使用率も改善しました。⑥後始末
④でtmpfsのマウントを実行した場合は元に戻しておきます。
sudo umount /tmp
- 投稿日:2021-01-13T22:52:51+09:00
【2025年の崖】経産省の「DXレポート2」が刊行されたので読んでみた
「2025年の崖」というキャッチーな用語などおよそ政府の刊行物とは思えないほどキレのある文面で話題になった経済産業省のDXレポート(@2018年)ですが、昨年の暮れに「DXレポート2」が刊行されていたのでそのレポートです。
なお、DXレポートについてご存知ない方のために抜粋をすると、DXレポートはこういうものです
「2018 年に公開した DX レポートにおいては、複雑化・ブラックボックス化した既存システムを解消できず DX が実現できない場合、デジタル競争の敗者になってしまうだけでなく、多額の経済損失が生じるとして警鐘を鳴らし(2025 年の崖)、この問題に対応するため、2025 年までに集中的にシステム刷新を実施する必要があると指摘した」
結構「2025年の崖」っていう言葉が話題になったんですよね。
昨年の12月29日に刊行されたDXレポート2もとても面白かったので、ITに携わる人はぜひ知っておいて良いことだと思ったのでQiitaに載せさせていただきました。各ユーザー企業におけるIT活用の指針に加えて、ベンダー企業のあるべき姿などかなり突っ込んだ内容となっており、前回にもましてキレのある文章で読み応えバッチリでした。「2020年の崖」に引くも劣らない名言揃いでしたので、章ごとにまとめていきたいと思います。
オリジナル
経産省のHPにあります。なるべく内容を損なわないようにしましたが、ぜひソースを当たっていただくといいと思います。
https://www.meti.go.jp/press/2020/12/20201228004/20201228004.html
エグゼクティブサマリ
それでは、まずは冒頭の「エグゼクティブサマリ」から追っていきます。
「エグゼクティブサマリ」という名前に負けず中身も迫真に迫るものがありました。まず、2018年のDXレポートでDXによる変革の警鐘を鳴らしたにも関わらずなかなか取り組みが進まないことを受けて下記のように断じます。
- 実に全体の9割以上の企業が DX にまったく取り組めていない(DX 未着手企業)レベルか、散発的な実施に留まっている(DX 途上企業)状況であることが明らかになった。
- 我が国企業全体における DX への取り組みは全く不十分なレベルにあると認識せざるを得ない
と断じます。
そして、結構大企業に勤めている人はニヤリとしてしまうかもしれませんが、それに対してこのようにコメントします
- DX =「レガシーシステムの刷新」などの本質ではない解釈が是となっていた
- DX の本質とは単にレガシーなシステムを刷新すると言ったことに留まるのではなく、事業環境の変化に迅速に適応する能力を身につけること、そしてその中で企業文化変革することにあると考えられる
そして、コロナ禍に言及した後、このようにサマリーを締めくくっています。
- 人々の固定観念が変化している今こそ「2025年の壁」問題の対処に向けて、企業文化を変革するある意味絶好(最後)の機会である
いや、コロナ禍に言及して「これが絶好で最後の機会」という部分が迫真に迫るものがありますね。それでは全体構成を紹介の後、本文を細かく見ていきます。
全体構成と読みどころ
ppt形式のサマリーとWord形式のレポートがあるのですが、全体の構成はこのようになっております(pptのサマリから転載)。
個人的には、読みどころは下記だと思いました。
- コロナ禍で表出した本質的な課題
- 企業の目指すべき事業変革の方向性
- ベンダー企業の目指すべき変革の方向性
- 企業の経営・戦略の変革の方向性について、コロナ禍を契機に企業が直ちに取り組むべきもの
- DX を進めるための短期的、中長期的な対応
- 変革を加速するための政府の取組
それでは、それぞれについて抜粋する形で紹介していきます。
2章:コロナ禍で表出した本質的な課題
1章はこれまでの部分で説明したので2章からの紹介です。結構大きな題目を掲げて「コロナ禍で表出した本質的な課題」とありますが、いったい何なのでしょうか。
まず、2020年を下記のように振り返ります。
- 2020 年初頭からの新型コロナウイルスの世界的な感染拡大により、企業は「感染拡大を防ぎ顧客・従業員の生命を守りながら、いかに事業を継続するか」という対応を否応なしに求められることとなった
そして、テレワークの増加や新しいデジタル技術を活用した楽しみが人々の中で広まりつつあることを踏まえて
「人々は新たな価値の重要性に気付き、コロナ禍において新しいサービスを大いに利用し、順応している」
と国民を評価します。
しかし、それに追いつける企業と追いつけない企業がいることを記載した上でこのように断じます。「ビジネスにおける価値創出の中心は急速にデジタル空間へ移行しており、今すぐ企業文化を刷新しビジネスを変革できない企業は、デジタル競争の敗者としての道を歩むことになるであろう」
「そして、デジタル技術によるサービスを提供するベンダー企業も、受託開発型の既存のビジネスモデルではこのような変革に対応できないことを認識すべき」これ政府の刊行物ぽくないですよね、?? そのように断じたのち、目指すべき方向についてテーマが移ります。
3章:企業の目指すべき方向性
3章は「デジタル企業の姿と産業の変革」という章で、ユーザ企業とベンダー企業がそれぞれ何を目指すべきかということを短期、中期長期の視点から分析しています。そして、前段でこのように名言が飛び出します。
- ビジネスにおける価値創出の源泉はデジタルの領域に移行しつつあり、この流れはコロナ禍が終息した後も元には戻らない
- 周囲の環境が変わっているにもかかわらず、これまで続けてきた業務形態やビジネスモデルは所与のものであるという固定観念に囚われてしまうと、抜本的な変革を実現することはできない
そして、ベンダー企業の目指すべき方向に章は進みます。
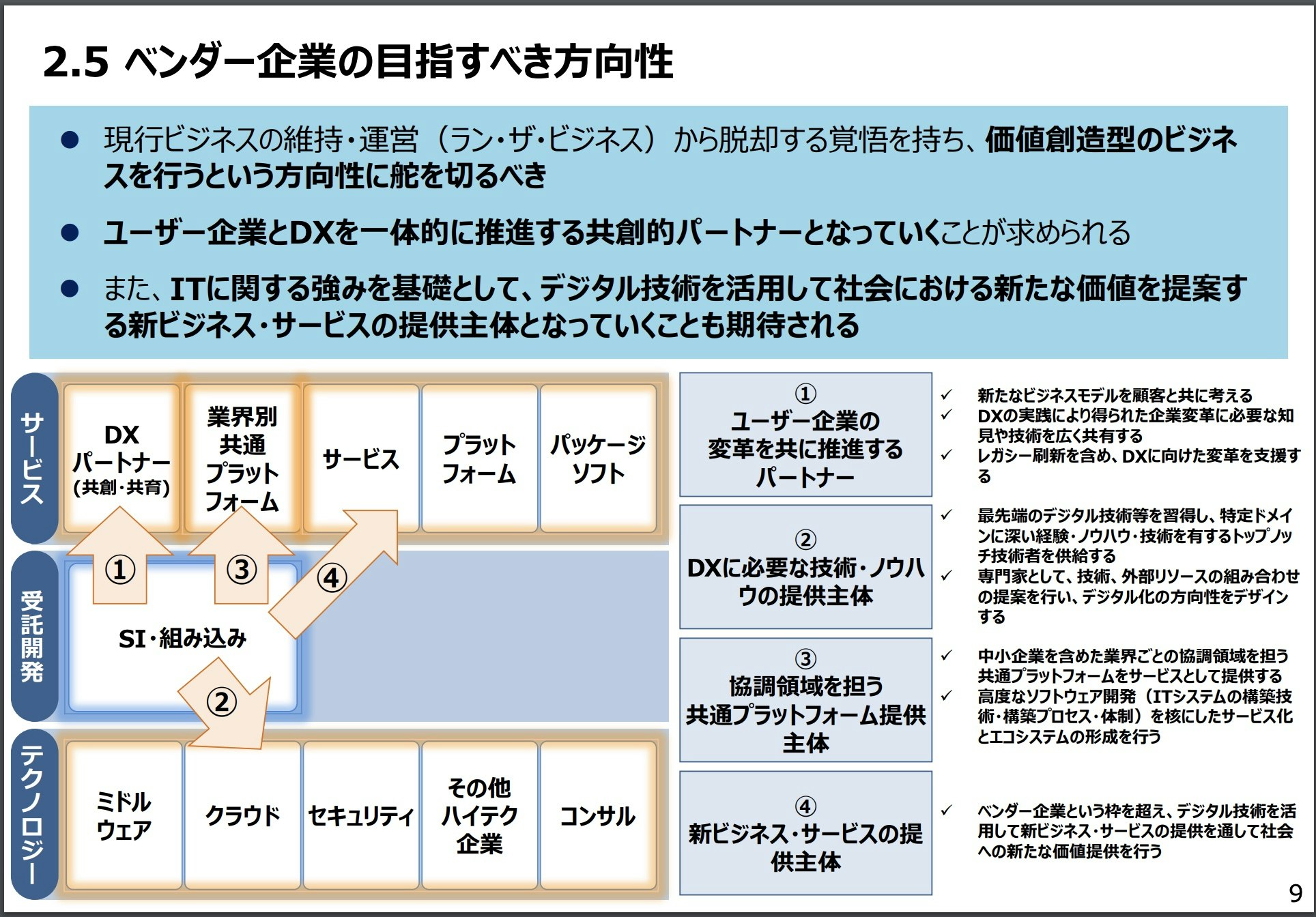
ベンダー企業の目指すべき方向性
- 価値創造型のビジネスにおいては、ユーザー企業は絶えず変化する顧客のニーズに対応するために自社の IT システムを迅速に更新し続ける必要がある。そのためには、最もニーズの高い機能を迅速に開発し,フィードバックしながら変化に迅速に対応できるアジャイル型に開発を変革しなければ変化の速さに対応できない
- 従来のウォーターフォール開発による受託開発型のビジネスに固執するベンダー企業は、今後ユーザー企業のニーズ・スピード感に応えられなくなる
そして問題点を指摘した後に目指すべき方向を論じます。
- 顧客や社会の課題を正確にとらえるために、ベンダー企業はユーザー企業と DX を一体的に推進する共創的パートナーとなっていくことが求められる
なぜなら、その心は、
「米国では、システム開発をユーザー企業で行う等、ベンダー企業との分野の境目がなくなる形で変化が加速している。しかし、わが国では IT 人材がベンダー企業に偏り、雇用環境も米国とは異なる」ためです。したがって「デジタル社会における将来のベンダー企業には、顧客企業と自社の DX をともに進めていくことが求められる」からです。
以上のことはppt形式サマリーのP9を見れば綺麗にまとまっていました。
そして次にユーザー企業を含む全体の話です。ユーザー企業はどうすればいいのでしょうか。
企業の経営・戦略の変革の方向性
短期、中長期にわけて章立てがありましたが、まずは短期の部分です。これは比較的内容が複雑なのでサマリにまとまっているものを転載させていただきます。政府刊行物のため転載が自由ということですので。
以下、各ポイントについての詳細です
DX推進に向けた関係者間の共通理解の形成
まず、DX推進に向けた関係者間の共通理解の形成が短期的にしなければならないことですよと言っているわけですが、これは前提として下記の2点があることを踏まえて
- DX の推進にあたっては、経営層、事業部門、IT 部門が協働してビジネス変革に向けたコンセプトを描いていく必要がある
- DX を推進する関係者の間で基礎的な共通理解を初めに形成することが必要
具体的には下記の方向を示しています。
経営層の課題をデータとデジタル技術を活用していかに解決していくかという視点に対しては、経営層や事業部門がアイデアを提示し、デジタルを活用することで可能となるまったく新たなビジネスを模索するという視点に対してはIT 部門がアイデアを提示し、仮説検証のプロセスを推進していくこと
そして最後にとても(!)いいことが書いてあります。
関係者間での協働を促すためにも、アジャイルマインド(俊敏に適応し続ける精神)や、心理的安全性を確保すること(失敗を恐れない・失敗を減点としないマインドを大切にする雰囲気づくり)が求められる
アジャイルマインドで心理的安全、いいですよね。。!
CIO/CDXO の役割・権限等の明確化
その他、短期的にやらないといけないこととしてCIO/CDXO の役割・権限等の明確化もあります。これは抜粋だけで。
- CIO/CDXO がどのような役割・権限を担うべきか明確にした上で、これに基づき、DX を推進するための適切な人材が配置されるようにするべき
- 適切なリーダーシップが欠如していると IT 部門が事業部門の現行業務の支援に留まり、業務プロセスが個別最適で縦割りとなってしまうため、DX の目標である事業変革を妨げる
- デジタル化に係る投資を行うためには、事業部門の業務プロセスの見直しを含めた IT 投資の効率化にとどまらず、場合によっては不要となる業務プロセスと対応する IT システムの廃止・廃棄にまでつなげることが必要
なるほど。
遠隔でのコラボレーションを可能とするインフラ整備
短期的にやること3つ目です。
- 新型コロナウイルスの感染を防止しながら事業を継続するためのツールとして、リモートワークを実現する IT インフラの整備が急速に進んでいる
- こうした遠隔でのコラボレーションを可能とするインフラは感染防止の観点にとどまらず、今後のイノベーション創出のインフラとなる可能性がある
業務プロセスの再設計
4つ目。
- 社会や企業においてこれまで当たり前のこととされていた業務プロセスの中には、前例を踏襲しているだけで実は見直しによって効率化可能なものや、過去の検討の結果積み重ねられてきた個別ルールによりかえって非効率となっているものが潜んでいる可能性がある
- 「人が作業することを前提とした業務プロセス」を、デジタルを前提とし、かつ顧客起点で見直しを行うことにより大幅な生産性向上や新たな価値創造が期待
最後の部分もポイントです。
- 業務プロセスの見直しを一度実施したとしても、そこで見直しの活動を停止してしまえば業務プロセスがレガシー化してしまう
- 業務プロセスが顧客への価値創出に寄与しているか否かという視点をもち、恒常的な見直しが求められる
いいこと言いますよね。
中長期的な対応
以上が短期的な対応で、中長期的な対応についてです。まずはppt形式のサマリーを転載させていただきます。これを見れば概ねわかると思います。
長期的に実施することについてもポイントを抜粋していきます。
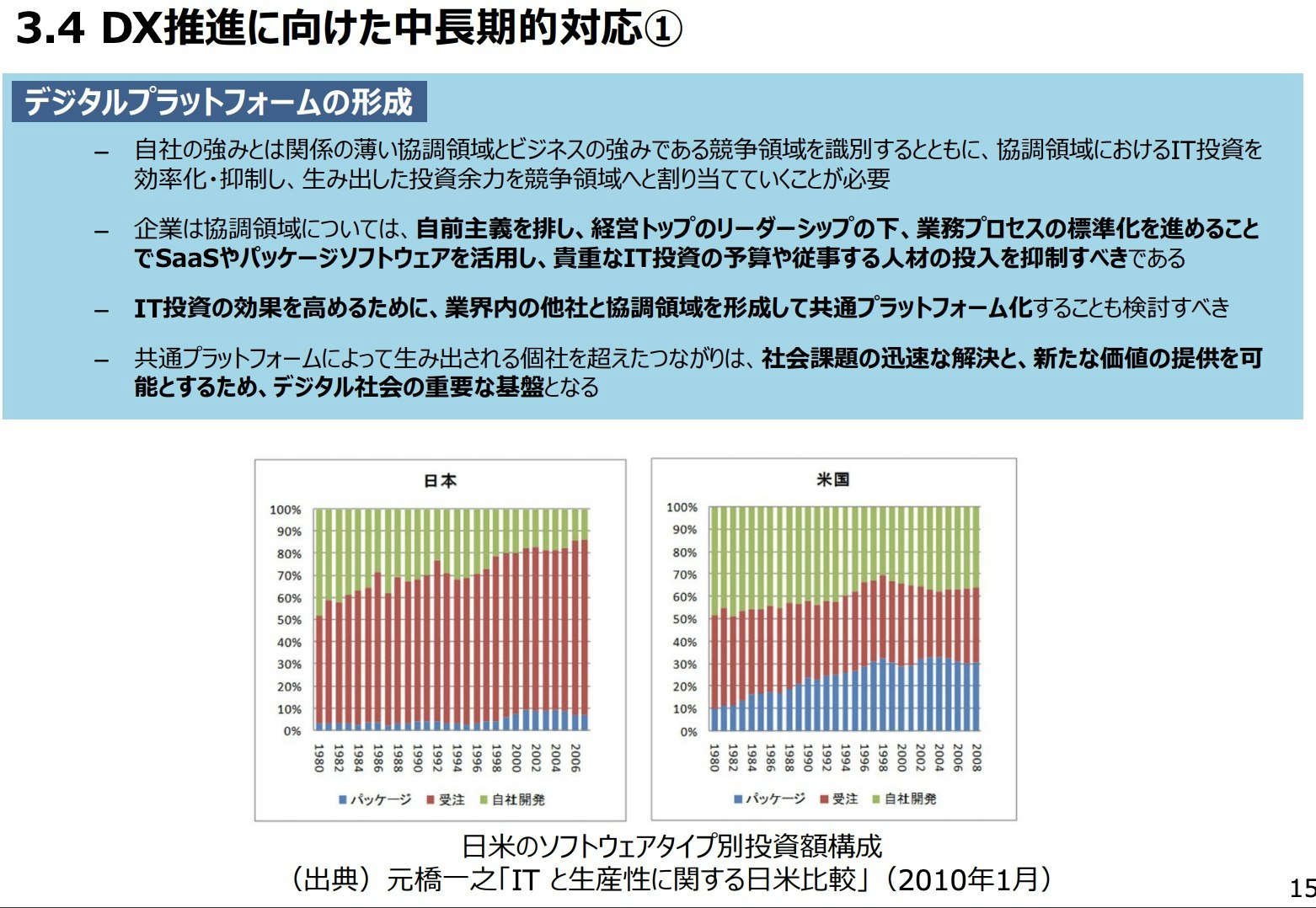
デジタルプラットフォームの形成
中長期的にやらなければならないこととして、まずデジタルプラットフォームの形成があると言っています。
- 企業は、協調領域については自前主義を排し、経営トップのリーダーシップの下、業務プロセスの標準化を進めることで SaaS、パッケージソフトウェアを活用し、貴重な IT 投資の予算や従事する人材の投入を抑制すべき
- IT 投資の効果を高めるために、業界内の他社と協調領域を形成して共通プラットフォーム化することも検討すべき
- 共通プラットフォームは、特定業界における協調領域をプラットフォーム化した業界プラットフォームや、特定の地域における社会課題の解決のための地域プラットフォーム等が想定
- こうした共通プラットフォームによって生み出される個社を超えたつながりは、社会課題の迅速な解決と、新たな価値の提供を可能とするため、デジタル社会の重要な基盤となる
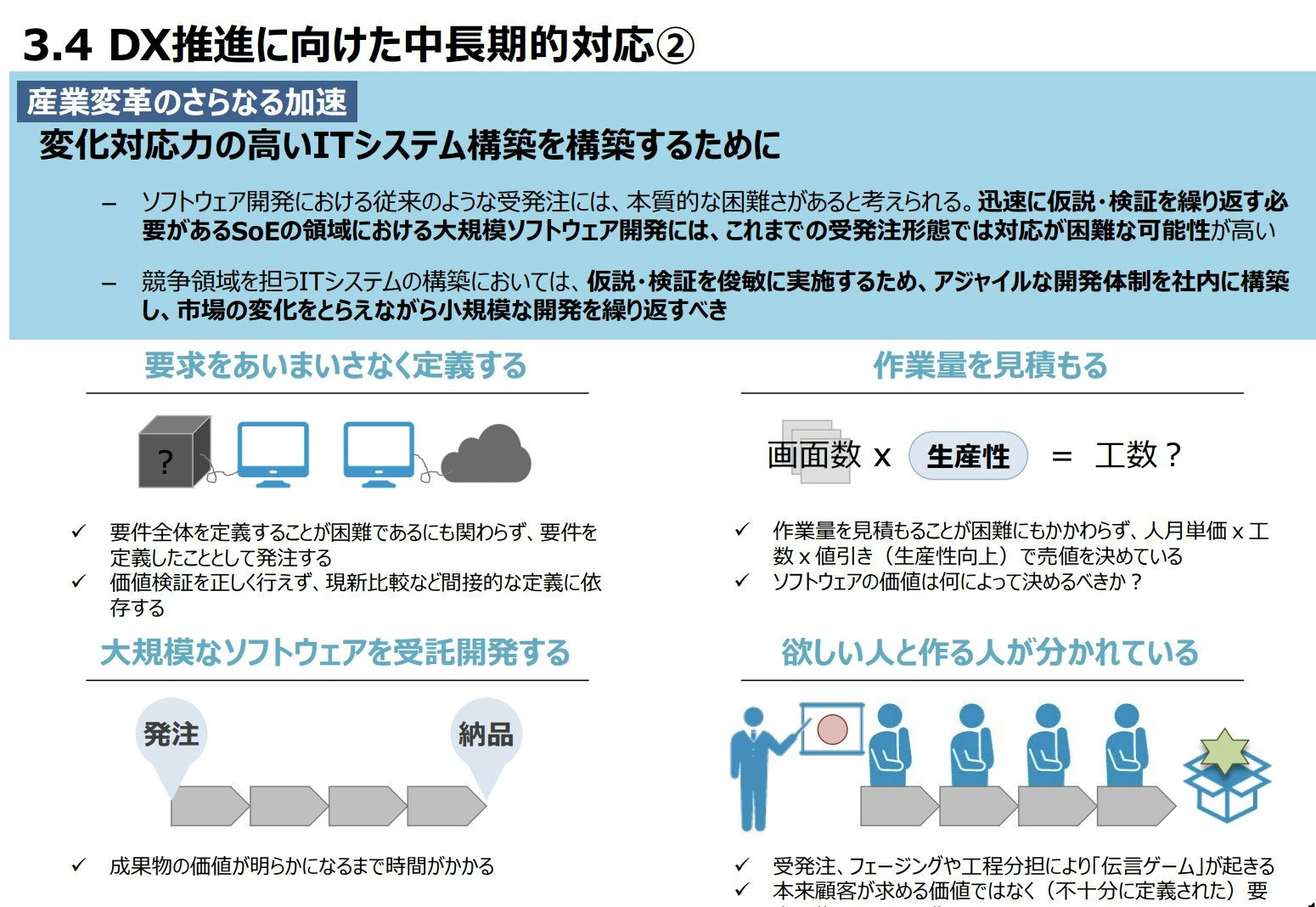
変化対応力の高い IT システムを構築するために
中長期的にやらなければならないことの2つ目は、変化対応力の高いIT システムを構築するということのようです。
- デジタル時代の特徴として、顧客や社会との接点(Engagement)を通して顧客や社会の課題を発見し、解決することで新たな価値提案を行うためのシステム、すなわち、SoE(Systems of Engagement)の領域が広がっている
- スモールスタートで迅速に仮説としての製品・サービスを市場に提示し、データドリブンで仮説の検証を実施するとともに、その結果を用いて製品・サービスの改善へとつなげる、というサイクルを繰り返すことで、より良い価値提案が可能となる
- SoE の領域において、大規模ソフトウェアを外部に開発委託することは、これまでの受発注形態では対応が困難
- 大規模なソフトウェア開発を一括発注し長期間をかけて開発するのではなく、アジャイルな開発体制を社内に構築し、市場の変化をとらえながら小規模な開発を繰り返すべき
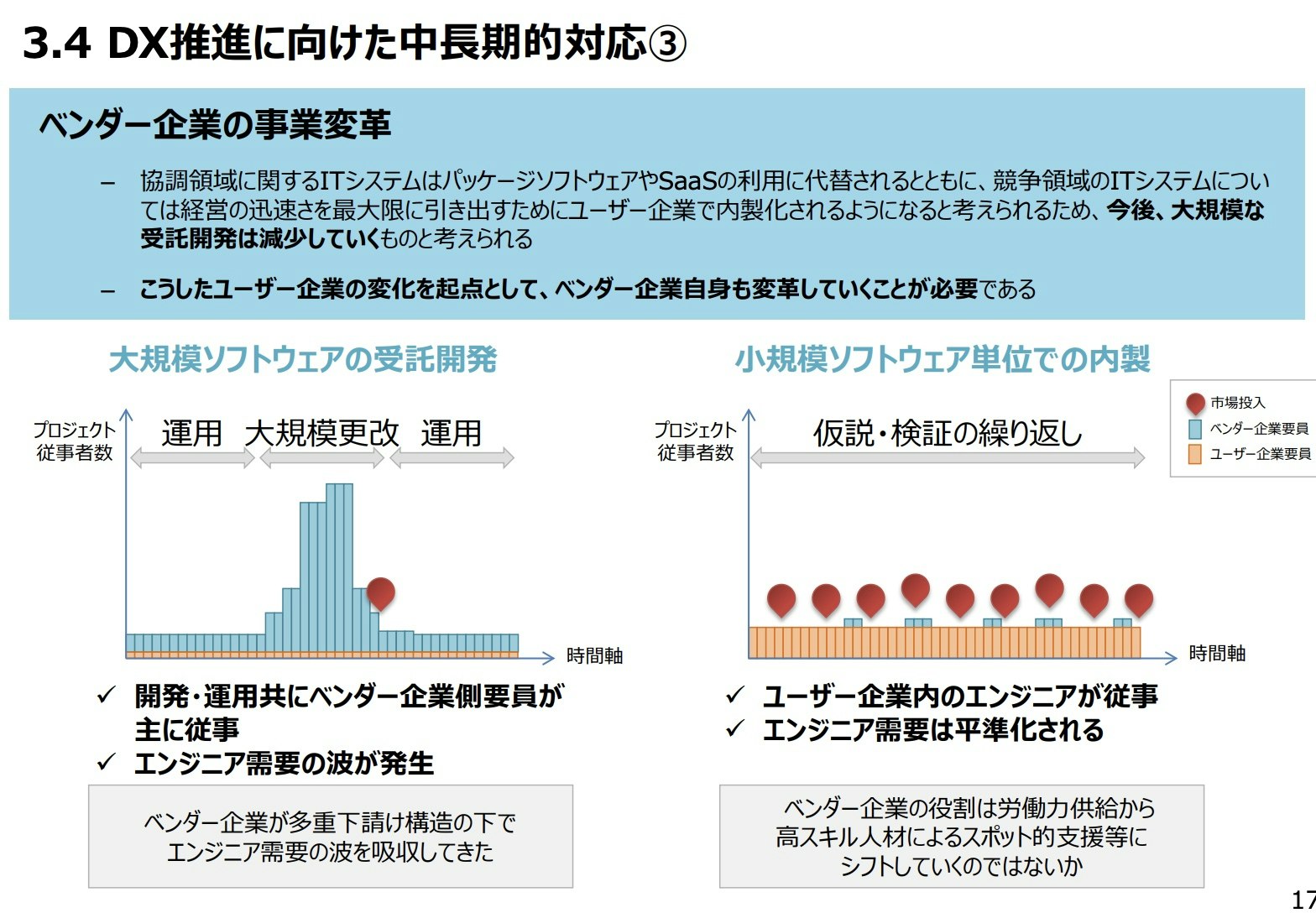
ベンダー企業の事業変革とユーザー企業とベンダー企業との新たな関係
中長期の3つ目です。
- 今後、大規模な受託開発は減少していく
- 今後、ユーザー企業において DX が進展すると、受託開発の開発規模や案件数が減少するとともに、アジャイル開発による内製が主流になる
- しかし、内製化する過程で必要となるアジャイル開発の考え方や、クラウドネイティブな開発技術等について、ユーザー企業の内部人材ではすぐに対応できないことが多いため、ベンダー企業が内製開発へ移行するための支援や、伴走しながらスキル移転することに対するニーズが高まる
- ベンダー企業はこうした事業機会を顧客企業への客先常駐ビジネスとするのではなく、対等なパートナーシップを体現できる拠点において、ユーザー企業とアジャイルの考え方を共有_しながらチームの能力を育て(共育)、内製開発を協力して実践する(共創)べき
ジョブ型人事制度の拡大とDX 人材の確保
中長期4つ目。
- DX を推進するために必要となる人材については(外部のベンダー企業に任せるのではなく)企業が自ら確保するべき
- DX の推進においては、企業が市場に対して提案する価値を現実のシステムへと落とし込む技術者の役割が極めて重要
- 副業・兼業を行いやすくし、人材流動や、社員が多様な価値観と触れる環境を整えることも重要
以上までが4章です。5章の政府の取り組みについてです。
政府の政策の方向性
5章の政府の取り組みについてです。非常に多くの良い取り組みをしてくれているんだと感じました。抜粋はしませんが、ぜひオリジナルでご一読いただくといいと思いました。
以下政府の実施内容です
共通理解形成のためのポイント集の策定,CIO/CDXO の役割再定義,DX 成功パターンの策定,DX 推進状況の把握,デジタルプラットフォームの形成,産業変革の制度的支援,ユーザー企業とベンダー企業の共創の推進,デジタル技術を活用するビジネスモデル変革の支援,研究開発に対する支援,DX 人材確保のためのリスキル・流動化環境の整備ということです。
結構いいことやってるんだなと思いました
最後に
DXレポート自身は6章目もあり、そこでは2018年のDXレポートでの指摘とその後の政策展開を振り返っていますが、今回はDXレポート2の振り返りなのでこちらは割愛させていただきます。最後に1パラグラムだけ6章から抜粋し、終わりたいと思います。
企業の行動変容が進まない理由は、生活習慣病のアナロジーで理解が可能である。誰しも、一般論としてメタボリックシンドロームの状態よりも痩せていたほうが良いことは理解している上、生活習慣病のリスクについても理解しているが、自分自身は健康だと信じている。企業の DX についても同様で、DX が必要だと理解はしていながらも、行動を変容できていない企業は多い
最後はメタボに掛けてわかりやすく説明いただきました。
この記事が役に立ったと思ったらLGTMお願いいたします
個人的にはこの流れだと、Python、JavaScript、クラウドがいま以上に熱くなると思いました。





- 投稿日:2021-01-13T21:19:04+09:00
AutoScalingグループのEC2インスタンスを定期リブート運用する
AutoScallingグループで構成されたEC2インスタンスを
決められたスケジュールでリブート運用してみます。AutoScallingで構成されたEC2を単純にリブートしてしまうとヘルスチェックに失敗してしまうため
以下のいずれかの対応を行う必要があります。
- インスタンスの状態をスタンバイにする
- AutoScallingグループからインスタンスをデタッチする
- AutoScallingのヘルスチェックプロセスを停止する
今回はインスタンスの状態をスタンバイにする方法でやってみます。
スタンバイ状態にすることでAutoScalingのインスタンスのヘルスチェックが実行されなくなります。
スケジューリングにはCloudWatchEventsを利用し、毎月第3日曜日の02:00時にリブートするよう設定します。■参考URL
Auto Scalingグループからのインスタンスの一時的な削除利用するサービス
- CloudWatchEvents
- Lambda
- EC2 AutoScalling
処理の流れ
- EC2インスタンスをスタンバイ状態に設定し、リブートを行うLambda関数を作成
- 「1」で作成したLambdaをスケジューリング実行するCloudWatchEventsルールを作成
今回はAutoScallingグループ配下に2つのインスタンスを起動した状態でテストします。
スケーリングの設定は以下に設定しておきます。
希望する容量;2
最小キャパシティ:0
最大キャパシティ;2Lambda関数実行用のIAM作成
Lambda関数実行用のIAMポリシーとロールを作成します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:*" }, { "Effect": "Allow", "Action": [ "ec2:StartInstances", "ec2:StopInstances", "ec2:RebootInstances" ], "Resource": "*" } ] }EC2をスタンバイ状態に変更するLambda関数の作成
指定したAutoScalling配下のインスタンスをスタンバイ状態に変更するLambda関数を作成します。EnteringStandby ⇒ Standby状態に変更になるまでは結構時間がかかります。
注意;
このサンプルではenter_standbyを呼び出しした際に「希望する容量」がデクリメントされます。
デクリメントしたくない場合は「shouldDecrementDesiredCapacity=False」とします。import boto3 def lambda_handler(event, context): # get autoscaling client as_client = boto3.client('autoscaling') as_groups = as_client.describe_auto_scaling_groups( AutoScalingGroupNames=[ 'asg-nginx' ]) # List to hold the instance-ids instance_ids = [] for i in as_groups['AutoScalingGroups']: for k in i['Instances']: instance_ids.append(k['InstanceId']) # enter standby response = as_client.enter_standby( InstanceIds=instance_ids, AutoScalingGroupName='asg-nginx', ShouldDecrementDesiredCapacity=True )EC2を停止するLambda関数
ここでは指定したオートスケーリンググループ配下のインスタンス一覧を
取得し停止しています。ここはタグから取得するなど色々なやり方もあると思います。import boto3 def lambda_handler(event, context): # get autoscaling client as_client = boto3.client('autoscaling') as_groups = as_client.describe_auto_scaling_groups( AutoScalingGroupNames=[ 'asg-nginx' ]) # List to hold the instance-ids instance_ids = [] for i in as_groups['AutoScalingGroups']: for k in i['Instances']: instance_ids.append(k['InstanceId']) # get ec2 client ec2_client = boto3.client('ec2') ec2_client.stop_instances(InstanceIds=instance_ids)EC2を開始するLambda関数
import boto3 def lambda_handler(event, context): # get autoscaling client as_client = boto3.client('autoscaling') as_groups = as_client.describe_auto_scaling_groups( AutoScalingGroupNames=[ 'asg-nginx' ]) # List to hold the instance-ids instance_ids = [] for i in as_groups['AutoScalingGroups']: for k in i['Instances']: instance_ids.append(k['InstanceId']) # get ec2 client ec2_client = boto3.client('ec2') ec2_client.start_instances(InstanceIds=instance_ids)Lambda関数のスケジューリング
Lambdaをスケジューリング実行するCloudWatchEventsルールを作成します。
例えば毎月第3日曜日の02:00時(UTC)に実行するのでcron式には以下を指定します。0 2 ? * 1#3 *参考:ルールのスケジュール式
時間的な制約が無く、厳密な状態チェック等も不要で単純に実施するだけなら
ルールを3つ準備し、スタンバイ状態変更⇒EC2停止⇒EC2開始をそれぞれ
時間を開けてスケジューリングすればOKです。以上
- 投稿日:2021-01-13T20:06:39+09:00
社内システムのAWS構成を紹介してみる
はじめに
初めての投稿になるので軽く自己紹介。
これまでアプリ開発(Java/PHP/Ruby)などの開発者からPLやPMなどを経験してきました。
今は社内システムのPLや受託案件のPMなどに従事してて、あとは案件の提案活動などをメインにやらしてもらっています。社内システムについて
弊社ではプロジェクト管理や勤怠管理などのシステムをフルスクラッチで開発・運用しており、私は主に運用保守や機能拡張の案件のリーダーに携わっています。
このシステムはAWSを利用していて、上記の業務の傍らAWSのサービスを触る機会が多く、
2年ほど前に試行錯誤しながらAWSのCode3兄弟と呼ばれるCodeCommit/CodeBuild/CodeDeployを使って
デプロイまでのプロセス自動化などAWSの構成を大きく変更してきたので紹介します。社内システムの構成
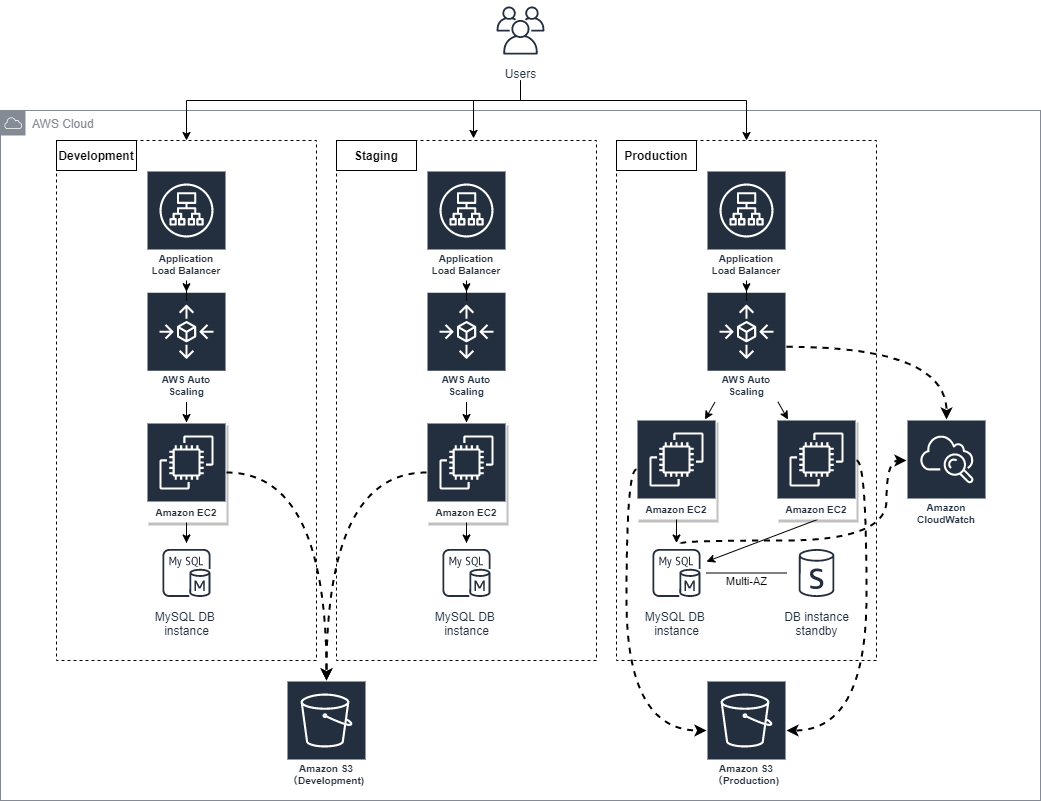
弊社の社内システムはこちらの構成になっています(2018年頃の構成図)
本番環境、STG環境、開発環境が3、4個あります。
※構成図では複数の開発環境は省略しています
当時の問題点
- 本番環境及び開発環境へのDeployはCodeDeploy単体で実施
- ソースはGithub上で環境はAWS上にあり管理が面倒
- その他も色々あったけど忘れましたw
当時色々調べた結果
- デプロイを開発者がプッシュしたら開発環境に自動反映させたい
- 当時はGit利用していたのでCodeCommitに移管する
- CodePipelineを導入して自動反映させる
テスト自動化もしたいけど、まずはCodePipelineでCodeCommitとCodeDeployを繋げて自動化しよう!って方針に決まりました。
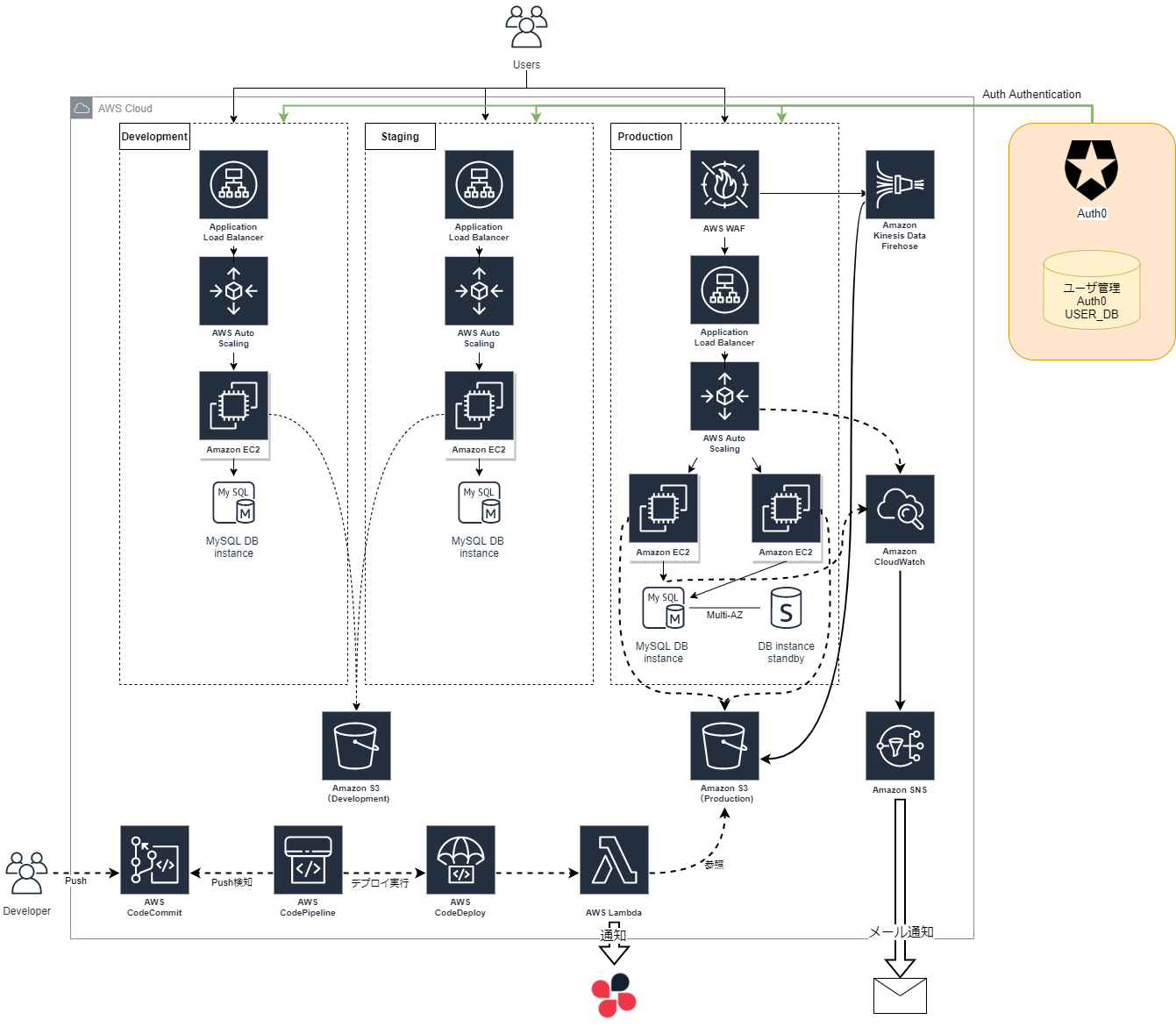
デプロイ自動化に併せてAWS構成を色々見直してみました。2021年時点の社内システムのAWS構成がこちら
- 開発者がブランチにプッシュするだけでデプロイまで自動で走って幸せ
- なんと言っても僕の運用への負担が大幅に減った
- これによって社内システム運用を強化するための時間が取れた
- Lambdaを使ってのデプロイ通知、プッシュ通知をチャット連携できた(開発者がチャット上で確認できる)
- 開発者用のチャットグループへデプロイ通知を行った
- これまでデプロイ担当者が「デプロイ完了しました」の通知を毎回行っていたのでその手間が省けた
- CloudWatch経由でのメール通知
- AWS WAFの導入
- 構成図からは省いていますがサブシステム構築があったためIDaaSサービスのAuth0を導入しました
積み残しの課題
- テスト自動化
- CodeBuildを挟んでJenkinsなどと連携してテスト自動化したいが、テストコード作成に手が回らない
- AWSからの通知内容
- JSONの生データをチャットで出力しているだけなんで、すぐに内容が読み取りづらい
- 本番環境も開発環境も全て同じAWSアカウント上に同居してる
- 運用ミスで本番環境へデプロイやシステム追加によるネットワーク周りの調査などが本番環境もいるんでやるの怖い・・
- その他色々・・・
もっとこういう構成あるよ!とかあればコメントください。
次回は今回追加したCodePipelineの細かい話やAuth0などの記事を書こうかと思います。
- 投稿日:2021-01-13T19:25:09+09:00
IMDSv2を強制した環境で暫くするとInspectorのawsagentがダウンする
Amazon Inspectorを利用するために、awsagentをインストールしている環境がありました。最初は問題無く動いていたawsagentが数時間後にエラーとなる事象にあったので情報残しておきます。
要点
IMDSv2の強制設定と、awsagentの起動は順序が大事。
IMDSv2強制設定⇒awsagentの起動事象
インストール後数時間は問題無く動くのですが、翌日などにInspectorの画面から見てみると以下の用にHealthyでなくUNKNOWNのステータスになっていることがありました。
ホストにログオンしてログを見てみたところです。起動後数時間後にエラーが出ているのがわかります。
$ sudo journalctl --full --no-pager -u awsagent.service #省略-- Jan 03 23:44:50 ip-xxx awsagent[4603]: Region : 'ap-northeast-1' Jan 03 23:44:50 ip-xxx awsagent[4603]: [ OK ] Jan 03 23:44:50 ip-xxx systemd[1]: Started LSB: Amazon Inspector service. Jan 03 23:47:57 ip-xxx awsagent[4669]: Core/MetaDataClient.cpp:88:HTTP Request on URL http://169.254.169.254/latest/api/token to EC2 metadata client service returned nullptr. Jan 03 23:47:57 ip-xxx awsagent[4669]: Core/MetaDataClient.cpp:106:HTTP Request on URL http://169.254.169.254/latest/meta-data/placement/availability-zone to EC2 metadata client service failed with HttpResponseError: 401 on retry 0. Jan 03 23:47:57 ip-xxx awsagent[4669]: Publishers/Publisher.cpp:382:Failed to retrieve availability zone: -97 Jan 04 00:48:06 ip-xxx awsagent[4669]: Publishers/ArsenalPublisher.cpp:1588:PublishEvents operation not permitted failure : Publishing data to service with no subscription. Jan 04 02:05:25 ip-xxx awsagent[4669]: Core/MetaDataClient.cpp:88:HTTP Request on URL http://169.254.169.254/latest/meta-data/placement/availability-zone to EC2 metadata client service returned nullptr. Jan 04 02:05:25 ip-xxx awsagent[4669]: Publishers/Publisher.cpp:382:Failed to retrieve availability zone: -1 Jan 04 02:58:07 ip-xxx awsagent[4669]: Core/MetaDataClient.cpp:106:HTTP Request on URL http://169.254.169.254/latest/meta-data/placement/availability-zone to EC2 metadata client service failed with HttpResponseError: 401 on retry 0. Jan 04 06:19:13 ip-xxx awsagent[4669]: Publishers/ArsenalPublisher.cpp:742:RequestConfig failure : Unable to parse ExceptionName: ExpiredTokenException Message: The security token included in the request is expired Jan 04 06:19:13 ip-xxx awsagent[4669]: Service/MainInspectorThread.cpp:79:Config retrieval failed : -97 Jan 04 06:21:13 ip-xxx awsagent[4669]: Publishers/ArsenalPublisher.cpp:557:UpdateHealth failure : Unable to parse ExceptionName: ExpiredTokenException Message: The security token included in the request is expired Msg: {"t":1609741273921,"proxy":0,"o":"Amazon Linux release 2 (Karoo)","k":"4.14.209-160.335.amzn2.x86_64","r":"Unrecognized failure : Unable to parse ExceptionName: ExpiredTokenException Message: The security token included in the request is expired","s":17,"d":0,"l":51,"m":0} Jan 04 06:21:13 ip-xxx awsagent[4669]: Service/MainInspectorThread.cpp:96:Regular health update failed : 0 Jan 04 07:19:20 ip-xxx awsagent[4669]: Publishers/ArsenalPublisher.cpp:742:RequestConfig failure : Unable to parse ExceptionName: ExpiredTokenException Message: The security token included in the request is expired Jan 04 07:19:20 ip-xxx awsagent[4669]: Service/MainInspectorThread.cpp:79:Config retrieval failed : -97 Jan 04 07:21:20 ip-xxx awsagent[4669]: Publishers/ArsenalPublisher.cpp:557:UpdateHealth failure : Unable to parse ExceptionName: ExpiredTokenException Message: The security token included in the request is expired Msg: {"t":1609744880720,"proxy":0,"o":"Amazon Linux release 2 (Karoo)","k":"4.14.209-160.335.amzn2.x86_64","r":"Unrecognized failure : Unable to parse ExceptionName: ExpiredTokenException Message: The security token included in the request is expired","s":17,"d":0,"l":132,"m":0} Jan 04 07:21:20 ip-xxx awsagent[4669]: Service/MainInspectorThread.cpp:96:Regular health update failed : 0気になるのは以下のメッセージです。
The security token included in the request is expired既にIMDSv2を有効化していくつもハマってきた後だったので、awsagentがIMDSv2に対応していないのではと疑ってサポートに聞いてみました。
解決
何度かやりとりして調査していった結果、要約に記載した通りです。
Inspector エージェントはawsagentはIMDSv1 および IMDSv2 の両方に対応しているのですが、バージョンの判別をサービス起動時に行うようです。
最初は起動テンプレート内のユーザデータに以下のように設定していました。これだとIMDSv2と判別されずトークンのやりとりが上手くいかなくなり、セッショントークンの期限切れと共にエラーとなります。
curl -o /tmp/install https://inspector-agent.amazonaws.com/linux/latest/install /bin/bash /tmp/install aws ec2 modify-instance-metadata-options \ --region ${REGION} \ --instance-id ${INSTANCE_ID} \ --http-tokens requiredということで以下のように起動テンプレート内の処理の順序を変えることで会場しました。
aws ec2 modify-instance-metadata-options \ --region ${REGION} \ --instance-id ${INSTANCE_ID} \ --http-tokens required # IMDSv2強制後にインストール curl -o /tmp/install https://inspector-agent.amazonaws.com/linux/latest/install /bin/bash /tmp/install # またはリスタートするなど /etc/init.d/awsagent restart

- 投稿日:2021-01-13T18:55:30+09:00
【Flutter】AWS Amplify / Firebaseエラーまとめ
Flutter投稿記事
参考文献
- cannot run amplify codegen #288
- cocoaPodsで「they required a higher minimum deployment target. 」というエラーが出た時の対処方法
- Androidの表示画面の回転固定
- add 'tools:replace=“android:label”' to element at AndroidManifest.xml:16:5-39:19 to override
- Getting started
- manual_migration_settings.gradle.md
1. settings_aar.gradleが存在しないエラー
◆ エラー内容
1. Copy `settings.gradle` as `settings_aar.gradle` 2. Remove the following code from `settings_aar.gradle`: def localPropertiesFile = new File(rootProject.projectDir, "local.properties") def properties = new Properties() assert localPropertiesFile.exists() localPropertiesFile.withReader("UTF-8") { reader -> properties.load(reader) } def flutterSdkPath = properties.getProperty("flutter.sdk") assert flutterSdkPath != null, "flutter.sdk not set in local.properties" apply from: "$flutterSdkPath/packages/flutter_tools/gradle/app_plugin_loader.gradle"◆ 解決策
setting_aar.gradleinclude ':app' def flutterProjectRoot = rootProject.projectDir.parentFile.toPath() def plugins = new Properties() def pluginsFile = new File(flutterProjectRoot.toFile(), '.flutter-plugins') if (pluginsFile.exists()) { pluginsFile.withReader('UTF-8') { reader -> plugins.load(reader) } } plugins.each { name, path -> def pluginDirectory = flutterProjectRoot.resolve(path).resolve('android').toFile() include ":$name" project(":$name").projectDir = pluginDirectory }2. amplify add codegen実行エラー
◆ エラー内容
Error: amplify-codegen-appsync-model-plugin not support language target flutter. Supported codegen targets arr java, android, swift, ios, javascript, typescript◆ 解決策
$ npm install -g @aws-amplify/cli $ amplify -v $ amplify upgrade 4.41.03. Podfile platformエラー
◆ エラー内容
they required a higher minimum deployment target.◆ 解決策
platform :ios, '8.0' // before platform :ios, '9.0' // after4. android:labelエラー
◆ エラー内容
Error: Attribute application@label value=(flutter_bloc_pattern) from AndroidManifest.xml:18:9-45 is also present at [:DynamsoftBarcodeReader] AndroidManifest.xml:13:9-41 value=(@string/app_name).◆ 解決策
AndroidManifest.xml<manifest xmlns:android="http://schemas.android.com/apk/res/android" xmlns:tools="http://schemas.android.com/tools" package="com.example.sample"> // 追記 <!-- io.flutter.app.FlutterApplication is an android.app.Application that calls FlutterMain.startInitialization(this); in its onCreate method. In most cases you can leave this as-is, but you if you want to provide additional functionality it is fine to subclass or reimplement FlutterApplication and put your custom class here. --> <application tools:replace="android:name" android:name="io.flutter.app.FlutterApplication" android:label="sample" android:icon="@mipmap/ic_launcher">5. Android画面固定
◆ 横画面固定
AndroidManifest.xml<activity android:name=".MainActivity" android:screenOrientation="landscape" </activity>◆ 縦画面固定
AndroidManifest.xml<activity android:name=".MainActivity" android:screenOrientation="portrait" </activity>
- 投稿日:2021-01-13T18:37:05+09:00
自前のCognitoをAmplifyでJavaScriptアプリに組み込む
はじめに
この記事は、
- 既に作成済みのCognitoをJavaScriptアプリに組み込みたいがどうすればいいかわからない人
- アプリとCognitoはもう作ってしまったのでなんとかドッキングさせたい人
- AmplifyCLIで簡単にCognitoの認証機能が作成できて喜んだのも束の間、使用できない機能が多いので自前のCognitoを使いたくなったがAmplifyのライブラリを使用してアプリに組み込めるのかわからず調査中の人
などに向けて、アプリ開発者目線で書かれたものです。
Cognitoの作成・設定方法やAmplifyCLIの使い方は取り扱いませんのでご注意ください。「AmplifyとCognitoすごく便利だと聞いたことあるけどまだ試したことない」という人や、「自前のアプリにCognitoでサクッと認証機能を実装したい」という人はAmplify公式ドキュメントのチュートリアルをまずは見てみることをオススメします。
驚くほど簡単に認証機能付きアプリが出来上がる感動体験ができますよ?概要
結論から言うと、自前のCognitoをAmplifyのライブラリを使ってJavaScriptアプリに組み込むことは可能です。
aws-amplifyライブラリのconfigureメソッドを使用して設定を上書きするとよいです。import Amplify from 'aws-amplify' Amplify.configure()以降は、私が実際に試したVue.js製のアプリケーションへの組み込みを例に手順を紹介したいと思います。
環境
- node.js 14.15.3
- vue 2.6.11
- aws-amplify 3.3.7
- aws-amplify-vue 2.1.3
手順
Amplifyのライブラリをインストールする
コマンドプロンプト等で下記コマンドを実行
npm install aws-amplify aws-amplify-vue --saveAmplify設定用ファイルを作成する
plugins配下にamplify.jsファイルを作成し、設定を上書きする記述を書く
amplify.jsimport Vue from 'vue' import Amplify, * as AmplifyModules from 'aws-amplify' import { AmplifyPlugin } from 'aws-amplify-vue' Amplify.configure({ Auth: { identityPoolId: '1.CognitoIDプールの識別ID', region: 'Cognitoの作成リージョン', userPoolId: '2.Cognitoユーザプールの識別ID', userPoolWebClientId: '3.CognitoのアプリクライアントID', oauth: { domain: '4.Cognitoユーザプールで設定されているドメイン', // 5.Cognitoユーザプールで許可されているスコープ scope: ['openid', 'aws.cognito.signin.user.admin'], redirectSignIn: '6.サインイン後に遷移するURL', redirectSignOut: '7.サインアウト後に遷移するURL', responseType: 'code' // とりあえずcodeにしておくとリフレッシュトークンが生成される様子 } } }) Vue.use(Amplify) Vue.use(AmplifyPlugin, AmplifyModules)AWSコンソールにログインし、使用するCognitoの設定を写していけばOKです。
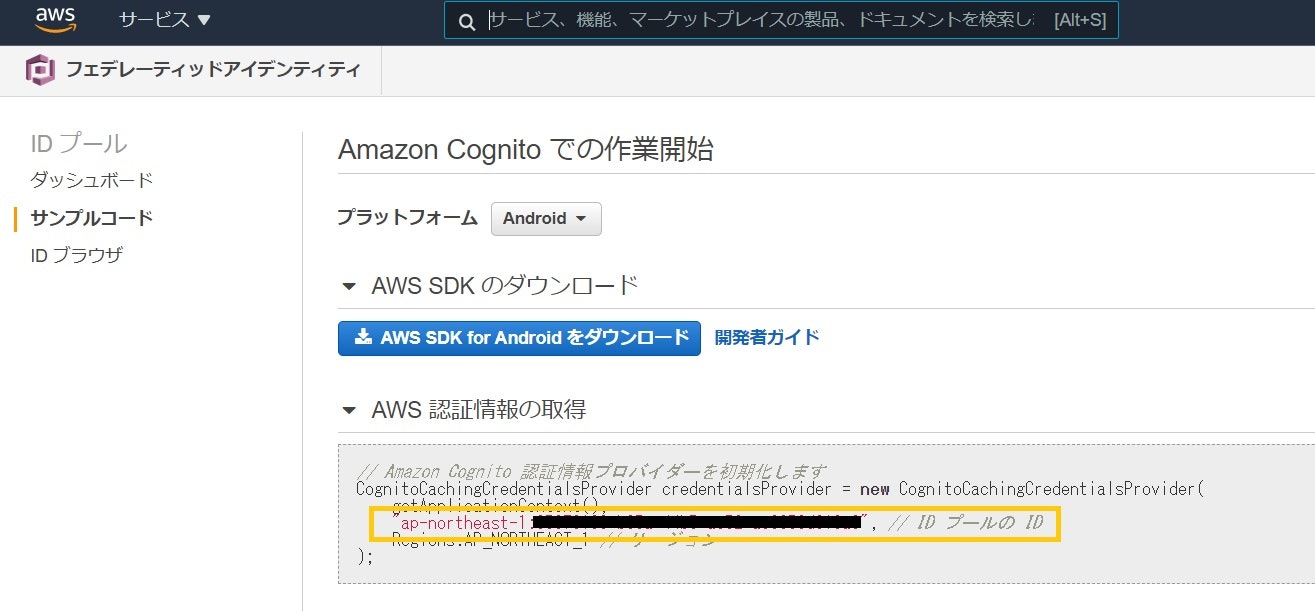
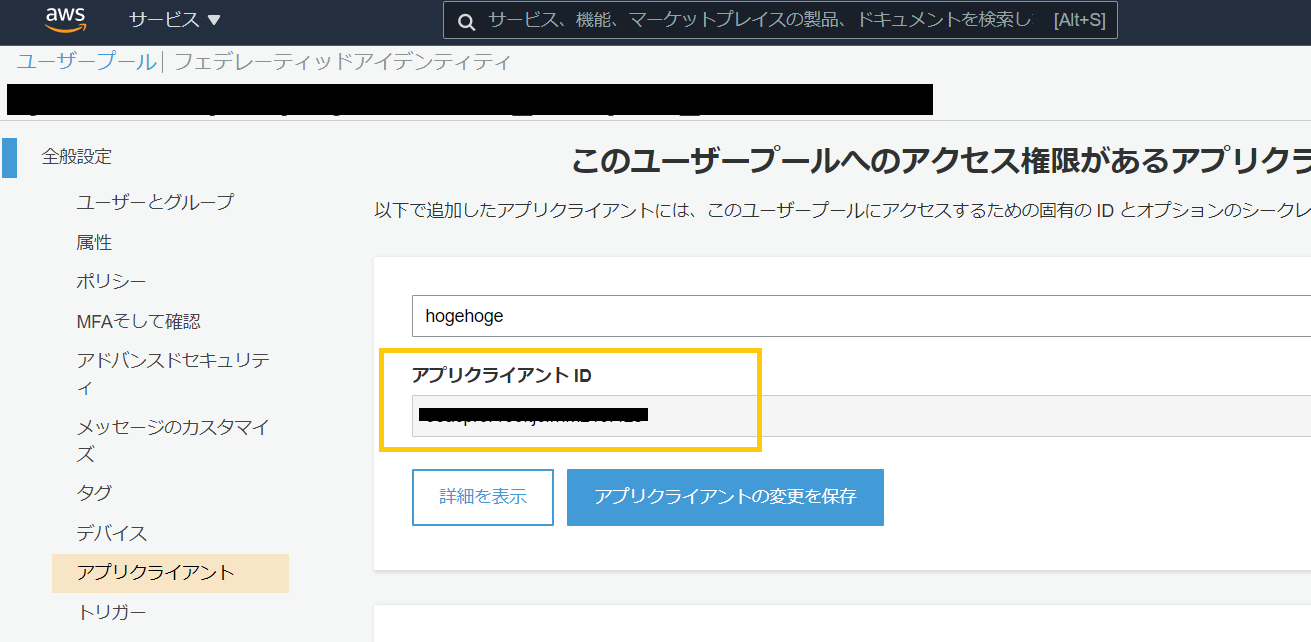
どこに記載があるのか見つけにくいものもあるので、順に記載個所を紹介します。1. CognitoIDプールの識別ID
1番見つけにくいかもしれません。
Cognitoのトップページまたはユーザプール表示時に画面左上に出ている「フェデレーティッドアイデンティティ」からIDプールの画面に遷移し、使用するIDプールを選択すると画像左側にあるサイドメニューが現れます。「サンプルコード」を選択し表示されたサンプル内にIDがあります。
(画像マスクが中途半端ですが、ap-northeast-1:xxxxx..とリージョン名から設定してください)2. Cognitoユーザプールの識別ID
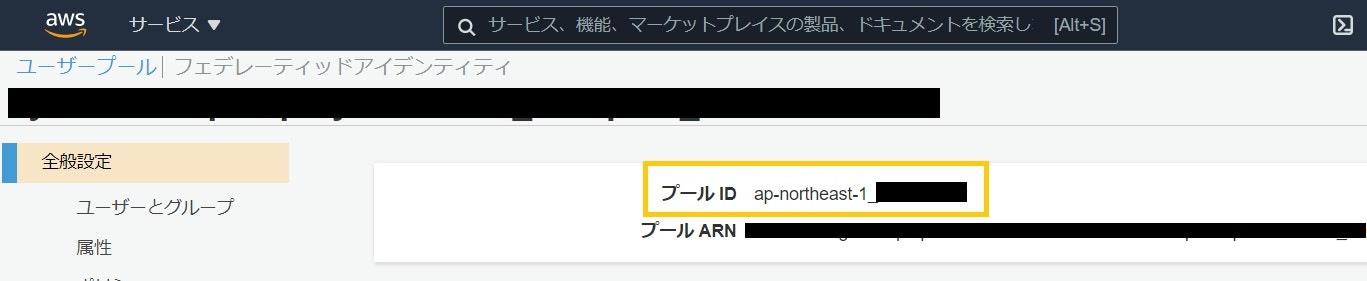
地味に見つけづらいです。
Cognitoのトップページからユーザプールに遷移し、サイドメニュー1番上「全般設定」の1番上にあります。こちらもリージョン名の部分から設定してください。3. CognitoのWebClientID
ユーザプール「全般設定>アプリクライアント」で発行したものです。4. Cognitoユーザプールで設定されているドメイン
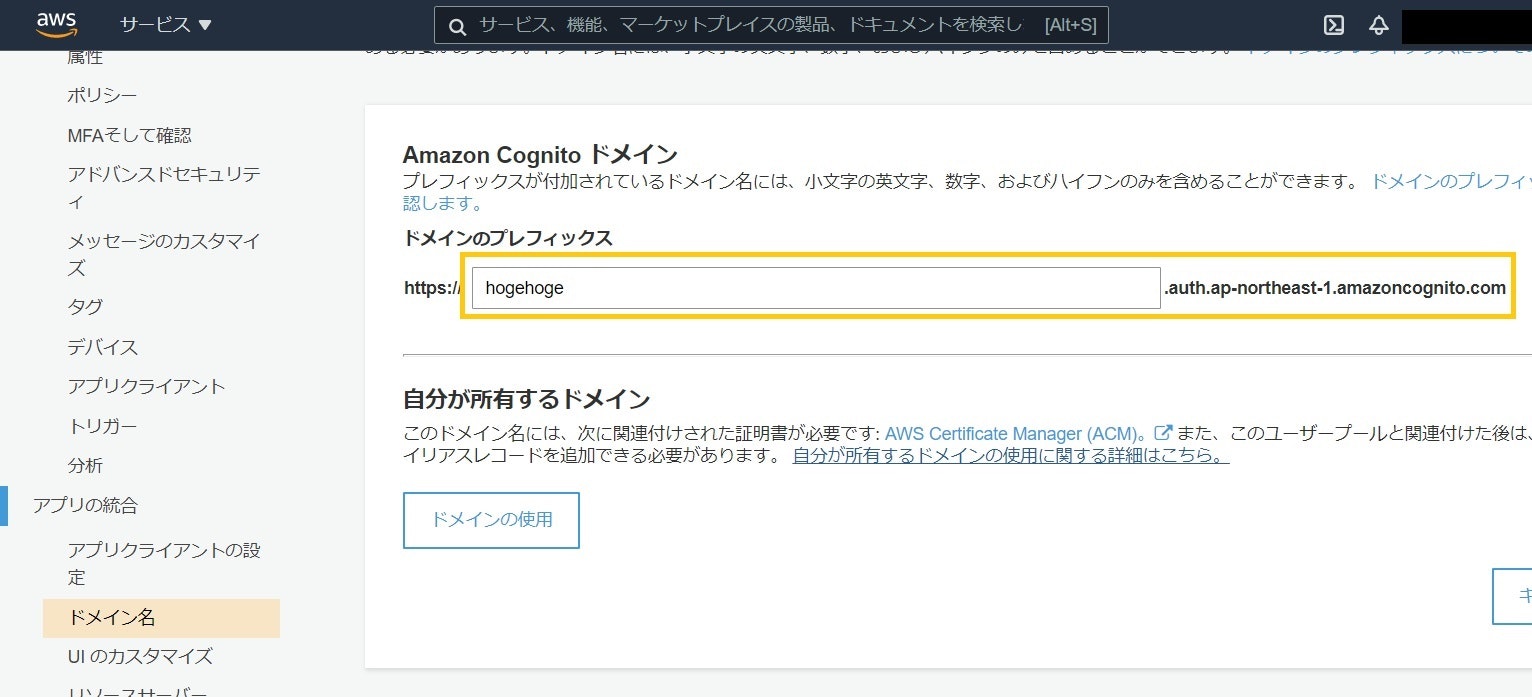
ユーザプールの「アプリの統合>ドメイン名」で自分で設定したものです。
ドメインなので、https://は除いて.comまでを設定します。5. Cognitoユーザプールで許可されているスコープ
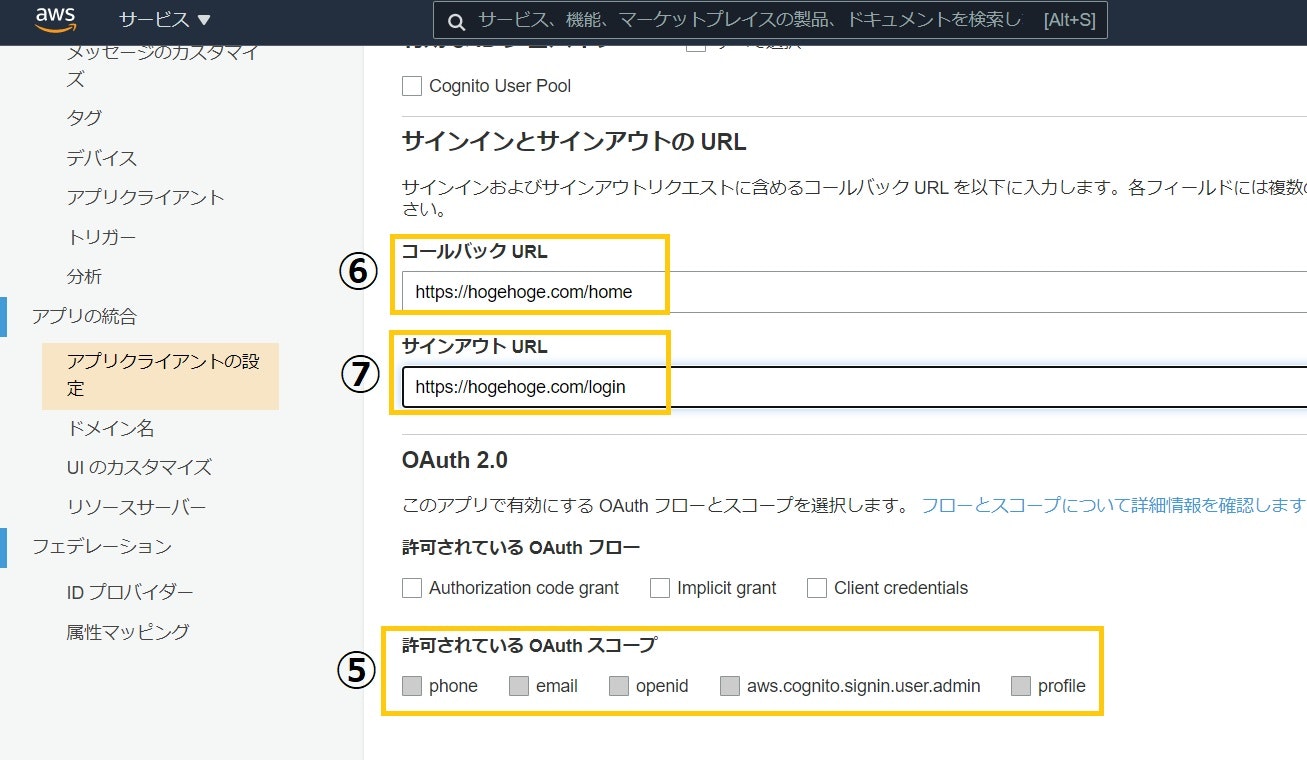
6. サインイン後に遷移するURL
7. サインアウト後に遷移するURL
ユーザプールの「アプリの統合>アプリクライアントの設定」から写します。
コールバックURL・サインアウトURLはCognitoの設定とAmplifyの設定が異なると認証時にエラーが出るのでご注意ください。Amplify設定用ファイルを読み込む
作成したamplify.jsをmain.jsで読み込ませる
main.jsimport './plugins/amplify'設定は完了です!
あとはAmplifyのドキュメントを参考に、ログイン・ログアウト始め好きなメソッドを使用することができます。認証を使用したいコンポーネントでAmplifyライブラリを読み込み使用する
下記の例ではAzureADを使用してシングルサインオンをさせていますが、シンプルにユーザ名とパスワードを使用したAuth.signInメソッド等でも使用できると思います。
Login.vue<template> <div> <button type="button" @click="login"> サインイン </button> </div> </template> <script> import { Auth } from 'aws-amplify' export default { name: 'Login', methods: { async login () { Auth.federatedSignIn({ provider: 'AzureADProvider' }) .then(value => { }) .catch(e => { console.log(e) }) } } } </script>参考リンク
https://docs.amplify.aws/lib/auth/start/q/platform/js#re-use-existing-authentication-resource
https://aws.amazon.com/jp/about-aws/whats-new/2020/10/use-existing-cognito-user-pools-identity-pools-for-amplify-project/
https://day-journal.com/memo/try-024/
- 投稿日:2021-01-13T18:30:40+09:00
CloudFrontキャッシュを削除状況をAWS CLIでチェックするシェルスクリプト
以前「CloudFrontキャッシュを削除するシェルスクリプトを書いてみた。」という記事を書きましたが、Invalidationはすぐ完了しない場合がもあるので処理状況をチェックすることがあるわけですが、それも AWS CLI でチェックすればいいやということで、シェルスクリプト書いたのでまとめます。
概要
AWS CLI で CloudFrontキャッシュの 削除リクエスト のステータスチェックをおこなう処理をシェルスクリプト化。
キャッシュ削除のスクリプトに組み込めないかなと思ったけど、チェックリクエストだけ何回かおこなう可能性があり、また、Completed ステータス判定もちょっと面倒そうだったので別スクリプトにしました。必要な準備
まずは AWS CLI の実行環境が必要なので、前回の記事の内容をやってみてください。
CloudFrontキャッシュを削除するシェルスクリプトを書いてみた。
状況チェックに必要なもの
aws cloudfront get-invalidationコマンドを叩くわけですが、引数に Distribution ID と Invalidation ID が必要になります。(AWS環境を複数持っている人は profile なども必要になります。)
Invalidation ID は Create Invalidation した時に発行されるIDです。ちなみに
aws cloudfront get-invalidationで、Invalidation ID の引数パラメータは id という名称になります。目的のシェルスクリプトを書く
第1引数に Invalidation ID を受け取れる想定
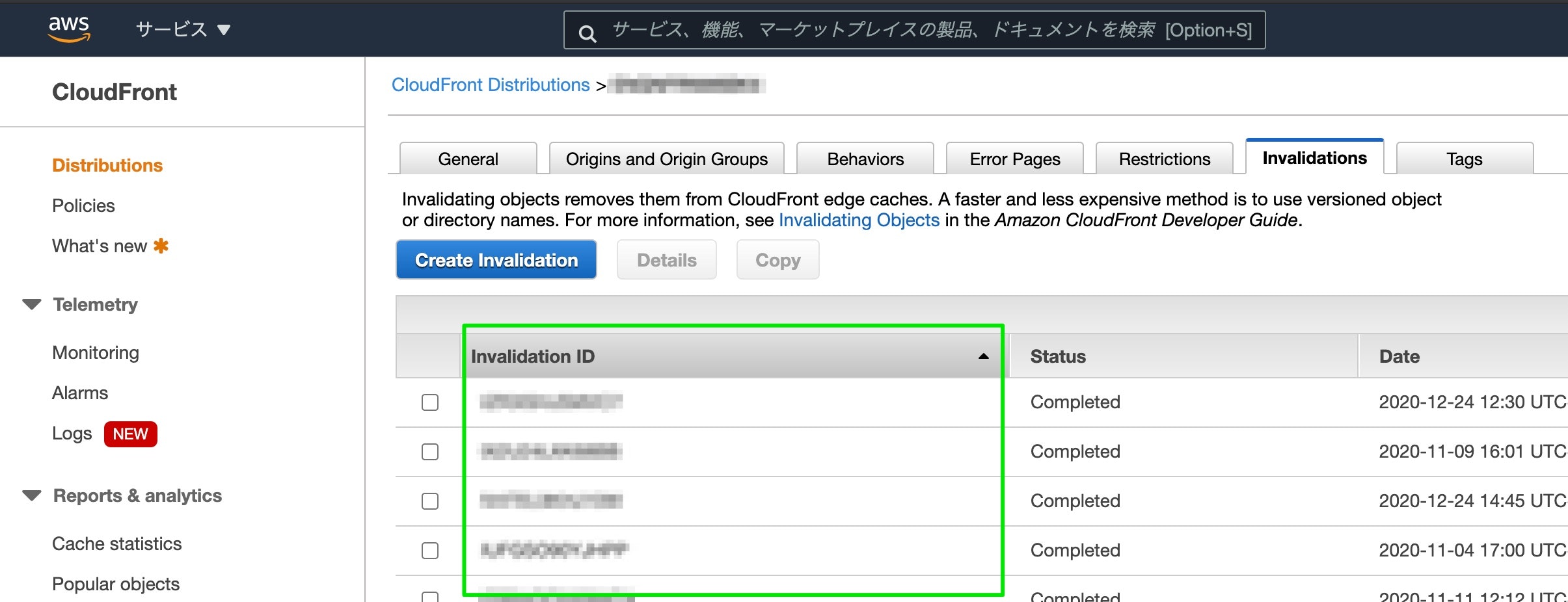
#!/bin/bash dist_id="ABCDEFGHIJKL" prof_name="hogehoge" id="$1" echo "CloudFront invalidation status check ..." echo "invalidation-id:$id, distribution-id:$dist_id, profile=$prof_name" echo -e `aws cloudfront get-invalidation --distribution-id $dist_id --id $id --profile $prof_name | jq -r '.Invalidation | {id: .Id, status: .Status}'`ちなみに Invalidation ID とは、Create Invalidation した時にAWSから自動的に払い出されるIDのことです。
(↓これです)
実行してみる
完了していない時のステータス
完了していない時のステータス❯ ./checkStatusInvalidation.sh LKJIHGFEDCBA CloudFront invalidation status check ... id:ABCDEFGHIJKL, distribution-id:ELKJIHGFEDCBA, profile=hogehoge { "id": "ABCDEFGHIJKL", "status": "InProgress" }完了している時のステータス
完了している時のステータス❯ ./checkStatusInvalidation.sh LKJIHGFEDCBA CloudFront invalidation status check ... invalidation-id:ABCDEFGHIJKL, distribution-id:ELKJIHGFEDCBA, profile=hogehoge { "id": "ABCDEFGHIJKL", "status": "Completed" }※AWSからのレスポンス(JSON)上、Invalidation ID のキー名は id と表記されています。
- 投稿日:2021-01-13T18:17:22+09:00
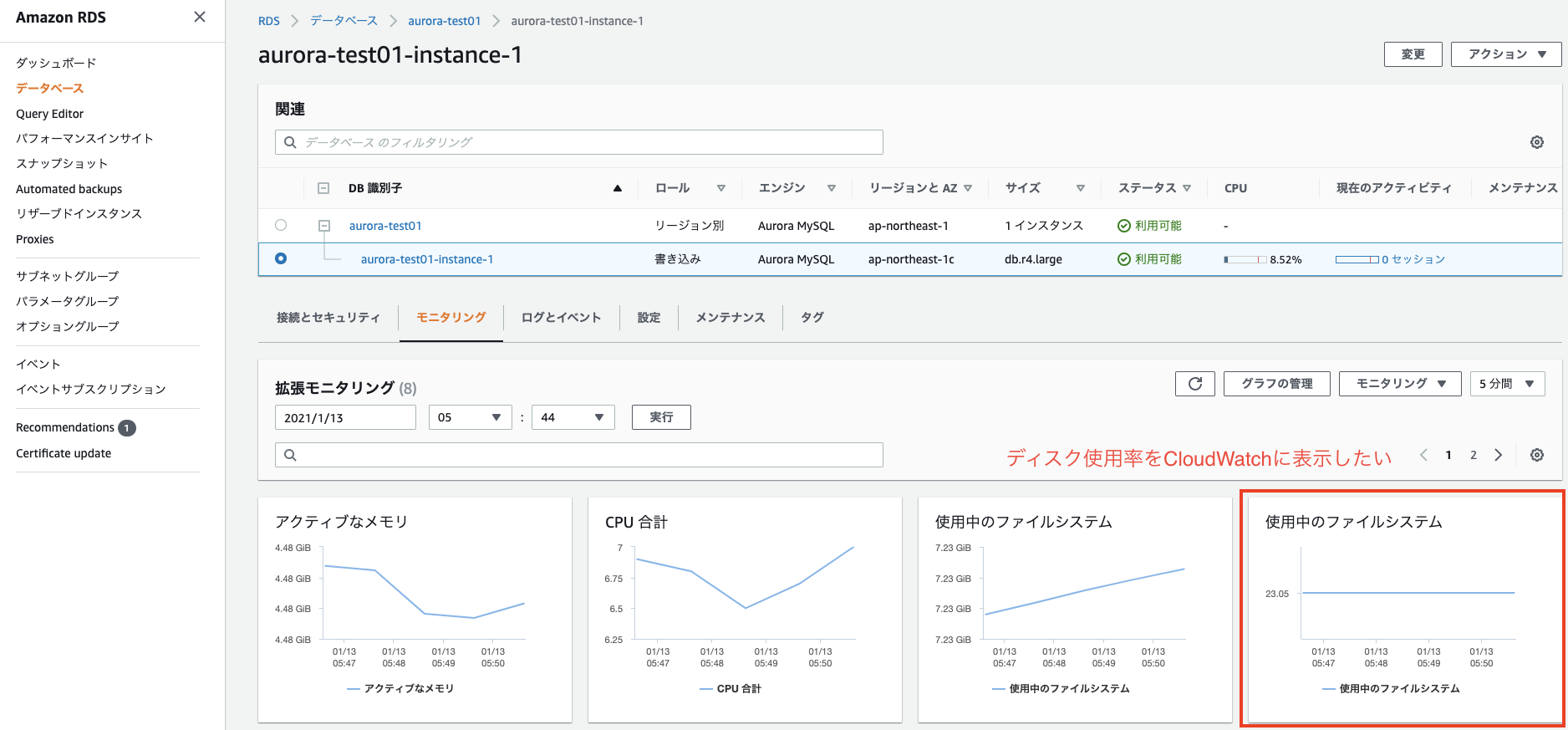
RDSの拡張モニタリングのメトリクスをCloudWatchに表示する
やりたい事
AWSのRDSで拡張モニタリングを有効にすると、見る事ができるメトリクスが増えます。
ですが、この拡張モニタリングのメトリクスはそのままではCloudWatch側に表示できません。
RDSのディスク使用率をCloudWatchのダッシュボードでまとめて見たかったので、
拡張モニタリングのメトリクスをCloudWatchで扱えるように設定してみました。(ここでは拡張モニタリングの有効化については記載しません)
CloudWatchLogsからカスタムメトリクスを登録する
CloudWatch Logs を使用した拡張モニタリングの表示
DB インスタンスの拡張モニタリングを有効にした後、CloudWatch Logs を使用して DB インスタンスのメトリクスを表示できます。
拡張モニタリングのデータはCloudWatchLogsに保存されているようです。
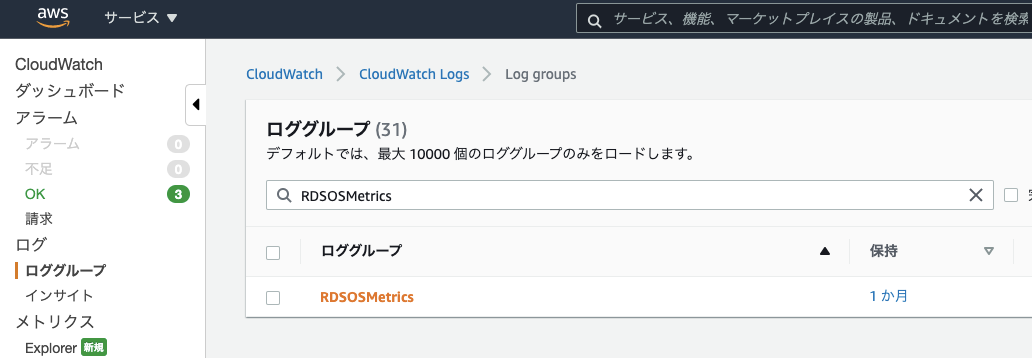
CloudWatchLogsからカスタムメトリクスを登録します。カスタムメトリクス登録手順
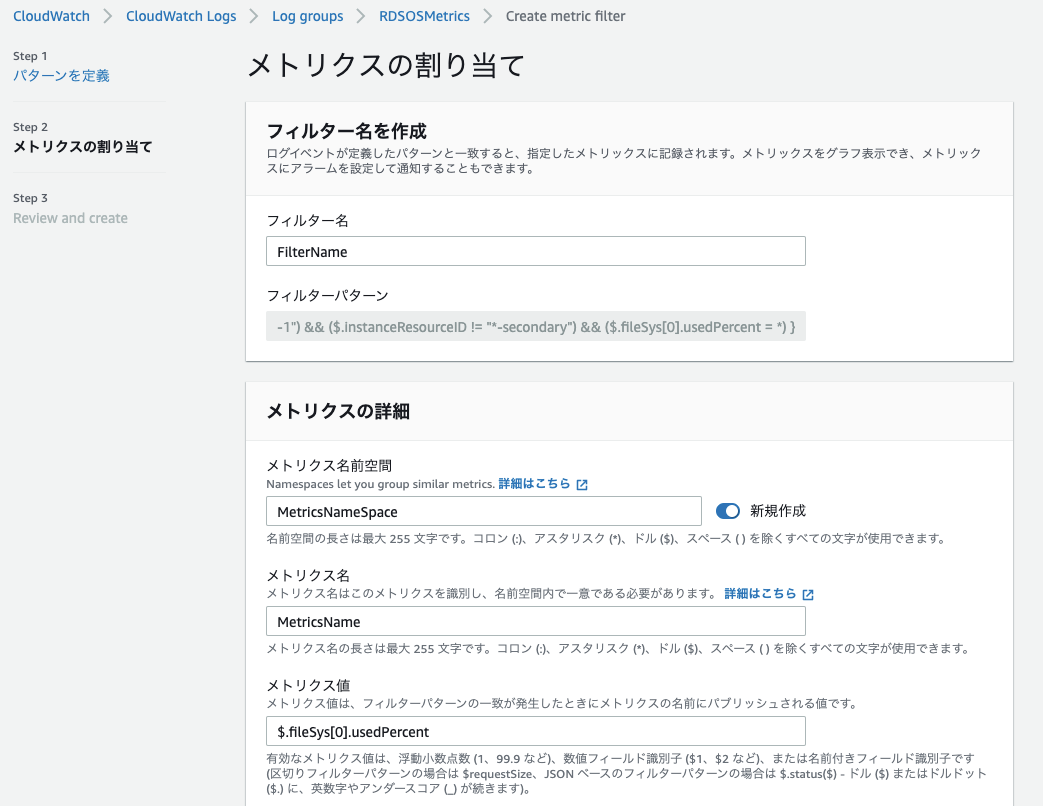
CloudWatchのロググループから
RDSOSMetricsを検索して選択します。
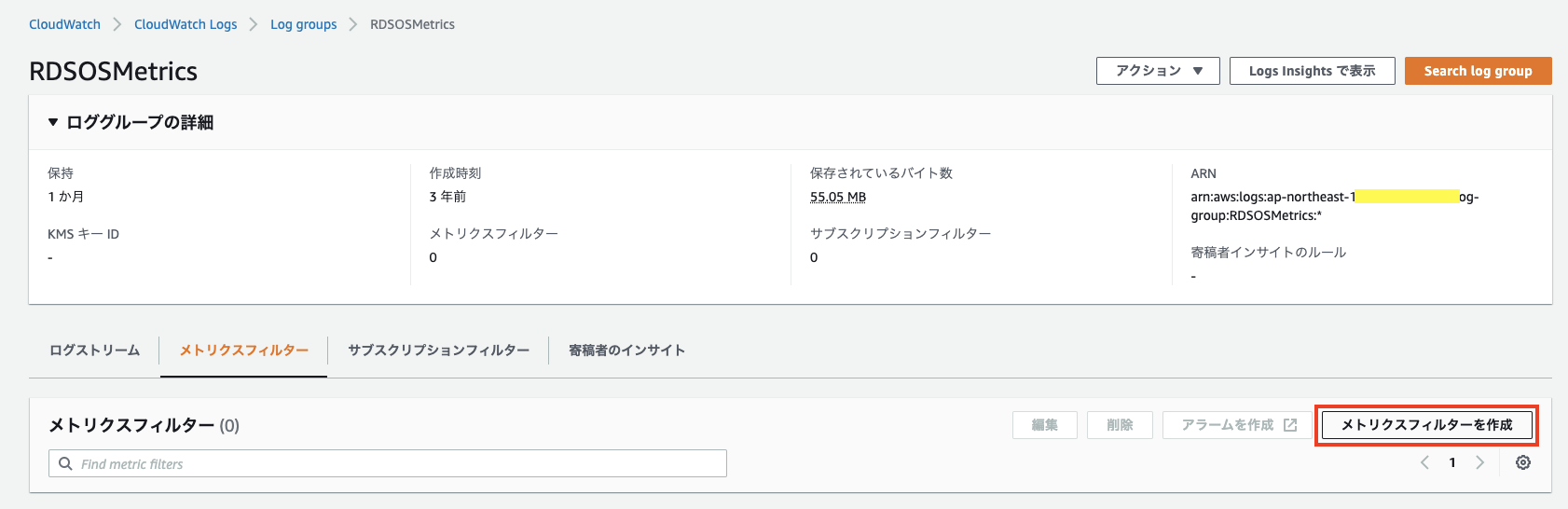
メトリクスフィルターを作成を選択します。
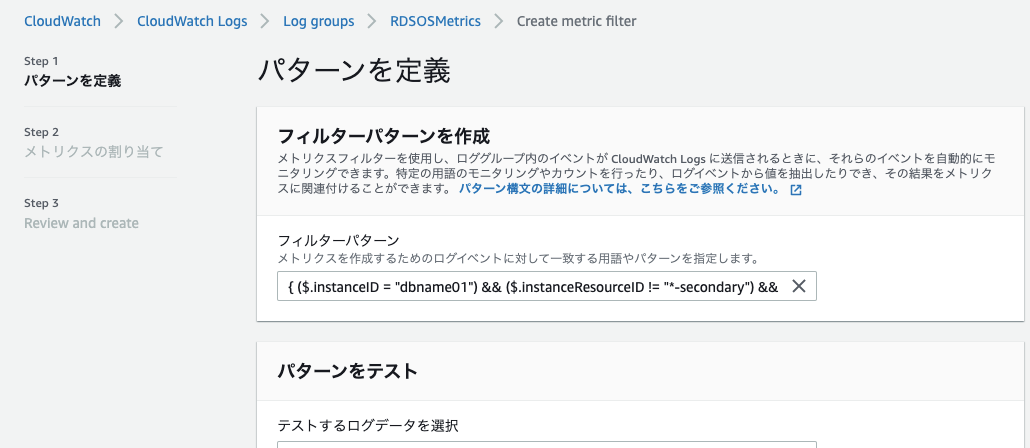
集計したいメトリクスに合わせた
フィルターパターンを設定します。
フィルターパターンについては後述します。
各種情報を入力して、メトリクスフィルターを作成します。
メトリクス名前空間名とメトリクス名は、次の手順の画像を見てください。
メトリクス値については、後述のフィルターパターンを参考にしてください。
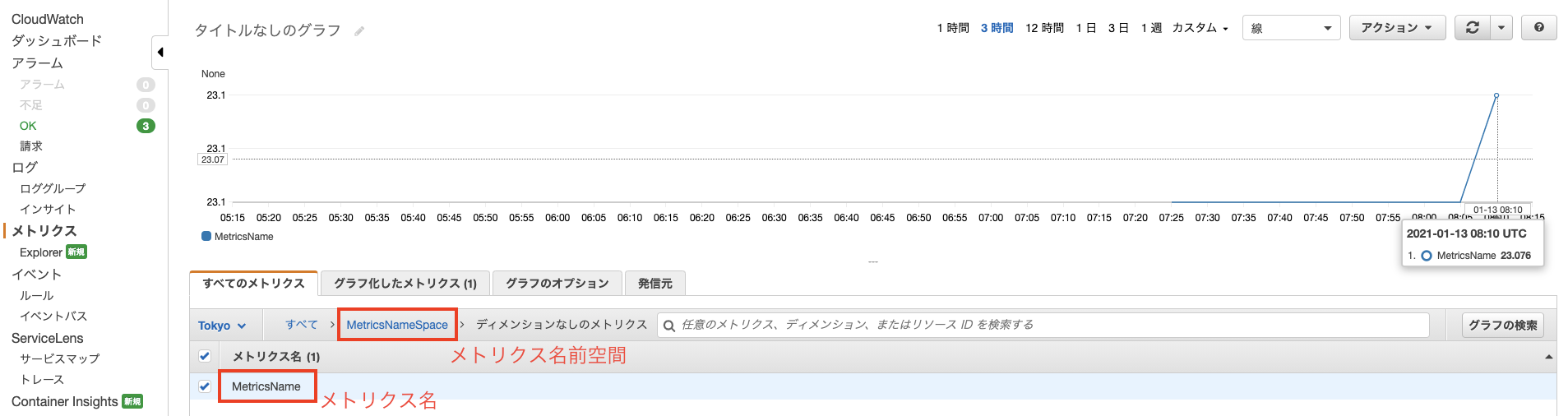
メトリクスにカスタムメトリクスが表示されるようになりました。
フィルターパターンについて
一番ポイントになりそうなフィルターパターンについて。
公式資料はこちら。
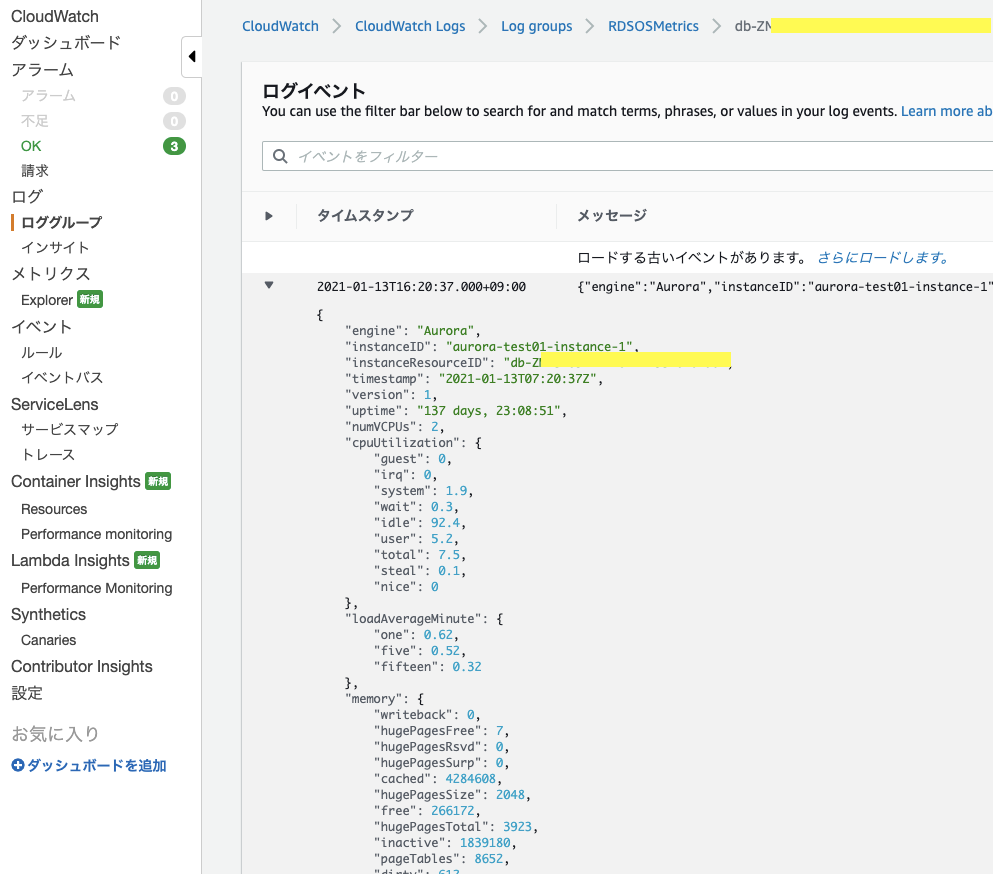
ログイベントの語句の一致拡張モニタリングのデータはJSON形式なので、JSONのパターンについて説明します。
利用できるメトリクスはここに一覧があります。
使用可能な OS メトリクスデータ構造は実際のデータ見た方が早いと思います。
メトリクスの指定方法はjqコマンドと同じ感じ。
正規表現ではなく、ワイルドカードとして*が使えます。(他にもあるかも)例として、Auroraのディスク使用率を取得するフィルターパターンはこんな感じでした。
"{ ($.instanceID = "dbname") && ($.instanceResourceID != "*-secondary") && ($.fileSys[0].usedPercent = *) }"そして、メトリクス値に
$.fileSys[0].usedPercentを指定すればディスク使用率を取得できました。さいごに
記事書いてる最中に見つけたのですが、似たような公式の記事もありました。
拡張モニタリングの CloudWatch Logs をフィルタリングして、Amazon RDS のために自動化されたカスタムメトリクスを生成するにはどうすればよいですか?若干手間ですが、目的は達成できました。
たくさん登録するならTerraformみたいなコード上でコピペが楽でした。
- 投稿日:2021-01-13T17:13:16+09:00
【AWS-SAA-C02対策】メモ
はじめに
udemyの下記講座の模擬試験問題の中で、私が見落としがちだった知識や間違えやすいと感じたポイントなどをまとめました。
〜参考〜
勉強期間 2020/11〜2021/01
受験日 2021/01/13*講座名*
- 【これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)】
- 【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
ワンポイント
S3
- デフォルト設定でパフォーマンスの最大化が可能
- CORS(Cross-Origin Resource Sharing)
アプリ上で複数ドメインからのコンテンツアクセスを有効化
→Ajax通信を使用したアプリケーションの構築が可能- 特定のIPアドレスからのアクセスはIAMロールで設定。SGでの制御はできない!
- デフォルトで高可用性であり1つのAZに依存していない
- S3のクロスリージョンレプリケーションとはS3のオブジェクトを別リージョンのバケットに自動複製するサービスであり、オブジェクトの登録と同時に実行される
- サーバーサイドの暗号化はSSE-S3(暗号化方式はAES-256)。暗号化、復号化は自動でS3が実施するため暗号化キーの管理に手間がかからない。バケットの暗号化によりログの暗号化も自動で実行される。
- Access Analyzerで不正アクセスの確認、アクセス権限の最小化構成のモニタリングが可能
- ストレージクラス分析で適切なデータをいつ適切なストレージクラスに移行するかを判断できる
- 全てのデータに対するパブリックアクセスを拒否する場合、S3パブリックアクセス設定機能でブロックを有効化する
- S3 Intelligent-Tieringで低頻度アクセスのオブジェクトを自動的に低頻度アクセス層に移動できる
- S3からwebサイトをホスティングした際のURL例
- 通常
http://【bucket-name】.s3-ap-northeast-1.amazonaws.com/ai.jpg
- 静的
http://【bucket-name】.s3-website-ap-northeast-1.amazonaws.comS3 Glacier
- データ取得時間
迅速 - 1~5分
標準 - 3~5時間
大容量 - 5~12時間
※Glacier Deep Archive
標準 - ~12時間
大容量 - ~48時間
- データ保持期間
最低 - 90日
CloudFront
- ウェブアプリケーションのコンテンツ配信処理を向上させる
- ALIASコード
*S3との連携がポイント!
- Amazon S3 Transfer AccelerationでクライアントとS3の間で長距離にわたるファイル転送を高速・簡単・安全に行う。
Transfer AccelerationはCroudFrontのエッジロケーションを利用- CloudFrontのディストリビューションにWAFで作成したWEB ACL(WAFの設定の塊)を関連づけることでアクセス制御が可能
×CroudFrontにおけるReferer制限を実施する 〇AWS WAFでRefererによって制御する。- オリジンアクセスアイデンティティ (OAI) と呼ばれる特別な CloudFront ユーザーを作成してアクセス制限が可能
Lambda
- 最大一時実行ボリューム 512MB
- デフォルトアイムアウト時間3秒。最大実行時間は15分
SQS
- メッセージサイズ
最大 - 256KB
※拡張クライアントライブラリを利用すると最大2GBまで- メッセージ保存期間
デフォルト - 4日
最小 - 60秒
最大 - 14日
- 優先度の設定が可能
- Auto Scalingトリガーを構成する場合はSQSのキューサイズを確認する
EBS
- DLM(Data Lifecycle Manager)を使用すると定時バックアップが可能
- EBS自体にSnapShotのライフサイクル機能、レプリケーションという機能はない
- バックアップは最初はフルバックアップでその後は増分バックアップ
- プロビジョンドIOPSのみ複数のEC2インスタンスをアタッチできる(2020/02~)
- アクセス頻度の低いが大切なデータの保存のストレージにはEBSのコールドHDDを選択
RDS
- マルチAZ配置を有効化することでDBインスタンスの高可用性及びフェイルオーバーサポートを提供
※RedshiftはマルチAZ構成は不可- 自動的にバックアップを取得しS3に保存
- スナップショットを元にDBインスタンスを作成してリストアが可能。データ復旧、災害対策、システム拡張に利用できる。
- フェールオーバーするとDBインスタンスのCNAMEレコードを自動で切り替える
- RDS ProxyがアプリとRDSを仲介する
LambdaをRDSと連携させたいときに利用。利用しないとデータセッションを効率的に継続できない- RDSの拡張モニタリングを有効化するとCPUの使用率がCloudWatchLogsで表示できる
- シャーディングが可能
DynamoDB
- メタデータ・ユーザー設定・セッションデータや一連のストリームデータを蓄積することでビッグデータ解析に利用できる
- DynamoDBストリームの有効化により、イベントによる通知処理などが可能(※DynamoDBイベントという機能は無い)
- DynamoDB Accelerator(DAX)は高い!リードレプリカを増設する際はDAXを有効化する必要がある
CloudWatch
- CloudWatchエージェントのインストールによりEC2とオンプレミスサーバーのログの詳細なログを収集し、CloudWatchLogsで取得したログを集約できる。
CloudFormation
- テンプレート
例)
NetworkACL
RuleNumber:100
RuleAction:allow
Egress:true ※アウトバウンドトラフィック設定。falseだとインバウンド。
・・・
(以下略)※port番号
80/HTTP
20/FTP
22/SSHElastiCache
- RDSなどのDB(NoSQL型)の読み込み処理を高速化する
- シンプルに利用する場合はMemcached、それ以外はRedis
- Redis
AWS Elastic Beanstalk
- Dockerの仕組みを利用して構成したアプリケーションを展開する
- アプリケーションのバージョン管理や状態の監視の詳細を自動化する
- ウェブアプリケーションやワーカー環境の構築に利用される
用語集
- RedShiftの拡張VPCルーティング
VPC内の全てのデータ移動のトラフィック制御・モニタリングが可能- プレイスメントグループ
単一のAZ内のEC2間の通信を高速化- Amazon FSx for Windows
ファイルシステムあたり最大2GB/秒のスループット、数百万のIOPS、一貫したミリ秒未満のレイテンシーという高速パフォーマンスが可能な高性能なストレージ。SMBプロトコルで転送を行う- Amazon EFS
NFSv4プロトコル- Amazon EMR
ビッグデータ解析処理(※AWS AppSync・・リアルタイム分析、ランキング処理)- AWS Cognito
アプリケーションの認証、許可、ユーザー管理をサポート- AWS Certificate manager
SSL証明書を集中管理する- AWS DataPipeline
定期的なデータ移動やデータ処理といったアクティビティのスケジュールを簡単に設定できるウェブサービス- Snowball Edge Storage Optimized
AWSとオンプレミス間でのデータ転送。利用可能な領域ー80TB- Aurora Serverless
Aurora 用のオンデマンドの Auto Scaling 設定。アプリケーションの使用状況に合わせて自動的に起動・シャットダウンを行う- カスタマーゲートウェイ
AWSでVPN接続を構成する際に利用する(カスタマーゲートウェイに静的ルートテーブルを構成)- AWS Transit Gateway
ネットワーク間の連携・管理を効率化する。Amazon VPC、オンプレミスのデータセンター、リモートオフィスそれぞれを連携してハブアンドスポーク型を構築する- SAML(Security Assertion Markup Language)
ユーザー情報を一元管理するActiveDirectoryやクラウドサービスとの連携、シングルサインオンを実現- AWS CloudTrail
ユーザーのアクティビティ、APIコールのログの取得。AWSアカウントのガバナンス・コンプライアンス・運用監査・リスク監査に利用する- AWS Step Functions
個々のサーバーレスの関数(Lambda、SQSなど)を簡単につないでプロセス処理を実行するアプリケーションを構築する。人間による操作を必要とするような半自動化されたワークフローの作成が可能
参考: Amazon SWF と AWS Step Functions の使い分けどっちか迷う問題
- S3へのアクセス制御
- バケットポリシー
対バケット- ACL
対バケット&個々のオブジェクト
※バケット‥オブジェクトの保存場所
オブジェクト‥ファイル
トラフィック制御
- セキュリティグループ
インスタンス間- ACL
サブネット間自動化
- Cloud formation
容易- Opsworks
ムズイ。異なるレイヤーを用意するのに相応しい。ストレージゲートウェイ
オンプレミスからクラウドストレージへのアクセスを提供する
- 保管型ボリューム
オンプレミスのサーバーにローカルストレージをプライマリーとして必要とする場合に選択- キャッシュボリューム
オンプレミスのサーバーにS3をプライマリーとして必要とする場合に選択CloudFrontが配信するコンテンツへのアクセス制御
- 署名付きURL
・・・- 署名付きcookie
現在のオブジェクトURLを変更したくないルーティングポリシー
- 位置情報ルーティングポリシー
ユーザーの位置に基づいてトラフィックをルーティング- 地理的近接性ルーティングポリシー
リソースの場所に基づいてトラフィックをルーティングAmazon Kinesis
- Streams
ストリームデータ処理用の分析システムやアプリケーションを構築するサービス- Firehose
各種DB(S3やRedShift)に配信・蓄積するためのストリーム処理を実施するDNSレコード
- CNAME
ドメインを別のドメインにマッピング!- A (AAAA)
ドメインとIPアドレスをマッピング- ALIAS
AWSサービスのエンドポイントのIPアドレスを返答物理対応可能なインスタンス
- ハードウェア専有インスタンス
同じAWSアカウントのインスタンスとはHWを共有する可能性がある物理サーバー- Dedicated Host
完全に1アカウントのユーザー専用として利用できる物理サーバーVPCエンドポイント
- ゲートウェイ型
特殊なルーティングを設定し、VPC 内部から直接外のサービスと通信する
対象サービス…S3/DynamoDB- プライベートリンク型
サブネットにエンドポイント用のプライベート IPアドレスを生成し、DNSが名前解決でルーティングするメモ
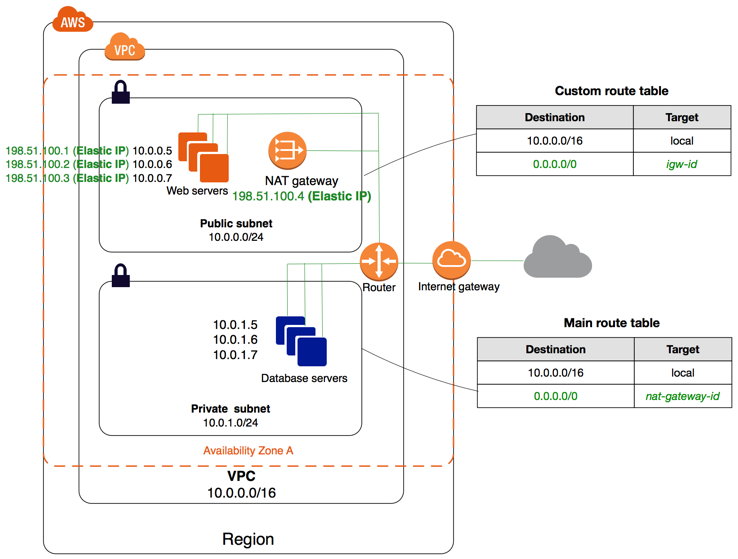
VPC内のEC2インスタンスにアクセスできない要因
- IGW(インターネットゲートウェイ)がサブネットに設定されていない
- パブリックIPアドレスが付与されていない
- ネットワークACLの設定でインターネットアクセス許可がない
- SG(セキュリティグループ)の設定でインターネットアクセス許可がない
参考: VPC本番環境のインスタンス削除防止法
- 開発者向けのアカウントを作成
- インスタンスにタグを付与
- 開発環境とのVPCを分割
注意
- RDSのAutoScalingはストレージ容量を増加させる仕組み。
- RDSではライフサイクルポリシーによるバックアップは設定できない
- VPCポイントはリージョン内のポイントのため、リージョン外からはアクセスできない
- インスタンスのトラフィック分散はRoute53ではなくELB
- ストリーミングデータはKenesisをとりあえず使うのが最適
- AZ内 or region内 のどちらの条件か
- スケジュール起動 or イベント起動 のどちらの条件か
- 費用対効果を考えているか否か
- 処理が重複しないか (例)ラムダとEC2
ざっと見とく
- AWS Lake Formation
S3を利用したデータレイク構成を容易に実現する- EBSのAutoScaling
スケールイン時にEBSボリュームのデータを保存したいとき→EBSのDeleteOnTerminationを非有効化する- AutoScaling
クールダウンのデフォルトタイム - 300秒
ウォームアップ条件はステップスケーリングポリシーによって設定する- AWS SMS(Server Migration Service)
オンプレミスシステムの多数のワークロードを移行できる- AWS SAM(Serverless Application Model)
サーバレスアプリケーション構築用のデプロイツール。CloudFormationと連携する- 高速コンピューティング
AI機能を実装できるGPUを利用可能なインスタンス- Amazon WorkSpaces
クラウド上でのデスクトップ管理を実施できる仮想デスクトップサービス- IAMデータベース認証
EC2が固有のプロファイル認証情報を利用してRDSにアクセス可能にする認証方法- Route Origin Authorization(ROA)
オンプレミス環境で利用していたホワイトリストに登録したIPアドレスをAWSに移行する方法- API Gatewayの処理性能の向上(最小の努力で実行可能)
API Gatewayのスロットリング制限設定とキャッシュを有効化する- IPフローティング
ELBやRoute53によるDNS情報の伝播の際の一定のダウンタイムを防止するため、仮想IPアドレスを使って可用性を高めるサービス- Amazon Simple Workflow (SWF)
分散アプリケーションコンポーネント間での作業の調整を用意にするサービス- パイロットライト
停止した状態の最小限の構成を別リージョンに用意しておき、障害発生時に立ち上げるもの- AD Connector
IAMとオンプレミス環境のADとを連携する- パブリックホストゾーン
インターネット上に公開されたDNSドメインレコードを管理するコンテナ- EC2 Image Builder
AMIの設定の更新の自動化- AWS IoT Core
デバイスを簡単かつ安全にクラウドに接続する- IAMのセキュリティ認証情報
アクセスキーIDとシークレットアクセスキーおわりに
普段業務等でAWSを利用する機会は無く、3ヶ月間自主的に勉強し受験しました。模擬試験問題集にある問題にはほぼ正解できるようにしたつもりでしたが…。
なんとか一発で合格はしたものの、テスト中は回答に自信がない問題も多かったです…。
- 投稿日:2021-01-13T14:59:36+09:00
Amazon Aurora Serverless の構築手順
Aurora Serverlessは一定時間利用されなくなると自動的にインタンスを落とすことで、
ランニングコストを抑えられるというメリットがあります。このメリットは、一時的に利用するシステムの一端を担うDBとしては最適でした。先日、期間限定のキャンペーンシステムを構築するにあたり、Auroraを活用する機会がありましたので、構築手順メモとして残しておきます。
リージョン:東京
データベース:Aurora(PostgreSQL互換)
※VPCやサブネットグループ、セキュリティグループに関しては詳しく書きません。Amazon Aurora Serverless の構築手順
Aurora公式
https://aws.amazon.com/jp/rds/aurora/serverless/Amazon RDSの画面からデータベースの作成をクリック。
https://ap-northeast-1.console.aws.amazon.com/rds/home?region=ap-northeast-1#databases:
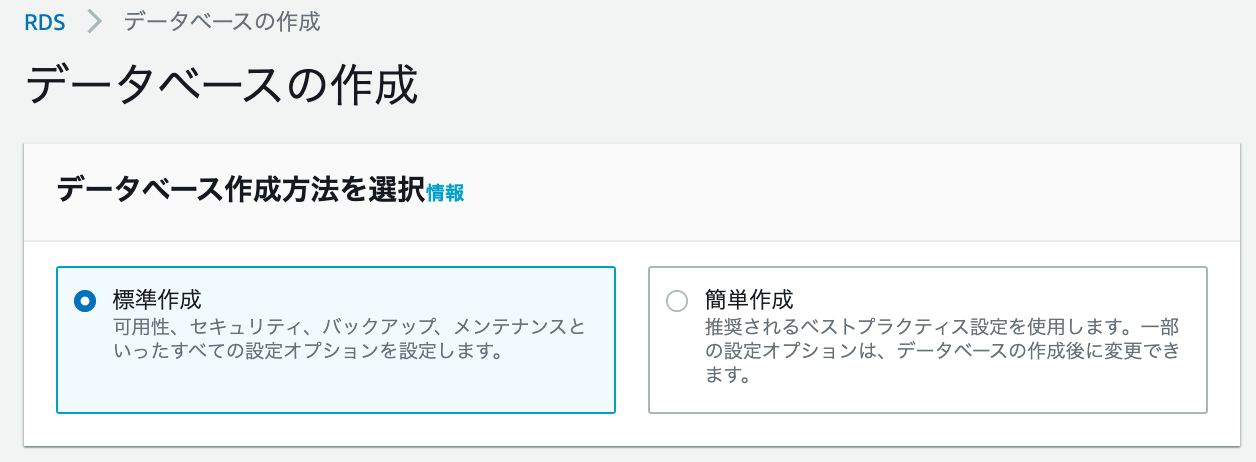
データベース作成方法を選択
?標準作成 を選択
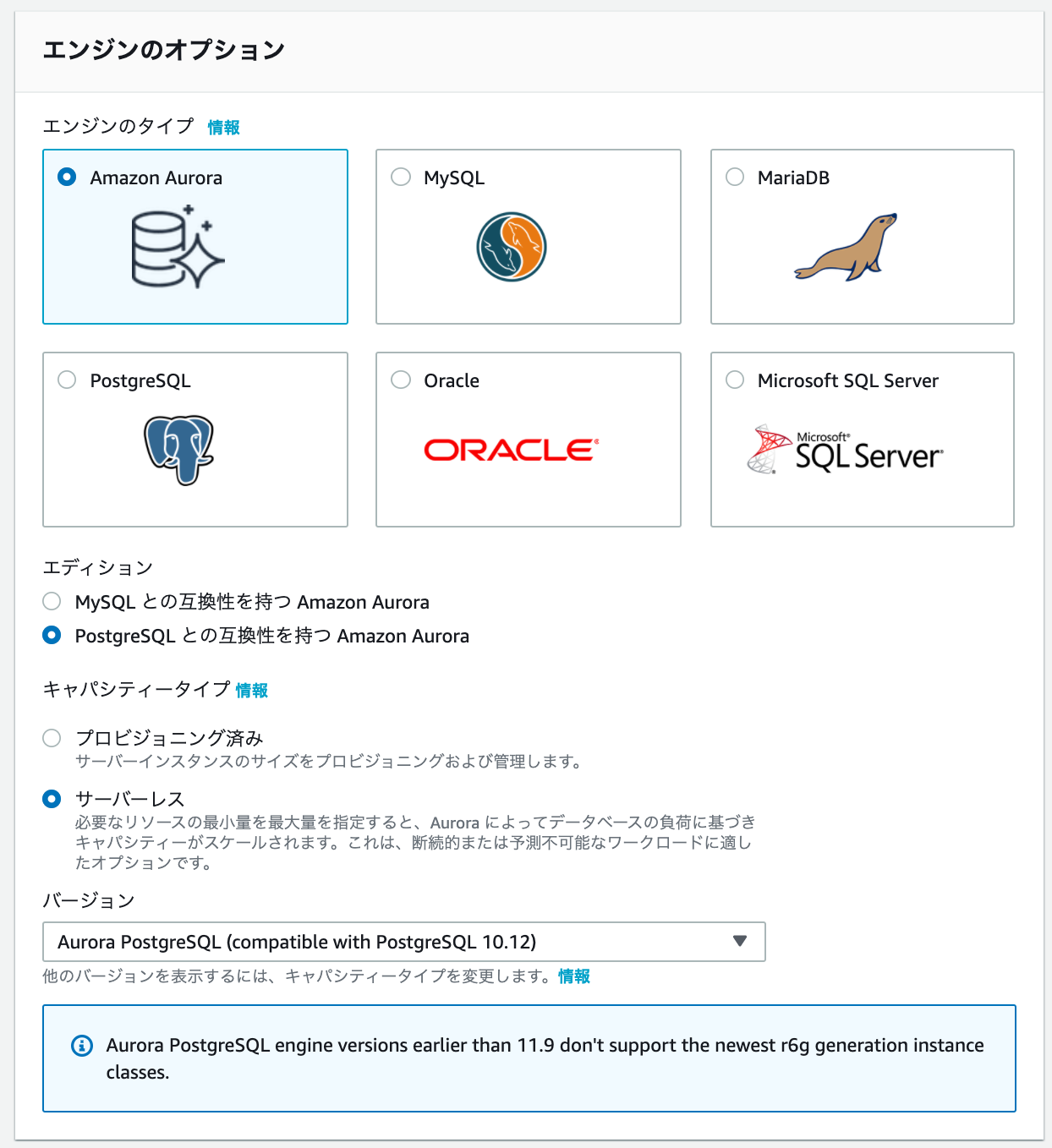
エンジンのオプション
エンジンのタイプ : ?Amazon Aurora
エディション: ?PostgreSQL との互換性を持つ Amazon Aurora
キャパシティータイプ : ?サーバーレス
バージョン : [Aurora PostgreSQL (compatible with PostgreSQL 10.12)]
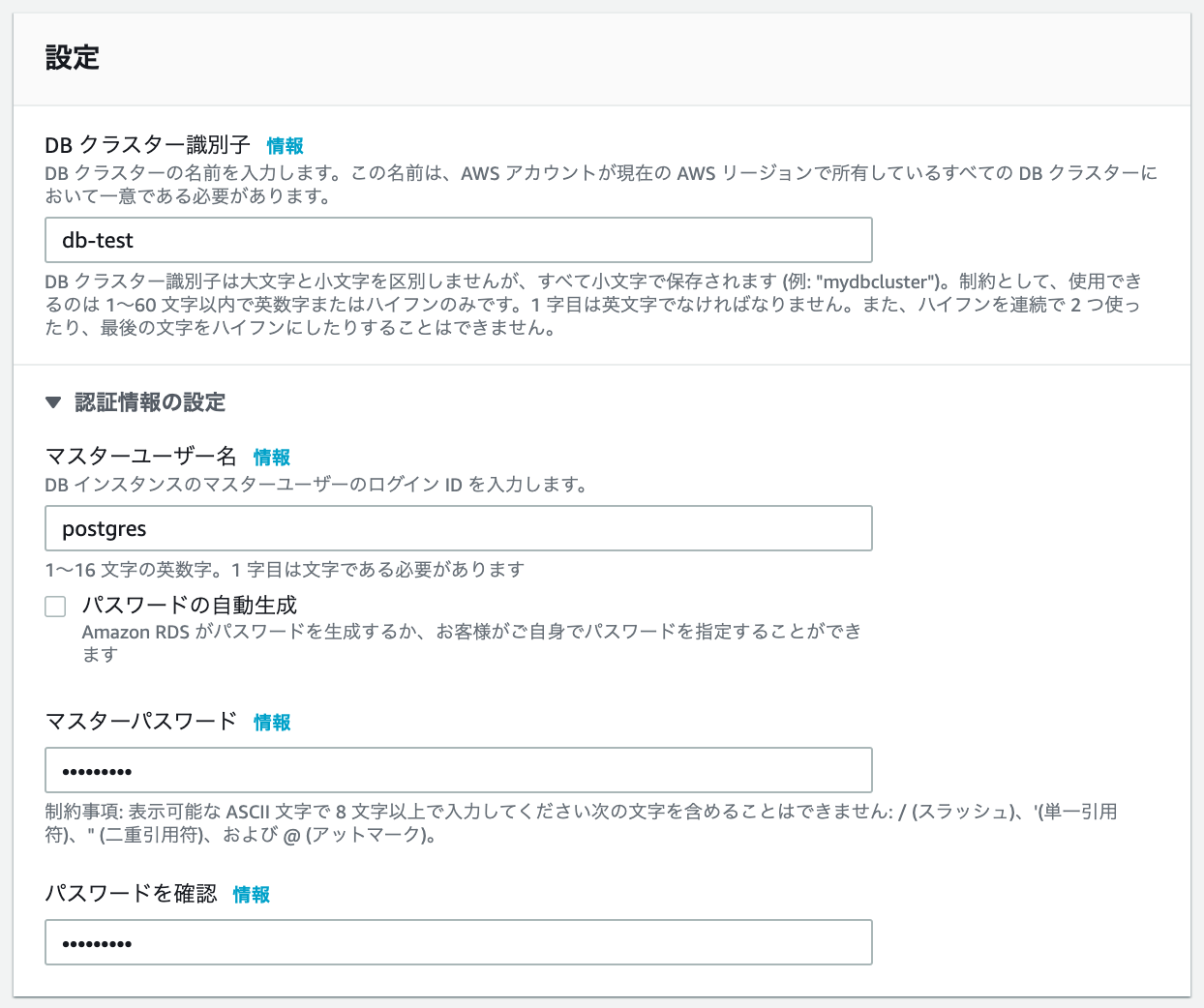
設定
・DB クラスター識別子 は、任意の名前を小文字で入力。
・マスターユーザー名 は、ログインに使う任意のIDを入力。
・マスターパスワード と パスワードを確認 に、同一のものを入力。
キャパシティの設定
最小 Aurora キャパシティーユニット と最大 Aurora キャパシティーユニット 任意で選択。
※キャパシティーユニットはメモリに相当する項目です。☐ タイムアウトに達すると、容量を指定された値に強制的にスケーリングします。
こちらを有効にすると、実行中のクエリやトランザクションがある場合や、テーブルがロックをされている場合に強制的にクエリを落としてくれます。実行中のクエリがキャンセルされる恐れがあるとのことで、チェックしていませんがAuroraのメリットでもあるので本来は有効にしたい項目です。☑ 数分間アイドル状態のままの場合はコンピューティング性能を一時停止する。
こちらを有効にすると、指定した時間アクセスが無いとインスタンスを自動で停止してくれます。再びリクエストが発生すると、インスタンスを自動で起動します。一瞬でインスタンスが立ち上げるわけではないので、即時レスポンスが必要なシステムで有効にすることはオススメ出来ません。
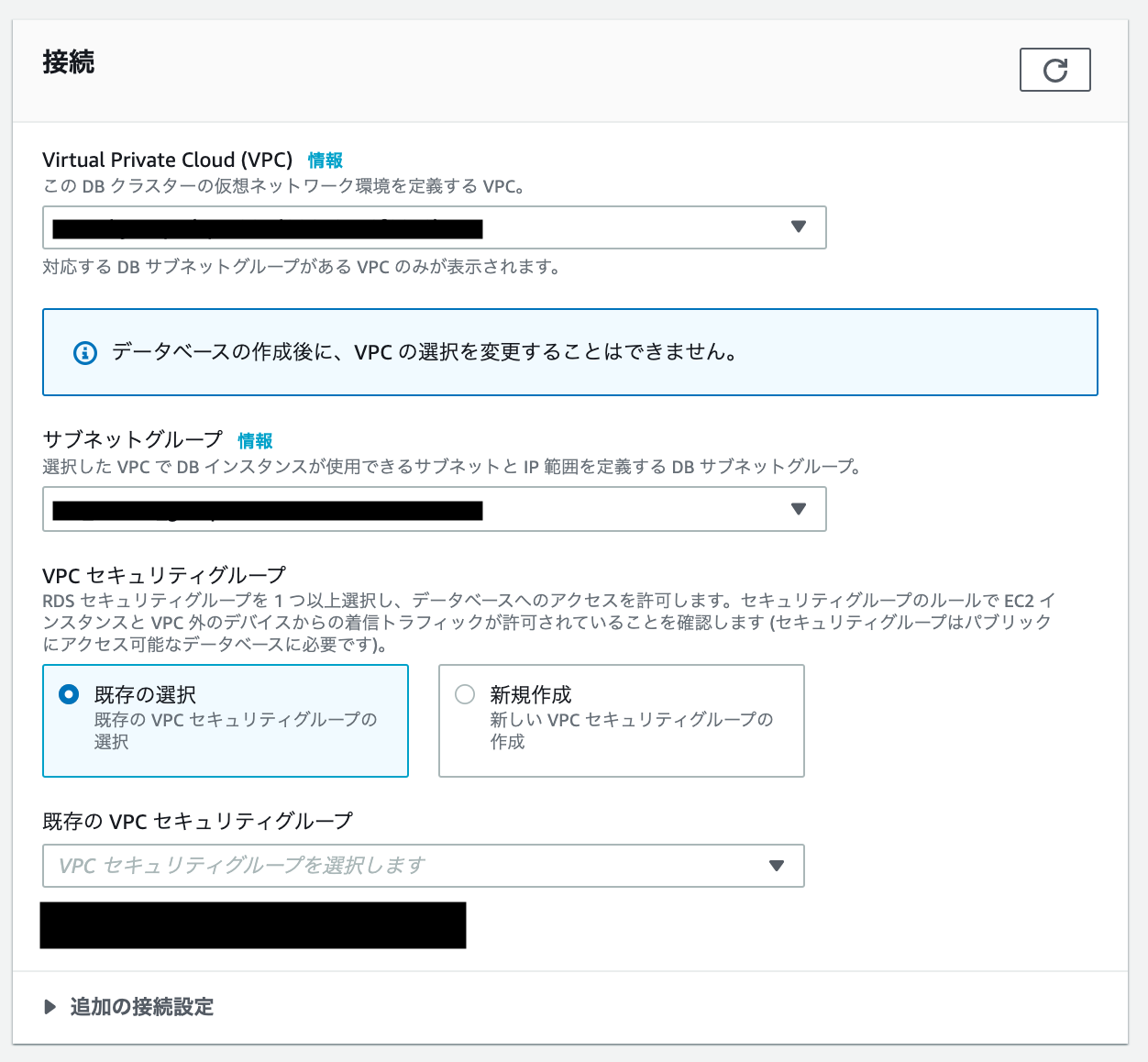
接続
VPC、サブネットグループ、VPCセキュリティグループは、全て既存の設定を利用します。
ここで新規に作成することも出来ますが、適当な名前で自動生成されるのでオススメしません。
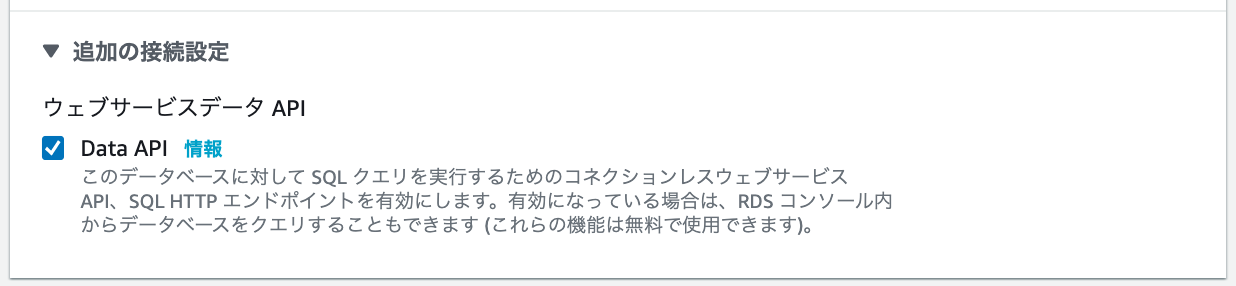
追加の接続設定から、Data APIを有効にしておきます。
データベース認証
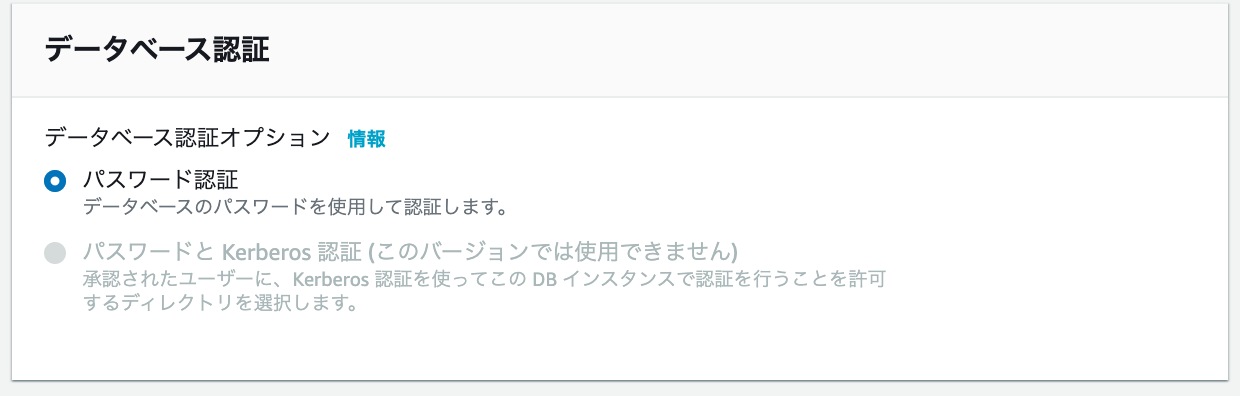
?パスワード認証 を選択。
※この項目は変更不可です。
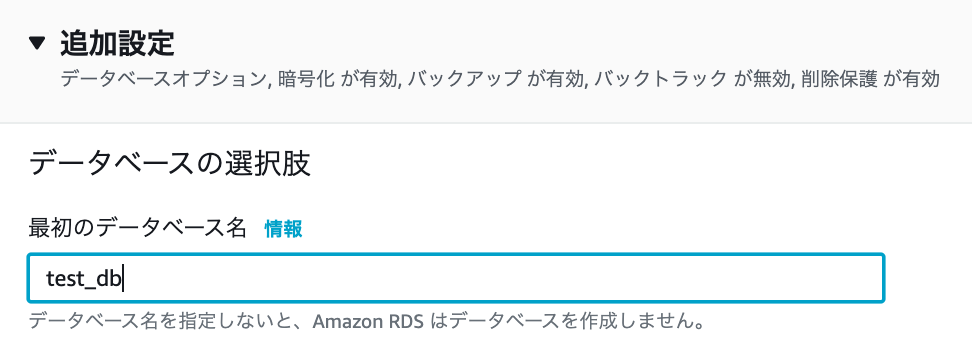
追加設定
データベース名を任意で入力します。その他の項目は変更しません。
最後に画面最下部の[データベースの生成]ボタンをクリックします。
データベース一覧画面に飛ばされ、データベースの作成が始まるので完了するまで待ちます。
作成したデータベースのステータスが[作成中]→[利用可能]に変われば、作成完了です。
※計測したところ、約3分後に作成されました。
クエリエディターでの接続テスト
クエリエディターで新規作成したDBにアクセスしてみましょう。クエリエディターを使うことで画面上からデータベースに接続し、クエリを発行することが出来ます。構築手順内でDataAPIを有効にしていれば利用可能です。
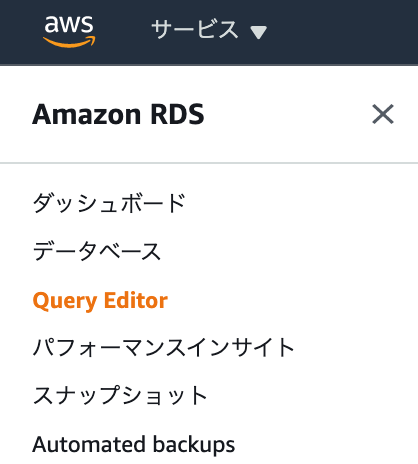
https://ap-northeast-1.console.aws.amazon.com/rds/home?region=ap-northeast-1#query-editor:クエリエディターへは、画面左のメニューから遷移出来ます。
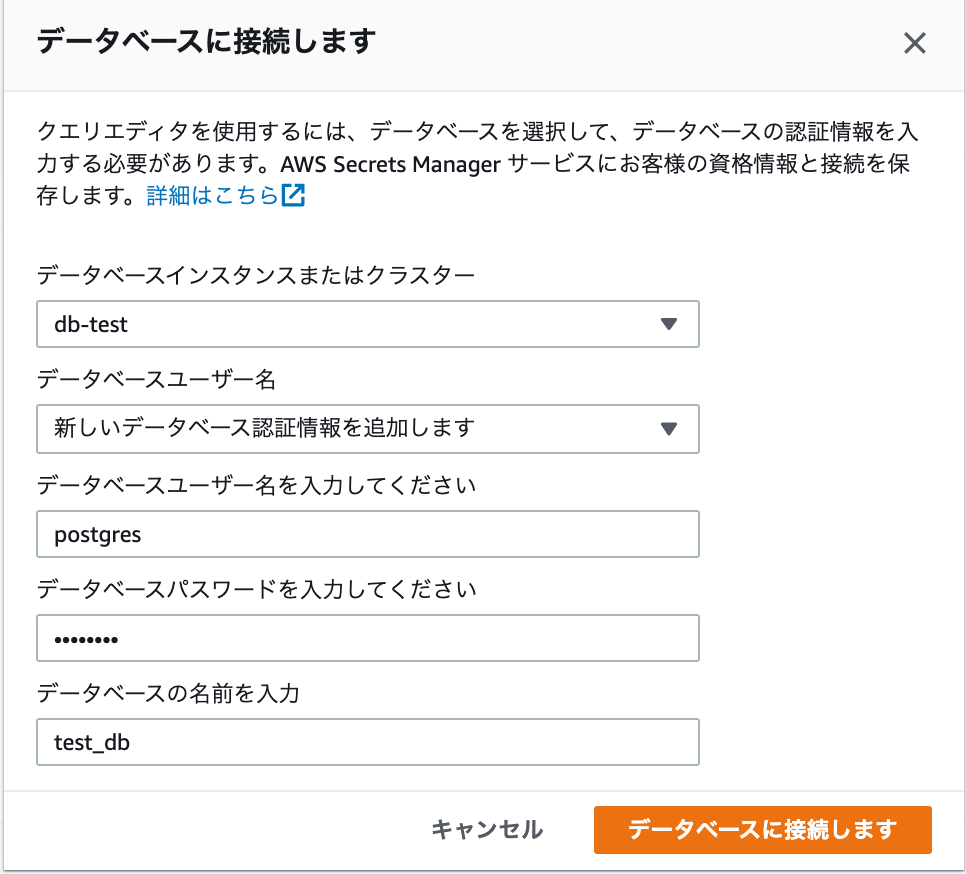
画面遷移するとダイアログが開かれるので、構築時に設定した値を入力し[データベースに接続します]をクリック。
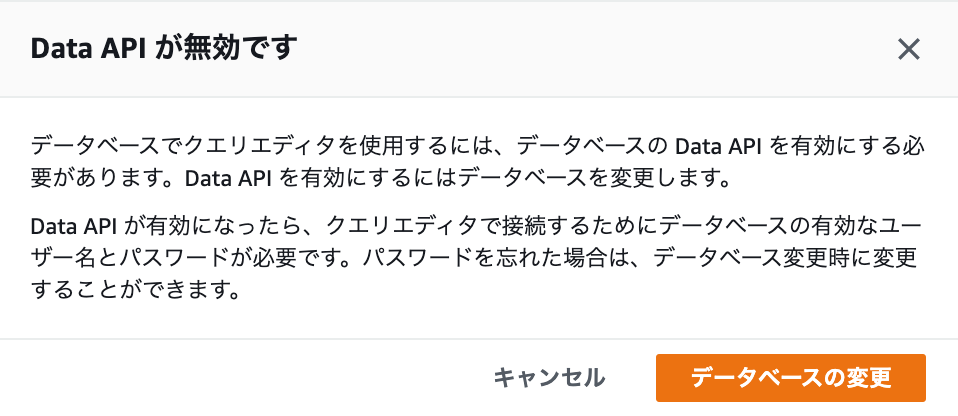
Data APIが無効になっている場合は、以下のダイアログが表示されるのでData APIを有効化してから再チャレンジしてください。
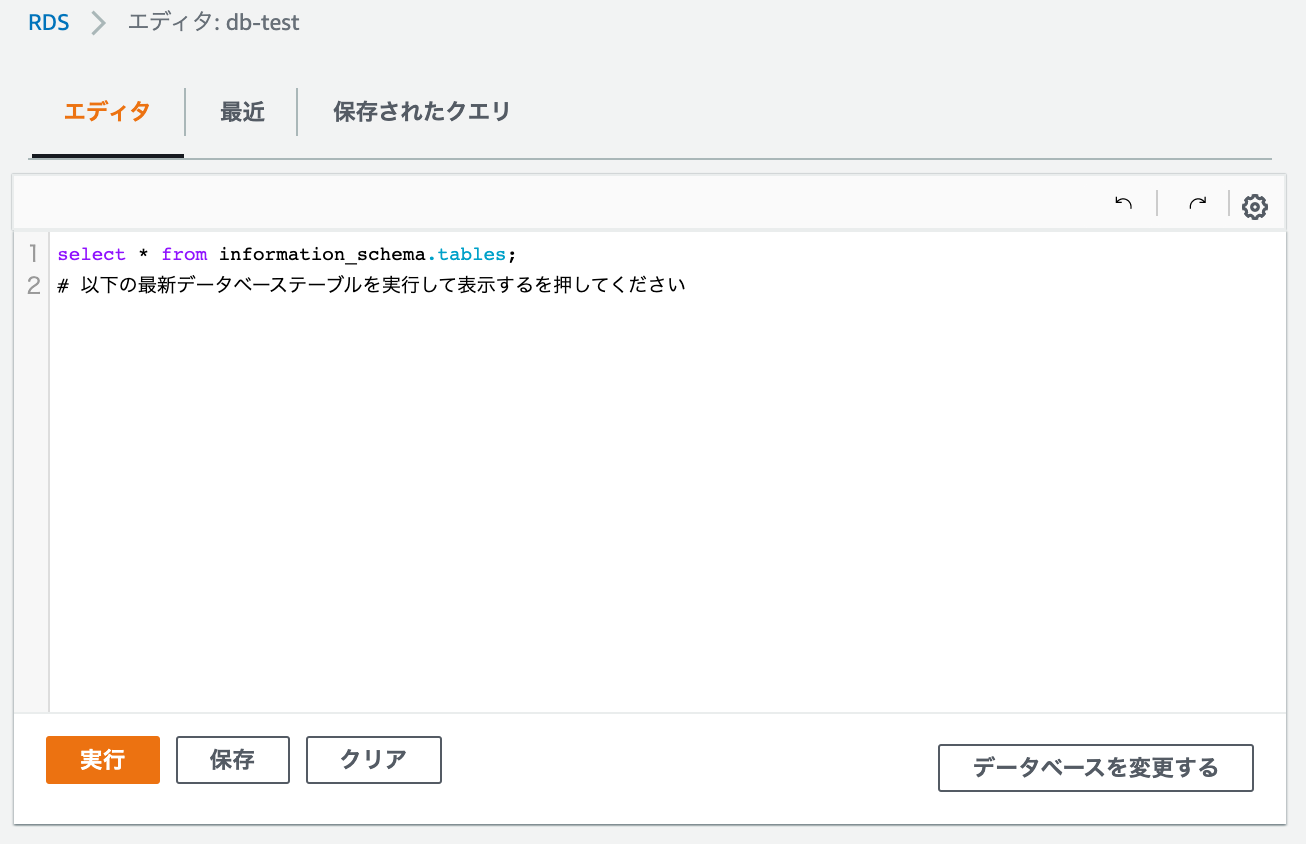
正常に接続出来ると以下のような画面になります。
エディタにクエリを入力し実行することで、Create文はもちろん自由にクエリを発行出来ます。クエリエディターは機能自体豊富では無いためを普段使いするのには微妙ですが、初回の接続確認や初期構築でのテーブル作成等をさくっとやりたいときに有効かなと思います。
さいごに
Aurora環境を構築するにあたって作っては壊しを数回繰り返しましたが、
作成から削除まで画面上から全て出来るのでそこまで時間を要しませんでした。Auroraの新規作成は手順さえ把握していれば1つのDBを構築するために10分もかからないので、
一度も構築したことの無い方は、自身のアカウントを作って一度試して見るのもアリかなと思います。




- 投稿日:2021-01-13T10:28:58+09:00
AWS Device FarmのホストマシンにAndroid SDKをインストールする
AWS Device FarmのホストマシンでAndroid SDKを利用する方法をメモする。
なお通常Device Farmのホストマシンでは、ビルド済みのapkを端末へインストールする程度のことしか行わないので、基本的にAndroid SDKは必要ない。(
adbなどの platform-tools はプリインストールされているので)とはいえ、あると便利な場合もまれにある(ホストマシン上でapkのビルドをしたいなど)ので、ここで方法をまとめる。
はじめに
AWS Device Farmのテスト実行環境は、
- モバイル端末(クライアント)
- そのクライアントと接続されたLinuxサーバー(ホスト)
から構成されている。
今回は、上記のホストマシンにAndroid SDKをインストールする方法をまとめる。
方法
Device Farmのカスタムテスト環境の機能を用いる。
適当なスタンダードテスト環境に対して、カスタマイズしたtest_spec.ymlをアップロードすれば良い。test_spec.ymlphases: install: commands: - mkdir ~/android_sdk - cd ~/android_sdk # download and install commandline tools - curl https://dl.google.com/android/repository/commandlinetools-linux-6858069_latest.zip -o sdk.zip - unzip sdk.zip # set environment variables for android sdk - export ANDROID_HOME_OLD=$ANDROID_HOME - export ANDROID_HOME=$HOME/android_sdk - export ANDROID_SDK_ROOT=$HOME/android_sdk # install android sdk - yes | $ANDROID_HOME/cmdline-tools/bin/sdkmanager "build-tools;28.0.3" "platforms;android-29" --sdk_root=$ANDROID_HOME # use existing platform-tools (which is a specific build for AWS device farm) - rm -rf $ANDROID_HOME/platform-tools - ln -s $ANDROID_HOME_OLD/platform-tools $ANDROID_HOME - export PATH="$PATH":"$ANDROID_HOME/platfom-tools" # return to the previous directory - cd -ポイントは下記3点:
1. commandline toolsを利用した最小限のインストール
Android Studioをインストールすると必要なものが全部入る認識だが、サイズが大きく不要なものも多いので、今回は利用しない。
sdkmanagerを利用すると、必要なものだけをインストールできる。参照また、Command line toolsのURLはこちらから入手できる。
2. platform-tools は既存の物を使う
新規にインストールされるplatform-toolsを利用すると、端末との通信ができなくなるなどの不具合があった。
もともとインストールされているplatform-toolsは、AWS Device Farm用にカスタマイズされたものらしい。
このため、新しい$ANDROID_HOME下にシンボリックリンクを張って、既存のplatform-toolsが参照されるようにする。3.
test_spec.ymlのアップロード方法文法はこちらを参照: Working with Custom Test Environments in AWS Device Farm
アップロードする際は、既存のスタンダードテスト環境をベースに、カスタムされたtest_spec.ymlをアップロードする形になる。
Appium等を用いる場合は、素直に対応する環境を選べば良い。
一方で、Flutter driveを用いる場合は、そもそも対応するスタンダード環境が存在しない。この場合は、適当な環境(e.g.
APPIUM_PYTHON)を選んだ上で、テストパッケージもアップロードし、その上で test_spec.yml をアップロードする。
次のStackoverflowに方法がまとめられている: Running Flutter Integration Tests in AWS Device Farm, Saucelabs, Firebase Test Lab etc以上です。
- 投稿日:2021-01-13T08:58:13+09:00
AWS ANS に向けての勉強 3. Cloud Front
参考
概要
- マネージドなCDNサービス
- AWS のエッジロケーションから提供されるEdge SErvice
ユースケース
https://docs.aws.amazon.com/ja_jp/AmazonCloudFront/latest/DeveloperGuide/IntroductionUseCases.html
- 静的ウェブサイトのコンテンツ配信の加速
- オンデマンドビデオおよびライブストリーミングビデオの配信
- システム処理全体で特定のフィールドを暗号化する
- エッジのカスタマイズ
- Lambda@Edge カスタマイズを使用したプライベートコンテンツの供給特徴
- 高性能な分散配信
- 高いパフォーマンス
- キャパシティアクセスからの解放
- ビルトインのセキュリティ機能
- 設定が容易で即時利用可能
- 充実したレポーティング
- 完全重量課金
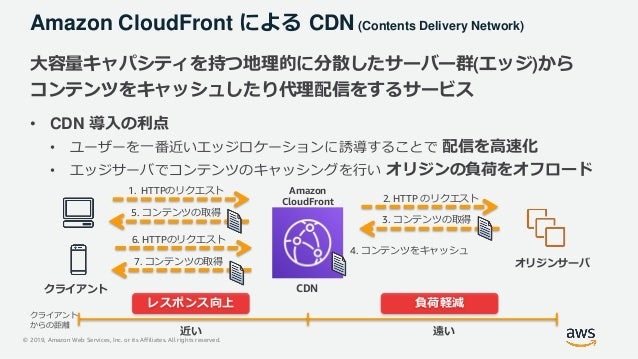
CloudFrontによるCDN
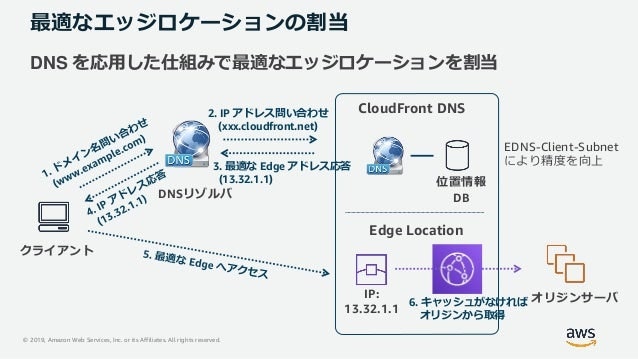
最適なエッジロケーションの割り当て
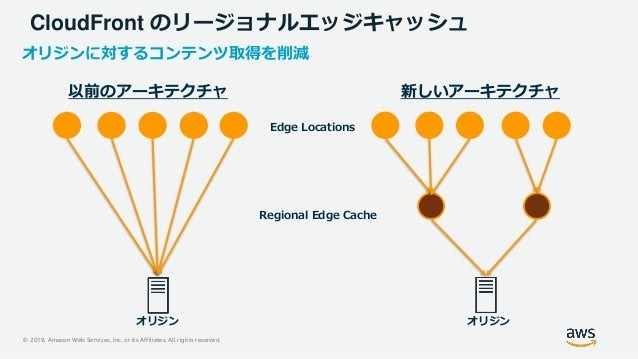
リージョナルエッジキャッシュ
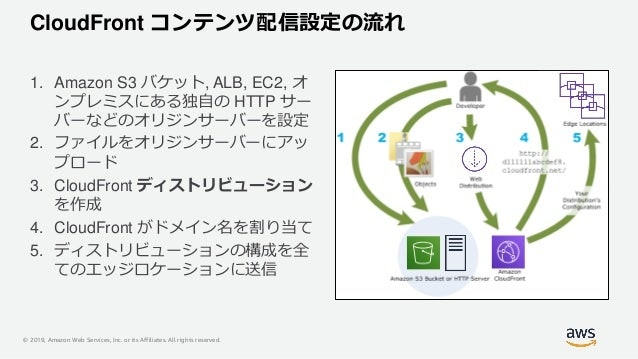
コンテンツ配信設定の流れ
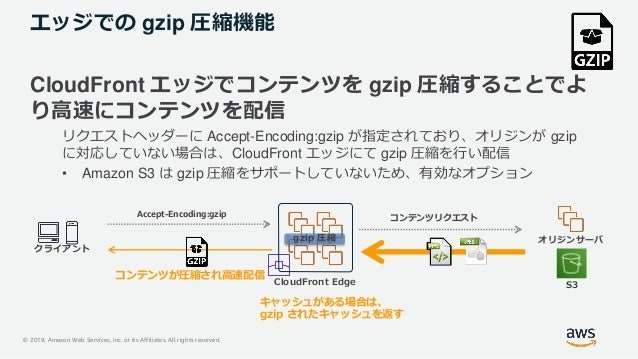
gzip圧縮機能
- S3は対応していないのでこちらを使う
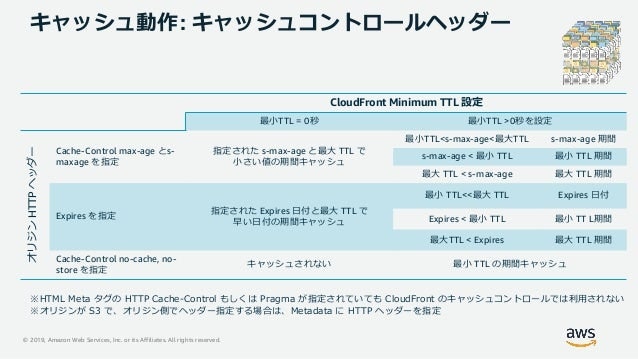
キャッシュ
キャッシュコントロール機能
- GET / HEAD / OPTIONのリクエストが対象
- 単一ファイルサイズのキャッシングは最大20GBまで
- URLパスごとにキャッシュ期間設定が可能
- フォワードオプション機能による動的ページ

キャッシュコントロールヘッダ
キャッシュファイルの無効化
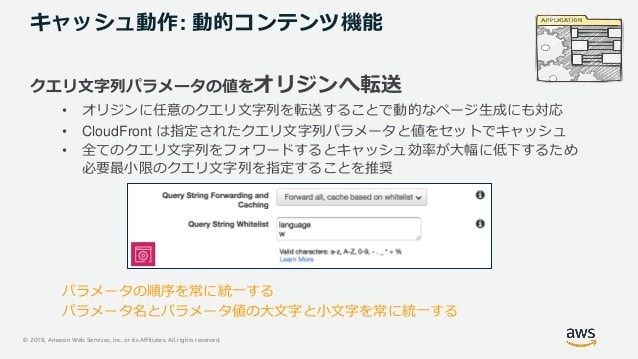
動的コンテンツ機能
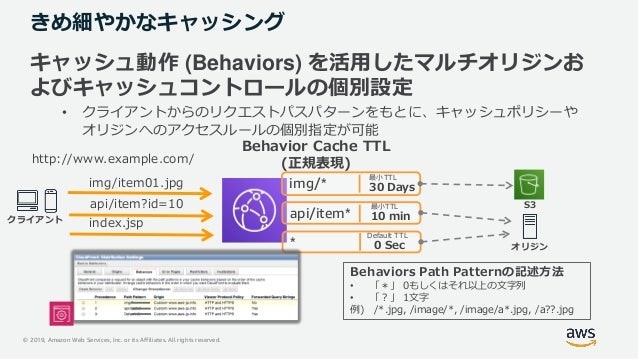
きめ細やかなキャッシング
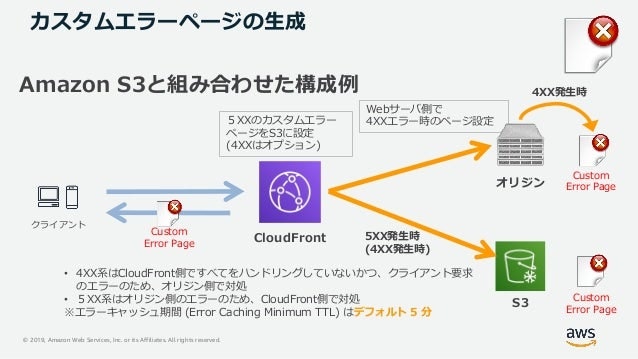
カスタムエラーページ
カスタムオリジンのタイムアウト
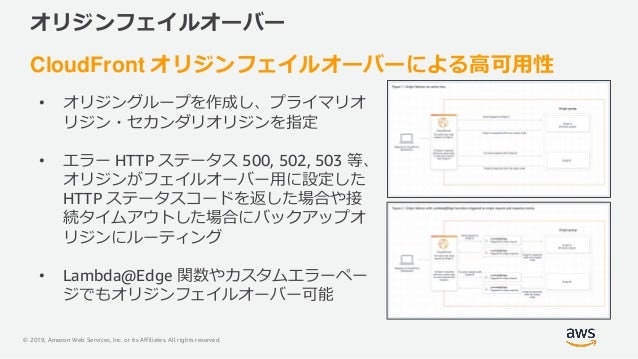
オリジンフェイルオーバー
データ保護機能
レポート & ロギング機能
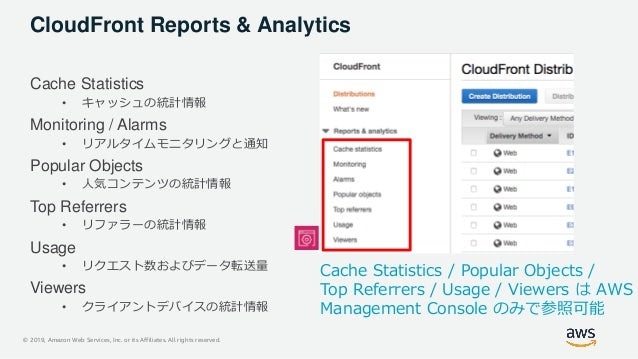
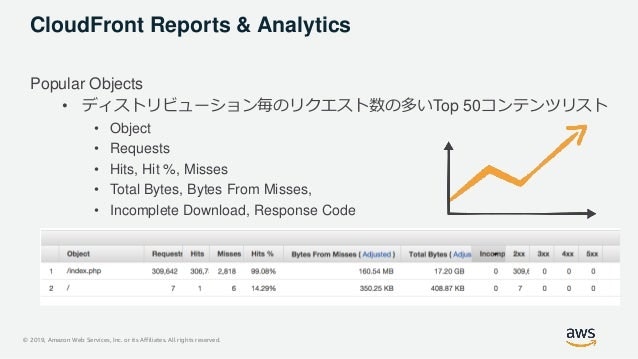
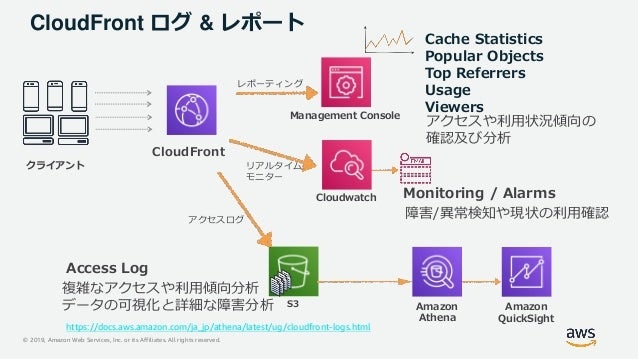
CloudFront Report
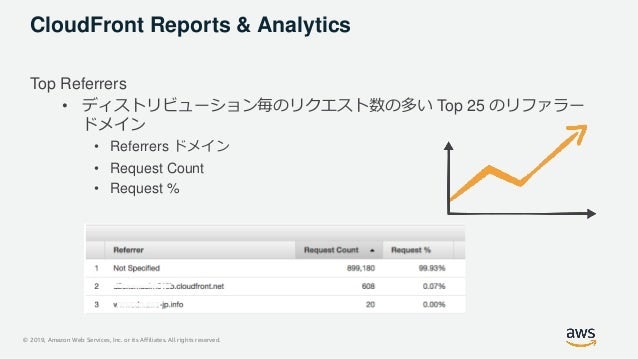
アクセスログ
TIPS
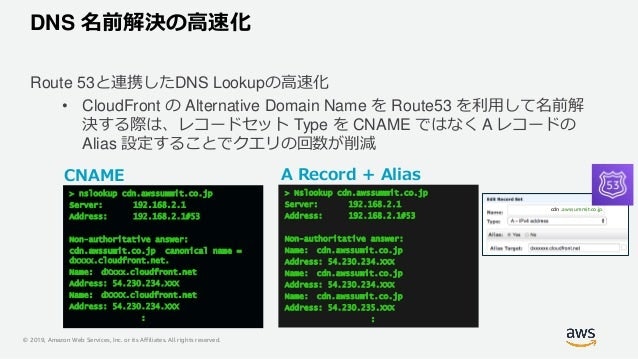
DNS 名前解決の高速化
リアルタイム障害・異常検知
S3 オリジン自動キャッシュの無効化
















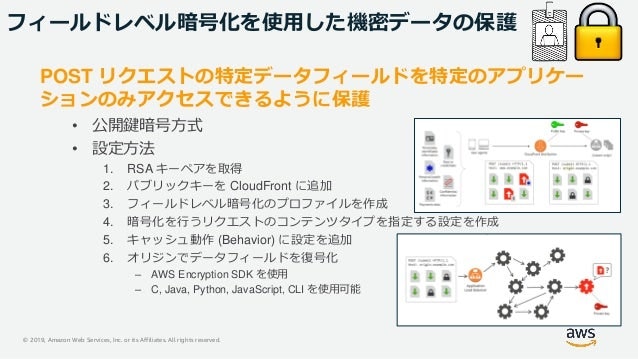
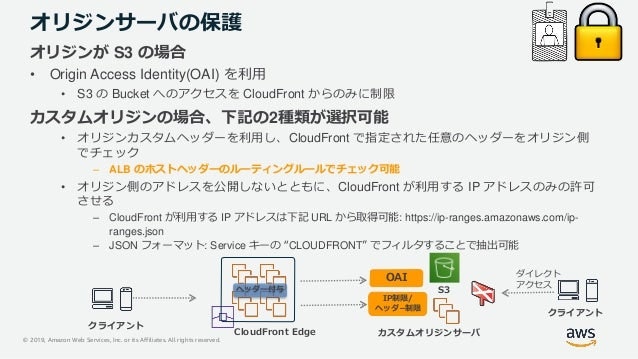
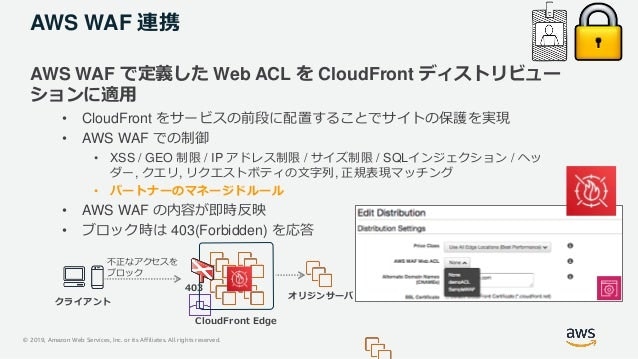
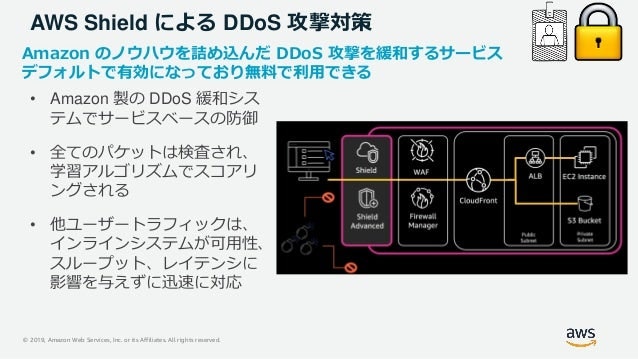









- 投稿日:2021-01-13T06:36:38+09:00
AWS Data Pipelineってどんなサービス?
勉強前イメージ
サービス間のデータの流れをいい感じにするやつ....
よくわからん!調査
AWS Data Pipelineとは
AWSのサービス間のデータの統合・処理を自動化するサービスです。
オンレプとの連携も可能です。
AWS Data Pipelineは保存場所にあるデータに定期的にアクセスを行い、必要なスケールでのリソースを使って処理を行います。
s3やRDS,EMRなど使用することが出来ます。
指定したスケジュールでの起動も可能で、shellも使用できるためcronの代わりにも使うことが可能です特徴
- マネージドサービスである
データの移行やELT処理(Extract(抽出)/Transform(変換)/Load(データを入れる))などを行う場合、
自前で実現しようとすると、基盤やソフトウェア・管理保守など準備が大変ですが、
AWS Data Pipeline であれば準備をすべてAWSが担ってくれているので、すぐに始めることが出来ます
- GUIでの操作も可能
開発用のGUIが用意されており、簡単なデータ移行であればGUIのみで実行することが出来ます。
複雑な変更や加工が必要な場合でも、自前のプログラムをData Pipelineに食わすことで実行させることができ、
簡単ながら拡張性があります。
- オンプレの処理を行える
クラウドサービスだが、オンプレの処理にも使用できます。
構築イメージ
イメージとしては以下の図です。
RDS から s3 にデータを処理して移動させたい場合に Data Pipeline を使用します。
データの移行条件や、フォーマット・スケジュールなどすべて Data Pipeline が行ってくれます。他にも以下のような選択肢があり、それでData Pipelineが作れます
- どこにデータが有るのか(Data Node) : データの場所やフォーマット
- どう処理するか(Activity) : データ処理のアクティビティ。パッケージ済みのも用意されている
- いつ処理するのか(Schedule) : 処理の実行スケジュール
- 誰が処理するのか(Resource) : 処理や条件をチェックするリソース
- どういう条件で処理するのか(Precondition) : 処理実行の条件
- 通知はどう送ればよいか(Action) : 通知の方法
勉強後イメージ
ニュアンス合ってなくもないw
サービス間で個別にデータの移動とかがめんどくさい!!!から、
AWS Data Pipelineを使えば、一貫の流れを管理できるしわかりやすい。参考

- 投稿日:2021-01-13T01:53:21+09:00
AWS Step Functions におけるクロスアカウントでの非同期処理を同期的に処理する
はじめに
AWS Step Functions は非常に素晴らしい機能です。
ただ生憎、クロスアカウントでの処理には対応していません。(2021年1月時点)
そのため、アカウントをまたいで別アカウントでLambdaを実行させるようなワークフローを実現するためには、SNSやSQSを介する必要があります。
ただし、ベタにSNS/SQSを介して別アカウントのLambdaを実行するだけでは、当該Lambdaの処理結果を管理することができません。
管理を行うには、当該Lambdaから、さらにSNSやSQSを介して、実行結果を連携する必要があります。
この一連の処理が、クロスアカウントのアクセスポリシーとあいまってなかなか設定が面倒だったため、当該構成の具体例を説明します。
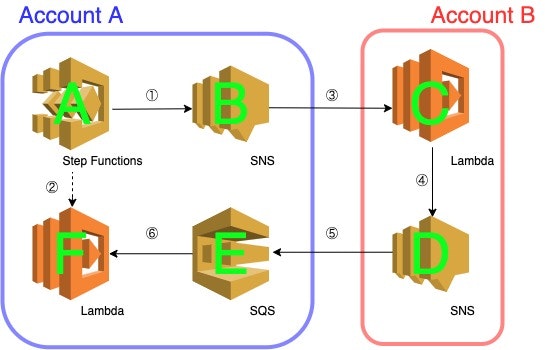
なお、Lambda関数の実装サンプルはPythonになります。概要
- はじめに、AccountAのStep Functions State Machine(A)から同一アカウント内のSNS(B)にメッセージを送信します。
- AccountAのStep Functions State Machine(A)から、一定時間の待機の後、AccountAのLambda(F)を起動します。
当該Lambdaは、AccountAのSQS(E)をPollingし、メッセージの有無を確認します。
メッセージがあれば、Step Functions State Machineは次の処理に進み、 メッセージがなければ、ふたたび一定時間の待機の後、AccountAのLambda(F)を再実行します。- AccountAのSNS(B)は、AccountBのLambda(C)によってSubscribeされています。そのため、AccountBのLambdaが起動します。
- AccountBのLambda(C)から、AccountBのSNS(D)にメッセージをPublishします。
- AccountAのSQS(E)は、AccountBのSNS(D)をSubscribeされています。そのため、AccountAのSQSにもメッセージがあります。
- AccountAのSQS(E)にメッセージが来たことによって、ついにAccountAのLambda(F)はメッセージを受領できます。
メッセージが来たことによって、Step Functions State Machineは次の処理に進みます。詳しい構築手順
- 以下のコマンドを実行し、AccountAのSNS(B)を用意します。
aws sns create-topic --name cross-account-a --profile account-a
- 以下のコマンドを実行し、AccountBのSNS(D)を用意します。
aws sns create-topic --name cross-account-b --profile account-b
- 以下のコマンドを実行し、AccountAのSQS(E)を用意します。
aws sqs create-queue --queue-name fetch-cross-account-b --profile account-a
- AccountAのSNS(B)に、AccountBによるSubscriptionを許可します。
aws sns add-permission \ --profile account-a \ --topic-arn arn:aws:sns:ap-northeast-1:111111111111:cross-account-a \ --label lambda-access \ --aws-account-id 222222222222 \ --action-name Subscribe ListSubscriptionsByTopic Receive
- AccountBのLambda(C)に、AccountAのSNSからの起動を許可します。
aws lambda add-permission \ --profile account-b \ --function-name send_message_to_sns \ --statement-id sns-invoke-from-account-111111111111 \ --action "lambda:InvokeFunction" \ --principal sns.amazonaws.com \ --source-arn arn:aws:sns:ap-northeast-1:111111111111:cross-account-
- AccountAのSQS(E)に、AccountBのSNS(D)に対するSendMessageを許可します。
AWS Management Consoleで、AccountAのSQSのアクセスポリシーを以下のように変更してください。
(本当はここもCLIでやりたかったのですが、面倒だったので……){ "Statement": [{ "Effect":"Allow", "Principal": { "Service": "sns.amazonaws.com" }, "Action":"sqs:SendMessage", "Resource":"arn:aws:sqs:ap-northeast-1:111111111111:fetch-cross-account-b", "Condition":{ "ArnEquals":{ "aws:SourceArn":"arn:aws:sns:ap-northeast-1:222222222222:cross-account-b" } } }] }
- AccountBのLambda(C)によって、AccountAのSNS(B)がSubscribeされるように設定します。
aws sns subscribe \ --profile account-b \ --topic-arn arn:aws:sns:ap-northeast-1:111111111111:cross-account-a \ --protocol lambda \ --notification-endpoint arn:aws:lambda:ap-northeast-1:222222222222:function:send_message_to_sns
- AccountAのSQS(E)によって、AccountBのSNS(D)がSubscribeされるように設定します。
aws sns subscribe \ --profile account-a \ --topic-arn arn:aws:sns:ap-northeast-1:222222222222:cross-account-b \ --protocol sqs \ --notification-endpoint arn:aws:sqs:ap-northeast-1:111111111111:fetch-cross-account-b
- 最後に、ここまでの設定を踏まえて、一連のワークフローをStep Functions State Machineに定義します。
以下、Definitionの内容です。
はじめにAccountAのSNS(B)にメッセージを発行し、Lambda(F)を呼び出し。
Lambda(F)の実行結果として、SQS(E)からメッセージを取得できなければ、再度Lambda(F)を実行。
メッセージを取得できれば、次のLambdaを呼び出す、という流れになっています。{ "Comment": "Sample AWS Step functions flow", "StartAt": "PutMessageToSns", "States": { "PutMessageToSns": { "Type": "Task", "Resource": "arn:aws:states:::sns:publish", "Parameters": { "TopicArn": "arn:aws:sns:ap-northeast-1:111111111111:cross-account-a", "Message": "Hello" }, "Next": "Wait" }, "Wait": { "Type": "Wait", "Seconds": 180, "Next": "WaitJobFinish" }, "WaitJobFinish": { "Type": "Task", "Resource": "arn:aws:lambda:ap-northeast-1:111111111111:function:wait_job_finish", "Next": "ChoiceJobStatus" }, "ChoiceJobStatus": { "Type": "Choice", "Default": "Wait", "Choices": [ { "Or": [ { "Variable": "$.job_status", "StringEquals": "finished" }, { "Variable": "$.job_status", "StringEquals": "error" } ], "Next": "AfterAll" } ] }, "AfterAll": { "Type": "Task", "Resource": "arn:aws:lambda:ap-northeast-1:111111111111:function:after_all", "End": true } } }Lambda関数
以下、構成図中に登場するLambda関数のサンプル実装を掲載します。
ただ、あくまでもサンプルなのでいろいろ適当です。
実際にこの構成を容れる際は、エラーハンドリングやロギングを実施した上で、ARNはハードコーディングでなく、環境変数から取得するようにするなどの変更が必要になると思います。
- AccountBにおける、SNSへのメッセージPublishを行う関数(C)
import boto3 def lambda_handler(event, context): TOPIC_ARN = u'arn:aws:sns:ap-northeast-1:111111111111:cross-account-b' msg = 'hello' subject = u'Hello' client = boto3.client('sns') request = { 'TopicArn': TOPIC_ARN, 'Message': msg, 'Subject': subject } response = client.publish(**request) print(response)
- AccountAにおける、SQSへのPollingを行う関数(F)
import boto3 def lambda_handler(event, context): # Create SQS client sqs = boto3.client('sqs') queue_url = 'https://sqs.ap-northeast-1.amazonaws.com/111111111111/fetch-cross-account-b' response = sqs.receive_message( QueueUrl=queue_url, AttributeNames=[ 'SentTimestamp' ], MaxNumberOfMessages=1, VisibilityTimeout=0, WaitTimeSeconds=0 ) try: message = response['Messages'][0] receipt_handle = message['ReceiptHandle'] sqs.delete_message( QueueUrl=queue_url, ReceiptHandle=receipt_handle ) event['job_status'] = 'finished' return event except KeyError: event['job_status'] = 'waiting' return event
- 投稿日:2021-01-13T00:04:32+09:00
Dockerが注目される理由。そもそもDockerとは?その使い方
はじめに
本記事は、Dockerの初学者を対象に基礎的な内容を学ぶための記事。
※追伸:こちらの記事よりも更に良い記事を見つけてしまったので、もっと詳しく知りたい方は以下をご参照ください。
・Dockerでプログラマが最低限知るべきことが、最速でわかるチュートリアルDockerとは
Dockerは仮想化の一つで、コンテナ型仮想化と呼ばれている。
コンテナ型仮想化はOSの上に「コンテナ」と呼ばれる仮想的な空間を作ることでOSの上に仮想的なOSを展開して、更にプロセスの実行空間を区分け(隔離)できる。仮想化サーバーとの違い・長所
- 起動速度がはやい
- 移動が可能
- 稼働が軽い
- リソースが有効活用可能
Dockerが注目されている理由
一番の理由は、移動ができてリソースを有効活用できるということである。未使用のコンピュータ資源をアクティブに入れ替えながら使うことでサーバの効率化ができることから、クラウドサービスといった変動費の費用が発生するものと相性が良い。Google社では全部のソフトウェアをコンテナに乗せており、アクティブに入れ替えながら使うことでサーバの効率化をしている。
他には従来、何かサービスをつくる場合、エンジニアは環境の制約を大きく受けていた。自分が書いたコードが本当にサーバー上で動くのか心配しながら開発を行わなければらなかった。しかし、Dockerを使うことで、自身のPCなどのdockerでコンテナを実行してながら開発をすることで、コードを仕上げ、最終的にコンテナを移動させるだけで、アプリケーションを動く状態にできるのだ。
このことから、Dockerはインフラエンジニアのスキルに止まらず、
→プログラマーの必須科目と言われているのである。Dockerを使う流れ
1Dockerインストール
・OS上にDockerをインストールします。macやWindows、Linuxにインストールできる。
2Dockerfileの作成
・Dockerfileは、Docker Imageを作成するための手順を決めるテキストファイル。したがって、Docker Imageの作成をしない場合は不要。
3Docker Imageの作成
・コンテナイメージを任意の場所から持ってきて作成します。Dockerインストール後初期段階では、当然コンテナイメージは存在しないので、インターネット上からコマンド入力で持ってきます。
・インターネット上の一般的なイメージ格納場所として、「Docker Hub」というところがあります。他には、AWSのECR、さまざまな企業に独自のリポジトリサーバーに構築されて格納・管理されています。
4コンテナ起動実際のコマンド入力
・インターネットからイメージを取得する
$ docker pull [イメージの名前]Docker Hubでアカウントをつくり、サービス名を検索することで、コピ&ペーストできるコマンドを見つけることもできます。Copy and paste to pull this imageのところ。
例)Apacheのイメージ取得
$ docker pull httpd・イメージが取れたのか確認
$ docker images・docker起動
→オプションについて
① -d バックグラウンドでdockerを実行する
② -p ポートの指定。[8088:80]は[ホストのポート:コンテナのポート]の関係。コンテナの80をホスト側の8088で待ち受けるという意味になる。
※docker runコマンドはone liner(一行だけ)で実行でき、イメージを取得するコマンドを省略して実行できる。その場合は、イメージを自動でローカルで参照して無いなら、Docker Hubからとってきてくれる。$ docker run -d -p 8088:80 httpd・コンテナの状況を見る
→コンテナIDやSTUTASの項目を見ることができる。docker ps -a・コンテナ停止
$ docker stop [コンテナID]・コンテナ自体の削除
$ docker rm [コンテナID]・イメージの削除
$ docker rmi [コンテナID]おわりに
今回の内容ではDockerの基礎的な知識をまとめた。
応用としては、Dockerfileの作成やdocker-composerを使い複数のコンテナを管理することなど、オーケストレーションツールを使って、複数のDockerのリソース管理をするといった内容がある。
