- 投稿日:2020-12-16T23:38:01+09:00
DockerでMacに超絶シンプルなPHP&Apache環境を整える
はじめに
PHP案件を頂いたため、MAMPでやるかぁーと思ったのですが、ふと、「MAMPの必要あるか…?
」となりました。
というのも、今回はDB使わないし、MacにはPHPもApacheも入ってるよなと思ったのです。
Terminal$ php -v PHP 7.3.11 (cli) (built: Jun 5 2020 23:50:40) ( NTS ) Copyright (c) 1997-2018 The PHP Group Zend Engine v3.3.11, Copyright (c) 1998-2018 Zend Technologies $ httpd -v Server version: Apache/2.4.41 (Unix) Server built: Jun 5 2020 23:42:06うんうん入ってる。
ただし、ソースが動く本番環境のPHPバージョンは5系だったので、PHPのバージョンを切り替える必要がありました。
開発環境を整える方法として思いついたのは3つ。
- HomebrewでPHPバージョンを切り替えて開発する
- MAMPをちょっといじってPHPバージョンを切り替えて開発する
- Dockerを建てちゃう
そんなにPHP案件が多いわけではないですが、ローカル環境をガチャガチャするのが嫌だし、LinuxライクにコマンドポチポチーでApache起動できる方が慣れているので、今回は3つめのDockerを採用することにしました。
前提
環境 バージョン等 MacBook Pro 2019年モデル OS macOS Catalina Docker Engine v19.03.13 PHP 5.4 1. Docker Desktopをインストールする
公式サイトのDownload for Macを選択し、Docker Desktopをダウンロードします。
Docker.dmgを実行し、インストールします。
インストール完了したら実行します。
実行後、パスワードを求められることがありますが、適宜入力してください。実行すると上のメニューバーの右側にクジラさんが現れます。(ちっちゃくてすみません)↓
試しにターミナルでコマンドを打ってみて確認します。
$ docker version Client: Docker Engine - Community Cloud integration: 1.0.2 Version: 19.03.13 API version: 1.40 Go version: go1.13.15 Git commit: 4484c46d9d Built: Wed Sep 16 16:58:31 2020 OS/Arch: darwin/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 19.03.13 API version: 1.40 (minimum version 1.12) Go version: go1.13.15 Git commit: 4484c46d9d Built: Wed Sep 16 17:07:04 2020 OS/Arch: linux/amd64 Experimental: false containerd: Version: v1.3.7 GitCommit: 8fba4e9a7d01810a393d5d25a3621dc101981175 runc: Version: 1.0.0-rc10 GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd docker-init: Version: 0.18.0 GitCommit: fec36832. Dockerfileを作成してビルドする
2.1. Dockerfileの作成
Dockerfileを書いてイメージを作成します。
適当なディレクトリを作成し、Dockerfileを作成します。
$ mkdir php5_apache $ cd php5_apache $ vim Dockerfile公式のDockerイメージを拝借しちゃいましょう。
php:<version>-apacheと記述することで、Apacheも含んだコンテナを建てられます。
今回使用するバージョンは5.4ですのでその通り記述します。DockerfileFROM php:5.4-apache2.2. ビルド
docker build <Dockerfileのパス> -t <イメージ名>:<タグ名>
でビルドをかけます。ここでは、イメージ名はphp5_apache、タグはバージョンとして1.0と指定しておきます。
-t: 名前とタグを指定するオプション$ docker build ./ -t php5_apache:1.0ビルドできたか確認しましょう。
$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE php5_apache 1.0 7246b9f23253 5 years ago 470MBちなみに、Docker Desktopのダッシュボードからも確認することができます。
3. コンテナを作成し、起動する
早速起動させていきましょう。
動かしたいソースは既に手元にあるので、マウントしちゃいます。
コマンドは以下の通り。
docker run -d -p <ホスト側ポート>:<コンテナ側ポート> -v <ホスト側パス>:<コンテナ側パス> php5_apache:1.0今回使用したオプションの説明は以下。
-d: デタッチドモードで起動する(バックグラウンド実行)-p: コンテナのポートをホスト側に公開する-v: ホスト側のディレクトリをコンテナにマウントする$ docker run -d -p 80:80 -v <作業ディレクトリ>:/var/www/html php5_apache:1.0無事に起動できたか確認しましょう。
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 469f65bd6a4f php5_apache:1.0 "apache2-foreground" About a minute ago Up About a minute 0.0.0.0:80->80/tcp recursing_hodgkin4. ブラウザで確認
80番ポートで開いたのでポート指定なしで
localhostをブラウザのアドレスバーに入力し開きます。
無事にPHP等が出力されていればOKです。5. コンテナの開始と停止
コンテナを一度作成してしまえば、
docker start <コンテナIDまたはコンテナ名>で起動、docker stop <コンテナIDまたはコンテナ名>で停止できます。今回はコンテナ名でやってみます。
recursing_hodgkinと名付けられていましたので、それで停止、開始してみます。$ docker stop recursing_hodgkin $ docker start recursing_hodgkin6. コンテナにログインする
以下でrootでログインできます。
ちなみにOSはDebianです。$ docker exec -it recursing_hodgkin /bin/bash出るときはおなじみの
exit。# exit7. おまけ
7.1. Apacheのエラー
ふとログを見てみるとなんかエラーっぽいログが吐かれていました。
$ docker logs recursing_hodgkin AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 172.17.0.2. Set the 'ServerName' directive globally to suppress this message AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 172.17.0.2. Set the 'ServerName' directive globally to suppress this message [Thu Dec 10 09:58:54.402679 2020] [mpm_prefork:notice] [pid 1] AH00163: Apache/2.4.10 (Debian) PHP/5.4.45 configured -- resuming normal operations [Thu Dec 10 09:58:54.402792 2020] [core:notice] [pid 1] AH00094: Command line: 'apache2 -D FOREGROUND'「ドメイン名設定されてないよぉー困るよぉー
」という内容です。
ご親切に「ServerNameディレクティブを設定しろ」と解決策まで書いてくれていますね。多分設定しなくても問題ないんですが、エラーが残っているのが気持ち悪いので設定してあげます。
(私はCentOSばっかりいじってたので、DebianのApacheの設定ファイルとかどこ〜〜〜〜ってなりました。)
まずは、dockerにログイン。
$ docker exec -it recursing_hodgkin /bin/bashvimが慣れているので一応インストール。
apt updateしないとvimがインストールできなかったのでやむなくしてます。
Dockerfileに最初から書いとけばよかったと思いつつ……コンテナ内# apt update # apt -y upgrade # apt install -y vim # vim /etc/apache2/conf-enabled/httpd.conf/etc/apache2/conf-enabled/*.confをconfigファイルとして読み込んでいるようなので、この中に記述していきます。
httpd.confServerName localhost:80Apacheサービス再起動。
# /etc/init.d/apache2 reload [ ok ] Reloading web server: apache2.CentOSいじってると
systemctl restart httpdで再起動なので、service apache2 restartで再起動したくなるんですが、これを実行したらコンテナも一緒にお亡くなりになられたので、上記コマンドを叩きます。7.2. マルチバイト文字使えないんだが
モジュール入れてないやろ。
どこからかそんな声が聞こえてきました。
モジュールを入れて、
# docker-php-ext-install mbstringiniに追記し有効化します。
php.iniextension=mbstring.so恒例のapache再起。
# /etc/init.d/apache2 reload終わりに
私もDockerに明るいわけではないので、備忘録的に残しました。
phpのエラーログとか出すようにしたり、おまけに書いた部分をDockerfileに記述したり等、実際に開発始める上で躓いたところがあったので、そこらへんもあとで記事にしておきたいと思います。



- 投稿日:2020-12-16T23:29:53+09:00
Docker volumeパフォーマンスチューニング
・Docker Desktop for Macでマウントしたボリュームはアクセス性能が低いと言われている。
・Docker 17.03から導入されたマウントオプションを使うことで改善できる。そもそもなぜ遅いか
Linuxではホストとコンテナ間でVFSを基盤にしているのでファイル同期によるオーバーヘッドがない。
macOSではホストとコンテナで完全な一貫性を保つために著しいオーバーヘッドがある。ファイル更新時の同期に時間がかかるだけで読み込みには時間がかからないということか。
チューニング方針
完全な一貫性を保つとするとオーバーヘッドで遅くなる。
一貫性が必要ないケースは多々ある。そのため一貫性を犠牲にすることで性能を上げる。マウント設定
Dockerでマウント指定する際にマウント方法を指定することで一貫性を取るか性能を取るか決められる。
・consistent : ホストとコンテナで完全に同期する。
・cached : ホストを更新した時に遅延してコンテナに反映される
・delegated(委任) :コンテナの更新時に遅延してホストに反映される-vオプションのコンテナpathの最後に:をつけて上記のパラメータを付与することで使用可能。
例$ docker run -v /host/hoge:/container/hoge:cached sample 複数のボリュームで別の指定をすることも可能 $ docker run -v /host/1:/container/1:cached -v /host/2:/container/2:delegated sampledelegated
一番性能が上がる。ホストは変更せず、コンテナ側から一方的に変更するものに使用するのが良さそう。
コンテナのファイル状態を正とし、コンテナを修正してもホストに遅れて反映される。
破損してもokな一時的なファイルや再生成可能なビルド物に向いている。
delegatedでマウントしている場所をcachedやconsistentでマウントするとその場所はそれぞれの指定に従う。
ホスト側で変更をしても、コンテナ側の同期によってその変更が消える可能性がある。cached
ホストを正にする。ホストの書き込みはコンテナにすぐに同期されるが、コンテナの変更は遅延してホストに同期される。
cachedでマウントしている箇所をconsistentでマウントするとconsistentの挙動になる。consistent
ホストとコンテナが完全に同期する。
デフォルトでこの指定。パフォーマンス測定
Laravelプロジェクトをマウントしマウント設定を変えてパフォーマンスを計測する。
まずはローカルで直接artisan serveを起動した状態。1秒で29リクエスト捌ける。
$ ab -c 5 -n 25 http://127.0.0.1:8000/ This is ApacheBench, Version 2.3 <$Revision: 1843412 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/ Benchmarking 127.0.0.1 (be patient).....done Server Software: Server Hostname: 127.0.0.1 Server Port: 8000 Document Path: / Document Length: 17473 bytes Concurrency Level: 5 Time taken for tests: 0.855 seconds Complete requests: 25 Failed requests: 0 Total transferred: 465475 bytes HTML transferred: 436825 bytes Requests per second: 29.22 [#/sec] (mean) Time per request: 171.097 [ms] (mean) Time per request: 34.219 [ms] (mean, across all concurrent requests) Transfer rate: 531.35 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 0 0.0 0 0 Processing: 43 148 35.2 161 179 Waiting: 41 147 35.4 159 177 Total: 43 149 35.2 161 179 Percentage of the requests served within a certain time (ms) 50% 161 66% 162 75% 164 80% 166 90% 172 95% 174 98% 179 99% 179 100% 179 (longest request)コンテナ側に/appでマウントすると、
$ tree -L 2 . ├── Dockerfile └── laravel ├── README.md ├── app ├── artisan ├── bootstrap ├── composer.json ├── composer.lock ├── config ├── database ├── docker-compose.yml ├── package.json ├── phpunit.xml ├── public ├── resources ├── routes ├── server.php ├── storage ├── tests ├── vendor └── webpack.mix.jsFROM centos:centos8 RUN dnf module install -y php:7.4 WORKDIR /app CMD [ "php", "artisan", "serve", "--port=80", "--host=0.0.0.0" ]マウントする
$ docker run -it --rm -v $(pwd)/laravel:/app/ -p 8080:80 ro_testこの状態で5人が5回、合計25アクセスした時のパフォーマンス
$ ab -c 5 -n 25 http://localhost:8080/ This is ApacheBench, Version 2.3 <$Revision: 1843412 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/ Benchmarking localhost (be patient).....done Server Software: Server Hostname: localhost Server Port: 8080 Document Path: / Document Length: 17473 bytes Concurrency Level: 5 Time taken for tests: 8.982 seconds Complete requests: 25 Failed requests: 0 Total transferred: 465475 bytes HTML transferred: 436825 bytes Requests per second: 2.78 [#/sec] (mean) Time per request: 1796.408 [ms] (mean) Time per request: 359.282 [ms] (mean, across all concurrent requests) Transfer rate: 50.61 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 0 0.0 0 0 Processing: 373 1578 436.6 1755 1863 Waiting: 373 1578 436.7 1755 1862 Total: 373 1578 436.6 1755 1863 Percentage of the requests served within a certain time (ms) 50% 1752 66% 1769 75% 1778 80% 1804 90% 1810 95% 1825 98% 1863 99% 1863 100% 1863 (longest request)パフォーマンス cached
cachedなので若干パフォーマンスが上がるはず
$ docker run -it --rm -v $(pwd)/laravel:/app/:cached -p 8080:80 ro_test計測。あまり変わらない。。。
$ ab -c 5 -n 25 http://localhost:8080/ This is ApacheBench, Version 2.3 <$Revision: 1843412 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/ Benchmarking localhost (be patient).....done Server Software: Server Hostname: localhost Server Port: 8080 Document Path: / Document Length: 17473 bytes Concurrency Level: 5 Time taken for tests: 8.948 seconds Complete requests: 25 Failed requests: 0 Total transferred: 465475 bytes HTML transferred: 436825 bytes Requests per second: 2.79 [#/sec] (mean) Time per request: 1789.501 [ms] (mean) Time per request: 357.900 [ms] (mean, across all concurrent requests) Transfer rate: 50.80 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 0 0.0 0 0 Processing: 353 1571 435.7 1750 1813 Waiting: 353 1571 435.8 1749 1813 Total: 353 1571 435.7 1750 1814 Percentage of the requests served within a certain time (ms) 50% 1749 66% 1762 75% 1777 80% 1791 90% 1795 95% 1812 98% 1814 99% 1814 100% 1814 (longest request)パフォーマンス delegated
$ docker run -it --rm -v $(pwd)/laravel:/app/:delegated -p 8080:80 ro_test計測。これもあんまり変わらない。むしろ遅くなっている。
$ ab -c 5 -n 25 http://localhost:8080/ This is ApacheBench, Version 2.3 <$Revision: 1843412 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/ Benchmarking localhost (be patient).....done Server Software: Server Hostname: localhost Server Port: 8080 Document Path: / Document Length: 17473 bytes Concurrency Level: 5 Time taken for tests: 9.187 seconds Complete requests: 25 Failed requests: 0 Total transferred: 465475 bytes HTML transferred: 436825 bytes Requests per second: 2.72 [#/sec] (mean) Time per request: 1837.459 [ms] (mean) Time per request: 367.492 [ms] (mean, across all concurrent requests) Transfer rate: 49.48 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 0 0.0 0 0 Processing: 391 1582 403.0 1740 1843 Waiting: 391 1581 402.9 1739 1843 Total: 391 1582 403.0 1740 1843 Percentage of the requests served within a certain time (ms) 50% 1739 66% 1753 75% 1765 80% 1770 90% 1841 95% 1842 98% 1843 99% 1843 100% 1843 (longest request)コードをコンテナの中に入れる
FROM centos:centos8 RUN dnf module install -y php:7.4 COPY ./laravel /app WORKDIR /app CMD ["php", "artisan", "serve", "--host=0.0.0.0"]計測。コンテナ使う上ではこれが一番速い。秒間15リクエスト捌ける。
ab -c 5 -n 25 http://localhost:8080/ This is ApacheBench, Version 2.3 <$Revision: 1843412 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/ Benchmarking localhost (be patient).....done Server Software: Server Hostname: localhost Server Port: 8080 Document Path: / Document Length: 17473 bytes Concurrency Level: 5 Time taken for tests: 1.682 seconds Complete requests: 25 Failed requests: 0 Total transferred: 465475 bytes HTML transferred: 436825 bytes Requests per second: 14.86 [#/sec] (mean) Time per request: 336.380 [ms] (mean) Time per request: 67.276 [ms] (mean, across all concurrent requests) Transfer rate: 270.27 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 0 0.0 0 0 Processing: 94 295 70.8 316 355 Waiting: 93 294 71.0 315 354 Total: 94 295 70.7 316 355 Percentage of the requests served within a certain time (ms) 50% 315 66% 328 75% 331 80% 333 90% 345 95% 348 98% 355 99% 355 100% 355 (longest request)書き込みパフォーマンス
ファイル書き込み時のパフォーマンスをチェックする
ローカルで計測した場合
$ time (for i in $(seq 1 10000);do echo $i >> a.txt; done) ======================== Program : ( for i in $(seq 1 10000); do; echo $i >> a.txt; done; ) CPU : 88% user : 0.110s system : 0.550s total : 0.746s ========================consistentでマウントした場合。
コンテナで書き込むと0.220s。とても遅い。
ホストで書き込むと0.119s。
同じくらいかかると思ったけどコンテナの方が遅い。$ docker run -it --rm -v $(pwd)/fuga:/fuga centos:centos8 [root@29e3d05941ce fuga]# time (for i in $(seq 1 10000);do echo $i >> a.txt; done) real 0m11.249s user 0m0.220s sys 0m0.700s $ time (for i in $(seq 1 10000);do echo $i >> b.txt; done) ======================== Program : ( for i in $(seq 1 10000); do; echo $i >> b.txt; done; ) CPU : 88% user : 0.119s system : 0.608s total : 0.817s ========================書き込みパフォーマンス cached
$ docker run -it --rm -v $(pwd)/fuga:/fuga:cached centos:centos8 [root@53b5e0d31c60 fuga]# time (for i in $(seq 1 10000);do echo $i >> aa.txt; done) real 0m13.132s user 0m0.271s sys 0m0.804s↓ホスト側。consistentの時より若干早くなっている
time (for i in $(seq 1 10000);do echo $i >> ab.txt; done) ======================== Program : ( for i in $(seq 1 10000); do; echo $i >> ab.txt; done; ) CPU : 89% user : 0.119s system : 0.597s total : 0.800s ========================書き込みパフォーマンス delegated
cachedより速くなってる。
$ docker run -it --rm -v $(pwd)/fuga:/fuga:delegated centos:centos8 [root@e8334765081e fuga]# time (for i in $(seq 1 10000);do echo $i >> ddd.txt; done) real 0m11.714s user 0m0.191s sys 0m0.780s↓ホスト側。cchedより遅い・・・?
$ time (for i in $(seq 1 10000);do echo $i >> affff.txt; done) ======================== Program : ( for i in $(seq 1 10000); do; echo $i >> affff.txt; done; ) CPU : 87% user : 0.123s system : 0.616s total : 0.849s ========================
- 投稿日:2020-12-16T22:35:41+09:00
WSL2でDOCKER_HOSTが指定されているとDockerが動かない
TL;DR
Windows 10でDocker for Desktopが動いている状態で、WSLのubuntuでは動いていたdockerが、WSL2にしたら動かなくなったのは、環境変数
DOCKER_HOSTが指定されていたため。unset DOCKER_HOSTすると動く。現象
WSLでdockerが使えていたのに、WSL2にしたら動かなくなった。
$ docker ps [~] Cannot connect to the Docker daemon at tcp://localhost:2375. Is the docker daemon running?実際にDockerは動いており、ポート2375が空いていることはPower Shellで確かめることができる。
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES $ Test-NetConnection -ComputerName localhost -Port 2375 ComputerName : localhost RemoteAddress : ::1 RemotePort : 2375 InterfaceAlias : Loopback Pseudo-Interface 1 SourceAddress : ::1 TcpTestSucceeded : TrueWSLのバージョン確認。
$ wsl -l -v NAME STATE VERSION * Ubuntu Running 2 docker-desktop-data Running 2 docker-desktop Running 2WSLのバージョンは2で、docker-desktopも動いていますね。
原因は、(僕の場合は.zshrcにて)環境変数
DOCKER_HOSTが指定されていたため。export DOCKER_HOST=tcp://localhost:2375確かWSLではこれが必要だった。しかし、WSL2では不要。これをunsetすると動くようになる。
$ unset DOCKER_HOST $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES動いた。めでたい。
個人的にものすごく困っていたので、同じ理由で困っている人のためにここに記録を残しておきます。
参考
- 投稿日:2020-12-16T18:29:43+09:00
Ruby on Railsプロジェクトの開発環境をDocker化する
ACCESS Advent Calendar 2020 の16日目の記事です。
概要
現在運用中のRuby on Railsプロジェクトの開発環境をDocker化する案件があり、その際に行った移行作業の手順を示します。
Dockerについて
Dockerとは、コンテナと呼ばれる仮想環境を構築・実行できるようにするためのプラットフォームです。
私は今回初めてDockerを触ったのですが、Dockerの理解にあたっては入門Dockerが大変参考になりました。
前提
バージョン
- macOS Catalina 10.15.7
- Docker 19.03.13
- docker-compose 1.27.4
- Ruby 2.4.5
- mongoDB 3.0.15
- postgres 10
システム構成
こちらのシステム構成図の通りにDocker化していきます。
(※大分簡略化しています)
初めにRailsアプリケーションのDocker Containerを作成し、
その後オーケストレーションツールであるdocker-composeによって、
RailsアプリケーションをmongoDB及びpostgreSQLに接続します。手順
Dockerのインストール
Docker HubよりDocker Desktop for Macを導入します。
ターミナルで下記の2つのコマンドが実行できればOKです。
$ docker -v Docker version 19.03.13, build 4484c46d9d $ docker-compose -v docker-compose version 1.27.4, build 40524192必要なファイルの作成
Docker及びdocker-composeを動かすのに必要なファイルをプロジェクトのルートに作成します。
Dockerfile
ruby 2.4.5環境が予めインストールされている
ruby:2.4.5-slimというDockerイメージをDocker Hubから取得し、そのイメージ上にRails環境をセットアップしています。DockerfileFROM ruby:2.4.5-slim # Dockerコンテナ上におけるプロジェクトルートを指定 ENV APP_ROOT=/app RUN mkdir $APP_ROOT WORKDIR $APP_ROOT # apt-utilsインストールの時の警告を抑制する # https://qiita.com/haessal/items/0a83fe9fa1ac00ed5ee9 ENV DEBCONF_NOWARNINGS yes # aptパッケージのインストール RUN apt-get update -y -qq && \ apt-get install -y -qq build-essential libpq-dev libmagickwand-dev # Railsのセットアップ COPY Gemfile Gemfile COPY Gemfile.lock Gemfile.lock RUN gem install bundler -v 1.17.3 && bundle install # プロジェクトディレクトリをDocker Imageにコピー COPY . $APP_ROOTdocker-compose.yml
postgres,mongo,webの3つのサービスを定義し、
webをpostgres及びmongoに依存させています。docker-compose.ymlversion: "3" services: # postgreSQL containerの定義 postgres: image: postgres:10 ports: # <Host Port>:<Container Port> - "5432:5432" environment: POSTGRES_USER: xxxxxx POSTGRES_PASSWORD: xxxxxx # mongoDB containerの定義 mongo: image: mongo:3.0.15 ports: - "27017:27017" # Rails app containerの定義 web: build: . env_file: .env # pid error の回避のため、server.pidを削除したのちにrails sを実行 # https://qiita.com/sakuraniumarete/items/ac07d9d56c876601748c command: /bin/sh -c "rm -f tmp/pids/server.pid && bundle exec rails s -p 3000 -b '0.0.0.0'" # 依存関係の定義 (webをビルドするとpostgresとmongoが同時にビルドされる) depends_on: - postgres - mongoビルド実行
これら2つのファイルを作成すると、
$ docker-compose buildでコンテナをビルドできるようになります。
DBの永続化
現在の状態ではDBがコンテナ内部のストレージに生成されており、
コンテナを削除して再ビルドすると、DBに保存されていたデータは全て消失してしまいます。DB上のデータを永続化するためには、Dockerが提供している
volumeという機能を利用します。
volumeは、Docker Containerのライフサイクルからは独立して生成されるデータ保存領域です。
volume上にDBを生成することにより、コンテナを再ビルドしてもDB上のデータが残り続けるようになります。
引用元: https://matsuand.github.io/docs.docker.jp.onthefly/storage/volumes/volumeを利用するためには、docker-compose.ymlに以下の内容を追記します。
docker-compose.ymlservices: postgres: + volumes: + - "postgres-data:/var/lib/postgresql/data" mongo: + volumes: + - "mongo-data:/data/db" + volumes: + postgres-data: + mongo-data:上記を追記した上で改めてビルドすると、Docker Volumeが作成されているはずです。
$ docker volume ls local mongo-data local postgres-dataホストとコンテナのソースコードを同期
現在の状態では、Dockerfileをビルドした時点で、ホストの全データををImageにコピーしています。
DockerfileCOPY . $APP_ROOTつまり、これより後にホスト側でソースコードを変更した場合、動作しているコンテナを一旦停止させ、
docker-compose buildからやり直す必要があります。開発環境において毎度ビルドからやり直しているのでは非常に効率が悪いので、
ホストのコード変更をコンテナに即時反映できるようにします。よくある方法は、下記のように、プロジェクトのルートディレクトリを無名volumeとしてコンテナにマウントする方法です。
docker-compose.ymlservices: # ${APP_ROOT}はDockerfileにおいてENVで定義した環境変数 web:.:${APP_ROOT}しかし上記の方法では、Docker for Mac特有のVolume I/Oの遅さがパフォーマンスへ影響を及ぼすという問題があります。
(この問題について、docker/for-macのGitHubリポジトリにおいて議論されています。)
手元の環境においては特にRSpecへの影響が顕著で、上記の方法でマウントした場合、普段5分ほどで完了していたテストが30分ほどかかりました...docker-sync
この問題の解決策として、docker-syncというサードパーティライブラリを利用することができます。
新たに
docker-sync.ymlとdocker-compose-dev.ymlを作成します。
作成にあたってはdocker-syncのドキュメントを参考にしました。docker-sync.ymlversion: "2" syncs: sync-volume: src: "." sync_excludes: - "log" - "tmp" - ".git"docker-compose-dev.ymlversion: "3" services: web: volumes: - "sync-volume:/app:nocopy" volumes: sync-volume: external: trueDBセットアップ
以下のコマンドで、postgreSQLとmongoDBをセットアップします。
$ docker-compose run --rm -e RAILS_ENV=development -T web rake db:setup $ docker-compose run --rm -e RAILS_ENV=devlopment -T web rake db:mongoid:create_indexes
docker-compose run --rm <container name> <command>は、
指定したコンテナサービスを起動し、任意のコマンドを実行後、そのコンテナを削除するというコマンドです。
DBはvolumeで永続化されているので、セットアップのためだけにコンテナを作成し、その後削除してしまっても問題ないということです。Railsサーバーの実行
ここまでの手順を実施した上で、下記コマンドを実行することでRailsサーバーが起動します。
$ docker-sync-stack startこれは以下のコマンドを短縮したものです。
$ docker-sync start $ docker-compose -f docker-compose.yml -f docker-compose.yml up
-fオプションを使って複数のdocker-composeファイルを指定すると、
コンテナ作成時の各種パラメーターを上書きすることができます。
参考: 設定の追加と上書き - Docker-docs-jaまた、上記はフォアグラウンドで起動するためのコマンドで、
バックグラウンドで起動する場合は以下のコマンドを実行します。# 起動 $ docker-sync start $ docker-compose -f docker-compose.yml -f docker-compose.yml up # 停止 $ docker-compose down $ docker-sync stopテスト実行
RSpecを実行するためには、サーバーを起動した状態で以下のコマンドを実行します。
$ docker-compose exec -e COVERAGE=true -T web bundle exec rspec
docker-compose execで、起動中のDockerコンテナに対して任意のコマンドを実行できます。もしくは、以下のようにコンテナに入って実行することもできます。
$ docker-compose exec web bash root@container:/app# bundle exec rspecCI対応
CIツールとしてJenkinsを使用しています。
テストを実行するシェルスクリプト
ビルドジョブにおいて、下記のシェルを実行することで自動テストが行われるようにしました。
# 終了時の処理 # docker-composeが失敗した際でもJenkinsビルドマシンにゴミが残らないよう後処理をかける # https://qiita.com/ryo0301/items/7bf1eaf00b037c38e2ea function finally { # Clean project docker-compose down --rmi local --volumes --remove-orphans } trap finally EXIT # 並列実行のために、プロジェクト名としてJenkinsの環境変数である$BUILD_TAGを指定 export COMPOSE_PROJECT_NAME=$BUILD_TAG # 環境変数で予めビルドするdocker-composeファイルを指定することで、 # -fオプションによる指定を省略できる # https://docs.docker.jp/compose/reference/envvars.html export COMPOSE_PATH_SEPARATOR=: export COMPOSE_FILE=docker-compose.yml:docker-compose-test.yml # Build Container docker-compose build --no-cache docker-compose up -d # Setup DB docker-compose exec -e RAILS_ENV=test -T web rake db:setup docker-compose exec -e RAILS_ENV=test -T web rake db:mongoid:create_indexes # Run RSpec docker-compose exec -e COVERAGE=true -T web bundle exec rspecビルドジョブを並列実行できるようにする
RailsプロジェクトをDocker化していない時の問題として、
2つ以上のビルドジョブを並列実行すると、同じマシン上でDBの取り合いが起こり、
エラーが発生する問題がありました。Docker化したことで、それぞれのビルドが独立したコンテナの中で実行されるようになり、
並列実行してもエラーが起こらないようになります。
ただし、並列ビルドの実行時にコンテナのポート番号が重複しないよう、
ポートフォワーディングの設定を変更する必要があります。
参考: ホスト上にコンテナのポートを割り当て - Docker-docs-jaexport COMPOSE_FILE=docker-compose.yml:docker-compose-test.ymlで指定している
docker-compose-test.ymlの中身でそれを行っています。docker-compose-test.ymlversion: "3" services: postgres: ports: - "5432" mongo: ports: - "27017" web: ports: - "3000"また、
docker-compose.ymlに記載したポート番号をdocker-compose-dev.ymlに移動する必要があります。docker-compose.ymlservices: postgres: - ports: - - "5432:5432" mongo: - ports: - - "27017:27017" web: - ports: - - "3000:3000"docker-compose-dev.ymlservices: postgres: + ports: + - "5432:5432" mongo: + ports: + - "27017:27017" web: + ports: + - "3000:3000"理由としては、このまま
docker-compose up -dを実行すると、docker-compose.ymlとdocker-compose-test.ymlがマージされ、
結果としてポートの指定が以下のようになってしまい、docker-compose-test.ymlでわざわざポート指定した意味がなくなってしまうためです。services: postgres: ports: - "5432:5432" - "5432" mongo: ports: - "27017:27017" - "27017" web: ports: - "3000:3000" - "3000"Railsサーバーの実行の項で、
-fオプションを使って複数のdocker-composeファイルを指定すると、
コンテナ作成時の各種パラメーターを上書きすることができます。と述べましたが、複数指定可能なパラメータの場合は設定値は上書きされずにマージされるので注意が必要です。
おまけ: RubyMineへの対応
JetBrainsのIDEであるRubyMineは、Docker Container上のRuby on Railsの開発環境に完全対応しており、以下の手順で設定することができます。
チュートリアル : リモートインタープリターとしての Docker Compose — RubyMineまとめ
今回新たに作成したファイル
開発環境をDocker化するにあたり、新たに作成したファイルは以下の通りです。
. ├── Dockerfile ├── docker-compose.yml ├── docker-compose-dev.yml ├── docker-compose-test.yml └── docker-sync.ymlその他
今回初めてコンテナ技術に触れ、Docker化にあたっては様々な試行錯誤を重ねました。
これまでに書いた中で、もっと良い対応方法がある、或いは対応方法として正しくない箇所があるかもしれませんが、その時はご指摘いただければ幸いです。


- 投稿日:2020-12-16T17:13:20+09:00
【AWS ELB】 ELBやDockerを使って、EC2にWEBサーバ用のドメインを二つ持たせる奇行
はじめに
「ELBを使って、EC2にWEBサーバ用のドメインを二つ持たせる」
つまり、「ELBのリスナーでWEBサーバ用のドメインを二つ登録し、同じEC2(WEBサーバ)をターゲットグループのターゲットとする」という、ほとんど奇行ですねということを行ったのでその時のメモを残します。
あくまでこういうこともできるんだくらいな温度感で・・・はい、ご了承ください。(笑)内容
以下のような構成にしました。
・ELBのリスナールールに二つのドメインを割り当てて、ターゲットグループで80と8080をルーティングするように設定
・Dockerでnginxを二つ起動させておきます「ELB」→「EC2」→「Docker」→「nginx」:80ポートで待ち構えている (nginx1とします。) →「nginx」:8080ポートで待ち構えている(nginx2とします。)そこで、
・「nginx1」には「https://hoge.com」でアクセスできるように・・・ ・「nginx2」には「https://fuga.com」でアクセスできるように・・・のようにします。
ドメインを二つ用意する必要あるので、サブドメイン切るなど行ってください。
うーん、それにしても奇行ですねー。
奇行までの環境構築
VPCやEC2、ELBの構築、ドメイン設定などは以下をご参照ください。
わかりやすく解説とともに構築までの流れを展開されています。・0から始めるAWS入門:概要
→ https://qiita.com/hiroshik1985/items/6433d5de97ac55fedfde
・0から始めるAWS入門①:VPC編
→ https://qiita.com/hiroshik1985/items/9de2dd02c9c2f6911f3b
・0から始めるAWS入門②:EC2編
→ https://qiita.com/hiroshik1985/items/f078a6a017d092a541cf
・0から始めるAWS入門③:ELB編
→ https://qiita.com/hiroshik1985/items/ffda3f2bdb71599783a3奇行
1. ターゲットグループを作成
一つ目の「nginx1」用のターゲットグループとして、
・ターゲットグループ構築画面で、「Instances」→「ターゲットグループ名記入」→「ポート80」→「作成したVPC」→あとは良しなに→「Next」を選択します ・Available instancesに構築したEC2を選択し、「Include as pending below」→「Create target group」を選択します二つ目の「nginx2」用のターゲットグループとして、
・ターゲットグループ構築画面で、「Instances」→「ターゲットグループ名記入」→「ポート8080」→「作成したVPC」→あとは良しなに→「Next」を選択します ・Available instancesに構築したEC2を選択し、「Include as pending below」→「Create target group」を選択します2. リスナーのルールに2つのドメインを追加
一つ目の「nginx1」用のリスナールールとして
・ロードバランサー構築画面で、対象のロードバランサーを選択し、「リスナー」タブを選択します ・ルール部分の「ルールの表示/編集」を選択します ・ルールの挿入を行い、条件に「ホストヘッダー...」を選択し、値に「WEBサーバドメイン」を入力します。 ・アクションの追加を選択し、「nginx1」用に作成したターゲットグループを割り当てます二つ目の「nginx2」用のリスナールールとして
・ロードバランサー構築画面で、対象のロードバランサーを選択し、「リスナー」タブを選択します ・ルール部分の「ルールの表示/編集」を選択します ・ルールの挿入を行い、条件に「ホストヘッダー...」を選択し、値に「WEBサーバドメイン」を入力します。 ・アクションの追加を選択し、「nginx2」用に作成したターゲットグループを割り当てます所感
本当に奇行だと思いますし、やらないと思いますが、
・サーバ構築するのめんどい ・ただ動くのみたいだけだからひとまず開発環境として作ってみる ・動いた ・プログラム問題ないな、じゃあ捨てますとかしたいときにいいと思います。
- 投稿日:2020-12-16T16:38:57+09:00
Docker/Postgresでpassword authentication failedが出た場合の対処法
エラー内容
Unable to connect to the database. error: password authentication failed for user "xxx"または
Password does not match for user “xxx”原因
一度Dockerを立ち上げた後、認証情報(
POSTGRES_USERやPOSTGRES_PASSWORD)を変更した場合に発生します。認証情報は、初期起動時に設定されます。その後、認証情報を変えて起動しようとしても、当初設定した値と一致しないので、エラーになります。
対応方法
- db volumeを削除して、起動する(※db volume内のデータは失われることに注意)。
## docker を削除 $ docker rm <xxx> $ docker volume ls DRIVER VOLUME NAME local some_db_data $ docker volume prune WARNING! This will remove all local volumes not used by at least one container. Are you sure you want to continue? [y/N] y ## 削除されていることを確認 $ docker volume ls参照先
https://stackoverflow.com/questions/54764965/password-does-not-match-for-user-postgres
- 投稿日:2020-12-16T15:48:45+09:00
Elastic Stack を Docker で構築し IIS ログを分析する
はじめに
Elasticsearch アドベントカレンダー(2020年)の23日目の記事です。
IIS ログをエクセルに張り付けてピボットテーブルを作成しピボットグラフにする原始的な作業をもうやりたくないので Elastic Stack を構築してみたところ簡単に分析出来るようになったので記事に起こしました。目次
各ソフトウェア概要
- Elastic Stack は Elasticsearch,Kibana,Beats,Logstash からなるプロダクト群の総称です。
- Beats はデータシッパーと呼ばれ,データ転送ツールとして用いられます。
- 自動でファイルの更新を検知し差分を転送してくれます。
- 今回は Filebeats を使用します。
- Logstash はデータ処理パイプラインと呼ばれ,データを取り込み,変換し Elasticsearch に格納することが出来ます。
- Elasticsearch は言わずと知れた全文検索エンジンです。データ投入時に内部で転置インデックスを作成することで大量のドキュメントを高速に検索出来るようにしてます。
- Kibana は Elasticsearch のデータを可視化するツールとして用いられます。
処理フロー
- 処理フローは [Filebeat -> Logstash -> Elasticsearch -> Kibana]
- Filebeat で IIS ログを監視し,更新を検知したら Logstash に転送します。
- Logstash で json に変換し,Elasticsearch に投入します。
- Kibana で Elasticsearch のデータを可視化します。
Docker Compose で Elastic Stack を構築する
Docker Compose で構築します。
docker-compose.yml があるディレクトリで docker-compose up -d でコンテナを起動します。> docker-compose up -d構成
- ./filebeat/log に IIS ログを格納します。
- コンテナが起動していれば自動で Elasticsearch に投入されます。
. ├─docker-compose.yml ├─.env ├─elasticsearch │ └─data ├─filebeat │ ├─conf │ │ └─filebeat.yml │ └─log │ └─u_exyyyymmdd.log └─logstash └─pipeline └─logstash.confdocker-compose.yml
- Elasticsearch,Kibana,Logstash,Filebeat を構築します。
- Elasticsearch はシングルノードで構築します。
- Elasticsearch のデータを保持できるようボリュームをローカルにマウントします。
- Kibana で作成したグラフやダッシュボードもここに格納されます。
- Logstash ではローカルの設定ファイルを読み込みます。
- Filebeat ではローカルの設定ファイルを読みこみます。
- Filebeat でローカルのログを参照できるようにボリュームをマウントします。
- Filebeat で Docker のソケットを参照するらしいのでマウントします。
version: "3" services: elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0 environment: - discovery.type=single-node - cluster.name=docker-cluster - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms4096m -Xmx4096m" ulimits: memlock: soft: -1 hard: -1 ports: - 9200:9200 volumes: - ./elasticsearch/data:/usr/share/elasticsearch/data kibana: image: docker.elastic.co/kibana/kibana:7.2.0 ports: - 5601:5601 logstash: image: docker.elastic.co/logstash/logstash:7.2.0 ports: - 5044:5044 environment: - "LS_JAVA_OPTS=-Xms4096m -Xmx4096m" volumes: - ./logstash/pipeline:/usr/share/logstash/pipeline filebeat: image: docker.elastic.co/beats/filebeat:7.2.0 volumes: - ./filebeat/conf/filebeat.yml:/usr/share/filebeat/filebeat.yml - ./filebeat/log:/usr/share/filebeat/log - /var/run/docker.sock:/var/run/docker.sock user: root.env
Docker for Windows で /var/run/docker.sock をマウント出来るようにします。
COMPOSE_CONVERT_WINDOWS_PATHS=1logstash.conf
- Filebeat からの転送を受け付けるように input を設定します。
- IIS ログを加工します。
- Elasticsearch に投入出来るよう output を設定します。
input { # input from Filebeat beats { port => 5044 } } filter { dissect { # log format is TSV mapping => { "message" => "%{ts} %{+ts} %{s-ip} %{cs-method} %{cs-uri-stem} %{cs-uri-query} %{s-port} %{cs-username} %{c-ip} %{cs(User-Agent)} %{cs(Referer)} %{sc-status} %{sc-substatus} %{sc-win32-status} %{time-taken}" } } date { match => ["ts", "YYYY-MM-dd HH:mm:ss"] timezone => "UTC" } ruby { code => "event.set('[@metadata][local_time]',event.get('[@timestamp]').time.localtime.strftime('%Y-%m-%d'))" } mutate { convert => { "sc-bytes" => "integer" "cs-bytes" => "integer" "time-taken" => "integer" } remove_field => "message" } } output { elasticsearch { hosts => [ 'elasticsearch' ] index => "iislog-%{[@metadata][local_time]}" } }filebeat.yml
- /usr/share/filebeat/log を参照するように input を設定します。
- 実際は ./filebeat/log を /usr/share/filebeat/log にマウントしているので ./filebeat/log に IIS ログを格納すれば Filebeat が自動で参照します。
- Logstash に転送するよう output を設定します。
filebeat.inputs: - type: log enabled: true paths: - /usr/share/filebeat/log/*.log exclude_lines: ['^#','HealthChecker'] output.logstash: hosts: ["logstash:5044"]IIS ログファイルを置く
IIS ログファイルを ./filebeat/log に置くと Filebeat がそれを検知し Logstash に送信します。
送信されたデータは Logstash で加工され,Elasticsearch に投入されます。Kibana で可視化する
Elasticsearch の Index 確認
http://localhost:5601 にアクセスします。
歯車アイコンをクリックし,Elasticsearch/Index Management をクリックします。
IIS ログの Index が作成されていることを確認します。
Kibana の Index Pattern 作成
Kibana/Index Patterns をクリックし,Create Index pattern をクリックします。
Index pattern を入力し Next step をクリックします。
Time Filter field name で @timestamp を選択し Create index pattern をクリックします。
ここで作成した Index pattern を選択しグラフを作成していきます。
グラフ作成
先ほど作成した Index pattern を指定します。
右上の表示期間を絞り込みます。
X 軸を指定します。
Aggregation を Date Histogram,Field を @timestamp,Minimum interval を Minute とし,▷をクリックします。
これで分間のリクエスト数がグラフに表示されました。
機能ごとの分間リクエスト数を表示するには Add filter をクリックし,Field(フィルターをかけたい項目),Operator(演算子),Value(値) を指定します。
ダッシュボード作成
作成したグラフをダッシュボードに並べることが出来ます。














- 投稿日:2020-12-16T15:42:33+09:00
【保存版】Docker × React × Railsで環境構築していく方法
はじめに
本記事へのアクセスありがとうございます。
投稿主はプログラミング初心者であり、この方法が「最適解」かは分かりません。
しかし、動作は検証済みであり同様な記事も確認できたので信憑性はあると思います。記事通りにコピペしていくだけで環境構築できますので、説明がいらない人はコードだけをコピペして行ってください。
想定読者
- Dockerインストール済み
- Docker初心者
- フロントエンド側とバックエンド側の開発環境を分けて構成したい
- 現在 ( 2020年12月 )にある同様なQiita記事でエラーで詰まってしまっている
最終ファイル構成
- apiの中にRailsファイルを格納されています。
- frontの中にReactファイルを格納されています。
さっそくスタート
初期ファイルを用意する
apiの中にはDockerfile , entrypoint.sh , Gemfile , Gemfile.lockの4つを作成する。
* Gemfile.lockは何も記述しないファイルとする。docker-compose.ymlの記述
docker-compose.ymlを記述していきます
docker-compose.ymlversion: '3' services: db: image: postgres:12.3 volumes: - postgres-data:/var/lib/postgresql/data environment: - POSTGRES_PASSWORD=password api: build: context: ./api/ dockerfile: Dockerfile command: /bin/sh -c "rm -f /myapp/tmp/pids/server.pid && bundle exec rails s -p 3000 -b '0.0.0.0'" image: rails:dev volumes: - ./api:/myapp - ./api/vendor/bundle:/myapp/vendor/bundle - ./api/vendor/node_modules:/myapp/vendor/node_modules environment: TZ: Asia/Tokyo RAILS_ENV: development ports: - "3000:3000" depends_on: - db front: build: context: ./front/ dockerfile: Dockerfile volumes: - ./front:/usr/src/app command: sh -c "cd react-sample && yarn start" ports: - "8000:3000" volumes: postgres-data: driver: local bundle: node_modules:api / Dockerfileの記述
Dockerfileを記述していきます
FROM ruby:2.7 RUN apt-get update -qq && apt-get install -y nodejs postgresql-client yarnpkg RUN ln -s /usr/bin/yarnpkg /usr/bin/yarn RUN mkdir /myapp WORKDIR /myapp COPY Gemfile /myapp/Gemfile COPY Gemfile.lock /myapp/Gemfile.lock RUN bundle install COPY . /myapp # Add a script to be executed every time the container starts. COPY entrypoint.sh /usr/bin/ RUN chmod +x /usr/bin/entrypoint.sh ENTRYPOINT ["entrypoint.sh"] EXPOSE 3000 # Start the main process. CMD ["rails", "server", "-b", "0.0.0.0"]api / entrypoint.shの記述
entrypoint.shを記述していきます
entrypoint.sh#!/bin/bash set -e # Remove a potentially pre-existing server.pid for Rails. rm -f /myapp/tmp/pids/server.pid # Then exec the container's main process (what's set as CMD in the Dockerfile). exec "$@"api / Gemfileの記述
Gemfileを記述していきます
source 'https://rubygems.org' gem 'rails', '~>6'front / Dockerfileの記述
Dockerfileを記述していきます
FROM node:10-alpine RUN mkdir /myapp WORKDIR /usr/src/app* node:10以上出ないと後々にcreate-react-app出来ないので注意してください
コマンドを実行する
まずは以下の3つのコマンドをターミナルで入力してください
$ docker-compose run api rails new . --force --no-deps --database=postgresql --api $ docker-compose build $ docker-compose run --rm front sh -c "npm install -g create-react-app && create-react-app react-sample"api/config/database.ymlを下記のように書き換えてください
api/config/database.ymldefault: &default adapter: postgresql encoding: unicode # For details on connection pooling, see Rails configuration guide # https://guides.rubyonrails.org/configuring.html#database-pooling host: db username: postgres password: password pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>次に以下のコマンドをターミナルで入力してください
$ docker-compose up以下のコマンドを現在まで使用しているターミナルとは別のターミナル(新規作成)で入力してください
$ docker-compose run api rake db:create以上で環境構築が完了です。
おわりに
この状況で...
localhost:3000にアクセスすると、Rails用のページにアクセスします。
localhost:8000にアクセスすると、React用のページにアクセスします。お疲れ様でした。
少しでも役に立ったと思う方がいましたらLGTMをお願いします?♂️
おまけ
Docker内で開発するときは以下のコマンドを利用します。
docker-compose run web bundle exec rails g コマンド


- 投稿日:2020-12-16T15:06:05+09:00
KoalasとElasticsearchが連携できるか試してみた
この記事は、NTTテクノクロスAdvent Calnder 2020の18日目です。
こんにちは、NTTテクノクロスの@yuyhiraka (平川) と申します。
普段は仮想化/コンテナ/クラウド基盤、小規模ネットワークあたりの先進技術のPoCを主に担当しています。この記事に記載の内容は個人的な取り組みの内容であり、所属する組織とは関係ありません。
はじめに
KoalasとElasticsearchが連携できるかを試してみました。
世の中的にApache Spark TMとElasticsearchの連携を試されている方々がいるのでその応用となる動作検証となります。
- Spark on elasticsearch-hadoop トライアル
- ElasticsearchのデータをApache Sparkで加工する
- Elasticsearchのクラスタを構築してSparkでIndexを作るまでの簡易手順
Elasticsearchとは
Elasticsearchは検索・分析のための検索エンジンおよびデータベースおよびエコシステムです。
Elasticsearchについての参考情報
Apache Spark TMとは
Apache Spark TMは高速なビッグデータ用の分散処理フレームワークです。Pythonにも対応しており特にPySparkと呼びます。
Apache Spark TMについての参考情報
- Apache Spark™ - Apache Spark とは~分散処理入門の方にもわかりやすくご紹介
- Apache Spark™ - Unified Analytics Engine for Big Data
pandasとは
pandasはPython用の強力なデータ分析ライブラリです。
pandasについての参考情報
Koalasとは
KoalasはApache Spark TMでpandasライクのデータ操作が可能になるラッパーライブラリです。 Apache Spark TMにはSpark Dataset/DataFrameと呼ばれるPandasのDataFrameに近い概念が存在しますが各種APIが異なるためpandas ⇔ Spark Dataset/DataFrame間でオブジェクト変換した際に混乱します。それを解決するアプローチがKoalasになります。
Koalasについての参考情報
- Koalas_ pandas API on Apache Spark
- Spark+AI Summit 2019参加レポート at San Francisco — Spark3.0/Koalas/MLflow/Delta Lake
ElasticsearchとApache Spark TMの連携について
同じバージョンが振られていることからElasticsearch-Hadoopプラグイン (elasticsearch-hadoop 7.10) を使えばElasticsearch 7.10とHadoopエコシステム (Apache Spark TM, Koalasを含む) の連携ができそうです。一方で2020年12月現在においてElasticsearch-Hadoopプラグインを用いてElasticsearchとApache Spark TM 3.0.xの連携ができないようです。
そこで今回は以下を満たすApache Spark TM 2.4.7を利用することにします。
- Koalasのサポートバージョン
- Elasticsearch-Hadoopプラグインのサポートバージョン
Elasticsearch-HadoopプラグインとElasticsearchのバージョンについての参考情報
ElasticsearchとApache Spark TM 3.0.xの連携についての参考情報
- Documentation Databricks Workspace guide Data guide Data sources ElasticSearch
- Restructure Spark Project Cross Compilation #1423
- [Feature] Spark3.0 support #1412
KoalasのDependenciesについての参考情報
検証環境の情報について
マシンスペック
- VirtualBox 6.1.10上のUbuntu 20.04 LTS
- vCPU 6コア
- vMem 32GB
- SSD 100GB
- via HTTP/HTTPS Proxy
(※HTTP/HTTPS Proxyの各種設定については手順上省略します。)Dockerバージョン
# docker version Client: Docker Engine - Community Version: 20.10.0Apache Spark TM 2.4.7のコンテナイメージを作成する
検証のための環境構築稼働を節約するためBuild an Image with a Different Version of Sparkを参考にPySpark2.4.7とJupyterLabがインストール済のコンテナイメージを作成します。
# mkdir ~/pyspark-notebook # curl -O https://raw.githubusercontent.com/jupyter/docker-stacks/master/pyspark-notebook/Dockerfile # mv Dockerfile ~/pyspark-notebook # docker build --rm --force-rm \ -t jupyter/pyspark-notebook:spark-2.4.7 ./pyspark-notebook \ --build-arg spark_version=2.4.7 \ --build-arg hadoop_version=2.7 \ --build-arg spark_checksum=0F5455672045F6110B030CE343C049855B7BA86C0ECB5E39A075FF9D093C7F648DA55DED12E72FFE65D84C32DCD5418A6D764F2D6295A3F894A4286CC80EF478 \ --build-arg openjdk_version=8上記のベースイメージに対してElasticsearch-HadoopプラグインとKoalasをインストールするためのDockerfileを作成します。しかし、PySpark2.4はそのままだとPython3.8.xで動作しないため対策としてPython3.7.xのconda仮想環境を作っておきます。
※cloudpickle.pyを差し替えたうえで改造するという方法もあるようですが今回は試しません。
# mkdir ~/koalas-spark # vi ~/koalas-spark/Dockerfile FROM jupyter/pyspark-notebook:spark-2.4.7 USER root RUN apt-get update RUN apt-get install -y curl USER jovyan RUN mkdir ~/jars RUN curl https://repo1.maven.org/maven2/org/elasticsearch/elasticsearch-hadoop/7.10.1/{elasticsearch-hadoop-7.10.1.jar} --output "/home/jovyan/jars/#1" RUN conda create -n py37 -c conda-forge python=3.7 jupyter pyspark=2.4 koalas=1.5 openjdk=8 -y作成したDockerfileを使ってコンテナイメージを作成します。
# docker image build --rm --force-rm -t koalas-spark:0.1 ~/koalas-spark/Elasticsearchのコンテナイメージをローカルに取得
大きめのコンテナイメージなので先に取得しておきます。
# docker pull elasticsearch:7.10.1Docker Composeでコンテナ起動
必要ディレクトリ作成とdocker-compose.yamlの作成を行います。
# mkdir /opt/es # mkdir /opt/koalas-spark/ # コンテナからアクセスできるようにパーミッションを緩める (手抜き) # chmod 777 /opt/es /opt/koalas-spark/ # vi docker-compose.yaml version: '3' services: elasticsearch: image: elasticsearch:7.10.1 container_name: elasticsearch environment: - discovery.type=single-node - cluster.name=docker-cluster - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms512m -Xmx512m" ulimits: memlock: soft: -1 hard: -1 ports: - 9200:9200 volumes: - /opt/es/:/usr/share/elasticsearch/data networks: - devnet koalas-spark: build: ./koalas-spark container_name: koalas-spark working_dir: '/home/jovyan/work/' tty: true volumes: - /opt/koalas-spark/:/home/jovyan/work/ networks: - devnet networks: devnet:Docker Composeを用いてKoalasコンテナとElasticsearchコンテナを立ち上げます。また、Elasticsearchコンテナが正常に起動していることを確認します。
# docker-compose build # docker-compose up -d # curl -X GET http://localhost:9200 { "name" : "6700fb19f202", "cluster_name" : "docker-cluster", "cluster_uuid" : "P-uVFNu6RZKKxdklnVypbw", "version" : { "number" : "7.10.1", "build_flavor" : "default", "build_type" : "docker", "build_hash" : "1c34507e66d7db1211f66f3513706fdf548736aa", "build_date" : "2020-12-05T01:00:33.671820Z", "build_snapshot" : false, "lucene_version" : "8.7.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search"Koalasコンテナの中に入る
起動しているコンテナ一覧の中からKoalasコンテナのコンテナIDを確認します。次にコンテナIDを指定しKoalasコンテナの中に入ります。 別解として
docker-compose execを使う方法もあります。# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e33681a37aea root_koalas-spark "tini -g -- start-no…" 2 minutes ago Up 2 minutes 8888/tcp koalas-spark fe65e3351bea elasticsearch:7.10.1 "/tini -- /usr/local…" 16 minutes ago Up 16 minutes 0.0.0.0:9200->9200/tcp, 9300/tcp elasticsearch # docker exec -it e33681a37aea bashcurlコマンドを用いてKoalasコンテナからElasticsearchコンテナへの疎通の確認をします。
$ curl -X GET http://elasticsearch:9200 { "name" : "6700fb19f202", "cluster_name" : "docker-cluster", "cluster_uuid" : "P-uVFNu6RZKKxdklnVypbw", "version" : { "number" : "7.10.1", "build_flavor" : "default", "build_type" : "docker", "build_hash" : "1c34507e66d7db1211f66f3513706fdf548736aa", "build_date" : "2020-12-05T01:00:33.671820Z", "build_snapshot" : false, "lucene_version" : "8.7.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search"KoalasからElasticsearchへの書き込み
引き続きKoalasコンテナで作業を進めます。
Python3.7環境に切り替えてPySpark (IPython) を起動しElasticsearchに対してデータの書き込みを行います。今回はSpark RDDの機能を用いて4行4列のデータを作成しています。それを一度Spark DataFrameに変換し、さらにKoalas DataFrameに変換しています。
$ conda activate py37 $ export PYARROW_IGNORE_TIMEZONE=1 $ pyspark --jars /home/jovyan/jars/elasticsearch-hadoop-7.10.1.jar import databricks.koalas as ks import pandas as pd import json, os, datetime, collections from pyspark.sql import SparkSession, SQLContext, Row from pyspark.sql.types import * esURL = "elasticsearch" rdd1 = sc.parallelize([ Row(col1=1, col2=1, col3=1, col4=1), Row(col1=2, col2=2, col3=2, col4=2), Row(col1=3, col2=3, col3=3, col4=3), Row(col1=4, col2=4, col3=4, col4=4) ]) df1 = rdd1.toDF() df1.show() kdf1 = ks.DataFrame(df1) print(kdf1) kdf1.to_spark_io(path="sample/test", format="org.elasticsearch.spark.sql", options={"es.nodes.wan.only": "false", "es.port": 9200, "es.net.ssl": "false", "es.nodes": esURL}, mode="Overwrite")PySpark (IPython) からCtrl + Dキー等で抜けます。そして、Elasticsearchにデータが格納されていることを確認します。
curl -X GET http://elasticsearch:9200/sample/test/_search?pretty { "took" : 3, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 4, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "sample", "_type" : "test", "_id" : "kaTbZXYBpKFycpUDLgjO", "_score" : 1.0, "_source" : { "col1" : 4, "col2" : 4, "col3" : 4, "col4" : 4 } }, { "_index" : "sample", "_type" : "test", "_id" : "kKTbZXYBpKFycpUDLgjG", "_score" : 1.0, "_source" : { "col1" : 2, "col2" : 2, "col3" : 2, "col4" : 2 } }, { "_index" : "sample", "_type" : "test", "_id" : "j6TbZXYBpKFycpUDLgjG", "_score" : 1.0, "_source" : { "col1" : 3, "col2" : 3, "col3" : 3, "col4" : 3 } }, { "_index" : "sample", "_type" : "test", "_id" : "jqTbZXYBpKFycpUDLgjD", "_score" : 1.0, "_source" : { "col1" : 1, "col2" : 1, "col3" : 1, "col4" : 1 } } ] } }まとめ
上記の通りElasticsearch-Hadoopプラグインを用いてKoalasからElasticsearchにデータを投入できることを確認することができました。
当初の想定では
PySpark (IPython) ⇒ JupyterLab
Docker Compose ⇒ Kubernetes
で検証する予定だったのですが本質ではないところに時間をかけるわけにもいかなかったので今回は妥協しています。おそらくJupyterLab/Kubernetesで実施しても同様にKoalasからElasticsearchに問題なくデータ投入することができるはずなので今後試してみたいと思います。また、要望がたくさん挙がってることから近いうちに対応しそうですがElasticsearch-HadoopプラグインがApache Spark TM 3.0.xでも利用できるようになることを強く望みます。
明日は@y-ohnukiによるNTTテクノクロスAdvent Calnder 2020の記事です。お楽しみに!
- 投稿日:2020-12-16T14:36:19+09:00
【Docker】環境構築時に起きたエラー一覧
はじめに
Dockerについて学習し、既存のRailsアプリにDockerを導入しようと思い、公式のクイックスタートなどを参照しながら行いました。
その時に発生したエラーを備忘録のため、投稿しています。環境
Ruby '2.6.5'
Rails '6.0.0'
Docker for Mac導入済みエラー事例①
状況
DockerfileFROM ruby:2.6.5 RUN curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - \ && echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list RUN apt-get update -qq && apt-get install -y build-essential libpq-dev nodejs yarn RUN mkdir /(アプリ名) WORKDIR /(アプリ名) COPY Gemfile /(アプリ名)/Gemfile COPY Gemfile.lock /(アプリ名)/Gemfile.lock RUN bundle install COPY . /(アプリ名) COPY entrypoint.sh /usr/bin/ RUN chmod +x /usr/bin/entrypoint.sh ENTRYPOINT ["entrypoint.sh"] EXPOSE 3000 CMD ["rails", "server", "-b", "0.0.0.0"]% docker-compose build で立ち上げようとすると下記のエラーが発生
エラー文
エラー文/usr/local/lib/ruby/2.6.0/rubygems.rb:283:in `find_spec_for_exe': Could not find 'bundler' (2.1.4) required by your /assist/Gemfile.lock. (Gem::GemNotFoundException) To update to the latest version installed on your system, run `bundle update --bundler`. To install the missing version, run `gem install bundler:2.1.4` from /usr/local/lib/ruby/2.6.0/rubygems.rb:302:in `activate_bin_path' from /usr/local/bin/bundle:23:in `<main>' ERROR: Service 'web' failed to build : The command '/bin/sh -c bundle install' returned a non-zero code: 1解決策
RUN gem install bundlerを挿入すると解決!
Dockerfile(中略) COPY Gemfile.lock /(アプリ名)/Gemfile.lock RUN gem install bundler RUN bundle install (中略)調べてみると、原因はlocal環境とDocker内でのbundlerのバージョンが違うため、エラーが出たそうです。gem install bundlerを入れるととりあえず解決。。。まだまだあります。。。
エラー事例②
状況
docker-compose.ymlversion: "3" services: db: image: mysql:5.6.47 environment: MYSQL_ROOT_PASSWORD: password MYSQL_DATABASE: root ports: - "3000:3000" volumes: - ./db/mysql/volumes:/var/lib/mysql web: build: . command: bash -c "rm -f tmp/pids/server.pid && bundle exec rails s -p 3000 -b '0.0.0.0'" stdin_open: true tty: true volumes: - .:/(アプリ名) - gem_data:/usr/local/bundle ports: - "3000:3000" depends_on: - db volumes: mysql_data: gem_data:docker-compose build成功後、docker-compose up -dコマンドを実行したところ、
エラー文
ERROR: for web Cannot start service web: driver failed programming external connectivity on endpoint myapp_web_1 (ae889e882d7c9f8b72f9c9b244159d86662f4abebef7d15fac4016573fe56de4): Bind for 0.0.0.0:3000 failed: port is already allocated ERROR: Encountered errors while bringing up the project.解決策
DBサーバーとWebサーバーのポート番号を3000で同じにしていたため、Webサーバーが立ち上がらないことが原因であると考えます。単純なミスでした。。
DBのポート番号を3306に変更し、修正しました。
docker-compose.yml(中略) ports: - "3306:3306"エラー事例③
状況
先ほどのエラーを解決後、もう一度、docker-compose upコマンド実行してみると、、下記のエラーが発生。
エラー文warning Integrity check: System parameters don't match error Integrity check failed error Found 1 errors. web_1 | web_1 | web_1 | ======================================== web_1 | Your Yarn packages are out of date! web_1 | Please run `yarn install --check-files` to update. web_1 | ======================================== web_1 | web_1 | web_1 | To disable this check, please change `check_yarn_integrity` web_1 | to `false` in your webpacker config file (config/webpacker.yml). web_1 | web_1 | web_1 | yarn check v1.22.5 web_1 | info Visit https://yarnpkg.com/en/docs/cli/check for documentation about this command. web_1 | web_1 | web_1 | Exiting見たところ、yarnのupgradeを行ってくださいかのように感じたため、yarn upgradeコマンドを実行するも、変わらず。。。
解決策
エラー文をよくよく見てみると、、、
web_1 | To disable this check, please change `check_yarn_integrity` web_1 | to `false` in your webpacker config file (config/webpacker.yml).のような記述があったため、早速該当のディレクトリに行ってみると
config/webpacker.yml(中略) check_yarn_integrity: falseありました!!defaultでtrueになっていたため、falseに書き換えると解決しました!!!最後の1個いきます。。。
エラー事例④
状況
docker-compose up -dが成功し、localhost:3000でアクセスしようとすると
ActiveRecord::NoDatabaseError
が発生。
解決策
単純でしたね。db:createコマンドを忘れていました。。。
ターミナル% docker-compose exec web rails db:create % docker-compose exec web rails db:migrate終わりに
ビューファイルが思いっきり崩れていたので、原因究明してきます。。。。
- 投稿日:2020-12-16T14:36:16+09:00
Alexaでサーバーやデータベースの起動・停止制御をしたい
はじめに
こんにちは。NTTドコモの矢吹です。
私のチームでは、ドコモの大規模データをストリーム処理しており、AWSを利用してシステムを開発しています。そのため、開発環境だけでも結構な費用になります。しかし、節約のためにサーバーやデータベースをこまめに停止したり起動するのは面倒くさいし、つい忘れてしまいがちです。そこで、Alexaを使って「アレクサ、開発環境でデータベース停止しておいて」という風に制御できれば何かと便利ですよね。ついでに、これで節約できれば「最近費用が予想より大幅に上振れしてる、アカン・・」と頭を抱えている上司に恩を売ることもできます。
そこで、今回はLambdaやAlexa Skills Kitなど触ったことのない素人が勉強がてら、AlexaでAWSリソースの起動・停止制御を行うスキル開発に取り組んでみます。
尚、「平日の勤務開始時間に起動して終了時間に停止するcronを書けばいいじゃん」「サーバーレスで開発しろよ」などの意見はごもっともですが、ここでは受け付けないこととします。目標
「アレクサ、開発環境でWebサーバー起動して」
「アレクサ、開発環境でデータベース停止しておいて」
といった感じで、音声だけでAWSリソースの起動・停止制御を行う。準備するもの
対象とする人
- Alexaスキルの開発の流れをざっくり掴みたい人
- AlexaでAWSのリソース制御 (EC2やRDSの起動・停止)を行いたい人
参考にした資料
下記の資料を大変参考にさせていただきました。
- Alexa Skills Kit(ASK) ドキュメント
- Alexa Skills Kit SDK for Python
- Amazon Echo (Alexa) のSkillの開発に必要な基本概念を押さえる
- AlexaスキルをPython/Lambdaで実装する
実装
Alexaスキルを作るには、音声入力のインターフェースの作成とリクエスト内容に応じて処理を行うバックエンドの実装が必要です。インターフェースの作成はAlexa開発者コンソールでWeb画面を操作しながら行います。バックエンドはPythonで実装し、Lambdaで実行するようにしたいと思います。
インターフェースの作成
まずは、Alexa開発者コンソールでインターフェースを作成していきます。今回は日本語のスキルでAWSアカウントのLambdaでホスティングしたいため、下図のように選択し、スキルを作成します。
テンプレートはスクラッチを選択します。
以上で基本的なテンプレートが作成されるので、呼び出し名やIntent, Slotなどの設定をしていきます。
Invocation Name
Alexaが作成したスキルに応答できるようにInvocation Name(呼び出し時のキーワード)を設定します。「開発環境でWebサーバー止めて」のように呼び出したいため、「開発環境」をキーワードとして設定しました。
Intent
次にIntentを作成します。ドキュメントでは、Intentは下記のように説明されています。
少しわかりづらいですが、自分なりに触ったりして解釈した結果、ある目的の音声リクエストを認識するための機能とすると腑に落ちました。Intentが音声リクエストを正しく認識できるように発話サンプルを定義してあげる必要があります。「Webサーバー止めて」「データベース起動して」のような発話が考えられますが、全て網羅するのは大変です。なので、
{resource}を{action}して
のように発話サンプルに引数を与えることができると何かと便利です。この引数のことをSlotと呼びます。今回は下図のようにResouceControlという名前のIntentを作成しました。発話サンプルは考えられるバリエーションをたくさん作ってあげると認識率が上がります。
Slot
次に先ほど説明したSlotを作成します。まずはSlot Typeのタブに移動し、以下のように
resourceを定義します。後のバックエンドの実装でこの値とリソースIDを紐付けて制御できるようにします。
続いて
actionを定義します。今回はリソースの起動と停止を行いたいので以下のようにしました。類義語も登録するとより汎用性が高くなります。
そして、再びIntentのタブに戻り、今定義したSlot TypeとIntent Slotを紐付けます。
これでインターフェイスの実装は一通り終わりました。ページ上部にある、Save Model と Build Model のボタンを押してモデルをの保存とビルドを行います。非常に簡単ですね。
バックエンドの実装
次にバックエンドの実装を行います。今回はせっかくなので先日発表されたLambdaのコンテナイメージサポート を試してみたいと思います。
フォルダ構成は下記のようになります。alexa/ ├── Dockerfile ├── app.py └── resource.jsonAWSが提供するLambda用のPythonイメージを使用します。
Alexaスキル開発用のライブラリ(ask-sdk)のみ追加でインストールします。また、起動後はhandlerが呼ばれるようにします。Dockerfile.FROM public.ecr.aws/lambda/python:3.8 RUN pip3 install --upgrade pip && \ pip3 install ask-sdk==1.15.0 COPY app.py resource.json ./ CMD ["app.handler"]制御したいリソースの名前とIDを下記のように記載します。各リソースのIDはAWSコンソール等などから確認して入力してください。このファイルはロジック部分で読み込んで使用します。
resource.json{ "ウェブサーバー": "your_web_server_id" , "api サーバー": "your_api_server_id" , "データベース": "your_db_cluster_id" }次にロジック部分です。公式ドキュメント のコードをコピペしたものがベースとなっています。実装の流れとしては、LaunchRequest(呼び出し名のみのリクエスト)やIntentRequest(先ほど定義したカスタムIntentや組み込みのCancelAndStopIntentなど、Intent付きのリクエスト)、SessionEndedRequest(会話終了のリクエスト)などが呼ばれた際に行う処理やアレクサに喋らせる内容などを実装していきます。
app.pyimport json from ask_sdk_core.dispatch_components import AbstractRequestHandler from ask_sdk_core.dispatch_components import AbstractExceptionHandler from ask_sdk_core.handler_input import HandlerInput from ask_sdk_core.skill_builder import SkillBuilder from ask_sdk_core.utils import get_slot_value_v2, is_intent_name, is_request_type from ask_sdk_model import Response from ask_sdk_model.ui import SimpleCard import boto3 sb = SkillBuilder() def get_resource_id(resource_name): with open('resource.json') as f: resource_list = json.load(f) return resource_list[resource_name] class LaunchRequestHandler(AbstractRequestHandler): def can_handle(self, handler_input): # type: (HandlerInput) -> bool return is_request_type('LaunchRequest')(handler_input) def handle(self, handler_input): # type: (HandlerInput) -> Response speech_text = 'どのAWSリソースを起動/停止しますか?' handler_input.response_builder.speak(speech_text).set_card( SimpleCard('AWS', speech_text)).set_should_end_session( False) return handler_input.response_builder.response class ResourceControlHandler(AbstractRequestHandler): def can_handle(self, handler_input): # type: (HandlerInput) -> bool return is_intent_name('ResourceControl')(handler_input) def handle(self, handler_input): # type: (HandlerInput) -> Union[None, Response] action = get_slot_value_v2(handler_input=handler_input, slot_name='action').value resource_name = get_slot_value_v2(handler_input=handler_input, slot_name='resource').value print(f'action: {action}') print(f'resource_name: {resource_name}') start_message = f'{resource_name}を起動しました' already_started_message = f'{resource_name}はすでに起動しています' stop_message = f'{resource_name}を停止しました' already_stopped_message = f'{resource_name}はすでに停止しています' end_session = True if resource_name in ['ウェブサーバー', 'api サーバー']: ec2 = boto3.client('ec2') ec2_status = ec2.describe_instances(InstanceIds=[get_resource_id(resource_name)])\ ["Reservations"][0]["Instances"][0]['State']['Name'] if action == '起動': if ec2_status == 'running' or ec2_status == 'pending': speech_text = already_started_message else: ec2.start_instances(InstanceIds=[get_resource_id(resource_name)]) speech_text = start_message elif action == '停止': if ec2_status == 'stopping' or ec2_status == 'stopped': speech_text = already_stopped_message else: ec2.stop_instances(InstanceIds=[get_resource_id(resource_name)]) speech_text = stop_message else: speech_text = f'{resource_name}をどうしますか?もう一回言ってください' end_session = False elif resource_name == 'データベース': rds = boto3.client('rds') if action == '起動': print('Start RDS') try: rds.start_db_cluster(DBClusterIdentifier=get_resource_id('データベース')) speech_text = start_message except Exception as e: print(e) speech_text = '起動に失敗しました。データベースはすでに起動しているかもしれません。' elif action == '停止': try: rds.stop_db_cluster(DBClusterIdentifier=get_resource_id('データベース')) speech_text = stop_message except Exception as e: print(e) speech_text = '停止に失敗しました。データベースはすでに停止しているかもしれません。' else: speech_text = f'{resource_name}をどうしますか?もう一回言ってください' end_session = False else: speech_text = 'チョットナニイッテルカワカリマセン。' end_session = False handler_input.response_builder.speak(speech_text).set_card( SimpleCard('Control AWS Resource', speech_text)).set_should_end_session(end_session) return handler_input.response_builder.response class HelpIntentHandler(AbstractRequestHandler): def can_handle(self, handler_input): # type: (HandlerInput) -> bool return is_intent_name('AMAZON.HelpIntent')(handler_input) def handle(self, handler_input): # type: (HandlerInput) -> Response speech_text = '例えば、web サーバーを起動して、と言って見てください' handler_input.response_builder.speak(speech_text).ask(speech_text).set_card( SimpleCard('Control AWS Resource', speech_text)) return handler_input.response_builder.response class CancelAndStopIntentHandler(AbstractRequestHandler): def can_handle(self, handler_input): # type: (HandlerInput) -> bool return is_intent_name('AMAZON.CancelIntent')(handler_input) or is_intent_name('AMAZON.StopIntent')(handler_input) def handle(self, handler_input): # type: (HandlerInput) -> Response speech_text = 'さようなら' handler_input.response_builder.speak(speech_text).set_card( SimpleCard('Control AWS Resource', speech_text)) return handler_input.response_builder.response class SessionEndedRequestHandler(AbstractRequestHandler): def can_handle(self, handler_input): # type: (HandlerInput) -> bool return is_request_type('SessionEndedRequest')(handler_input) def handle(self, handler_input): # type: (HandlerInput) -> Response # クリーンアップロジックをここに追加します return handler_input.response_builder.response class AllExceptionHandler(AbstractExceptionHandler): def can_handle(self, handler_input, exception): # type: (HandlerInput, Exception) -> bool return True def handle(self, handler_input, exception): # type: (HandlerInput, Exception) -> Response # CloudWatch Logsに例外を記録する print(exception) speech = 'すみません、わかりませんでした。もう一度言ってください。' handler_input.response_builder.speak(speech).ask(speech) return handler_input.response_builder.response sb.add_request_handler(LaunchRequestHandler()) sb.add_request_handler(ResourceControlHandler()) sb.add_request_handler(HelpIntentHandler()) sb.add_request_handler(CancelAndStopIntentHandler()) sb.add_request_handler(SessionEndedRequestHandler()) sb.add_exception_handler(AllExceptionHandler()) handler = sb.lambda_handler()コードを見てわかる通り、ResourceControlのIntentを処理するためのクラス(ResourceControlHandler)の実装がメインとなります(その他はほとんどコピペ)。このクラスでは、リクエストのactionとresourceのSlot値を取り出し、値に応じて処理を変えるようにしています。例えば、resourceがウェブサーバーやAPIサーバーの場合、ec2クライアントを呼び出してactionの値に応じて起動や停止の操作をします。
また、喋らせる内容はspeech_textに設定します。正常終了したため会話を終了したい、もしくはリクエストがおかしいので聞き返して会話を継続したい、などはend_sessionの値で制御します。最後にspeech_textやend_sessionなどの値でレスポンス内容を組み立ててアレクサに喋らせるための値を返します。こちらも簡単ですね。
実装が完了したら、コンテナイメージをビルドしてECRにプッシュします。(割愛)Lambdaの設定
次にLambda関数を作っていきます。今回はランタイムとしてコンテナを利用するため、コンテナイメージを選択し、関数名と先ほどECRにプッシュしたイメージのURIを指定します。アクセス権限はLambdaがEC2やRDSなどのリソースを操作できるように適切なIAMロールを作成し、それを使用するようにします。
関数作成後、LambdaのARNをコピーして再びAlexa開発者コンソールに戻り、下記のようにエンドポイントの設定を行います。
Lambdaの設定画面に戻り、下記のようにトリガーを設定します。
以上で実装は完了です。Alexa開発者コンソールに戻り、作成したスキルの動作確認をしましょう。
動作確認
テキスト入力による動作確認
テストタブに移動し、下記のようにスキルの動作確認を行うことができます。正しく動作していそうですね。AWSコンソールで確認したところ、きちんとデータベースは起動されていました。
音声入力による動作確認
「開発環境でAPIサーバー停止して」と言ってみます。
・・・自分が滑舌悪いこと忘れてました。
対象とする人(改)
- Alexaスキルの開発の流れをざっくり掴みたい人
- AlexaでAWSのリソース制御 (EC2やRDSの起動・停止)を行いたい人
- 滑舌が良い人
おわりに
Alexaスキルの開発を一通り体験してみましたが、IntentやSlotなどの概念さえを理解できれば意外と簡単に作れるんだなというのが作ってみての所感です。また、滑舌が悪い人には音声インターフェースは扱いづらいなということを改めて実感できました。ここまで作っといてアレですが、このスキルは使わずにシェルスクリプトを書いて実行するようにしようかなと思います。













- 投稿日:2020-12-16T10:00:15+09:00
Auth0のQuick StartにあるAngularのサンプルをDockerで実行してみた
Auth0の各サンプルソースを覗いてみると
Dockerfileを用意してくれてたので環境構築してみました。Auth0について
下記に概要をまとめていますので、ご参考ください。
Auth0の機能を調べてみた - Qiita
https://qiita.com/kai_kou/items/b3dd64e4f8f53325020eAuth0(オースゼロ)とはAuth0, Inc.が提供するiDaaS(アイダース)で、Identity as a Serviceの略となりクラウドでID管理・認証機能などを提供してくれるサービスです。
iDaaSが提供する機能としては認証・シングルサインオン、ID管理・連携、認可、ログなどによる監査などがあり、Auth0もそれらを提供しています。アカウント作成
Auth0のアカウント作成については下記をご参考ください。
Auth0のJavaScriptチュートリアルをシンプルな構成で試してみた - Qiita
https://qiita.com/kai_kou/items/51ce27a8f98a14263e26#%E3%82%A2%E3%82%AB%E3%82%A6%E3%83%B3%E3%83%88%E3%82%92%E4%BD%9C%E6%88%90%E3%81%99%E3%82%8BAuth0の設定
Auth0のアカウントが用意できたらサンプルアプリで利用するAuth0の設定を行います。
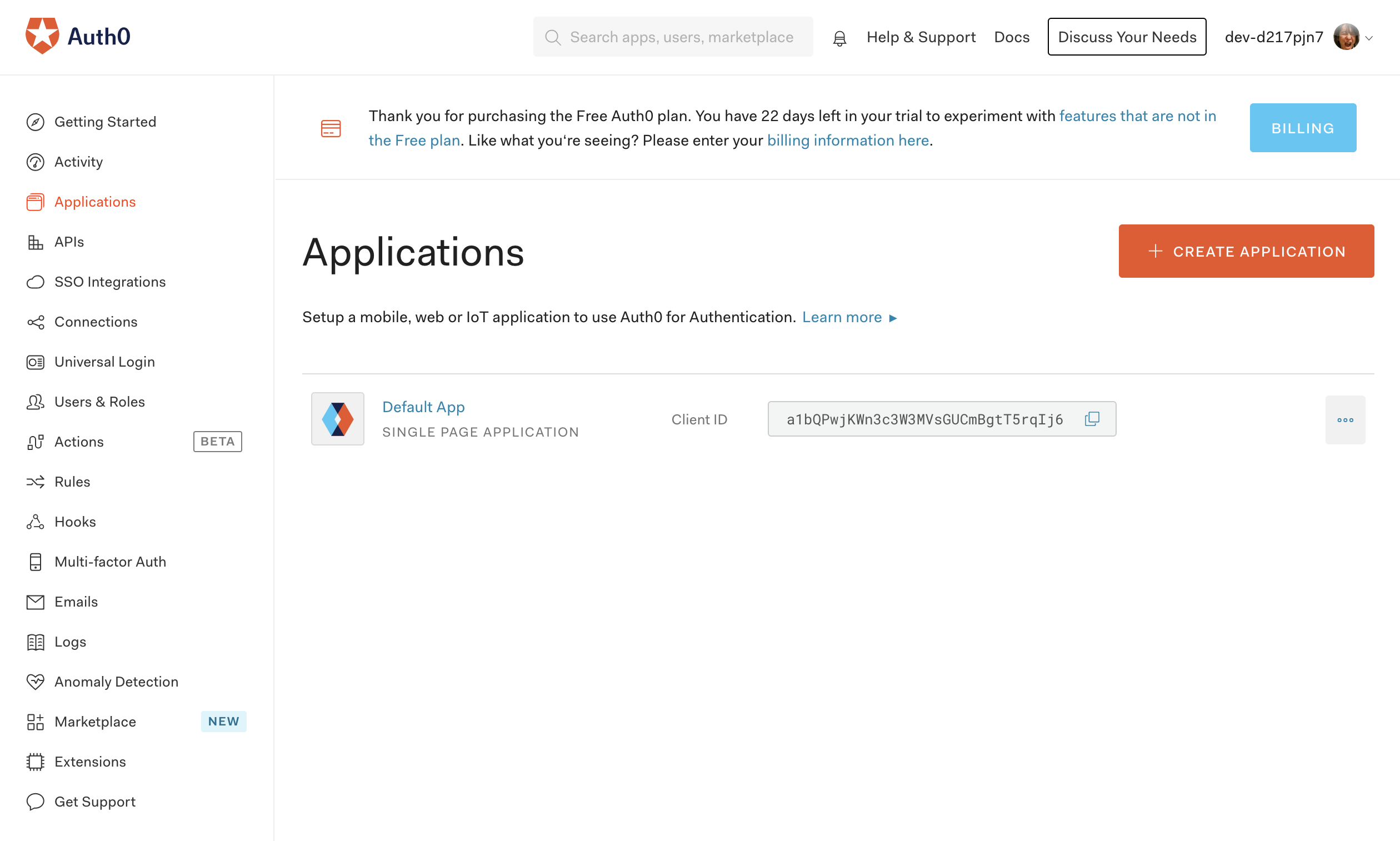
アプリケーションの設定
Auth0のダッシュボード左メニューの「Applications」でApplication画面を開き、最初からある「Default App」の設定を開きます。
Application URIsを下記の用に設定して保存します。
http://localhost:4200はサンプルアプリのURLになります。
- Allowed Callback URLs:
http://localhost:4200- Allowed Logout URLs:
http://localhost:4200- Allowed Web Origins:
http://localhost:4200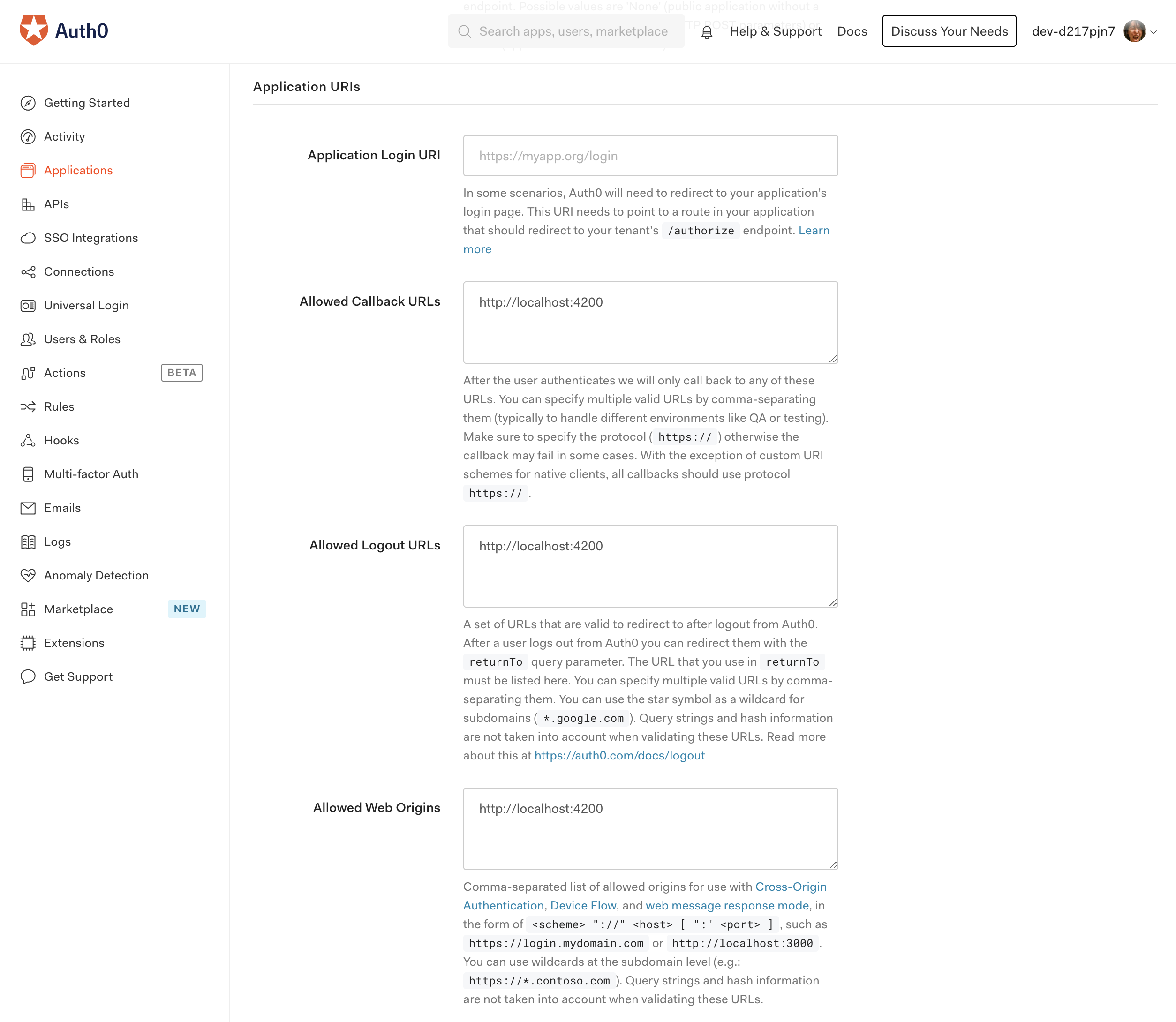
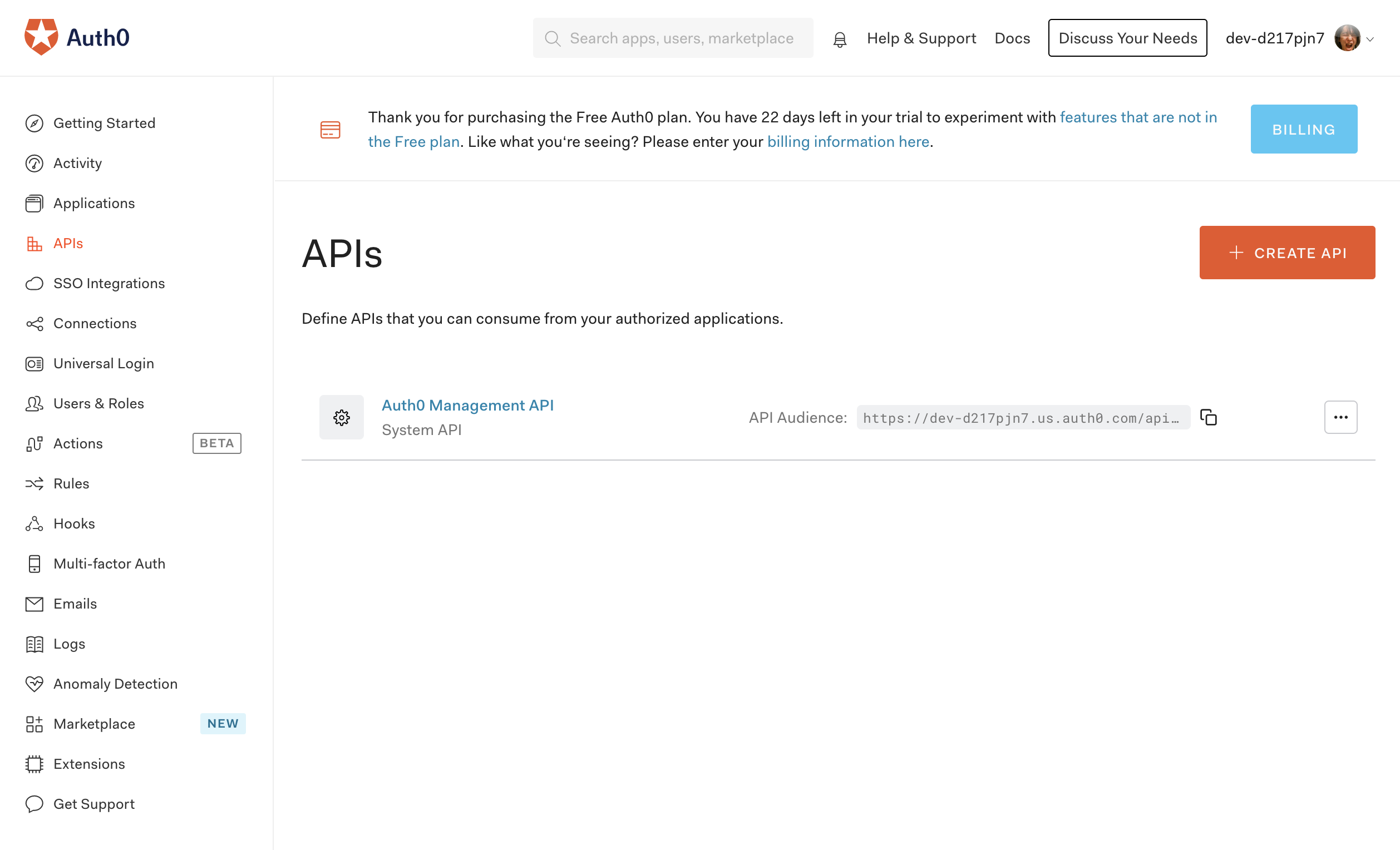
APIの作成
AngularのサンプルではAuth0のCustomAPIを利用しているので、APIを作成します。
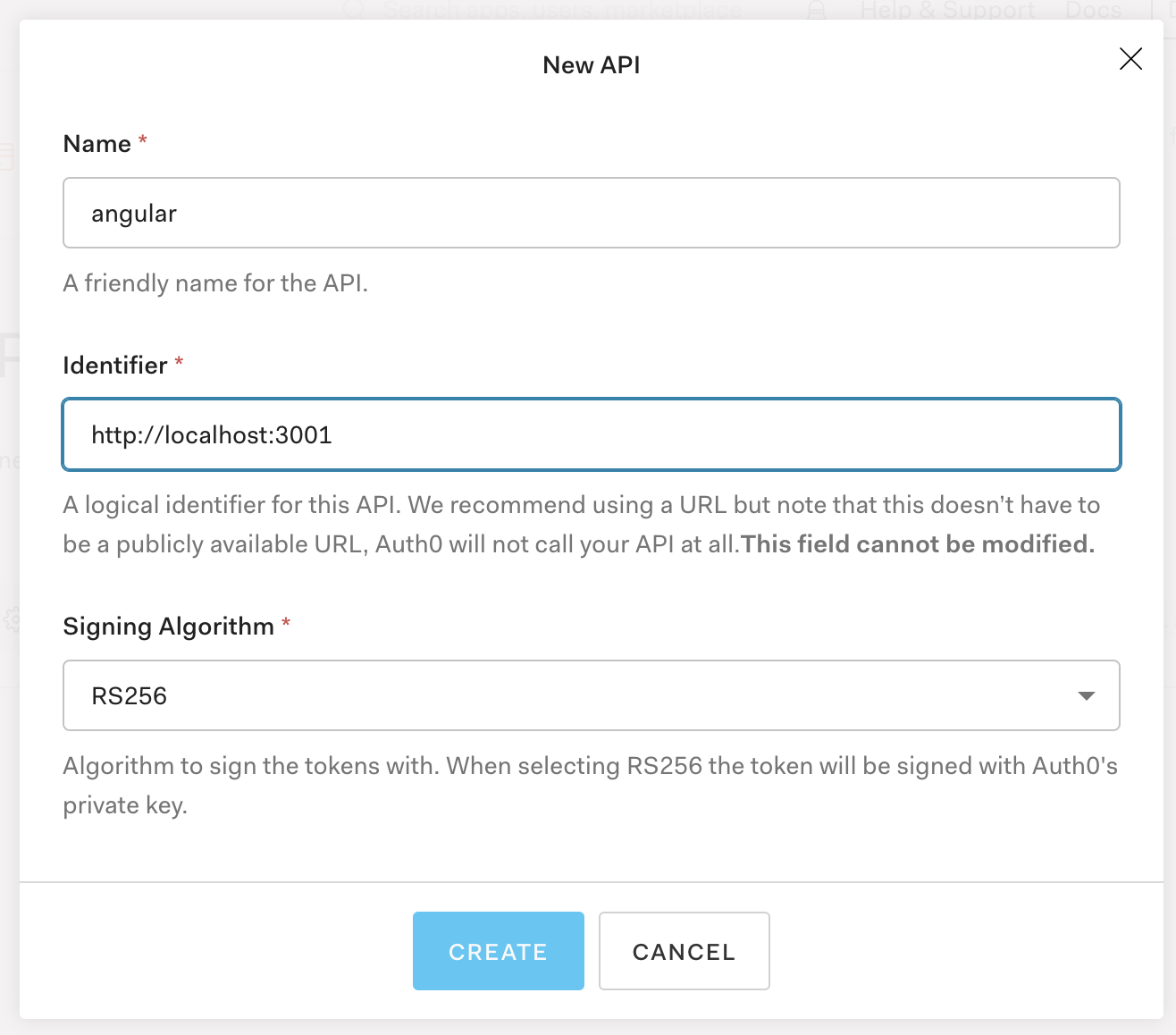
Auth0のダッシュボード左メニューの「APIs」からAPI画面を開き、「+CREATE API」ボタンをクリックします。
API作成ダイアログで下記の用に設定します。
- Name: 任意の名前(ここでは
angular)- Identifier:
http://localhost:3001
- サンプルアプリにあるAPIのURLになります
ユニバーサルログインの設定
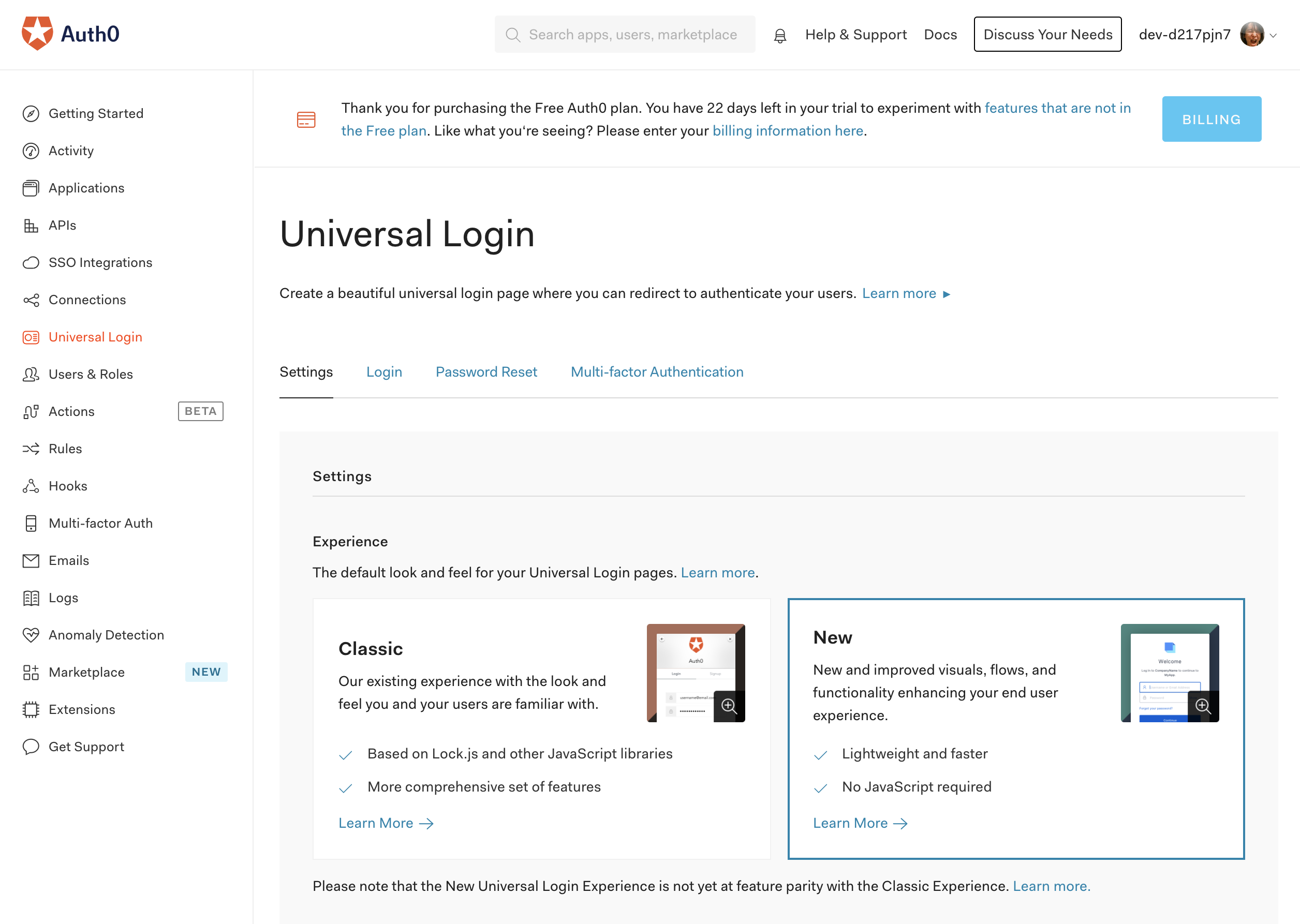
Auth0のダッシュボード左メニューから「Universal Login」を選び、Experienceを
Newに変更します。
これでAuth0側の設定は完了です。
サンプルソースのURL取得
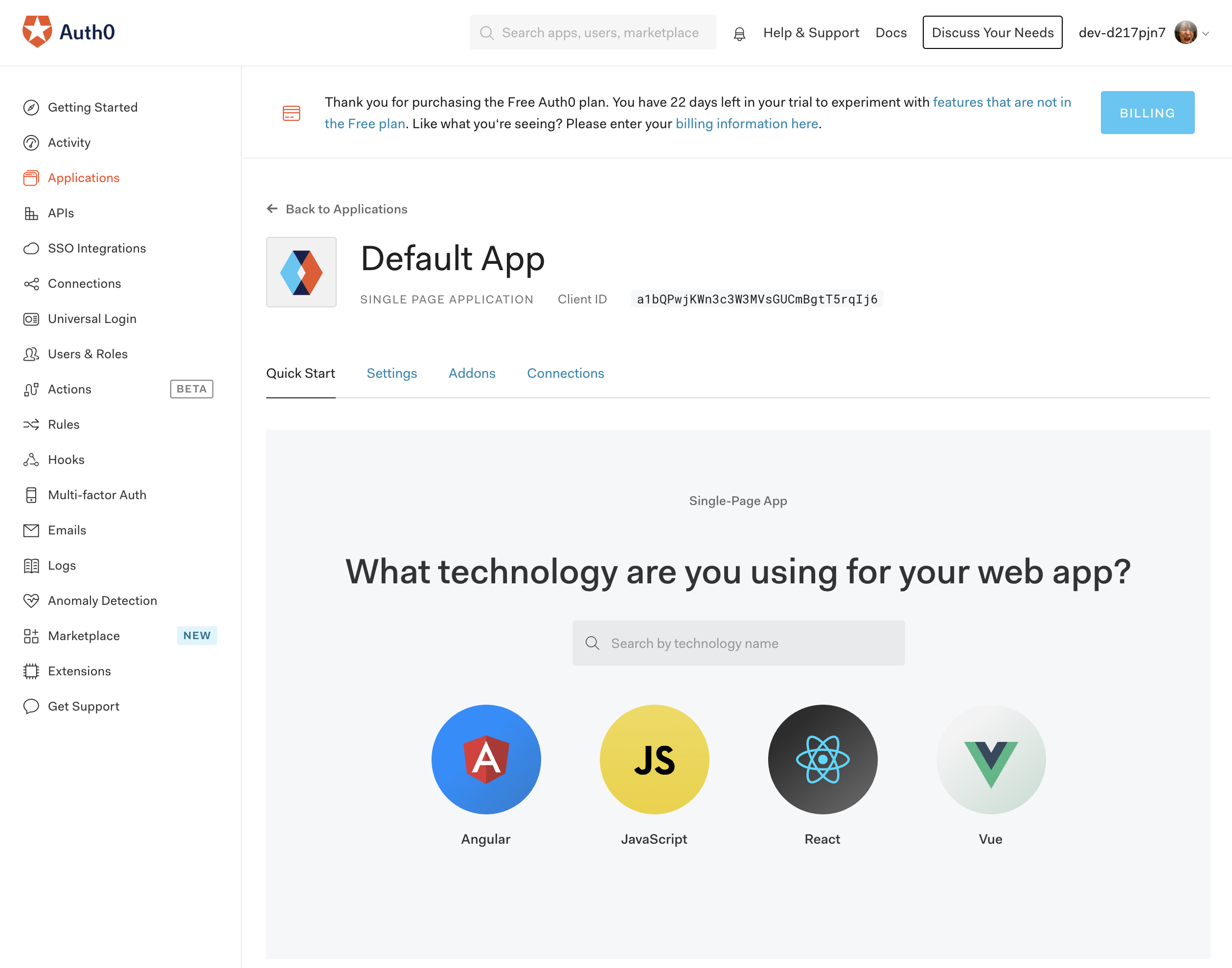
Angular用のサンプルソースを取得します。Auth0のダッシュボード左メニュー「Applications」を選び、Application「Default App」を開いて、「Quick Start」タブを選びます。
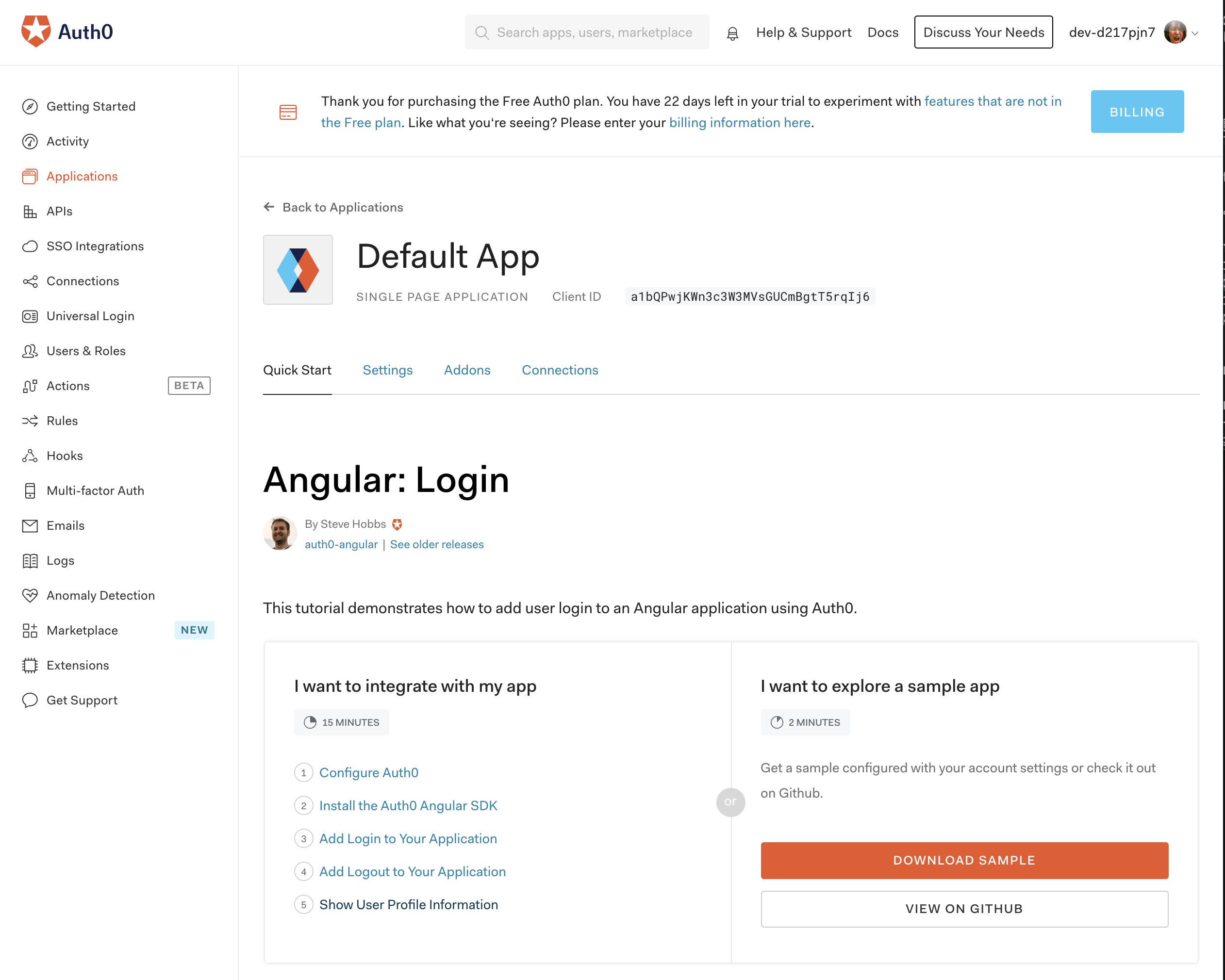
Angularを選ぶと、Auth0を利用するチュートリアルが表示されます。
「I want to explore a sample app」にある「VIEW ON GITHUB」ボタンをクリックするとGithubページが表示されます。
GitHubリポジトリのルートへ上がり「Code」からリポジトリのURLを取得します。
サンプルソースのビルド・実行
GitHubからリポジトリをクローンして必要な設定ファイルを用意してDockerイメージを作成して、コンテナを実行します。
domainとclientIdはAuth0の「Default App」アプリケーションから取得します。
>cd 任意のディレクトリ >git clone https://github.com/auth0-samples/auth0-angular-samples.git >cd auth0-angular-samples/Sample-01 >cat << EOF > auth_config.json { "domain": "<自身のdomein>", "clientId": "<自身のclientId>", "audience": "http://localhost:3001", "apiUri": "http://localhost:3001", "appUri": "http://localhost:4200"} EOF >docker build -t auth0-angular-samples ./ >docker run -it --rm -p 3000:4200 -p 4200:3001 auth0-angular-samples > login-demo@0.0.0 prod /app > npm-run-all --parallel server:app server:api > login-demo@0.0.0 server:app /app > node server.js > login-demo@0.0.0 server:api /app > node api-server.js App server listening on port 4200 Api started on port 3001実行してみる
Dockerコンテナが立ち上がったらブラウザで
http://localhost:4200を開きます。
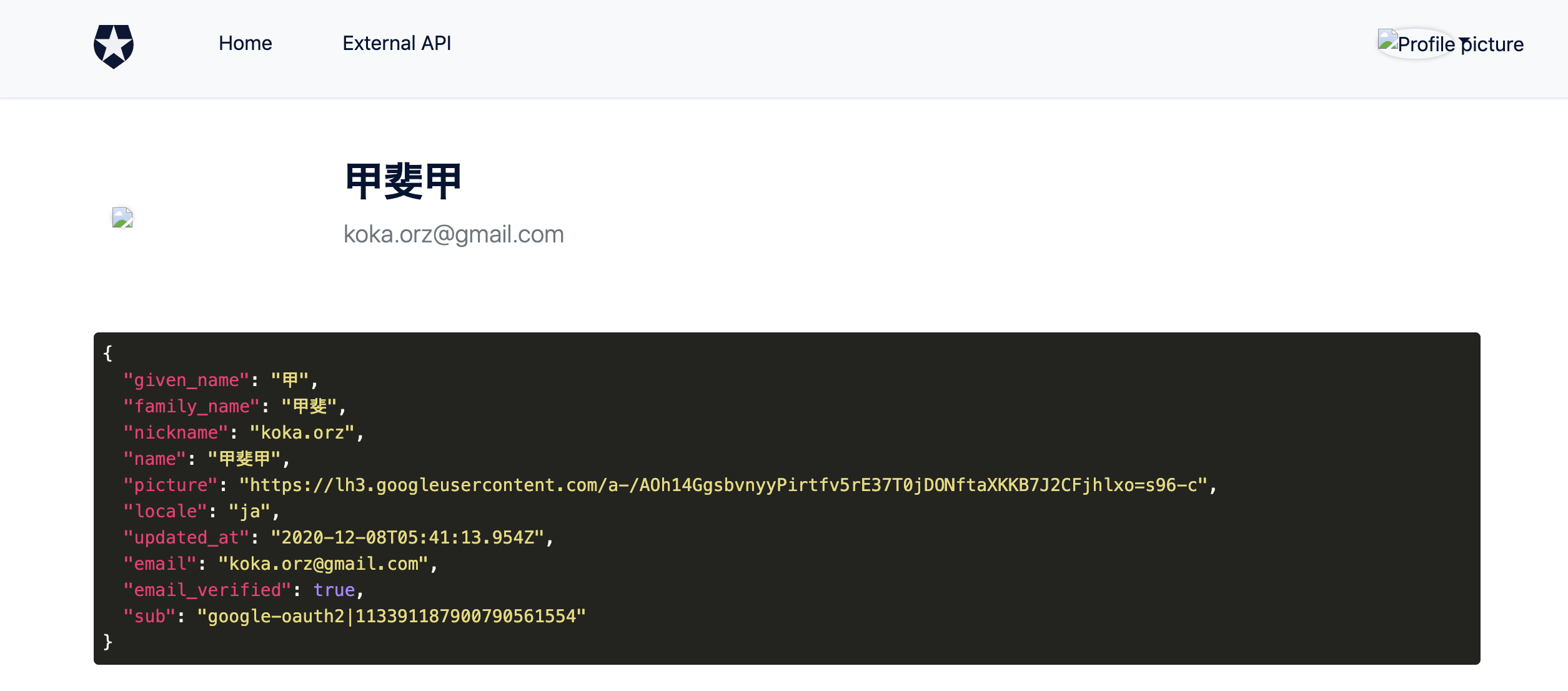
Angularのアプリが開いたら右上にある「Log in」ボタンをクリックします。
Auth0のログイン画面へ遷移したらメールアドレスかGoogleでログインします。
ログインできたら右上がログイン状態に変わります。プロフィール画像は(多分)手元が
httpなため表示されませんが今回やりたいことができました。うぇーい
右上メニューの「Profile」メニューからログインしたユーザーの情報も確認することができます。
まとめ
サクッとAuth0の機能を確認するにはとてもよいサンプルが用意されていて助かります。
参考
Auth0の機能を調べてみた - Qiita
https://qiita.com/kai_kou/items/b3dd64e4f8f53325020eAuth0のJavaScriptチュートリアルをシンプルな構成で試してみた - Qiita
https://qiita.com/kai_kou/items/51ce27a8f98a14263e26#%E3%82%A2%E3%82%AB%E3%82%A6%E3%83%B3%E3%83%88%E3%82%92%E4%BD%9C%E6%88%90%E3%81%99%E3%82%8B





- 投稿日:2020-12-16T09:12:55+09:00
Docker の仕組み 〜 コンテナを 60 行で実装する
概要
本記事では、普段 Docker をブラックボックスとして扱っている方々を対象として、コンテナが動く仕組みを低レイヤーから解説します。
そのために Go 言語を使って、ゼロからコンテナを実装し動かしながら学ぶアプローチを取ります。コンテナの基礎的な原理は意外にも簡単で、この記事の最後に出来上がるコードは僅か 60 行ほどです。
なお、完成したコードは GitHub レポジトリに置かれています。
コンテナとは何か
コンテナと仮想マシン (VM) の違いを説明する際に、よく次のような図が使われます。
(Docker 公式サイトより引用)VM とコンテナを比較した時の最大の特徴は、一つ一つのコンテナを作る際にゲスト OS を起動しないことです。
コンテナは全て、同じホスト OS の中で動くプロセスとして存在します。しかし当然ながら、通常のプロセスはファイルなどのリソースを他のプロセスと共有しており、環境依存性を強く持ちます。
そこで、プロセスを論理的に隔離された状態で動かすために、 Linux カーネル の持つ chroot や namespace などの機能を利用します。これにより 隔離されたプロセス のことをコンテナと呼びます。Linux カーネルとは何か
カーネルとは、文字通り OS の中核に当たる重要な部分です。
Linux マシンを次のような 3 層構造と捉えた時、カーネルはちょうど中間に位置します。
- ハードウェア : メモリや CPU などの物理デバイス
- Linux カーネル
- ユーザープロセス : シェルやエディターなど、ほぼ全てのプログラム
カーネルはハードウェアを直接操作できる特権を持ち、メモリーやプロセスの管理、デバイスドライバーなどの仕事を行います。
一方で、ユーザープロセスはハードウェアに対するアクセスが大きく制限されています。そのため、ファイル操作やプロセス作成などを実行するには、システムコールを通じてカーネルに依頼しなければなりません。
コンテナを作成するプログラムを実装する際にも、 chroot や namespace などを利用するためにシステムコールを多用します。
特に Go 言語のコードでシステムコールを行う場合には、公式パッケージ golang.org/x/sys を使うのが標準的です。
ゼロからのコンテナ実装
以降では Go 言語のプログラムで実際にコンテナを作成します。
コードを実行するためには、 Go コンパイラがインストールされた Linux 環境が必要です。 GitHub レポジトリに含まれている
docker-compose.ymlファイルを使えば、環境構築の手間無しですぐに試すことができます。$ git clone $ cd minimum-container $ docker-compose run app root@linux-env:/work_dir# go run main.go run shchroot
chroot は、現在実行中のプロセス(と子プロセス)のルートディレクトリを変更します。そのディレクトリより上の階層にはアクセスできず存在を認識することもできない状態になるため、俗に chroot 監獄と呼ばれます。
GitHub レポジトリの chroot ブランチ に、 chroot を使ったコンテナもどきのコード例があります。これはルートディレクトリを
./rootfsに変更した上で、与えられた引数をコマンドとして実行します。main.go// 隔離されたプロセスの中で cmd を引数 arg と共に実行 func execute(cmd string, args ...string) { // ルートディレクトリとカレントディレクトリを ./rootfs に設定 unix.Chroot("./rootfs") unix.Chdir("/") command := exec.Command(cmd, args...) command.Stdin = os.Stdin command.Stdout = os.Stdout command.Stderr = os.Stderr command.Run() }早速この
main.goを実行してみると、次のようなエラーが発生するはずです。$ go run main.go run sh panic: exec: "sh": executable file not found in $PATHこれは、まだ
./rootfsに何もファイルが入っていないために起きるエラーです。 chroot 実行後のコンテナ内では、ルートディレクトリが空の状態と同然のため、shのバイナリすら有りません。そこで便利なのが docker export です。下記のコマンドを打ち込むと、任意の Docker イメージに含まれる全ファイルを
./rootfsの下に展開することができます。$ docker export $(docker create <イメージ>) | tar -C rootfs -xvf -
.rootfsにファイルを用意した状態で、改めてコンテナを実行してみましょう。lsコマンドを使ったり、ファイルを作成したりして、コンテナ内の/ディレクトリがホストのrootfsディレクトリとリンクしていることを確かめてみてください。root@linux-env:/work_dir# go run main.go run sh / # ls / bin dev etc home proc root sys tmp usr var / # touch /tmp/hoge / # exit root@linux-env:/work_dir# ls rootfs/tmp hogenamespace
Linux namespace は、マウントファイルシステムや PID など諸々のリソースを隔離できる機能です。
この機能の必要性を理解するために、前節で作成したコンテナもどきの中で
psコマンドを実行してみましょう。root@linux-host:/work_dir# go run main.go run ps PID USER TIME COMMAND結果は何も表示されないはずです。その原因は
psコマンドが/procディレクトリを参照していることにあります。通常/procディレクトリには、プロセス情報などを取得できる特殊な擬似ファイルシステムがマウントされていますが、コンテナもどきの中ではルートディレクトリを変更しているので/procにはまだ何も有りません。事前に
/procディレクトリをマウントしてpsを再度実行してみましょう。root@linux-host:/work_dir# go run main.go run sh / # mount proc /proc -t proc / # ps PID USER TIME COMMAND 1 root 0:00 bash 100 root 0:00 go run main.go run sh 154 root 0:00 /tmp/go-build474892034/b001/exe/main run sh 160 root 0:00 sh 163 root 0:00 psここで問題が二つ生じます。一つはコンテナ外で動いているプロセス (PID 1, 100, 154) が見えている点、もう一つは、コンテナ内で設定したマウントがホストにも反映される点です。これでは外部環境からの隔離が充分とは言えません。
root@linux-host:/work_dir# cat /proc/mounts | grep proc proc /proc proc rw,nosuid,nodev,noexec,relatime 0 0 proc /work_dir/rootfs/proc proc rw,relatime 0 0 <- コンテナ内で追加した proc マウントLinux namespace を使うと、リソースの名前空間をプロセス単位で別々に設定することができます。異なる名前空間に属するリソースは見ることも操作することもできないため、前述の問題が解決されます。
記事執筆時点で Linux namespace は 8 種類存在し、システムコールの clone, setns, unshare などでフラッグを指定します。
名前空間 フラッグ 隔離されるリソース Mount CLONE_NEWNS ファイルシステムのマウントポイント PID CLONE_NEWPID PID UTS CLONE_NEWUTS ホスト名 Network CLONE_NEWNET ネットワークデバイスやポートなど Time CLONE_NEWTIME clock_gettime で取得できる時刻 (monotonic, boot) IPC CLONE_NEWIPC プロセス間通信 Cgroup CLONE_NEWCGROUP cgroup ルートディレクトリ User CLONE_NEWUSER UID, GID Go 言語で Linux namespace を設定するには、
Cmd構造体のSysProcAttrにCloneflagsをセットします。実際に Mount, PID, UTS namespace を使ってコンテナを作成する例が GitHub レポジトリの namespace ブランチ にあります。main.gofunc execute(cmd string, args ...string) { unix.Chroot("./rootfs") unix.Chdir("/") command := exec.Command(cmd, args...) command.Stdin = os.Stdin command.Stdout = os.Stdout command.Stderr = os.Stderr // Linux namespace を設定 command.SysProcAttr = &unix.SysProcAttr{ Cloneflags: unix.CLONE_NEWNS | unix.CLONE_NEWPID | unix.CLONE_NEWUTS, } command.Run() }このコードで改めてコンテナを作成し、先程と同様に
psを実行すると、コンテナ内のプロセスだけが表示されることを確認できます。root@linux-host:/work_dir# go run main.go run sh / # mount proc /proc -t proc / # ps PID USER TIME COMMAND 1 root 0:00 sh 4 root 0:00 psまた、 UTS namespace によって、コンテナ内でホスト名を変更しても外部に影響しなくなりました。
root@linux-host:/work_dir# go run main.go run sh / # hostname my-container / # hostname my-container / # exit root@linux-host:/work_dir# hostname linux-hostコンテナの初期化
前節では、コンテナを立ち上げた後に手動で
/procのマウントやホスト名の設定をしていました。このままでは不便なので、コンテナ作成と同時にこれらの初期化処理も行うようにプログラムを変更しましょう。ここで問題となるのが、初期化を実行するタイミングです。コンテナ作成は
- namespace を設定した子プロセスを作成
- 子プロセスを初期化 (
/procマウントなど)- ユーザー指定のコマンド (
shなど) を実行という順序で行う必要がありますが、 1. と 3. の間に割り込めるフックなどは存在しません。そこで、 2. と 3. を両方とも実行するコードを書き、 namespace を設定したプロセス上でそのコードを実行します。
実装例は GitHub レポジトリの reexec ブランチ です。
main.go// コマンドライン引数の処理 // go run main.go run <cmd> <args> func main() { switch os.Args[1] { case "run": initialize(os.Args[2:]...) case "child": execute(os.Args[2], os.Args[3:]...) default: panic("コマンドライン引数が正しくありません。") } } // Linux namespace を設定した子プロセスで、execute 関数を実行する func initialize(args ...string) { // このプログラム自身に引数 child <cmd> <args> を渡す arg := append([]string{"child"}, args...) command := exec.Command("/proc/self/exe", arg...) command.Stdin = os.Stdin command.Stdout = os.Stdout command.Stderr = os.Stderr command.SysProcAttr = &unix.SysProcAttr{ Cloneflags: unix.CLONE_NEWNS | unix.CLONE_NEWPID | unix.CLONE_NEWUTS, } command.Run() } // namespace 設定後の初期化処理と、ユーザー指定のコマンドを実行する func execute(cmd string, args ...string) { // ルートディレクトリとカレントディレクトリを ./rootfs に設定 unix.Chroot("./rootfs") unix.Chdir("/") unix.Mount("proc", "proc", "proc", 0, "") unix.Sethostname([]byte("my-container")) command := exec.Command(cmd, args...) command.Stdin = os.Stdin command.Stdout = os.Stdout command.Stderr = os.Stderr command.Run() }一つの実行ファイルで完結させるために、少しトリッキーな方法を使っています。ポイントは
initialize関数の中で/proc/self/exeをコマンドとして実行している部分です。/proc/self/exeも proc ファイルシステムの一部で、現在のプロセスの実行ファイルのパスを返します。これを利用して、プログラムが自分自身を再帰的に実行することができます。上記コード実行時の流れを順に追っていくと
- コマンド
go run main.go run <cmd> <args>を実行- main.go が実行され
initialize関数に分岐- namespace を設定したプロセスを作成
- コマンド
/proc/self/exe init <cmd> <args>を実行- main.go が実行され
execute関数に分岐/procマウントなどの初期化処理を実行- プロセスを作成
- ユーザー指定のコマンドを実行
この時、ユーザーコマンド実行のために作られる孫プロセスにも ルートディレクトリと namespace の設定が継承され、コンテナとして機能します。
コンテナの標準仕様
以上でコンテナの基礎に当たる機能を実装できましたが、まだ欠けている部分がたくさんあります。この記事で全てを詳細に説明することはできませんが、大まかな全体像を伝えるために重要な標準仕様を 2 つ紹介します。
仕様 代表的な実装 OCI Runtime Specification runc OCI Image Format Specification containerd OCI Runtime Spec はコンテナのライフサイクルと filesystem bundle のフォーマットを規定します。filesystem bundle とは、コンテナの各種設定値を記載した
config.jsonと、ルートファイルシステムとなるrootfsディレクトリをまとめて tar アーカイブにしたものです。一方で OCI Image Spec は、コンテナイメージのフォーマットと、イメージを filesystem bundle に変換する方法を規定します。イメージとは、 Dockerfile をビルドして得られるお馴染みのあのイメージのことです。
filesystem bundle に
rootfsディレクトリが含まれることから推測できるように、この記事で実装したのは OCI Runtime Spec の触りの部分に当たります。 OCI Image Spec やその他の要素にはノータッチなので、興味のある方はさらに詳しく調べてみることをお勧めします。まとめ
- コンテナは Linux カーネルの機能によって隔離された特殊なプロセス
- chroot: ルートファイルシステムを隔離
- namespace: PID、ファイルマウント、ホスト名など様々なグローバルリソースを隔離
- コンテナに関する重要な標準仕様
- OCI Runtime Specification
- OCI Image Format Specification
- 本記事と関連が深いのは runtime spec
参考リンク



- 投稿日:2020-12-16T07:09:21+09:00
WSL2 と Docker を利用して Windows 上でお手軽に Redmine を構築する
※ 本記事は Redmine Advent Calendar 2020 の 16 日目の記事です。
はじめに
みなさん、自分で好き勝手に使える Redmine の環境はお持ちでしょうか?
Redmine はシステム管理者権限を持っていないとすべての機能や設定を操作することができません。また、他の利用者がいる環境では好き勝手に設定を変更するわけにはいかなくなります。
とはいえ、Redmine はサーバーアプリケーションですので、セットアップするためにそれなりの知識や作業の手数が必要です。また、Redmine を含む多くのサーバーアプリケーションは、 Windows 上に構築しようとすると Linux よりも多くの手間がかかります。多くの IT エンジニアにとって Linux は慣れ親しんだものだとは思いますが、Redmine は非エンジニアにも広く利用されていることを考えると、Redmine を自分で自由に使ってみたい方の中には「Linux なんてよくわからない」「手元には Windows の PC しかない」という方も多くいらっしゃるのではないかと想像します。
そこで本記事では、手元の Windows PC 上に WSL2(Windows Subsystem For Linux 2) を使って Linux の環境を構築し、Docker を使って少ない手数で Redmine を構築する手順を説明します。
おことわり
本記事では、WSL2 や Docker の説明は割愛します。(ぶっちゃけると説明が面倒というのもあるのですが…) WSL2 や Docker の説明を真面目にするとかなりの分量になります。本記事は、お手軽に Redmine が構築できるということを知っていただき、みなさんにも気軽に試していただきたいという願いがありますので、理論的なところはあまり触れずに進めさせていただきます。実際に動く環境が手元に出来上がったら、それをきっかけに学ぼうという気持ちも湧いてくるんじゃないかと思いますので、そこから WSL2 や Docker について調べていただいた方が学習効率も良いのではないかと思います。
また、本記事で説明する内容は執筆時点の情報になります。WSL2 や Docker に関連する技術は目まぐるしくアップデートされておりますので、本記事もすぐに陳腐化する可能性もあることをご承知おき願います。本記事と実態が食い違っているときは一次情報をあたるようにしてください。
動作環境
WSL2 を動作させるには比較的新しい Windows 10 が必要です。以前は 2004 が必須でしたが、現在では 1903/1909 でも動作するとのことです。また、以前は Windows 10 Pro しか対応していなかったですが、現在では Windows 10 Home でも利用可能です。
CPU やメモリはそれほど潤沢になくても WSL2 や Docker は動作します。ただし、Docker イメージのサイズがそれなりに大きいので空きディスク領域は確保しておいた方がよいです。(今回扱う Redmine のイメージだけでも 500MB 以上あります)
※ 2020/12/17 追記:よくよく考えたらメモリは多い方がいいです。(手元の環境は 16GB でした…)
構築手順
構築に必要な手順は以下の 3 ステップです。
- WSL2 のインストール
- Docker Desktop のインストール
- Redmine コンテナの起動
WSL2 のインストール
Windows 10 用 Windows Subsystem for Linux のインストール ガイド を参考にしてください。
手順の中で PowerShell コマンドを使うので不慣れな方にはちょっとハードルが高く感じられるかもしれませんが、以下のコマンドを順番に実行するだけですので心配しなくて大丈夫です。
※ どうやら将来的にはこのあたりの手順も簡略化されて
wsl --installだけでいけるようになるようです。(現時点では開発者向けのみ公開されています)dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart※ ここで再起動して、x64 マシン用 WSL2 Linux カーネル更新プログラム パッケージ をインストールする。
wsl --set-default-version 2ここまで終われば、あとは Linux をインストールするだけです。今回は Ubuntu 20.04 LTS を選びます。Docker を動かすときによく選択されるディストリビューションです。
Docker Desktop のインストール
WSL 2 での Docker リモート コンテナーの概要 の「Docker Desktop のインストール」の章を参考にしてください。その先に開発者向けの情報がありますが、すべて読み飛ばして大丈夫です。
Docker Desktop をインストールして、設定を一部変更するだけです。
Redmine コンテナの起動
※ 2020/12/17 一部訂正、追記しました。
ここまで来たらあと一息です。せっかくですので、先日リリースされたばかりの RedMica 1.2 を試してみましょう。
先ほどインストールした Ubuntu を起動して以下のコマンドを実行すれば OK です。
sudo docker run -d -p 8000:3000 --name some-redmica redmica/redmica
http://localhost:8000にアクセスすれば Redmine が表示されます。初期ユーザー/パスワードはどちらもadminです。ね、簡単でしょ?
ここから先は Redmineガイド の「システム管理者向けガイド」を参考にしながら色々お試しください。
補足: Docker のコマンドを実行するユーザーについて
Docker のコマンドはデフォルトでは root 権限(Windows で言えば管理者権限のような位置づけのようなもの)をもつスーパーユーザーでしか実行できません。Ubuntu は一時的にスーパーユーザーの権限を使ってコマンドを実行するときに
sudoというコマンドを使います。ちなみに、Docker コマンドは現在ログインしているユーザーでも実行することが可能です。以下のコマンドを実行した後、Ubuntu に再ログインすれば
sudoなしでも Docker コマンドが実行できます。sudo usermod -aG docker (Ubuntu のセットアップ時に作成したユーザー名)たとえば、Ubuntu のセットアップ時に作成したユーザー名が
aliceだった場合、実際に実行するコマンドは以下のようになります。sudo usermod -aG docker alice注意事項
上記の手順は Redmine コンテナを起動するまでの最小の手順です。本格的に利用するにはデータベースの情報を永続化するための設定などが必要になります。詳しい使い方は Docker Hub の redmica/redmica を参照してください。最初は何を書いてるかわからなくてつらいかもですが、Docker に慣れ親しむうちに理解できるようになると思います。
また、Dokcer コンテナの性質を正しく理解しておかないと、永続化していたつもりのデータが消失するなどのトラブルが起きることも考えられます。ただし、それは決して恐ろしいことではなく、正しく理解しておけば特に問題になりません。それを知らずに思い込みで進めてしまうと危険な目に遭うかもしれないということです。このあたりは Dokcer コンテナとボリュームについて調べていただくのがよいと思います。わからないことがあれば Twitter 等で僕に直接ご質問いただいても OK です。
熱いダイマ
Docker Compose を使った自分好みの Redmine 実行環境 というものを作っています。今回インストールした WSL2 の Ubuntu でも動作するものですので、ご興味のある方は是非ともお試しいただけたらと思います。
おわりに
WSL2 と Docker を利用すると Redmine がお手軽に構築できます。Redmine だけでなく多くのサーバーアプリケーションも Docker を使うとお手軽に構築できます。これをきっかけに Docker の知識を身につけてスキルアップを図るのもよいかもしれません。
そして、みなさんが快適な Redmine ライフを過ごせるようになることを願っています。
- 投稿日:2020-12-16T02:01:56+09:00
【備忘録】Dockerfile/docker-compose.yamlの書き方
1.Dockerfileの命令
命令FROM #ベースイメージの指定 RUN #コマンド実行 CMD #コンテナ実行コマンド LABEL #ラベルを設定 EXPOSE #ポートのエクスポート ENV #環境変数 ADD #ファイル/ディレクトリの追加 COPY #ファイルのコピー ENTRYPOINT #コンテナの実行コマンド VOLUME #ボリュームのマウント USER #ユーザーの指定 WORKDIR #作業ディレクトリ ARG #Dockerfile内の変数 ONBUILD #ビルド完了後に実行されるコマンド STOPSIGNAL #システムコールシグナルの設定 HEALTHCHECK #コンテナのヘルスチェック SHELL #デフォルトシェルの指定1-1.ベースイメージの指定(FROM命令)
Dockerfile内での必須項目。「DockerコンテナをどのDockerイメージから生成するか」の情報を記載。
FROMFROM [IMAGE_NAME] FROM [IMAGE_NAME]:[TAG_NAME] FROM [IMAME_NAME]@[DIGEST] #記述例 FROM centos:centos71-2.コマンド実行(RUN命令)
FROM命令で指定したベースイメージに対して、ライブラリのインストール、環境構築用のコマンドの実行など何らかのコマンドを実行する場合に記載。
RUNRUN [COMMAND_FOR_IMAGE_CREATION] #記述例(Shell形式) RUN apt-get install -y nginx #記述例(Exec形式) RUN ["/bin/bash", "-c", "apt-get install -y nginx"]1-3.デーモンの実行(CMD命令)
イメージをもとに生成したコンテナ内でコマンドを実行する際に記載。
CMDCMD [COMMAND_EXECUTED_AFTER_IMAGE_CREATION] #記述例(Shell形式) CMD nginx -g 'daemon off;' #記述例(Exec形式) CMD ["nginx", "-g", "daemon off;"]1-4.デーモンの実行(ENTRYPOINT命令)
DockerfileからビルドしたイメージからDockerコンテナを起動するためにdocker container runコマンドを実行した時に実行されるコマンドを記載。
ENTRYPOINTENTRYPOINT [COMMAND_EXECUTED_WHEN_THE_CONTAINER_RUNS] #記述例(Shell形式) ENTRYPOINT nginx -g 'daemon off;' #記述例(Exec形式) ENTRYPOINT ["nginx", "-g", "daemon off;"]1-5.ビルド完了後に実行されるコマンド(ONBUILD命令)
ビルドしたイメージが他のDockerfileでベースイメージとして設定してビルドしたときに実行させるコマンドを記載。
ONBUILDONBUILD [COMMAND_EXECUTED_WHEN_THE_NEXT_BUILD]1-6.システムコールシグナルの設定(STOPSIGNAL命令)
コンテナを終了するときに送信するシグナルを設定する。
STOPSIGNALSTOPSIGNAL [SIGNAL_NUMBER] STOPSIGNAL [SIGNALNAME] #記述例 STOPSIGNAL 9 STOPSIGNAL SIGKILL1-7.コンテナのヘルスチェック命令(HEALTHCHECK命令)
コンテナ内のプロセスが正しく動作しているかをチェックする。
HEALTHCHECKHEALTHCHECK [OPTION] CMD [COMMAND_EXECUTED_AFTER_IMAGE_CREATION] #記述例 HEALTHCHECK --interval=30s CMD ~ HEALTHCHECK --timeout=30s CMD ~ HEALTHCHECK --retries=3 CMD ~
設定できるオプション
・--interval=n ⇨ ヘルスチェックの間隔
・--timeout=n ⇨ ヘルスチェックのタイムアウト
・--retries=n タイムアウトの回数
1-8.環境変数の設定(ENV命令)
Dockerfile内で環境変数を設定する
ENVENV [KEY] [VALUE] ENV [KEY]=[VALUE] #記述例 ENV MyName glaceon ENV MyName=glaceon1-9.作業ディレクトリの指定(WORKDIR命令)
Dockerfileに書かれた以下の命令を実行するための作業用ディレクトリを指定する。
指定したディレクトリが存在しなければ、新たに作成する。
・RUN命令
・CMD命令
・ENTRYPOINT命令
・COPY命令
・ADD命令WORKDIRWORKDIR [PATH_OF_THE_WORKING_DIRECTORY] #記述例 WORKDIR ./working_dir1-10.ラベルの指定(LABEL命令)
イメージにバージョン情報や作成者情報、コメントなどの情報を持たせる。
LABELLABEL <KEY>=<"VALUE"> #記述例 LABEL maintainer "Glaceon" LABEL title="docker-container" LABEL version="1.0"上記の命令をもとにDockerfileをビルドし、生成されたsampleという名前のイメージ詳細を確認すると、
LABEL命令で指定した情報が設定される。イメージ詳細$ docker image inspect --formats="{{ .Config.Labels }}" label-sample map[title:docker-container version:1.0 maintainer:"Glaceon"]1-11.ユーザの指定(USER命令)
イメージ実行やDockerfileの以下の命令を実行するためのユーザーを指定する。
・RUN命令
・CMD命令
・ENTRYPOINT命令USERUSER [USER_NAME/UID] #記述例 USER glaceon※USER命令で指定するユーザーは、予めRUN命令で作成する必要がある。(詳細は後日記載)
1-12.ポートの設定(EXPOSE命令)
コンテナの公開するポート番号を指定する。
EXPOSEEXPOSE <PORT_NUMBER> #記述例 EXPOSE 80801-13.Dockerfile内変数の設定(ARG命令)
Dockerfile内で使用する変数を定義する。
ARGARG <NAME>=<VALUE> #記述例 ARG YOURNAME="glaceon"1-14.デフォルトシェルの設定(SHELL命令)
シェル形式でコマンド実行する際のデフォルトのシェル設定を行う。
SHELLSHELL ["PATH OF SHELL", "PARAMETER"] #記述例 SHELL ["/bin/bash", "-c"]1-15.ファイル/ディレクトリの追加(ADD命令)
イメージにホスト上のファイルやディレクトリを追加する。
ADDADD <HOST_FILE_PATH> <DOCKER_IMAGE_FILE_PATH> ADD ["<HOST_FILE_PATH>", "<DOCKER_IAMGE_FILE_PATH>"] #記述例 ADD host.html /docker_dir/1-16.ファイルのコピー(COPY命令)
イメージにホスト上のファイルやディレクトリをコピーする。
COPYCOPY <HOST_FILE_PATH> <DOCKER_IMAGE_FILE_PATH> COPY ["<HOST_FILE_PATH>", "<DOCKER_IAMGE_FILE_PATH>"] #記述例 COPY host.html /docker_dir/※ADD命令はリモートファイルのダウンロードやアーカイブの解凍などの機能を持つが、
COPY命令はホスト上のファイルをイメージ内に「コピーする」処理だけを行う。1-17.ボリュームのマウント(VOLUME命令)
イメージにボリュームを割り当てる。
VOLUMEVOLUME ["/MOUNT_POINT"] #記述例 VOLUME ["/var/log/"]
- 投稿日:2020-12-16T00:25:58+09:00
Azure Container InstancesでNervesアプリを開発する
この記事は、「Docker Advent Calendar 2020」 7日目です。
あいていたので埋めました。
前日は、@c3driveさんのAWSにコンテナ環境を構築するはじめに
- Nervesは、
- Elixirというプログラミング言語でIoT開発を楽しむことができます
- Nervesは環境設定がいろいろ必要です
- 慣れてしまえばそうでもないのですがはじめてやるにはいろいろ罠があるというか
- それで、@takasehideki 先生がElixirでIoT#4.1.2:[使い方篇] Docker(とVS Code)だけ!でNerves開発環境を整備するを公開してくれました
- 知り合いにすぐ試してもらいたい!
- NervesJPというグループの会合で、このコンテナをAzure Container Instancesで動かせないの? みたいな話がでたので、いいネタだとおもってかきました
- macOS 10.15.7
- Docker 20.10.0
Dockerfile
# docker-elixir 1.11.2 # https://hub.docker.com/_/elixir FROM elixir:1.11.2 ENV DEBCONF_NOWARNINGS yes # Install libraries for Nerves development RUN apt-get update && \ apt-get install -y build-essential automake autoconf git squashfs-tools ssh-askpass pkg-config curl openssh-server && \ rm -rf /var/lib/apt/lists/* RUN mkdir /var/run/sshd RUN sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin prohibit-password/' /etc/ssh/sshd_config COPY ./config_files/id_rsa.pub /root/.ssh/authorized_keys EXPOSE 22 # [Optional] Uncomment this section to install libraries for customizing Nerves System #RUN apt-get update && \ # apt-get install -y libssl-dev libncurses5-dev bc m4 unzip cmake python && \ # rm -rf /var/lib/apt/lists/* # Install fwup (https://github.com/fhunleth/fwup) ENV FWUP_VERSION="1.8.2" RUN wget https://github.com/fhunleth/fwup/releases/download/v${FWUP_VERSION}/fwup_${FWUP_VERSION}_amd64.deb && \ apt-get install -y ./fwup_${FWUP_VERSION}_amd64.deb && \ rm ./fwup_${FWUP_VERSION}_amd64.deb && \ rm -rf /var/lib/apt/lists/* # Install hex and rebar RUN mix local.hex --force RUN mix local.rebar --force # Install Mix environment for Nerves RUN mix archive.install hex nerves_bootstrap 1.10.0 --force CMD ["/usr/sbin/sshd", "-D"]
- https://github.com/NervesJP/docker-nerves/blob/v0.2/Dockerfileをベースに
ssh接続できるようにしましたssh接続は、@kuboshu83 さんの[Docker入門]コンテナにsshでアクセスするための設定メモ を参考にしました
- ありがとうございます!
- https://github.com/NervesJP/docker-nerves/blob/v0.2/Dockerfileを書き換えることなく、もっとスマートにやるやり方があるかもしれません
- 私にはこの
ssh接続できるようにするという方法しかおもいつきませんでしたconfig_files/id_rsa.pubをおいています
id_rsa.pubはすでに~/.ssh/につくっていたものを使いました- そんなファイルがない場合は
ssh-keygenでググっていただければ、きっと答えはみつかるでしょう$ mkdir config_files $ cp ~/.ssh/id_rsa.pub config_files/ $ docker build -t docker-nerves .
- イメージを作ったら、あとの手順は以下のような感じです
- 1. Azure Container Registryにイメージを登録
- 2. Azure Container Instancesでそのカスタムイメージを使うように設定する
- 3.
sshで接続してNervesアプリの開発をする- 以下、もう少し詳しくみていきます
1. Azure Container Registryにイメージを登録
- クイック スタート:Azure portal を使用して Azure コンテナー レジストリを作成する
だいたいここに書いてある通りにやっていけばよいです
- 私はイメージのプッシュにAzure CLIなるものは一切つかいませんでした
- Azure Container Registryのコンソールに「クイック スタート」というページがあるのでそこを参考にするとよいです
- まず「アクセスキー」というページに行って、管理者ユーザーを有効にしておきます
- そこに書いてあるユーザー名とpasswordは
docker loginでつかいます$ docker login xxx.azurecr.io $ docker tag docker-nerves xxx.azurecr.io/docker-nerves $ docker push xxx.azurecr.io/docker-nerves
- xxxは、Azure Container Registryを作るときに決めた名前(値)がはいります
2. Azure Container Instancesでそのカスタムイメージを使うように設定する
- クイック スタート:Azure portal を使用してコンテナー インスタンスを Azure 内にデプロイするな感じですすめます
- ネットワークは
パプリックにして、ポート22を開けておきます- 設定するのはそれくらいで、あとは
次へ次へです- しばらくするとコンテナが立ち上がるので割り振られたIPアドレスを覚えておきます
- 以下、
20.43.93.225だとします- このコンテナは記事を書いたあとに消しました
3.
sshで接続してNervesアプリの開発をする$ ssh root@20.43.93.225
コンテナの中での操作
$ cd ~/.ssh $ ssh-keygen -t rsa -b 4096 $ cd $ mix nerves.new hello_nerves $ cd hello_nerves $ export MIX_TARGET=rpi4 $ mix deps.get $ mix firmwareで、無事にコンテナの中にファームウェア
/root/hello_nerves/_build/rpi4_dev/nerves/images/hello_nerves.fwができます
Raspberry Pi 4以外の場合は、Targetsから値を選んでください。
開発マシンにもどって
$ scp root@20.43.93.225:/root/hello_nerves/_build/rpi4_dev/nerves/images/hello_nerves.fw .
- クラウドにあるコンテナからファームウェアをもってきて
- microSDカードを開発マシンに挿して
$ fwup hello_nerves.fw
- あっ、fwupのインストール方法を説明していない。。。
- そこは
- fwupのインストール

- クラウドのコンテナからRaspberry Piに
mix upload(つまりssh)したいという話がでていた部分はこの記事ではなにもできていませんメモ
mixコマンドを実行したときに、warning: the VM is running with native name encoding of latin1 which may cause Elixir to malfunction as it expects utf8. Please ensure your locale is set to UTF-8 (which can be verified by running "locale" in your shell)という警告がちょいちょいでていました。
Nervesで一体何がつくれるの?
- いろいろ作れます

- 簡単な作例をご紹介します
- 手前味噌です
- Raspberry Pi 4 + Grove Base HAT for Raspberry Pi + Grove Buzzer + Grove ButtonでつくるNervesアラーム
おまけ2 どうやってコンテナの中の
.exを編集するの?
- Visual Studio Codeでいけちゃいます
- Remote Development using SSHを参考にしてください
- こんな感じで、ローカルファイルを編集している感覚で開発を進めることができます
Wrapping Up

- @takasehideki 先生の
Dockerfileは書き換えずにそのままで対応できるもっとスマートな方法があるかもしれません- クラウドのコンテナからRaspberry Piに
mix upload(つまりssh)したい!? というような話には踏み込めていません- Enjoy Elixir !!!
- この記事をきっかけにNervesに興味をもっていただけましたら、ぜひNervesJPのSlackでお待ちしています!
- 愉快なfolksたちが歓迎します!!!
明日は、@kosuketakeiさんの文系出身業務経験なしのプログラマーがDocker使ってみた です。引き続きお楽しみください。



