- 投稿日:2020-12-16T23:58:05+09:00
GoでRustを呼ぶ。そしてRustでGoを呼ぶ。
はじめに
Question. GoとRustどちらが優れている?
Answer. どちらも優れてる!
Indeed!
— Go (@golang) July 25, 2019この記事ではそれぞれの特徴には言及しません。この記事ではGo側からRustのライブラリを呼ぶ方法と、逆にRust側からGoのライブラリを呼ぶ方法を紹介します。
FFI (バインディング)
あるプログラミング言語から別のプログラミング言語で定義された関数などを利用するための仕組みをFFI(Foreign Function Interface)またはバインディングと言います。
FFIはその言語のライブラリ・ツールとして実現されていることがほとんどです。Go言語の場合はcgoという実装、Pythonではctypesという実装がそれぞれの代表的なFFIということになります。
少なくともGoとRustに関してはそれぞれのFFIはC言語のオブジェクトとのみやり取りができ、その部分は処理系(コンパイラとリンカ)がABI(Application Binary Interface)での呼出規約に基づいて実施します。1
そのため、呼ばれる側の言語は呼ぶ側の言語のFFIが呼べるようにC言語オブジェクトな形にする必要があります。
GoでRustを呼ぶ
サンプルプログラムの内容
Rust側のライブラリは入力された文字列の後ろに
(V)[0-0](V)というカニの顔文字を追加した文字列を返す関数でGo側はその関数を呼びます。構成
以下のようになっています。
. ├── Makefile ├── lib │ ├── rustaceanize │ │ ├── Cargo.lock │ │ ├── Cargo.toml │ │ └── src │ │ └── lib.rs │ └── rustaceanize.h └── main.goRust側(ライブラリ)の実装
入力文字列へ文字追加して返す関数が以下の
rustaceanize関数です。lib/rustaceanize/src/lib.rsextern crate libc; use std::ffi::{CStr, CString}; #[no_mangle] // no_mangle はRustコンパイラが関数名を変えたり削除しないように必要 pub extern "C" fn rustaceanize(name: *const libc::c_char) -> *const libc::c_char { let cstr_name = unsafe { CStr::from_ptr(name) }; let mut str_name = cstr_name.to_str().unwrap().to_string(); println!("Rustaceanizing \"{}\"", str_name); let r_string: &str = " (V)[0-0](V)"; str_name.push_str(r_string); CString::new(str_name).unwrap().into_raw() }
*const libc::c_char型はC言語(GoもRustもC言語型を通したFFIである)が用意した生のcharポインタです。重要なのはこれがC言語側のポインタなのでRustのメモリ管理領域からは外れているという点です。それに対して、CStr::from_ptr関数を通してstd::ffi::CStrというRust側で定義したC言語文字列用型のポインタに変換させています。この処理はunsafeスコープ内で処理される必要があります。その理由は公式ドキュメントから以下になります。(筆者訳)
*const libc::c_charの値が有効(validity)である保証がない。- 返り値のライフタイムが実際のポインタのライフタイムである保証がない。
*const libc::c_charポインタへのメモリが有効なnul終端文字を含んでいる保証がない。*const libc::c_charポインタへのメモリがCStrが消える前に変更されることはない、という保証がない。関数の最後で
CString::new(str_name).unwrap().into_raw()のようにしてC言語が扱えるように生のポインタに変換しています。また、後述のGo言語側でのコンパイルにて関数シンボルが必要になるため以下のようなヘッダーファイルを用意します。
lib/rustaceanize.hchar* rustaceanize(char *name);Go側のコード
上述のRustでできるバイナリとビルドするためにGo側では以下の実装になります。
main.gopackage main /* #cgo LDFLAGS: -L./lib -lrustaceanize #include <stdlib.h> #include "./lib/rustaceanize.h" */ import "C" import ( "fmt" "unsafe" ) func main() { s := "I'm a Gopher" input := C.CString(s) // Goの管理化のポインタではなくなる。 defer C.free(unsafe.Pointer(input)) // そのためメモリ解放を実装する必要がある。 // 以下の場合はinputのメモリはGoの管理化である。 // このときGo側でGCが働くのでこのプログラムではランタイムエラーが発生する! // data := (*reflect.StringHeader)(unsafe.Pointer(&s)).Data // input := (*C.char)(unsafe.Pointer(data)) o := C.rustaceanize(input) output := C.GoString(o) fmt.Printf("%s\n", output) }cgoがFFIとして働いています。
LDFLAGS: -L./lib -lrustaceanizeはRustが作るバイナリをビルド時にリンク(go tool link)させるためのオプションです。
C.CStringとC.GoStringはそれぞれ文字列をCの構造、Goの構造に変換させるメソッドです。コメントとしても記載していますが、C.CStringで作られるポインタはGo言語の管理化ではないです。つまりGoのガベージコレクション対象外のポインタになります。そのため上記の例ではC言語のようにメモリ解放を実装しています。Build
上述のRustとGoのコードをビルドするために、Rustでは
Cargo.tolmに下記のようにcrate-type = ["cdylib"]を指定することでよそ行きのバイナリを作成することができます。lib/rustaceanize/Cargo.toml[package] name = "rustaceanize" version = "0.1.0" [lib] crate-type = ["cdylib"] [dependencies] libc = "0.2.2"ビルドするためのMakefileが以下になります。2
MakefileROOT_DIR := $(dir $(realpath $(lastword $(MAKEFILE_LIST)))) build: cd lib/rustaceanize && cargo build --release cp lib/rustaceanize/target/release/librustaceanize.dylib lib/ echo 'ROOT_DIR is $(ROOT_DIR)' go build -ldflags="-r $(ROOT_DIR)lib" main.goRustが生成したバイナリに対してgo buildで
-ldflags="-r $(ROOT_DIR)lib"のオプションをつけることでGoビルドでのリンカでGoからRustへの呼び出しを紐付けることができます。実行
実行すると期待どおりに動きます。
$ make build $ ./main Rustaceanizing "I'm a Gopher" I'm a Gopher (V)[0-0](V)RustでGoを呼ぶ
サンプルプログラムの内容
GoでRustを呼ぶのときと同じ内容です。こっちではGo側はゴーファー君顔文字
ʕ ◔ϖ◔ʔを追加して返す関数にします。構成
構成は以下のようになっています。
. ├── Cargo.lock ├── Cargo.toml ├── Makefile ├── build.rs ├── golib │ └── main.go └── src └── main.rsGo側(ライブラリ)の実装
入力文字列へ文字追加して返す関数が以下の
Gophernize関数になります。golib/main.gopackage main // ① import "C" // ② // ③ //export Gophernize func Gophernize(name string) *C.char { str := name + " ʕ ◔ϖ◔ʔ" return C.CString(str) } func main() {} // ④Goが他言語が利用できる関数があるバイナリを作成するためにソースコードでは以下を守る必要があります。3
- ①
mainpackage を利用すること。Goコンパイラはmainpackageをビルドしすべての依存モジュール含めてシングルバイナリとして生成される。- ② コードでは必ず
"C"をインポートする必要がある。- ③ 他言語からアクセスさせるために対象の関数上に
//exportのコメントを注釈づけ(annotate)させる。- ④ 空の
main関数を宣言しておく必要がある。Rust側のコード
Rust側のコードは以下のようになります。
src/main.rsuse std::ffi::{CStr, CString}; use std::os::raw::c_char; extern "C" { fn Gophernize(name: GoString) -> *const c_char; } #[repr(C)] struct GoString { a: *const c_char, b: i64, } fn main() { let s = CString::new("I'm a Rustacean").expect("CString::new failed"); let ptr = s.as_ptr(); let input = GoString { a: ptr, b: s.as_bytes().len() as i64, }; let result = unsafe { Gophernize(input) }; let c_str = unsafe { CStr::from_ptr(result) }; let output = c_str.to_str().expect("to_str failed"); println!("{}", output); }Go関数への引数となる
GoString型にある#[repr(C)]はC言語のメモリレイアウトにさせるマクロです。CStrとCStringはRust側でCメモリからRustで扱える形で処理するためのもので、C側に渡す場合は#[repr(C)]がFFIになるようです。
Gophernizeはexternな外部の関数なので"unsafe function"にあたります。なので呼び出しもunsafeスコープで囲う必要があります。
CStr::from_ptrはGoでRustを呼ぶときと同様な理由でunsafeスコープで囲まれる必要があります。Build
Go言語の場合はgo buildにLDFALGオプションを指定してビルド時にリンカへ指示を与えることができましたが、Rustの場合は
build.rsというファイルにてリンクさせるための情報を記載する必要があります。 4今回の場合は以下のような内容です。
build.rsfn main() { let path = "./golib"; let lib = "gophernize"; println!("cargo:rustc-link-search=native={}", path); println!("cargo:rustc-link-lib=static={}", lib); }
Makefileの中身は以下のようになっています。Makefilebuild: cd golib && go build -buildmode=c-archive -o libgophernize.a main.go cargo buildGo側にて
-buildmode=c-archiveのオプションをつけることがポイントになります。これはRustの場合でのcrate-type = ["cdylib"]と同様によそ行き用のバイナリにするために必要なオプションになります。実行
$ make build $ ./target/debug/call-go-from-rust I'm a Rustacean ʕ ◔ϖ◔ʔおわりに
FFIの部分やリンカについて個人的に色々勉強になりました。これからもGoもRustも使っていこう。
参考
- Software Design 2020年12月号 "作品でみせるGoプログラミング"
- https://qiita.com/yugui/items/e71d3d0b3d654a110188
- https://blog.arranfrance.com/post/cgo-sqip-rust/
- https://github.com/vladimirvivien/go-cshared-examples
- https://github.com/mediremi/rust-plus-golang
- https://github.com/arranf/responsive-image-to-hugo-shortcode
- https://github.com/arranf/sqip-ffi
- https://www.altoros.com/blog/golang-internals-part-3-the-linker-object-files-and-relocations/
- https://stackoverflow.com/questions/47074919/how-can-i-call-a-rust-function-from-go-with-a-slice-as-a-parameter
- https://speakerdeck.com/filosottile/calling-rust-from-go-without-cgo-at-gothamgo-2017
- 投稿日:2020-12-16T23:57:54+09:00
Go言語の基本文法(定義編)
スターフェスティバル Advent Calendar 2020 の16日目です。
弊社のプロダクト「ごちクル」の一部処理がGoに改修されたこともあり勉強し始めたので基本的な文法(主に変数などの定義)をまとめてみました。
※ Udemyのこちらの教材を参照元にしています。
packageとimport
Goではプログラムのエントリーポイントとなるのが
mainパッケージのmain関数。
パッケージのグループは名前空間とも呼ばれる。// パッケージの宣言 package main // ライブラリ import "fmt" // main関数の定義と実行 func main() { fmt.Println("こんにちは!") } // こんにちは!ソースファイルは
必ず1つのパッケージに所属させる必要があるため、
今回の場合はmain宣言とmain関数が存在しないとエラーになる。
また1つのファイルに複数のパッケージを設定することはできない。パッケージはディレクトリ単位で管理される。
1つのディレクトリに複数のパッケージは置けない。fmt(フォーマット)は、Goが標準で提供するライブラリ(パッケージ)の1つ。
変数宣言
varを使った変数宣言の場合package main import "fmt" func main() { // 色々な型で変数宣言 var i = 1 var f64 float64 = 1.2 var s string = "test" var t, f bool = true, false // 複数の変数宣言も可能 // 出力 fmt.Println(i, f64, s, t, f) } // 1 1.2 test true falsevar変数を
()丸括弧で囲ってまとめて宣言することもできる。// 省略 func main() { var ( i int = 1 f64 float64 = 1.2 s string = "test" t, f bool = true, false ) fmt.Println(i, f64, s, t, f) } // 1 1.2 test true false
:=を使った変数宣言
:=を使った Short variable declaration の書き方はこう。// 省略 func main() { xi := 1 xf64 := 1.2 xs := "test" xt, xf := true, false fmt.Println(xi, xf64, xs, xt, xf) } // 1 1.2 test true false
:=使った変数宣言のvarとの違いは、
関数の中でしか宣言できないこと。
上記例の場合、func main() {}の外で宣言すると、エラーになる。この宣言では型が指定されていない
untypedとなり、型は自動判定される。
このuntypedの変数に型を付けたい場合は、下記のようにする。// 省略 func main() { xf64 := 1.2 fmt.Printf("%T", xf64) // 型を確認できるPrintfで確認 // float64 var xf32 float32 = 1.2 // 型をfloat32と明示的に宣言 fmt.Printf("%T", xf32) // 型を確認できるPrintfで確認 // float32 }型を明示的に宣言したいときは
varで、
簡単に宣言したいときは:=を使う。
constを使った変数宣言
constは定数宣言。
変数名は、頭文字を大文字にすると他のファイルからも参照できるグローバル変数になる。const Pi = 3.14constも型を指定しない
untypedの変数。型について
数字型
数値型は下記のように宣言する。
数値型の一覧ドキュメントはこちら。package main import "fmt" func main() { var ( u8 uint8 = 225 i8 int8 = 127 f32 float32 = 0.2 c64 complex64 = -5 + 12i ) fmt.Println(u8, i8, f32, c64) fmt.Printf("type=%T value=%v", u8, u8) } // 225 127 0.2 (-5+12i) // type=uint8 value=225(Printfのドキュメントはこちら)
Printfで型やvalueを確認することができる。// 省略 x := 1 + 1 fmt.Println(x) fmt.Println("1 + 1 =", 1+1) fmt.Println("10 - 1 =", 10-1) fmt.Println("10 / 2 =", 10/2) fmt.Println("10 / 3 =", 10/3) fmt.Println("10.0 / 3 =", 10.0/3) fmt.Println("10 / 3.0 =", 10/3.0) fmt.Println("10 % 2 =", 10%2) fmt.Println("10 % 3 =", 10%3) } // 2 // 1 + 1 = 2 // 10 - 1 = 9 // 10 / 2 = 5 // 10 / 3 = 3 // 10.0 / 3 = 3.3333333333333335 // 10 / 3.0 = 3.3333333333333335 // 10 % 2 = 0 // 10 % 3 = 1インクリメントを使うこともできる。
// 省略 x := 0 fmt.Println(x) // 0 x++ fmt.Println(x) // 1 x-- fmt.Println(x) // 0 }文字列型
文字列型は下記のように定義できる。
package main import "fmt" func main() { fmt.Println("Hello World") fmt.Println("Hello " + "World") } // Hello World // Hello Worldstringのキャスト
文字列の一番初めの文字を表示したい時、
fmt.Println("Hello World"[0])このようにインデックスを指定するだけでは、アスキーコードが取得されてしまい、取得できない。
stringを使ってキャストする必要がある。package main import ( "fmt" "strings" //追加 ) func main() { fmt.Println("Hello World"[0]) // 72 fmt.Println(string("Hello World"[0])) // H }エスケープ
バッククオートで囲うと、エディタの改行がそのまま反映できる。
ダブルクオートの中にダブルクオートを入れたい場合は \(バックスラッシュ)でエスケープfmt.Println(`Test Test`) fmt.Println("\"") } // Test // Test // "論理値型
package main import "fmt" func main() { // %T = 型 // %v = 値 // %t = 単語、true または false 指定した型じゃないと正しく表示されない // var t, f bool = true, false t, f := true, false fmt.Printf("%T %v %t\n", t, t, t) fmt.Printf("%T %v %t\n", f, f, f) // 論理演算子 && (and) fmt.Println(true && true) // 真かつ真 = 真 fmt.Println(true && false) // 真かつ偽 = 偽 fmt.Println(false && false) // 偽かつ偽 = 偽 // 論理演算子 || (or) fmt.Println(true || true) // 真もしくは真 = 真 fmt.Println(true || false) // 真もしくは偽 = 真 fmt.Println(false || false) // 偽もしくは偽 = 偽 // 論理演算子 ! (not) fmt.Println(!true) // false 条件の反対の結果 fmt.Println(!false) // true 条件の反対の結果 }型変換(キャスト)
Goでは
integer -> floatのような数値同士の型変換は簡単にできるが、文字列 -> 数値のような型変換は少しコツがいる。integer->floatへの型変換(簡単)
下記のようにスムーズに変換できる。
(Printfのドキュメントはこちら)package main import "fmt" func main() { var x int = 1 xx := float64(x) // int を float64 に型変換 fmt.Printf("%T %v %f\n", xx, xx, xx) } // float64 1 1.000000 // int -> float64 へ型変換できている
string -> intに型変換(ちょっとコツいる)文字列の相互変換(コンバージョン)用のライブラリ
strconvを使用して型変換する。
(strconvのドキュメントはこちら)package main import ( "fmt" "strconv" //追加 } func main() { var s string = "14" i, _ := strconv.Atoi(s) // int型に変換 fmt.Printf("%T %v\n", i, i) } // int 14 // string -> int へ型変換できているAtoi関数はAscii to integerの略。
i, _ := strconv.Atoi(s)の_について。
Atoiは返り値を2つ(int, error)返す関数。2つ目の返り値はエラーハンドリング用だが、
i := strconv.Atoi(s)このように省略するとエラーになってしまう。今回のように使わない場合は
_で省略することができる。配列
goでの配列の基本的な書き方はこんな感じ。
[]スクエアブラケットの中身は、配列の個数が入る。
配列の場合は、[2]intこの部分が型になる。package main import "fmt" func main() { // 配列 var a [2]int a[0] = 100 a[1] = 200 fmt.Println(a) // この書き方も可 var b [2]int = [2]int{100, 200} fmt.Println(b) } // [100 200] // [100 200]配列は
[2]intこのように配列の個数と型が決まっているため、配列にappendなどで追加してリサイズすることはできず、エラーとなる。// 省略 func main() { var b [2]int = [2]int{100, 200} b = append(b, 300) //このように配列に追加しようとするとエラー fmt.Println(b) } // first argument to append must be slice; have [2]int // b redeclared in this blockではどうやって追加するのか?
配列ではなくスライスを使用する。スライス
スライスは配列と違い、個数を指定せず下記のように宣言する。
// 配列 var b [2]int = [2]int{100, 200} // スライス var b []int = []int{100, 200}スライスは個数を追加することができる。
package main import "fmt" func main() { n := []int{1, 2, 3, 4, 5, 6} // スライスに値を追加 n = append(n, 100, 200, 300, 400) fmt.Println(n) } // [1 2 3 4 5 6 100 200 300 400]配列はリサイズできない。
スライスはリサイズできる。スライスにインデックスを指定する
スライスをインデックス指定で取得できる。
●〜●番目という風にレンジで取得する際の数え方が独特。package main import "fmt" func main() { n := []int{1, 2, 3, 4, 5, 6} // 配列の●番目 fmt.Println(n[2]) // 配列の●〜●番目 fmt.Println(n[2:4]) // 配列の〜●番目まで fmt.Println(n[:2]) // 配列の●番目以降 fmt.Println(n[2:]) // 配列すべて表示 fmt.Println(n[:]) } // 3 // [3 4] // [1 2] // [3 4 5 6] // [1 2 3 4 5 6]スライスの値を書き換える
指定したインデックスの値を書き換える。
// 省略 func main() { n := []int{1, 2, 3, 4, 5, 6} n[2] = 100 fmt.Println(n) } // [1 2 100 4 5 6]スライスを入れ子にする
// 省略 func main() { n := []int{1, 2, 3, 4, 5, 6} var board = [][]int{ []int{0, 1, 2}, []int{3, 4, 5}, []int{6, 7, 8}, fmt.Println(board) } // [[0 1 2] [3 4 5] [6 7 8]]スライスに追加する
// 省略 func main() { n := []int{1, 2, 3, 4, 5, 6} n = append(n, 100, 200, 300, 400) fmt.Println(n) } // [1 2 3 4 5 6 100 200 300 400]map(連想配列)
mapの基本的な書き方は下記の通り。
package main import "fmt" func main() { m := map[string]int{"apple": 100, "banana": 200} fmt.Println(m) } // map[apple:100 banana:200]mapをキーを指定して取り出し
// 省略func main() { m := map[string]int{"apple": 100, "banana": 200} // キーを指定してvalueを取り出す fmt.Println(m["apple"]) // banana のvalueを 300 で上書き m["banana"] = 300 fmt.Println(m) } // 100 // map[apple:100 banana:300]mapに追加する
// 省略 func main() { m := map[string]int{"apple": 100, "banana": 200} // 追加する m["new"] = 500 fmt.Println(m) } // map[apple:100 banana:300 new:500]mapで存在しないキーを使った場合
存在しないキーを指定した場合は
0が返る。
mapの宣言の際、2つ目の返り値を指定すると、値が存在するかどうかbool型で確かめることができる。// 省略 func main() { m := map[string]int{"apple": 100, "banana": 200} // 存在しないキーを指定 fmt.Println(m["nothing"]) // 2つ目の返り値を指定 v, ok := m["apple"] fmt.Println(v, ok) } // 0 // 100 truemakeを使ったmapの初期化
makeを使うと、空のmapを作成できる。
下記では空のmapを:=で定義した。func main() { m := make(map[string]int) m["pc"] = 5000 fmt.Println(m) } // m["pc"] = 5000対して
varで同じように定義すると、panicというエラーが起きる。func main() { var m map[string]int m["pc"] = 5000 fmt.Println(m) } // panic: assignment to entry in nil mapこれは宣言はしているものの、メモリー上に入れるmapがないのでエラーとなる。
以上、Goの色々な定義の仕方をまとめてみました。
定義編はここまでにします。
また後日、続きを書きたいと思います。
- 投稿日:2020-12-16T22:47:02+09:00
LeetCodeに毎日挑戦してみた 111. Minimum Depth of Binary Tree(Python、Go)
Leetcodeとは
leetcode.com
ソフトウェア開発職のコーディング面接の練習といえばこれらしいです。
合計1500問以上のコーデイング問題が投稿されていて、実際の面接でも同じ問題が出されることは多いらしいとのことです。golang入門+アルゴリズム脳の強化のためにgoとPythonで解いていこうと思います。(Pythonは弱弱だが経験あり)
26問目(問題111)
111. Minimum Depth of Binary Tree
問題内容
Given a binary tree, find its minimum depth.
The minimum depth is the number of nodes along the shortest path from the root node down to the nearest leaf node.
Note: A leaf is a node with no children.
(日本語訳)
二分木が与えられたら、その最小の深さを見つけます。
最小深度は、ルートノードから最も近いリーフノードまでの最短パスに沿ったノードの数です。
注: リーフは子のないノードです
Example 1:
Input: root = [3,9,20,null,null,15,7] Output: 2Example 2:
Input: root = [2,null,3,null,4,null,5,null,6] Output: 5考え方
再帰処理を用います
rootのleft,rightをそれぞれ潜っていって、noneになったらreturnします。
左右どちらもnoneでなかったらreturnされた合計の小さい方をreturnします
最終的に最小の深さを戻り値とします
解答コード
class Solution: def minDepth(self, root): if root == None: return 0 if root.left==None or root.right==None: return self.minDepth(root.left)+self.minDepth(root.right)+1 return min(self.minDepth(root.right),self.minDepth(root.left))+1
- Goでも書いてみます!
func minDepth(root *TreeNode) int { if root == nil { return 0 } if root.Left == nil { return minDepth(root.Right) + 1 } if root.Right == nil { return minDepth(root.Left) + 1 } return min(minDepth(root.Right), minDepth(root.Left)) + 1 } func min(a int, b int) int { if a < b { return a } return b }

- 投稿日:2020-12-16T22:33:43+09:00
【Go言語】構造体(struct)について
構造体等とは何か
色々あるデータを1つにまとめたもの。
Go言語にはクラスというものが存在しないが、構造体を使用することでクラスのような振る舞いをすることができる。定義方法
main.gopackage main func main() { type people struct { name string age int gender string } } }初期化方法
main.gopackage main func main() { type people struct { name string age int gender string } //people型で変数を定義 var people1 people //それぞれに値を代入 people1.name = " yamada" people1.age = 21 people1.gender = "man" //出力 fmt.Println(people1.name) //yamada fmt.Println(people1.age) //21 fmt.Println(people1.gender) //man }上記のように構造体を使うとクラスっぽい振る舞いができます。
- 投稿日:2020-12-16T22:31:51+09:00
【Go言語】AgoutiでGoogleChromeを自動で操作する
事前準備
Agoutiのインストール
以下のコマンドでAgoutiをインストールします。
$ go get github.com/sclevine/agoutiChrome Driverをインストール
続いて自動で操作したブラウザに対応したWebDriverをインストールします。
今回はGoogleChromeを操作したいので、以下のコマンドでGoogleChromeのWebDriver(chromedriver)をインストールします。$ brew install chromedriverGoogleChromeのバージョンによって上手くいかない場合はChromeのバージョンを確認し、以下のサイトよりDriverをダウンロードしてください。
https://chromedriver.storage.googleapis.com/index.html
自動操作
事前準備が完了したら、ブラウザを自動操作するコードを書いていきます。
今回は、Go言語の公式ページを開き、Documentsまでの遷移する動きを自動化してみます。
以下、自動操作のためのコードです。
それぞれのコードの意味はコメントアウトで記述しています。main.gopackage main import ( "log" "github.com/sclevine/agouti" ) func main() { //ChromeDriverを使用するための記述 driver := agouti.ChromeDriver() //WebDriverプロセスを開始する err := driver.Start() if err != nil { log.Fatal(err) } //WebDriverプロセスを停止する(main関数の最後で停止したいのでdeferで処理) defer driver.Stop() if err != nil { log.Fatal(err) } //NewPage()でDriverに対応したページを返す。(今回はChrome) page, err := driver.NewPage() //Navigate()の引数にURLを渡し、ページの遷移を行う err = page.Navigate("https://golang.org/") //Screenshot()で開いているページのスクリーンショットを撮る。保存名は引数で指定。(保存場所も相対パスor絶対パスで指定可能) page.Screenshot("Go言語公式HP.png") if err != nil { log.Fatal(err) } //FindByLink() で引数に指定したaタグのテキストを検索し、Click()でクリックする page.FindByLink("Documents").Click() //上記のScreenshot()と同様の動き page.Screenshot("Go言語Documents.png") }以下、page.Screenshot()で撮影したスクリーンショットです。
Go言語公式HP.png
Go言語Documents.png


- 投稿日:2020-12-16T22:30:33+09:00
【Go言語】logを別ファイルに出力する
方法
logパッケージの「SetOutput」関数を使う
書き方
main.gopackage main import ( "log" "os" ) func main() { // ファイルを開く。(引数はテストの名前 、flag、perm) logfile, err := os.OpenFile("./test.log", os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0666) if err != nil { panic("cannnot open test.log:" + err.Error()) } //main関数の最後にファイルを閉じるためdeferを記述 defer logfile.Close() //標準ロガーの出力先を設定(定義したlogfileに出力するように記述) log.SetOutput(logfile) log.Println("TestLog") }main.goを実行すると、ディレクトリ内にtest.logが作成され、中身には「Testlog」と表示されます。
test.log2020/12/16 22:18:56 TestLog補足
上記を試すと、ターミナルには log.Printlnの出力がされないと思います。
ターミナルにもファイルにもログを出力をさせたい場合ioパッケージのMultiWriterメソッドを使用します。
具体的にはこのように書きます。main.gopackage main import ( "io" "log" "os" ) func main() { logfile, err := os.OpenFile("./test.log", os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0666) if err != nil { panic("cannnot open test.log:" + err.Error()) } defer logfile.Close() // SetOutputの引数を追記 log.SetOutput(io.MultiWriter(logfile, os.Stdout)) log.Println("Testlog(ファイルにもターミナルにも出力される)") }ターミナルにもファイルにも出力できましたでしょうか。
このように書くと、ターミナルにもファイルにもログを出力させることができます。
- 投稿日:2020-12-16T21:48:55+09:00
Goを学び始めた
Goを学び始めた(のでとりあえずDiscord botを作った)
この記事はアドベントカレンダー16日目です。
親知らず抜歯して元気だったら書きます と宣言したのですが、本当に元気だったので書いています。
昨日はikkyuのダークウェブをのぞいてみるでした。
Torについては2018年の映画「名探偵コナン ゼロの執行人」にて、少しもじった「Nor」が出てきたことからも少し話題になりましたね!(自分の周りだけかもしれない)
さて、今年の3月に「プログラミング言語Go完全入門」の期間限定公開のお知らせを見ました。
それから私はしばらく冬眠していたのですが、8月に「プログラミング言語Go完全入門」の「完全」公開のお知らせと更新されており、以前からGolang自体には触れてみたいと思っていたところではあったので、これを機に遊んでみました。
Go習得について、参考にしたもの
ここではGoに関する環境構築や詳しい書き方などについては省略します。Qiitaにもより良い記事がありますし、上に紹介した「プログラミング言語Go完全入門」は非常に学びやすいと思います。
そう前置きした上で、Goに触れてみての感想と、参考にしたものや辿ったものを簡単に紹介します。
タイトルにDiscord botを作った、と書きましたが、これについては非常に長くなるので別の記事にまとめます。
A tour of Go
Goのチュートリアルといえば、というぐらいメジャーなのがA tour of Goですね。(日本語版)
ローカルに環境を作らなくても常に画面の右側にPlaygroundがあるのでしっかり演習しながら進めることができます。演習問題は、完全なプログラミング初心者に向けたチュートリアルとしてはやや難しく、個人的には多言語から来た人にちょうどいいぐらいのものが多いイメージでした。
Dockerで環境が作れるとはいえ、若干環境構築が面倒臭いと感じていたのでこれで言語仕様を学んでモチベーションを上げつつ学習を開始しました。
プログラミング言語Go完全入門
Googleスライドに14章までまとめられていて、網羅的かつ演習つきなので完遂すればある程度は書けるようになっていると思います。
SlackチャンネルGopher Dojoへ参加することで動画コンテンツも参照することができます。私はインターフェースとゴールーチンあたりで若干こんがらがったので動画で学習しました。
また、スライド内で出される課題についてもSlackにてレビューしてもらえるそう。
その他参考にした記事など
めちゃくちゃ有名な記事ですが、環境構築で詰まった時に他言語から来た人がGoを使い始めてすぐハマったこととその答えを読みました。
Discord botを実際に作るとき、エラーハンドリングでかなり苦戦したので、Go言語のエラーハンドリングについてを参考にしました。
Goを触ってみての所感
とりあえずなんとかDiscord botが動く程度には習得しました。
兎にも角にもエラーハンドリングに苦戦しました。
私は複数のエラーをハンドリングする、という点でかなり詰まりましたが、たとえひとつやふたつのエラーであっても適切に処理するのは初心者には若干難しいなあ、と思いました。
また、どうしても
if err != nil {を無限に書いてしまい、結果的にきちんと網羅できているか怪しくなる(errcheckを使えという話ではありますが)という気がしてならないところではあります。この辺りの感覚はまだ書き始めたばかりというのもあり、上級者からするとしょうもないことで悩んでいるな、といったものなのかもしれません。
とりあえず上質なコードをいっぱい読みながらDiscord botの機能充実に向けて頑張りたいと思います。
あとEbitenも気になっている。

- 投稿日:2020-12-16T21:32:39+09:00
Goクイズアドベントカレンダー 14日目
問題
Q. 以下のコードを実行するとどうなるでしょう?
package main import ( "fmt" ) func main() { type A float64 type B = float64 // 2の128乗より少し小さいくらい const a = 50000000000000000000000000000000000000000000000000000000000000000000000000000 var b B = B(a) var c A = A(a) fmt.Printf("%T %T %T", a, b, c) }
int, float64, main.Aと表示されるfloat64, main.B, main.Aと表示されるuntyped int, float64, main.Aと表示される- コンパイルエラー
以下解答&解説
↓
↓
↓
↓
↓
↓
↓
↓
↓
↓
↓
↓
↓
↓
↓
↓解答
正解は 4. コンパイルエラー でした。 → 答え合わせ
$ go run prog.go ./prog.go:17:13: constant 50000000000000000000000000000000000000000000000000000000000000000000000000000 overflows intというエラーメッセージが表示されます。
ちなみに、余談ですが最新版のGoland(2020.3)では、上記のコードのコンパイルエラーを検出できません。解説
このコードがコンパイルエラーになることを理解するためには、次の知識が必要です。
- 型無し定数
- 型無し定数のデフォルト型
- 代入できる値とできない値の区別
それでは、順を追って解説していきます。
型無し定数とは
Goには「型無し定数(untyped constants)」というものが存在します。
仕様書では Constantsの章 で触れられています。Constants may be typed or untyped. Literal constants, true, false, iota, and certain constant expressions containing only untyped constant operands are untyped.
(直訳)
定数は型付きでも型なしでもかまいません。リテラル定数、true、false、iota、および型指定されていない定数オペランドのみを含む特定の定数式は型指定されていません。今回のコードで定数
aとして定義している50000000000000000000000000000000000000000000000000000000000000000000000000000はリテラル定数なので
untyped integer constant となります。また、定数
aはもっとも大きい整数型であるuint64に収まらないほど大きな数ですが、仕様書にも次のように書かれているとおり、
大きな定数を定義すること自体はコンパイルエラーになりません。Rune, integer, floating-point, and complex constants are collectively called numeric constants.
〜中略〜
Numeric constants represent exact values of arbitrary precision and do not overflow.
(直訳)
Rune、整数、浮動小数点数、複素数の定数は数値定数と総称されます。
数値定数は任意精度の正確な値を表し、オーバーフローしません。ただし、無限大の精度の数値を扱えるのはあくまで仕様上の話であり、実際の計算機でそのような処理系を作ることは不可能なので、仕様書には次のようにも書かれています。
Implementation restriction: Although numeric constants have arbitrary precision in the language, a compiler may implement them using an internal representation with limited precision. That said, every implementation must:
- Represent integer constants with at least 256 bits.
- Represent floating-point constants, including the parts of a complex constant, with a mantissa of at least 256 bits and a signed binary exponent of at least 16 bits.
- Give an error if unable to represent an integer constant precisely.
- Give an error if unable to represent a floating-point or complex constant due to overflow.
- Round to the nearest representable constant if unable to represent a floating-point or complex constant due to limits on precision.
(直訳)
実装の制限:数値定数は言語で任意の精度を持っていますが、コンパイラーは制限された精度の内部表現を使用してそれらを実装する場合があります。とはいえ、すべての実装は次のことを行う必要があります。
- 256ビット以上の整数定数を表します。
- 少なくとも256ビットの仮数と少なくとも16ビットの符号付き2進指数を使用して、複素定数の一部を含む浮動小数点定数を表します。
- 整数定数を正確に表すことができない場合はエラーを出します。
- オーバーフローのために浮動小数点または複素定数を表すことができない場合は、エラーを出します。
- 精度の制限により浮動小数点または複素定数を表現できない場合は、最も近い表現可能な定数に丸めます。定数
aは64bitには収まらなくても、256bitには収まるため、全ての処理系で正確に表せる整数定数であることが保証されています。型無し定数のデフォルト型
型無し定数には型がありませんが、型無し定数を使うときには型が確定します。
例えば、次の例では、
12345は型無し定数ですが、hogeに代入するときに明示されているuint16型に確定します。var hoge uint16 = 12345しかし、型の宣言を省いた場合、型を確定させられないように見えます。
hoge := 12345Goではこのようなケースに対応するために、それぞれの型無し定数にはデフォルト型が定められています。
仕様書では Constantsの章 で触れられています。The default type of an untyped constant is bool, rune, int, float64, complex128 or string respectively, depending on whether it is a boolean, rune, integer, floating-point, complex, or string constant.
(直訳)
型なし定数のデフォルトの型は、ブール定数、ルーン定数、整数、浮動小数点定数、複素定数、または文字列定数のいずれであるかに応じて、それぞれbool、rune、int、float64、complex128、またはstringです。つまり、
hogeの型は型無し整数定数である12345のデフォルト型 =int型 になります。今回の問題でコンパイルエラーになっている行を読むと、型無し整数定数である
aをinterface{}に渡そうとしています。fmt.Printf("%T, %T, %T, %T", a, b, c, d)
interface{}の動的型を決定する必要がありますが、明示的な型指定をしていないため、定数aのデフォルト型が適用されてint型となることが分かります。代入できる値とできない値の区別
値の代入可能性については Assignabilityの章 で触れられています。
この章では、ずばり代入できる条件が列挙されています。A value x is assignable to a variable of type T ("x is assignable to T") if one of the following conditions applies:
- x's type is identical to T.
- x's type V and T have identical underlying types and at least one of V or T is not a defined type.
- T is an interface type and x implements T.
- x is a bidirectional channel value, T is a channel type, x's type V and T have identical element types, and at least one of V or T is not a defined type.
- x is the predeclared identifier nil and T is a pointer, function, slice, map, channel, or interface type.
- x is an untyped constant representable by a value of type T.
(直訳)
次の条件のいずれかが当てはまる場合、値xは型Tの変数に割り当てることができます(「xはTに割り当てることができます」)。
- xのタイプはTと同じである。
- xの型VとTは同一の基になる型を持ち、VまたはTの少なくとも1つは定義された型ではない。
- Tはインターフェイスタイプであり、xはTを実装している。
- xは双方向チャネル値、Tはチャネルタイプ、xのタイプVとTは同一の要素タイプを持ち、VまたはTの少なくとも1つは定義されたタイプではありません。
- xは事前に宣言された識別子nilであり、Tはポインタ、関数、スライス、マップ、チャネル、またはインターフェイスタイプである。
- xは、型Tの値で表すことができる型無し定数である。今回は型無し整数定数を
int型として代入しようとしているため、「定数aがint型の値で表すことができるかどうか」が争点になります。
型無し定数が型Tの値で表せるかどうかの条件は、 Representabilityの章に書かれています。A constant x is representable by a value of type T if one of the following conditions applies:
- x is in the set of values determined by T.
- T is a floating-point type and x can be rounded to T's precision without overflow. Rounding uses IEEE 754 round-to-even rules but with an IEEE negative zero further simplified to an unsigned zero. Note that constant values never result in an IEEE negative zero, NaN, or infinity.
- T is a complex type, and x's components real(x) and imag(x) are representable by values of T's component type (float32 or float64).
(直訳)
次の条件のいずれかが当てはまる場合、定数xはタイプTの値で表すことができます。
- xは、Tによって決定される値のセットに含まれる。
- Tは浮動小数点型であり、xはオーバーフローすることなくTの精度に丸めることができる。丸めにはIEEE754の丸め規則が使用されますが、IEEEの負のゼロはさらに単純化されて符号なしゼロになります。定数値がIEEEの負のゼロ、NaN、または無限大になることは決してないことに注意してください。
- Tは複素数型であり、xの成分real(x)およびimag(x)は、Tの成分型(float32またはfloat64)の値で表すことができる。定数
aは整数であり、浮動小数点数でも複素数でもないため、1つ目の条件が適用され、int型の範囲に収まっていれば、無事代入可能であることが分かります。
int型の精度は処理系によって異なりますが、Numeric Typesの章には次のように書かれています。uint either 32 or 64 bits
int same size as uint
(直訳)
uint 32もしくは64ビット
int uintと同じつまり
int型の精度はint32かint64と同じです。
しかし定数aは非常に大きく、2の127乗 < a < 2の128乗程度の値のためint32はおろかint64にも到底収まりません。まとめ
よって、今回の問題のコードは、
fmt.Printf()のinterface{}型の引数に型無し整数定数aを与えようとする
→ 型を指定していないためデフォルト型のint型として代入しようとする
→int型に収まらないくらい大きい値のため、 定数aはint型として表すことができない。
→ 代入できる条件を満たさないというステップを経てコンパイルエラーになっているのでした。
おまけ
それぞれの選択肢がどういったシナリオを想定していたのかも書いておきます。
int, float64, main.Aを選んだ人
- 型無し整数定数のデフォルト型が
int型であることを知っていたが、int型に収まらない大きさの場合にどうなるか知らなかった- 型エイリアスを
%Tで表示しても元の型が表示されることを知っていた- ちなみに、定数
aがint型に収まる大きさだった場合は、この選択肢が正解です。float64, main.B, main.Aを選んだ人
- 定数
aはint型には収まらないが、float64には収まるため変換されると勘違いしていたtype B = float64という型定義は、float64のエイリアスを作っているだけなので、%Tで表示してもfloat64と表示されることを知らなかったuntyped int, float64, main.Aを選んだ人
- 定数
aが型無し整数定数であることを見抜いていたが、引数に渡されるときに型が確定してしまうことを忘れていた- 型エイリアスを
%Tで表示しても元の型が表示されることを知っていた- ちょっと詳しい人を引っ掛けたくてこの選択肢を用意しました
- 投稿日:2020-12-16T18:20:22+09:00
結局、Go言語をやめる理由はなかった件
この記事は Go 2 Advent Calendar 14日目の穴埋め記事です。
はじめに
@okdyy75 さんによる Go 5 Advent Calendar 14日目の の記事「だから僕はGo言語を辞めた」 が「ベンチマークっていうのはこうやるんだよ」というのを説明するために反面教師的な意味で良い教材だと思ったので、反証記事を書きたいと思います。
ベンチマークを取りながらコードを改善して、最終的にGoは遅くないからやめる必要はないということ、そして、なぜ遅いという結論になってしまったのかを掘り下げていきたいと思います。下準備
幸いなことに、ベンチマークのソースコードがGitHubにある ので、こちらを実行しながら問題点を改善していきましょう。
ちゃんとコードが上がっているのは素晴らしいですね!一方で、元記事には測定環境が明記されていませんでしたので、同じ環境で測定することはできませんでした。
今回は誰でも追試できるように、AWS EC2 の m5d.large インスタンスを使うことにしました。m5d.large インスタンスのスペックは次のようになっています:
- vCPU: 2
- Intel(R) Xeon(R) Platinum 8175M CPU @ 2.50GHz (最大3.1GHz)
- メモリ: 8 GiB
- ストレージ: 1 x 75 GiB NVMe SSD
- OS: Amazon Linux 2
今回、m5d.large インスタンスを採用したのは次の理由からです:
- 汎用ワークロード向けインスタンスである
- Docker Composeを使うため、メモリに余裕をもたせて8GB用意する
- MySQLでストレージがボトルネックになることを少しでも抑えるため、NVMe SSD を使う
注意点として、同じ汎用ワークロード向けでもバースト可能なT系インスタンスはベンチマークを取る際には避けたほうが良いです。バースト可能インスタンスはCPUクレジットが切れるとパフォーマンスが著しく制限されるため、性能が安定しないからです。(バーストリミットを外すという手もありますが、そうすると課金が青天井になります。富豪じゃないので、怖くてとてもリミットは外せません(^q^))
それではリポジトリをクローンして始めていきましょう:
$ git clone https://github.com/okdyy75/bench-docker.git $ cd bench-docker
docker-compose.ymlがあるので、docker-composeで起動します:$ docker-compose up -dとりあえず測ってみる
とりあえず、Go実装のベンチマークプログラムを実行させてみましょう:
$ sudo docker-compose run --rm golang sh -c 'cd go; go build . && ./go' Creating bench-docker_golang_run ... done Go go1.15.6 . . . (snip) . . . 平均秒数:9.78155623 (0x0,0x0)元記事よりもずいぶん速いですね。まぁ、実行環境が違うので仕方ありませんね。
次に比較対象として、元記事で最速だった Python実装の時間を計測してみましょう:
$ sudo docker-compose run --rm python sh -c 'cd python; pip install -r ./requirements.txt && python bench.py' Creating bench-docker_python_run ... done . . . (snip) . . . Python 3.9.1 (default, Dec 11 2020, 14:29:41) . . . (snip) . . . 平均秒数:9.155766, 標準偏差: 0.6なるほど、元記事ほどの差はありませんが、たしかにPythonのほうが良い結果が出ていますね。
測定結果の "ブレ" はどれくらい?
ここでGoの実行結果をよく見ると、各試行の実行時間にだいぶブレがあることに気づきます:
$ sudo docker-compose run --rm golang sh -c 'cd go; go build . && ./go' Creating bench-docker_golang_run ... done Go go1.15.6 ...(snip)... 9.5253088 (0x0,0x0) ...(snip)... 9.8432198 (0x0,0x0) ...(snip)... 10.5489359 (0x0,0x0) ...(snip)... 10.4082789 (0x0,0x0) ...(snip)... 10.4875889 (0x0,0x0) ...(snip)... 9.4180508 (0x0,0x0) ...(snip)... 9.1494458 (0x0,0x0) ...(snip)... 9.1779438 (0x0,0x0) ...(snip)... 9.5848948 (0x0,0x0) ...(snip)... 9.6719018 (0x0,0x0) 平均秒数:9.78155623 (0x0,0x0)ちなみに、今回のベンチマークでは、対象処理を10回試行して、その平均秒数を表示するようになっています。
Go と Python の実行時間の差はこのブレ、つまり誤差の中に収まってしまうのではないか?というわけで、標準偏差も計算して表示するようにプログラムを次のように書き換えました:$ git diff diff --git a/www/go/bench.go b/www/go/bench.go index 5c56714..878b95a 100644 --- a/www/go/bench.go +++ b/www/go/bench.go @@ -5,6 +5,7 @@ import ( "encoding/csv" "fmt" "io" + "math" "os" "runtime" "time" @@ -281,6 +282,12 @@ func main() { sum += s } avg := float64(sum / float64(len(times))) - println(fmt.Printf("平均秒数:%f", avg)) + // 標準偏差を計算 + sdev := 0.0 + for _, t := range times { + sdev += math.Pow(avg-t, 2) + } + sdev = math.Sqrt(sdev / float64(len(times))) + println(fmt.Printf("平均秒数:%f, 標準偏差: %.1f", avg, sdev)) } diff --git a/www/python/bench.py b/www/python/bench.py index 2639925..8050297 100644 --- a/www/python/bench.py +++ b/www/python/bench.py @@ -1,4 +1,5 @@ import csv +import math import os import sys from itertools import zip_longest @@ -179,7 +180,12 @@ def main(): times.append(s) svg = sum(times) / len(times) - print('平均秒数:%f' % svg) + # 標準偏差を計算 + sdev = 0.0 + for t in times: + sdev += (t - svg) ** 2 + sdev = math.sqrt(sdev / len(times)) + print('平均秒数:%f, 標準偏差: %.1f' % (svg, sdev)) if __name__ == '__main__':ちなみに、Pythonの標準的なテスト/ベンチマークツールである pytest を使うと、この標準偏差や最小値、最大値といった数値をまとめて表示してくれるので便利です。
よく使われているベンチマークツール/フレームワークを利用すれば先人の知恵の恩恵にあやかることができるので、可能な場合は是非利用しましょう。書き換えたプログラムの実行結果は次のようになります:
Go実装:
$ sudo docker-compose run --rm golang sh -c 'cd go; go build . && ./go' ...(snip).. 平均秒数:9.945593, 標準偏差: 0.342 (0x0,0x0)Python実装:
$ sudo docker-compose run --rm python sh -c 'cd python; pip install -r ./requirements.txt && python bench.py' ...(snip)... 平均秒数:8.899219, 標準偏差: 0.1たしかに Go実装のほうが標準偏差が大きいですが、しかし両者の差が誤差の範囲とは言えませんね。
では、いったい何にそんなに時間がかかっているのでしょうか?どんな処理に時間がかかっているのかざっくり知る
プログラムの実行時間は次のような時間の合計です:
- ユーザー空間で実行されてる時間(user time)
- カーネル空間で実行されている時間(system time)
- ファイルやネットワークなどの入出力結果を待っている時間(idle time)
1 は自分や自分が利用しているライブラリのコードが実行されている時間です。普通はチューニングや高速化といったらまずはここを改善します。
2 はOS(カーネル)のコードが実行されている時間です。カーネルの中に手を入れてチューニングするということは普通はしないので、2の時間を縮めるためにはカーネル機能(システムコール)を呼び出す回数を減らすことを考えます。特に、システムコールを呼んだときは、プロセスの実行が通常の権限で動くユーザー空間から特権で動くカーネル空間へと切り替わりますが、この切り替え処理はかなり重い処理です。そのため、一度のシステムコールでなるべく多くの仕事をするようにしてシステムコールを呼ぶ回数を減らすことが、プログラムの効率化につながります。(I/Oのバッファリングはこの典型的な手法ですね)
最後に 3 は、ソフトウェアではどうにもできないことが多いです。2 のチューニングでシステムコールを呼ぶ回数を減らしたあとは、もうハードウェアのスペックを上げたり、ネットワーク遅延を下げたりすることで改善することになります。(基本的には札束で殴るのが効果的な世界)では、今回のケースではどこに時間が使われているのでしょう?
これをざっくり知るためのもっとも簡単な方法は
timeコマンドです。
測定したいコマンドの前にtimeを置くだけで、上記1、2、3を表示してくれます:Go実装:
$ sudo /usr/local/bin/docker-compose run --rm golang sh -c 'cd go; go build . && time ./go' ...(snip)... 平均秒数:9.182259, 標準偏差: 0.142 (0x0,0x0) real 1m 31.83s user 0m 6.06s sys 0m 8.80sPython実装:
$ sudo /usr/local/bin/docker-compose run --rm python sh -c 'cd python; pip install -r ./requirements.txt && time python bench.py' ...(snip)... 平均秒数:9.029642, 標準偏差: 0.6 real 1m 30.32s user 0m 8.65s sys 0m 2.45s
realが実際にプログラムを頭から終わりまで実行するのにかかった実際の時間です。(しばしばCPU時間と区別するために wall-clock timeも呼ばれます)
userが上記1のuser time、sysが 上記2のsystem timeです。したがって、realからuserとsysを引いた時間が上記3のidle timeになります。見ておわかりの通り、どちらのプログラムも
realは 90秒程度なのに対し、user+sysは 10~15秒くらいしかありません。つまり、実行時間のうち85%くらいの時間は、ただI/Oの結果を待っているだけの ヒマしている時間 なのです。さらによく見てみると、Python実装の user time が8.65秒、system time が 2.45秒なのに対し、Go実装の user time が 6.06秒、system time が 8.80秒と、それぞれの実行時間が逆転しています。
Goの場合は user time ≒ Goで実装されたコードの実行時間ですから、Goで書かれたコードが実行されている時間のほうがPythonで書かれたコードが実行されている時間よりも短いと言えます。
ではなぜ、system time(OSカーネルが動いている時間)が8.80秒もかかっているのでしょうか?経験豊富な方はもうこのあたりでピンと来ていると思いますが、もう少し詳しく調べてみましょう。
プロファイリングしてみる
Go実装のどこに時間がかかっているのか、プロファイリングしてみることにします。
ありがたいことに、Goには標準でプロファイリングのためのツールが付いてきます。
プロファイリングを行うには、pprof パッケージを使います。
詳しい使い方は Go Blogの記事 を参照していただくこととして、次のようにmain関数に追加します:$ git diff diff --git a/www/go/bench.go b/www/go/bench.go index 878b95a..e2f7731 100644 --- a/www/go/bench.go +++ b/www/go/bench.go @@ -8,6 +8,7 @@ import ( "math" "os" "runtime" + "runtime/pprof" "time" _ "github.com/go-sql-driver/mysql" @@ -250,6 +251,17 @@ func printTime(message string) { // メイン処理 func main() { + f, err := os.Create("cpuprofile") + if err != nil { + fmt.Fprintln(os.Stderr, "could not create file: ", err) + os.Exit(1) + } + defer f.Close() + if err := pprof.StartCPUProfile(f); err != nil { + fmt.Fprintln(os.Stderr, "could not start CPU profile: ", err) + os.Exit(1) + } + defer pprof.StopCPUProfile() println("Go " + runtime.Version())こうしてプログラムを実行すると、実行時に情報が集められてその結果が
cpuprofileという名前のファイルに保存されます:$ sudo docker-compose run --rm golang sh -c 'cd go; go build . && ./go' ...(snip)... 平均秒数:9.895000, 標準偏差: 0.442 (0x0,0x0) real 1m 39.11s user 0m 6.03s sys 0m 9.34s $ ls www/go bench.go cpuprofile export_users.csv go README.mdプロファイリングの処理が追加されるので、当然ながら実行速度は少し遅くなります。
プロファイリング結果を見る方法も、標準のGoコマンドについてきます。見た目きれいに見えるので、次のコマンドでWebブラウザで見る方法がおすすめです:
$ go tool pprof -http=localhost:9090 cpuprofileブラウザが開いて、次のような図が表示されるはずです:
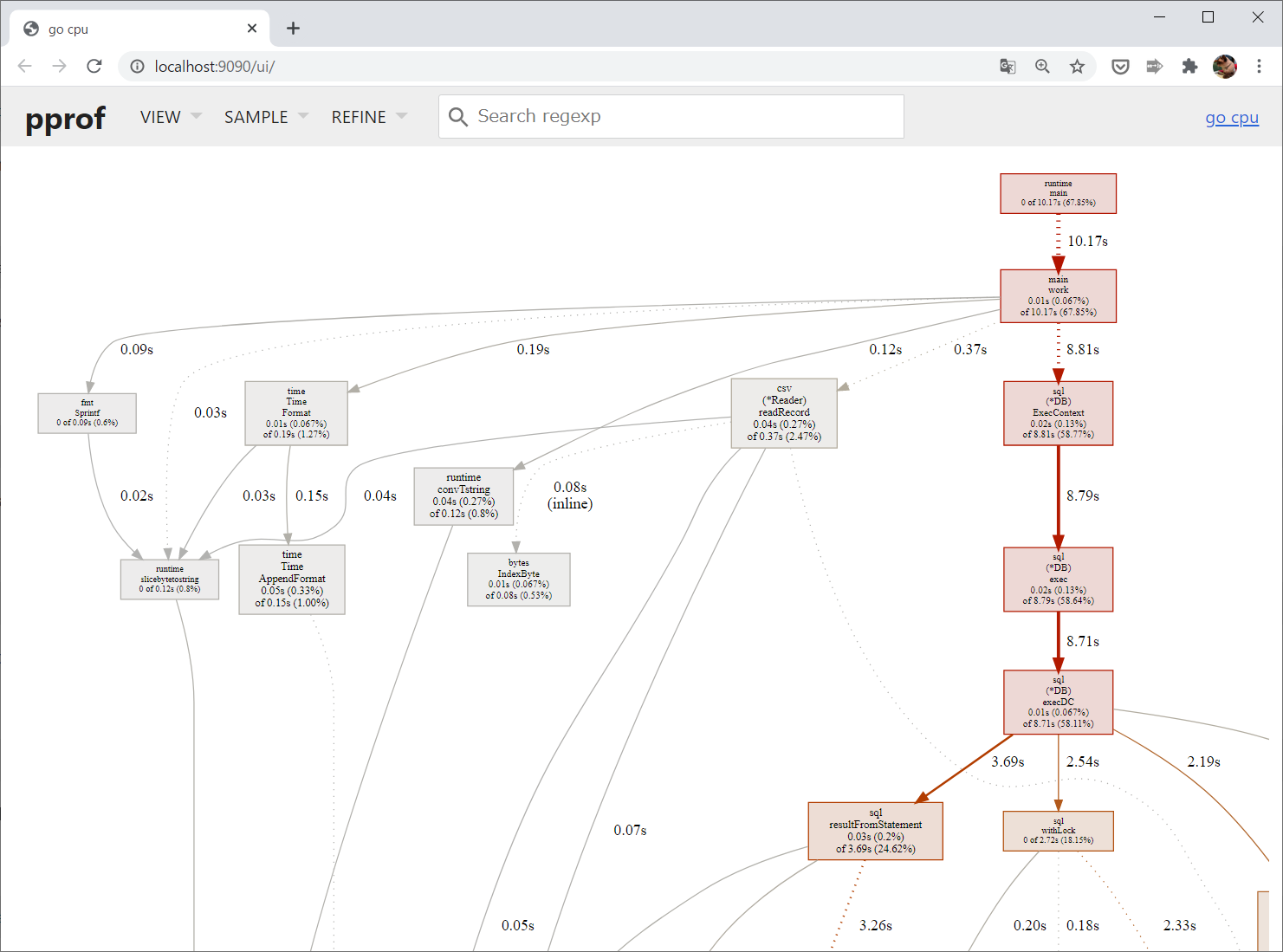
これはどの関数がどの関数を呼び出したのかを示すコールグラフという図です。さらに、それぞれにどれくらいの時間がかかっているのかが表示されています。
ただし、実行時のサンプリングによって得られた結果ですので、実際には実行されているはずの関数が表示されていなかったり、厳密に計測した実行時間とはズレがあります。それでも、どこの処理に時間がかかっているのかを知るには十分です。赤く色がついているパスが一番実行時間がかかっているクリティカルパスなので、基本的にはここを改善することになります:
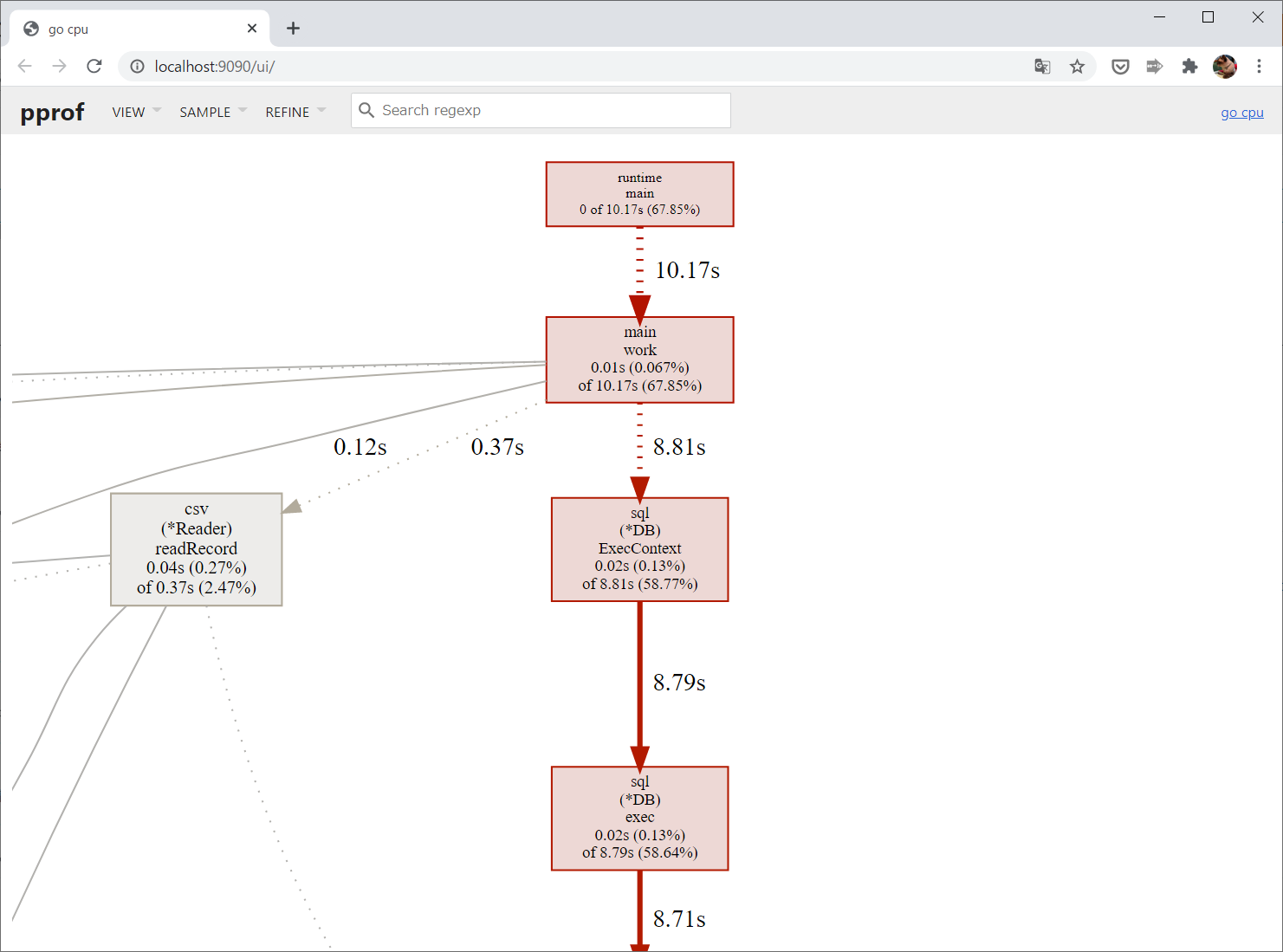
SQLデータベースにアクセスする部分に時間がかかっているようですね。
これを下にどんどんたどっていくと……ひときわ大きな赤い四角がありました:
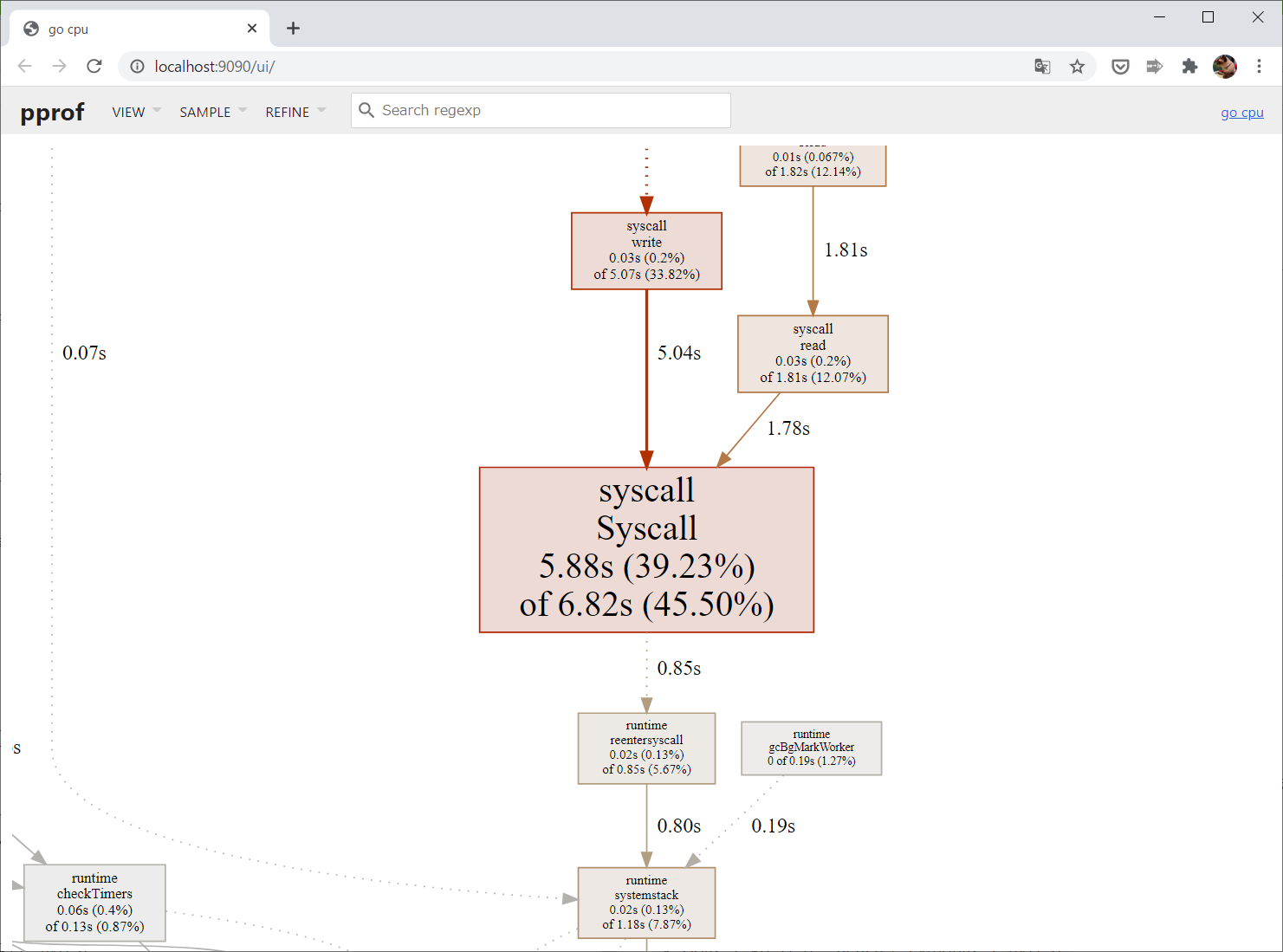
この
syscall.Syscallというのが、GoがOSのシステムコールを呼ぶときに必ず通る部分です。
この処理に6.82秒かかっているということで、上でtimeコマンドを使って測った system time とほぼ同じになっていますね。
コールグラフをたどってわかったように、SQLドライバの処理が何度もシステムコールを呼んでいるため、system time が長くなっているようです。それにしても、どうしてこんなにシステムコールを呼んでいるのでしょう?
というわけでソースコードを見てみると、どうやら原因は bench.go の147行目からの処理のようです:rows, err = db.Query("select * from users order by id") . . . (中略) . . . var user User for rows.Next() { err = rows.Scan( &user.ID, &user.Name, &user.Email, &user.EmailVerifiedAt, &user.Password, &user.RememberToken, &user.CreatedAt, &user.UpdatedAt, ) . . . (略)この処理では、MySQLデータベースから1行ずつ結果を取ってくるようになっています。
一方でPython実装では、これに相当する処理は
fetchallを使って一括で取得しています:cur = db.cursor() cur.execute('select * from users order by id') users = cur.fetchall()
fetchallなら、ネットワークからの入力を(可能ならば)1度のシステムコールで読み込むことができますが、1行ずつ読み込む場合は必要な分だけをネットワークデバイスに読み込みにいくことになるため、何度もシステムコールを呼ぶことになります。
上で述べたように、システムコール呼び出しはそれ自体が重い処理なので、一度に全部読み込めるなら一度で済ませてしまったほうが、CPUとしては効率的なプログラムになります。ところが、Goの標準ライブラリである
database/sqlにはfetchallのような一度に全部の結果を読み込むためのAPIがありません。したがって、Goでは一度にすべてを読み込むことは(標準の方法では)不可能なのです。
実はこれは既知のissueでして、Go2で実装してほしいことのリクエストにも上がっている問題だったりします。議論すべきポイント
さて、少なくとも現状のGoではシステムコール呼び出しを減らす方法はなさそうだ、という話になりました。
しかしここで考えたいのは、果たしてfetchallを使った実装が "お行儀のいい" 実装なのか、ということです。たしかに、システムコール呼び出しの回数が少なくなるのはCPUの観点からは高速ですし、少ない文字数で簡潔に書けるという点からも便利な方法なのは間違いないでしょう。
しかし、もしデータベースに大量のデータがあったらどうなるでしょうか?
当然、一度にすべてのデータを読み込むと大量のメモリを必要としますし、最悪の場合はOut of Memoryで死にます。
ここで、今回のワークロード(CSVファイルから情報を読み込んでデータベースに保存し、データベースから行を読み込んでCSVファイルに書き出す)において実行速度が重要になる状況というのは、当然ながら読み書きする行が大量になったときです。 行が少ないならば、そもそも実行時間なんて気にする必要はなく、人間にとって一番効率の良い方法で実装するべきです。 それこそ、シェルスクリプトのほうが速く書けるのではないでしょうか?
つまり、そもそもが大量の行を扱うという前提があるわけですから、すべての行をデータベースから一度に読み込むという実装を書くべきではありません。これは個人的な推測ですが、Goが標準のAPIで
fetchallのようなものを用意していないのは、こういう思想があるからだと思います。
つまり、Goはメモリ安全で効率的なプログラムを、誰でも比較的容易に書けるようにすることを目指しているのだから、メモリ溢れを助長するような書き方はそもそもできないようにしているのではないかと思っています。
私はこの思想に肯定的ですが、一方で、メモリが溢れないとわかっているときには効率的に書ける方法を用意しておいてくれてもいいじゃないか、という意見もわかります。1
Goの場合でも、どうしてもやりたければCgoを使ったり自分でショートカットをゴリゴリ実装すればできないことはないです。推奨されないやり方を敢えて実行するためのハードルをすごく高くしているという感じですね。いずれにしても、もし今回の
fetchallを使った方法を本番環境で使っていたら、早晩メモリ不足でサーバーがダウンしていたことでしょうから、比較としてフェアではないと思います。
ちなみに、他の言語のベンチマークプログラムも、みんなfetchallに類するものを使っていましたので、今回はGoだけがハンデを背負っていました。たとえハンデがあったとしても
というわけで、今回のベンチマークはGoにとって完全にハンデ戦なわけですが、それでもまだ改善できる部分があります。
上のコールグラフでは
syscall.Syscallで 6.82秒かかっていたわけですが、sql.exec全体では 8.81秒かかっていることが見て取れます。残りの約2秒は何に時間がかかっているのでしょうか?答えは、Go実装でデータベースにインサートしている部分を見てください:
for { lines, err = reader.Read() if err != nil { break } // lines[0]はidのため1から _, err = db.Exec(` INSERT INTO users ( name, email, email_verified_at, password, remember_token, created_at, updated_at ) values ( ?, ?, ?, ?, ?, ?, ? ); `, lines[1], lines[2], lines[3], lines[4], lines[5], lines[6], lines[7]) if err != nil { panic(err) } }なんと、for文の中で繰り返し
db.ExecにSQL文を文字列で渡しています。
知らないと驚かれるかもしれませんが、Go のdatabase/sql(正確にいうとgo-sql-driver/mysql)ではExecのSQL文のパース結果をキャッシュしません。そのため、毎回SQL文のパース処理が行われます。
Python や PHP など他の言語の標準ライブラリではライブラリ内部でキャッシュすることが多いです。
これも賛否が分かれるところですが、Goではキャッシュのために勝手にメモリを使うことを是としていないのだと思います。特に、PythonのようにGlobalキャッシュを使っていると、ユーザーがMySQLとの接続を追えたあともメモリ上に残り続けてしまって、メモリをムダに消費し続けます。
Goの場合は、何度も同じSQL文を実行するなら明示的にPrepareを使うべきです。というわけで、次のように書き換えました:$ git diff diff --git a/www/go/bench.go b/www/go/bench.go index e2f7731..f15f0ea 100644 --- a/www/go/bench.go +++ b/www/go/bench.go @@ -115,6 +115,23 @@ func work(db *sql.DB) { } defer file.Close() + stmt, err := db.Prepare(` + INSERT INTO users ( + name, + email, + email_verified_at, + password, + remember_token, + created_at, + updated_at + ) values ( + ?, ?, ?, ?, ?, ?, ? + ); + `) + if err != nil { + panic(err) + } + reader = csv.NewReader(file) _, err = reader.Read() // ヘッダースキップ for { @@ -124,19 +141,7 @@ func work(db *sql.DB) { } // lines[0]はidのため1から - _, err = db.Exec(` - INSERT INTO users ( - name, - email, - email_verified_at, - password, - remember_token, - created_at, - updated_at - ) values ( - ?, ?, ?, ?, ?, ?, ? - ); - `, lines[1], lines[2], lines[3], lines[4], lines[5], lines[6], lines[7]) + _, err = stmt.Exec(lines[1], lines[2], lines[3], lines[4], lines[5], lines[6], lines[7]) if err != nil { panic(err) }
実のところ、この書き換えもフェアとは言えません。
Pythonの場合は、ベンチマークの10回の試行の内、最初に1回だけパース処理をして、あとの9回はキャッシュした結果が使い回せますが、Goの場合は10回の試行の毎回パース処理が走ります。
とはいえ、1回だけにするためにPrepareを初期化処理の中でやってしまうと、パースにかかった時間が計測されなくなってしまってそれはそれでフェアじゃないかなぁ、と思ったので、毎回やることにしました。
つまり、まだPythonに対してハンデをつけてあげています。※追記: この辺りは自分の勘違いでした。詳しくは下の @methane さんのコメントをご覧ください。
実行結果は次のとおり(※速度が重要なので、プロファイリングは外してあります):
$ sudo /usr/local/bin/docker-compose run --rm golang sh -c 'cd go; go build . && time ./go' ...(snip)... 平均秒数:8.116856, 標準偏差: 0.342 (0x0,0x0)はい、上のPythonの実行結果を逆転しました!
元記事ではPythonが最速だったので、Goが最速の座を奪い取りましたね。しかも これだけのハンデを負っていても勝っています。フェアな条件を設定してまともなプログラムを書いて比較したら、もっと差がつけられそうですね。結論
Goが最速だったので、やっぱりGo言語を辞める必要はありませんでした。
本日の教訓
- ベンチマークをする時には制約条件を明確にしましょう
- 想定するデータの制約
- 利用可能なメモリの制約
- 利用していい手段の制約(たとえばCgoとかCFFIを使ってCでゴリゴリにチューニングするのはアリか?)
- ベンチマークをするときには、何を測定しているのかを明確にしましょう
- ネットワーク遅延も含めたワークロード全体?
- CPUが仕事をしている時間?
- ユーザー空間でCPUを使っている時間?
- 自分が書いた部分のコードがCPUを使っている時間?
- ベンチマークをするときは、結果を再現可能するための情報を可能な限り記録しましょう
- 実行環境(マシンの種類、CPU、RAM等)
- 実行したコード
- 実行したコマンドの履歴
- ベンチマークをするときは、標準的なツールを使いましょう
- Goなら
go test -bench、Pythonならpytest- ただし、異なる言語間での比較をしたい場合はツールを揃えるのは難しい
- でも、
timeコマンドはほぼすべてのUNIX-like環境で使えるちなみに、、、
元記事の計測結果では、Go実装がCSVの書き込みにすごい時間がかかっていた(約4.7秒)のですが、自分の環境では再現することができませんでした。
元記事の実行環境が明記されていないので推測でしかありませんが、もしかすると Docker Desktop on Windows を使って計測していたのかな、と思っています。
今回の計測では各言語の実装コードやベンチマークファイルはホスト上のディレクトリにあり、dockerコンテナからはそのホストのディレクトリをマウントして実行するようになっています。実行結果(CSVファイル)もマウントしたディレクトリに書き出されます。Docker Windowsでは、ホスト(Windows)のディレクトリへのアクセスはものすごく遅く、しかもGoの実装では Write I/O がバッファリングされていなかったので、ここがボトルネックになっていたのではないかと推測しています。(コメント欄で @makiuchi-d さんが指摘されている通り)
ですが、Linuxホスト上ではここはボトルネックになっていませんでした。※追記:ご本人から回答をいただきました
元記事ではDocker Desktop for Macを使って測定していたとのことです。
詳しくは下のコメント欄をご覧ください。
- 投稿日:2020-12-16T17:04:31+09:00
東京五輪開催で夏の祝日が移動 〜各言語の祝日ライブラリの2021年の祝日対応を追ってみる〜
大遅刻をしてしまいましたが、これはミクシィグループ Advent Calendar 2020 12日目の記事です。
以前、2018年の年末に「#平成最後 のクリスマスに贈る、2019年の祝日対応と改元の話」という記事を書いたことがあります。この記事を書いたときは、祝日について考えることなんて当分ないだろうと考えていたんですが、2年後の今年、また祝日について考えなければならないようです……。
COVID-19による東京オリンピック 2020の延期
みなさんご存知のとおり、2020年の年初から世界中で新型コロナウイルス COVID-19が猛威をふるい、2020年の夏に東京で開催予定だった 東京オリンピック2020も2021年に延期となりました。
日本では、2020年のオリンピックの開催に合わせ、法律を改正(平成三十二年東京オリンピック競技大会・東京パラリンピック競技大会特別措置法及び平成三十一年ラグビーワールドカップ大会特別措置法の一部を改正する法律)し一部の祝日を移動し開会式と閉会式前後を連休にして、通勤・通学者を減らし、混乱を和らげるようにしていました。
東京オリンピック 2020が2021年に延期されたことで、同じように2021年の祝日も一部移動させ、開会式と閉会式前後を連休にしようという案が2020年5月29日に内閣府から提出されていました(平成三十二年東京オリンピック競技大会・東京パラリンピック競技大会特別措置法等の一部を改正する法律案)。
2020年11月27日に衆参両院でその案が可決され、平成三十二年東京オリンピック競技大会・東京パラリンピック競技大会特別措置法
等の一部を改正する法律として、2020年12月4日に公布されました。2021年の祝日
平成三十二年東京オリンピック競技大会・東京パラリンピック競技大会特別措置法
等の一部を改正する法律 で変更される祝日をまとめると、以下のようになります。
祝日名 本来の日付 2021年 海の日 7月 第3月曜日 7月22日 木曜日 スポーツの日 10月 第2月曜日 7月23日 金曜日 山の日 8月11日 8月8日 日曜日 山の日 振替休日 - 山の日が日曜日なのでその振替休日 ちょっと分かりづらいのでカレンダーにしてみます。
祝日ライブラリの対応状況
祝日を自分で判定するのは骨が折れるので、たいていの場合はライブラリを利用すると思います。
2021年の祝日について、各言語の祝日判定機能を提供してくれるライブラリの対応状況を見ていきたいと思います。日本の祝日データセット holiday-jp/holiday_jp
まず、日本の祝日のデータセットを提供している holiday-jp/holiday_jp について確認しておきます。
「Holiday accompanying coronation day #101」という、前述した2021年の祝日をデータセットに追加するプルリクが11月26日に出されています。
祝日についての法案が可決されたのが11月27日なので、毎度とても早い初動ですね。
実際の公布・施行を待ち、テストなどの修正をしたのち、12月2日にmasterへマージされています。これから紹介するいくつかのライブラリはこのデータセットを利用しています。
しかしながら、このデータセットの更新を取り込んでいるかどうかはライブラリ次第なので、それぞれ確認が必要です。Perl
Calendar::Japanese::Holiday : 対応済み(2020/12/11)
2020年12月11日に2021年の祝日に対応した バージョン 0.07 がリリースされました。
Ruby
holiday_jp : 対応済み(2020/12/09)
バージョン 0.8.0 で2021年の祝日に対応しました。
date-holiday : 未対応(2020/12/16 現在)
現在のバージョンは 2018/12/14 にリリースされた 0.0.5 で、2021年の祝日には対応していません。
0.0.5 のリリースの際に、2019年、2020年の祝日への対応をしていたので、一応アクティブな gem ではあるはずです。holidays : 未対応(2020/12/16 現在)
全世界の祝日を集め、判定を行うライブラリです。現時点での最新のバージョンは 8.3.0 です。
これも、ライブラリとは別にデータセットを提供しているリポジトリが別に存在しています。
データセットも現時点では2021年の祝日には対応しておらず、2021年の祝日を追加する Add 2021 jp holiday という PR が GitHub 上で出されています。holiday_japan : 対応済み(2020/11/27)
内閣府から改正案が出せれた 5/29 に move Marine day, Sports day, Mountain day for 2021 Olympic という commit が master ブランチへ push されていて、最終的に改正案が可決された 11/27 に 1.4.4 として RubyGems へリリースされています。
祝日ライブラリ界では最速の対応と言っていいかもしれません。holiday : 未対応(2020/12/16 現在)
指定の形式のYAMLファイルを用意し、読み込ませることで祝日かどうかを判定できるライブラリのようです。
初回リリースの2011年9月からメンテナンスもされていないので、利用は推奨しません。JavaScript
@holiday-jp/holiday_jp : 対応済み(2020/12/06)
holiday_jp データセットを利用しており、最新版のデータを取り込んだ差分が、v2.3.0 としてリリースされています。
PHP
holiday_jp : 対応済み(2020/12/06)
holiday_jp データセットを利用しており、最新版のデータを取り込んだ差分が、v2.3.0 としてリリースされています。
Java
holidayjp(holiday_jp) : 未対応(2020/12/16 現在)
holiday_jp データセットを利用していますが、最新版の取り込みはまだされていません。
現在の最新のバージョンは、2.0.1 です。Swift
HolidayJp(holiday_jp) : 未対応(2020/12/16 現在)
holiday_jp データセットを利用していますが、最新版の取り込みはまだされていません。
最新のバージョンは、0.2.1 です。Go
flagday : 対応済み(2020/09/01)
09/01 に Add holiday definitions in 2021 with postponement of the Olympics という PR で対応されていました。
holiday_jp : 未対応(2020/12/16 現在)
holiday_jp データセットを利用していますが、最新版の取り込みはまだされていません。
参照している holiday_jp データセットも、2019年にあった天皇の退位・即位による4月から5月にかけての10連休に対応していない少し古いものを参照しているようです。Elixir
holiday_jp : 未対応(2020/12/16 現在)
holiday_jp データセットを利用していますが、最新版の取り込みはまだされていません。
現在の最新のバージョンは、0.3.6 です。

- 投稿日:2020-12-16T14:04:17+09:00
Go リフレクション入門
QualiArts Advent Calendar 2020、17日目担当のs9iです。
今回はGoにおけるリフレクションの基本的な使用方法について書いていきます。
リフレクションとは
プログラム実行時に、動的にプログラムの構造を読み取ったり書き換えたりする手法です。
可読性が低い、パフォーマンスが悪い等の理由により使う機会は多くはありませんが、通常の実装では手が出せないようなことができる場合もあります。Goにおけるリフレクション
リフレクションの機能は標準パッケージのreflectで提供されています。
Goでのリフレクションは、以下の法則に則ります。1.Reflection goes from interface value to reflection object.
2.Reflection goes from reflection object to interface value.
3.To modify a reflection object, the value must be settable.The Laws of Reflection - The Go Blog
Google先生に翻訳してもらうと、以下のようになります。
1. リフレクションは、インターフェイス値からリフレクションオブジェクトに移動します。
2. リフレクションは、リフレクションオブジェクトからインターフェイス値に移動します。
3. リフレクションオブジェクトを変更するには、値を設定可能にする必要があります。順を追って見ていきましょう。
なお、本記事のサンプルではGo 1.15.5を使用しています。リフレクションオブジェクトの取得
まず1つ目の法則です。
Reflection goes from interface value to reflection object. (リフレクションは、インターフェイス値からリフレクションオブジェクトに移動します。)
GoではJAVAやC#のように、型定義から直接リフレクションオブジェクトを生成することはできません。interface{}型の値からリフレクションオブジェクトを生成する必要があります。
型情報の取得
reflect.TypeOf関数により、型の情報を表すreflect.Typeを取得できます。
定義func TypeOf(i interface{}) Typeサンプルfunc main() { stringValue := "test" intValue := 12345 fmt.Println("=== int ===") print(intValue) fmt.Println("=== string ===") print(stringValue) fmt.Println("=== *string ===") print(&stringValue) } func print(v interface{}) { tv := reflect.TypeOf(v) fmt.Println("Kind:", tv.Kind(), "Name:", tv.Name()) }出力=== int === Kind: int Name: int === string === Kind: string Name: string === *string === Kind: ptr Name:Kindは型の種類を表す値で、以下のように定義されています。
Kindconst ( Invalid Kind = iota Bool Int Int8 Int16 Int32 Int64 Uint Uint8 Uint16 Uint32 Uint64 Uintptr Float32 Float64 Complex64 Complex128 Array Chan Func Interface Map Ptr Slice String Struct UnsafePointer )リフレクションを使った実装では、基本的にKind毎に処理を分岐して個別の処理を記述していく形になります。
Kindによる処理の分岐switch t := reflect.TypeOf(v); t.Kind() { case reflect.String: fmt.Println(v.String()) case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64: fmt.Println(v.Int()) default: ... }値情報の取得
reflect.ValueOf関数により、値の情報を表すreflect.Valueを取得できます。
先述のreflect.Typeと同名のメソッドもありますが、挙動は異なるので注意が必要です。定義func ValueOf(i interface{}) ValueInterface()メソッドでinterface{}としての値を取得することができます。
サンプルfunc main() { stringValue := "test" intValue := 12345 fmt.Println("=== int ===") printValue(intValue) fmt.Println("=== string ===") printValue(stringValue) fmt.Println("=== *string ===") printValue(&stringValue) } func printValue(v interface{}) { rv := reflect.ValueOf(v) fmt.Println("Kind:", rv.Kind(), "Type:", rv.Type(), "Interface:", rv.Interface()) }出力=== int === Kind: int Type: int Interface: 12345 === string === Kind: string Type: string Interface: test === *string === Kind: ptr Type: *string Interface: 0xc000010200構造体の情報取得
フィールド情報の取得
構造体の型情報や値情報を取得し、Field()やFieldByName()を使用することでフィールドの情報を取得することができます。
サンプルtype User struct { NickName string Age int32 } func main() { user := User{ NickName: "user1", Age: 30, } fmt.Println("=== Type ===") tv := reflect.TypeOf(user) fmt.Println("Kind:", tv.Kind()) fmt.Println("Name:", tv.Name()) fmt.Println("NumField:", tv.NumField()) fmt.Println("Field:", tv.Field(0)) f, _ := tv.FieldByName("Age") // フィールドが存在しない場合は第二戻り値がfalseを返す fmt.Println("FieldByName:", f) fmt.Println() fmt.Println("=== Value ===") rv := reflect.ValueOf(user) fmt.Println("Kind:", rv.Kind()) fmt.Println("Type:", rv.Type()) fmt.Println("Interface:", rv.Interface()) fmt.Println("NumField:", rv.NumField()) fmt.Println("Field:", rv.Field(0)) fmt.Println("FieldByName:", rv.FieldByName("Age")) }出力=== Type === Kind: struct Name: User NumField: 2 Field: {NickName string 0 [0] false} FieldByName: {Age int32 16 [1] false} === Value === Kind: struct Type: main.User Interface: {user1 30} NumField: 2 Field: user1 FieldByName: 30全フィールドを参照したい場合は、NumField()でフィールド数を取得して、ループでField()を使用して各フィールドにアクセスします。
サンプルtype User struct { NickName string Age int32 } func main() { user := User{ NickName: "user1", Age: 30, } fmt.Println("=== Type ===") tv := reflect.TypeOf(user) for i := 0; i < tv.NumField(); i++ { t := tv.Field(i) fmt.Println("Name:", t.Name, "Type:", t.Type) } fmt.Println() fmt.Println("=== Value ===") rv := reflect.ValueOf(user) for i := 0; i < rv.NumField(); i++ { v := rv.Field(i) fmt.Println("Kind:", v.Kind(), "Type:", v.Type()) } }出力=== Type === Name: NickName Type: string Name: Age Type: int32 === Value === Kind: string Type: string Kind: int32 Type: int32メソッド情報の取得
Method()やMethodByName()を使用してメソッドの情報も取得できます。
フィールドの場合と同様に、NumMethod()でメソッド数を取得してループで各メソッドを参照することも可能です。サンプルtype User struct { NickName string Age int32 } func (u User) GetNickName() string { return u.NickName } func (u User) GetAge() int32 { return u.Age } func main() { user := User{ NickName: "user1", Age: 30, } fmt.Println("=== Type ===") tv := reflect.TypeOf(user) tm, _ := tv.MethodByName("GetAge") // メソッドが存在しない場合は第二戻り値がfalseを返す fmt.Println("Name:", tm.Name, "Type:", tm.Type) for i := 0; i < tv.NumMethod(); i++ { t := tv.Method(i) fmt.Println(i+1, "Name:", t.Name, "Type:", t.Type) } fmt.Println() fmt.Println("=== Value ===") rv := reflect.ValueOf(user) rm := rv.MethodByName("GetAge") fmt.Println("Kind:", rm.Kind(), "Type:", rm.Type()) for i := 0; i < rv.NumMethod(); i++ { v := rv.Method(i) fmt.Println(i+1, "Kind:", v.Kind(), "Type:", v.Type()) } }出力=== Type === Name: GetAge Type: func(main.User) int32 1 Name: GetAge Type: func(main.User) int32 2 Name: GetNickName Type: func(main.User) string === Value === Kind: func Type: func() int32 1 Kind: func Type: func() int32 2 Kind: func Type: func() stringフィールドのスコープ
reflectにおいては非公開のフィールドの情報も取得することができますが、一部のメソッドを実行するとpanicが発生します。また、後述の値の書き換えを行うこともできません。公開フィールドかどうかはreflect.TypeのPkgPathが空文字かどうかで判定することが可能です。NumField()の数には非公開のフィールドも含まれているので、この値を用いてループを行う場合は注意しましょう。
サンプルtype User struct { NickName string Age int32 password string } func main() { user := User{ NickName: "user1", Age: 30, password: "pass", } tv := reflect.TypeOf(user) rv := reflect.ValueOf(user) f := rv.FieldByName("password") fmt.Println("String:", f.String()) // panicが発生する // fmt.Println("Interface:", f.Interface()) for i := 0; i < rv.NumField(); i++ { t := tv.Field(i) v := rv.Field(i) fmt.Println("=== ", t.Name, "===") fmt.Println("Kind:", v.Kind()) fmt.Println("Type:", v.Type()) // 公開フィールドの場合は空文字 fmt.Println("PkgPath:", t.PkgPath) if t.PkgPath == "" { fmt.Println("Interface:", v.Interface()) } } }出力String: pass === NickName === Kind: string Type: string PkgPath: Interface: user1 === Age === Kind: int32 Type: int32 PkgPath: Interface: 30 === password === Kind: string Type: string PkgPath: mainメソッドのスコープ
フィールドとは異なり、非公開のメソッドは参照することができず、NumMethod()の数にも含まれません。
サンプルtype User struct { NickName string Age int32 Password string Address string } func (u User) GetNickName() string { return u.NickName } func (u *User) GetAge() int32 { return u.Age } func (u User) getPassword() string { return u.Password } func (u *User) getAddress() string { return u.Address } func main() { user := User{ NickName: "user1", Age: 30, Password: "pass", Address: "address", } tv := reflect.TypeOf(user) // 非公開のメソッドは参照できない _, ok := tv.MethodByName("getPassword") fmt.Println("IsReferable:", ok) fmt.Println("=== Type ===") for i := 0; i < tv.NumMethod(); i++ { t := tv.Method(i) fmt.Println("Name:", t.Name, "Type:", t.Type) } fmt.Println() fmt.Println("=== Value ===") rv := reflect.ValueOf(user) for i := 0; i < rv.NumMethod(); i++ { v := rv.Method(i) fmt.Println("Kind:", v.Kind(), "Type:", v.Type()) } }実体とポインタのメソッドは区別されるため、GetAge()は出力されません。
出力IsReferable: false === Type === Name: GetNickName Type: func(main.User) string === Value === Kind: func Type: func() stringメソッドの実行
取得したメソッドのreflect.ValueはCall()により実行することができます。
引数、戻り値はreflect.Valueのスライスとなっています。サンプルtype User struct { NickName string Age int32 } func (u User) GetAge() int32 { return u.Age } func (u User) CalcAge(year int32) (int32, error) { return u.Age + year, errors.New("error_message") } func main() { user := User{ NickName: "user1", Age: 30, } rv := reflect.ValueOf(user) f1 := rv.MethodByName("GetAge") fmt.Println(f1.Call(nil)[0].Int()) f2 := rv.MethodByName("CalcAge") args := []reflect.Value{reflect.ValueOf(int32(1))} rets := f2.Call(args) fmt.Println(rets[0].Int(), rets[1].Interface()) }出力30 31 error_messageタグ情報の取得
jsonエンコード等で馴染みがあるように、構造体のフィールドにはタグを設定することができます。
タグの情報についてもreflect.TypeのTagフィールド(reflect.StructTag型)で参照することが可能です。
Get()で指定タグの値を取得することができます。Lookup()でも指定のタグを取得することができ、こちらは第二戻り値に該当のタグが存在するかどうかの真偽値を返します。サンプルtype User struct { Name string `json:"name"` Age int32 } func main() { user := User{ NickName: "user1", Age: 30, } tv := reflect.TypeOf(user) for i := 0; i < tv.NumField(); i++ { f := tv.Field(i) fmt.Println("===", f.Name, "===") fmt.Println("Get:", f.Tag.Get("json")) t, ok := f.Tag.Lookup("json") fmt.Println("Lookup:", t, ok) } }出力=== NickName === Get: nickName Lookup: nickName true === Age === Get: Lookup: falseスライスの情報取得
スライスの場合はLen()やCap(), Index()といったメソッドが使用できます。
また、Slice()ではスライス式と同等の処理を行います。サンプルfunc main() { s := []string{"user1", "user2", "user3"} rs := reflect.ValueOf(s) fmt.Println("Kind:", rs.Kind()) fmt.Println("Len:", rs.Len()) fmt.Println("Cap:", rs.Cap()) fmt.Println("Index:", rs.Index(0)) fmt.Println("Type:", rs.Type()) fmt.Println("Interface:", rs.Interface()) fmt.Println("Slice:", rs.Slice(1, 3)) }出力Kind: slice Len: 3 Cap: 3 Index: user1 Type: []string Interface: [user1 user2 user3] Slice: [user2 user3]マップの情報取得
マップの場合はLen()やMapKeys(), MapIndex()といったメソッドが使用できます。
また、MapRange()でイテレータを取得し、各要素を取得することもできます。サンプルfunc main() { m := map[int]string{1: "user1", 2: "user2", 3: "user3"} rm := reflect.ValueOf(m) fmt.Println("Kind:", rm.Kind()) fmt.Println("Len:", rm.Len()) fmt.Println("Type:", rm.Type()) fmt.Println("MapKeys:", rm.MapKeys()) fmt.Println("MapIndex:", rm.MapIndex(reflect.ValueOf(3))) iter := rm.MapRange() for iter.Next() { fmt.Println("Key:", iter.Key(), "Value:", iter.Value()) } }出力Kind: map Len: 3 Type: map[int]string MapKeys: [<int Value> <int Value> <int Value>] MapIndex: user3 Key: 1 Value: user1 Key: 2 Value: user2 Key: 3 Value: user3インターフェースの情報取得
ポインタ型を指定することで値がnilの場合でも型情報を取得することができます。更にElem()を使用することでポインタが指す実際の値の型情報を取得できます。
以下の処理では、この方法を利用してインターフェースと構造体の情報を取得しています。Implementsメソッドを使用すると、該当のインターフェースを実装しているか判定することができます。サンプルtype User struct { NickName string Age int32 } func (u User) GetNickName() string { return u.NickName } type UserInterface interface { GetNickName() string } func main() { ri := reflect.TypeOf((*UserInterface)(nil)).Elem() fmt.Println("===", ri.Name(),"===") fmt.Println("String:", ri.String()) fmt.Println("Kind:", ri.Kind()) rt := reflect.TypeOf((*User)(nil)).Elem() fmt.Println("===", rt.Name(),"===") fmt.Println("String:", rt.String()) fmt.Println("Kind:", rt.Kind()) fmt.Println("User Implements UserInterface:", rt.Implements(ri)) }出力=== UserInterface === String: main.UserInterface Kind: interface === User === String: main.User Kind: struct User Implements UserInterface: trueリフレクションオブジェクトによる値の生成
続いて2つ目の法則です。
Reflection goes from reflection object to interface value. (リフレクションは、リフレクションオブジェクトからインターフェイス値に移動します。)
リフレクションオブジェクトから値を生成するには、生成したい型のreflect.Typeを取得し、reflectパッケージで提供される各種生成メソッドを使用します。
基本型の生成
基本型の値を生成するには、reflect.New()を使用します。reflect.New()にreflect.Typeを与えると、該当の型のゼロ値へのポインタを表すリフレクションオブジェクトを取得することができます。interface()で値を取り出し該当の型にキャストするか、各型への変換メソッドを利用するかして実際の値を取得します。
サンプルfunc main() { tInt := reflect.TypeOf(10) i1 := *(reflect.New(tInt).Interface().(*int)) i1 = 1 fmt.Println(i1) i2 := reflect.New(tInt).Elem().Int() i2 = 2 fmt.Println(i2) }出力1 2構造体の生成
構造体の生成についても同じようにreflect.New()を使用します。
サンプルtype User struct { NickName string Age int32 } func main() { tStruct := reflect.TypeOf(User{}) vStruct := reflect.New(tStruct) user := vStruct.Interface().(*User) user.NickName = "user1" user.Age = 10 fmt.Println(user) }出力&{user1 10}スライスの生成
スライスの生成にはreflect.MakeSlice()を使用します。
第二引数はスライスの長さ、第三引数はスライスの容量を指定します。サンプルtype User struct { NickName string Age int32 } func main() { tSlice := reflect.TypeOf([]User{}) vSlice := reflect.MakeSlice(tSlice, 0, 2) users := vSlice.Interface().([]User) users = append(users, User{ NickName: "user2", Age: 20, }) fmt.Println(users) }出力[{user2 20}]マップの生成
reflect.MakeMap()を使用します。
サンプルtype User struct { NickName string Age int32 } func main() { tMap := reflect.TypeOf(map[string]User{}) vMap := reflect.MakeMap(tMap) userMap := vMap.Interface().(map[string]User) userMap["hoge"] = User{ NickName: "user3", Age: 30, } fmt.Println(userMap) }出力map[hoge:{user3 30}]関数の生成
reflect.MakeFunc()を使用します。
第二引数には、reflect.Valueのスライスを引数、戻り値とする関数を指定する必要があります。サンプルtype User struct { NickName string Age int32 } func main() { var intSwap func(int, int) (int, int) tFunc := reflect.TypeOf(intSwap) swap := func(in []reflect.Value) []reflect.Value { return []reflect.Value{in[1], in[0]} } vFunc := reflect.MakeFunc(tFunc, swap) f := vFunc.Interface().(func(int, int) (int, int)) fmt.Println(f(0, 1)) }出力1 0リフレクションオブジェクトの書き換え
最後に3つ目の法則です。
To modify a reflection object, the value must be settable. (リフレクションオブジェクトを変更するには、値を設定可能にする必要があります。)
リフレクションオブジェクトを書き換える場合は、値がセット可能である必要があります。セット不可のリフレクションオブジェクトに対して値を書き換えようとするpanicが発生してしまいます。値のセットが可能かはCanSet()メソッドにより判定することができます。
リフレクションオブジェクト経由で元の値を書き換える手順は以下のようになります。
- 更新したい値のポインタからリフレクションオブジェクト(reflect.Value)を生成
- 1で取得したリフレクションオブジェクトのElem()メソッドでポインタが指す値のリフレクションオブジェクトを取得
- 2で取得したリフレクションオブジェクトのセッターメソッドを利用して値を更新
基本型の書き換え
サンプルfunc main() { x := 3.4 xv := reflect.ValueOf(x) fmt.Println("type of xv:", xv.Type()) fmt.Println("kind of xv:", xv.Kind()) fmt.Println("settability of xv:", xv.CanSet()) fmt.Println() // step1 xp := reflect.ValueOf(&x) fmt.Println("type of xp:", xp.Type()) fmt.Println("kind of xp:", xp.Kind()) fmt.Println("settability of xp:", xp.CanSet()) fmt.Println() // step2 xe := xp.Elem() fmt.Println("type of xe:", xe.Type()) fmt.Println("kind of xe:", xe.Kind()) fmt.Println("settability of xe:", xe.CanSet()) fmt.Println() // step3 xe.SetFloat(5.0) fmt.Println(x) }出力type of xv: float64 kind of xv: float64 settability of xv: false type of xp: *float64 kind of xp: ptr settability of xp: false type of xe: float64 kind of xe: float64 settability of xe: true 5少し複雑に感じるかもしれませんが、そのリフレクションオブジェクトが何を指しているのか(実際の値なのか、ポインタなのか)をしっかり把握しておくと理解しやすいと思います。
構造体の書き換え
構造体のフィールドについても同様の手順で書き換えが可能です。
サンプルtype User struct { Name string Age int32 } func main() { u := User{ Name: "user1", Age: 10, } // step1 uv := reflect.ValueOf(u) fmt.Println("type of uv:", uv.Type()) fmt.Println("kind of uv:", uv.Kind()) fmt.Println("settability of uv:", uv.CanSet()) fmt.Println() // step2 up := reflect.ValueOf(&u) fmt.Println("type of up:", up.Type()) fmt.Println("kind of up:", up.Kind()) fmt.Println("settability of up:", up.CanSet()) fmt.Println() // step3 ue := up.Elem() fmt.Println("type of ue:", ue.Type()) fmt.Println("kind of ue:", ue.Kind()) fmt.Println("settability of ue:", ue.CanSet()) fmt.Println() ue.FieldByName("Name").SetString("user2") fmt.Println(u) }出力type of uv: main.User kind of uv: struct settability of uv: false type of up: *main.User kind of up: ptr settability of up: false type of ue: main.User kind of ue: struct settability of ue: true {user2 10}まとめ
本記事ではGoのリフレクションの法則や基本的な使用方法について紹介しました。
最後にまとめです。
- reflectパッケージを用いて動的に型の情報を取得、操作することができる
- Goのリフレクションは3つの法則に則る
- 可読性やパフォーマンスを意識しながら用法用量を守って使う
Goでは自動生成を使う機会が多いのでリフレクションを使う機会はあまりないかもしれませんが、うまく使えば有用なケースもあるので、選択肢の1つとして頭の片隅においておくと良いかもしれません。
以上、最後までお読みいただきありがとうございました。
- 投稿日:2020-12-16T10:51:10+09:00
【React/Go】ユーザー認証をCognito + Amplifyで構築してみた ~ユーザ登録/削除編~
はじめに
Reactで作成したWebアプリケーションのユーザー認証部分をCognito + Amplifyフレームワークで構築してみました。構築の基本部分については「【React】ユーザー認証をCognito + Amplifyで構築してみた」の構築準備編と構築完成編をご覧ください。
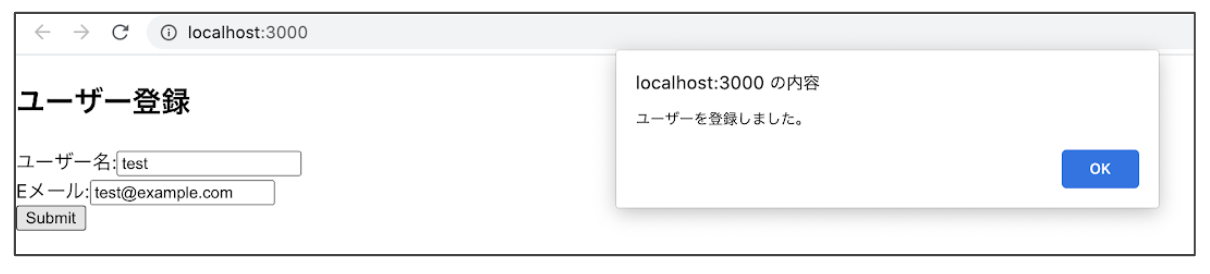
本記事は、アプリケーションからユーザーを登録、削除する方法についてまとめています。完成画面
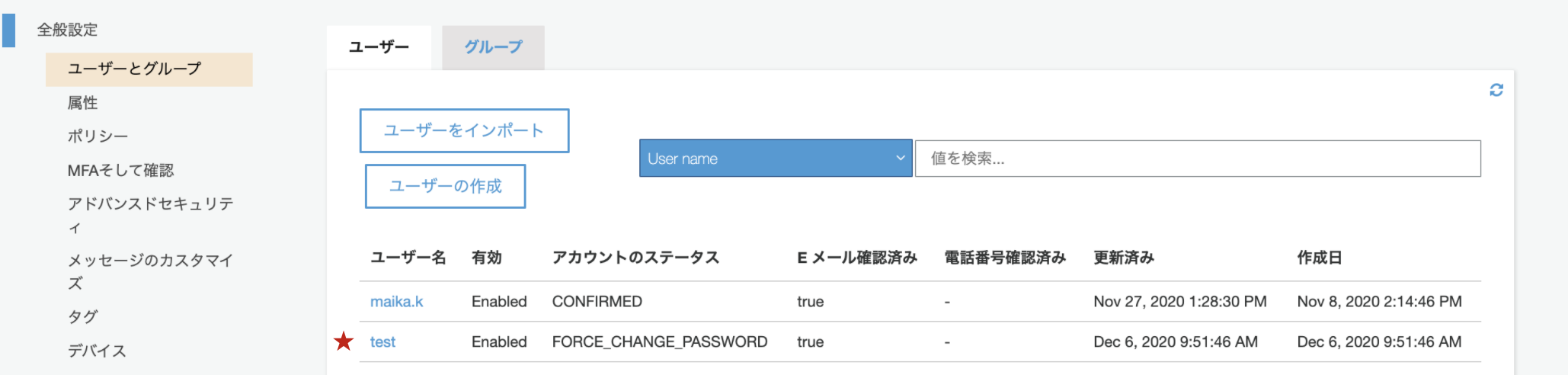
今回は、アプリケーションからユーザーを登録すると、ユーザープールとDBそれぞれにユーザーが登録されて、画面には「ユーザーを登録しました。」というアラートが出力されるようにします。
[Submit]をクリックすると↓↓↓
画面
Cognitoユーザープール管理画面
DB(userテーブル)※一部抜粋
+----+-----------+------------------+ | id | user_name | email | +----+-----------+------------------+ | 2 | test | test@example.com | +----+-----------+------------------+方法検討
要件
構築方法を考えるにあたり、条件は以下の通りです。
- 静的コンテンツをS3に置いている
- アプリケーション部分はLambda + RDS Proxy + RDSで実装している
- ユーザーデータはCognitoユーザープール以外に、RDSに保存している
- NATゲートウェイはコストが高いので使いたくない
現在の構成図(ユーザー認証付加前)
ユーザー認証付加前のアプリケーション部分の構成図は下記の通りです。
VPC Lambdaによる弊害
ここで、LambdaをVPC内に設置していることで、Cognitoにアクセスできないことに気付きました。パブリックサブネットに置いているんだから、アクセスできると勝手に思っていました。
AWS開発者ガイドによると、次のように説明されています。
プライベートリソースにアクセスするには、関数をプライベートサブネットに接続します。関数にインターネットアクセスが必要な場合は、ネットワークアドレス変換 (NAT) を使用します。関数をパブリックサブネットに接続しても、インターネットアクセスやパブリック IP アドレスは提供されません。
Lambda関数をパブリックサブネットに接続しても、インターネットアクセスやパブリック IP アドレスは提供されないんです。NATゲートウェイを使用する場合にもLambda関数はプライベートサブネットに置くべきだそうです。パブリックサブネットにLambdaを置いておくメリットはなさそうなので、VPC Lambdaはプライベートサブネットに置きましょう!!!
結論
この条件に沿ってアプリケーションの登録、削除処理を考えた結果、VPC Lambdaをプライベートサブネットに移動させ、NATゲートウェイは使いたくないので、強引にLambdaからLambdaを呼び出すことにしました。
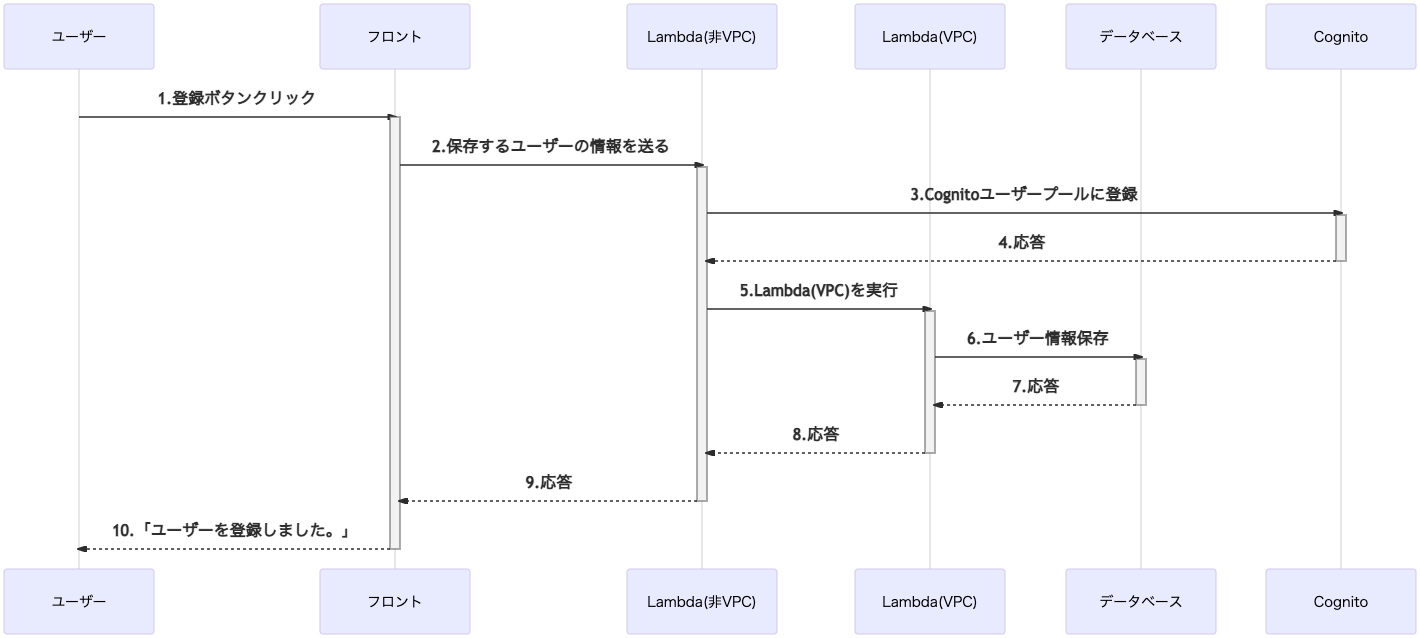
シーケンス図
シーケンス図を書くと次のようになります。
構成図(ユーザー認証付加後)
構成は下図の通りになりました。
手順
下記の流れで進めていきます。
- RDSを更新するLambda関数:Lambda(VPC) の作成
- Cognitoを更新するLambda関数:Lambda(非VPC) の作成
- API Gatewayの作成
- フロントの実装
ユーザーを登録する
1. DBを更新するLambda関数:Lambda(VPC) の作成
Lambda(非VPC)の作成時につけるIAMロールにLambda(VPC)のarnが必要なので、先にLambda(VPC)から作成します。
VPC内に設置してRDSに情報を書き込むLambdaを作成していきます。このLambdaに関しては、RDSにデータが保存できれば良く、特に既存のLambdaと変わりないので割愛します。
祝GA‼︎【Go】Lambda + RDS 接続にRDS Proxyを使ってみたの「8. Lambda関数の作成」を参考に作成しました。ソースコード
ソースコードはこのような感じです。
※↓クリックするとソースコードが見れます。
ソースコード
lambda_vpc.gopackage main import ( "database/sql" "fmt" "github.com/aws/aws-lambda-go/lambda" _ "github.com/go-sql-driver/mysql" "os" ) type MyEvent struct { UserName string `json:"userName"` Email string `json:"email"` } // os.Getenv()でLambdaの環境変数を取得 var dbEndpoint = os.Getenv("dbEndpoint") var dbUser = os.Getenv("dbUser") var dbPass = os.Getenv("dbPass") var dbName = os.Getenv("dbName") func RDSConnect() (*sql.DB, error) { connectStr := fmt.Sprintf( "%s:%s@tcp(%s:%s)/%s?charset=%s", dbUser, dbPass, dbEndpoint, "3306", dbName, "utf8", ) db, err := sql.Open("mysql", connectStr) if err != nil { return nil, err } return db, nil } func RDSProcessing(event MyEvent, db *sql.DB) (interface{}, error) { tx, err := db.Begin() if err != nil { return nil, err } defer tx.Rollback() // ユーザーテーブルに情報を登録 stmt, err := tx.Prepare("INSERT INTO user(user_name, email) VALUES (?, ?) ") if err != nil { return nil, err } defer stmt.Close() if _, err := stmt.Exec(event.UserName, event.Email); err != nil { return nil, err } if err := tx.Commit(); err != nil { return nil, err } response := "正常に処理が完了しました。" return response, nil } func run(event MyEvent) (interface{}, error) { fmt.Println("RDS接続 start!") db, err := RDSConnect() if err != nil { fmt.Println("DBの接続に失敗しました。") panic(err.Error()) } fmt.Println("RDS接続 end!") fmt.Println("RDS処理 start!") response, err := RDSProcessing(event, db) if err != nil { fmt.Println("DB処理に失敗しました。") panic(err.Error()) } fmt.Println("RDS処理 end!") return response, nil } /************************** メイン **************************/ func main() { lambda.Start(run) }2. Cognitoを更新するLambda関数:Lambda(非VPC) の作成
VPCの外に置いて、Cognitoユーザープールへの登録とRDSを更新するLambda(VPC)を実行するLambdaを作成していきます。
IAMロール
下記の2つの権限をつけたポリシーを作成してアタッチします。
- Cognitoユーザープールにユーザーを登録/削除する権限
- Lambda(VPC)を実行する権限
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "cognito-idp:AdminDeleteUser", "cognito-idp:AdminCreateUser" ], "Resource": "<Cognitoのarn>" }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": "lambda:InvokeFunction", "Resource": "<Lambda(VPC)のarn>" } ] }ソースコード
lambda_no_vpc.gopackage main import ( "encoding/json" "fmt" "os" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/cognitoidentityprovider" "github.com/aws/aws-sdk-go/service/cognitoidentityprovider/cognitoidentityprovideriface" l "github.com/aws/aws-sdk-go/service/lambda" "github.com/aws/aws-sdk-go/service/lambda/lambdaiface" ) type MyEvent struct { UserName string `json:"userName"` Email string `json:"email"` } func AddCognitoUser(svc cognitoidentityprovideriface.CognitoIdentityProviderAPI, event MyEvent) error { // 登録時にユーザーにメール送信 desiredDeliveryMediums := []*string{aws.String("EMAIL")} // メールアドレスとメールアドレス検証済みを設定 userAttributes := []*cognitoidentityprovider.AttributeType{ { Name: aws.String("email"), Value: aws.String(event.Email), }, { Name: aws.String("email_verified"), Value: aws.String("true"), }, } // ユーザープールの設定 // os.Getenv()でLambdaの環境変数を取得 userPoolId := aws.String(os.Getenv("userPoolId")) // ユーザー名の設定 username := aws.String(event.UserName) // Inputの作成 input := &cognitoidentityprovider.AdminCreateUserInput{} input.DesiredDeliveryMediums = desiredDeliveryMediums input.UserAttributes = userAttributes input.UserPoolId = userPoolId input.Username = username // 処理実行 result, err := svc.AdminCreateUser(input) if err != nil { fmt.Println(err.Error()) return err } fmt.Println(result) return nil } func AddDbUser(svc lambdaiface.LambdaAPI, event MyEvent) error { // ValidateLambdaに送る情報の作成 jsonBytes, _ := json.Marshal(event) // Inputの作成 input := &l.InvokeInput{} input.FunctionName = aws.String(os.Getenv("arn")) input.Payload = jsonBytes input.InvocationType = aws.String("RequestResponse") // 同期実行 // 処理実行 result, err := svc.Invoke(input) if err != nil { fmt.Println(err.Error()) return err } fmt.Println(result) fmt.Println(string(result.Payload)) return nil } func run(event MyEvent) (interface{}, error) { fmt.Println("Cognito登録 start!") // セッション作成 csvc := cognitoidentityprovider.New(session.Must(session.NewSession())) if err := AddCognitoUser(csvc, event); err != nil { fmt.Println("ユーザー登録に失敗しました。") panic(err.Error()) } fmt.Println("Cognito登録 end!") fmt.Println("db登録 start!") // セッションの作成 lsvc := l.New(session.Must(session.NewSession())) if err := AddDbUser(lsvc, event); err != nil { fmt.Println("ユーザー登録に失敗しました。") panic(err.Error()) } fmt.Println("db登録 end!") fmt.Println("end!") response := "正常に処理が完了しました。" return response, nil } /************************** メイン **************************/ func main() { lambda.Start(run) }3. API Gatewayの作成
REST APIでPOSTメソッドを作成し、Lambda(非VPC)を紐付けます。
特に特別な設定は不要なので省略します。4. フロントの実装
登録画面を作成します。今回は、ユーザー名とメールアドレスが必須項目なので、その2つを登録できる入力欄と登録ボタンを簡単に作成しています。登録が完了すると「ユーザーを登録しました。」というアラートが出ます。
axiosのインストール
API Gatewayを叩くのに
axiosを使うために、プロジェクトにaxiosを追加します。$ yarn add axiosソースコード
axiosの使い方はaxiosライブラリを使ってリクエストするを参考にしました。RegistrationForm.jsimport React from "react"; import axios from "axios"; function RegistrationForm() { const API_ADD_URL = "<API Gatewayで取得したURL>" const [userName, setUserName] = React.useState(""); const [email, setEmail] = React.useState(""); const handleNameChange = event => { setUserName(event.target.value); }; const handleEmailChange = event => { setEmail(event.target.value); } const handleSubmit = event => { axios.post(API_ADD_URL, {userName: userName, email: email}) .then((response) => { if(response.data === "正常に処理が完了しました。"){ alert("ユーザーを登録しました。") console.log(response); } else { throw Error(response.data.errorMessage) } }).catch((response) => { alert("登録に失敗しました。もう一度登録してください。"); console.log(response); }); event.preventDefault(); } return ( <div> <h2>ユーザー登録</h2> <form onSubmit={handleSubmit} > <label > ユーザー名: <input type="text" value={userName} onChange={handleNameChange} /><br/> </label> <label > Eメール: <input type="text" value={email} onChange={handleEmailChange} /><br/> </label> <input type="submit" value="Submit" /> </form> </div> ); } export default RegistrationForm;ユーザーを削除する
ユーザーから削除する場合も、基本的に登録するのと同じです。ユーザープールから削除するにはSDKの
AdminDeleteUserを使用します。実行結果
無事冒頭の完成画面のように動くようになりました!
おわりに
LambdaからLambdaを実行することで、NATゲートウェイを使わずにCognitoとDBの両方にユーザーを登録することができました!今考えると、Cognitoユーザープールに登録するのはAmplifyでAdmin Queries APIを使うようにして、DBに保存するのは既存のようにLambdaを呼び出すようにするのでも良かったかなとも思います!
次回は、サインインページにある、使用しないアカウント作成ボタンを消したいと思います!




- 投稿日:2020-12-16T09:12:55+09:00
Docker の仕組み 〜 コンテナを 60 行で実装する
概要
本記事では、普段 Docker をブラックボックスとして扱っている方々を対象として、コンテナが動く仕組みを低レイヤーから解説します。
そのために Go 言語を使って、ゼロからコンテナを実装し動かしながら学ぶアプローチを取ります。コンテナの基礎的な原理は意外にも簡単で、この記事の最後に出来上がるコードは僅か 60 行ほどです。
なお、完成したコードは GitHub レポジトリに置かれています。
コンテナとは何か
コンテナと仮想マシン (VM) の違いを説明する際に、よく次のような図が使われます。
(Docker 公式サイトより引用)VM とコンテナを比較した時の最大の特徴は、一つ一つのコンテナを作る際にゲスト OS を起動しないことです。
コンテナは全て、同じホスト OS の中で動くプロセスとして存在します。しかし当然ながら、通常のプロセスはファイルなどのリソースを他のプロセスと共有しており、環境依存性を強く持ちます。
そこで、プロセスを論理的に隔離された状態で動かすために、 Linux カーネル の持つ chroot や namespace などの機能を利用します。これにより 隔離されたプロセス のことをコンテナと呼びます。Linux カーネルとは何か
カーネルとは、文字通り OS の中核に当たる重要な部分です。
Linux マシンを次のような 3 層構造と捉えた時、カーネルはちょうど中間に位置します。
- ハードウェア : メモリや CPU などの物理デバイス
- Linux カーネル
- ユーザープロセス : シェルやエディターなど、ほぼ全てのプログラム
カーネルはハードウェアを直接操作できる特権を持ち、メモリーやプロセスの管理、デバイスドライバーなどの仕事を行います。
一方で、ユーザープロセスはハードウェアに対するアクセスが大きく制限されています。そのため、ファイル操作やプロセス作成などを実行するには、システムコールを通じてカーネルに依頼しなければなりません。
コンテナを作成するプログラムを実装する際にも、 chroot や namespace などを利用するためにシステムコールを多用します。
特に Go 言語のコードでシステムコールを行う場合には、公式パッケージ golang.org/x/sys を使うのが標準的です。
ゼロからのコンテナ実装
以降では Go 言語のプログラムで実際にコンテナを作成します。
コードを実行するためには、 Go コンパイラがインストールされた Linux 環境が必要です。 GitHub レポジトリに含まれている
docker-compose.ymlファイルを使えば、環境構築の手間無しですぐに試すことができます。$ git clone $ cd minimum-container $ docker-compose run app root@linux-env:/work_dir# go run main.go run shchroot
chroot は、現在実行中のプロセス(と子プロセス)のルートディレクトリを変更します。そのディレクトリより上の階層にはアクセスできず存在を認識することもできない状態になるため、俗に chroot 監獄と呼ばれます。
GitHub レポジトリの chroot ブランチ に、 chroot を使ったコンテナもどきのコード例があります。これはルートディレクトリを
./rootfsに変更した上で、与えられた引数をコマンドとして実行します。main.go// 隔離されたプロセスの中で cmd を引数 arg と共に実行 func execute(cmd string, args ...string) { // ルートディレクトリとカレントディレクトリを ./rootfs に設定 unix.Chroot("./rootfs") unix.Chdir("/") command := exec.Command(cmd, args...) command.Stdin = os.Stdin command.Stdout = os.Stdout command.Stderr = os.Stderr command.Run() }早速この
main.goを実行してみると、次のようなエラーが発生するはずです。$ go run main.go run sh panic: exec: "sh": executable file not found in $PATHこれは、まだ
./rootfsに何もファイルが入っていないために起きるエラーです。 chroot 実行後のコンテナ内では、ルートディレクトリが空の状態と同然のため、shのバイナリすら有りません。そこで便利なのが docker export です。下記のコマンドを打ち込むと、任意の Docker イメージに含まれる全ファイルを
./rootfsの下に展開することができます。$ docker export $(docker create <イメージ>) | tar -C rootfs -xvf -
.rootfsにファイルを用意した状態で、改めてコンテナを実行してみましょう。lsコマンドを使ったり、ファイルを作成したりして、コンテナ内の/ディレクトリがホストのrootfsディレクトリとリンクしていることを確かめてみてください。root@linux-env:/work_dir# go run main.go run sh / # ls / bin dev etc home proc root sys tmp usr var / # touch /tmp/hoge / # exit root@linux-env:/work_dir# ls rootfs/tmp hogenamespace
Linux namespace は、マウントファイルシステムや PID など諸々のリソースを隔離できる機能です。
この機能の必要性を理解するために、前節で作成したコンテナもどきの中で
psコマンドを実行してみましょう。root@linux-host:/work_dir# go run main.go run ps PID USER TIME COMMAND結果は何も表示されないはずです。その原因は
psコマンドが/procディレクトリを参照していることにあります。通常/procディレクトリには、プロセス情報などを取得できる特殊な擬似ファイルシステムがマウントされていますが、コンテナもどきの中ではルートディレクトリを変更しているので/procにはまだ何も有りません。事前に
/procディレクトリをマウントしてpsを再度実行してみましょう。root@linux-host:/work_dir# go run main.go run sh / # mount proc /proc -t proc / # ps PID USER TIME COMMAND 1 root 0:00 bash 100 root 0:00 go run main.go run sh 154 root 0:00 /tmp/go-build474892034/b001/exe/main run sh 160 root 0:00 sh 163 root 0:00 psここで問題が二つ生じます。一つはコンテナ外で動いているプロセス (PID 1, 100, 154) が見えている点、もう一つは、コンテナ内で設定したマウントがホストにも反映される点です。これでは外部環境からの隔離が充分とは言えません。
root@linux-host:/work_dir# cat /proc/mounts | grep proc proc /proc proc rw,nosuid,nodev,noexec,relatime 0 0 proc /work_dir/rootfs/proc proc rw,relatime 0 0 <- コンテナ内で追加した proc マウントLinux namespace を使うと、リソースの名前空間をプロセス単位で別々に設定することができます。異なる名前空間に属するリソースは見ることも操作することもできないため、前述の問題が解決されます。
記事執筆時点で Linux namespace は 8 種類存在し、システムコールの clone, setns, unshare などでフラッグを指定します。
名前空間 フラッグ 隔離されるリソース Mount CLONE_NEWNS ファイルシステムのマウントポイント PID CLONE_NEWPID PID UTS CLONE_NEWUTS ホスト名 Network CLONE_NEWNET ネットワークデバイスやポートなど Time CLONE_NEWTIME clock_gettime で取得できる時刻 (monotonic, boot) IPC CLONE_NEWIPC プロセス間通信 Cgroup CLONE_NEWCGROUP cgroup ルートディレクトリ User CLONE_NEWUSER UID, GID Go 言語で Linux namespace を設定するには、
Cmd構造体のSysProcAttrにCloneflagsをセットします。実際に Mount, PID, UTS namespace を使ってコンテナを作成する例が GitHub レポジトリの namespace ブランチ にあります。main.gofunc execute(cmd string, args ...string) { unix.Chroot("./rootfs") unix.Chdir("/") command := exec.Command(cmd, args...) command.Stdin = os.Stdin command.Stdout = os.Stdout command.Stderr = os.Stderr // Linux namespace を設定 command.SysProcAttr = &unix.SysProcAttr{ Cloneflags: unix.CLONE_NEWNS | unix.CLONE_NEWPID | unix.CLONE_NEWUTS, } command.Run() }このコードで改めてコンテナを作成し、先程と同様に
psを実行すると、コンテナ内のプロセスだけが表示されることを確認できます。root@linux-host:/work_dir# go run main.go run sh / # mount proc /proc -t proc / # ps PID USER TIME COMMAND 1 root 0:00 sh 4 root 0:00 psまた、 UTS namespace によって、コンテナ内でホスト名を変更しても外部に影響しなくなりました。
root@linux-host:/work_dir# go run main.go run sh / # hostname my-container / # hostname my-container / # exit root@linux-host:/work_dir# hostname linux-hostコンテナの初期化
前節では、コンテナを立ち上げた後に手動で
/procのマウントやホスト名の設定をしていました。このままでは不便なので、コンテナ作成と同時にこれらの初期化処理も行うようにプログラムを変更しましょう。ここで問題となるのが、初期化を実行するタイミングです。コンテナ作成は
- namespace を設定した子プロセスを作成
- 子プロセスを初期化 (
/procマウントなど)- ユーザー指定のコマンド (
shなど) を実行という順序で行う必要がありますが、 1. と 3. の間に割り込めるフックなどは存在しません。そこで、 2. と 3. を両方とも実行するコードを書き、 namespace を設定したプロセス上でそのコードを実行します。
実装例は GitHub レポジトリの reexec ブランチ です。
main.go// コマンドライン引数の処理 // go run main.go run <cmd> <args> func main() { switch os.Args[1] { case "run": initialize(os.Args[2:]...) case "child": execute(os.Args[2], os.Args[3:]...) default: panic("コマンドライン引数が正しくありません。") } } // Linux namespace を設定した子プロセスで、execute 関数を実行する func initialize(args ...string) { // このプログラム自身に引数 child <cmd> <args> を渡す arg := append([]string{"child"}, args...) command := exec.Command("/proc/self/exe", arg...) command.Stdin = os.Stdin command.Stdout = os.Stdout command.Stderr = os.Stderr command.SysProcAttr = &unix.SysProcAttr{ Cloneflags: unix.CLONE_NEWNS | unix.CLONE_NEWPID | unix.CLONE_NEWUTS, } command.Run() } // namespace 設定後の初期化処理と、ユーザー指定のコマンドを実行する func execute(cmd string, args ...string) { // ルートディレクトリとカレントディレクトリを ./rootfs に設定 unix.Chroot("./rootfs") unix.Chdir("/") unix.Mount("proc", "proc", "proc", 0, "") unix.Sethostname([]byte("my-container")) command := exec.Command(cmd, args...) command.Stdin = os.Stdin command.Stdout = os.Stdout command.Stderr = os.Stderr command.Run() }一つの実行ファイルで完結させるために、少しトリッキーな方法を使っています。ポイントは
initialize関数の中で/proc/self/exeをコマンドとして実行している部分です。/proc/self/exeも proc ファイルシステムの一部で、現在のプロセスの実行ファイルのパスを返します。これを利用して、プログラムが自分自身を再帰的に実行することができます。上記コード実行時の流れを順に追っていくと
- コマンド
go run main.go run <cmd> <args>を実行- main.go が実行され
initialize関数に分岐- namespace を設定したプロセスを作成
- コマンド
/proc/self/exe init <cmd> <args>を実行- main.go が実行され
execute関数に分岐/procマウントなどの初期化処理を実行- プロセスを作成
- ユーザー指定のコマンドを実行
この時、ユーザーコマンド実行のために作られる孫プロセスにも ルートディレクトリと namespace の設定が継承され、コンテナとして機能します。
コンテナの標準仕様
以上でコンテナの基礎に当たる機能を実装できましたが、まだ欠けている部分がたくさんあります。この記事で全てを詳細に説明することはできませんが、大まかな全体像を伝えるために重要な標準仕様を 2 つ紹介します。
仕様 代表的な実装 OCI Runtime Specification runc OCI Image Format Specification containerd OCI Runtime Spec はコンテナのライフサイクルと filesystem bundle のフォーマットを規定します。filesystem bundle とは、コンテナの各種設定値を記載した
config.jsonと、ルートファイルシステムとなるrootfsディレクトリをまとめて tar アーカイブにしたものです。一方で OCI Image Spec は、コンテナイメージのフォーマットと、イメージを filesystem bundle に変換する方法を規定します。イメージとは、 Dockerfile をビルドして得られるお馴染みのあのイメージのことです。
filesystem bundle に
rootfsディレクトリが含まれることから推測できるように、この記事で実装したのは OCI Runtime Spec の触りの部分に当たります。 OCI Image Spec やその他の要素にはノータッチなので、興味のある方はさらに詳しく調べてみることをお勧めします。まとめ
- コンテナは Linux カーネルの機能によって隔離された特殊なプロセス
- chroot: ルートファイルシステムを隔離
- namespace: PID、ファイルマウント、ホスト名など様々なグローバルリソースを隔離
- コンテナに関する重要な標準仕様
- OCI Runtime Specification
- OCI Image Format Specification
- 本記事と関連が深いのは runtime spec
参考リンク



- 投稿日:2020-12-16T06:51:37+09:00
テスト駆動開発(本)を Go 言語で取り組んでみる
はじめに
それに触発され、t_wada さんが訳されたテスト駆動開発を、現在学習中の Go 言語で取り組んでみました。
本記事中の引用は、特に断りがない限りこの本の引用になります。
※第Ⅰ部まで終了
リポジトリ
https://github.com/eyuta/golang-tdd
前提
筆者の Go の習熟度はA Tour of Goを終了したくらいです。
バージョン
go version go1.15.6 windows/amd64テスト方法について
今回は、Go の標準の testing パッケージと、こちらサードパーティのassertパッケージを使用しています。
Go の標準の testing パッケージには、Assert が含まれておらず、推奨もされていません。
理由については、以下の記事が詳しいです。
ただ、今回は testing としてのテストではなく、checking としてのテストがメインであることから、手軽にテストケースを記述できる Assert パッケージを使用しています。参考記事
testing パッケージの使い方は以下を参照しました。
本編
TDD について
TDD のルール
コードを書く前に、失敗する自動テストコードを必ず書く。
重複を除去する。TDD のリズム
- まずはテストを 1 つ書く
- すべてのテストを走らせ、新しいテストの失敗を確認する
- 小さな変更を行う
- すべてのテストを走らせ、すべて成功することを確認する
- リファクタリングを行って重複を除去する
第 I 部 多国通貨
第 1 章 仮実装
第 1 章の振り返り
- 書くべきテストのリストを作った。
- どうなったら嬉しいかを小さいテストコードで表現した。
- 空実装を使ってコンパイラを通した。
- 大罪を犯しながらテストを通した。
- 動くコードをだんだんと共通化し、ベタ書きの値を変数に置き換えていった。
- TODO リストに項目を追加するに留め、一度に多くのものを相手にすることを避けた。
第 1 章の TODO リスト
- \$5+10CHF=$10(レートが 2:1 の場合)
- \$5*2=$10
- amount を private にする
- Dollar の副作用どうする?
- Money の丸め処理どうする?
第 1 章終了時のコード
multiCurrencyMoney.gotype Dollar struct { amount int } func (d *Dollar) times(multiplier int) { d.amount *= multiplier }multiCurrencyMoney_test.gofunc TestMultiCurrencyMoney(t *testing.T) { t.Run("$5 * 2 = $10", func(t *testing.T) { five := Dollar{5} five.times(2) assert.Equal(t, 10, five.amount) }) }第 2 章 明確な実装
第 2 章の振り返り
- 設計の問題点(今回は副作用)をテストコードに写し取り、その問題点のせいでテストが失敗するのを確認した。
- 空実装でさっさとコンパイルを通した。
- 正しいと思える実装をすぐに行い、テストを通した。
第 2 章の TODO リスト
- \$5+10CHF=$10(レートが 2:1 の場合)
- \$5*2=$10
- amount を private にする
- Dollar の副作用どうする?
- Money の丸め処理どうする?
第 2 章終了時のコード
multiCurrencyMoney.gotype Dollar struct { amount int } func (d *Dollar) times(multiplier int) Dollar { return Dollar{d.amount * multiplier} }multiCurrencyMoney_test.gofunc TestMultiCurrencyMoney(t *testing.T) { t.Run("何度でもドルの掛け算が可能である", func(t *testing.T) { five := Dollar{5} product := five.times(2) assert.Equal(t, 10, product.amount) product = five.times(3) assert.Equal(t, 15, product.amount) }) }第 3 章 三角測量
型のコンバージョンは、Type Assertionを利用した。
第 3 章の振り返り
- Value Object パターンを満たす条件がわかった。
- その条件を満たすテストを書いた。
- シンプルな実装を行った。
- すぐにリファクタリングを行うのではなく、もう 1 つテストを書いた。
- 2 つのテストを同時に通すリファクタリングを行った。
第 3 章の TODO リスト
- \$5+10CHF=$10(レートが 2:1 の場合)
- \$5*2=$10
- amount を private にする
- Dollar の副作用どうする?
- Money の丸め処理どうする?
- equals()
- hashCode()
- null との等価性比較
- 他のオブジェクトとの等価性比較
第 3 章終了時のコード
multiCurrencyMoney.gotype Object interface{} type Dollar struct { amount int } func (d Dollar) times(multiplier int) Dollar { return Dollar{d.amount * multiplier} } func (d Dollar) equals(object Object) bool { dollar := object.(Dollar) return d.amount == dollar.amount }multiCurrencyMoney_test.gofunc TestMultiCurrencyMoney(t *testing.T) { t.Run("何度でもドルの掛け算が可能である", func(t *testing.T) { five := Dollar{5} product := five.times(2) assert.Equal(t, 10, product.amount) product = five.times(3) assert.Equal(t, 15, product.amount) }) t.Run("同じ金額が等価である", func(t *testing.T) { assert.True(t, Dollar{5}.equals(Dollar{5})) assert.False(t, Dollar{5}.equals(Dollar{6})) }) }第 4 章 意図を語るテスト
第 4 章の振り返り
- 作成したばかりの機能を使って、テストを改善した。
- そもそも正しく検証できていないテストが 2 つあったら、もはやお手上げだと気づいた。
- そのようなリスクを受け入れて先に進んだ。
- テスト対象オブジェクトの新しい機能を使い、テストコードとプロダクトコードの間の結合度を下げた。
第 4 章終了時のコード
multiCurrencyMoney.go// 変化なしmultiCurrencyMoney_test.gofunc TestMultiCurrencyMoney(t *testing.T) { t.Run("ドルの掛け算が可能である", func(t *testing.T) { five := Dollar{5} assert.Equal(t, Dollar{10}, five.times(2)) assert.Equal(t, Dollar{15}, five.times(3)) }) t.Run("同じ金額が等価である", func(t *testing.T) { assert.True(t, Dollar{5}.equals(Dollar{5})) assert.False(t, Dollar{5}.equals(Dollar{6})) }) }第 5 章 原則をあえて破るとき
第 5 章の振り返り
- 大きいテストに立ち向かうにはまだ早かったので、次の一歩を進めるために小さなテストをひねり出した。
- 恥知らずにも既存のテストをコピー&ペーストして、テストを作成した。
- さらに恥知らずにも、既存のモデルコードを丸ごとコピー&ペーストして、テストを通した。
- この重複を排除するまでは家に帰らないと心に決めた。
第 5 章の TODO リスト
- \$5+10CHF=$10(レートが 2:1 の場合)
- \$5*2=$10
- amount を private にする
- Dollar の副作用どうする?
- Money の丸め処理どうする?
- equals()
- hashCode()
- null との等価性比較
- 他のオブジェクトとの等価性比較
- 5CHF*2=10CHF
- Dollar と Franc の重複
- equals の一般化
- times の一般化
第 5 章終了時のコード
multiCurrencyMoney.gotype Franc struct { amount int } func (f Franc) times(multiplier int) Franc { return Franc{f.amount * multiplier} } func (f Franc) equals(object Object) bool { franc := object.(Franc) return f.amount == franc.amount }multiCurrencyMoney_test.got.Run("フランの掛け算が可能である", func(t *testing.T) { five := Franc{5} assert.Equal(t, Franc{10}, five.times(2)) assert.Equal(t, Franc{15}, five.times(3)) }) t.Run("同じ金額のフランが等価である", func(t *testing.T) { assert.True(t, Franc{5}.equals(Franc{5})) assert.False(t, Franc{5}.equals(Franc{6})) })第 6 章 テスト不足に気づいたら
- Go には継承の概念が無いため、本章では composition を用いて実装する。
- Dollar, Franc を生成するためのコンストラクタにあたるものを用意した(以下を参考にした)。 Constructors and composite literals
multiCurrencyMoney.goをmoney.go,dollar.go,franc.goに分割したmultiCurrencyMoney_test.goをmoney_test.goに改名し、package 名をmoney_testとしたmoney.goとmoney_test.goの package 名が異なるため、プライベートメソッド(小文字のメソッド)が参照できなくなったので、equals,timesメソッドをパブリックメソッドに変更した- パブリックメソッドにはコメントが必要になるので、簡単なコメントを追加した 参考: Godoc: documenting Go code
第 6 章の振り返り
このあたりから、言語仕様の違いによりコーディング内容が本と異なってくる
- Dollar クラスから親クラス Money へ段階的にメソッドを移動した。
- 2 つ目のクラス(Franc)も同様にサブクラス化した。
- 2 つの equals メソッドの差異をなくしてから、サブクラス側の実装を削除した。
第 6 章の TODO リスト
- \$5+10CHF=$10(レートが 2:1 の場合)
- \$5*2=$10
- amount を private にする
- Dollar の副作用どうする?
- Money の丸め処理どうする?
- equals()
- hashCode()
- null との等価性比較
- 他のオブジェクトとの等価性比較
- 5CHF*2=10CHF
- Dollar と Franc の重複
- equals の一般化
- times の一般化
- Franc と Dollar を比較する
第 6 章終了時のコード
量が増えてきたので、主な変更点のみ抜粋して表示する
全文: githubmoney.gopackage money // AmountGetter is a wrapper of amount. type AmountGetter interface { getAmount() int } // Money is a struct that handles money. type Money struct { amount int } // Equals checks if the amount of the receiver and the argument are the same func (m Money) Equals(a AmountGetter) bool { return m.getAmount() == a.getAmount() } func (m Money) getAmount() int { return m.amount }money_test.gopackage money_test import ( "testing" "github.com/eyuta/golang-tdd/money" "github.com/stretchr/testify/assert" ) func TestMultiCurrencyMoney(t *testing.T) { t.Run("ドルの掛け算が可能である", func(t *testing.T) { five := money.NewDollar(5) assert.Equal(t, money.NewDollar(10), five.Times(2)) assert.Equal(t, money.NewDollar(15), five.Times(3)) }) }第 7 章 疑念をテストに翻訳する
- 今回の修正とは関係ないが、
Go: Test On SaveSetting をチェックすることで保存時にテストが走るようになった。
第 7 章の振り返り
- 頭の中にある悩みをテストとして表現した。完璧ではないものの、まずまずのやり方(getClass)でテストを通した。
- さらなる設計は、本当に必要になるときまで先延ばしにすることにした
- Money に新しく Name フィールドを追加した
- 上記の
getClassの代替。struct の入れ子の場合、レシーバは常に Money になるので、type の比較ができないため第 7 章の TODO リスト
- \$5+10CHF=$10(レートが 2:1 の場合)
- \$5*2=$10
- amount を private にする
- Dollar の副作用どうする?
- Money の丸め処理どうする?
- equals()
- hashCode()
- null との等価性比較
- 他のオブジェクトとの等価性比較
- 5CHF*2=10CHF
- Dollar と Franc の重複
- equals の一般化
- times の一般化
- Franc と Dollar を比較する
- 通貨の概念
第 7 章終了時のコード
全文: github
money.gopackage money // Accessor is a accessor of Money type Accessor interface { Amount() int Name() string } // Money is a struct that handles money. type Money struct { amount int name string } // Equals checks if the amount of the receiver and the argument are the same func (m Money) Equals(a Accessor) bool { return m.Amount() == a.Amount() && m.Name() == a.Name() } // Amount returns amount field func (m Money) Amount() int { return m.amount } // Name returns name field func (m Money) Name() string { return m.name }money_test.got.Run("同じ金額のドルとフランが等価ではない", func(t *testing.T) { assert.False(t, money.NewFranc(5).Equals(money.NewDollar(5))) })dollar.gofunc NewDollar(a int) Dollar { return Dollar{Money{amount: a, name: "Dollar"}} }第 8 章 実装を隠す
第 8 章の振り返り
- 重複を除去できる状態に一歩近づけるために、Dollar と Franc にある 2 つの times メソッドのシグニチャを合わせた。
- Factory Method パターンを導入して、テストコードから 2 つのサブクラスの存在を隠した。
- サブクラスを隠した結果、いくつかのテストが冗長なものになったことに気がついたが、いまはそのままにしておいた。
- Go には抽象クラスの概念が無いため、Times メソッドについては一足先に実装もろとも Money に移行した
- それにより、Dollar, Franc の 2 つの構造体が使われなくなったが、一旦取っておくことにする
第 8 章の TODO リスト
- \$5+10CHF=$10(レートが 2:1 の場合)
- \$5*2=$10
- amount を private にする
- Dollar の副作用どうする?
- Money の丸め処理どうする?
- equals()
- hashCode()
- null との等価性比較
- 他のオブジェクトとの等価性比較
- 5CHF*2=10CHF
- Dollar と Franc の重複
- equals の一般化
- times の一般化
- Franc と Dollar を比較する
- 通貨の概念
- testFrancMultiplication を削除する?
第 8 章終了時のコード
全文: github
money.gopackage money // Accessor is a accessor of Money type Accessor interface { Amount() int Name() string } // Money is a struct that handles money. type Money struct { amount int name string } // NewDollar is constructor of Dollar. func NewDollar(a int) Money { return Money{ amount: a, name: "Dollar", } } // NewFranc is constructor of Dollar. func NewFranc(a int) Money { return Money{ amount: a, name: "Franc", } } // Times multiplies the amount of the receiver by a multiple of the argument func (m Money) Times(multiplier int) Money { return Money{ amount: m.amount * multiplier, name: m.name, } } // Equals checks if the amount of the receiver and the argument are the same func (m Money) Equals(a Accessor) bool { return m.amount == a.Amount() && m.name == a.Name() } // Amount returns amount field func (m Money) Amount() int { return m.amount } // Name returns name field func (m Money) Name() string { return m.name }dollar.gopackage money // Dollar is a struct that handles dollar money. type Dollar struct { Money }第 9 章 歩幅の調整
第 9 章の振り返り
- 大きめの設計変更にのめり込みそうになったので、その前に手前にある小さな変更に着手した。
- 差異を呼び出し側(FactoryMethod 側)に移動することによって、2 つのサブクラスのコンストラクタを近づけていった。
- リファクタリングの途中で少し寄り道して、times メソッドの中で FactoryMethod を使うように変更した。
- Franc に行ったリファクタリングを Dollar にも同様に、今度は大きい歩幅で一気に適用した。
- 完全に同じ内容になった 2 つのコンストラクタを親クラスに引き上げた。
currency field は第 7 章で作成した name field を currency に改名しただけになる
第 9 章の TODO リスト
- \$5+10CHF=$10(レートが 2:1 の場合)
- \$5*2=$10
- amount を private にする
- Dollar の副作用どうする?
- Money の丸め処理どうする?
- equals()
- hashCode()
- null との等価性比較
- 他のオブジェクトとの等価性比較
- 5CHF*2=10CHF
- Dollar と Franc の重複
- equals の一般化
- times の一般化
- Franc と Dollar を比較する
- 通貨の概念
- testFrancMultiplication を削除する?
第 9 章終了時のコード
全文: github
money.gopackage money // Accessor is a accessor of Money type Accessor interface { Amount() int Currency() string } // Money is a struct that handles money. type Money struct { amount int currency string } // NewMoney is constructor of Money. func NewMoney(a int, c string) Money { return Money{ amount: a, currency: c, } } // NewDollar is constructor of Dollar. func NewDollar(a int) Money { return NewMoney(a, "USD") } // NewFranc is constructor of Dollar. func NewFranc(a int) Money { return NewMoney(a, "CHF") } // Times multiplies the amount of the receiver by a multiple of the argument func (m Money) Times(multiplier int) Money { return Money{ amount: m.amount * multiplier, currency: m.currency, } } // Equals checks if the amount of the receiver and the argument are the same func (m Money) Equals(a Accessor) bool { return m.amount == a.Amount() && m.currency == a.Currency() } // Amount returns amount field func (m Money) Amount() int { return m.amount } // Currency returns name field func (m Money) Currency() string { return m.currency }money_test.got.Run("通貨テスト", func(t *testing.T) { assert.Equal(t, "USD", money.NewDollar(1).Currency()) assert.Equal(t, "CHF", money.NewFranc(1).Currency()) })第 10 章 テストに聞いてみる
第 10 章の振り返り
times メソッドについては既に共通化しているため、ログ出力用の String メソッドのみ実装した。
第 10 章終了時のコード
全文: github
money.gofunc (m Money) String() string { return fmt.Sprintf("{Amount: %v, Currency: %v}", m.amount, m.currency) }第 11 章 不要になったら消す
第 11 章の振り返り
- サブクラスの仕事を減らし続け、とうとう消すところまでたどり着いた。
- サブクラス削除前の構造では意味があるものの、削除後は冗長になってしまうテストたちを消した。
第 11 章の TODO リスト
- \$5+10CHF=$10(レートが 2:1 の場合)
- \$5*2=$10
- amount を private にする
- Dollar の副作用どうする?
- Money の丸め処理どうする?
- equals()
- hashCode()
- null との等価性比較
- 他のオブジェクトとの等価性比較
- 5CHF*2=10CHF
- Dollar と Franc の重複
- equals の一般化
- times の一般化
- Franc と Dollar を比較する
- 通貨の概念
- testFrancMultiplication を削除する?
第 11 章終了時のコード
dollar.go, franc.go,ファイルを削除した。
全文: github
第 12 章 設計とメタファー
第 12 章の振り返り
- 大きいテスト($5 + 10 CHF)を分解して。進み具合がわかる小さいテスト($5+$5)を作成した。
- これから行う計算のためのメタファーについて深く考えた。
- テストがコンパイルできるところまで早足で進んだ。
- テストを通した。
- 本当の実装を導くためのリファクタリングを楽しみにしつつ、少し不安も感じている。
第 12 章の TODO リスト
- \$5+10CHF=$10(レートが 2:1 の場合)
- $5 + $5 = $10
第 12 章終了時のコード
全文: github
money.go// Plus adds an argument to the amount of receiver func (m Money) Plus(added Money) Expression { return NewMoney(m.amount+added.amount, m.currency) }bank.gopackage money // Bank calculates using exchange rates type Bank struct { } // Reduce applies the exchange rate to the argument expression func (b Bank) Reduce(source Expression, to string) Money { return NewDollar(10) }expression.gopackage money // Expression shows the formula of currency (regardless of the difference in exchange rate) type Expression interface { }money_test.got.Run("ドル同士の足し算が可能である", func(t *testing.T) { five := money.NewDollar(5) sum := five.Plus(five) bank := money.Bank{} reduced := bank.Reduce(sum, "USD") assert.Equal(t, money.NewDollar(10), reduced) })第 13 章 実装を導くテスト
第 13 章の振り返り
- 重複を除去出来ていないので、TODO リストの項目を「済」にしなかった。
- 実装の着想を得るためにさらに先に進むことにした。
- 速やかに実装を行った(Sum のコンストラクタ)
- キャストを使って 1 カ所で実装した後で、テストが通る馬で本来あるべき場所にコードを移した。
- ポリモフィズムを使って、明示的なクラスチェックを置き換えた。
第 13 章の TODO リスト
- \$5+10CHF=$10(レートが 2:1 の場合)
- $5 + $5 = $10
- $5 + $5 が Money を返す
- Bank.reduce(Money)
- Money を変換して換算を行う
- Reduce(Bank, String)
第 13 章終了時のコード
全文: github
maoney_test.got.Run("ドル同士の足し算が可能である", func(t *testing.T) { five := money.NewDollar(5) result := five.Plus(five) sum := result.(money.Sum) assert.Equal(t, five, sum.Augend) assert.Equal(t, five, sum.Added) }) t.Run("Sumで足されるお金の通貨が同じなら、足し算の結果が同じになる", func(t *testing.T) { sum := money.Sum{ Augend: money.NewDollar(3), Added: money.NewDollar(4), } bank := money.Bank{} result := bank.Reduce(sum, "USD") assert.Equal(t, money.NewDollar(7), result) }) t.Run("moneyをreduceしても、reduceに渡す通貨が同じであれば同じ値が返る", func(t *testing.T) { bank := money.Bank{} result := bank.Reduce(money.NewDollar(1), "USD") assert.Equal(t, money.NewDollar(1), result) })money.go// Plus adds an argument to the amount of receiver. func (m Money) Plus(added Money) Expression { return Sum{ Augend: m, Added: added, } } // Reduce applies the exchange rate to receiver. func (m Money) Reduce(to string) Money { return m }bank.go// Reduce applies the exchange rate to the argument expression func (b Bank) Reduce(source Expression, to string) Money { return source.Reduce(to) }expression.go// Expression shows the formula of currency (regardless of the difference in exchange rate) type Expression interface { Reduce(string) Moneysum.gopackage money // Sum 合計は通貨の加算を行います type Sum struct { Augend Money Added Money } // Reduce applies the exchange rate to the result of the addition func (s Sum) Reduce(to string) Money { amount := s.Augend.amount + s.Added.amount return NewMoney(amount, to) }第 14 章 学習用テストと回帰テスト
第 14 章の振り返り
- 必要になると予想されたパラメータ追加をすぐに行った。
- コードとテストの間のデータ重複をくくりだした。
- 内部実装で使うためだけのヘルパークラスを個別のテスト無しで作成した。
- リファクタリング中にミスを犯したが、問題を再現するテストを追加して、着実に前進した。
今回、本にあるような Pair.go ファイルを作成せず、Pair struct のみ Bank ファイルに記述した。
Java オブジェクトの
equalsによる比較は等値比較だが、Go の struct の==による比較は等価比較になるため。ただし、struct に map や slice といった等価比較できないフィールドが存在する場合は、コンパイル時にエラーになる。
そういった場合は
reflect.DeepEqualを使って比較を行う参考:How to compare if two structs, slices or maps are equal?
type s struct { a int } s1 := s{1} s2 := s{1} fmt.Println(s1 == s2) // truetype s struct { a int b []int } s1 := s{1, make([]int, 0)} s2 := s{1, make([]int, 0)} fmt.Println(reflect.DeepEqual(s1, s2)) // true fmt.Println(s1 == s2) // invalid operation: s1 == s2 (struct containing []int cannot be compared)ちなみに、
assert.Equalも内部でreflect.DeepEqualを使用している。// This function does no assertion of any kind. func ObjectsAreEqual(expected, actual interface{}) bool { if expected == nil || actual == nil { return expected == actual } exp, ok := expected.([]byte) if !ok { return reflect.DeepEqual(expected, actual) // ここ } act, ok := actual.([]byte) if !ok { return false } if exp == nil || act == nil { return exp == nil && act == nil } return bytes.Equal(exp, act) }第 14 章の TODO リスト
- \$5+10CHF=$10(レートが 2:1 の場合)
- $5 + $5 = $10
- $5 + $5 が Money を返す
- Bank.reduce(Money)
- Money を変換して換算を行う
- Reduce(Bank, String)
第 14 章終了時のコード
全文: github
money_test.got.Run("1 CHF = $2", func(t *testing.T) { bank := money.NewBank() bank.AddRate("CHF", "USD", 2) result := bank.Reduce(money.NewFranc(2), "USD") assert.Equal(t, money.NewDollar(1), result) }) t.Run("同量テスト", func(t *testing.T) { bank := money.NewBank() assert.Equal(t, 1, bank.Rate("USD", "USD")) })money.go// Reduce applies the exchange rate to receiver. func (m Money) Reduce(b Bank, to string) Money { rate := b.Rate(m.currency, to) return NewMoney(m.amount/rate, to) }bank.go// Bank calculates using exchange rates type Bank struct { rates map[Pair]int } // Pair associates two currencies type Pair struct { from, to string } // NewBank is a constructor of Bank func NewBank() Bank { b := Bank{} b.rates = make(map[Pair]int) return b } // Reduce applies the exchange rate to the argument expression func (b *Bank) Reduce(source Expression, to string) Money { return source.Reduce(*b, to) } // AddRate adds exchange rate func (b *Bank) AddRate(from, to string, rate int) { b.rates[Pair{from: from, to: to}] = rate } // Rate adds exchange rate func (b *Bank) Rate(from, to string) int { if from == to { return 1 } p := Pair{from: from, to: to} return b.rates[p] }expression.go// Expression shows the formula of currency (regardless of the difference in exchange rate) type Expression interface { Reduce(Bank, string) Money }sum.go// Reduce applies the exchange rate to the result of the addition func (s Sum) Reduce(b Bank, to string) Money { amount := s.Augend.amount + s.Added.amount return NewMoney(amount, to) }第 15 章 テスト任せとコンパイラ任せ
第 15 章の振り返り
- こうなったら良いというテストを書き、次にまず一歩で動かせるところまでそのテストを少し後退させた。
- 一般化(より抽象度の高い型で宣言する)作業を、末端から開始して頂点(テストケース)まで到達させた。
- 変更の際にコンパイラに従い(fiveBucks 変数の Expression 型への変更)、変更の連鎖を 1 つずつ仕留めた(Expression インターフェースへの Plus メソッドの追加等)。
どうでもいいが、Dollar の代わりに Bucks が使われることを初めて知った。
第 15 章の TODO リスト
- \$5+10CHF=$10(レートが 2:1 の場合)
- $5 + $5 = $10
- $5 + $5 が Money を返す
- Bank.reduce(Money)
- Money を変換して換算を行う
- Reduce(Bank, String)
- Sum.Plus
- Expression.Times
第 15 章終了時のコード
全文: github
money_test.got.Run("$5 + 10 CHF = $10 (レートが2:1の場合)", func(t *testing.T) { fiveBucks := money.Expression(money.NewDollar(5)) tenFrancs := money.Expression(money.NewFranc(10)) bank := money.NewBank() bank.AddRate("CHF", "USD", 2) result := bank.Reduce(fiveBucks.Plus(tenFrancs), "USD") assert.Equal(t, money.NewDollar(10), result) })money.go// Times multiplies the amount of the receiver by a multiple of the argument func (m Money) Times(multiplier int) Expression { return NewMoney(m.amount*multiplier, m.currency) } // Plus adds an argument to the amount of receiver. func (m Money) Plus(added Expression) Expression { return Sum{ Augend: m, Added: added, } }expression.go// Expression shows the formula of currency (regardless of the difference in exchange rate) type Expression interface { Reduce(Bank, string) Money Plus(Expression) Expression }sum.go// Reduce applies the exchange rate to the result of the addition func (s Sum) Reduce(b Bank, to string) Money { amount := s.Augend.Reduce(b, to).amount + s.Added.Reduce(b, to).amount return NewMoney(amount, to) } // Plus adds an argument to the amount of receiver. func (s Sum) Plus(added Expression) Expression { return Sum{} }第 16 章 将来の読み手を考えたテスト
第 16 章の振り返り
- 将来読む人のことを考えながらテストを書いた
- これまえのプログラミングスタイルと TDD との比較を自分自身で行うことが大事だと伝えた。
- 再び連鎖的に波及する定義変更を行い、コンパイラに導かれながら修正を行った。
- 最後に簡単な実験を行い、うまく機能しないと分かっていたので破棄して引き返した。
文中で、
テストを書くのは、(中略) いま考えていることを将来の仲間に伝えるロゼッタストーンの役割も担ってほしいからだ。
とあるが、この場合のロゼッタストーンとは
one that gives a clue to understanding、日本語で理解の手がかりを与えるものという意味があるそうだ。参考: Rosetta stone
元々はエジプトのロゼッタで発見された古代の石碑のこと。
第 16 章の TODO リスト
- \$5+10CHF=$10(レートが 2:1 の場合)
- $5 + $5 = $10
- $5 + $5 が Money を返す
- Bank.reduce(Money)
- Money を変換して換算を行う
- Reduce(Bank, String)
- Sum.Plus
- Expression.Times
第 16 章終了時のコード
全文: github
money_test.got.Run("$5 + 10 CHF + $5 = $15 をSum structを使って行う", func(t *testing.T) { fiveBucks := money.Expression(money.NewDollar(5)) tenFrancs := money.Expression(money.NewFranc(10)) bank := money.NewBank() bank.AddRate("CHF", "USD", 2) sum := money.Sum{Augend: fiveBucks, Added: tenFrancs}.Plus(fiveBucks) result := bank.Reduce(sum, "USD") assert.Equal(t, money.NewDollar(15), result) }) t.Run("($5 + 10 CHF) * 2 = $20 をSum structを使って行う", func(t *testing.T) { fiveBucks := money.Expression(money.NewDollar(5)) tenFrancs := money.Expression(money.NewFranc(10)) bank := money.NewBank() bank.AddRate("CHF", "USD", 2) sum := money.Sum{Augend: fiveBucks, Added: tenFrancs}.Times(2) result := bank.Reduce(sum, "USD") assert.Equal(t, money.NewDollar(20), result) })expression.go// Expression shows the formula of currency (regardless of the difference in exchange rate) type Expression interface { Reduce(Bank, string) Money Plus(Expression) Expression Times(int) Expression }sum.go// Plus adds an argument to the amount of receiver. func (s Sum) Plus(added Expression) Expression { return Sum{ Augend: s, Added: added, } } // Times multiplies the amount of the receiver by a multiple of the argument func (s Sum) Times(multiplier int) Expression { return Sum{ Augend: s.Augend.Times(multiplier), Added: s.Added.Times(multiplier), } }参考文献
- 投稿日:2020-12-16T02:04:20+09:00
GinkgoのDesrcibeTableの使い方
Ginkgoには、DescribeTableというTable Driven Testの仕組みが用意されています。
DescribeTableを使わないでfor文でテストデータの数だけIt()を呼ぶ方法もありますが、テストデータをハードコーディングする場合はDescribeTableを使うと便利です。以下、DescribeTableの使い方の例を示します。
BeforeEach/BeforeSuiteの実行前にテストデータが作れる場合
公式のサンプルコードそのまま。
import ( . "github.com/onsi/ginkgo/extensions/table" . "github.com/onsi/ginkgo" . "github.com/onsi/gomega" ) var _ = Describe("Math", func() { DescribeTable("the > inequality", func(x int, y int, expected bool) { Expect(x > y).To(Equal(expected)) }, Entry("x > y", 1, 0, true), Entry("x == y", 0, 0, false), Entry("x < y", 0, 1, false), ) })BeforeEach/BeforeSuiteの実行後でないとテストデータが作れない場合
bookという変数があり、テストデータを作るのにbookを作る必要があるが、bookはBeforeEachでないと作れない状況を考えます。
var _ = Describe("Book", func() { // ここでは、テストデータを作るのに必要。BeforeEachでないと作れないとする。 var book Book BeforeEach(func() { book = CreateBook() }) type TestData struct { id int expected bool } DescribeTable("Find", func(lazyTestData func() TestData) { // テストデータを生成する: testParam := lazyTestData() Expect(DoesExist(testParam.id)).To(Equal(testParam.expected)) }, // テストデータそのものではなく、テストデータを作る関数を渡す。 // このコード実行時点では、テストデータを生成するのに必要なbookが作られていないため Entry("本が見つかること", func() TestData { return TestData{ id: book.ID, expected: true, } }), Entry("本が見つからないこと", func() TestData { return TestData{ id: -1, expected: false, } })) })最初に示した例のように、Entry()の引数に直接テストデータを渡すことはできません。DescribeTable()の実行時点では、BeforeEachが呼ばれていないので、テストデータを作れていないからです。
そこで、テストデータそのものではなく、テストデータを作成する関数をDescribeTableには渡します。最終的には、テスト実行時(DescribeTableの第2引数の関数の実行時)に、テストデータを作成する関数を呼び出すことでテストデータを作ります。このタイミングであれば、BeforeEachが呼ばれているので、テストデータは作れます。
示してみたもののこのパターンとのときは、素直にIt()を1つずつ書く、各Itの中でテストデータを作る、検証処理は関数化して各Itで呼ぶ、とした方が分かりやすいかと思います。
- 投稿日:2020-12-16T00:00:13+09:00
Golangの学習経験を通じて気づいたこと
Classi Advent Calendar 2020の16日目の記事をご覧いただき,ありがとうございます!
サーバーサイドエンジニア@willsmileです.最近,住宅と車に関心を持つようになり,具体例で物事を考える時に,それらのことが“自然に”登場してしまうという“不自然さ”を自覚している者です.
まえがき
本記事のタイトルをみて,“なぜGolangを学んだのか”という疑問に感じる方が多いかもしれないので,以下の本題でその学習目標を詳しく説明します.その前に,職歴1年9ヶ月の自分が考えている今年度の成長目標(キャリア)について触れたいと思います.
一言でいうと,今年は“複眼”になることを目標としています.“複眼”の言葉は苅谷氏の知的複眼思考法といった本(とても面白い本なので,おすすめします)のタイトルから借りました.ここで表したいのは,自分と異なる立場・専門の方とのコラボレーションを円滑するために,相手が持つ観点と大事にすること,およびなぜなのかを理解できること,または理解するための行動を起こせることです.
本題
なぜGolangを学習の対象として選んだのか?
上述の目標を踏まえて説明すると,業務中メインで使っているRuby言語と異なるスタイルのプログラミング言語を学んで,比較してみて,何か違うのかを知りたいです.
そのために,以下の言語を候補として挙げたが,自分がよく使うツールの中で,Go製のもの(例えば,yay, direnv, Hugo)が多いため,ソースコードなどの学習資源の豊富さの観点を考えて,Golangを更に学ぶことにしました.
1. Golang
2. Elm
3. Haskellどのように学ぶのか?
ざっくり言うと,以下のような4つの段階で自身の学びを設計しました.(いまの自分は段階3にいます)
- 段階1:何かを作れるように,最低限必要な知識を公式ドキュメントから獲得すること
- 実際作ったものはこちらのツール(s2test: A Simple Smoke Test Tool)です.いまの自分からみると,とてもRubyらしくGolangを使ってしまった感があります.
- 段階2:Golangに関する面白い記事・講演ビデオを広く読む・見て,言語を作った・使っている人がどう思っているのか(言語の特徴)を知ること
- スキマ時間の活用と学びの“冗長性”向上の観点から,この段階2をダラダラやるのは個人的にとても好きですが,効率を求める場合,この段階を一旦飛ばしてもいいと思います.
- 段階3:Golangに関する良い本を選んで,その中のGolang特徴である部分の内容を精読すること
- 実際読んでいる本は,こちら(The Go Programming Language)です.
- 段階4:上記の過程から学んだことを踏まえて,段階1で作ったものを作り直すこと
いままでの学びを通じて何を気づきたのか?
結論から言うと,“継承は使っちゃいけない場合はある”ということです.以下はそれを気づいたプロセスを詳しく説明します.
Golangにおける“継承”
よく知られていることですが,Golangには,(OOPの文脈で使われる)継承という概念自体がありません.継承と類似するものは,構造体の埋め込み(Embedding)とインタフェース(Interface)があります(あくまでも類似で,同じと思っちゃいけないです).
構造体の埋め込み(Embedding)
言葉通りの意味で,構造体に構造体を埋め込むということです.
以下のコードの具体例で示したように,自動車(Motorcar)と自転車(Bicycle)に人工物(Artifact)を埋め込むことで,人工物で定義した製造者(Manufacturer)のフィールドが自動車と自転車にも使えるようになります.さらに,人工物を扱うそメソッドは自動車と自転車を扱えるようになります.このように,“疑似的なis-a関係”が構築されます.
ただ,注意点としては,人工物が個別のエンティティでありながら自動車(あるいは自転車)内に存在しているということで,親子関係と言えないです.この点は,以下のソースコードの中での変数mcの宣言・代入の仕方(Artifactは省略不可)から読み取れます.
main.gopackage main import "fmt" type Artifact struct { Manufacturer string } type Motorcar struct { Artifact HorsePower int } type Bicycle struct { Artifact NormalSpeed int } func (a Artifact) Info() { fmt.Printf("Made by %s\n", a.Manufacturer) } func main() { mc := Motorcar{ Artifact: Artifact{ Manufacturer: "Toyota", }, HorsePower: 100, } bc := Bicycle{} bc.Manufacturer = "Bianchi" bc.NormalSpeed = 20 mc.Info() bc.Info() }インタフェース(Interface)
「インタフェースとは何か?」を簡潔に説明することは難しいと気づいたので,@tenntennさんの言葉を借りて説明します.Golangでは”抽象化の概念はインタフェースしかない”ということです.プログラミングにおいて,抽象化の目的は,モジュール結合度を低くすること,つまり,関心の分離です.
以下のコードの具体例で示したように,自動車(Motorcar)と自転車(Bicycle)の運ぶ(Transport)という振る舞いに着目し,それが持つものを輸送機関(Vehicle)をインタフェースとして定義します.それによって,自動車と自転車のそれぞれが持つフィールド(HorsePower,NormalSpeed)とメソッドで定義した運ぶの処理方法(詳細はコメントでの記述をご覧ください)といった相違点を一旦無視して,運ぶことができる輸送機関として扱えます.
main.gopackage main import "fmt" type Motorcar struct { HorsePower int } type Bicycle struct { NormalSpeed int } type Vehicle interface { Transport() } func (m Motorcar) Transport() { // エンジンの性能による速度が決まる fmt.Printf("Moving by a motor which provides power of %d kW.\n", m.HorsePower) } func (b Bicycle) Transport() { // 車体の構造上の性質による速度が決まる fmt.Printf("Moving by a human and generally run at speed of %d km/h.\n", b.NormalSpeed) } func main() { var mc, bc Vehicle mc = Motorcar{ HorsePower: 100, } bc = Bicycle{ NormalSpeed: 20, } mc.Transport() bc.Transport() }いったいなぜなのか?
Golangの構造体の埋め込みとインタフェースを学ぶ時に,「なぜ継承でダメなのか?」,「なぜ言語を設計する時に,わざと継承を除外したのか?」という疑問を頭の中に浮かべました.いろいろ調べて,“場合によって,継承を使うと,そのデメリットが大きい”ということを気づきました.
その答えの詳細を説明すると,話が長くなるので,ここで割愛します.詳しく知りたい方は,参考文献の3(本,第6章 Acquiring Behavior through Inheritance,第7章 Sharing Role Behavior with Modules)と4(記事)を読むことにおすすめします.
あとがき
この経験から学んだことは,プログラミング言語でも,人でも,異なる考えで設計されたことがあるし,異なる考えを持つことがあります.異なるところに「好き・嫌い」を分けることより,その違いを認識して,なぜなのかを考えることで,有益な気づきを得られるだろうと感じました.
参考文献