- 投稿日:2020-11-22T23:17:14+09:00
LeetCodeに毎日挑戦してみた 20. Valid Parentheses(Python、Go)
はじめに
無料英単語サイトE-tanを運営中の@ishishowです。
プログラマとしての能力を上げるために毎日leetcodeに取り組み、自分なりの解き方を挙げていきたいと思います。
Leetcodeとは
leetcode.com
ソフトウェア開発職のコーディング面接の練習といえばこれらしいです。
合計1500問以上のコーデイング問題が投稿されていて、実際の面接でも同じ問題が出されることは多いらしいとのことです。Go言語入門+アルゴリズム脳の強化のためにGolangとPythonで解いていこうと思います。(Pythonは弱弱だが経験あり)
6問目(問題20)
20. Valid Parentheses
- 問題内容(日本語訳)
文字列を考える
sだけで文字を含む'('、')'、'{'、'}'、'['と']'、入力文字列が有効であるかどうかを決定。入力文字列は、次の場合に有効です。
- 開いたブラケットは、同じタイプのブラケットで閉じる必要があります。
- 開いたブラケットは正しい順序で閉じる必要があります。
Example 1:
Input: s = "()" Output: trueExample 2:
Input: s = "()[]{}" Output: trueExample 3:
Input: s = "(]" Output: falseExample 4:
Input: s = "([)]" Output: falseExample 5:
Input: s = "{[]}" Output: true考え方
- stack配列と辞書(map)を用意する。
- mapには対応する記号を入力
- 文字列を一文字ずつ見ていき、括弧の始まりならstackに追加し、閉じ括弧ならstackの直近のものを取り出して合っているかどうか確認。
説明
- stackとdict(map)を定義する。
- dict = {"]":"[", "}":"{", ")":"("}
- for文で文字を一文字ずつみていきます。
- 解答コード
class Solution: def isValid(self, s): stack = [] dict = {"]":"[", "}":"{", ")":"("} for char in s: if char in dict.values(): stack.append(char) elif char in dict.keys(): if stack == [] or dict[char] != stack.pop(): return False else: return False return stack == [] if char in dict.values(): で括弧始まりかどうか
elif char in dict.keys(): で括弧終わりかどうか
popで最新のstackの文字を取得
appendでstackに代入です。
- Goでも書いてみます!
func isValid(s string) bool { stack := make([]rune, 0) m := map[rune]rune{ ')': '(', ']': '[', '}': '{', } for _, c := range s { switch c { case '(', '{', '[': stack = append(stack, c) case ')', '}', ']': if len(stack) == 0 || stack[len(stack)-1] != m[c] { return false } stack = stack[:len(stack)-1] } } return len(stack) == 0 }こちらのコードは少し難しいですが、Goで文字列を一文字ずつ見るためにこのコードになりました。
for _, c := range s のループ処理では文字列stringsを一文字ずつ読み取ります。その時cはrune型になるのでmapやスタックもrune型で定義しました。
せっかくGolang書いてるからswitich文で処理を書きました。
- 自分メモ(Go)
文字列を一文字ずつ見るとrune
スライスにappend(固定長でないのでok)
- 投稿日:2020-11-22T23:04:49+09:00
AtCoder Beginner Contest 184 参戦記
AtCoder Beginner Contest 184 参戦記
ABC でC問題解けなかったの初めて…….
ABC184A - Determinant
1分で突破. 書くだけ.
a, b = map(int, input().split()) c, d = map(int, input().split()) print(a * d - b * c)ABC184B - Quizzes
3分で突破. 書くだけ.
N, X = map(int, input().split()) S = input() result = X for c in S: if c == 'o': result += 1 elif c == 'x': if result != 0: result -= 1 print(result)ABC184C - Super Ryuma
突破できず. 頭真っ白になりました.
ABC184D - increment of coins
突破できず. 入出力例でも TLE したり、NaN になったりと上手く行かず.
ABC184E - Third Avenue
CとDを諦めてから始めたので何分かかったのか不明. 56分未満なのは確か. 見るからに難しそうなところが何もなく、何か罠があるのかと思いながら実装したけど、何も罠はなかった(笑). ワープだけは繰り返しトライするとヤバそうだったので、一回しかトライしないようにしたけど、これは見え見えすぎて罠ではないな(笑).
from collections import deque INF = 10 ** 9 H, W = map(int, input().split()) a = [input() for _ in range(H)] d = {} for h in range(H): for w in range(W): c = a[h][w] if c in 'SG': d[c] = (h, w) elif c in '.#': continue else: if c in d: d[c].append((h, w)) else: d[c] = [(h, w)] not_warped = {} for c in 'abcdefghijklmnopqrstuvwxyz': not_warped[c] = True def move(h, w, p): c = a[h][w] if c == '#': return if t[h][w] > p: t[h][w] = p q.append((h, w)) t = [[INF] * W for _ in range(H)] h, w = d['S'] t[h][w] = 0 q = deque([(h, w)]) while q: h, w = q.popleft() c = a[h][w] p = t[h][w] + 1 if 'a' <= c <= 'z' and not_warped[c]: for nh, nw in d[c]: if t[nh][nw] > p: t[nh][nw] = p q.append((nh, nw)) not_warped[c] = False if h != 0: move(h - 1, w, p) if h != H - 1: move(h + 1, w, p) if w != 0: move(h, w - 1, p) if w != W - 1: move(h, w + 1, p) h, w = d['G'] if t[h][w] == INF: print(-1) else: print(t[h][w])
- 投稿日:2020-11-22T22:48:41+09:00
愛知県の新型コロナ発生事例のPDFをCSVに変換
import datetime import pathlib import re from urllib.parse import urljoin import pandas as pd import pdfplumber import requests from bs4 import BeautifulSoup def fetch_file(url, dir="."): r = requests.get(url) r.raise_for_status() p = pathlib.Path(dir, pathlib.PurePath(url).name) p.parent.mkdir(parents=True, exist_ok=True) with p.open(mode="wb") as fw: fw.write(r.content) return p def days2date(s): y = dt_now.year days = re.findall("[0-9]{1,2}", s) if len(days) == 2: m, d = map(int, days) return pd.Timestamp(year=y, month=m, day=d) else: return pd.NaT def wareki2date(s): m = re.search("(昭和|平成|令和)([ 0-9元]{1,2})年(\d{1,2})月(\d{1,2})日", s) if m: year, month, day = [1 if i == "元" else int(i.strip()) for i in m.group(2, 3, 4)] if m.group(1) == "昭和": year += 1925 elif m.group(1) == "平成": year += 1988 elif m.group(1) == "令和": year += 2018 return datetime.date(year, month, day) else: return dt_now.date url = "https://www.pref.aichi.jp/site/covid19-aichi/" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko" } JST = datetime.timezone(datetime.timedelta(hours=+9), "JST") dt_now = datetime.datetime.now(JST) r = requests.get(url, headers=headers) r.raise_for_status() soup = BeautifulSoup(r.content, "html.parser") dfs = [] dt_text = "" for tag in soup.find("span", text="▶ 愛知県内の発生事例").parent.find_all( "a", href=re.compile(".pdf$") )[::-1]: link = urljoin(url, tag.get("href")) path_pdf = fetch_file(link) with pdfplumber.open(path_pdf) as pdf: for page in pdf.pages: if page.page_number == 1: dt_text = page.within_bbox((0, 80, page.width, 90)).extract_text() table = page.extract_table() df_tmp = pd.DataFrame(table[1:], columns=table[0]) dfs.append(df_tmp) df = pd.concat(dfs).set_index("No") df["発表日"] = df["発表日"].apply(days2date) df.dropna(subset=["発表日"], inplace=True) # 年代と性別を分割 df_ages = df["年代・性別"].str.extract("(.+)(男性|女性)").rename(columns={0: "年代", 1: "性別"}) df = df.join(df_ages) dt_update = wareki2date(dt_text) path_csv = pathlib.Path(dt_update.strftime("%Y%m%d") + ".csv") df.to_csv(path_csv, encoding="utf_8_sig")
- 投稿日:2020-11-22T22:47:14+09:00
画像処理100本ノック!!(021 - 030)一息入れたい・・・
1. はじめに
画像の前処理の技術力向上のためにこちらを実践 画像処理100本ノック!!
とっかかりやすいようにColaboratoryでやります。
目標は2週間で完了できるようにやっていきます。丁寧に解説します。質問バシバシください!
001 - 010 は右のリンク 画像処理100本ノック!!(001 - 010)丁寧にじっくりと
011 - 020 は右のリンク 画像処理100本ノック!!(011 - 020)序盤戦2. 前準備
ライブラリ等々を以下のように導入。
# ライブラリをインポート from google.colab import drive import numpy as np import matplotlib.pyplot as plt import cv2 from google.colab.patches import cv2_imshow # 画像の読み込み img = cv2.imread('画像のパス/imori.jpg') img_noise = cv2.imread('画像のパス/imori_noise.jpg') img_dark = cv2.imread('画像のパス/imori_dark.jpg') img_gamma = cv2.imread('画像のパス/imori_gamma.jpg') # グレースケール画像 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) gray_noise = cv2.cvtColor(img_noise, cv2.COLOR_BGR2GRAY) gray_dark = cv2.cvtColor(img_dark, cv2.COLOR_BGR2GRAY) # 画像保存用 OUT_DIR = '出力先のパス/OUTPUT/'3.解説
Q.21. ヒストグラム正規化
ヒストグラム正規化を実装せよ。
ヒストグラムは偏りを持っていることが伺える。 例えば、0に近い画素が多ければ画像は全体的に暗く、255に近い画素が多ければ画像は明るくなる。 ヒストグラムが局所的に偏っていることをダイナミックレンジが狭いなどと表現する。 そのため画像を人の目に見やすくするために、ヒストグラムを正規化したり平坦化したりなどの処理が必要である。
このヒストグラム正規化は濃度階調変換(gray-scale transformation) と呼ばれ、[c,d]の画素値を持つ画像を[a,b]のレンジに変換する場合は次式で実現できる。 今回はimori_dark.jpgを[0, 255]のレンジにそれぞれ変換する。
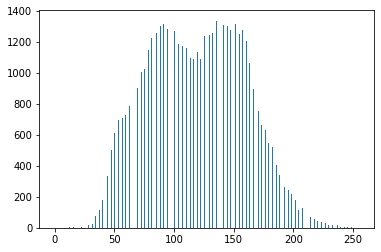
A21def hist_normalization(img, a=0, b=255): """ ヒストグラム正規化 params ---------------------------- param1: numpy.ndarray形式のimage param2: ヒストグラムレンジの最小値 param3: ヒストグラムレンジの最大値 returns ---------------------------- numpy.ndarray形式のimage """ # ヒストグラム(rgb)の最大値・最小値の値 c = img.min() # 60 d = img.max() # 141 # コピー out = img.copy() # 正規化 out = (b - a) / (d - c) * (out - c) + a out[out < a] = a out[out > b] = b out = out.astype(np.uint8) return out # 画像の高さ、幅、色を取得 H, W, C = img_dark.shape # ヒストグラム正規化 out = hist_normalization(img_dark) # ヒストグラムを表示する plt.hist(out.ravel(), bins=255, rwidth=0.8, range=(0, 255)) plt.savefig("img21.png") plt.show()
画像もかなり鮮明になった。Q.22. ヒストグラム操作
ヒストグラムの平均値をm0=128、標準偏差をs0=52になるように操作せよ。
これはヒストグラムのダイナミックレンジを変更するのではなく、ヒストグラムを平坦に変更する操作である。
平均値m、標準偏差s、のヒストグラムを平均値m0, 標準偏差s0に変更するには、次式によって変換する。
A22def hist_mani(img, m0=128, s0=52): """ ヒストグラムの平均値をm0=128、標準偏差をs0=52になるように操作 params -------------------------------------- param1: numpy.ndarray形式のimage param2: 平均値 param3: 標準偏差 returns -------------------------------------- numpy.ndarray形式のimage """ # 平均値 m = np.mean(img) # 標準偏差 s = np.std(img) # 画像のコピー out = img.copy() # 計算式通りに計算 out = s0 / s * (out - m) + m0 out[out < 0] = 0 out[out > 255] = 255 out = out.astype(np.uint8) return out # ヒストグラムを操作 out = hist_mani(img_dark) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans22_1.jpg', out) # 画像を表示 cv2_imshow(out) cv2.waitKey(0) cv2.destroyAllWindows() # ヒストグラムを表示する plt.hist(out.ravel(), bins=255, rwidth=0.8, range=(0, 255)) plt.savefig("img22_2.png") plt.show()
Q.23. ヒストグラム平坦化
ヒストグラム平坦化を実装せよ。
ヒストグラム平坦化とはヒストグラムを平坦に変更する操作であり、上記の平均値や標準偏差などを必要とせず、ヒストグラム値を均衡にする操作である。
これは次式で定義される。 ただし、S ... 画素値の総数、Zmax ... 画素値の最大値、h(z) ... 濃度zの度数
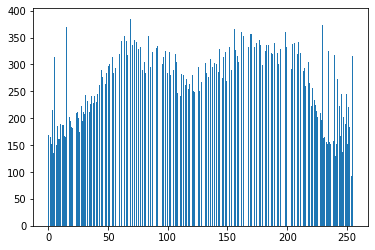
A23def hist_equal(img, z_max=255): """ ヒストグラム平坦化 params -------------------------------------- param1: numpy.ndarray形式のimage param2: 画素値の最大値 returns -------------------------------------- numpy.ndarray形式のimage """ # 画像の高さ、幅、色を取得 H, W, C = img.shape # 画素値の総数(画像高さx画像幅x色数) S = H * W * C * 1. # 49152.0 # 画像のコピー out = img.copy() # 濃度の度数 sum_h = 0. # 画像の濃度0~255までそれぞれの度数 for i in range(256): # 濃度が一致する箇所 ind = np.where(img==i) # 一致した濃度の度数 sum_h += len(img[ind]) # ヒストグラム値を均衡(計算式参照) z_prime = z_max / S * sum_h out[ind] = z_prime out = out.astype(np.uint8) return out # ヒストグラムを操作 out = hist_equal(img) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans23_1.jpg', out) # 画像を表示 cv2_imshow(out) cv2.waitKey(0) cv2.destroyAllWindows() # ヒストグラムを表示する plt.hist(out.ravel(), bins=255, rwidth=0.8, range=(0, 255)) plt.savefig("img23_2.png") plt.show()
Q.24. ガンマ補正
imori_gamma.jpgに対してガンマ補正(c=1, g=2.2)を実行せよ。
ガンマ補正とは、カメラなどの媒体の経由によって画素値が非線形的に変換された場合の補正である。 ディスプレイなどで画像をそのまま表示すると画面が暗くなってしまうため、RGBの値を予め大きくすることで、ディスプレイの特性を排除した画像表示を行うことがガンマ補正の目的である。
非線形変換は次式で起こるとされる。 ただしxは[0,1]に正規化されている。 c ... 定数、g ... ガンマ特性(通常は2.2)
そこで、ガンマ補正は次式で行われる。
A24def gamma_correction(img, c=1, g=2.2): """ ガンマ補正・・・画像の明るさを調整する方法 params -------------------------------------- param1: numpy.ndarray形式のimage param2: 定数 param3: ガンマ特性 returns -------------------------------------- numpy.ndarray形式のimage """ # 画像のコピー out = img.copy().astype(np.float) # 255で割る(Iinに変換) out /= 255. # ガンマ補正の式 out = (1/c * out) ** (1/g) # 255をかける out *= 255 out = out.astype(np.uint8) return out # ガンマ補正 out = gamma_correction(img_gamma) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans24.jpg', out) # 画像を表示 cv2_imshow(out) cv2.waitKey(0) cv2.destroyAllWindows()
参考: Pythonやってみる!
Q.25. 最近傍補間
最近傍補間により画像を1.5倍に拡大せよ。
最近傍補間(Nearest Neighbor)は画像の拡大時に最近傍にある画素をそのまま使う手法である。 シンプルで処理速度が速いが、画質の劣化は著しい。
次式で補間される。 I' ... 拡大後の画像、 I ... 拡大前の画像、a ... 拡大率、[ ] ... 四捨五入
A25""" 最近傍補間 cv2.resize(src, dsize[, interpolation]) src 入力画像 dsize 変更後の画像サイズ interpolation 補間法(最近傍補間ならcv2.INTER_NEAREST) """ # 最近傍補間 # 変更後の画像サイズ: img.shape>>>(高さ、幅、色) out = cv2.resize( img, (int(img.shape[1]*1.5), int(img.shape[0]*1.5)), interpolation=cv2.INTER_NEAREST) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans25.jpg', out) # 画像を表示 cv2_imshow(out) cv2.waitKey(0) cv2.destroyAllWindows()
参考: 【Python/OpenCV】画像の拡大・縮小(最近傍補間法、バイリニア補間法、バイキュービック補間法)
Q.26. Bi-linear補間
Bi-linear補間により画像を1.5倍に拡大せよ。
Bi-linear補間とは周辺の4画素に距離に応じた重みをつけることで補完する手法である。 計算量が多いだけ処理時間がかかるが、画質の劣化を抑えることができる。A26""" バイリニア補間法(Bi-linear interpolation)は、周囲の4つの画素を用いた補間法 cv2.resize(src, dsize[, interpolation]) src 入力画像 dsize 変更後の画像サイズ interpolation 補間法(バイリニア補間ならcv2.INTER_LINEAR) """ # バイリニア補間法 # 変更後の画像サイズ: img.shape>>>(高さ、幅、色) out = cv2.resize( img, (int(img.shape[1]*1.5), int(img.shape[0]*1.5)), interpolation=cv2.INTER_LINEAR) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans26.jpg', out) # 画像を表示 cv2_imshow(out) cv2.waitKey(0) cv2.destroyAllWindows()
参考: 【Python/OpenCV】画像の拡大・縮小(最近傍補間法、バイリニア補間法、バイキュービック補間法)
Q.27. Bi-cubic補間
Bi-cubic補間により画像を1.5倍に拡大せよ。
Bi-cubic補間とはBi-linear補間の拡張であり、周辺の16画素から補間を行う。A27""" バイキュービック補間法では、周囲16画素の画素値を利用 cv2.resize(src, dsize[, interpolation]) src 入力画像 dsize 変更後の画像サイズ interpolation 補間法(バイキュービック補間ならcv2.INTER_CUBIC) """ # バイキュービック補間 # 変更後の画像サイズ: img.shape>>>(高さ、幅、色) out = cv2.resize( img, (int(img.shape[1]*1.5), int(img.shape[0]*1.5)), interpolation=cv2.INTER_CUBIC) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans27.jpg', out) # 画像を表示 cv2_imshow(out) cv2.waitKey(0) cv2.destroyAllWindows()
参考: 【Python/OpenCV】画像の拡大・縮小(最近傍補間法、バイリニア補間法、バイキュービック補間法)
Q.28. アフィン変換(平行移動)
アフィン変換を利用して画像をx方向に+30、y方向に-30だけ平行移動させよ。
アフィン変換とは3x3の行列を用いて画像の変換を行う操作である。A28""" アフィン変換 cv2.warpAffine(src, M, dsize[, dst[, flags[, borderMode[, borderValue]]]]) 第一引数に元画像(NumPy配列ndarray)、 第二引数に2 x 3の変換行列(NumPy配列ndarray)、 第三引数に出力画像のサイズ(タプル)を指定する。 """ # 画像の高さ、幅、色を取得 H, W, C = img.shape # 平行移動[[1,0,横方向への移動量],[0,1,縦方向への移動量]]の2x3行列 M = np.float64([[1, 0, 30], [0,1,-30]]) # アフィン変換 out = cv2.warpAffine(img, M, (W, H)) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans28.jpg', out) # 画像を表示 cv2_imshow(out) cv2.waitKey(0) cv2.destroyAllWindows()
参考: 【Python/OpenCV】アフィン変換で画像の回転
Q.29. アフィン変換(拡大縮小)
アフィン変換を用いて、(1)x方向に1.3倍、y方向に0.8倍にリサイズせよ。
また、(2) (1)の条件に加えて、x方向に+30、y方向に-30だけ平行移動を同時に実現せよ。A29def affine_expand(img, ratio_x, ratio_y): """ アフィン変換で拡大 params ------------------------------- param1: numpy.ndarray形式のimage param2: x方向の比率 param3: y方向の比率 returns ------------------------------- numpy.ndarray形式のimage """ # 画像の高さ、幅 H, W = img.shape[:2] # xy座標をnp.float32型 src = np.array([[0.0, 0.0],[0.0, 1.0],[1.0, 0.0]], np.float32) # x, yそれぞれ比率をかける dest = src.copy() dest[:,0] *= ratio_x dest[:,1] *= ratio_y """ アフィン変換の変換行列を生成: cv2.getAffineTransform(src, dest) src: 変換前の3点の座標 dest: 変換後の3点の座標をNumPy配列ndarrayで指定 """ affine = cv2.getAffineTransform(src, dest) """ アフィン変換 cv2.warpAffine(src, M, dsize[, dst[, flags[, borderMode[, borderValue]]]]) 第一引数に元画像(NumPy配列ndarray)、 第二引数に2 x 3の変換行列(NumPy配列ndarray)、 第三引数に出力画像のサイズ(タプル)を指定する。 INTER_LANCZOS4 – 8×8 の近傍領域を利用するLanczos法での補間 """ return cv2.warpAffine(img, affine, (int(W*ratio_x), int(H*ratio_y)), cv2.INTER_LANCZOS4) # 補間法も指定できる # アフィン変換で拡大 out = affine_expand(img, 1.3, 0.8) # 平行移動[[1,0,横方向への移動量],[0,1,縦方向への移動量]]の2x3行列 H, W = out.shape[:2] M = np.float64([[1, 0, 30], [0,1,-30]]) out2 = cv2.warpAffine(out, M, (W, H)) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans29_1.jpg', out) cv2.imwrite(OUT_DIR + 'ans29_2.jpg', out2) # 画像を表示 cv2_imshow(out) cv2_imshow(out2) cv2.waitKey(0) cv2.destroyAllWindows()

参考: 完全に理解するアフィン変換
Q.30. アフィン変換(回転)
(1)アフィン変換を用いて、反時計方向に30度回転させよ。
(2) アフィン変換を用いて、反時計方向に30度回転した画像で中心座標を固定することで、なるべく黒い領域がなくなるように画像を作成せよ。 (ただし、単純なアフィン変換を行うと画像が切れてしまうので、工夫を要する。)A30def affin_rotate(img, x, y, theta, scale): """ アフィン変換で回転 params ------------------------------- param1: numpy.ndarray形式のimage param2: 回転軸のx座標 param3: 回転軸のy座標 param4: 回転角 param5: 回転角度・拡大率 returns ------------------------------- numpy.ndarray形式のimage """ """ 2次元回転を表すアフィン変換 cv2.getRotationMatrix2D(center, angle, scale) center: 回転の原点となる座標 angle: 回転の角度(ラジアンではなく度degree) scale: 拡大・縮小倍率。 """ # 回転変換行列の算出 R = cv2.getRotationMatrix2D((x, y), theta, scale) """ アフィン変換 cv2.warpAffine(src, M, dsize[, dst[, flags[, borderMode[, borderValue]]]]) 第一引数に元画像(NumPy配列ndarray)、 第二引数に2 x 3の変換行列(NumPy配列ndarray)、 第三引数に出力画像のサイズ(タプル)を指定する。 cv2.INTER_CUBIC: バイキュービック """ # アフィン変換 dst = cv2.warpAffine(img, R, gray.shape, flags=cv2.INTER_CUBIC) return dst # 画像の中心座標 oy, ox = int(img.shape[0]/2), int(img.shape[1]/2) # 反時計方向に30度回転 out1 = affin_rotate(img, 0, 0, 30, 1) # 反時計方向に30度回転した画像で中心座標を固定 out2 = affin_rotate(img, ox, oy, 30, 1) # 結果を保存する cv2.imwrite(OUT_DIR + 'ans30_1.jpg', out1) cv2.imwrite(OUT_DIR + 'ans31_2.jpg', out2) # 画像を表示 cv2_imshow(out1) cv2_imshow(out2) cv2.waitKey(0) cv2.destroyAllWindows()

参考: Python, OpenCVで幾何変換(アフィン変換・射影変換など)
参考: 【Python/OpenCV】アフィン変換で画像の回転感想
レベルが徐々に上がっているように感じる。可能な限りOpenCVでの実装を心がける。
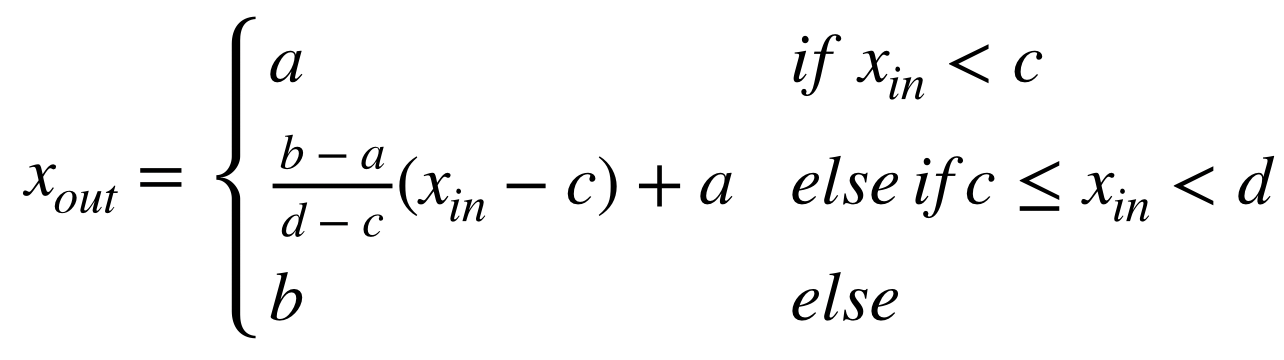




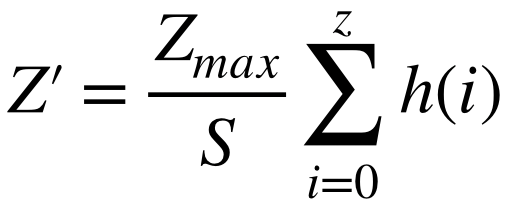

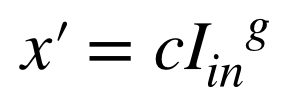
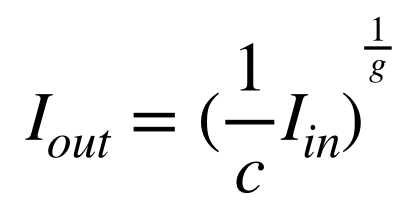








- 投稿日:2020-11-22T22:32:32+09:00
pythonコメントアウト
・行単位のコメントは、#に続けて記述
# Hello, world!を表示 print "Hello, world!"・複数行にまたがるコメントアウト
'''(シングルクォーテーション3つ)あるいは"""(ダブルクォーテーション3つ)で囲まれた部分が
コメントアウトされる''' この行はコメントです。 この行もコメントです。 '''
- 投稿日:2020-11-22T21:10:18+09:00
【Python】Beautiful SoupでWeb上の画像を一括で保存する方法
はじめに
ここではWebスクレイピングで『Web上の画像を一括で保存する方法』について紹介します。
注意
著作権で保護されている場合や著作権的にはOKだが利用規約でスクレイピングを禁止している場合、損害賠償請求などの可能性があるのでしっかり著作権法や利用規約を理解した上でWebスクレイピングを行いましょう。目次
1. Webスクレイピングを行う方法
Webスクレイピングを行うためには「Ruby」や「PHP」、「Javascript」など様々な言語で可能ですが、今回はPythonの『Beautiful Soup』を用いた方法を紹介します。
2. 実際に画像を保存してみる
① pipでbeautifulsoup4をインストールする
pip install beautifulsoup4② Webスクレイピングを行うサイトを決める
※今回は『いらすとや』の画像をダウンロードしていきます。
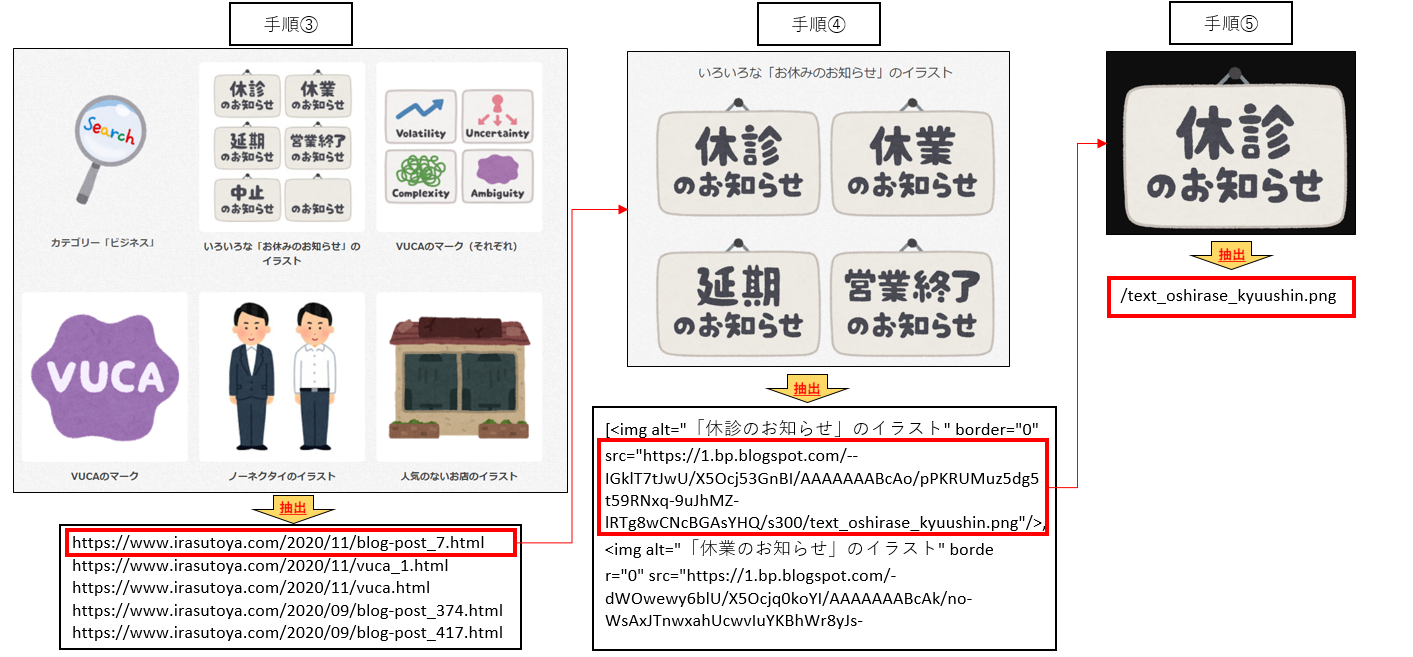
https://www.irasutoya.com/search/label/%E3%83%93%E3%82%B8%E3%83%8D%E3%82%B9③ 一覧ページから各画像リンクページURLを取得する
url = "https://www.irasutoya.com/search/label/%E3%83%93%E3%82%B8%E3%83%8D%E3%82%B9" # 画像ページのURLを格納するリストを用意 link_list = [] response = urllib.request.urlopen(url) soup = BeautifulSoup(response, "html.parser") # 画像リンクのタグをすべて取得 image_list = soup.select('div.boxmeta.clearfix > h2 > a') # 画像リンクを1つずつ取り出す for image_link in image_list: link_url = image_link.attrs['href'] link_list.append(link_url)④ 画像ファイルのタグをすべて取得する
for page_url in link_list: page_html = urllib.request.urlopen(page_url) page_soup = BeautifulSoup(page_html, "html.parser") # 画像ファイルのタグをすべて取得 img_list = page_soup.select('div.separator > a > img')⑤ imgタグを1つずつ取り出し、画像ファイルのURLを取得する
for img in img_list: # 画像ファイルのURLを取得 img_url = (img.attrs['src']) file_name = re.search(".*/(.*png|.*jpg)$", img_url) save_path = output_folder.joinpath(file_name.group(1))⑥ 画像ファイルのURLからデータをダウンロード
try: # 画像ファイルのURLからデータを取得 image = requests.get(img_url) # 保存先のファイルパスにデータを保存 open(save_path, 'wb').write(image.content) # 保存したファイル名を表示 print(save_path) except ValueError: print("ValueError!")手順としては以上です。
↓ ↓ 実行結果 ↓ ↓
3. 抽出の流れ
手順③~⑤が少しイメージしづらいと思ったので、大まかな抽出の流れを作成してみました。
また、今回のソースはGithubにも掲載してありますので、下記からご参照ください。
https://github.com/miyazakikna/SaveLocalImageWebScraping.git4. まとめ
ここではPythonのBeatiful Soupを使って画像を一括で保存する方法について解説しました。
今回はいらすとやの画像を取得しましたが、他のサイトでも基本的に同じ要領で画像がダウンロードできるかと思いますので、是非活用してみてください。5. おまけ
画像ダウンロード後、ファイル名を一括で変更する方法はこちら↓↓
【仕事効率化】Pythonでファイル名を一括変更する方法6. 参考

- 投稿日:2020-11-22T20:46:23+09:00
小プロセスを含めたkill
概要
小プロセスを含め、killをするためのツールです。python用です。
(pythonのプロセスで縛りを掛けています。)
検証はlinuxのみしてあります。使い方は、
そのまま実行すると、小プロセスを持つ親プロセスの一覧が表示されるので、
(例としてproc_01.py proc_02.pyの小プロセスを持つプログラムが実行中とします。)$ python terminate_children_process.py python 関連の小プロセスを持つprocess一覧 コマンドラインにPIDを指定すると、小プロセスを含めてterminate します。 {'pid': 26727, 'cmdline': ['python', 'proc_01.py']} {'pid': 26747, 'cmdline': ['python', 'proc_02.py']}終了させたいpidを指定し再び実行します。
$ python terminate_children_process.py 26747 terminate 子プロセス 26849 terminate 子プロセス 26850 terminate 子プロセス 26851 terminate 親プロセス 26747ソース(terminate_children_process.py)
#terminate_children_process.py import sys import psutil if len(sys.argv)==1: #python 関連の小プロセスを持つprocessの表示 print("python 関連の小プロセスを持つprocess一覧") print("コマンドラインにPIDを指定すると、小プロセスを含めてterminate します。") PROCNAME = "python" for proc in psutil.process_iter([ "pid" , 'cmdline' ]): if proc.name()[:len(PROCNAME)] == PROCNAME: p = psutil.Process(proc.pid) if len(p.children()) >0: print(proc.info) else: #指定したPIDとその小プロセスを含めてterminate target_pid=int(sys.argv[1]) p = psutil.Process(target_pid) #子のterminate pid_list=[pc.pid for pc in p.children(recursive=True)] for pid in pid_list: psutil.Process(pid).terminate () print("terminate 子プロセス {}" .format(pid)) #親のterminate p.terminate () print("terminate 親プロセス {}" .format(target_pid))参考
- 投稿日:2020-11-22T20:28:42+09:00
Python + Selenium + Chromeでよく使うオプションをメモ
はじめに
Python + Selenium + Chromeでよく使うオプションをメモ
環境情報
- python: 3.9.0
- chrome: 86.0.4240.198
- selenium: 3.141.0
Python + Selenium + Chromeでよく使うオプション
from selenium import webdriver options = webdriver.chrome.options.Options() # 画面を非表示 options.add_argument('--headless') # 必須らしい options.add_argument('--disable-gpu') # サイズ指定 options.add_argument('--window-size=1920,1080') # コンテナの権限不足回避 options.add_argument('--no-sandbox') # 画像を読み込まない options.add_argument('--blink-settings=imagesEnabled=false') # 通知を無効 options.add_argument('--disable-desktop-notifications') # 拡張機能を無効 options.add_argument('--disable-extensions') # SSLを無視 options.add_argument('--ignore-certificate-errors') # Webセキュリティを無効 options.add_argument('--disable-web-security') driver = webdriver.Chrome(chrome_options=options)
- 投稿日:2020-11-22T19:59:57+09:00
Pythonでのアスタリスク(*)の使われ方
概要
Pythonでのアスタリスク(*)の使われ方が、よくわからなかったので調べた。
リファレンスでの説明を確認した。この記事のポイントは、リファレンスで、どこで説明されているかを示したこと。あと、関数の引数でのアスタリスクは有名だが、引数だけで、極端な使い方の特殊がされているわけでない、ことを示したい( したい)と感じたため。
引用は、すべて、
https://docs.python.org/ja/3.7/reference/結果
使い方1(乗算演算)
使い方2(べき乗演算)
使い方3(引数リストのアンパック)
使い方4(辞書のアンパック)
例↓。これは、あまり使う可能性がない。
>>> >>> ff = {'a':1,'b':2} >>> gg = {**ff,'c':3} >>> gg {'a': 1, 'b': 2, 'c': 3} >>>使い方5(イテラブルのアンパック)
例↓。これは、使うことがあるかも。
>>> >>> (hh,*ii)=1,2,3,4,5,6 >>> ii [2, 3, 4, 5, 6] >>>まとめ
特にありません。
コメントなどあれば、お願いします。









- 投稿日:2020-11-22T19:59:10+09:00
Python + Selenium + ChromeでChromeバージョンに合ったChromeDriverを自動インストールする方法
はじめに
selenium + python + chrome でChromeDriverのバージョンエラーに悩まされたので、対処方法をメモ
環境情報
- python: 3.9.0
- chrome: 86.0.4240.198
- selenium: 3.141.0
Chromeバージョンに合ったChromeDriverを自動インストールする方法
下記のように設定すると、Chromeバージョンに合ったChromeDriverが自動インストールされます!
import requests from selenium import webdriver from webdriver_manager.utils import chrome_version from webdriver_manager.chrome import ChromeDriverManager version = chrome_version() url = 'http://chromedriver.storage.googleapis.com/LATEST_RELEASE_' + version response = requests.get(url) driver = webdriver.Chrome(executable_path=ChromeDriverManager(response.text).install())
- 投稿日:2020-11-22T19:44:44+09:00
PythonのSeleniumからChromeでファイルダウンロードを行う方法
はじめに
selenium + python + chrome でファイルダウンロードを行う方法をメモ
環境情報
- python: 3.9.0
- chrome: 86.0.4240.198
- selenium: 3.141.0
ファイルダウンロード設定
下記のように設定すると、【ダウンロード先のパス】にダウンロードされます!
from selenium import webdriver from selenium.webdriver.chrome.options import Options options = Options() driver = webdriver.Chrome(chrome_options=options) driver.command_executor._commands["send_command"] = ( "POST", '/session/$sessionId/chromium/send_command' ) params = { 'cmd': 'Page.setDownloadBehavior', 'params': { 'behavior': 'allow', 'downloadPath': 【ダウンロード先のパス】 } } driver.execute("send_command", params=params)
- 投稿日:2020-11-22T19:00:41+09:00
pythonでWEBスクレイピングして、レビューからワードクラウドを作ってみる
この記事の内容
MeCabやBeautiful Soupのインポートから、WEBスクレイピングし口コミ、レビューを抽出。それをwordcloudにし、どんな事が書かれているのか可視化してやろう!という内容です。
できるようになること
例えばトリップアドバイザーの「口コミ」これをワードクラウド(頻出単語≒多くの人がわざわざ口コミで言及しているトピック、の可視化)ができます。
東京タワーとスカイツリー、東京タワーと通天閣の可視化などして比較すると差異が見えて面白いかも。。。という発想です。
赤枠の「口コミ」から、こんなものを作ります。
参考にさせていただいたサイト、記事
初めてWEBスクレイピングに挑戦し、wordcloudまで作ったのですが、その際に参考にさせていただいたサイトを先に紹介させていただきます。
レビューサイトをスクレイピングして単語数を調査する
【初心者向け】PythonでWebスクレイピングをやってみる
PythonでMeCabを利用する方法を現役エンジニアが解説【初心者向け】
wordcloud を Windows で Anaconda / Jupyter で使う(Tips)ライブラリのインストール
まずは必要なライブラリのインストールから行います。(すでに入ってる方は飛ばしてください。)
ちなみに私の環境はWindows 10、Anaconda(jupyter)で行ってます。Beautiful Soup、request、wordcloud
Ancaonda Promptを起動し、
Beautiful Soupとrequestをインストールします。conda install beautifulsoup4 conda install request conda install -c conda-forge wordcloudMeCab
公式サイトから「Binary package for MS-Windows」をダウンロードし、インストールします。これなら辞書が最初から入っています。慣れてきたら他の辞書に変えても良いでしょう。
インストール途中で文字コードを聞かれますが、「UTF-8」に!他はそのままでOK。
インストールが終わったら、環境変数の設定を行います。
・(おそらくタスクバー左下に合う検索窓で)「システムの詳細」と検索
・「環境変数」を選択
・システム環境変数の「Path」を選択
・編集をクリックし、新規を選択
・「C:\Program Files (x86)\MeCab\bin」と入力
・OKを選択し、画面を閉じる
PythonでMeCabを利用する方法を現役エンジニアが解説【初心者向け】 さんに手順が書いてありますので、そちらもぜひご覧ください。ここから本番
ここまでで下準備は終わったので、ここからコードを書いていきます。
まずはインポートimport requests from bs4 import BeautifulSoup import re import pandas as pdここまでできたら、スクレイピングしたいサイトに行きます。
今回の例ではTrip advisorの東京タワーのページ。
以下の2つを確認します。
・URL
・HTMLのどこにスクレイピングしたいもの(今回は口コミ)があるか。まずURLはそのまま見ればわかるので、説明は省略します。
後者は「F12」を押しデベロッパーツールを起動します。
上記のようなウィンドウが表示されます。
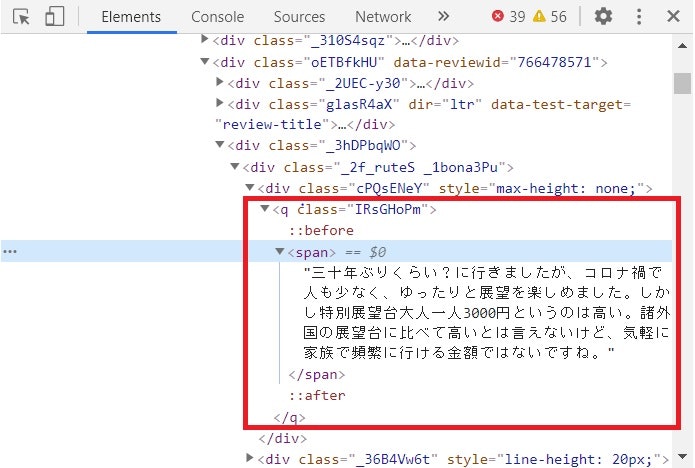
ここから口コミがどこに、どのように格納されているかを確認します。確認方法は簡単で、「Shift + Ctrl + C」をクリックした後、記事の口コミ部分をCLICKします。
すると、先のウィンドウで該当部分が選択されます。
口コミはqのclass「IRsGHomP」に格納されていることがわかります。あとはコード上でこのURL、場所を指定しスクレイピングを実行します。
# スクレイピングした口コミをdf_listに格納していく df_list = [] # 20ページ分スクレイピング行う。 pages = range(0, 100, 5) for page in pages: # 1ページ目と2ページ目以降で若干URLが異なるのでIFで分岐 if page == 0: urlName = 'https://www.tripadvisor.jp/Attraction_Review-g14129730-d320047-Reviews-Tokyo_Tower-Shibakoen_Minato_Tokyo_Tokyo_Prefecture_Kanto.html' else: urlName = 'https://www.tripadvisor.jp/Attraction_Review-g14129730-d320047-Reviews-or' + str(page) + '-Tokyo_Tower-Shibakoen_Minato_Tokyo_Tokyo_Prefecture_Kanto.html' url = requests.get(urlName) soup = BeautifulSoup(url.content, "html.parser") # HTMLの中からタグqのClass 'IRsGHoPm'を指定 review = soup.find_all('q', class_ = 'IRsGHoPm') # 抜き出した口コミを順番に格納 for i in range(len(review)): _df = pd.DataFrame({'Number':i+1, 'review':[review[i].text]}) df_list.append(_df)ここまで行うと、df_listには以下が入っているはずです。
df_review = pd.concat(df_list).reset_index(drop=True) print(df_review.shape) df_review
wordcloudの作成
まずはMeCabやWordCloudのインポート
import MeCab import matplotlib.pyplot as plt from wordcloud import WordCloudレビューサイトをスクレイピングして単語数を調査するを参考にさせて頂き、コードを記入。
# MeCab準備 tagger = MeCab.Tagger() tagger.parse('') # 全テキストデータを結合 all_text= "" for s in df_review['review']: all_text += s node = tagger.parseToNode(all_text) # 名詞を抽出しリストに word_list = [] while node: word_type = node.feature.split(',')[0] if word_type == '名詞': word_list.append(node.surface) node = node.next # リストを文字列に変換 word_chain = ' '.join(word_list)あとはwordcloudを実行すればokです。
# ストップワード(除外するワード)の作成 stopwords = [''] # ワードクラウド作成 W = WordCloud(width=500, height=300, background_color='lightblue', colormap='inferno', font_path='C:\Windows\Fonts\yumin.ttf', stopwords = set(stopwords)).generate(word_chain) plt.figure(figsize = (15, 12)) plt.imshow(W) plt.axis('off') plt.show()すると下記のように作成されます。
ただ、「の」や「こと」「ため」とうは不要なので除こうと思います。
そこで、上記のストップワードの出番です。# ストップワード(除外するワード)の作成 stopwords = ['の', 'こと', 'ため'] # ワードクラウド作成 W = WordCloud(width=500, height=300, background_color='lightblue', colormap='inferno', font_path='C:\Windows\Fonts\yumin.ttf', stopwords = set(stopwords)).generate(word_chain) plt.figure(figsize = (15, 12)) plt.imshow(W) plt.axis('off') plt.show()すると下記のようになります。
何かわかるような、何もわからんような。。。
スカイツリーと比較している人が多いのか、「スカイツリーも見えます」という人が多いのか、、とはいえ「スカイツリー」が東京タワー利用者の関心の対象となっていることは間違いなさそうです。
そこでスカイツリーの口コミもワードクラウドにしたものが下記です。
こちらは「エレベーター」や「チケット」など東京タワーではあまり言及のなかった(文字の大きくなかった)ワードが目立ちます。また「東京タワー」は目立ちません。このあたりは東京タワーとスカイツリーの差異と言えそうです。
おわり。
補足
Open Workなど企業の口コミサイトで、自社と競合を比べてみたりしても面白いかもしれませんし、
札幌ドーム、東京ドーム、名古屋ドーム、大阪ドーム、福岡ドームの五大ドームの口コミ比較もなど、類似施設を比較することで見えてくるものもありそうです。
ちなにみOpen Workのスクレイピングはheaderの設定が必要です。
詳細は下記をご参照ください。
【Python】スクレイピングで403 Forbidden:You don’t have permission to access on this serverが出た際の対処法







- 投稿日:2020-11-22T18:57:55+09:00
Twitter Developer + Tweepy でpythonからつぶやく
Twitter Developerの登録はこちらを参照:2度目のTwitter Developer登録で苦労した話
初めての登録なら苦労はしないはず.アクセストークンを手に入れよう
プロジェクト作成
Twitter Developerに申請済みのアカウントにログイン後,ダッシュボードにアクセス.
まだProjectがなくまっさらの状態なので,+ Create Project からプロジェクトを作成する.
この後入力する情報は以下の通り.
1. プロジェクト名(自由入力)
2. 自分の立場(選択式)
3. プロジェクトの説明(自由入力)
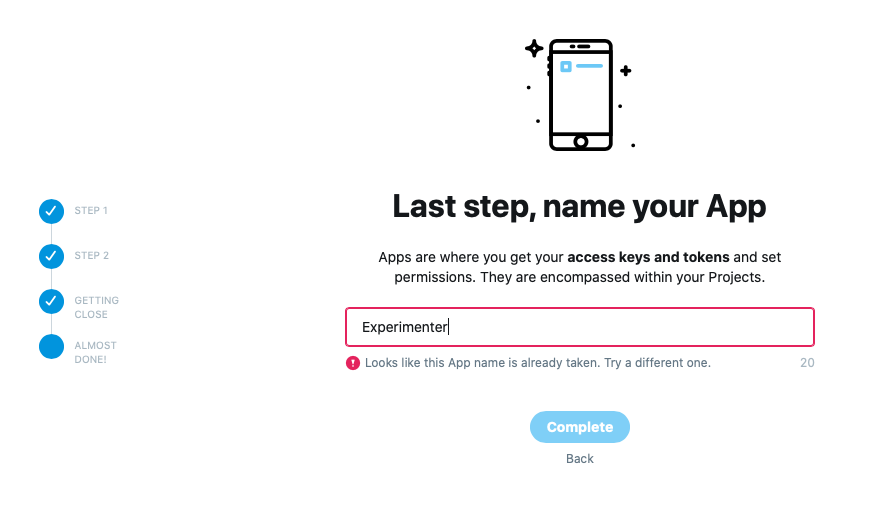
4. App名(自由入力)プロジェクト名とは別にアプリ名も決める必要がある.
例:プロジェクト名は「TestProject」,アプリ名は「MyTestApp」のような命名にするなど自分の立場は,Twitter Developerに登録する際と同じ選択肢.
今回のプロジェクトに最も見合う立場を選択しよう.
またアプリ名は既に存在するアプリとかぶると使用できない.
無事アプリ名が決まると以下の画面に遷移する.
これらの情報は後から確認できるので,まずは App settings から設定に移ろう.
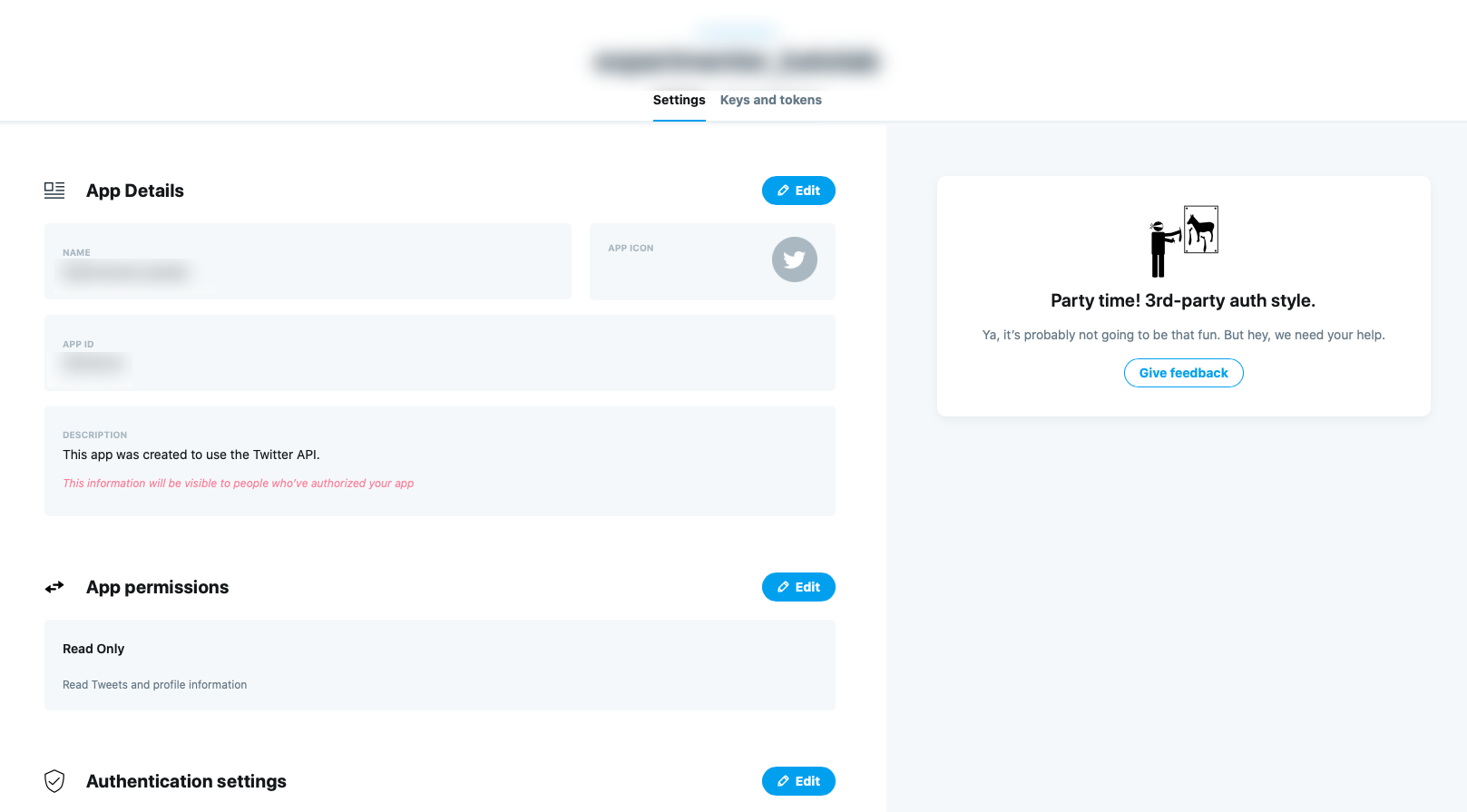
権限の設定
App settingsをクリックすると,作成したプロジェクトのページに遷移する.
ここからTweepyで使用するtokenを手に入れるための設定を行う.
まずはAppsの作成したアプリにある歯車をクリック.
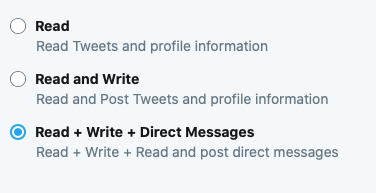
アプリの画面に遷移するので,App permissionsのEditからアプリの権限を変更する.
TweepyからつぶやくためにはWriteの権限が必要であるため,Read and WriteもしくはRead + Write + Direct Messagesを選択する.セーブも忘れずに.
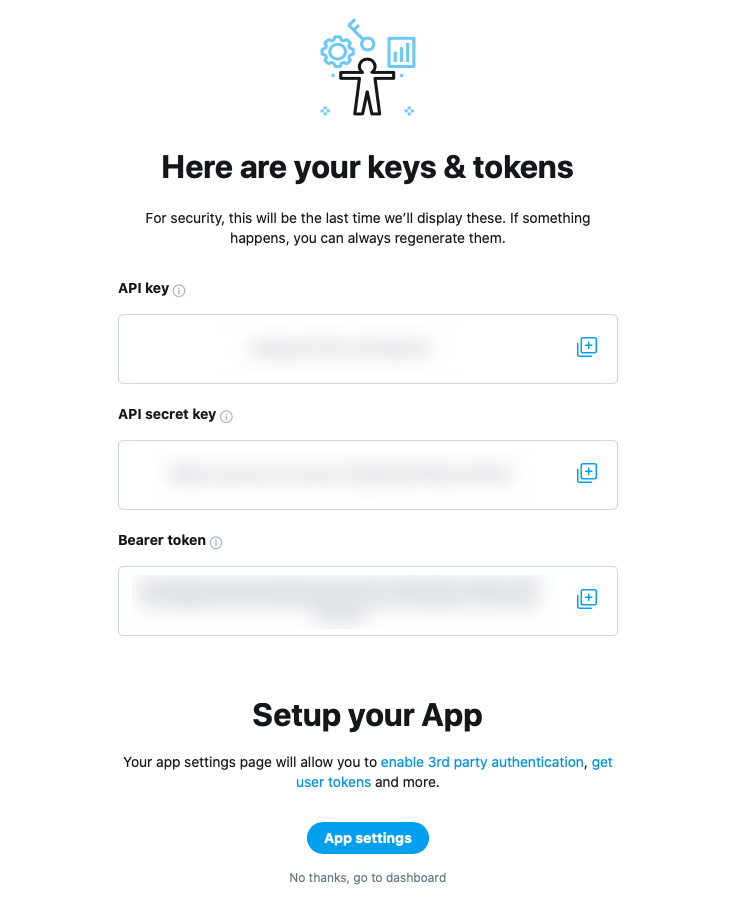
トークンの取得
次にアプリの画面のKeys and tokensに移動する.
API key & secretは,View Keysから何度でも確認できる.
しかしセキュリティの問題で約1年経過すると確認できなくなるため,手元にメモを残すのを忘れずに.
Access token & secretは1度生成したあと確認し直すことはできないので注意.
メモを取り忘れた/なくした場合,無効化もしくは再生成しかできない.
Tweepyでpythonからつぶやく
ここからはpythonに移行する.
pip install tweepy でtweepyをインストールしておく.tweet.pyimport tweepy Consumer_key = '取得したApi key' Consumer_secret = '取得したAPI Key secret' Access_token = '取得したAccess token' Access_secret = '取得したAccess token secret' # OAuth handler を作成する auth = tweepy.OAuthHandler(Consumer_key, Consumer_secret) # OAuth handler にアクセストークンを伝える auth.set_access_token(Access_token, Access_secret) # APIを作成する api = tweepy.API(auth_handler=auth) # ツイート api.update_status('APIでツイートしています。')これだけ!
tokenのベタ書きは危なくない?
もしこのプログラムをGitにあげるとなると,秘密にすべきトークンが全世界に筒抜けになってしまう.
かといってコードが複雑になるとGit管理もしたくなるもの……。解決策の1つとして,環境変数にトークンを書き込んでしまおう!がある.
Windowsの場合は設定から環境変数の追記が可能.
macの場合,bashを使用しているなら.bashrcに,zshを使用しているなら.zshrcに,以下の4行を書き込む.
(xxxxは各自のkeyに変更.'(クォーテーション)や"(ダブルクォーテーション)は必要ない.)
その後ターミナル上で source ~/.bashrc もしくは source ~/.zshrcで設定を反映させる..bashrc/.zshrcexport TWITTER_CK=xxxx export TWITTER_CS=xxxx export TWITTER_AT=xxxx export TWITTER_AS=xxxx無事環境変数に反映できたら,先程のプログラムを以下のように書き換える.
tweet2.pyimport tweepy import os Consumer_key = str(os.getenv('TWITTER_CK')) Consumer_secret = str(os.getenv('TWITTER_CS')) Access_token = str(os.getenv('TWITTER_AT')) Access_secret = str(os.getenv('TWITTER_AS')) # OAuth handler を作成する auth = tweepy.OAuthHandler(Consumer_key, Consumer_secret) # OAuth handler にアクセストークンを伝える auth.set_access_token(Access_token, Access_secret) # APIを作成する api = tweepy.API(auth_handler=auth) # ツイート api.update_status('APIでツイートしています。')これで公開しても安全!



- 投稿日:2020-11-22T18:21:06+09:00
[Python]〇×ゲームの敵AIをミニマックス法で作る
- 〇×ゲーム(三目並べ・Tic-Tac-Toe)の敵のAIのミニマックス法というアルゴリズムで作ります。
- 勉強のため、Pythonの標準モジュールを中心に使って自分でコードを書いていって理解を深めます。
ミニマックス法とは
英語ではMinimax algorithm。
ターン制のゲームなどでの敵AIでよく使われる、好ましい選択肢の算出用の探索アルゴリズムです。
〇×ゲーム(三目並べ)やオセロ、チェスなど様々なゲームのAIとして使うことができます。
取れる選択肢がどのくらい性能が良いのかを評価する評価関数を設け、なるべく「自分のターンでは評価が最大(max側)になる」選択肢を選択し、逆に「相手のターンでは自分の評価値が最小になる選択を相手は取ってくる」と想定して選択肢を選び、結果的に得られる評価値を取得するといったアルゴリズムになります。
各選択での評価値を得られるので、結果的にAI側がどの選択をすれば強いのかを計算することができます。
どんな計算なのか
説明のため、〇×ゲームで先攻がプレイヤー、後攻がミニマックス法を使ったAIで話を進めます。
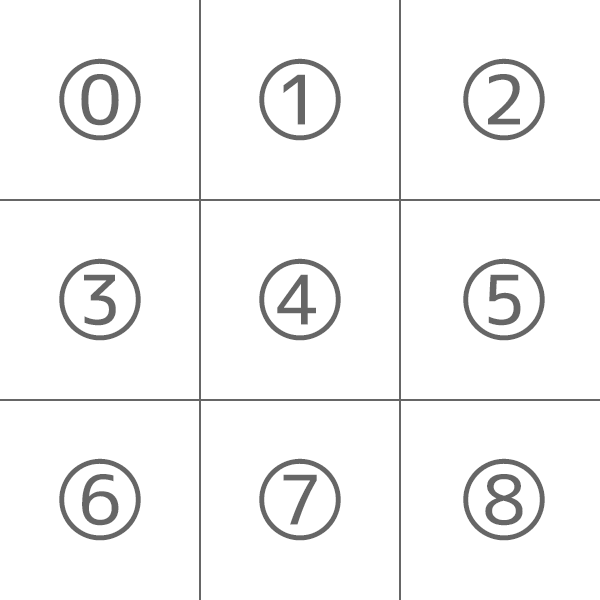
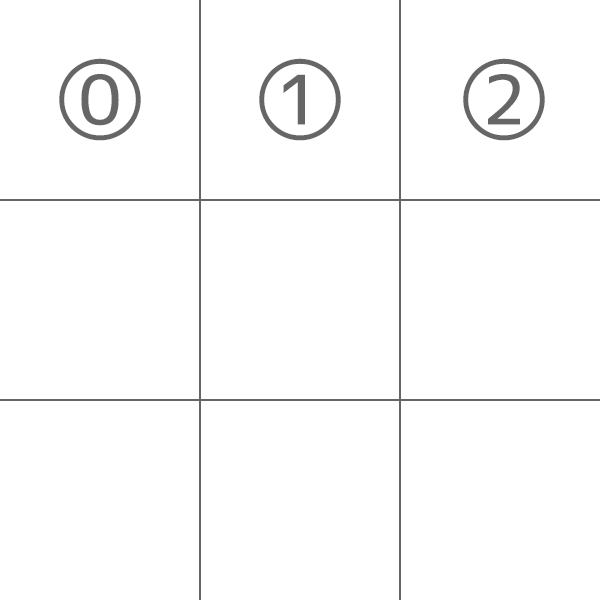
また、以下のように各マスに番号を付けておきます(コードで対応する際の1次元の配列のインデックスにそのまま該当します)。
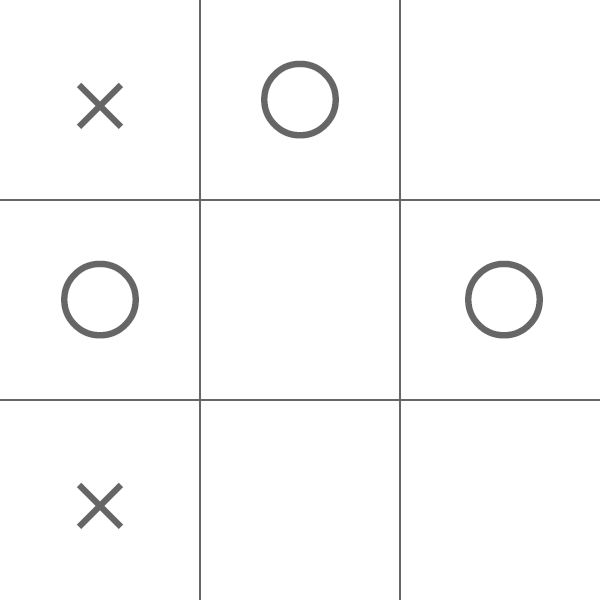
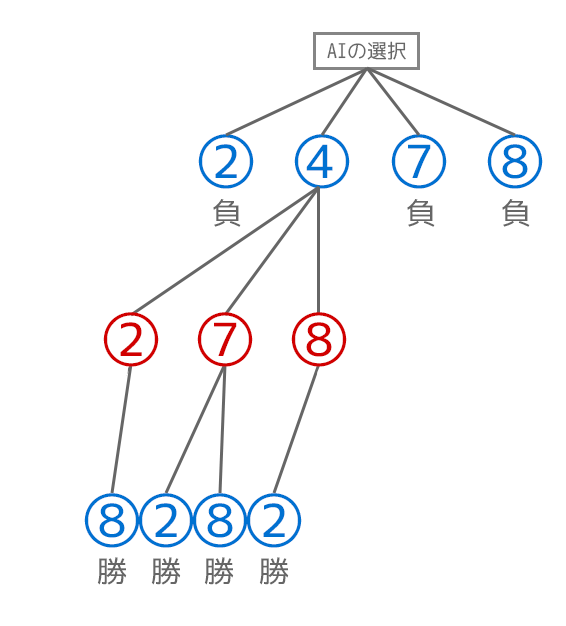
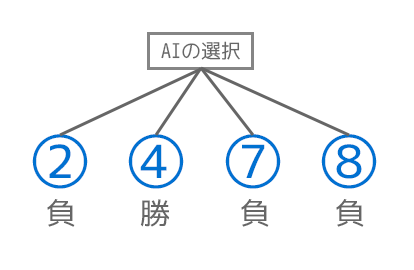
先攻で負けるケースはあまりありませんが、わざと先攻の〇(プレイヤー)側が負けるような以下のケースを考えます。
×(AI)側はどこを選ぶべきでしょう?答えは真ん中で、そうすると右上と左下の2つでリーチとなるのでAI側が勝利することができます。
この真ん中のマスを算出する際の計算を考えてみます。
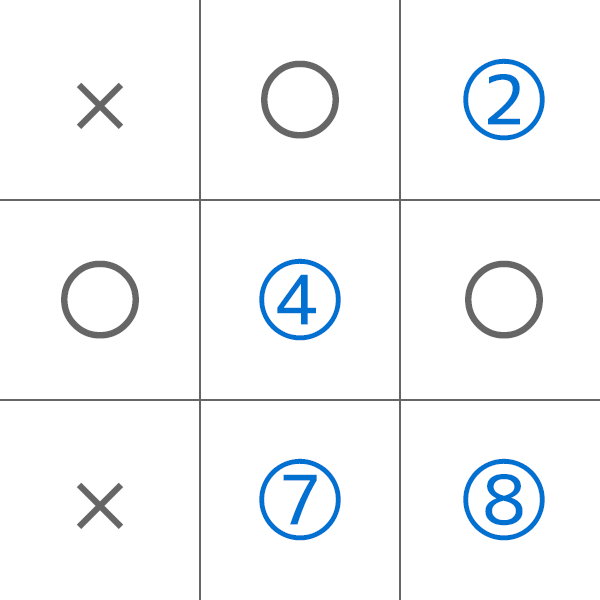
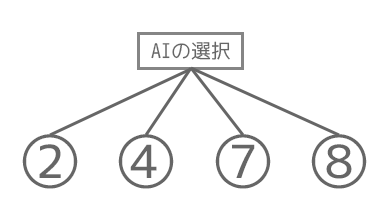
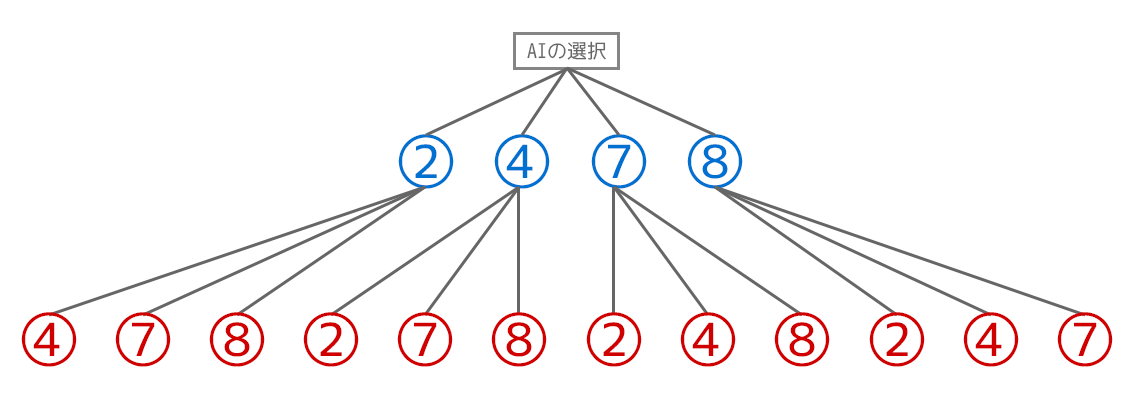
AI側が取れる選択肢は以下の2, 4, 7, 8のマス(青い数字部分)となります。
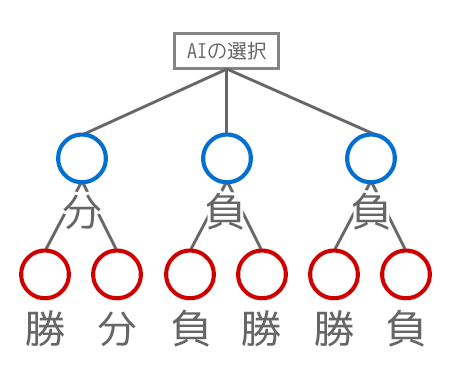
これをゲーム木と呼ばれる選択肢の木の有向グラフで表現すると以下のようになります。
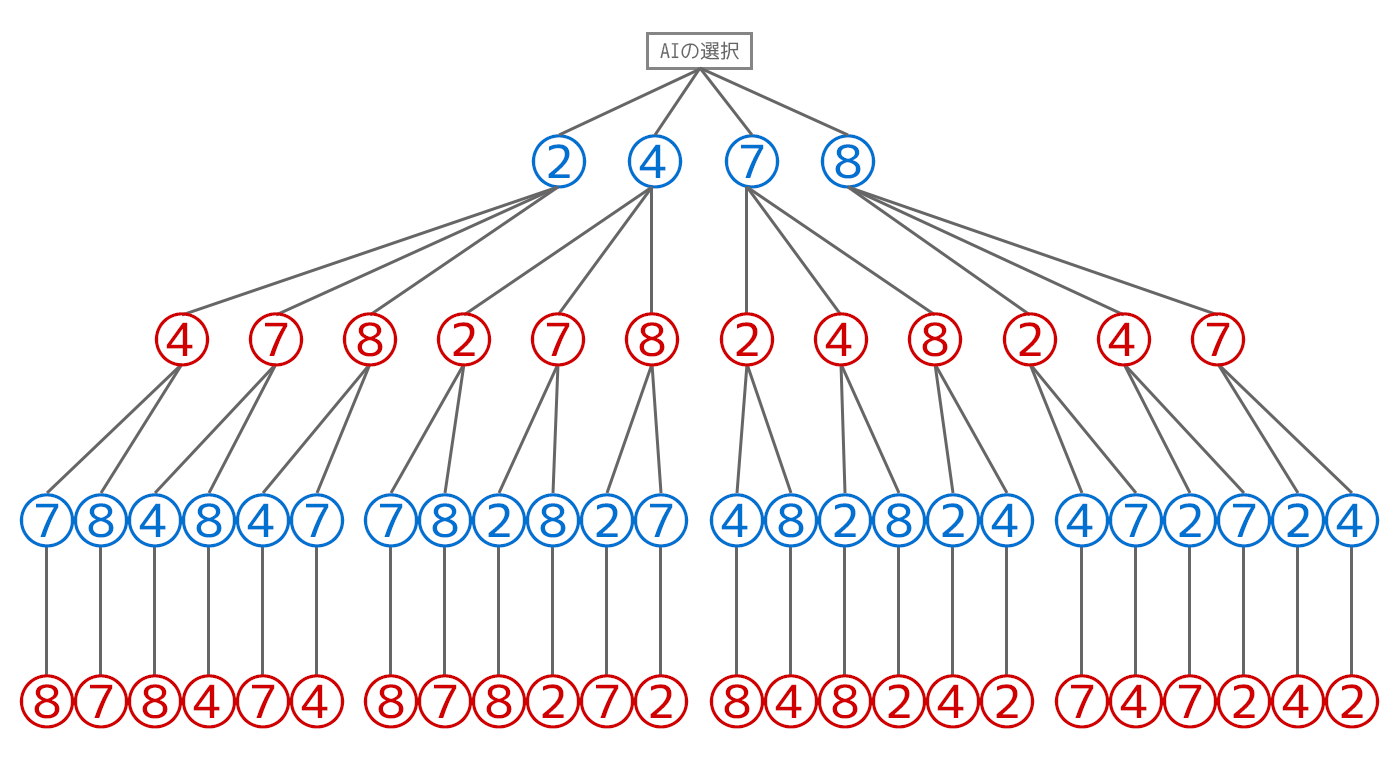
それぞれのAI側の選択の後には、プレイヤー側がとりうる選択肢が以下のように3つずつ、計12個が以下の画像のように存在します。青の数字をAI側の選択肢、赤の選択肢をプレイヤー側の選択肢にしてあります。
同様に最後の1マスまでゲーム木で表現すると以下のようになります。以降、小さい画像に関しては必要な場合はクリックしてご確認ください。
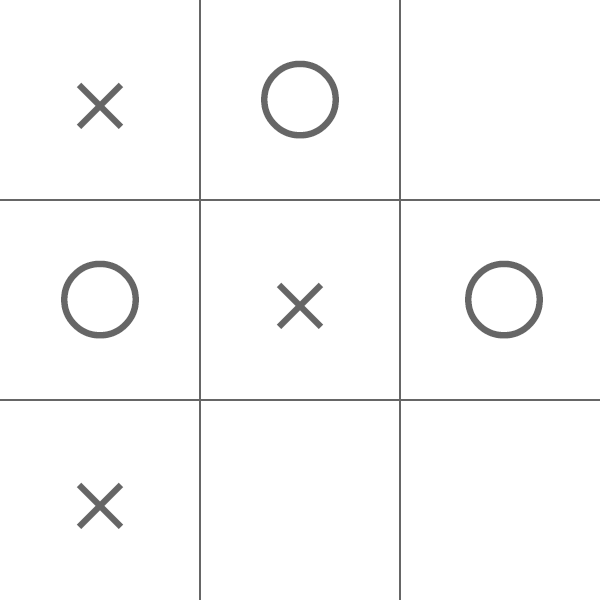
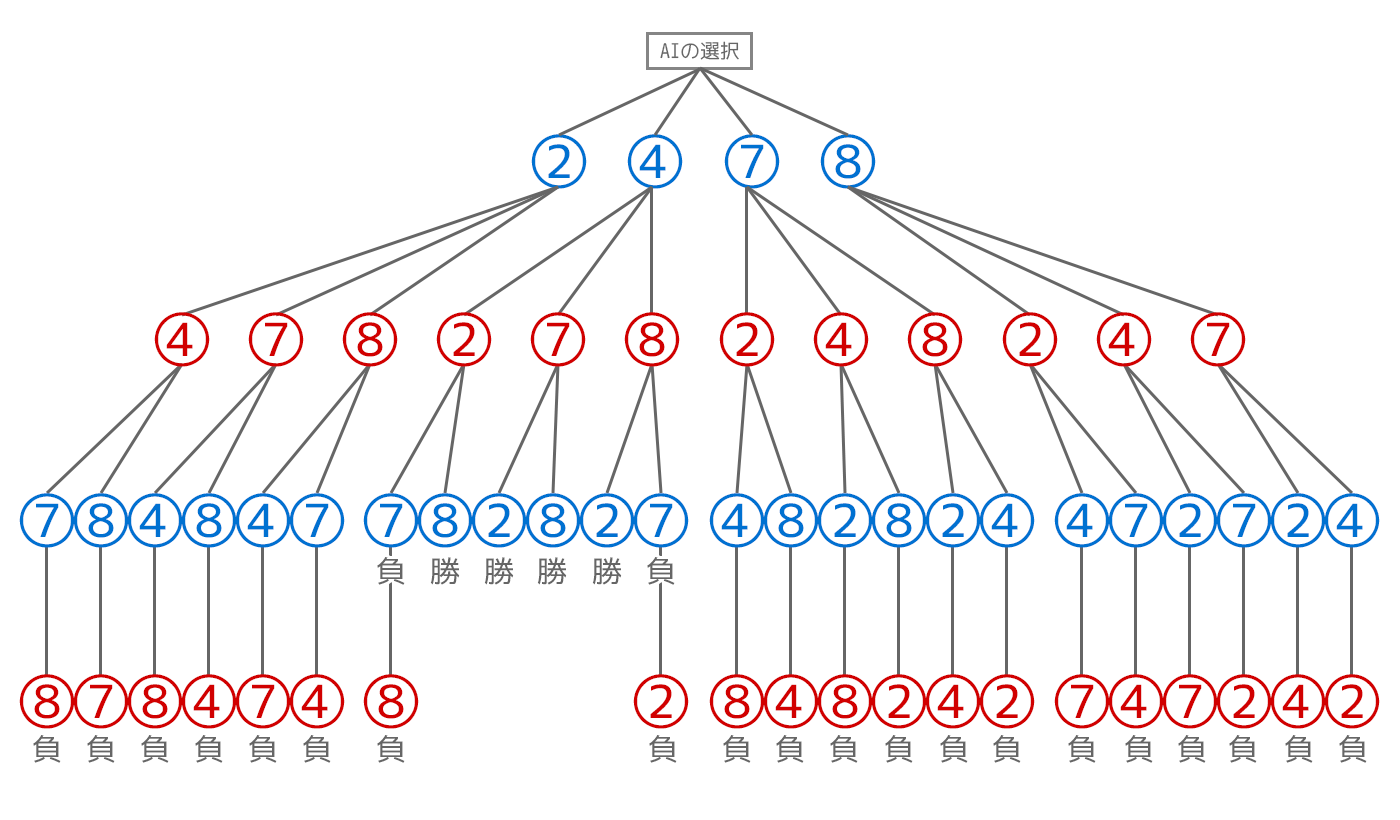
ここで対象の選択肢のリストを見てみると、4(真ん中)以外を選択すると真ん中の行で〇が揃ってしまうので×(AI)側が負けてしまうことが分かります。
ゲーム木の末端に勝敗を反映すると以下のようになります。
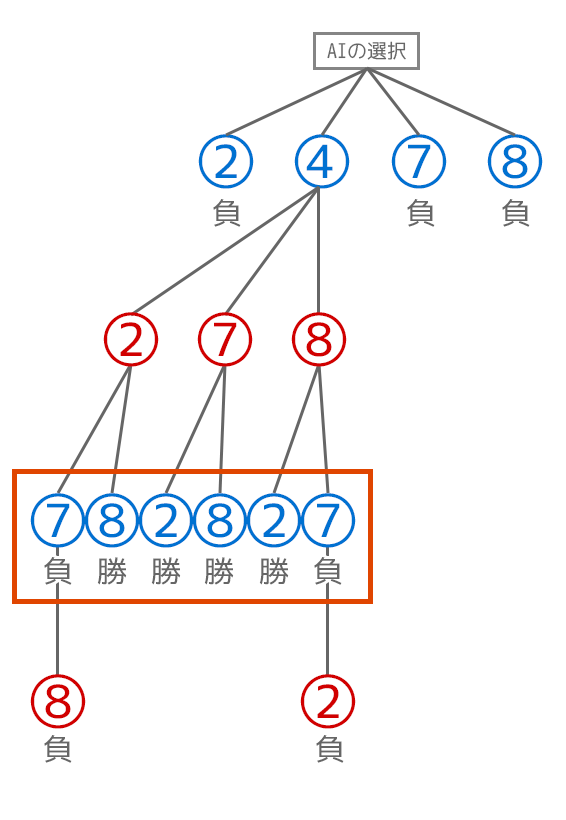
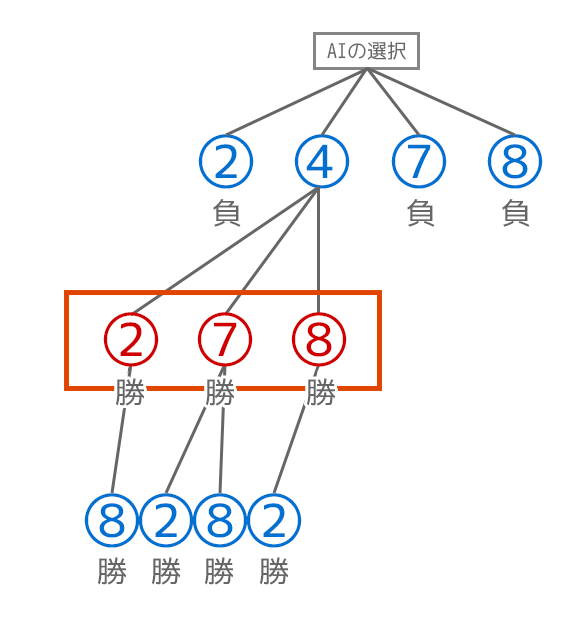
最初に4を選ぶ以外の選択はどう選択しても負けになるので、4を選んだ時のMinimaxの計算にフォーカスしてみます。
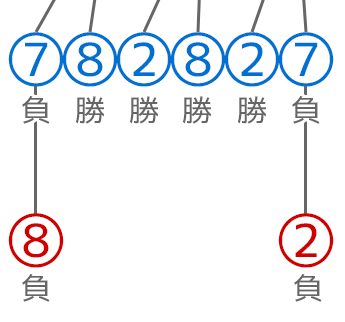
×(AI・青の数字)側のオレンジ色の枠部分の階層について考えてみます。
評価の指標として、勝ちを1ポイント・引き分けを0ポイント・分けを-1ポイントと評価するとしましょう。
前述したようにミニマックス法ではAI側の計算で評価が最大(max側)になる選択を取ります。つまり7の選択をすると(負けてしまって)評価値が最大にならないので7の選択肢を消します。
また、真ん中の2と8という選択肢の部分に関してはどちらを選択しても勝ちで評価値は一緒なので先頭の方の2を残します。
一つ上の〇の階層(プレイヤー・赤の数字)を見てみます。今度はプレイヤー側となるので評価値が最小(min)になるような選択(つまりAI側がなるべく負けるようになる選択)をするようにします。ただしこの例だとどこもAI側の勝利となる選択肢しか残っていないので勝ちの評価を上の階層に伝搬させます。
4を選んだ時には勝ちの分岐しかなくなったため、そのまま上まで勝ちの評価を伝搬させます。
結果的に2, 4, 7, 8それぞれにミニマックス法を反映すると、2 = -1(負け), 4 = 1(勝ち), 7 = -1(負け), 8 = -1(負け)となり、AI側としては評価結果が最大になる選択肢を取ればいいので2を選択すれば良いということになります。
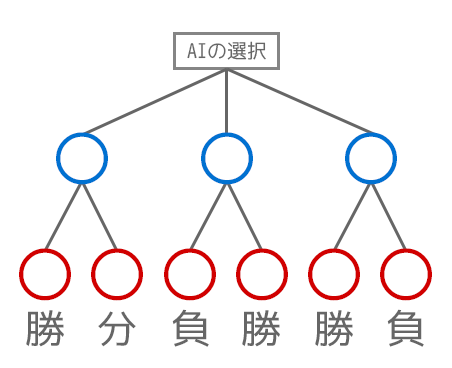
最小化の計算が上記の例だと微妙なので補足として以下のような数字などを割愛したシンプルな例を見ていきます。
プレイヤー側(赤の数字)部分では最小化(min側)を行う(AI側がなるべく負けるようにする)形で伝搬をさせるため、「左の勝ちと引き分けの分岐では引き分けを」「真ん中の負けと勝ちの分岐では負けを」「右の勝ちと負けの分岐では負けを」上の階層に渡すようになります。
つまりAI側の選択肢としては勝ちが無くなります。一番良い選択肢でも左の引き分けとなります(引き分け・負け・負けの中で評価値を最大化する形で、引き分けを選択)。
ミニマックス法の特徴
前述のように、算出にはゲーム木を使うため、下の階層にいくために再帰的に計算をする必要が出てきます。計算を行う最大の階層数増やす程精度が高くなりますが、その分計算量がたくさん必要になってきます(チェスなどで言うと、階層数が「何手先まで読むか」といったような感じになってきます。先をたくさん読めば読むほどたくさん計算が必要になります)。
また、相手が取れる選択肢が分からないとゲーム木が組めないため、そういった相手の選択肢が分かるいわゆる「完全情報ゲーム」と呼ばれるゲームにしか反映ができません(〇×ゲームやオセロ、チェスなど)。
たとえば手札がAI側から見えないといったような「不完全情報ゲーム」(相手が何の手札を持っているか分からないようなゲーム)と呼ばれるものではミニマックス法は使えません。
Pythonでの実装
実際に〇×ゲームとミニマックス法を勉強のためにPythonで書いていってみます。
今回使うもの
- Python 3.8.5
- VS Code
- Pylance(型チェック用)
※他の記事と同様に勉強のため基本的にPythonの標準モジュールを中心に使って対応していきます。
今回触れないもの
ベーシックなMinimax法を発展・計算の効率化などがされたもの(alpha-beta法など)は今回は触れません。
必要なもののimport
まずは利用するモジュールのimportを行います。
from __future__ import annotations from typing import List, Tuple from enum import Enum from copy import deepcopyannotationsはPython3.10以降でデフォルトになる型アノテーションの機能を利用するためにimportしています(今回の記事ではPython3.8.5を使っています)。
ListとTupleも型アノテーション用です。Python3.9からはimportが不要になります(listやtupleで直接アノテーションができる形に)。
deepcopy関数はミニマックス法の過程で算出のパターンを何度も盤面を元のものを利用したりするため、元の盤面の状態のものをディープコピーするために利用します。
〇×のマーク用のクラスを定義する
Enumを継承する形で、盤面上のマークを扱うためのクラスを定義します。〇をO、×をX、空のマスをEとして定数を定義しています。
class Mark(Enum): """ 〇×ゲームの各マスの1つ分のマークの値を扱うクラス。 Attributes ---------- O : str 〇に該当するマーク。 X : str ×に該当するマーク。 E : str マスにマークが設定されていない場合の値(empty)。 空のスペースが設定される。 """ O = 'O' X = 'X' E = ' ' def get_opponent(self) -> Mark: """ 相手側のセルの値を取得する。 Returns ------- opponent : Piece 相手側のセルの値。〇であれば×が、×であれば〇が設定される。 空の値の場合はそのまま空の値が設定される。 """ if self == Mark.O: return Mark.X if self == Mark.X: return Mark.O return Mark.E def __str__(self) -> str: """ マークの文字を返却する。 Returns ------- mark : str 定義されているいずれかのマークの文字。 """ return self.value
get_opponentメソッドはターン切り替えの際のために利用します。現在〇であれば×を、現在×であれば〇を返却する挙動をします。マスの位置を扱うクラスの定義
マスの位置を扱うクラスを追加していきます。以下の画像のように行列ではなく1次元で、0~8のインデックスで扱う形で進めます。
class Position: def __init__(self, index: int) -> None: """ マスのインデックスを扱うクラス。インデックスは1次元で0~8の範囲で 以下のような位置が該当する。 0 1 2 3 4 5 6 7 8 Parameters ---------- index : int 対象のインデックス(0~8)。 Raises ------ ValueError 範囲外のインデックスが指定された場合。 """ index_range: List[int] = list(range(0, 9)) if index not in index_range: raise ValueError('指定されたインデックスが範囲外の値です : %s' % index) self.index = index def __eq__(self, obj: object) -> bool: """ 他のPositionクラスと同値かどうかの比較を行う。 Parameters ---------- obj : * 比較対象のオブジェクト。 Returns ------- result : bool 比較結果。対象がPositionクラスで、且つインデックスの 値が同じ場合にはTrueが設定される。 """ if not isinstance(obj, Position): return False if self.index == obj.index: return True return False def __repr__(self) -> str: """ 文字列変換した際の表示値を返却する。 Returns ------- repr_str : str インデックスの値の文字が設定される。 """ return repr(self.index)クラスのインスタンス同士での比較を計算過程でするため、
__eq__などのメソッドを追加しています。〇×ゲームの盤面の状態などを扱うためのクラスの定義
続いて〇×ゲームの盤面用のクラスを追加していきます。〇×ゲーム(三目並べ)は英語でtic-tac-toeなのでクラス名はTicTacToeとしてあります。
class TicTacToe: def __init__(self, turn: Mark, marks: List[Mark]=None) -> None: """ 〇×ゲーム(tic-tac-toe)を扱うクラス。 Parameters ---------- turn : Mark 現在のターンのマーク。Mark.OもしくはMark.Xが必要になる。 marks : list of Mark, default None 現在の各マスに設定されているマークのリスト。1次元のリストで、 以下のような割り振りで0~8のインデックスで設定する。 0 1 2 3 4 5 6 7 8 デフォルト値が指定された場合には全てのマスが空の状態が 設定される。 """ if marks is None: marks = [Mark.E] * 9 self._turn = turn self.marks = marks基本的にこのクラスのインスタンスはターン切り替えや他のマスの選択の計算をする時などに都度インスタンスを生成する形で利用するため、次の1手が〇なのか×なのかのターンの識別用の値をコンストラクタで扱うようにします。
また、現在の盤面のマークの配置を扱うリストも同様にコンストラクタで属性に設定しています。こちらの値はNoneが設定された場合には9個の空のマーク(Mark.E)で初期化しています。
続いて特定のマスに新しい〇か×のマークを配置し、ターンの切り替えを行うメソッドを追加します。
def set_new_mark_and_change_turn( self, position: Position) -> TicTacToe: """ 特定のマスの位置に〇もしくは×のマークを設定する。 Notes ----- 設定されるマークはこのクラスに設定されているターンの属性に依存する。 Parameters ---------- position : Position マークを設定する位置。 Raises ------ ValueError すでにマークが設定されているマスの位置が指定された場合。 Returns ------- new_tic_tac_toe : TicTacToe マークの設定とターンの切り替え後の〇×ゲームのインスタンス。 ※各探索でループで元のインスタンスも利用するため、 ディープコピーされたインスタンスが設定される。 """ current_mark: Mark = self.marks[position.index] if current_mark != Mark.E: raise ValueError( '対象のマスに既にマークが設定されています : ' f'position: {position}, mark: {current_mark}' ) new_marks: List[Mark] = deepcopy(self.marks) new_marks[position.index] = self._turn new_turn: Mark = self._turn.get_opponent() new_tic_tac_toe: TicTacToe = TicTacToe( turn=new_turn, marks=new_marks) return new_tic_tac_toe引数に渡した〇×ゲームのインスタンスは,ゲーム木のグラフの別のノードの検証でも再利用するため、このメソッドで影響を出さないように盤面の状態をディープコピーして指定された位置へのマークの配置、ターンの切り替え(get_opponentによる、〇であれば×、×であれば〇への切り替え)を行い、変化させた後の新しい〇×ゲームのインスタンスを返却するようにしています。
元のインスタンスへは変更は加えていません。プレイヤーやAIの、マーク配置箇所の選択用に、マークが配置されていない空の位置(Mark.E)のリスト取得用のメソッドと該当の位置が空のマスかどうかの判定用のメソッドを追加します。
def get_empty_positions(self) -> List[Position]: """ 空いている(マークの設定されていない)マスの位置のリストを 取得する。 Returns ------- empty_positions : list of Position 空いている(マークの設定されていない)マスの位置のリスト。 """ empty_positions: List[Position] = [] for index, mark in enumerate(self.marks): if mark != Mark.E: continue empty_positions.append(Position(index=index)) return empty_positions def is_empty_position(self, position: Position) -> bool: """ 指定された位置が空のマスかどうかの真偽値を取得する。 Parameters ---------- position : Position 判定対象の位置。 Returns ------- result : bool もし空のマスの位置であればTrueが設定される。 """ empty_positions: List[Position] = self.get_empty_positions() for empty_position in empty_positions: if position == empty_position: return True return False続いて勝利判定に使うための定数を設けます。勝利判定の基準となる3つの位置のセットを定義します。3つの位置(Position)の値を格納するタプルのリストで扱います。
_ConditionPositions = Tuple[Position, Position, Position] _CONDITION_POSITIONS: List[_ConditionPositions] = [ (Position(0), Position(1), Position(2)), (Position(3), Position(4), Position(5)), (Position(6), Position(7), Position(8)), (Position(0), Position(3), Position(6)), (Position(1), Position(4), Position(7)), (Position(2), Position(5), Position(8)), (Position(0), Position(4), Position(8)), (Position(2), Position(4), Position(6)), ]
_ConditionPositionsはこの型は他でも型アノテーションで利用するので、長くなりすぎたり重複した記述が多くなって煩雑なので、型エイリアスとして設定しています。例えば
(Position(0), Position(1), Position(2))という部分でいえば、0, 1, 2のインデックスは以下の画像のように上の行の三つの部分に該当します。
勝利判定用の処理を追加していきます。
@property def is_player_win(self) -> bool: """ プレイヤー側が勝利したかどうか。 Returns ------- result : bool プレイヤー側が勝利しているかどうか。 """ return self._is_target_mark_win(mark=Mark.O) @property def is_ai_win(self) -> bool: """ AI側が勝利したかどうか。 Returns ------- result : bool AI側が勝利しているかどうか。 """ return self._is_target_mark_win(mark=Mark.X) def _is_target_mark_win(self, mark: Mark) -> bool: """ 指定されたマーク側が勝利しているかどうかの真偽値を取得する。 Parameters ---------- mark : Mark 判定対象のマーク。 Returns ------- result : bool 勝利している場合にはTrueが設定される。 """ for condition_positions in self._CONDITION_POSITIONS: condition_satisfied: bool = \ self._is_condition_satisfied_positions( condition_positions=condition_positions, target_mark=mark) if condition_satisfied: return True return False def _is_condition_satisfied_positions( self, condition_positions: _ConditionPositions, target_mark: Mark) -> bool: """ 条件を満たしている位置の組み合わせ(3つ同じマークが並んでいるか)が 存在するかどうかの真偽値を取得する。 Parameters ---------- condition_positions : _ConditionPositions チェック対象の3つの位置の組み合わせを格納したタプル。 target_mark : Mark 対象のマーク。 Returns ------- result : bool 条件を満たせばTrueが設定される。 """ is_target_marks: List[bool] = [] for condition_position in condition_positions: mark: Mark = self.marks[condition_position.index] if mark == target_mark: is_target_marks.append(True) continue is_target_marks.append(False) return all(is_target_marks)現在の盤面状況が、プレイヤー側が勝利しているか(is_player_win)もしくはAI側が勝利しているか(is_ai_win)の属性を設けています。
内部では先ほど用意したタプルの3つの位置の値が全て対象のマーク(プレイヤー側であれば〇、AI側であれば×)になっているかどうかで判定しています。
引き分け判定も追加していきます。こちらは勝利判定よりもシンプルです。
@property def is_draw(self) -> bool: """ 引き分けの状態かどうかの真偽値。 Returns ------- result : bool 引き分けかどうかの真偽値。勝敗が付いていない状態で、 且つ空いているマスが無くなった状態でTrueとなる。 """ empty_position_num: int = len(self.get_empty_positions()) if self.is_player_win: return False if self.is_ai_win: return False if empty_position_num != 0: return False return True以下のような条件で判定がされます。
- プレイヤーもしくはAIが勝利していないこと。
- 空いているマスが⓪になっていること。
現在の盤面の状態の評価値を取るためのメソッドを追加していきます。評価関数に該当します。
def evaluate(self) -> int: """ AI側のマーク配置の選択結果の性能評価のための評価関数としてのメソッド。 Parameters ---------- target_mark : Mark 判定側となるマーク。〇側での評価をしたい場合には Mark.O を、 ×側で評価をしたい場合には Mark.X を指定する。 Returns ------- evaluation_value : int 評価結果の値。勝利している場合には1、敗北している場合には-1、 勝敗がついていない場合には0が設定される。 """ if self.is_ai_win: return 1 if self.is_player_win: return -1 return 0ミニマックス法の計算の説明で前述したように、AI側が勝っていれば1、プレイヤー側が勝っていれば(AI側が負けていれば)-1、それ以外(引き分けもしくは勝敗が付いていない段階)では0としています。
これは対象とするゲームによって様々な形に都度設定します。例えば四目並べで2つ揃えば10、3つ揃えば50、4つ揃えば200・・・みたいな評価の値を設定して、なるべく揃っている数を増やす形にするようなケースも出てきます。
最後に、プレイの過程を可視化するための文字列出力用のメソッドを追加しておきます。
def __str__(self) -> str: """ 現在の各マスの内容の可視化用の文字列を返却する。 Returns ------- info : str 現在の各マスの内容の可視化用の文字列。以下のような フォーマットの文字列が設定される。 O| |X ----- |O|X ----- O|X| """ info: str = '' for i in range(9): if i % 3 == 0 and i != 0: info += '\n-----\n' if not info.endswith('\n') and i != 0: info += '|' info += str(self.marks[i]) return infoこれでTicTacToeクラスをprint関数などに通すと、以下のように出力されるようになります。
O|X|O ----- O|X| ----- X| |ミニマックス法のアルゴリズムの実装
ミニマックス法での探索が終了しているかのは判定用の関数の追加
計算方法の箇所で説明したように、ミニマックス法ではゲーム木による有向グラフで計算を行います。
このグラフの各ノードで、末端まで達したかどうかの判定を行うための関数を追加します。
ゲーム木の例で前述したものを利用すると、以下の画像のように「勝敗が付いたかどうか」もしくは「最後の空いているマスにマークが配置されたか」の部分が該当します。
def is_search_ended( current_tic_tac_toe: TicTacToe, remaining_depth: int) -> bool: """ Minimaxによる探索が終了している状態かどうかの真偽値を取得する。 Parameters ---------- current_tic_tac_toe : TicTacToe 対象の盤面の状態を保持した〇×ゲームのインスタンス。 remaining_depth : int 残っている探索の深さ。最後の探索範囲に達している場合には0を指定する。 Returns ------- result : bool 探索が終了している状態かどうかの真偽値。終了していればTrueが 設定される。盤面で勝敗が付いている(勝利もしくは引き分け)場合 もしくは指定され探索の木の深さにまで達している場合にTrueとなる。 """ if current_tic_tac_toe.is_player_win: return True if current_tic_tac_toe.is_ai_win: return True if current_tic_tac_toe.is_draw: return True if remaining_depth == 0: return True return False最大値(max)と最小値の計算の追加
ミニマックス法における選択肢の中で最大値を計算する処理を書いていきます。
途中で出てくる minimax 関数は次の節で書いていくのでまだここでは実装されていません。
def get_maximized_evaluation_value( current_tic_tac_toe: TicTacToe, remaining_depth: int) -> int: """ Minimaxにおける、最大化された評価値の取得を行う。 Parameters ---------- current_tic_tac_toe : TicTacToe 対象の現在の(盤面の状態の)〇×ゲームのインスタンス。 remaining_depth : int 残っている探索の深さ。最後の探索範囲に達している場合には0を指定する。 Returns ------- maximized_evaluation_value : int 最大化された評価値。 """ maximized_evaluation_value: int = -1 empty_positions: List[Position] = \ current_tic_tac_toe.get_empty_positions() for empty_position in empty_positions: new_tic_tac_toe = current_tic_tac_toe.set_new_mark_and_change_turn( position=empty_position) # 再帰的な次の階層への木の探索処理。次は最小化される形となるので、 # maximizing=Falseを設定する。また、残りの深さの指定は1つ分減算する。 evaluation_value: int = minimax( current_tic_tac_toe=new_tic_tac_toe, maximizing=False, remaining_depth=remaining_depth - 1) maximized_evaluation_value = max( evaluation_value, maximized_evaluation_value) return maximized_evaluation_value def get_minimized_evaluation_value( current_tic_tac_toe: TicTacToe, remaining_depth: int) -> int: """ Minimaxにおける、最小化された評価値の取得を行う。 Parameters ---------- current_tic_tac_toe : TicTacToe 対象の現在の(盤面の状態の)〇×ゲームのインスタンス。 remaining_depth : int 残っている探索の深さ。最後の探索範囲に達している場合には0を指定する。 Returns ------- minimized_evaluation_value : int 最小化された評価値。 """ minimized_evaluation_value: int = 1 empty_positions: List[Position] = \ current_tic_tac_toe.get_empty_positions() for empty_position in empty_positions: new_tic_tac_toe = current_tic_tac_toe.set_new_mark_and_change_turn( position=empty_position) # 再帰的な次の階層への木の探索処理。次は最大化される形となるので、 # maximizing=Trueを設定する。また、残りの深さの指定は1つ分減算する。 evaluation_value: int = minimax( current_tic_tac_toe=new_tic_tac_toe, maximizing=True, remaining_depth=remaining_depth - 1) minimized_evaluation_value = min( evaluation_value, minimized_evaluation_value) return minimized_evaluation_valueこれらの関数は minimax から呼ばれますが、この2つの関数内でも minimax を再帰的に呼び出しています。
これは、ゲーム木で各ノードでどんどん下にいかないと評価値が算出できない(勝敗が分からない)ためこのようになっています。
また、ミニマックス法が以下の画像の青と赤が交互に切り替わるように、最大値の算出と最小値の算出が順番に切り替わるアルゴリズムなので、 get_maximized_evaluation_value 関数で最大値を求めたら内部では次は最小値を求めるように minimax 関数を呼び出しています。逆に get_minimized_evaluation_value では内部では次は最大値を求めるように minimax 関数を読んでいます。
ミニマックス法のための関数の追加
いよいよミニマックス法の関数を追加していきます。ここまでの準備で必要なものは諸々書いてきているので、この節で追加になること自体は少なくシンプルです。
def minimax( current_tic_tac_toe: TicTacToe, maximizing: bool, remaining_depth: int) -> int: """ Minimaxのアルゴリズムを実行し、結果の評価値を取得する。 Notes ----- - 呼び出し後、最大で指定された深さ分再帰的に実行される。 - AI側を前提としたコードになっている(マークは×側が利用される)。 Parameters ---------- current_tic_tac_toe : TicTacToe 対象の現在の(盤面の状態の)〇×ゲームのインスタンス。 maximizing : bool 評価値を最大化するかどうかの真偽値。Falseの場合は逆に最小化 する処理が実行される。次のアクションがプレイヤー側であればFalse、 AI側であればTrueを指定する。 remaining_depth : int 探索の木の最大の深さ。多くする程計算に時間がかかるようになる。 最初に呼び出す際には〇×ゲームの場合には最大で8階層となるので、 8以内の値を指定する。再帰的に実行する際に、階層が深くなる度に -1されていく形で値が設定される(0になった時点で探索が停止する)。 Returns ------- evaluation_value : int Minimax実行後の評価値。 """ _is_search_ended: bool = is_search_ended( current_tic_tac_toe=current_tic_tac_toe, remaining_depth=remaining_depth) if _is_search_ended: # 探索が終了する条件(木の末端に達しているか勝敗が付いた場合)には # 現在の盤面での評価値を返却する。 return current_tic_tac_toe.evaluate() # 最大化する場合(AI側のターン想定の木の深さ)のケース。 if maximizing: maximized_evaluation_value: int = get_maximized_evaluation_value( current_tic_tac_toe=current_tic_tac_toe, remaining_depth=remaining_depth, ) return maximized_evaluation_value # 最小化する場合(プレイヤー側のターン想定の木の深さ)のケース。 minimized_evaluation_value: int = get_minimized_evaluation_value( current_tic_tac_toe=current_tic_tac_toe, remaining_depth=remaining_depth, ) return minimized_evaluation_valueまずはゲーム木の末端に達したかどうかを判定しています(is_search_ended部分)。
もし末端に達していれば、評価値を得られるのでevaluateメソッドで評価値を取得して対象のグラフの経路の計算を終えます。もしまだ途中のノード(末端に達していない)場合には引数に指定された値に応じて最大値を取得して伝搬させていくのか、最小値を取得して伝搬させていくのか分岐させます。この最大値・最小値は前述の通りゲーム木で下の階層に行くたびに交互に切り替わります。
もっとも評価値の高い選択肢を求めるための関数の追加
ミニマックス法の関数は追加できましたが、追加でAI側で「どの選択肢を取るべきか」といった、各選択肢ごとの評価値を取ってどれがベストな選択なのかを算出する処理が必要になるため追加していきます。
以下の画像のように、ゲーム木の一番上の部分が該当します。画像の例で言えば、4つの選択肢それぞれにミニマックス法の関数を反映してみて、一番評価値の高い選択肢がどれなのかを計算します。
def find_best_position( current_tic_tac_toe: TicTacToe, max_depth: int) -> Tuple[Position, int]: """ 空いているマスの中で、ベストな位置をMinimaxで算出する。 空いている各マスに対してMinimaxの実行がされ、評価値が最大の マスの位置が返却される。 Parameters ---------- current_tic_tac_toe : TicTacToe 対象の現在の(盤面の状態の)〇×ゲームのインスタンス。 max_depth : int 探索の木の最大の深さ。 Raises ------ ValueError 空いているマスが存在しない状態で実行された場合。 Returns ------- best_position : Position 算出されたベストな位置。 best_evaluation_value : int ベストな位置における評価値の最大値(-1, 0, 1のいずれかが 設定される)。 """ best_evaluation_value: int = -1 empty_positions: List[Position] = \ current_tic_tac_toe.get_empty_positions() if not empty_positions: raise ValueError('空いているマスが存在しません。') best_position: Position = empty_positions[0] for empty_position in empty_positions: current_loop_tic_tac_toe: TicTacToe = \ current_tic_tac_toe.set_new_mark_and_change_turn( position=empty_position) # 今回Minimaxで算出したいものがAI側(maximizing=True)なので、 # 探索自体は次の階層のプレイヤー側のところからとなるため、 # Minimaxでの最初のmaximizingの指定はFalseとなる。 evaluation_value: int = minimax( current_tic_tac_toe=current_loop_tic_tac_toe, maximizing=False, remaining_depth=max_depth) if evaluation_value <= best_evaluation_value: continue best_evaluation_value = evaluation_value best_position: Position = empty_position return best_position, best_evaluation_value内容としては get_empty_positions 関数で取れる選択肢(画像の例だと2, 4, 7, 8のマス)を取得し、ループで回してそれぞれに対してミニマックス法の関数を実行し、得られた各評価値の中での最大値の位置などを返却しています。
プレイヤーの入力値を取得するための関数を追加
続いて、input関数を使ったプレイヤー側のターンのマーク設定位置取得処理を追加していきます。
def get_player_input_position(current_tic_tac_toe: TicTacToe) -> Position: """ プレイヤー側のマーク配置位置の入力を取得する。 Parameters ---------- current_tic_tac_toe : TicTacToe 対象の現在の(盤面の状態の)〇×ゲームのインスタンス。 Returns ------- players_selected_position : Position プレイヤー側が選択したマーク配置位置。 """ is_empty_position: bool = False players_selected_position: Position = Position(index=0) while not is_empty_position: empty_positions: List[Position] = \ current_tic_tac_toe.get_empty_positions() msg: str = ( '〇を配置したいマスのインデックスを選択してください' '(選択可能なインデックス : %s):' % empty_positions ) input_val: str = input(msg) try: input_index: int = int(input_val) players_selected_position = Position(index=input_index) except Exception: continue is_empty_position = current_tic_tac_toe.is_empty_position( position=players_selected_position) return players_selected_positionプレイヤーのターンにコンソールに以下のようなものが表示され、入力待ちの状態になります。
〇を配置したいマスのインデックスを選択してください(選択可能なインデックス : [1, 2, 5, 7, 8]):whileループで、入力値が有効な値ではない場合(空いてないマスのインデックスや整数値ではない場合など)は再度入力待ちの状態になります。
ゲームプレイのための処理を追加
最後です。ゲームプレイの処理を書いていきます。
def _main(): """ 〇×ゲームの実行を行う。 """ tic_tac_toe: TicTacToe = TicTacToe(turn=Mark.O) while True: # プレイヤー側のマーク配置の制御。 player_selected_position: Position = \ get_player_input_position(current_tic_tac_toe=tic_tac_toe) print('-' * 20) tic_tac_toe = tic_tac_toe.set_new_mark_and_change_turn( position=player_selected_position) if tic_tac_toe.is_player_win: print('プレイヤー側が勝利しました。') print(tic_tac_toe) break if tic_tac_toe.is_draw: print('引き分けです。') print(tic_tac_toe) break print(tic_tac_toe) # AI側のマーク配置の制御。 print('AI側でマスを選択中です...') ai_selected_position: Position evaluation_value: int ai_selected_position, evaluation_value = find_best_position( current_tic_tac_toe=tic_tac_toe, max_depth=8) print( f'AIは{ai_selected_position}のインデックスを選択しました' f'(評価値 : {evaluation_value})。') tic_tac_toe = tic_tac_toe.set_new_mark_and_change_turn( position=ai_selected_position) if tic_tac_toe.is_ai_win: print('AI側が勝利しました。') print(tic_tac_toe) break if tic_tac_toe.is_draw: print('引き分けです。') print(tic_tac_toe) break print(tic_tac_toe) if __name__ == '__main__': _main()やっていることは以下の通りです。
- ゲームが終了するまでwhileループで回し続ける。
- プレイヤー側でマークを配置したい位置の入力を求める。
- プレイヤー側の位置の選択結果に応じた〇マークの配置を行う。
- プレイヤー側の配置結果に応じて、プレイヤー側が勝利したか判定する。
- ゲームが引き分けになったかどうかを確認する。
- ゲームが終了していなかったら、AI側でミニマックス法で最適なマスの選択を行う。
- ミニマックス法で算出したマスに×マークの配置を行う。
- プレイヤー側と同様に、AI側が勝利したか、もしくは引き分けになったかを判定する。
- 都度、各フェーズで盤面をprint関数で出力する。
- もしゲームが終了していなければ、前述の流れをまた繰り返す。
なお、AI側は後攻としているので残りは8マスです。そのため
max_depth=8としており、ゲーム木で8階層の深さまで最大探索を行います(今回の〇×ゲームでは全てのパターンを計算しています)。ミニマックス法で得られる評価値は-1, 0, 1のどれかです。後攻の方が不利なので、基本的に-1(負け)か0(引き分け)が多くなります。
実際に動かしてみる
実際にPythonスクリプトを実行して試してみましょう。
初手からAIに取っていじわるなことをしてみます。
覚えることは2つだけ! 「○×ゲーム」の最も簡単な勝ち方を解説した動画が話題に
上記の記事によると、先攻は左上・右上・左下・右下に〇を配置すると、後攻側は真ん中を取らないと負けてしまうそうです。実際にその配置をしてみて後攻のAI側が真ん中を選択できるか試してみます。
〇を配置したいマスのインデックスを選択してください(選択可能なインデックス : [0, 1, 2, 3, 4, 5, 6, 7, 8]):0O| | ----- | | ----- | |AI側でマスを選択中です... AIは4のインデックスを選択しました(評価値 : 0)。 O| | ----- |X| ----- | |無事後攻のAIが真ん中を選択してきました。なお、最初の1回目は残っているマスが多い(ゲーム木が深い)ためAI側の計算で少し時間がかかります。2回目以降は段々さくっと終わるようになってきます。
次は1のインデックスを選択してみましょう。〇側がリーチとなるので後攻のAIは2のインデックスを選択しないと負けてしまいます。
〇を配置したいマスのインデックスを選択してください(選択可能なインデックス : [1, 2, 3, 5, 6, 7, 8]):1O|O| ----- |X| ----- | |AIは2のインデックスを選択しました(評価値 : 0)。 O|O|X ----- |X| ----- | |×側が斜めでリーチになっているので、プレイヤー側は左下以外選択肢が無くなっています。そのため今度は左下の6のインデックスを選択してみます。
〇を配置したいマスのインデックスを選択してください(選択可能なインデックス : [3, 5, 6, 7, 8]):6O|O|X ----- |X| ----- O| |〇が左の列の縦方向でリーチになっているので、AI側は真ん中の行の左の列の3のインデックス以外選択肢が無くなります。
AI側でマスを選択中です... AIは3のインデックスを選択しました(評価値 : 0)。 O|O|X ----- X|X| ----- O| |無事想定通りの選択をAI側がやってくれています。
続いてプレイヤー側では真ん中の行で×がリーチになっているので、真ん中の行の右の5のインデックス以外選択肢がありませんので5を選択してみます。
〇を配置したいマスのインデックスを選択してください(選択可能なインデックス : [5, 7, 8]):5O|O|X ----- X|X|O ----- O| |AI側でマスを選択中です... AIは7のインデックスを選択しました(評価値 : 0)。 O|O|X ----- X|X|O ----- O|X|残りは8のインデックスのみです。引き分けとなりました。
〇を配置したいマスのインデックスを選択してください(選択可能なインデックス : [8]):8引き分けです。 O|O|X ----- X|X|O ----- O|X|O基本的に〇×ゲームでは先攻がミスしない限り、後攻は引き分けが一番良い結果となります。また、後攻もミスしなければ負けることはありません。無事引き分けになってくれたので、コードをミスしていてポンコツなAIにはなっていないようです。
実は,先攻も後攻も頑張れば必ず引き分けになることが知られています。どちらにも必勝法はありません。
マルバツゲームは引き分けになる今度はわざとプレイヤーがミスするようなケースを試してみます。前述のミニマックスの計算の説明で例を上げたような盤面で進めます。具体的には、プレイヤー側が1, 3, 5のインデックスを選択していってみます。
〇を配置したいマスのインデックスを選択してください(選択可能なインデックス : [0, 1, 2, 3, 4, 5, 6, 7, 8]):1|O| ----- | | ----- | |AI側でマスを選択中です... AIは0のインデックスを選択しました(評価値 : 0)。 X|O| ----- | | ----- | |〇を配置したいマスのインデックスを選択してください(選択可能なインデックス : [2, 3, 4, 5, 6, 7, 8]):3X|O| ----- O| | ----- | |AI側でマスを選択中です... AIは4のインデックスを選択しました(評価値 : 0)。 X|O| ----- O|X| ----- | |続いてプレイヤーが5を選択した時には、AI側が2もしくは6を選択すれば残りのゲーム木の内容的にAI側の勝ちが確定します(評価値が0から1になっていることが確認できます)。
〇を配置したいマスのインデックスを選択してください(選択可能なインデックス : [2, 5, 6, 7, 8]):5X|O| ----- O|X|O ----- | |AI側でマスを選択中です... AIは2のインデックスを選択しました(評価値 : 1)。 X|O|X ----- O|X|O ----- | |無事AI側が2のインデックスを選択し、評価値が1となりました(×のリーチが2つになったのでAI側の勝ちが確定)。
〇を配置したいマスのインデックスを選択してください(選択可能なインデックス : [6, 7, 8]):6X|O|X ----- O|X|O ----- O| |AI側でマスを選択中です... AIは8のインデックスを選択しました(評価値 : 1)。 AI側が勝利しました。 X|O|X ----- O|X|O ----- O| |X無事作れたようなので、本記事はこれで終わりです。お疲れさまでした!
コード全体
from __future__ import annotations from typing import List, Tuple from enum import Enum from copy import deepcopy class Mark(Enum): """ 〇×ゲームの各マスの1つ分のマークの値を扱うクラス。 Attributes ---------- O : str 〇に該当するマーク。 X : str ×に該当するマーク。 E : str マスにマークが設定されていない場合の値(empty)。 空のスペースが設定される。 """ O = 'O' X = 'X' E = ' ' def get_opponent(self) -> Mark: """ 相手側のセルの値を取得する。 Returns ------- opponent : Piece 相手側のセルの値。〇であれば×が、×であれば〇が設定される。 空の値の場合はそのまま空の値が設定される。 """ if self == Mark.O: return Mark.X if self == Mark.X: return Mark.O return Mark.E def __str__(self) -> str: """ マークの文字を返却する。 Returns ------- mark : str 定義されているいずれかのマークの文字。 """ return self.value class Position: def __init__(self, index: int) -> None: """ マスのインデックスを扱うクラス。インデックスは1次元で0~8の範囲で 以下のような位置が該当する。 0 1 2 3 4 5 6 7 8 Parameters ---------- index : int 対象のインデックス(0~8)。 Raises ------ ValueError 範囲外のインデックスが指定された場合。 """ index_range: List[int] = list(range(0, 9)) if index not in index_range: raise ValueError('指定されたインデックスが範囲外の値です : %s' % index) self.index = index def __eq__(self, obj: object) -> bool: """ 他のPositionクラスと同値かどうかの比較を行う。 Parameters ---------- obj : * 比較対象のオブジェクト。 Returns ------- result : bool 比較結果。対象がPositionクラスで、且つインデックスの 値が同じ場合にはTrueが設定される。 """ if not isinstance(obj, Position): return False if self.index == obj.index: return True return False def __repr__(self) -> str: """ 文字列変換した際の表示値を返却する。 Returns ------- repr_str : str インデックスの値の文字が設定される。 """ return repr(self.index) class TicTacToe: def __init__(self, turn: Mark, marks: List[Mark]=None) -> None: """ 〇×ゲーム(tic-tac-toe)を扱うクラス。 Parameters ---------- turn : Mark 現在のターンのマーク。Mark.OもしくはMark.Xが必要になる。 marks : list of Mark, default None 現在の各マスに設定されているマークのリスト。1次元のリストで、 以下のような割り振りで0~8のインデックスで設定する。 0 1 2 3 4 5 6 7 8 デフォルト値が指定された場合には全てのマスが空の状態が 設定される。 """ if marks is None: marks = [Mark.E] * 9 self._turn = turn self.marks = marks def set_new_mark_and_change_turn( self, position: Position) -> TicTacToe: """ 特定のマスの位置に〇もしくは×のマークを設定する。 Notes ----- 設定されるマークはこのクラスに設定されているターンの属性に依存する。 Parameters ---------- position : Position マークを設定する位置。 Raises ------ ValueError すでにマークが設定されているマスの位置が指定された場合。 Returns ------- new_tic_tac_toe : TicTacToe マークの設定とターンの切り替え後の〇×ゲームのインスタンス。 ※各探索でループで元のインスタンスも利用するため、 ディープコピーされたインスタンスが設定される。 """ current_mark: Mark = self.marks[position.index] if current_mark != Mark.E: raise ValueError( '対象のマスに既にマークが設定されています : ' f'position: {position}, mark: {current_mark}' ) new_marks: List[Mark] = deepcopy(self.marks) new_marks[position.index] = self._turn new_turn: Mark = self._turn.get_opponent() new_tic_tac_toe: TicTacToe = TicTacToe( turn=new_turn, marks=new_marks) return new_tic_tac_toe def get_empty_positions(self) -> List[Position]: """ 空いている(マークの設定されていない)マスの位置のリストを 取得する。 Returns ------- empty_positions : list of Position 空いている(マークの設定されていない)マスの位置のリスト。 """ empty_positions: List[Position] = [] for index, mark in enumerate(self.marks): if mark != Mark.E: continue empty_positions.append(Position(index=index)) return empty_positions def is_empty_position(self, position: Position) -> bool: """ 指定された位置が空のマスかどうかの真偽値を取得する。 Parameters ---------- position : Position 判定対象の位置。 Returns ------- result : bool もし空のマスの位置であればTrueが設定される。 """ empty_positions: List[Position] = self.get_empty_positions() for empty_position in empty_positions: if position == empty_position: return True return False _ConditionPositions = Tuple[Position, Position, Position] _CONDITION_POSITIONS: List[_ConditionPositions] = [ (Position(0), Position(1), Position(2)), (Position(3), Position(4), Position(5)), (Position(6), Position(7), Position(8)), (Position(0), Position(3), Position(6)), (Position(1), Position(4), Position(7)), (Position(2), Position(5), Position(8)), (Position(0), Position(4), Position(8)), (Position(2), Position(4), Position(6)), ] @property def is_player_win(self) -> bool: """ プレイヤー側が勝利したかどうか。 Returns ------- result : bool プレイヤー側が勝利しているかどうか。 """ return self._is_target_mark_win(mark=Mark.O) @property def is_ai_win(self) -> bool: """ AI側が勝利したかどうか。 Returns ------- result : bool AI側が勝利しているかどうか。 """ return self._is_target_mark_win(mark=Mark.X) def _is_target_mark_win(self, mark: Mark) -> bool: """ 指定されたマーク側が勝利しているかどうかの真偽値を取得する。 Parameters ---------- mark : Mark 判定対象のマーク。 Returns ------- result : bool 勝利している場合にはTrueが設定される。 """ for condition_positions in self._CONDITION_POSITIONS: condition_satisfied: bool = \ self._is_condition_satisfied_positions( condition_positions=condition_positions, target_mark=mark) if condition_satisfied: return True return False def _is_condition_satisfied_positions( self, condition_positions: _ConditionPositions, target_mark: Mark) -> bool: """ 条件を満たしている位置の組み合わせ(3つ同じマークが並んでいるか)が 存在するかどうかの真偽値を取得する。 Parameters ---------- condition_positions : _ConditionPositions チェック対象の3つの位置の組み合わせを格納したタプル。 target_mark : Mark 対象のマーク。 Returns ------- result : bool 条件を満たせばTrueが設定される。 """ is_target_marks: List[bool] = [] for condition_position in condition_positions: mark: Mark = self.marks[condition_position.index] if mark == target_mark: is_target_marks.append(True) continue is_target_marks.append(False) return all(is_target_marks) @property def is_draw(self) -> bool: """ 引き分けの状態かどうかの真偽値。 Returns ------- result : bool 引き分けかどうかの真偽値。勝敗が付いていない状態で、 且つ空いているマスが無くなった状態でTrueとなる。 """ empty_position_num: int = len(self.get_empty_positions()) if self.is_player_win: return False if self.is_ai_win: return False if empty_position_num != 0: return False return True def evaluate(self) -> int: """ AI側のマーク配置の選択結果の性能評価のための評価関数としてのメソッド。 Parameters ---------- target_mark : Mark 判定側となるマーク。〇側での評価をしたい場合には Mark.O を、 ×側で評価をしたい場合には Mark.X を指定する。 Returns ------- evaluation_value : int 評価結果の値。勝利している場合には1、敗北している場合には-1、 勝敗がついていない場合には0が設定される。 """ if self.is_ai_win: return 1 if self.is_player_win: return -1 return 0 def __str__(self) -> str: """ 現在の各マスの内容の可視化用の文字列を返却する。 Returns ------- info : str 現在の各マスの内容の可視化用の文字列。以下のような フォーマットの文字列が設定される。 O| |X ----- |O|X ----- O|X| """ info: str = '' for i in range(9): if i % 3 == 0 and i != 0: info += '\n-----\n' if not info.endswith('\n') and i != 0: info += '|' info += str(self.marks[i]) return info def is_search_ended( current_tic_tac_toe: TicTacToe, remaining_depth: int) -> bool: """ Minimaxによる探索が終了している状態かどうかの真偽値を取得する。 Parameters ---------- current_tic_tac_toe : TicTacToe 対象の盤面の状態を保持した〇×ゲームのインスタンス。 remaining_depth : int 残っている探索の深さ。最後の探索範囲に達している場合には0を指定する。 Returns ------- result : bool 探索が終了している状態かどうかの真偽値。終了していればTrueが 設定される。盤面で勝敗が付いている(勝利もしくは引き分け)場合 もしくは指定され探索の木の深さにまで達している場合にTrueとなる。 """ if current_tic_tac_toe.is_player_win: return True if current_tic_tac_toe.is_ai_win: return True if current_tic_tac_toe.is_draw: return True if remaining_depth == 0: return True return False def get_maximized_evaluation_value( current_tic_tac_toe: TicTacToe, remaining_depth: int) -> int: """ Minimaxにおける、最大化された評価値の取得を行う。 Parameters ---------- current_tic_tac_toe : TicTacToe 対象の現在の(盤面の状態の)〇×ゲームのインスタンス。 remaining_depth : int 残っている探索の深さ。最後の探索範囲に達している場合には0を指定する。 Returns ------- maximized_evaluation_value : int 最大化された評価値。 """ maximized_evaluation_value: int = -1 empty_positions: List[Position] = \ current_tic_tac_toe.get_empty_positions() for empty_position in empty_positions: new_tic_tac_toe = current_tic_tac_toe.set_new_mark_and_change_turn( position=empty_position) # 再帰的な次の階層への木の探索処理。次は最小化される形となるので、 # maximizing=Falseを設定する。また、残りの深さの指定は1つ分減算する。 evaluation_value: int = minimax( current_tic_tac_toe=new_tic_tac_toe, maximizing=False, remaining_depth=remaining_depth - 1) maximized_evaluation_value = max( evaluation_value, maximized_evaluation_value) return maximized_evaluation_value def get_minimized_evaluation_value( current_tic_tac_toe: TicTacToe, remaining_depth: int) -> int: """ Minimaxにおける、最小化された評価値の取得を行う。 Parameters ---------- current_tic_tac_toe : TicTacToe 対象の現在の(盤面の状態の)〇×ゲームのインスタンス。 remaining_depth : int 残っている探索の深さ。最後の探索範囲に達している場合には0を指定する。 Returns ------- minimized_evaluation_value : int 最小化された評価値。 """ minimized_evaluation_value: int = 1 empty_positions: List[Position] = \ current_tic_tac_toe.get_empty_positions() for empty_position in empty_positions: new_tic_tac_toe = current_tic_tac_toe.set_new_mark_and_change_turn( position=empty_position) # 再帰的な次の階層への木の探索処理。次は最大化される形となるので、 # maximizing=Trueを設定する。また、残りの深さの指定は1つ分減算する。 evaluation_value: int = minimax( current_tic_tac_toe=new_tic_tac_toe, maximizing=True, remaining_depth=remaining_depth - 1) minimized_evaluation_value = min( evaluation_value, minimized_evaluation_value) return minimized_evaluation_value def minimax( current_tic_tac_toe: TicTacToe, maximizing: bool, remaining_depth: int) -> int: """ Minimaxのアルゴリズムを実行し、結果の評価値を取得する。 Notes ----- - 呼び出し後、最大で指定された深さ分再帰的に実行される。 - AI側を前提としたコードになっている(マークは×側が利用される)。 Parameters ---------- current_tic_tac_toe : TicTacToe 対象の現在の(盤面の状態の)〇×ゲームのインスタンス。 maximizing : bool 評価値を最大化するかどうかの真偽値。Falseの場合は逆に最小化 する処理が実行される。次のアクションがプレイヤー側であればFalse、 AI側であればTrueを指定する。 remaining_depth : int 探索の木の最大の深さ。多くする程計算に時間がかかるようになる。 最初に呼び出す際には〇×ゲームの場合には最大で8階層となるので、 8以内の値を指定する。再帰的に実行する際に、階層が深くなる度に -1されていく形で値が設定される(0になった時点で探索が停止する)。 Returns ------- evaluation_value : int Minimax実行後の評価値。 """ _is_search_ended: bool = is_search_ended( current_tic_tac_toe=current_tic_tac_toe, remaining_depth=remaining_depth) if _is_search_ended: # 探索が終了する条件(木の末端に達しているか勝敗が付いた場合)には # 現在の盤面での評価値を返却する。 return current_tic_tac_toe.evaluate() # 最大化する場合(AI側のターン想定の木の深さ)のケース。 if maximizing: maximized_evaluation_value: int = get_maximized_evaluation_value( current_tic_tac_toe=current_tic_tac_toe, remaining_depth=remaining_depth, ) return maximized_evaluation_value # 最小化する場合(プレイヤー側のターン想定の木の深さ)のケース。 minimized_evaluation_value: int = get_minimized_evaluation_value( current_tic_tac_toe=current_tic_tac_toe, remaining_depth=remaining_depth, ) return minimized_evaluation_value def find_best_position( current_tic_tac_toe: TicTacToe, max_depth: int) -> Tuple[Position, int]: """ 空いているマスの中で、ベストな位置をMinimaxで算出する。 空いている各マスに対してMinimaxの実行がされ、評価値が最大の マスの位置が返却される。 Parameters ---------- current_tic_tac_toe : TicTacToe 対象の現在の(盤面の状態の)〇×ゲームのインスタンス。 max_depth : int 探索の木の最大の深さ。 Raises ------ ValueError 空いているマスが存在しない状態で実行された場合。 Returns ------- best_position : Position 算出されたベストな位置。 best_evaluation_value : int ベストな位置における評価値の最大値(-1, 0, 1のいずれかが 設定される)。 """ best_evaluation_value: int = -1 empty_positions: List[Position] = \ current_tic_tac_toe.get_empty_positions() if not empty_positions: raise ValueError('空いているマスが存在しません。') best_position: Position = empty_positions[0] for empty_position in empty_positions: current_loop_tic_tac_toe: TicTacToe = \ current_tic_tac_toe.set_new_mark_and_change_turn( position=empty_position) # 今回Minimaxで算出したいものがAI側(maximizing=True)なので、 # 探索自体は次の階層のプレイヤー側のところからとなるため、 # Minimaxでの最初のmaximizingの指定はFalseとなる。 evaluation_value: int = minimax( current_tic_tac_toe=current_loop_tic_tac_toe, maximizing=False, remaining_depth=max_depth) if evaluation_value <= best_evaluation_value: continue best_evaluation_value = evaluation_value best_position: Position = empty_position return best_position, best_evaluation_value def get_player_input_position(current_tic_tac_toe: TicTacToe) -> Position: """ プレイヤー側のマーク配置位置の入力を取得する。 Parameters ---------- current_tic_tac_toe : TicTacToe 対象の現在の(盤面の状態の)〇×ゲームのインスタンス。 Returns ------- players_selected_position : Position プレイヤー側が選択したマーク配置位置。 """ is_empty_position: bool = False players_selected_position: Position = Position(index=0) while not is_empty_position: empty_positions: List[Position] = \ current_tic_tac_toe.get_empty_positions() msg: str = ( '〇を配置したいマスのインデックスを選択してください' '(選択可能なインデックス : %s):' % empty_positions ) input_val: str = input(msg) try: input_index: int = int(input_val) players_selected_position = Position(index=input_index) except Exception: continue is_empty_position = current_tic_tac_toe.is_empty_position( position=players_selected_position) return players_selected_position def _main(): """ 〇×ゲームの実行を行う。 """ tic_tac_toe: TicTacToe = TicTacToe(turn=Mark.O) while True: # プレイヤー側のマーク配置の制御。 player_selected_position: Position = \ get_player_input_position(current_tic_tac_toe=tic_tac_toe) print('-' * 20) tic_tac_toe = tic_tac_toe.set_new_mark_and_change_turn( position=player_selected_position) if tic_tac_toe.is_player_win: print('プレイヤー側が勝利しました。') print(tic_tac_toe) break if tic_tac_toe.is_draw: print('引き分けです。') print(tic_tac_toe) break print(tic_tac_toe) # AI側のマーク配置の制御。 print('AI側でマスを選択中です...') ai_selected_position: Position evaluation_value: int ai_selected_position, evaluation_value = find_best_position( current_tic_tac_toe=tic_tac_toe, max_depth=8) print( f'AIは{ai_selected_position}のインデックスを選択しました' f'(評価値 : {evaluation_value})。') tic_tac_toe = tic_tac_toe.set_new_mark_and_change_turn( position=ai_selected_position) if tic_tac_toe.is_ai_win: print('AI側が勝利しました。') print(tic_tac_toe) break if tic_tac_toe.is_draw: print('引き分けです。') print(tic_tac_toe) break print(tic_tac_toe) if __name__ == '__main__': _main()参考サイト・参考文献
- 投稿日:2020-11-22T18:17:14+09:00
順列の全探索をするプログラム(競技プログラミング向け)
順列をすべて列挙するプログラムを各言語で書きました。
10,20,30,40の4つの要素があったとして次のような出力をします。要素が $ n $ 個あれば、 $ n! $ 行の出力をします。出力するところになにか処理を書けば順列の全探索ができます。10 20 30 40 10 20 40 30 10 30 20 40 10 30 40 20 10 40 20 30 10 40 30 20 20 10 30 40 20 10 40 30 ...書いた言語:
- ライブラリ使用: C++, Scala, Ruby, Python
- 独自実装: C言語, Java, JavaScript, Elixir
経緯:
AtCoderのABC183 C - Travelでは順列の列挙が必要でした。順列列挙のアルゴリズムがわからず、競技中は無理やり書いてACは取れたのですが、解説を読むともっとスマートなアルゴリズムがありました。しかもいくつかの言語では順列を列挙するライブラリも標準装備されていました。
悔しかったので各言語で順列を全部列挙するプログラムを書いたものです。
参考:
C++
C++には
next_permutationという関数があります。#include <iostream> #include <vector> #include <algorithm> using namespace std; int main() { int len = 4; vector<int> vec(len); for (int i = 0; i < len; i++) vec[i] = 10 * (i+1); do { for (int i = 0; i < len; i++) cout << " " << vec[i]; cout << endl; } while (next_permutation(vec.begin(), vec.end())); }Scala
Scalaには
permutationsというメソッドがあります。object Main extends App { val len = 4; val seq = (1 to len).map(10 * _); seq.permutations.foreach { seq => println(" " + seq.mkString(" ")); } }Ruby
Rubyには
permutationというメソッドがあります。len = 4 arr = (1 .. len).map do |i| 10 * i end arr.permutation do |arr| puts(" " + arr.join(" ")) endPython
Pythonには
itertools.permutationsという関数があります。import itertools len = 4 lst = [10 * (i+1) for i in range(len)] for lst2 in itertools.permutations(lst): print(" " + " ".join(map(str, lst2)))C言語
C++の
next_permutationを自分で実装しています。(ほとんどAtCoderの解説そのままです)#include <stdio.h> int next_permutation(int *arr, int len) { int left = len - 2; while (left >= 0 && arr[left] >= arr[left+1]) left--; if (left < 0) return 0; int right = len - 1; while (arr[left] >= arr[right]) right--; { int t = arr[left]; arr[left] = arr[right]; arr[right] = t; } left++; right = len - 1; while (left < right) { { int t = arr[left]; arr[left] = arr[right]; arr[right] = t; } left++; right--; } return 1; } int main() { int len = 4; int arr[len]; for (int i = 0; i < len; i++) arr[i] = 10 * (i+1); do { for (int i = 0; i < len; i++) printf(" %d", arr[i]); printf("\n"); } while (next_permutation(arr, len)); }Java
C言語で実装した
next_permutationと同じ実装です。class Main { public static boolean nextPermutation(int[] arr) { int len = arr.length; int left = len - 2; while (left >= 0 && arr[left] >= arr[left+1]) left--; if (left < 0) return false; int right = len - 1; while (arr[left] >= arr[right]) right--; { int t = arr[left]; arr[left] = arr[right]; arr[right] = t; } left++; right = len - 1; while (left < right) { { int t = arr[left]; arr[left] = arr[right]; arr[right] = t; } left++; right--; } return true; } public static void main(String[] args) { int len = 4; var arr = new int[len]; for (int i = 0; i < len; i++) { arr[i] = 10 * (i+1); } do { var sb = new StringBuilder(); for (int i = 0; i < len; i++) { sb.append(String.format(" %d", arr[i])); } System.out.println(sb); } while (nextPermutation(arr)); } }JavaScript
C言語やJavaで実装した
next_permutationと同じ実装です。function next_permutation(arr) { const len = arr.length; let left = len - 2; while (left >= 0 && arr[left] >= arr[left+1]) left--; if (left < 0) return false; let right = len - 1; while (arr[left] >= arr[right]) right--; { const t = arr[left]; arr[left] = arr[right]; arr[right] = t; } left++; right = len - 1; while (left < right) { { const t = arr[left]; arr[left] = arr[right]; arr[right] = t; } left++; right--; } return true; } const len = 4; const arr = []; for (let i = 0; i < len; i++) arr.push(10 * (i+1)); do { let str = ""; for (let i = 0; i < len; i++) str += " " + arr[i]; console.log(str); } while (next_permutation(arr));Elixir
C言語やJavaでの実装とは異なるアルゴリズムです。
next_permutationと違って、順列の全パターンを始めに作成しています。defmodule Main do def permutations([]), do: [[]] def permutations(list) do for elem <- list, p <- permutations(list -- [elem]), do: [elem | p] end def main do len = 4 list = (1 .. len) |> Enum.map(fn x -> 10 * x end) permutations(list) |> Enum.each(fn l -> IO.puts(" " <> Enum.join(l, " ")) end) end end
- 投稿日:2020-11-22T18:00:20+09:00
Virus TotalのAPIを利用してハッシュ値から検体のレポートを取得する方法
はじめに
手元に検体のハッシュ値情報はあるが,多すぎて手作業で調査するのは大変なので,自動的にVirus Total からレポート情報を取得するプログラムを作成しました.プログラムはPython3 で作成および動作確認しています.
同じような記事が多数ありますが,Python2系で記述されていたり,公式ドキュメントのサンプルと微妙に異なる書き方してあったりするので,記事を作成することにしました.Virus Total は参考文献にある通り,API を提供しているので,情報の取得にはAPIを使用するのが効率的です.
Virus Total のAPI key は,アカウントを作成することで無料で入手できます.
第三者に漏洩すると悪用される恐れがあるので,プログラムにハードコーディングする際は公開や共有時に注意ください.
(自分しか使わないならハードコーディングしても良いかと思いますが,外部公開を考えると外部入力したほうが無難かもしれません)プログラム
公式ドキュメントに沿って,以下の内容で作成しました.
apikey の部分はあなた自身のapi key の値を記述してください.(前述した通り外部入力の形でも結構です.)また,本プログラムは検体のハッシュ値情報をほかのテキストファイルから受け取る形で実装しています.こちらもハードコーディングするか,実行時の引数で取得するかはやりやすい方法で実装してください.
get_vt.pyimport sys import json import time import requests url = 'https://www.virustotal.com/vtapi/v2/file/report' count = 0 file = open('hash.txt', 'r') for hash in file: params = {'apikey': 'your api key value', 'resource': hash} response = requests.get(url, params=params) print(response.json()) count = count + 1 if count % 4 == 0: time.sleep(65) file.close()よく聞く話なのですが,API に断続的にアクセスするとアクセスに制限が適用されてしまうことがあるらしく,Virus Total だと4回続いた後は60秒空ける必要があるという噂を聞いたので,4回に1回は念を含めて65秒動作をストップするようにしています.
実行方法
ただのPythonスクリプトなので,以下の方法で実行します.結果はJSON フォーマットで返ってくるので,jsonファイルに出力させます.
get_vt.pyの実行方法$ python3 get_vt.py > vt_result.json以下は,ハッシュ値 a5a0420200af84fdb5674569f1a8eafe7ef7b41b で検索した場合の取得結果です.アンチウイルス製品名に続いて,マルウェア判定の結果がdetected にTrue or False で記述されるみたいです.マルウェア名も取得できるようで,見る限りはMirai っぽいです.
取得結果{'scans': {'Bkav': {'detected': False, 'version': '1.3.0.9899', 'result': None, 'update': '20200819'}, 'MicroWorld-eScan': {'detected': False, 'version': '14.0.409.0', 'result': None, 'update': '20200820'}, 'FireEye': {'detected': True, 'version': '32.36.1.0', 'result': 'Trojan.Linux.Mirai.1', 'update': '20200820'}, 'CAT-QuickHeal': {'detected': False, 'version': '14.00', 'result': None, 'update': '20200820'}, 'McAfee': {'detected': True, 'version': '6.0.6.653', 'result': 'RDN/Generic BackDoor', 'update': '20200820'}, 'Malwarebytes': {'detected': False, 'version': '3.6.4.335', 'result': None, 'update': '20200820'}, 'Zillya': {'detected': True, 'version': '2.0.0.4158', 'result': 'Backdoor.Mirai.Linux.91998', 'update': '20200820'}, 'SUPERAntiSpyware': {'detected': False, 'version': '5.6.0.1032', 'result': None, 'update': '20200814'}, 'Sangfor': {'detected': False, 'version': '1.0', 'result': None, 'update': '20200814'}, 'K7AntiVirus': {'detected': False, 'version': '11.131.35049', 'result': None, 'update': '20200820'}, 'K7GW': {'detected': False, 'version': '11.131.35050', 'result': None, 'update': '20200820'}, 'Baidu': {'detected': False, 'version': '1.0.0.2', 'result': None, 'update': '20190318'}, 'F-Prot': {'detected': False, 'version': '4.7.1.166', 'result': None, 'update': '20200820'}, 'Symantec': {'detected': True, 'version': '1.11.0.0', 'result': 'Trojan.Gen.NPE', 'update': '20200820'}, 'ESET-NOD32': {'detected': True, 'version': '21852', 'result': 'a variant of Linux/Mirai.OX', 'update': '20200820'}, 'TrendMicro-HouseCall': {'detected': False, 'version': '10.0.0.1040', 'result': None, 'update': '20200820'}, 'Avast': {'detected': True, 'version': '18.4.3895.0', 'result': 'Other:Malware-gen [Trj]', 'update': '20200820'}, 'ClamAV': {'detected': True, 'version': '0.102.4.0', 'result': 'Unix.Dropper.Mirai-7135870-0', 'update': '20200817'}, 'Kaspersky': {'detected': True, 'version': '15.0.1.13', 'result': 'HEUR:Backdoor.Linux.Mirai.b', 'update': '20200820'}, 'BitDefender': {'detected': True, 'version': '7.2', 'result': 'Trojan.Linux.Mirai.1', 'update': '20200820'}, 'NANO-Antivirus': {'detected': True, 'version': '1.0.134.25140', 'result': 'Trojan.Mirai.hrbzkk', 'update': '20200820'}, 'ViRobot': {'detected': False, 'version': '2014.3.20.0', 'result': None, 'update': '20200820'}, 'Tencent': {'detected': True, 'version': '1.0.0.1', 'result': 'Backdoor.Linux.Mirai.wao', 'update': '20200820'}, 'Ad-Aware': {'detected': False, 'version': '3.0.16.117', 'result': None, 'update': '20200820'}, 'TACHYON': {'detected': False, 'version': '2020-08-20.02', 'result': None, 'update': '20200820'}, 'Comodo': {'detected': True, 'version': '32668', 'result': '.UnclassifiedMalware@0', 'update': '20200728'}, 'F-Secure': {'detected': True, 'version': '12.0.86.52', 'result': 'Malware.LINUX/Mirai.lpnjw', 'update': '20200820'}, 'DrWeb': {'detected': True, 'version': '7.0.46.3050', 'result': 'Linux.Mirai.671', 'update': '20200820'}, 'VIPRE': {'detected': False, 'version': '86068', 'result': None, 'update': '20200820'}, 'TrendMicro': {'detected': True, 'version': '11.0.0.1006', 'result': 'Backdoor.Linux.MIRAI.USELVH120', 'update': '20200820'}, 'CMC': {'detected': False, 'version': '2.7.2019.1', 'result': None, 'update': '20200820'}, 'Sophos': {'detected': True, 'version': '4.98.0', 'result': 'Linux/DDoS-CIA', 'update': '20200819'}, 'Cyren': {'detected': False, 'version': '6.3.0.2', 'result': None, 'update': '20200820'}, 'Jiangmin': {'detected': False, 'version': '16.0.100', 'result': None, 'update': '20200820'}, 'Avira': {'detected': True, 'version': '8.3.3.8', 'result': 'LINUX/Mirai.lpnjw', 'update': '20200820'}, 'Fortinet': {'detected': True, 'version': '6.2.142.0', 'result': 'ELF/DDoS.CIA!tr', 'update': '20200820'}, 'Antiy-AVL': {'detected': False, 'version': '3.0.0.1', 'result': None, 'update': '20200820'}, 'Kingsoft': {'detected': False, 'version': '2013.8.14.323', 'result': None, 'update': '20200820'}, 'Arcabit': {'detected': True, 'version': '1.0.0.877', 'result': 'Trojan.Linux.Mirai.1', 'update': '20200820'}, 'AegisLab': {'detected': True, 'version': '4.2', 'result': 'Trojan.Linux.Mirai.K!c', 'update': '20200820'}, 'AhnLab-V3': {'detected': False, 'version': '3.18.1.10026', 'result': None, 'update': '20200820'}, 'ZoneAlarm': {'detected': True, 'version': '1.0', 'result': 'HEUR:Backdoor.Linux.Mirai.b', 'update': '20200820'}, 'Avast-Mobile': {'detected': False, 'version': '200820-00', 'result': None, 'update': '20200820'}, 'Microsoft': {'detected': True, 'version': '1.1.17300.4', 'result': 'Trojan:Win32/Skeeyah.A!rfn', 'update': '20200820'}, 'Cynet': {'detected': True, 'version': '4.0.0.24', 'result': 'Malicious (score: 85)', 'update': '20200815'}, 'TotalDefense': {'detected': False, 'version': '37.1.62.1', 'result': None, 'update': '20200820'}, 'BitDefenderTheta': {'detected': False, 'version': '7.2.37796.0', 'result': None, 'update': '20200819'}, 'ALYac': {'detected': False, 'version': '1.1.1.5', 'result': None, 'update': '20200820'}, 'MAX': {'detected': True, 'version': '2019.9.16.1', 'result': 'malware (ai score=89)', 'update': '20200820'}, 'VBA32': {'detected': False, 'version': '4.4.1', 'result': None, 'update': '20200819'}, 'Zoner': {'detected': False, 'version': '0.0.0.0', 'result': None, 'update': '20200819'}, 'Rising': {'detected': True, 'version': '25.0.0.26', 'result': 'Backdoor.Mirai/Linux!1.BAF6 (CLASSIC)', 'update': '20200820'}, 'Yandex': {'detected': False, 'version': '5.5.2.24', 'result': None, 'update': '20200707'}, 'Ikarus': {'detected': True, 'version': '0.1.5.2', 'result': 'Trojan.Linux.Mirai', 'update': '20200820'}, 'MaxSecure': {'detected': False, 'version': '1.0.0.1', 'result': None, 'update': '20200819'}, 'GData': {'detected': True, 'version': 'A:25.26670B:27.19869', 'result': 'Trojan.Linux.Mirai.1', 'update': '20200820'}, 'AVG': {'detected': True, 'version': '18.4.3895.0', 'result': 'Other:Malware-gen [Trj]', 'update': '20200820'}, 'Panda': {'detected': False, 'version': '4.6.4.2', 'result': None, 'update': '20200819'}, 'Qihoo-360': {'detected': True, 'version': '1.0.0.1120', 'result': 'Linux/Backdoor.6f4', 'update': '20200820'}}, 'scan_id': '0aa5949d00c05b62cb5e9ac24f11b08cd5ed13f089b628220d6cc27b5147230c-1597909074', 'sha1': 'a5a0420200af84fdb5674569f1a8eafe7ef7b41b', 'resource': '0aa5949d00c05b62cb5e9ac24f11b08cd5ed13f089b628220d6cc27b5147230c', 'response_code': 1, 'scan_date': '2020-08-20 07:37:54', 'permalink': 'https://www.virustotal.com/gui/file/0aa5949d00c05b62cb5e9ac24f11b08cd5ed13f089b628220d6cc27b5147230c/detection/f-0aa5949d00c05b62cb5e9ac24f11b08cd5ed13f089b628220d6cc27b5147230c-1597909074', 'verbose_msg': 'Scan finished, information embedded', 'total': 59, 'positives': 29, 'sha256': '0aa5949d00c05b62cb5e9ac24f11b08cd5ed13f089b628220d6cc27b5147230c', 'md5': '1e0621f530a9f1cb000d670c54a789c9'}まとめ
Virus Total のAPI を利用してハッシュ値からレポート情報を取得するプログラムを作成した.今後は,得られた出力情報の利用方法やほかのAPI の利用方法などについて検討していく.
参考文献
- 投稿日:2020-11-22T16:56:41+09:00
3. Pythonによる自然言語処理 3-1. 重要語抽出ツール TF-IDF分析[原定義]
- 自然言語処理を行うとき、具体的な狙いの一つとして「ある文章を特徴づけるような重要語を抽出したい」ということがあります。
- 単語を抽出するとき、まずはテキスト内で出現回数の多い単語を拾います。出現頻度順のリストの上位に挙がってくるのは、あらゆる文章に共通して頻繁に使われる語ばかりです。
- 品詞情報を使って名詞に限定しても、例えば「事」や「時」などのように特定の意味をなさない汎用的な単語が上位に多数出てくるので、それらをストップワードとして除外するなどの処理が必要です。
⑴ TF-IDFという考え方
- TF-IDF(Term Frequency - Inverse Document Frequency)、直訳すると「用語頻度 - 逆文書頻度」です。
- 出現回数は多いが、その語が出てくる文書の数が少ない、つまりどこにでも出てくるわけではない単語を特徴的で重要な語であると判定する考え方です。
- 多くは単語を対象とするものですが、文字や句(フレーズ)にも適用できますし、文書(ドキュメント)の単位もいろいろ応用がききます。
⑵ TF-IDF値の定義
出現頻度 $tf$ に、希少性の指標となる係数 $idf$ を掛け算する
- $tfidf=tf×idf$
- $tf_{ij}$ (単語$i$の文書$j$における出現頻度) × $idf_{i}$(単語$i$を含む文書の数の逆数の$log$)
出現頻度 $tf$ と係数 $idf$ はそれぞれ次のように定義されます
- $tf_{ij}=\dfrac{n_{ij}}{\sum_{k}n_{kj}} = \dfrac{単語iの文書jにおける出現回数}{文書jにおける全ての単語の出現回数の和}$
- $idf_{i}=\log \dfrac{|D|}{|{d:d∋t_{i}}|} = \log{\dfrac{全文書の数}{単語iを含む文書の数}}$
⑶ 原定義による計算のしくみ
# 数値計算ライブラリのインポート from math import log import pandas as pd import numpy as np➀ 単語データリストを用意
- すでに形態素解析などの前処理を済ませて、6つの文書について次のような単語のリストができているという想定で、対象となる3つの単語の$tfidf$を計算します。
docs = [ ["語1", "語3", "語1", "語3", "語1"], ["語1", "語1"], ["語1", "語1", "語1"], ["語1", "語1", "語1", "語1"], ["語1", "語1", "語2", "語2", "語1"], ["語1", "語3", "語1", "語1"] ] N = len(docs) words = list(set(w for doc in docs for w in doc)) words.sort() print("文書数:", N) print("対象となる単語:", words)
➁ 計算用の関数を定義
- あらかじめ出現頻度 $tf$、係数 $idf$、それらを掛け合わせた $tfidf$ をそれぞれ計算する関数を定義します。
# 関数tfの定義 def tf(t, d): return d.count(t)/len(d) # 関数idfの定義 def idf(t): df = 0 for doc in docs: df += t in doc return np.log10(N/df) # 関数tfidfの定義 def tfidf(t, d): return tf(t,d) * idf(t)➂ TFの計算結果を観察
- 参考までに、段階的に $tf$ 及び $idf$ の計算結果をみておきましょう。
# tfを計算 result = [] for i in range(N): temp = [] d = docs[i] for j in range(len(words)): t = words[j] temp.append(tf(t,d)) result.append(temp) pd.DataFrame(result, columns=words)
➃ IDFの計算結果を観察
# idfを計算 result = [] for j in range(len(words)): t = words[j] result.append(idf(t)) pd.DataFrame(result, index=words, columns=["IDF"])
- 6つの文書すべてに出てくる語1の係数 $idf$ は 0 となり、また1つの文書にしか出てこない語2は最も大きく0.778151 となっています。
➄ TF-IDFの計算
# tfidfを計算 result = [] for i in range(N): temp = [] d = docs[i] for j in range(len(words)): t = words[j] temp.append(tfidf(t,d)) result.append(temp) pd.DataFrame(result, columns=words)
- 語1の $tfidf$ は、係数 $idf$ が 0 なので 、たとえ出現回数がどんなに多くても一律 0 になってしまいます。
- また、TF-IDFはそもそも情報検索の目的で提案された指標であり、1回も出現しない語に対しては $idf$ を計算する上で分母が 0(いわゆるゼロ除算)となってエラーになってしまいます。
⑷ scikit-learnによる計算
- そうした問題点に対応して scikit-learn の TF-IDF ライブラリ
TfidfVectorizerは、原定義とはやや異なる定義で実装されています。# scikit-learnのTF-IDFライブラリをインポート from sklearn.feature_extraction.text import TfidfVectorizer
- 先の6つの文書の単語データリストを対象に
TfidfVectorizerをつかって $tfidf$ を計算してみます。# 1次元のリスト docs = [ "語1 語3 語1 語3 語1", "語1 語1", "語1 語1 語1", "語1 語1 語1 語1", "語1 語1 語2 語2 語1", "語1 語3 語1 語1" ] # モデルを生成 vectorizer = TfidfVectorizer(smooth_idf=False) X = vectorizer.fit_transform(docs) # データフレームに表現 values = X.toarray() feature_names = vectorizer.get_feature_names() pd.DataFrame(values, columns = feature_names)
- 語1の $tfidf$ は各文書で 0 ではなくなり、また語2、語3においては元から 0 であった文書を除いて原定義とは異なる値になっています。
- そこで、原定義に基づいて scikit-learn の結果を再現してみます。
⑸ scikit-learnの結果を再現
➀ IDFの計算式を変更
# 関数idfの定義 def idf(t): df = 0 for doc in docs: df += t in doc #return np.log10(N/df) return np.log(N/df)+1
np.log10(N/df)をnp.log(N/df)+1に修正- つまり底を10とする常用対数から、底をネイピア数eとする自然対数に変えて、さらに+1します。
# idfを計算 result = [] for j in range(len(words)): t = words[j] result.append(idf(t)) pd.DataFrame(result, index=words, columns=["IDF"])
➁ TF-IDFの計算結果を観察
# tfidfを計算 result = [] for i in range(N): temp = [] d = docs[i] for j in range(len(words)): t = words[j] temp.append(tfidf(t,d)) result.append(temp) pd.DataFrame(result, columns=words)
➂ TF-IDF計算結果をL2正則化
- 最後に $tfidf$ の計算結果をL2正則化します。
- つまり値をスケーリングして、それらがすべて2乗されて合計すると1になるように変換します。
- なぜ正則化が必要かといえば、各単語が各文書に出現する回数を数えているわけですが、各文書は長さが異なりますので、文書が長いほど単語の数は多くなりがちです。
- そうした単語の合計数による影響を取り除くことによって、単語の出現頻度を相対的に比較することが可能となります。
# 試しに文書1のみ定義に従ってノルム値を計算 x = np.array([0.60, 0.000000, 0.839445]) x_norm = sum(x**2)**0.5 x_norm = x/x_norm print(x_norm) # それらを2乗して合計し、1になることを確認 np.sum(x_norm**2)
- ここは scikit-learn を利用して楽をしましょう。
# scikit-learnの正則化ライブラリをインポート from sklearn.preprocessing import normalize # L2正則化 result_norm = normalize(result, norm='l2') # データフレームに表現 pd.DataFrame(result_norm, columns=words)
- 整理しておくと、scikit-learn の TF-IDF は、原定義のもつ2つの難点を解消するものとなっています。
- 係数 $idf$ の計算式に自然対数を用い、かつ+1することによってゼロを回避する。ちなみに常用対数から自然対数への変換は約 2.303 倍になります。
- さらにL2正則化によって、文書ごとの長短に伴う単語数の差の影響が排除されています。
- TF-IDF の原理はとてもシンプルなものですが、scikit-learn にはパラメータもいろいろありますし、課題によってチューニングしていく余地もありそうです。


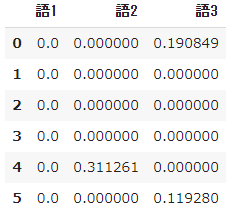
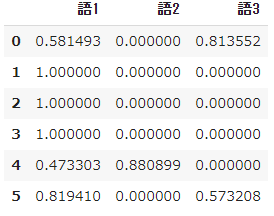
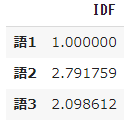
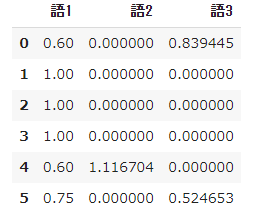

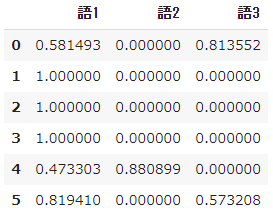
- 投稿日:2020-11-22T16:21:47+09:00
数理最適化でアナグラム生成AIを作る 〜クラウドはXIII機関になれるか〜
エイチームフィナジーのアドベントカレンダー1日目は、s2terminalが担当します!
※本稿はスクウェア・エニックス社が2005年に発売したプレイステーション2用ゲームソフト「キングダムハーツ2」について一部ネタバレを含みます。
現在私のチーム(というかこの問題に取り組んでいるのはほぼ私一人ですが)は、ウェブサイト内のコンテンツ掲載順序の最適化について研究開発しています。この記事では、そこで使った技術や使わなかった技術たちを応用して、アナグラムの自動生成に取り組んでみたいと思います。アナグラムの自動生成プログラムの開発を通して、最適化の手法や用語を少しずつ紹介していきます。最適化の手法がなにかの役に立つきっかけとなれば幸いです。
本稿では題材として、スクウェア・エニックス社から発売されているゲームシリーズ「キングダムハーツ」シリーズに登場するXIII機関(じゅうさんきかん、Organization Thirteen)のような、「元の名前に
X(エックス)を足して並び替えた結果を、新しい名前とする」アナグラムを題材とします。たとえば、
sora(ソラ)という文字列を受け取って、roxas(ロクサス)のような文字列を返す関数の作成を目標とします。実行環境
- Python 3.8.6
またPythonの実行環境構築には下記を利用しています。
- Docker 19.03.13
- docker compose 1.27.4
- Poetry 1.1.4
Pythonプログラムの実行に必要なコマンドが本文記載の内容とは一部異なりますが、本文中では省略しています。例えば
$ python main.pyと表記している箇所は、実際には$ docker-compose exec app poetry run python main.pyというコマンドを実行しています。
これらを含めた実際のプログラムはGitHubに公開しています。https://github.com/s2terminal/xname
総当たりでのアナグラムの生成
さっそく「元の名前に
X(エックス)を足して並び替えた結果を、新しい名前とする」アナグラムの自動生成をする関数を開発していきます。まずはシンプルに、与えられた文字列のアナグラムを全パターン列挙するプログラムを書いていきます。これは文字列を配列化して、itertools.permutationsを使えば簡単に実現できます。
from itertools import permutations original_name = "abe" for x in permutations([ a for a in original_name ]): print("".join(x))abe aeb bae bea eab eba取りうるアナグラムの列挙はできました。この中からひとつ選んで返す必要があります。そのために、これらのアナグラムのうちどの文字列が良いか、あるいは悪いのか、評価を定義していきます。
「名前らしさ」をあらわすアナグラムの評価関数の定義
たとえば
ROXASのアナグラムとして、ただ適当に並び替えるとSRXAOといった読めない名前も登場してしまいます。そこで「文字列が"名前らしい"かどうか」を何らかの方法で判定する必要があります。ここでは簡単のため、条件はただひとつだけ
- 子音が2つ以上連続していないこと
とします。また、母音も
a,e,i,o,uの5文字のみとします。より厳密には、長さ$n$の文字列$\{x_i\}$から隣接する2文字$x_i,x_{i+1}$を取って
- $x_i$と$x_{i+1}$のいずれも子音だった場合は、0
- $x_i$と$x_{i+1}$のいずれかが母音だった場合は、1
...とした数列(長さ$n-1$)の、平均値を評価関数とします。例えば
SRXAOは0.5、ROXASは1.0となります。プログラムにすると以下のようになります。
src/bruteforce.pyvowels = [ a for a in "aiueo" ] def name_score(name: str, original: str) -> int: score = 0 is_vowel = None for s in name: if (is_vowel is not None and (is_vowel or (s in vowels))): score += 1 is_vowel = (s in vowels) score /= (len(name) - 1) return score「この値が最大になる文字列が、アナグラムとして適切である」として、探索していきます。
探索の実行
先述の評価関数部分を除いた、プログラムの全体像は下記のようになります。
src/bruteforce.pydef search_xname(original_name: str): best_score = 0 best_name = original_name for v in permutations([ n for n in original_name ]): name = "".join(v) score = name_score(name, original_name) if (best_score < score): best_score = score best_name = name return (best_name, best_score) if __name__ == '__main__': original_name = input('input name: ') max_names, score = search_xname(original_name) print("{}は{}になりました。スコア: {}".format(original_name, max_names, score))実行してみましょう。
$ python src/bruteforce.py input name: ora soraはsoraxになりました。スコア: 1.0できました!
soraにxを足したアナグラムはsorax(ソーラックス)になりました。このように、ある条件を満たす解候補の中から最も最適な解を見つけることを最適化と言います。特に、最適化の対象や解候補の条件が数式で表されてる最適化を数理最適化と言います。1 このプログラムでいう
name_score()のように、数理最適化において最適化対象となる関数を目的関数と呼びます。レーベンシュタイン距離による目的関数へのペナルティの導入で、元の名前と"似ていない"名前を探索する
しかし。
soraにxを足して探索したアナグラムがsoraxというのは、「末尾に文字を付けただけでは...」となって、なんだか"面白み"に欠ける結果です。なぜ面白くないのでしょうか。ここでは「元の名前と似ているから面白くない」と仮定します。もう少し面白いアナグラムになるよう、プログラムを改良してみましょう。
そこで「元の名前と似ていないアナグラム」を探すために、「元の名前とどれくらい似ているか」を定量化します。ここではレーベンシュタイン距離を導入します。
レーベンシュタイン距離とは、元の文字列から挿入・削除・置換・交換といった操作を何回行えば目的の文字列を得られるか、という指標です。「距離」とあるだけあって、多ければ多いほど遠いです。例えば「sora」と「sorax」のレーベンシュタイン距離は、「x」を挿入する1回の操作だけで目的の文字列が得られるため、1です。
ここでは、文字列の長さが変わっても同じ指標で比べられるように、レーベンシュタイン距離を目的の文字列の長さで割ることで0〜1の値を取るように標準化した値を用います。
各文字列のレーベンシュタイン距離の例は以下です。
元の文字列 目的の文字列 レーベンシュタイン距離 標準化レーベンシュタイン距離 元の文字と似てるように見えるか sora sorax 1 0.2 似てる sora roxas 3 0.6 似てない sora srxao 3 0.6 似てない ansem xansem 1 0.16666666666666666 似てる ansem xemnas 6 1.0 似てない 標準化したレーベンシュタイン距離の小ささをペナルティとして与えた改善評価関数は以下のようになります。事前にpython-Levenshteinライブラリをインストール・インポートしておく必要があります。
src/bruteforce.pyvowels = [ a for a in "aiueo" ] def name_score(name: str, original: str) -> int: score = 0 is_vowel = None for s in name: if (is_vowel is not None and (is_vowel or (s in vowels))): score += 1 is_vowel = (s in vowels) score /= (len(name) - 1) + score -= (1 - (Levenshtein.distance(name, original)) / (len(name))) return score$ python src/bruteforce.py input name: Sora SoraはSaxorになりました。スコア: 0.8
Saxor(サクソー)という名前が得られました。元のプログラムで得られたSoraxよりは、結構"面白い"結果だと言えるのではないでしょうか。このように目的関数にペナルティを与える等で調整していくと、最適化によって得られる結果がより求められる結果に近づいていきます。
この方法での問題点
さあ、これでどんな名前でもアナグラムが生成できるようになりました。
試しに、スクウェア・エニックスから発売されているゲーム「ファイナルファンタジーVII」に登場する架空のキャラクター「クラウド(Cloud)」の名前を入力してみましょう。
$ python src/bruteforce.py input name: cloud cloudはluxcodになりました。スコア: 0.8おっと、いけません。クラウドの本名はクラウドストライフ(Cloud Strife)と言うのでした。こちらで入力してみましょう。
$ python src/bruteforce.py input name: cloudstrife...なかなか結果が返ってこないと思います。
それでは、バンダイナムコゲームスから発売されている「エースコンバット7」に登場するライバルキャラクター「ミハイ」の本名「Mihaly Dumitru Margareta Corneliu Leopold Blanca Karol Aeon Ignatius Raphael Maria Niketas A Shilage(ミハイドゥミトルマルガレータコルネリウレオポルドブランカカロルイオンイグナチウスラファエルマリアニケタスアシラージ)」の名前を入力してみましょう。
$ python src/bruteforce.py input name: mihalydumitrumargaretacorneliuleopoldblancakarolaeonignatiusraphaelmarianiketasashilage......。
............。
........................結果は全然返って来ないと思います。
このプログラムは順列を探索しています。順列というのは、要素の数が増えるほどパターン数は爆発的に多くなります。以下、パターン数と私のPCでのプログラム実行時間を記します。
文字列 パターン数 実行時間 sora + x 5!=120 0.0018秒 ansem + x 6!=720 0.0133秒 lauriam + x 8!=40,320 0.9546秒 elizabeth + x 10!=3,628,800 145.5917秒 cloudstrife + x 12!=479,001,600 -- mihaly(中略)shilage + x 88!≒$10^{134}$ -- 「mihalydumitrumargaretacorneliuleopoldblancakarolaeonignatiusraphaelmarianiketasashilage」という名前にxを足したアナグラムの探索は、全部で88!=185482642257398439114796845645546284380220968949399346684421580986889562184028199319100141244804501828416633516851200000000000000000000通りの探索となります。これはとても一般的なコンピュータで全部の数値を計算することはできない量です。このプログラムで解を求められるのは、高々10文字くらいの名前が限界だと思います。
このように長い文字列のアナグラムにおいて、今まで述べたような総当たりで厳密な最適解を求めるのは現実的ではありません。このような時でも"だいたいそれらしい"解が得られるように、厳密解ではなく近似解、最大値ではないかもしれない(最大値かもしれない)解を得る方法を見ていきます。
ランダム法による近似解法
解になりうるパターンから適当にいくつか選んで目的関数を計算し、最大値となるパターンを選んでみます。ここで「順列」の中から適当にパターンを選ぶ必要があるのですが、まず「文字数と同じ数の乱数を生成し、昇順に並び替える」方法で、ランダムな順列を得ていきます。各文字に重み付けをしていくようなイメージです。乱数の列をいくつか探索し、その中で最適な物を選んでいきます。
たとえば元の文字列が
soraxであれば、乱数を5個生成し、「5」「2」「1」「4」「3」となればrが1番目、oが2番目...となって最終的にroxasという文字列が解候補として得られます。なお乱数で同じ数字が出た時の挙動を一意にするために、長さ$n$の文字列の$i$番目の文字に対して、0から$n-1$までの乱数$r(n)$を得たときに、$r(n) + i/n$で重み付けをしていきます。
random_search.pyimport random def name_generator(name: str): size = len(name) x = [random.randint(0, size - 1) + i/size for i in range(0, size)] name_list = list(zip([a for a in name], x)) return "".join([x[0] for x in sorted(name_list, key=lambda x: x[1])])これを適当な回数繰り返して探索し、最もいいスコアになった物を最適解として返します。
random_search.pyfrom typing import Callable, List def random_search_base(name: str, name_generator: Callable[[str], str], times: int): original_name = name best_score = -float('inf') best_name = name for _ in range(0, times): tmp_name = name_generator(name) tmp_score = name_score(tmp_name, original_name) if (best_score < tmp_score): best_score = tmp_score best_name = tmp_name return best_name, best_score def search_ary(name: str, times=10): return random_search_base(name, name_generator, times)$ python src/random_search.py input name: cloudstrife ('lscetfdorxui', 0.46212121212121204)
cloudstrifeにxを足したアナグラムとしてlscetfdorxui(ルスセトフドークシー)という結果が得られました。探索回数にもよりますが、1,000回程度であればすぐに結果が返ってきます。(記載したプログラムは10回)実行可能領域への写像を調整する
ここで言う「与えられた文字列のアナグラム」のような、解の候補となる条件を満たした要素のことを数理最適化の用語で実行可能解と呼びます。実行可能解の集合を実行可能領域と呼びます。
このプログラムでの探索空間である「n個の乱数の集合」というのは、「実行可能領域」と1対1で対応しておらず、重複があります。例えば乱数のうち「1,2,3,4,5」も「1,1,1,2,3」も、同じ実行可能解になってしまいます。厳密に言うと、探索空間から実行可能領域への写像が、全射ではありますが単射になっていません。単射になるような写像を定義することで、探索の効率を変えてみましょう。
いままでは$n$通りの乱数を$n$個受け取っていました。
代わりに$n!$通りの乱数をひとつだけ受け取って、$n$で割った余り(0〜$n-1$の$n$通り)をキーとする配列の要素を抽出し、$n$で割った商について同じ手続きを繰り返す、という関数を定義してみます。文字で説明するとなんだかややこしいですが、プログラムにすると下記です。def func(ary: typing.List, i: int) -> typing.List: n = len(ary) if n <= 1: return ary val = ary.pop(i % n) ret = func(ary, i // n) ret.extend([val]) return retこの関数はこんな挙動をします。
l = [1,2,3,4] print(func(l, 0)) print(func(l, 1)) print(func(l, 2)) print(func(l, 3)) print(func(l, 4))python src/opt.py [4, 3, 2, 1] [1, 2, 4, 3] [3, 2, 1, 4] [1, 2, 3, 4] [4, 2, 3, 1]写像$f:N^1\rightarrow N^n$をひとつ挟むことで、探索空間をn次元から1次元に削減しました。プログラムで言うと、生成する乱数がn個から1個に減り、単射になっているので効率が良くなります。
random_search.pydef search_map(name: str, times=DEFAULT_SEARCH_TIMES): name_generator = lambda name: "".join( func([a for a in name], random.randint(0, math.factorial(len(name)) - 1)) ) return random_search_base(name, name_generator, times)実行してみます。
$ python src/random_search.py input name: cloudstrife ('tslrxoiceduf', 0.6363636363636364)
tslrxoiceduf(ツルルクソイセダフ)という結果が得られました。長い文字列でもちゃんと結果が返ってきます。
$ python src/opt.py input name: mihalydumitrumargaretacorneliuleopoldblancakarolaeonignatiusraphaelmarianiketasashilage ('culrlruetailiolkgleapyixanaaphoittnaurimrbsheanlasohamlagsoraritmacdakuenraenelgodmeaaii', 0.5993991640543365)「カルルルルータイリアルクグリーピクサナーフォイトノーリムルブシーンラソハムラグソーラーリトマクダクーンラエネルゴドミーエーイー」という結果が得られました。
このように実行可能領域とは異なる探索空間を定義し、実行可能領域への写像を定義することで探索ができるようになります。この方法を取った場合は、写像や探索空間の定義を工夫することで、最適化の性能を調整できます。実際にはBottom-Left法2のように、実行可能領域が広大で探索が大変な場合等に、より"狭い"探索空間を探索する方法として使われています。
また本稿では乱数を使いましたが、たとえば乱数が1と2とでそれぞれ評価関数にかけた場合に"近い"スコアが結果として得られる場合など、探索空間上の評価関数値が何らかの法則(関数)に沿って分布している場合は、乱数ではなくベイズ最適化(Bayesian Optimization)3など別のブラックボックス最適化の手法を使うことで、より効率的に探索できると思います。
交換近傍による局所探索法
いままでは「実行可能領域は未知のものである」として、乱数列を探索空間として実行可能領域への写像を定義することで、最適化できるようにしてきました。ですが本稿で題材としているのはアナグラムであり、列挙可能な有限個の順列からなる集合です。この実行可能領域の特徴を踏まえて直接探索する方法を紹介します。
アナグラムの探索において、元の文字列に対して「元の文字列をちょっとだけ変えた文字列」を探索していって、目的関数に改善が見られたらその文字列に移動する、という方法が取れます。例えば最初の出発点が
soraxであれば、soraxの目的関数のスコアは0.0ですが、最初と最後の文字だけ入れ替えたxorasという文字列のスコアは0.4です。元の文字列をちょっとだけ変えた文字列の探索を続けていくことで、実行可能領域が広大だったとしてもより良い解を探索できます。このように、ある実行可能解を少しだけ変更した解のことを近傍(Neighborhood)と呼び、解候補の近傍の中からより良い解があれば移動する、という手順を繰り返していく最適化手法のことを局所探索法(Local Search)と呼びます。
まずは「元の文字列から、任意の2文字を選択して入れ替えたもの」を近傍として定義しましょう。このような近傍を交換近傍(Swap-based Neighborhood)と呼びます。Pythonのプログラムで書くと、以下のようなイテレータで表現できます。
local_search.pydef swap_two_any_neighbor(name: str) -> Iterator[int]: size = len(name) for i in range(0, size - 1): for j in range(i + 1, size): yield (i, j)
swap_two_any_neighbor()による近傍を一通り探索するメソッドswap_two_base()を定義します。local_search.pydef swap_two_base(local_best_name: str, original_name: str): best_score = -float('inf') best_name = local_best_name for (i, j) in swap_two_any_neighbor(local_best_name): tmp_name = swap_name(local_best_name, [i,j]) tmp_score = name_score(tmp_name, original_name) if (best_score < tmp_score): best_score = tmp_score best_name = tmp_name return (best_name, best_score) def swap_name(name: str, swaps: Tuple[int, int]) -> str: name_ary = [a for a in name] ret = "" for i in range(len(name)): key = i if i == swaps[0]: key = swaps[1] elif i == swaps[1]: key = swaps[0] ret += name_ary[key] return retそして、
swap_two_base()による手続きを適当な回数(一般的には、目的関数の改善が見られなくなるまで)繰り返します。local_search.pydef local_search_base(original_name: str, times=None): if times is None: times = len(original_name) best_score = -float('inf') best_name = original_name for _ in range(times): (tmp_name, tmp_score) = swap_two_base(best_name, original_name) if (best_score < tmp_score): best_score = tmp_score best_name = tmp_name else: break return (best_name, best_score)実行してみましょう。
$ python src/local_search.py input name: cloudstrife ('dilecufxotsr', 0.7272727272727273)
dilecufxotsr(ディレカフクソツ)という結果が得られました。隣接交換近傍による局所探索法
先のプログラムでは近傍の定義を「任意の2文字を入れ替える」としましたが、ここを変更して「隣接した2文字を入れ替える」としてみます。このような近傍を隣接交換近傍と呼びます。プログラムで表現すると下記です。
local_search.pydef swap_two_adjacent_neighbor(name: str) -> Iterator[int]: size = len(name) for i in range(0, size - 1): yield (i, i + 1)実行してみましょう。
$ python src/local_search.py input name: cloudstrife ('xolusdtirefx', 0.31060606060606066)
colusdtirefx(コラスドティレフクス)という結果が得られました。なんとなく元の文字列に似ているように見えますし、スコアも悪くなってしまっています。このように局所探索法において近傍の定義は複数あり、差し替えることで最適化の結果も変わってきます。本稿で紹介した交換近傍の他に挿入近傍や2-opt近傍といった物があり、問題によって最適な近傍も変わってきます。
局所探索法のスタート点
実際に局所探索法を行う時は、出発点としてそれなりに"良い"解候補から探索を始める事が大切です。しかしこのプログラムでは出発点が元の文字列、つまりレーベンシュタイン距離が最も小さく、スコアの悪い出発点になっています。例えば以下のように、元の文字列を逆順にした文字列を出発点とするような工夫をすると、より良い結果が得られます。
local_search.pydef local_search_base(original_name: str, neighbor_generator: Callable[[int], Iterator[int]], times=None): if times is None: times = len(original_name) best_score = -float('inf') - best_name = original_name + best_name = ''.join(list(reversed(original_name)))この方法の応用として、複数の出発点から局所探索法で解候補を探索していく多スタート局所探索法(multi-start local search)という手法もあります。
線形計画問題としての方法
最後にPuLPというライブラリを用いて、巡回セールスマン問題(Travelling Salesman Problem、TSP)の解き方を応用してみます。本稿で取り上げるアナグラム探索問題はTSPではないためTSPそのものについては説明しませんが、少し知っていたほうが本稿は読みやすいと思います。
数理最適化問題のうち、目的関数と制約条件とが線形(1次式。$c_1x_1+c_2x_2+...$のような形式)で表現できる問題を線形計画問題と言います。PuLPはざっくりいうと、線形計画問題(Linear Programming、LP)を解くライブラリ4です。軽くPuLP自体の紹介をします。
以下は、PuLPのREADMEに載っている線形計画問題の例です。
\begin{eqnarray} \text{Minimize}& &-4x+y \\ \text{Subjet to}& &x+y \leq 2\\ & & 0 \leq x \leq 3 \\ & & 0 \leq y \leq 1 \\ \end{eqnarray}これは、変数$x$は0から3、変数$y$は0から1の値を取るとして、目的関数$x+y$が2以下になるような$(x,y)$の中で、$-4x + y$を最小化するような$(x,y)$を求める、という問題の定式化です。ちなみに答えは$x=2,y=0$です。
この問題をPuLPを使って解くと、以下のようになります。
import pulp # 変数x,yの定義 x = pulp.LpVariable("x", 0, 3) y = pulp.LpVariable("y", 0, 1) # 最小化(Minimize)問題オブジェクトを生成 prob = pulp.LpProblem("myProblem", pulp.LpMinimize) # 制約条件の追加 (問題オブジェクトに式を+=すると条件を追加できる) prob += x + y <= 2 # 目的関数の追加 (等号・不等号の無い式を+=すると制約条件ではなく目的関数の追加となる) prob += -4*x + y # 解の探索 status = prob.solve() # 結果の出力 pulp.LpStatus[status], x.value(), y.value()
('Optimal', 2.0, 0.0)という出力が得られます。Optimal(status=1)というのは、厳密解が得られたという事です。厳密解ではなく近似解が得られた場合は別の出力が得られます。PuLP自体はそこまで複雑ではないものの、通常のプログラミングとはちょっと変わった使い方のライブラリなので戸惑う人もいるかもしれません(筆者がそうでした)。PuLPの詳しい使い方については、PuLPによるモデル作成方法 — Pythonオンライン学習サービス PyQ(パイキュー)等を参考にしてください。
さて、アナグラムの問題に話を戻します。結論から言うと、本稿で取り上げているアナグラムの探索問題を少し簡略化したものが、以下のように一次式で定式化できます。
\begin{eqnarray} &\text{Maximize}\ & CX&&\\ &\text{Subject to}\ & \sum_{i\in V} \sum_{j\in V} x_{ij} = n - 1\\ && \sum_{j\in V} x_{ij}\leq 1 ,\:\sum_{j\in V} x_{ji}\leq 1\:& &(\forall i \in V)\\ && \sum_{j\in V} x_{ij} + \sum_{j\in V} x_{ji} \geq 1\:& &(\forall i \in V) \\ && x_{ii} = 0\:& &(\forall i \in V)\\ \end{eqnarray}\\順に説明していきます。
バイナリ変数から文字列を得る
数理最適化の定式化において、変数をゼロかイチかのバイナリ変数で定義すると、表現力が高まります。そこで、アナグラムにおいて「ある文字の次がある文字である」時に1、そうでない時に0、を取るような変数を使って、この問題を定式化してみます。
$n$文字のアナグラムにおいて、ゼロかイチかを取る変数$x$を$n^2$個用意します。元の文字列の$i$文字目の次が、元の文字列の$j$文字目であるときに$x_{ij}=1$、そうでないときは$x_{ij}=0$となるように定義します。するとアナグラムを探索する問題は、行列$X = \{ x_{ij} \mid x_{ij} \in \{0,1\} \}$を探索する問題であると捉えることができます。
例えば元の文字列として
soraxという文字列があって、アナグラムの最初はroから始まるとしたら、rは3文字目、oは2文字目なので、$x_{32}=1$というように定義していきます。x_{31}=0\\ x_{32}=1\\ x_{33}=0\\ x_{34}=0\\ x_{35}=0\\つまり
x_{3j} = \begin{pmatrix} 0 & 1 & 0 & 0 & 0 \end{pmatrix}同様にして、soraxからroxasというアナグラムを得ることを表す$x$は、以下のように行列で定義できます。
X = \{x_{ij}\} = \begin{pmatrix} 0 & 0 & 0 & 0 & 0\\ 0 & 0 & 0 & 0 & 1\\ 0 & 1 & 0 & 0 & 0\\ 1 & 0 & 0 & 0 & 0\\ 0 & 0 & 0 & 1 & 0\\ \end{pmatrix}このような名前のバイナリ行列$X$を探索する問題であると定義することができます。
行列の扱いはプログラムでは簡単です。今回は多次元Listを用いて定義します。名前のバイナリ行列から実際の名前を得る関数は下記のように定義できます。
pulp_search.pydef target_name(xs, name: str): size = len(name) start = 0 # 最初の1文字を探す for j in range(size): if (all([xs[i][j] == 0 for i in range(size)])): start = j ret = name[start] current = start for _ in range(size - 1): for j in range(size): if xs[current][j] == 1: ret += name[j] current = j break return ret目的関数の定式化
名前のバイナリ行列と同様の手順で、元の文字列に対して母音が連続している箇所を示す下記のような定数行列を導入します。
cs = [] for i in range(size): cs.append([]) for j in range(size): if name[i] in vowels or name[j] in vowels: cs[i].append(1) else: cs[i].append(0)この$X$と$C$の内積を最大化する問題である、と言えます。
\text{Maximize}\ CX\\これをPulPプログラムで表すと、下記のようになります。
prob = pulp.LpProblem('myprob', sense=pulp.LpMaximize) prob += pulp.lpSum([pulp.lpDot(c, x) for c, x in zip(cs, xs)])制約条件の定義
定義したバイナリ文字列は制約が無さすぎます。今回のアナグラム問題に適用できるよう、制約を追加していきます。
まず「探索する対象はn文字の文字列である」という条件は「文字の連続がn-1回だけ起きる」と言えるため、つまりイチになっている箇所がn-1個だけあれば良いわけです。数式だと以下のように表現できます。
なお、以下$V$を1から$n$までの整数の集合$V=\{ i \mid i \in \mathbb{N}, 1 \leq i \leq n \}$とします。
\sum_{i\in V} \sum_{j\in V} x_{ij} = n - 1\\prob += pulp.lpSum([pulp.lpSum([x2 for x2 in x1]) for x1 in xs]) == size - 1「各文字への行きと帰りは、それぞれ一度しか選ばれない」という条件は、「バイナリ行列$X$のどの行または列も、合計値が1以下」と言えます。(「1になる」ではなく「1以下」としているのは、「最初の文字へ帰る文字」と「最後の文字から行く文字」が無いからです)
\sum_{j\in V} x_{ij}\leq 1 ,\:\sum_{j\in V} x_{ji}\leq 1\: (\forall i \in V)\\プログラムにすると以下のように書けます。
for i in range(size): prob += pulp.lpSum([xs[j][i] for j in range(size)]) <= 1 prob += pulp.lpSum([xs[i][j] for j in range(size)]) <= 1また、「すべての文字は、行きか帰りに最低一度は選ばれる」という制約が必要です。
\sum_{j\in V} x_{ij} + \sum_{j\in V} x_{ji} \geq 1\: (\forall i \in V) \\for i in range(size): prob += pulp.lpSum([xs[i][j] for j in range(size)]) + pulp.lpSum([xs[j][i] for j in range(size)]) >= 1「同じ文字には連続しない」という制約は下記です。
x_{ii} = 0\: (\forall i \in V)for i in range(size): prob += xs[i][i] == 0また、部分順回路(subtour)を排除する必要があります。たとえばここまでの制約だけだと、
cloudstrifexという文字列のアナグラムを探索した時にx→l→r→x→...のように、すべての文字列を回ること無く一部だけでループした結果が得られてしまいます。このような結果の対策となる制約条件を追加します。詳細は、TSPの例ですがこの記事やこの記事を読んでください。なおTSPのようなハミルトン閉路では$i,j = 0$のとき制約を追加しないのですが、今回アナグラムの探索は閉路ではない(最後の文字と最初の文字が繋がっているわけではない)ので、そのような対応はしていません。for i in range(size): for j in range(size): if i != j: prob += u[i] - u[j] <= (1 - xs[i][j]) * size - 1以上で準備完了です。実行してみましょう。
$ run python src/pulp_search.py (中略) ('xrdsucelifot', 0.5606060606060607)
xrdsucelifot(クスルドスーセリフォット)という結果が得られました!...結構大変だった割に、あまり"スコア"が高くないですね。ここまで読んだ方は気づいたかもしれませんが、今までの手法と異なりPuLPでの探索時にはレーベンシュタイン距離によるペナルティを導入できていません。このように、現実の問題はすべて一次式で表現できるわけではないのですが、一次式で表現できない制約は盛り込むことができない点が線形計画法のライブラリを使う際の弱点になります。レーベンシュタイン距離ではなく一次式で表現できるような何らかの距離を代替として導入できれば、改善できると思います。
まとめ
cloudstrifeにxを加えた文字列から得られたアナグラムをまとめると下記になります。どの結果が気に入りましたか?
手法 得られたアナグラム (よみ) スコア 総当たり - - - N次元探索空間ランダム Lscetfdorxui ルスセトフドークシー 0.46212121212121204 1次元探索空間ランダム Tslrxoiceduf ツルルクソイセダフ 0.6363636363636364 交換近傍による局所探索 Dilecufxotsr ディレカフクソツ 0.7272727272727273 隣接交換近傍による局所探索 Colusdtirefx コラスドティレフクス 0.31060606060606066 PuLP Xrdsucelifot クスルドスーセリフォット 0.5606060606060607 本稿では、要素の並び替え問題をプログラムによって自動で解く方法を紹介しました。「ランダム法」「局所探索法」「線形計画法」を利用してアナグラムを得ることができ、またそれらの改善余地について明らかにしました。本稿ではアナグラムを題材としましたが、順列を最適化するような問題にはこれら技術の一部または全部を応用することができると思います。
冒頭に述べたとおり、私のチームではWebサイト上の掲載コンテンツ表示順序を最適化するためにこの技術を研究しており、本稿で最初から述べてきたのとほぼ同じ手順で調査・開発してきたものになります。そのため本稿自体はアナグラムの探索やTSPの解法としては非効率な手順も紹介していますが、最適化手法を一部でもなにかに応用するような時に、参考になればと思います。
もし実際にアナグラムを自動生成するときは、単なる順列ではなく要素に重複がある問題となるため、工夫をすることで探索空間を大幅に削減できると思います。また、現行のプログラムでは
MarluxiaやXemnasといった文字列は正しい名前である5ものの目的関数による評価値が最大になりません。「名前らしさ」の定義をより厳密にすることで、より良いアナグラムが得られるプログラムになると思います。参考文献
- 朝倉書店|Pythonによる 数理最適化入門
- 最適化手法入門 | 書籍情報 | 株式会社 講談社サイエンティフィク
- 局所探索法とその拡張—タブー探索法を中心として Local Search and its Extensions—Focusing on Tabu Search 野々部 宏司* 柳浦 睦憲**
- 線形順序付け問題の解法 櫻庭 セルソ 智,柳浦 睦憲
- 組み合わせ最適化問題に対する近似解法
- PuLP による数理最適化超入門
- 巡回セールスマン問題 | Code Craft House
- XIII機関 - Wikipedia
- エースコンバット7 スカイズ・アンノウン - Wikipedia
また、本文中の架空の英語文字列のカタカナ表記は英語→カタカナ変換機によって機械的に生成しました。
http://www.msi.co.jp/nuopt/glossary/term_4497146a690870abd1038155739dc60e78d8f20c.html ↩
https://tech.preferred.jp/ja/blog/high-dimensional-black-box-optimization-using-bayesian-optimization/ ↩
厳密にはPuLPは線形計画問題ソルバーのラッパーライブラリであり、デフォルトでCBCというソルバーが設定されています。 ↩
- 投稿日:2020-11-22T15:43:06+09:00
Qiskit: VQEを実装してみた
QiskitでVQEを実装してみた.
今回はIBMが提供している量子コンピュータ用のオープンソースフレームワークを用いてVQE(Variational Quantum Eigensolver)を実装していきます.このアルゴリズムは量子化学への応用が期待されているアルゴリズムです.理論的な解説はQuantum Native Dojoを参照お願いします.
VQEの実装記事は複数あるとは思いますが,日本語記事の殆どはQulacsやBlueqatを用いて書かれているので今回Qiskitで実装を試みてみました.過去にQAOAやQCLの記事も書いているので是非みてみてください.
Qiskit Aquaを使わないQAOAの実装
Quantum Circuit Learningの実装実装
ライブラリのimport
from qiskit import Aer, execute from qiskit import QuantumCircuit from qiskit.aqua.utils import tensorproduct from qiskit.quantum_info.analysis import average_data from scipy.optimize import minimize import numpy as np初期化
class VQE: def __init__(self, n_qubits, observable, layer, backend): self.n_qubits = n_qubits self.OBS = observable self.Layer = layer self.backend = backend今回はHamiltonianも入力として扱います.
回路の作成
def make_circuit(self, Params): def make_U_circuit(circ, params): for n in range(self.n_qubits): param = params[3*n:3*(n+1)] circ.rz(param[0], n) circ.rx(param[1], n) circ.rz(param[2], n) return circ def make_Ent(circ): for n in range(self.n_qubits-1): circ.cx(n, n+1) return circ # 回路を設定 circ = QuantumCircuit(self.n_qubits, self.n_qubits) for l in range(self.Layer): # parameter circuitの作成 params = Params[3*self.n_qubits*l:3*self.n_qubits*(l+1)] # entanglementの作成 make_U_circuit(circ, params) # Layerの数-1にしなければならないので if l != self.Layer-1: make_Ent(circ) # 測定 circ.measure(circ.qregs[0], circ.cregs[0]) return circVQE実行フェーズ
def outputlayer(self, params): circ = self.make_circuit(params) counts = execute(circ, backend=self.backend, shots=8192).result().get_counts() return average_data(counts, self.OBS) def initial_params(self): # 初期parameterの作成 init = [0.1 for _ in range(3 * self.Layer * self.n_qubits)] return np.array(init) def minimize(self): initial_params = self.initial_params() # 最適化の実行 opt_params, opt_cost = classica_minimize(self.outputlayer, initial_params, options={'maxiter':500}) circ = self.make_circuit(opt_params) counts = execute(circ, backend=self.backend, shots=8192).result().get_counts() ans = sorted(counts.items(), key=lambda x: x[1], reverse=True) print(ans) return opt_costなお,他の記事と異なりlayerというのを使用しています.これは参考文献[1]に載っているものです.軽く解説させていただきます.
$\theta=(\theta_1, \theta_2, \cdots, \theta_d)$をパラメータの集合とした時,回路はU(\theta) = U_d(\theta_d)U_{ENT} \cdots U_1(\theta_1)U_{ENT}U_0(\theta_0)と書けます.この時の$d$がlayer数となります.$d=2$とすることで他の記事と同じ回路を作成することが可能となります.
実行
今回はHamiltonianとして他の記事でも扱っている式を用います.
Supplementary Informationdef sample_hamiltonian(): ''' https://dojo.qulacs.org/ja/latest/notebooks/5.1_variational_quantum_eigensolver.html のHamiltonianを使用. ''' I_mat = np.array([[1, 0], [0, 1]]) X_mat = np.array([[0, 1], [1, 0]]) Z_mat = np.array([[1, 0], [0, -1]]) obs = np.zeros((4, 4)) obs += -3.8505 * tensorproduct(I_mat, I_mat) obs += -0.2288 * tensorproduct(I_mat, X_mat) obs += -1.0466 * tensorproduct(I_mat, Z_mat) obs += 0.2613 * tensorproduct(X_mat, X_mat) obs += 0.2288 * tensorproduct(X_mat, Z_mat) obs += -1.0466 * tensorproduct(Z_mat, I_mat) obs += 0.2288 * tensorproduct(Z_mat, X_mat) obs += 0.2356 * tensorproduct(Z_mat, Z_mat) return obs / 2また,古典最適化として私が書いている他の記事でも用いている関数を使います.
def classica_minimize(cost_func, initial_params, options, method='powell'): print('classical minimize is starting now... ') result = minimize(cost_func, initial_params, options=options, method=method) print('opt_cost: {}'.format(result.fun)) print('opt_params: {}'.format(result.x)) return result.x, result.fun実行です.
if __name__ == '__main__': backend = Aer.get_backend('qasm_simulator') obs = sample_hamiltonian() vqe = VQE(2, obs, 2, backend) vqe.minimize()実行結果
-2.85405 # vqeの結果 -2.8626207640766816 # 最小固有値他の記事と比較すると精度は落ちますけど一応成功ですかね...?
まとめ
Qiskitを用いてVQEの実装を行ってみました.
正直私自身はVQEよりも古典的問題に適しているQAOAの方が好きなので完全に実装を目的として記事を書かせていただきました.
理論等に関してはご自身でお願いします...参考文献
[1] Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets
[2] Quantum Native Dojo
- 投稿日:2020-11-22T15:40:18+09:00
〔備忘録〕プログラミング事始め
はじめに
現在私は自然科学系の調査を生業としています。そこまで解析が困難な膨大なデータを扱うわけではなく、データ解析にはエクセルがあればほぼ十分。少し難しい解析はRがあればほぼすべてをカバーできるような状況です。ただ、最近機械学習だとか、電子工作だとか、業務の自動化だとか目にすると先々なにか役に立つのではないかということでプログラミングは未経験だけどなにか初めて見ようかなと思った次第です。
勉強したいこと
1.python
機械学習に特化しており、自分の業務になんらかの関連性を見出したからです。
2.電子工作
ArduinoとかESP8266とかラズパイとか。先端技術とは程遠いわが研究分野になんらかの光をさしてくれそうだから。心掛けること
今までは本ばっかり読んでなんらアウトプットはしてきませんでした。なるべく勉強結果をそのまま記載するでもいいからアウトプットを心掛けるようにしたいです。アウトプットしないとまったく覚えていられないんです。いつまで続くかはわかりませんが頑張りたいです。
- 投稿日:2020-11-22T14:27:05+09:00
Webセーフカラーコード一覧
Webセーフカラー カラーコード一覧
Webセーフカラーについて勉強したので、カラーコード一覧をつくってみました。
カラーコード (R, G, B) 補色 反対色 #000000(0, 0, 0)#000000#ffffff#000033(0, 0, 51)#333300#ffffcc#000066(0, 0, 102)#666600#ffff99#000099(0, 0, 153)#999900#ffff66#0000cc(0, 0, 204)#cccc00#ffff33#0000ff(0, 0, 255)#ffff00#ffff00#003300(0, 51, 0)#330033#ffccff#003333(0, 51, 51)#330000#ffcccc#003366(0, 51, 102)#663300#ffcc99#003399(0, 51, 153)#996600#ffcc66#0033cc(0, 51, 204)#cc9900#ffcc33#0033ff(0, 51, 255)#ffcc00#ffcc00#006600(0, 102, 0)#660066#ff99ff#006633(0, 102, 51)#660033#ff99cc#006666(0, 102, 102)#660000#ff9999#006699(0, 102, 153)#993300#ff9966#0066cc(0, 102, 204)#cc6600#ff9933#0066ff(0, 102, 255)#ff9900#ff9900#009900(0, 153, 0)#990099#ff66ff#009933(0, 153, 51)#990066#ff66cc#009966(0, 153, 102)#990033#ff6699#009999(0, 153, 153)#990000#ff6666#0099cc(0, 153, 204)#cc3300#ff6633#0099ff(0, 153, 255)#ff6600#ff6600#00cc00(0, 204, 0)#cc00cc#ff33ff#00cc33(0, 204, 51)#cc0099#ff33cc#00cc66(0, 204, 102)#cc0066#ff3399#00cc99(0, 204, 153)#cc0033#ff3366#00cccc(0, 204, 204)#cc0000#ff3333#00ccff(0, 204, 255)#ff3300#ff3300#00ff00(0, 255, 0)#ff00ff#ff00ff#00ff33(0, 255, 51)#ff00cc#ff00cc#00ff66(0, 255, 102)#ff0099#ff0099#00ff99(0, 255, 153)#ff0066#ff0066#00ffcc(0, 255, 204)#ff0033#ff0033#00ffff(0, 255, 255)#ff0000#ff0000#330000(51, 0, 0)#003333#ccffff#330033(51, 0, 51)#003300#ccffcc#330066(51, 0, 102)#336600#ccff99#330099(51, 0, 153)#669900#ccff66#3300cc(51, 0, 204)#99cc00#ccff33#3300ff(51, 0, 255)#ccff00#ccff00#333300(51, 51, 0)#000033#ccccff#333333(51, 51, 51)#333333#cccccc#333366(51, 51, 102)#666633#cccc99#333399(51, 51, 153)#999933#cccc66#3333cc(51, 51, 204)#cccc33#cccc33#3333ff(51, 51, 255)#ffff33#cccc00#336600(51, 102, 0)#330066#cc99ff#336633(51, 102, 51)#663366#cc99cc#336666(51, 102, 102)#663333#cc9999#336699(51, 102, 153)#996633#cc9966#3366cc(51, 102, 204)#cc9933#cc9933#3366ff(51, 102, 255)#ffcc33#cc9900#339900(51, 153, 0)#660099#cc66ff#339933(51, 153, 51)#993399#cc66cc#339966(51, 153, 102)#993366#cc6699#339999(51, 153, 153)#993333#cc6666#3399cc(51, 153, 204)#cc6633#cc6633#3399ff(51, 153, 255)#ff9933#cc6600#33cc00(51, 204, 0)#9900cc#cc33ff#33cc33(51, 204, 51)#cc33cc#cc33cc#33cc66(51, 204, 102)#cc3399#cc3399#33cc99(51, 204, 153)#cc3366#cc3366#33cccc(51, 204, 204)#cc3333#cc3333#33ccff(51, 204, 255)#ff6633#cc3300#33ff00(51, 255, 0)#cc00ff#cc00ff#33ff33(51, 255, 51)#ff33ff#cc00cc#33ff66(51, 255, 102)#ff33cc#cc0099#33ff99(51, 255, 153)#ff3399#cc0066#33ffcc(51, 255, 204)#ff3366#cc0033#33ffff(51, 255, 255)#ff3333#cc0000#660000(102, 0, 0)#006666#99ffff#660033(102, 0, 51)#006633#99ffcc#660066(102, 0, 102)#006600#99ff99#660099(102, 0, 153)#339900#99ff66#6600cc(102, 0, 204)#66cc00#99ff33#6600ff(102, 0, 255)#99ff00#99ff00#663300(102, 51, 0)#003366#99ccff#663333(102, 51, 51)#336666#99cccc#663366(102, 51, 102)#336633#99cc99#663399(102, 51, 153)#669933#99cc66#6633cc(102, 51, 204)#99cc33#99cc33#6633ff(102, 51, 255)#ccff33#99cc00#666600(102, 102, 0)#000066#9999ff#666633(102, 102, 51)#333366#9999cc#666666(102, 102, 102)#666666#999999#666699(102, 102, 153)#999966#999966#6666cc(102, 102, 204)#cccc66#999933#6666ff(102, 102, 255)#ffff66#999900#669900(102, 153, 0)#330099#9966ff#669933(102, 153, 51)#663399#9966cc#669966(102, 153, 102)#996699#996699#669999(102, 153, 153)#996666#996666#6699cc(102, 153, 204)#cc9966#996633#6699ff(102, 153, 255)#ffcc66#996600#66cc00(102, 204, 0)#6600cc#9933ff#66cc33(102, 204, 51)#9933cc#9933cc#66cc66(102, 204, 102)#cc66cc#993399#66cc99(102, 204, 153)#cc6699#993366#66cccc(102, 204, 204)#cc6666#993333#66ccff(102, 204, 255)#ff9966#993300#66ff00(102, 255, 0)#9900ff#9900ff#66ff33(102, 255, 51)#cc33ff#9900cc#66ff66(102, 255, 102)#ff66ff#990099#66ff99(102, 255, 153)#ff66cc#990066#66ffcc(102, 255, 204)#ff6699#990033#66ffff(102, 255, 255)#ff6666#990000#990000(153, 0, 0)#009999#66ffff#990033(153, 0, 51)#009966#66ffcc#990066(153, 0, 102)#009933#66ff99#990099(153, 0, 153)#009900#66ff66#9900cc(153, 0, 204)#33cc00#66ff33#9900ff(153, 0, 255)#66ff00#66ff00#993300(153, 51, 0)#006699#66ccff#993333(153, 51, 51)#339999#66cccc#993366(153, 51, 102)#339966#66cc99#993399(153, 51, 153)#339933#66cc66#9933cc(153, 51, 204)#66cc33#66cc33#9933ff(153, 51, 255)#99ff33#66cc00#996600(153, 102, 0)#003399#6699ff#996633(153, 102, 51)#336699#6699cc#996666(153, 102, 102)#669999#669999#996699(153, 102, 153)#669966#669966#9966cc(153, 102, 204)#99cc66#669933#9966ff(153, 102, 255)#ccff66#669900#999900(153, 153, 0)#000099#6666ff#999933(153, 153, 51)#333399#6666cc#999966(153, 153, 102)#666699#666699#999999(153, 153, 153)#999999#666666#9999cc(153, 153, 204)#cccc99#666633#9999ff(153, 153, 255)#ffff99#666600#99cc00(153, 204, 0)#3300cc#6633ff#99cc33(153, 204, 51)#6633cc#6633cc#99cc66(153, 204, 102)#9966cc#663399#99cc99(153, 204, 153)#cc99cc#663366#99cccc(153, 204, 204)#cc9999#663333#99ccff(153, 204, 255)#ffcc99#663300#99ff00(153, 255, 0)#6600ff#6600ff#99ff33(153, 255, 51)#9933ff#6600cc#99ff66(153, 255, 102)#cc66ff#660099#99ff99(153, 255, 153)#ff99ff#660066#99ffcc(153, 255, 204)#ff99cc#660033#99ffff(153, 255, 255)#ff9999#660000#cc0000(204, 0, 0)#00cccc#33ffff#cc0033(204, 0, 51)#00cc99#33ffcc#cc0066(204, 0, 102)#00cc66#33ff99#cc0099(204, 0, 153)#00cc33#33ff66#cc00cc(204, 0, 204)#00cc00#33ff33#cc00ff(204, 0, 255)#33ff00#33ff00#cc3300(204, 51, 0)#0099cc#33ccff#cc3333(204, 51, 51)#33cccc#33cccc#cc3366(204, 51, 102)#33cc99#33cc99#cc3399(204, 51, 153)#33cc66#33cc66#cc33cc(204, 51, 204)#33cc33#33cc33#cc33ff(204, 51, 255)#66ff33#33cc00#cc6600(204, 102, 0)#0066cc#3399ff#cc6633(204, 102, 51)#3399cc#3399cc#cc6666(204, 102, 102)#66cccc#339999#cc6699(204, 102, 153)#66cc99#339966#cc66cc(204, 102, 204)#66cc66#339933#cc66ff(204, 102, 255)#99ff66#339900#cc9900(204, 153, 0)#0033cc#3366ff#cc9933(204, 153, 51)#3366cc#3366cc#cc9966(204, 153, 102)#6699cc#336699#cc9999(204, 153, 153)#99cccc#336666#cc99cc(204, 153, 204)#99cc99#336633#cc99ff(204, 153, 255)#ccff99#336600#cccc00(204, 204, 0)#0000cc#3333ff#cccc33(204, 204, 51)#3333cc#3333cc#cccc66(204, 204, 102)#6666cc#333399#cccc99(204, 204, 153)#9999cc#333366#cccccc(204, 204, 204)#cccccc#333333#ccccff(204, 204, 255)#ffffcc#333300#ccff00(204, 255, 0)#3300ff#3300ff#ccff33(204, 255, 51)#6633ff#3300cc#ccff66(204, 255, 102)#9966ff#330099#ccff99(204, 255, 153)#cc99ff#330066#ccffcc(204, 255, 204)#ffccff#330033#ccffff(204, 255, 255)#ffcccc#330000#ff0000(255, 0, 0)#00ffff#00ffff#ff0033(255, 0, 51)#00ffcc#00ffcc#ff0066(255, 0, 102)#00ff99#00ff99#ff0099(255, 0, 153)#00ff66#00ff66#ff00cc(255, 0, 204)#00ff33#00ff33#ff00ff(255, 0, 255)#00ff00#00ff00#ff3300(255, 51, 0)#00ccff#00ccff#ff3333(255, 51, 51)#33ffff#00cccc#ff3366(255, 51, 102)#33ffcc#00cc99#ff3399(255, 51, 153)#33ff99#00cc66#ff33cc(255, 51, 204)#33ff66#00cc33#ff33ff(255, 51, 255)#33ff33#00cc00#ff6600(255, 102, 0)#0099ff#0099ff#ff6633(255, 102, 51)#33ccff#0099cc#ff6666(255, 102, 102)#66ffff#009999#ff6699(255, 102, 153)#66ffcc#009966#ff66cc(255, 102, 204)#66ff99#009933#ff66ff(255, 102, 255)#66ff66#009900#ff9900(255, 153, 0)#0066ff#0066ff#ff9933(255, 153, 51)#3399ff#0066cc#ff9966(255, 153, 102)#66ccff#006699#ff9999(255, 153, 153)#99ffff#006666#ff99cc(255, 153, 204)#99ffcc#006633#ff99ff(255, 153, 255)#99ff99#006600#ffcc00(255, 204, 0)#0033ff#0033ff#ffcc33(255, 204, 51)#3366ff#0033cc#ffcc66(255, 204, 102)#6699ff#003399#ffcc99(255, 204, 153)#99ccff#003366#ffcccc(255, 204, 204)#ccffff#003333#ffccff(255, 204, 255)#ccffcc#003300#ffff00(255, 255, 0)#0000ff#0000ff#ffff33(255, 255, 51)#3333ff#0000cc#ffff66(255, 255, 102)#6666ff#000099#ffff99(255, 255, 153)#9999ff#000066#ffffcc(255, 255, 204)#ccccff#000033#ffffff(255, 255, 255)#ffffff#000000Webセーフカラー
Webセーフカラーとは、ブラウザやOSといった環境が異なっても同じように表示されるカラーのこと。
RGBをそれぞれ6段階(16進数表記の場合、00、33、66、99、CC、FF)に分け、それらの組み合わせでできる色。
全216色。Pythonコード
上記を出力したPythonコードは以下です。
環境は、Google Colaboratoryを使用しました。print('|カラーコード|(R, G, B)|補色|反対色|') print('|:---:|:---:|:---:|:---:|') for r in range(0, 256, 51): for g in range(0, 256, 51): for b in range(0, 256, 51): # 補色の計算 tmp = max(r, g, b) + min(r, g, b) r_c = tmp - r g_c = tmp - g b_c = tmp - b # 反対色の計算 r_o = 255 - r g_o = 255 - g b_o = 255 - b color_code = '#' + format(r, '02x') + format(g, '02x') + format(b, '02x') # 16進数に変換 rgb = '({}, {}, {})'.format(r, g, b) color_code_comp = '#' + format(r_c, '02x') + format(g_c, '02x') + format(b_c, '02x') color_code_opposit = '#' + format(r_o, '02x') + format(g_o, '02x') + format(b_o, '02x') print('|`{}`|`{}`|`{}`|`{}`|'.format(color_code, rgb, color_code_comp, color_code_opposit))補色
補色は、RGB値の最大値と最小値を足した値から、RGBそれぞれの値を引いたものになります。
反対色
反対色は、255からRGBそれぞれの値を引いたものになります。
参考
- 投稿日:2020-11-22T14:27:05+09:00
Webセーフカラーのカラーコード一覧
Webセーフカラー カラーコード一覧
Webセーフカラーについて勉強したので、カラーコード一覧をつくってみました。
カラーコード (R, G, B) 補色 反対色 #000000(0, 0, 0)#000000#ffffff#000033(0, 0, 51)#333300#ffffcc#000066(0, 0, 102)#666600#ffff99#000099(0, 0, 153)#999900#ffff66#0000cc(0, 0, 204)#cccc00#ffff33#0000ff(0, 0, 255)#ffff00#ffff00#003300(0, 51, 0)#330033#ffccff#003333(0, 51, 51)#330000#ffcccc#003366(0, 51, 102)#663300#ffcc99#003399(0, 51, 153)#996600#ffcc66#0033cc(0, 51, 204)#cc9900#ffcc33#0033ff(0, 51, 255)#ffcc00#ffcc00#006600(0, 102, 0)#660066#ff99ff#006633(0, 102, 51)#660033#ff99cc#006666(0, 102, 102)#660000#ff9999#006699(0, 102, 153)#993300#ff9966#0066cc(0, 102, 204)#cc6600#ff9933#0066ff(0, 102, 255)#ff9900#ff9900#009900(0, 153, 0)#990099#ff66ff#009933(0, 153, 51)#990066#ff66cc#009966(0, 153, 102)#990033#ff6699#009999(0, 153, 153)#990000#ff6666#0099cc(0, 153, 204)#cc3300#ff6633#0099ff(0, 153, 255)#ff6600#ff6600#00cc00(0, 204, 0)#cc00cc#ff33ff#00cc33(0, 204, 51)#cc0099#ff33cc#00cc66(0, 204, 102)#cc0066#ff3399#00cc99(0, 204, 153)#cc0033#ff3366#00cccc(0, 204, 204)#cc0000#ff3333#00ccff(0, 204, 255)#ff3300#ff3300#00ff00(0, 255, 0)#ff00ff#ff00ff#00ff33(0, 255, 51)#ff00cc#ff00cc#00ff66(0, 255, 102)#ff0099#ff0099#00ff99(0, 255, 153)#ff0066#ff0066#00ffcc(0, 255, 204)#ff0033#ff0033#00ffff(0, 255, 255)#ff0000#ff0000#330000(51, 0, 0)#003333#ccffff#330033(51, 0, 51)#003300#ccffcc#330066(51, 0, 102)#336600#ccff99#330099(51, 0, 153)#669900#ccff66#3300cc(51, 0, 204)#99cc00#ccff33#3300ff(51, 0, 255)#ccff00#ccff00#333300(51, 51, 0)#000033#ccccff#333333(51, 51, 51)#333333#cccccc#333366(51, 51, 102)#666633#cccc99#333399(51, 51, 153)#999933#cccc66#3333cc(51, 51, 204)#cccc33#cccc33#3333ff(51, 51, 255)#ffff33#cccc00#336600(51, 102, 0)#330066#cc99ff#336633(51, 102, 51)#663366#cc99cc#336666(51, 102, 102)#663333#cc9999#336699(51, 102, 153)#996633#cc9966#3366cc(51, 102, 204)#cc9933#cc9933#3366ff(51, 102, 255)#ffcc33#cc9900#339900(51, 153, 0)#660099#cc66ff#339933(51, 153, 51)#993399#cc66cc#339966(51, 153, 102)#993366#cc6699#339999(51, 153, 153)#993333#cc6666#3399cc(51, 153, 204)#cc6633#cc6633#3399ff(51, 153, 255)#ff9933#cc6600#33cc00(51, 204, 0)#9900cc#cc33ff#33cc33(51, 204, 51)#cc33cc#cc33cc#33cc66(51, 204, 102)#cc3399#cc3399#33cc99(51, 204, 153)#cc3366#cc3366#33cccc(51, 204, 204)#cc3333#cc3333#33ccff(51, 204, 255)#ff6633#cc3300#33ff00(51, 255, 0)#cc00ff#cc00ff#33ff33(51, 255, 51)#ff33ff#cc00cc#33ff66(51, 255, 102)#ff33cc#cc0099#33ff99(51, 255, 153)#ff3399#cc0066#33ffcc(51, 255, 204)#ff3366#cc0033#33ffff(51, 255, 255)#ff3333#cc0000#660000(102, 0, 0)#006666#99ffff#660033(102, 0, 51)#006633#99ffcc#660066(102, 0, 102)#006600#99ff99#660099(102, 0, 153)#339900#99ff66#6600cc(102, 0, 204)#66cc00#99ff33#6600ff(102, 0, 255)#99ff00#99ff00#663300(102, 51, 0)#003366#99ccff#663333(102, 51, 51)#336666#99cccc#663366(102, 51, 102)#336633#99cc99#663399(102, 51, 153)#669933#99cc66#6633cc(102, 51, 204)#99cc33#99cc33#6633ff(102, 51, 255)#ccff33#99cc00#666600(102, 102, 0)#000066#9999ff#666633(102, 102, 51)#333366#9999cc#666666(102, 102, 102)#666666#999999#666699(102, 102, 153)#999966#999966#6666cc(102, 102, 204)#cccc66#999933#6666ff(102, 102, 255)#ffff66#999900#669900(102, 153, 0)#330099#9966ff#669933(102, 153, 51)#663399#9966cc#669966(102, 153, 102)#996699#996699#669999(102, 153, 153)#996666#996666#6699cc(102, 153, 204)#cc9966#996633#6699ff(102, 153, 255)#ffcc66#996600#66cc00(102, 204, 0)#6600cc#9933ff#66cc33(102, 204, 51)#9933cc#9933cc#66cc66(102, 204, 102)#cc66cc#993399#66cc99(102, 204, 153)#cc6699#993366#66cccc(102, 204, 204)#cc6666#993333#66ccff(102, 204, 255)#ff9966#993300#66ff00(102, 255, 0)#9900ff#9900ff#66ff33(102, 255, 51)#cc33ff#9900cc#66ff66(102, 255, 102)#ff66ff#990099#66ff99(102, 255, 153)#ff66cc#990066#66ffcc(102, 255, 204)#ff6699#990033#66ffff(102, 255, 255)#ff6666#990000#990000(153, 0, 0)#009999#66ffff#990033(153, 0, 51)#009966#66ffcc#990066(153, 0, 102)#009933#66ff99#990099(153, 0, 153)#009900#66ff66#9900cc(153, 0, 204)#33cc00#66ff33#9900ff(153, 0, 255)#66ff00#66ff00#993300(153, 51, 0)#006699#66ccff#993333(153, 51, 51)#339999#66cccc#993366(153, 51, 102)#339966#66cc99#993399(153, 51, 153)#339933#66cc66#9933cc(153, 51, 204)#66cc33#66cc33#9933ff(153, 51, 255)#99ff33#66cc00#996600(153, 102, 0)#003399#6699ff#996633(153, 102, 51)#336699#6699cc#996666(153, 102, 102)#669999#669999#996699(153, 102, 153)#669966#669966#9966cc(153, 102, 204)#99cc66#669933#9966ff(153, 102, 255)#ccff66#669900#999900(153, 153, 0)#000099#6666ff#999933(153, 153, 51)#333399#6666cc#999966(153, 153, 102)#666699#666699#999999(153, 153, 153)#999999#666666#9999cc(153, 153, 204)#cccc99#666633#9999ff(153, 153, 255)#ffff99#666600#99cc00(153, 204, 0)#3300cc#6633ff#99cc33(153, 204, 51)#6633cc#6633cc#99cc66(153, 204, 102)#9966cc#663399#99cc99(153, 204, 153)#cc99cc#663366#99cccc(153, 204, 204)#cc9999#663333#99ccff(153, 204, 255)#ffcc99#663300#99ff00(153, 255, 0)#6600ff#6600ff#99ff33(153, 255, 51)#9933ff#6600cc#99ff66(153, 255, 102)#cc66ff#660099#99ff99(153, 255, 153)#ff99ff#660066#99ffcc(153, 255, 204)#ff99cc#660033#99ffff(153, 255, 255)#ff9999#660000#cc0000(204, 0, 0)#00cccc#33ffff#cc0033(204, 0, 51)#00cc99#33ffcc#cc0066(204, 0, 102)#00cc66#33ff99#cc0099(204, 0, 153)#00cc33#33ff66#cc00cc(204, 0, 204)#00cc00#33ff33#cc00ff(204, 0, 255)#33ff00#33ff00#cc3300(204, 51, 0)#0099cc#33ccff#cc3333(204, 51, 51)#33cccc#33cccc#cc3366(204, 51, 102)#33cc99#33cc99#cc3399(204, 51, 153)#33cc66#33cc66#cc33cc(204, 51, 204)#33cc33#33cc33#cc33ff(204, 51, 255)#66ff33#33cc00#cc6600(204, 102, 0)#0066cc#3399ff#cc6633(204, 102, 51)#3399cc#3399cc#cc6666(204, 102, 102)#66cccc#339999#cc6699(204, 102, 153)#66cc99#339966#cc66cc(204, 102, 204)#66cc66#339933#cc66ff(204, 102, 255)#99ff66#339900#cc9900(204, 153, 0)#0033cc#3366ff#cc9933(204, 153, 51)#3366cc#3366cc#cc9966(204, 153, 102)#6699cc#336699#cc9999(204, 153, 153)#99cccc#336666#cc99cc(204, 153, 204)#99cc99#336633#cc99ff(204, 153, 255)#ccff99#336600#cccc00(204, 204, 0)#0000cc#3333ff#cccc33(204, 204, 51)#3333cc#3333cc#cccc66(204, 204, 102)#6666cc#333399#cccc99(204, 204, 153)#9999cc#333366#cccccc(204, 204, 204)#cccccc#333333#ccccff(204, 204, 255)#ffffcc#333300#ccff00(204, 255, 0)#3300ff#3300ff#ccff33(204, 255, 51)#6633ff#3300cc#ccff66(204, 255, 102)#9966ff#330099#ccff99(204, 255, 153)#cc99ff#330066#ccffcc(204, 255, 204)#ffccff#330033#ccffff(204, 255, 255)#ffcccc#330000#ff0000(255, 0, 0)#00ffff#00ffff#ff0033(255, 0, 51)#00ffcc#00ffcc#ff0066(255, 0, 102)#00ff99#00ff99#ff0099(255, 0, 153)#00ff66#00ff66#ff00cc(255, 0, 204)#00ff33#00ff33#ff00ff(255, 0, 255)#00ff00#00ff00#ff3300(255, 51, 0)#00ccff#00ccff#ff3333(255, 51, 51)#33ffff#00cccc#ff3366(255, 51, 102)#33ffcc#00cc99#ff3399(255, 51, 153)#33ff99#00cc66#ff33cc(255, 51, 204)#33ff66#00cc33#ff33ff(255, 51, 255)#33ff33#00cc00#ff6600(255, 102, 0)#0099ff#0099ff#ff6633(255, 102, 51)#33ccff#0099cc#ff6666(255, 102, 102)#66ffff#009999#ff6699(255, 102, 153)#66ffcc#009966#ff66cc(255, 102, 204)#66ff99#009933#ff66ff(255, 102, 255)#66ff66#009900#ff9900(255, 153, 0)#0066ff#0066ff#ff9933(255, 153, 51)#3399ff#0066cc#ff9966(255, 153, 102)#66ccff#006699#ff9999(255, 153, 153)#99ffff#006666#ff99cc(255, 153, 204)#99ffcc#006633#ff99ff(255, 153, 255)#99ff99#006600#ffcc00(255, 204, 0)#0033ff#0033ff#ffcc33(255, 204, 51)#3366ff#0033cc#ffcc66(255, 204, 102)#6699ff#003399#ffcc99(255, 204, 153)#99ccff#003366#ffcccc(255, 204, 204)#ccffff#003333#ffccff(255, 204, 255)#ccffcc#003300#ffff00(255, 255, 0)#0000ff#0000ff#ffff33(255, 255, 51)#3333ff#0000cc#ffff66(255, 255, 102)#6666ff#000099#ffff99(255, 255, 153)#9999ff#000066#ffffcc(255, 255, 204)#ccccff#000033#ffffff(255, 255, 255)#ffffff#000000Webセーフカラー
Webセーフカラーとは、ブラウザやOSといった環境が異なっても同じように表示されるカラーのこと。
RGBをそれぞれ6段階(16進数表記の場合、00、33、66、99、CC、FF)に分け、それらの組み合わせでできる色。
全216色。Pythonコード
上記を出力したPythonコードは以下です。
環境は、Google Colaboratoryを使用しました。print('|カラーコード|(R, G, B)|補色|反対色|') print('|:---:|:---:|:---:|:---:|') for r in range(0, 256, 51): for g in range(0, 256, 51): for b in range(0, 256, 51): # 補色の計算 tmp = max(r, g, b) + min(r, g, b) r_c = tmp - r g_c = tmp - g b_c = tmp - b # 反対色の計算 r_o = 255 - r g_o = 255 - g b_o = 255 - b color_code = '#' + format(r, '02x') + format(g, '02x') + format(b, '02x') # 16進数に変換 rgb = '({}, {}, {})'.format(r, g, b) color_code_comp = '#' + format(r_c, '02x') + format(g_c, '02x') + format(b_c, '02x') color_code_opposit = '#' + format(r_o, '02x') + format(g_o, '02x') + format(b_o, '02x') print('|`{}`|`{}`|`{}`|`{}`|'.format(color_code, rgb, color_code_comp, color_code_opposit))補色
補色は、RGB値の最大値と最小値を足した値から、RGBそれぞれの値を引いたものになります。
反対色
反対色は、255からRGBそれぞれの値を引いたものになります。
参考
- 投稿日:2020-11-22T14:09:00+09:00
深層強化学習3 実践編:ブロック崩し
Aidemy 2020/11/22
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、深層強化学習の3つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・
・ブロック崩しによる強化学習実践
環境の作成
・Chapter2と同じ方法(gym.make())で環境を作成する。ブロック崩しの場合、引数には「BreakoutDeterministic-v4」を指定する。
・行動数は「env.action_space.n」で確認できる。・コード
モデルの構築
・ここでは多層ニューラルネットワークを構築する。入力は「ブロック崩しの画面4フレーム分」とする。また、計算量を少なくするために、画像はグレースケールの84×84画素にリサイズする。
・モデルはSequential()を使用する。Chapter2と同様にFlatten()で入力を平滑化し、全結合層はDense、活性化関数はActivationで追加する。
・今回は画像(二次元)の入力なので、二次元の畳み込み層である「Convolution2D()」を使用する。第一引数は「filter」で、出力空間の次元数を指定し、第二引数は「kernel_size」で、畳み込んだウィンドウの幅と高さを指定する。「strides」は歩幅、つまりウィンドウの一度に動く幅と高さを指定する。・コード
履歴と方策の設定
・ここもChapter2と同様に、エージェントの作成に必要な履歴と方策を設定する。
・履歴は「SequentialMemory()」を使う。引数にはlimitとwindow_lengthを指定する。
・方策は、ボルツマン方策をとる場合は「BoltzmannQPolicy()」、ε-greedy手法をとる場合は「EpsGreedyQPolicy()」を使う。
・また、パラメータεを線形に変化させるときは、「LinearAnnealedPolicy()」を使用する。引数は、以下のコードのように指定すると、トレーニングの際にパラメータεを10ステップで最大1.0最小0.1の線形に変形し、テストの時は0.05で固定するという意味を表す。・コード
エージェントの設定
・エージェントは「DQNAgent()」の引数にmodel,memory,policy,nb_actions,nb_steps_warmupを渡すことで作成できる。あとは「dqn.compile()」で学習方法を指定すれば良い。第一引数には最適化アルゴリズムを指定し、第二引数には評価関数を指定する。
・コード
学習の実施
・前項の設定まで終わったら、次にDQNアルゴリズムを使って学習を行う。「dqn.fit()」で行い、第一引数には環境、第二引数には「nb_steps」で何ステップ学習するかを指定する。
・また、学習結果は「dqn.save_weights()」でhdf5の形式で保存できる。第一引数にはファイル名、第二引数には「overwrite」で上書き可能にするかを指定する。・コード
テストの実施
・学習させたエージェントでテストを行う。「dqn.test()」で行う。引数はfitと同じで、ステップ数nb_stepsの代わりにエピソード数「nb_episodes」を指定する。
・ちなみに、今回のブロック崩しでは、ボールを落とすまでが1エピソードである。Dueling DQN
Dueling DQNとは
・Dueling DQN(DDQN)はDQNの発展版で、DQNのネットワーク層の最後を変更したものである。
・DQNでは、最初に「convolution層」が3つの後に、全結合層を経てQ値を出力していたが、DDQNはこの全結合層を2つにわけ、一方では状態価値Vを出力し、もう一方では行動Aを出力する。この2つを入力とした最後の全結合層からQ値を求めることで、DQNよりも性能が上がる。・図
Dueling DQNの実装
・Dueling DQNの実装は、層の追加まではDQNと同じである。エージェントの設定時(DQNAgent())に、引数で「enable_dueling_network=True」とし、Q値の求め方「dueling_type」を指定することで実装できる。dueling_typeには「'avg','max','naive'」を指定できる。
・コード
・結果
まとめ
・ブロック崩しでも、Chapter2の時のように環境などを定義できる。
・モデルの構築については、今回は二次元の画像認識であるので、畳み込みを使用する。「Convolution2D」層を使用する。
・今回の方策ではε-greedy手法を使うのだが、パラメータεは線形に変化させる必要がある。このような時は、「LinearAnnealedPolicy()」を使って線形に変化させる。
・学習まで行ったモデルは「dqn.save_weights()」を使うことでhdf5の形式で保存できる。
・DuelingDQNは全結合を2つに分け、それぞれ状態価値Vと行動Aを算出し、最後の層で、その二つからQ値を求めるDQNである。実装はDQNAgent()に「enable_dueling_network」と「dueling_type」を指定すれば良い。







- 投稿日:2020-11-22T14:06:18+09:00
Pythonでthisを使う(バッド)プラクティス
概要
某OSSで見つけたテクニック。
bs = BookShelf('XX入門', '初めてのYY', '今さら聞けないZZ') bs.map_(lambda: print(this))stdoutXX入門 初めてのYY 今さら聞けないZZ唐突に出現した
this。一体どこから生えてきたのか?種明かし
コールバック呼び出し前に細工をしていた。
class Book: def __init__(self, name): self._name = name def __str__(self): return self._name class BookShelf: def __init__(self, *book_names): self._books = [*map(Book, book_names)] def map_(self, callback): for book in self._books: callback.__globals__['this'] = book callback() del callback.__globals__['this']分かってみれば大したこと無いが、
インタプリタやIDEの拡張を疑いしばらく悩みこんでしまった。バッドプラクティスだと思う理由
次のように、引数として渡した方がPythonicだと思うから。
class BookShelf: def __init__(self, *book_names): self._books = [*map(Book, book_names)] def map_(self, callback): for book in self._books: callback(book) bs = BookShelf('XX入門', '初めてのYY', '今さら聞けないZZ') bs.map_(lambda this: print(this))Zen of Python を大事にしたい。
Explicit is better than implicit.
暗示するより明示するほうがいい。
- 投稿日:2020-11-22T13:51:10+09:00
リアルガチで言語別単価データを集計&比較してみた by Python
前々からフリーランス案件の言語別単価を比較&集計してみたかったので実際に調査してみました
フリーランス案件の情報は下記サイトを元に集計しました
各言語のページに集計情報があったのでそれを元にしていますレバテックフリーランス
https://freelance.levtech.jp※2020年11月21日時点のデータです
Cloud.csv
created_at,skill,count,avg_price,max_price,min_price 20201121,OpenShift,5,62,65,60 20201121,Amazon VPC,1,70,70,70 20201121,Google Cloud Platform,55,80,105,53 20201121,Dynamics CRM,1,65,65,65 20201121,Amazon S3,2,80,85,75 20201121,Amazon EC2,2,74,85,64 20201121,AWS,1926,76,135,20 20201121,Google App Engine,7,77,95,60 20201121,Amazon SimpleDB,1,80,80,80 20201121,Force.com,2,70,70,70 20201121,Office 365,9,56,65,40 20201121,Microsoft Azure,141,67,90,50 20201121,OpenStack,21,64,80,45 20201121,Heroku,29,75,102,55
DB.csv
created_at,skill,count,avg_price,max_price,min_price 20201121,Kyoto Tycoon,1,75,75,75 20201121,SQLite,20,72,90,55 20201121,MySQL,1465,75,125,35 20201121,Symfoware Server,4,60,65,55 20201121,Cassandra,14,62,80,45 20201121,PostgreSQL,487,71,135,35 20201121,Riak,5,63,100,45 20201121,Bigtable,3,86,95,80 20201121,SQL Server,375,65,95,35 20201121,Redis,296,78,105,39 20201121,Hbase,5,68,75,60 20201121,Oracle,971,66,115,25 20201121,Sybase,6,75,85,65 20201121,IMS,3,58,64,55 20201121,Access,88,60,145,40 20201121,DB2,79,64,95,35
FrameWork.csv
created_at,skill,count,avg_price,max_price,min_price 20201121,Pyramid,12,77,105,65 20201121,Rails,237,81,115,45 20201121,MyBatis,61,71,85,55 20201121,Node.js,256,77,125,45 20201121,Backbone.js,77,76,115,39 20201121,Knockout.js,4,72,90,55 20201121,AngularJS,152,74,105,47 20201121,Laravel,343,73,125,40 20201121,JUnit,80,73,125,50 20201121,Wicket,3,82,95,70 20201121,Django,89,83,115,55 20201121,Padrino,2,82,85,80 20201121,iBATIS,14,67,80,55 20201121,Silex,4,76,80,75 20201121,FuelPHP,101,76,115,50 20201121,MVC,69,68,95,37 20201121,CodeIgniter,39,74,105,45 20201121,Liferay,1,70,70,70 20201121,React,378,77,115,40 20201121,Spark,19,82,95,55 20201121,PhoneGap,3,86,95,80 20201121,JSF,18,64,75,55 20201121,jQuery,354,71,95,35 20201121,Seasar2,32,70,95,49 20201121,Spring,362,71,115,45 20201121,Bottle,1,75,75,75 20201121,Catalyst,26,64,72,55 20201121,intra-mart,14,70,135,50 20201121,SAStruts,16,71,95,57 20201121,Flask,25,82,125,65 20201121,Sinatra,6,78,85,75 20201121,Struts,129,67,95,45 20201121,Symfony,55,74,95,55 20201121,CakePHP,149,71,95,50
Language.csv
created_at,skill,count,avg_price,max_price,min_price 20201121,PHP,1560,72,145,35 20201121,CSS,650,70,125,35 20201121,C言語,269,68,115,35 20201121,UML,7,70,85,50 20201121,C++,374,72,125,45 20201121,C#.NET,147,62,80,32 20201121,Transact-SQL,6,65,75,55 20201121,Kotlin,270,83,125,45 20201121,VB,83,62,85,40 20201121,HTML5,305,72,115,35 20201121,VC,8,61,66,50 20201121,C#,706,68,115,35 20201121,Apex,49,79,135,55 20201121,VBA,165,60,145,30 20201121,ASP.NET,161,65,95,48 20201121,Go,361,81,125,39 20201121,PL/SQL,146,63,85,45 20201121,COBOL,81,61,95,37 20201121,LESS,9,74,115,55 20201121,Swift,407,81,125,50 20201121,VC++,30,65,90,52 20201121,HTML,674,69,125,35 20201121,CSS3,209,75,115,35 20201121,Java,2484,70,145,25 20201121,JSP,54,68,105,55 20201121,Sass,55,71,115,45 20201121,SQL,881,65,145,33 20201121,VBScript,44,62,75,45 20201121,Objective-C,247,76,115,40 20201121,CoffeeScript,16,81,95,65 20201121,JavaScript,1749,72,125,20 20201121,Lua,6,73,80,65 20201121,R言語,19,78,95,65 20201121,Smalltalk,2,75,80,70 20201121,Scala,117,83,115,55 20201121,Perl,108,73,110,50 20201121,Shell,193,64,95,45 20201121,SAS,12,61,75,50 20201121,Ruby,652,80,125,39 20201121,ABAP,12,67,80,55 20201121,Python,669,78,145,32 20201121,VB.NET,284,62,85,40
OS.csv
created_at,skill,count,avg_price,max_price,min_price 20201121,Windows,998,63,135,25 20201121,Red Hat,92,66,95,40 20201121,Solaris,37,61,80,40 20201121,AIX,77,63,90,52 20201121,Ubuntu,39,75,90,45 20201121,Unix,236,69,100,40 20201121,AS/400,1,65,65,65 20201121,FreeBSD,3,70,75,62 20201121,HP-UX,21,62,75,55 20201121,Windows Server,387,62,100,33 20201121,Android,563,78,125,35 20201121,Linux,2266,69,135,30グラフ画像出力ソースがこちら
print_graph.py
import datetime import os import pandas as pd import numpy as np import matplotlib.pyplot as plt """ 共通変数・定数設定 """ DATA_PATH = 'data' now = datetime.datetime.today() CATEGORIES = { 'Language', 'FrameWork', 'DB', 'OS', 'Cloud' } """ メイン処理 """ def main() -> None: make_date = now.strftime("%Y%m%d") # ディレクトリ作成 os.makedirs(DATA_PATH + '/graphs/' + make_date, exist_ok=True) price_graph(make_date) count_graph(make_date) mix_graph(make_date) """ 単価グラフ作成 """ def price_graph(make_date: str) -> None: for category_key in CATEGORIES: df = pd.read_csv(DATA_PATH + '/levtech/' + category_key + '.csv') df = df.sort_values(by=['avg_price'], ascending=False) labels = df['skill'].str.replace('[ぁ-んァ-ン一-龥]+', '', regex=True) # 日本語削除 y_list1 = df['avg_price'] fig = plt.figure(figsize=(14, 7)) ax1 = fig.add_subplot(1, 1, 1) ax1.bar(labels, y_list1, color='tab:blue') ax1.set_ylabel('price') ax1.set_title(category_key) # X軸を縦書き表示 ax1.set_xticklabels(labels, rotation=90) # 棒グラフに数値追記 for x, y in zip(labels, y_list1): ax1.text(x, y, y, ha='center', va='bottom') # plt.show() fig.savefig(DATA_PATH + '/graphs/' + make_date + '/levtech-' + category_key + '-price.png', bbox_inches='tight', format='png', dpi=300) """ 案件数グラフ作成 """ def count_graph(make_date: str) -> None: for category_key in CATEGORIES: df = pd.read_csv(DATA_PATH + '/levtech/' + category_key + '.csv') df = df.sort_values(by=['count'], ascending=False) labels = df['skill'].str.replace('[ぁ-んァ-ン一-龥]+', '', regex=True) # 日本語削除 y_list1 = df['count'] fig = plt.figure(figsize=(14, 7)) ax1 = fig.add_subplot(1, 1, 1) ax1.bar(labels, y_list1, color='tab:orange') ax1.set_ylabel('count') ax1.set_title(category_key) # X軸を縦書き表示 ax1.set_xticklabels(labels, rotation=90) # 棒グラフに数値追記 for x, y in zip(labels, y_list1): ax1.text(x, y, y, ha='center', va='bottom', fontsize='small') # plt.show() fig.savefig(DATA_PATH + '/graphs/' + make_date + '/levtech-' + category_key + '-count.png', bbox_inches='tight', format='png', dpi=300) """ 単価&案件数グラフ作成 """ def mix_graph(make_date: str) -> None: for category_key in CATEGORIES: df = pd.read_csv(DATA_PATH + '/levtech/' + category_key + '.csv') df = df.sort_values(by=['avg_price'], ascending=False) labels = df['skill'].str.replace('[ぁ-んァ-ン一-龥]+', '', regex=True) # 日本語削除 y_list1 = df['avg_price'] y_list2 = df['count'] fig = plt.figure(figsize=(14, 7)) left = np.arange(len(labels)) width = 0.3 ax1 = fig.add_subplot(1, 1, 1) ax1.bar(labels, y_list1, width=width, color='tab:blue', label='price') ax1.set_ylabel('price') ax1.set_title(category_key) ax2 = ax1.twinx() ax2.bar(left + width, y_list2, width=width, color='tab:orange', label='count') ax2.set_ylabel('count') # X軸を縦書き表示 ax1.set_xticklabels(labels, rotation=90) # 棒グラフに数値追記 for x, y in zip(labels, y_list1): ax1.text(x, y, y, ha='center', va='bottom') for x, y in zip(left + width, y_list2): ax2.text(x, y, y, ha='center', va='bottom', fontsize='small') # 凡例を出力 handler1, label1 = ax1.get_legend_handles_labels() handler2, label2 = ax2.get_legend_handles_labels() ax1.legend(handler1 + handler2, label1 + label2) # plt.show() fig.savefig(DATA_PATH + '/graphs/' + make_date + '/levtech-' + category_key + '-mix.png', bbox_inches='tight', format='png', dpi=300) if __name__ == '__main__': main()実際のグラフ
- priceが平均単価(万円)
- countが案件数です
- 単価と案件数が混ざったグラフは、単価が高い順です
言語
単価別
案件数別
単価と案件数mix
トップはKotlinですね。今Androidエンジニアが不足していると聞くので納得。
web系なら案件数と単価で見るとRuby、Python、goがコスパ良さそうですね。
Javaはとりあえず単価が高いイメージがあったんですが、PHPの方が高いというのは意外、、、需要が高すぎるんでしょうか?次にフレームワーク
単価別
案件数別
単価と案件数mix
トップはPhoneGapですね。自分は初めて聞いたんですが、Nitobiが開発,公開しているクロスプラットフォーム・モバイルアプリケーションの開発フレームワークらしいです。
web系だとこれまたDjangoやRailsがコスパ良さそうですね。Reactはwebなりアプリ開発に使われているので案件数も単価も良さげ。Vueはサイト元に情報が無かったです。。DB
単価別
案件数別
単価と案件数mix
トップはBigtableです。Bigqueryはよく聞くんですが、違いはBigqueryより高速に動く大規模DBみたいな感じらしいです。
DBに関してはコスパで言うとMySQL覚えておけば間違い無いですね。Oracle、SQLServerは意外と低い。どうして、、、Cloud
単価別
案件数別
単価と案件数mix
単価トップはGCPですね!案件数でいくとAWSが圧倒的!とりあえずAWSは最低限覚えた方が良さそうですね
需要が高くなりすぎると単価が安くなる傾向が見られるので、これからのことを考えるとGCPも覚えた方がいいかも?
Azureは案件数も単価数も微妙ですね感想
なかなか面白い結果になりました!
これからweb系やるならPythonが伸びしろあるかもです。実際触ってみて、環境構築が手軽。ライブラリが豊富。特にCSV→グラフ作成がこんなに簡単にできるのには感動しました!
わざわざhtmlやjsのライブラリを使ってゴニョゴニョするよりバックエンドでさくっと作って画像化出来るのがとてもイイですね〜今回はあくまで案件サイトの一つを調査した結果なので参考程度にしていただけると!
VueやGraphql、Rustの情報が載っていなかったのでそこらへんも気になるところですね〜

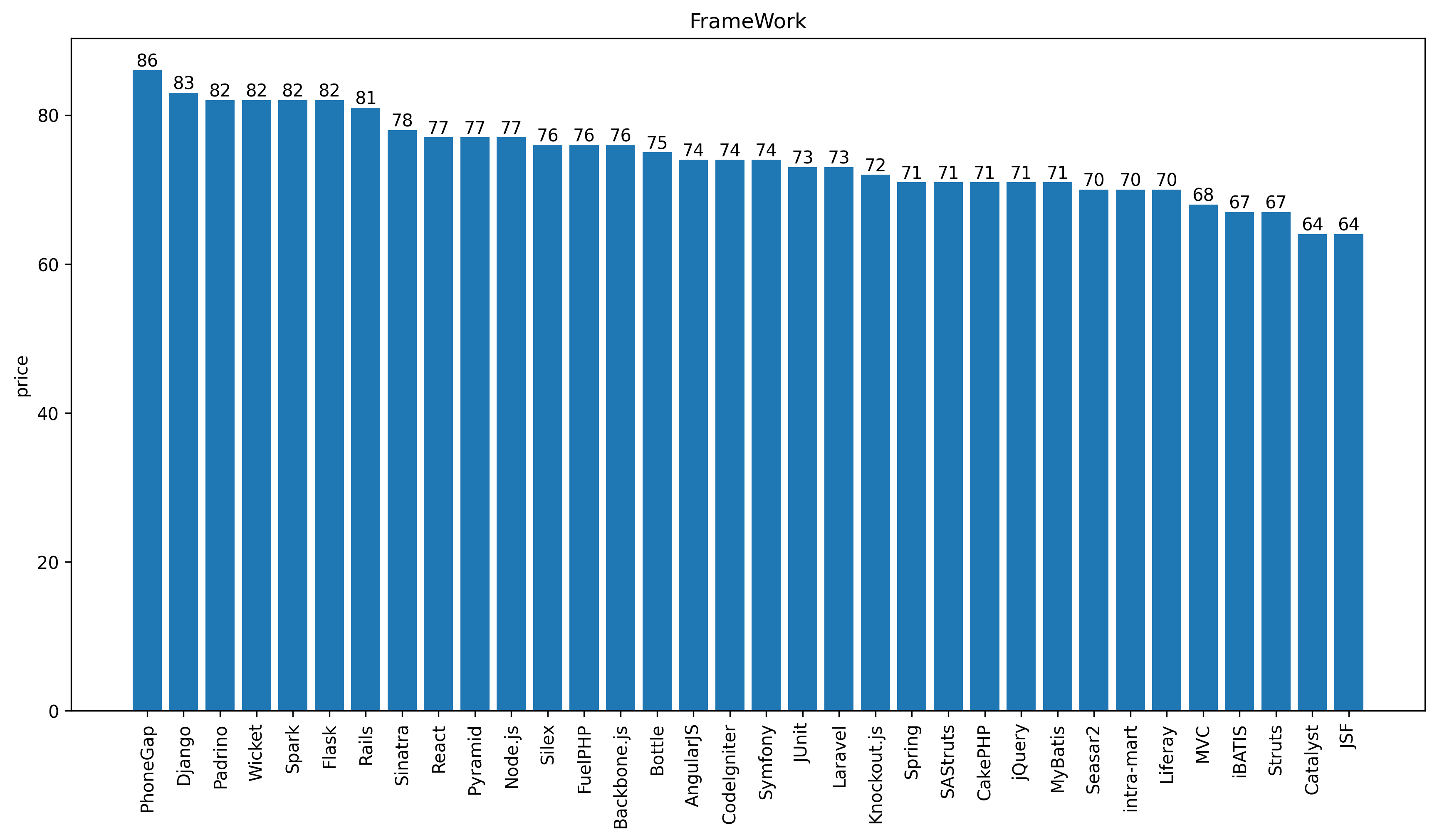
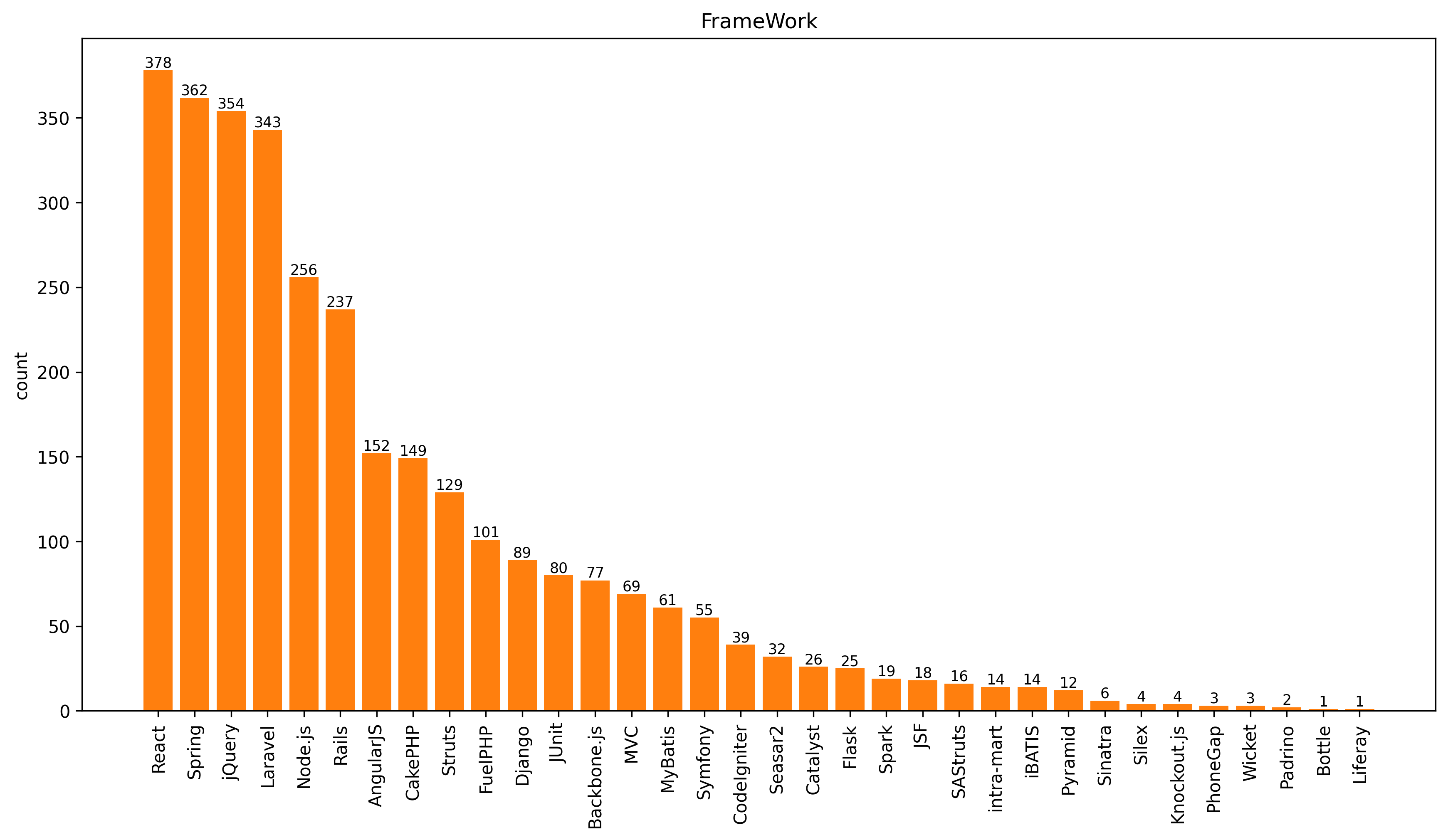
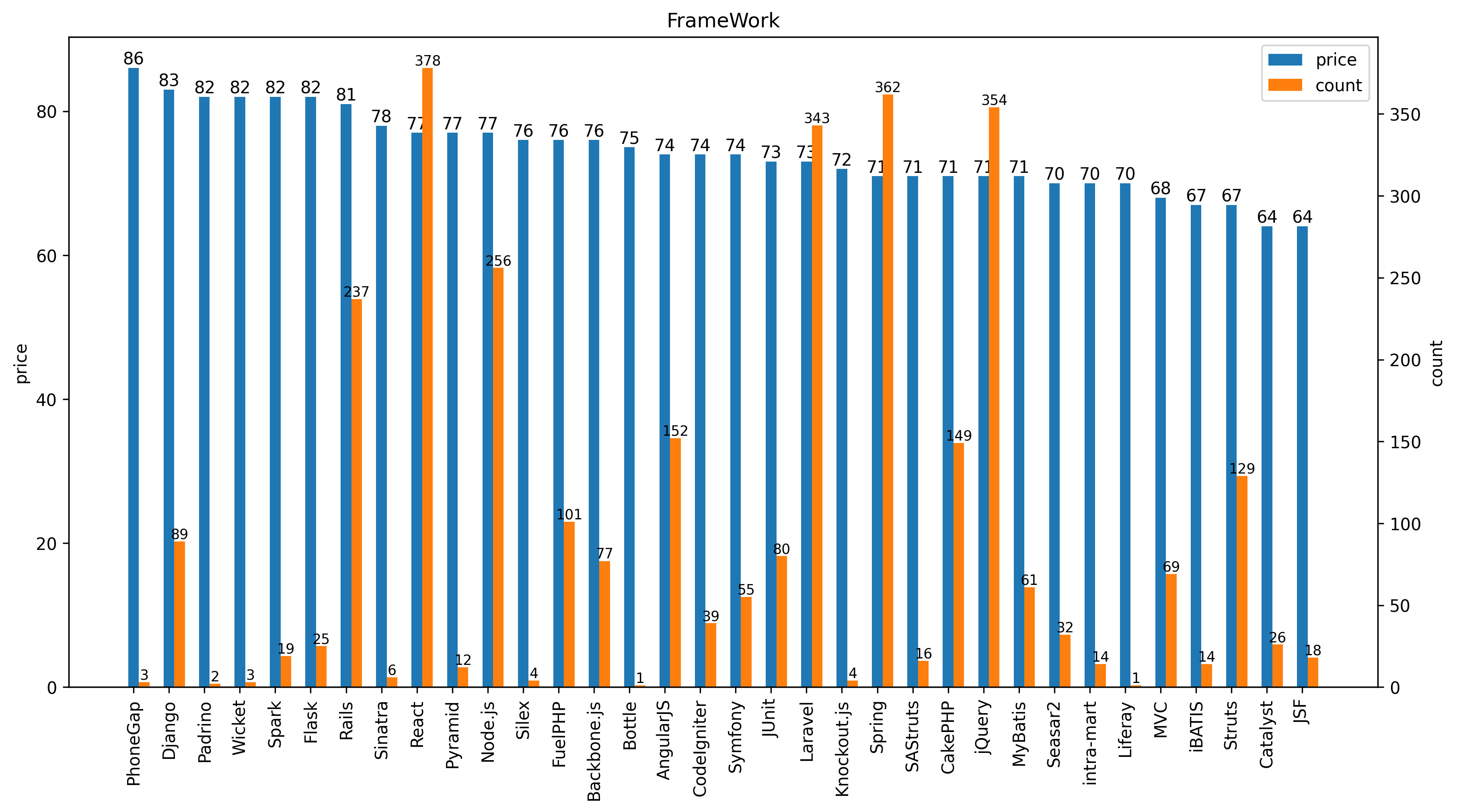
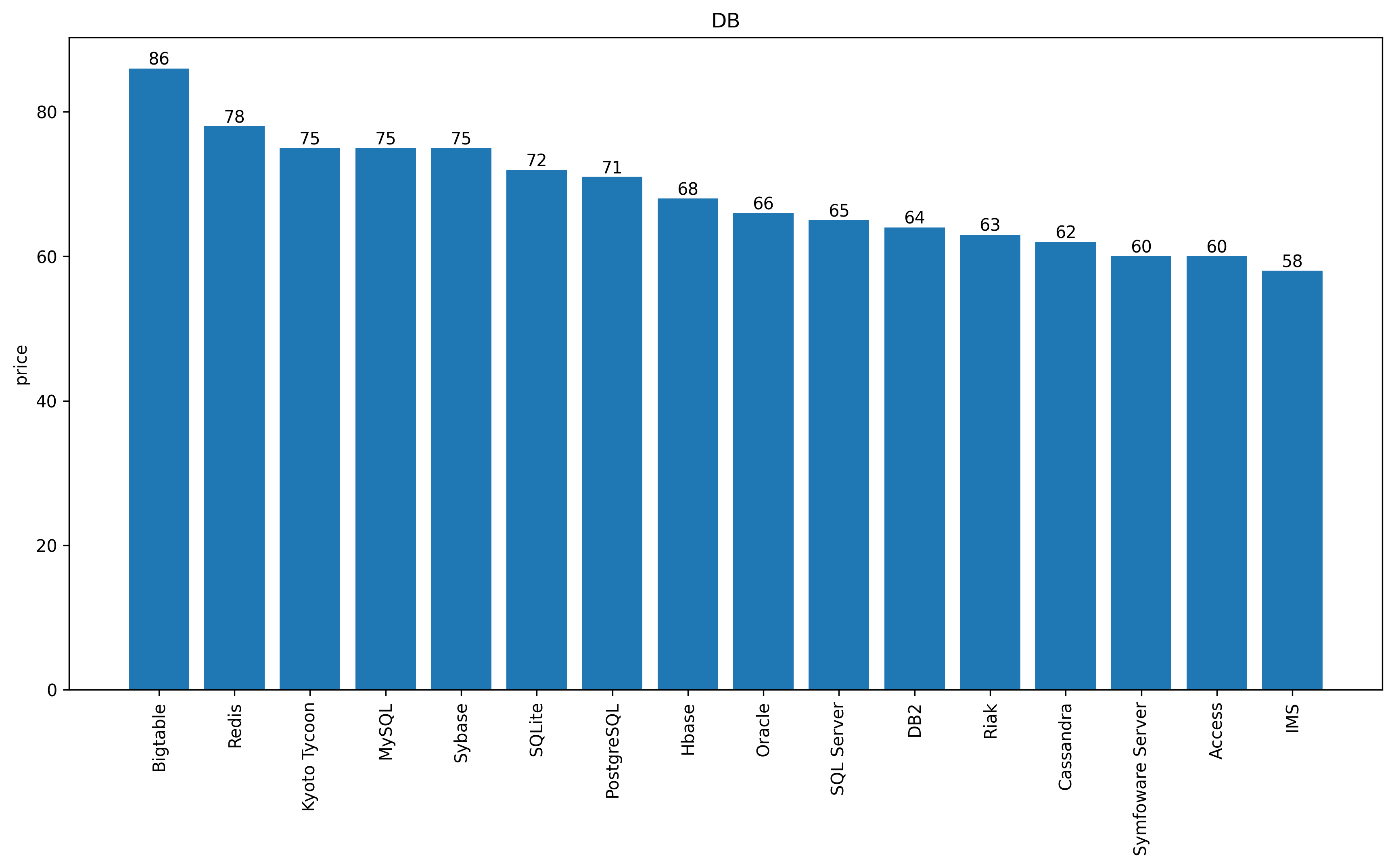
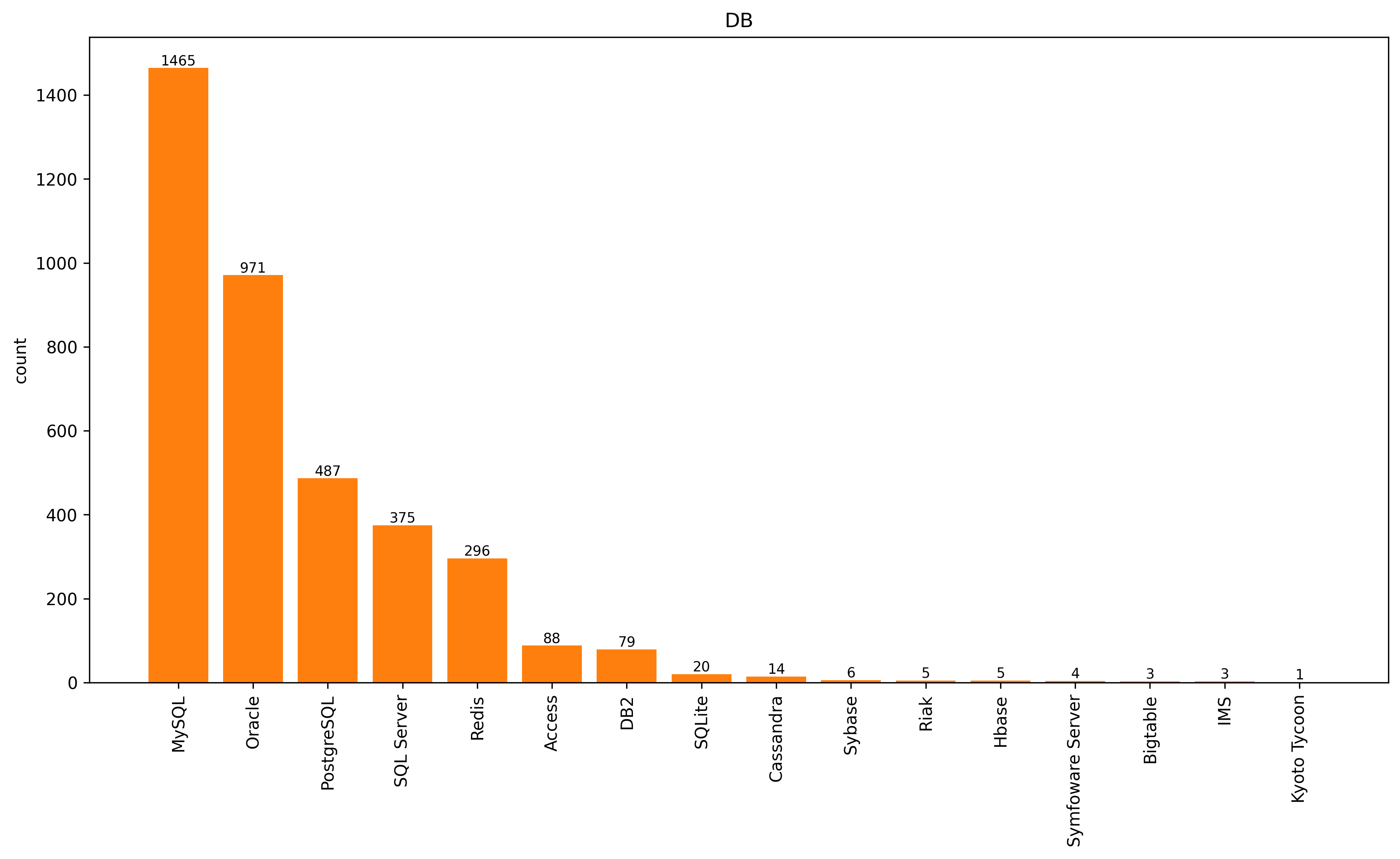
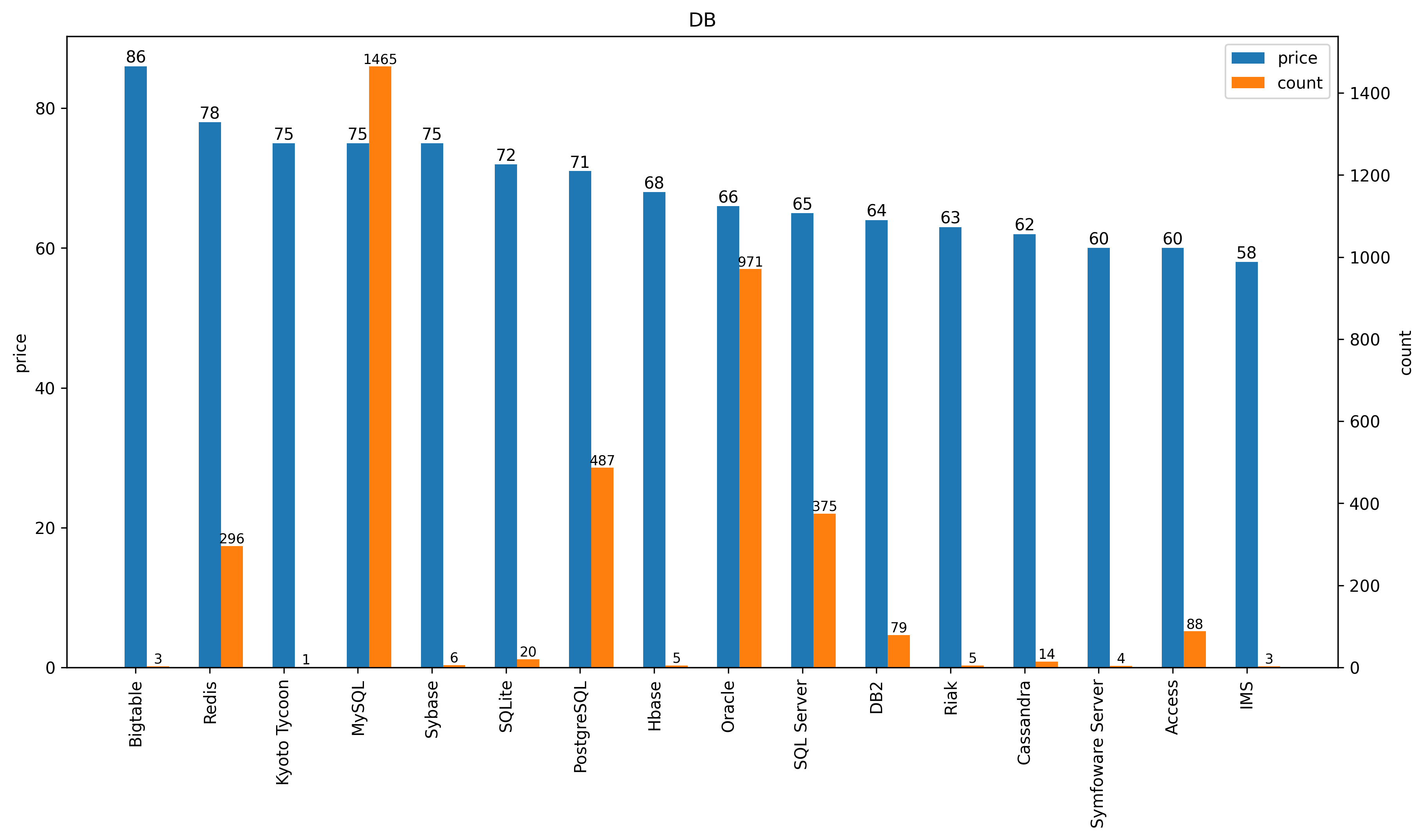
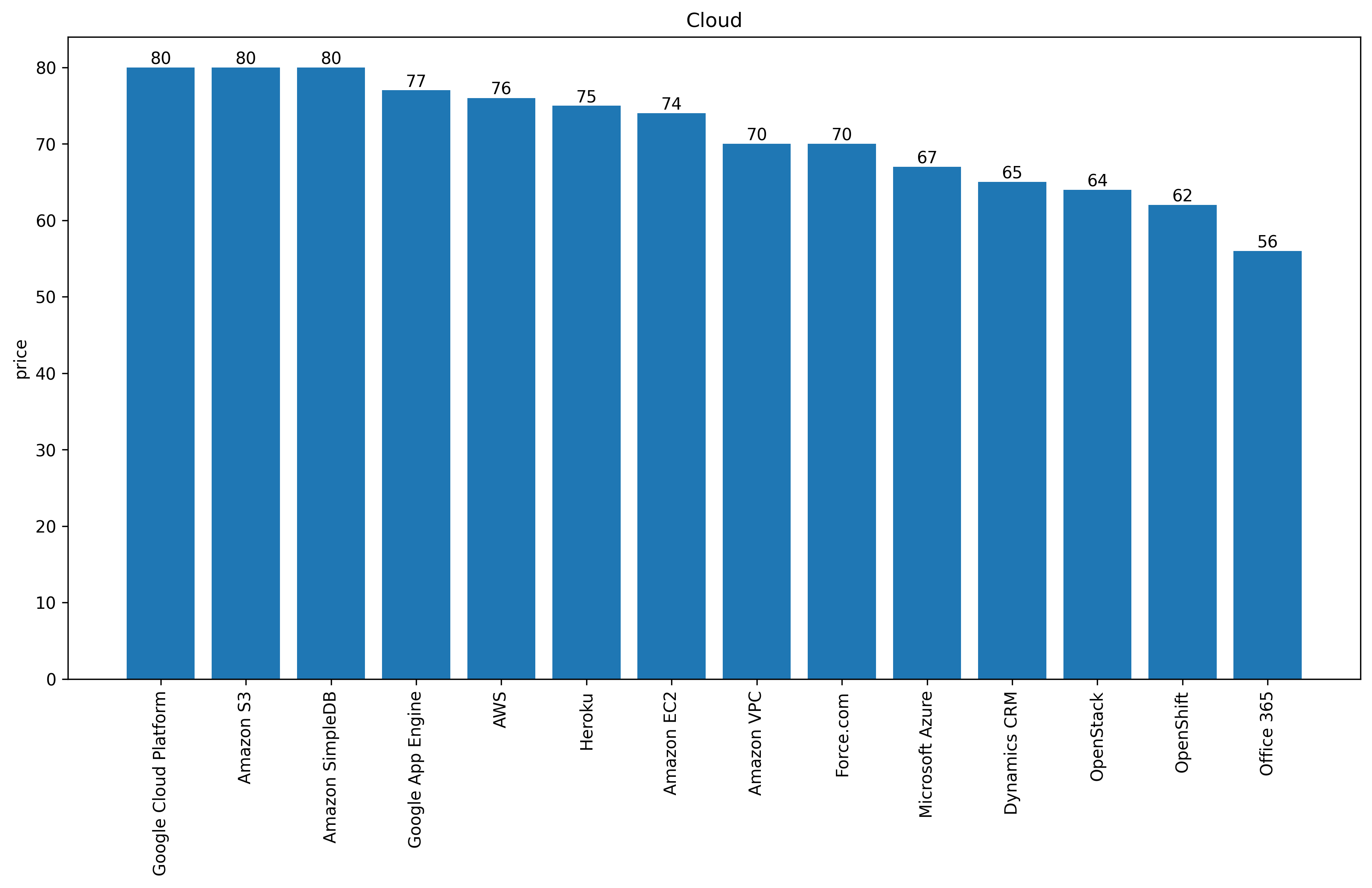
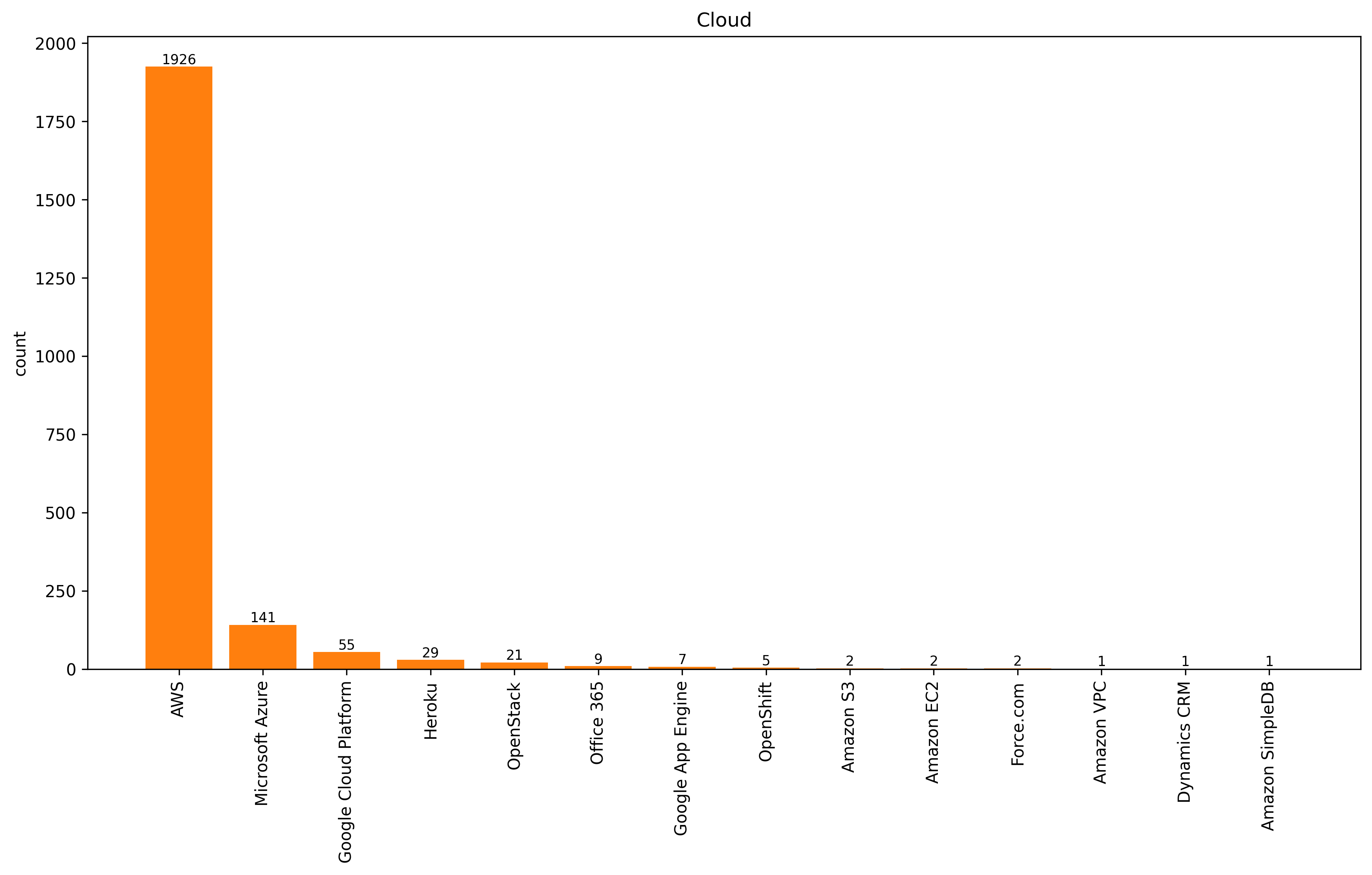
- 投稿日:2020-11-22T13:48:07+09:00
深層強化学習2 強化学習の実装
Aidemy 2020/11/22
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、深層強化学習の2つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・強化学習の実装強化学習の実装
環境作成
・「強化学習」のChapterでは、環境などを自分で定義していたが、今回は強化学習用のさまざまな環境を用意しているライブラリを使用して環境などを作成していく。
・使用するライブラリは「keras-rl」というもので、これはKerasとOpenAIGym(Gym)というライブラリで構成される。今回はこれを使ってカートポールのデモをDQNで学習する。・まずは環境を作成する。方法は「env=gym.make()」とするだけで良い。引数には環境の種類を指定する。カートポールの環境は「"CartPole-v0"」と指定する。以降はenvインスタンスにアクセスすることで操作できる。
・今回のカートポールでは、行動は「カートを右に移動させる」「カートを左に移動させる」の2つであり、これを取得するには「env.action_space.n」とすれば良い。・コード
モデルの構築
・環境を作成したら、Kerasの関数を使って多層ニューラルネットワークを構築する。モデルはSequentialモデルで構築する。次に、Flatten()で多次元の入力を一次元に変換する。入力の形「input_shape」には、カートポールの現在の状態を指定するため、「env.observation_space.shape」を使う。
・層の追加は「model.add()」で行えば良い。全結合層はDense、活性化関数の指定はActivation()で行う。引数には「relu」「linear」などを指定する。・コード
エージェントの設定1 履歴と方策
・ここでは強化学習の本体であるエージェントの設定を行う。まずは、この設定に必要な履歴と方策を設定する。(履歴はそのまま「過去にどのような行動をしたかの履歴」)
・履歴は「SequentialMemory(limit,window_length)」で設定できる。limitは記憶しておくメモリの数である。
・方策については、ボルツマン方策をとる時には「BoltzmannQPolicy()」を使い、ε-greedy手法をとる時には「EpsGreedyQPolicy()」を使う。・コード
エージェントの設定2
・前項の履歴と方策を使って、エージェントを設定する。DQNアルゴリズムが実装されている「DQNAgent()」を呼び出し、以下の引数を与えれば良い。
・引数には、モデル「model」、履歴「memory」、方策「policy」、行動数「nb_actions」、初めの何ステップを強化学習に使わないのかを指定する「nb_steps_warmup」を設定する。
・上記を「dqn」という変数に入れたとすると、「dqn.compile()」でエージェントの学習方法を指定する。第一引数としては最適化関数を指定し、第二引数としてはmetricsで表される評価関数を指定できる。・コード(modelなどは前項のものを使用)
テストの実施
・前項のdqnエージェントを学習させるには「dqn.fit()」を使えば良い。引数としては、環境(コード上ではenv)、エピソード数「nb_steps」、可視化するかどうか「visualize」、ログを出力するかどうか「verbose」がある。
・エージェントに学習させたら、これをテストする。テストは、エージェントを実行し、実際どのぐらいの報酬が得られるかを評価する。これは「dqn.test()」で行える。引数は「dqn.fit()」と同じだが、エピソード数のみ「nb_episodes」とする。まとめ
・ライブラリを使用して強化学習を行うときは、keras-rlを使う。
・「gym.make()」で環境を作成したら、モデルを作成して層を追加していく。また、履歴と方策を設定し、これらを使ってエージェントも作成する。
・作成したdqnエージェントを「dqn.fit()」で学習させ、「dqn.test()」でテストする。今回は以上です。ここまで読んでくださり、ありがとうございました。




- 投稿日:2020-11-22T12:05:41+09:00
【 Python】InvalidSchema: No connection adapters were found for[画像URL]の対処方法
自分用のメモに記載しているので、文章はかなり雑です。
python.pyimport requests as req #まずは1枚の画像を取得するところから test_url="https://papimo.jp/h/00031715/hit/view/605" soup = BeautifulSoup(html, "html.parser") img_url=[] img_tags=soup.find("table",attrs={"class":"graph-some"}).find_all("img")[-1] img_tag=img_tags.get("src") img_url.append(img_tag) reqData1 = req.get(img_url) with open('/content/gdrive/MyDrive/Colab Notebooks/iland_img/605.png', 'wb') as file: file.write(reqData1.content)テスト用でとりあえず1つダウンロードしたかっただけなので、for文で回す必要がないと思っていたけども。
実際実行してみるとpython.pyInvalidSchema: No connection adapters were found for[画像URL]というエラーが発生。
問題だったのはreq.getにリストをそのまま渡してしまっていたこと。
普通にfor文で回したら、解決python.pyimport requests as req #まずは1枚の画像を取得するところから test_url="https://papimo.jp/h/00031715/hit/view/605" soup = BeautifulSoup(html, "html.parser") img_url=[] img_tags=soup.find("table",attrs={"class":"graph-some"}).find_all("img")[-1] img_tag=img_tags.get("src") img_url.append(img_tag) for i_url in img_url: reqData1 = req.get(i_url) with open('/content/gdrive/MyDrive/Colab Notebooks/iland_img/605.png', 'wb') as file: file.write(reqData1.content)
- 投稿日:2020-11-22T11:47:56+09:00
自己相関係数の計算の方法
1 この記事は
自己相関係数をpythonで計算する方法を説明する。
2 方法
3日周期が存在するデータの自己相関係数を自動計算する。(plot_acfを使う)
sample.py#dataを定義する。 from statsmodels.graphics.tsaplots import plot_acf import pandas as pd import numpy as np dat = [ ['07-01',1], ['07-02',10], ['07-03',20], ['07-04',2], ['07-05',11], ['07-06',21], ['07-07',3], ['07-08',22], ['07-09',32], ['07-10',4], ['07-11',23], ['07-12',33], ] #datをDataFrame型変数dfに格納する。 df = pd.DataFrame(dat,columns=["A","B"]) print("dfを表示する","\n",df) fig, ax = plt.subplots(ncols=2, figsize=(15, 4)) sns.lineplot(x="A", y="B", data=df,ax=ax[0]) plot_acf(df["B"].dropna(), lags=10, zero=False,ax=ax[1]) #自己相関算出時、NAがあると正しく計算できない。
- 投稿日:2020-11-22T11:12:05+09:00
Mendeley 上の論文読者数をPythonで取得する
はじめに
研究者の方々は、目にした/書いた学術論文の引用数が気になることがあると思います。
引用数はGoogle scholar 等で簡単に確認することができます。
引用数の前駆的な指標として、文献管理ソフトMendeley における読者数というものもあります。
こちらは少なくとも、Mendeleyを開かなければわからないように思えます。
そこで、スクレイピングの練習がてら、Mendeley reader 数を取得するスクリプトを作成してみました。参考にした記事
[1] pythonでwebスクレイピング
[2] Webスクレイピングの注意事項一覧環境
Windows
Python 3スクリプト
全文は以下の通りです。
以下解説が続きます。a.py# Modules import requests # Constants Mendeley = 'https://www.mendeley.com/catalogue/' PaperID = [] PaperID.append("5a856ac7-0d75-3560-8824-9f9061f3eb50/") # Functions def SandwitchedText(text_source,text_1, text_2): return text_source.split(text_1)[1].split(text_2)[0] for a in PaperID: r = requests.get(Mendeley + a) text = r.text print("Title : " + SandwitchedText(text, "\"title\":\"", "\",\"detail")) print("readers : " + SandwitchedText(text, "readers:", ":")) print("citations : " + SandwitchedText(text, "citations:", ":"))
- requests はスクレイピングに使えるパッケージです[1]。使用時はスクレイピングのルールに注意しましょう[2]。
- データを取得したい論文の情報として対応するURLを与えます。本記事では、有名な高温超伝導の論文を題材とします。スクリプト中変数Mendeleyの部分は固定で、URLのうち論文ごとに異なる部分をPaperIDのリストに与えてゆきます。
- SandwitchedTextとして、与えられた文字列text_sourceからtext_1, text_2で挟まれた部分を返す関数を定義しています。
- requests.get(url).text でURL に対応するページのソースを得ることができます。スクリプトでは、textの中にソースが文字列として格納されます。
- 最後に、ページのソースから、論文のタイトル、mendeley reader 数、引用数を取得、コンソールに出力します。ここで、ページのソースとにらめっこして、ソース中どこに必要な情報があるかを探し、SandwitchedText関数を使って情報を取得します。
終わりに
リスト内の論文の数を増やしていけば、いくつかの論文の情報をまとめて得られます。
論文のURLではなく、タイトルを与えられるともう少しスマートだと思います。
- 投稿日:2020-11-22T08:06:39+09:00
Django 選択肢を自分の所属している施設のみにする
開発は、以前と同じペースで進めていますが、投稿がいまいちできていません。
今回は、何かを登録するときに、自分が所属している店のみ選択できるようにしようと思います。自分が、Pu-a-Puにのみ所属しているのに、希望シフトを登録するときに、間違えて縁宅って選んでしまうことを防ぐためです。
修正前
調べると、forms.pyとviewsの追記で対応できました。
views.pydef get_form_kwargs(self): kwargs = super(KibouCreate, self).get_form_kwargs() kwargs['user'] = self.request.user return kwargs独学でやっているためイメージがつかめていいないですが、form情報を取得する際に、自分自身の情報を渡して、formで処理した結果を取得してHtmlに返すってことだと想像しています。
forms.pyclass kibouCreateForm(forms.ModelForm): class Meta: shift_object = Shift.objects.all() model = KibouShift fields = ('user', 'date', 'shift_name_1', 'shisetsu_name_1', 'shift_name_2', 'shisetsu_name_2', 'shift_name_3', 'shisetsu_name_3', 'shift_name_4', 'shisetsu_name_4') widgets = { 'date': datetimepicker.DatePickerInput( format='%Y-%m-%d', options={ 'locale': 'ja', 'dayViewHeaderFormat': 'YYYY年 MMMM', 'ignoreReadonly': True, 'allowInputToggle': True, } ), } def __init__(self, *args, **kwargs): #所属リストのみ選択可能とする user = kwargs.pop('user') UserShozoku_list = UserShozokuModel.objects.filter(user = user.id).values_list("shisetsu_name", flat=True) UserShozoku_list = list(UserShozoku_list) super(kibouCreateForm, self).__init__(*args, **kwargs) self.fields['shisetsu_name_1'].queryset = Shisetsu.objects.filter(id__in = UserShozoku_list).all() self.fields['shisetsu_name_2'].queryset = Shisetsu.objects.filter(id__in = UserShozoku_list).all() self.fields['shisetsu_name_3'].queryset = Shisetsu.objects.filter(id__in = UserShozoku_list).all() self.fields['shisetsu_name_4'].queryset = Shisetsu.objects.filter(id__in = UserShozoku_list).all() """ 締め日チェック """ def clean_date(self): dt_now = datetime.datetime.now() dt_date = self.cleaned_data.get('date') #5日になったら20日以降のみ入力 if dt_now.day > 5: startdate = datetime.date(dt_now.year,dt_now.month,20) + relativedelta(months=1) if dt_date < startdate: raise forms.ValidationError( "締め日が過ぎていますので、管理者にご連絡をお願いします", ) else: startdate = datetime.date(dt_now.year,dt_now.month,20) if dt_date < startdate: raise forms.ValidationError( "締め日が過ぎていますので、管理者にご連絡をお願いします", ) return self.cleaned_data.get('date') def clean(self): ############ # 重複チェック ############ dt_user = self.cleaned_data.get('user') dt_date = self.cleaned_data.get('date') if KibouShift.objects.filter(user=dt_user, date=dt_date).count() > 0: raise forms.ValidationError("同じ日の希望シフトがすでに登録されているので登録ができません。修正で対応をお願いします。") dt_shift_name1 = self.cleaned_data.get('shift_name_1') dt_shift_name2 = self.cleaned_data.get('shift_name_2') dt_shift_name3 = self.cleaned_data.get('shift_name_3') dt_shift_name4 = self.cleaned_data.get('shift_name_4') dt_shisetsu_name_1 = self.cleaned_data.get('shisetsu_name_1') dt_shisetsu_name_2 = self.cleaned_data.get('shisetsu_name_2') dt_shisetsu_name_3 = self.cleaned_data.get('shisetsu_name_3') dt_shisetsu_name_4 = self.cleaned_data.get('shisetsu_name_4') #シフトが休みなら施設は未入力とする if str(dt_shift_name1) == "休" or str(dt_shift_name1) == "有" or str(dt_shift_name1) == "不": if dt_shift_name2 != None or dt_shift_name3 != None or dt_shift_name4 != None or dt_shisetsu_name_1 != None or dt_shisetsu_name_2 != None or dt_shisetsu_name_3 != None or dt_shisetsu_name_4 != None: raise forms.ValidationError("シフト「休」「有」「不」の場合は、ほかの入力は不要です")そうすると、
所属している施設だけになりました。
ついでに、スケジュールを追加する権限者以外は、ユーザー選択をできないようにしたいと思います。
少し追記しただけでできました。
っていっても、1時間ぐらい調べて実装ですが(笑)本来は、選択されたユーザーごとに施設を選べることがベストだと思うのですが、javascriptでの実装か、ボタン押下で取得させる等、工夫が必要です。
今後、スキルアップしていく必要がありますね
forms.pydef __init__(self, *args, **kwargs): #所属リストのみ選択可能とする user = kwargs.pop('user') UserShozoku_list = UserShozokuModel.objects.filter(user = user.id).values_list("shisetsu_name", flat=True) UserShozoku_list = list(UserShozoku_list) super(kibouCreateForm, self).__init__(*args, **kwargs) self.fields['shisetsu_name_1'].queryset = Shisetsu.objects.filter(id__in = UserShozoku_list).all() self.fields['shisetsu_name_2'].queryset = Shisetsu.objects.filter(id__in = UserShozoku_list).all() self.fields['shisetsu_name_3'].queryset = Shisetsu.objects.filter(id__in = UserShozoku_list).all() self.fields['shisetsu_name_4'].queryset = Shisetsu.objects.filter(id__in = UserShozoku_list).all() #選択されたユーザー毎の変更をする方がよいがジャバスクリプトかボタンで取得動作させるか必要 #スケジュール追加権限があればユーザー選択を変更 permissions = Permission.objects.filter(user=user) if user.has_perm('schedule.add_KibouShift'): self.fields['user'].queryset = CustomUser.objects.all() else: self.fields['user'].queryset = CustomUser.objects.filter(username=user.username).all()ちなみに、もともと用意されているUserオブジェクトではなく、CustomUserに変更しました。データベースをクリアしてやり直したのでデータがパーになりました。

