- 投稿日:2020-11-22T22:56:30+09:00
AWS ソリューションアーキテクトアソシエイト向け問題 セキュリティ編
概要
今回は会社の後輩向けにAWS ソリューションアーキテクトアソシエイト向けの問題を作成したのでそちらの公開を。
元ネタは公式の問題、BlackBelt、公式サイトなどからとっております。内容としては簡単すぎかもしれません・・・KMS
- KMSの特徴について説明している文で以下の中から正しいものを1つ選択してください。
- 複数のリージョンで同一のキーを使用できる。
- 顧客側がキーを提供しサーバで暗号化を実施できる。
- EBSを暗号化する際は作成済みのEBSについても暗号化できる。
- 複数のアカウントで暗号化キーを共有することはできない。
- キーのローテーションは自動でのみ実施される。
回答
- 正解は
2. 顧客側がキーを提供しサーバで暗号化を実施できる。 * 顧客側がオンプレ環境の暗号化を使いたい場合でも対応できます
- 以下不正解の理由
1. キーはリージョン単位のため別のリージョンに移すときは暗号化キーを用意する必要がある 3. EBSの暗号化の際には作成時に指定する必要がある。既存のEBSを暗号化したいときはスナップショットを取得しコピーを作成するときに暗号化を指定する必要がある。 4. IAMユーザ、ロールを使ってのアクセス制御が行えるため他のアカウントを設定することで可能となる。 5. デフォルトは1年でローテーションされるが、1年では長い場合に手動でローテーションを行うことも可能。AWS Shield
- AWS Shieldの特徴について説明している文で以下の中から正しいものを1つ選択してください。
- AWS Shield Standardを使用することで追加料金なしでレイヤ 3 および 4の保護を行うことができる。
- AWS Shield Advanced を使用することで AWS WAF および AWS Firewall Manager を通常より少ない金額で使用することができる。(無料ではないが大幅な割引が行われる)
- AWS Shield Standardを使用することで一般的なネットワークおよびトランスポートレイヤーの DDoS 攻撃から保護される。
- AWS Shield Standard を使用することでDDoS攻撃等でオートスケールが行われることで発生する追加分の費用が返還される。
- AWSでホストされていないと AWS Shieldを使用することはできない。
回答
- 正解は
3. AWS Shield Standardを使用することで一般的なネットワークおよびトランスポートレイヤーの DDoS 攻撃から保護される。 * AWS Shield Standard でも通常のDDoS攻撃からの保護は機能する。またこちらは無料でも使えるのでとりあえず設定することが勧められている。
- 以下不正解の理由
1. レイヤ3,4の保護はAWS Shield Advancedの機能 2. AWS Shield Advanced ではAWS WAF および AWS Firewall Manager を無料で利用できる。 4. スケーリング用 DDoS コスト保護は AWS Shield Advanced の機能です。対象はAmazon EC2、Elastic Load Balancing (ELB)、Amazon CloudFront、AWS Global Accelerator、Amazon Route 53 となっている。 5. Amazon CloudFront のカスタムオリジンとしてAWS外のWEBサーバを使用することでAWSでホストしていないとしても使用することができる。
- 投稿日:2020-11-22T20:04:02+09:00
AWS ソリューションアーキテクト・アソシエイトの勉強
AWS ソリューションアーキテクト・アソシエイトを以前とった時の勉方法を記載します。
私の場合の勉強期間は2~3週間ほどでした。それまで実務でのAWS利用はありませんでした。教材
・AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイト
https://www.amazon.co.jp/gp/product/479739739X/ref=ppx_yo_dt_b_asin_title_o03_s00?ie=UTF8&psc=1・(Udemy)【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
https://www.udemy.com/course/aws-knan/勉強方法
①オレンジ本(AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイト)を何周か読んで本の内容を大体理解します。一周目は時間がかかるかもしれませんが、2週目以降から楽になってきます。
②Udemyの問題集(390問)を使います。この問題集は65問×6個つで構成されています。
この問題集の模擬試験①の解答をはじめから表示し、問題文と一緒に読んでから模擬試験します。
85点以上取れたら模擬試験②~で同じことをします。この問題集のすべての模擬試験で85点以上取れたら資格取得は問題ないと思います。
補足
そもそもクラウドって何?状態の人はまずクラウドプラクティショナーの取得、またはクラウドプラクティショナー用の参考書を読むことから始めるのをおすすめします!
まずは入門編であるクラウドプラクティショナーの参考書を読むことでその後の理解が格段に早まると感じました。
参考書は体系的にわかりやすくまとめてくれているものが多いので、積極的に使いたいです。
また、入門編の学習はそんなに時間がかからないと思うのでやりやすいです。多分1日2日くらいあれば。。あと気を付けた事はエビングハウスの忘却曲線です。
試験を受けてみての感想
実際の試験では問題文の日本語がちょっとわかりにくかったので、心の準備だけしておくといいかもしれません。
問題文の表記はいつでも英語に切り替えられるので、英語が得意な人は切り替えたほうがいいらしいです。。試験時間は割と余裕あります。すべての回答を見直しても時間に余裕がある状態です。
蛇足
プロフェショナルも取りたいので取れたら方法を載せます。
- 投稿日:2020-11-22T19:21:12+09:00
【AWS】ソリューションアーキテクト-アソシエイト(SAA)合格記
はじめに
AWS認定試験-ソリューションアーキテクト-アソシエイト(SAA)に合格したので、合格までの道のりを残しておこうと思います。
CLF合格記は以下をご覧ください。
【AWS】クラウドプラクティショナー(CLF)合格記SAAはCLF合格後すぐに勉強を始めました。
What's SAA?
まずは、SAA試験について
AWS認定 ソリューションアーキテクト – アソシエイト上記サイトによると、認定によって検証される能力は以下のようです。
- AWS のテクノロジーを使用して安全で堅牢なアプリケーションを構築およびデプロイするための知識を効果的に証明すること
- 顧客の要件に基づき、アーキテクチャ設計原則に沿ってソリューションを定義できること
- プロジェクトのライフサイクルを通して、ベストプラクティスに基づく実装ガイダンスを組織に提供できること
SAAはCLFよりもベストプラクティスに基づいた設計ができるかどうかの要素が大きいように思います。
試験に向けて
公式サンプル問題
これはCLFと変わらず事前に受けて現状のレベルの確認をします。
私は50%ほどの出来でした。参考書を読む
私は以下の本を読みました。
AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイトホワイトペーパーを読む
CLFと同じくホワイトペーパーを読みました。
ハンズオンに参加する
幸いなことに会社から研修への参加許可が出たので、「Architecting on AWS」に参加しました。
こちらは、実機にて設定ができるので参加してよかったと思います。Black Beltを読む
こちらもCLFと同じくBlack Beltを読みました。
試験当日
上記対策を計2週間(延べ18時間程度)行い、試験に臨みました。
結果は、660点(720点以上で合格)で不合格でした。
試験に向けて(2)
前回は問題演習が少なかったと反省したので、上記復習に加えて、以下のサイトにて問題演習を行いました。
問題を解く
こちらのサイトは一問ごとに解説が表示され、都度確認ができ、BlackBeltやホワイトペーパーへのリンクもあるので、勉強しやすかったです。
試験当日(2)
上記対策を2週間(延べ20時間程度)行い、試験に臨みました。
結果は、725点(720点以上で合格)で、なんとか合格でした。
感想
CLFよりもやはり難易度は非常に高く、より設計にフォーカスする部分が多かったように思います。
また、コストを優先するのか、期間を優先するのかなど、問題によって観点が変わるので、そこに注意する必要がありました。各サービスのより深い部分(S3のライフサイクルや、セキュリティグループの設定内容、ACLの設定内容など)に言及する部分が多かったので、その点を勉強してもらえれば一発合格できると思います。
今後は他のアソシエイト試験の記事も書いていきますので、興味があれば見てみてください。
- 投稿日:2020-11-22T18:27:30+09:00
【Rails】RailsアプリをAWSへデプロイする際に特定のgemがあることでCMake Errorになりデプロイできない場合
環境
- Rails 6.0.3
- ruby 2.6.6
- AWS
- EC2
- nginx
- Capistrano
内容
RailsアプリをAWSへデプロイする際に、特定のgemがあることで、CMake Error となり、デプロイに失敗したときのメモです。今回の場合、特定のgemとは
qiita-markdownになります。説明
下記コマンドでデプロイを実施。
ローカル環境のターミナル(Railsアプリのルートディレクトリ)$ bundle exec cap production deployその後途中まで順調に進みますが、
bundler:installの部分でエラーがはかれ、デプロイに失敗しました。
エラー文が長いので割愛しますが、原因に直結する部分だけ載せます。エラー文----------- 略 ----------- bundler:install ----------- 略 ----------- 01 Gem::Ext::BuildError: ERROR: Failed to build gem native extension. ----------- 略 ----------- 01 CMake Error at CMakeLists.txt:15 (CMAKE_MINIMUM_REQUIRED): 01 CMake 3.5.1 or higher is required. You are running version 2.8.12.2 ----------- 略 ----------- In Gemfile: qiita-markdown was resolved to 0.27.0, which depends on github-linguist was resolved to 4.8.18, which depends on ruggedエラー文を見る限り、CMakeのバージョンが古いことが直接的な原因でした。
特別なgem(今回の場合は
qiita-markdown)が入っている場合は先に依存関係のあるパッケージをEC2にインストールしておく必要があります。こちらの記事を参考に、
CMakeをアップデートすることにしました。
また、記事投稿時点でのCMakeの最新バージョンが3.19.0だったので、このバージョンでアップデートすることにしました。
→CMakeの最新バージョンはCMakeのホームページで確認できます。下記が一連のコマンドの流れです。
サーバー環境のターミナル$ sudo yum remove cmake $ wget https://cmake.org/files/v3.19/cmake-3.19.0.tar.gz $ tar xvzf cmake-3.19.0.tar.gz $ cd cmake-3.19.0 $ ./bootstrap (少し時間がかかります) $ make (結構時間がかかります) $ sudo make install上記が完了後、再度下記コマンドでデプロイを実施。
ローカル環境のターミナル(Railsアプリのルートディレクトリ)$ bundle exec cap production deployこれで無事にデプロイが完了しました!
こちらの回答に導いてくれた@take18k_techさんに感謝します!
- 投稿日:2020-11-22T17:21:06+09:00
【AWS】クラウドプラクティショナー(CLF)合格記
はじめに
少し前のことですが、AWS認定試験-クラウドプラクティショナー(CLF)に合格したので、合格までの道のりを書いておこうと思います。
About Me
私はSIer2年目で、オンプレサーバー設計・構築を行っています。
パブクラの知識・経験は0からのスタートでしたが、何とか1発合格することができました。What's CLF?
まずは、クラウドプラクティショナーについて
AWS認定試験-クラウドプラクティショナー上記サイトによると、認定によって検証される能力は以下のようです。
- AWS クラウドとは何かということ、およびベーシックなグローバルインフラストラクチャについて定義できる
- AWS クラウドのベーシックなアーキテクチャ原理を説明できる
- AWS クラウドの価値提案について説明できる
- AWS プラットフォームの主なサービスと一般的なユースケース (例: コンピューティング、分析など) について説明できる
- AWS プラットフォームのセキュリティとコンプライアンスのベーシックな側面、および共有セキュリティモデルについて説明できる
- 請求、アカウントマネジメント、料金モデルを明確に理解している
- ドキュメントや技術サポートのソースを特定できる (例: ホワイトペーパー、サポートチケットなど)
- AWS クラウドにおけるデプロイと運用のベーシックで重要な特徴を説明できる
つまり、AWSを使って何ができるか、使う利点は何かなどの基本的な点が問われます。
先に言っておくと、CLFは広く浅くサービスを勉強することが大切だと思います。
サービスの数は出てきますが、内容がそこまで深くなることはあまりありませんでした。試験に向けて
公式サンプル問題
これは受験を決めて一番最初に取り組みました。
どんな問題形式で出るのか、どのレベルの問題が出るのかを把握するためです。参考書を読む
私は以下の本を読みました。
ひとまず1周目はざっとどんなサービスがあるのか、略称などを勉強し、2周目により細かい部分を読み込みました。
AWS認定資格試験テキスト AWS認定 クラウドプラクティショナーホワイトペーパーを読む
本の中で理解できない部分はAWSが公式に出しているホワイトペーパーを読みました。
ホワイトペーパーBlack Beltの資料を読む
ホワイトペーパーに加えてブラックベルト資料を読みました。
Black Belt公式ビデオを見る
AWS認定のトレーニングライブラリの動画で片手間勉強しました。
トレーニングライブラリ試験当日
上記対策を計3週間(延べ30時間程度)行い、試験に臨みました。
結果は、755点(700点以上で合格)でした。
感想
試験時間は余裕があり、じっくり考えて取り組むことができました。
試験問題の中で日本語が変な部分がありますが、英語に切り替えることができるので、そちらで確認した方が良いです。問題で何を聞かれているのか(コスト?運用?)などを読み取っていくことが大切です。
問題をもっと解いて対策したいという方にはUdemyなどの問題集がおススメです。(セール中に買い溜めをしておきましょう。)
あとはハンズオンなどが出来れば、より理解は早いと思います。今後はアソシエイト試験の記事を書いていこうと思います。
- 投稿日:2020-11-22T16:35:01+09:00
Railsアプリのデプロイで「応答時間が長すぎます。」のserver errorに出くわした話
概要
Railsアプリを本番環境(AWS/EC2)にデプロイしようとIPアドレスでサーバーへ接続した際、「このサイトにアクセスできません。●●(IP),応答時間が長すぎます」とのエラーで長時間ハマったため、備忘録 兼 同じ境遇の方の参考になればと思い投稿しました。
実行環境
・Rails v5.1.7
・Ruby v2.7.0
・DB mysql
・AWS, EC2(本番環境)
・unicorn
・nginx結論 : config.force_ssl = true を有効にしていたことが原因
config/production.rbconfig.force_ssl = trueを
config/production.rbconfig.force_ssl = falseに変更することで改善出来ました。
config.force_ssl って何?
ずばり、IPアドレスへのアクセスを全てhttps形式として通信させる設定です。
つまり上記画像のように、意図せずとも自動でhttpsになるということ。
こちらのコードが書かれているconfig/production.rbはrailsアプリを本番環境上の設定を決めるファイル内にあります。 config.force_ssl = true のコードは通常コメントアウトされているのですが、開発中に外したことが原因となっていました。
今回私が立てたAWSのEC2サーバーは、通信形式をhttp形式のポート範囲でのみ設定しており、延々と許可していないhttps形式でアクセス処理をしていたことで、「応答時間が長すぎます」とのエラーが発生しました。環境によってはこのようなエラーも発生しなかった訳ですね...
余談ですが、解決までに悪戦苦闘し、自分なりに大切だなと思ったポイントを書かせて頂きます。
初心者の戯言だと思って鼻くそをほじりながらご覧になってください。笑サーバー通信エラー解決のポイント
①問題が起きているサーバー通信がどこなのかを特定する
②問題が起きているサーバーのログを読む
③ログを読んでもわからない場合は怪しいところをコピペしてひたすらググる!笑もう少しだけ掘り下げて書いていきます。
①について
クライアントがリンクをクリックしてアクセスしてからアプリケーションが表示されるまで、どのような通信が走っているのかを調べ以下の構造になっていることを学習しました。・EC2サーバー(ローカル環境の場合ここはスルー)
⬇︎
・webサーバー(今回の場合Nginx)
⬇︎
・アプリケーションサーバー(今回の場合Unicorn)そして、上記の順番に習い、1つずつ正しくアクセス出来ているか確認しました。
結果として、私の場合はEC2➡︎Nginxへの通信が原因でした。その確認方法については次の項で。
また、AWSへのデプロイに伴い、こちらの記事を参考にさせて頂きました。画像や細かいポイント付きでとてもわかりやすかったので、実行環境がマッチしていて上手くデプロイ出来ない方は是非参考にしてください!https://qiita.com/Yuki_Nagaoka/items/5be084c6efe1f797fd94
②について
・EC2サーバー
VPC,EC2等作成して公開鍵でログイン出来ていれば問題ないかなと思います。・webサーバー(私の場合ここが原因でした)
Nginx、デプロイするアプリ、Unicorn全てインストールし、ファイル設定を何度確認してもサーバーエラーでしたが、Nginxログが解決の糸口となりました!・nginx.access.log
・nginx.error.log
・Unicorn.lognginxやunicornでは、リアルタイムでアクセス履歴を記録してくれる上記ファイルが自動作成されています。そのファイルの中身を確認しましょう。ログファイルの場所は環境毎に違うかもしれません。私の場合、参考記事の作業で生成した /etc/nginx/conf.d/●●.confファイルの中で設定した場所に生成されていました)
cat /var/www/rails/アプリ名/log/nginx.access.log上記コマンドでnginx.access.logを表示し、IPアドレスにアクセスして再度logを確認。
すると、何度アクセスしてもアクセス履歴が更新されていないことに気付きました。
ここで初めて、webサーバー(Nginx)に上手く接続出来ていないこと(EC2➡︎webサーバーの通信が上手くいっていないこと)がわかり、ポイント③のようにググって記事を漁り、なんとか自力で解決に至りました!
ログを確認することの大切さをここでやっと理解しました。
今回は活用する必要がありませんでしたが、Nginxにアクセス出来ていると確認出来た場合は・同様の方法で、同ディレクトリのnginx.error.logの中身を確認。
tail -f /var/www/rails/アプリ名/log/nginx.error.log※tail -f :ファイルの最後に追加される文字をリアルタイムに表示するコマンド
(エラーが特定しづらい場合はcatコマンドで全て表示させて確認してください)エラーが起きている場合、Nginxのサーバー内での問題の可能性が高い
(Webサーバー➡︎アプリケーションサーバーの通信が上手くいっていない)・エラーがない場合は、
同ディレクトリのunicorn.logを確認。unicornの中で問題が起きていないか確認しましょう。
(アプリケーションサーバー内(アプリ内で)で問題が起きている)あとは③の通り、ログで見つけた怪しい部分をひたすら読む、ググるの繰り返しです笑
最後に
拙い記事にも関わらずここまで読んで頂きありがとうございます!
この記事が少しでも誰かのエラー解決の手助けになれば幸いです。
また、コードや考え方など間違っている可能性も十分にあります。その場合すぐに修正致しますので、気軽にコメントでご指摘頂ければと思います!
- 投稿日:2020-11-22T16:29:51+09:00
seleniumとheadless-chromiumを使ってaws上で情報送信botを作った話
基本的には、以下のページを元に作成していきました。
何点か躓いた場所があったので、その点だけ備忘録として残しておきます。毎朝5時にGoogle Formに自動回答したい
https://qiita.com/kota-yata/items/9d4124ec7a7dd4e3d4f0AWS Lambda(Python)でSelenium + Headless Chromeの実行
https://masakimisawa.com/selenium_headless-chrome_python_on_lambda/つまづいた点
headless-chromiumのサイズオーバー
詳細
layerへのuploadの上限が50MBであったが、最新バージョン(v1.0.0-57:2020/11/21時点)のサイズが50MB以上あり、lambdaのlayerへのupload上限である50MBを超えてしまっていた。
対応
一つ前のバージョン(v1.0.0-55)の方がサイズが小さく、45MBほどであったため、そちらを採用した。
https://github.com/adieuadieu/serverless-chrome/releases/ 参照。
lambda関数のメモリ不足によるタイムアウトエラー
詳細
上ページを参考にコーディング・セッティングを行なったが、lambda上でタイムアウトエラーが発生した
対応
待ち時間を10分にし、メモリサイズを512MBとして解決
- 投稿日:2020-11-22T15:49:23+09:00
AWSのEC2インスタンスにカラム名の変更が反映されているのに変更前のカラム名がunknown attributeだというエラーが出る
起きたこと
データベースのカラムを変更するため、マイグレーションファイルを書き換えました。
その後、自動デプロイツールであるCapstranoでデプロイを更新しました。
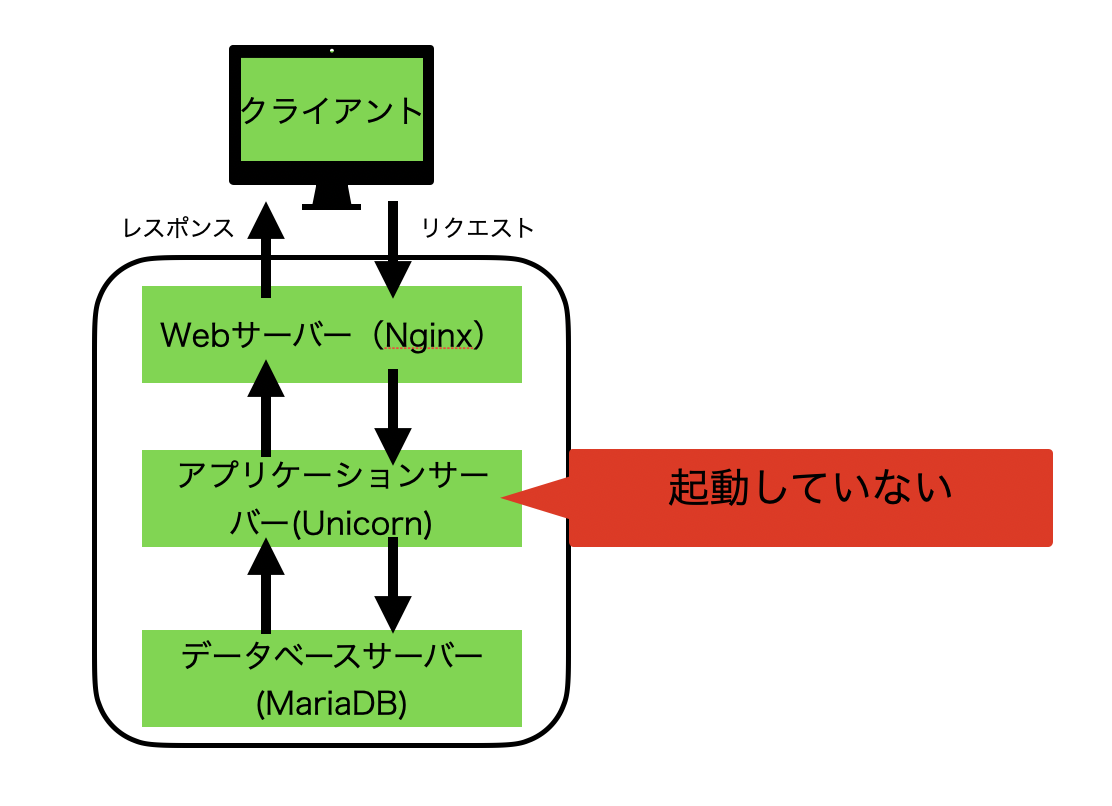
動作を確認したところ、カラムを変更したフォームに入力する画面に遷移しようとした時に、unknown attributeというエラーが出ました。結論
teratailで質問をしたところ「アプリケーションサーバーの再起動はできているのか」とアドバイスいただきまして、Unicornのプロセスを確認したところ起動していませんでした。
Uniconが起動していなかった原因はわかりませんが、起動したところエラーがなくなり変更したカラムにも値が保存されるようになりました。下の図のようにアプリケーションサーバーが起動していなかったため、ビューなどは表示できたが、処理を行ったりDBへアクセスができずエラーになったと考えました。
teratailでの質問:https://teratail.com/questions/304282
質問前に行ったこと3つ
1. DBのカラム名確認
EC2内のDBであるMariaDBの中身を確認しました。
[ec2-user@ip-..... ~]$ mysql -u root -pでデータベースにアクセスした後は
USE アプリ名_productionでデータベースを指定し、
DESCRIBE テーブル名で確認するとカラムがみられます。
これでチェックしたところ、変更されていました。2.データベースとWebサーバーのリスタート
[ec2-user@ip-・・・・ ~]$ sudo systemctl restart mariadb [ec2-user@ip-・・・・ ~]$ sudo systemctl restart nginxこれでも変わりませんでした。
3. データベースをリセット
投稿していた中身は消えてしまいますが、以下の記事を参考に、EC2インスタンスのcurrentディレクトリに移動した後、以下の4つを実行してリセットしました。
$ RAILS_ENV=production DISABLE_DATABASE_ENVIRONMENT_CHECK=1 bundle exec rake db:drop $ rake db:create RAILS_ENV=production $ rake db:migrate RAILS_ENV=production $ rake db:seed RAILS_ENV=production参考:https://qiita.com/iczo32/items/84719b5aff8a6b9e37bd
以上
- 投稿日:2020-11-22T15:41:47+09:00
Golangはじめて物語(第5話: DynamoDBで1MB以上のアイテムリストをクエリする)
はじめに
Golang + DynamoDB は高速で便利!だが、DynamoDB のアトリビュートと Golang の map の関連が分かりにくかったり、慣れないとハマりどころがけっこうある。
今回は、1MB以上のアイテムリストを取得するクエリを発行する場合のコードを書いてみる。
DynamoDBのテーブル定義
以下のようなテーブルを用意する。
- idをハッシュキーとする
- nameをレンジキーとする
※実際のデータモデルでこんなものは滅多にないと思うが、同じIDに複数の名前が連なっているというモデルを考える。今回、簡略化するために、同一 ID で異なる 1000Byte の name 1500 レコードある状態で、ID 指定のクエリを発行して、name の一覧を取得するような Golang のソースを書く。
ソースコード
type item struct { Id string `dynamodbav:"id"` Name string `dynamodbav:"name"` } func main() { var ( LastEvaluatedKey map[string]*dynamodb.AttributeValue ) sess := session.Must(session.NewSessionWithOptions(session.Options{ SharedConfigState: session.SharedConfigEnable, })) svc := dynamodb.New(sess) for { result, err := svc.Query(&dynamodb.QueryInput{ TableName: aws.String("[テーブル]"), KeyConditionExpression: aws.String("#ID=:id"), ExpressionAttributeNames: map[string]*string{ "#ID": aws.String("id"), }, ExpressionAttributeValues: map[string]*dynamodb.AttributeValue{ ":id": { S: aws.String("00001"), }, }, ExclusiveStartKey: LastEvaluatedKey, }) if err != nil { log.Println("Got error calling Query:") log.Println(err.Error()) return } log.Println(result) if len(result.LastEvaluatedKey) == 0 { break } else { LastEvaluatedKey = result.LastEvaluatedKey } } return }LastEvaluatedKey
DynamoDB は1回の Query 関数で取得し切れない場合、「ここから続けてね」という情報を QueryOutput 構造体の LastEvaluatedKey に格納して返してくる。
この情報を持ち廻って、Query の ExclusiveStartKey に設定することで、次の Query では続きを取得してくれる。なお、LastEvaluatedKey が設定される場合は以下のような中身になっている。
LastEvaluatedKey: { name: { S: "01022xxxxx(中略)xxxxx" }, id: { S: "00001" } },では、このレコードは初回呼び出しと次の呼び出し、どちらに格納されるかというと、初回側に
Items: [ { id: { S: "00001" }, name: { S: "00001xxxxx(中略)xxxxx" } }, (中略) { id: { S: "00001" }, name: { S: "01022xxxxx(中略)xxxxx" } } ],といった具合に、Item 配列の最後に同じレコードの情報が格納されていて、2回目呼び出しの Item 配列には上記レコードが含まれていない。要は、重複や漏れを考える必要なく、Item 配列を扱っておけば、取得したアイテムリストはそのまま使えると考えれば良い。
LastEvaluatedKey は初期化した状態で渡せば、クエリのオプションで指定しなかった場合と同等の動作となるため、上記のコードは先に LastEvaluatedKey を宣言しておき、do while 的なループの回し方をしている(Golang には do while がなく for に一本化されているので、上記のような方式となる)。
Lambdaで扱う場合、Golang の var で毎回初期化してくれるかが分からないので、ループに入る前に一度初期化しておくのが安全だろう。
これで、大量データを処理するクエリも問題なく扱えるようになった!
- 投稿日:2020-11-22T15:33:10+09:00
AWS Certified Solutions Architect - Associate(SAA) 合格記
はじめに
2020年3月頃の話です。
DVA試験を受けようと思いその前に、
SAA試験でどれくらい勉強に時間がかかって、どんな教材を使っていたのか振り返るために書きました。受験のきっかけ
今までレガシーな技術に触れることが多く、精神的に参ってしまうことが多々ありました。
なんとかモダンな技術に触れる機会を作れないかなと考えていましたが、
自分に技術力がないことには何もできないですし、
今後、バックエンドの開発者としてやっていくにはAWSは必須な技術かなと思って受験することにしました。学習前のスキルセット
* 業務でのAWS経験なし * プライベートでもAWSに触れたことがない * EC2,S3という名前すら聞いたことがないレベル学習期間と勉強方法
12月から3月の試験まで約90時間程、費やしました。
12月頃:書籍 (約20時間)
とりあえず、AWSとはどんなものかとっかかりとして書籍を選びました。
通勤の合間に数冊読んでみましたが、
どの本も内容にそれほど差はなかったので1冊で良かったかなと思います。個人的には AWS認定資格試験テキスト の本がサービスごとに記載されていてわかりやすかったかなと思いました。
AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイト
徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト
1月:udemyの講座 (約40時間)
業務で使えるようになるためには、知識だけではなく実際に触ってみることは大事だと思ったので、
AWSのサービスに触れられる、udemyの講座を受けてみました。
AWS初心者的にとっては様々なサービスに触れられるいい機会になりました。
ちなみに、udemyはいつもセールをやっているのでそのタイミングで買うとお得です。これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座
講座の最後にある模擬試験は全て回答しないと解説が見られないので、
次のkoiwaclubの問題集を解いた後にやった方がいいかもしれません。2月:koiwaclubの問題集 (約30時間)
実際の試験に近い問題集があるということでkoiwaclubさんの問題集を解いてみました。
AWS WEB問題集で学習しよう本も読んで実際に触って、そこそこ答えられるんじゃないかと思っていましたが、
2,3割しか分からず悲惨な状態でした。
2周ほどして、試験前には7,8割くらいは解けていたかなという感じでした。2月下旬:模擬試験
最後にAWSの公式の模擬試験を受験しました。
費用は2,000円程度でした。
AWS 認定試験に備える結果が良すぎて、結構驚きでした。。
今思うと、簡単な問題ばかりだったのかもしれません。総合スコア: 92% トピックレベルスコア: 1.0 Design Resilient Architectures: 100% 2.0 Define Performant Architectures: 100% 3.0 Specify Secure Applications and Architectures: 66% 4.0 Design Cost-Optimized Architectures: 100% 5.0 Define Operationally-Excellent Architectures: 100%3月上旬:試験本番
銀座のテストセンターで受験してきました。
見知った問題が10問あるかないかしかなく、試験中は結構不安でした。
確信の持てない問題も10~20程あり、本番試験の方が問題集や模擬試験より難易度が高かったなという印象です。
そんな焦りもありましたが、2,3回見直しができる程、時間には余裕がありました。試験結果
ぎりぎり合格でした。
模擬試験で安心しすぎたかなという感じがありました。
最後に
実際にAWSのサービスを触ってから受験しましたが、
触らなくても合格まで行けそうだないう気がしました。
サービスを触らずに合格できたという合格記をちらほら見かけたのも納得です。blackbeltやよくある質問ページをあまり読み込んでいなかったので、
DVAやSysOps試験の時にはこちらも読むようにすれば得点アップを狙えるんじゃないかなと思っています。インフラ初心者でも時間をかければ、なんとか合格できることがわかりました。
この記事が、誰かの参考になれば幸いです。

- 投稿日:2020-11-22T11:13:52+09:00
AWS Amplifyで環境変数を設定し、Reactアプリで読み込む
GitHubなどからWebアプリのCI/CDができるAWS Amplifyですが、
今回は環境変数の設定方法と、AmplifyでホストしているReactアプリから読み込む方法を備忘録として残しておきます。
(あと以外と日本語のドキュメントがなかった)ReactなどのWebアプリでは.envファイルなどに環境変数を定義しておいて、
process.env.{任意の名前}で読み込むことがあると思いますが、
認証情報などを記載している場合はソース管理には載せられませんし、Amplifyで環境変数を設定して読み込む必要があります。ちなみにAmplifyではバックエンドの構築も可能ですが、環境変数の利用はフロントエンドのみのアプリでもできます。
ちょっとしたフロントエンドだけのアプリ作って環境変数の読み込みだけしたい場合、Amplify CLIを使ったバックエンドの構築などはせずに環境変数の設定、利用が可能です。環境変数の設定
環境変数の登録
Amplifyで環境変数を定義するにはまずAWS ConsoleでAmplifyのページに飛び、
サイドメニューから「環境変数」を選択します。
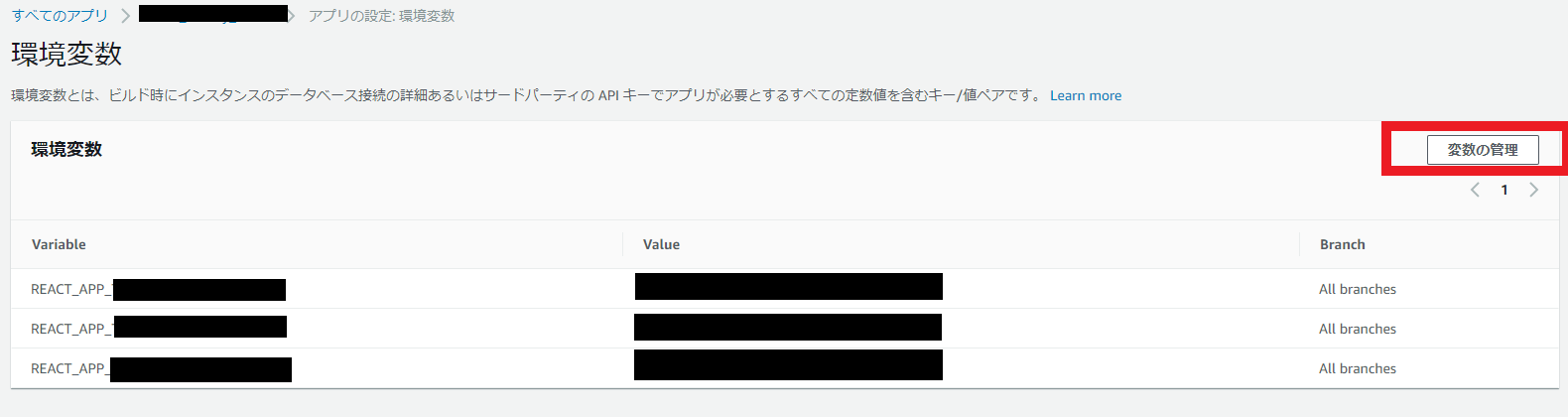
環境変数のメニューが開くので「変数の管理」から変数の登録・編集ができます。
今回はReactアプリで読み込むのでREACT_APP_を変数名にプレフィックスとしてつけておきます。
また、複数ブランチをホストしている場合には、ブランチごとに変数を設定することが可能です。
ビルドの設定
続いてメニューから「ビルドの設定」を選択し、以下の画面を開きます。
ここではデプロイ時のビルドの設定をyaml形式で定義することができるので、ここで環境変数のエクスポートをします。
buildのcommandsに↓こんな感じで書いておきます。
出力するパスはアプリに応じて変更します。今回はルートに書きだしています。echo "REACT_APP_HOGE=$REACT_APP_HOGE" >> .envアプリからの読み込み
あとはアプリから
process.env.REACT_APP_HOGEで読み込めば完了です。
参考

- 投稿日:2020-11-22T11:13:18+09:00
EKS 周辺に対してできたこと 2020
この記事は Voicy Advent Calendar 2020 の 7 日目の記事です。
先日は, @saicologic さんの 忘年会の余興に使えるSlackスタンプ活用術 でした。明日は, @tamo_hory さんの ~ です。はじめに
去年, 一昨年それ以前ぐらいだと k8s を立てるといえば GKE みたいな感じでした。(少なくとも個人的には)
しかし, EKS さん負けてない。今年辺りから料金が下がったり, EKS の採用事例も表に出てきていて盛り上がってますね。僕も業務の一環で EKS に触れることが多い 1 年でした。実際触れてみると, 潤沢な AWS リソースとの紐付けが容易みたいなところがあって直感的なところも多いのがメリットだな〜と感じます。そんな EKS に対して僕が今年できたことを振り返ります。
まとめ
- マネージド型ノードグループの冗長化
- Service NodePort に対する NLB の IaC
- アプリケーションデプロイパイプラインの GitOps 化
- 既存の eks マニフェストファイルの GitOps 統一
- EKS クラスターの kuberntes バージョン更新
- ALB+envoy+EKS 技術検証
- private Aurora に対して接続するためのプロキシを立てる
細かいところ
マネージド型ノードグループの冗長化
EKS のノードグループについて詳細はこちら。k8s node を AWS の Auto Scaling Group (EC2) などで実現しているものです。
EKS の場合, 仕様として単一のノードグループの中で 3AZ 冗長化対応済みのため, 単純に耐障害性を高めるだけならノードグループ内でインスタンス数を増やせば大丈夫です。
課題になってくるのが, 「ノードグループ単位でインスタンスクラスが決定される。」とか「インスタンスクラスをスケールさせる場合, ダウンタイムが発生する。」と言った辺りで, この辺りを解決するためにはノードグループ自体を冗長化させる必要があります。
IaC する場合, terraform eks_node_group resource 。しない場合は単純にコンソールなり eksctl なりから追加可能です。
参考リンク: マネージド型ノードグループの作成
Service NodePort に対する NLB の IaC
k8s は Service に Type: LoadBalancer を指定できる仕様があって, そこから AWS の場合 NodePort 用の NLB を作成できます。
apiVersion: v1 kind: Service metadata: name: *** namespace: *** labels: app: *** annotations: service.beta.kubernetes.io/aws-load-balancer-type: "nlb" spec: externalTrafficPolicy: Local ports: - name: http port: 80 protocol: TCP targetPort: 80 selector: app: *** type: LoadBalancerコレ自体はめちゃめちゃ便利で(後々削除予定とかの)一時的な接続先が欲しいとかの場合は十分だと思います。が terraform 管理のインフラとコンフリクトして問題になったことがあって, 「AWSにおけるLBは明確にインフラ」と定義して IaC することにという経緯です。
terraform で IaC するとなったとき, マネージド型ノードグループの場合, Auto Scaling Group として実装されている都合, そちらに対する追加の記述が必要になります。また, IaC する際に terraform 側に nodePort を記す必要がある都合上, マニフェストの方に nodePort を明示する必要があります。
+ nodePort: 32323 # memo: nodePort の指定しない場合, 30000〜32767 からランダムな port で待機するようになる -> tg 作成をコーディングする都合上指定は必須
- resource aws_lb で LB を作る
- resource aws_lb_target_group で TG を作る
- ここで指定する port を nodePort のポートにする必要がある
- resource aws_autoscaling_attachment で node group の Auto Scaling Group と TG を結びつける
- resource aws_lb_listener で LB→TG 転送設定を作る
- (ついでに) aws_route53_record から LB に対する DNS をつける
この辺りは, nodePort に対する LB を立てようとなるたびにセットで必要になる部分になります(private, public を分けたい。とか色々都合で別の窓口が欲しいとなったとき)。なので, まとめてモジュール管理しておくのが無難なのかなと思います。
アプリケーションデプロイパイプラインの GitOps 化
EKS へのアプリケーションデプロイです。 skaffold を使って build → deploy したり, 単に docker cli, kubectl, などから反映など色々手法としてはありそうです。
k8s のマニフェストは統一して管理されてる方が責務の都合上良いなどの理由から GitOps を採用しました。
GitOps 自体については, 解説してる記事は Qiita 上でもたくさんあったので割愛します。
簡易で説明しておくと
GCP 流にいうと, git 管理されたインフラコードをパブリッククラウドにデプロイすることが自動化されている状態, みたいなものを総じて GitOps と表現してたりします。
が, ここでの GitOps は, Weaveworks が提唱した kuberntes のデプロイマネージメントのことを指してます。k8sマニフェスト管理用の repository があり, EKS へのアプリケーション反映が常にそのマニフェストと同期されている状態。という感じです。
コレを実現するためのツールは色々あります。
それこと単に CI ツールを使っても実現可能です。有名所は上述した Weaveworks の Flux とか ArgoCD があります。
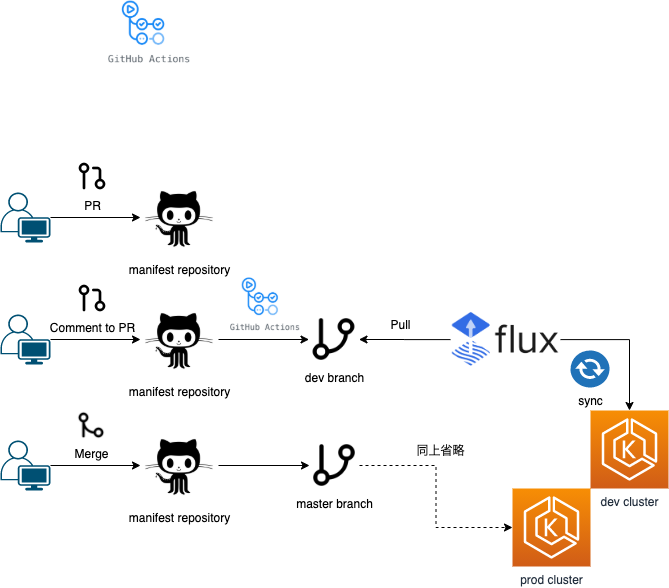
日本での採用事例を見てみると, ArgoCD の方が好まれる傾向にあるっぽいです(GUIから操作できたりなど)今回はとりあえず公式感のある所から GitOps という考えに触れるところからスタートみたいな所があったため Flux を採用してみました。
https://github.com/fluxcd/flux
こんな感じで運用してます。
GitHub Actions で, Atlantis terraform のような CD フロー(PR のコメント発火) を実現させるには, issue_comment を使います。
on: issue_comment: types: [created]肝心のコメント内容については, issue_comment 時の context に含まれていて取得できます。
echo ::set-output name=cmd::${{ github.event.comment.body }}ちなみに, この辺りの context については現状
${{ toJson(github) }}などで各自ダンプして確認することになってそうです。dev, stage 環境の反映のみコメントで対応みたいなのは, こんな感じで if 分岐を Actions に記述できます。発火させたい内容が完全に 1 スクリプトで完結する(他 Actions の利用を挟まない)なら, 単にスクリプトの引数として渡すというのも良さそうだなと思ったりしました。
if: ${{ steps.trigger.outputs.cmd == 'dev' || steps.trigger.outputs.cmd == 'stage' }}PR 上のコメントから発火した Actions の結果を PR に反映させたい。みたいな所は GitHub の特性を利用して, 「 commit に PR 番号を載せる。」と簡単に実現できます。
git commit -m "#${pr_number} Update ${target} from ${pr_label}"こういう形でコミットを残して置くと, 「dev コメント→ dev 反映内容」 みたいなのをセットで PR 上で確認できます。
コレで現時点の規模ならなんとかなってるんですが,
- もっと細かくデプロイを制御したい(負荷分散とか)
- 反映状況とかは GUI で確認したい
とかとかがやっぱり出てくるので, ArgoCD とか比較したいですね。
既存の eks マニフェストファイルの GitOps 統一
「既に EKS 上に立っている Pod について, 上記 Flux にマージするには?」という点についてです。
コレについては簡単で, 「マニフェストレポジトリ上に対象ファイルを反映してく。」でいけました。「Flux が repository を監視してタグの自動更新を行う。」辺りは, metadata の annotations から指定できます。
metadata: ... ... annotations: # Container Image Automated Updates flux.weave.works/automated: "true"この指定をなくせば, とりあえずマニフェスト結合みたいな所は実現できます。
EKS クラスターの kuberntes バージョン更新
k8s を扱う上で避けて通れないのがバージョン更新です。EKS の場合, 4 世代程度のバージョンをサポートしているんですが, k8s は 1 年辺り 4 世代更新となっているため, 最低でも 1 年に一度は起きるイベントとなっているためここに対する考慮は必須です。
アップデート戦略としては大きく分けて二つあると言われてます。
- ライブアップグレード
- ブルーグリーンアップグレード
ライブアップデートは, コンソールとか CLI とか API 経由でポチポチで更新していく方向です。
ブルーグリーンアップデートは, バージョン更新された別クラスタを立ててそちらに乗り換える。という戦略です。現時点の AWS コンソール API 経由からのインプレースな更新にはダウンタイムが発生します。
なら, ブルーグリーンだとなってるのが一般論です。ただ, EKS で純粋にブルーグリーンをやると「クラスタ名を後々変更できない。」などの制約から若干都合の悪い部分が出てきます。(特に色々な CI でクラスタ名に依存してたりする箇所とかあったりすると)
というのもあって戦略としては, 「ブルーグリーンで一時的にグリーンにトラフィックを流した状態で, 元のクラスタについてライブアップデートする。」という複合戦略で実施しました。現時点の EKS でのアップデート戦略としては一番安全な戦略かなと自負してます。
この変は, 僕ともう一人と協力で進めていきました。
グリーンクラスタの準備, Route53 の加重ルーティング設定みたいな IaC の担当と上記の GitOps 化辺りです。
この辺の対応を終えたおかげで, 「グリーンクラスタを既存クラスタから置き換える。」みたいなところまでは比較的楽に行うことができました。チームだいじ。あとは何もなかったか?というともちろんそんなことはなく,
公式リンク: Amazon EKS クラスターの Kubernetes バージョンの更新
こちらにある通り, インプレースな更新を行った場合, 「手動での API 更新」が必要になります。
ここの手順を見逃してて, かつこの時のエラーがめちゃめちゃ分かりづらく( node の準備が終わってない。みたいな)かなり苦労させられた思い出があります。なんとか一度戦略を立てたので, 「さぁメジャーアップデートどんとこい!」...とは現状思えなく, EKS 自体にも継続的に改善が加わってるので, 「絶対次のアップデートも大変だろうな。。。」という気持ちでいっぱいです。
ここは避けて通れないのでしょうがない。
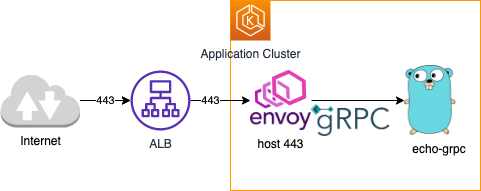
ALB+envoy+EKS (gRPC) 技術検証
上述の通り基本的には NLB を利用していて, プロキシとしては envoy が使われます。一部 gRPC アプリケーションがあり, その都合 NLB+envoy の技術スタックが利用されていた。という背景です。
そんな中, ALB が gRPC に対応した。というニュースが上がりました。朗報
https://aws.amazon.com/jp/blogs/aws/new-application-load-balancer-support-for-end-to-end-http-2-and-grpc/こちらの検証にあたって便利だったのが以下の記事です。
こちらは, GKE+envoy+gRPC という技術スタックになります。
https://cloud.google.com/solutions/exposing-grpc-services-on-gke-using-envoy-proxy?hl=jak8s の利点として, インターフェースが共通化されているのでプラットフォームが移っても大体同じことができる。があります。ここはかなり強力です。
上記についてもほぼほぼなんの苦労もなく, GKE→EKS への置き換えが可能でした。
一部差分としては, 以下辺りでした。
- ALB は自前で (IaC するなり) 立てた方がいい
- オレオレ証明書に渡す EXTERNAL_IP は ALB DNS でいい
- envoy が 443 待機することになる(サンプルの envoy 構成だと)ので, Target Group としても 443 に飛ばせばいい
このニュースの本質は,
HTTP2→ALB→HTTP1となっていた点がHTTP2→ALB→HTTP2に対応した。点にあります。他にも ALB の場合, セキュリティグループでの IP 制限も容易みたいなところもあります。ので, gRPC に限らず ALB を採用する。という選択肢もありなんじゃないでしょうか!?private Aurora に対して接続するためのプロキシを立てる
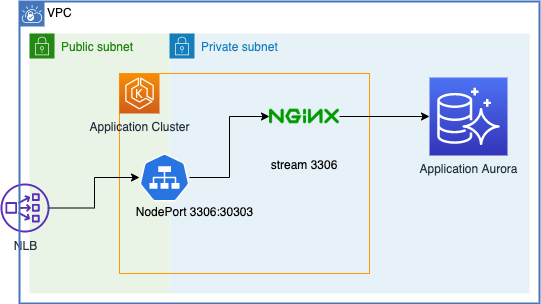
public endpoint を持つ Aurora に対してセキュリティグループで IP 制限よりは, private endpoint しか持たず, 前段で通信制御が行える。という方がセキュリティ的にも良かろう。みたいな背景から EKS 上にプロキシを立てるにはみたいなところを実現するための手法の一つです。
ここには色々と案があって, NLB で直接 Aurora の IP を指定して接続だったり, EC2 インスタンスを踏み台としたり, EKS 上の Service で IP を指定したり ... etc です。
IP 直接指定だと, クラスタのフェイルオーバーへの追従が行えないというデメリットが大きく, 今回は nginx をプロキシとして採用してる感じです。
nginx → mysql な proxy はググると色々出てきます。
https://tech-lab.sios.jp/archives/10761nginx のもつ stream block の機能でお手軽に実現できて良いです。
実際の config は ConfigMap として, EKS に持って, Deployment でマウントするイメージです。apiVersion: v1 kind: ConfigMap metadata: name: proxy-conf namespace: entry-point data: nginx.conf: | user nginx; worker_processes 1; error_log /dev/stderr warn; pid /var/run/nginx.pid; events { worker_connections 1024; } stream { log_format basic '$remote_addr [$time_local] ' '$protocol $status $bytes_sent $bytes_received ' '$session_time'; access_log /dev/stdout basic; include /etc/nginx/whitelist.conf; deny all; upstream db { include /etc/nginx/upstream.conf; } server { listen 3306; proxy_pass db; } }環境毎に異なる設定(許可IPリストとか接続先DNSとか)は別ファイルとして設定できるように。
apiVersion: v1 kind: ConfigMap metadata: name: proxy-add-conf namespace: entry-point data: upstream.conf: | server {dns}:3306; whitelist.conf: | allow *.*.*.*; allow *.*.*.*; ...volumeMount 辺り以外は普通の Deployment と共通です。
apiVersion: apps/v1 kind: Deployment metadata: name: proxy namespace: entry-point spec: selector: matchLabels: app: proxy replicas: 1 template: metadata: labels: app: proxy spec: containers: - name: proxy image: nginx:1.18.0 # 2020.11.20 時点の stable ports: - containerPort: 3306 volumeMounts: - name: config mountPath: /etc/nginx/nginx.conf subPath: nginx.conf readOnly: true - name: add-config mountPath: /etc/nginx/upstream.conf subPath: upstream.conf readOnly: true - name: add-config mountPath: /etc/nginx/whitelist.conf subPath: whitelist.conf readOnly: true volumes: - name: config configMap: name: proxy-conf - name: add-config configMap: name: proxy-add-confちょっと運用を見てみないと掴めない部分もあるんですが, このプロキシ自体は一時的なものになるんじゃないかなと思います。
一時的なリソースもサッと他に影響なく追加できるというのは, k8s のいいところですね!おわり
振り返ってみると色々とやったな〜と思います。ここに書かれていない部分でも色々と変化(改修)を見たりしました。
他にも, 社内では k8s コードリーディングやったり と一気に k8s に強くなれた一年でした。今後もしばらく k8s と戯れる日々になりそうだなと思います。また, これからやりたいこともたくさんあります。
- 一部リソースを喰いがちな CronJob 処理で Fargate を使ってみたり → コレ のイメージ
- IaC 整理, モジュール化(アップデート, 冗長構成に対して柔軟に)
- イベント通知(Pod 立ったよみたいな)周り
- 都度バージョン更新で出る機能あれば
- サービスメッシュ検討
- GitOps 比較
- ...... etc
変化の多い k8s 周り来年にどうなってるか楽しみです!