- 投稿日:2020-11-14T23:58:33+09:00
macOS で pandas をインポートしようとしたら No module named '_bz2' というエラーが出る
環境
- macOS Big Sur バージョン 11.0.1
- pyenv で python をインストール
問題
python で何気なく pandas をインポートしようとしたところ、
import pandas as pd次のようなエラーが発生しました。
Traceback (most recent call last): ...(中略) ImportError: No module named '_bz2'原因
pyenv で python をインストールする際に、コンパイラが bzip2 というパッケージを認識していなかったために、python の bz2 ライブラリがインストールされず不完全な状態になっていると予想できます。
なので、pyenv でインストールした時に次のような warning が表示されていたことでしょう。
$ pyenv install 3.9.0 ...(中略) WARNING: The Python bz2 extension was not compiled. Missing the bzip2 lib?解決方法
コンパイラに bzip2 ライブラリを認識させた状態で、 pyenv を使って python を再インストールします。
1. bzip2 パッケージをインストール
$ brew install bzip2インストールの途中で、おそらく次のようなメッセージが出てくると思います。これが非常に重要です。
For compilers to find bzip2 you may need to set: export LDFLAGS="-L/usr/local/opt/bzip2/lib" export CPPFLAGS="-I/usr/local/opt/bzip2/include"2. LDFLAGS と CPPFLAGS を設定
brew でインストールしただけでは、 pyenv で python をビルドする際に bzip2 パッケージをコンパイラは認識してくれません。
コンパイラに認識させるためには、先ほど出てきたメッセージの通り、LDFLAGSとCPPFLAGSを設定する必要があります。
そのために、.zprofile または .bash_profile の中に次の文を付け加えます。export LDFLAGS="-L/usr/local/opt/bzip2/lib" export CPPFLAGS="-I/usr/local/opt/bzip2/include"前に別の
LDFLAGSとCPPFLAGSを設定していた場合、これらの FLAG はスペースでつなげることで複数指定することができるので、次のようにしても良いでしょう。export LDFLAGS="$LDFLAGS -L/usr/local/opt/bzip2/lib" export CPPFLAGS="$CPPFLAGS -I/usr/local/opt/bzip2/include"3. python を再インストール
pyenv でお好みのバージョンをインストールします。
$ pyenv install <version>おそらく先ほどの warning は消えていたと思います。
その後は、いつもの pyenv によるインストール手順に従い、メインで使う python のバージョンを指定し、シェルをリロードします。
$ pyenv global <先ほどインストールしたバージョン> $ exec $SHELL -lおそらく pandas を読み込めるようになっているはずです。
(参考) Linux の場合
以下の記事が参考になります。
scikit-learn で No module named '_bz2' というエラーがでる問題感想
Linux で同じエラーに対処する方法はたくさん見つかったのですが、macOS でのエラー対処法は見つからなかったので、自力で解決するしかなく大変でした。
- 投稿日:2020-11-14T22:59:24+09:00
pythonをインストールしてるのにimportエラー
- 投稿日:2020-11-14T22:04:26+09:00
OptunaでLightGBMのパラメータ調整
※Colabで動くことを確認しました.
参考
https://tech.preferred.jp/ja/blog/hyperparameter-tuning-with-optuna-integration-lightgbm-tuner/
Optunaのインストール
pip install optunaパラメータ探索
import optuna def objective(trial): #x_train, y_train, x_test, y_testを準備 dtrain = lgb.Dataset(x_train, label=y_train) param = { 'objective': 'binary', 'metric': 'binary_logloss', 'lambda_l1': trial.suggest_loguniform('lambda_l1', 1e-8, 10.0), 'lambda_l2': trial.suggest_loguniform('lambda_l2', 1e-8, 10.0), 'num_leaves': trial.suggest_int('num_leaves', 2, 256), 'feature_fraction': trial.suggest_uniform('feature_fraction', 0.4, 1.0), 'bagging_fraction': trial.suggest_uniform('bagging_fraction', 0.4, 1.0), 'bagging_freq': trial.suggest_int('bagging_freq', 1, 7), 'min_child_samples': trial.suggest_int('min_child_samples', 5, 100), } gbm = lgb.train(param, dtrain) preds = gbm.predict(x_test) pred_labels = np.rint(preds) #pred_labelsとy_testで評価値を算出 return precision #今回はprecisionでパラメータ探索 study = optuna.create_study(direction='maximize') study.optimize(objective, n_trials=100) print('Number of finished trials:', len(study.trials)) print('Best trial:', study.best_trial.params)
- 投稿日:2020-11-14T20:42:52+09:00
2020年11月版 Pythonデータ分析試験 合格体験記
はじめに
2020年10月の転職に伴ってデータ分析に入門したのもあり、体系的に学びたいと思い、Python3エンジニア認定データ分析試験に取り組みました。
比較的新しい試験で、Web上にあった情報と少し違うこともあったので、体験を共有させてもらいます。これから受験される方の、一助になれば嬉しいです。僕のバックボーン
この記事を書いている、僕自身のことも書いておきます。
こういう人間の感想なんだなーと思ってもらえれば良いかと思います。
地頭の良い人が言う「簡単」ほど、あてにならないものはありません。笑コーディングの技術
- ITエンジニア歴2年
- キャリアのほとんどが、Golangを使ったWeb系のバックエンド開発
- Python歴は、転職してからの直近1ヶ月程度
数学的な知識
- 工業高校卒
- 普通科高校とカリキュラムが違うので、そもそも習わないことがあったりする。
- Fラン大学中退 (非情報系学部)
- おそらく、数学的な教養はかなり乏しい方かと思われます。
その他
- 大阪在住
- 32歳
- 妻子あり (子どもは新生児)
- 試験勉強期間の残業は、およそ10時間/月くらい
試験に取り組んでみた感想
- 狙い通り、Pythonを使ったデータ分析について、しっかり体系的に勉強ができて良かった。
- NumPyやpandas等の「定番」ライブラリについての理解が深められて良かった。
- 機械学習やグラフ描画のライブラリを使うのが初めだったが、基礎からしっかり学べて良かった。
- 本試験に比べて (後述の) 模擬試験の難易度がかなり高く、本試験を受けるまでヒヤヒヤした。
- 個人的には、数学基礎が難しく感じた。
- 試験中、計算やメモの用紙が禁止だと言われ、暗算で解く必要があり解きにくかった。
- 受験申し込みが試験会場に直接連絡するシステムで、申し込み時に直接支払いに行ったり等、手間を感じた。
試験の概要
この試験には主教材として、翔泳社「Pythonによるあたらしいデータ分析の教科書」が指定されています。基本的に、問題はここからしか出題されません。
公式サイトでは、以下の範囲と割合で出題されました。
章 節 問題数 問題割合 1 データエンジニアの役割 2 5.0% 2 Pythonと環境 1 実行環境構築 1 2.5% 2 Pythonの基礎 3 7.5% 3 Jupyter Notebook 1 2.5% 3 数学の基礎 1 数式を読むための基礎知識 1 2.5% 2 線形代数 2 5.0% 3 基礎解析 1 2.5% 4 確率と統計 2 5.0% 4 ライブラリによる分析実践 1 NumPy 6 15.0% 2 pandas 7 17.5% 3 Matplotlib 6 15.0% 4 scikit-learn 8 20.0% 5 応用: データ収集と加工 0 0% 表の通り、4つのライブラリの使い方が、配点の67.5%を締めていて、明らかにここが重要ポイントでした。
受験勉強
以下、今回の受験に際して勉強した内容です。
主教材
教材をさらっと一読して、4章のところではJupyter Notebookで動作確認をしました。
また、この教材を元に一問一答みたいな問題を作って、自分で反復して解いていました。
ちなみに、先述の通りこの試験は出題範囲に結構偏りがあるので、数学基礎はある程度学習した後、ライブラリの学習に注力する方針で対応しました。模擬試験
- DIVE INTO EXAM
- 1回分の模擬試験が受けられる。
- 僕は、この模擬試験を2回受けた。
- 難易度は、本試験と同じくらいか、やや難しい印象。
- 無料会員登録して、受験するシステム。
- PRIME STUDY
- 3回分の模擬試験が受けられる。
- 僕はこのサービスの模試は、1回分を2回受けた。
- 難易度は、本試験よりもかなり高かった。
- 僕はこの模擬試験で正答率45%でしたが、本試験では正答率85%でした。
- 1回目の数問だけ動画解説がある。
- この動画解説が、かなり分かりやすかった。追加でアップしてほしい。
- 結果を受け取る用のメールアドレスだけ入力して、受験するシステム。
さいごに
以上、簡単ながら体験記でした。
何か質問等あれば、ぜひぜひコメントお待ちしております。
最後まで、読んで頂いてありがとうございました。参考
- 投稿日:2020-11-14T20:42:52+09:00
2020年11月版 Python3エンジニア認定データ分析試験
はじめに
2020年10月の転職に伴ってデータ分析に入門したのもあり、体系的に学びたいと思い、Python3エンジニア認定データ分析試験に取り組みました。
比較的新しい試験で、Web上にあった情報と少し違うこともあったので、体験を共有させてもらいます。これから受験される方の、一助になれば嬉しいです。僕のバックボーン
この記事を書いている、僕自身のことも書いておきます。
こういう人間の感想なんだなーと思ってもらえれば良いかと思います。
地頭の良い人が言う「簡単」ほど、あてにならないものはありません。笑コーディングの技術
- ITエンジニア歴2年
- キャリアのほとんどが、Golangを使ったWeb系のバックエンド開発
- Python歴は、転職してからの直近1ヶ月程度
数学的な知識
- 工業高校卒
- 普通科高校とカリキュラムが違うので、そもそも習わないことがあったりする。
- Fラン大学中退 (非情報系学部)
- おそらく、数学的な教養はかなり乏しい方かと思われます。
その他
- 大阪在住
- 32歳
- 妻子あり (子どもは新生児)
- 試験勉強期間の残業は、およそ10時間/月くらい
試験に取り組んでみた感想
- 狙い通り、Pythonを使ったデータ分析について、しっかり体系的に勉強ができて良かった。
- NumPyやpandas等の「定番」ライブラリについての理解が深められて良かった。
- 機械学習やグラフ描画のライブラリを使うのが初めだったが、基礎からしっかり学べて良かった。
- 本試験に比べて (後述の) 模擬試験の難易度がかなり高く、本試験を受けるまでヒヤヒヤした。
- 個人的には、数学基礎が難しく感じた。
- 試験中、計算やメモの用紙が禁止だと言われ、暗算で解く必要があり解きにくかった。
- 受験申し込みが試験会場に直接連絡するシステムで、申し込み時に直接支払いに行ったり等、手間を感じた。
試験の概要
この試験には主教材として、翔泳社「Pythonによるあたらしいデータ分析の教科書」が指定されています。基本的に、問題はここからしか出題されません。
公式サイトでは、以下の範囲と割合で出題されました。
章 節 問題数 問題割合 1 データエンジニアの役割 2 5.0% 2 Pythonと環境 1 実行環境構築 1 2.5% 2 Pythonの基礎 3 7.5% 3 Jupyter Notebook 1 2.5% 3 数学の基礎 1 数式を読むための基礎知識 1 2.5% 2 線形代数 2 5.0% 3 基礎解析 1 2.5% 4 確率と統計 2 5.0% 4 ライブラリによる分析実践 1 NumPy 6 15.0% 2 pandas 7 17.5% 3 Matplotlib 6 15.0% 4 scikit-learn 8 20.0% 5 応用: データ収集と加工 0 0% 表の通り、4つのライブラリの使い方が、配点の67.5%を締めていて、明らかにここが重要ポイントでした。
受験勉強
以下、今回の受験に際して勉強した内容です。
主教材
教材をさらっと一読して、4章のところではJupyter Notebookで動作確認をしました。
また、この教材を元に一問一答みたいな問題を作って、自分で反復して解いていました。
ちなみに、先述の通りこの試験は出題範囲に結構偏りがあるので、数学基礎はある程度学習した後、ライブラリの学習に注力する方針で対応しました。模擬試験
- DIVE INTO EXAM
- 1回分の模擬試験が受けられる。
- 僕は、この模擬試験を2回受けた。
- 難易度は、本試験と同じくらいか、やや難しい印象。
- 無料会員登録して、受験するシステム。
- PRIME STUDY
- 3回分の模擬試験が受けられる。
- 僕はこのサービスの模試は、1回分を2回受けた。
- 難易度は、本試験よりもかなり高かった。
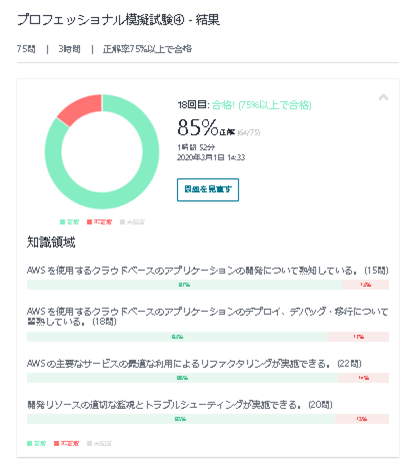
- 僕はこの模擬試験で正答率45%でしたが、本試験では正答率85%でした。
- 1回目の数問だけ動画解説がある。
- この動画解説が、かなり分かりやすかった。追加でアップしてほしい。
- 結果を受け取る用のメールアドレスだけ入力して、受験するシステム。
さいごに
以上、簡単ながら体験記でした。
何か質問等あれば、ぜひぜひコメントお待ちしております。
最後まで、読んで頂いてありがとうございました。参考
- 投稿日:2020-11-14T20:42:52+09:00
2020年11月版 データ分析試験 合格体験記
はじめに
2020年10月の転職に伴ってデータ分析に入門したのもあり、体系的に学びたいと思い、Python3エンジニア認定データ分析試験に取り組みました。
比較的新しい試験で、Web上にあった情報と少し違うこともあったので、体験を共有させてもらいます。これから受験される方の、一助になれば嬉しいです。僕のバックボーン
この記事を書いている、僕自身のことも書いておきます。
こういう人間の感想なんだなーと思ってもらえれば良いかと思います。
地頭の良い人が言う「簡単」ほど、あてにならないものはありません。笑コーディングの技術
- ITエンジニア歴2年
- キャリアのほとんどが、Golangを使ったWeb系のバックエンド開発
- Python歴は、転職してからの直近1ヶ月程度
数学的な知識
- 工業高校卒
- 普通科高校とカリキュラムが違うので、そもそも習わないことがあったりする。
- Fラン大学中退 (非情報系学部)
- おそらく、数学的な教養はかなり乏しい方かと思われます。
その他
- 大阪在住
- 32歳
- 妻子あり (子どもは新生児)
- 試験勉強期間の残業は、およそ10時間/月くらい
試験に取り組んでみた感想
- 狙い通り、Pythonを使ったデータ分析について、しっかり体系的に勉強ができて良かった。
- NumPyやpandas等の「定番」ライブラリについての理解が深められて良かった。
- 機械学習やグラフ描画のライブラリを使うのが初めだったが、基礎からしっかり学べて良かった。
- 本試験に比べて (後述の) 模擬試験の難易度がかなり高く、本試験を受けるまでヒヤヒヤした。
- 個人的には、数学基礎が難しく感じた。
- 試験中、計算やメモの用紙が禁止だと言われ、暗算で解く必要があり解きにくかった。
- 受験申し込みが試験会場に直接連絡するシステムで、申し込み時に直接支払いに行ったり等、手間を感じた。
試験の概要
この試験には主教材として、翔泳社「Pythonによるあたらしいデータ分析の教科書」が指定されています。基本的に、問題はここからしか出題されません。
公式サイトでは、以下の範囲と割合で出題されました。
章 節 問題数 問題割合 1 データエンジニアの役割 2 5.0% 2 Pythonと環境 1 実行環境構築 1 2.5% 2 Pythonの基礎 3 7.5% 3 Jupyter Notebook 1 2.5% 3 数学の基礎 1 数式を読むための基礎知識 1 2.5% 2 線形代数 2 5.0% 3 基礎解析 1 2.5% 4 確率と統計 2 5.0% 4 ライブラリによる分析実践 1 NumPy 6 15.0% 2 pandas 7 17.5% 3 Matplotlib 6 15.0% 4 scikit-learn 8 20.0% 5 応用: データ収集と加工 0 0% 表の通り、4つのライブラリの使い方が、配点の67.5%を締めていて、明らかにここが重要ポイントでした。
受験勉強
以下、今回の受験に際して勉強した内容です。
主教材
教材をさらっと一読して、4章のところではJupyter Notebookで動作確認をしました。
また、この教材を元に一問一答みたいな問題を作って、自分で反復して解いていました。
ちなみに、先述の通りこの試験は出題範囲に結構偏りがあるので、数学基礎はある程度学習した後、ライブラリの学習に注力する方針で対応しました。模擬試験
- DIVE INTO EXAM
- 1回分の模擬試験が受けられる。
- 僕は、この模擬試験を2回受けた。
- 難易度は、本試験と同じくらいか、やや難しい印象。
- 無料会員登録して、受験するシステム。
- PRIME STUDY
- 3回分の模擬試験が受けられる。
- 僕はこのサービスの模試は、1回分を2回受けた。
- 難易度は、本試験よりもかなり高かった。
- 僕はこの模擬試験で正答率45%でしたが、本試験では正答率85%でした。
- 1回目の数問だけ動画解説がある。
- この動画解説が、かなり分かりやすかった。追加でアップしてほしい。
- 結果を受け取る用のメールアドレスだけ入力して、受験するシステム。
さいごに
以上、簡単ながら体験記でした。
何か質問等あれば、ぜひぜひコメントお待ちしております。
最後まで、読んで頂いてありがとうございました。参考
- 投稿日:2020-11-14T20:35:22+09:00
selfの持つ意味
selfがないと、、、ローカル変数(関数内部で初期化される変数)と区別ができなくなる。
class Sample: num = 100 def show_num(self): num = 200 print(self.num) print(num) a= Sample() a.show_num()出力は以下の通り
>>>100 >>>200print(self.num)とprint(num)でうまく区別されているということになります。
- 投稿日:2020-11-14T19:44:35+09:00
Import Error: libffi.so.6: cannot open shared object file: No such file or directory
TL;DR
ファイル
libffi.so.6がimportできなかったことにより、Jupyter notebookの起動に失敗したときの解決法です。私の環境ではpyenvでpythonのversion管理を行っていたので、同様の管理をしている方向けです。Error
% jupyter notebook Import Error: libffi.so.6: cannot open shared object file: No such file or directory解決法
こちら1より、
% pyenv version i.j.k(set by $HOME/.pyenv/versions/i.j.k) % pyenv install i.j.k Installed Python-i.j.k to $HOME/.pyenv/versions/i.j.kと使用していたversionのPythonをインストールし直せば良いです。これで起動できるようになっている筈です。
- 投稿日:2020-11-14T19:18:40+09:00
[Python]個人的にまとめた件について。
Pythonについて、理解を深めるためにまとめる。
随時更新していく。参考文献
☆国本大悟/須藤秋良『スッキリわかるPython入門』流れ
①ソースコードの作成
ソースファイルの拡張子は
「.py」②実行
・
Pythonインタプリタ(:ソフトウェア)によって
ソースコードをマシン語(:コンピュータが理解できる言葉)に変換する
・文法上誤りがあればSyntaxError(構文エラー)が表示される
・例外(Exception)(:実行時のエラー)時は実行が中止になる式
【算術演算子】
//:割り算の商(答えは整数)
**:べき乗
*:文字列の反復(文字列 * 数値もしくは数値 * 文字列)[優先順位]
高:**
中:*、/、%
低:+、-print(1 + 1 * 7) --8 print((1 + 1) * 7) --14、丸かっこで優先度を上げることが可能【エスケープシーケンス】
print('おはよう\n諸君\\') print('\"と\'')文字列リテラルの使用時に用いられる特殊記号
\n:改行
\\:バックスラッシュ
\':シングルクォーテーション
\":ダブルクォーテーション変数
変数名 = 値 #変数の代入 変数名 #変数の参照 print('半径7の円直径は') ans = 7 * 2 --代入 print(ans) --参照 print('円周は') print(ans * 3.14) name, age = 'John', 33 --アンパック代入(:複数の変数をまとめて定義する方法)【予約語】
import keyword print(keyword.kwlist)・
識別子(:名前に使う文字や数字の並び)として利用不可の単語
・上記コードで確認できる
・中身を固定したい時は、大文字で名付けることが多い【複合代入演算子】
age += 1 --「age = age + 1」と同じ price *= 1.1 --「price = price * 1.1」と同じ【input関数】
変数名 = input(文字列) name = input('名前教えて!') print('ようこそ!' + name)キーボードからの入力を変数へ代入する
データ型はstr型データ型
[主な一覧]
int:整数
flaot:小数
str:文字列
bool:真偽値[変換]
int関数:小数以下は切り捨て、文字列はエラーになる
float関数:文字列はエラーになる
str関数
bool関数・演算は
文字列もしくは数値同士のみ連結が可能
・Pythonは暗黙の型変換(:自動的に型変換が行われる仕組み)がないため、
明示的な型変換を行わなければならない【type関数】
type(変数名) int(変数名) float(変数名) str(変数名) bool(変数名) x = 3.14 y = int(x) --int関数 print(y) print(type(y)) --type関数 z = str(x) --str関数 print(z) print(type(z)) print(z * 2)変数はデータ型を持たない(=
どのデータ型の値でも代入が可能)
➡︎どのデータ型が格納されているかを調べる【format関数】
'{}を含む文字列'.format(値1,値2・・・) name = '神' age = 77 print('我が名は{}、年は{}である').format(name,age) --{}が値を埋め込む場所文字列に値を埋め込むことができる
{}=プレースホルダー【f-string関数】
print(f'我が名は{name}、年は{age}である')Python3.6から導入された機能
プレースホールダー内に変数名(式もOK)を直接指定することが可能
- 投稿日:2020-11-14T19:18:40+09:00
[Python]基本文法を個人的にまとめた件について。
Pythonについて、理解を深めるためにまとめる。
随時更新していく。参考文献
☆国本大悟/須藤秋良『スッキリわかるPython入門』流れ
①ソースコードの作成
ソースファイルの拡張子は
「.py」②実行
・
Pythonインタプリタ(:ソフトウェア)によって
ソースコードをマシン語(:コンピュータが理解できる言葉)に変換する
・文法上誤りがあればSyntaxError(構文エラー)が表示される
・例外(Exception)(:実行時のエラー)時は実行が中止になる式
【算術演算子】
//:割り算の商(答えは整数)
**:べき乗
*:文字列の反復(文字列 * 数値もしくは数値 * 文字列)[優先順位]
高:**
中:*、/、%
低:+、-print(1 + 1 * 7) --8 print((1 + 1) * 7) --14、丸かっこで優先度を上げることが可能【エスケープシーケンス】
print('おはよう\n諸君\\') print('\"と\'')文字列リテラルの使用時に用いられる特殊記号
\n:改行
\\:バックスラッシュ
\':シングルクォーテーション
\":ダブルクォーテーション変数
変数名 = 値 #変数の代入 変数名 #変数の参照 print('半径7の円直径は') ans = 7 * 2 --代入 print(ans) --参照 print('円周は') print(ans * 3.14) name, age = 'John', 33 --アンパック代入(:複数の変数をまとめて定義する方法)【予約語】
import keyword print(keyword.kwlist)・
識別子(:名前に使う文字や数字の並び)として利用不可の単語
・上記コードで確認できる
・中身を固定したい時は、大文字で名付けることが多い【複合代入演算子】
age += 1 --「age = age + 1」と同じ price *= 1.1 --「price = price * 1.1」と同じ【input関数】
変数名 = input(文字列) name = input('名前教えて!') print('ようこそ!' + name)キーボードからの入力を変数へ代入する
データ型はstr型データ型
[主な一覧]
int:整数
flaot:小数
str:文字列
bool:真偽値[変換]
int関数:小数以下は切り捨て、文字列はエラーになる
float関数:文字列はエラーになる
str関数
bool関数・演算は
文字列もしくは数値同士のみ連結が可能
・Pythonは暗黙の型変換(:自動的に型変換が行われる仕組み)がないため、
明示的な型変換を行わなければならない【type関数】
type(変数名) int(変数名) float(変数名) str(変数名) bool(変数名) x = 3.14 y = int(x) --int関数 print(y) print(type(y)) --type関数 z = str(x) --str関数 print(z) print(type(z)) print(z * 2)変数はデータ型を持たない(=
どのデータ型の値でも代入が可能)
➡︎どのデータ型が格納されているかを調べる【format関数】
'{}を含む文字列'.format(値1,値2・・・) name = '神' age = 77 print('我が名は{}、年は{}である').format(name,age) --{}が値を埋め込む場所文字列に値を埋め込むことができる
{}=プレースホルダー【f-string関数】
print(f'我が名は{name}、年は{age}である')Python3.6から導入された機能
プレースホールダー内に変数名(式もOK)を直接指定することが可能
- 投稿日:2020-11-14T17:17:25+09:00
【Python】pythonで簡単に機械学習入門(SVM)
はじめに
機械学習に関する入門サイト見ていると、難しいことが書いてあったりして、知識0の人がとっつきにくい印象があります。
まあテーマとして確かに難しいのでしょうがないですが....
「数学や機械学習の知識が0でも、pythonの知識さえあれば誰でも実装できる」というのを目標に記事を書いていきたいと思います。
今回の記事では難しいことは説明せず、とりあえず機械学習というものに触れてみるというスタンスで、進めていきます。対象者
・pythonがある程度わかる
・機械学習に興味があるけど、何も知らない
・大学の授業で概要は学んだけど、実際にどう実装すればいいかわからない環境
python 3.8.5
scikit-learn 0.231まずはインストール
pythonのバージョンが3.8.5以下でないとでないとインストールできないようです。
pip install scikit-learncsvファイルの読み込みにnumpyを使うのでインストール済みでない方はインストールしてください。
pip install numpy用語解説
scikit-learn とは
scikit-learn (サイキット・ラーン)(旧称:scikits.learn) はPythonのオープンソース機械学習ライブラリ[2]である。サポートベクターマシン、ランダムフォレスト、Gradient Boosting(英語版)、k近傍法、DBSCANなどを含む様々な分類、回帰、クラスタリングアルゴリズムを備えており、Pythonの数値計算ライブラリのNumPyとSciPyとやり取りするよう設計されている。(wikipediaより)うん、まあこれを見ても意味がわからないと思うので、今回は簡単に、「機械学習をサポートしてくれるライブラリ」と覚えておきましょう。
SVMとは
サポートベクターマシン(英: support vector machine, SVM)は、教師あり学習を用いるパターン認識モデルの一つである。分類や回帰へ適用できる。
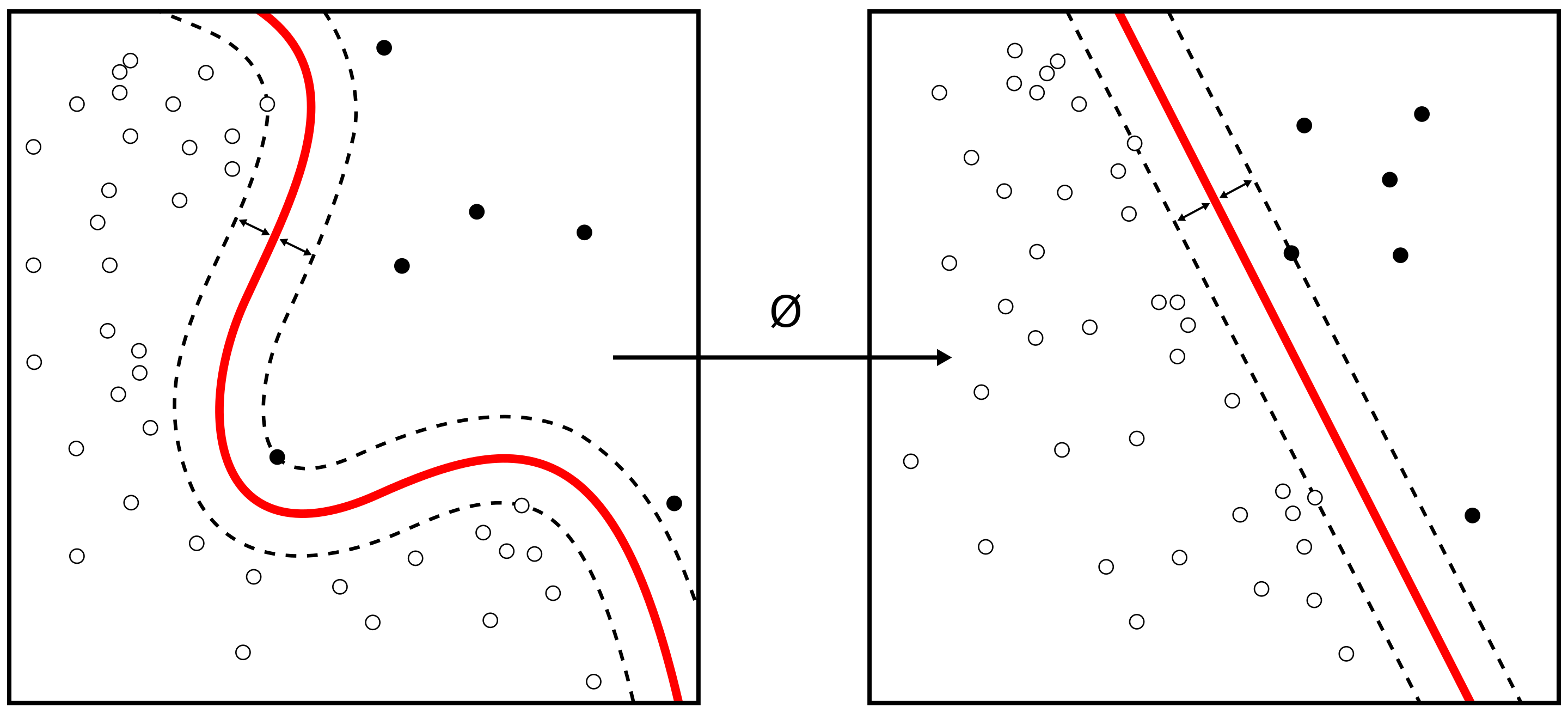
サポートベクターマシンは、現在知られている手法の中でも認識性能が優れた学習モデルの一つである。サポートベクターマシンが優れた認識性能を発揮することができる理由は、未学習データに対して高い識別性能を得るための工夫があるためである。(wikipediaより)簡単に言うと、下記の画像のように線を引いて、データを分類していく機械学習手法のことです。
一口に機械学習といっても様々な方法が存在します。
SVM(サポートベクターマシン)はその一つです。
https://upload.wikimedia.org/wikipedia/commons/thumb/f/fe/Kernel_Machine.svg/2880px-Kernel_Machine.svg.png
(wikipediaより)目的変数とは
機械学習で予測したい対象です。
例えば、天気を予測したいときの目的変数は晴れや、曇りや雨などになります。
説明変数とは
予測するために必要な情報のことです。
例えば、天気を予測したいときに必要な、降水量や湿度などがこれにあたります。データ
データは基本的には数が多いほど精度が高くなりますが、今回はお試しなので、少なめのデータを用意します。
このデータは今年の天気のデータです。
まあ天気データは気象庁のHPにいくらでもあるので、興味が湧いたら見てみてください。
左から、
気温、降水量、日照時間、湿度、天気(0:晴れ、1:曇り、2:雨)
を表しています。
このデータで言うと、気温、降水量、日照時間、湿度までが説明変数、天気(0:晴れ、1:曇り、2:雨)が目的変数です。data.csv6.6,0,8.2,47,0 7.1,0,5.7,57,1 7.1,0,9.3,62,0 8.1,0,4.7,53,1 6.5,0,9.7,54,0 8,0,8.1,42,1 6.6,1.5,0.5,68,2 5.7,21.5,2.7,94,2 11.2,0,9.3,47,0 9,0,7.9,57,1 8,0,4.5,66,1 7.7,0,1.8,66,2 9.1,0,9.3,70,0 9.1,0,8.3,70,0 7.8,11.5,3.6,79,2 7.6,0,4.4,46,1 7.6,0,3.6,58,1 3.8,13.5,0,87,2 7.3,0,8,62,1 8.3,0,9.7,60,0ソースコード
weatherを自分の好きな値に変えることで、その条件の時の天気を予測することができます。(ただ、データ数が少ないので、精度は悪いです)
weatherの中でも左から順に
気温、降水量、日照時間、湿度
で並んでいるので、この順に条件を入れてみてください。weather_learn.pyimport numpy as np from sklearn import svm #csvファイルの読み込み npArray = np.loadtxt("data.csv", delimiter = ",", dtype = "float") # 説明変数の格納 x = npArray[:, 0:4] #目的変数の格納 y = npArray[:, 4:5].ravel() #学習手法にSVMを選択 clf = svm.SVC() #学習 clf.fit(x,y) #評価データ(ここは自分で好きな値を入力) weather = [[9,0,7.9,6.5]] #predict関数で、評価データの天気を予測 print(clf.predict(weather))おわりに
今回もお疲れ様でした。
実際に自分が作ったものがこうして結果を吐いてくれるのは嬉しいものがありますよね。
自分が機械学習に初めて触れたときはあまりの情報量の多さに行き詰まったことが何度もありました。
この記事では知識はないけど、機械学習に触れてみたいという方に向けてわかりやすく書いたつもりですが、疑問点やミスがありましたらコメントください。
それでは、また。
- 投稿日:2020-11-14T17:15:07+09:00
多変量統計的プロセス管理(MSPC)を実装してみた
- 製造業出身のデータサイエンティストがお送りする記事
- 今回は製造業で使える異常検知手法を実装し整理しました。
はじめに
最近では製造業の現場でも機械学習を活用した取組みが増え始めていると思います。
今回は、異常検知プロジェクトで活用した多変量統計的プロセス管理(MSPC)を整理しました。製造業における異常検知とは
製造業では、予防保全という言葉があります。予防保全とは、生産ラインにおける機械設備の故障、不具合発生、性能低下などを未然に防ぐ保全方法を指しており、設備が壊れて生産ラインがストップすることを防ぐ目的で行っております。
他にも通常操業から異常な製品が生産されることを未然に防ぐために操業の異常検知などもあります。今回、ご紹介する異常検知手法(MSPC)はどちらにも活用できる手法となっております。
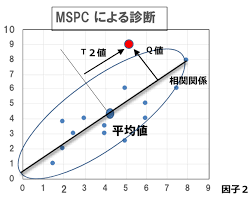
多変量統計的プロセス管理(MSPC)とは
MSPCで使用するでーたは、使用するデータは正常データのみで学習を行います。
一般的に機械学習などで分類を行う際は、正常データと異常データを同程度のサンプルを集めないと適切な分類ができないと思われがちですが、実際の現場では異常データはほとんど無く、正常データのみたくさんある状況です。
(実際、「異常データ=設備が故障する」と言うことなので、工場の生産がストップした際のデータになります。そんなデータが少ないのは当たり前です。そのために、製造現場では予防保全に力を入れており、少し過剰なぐらいのレベルで保全活動を行っております。)基本的な異常検知の考え方は、多次元空間内に正常データが存在する領域を設定し、その領域から逸脱したデータを観測した際に異常と判定します。そのため、正常データのみ学習することで異常検知モデルを構築する事ができます。
次に正常状態と異常状態の境界となる管理限界の設定の仕方について説明します。
少し天下り的になりますが、通常、変数間には何かしらの関係(相関関係)があり、正常データが含まれる領域を適切に定める際に変数間の関係性を捉える必要があります。つまり、2変数なら楕円、n変数なら超楕円を用意する必要があります。
MCPCでは変数間の関係性を考慮する手法として、主成分分析(PCA)を活用してマハラノビス距離を計算します。PCAを活用して超楕円を構築し、管理限界を設定してそこからデータが逸脱するのかどうかを判断する手法がMSPCになります。MSPCでは、PCAを活用して各主成分の分散を1に規格化し、マハラノビス距離を算出する際に全ての主成分を分散1に規格化しません。主要な主成分のみを分散1に規格化して、原点からの距離を算出します。この距離の2乗は$Hotelling'sT^2$統計量と呼ばれております。一方、主要ではない主成分は、Q統計量(二乗予測誤差:Squared Prediction Error)と呼ばれ、主要な主成分で張られる部分空間からの距離(予測誤差)の二乗で定義されます。
MSPCのまとめ
MSPCの手順を下記に整理します。
- 正常データを取得
- 正常データをPCAを活用する
- 主要な主成分の数を決める
- 主要な主成分は$T^2$統計量を算出し、その他の主成分は$Q$統計量を算出する。
- $T^2$統計量、$Q$統計量の管理限界を設定する
MSPCの実装
今回、テスト用に(サンプルデータ数:2,756 カラム数:90)のデータを用意しました。
正常データを1000件、残りの1,756件を評価データとして正常状態からどれだけ逸脱しているのかを見ました。pythonのコードは下記の通りです。
# 必要なライブラリーのインポート import pandas as pd import numpy as np from matplotlib import pyplot as plt %matplotlib inline from sklearn.preprocessing import StandardScaler from scipy import stats from sklearn.neighbors.kde import KernelDensity from sklearn.decomposition import PCA df = pd.read_csv('test_data.csv', encoding='shift_jis', header=1, index_col=0) df.head()
インプットデータは上記のような感じです。
今回は各カラムには適当は乱数を入れております。次に学習データと評価データを分割し、標準化を行っていきます。
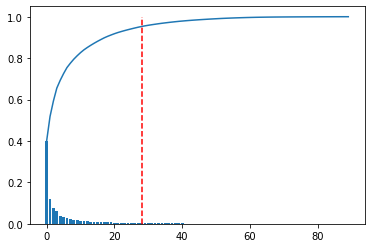
# 分割ポイント split_point = 1000 # 学習データ(train)と評価データ(test)に分割 train_df = df.iloc[:(split_point-1),] test_df = df.iloc[split_point:,] # データを標準化 sc = StandardScaler() sc.fit(train_df) train_df_std = sc.transform(train_df)次に主成分分析を行って主要な主成分を決めていきます。
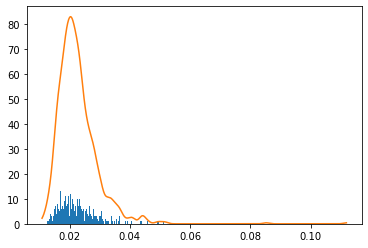
今回は累積寄与率が95%までの部分を主要な主成分としました。# PCA pca = PCA() pca.fit(train_df_std) # 累積寄与率のグラフ plt.figure() variance = pca.explained_variance_ratio_ variance_total = np.zeros(np.shape(variance)[0]) plt.bar(range(np.shape(variance)[0]), variance) for i in range(np.shape(variance)[0]): variance_total[i] = np.sum(variance[0:i+1]) plt.plot(variance_total) NumOfScore = np.min(np.where(variance_total>0.95)) x1=[NumOfScore,NumOfScore] y1=[0,1] plt.plot(x1,y1,ls="--", color = "r") pca = PCA(n_components = NumOfScore) pca.fit(train_df_std)
次にQ統計量を求めます。
# Q統計量 scores = pca.transform(train_df_std) residuals = pca.inverse_transform(scores)-train_df_std dist = np.sqrt(np.sum(np.power(residuals,2),axis=1))/(np.shape(train_df_std)[1])正常データから管理限界を設定しなければいけないため、カーネル密度推定を用いて管理限界を設定しました。
# コントロールリミット(カーネル密度推定) cr = 0.99 X = dist.reshape(np.shape(dist)[0],1) bw= (np.max(X)-np.min(X))/100 kde = KernelDensity(kernel='gaussian', bandwidth=bw).fit(X) X_plot = np.linspace(np.min(X), np.max(X), 1000)[:, np.newaxis] log_dens = kde.score_samples(X_plot) plt.figure() plt.hist(X, bins=X_plot[:,0]) plt.plot(X_plot[:,0],np.exp(log_dens)) prob = np.exp(log_dens) / np.sum(np.exp(log_dens)) calprob = np.zeros(np.shape(prob)[0]) calprob[0] = prob[0] for i in range(1,np.shape(prob)[0]): calprob[i]=calprob[i-1]+prob[i] cl = X_plot[np.min(np.where(calprob>cr))]
次にテストデータが正常データの領域からいつだつしていないのかを確認します。
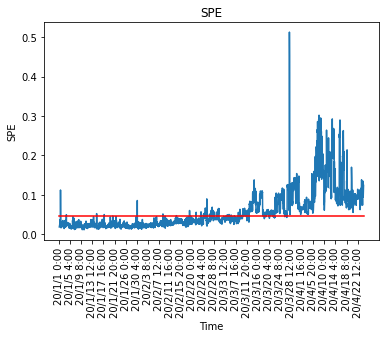
# データを標準化 test_df_std = sc.transform(test_df) # Test Data newscores = pca.transform(test_df_std) newresiduals = pca.inverse_transform(newscores)-test_df_std newdist = np.sqrt(np.sum(np.power(newresiduals,2),axis=1))/(np.shape(test_df_std)[1])最後にQ統計量(学習とテストデータ含む)とカーネル密度推定で算出した管理限界を設定します。
# Q統計量のプロット SPE = np.r_[dist,newdist] plt.figure() x = range(0,np.shape(df.index)[0],100) NewTimeIndices = np.array(df.index[x]) x2 = [0, np.shape(SPE)[0]] y2 = [cl,cl] plt.title('SPE') plt.plot(SPE) plt.xticks(x,NewTimeIndices,rotation='vertical') plt.plot(x2,y2,ls="-", color = "r") #plt.ylim([0,1]) plt.xlabel("Time") plt.ylabel("SPE") # contribution plot plt.figure() total_residuals= np.r_[residuals,newresiduals] CspeTimeseries = np.power(total_residuals,2) cspe_summary=np.zeros([np.shape(CspeTimeseries)[0],10])
本当はここから寄与プロットを算出し、管理限界を超えた際にどの説明変数が影響して異常になったのかを算出します。
また、$T^2$管理図も同様に管理し、管理限界を逸脱した際にどの説明変数が影響しているのか確認することができます。MSPCを用いることによって、90変数あるセンサーデータも2つの管理図で監視する事ができ、アラームが鳴った際にどのセンサーが異常なのかを特定することができますので、製造現場での監視負荷も下がります。
また、変数同士の関係性が線形でないなら、PCAの代わりにカーネルPCAを活用することも可能です。さいごに
最後まで読んで頂き、ありがとうございました。
今回は、製造現場で必要とされる異常検知手法(MSPC)について実装しました。
実際の現場では、正常状態の既定方法や管理限界の設定などチューニング要素は多数ありますが、現場で運用しながら設定していくのが良いと思います。訂正要望がありましたら、ご連絡頂けますと幸いです。
- 投稿日:2020-11-14T16:52:17+09:00
pythonによる音声分析
FFT
下に示すプログラムが実験で作成したプログラム
FFT.pyF = np.fft.fft(Y) Amp = np.abs(F/(frames/2)) freq = np.fft.fftfreq(frames, 1/Fs) plt.plot(freq[1:int(frames/2)],Amp[1:int(frames/2)]) plt.xlabel("Freqency [Hz]") fig.savefig("FFT.png") plt.show() plt.close()↓実行結果
Y : 音声データ
Fs : 20000 Hz (サンプリング周波数)FFTではサンプリング周波数の半分の周波数(ナイキスト周波数)までしか見ることができない。

- 投稿日:2020-11-14T16:40:43+09:00
資格取得に向けたUdemy活用術【2020年12月時点】
今年度はとにかくUdemyにお世話になったので、感謝の気持ちを込めて「Udemy Advent Calendar 2020」に投稿することにしました。
■Udemyとの出会い
私がUdemyを活用しだしたのはAWSの資格取得を目指していた時でした。
AWSの資格は「アソシエイト」という中級資格と「プロフェッショナル」という上級資格があります。「アソシエイト」までは参考書や問題集が何種類か販売されていて、それを購入して乗り切れました。しかし、「プロフェッショナル」は当時問題集がほとんどなく、初回の受験では不合格となってしまいました。模擬問題の実施不足が影響したと考えた私は、とにかく手当たり次第に模擬問題集を探して実施することにしました。その際に見つけたのがUdemyの講座でした。■AWS Certified Solutions Architect Professional資格試験での活用
『AWS 認定ソリューションアーキテクト プロフェッショナル模擬試験問題集(全5回分375問)』
その当時珍しかった「プロフェッショナル試験」の問題集でした。とにかく問題数が多く説明もしっかりついているので、学習するのに非常に役立ちました。特に問題の正解以外の選択肢に関して、間違っている理由を解説してくれているのがよかったです。
また、Udemyはスマホのアプリでも閲覧できるので、職場への往復時間はUdemyでずっとこの問題を解いていました。75問×5回の問題があり、問題を開始すると時間もカウントされるので、本番の試験を意識した学習が可能でした。
『AWS Certified Solutions Architect Professional Practice Exam』
問題集を何度もやっていると答えを覚えてしまいます。当時一度試験に落ちていたこともあり、不安だった私が追加で購入した問題集です。その当時他に日本語の問題集が存在せず「英語」の問題集に手を出しました。
英語力のない私には日本語翻訳は必須です。Udemyをパソコンで実施してWebの日本語翻訳機能を使用することで、日本語訳で学習することができました。ただ、スマホのアプリでは日本語訳がうまくいかず、もっぱら帰宅後にパソコンで学習しました。AWSのように模擬問題をどれだけこなすかがポイントになる試験では、Udemyの英語問題集は役に立ちます。
■AWS Certified DevOps Engineer Professional資格試験での活用
『AWS Certified DevOps Engineer Professional』
AWSのプロフェッショナル試験は2つあり、もう一つの試験です。こちらは「AWS Certified Solutions Architect Professional」と違い、当時は本当に日本語版の模擬問題集がありませんでした。その為、引き続き「英語」の問題集を購入して試験勉強しました。こちらは問題数が少なかったですが、問題の傾向を掴むのに役立ってくれました。
資格試験の体験談は別記事「【AWS認定試験】6試験(CLF・SAA・SAP・SOA・DVA・DOP)合格までの道のりと勉強方法について(2020年4月時点)」に記載しています。
■Python3エンジニア認定データ分析試験での活用
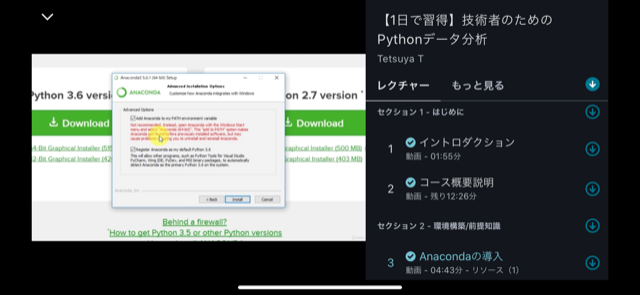
【1日で習得】技術者のためのPythonデータ分析
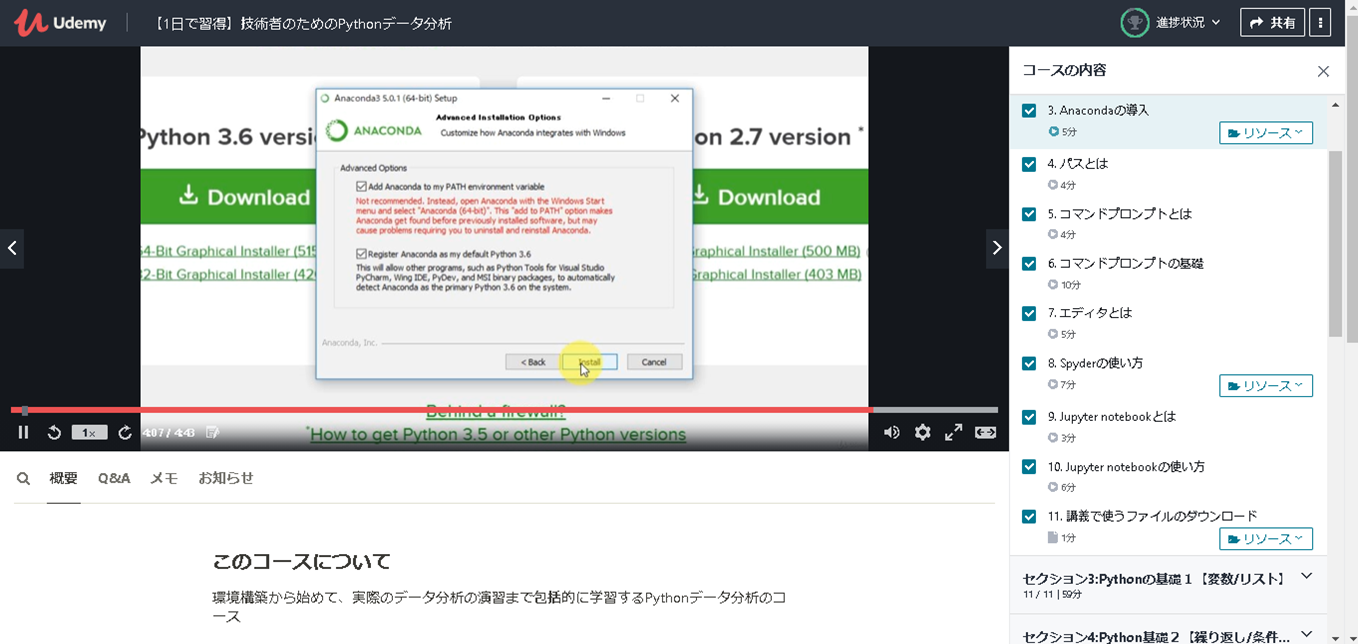
「Python3エンジニア認定データ分析試験」の試験勉強を実施しましたが、初心者の私は「公式テキスト」の内容を理解するのに苦しんでいました。なんとか打開すべく見つけたのが、この講座です。
動画でAnacondaのインストールやSpyder、Jupyter notobookの使い方、Pythonの基本的な操作方法に触れており、非常に解りやすかったです。Numpyより前の章に関しては、「Python3 エンジニア認定基礎試験」を受験する人にもおススメできる内容だと思います。ただし、後の章は「Matplotlib」や「scipy」辺りは難しくなるので、そこら辺と演習問題は最初は流し見をして、2周目で理解する形がよいかと思います。データ分析試験の試験範囲から考えると「数学の基礎」と「scikit-learn」が不足しているので、そこは他の方法で補う必要があります。
ただ、やはり動画の解りやすさは最高でした。
例えば以下の画像はANACONDAのインストール手順の説明です。動画で画面遷移やポイント箇所もすべて丁寧に説明してくれるので間違えることがありません。環境的な部分は文書で読むより動画を一度見た方が理解が何倍も速いです。
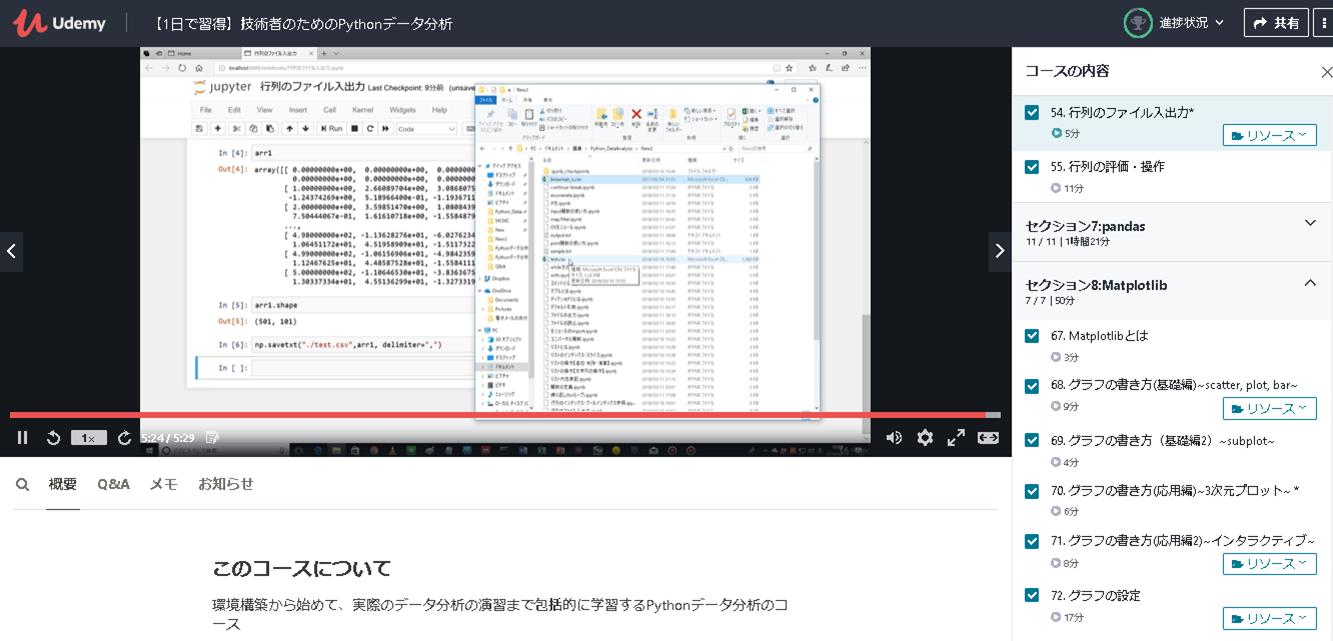
こちらはファイル出力・入力等の処理になりますが、非常に理解しやすかったです。
この講座受講が取っ掛りとなり、基礎が理解できたので、試験勉強がスムーズに進みました。
資格試験の体験談は別記事「Python初心者によるPython3エンジニア認定データ分析試験の勉強方法(2020年9月合格)」に記載しています。
■Udemyのよいところ(まとめ)
上記で記載した通りUdemyは資格試験勉強で大いに活用可能です。
私が感じているUdemyのメリットについて以下に纏めて記載ます。
ポイント1:Webならではの機能が使える!
例えば紙の問題集を購入した場合、問題と解答ページを行ったり来たりになりますが、
Udemyなら問題回答後に正誤と解説が表示されるのでスムーズに勉強できます。
問題集などでは終了後に正解率が表示されたり、過去の正解率や問題の正誤結果が表示できます。
そういった学習履歴を管理できる面でも優れていると思います。
ポイント2:スマホでも学習できる!
スマホのアプリがあるので会社への往復時間で学習できます。
進捗は連携されているので、家のPCでログインすればスマホで進んだ部分から学習可能です。
以下はスマホのアプリで表示した際の画面です。
ポイント3:内容が随時更新される!
模擬問題集だと、問題が追加されたりします。
私が購入した問題集に関しては、あとから更新されて150問程度の問題が追加されました。
また、説明内容が古くなったり間違っている場合は、内容が更新されたり注釈が入ったりします。
一度購入したあとに追加費用なく更新を受けることができるのは大きなメリットだと思います。例えば私の受講した『AWS 認定ソリューションアーキテクト プロフェッショナル模擬試験問題集(全5回分375問)』のアップデート履歴では以下のような内容があります。
■演習問題の解説内容をより詳細にアップグレードいたしました。
プロフェッショナル問題がリリースされてから、様々なご質問をいただきまして、解説では詳細がわかりにくい問題があることが判明したため、本日までにすべての演習問題の問題文と解説の全面的なアップグレードをさせていただきました。問題内容自体は同じものとなっておりますが、解説で不正解理由なども詳細にわかるようにしております。こちらからの質問事項等を反映して解説をアップグレードして頂きました。
■模擬試験4の提供開始
模擬試験④を提供開始しました。
過去の3題となるべく新しい範囲と形式の問題としています。新規に模擬問題が追加されました。
このように随時アップデートされていくことは嬉しいところです。
ポイント4:やっぱり動画は最高に解りやすい!
文書がメインのテキストで解らないことも、動画だとすぐに解ったりします。
私も試験勉強中に理解できない部分があるとYoutubeで検索したりして動画を探して視聴すると、一気に理解できて解決することが多々ありました。Udemyでは私が助けられたPythonの講座を含め多くの動画学習ができるコンテンツがあり、非常にお勧めです。ポイント5:外国の模擬問題集講座が活用できる!
AWSのように日本で模擬問題集が発売されていないような資格試験もあります。
そのような試験に関して外国語の講座も公開されています。
現在はWebの日本語翻訳機能も非常に優秀で、模擬問題を少しでも実施したい場合などはお勧めします。英語の翻訳には苦心したので、ポイントを別記事「英語力が無いSEの暫定的な翻訳ツール活用術(2020年9月時点)」に記載しています。もし効率的な翻訳方法知りたい方は参照ください。
ポイント6:製作者に質問ができる!
Udemyでは講義の配信者とUdemy上のメッセージ機能を利用してやり取りが可能です。
こちらの解りにくかったところを製作者に伝えて反映してもらうことも可能です。
相互にやり取りを実施して、アップデートしていけるところも魅力の一つです。
今回、講義画像を利用しているのも、このメッセージ機能で了解を頂いています。■Udemyの注意点(まとめ)
ポイント1:購入するタイミングに注意しよう!
Udemyで教材を購入する時は3か月に1度くらいで開催されるタイムセールスの際に購入することをお勧めします。90%OFFくらいの値引きも多く、例えば、Pythonの講座は普段は10,800円しますが、タイムセールの期間だけ1,400円くらいまで値段が下がっていました。お金のある人は定価で購入して還元してあげてほしいですが、費用を抑えたい人は、タイムセールスの際に購入することを強くおすすめします。ほしい講座を見繕っておいて、タイムセールスのタイミングを狙いましょう。
タイムセールスの際にはWeb画面上に以下のような表示がされます。
その期間だけ驚きの値引きが実施されます・・・・
ポイント2:購入する前に自分の想定している講座か確認しよう!
レビューが記載されているので、レビュー内容を読んで自分の思っている内容か確かめてください。
また、教材の中の「コースの内容」という部分で幾つかの動画がサンプルとして公開されています。この内容を閲覧して、自分に合いそうだと思ってから購入したほうがよいと思います。どんな評価の高い講座でも、自分にあうとは限りません。
ポイント3:最終更新日を確認しよう!
購入する際は最終更新日を注意深く確認しましょう。
定期的に更新されている講座もあれば、全く更新されていない講座もあります。直近で更新されている講座は内容の修正や追加がされている可能性もあります。
これは非常に重要です。
例えば資格試験の場合、試験内容が変更になることが多々あります。せっかく勉強したのに旧試験内容だったでは、せっかくの努力も無駄になってしまいます。また、技術的な動画に関しても更新時期は非常に重要です。私もパブリッククラウドの操作説明動画を購入したりしたのですが、クラウドの操作画面が大きく変わっており、動画の通り実施しようとしてもできない場合がありました。クラウドサービスなどは進化が早く、古い動画だと役に立たない場合もあります。
私はこのポイントが非常に重要だと思っているので、自分がQiitaに投稿する際には年度や記載月を明確に記載するようにしています。その時のベストが今のベストとは限りません。それくらい情報の記載時期というのは重要だと思います。
ポイント4:外国の動画講座は要注意!
よいところ、として外国の模擬問題集を記載しましたが、こちらは動画講座の話です。
模擬問題集はいいです。Webの日本語翻訳機能が非常に優秀なので役に立ちました。
しかし、動画講座は個人的には失敗でした。
一応、日本語の字幕はできるのですが、字幕と動画の内容両方一緒に追えないので、結局英語が苦手な私は活用することができませんでした。外国の動画講座こそ、サンプル動画を必ず視聴してから購入するようにしたほうがよいと思います。■さいごに
どんなものにも良い部分と注意すべき部分があります。
Udemyを活用できるかどうかは本人次第だと思います。
私は少なくともUdemyに幾度となく助けられました。
そしてこれからも助けてもらうと思います。自分に合うかどうかは一度使ってみないと解らないと思います。
自分に合う講座があるか検索して頂き、タイムセールスの際に、是非一度購入してみてください。もし役に立つと思えれば、是非来年度のQiitaの「Udemy Advent Calendar」で投稿してみてください。
アウトプットは非常に大切です。







- 投稿日:2020-11-14T16:17:00+09:00
Python Pandas PyInstallerでCSV整形ツールを作る
おさらい
Python、Pandasのインストール
CSVのソート
カラム整形、PyInstaller
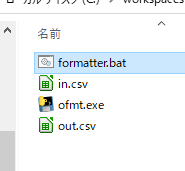
*.batをつくる
test.batcd /d %~dp0 call firstpandas.exe同フォルダにはこんな感じ
in.csvを読み込んでout.csvにするだけのfirstpandas.exeがいます。実際もらうファイルは in.csv でもなんでも無いので今度は*.batで引数で受け取ったcsvをin.csvにしてやるとかかなあ。
カラムの存在チェック
ところでファイル形式にいくつか種類があったので変更。
How to check if a column exists in Pandas
https://stackoverflow.com/questions/24870306/how-to-check-if-a-column-exists-in-pandasfirstpandas.pyimport pandas as pd df = pd.read_csv('oplog20201112.csv',encoding="SHIFT-JIS") # print(df) if '実行時刻' in df: df_s = df.sort_values('実行時刻') df_s = df_s.reindex(columns=['実行時刻', '機能名', 'ユーザーID', 'クライアント名', 'WindowsログインID', '端末ID', 'ログイン時刻', 'ログアウト時刻']) if 'PRC_DATE' in df: df_s = df.sort_values('PRC_DATE') df_s = df_s.reindex(columns=['PRC_DATE', 'DETAIL1', 'USERID', 'TERM_ID']) df_s.to_csv('out.csv')ファイルのエンコード
以下が出る時がある。
UnicodeDecodeError: 'shift_jis' codec can't decode byte 0x87 in position 22224: illegal multibyte sequenceと思っていたが、
pandasにexcel出力のcsvを読ませる時に注意する点
https://minus9d.hatenablog.com/entry/2015/07/30/225841
https://stackoverflow.com/questions/6729016/decoding-shift-jis-illegal-multibyte-sequenceに倣いencodingを更に変更。
firstpandas.pyimport pandas as pd # df = pd.read_csv('in.csv',encoding="SHIFT-JIS") df = pd.read_csv('in.csv',encoding="shift_jisx0213") # print(df) if '実行時刻' in df: df_s = df.sort_values('実行時刻') df_s = df_s.reindex(columns=['実行時刻', '機能名', 'ユーザーID', 'クライアント名', 'WindowsログインID', '端末ID', 'ログイン時刻', 'ログアウト時刻']) if 'PRC_DATE' in df: df_s = df.sort_values('PRC_DATE') df_s = df_s.reindex(columns=['PRC_DATE', 'DETAIL1', 'USERID', 'TERM_ID']) df_s.to_csv('out.csv')ほか参考
https://techacademy.jp/magazine/23367最終的に
formatter.batcd /d %~dp0 copy %1 in.csv call ofmt.exe echo "see out.csv!" pauseこんな感じになりましたとさ

- 投稿日:2020-11-14T15:20:59+09:00
Python Seleniumを使用してhtmlのカスタムデータ属性を要素として取得したい
HTML文書で、idは文書中で一意ですがclassはそうでないので、文書中に同一class名が複数ある場合はfind_elements_by_class_name()の結果を回す必要がある場合があります(elementにsがついてます)。
たとえば、属性を含めると一意になるのであれば、get_attribute()を使用して属性を取得し、自分の考えるものであれば、自分の行いたい処理(たとえばクリックとか)をすれば良いです(下記コード参照)。
そうでなければ、一意になる方法をその文書で考えて対応しなければならないと思います。
ブラウザの開発ツールで取得できるxpathやcssセレクターは一意になるので有効だと思うんですけどね。elems = driver.find_elements_by_class_name("クラス名(*1)") # *1:適切なクラス名を指定してください。 for elem in elems: attr = elem.get_attribute("属性名(*2)") # *2:適切な属性名を指定してください。 if (attr == "自分が一致すると思われる属性値"): elem.click()
- 投稿日:2020-11-14T14:27:22+09:00
【Tips編】集計からダッシュボードの作成まで一本化!PythonとDashによるデータ可視化アプリ開発 〜様々なグラフを作成する〜
本記事は、2020年10月16日に作成されました。
はじめに
マーケティングリサーチプラットフォームを提供している株式会社マーケティングアプリケーションズの今井です。
弊社では、Dashに関した内容を、基礎編、Tips編、実践編の3つに分けてQiitaで投稿していきます。
Tips編(本記事)
バブルチャート、複合グラフ、帯グラフ、レーダーチャートなど様々なグラフの可視化や、グラフをより見やすく、かつわかりやすくするための応用的な手法を紹介します。
サンプルを動かしている動画はこちらです。
読んで良かった、参考になったという方は、ぜひLGTMボタンを押してください。???
グラフを作成する2種類の方法
Dashには、主にグラフを作成する方法として、2種類の方法が用意されています。
1つは、前回の記事で紹介した「plotly.express」です。
これは、グラフ全体を一度に作成できる高レベルなAPIでした。もう1つは、「plotly.graph_objects」です。「plotly.express」では、「px.bar(df, x="Fruit", y="Amount", color="City", barmode="group")」と、X軸、Y軸、色にそれぞれ使用するデータの列の名前を指定してあげるだけでグラフの作成ができましたが、「plotly.graph_objects」では、データ加工後の集計値をリストにして扱うことができたり、散布図を例にすると、マーカーのみ表示させる、マーカーとラベルをつけて表示させる、1部分のマーカーだけ強調をさせるなど、カスタマイズが非常にしやすいためグラフをよりわかりやすくすることが可能です。
ですので、グラフ作成においては、「plotly.graph_objects」を使用することをオススメします。
本シリーズでは、「plotly.graph_objects」を使用したグラフの作成を行っていきます。必要なライブラリを追加する
グラフを作成していくため、plotly.graph_objsとplotly.subplotをインポートします。
app.pyimport dash import dash_core_components as dcc import dash_html_components as html import pandas as pd import plotly.express as px # plotly.graph_objsとplotly.subplotsを追加 import plotly.graph_objs as go from plotly.subplots import make_subplots今回作成するダッシュボードのサンプルと構造
まずは、全体感を把握します。今回作成するダッシュボードのサンプルはこちらです。
前回の基礎編でもお伝えしたように、今回のコードも3つの工程で作られています。
準備:必要なライブラリをインポートする、データを作成する、データを使ってグラフを作成する
表示:app.layout内で必要な装飾をする、準備で用意したデータを代入する
実行:アプリを実行するただ、今回は、「plotly.express」を使用していないため、グラフのレイアウトも作成する必要があります(グラフう内のタイトルや、高さ、長さなど・・・)。ですので、準備するところでグラフのレイアウトも作成します。
バブルチャートを作成する工程で具体的に説明すると
準備:必要なライブラリをインポートする、データを作成する、レイアウトを作成する、データとレイアウトをまとめた変数を作成する
表示:app.layout内で必要な装飾をする、作成したバブルチャートのデータとレイアウトの情報を持った変数を代入するという工程です。
ここからは、app.layout内で表示させる各グラフのdataとlayoutの作成方法と
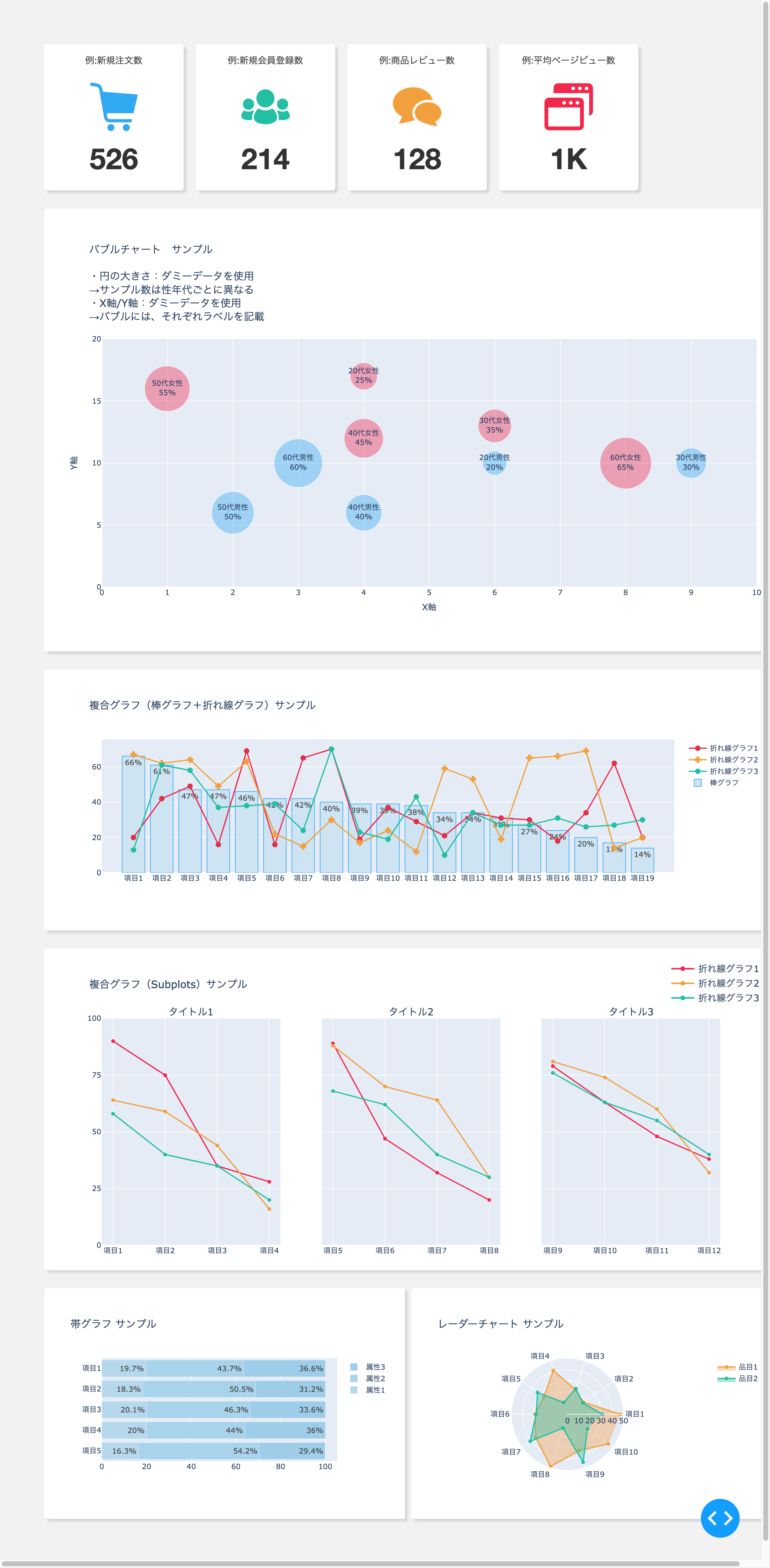
グラフをわかりやすく表現するための方法も説明していきます。画像と数値を組み合わせたブロックの作成方法
作成イメージです。
app.py# ============================================ # 画像と数値を組み合わせたブロック サンプル # ============================================ new_orders = 526 new_users = 214 reviews = 128 ave_page_views = '1K'app.py# 画像と数値を組み合わせたブロック html.Div( [ # 例:新規注文数ブロック html.Div( [ html.Span( ['例:新規注文数', html.Br()] ), html.Br(), html.Img( title="例:新規注文数", src=app.get_asset_url( "cart_icon.png"), id="", style={ "height": "80px", "width": "80px", "margin-bottom": "0px", }, ), html.Br(), html.Span( new_orders, style={'font-size': 'xxx-large', 'font-weight': 'bold'} ), ], style={'background-color': '#ffffff', 'text-align': 'center', 'border-radius': '5px', 'width': '200px', 'margin': '10px 10px 0px 10px', 'padding': '15px', 'position': 'relative', 'box-shadow': '4px 4px 4px lightgrey' } ), # 例:新規会員登録数ブロック html.Div( [ html.Span( ['例:新規会員登録数', html.Br()] ), html.Br(), html.Img( title="例:新規会員登録数", src=app.get_asset_url( "user_icon.png"), id="", style={ "height": "80px", "width": "80px", "margin-bottom": "0px", }, ), html.Br(), html.Span( new_users, style={'font-size': 'xxx-large', 'font-weight': 'bold'} ), ], style={'background-color': '#ffffff', 'text-align': 'center', 'border-radius': '5px', 'width': '200px', 'margin': '10px 10px 0px 10px', 'padding': '15px', 'position': 'relative', 'box-shadow': '4px 4px 4px lightgrey' } ), # 例:商品レビュー数ブロック html.Div( [ html.Span( ['例:商品レビュー数', html.Br()] ), html.Br(), html.Img( title="例:商品レビュー数", src=app.get_asset_url( "comments_icon.png"), id="", style={ "height": "80px", "width": "80px", "margin-bottom": "0px", }, ), html.Br(), html.Span( reviews, style={'font-size': 'xxx-large', 'font-weight': 'bold'} ), ], style={'background-color': '#ffffff', 'text-align': 'center', 'border-radius': '5px', 'width': '200px', 'margin': '10px 10px 0px 10px', 'padding': '15px', 'position': 'relative', 'box-shadow': '4px 4px 4px lightgrey' } ), # 例:平均ページビュー数ブロック html.Div( [ html.Span( ['例:平均ページビュー数', html.Br()] ), html.Br(), html.Img( title="例:平均ページビュー数", src=app.get_asset_url( "page_view_icon.png"), id="", style={ "height": "80px", "width": "80px", "margin-bottom": "0px", }, ), html.Br(), html.Span( ave_page_views, style={'font-size': 'xxx-large', 'font-weight': 'bold'} ), ], style={'background-color': '#ffffff', 'text-align': 'center', 'border-radius': '5px', 'width': '200px', 'margin': '10px 10px 0px 10px', 'padding': '15px', 'position': 'relative', 'box-shadow': '4px 4px 4px lightgrey' } ), ], style={'display': 'flex', 'margin': '0px 0px 30px 0px'}, ),<作成するためのポイント>
・html.Div()の箱の中に必要な要素を入れていく
・html.Br()で改行
・各要素にスタイルシートの適用可能
・html.Img()で画像も使用可能(高さや長さも指定可能)
・今回は、集計した値を変数に入れてhtml.Span()で表示させている
・html.br()は「html.Br()」、html.imgは「html.Img」と書かないとエラーになるので注意バブルチャートの作成方法
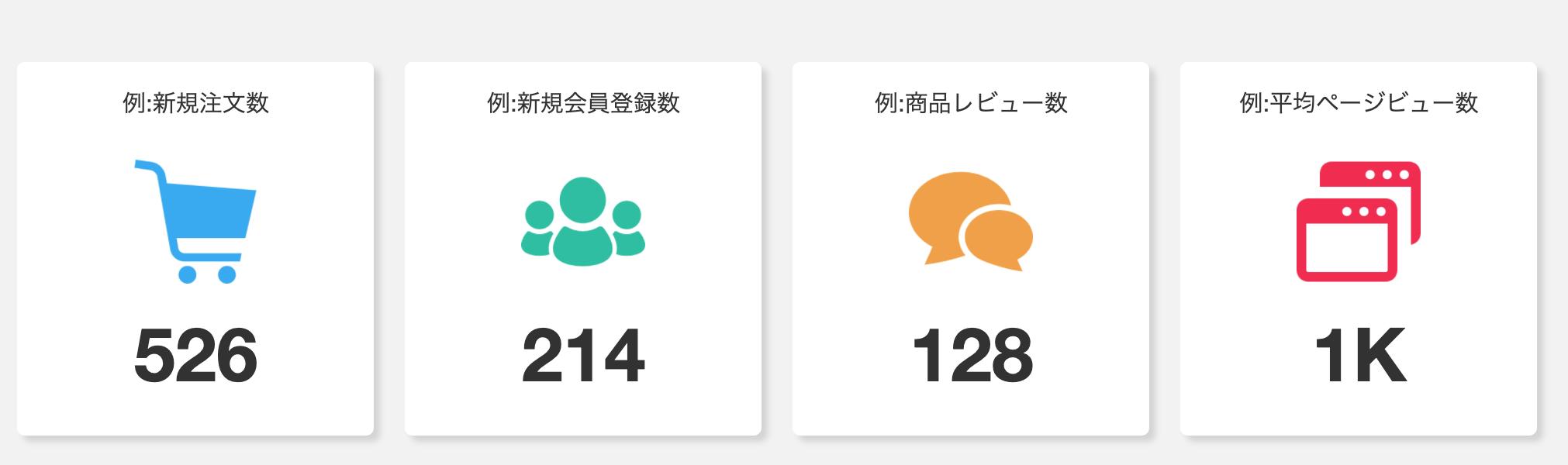
作成イメージです。
app.py# ============================================ # バブルチャート サンプル # ============================================ # バブルチャート ▶︎ # データの入力、データの表示を制御する場所 # (X軸・Y軸・バブルサイズへのデータの入力、マーカーの表示、ラベルの表示など) # ============================================ bubble_chart_sample_data = go.Scatter( x=[6, 9, 4, 2, 3, 4, 6, 4, 1, 8], y=[10, 10, 6, 6, 10, 17, 13, 12, 16, 10], mode='markers+text', text=['20代男性<br>20%', '30代男性<br>30%', '40代男性<br>40%', '50代男性<br>50%', '60代男性<br>60%', '20代女性<br>25%', '30代女性<br>35%', '40代女性<br>45%', '50代女性<br>55%', '60代女性<br>65%', ], textposition=['middle center', 'middle center', 'middle center', 'middle center', 'middle center', 'middle center', 'middle center', 'middle center', 'middle center', 'middle center', ], marker=dict( color=['#30A8F2', '#30A8F2', '#30A8F2', '#30A8F2', '#30A8F2', '#F2274C', '#F2274C', '#F2274C', '#F2274C', '#F2274C'], opacity=[0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4], size=[40, 50, 60, 70, 80, 45, 55, 65, 75, 85], ) ) # バブルチャート ▶︎ # レイアウトを決める場所(タイトル、高さ、長さ、X軸、Y軸、余白など) # ============================================ bubble_chart_sample_layout = go.Layout( title=dict( text='バブルチャート サンプル<br><br>・円の大きさ:ダミーデータを使用<br>' '→サンプル数は性年代ごとに異なる<br>' '・X軸/Y軸:ダミーデータを使用<br>' '→バブルには、それぞれラベルを記載', y=0.91, yanchor="top" ), height=650, width=1180, xaxis=dict( title_text="X軸", range=[0, 10], dtick=1 ), yaxis=dict( title_text="Y軸", range=[0, 20] ), margin=dict(t=200, r=20, b=0) ) # バブルチャート ▶︎ # 2つをまとめて出力する場所 # ============================================ bubble_chart_sample = go.Figure( data=bubble_chart_sample_data, layout=bubble_chart_sample_layout )<作成するためのポイント>
go.Scatterで・・・
・X軸となる変数Xに、Y軸となる変数Yにリストで値を代入
・mode:
markers+text マーカーとデータのラベルどっちも表示させる
markers マーカーのみ表示させる
text データのラベルのみ表示させる
・text:データのラベルをリストで代入
・textposition:リストの値ごとにデータのラベルの位置を指定
下記が使用できる
'top left', 'top center', 'top right', 'middle left',
'middle center', 'middle right', 'bottom left',
'bottom center', 'bottom right'
・marker:
color マーカーの色の指定
opacity マーカー透過度の指定
size マーカーサイズの指定go.Layoutで・・・
・title
text タイトルのテキストを指定
y yanchorからどのくらいズラすかを指定
yanchor 位置を指定
xaxis X軸の調整
yaxis Y軸の調整
range 目盛りの範囲
dtick 刻む目盛りを指定
・margin 余白を指定app.layout内でのコード
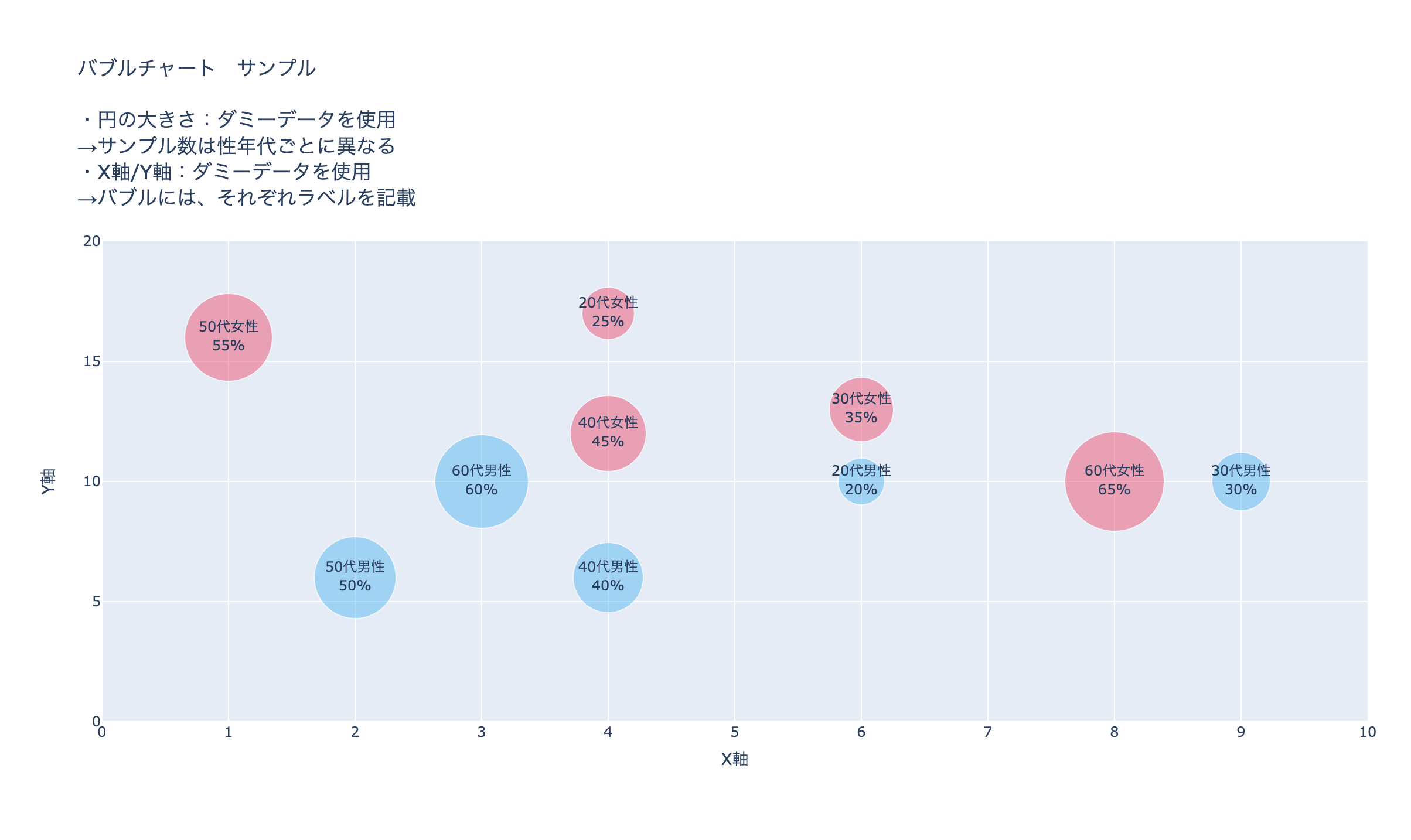
app.py# バブルチャート サンプル html.Div( [ dcc.Graph( id='', figure=bubble_chart_sample ), # スタイルシートを適用 ], style={'background-color': '#ffffff', 'text-align': 'center', 'border-radius': '5px 0px 0px 5px', 'height': '700px', 'width': '1185px', 'margin': '0px 0px 30px 10px', 'padding': '15px', 'position': 'relative', 'box-shadow': '4px 4px 4px lightgrey', } ),複合グラフ(棒グラフ+折れ線グラフ)サンプルの作成方法
作成イメージです。
app.py# ============================================ # 複合グラフ(棒グラフ+折れ線グラフ)サンプル # ============================================ item = ['項目1', '項目2', '項目3', '項目4', '項目5', '項目6', '項目7', '項目8', '項目9', '項目10', '項目11', '項目12', '項目13', '項目14', '項目15', '項目16', '項目17', '項目18', '項目19'] # 複合グラフ(棒グラフ+折れ線グラフ) ▶︎ # 空のGraph Objectsを作成 # ============================================ multiple_chart_sample = go.Figure() # 複合グラフ(棒グラフ+折れ線グラフ) ▶︎ # 折れ線グラフ1を作成 # ============================================ multiple_chart_sample.add_trace( go.Scatter( x=item, y=['20%', '42%', '49%', '16%', '69%', '16%', '65%', '70%', '19%', '37%', '29%', '21%', '34%', '31%', '30%', '18%', '34%', '62%', '20%'], name='折れ線グラフ1', marker=dict( color='#F2274C', size=8, line=dict( color='#b24644', width=1 ) ) ) ) # 複合グラフ(棒グラフ+折れ線グラフ) ▶︎ # 折れ線グラフ2を作成 # ============================================ multiple_chart_sample.add_trace( go.Scatter( x=item, y=['67%', '62%', '64%', '49%', '63%', '22%', '15%', '30%', '17%', '24%', '12%', '59%', '53%', '19%', '65%', '66%', '69%', '14%', '20%'], name="折れ線グラフ2", marker=dict( symbol='cross', color='#F2A03D', size=8, line=dict( color='#F2A03D', width=1 ) ) ) ) # 複合グラフ(棒グラフ+折れ線グラフ) ▶︎ # 折れ線グラフ3を作成 # ============================================ multiple_chart_sample.add_trace( go.Scatter( x=item, y=['13%', '61%', '58%', '37%', '38%', '39%', '24%', '70%', '23%', '19%', '43%', '10%', '34%', '27%', '27%', '31%', '26%', '27%', '30%'], name="折れ線グラフ3", marker=dict( color='#21BFA2', size=8, line=dict( color='#21BFA2', width=1 ) ) ) ) # 複合グラフ(棒グラフ+折れ線グラフ) ▶︎ # 棒グラフを作成 # ============================================ multiple_chart_sample.add_trace( go.Bar( x=item, y=['66%', '61%', '47%', '47%', '46%', '42%', '42%', '40%', '39%', '39%', '38%', '34%', '34%', '31%', '27%', '24%', '20%', '17%', '14%'], name="棒グラフ", text=['66%', '61%', '47%', '47%', '46%', '42%', '42%', '40%', '39%', '39%', '38%', '34%', '34%', '31%', '27%', '24%', '20%', '17%', '14%'], textposition="auto", marker=dict( color='#CEE4F2', line=dict( color='#30A8F2', width=1 ) ) ) ) # 複合グラフ(棒グラフ+折れ線グラフ) ▶︎ # レイアウトを更新 # ============================================ multiple_chart_sample.update_layout(height=400, width=1180, showlegend=True, autosize=False, title_text='複合グラフ(棒グラフ+折れ線グラフ)サンプル')<作成するためのポイント>
空のGraph Objectsを作成して、そこに折れ線グラフ、棒グラフを作成していきます。
update_layoutのshowlegend=Trueで凡例を表示、Falseで非表示、app.layout内でのコード
app.py# 複合グラフ(棒グラフ+折れ線グラフ)サンプル html.Div( [ dcc.Graph( id='', figure=multiple_chart_sample ), # スタイルシートを適用 ], style={'background-color': '#ffffff', 'text-align': 'center', 'border-radius': '5px 0px 0px 5px', 'height': '400px', 'width': '1185px', 'margin': '0px 0px 30px 10px', 'padding': '15px', 'position': 'relative', 'box-shadow': '4px 4px 4px lightgrey', } ),複合グラフ(Subplots)サンプルの作成方法
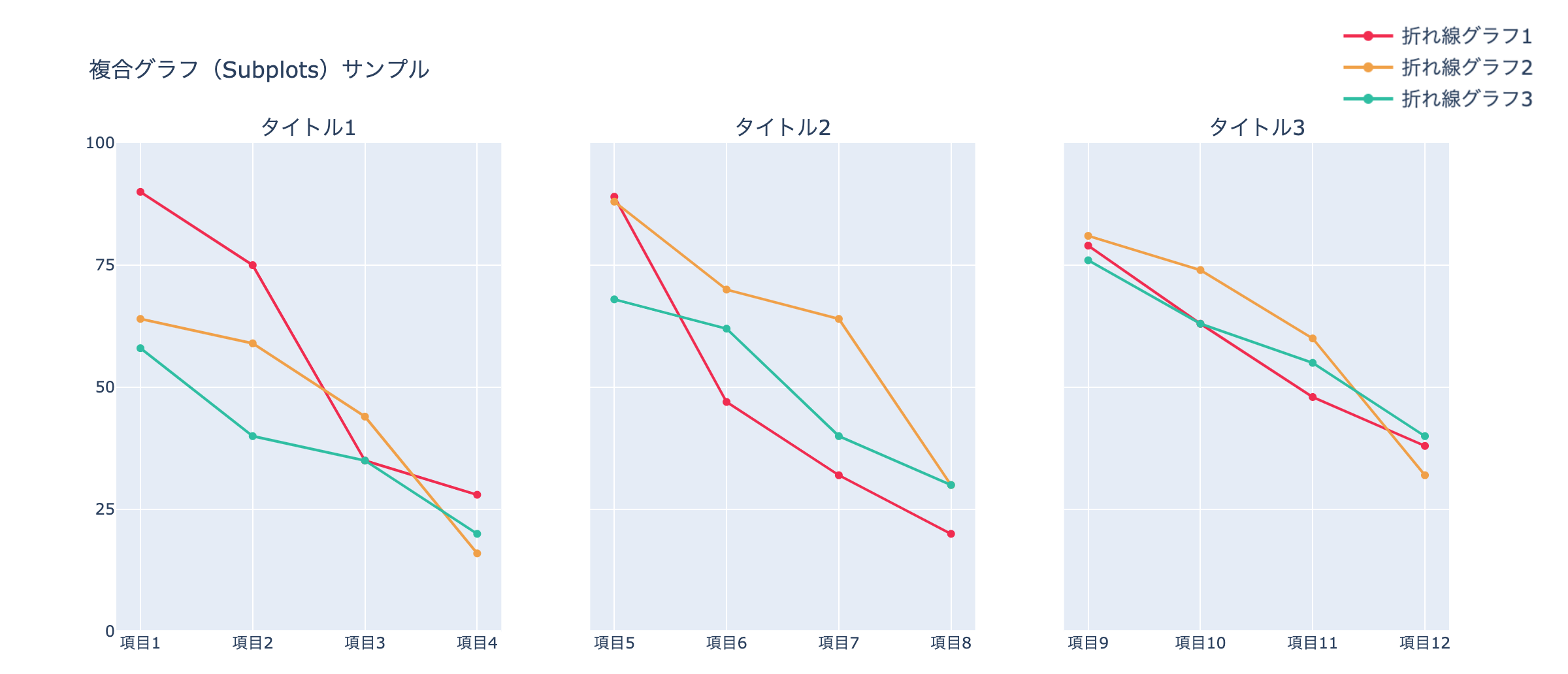
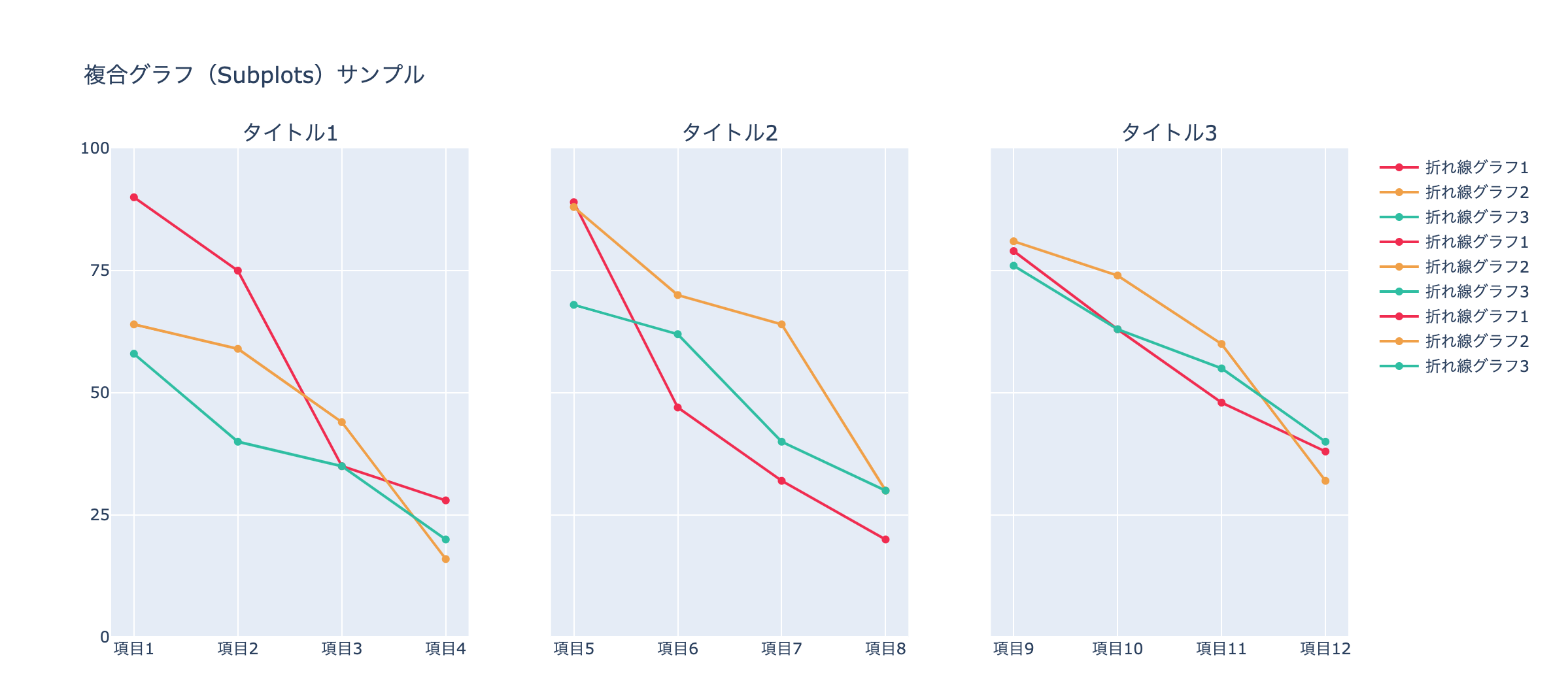
作成イメージです。
app.py# ============================================ # 複合グラフ(Subplots)サンプル # ============================================ # 複合グラフ(Subplots) ▶︎ # 空のGraph Objectsを作成 # ============================================ subplots_chart_sample = go.Figure() # 複合グラフ(Subplots) ▶︎ # rows, cols, subplot_titlesを入力 # ============================================ subplots_chart_sample = make_subplots(rows=1, cols=3, shared_yaxes=True, subplot_titles=("タイトル1", "タイトル2", "タイトル3")) # 複合グラフ(Subplots) ▶︎ # 折れ線グラフを各ブロックごとに作成 # ============================================ subplots_chart_sample.add_trace(go.Scatter(x=["項目1", "項目2", "項目3", "項目4"], y=[90, 75, 35, 28], marker_color='#F2274C', name="折れ線グラフ1"), row=1, col=1) subplots_chart_sample.add_trace(go.Scatter(x=["項目1", "項目2", "項目3", "項目4"], y=[64, 59, 44, 16], marker_color='#F2A03D', name="折れ線グラフ2"), row=1, col=1) subplots_chart_sample.add_trace(go.Scatter(x=["項目1", "項目2", "項目3", "項目4"], y=[58, 40, 35, 20], marker_color='#21BFA2', name="折れ線グラフ3"), row=1, col=1) subplots_chart_sample.add_trace(go.Scatter(x=["項目5", "項目6", "項目7", "項目8"], y=[89, 47, 32, 20], marker_color='#F2274C', name="折れ線グラフ1"), row=1, col=2) subplots_chart_sample.add_trace(go.Scatter(x=["項目5", "項目6", "項目7", "項目8"], y=[88, 70, 64, 30], marker_color='#F2A03D', name="折れ線グラフ2"), row=1, col=2) subplots_chart_sample.add_trace(go.Scatter(x=["項目5", "項目6", "項目7", "項目8"], y=[68, 62, 40, 30], marker_color='#21BFA2', name="折れ線グラフ3"), row=1, col=2) subplots_chart_sample.add_trace(go.Scatter(x=["項目9", "項目10", "項目11", "項目12"], y=[79, 63, 48, 38], marker_color='#F2274C', name="折れ線グラフ1"), row=1, col=3) subplots_chart_sample.add_trace(go.Scatter(x=["項目9", "項目10", "項目11", "項目12"], y=[81, 74, 60, 32], marker_color='#F2A03D', name="折れ線グラフ2"), row=1, col=3) subplots_chart_sample.add_trace(go.Scatter(x=["項目9", "項目10", "項目11", "項目12"], y=[76, 63, 55, 40], marker_color='#21BFA2', name="折れ線グラフ3"), row=1, col=3) # 複合グラフ(Subplots) ▶︎ # 画像を添付 # ============================================ subplots_chart_sample.add_layout_image( dict( source=app.get_asset_url("subplots_chart_sample_image2.png"), xref="paper", yref="paper", x=1.07, y=1.06, sizex=0.2, sizey=0.2, xanchor="right", yanchor="bottom" ), ) # 複合グラフ(Subplots) ▶︎ # レイアウトを更新 # ============================================ subplots_chart_sample.update_yaxes(range=[0, 100], dtick=25) subplots_chart_sample.update_layout(height=500, width=1180, margin=dict(b=10), title_text="複合グラフ(Subplots)サンプル", showlegend=False)<作成するためのポイント>
make_subplots rowsで何行か指定, colsで何列か指定
subplot_titlesでそれぞれのグラフのタイトルを指定グラフの位置を列と行で指定して重ねていく
下記は、折れ線グラフ1と2を1行目と1列目に位置を指定して重ねる
subplots_chart_sample.add_trace(go.Scatter(x=["項目1", "項目2", "項目3", "項目4"], y=[90, 75, 35, 28], marker_color='#F2274C', name="折れ線グラフ1"),
row=1, col=1)subplots_chart_sample.add_trace(go.Scatter(x=["項目1", "項目2", "項目3", "項目4"], y=[90, 75, 35, 28], marker_color='#F2274C', name="折れ線グラフ2"),
row=1, col=1)下記は、折れ線グラフ1と2を1行目と2列目に位置を指定して重ねる
subplots_chart_sample.add_trace(go.Scatter(x=["項目5", "項目6", "項目7", "項目8"], y=[89, 47, 32, 20], marker_color='#F2274C', name="折れ線グラフ1"),
row=1, col=2)subplots_chart_sample.add_trace(go.Scatter(x=["項目5", "項目6", "項目7", "項目8"], y=[88, 70, 64, 30], marker_color='#F2A03D', name="折れ線グラフ2"),
row=1, col=2)※subplotsでの凡例の付け方
subplotsでは、一つ一つのグラフの凡例を表示させることができます。
しかし、下記のように分けられたレイアウト内で、同じグラフを使用する時は、内容が重複してしまいます。この問題を解決させるため、一部分を画像化して貼り付ける作業を行います。
一部分を抽出
グラフの外側に画像を入れることも可能なので、これを使用する
app.pysubplots_chart_sample.add_layout_image( dict( source=app.get_asset_url("subplots_chart_sample_image2.png"), xref="paper", yref="paper", x=1.07, y=1.06, sizex=0.2, sizey=0.2, xanchor="right", yanchor="bottom" ), )xanchorとyanchorで大まかな位置を決めてxとyで細かい位置調整を行っていく。
app.layout内でのコード
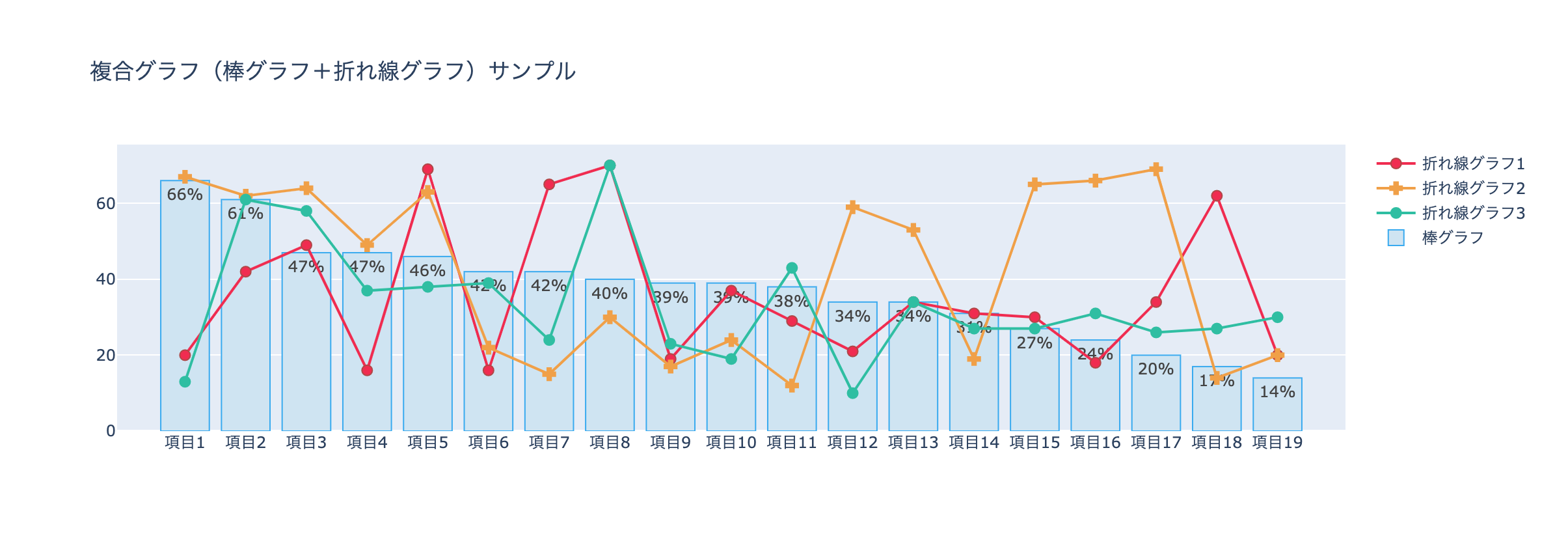
app.py# 複合グラフ(Subplots)サンプル html.Div( [ dcc.Graph( id='', figure=subplots_chart_sample ), # スタイルシートを適用 ], style={'background-color': '#ffffff', 'text-align': 'center', 'border-radius': '5px 0px 0px 5px', 'height': '500px', 'width': '1185px', 'margin': '0px 0px 30px 10px', 'padding': '15px', 'position': 'relative', 'box-shadow': '4px 4px 4px lightgrey', } ),帯グラフ サンプルの作成方法
作成イメージです。
app.py# ============================================ # 帯グラフ サンプル # ============================================ # 帯グラフ ▶︎ # データの入力、データの表示を制御する場所 # (X軸・Y軸・データの入力、マーカーの表示、ラベルの表示など) # ============================================ trace0 = go.Bar( x=['16.3%', '20%', '20.1%', '18.3%', '19.7%'], y=['項目5', '項目4', '項目3', '項目2', '項目1'], name='属性1', text=['16.3%', '20%', '20.1%', '18.3%', '19.7%'], textposition="inside", orientation='h', marker=dict( color='#b5d8ed', ) ) trace1 = go.Bar( x=['54.2%', '44%', '46.3%', '50.5%', '43.7%'], y=['項目5', '項目4', '項目3', '項目2', '項目1'], text=['54.2%', '44%', '46.3%', '50.5%', '43.7%'], name='属性2', orientation='h', textposition='auto', marker=dict( color='#a7d3eb', ) ) trace2 = go.Bar( x=['29.4%', '36%', '33.6%', '31.2%', '36.6%'], y=['項目5', '項目4', '項目3', '項目2', '項目1'], text=['29.4%', '36%', '33.6%', '31.2%', '36.6%'], name='属性3', orientation='h', textposition='auto', marker=dict( color='#9dcde9', ), ) # 帯グラフ ▶︎ # データを集約 # ============================================ band_graph_sample_data = [trace0, trace1, trace2] # 帯グラフ ▶︎ # レイアウトを決める場所(タイトル、高さ、長さ、X軸、Y軸、余白など) # ============================================ band_graph_sample_layout = go.Layout( title='帯グラフ サンプル', barmode='stack', height=350, width=565 ) # 帯グラフ ▶︎ # データとレイアウトをまとめる場所 # ============================================ band_graph_sample = go.Figure( data=band_graph_sample_data, layout=band_graph_sample_layout)<作成するためのポイント>
orientation hでグラフの向きを横に指定
barmode stackで積み上げるレーダーチャート サンプルの作成方法
作成イメージです。
app.py# ============================================ # レーダーチャート サンプル # ============================================ # レーダーチャート ▶︎ # 空のGraph Objectsを作成 # ============================================ radar_chart_sample = go.Figure() radar_item = ['項目1', '項目2', '項目3', '項目4', '項目5', '項目6', '項目7', '項目8', '項目9', '項目10'] # レーダーチャート ▶︎ # レーダーチャートを作成 # ============================================ radar_chart_sample.add_trace(go.Scatterpolar( r=[47, 18, 23, 41, 26, 29, 35, 49, 34, 45], theta=radar_item, fill='toself', fillcolor='rgba(242, 160, 76, 0.4)', textposition='bottom center', marker=dict(color='#f2a03d'), name='品目1' )) radar_chart_sample.add_trace(go.Scatterpolar( r=[31, 17, 24, 11, 33, 28, 41, 13, 45, 22], theta=radar_item, fill='toself', fillcolor='rgba(33, 191, 162, 0.4)', textposition='bottom center', marker=dict(color='#21bfa2'), name='品目2' )) # レーダーチャート ▶︎ # レイアウトを更新 # ============================================ radar_chart_sample.update_layout( title='レーダーチャート サンプル', height=365, width=365, polar=dict( radialaxis=dict( visible=True, range=[0, 50] ) ), margin=dict( l=10 ), showlegend=True )<作成するためのポイント>
fill 塗り潰しを指定
fillcolor 色の指定
rgbaで色を指定して透過度も指定すると、複数の図を重ねたときに比較が用意になりますapp.layout内でのコード
app.pyhtml.Div( [ # 帯グラフ サンプル html.Div( [ dcc.Graph( id='', figure=band_graph_sample ), # スタイルシートを適用 ], style={'background-color': '#ffffff', 'text-align': 'center', 'border-radius': '5px 0px 0px 5px', 'height': '350px', 'width': '572px', 'margin': '0px 0px 30px 10px', 'padding': '15px', 'position': 'relative', 'box-shadow': '4px 4px 4px lightgrey', } ), # レーダーチャート サンプル html.Div( [ dcc.Graph( id='', figure=radar_chart_sample ), # スタイルシートを適用 ], style={'background-color': '#ffffff', 'text-align': 'center', 'border-radius': '5px 0px 0px 5px', 'height': '350px', 'width': '572px', 'margin': '0px 0px 30px 10px', 'padding': '15px', 'position': 'relative', 'box-shadow': '4px 4px 4px lightgrey', } ), ], style={'display': 'flex'} ),次回はラスト。Pythonで集計、関数化して可視化まで行う実践編です。
ここまで、お疲れ様でした。
次回は、実データを集計、関数化して可視化まで行う実践編です。実践編(作成中。記事公開後、リンクいたします)







- 投稿日:2020-11-14T14:26:49+09:00
polyglotを使ってpythonで形態素解析をする準備から品詞タグ付けまで
準備
polyglot (ドキュメント) を使っていく.
以下は Python 3.8.5 で動作を確認した.
まず,pip install numpy pip install polyglot pip install six pip install pycld2 pip install morfessor pip install pyicuの順番でインストール.
ただし,ModuleNotFoundError でicuを入れろと言われた時はpip install icuではなく
pip install pyicuとする.
icuをインストールして使おうとするとcannot import name xxxのエラーが出てくるはず.別物なので注意.ここでうまくいかない時は,Error installing pip pyicu を見る.
解析していく
公式の Part of Speech Tagging を見て,品詞を調べてみる.
from polyglot.text import Text blob = "You never fail until you stop trying." tokens = Text(blob) print(tokens.pos_tags)これで文章中の全ての単語の品詞がわかるはずだが,エラーが出るはず.
ValueError: This resource is available in the index but not downloaded, yet. Try to run polyglot download embeddings2.enというわけで
git clone https://github.com/web64/nlpserver.gitした後に,
nlpserver.pyの 14 行目にapp.config['JSON_AS_ASCII'] = Falseを追加した後に,
polyglot download embeddings2.en polyglot download pos2.enを入れる.この部分は,Not able to pull polyglot files に書いてあった.
これで英語の解析ができるようになったので,先ほどのコードは動き,
from polyglot.text import Text blob = "You never fail until you stop trying." tokens = Text(blob) print(tokens.pos_tags)の結果として
[('You', 'PRON'), ('never', 'ADV'), ('fail', 'VERB'), ('until', 'SCONJ'), ('you', 'PRON'), ('stop', 'VERB'), ('trying', 'VERB'), ('.', 'PUNCT')]が得られる.
結果が一行じゃ見にくいから,最後の行をpprintを使ってimport pprint pprint.pprint(tokens.pos_tags)とすることで
[('You', 'PRON'), ('never', 'ADV'), ('fail', 'VERB'), ('until', 'SCONJ'), ('you', 'PRON'), ('stop', 'VERB'), ('trying', 'VERB'), ('.', 'PUNCT')]とする,など工夫しても良い.
品詞の名前は以下の通り.省略名と説明 (英語) の部分は Part of Speech Tagging から持ってきた.
省略名 説明 (英語) 説明 (日本語) ADJ adjective 形容詞 ADP adposition 接置詞 ADV adverb 副詞 AUX auxiliary verb 助動詞 CONJ coordinating conjunction 等位接続詞 DET determiner 限定詞 INTJ interjection 間投詞 NOUN noun 名詞 NUM numeral 数詞 PART particle 不変化詞 PRON pronoun 代名詞 PROPN proper noun 固有名詞 PUNCT punctuation 句読点 SCONJ subordinating conjunction 従属接続し SYM symbol 記号 VERB verb 動詞 X other そのほか 参考
インストールの参考
https://qiita.com/sawada/items/528da0b22546045122b2polyglot の特徴についての参考
http://lab.astamuse.co.jp/entry/try-polyglot
- 投稿日:2020-11-14T14:10:46+09:00
AtCoder writer毎のコンテストを集計するスクリプトを書いてみた
概要
AtCoderの問題について、どのwriterがどのコンテストの問題を作成したかを集計するため、AtCoderの告知サイトをスクレイピングスクリプトを作成した。
背景
AtCoderの問題は毎回異なるけど、writer毎にやっぱり癖はあるよね(?)
ということで、コンテスト前にそのwriterが作成した過去問をやれば、writerの問題(癖)に慣れることができるかも。しらんけど。ソース
import requests from bs4 import BeautifulSoup def main(): writers = dict() for i in range(1,600): #告知はhttps://atcoder.jp/posts/+番号の形式 #for文のrange内の600は適宜変更して実行する必要がある(何番まで告知があるかわからんので) load_url = "https://atcoder.jp/posts/" + str(i) html = requests.get(load_url) soup = BeautifulSoup(html.content, "html.parser") title = soup.title.text #コンテストの告知の時のみ処理をする if title.find("告知") >=0 : contestName = title[0:title.find("告知")-1] #writer名等はエスケープされているため、再度text内のhtml部分を解析 soup2 = BeautifulSoup(soup.text,"html.parser") username_elements = soup2.find_all('a', class_='username') if len(username_elements) > 0: for item in username_elements: #item.textにwriter名が格納されている if item.text in writers: writers[item.text].append(contestName) else: writers[item.text] = [contestName] #出力 for writer in writers: print(writer, writers[writer]) if __name__ == '__main__': main()結果
※見にくくてスミマセン。
2020/11/14現在の結果です
snuke ['AtCoder Grand Contest 001', 'CODE FESTIVAL 2016', 'CODE FESTIVAL 2016', 'CODE FESTIVAL 2017 Qualification Round B', 'Chokudai SpeedRun 002']
cgy4ever ['AtCoder Grand Contest 001']
DEGwer ['AtCoder Grand Contest 001', 'AtCoder Grand Contest 003', 'CODE FESTIVAL 2016 予選 B', 'AtCoder Grand Contest 009', 'AtCoder Grand Contest 015', 'AtCoder Regular Contest 076 / Beginner Contest 065', 'CODE FESTIVAL 2017 Qual A', 'Tenka1 Programmer Contest', 'AtCoder Regular Contest 084 / Beginner Contest 077', 'COLOCON -Colopl programming contest 2018- 予', 'AtCoder Regular Contest 088 / Beginner Contest 083', 'AtCoder Grand Contest 024', 'Mujin Programming Challenge 2018', 'AtCoder Beginner Contest 105', 'AtCoder Regular Contest 102 / Beginner Contest 108', 'Tenka1 Programmer Contest / Tenka1 Programmer Beginner Contest', 'CADDi 2018 / CADDi 2018 for Beginners', 'AtCoder Grand Contest 030', '「みんなのプロコン 2019」', 'AtCoder Grand Contest 031 と World Tour Finals 2019/20 ', 'Tenka1 Programmer Contest 2019 / Tenka1 Programmer Beginner Contest 2019', 'AtCoder Beginner Contest 130', 'AtCoder Beginner Contest 131', 'AtCoder Beginner Contest 132', 'AtCoder Grand Contest 035', 'AtCoder Beginner Contest 134', 'AtCoder Beginner Contest 136', 'AtCoder Beginner Contest 137', 'AtCoder Grand Contest 039', 'AtCoder Beginner Contest 148', 'AtCoder Beginner Contest 149', 'AtCoder Beginner Contest 150', 'AtCoder Beginner Contest 151', 'AtCoder Beginner Contest 152', 'AtCoder Beginner Contest 154', 'AtCoder Beginner Contest 159', 'AtCoder Beginner Contest 160', 'AtCoder Beginner Contest 165', 'AtCoder Grand Contest 046']
Um_nik ['AtCoder Grand Contest 001']
yosupo ['AtCoder Grand Contest 001', 'AtCoder Regular Contest 058 / Beginner Contest 042', 'AtCoder Grand Contest 005', 'AtCoder Regular Contest 073 / Beginner Contest 060', 'AtCoder Regular Contest 079 / Beginner Contest 068', 'AtCoder Regular Contest 085 / AtCoder Beginner Contest 078', 'AtCoder Petrozavodsk Contest 001', 'AtCoder Regular Contest 092 / Beginner Contest 091', 'AtCoder Grand Contest 026', 'AtCoder Grand Contest 031 と World Tour Finals 2019/20 ', 'AtCoder Grand Contest 034', 'AtCoder Beginner Contest 130', 'AtCoder Beginner Contest 133', 'AtCoder Beginner Contest 138', 'AtCoder Grand Contest 043', 'ACL Contest 1', 'ACL Contest 2', 'AtCoder Regular Contest 107', 'AtCoder Grand Contest 049']
jcvb ['AtCoder Grand Contest 001']
kyuridenamida ['AtCoder Regular Contest 058 / Beginner Contest 042']
sugim48 ['AtCoder Grand Contest 002', 'AtCoder Grand Contest 004', 'CODE FESTIVAL 2016 予選 A', 'AtCoder Grand Contest 006', 'AtCoder Regular Contest 064 / Beginner Contest 048', 'AtCoder Grand Contest 008', 'AtCoder Regular Contest 074 / Beginner Contest 062', 'AtCoder Grand Contest 016', 'AtCoder Regular Contest 080 / AtCoder Beginner Contest 069', 'CODE FESTIVAL 2017 Qual A', 'CODE FESTIVAL 2017 Qual C', 'AtCoder Regular Contest 087 / Beginner Contest 082', 'AtCoder Petrozavodsk Contest 001', 'AtCoder Grand Contest 026', 'AtCoder Regular Contest 101 / Beginner Contest 107', 'AtCoder Grand Contest 027', 'AtCoder Grand Contest 030', 'AtCoder Grand Contest 032', 'AtCoder Grand Contest 048']
sigma425 ['AtCoder Regular Contest 059 / Beginner Contest 043', 'AtCoder Regular Contest 062 / Beginner Contest 046', 'CODE FESTIVAL 2016 予選 C', 'AtCoder Regular Contest 070 / Beginner Contest 056', 'AtCoder Regular Contest 082 / AtCoder Beginner Contest 072', 'AtCoder Regular Contest 089 / Beginner Contest 086', 'AtCoder Petrozavodsk Contest 001', 'AtCoder Regular Contest 097 / Beginner Contest 097', 'AtCoder Grand Contest 034', 'AtCoder Beginner Contest 135', 'AtCoder Grand Contest 043', 'AtCoder Regular Contest 107']
evima ['AtCoder Regular Contest 059 / Beginner Contest 043', 'AtCoder Regular Contest 075 / Beginner Contest 063', 'AtCoder Beginner Contest 085', 'AtCoder Regular Contest 096 / Beginner Contest 095', 'AtCoder Beginner Contest 104', 'AtCoder Beginner Contest 114', 'CADDi 2018 / CADDi 2018 for Beginners', 'AtCoder Beginner Contest 119', 'AtCoder Beginner Contest 122', 'AtCoder Beginner Contest 133', 'AtCoder Beginner Contest 134', 'AtCoder Beginner Contest 135', 'AtCoder Beginner Contest 136', 'AtCoder Beginner Contest 138', 'AtCoder Beginner Contest 139', 'AtCoder Beginner Contest 158', 'AtCoder Beginner Contest 161', 'AtCoder Beginner Contest 170', 'AtCoder Beginner Contest 171', 'AtCoder Beginner Contest 172', 'AtCoder Beginner Contest 173', 'AtCoder Beginner Contest 174', 'AtCoder Beginner Contest 181', 'AtCoder Beginner Contest 182']
climpet ['AtCoder Regular Contest 060 / Beginner Contest 044']
tozangezan ['AtCoder Regular Contest 061 / Beginner Contest 045', 'AtCoder Beginner Contest 126', 'AtCoder Beginner Contest 127', 'AtCoder Beginner Contest 128', 'AtCoder Beginner Contest 129', 'AtCoder Beginner Contest 132', 'AtCoder Beginner Contest 138', 'AtCoder Beginner Contest 148', 'AtCoder Beginner Contest 149', 'AtCoder Beginner Contest 150', 'AtCoder Beginner Contest 151', 'AtCoder Beginner Contest 152', 'AtCoder Beginner Contest 154', 'AtCoder Beginner Contest 159', 'AtCoder Beginner Contest 161', 'AtCoder Beginner Contest 164', 'AtCoder Beginner Contest 165', 'AtCoder Beginner Contest 170', 'AtCoder Beginner Contest 171', 'AtCoder Beginner Contest 172', 'HHKB プログラミングコンテスト 2020', 'AtCoder Beginner Contest 181']
chokudai ['DISCO presents ディスカバリーチャンネル コードコンテスト2016 予選', 'DISCO presents ディスカバリーチャンネル コードコンテスト2016 予選', 'CODE FESTIVAL 2016', 'CODE FESTIVAL 2016', 'CODE FESTIVAL 2016', 'CADDi 2019', 'AtCoder Grand Contest 035', 'AtCoder Beginner Contest 161']
camypaper ['DISCO presents ディスカバリーチャンネル コードコンテスト2016 予選', 'DISCO presents ディスカバリーチャンネル コードコンテスト2016 予選', ' AtCoder Regular Contest 069 / Beginner Contest 055', 'AtCoder Grand Contest 012', 'AtCoder Regular Contest 078 / Beginner Contest 067', 'AtCoder Grand Contest 027', 'AtCoder Grand Contest 032', 'エクサウィザーズ 2019', 'diverta 2019 Programming Contest', 'AtCoder Beginner Contest 133', 'AtCoder Grand Contest 035', 'AtCoder Beginner Contest 138', 'AtCoder Beginner Contest 150', 'AtCoder Beginner Contest 162', 'エイシング プログラミング コンテスト 2020', 'AtCoder Regular Contest 105']
japlj ['AtCoder Regular Contest 063 / Beginner Contest 047']
dreamoon ['AtCoder Grand Contest 007']
yutaka1999 ['CODE FESTIVAL 2016', 'CODE FESTIVAL 2016', 'CODE FESTIVAL 2016', 'AtCoder Grand Contest 010', 'AtCoder Grand Contest 014', 'AtCoder Grand Contest 025', 'AtCoder Grand Contest 029', 'AtCoder Grand Contest 031 と World Tour Finals 2019/20 ', 'AtCoder Grand Contest 033', 'AtCoder Grand Contest 037', '第二回全国統一プログラミング王決定戦予選', '東京海上日動\u3000プログラミングコンテスト2020']
catupper ['CODE FESTIVAL 2016']
rng_58 ['CODE FESTIVAL 2016', 'CODE FESTIVAL 2017 Qualification Round B', 'AtCoder Beginner Contest 155']
hogloid ['AtCoder Regular Contest 065 / Beginner Contest 049', 'AtCoder Regular Contest 072 / Beginner Contest 059', 'AtCoder Grand Contest 031 と World Tour Finals 2019/20 ']
maroonrk ['AtCoder Regular Contest 066 / Beginner Contest 050', 'AtCoder Regular Contest 067 / Beginner Contest 052', 'AtCoder Grand Contest 013', 'AtCoder Grand Contest 018', 'CODE FESTIVAL 2017 Qualification Round B', 'AtCoder Grand Contest 023', 'AtCoder Regular Contest 098 / Beginner Contest 098', 'AtCoder Regular Contest 100 / Beginner Contest 102', 'AtCoder Grand Contest 028', 'AtCoder Grand Contest 031 と World Tour Finals 2019/20 ', 'AtCoder Grand Contest 034', 'AtCoder Grand Contest 036', 'AtCoder Grand Contest 038', 'AtCoder Grand Contest 040', 'AtCoder Grand Contest 043', 'AtCoder Grand Contest 045', 'ACL Contest 1', 'ACL Contest 2', 'AtCoder Grand Contest 048', 'AtCoder Regular Contest 107', 'AtCoder Grand Contest 049']
hec ['AtCoder Beginner Contest 051', 'AtCoder Beginner Contest 054', 'AtCoder Beginner Contest 057', 'AtCoder Beginner Contest 061']
semiexp ['AtCoder Grand Contest 011', 'AtCoder Grand Contest 017', 'AtCoder Regular Contest 081 / AtCoder Beginner Contest 071', 'AtCoder Regular Contest 086 / Beginner Contest 081', 'AtCoder Regular Contest 095 / Beginner Contest 094', 'AtCoder Regular Contest 099 / Beginner Contest 101', 'AtCoder Regular Contest 103 / Beginner Contest 111', 'CADDi 2018 / CADDi 2018 for Beginners', 'AtCoder Grand Contest 030', 'エクサウィザーズ 2019']
nuip ['AtCoder Regular Contest 071 / Beginner Contest 058', 'AtCoder Regular Contest 077 / Beginner Contest 066', 'AtCoder Regular Contest 095 / Beginner Contest 094', 'AtCoder Regular Contest 103 / Beginner Contest 111', 'AtCoder Beginner Contest 163']
e869120 ['AtCoder Beginner Contest 064', 'AtCoder Beginner Contest 076', 'AtCoder Beginner Contest 088', 'AtCoder Beginner Contest 096', 'AtCoder Beginner Contest 100']
square1001 ['AtCoder Beginner Contest 064', 'AtCoder Beginner Contest 076', 'AtCoder Beginner Contest 088', 'AtCoder Beginner Contest 096', 'AtCoder Beginner Contest 100', 'AtCoder Beginner Contest 105', 'AtCoder Beginner Contest 106', 'AtCoder Beginner Contest 123', 'diverta 2019 Programming Contest 2', 'AtCoder Beginner Contest 139', 'DISCO presents ディスカバリーチャンネル コードコンテスト2020 予選', '三井住友信託銀行プログラミングコンテスト2019', 'M-SOLUTIONS プロコンオープン 2020']
tourist ['AtCoder Grand Contest 019', 'AtCoder Grand Contest 020', 'AtCoder Grand Contest 041']
wo01 ['AtCoder Regular Contest 083 / AtCoder Beginner Contest 074', 'CODE FESTIVAL 2017 Qual C', 'AtCoder Regular Contest 090 / Beginner Contest 087', 'AtCoder Regular Contest 093 / Beginner Contest 092', 'エイシング プログラミング コンテスト 2019', 'AtCoder Beginner Contest 139', 'キーエンス プログラミング コンテスト 2020', 'AtCoder Beginner Contest 164']
hasi ['Tenka1 Programmer Contest']
namonakiacc ['DISCO presents ディスカバリーチャンネル コードコンテスト2017 予選', 'AtCoder Beginner Contest 079', 'AtCoder Beginner Contest 080', 'AtCoder Beginner Contest 084', 'AtCoder Beginner Contest 089', 'AtCoder Beginner Contest 099', 'AtCoder Beginner Contest 159', 'AtCoder Beginner Contest 161']
degwer ['AtCoder Grand Contest 021', 'AtCoder Regular Contest 091 / Beginner Contest 090', 'AtCoder Regular Contest 094 / Beginner Contest 093']
zscoder ['AtCoder Grand Contest 022']
drafear ['AtCoder Beginner Contest 103', 'AtCoder Beginner Contest 117', 'AtCoder Beginner Contest 118', 'AtCoder Beginner Contest 120', 'AtCoder Beginner Contest 121', 'AtCoder Beginner Contest 124', 'AtCoder Beginner Contest 125', 'AtCoder Beginner Contest 126', 'AtCoder Beginner Contest 127', 'AtCoder Beginner Contest 128', 'AtCoder Beginner Contest 133', 'AtCoder Beginner Contest 134', 'AtCoder Beginner Contest 135', 'AtCoder Beginner Contest 136', 'AtCoder Beginner Contest 137', '第一回日本最強プログラマー学生選手権-予選-', 'AtCoder Beginner Contest 139', 'AtCoder Beginner Contest 140', 'AtCoder Beginner Contest 141', 'AtCoder Beginner Contest 142', 'AtCoder Beginner Contest 152', 'AtCoder Beginner Contest 155']
satashun ['Mujin Programming Challenge 2018', 'キーエンス プログラミング コンテスト 2019', 'AtCoder Beginner Contest 127', 'AtCoder Beginner Contest 128', 'AtCoder Beginner Contest 129', 'diverta 2019 Programming Contest 2', 'AtCoder Beginner Contest 130', 'AtCoder Beginner Contest 131', 'AtCoder Beginner Contest 136', 'AtCoder Beginner Contest 147', 'AtCoder Beginner Contest 150', 'AtCoder Beginner Contest 151', 'AtCoder Beginner Contest 158', 'AtCoder Beginner Contest 159', 'AtCoder Beginner Contest 160', 'NOMURA プログラミングコンテスト 2020', 'AtCoder Beginner Contest 175', 'AtCoder Beginner Contest 179', 'AtCoder Regular Contest 104']
E869120 ['AtCoder Beginner Contest 105', 'AtCoder Beginner Contest 106', 'AtCoder Beginner Contest 123', 'diverta 2019 Programming Contest 2', 'AtCoder Beginner Contest 139', 'DISCO presents ディスカバリーチャンネル コードコンテスト2020 予選', '三井住友信託銀行プログラミングコンテスト2019', 'M-SOLUTIONS プロコンオープン 2020']
IH19980412 ['キーエンス プログラミング コンテスト 2019', 'AtCoder Grand Contest 031 と World Tour Finals 2019/20 ', 'AtCoder Beginner Contest 137', 'AtCoder Beginner Contest 149', 'AtCoder Beginner Contest 152']
['AtCoder Beginner Contest 116']
gazelle ['AtCoder Beginner Contest 126', 'AtCoder Beginner Contest 128', 'AtCoder Beginner Contest 130', 'AtCoder Beginner Contest 131', 'AtCoder Beginner Contest 132', 'AtCoder Beginner Contest 134', 'AtCoder Beginner Contest 135', 'AtCoder Beginner Contest 137', '第一回日本最強プログラマー学生選手権-予選-', 'AtCoder Beginner Contest 139', 'AtCoder Beginner Contest 140', 'AtCoder Beginner Contest 143', 'AtCoder Beginner Contest 148', 'AtCoder Beginner Contest 150', 'AtCoder Beginner Contest 156', 'AtCoder Beginner Contest 162', 'AtCoder Beginner Contest 163', 'AtCoder Beginner Contest 166', 'AtCoder Beginner Contest 167', 'NOMURA プログラミングコンテスト 2020', 'AtCoder Beginner Contest 170', 'AtCoder Beginner Contest 171', 'AtCoder Beginner Contest 173']
potetisensei ['AtCoder Beginner Contest 127', 'AtCoder Beginner Contest 128', 'AtCoder Beginner Contest 129', 'AtCoder Beginner Contest 132', 'AtCoder Beginner Contest 133', 'AtCoder Beginner Contest 134', 'AtCoder Beginner Contest 137', 'AtCoder Beginner Contest 167']
yuma000 ['AtCoder Beginner Contest 128', 'AtCoder Beginner Contest 129', 'diverta 2019 Programming Contest 2', 'AtCoder Beginner Contest 130', 'AtCoder Beginner Contest 131', 'AtCoder Beginner Contest 132', 'AtCoder Beginner Contest 133', 'AtCoder Beginner Contest 134', 'AtCoder Beginner Contest 139', 'AtCoder Beginner Contest 149', 'AtCoder Beginner Contest 150', 'AtCoder Beginner Contest 163', 'AtCoder Beginner Contest 169', 'AtCoder Beginner Contest 170', 'AtCoder Beginner Contest 182']
yokozuna57 ['M-SOLUTIONS プロコンオープン', 'AtCoder Beginner Contest 137', 'AtCoder Beginner Contest 152', 'AtCoder Beginner Contest 159']
sheyasutaka ['AtCoder Beginner Contest 129', 'AtCoder Beginner Contest 131', 'AtCoder Beginner Contest 135', 'AtCoder Beginner Contest 138', '第一回日本最強プログラマー学生選手権-予選-', 'AtCoder Beginner Contest 141', 'AtCoder Beginner Contest 144', 'AtCoder Beginner Contest 147', 'AtCoder Beginner Contest 148', 'AtCoder Beginner Contest 154', 'AtCoder Beginner Contest 155', 'AtCoder Beginner Contest 161', 'AtCoder Beginner Contest 165', 'AtCoder Beginner Contest 166', 'AtCoder Beginner Contest 167', 'AtCoder Beginner Contest 168', 'AtCoder Beginner Contest 171', 'AtCoder Beginner Contest 172', 'AtCoder Beginner Contest 173', 'AtCoder Beginner Contest 180']
beet ['AtCoder Beginner Contest 140', 'AtCoder Beginner Contest 141', 'AtCoder Beginner Contest 142', 'AtCoder Beginner Contest 143', 'AtCoder Beginner Contest 146', 'AtCoder Beginner Contest 148', 'AtCoder Beginner Contest 149', 'AtCoder Beginner Contest 151', 'AtCoder Beginner Contest 152', 'AtCoder Beginner Contest 155', '日立製作所 社会システム事業部 プログラミングコンテスト2020', 'AtCoder Beginner Contest 165', 'AtCoder Beginner Contest 172', 'AtCoder Beginner Contest 179', 'AtCoder Regular Contest 106']
kort0n ['AtCoder Beginner Contest 140', 'AtCoder Beginner Contest 141', 'AtCoder Beginner Contest 142', 'AtCoder Beginner Contest 143', 'AtCoder Beginner Contest 144', 'AtCoder Beginner Contest 145', 'AtCoder Beginner Contest 146', 'AtCoder Beginner Contest 147', 'AtCoder Beginner Contest 151', 'AtCoder Beginner Contest 156', 'AtCoder Beginner Contest 157', '日立製作所 社会システム事業部 プログラミングコンテスト2020', 'AtCoder Beginner Contest 165', 'AtCoder Beginner Contest 166', 'AtCoder Beginner Contest 167', 'AtCoder Beginner Contest 170', 'AtCoder Beginner Contest 176', 'AtCoder Regular Contest 106']
ynymxiaolongbao ['AtCoder Beginner Contest 142', 'AtCoder Beginner Contest 145', 'AtCoder Beginner Contest 160', 'AtCoder Beginner Contest 161', 'AtCoder Beginner Contest 162', 'AtCoder Beginner Contest 163', 'AtCoder Beginner Contest 164', 'AtCoder Beginner Contest 165', 'AtCoder Beginner Contest 166', 'AtCoder Beginner Contest 169', 'AtCoder Beginner Contest 170', 'AtCoder Beginner Contest 172', 'AtCoder Beginner Contest 173', 'AtCoder Beginner Contest 174', 'AtCoder Beginner Contest 176', 'AtCoder Beginner Contest 177', 'AtCoder Beginner Contest 178', 'AtCoder Beginner Contest 180', 'AtCoder Beginner Contest 181']
kyopro_friends ['AtCoder Beginner Contest 144', 'AtCoder Beginner Contest 145', 'AtCoder Beginner Contest 146', 'AtCoder Beginner Contest 147', 'AtCoder Beginner Contest 148', 'AtCoder Beginner Contest 149', 'AtCoder Beginner Contest 150', 'AtCoder Beginner Contest 151', 'AtCoder Beginner Contest 152', 'AtCoder Beginner Contest 153', 'AtCoder Beginner Contest 154', 'AtCoder Beginner Contest 159', 'AtCoder Beginner Contest 160', 'AtCoder Beginner Contest 161', 'AtCoder Beginner Contest 162', 'AtCoder Beginner Contest 163', 'AtCoder Beginner Contest 164', 'AtCoder Beginner Contest 166', 'AtCoder Beginner Contest 167', 'AtCoder Beginner Contest 169', 'AtCoder Beginner Contest 171', 'AtCoder Beginner Contest 172', 'AtCoder Beginner Contest 173', 'AtCoder Beginner Contest 174', 'AtCoder Beginner Contest 176', 'AtCoder Beginner Contest 177', 'AtCoder Beginner Contest 179', 'AtCoder Beginner Contest 180', 'AtCoder Beginner Contest 182']
tempura0224 ['AtCoder Beginner Contest 146', 'AtCoder Beginner Contest 158', '日立製作所 社会システム事業部 プログラミングコンテスト2020', 'AtCoder Beginner Contest 159', 'AtCoder Beginner Contest 162', 'AtCoder Beginner Contest 167', 'AtCoder Beginner Contest 169', 'AtCoder Regular Contest 106', 'AtCoder Beginner Contest 181']
latte0119 ['AtCoder Beginner Contest 152', 'AtCoder Beginner Contest 154', 'AtCoder Beginner Contest 159', 'AtCoder Beginner Contest 160', 'AtCoder Beginner Contest 161', 'AtCoder Beginner Contest 163', 'AtCoder Beginner Contest 164', 'AtCoder Beginner Contest 169']
heno239 ['日立製作所 社会システム事業部 プログラミングコンテスト2020', 'AtCoder Regular Contest 106']
rng58_admin ['パナソニックプログラミングコンテスト2020', 'ACL Contest 1', 'ACL Beginner Contest']
Kmcode ['AtCoder Beginner Contest 164', 'AtCoder Beginner Contest 171']
dario2994 ['AtCoder Grand Contest 044']
kobae964 ['NOMURA プログラミングコンテスト 2020']
wata ['Introduction to Heuristics Contest', 'HACK TO THE FUTURE 2021 予選']
Errichto ['AtCoder Grand Contest 047']
tatyam ['AtCoder Beginner Contest 181']
June_boy ['AtCoder Beginner Contest 182']
QCFium ['AtCoder Beginner Contest 182']
注意/免責事項
本スクリプト 及び 結果により発生した損害、及び コンテストの結果に対し、mizoonoはいかなる責任も負いません。
- 投稿日:2020-11-14T13:32:42+09:00
CBC(Pulp, python-mip)ソルバーのログの読み方
Pulp1やpython-mip2からフリーで動かせるCBC(COIN-OR Brand-and-Cut)ソルバーのログの読み方をまとめてみました。
(個人的なメモとしてまとめたので間違いなどがあればご指摘お願いします。)内容は以下のpdfのほぼ翻訳になります。
- CBC : COIN-OR Branch-and-Cut (A Short Guide to the CBC Command Line Interface)
http://www.decom.ufop.br/haroldo/files/cbcCommandLine.pdfはじめに
上のpdfではメッセージ7までは
air03と呼ばれるSet Partitioning問題のベンチマークを計算した時のログを使って説明されています。
メッセージ7以降は`air04'を用いて説明が行われています。http://miplib2017.zib.de/instance_details_air03.html
http://miplib2017.zib.de/instance_details_air04.html上のリンクから
mpsファイルが入手できます。
python-mipのreadを使って問題を読み込み計算することが出来ます。
(Pulpではread関数が準備されていない...。writeはありますが。)ログの読み方
メッセージ1~3
メッセージ1
Continuous objective value is 338864 - 0.05 secondsモデルの線型緩和解を解いた時の目的項の値(コスト)と計算時間が表示されています。
この例ではコストが338864の線型緩和解が0.05秒で得られています。
この値が元の問題の上界下界になります。
(最小化の場合は下界、最大化の場合は上界になります。以降では最小化問題を考えます。)
何も特別な操作を行っていないので最もラフに見積もった下界になります。メッセージ2
Cgl0004I processed model has 120 rows, 8456 columns (8456 integer) and 71651 elements
Cglと記載された行では前処理が行われています。
CglはCut Generation Library3の略のようです。前処理で削減した後の制約条件(
rows)、変数(columns)、非ゼロ要素の数(elements)が最後の行に表示されています。
前処理を行うと以下のように問題のサイズが小さくなっています。
制約条件 変数 非ゼロ要素 前処理前 823 8904 72965 前処理後 120 8456 71651 前処理で問題のサイズが小さくなればなるほどMIPソルバーにとって解きやすい定式化になっているそうです。
メッセージ3
Cbc0038I Pass 1: suminf. 8.33333 (22) obj. 341524 iterations 106 Cbc0038I Pass 2: suminf. 8.33333 (22) obj. 341524 iterations 3 Cbc0038I Pass 3: suminf. 8.33333 (22) obj. 341524 iterations 70 Cbc0038I Pass 4: suminf. 7.20000 (20) obj. 342390 iterations 75 Cbc0038I Pass 5: suminf. 1.50000 (3) obj. 343697 iterations 45 Cbc0038I Pass 6: suminf. 1.50000 (3) obj. 343697 iterations 55 ... Cbc0038I Pass 12: suminf. 0.00000 (0) obj. 362176 iterations 144 Cbc0038I Solution found of 362176
Cbc0038Iが始まったことを表しています。
Cbc0038IではFeasibility Pump (M. Fischetti, Glover, & Lodi, 2005)4,5と呼ばれる手法を用いて実行可能解となる初期解(暫定解)を探索しているようです。
(IはInitialの略でしょうか。)
12のPassが終了した後にCbc0038I Solution found of 362176と表示されており、コストが362176の暫定解が得られたことが分かります。
メッセージ1に表示されていた下界が338864だったので、少なくとも[338864, 362176]の範囲に最適解(厳密解)があることが分かります。
暫定解のコストと下界との差(ギャップ)が小さいほどCBCの性能は良くなります。メッセージ4~6
メッセージ4
Cbc0012I Integer solution of 340160 found by DiveCoefficient after 14 iterations and 0 n odes (0.97 seconds)DiveCoefficient5,6と呼ばれる前処理の結果が表示されています。
(私は詳細を知りません。)
その結果さらに暫定解が更新されてギャップが[338864, 340160]の区間になっています。メッセージ5
Cbc0013I At root node, 5 cuts changed objective from 338864.25 to 340160 in 2 passesカット系のアルゴリズムが実行されているようです。
特に双対問題の上界下界を改善するために、得られた緩和解の小数値を取り除くカットをいくつか試しているみたいです。
この例では5種類のカットが実行されたようです。
詳しい内容がログの下の方に表示されています。Cbc0014I Cut generator 0 (Probing) - 0 row cuts average 0.0 elements, 160 column cuts (160 active) in 0.840 seconds - new frequency is 1 Cbc0014I Cut generator 1 (Gomory) - 4 row cuts average 1257.2 elements, 0 column cuts (3 active) in 0.020 seconds - new frequency is -100 Cbc0014I Cut generator 2 (Knapsack) - 0 row cuts average 0.0 elements, 0 column cuts (0 active) in 0.020 seconds - new frequency is -100 Cbc0014I Cut generator 3 (Clique) - 10 row cuts average 3.7 elements, 0 column cuts (0 active) in 0.000 seconds - new frequency is 1 Cbc0014I Cut generator 6 (TwoMirCuts) - 0 row cuts average 0.0 elements, 0 column cuts (0 active) in 0.030 seconds - new frequency is -100この問題では0,1,3番目のカットで十分のようです。
(Gomory Cut7とClique Cutが特に有効であることが分かります。)
双対問題の上界が340160であることが判定できました。
暫定解のコストも340160であるので最適解であることが分かります。メッセージ6
Result - Finished objective 340160 after 0 nodes and 11 iterations - took 4.75 seconds (total time 5.06) Total time 5.14最終的なコストの値と計算時間が表示されています。
今回の問題はroot nodeで十分良い実行可能解や双対問題の上界が得られているのでこれ以上分枝カット法の枝刈りは行われていません。メッセージ7, 8
これらのメッセージはより難しい問題(
air04)を計算したときに表示されるログになります。
air04では分枝限定法の前にこの探索が行われているようです。
分子限定法の木構造の探索で探索したノードの数、探索がまだ終わっていないノードの数がそれぞれ表示されています。
新しい整数が得られるたびにそのコストや用いた手法に関する情報が表示されています。(メッセージ8)以上がログの読み方になります。
参考までにpython-mipを使ってair03,air04を計算した時のログを以下にUpしました。
https://github.com/Noriaki416/Qiita/tree/master/CBC_log
air0#_cbc_log.txtがログになります。チューニング
ログを読むことでどのプロセスが問題を解く上でネックになっているのかが分かります。
その原因を特定してチューニングを行うことで求解性能を改善できるはずです。
冒頭のpdfのp6以降に詳細なチューニングパラメータが記載されています。Pulpを使ってチューニングする場合は
optionsで指定すればいいみたいです。
下のブログで詳しく解説されています。https://inarizuuuushi.hatenablog.com/entry/2019/03/07/090000
optionsではそれ以外のCBCオプションを設定できます.
例えばmaxsolオプションを使用する場合は options = ['maxsol 1']とします.
maxsolオプションは, 暫定解が何個見つかった時に計算を終了するかを指定できます. 最適解でなくても実行可能解が1つ欲しい場合はmaxsol 1とすればより速い時間で求めることができます.
maxsol以外のパラメータについてもGAMS8のサイトに記載されています。
色々弄ってみると違いが見えて面白いのかもしれません。以上になります。
ご指摘などありましたら遠慮なくお願いします。
http://www.dei.unipd.it/~fisch/papers/feasibility_pump.pdf ↩
https://www.zib.de/berthold/primal_heuristics.pdf (SCIPのpdfですがFeasibility PumpやDiving~に関する説明が記述されています。) ↩
https://www.google.co.jp/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwiZ9Y-RhoDtAhUDEqYKHZJvD58QFjABegQIBhAC&url=https%3A%2F%2Fopus4.kobv.de%2Fopus4-zib%2Ffiles%2F1029%2FBerthold_Primal_Heuristics_For_Mixed_Integer_Programs.pdf&usg=AOvVaw3F8ik1VHxnn_3GdP_rk89N ↩
http://dopal.cs.uec.ac.jp/okamotoy/lect/2013/opt/handout06.pdf ↩



- 投稿日:2020-11-14T13:23:01+09:00
pythonのopenでチルダ(~)で始まるパスを指定したら行方不明になった話
path = '~/.config/remind_task/tasks.yml' dir_name = os.path.dirname(path) os.makedirs(dir_name, exist_ok=True) # 上位ディレクトリが存在しなければ掘る with open(path, mode="w") as f: f.write("hoge")このようにファイルを開きファイルを作成するとホームディレクトリの
.config/remind_task/tasks.ymlにファイルが作成されると思ってしまう。
上のコードを実行するとファイルは作成される。しかし無い。> cat ~/.config/remind_task/tasks.yml cat: /Users/atu/.config/remind_task/tasks.yml: No such file or directoryしかしファイルは作成されている。どこにあるのか探し回った結果、カレントディレクトリに作られていた。
この場合は/Users/atu/Documents/python/remind_task/~/.config/remind_task/tasks.ymlにあった。> cat "/Users/atu/Documents/python/remind_task/~/.config/remind_task/tasks.yml" hogeチルダで始まるパスを扱う場合には以下のようにすればOKです。
import pathlib path = pathlib.Path("~/.config/remind_task/tasks.yml").expanduser() print("path", path) ## path /Users/atu/.config/remind_task/tasks.yml
- 投稿日:2020-11-14T12:44:18+09:00
【仕事効率化】Pythonでファイル名を一括変更する方法
はじめに
皆さんは大量のテキストファイルや画像ファイルのファイル名を一括変更したいときはありませんか?今回はそんな「ファイル名を一括で変更する方法」について解説していきます。
目次
1. 事前準備
リネームするファイルを用意します。ファイルはテキストファイルや画像ファイル、音楽ファイル、動画ファイル何でも大丈夫です。お好きなファイルを用意しましょう。
↓↓ 今回は画像ファイルを用意しています ↓↓
注意
失敗しても大丈夫なように必ずデータのバックアップをとっておきましょう!!
2. リネームするには
ファイル名をリネームするには「os.rename()」関数を使用します。
第一引数に変更前のファイル、第二引数に変更後のファイルを指定することでリネームできます。import os os.rename(変更前ファイル, 変更後ファイル)※ファイルが存在しない場合は、「FileNotFoundError」例外が発生します。
3. 実際に一括でファイル名を変更してみる
# coding: utf-8 import glob import os # 拡張子.pngの画像ファイルを取得する path = './dir/*.png' i = 1 # 画像ファイルを取得する before_file_list = glob.glob(path) print('変更前') print(before_file_list) # ファイル名を一括で変更する for file in before_file_list: os.rename(file, './dir/icon' + str(i) + '.png') i += 1 after_file_ist = glob.glob(path) print('変更後') print(after_file_ist)↓↓ リネーム後の画像ファイルです ↓↓
今回のサンプルソースはGithubにも掲載してあります。
Github:https://github.com/miyazakikna/RenameFile.git4. 最後に
ここではPythonを使ってファイル名を一括変更する方法を解説しました。
シンプル、且つ、簡単に大量のファイル名を一括変更できるので個人的に重宝しております。

- 投稿日:2020-11-14T11:51:24+09:00
【3】UbuntuにAnacondaで構築するTensorFlow-GPU環境構築〜Anaconda仮想環境作成編〜
TensorFlowのGPU版(tensorflow-gpu)を動かすために必要なこととは?
- Deep Learningを行う計算力(compute capability)のある比較的新しいGPU(nVidia社製)を搭載していること。
- GPUの適切なドライバがOSに入っていて、使用可能な状態になっていること
- tensorflow-gpuやGPUのドライバ(CUDA)、Deep Learning用のライブラリ(cuDNN)を入れる環境を作るため、Anacondaがインストールされていること。?今ここ
- Pythonや必要なライブラリがバージョンの互換性を持っていること
この記事ののゴール
AnacondaをインストールしてGPUを動かす土台となる仮想環境を作ること
仮想環境とは?
例えば、通常ではPythonをインストールしたらpipコマンドでライブラリをインストールしてプログラムを動かす『環境』を構築していきます。ライブラリ間にはバージョンによって互換しないものがあったり、煩雑になったりするのでひとつの環境になんでもかんでも入れていくのは好ましくはないです。そこで用途ごとに仮想的な環境を作成してそこに必要なものだけインストールしていくというのが便利です。今回はtensorflow-gpuを動かすためという用途で仮想環境をひとつ作りましょう。
Anacondaのインストール
archコマンドを実行すると、どのアーキテクチャ用のディストリビューションをインストールすれば分かります。この場合は×86_64と判明したので、正しく選択してシェルスクリプトをダウンロードする。
$ arch x86_64シェルスクリプトを実行してAnacondaをインストールしてください(記事がいっぱいあるのでここは割愛します)。
注意点⚠️:起動時にアナコンダのbase環境をactivateするように.bashrcを編集するかを問う項目もあるはずなので、やたらとEnterを押さないようにしてください(自動Activateには危険な部分もあるので考えてから)。
.bashrcを書き換えた場合:ターミナルを再起動したとき以下のようになっているはずです。(base)$.bashrcを書き換えなかった場合: 次のコマンドでbase環境をactivateします。
$ conda activate (base)$condaコマンドが使えるか確認してみましょう(-Vはcondaコマンドのバージョンを確認するオプション)。
(base)$ conda -V conda 4.8.4conda create -n (仮想環境の名前)でライブラリが何も入っていないまっさらな仮想環境を作成することができる(例ではibio_envという名前の仮想環境を作成しています)。
(base)$ conda create -n ibio_env次のようにして仮想環境をactivateする。
(base)$ conda activate ibio_envconda listコマンドで、ライブラリが何も入っていないことを確認できます。
(ibio_env)$ conda list # packages in environment at /home/usr/anaconda3/envs/ibio_env: # # Name Version Build ChannelAnacondaにTensorFlowなどのライブラリをインストールする土台となるまっさらな仮想環境を立ててることができました。
Anacondaで仮想環境を作成できたら
次はtensorflow-gpuを始め、様々なライブラリを互換性に気をつけながらインストールしていきます。
- 投稿日:2020-11-14T11:30:47+09:00
AtCoder精進メモ(11/12)
AtCoderにおける精進のメモです。ですます調とである調が混在している点は申し訳ないです。
AGC008B - Contiguous Repainting
diff:1821
結果:考察20分,基本の実装10分,バグ取りに∞分→accumulate関数のlambda式が間違っていた提出:https://atcoder.jp/contests/agc008/submissions/18058051
考察
まず、できるだけ多くの部分を都合よく塗る($a_i \geqq 0$の場合は黒色で,$a_i <0$の場合は白色で)ことを考えます。この時、適当な塗り方をしても埒が明かなそうだったので、端から順に塗っていくことを考えました。この時、端の$k$個のマス以外は都合よく塗ることができ、端の$k$個のマスは全て黒または白に塗ることができます。従って、左端の$k$個のマスを都合よく塗れない場合と右端の$k$個のマスを都合良く塗れば良いのではと考えたのですが、サンプル2のように間の$k$個のマスだけ都合良く塗れない場合が最適であることもあります。従って、これらを一般化すれば、連続する$k$個のマスは白または黒で一色に、その部分以外は都合の良いように塗れば良いのではと考えました。このとき、十分性しか示さずに解いたのですが、冷静になれば最後に上書きをすることで一色で連続する$k$個のマスが現れるので、必要性も示すことができます。よって、これを累積和を用いて実装するだけで、図で書くなら以下のようになります。
ここまで来たら実装するだけなのですが、accumulate関数に渡す関数にlambda式を使ったが故にミスをしてしまいました。accumulate関数には前処理済みのイテラブルを渡すようにしようと思います。
また、上書きをする問題では操作を逆順にするのは典型的な考え方なようです。確かにそれはそうで、上書きは破壊的な操作であるのに対し、逆順にすることで非破壊的な操作にできるので、都合が良いです。これは、UnionFind的な問題で辺を切っていく際に逆順として捉えることで都合が良くなることと似ている気がします。
反省
コードを簡潔にしようとしていたために間違ってしまった,直前の問題同様実装をサボらない(学んで…)、考察があってるの悔しい…
DDPC2020予選 D - Digit Sum Replace
diff:1650
結果:考察:25分くらい,実装:無,でAC
提出:https://atcoder.jp/contests/ddcc2020-qual/submissions/18059365考察
初めは実験をして最小となるような数の組み合わせがどうなるかなどと考えていたが、数が大きいので愚直にシミュレーションをするのが難しいと思った。
そこで、操作に注目すると、①桁数を減らす操作と②桁数を減らさない操作に分けられることに気づいた。このとき、①の場合は桁数が減るだけで数字和は変わらず、②の場合は桁数は減らないが数字和が一律に9だけ減ることに気づいた。
ここで、最終的な条件を①と②の操作に合うように言い換えると、桁数が一桁かつ数字和が9以下になれば良いことがわかる。また、①と②の操作は互いに独立で干渉しないので、その回数はそれぞれ元の桁数と元の数字和から一意に決まることに気づいた。ここで、前者は(元の桁数)-1で簡単に求められるが、後者は(元の数字和を9で割った商)ではなく、9で割った余りが0の時はその値から-1することが必要である。よって、①と②の操作回数を足したものが最大のラウンド回数である。
✳︎数字和…それぞれの桁の数の合計
反省
ギャグに気づくまで時間がかかった、気づいたら一瞬、こういうタイプは難しいけど操作の変化量に注目すると良い?
AGC002C - Knot Puzzle
diff:1564
結果:考察+実装:15分,嘘解法を直すのに15分,でAC
提出:https://atcoder.jp/contests/agc002/submissions/18058456考察
まず、切れば切るほどロープは短くなるので、後の方にできるだけ長いロープを残したいです。また、内側の結び目を切ることで都合が良くなることはないので、端の結び目を切ります。
つまり、端の二本のロープのうち短い方を切っていく貪欲法でできるのではないかと考えたのですが、これはロープの長さが等しい時にどちらのロープを切るかで答えが変わってしまい、この方法では難しいです。例えば、以下のような場合がコーナーケースとして存在します。(後から気づきましたが、この方法では一番長いロープが一方として残りますが、そのロープの横が短いロープの場合は最適な切り方ではないです…)
しかし、この考察を考えていた際に、端から切っていくことで最終的に残るのは二本のロープであり、このロープの長さが$L$以上であればそれ以前のロープについても常に長さが$L$以上であることに気づきました。また、最終的に残る二本のロープは初めの状態でも隣り合ってるので、隣り合うロープの組($N-1$通り)を全探索して$L$以上のものがあるかを探せば良いです。(最終状態に注目!)
反省
感想:嘘解法だろうなと思って実装してしまったが、考察を深めたところACできた、投げやりにならずに考察をしきるのが大事!
- 投稿日:2020-11-14T11:29:48+09:00
【調査中】Logistic回帰 @ scikit-learnのPenaltyとSolverのディープな関係
scikit-learnの
LogisticRegressionモジュールを利用した時にPenaltyとSolverの対応関係が分からず公式ドキュメントを調べましたが,一目で分かる状態になっておらず,しばし頭が混乱しました。。。そこでまずはPenaltyとSolverの対応/非対応関係を一覧表にまとめ,更に今後SolverやPenaltyの詳細な情報も追加していこうと思います。PenaltyとSolverの対応/非対応関係
Penalty / Solver newton-cg lbfgs(default) liblinear sag saga L1 × × ○ × ○ L2(default) ○ ○ × ○ ○ Elasticnet × × × × ○ None ○ ○ × ○ ○ Penalty / Solverの解説
- 今後追加予定(調査中)
- 投稿日:2020-11-14T10:03:45+09:00
pandas_datareaderのインストール方法と使い方について【Python】
この記事では、
pandas_datareaderのインストール方法と使い方について
を書いていきます。pandas_datareaderとは
pandas_datareaderはPythonのライブラリで、経済データや金融商品の価格データが取ることができます。
pandasという名が入っているので、pandasと共に入ってそうですが(昔は入っていたような)、別モンになっています。Anacondaでも入っておらず、インストールしないといけません。
Pythonのライブラリpandas_datareaderでデータを取得する - Pythonと本と子供と雑談とライブラリ↓
pandas-datareader — pandas-datareader 0.9.0rc1+2.g427f658 documentationインストール方法
上記の通り、pandas_datareaderはPythonのライブラリです。Anacondaでも入っていないので、インストールしていきます。インストールはpipでやります。
pip install pandas_datareaderこれでインストールが完了です。
使い方の例
importしてそれを使い株価を取得してみます。
今回は、トヨタ自動車の株価を見てみます。
証券番号は'7203'なので、DataReaderの第一引数に'7203.JP'、第二引数に'stooq'を渡します。
'stooq'に関しては、僕自身も深く理解していませんが、'stooq'というサイトから株価を引っ張ってくるというイメージだと思います。(参考にしないでください)from pandas_datareader import data df = data.DataReader('7203.JP', 'stooq') df.head()実行結果
細かいことについては省略しますが、これで株価を取得することができました。まとめ
今回は、
pandas_datareaderのインストール方法と使い方について
を書いていきました。株価を取得してグラフ化したりする際にできないと困るので、覚えておきましょう。
今後、グラフ化やデータ分析などについても上げていく予定です。参照
Pythonのライブラリpandas_datareaderでデータを取得する - Pythonと本と子供と雑談と
pandas-datareader — pandas-datareader 0.9.0rc1+2.g427f658 documentation注意
この記事は、プログラミング初学者が書いており、内容に誤りがある場合がございます。
あしからずご了承願います。
また、誤りにお気づきの場合にはご指摘いただけると幸いです。
よろしくお願いいたします。
- 投稿日:2020-11-14T09:36:29+09:00
【Python】1つ上の階層のモジュールをimport
mydir
└ parent.py
└ child.pyといったフォルダ構造にて,child.pyからparent.pyをimportする方法
child.pyimport sys import pathlib # ひとつ上の階層の絶対パスを取得 parent_dir = str(pathlib.Path(__file__).parent.parent.resolve()) # モジュール検索パスに,ひとつ上の階層の絶対パスを追加 sys.path.append(parent_dir) import parent
- 投稿日:2020-11-14T09:31:23+09:00
Pandasを使ってBootstrap sampling
PandasでBootstrap samplingするためのちょっとしたスクリプト
Bootstrap samplingは、データをサンプルの中から重複を許してランダムに取得して、元とはちょっと違った集団を作り出すのに使われる。 例えばそれを1000回とか繰り返したりして統計をとったりする。
Pandasでやるのにどうしたらいいか考えたのでメモっておく。アヤメのサンプルを使ってみる
pandasとアヤメのサンプル取得、あとはランダムサンプリングに使う乱数モジュールをインポートする。
import pandas as pd import random from sklearn.datasets import load_irisそしてデータをロードしてpandasのデータフレームにのせる。
iris_dataset = load_iris() df = pd.DataFrame(data=iris_dataset.data, columns=iris_dataset.feature_names)
df.describe()でデータを見てみる。sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) count 150.000000 150.000000 150.000000 150.000000 mean 5.843333 3.057333 3.758000 1.199333 std 0.828066 0.435866 1.765298 0.762238 min 4.300000 2.000000 1.000000 0.100000 25% 5.100000 2.800000 1.600000 0.300000 50% 5.800000 3.000000 4.350000 1.300000 75% 6.400000 3.300000 5.100000 1.800000 max 7.900000 4.400000 6.900000 2.500000そしてデータをランダムサンプリングする関数を定義する。
まず元のデータフレームのcolumnsを使って空のデータフレームをpd.DataFrame(columns=a_data_frame.columns)で作成し、そこに乱数selected_num = random.choice(range(a_data_frame.shape[0]))で選ばれた行のフレームa_data_frame[selected_num : selected_num + 1]をappendで追加していく。
pandasのdata frameでは単行を選択(たとえばnumpyなら[0])するのにも範囲選択([0:1])する必要があるみたいなので注意。def btstrap(a_data_frame): btstr_data = pd.DataFrame(columns=a_data_frame.columns) for a_data in range(a_data_frame.shape[0]): selected_num = random.choice(range(a_data_frame.shape[0])) btstr_data = btstr_data.append(a_data_frame[selected_num : selected_num + 1]) return btstr_data
btstr_data = btstrap(df)とかやってランダムサンプリング後のデータをbtstr_data.describe()で確認。sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) count 150.000000 150.000000 150.000000 150.000000 mean 5.750000 3.040667 3.660667 1.176000 std 0.728034 0.410287 1.716634 0.766644 min 4.300000 2.000000 1.100000 0.100000 25% 5.100000 2.800000 1.500000 0.200000 50% 5.700000 3.000000 4.250000 1.300000 75% 6.300000 3.300000 5.000000 1.800000 max 7.700000 4.400000 6.700000 2.500000これを1000回とかループで回してフィッティングなり変数選択なりした結果を取得する。
- 投稿日:2020-11-14T09:11:22+09:00
【機械学習超入門】Pytorchのチュートリアルを学ぶ
全体像もまだ把握しきれていない著者が、メモ代わりに記載したものをまとめたものです。
Pytorchのチュートリアルの内容+αで調べた内容をまとめます。
(・・・と、書きましたがほとんどチュートリアルに準拠してません。)自在に使えることを目標にして、わかるものを確定させてから、
コツコツと実装していく方針で勉強します。今回は第2章です。
前 -> https://qiita.com/akaiteto/items/9ac0a84377600ed337a6はじめに
前回、ニュートラルネットワークの各層の処理を見るだけに終わったので、
今回は最適化を中心に勉強します。前提として、MNISTのサンプルソースをただ動かすだけなのは少しわかりにくいと感じたので、
できるだけシンプルな例を位置から組んで実際に動かしてから、
そこから自力で各種手法を自力で実装する事を目標に勉強します。
ついでに自作の最適化手法をニュートラルネットワークに組み込んでみます。
なお、実装するものはただの最急降下法です。
ニュートラルネットワークに自作の最適化手法を実装するときの参考になるかもしれません。ネットワークの学習
前回の勘違い
前回、損失関数の説明で以下のような計算結果を提示しました。
やったこととしては至ってシンプルです。
まず適用な入力データを定義したネットワークに入力し、
出力値(特徴の情報が入ったデータ)を取得しました。その後、その他いろんな入力データに対しても同様に行い、
最初に計算した出力地との「誤差」を計算し、それを「評価」として出力しました。# 実行結果 *****学習フェーズ***** ネットワーク学習用の入力データ tensor([[[[0., 1., 0., 1.], [0., 0., 0., 0.], [0., 1., 0., 1.], [0., 0., 0., 0.]]]]) *****評価フェーズ***** 同じデータを入力 input: tensor([[[[0., 1., 0., 1.], [0., 0., 0., 0.], [0., 1., 0., 1.], [0., 0., 0., 0.]]]]) 評価 tensor(0., grad_fn=<MseLossBackward>) ちょっと違うデータを入力 input: tensor([[[[0., 2., 0., 2.], [0., 0., 0., 0.], [0., 2., 0., 2.], [0., 0., 0., 0.]]]]) 評価 tensor(0.4581, grad_fn=<MseLossBackward>) ぜんぜん違うデータを入力 input: tensor([[[[ 10., 122., 10., 122.], [1000., 200., 1000., 200.], [ 10., 122., 10., 122.], [1000., 200., 1000., 200.]]]]) 評価 tensor(58437.6680, grad_fn=<MseLossBackward>)「きっとこの評価値を閾値で判定して同じものかどうか判断するんだろうなー」
と、当時の私は思いました。
0.5以上離れてたら違うデータとしてみなすのかな?くらいの認識です。出力された値とは、いわば各データの特徴を抽出した数値。
だから、CNNというのはその特徴がどれくらい近いか見るための物なんだ!と。・・・が、これはいろいろやることが足りていません。
今のままではただフィルターをかけただけです。学習というものを私は正しく理解していませんでした。正解データA tensor([[[[0., 2., 0., 2.], [0., 0., 0., 0.], [0., 2., 0., 2.], [0., 0., 0., 0.]]]]) 入力データB tensor([[[[0., 1., 0., 1.], [0., 0., 0., 0.], [0., 1., 0., 1.], [0., 0., 0., 0.]]]]) 評価 tensor(0.4581, grad_fn=<MseLossBackward>)学習フェーズにおける神髄、それは、
「微妙に違うけど実は同じものを指している入力データA、Bを、
同じものとして認識できるようにしようぜ!!」ということです。評価 tensor(0.4581, grad_fn=<MseLossBackward>)誤差として出力されたこの数値。
この数値は入力データAとBがどれくらいズレているか表すもの。数値上では誤差が発生していますが、実はAとBは同じものなので、
誤差は理想的には「0」でなければならないのです。すなわち、学習の本質とは
入力データAとBの大きい誤差、「0.4581」と出力されたものを
限りなく「0」で出力されるように「小手先を加える」こと、これこそが本質。誤差を0として出力するようにネットワークの各層の「重み」を調整することで、
「誤差はないよーAとBは同じだよー」と”学習”させる事が本質なのです。最適化してみる
最適化(思考停止)
重みの調整はどんな計算式で調整しているのかな?
・・・というのは一旦おいておいて、まずは思考停止でpytorchで学習させてみます。わけもわからずいきなりMNISTの例でいろんなかっこいい層を使うのは嫌なので、
理解している範囲でよりシンプルな例でテストしてみます。パターンA tensor([[[[0., 1., 0., 1.], [0., 1., 0., 1.], [0., 1., 0., 1.], [0., 1., 0., 1.]]]]) パターンB tensor([[[[1., 1., 1., 1.], [0., 1., 0., 1.], [0., 1., 0., 1.], [1., 1., 1., 1.]]]])上記の2つのパターンを学習・テストさせてみましょう。
全体
test.pyimport torch.nn as nn import torch.nn.functional as F import torch from torch import optim import matplotlib.pyplot as plt import numpy as np class DataType(): TypeA = "TypeA" TypeA_idx = 0 TypeB = "TypeB" TypeB_idx = 1 TypeOther_idx = 1 def outputData_TypeA(i): npData = np.array([[0,i,0,i], [0,i,0,i], [0,i,0,i], [0,i,0,i]]) tor_data = torch.from_numpy(np.array(npData).reshape(1, 1, 4, 4).astype(np.float32)).clone() return tor_data def outputData_TypeB(i): npData = np.array([[i,i,i,i], [0,i,0,i], [0,i,0,i], [i,i,i,i]]) tor_data = torch.from_numpy(np.array(npData).reshape(1, 1, 4, 4).astype(np.float32)).clone() return tor_data class Test_Conv(nn.Module): kernel_filter = None def __init__(self): super(Test_Conv, self).__init__() ksize = 4 self.conv = nn.Conv2d( in_channels=1, out_channels=4, kernel_size=4, bias=False) def forward(self, x): x = self.conv(x) x = x.view(1,4) return x # テスト時データ準備 input_data = [] strData = "data" strLabel = "type" for i in range(20): input_data.append({strData:outputData_TypeA(i),strLabel:DataType.TypeA}) for i in range(20): input_data.append({strData:outputData_TypeB(i),strLabel:DataType.TypeB}) print("以下のパターンのテストデータを計200個準備") print("パターンA") print(outputData_TypeA(1)) print("パターンB") print(outputData_TypeB(1)) print("この2つのパターンが識別できるか確かめます。") print("\n\n") # ネットワーク定義 Test_Conv = Test_Conv() # 入力 import torch.optim as optim criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(Test_Conv.parameters(), lr=0.001, momentum=0.9) print("***学習させる前にやってみる***") ##学習したモデルで適当なデータを入れてみる。 NG_data = outputData_TypeA(999999999) answer_data = [DataType.TypeA_idx] answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone() print("\n\n") outputs = Test_Conv(NG_data) _, predicted = torch.max(outputs.data, 1) correct = (answer_data == predicted).sum().item() print("正答率: {} %".format(correct / len(predicted) * 100.0)) print("***学習フェーズ***") epochs = 2 for i in range(epochs): for dicData in input_data: # 学習用データの準備 train_data = dicData[strData] # 正解用データの準備 answer_data = [] label = dicData[strLabel] if label == DataType.TypeA: answer_data = [DataType.TypeA_idx] elif label == DataType.TypeB: answer_data = [DataType.TypeB_idx] else: answer_data = [DataType.TypeOther_idx] answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone() # 最適化処理 optimizer.zero_grad() outputs = Test_Conv(train_data) loss = criterion(outputs, answer_data) # print(train_data.shape) # print(outputs.shape) # print(answer_data.shape) # # exit() loss.backward() optimizer.step() print("\t", i, " : 誤差 = ",loss.item()) print("\n\n") print("***テストフェーズ***") ##学習したモデルで適当なデータを入れてみる。 input_data = outputData_TypeA(999999999) answer_data = [DataType.TypeA_idx] answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone() outputs = Test_Conv(input_data) _, predicted = torch.max(outputs.data, 1) correct = (answer_data == predicted).sum().item() print("正答率: {} %".format(correct / len(predicted) * 100.0)) exit()以下のパターンのテストデータを計200個準備 パターンA tensor([[[[0., 1., 0., 1.], [0., 1., 0., 1.], [0., 1., 0., 1.], [0., 1., 0., 1.]]]]) パターンB tensor([[[[1., 1., 1., 1.], [0., 1., 0., 1.], [0., 1., 0., 1.], [1., 1., 1., 1.]]]]) この2つのパターンが識別できるか確かめます。 ***学習させる前にやってみる*** 正答率: 0.0 % ***学習フェーズ*** 0 : 誤差 = 1.3862943649291992 0 : 誤差 = 1.893149733543396 0 : 誤差 = 2.4831488132476807 0 : 誤差 = 3.0793371200561523 0 : 誤差 = 3.550563335418701 0 : 誤差 = 3.7199602127075195 0 : 誤差 = 3.3844733238220215 0 : 誤差 = 2.374782085418701 0 : 誤差 = 0.8799697160720825 0 : 誤差 = 0.09877146035432816 0 : 誤差 = 0.006193255074322224 0 : 誤差 = 0.00034528967808000743 0 : 誤差 = 1.8000440832111053e-05 0 : 誤差 = 8.344646857949556e-07 0 : 誤差 = 0.0 0 : 誤差 = 0.0 0 : 誤差 = 0.0 0 : 誤差 = 0.0 0 : 誤差 = 0.0 0 : 誤差 = 0.0 0 : 誤差 = 0.0 0 : 誤差 = 0.0 0 : 誤差 = 0.0 . . . ***テストフェーズ*** 正答率: 100.0 %シンプルなソースですが一つずつ見てみます。
ネットワークの定義
test.pyclass Test_Conv(nn.Module): kernel_filter = None def __init__(self): super(Test_Conv, self).__init__() ksize = 4 self.conv = nn.Conv2d( in_channels=1, out_channels=4, kernel_size=4, bias=False) def forward(self, x): x = self.conv(x) x = x.view(1,4) return xMNISTでは入力データとして一度にすべてのデータを入れていました。
ですがそれだと規模が大きくなりすぎて直観的にわかりづらそうだったので、
1枚1枚モノクロの画像をいれていくように設定しています。畳み込み層$out_channels=4$なので4つの特徴をフィルターで抽出し、
$x.view$では正解のラベルと比較するために次元を整えています。学習させる前に適用してみる
test.pyprint("***学習させる前にやってみる***") ##学習したモデルで適当なデータを入れてみる。 NG_data = outputData_TypeA(999999999) answer_data = [DataType.TypeA_idx] answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone() print("\n\n") outputs = Test_Conv(NG_data) _, predicted = torch.max(outputs.data, 1) correct = (answer_data == predicted).sum().item() print("正答率: {} %".format(correct / len(predicted) * 100.0))学習させる前にやってみます。
コードは違いますが、「前回の勘違い」の再現です。案の定、正解率は0%です。ネットワークの学習
test.py# 学習用データの準備 train_data = dicData[strData] # 正解用データの準備 answer_data = [] label = dicData[strLabel] if label == DataType.TypeA: answer_data = [DataType.TypeA_idx] elif label == DataType.TypeB: answer_data = [DataType.TypeB_idx] else: answer_data = [DataType.TypeOther_idx] answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone() # 最適化処理 optimizer.zero_grad() outputs = Test_Conv(train_data) loss = criterion(outputs, answer_data) loss.backward() optimizer.step() print("\t", i, " : 誤差 = ",loss.item())「前回の勘違い」の項の中で、以下のように書きました
入力データAとBの大きい誤差、「0.4581」と出力されたものを 限りなく「0」で出力されるように「小手先を加える」こと、これこそが本質。ネットワークの学習ではこの処理を行っています。
処理のはじめには、まず$train_data$にパターンA・パターンBのいずれかのデータを一つだけ入れます。test.pyoutputs = Test_Conv(train_data)ネットワーク内部では4つのフィルターをかけることで4つの特徴を計算し、
「1つ」のデータあたり4つの特徴を内包したデータを出力します。
次元で言えば[1,4]のデータです。続けて、正解データについても準備します。
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()出力された「1つのデータ」に対する正解を設定します。
文字列は設定できないので、パターンAのデータであれば「0」、
パターンBのBであれば「1」と設定します。
1つのデータに対する正解データなので、正解データの次元は[1]のデータです。次元のイメージ図 # 今回の例 [出力データの構造] - データ - 1つ目の特徴 - 2つ目の特徴 - 3つ目の特徴 - 4つ目の特徴 [正解データの構造] - データに対する回答(1?0?)test.pyloss = criterion(outputs, answer_data)そして誤差を計算します。
各正解ラベルごとに重みを調整するので、正解ラベルも一緒に入れます。optimizer.step()そして最適化、というこれまでにはまだ出てきていない新たな処理を実行します。
forループの中でタイプA、タイプBごとの出力データをポンポン入れていき、
各タイプ内での誤差が0に近づくように、重みを調整しているのだと思います。
(今は思考停止フェーズなので、どんな調整を行っているかは後々勉強します!)最適化とは何か。
wikipediaまんまですが、プログラムの最適な状態をさがすことを最適化といいます。
ここでは、誤差が最小になるのはどこなのかを計算することで、最適化を行います。実行結果
実行結果を見てみます。
***テストフェーズ*** 正答率: 100.0 %はい、100%になっていますね。
学習前は0%だったものが、無事学習できました。最適化(自分で実装)
処理の肝は$optimizer.step()$で行われる最適化処理です。
pytorchで使える最適化の手法はたくさんあり、今回はSGD(確率的勾配降下法)というものを選びました。ここまでおこなった最適化処理を振り返ると、
pytorchですでに実装された関数を使っているだけで、私はなにもやっていません。論文で何かの最適化手法を実装したいと思ったとき、
具体的にはどうすればよいのでしょうか?・・・ということで、
「最急降下法(GD)」というシンプルな最適化手法を例にまずは実装します。
先に言いますと、最急降下法は実用的ではないです。
今回使用したSGDから時代が逆行しています。ただ、勉強には向いている気がするので、
最急降下法を実装してみます。最適化のイメージ
最適化ってなにやるの?というのを直観的なイメージをかためるために、簡単に式で表してみます。
(これを作った時点で私は論文も何も読んでません。
イメージなので厳密な意味で間違えてます。軽く参考にする程度で・・・)y = f(x)ネットワークに入力データを入れたら特徴の値が数値で帰ってきました。
言い換えるなら、入力データ$x$を入れたら出力として$y$が返ってきた状態です。
これを$y=f(x)$とします。gosa = |f(A)-f(B)|そしてこの式に対して、入力データ$A$と$B$を与えたとき、
差が最小値になるように調整したいわけです。
AとBは実は同じデータなので、同じ出力結果を得たいわけです。gosa(weight) = |g(A)-g(B)|\\ g(x) = weight * f(x)ここでパラメータ$weight$を導入します。
ネットワークの関数である$f(x)$に重みを与えてやります。
この式の導入により、誤差を最小にしたいという問題は、
誤差を最小にできるパラメータ$weight$を発見することに置き換わります。$gosa(weight)$が最小となる$weight$を見つけさえすれば良いわけです。
簡単なグラフで最適化
簡単な式で最適化してみます。
最小化問題と言うと、中学生のころに$y=x^2$の問題をやりました。
当時は、手動の計算を前提として、非常に限定的な計算式で最小値を求めていましたね。ここでは、$y=x^2$を$gosa(weight)$であると仮定して、
最急降下法という最適化手法で解いてみます。y = x^2\\ \frac{d}{dy} = 2x$y=x^2$の微分$\frac{d}{dy}$は上記のようになります。
$y=x^2$と言うグラフは、$\frac{d}{dy}$という最小の単位で徐々に変化していくグラフとなります。最急降下法とは、微小変化分だけ徐々に徐々に移動させて、
微小変化分が完全に0になった地点が最小値であるとみなす手法です。
(中学の頃、傾きが0になる地点は最小・最大になるみたいな問題がありましたね。)ということで、pytorchの自動微分機能を使ってやってみます。
画像の通り、徐々に最小値に向かっていることがわかります。
このようにして、最小値に対する最適化が行われます。以下、ソース。
test.pyif __name__ == '__main__': import matplotlib.pyplot as plt from matplotlib.animation import FuncAnimation import numpy as np import torch import torchvision import torchvision.transforms as transforms def func(x): return x[0] ** 2 fig, ax = plt.subplots() artists = [] im, = ax.plot([], []) # グラフの範囲 ax.set_xlim(-1.0, 1.0) ax.set_ylim(0.0, 1.0) # f = x*xの定義用 F_main = np.arange(-1.0, 1.0, 0.01) n_epoch = 800 # 学習回数 eta = 0.01 # ステップ幅 x_arr = [] f_arr = [] x_tor = torch.tensor([1.0], requires_grad=True) for epoch in range(n_epoch): # 最適化する関数の定義 f = func(x_tor) # x_tor地点での勾配を計算 f.backward() with torch.no_grad(): # 1.勾配法 # x_torから微小変化分を少しずつ引いて行って、 # 最小値に少しずつ近づけていく x_tor = x_tor - eta * x_tor.grad # 2.ここはアニメーション用の処理 f = x_tor[0] ** 2 x_arr.append(float(x_tor[0])) f_arr.append(float(f)) x_tor.requires_grad = True def update_anim(frame): # gif保存するための処理 # FuncAnimation実行後、自動で繰り返し実行される。(frame = フレーム数) ims = [] if frame == 0: y = f_arr[frame] x = x_arr[frame] else: y = [f_arr[frame-1],f_arr[frame]] x = [x_arr[frame-1],x_arr[frame]] ims.append(ax.plot(F_main ,F_main*F_main,color="b",alpha=0.2,lw=0.5)) ims.append(ax.plot(x ,y,lw=10,color="r")) # im.set_data(x, y) return ims anim = FuncAnimation(fig, update_anim, blit=False,interval=50) anim.save('GD_パターン1.gif', writer="pillow") exit()最適化の実装(最急降下法)
実装してみます。
なお、この項の目的は最急降下法を実装することそのものではなく、
「こうやって自作の最適化関数実装するんだー」というのを確認するための検証です。また長々と書くのは何なので、要点だけ書きます。
test.pyoptimizer = optim.SGD(Test_Conv.parameters(), lr=0.001, momentum=0.9)pytorchでは、optimから様々な最適化手法を選択します。
各手法の実装は、$torch.optim.Optimizer$というクラスを継承することで作成されます。
裏を返せば、$torch.optim.Optimizer$の継承クラスを自作すれば簡単に自作できます。
ということで、先ほどと同様に$y=x^2$に対して最適化します。この例ではニュートラルネットワークは使っていませんが、
私が定義した$SimpleGD$を同じように定義すれば、ニュートラルネットワークでも変わらず使えます。↓↓↓全体のソース↓↓↓
test.pyimport matplotlib.pyplot as plt from matplotlib.animation import FuncAnimation import numpy as np import torch import torchvision import torchvision.transforms as transforms class SimpleGD(torch.optim.Optimizer): def __init__(self, params, lr): defaults = dict(lr=lr) super(SimpleGD, self).__init__(params, defaults) @torch.no_grad() def step(self, closure=None): loss = None if closure is not None: with torch.enable_grad(): loss = closure() for group in self.param_groups: for p in group['params']: if p.grad is None: continue d_p = p.grad # tensorの足し算 # p = p - d/dp(微小変化) * lr # (lrは微小変化だけだと変化の幅が小さすぎるので掛け合わせている) p.add_(d_p*-group['lr']) return loss def func(x): return x[0] ** 2 fig, ax = plt.subplots() artists = [] im, = ax.plot([], []) # グラフの範囲 ax.set_xlim(-1.0, 1.0) ax.set_ylim(0.0, 1.0) # f = x*xの定義用 F_main = np.arange(-1.0, 1.0, 0.01) n_epoch = 50 # 学習回数 eta = 0.01 # ステップ幅 x_tor = torch.tensor([1.0], requires_grad=True) param=[x_tor] optimizer = SimpleGD(param, lr=0.1) for epoch in range(n_epoch): optimizer.zero_grad() # 最適化する関数の定義 f = func(x_tor) # x_tor地点での勾配を計算 f.backward() optimizer.step() x_tor.requires_grad = True # 徐々にy=x*xの最小値=0.0に向かっていく # print(x_tor) exit()このうち、特に重要なのは、
自作の最適化関数を宣言した「class SimpleGD」の部分です。test.pyclass SimpleGD(torch.optim.Optimizer): def __init__(self, params, lr): defaults = dict(lr=lr) super(SimpleGD, self).__init__(params, defaults) @torch.no_grad() def step(self, closure=None): loss = None if closure is not None: with torch.enable_grad(): loss = closure() for group in self.param_groups: for p in group['params']: if p.grad is None: continue d_p = p.grad # tensorの足し算 # p = p - d/dp(微小変化) * lr # (lrは微小変化だけだと変化の幅が小さすぎるので掛け合わせている) p.add_(d_p*-group['lr']) return loss詳しく見てみます。
まずinit部分について。test.pydef __init__(self, params, lr): defaults = dict(lr=lr) super(SimpleGD, self).__init__(params, defaults)lrというのは、微小変化分を差し引いていくときに、
微小変化だけだと変化の幅が小さすぎる・大きすぎるので、
微小変化にかけあわせてやるパラメータを指定しています。SimpleGDではlrが必要だったのでここに宣言しました。
他にも必要な場合はinitの引数に追加して、dictの中にもしっかり宣言を追加して下さい。test.py@torch.no_grad() def step(self, closure=None):torch.optim.Optimizerクラス継承時に、宣言しなければならない関数です。
学習中にこの関数を呼び出すことで、最適化が行われます。self.param_groupsは、SimpleGDのインスタンスを作成したときに渡したparamsです。
backward()で勾配(微小変化)が計算済みであれば、ここから勾配も取得できます。test.pyd_p = p.grad # tensorの足し算 # p = p - d/dp(微小変化) * lr # (lrは微小変化だけだと変化の幅が小さすぎるので掛け合わせている) p.add_(d_p*-group['lr'])p.grad、すなわち微小変化分を取得し、
その微小変化分をp=テンソルに反映させています。
この操作により、徐々に徐々にパラメーターが最小値へと向かっていきます。・・・・なお、最急降下法は微小分を引いてるだけなので、局所解に簡単に陥ります。
局所解。$y=x^2$のような凸がたくさんあるグラフを想像してください。
最急降下法は傾きが0になる場所を最小値とみなすので、
この凸の先っちょのどれかに到達すると必ず極値とみなしてしまいます。このことから、この手法はどんなデータに対しても頑強ではないといえます。
おわりに
1章2章でなんとなくのネットワークの概要がすこしだけわかりました。
次回以降の予定としては、
一番勉強したかった点群系の機械学習の勉強、
特にPointNetについて勉強します。それ以降は、RNN、オートエンコーダ、GAN 、DQNをざっくり勉強します。
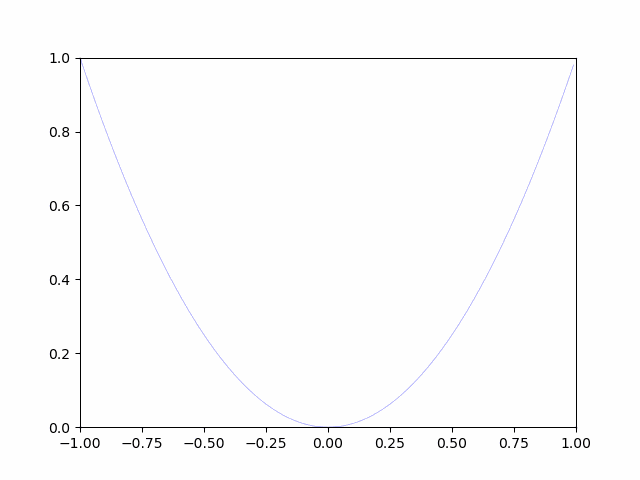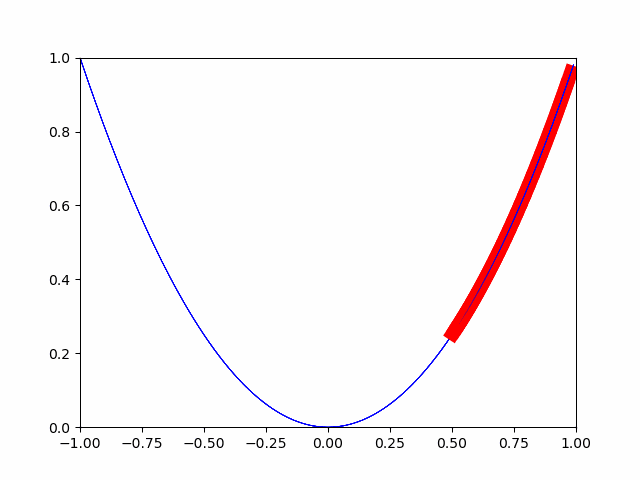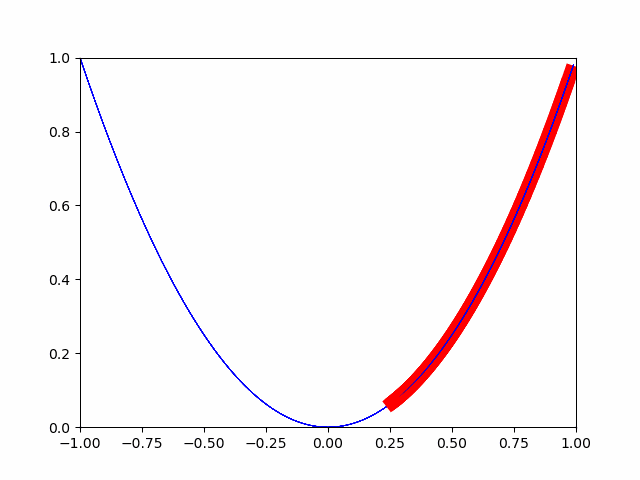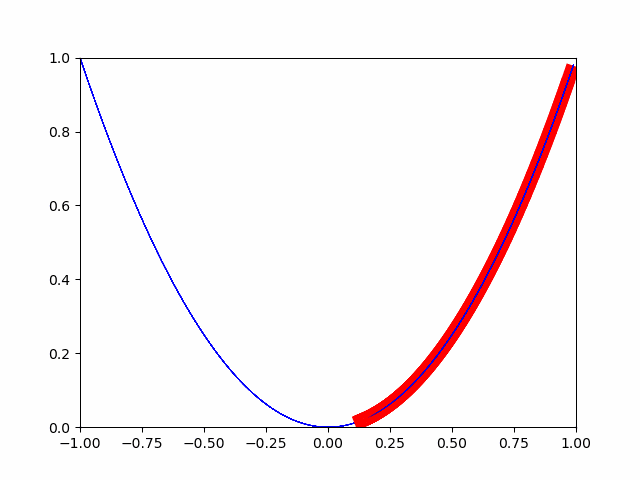
- 投稿日:2020-11-14T08:33:43+09:00
「伸び悩んでいる3年目Webエンジニアのための、Python Webアプリケーション自作入門」を更新しました
本を更新しました
チャプター「リクエストを並列処理する」 を更新しました。
続きを読みたい方は、ぜひBookの「いいね」か「筆者フォロー」をお願いします ;-)
以下、書籍の内容の抜粋です。
現状の問題点
pythonはソースコードを上から順に読み込み、ある1行の処理が完了すれば次の1行、というふうに順番に実行していきます。
そのため、現状のソースコードだと、
- クライアントからの接続を受け付ける(
.accept())- クライアントからのリクエストを処理する(
.handle_client())- (必要であれば例外処理をしたあと)クライアントとの通信を終了する(
.close())- クライアントからの接続を受け付ける(
.accept())- ...
必ずこの順序を守って実行されます。
言い換えると、
「1つのリクエストの処理が全て完了するまで、次のリクエストの受付が始まらない」
ということになります。
これはリクエストの数が増えてくると大きな問題になります。
例えば10件のリクエストが同時にきたとします。
このとき、サーバーは早いもの勝ちで最初に来たリクエストの処理を開始します。
そしてこの最初のリクエストの処理がとても時間がかかる処理の場合、処理が完了するまで後続の9件のリクエストは待たされることになってしまいます。よくあるのは、複雑な検索条件のクエリをDBサーバーに投げて応答を30秒間ずっと待ってるなどのケースです。
DBからの応答を待つ30秒の間、マシンが他の9件のリクエストを処理してくれたら全体的なパフォーマンスはぐっと向上します。このように、とあるプログラムが待ち状態に入った時、その間に裏で別のプログラムを実行させることを 並列処理または並行処理と呼びます。
この並列処理は一般的なWebサーバーであれば当たり前に実装されていますので、私達も実装していくことにしましょう。
コラム: 「並列処理」と「並行処理」
「並列処理」と「並行処理」の違いについて説明しておきましょう。
世間一般では、複数のモノゴトを同時に処理することを「並列処理」と呼びます。
コンピュータの世界においては、実際に何か処理をするのは全てCPUが担うのですが、1つのCPUは常に1つの仕事しか同時にはこなせません。
ですので、厳密な意味では1つのCPUでは「並列処理」は実現できません。しかし、人間の感覚からするとCPUの処理はあまりに高速なので、
「こっちの仕事をして"待ち"になったら別の仕事に切り替えて、また"待ち"になったら更にべつの仕事をする」
と次々と取り組む処理を切り替えることで、人間の目にはまるで同時にタスクをこなしているように見せることができます。
(OSにもよりますが、CPUは大体0.2秒以下で次々と仕事を切り替えています)その昔は1つのコンピュータには1つのCPUというのが当たり前でしたので、コンピュータの世界ではこの「疑似並列処理」のこと単に「並列処理」と読んでも特に問題がありませんでした。
ところが、2000年ごろデュアルコアのCPUが発売/普及すると共に1つのコンピュータに2つ、4つのCPU(正確にはCPUコア)が搭載されるようになり、これらのCPUを同時に動かすことで「疑似並列処理」ではない「本当の並列処理」が可能になってしまいました。そこで、プログラマたちは「これまで単に並列処理と読んでいた疑似並列処理」と「本当の並列処理」を区別するために、「疑似並列処理」のことを「並行処理」と呼ぶようになりました。
「並行処理」と「並列処理」を人間が表面上で見分けることは極めて困難ですし、マシンのパフォーマンスチューニングが必要になるまでプログラミング上もこの2つを区別して扱う必要はほとんど必要ありません。
そのため、本書ではこれらを特に区別せず統一して「並列処理」と呼ぶことにします。どのような場合に並行処理と並列処理が使い分けられるのか、パフォーマンスにどのように影響するのかは非常に込み入った話になるため。本書では割愛します。
このトピックに関してはインターネット上でも非常にたくさんの情報が提供されていますので、興味がある方は調べてみてください。ソースコード
並列処理を行うように改良したソースコードがこちらです。
ファイルが2つになっていますので、ご注意ください。
study/WebServer.py
https://github.com/bigen1925/introduction-to-web-application-with-python/blob/main/codes/chapter13/WebServer2.py
study/WorkerThread.py
https://github.com/bigen1925/introduction-to-web-application-with-python/blob/main/codes/chapter13/WebServer2.py解説
共通ファイルを分けたので、処理の記録を示すログにそれぞれ
Server:,Worker:という文字を出力ようにしています。
例)print("=== Server: サーバーを起動します ===")print("=== Worker: クライアントとの通信を終了します ===")
WebServer.py28-31行目
# クライアントを処理するスレッドを作成 thread = WorkerThread(client_socket) # スレッドを実行 thread.start()コネクションを確立したクライアントを処理するスレッドを作成し、スレッドの処理を開始させます。
前回まで.handle_client()というメソッドで行っていた処理と、前後の例外処理は全てこのスレッド内の処理にお引越ししました。スレッドとはコンピュータが並列に処理を行うことが可能な処理系列のことで、後ほど詳細を説明します。
WorkerThread.py9行目-57行目
class WorkerThread(Thread): # 実行ファイルのあるディレクトリ BASE_DIR = os.path.dirname(os.path.abspath(__file__)) # 静的配信するファイルを置くディレクトリ DOCUMENT_ROOT = os.path.join(BASE_DIR, "static") def __init__(self, client_socket: socket): super().__init__() self.client_socket = client_socket def run(self) -> None: """ クライアントと接続済みのsocketを引数として受け取り、 リクエストを処理してレスポンスを送信する """ # クライアントへ対応する処理...
Threadはpythonの組み込みライブラリであるthreadingモジュールに含まれるクラスで、スレッドを簡単に作成するためのベースクラスです。
Threadを利用する際は、Threadを継承したクラスを作成し、.run()メソッドをオーバーライドします。
このクラスのインスタンスは.start()メソッドを呼び出すことで新しいスレッドを作成し、.run()メソッドにかかれた処理を開始します。
CPUは1つのスレッド内で実行されるプログラムは並列処理できませんが、複数のスレッドに分かれて実行されるプログラムは並列処理することが可能です。
これまでは、1つのスレッド内で
WebServerクラスが全てのクライアントの対応を逐次に処理していました。
しかし今回からは、スレッドを利用することで
WebServerクラスはクライアントとのコネクション確立までは行うものの、リクエスト内容への対応は別スレッドで並列処理するようになりました。
これにより、とあるリクエストの処理が長引いてるせいで他のリクエストが受け付けられない、という状況が回避されます。
コラム: スレッドを扱う際の注意点
基本的に別々のスレッドの処理は別々のプログラムとして動くことになるので、あるスレッドで例外が発生しても別スレッドには伝搬しないということです。
例えば、以前までは同一スレッド内でリクエストを処理していたため、リクエストの処理中に例外が発生した場合、例外のハンドリングを行わなければメインの処理(リクエストの受付処理)まで終了していました。
今回からは別々のスレッド内でリクエストを処理しているため、とあるスレッドでリクエストの処理中に例外が発生しても、例外ハンドリングがない場合はそのスレッドが終了するだけでメインスレッドには影響がありません。一見ありがたいようにも見えますが、サーバー全体に影響のある異常事態が発生した場合にも処理が続行してしまうようではいけません。
スレッドを使う際は、例外処理に敏感になっておきましょう。
また、スレッドをどんどん分岐させれば、処理はどこまでも早くなるというわけでもありません。
CPUが同時に処理できる量には限界があります。
並列実行している処理の多くがCPUを大量に利用するような状況では、CPUの処理量が限界に達して並列実行が滞り、パフォーマンスが上がらないor却って下がるケースがあります。
このようにCPUの性能がネックになって処理速度の限界を迎えるような処理を、CPUバウンドな処理と言います。CPUバウンドな処理が多いWebサービスでは、むやみにスレッドを増やしすぎるとCPUの処理量が限界を迎えて他のプログラムの実行速度に影響を与えてしまうこともあります。
Webサーバーの多くがスレッド数やプロセス数に上限を設定できるのは、これを防ぐためです。自分のプログラムが、最悪のケースでどれぐらいのスレッド分岐が行われるのかには十分気をつけましょう。
本書でも、本来は分岐できるスレッド数に上限を設けるべきで、pythonにはそのための
ThreadPoolExecutorというクラスが用意されています。
興味がある方は調べてみてください。動かしてみる
では、実際に動かしてみましょう。
続きはBookで!