- 投稿日:2020-11-14T22:03:58+09:00
ELBを含めてVPC + EC2でアプリを構築する。
はじめに
本稿は『VPC + EC2 + Docker でアプリケーションをデプロイする。』の補足として書いています。
何か詰まるところがあれば、上記の記事をみていただけるといいかと思います。対象読者
- ELB(ALB)の構築方法を知りたい方
- 安定したサービスをデプロイしたい方
- 自分
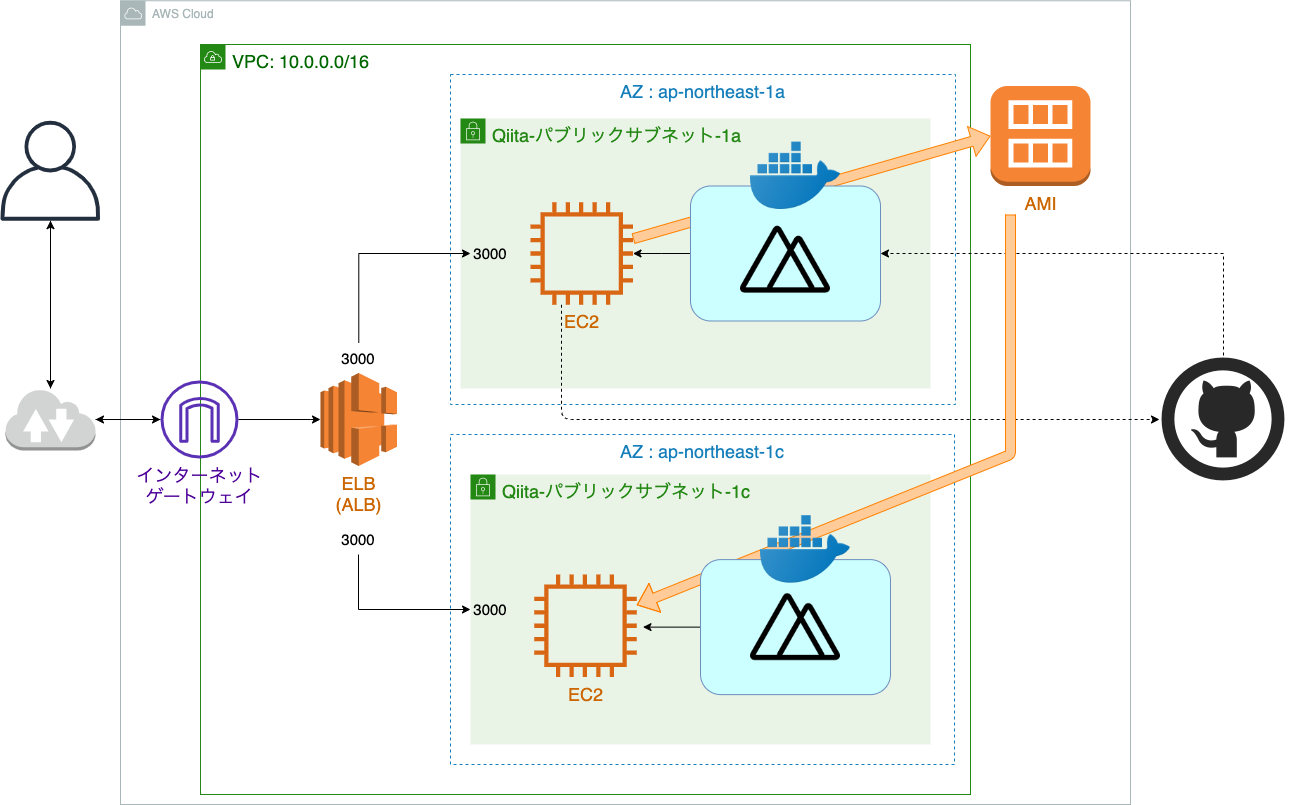
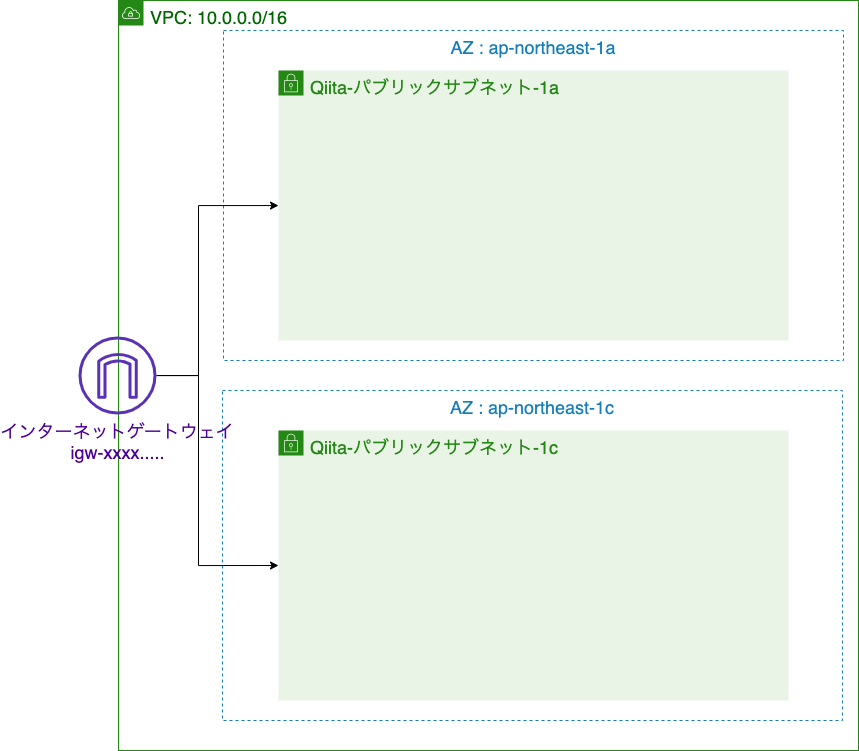
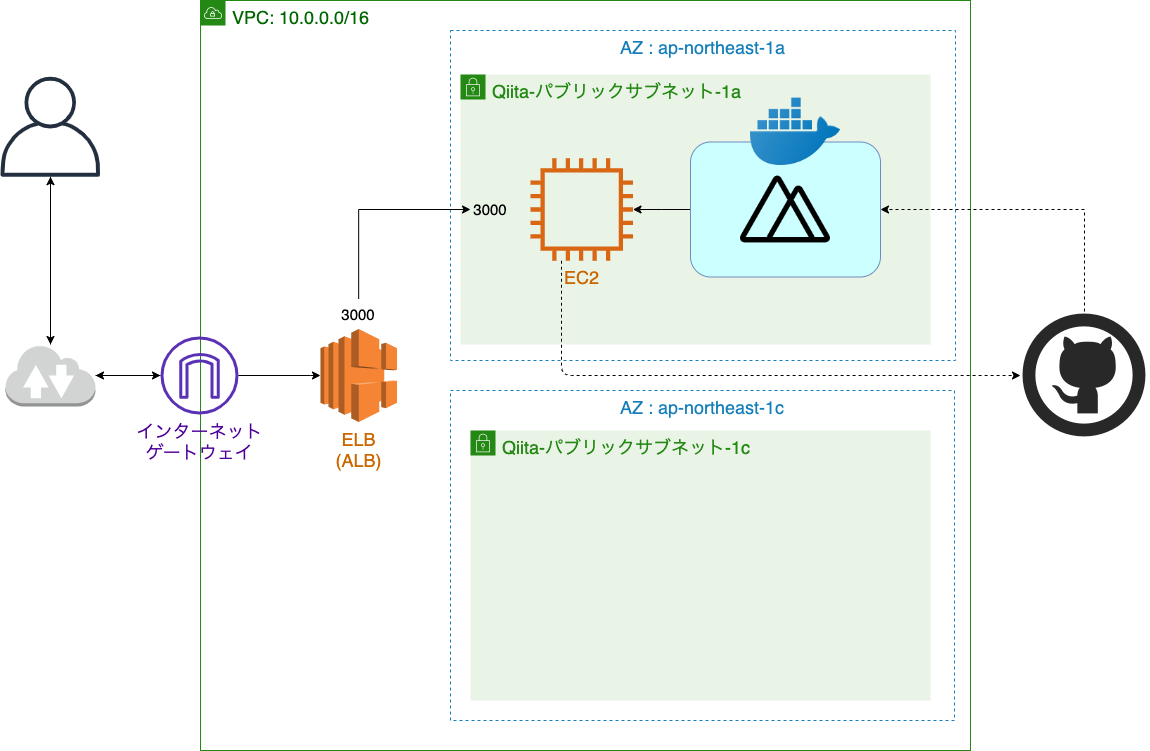
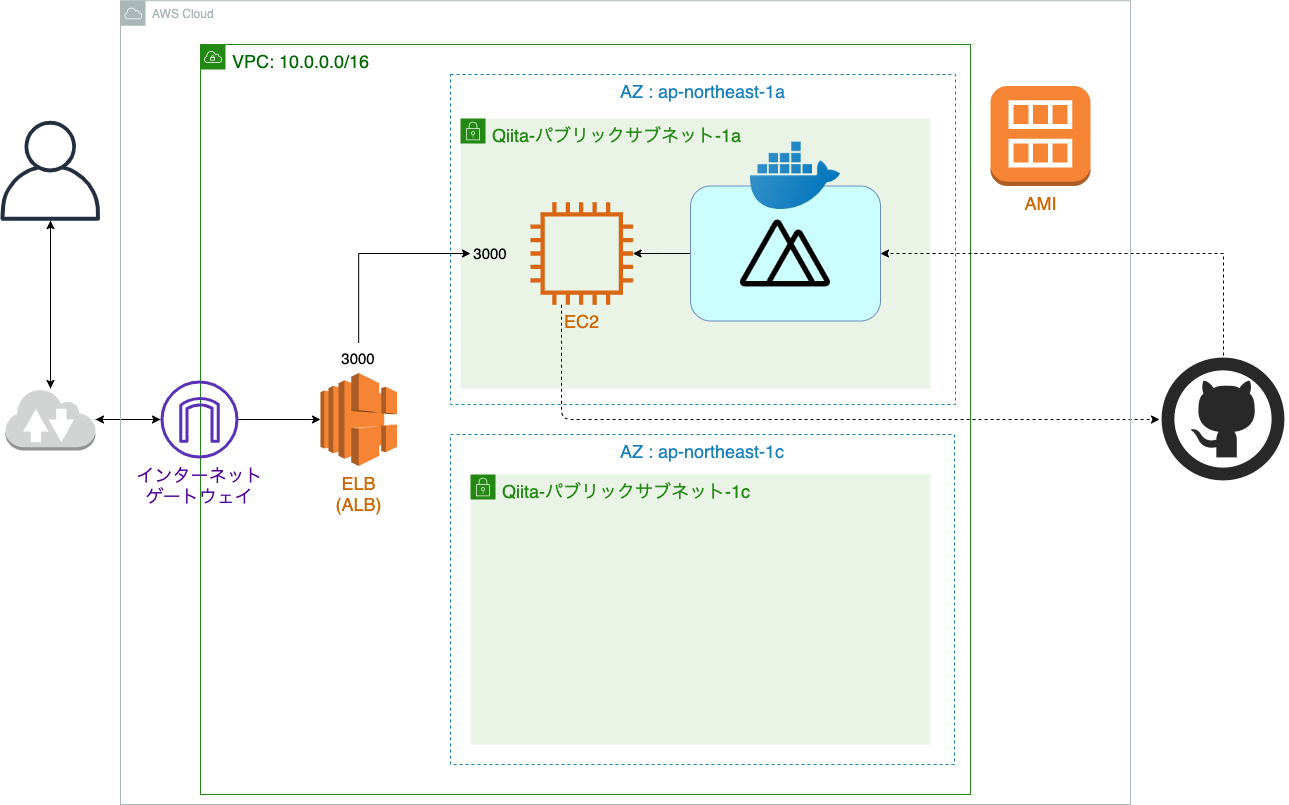
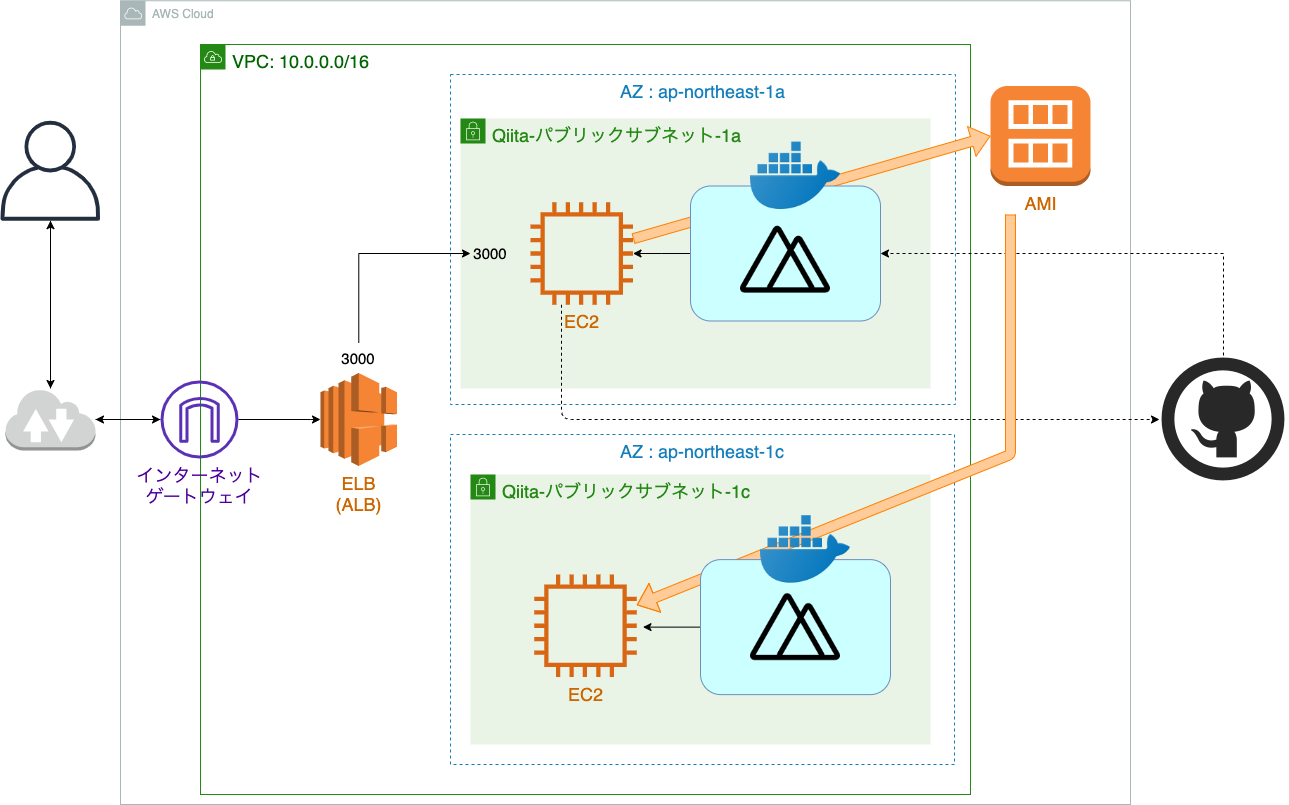
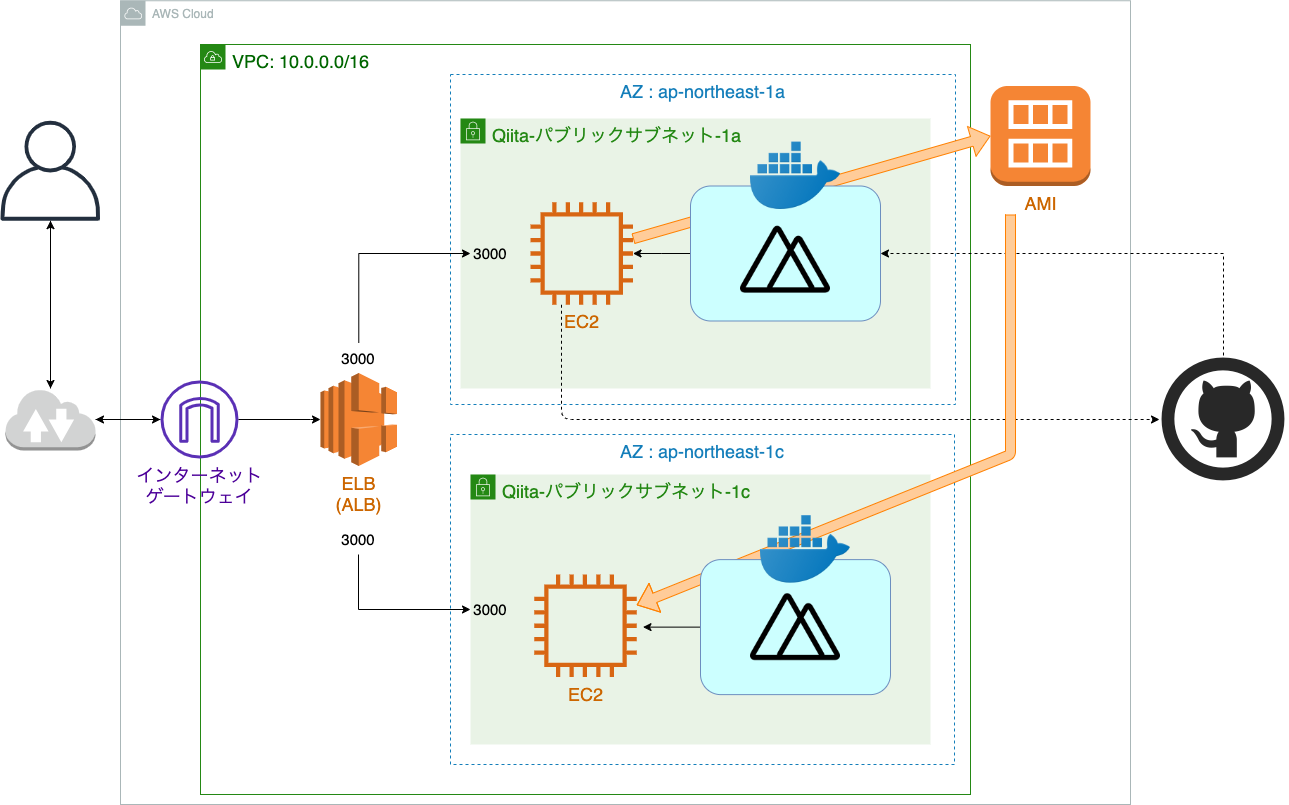
全体構造
ELB
ELBとは
ELBとは、Elastic Load Balancingの略称でアプリケーションのトラフィックを自動的に複数のターゲットに分散してくれる機能です。
また、トラフィックを複数のAZに分散することもできるので、瞬間的な同時アクセスや何かしらの障害によってAZがダウンしたとしても、他のAZさえ生き残っていればサービスを継続させることができます。すごいです。
今回は、ELBの3つのロードバランサーの1つである、ALBを使用します。
違いは、この記事がさっくりしていてわかりやすかったです。ELBを含めた設計の流れ
VPCの構築
まずは、前回と同様にどおりVPCとサブネットを構築していきます。
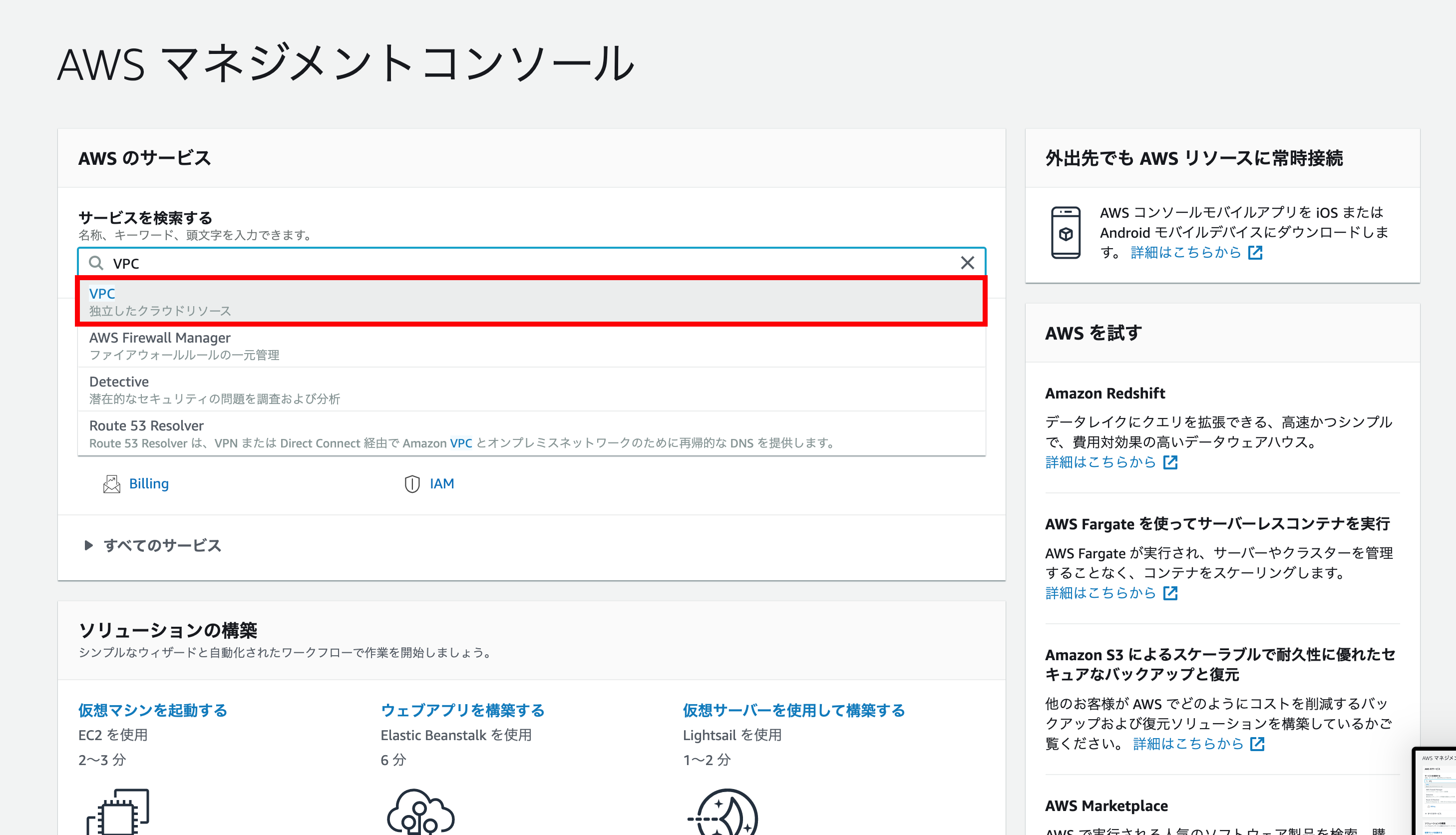
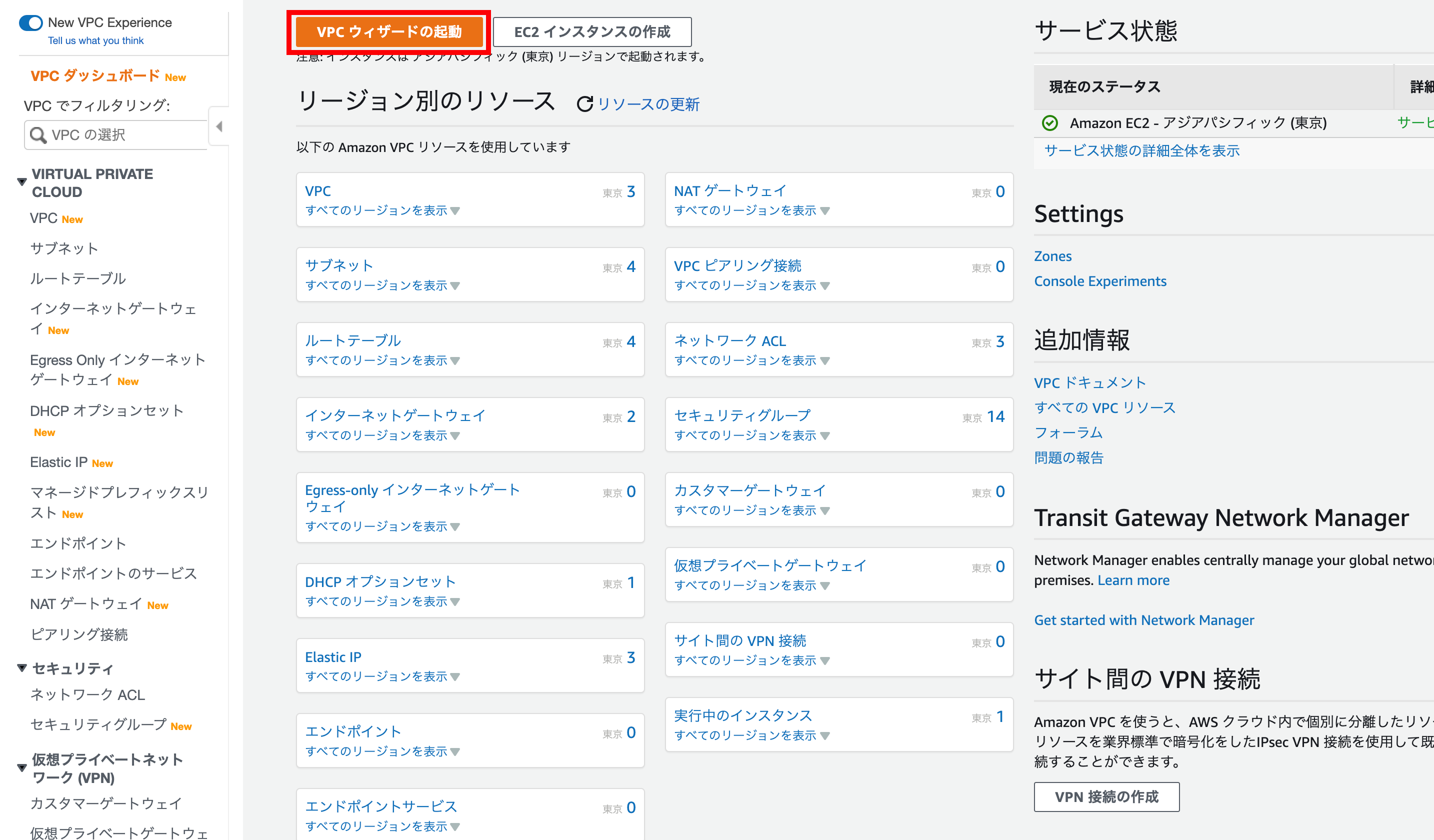
まずはAWSのトップ画面の『サービスを検索する』から『VPC』を選択。
『VPCウィザードの起動』を押下。
『選択』を押下。
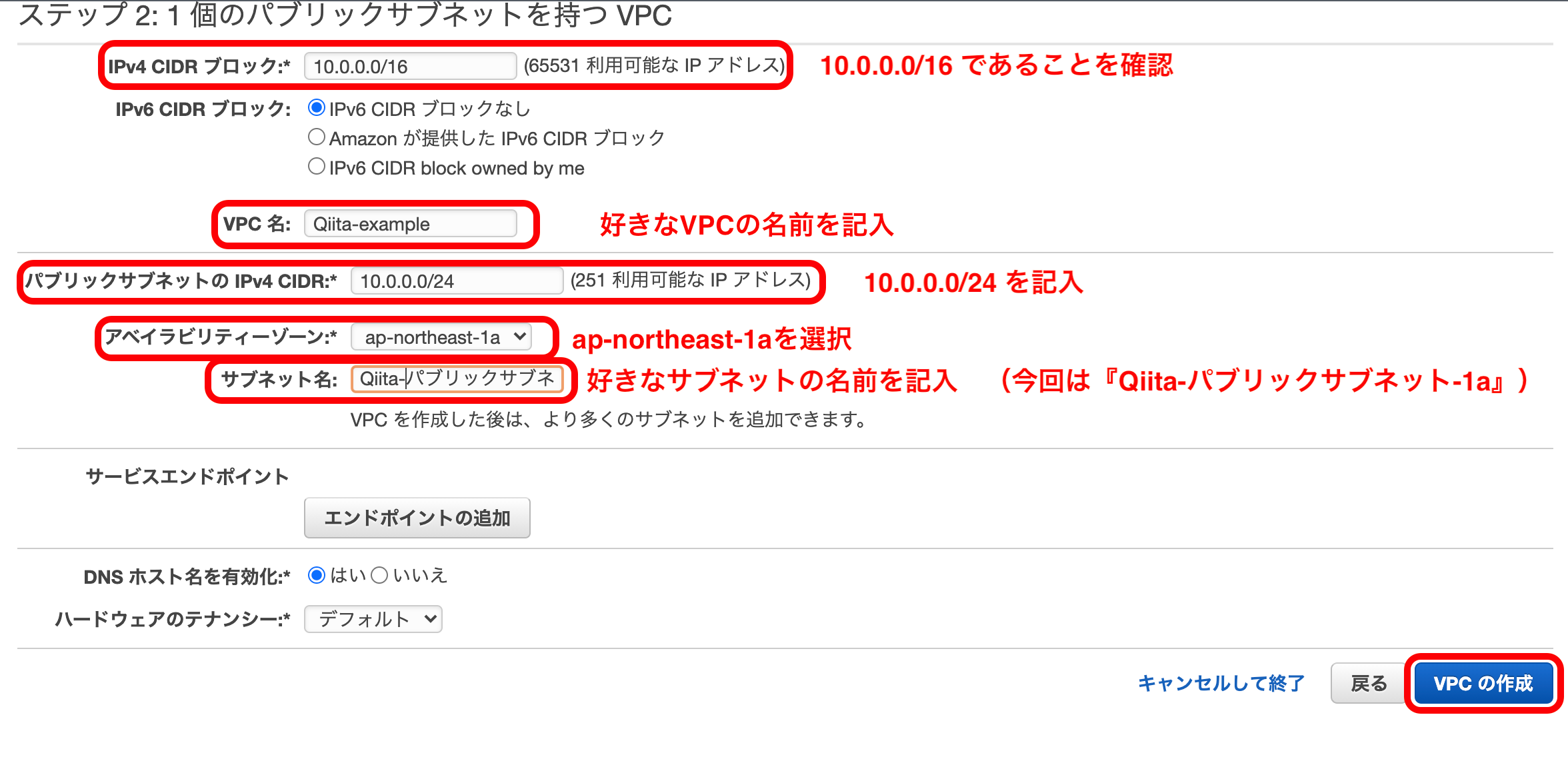
それぞれ以下のように記入して『VPCの作成』を押下。
『OK』を押下
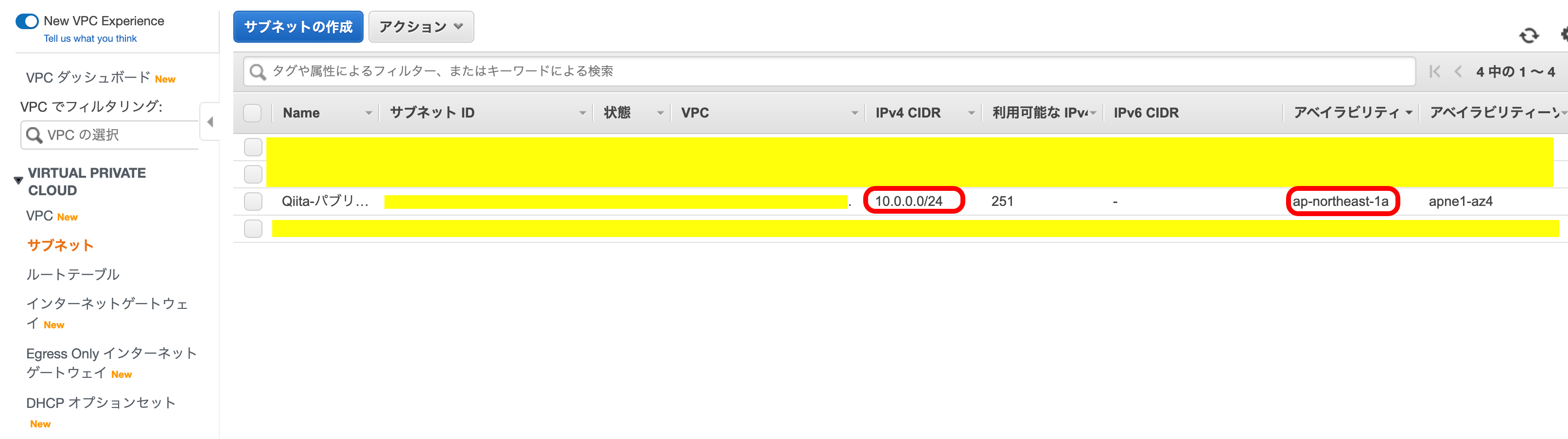
現在のサブネットの状況です。
着目すべきは、IPv4とアベイラリティゾーンです。
先ほど作ったサブネットは、『ap-northeast-1a』というAZで、『10.0.0.0/24』のIPを持っています。
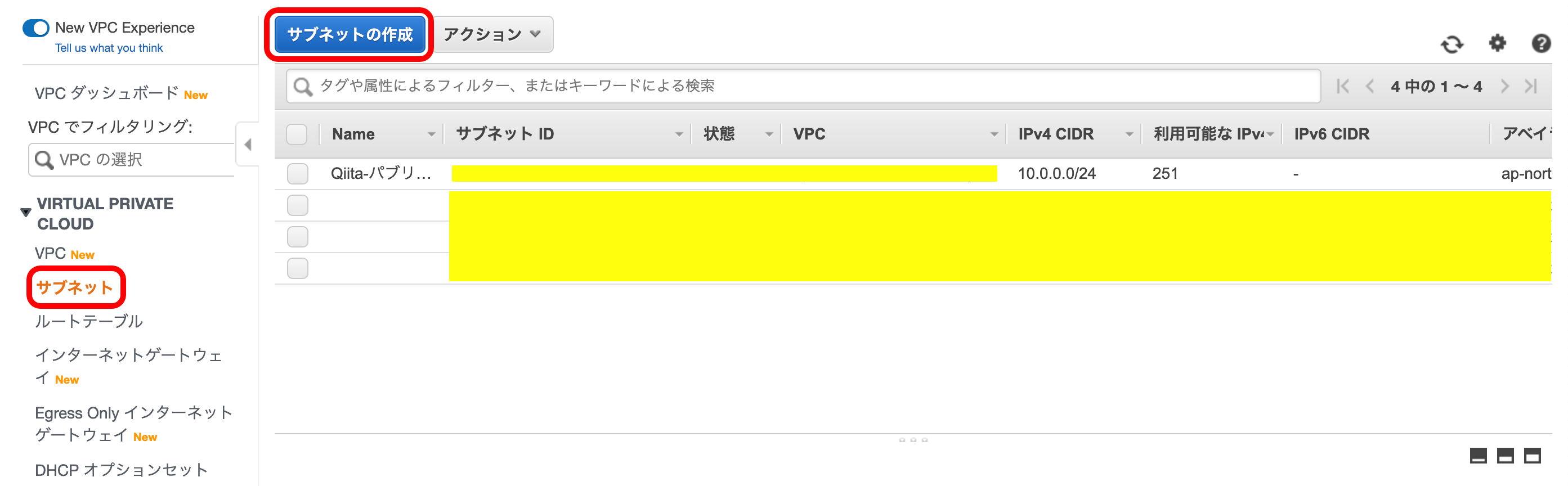
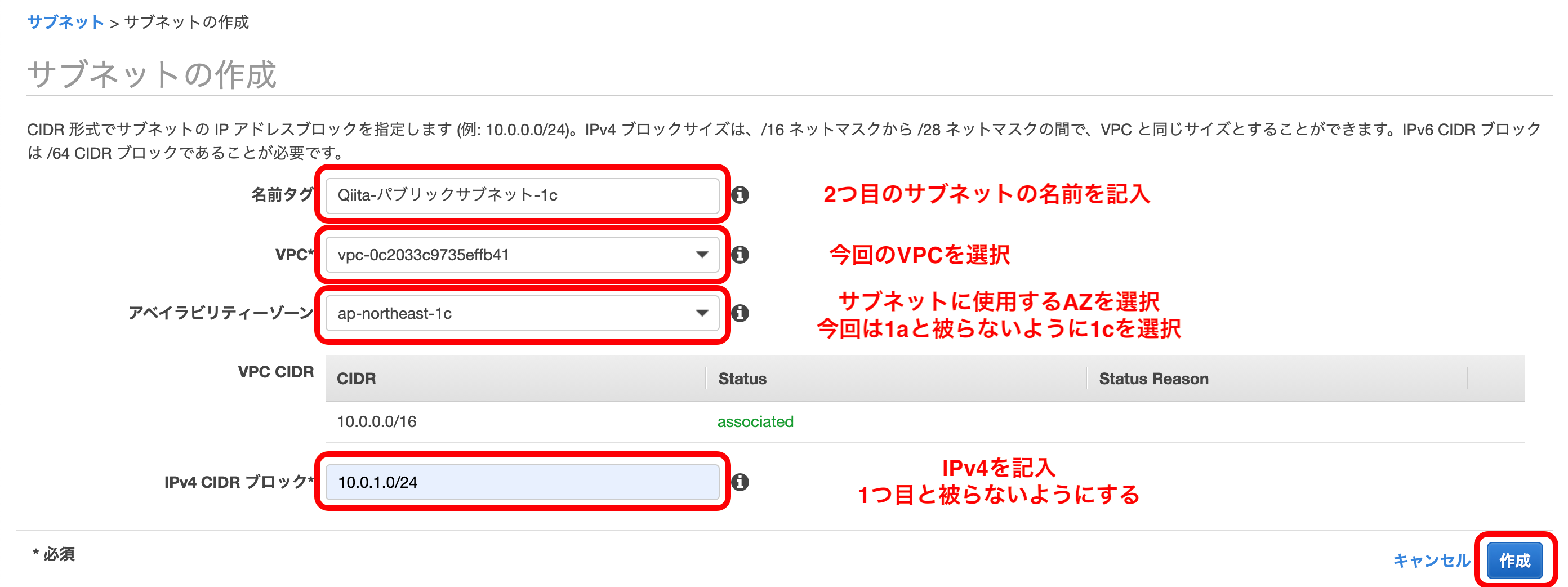
では、これと被らないように他のAZでパブリックサブネットをもう1個作ります。VPCのメニューの『サブネット』を選択。
『サブネットの作成』を押下。
以下のようにして、2つ目のサブネットを作成。
IPv4は、『パブリックサブネット-1a』で『10.0.0.0/24』を使用しているので、今回は『10.0.1.0/24』を使う。
VPCウィザードで構築した1つ目のサブネットは自動でIGWのルーティングがされていますが、2つ目以降は自分で行わなければいけません。
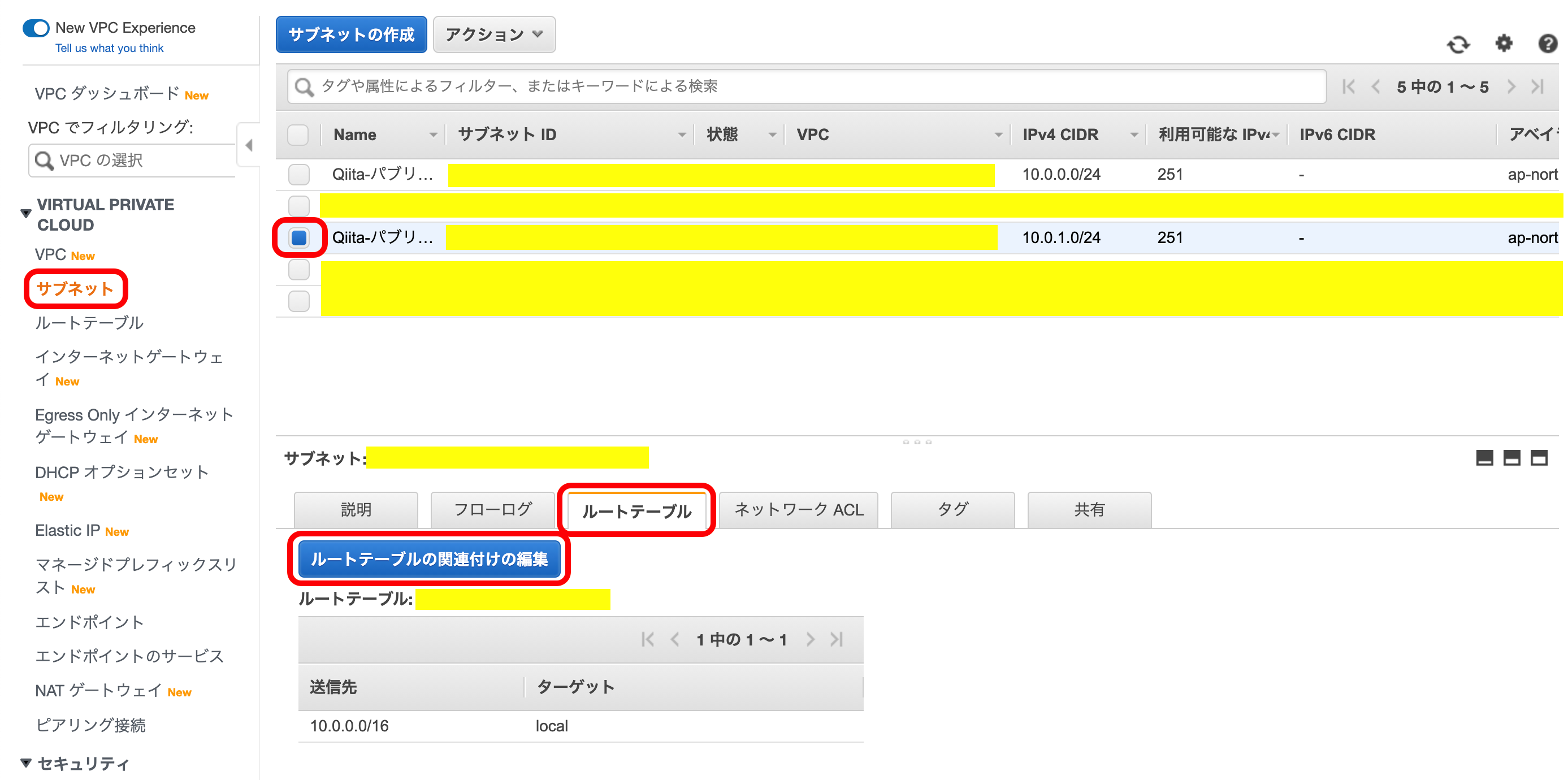
なので、このサブネットのルートテーブルを変更します。VPCメニューから『サブネット』を選択。
2つ目に作成した、サブネットを選択。
下のメニューの中から『ルートテーブル』を選択して、『ルートテーブルの関連付けの意義』を押下。
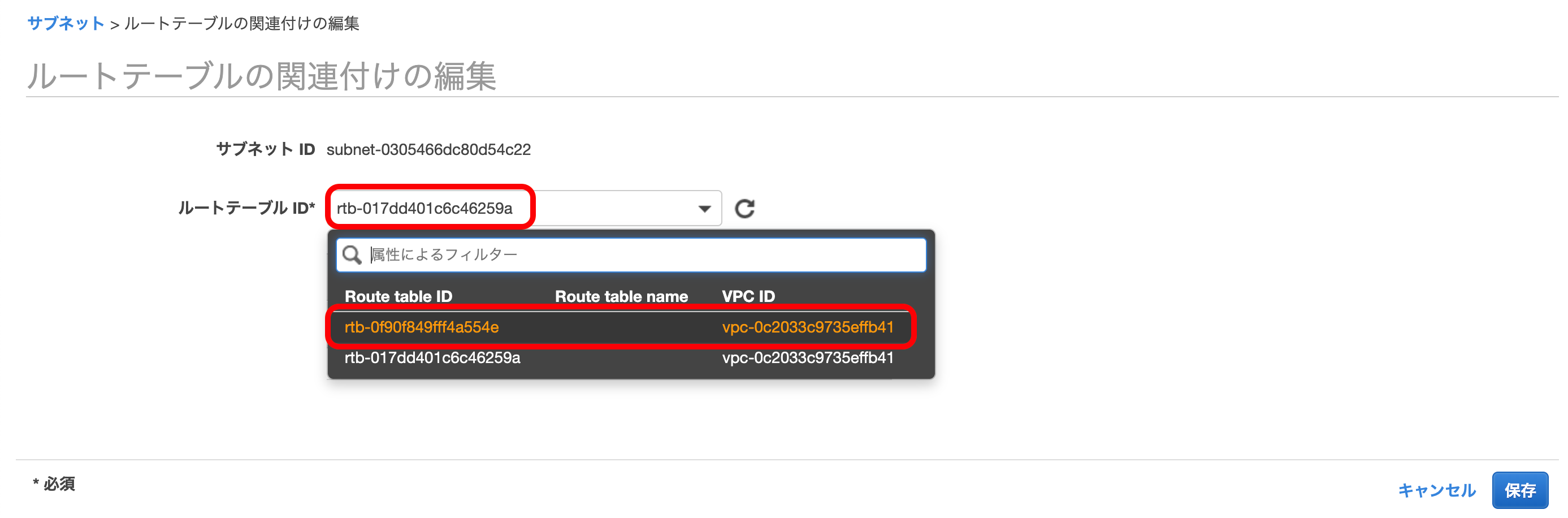
すでに選択されているルートテーブルとは違う方を選択。
(この時、このVPCには2つしかルートテーブルが存在しないはず)
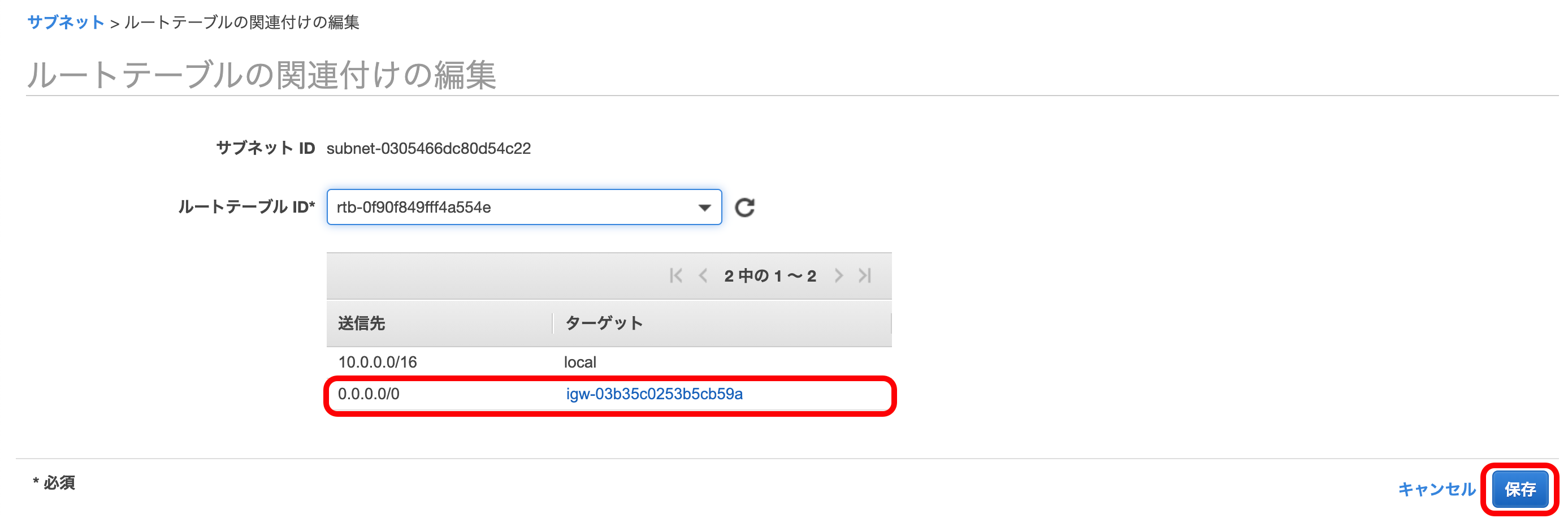
ルートの向き先にIGWが存在することを確認して、『保存』を押下。
これで今回使うサブネットの作成が完了しました。
現在の構成図
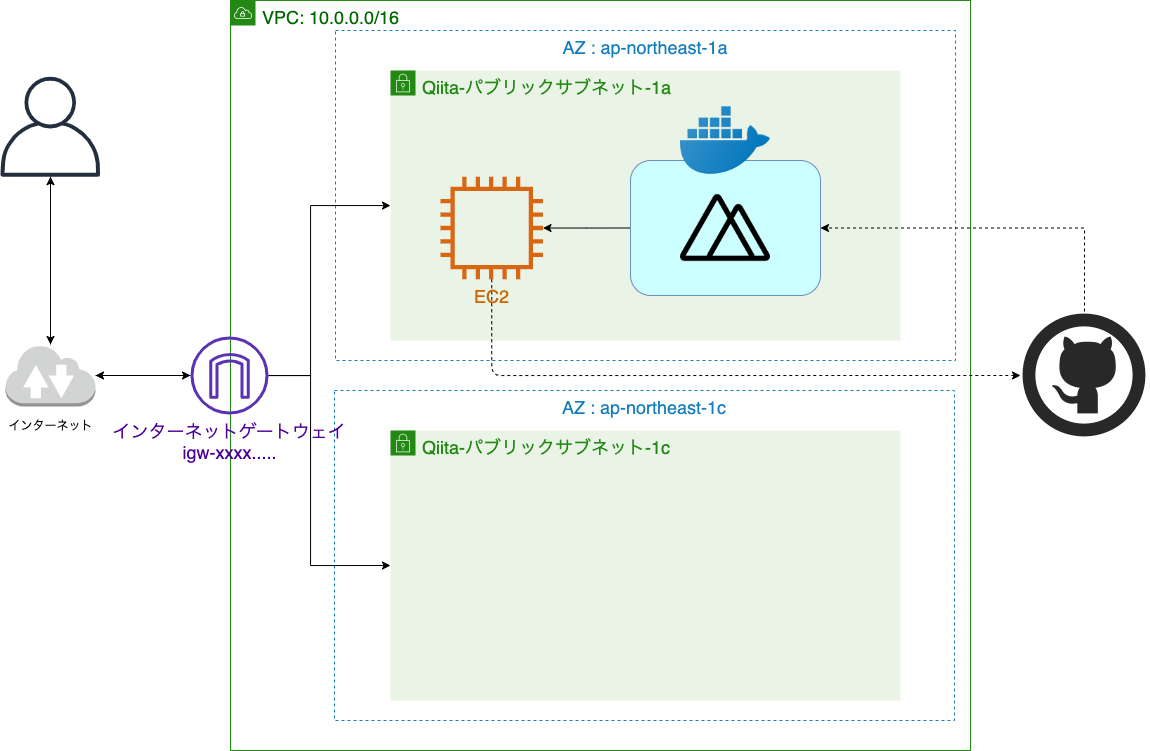
EC2の作成
前回の記事と変わるところはありません。
ので、1つ目のサブネットにデプロイするとこまではスキップします。現在の構成図
ELBの構築
いよいよELBを構築していきます。
ELBの細かい説明に関しては、こちらをご覧ください。メインメニューから『EC2』を選択。
EC2メニューから、『ロードバランサー』を選択。
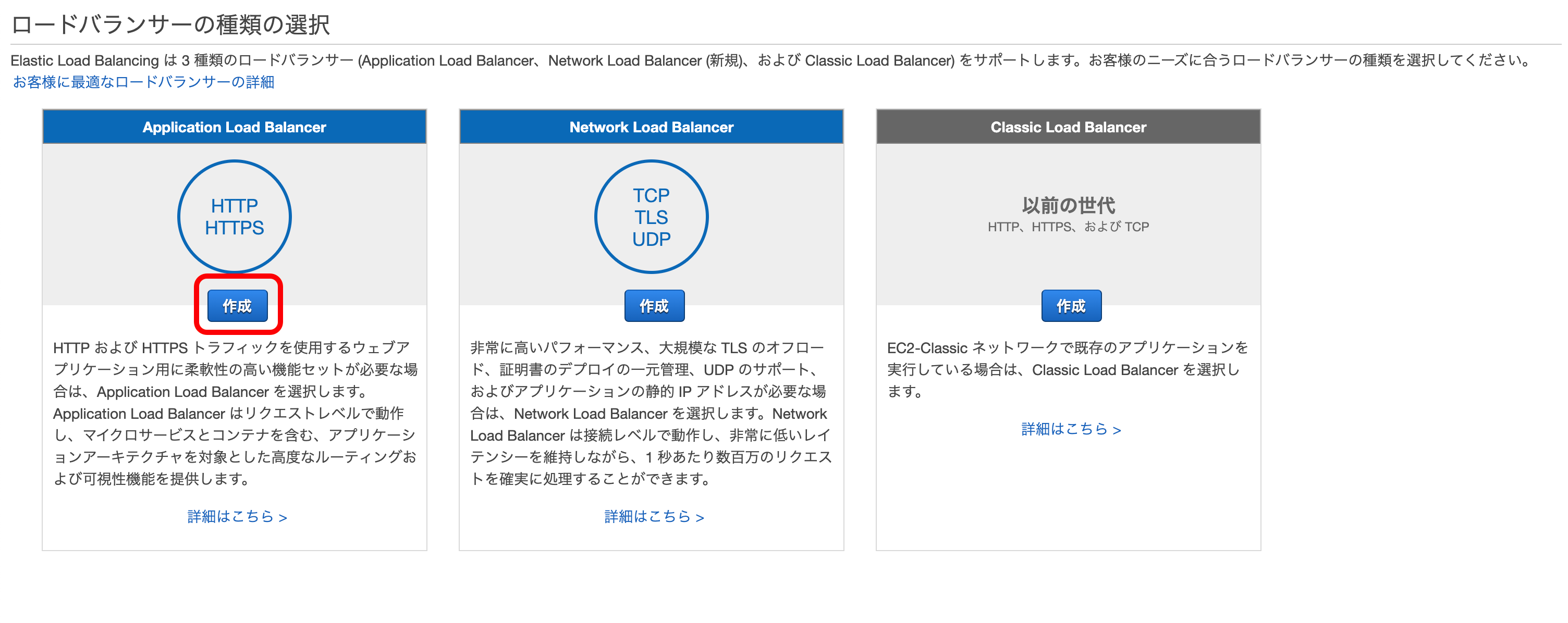
『ロードバランサーの作成』を押下。
Application Load Balancerの『作成』を押下。
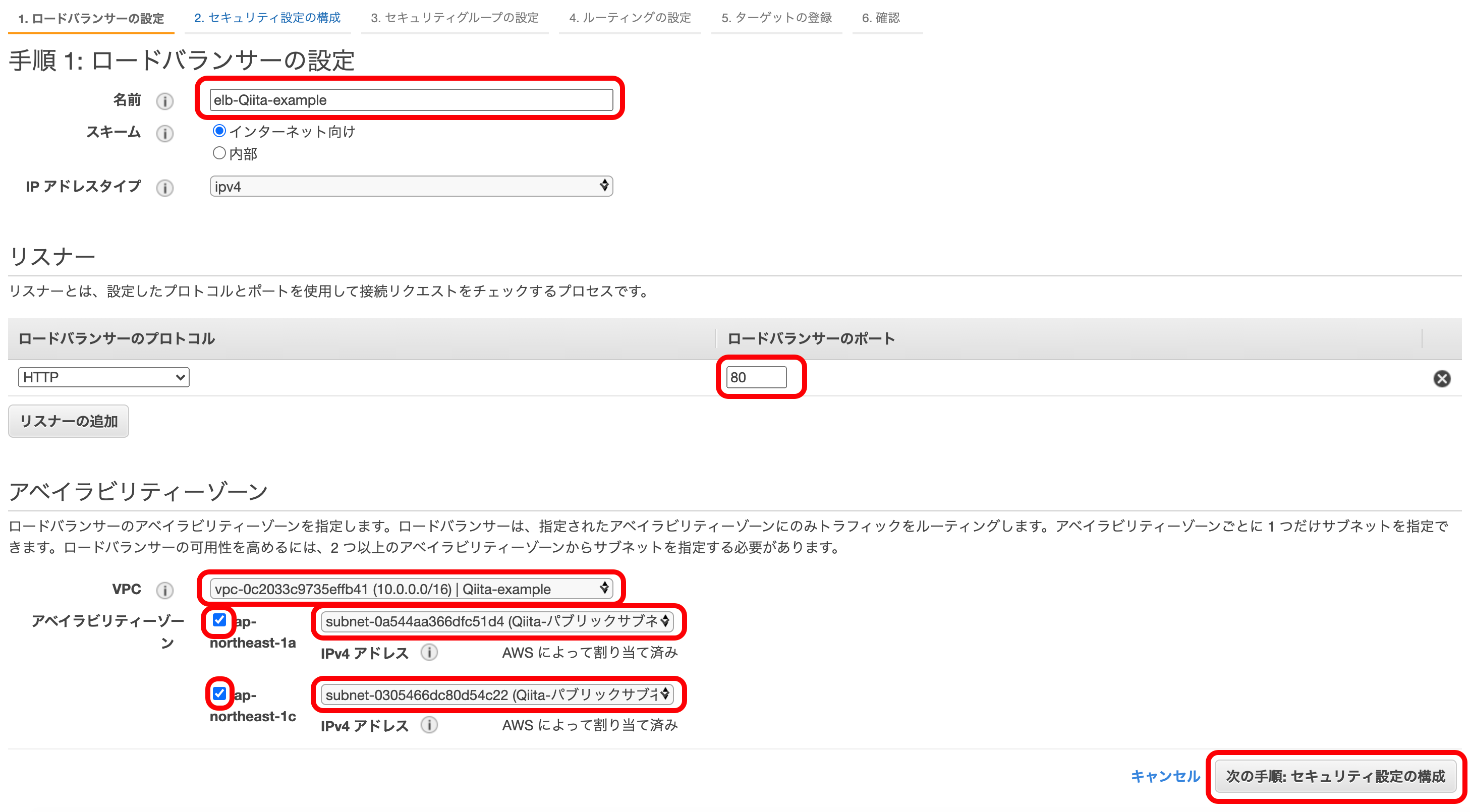
以下のようにELBに好きな名前をつける。
ロードバランサーが通信を受ける外部のポート番号を入力。
自分のVPCを選択。
アベイラリティゾーンにチェックを入れ、ELBにつなげるサブネットを選択する。
『次の手順を押下』する。
ちなみに、今回のdocker-compose.ymlは
docker-compose.ymlversion: '3.7' services: web: ~~ 省略 ~~ ports: - '3000:3000' environment: PORT: 3000 HOST: 0.0.0.0 ~~ 省略 ~~としています。
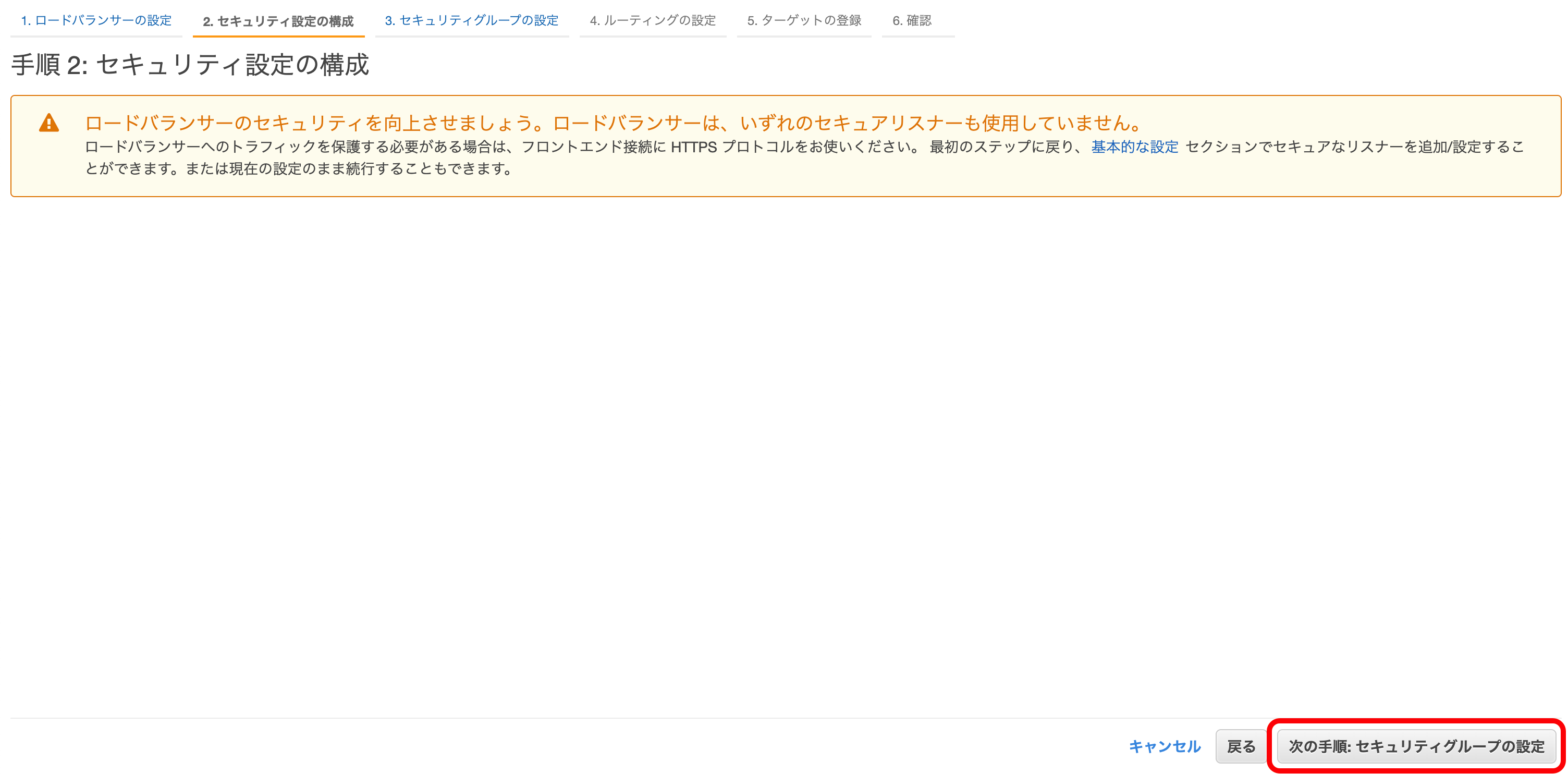
『次の手順』を押下。
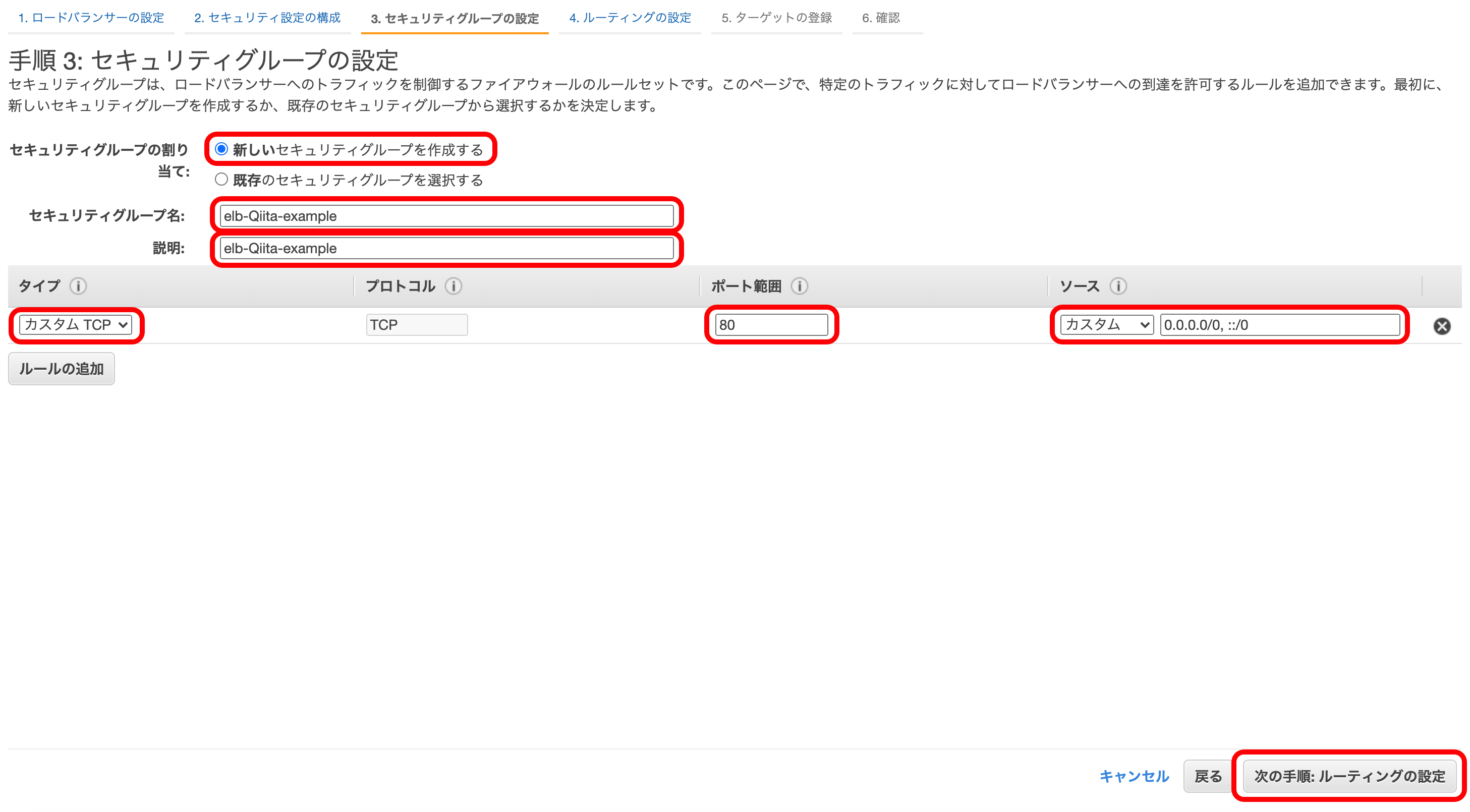
『新しいセキュリティグループを作成する』を選択。
『セキュリティグループ名』に今回のセキュリティグループの名前(説明も名前と一緒でOK)を記入。
『タイプ』は『カスタムTCP』を選択。
『ポート範囲』は『80』を選択。
『ソース』は『カスタム』『0.0.0.0. ::/0』を選択。
『次の手順』を押下。
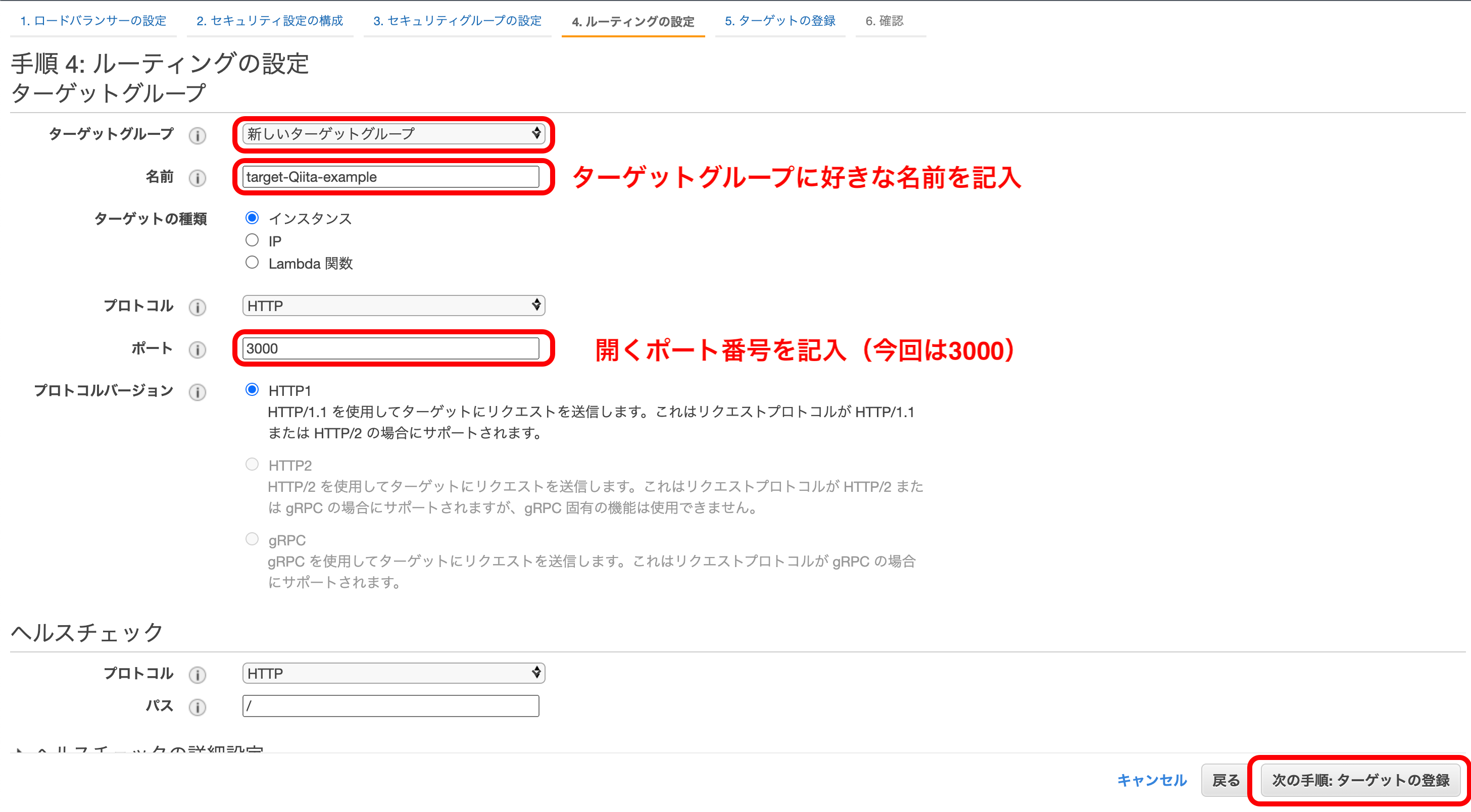
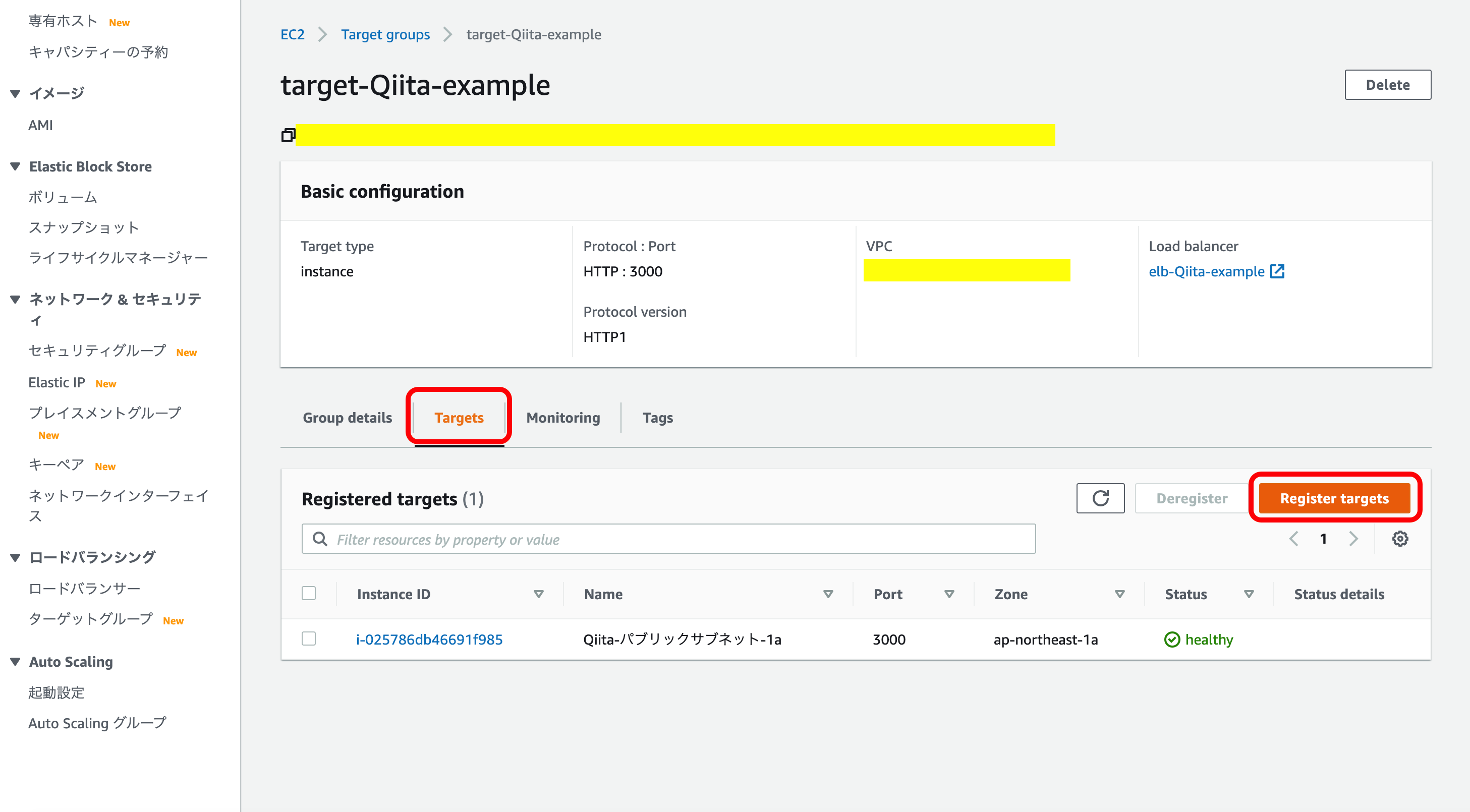
『新しいターゲットグループ』を選択して名前を記入。
『ポート』に自分が開くポート番号を記入
『次の手順』を押下。
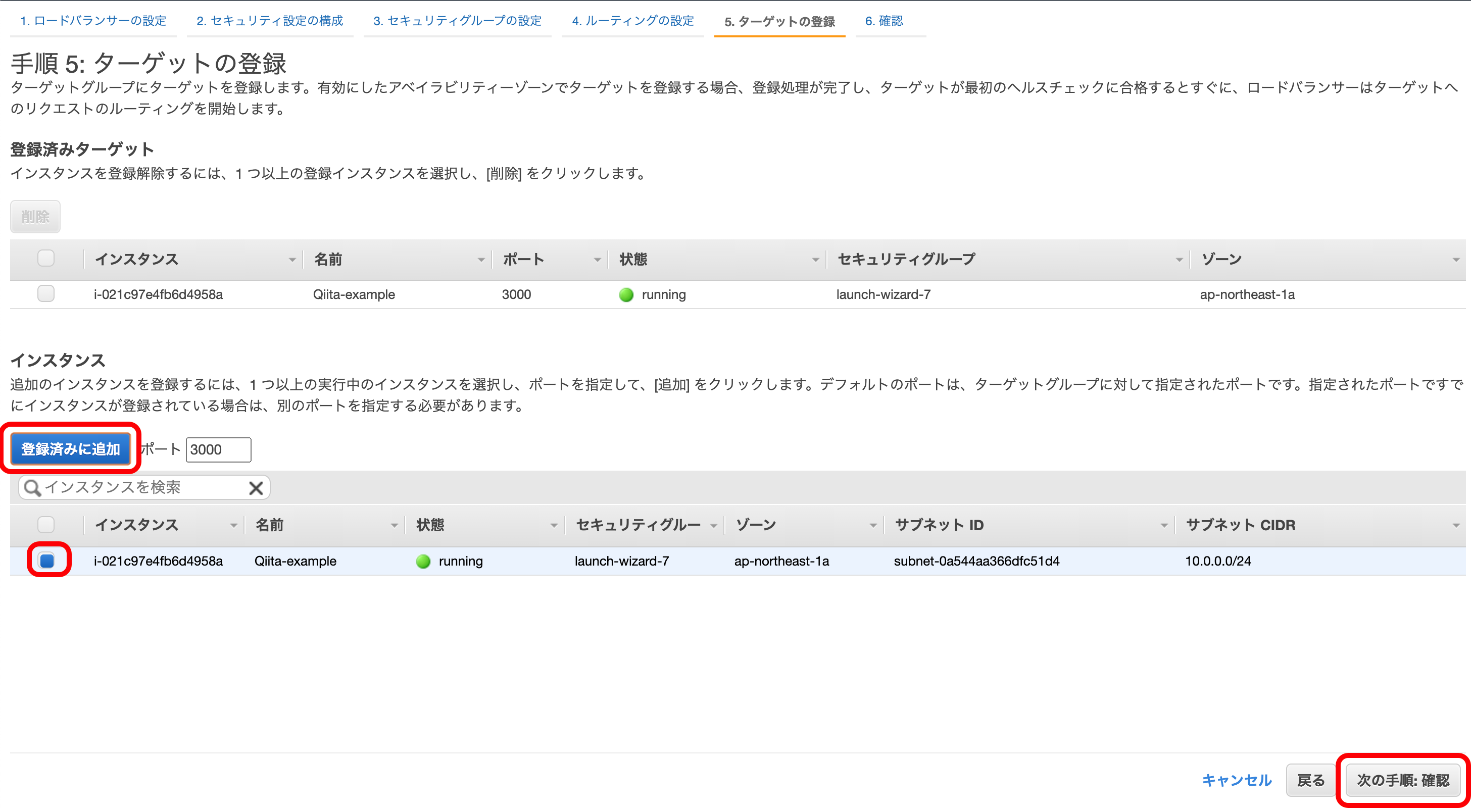
『登録済みに追加』を押下。
『登録済みターゲット』にEC2のインスタンスが追加されているか確認。
『次の手順』を押下。
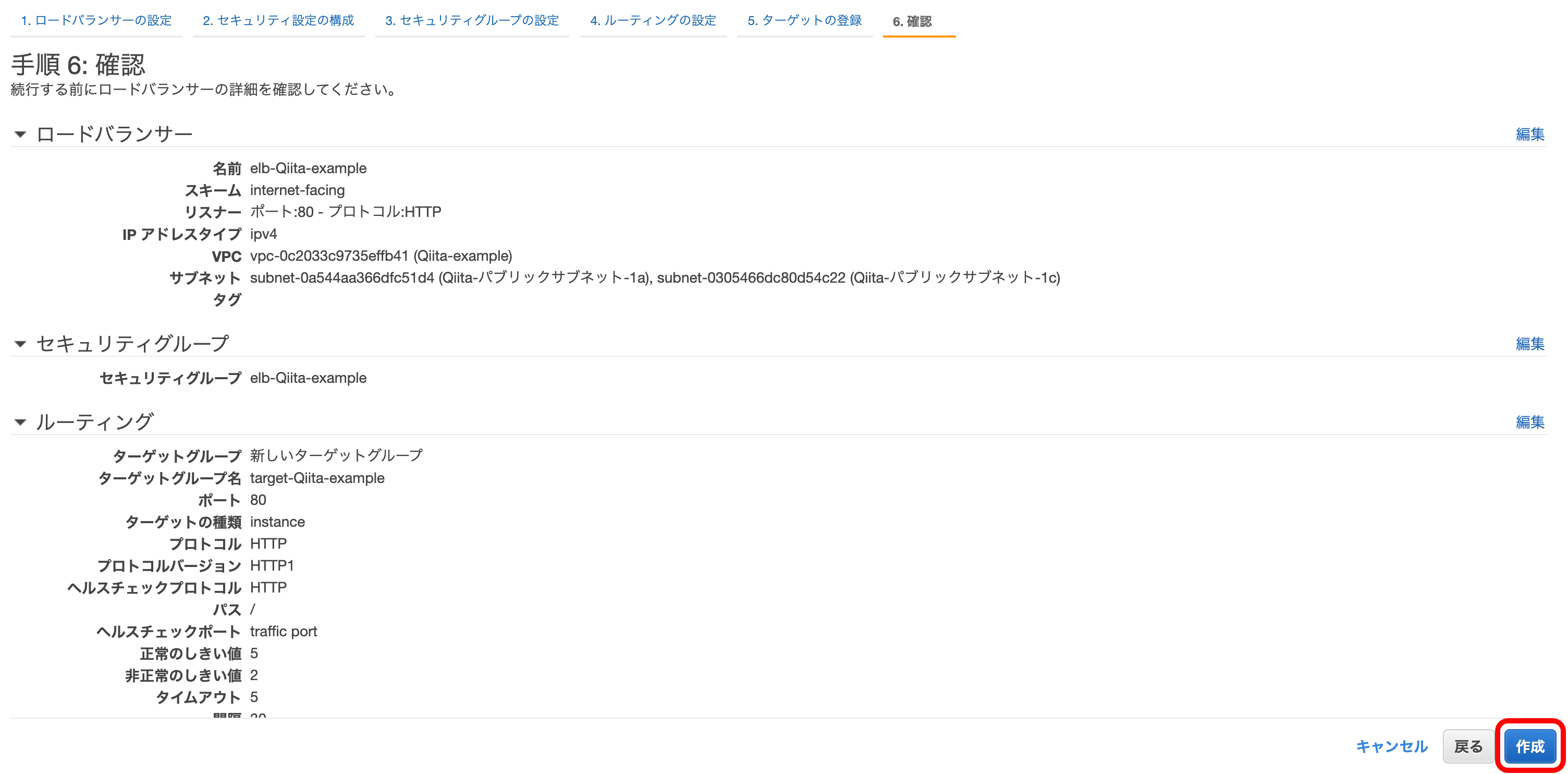
『作成』を押下。
以上でELBの作成が完了します。
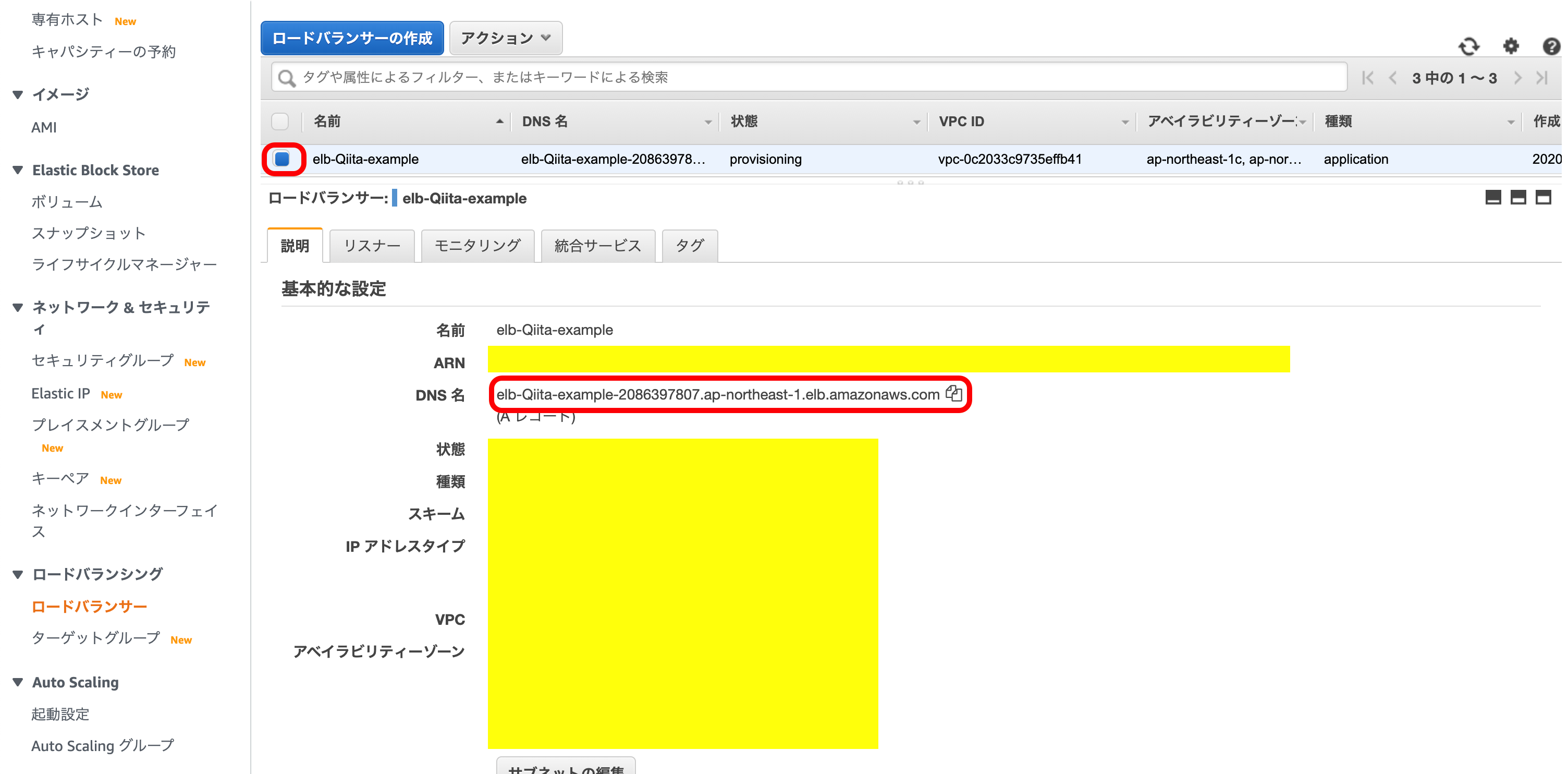
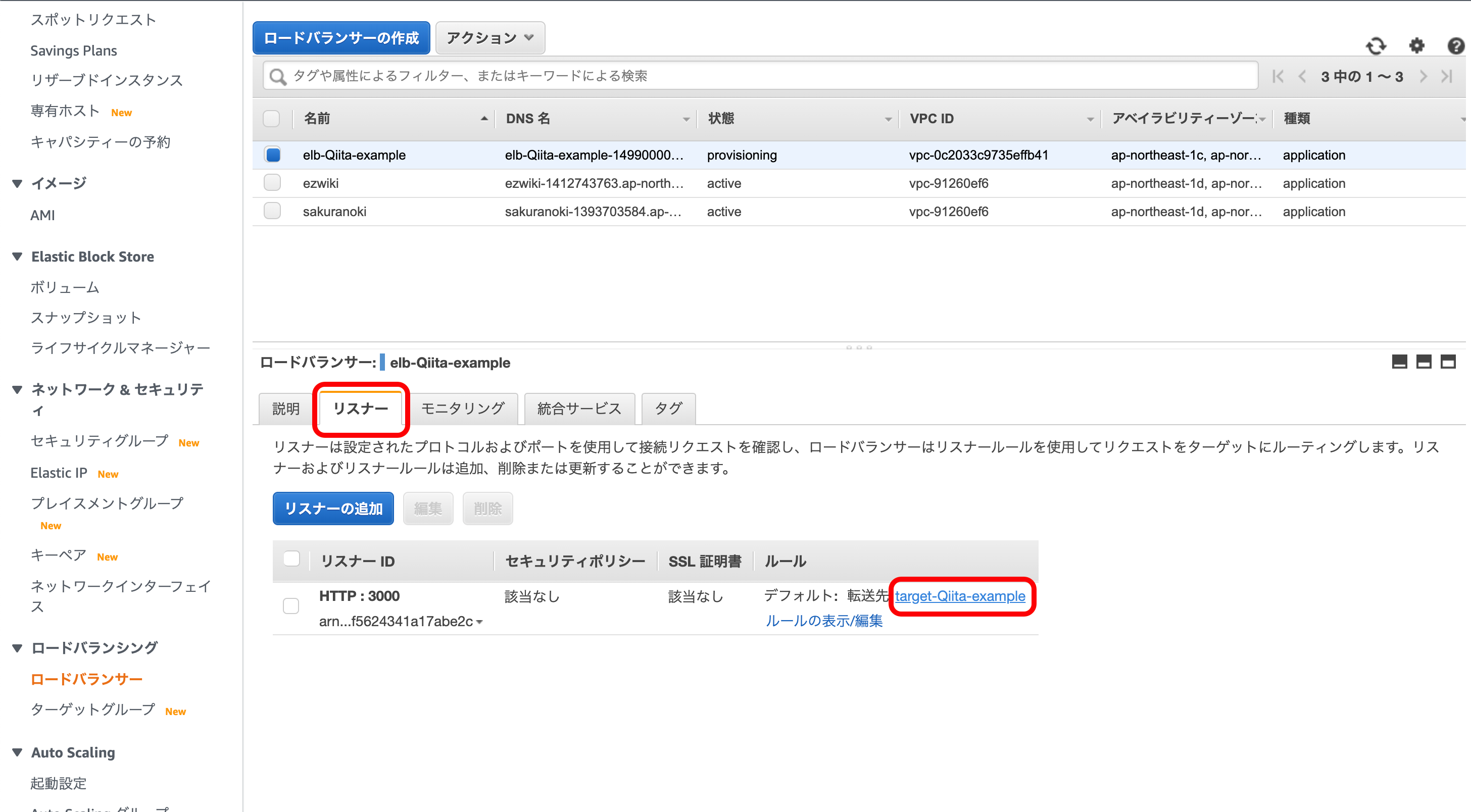
次に、作成したELBを確認します。
先ほど作成したELBを選択。
『リスナー』を選択。
『転送先』の自分で設定したターゲット名を押下。
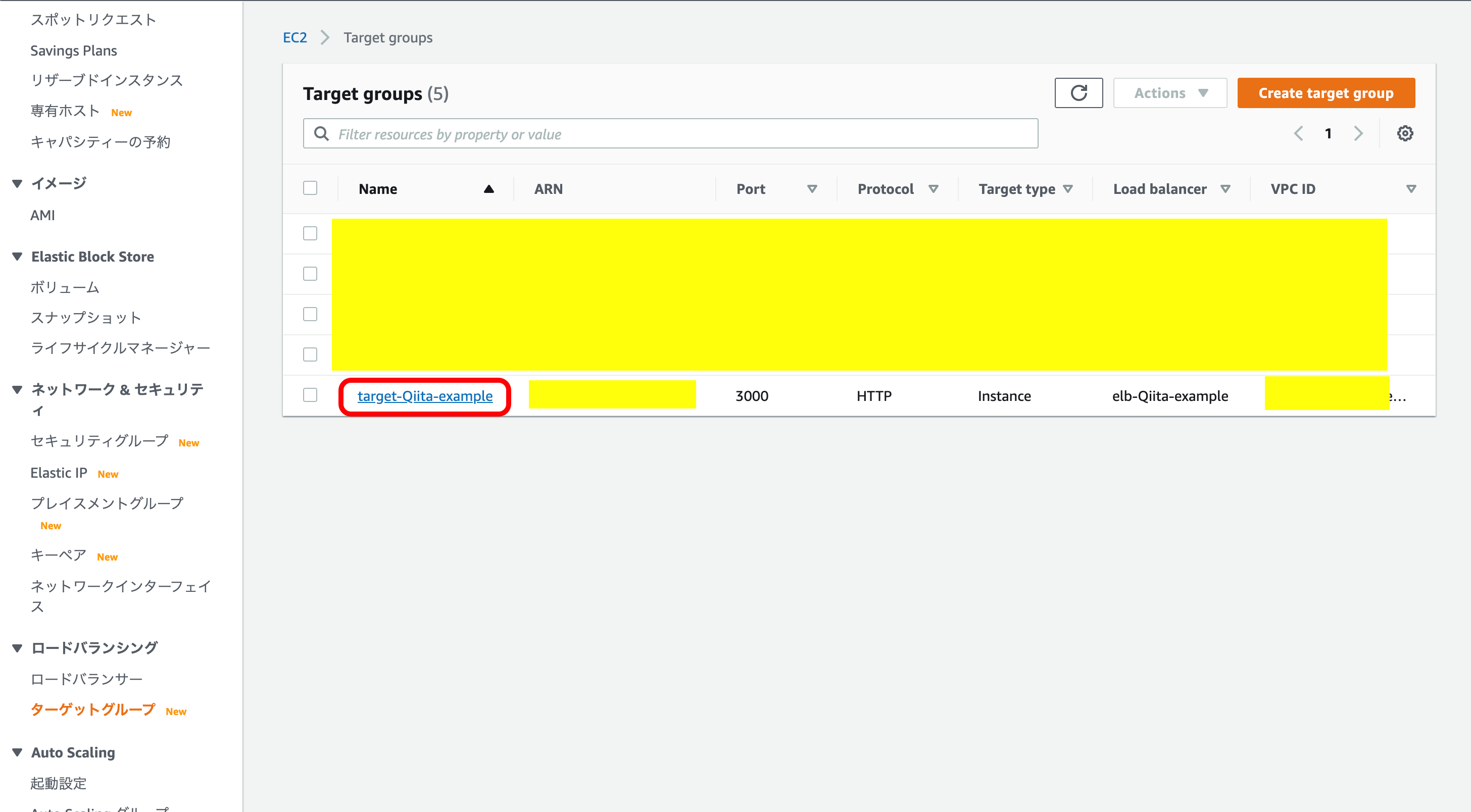
一覧の中からさきほど作成した、ターゲットグループを押下。
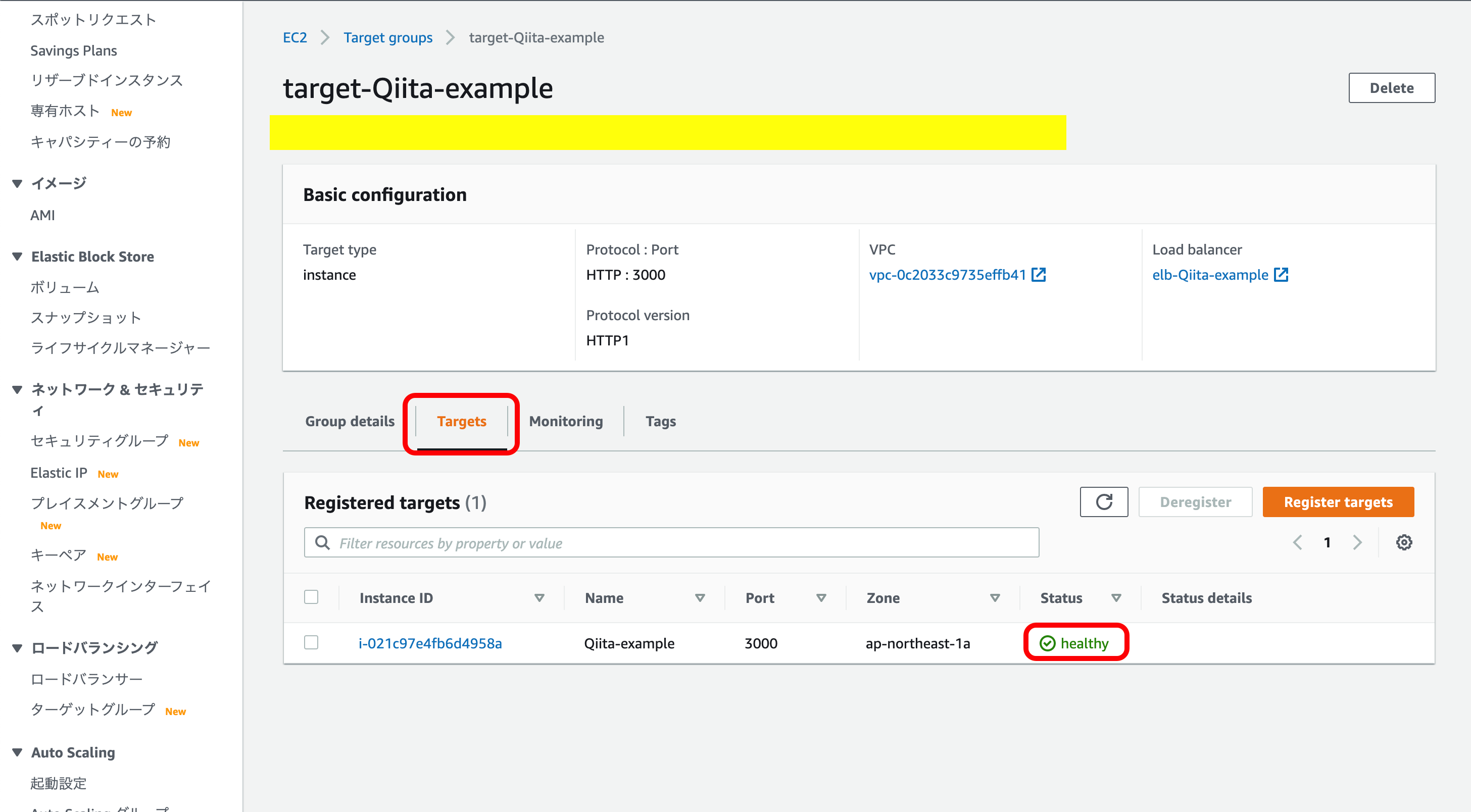
下のメニューの中にある『Target』を押下。
インスタンスとの接続状況はStatusで見ることができます。
最初は『initial』と表示されていると思いますが、インスタンスとの接続が上手くいけば『healthy』になります。
これでELBの作成はいったん完成です。
現在の構成図
AMI
現在のままでは、ELBとしての機能がほぼ死んでます。笑
そのため、ELBが結びつく先のサブネットを増やしてあげます。
増やすサブネットの内容はパブリックサブネット-1aと同じ物なので、そのままコピーしてきます。
この時に、使用するサービスがAMIです。AMIとは
公式によると、
Amazon マシンイメージ (AMI) は、ソフトウェア構成 (オペレーティングシステム、アプリケーションサーバー、アプリケーションなど) を記録したテンプレートです。AMI から、クラウドで仮想サーバーとして実行される AMI のコピーであるインスタンスを起動します。以下の図に示すように、1 つの AMI の複数のインスタンスを起動することができます。
要するに、Dockerのインスタンス版だと考えていいと思います。
AMIの作成
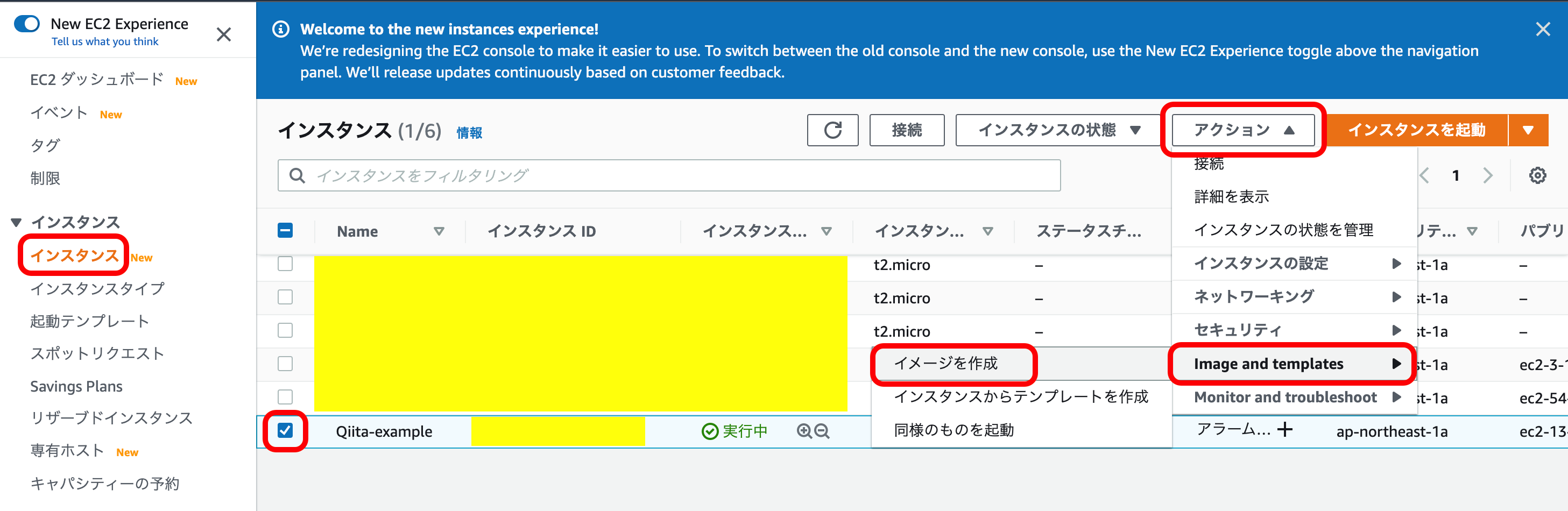
EC2メニューから『インスタンス』を選択。
自分の複製したいインスタンスを選択。
『アクション』を押下。
『Image and Template』を押下。
『イメージを作成』を押下。
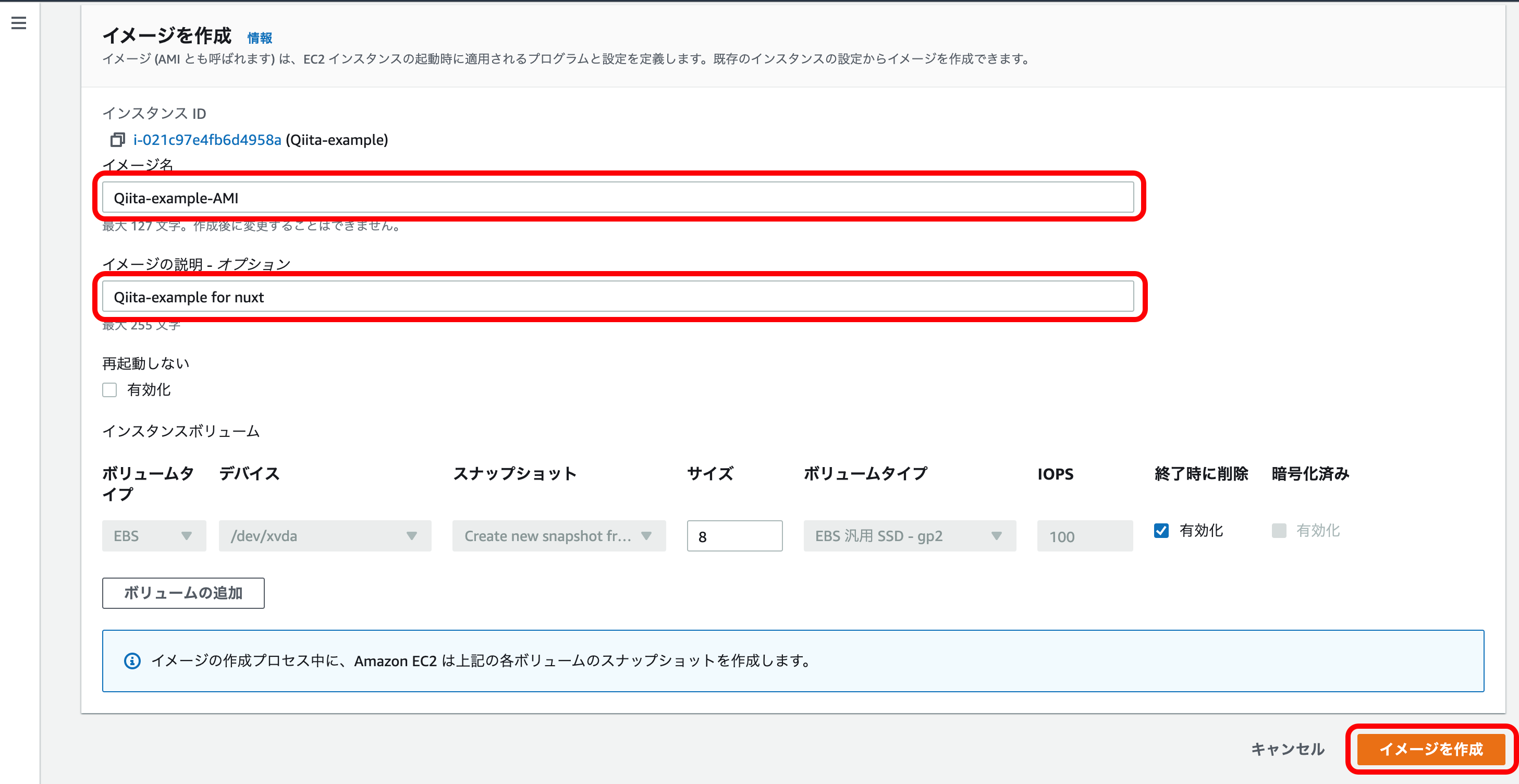
『イメージ名』『イメージの説明』でAMIにつける名前・説明を記入。
『イメージの作成』を押下。
これで、AMIの作成が完了です。
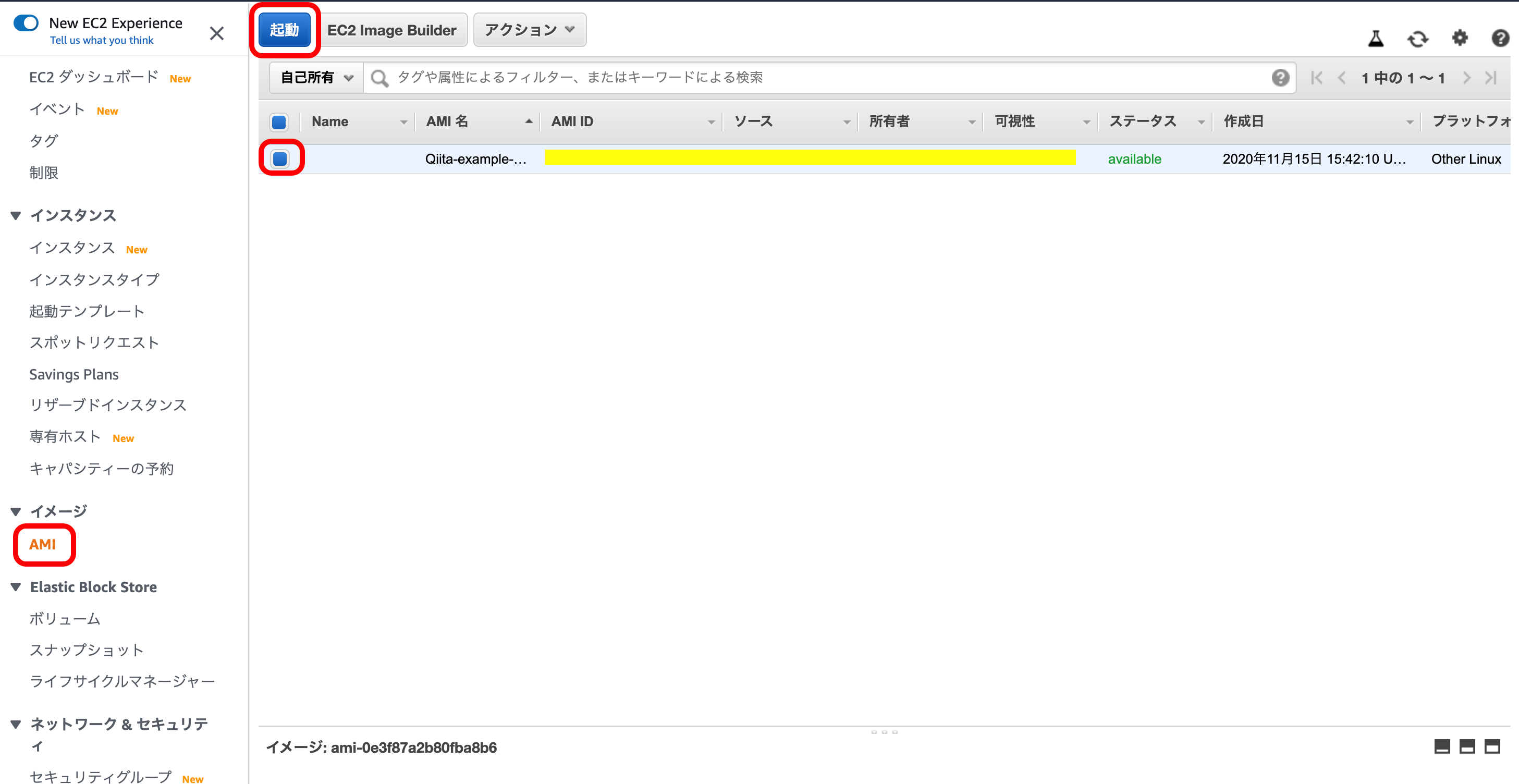
一応確認してみます。EC2メニューから『AMI』を選択。
先ほど作成されたAMIのステータスがpendingからavailableになれば、無事成功です。
現在の構成図
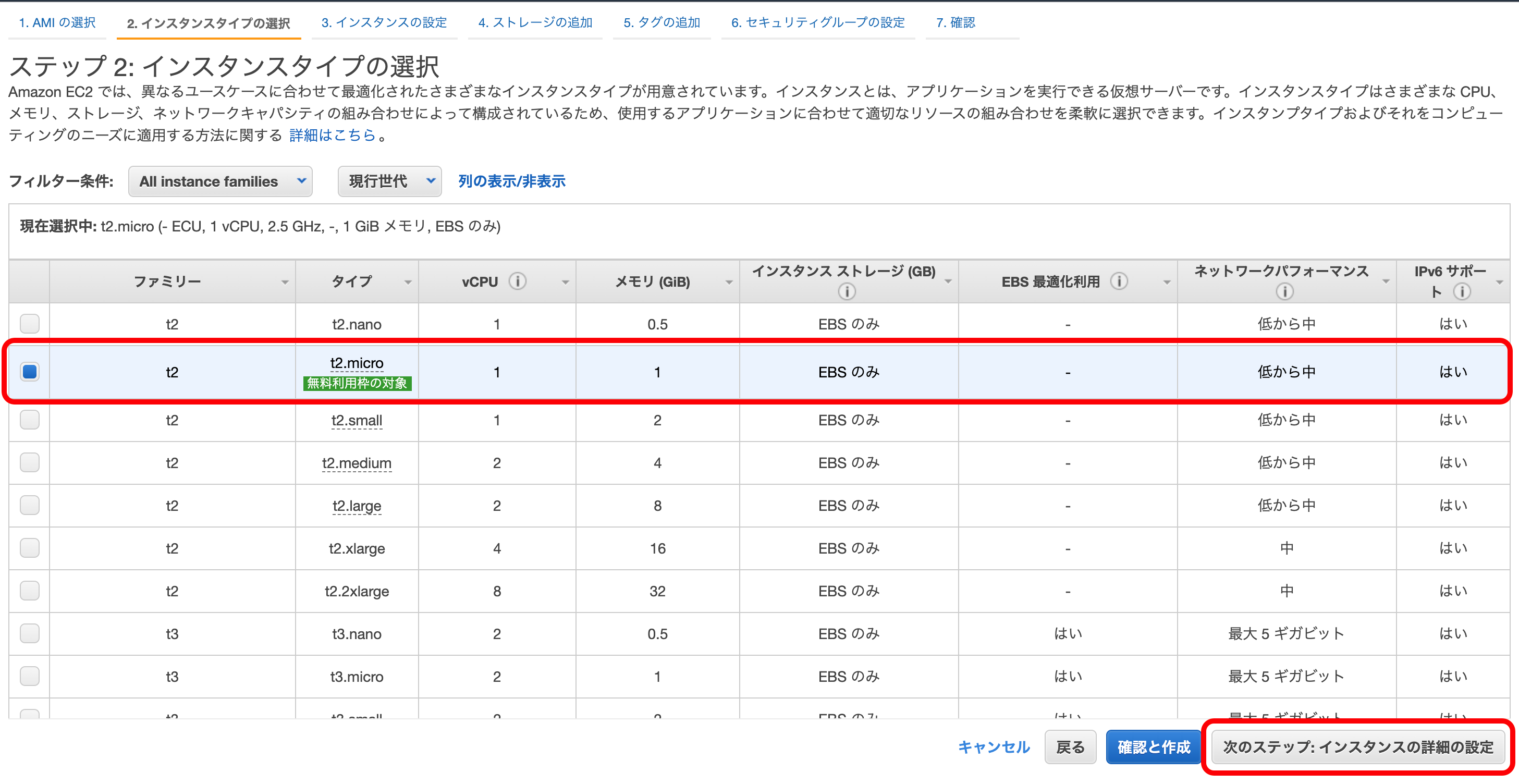
2つ目のインスタンスの作成
AMIを利用して、2つ目のインスタンスを作成したいと思います。
EC2メニューから、『AMI』を選択。
自分の作成した、AMIを選択。
『起動』を押下。
今回は、『t2.micro』が選択されていることを確認。
『次のステップ』を押下。
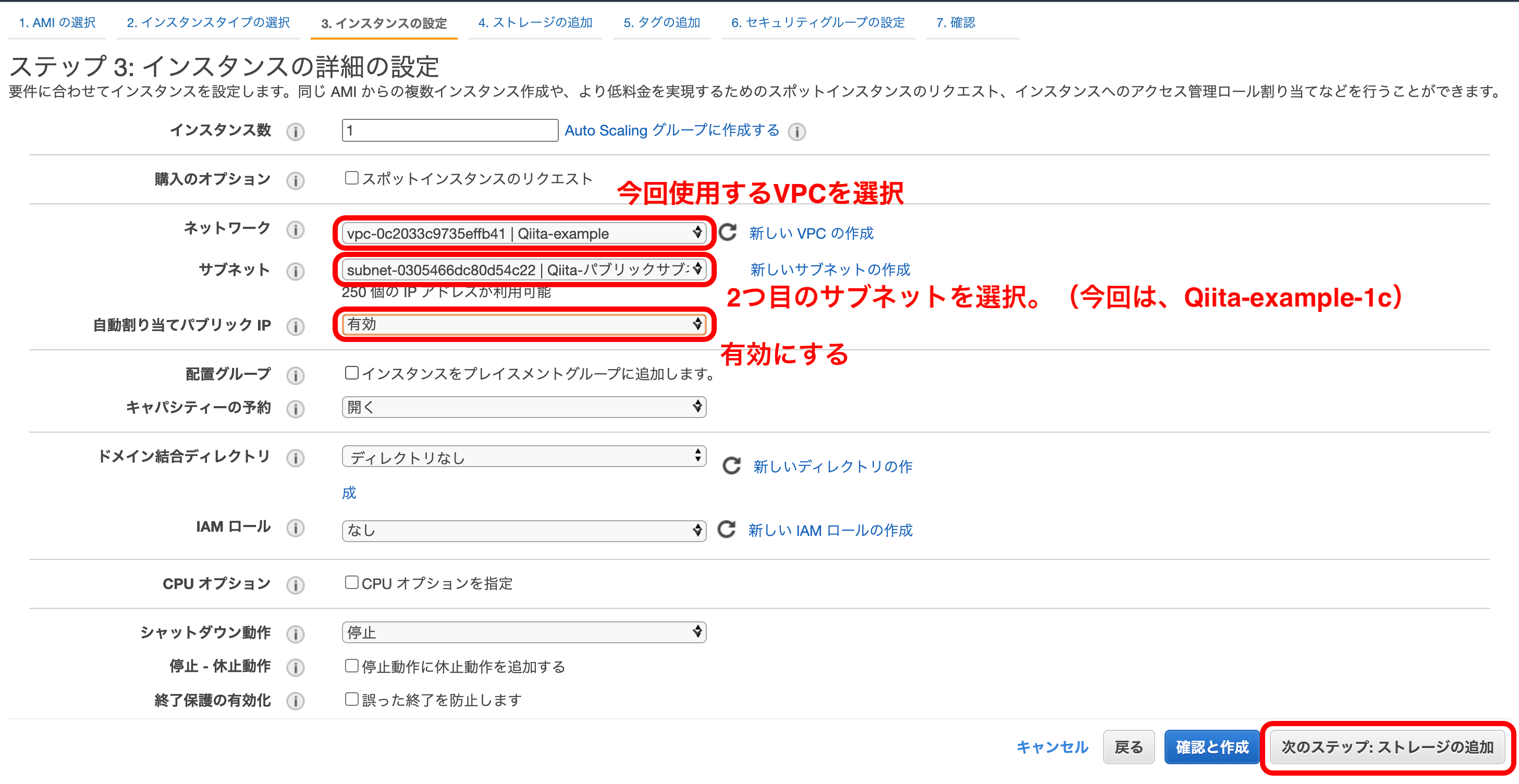
『ネットワーク』に今回使用するVPCを、『サブネット』に今回使用するサブネットをそれぞれ選択。
『自動割り当てパブリックIP』は『有効』にしておく。
『次のステップ』を押下。
そのまま『次のステップ』を押下。
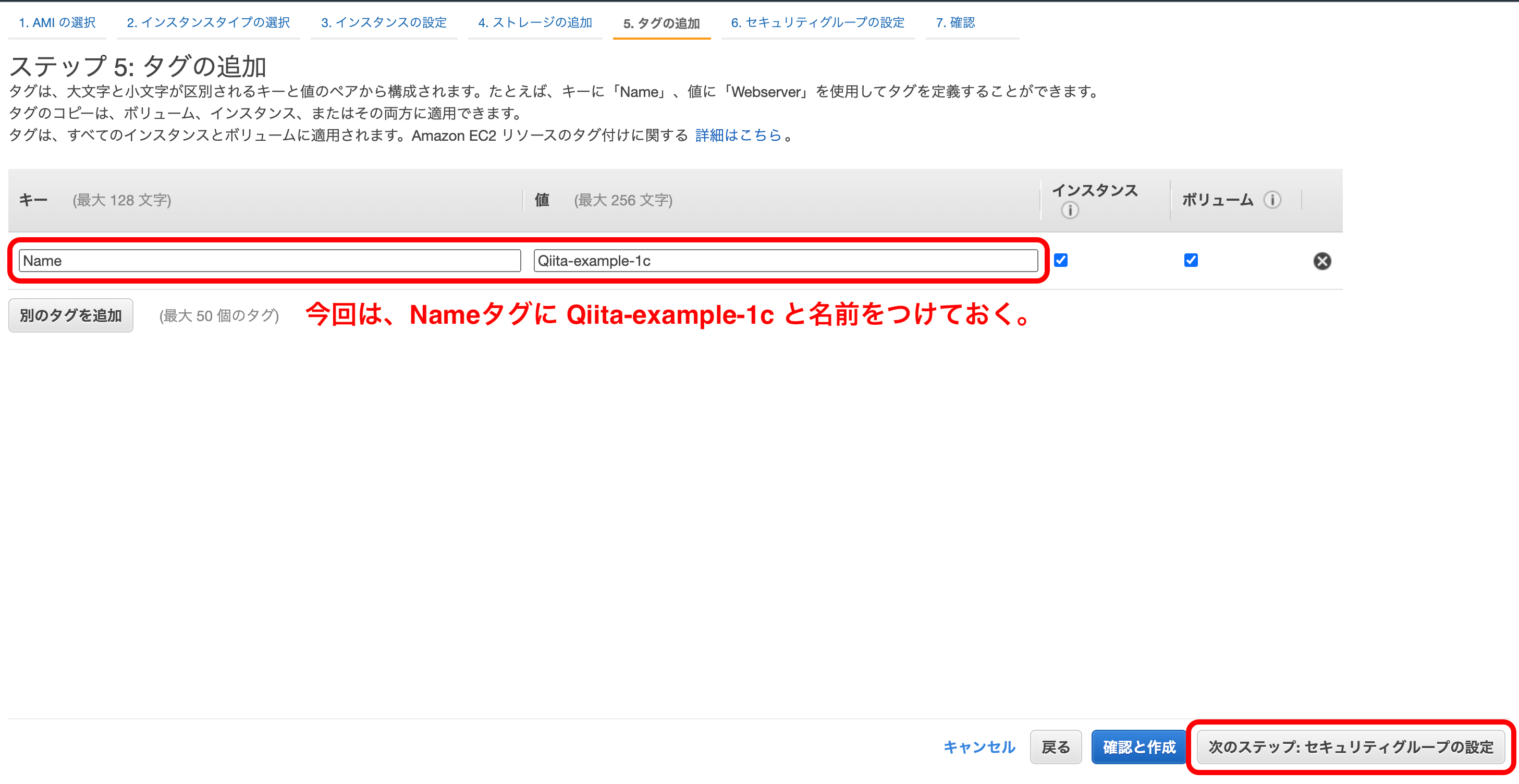
好みでタグをつけておく。
今回は以下のようにしておく。
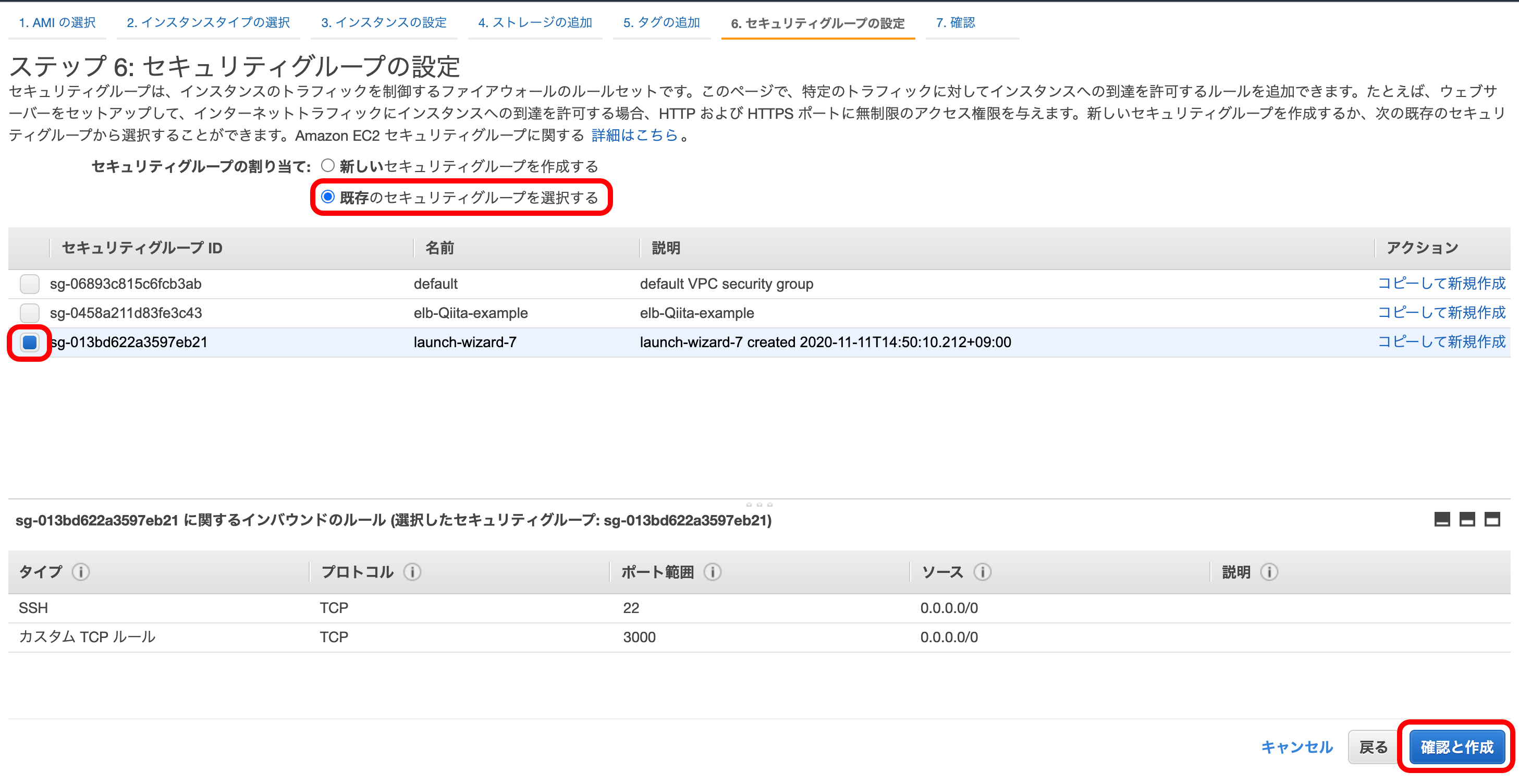
『既存のセキュリティグループを選択する』を選択。
1つ目のインスタンスと同じセキュリティグループを選択。
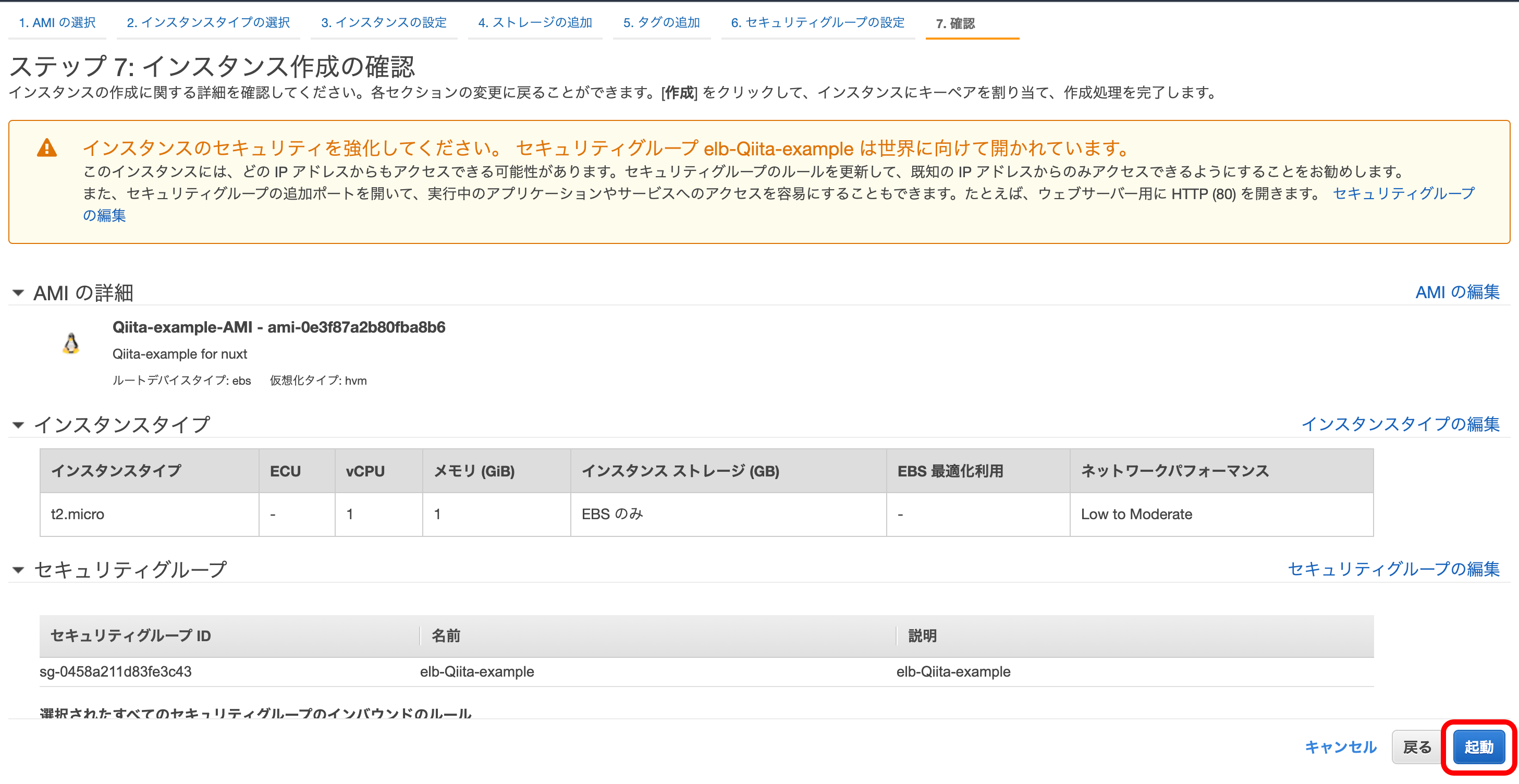
『確認と作成』を押下。
そのまま『起動』を押下。
そのまま『インスタンスの表示』を押下。
現在の構成図
2つ目のインスタンスをELBに追加
上の構成図を見ると残った工程は、2つ目のインスタンスをELBの行先に追加してあげることのみです。
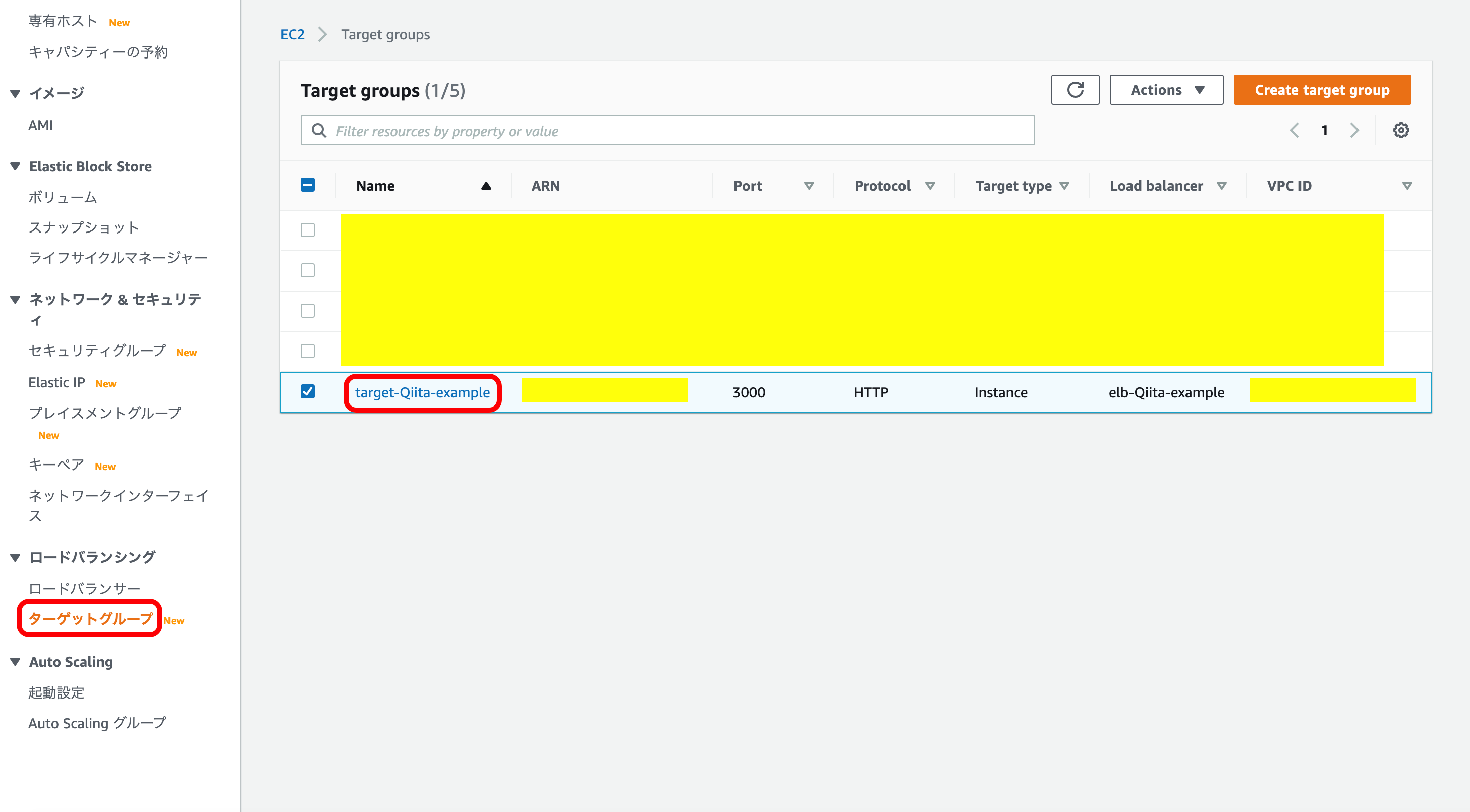
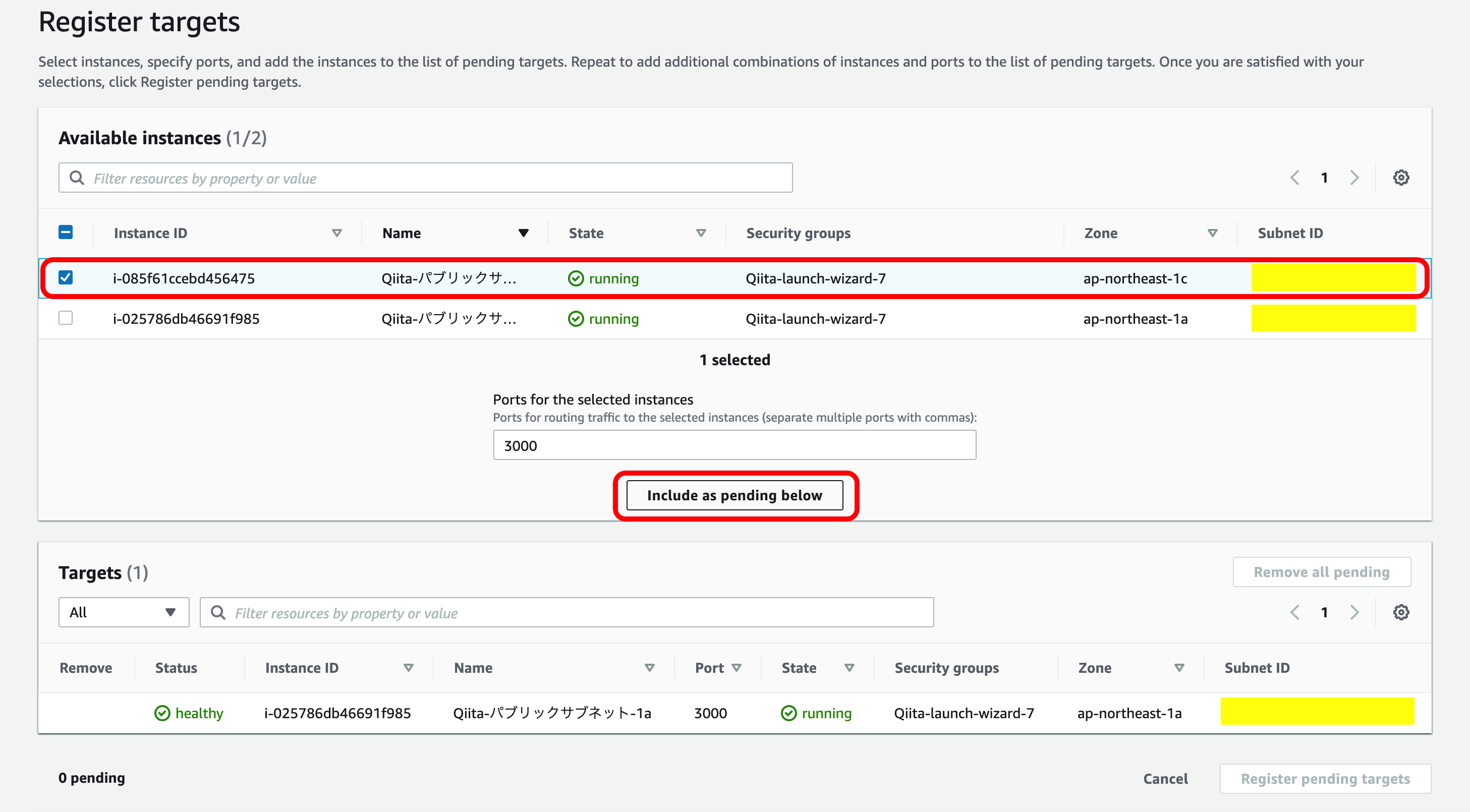
では早速やっていきましょう。EC2メニューから『ターゲットグループ』を選択。
今回使用するターゲットグループを押下。
『Target』を選択。
『Register targets』を押下。
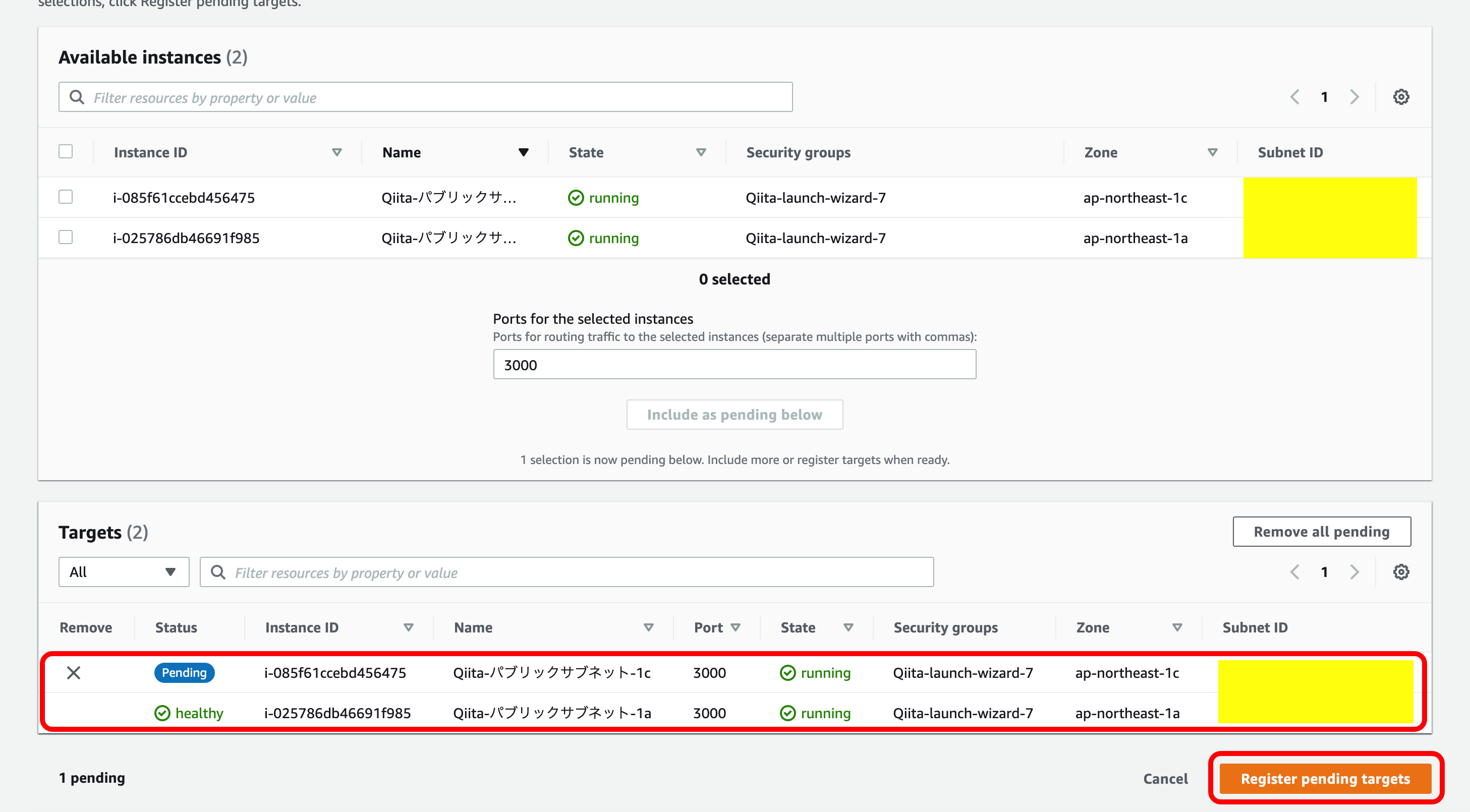
2つ目のインスタンス(ap-northeast-1c)を選択。
『Include as pending below』を押下。
このように『Targets』に2個インスタンスが出てくればOK。
前回記事と同じように2つ目のインスタンスにssh接続して docker を起動すればELBの接続が完了です。
現在の構成図
まとめ
以上でELBを使ってデプロイすることができました。
次回は、Route53を使って、DNSを構築していきたいと思います。



- 投稿日:2020-11-14T21:40:51+09:00
Lightsail の FreeBSD インスタンスにストレージを接続する方法
概要
AWS lightsail の FreeBSD インスタンスでは、lightsail のストレージ画面に表示されるディスクのパス
/dev/xvdfが当てにならないのと、ドキュメントに出てくるコマンドlsblkも存在しないので、FreeBSD流の方法でやりなおしてみました。camcontrolではなくgeomを使うのがポイントです。https://lightsail.aws.amazon.com/ls/docs/ja_jp/articles/create-and-attach-additional-block-storage-disks-linux-unix
この記事のステップ1までは同じ操作で、ステップ2をどうするか、という話です。
ステップ1で32GBのディスクを作成し、backupstorage という名前でアタッチしています。ディスクのパスは/dev/xvdfとなっています。FreeBSD版のステップ2
1. ディスクを見つける
geom disk listコマンドを実行します。geom$ geom disk list Geom name: ada0 Providers: 1. Name: ada0 Mediasize: 21474836480 (20G) Sectorsize: 512 Mode: r1w1e3 descr: (null) ident: (null) rotationrate: unknown fwsectors: 0 fwheads: 0 Geom name: xbd5 Providers: 1. Name: xbd5 Mediasize: 34359738368 (32G) Sectorsize: 512 Mode: r0w0e0 descr: (null) ident: (null) rotationrate: unknown fwsectors: 0 fwheads: 0ストレージの容量から、デバイス名(geomでいうところのprovider)は
xbd5であることが分かります。ファイルシステムの有無を確認する
AWSのドキュメントと同様に、fileコマンドを実行する方法で確かめることができます。
file命令をrootで実行する# file -s /dev/xbd5 /dev/xbd5: data # file -s /dev/ada0 /dev/ada0: DOS/MBR boot sector; partition 1 : ID=0xee, start-CHS (0x0,0,2), end-CHS (0x3ff,255,63), startsector 1, 41943039 sectors今回の場合、
xbd5にファイルシステムはありません。ada0のようにパーティションが存在する場合の表示と比較してみてください。あるいは、
geom -tコマンドの実行結果を見ると、geomの確認$ geom -t Geom Class Provider ada0 DISK ada0 ada0 PART ada0p1 ada0p1 LABEL gpt/bootfs gpt/bootfs DEV ada0p1 LABEL gptid/97f64d0b-fc77-11e9-90a5-0cc47ad8b808 gptid/97f64d0b-fc77-11e9-90a5-0cc47ad8b808 DEV ada0p1 DEV ada0 PART ada0p2 ada0p2 LABEL gpt/rootfs ffs.gpt/rootfs VFS gpt/rootfs DEV ada0p2 DEV ada0 DEV xbd5 DISK xbd5 xbd5 DEVであるので、
xbd5にはそもそもパーティションすら存在しないことが分かります。2. GPTパーティションを作成する
まず、ディスクにGPTスキームでパーティションを作るよう設定します。
gpartでパーティションスキームを設定する# gpart create -s GPT xbd5 xbd5 created # gpart show xbd5 => 40 67108784 xbd5 GPT (32G) 40 67108784 - free - (32G) #次に、
xbd5にあるディスクの空き容量すべてをファイルシステムfreebsd-ufsとするパーティションを作成します。このパーティションにはebs32gというラベルを付けておくことにします。gpartでパーティションを作成する# gpart add -t freebsd-ufs -l ebs32g xbd5 xbd5p1 added # gpart show xbd5 => 40 67108784 xbd5 GPT (32G) 40 67108784 1 freebsd-ufs (32G) # geom -t Geom Class Provider (中略) xbd5 DISK xbd5 xbd5 PART xbd5p1 xbd5p1 LABEL gpt/ebs32g gpt/ebs32g DEV xbd5p1 LABEL gptid/c07635f0-265d-11eb-831e-5dad1bdd57fb gptid/c07635f0-265d-11eb-831e-5dad1bdd57fb DEV xbd5p1 DEV xbd5 DEV
xbd5p1というパーティションが出来ており、ラベルとしてebs32gという文字列が設定されていることが分かります。このラベルは/dev/gpt/以下に現れ、パーティションをマウントするときに使えます。3. パーティションをフォーマットする
freebsd-ufsとして確保したパーティションをフォーマットするには
newfsを使います。newfs# file -s /dev/xbd5p1 /dev/xbd5p1: data # newfs -j /dev/xbd5p1 /dev/xbd5p1: 32768.0MB (67108784 sectors) block size 32768, fragment size 4096 using 53 cylinder groups of 626.09MB, 20035 blks, 80256 inodes. with soft updates super-block backups (for fsck_ffs -b #) at: 192, 1282432, 2564672, 3846912, 5129152, 6411392, 7693632, 8975872, 10258112, 11540352, 12822592, 14104832, 15387072, 16669312, 17951552, 19233792, 20516032, 21798272, 23080512, 24362752, 25644992, 26927232, 28209472, 29491712, 30773952, 32056192, 33338432, 34620672, 35902912, 37185152, 38467392, 39749632, 41031872, 42314112, 43596352, 44878592, 46160832, 47443072, 48725312, 50007552, 51289792, 52572032, 53854272, 55136512, 56418752, 57700992, 58983232, 60265472, 61547712, 62829952, 64112192, 65394432, 66676672 Using inode 4 in cg 0 for 33554432 byte journal newfs: soft updates journaling set
-jオプションは soft-updates journaling (SUJ) と呼ばれるオプションです。journaling を使わない-Uとするものもよく見かけます。GEOM journaling (gjournal)を設定する-Jとは別の仕組みです。今回は特に理由なく設定してみましたが、journalingに伴うファイルシステムの性能の低下を嫌うのであれば、-Uでも良いと思います。作成したファイルシステムの情報を表示# file -s /dev/xbd5p1 /dev/xbd5p1: Unix Fast File system [v2] (little-endian) last mounted on , last written at Sat Nov 14 10:24:42 2020, clean flag 1, readonly flag 0, nu mber of blocks 8388598, number of data blocks 8121877, number of cylinder groups 53, block size 32768, fragment size 4096, average file size 16384, a verage number of files in dir 64, pending blocks to free 0, pending inodes to free 0, system-wide uuid 0, minimum percentage of free blocks 8, TIME o ptimization # tunefs -p /dev/xbd5p1 tunefs: POSIX.1e ACLs: (-a) disabled tunefs: NFSv4 ACLs: (-N) disabled tunefs: MAC multilabel: (-l) disabled tunefs: soft updates: (-n) enabled tunefs: soft update journaling: (-j) enabled tunefs: gjournal: (-J) disabled tunefs: trim: (-t) disabled tunefs: maximum blocks per file in a cylinder group: (-e) 4096 tunefs: average file size: (-f) 16384 tunefs: average number of files in a directory: (-s) 64 tunefs: minimum percentage of free space: (-m) 8% tunefs: space to hold for metadata blocks: (-k) 6408 tunefs: optimization preference: (-o) time tunefs: volume label: (-L)いくつかの設定がenabledになっていることがわかります。
4. パーティションをマウントする
マウントポイント
/backupfsを作成し、パーティション情報を元にマウントします。パーティション情報を元にマウントする# gpart show -p xbd5 => 40 67108784 xbd5 GPT (32G) 40 67108784 xbd5p1 freebsd-ufs (32G) # mkdir /backupfs # mount /dev/xbd5p1 /backupfs # cd /backupfs/ # ls -la total 32840 drwxr-xr-x 3 root wheel 32768 Nov 14 10:24 . drwxr-xr-x 20 root wheel 512 Nov 14 10:46 .. drwxrwxr-x 2 root operator 512 Nov 14 10:24 .snap -r-------- 1 root wheel 33554432 Nov 14 10:24 .sujournalSUJを有効にしたので、いくつか隠しファイルが存在しています。
5. fstabに記述する
FreeBSDにおいても
/etc/fstabを書くと自動的にマウントされるようになります。/etc/fstab# Device Mountpoint FStype Options Dump Pass# /dev/gpt/rootfs / ufs rw 1 1 /deb/gpt/ebs32g /backupfs ufs rw 0 2rootfs は参考のために記載しています。
Pass#を2にしているのは、journaling を行うファイルシステムを選んだので fsck をかけてから mount したほうが良いだろうと思ったためです。アタッチ直後のディスクはFreeBSDからどう見えるか?
dmesgのログxbd0: 20480MB <Virtual Block Device> at device/vbd/768 on xenbusb_front0 xbd0: attaching as ada0 xbd5: 32768MB <Virtual Block Device> at device/vbd/51792 on xenbusb_front0 Trying to mount root from ufs:/dev/gpt/rootfs [rw]...FreeBSD のハードディスクデバイスとして読み替えられていません。
/dev/の下$ ls -lad /dev/ada* /dev/x* crw-r----- 1 root operator 0x54 Nov 14 07:56 /dev/ada0 crw-r----- 1 root operator 0x55 Nov 14 07:56 /dev/ada0p1 crw-r----- 1 root operator 0x56 Nov 14 07:56 /dev/ada0p2 crw-r----- 1 root operator 0x57 Nov 14 07:56 /dev/xbd5 dr-xr-xr-x 2 root wheel 512 Nov 14 07:56 /dev/xen crw------- 1 root operator 0x3f Nov 14 07:56 /dev/xpt0
xbd0から読み替えられたada0にはパーティションがあるようですが、xbd5には何もないようです。camcontrolの実行結果# camcontrol devlist -v scbus0 on ata0 bus 0: <> at scbus0 target -1 lun ffffffff () scbus1 on ata1 bus 0: <> at scbus1 target -1 lun ffffffff () scbus-1 on xpt0 bus 0: <> at scbus-1 target -1 lun ffffffff (xpt0)見えていません。ada0 に読み替えられたはずのデバイスも見当たらないのがちょっと不思議。
geomの表示$ geom -t Geom Class Provider ada0 DISK ada0 ada0 PART ada0p1 ada0p1 LABEL gpt/bootfs gpt/bootfs DEV ada0p1 LABEL gptid/87a6c21c-2650-11eb-831e-5dad1bdd57fb gptid/87a6c21c-2650-11eb-831e-5dad1bdd57fb DEV ada0p1 DEV ada0 PART ada0p2 ada0p2 LABEL gpt/rootfs ffs.gpt/rootfs VFS gpt/rootfs DEV ada0p2 DEV ada0 DEV xbd5 DISK xbd5 xbd5 DEVgpart$ gpart show => 3 41943029 ada0 GPT (20G) 3 116 1 freebsd-boot (58K) 119 41942913 2 freebsd-ufs (20G)MBRもGPTも切ってないので見えるのは既存のストレージだけです。/dev/gpt 以下にも新しいストレージの情報は当然ありません。
参考記事
追加のブロックストレージディスクを作成して Linux ベースの Lightsail インスタンスにアタッチする
GEOM jounral の設定: uyota 匠の一手
FreeBSD Soft Updatesの弱点を克服するジャーナル機能 - BSDCan 2010
- 投稿日:2020-11-14T20:09:21+09:00
EIP+セキュリティグループでセキュアにしたAWS Transfer for SFTPをTerraformで構築する
はじめに
AWS Transfer for SFTPはマネージドなSFTPサーバをサクッと立てることができる素晴らしいサービス。
素のままではVPCのリソースではないが、2020年の1月にVPC経由でEIPをアタッチしてセキュリティグループによりセキュアにアクセスできるようになった。構成図についてはクラスメソッド先生のこの記事が分かりやすい。
この構成は、マネージメントコンソールでは簡単に作れるが、Terraformで実現しようとするとちょっとクセがある部分があるため、そこも含めてどうやって実装するかを検討する(2020年11月時点の話。将来的にはもっと簡単に作れるようになると思う)。
全体構成
全体構成としては以下のようになる。
ただし、VPC とパブリックなサブネット2つ、SSH のインバウンド通信を許容するセキュリティグループは既に作ってあって、data source で参照する前提とする。terraform/ ├── 01_main.tf ├── 02_variable.tf ├── 03_datasource.tf ├── 11_eip.tf ├── 12_iam.tf ├── 13_s3.tf ├── 14_transfer.tf └── 15_vpcendpoint.tfTerraformリソース
EIP
これは特に難しいことはない。パブリックなサブネット2つにアタッチするEIPを用意しておけばよい。
※たぶん1つでも問題ない11_eip.tf############################################################################### # EIP # ############################################################################### resource "aws_eip" "sftp1" { vpc = true } resource "aws_eip" "sftp2" { vpc = true }IAM
IAM については、AWS Transfer for SFTP のサーバが CloudWatch Logs にログを出力するための権限と、接続してくるユーザが S3 にアクセスするための権限を用意する必要がある。
いずれも principals はtransfer.amazonaws.comで良い。12_iam.tf################################################################################ # IAM Role for Transfer for SFTP Server # ################################################################################ resource "aws_iam_role" "sftp_server" { name = local.sftp_server_role_name assume_role_policy = data.aws_iam_policy_document.sftp_server_assume.json } data "aws_iam_policy_document" "sftp_server_assume" { statement { effect = "Allow" actions = [ "sts:AssumeRole", ] principals { type = "Service" identifiers = [ "transfer.amazonaws.com", ] } } } resource "aws_iam_role_policy_attachment" "sftp_server" { role = aws_iam_role.sftp_server.name policy_arn = aws_iam_policy.sftp_server.arn } resource "aws_iam_policy" "sftp_server" { name = local.sftp_server_policy_name policy = data.aws_iam_policy_document.sftp_server_custom.json } data "aws_iam_policy_document" "sftp_server_custom" { statement { effect = "Allow" actions = [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", ] resources = [ "*", ] } } ################################################################################ # IAM Role for Transfer for SFTP User # ################################################################################ resource "aws_iam_role" "sftp_user" { name = local.sftp_user_role_name assume_role_policy = data.aws_iam_policy_document.sftp_user_assume.json } data "aws_iam_policy_document" "sftp_user_assume" { statement { effect = "Allow" actions = [ "sts:AssumeRole", ] principals { type = "Service" identifiers = [ "transfer.amazonaws.com", ] } } } resource "aws_iam_role_policy_attachment" "sftp_user" { role = aws_iam_role.sftp_user.name policy_arn = aws_iam_policy.sftp_user.arn } resource "aws_iam_policy" "sftp_user" { name = local.sftp_user_policy_name policy = data.aws_iam_policy_document.sftp_user_custom.json } data "aws_iam_policy_document" "sftp_user_custom" { statement { effect = "Allow" actions = [ "s3:*", ] resources = [ "${aws_s3_bucket.sftp.arn}", "${aws_s3_bucket.sftp.arn}/*", ] } }S3バケット
S3 のバケットは、最小権限を考えると個別に用意し、IAMで↑のようにアクセス範囲を絞った方が良い。
なお、外部ユーザのアクセスではあるが、IAMで制御しているため、ACL はprivateで問題ない。13_s3.tf################################################################################ # S3 # ################################################################################ resource "aws_s3_bucket" "sftp" { bucket = local.bucket_name acl = "private" }AWS Transfer for SFTP
いよいよ本題。
サーバ、ユーザ、SSHキーの設定をすることになる。サーバ
今回の、EIP+セキュリティグループを使う場合は、
endpoint_typeにVPCを設定しよう。
その上で、endpoint_detailsで VPC、サブネット、EIPのIPアドレス情報を設定する。14_transfer.tf(抜粋)############################################################################### # Transfer for SFTP # ############################################################################### resource "aws_transfer_server" "sftp" { identity_provider_type = "SERVICE_MANAGED" endpoint_type = "VPC" endpoint_details { vpc_id = data.aws_vpc.my.id subnet_ids = data.aws_subnet_ids.my_vpc.ids address_allocation_ids = [ aws_eip.sftp1.id, aws_eip.sftp2.id, ] } logging_role = aws_iam_role.sftp_server.arn }ユーザ
ユーザの設定では、ホームディレクトリのマッピングをする。
entryが、sftp 接続をした際のデフォルトパスで、targetが実際のパスになる。
下記の設定をすることで、トップディレクトリが今回のために用意したバケットになり、../ にアクセスしても上位のバケット一覧は取れなくなっていてセキュアだ。14_transfer.tf(抜粋)resource "aws_transfer_user" "sftp_user" { server_id = aws_transfer_server.sftp.id user_name = local.sftp_user_name role = aws_iam_role.sftp_user.arn home_directory_type = "LOGICAL" home_directory_mappings { entry = "/" target = "/${local.bucket_name}" } }SSHキー
SSHキーは、自分で
$ ssh-keygen -P "" -f [鍵ファイル名]しても良いが、せっかくだから全部Terraformで書いてみよう。
tls_private_keyのプロバイダを使い、公開鍵をSFTPのユーザに設定し、秘密鍵でアクセスすることが可能だ。
local_fileでprovisionerを使っているのは、SSHでは鍵ファイルのパーミッションで自分以外に権限がついているとエラーになるためだ。14_transfer.tf(抜粋)resource "aws_transfer_ssh_key" "sftp" { server_id = aws_transfer_server.sftp.id user_name = aws_transfer_user.sftp_user.user_name body = tls_private_key.sftp.public_key_openssh } resource "tls_private_key" "sftp" { algorithm = "RSA" rsa_bits = 2048 } resource "local_file" "private_key" { filename = local.private_key_file content = tls_private_key.sftp.private_key_pem provisioner "local-exec" { command = "chmod 600 ${local.private_key_file}" } }さて、ここで準備が完了したので
terraform applyしてアクセスしようとしても到達しない。
ここまで読んで既に気付いている人もいるだろうが、セキュリティグループの設定がここまで登場しない。この構成のミソは、セキュリティグループはSFTPサーバではなく、あくまでもVPCエンドポイントにアタッチされているということだ。マネージメントコンソールでは、TransferをVPCタイプで起動した際に良い感じにこのアタッチをしてくれているだけだ。
そして、2020年11月時点では、1回の apply ではVPCタイプのVPCエンドポイントの情報を取得することはできないし、自分で定義したものを紐付けることもできない。
VPCエンドポイント
仕方がないので、一旦ここで区切って、
$ terraform import aws_vpc_endpoint.sftp [払い出されたVPCエンドポイントID]でインポートしてあげよう。
インポートの際には、以下のリソースを準備しておく。15_vpcendpoint.tf############################################################################### # VPC Endpoint # ############################################################################### resource "aws_vpc_endpoint" "sftp" { # count = 0 vpc_endpoint_type = "Interface" service_name = "com.amazonaws.ap-northeast-1.transfer.server.c-0002" vpc_id = data.aws_vpc.my.id subnet_ids = data.aws_subnet_ids.my_vpc.ids security_group_ids = [ data.aws_security_group.ssh.id, ] tags = { Name = local.sftp_vpce_name } }初回の apply 時にはこのリソースは邪魔になるので
count = 0を入れておき、import が完了したらこの行をコメントアウトして再度 apply することで、エンドポイントにアタッチされたデフォルトのセキュリティグループを消しつつ、SSHのセキュリティグループを設定することが可能だ。ついでに Name で識別子を設定しておこう。いざ、動かす!
さて、ここまで完了したは後はアクセスするだけだ。
$ sftp -i [HCL:14_transfer.tfで作成した秘密鍵] [ユーザ名]@s-xxxxxxxxxxxxxxxxx.server.transfer.[リージョン].amazonaws.com Connected to s-xxxxxxxxxxxxxxxxx.server.transfer.ap-northeast-1.amazonaws.com. sftp>よし!接続することができた!もちろん、ちゃんと
lsもputもできるので、色々試してみよう!
- 投稿日:2020-11-14T18:25:16+09:00
Web Identity Federation、Cognitoをざっくり理解する
Web Identity Federationとは?
例えば、
DynamoDB SDKを使ってDynamoDBにアクセスする際にアクセスキーが必要となりますが、アプリに埋め込むのは当然ながら非推奨デス。これをいい感じに解決しAWSリソースに対するアクセスを許可させる方法が
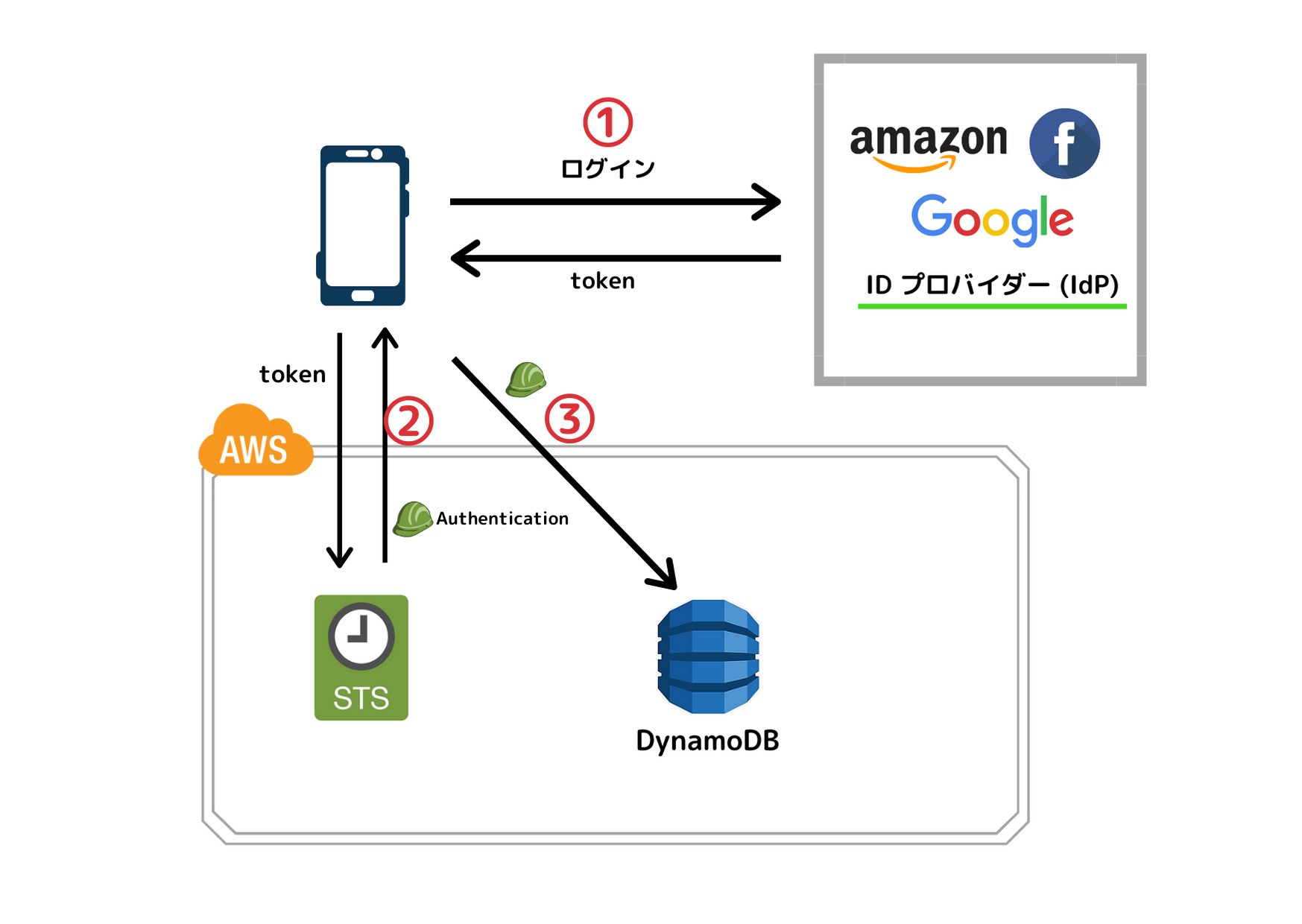
SecurityTokenService(STS)を用いたWeb Identity Federationです。①ユーザーに一般的なサードパーティー ID プロバイダー (Login with Amazon、Facebook、Google、OpenID Connect (OIDC) 2.0 互換の任意のプロバイダーなど) を使用したサインインを求めることができます。②,③そのプロバイダーの認証情報を AWS アカウントのリソースを使用するための一時的なアクセス許可に変換することができます。 IAM の一時的なセキュリティ認証情報
①amazonのアカウントにログイン、amazon(IdP)からtokenが返ってくる。
②そのtokenをSTSに渡すとSTSは期限つきのIAMロール(AssumeRole)を発行
③AssumeRoleを使いDynamoDBにアクセス①が認証、②③が認可という関係になりますね。
簡単に書きましたが実装にはIAM側での設定などが必要になります。IAM ID プロバイダーの作成そんな
Web Identity Federationをアプリケーションで使う際に推奨されているのがAWS Cognito!AWS Cognitoとは?
ウェブアプリケーションやモバイルアプリケーションの認証、許可、ユーザー管理をサポートしてくれます!
Cognitoのコンポーネント
コンポーネントは主にユーザープール、IDプールの2つで構成されています。
◯ユーザープール
ユーザープールはユーザーの認証と管理を行うコンポーネント
■ 認証方法
ユーザー名 (設定でメールアドレスや電話番号も使用可) とパスワードを入力してログイン認証(Cognitoユーザープールが提供する認証機能)
外部IDプロバイダーと連携した認証(Facebook, Google, Amazon, Apple)
Cognitoユーザープールが提供する認証機能はユーザー自身がサインアップを行い登録、また管理者が事前に登録する事もできます。
■ 認証されたユーザー情報はどこに登録される?
認証されたユーザー情報はユーザープールに登録されます。
認証された証としてIDトークンが発行され、このIDトークンを使い、アプリケーションがユーザーを特定したり、他のサービスとの連携を行うことが出来ます。◯IDプール
外部IDプロバイダーによって認証されたIDに対して、AWSへのアクセス権限を持つ
一時クレデンシャルを返すコンポーネント■ 認証方法
- 外部IDプロバイダー認証(Cognitoユーザープール, Amazon, Facebook, Google, Twitter, OIDCに準拠したプロバイダー, SAMLに準拠したプロバイダー)
■ ユーザープールとの違いは?
- ユーザープールは認証を行うコンポーネント
- IDプールは認可を行うコンポーネント
どちらのコンポーネントも外部プロバイダー認証(IdP)を使えますが、IDプールでは認証後に付与される
一時クレデンシャルを使い、アクセスが許可されているAWSリソースに対してアクセスすることができます。◯ユーザープールとIDプール
IDプールのIdPにユーザープールを指定可能です。つまり、ユーザープールトークンとIDプールトークン (STS)は交換することが可能です。
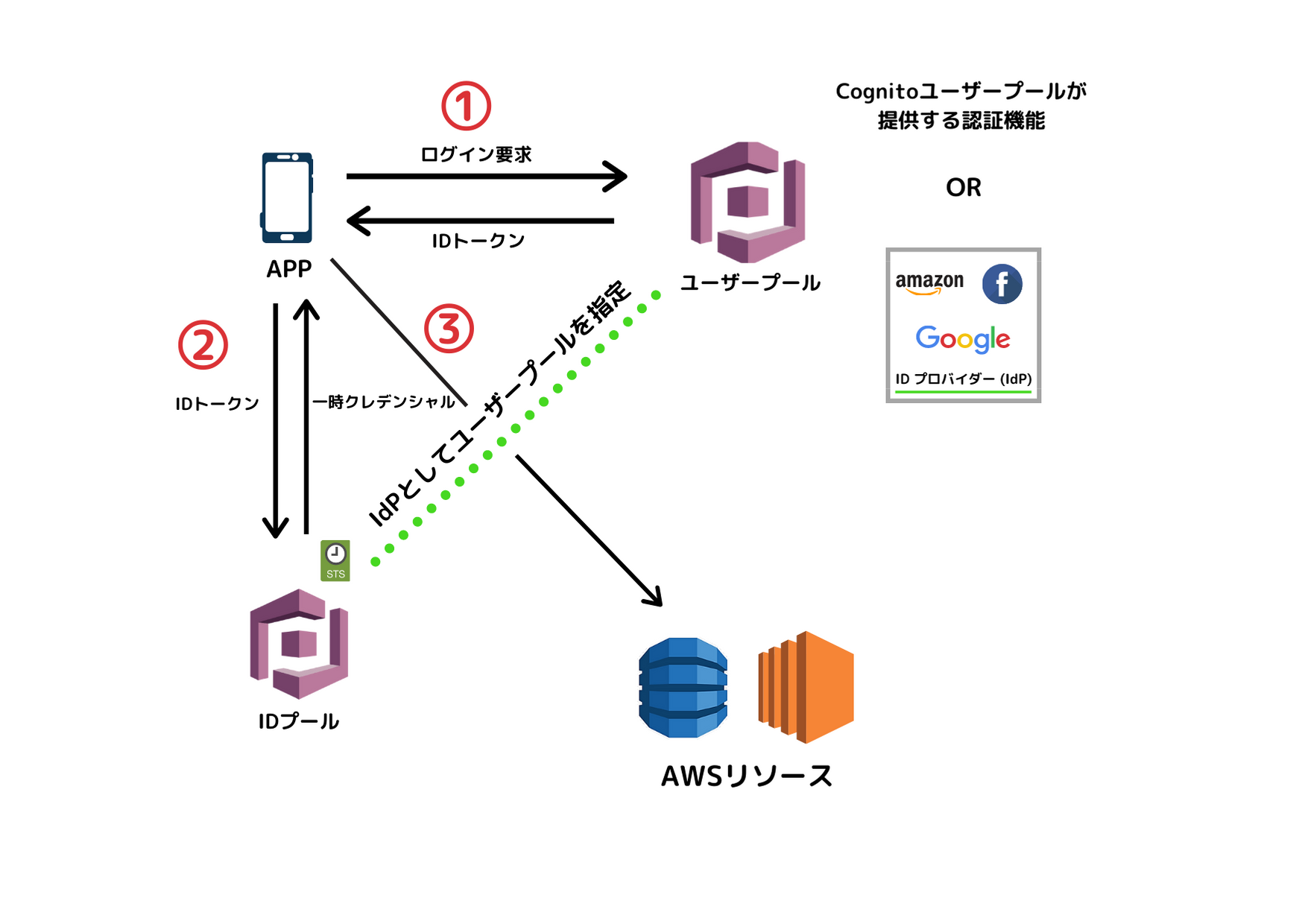
下の図を見るとわかりやすいと思います!
①アプリにアクセスするとログイン画面にリダイレクト認証を行う
②IDプールのIdPとしてユーザープールを指定することでユーザープールのIDトークンから一時クレデンシャルを返す
③一時クレデンシャルを使いアクセスが許可されているAWSリソースに対してアクセスハンズオンも書く予定でしたが疲れたので次回にします
笑
Cognito初心者なので間違ってるところあれば教えてください!参考
ウェブ ID フェデレーションについて
AWS再入門ブログリレー Amazon Cognito編
[AWS Black Belt Online Seminar] Amazon Cognito 資料及び QA 公開
- 投稿日:2020-11-14T18:25:16+09:00
WebIdentityFederationとCognitoをざっくり
Web Identity Federationとは?
例えば、
DynamoDB SDKを使ってDynamoDBにアクセスする際にアクセスキーが必要となりますが、アプリに埋め込むのは当然ながら非推奨デス。これをいい感じに解決しAWSリソースに対するアクセスを許可させる方法が
SecurityTokenService(STS)を用いたWeb Identity Federationです。①ユーザーに一般的なサードパーティー ID プロバイダー (Login with Amazon、Facebook、Google、OpenID Connect (OIDC) 2.0 互換の任意のプロバイダーなど) を使用したサインインを求めることができます。②,③そのプロバイダーの認証情報を AWS アカウントのリソースを使用するための一時的なアクセス許可に変換することができます。 IAM の一時的なセキュリティ認証情報
①amazonのアカウントにログイン、amazon(IdP)からtokenが返ってくる。
②そのtokenをSTSに渡すとSTSは期限つきのIAMロール(AssumeRole)を発行
③AssumeRoleを使いDynamoDBにアクセス①が認証、②③が認可という関係になりますね。
簡単に書きましたが実装にはIAM側での設定などが必要になります。IAM ID プロバイダーの作成そんな
Web Identity Federationをアプリケーションで使う際に推奨されているのがAWS Cognito!AWS Cognitoとは?
ウェブアプリケーションやモバイルアプリケーションの認証、許可、ユーザー管理をサポートしてくれます!
Cognitoのコンポーネント
コンポーネントは主にユーザープール、IDプールの2つで構成されています。
◯ユーザープール
ユーザープールはユーザーの認証と管理を行うコンポーネント
■ 認証方法
ユーザー名 (設定でメールアドレスや電話番号も使用可) とパスワードを入力してログイン認証(Cognitoユーザープールが提供する認証機能)
外部IDプロバイダーと連携した認証(Facebook, Google, Amazon, Apple)
Cognitoユーザープールが提供する認証機能はユーザー自身がサインアップを行い登録、また管理者が事前に登録する事もできます。
■ 認証されたユーザー情報はどこに登録される?
認証されたユーザー情報はユーザープールに登録されます。
認証された証としてIDトークンが発行され、このIDトークンを使い、アプリケーションがユーザーを特定したり、他のサービスとの連携を行うことが出来ます。◯IDプール
外部IDプロバイダーによって認証されたIDに対して、AWSへのアクセス権限を持つ
一時クレデンシャルを返すコンポーネント■ 認証方法
- 外部IDプロバイダー認証(Cognitoユーザープール, Amazon, Facebook, Google, Twitter, OIDCに準拠したプロバイダー, SAMLに準拠したプロバイダー)
■ ユーザープールとの違いは?
- ユーザープールは認証を行うコンポーネント
- IDプールは認可を行うコンポーネント
どちらのコンポーネントも外部プロバイダー認証(IdP)を使えますが、IDプールでは認証後に付与される
一時クレデンシャルを使い、アクセスが許可されているAWSリソースに対してアクセスすることができます。◯ユーザープールとIDプール
IDプールのIdPにユーザープールを指定可能です。つまり、ユーザープールトークンとIDプールトークン (STS)は交換することが可能です。
下の図を見るとわかりやすいと思います!
①アプリにアクセスするとログイン画面にリダイレクト認証を行う
②IDプールのIdPとしてユーザープールを指定することでユーザープールのIDトークンから一時クレデンシャルを返す
③一時クレデンシャルを使いアクセスが許可されているAWSリソースに対してアクセスハンズオンも書く予定でしたが疲れたので次回にします
Cognito初心者なので間違ってるところあれば教えてください!参考
ウェブ ID フェデレーションについて
AWS再入門ブログリレー Amazon Cognito編
[AWS Black Belt Online Seminar] Amazon Cognito 資料及び QA 公開
- 投稿日:2020-11-14T18:25:16+09:00
WebIdentityFederationとCognito
Web Identity Federationとは?
例えば、
DynamoDB SDKを使ってDynamoDBにアクセスする際にアクセスキーが必要となりますが、アプリに埋め込むのは当然ながら非推奨デス。これをいい感じに解決しAWSリソースに対するアクセスを許可させる方法が
SecurityTokenService(STS)を用いたWeb Identity Federationです。①ユーザーに一般的なサードパーティー ID プロバイダー (Login with Amazon、Facebook、Google、OpenID Connect (OIDC) 2.0 互換の任意のプロバイダーなど) を使用したサインインを求めることができます。②,③そのプロバイダーの認証情報を AWS アカウントのリソースを使用するための一時的なアクセス許可に変換することができます。 IAM の一時的なセキュリティ認証情報
①amazonのアカウントにログイン、amazon(IdP)からtokenが返ってくる。
②そのtokenをSTSに渡すとSTSは期限つきのIAMロール(AssumeRole)を発行
③AssumeRoleを使いDynamoDBにアクセス①が認証、②③が認可という関係になりますね。
簡単に書きましたが実装にはIAM側での設定などが必要になります。IAM ID プロバイダーの作成そんな
Web Identity Federationをアプリケーションで使う際に推奨されているのがAWS Cognito!AWS Cognitoとは?
ウェブアプリケーションやモバイルアプリケーションの認証、許可、ユーザー管理をサポートしてくれます!
Cognitoのコンポーネント
コンポーネントは主にユーザープール、IDプールの2つで構成されています。
◯ユーザープール
ユーザープールはユーザーの認証と管理を行うコンポーネント
■ 認証方法
ユーザー名 (設定でメールアドレスや電話番号も使用可) とパスワードを入力してログイン認証(Cognitoユーザープールが提供する認証機能)
外部IDプロバイダーと連携した認証(Facebook, Google, Amazon, Apple)
Cognitoユーザープールが提供する認証機能はユーザー自身がサインアップを行い登録、また管理者が事前に登録する事もできます。
■ 認証されたユーザー情報はどこに登録される?
認証されたユーザー情報はユーザープールに登録されます。
認証された証としてIDトークンが発行され、このIDトークンを使い、アプリケーションがユーザーを特定したり、他のサービスとの連携を行うことが出来ます。◯IDプール
外部IDプロバイダーによって認証されたIDに対して、AWSへのアクセス権限を持つ
一時クレデンシャルを返すコンポーネント■ 認証方法
- 外部IDプロバイダー認証(Cognitoユーザープール, Amazon, Facebook, Google, Twitter, OIDCに準拠したプロバイダー, SAMLに準拠したプロバイダー)
■ ユーザープールとの違いは?
- ユーザープールは認証を行うコンポーネント
- IDプールは認可を行うコンポーネント
どちらのコンポーネントも外部プロバイダー認証(IdP)を使えますが、IDプールでは認証後に付与される
一時クレデンシャルを使い、アクセスが許可されているAWSリソースに対してアクセスすることができます。◯ユーザープールとIDプール
IDプールのIdPにユーザープールを指定可能です。つまり、ユーザープールトークンとIDプールトークン (STS)は交換することが可能です。
下の図を見るとわかりやすいと思います!
①アプリにアクセスするとログイン画面にリダイレクト認証を行う
②IDプールのIdPとしてユーザープールを指定することでユーザープールのIDトークンから一時クレデンシャルを返す
③一時クレデンシャルを使いアクセスが許可されているAWSリソースに対してアクセスハンズオンも書く予定でしたが疲れたので次回にします
Cognito初心者なので間違ってるところあれば教えてください!参考
ウェブ ID フェデレーションについて
AWS再入門ブログリレー Amazon Cognito編
[AWS Black Belt Online Seminar] Amazon Cognito 資料及び QA 公開
- 投稿日:2020-11-14T17:34:47+09:00
AWS12ヵ月無料利用期間終了後に利用予想額:48,258円で恐怖した話
私がAWSアカウントを作成してから1年が経過しました。
AWSには無料利用枠があります。その中でも「12ヵ月無料利用枠」というものがあり、これを経過したあとに課金された悲劇の記事は幾度となく目にしてきました。例えば以下のようなEC2サービスやS3サービスがそれにあたります。
私は先人の失敗を糧として、10月中に不要なリソースはすべて削除しておきました。
恐怖体験
そして、迎えた無料期間終了後の11月。
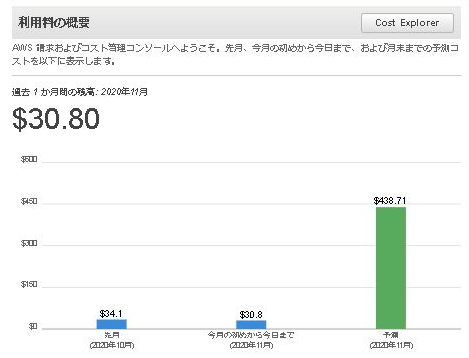
私はログインして「請求情報とコスト管理ダッシュボード」で状況を確認してみました。
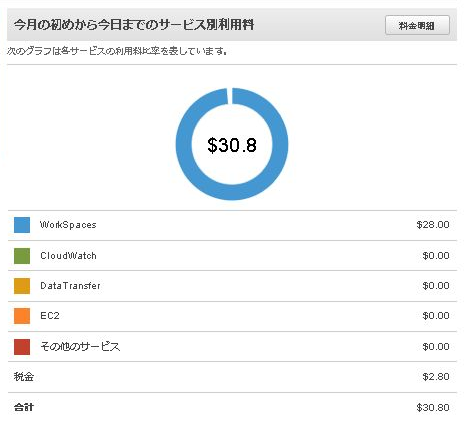
えっ、
『$ 438.71』(1ドル110円換算で48,258円)
…
…
…
…
11月の「予想」額が5万円近くになっていたのです・・・・
久々に焦りました。
不要なAWSサービスはすべて消したはずなのに、何故予想額がこんな金額に!!!
まだ消し忘れているサービスがあるのでは???かなり焦って色々と調べました。
結論
原因は「WorkSpaces」と「請求情報とコスト管理ダッシュボード」の「予想」機能の仕様でした。
私は「WorkSpaces」を検証中のため残していたのですが、「WorkSpaces」は月額固定利用なので月頭に月額$28が課金されています。どうやら「請求情報とコスト管理ダッシュボードの「予想」機能は月額のサービスかどうかは関係なく、その期間の利用料で11月中使用し続けた場合の金額を単純に算出しているだけのようなのです。
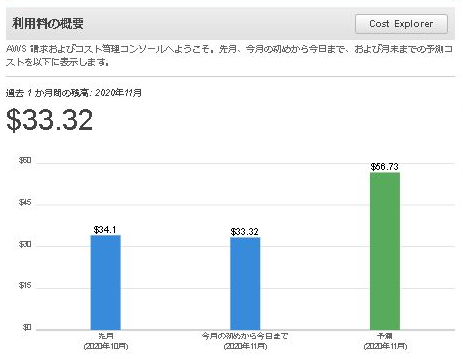
当初の予想は11月3日時点のものでしたが、11月14日時点では『$ 56.73』(1ドル110円換算で6,240.3円)まで落ちていました。日夜予想額は下がっていっています。
AWSの「予想」機能は月額固定利用サービスとか関係なしの様です。
とにかく、かなり驚かされました。
同じ失敗をしない為にも、ここに記録を残しておきます。
無料利用枠が終了する方は、私と同じ点で驚かないようにご注意ください。
- 投稿日:2020-11-14T17:34:47+09:00
AWS12ヵ月無料利用期間終了後に利用予想額:48,258円で恐怖した話(2020年11月)
私がAWSアカウントを作成してから1年が経過しました。
AWSには無料利用枠があります。その中でも「12ヵ月無料利用枠」というものがあり、これを経過したあとに課金された悲劇の記事は幾度となく目にしてきました。例えば以下のようなEC2サービスやS3サービスがそれにあたります。
私は先人の失敗を糧として、10月中に不要なリソースはすべて削除しておきました。
恐怖体験
そして、迎えた無料期間終了後の11月。
私はログインして「請求情報とコスト管理ダッシュボード」で状況を確認してみました。
えっ、
『$ 438.71』(1ドル110円換算で48,258円)
…
…
…
…
11月の「予想」額が5万円近くになっていたのです・・・・
久々に焦りました。
不要なAWSサービスはすべて消したはずなのに、何故予想額がこんな金額に!!!
まだ消し忘れているサービスがあるのでは???かなり焦って色々と調べました。
結論
原因は「WorkSpaces」と「請求情報とコスト管理ダッシュボード」の「予想」機能の仕様でした。
私は「WorkSpaces」を検証中のため残していたのですが、「WorkSpaces」は月額固定利用なので月頭に月額$28が課金されています。どうやら「請求情報とコスト管理ダッシュボードの「予想」機能は月額のサービスかどうかは関係なく、その期間の利用料で11月中使用し続けた場合の金額を単純に算出しているだけのようなのです。
当初の予想は11月3日時点のものでしたが、11月14日時点では『$ 56.73』(1ドル110円換算で6,240.3円)まで落ちていました。日夜予想額は下がっていっています。
AWSの「予想」機能は月額固定利用サービスとか関係なしの様です。
とにかく、かなり驚かされました。
同じ失敗をしない為にも、ここに記録を残しておきます。
無料利用枠が終了する方は、私と同じ点で驚かないようにご注意ください。

- 投稿日:2020-11-14T17:34:47+09:00
AWS12ヵ月無料利用期間終了後に利用予想額:48,258円の恐怖体験(2020年11月)
私がAWSアカウントを作成してから1年が経過しました。
AWSには無料利用枠があります。その中でも「12ヵ月無料利用枠」というものがあり、これを経過したあとに課金された悲劇の記事は幾度となく目にしてきました。例えば以下のようなEC2サービスやS3サービスがそれにあたります。
私は先人の失敗を糧として、10月中に不要なリソースはすべて削除しておきました。
恐怖体験
そして、迎えた無料期間終了後の11月。
私はログインして「請求情報とコスト管理ダッシュボード」で状況を確認してみました。
えっ、
『$ 438.71』(1ドル110円換算で48,258円)
…
…
…
…
11月の「予想」額が5万円近くになっていたのです・・・・
久々に焦りました。
不要なAWSサービスはすべて消したはずなのに、何故予想額がこんな金額に!!!
まだ消し忘れているサービスがあるのでは???かなり焦って色々と調べました。
結論
原因は「WorkSpaces」と「請求情報とコスト管理ダッシュボード」の「予想」機能の仕様でした。
私は「WorkSpaces」を検証中のため残していたのですが、「WorkSpaces」は月額固定利用なので月頭に月額$28が課金されています。どうやら「請求情報とコスト管理ダッシュボードの「予想」機能は月額のサービスかどうかは関係なく、その期間の利用料で11月中使用し続けた場合の金額を単純に算出しているだけのようなのです。
当初の予想は11月3日時点のものでしたが、11月14日時点では『$ 56.73』(1ドル110円換算で6,240.3円)まで落ちていました。日夜予想額は下がっていっています。
AWSの「予想」機能は月額固定利用サービスとか関係なしの様です。
とにかく、かなり驚かされました。
同じ失敗をしない為にも、ここに記録を残しておきます。
無料利用枠が終了する方は、私と同じ点で驚かないようにご注意ください。

- 投稿日:2020-11-14T16:40:43+09:00
資格取得に向けたUdemy活用術【2020年12月時点】
今年度はとにかくUdemyにお世話になったので、感謝の気持ちを込めて「Udemy Advent Calendar 2020」に投稿することにしました。
■Udemyとの出会い
私がUdemyを活用しだしたのはAWSの資格取得を目指していた時でした。
AWSの資格は「アソシエイト」という中級資格と「プロフェッショナル」という上級資格があります。「アソシエイト」までは参考書や問題集が何種類か販売されていて、それを購入して乗り切れました。しかし、「プロフェッショナル」は当時問題集がほとんどなく、初回の受験では不合格となってしまいました。模擬問題の実施不足が影響したと考えた私は、とにかく手当たり次第に模擬問題集を探して実施することにしました。その際に見つけたのがUdemyの講座でした。■AWS Certified Solutions Architect Professional資格試験での活用
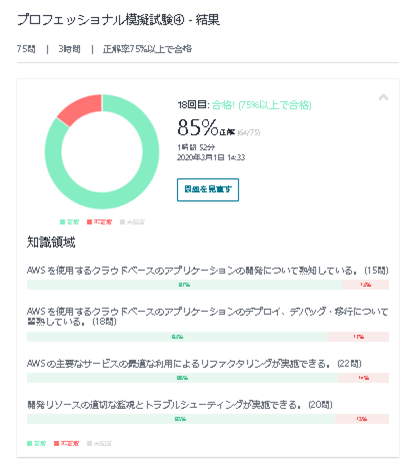
『AWS 認定ソリューションアーキテクト プロフェッショナル模擬試験問題集(全5回分375問)』
その当時珍しかった「プロフェッショナル試験」の問題集でした。とにかく問題数が多く説明もしっかりついているので、学習するのに非常に役立ちました。特に問題の正解以外の選択肢に関して、間違っている理由を解説してくれているのがよかったです。
また、Udemyはスマホのアプリでも閲覧できるので、職場への往復時間はUdemyでずっとこの問題を解いていました。75問×5回の問題があり、問題を開始すると時間もカウントされるので、本番の試験を意識した学習が可能でした。
『AWS Certified Solutions Architect Professional Practice Exam』
問題集を何度もやっていると答えを覚えてしまいます。当時一度試験に落ちていたこともあり、不安だった私が追加で購入した問題集です。その当時他に日本語の問題集が存在せず「英語」の問題集に手を出しました。
英語力のない私には日本語翻訳は必須です。Udemyをパソコンで実施してWebの日本語翻訳機能を使用することで、日本語訳で学習することができました。ただ、スマホのアプリでは日本語訳がうまくいかず、もっぱら帰宅後にパソコンで学習しました。AWSのように模擬問題をどれだけこなすかがポイントになる試験では、Udemyの英語問題集は役に立ちます。
■AWS Certified DevOps Engineer Professional資格試験での活用
『AWS Certified DevOps Engineer Professional』
AWSのプロフェッショナル試験は2つあり、もう一つの試験です。こちらは「AWS Certified Solutions Architect Professional」と違い、当時は本当に日本語版の模擬問題集がありませんでした。その為、引き続き「英語」の問題集を購入して試験勉強しました。こちらは問題数が少なかったですが、問題の傾向を掴むのに役立ってくれました。
資格試験の体験談は別記事「【AWS認定試験】6試験(CLF・SAA・SAP・SOA・DVA・DOP)合格までの道のりと勉強方法について(2020年4月時点)」に記載しています。
■Python3エンジニア認定データ分析試験での活用
【1日で習得】技術者のためのPythonデータ分析
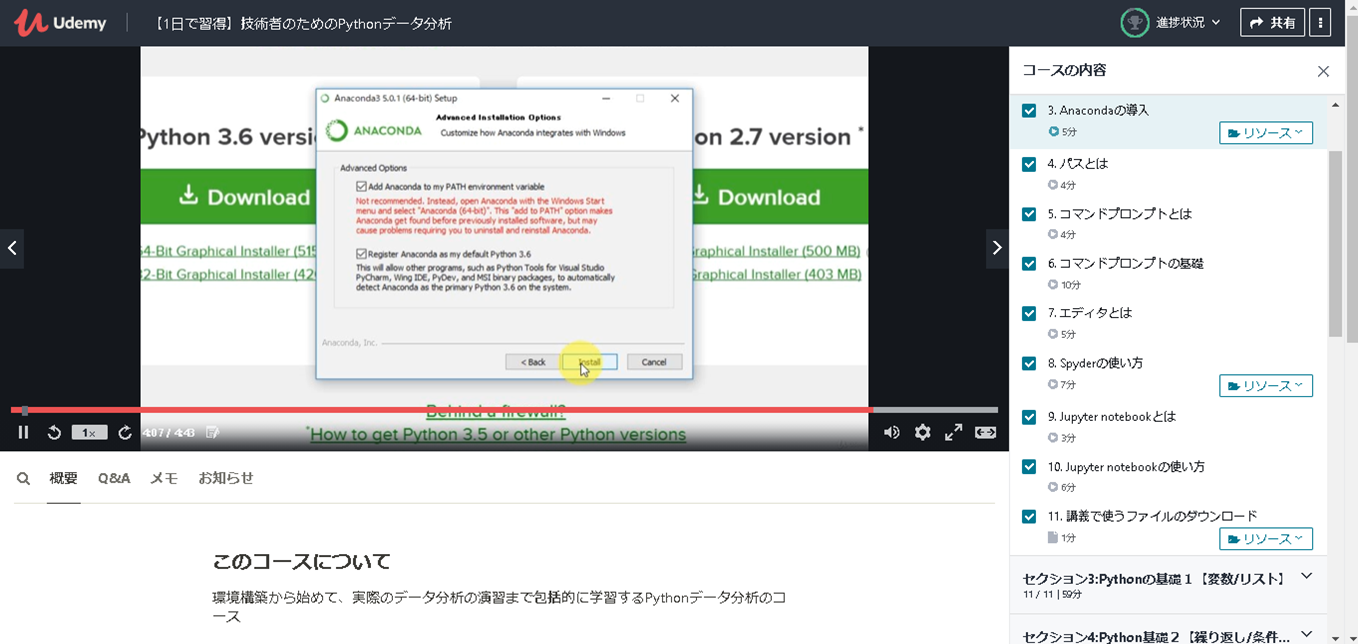
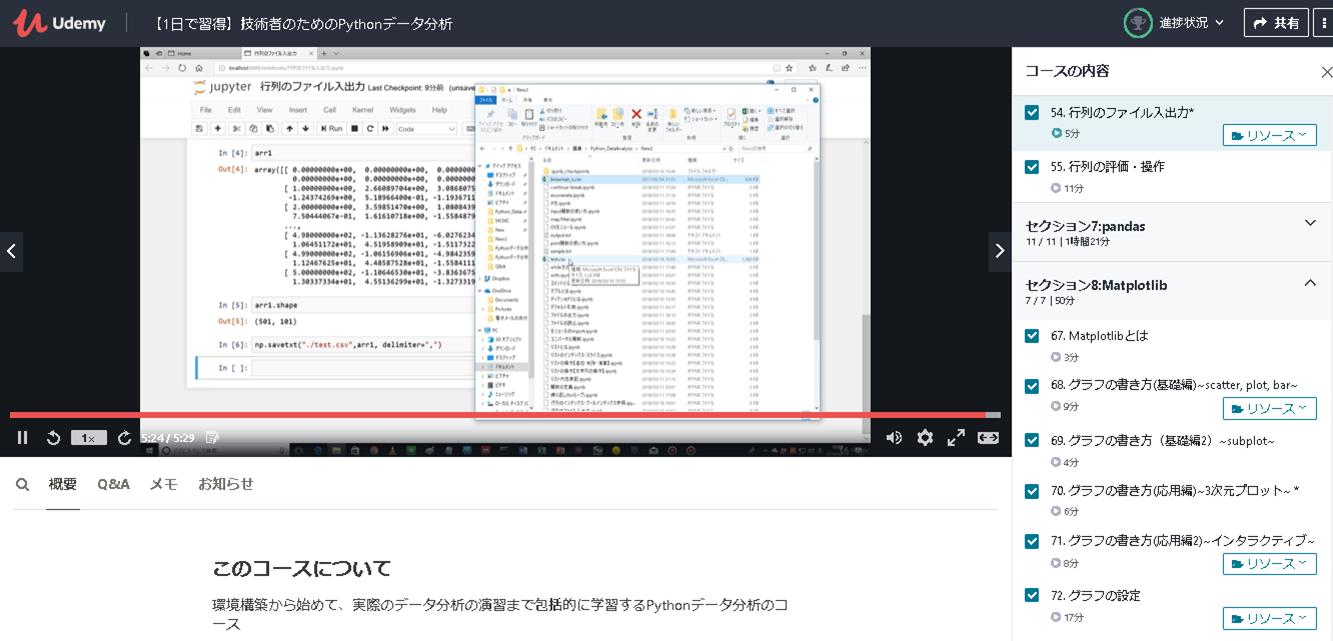
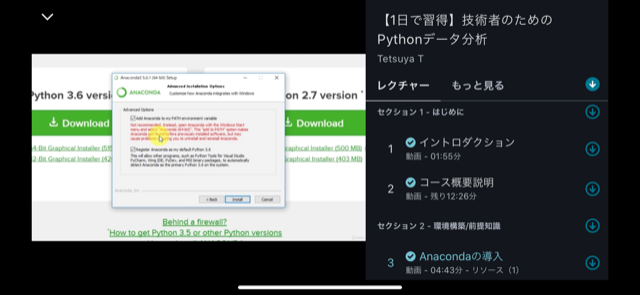
「Python3エンジニア認定データ分析試験」の試験勉強を実施しましたが、初心者の私は「公式テキスト」の内容を理解するのに苦しんでいました。なんとか打開すべく見つけたのが、この講座です。
動画でAnacondaのインストールやSpyder、Jupyter notobookの使い方、Pythonの基本的な操作方法に触れており、非常に解りやすかったです。Numpyより前の章に関しては、「Python3 エンジニア認定基礎試験」を受験する人にもおススメできる内容だと思います。ただし、後の章は「Matplotlib」や「scipy」辺りは難しくなるので、そこら辺と演習問題は最初は流し見をして、2周目で理解する形がよいかと思います。データ分析試験の試験範囲から考えると「数学の基礎」と「scikit-learn」が不足しているので、そこは他の方法で補う必要があります。
ただ、やはり動画の解りやすさは最高でした。
例えば以下の画像はANACONDAのインストール手順の説明です。動画で画面遷移やポイント箇所もすべて丁寧に説明してくれるので間違えることがありません。環境的な部分は文書で読むより動画を一度見た方が理解が何倍も速いです。
こちらはファイル出力・入力等の処理になりますが、非常に理解しやすかったです。
この講座受講が取っ掛りとなり、基礎が理解できたので、試験勉強がスムーズに進みました。
資格試験の体験談は別記事「Python初心者によるPython3エンジニア認定データ分析試験の勉強方法(2020年9月合格)」に記載しています。
■Udemyのよいところ(まとめ)
上記で記載した通りUdemyは資格試験勉強で大いに活用可能です。
私が感じているUdemyのメリットについて以下に纏めて記載ます。
ポイント1:Webならではの機能が使える!
例えば紙の問題集を購入した場合、問題と解答ページを行ったり来たりになりますが、
Udemyなら問題回答後に正誤と解説が表示されるのでスムーズに勉強できます。
問題集などでは終了後に正解率が表示されたり、過去の正解率や問題の正誤結果が表示できます。
そういった学習履歴を管理できる面でも優れていると思います。
ポイント2:スマホでも学習できる!
スマホのアプリがあるので会社への往復時間で学習できます。
進捗は連携されているので、家のPCでログインすればスマホで進んだ部分から学習可能です。
以下はスマホのアプリで表示した際の画面です。
ポイント3:内容が随時更新される!
模擬問題集だと、問題が追加されたりします。
私が購入した問題集に関しては、あとから更新されて150問程度の問題が追加されました。
また、説明内容が古くなったり間違っている場合は、内容が更新されたり注釈が入ったりします。
一度購入したあとに追加費用なく更新を受けることができるのは大きなメリットだと思います。例えば私の受講した『AWS 認定ソリューションアーキテクト プロフェッショナル模擬試験問題集(全5回分375問)』のアップデート履歴では以下のような内容があります。
■演習問題の解説内容をより詳細にアップグレードいたしました。
プロフェッショナル問題がリリースされてから、様々なご質問をいただきまして、解説では詳細がわかりにくい問題があることが判明したため、本日までにすべての演習問題の問題文と解説の全面的なアップグレードをさせていただきました。問題内容自体は同じものとなっておりますが、解説で不正解理由なども詳細にわかるようにしております。こちらからの質問事項等を反映して解説をアップグレードして頂きました。
■模擬試験4の提供開始
模擬試験④を提供開始しました。
過去の3題となるべく新しい範囲と形式の問題としています。新規に模擬問題が追加されました。
このように随時アップデートされていくことは嬉しいところです。
ポイント4:やっぱり動画は最高に解りやすい!
文書がメインのテキストで解らないことも、動画だとすぐに解ったりします。
私も試験勉強中に理解できない部分があるとYoutubeで検索したりして動画を探して視聴すると、一気に理解できて解決することが多々ありました。Udemyでは私が助けられたPythonの講座を含め多くの動画学習ができるコンテンツがあり、非常にお勧めです。ポイント5:外国の模擬問題集講座が活用できる!
AWSのように日本で模擬問題集が発売されていないような資格試験もあります。
そのような試験に関して外国語の講座も公開されています。
現在はWebの日本語翻訳機能も非常に優秀で、模擬問題を少しでも実施したい場合などはお勧めします。英語の翻訳には苦心したので、ポイントを別記事「英語力が無いSEの暫定的な翻訳ツール活用術(2020年9月時点)」に記載しています。もし効率的な翻訳方法知りたい方は参照ください。
ポイント6:製作者に質問ができる!
Udemyでは講義の配信者とUdemy上のメッセージ機能を利用してやり取りが可能です。
こちらの解りにくかったところを製作者に伝えて反映してもらうことも可能です。
相互にやり取りを実施して、アップデートしていけるところも魅力の一つです。
今回、講義画像を利用しているのも、このメッセージ機能で了解を頂いています。■Udemyの注意点(まとめ)
ポイント1:購入するタイミングに注意しよう!
Udemyで教材を購入する時は3か月に1度くらいで開催されるタイムセールスの際に購入することをお勧めします。90%OFFくらいの値引きも多く、例えば、Pythonの講座は普段は10,800円しますが、タイムセールの期間だけ1,400円くらいまで値段が下がっていました。お金のある人は定価で購入して還元してあげてほしいですが、費用を抑えたい人は、タイムセールスの際に購入することを強くおすすめします。ほしい講座を見繕っておいて、タイムセールスのタイミングを狙いましょう。
タイムセールスの際にはWeb画面上に以下のような表示がされます。
その期間だけ驚きの値引きが実施されます・・・・
ポイント2:購入する前に自分の想定している講座か確認しよう!
レビューが記載されているので、レビュー内容を読んで自分の思っている内容か確かめてください。
また、教材の中の「コースの内容」という部分で幾つかの動画がサンプルとして公開されています。この内容を閲覧して、自分に合いそうだと思ってから購入したほうがよいと思います。どんな評価の高い講座でも、自分にあうとは限りません。
ポイント3:最終更新日を確認しよう!
購入する際は最終更新日を注意深く確認しましょう。
定期的に更新されている講座もあれば、全く更新されていない講座もあります。直近で更新されている講座は内容の修正や追加がされている可能性もあります。
これは非常に重要です。
例えば資格試験の場合、試験内容が変更になることが多々あります。せっかく勉強したのに旧試験内容だったでは、せっかくの努力も無駄になってしまいます。また、技術的な動画に関しても更新時期は非常に重要です。私もパブリッククラウドの操作説明動画を購入したりしたのですが、クラウドの操作画面が大きく変わっており、動画の通り実施しようとしてもできない場合がありました。クラウドサービスなどは進化が早く、古い動画だと役に立たない場合もあります。
私はこのポイントが非常に重要だと思っているので、自分がQiitaに投稿する際には年度や記載月を明確に記載するようにしています。その時のベストが今のベストとは限りません。それくらい情報の記載時期というのは重要だと思います。
ポイント4:外国の動画講座は要注意!
よいところ、として外国の模擬問題集を記載しましたが、こちらは動画講座の話です。
模擬問題集はいいです。Webの日本語翻訳機能が非常に優秀なので役に立ちました。
しかし、動画講座は個人的には失敗でした。
一応、日本語の字幕はできるのですが、字幕と動画の内容両方一緒に追えないので、結局英語が苦手な私は活用することができませんでした。外国の動画講座こそ、サンプル動画を必ず視聴してから購入するようにしたほうがよいと思います。■さいごに
どんなものにも良い部分と注意すべき部分があります。
Udemyを活用できるかどうかは本人次第だと思います。
私は少なくともUdemyに幾度となく助けられました。
そしてこれからも助けてもらうと思います。自分に合うかどうかは一度使ってみないと解らないと思います。
自分に合う講座があるか検索して頂き、タイムセールスの際に、是非一度購入してみてください。もし役に立つと思えれば、是非来年度のQiitaの「Udemy Advent Calendar」で投稿してみてください。
アウトプットは非常に大切です。







- 投稿日:2020-11-14T15:46:30+09:00
Presigned URLでAWS S3に動画をアップロードするときのファイルの渡し方
Presigned URLを使ってAWS S3に動画をアップロードするとき,ファイルの渡し方を間違えてかなり時間を無駄にしてしまったので,その知見を共有します.
結論から言うと,HTML5のFileオブジェクトをそのまま渡すとうまくいきました.
FileReaderを使ってDataURIを送ると,データが壊れてしまって再生できないようです.※注意※
- この例ではVue.js+Vuetifyを使用しています.
- ただし,やることは単純なので参考文献等を見ながら適宜読み替えてもらえば,問題ないと思います.1. 成功例
ファイルが選択されたとき,
onVideoPickedにそのFileオブジェクトを渡しています.
そのオブジェクトをそのまま,Presigned URLでPUTすればOKでした.
この例では,他にも送信するものがあるので変数に格納しています.Presigned URLでAWS S3にアップロードする過程は,色々な事例がインターネットにありますので,そちらを参考にしてください.本記事の参考文献にもリンクがあります.
<v-file-input @change="onVideoPicked" ></v-file-input>onVideoPicked(file) { if (file !== undefined && file !== null) { if (file.name.lastIndexOf(".") <= 0) { return; } this.video = file; } else { this = ""; } }2. 失敗例
こちらの例では,ファイルが選択されたときに
FileReaderを使ってDataURIとしています.
これだと,アップロード後にファイルが壊れてしまってうまく再生できませんでした.
また,大きいファイルを選択したとき,非常に時間がかかるか,場合によっては選択できないこともありました.<v-file-input @change="onVideoPicked" ></v-file-input>onVideoPicked(file) { if (file !== undefined && file !== null) { if (file.name.lastIndexOf(".") <= 0) { return; } const fr = new FileReader(); fr.readAsDataURL(file); fr.onload = () => { this.video = fr.result; }; } else { this.video = ""; } }3. 終わり
フロントエンドは罠がいっぱいだと思いました!
4. 参考文献
- 投稿日:2020-11-14T12:29:43+09:00
AWS Direct Connect ってどういうサービス?
勉強前イメージ
オンプレとクラウドを仮想専用線のような機構で繋げる?
調査
AWS Direct Connect とは
オンプレからAWSへの専用ネットワーク接続の構築をするAWSのサービス。
AWS とデータセンター、オフィス、またはコロケーション環境との間にプライベート接続を確立することができます。
ユーザのネットワークといずれかのロケーションとの間に専用のネットワーク接続を確立することができます。
→ AWSと専用線を引くの!?そもそもAWSと接続する方法
SSH接続
オンプレと接続する方法として一番簡潔に行えるのがこのSSH接続。
SSHを使うことによって通信を暗号化しセキュリティを担保します。
こちらは一般のインターネット接続をするので、通信要件がない場合、メンテナンス用途などに適しています。VPN接続
オンプレのシステムの中にVPNルータを設置し、AWSに構築したVPCとVPN接続することで使用できます。
VPN接続でもインターネット回線を使用するため速度はベストエフォート。
ギチギチの要件がある場合は厳しいかもしれないです。AWS Direct Connect
VPN接続でも要件が厳しい..ってときに使われるのがAWS Direct Connect。
オンプレのシステムからAWSまでインターネットを経由しないプライベート接続を実現出来ます。
それ故、他の回線状況の影響を受けないといったメリットがあります。
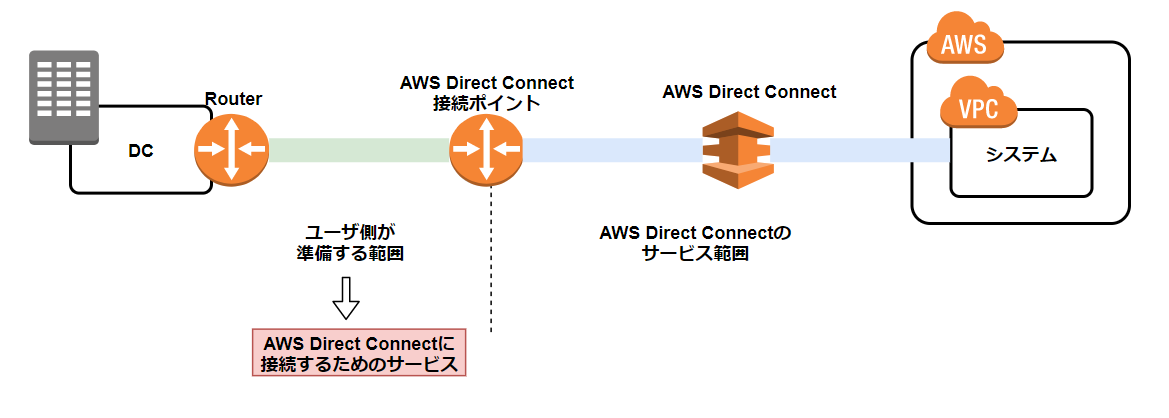
→ オンプレ から AWSまで回線引くってこと???イメージ
- ユーザが準備する範囲 : オンプレ ~ AWS Direct Connectの接続ポイントまで
- AWS Direct Connectのサービス範囲 : AWS Direct Connectの接続ポイント ~ VPNまで
ユーザでAWS Direct Connectの接続ポイントまでは準備をしないといけません
しかしそれはなかなか難しいので、AWS Direct Connectに接続するためのサービスというのが各社あるので、
そちらを利用することで、以下のようになります。
- AWS Direct Connectに接続するためのサービスの範囲 : オンプレ ~ AWS Direct Connectの接続ポイントまで
- AWS Direct Connectのサービス範囲 : AWS Direct Connectの接続ポイント ~ VPNまで
要するに、あまり手間がかからない。
勉強後イメージ
VPNじゃなくて本当にDirect Connectで専用線だったんだ....
要件が厳しいときは、こちらを使えばいいのね。参考
- 投稿日:2020-11-14T12:18:55+09:00
【AWS】AWS認定クラウドプラクティショナー試験前のメモ
勉強する中で、特に覚えにくかったことを断片的にメモ(圧倒的自分用)
フェデレーション
アイデンティティ(本人確認の情報)の連携のこと。
Gmail, Facebook, Twitterなどのログイン時の本人確認情報を、
スマホアプリの本人確認時に利用する仕組み。
SMAL, OpenIDといった技術が利用される。Storage Gateway
ハイブリッドクラウドストレージサービス。
オンプレスから、様々なAWSのストレージを利用できるサービス。
接続には、NFS, SMB, iSCSIなどの標準ストレージプロトコルを使用。
S3, EBS, Backupといったストレージサービスの接続に利用できる。Snowファミリー
ストレージサービス。
物理的デバイスであり、期間限定で利用者に貸し出される。-Snowball
アタッシュケースのようなもの。
~80TBまでの大規模データ転送に適している。-Snowmobile
トラック。
最大100PB(ペタバイト)のデータをコンテナトラックで輸送する。
エクサバイト規模のデジタルメディアの移行に適している。AWS X-Ray
アプリケーション分析・デバックツール。
マイクロサービス間の依存関係を可視化、詳細なトレースデータの提供。AWS Congnito
スマホアプリなどのユーザーアクセスに対するID発行管理サービス。
Amazon Macie
個人情報確認サービス
アセット管理
アセットとは、設備や機器などの資産のこと。
Amazon Lex
チャットボットなどの作成ができるサービス。
Amazon Comprehend
メールやツイートの文章を判別し、分類できるサービス。
Amazon EC2 Auto Scalingグループ
複数のアベイラビリティゾーンでインスタンスの追加や移動ができる。
移動ができる、ってのはポイントのひとつ。Amazon Systems Manager
AWSリソースをグループ化して可視化できるサービス。
アプリやサービスの運用実態を把握することができる。AWS Service Catalog
企業独自のコンプライアンス要件を管理できるCloudFormationテンプレートのまとまり。
コンプライアンス要件を満たしたリソースのプロビジョニングができる。TAM
テクニカルアカウントマネージャの略。
AWSサポートという技術サポートプランで、最上位プランにあたるエンタープライズサポートプランには、このTAMと直接連絡を取ることができる。Amazon Inspector
自動化されたセキュリティ評価サービスにより、 AWS にデプロイされたアプリケーションのセキュリティとコンプライアンスの改善をサポートする。
https://aws.amazon.com/jp/inspector/
- 投稿日:2020-11-14T11:54:49+09:00
未経験者がLaravelでポートフォリオを作成した話【学習開始〜AWSデプロイまで】
簡単に自己紹介
・東京で土木の構造設計をやっている30代前半
・働きつつ、これから転職活動するところ
・健康好きで趣味はアンチエイジングどんなアプリ? 何ができる?
ひとことで言うと
「パレオダイエッター(という健康法をやってる人)向けのコミュニティ+計算機能ツール」
です。
基本的なユースケースとしては、
・「ユーザー登録/ログイン/プロフィール編集」
・「文字や画像を投稿・編集/いいね/コメントで交流」
・「筋肉をつける・腹筋を割るための目標カロリー算出→マイページ登録」
という感じになります。もう少し機能を細分化すると、
・ユーザー登録・ログイン機能・ゲストログイン機能
・プロフィール編集機能(自己紹介文とアバター画像)
・投稿作成機能(モーダル画面,文字数カウント,画像投稿)
・コメント機能
・投稿とコメントの編集・削除機能
・いいね機能(Ajax利用,リレーション数取得)
・効率よく筋肉をつけるための目標摂取カロリーおよび三大栄養素の計算機能(Ajax)
・最速で腹筋を割るための目標摂取カロリーおよび三大栄養素の計算機能(Ajax)
・投稿の検索機能とページネーション
といった具合です。使用技術と環境は?
・言語:PHP7, JavaScript(jQuery), Bootstrap, HTML, CSS(Sass)
・フレームワーク:Laravel7
・DBMS:MySQL
・インフラ:AWS(EC2,RDS,ELB,S3,Route53,ACM)
・Webサーバー:Amazon Linux OS 2, Apache
・開発環境:ローカル環境(MacOS), VSCode
(本当はDockerなども導入したかったですが..)作った背景と目的
ポートフォリオを作った理由は、
①転職時に必要不可欠と考えるため
②アプリ開発を経験することで成長したいため
③必要な機能を実装して価値を提供したいため
の3つです。①転職時に必要不可欠と考えるため
職務経歴や経験で充分にスキルを示せる場合は別ですが、そうでない場合は何かモノを作っていないとスキルを定量的に示すことができないかなぁと思います。
これは、もし自分が評価する側だったら「勉強してますが何も作ったことはありません」だと、その人がこれから活躍していく姿をうまくイメージするのは難しいと考えるためです。②ゼロからアプリ開発を経験することで成長したいため
Progateなどの教材はとても分かりやすいですが、環境構築や設計、エラー解消といった場面に遭遇することはありません。
また書籍や動画の教材もそうですが何か問題に遭遇してもそこに答えのコードがあるので、実際にロジックを考えることはほぼ無いと言えます。(書いてあるコードを再現すれば動く)やはり実際に
「こんなものを作りたい」→「そのために必要なことは?」→「問題が発生」→「試行錯誤」→「解決!」といったプロセスを経験することで得られる学びは計り知れないほど大きいと思います。③必要な機能を実装して価値を提供したいため
私自身、人に貢献することが好きなのでアプリ制作をするなら
誰かに価値を提供できるものにしたいと思いました。しかし実際に人に利用してもらえるサービスを提供するとなるとマーケティングや運用保守の要素がかなりに必要になりますし、初学の段階で「誰かに使ってもらうこと」に期待しすぎても学習の挫折要因になりかねないとも考えます。
そのため
「自分でこんなのがあったら良いな」を少しずつ実現することを目的のひとつとしました。
具体的には「情報交換したいなぁ」「カロリー計算とかエクセルでやるの面倒だな」という課題ですね。前提条件(学習期間)と開発期間は?
プログラミング学習を開始したのが2020年5月末。
仕事をしつつ6月は主にProgateで勉強し、10種類以上のコースを各1周。
HTML&CSS,Python,Java,PHP,SQL,Git,Sass,Rubyあたり。JavaScripとRailsも途中まで。7月に小さなプログラミングスクールに入校。(コロナの影響でほぼオンライン)
内容は
・PHP/Laravelの3ヶ月コース。
・テキストベースのカリキュラムでHTML、PHP、Laravelを学びつつ課題をこなしていく形。
・開発環境はAWSのCloud9。
・週に1回オンラインで1時間のメンタリング。
という感じ。8月上旬にはカリキュラムを終了し、
オリジナルアプリの制作に向けて企画/設計やER図作成を開始。
8月中旬から実際の開発作業に着手。
9月末でスクールは退会。
10月にAWSの学習とデプロイ作業。
という流れです。開発期間としては、働きながら&勉強しながらとはいえ3ヶ月程度費やしていることになりますね。
時間をすべて記録していたわけではないので何とも言えませんが、
まず可処分時間は平均しておおよそ3時間/日程度を確保。
テレビはコンセントを抜き、Youtube等は撤廃、食事や大好きな読書も最小限にしました。ITパスや基本情報技術者、AWSや各種技術書などの勉強も行っていたので、その半分の1.5時間をアプリ開発に充てたと考えると3ヶ月でだいたい150時間は費やしていることになります。
(6月からの学習時間や資格勉強などを全てトータルすると450時間ほどのプレイ時間になりますね..)ここでやはり感じたのはエラーと戦ったり調べたりしている時間がほとんどで、
実際にコードを書いてる時間は少ないということですね。。企画/設計はどんな感じで行った?
・アイディア出し、ペルソナ設定
・リーンキャンバスの作成
・エレベータピッチ、ユーザーストーリーマッピング、MVPの設定
・ワイヤーフレームの作成(手書き)
・ER図の作成(手書き)
という手順で行いました。収益化が主目的ではないのでリーンキャンバスは埋められる範囲で、という感じですね。(KPIなど省略)
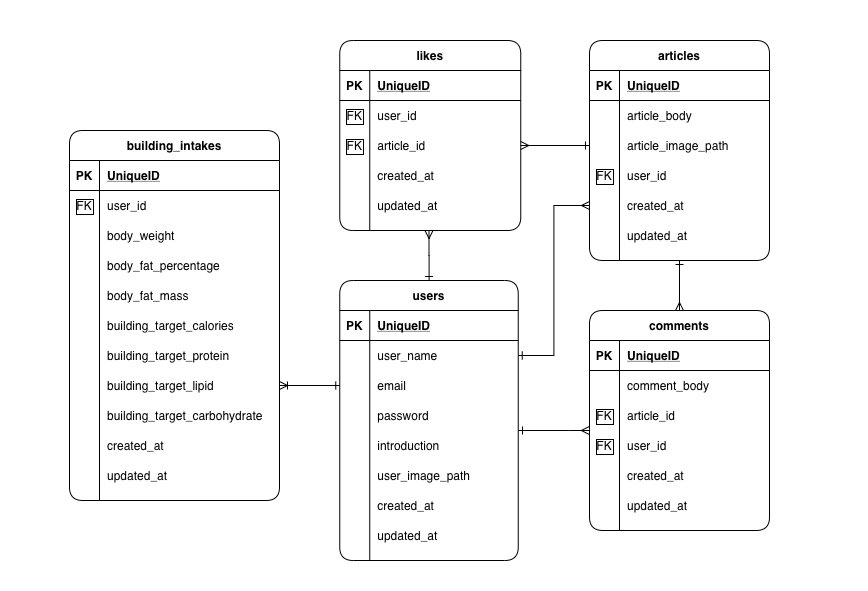
今思うとこのフェーズでもう少しアプリケーションのロジックの部分の設計ができていればなぁとも思いますが、「走りながら考える」というのもまた正解でもあるので、何とも言えないですね。データベース設計(ER図)はどうなってる?
最初に手書きで簡単に作りつつも、開発しながら随時テーブルは更新/拡張していき、
結局はこのような形になりました。
実装してみるとやはりテーブルの関連付けの部分が難しく、キー制約や正規化などDBの奥の深さや面白さを感じました。どうしても開発前の構想とはやっているうちに変わっていくのでMigrationファイルがやや散らかってしまいました。。インフラ構成はどうなってる??
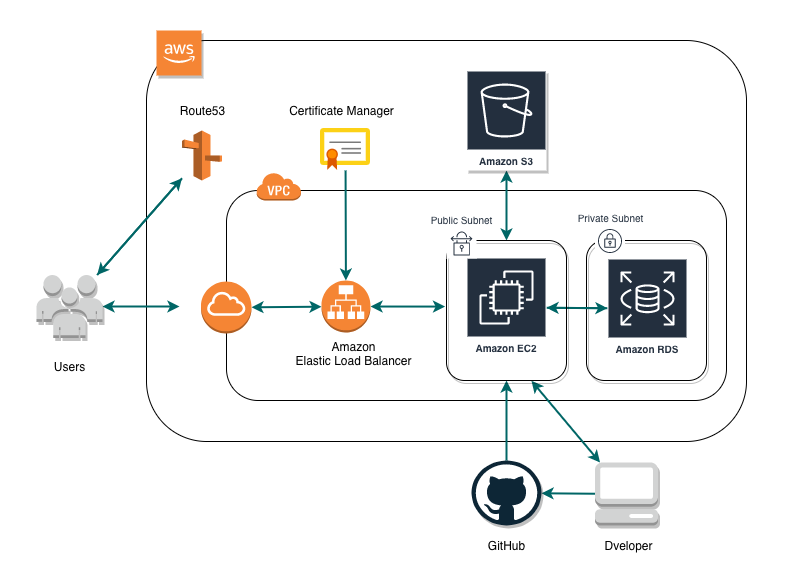
すべてAWSで構成。主に使用したのはEC2、RDS、ELB、S3、Route53、ACMです。
本来はWebサーバーやDBサーバーは冗長化させて、S3もCloud Frontで..という想いはあるのですが、あくまで学習用。無料枠の中でということで断念しました。
ELBはロードバランサーというよりAmazon Certificate Managerで無料でhttps化(証明書発行)する目的で使用しています。(EC2インスタンスは1つで、ダミーのAZを設定)またAWSを利用する上でルートユーザーはMFAでログイン、IAMユーザーに最小限の権限を持たせて作業、アクセスキーは厳重に管理、といったセキュリティ面は留意しました。(少し痛い目にあったので..)
アプリ制作する上で意識したことは?
ひとりチーム開発
まず、実務を想定した「ひとりチーム開発」を意識しました。
スクール等でチームを組んで共同開発..というのがひとつの理想ではありますが、個人開発なので「どうやったら実務でスムーズにキャッチアップできるか?」ということを考え、
・Git/GitHubによるソース管理
・issueを作成し、featureブランチを切って作業
・こまめにコミットし、プルリクエスト。
といった形で開発を進めました。アプリ開発用にGitHubの新規アカウントを作成し、contributionsはこのようになりました。(これからも更新していきます)
もちろん実務ではDockerでの開発環境、CI/CDパイプライン等いろいろと必要な事項があると思いますが「まずはアプリ自体を完成させなければ..」という想いから、このあたりの技術は転職活動〜入社の期間で少しずつ習得していこうと考えています。
わかりやすいコードにする
また「後から見た時に分かりやすいコード」を意識しました。
現職でも(構造設計の仕事してます)ドキュメントやメモをマメに残すようにしていて、自分で分かりやすいように意識してコメントは書いていたのですが、開発途中で書籍「リーダブルコード(O'RELLY社)」を読んで、リファクタリングを意識的に行うようになりました。
書籍の中では「そもそも最小限のコメントで分かるような変数名やロジックにする」というのが一番感銘を受けたポイントですね。。
変数やファイルの命名センスは大事。ロジックもコメントもセンスが大事。
(コードの美しさとは何か?みたいなテーマで飲みながら語らえるようになりたい)インフラにAWSを使う
少し話が脱線してしまいましたが..
他には「インフラにAWSを使う」というのも実務を意識した点です。
なぜAWSか? については、
・教材でherokuにデプロイは経験していた(あとは読み込みも遅いとかドメイン名が長いとか)
・インフラ設計や構築について実際に手を動かして学びたかったから(分かってくるとインフラは楽しい)
・業務で最も使われているから(AzureやGCPも気になりますが)
です。苦労した点は?
これはもう、とにかくたくさんあるのですが、、
・エラーや不具合にハマったとき(ほぼ毎日)
・投稿した画像を自動で加工する機能のあれこれ(InterventionImageを使いましたが色々問題発生)
・Ajaxでの計算機能,いいね機能の実装と理解(ControllerとViewとJSの処理のロジックが難しかった..)
・Gitでコンフリクトが生じた時(コミット打ち消しを行ったことなどに起因..)
・AWSの概念理解とデプロイ作業(https化も意外と大変だった..)
・環境構築の問題いろいろ(Composerメモリ足りない→php.iniとswapで対処等)
などなど、多岐にわたります。ほとんど独習だったので「調べつつメンター契約して即時解決」というほうが良かったかも、、
ただ、苦労はしたけど"勉強が辛い"という感じはしなかったですね。(たぶん学習レベルだからですが)全体的な感想
まずWebアプリを作ることは楽しいということ。
もちろん大変なことや覚えなければならないことは山ほどありますが、
・ロジックを考えてそれが実装できたとき
・エラーやデプロイの問題が解決できたとき
はガッツポーズしてしまうほどの達成感です。
また日々自分が成長していくことにもやりがいを感じます。
あとは同じ問題で困っている人に教えてあげることにも喜びを感じました。
実際にサービスを提供して誰かの課題を解決できたら最高かもしれないですね。それと蛇足ですが..
プログラミングスクールは通う必要はないかなぁと個人的には思いました。
もちろん「大金を払っているので後戻りできない」とか「カリキュラムが系統的になっている」とか「質問できる環境」というメリットはありますが、、
今はもっと分かりやすい教材もありますし、google等で何でも調べられるので「独学で充分できるかも..」と後から感じています。実際アプリケーション自体やインフラの構築は独学で学んだことがほとんどですしね。
(当時にもう少し情報の収集力があれば良かった..けど後からなら何でも言えますね)今後の課題など
・Docker,CI/CDなど、開発環境,テスト,自動デプロイあたりについて学ぶ
・ユーザー登録時にメール認証させたりセキュリティ面もきちんと考える
・PHPを生の言語としてもっと深く学ぶ
・インフラ、ネットワーク、Linuxの基本をしっかり学ぶ実際にサービスを運用するとなるとやるべきことはもっとあると思いますが、、少しずつ着実に力をつけていきたいなと考えております。
以上、最後までご覧いただきありがとうございました。
「おつかれ」「もっと頑張れよ」と思った方、LGTM!していただけたら今後の励みになります^^;
- 投稿日:2020-11-14T11:40:36+09:00
【UnauthorizedOperation】EC2インスタンス作成時にエラーが起きたので備忘録
概要
DockerホストからEC2インスタンス上でコンテナ起動時にエラーがおきました。
AWSもDockerもDockerマシンも学習中を始めたばかりでエラーが起きたときに手探りで進めているという感覚ですが、解決できたので備忘録としてまとめさせていただきます。また、同じエラーに悩まれている方がいれば、その方の一助となれば幸いです。遠回りをしているかもしれませんが、そのときはご意見を頂きたく存じます。仮説検証
まずこちらが今回のエラー文です。エラー文から考えられることを仮説検証してエラーを解決していきます。
ターミナル% docker-machine create --driver amazonec2 --amazonec2-open-port 8000 --amazonec2-vpc-region ap-northeast-1 <EC2インスタンス名> (EC2インスタンス名) Couldn't determine your account Default VPC ID : "UnauthorizedOperation: You are not authorized to perform this operation.\n\tstatus code: 403, request id: <~~request id~~>" Error setting machine configuration from flags provided: amazonec2 driver requires either the --amazonec2-subnet-id or --amazonec2-vpc-id option or an AWS Account with a default vpc-id1.デフォルトのVPCがない
VPCダッシュボードを確認したところ存在していたので、原因はこれではなかったみたいです。vpc-idを引数で直接指定しましたが、それでもEC2インスタンス作成することはできませんでした。
2.UnauthorizedOperation
この操作を操作する権限がないというエラー。
こういうときは極力一次情報を見て解決したほうが今後の応用も効くし間違いない情報なので確認していきました。
さっそく解決方法の手順を踏んで解決していこうかとおもっていたところ、出鼻をくじかれました。
ターミナル% aws --versionawsのコマンドが使えない
command not found:awsというエラー文。ということでまずは
amazon cliのインストールからしていきます。
AWS CLI の パス を通す
AWSのPATHを通す方法はこちらの記事を参考にさせていただきました。3.エラーが変わらず出ていたので、権限がないというのはどういうことか現状把握
そもそもIAMユーザーの認証情報を使って、DockerホストからEC2インスタンスを作成しようとしています。そのため、認証情報の記述に問題があるのではないか?と考えました。
そこでまず、環境変数を疑いました。
以前にAWS IAMのアクセスキーを環境変数にいれていた。
今回別のIAMユーザーのアクセスキーを扱っています。ところが、前回作成したIAMユーザーのアクセスキーを環境変数に入れてPATHを通している状態でした。そのIAMには権限を与えていないので
UnauthorizedOperationと警告されているのかなと思いました。
そのため、前回のIAMユーザーのアクセスキー(環境変数)を一度削除しました。ディレクトリごとに、PATHを通す方法のほうが良いかと思いますが、今回は削除いたしました。以下の記述で設定した環境変数を削除しました。※お使いのPCのバージョンにより設定方法が異なるかもしれません。
ターミナルvim ~/.zshrc
iでインサートモード(記述できる)に変える。変更を加えたらesc、:wq、Enterで完了。
これだとまだPATHが反映されていないので、下記を実行。ターミナルsource ~/.zshrcこれでDockerホストからEC2インスタンスを作成できる!と思いきや、別のエラーが。
別のエラーが出ましたが、エラーが変わったのを見ると、やはり権限がないIAM(前回作成したIAM)からEC2インスタンスを作成しようとしていたみたいです。
別のエラーというのはファイルの記述が間違っているというエラーでした。( ターミナルのエラーをメモし忘れました。。)
そのため以下~/.aws.credentialsファイルの修正。修正前[default] aws_access_key = <認証キー> aws_secret_access_key = <認証キー>修正後[default] aws_access_key_id = <認証キー> aws_secret_access_key = <認証キー>
~/.aws.credentialsファイルを確認。
を作成したときに自動的にファイル内に記述された型をよく見てみると、aws_access_keyの_idが抜けておりました。
自動生成された型だったので、安心していましたがそんなことはないみたいです。コード修正後再度、EC2インスタンスの作成を実行。
DockerホストからのEC2インスタンスの作成を成功しました!!
結論
今回はエラーの原因が一つではなかったので、仮説を立て最善なものを選び検証していくしかないのかなと思いました。エラーが起きたときは自分の理解できていない部分が浮き彫りになっていくので、ものすごく勉強になります。今回で言えば、環境変数やAWS、Linuxについても理解が足りていないなと強く感じました。エラーが起きたらそれに関連することも調べなければ解決できないので、エラーが起きてもポジティブに対処していくことで今後に応用していきます。
まとめ
- エラーが起きた時原因が一つとは限らない。
- 仮説を立て検証し最善なものを1つ1つエラーを解決していく。
- 自動生成されたものでも疑う目をもつ(特に環境構築やセキュリティーに関わるところ)。
参考文献
この記事は以下の情報を参考にして執筆しました。
- 投稿日:2020-11-14T11:25:55+09:00
Elastic BeanstalkでLaravelとNuxt.jsをデプロイした時のメモ
概要
- 構成
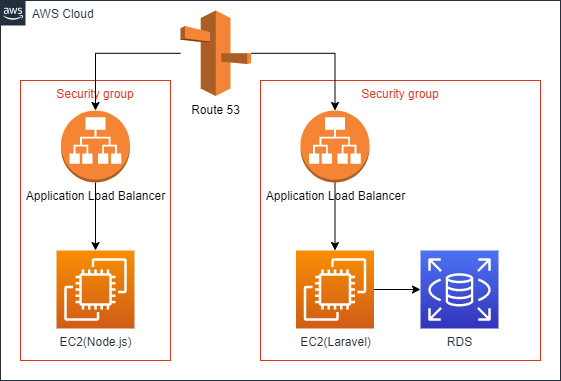
- Elastic BeanstalkでEC2とRDSを立てる
- ドメインと証明書を取得して設定する
- ロードバランサーとセキュリティグループを設定する
- EB Cliを使用する
Elastic BeanstalkでNuxt.jsをデプロイ
AWSコンソール
- Elastic BeanstalkでNode.jsプラットフォームの環境を作成
- [設定] - [ソフトウェア] - [変更]でノードコマンドにnpm run eb-startを入力
- [設定] - [ソフトウェア] - [変更]で環境変数を設定ローカル環境
- eb initを実行
- /package.json内のscriptsに"eb-start": "npm run build && npm run start",を追加
- npm installで失敗する場合
- /.npmrcファイルを作成してunsafe-perm=trueと入力
- 下記の内容で/.ebextensions/chown.configを作成
commands:
chown:
command: chown -R nodejs:nodejs /tmp/.config
test: cd /tmp/.config
- /Procfileがある場合は/.ebignoreファイルを作成してProcfileをデプロイしないようにするeb deployでデプロイ
Elastic BeanstalkでLaravelをデプロイ
AWSコンソール
- Elastic BeanstalkでPHPプラットフォームの環境を作成
- [設定] - [ソフトウェア] - [変更]で環境設定でドキュメントルートに/publicを設定
- [設定] - [ソフトウェア] - [変更]で環境変数を設定
- [設定] - [データベース] - [変更] からRDSインスタンスを作成ローカル環境
- eb init
- 下記の内容で/.ebextensions/permission.configを作成
files:
"/opt/elasticbeanstalk/hooks/appdeploy/post/99_change_permissions.sh":
mode: "000755"
owner: root
group: root
content: |
#!/usr/bin/env bash
sudo chmod -R 777 /var/app/current/storage
eb deployでデプロイ
Route53でドメインを設定
下のページを参考にドメインと証明書を取得
https://qiita.com/sk565/items/2da1fc0c5fc676f54994
現在は東京リージョンでも証明書の発行ができるようだ
https://aws.amazon.com/jp/about-aws/global-infrastructure/regional-product-services/セキュリティグループを修正
VPCのメニューからElastic Beanstalkで作成されたセキュリティグループを修正
- Nuxt.jsのセキュリティグループのインバウンドルールにHTTPSを追加
- LaravelのセキュリティグループのインバウンドルールにHTTPSとRDSのドライバを追加ロードバランサーを作成
EC2のメニューからターゲットグループとロードバランサーを作成
- Nuxt.jsのインスタンスに80番ポートで接続するターゲットグループを作成
- Laravelのインスタンスに80番ポートで接続するターゲットグループを作成
- Nuxt.js用のロードバランサーを作成
- Nuxt.jsのセキュリティグループを紐づける
- リスナーの転送先にNuxt.jsのターゲットグループを設定
- Laravel用のロードバランサーを作成
- Laravelのセキュリティグループを紐づける
- リスナーの転送先にLaravelのターゲットグループを設定ホストゾーンを作成
Route 53のでホストゾーンを作成
- ホストゾーンを作成
- レコードを作成
- ドメインとロードバランサーを設定
- 投稿日:2020-11-14T09:53:06+09:00
Ansibleでユーザパスワードを変更してSSMパラメータストアにパスワードを保存する
実現したいこと
Ansibleを使用してTargetサーバのユーザのパスワードを変更します。
変更後のパスワードはAWS Systems Managerの一機能であるパラメータストアに保存したいと思います。
パラメータストアは無料でリージョンごとに10000個までのパラメータを管理することができます。前回に引き続き、Docker + Ansibleの環境で以下を実現します。
①ランダムパスワードを生成する
②ユーザのパスワードを変更する
③SSMパラメータストアにパスワードを保存する設定
DockerとAnsibleの細かい設定は前回の記事と同じであるため省略します。
変更するのはmain.ymlです。まずは、15文字のランダムなパスワードを生成します。
次に、生成されたパスワードを表示します。
生成されたパスワードを対象のユーザに設定します。
最後にAWS CLIコマンドでパラメータストアにパスワードを保存します。ssm put-parameterの補足説明です。
・パスワードと紐づける名前を--nameで指定。また、"/"を使用して階層を設定
・typeにSecureStringを指定して、デフォルトのAWS KMS Keyを使用してパラメータを暗号化
(デフォルトのAWSマネージドキーの場合はKey IDを指定しない)
・regionを指定する (.aws/configにリージョンを設定していても、明示的に指定しないとエラーになる)main.yml- hosts: targets become: yes gather_facts: no tasks: ################################################## # Generate new password ################################################## - name: Generate new password shell: cat /dev/urandom | base64 | fold -w 15 | head -n1 register: random_password ################################################## # Display the output ################################################## - name: Output debug: msg: Password -> [ {{random_password.stdout_lines[0]}} ] ################################################## # Change password of the user ################################################## - name: Change password user: name: test-user password: "{{ random_password.stdout_lines[0] | password_hash('sha512') }}" ################################################## # Add the password to Parameter Store ################################################## - name: Put password become: yes shell: > aws ssm put-parameter --name "/Passwords/test-user" --type "SecureString" --value {{random_password.stdout_lines[0]}} --region ap-northeast-1IAMポリシー
EC2からSystems Managerへパラメータを設定できるようにするため、最低限以下のポリシーをEC2に設定したIAMロールに与える必要があります。
・ssm:PutParameter実行結果
では、AnsibleのPlaybookを実行します。
ansible-playbook -i ./inventory ./main.yml PLAY [targets]**************************************************************************************************** TASK [Generate new password] ************************************************************************************* changed: [10.0.1.100] TASK [Output] **************************************************************************************************** ok: [10.0.1.100] => { "msg": "Password -> [ LAnjvZ5d/CdrFEE ]" } TASK [Change password] ******************************************************************************************* changed: [10.0.1.100] TASK [Put password] ********************************************************************************************** changed: [10.0.1.100] PLAY RECAP ******************************************************************************************************* 10.0.1.100 : ok=4 changed=3 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0変更後のパスワードでサーバにログイン
無事に変更後のパスワードでSSH接続ができました。
1つ注意点として、Ansibleコマンドでパスワードを変更する際に、password_hash('sha512')で
hash化しなければ、パスワードが変更されてもSSHでログインできません。以下のように警告が表示されます。
[WARNING]: The input password appears not to have been hashed. The 'password'
argument must be encrypted for this module to work properly.AWSマネジメントコンソールでの結果確認
パラメータストアを確認します。
階層が設定されていますが、数が多くなると見づらくなりそうです。
test-userのパスワードを確認します。
暗号化したので、値のところにある「表示」をクリックすると平文で見えるようになります。


- 投稿日:2020-11-14T09:02:55+09:00
【AWS】より安全に使うためにCloudWatchを設定する
AWSを利用してからルートユーザー、IAMユーザー共にMFA(多要素認証)は設定していましたが、コストに関して通知(CloudWatch)が来るように設定できることは後から知りました。
それぞれの目的
・MFA→不正アクセスを防ぐ
・CloudWatch→サービスの使い過ぎを防ぐ(指定した金額以上になったら通知が来る)その際の設定を備忘録として書いていきます。
ログイン後、サービスの検索からCloudWatchを検索。
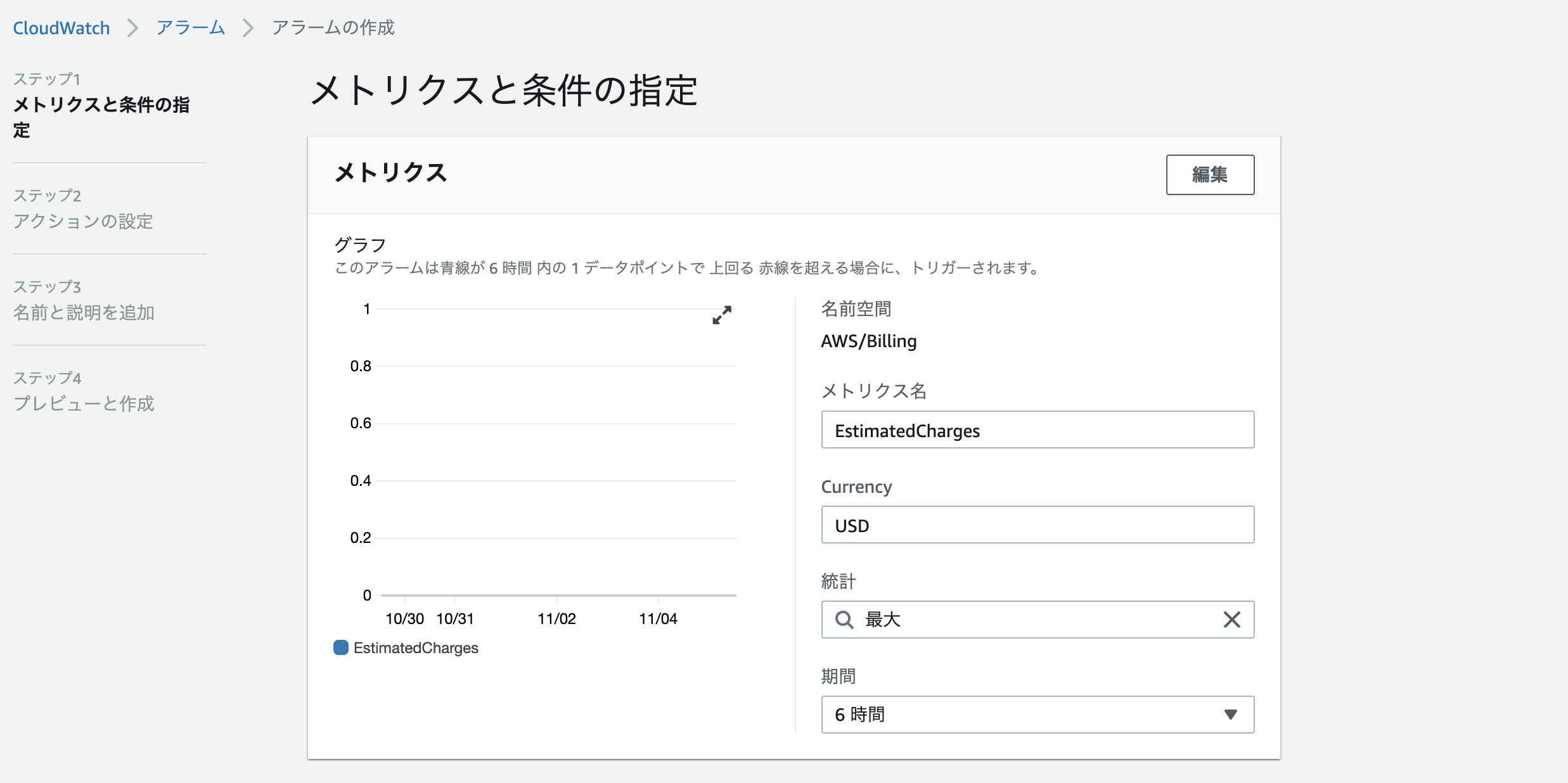
CloudWatchを選択。
右上のリージョンをバージニア北部に変更し、左側のメニューから請求を選択
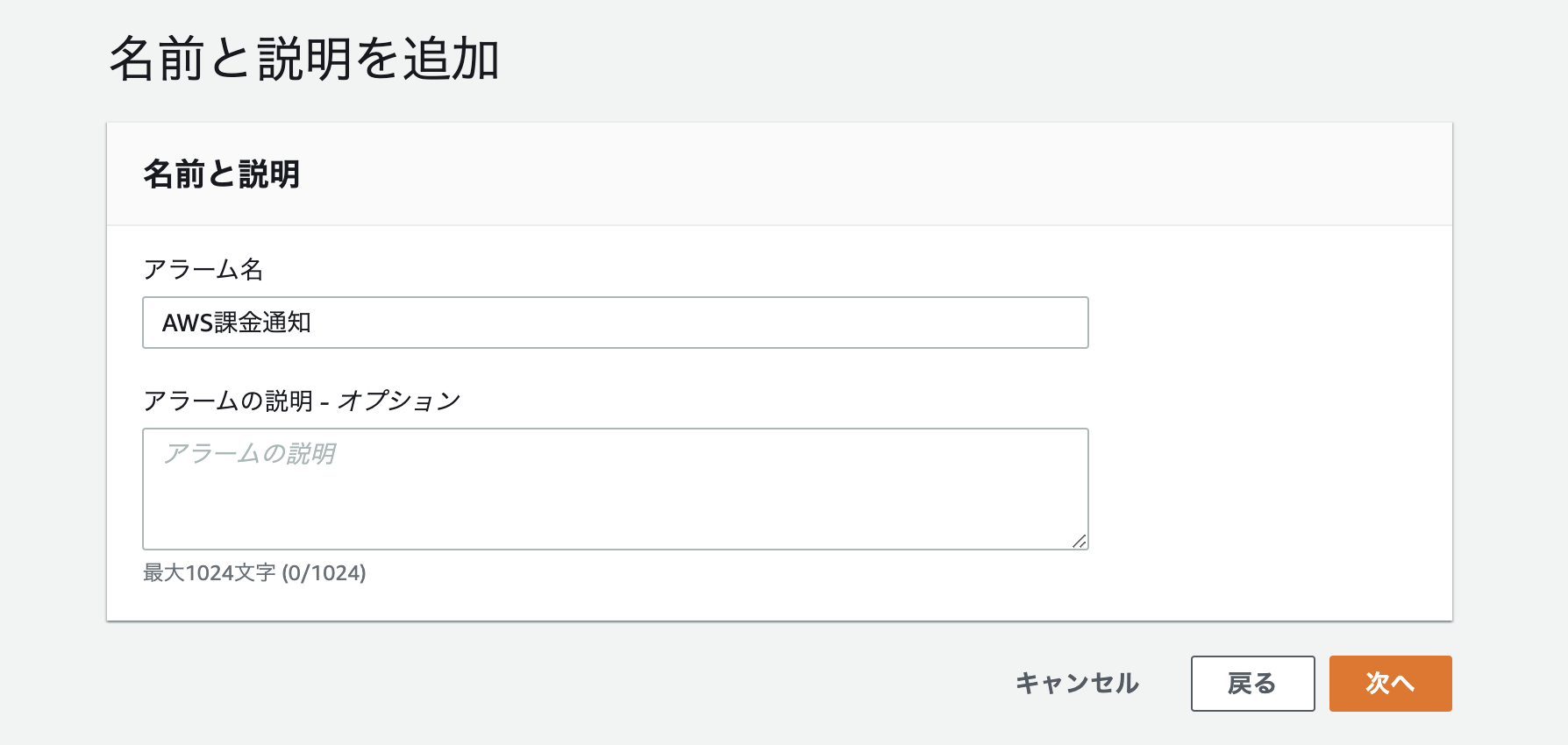
請求選択後に画面が切り替わったら、画像下部のアラームの作成をクリック。
この画面では、デフォルトのままでOKです。
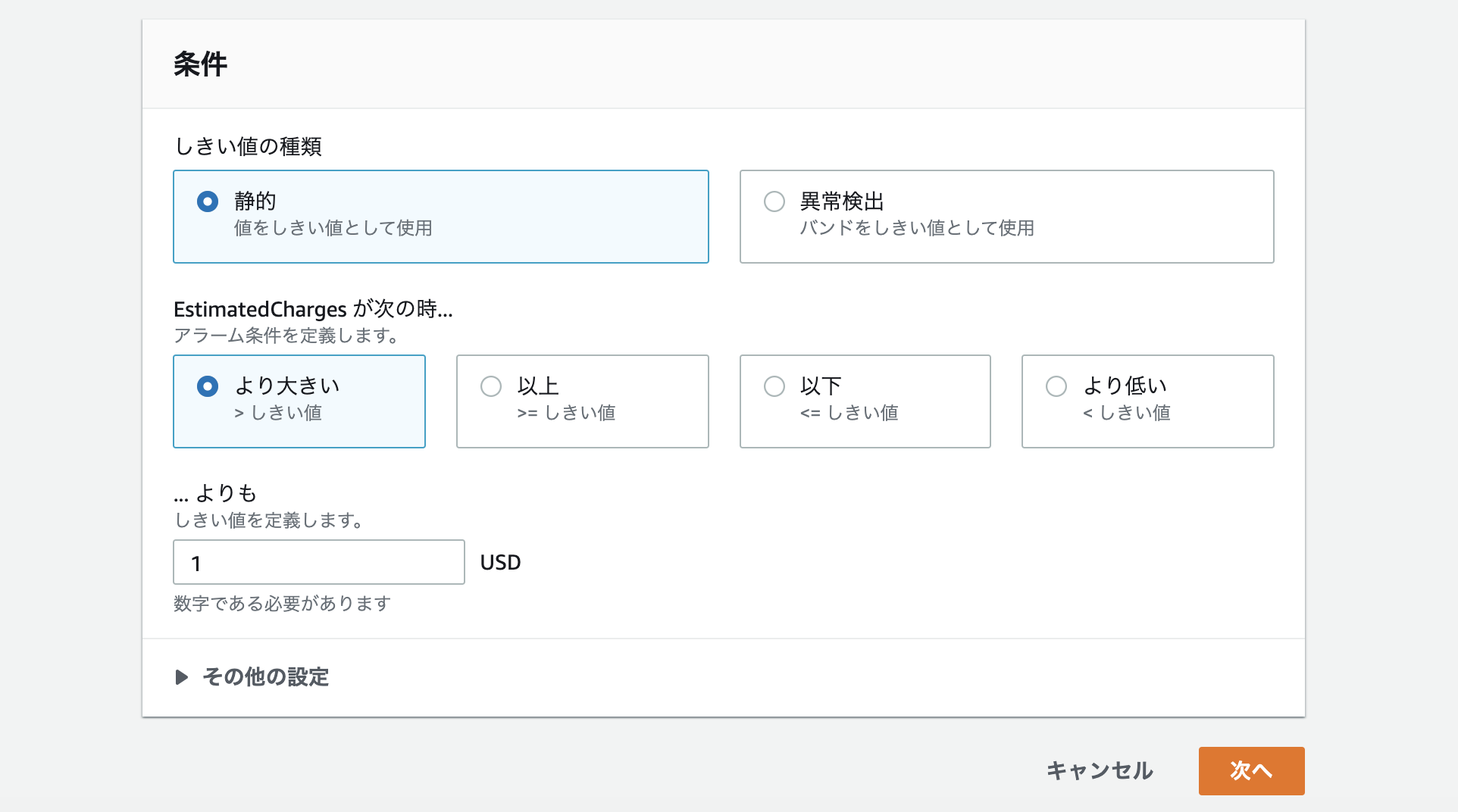
課金がいくらになればアラーム通知が鳴るか設定します。設定後下部の次へをクリック。
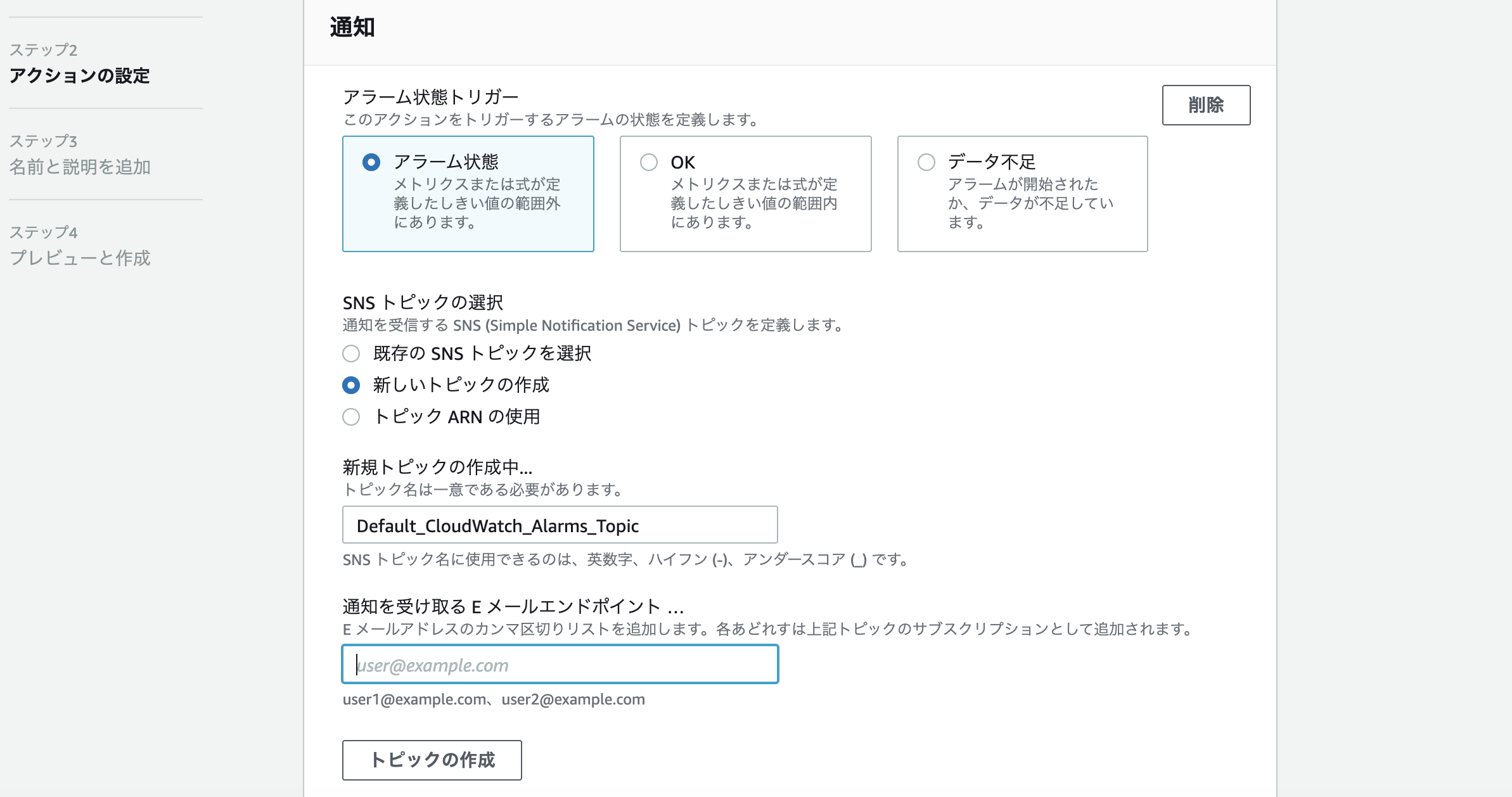
通知を受け取るメールアドレスを入力しトピック作成。
トピック作成後にメールアドレス宛に、通知を送っても良いですか?というような確認メールが来るのでConfirmをクリックしてアドレスの設定を完了させます。
中々メールが届かないようであれば、迷惑メールにきている可能性があります。
※この作業をしないとステータスが確認中のままとなり、通知がきません。
メールアドレスの入力が完了したら、下までスクロールし次へをクリック。
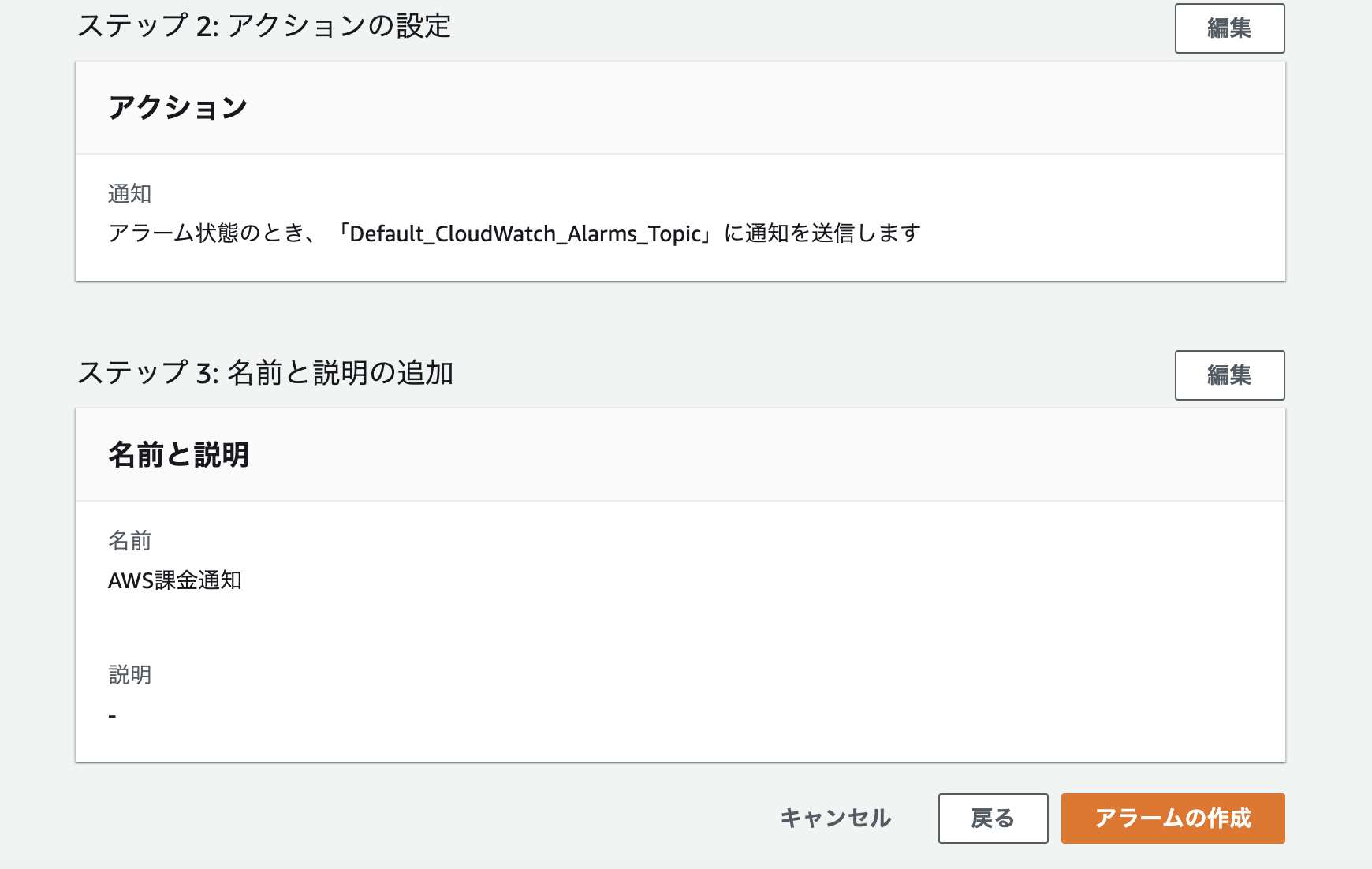
適当にアラーム名を入力し、次へをクリック。
最後に今まで設定した内容の確認画面となり、下部にスクロール後アラームの作成をクリック。
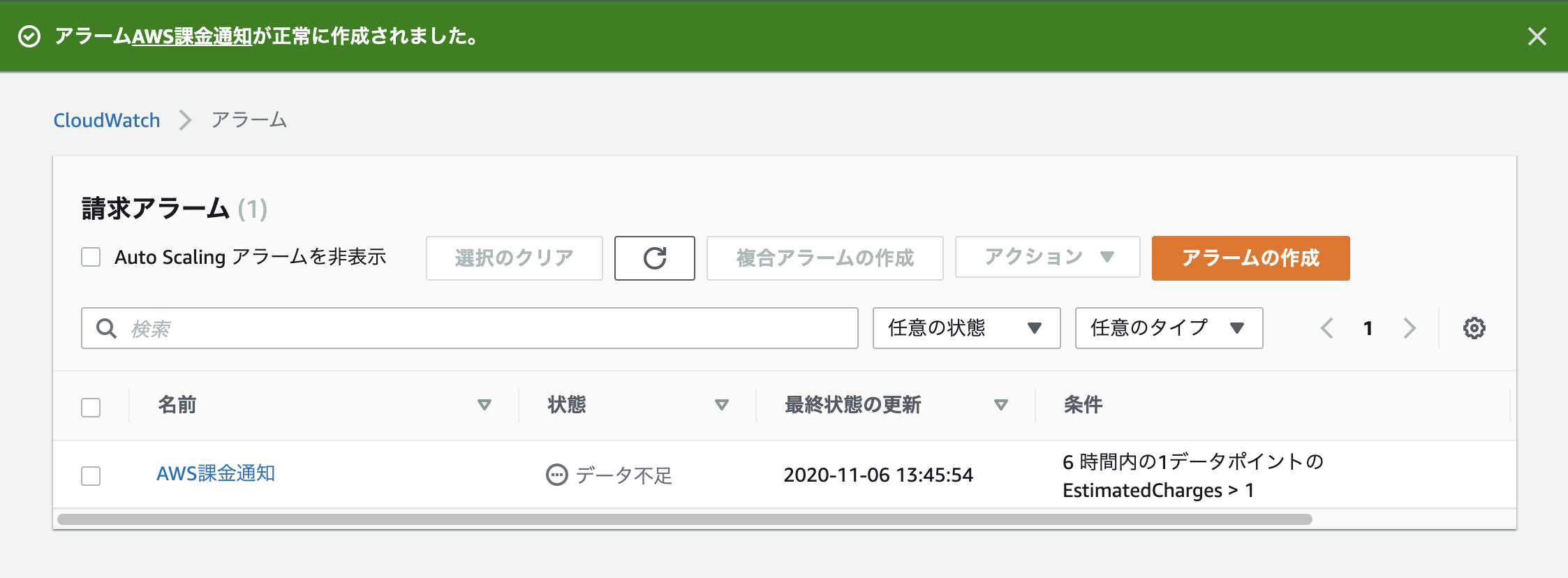
正常に作成されました。設定は以上です。
今のところ、アラームは1個で十分ですが、アラーム数10個までであれば毎月無料で使用することができます。
アラームを削除したい場合は、アラーム名の左にチェックを入れて上部のアクションをクリック後削除を選択することで削除できます。設定のし過ぎで課金されないようにしましょう。
- 投稿日:2020-11-14T08:50:14+09:00
Snowball Edgeが自宅に届いてからS3にインポートするまでの記録(2020年11月)
はじめに
Snowballといえば、AWSソリューションアーキテクト・アソシエイトを受験されたことのある方なら「テラバイト級のデータをS3のバケットにインポートする、ときたらSnowball一択」でおなじみかと思います。マイナーなサービスでありながらアソシエイト試験の常連なのは、やはり宣伝の意味なのでしょうか。
本記事は、Snowball Edgeデバイス(以下「デバイス」)が自宅に到着後、データをデバイスにコピー、S3のバケットにデータのインポートが完了するまでの手順を記録したものです。そもそもSnowballとは何か?は、以下のドキュメントをご覧なさい。本記事では、公式ドキュメントには載ってない気づきを積極的に記録してみました。
なお、本記事でSnowballEdgeクライアントやAWS CLIをインストールしたOSはWindows 10です。
Snowball Edge利用時の全体の流れ
- AWSマネージメントコンソールからジョブの作成
- AWSからデバイスの発送
- デバイスの受取り
- 事前準備
- デバイスのIPアドレス設定とLANへの接続
- Snowballのジョブダッシュボードからアンロックコードとマニフェストファイルの取得
- SnowballEdgeクライアントのセットアップ
- デバイスのロック解除
- (S3 Adapter利用時)ローカルのAmazon S3認証情報(AWS署名バージョン4)の取得
- (ファイルインタフェース利用時)仮想ネットワークインタフェースの作成
- (ファイルインタフェース利用時)PCからデバイス内のバケットにマウント
- デバイスへファイル転送
- 西濃運輸さんのWebサイトで集荷依頼の申込み
- AWSへデバイスの返送
- AWSにてデバイス内のファイルをS3へインポート
ジョブ作成からS3へのインポートまでのタイムライン
Snowballジョブでは、ジョブのステータスが更新される度にAmazon SNS経由でメールが送信されますが、このメールのタイムスタンプをもとに、各イベントのタイムラインをまとめてみました。
1. AWSから自宅へのデバイスの配送
今回は、ジョブ作成から約26時間後にデバイスが到着しました(土日祝日は挟まず)。受取日時の指定はできないため、例えばオンプレのデータセンターでデバイスを受取る場合、データセンターの入館証の発行申請とタイミングを合わせることは難しいため、代理人にデバイスの受取りを依頼するなど、そこら辺の手配がちょっと面倒かと思います。
日時 ステータス 11/05 10:09 ジョブ作成完了 11/05 11:09 AWSにてデバイスの手配開始 11/05 12:27 配送開始 11/06 12:20 運送会社からデバイスを受取り(自宅に到着) 2. 自宅からAWSへのデバイスの返送
デバイス返送後は、運送会社がデバイスを集荷してから、約1日18時間後にインポート完了しました(土日祝日は挟まず)。今回は、インポートしたデータ量が少なかったのでこの時間です。
集荷依頼時に集荷日時の指定はできますが、昨今のご時世もあり、指定時刻通りに集荷してもらうことはなかなか難しいようです(今回は集荷を10時に指定しましたが、実際には当日の18時頃に集荷していただけました)。
日時 ステータス 11/16 18:16 運送会社にデバイスを引渡し(自宅に集荷) 11/17 17:09 仕分け施設に到着 11/18 11:20 デバイスがAWSに到着 11/18 11:30 インポート開始 11/18 11:40 インポート完了 ジョブの作成
まず、Snowballダッシュボードから、ジョブを作成します。ジョブとは、デバイスの配送からS3へのインポートまでの1回のフローを表す概念です。
今回は、デバイスは
Snowball Edge Storage Optimized (100TB)を選択しました。現在では、デバイスにSnowball(Snowball Edgeでない)は選択できないようです。また、ストレージサイズの小さいSnowconeというデバイスもありますが、Snowconeは東京リージョンでは提供されていません(2020年11月現在)。
ジョブ作成画面で、S3のバケットへのアクセスを許可するためのロールを作成または選択します。IAMコンソールから作成したロールやポリシーを指定することも可能です。なお、指定可能なポリシーはインラインポリシーのみです。参考として、以下はロールとポリシーのJSONです。
ロールの信頼関係{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "importexport.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": { "StringEquals": { "sts:ExternalId": "AWSIE" } } } ] }ポリシー(インラインポリシー){ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetBucketPolicy", "s3:GetBucketLocation", "s3:ListBucketMultipartUploads" ], "Resource": "arn:aws:s3:::*" }, { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:AbortMultipartUpload", "s3:ListMultipartUploadParts", "s3:PutObjectAcl" ], "Resource": "arn:aws:s3:::*" } ] }
- デバイスにファイルを読み書きするのに、S3 Adapterとファイルインタフェースを使用する場合、それぞれで使用するバケットを個別に作成することをおすすめします。同一バケットに、S3 Adapterとファイルインタフェースの両方で読み書きした場合の動作は保証されません。
デバイスの配送
今回はジョブ作成後、約26時間後にデバイスが自宅に到着しました。ただし、AWSや運送業者さん(西濃シェンカー)の配送業務が平日のみの対応となる場合もありますので、配送が土日祝日に重なる場合はご注意ください。
デバイスが届いてから
1. 返送用伝票の確認
デバイスの側面に、デバイス返送時の手順が書かれたお知らせと、返送用伝票の入ったビニール袋が貼付されていました。
デバイス返送時の配送用伝票です。「ご依頼人」(発送主)の住所・氏名・電話番号は(画像ではマスキングしましたが)印字済みのため、自分で記入する項目は特になさそうです。
2. カバーの開け方
カバーの開け方ですが、丸い金属ボタンを押したまま、金具をボタン方向にスライドすると、カバーが開きます。
上面には、電源ケーブルが収納されています。ケーブル長は約1.8mです。
前面・背面のカバーは、90度開いた状態で奥にスライドすると収納できます(前面パネルの上部のオレンジの丸いボタンが電源ボタンです)。
3. ケーブルの接続
背面に電源ケーブルとLANケーブルを差します。左上にUSB3.1ポートx 2も見えますが、拡張用でしょうか。また、RJ45ポートの右側に怪しいポートがありますが、フタをスライドしてみたところ穴が塞がれていました。
4. デバイスの起動
電源ケーブルを差した瞬間、デバイスが起動を開始し、前面のLCDパネルに起動画面が流れます。起動音がけっこうな轟音なので最初はビビりますが、2分ぐらいで静かになります。
【YouTube】Snowball Edge startup screen
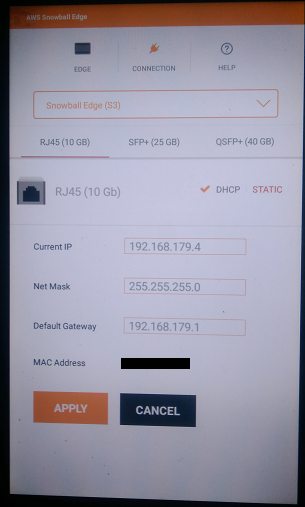
5. IPアドレスの設定
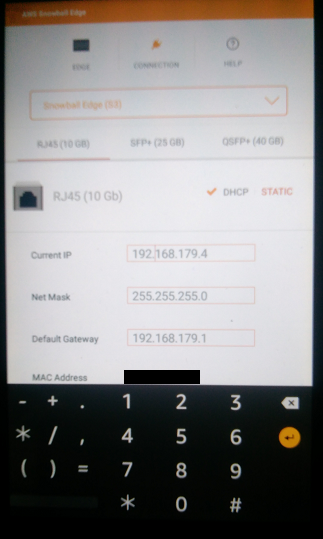
前面のLCDパネルから、Snowball EdgeにIPアドレス等を設定します。固定IPでも、DHCPでの設定でも可能です。
6. Snowball Edgeクライアントの入手
Snowballに関連するツールとして、以下の3つが登場します。
- Snowball Edgeクライアント … デバイスのロック解除など、デバイスの設定周りを行うCLIです。あくまでデバイスを制御するためのツールなので、このCLIでSnowball Edgeにファイル転送するわけではありません。
- AWS OpsHub … Snowball EdgeクライアントのGUI版です。
- S3 Adapter … デバイスにファイルをコピーをするツールです。といっても「S3 Adapter」という名前のツールがあるわけではなく、実体としてAWS CLIのS3コマンドやS3 APIを指します。ただし、開発者ガイドで「APIオペレーションのサブセットがサポート」と表現されているように、Snowball EdgeではAWS CLIやS3 APIの使用可能なパラメータは制限されています。また、開発者ガイドで指定されているように、Snowball EdgeではAWS CLIバージョン1.16.14を使用します。
このうち、Snowball Edgeクライアント(CLI)とAWS OpsHub(GUI)は用途が同じツールなので、いずれか一方をインストールすればよいです。EC2インスタンスをホスティングするなら、AWS OpsHubのほうが使い勝手が良いですかね。今回は、Snowball Edgeクライアントを使用しました。
後述しますが、ファイル転送はS3 Adapterだけでなく、ファイルインタフェース(NFS)でも可能です。
以下から、Snowball Edgeクライアントをダウンロードし、インストールします。
7. Snowball Edgeクライアントの設定
Snowball Edgeクライアントのインストールが完了したら、プロフィールを設定します。
プロフィールの設定には、以下の情報が必要となります。
- マニフェストファイル … マネージメントコンソールのSnowballのジョブダッシュボードの、ジョブの詳細からダウンロードできます。
Snowball Edge Manifest Pathに絶対パスを指定します。- アンロックコード … ジョブの詳細の「クライアント解除コード」に表示される、ハイフン区切りのコードです。
Unlock Codeに指定します。- デフォルトエンドポイント … デバイス内のS3のURL(
https://IPアドレス)です。IPアドレスは、前面のLCDパネルで設定したIPアドレスです。Default Endpointに指定します。(初回のみ)SnowballEdgeクライアント用のプロフィールの設定>snowballEdge configure Configuration will stored at C:\Users\yz2cm\.aws\snowball\config\snowball-edge.config Snowball Edge Manifest Path: G:\local\aws\snowball\JIDxxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx_manifest.bin Unlock Code: xxxxx-xxxxx-xxxxx-xxxxx-xxxxx Default Endpoint: https://192.168.179.48. デバイスのロック解除
ロックの解除は、デバイスを起動する毎に行います。
事前にデバイスの状態を確認します。
ロック解除前は、StateがLOCKEDとなっていることが分かります。デバイスのステータス表示>snowballEdge describe-device { "DeviceId" : "JIDa462ddf6-68a4-496d-a8f4-b6ead73396ad", "UnlockStatus" : { "State" : "LOCKED" },以下コマンドで、ロックを解除します。
デバイスのロック解除>snowballEdge unlock-device Your Snowball Edge device is unlocking. You may determine the unlock state of your device using the describe-device command. Your Snowball Edge device will be available for use when it is in the UNLOCKED state.
UnlockStatusがLOCKED→UNLOCKING→UNLOCKEDに遷移します。UNLOCKEDになった時点でアクセス可能となります。デバイスのステータス表示>snowballEdge describe-device { "DeviceId" : "JIDa462ddf6-68a4-496d-a8f4-b6ead73396ad", "UnlockStatus" : { "State" : "UNLOCKED" },S3 Adapterを使用したファイル転送
1. ローカルのAmazon S3認証情報(アクセスキーID、シークレットアクセスキー)の取得
S3 Adapterを使用したファイル転送には、ローカルのAmazon S3認証情報(AWS署名バージョン4)(アクセスキーIDとシークレットアクセスキー)が必要です。この認証情報は、AWSクラウドのIAMユーザのアクセスキーIDとシークレットアクセスキーとは異なるものです。
以下のコマンドを実行して、認証情報を取得します。
アクセスキーIDの表示>snowballEdge list-access-keys { "AccessKeyIds" : [ "AKIAIOSFODNN7EXAMPLE" ] }シークレットアクセスキーの表示>snowballEdge get-secret-access-key --access-key-id AKIAIOSFODNN7EXAMPLE [snowballEdge] aws_access_key_id = AKIAIOSFODNN7EXAMPLE aws_secret_access_key = wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY以上で得られた認証情報を、
aws configureでコンフィグファイルに設定します。
Snowballダッシュボードの画面上部の注意書き(以下)にもあるように、リージョン名にはsnowを指定します。
アクセスキーとシークレットアクセスキーをコンフィグファイルへ保存>aws configure --profile snowballEdge AWS Access Key ID [None]: AKIAIOSFODNN7EXAMPLE AWS Secret Access Key [None]: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY Default region name [None]: snow Default output format [None]: json以上で、AWS CLIでデバイスにファイル転送する準備ができました。
S3 AdapterはAWS CLIやS3 APIのサブセットです。AWS CLIのサポートされているコマンド、サポートされているS3 APIは、開発者ガイドを参照してください。
S3_Adapterでのファイル転送aws s3 cp sample.txt s3://sample-bucket/sample.txt --profile snowballEdge --endpoint http://192.168.179.4:8080 --region snow aws s3 ls s3://sample-bucket --recursive --profile snowballEdge --endpoint http://192.168.179.4:8080 --region snowファイルインタフェースを使用したファイル転送
AWS CLIを使用するほかに、デバイス内のバケットをマウントして、ファイルインタフェース経由でファイル転送もすることも可能です。分かりやすく言うと、デバイス内のストレージをPCにマウントして、NFS経由でファイルコピーすることです。
ファイルインタフェースはデフォルト設定では使用できませんので、事前準備として以下の手順を実施します。
- 仮想ネットワークインタフェースの作成(
snowballEdge create-virtual-network-interface)- 作成した仮想ネットワークインタフェースのARNの確認(
snowballEdge describe-virtual-network-interfaces)- ファイルインタフェースサービスの起動(
snowballEdge start-service)- NFSクライアントの有効化(Windowsの設定変更)
- バケットをマウント(
mount)1.仮想ネットワークインタフェースの作成
まず、以下コマンドで、物理ネットワークインタフェース(本記事ではRJ45)の物理ネットワークインタフェースIDを確認します。
PhysicalConnectorTypeがRJ45であるところのPhysicalNetworkInterfaceIdの値(例:s.ni-8409e6b33247333d6)をメモします。>snowballEdge describe-device { "DeviceId" : "JIDa462ddf6-68a4-496d-a8f4-b6ead73396ad", "UnlockStatus" : { "State" : "UNLOCKED" }, "ActiveNetworkInterface" : { "IpAddress" : "192.168.179.4" }, "PhysicalNetworkInterfaces" : [ { "PhysicalNetworkInterfaceId" : "s.ni-89b8db4ee981cdf40", "PhysicalConnectorType" : "QSFP", "IpAddressAssignment" : "STATIC", "IpAddress" : "0.0.0.0", "Netmask" : "0.0.0.0", "DefaultGateway" : "192.168.179.1", "MacAddress" : "00:00:5E:00:53:fc" }, { "PhysicalNetworkInterfaceId" : "s.ni-89053899faa1a9aa5", "PhysicalConnectorType" : "SFP_PLUS", "IpAddressAssignment" : "STATIC", "IpAddress" : "0.0.0.0", "Netmask" : "0.0.0.0", "DefaultGateway" : "192.168.179.1", "MacAddress" : "00:00:5E:00:53:fd" }, { "PhysicalNetworkInterfaceId" : "s.ni-8409e6b33247333d6", "PhysicalConnectorType" : "RJ45", "IpAddressAssignment" : "STATIC", "IpAddress" : "192.168.179.4", "Netmask" : "255.255.255.0", "DefaultGateway" : "192.168.179.1", "MacAddress" : "00:00:5E:00:53:fb" } ], ...以下コマンドで、仮想ネットワークインタフェースを作成します。
メモしたPhysicalNetworkInterfaceIdの値を、--physical-network-interface-idに指定して以下コマンドを実行します。仮想ネットワークインタフェースはSnowballEdgeを再起動しても消滅しませんので、以下コマンドは初回設定時のみ実行します。
(初回のみ)仮想ネットワークインタフェースの作成>snowballEdge create-virtual-network-interface ^ --physical-network-interface-id s.ni-8409e6b33247333d6 ^ --ip-address-assignment STATIC ^ --static-ip-address-configuration IpAddress=192.168.179.10,Netmask=255.255.255.0 { "VirtualNetworkInterface" : { "VirtualNetworkInterfaceArn" : "arn:aws:snowball-device:::interface/s.ni-8e9c511fe6515c86c", "PhysicalNetworkInterfaceId" : "s.ni-8409e6b33247333d6", "IpAddressAssignment" : "STATIC", "IpAddress" : "192.168.179.10", "Netmask" : "255.255.255.0", "DefaultGateway" : "192.168.179.1", "MacAddress" : "00:00:5E:00:53:89" } }2. 作成した仮想ネットワークインタフェースのARNの確認
仮想ネットワークインタフェースのARNはサービス起動毎に変化しますので、以下のコマンドでARNを確認します。
仮想ネットワークインタフェースのARNの表示>snowballEdge describe-virtual-network-interfaces { "VirtualNetworkInterfaces" : [ { "VirtualNetworkInterfaceArn" : "arn:aws:snowball-device:::interface/s.ni-8e9c511fe6515c86c", "PhysicalNetworkInterfaceId" : "s.ni-8409e6b33247333d6", "IpAddressAssignment" : "STATIC", "IpAddress" : "192.168.179.10", "Netmask" : "255.255.255.0", "DefaultGateway" : "192.168.179.1", "MacAddress" : "00:00:5E:00:53:45" } ] }3. ファイルインタフェースサービスの起動
上記コマンドの結果の
VirtualNetworkInterfaceArnに表示された値(arn:aws:snowball-device:::interface/s.ni-8e9c511fe6515c86c)を指定して、以下コマンドでファイルインタフェースサービスを起動します。>snowballEdge start-service ^ --service-id fileinterface ^ --virtual-network-interface-arns arn:aws:snowball-device:::interface/s.ni-8e9c511fe6515c86c Starting the service on your Snowball Edge. You can determine the status of the service using the describe-service command.以下コマンドで、ファイルインタフェースのステータスを確認します。
StateがACTIVEになればアクティベート完了です。1~2分で完了する時もあれば、10分以上かかる時もあります(開発者ガイドには「1時間以上かかる場合もある」とあります)。Stateは、INACTIVE→ACTIVATING→ACTIVEと変遷します。ファイルインタフェース(アクティベート中)>snowballEdge describe-service --service-id fileinterface { "ServiceId" : "fileinterface", "Status" : { "State" : "ACTIVATING" }, "ServiceCapacities" : [ { "Name" : "S3 Storage", "Unit" : "Byte", "Used" : 2919552, "Available" : 92451374477312 } ] }ファイルインタフェース(アクティベート完了)>snowballEdge describe-service --service-id fileinterface { "ServiceId" : "fileinterface", "Status" : { "State" : "ACTIVE" }, "ServiceCapacities" : [ { "Name" : "S3 Storage", "Unit" : "Byte", "Used" : 2919552, "Available" : 92451374477312 } ] }4. NFSクライアントの有効化(Windows 10)
「ファイル名を指定して実行」から
appwiz.cplを実行し「プログラムと機能」を開きます。
「Windowsの機能の有効化または無効化」をクリックして、「NFS用サービス」の「NFSクライアント」のチェックをオンにします。
5. バケットをマウント
mountコマンドで、SnowballEdgeのバケットをマウントします。
バケットをマウント>mount -o nolock 192.168.179.10:/sample-bucket Z: Z: は 192.168.179.10:/sample-bucket に正常に接続しました コマンドは正常に終了しました。マウント完了後は、エクスプローラ経由でファイルをコピーすることができるようになります。
6. ファイルインタフェースサービスの停止
以下コマンドで、バッファの内容をファイルにフラッシュし、サービスを終了します。
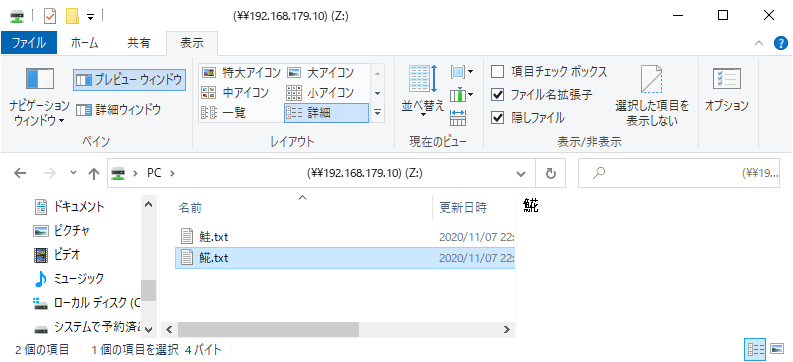
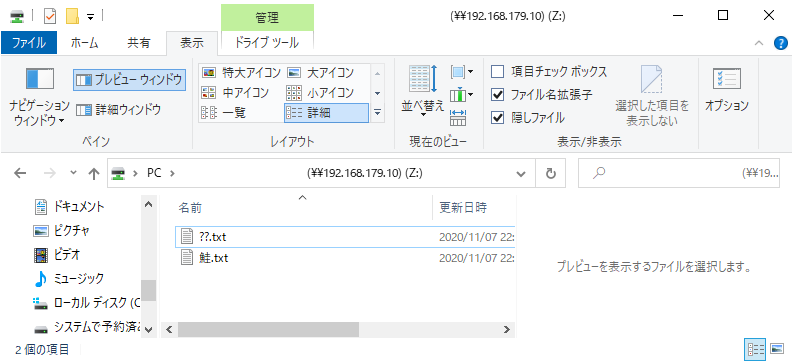
>snowballEdge stop-service --service-id fileinterface Stopping the service on your Snowball Edge. You can determine the status of the service using the describe-service command.【補足1】ファイル名の文字コード
SnowballおよびS3は、ファイル名のエンコーディングはUTF8が推奨されています。
しかし、Windowsの
mountではマウントするドライブの文字コードにUTF8を指定できないようです。ですので、Windowsから日本語ファイル名のファイルをファイルインタフェースで転送するとファイル名をSJISで渡すことになるため、実質上、日本語のファイル名は使用できません。例えば、ファイル名の「あああ」という文字列は、S3へインポート後「������」に文字化けしていました。
余談ですが、サロゲートペア文字を含むファイル名(
?.txt)を転送し、エクスプローラの表示を更新したところ、ファイル名「??」でファイルを作成されてしまいました。
そして、なぜか
??.txtを削除できなくなりました。もう一度?.txtをデバイスにコピーして、エクスプローラの表示を更新せずに?.txtを削除すると、削除できなかった??.txtが削除されました(?.txtも削除された)。Windows(のNFSクライアント)では、ファイルインタフェース利用時に日本語のファイル名を使用できないのは注意点です。
【補足2】ETagのMD5ダイジェスト
ファイルインタフェースでファイルコピーしたファイルは属性値が付与されます。
ETagにはMD5ダイジェストが付与されますが、一定サイズを超えるファイルのETagの形式は、マルチパートアップロード時と同様にMD5ダイジェスト-チャンク数となります。マルチパートアップロードが適用される閾値を二分木探索で探ってみたところ、
6,291,433バイトでした。{ "Key": "6291432B.bin", "LastModified": "2020-11-13T11:16:01.536Z", "ETag": "\"d5decd733aebd2c6d10e894b7820b30c\"", "Size": 6291432 }, { "Key": "6291433B.bin", "LastModified": "2020-11-13T11:16:01.645Z", "ETag": "\"776a1df683a4436d6271a74b42ea57d9-2\"", "Size": 6291433 },では、チャンクサイズはいくつか?ということで、ファイルサイズを変えて実験してみました。
ファイルサイズ チャンク数 チャンクサイズ 1GB 171 約6MB 1.5GB 210 約7.3MB 2GB 220 約9.3MB 5GB 277 約18.5MB 10GB 371 約27.6MB …どうやらチャンクサイズは固定ではないようです。
しかも、S3へインポート後のETagの値を確認すると、デバイス内にある時の値とは異なっているケースがありました。ファイルコンテンツは全く同じなのに。
- デバイスでのETag …
d5decd733aebd2c6d10e894b7820b30- S3のバケットへインポート後のETag …
828852475ee270da8a8a31e0f9809fc8-1デバイスからS3のバケットへのインポートではStrageGatewayが使われているようですが(根拠はバケット内のファイルのメタデータ)、StrageGatewayのマルチパートアップロードの閾値は、SnowballEdgeのファイルインタフェースでのマルチパートアップロードの閾値が違うなど、あるのかもしれません。
いずれにせよ、ファイルインタフェースで転送されたファイルのETagはあてにしてはいけないようです。
【補足3】ストレージの空き容量
開発者ガイドにもあるように、SnowballEdgeのストレージ容量超えないように注意する必要がありますが、ストレージの空きサイズをエクスプローラで確認しても、いつまでも0バイトのままです。デバイスのLCDパネルで確認するしかありません。
デバイスの返送
西濃運輸さんのWebサイトの集荷依頼のページから配送を依頼します。
https://track.seino.co.jp/CallCenterPlusOpen/PickupOpen.do注意点ですが、配送時と同様、配送業者さん(西濃シェンカー)の担当営業所が土日祝日の集荷に対応してない場合があります。ネット上では「日時指定の場合は土日祝日も対応してくれる」との情報がありましたが、私の担当営業所は日時指定の場合でも土日祝日は集荷業務をされていないようでした。ご注意下さい。
S3へのインポート完了後
インポート完了後、Snowballジョブダッシュボードから、以下のファイルがダウンロードできるようになります。
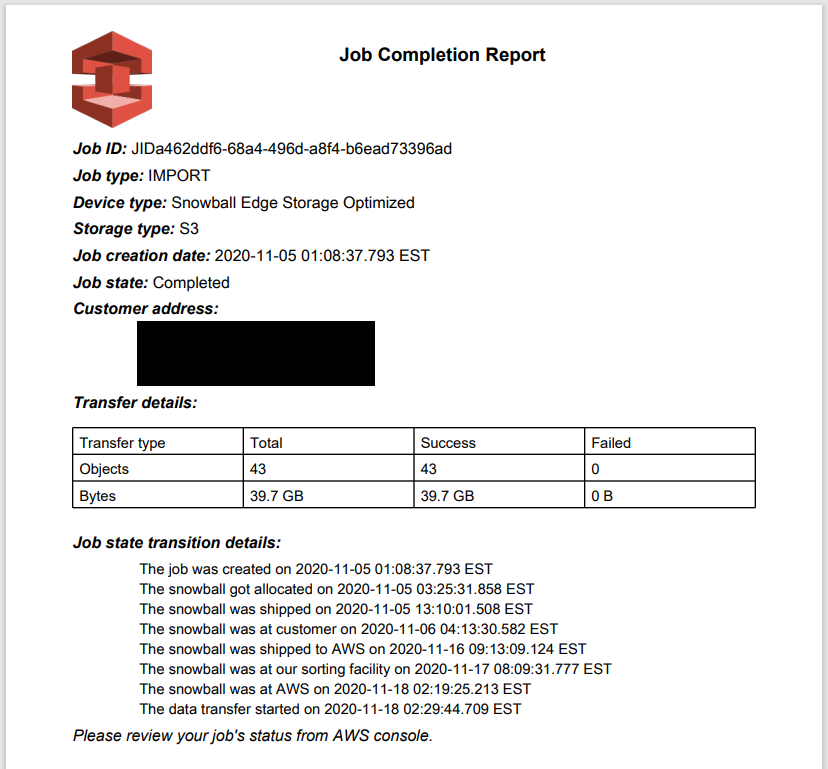
- ジョブレポート
- 成功ログ、失敗ログ
1. ジョブレポート(PDF形式)
ジョブレポートには、インポートに成功した(または失敗した)ファイル数と合計サイズ、ジョブのタイムラインが記載されます。
日時はUTCで表記されています(「EST」(米国東部標準時)と表記されてますが、おそらく誤りです。EST+14時間=JSTなので、UTCでないと辻褄が合いません)。
2. 成功ログ、失敗ログ(CSV形式)
成功ログ・失敗ログは、バケットへのインポートに成功したファイル、失敗したファイルが記録されたテキストファイルです(情報は、バケット名・オブジェクトキー名・バイトサイズ)。
- ファイルのエンコーディング方式は
UTF-8(BOMなし)、改行コードはLFです。- エントリが0件の場合、ヘッダ行もフッタ行も存在しない、0バイトの空ファイルとなります。
成功ログ・失敗ログ(サンプル)"S3 Transfer Results Begin" "Bucket Name","S3 Key","Size" "yz2cm-tokyo-snowball","foo.txt","4" "yz2cm-tokyo-snowball","bar/あああ.txt","9" "yz2cm-tokyo-snowball","fizz.txt","6" "yz2cm-tokyo-snowball","bazz.txt","0" "S3 Transfer Results End"3. メタデータ
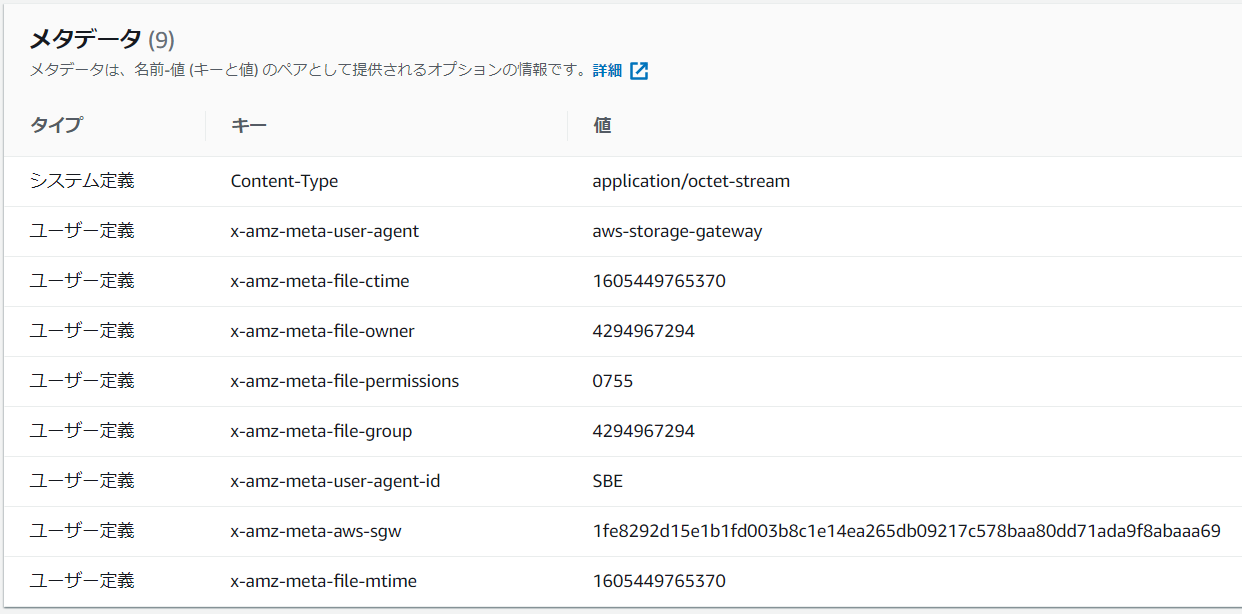
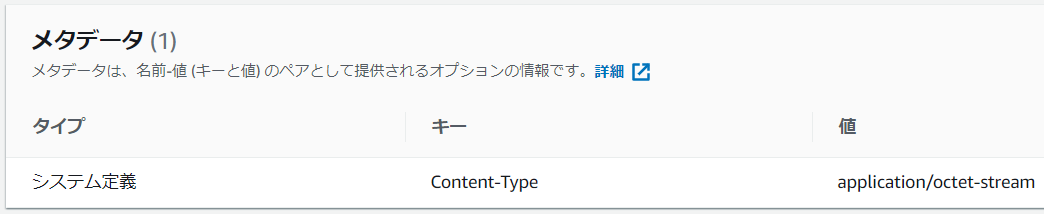
ファイルインタフェースでデバイスにファイル転送したファイルについて、S3へインポート後のキーオブジェクトには以下のメタデータが付与されます。
比較対象として、AWS CLIでデバイスにファイル転送したファイルについて、S3へインポートした後のメタデータを以下に示します。
利用料金(実績)
今回のSnowball利用のコストは、合計420ドル(送料込み)でした。
以下は、2020年11月時点の状況です。
- 東京リージョンでは、到着日と発送日を除く10日間のデバイス保有で300ドル(送料別)です。10日間を超えると、1日30ドルの追加料金が発生します。
- 上記に加えて、往復の配送料120ドルが請求されます(地域によって異なるかもしれません)。

おわりに
これでおわりです。世界中のSnowballユーザーに幸あれ。










- 投稿日:2020-11-14T07:17:07+09:00
Udemyと歩んだAWSアソシエイト3冠
この記事はUdemy Advent Calendar 2020の17日目の記事です?
今年はUdemyをめちゃくちゃ活用できた年でした。
↓今年買ったUdemy教材の一部
中でも、AWSに関してはアソシエイト3冠を達成することができ、Udemyを使用したインプットの成果としても良いものが出せたと思います。
本記事では私がどのようにUdemyを活用してアソシエイト3冠を達成できたのかを紹介しようと思います。全資格共通の流れ
アソシエイト系の資格を取得するにあたって実施したことは、
- Udemyで講座を見る
- 実際に触ってみる
- Web問題集を解く
- 習得した知識をアウトプットする
です。
ラーニングピラミッドに沿ったシンプルかつ基本的な学習方法ですが、知識の定着に大きな力を発揮してくれるサイクルだと思います。Udemyで講座を見る→実際に触ってみる
正直これに尽きると思います。
Udemyでマネージメントコンソールベースの講義を見ながら自分でも同じように動かしてみる。
これだけでも結構力になります。使用した講座
SAAに関しては、今はもう見れなくなってしまっていますがketancho ?|Kei Kanazawaさんが公開していた講座を利用していました。
AWS学習の0→1をサポートする講座「手を動かしながら2週間で学ぶ AWS 基本から応用まで」をUdemyでリリースしました※現在SAAはいろいろな対策講座や書籍が公開・販売されているためインプットには困らないと思います。
SOAとDVAですが、同じ講師が公開している講座を活用しました。
DVA
Ultimate AWS Certified Developer Associate 2020 - NEW!
SOA
Ultimate AWS Certified SysOps Administrator Associate 2020
講座名がどことなく胡散臭いですが内容はガチです。
↓のような感じで
サービス概要説明→ハンズオン→理解度確認
の流れを単元単位で実施することができます。
(元講座は英語ですがページ全体をGoogle翻訳してます。)無料プレビューが公開されているので詳しい内容はそちらを確認してみてください。
英語わからないんだけど?
私もわからないですがGoogle翻訳を使うと英語がわかるようになります(?)
プレイヤー下部の「トランスクリプション」を押すと画面右に字幕が表示されます。
その字幕を翻訳すると結構ストレスなく見ることができます。↓無料プレビュー部分で試してみるとこんな感じ
Udemyで講座を見るのと実際に触ってみるのとはこれでカバーできると思います。
Web問題集を解く
インプットが終わったら次は理解度確認です。
私は一貫してWhizlabsというサービスを使用していました。
基本的に全問題を2周しました。※UdemyのAdvent Calendar記事なので詳しくは割愛します。
この記事でWhizlabsについて紹介しているのでよければ参考にしてください!習得した知識をアウトプットする
ここが学習の肝です。
アウトプットをするかどうかで定着度が大幅に変わります。私はUdemyでやったハンズオン内容をまとめたり、実際に学習したサービスを使ってなにかを「やってみた」ことをブログにアウトプットしていました。
Blue-Greenデプロイとは何かElastic Beanstalkで学ぶ
CodeCommitのプルリクエストをAWS Chatbotを経由してSlackで通知するブログやってないよーって方はqiitaに記事を投稿するところから始めてみましょう!
ここまでやって何点取れるの?
あくまで私の場合ですが、900点くらい取れました。
終わりに
Udemyの強みは講座の質や学習効率はもちろんのことですが、講座を購入することが学習を始めるトリガーになることにあると思います。
AWSを勉強してみたいけど何を参考にすればいいかわからない人や、
SAAに合格してアソシエイト3冠してみようか迷ってる人は講座を購入してみることから始めてみてもいいかもしれませんね。是非、皆さんもUdemyを活用して快適なラーニングライフを送ってください:)