- 投稿日:2020-10-11T19:23:47+09:00
Tensorflow 2で1系記法のCNNを動かす方法
想定読者
- Tensorflow 2の環境で1系のコードで書かれたCNN(畳み込みNN)を動かそうと試行錯誤している人
前提
実行環境
- macOS High Sierra
- Python 3.7.8
- Tensorflow 2.3.1
CNNのコードについて
コードは諸事情により載せませんが、
- MNISTのデータ取得に
tf.keras.*を使用- その他
tf.nn.*,tf.train.*,tf.*を使用して、CNNを実行しているコードです。
1系から2系への主な変更点
Tensorflow 1から2への主な変更点については、 こちら 等いろいろな記事を拝見しましたが、CNNを実行する上で直接影響のあったものは以下でした。
- Eager Executionのデフォルト化
- Session, Placeholderの廃止
※ CNNの実装方法によっては他にもあるかもしれませんがその点はご容赦ください。
1系記法のコードを2系で動かす方法
1系記法のCNNを2系で動かす(ためにコードを変更する)方法は以下の3つがあるようです。
- 変更のあったAPIを地道に書き換える
- アップデートスクリプトを活用する
- 2系挙動を無効化する
1. 変更のあったAPIを地道に書き換える
賢い方法ではありませんが、変更箇所が少なければ該当箇所を地道に書き換えるというのもなくはないかと思います。CNNを動かすために要した修正を以下に示します。
(1) Eager Executionの無効化
import tensorflow as tfの直後に以下を追記し、Eager Executionを無効化する。tf.compat.v1.disable_eager_execution()(2) いくつかのAPIの記法変更
コード内の '1系' の列に該当するAPIを '2系' にある記載の通りに変更する。
# 1系 2系 1 tf.placeholder tf .compat.v1.placeholder 2 tf.random_uniform tf.random.uniform 3 tf.add_to_collection tf .compat.v1.add_to_collection 4 tf.get_collection('costs') tf .compat.v1.get_collection 5 tf.train.AdamOptimizer tf .compat.v1.train.AdamOptimizer 6 tf.Session() tf .compat.v1.Session() #2のような単純に
compat.v1を追加ではないものもありました。
上記以外でcompat.v1の追加が必要なAPIについては、Tensorflow Module: tf.compat.v1をご参照ください。2. アップデートスクリプトを活用する
コードをTensorFlow 2に自動的にアップグレードするを参考に、アップデートスクリプトを用いて、コードを2系記法に変換する方法もあるようです。1の手動変換よりは安全かと思いますが、一部手動変換を要する箇所もあるような記述もあり、全自動ではなさそうです。
3. 2系挙動を無効化する
TensorFlow1コードをTensorFlow2に移行しますによると、
Tensorflowのインポート文import tensorflow as tfを
import tensorflow.compat.v1 as tf tf.disable_v2_behavior()のように変更して2系挙動を無効化することで、1系記法のコードが実行できるようになるようです。(私のコードでは実行が確認できました)
終わりに
3の方法で動いたら一番嬉しいですね。
私は1をした後に3の方法を見つけたのでそういう人が出ないようにこれを書きました。
どんどんTensorflowに慣れていきたいものです。
- 投稿日:2020-10-11T18:04:10+09:00
動くConvolutional VAEコード [Keras@TF2.0]
はじめに
Tensorflowが2.0となりKerasが統合されました。
参考記事 Tensorflow 2.0 with Keras
その結果、これまでkerasで書かれた畳み込み変分オートエンコーダー(Convolutional Variational Auto Encoder)のコードが動かない事情が発生しました。そこで、いくつの最新情報を集め、とりあえず動くコードを作成し、アップしておきます。
環境
tensorflow==2.1
コード
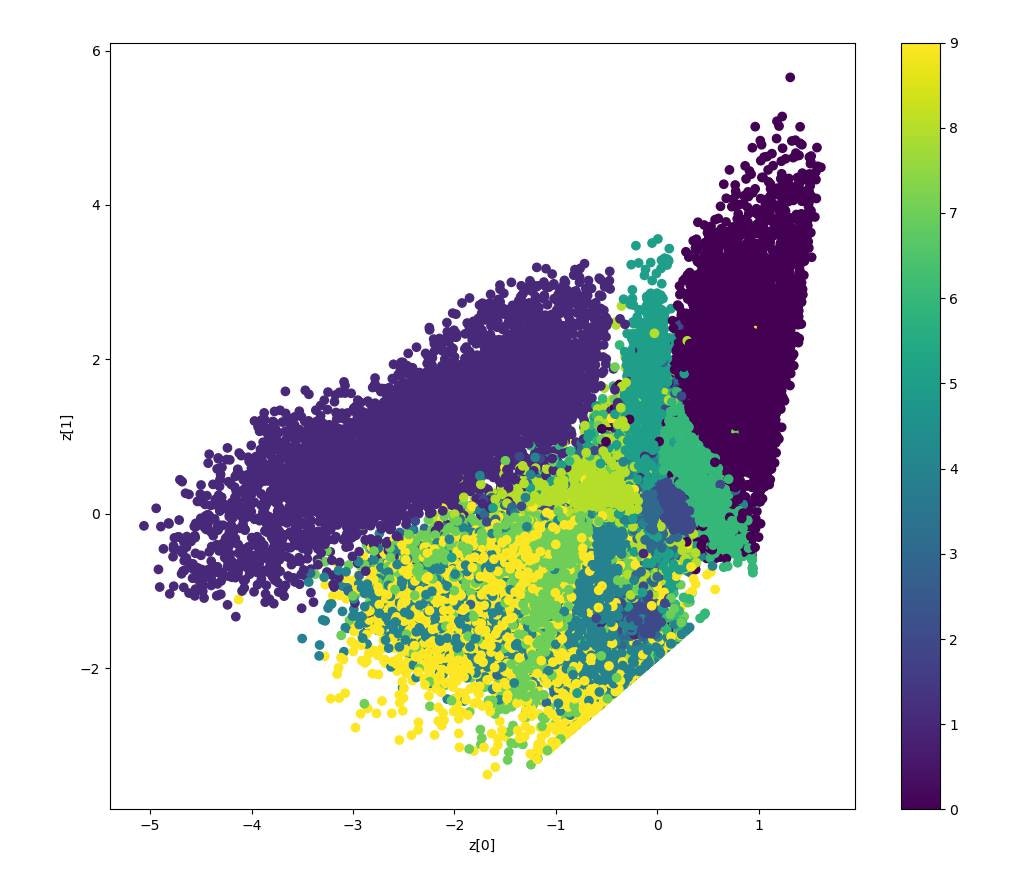
VAE_202010_tf21.pyimport tensorflow as tf import numpy as np import matplotlib.pyplot as plt from tensorflow.keras.datasets import mnist from tensorflow.keras.models import Model from tensorflow.keras.layers import Input, Dense, Lambda, Conv2D, Flatten, Conv2DTranspose, Reshape from tensorflow.keras import backend as K from tensorflow.keras import losses from tensorflow.keras.optimizers import Adam #01. Datasets (x_train, _), (x_test, _) = mnist.load_data() mnist_digits = np.concatenate([x_train, x_test], axis=0) mnist_digits = np.expand_dims(mnist_digits, -1).astype("float32") / 255 print('mnist_train',mnist_digits.shape) print('x_train',x_train.shape) #0-1正規化 x_train = x_train / 255.0 x_test = x_test / 255.0 #2 Setting Autoencoder epochs = 100 batch_size = 256 n_z = 2 # 潜在変数の数(次元数) #3 潜在変数をサンプリングするための関数 # args = [z_mean, z_log_var] def func_z_sample(args): z_mean, z_log_var = args epsilon = K.random_normal(shape=K.shape(z_log_var), mean=0, stddev=1) return z_mean + epsilon * K.exp(z_log_var/2) # VAE Network # Building the Enocoder encoder_inputs = Input(shape=(28,28,1)) x = Conv2D(32,3,activation='relu',strides=2,padding='same')(encoder_inputs) x = Conv2D(64,3,activation='relu',strides=2, padding='same')(x) x = Flatten()(x) x = Dense(16, activation='relu')(x) z_mean = Dense(n_z, name='z_mean')(x) z_log_var = Dense(n_z, name='z_log_var')(x) z = Lambda(func_z_sample, output_shape=(n_z))([z_mean, z_log_var]) encoder = Model(encoder_inputs, [z_mean, z_log_var,z], name='encoder') encoder.summary() # Building the Decoder latent_inputs = Input(shape=(n_z,)) x = Dense(7*7*64, activation='relu')(latent_inputs) x = Reshape((7,7,64))(x) x = Conv2DTranspose(64,3, activation='relu', strides=2, padding='same')(x) x = Conv2DTranspose(32,3, activation='relu', strides=2, padding='same')(x) decoder_outputs = Conv2DTranspose(1,3, activation='sigmoid', padding='same')(x) decoder = Model(latent_inputs, decoder_outputs, name='decoder') decoder.summary() class VAE(Model): def __init__(self, encoder, decoder, **kwargs): super(VAE, self).__init__(**kwargs) self.encoder = encoder self.decoder = decoder def train_step(self,data): if isinstance(data, tuple): data = data[0] with tf.GradientTape() as tape: z_mean, z_log_var, z = encoder(data) reconstruction = decoder(z) reconstruction_loss = tf.reduce_mean( losses.binary_crossentropy(data,reconstruction) ) reconstruction_loss *= 28 * 28 kl_loss = 1 + z_log_var -tf.square(z_mean) - tf.exp(z_log_var) kl_loss = tf.reduce_mean(kl_loss) kl_loss *= -0.5 total_loss = reconstruction_loss + kl_loss grads = tape.gradient(total_loss, self.trainable_weights) self.optimizer.apply_gradients(zip(grads, self.trainable_weights)) return{ "loss": total_loss, "reconstruction loss": reconstruction_loss, "kl_loss": kl_loss, } vae = VAE(encoder, decoder) vae.compile(optimizer=Adam()) vae.fit(mnist_digits, epochs=epochs, batch_size=batch_size) #Display how the latent space clusters different digit classes def plot_label_clusters(encoder, decoder, data, labels): # display a 2D plot of the digit classes in the latent space z_mean, _, _ = encoder.predict(data) plt.figure(figsize=(12, 10)) plt.scatter(z_mean[:, 0], z_mean[:, 1], c=labels) plt.colorbar() plt.xlabel("z[0]") plt.ylabel("z[1]") plt.show() (x_train, y_train), _ = mnist.load_data() x_train = np.expand_dims(x_train, -1).astype("float32") / 255 plot_label_clusters(encoder, decoder, x_train, y_train)結果
2次元の潜在空間での0~9の分布
参考資料
- 投稿日:2020-10-11T18:04:10+09:00
動くConvolutional VAEコード
はじめに
Tensorflowが2.0となりKerasが統合されました。
参考記事 Tensorflow 2.0 with Keras
その結果、これまでkerasで書かれた畳み込み変分オートエンコーダー(Convolutional Variational Auto Encoder)のコードが動かない事情が発生しました。そこで、いくつの最新情報を集め、とりあえず動くコードを作成し、アップしておきます。
環境
tensorflow==2.1
コード
VAE_202010_tf21.pyimport tensorflow as tf import numpy as np import matplotlib.pyplot as plt from tensorflow.keras.datasets import mnist from tensorflow.keras.models import Model from tensorflow.keras.layers import Input, Dense, Lambda, Conv2D, Flatten, Conv2DTranspose, Reshape from tensorflow.keras import backend as K from tensorflow.keras import losses from tensorflow.keras.optimizers import Adam #01. Datasets (x_train, _), (x_test, _) = mnist.load_data() mnist_digits = np.concatenate([x_train, x_test], axis=0) mnist_digits = np.expand_dims(mnist_digits, -1).astype("float32") / 255 print('mnist_train',mnist_digits.shape) print('x_train',x_train.shape) #0-1正規化 x_train = x_train / 255.0 x_test = x_test / 255.0 #2 Setting Autoencoder epochs = 100 batch_size = 256 n_z = 2 # 潜在変数の数(次元数) #3 潜在変数をサンプリングするための関数 # args = [z_mean, z_log_var] def func_z_sample(args): z_mean, z_log_var = args epsilon = K.random_normal(shape=K.shape(z_log_var), mean=0, stddev=1) return z_mean + epsilon * K.exp(z_log_var/2) # VAE Network # Building the Enocoder encoder_inputs = Input(shape=(28,28,1)) x = Conv2D(32,3,activation='relu',strides=2,padding='same')(encoder_inputs) x = Conv2D(64,3,activation='relu',strides=2, padding='same')(x) x = Flatten()(x) x = Dense(16, activation='relu')(x) z_mean = Dense(n_z, name='z_mean')(x) z_log_var = Dense(n_z, name='z_log_var')(x) z = Lambda(func_z_sample, output_shape=(n_z))([z_mean, z_log_var]) encoder = Model(encoder_inputs, [z_mean, z_log_var,z], name='encoder') encoder.summary() # Building the Decoder latent_inputs = Input(shape=(n_z,)) x = Dense(7*7*64, activation='relu')(latent_inputs) x = Reshape((7,7,64))(x) x = Conv2DTranspose(64,3, activation='relu', strides=2, padding='same')(x) x = Conv2DTranspose(32,3, activation='relu', strides=2, padding='same')(x) decoder_outputs = Conv2DTranspose(1,3, activation='sigmoid', padding='same')(x) decoder = Model(latent_inputs, decoder_outputs, name='decoder') decoder.summary() class VAE(Model): def __init__(self, encoder, decoder, **kwargs): super(VAE, self).__init__(**kwargs) self.encoder = encoder self.decoder = decoder def train_step(self,data): if isinstance(data, tuple): data = data[0] with tf.GradientTape() as tape: z_mean, z_log_var, z = encoder(data) reconstruction = decoder(z) reconstruction_loss = tf.reduce_mean( losses.binary_crossentropy(data,reconstruction) ) reconstruction_loss *= 28 * 28 kl_loss = 1 + z_log_var -tf.square(z_mean) - tf.exp(z_log_var) kl_loss = tf.reduce_mean(kl_loss) kl_loss *= -0.5 total_loss = reconstruction_loss + kl_loss grads = tape.gradient(total_loss, self.trainable_weights) self.optimizer.apply_gradients(zip(grads, self.trainable_weights)) return{ "loss": total_loss, "reconstruction loss": reconstruction_loss, "kl_loss": kl_loss, } vae = VAE(encoder, decoder) vae.compile(optimizer=Adam()) vae.fit(mnist_digits, epochs=epochs, batch_size=batch_size) #Display how the latent space clusters different digit classes def plot_label_clusters(encoder, decoder, data, labels): # display a 2D plot of the digit classes in the latent space z_mean, _, _ = encoder.predict(data) plt.figure(figsize=(12, 10)) plt.scatter(z_mean[:, 0], z_mean[:, 1], c=labels) plt.colorbar() plt.xlabel("z[0]") plt.ylabel("z[1]") plt.show() (x_train, y_train), _ = mnist.load_data() x_train = np.expand_dims(x_train, -1).astype("float32") / 255 plot_label_clusters(encoder, decoder, x_train, y_train)結果
2次元の潜在空間での0~9の分布
参考資料
- 投稿日:2020-10-11T16:52:00+09:00
TensorBoard 2.2.1 at http://localhost:6006/
$ tensorboard --logdir ./resultsと打ち、
TensorBoard 2.2.1 at http://localhost:6006/ (Press CTRL+C to quit)が出力されたが、
http://localhost:6006/でtensorboardが見れないとき
- 投稿日:2020-10-11T16:52:00+09:00
TensorBoard at http://localhost:6006/
$ tensorboard --logdir ./と打ち、
TensorBoard 2.2.1 at http://localhost:6006/ (Press CTRL+C to quit)が出力されたが、
http://localhost:6006/でtensorboardが見れないとき。環境
自分のPCはwindows
リモートサーバーはlinux経緯
puttyを使いリモートログインをしてサーバーにログインした。
そこでtensorboardを使った。
アウトプットされたサイトにアクセスできなかった。解決策前提
user名remoteでサーバー名serverを使ってリモートログインする。
remote@server's password:passward現在のディレクトリに入っているtensorboardを起動。
[remote@server ~]$ tensorboard --logdir ./ Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all TensorBoard 2.2.1 at http://localhost:6006/ (Press CTRL+C to quit)解決策
あなたのPCのターミナルを開く。
user名userのコマンドプロンプトを開く。このuser名は例。
そして以下のように入力する。C:\Users\user>ssh -L (ポート番号):localhost:6006 (リモート側のuser名)@(リモート側のサーバーのIPアドレス)(ポート番号)には49513~65535のような空いているポート番号。
(リモート側のuser名)remoteのような名前。
(リモート側のサーバーのIPアドレス)987.098.082.99 のような数字。上記のコードをコマンドプロンプトに打ち込むことで、
http://localhost:(ポート番号)/
からtensorflowが見れる。私の場合
C:\Users\user>ssh -L 49513:localhost:6006 remote@987.098.082.99http://localhost:49513/からtensorboardが見れる。
補足
(リモート側のサーバーのIPアドレス)は非常にプライベートな数字である。
もし自分のサーバーでない他のサーバーにリモートログインするとき、(リモート側のサーバーのIPアドレス)は見れないようになっている時がある。
そのときは、そのサーバーの管理者に(リモート側のサーバーのIPアドレス)を聞こう。

- 投稿日:2020-10-11T12:45:38+09:00
超解像手法/SRCNNを組んでみた③
概要
前回の続きです。part3、ラスト記事になります。
前回:超解像手法/SRCNNを組んでみた①
前回:超解像手法/SRCNNを組んでみた②目次
1.はじめに
2.PC環境
3.コード説明
4.終わりに1.はじめに
超解像とは、解像度が低い画像や動画像に対して解像度を向上させる技術のことであり、SRCNNは深層学習(Deep Learning)を用いて従来の手法に比べて、精度の高い結果を計測した手法のことです。(3回目)
コードの全容はGitHubにも投稿しているのでそちらをご確認ください。
https://github.com/morisumori/srcnn_keras2.PC環境
cpu : intel corei7 8th Gen
gpu : NVIDIA GeForce RTX 1080ti
os : ubuntu 20.043.コード説明
GitHubを見ていただくと分かるのですが、主に3つのコードからなっています。
・datacreate.py → データセット生成プログラム
・model.py → SRCNNのプログラム
・main.py → 実行プログラム
datacreate.pyとmodel.pyで関数を作成し、main.pyで実行しています。今回はいよいよmain.pyを説明します。
model.pyの説明
model.pyimport model import data_create import argparse import os import cv2 import numpy as np import tensorflow as tf if __name__ == "__main__": def psnr(y_true, y_pred): return tf.image.psnr(y_true, y_pred, 1, name=None) train_height = 33 train_width = 33 test_height = 700 test_width = 700 mag = 3.0 cut_traindata_num = 10 cut_testdata_num = 1 train_file_path = "./train_data" test_file_path = "./test_data" BATSH_SIZE = 240 EPOCHS = 1000 opt = tf.keras.optimizers.Adam(learning_rate=0.0001) parser = argparse.ArgumentParser() parser.add_argument('--mode', type=str, default='srcnn', help='srcnn, evaluate') args = parser.parse_args() if args.mode == "srcnn": train_x, train_y = data_create.save_frame(train_file_path, #切り取る画像が含まれたファイルのpath cut_traindata_num, #データセットの生成数 train_height, #保存サイズ train_width, mag) #倍率 model = model.SRCNN() model.compile(loss = "mean_squared_error", optimizer = opt, metrics = [psnr]) #https://keras.io/ja/getting-started/faq/ model.fit(train_x, train_y, epochs = EPOCHS) model.save("srcnn_model.h5") elif args.mode == "evaluate": path = "srcnn_model" exp = ".h5" new_model = tf.keras.models.load_model(path + exp, custom_objects={'psnr':psnr}) new_model.summary() test_x, test_y = data_create.save_frame(test_file_path, #切り取る画像が含まれたファイルのpath cut_testdata_num, #データセットの生成数 test_height, #保存サイズ test_width, mag) #倍率 pred = new_model.predict(test_x) path = "resurt_" + path os.makedirs(path, exist_ok = True) path = path + "/" ps = psnr(tf.reshape(test_y[0], [test_height, test_width, 1]), pred[0]) print("psnr:{}".format(ps)) before_res = tf.keras.preprocessing.image.array_to_img(tf.reshape(test_x[0], [test_height, test_width, 1])) change_res = tf.keras.preprocessing.image.array_to_img(tf.reshape(test_y[0], [test_height, test_width, 1])) y_pred = tf.keras.preprocessing.image.array_to_img(pred[0]) before_res.save(path + "low_" + str(0) + ".jpg") change_res.save(path + "high_" + str(0) + ".jpg") y_pred.save(path + "pred_" + str(0) + ".jpg") else: raise Exception("Unknow --mode")メインは結構長いのですが、短くできるならもっとできるかなぁというのが感想です。
以下で、中身の説明をしていこうと思います。import model import data_create import argparse import os import cv2 import numpy as np import tensorflow as tfここでは、関数や同じディレクトリ にある別のファイルを読み込んでいます。
datacreate.pyとmodel.pyとmain.pyは同じディレクトリにおいてください。def psnr(y_true, y_pred): return tf.image.psnr(y_true, y_pred, 1, name=None)今回は、生成画像の良し悪しの判断基準にpsnrを使用しましたので、そこの定義です。
psnrはピーク信号対雑音比という名前で、簡単に言うと比較したい画像の画素値の差分を計算するって感じです。ここでは詳細の説明を省きますが、この記事とかは割と詳しく、複数の評価法が記載されています。train_height = 33 #trainデータのサイズ train_width = 33 test_height = 700 #testデータのサイズ test_width = 700 mag = 3.0 #使わないですが、関数に含めてしまいました。 cut_traindata_num = 10 #trainデータ生成において1つの写真から何枚データを生成するか。 cut_testdata_num = 1 #testデータ生成において1つの写真から何枚データを生成するか。 train_file_path = "./train_data" #切り取る画像が含まれたファイルのpath test_file_path = "./test_data" BATSH_SIZE = 240 #batchsize EPOCHS = 1000 #epoch数 opt = tf.keras.optimizers.Adam(learning_rate=0.0001) #optimizerここは、今回使用する値を設定しています。config.pyとして別にしている方もgithubを見ていたら結構いますが、大規模プログラムではないため、まとめています。
学習データのサイズは、trainデータは論文が33*33と書いてあったのでそれを採用しました。testは見やすいように大きめにしているだけです。
データの数はファイルに含まれている画像の数の10倍です。(800枚であればデータ数は8,000)今回、データに使用したのはよく超解像で使われているDIV2K Datasetです。データの質がいいので、少ないデータである程度の精度が出ると言われています。
parser = argparse.ArgumentParser() parser.add_argument('--mode', type=str, default='srcnn', help='srcnn, evaluate') args = parser.parse_args()ここは、モデルの学習と評価を分けたかったのでこのような形にして、--modeで選択できるようにしました。
詳細の説明はしないので、python公式のドキュメントを載せておきます。
https://docs.python.org/ja/3/library/argparse.htmlif args.mode == "srcnn": train_x, train_y = data_create.save_frame(train_file_path, #切り取る画像が含まれたファイルのpath cut_traindata_num, #データセットの生成数 train_height, #保存サイズ train_width, mag) #倍率 model = model.SRCNN() model.compile(loss = "mean_squared_error", optimizer = opt, metrics = [psnr]) #https://keras.io/ja/getting-started/faq/ model.fit(train_x, train_y, epochs = EPOCHS) model.save("srcnn_model.h5")ここで、学習させています。srcnnと選択(後ほどやり方は記載)するとこのプログラムが動きます。
data_create.save_frameで、data_create.pyのsave_frameという関数を読み込んで、使えるようにしています。ここで、train_xとtrain_yにデータが入ったので、モデルを同様に読み込んで、compile, fitを行います。
compileなどの詳細の説明はkerasのドキュメントをご覧ください。割と論文と同じものを採用して行っています。
最後にモデルを保存してお終いです。
elif args.mode == "evaluate": path = "srcnn_model" exp = ".h5" new_model = tf.keras.models.load_model(path + exp, custom_objects={'psnr':psnr}) new_model.summary() test_x, test_y = data_create.save_frame(test_file_path, #切り取る画像が含まれたファイルのpath cut_testdata_num, #データセットの生成数 test_height, #保存サイズ test_width, mag) #倍率 pred = new_model.predict(test_x) path = "resurt_" + path os.makedirs(path, exist_ok = True) path = path + "/" ps = psnr(tf.reshape(test_y[0], [test_height, test_width, 1]), pred[0]) print("psnr:{}".format(ps)) before_res = tf.keras.preprocessing.image.array_to_img(tf.reshape(test_x[0], [test_height, test_width, 1])) change_res = tf.keras.preprocessing.image.array_to_img(tf.reshape(test_y[0], [test_height, test_width, 1])) y_pred = tf.keras.preprocessing.image.array_to_img(pred[0]) before_res.save(path + "low_" + str(0) + ".jpg") change_res.save(path + "high_" + str(0) + ".jpg") y_pred.save(path + "pred_" + str(0) + ".jpg") else: raise Exception("Unknow --mode")いよいよラストの説明です。
まずは、psnrが使えるように先ほど保存したモデルを読み込みます。
次に、test用のデータセットを生成し、predictで画像を生成します。psnr値をその場で知りたかったので、計算してます。
画像を保存したかったので、tensorからnumpy配列に変換して、保存してついに終わりです!
これが高画質画像。(元画像)
これがガウシアンフィルタをかけた低画質画像。
これがモデルで生成した画像。
綺麗になってますね。psnr値は34ほどだったかと。4.終わりに
3つの記事に分けてしまって長くなってしまいましたが、読んでくださりありがとうございました。
今後も色々組んでみようと思います。
何かあれば質問やコメントなどよろしくお願いします!



- 投稿日:2020-10-11T00:09:22+09:00
DeepLabv3+を自前のデータセットで学習させる
DeepLabv3+をオリジナルデータセットでトレーニングできます。
TensorFlow公式モデルをつかいます。
DeepLabの使い方は基本的に公式リポジトリに書いてあります。
わからないところがあったらこの記事など読んでください。

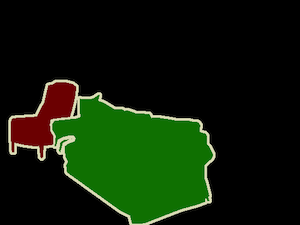
画像はPASCAL VOCデータセットですが、自分のデータセットでもちゃんとトレーニングできます。手順
1、モデル、モジュールを設定
1、公式モデルリポジトリをクローン
git clone https://github.com/tensorflow/models2、researchディレクトリで作業します。
cd models/research3、Colabで作業する場合はTensorFlow1を選択。
%tensorflow_version 1.x4、tf_slimをインストール。
pip install tf_slim必要なモジュールは、
Numpy
Pillow 1.0
tf Slim (which is included in the "tensorflow/models/research/" checkout)
Jupyter notebook
Matplotlib
Tensorflow
です。入れてない場合はインストールしてください。5、tensorflow / models / research /ディレクトリをPYTHONPATHに追加して、ライブラリを使えるようにする。
# tensorflow/models/research/ から実行 export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim*ちなみに、Colabのパスの通し方がわからなかったので、僕はスクリプトのfrom deeplab.。。。import 。。。のdeeplabの部分を全部消しました。。。
あと、research/slimからnetをdeeplabに移動させました。。。2、データを用意する
以下を用意します。
1、元画像
2、ラベル画像
輪郭線はあってもなくてもかまいません。・画像要件
・それぞれディレクトリにまとめる。
元画像のディレクトリ名:JPEGImage
ラベル画像のディレクトリ名:SegmetationClass
・元画像とラベル画像の数と名前(拡張子抜きの名前)は同じにする
・画像サイズは任意。トレーニング時に513,513にクロップされることを念頭に。
(画像全体を収めたい場合は513,513以下を推奨)セグメンテーションデータ作りにはlabelmeなどのツールが使えるそうです。
3、データを前処理する
1、ラベル画像がカラーの場合は白黒のラベル画像にします。
input_dir = "{データセットのパス}/SegmentationClass" mkdir "{データセットのパス}/SegmentationClassRaw" output_dir = "{データセットのパス}/SegmentationClassRaw" # SegmentationClassRawディレクトリを作っておく python deeplab/datasets/remove_gt_colormap.py \ --original_gt_folder=input_dir \ --output_dir=output_dirSegmentationClassRawディレクトリに白黒に変換した画像が保存されます。
小さなラベル値の白黒画像になるので、ほぼ真っ黒です。2、画像ファイル名一覧のテキストファイルを作ります。
image0
image1
image3という拡張子抜きの形式で、ファイル名一覧のテキストファイルを作ります。
以下の3テキストファイルを作ります。
1、trainval.txt :全画像ファイル名
2、train.txt :trainval.txtのうち、トレーニング用セット(全ファイルの9割くらいを割り当てる?)
3、val.txt :trainval.txtのうち、内検証用セット(全ファイルの1割くらいを割り当てる?)トレーニングと検証の割り振りは、最適なバランスは諸説あるようです。
テキストの抜き出し方はこちらの記事など参考にしてください。
ファイル名一覧をテキスト(.txt)ファイルに書き込む【Python】3、データセットをTFRecord形式にします。
TensorFlowでのトレーニングで効率的に読み込めるTFRcord形式にします。
python deeplab/datasets/build_voc2012_data.py \ --image_folder="{データセットのパス}/JPEGImages" \ --semantic_segmentation_folder="{データセットのパス}/SegmentationClassRaw" \ --list_folder="{データセットのパス}//ImageSets/Segmentation" \ --image_format="jpg" \ --output_dir="{データセットのパス}/tfrecord/"4、トレーニングの設定をする
1、deeplab/datasets/data_generator.pyを自前データに合わせて書き換えます。
data_generator.py_PASCAL_VOC_SEG_INFORMATION = DatasetDescriptor( splits_to_sizes={ 'train': 4552, # トレーニングイメージファイル数に書き換える 'train_aug': 10582, # そのままでOK 'trainval': 5088, # 全イメージファイル数に書き換える 'val': 536, # 検証イメージファイル数に書き換える }, num_classes=21, # そのままでOK ignore_label=255, # そのままでOK )2、事前学習済みモデルをダウンロードします。
転移学習のために事前学習済みモデルの重みを使います。
公式リポジトリのリンクから好みのチェックポイントをダウンロードします。
MobileNetv2ベース(22MB)とXceptionベース(439MB)があります。5、トレーニング
1、MobileNetv2バックボーンの場合
python deeplab/train.py --logtostderr \ --training_number_of_steps=30000 \ --train_split="train" \ --model_variant="mobilenet_v2" \ --output_stride=16 \ --decoder_output_stride=4 \ --train_crop_size="513,513" \ --train_batch_size=1 \ --dataset="pascal_voc_seg" \ --tf_initial_checkpoint="{チェックポイントのパス}/deeplabv3_mnv2_pascal_train_aug/model.ckpt-30000" \ --train_logdir="{データセットのパス}/checkpoint" \ # 先にチェックポイント書き込み先ディレクトリを作っておきます --dataset_dir="{データセットのパス}/tfrecord" \ --fine_tune_batch_norm=false \ # CPUのみの場合は”true” --initialize_last_layer=true \ --last_layers_contain_logits_only=false2、Xception_65バックボーンの場合
python deeplab/train.py --logtostderr \ --training_number_of_steps=30000 \ --train_split="train" \ --model_variant="xception_65" \ --atrous_rates=6 \ --atrous_rates=12 \ --atrous_rates=18 \ --output_stride=16 \ --decoder_output_stride=4 \ --train_crop_size="513,513" \ --train_batch_size=1 \ --dataset="pascal_voc_seg" \ --tf_initial_checkpoint="{チェックポイントのパス}/deeplabv3_pascal_train_aug/model.ckpt" \ --train_logdir="{データセットのパス}/checkpoint" \ # 先にチェックポイント書き込み先ディレクトリを作っておきます --dataset_dir="{データセットのパス}/tfrecord" \ --fine_tune_batch_norm=false \ # CPUのみの場合は”true” --initialize_last_layer=true \ --last_layers_contain_logits_only=false1200秒(20分)に一回、チェックポイントが保存されます。save_interval_secsで保存インターバルを指定できます。トレーニング終了後も保存されます。
*参考結果
5000画像、30000エポック、MobileNetv2バックボーン、ColabGPUでトレーニングしたところ、1時間ぐらいでした。
セグメントしたい物体が一つ(2ラベル)だったせいか、結果は大満足でした。6、テスト
検証セットを使ってテストします。
元画像とカラーセグメンテーションマップ画像がログディレクトリに保存されます。
python deeplab/vis.py --logtostderr \ --vis_split="val" \ --model_variant="mobilenet_v2" \ --output_stride=16 \ --decoder_output_stride=4 \ --vis_crop_size="513,513" \ --dataset="pascal_voc_seg" \ --checkpoint_dir="{チェックポイントのパス}/checkpoint" \ --vis_logdir="{結果画像の書き込み先ディレクトリパス(作っておく)}" \ --dataset_dir="{データセットのパス}/tfrecord" \ --max_number_of_iterations=1 --eval_interval_secs=0
凍結グラフにして保存する
python export_model.py --model_variant="mobilenet_v2" --checkpoint_path="{チェックポイントを保存したディレクトリ}/model.ckpt-30000" --export_path="{凍結グラフを保存するディレクトリ}/frozen_graph.pb"?
お仕事のご相談こちらまで
rockyshikoku@gmail.comCore MLを使ったアプリを作っています。
機械学習関連の情報を発信しています。