- 投稿日:2020-10-11T23:58:29+09:00
データハンドリング3(発展) データ形式について
Aidemy 2020/10/
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、データハンドリングの3つめの投稿になります。どうぞよろしくお願いします。*この章は難解で私自身も十分理解しているわけではないので、予めご了承下さい。
*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・Protocol Buffersについて
・hdf5について
・TFRecordについてProtocol Buffersについて(発展)
Protocol Buffersとは
Protocol BuffersはGoogleではデータの保存や構造化されたあらゆる種類の情報の交換で用いられている。
(引用:wikipedia Protocol Buffers "https://ja.wikipedia.org/wiki/Protocol_Buffers")・データ処理の方法としては、予めMessage Typeというものを定義して行われる。
・Message Typeはクラスのようなもので、proto2という言語で定義される。Message Typeの定義
・はじめに、家族構成についてまとめられたMessage Typeのソースコードを参考に、書き方を見ていく。
・コード
・「syntax = "proto2";」でproto2の使用を宣言。「;」は行末に必ずつける。
・「message Person{}」は「Person」というクラスを表している。
・コメントは、一行なら「//」、複数行なら「/* */」で表せる。
・「required string name = 1;」について、「string name」は「name」がstr型であることを表す。このような二単語を合わせてfieldという。「=1」の部分はタグと呼ばれ、データ出力の際にデータを見分ける役割を持つ。「required」は「必須項目」につける必要がある。
・同様に、「required int32 age = 2;」なら、「age」がint型であり、タグが2であることを表す。・「enum Relationship{}」は、strやintのような「型」を新しく定義している。ここでは「Relationship型」ということになる。
・enumの中では、各値(MOTHERなど)に対して新しくタグをつける必要がある。enum内のタグは「0」から始める。
・「required Relationship relationship = 4;」は「str name」と同じで、「relationship」がRelationship型であることを示し、タグが4であるという意味である。・「message Family{}」はPersonと同じでFamilyクラスを表す。
・「repeated Person person = 1;」の「repeated」は、「リスト」のようなものであり、この場合Person型のデータがリスト化される。Message Typeをpythonで扱えるようにする
・以上のコードが書かれたファイルを「family.proto」とする。このファイルをpythonで扱えるようにするには、コマンドで
protoc --python_out = 保存先のファイルパス Message Typeファイル名
と入力する。Pythonでデータを記述する
・Message Typeファイルをpython内で読み込むことで、その中で定義した型(family.protoで言えばFamily型など)を使うことができる。これを使って、実際にpython内でデータを入力していく。
・コード
・結果(一部のみ)
hdf5について
hdf5とは
・hdf5とは、kerasで使われるデータ形式のことで、例えばkerasで作成した学習モデルを保存するときに使われる。
・hdf5では、階層的な構造を1ファイル内で完結させることができる。つまり、複数のフォルダ(ディレクトリ)が階層的に作られていたとしても、hdf5側ではそれを包括してファイルが作成できる。hdf5ファイルの作成
・作成にはh5pyというライブラリとPandasを使う。
・以下では、A県の人口を例に、hdf5ファイルを作成する。・コード
・hdf5ファイルを開く:hdf5.File("ファイル名")
・グループ(ディレクトリ)の作成:ファイル.create_group("グループ名")
・ファイルの書き込みはflush(),閉じるのはclose()で行う。TFRecordについて
TFRecordとは
TFRecordは、「メモリに収まらないような大きなデータを処理できるようにしたもので、シンプルなレコード指向のバイナリのフォーマット」ということです。
引用:tdl TensorFlow推奨フォーマット「TFRecord」の作成と読み込み方法
[https://www.tdi.co.jp/miso/tensorflow-tfrecord-01#:~:text=TFRecord%E3%81%AF%E3%80%81%E3%80%8C%E3%83%A1%E3%83%A2%E3%83%AA%E3%81%AB%E5%8F%8E%E3%81%BE%E3%82%89,%E3%81%AE%E3%83%95%E3%82%A9%E3%83%BC%E3%83%9E%E3%83%83%E3%83%88%E3%80%8D%E3%81%A8%E3%81%84%E3%81%86%E3%81%93%E3%81%A8%E3%81%A7%E3%81%99%E3%80%82]・TFRecordはTensorFlowで使われるデータ形式のことで、上記のように、大きなデータを処理できるようにするものである。
画像をTFRecord形式にして別ファイルに書き出す。
・流れとしては「画像を読み込む」「書き出す内容の定義」「書き込む」という感じ。
・以下で実際に行う(ファイルパスは架空のもの)・コード
・「書き出すデータの定義」の箇所について、「tf.train.Example()」「tf.train.Features()」「tf.train.Feature()」「tf.train.ByteList()」といった多くのインスタンスが階層的に生成されているが、それぞれに役割がある。
・「tf.train.ByteList(value=[データ])」について、これは[]内のデータをもつインスタンスを生成する。このデータはbyte型である必要があるので、tobytes()を使用する。
・「'キー':tf.train.Feature()」は、ByteListインスタンスから、キーを持ったFeatureインスタンスを生成する。
・「tf.train.Features()」は、複数のFeatureインスタンスを辞書としてまとめる。
・「tf.train.Example()」は、FeaturesインスタンスからExampleインスタンスを生成する。これにより、ファイルに書き込むことが可能になる。・「書き込む」の箇所について、「tf.python_io.TFRecordWriter('ファイル名')」は、TFRecord版の「open('w')」である。
・「fp.write(my_Example.SerializePartialToString())」で、最終的に書き込めば完了。可変長と固定長のリスト
・リストには、長さを変えられる一般的な可変長と、決められたデータしか入れられない固定長がある。
・pythonのリストは普通可変長であるが、前項の「tf.train.Example()」は固定長である。
・可変長のデータを生成する時は「tf.train.SequenceExample()」とする。今回は以上です。最後まで読んでいただきありがとうございます。




- 投稿日:2020-10-11T23:57:10+09:00
データハンドリング2 様々なデータフォーマットの解析
Aidemy 2020/10/11
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、データハンドリングの二つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・pandasで変換できるフォーマットの紹介
・pandasを使ったデータフォーマットの変換
・CSVファイルをグラフ化データフォーマットの解析
pandasを使ったファイルの入出力
・HTML,JSON,CSV,Excelは、それぞれ、Webページ,WebAPI,データ整理など用途が異なる。これらのデータ形式についてpandasを使えば相互に変換が可能になる。
pandasでHTMLのスクレイピング
・基本的に、HTMLの<h1>や<p>などのタグ要素はBeautifulSoupでスクレイピングするが、テーブル要素<table>に関しては、pandasでスクレイピングする。
JSONについて
・JSONとは、"JavaScript Object Notation"の略で、異なるプログラミング言語のデータのやり取りをサポートする物である。
・JSONファイルの構造は基本的にはPythonの辞書型変数の構造と同じで、{key:value,}のような形で表される。CSVファイルについて
・CSVとは"Comma Separated Values"すなわち「カンマで区切られた値」のことである。軽量で簡単なデータ構造のため、古くからデータのやり取りなどで使われる。
・CSVファイルは「a, b, c, 」のように、値ごとに間まで区切られているだけの構造である。Excelについて
・Excelは言うまでもなく表計算ソフトのことである。広く使われていることから、Excelのスクレイピングができるようになるとデータ解析の幅が広がる。
・Excelの各名称について、まず、ファイルのことを「book」とよび、ファイル内の表のことを「sheet」、そのうち縦が「column(列)」横が「row(行)」であり、一つ一つの項目を「cell」と言う。データフォーマットの変換
ファイルをDataFrameで読み込む
・先述のデータフォーマットを実際に変換していく。まず、ファイルの読み込みは、
pd.read_データ型("ファイル名") で行う。例えばHTMLなら「pd.read_html()」、Excelなら「pd.read_excel()」となる。・ファイルの書き出しは、pd.to_データ型("ファイル名")で行う。また、ここでは「pd」としているが、DataFrame型のオブジェクト「df」をHTMLファイルに書き出したいのであれば「df.to_html()」となる。
CSVファイルのデータをグラフ化する
グラフ化の手順
・「CSVファイルを読み込む(read_csv)」「pandasでグラフの作成」「matplotlibでグラフを描画(plt.show)」
・このうち、「pandasでグラフの作成」が新出。方法は「df.plot()」でOK。data=pd.read_csv("data.csv") data.plot() plt.show()まとめ
・pandasによって、様々なデータフォーマット間のデータのやり取りができる。
・pythonに他のデータフォーマットを読み込んだり書き出したりする時は「pd.read_csv()」「df.to_html()」のように表す。
・読み込んだCSVファイルは、df.plot()のようにしてグラフを作ることができる。今回は以上です。最後まで読んでいただき、ありがとうございました。
- 投稿日:2020-10-11T23:53:29+09:00
データハンドリング1 データの整形とファイルの入出力
Aidemy 2020/10/11
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、データハンドリングの一つめの投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・テキストデータの変形の方法
・文字列の分割の方法
・ファイルの出入力の方法(一部復習)テキストデータの整形
オブジェクトを文字列(str)に変換する
・str(オブジェクト)で文字列型に変換できる。
文字列に、変数を埋め込む
name="んがょぺ" print("私は{}です".format(name)) #私はんがょぺですformat()の引数に辞書型を指定したとき
・format()の文字列に含まれる{}のなかに辞書のキーを指定すると、キーの値を出力できる。
dic={"name":"ヒトカゲ", "gen":1} print("{0[name]}、君に決めた!".format(dic)) #ヒトカゲ、君に決めた!文字幅を指定する
・format()が入る{}に、以下のように指定すると、文字の幅を指定できる。
・中央に寄せる:{:^10}.format()
・左に寄せる:{:<10}.format()
・右に寄せる:{:>10}.format()文字列の分割
分割してリストに入れる
・分割は.split("区切る文字(記号)")でできる。
poke="フシギダネ、ヒトカゲ、ゼニガメ、ピカチュウ" print(poke.split("、")) #["フシギダネ","ヒトカゲ","ゼニガメ","ピカチュウ"]リストを一つの文字列にする(splitの逆)
・"つなげたい文字(記号)".join(リスト)でつなげられる。
list=["2020","10","4"] print("-".join(list)) #2020-10-4ファイルの入出力
ファイルを開く
・プログラム上でファイルを扱いたいとき(例えばWebから取得したデータファイル)は
open(ファイル名,モード)で開くことができる。
・モードは、書き込み可能な「"w"(上書き)」「"a"(追記)」、読み込み可能な「"r"」、読み込みも書き込みも可能な「"r+"」がある。ファイルを閉じる
・ファイルを開いたら、必ず閉じなければならない(処理が重くなるため)。
・ファイル.close()で閉じることができる。ファイルに書き込む
・f.write("内容")で書き込める。
・"w"モードの場合、この「内容」で上書きされてしまうので注意。ファイルを読み込む
・ファイルのモードが"r"または"r+"になっているとき、f.read()で読み込める。
・一行だけ読み込みたい時はf.readline()を使う。ファイルの開閉を自動で行う
・with open("ファイル名","モード")as f: のように、with文を使えば自動でファイルを閉じてくれるようになる。そのため、実務では普通with文を使ってファイルを扱う。
#read.txtをwith文で読み込む with open("read.txt","r") as f: f.read() #text.txtをwith文で上書き with open("text.txt","w") as f: f.write("私はんがょぺです")まとめ
・.format()で文字列の{}に文字を埋め込める。埋め込む文字は辞書型やリスト型でも可能。
・{}のなかで:^10などとすれば、文字を幅寄せできる。
・split()で文字列を分解できる。
・open()でファイルが開ける。close()でファイルを閉じ、書き込むのは.write()、読み込むのはread()で行える。
・ファイルを扱う時はwith文の中で行うことで、閉じる必要がなくなるので便利。今回は以上です。最後まで読んでいただき、ありがとうございました。
- 投稿日:2020-10-11T23:50:12+09:00
【Python】簡易的な仕分け機能付き画像ビューワー作ってみた
背景
仕事で大量の画像を分類分けしないといけない。
フリーソフトを使えば効率よく仕分けられる気がするが、残念ながら弊社はフリーソフトは原則禁止。
ならば作ってしまえの精神で、簡易的な仕分け機能付きの画像ビューワー作ってみた。仕上がりイメージ
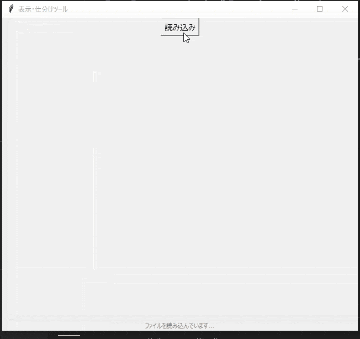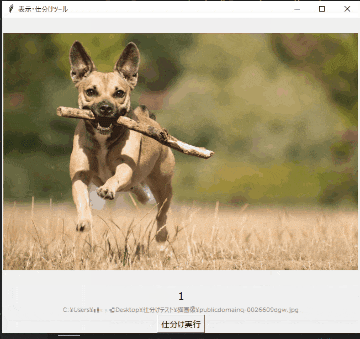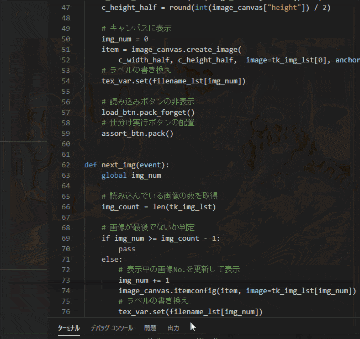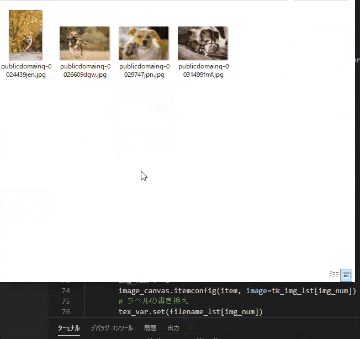
例:猫画像の中に紛れてしまった犬画像をラベル「1」をつけて抽出する。
- 「読み込み」ボタンを押したあと、フォルダを指定する。するとサブディレクトリを含めたディレクトリ配下の画像すべてを読み込まれる。
- 「←」「→」で画像を送り、数字キーを押すと表示中の画像に押されたキー番号をラベリングする。 (ファイル名の下にラベリング=入力したキー(数字)が表示される。ちなみに0を押すとラベリング解除)
- 「仕分け実行」ボタンでラベリングした内容をもとにフォルダ分けを実行する。
- その後、「フォルダを開く」ボタンを押すと読み込んだ画像ファイルのフォルダを開くことができる。
コード全文
仕分けツールの本体はコチラ↓
仕分けツール(クリックしてコードを表示)
仕分けツール.pyfrom file_walker import folder_walker # 自作関数 from folder_selecter import file_selecter # 自作関数 import os import shutil import subprocess import tkinter as tk from tkinter import Label, Tk, StringVar from PIL import Image, ImageTk # 外部ライブラリ # ファイル読み込み - - - - - - - - - - - - - - - - - - - - - - - - def load_file(event): global img_num, item, dir_name # ファイルを読み込み tex_var.set("ファイルを読み込んでいます...") dir_name = file_selecter(dir_select=True) if not dir_name == None: file_list = folder_walker(dir_name) # ファイルから読み込める画像をリストに列挙 for f in file_list: try: img_lst.append(Image.open(f)) filename_lst.append(f) except: pass # ウィンドウサイズに合わせてキャンバスサイズを再定義 window_resize() # 画像変換 for f in img_lst: # キャンバス内に収まるようリサイズ resized_img = img_resize_for_canvas(f, image_canvas) # tkinterで表示できるように画像変換 tk_img_lst.append(ImageTk.PhotoImage( image=resized_img, master=image_canvas)) # キャンバスの中心を取得 c_width_half = round(int(image_canvas["width"]) / 2) c_height_half = round(int(image_canvas["height"]) / 2) # キャンバスに表示 img_num = 0 item = image_canvas.create_image( c_width_half, c_height_half, image=tk_img_lst[0], anchor=tk.CENTER) # ラベルの書き換え tex_var.set(filename_lst[img_num]) # 読み込みボタンの非表示 load_btn.pack_forget() # 仕分け実行ボタンの配置 assort_btn.pack() # 次の画像へ - - - - - - - - - - - - - - - - - - - - - - - - def next_img(event): global img_num # 読み込んでいる画像の数を取得 img_count = len(tk_img_lst) # 画像が最後でないか判定 if img_num >= img_count - 1: pass else: # 表示中の画像No.を更新して表示 img_num += 1 image_canvas.itemconfig(item, image=tk_img_lst[img_num]) # ラベルの書き換え tex_var.set(filename_lst[img_num]) # ラベリングを表示 if filename_lst[img_num] in assort_dict: assort_t_var.set(assort_dict[filename_lst[img_num]]) else: assort_t_var.set("") # 前の画像へ - - - - - - - - - - - - - - - - - - - - - - - - def prev_img(event): global img_num # 画像が最初でないか判定 if img_num <= 0: pass else: # 表示中の画像No.を更新して表示 img_num -= 1 image_canvas.itemconfig(item, image=tk_img_lst[img_num]) # ラベルの書き換え tex_var.set(filename_lst[img_num]) # ラベリングを表示 if filename_lst[img_num] in assort_dict: assort_t_var.set(assort_dict[filename_lst[img_num]]) else: assort_t_var.set("") # ウィンドウサイズからキャンバスサイズを再定義 - - - - - - - - - - - - - - - - - def window_resize(): image_canvas["width"] = image_canvas.winfo_width() image_canvas["height"] = image_canvas.winfo_height() # キャンバスサイズに合わせて画像を縮小 - - - - - - - - - - - - - - - - - - - - def img_resize_for_canvas(img, canvas, expand=False): size_retio_w = int(canvas["width"]) / img.width size_retio_h = int(canvas["height"]) / img.height if expand == True: size_retio = min(size_retio_w, size_retio_h) else: size_retio = min(size_retio_w, size_retio_h, 1) resized_img = img.resize((round(img.width * size_retio), round(img.height * size_retio))) return resized_img # 画像表示 - - - - - - - - - - - - - - - - - - - - - - - - def image_show(event): img_lst[img_num].show() # 画像に対しラベリング - - - - - - - - - - - - - - - - - - - - - - - - def file_assort(event): if str(event.keysym) in ["1", "2", "3", "4", "5", "6", "7", "8", "9"]: assort_dict[filename_lst[img_num]] = str(event.keysym) elif str(event.keysym) == "0": del assort_dict[filename_lst[img_num]] # ラベリングを表示 if filename_lst[img_num] in assort_dict: assort_t_var.set(assort_dict[filename_lst[img_num]]) else: assort_t_var.set("") print(assort_dict[filename_lst[img_num]]) # フォルダ分け実行 - - - - - - - - - - - - - - - - - - - - - - - - def assort_go(event): global f_dir for f in assort_dict: # 仕分け前後のファイル名・フォルダ名を取得 f_dir = os.path.dirname(f) f_basename = os.path.basename(f) new_dir = os.path.join(f_dir, assort_dict[f]) new_path = os.path.join(new_dir, f_basename) # ディレクトリの存在チェック if not os.path.exists(new_dir): os.mkdir(new_dir) # ファイルの移動実行 shutil.move(f, new_path) # 各種ボタンの表示・非表示 assort_btn.pack_forget() open_folder_btn.pack() print(new_path) # フォルダーを開く - - - - - - - - - - - - - - - - - - - - - - - - def folder_open(event): # パスをエクスプローラーで開けるように変換 open_dir_name = f_dir.replace("/", "\\") # エクスプローラーで開く subprocess.Popen(['explorer', open_dir_name]) # tkinterウィンドウを閉じる root.destroy() print(open_dir_name) # メイン処理 ------------------------------------------------------- if __name__ == "__main__": # グローバル変数 img_lst, tk_img_lst = [], [] filename_lst = [] assort_file_list = [] assort_dict = {} img_num = 0 f_basename = "" # tkinter描画設定 root = tk.Tk() root.title(u"表示・仕分けツール") root.option_add("*font", ("Meiryo UI", 11)) # 読み込みボタン描画設定 load_btn = tk.Button(root, text="読み込み") load_btn.bind("<Button-1>", load_file) load_btn.pack() # キャンバス描画設定 image_canvas = tk.Canvas(root, width=640, height=480) image_canvas.pack(expand=True, fill="both") # 仕分け結果表示 assort_t_var = tk.StringVar() assort_label = tk.Label( root, textvariable=assort_t_var, font=("Meiryo UI", 14)) assort_label.pack() # ファイル名ラベル描画設定 tex_var = tk.StringVar() tex_var.set("ファイル名") lbl = tk.Label(root, textvariable=tex_var, font=("Meiryo UI", 8)) lbl["foreground"] = "gray" lbl.pack() # 右左キーで画像送りする動作設定 root.bind("<Key-Right>", next_img) root.bind("<Key-Left>", prev_img) # 「Ctrl」+「P」で画像表示 root.bind("<Control-Key-p>", image_show) # 数字キーで仕分け対象設定 root.bind("<Key>", file_assort) # 仕分け実行ボタン assort_btn = tk.Button(root, text="仕分け実行") assort_btn.bind("<Button-1>", assort_go) # フォルダを開くボタン open_folder_btn = tk.Button(root,text="フォルダーを開く") open_folder_btn.bind("<Button-1>", folder_open) root.mainloop()フォルダを指定する動作、指定フォルダからファイルリストを取得する動作は作成した自作関数を用いた。
上記の仕分けツール.pyと同じフォルダ内に下記.pyファイルを格納しておく。
file_selector.py(クリックしてコードを表示)
file_selector.pyimport os import sys import tkinter as f_tk from tkinter import filedialog def file_selecter(ini_folder_path = str(os.path.dirname(sys.argv[0])), multiple= False, dir_select = False): """ ダイアログを開いて、ファイルやフォルダを選択する。 初期フォルダを指定しなかった場合、ファイル自体のフォルダを開く。 オプションでフォルダ選択、ファイル選択(複数・単一)を選択できる。 Parameters ---------- ini_folder_path : str 初期に開くフォルダ。既定値は実行ファイルのフォルダパス multiple : bool ファイルを複数選択可能にするか否か。既定値はFalseで単一選択。 dir_select : bool フォルダ選択モード。既定値はFalseでファイル選択モードに。 """ root_fileselect=f_tk.Tk() root_fileselect.withdraw() # ウィンドウを非表示する if os.path.isfile(ini_folder_path): ini_folder_path = os.path.dirname(ini_folder_path) # 初期フォルダ指定にファイル名が入っていた場合、ファイルのフォルダを返す if dir_select: select_item = f_tk.filedialog.askdirectory(initialdir=ini_folder_path) # ディレクトリ選択モード elif multiple: select_item = f_tk.filedialog.askopenfilenames(initialdir=ini_folder_path) # ファイル(複数)選択モード else: select_item = f_tk.filedialog.askopenfilename(initialdir=ini_folder_path) # ファイル(単一)選択モード root_fileselect.destroy() if not select_item =="": return select_item
file_walker.py(クリックしてコードを表示)
file_walker.pyimport os import pathlib def folder_walker(folder_path, recursive = True, file_ext = ".*"): """ 指定されたフォルダのファイル一覧を取得する。 引数を指定することで再帰的にも、非再帰的にも取得可能。 Parameters ---------- folder_path : str 対象のフォルダパス recursive : bool 再帰的に取得するか否か。既定値はTrueで再帰的に取得する。 file_ext : str 読み込むファイルの拡張子を指定。例:".jpg"のようにピリオドが必要。既定値は".*"で指定なし """ p = pathlib.Path(folder_path) if recursive: return list(p.glob("**/*" + file_ext)) # **/*で再帰的にファイルを取得 else: return list(p.glob("*" + file_ext)) # 再帰的にファイル取得しない勉強したこと
Tkinterウィンドウの親子関係
フォルダの選択にもTkinterの
filedialogを使用しているのだが、最初、フォルダを選択した後にメインウィンドウのrootを描画するようにしていた。そうすると、継承とかの関係なのか、メインのrootがうまく表示されなかったり、アクティブにならなかったりして苦労した。
結局、メインのrootを描画したあとにfiledialogを呼び出すようにしたら問題なくrootも描画できた。ガベージコレクションの概念
最初、キャンバスや
tk.StringVar()を埋め込んだラベルの中身が一切表示されなくて焦った。
色々調べた結果、pythonにはガベージコレクションという概念があり、不要(=アクセスがない)と判断された変数の中身は自動的に削除されてしまう。結果、キャンバスがオブジェクトを参照しようとしたときに、その中身が無くなっているため、描画できないという事態になってしまっていた。
これを回避するためには、あらかじめグローバル変数として読み込むか、クラスのインスタンスにオブジェクトを読み込ませる方法がある。詳細は下記参照。
参考ページ:【Python】Tkinter で画像などのオブジェクトが描画できない時の対処法
https://daeudaeu.com/create_image_problem/tkinterウィジェットのパラメータを参照する
ウィジェットのパラメータを参照する方法を探すのに意外と苦労した。
結局、下記のようにウィジェット名["パラメータ名"]で取得すればよいだけだった。canvas_w = int(image_canvas["width"])(今回の場合、ウィンドウサイズを可変にしたため、キャンバスの中心を割り出せるようキャンバスサイズを取得する必要があった。)
所感・今後
シンプルな動作なので簡単に作れるだろうと思ったていたら、知識不足のため意外と苦労した。
今後は、今回作成したものをベースに、色々修正してより使い勝手のよいツールに仕上げていきたい。具体的には、
- 設定ファイル(iniファイル)を読み込んで、ファイルを開く場所を記憶させたり、 ラベリングしたキーに基づいてフォルダ名を自動的にラベル名(例えば「01 犬」等)に変換する機能などを付けたい。
- とりあえずのGUIで作ったので、もう少し使いやすいUIに修正したい。そのため、pack()で配置するのではなく、 grid()で配置できるようになりたい。
- ズーム機能
- そもそもpythonの使用許可をもらえてないので、上司に有用性を説明して使用許可を得る。
(pythonぐらい無条件で使用許可出してくれよ。。。)等。
- 投稿日:2020-10-11T22:51:43+09:00
乃木坂認識プログラム(Yolov5を利用)目次
この記事はあくまで目次です.
目次(Yolov5)
⓵システム導入
https://qiita.com/asmg07/items/e3be94a3e0f0195c383b
⓶学習編
https://qiita.com/asmg07/items/01b429ad8443ac346f7f
⓷モデル構築について
https://qiita.com/asmg07/items/8502fe59b65f92d1e379
④GPUを使ったYoloの学習について
https://qiita.com/asmg07/items/0abad3e16886cb60ecef
⑤最後
https://qiita.com/asmg07/items/979d054d1b813afc8c74
- 投稿日:2020-10-11T22:47:39+09:00
real-time-Personal-estimation(カテゴリ外の画像を推定させない為にはどうしたらいいか)※失敗です.
前回までの記事
前回は,yolov5をローカルマシンを使ってGPU利用の学習を行った.
https://qiita.com/asmg07/items/0abad3e16886cb60ecef
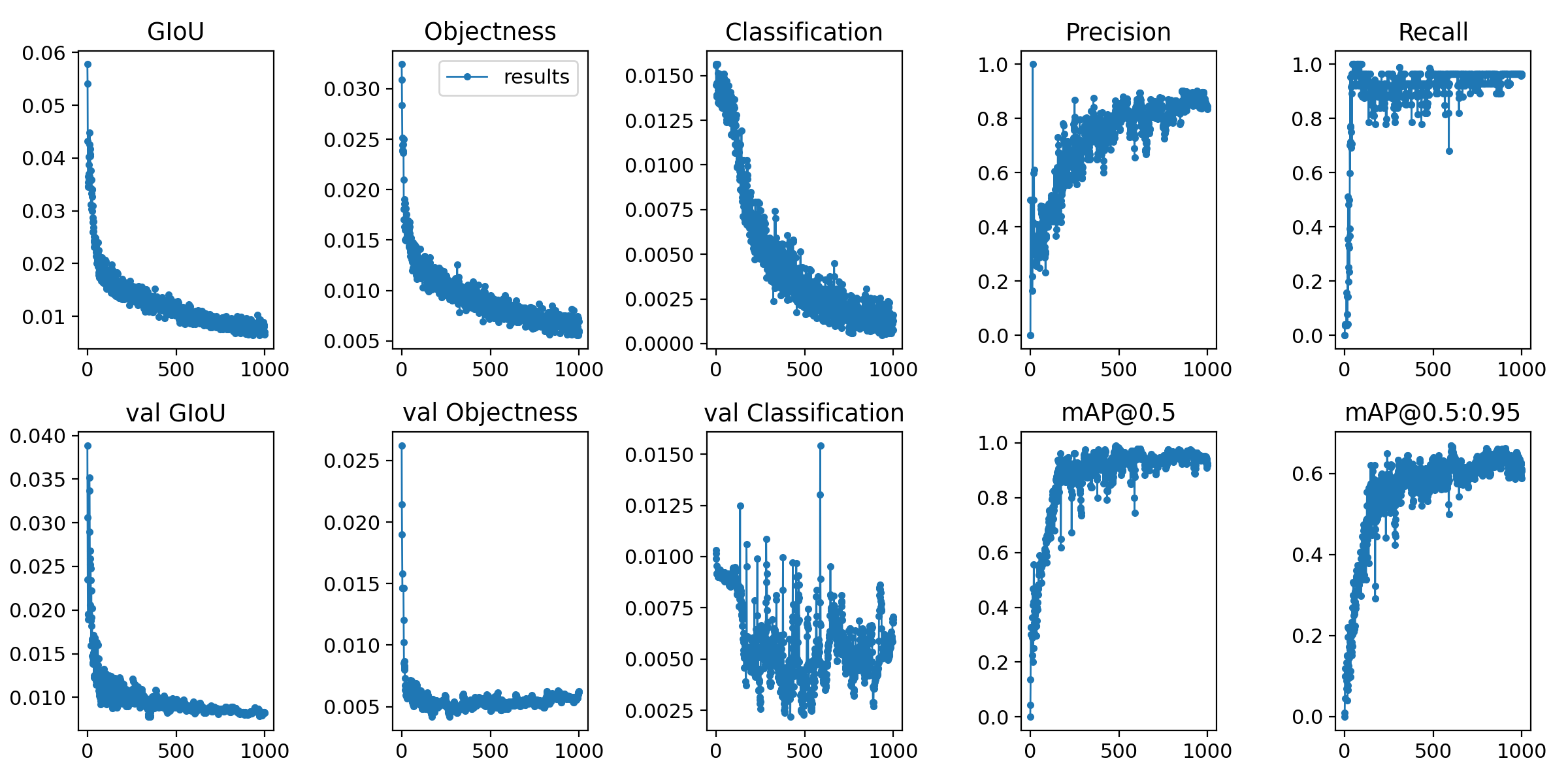
ここでテストとして,epochs 1000で学習をさせ結果は以下のようになった.
このモデルをもとにテストをしてみた結果以下のように全くうまく学習できていないことが判明する.
カテゴリ外の画像
カテゴリ内の画像
この結果からわかる問題点はカテゴリ外の画像を推定させない為には,どうしたらいいかを考える必要がある.今回の記事の概要
とりあえず学習させる画像を約100枚から数百枚もしくは数千枚に増やしたらどうなるのかを実際にやってみたいと思う.
アノテーション
画像収拾については前記事で示しているので今回は割愛する.当該記事を下記に示す.
記事内search.py https://qiita.com/asmg07/items/8502fe59b65f92d1e379
アノテーションについては Vottを使っている.
画像データは
・斎藤飛鳥 350枚
・与田祐希 350枚
でいこうと考えている.
なお,search.pyで吸い上げた画像から使えそうな画像だけを残してそこからアノテーション
を行うからここをまず根気よくやる必要がある.学習について
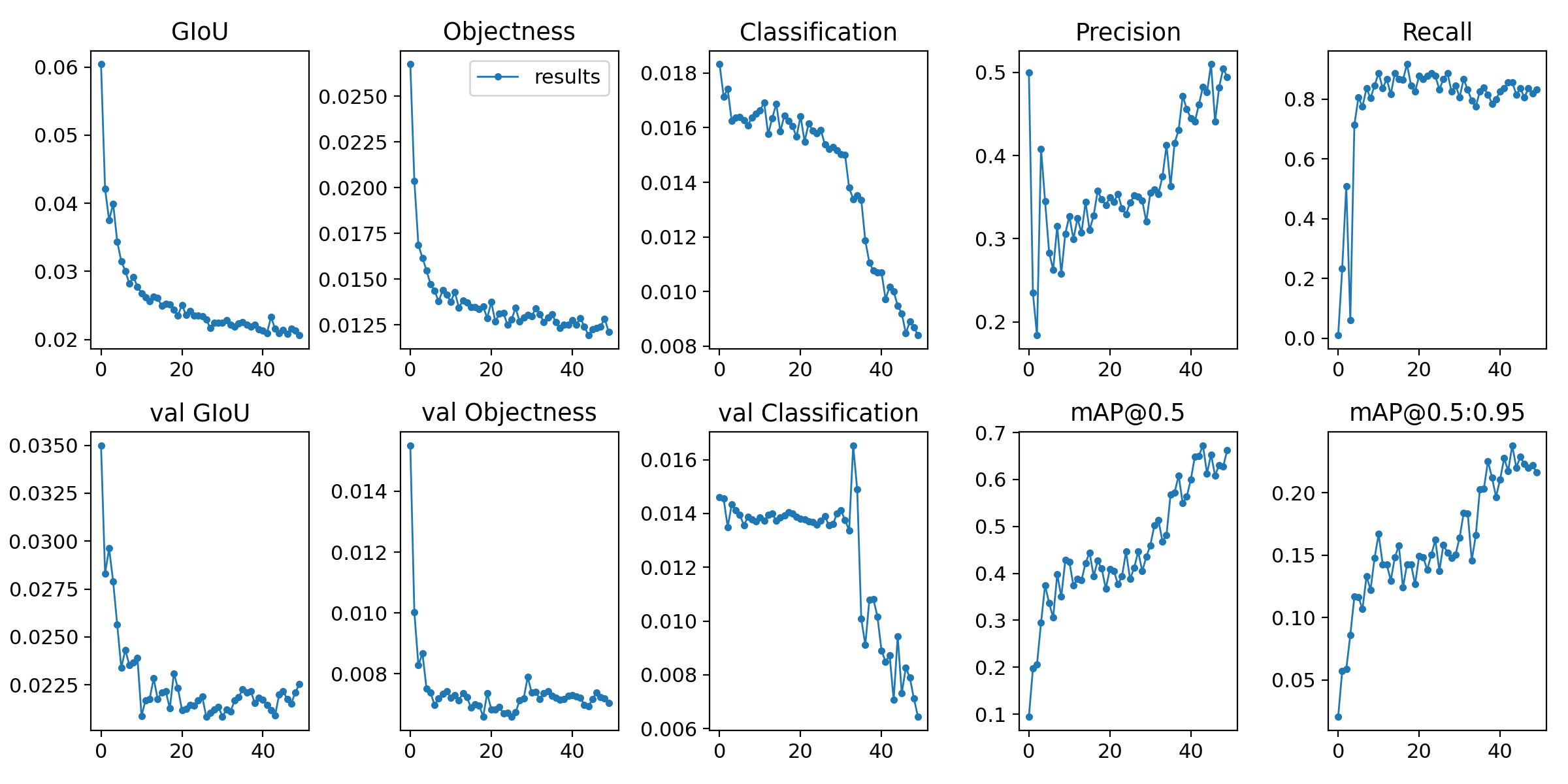
epochs50回
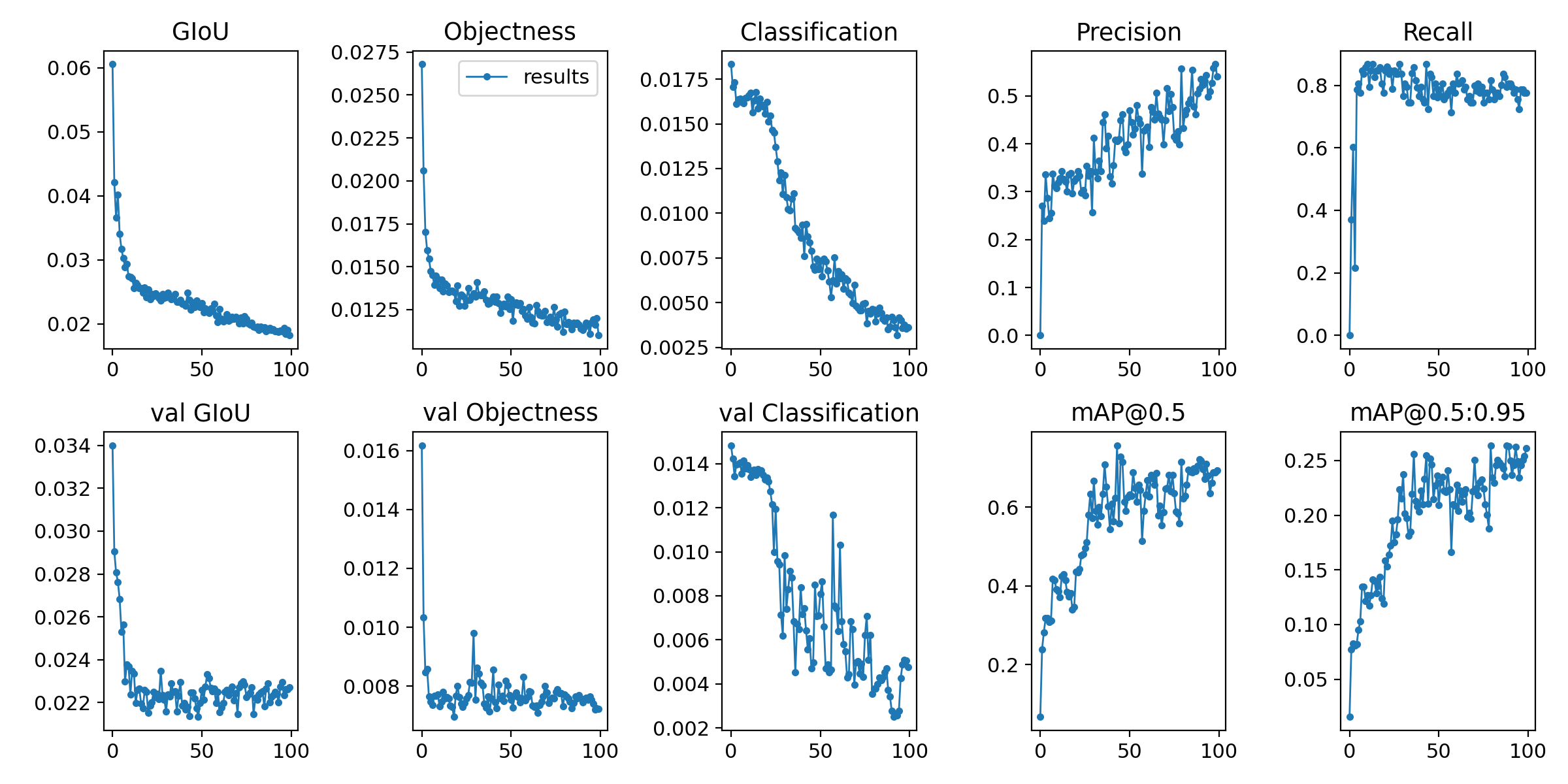
epochs100回
結論
yoloを使った乃木坂認識自体は失敗に終わった.
理由としては,人という認識においては優れているけど,人個人を認識するのは難しい.
理由はまだわかってません.
ってことでyoloを使った開発は続けていきますが,乃木坂認識プロジェクトはとりあえず保留です.
ありがとうございました.




- 投稿日:2020-10-11T22:39:31+09:00
Pythonで二分探索
二分探索のコードは以下です。
def binary_search(src, target_value): result = False lower_index = 0 higher_index = len(src)-1 while True: dst = src[lower_index:higher_index+1] medium_index = (lower_index + higher_index) // 2 if src[medium_index] == target_value: result = True break if (higher_index - lower_index) == 1: break if target_value >= dst[medium_index]: lower_index = medium_index else: higher_index = medium_index return result def main(): src = [1, 2, 3, 4, 5, 6] # すでにソート済み target_value = 4 if binary_search(src, target_value): print('Found!') else: print('Not Found') if __name__ == '__main__': main()実行結果は以下になります。
Found!最後まで読んでいただきありがとうございました。
またお会いしましょう。
- 投稿日:2020-10-11T22:26:12+09:00
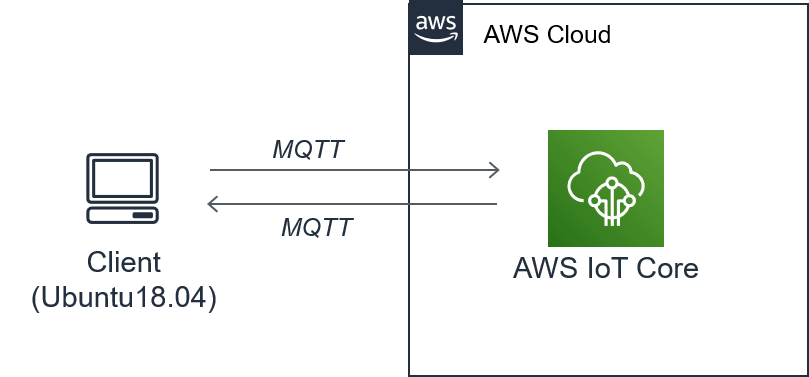
AWS Iotをやってみた
はじめに
とりあえずAWS IoTを体験してみたい人向けの記事です。
クラウドと自端末を繋げてみる記事です。
環 境
端末
OS:Ubuntu18.04LTS(VMware内で起動)
Python:3.6.9構築手順
下記手順に従って、クラウド⇔クライアントの通信環境を構築します。
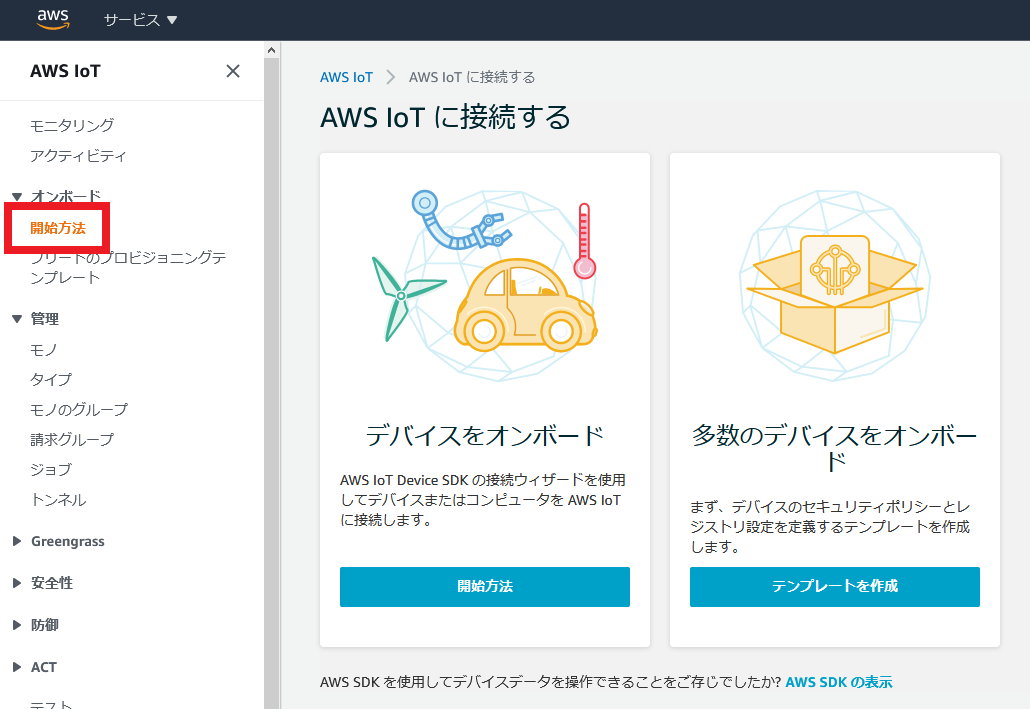
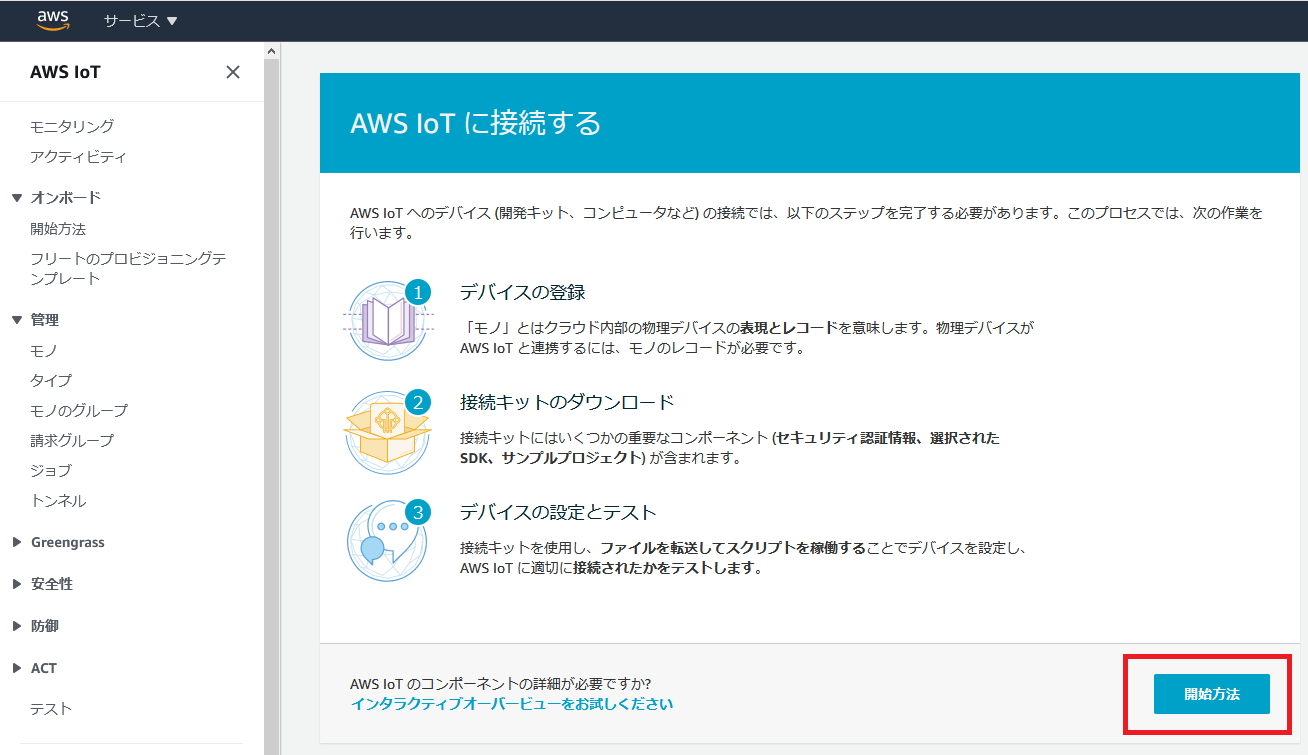
AWS IoTに接続する
AWS IoTにアクセスし、「開始方法」をクリックします。
説明がでてきますが、気にせず「開始方法」をクリック。
相変わらず日本語下手過ぎて、何言ってるか分からないですね。
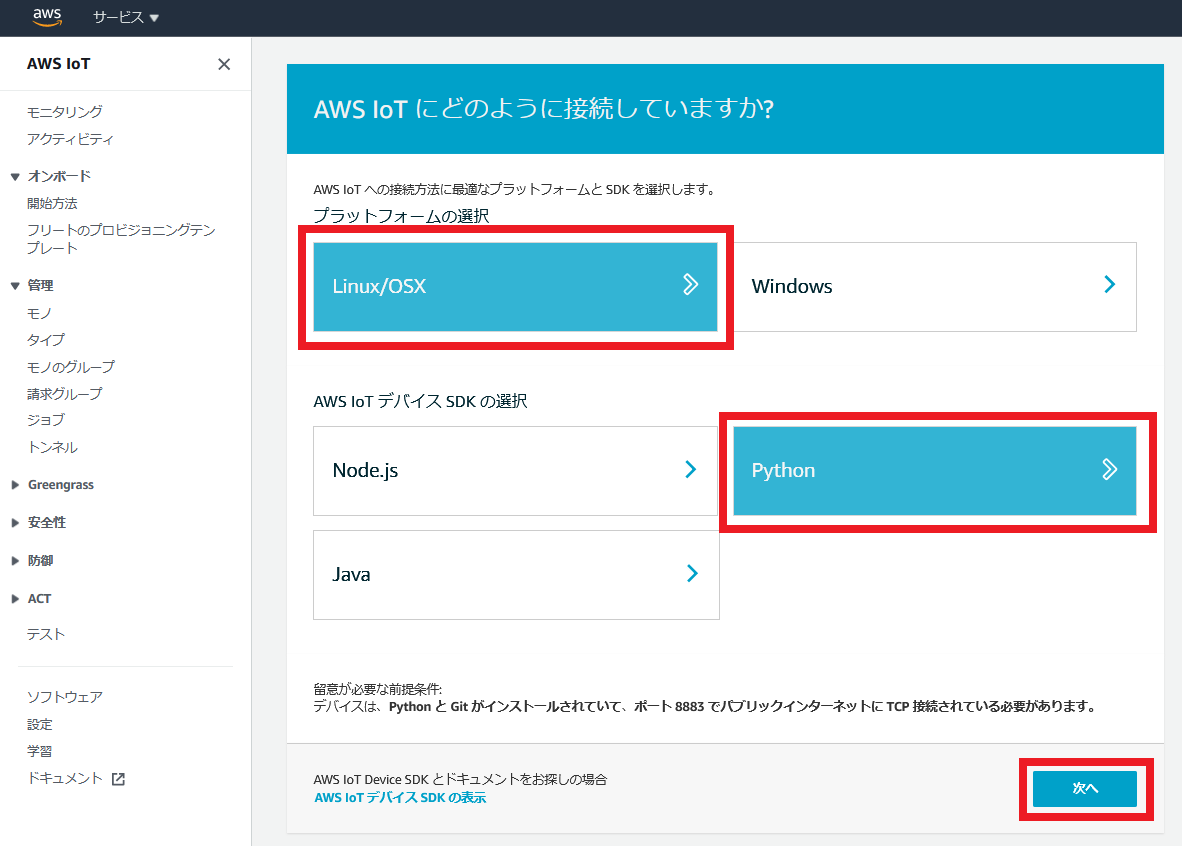
AWS IoTにどのように接続していますか?
接続機器のプラットフォーム(OS)、接続用のSDKのプログラミング言語を選択します。
今回はUbuntuをクライアントとして利用するので、
プラットフォームは「Linux/OSX」を選択。
SDKはどれでもいいですが、今回は「Python」を選択。
最後に次へを押します。
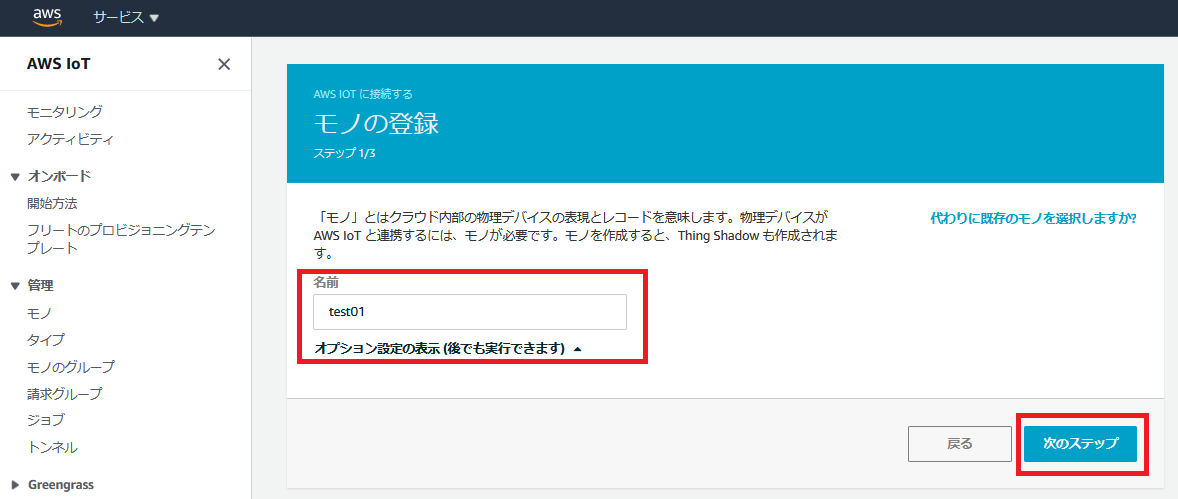
モノの登録
モノ登録を行います。
適当に「モノ」の名前を付けます。
今回は”test01”にしました。
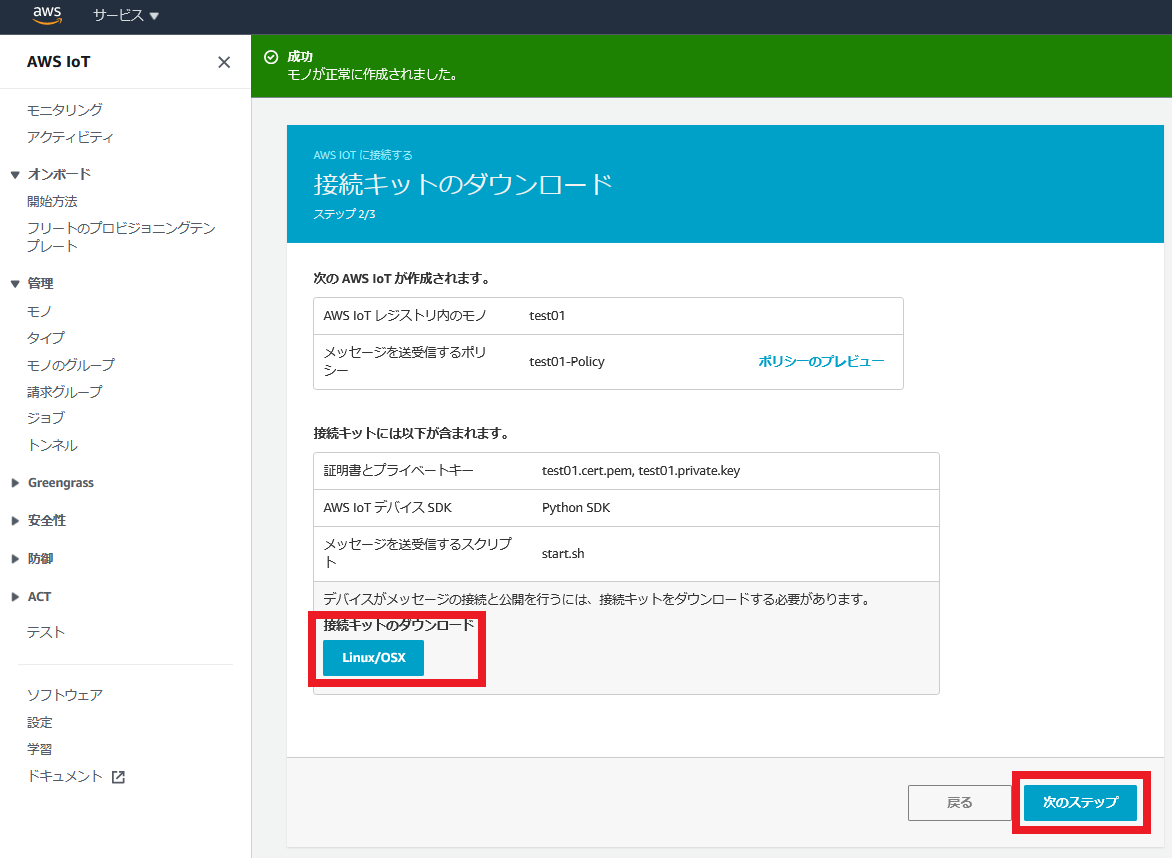
接続キットのダウンロード
接続キットのダウンロードを行います。
ダウンロードしたファイル(connect_device_package.zip)は端末(今回であればUbuntu)にコピーします。
接続キットには、
・SDK:aws-iot-device-sdk-python
・AWSの証明書:root-CA.crt
・「モノ」用の秘密鍵:test01.private.key
・「モノ」用の公開鍵:test01.public.key
・「モノ」用の証明書:test01.cert.pem
が入っており、至れり尽くせりです。
しかも中のスクリプトファイル(start.sh)を実行するだけで、SDKのインストールからサンプルファイル(basicPubSub.py)の実行までやってくれます。
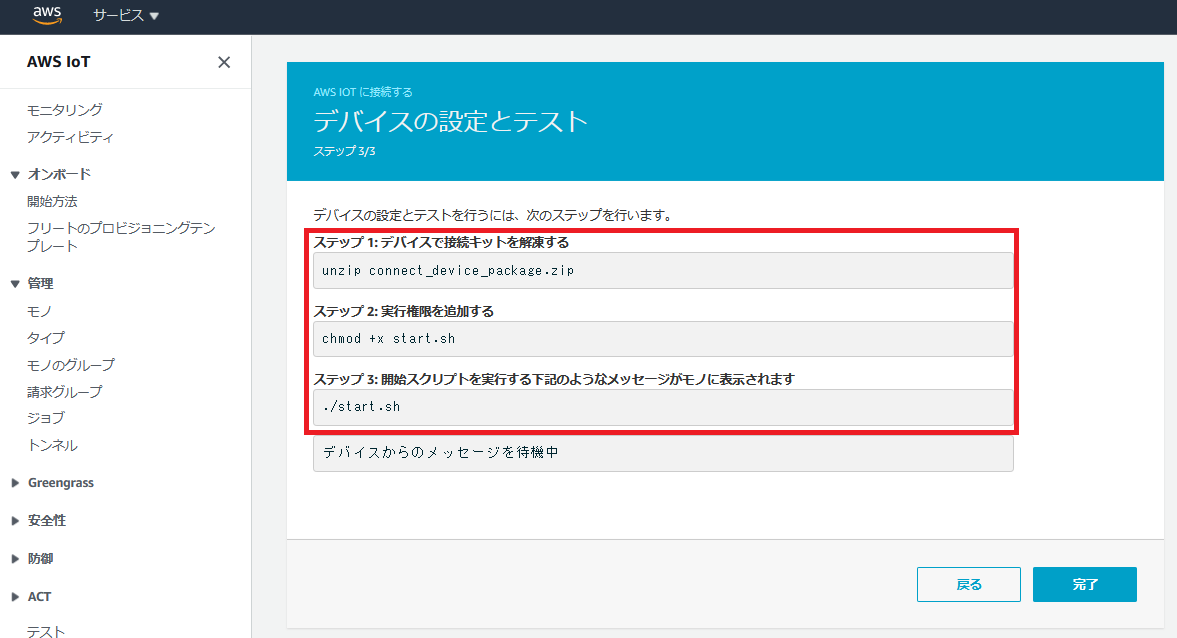
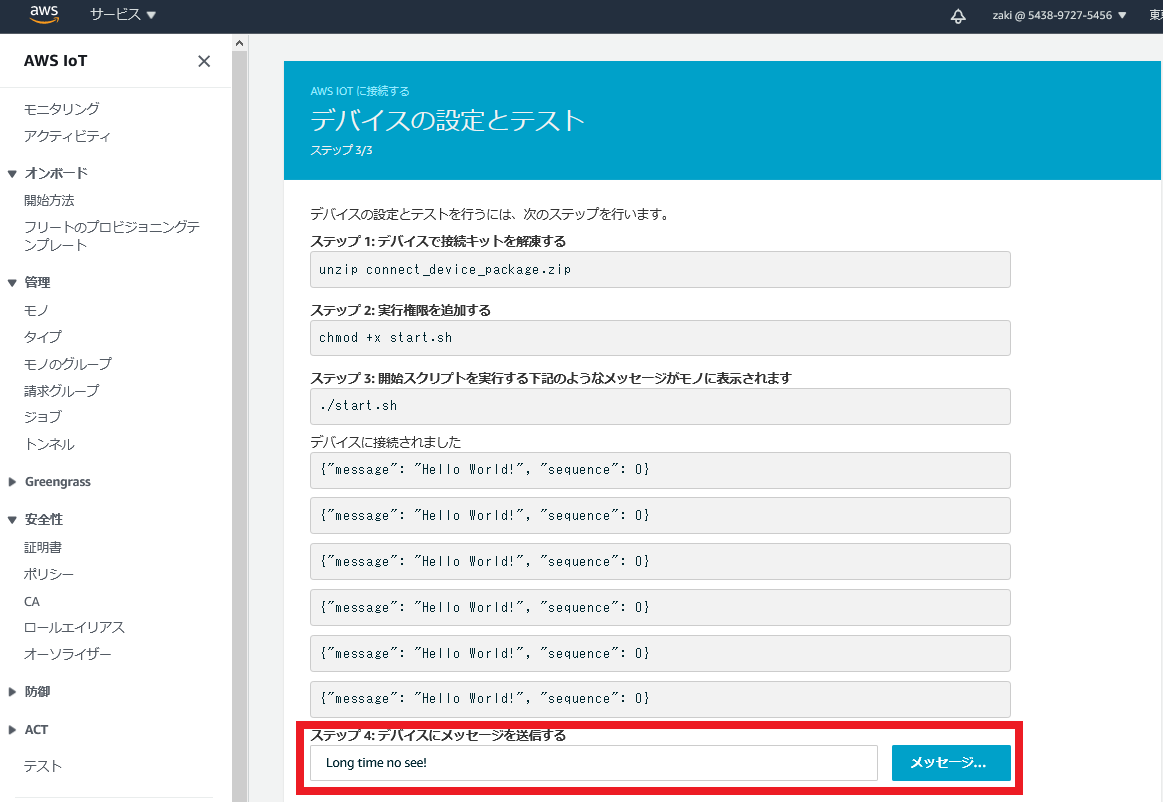
ちなみにAWSの証明書はリージョン(サーバ群が設置されている国)によって異なりますが、日本リージョン(ap-northeast-1)にアクセスしている場合は勝手に日本リージョンの証明書がダウンロードされます。デバイスの接続とテスト
まだ完了を押してはいけません。
ダウンロードしたファイルのあるディレクトリで、赤枠のコマンドを順に実行していきます。
他サイトを見ると管理者権限(sudo)でやっている人がいますが、ユーザ権限で大丈夫です。
ただし、多くの場合はライブラリ不足でこけると思います。
自分の場合はAWSIoTPythonSDKフォルダの作成権限がないと怒られました。error: could not create '/usr/local/lib/python3.6/dist-packages/AWSIoTPythonSDK': Permission denied実はこのエラー、権限エラーのように見えて、本当はAWSIoTPythonSDKがインストールされていないために起こるエラーです。
下記コマンドを入れて、AWSIoTPythonSDKをインストールすれば直ります。pip install AWSIoTPythonSDKもし、pipも入っていない人は次のコマンドでインストールします。
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py python get-pip.py参考URL:https://pip.pypa.io/en/stable/installing/
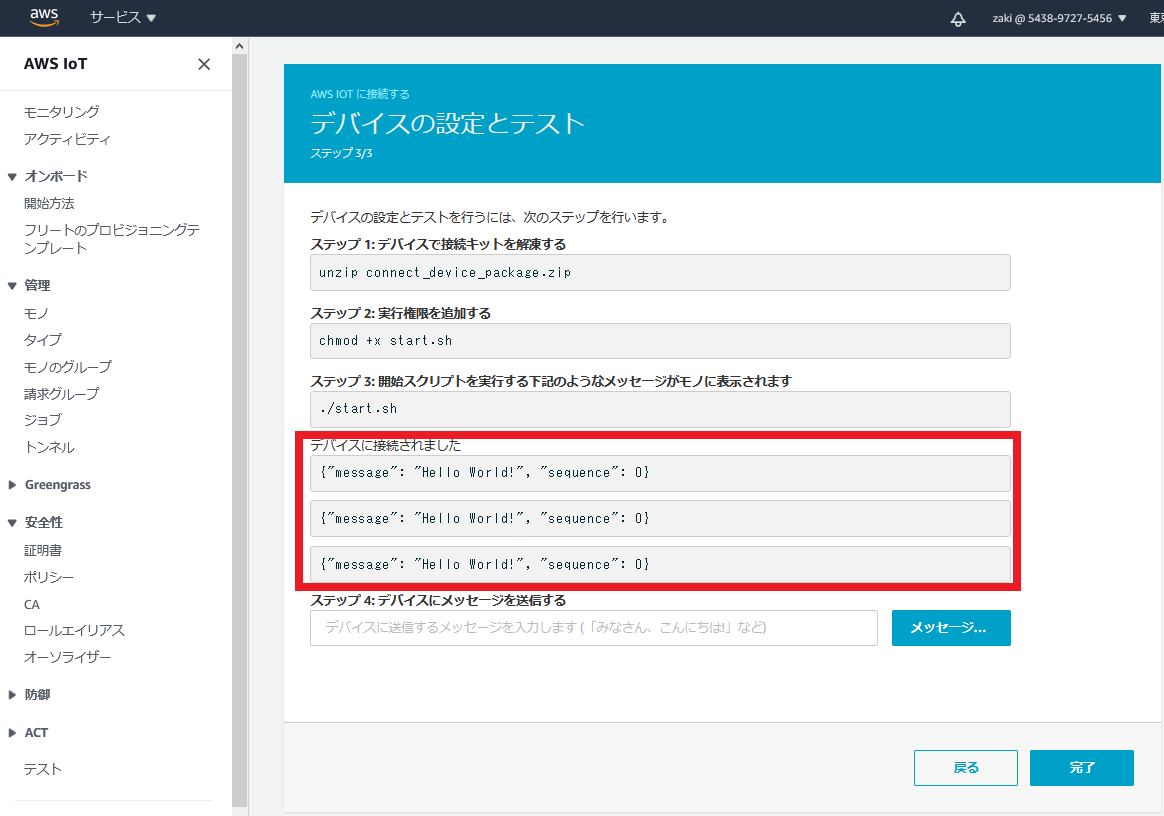
実行に成功すると、Ubuntuのコンソール画面に下記内容が出力されます。
Hello World!がPublishされていることを確認します。2020-10-11 21:09:20,862 - AWSIoTPythonSDK.core.protocol.internal.clients - DEBUG - Invoking custom event callback... 2020-10-11 21:09:20,862 - AWSIoTPythonSDK.core.protocol.mqtt_core - INFO - Performing sync subscribe... 2020-10-11 21:09:20,862 - AWSIoTPythonSDK.core.protocol.internal.workers - DEBUG - Adding a new subscription record: sdk/test/Python qos: 1 2020-10-11 21:09:20,862 - AWSIoTPythonSDK.core.protocol.internal.clients - DEBUG - Filling in custom suback event callback... 2020-10-11 21:09:20,927 - AWSIoTPythonSDK.core.protocol.internal.workers - DEBUG - Produced [suback] event 2020-10-11 21:09:20,927 - AWSIoTPythonSDK.core.protocol.internal.workers - DEBUG - Dispatching [suback] event 2020-10-11 21:09:20,927 - AWSIoTPythonSDK.core.protocol.internal.clients - DEBUG - Invoking custom event callback... 2020-10-11 21:09:20,927 - AWSIoTPythonSDK.core.protocol.internal.clients - DEBUG - This custom event callback is for pub/sub/unsub, removing it after invocation... 2020-10-11 21:09:22,930 - AWSIoTPythonSDK.core.protocol.mqtt_core - INFO - Performing sync publish... 2020-10-11 21:09:22,930 - AWSIoTPythonSDK.core.protocol.internal.clients - DEBUG - Filling in custom puback (QoS>0) event callback... 2020-10-11 21:09:22,954 - AWSIoTPythonSDK.core.protocol.internal.workers - DEBUG - Produced [puback] event 2020-10-11 21:09:22,955 - AWSIoTPythonSDK.core.protocol.internal.workers - DEBUG - Dispatching [puback] event 2020-10-11 21:09:22,955 - AWSIoTPythonSDK.core.protocol.internal.clients - DEBUG - Invoking custom event callback... 2020-10-11 21:09:22,955 - AWSIoTPythonSDK.core.protocol.internal.clients - DEBUG - This custom event callback is for pub/sub/unsub, removing it after invocation... 2020-10-11 21:09:22,983 - AWSIoTPythonSDK.core.protocol.internal.workers - DEBUG - Produced [message] event 2020-10-11 21:09:22,984 - AWSIoTPythonSDK.core.protocol.internal.workers - DEBUG - Dispatching [message] event Received a new message: b'{"message": "Hello World!", "sequence": 0}' from topic: sdk/test/Python --------------IoT機器側でうまくPublishできていると、下記画像のように画面に表示されます。
今度は逆に、クラウドからIoT機器にPublishします。
「ステップ4:デバイスにメッセージを送信する」の枠内に、適当に文字を入力します。
今回は、「Long time no see!」を入れてみました。
「メッセージ送信」クリックします。
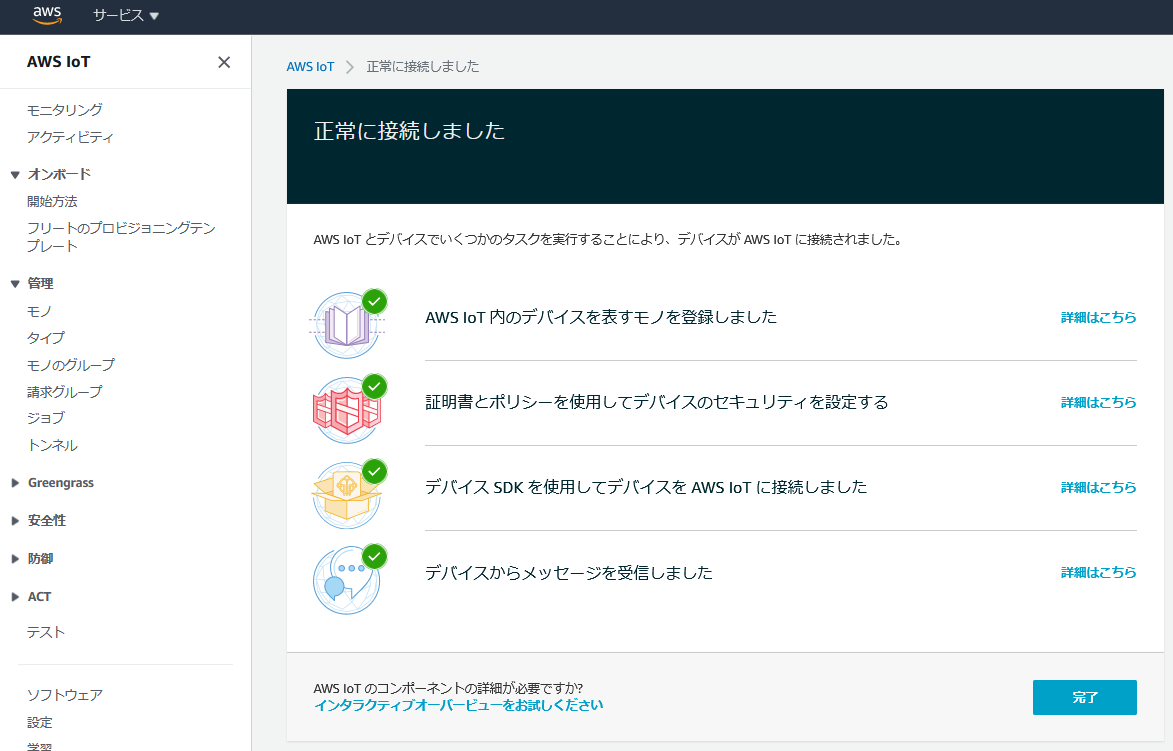
うまくいくと、下記内容がstart.shを実行したターミナルに出力されます。Received a new message: b'Long time no see!' from topic: sdk/test/Python --------------「完了」を押すと、最後の確認画面が出ます。
気にせず、「完了」を押します。
おつかれさまでした。
まとめ
シンプルなAWS IoTを実装し、クライアント⇔クラウドの通信を体験しました。
次回はセンサー情報をやり取りさせたいと思います。参考URL
MQTTについて
https://myenigma.hatenablog.com/entry/2019/10/27/194549
- 投稿日:2020-10-11T22:14:48+09:00
将棋AIで学ぶディープラーニング on Mac and Google Colab 第12章3
expand_node()
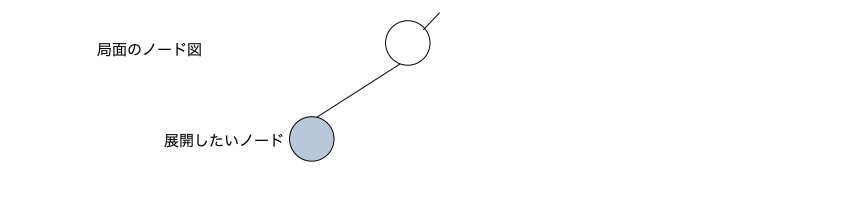
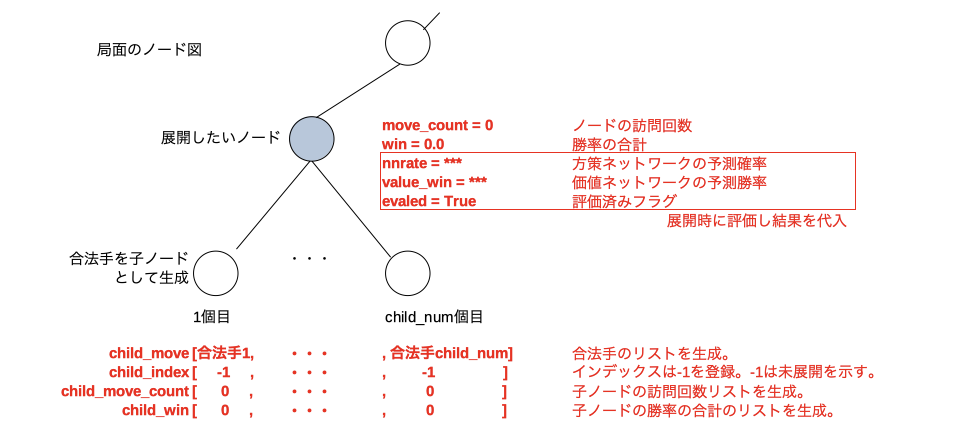
未展開のノードを展開するメソッド。例えば下図のような展開したいノードが有ったとする。
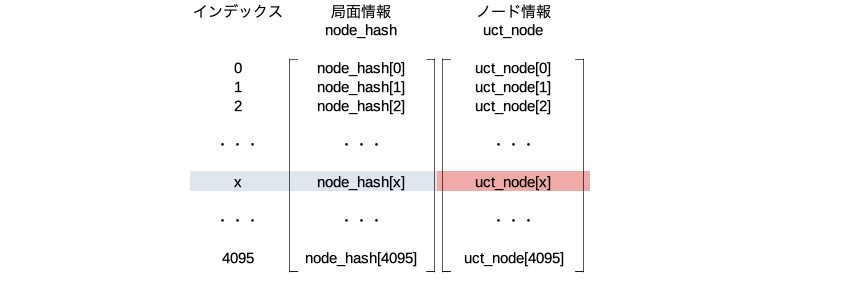
node_expand()を行うと、そのノードのハッシュからインデックス(ここではxとする)を決めてnode_hash[x]とuct_node[x]をこのノード用に割り当てる。赤文字部分に示す9個のパラメータを生成しuct_node[x]のメンバ変数として保存する。
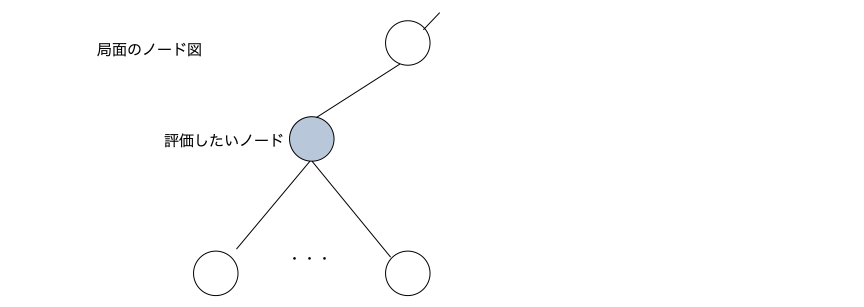
eval_node()
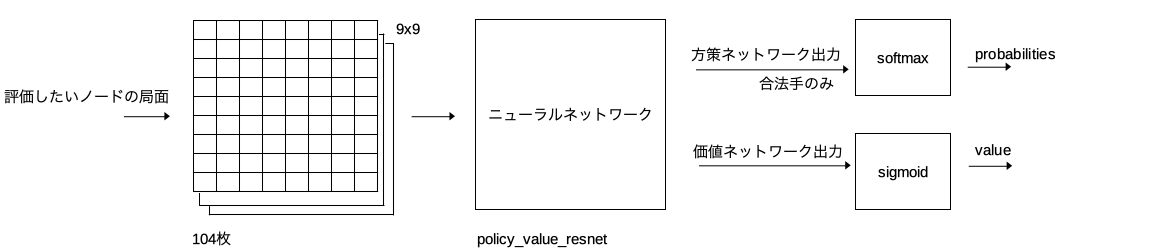
評価したいノードの局面を入力とし方策ネットワークの予測確率と価値ネットワークの予測勝率を出力するメソッド。例えば下図のような評価したいノードが有ったとする。
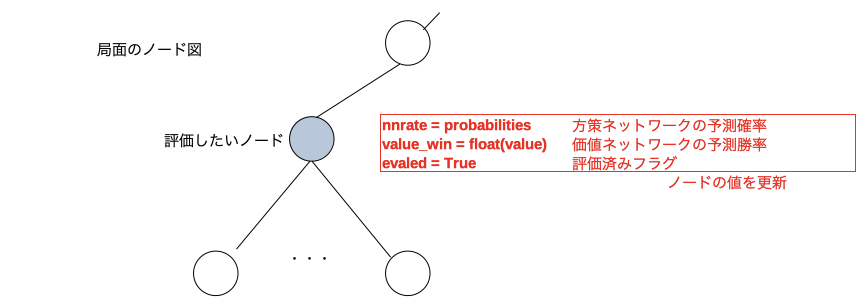
局面情報をニューラルネットワークに入力して方策ネットワークの予測確率と価値ネットワークの予測勝率を得る。
ノード情報(赤文字の3つ)を更新する。
- 投稿日:2020-10-11T21:59:40+09:00
Pythonとpipの素性を知りたい
MacやLinuxでPythonを触る時はバージョンが混在していることが多く結構困る。触っているPythonやpipがどこのフォルダにあるものかを調べるためのコマンド
Pythonの場所
terminalwhich python which python3 which python2で確認する
出力結果
output/usr/local/bin/python他の方法
terminal他の方法type python where pythonでも行けました。@shiracamus様、コメントありがとうございます!
pipの場所
terminalpip -V pip3 -Vで確認する
出力結果
outputpip 20.2.3 from /home/myName/.linuxbrew/opt/python@3.8/lib/python3.8/site-packages/pip (python 3.8)Windowsだと困ったことない。
- 投稿日:2020-10-11T21:52:46+09:00
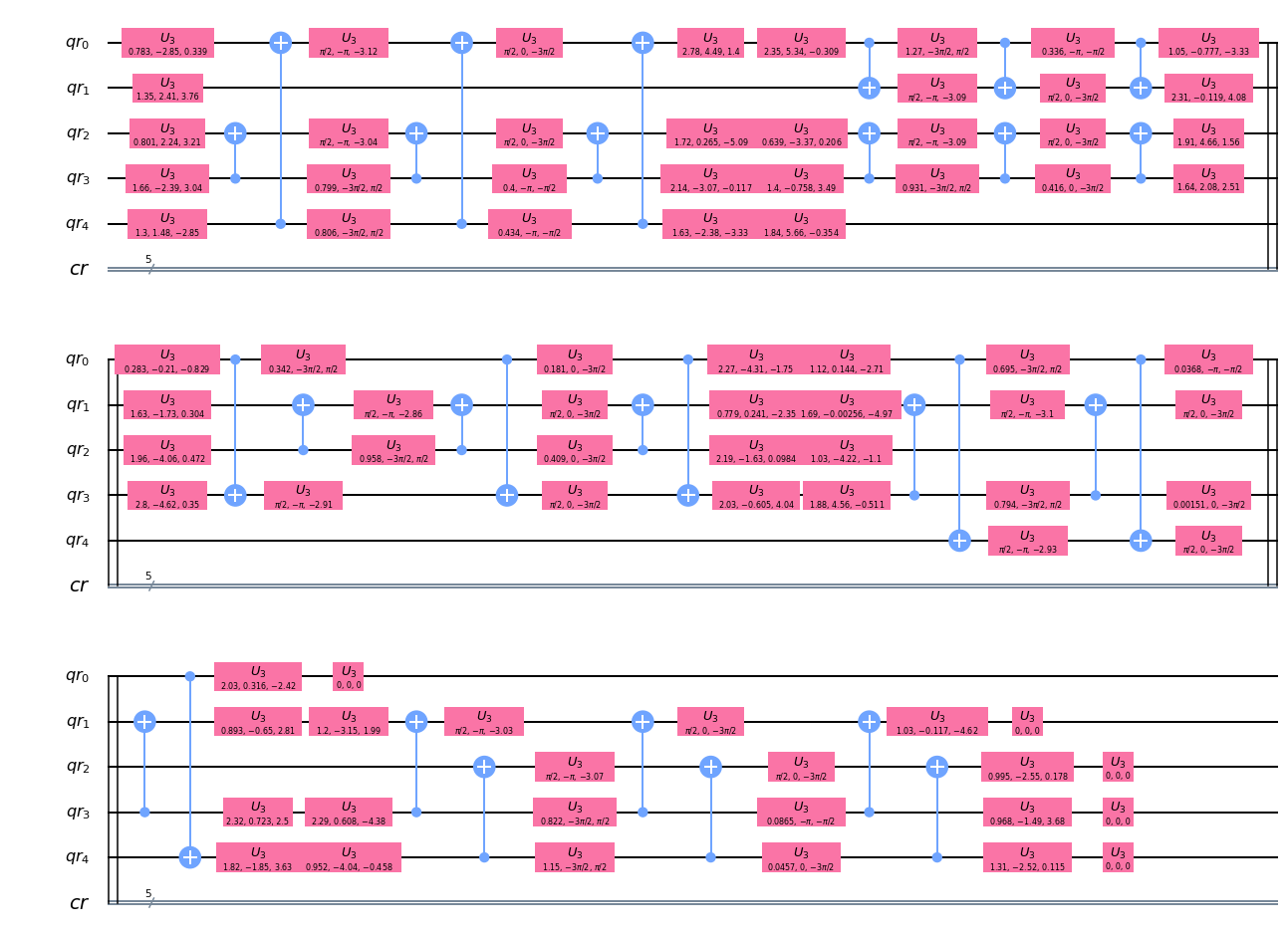
Qiskit における depth について(通常回路とQuantumVolume)
Qiskit の depth について
- とある場で「QuantumVolumeのdepth値って実質どのくらい?」という話題が出たので整理しておく。
- Qiskitには複数の
depthの使い方がある。- 具体的には通常の回路の深さを表すものと、QuantumVolumeの指標となるものがある。
- これらを順番に確認する。
■ 通常の回路の深さを表す
depth
- ここでは
random_circuitで回路を生成し、depthの意味を確認する。- Qiskit document - random_circuit
- depth値を指定により、どのような回路が生成されるか確認する。
from qiskit.circuit.random import random_circuit①量子ビット数:1、depth値:5
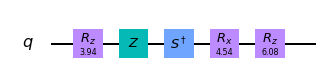
circ_r1 = random_circuit(num_qubits=1, depth=5) print('depth =', circ_r1.depth()) circ_r1.draw(output='mpl')depth = 5
②量子ビット数:5、depth値:5
circ_r2 = random_circuit(num_qubits=5, depth=5) print('depth =', circ_r2.depth()) circ_r2.draw(output='mpl')depth = 5
③量子ビット数:1、depth値:10、
circ_r3 = random_circuit(num_qubits=1, depth=10) print('depth =', circ_r3.depth()) circ_r3.draw(output='mpl')depth = 10
④量子ビット数:5、depth値:10
circ_r4 = random_circuit(num_qubits=5, depth=10) print('depth =', circ_r4.depth()) circ_r4.draw(output='mpl')depth = 10
量子ビット数(num_qubits)が複数になるとdepth値が直感的にわかりずらいが、量子ビット数を1に設定すればdepthの数はゲートの数と同じになることがわかる。
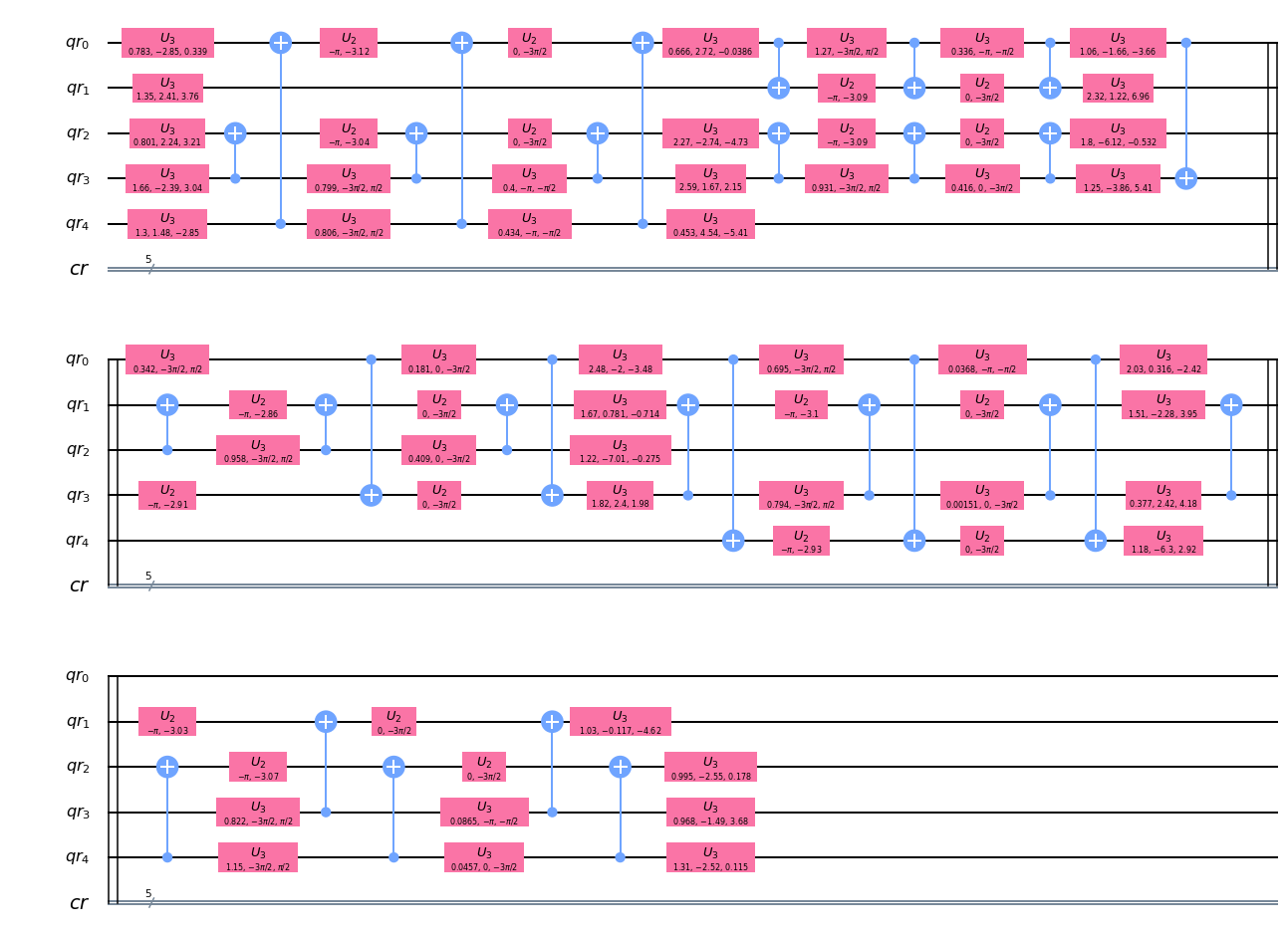
■ QuantumVolume(QV) における
depth
- Qiskit Document - QuantumVolume
- QV値の計測は、QuantumVolume計測用の回路を生成して行う。
- QV用回路の生成時に
depth値を指定するが、通常の回路のdepthとは意味合いが異なる。- 実際にQV用回路を生成し、
depthを計測して確認する。from qiskit.circuit.library import QuantumVolume①量子ビット数:5、(QV)depth値:5
circ_q1 = QuantumVolume(num_qubits=5, depth=5) print('depth =', circ_q1.depth()) circ_q1.draw('mpl')depth = 1
上図はさまざまなゲートがひとつにまとめられている状態。
このままdepthを計測すると、見た目通りの「1」となる。
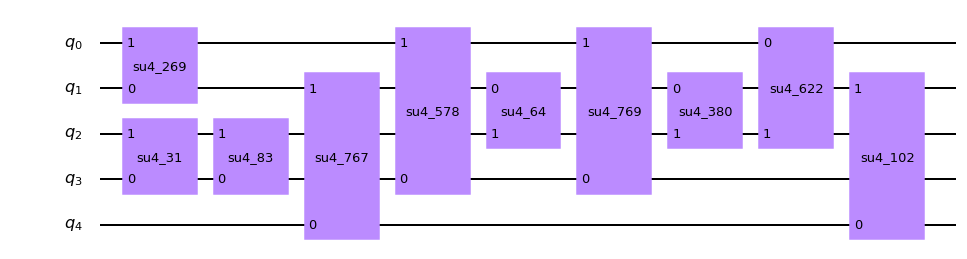
このままではよくわからないので、decompose(分解=回路の展開)して確認する。circ_q1_d1 = circ_q1.decompose() print('depth =', circ_q1_d1.depth()) circ_q1_d1.draw('mpl')depth = 5
展開はされたものの、まだ複数ゲートがまとめられている。
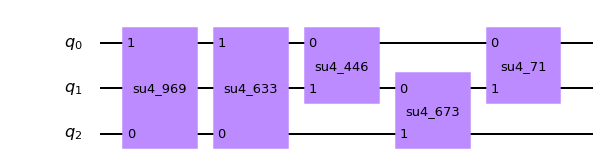
少々わかりづらいが、2列目のゲート(su4_83)と3列目のゲート(su4_767)はそれぞれ異なる量子ビットに対して操作を行っているため、前詰めにして「1」と数えることができる。以下のドキュメントのgifがわかりやすい。
Qiskit Document - circuit ※Quantum Circuit Properties を展開するとgifがある。ちなみに、
su4は4×4のランダムなユニタリ行列のゲートである。ここからさらに
decomposeして、通常のゲート単位にする。circ_q1_d2 = circ_q1_d1.decompose() print('depth =', circ_q1_d2.depth()) circ_q1_d2.draw('mpl')depth = 35
su4は、CNOTとU3ゲートから構成されていることがわかる。
また、QV用のdepth値が5の場合、通常回路でのdepth値は35であることがわかる。②量子ビット数:3、(QV)depth値:5
今度は量子ビット数を減らして(5→3)確認する。
circ_q2 = QuantumVolume(num_qubits=3, depth=5) print('depth =', circ_q2.depth()) circ_q2.draw('mpl')depth = 1
circ_q2_d1 = circ_q2.decompose() print('depth =', circ_q2_d1.depth()) circ_q2_d1.draw('mpl')depth = 5
circ_q2_d2 = circ_q2_d1.decompose() print('depth =', circ_q2_d2.depth()) circ_q2_d2.draw('mpl')depth = 35
量子ビット数に関わらずQVのdepth値が5の場合は、通常回路のdepth値は35になることがわかる。
③量子ビット数:3、(QV)depth値:3
さらにdepth値を減らして(5→3)確認する。
circ_q3 = QuantumVolume(num_qubits=3, depth=3) print('depth =', circ_q3.depth()) circ_q3.draw('mpl')depth = 1
circ_q3_d1 = circ_q3.decompose() print('depth =', circ_q3_d1.depth()) circ_q3_d1.draw('mpl')depth = 3
circ_q3_d2 = circ_q3_d1.decompose() print('depth =', circ_q3_d2.depth()) circ_q3_d2.draw('mpl')depth = 21
QVのdepth値が変わると、通常回路のdepth値も変わることがわかる。
QV回路の生成方法
- ここまでは
QuantumVolumeを利用して回路を生成してきたが、別の生成方法として qv_circuits の利用がある。- ソースを見ればわかるが、qv_circuits では内部的に QuantumVolume を利用してQV回路が生成されている。
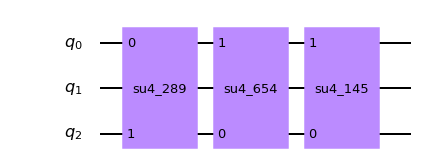
import qiskit.ignis.verification.quantum_volume as qvqubit_lists = [[0,1,3,5,7]] ntrials = 50 qv_circs, qv_circs_nomeas = qv.qv_circuits(qubit_lists, ntrials)生成される回路は測定あり(
qv_circs)と測定なし(qv_circs_nomeas)の2種類となる。
まずは測定ありの回路から確認する。print("depth =", qv_circs[0][0].decompose().depth()) qv_circs[0][0].decompose().draw('mpl')depth = 36
depth値が36になっている。
QVのdepth値が5の場合、通常回路のdepth値は35だが、測定操作が追加されたことにより+1となっている。続けて、測定なしの回路を確認する。
print("depth =", qv_circs_nomeas[0][0].decompose().depth()) qv_circs_nomeas[0][0].decompose().draw('mpl')depth = 36
depth値が同様に36となっているが、最後のレイヤーが実質的に操作のないU3ゲートとなっているため、depth値としては35と捉えることができる。
次は、測定なしの回路をトランスパイラで変換してからdepthを確認してみる。
import qiskit.compiler.transpileqv_circs_nomeas[0] = qiskit.compiler.transpile(qv_circs_nomeas[0], basis_gates=['u1','u2','u3','cx']) print("depth =", qv_circs_nomeas[0].depth()) qv_circs_nomeas[0].draw('mpl')depth = 31
depth値は31となった。
トランスパイラによりゲート数が変わったため当然の結果ではあるが、QV値の測定に通常回路のdepth値は直接的には関係ないということがわかる。Reference






- 投稿日:2020-10-11T21:52:46+09:00
Qiskit における depth について
Qiskit の depth について
- とある場で「QuantumVolumeのdepth値って実質どのくらい?」という話題が出たので整理しておく。
- Qiskitには複数の
depthの使い方がある。- 具体的には通常の回路の深さを表すものと、QuantumVolumeの指標となるものがある。
- これらを順番に確認する。
■ 通常の回路の深さを表す
depth
- ここでは
random_circuitで回路を生成し、depthの意味を確認する。- Qiskit document - random_circuit
- depth値を指定により、どのような回路が生成されるか確認する。
from qiskit.circuit.random import random_circuit①量子ビット数:1、depth値:5
circ_r1 = random_circuit(num_qubits=1, depth=5) print('depth =', circ_r1.depth()) circ_r1.draw(output='mpl')depth = 5
②量子ビット数:5、depth値:5
circ_r2 = random_circuit(num_qubits=5, depth=5) print('depth =', circ_r2.depth()) circ_r2.draw(output='mpl')depth = 5
③量子ビット数:1、depth値:10、
circ_r3 = random_circuit(num_qubits=1, depth=10) print('depth =', circ_r3.depth()) circ_r3.draw(output='mpl')depth = 10
④量子ビット数:5、depth値:10
circ_r4 = random_circuit(num_qubits=5, depth=10) print('depth =', circ_r4.depth()) circ_r4.draw(output='mpl')depth = 10
量子ビット数(num_qubits)が複数になるとdepth値が直感的にわかりずらいが、量子ビット数を1に設定すればdepthの数はゲートの数と同じになることがわかる。
■ QuantumVolume(QV) における
depth
- Qiskit Document - QuantumVolume
- QV値の計測は、QuantumVolume計測用の回路を生成して行う。
- QV用回路の生成時に
depth値を指定するが、通常の回路のdepthとは意味合いが異なる。- 実際にQV用回路を生成し、
depthを計測して確認する。from qiskit.circuit.library import QuantumVolume①量子ビット数:5、(QV)depth値:5
circ_q1 = QuantumVolume(num_qubits=5, depth=5) print('depth =', circ_q1.depth()) circ_q1.draw('mpl')depth = 1
上図はさまざまなゲートがひとつにまとめられている状態。
このままdepthを計測すると、見た目通りの「1」となる。
このままではよくわからないので、decompose(分解=回路の展開)して確認する。circ_q1_d1 = circ_q1.decompose() print('depth =', circ_q1_d1.depth()) circ_q1_d1.draw('mpl')depth = 5
展開はされたものの、まだ複数ゲートがまとめられている。
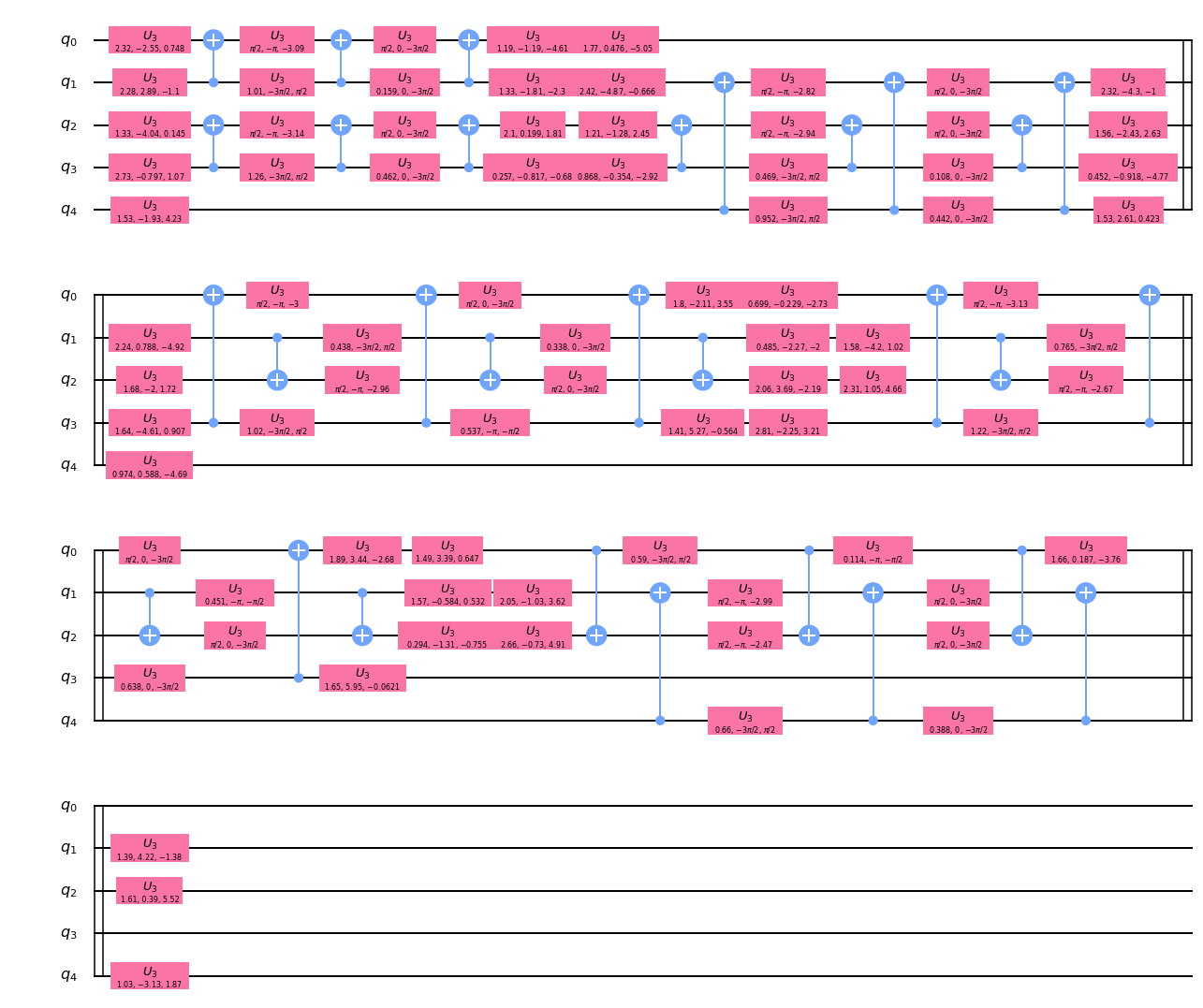
少々わかりづらいが、最初のゲート(su4_666)と二つ目のゲート(su4_851)はそれぞれ異なる量子ビットに対して操作を行っているため、前詰めにして「1」と数えることができる。以下のドキュメントのgifがわかりやすい。
Qiskit Document - circuit ※Quantum Circuit Properties を展開するとgifがある。ちなみに、
su4は4×4のランダムなユニタリ行列のゲートである。ここからさらに
decomposeして、通常のゲート単位にする。circ_q1_d2 = circ_q1_d1.decompose() print('depth =', circ_q1_d2.depth()) circ_q1_d2.draw('mpl')depth = 35
su4は、CNOTとU3ゲートから構成されていることがわかる。
また、QV用のdepth値が5の場合、通常回路でのdepth値は35であることがわかる。②量子ビット数:3、(QV)depth値:5
今度は量子ビット数を減らして(5→3)確認する。
circ_q2 = QuantumVolume(num_qubits=3, depth=5) print('depth =', circ_q2.depth()) circ_q2.draw('mpl')depth = 1
circ_q2_d1 = circ_q2.decompose() print('depth =', circ_q2_d1.depth()) circ_q2_d1.draw('mpl')depth = 5
circ_q2_d2 = circ_q2_d1.decompose() print('depth =', circ_q2_d2.depth()) circ_q2_d2.draw('mpl')depth = 35
量子ビット数に関わらずQVのdepth値が5の場合は、通常回路のdepth値は35になることがわかる。
③量子ビット数:3、(QV)depth値:3
さらにdepth値を減らして(5→3)確認する。
circ_q3 = QuantumVolume(num_qubits=3, depth=3) print('depth =', circ_q3.depth()) circ_q3.draw('mpl')depth = 1
circ_q3_d1 = circ_q3.decompose() print('depth =', circ_q3_d1.depth()) circ_q3_d1.draw('mpl')depth = 3
circ_q3_d2 = circ_q3_d1.decompose() print('depth =', circ_q3_d2.depth()) circ_q3_d2.draw('mpl')depth = 21
QVのdepth値が変わると、通常回路のdepth値も変わることがわかる。
QV回路の生成方法
- ここまでは
QuantumVolumeを利用して回路を生成してきたが、別の生成方法として qv_circuits の利用がある。- ソースを見ればわかるが、qv_circuits では内部的に QuantumVolume を利用してQV回路が生成されている。
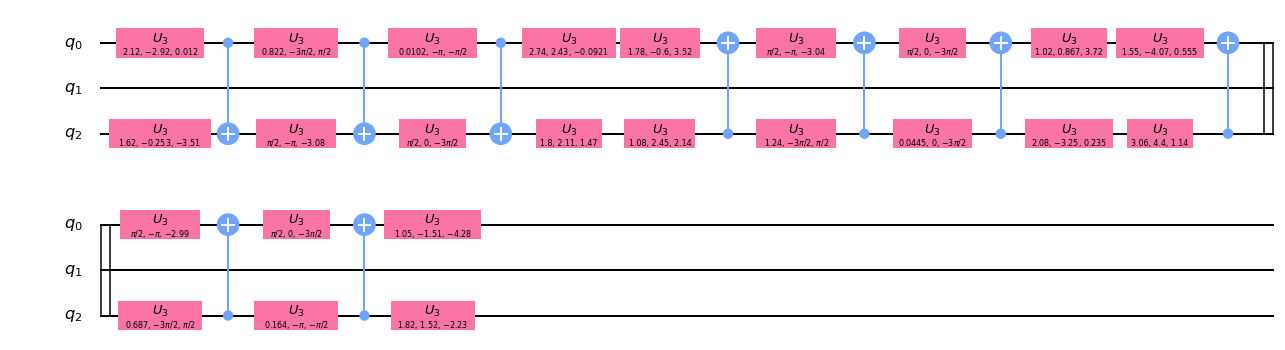
import qiskit.ignis.verification.quantum_volume as qvqubit_lists = [[0,1,3,5,7]] ntrials = 50 qv_circs, qv_circs_nomeas = qv.qv_circuits(qubit_lists, ntrials)生成される回路は測定あり(
qv_circs)と測定なし(qv_circs_nomeas)の2種類となる。
まずは測定ありの回路から確認する。print("depth =", qv_circs[0][0].decompose().depth()) qv_circs[0][0].decompose().draw('mpl')depth = 36
depth値が36になっている。
QVのdepth値が5の場合、通常回路のdepth値は35だが、測定操作が追加されたことにより+1となっている。続けて、測定なしの回路を確認する。
print("depth =", qv_circs_nomeas[0][0].decompose().depth()) qv_circs_nomeas[0][0].decompose().draw('mpl')depth = 36
depth値が同様に36となっているが、最後のレイヤーが実質的に操作のないU3ゲートとなっているため、depth値としては35と捉えることができる。
次は、測定なしの回路をトランスパイラで変換してからdepthを確認してみる。
import qiskit.compiler.transpileqv_circs_nomeas[0] = qiskit.compiler.transpile(qv_circs_nomeas[0], basis_gates=['u1','u2','u3','cx']) print("depth =", qv_circs_nomeas[0].depth()) qv_circs_nomeas[0].draw('mpl')depth = 31
depth値は31となった。
トランスパイラによりゲート数が変わったため当然の結果ではあるが、QV値の測定に通常回路のdepth値は直接的には関係ないということがわかる。Reference
- 投稿日:2020-10-11T21:27:33+09:00
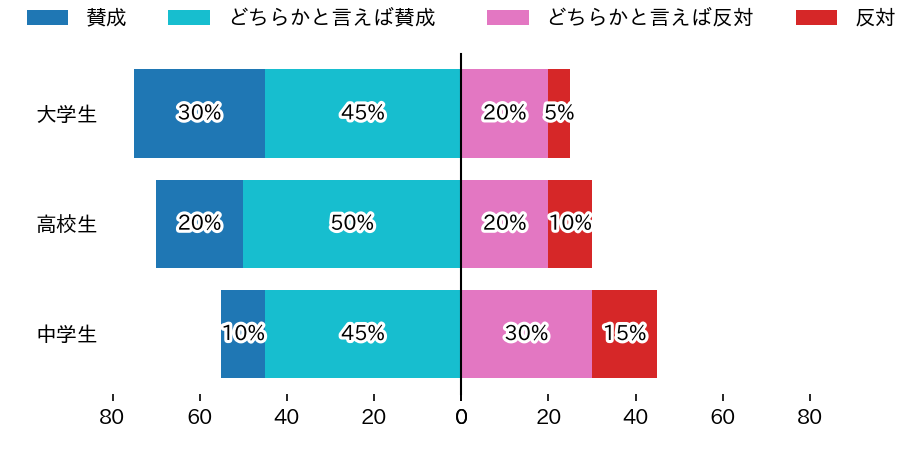
matplotlibで正負の両方向に対応した積み上げグラフを作成
概要
次のような正方向と負方向の両方向に対応した積み上げグラフを作成します。
動作を確認した環境
Google Colab. で作成・動作確認しました。
python version 3.6.9 numpy version 1.18.5 pandas version 1.1.2 matplotlib version 3.2.2準備
matplotlibグラフのなかで日本語が使えるようにします。
!pip install japanize_matplotlibライブラリを読み込みます。
%reset -f import sys import pandas as pd import numpy as np import japanize_matplotlib import matplotlib import matplotlib.pyplot as plt import matplotlib.patheffects as pe pv = '.'.join([ str(v) for v in sys.version_info[:3] ]) print(f'python version {pv}') print(f'numpy version {np.__version__}') print(f'pandas version {pd.__version__}') print(f'matplotlib version {matplotlib.__version__}')サンプルデータを準備します。
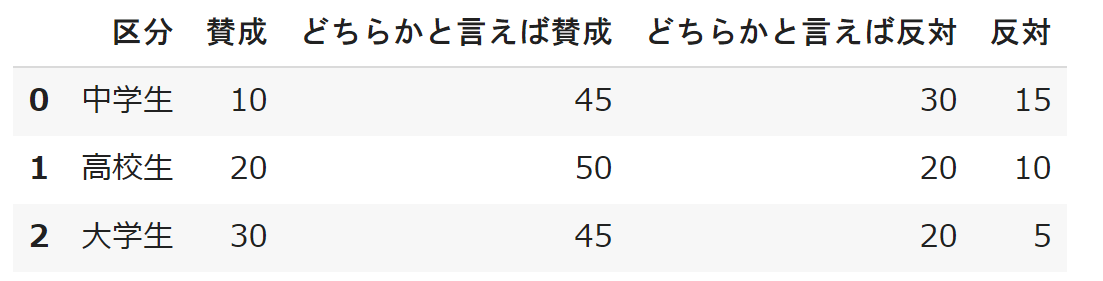
df = pd.DataFrame() df['区分']=['中学生','高校生','大学生'] df['賛成']=[10,20,30] df['どちらかと言えば賛成']=[45,50,45] df['どちらかと言えば反対']=[30,20,20] df['反対']=[15,10,5] display(df)
このデータについて「賛成」と「どちらかと言えば賛成」を左側に、「どちらかと言えば反対」と「反対」を右側に積み上げていきます。
コード
def draw(df, y_column,x_columns,colors,x_range): left_columns ,right_columns = x_columns left_colors,right_colors = colors # 1行2列のグラフを作成 fig,ax = plt.subplots(nrows=1, ncols=2, figsize=(6,3), facecolor='white',sharey='row',dpi=150) # 枠線を消す for a in ax: for x in ['top','bottom','left','right']: a.spines[x].set_visible(False) a.tick_params(axis='y',left=False) # 左側のグラフ acc = np.zeros(len(df)) for colum,color in reversed(list(zip(left_columns ,left_colors))): s = df[colum] ax[0].barh(df[y_column],s,left=acc,color=color,label=colum) for i in range(len(df)): t = ax[0].text(acc[i]+s[i]/2,i,f'{s[i]}%', ha='center',va='center') t.set_path_effects([pe.Stroke(linewidth=3, foreground='white'), pe.Normal()]) acc+=s # 右側のグラフ acc = np.zeros(len(df)) for colum,color in zip(right_columns,right_colors): s = df[colum] ax[1].barh(df[y_column],s,left=acc,color=color,label=colum) for i in range(len(df)): t = ax[1].text(acc[i]+s[i]/2,i,f'{s[i]}%', ha='center',va='center') t.set_path_effects([pe.Stroke(linewidth=3, foreground='white'), pe.Normal()]) acc+=s # 凡例 ha,la = ax[0].get_legend_handles_labels() ax[0].legend(reversed(ha),reversed(la),bbox_to_anchor=(0.95, 1.05), loc='lower right',ncol=len(left_columns), borderaxespad=0,frameon=False) ax[1].legend(bbox_to_anchor=(0.05, 1.05), loc='lower left',ncol=len(right_columns), borderaxespad=0,frameon=False) # 中心に線を引く ax[1].axvline(x=0,ymin=0,ymax=1,clip_on=False,color='black',lw=1) ax[0].set_xlim(x_range[0],0) # 左側グラフはX軸を反転 ax[1].set_xlim(0,x_range[1]) fig.subplots_adjust(wspace=0.0) # 左右のグラフの間隔をゼロに設定 plt.savefig('test.png') plt.show() # サンプルデータを与えてグラフを作成 draw(df,'区分', [['賛成','どちらかと言えば賛成'],['どちらかと言えば反対','反対']], [['tab:blue','tab:cyan'],['tab:pink','tab:red']],[80,80])実行結果
- 投稿日:2020-10-11T21:22:14+09:00
Chainerによる機械学習のためのPython学習メモ 4章 ~ 6章 数学編
What
Chainerを利用して機械学習を学ぶにあたり、私自身が、気がついた点、リサーチした内容をまとめる記事になります。今回は、機械学習に必要な数学を抜粋して勉強します。
私の理解に基づいて記述しているため、間違っている場合があります。間違いは都度修正するつもりです、ご容赦ください。
Content
微分
線形性
関数、定数a, b, 変数xに対し
f(ax + b) = a * f(x) + b
と分離できる場合、線形であるという連鎖律
合成関数の微分の公式のことをいうらしい(・・・忘れた)機械学習で取り扱う入力は多変数となる場合が多いので、個々の変数との出力の関係は多変数解析(要は偏微分)が必要になる。
線形代数
テンソル
ちょっと理解ができていないところがあるのでテキスト抜粋テンソル (tensor) はベクトルや行列を一般化した概念です。 例えば、ベクトルは 1 方向に、行列は 2 方向にスカラが並んでいます。これは「ベクトルは 1 階のテンソルで、行列は 2 階のテンソルである」であることを意味します。 この考え方をさらに進めて、下図のように行列を奥行き方向にさらに並べたものを3階のテンソルと呼びます。例えば、カラー画像をデジタル表現する場合、1 枚の画像は RGB (Red Green Blue) の3枚のレイヤー(チャンネルと呼びます)を持つのが一般的です。 各チャンネルは行列として表され、その行列がチャンネル方向に複数積み重なっているため、画像は 3 階テンソルとみなすことができます。 3 階のテンソルは、特定の要素を指定するのに「上から 3 番目、左から 2 番目、手前から 5 番目」のように整数(インデックス)を3個必要とします。
恥ずかしながら今更しりました。定義自体はシンプルですね。
確率・統計
機械学習では良質なデータが大量にあるほど良い、つまり大量のデータを扱う分野であるという認識は持っていたのでやはり確率・統計も出てくるよな〜と思いました。ここがミソなんでしょうね。では、中身を見ていきます。
人間がパッと気が付かないような法則や特徴どうやって見つけ出すか?考えた時に、科学的根拠に基づいた方法として確率、統計が出てくるというのも納得がいきます。ある結果が観測されたというとき、ある事象が原因である確率を考えるにはどうしたら良いでしょうか。
サイコロで例えるなら、①2つのサイコロを投げた時、その積が12でした。組み合わせが6,2である確率は?といった感じ?
②サイコロを2回投げて6, 2が出る確率と違いはある?
②なら2 / 36 = 1 /18 ①なら2 / 4 = 1/ 2[(2, 6), (3, 4)]で①と②で結果が異なるってことを言いたいのかな。これをベイズの定理というらしい。
数式は後で、じっくり読み込むとして、ベイズの定理は何を解決できる定理かが抑えられればいいかな。尤度(ゆうど)
初見の言葉です。犬みたいな感じを書いてゆうどと読むみたいです。
カリキュラムだけではちょっと理解が難しかったので、下記サイトを参考にしました。
https://qiita.com/kenmatsu4/items/b28d1b3b3d291d0cc698尤度関数の基本概念は、「サンプリングしてデータが観測された後、そのデータは元々どういうパラメーターを持つ確率分布から生まれたものだったか?」と言う問いに答えるためのものです。なので、逆確率的なベイズの定理っぽさがあると自分は思っています。(実際、尤度はベイズの定理を構成する1要素となっています)
この説明はわかりやすいですね。尤度が最大になる時が尤もらしい推定モデルになるというのも理解しやすいです。
複数データに対する尤度は、 1 より小さな値の積となるため、結果は非常に小さな数になり、コンピュータでこの計算を行う際にはアンダーフローという問題が発生しやすくなります。
デジタルとアナログの変換で生じる問題ですね。どのくらい問題になるか、現時点でイメージは持てないですが。
事後確率最大化推定(MAP推定)
与ええられたデータ群から尤もらしい確率分布を推定するのが、尤度ですが、尤もらしいモデルではないモデルから生じた確率モデルを予測する手段がMAP推定。例えば、ベルヌーイ分布から生じた,[表、表、表、表、表]というデータ群から、データ群から得られる以外の情報(例:裏が出ることもある等)を与えてできるだけ元のベルヌーイ分布を推定するにはどうすれば良いかを考える理論。実際には、データを扱う人の推測を確率モデルに組み込めるよって話。ある意味センス???笑
分散
久しぶりに復讐したので忘れてる部分もありました。母分散、標本分散、不変分散の関係は以下のサイトが参考になりました。分散の平方根が標準偏差
https://staff.aist.go.jp/t.ihara/dispersion.html相関係数
2 種類のデータ間の相関が強いほど ? の絶対値は大きくなります。
rの値で、相関があるかを判断する指標はない。せいぜい大小で議論するか、判断基準を任意に設定するか。大学の時に買った統計の本いつでも見れるようにしておこう。Comment
なんとか準備編読了です。Pythonの学習と思い出し作業が大半でした。早くコードを書きたいのですが、、、入り口が長いですね。
最近何かとAWSが話題ですが、AWSのコンテンツの中にも機械学習があるみたいなんですよね。
今の学習が終わったら、ちょっと調べてみたいと思ってるんですが、何ができるんでしょう???というよりも、AWSをきちんと理解したい。。。わかりにくくていまいち掴めないんです
- 投稿日:2020-10-11T21:12:09+09:00
Go To トラベルの宿泊施設をスクレイピング
Go To トラベルの宿泊施設のリストは
https://goto.jata-net.or.jp/assets/data/stay.csv
にcsvデータがあるのでスクレイピングしなくても取得できます
開発ツール
https://developer.mozilla.org/ja/docs/Tools
ネットワークモニターでリクエスト内容を確認できます
import pandas as pd df = pd.read_csv("https://goto.jata-net.or.jp/assets/data/stay.csv") df["都道府県"].value_counts()
都道府県 東京都 2551 長野県 2328 京都府 2235 北海道 1965 沖縄県 1886 静岡県 1629 大阪府 1494 神奈川県 1018 山梨県 956 兵庫県 904 千葉県 864 新潟県 855 愛知県 833 群馬県 806 福岡県 783 栃木県 715 岐阜県 661 大分県 647 福島県 631 鹿児島県 549 熊本県 537 三重県 525 石川県 521 和歌山県 484 広島県 444 山形県 409 宮城県 407 長崎県 385 茨城県 364 福井県 352 岩手県 335 香川県 328 岡山県 327 埼玉県 312 奈良県 298 愛媛県 295 滋賀県 287 富山県 259 島根県 240 高知県 225 鳥取県 221 宮崎県 221 青森県 220 秋田県 204 山口県 201 徳島県 184 佐賀県 168
- 投稿日:2020-10-11T20:55:10+09:00
【初心者】【Python/Django】駆け出しWebエンジニアがDjangoチュートリアルをやってみた~その5~
はじめに
みなさん、初めまして。
Djangoを用いた投票 (poll) アプリケーションの作成過程を備忘録として公開していこうと思います。
Qiita初心者ですので読みにくい部分もあると思いますがご了承ください。シリーズ
- 【初心者】【Python/Django】駆け出しWebエンジニアがDjangoチュートリアルをやってみた~その0~
- 【初心者】【Python/Django】駆け出しWebエンジニアがDjangoチュートリアルをやってみた~その1~
- 【初心者】【Python/Django】駆け出しWebエンジニアがDjangoチュートリアルをやってみた~その2~
- 【初心者】【Python/Django】駆け出しWebエンジニアがDjangoチュートリアルをやってみた~その3~
- 【初心者】【Python/Django】駆け出しWebエンジニアがDjangoチュートリアルをやってみた~その4~
作業開始
自動テストの導入
Djangoの自動テスト機能で使用するコードを書いていきます。
初めてのテスト作成
Djangoのテストとはどのようなコードが必要でしょうか。
まずは対話形式でテストを実行します。テスト内容:Questionのpub_dateが未来の日付(今日から30日後)になっている場合にwas_published_recently関数がFalseとなることを確認する
テスト結果:FAILD(was_published_recentlyの期待する動作はFalseであるが、実動作はTrueとなっている)(poll-HcNSSqhc) C:\django\poll>python manage.py shell Python 3.8.6 (tags/v3.8.6:db45529, Sep 23 2020, 15:37:30) [MSC v.1927 32 bit (Intel)] on win32 Type "help", "copyright", "credits" or "license" for more information. (InteractiveConsole) >>> >>> import datetime >>> from django.utils import timezone >>> from polls.models import Question >>> >>> future_question = Question(pub_date=timezone.now()+datetime.timedelta(days=30)) >>> future_question.was_published_recently() True >>>これをコード化します。
self.assertIsで期待する動作はFalseであるとしています。polls/tests.pyfrom django.test import TestCase import datetime from django.utils import timezone from .models import Question # Create your tests here. class QuestionModelTests(TestCase): def test_was_published_recently_whit_future_question(self): future_question = Question(pub_date=timezone.now() + datetime.timedelta(days=30)) self.assertIs(future_question.was_published_recently(), False)続いてテストを実行しましょう。もちろん対話型ではありませんよ。
(poll-HcNSSqhc) C:\django\poll>python manage.py test polls Creating test database for alias 'default'... System check identified no issues (0 silenced). F ====================================================================== FAIL: test_was_published_recently_whit_future_question (polls.tests.QuestionModelTests) ---------------------------------------------------------------------- Traceback (most recent call last): File "C:\django\poll\polls\tests.py", line 13, in test_was_published_recently_whit_future_question self.assertIs(future_question.was_published_recently(), False) AssertionError: True is not False ---------------------------------------------------------------------- Ran 1 test in 0.002s FAILED (failures=1) Destroying test database for alias 'default'... (poll-HcNSSqhc) C:\django\poll>しっかりとFAILDを返しています。(was_published_recentlyの期待する動作はFalseであるが、実動作はTrueとなっている)
ではデバッグしましょう。
polls/models.pydef was_published_recently(self): return timezone.now() - datetime.timedelta(days=1) <= self.pub_date <= timezone.now()(poll-HcNSSqhc) C:\django\poll>python manage.py test polls Creating test database for alias 'default'... System check identified no issues (0 silenced). . ---------------------------------------------------------------------- Ran 1 test in 0.002s OK Destroying test database for alias 'default'... (poll-HcNSSqhc) C:\django\poll>OKとなりました。(was_published_recentlyの期待する動作はFalseであり、実動作はFalseとなっている)
より包括的なテスト
同じクラスに対してさらにテスト項目を追加しましょう。限界値テスト項目を追加しています。
polls/tests.pydef test_was_published_recently_with_old_question(self): old_question = Question(pub_date=timezone.now() - datetime.timedelta(days=1, seconds=1)) self.assertIs(old_question.was_published_recently(), False) def test_was_published_recently_with_recently_question(self): recently_question = Question(pub_date=timezone.now( ) - datetime.timedelta(hours=23, minutes=59, seconds=59)) self.assertIs(recently_question.was_published_recently(), True)(poll-HcNSSqhc) C:\django\poll>python manage.py test polls Creating test database for alias 'default'... System check identified no issues (0 silenced). ... ---------------------------------------------------------------------- Ran 3 tests in 0.004s OK Destroying test database for alias 'default'... (poll-HcNSSqhc) C:\django\poll>OKと表示されました。
ビューをテストする
DjangoでビューのテストをするためにはClientクラスを使います。
まずは対話形式でテストを実行します。テスト内容:「http://127.0.0.1/polls」のビューが存在すること
テスト結果:HTTP200、およびコンテンツが取得できている(poll-HcNSSqhc) C:\django\poll>python manage.py shell Python 3.8.6 (tags/v3.8.6:db45529, Sep 23 2020, 15:37:30) [MSC v.1927 32 bit (Intel)] on win32 Type "help", "copyright", "credits" or "license" for more information. (InteractiveConsole) >>> >>> >>> from django.test.utils import setup_test_environment >>> setup_test_environment() >>> from django.test import Client >>> from django.urls import reverse >>> client = Client() >>> response = client.get(reverse('polls:index')) >>> >>> response.status_code 200 >>> >>> response.content b'\n <ul>\n \n <li><a href="/polls/5/">What's this?</a></li>\n \n </ul>\n' >>> >>> response.context['latest_question_list'] <QuerySet [<Question: What's this?>]> >>>ビューを改良する
未来の日付になっている投票を表示する問題がありますので、改修しましょう。
Question.objects.filter()はフィルタすることを意味し、pub_date__lte=timezone.now()はpub_dateがtimezone.now()以下(less than equal)の条件式となります。
polls/views.pyfrom django.utils import timezone class IndexView(generic.ListView): *** def get_queryset(self): return Question.objects.filter(pub_date__lte=timezone.now()).order_by('-pub_date')[:5]新しいビューをテストする
テストコードを用意します。
polls/tests.pyfrom django.urls import reverse def create_question(question_text, days): time = timezone.now() + datetime.timedelta(days=days) return Question.objects.create(question_text=question_text, pub_date=time) class QuestionIndexViewTest(TestCase): # HTTP200、画面メッセージ:No polls are available.、質問リスト:空 def test_no_question(self): response = self.client.get(reverse('polls:index')) self.assertEqual(response.status_code, 200) self.assertContains(response, "No polls are available.") self.assertQuerysetEqual(response.context['latest_question_list'], []) # 質問リスト:Past question. def test_past_question(self): create_question(question_text="Past question.", days=-30) response = self.client.get(reverse('polls:index')) self.assertQuerysetEqual(response.context['latest_question_list'], [ '<Question: Past question.>']) # 質問リスト:空(未来の質問は表示されない) def test_feature_question(self): create_question(question_text="Feature question.", days=30) response = self.client.get(reverse('polls:index')) self.assertContains(response, "No polls are available.") self.assertQuerysetEqual(response.context['latest_question_list'], []) # 質問リスト:Past question.(未来の質問は表示されない) def test_feature_question_and_past_question(self): create_question(question_text="Feature question.", days=30) create_question(question_text="Past question.", days=-30) response = self.client.get(reverse('polls:index')) self.assertQuerysetEqual(response.context['latest_question_list'], [ '<Question: Past question.>']) # 質問リスト:Past question1.、Past question2. # 質問リストは最新投稿順に取得されるため、作成順序と取得順序が弱になることに注意 def test_tow_past_question(self): create_question(question_text="Past question1.", days=-30) create_question(question_text="Past question2.", days=-10) response = self.client.get(reverse('polls:index')) self.assertQuerysetEqual(response.context['latest_question_list'], [ '<Question: Past question2.>', '<Question: Past question1.>'])(poll-HcNSSqhc) C:\django\poll>python manage.py test polls Creating test database for alias 'default'... System check identified no issues (0 silenced). ........ ---------------------------------------------------------------------- Ran 8 tests in 0.063s OK Destroying test database for alias 'default'... (poll-HcNSSqhc) C:\django\poll>OKと表示されました。
DetailView のテスト
detailビューも未来の日付の質問詳細が表示できる状態となっているので改修しましょう。
polls/views.pyclass DetailView(generic.DetailView): *** def get_queryset(self): return Question.objects.filter(pub_date__lte=timezone.now())polls/tests.pyclass QuestionDetailViewTests(TestCase): def test_future_question(self): future_question = create_question(question_text="Future question.", days=5) url = reverse('polls:detail', args=(future_question.id,)) response = self.client.get(url) self.assertEqual(response.status_code, 404) def test_past_question(self): past_question = create_question(question_text="Past question.", days=-5) url = reverse('polls:detail', args=(past_question.id,)) response = self.client.get(url) self.assertContains(response, past_question.question_text)(poll-HcNSSqhc) C:\django\poll>python manage.py test polls Creating test database for alias 'default'... System check identified no issues (0 silenced). .......... ---------------------------------------------------------------------- Ran 10 tests in 0.088s OK Destroying test database for alias 'default'... (poll-HcNSSqhc) C:\django\poll>今日はここまでにします。ありがとうございました。
- 投稿日:2020-10-11T20:17:45+09:00
AIで請求項を見える化する
0.ポイント
1.特許権の権利範囲は請求項として、言葉で表される。
2.請求項は、記載が厳密であるだけに、文章の構造が複雑になることも多く、読み手によっては、誤解が生じる可能性もある。
3.発明者や弁理士、審査官の間で、認識の齟齬が生じないよう、請求項を見える化してみた。
(下の絵は、見える化の一部分です。)
1.経緯
知的財産権、なかでも特許権は、新しい時代を切り開く、強力な武器だ。その特許権の効力は、「請求の範囲」に記載された文章(請求項)によって定義される。
当然のことながら、請求項の一つ一つについて、特許権の構成要素が「必要」「十分」になるよう、厳密な書き方がされているため、複雑な文章構造になることも多い。
例えば、トヨタが自動運転に関して出願した特許(「自律型車両向けの交通状況認知」、JP2018198422A)の「請求の範囲」は以下の通りとなっている(抜粋)。JP2018198422A.txt車両に備えられた外部センサから、前記車両の外部環境をセンシングして得られたセンサデータを取得する取得ステップと、 前記センサデータを分析して、前記車両の外部における交通状況を識別する識別ステップと、 前記交通状況に関する情報を視覚的に描写する視覚フィードバックを表示させるためのグラフィックデータを生成する生成ステップと、 インタフェース装置に前記視覚フィードバックを表示させるために、前記グラフィックデータを前記インタフェース装置に送信する送信ステップと、 を含む、方法。何を言っているか、お分かりになるだろうか。最初に読んだとき、正直、僕には、何が何だか、よく分からなかった(笑)。
読み直してみて、分かったことは、①方法に関する特許であること、②その方法が4つのステップを含むこと、の2点だ。一つ一つのステップの詳細は、正直、読んでいても、「すぐには、頭に入らない」という感じ。もちろん、悪いのは発明ではなく、僕の頭の方だ(笑)。
そういう状況を踏まえて、請求項を見える化できないか、試しにやってみた。2.準備
さて、見える化だが、AIの定番言語と言って良いPythonを使う。今回は、文章の構造を係り受けとして考えて、Cabochaを利用する。
まず、準備だが、MeCab、CRF++、Cabocha の3つが必要。インストール方法は、とっても良い記事があるので、参考に見てみて下さい。僕も参考にさせて頂きました。サイト作成者の方には、この場を借りて、御礼を申し上げます。
Google Colab で MeCab と CaboCha を使う最強の方法
▲心くじけず言語処理100本ノック==5章下準備==形態素解析のMeCabが正しくインストールできれば、以下の通りとなる。
import MeCab tagger = MeCab.Tagger() print(tagger.parse("隣の客はよく柿食う客だ"))output隣 トナリ トナリ 隣り 名詞-普通名詞-一般 0 の ノ ノ の 助詞-格助詞 客 キャク キャク 客 名詞-普通名詞-一般 0 は ワ ハ は 助詞-係助詞 よく ヨク ヨク 良く 副詞 1 柿 カキ カキ 柿 名詞-普通名詞-一般 0 食う クー クウ 食う 動詞-一般 五段-ワア行 連体形-一般 1 客 キャク キャク 客 名詞-普通名詞-一般 0 だ ダ ダ だ 助動詞 助動詞-ダ 終止形-一般 EOSまた、係り受け分析に必要なCRF++、Cabochaが正しくインストールされれば、以下の通りとなる。
import CaboCha cp = CaboCha.Parser() print(cp.parseToString("隣の客はよく柿食う客だ"))output隣の-D 客は-------D よく---D | 柿-D | 食う-D 客だ EOS3.データの加工
さて、インストールが出来たところで、データを加工しよう。
まずは、用意したテキストデータを読み込み、各行ごとに形態素解析を行う。それから、Cabochaを使って、係り受け分析をする。file_path = 'JP2018198422A.txt' #空のリストの用意 c_list = [] c = CaboCha.Parser() #テキストデータの読み込み with open(file_path) as f: text_list = f.read() #改行で切り分けて各行ごとに形態素解析を行います。 for i in text_list.split('\n'): cabo = c.parse(i) #用意したc_listに格納します。 c_list.append(cabo.toString(CaboCha.FORMAT_LATTICE))結果をファイルに保存し、データの加工は終了。
#書き出し path_w = 'JP2018198422A.txt.cabocha' #リスト型を書き込むときはwritelines() with open(path_w, mode='w') as f: f.writelines(c_list)4.見える化に挑戦
それでは、いよいよ、見える化に挑戦する。
まずは、係り受け分析の結果を読み込む。#係り受け分析の結果データの読み込み path = 'JP2018198422A.txt.cabocha' import re with open(path, encoding='utf-8') as f: _data = f.read().split('\n')次に、形態素を表すクラスMorphを実装する。このクラスは表層形(surface)、基本形(base)、品詞(pos)、品詞細分類1(pos1)をメンバ変数に持つ。
class Morph: def __init__(self, word): self.surface = word[0] self.base = word[7] self.pos = word[1] self.pos1 = word[2] #一文ずつにまとめたリスト sent = [] #sentに入れるリストの仮置き場 temp = [] for line in _data[:-1]: #リスト内の各要素を分割します。 #集合[]で「\t」と「,」と「 (スペース)」を指定します。 text = re.split("[\t, ]", line) #「EOS」を目印に1文ごとにリストにまとめます。 if text[0] == 'EOS': sent.append(temp) #次の文に使用するために空にします。 temp = [] #係り受け解析の行は今回は不要なのでcontinue elif text[0] == '*': continue #形態素解析の結果から指定の要素をMorphオブジェクトのリストとしてtempに格納します。 else: morph = Morph(text) temp.append(morph)それから、文節を表すクラスChunkを実装する。このクラスは形態素(Morphオブジェクト)のリスト(morphs)、係り先文節インデックス番号(dst)、係り元文節インデックス番号のリスト(srcs)をメンバ変数に持つ。
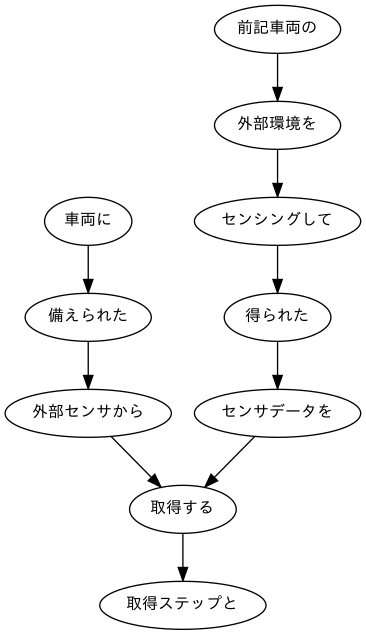
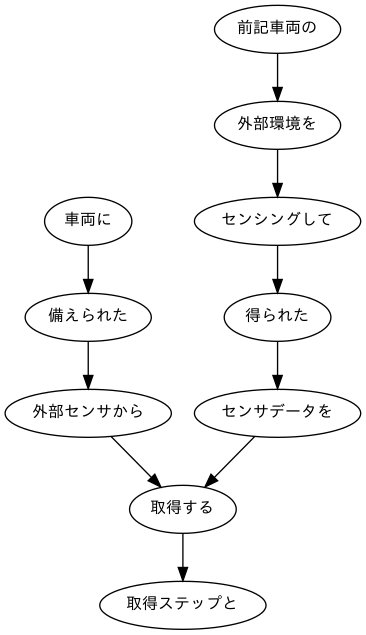
#クラスChunk class Chunk: def __init__(self, idx, dst): self.idx = idx #文節番号 self.morphs = [] #形態素(Morphオブジェクト)のリスト self.dst = dst #係り先文節インデックス番号 self.srcs = [] #係り元文節インデックス番号のリスト import re #1文ごとのリスト s_list = [] #Chunkオブジェクト sent = [] #形態素解析結果のMorphオブジェクトリスト temp = [] chunk = None for line in _data[:-1]: #集合[]で「\t」と「,」と「 (スペース)」を区切りを指定します。 text = re.split("[\t, ]", line) #係り受け解析の行の処理 if text[0] == '*': idx = int(text[1]) dst = int(re.search(r'(.*?)D', text[2]).group(1)) #Chunkオブジェクトへ chunk = Chunk(idx, dst) sent.append(chunk) #EOSを目印に文ごとにリスト化 elif text[0] == 'EOS': if sent: for i, c in enumerate(sent, 0): if c.dst == -1: continue else: sent[c.dst].srcs.append(i) s_list.append(sent) sent = [] else: morph = Morph(text) chunk.morphs.append(morph) temp.append(morph) #1行目の表示 for m in s_list[0]: print(m.idx, [mo.surface for mo in m.morphs], '係り元:' + str(m.srcs),'係り先:' + str(m.dst))output0 ['車両', 'に'] 係り元:[] 係り先:1 1 ['備え', 'られ', 'た'] 係り元:[0] 係り先:2 2 ['外部', 'センサ', 'から', '、'] 係り元:[1] 係り先:8 3 ['前記', '車両', 'の'] 係り元:[] 係り先:4 4 ['外部', '環境', 'を'] 係り元:[3] 係り先:5 5 ['センシング', 'し', 'て'] 係り元:[4] 係り先:6 6 ['得', 'られ', 'た'] 係り元:[5] 係り先:7 7 ['センサデータ', 'を'] 係り元:[6] 係り先:8 8 ['取得', 'する'] 係り元:[2, 7] 係り先:9 9 ['取得', 'ステップ', 'と', '、'] 係り元:[8] 係り先:-1さらに、係り元の文節と係り先の文節のテキストを抽出する。
for s in s_list: for m in s: #係り先がある文節の場合、 if int(m.dst) != -1: #形態素解析結果のposが'記号'以外のものをrタブ区切りで表示します。 print(''.join([b.surface if b.pos != '記号' else '' for b in m.morphs]), ''.join([b.surface if b.pos != '記号' else '' for b in s[int(m.dst)].morphs]), sep='\t')output車両に 備えられた 備えられた 外部センサから 外部センサから 取得する 前記車両の 外部環境を 外部環境を センシングして センシングして 得られた 得られた センサデータを センサデータを 取得する 取得する 取得ステップと 前記センサデータを 分析して 分析して 識別する 前記車両の 外部における 外部における 交通状況を 交通状況を 識別する 識別する 識別ステップと 前記交通状況に関する 情報を 情報を 描写する 視覚的に 描写する 描写する 視覚フィードバックを 視覚フィードバックを 表示させる 表示させる ための ための グラフィックデータを グラフィックデータを 生成する 生成する 生成ステップと インタフェース装置に 表示させる 前記視覚フィードバックを表示させる 表示させる ために ために 送信ステップと 前記グラフィックデータを 送信する 前記インタフェース装置に 送信する 送信する 送信ステップと を 含む 含む 方法最後に、係り受け木を有向グラフとして可視化する。見やすさを優先して、最初のステップのみ、見える化する。
#最初の部分を試しにやってみます v = s_list[0] #文節のセットを格納するリストの作成 s_pairs = [] for m in v: if int(m.dst) != -1: a = ''.join([b.surface if b.pos != '記号' else '' for b in m.morphs]) b = ''.join([b.surface if b.pos != '記号' else '' for b in v[int(m.dst)].morphs]) c = a, b s_pairs.append(c) #係り受け木の描画 import pydot_ng as pydot img = pydot.Dot(graph_type='digraph') #日本語に対応しているフォントを指定します img.set_node_defaults(fontname='Meiryo UI', fontsize='12') for s, t in s_pairs: img.add_edge(pydot.Edge(s, t)) img.write_png('pic')出来上がりは下の通り。最初に掲載したものと同じものだが、再掲する。
如何だろう。どんなステップなのか、頭に入りやすくなったのではないだろうか。
5.最後に
特許権が、基本的には言葉で決まっていることを初めて知った時、正直、驚いた。もちろん、図面も重要な書類であるが、特許になるか否か、また、権利範囲の確定は、直接的には、言葉で表される。そういった事実を考えると、文章構造の見える化は、とても重要だと思う。
なお、例に使わせていただいたトヨタの自動運転に関する特許は、ステイタスはペンディング。特許になるのは、大変だ。
コーデイングについては、以下のサイトを参考にさせて頂きました。とっても良いサイトで、大変、勉強になりました。この場を借りて、御礼を申し上げます。
▲心くじけず言語処理100本ノック==40~44==
- 投稿日:2020-10-11T20:15:24+09:00
PANDASで効率よくデータ加工する事例
初めに
PANDASは、データサイエンティスト向けの最高のデータ処理ライブラリですが、数百万行のデータを取り扱う際にパフォーマンスの落とし穴を回避するように注意する必要があります。今回は仕事の中で学んできたいくつのテクニックを紹介したいと思います。
DataFrame
PANDASは列志向のデータ構造なので、列ごとの処理は得意です。
DataFrameの作成には「1レコード1行」形式で、1レコードに対してすべての測定可能の値(湿度、値段、座標など)はカラムごとに行うことを推奨します。しかし、膨大なデータ加工において行ごとのforループ処理したらパフォーマンスを格段に落とす。本記事はパフォーマンスを考えて頭よくデータ加味を行う方法を紹介したいと思います。
まずはサンプル用のテーブルを作ります。
data = {'Team': ['Tiger', 'Tiger', 'Rabbit', 'Rabbit', 'Cat', 'Cat', 'Cat', 'Cat', 'Tiger', 'Human', 'Human', 'Tiger'], 'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2], 'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017], 'Points':[876,789,863,673,741,812,756,788,694,701,804,690]} df= pd.DataFrame(data) print(team_dashboard) ''' Team Rank Year Points 0 Tiger 1 2014 876 1 Tiger 2 2015 789 2 Rabbit 2 2014 863 3 Rabbit 3 2015 673 4 Cat 3 2014 741 5 Cat 4 2015 812 6 Cat 1 2016 756 7 Cat 1 2017 788 8 Tiger 2 2016 694 9 Human 4 2014 701 10 Human 1 2015 804 11 Tiger 2 2017 690 ''' print(df.columns) # 列ラベルの取得 ''' Index(['Team', 'Rank', 'Year', 'Points'], dtype='object') ''' print(df.index) # row indexの取得 ''' RangeIndex(start=0, stop=12, step=1) '''DataFrameにはindexと呼ばれる特殊なリストがある。上の例では
['Team', 'Rank', 'Year', 'Points']のように各列を表す要素をラベルと、左側の0, 1, 2, 3, ...のように各行を表すrow indexがある。groupby()
groupbyは、同じ値を持つデータをまとめて、それぞれのグループに対して共通の操作を行いたい時に使います。データ加工において定番になっているが、groupbyは多様な使い方があるので最初はなかなか難しいです。
では、さっそぐ例を見ていきましょう。groupby()メソッドにカラム名を入れたらGroupByオブェクトを返す。# 1個レベル df_g = df.groupby(by=['Team']) print(df_g.groups) ''' {'Cat': Int64Index([4, 5, 6, 7], dtype='int64'), 'Human': Int64Index([9, 10], dtype='int64'), 'Rabbit': Int64Index([2, 3], dtype='int64'), 'Tiger': Int64Index([0, 1, 8, 11], dtype='int64')} ''' # 2個(複数)ラベル df_g = df.groupby(by=['Team', 'Year']) print(df_g.groups) ''' {('Cat', 2014): Int64Index([4], dtype='int64'), ('Cat', 2015): Int64Index([5], dtype='int64'), ('Cat', 2016): Int64Index([6], dtype='int64'), ('Cat', 2017): Int64Index([7], dtype='int64'), ('Human', 2014): Int64Index([9], dtype='int64'), ('Human', 2015): Int64Index([10], dtype='int64'), ('Rabbit', 2014): Int64Index([2], dtype='int64'), ('Rabbit', 2015): Int64Index([3], dtype='int64'), ('Tiger', 2014): Int64Index([0], dtype='int64'), ('Tiger', 2015): Int64Index([1], dtype='int64'), ('Tiger', 2016): Int64Index([8], dtype='int64'), ('Tiger', 2017): Int64Index([11], dtype='int64')} '''こうして
{列ラベル: [行ラベル, 行ラベル, ...]}のような形で、どのグループにどの列が入ったか分かる。各ラベルに対して同じラベルの持っているデータのrow indexリストが収納されている。ちなみにグループ内のデータを取得には
get_group()にグループキーを渡す。df_oneGroup = df_g.get_group('Rabbit') print(df_oneGroup) ''' Team Rank Year Points 2 Rabbit 2 2014 863 3 Rabbit 3 2015 673 ''' df_oneGroup = df_g.get_group(('Cat', 2014)) print(df_oneGroup) ''' Team Rank Year Points 4 Cat 3 2014 741 '''まあ、実際
get_group()はデバッグ以外にあまり使わないですが、GroupByオブジェクトでグループごとにさまざま演算ができる。例えば各チームに年ごとのRankとPointsの平均をとるにはmean()メソッドを呼び出す。ほかにはsum()、mode()などたくさんのメソッドが提供されてる。ちなみに、as_index=Falseするとデフォルトのグループラベルをリセットされ、[0, 1, 2, ..., n]になるdf_mean = team_dashboard.groupby(by=['Team', 'Year']).mean() print(df_mean) ''' Rank Points Team Year Cat 2014 3 741 2015 4 812 2016 1 756 2017 1 788 Human 2014 4 701 2015 1 804 Rabbit 2014 2 863 2015 3 673 Tiger 2014 1 876 2015 2 789 2016 2 694 2017 2 690 ''' df_mean = team_dashboard.groupby(by=['Team', 'Year'], as_index=False).mean() print(df_mean) ''' Team Year Rank Points 0 Cat 2014 3 741 1 Cat 2015 4 812 2 Cat 2016 1 756 3 Cat 2017 1 788 4 Human 2014 4 701 5 Human 2015 1 804 6 Rabbit 2014 2 863 7 Rabbit 2015 3 673 8 Tiger 2014 1 876 9 Tiger 2015 2 789 10 Tiger 2016 2 694 11 Tiger 2017 2 690 '''
agg()を使ってグループごとに複数行を返す先ほどの
GroupBy.mean()のように、グループごとに数値を求められますが、もしグループに別々に数値を求めようとするときはagg()(Aggregration)を使う。Aggregationに使う関数がstring、numpyメソッド、自作関数、ラムダ式で呼び出せる。agg()を使うにはdict()に定義して以下のように渡すと実装できる。''' location col1 col2 col3 col4 0 a True 2 1 4 1 a False 6 2 6 2 b True 7 6 3 3 b True 3 3 4 4 b False 8 4 6 5 c True 9 57 8 6 d False 1 74 9 ''' func_dict = {'col1': lambda x: x.any(), # 欠損状態の確認 'col2': np.mean, # 平均 'col3': np.sum, # 合計 'col4': lambda S: S.mode()[0]} # 最頻値 df_agg = df.groupby('location').agg(func_dict).reset_index() print(df_agg) ''' location col1 col2 col3 col4 0 a True 4 3 4 1 b True 6 13 3 2 c True 9 57 8 3 d False 1 74 9 '''
cut()を使って任意の境界値でカテゴリ変数を数値に変換するデータをカテゴリ化する際に、指定した境界値でカテゴリ化を行う
cut()を紹介します。例えば、「深夜、午前、正午、午後、夜」と五つのカテゴリでデータ全体を等分するときは容易に行えます。prods = pd.DataFrame({'hour':range(0, 24)}) b = [0, 6, 11, 12, 17, 24] l = ['深夜', '午前','正午', '午後', '夜'] prods['period'] = pd.cut(prods['hour'], bins=b, labels=l, include_lowest=True) print(prods) ''' hour period 0 0 深夜 1 1 深夜 2 2 深夜 3 3 深夜 4 4 深夜 5 5 深夜 6 6 深夜 7 7 午前 8 8 午前 9 9 午前 10 10 午前 11 11 午前 12 12 正午 13 13 午後 14 14 午後 15 15 午後 16 16 午後 17 17 午後 18 18 夜 19 19 夜 20 20 夜 21 21 夜 22 22 夜 23 23 夜 '''
resample()を使って時系列データをグループ化して加工する今回は「1時間ごとの累積件数を計算する」とします。ここは
pd.cumsum()を使ってみようかなと思うので、予めでnum_ride_1hカラムを作っておいて「1」を与える。そうしたらresample()でtimestampカラムで1時間ごとにグループ化した後、各グループにはcumsum()メソッドを呼び出すことで完成できる。df_raw= make_classification(n_samples, n_features+1) df_raw['timestamp'] = random_datetimes_or_dates(start, end, n=n_samples) df_raw['num_ride_1h'] = 1 print(df_raw) ''' var_0 var_1 var_2 class timestamp num_ride_1h 0 1.062513 -0.056001 0.761312 0 2020-09-21 00:01:57 1 1 -2.272391 1.307474 -1.276716 0 2020-09-21 00:14:49 1 2 -1.470793 1.245910 -0.708071 2 2020-09-21 00:17:46 1 3 -1.827838 1.365970 -0.933938 0 2020-09-21 00:25:13 1 4 -1.115794 -0.045542 -0.830372 0 2020-09-21 00:31:45 1 .. ... ... ... ... ... ... 95 0.247010 0.903812 0.448323 0 2020-09-21 23:29:25 1 96 -0.665399 1.861112 0.063642 1 2020-09-21 23:32:51 1 97 0.875282 0.028704 0.649306 2 2020-09-21 23:36:21 1 98 2.159065 -1.155290 1.238786 0 2020-09-21 23:37:23 1 99 1.739777 -1.775147 0.748372 2 2020-09-21 23:56:04 1 ''' df_raw['num_ride_1h'] = df_raw.resample('1H', on='timestamp')['num_ride_1h'].cumsum() ''' var_0 var_1 var_2 class timestamp num_ride_1h 0 -1.331170 -0.274703 0.809738 1 2020-10-11 00:10:54 1 1 -1.373495 -1.067991 1.738302 1 2020-10-11 00:14:24 2 2 -1.471448 0.216404 0.296618 0 2020-10-11 00:43:29 3 3 -2.282394 -1.528916 2.605747 1 2020-10-11 00:48:52 4 4 0.162427 0.524188 -0.663437 2 2020-10-11 00:51:23 5 .. ... ... ... ... ... ... 95 1.197076 0.274294 -0.759543 1 2020-10-11 22:23:50 3 96 -0.459688 0.646523 -0.573518 0 2020-10-11 23:00:20 1 97 0.212496 0.773962 -0.969428 2 2020-10-11 23:11:43 2 98 1.578519 0.496655 -1.156869 1 2020-10-11 23:14:31 3 99 1.318311 -0.324909 -0.114971 0 2020-10-11 23:46:46 4 '''
pd.Grouper()を使うことも可能。どららも同じ結果を出せる。df_raw['num_ride_1h'] = df_raw.groupby(pd.Grouper(key='timestamp', freq='1h'))['num_ride_1h'].cumsum()最後に
ほかにいくつ紹介したい例がありますが、今回はここで終わりたいと思います。次の機会があれば時系列データを中心にしたデータ加工についてまとめて紹介します。
【株式会社クアンド】
私が勤めしている株式会社クアンドは地方産業アップグレードに活動しています。
ぜひご覧になってください。
http://quando.jp/
- 投稿日:2020-10-11T19:56:01+09:00
【Python】 統計値(特徴量)の種類と計算方法
インポート
numpyとscipyを使いますので、はじめにインポートしてください。
importimport numpy as np import scipy.stats最大値、最小値
max,min#最大値 np.max(data) # 最小値 np.min(data)中央値
median# 中央値 np.median(data)平均、分散、標準偏差
Numpyを使って分散、標準偏差を求めた場合、デフォルトで不偏分散・不偏標準偏差が返される。
mean,var,std# 平均 np.mean(data) # 分散 np.var(data) # 標準偏差 np.std(data)歪度、尖度
skew,kurt# 歪度 scipy.stats.skew(data) # 尖度 scipy.stats.kurtosis(data)自乗平均平方根
rms# 自乗平均平方根 np.sqrt(np.square(data).mean())周波数領域エントロピー
ent# FFT fft_data = np.fft.fft(data) # パワースペクトル power_data = abs(fft_data)**2 # パワースペクトルの割合 p = power_data / sum(power_data) # 周波数領域エントロピー ent(data) def ent(data): ent = 0 for i in range(data_size): ent += data[i]*np.log2(data[i]) return -ent
- 投稿日:2020-10-11T19:23:47+09:00
Tensorflow 2で1系記法のCNNを動かす方法
想定読者
- Tensorflow 2の環境で1系のコードで書かれたCNN(畳み込みNN)を動かそうと試行錯誤している人
前提
実行環境
- macOS High Sierra
- Python 3.7.8
- Tensorflow 2.3.1
CNNのコードについて
コードは諸事情により載せませんが、
- MNISTのデータ取得に
tf.keras.*を使用- その他
tf.nn.*,tf.train.*,tf.*を使用して、CNNを実行しているコードです。
1系から2系への主な変更点
Tensorflow 1から2への主な変更点については、 こちら 等いろいろな記事を拝見しましたが、CNNを実行する上で直接影響のあったものは以下でした。
- Eager Executionのデフォルト化
- Session, Placeholderの廃止
※ CNNの実装方法によっては他にもあるかもしれませんがその点はご容赦ください。
1系記法のコードを2系で動かす方法
1系記法のCNNを2系で動かす(ためにコードを変更する)方法は以下の3つがあるようです。
- 変更のあったAPIを地道に書き換える
- アップデートスクリプトを活用する
- 2系挙動を無効化する
1. 変更のあったAPIを地道に書き換える
賢い方法ではありませんが、変更箇所が少なければ該当箇所を地道に書き換えるというのもなくはないかと思います。CNNを動かすために要した修正を以下に示します。
(1) Eager Executionの無効化
import tensorflow as tfの直後に以下を追記し、Eager Executionを無効化する。tf.compat.v1.disable_eager_execution()(2) いくつかのAPIの記法変更
コード内の '1系' の列に該当するAPIを '2系' にある記載の通りに変更する。
# 1系 2系 1 tf.placeholder tf .compat.v1.placeholder 2 tf.random_uniform tf.random.uniform 3 tf.add_to_collection tf .compat.v1.add_to_collection 4 tf.get_collection('costs') tf .compat.v1.get_collection 5 tf.train.AdamOptimizer tf .compat.v1.train.AdamOptimizer 6 tf.Session() tf .compat.v1.Session() #2のような単純に
compat.v1を追加ではないものもありました。
上記以外でcompat.v1の追加が必要なAPIについては、Tensorflow Module: tf.compat.v1をご参照ください。2. アップデートスクリプトを活用する
コードをTensorFlow 2に自動的にアップグレードするを参考に、アップデートスクリプトを用いて、コードを2系記法に変換する方法もあるようです。1の手動変換よりは安全かと思いますが、一部手動変換を要する箇所もあるような記述もあり、全自動ではなさそうです。
3. 2系挙動を無効化する
TensorFlow1コードをTensorFlow2に移行しますによると、
Tensorflowのインポート文import tensorflow as tfを
import tensorflow.compat.v1 as tf tf.disable_v2_behavior()のように変更して2系挙動を無効化することで、1系記法のコードが実行できるようになるようです。(私のコードでは実行が確認できました)
終わりに
3の方法で動いたら一番嬉しいですね。
私は1をした後に3の方法を見つけたのでそういう人が出ないようにこれを書きました。
どんどんTensorflowに慣れていきたいものです。
- 投稿日:2020-10-11T19:11:48+09:00
大阪府の Go To EATの加盟店舗をスクレイピングしCSVに変換
Go To Eat大阪キャンペーンの加盟店をスクレイピング
import time import requests from bs4 import BeautifulSoup import pandas as pd result = [] url = "https://goto-eat.weare.osaka-info.jp/?search_element_0_0=2&search_element_0_1=3&search_element_0_2=4&search_element_0_3=5&search_element_0_4=6&search_element_0_5=7&search_element_0_6=8&search_element_0_7=9&search_element_0_8=10&search_element_0_9=11&search_element_0_cnt=10&search_element_1_0=12&search_element_1_1=13&search_element_1_2=14&search_element_1_3=15&search_element_1_4=16&search_element_1_5=17&search_element_1_6=18&search_element_1_7=19&search_element_1_8=20&search_element_1_9=21&search_element_1_10=22&search_element_1_11=23&search_element_1_12=24&search_element_1_13=25&search_element_1_14=26&search_element_1_15=27&search_element_1_16=28&search_element_1_17=29&search_element_1_cnt=18&searchbutton=%E5%8A%A0%E7%9B%9F%E5%BA%97%E8%88%97%E3%82%92%E6%A4%9C%E7%B4%A2%E3%81%99%E3%82%8B&csp=search_add&feadvns_max_line_0=2&fe_form_no=0" while True: r = requests.get(url) r.raise_for_status() soup = BeautifulSoup(r.content, "html.parser") for li in soup.select("div.search_result_box > ul > li"): data = {} data["店舗名"] = li.select_one("p.name").get_text(strip=True) data["ジャンル"], data["地域"] = li.select_one("ul.tag_list").stripped_strings for tr in li.table.select("tr"): k = tr.th.get_text(strip=True) if k == "住所": v = list(tr.td.stripped_strings) data["郵便番号"] = v[0] data[k] = " ".join(v[-1].split()) else: data[k] = tr.td.get_text(strip=True) result.append(data) tag = soup.select_one("div.wp-pagenavi > a.nextpostslink") if tag: url = tag.get("href") else: break time.sleep(1) df = pd.DataFrame(result).reindex( columns=["店舗名", "ジャンル", "地域", "郵便番号", "住所", "TEL", "営業時間", "定休日"] ) df.to_csv("osaka.csv", encoding="utf_8_sig")
- 投稿日:2020-10-11T18:13:35+09:00
Mobilenetv2でFineTuningいろいろ
はじめに
思い立ったのでおうちで画像分類してみました.
ついでに気になったのでMobilenetv2でFine tuningの精度をいろいろ比べてみたのを記事にします.※おうちPC環境
iMac (Retina 4K, 21.5-inch, 2017)
3.6 GHz クアッドコアIntel Core i7
16 GB 2400 MHz DDR4忙しい人のためのなんちゃら
・Mobilenetv2でFineTuningいろいろしてみたよ
・犬/猫/鳥の3分類のタスクだよ
・Flickrで画像収集したよ
・FineTuningなし/16,15,14,13,12,11,10,9,8,7,6,5,4,3,2,1層目以降を再学習/全て再学習で精度を比べてみたよ
・今回は14層目以降学習と11層目以降学習が同じ正解率(94.4%)で精度が良かったよタスクの設定と画像収集
2値分類だとなんとなくなんでもできちゃいそうだから3値分類,でもわかりやすく結果が出るのがいいから動物の分類やってみたいなと思い,よくやられている「犬」「猫」の分類に「鳥」を付け加えた3値分類やってみることにしました.
そうと決まれば画像の収集です.
ウェブから集めたくてなんかいろいろみてみていたらflickrで集めるのが良さそうだったのでflickrで集めることにしました.
参考にしたのはこちらの記事です.
pythonでflickrから画像データをスクレイピングする方法115*115サイズの画像を最大500枚まで一度にダウンロードできます.(欲張って1000枚ダウンロードしようとしたら500枚しかできなかった)
「dog」「cat」「bird」を引数にそれぞれ500枚ずつ集めました.
その中から被写体が小さすぎる画像やら人間や他の動物が入っちゃってる画像やらを取り除いて450枚ずつを採用することにしました.
その中から30枚ずつをtest,validationに振り分け,残りの390枚をtrainに使いました.
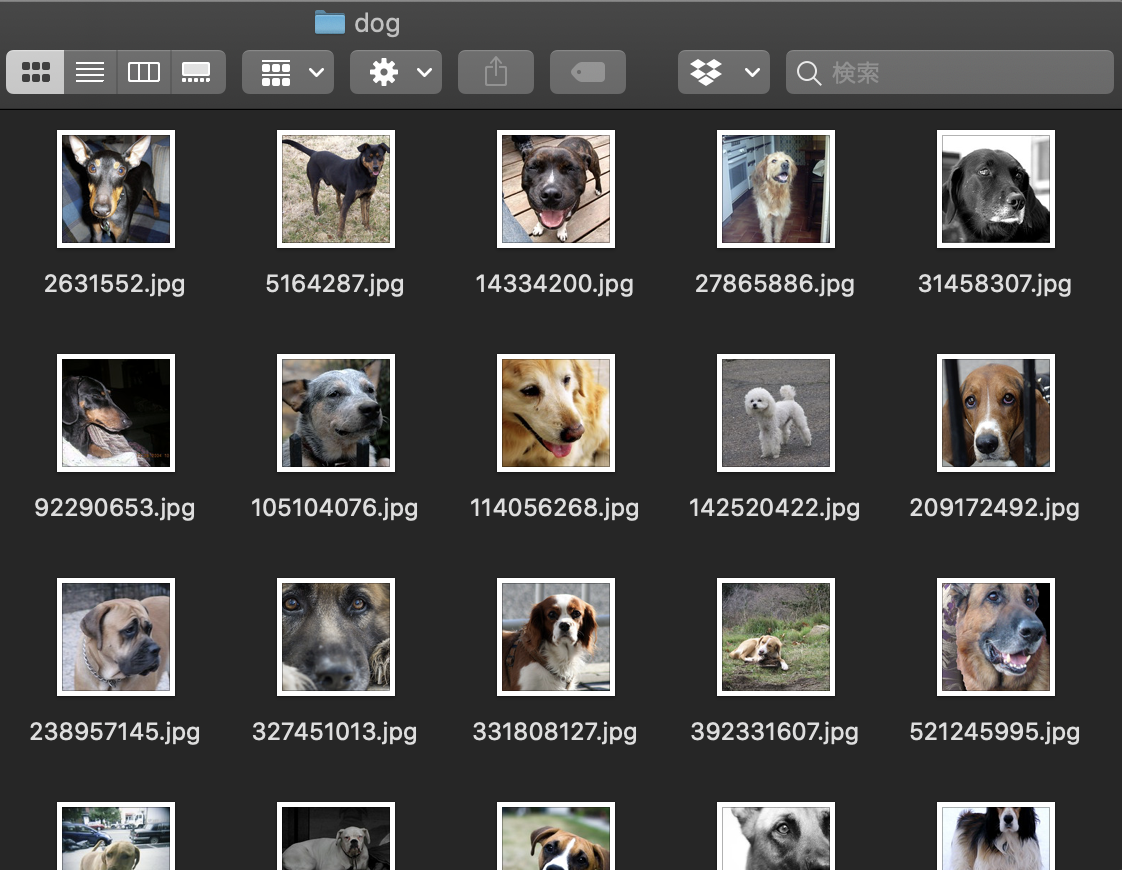
画像はこんな感じ.PCがかわいい犬まみれです.
以下のような構成のフォルダにそれぞれ画像を振り分けます.
├── data
│ ├── test
│ │ ├── bird
│ │ ├── cat
│ │ └── dog
│ ├── train
│ │ ├── bird
│ │ ├── cat
│ │ └── dog
│ └── val
│ ├── bird
│ ├── cat
│ └── dog学習とFineTuning
コードはこちら
https://github.com/kiii142/mobilenetv2_kerasFineTuningの層の設定は,いつも参考にさせていただいているこちらのページを参考にしました.
TensorFlow, Kerasで転移学習・ファインチューニング(画像分類の例)fineTuningしていない学習は学習率0.001始まり,50epoch学習させました.
fineTuningした学習は一律学習率0.0001始まり,30epoch学習させました.
バッチサイズは一律8に,画像は96*96にリサイズしています(学習済み重みが96*96のものがあるため)
今回Optimizerは論文にならってRMSpropを使っています.(はじめSGDを使っていたけどそれよりRMSpropの方が精度出ました.今回は詳しくやってませんがこの辺比べてみるのも面白いのかも)以下結果です.
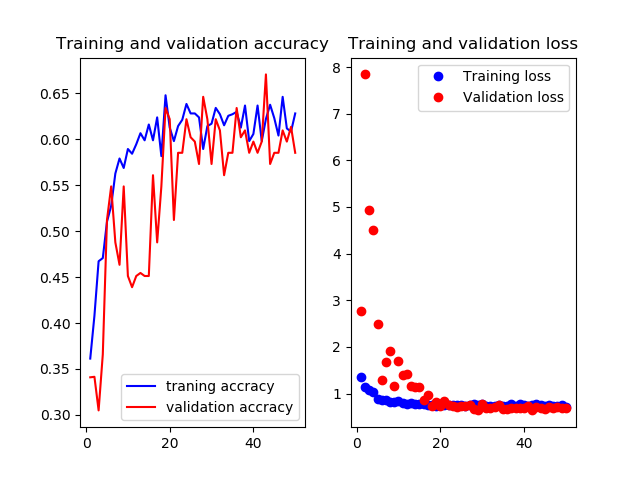
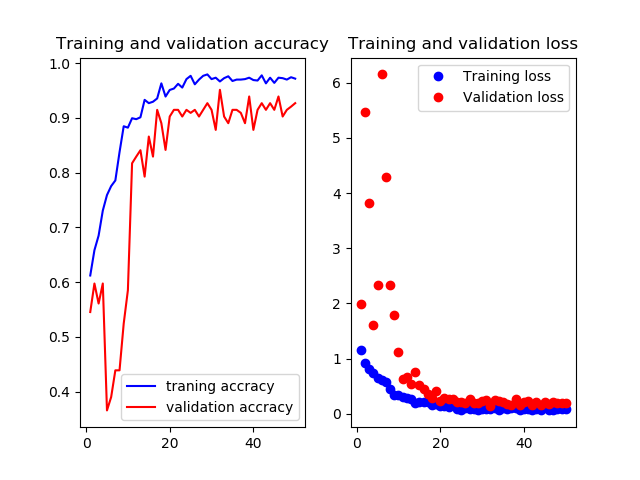
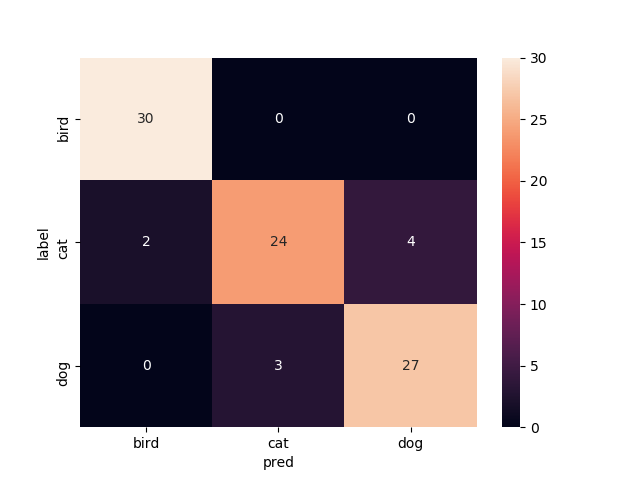
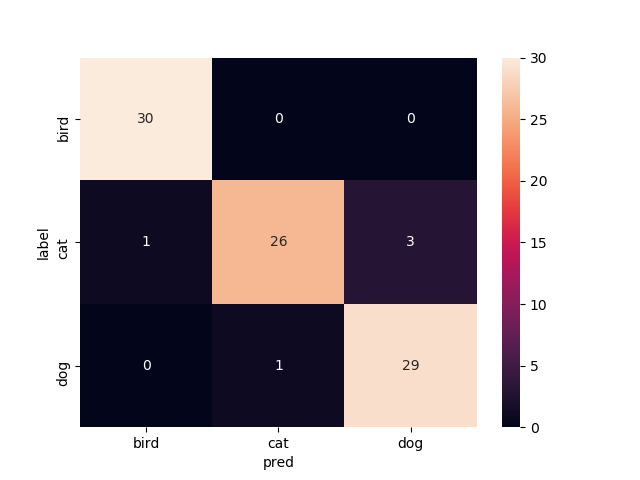
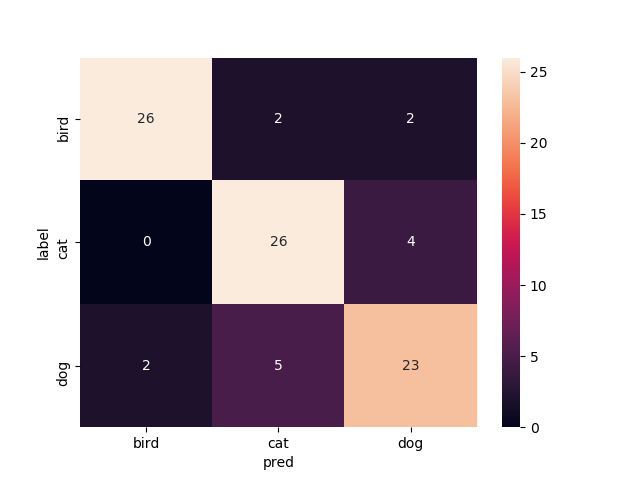
学習曲線とテスト画像での結果のコンフュージョンマトリックスを示します.学習曲線はお恥ずかしながら軸がなんなのか書き忘れてしまったんですけど,縦軸がそれぞれ(正解率とloss)の値,横軸がepoch数です.FineTuningなし
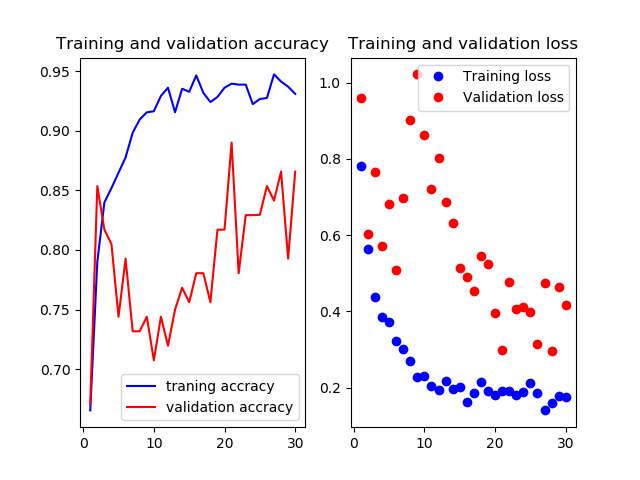
Mobilenetv2のweightをNoneで学習させたものです.
いい感じで学習できてますがtrainもvalも正解率が60%前後をうろうろしてます.もうちょっと精度出て欲しいですね
test画像での正解率は68.9%です
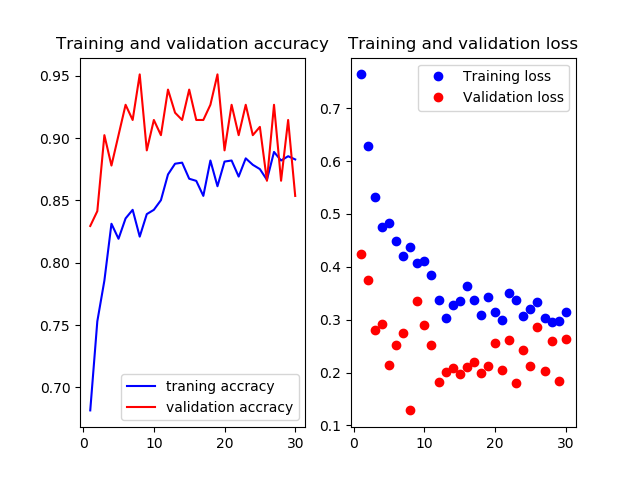
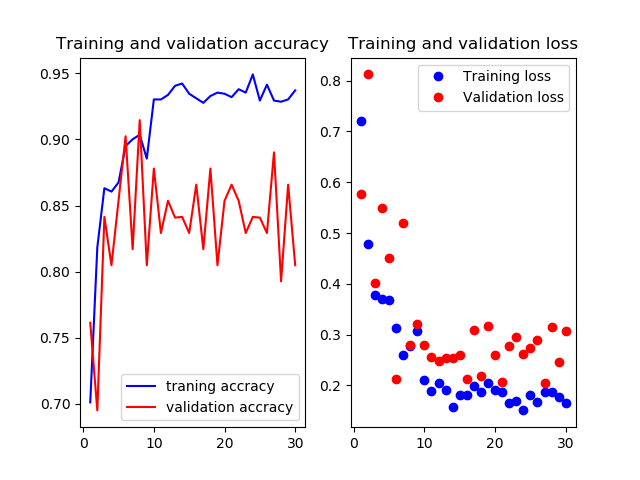
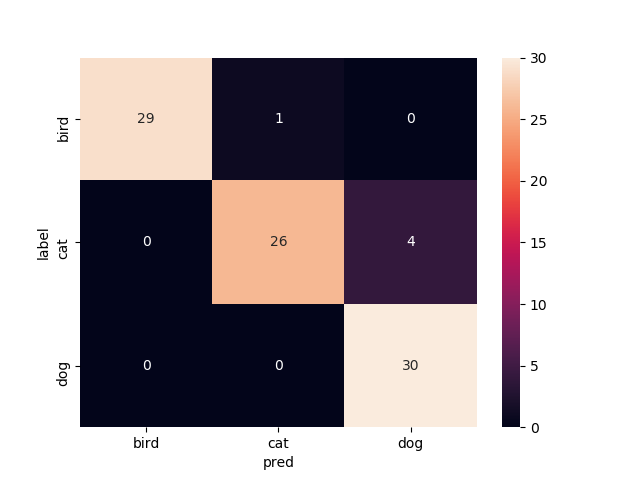
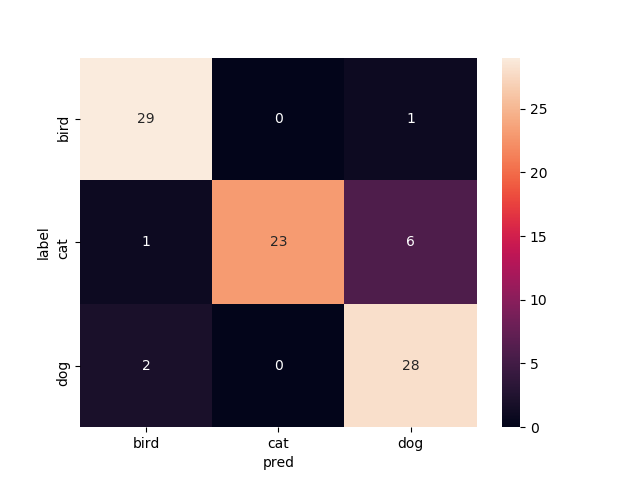
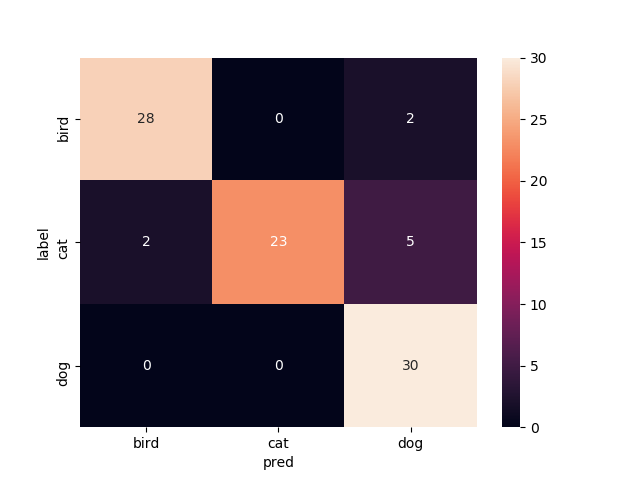
16層目以降を再学習
Mobilenetv2のweightをimagenetにし,16層目以降を再学習させたものです
valの正解率がやたら高いですね.
test画像での正解率は93.3%です
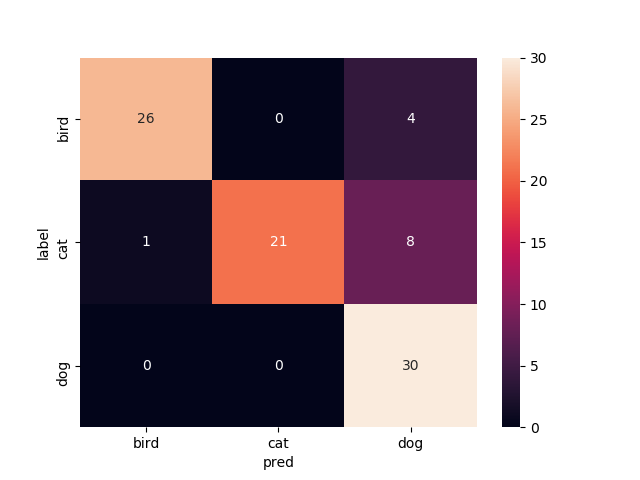
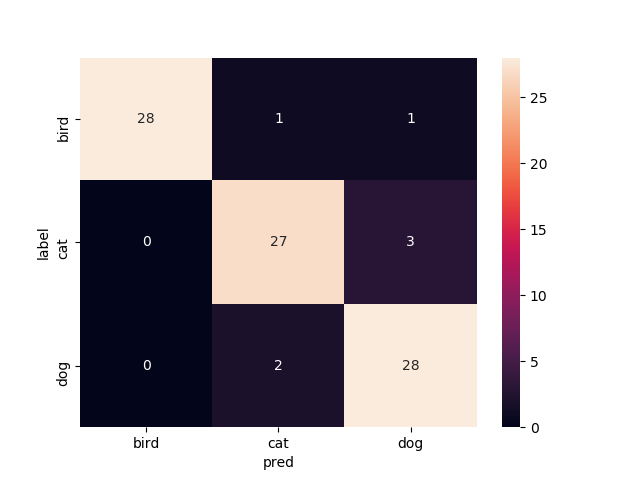
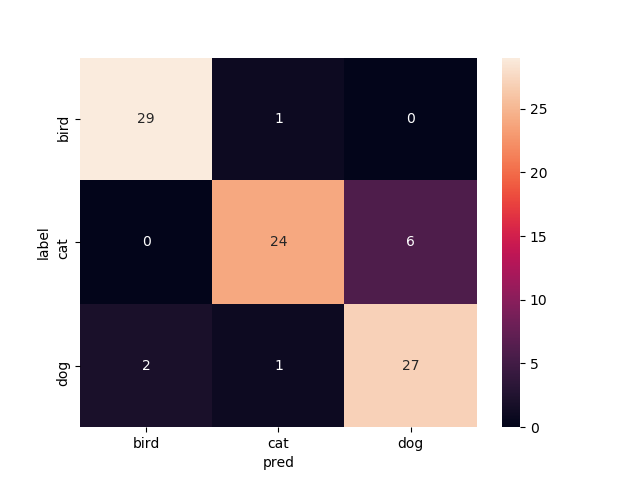
15層目以降を再学習
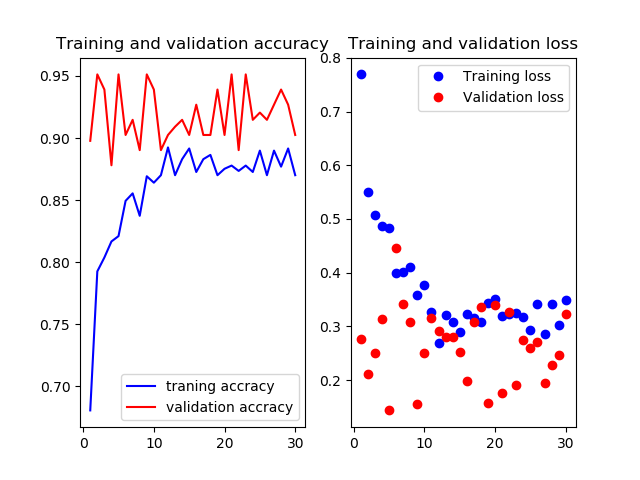
Mobilenetv2のweightをimagenetにし,15層目以降を再学習させたものです
これまたvalの正解率がやたら高いですね.
test画像での正解率は90.0%です
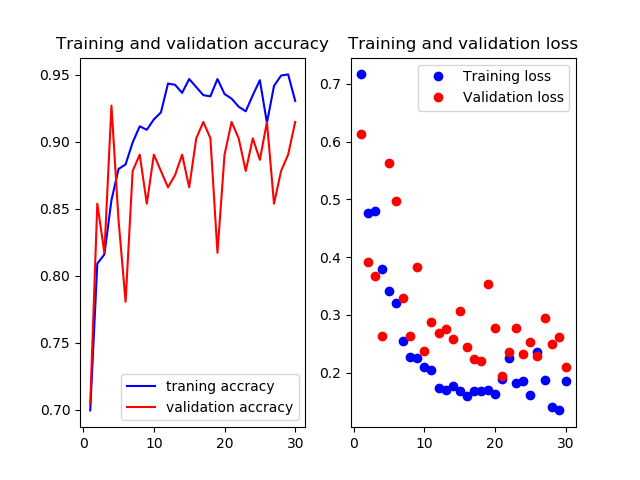
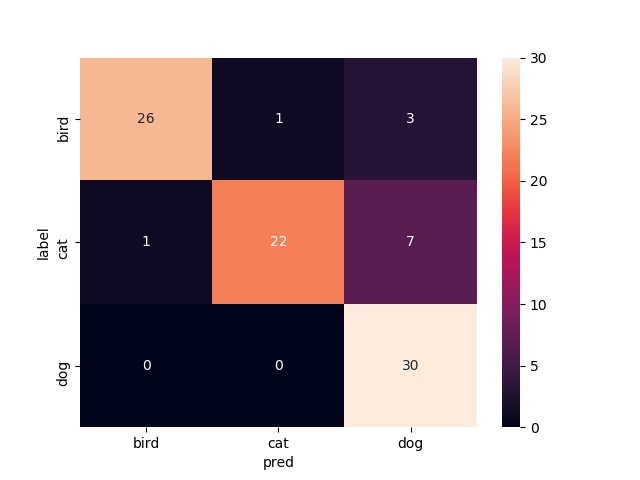
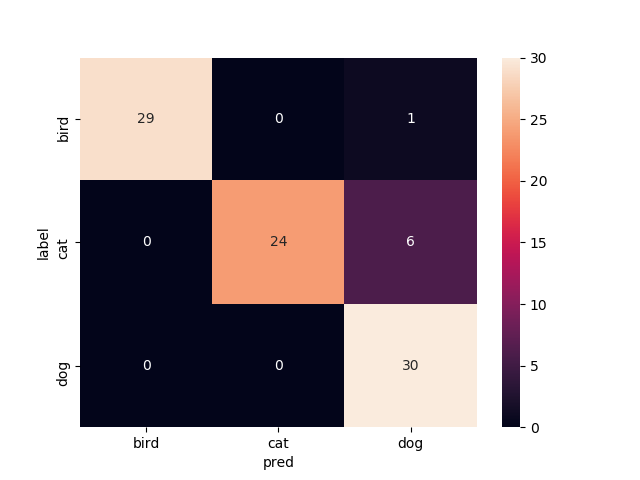
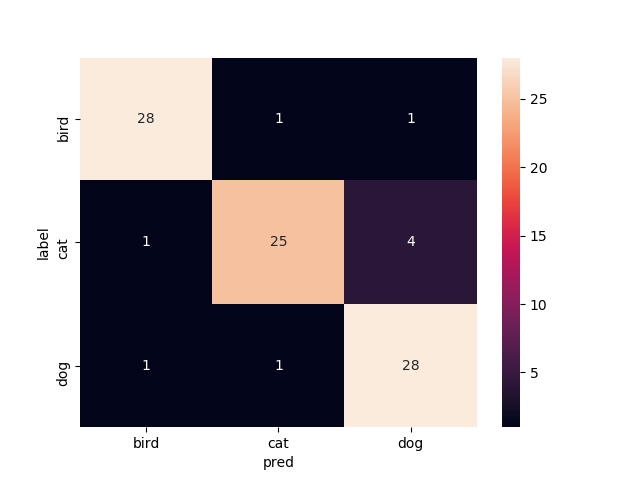
14層目以降を再学習
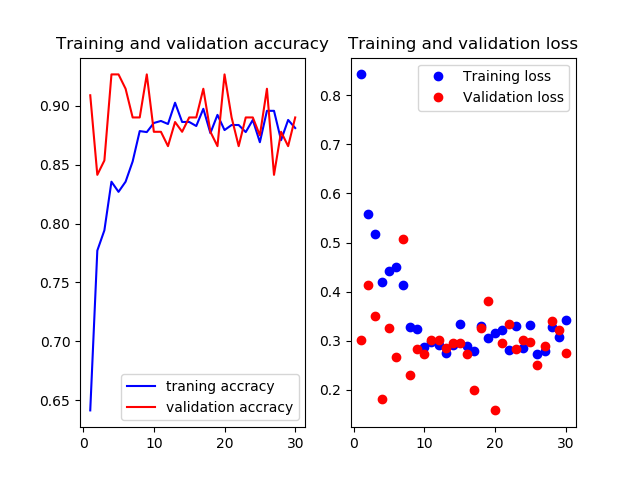
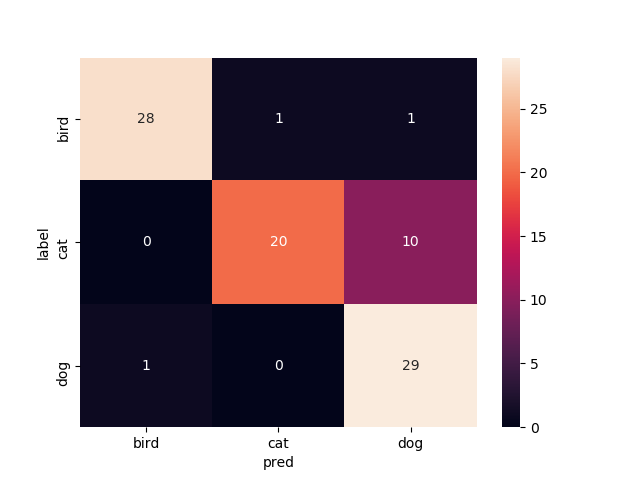
Mobilenetv2のweightをimagenetにし,14層目以降を再学習させたものです
test画像での正解率は94.4%.いい感じです.
13層目以降を再学習
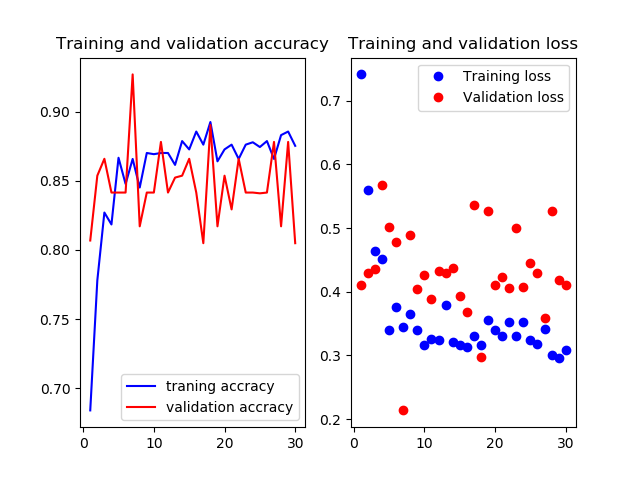
Mobilenetv2のweightをimagenetにし,13層目以降を再学習させたものです
test画像での正解率は86.7%です.ちょっと下がった?
12層目以降を再学習
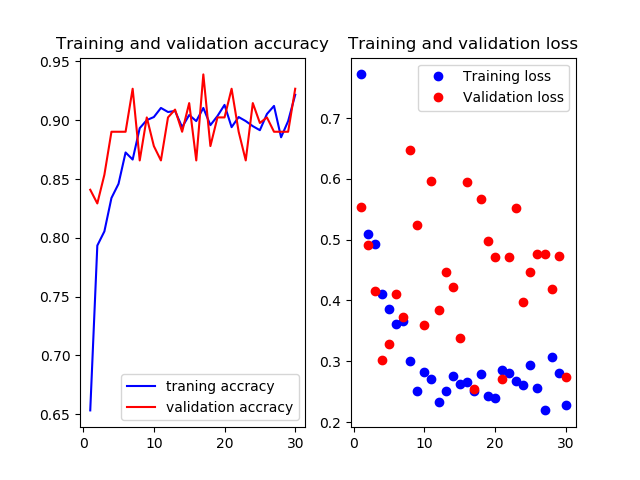
Mobilenetv2のweightをimagenetにし,12層目以降を再学習させたものです
test画像での正解率は86.6%です
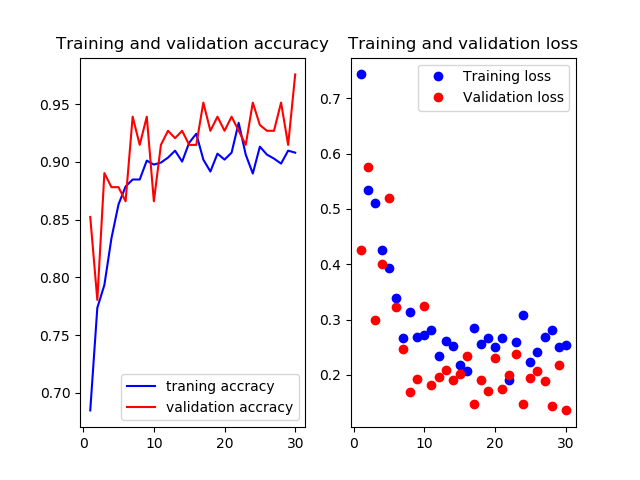
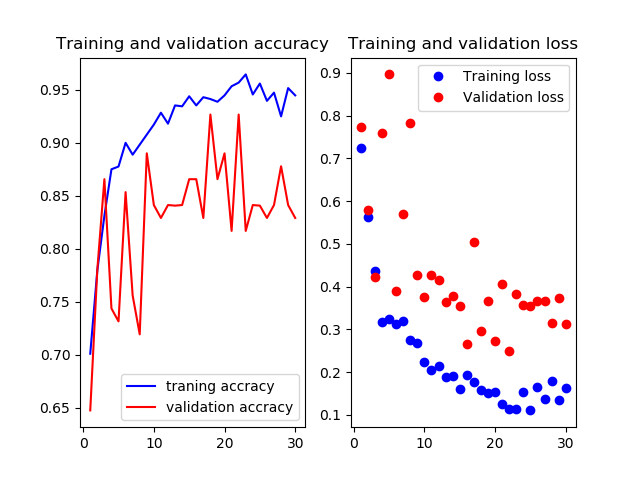
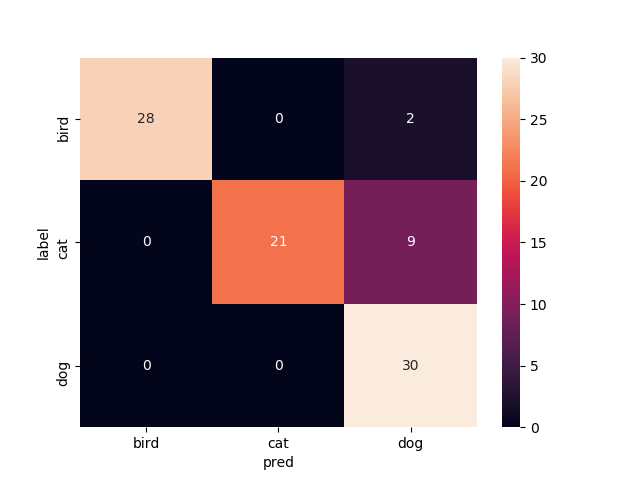
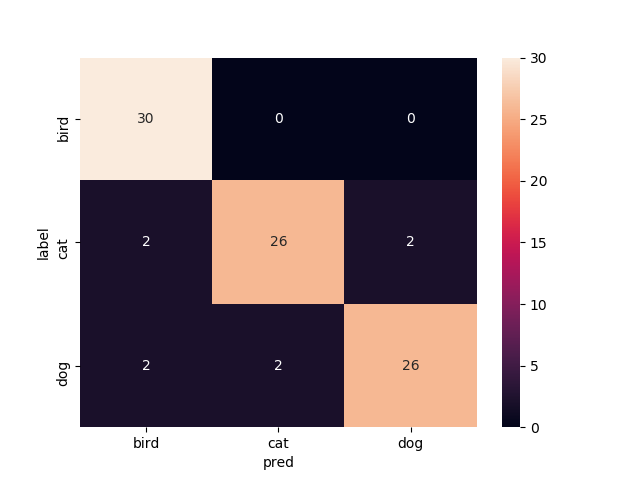
11層目以降を再学習
Mobilenetv2のweightをimagenetにし,11層目以降を再学習させたものです
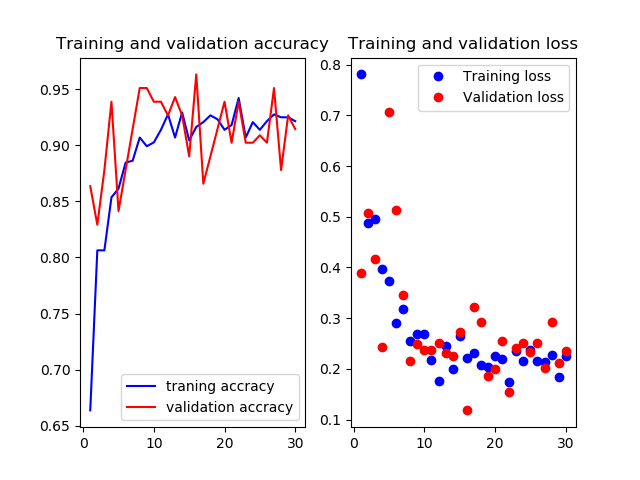
test画像での正解率は94.4%です.ここに来てまた上がった
10層目以降を再学習
Mobilenetv2のweightをimagenetにし,10層目以降を再学習させたものです
test画像での正解率は88.9%です
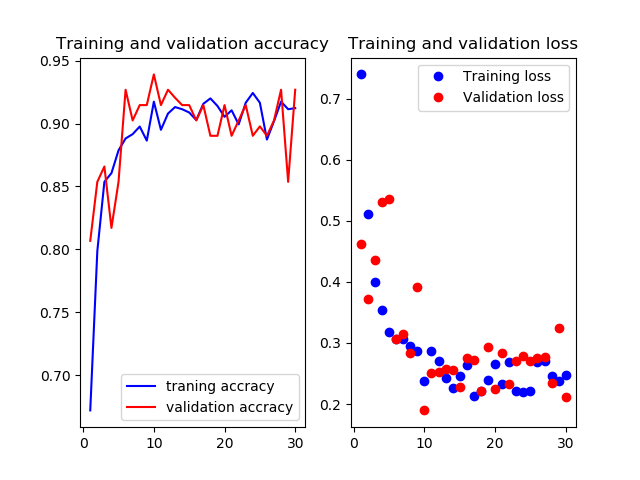
9層目以降を再学習
Mobilenetv2のweightをimagenetにし,9層目以降を再学習させたものです
test画像での正解率は92.2%です
8層目以降を再学習
Mobilenetv2のweightをimagenetにし,8層目以降を再学習させたものです
test画像での正解率92.2%です
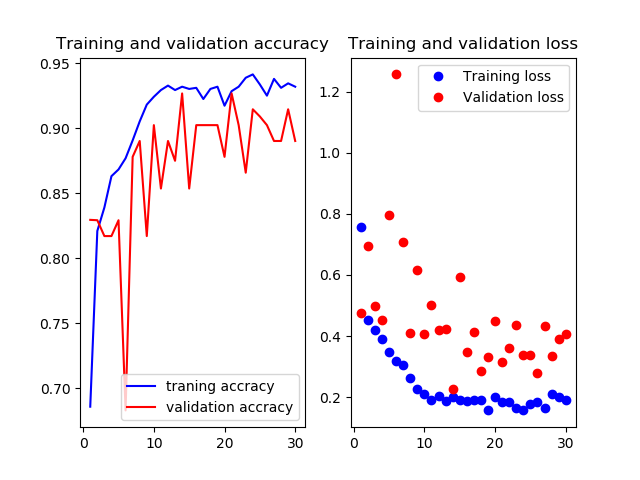
7層目以降を再学習
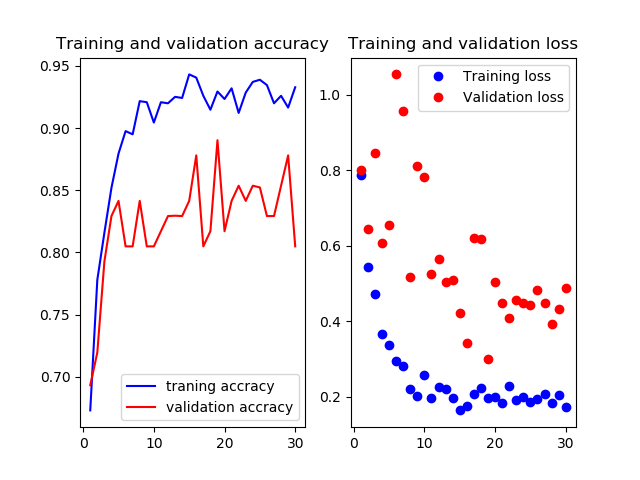
Mobilenetv2のweightをimagenetにし,7層目以降を再学習させたものです
test画像での正解率は85.6%です
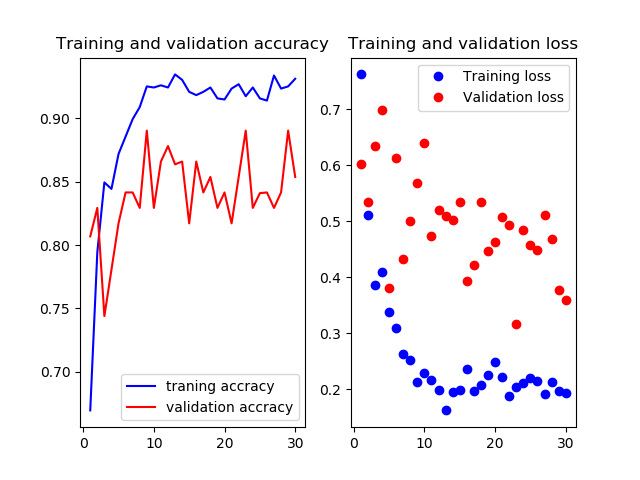
6層目以降を再学習
Mobilenetv2のweightをimagenetにし,6層目以降を再学習させたものです
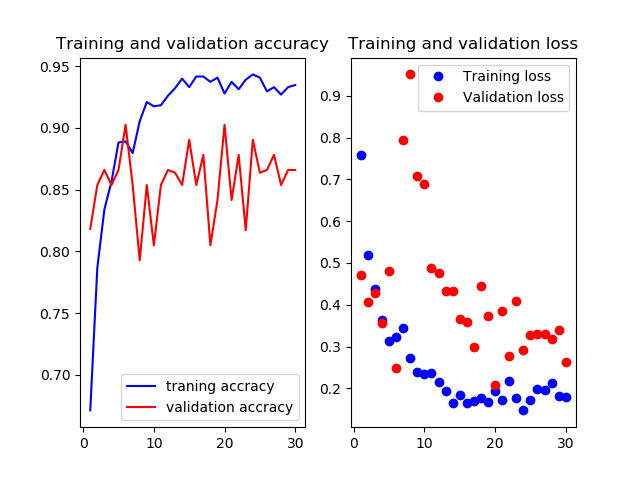
test画像での正解率は87.8%です
5層目以降を再学習
Mobilenetv2のweightをimagenetにし,5層目以降を再学習させたものです
test画像での正解率は90.0%です
4層目以降を再学習
Mobilenetv2のweightをimagenetにし,4層目以降を再学習させたものです
test画像での正解率は86.7%です
3層目以降を再学習
Mobilenetv2のweightをimagenetにし,3層目以降を再学習させたものです
test画像での正解率は88.9%です
2層目以降を再学習
Mobilenetv2のweightをimagenetにし,2層目以降を再学習させたものです
test画像での正解率は83.3%です
1層目以降を再学習
Mobilenetv2のweightをimagenetにし,1層目以降を再学習させたものです
test画像での正解率は90.0%です
全てを再学習
Mobilenetv2のweightをimagenetにし,どの層もFreezeさせずに学習してみた結果です.
test画像での正解率は91.1%です
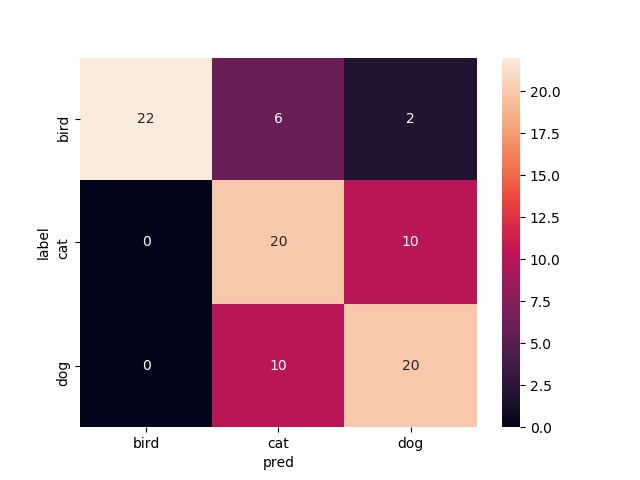
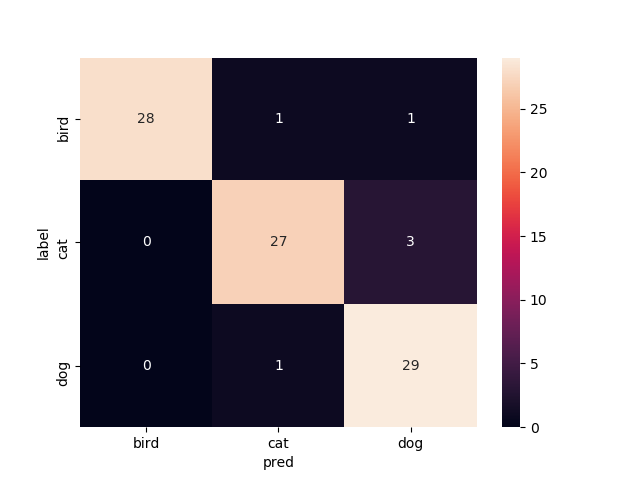
まとめ
今回の正解率だけでみると14層目以降再学習と11層目以降再学習が同点(94.4%)で良い,という結果になりました.
なんとなく終わりの層の方だけを再学習させて精度出るのがFineTuningで,前の層の方まで再学習させていくと精度悪くなっていくのかなあと思ってましたがそこまで悪くなんなかったなってのが印象です.
そもそもimagenetの重み使って学習するだけでだいぶ精度が向上するので,そんなに違いがでないってところなのかなあと思ったりしています.終わりに
正直全部結果載せるのめちゃめんどくさかっt・・・
しかしながらなんとなく,これからは14層目以降再学習のFineTuningをまず試してみようかなという指標はできました.
そういう意味ではやって良かった気がします
休みの日に余力があったらこれをスマホアプリとして実装してみたいなあなんて思っているので,これからもぼちぼちやろうと思います.

- 投稿日:2020-10-11T18:04:10+09:00
動くConvolutional VAEコード [Keras@TF2.0]
はじめに
Tensorflowが2.0となりKerasが統合されました。
参考記事 Tensorflow 2.0 with Keras
その結果、これまでkerasで書かれた畳み込み変分オートエンコーダー(Convolutional Variational Auto Encoder)のコードが動かない事情が発生しました。そこで、いくつの最新情報を集め、とりあえず動くコードを作成し、アップしておきます。
環境
tensorflow==2.1
コード
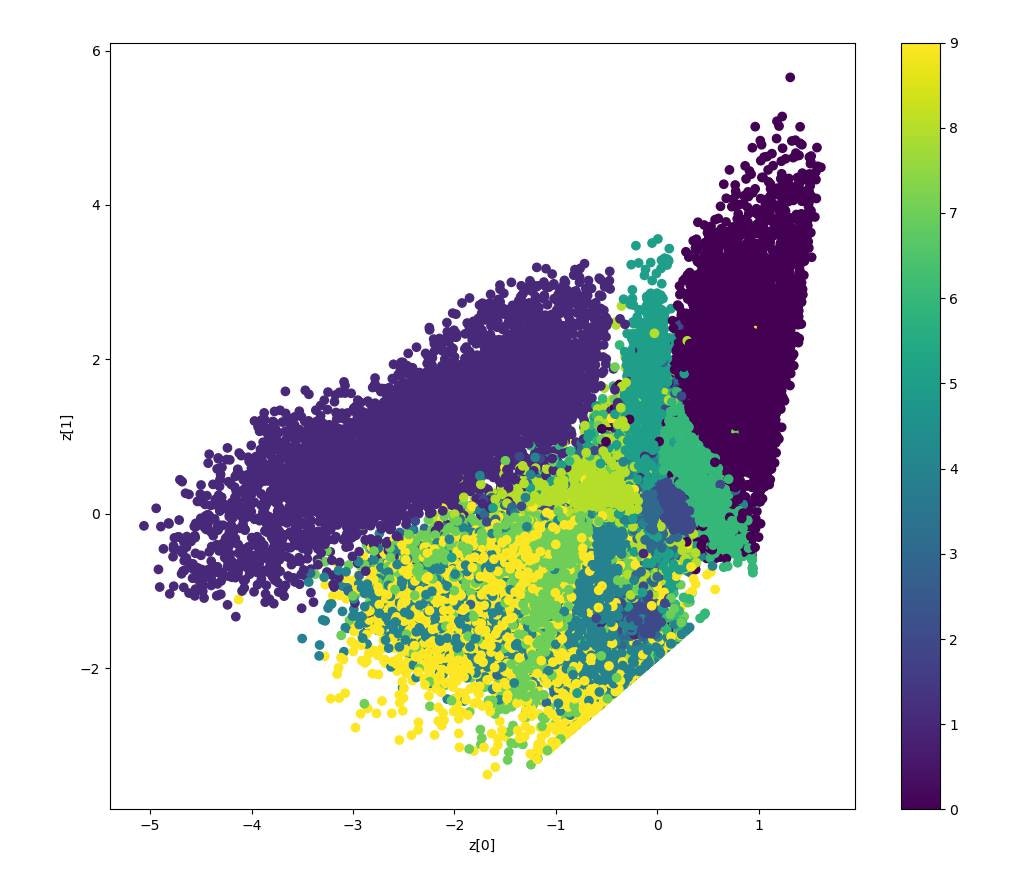
VAE_202010_tf21.pyimport tensorflow as tf import numpy as np import matplotlib.pyplot as plt from tensorflow.keras.datasets import mnist from tensorflow.keras.models import Model from tensorflow.keras.layers import Input, Dense, Lambda, Conv2D, Flatten, Conv2DTranspose, Reshape from tensorflow.keras import backend as K from tensorflow.keras import losses from tensorflow.keras.optimizers import Adam #01. Datasets (x_train, _), (x_test, _) = mnist.load_data() mnist_digits = np.concatenate([x_train, x_test], axis=0) mnist_digits = np.expand_dims(mnist_digits, -1).astype("float32") / 255 print('mnist_train',mnist_digits.shape) print('x_train',x_train.shape) #0-1正規化 x_train = x_train / 255.0 x_test = x_test / 255.0 #2 Setting Autoencoder epochs = 100 batch_size = 256 n_z = 2 # 潜在変数の数(次元数) #3 潜在変数をサンプリングするための関数 # args = [z_mean, z_log_var] def func_z_sample(args): z_mean, z_log_var = args epsilon = K.random_normal(shape=K.shape(z_log_var), mean=0, stddev=1) return z_mean + epsilon * K.exp(z_log_var/2) # VAE Network # Building the Enocoder encoder_inputs = Input(shape=(28,28,1)) x = Conv2D(32,3,activation='relu',strides=2,padding='same')(encoder_inputs) x = Conv2D(64,3,activation='relu',strides=2, padding='same')(x) x = Flatten()(x) x = Dense(16, activation='relu')(x) z_mean = Dense(n_z, name='z_mean')(x) z_log_var = Dense(n_z, name='z_log_var')(x) z = Lambda(func_z_sample, output_shape=(n_z))([z_mean, z_log_var]) encoder = Model(encoder_inputs, [z_mean, z_log_var,z], name='encoder') encoder.summary() # Building the Decoder latent_inputs = Input(shape=(n_z,)) x = Dense(7*7*64, activation='relu')(latent_inputs) x = Reshape((7,7,64))(x) x = Conv2DTranspose(64,3, activation='relu', strides=2, padding='same')(x) x = Conv2DTranspose(32,3, activation='relu', strides=2, padding='same')(x) decoder_outputs = Conv2DTranspose(1,3, activation='sigmoid', padding='same')(x) decoder = Model(latent_inputs, decoder_outputs, name='decoder') decoder.summary() class VAE(Model): def __init__(self, encoder, decoder, **kwargs): super(VAE, self).__init__(**kwargs) self.encoder = encoder self.decoder = decoder def train_step(self,data): if isinstance(data, tuple): data = data[0] with tf.GradientTape() as tape: z_mean, z_log_var, z = encoder(data) reconstruction = decoder(z) reconstruction_loss = tf.reduce_mean( losses.binary_crossentropy(data,reconstruction) ) reconstruction_loss *= 28 * 28 kl_loss = 1 + z_log_var -tf.square(z_mean) - tf.exp(z_log_var) kl_loss = tf.reduce_mean(kl_loss) kl_loss *= -0.5 total_loss = reconstruction_loss + kl_loss grads = tape.gradient(total_loss, self.trainable_weights) self.optimizer.apply_gradients(zip(grads, self.trainable_weights)) return{ "loss": total_loss, "reconstruction loss": reconstruction_loss, "kl_loss": kl_loss, } vae = VAE(encoder, decoder) vae.compile(optimizer=Adam()) vae.fit(mnist_digits, epochs=epochs, batch_size=batch_size) #Display how the latent space clusters different digit classes def plot_label_clusters(encoder, decoder, data, labels): # display a 2D plot of the digit classes in the latent space z_mean, _, _ = encoder.predict(data) plt.figure(figsize=(12, 10)) plt.scatter(z_mean[:, 0], z_mean[:, 1], c=labels) plt.colorbar() plt.xlabel("z[0]") plt.ylabel("z[1]") plt.show() (x_train, y_train), _ = mnist.load_data() x_train = np.expand_dims(x_train, -1).astype("float32") / 255 plot_label_clusters(encoder, decoder, x_train, y_train)結果
2次元の潜在空間での0~9の分布
参考資料
- 投稿日:2020-10-11T18:04:10+09:00
動くConvolutional VAEコード
はじめに
Tensorflowが2.0となりKerasが統合されました。
参考記事 Tensorflow 2.0 with Keras
その結果、これまでkerasで書かれた畳み込み変分オートエンコーダー(Convolutional Variational Auto Encoder)のコードが動かない事情が発生しました。そこで、いくつの最新情報を集め、とりあえず動くコードを作成し、アップしておきます。
環境
tensorflow==2.1
コード
VAE_202010_tf21.pyimport tensorflow as tf import numpy as np import matplotlib.pyplot as plt from tensorflow.keras.datasets import mnist from tensorflow.keras.models import Model from tensorflow.keras.layers import Input, Dense, Lambda, Conv2D, Flatten, Conv2DTranspose, Reshape from tensorflow.keras import backend as K from tensorflow.keras import losses from tensorflow.keras.optimizers import Adam #01. Datasets (x_train, _), (x_test, _) = mnist.load_data() mnist_digits = np.concatenate([x_train, x_test], axis=0) mnist_digits = np.expand_dims(mnist_digits, -1).astype("float32") / 255 print('mnist_train',mnist_digits.shape) print('x_train',x_train.shape) #0-1正規化 x_train = x_train / 255.0 x_test = x_test / 255.0 #2 Setting Autoencoder epochs = 100 batch_size = 256 n_z = 2 # 潜在変数の数(次元数) #3 潜在変数をサンプリングするための関数 # args = [z_mean, z_log_var] def func_z_sample(args): z_mean, z_log_var = args epsilon = K.random_normal(shape=K.shape(z_log_var), mean=0, stddev=1) return z_mean + epsilon * K.exp(z_log_var/2) # VAE Network # Building the Enocoder encoder_inputs = Input(shape=(28,28,1)) x = Conv2D(32,3,activation='relu',strides=2,padding='same')(encoder_inputs) x = Conv2D(64,3,activation='relu',strides=2, padding='same')(x) x = Flatten()(x) x = Dense(16, activation='relu')(x) z_mean = Dense(n_z, name='z_mean')(x) z_log_var = Dense(n_z, name='z_log_var')(x) z = Lambda(func_z_sample, output_shape=(n_z))([z_mean, z_log_var]) encoder = Model(encoder_inputs, [z_mean, z_log_var,z], name='encoder') encoder.summary() # Building the Decoder latent_inputs = Input(shape=(n_z,)) x = Dense(7*7*64, activation='relu')(latent_inputs) x = Reshape((7,7,64))(x) x = Conv2DTranspose(64,3, activation='relu', strides=2, padding='same')(x) x = Conv2DTranspose(32,3, activation='relu', strides=2, padding='same')(x) decoder_outputs = Conv2DTranspose(1,3, activation='sigmoid', padding='same')(x) decoder = Model(latent_inputs, decoder_outputs, name='decoder') decoder.summary() class VAE(Model): def __init__(self, encoder, decoder, **kwargs): super(VAE, self).__init__(**kwargs) self.encoder = encoder self.decoder = decoder def train_step(self,data): if isinstance(data, tuple): data = data[0] with tf.GradientTape() as tape: z_mean, z_log_var, z = encoder(data) reconstruction = decoder(z) reconstruction_loss = tf.reduce_mean( losses.binary_crossentropy(data,reconstruction) ) reconstruction_loss *= 28 * 28 kl_loss = 1 + z_log_var -tf.square(z_mean) - tf.exp(z_log_var) kl_loss = tf.reduce_mean(kl_loss) kl_loss *= -0.5 total_loss = reconstruction_loss + kl_loss grads = tape.gradient(total_loss, self.trainable_weights) self.optimizer.apply_gradients(zip(grads, self.trainable_weights)) return{ "loss": total_loss, "reconstruction loss": reconstruction_loss, "kl_loss": kl_loss, } vae = VAE(encoder, decoder) vae.compile(optimizer=Adam()) vae.fit(mnist_digits, epochs=epochs, batch_size=batch_size) #Display how the latent space clusters different digit classes def plot_label_clusters(encoder, decoder, data, labels): # display a 2D plot of the digit classes in the latent space z_mean, _, _ = encoder.predict(data) plt.figure(figsize=(12, 10)) plt.scatter(z_mean[:, 0], z_mean[:, 1], c=labels) plt.colorbar() plt.xlabel("z[0]") plt.ylabel("z[1]") plt.show() (x_train, y_train), _ = mnist.load_data() x_train = np.expand_dims(x_train, -1).astype("float32") / 255 plot_label_clusters(encoder, decoder, x_train, y_train)結果
2次元の潜在空間での0~9の分布
参考資料
- 投稿日:2020-10-11T17:58:51+09:00
【python】二次元系 点図形内外問題
考え方はこちらをクリック
環境
python3.7
問題
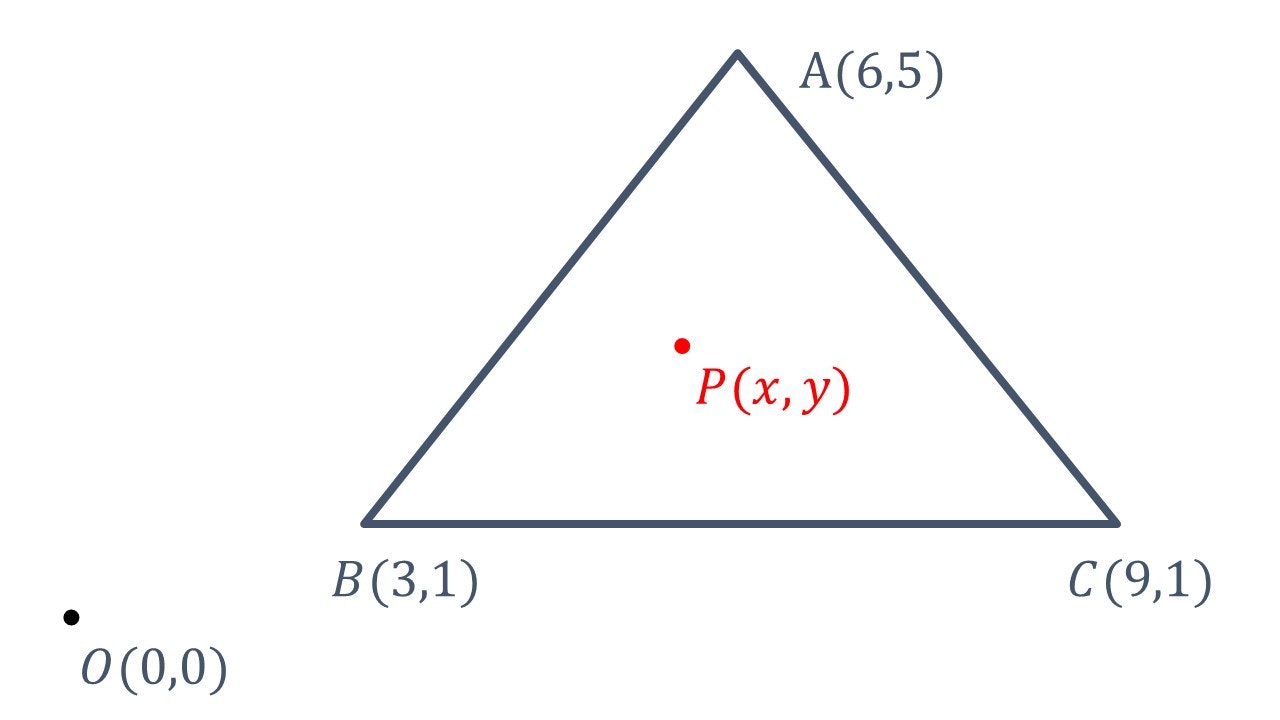
以下のような図の点Pが図形の中か外かを計算する。
O(0,0)は原点を表している。また、A(2,2)、B(3,1)、C(3,3)は図形の頂点を表している。P(x,y)は任意の点である。
計算
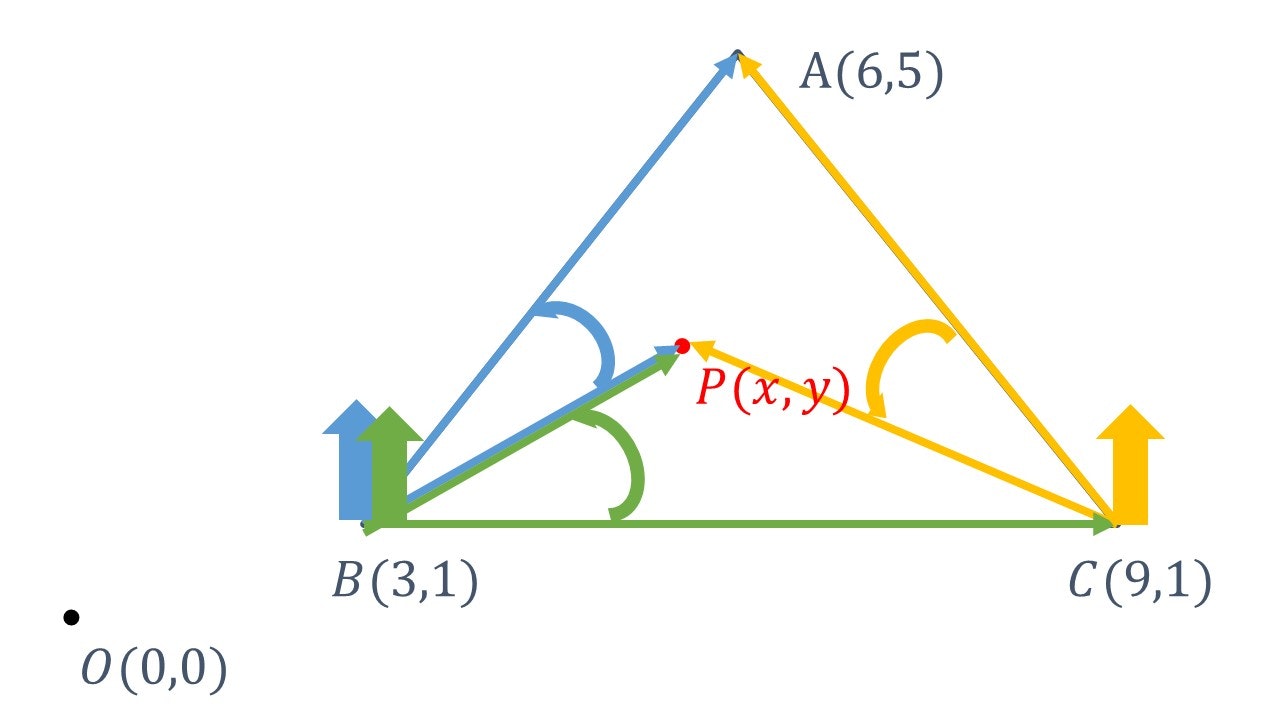
下図のように外積の向きが同じになるように計算する。
座標の定義↓
import numpy #点Aの座標 A = numpy.array((6, 5)) #点Bの座標 B = numpy.array((3, 1)) #点Cの座標 C = numpy.array((9, 1))外積計算↓
#点Pが図形の中にあるかどうか def p(x, y): #点Pの座標 P = numpy.array((x, y)) #ベクトルBPとベクトルBAの外積 abp = numpy.outer(P-B, A-B) #ベクトルBCとベクトルBPの外積 pbc = numpy.outer(C-B, P-B) #ベクトルCAとベクトルCPの外積 apc = numpy.outer(A-C, P-C) #ベクトルBPとベクトルBAの外積の行列式 abp = numpy.linalg.det(abp) #ベクトルBCとベクトルBPの外積の行列式 pbc = numpy.linalg.det(pbc) #ベクトルCAとベクトルCPの外積の行列式 apc = numpy.linalg.det(apc) #ベクトルBPとベクトルBAの外積の行列式が他の行列式の符号と一致したら、Trueを返す if numpy.sign(abp)==numpy.sign(pbc) and numpy.sign(abp)==numpy.sign(pbc): return True #ベクトルBPとベクトルBAの外積の行列式が他の行列式の符号と一致しなかったら、Falseを返す else: return Falseすべてのコードと結果
コード
code.pyimport numpy #点Aの座標 A = numpy.array((6, 5)) #点Bの座標 B = numpy.array((3, 1)) #点Cの座標 C = numpy.array((9, 1)) #点Pが図形の中にあるかどうか def p(x, y): #点Pの座標 P = numpy.array((x, y)) #ベクトルBPとベクトルBAの外積 abp = numpy.outer(P-B, A-B) #ベクトルBCとベクトルBPの外積 pbc = numpy.outer(C-B, P-B) #ベクトルCAとベクトルCPの外積 apc = numpy.outer(A-C, P-C) #ベクトルBPとベクトルBAの外積の行列式 abp = numpy.linalg.det(abp) #ベクトルBCとベクトルBPの外積の行列式 pbc = numpy.linalg.det(pbc) #ベクトルCAとベクトルCPの外積の行列式 apc = numpy.linalg.det(apc) #ベクトルBPとベクトルBAの外積の行列式が他の行列式の符号と一致したら、Trueを返す if numpy.sign(abp)==numpy.sign(pbc) and numpy.sign(abp)==numpy.sign(pbc): return True #ベクトルBPとベクトルBAの外積の行列式が他の行列式の符号と一致しなかったら、Falseを返す else: return False print(p(3, 1))#出力結果:True print(p(2, 2))#出力結果:True print(p(8,14))#出力結果:False補足
点Pを線上にあるとした時、点Pは図形の中にあるものとして計算している。
- 投稿日:2020-10-11T17:17:29+09:00
HR図をastroqueryを用いて簡単にプロットする方法
HR図とastroquery
ヘルツシュプルング・ラッセル図(通称HR図)を astroquery という宇宙天文のデータベースを用いてプロットする手法を用いて簡単にプロットを紹介する。苦手意識がある人もとりあえずプロットしてみる親しみが沸くこともあるだろう。
コードだけあればOKな人は、google Colab のページを参照されたい。
astroquery の install
pip install astroqueryで、astroquery を入れる。
astroquery を用いてデータを取得
データはVizierというデータベースから、
にあるヒッパルコス衛星のデータを使う。
from astroquery.vizier import Vizier v = Vizier(catalog="I/239/hip_main",columns=['HIP',"Vmag","B-V","Plx"],row_limit=-1) data = v.query_constraints() vmag = data[0]["Vmag"] bv = data[0]["B-V"] plx = data[0]["Plx"]必要なのは、3つだけ。
- Vmag : Vバンドの輝度
- BV : BバンドとVバンドの明るさの比 (B-Vと書くが等級はログなので比であることに注意。)
- plx : 年周視差。単に距離の情報が必要なだけ。近傍の星は三角測量で距離を測定しているので、annual parallax から距離に変換する。
である。
オプションの意味は、catalog="I/239/hip_main" でカタログを指定して、columns=['HIP',"Vmag","B-V","Plx"] でコラムを指定して、row_limit=-1 で上限を外してデータを全部取得する。
HR図を作成
年周視差が、20 ~ 25 mili arcsec (つまり、距離で 40-50 pc 程度)の星についてプロットしてみる。
def to_parsec(marcsec): return 1./(1e-3*marcsec) # pc pmin=20 # m arcsec pmax=25 # m arcsec dmax = to_parsec(pmin) dmin = to_parsec(pmax) dlabel = str("%3.1f" % dmin) + " pc to " + str("%3.1f" % dmax) + " pc" print (dlabel) vmag_cut = vmag[ (plx > pmin) & (plx < pmax)] bv_cut = bv [ (plx > pmin) & (plx < pmax)] from matplotlib import pyplot as plt plt.title(dlabel) plt.xlim(-0.1,2) plt.ylim(-13,0) plt.xlabel("B-V") plt.ylabel("Vmag") plt.scatter(bv_cut, -vmag_cut, s=1)とすると、
このようにHR図がかける。
関連ページ
- 投稿日:2020-10-11T16:56:11+09:00
PySpark/SparkMLでTitanicしてみる【Kaggle】
TL;DR
Kaggleの"Hello world!"的位置付けのコンペである "Titanic: Machine Learning from Disaster" に、Python機械学習で定番のpandasやscikit-learnといったライブラリを使わず、あえてPySparkのみでSubmissionまでしてみようというもの。
実行環境
- macOS X Catalina 10.15.6
- Jupyter Lab : 2.2.8
- Spark : 2.4.4
ライブラリの読み込み
Inimport os, sys import datetime import numpy as np import warnings warnings.simplefilter('ignore') from pyspark.sql import SparkSession from pyspark.sql import functions as F from pyspark.sql.types import IntegerType from pyspark.ml import Pipeline from pyspark.ml.feature import StringIndexer, VectorIndexer from pyspark.ml.feature import VectorAssembler from pyspark.ml.classification import RandomForestClassifier from pyspark.ml.tuning import ParamGridBuilder, TrainValidationSplit from pyspark.ml.evaluation import BinaryClassificationEvaluator from pyspark.ml.evaluation import MulticlassClassificationEvaluatorSparkSessionインスタンスの生成
SparkSessionインスタンスを生成する。環境変数
SPARK_HOMEは事前に設定しておく。
Py4jのバージョンは環境に合わせて適宜読み替える。Inspark_home = os.environ.get('SPARK_HOME', None) sys.path.insert(0, spark_home + '/python') sys.path.insert(0, os.path.join(spark_home, 'python/lib/py4j-<version>-src.zip')) spark = SparkSession.builder.appName('Titanic').getOrCreate()データの読み込み・前処理
Kaggle のページからダウンロードしたデータを PySpark の DataFrameに読み込む。
header=Trueで先頭行をヘッダーとして読み込む。inferSchema=Trueでデータ型をよしなに推定してくれる。Intrain = spark.read.csv('data/train.csv', header=True, inferSchema=True) test = spark.read.csv('data/test.csv', header=True, inferSchema=True)trainの各フィールドのデータ型を確認する。数値データがintやdoubleとして認識されている。
Intrain.dtypesOut[('PassengerId', 'int'), ('Survived', 'int'), ('Pclass', 'int'), ('Name', 'string'), ('Sex', 'string'), ('Age', 'double'), ('SibSp', 'int'), ('Parch', 'int'), ('Ticket', 'string'), ('Fare', 'double'), ('Cabin', 'string'), ('Embarked', 'string')]train, testそれぞれのデータサイズを確認する。(pandasの
.shapeのようなものは用意されていない。多分)Inprint(train.count(), len(train.columns)) print(test.count(), len(test.columns))Out891 12 418 11pandasの
.describe()にあたる関数がPySparkにも用意されている。データ型がString型のフィールドも平均や標準偏差はnullとなって表示される。(pandasでは省略される)Intrain.describe().show()Out+-------+-----------------+-------------------+------------------+--------------------+------+------------------+------------------+-------------------+------------------+-----------------+-----+--------+ |summary| PassengerId| Survived| Pclass| Name| Sex| Age| SibSp| Parch| Ticket| Fare|Cabin|Embarked| +-------+-----------------+-------------------+------------------+--------------------+------+------------------+------------------+-------------------+------------------+-----------------+-----+--------+ | count| 891| 891| 891| 891| 891| 714| 891| 891| 891| 891| 204| 889| | mean| 446.0| 0.3838383838383838| 2.308641975308642| null| null| 29.69911764705882|0.5230078563411896|0.38159371492704824|260318.54916792738| 32.2042079685746| null| null| | stddev|257.3538420152301|0.48659245426485753|0.8360712409770491| null| null|14.526497332334035|1.1027434322934315| 0.8060572211299488|471609.26868834975|49.69342859718089| null| null| | min| 1| 0| 1|"Andersson, Mr. A...|female| 0.42| 0| 0| 110152| 0.0| A10| C| | max| 891| 1| 3|van Melkebeke, Mr...| male| 80.0| 8| 6| WE/P 5735| 512.3292| T| S| +-------+-----------------+-------------------+------------------+--------------------+------+------------------+------------------+-------------------+------------------+-----------------+-----+--------+欠損値の処理
各フィールドの欠損値の個数を確認する。pandasに比べるとやや煩雑。
Intrain.select([F.count(F.when(F.isnull(col), col)).alias(col) for col in train.columns]).show()Out+-----------+--------+------+----+---+---+-----+-----+------+----+-----+--------+ |PassengerId|Survived|Pclass|Name|Sex|Age|SibSp|Parch|Ticket|Fare|Cabin|Embarked| +-----------+--------+------+----+---+---+-----+-----+------+----+-----+--------+ | 0| 0| 0| 0| 0|177| 0| 0| 0| 0| 687| 2| +-----------+--------+------+----+---+---+-----+-----+------+----+-----+--------+数値型のフィールドとしては年齢(Age)にnullが存在するので、これをとりあえず平均年齢に置き換える。
stats = train.agg(F.avg('Age').alias('Age')) age_avg = stats.first()[0] train = train.na.fill({'Age': age_avg})その他の欠損値はすべてString型のフィールドに存在しているので、データと被らない適当な文字列で置き換える。
Intrain = train.na.fill('nodata')DataFrameの中身と欠損値の数を確認する。
Intrain.show(5)Out+-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+------+--------+ |PassengerId|Survived|Pclass| Name| Sex| Age|SibSp|Parch| Ticket| Fare| Cabin|Embarked| +-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+------+--------+ | 1| 0| 3|Braund, Mr. Owen ...| male|22.0| 1| 0| A/5 21171| 7.25|nodata| S| | 2| 1| 1|Cumings, Mrs. Joh...|female|38.0| 1| 0| PC 17599|71.2833| C85| C| | 3| 1| 3|Heikkinen, Miss. ...|female|26.0| 0| 0|STON/O2. 3101282| 7.925|nodata| S| | 4| 1| 1|Futrelle, Mrs. Ja...|female|35.0| 1| 0| 113803| 53.1| C123| S| | 5| 0| 3|Allen, Mr. Willia...| male|35.0| 0| 0| 373450| 8.05|nodata| S| +-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+------+--------+ only showing top 5 rowsIntrain.select([F.count(F.when(F.isnull(col), col)).alias(col) for col in train.columns]).show()Out+-----------+--------+------+----+---+---+-----+-----+------+----+-----+--------+ |PassengerId|Survived|Pclass|Name|Sex|Age|SibSp|Parch|Ticket|Fare|Cabin|Embarked| +-----------+--------+------+----+---+---+-----+-----+------+----+-----+--------+ | 0| 0| 0| 0| 0| 0| 0| 0| 0| 0| 0| 0| +-----------+--------+------+----+---+---+-----+-----+------+----+-----+--------+このあたりで、今回の分析に利用しない特徴量をDataFrameからdropしておく。
Intrain = train.drop('Name') train = train.drop('Ticket') train = train.drop('Cabin') train.show(5)Out+-----------+--------+------+------+----+-----+-----+-------+--------+ |PassengerId|Survived|Pclass| Sex| Age|SibSp|Parch| Fare|Embarked| +-----------+--------+------+------+----+-----+-----+-------+--------+ | 1| 0| 3| male|22.0| 1| 0| 7.25| S| | 2| 1| 1|female|38.0| 1| 0|71.2833| C| | 3| 1| 3|female|26.0| 0| 0| 7.925| S| | 4| 1| 1|female|35.0| 1| 0| 53.1| S| | 5| 0| 3| male|35.0| 0| 0| 8.05| S| +-----------+--------+------+------+----+-----+-----+-------+--------+ only showing top 5 rowsカテゴリカル変数の変換
予測に使用する説明変数の中で性別(Sex)と乗船港(Embarked)がカテゴリカル変数になっているので、これらを数値データに変換していく。scikit-learnではLabelEncoderを使用すれば良いが、PySparkではStringIndexerを用いて同様の処理を実現できる。
In# Sex Indexing SexIndexer = StringIndexer(inputCol='Sex', outputCol='IndexSex') SexIndexer = SexIndexer.fit(train) train = SexIndexer.transform(train) train = train.drop('Sex') # Embarked Indexing EmbarkedIndexer = StringIndexer(inputCol='Embarked', outputCol='IndexEmbarked') EmbarkedIndexer = EmbarkedIndexer.fit(train) train = EmbarkedIndexer.transform(train) train = train.drop('Embarked')モデル訓練時に、ラベルに対してlabelというフィールド名が必要なので、目的変数であるSurvivedに対してもIndexingする。
InLabelIndexer = StringIndexer(inputCol='Survived', outputCol='label') LabelIndexer = LabelIndexer.fit(train) train = LabelIndexer.transform(train) train = train.drop('Survived')説明変数ベクトルの作成
scikit-learnではモデル訓練に際してDataFrameごと説明変数として入力するが、PySparkではデータフィールドの中から説明変数を指定する形で入力する。そのため、説明変数を一つのデータフィールドにベクトルとして格納する。
ベクトル化にはPySparkの提供するVectorAssemblerを使用する。ラベル込みのデータフレームなので、ここでは変数名をXyとしておく。InfeatureCols = train.columns featureCols.remove('PassengerId') featureCols.remove('label') print(featureCols)Out['Pclass', 'Age', 'SibSp', 'Parch', 'Fare', 'IndexSex', 'IndexEmbarked']Inassembled_feature = VectorAssembler(inputCols=featureCols, outputCol='features') pipline = Pipeline(stages=[assembled_feature]) pipline = pipline.fit(train) Xy = pipline.transform(train) Xy.select('features').show(5)Out+--------------------+ | features| +--------------------+ |[3.0,22.0,1.0,0.0...| |[1.0,38.0,1.0,0.0...| |[3.0,26.0,0.0,0.0...| |[1.0,35.0,1.0,0.0...| |(7,[0,1,4],[3.0,3...| +--------------------+ only showing top 5 rowsデータ分割
モデルの訓練用と検証用にデータを分割する。(scikit-learnでいうところのtrain_test_split)
InXy_train, Xy_valid = Xy.randomSplit([0.8, 0.2])それぞれのデータサイズを確認する。
Inprint(Xy_train.count(), len(Xy_train.columns)) print(Xy_valid.count(), len(Xy_valid.columns))Out716 10 175 10モデルの定義・訓練
ここではRandomForestで訓練・予測を行うので、PySparkの提供するものを使用する。
ParamGridBuilder, TrainValidationSplitを使用することでハイパーパラメータのグリッドサーチを行うことができる。(scikit-learnでいうところのGridSearchCV)Inrfc = RandomForestClassifier( labelCol='label', featuresCol='features', seed=42) paramGrid = ParamGridBuilder()\ .addGrid(rfc.numTrees, [20, 50, 100])\ .addGrid(rfc.maxDepth, range(3, 10))\ .build() tvs = TrainValidationSplit(estimator=rfc, estimatorParamMaps=paramGrid, evaluator=BinaryClassificationEvaluator(), trainRatio=0.8)scikit-learn同様、
.fit()で定義したモデルの訓練を行う。Inmodel = tvs.fit(Xy_train)モデルの評価
検証用に作成したXy_validを用いてモデルの精度(Accuracy)を算出していく。
Inresults = model.transform(Xy_valid) results.show(5)Out+-----------+------+-----------------+-----+-----+----+--------+-------------+-----+--------------------+--------------------+--------------------+----------+ |PassengerId|Pclass| Age|SibSp|Parch|Fare|IndexSex|IndexEmbarked|label| features| rawPrediction| probability|prediction| +-----------+------+-----------------+-----+-----+----+--------+-------------+-----+--------------------+--------------------+--------------------+----------+ | 4| 1| 35.0| 1| 0|53.1| 1.0| 0.0| 1.0|[1.0,35.0,1.0,0.0...|[0.23165745048233...|[0.00231657450482...| 1.0| | 18| 2|29.69911764705882| 0| 0|13.0| 0.0| 0.0| 1.0|(7,[0,1,4],[2.0,2...|[90.7208293296858...|[0.90720829329685...| 0.0| | 21| 2| 35.0| 0| 0|26.0| 0.0| 0.0| 0.0|(7,[0,1,4],[2.0,3...|[91.7482262785935...|[0.91748226278593...| 0.0| | 24| 1| 28.0| 0| 0|35.5| 0.0| 0.0| 1.0|(7,[0,1,4],[1.0,2...|[54.9648092296785...|[0.54964809229678...| 0.0| | 33| 3|29.69911764705882| 0| 0|7.75| 1.0| 2.0| 1.0|[3.0,29.699117647...|[19.2563286505712...|[0.19256328650571...| 1.0| +-----------+------+-----------------+-----+-----+----+--------+-------------+-----+--------------------+--------------------+--------------------+----------+ only showing top 5 rows予測結果のデータフレームを確認すると、rawPrediction, probability, predictionといったデータフィールドが追加されている。labelとpredictionを並べると、それなりに予測できていることが確認できる。
Inresults.select('label', 'prediction').show()Out+-----+----------+ |label|prediction| +-----+----------+ | 1.0| 1.0| | 1.0| 0.0| | 0.0| 0.0| | 1.0| 0.0| | 1.0| 1.0| | 0.0| 1.0| | 1.0| 0.0| | 1.0| 1.0| | 1.0| 1.0| | 1.0| 1.0| | 0.0| 0.0| | 1.0| 1.0| | 0.0| 0.0| | 0.0| 0.0| | 0.0| 0.0| | 0.0| 0.0| | 0.0| 0.0| | 0.0| 0.0| | 1.0| 0.0| | 0.0| 0.0| +-----+----------+ only showing top 20 rowsMulticlassClassificationEvaluatorでAccuracyの計算を行う。(BinaryClassificationEvaluatorではmetricNameに'accuracy'を指定できないっぽい)
InMultiEvaluator = MulticlassClassificationEvaluator( labelCol = 'label', predictionCol = 'prediction', metricName = 'accuracy', ) acc = MultiEvaluator.evaluate(results) print(acc)Out0.8114285714285714まずまずの精度なのでテストデータで予測を行っていく。
テストデータによる予測
特徴量ベクトルの作成
訓練用データと同じ要領で特徴量ベクトル
X_testを作成していく。Intest.select([F.count(F.when(F.isnull(col), col)).alias(col) for col in test.columns]).show()Out+-----------+------+----+---+---+-----+-----+------+----+-----+--------+ |PassengerId|Pclass|Name|Sex|Age|SibSp|Parch|Ticket|Fare|Cabin|Embarked| +-----------+------+----+---+---+-----+-----+------+----+-----+--------+ | 0| 0| 0| 0| 86| 0| 0| 0| 1| 327| 0| +-----------+------+----+---+---+-----+-----+------+----+-----+--------+テストデータでは運賃(Fare)にも欠損値が存在するので、年齢(Age)と合わせて平均値と置き換える。
Instats = test.agg(F.avg('Age').alias('Age')) age_avg = stats.first()[0] test = test.na.fill({'Age': age_avg}) stats = test.agg(F.avg('Fare').alias('Fare')) fare_avg = stats.first()[0] test = test.na.fill({'Fare': fare_avg})利用しないデータフィールドをdropする。
Intest = test.drop('Name') test = test.drop('Ticket') test = test.drop('Cabin')訓練データで生成したIndexerを用いて、カテゴリカル変数を数値化する。
In# Sex Indexing test = SexIndexer.transform(test) test = test.drop('Sex') # Embarked Indexing test = EmbarkedIndexer.transform(test) test = test.drop('Embarked')訓練データで生成したPipelineで特徴量ベクトルを作成する。
InX_test = pipline.transform(test) X_test.select('features').show(5)Out+--------------------+ | features| +--------------------+ |[3.0,34.5,0.0,0.0...| |[3.0,47.0,1.0,0.0...| |[2.0,62.0,0.0,0.0...| |(7,[0,1,4],[3.0,2...| |[3.0,22.0,1.0,1.0...| +--------------------+ only showing top 5 rows予測、ファイル書き出し
提出ファイルの様式に合わせて、予測値をint型にキャストした上でデータフィールド名をSurvivedとする。
Insubmission = model.transform(X_test) submission = submission.withColumn('Survived', submission['prediction'].cast('int')) submission = submission.select('PassengerId', 'Survived') submission.show(5)Out+-----------+--------+ |PassengerId|Survived| +-----------+--------+ | 892| 0| | 893| 0| | 894| 0| | 895| 0| | 896| 0| +-----------+--------+ only showing top 5 rowscsv形式でファイルに書き出す。
Innow = datetime.datetime.now() timestamp = now.strftime('%Y%m%d-%H%M%S') submission.write.option('header', 'true').csv('output/pyspark-rfc_{}.csv'.format(timestamp))提出?
- 投稿日:2020-10-11T16:52:00+09:00
TensorBoard 2.2.1 at http://localhost:6006/
$ tensorboard --logdir ./resultsと打ち、
TensorBoard 2.2.1 at http://localhost:6006/ (Press CTRL+C to quit)が出力されたが、
http://localhost:6006/でtensorboardが見れないとき
- 投稿日:2020-10-11T13:37:29+09:00
YouTube 動画コメント、リプライ含めて全部読む
YouTube動画のリプライ含めた全コメントをpythonスクリプトで取得してみた
YouTube動画コメント読めない問題
YouTube動画で、時々異様にたくさんのコメントがついてるものがありますが、これをブラウザやアプリから読もうと頑張ると
止まる。
ぴたっと止まります。PCなめんなと久々に火を入れてもブラウザがぴたりと止まります。
YouTube API/スクリプトで読んでみる
そういうときにYouTube APIという便利なものがあるらしく、すでに公開されているスクリプトも多数あります。が、コメントリプライまで全部取得できるものは見つけられなかったので、リプライ含めて全コメントを取得できるようにしてみました。
スクリプト
getComments.pyimport datetime import json import requests URL = 'https://www.googleapis.com/youtube/v3/' API_KEY = 'xxx' VIDEO_ID = 'yyy' def get_video_comment(video_id, n): try: next_page_token except NameError: params = { 'key': API_KEY, 'part': 'replies, snippet', 'videoId': VIDEO_ID, 'order': 'time', 'textFormat': 'plaintext', 'maxResults': n, } else: params = { 'key': API_KEY, 'part': 'replies, snippet', 'videoId': VIDEO_ID, 'order': 'time', 'textFormat': 'plaintext', 'pageToken': next_page_token, 'maxResults': n, } response = requests.get(URL + 'commentThreads', params=params) resource = response.json() return resource def print_video_comment_replies(match): for comment_info in match['items']: author = comment_info['snippet']['authorDisplayName'] pubdate = comment_info['snippet']['publishedAt'] text = comment_info['snippet']['textDisplay'] pubdate = datetime.datetime.strptime(pubdate, '%Y-%m-%dT%H:%M:%SZ') pubdate = pubdate.strftime("%Y/%m/%d %H:%M:%S") print('\t___________________________________________\n') print("\n\tReply :\n\t{}\n\n\tby: {} date: {}".format(text, author, pubdate), "\n") def print_video_comment(match): global parentId for comment_info in match['items']: parentId = comment_info['id'] author = comment_info['snippet']['topLevelComment']['snippet']['authorDisplayName'] pubdate = comment_info['snippet']['topLevelComment']['snippet']['publishedAt'] text = comment_info['snippet']['topLevelComment']['snippet']['textDisplay'] like_cnt = comment_info['snippet']['topLevelComment']['snippet']['likeCount'] reply_cnt = comment_info['snippet']['totalReplyCount'] pubdate = datetime.datetime.strptime(pubdate, '%Y-%m-%dT%H:%M:%SZ') pubdate = pubdate.strftime("%Y/%m/%d %H:%M:%S") print('---------------------------------------------------\n') print('{}\n\n by: {} date: {} good: {} reply: {}\n'.format(text, author, pubdate, like_cnt, reply_cnt)) if reply_cnt > 0: replyMatch = treat_reply(match) print_video_comment_replies(replyMatch) global reply_next_page_token try: reply_next_page_token = replyMatch["nextPageToken"] except KeyError: pass else: while 'reply_next_page_token' in globals(): replyMatch = treat_reply(match) print_video_comment_replies(replyMatch) try: reply_next_page_token = replyMatch["nextPageToken"] except KeyError: reply_next_page_token = None del reply_next_page_token reply_next_page_token = None del reply_next_page_token def treat_reply(match): for comment_info in match['items']: try: comment_info['replies'] except KeyError: pass else: try: reply_next_page_token except NameError: params = { 'key': API_KEY, 'part': 'id, snippet', 'parentId': parentId, 'textFormat': 'plaintext', 'maxResults': 100, 'order': 'time', } else: params = { 'key': API_KEY, 'part': 'id, snippet', 'parentId': parentId, 'textFormat': 'plaintext', 'maxResults': 100, 'order': 'time', 'pageToken': reply_next_page_token, } response = requests.get(URL + 'comments', params=params) resource = response.json() return resource # Main key = None while 'key' in locals(): match = get_video_comment(VIDEO_ID, 100) print_video_comment(match) try: next_page_token = match["nextPageToken"] except KeyError: next_page_token = None del next_page_token del keyスクリプト内の変数API_KEYとVIDEO_IDはそれぞれ適当に設定してください。VIDEO_IDは動画URLのアレです。
ポイント
- コメントはCommentThreadsで取得
- コメントリプライはCommentsで取得
しているところです。まぁマニュアルに書いてある通りなんですが・・・・
https://developers.google.com/youtube/v3/docs/commentThreads#resource
To retrieve all of the replies for the top-level comment, you need to call the comments.list method and use the parentId request parameter to identify the comment for which you want to retrieve replies.
コメント->コメントリプライの切り替えはできたらmain処理のなかでやりたかったのですが、そうするためにはCommentThreadsのパラメータmaxResultsを1にするしか私には思いつかず、それはそれでコメント数分のAPI発行をするという馬鹿げた(というか場合によっては十分怒られる)ことになってしまいますので、print_video_comment()内で更にコメントリプライ用関数を呼び出すというちょっとイマイチな構造になってます。
変数reply_next_page_tokenは関数間で使い回すので、global宣言が必要です。(最初気づかずハマりました。)その他
変数有無の確認方法がスクリプト内で統一されてないですが気にしないでください・・・・
参考
API Reference - CommentThreads
API Reference - Comments
Youtube のコメントを取得する in Python
- 投稿日:2020-10-11T13:00:31+09:00
word2vecで学習済みのベクトルをLSTMのEmbedding層で利用する
はじめに
word2vecのベクトルをseq2seqなどのembedding層などで利用したいと思い、word2vecの役立つ関数などについてまとめました。例では、東北大の学習済みベクトル( http://www.cl.ecei.tohoku.ac.jp/~m-suzuki/jawiki_vector/ )を利用した方法で解説していきます。
モデル読み込み
まずはモデルを読み込みます。model_dirにはダウンロードした(entity_vector.model.bin)のパスを入れてください。
from gensim.models import KeyedVectors model_dir = 'entity_vector.model.bin のパス' model = KeyedVectors.load_word2vec_format(model_dir, binary=True)ベクトルの出力
単語のベクトルは以下のように取得することが可能です。
print(model['私'])出力[-0.9154563 0.97780323 -0.43780354 -0.6441212 -1.6350892 0.8619687 0.41775486 -1.094953 0.74489385 -1.6742945 -0.34408432 0.5552686 -3.9321985 0.3369842 1.5550056 1.3112832 -0.64914817 0.5996928 1.6174266 0.8126016 -0.75741744 1.7818885 2.1305397 1.8607832 3.0353768 -0.8547809 -0.87280065 -0.54103154 0.752979 3.8159864 -1.4066186 0.78604376 1.2102902 3.9960158 2.9654515 -2.6870391 -1.3829899 0.993459 0.86303824 0.29373714 4.0691266 -1.4974884 -1.5601915 1.4936608 0.550254 2.678553 0.53790915 -1.7294457 -0.46390963 -0.34776476 -1.2361934 -2.433244 -0.21348757 0.0488718 0.8197853 -0.59188586 1.7276062 0.9713122 -0.06519659 2.4763248 -0.93890053 0.36217824 1.887851 -0.0175399 -0.21866432 -0.81253886 -3.9667509 2.5340643 0.02985824 0.338091 -1.3745826 -2.3509336 -1.5615206 0.8273324 -1.263886 -1.2259561 0.9079302 2.0258994 -0.8576754 -2.5492477 -2.45557 -0.5216256 -1.3474834 2.3590422 1.0459667 2.0919168 1.6904455 1.7064931 0.7376105 0.2567448 -0.8194208 0.8788849 -0.89287275 -0.22960001 1.8320689 -1.7200342 0.8977642 1.5119879 -0.3325551 0.7429934 -1.2087826 0.5350336 -0.03887295 -1.9642036 1.0406445 -0.80972534 0.49987233 2.419521 -0.30317742 0.96494234 0.6184119 1.2633535 2.688754 -0.7226699 -2.8695397 -0.8986926 0.1258761 -0.75310475 1.099076 0.90656924 0.24586082 0.44014114 0.85891217 0.34273988 0.07071286 -0.71412176 1.4705397 3.6965442 -2.5951867 -2.4142458 1.2733719 -0.22638321 0.15742263 -0.717717 2.2888887 3.3045793 -0.8173686 1.368556 0.34260234 1.1644434 2.2652006 -0.47847173 1.5130697 3.481819 -1.5247481 2.166555 0.7633031 0.61121356 -0.11627229 1.0461875 1.4994645 -2.8477156 -2.9415505 -0.86640745 -1.1220155 0.10772963 -1.6050811 -2.519997 -0.13945188 -0.06943721 0.83996797 0.29909992 0.7927955 -1.1932545 -0.375592 0.4437512 -1.4635806 -0.16438413 0.93455386 -0.4142645 -0.92249537 -1.0754105 0.07403489 1.0781559 1.7206618 -0.69100255 -2.6112185 1.4985414 -1.8344582 -0.75036854 1.6177907 -0.47727013 0.88055164 -1.057859 -2.0196638 -3.5305111 1.1221203 3.3149185 0.859528 2.3817215 -1.1856595 -0.03347144 -0.84533554 2.201596 -2.1573794 -0.6228852 0.12370715 3.030279 -1.9215534 0.09835044]このように200次元のベクトルが出力されます。
word2vecの全ベクトルをnumpy配列として取得
以下のコードで全単語のベクトルを取得できます。
w2v_vector = model.wv.syn0次元数を確認します。
print(w2v_vector.shape)出力(1015474, 200)この出力結果から、1015474単語が200次元のベクトルとして保存されていることがわかります。
学習済み単語のindexを取得
全単語に対するベクトルを取得することはできましたが、今のままでは単語がどのベクトルに対応するかが分かりません。ですので、word2vec上の単語IDを取得してみます。
print(model.vocab['私'].index)出力1027「私」という単語が1027番目に対応していることが分かりました。
では、1027番目のベクトルを出力してみます。print(w2v_vector[model.vocab['私'].index])出力[-0.9154563 0.97780323 -0.43780354 -0.6441212 -1.6350892 0.8619687 0.41775486 -1.094953 0.74489385 -1.6742945 -0.34408432 0.5552686 -3.9321985 0.3369842 1.5550056 1.3112832 -0.64914817 0.5996928 1.6174266 0.8126016 -0.75741744 1.7818885 2.1305397 1.8607832 3.0353768 -0.8547809 -0.87280065 -0.54103154 0.752979 3.8159864 -1.4066186 0.78604376 1.2102902 3.9960158 2.9654515 -2.6870391 -1.3829899 0.993459 0.86303824 0.29373714 4.0691266 -1.4974884 -1.5601915 1.4936608 0.550254 2.678553 0.53790915 -1.7294457 -0.46390963 -0.34776476 -1.2361934 -2.433244 -0.21348757 0.0488718 0.8197853 -0.59188586 1.7276062 0.9713122 -0.06519659 2.4763248 -0.93890053 0.36217824 1.887851 -0.0175399 -0.21866432 -0.81253886 -3.9667509 2.5340643 0.02985824 0.338091 -1.3745826 -2.3509336 -1.5615206 0.8273324 -1.263886 -1.2259561 0.9079302 2.0258994 -0.8576754 -2.5492477 -2.45557 -0.5216256 -1.3474834 2.3590422 1.0459667 2.0919168 1.6904455 1.7064931 0.7376105 0.2567448 -0.8194208 0.8788849 -0.89287275 -0.22960001 1.8320689 -1.7200342 0.8977642 1.5119879 -0.3325551 0.7429934 -1.2087826 0.5350336 -0.03887295 -1.9642036 1.0406445 -0.80972534 0.49987233 2.419521 -0.30317742 0.96494234 0.6184119 1.2633535 2.688754 -0.7226699 -2.8695397 -0.8986926 0.1258761 -0.75310475 1.099076 0.90656924 0.24586082 0.44014114 0.85891217 0.34273988 0.07071286 -0.71412176 1.4705397 3.6965442 -2.5951867 -2.4142458 1.2733719 -0.22638321 0.15742263 -0.717717 2.2888887 3.3045793 -0.8173686 1.368556 0.34260234 1.1644434 2.2652006 -0.47847173 1.5130697 3.481819 -1.5247481 2.166555 0.7633031 0.61121356 -0.11627229 1.0461875 1.4994645 -2.8477156 -2.9415505 -0.86640745 -1.1220155 0.10772963 -1.6050811 -2.519997 -0.13945188 -0.06943721 0.83996797 0.29909992 0.7927955 -1.1932545 -0.375592 0.4437512 -1.4635806 -0.16438413 0.93455386 -0.4142645 -0.92249537 -1.0754105 0.07403489 1.0781559 1.7206618 -0.69100255 -2.6112185 1.4985414 -1.8344582 -0.75036854 1.6177907 -0.47727013 0.88055164 -1.057859 -2.0196638 -3.5305111 1.1221203 3.3149185 0.859528 2.3817215 -1.1856595 -0.03347144 -0.84533554 2.201596 -2.1573794 -0.6228852 0.12370715 3.030279 -1.9215534 0.09835044]最初のベクトル出力結果と照らし合わせてみると、同じ出力結果になっていることが分かります。
最後に
word2vecのベクトルを利用する準備ができましたので、次回はseq2seq・EncoderモデルのEmbedding層にword2vecのベクトルを利用して学習してみようと思います。