- 投稿日:2020-10-11T22:03:27+09:00
PIDファイルがなくてMySQLが起動しない
前提条件
自分の環境は以下の通りです。
- MacOS Catalina バージョン10.15.6
- MySQL5.7
起動しなくなった原因
MySQLのサーバーが立ち上がっている状態でPCが再起動してしまった...
つまり、下のような状態で再起動しました。
$ mysql.server start Starting MySQL .. SUCCESS!エラーの内容
mysql.server startを叩いて
MySQLを起動しようとしたら以下のエラーが発生しました。ERROR! MySQL server PID file could not be found!解決方法
以下のコマンドを叩くと解消しました。
[user] 1の部分は適宜読み替えてください。$ sudo chown -R [user]:_mysql /usr/local/var/mysqlさいごに
ネットで検索しても解決方法がバラバラで、片っ端から試してみたものの解決しませんでした。
なので、自分と同じ方法で解消する方がいたら良いなと思い、備忘録ついでに投稿しました。
ターミナルのこの部分で確認できます
[user]@[machine]~ $↩
- 投稿日:2020-10-11T17:28:44+09:00
【RubyonRails】地域猫を幸せにするサービスを作ってみる
はじめに
猫が好きです。
通勤で見かける猫、人の家の猫、癒しです。
幸せな猫が増えて欲しいと切に願っています。
昨年から、近所の駅に黒猫が住み着き、以降その子をダイコクちゃんと勝手に命名し、可愛がっています。一方、野良猫には手放しに可愛いだけで済まない問題も含まれています。
虐待や無責任な餌やりなど。
地域猫に対する様々な活動がありました。その中で、TNR活動なるものがあることを知りました。
さくらねこ♥TNRとは (TNR先行型地域猫) – どうぶつ基金このような活動が広まったり、無責任な餌やりによって不幸になる猫が減ることを願い、今回のサービスを考えました。
地域猫を住民でしっかり管理できるようなサービスとなれば幸いです。
環境
MacBook Air2020
Ruby2.7.1
Rails6.0.3.4
MySQL構想
ユーザー(住民)は以下のことが可能です
- 健康状態や食事、去勢手術の状況の情報確認
- 地域猫の餌やりや去勢手術の状況を確認できる
- 地域猫の画像閲覧
- 地域猫の登録
- 地域猫の餌やり情報の登録、画像投稿
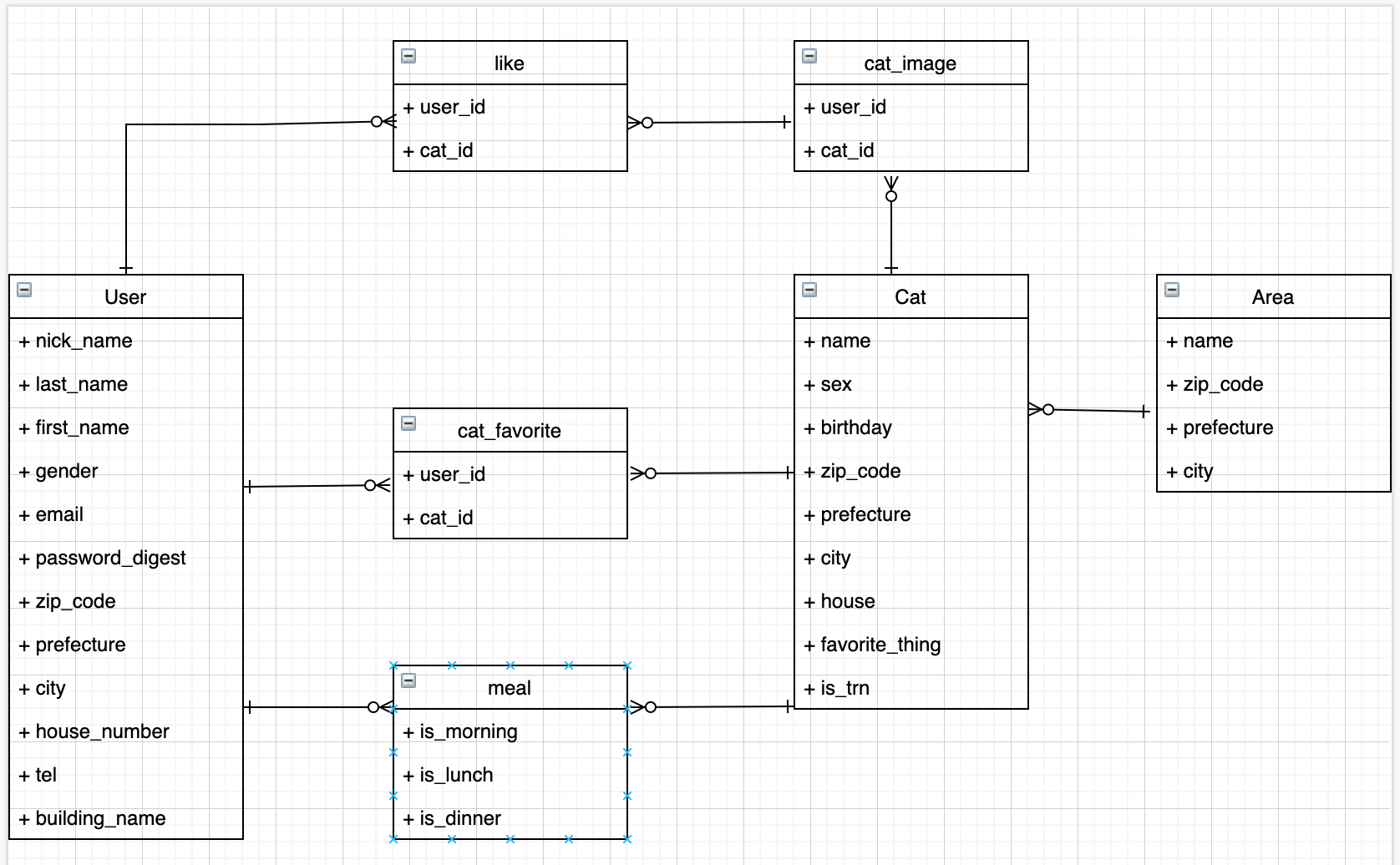
設計(ER図)
最後に
今後、地道に作成していきます。
進捗をお伝えしていくつもりですのでよろしくお願いします。
- 投稿日:2020-10-11T15:38:48+09:00
Java・ツイッタークローン・タスク管理システム①データベースを作成する
はじめに
Javaを使って初めてアプリケーションを作成する人にむけて記事を書いてみようと思います。
ポートフォリオや、会社の研修課題作成の参考にしていただければ幸いです。
今回は、タスクマネージャーを作成します。
これを応用することで、ツイッタークローンの作成にも活かすことができます。アプリケーションの機能ごとに記事を投稿していきます。
1.データベース作成
2.ログイン機能
3.タスクの登録機能
4.一覧表示
-ソート機能
-検索機能
5.編集機能
6.削除機能
7.排他制御について*詳しい説明はコード内に書いてありますので、コピペする人は消して使ってください
実行環境
eclipse4.16.0
Tomcat9
Java11
Mysql5.7目次
1.データベース概要
2.SQL文
3.Bean作成
4.データベースとの接続
5.次回予告データベース概要
データベース名task_db
権利ユーザ名testuser
パスワードpassword
テーブル ユーザのマスターテーブル
カテゴリーのマスターテーブル
ステータスのマスターテーブル
タスクテーブル(ユーザID、カテゴリーID、ステータスIDのForeignKeyを持ちます)
コメントテーブル(ユーザID、タスクIDのForeignKeyを持ちます)SQL文
①データベース作成
create databasetask_db②ユーザ作成
まずrootユーザになってパスワードのバリデーションを変更しますSet global validate_password.length=6; パスワードの長さを6に set global validate_password.policy=LOW; ポリシーを変更次にパスワード付きでユーザ作成
create user testuser identified by 'password'③ユーザへtask_dbの全権限を与える
grant all on task_db.* to testuser以上で準備は完了です。
④それぞれのテーブルを作成していきます。
--------ユーザのマスターテーブル create table m_user ( user_id varchar(24) primary key, password varchar(32) not null, user_name varchar(20) not null unique, update_datetime timestamp not null default current_timestamp on update current_timestamp ); --------カテゴリのマスターテーブル create table m_category ( category_id int primary key auto_increment, category_name varchar(20) not null unique, update_datetime timestamp not null default current_timestamp on update current_timestamp ); --------ステータスのマスターテーブル create table m_status ( status_code char(2) primary key, status_name varchar(20) unique not null, update_datetime timestamp not null default current_timestamp on update current_timestamp ); --------タスクテーブル create table t_task ( task_id int auto_increment primary key, task_name varchar(50) not null, category_id int not null, limit_date date, user_id varchar(24) not null, status_code char(2) not null, memo varchar(100), create_datetime timestamp default current_timestamp not null, update_datetime timestamp default current_timestamp not null on update current_timestamp, foreign key(category_id) references m_category(category_id), foreign key(user_id) references m_user(user_id), foreign key(status_code) references m_status(status_code) ); --------コメントテーブル create table t_comment( comment_id int auto_increment primary key, task_id int, user_id varchar(100) not null, comment varchar(100) not null, update_datetime timestamp default current_timestamp not null on update current_timestamp, foreign key(task_id) references t_task(task_id) on delete set null on update cascade, foreign key(user_id) references m_user(user_id) );次に初期データを入れておきます。
-------カテゴリーレコード作成 insert into m_category (category_name) value("新商品A:開発プロジェクト"); insert into m_category (category_name) value("既存商品B:改良プロジェクト"); select * from m_category; --------ステータスレコード作成 insert into m_status ( status_code, status_name) values("00", "未着手"); insert into m_status ( status_code, status_name) values("50", "着手"); insert into m_status ( status_code, status_name) values("99", "完了"); select * from m_status; --------ユーザーレコード作成 insert into m_user(user_id, password, user_name) values("testid", "password", "testuser"); insert into m_user(user_id, password, user_name) values("testid2", "password", "testuser2"); --------タスクレコード作成 insert into t_task(task_name, category_id, limit_date, user_id, status_code, memo) values("サンプルタスク1", 1, "2022-10-01", "testid", "99", "テスト入力"); insert into t_task(task_name, category_id, limit_date, user_id, status_code, memo) values("サンプルタスク2", 2, "2020-07-05", "testid", "50", "テスト入力"); insert into t_task(task_name, category_id, limit_date, user_id, status_code, memo) values("サンプルタスク2", 1, "2020-09-30", "testid", "00", "テスト入力"); insert into t_task(task_name, category_id, limit_date, user_id, status_code, memo) values("サンプルタスク3", 2, "2002-08-30", "testid", "99", "テスト入力"); insert into t_task(task_name, category_id, limit_date, user_id, status_code, memo) values("サンプルタスク4", 1, "2000-09-30", "testid", "00", "テスト入力"); insert into t_task(task_name, category_id, limit_date, user_id, status_code, memo) values("サンプルタスク5", 2, "2025-09-30", "testid", "50", "テスト入力"); insert into t_task(task_name, category_id, limit_date, user_id, status_code, memo) values("サンプルタスク6", 1, "1998-09-30", "testid", "00", "テスト入力"); insert into t_task(task_name, category_id, limit_date, user_id, status_code, memo) values("サンプルタスク7", 2, "2020-09-30", "testid", "99", "テスト入力"); insert into t_task(task_name, category_id, limit_date, user_id, status_code, memo) values("サンプルタスク8", 1, "2020-10-30", "testid", "00", "テスト入力");Bean作成
ここでは、それぞれのテーブルのBeanを作成していきます。
フィールド、コンストラクタ、getterとsetterを記述しているだけです。
確認したらコピペでオッケーですmodel.entity.TaskBean.javapublic class TaskBean { /** * フィールド */ private int task_id; private String task_name; private int category_id; private Date limit_date; private String user_id; private String status_code; private String memo; private Timestamp create_datetime; private Timestamp update_datetime; private int version; /** * コンストラクタ */ public TaskBean(){ } /** * メソッド */ public int getTask_id() { return task_id; } public void setTask_id(int task_id) { this.task_id = task_id; } public String getTask_name() { return task_name; } public void setTask_name(String task_name) { this.task_name = task_name; } public int getCategory_id() { return category_id; } public void setCategory_id(int category_id) { this.category_id = category_id; } public Date getLimit_date() { return limit_date; } public void setLimit_date(Date limit_date) { this.limit_date = limit_date; } public String getUser_id() { return user_id; } public void setUser_id(String user_id) { this.user_id = user_id; } public String getStatus_code() { return status_code; } public void setStatus_code(String status_code) { this.status_code = status_code; } public String getMemo() { return memo; } public void setMemo(String memo) { this.memo = memo; } public Timestamp getCreate_datetime() { return create_datetime; } public void setCreate_datetime(Timestamp create_datetime) { this.create_datetime = create_datetime; } public Timestamp getUpdate_datetime() { return update_datetime; } public void setUpdate_datetime(Timestamp update_datetime) { this.update_datetime = update_datetime; } public int getVersion() { return version; } public void setVersion(int version) { this.version = version; } }model.entity.UserBean.javapublic class UserBean { /** * フィールド */ private String user_id; private String password; private String user_name; /** * コンストラクタ */ public UserBean(){ } /** * メソッド */ public String getUser_id() { return user_id; } public void setUser_id(String user_id) { this.user_id = user_id; } public String getPassword() { return password; } public void setPassword(String password) { this.password = password; } public String getUser_name() { return user_name; } public void setUser_name(String user_name) { this.user_name = user_name; } }model.entity.StatusBean.javapublic class StatusBean { /** * フィールド */ private String status_code; private String status_name; /** * コンストラクタ */ public StatusBean(){ } /** * メソッド */ public String getStatus_code() { return status_code; } public void setStatus_code(String status_code) { this.status_code = status_code; } public String getStatus_name() { return status_name; } public void setStatus_name(String status_name) { this.status_name = status_name; } }model.entity.CategoryBean.javapublic class CategoryBean { /** * フィールド */ private int category_id; private String category_name; /** * コンストラクタ */ public CategoryBean(){ } /** * メソッド */ public int getCategory_id() { return category_id; } public void setCategory_id(int category_id) { this.category_id = category_id; } public String getCategory_name() { return category_name; } public void setCategory_name(String category_name) { this.category_name = category_name; } }model.entity.CommentBean.javapublic class CommentBean { /** * フィールド */ private int comment_id; private int task_id; private String user_id; private String comment; private Timestamp update_datetime; /** * コンストラクタ */ public CommentBean() { } /** * メソッド */ public int getComment_id() { return comment_id; } public void setComment_id(int comment_id) { this.comment_id = comment_id; } public int getTask_id(){ return task_id; } public void setTask_id(int task_id) { this.task_id = task_id; } public String getUser_id() { return user_id; } public void setUser_id(String user_id) { this.user_id = user_id; } public String getComment() { return comment; } public void setComment(String comment) { this.comment = comment; } public Timestamp getUpdate_datetime() { return update_datetime; } public void setUpdate_datetime(Timestamp update_datetime) { this.update_datetime = update_datetime; } }データベースとの接続
①JDBCをプロジェクトのWebContent-Web-INF-libの中に入れる
②ビルドパスの構成から追加をしておきます
③コネクションマネージーを作成
変数USERと変数PASSWORDはパスワードとユーザ名はそれぞれtestuserとpasswordでやっております。model.dao.ConnectionManager.javapublic class ConnectionManager { //データベースの情報 private final static String URL = "jdbc:mysql://localhost:3306/task_db?useSSL=false&serverTimezone=JST"; private final static String USER = "testuser"; private final static String PASSWORD = "password"; //データベースへの接続メソッド public static Connection getConnection() throws SQLException, ClassNotFoundException{ Class.forName("com.mysql.cj.jdbc.Driver"); return DriverManager.getConnection(URL, USER, PASSWORD); } }次回予告
今回は、データベースの作成からBean作成とmysqlとの接続までやってまいりました。
作成いしたm_userテーブルを使って次回は、ログイン機能をつけていきます。
- 投稿日:2020-10-11T13:50:59+09:00
MySQLの文字の比較ルール! Aとaを区別するには? Weightって何?
はじめに
Hello World!
YouTubeでエンジニア向けのTipsを紹介しているやっすんです!!突然ですが、文字列の順序のルール (Collation) って、どういうものがあるか知っていますか?
今回はMySQLのCollationについて詳しく紹介していきます。【YouTube動画】 MySQL みんながよくわかっていない Collation について解説します! 並び替えに使うよ!
Collationの復習
utf8mb4_ja_0900_as_cs_ks という文字列がどういう意味か不安な方は以下のQiita記事か動画を確認してください!
【Qiita】MySQLがバージョン5から8に飛んだ謎、意外と知らないCharset、Collationのこと#Collationについて
【YouTube動画】MySQLがバージョン5から8に飛んだ謎、意外と知らないCharset、Collationのこと
Collationごとの文字の比較
Collationの違いによって区別する文字と区別しない文字に差があります!
今回、下に表でまとめました!動画の方が見やすいと思うので、以下リンクを貼っておきます。
Collationとは何か基本的には、Collationにciがあれば半角・全角関係なく、大文字と小文字を区別しません。
そのため、「A」と「a」または「A」と「a」を区別するのはutf8mb4_binとcsが付いているところです。
binはバイナリの略で、文字が異なれば区別します。日本語の「あ」と「ぁ」も大文字と小文字の違いで区別されそうですが、ここがややこしいです。
なぜかgeneral_ciの場合、「あ」と「ぁ」を区別します。
general_ciは今では使わない方が良いと言われているので、深くは追いませんが、参考程度に知っておくと良いと思います。半角の「A」と全角の「A」もややこしいです。
日本語版であるutf8mb4_ja_0900_の場合、両者を区別しません。
しかし、general_ciでは区別します。utf8mb4とutf8mb4_jaでは平仮名・片仮名の扱いが異なります。
前者ではcsで平仮名・片仮名・大文字・小文字を区別しますが、後者ではcsでは片仮名・平仮名を区別しません。このようにCollationによって、文字の扱いが直感的でないということは頭に入れておくと、いざという時役立つと思います!
utf8mb4_0900_ ai_ci as_ci as_cs A, a 区別しない 区別しない 区別する A, a 区別しない 区別しない 区別する A, A 区別しない 区別しない 区別する あ, ぁ 区別しない 区別しない 区別する あ, ア 区別しない 区別しない 区別する は, ば, ぱ 区別しない 区別する 区別する
utf8mb4_ja_0900_ as_cs as_cs_ks A, a 区別する 区別する A, a 区別する 区別する A, A 区別しない 区別しない あ, ぁ 区別する 区別する あ, ア 区別しない 区別する は, ば, ぱ 区別する 区別する
utf8mb4_ bin general_ci A, a 区別する 区別しない A, a 区別する 区別しない A, A 区別する 区別する あ, ぁ 区別する 区別する あ, ア 区別する 区別する は, ば, ぱ 区別する 区別する [参考]
MySQL徹底入門 第4版 MySQL 8.0対応utf8mb4_ja_0900_as_csとutf8mb4_0900_as_csの違い
*動画ではこの部分で説明しています。
utf8mb4_ja_0900_as_csは平仮名・片仮名を区別せず、utf8mb4_0900_as_csは区別しません。
それ以外にソートにも違いがあります。utf8mb4_ja_0900_as_csの方は文字を音読みでソートします!
例えば、「亜」「伊」「宇」「栄」「奥」という文字があったとき、それぞれ以下のようにソートします。
utf8mb4_ja_0900_as_csの場合 亜 < 伊 < 宇 < 栄 < 奥 utf8mb4_0900_as_csの場合 亜 < 伊 < 奥< 宇 < 栄ソートの計算 (Unicode Collation Algorithm)
*動画ではこの部分で説明しています。
文字には以下のように、Weightと呼ばれる0000で区切られた値が割り当てられています。
例えば、「a」と「A」の場合は以下のような値になります。
はじめの1C47は文字の種類、次の0020はアクセント、最後の0002が大文字・小文字を表しています。aのWeight => 1C47 0000 0020 0000 0002Weightの値はCollationによって変わることがありますが、以下のようにして求めることができます。
mysql> SET NAMES utf8mb4 COLLATE utf8mb4_0900_as_cs; mysql> SELECT HEX(WEIGHT_STRING('a')); 1C470000002000000002 mysql> SELECT HEX(WEIGHT_STRING('A')); 1C470000002000000008この値の大小によって文字をソートしていきます。
そのため、aとAを比べた場合、a < Aの順に並びます。ちなみに文字列の場合、a9とA0の場合はどうなるでしょうか?
Weightを合わせて、その結果でソートしていきます。まずaと9のWeightは以下のようになります。
a => 1C47 0000 0020 0000 0002 9 => 1C46 0000 0020 0000 0002文字列では単純にWeightを足すのではなく、種類の同じものを後ろに挿入していく形式になります。
そのため、以下のような値になります。1C47 1C46 0000 0020 0020 0000 0002 0002足算にすると、異なる文字列なのに同じになってしまう問題が発生してしまうため、このようになっているのだと思います。
上記のような計算をするため、a9とA0を比較した場合、A0 < a9の順になります。0 => 1C3D 0000 0020 0000 0002 9 => 1C46 000 000 200 000 0002 0は1c3Dで9よりもWeightが小さい! 合わせると、1C47 1C3D (a9の初めの部分)と1C47 1C46 (A0の初めの部分)で比較することになるので、A0の方が小さい!まとめ
今回は大変ややこしく、混乱しやすいCollationについて解説しました。
何か間違いや指摘、感想等ありましたら、コメントよろしくお願いします。

- 投稿日:2020-10-11T00:14:17+09:00
MySQL応用編! いろんなSQL Vol.3
前回の記事で投稿した いろんなSQL Vol.2 のつづきの記事となります。
環境
Windows 10
MySQL : version(5.7.28)
使用アプリ
コマンドプロンプト(Windowsマーク押して「cmd」って打ったら出てくるやつ)
16 外部キー制約の設定
今回は会社の部署と社員を管理するデータを作って試してみます。
まずは親テーブルを作成(データ挿入済み)-- 親テーブル mysql> select * from divtb1; +------------+ | division | +------------+ | Accounting | | Marketing | | Research | | sales | +------------+子テーブル(参照するテーブル)を作成するときに親テーブル(参照されるテーブル)のdivision カラムに対してFOREIGN KEY制約を設定しています。
書式はこちら↓CREATE TABLE staff( id INT, name VARCHAR(10), division VARCHAR(10), INDEX div_index(division), FOREIGN KEY fk_division(division) REFERENCES divtb1(dvision) );問題なくデータが入るか確認
INSERT INTO staff VALUES (1, 'Yamada', 'sales'); (2, 'Suzuki', 'Marketing'); (3, 'Okada', 'sales'); (4, 'Tanaka', 'Research'); -- 子テーブル mysql> select * from staff; +------+--------+-----------+ | id | name | division | +------+--------+-----------+ | 1 | Yamada | Sales | | 2 | Suzuki | Marketing | | 3 | Okada | Sales | | 4 | Tanaka | Research | +------+--------+-----------+ちゃんと入っています。
次に親テーブルの参照先カラムにない値を含むデータを追加して、ちゃんとエラーが出るか確認してみます。
INSERT INTO staff VALUES (5, 'Hatakeyama', 'Manager');上記のクエリを実行すると
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`shop03`.`staff`, CONSTRAINT `staff_ibfk_1` FOREIGN KEY (`division`) REFERENCES `divtb1` (`division`))FOREIGN KEY設定がうまくできていることがわかります。
注意点
- 親テーブル及び子テーブルでは制約の対象となるカラムに対してインデックスが必要
- 親テーブルと子テーブルは同じストレージエンジンを使用する必要がある
- MySQLでFOREIGN KEYを使用できるストレージエンジンはInnoDBとNDB
- 子テーブルの対象カラムと親テーブルの対象カラムは同じデータ型である必要がある。非バイナリ型の場合は文字セットと照合順序は同じでないといけない
外部キーに関する情報を取得する方法
INFORMATION_SCHEMA.KEY_COLUMN_USAGE テーブルを参照することで外部キーに関する情報を取得することができる
実行方法はこちら↓(最後の;をメタコマンドの\Gにすると、結果を縦に表示してくれて見やすくなる)
SELECT * FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE WHERE table_schema='db_name'¥G*************************** 3. row *************************** CONSTRAINT_CATALOG: def CONSTRAINT_SCHEMA: shop03 CONSTRAINT_NAME: PRIMARY TABLE_CATALOG: def TABLE_SCHEMA: shop03 TABLE_NAME: divtb1 COLUMN_NAME: division ORDINAL_POSITION: 1 POSITION_IN_UNIQUE_CONSTRAINT: NULL REFERENCED_TABLE_SCHEMA: NULL REFERENCED_TABLE_NAME: NULL REFERENCED_COLUMN_NAME: NULL *************************** 4. row *************************** CONSTRAINT_CATALOG: def CONSTRAINT_SCHEMA: shop03 CONSTRAINT_NAME: staff_ibfk_1 TABLE_CATALOG: def TABLE_SCHEMA: shop03 TABLE_NAME: staff COLUMN_NAME: division ORDINAL_POSITION: 1 POSITION_IN_UNIQUE_CONSTRAINT: 1 REFERENCED_TABLE_SCHEMA: shop03 REFERENCED_TABLE_NAME: divtb1 REFERENCED_COLUMN_NAME: division関係性
親テーブル : divtb1
子テーブル : staff (こちらのテーブルでFOREIGN KEY制約の設定をしています)目的 : 外部キーの制約によって変なデータが追加されなくなるので、データの整合性が保たれる。
17 紐づいたレコードの更新と削除
ON DELETE CASCADE⇒ 削除
ON UPDATE CASCADE⇒ 更新
Twitterのような投稿サイトをイメージしたデータを以下のように作成しました。
テーブル作成時に子テーブルのFOREIGN KEY以下に削除と更新のクエリ文の記述が必要になる。-- 親テーブル mysql> CREATE TABLE 投稿一覧 ( -> id INT NOT NULL AUTO_INCREMENT, -> メッセージ VARCHAR(140), -> PRIMARY KEY(id) -> ); Query OK, 0 rows affected (0.05 sec) -- 子テーブル mysql> CREATE TABLE コメント一覧( -> id INT NOT NULL AUTO_INCREMENT, -> 投稿一覧_id INT, -> コメント VARCHAR(140), -> PRIMARY KEY(id) -> FOREIGN KEY (投稿一覧_id) REFERENCES 投稿一覧(id) -> ON DELETE CASCADE -- FOREIGN KEY制約で紐付いたレコードの削除 -> ON UPDATE CASCADE -- FOREIGN KEY制約で紐付いたレコードの更新 -> ); Query OK, 0 rows affected (0.03 sec)18 LAST_INSERT_ID()
直前に挿入されたレコードのIDを調べてくれる命令文
現在のテーブル状況を確認
mysql> SELECT * FROM 投稿一覧; +----+---------------------------------------+ | id | メッセージ | +----+---------------------------------------+ | 1 | はじめまして | | 2 | 春になったら行きたいところ | +----+---------------------------------------+ mysql> SELECT * FROM コメント一覧; +----+-----------------+-------------------------------+ | id | 投稿一覧_id | コメント | +----+-----------------+-------------------------------+ | 1 | 1 | よろしくおねがいします。 | | 2 | 1 | はじめまして!! | +----+-----------------+-------------------------------+ -- 新しい投稿を追加 mysql> INSERT INTO 投稿一覧 (メッセージ) VALUES -> ("ドライブスポット教えて"); Query OK, 1 row affected (0.01 sec) -- LAST_INSERT_ID() を使ってidを自動挿入 mysql> INSERT INTO コメント一覧 (投稿一覧_id, コメント) VALUES -> (LAST_INSERT_ID(), "箱根スカイラインがおすすめ!"); Query OK, 1 row affected (0.00 sec) -- 確認 mysql> select * from 投稿一覧; +----+----------------------------------------+ | id | メッセージ | +----+----------------------------------------+ | 1 | はじめまして | | 2 | 春になったら行きたいところ | | 4 | ドライブスポット教えて | +----+----------------------------------------+ mysql> SELECT * FROM コメント一覧; +----+-----------------+--------------------------------+ | id | 投稿一覧_id | コメント | +----+-----------------+--------------------------------+ | 1 | 1 | よろしくおねがいします。 | | 2 | 1 | はじめまして!! | | 4 | 4 | 箱根スカイラインがおすすめ! | +----+-----------------+--------------------------------+※
LAST_INSERT_ID()をする前に投稿一覧にid3の投稿を作って、削除していた経緯がありidが4になっています。わかりづらくなってしまい、申し訳ありません。19 コメントにコメントをつける
現在のテーブルを確認
mysql> SELECT * FROM 投稿一覧; +----+---------------------------------------+ | id | メッセージ | +----+---------------------------------------+ | 1 | はじめまして | | 2 | 春になったら行きたいところ | | 3 | ドライブスポット教えて | +----+---------------------------------------+ mysql> SELECT * FROM コメント一覧; +----+-----------------+--------------------------------+ | id | 投稿一覧_id | コメント | +----+-----------------+--------------------------------+ | 1 | 1 | よろしくおねがいします。 | | 2 | 1 | はじめまして!! | | 3 | 3 | 箱根スカイラインがおすすめ! | +----+-----------------+--------------------------------+子テーブル作成時に親テーブルの投稿についたコメントと紐付けるカラムを追加
mysql> CREATE TABLE コメント一覧 ( -> id INT NOT NULL AUTO_INCREMENT, -> 投稿一覧_id INT, -> コメント VARCHAR(140), -> 投稿コメント_id INT, -- 親テーブルの投稿についたコメントと紐付けるカラムを作成 -> PRIMARY KEY (id), -> FOREIGN KEY (投稿一覧_id) REFERENCES 投稿一覧(id) -> ON DELETE CASCADE -> ON UPDATE CASCADE -> ); Query OK, 0 rows affected (0.01 sec)レコード挿入時に
投稿コメント_idを追加(コメントから見て親となるコメントがないものはNULLを、親となるコメントがあるものはINSERT文の上から順番に数えていった数を値として書く)mysql> INSERT INTO コメント一覧 (投稿一覧_id, コメント, 投稿コメント_id) VALUES -> (1, 'よろしくおねがいします', NULL), -> (1, 'はじめまして!!', NULL), -> (3, '箱根スカイラインがおすすめ!', NULL), -> (3, '途中、箱根芦ノ湖展望公園に寄ってみて', 3), -> (1, 'はじめまして!', 2), -> (3, 'あそこいいよね!富士山が見える', 4); Query OK, 6 rows affected (0.00 sec)20 コメントのコメントを抽出する
現在のテーブルを確認
mysql> SELECT * FROM 投稿一覧; +----+-----------------------------------------+ | id | メッセージ | +----+-----------------------------------------+ | 1 | はじめまして | | 2 | 春になったら行きたいところ | | 3 | ドライブスポット教えて | +----+-----------------------------------------+ mysql> SELECT * FROM コメント一覧; +----+-----------------+------------------------------------+------------------+ | id | 投稿一覧_id | コメント 投稿コメント_id +----+-----------------+------------------------------------+------------------+ | 1 | 1 | よろしくおねがいします | NULL | | 2 | 1 | はじめまして!! | NULL | | 3 | 3 | 箱根スカイラインがおすすめ! | NULL | | 4 | 3 | 途中、箱根芦ノ湖展望公園に寄ってみて | 3 | | 5 | 1 | はじめまして! | 2 | | 6 | 3 | あそこいいよね!富士山が見える | 4 | +----+-----------------+-------------------------------------+-----------------+抽出したいコメントを選んで、
UNION ALLを使って並べるSELECT * FROM コメント一覧 WHERE 投稿コメント_id = 3 UNION ALL SELECT コメント一覧.* FROM コメント一覧 JOIN ( SELECT * FROM コメント一覧 WHERE 投稿コメント_id = 3 ) AS t ON コメント一覧.投稿コメント_id = t.id; +----+-----------------+-----------------------------------------------------+-----------------------+ | id | 投稿一覧_id | コメント | 投稿コメント_id | +----+-----------------+-----------------------------------------------------+-----------------------+ | 4 | 3 | 途中、箱根芦ノ湖展望公園に寄ってみて | 3 | | 6 | 3 | あそこいいよね!富士山が見える | 4 | +----+-----------------+----------------------------------------------------+-----------------------+ 2 rows in set (0.01 sec)補足(MySQL 8.0 から使えるようになったものを紹介)
1. OVERを使ったWindow関数はMySQL 8.0から対応可能となりました。
2. 再帰的ではないCTE(Common Table Expression)
WITH t AS ( SELECT * FROM コメント一覧 WHERE 投稿コメント_id = 3 ) SELECT コメント一覧.* FROM コメント一覧 JOIN t ON コメント一覧.投稿コメント_id = t.id;#20と同じ結果が得られます。
3. 再帰的なCTE
-- 再帰的なCTE
WITH RECURSIVE [CTE_Name] AS (
-- 最初に実行する処理
UNION ALL
-- 2回目以降に再帰的に実行する処理
)
SELECT * FROM [CTE_Name];WITH RECURSIVE t AS ( SELECT * FROM コメント一覧 WHERE 投稿コメント_id = 3 UNION ALL SELECT コメント一覧.* FROM コメント一覧 JOIN t ON コメント一覧.投稿コメント_id = t.id ) SELECT * FROM t;CTEを用いでSQLを書くことで、コメント一覧テーブルに新しいコメントが付いても、そのデータをちゃんと抽出することができる
おわりに
文法は間違っていないのに、syntax errorが出て動かない。うーん、なんでだ....?
みたいな感じで、少し沼にハマりかけた今回でしたが、よくよくエラー文を確認してみると「MySQLのversionの確認してみ?」的な文章があったので、そこからググると自身の環境ではサポートされていなかったことがわかりました。
エラー文をよく読むようにクセづけていたのでそれが功を奏したのかも知れません。まだMySQL 8.0のインストールはしていないのですが、MySQL 5.x ではサポートされていなかった機能が多く追加されているので、そのうちインストールしてみようと思います。