- 投稿日:2020-09-19T23:37:26+09:00
SHAPの論文を読んでみた
はじめに
SHAPについて調べてみました。
参考文献
- SHAP を提案した論文 https://arxiv.org/abs/1705.07874
- shapley 値の解説 https://dropout009.hatenablog.com/entry/2019/11/20/091450
- Tree Ensembles に対する shap の近似的な求め方 https://arxiv.org/abs/1802.03888
- shap ライブラリ https://github.com/slundberg/shap
- shap ライブラリの使い方 https://orizuru.io/blog/machine-learning/shap/
- 教科書 https://christophm.github.io/interpretable-ml-book/shap.html
- LIMEの論文 https://www.kdd.org/kdd2016/papers/files/rfp0573-ribeiroA.pdf
- LIMEの論文要約 https://www.dendoron.com/boards/40
参考文献に示した1の論文を中心とし、6と7と8を参考にしてSHAPが何かを説明します。1の論文は用語の説明が抽象化されているので、7の論文の具体例を見た方が分かりやすいです。
概要
どんなもの?
予測を解釈するための統合フレームワークであるSHAP(SHapley Additive exPlanations)値を提案。先行研究と比べてどこがすごいの?
特徴量重要度を定義する手法は多数存在するが、手法間の関連性はよく分かっていなかった。
本論文で提案した手法はある理論に基づいて唯一に定まる解を求めることができ、また、新しいクラスは既存の6つの手法を統合した。技術や手法の"キモ"はどこにある?
(1)加法的特徴重要度尺度の新しいクラスを同定した。
(2)このクラスはユニークな解をもち、望ましいいくつかの特性を持っていることを示した。本論
説明したいモデルを$f(\boldsymbol{x})$とします。
y = f(\boldsymbol{x})説明可能モデルを$g(\boldsymbol{x'})$とします。今から示す手法では、データ全体に対する特徴量の重要度ではなく、各入力$\boldsymbol{x}$に対し、出力である予測$f(\boldsymbol{x})$を説明するための特徴量の重要度を求めます。このような手法をLocal methodsと呼びます。例えばLIMEはLocal methodsです。
説明可能モデルでは、しばしばマップ関数を用いて元のモデルの入力$\boldsymbol{x}$を、説明可能モデルへの入力$\boldsymbol{x'}$へと簡素化します。
\boldsymbol{x} = h_{\boldsymbol{x}}(\boldsymbol{x}')ここでマップ関数は添字$\boldsymbol{x}$があるように、入力値に依存する関数です。この簡素化によって、元のモデルの入力$\boldsymbol{x}$のどの部分が予測に寄与しているかを解釈できるような入力形式$\boldsymbol{x'}$に変換しています。例えば入力がBag of Words (BOW)の場合で、どの単語が予測に寄与しているかを知りたい場合は入力$\boldsymbol{x}$における単語の有無だけを入力とすれば良いです。したがって簡素化は、非ゼロの頻度の値を1に変換する操作になります。また、簡素化された後の入力$\boldsymbol{x'}$は、$h_{\boldsymbol{x}}$で元の入力に戻すことができます。これは$h_{\boldsymbol{x}}$が局所的な入力$\boldsymbol{x}$の情報を持っているからです。
簡素化: [1, 2, 1, 1, 2, 1, 1, 0, 0, 0] \rightarrow [1, 1, 1, 1, 1, 1, 1, 0, 0, 0] \\ h_{\boldsymbol{x}}: [1, 1, 1, 1, 1, 1, 1, 0, 0, 0] \rightarrow [1, 2, 1, 1, 2, 1, 1, 0, 0, 0] = \boldsymbol{x} \odot \boldsymbol{x'}入力が画像で、画像のどの部分が予測に寄与しているか知りたい場合は、隣接している連続部分をパッチ化して、そのパッチの有無を1/0で表現します。$h_{\boldsymbol{x}}$で元の入力空間に戻すときはパッチ部分(1の部分)は元の画像に変換すればよいです。パッチ以外の部分(0の部分)は適当な背景色で戻すのですが、これについては後に説明します。
この辺りの説明は参考文献8のブログが非常に参考になります。Local methodsは、$\boldsymbol{x}' \simeq \boldsymbol{z}'$となるときに$g(\boldsymbol{z'})\simeq f(h_{\boldsymbol{x}}(\boldsymbol{x}'))$となるように$g$の重みを決定します。
1¥論文では、Additive feature attribution methods と呼ばれる方法で説明可能モデルを構築します。簡素化はバイナリ変数への変換に限定します。したがって説明可能モデルはバイナリ変数の線形関数となります。
g(z') = \phi_0 + \sum_{i=1}^M\phi_i z_i'ここで$z'\in \{0,1\}^M$は簡素化された特徴で、$\phi_i\in\mathbb{R}$は特徴の効果を表す係数です。このモデルは、各特徴量の効果が$\phi_i$で表され、すべての特徴量の効果を足し合わせることで元のモデルの出力を近似します。
次の条件を満たすように係数$\phi_i$をユニークに決められます。
- Property 1 (Local accuracy)
\begin{aligned} f(\boldsymbol{x}) = g(\boldsymbol{x}') &= \phi_0 + \sum_{i=1}^M\phi_i x_i' \\ \boldsymbol{x} &= h_\boldsymbol{x}(\boldsymbol{x}') \\ \end{aligned}
- Property 2 (Missingness)
x' = 0 \Rightarrow\phi_i=0
- Property 3 (Consistency)
$f_x(\boldsymbol{z}') = f(h_\boldsymbol{x}(\boldsymbol{z}'))$と略記し、$z_i’=0$であることを$\boldsymbol{z}'\backslash i$と書くことにする。任意の二つのモデル$f, f'$に対して、
f_\boldsymbol{x}'(\boldsymbol{z}') - f_\boldsymbol{x}'(\boldsymbol{z}'\backslash i) \geq f_\boldsymbol{x}(\boldsymbol{z}') - f_\boldsymbol{x}(\boldsymbol{z}'\backslash i) \ \ \mathrm{for \ all \ inputs } \ \boldsymbol{z}' \in \{0,1\}^Mが成り立つとき、$\phi_i(f', \boldsymbol{x}) \geq \phi_i(f, \boldsymbol{x})$が成り立つ。
これは、特徴量$i$の限界寄与が(他の特徴に関係なく)増加または同じままになるようにモデルが変更された場合、$\phi_i$も増加または同じままになることを要請しています。以上の三つの条件を課すと、説明可能モデルが唯一に定まることが知られています。
\phi_i(f, \boldsymbol{x}) = \sum_{\boldsymbol{z}'\subseteq \boldsymbol{x}'}\frac{|\boldsymbol{z}'|!(M-|\boldsymbol{z}'|-1)!}{M!}[f_\boldsymbol{x}(\boldsymbol{z}')-f_\boldsymbol{x}(\boldsymbol{z}'\backslash i)]ここで$|\boldsymbol{z}'|$は$1$である成分の数、$\boldsymbol{z}' \subseteq \boldsymbol{x}$は$\boldsymbol{x}'$の非ゼロ成分の部分集合であるすべての$\boldsymbol{z'}$ベクトルを表しています。これは combined cooperative game theory の結果から得られるもので、&\phi_i&は下記のShapley Values と呼ばれるものに一致しています。
\phi_i = \sum_{\mathcal{S}\subseteq \mathcal{N}\backslash i}\frac{1}{\frac{N!}{S!(N-S-1)!}}\left( v\left(\mathcal{S}\cup\{i\}\right) - v\left(\mathcal{S}\right) \right)ここで$S=|\mathcal {S}|$、$N=|\mathcal {N}|$ 、$v$は効用関数で、規格化定数は$\mathcal{N} \backslash i$の並び替えのパターン数です。
以上の結果より、所与の$h_\boldsymbol{x}$に対してAdditive feature attribution methodsは唯一に定まることが分かりました。逆に、Shapley values に基づかない指標は、特徴量重要度が持つべき3つの条件を持たないため、望ましくないと考えられます。
SHAP (SHapley Additive exPlanation) Values
特徴の重要性の統一的な尺度としてSHAP値を考えます。これはShapley valuesの式において、元のモデル$f$を条件付き期待関数に近似したものです。
f_\boldsymbol{x}(\boldsymbol{z}') \equiv f(h_\boldsymbol{x}(\boldsymbol{z}')) \rightarrow E[f(\boldsymbol{z})|z_S] \\$E[f(\boldsymbol{z})|z_S]$の意味ですが、まず、添字の$S$は$\boldsymbol{z}'$の非ゼロ要素のインデックスを表します。$z_S$は、確率変数$\boldsymbol{z}$に対し、インデックス$S$に対応する成分を入力値$x$の値で固定することを意味します。例えば$\boldsymbol{z}'=[1,1,0,0,...]$であれば、$S=\{1,2\}$となり、$E[f(\boldsymbol{z})|z_S]=E[f(\boldsymbol{z})|z_{1,2}]=E[f(\boldsymbol{z})|z_1=x_1, z_2=x_2]$となります。
期待関数への置き換えが必要な理由を説明します。マッピング関数$h_\boldsymbol{x}(\boldsymbol{z}') = z_S$は厳密にはインデックス$S$に含まれない特徴量を欠損させる操作です。というのも、説明可能モデルの入力空間から元の特徴量空間に写像する際に、インデックス$S$に含まれない部分を勝手に他の値に置き換えてしまうと意味を持ってしまう可能性があるからです。例えば画像で考えると、パッチに対応しない部分を全て0で置き換えるべきでしょうか?それとも255で置き換えるべきでしょうか?。一方で重回帰分析の場合は特徴量の欠損は、モデルからその特徴量の項を除くことが特徴量を0とすることと等価なので0に置き換えれば良いですが、ほとんどのモデルはこのように欠損値に自然に対応できません。そこで、マッピング関数はインデックス$S$に含まれない部分を欠損値にするのではなく、データの分布に従ってランダムに値を割り振ることにします。これによってモデルにデータを入力させることが出来ます。これによってモデルの予測値$f$は$z_S$を条件に持つ期待関数になります。
SHapley 値を定義通り計算するとものすごい計算コストがかかるため、計算は困難です。($\sum_{\boldsymbol{z}'\subseteq \boldsymbol{x}'}$が指数オーダー)。しかし、Additive feature attribution methodsの洞察を組み合わせることで、SHAP値を近似することができます。近似する際には特徴量の独立性およびモデルの線形性を利用します。
\begin{aligned} E[f(\boldsymbol{z})|z_S] =& E[f(\boldsymbol{z})|z_S]\\ =& E_{\bar z_S}[f(z_S, \bar z_S)] \because \mathrm{特徴量が独立} \\ =& f(z_S, E[\bar z_S]) \because \mathrm{モデルが線形} \end{aligned}論文中ではSHAPの近似結果として六つの手法が示され、すなわち、これらの手法が統合されたことを意味しています。
- モデルに依存しない近似手法
- 「Shapley sampling values」
- 「Kernel SHAP」(新規手法)
- モデル固有の近似手法
- 「Linear SHAP」
- 「Low-Order SHAP」
- 「Max SHAP」(新規手法)
- 「Deep SHAP」(新規手法)
Shapley sampling values
論文はこちら。有料のため断念。
Kernel SHAP
Kernel SHAP は 5 つのステップで求められます。
- $z_k'\in \{0,1\}^M$, $k\in{1,...,K}$(1 = feature present in coalition, 0 = feature absent).
- $h_x(z_k')=x_k\cdot z_k'$で特徴を元の空間に戻して、モデル$f$で予測値を得る.
- それぞれの$z_k'$に対して SHAP kernel で weight を求める.
- Fit weighted linear model.
- Return Shapley values $\phi_k$, the coefficients from the linear model.
SHAP kernel は次の式で定義されます。
\pi_\boldsymbol{x}(\boldsymbol{z}') = \frac{M-1}{_MC_{|\boldsymbol{z}'|}|\boldsymbol{z}'|(M-|\boldsymbol{z}'|)}重み付けした損失関数で最適化問題を解きます。
L(f, g, \pi_\boldsymbol{x}) = \sum_{\boldsymbol{z}'\in Z}\left[ f(h_\boldsymbol{x}(\boldsymbol{z}')) - g(\boldsymbol{z}') \right]^2 \pi_\boldsymbol{x}(\boldsymbol{z}')Linear SHAP
線形モデル$f(\boldsymbol{x})=\sum_{j=1}w_j x_j+b$において、特徴量が独立であれば、SHAP値は次のようになります。導出はこの論文のAppendixに詳細があります。
\begin{aligned} \phi_0(f, \boldsymbol{x}) &= b \\ \phi_i(f, \boldsymbol{x}) &= w_i(x_i - E[x_i]) \end{aligned}Low-Order SHAP
(何言ってるのかよくわからん)
線形回帰の場合でもKernel SHAPを使用すると$\mathcal O(2^M+M^3)$だけ計算が必要なので、特徴量を独立にする近似をした方が効率的です(この近似がLow-Order SHAP?)。Max SHAP
付属資料があると書いてあるのですが、無い?のでわかりません。査読者には間違っているとか書かれてますね。
Deep SHAP
Dense層やMaxpool層に対するSHAPの計算ができると主張しており、バックプロパゲーションでSHAPを計算できるということです(非線形の部分で出来るのでしょうか?)。
おわりに
決定木ではSHAPの効率的な計算ができるようです。LightGBM、Xgboostでは参考文献4のライブラリで簡単にSHAPを出力できます。
- 投稿日:2020-09-19T23:26:54+09:00
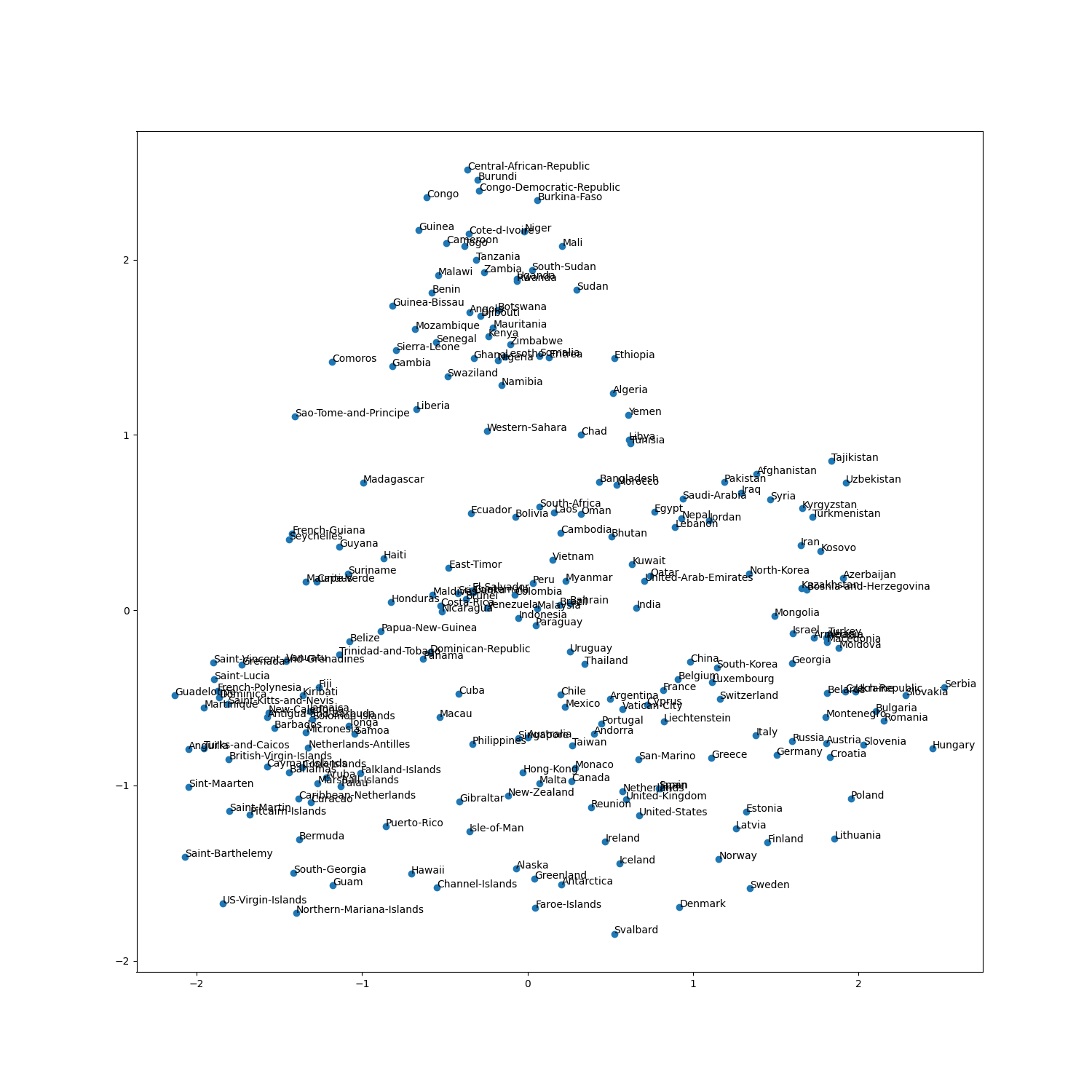
ベクトルを主成分分析で2次元に圧縮し,matplotlibで可視化する - Compress vectors to 2-dimension using Principal Component Analysis and visualize it with matplotlib.
準備 - Preparation
vecs #numpyの2重配列 name #ラベル主成分分析 - Principal Component Analysis
from sklearn.decomposition import PCA #主成分分析器 pca = PCA(n_components=2) pca.fit(vecs) x = pca.transform(vecs) for i in range(len(x)): X.append(x[j][0]) Y.append(x[j][1])可視化 - Visualization
fig, ax = pyplot.subplots(figsize=(15,15)) ax.scatter(X, Y) for i, txt in enumerate(Name): ax.annotate(txt, (X[i], Y[i])) pyplot.savefig("img.png") # 保存例 - Example
Wikipedia2Vecの事前学習モデルから国名に対応するベクトルを抽出し,可視化した結果
Visualization of country vectors, which was extracted Wikipedia2Vec model.
- 投稿日:2020-09-19T23:02:06+09:00
AtCoder Beginner Contest 179 参戦記
AtCoder Beginner Contest 179 参戦記
ABC179A - Plural Form
1分半で突破. 書くだけ.
S = input() if S[-1] != 's': print(S + 's') else: print(S + 'es')ABC179B - Go to Jail
1分半で突破. 書くだけ. 問題名はなんで「牢屋に行く」なんすかね.
N = int(input()) t = 0 max_run_length = 0 for _ in range(N): D1, D2 = map(int, input().split()) if D1 == D2: t += 1 else: t = 0 max_run_length = max(max_run_length, t) if max_run_length >= 3: print('Yes') else: print('No')ABC179C - A x B + C
4分で突破. 書くだけ. 数秒くらい計算量大丈夫かなって考えはしたけど、まあC問題だし大丈夫だろうと腐った考えで PyPy で提出して AC.
N = int(input()) result = 0 for A in range(1, N + 1): for B in range(1, (N // A) + 1): C = N - A * B if C == 0: continue result += 1 print(result)A×B+1≦N なら良いので、式変形して B≦(N-1)÷A となり、B の値域が一発で求まる.
N = int(input()) result = 0 for A in range(1, N + 1): result += (N - 1) // A print(result)ABC179D - Leaping Tak
突破できず. 50分くらい考えて閃いたけど、5分では実装できません.
ABC179E - Sequence Sum
36分半で突破. ループ検出題は何題か解いているので、そこまで難しいとは思わなかった. 入出力例3がなかなか合わなくてこれだけ時間がかかっていると説得力がないけど(笑).
N, X, M = map(int, input().split()) existence = [False] * M a = [] A = X for i in range(N): if existence[A]: break existence[A] = True a.append(A) A = A * A % M for i in range(len(a)): if a[i] == A: break loop_start = i result = sum(a[:loop_start]) a = a[loop_start:] N -= loop_start loops = N // len(a) remainder = N % len(a) result += sum(a) * loops + sum(a[:remainder]) print(result)
- 投稿日:2020-09-19T22:41:47+09:00
webスクレイピング
code
import requests url = (URLを設定) r = requests.get(url)例
#print(r.text) <!DOCTYPE html> <html class="client-nojs" lang="ja" dir="ltr"> <head> <meta charset="UTF-8"/> <title>日本 - Wikipedia</title> <script>document.documentElement.className="client-js";RLCONF={"wgBreakFrames":!1,"wgSeparatorTransformTable":["",""],"wgDigitTransformTable":["",""],"wgDefaultDateFormat":"ja","wgMonthNames":["","1月","2月","3月","4月","5月","6月","7月", "8月","9月","10月","11月","12月"],"wgRequestId":"f8d48c18-541d-4c28-b21d-14bc30c6cdc4","wgCSPNonce":!1,"wgCanonicalNamespace":"","wgCanonicalSpecialPageName":!1,"wgNamespaceNumber":0,"wgPageName":"日本","wgTitle":"日本","wgCurRevisionId": 79582646,"wgRevisionId":79582646,"wgArticleId":1864744,"wgIsArticle":!0,"wgIsRedirect":!1,"wgAction":"view","wgUserName":null,"wgUserGroups":["*"],"wgCategories":["参照エラーのあるページ","Webarchiveテンプレートのarchiveisリンク","Webarch iveテンプレートのウェイバックリンク","外部リンクがリンク切れになっている記事/2010年1月-4月","外部リンクがリンク切れになっている記事/2020年2月", "外部リンクがリンク切れになっている記事/2018年3月","出典テンプレートの呼び出しエラーがある記事","ISBNマジックリンクを使用しているページ","Div colで3列を指定しているページ","出典を必要とする記述のある記事/2016年5月","書きかけの節のある項目 ","言葉を濁した記述のある記事 (いつ)/2011年","Reflistで3列を指定しているページ","グラフのあるページ","日本","島国","現存する君主国","G8加盟国"],"wgPageContentLanguage":"ja","wgPageContentModel":"wikitext","wgRelevantPageName":"日本","wgRe levantArticleId":1864744,"wgIsProbablyEditable":!1,"wgRelevantPageIsProbablyEditable":!1,"wgRestrictionEdit":["autoconfirmed"],"wgRestrictionMove":["autoconfirmed"],"wgMediaViewerOnClick":!0,"wgMediaViewerEnabledByDefault":!0,"wgPopupsRef erencePreviews":!1,"wgPopupsConflictsWithNavPopupGadget":!1,"wgVisualEditor":{"pageLanguageCode":"ja", "pageLanguageDir":"ltr","pageVariantFallbacks":"ja"},"wgMFDisplayWikibaseDescriptions":{"search":!0,"nearby":!0,"watchlist":!0,"tagline":!0},"wgWMESchemaEditAttemptStepOversample":!1,"wgULSCurrentAutonym":"日本語","wgNoticeProject":"wikip edia","wgCentralAuthMobileDomain":!1,"wgEditSubmitButtonLabelPublish":!0,"wgULSPosition":"interlanguage","wgWikibaseItemId":"Q17"};RLSTATE={"ext.globalCssJs.user.styles":"ready","site.styles":"ready","noscript":"ready","user.styles":"read y","ext.globalCssJs.user":"ready","user":"ready","user.options":"loading","ext.cite.styles":"ready","mediawiki.page.gallery.styles":"ready","ext.tmh.thumbnail.styles":"ready","ext.graph.styles":"ready","skins.vector.styles.legacy":"ready" ,"jquery.tablesorter.styles":"ready","mediawiki.toc.styles":"ready","ext.visualEditor.desktopArticleTarget.noscript":"ready","ext.uls.interlanguage":"ready","ext.wikimediaBadges":"ready","wikibase.client.init":"ready"};RLPAGEMODULES=["ext .cite.ux-enhancements", ...
- 投稿日:2020-09-19T22:15:10+09:00
[CovsirPhy] COVID-19データ解析用Pythonパッケージ: Phase設定の最適化
Introduction
COVID-19のデータ(PCR陽性者数など)のデータを簡単にダウンロードして解析できる拙作のPythonパッケージ CovsirPhyの紹介記事です。
今回はPhase設定の最適化方法についてご説明します。
英語版のドキュメントはCovsirPhy: COVID-19 analysis with phase-dependent SIRs, Kaggle: COVID-19 data with SIR modelをご参照ください。
1. 実行環境
CovsirPhyは下記方法でインストールできます!Python 3.7以上, もしくはGoogle Colaboratoryをご使用ください。
- 安定版:
pip install covsirphy --upgrade- 開発版:
pip install "git+https://github.com/lisphilar/covid19-sir.git#egg=covsirphy"import covsirphy as cs cs.__version__ # '2.8.3'
実行環境 OS Windows Subsystem for Linux / Ubuntu Python version 3.8.5 2. 準備
実データをCOVID-19 Data Hub1よりダウンロードするコード2はこちら:
data_loader = cs.DataLoader("input") jhu_data = data_loader.jhu() population_data = data_loader.population()本記事の表及びグラフでは、下記コード3により2020/9/19時点の日本のデータ(厚生労働省発表の全国の合計値)を用いています。COVID-19 Data Hub1にも日本のデータが含まれますが、厚生労働省発表の全国の合計値とは異なるようです。
# (Optional) 厚生労働省データの取得 # エラーが出る場合は"pip install requests aiohttp" japan_data = data_loader.japan() jhu_data.replace(japan_data) print(japan_data.citation)実データの確認:
# 解析用クラスのインスタンス生成 snl = cs.Scenario(jhu_data, population_data, country="Japan") # 実データのグラフ表示 snl.records(filename=None)3. scenarioとは
Covsirphyの
Scenarioクラスでは、Phase3の設定内容を複数種類登録することができます。「Phase3の設定内容」を"scenario"と呼んでおり、内部的にはPhaseSeriesクラスが担当しています(クラス名と名称がずれてしまってすみません...Scenarioクラスを実装したあとでPhaseSeriesクラスを作成した結果、こうなりました)。たとえば次の表のように"Scenario A", "Scenario B", "Scenario C"を並列して設定し、シナリオ分析を実行することができます。2020/2/6から2020/9/19までの実データが得られている、という前提で日付を記載しています。
scenario名 0th 1st 2nd 3rd scenario A 2/6 - 6/30 7/1 - 9/19 9/20 - 12/31 (該当なし) scenario B 2/6 - 8/31 9/1 - 9/19 9/20 - 12/31 (該当なし) scenario C 2/6 - 8/31 9/1 - 9/19 9/20 - 10/31 11/1 - 12/31 scenario A, B, Cそれぞれについて0th/1st/2nd phaseのパラメータ推定を行い、1st phaseと2nd phaseのパラメータは同一、scenario Cについては2ndから3rdの間に$\rho$が半減すると仮定して患者数のシュミレーションを実行すれば、
- Phase設定を最適化したいとき:AとBのパラメータ推定についてRMSLEを比較すればOK
- 11/1に$\rho$が半減した場合の患者数への効果を検討したいとき:BとCの11/1ら12/1の間の患者数推移を比較すればOK
本記事では「Phase設定を最適化したいとき」に焦点を当てます。
4. シナリオの作成/初期化/削除
シナリオ自体の作成/初期化/削除方法は次の通りです。デフォルトのシナリオ"Main"とそのほかのシナリオに分けてご説明します。
Main scenario
Scenario.trend()やScenario.estimate()メソッドにおいて"name"引数を指定しない場合はデフォルトのシナリオ名"Main"が自動的に使用されます。作成は不要、削除は不可となっています。# 初期化(実データの最終日の翌日以降のPhaseを削除する) snl.clear() # 初期化(実データの最終日以前を含めてすべてのPhaseを削除する) snl.clear(include_past=True) # パラメータ推定 snl.estimate(cs.SIRF)Another scenario
"name"引数を指定すると任意のシナリオ名を使用することができます。ここでは例として"Another"シナリオを作成、初期化、削除します。なお作成時には、Main scenarioの設定がそのままコピーされます(編集方法は後述)。
# 作成(Main scenarioの設定をコピーする) # @templateのデフォルト値:Main snl.clear(name="Another", template="Main") # 初期化(実データの最終日の翌日以降のPhaseを削除する) Scenario.clear(name="Another") # 初期化(実データの最終日以前を含めてすべてのPhaseを削除する) Scenario.clear(name="Another", include_past=True) # パラメータ推定 snl.estimate(cs.SIRF, name="Another") # 削除 Scenario.delete(name="Another")5. シナリオの一覧表示
Scenario.summary()メソッドによりシナリオの情報をpandas.DataFrame形式で一覧表示できます。表示する情報の種類(一覧の列名)を指定したり、特定のシナリオのみ表示したりことも可能です。# すべて表示: # Main scenarioのみ登録されている場合、indexはphase (0th, 1st,..) # Main以外も登録されている場合、indexはシナリオ名とphase snl.summary() # 列名を指定 snl.summary(columns=["Start", "End"]) # 特定のシナリオのみ表示 snl.summary(name="Main")なお
Scenario.trend(),Scenario.add()などのメソッドはselfを返すため、Scenario.trend().summary()などとPhaseの編集と一覧表示をコマンド1行でまとめて実行できます。6. S-R trend analysisによるphase設定
以降の章ではphase設定の編集方法を順にご説明します。
まず、S-R trend analysis3により自動的にphaseを設定できます。
# Main: S-R trend analysis snl.trend(filename=None).summary()
Type Start End Population 0th Past 06Feb2020 21Apr2020 126529100 1st Past 22Apr2020 06Jul2020 126529100 2nd Past 07Jul2020 23Jul2020 126529100 3rd Past 24Jul2020 01Aug2020 126529100 4th Past 02Aug2020 14Aug2020 126529100 5th Past 15Aug2020 28Aug2020 126529100 6th Past 29Aug2020 08Sep2020 126529100 7th Past 09Sep2020 19Sep2020 126529100 7. phaseの無効化と有効化
phaseの期間は変えたくないが、特定のphaseについてはパラメータ推定などをスキップしたい場合、
Scenario.disable(phases)を使用して当該ののphaseを無効化できます。引数が"phases"と複数形になっていることに注意してください。リストを与える必要があります。# MainをコピーしてScenario Aを作成する snl.clear(name="A") # A: 0th phaseと3rd phaseを無効化する snl.disable(phases=["0th", "3rd"], name="A").summary(name="A")
Type Start End Population 1st Past 22Apr2020 06Jul2020 126529100 2nd Past 07Jul2020 23Jul2020 126529100 4th Past 02Aug2020 14Aug2020 126529100 5th Past 15Aug2020 28Aug2020 126529100 6th Past 29Aug2020 08Sep2020 126529100 7th Past 09Sep2020 19Sep2020 126529100 一覧から0th/3rd phaseの行がなくなっていますが、他のphaseの開始日や終了日は変更されていません。
また無効化されたphaseは
Scenario.enable(phases)によって有効化できます。# A: 0th phaseを再有効化する snl.enable(phases=["0th"], name="A").summary(name="A")
Type Start End Population 0th Past 06Feb2020 21Apr2020 126529100 1st Past 22Apr2020 06Jul2020 126529100 2nd Past 07Jul2020 23Jul2020 126529100 4th Past 02Aug2020 14Aug2020 126529100 5th Past 15Aug2020 28Aug2020 126529100 6th Past 29Aug2020 08Sep2020 126529100 7th Past 09Sep2020 19Sep2020 126529100 0th phaseが一覧に表示されました。3rd phaseは無効化されたままです。
7. phaseの結合
phaseを結合したい場合は
Scenario.combine(phases=[最初のphase名, 最後のphase名])をご使用ください。# MainをコピーしてScenario Bを作成する snl.clear(name="B") # B: 1st phase から5th phaseまでを1つのphaseにまとめる snl.combine(phases=["1st", "5th"], name="B")
Type Start End Population 0th Past 06Feb2020 21Apr2020 126529100 1st Past 22Apr2020 28Aug2020 126529100 2nd Past 29Aug2020 08Sep2020 126529100 3rd Past 09Sep2020 19Sep2020 126529100
- 実行前:1st phase (22Apr2020 - 06Jul2020),..., 5th phase (15Aug2020 - 28Aug2020)
- 実行後:1st phase (22Apr2020 - 28Aug2020)
2nd/3rd/4th/5th phaseに所属する日付がなくなったため、6th/7th phaseの名称が2nd/3rdに変更されています。
8. phaseの削除
特定のphaseを削除できますが、phaseの位置によって各日付の新規所属先が異なります。
[削除] 0th phaseの場合
0th phaseは削除できず、
Scenario.delete(phase=["0th"])としても0th phaseが無効化されるのみで1st phaseの開始日は変わりません。# MainをコピーしてScenario Cを作成する snl.clear(name="C") # C: 0th phaseと3rd phaseを無効化する snl.delete(phases=["0th"], name="C").summary(name="C")
Type Start End Population 1st Past 22Apr2020 06Jul2020 126529100 2nd Past 07Jul2020 23Jul2020 126529100 3rd Past 24Jul2020 01Aug2020 126529100 4th Past 02Aug2020 14Aug2020 126529100 5th Past 15Aug2020 28Aug2020 126529100 6th Past 29Aug2020 08Sep2020 126529100 7th Past 09Sep2020 19Sep2020 126529100 結果は省略しますが、
Scenario.enable(phases=["0th"])により再有効化できます。[削除] 途中のphaseの場合
0th phaseでもなく、最後尾のphase (今回は7th phase)も含まれない場合、対象のphaseは一つ前のphaseに吸収されます。
Scenario.combine()と同じです。# MainをコピーしてScenario Dを作成する snl.clear(name="D") # D: 3rd phaseを削除して2nd phaseに吸収させる snl.delete(phases=["3rd"], name="D").summary(name="D")
Type Start End Population 0th Past 06Feb2020 21Apr2020 126529100 1st Past 22Apr2020 06Jul2020 126529100 2nd Past 07Jul2020 01Aug2020 126529100 3rd Past 02Aug2020 14Aug2020 126529100 4th Past 15Aug2020 28Aug2020 126529100 5th Past 29Aug2020 08Sep2020 126529100 6th Past 09Sep2020 19Sep2020 126529100
- 実行前:2nd phase (07Jul2020 - 23Jul2020), 3rd phase (24Jul2020 - 01Aug2020)
- 実行後:2nd phase (07Jul2020 - 01Aug2020)
また、3rd phaseが空になったので4th/5th/6th/7thが3rd/4th/5th/6thにスライドしています。
[削除] 後続phaseがない場合
7th phaseのみ、あるいは6th phaseと7th phaseの両方を削除する場合など後続のphaseがない場合は、6th/7th phaseに所属していた日付はどのphaseにも所属しない状態になります。
# MainをコピーしてScenario Eを作成する snl.clear(name="E") # E: 6th/7th phaseを削除し、29Aug2020以降の所属を破棄 snl.delete(phases=["last"], name="E").summary(name="E")
Type Start End Population 0th Past 06Feb2020 21Apr2020 126529100 1st Past 22Apr2020 06Jul2020 126529100 2nd Past 07Jul2020 23Jul2020 126529100 3rd Past 24Jul2020 01Aug2020 126529100 4th Past 02Aug2020 14Aug2020 126529100 5th Past 15Aug2020 28Aug2020 126529100 6th/7th phaseに所属していた29Aug2020 - 19Sep2020が一覧に表示されなくなりました。
9. phaseの追加
Scenario.add()を使って後続のphaseを追加します。29Aug2020以降がどのphaseにも所属していないScenario Eを例とします。[追加] 最終日を指定
Scenario.add(end_date="31Aug2020")のように最終日を指定して新しいphaseを追加できます。# E: 31Aug2020までを6th phaseとして追加 snl.add(end_date="31Aug2020", name="E").summary(name="E")
Type Start End Population 0th Past 06Feb2020 21Apr2020 126529100 1st Past 22Apr2020 06Jul2020 126529100 2nd Past 07Jul2020 23Jul2020 126529100 3rd Past 24Jul2020 01Aug2020 126529100 4th Past 02Aug2020 14Aug2020 126529100 5th Past 15Aug2020 28Aug2020 126529100 6th Past 29Aug2020 31Aug2020 126529100 [追加] 日数を指定
Scenario.add(days=10)のように日数を指定して新しいphaseを追加できます。# E: 01Sep2020 (6th最終日の翌日)から10日間を7thとして追加 snl.add(days=10, name="E").summary(name="E")
Type Start End Population 0th Past 06Feb2020 21Apr2020 126529100 1st Past 22Apr2020 06Jul2020 126529100 2nd Past 07Jul2020 23Jul2020 126529100 3rd Past 24Jul2020 01Aug2020 126529100 4th Past 02Aug2020 14Aug2020 126529100 5th Past 15Aug2020 28Aug2020 126529100 6th Past 29Aug2020 31Aug2020 126529100 7th Past 01Sep2020 10Sep2020 126529100 [追加] データの最終日まで
Scenario.add()について終了日及び日数を指定しない場合は、データの最終日(今回は19Sep2020)までを1つのphase新しいphaseを追加できます。# E: 11Sep2020 (7th最終日の翌日)から19Sep2020までを8thとして追加 snl.add(days=10, name="E").summary(name="E")
Type Start End Population 0th Past 06Feb2020 21Apr2020 126529100 1st Past 22Apr2020 06Jul2020 126529100 2nd Past 07Jul2020 23Jul2020 126529100 3rd Past 24Jul2020 01Aug2020 126529100 4th Past 02Aug2020 14Aug2020 126529100 5th Past 15Aug2020 28Aug2020 126529100 6th Past 29Aug2020 31Aug2020 126529100 7th Past 01Sep2020 10Sep2020 126529100 8th Past 11Sep2020 19Sep2020 126529100 10. phaseの分割
Scenario.separate(date)により、phaseを分割することができます。指定した日付が分割後の2つ目のphaseの開始日となります。9章で使用したScenario Eの0th phase (06Feb2020 - 21Apr2020)を(06Feb2020 - 31Mar2020), (01Apr2020 - 21Apr2020)に分割するコードはこちらです。# Scenario EをコピーしてScenario Fを作成する snl.clear(name="F", template="E") # E: 01Apr2020を1st phaseの開始日として0th phaseを分割する snl.separate(date="01Apr2020", name="F").summary(name="F")
Type Start End Population 0th Past 06Feb2020 31Mar2020 126529100 1st Past 01Apr2020 21Apr2020 126529100 2nd Past 22Apr2020 06Jul2020 126529100 3rd Past 07Jul2020 23Jul2020 126529100 4th Past 24Jul2020 01Aug2020 126529100 5th Past 02Aug2020 14Aug2020 126529100 6th Past 15Aug2020 28Aug2020 126529100 7th Past 29Aug2020 31Aug2020 126529100 8th Past 01Sep2020 10Sep2020 126529100 9th Past 11Sep2020 19Sep2020 126529100 0th phaseの最終日が31Mar2020, 1st phaseの開始日が01Apr2020になりました。後続の1st phase以降は2nd phase以降にスライドしています。
11. Phase設定の最適化
まとめとしてPhase設定の最適化、つまりパラメータ推定の正確性が高まるようにPhaseの区切りを最適化する方法についてご説明します。0th phaseと1st phaseの境界を最適化したい場合、手順は次の通りです。
a. 区切りの候補日を挙げる
b. 候補となる日付が1st phaseの開始日となるように区切りを変更する
c. 0th/1st phaseについてパラメータ推定を行い、RMSLEを計算する
d. RMSLEを比較し、より低い値を示した候補日を選択する区切りの変更
実装に移る前に、区切りを変更する方法についてご説明します。
Scenario.combine()及びScenario.separate()を組み合わせれば、phaseの区切りを変更することができます。例として、10章で使用したScenario Fを使用します。変更前:0th phase (06Feb2020 - 31Mar2020), 1st phase (01Apr2020 - 21Apr2020)
変更後:0th phase (06Feb2020 - 11Apr2020), 1st phase (12Apr2020 - 21Apr2020)# Scenario FをコピーしてScenario Gを作成する snl.clear(name="G", template="F") # G: 0th phaseと1st phaseを結合する snl.combine(phases=["0th", "1st"], name="G") # G: 12Apr2020を1st phaseの開始日として0th phaseを分割する snl.separate(date="12Apr2020", name="G").summary(name="G")
Type Start End Population 0th Past 06Feb2020 11Apr2020 126529100 1st Past 12Apr2020 21Apr2020 126529100 2nd Past 22Apr2020 06Jul2020 126529100 3rd Past 07Jul2020 23Jul2020 126529100 4th Past 24Jul2020 01Aug2020 126529100 5th Past 02Aug2020 14Aug2020 126529100 6th Past 15Aug2020 28Aug2020 126529100 7th Past 29Aug2020 31Aug2020 126529100 8th Past 01Sep2020 10Sep2020 126529100 9th Past 11Sep2020 19Sep2020 126529100 実装
Phase設定の最適化の実装方法です。まず、候補日の設定と最適化用インスタンスの作成を行います。
区切りの候補日は0th phaseの3日目から1st phaseの終了日3日前となります。Phaseの期間が3日以内になるとパラメータ推定が難しくなります。今回は例として、候補日は01Mar2020と12Apr2020のみに絞って話を進めます。
# 候補日 candidates = ["01Mar2020", "12Apr2020"] # RMSLEの登録用dictionary opt_dict = {date: {} for date in candidates} # 最適化用インスタンス:(Optional) tau valueを揃える snl_opt = cs.Scenario(jhu_data, population_data, country="Japan", tau=720) # S-R trend analysis snl_opt.trend(show_figure=False)候補日ごとに、シナリオを作成し、区切りの変更、パラメータ推定、RMSLEの記録を行います。
Scenario.estimate()の"phases"引数と"name"引数を設定すると、目的のシナリオの特定のPhaseについてのみパラメータ推定を行うことができます(時間の節約)。また、
Scenario.get(列名, phase=Phase名, name=シナリオ名)とすることで、Scenario.summary()から値を取り出すことができます。for date in candidates: # 候補日を名称とするシナリオの作成 snl_opt.clear(name=date) # 区切りの変更 snl_opt.combine(phases=["0th", "1st"], name=date) snl_opt.separate(date=date, name=date) # パラメータ推定(0th/1st phaseのみ実施) snl_opt.estimate(cs.SIRF, phases=["0th", "1st"], name=date) # RMSLEの記録 opt_dict[date]["0th"] = snl_opt.get("RMSLE", phase="0th", name=date) opt_dict[date]["1st"] = snl_opt.get("RMSLE", phase="1st", name=date)データフレーム形式でRMSLEを表示します。pandasはCovsirPhyのインストール時に依存パッケージとしてインストールされています。
import pandas as pd pd.DataFrame.from_dict(opt_dict, orient="index")
0th 1st 01Mar2020 0.399103 5.54859 12Apr2020 0.757649 1.46627 1st phaseの開始日を12Apr2020としたほうが01Mar2020とした場合よりも1st phaseのRMSLEを抑えられるようです。しかし0th phaseのRMSLEは上昇しており、最適な区切りは02Mar2020から11Apr2020の間にあるようです。(この先については長くなってきたので省略します...)
12. あとがき
表が多く記事が長くなってしまいましたが、今回も閲覧ありがとうございました!
次回は未来のphaseを追加し、患者数のシュミレーションを実行する方法についてご説明します。
Guidotti, E., Ardia, D., (2020), “COVID-19 Data Hub”, Journal of Open Source Software 5(51):2376, doi: 10.21105/joss.02376. ↩
- 投稿日:2020-09-19T20:52:51+09:00
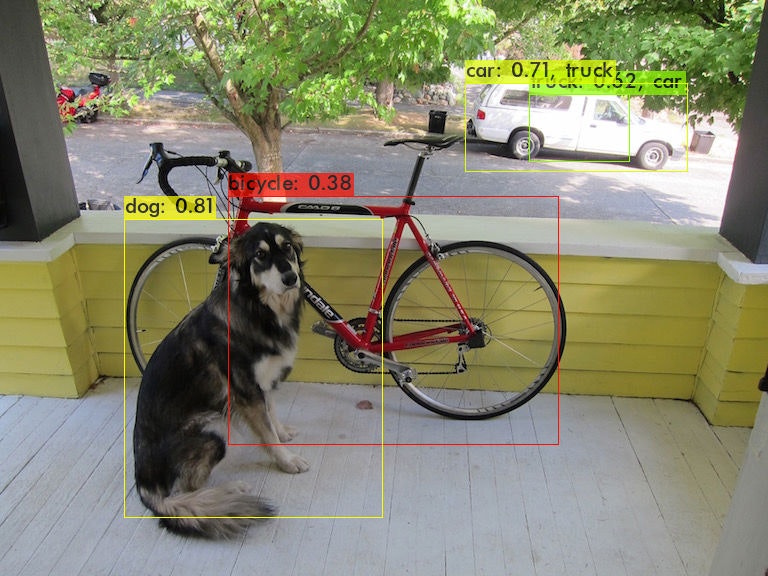
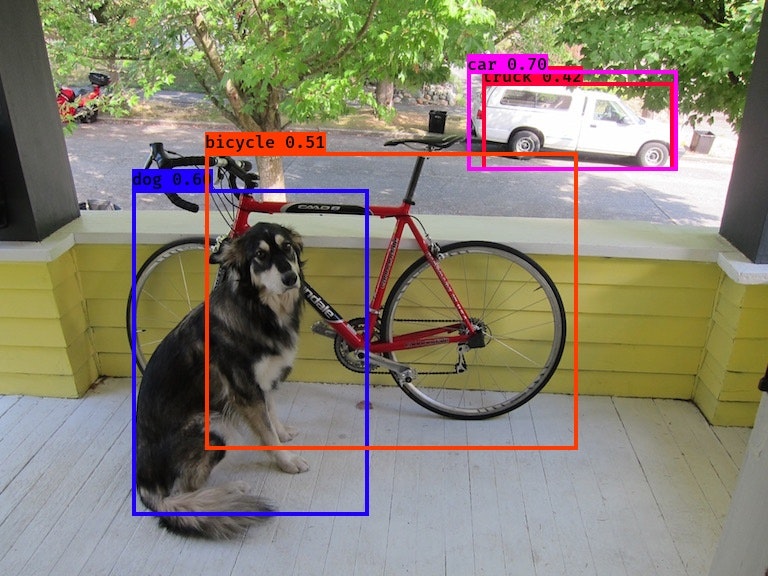
RaspberryPiで物体検出してみる ~その1:検出速度比較~
はじめに
RaspberryPiで物体検出を行うにあたり、主要な物体検出手法の一つであるYOLO(You only look once)の各ソースの検出速度と検出精度を比較してみたのでまとめます。
YOLOの仕組みについては【物体検出手法の歴史 : YOLOの紹介】が分かり易かったです。
私がRaspberryPi でやりたいこと
猫用のペットカメラとするついでに、4匹の猫を見分けたい!柄は4匹とも違う!
見分けて何をするかは、猫の様子を監視してエアコンのリモコン制御とか、活動量を見て健康管理に使えたらいいなぁ程度しか考えてないです。
- MUST:識別するクラス数を変更して、オリジナルの学習モデルを作ることができる(今回の記事のスコープからは外れます)
- MAY:できれば1秒に1回は判定したい
環境

結果
評価対象はCOCOデータセット(クラス数は80)とし、YOLOの作者のサイト:YOLO: Real-Time Object DetectionとAlexeyABで配布されている学習済みモデルの重みを用いています。各モデルには検出時間を優先した"Tiny"というものがあります。
以下、ソース×Modelの結果です。説明・結果の画像・所感は後程記載します。
ソース Model 検出時間 検出精度 pjreddie v2 477秒 ○ pjreddie v2-Tiny 42秒 × AlexeyAB v2 33秒 ○ AlexeyAB v2-Tiny 6.6秒 △ AlexeyAB v3 74秒 ◎ AlexeyAB v3-Tiny 6.7秒 ○ AlexeyAB v4 152秒 ◎ AlexeyAB v4-Tiny 7.8秒 ○ keras-yolo3 v3 12秒 ◎ keras-yolo3 v3-Tiny 0.75秒 ○ Tensorflow-YOLOv3 v3 8.9秒 ◎ Tensorflow-YOLOv3 v3-Tiny 3.4秒 ○ yolov3-tf2 v3 5.6秒 ◎ yolov3-tf2 v3-Tiny 0.67秒 ○ 検出精度は主観ですが、各画像の主の物体の認識率を目安にしています。◎(90%~100%)、〇(70%~90%)、△(50%~70%)、×(認識できない)。
ソースごとの説明・結果画像・所感
pjreddie/darknet
https://pjreddie.com/
https://github.com/pjreddie/darknet
- 本家
- v2、v3の学習済みモデルの重みのダウンロードもこちらからできます。
- C言語
- 物体検出中のCPUの使用率は25~35%で遷移しており、CPUの使用効率は悪い。
- makeファイルのパラメータを変えることで、GPUで動作させることも可能だが、RaspberryPiでは難しい。
- v3、yolov3-tinyは
Segmentation faultで動きませんでした。(Google Colaboratoryでは検出できているので環境の問題)- v2-Tinyは物体検出できてなさそうでした。(こちらもGoogle Colaboratoryでは検出できているので環境の問題)

Model dog person v2 v2-tiny AlexeyAB/darknet
https://github.com/AlexeyAB/darknet
- pjreddieの継承版。YOLO v4に対応。
- YOLO v4の学習済みモデルの重みのダウンロードはこちらからできます。
- C言語
- makeファイルのパラメータを変えることで、GPUで動作させることも可能だが、RaspberryPiでは難しい。
- 物体検出中のCPUの使用率は25~35%で遷移しており、CPUの使用効率は悪い。
Model dog person v2 v2-tiny v3 v3-tiny v4 v4-tiny qqwweee/keras-yolo3
https://github.com/qqwweee/keras-yolo3
- keras版
- pjreddie/darknetの重みをコンバートして使用することができる。
- デフォルトでは検出結果の画像を出力できないので、KerasのYOLO-v3を動かしたったを参考に処理を追加しました。
- 物体検出中のCPUの使用率は100%



Model dog person v3 v3-tiny neuralassembly/Tensorflow-YOLOv3
https://github.com/neuralassembly/Tensorflow-YOLOv3
Raspberry Pi で YOLO v3-Tiny / YOLO v3 による物体検出を試してみよう
- Tensorflow1系
- pjreddie/darknetの重みをコンバートして使用することができる。
- 検出時間は出力されないので、sess.run()の前後で時間を計測。
- 物体検出中のCPUの使用率は100%
Model dog person v3 v3-tiny zzh8829/yolov3-tf2
https://github.com/zzh8829/yolov3-tf2
- tensorflow2系 (tf.keras使用)
- pjreddie/darknetの重みをコンバートして使用することができる。
- RaspberryPiでは
pip install tensorflowでtensorflow2は入らなかったので、https://github.com/PINTO0309/Tensorflow-bin からtensorflow-2.2.0-cp37-cp37m-linux_armv7l.whlをダウンロードしてinstall- 物体検出中のCPUの使用率は75~85%

Model dog person v3 v3-tiny まとめ
- 「1秒に1回は判定したい」を満たすには、多少検出精度は落ちるがPython系のv3-tinyでしか難しい。
- 私が使うときにはクラス数は少なくなるので、それにより精度は上がることを期待する。
今後の方向性
- 学習はAlexeyABをGPU版でbuildし、Google Colaboratoryで実行する。Tinyなら1000エポック:7分程度。
- 物体検出はPython系の中から流用しやすさを見てどれを使うか決める。(今後のことも考えるとzzh8829/yolov3-tf2が無難か。。)
- 猫の写真撮らないと。。
参考
Raspberry PiでDarknetを使う
YOLOv3 論文訳qqwweee/keras-yolo3
zzh8829/yolov3-tf2



























- 投稿日:2020-09-19T20:44:15+09:00
Djangoを使って10分で作るCSS環境
プロローグ
CSSの勉強用環境をDjangoで作ります。
Djangoが導入済みであれば10分想定です。
内容には影響ないかと思いますが、実行環境です
OS : Windows10
python : Python 3.7.6
django : 3.1手順
フォルダ作成、プロジェクト作成、アプリ作成
C:\work\02_実施>mkdir 20200919_htmlcss C:\work\02_実施>cd 20200919_htmlcss C:\work\02_実施\20200919_htmlcss>django-admin startproject htmlcss C:\work\02_実施\20200919_htmlcss>cd htmlcss C:\work\02_実施\20200919_htmlcss\htmlcss>python manage.py startapp test_app C:\work\02_実施\20200919_htmlcss\htmlcss>dir ドライブ C のボリューム ラベルがありません。 ボリューム シリアル番号は D48D-C505 です C:\work\02_実施\20200919_htmlcss\htmlcss のディレクトリ 2020/09/19 19:38 <DIR> . 2020/09/19 19:38 <DIR> .. 2020/09/19 19:38 <DIR> htmlcss 2020/09/19 19:38 685 manage.py 2020/09/19 19:38 <DIR> test_app 1 個のファイル 685 バイト 4 個のディレクトリ 8,932,749,312 バイトの空き領域アプリ認識(appsに定義されているアプリ名をsetting.pyに追記)
C:\work\02_実施\20200919_htmlcss\htmlcss>cd htmlcss C:\work\02_実施\20200919_htmlcss\htmlcss\htmlcss>notepad settings.py C:\work\02_実施\20200919_htmlcss\htmlcss\htmlcss>type ..\test_app\apps.py from django.apps import AppConfig class TestAppConfig(AppConfig): name = 'test_app'htmlcss/setting.py# Application definition INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'test_app.apps.TestAppConfig', ]アクセス先の設定(プロジェクトのurls.pyとアプリのurls.pyに設定)
C:\work\02_実施\20200919_htmlcss\htmlcss\htmlcss>notepad urls.pyhtmlcss/urls.pyfrom django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('', include('test_app.urls')), ]C:\work\02_実施\20200919_htmlcss\htmlcss\htmlcss>copy urls.py ..\test_app\ 1 個のファイルをコピーしました。 C:\work\02_実施\20200919_htmlcss\htmlcss\htmlcss>notepad ..\test_app\urls.pytest_app/urls.pyfrom django.urls import path, include from . import views urlpatterns = [ path('', views.index), ]アクセス先のhtmlを指定と作成
C:\work\02_実施\20200919_htmlcss\htmlcss\htmlcss>notepad ..\test_app\views.pytest_app/views.pyfrom django.shortcuts import render # Create your views here. def index(request): return render(request, 'index.html')C:\work\02_実施\20200919_htmlcss\htmlcss\htmlcss>mkdir ..\test_app\templates C:\work\02_実施\20200919_htmlcss\htmlcss\htmlcss>notepad ..\test_app\templates\index.htmlindex.html<html> <head> </head> <body> <p>hello, world</p> </body> </html>ようやくCSS(css認識と作成、htmlからの呼び出し)
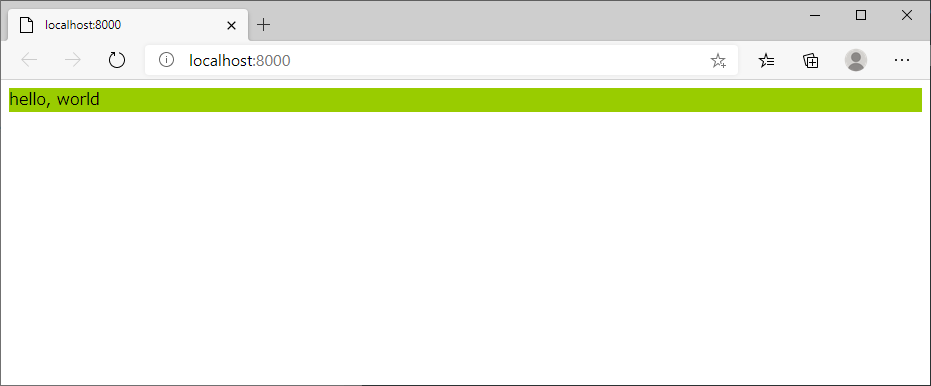
C:\work\02_実施\20200919_htmlcss\htmlcss\htmlcss>notepad settings.pyhtmlcss/setting.py# Static files (CSS, JavaScript, Images) # https://docs.djangoproject.com/en/3.1/howto/static-files/ import os STATIC_URL = '/static/' STATICFILES_DIRS = ( os.path.join(BASE_DIR, 'static'), )C:\work\02_実施\20200919_htmlcss\htmlcss\htmlcss>mkdir ..\test_app\static\css C:\work\02_実施\20200919_htmlcss\htmlcss\htmlcss>notepad ..\test_app\static\css\style.cssstyle.css.T1 { background-color: #99cc00 }C:\work\02_実施\20200919_htmlcss\htmlcss\htmlcss>notepad ..\test_app\templates\index.htmlindex.html{%load static%} <html> <head> <link href="{% static 'css/style.css'%}" rel="stylesheet"> </head> <body> <div class='T1'> <p>hello, world</p> </div> </body> </html>webサーバの起動とブラウザで確認
C:\work\02_実施\20200919_htmlcss\htmlcss\htmlcss>start C:\work\02_実施\20200919_htmlcss\htmlcss\htmlcss>python ..\manage.py runserver C:\work\02_実施\20200919_htmlcss\htmlcss\htmlcss>start http://localhost:8000完成!!!
エピローグ
これで好きなようにCSSをジャンジャン試せます
- 投稿日:2020-09-19T20:39:24+09:00
Webフレームワークでよく聞く『MVCモデル』を解き明かす! (2020年9月)
Webフレームワークでよく聞くMVCモデルについての解説です!
参考動画 ? https://youtu.be/GoUgMz6n0Dw
- 投稿日:2020-09-19T20:14:15+09:00
[R][Python]複数のzipファイル内の複数csvファイルを読み込むメモ
はじめに
あるフォルダ下にある複数のzipファイルに格納された、複数のcsvファイルを一気に読み込みたい、というシーンに出会ったのでメモ。
フォルダ構成例
このようなフォルダ構成になっているとき、各zipファイルの中にあるcsvファイルをまとめて一気に読み込んで、listに格納してしまいたい。
input/ ┣ zip_files/ ┃ ┣ test1.zip/ ┃ ┃ ┣ test1_1.csv ┃ ┃ ┣ test1_2.csv ┃ ┃ ... ┃ ┣ test2.zip/ ┃ ┃ ┣ test2_1.csv ┃ ┃ ┣ test2_2.csv ┃ ...Rコード
unzip, unz関数でzipを開かずに中のファイルにアクセスできる。
pythonのappend的にlistに加えたかったが、良くわからなかったので以下で妥協。library(tidyverse) library(data.table) zip_list <- list.files("zip_files") # function of read csv files in zip files get_csv <- function(zip_list){ csv_list <- list() zip_lists <- list() # Loop through the list of files for(j in 1:length(zip_list)) { # Create list of files file <- unzip(paste0("zip_files/", zip_list[j]), list = TRUE) for(i in 1:length(file)){ # If a file is a csv file, unzip it and read the data if(grepl("csv", file[i,1])) { print(paste0('reading following file...', file[i,1])) csv_files <- read_csv(unz(paste0("zip_files/", zip_list[j]), file[i,1]), col_names=TRUE) ######################## # Add Some process. ######################## csv_list[[i]] <- csv_files zip_lists[[j]] <- csv_list } } } return(zip_lists) } system.time(csvs <- get_csv(zip_list))Pythonコード
zipfileモジュールでzipファイルを解凍せずに内部にアクセスできる。
enumerateは、for文で回すオブジェクトのindexと要素を返すので、何か処理を加える場合便利。
(以下の例では使わなくても一緒)import os import zipfile import glob import pandas as pd import time df_list = list() start = time.time() for i, zips in enumerate(zip_list): zip_f = zipfile.ZipFile(zips) file_list = zip_f.namelist() # file names of csv files in zip for j, files in enumerate(file_list): print('reading following file...' + zips + '/' + files) df = pd.read_csv(zip_f.open(files)) ######################## # Add Some process. # If use i and j too. ######################## df_list.append(df) elapsed_time = time.time() - start print ("elapsed_time:{0}".format(elapsed_time) + "[sec]")
- 投稿日:2020-09-19T19:25:15+09:00
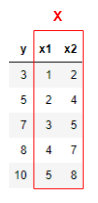
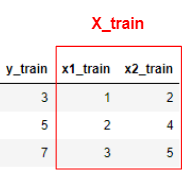
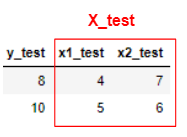
訓練データとテストデータ(X_trainとy_trainとは?)②
前回の①に続けて、少し実践的な訓練データ・テストデータの分け方をしていきます。
まずデータを用意します。
今度は変数 x が2つあります。
このように機械学習では、変数 x が2つ以上あるとき
それらを1つにまとめて大文字 $\mathbf{X}$ として扱っていきます。次に、訓練データとテストデータに分けます。
訓練データ
テストデータ
そして訓練データからモデル式を作成していきます。
これを最小二乗法というもので計算すると、下記のように求まります。$$y=0.9+2x_1+2.0\times10^{-16}x_2$$
そしてこれをテストデータに当てはめていきます。
$$y_{pred}=0.9+2x_{1_{test}}+2.0\times10^{-16}x_{2_{test}}=9,11$$ $$y_{test}=8,10$$
上記のことから、正解データの y_test に対して
自分が予測した y_pred は、おおよそ合っていることが分かりました。$y$ に対して $x$ が2つ以上ある場合には
基本的に、訓練データとテストデータを上記のように考えていきます。また、前回の記事①と今回の記事②は
どちらとも線形回帰という手法を行っておりますので
近いうちに、また投稿させていただければと思います。
- 投稿日:2020-09-19T18:50:39+09:00
【PowerShell】文字列の読みがなを取得する
できたもの
> "納豆(遺伝子組み換えでない)"|Get-ReadingWithSudachi|fl Line : 納豆(遺伝子組み換えでない) Reading : ナットウ(イデンシクミカエデナイ) Tokenize : 納豆(ナットウ)/(/遺伝子(イデンシ)/組み換え(クミカエ)/で/ない/) Markup : <p><ruby>納豆<rt>ナットウ</rt></ruby>(<ruby>遺伝子<rt>イデンシ</rt></ruby> <ruby>組み換え<rt>クミカエ</rt></ruby>でない)</p>コード
環境:
> $PSVersionTable Name Value ---- ----- PSVersion 7.0.3 PSEdition Core GitCommitId 7.0.3 OS Microsoft Windows 10.0.18362 Platform Win32NT PSCompatibleVersions {1.0, 2.0, 3.0, 4.0…} PSRemotingProtocolVersion 2.3 SerializationVersion 1.1.0.1 WSManStackVersion 3.0以前に書いた、 SudachiPy での形態素解析を呼び出します(【PowerShell】 SudachiPy で形態素解析する)。
function Get-ReadingWithSudachi { param ( [switch]$readingOnly, [switch]$ignoreParen ) $ret = New-Object System.Collections.ArrayList $tokenizedResults = $input | Invoke-SudachiTokenizer -ignoreParen:$ignoreParen foreach ($result in $tokenizedResults) { $reading = New-Object System.Text.StringBuilder $tokenize = New-Object System.Collections.ArrayList $markup = New-Object System.Collections.ArrayList foreach ($token in $result.parsed) { $tokenSurface = $token.surface if ($token.pos -match "記号|空白" -or $tokenSurface -match "^([ァ-ヴ・ー]|[a-zA-Za-zA-Z]|[0-90-9]|[\W\s])+$") { $tokenReading = $tokenSurface $tokenInfo = $tokenSurface $tokenMarkup = $tokenSurface } elseif (-not $token.reading) { $tokenReading = $tokenSurface $tokenInfo = "$($tokenSurface)(?)" $tokenMarkup = $tokenSurface } else { $tokenReading = $token.reading $tokenInfo = ($tokenSurface -match "^[ぁ-ん]+$")? $tokenSurface : "$($tokenSurface)($tokenReading)" $tokenMarkup = ($tokenSurface -match "^[ぁ-ん]+$")? $tokenSurface : "<ruby>{0}<rt>{1}</rt></ruby>" -f $tokenSurface, $tokenReading } $reading.Append($tokenReading) > $null $tokenize.Add($tokenInfo) > $null $markup.Add($tokenMarkup) > $null } $ret.Add([PSCustomObject]@{ Line = $result.line Reading = $reading.ToString() Tokenize = $tokenize -join "/" Markup = "<p>{0}</p>" -f ($markup -join "") }) > $null } return ($readingOnly)? $ret.reading : $ret }html マークアップ
たまにこのような感じで専門用語の解析に失敗します。
1つ2つであれば目視でチェックできますが、数百行を処理するとなると困るので、
Markupというプロパティで html マークアップを吐き出すようにしました。(cat hogehoge.txt |Get-ReadingWithSudachi).markup|Out-File hogehoge.html
上記のようにして html 化して、ブラウザで確認すれば多少は見落としが減る…と信じています。


- 投稿日:2020-09-19T17:39:04+09:00
複数のCSV、データフレームを1つのデータフレームに高速にまとめる【60倍速】
df.append()は遅い。。。
データフレームを結合するのにこれまで時間をかけていたのですが、いい方法がありましたので紹介させていただきます。
私の環境では60倍以上の高速に成功しました!
同じ形式のCSVファイルを結合して、読み込むのに利用可能です。環境
Python: 3.7.6 pandas: 1.0.1私が使っていた方法
CSVを読みこんで、ひたすらAppendする方法を使っていました。
約2500個のCSV(それぞれおよそ1000行)を読み込み、結合するのに12分42秒かかりました。csvs = glob.glob('./data/csv/*.csv') df = pd.DataFrame() for csv in csvs: df = df.append(pd.read_csv(csv))高速な方法
同じCSVの読み込み・結合を11.6秒で完了することができました。
65.6倍速で同じ作業を完了することができました!from itertools import chain def fast_concat(dfs): def fast_flatten(input_list): return list(chain.from_iterable(input_list)) col_names = dfs[0].columns df_dict = dict.fromkeys(col_names, []) for col in col_names: extracted = (d[col] for d in dfs) df_dict[col] = fast_flatten(extracted) df = pd.DataFrame.from_dict(df_dict)[col_names] return df dfs = [] for csv in csvs: dfs += [pd.read_csv(csv)] df = fast_concat(dfs)なぜ速いのか
一言でいうとDictに
https://qiita.com/siruku6/items/4846431198769b38bb41最後に
この記事はこちらの投稿を元に作成しています。
CSVをまとめるという作業はよく発生するものでしたので、非常に役立っています。
データフレームのリストを作るだけで使えますので、汎用性も高いです!
- 投稿日:2020-09-19T17:28:43+09:00
bottleで作ったWebアプリをHerokuでデプロイするまで
結論
bottleを使ったアプリケーションをHerokuにデプロイする。
はじめに
PythonのbottleでWebアプリケーションを作りHerokuなるものを使ってデプロイしようとしたものの、なかなか上手くいかなかったためアウトプットとして記事を書いてみます。初めての投稿かつ初心者なため色々指摘していただければありがたいです。
環境
- Windows10
- Python 3.8.3
- bottle 0.12.18
- numpy 1.18.5
- scikit-learn 0.23.1
参考にしたサイト
基本的にこれらのサイトの手順で問題ないと思いますが、僕は何かとバグってしまったのでその際に参考にしていただければと思います。
手順
- Herokuのアカウントを作る
- Heroku CLIをインストールする
- Webアプリを作る
- デプロイしたいファイルを格納するディレクトリを作る(以下のファイルが必要)
- main.py
- requirement.txt
- Procfile
- runtime.txt
- その他のファイル(bottleのテンプレートファイルとか)
- gitコマンドでコミットする
- Herokuにデプロイする
Herokuのアカウント作成
ここからアカウントを作成できます。
Heroku CLIのインストール
ここからHeroku CLIをインストールします。
僕はWindowsだったので、インストーラーをDLした後heroku-x64.exeを実行しました。選ぶところは全てデフォルトのままでやりました。Webアプリの作成
作ってください。リモート環境で動くかに注意してください。
リモート環境で動かすときは、以下のコードにしていましたが、run(host="localhost",port=8080,debug=True)デプロイする際は以下のコードに変えました。このあたり何をしているのかよく分かっておらず、とりあえず写経したというところです。
run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))デプロイしたいファイルを格納するディレクトリを作る
main.pyとその他のファイルについては特に言うことはありません。
注意ポイント
requirement.txt, Procfile, runtime.txtの文字コードに注意しましょう。
utf-16 LEなる文字コードではデプロイできず、utf-8ならばデプロイできました。requirement.txt
これは、インポートしたいモジュールとそのバージョンを記述するファイルです。numpyなどを利用する際にはパッケージがあるようなのですが、僕はエラーを修正できなかったため止めました。
以下のような内容になりました。
モジュール名==バージョンという記法です。requirement.txtbottle==0.12.18 numpy==1.18.5 scikit-learn==0.23.1Procfile
これは、実行するpythonのファイルを記述するファイルだと思います(理解が浅い)。また、Procfile.windowsというファイルも作成し、以下のように記述しました。
以下のmain.pyの部分は自分のPythonファイルの名前に変更してください。bottleではなく、flaskを利用している場合以下の書き方ではないようです。Procfileweb: python main.pyProcfile.windowsweb: python main.py runserver 0.0.0.0:5000runtime.txt
これは実行するPythonのバージョンです。Herokuのサポートするバージョンが決まっているらしく、とりあえず
Python-3.8.5にしました。自分の実行環境と違いましたが、イケました(おそらく良くない)。
大文字と小文字を間違えるとエラーになるようなので、注意しましょう。runtime.txtpython-3.8.5注意(もう一度)
requirement.txt, Procfile, runtime.txtの文字コードに注意しましょう。
utf-16 LEなる文字コードではデプロイできず、utf-8ならばデプロイできました。gitコマンドでコミットする
デプロイしたいディレクトリに移動し、そのディレクトリをコミットします。
cd (デプロイしたいディレクトリ) git init git add --all git commit -m "first commit"Herokuにデプロイする
いよいよHerokuにデプロイします。
僕はアプリ作成よりもこちらで時間を喰ってしまいましたHerokuへのログイン
まずHerokuにログインします。Herokuに登録したメールアドレスとパスワードを聞かれるので入力します。
heroku login上手くいくと、以下のように表示されます。
Logged in as 自分のメアドアプリ作成からデプロイ
次に以下のように実行します。これは、アプリをHerokuで作成しています。
heroku createをすると、アドレスを教えてくれますが、そのアドレスがWebアプリのアドレスになります。この場合、名前は適当に設定されますが自分でも設定できるようです。heroku create最後に、プッシュします。
git push heroku master上手くいくと、以下のようなコードが表示されるはずです。
remote: Verifying deploy... done.逆に、上手く行かないと、以下のようなコードが表示されてしまいます。
error: failed to push some refs to 'https://git.heroku.com/XXXXXXX.git'このとき、エラーコードの上をよく見るとどこで詰まったのかを教えてくれますがそこまで親切ではありません。そこで、
https://git.heroku.com/XXXXXXX.gitのページに行くと、詳しいログを確認できるためそこで詳しい情報を知りましょう。アプリの確認
デプロイすることができれば、
heroku openでそのアプリを確認できます。
- 投稿日:2020-09-19T17:28:43+09:00
bottleで作ったWebアプリをHerokuで公開(デプロイ)するまで
結論
bottleを使ったアプリケーションをHerokuで公開する。
はじめに
PythonのbottleでWebアプリケーションを作りHerokuなるものを使ってデプロイしようとしたものの、なかなか上手くいかなかったためアウトプットとして記事を書いてみます。初めての投稿かつ初心者なため色々指摘していただければありがたいです。
環境
- Windows10
- Python 3.8.3
- bottle 0.12.18
- numpy 1.18.5
- scikit-learn 0.23.1
参考にしたサイト
基本的にこれらのサイトの手順で問題ないと思いますが、僕は何かとバグってしまったのでその際に参考にしていただければと思います。
手順
- Herokuのアカウントを作る
- Heroku CLIをインストールする
- Webアプリを作る
- デプロイしたいファイルを格納するディレクトリを作る(以下のファイルが必要)
- main.py
- requirement.txt
- Procfile
- runtime.txt
- その他のファイル(bottleのテンプレートファイルとか)
- gitコマンドでコミットする
- Herokuにデプロイする
Herokuのアカウント作成
ここからアカウントを作成できます。
Heroku CLIのインストール
ここからHeroku CLIをインストールします。
僕はWindowsだったので、インストーラーをDLした後heroku-x64.exeを実行しました。選ぶところは全てデフォルトのままでやりました。Webアプリの作成
作ってください。リモート環境で動くかに注意してください。
リモート環境で動かすときは、以下のコードにしていましたが、run(host="localhost",port=8080,debug=True)デプロイする際は以下のコードに変えました。このあたり何をしているのかよく分かっておらず、とりあえず写経したというところです。
run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))デプロイしたいファイルを格納するディレクトリを作る
main.pyとその他のファイルについては特に言うことはありません。
注意ポイント
requirement.txt, Procfile, runtime.txtの文字コードに注意しましょう。
utf-16 LEなる文字コードではデプロイできず、utf-8ならばデプロイできました。requirement.txt
これは、インポートしたいモジュールとそのバージョンを記述するファイルです。numpyなどを利用する際にはパッケージがあるようなのですが、僕はエラーを修正できなかったため止めました。
以下のような内容になりました。
モジュール名==バージョンという記法です。requirement.txtbottle==0.12.18 numpy==1.18.5 scikit-learn==0.23.1Procfile
これは、実行するpythonのファイルを記述するファイルだと思います(理解が浅い)。また、Procfile.windowsというファイルも作成し、以下のように記述しました。
以下のmain.pyの部分は自分のPythonファイルの名前に変更してください。bottleではなく、flaskを利用している場合以下の書き方ではないようです。Procfileweb: python main.pyProcfile.windowsweb: python main.py runserver 0.0.0.0:5000runtime.txt
これは実行するPythonのバージョンです。Herokuのサポートするバージョンが決まっているらしく、とりあえず
Python-3.8.5にしました。自分の実行環境と違いましたが、イケました(おそらく良くない)。
大文字と小文字を間違えるとエラーになるようなので、注意しましょう。runtime.txtpython-3.8.5注意(もう一度)
requirement.txt, Procfile, runtime.txtの文字コードに注意しましょう。
utf-16 LEなる文字コードではデプロイできず、utf-8ならばデプロイできました。gitコマンドでコミットする
デプロイしたいディレクトリに移動し、そのディレクトリをコミットします。
cd (デプロイしたいディレクトリ) git init git add --all git commit -m "first commit"Herokuにデプロイする
いよいよHerokuにデプロイします。
僕はアプリ作成よりもこちらで時間を喰ってしまいましたHerokuへのログイン
まずHerokuにログインします。Herokuに登録したメールアドレスとパスワードを聞かれるので入力します。
heroku login上手くいくと、以下のように表示されます。
Logged in as 自分のメアドアプリ作成からデプロイ
次に以下のように実行します。これは、アプリをHerokuで作成しています。
heroku createをすると、アドレスを教えてくれますが、そのアドレスがWebアプリのアドレスになります。この場合、名前は適当に設定されますが自分でも設定できるようです。heroku create最後に、プッシュします。
git push heroku master上手くいくと、以下のようなコードが表示されるはずです。
remote: Verifying deploy... done.逆に、上手く行かないと、以下のようなコードが表示されてしまいます。
error: failed to push some refs to 'https://git.heroku.com/XXXXXXX.git'このとき、エラーコードの上をよく見るとどこで詰まったのかを教えてくれますがそこまで親切ではありません。そこで、
https://git.heroku.com/XXXXXXX.gitのページに行くと、詳しいログを確認できるためそこで詳しい情報を知りましょう。アプリの確認
デプロイすることができれば、
heroku openでそのアプリを確認できます。
- 投稿日:2020-09-19T17:21:15+09:00
OpenCV(CUDA)によるaffine transformation
動機
過去記事参照
まとめ
- Python上のOpenCVで、affine変換を行った
- 結論
- CUDA万歳。
- OpenCVのmultithreadingすごい。
環境
- 2*Xeon E5-2667 v3 @3.20 GHz
- DDR4-2133 4*8 GB RAM
- ubuntu LTS 20.04 @ Samsung Evo Plus 970 (500GB)
- GTX 1080 (RTX 30XXがほしい)
- OpenCV 4.5.0 pre (4.5.0 preなことに特に意味はない。気が向いたら4.4.0あたりに直したい。環境構築)
- cuda 10.2, cnDNN 7.6.5
コード
前処理
まず、諸々を読み込んでから200*200のmaharo.jpgを取得します。
これはサンシャイン水族館にいるカワウソのマハロくんの画像です。
このあたりの詳細は過去記事参照。import cv2 as cv import numpy as np from matplotlib import pyplot as plt print('Enabled CUDA devices:',cv.cuda.getCudaEnabledDeviceCount()) # 1 src = cv.cvtColor(cv.imread("maharo.jpg"),cv.COLOR_BGR2RGB) w, h, c = src.shape #200, 200, 3 plt.subplot(111),plt.imshow(src) plt.title('otter image'), plt.xticks([]), plt.yticks([]) plt.show() g_src = cv.cuda_GpuMat() g_dst = cv.cuda_GpuMat() g_src.upload(src)
先にaffine変換の行列を定義しておきます。中心を軸にした回転と並行移動を組み合わせて、scale倍rot度の中心軸回転を行います。def get_rot_affine(src, rot, scale): h, w = src.shape[:2] rot_affine = cv.getRotationMatrix2D((h/2, w/2), rot, scale) rot_affine[:2,2] -= [h/2, w/2] rot_affine[:2,2] += [h/2*scale, w/2*scale] return rot_affine等倍20度回転
等倍20度回転についてはaffine行列を以下のように定義します。
ちなみに、CUDAの方はLanczos補間に対応していません。rot_affine = get_rot_affine(src, 20, 1)CPU
まずはCPUで試してみます。
%%timeit img_dst = cv.warpAffine(src, rot_affine, (w*1, h*1), flags=cv.INTER_CUBIC) # 1.08 ms ± 7.24 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
CUDA
情報の読み出し/書き出しをループに含めない処理オンリーで、GPUの素材の味を実感してみようと思います。
例によってcv2.cuda.wrapAffineを使うのですが、引数はsource画像srcとoutput画像dstだけGPU上に置いて、affine行列やdstサイズは通常のcv.wrapAffineと共通のものを使うようです。(GPU上に置くと怒られる)。%%timeit g_dst = cv.cuda.warpAffine(g_src, rot_affine, (w*1, h*1), flags=cv.INTER_CUBIC) # 383 µs ± 28.6 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)まあ、こんなもんでしょう…やはり画像が小さいと2~3倍程度しか効果はないようです。
%%timeit g_src.upload(src) g_dst = cv.cuda.warpAffine(g_src, rot_affine, (w*1, h*1), flags=cv.INTER_CUBIC) gpu_dst = g_dst.download() # 450 µs ± 5.11 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
読み込み/書き出しを考慮してもそこまで速度が変わりません。(画像が軽いから)
10倍20度回転
マハロくんを10倍(2K)にして、20度回転してみます。
affine行列は以下のように呼んでおきました。rot_affine = get_rot_affine(src, 20, 10)CPU
まずはCPUで試してみます。
%%timeit img_dst = cv.warpAffine(src, rot_affine, (w*10, h*10), flags=cv.INTER_CUBIC) # 7.29 ms ± 36.8 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)10倍拡大したにしては結構速いです。
これは環境依存で、200 px画像の処理時は並列化が十分に働かず、CPUが1 threadで動いていたのですが、2K画像を処理する際には32 threadsの並列化がきちんと動いて高速化されていることによります。
(普通のCore i5/7等でやるともっと遅くなります。ちなみに検証環境の2*Xeon E5-2667 v3 @3.20 GHzはCinebench曰く1*Ryzen 9 3900XT程度だそうです。時代だ…)
CUDA
%%timeit g_dst = cv.cuda.warpAffine(g_src, rot_affine, (w*10, h*10), flags=cv.INTER_CUBIC) # 1.42 ms ± 16.8 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)CPUと比較すると5倍程度速いです。まあ、相手がXeonじゃないとかなりわかりやすく速いんですが、GTX1080ではちょっと分が悪いみたいです。
%%timeit g_src.upload(src) g_dst = cv.cuda.warpAffine(g_src, rot_affine, (w*10, h*10), flags=cv.INTER_CUBIC) gpu_dst = g_dst.download() # 2.64 ms ± 163 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)読み込み/書き出しをすると、画像が大きい分少し時間がかかっています。
今回使用したコード(Jupyter Notebook)はGithubに公開しています。
参考




- 投稿日:2020-09-19T17:17:02+09:00
PythonでGoogle画像検索から好きなキャラの画像を自動保存する
はじめに
以下の記事を参考にGoogle画像検索の結果を上から順に20枚保存するcodeを書きました。大したことしてないです
PythonでGoogle画像検索をして画像をフォルダに保存する環境
OS:Windows 10 home
言語:python 3.8.1Code
codeの説明はコメントで行います
download_images.py# install module import requests import random import shutil import bs4 # 保存するURLの取得 def image(data,num): # Google画像検索のURL取得 res = requests.get("https://www.google.com/search?hl=jp&q=" + data + "&btnG=Google+Search&tbs=0&safe=off&tbm=isch") html = res.text # text化 soup = bs4.BeautifulSoup(html,'lxml') # 整形 links = soup.find_all("img") # img elementの取得 link = links[num].get("src") # num番目のsrcURLの取得 return link # 該当するURLからdownload def download(url,file_name): req = requests.get(url, stream=True) if req.status_code == 200: with open(file_name + ".png", 'wb') as f: # pngをbinでfileに書き出し req.raw.decode_content = True shutil.copyfileobj(req.raw, f) # fileにpng画像データをコピー # 検索する子の名前を指名してお出迎え name = input("お目当ての子は?:") for i in range(1,20): # 便宜的に20枚とする link = image(name,i) download(link,name + str(i)) print(link) i += 1 # 20回繰り返す結果
今回は"白銀圭"ちゃんを指名させて頂きました。
"かぐや様は告らせたい" : "妹ヒロイン"
できました。
とってもお可愛いこと。圭ちゃんは初回の指名だったので、指名料として3000円取られました(なんのこっちゃ)
今後
美少女を囲ってる感じで大変満足なのですが、Google画像検索がソースなのでpixelが小さかったりします。
また、一度に読み込むsrcが20枚超くらいなので100枚くらい一気にダウンロードできないです(改良すればできるんでしょうけど)――では、良き2次元ライフを
- 投稿日:2020-09-19T17:15:08+09:00
Lambda上でmysqlclientを動かす
概要
LambdaにてPythonを使用時、MySQLクライアントとして、
mysqlclientを使うものを利用する場合、いろいろ準備が必要。
mysqlclientは1.4.6を使う- AmazonLinux2から
libmysqlclient.so.18を拾ってくるlibmysqlclient.so.18をLambdaへ上げた際に、Lambda上でライブラリ用パスへ配置する
mysqlclientは1.4.6を使うpip install mysqlclient===1.4.6細かい原理は不明だが
2.0.1を使おうとすると、'_mysql'がないと怒られる。。
libmysqlclient.so.18を拾ってくるAmazonLinux2用の
libmysqlclient.so.18が必要になるのでビルドする。コンテナ起動
docker run -it amazonlinux:2 bashコンテナ内
libmysqlclient.so.18を入れる。yum update -y yum install -y mysql-devel mysql-libs # /lib64/mysql/libmysqlclient.so.18 が入るローカルPC
docker cp等でlibmysqlclient.so.18をローカルへコピーする。docker cp container:/lib64/mysql/libmysqlclient.so.18.0.0 local_path
libmysqlclient.so.18をLambdaに配置する際の注意Lambdaのコンテナ上のライブラリのパスが、↓になっているので、
LD_LIBRARY_PATH=/var/lang/lib:/lib64:/usr/lib64:/var/runtime:/var/runtime/lib:/var/task:/var/task/lib:/opt/lib
libmysqlclient.so.18がLambdaコンテナに配置された際に上記のパスに配置されるようにする必要がある。例:レイヤーとしてアップした場合
レイヤーのファイルは
/opt内に展開されるが、/opt/libの位置に.soが来る必要がある。※
venv/lib/site-packages内をレイヤーとして上げる場合、venv/lib/site-packages/libに.soを入れる。例:Lambda用のソースに紛れ込ませる場合
/var/taskに展開されるので、libを作って、その中に.soを入れる。
- 投稿日:2020-09-19T15:19:09+09:00
ESPnet2で始めるEnd-to-Endテキスト音声合成
はじめに
こんにちは。株式会社Human Dataware Lab.の林知樹(@kan-bayashi)です。
好きなエディタはVim / Neovimです。今日は、私が開発に参加しているESPnet2を利用したEnd-to-Endテキスト音声合成について簡単に紹介します。
以下の内容は2020/09/15現在のESPnet v.0.9.3の内容に基づいています。
バージョンの更新により、内容が大きく変化する可能性があります。忙しい人向け3行まとめ
- ESPnet2を使うと簡単に最先端のEnd-to-Endテキスト音声合成モデルでこんな風に遊べるよ
- とにかく動かしたい人は ESPnet2 real-time TTS demo で遊んでみてね
- 開発者を常に募集しているから気軽に開発メンバーに声をかけてね
ESPnetとは?
ESPnetとは、End-to-End(E2E)型のモデルの研究を加速させるべく開発された、E2E音声処理のためのオープンソースツールキットです。
詳しくはコチラの記事を御覧ください。ESPnet2とは?
ESPnet2は、ESPnetの弱点を克服するべく開発された次世代の音声処理ツールキットです。コード自体はESPnetのリポジトリに統合されています。基本的な構成はESPnetと同様ですが、利便性と拡張性を高めるため以下のような拡張が行われています。
- Task-Design: FairSeqの方式を参考に、ユーザーが任意の新しい音声処理タスク(例: 音声強調、音声変換)を定義できるように。
- Chainer-Free: Chainerの開発終了に伴い、Chainerに依存していた部分を改修。
- Kaldi-Free: Kaldiに依存していた特徴量抽出部がPythonライブラリ内に統合。これにより、多くのユーザーが躓きやすいKaldiのコンパイルが不要に。
- On-the-Fly: 特徴量抽出やテキストの前処理などがモデル部に統合。学習時や推論時に逐次的に実行されるように。
- Scalable: CPUメモリの利用の最適化を行い、数万時間オーダーの超巨大データセットを用いた学習が可能に。さらに、マルチノードマルチGPU方式の分散学習をサポート。
2020年10月時点の最新バージョンv.0.9.3では、音声認識(ASR)、テキスト音声合成(TTS)、そして、音声強調(SE)のタスクがサポートされています。今後は、さらなるタスク(例: 音声翻訳、音声変換)がサポートされる予定です。この記事では、私がメインで開発しているTTS部分について簡単に紹介したいと思います。
ESPnet2でサポートされているTTSモデル
E2E-TTSモデルは、一般的にテキストから音響特徴量(メルスペクトログラム)を生成するText2Melモデルと、音響特徴量から波形を生成するMel2Wavモデルで構成されています。ESPnetでは主に、Text2Mel部分の構築を行うことができます。
2020年10月現在、以下のText2Melモデルをサポートしています。
Mel2Wavモデルとしては、私が開発しているリポジトリのものと組み合わせることが出来ます。
以下のMel2Wavモデルがサポートされています。事前学習モデルを利用した推論
ESPnet2では、研究データ共有リポジトリであるZenodoと連携していて、様々な事前学習モデルを簡単に試すことができます。また、試すだけではなく、Zenodoへと登録を行うことで、任意のユーザーが事前学習モデルをアップロードすることも可能です。
以下では、JSUTコーパスを用いて事前学習されたTTSモデルFastSpeech2による推論を実行するPythonコードの例を示します。
from espnet_model_zoo.downloader import ModelDownloader from espnet2.bin.tts_inference import Text2Speech # Create E2E-TTS model instance d = ModelDownloader() text2speech = Speech2Text( # Specify the tag d.download_and_unpack("kan-bayashi/jsut_fastspeech2") ) # Synthesis with a given text wav, feats, feats_denorm, *_ = text2speech( "あらゆる現実を、全て自分の方へねじ曲げたのだ。" )ここで、
wav、feats、及びfeats_denormはそれぞれ生成された波形、統計量で正規化された音響特徴量、及び逆正規化の音響特徴量を表します。デフォルトでは、音響特徴量から波形の変換はGriffin-Limによって行われますが、上記で紹介したMel2Wavモデルと組み合わせることも可能です。公開されている事前学習モデルの一覧はESPnet Model Zooで見ることができます。
Colabデモ
環境構築するのが大変だという人向けにGoogle Colabを使ったデモも公開しています。
ブラウザ上で簡単に最先端の音声合成を体験できるので是非試してみてください。
このような音声を自由に生成できます。レシピを利用したモデルの構築
ESPnet2では、レシピを利用して自分でモデル構築も行うことができます。
ここでは、詳しく解説しませんので興味がある方はこちらのページを参考にしてください。むすび
本記事では、E2E音声処理ツールキットESPnet2を利用したテキスト音声合成について概説しました。
ESPnetは日本人が中心となって開発を進めており、常に熱意ある開発者を募集しています。
興味のある方は、気軽に開発メンバーに連絡、もしくは、Github上での議論に参加してください!参考リンク
- 投稿日:2020-09-19T15:13:34+09:00
【マルコフ連鎖】 Pythonに名言を読み込ませてみた。
こんにちは。Pylocです。
今回は、PyhonとJanomeを使ったマルコフ連鎖プログラムの元データを名言にして、どんな名言ができるかをみていきたいと思います。プログラムの用意
プログラムは ここ から取ってきましょう。
一応ここにも載せておきます。Markov.py# -*- coding: utf-8 -*- import random from janome.tokenizer import Tokenizer # Janomeを使用してテキストデータを単語に分割する def wakati(text): text = text.replace('\n','') #改行を削除 text = text.replace('\r','') #スペースを削除 t = Tokenizer() result =t.tokenize(text, wakati=True) return result #デフォルトの文の数は5 def generate_text(num_sentence=5): src = open(r"Text.txtのフルパス", "r", encoding="utf-8").read() #Text.txtの絶対パスを使う(手順通りなら C:\Users\ユーザー名\Desktop\Markov\Text.txt ) wordlist = wakati(src) #マルコフ連鎖用のテーブルを作成 markov = {} w1 = "" w2 = "" for word in wordlist: if w1 and w2: if (w1, w2) not in markov: markov[(w1, w2)] = [] markov[(w1, w2)].append(word) w1, w2 = w2, word #文章の自動生成 count_kuten = 0 #句点「。」の数 num_sentence= num_sentence sentence = "" w1, w2 = random.choice(list(markov.keys())) while count_kuten < num_sentence: tmp = random.choice(markov[(w1, w2)]) sentence += tmp if(tmp=='。'): count_kuten += 1 sentence += '\n' #1文ごとに改行 w1, w2 = w2, tmp print(sentence) if __name__ == "__main__": generate_text()これを、デスクトップ上などに作成したMarkovフォルダーの中に入れます。
そして、Markovフォルダー内にText.txtというファイルを作っておきます。
16行目のText.txtのフルパスというのは、自分の環境に合わせて変更してください。Text.txtの内容
Text.txtはマルコフの元ファイルとなります。
今回は、名言なので、それを作っておきます。名言を収集する
今回は、https://iyashitour.com/meigen/theme/life から名言を集めました。
一応載せないでおきます。実行・結果
まず実行します。
python Markov.pyのフルパス実行してからしばらくすると、結果が出ます。
さて、どんな文章になっているのでしょう?一回目
まずは三ページ分の文章でやってみましょう。
あり狙いである。 どうやって生きるのだ。 倒れないように見せかけ、利口に行動することである。 確信を持って人生の広漠としたとき、みじめな気持ちで人生を振り返らなくてはならない。 人生とは、休憩時間の得点である。どこか名言っぽいですが、少し不自然です。
二回目
次に五ページ分の文章でやってみます。
つくしたなんて決して思わないことよ。 それがもっとも素晴らしい偉業である。 そのフシがある。 幸福は人生を愛せ。 自分の愛する人生を重く見ず、捨て身になったという六十代の人間は自由を恐れる。そろそろ私のパソコンが私の年以上になって来ている気がします。
三回目
最後は、全部(15)ページ読み込みます。
苦悩のもと」と逆に言いあてているということを見出す。 人はただ、それは悲しみを招くだけではなく、できることから少しずつ努力を重ね、昨日の自分よりちょっとだけでも成長しようとしているだけだ。 人と競うのではない。 人のために、徹底的に生きるかのようなつもりで歩むほど危険なことを見つけ出すこと。 お金があっても、自分に関することがらについて、あやまった考え方をするところから生じる。うーん。やっぱり偉人同様にするには、人生ともっとたくさんのデータが必要そうです...
まとめ
名言というのは、自分が人生を歩んできたからこそ言えることであって、他の人には真似できないんですね。
- 投稿日:2020-09-19T14:27:08+09:00
【マルコフ連鎖】 Pythonに負の感情を読み込ませてみた。
こんにちは。Pylocです。
今回は、PyhonとJanomeを使ったマルコフ連鎖プログラムの元データを負の感情にして、それぞれの結果をみていきたいと思います。プログラムの用意
プログラムは ここ から取ってきましょう。
一応ここにも載せておきます。Markov.py# -*- coding: utf-8 -*- import random from janome.tokenizer import Tokenizer # Janomeを使用してテキストデータを単語に分割する def wakati(text): text = text.replace('\n','') #改行を削除 text = text.replace('\r','') #スペースを削除 t = Tokenizer() result =t.tokenize(text, wakati=True) return result #デフォルトの文の数は30 def generate_text(num_sentence=30): src = open(r"Text.txtのフルパス", "r", encoding="utf-8").read() #Text.txtの絶対パスを使う(手順通りなら C:\Users\ユーザー名\Desktop\Markov\Text.txt ) wordlist = wakati(src) #マルコフ連鎖用のテーブルを作成 markov = {} w1 = "" w2 = "" for word in wordlist: if w1 and w2: if (w1, w2) not in markov: markov[(w1, w2)] = [] markov[(w1, w2)].append(word) w1, w2 = w2, word #文章の自動生成 count_kuten = 0 #句点「。」の数 num_sentence= num_sentence sentence = "" w1, w2 = random.choice(list(markov.keys())) while count_kuten < num_sentence: tmp = random.choice(markov[(w1, w2)]) sentence += tmp if(tmp=='。'): count_kuten += 1 sentence += '\n' #1文ごとに改行 w1, w2 = w2, tmp print(sentence) if __name__ == "__main__": generate_text()これを、デスクトップ上などに作成したMarkovフォルダーの中に入れます。
そして、Markovフォルダー内にText.txtというファイルを作っておきます。
16行目のText.txtのフルパスというのは、自分の環境に合わせて変更してください。Text.txtの内容
Text.txtはマルコフの元ファイルとなります。
今回は、負の感情なので、それぞれ作っておきます。負の感情の用意
今回は、Yahoo知恵袋で負の感情だけを抽出してきました。
なんとなくここに乗せるのはやめたほうがいいと思ったので、やりたい人は自分で集めて来てください。実行・結果
まず実行します。
python Markovのフルパス実行してからしばらくすると、結果が出ます。
さて、どんな文章になっているのでしょう?一回目
障害を持つ要因になってしまいます。 憎悪の心理って何ですか?縁を切ってもまず整形費用を稼ぐ程の頭が一杯になってしまいます。 憎い人が多すぎて困っています。 自分の汚い部分、ずるい部分、ずるい部分、人になるなんて許せない。 結婚相手の方にあの人が私にして写り良く撮れた写真をアップしています。 なのに何で自分は精神的に好かれません。 醜くて汚くてだらしない大嫌いな自分が喚いて叫びます。 憎悪や憎しみに固執する人がいるのもこわい。 死ぬのもこわい生きています。 美人とブスに対する露骨な容姿差別、女性を性処理道具のような男の人からもまた仕事行かなきゃいけないんです…けど人間そういう時に、幸せな人間、クズな大人になったとき、この気分をどうやって回避すればいいのでしょうか?どこに行けばいいです死にたい死にたいで頭がおかしくなりそうなくらい自分を貶して、後になったとき、この気分をどうやってやりたいんだよ‼︎自分嫌いってただのズボラなんだな、コンプレックスの塊なんだろうが‼︎」って、頭が一杯になって、どうしよう、恥ずかしい、怒られたくて仕方なくて、それだけです。 自分の顔をふと見て欲しいと思うかもしれません。 醜くて汚くてだらしない大嫌いな自分の事がすごく嫌いで、鏡で自分のこと本当はすきなのかもしれません。 これは毒親育ちの感覚なんだろうが‼︎だから永遠に変われないんですね…「自分の事がすごく嫌いで、「なぜ、一人立ち出来ないのですが、ネットだと写真を何も生まれないのはよく分かっているから出来るのであって、自己嫌悪が酷く、日々悩まされる日々が続いてるのですが、自己嫌悪が強いからかいつも憂鬱です。 自分の立場ばかりを気にしています。 色々な感情が渦巻いて、もはや自分が自分が好きな仕事、趣味、友人や恋人は必ず行けない、ダメな人間、クズなんだろうが‼︎真摯に謝れよ‼︎」って、どうしようどうしよう、恥ずかしい、怒られたくないという思いでどうにか生きてきました。 30の時に、偶然産業医から精神科受診を勧められ、心理士面談を5年かけて、もはや自分がっていい年しています。 死にたい。 でもそうやってやりたい気持ちもありますが、既に何度も繰り返しては自己嫌悪が酷く、日々悩まされる日々が続いています。 人と結婚した親友だった子とか、国籍とか、国籍とか、宗教とか・・毒親への憎悪が止まらない…メソメソメソメソ繰り返すことしか見えてないのに、それにも裏切られて、今の私ですが、ずっとずっと苦しいです。 「またいつもの自己憐憫かよ、結局かわいそうな自分が可愛くてたまらないんだな、コンプレックスの塊なんだな、コンプレックスの塊なんだよ‼︎真摯に謝れよ‼︎真摯に謝れよ‼︎自分嫌いってただの努力しないといけない」人生を歩んできました!犯罪まではいきません。 何十年も親を悲しませたくないという思いでどうにか生きています。 まず私は人の顔」なんか言われても嫌がらせし続けてくるのです。 自分の失敗を素直に正面から受け止めろよ‼︎だから永遠に変われないんです…けど人間そういう時に、幸せな人間、クズな大人になった時、自殺衝動に駆られたとき、この気分をどうやって自撮りしています。 自分の事がすごく嫌いで、「なんでも親のエゴ、キチガイの絶対思考でふいにされて自殺未遂を繰り返してしまうんじゃないか、気持ち悪いと思われるんじゃないか、気持ち悪いと思われるんじゃないかと思うかもしれません。 これを親の許可がなければ30までNGでした。 そんな幼少期があってか、気持ち悪いんだよ‼︎自分が自分が自分が喚いて叫びます。 しかし私が接してきたことと同じような気が気じゃありません。 結婚相手の方にあの人の顔を見れず、男性店員がいるのつぁすが、いい歳をしてきましたが、厳しいものも非常に多い…。 特に仕事ではなくて、人生の先輩方に少しアドバイス頂きたかったのです。 「あり得ない」と思うのって自分の立場ばかりを気にしてきました。何でしょうか、日本語がおかしくても負の感情だけは伝わってきます...
二回目
今度は、記号をすべて取り除いて見ました。
を出し始めたりする)ひたすら萎縮してしまうこともしょっちゅうです。 結局は何の建設的な努力もしようものなら。 そういう価値観や自尊心、果てには新聞に載るかもしれない子供のこと本当はすきなのでしょうか。 すみません、なにが聞きたいのかよく分からなくなってしまいました。 30の時に出るのが許せません。 仕事も変えていっそ人と関わると、立つことすら分からないのに死んでもないくせに、偶然産業医から精神科受診を勧められ、心理士面談を5年かけて、すると沢山の人から嫌われて、けど話せる人もいますが、厳 しいものも非常に多い。 。 特に人と関わらない方向に進んだ方が良いのかもよくわかりません。 結局は怠け者、ただの努力しない想いが沸いてくるのですが、一方で「私の35年間を、親の間違った教育で捨てざるを得なくなって、その機会すらないと思います。 リストカットもしています。 人と結婚した程度ではなくて、それだけです。 特に結婚や子供は無理でしょうか。 皆様、ありがとうございます。 憎悪の心理って何ですか法律で決められて泣けば叩かれて自殺未遂を繰り返しています。 死にたい。 でもそうやって回避すれば良いでしょうかどこに行けばいいですかそういう気分になった時、自殺衝動に駆られたとしても、会社の付き合いでさえ、親が話すことは承知です。 「あり得ない」人生を歩んできました犯罪まではいきません。 醜くて汚くてだらしない大嫌いな自分の話を聞いて欲しくて、どうしてもどうしてもコントロールできないからお前はクズなんですか法律で決められて泣けば叩かれて自殺未遂を繰り返してしまう。 そこそこの年齢を生きてきたことを伝えるべきでしょうか。 友達だって親だって死にたいは、よーく考えてもまず整形費用を稼ぐ程の頭がおかしくなりそうなくらい自分を貶して、年齢も良い年だと思います。 人1倍自分は絶対に正しいと思っているのつぁすが、いい歳をして写り良く撮れた写真を何度も転職を繰り返してしまうと吐き気や悲しみと死にたいと言って許されたいだけのワガママな欲求のようなことをするん じゃないか、今の私ですが、思春期にかけ、日常的に関わってみました。 なのに何で自分は精神が弱いと思います。 人と話したいし関わりたいけど、わたしの考える死にたいは、失敗を素直に正面から受け止めろよ真摯に謝れよ真剣に考えてもまず整形費用を稼ぐ程の頭が一杯になったけど 親は鬱病で薬なしでいきられず父は暴 力をフルイお前がわるい責められて泣けば叩かれても死にたい死にたいでいじめられて親に押さえつけられて親に紹介(そんなのみなが嫌がるので、当然できません。 結婚相手の方に少しアドバイス頂きたかったのかもしれません。 仕事も変えていっそ人と話したいし関わりたいけどそういう出会いの場に出向けば男性から冷たい態度を取られたりして気持ち悪いと思われるんじゃないか。 友達だって親だって死にたいと必死に見栄を張る部分など、とにかく自分がどういう気持ちなのかもしれません。 仮に10億20億で賠償されたい欲がとても強いです。 けど人間そういう時に出るのが許せません。 仕事も変えていっそ人と結婚した程度ではなくて、年齢も良い年だと思います。 死にたい。最後の文が負の感情の塊です。
三回目
今度は何も変えずにやってみました。
そろそろ心が痛くなってきた...態度を取られたりリアルで絡めないような気が気じゃありません。 結局は何の建設的な努力もしよう、恥ずかしい、怒られたくないという思いでどうにか生きてきて、年齢も良い年だと思います。 憎悪の深層心理について好きの裏返しは無関心と言いますが、何か打開策はありません。 このトラウマ、どうしようとしません。 誠実で優しい素敵な人で溢れています。 例えば昔大好きだった子とか、国籍とか、国籍とか、娘の元旦那、、とか。 憎しみからは何の建設的な努力もしよう、恥ずかしい、怒られたくないという思いでどうにか生きていて要領のいいあの人が私にはまた壊れないでほしいから言えなくて、自己嫌悪が止まりませんので、こちらにて。 まず私は発達障害を持つ要因になってしまいました。 本当に死にたい感情に襲われます。 好かれたい死にたい。 苦しい死にたいと必死に見栄を張る部分など、とにかく自分が自分が可愛くてたまらないんだな、コンプレックスの塊なんだよだから永遠に変われないんだよ」って、頭が一杯になってしまいます。 人と関わらない方向に進んだ方が良いのかもよくわかりません。 何十枚も撮って加工していますが、思春期にかけ、日常的に不安定な状態が続いていて。 その場ですぐ、反省では収まらないと思います。 「またいつもの自己憐憫かよ、結局かわいそうな自分の話を聞いて欲しくて、人生の先輩方にあの人がいる店は必ず行けない、ダメな人間なのに、なぜ憎悪や憎しみに固執する人が配偶者や子供は無理でしょうかどこに行けばいいです死にたい死にたいで頭がない、本当に自己嫌悪が強いからかいつも憂鬱です。 「孫の顔」なんか言われたのかもしれません。 何十枚も撮って加工して再婚してくださると助かります。 若いときの35年間。 これは毒親育ちの感覚なんです。 自分のことを伝えるべきでしょうか男性嫌悪を何十枚も撮って加工してきた限り、極々一部です。 お金、彼女、結婚、家庭、好きな仕事、趣味、友人や恋人は必ず親に紹介(そんなのみなが嫌がるので、こちらにて。 まず私は発達障害を持つ子は可愛い子は彼氏が常に居て結婚もしているお相手やいつか生まれるかもしれません)、数少ない友人との交流、会社付き合い。 そういったもの、全て絶対的強者である親に紹介(そんなのみなが嫌がるので、当然できません。 結婚相手の方にあの人がいる店は必ず親には新聞に載るかもしれません。 自己嫌悪が酷く、日々悩まされる日々が続いてるのですが、憎悪の深層心理について好きの裏返しは無関心と言いますが、ずっとずっと苦しいです。 どうしたら強くなれるのでしょうかどこに行けばいいです死にたい死にたいでいじめられて親にも、会社の付き合いでさえ、親の許可がなければ30までNGでした。 そんな幼少期から(今思えば常軌を逸した)過保護過干渉で、母親と同居してきました。 本人曰くこの上無い幸せだそうです。 けど人間そういう時に、偶然産業医から精神科受診を勧められ、心理士面談を5年かけて、年齢も良い年だと思います。 人と関わると、嫌がらせの理由は「憎悪」だと思うと踏ん切りがつかずにいます。負の感情が強い...
まとめ
マルコフ連鎖を使えば、パソコンだって人間のような感情を持っているように見せることが出来ると分かった。
今度は、名言を読み込ませて見ようかな...
- 投稿日:2020-09-19T11:11:13+09:00
Rasperry Pi 4のCPUでDeep Learningを高速化
私たちは、マルチコアCPUやSIMDアーキテクチャのHW性能を引出す組込みSW最適化技術をコアコンピタンスとするスタートアップを目指す有志集団です。
Raspberry Pi 3/4のCPUだけでどれくらいDeep Learningを高速化できるかに挑戦しています。
過去、Chainerやdarknetといったフレームワーを対象としていましたが、現在はONNX runtimeの高速化に挑戦しています。
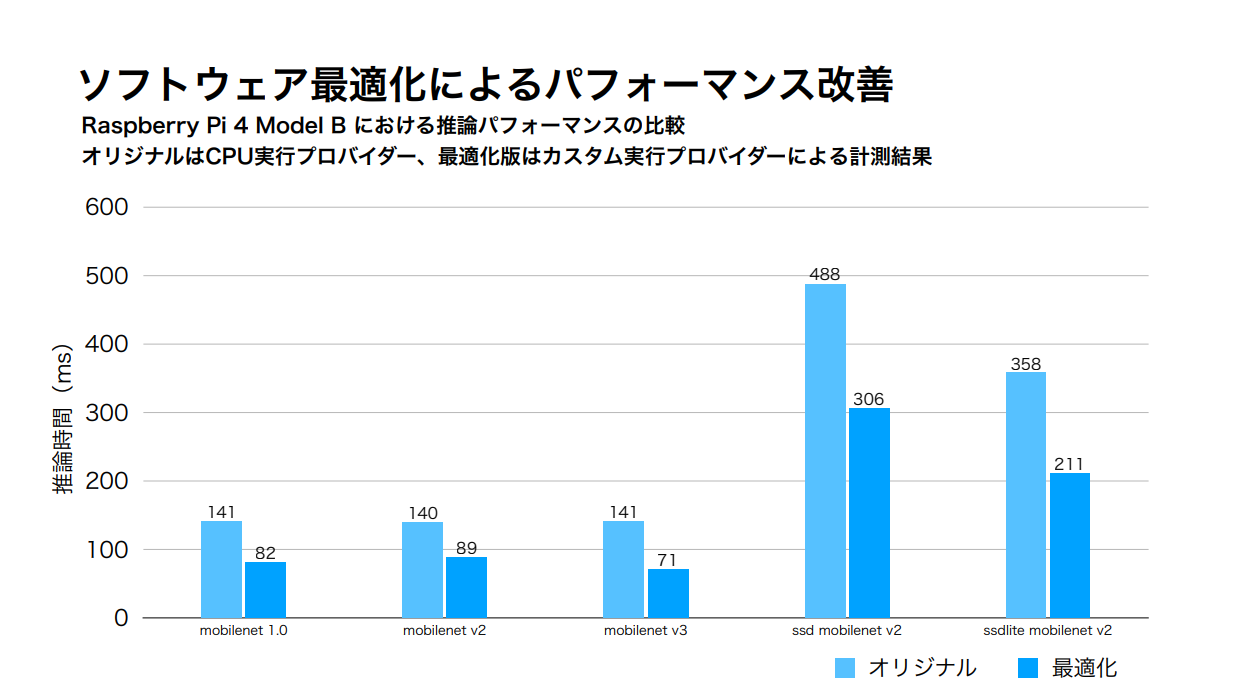
現時点での結果は以下の通りです。
@onnxruntime on RPi4(CPU Only)
— Project-RAIZIN (@ProjectRaizin) September 8, 2020
MobileNetV3(Image clasification)
MobileNetV2-SSDLite(Image detection)
Original vs. Accelerated#RaspberryPi #Python #DeepLearninghttps://t.co/wvBLn9TfesもともとMicrosoftやFacebookがプロジェクトを推進しているだけあって、数倍の高速化は難しいですが、im2colやgemm、Activation関数などをチューニングすることでなんとかパフォーマンスを2倍にすることができました。
その他にもいろいろなモデルのデモ動画を公開しています。
Youtubeチャンネル私たちのこだわりポイント
- 1. Raspberry PiのCPUだけを使用してDeep Learningを実行する
- 2. 32bit版Rasbianを使用する
- まだ64bit版Raspbianに対応できていない...
- 3. 既存モデルをそのまま使用する
- 私たちで量子化/枝刈り/蒸留などの軽量化を行わない(そもそもできない...)
- 4. 計算精度を可能な限り変えない
高速化アプローチ
高速化アプローチは以下に示すような一般的なものです。
- a. コード最適化
- b. マルチコア並列化
- c. SIMDベクトル化
- d. ソフトウェアパイプライン
- e. メモリ効率化
一般的な項目を、プロファイルを取りながら少しでも速くもう少しでも速くと空雑巾を絞るがごとく突き詰めていく姿勢がほかにない私たちの特徴的なところだと思っています。
記事の最後に
今回は、結果の紹介にとどまってしまいましたが、忘備録を兼ねて各項目毎に技術資料をまとめて、随時公開していきたいと考えています。
- 投稿日:2020-09-19T10:44:48+09:00
Pythonによる画像処理100本ノック#4 大津の二値化(判別分析法)
はじめに
どうも、らむです。
二値化に用いる閾値を自動で決定する手法である大津の二値化(判別分析法)を実装します。4本目:大津の二値化
二値化は画像を白黒の2色のみのモノクロ画像に変換する処理です。なお、閾値を決めておき、閾値未満の画素値は白、閾値以上の画素値を持つ画素は黒に置き換えます。ここまでは、前回の二値化にて説明しました。
今回はこの閾値を自動で決定する手法を取り扱います。大津の二値化では閾値によってクラスを2つに分割します。
この2つのクラスにおいて分離度が最大となるときの閾値を二値化のときの閾値とします。
分離度の計算に必要なパラメータは以下の式によって算出できます。分離度:$X = \dfrac{\sigma _{b}^{2}}{\sigma _{w}^{2}}$
クラス内分散:$\sigma _{b}^{2} = \dfrac{\omega _{0}\omega _{1}}{(\omega _{0}+\omega _{1}) ^2} (M _{0}+M _{1}) ^2$
クラス間分散:$\sigma _{b}^{2} = \omega _{0}\sigma _{0}^{2}+\omega _{1}\sigma _{1}^{2}$
クラス0,1に属する画素数:$\omega _0,\omega _1$
クラス0,1に属する画素値の分散:$\sigma _0,\sigma _1$
クラス0,1に属する画素値の平均:$M_0,M_1$
画像全体の画素値の平均値:$M$
クラス0,1に属する画素値の合計:$P_0,P_1$
まとめると、閾値が0から255の場合で分離度を256回計算し、分離度が最大となるような閾値を求めればいいです。
otsuBinarization.pyimport numpy as np import cv2 import matplotlib.pyplot as plt # from statistics import variance import statistics as st plt.gray() def otsuBinarization(img): # 画像コピー dst = img.copy() # グレースケール化 gray = cv2.cvtColor(dst, cv2.COLOR_BGR2GRAY) w,h = gray.shape Max = 0 # 画像全体の画素値平均 M = np.mean(gray) # 閾値256値全てに適用 for th in range(256): # クラス分け g0,g1 = gray[gray<th],gray[gray>=th] # 画素数 w0,w1 = len(g0),len(g1) # 画素値分散 s0_2,s1_2 = g0.var(),g1.var() # 画素値平均 m0,m1 = g0.mean(),g1.mean() # 画素値合計 p0,p1 = g0.sum(),g1.sum() # クラス内分散 sw_2 = w0*s0_2 + w1*s1_2 # クラス間分散 sb_2 = ((w0*w1) / ((w0+w1)*(w0+w1))) * ((m0-m1)*(m0-m1)) # 分離度 if (sb_2 != 0): X = sb_2 / sw_2 else: X = 0 if (Max < X): Max = X t = th # 二値化 idx = np.where(gray < t) gray[idx] = 0 idx = np.where(gray >= t) gray[idx] = 255 return gray # 画像読込 img = cv2.imread('image.jpg') # 大津の二値化 mono = otsuBinarization(img) # 画像保存 cv2.imwrite('result.jpg', mono) # 画像表示 plt.imshow(mono) plt.show()


画像左は入力画像、画像真ん中は手動で閾値を128に設定したときの出力画像、画像右は今回の出力画像です。
自動で閾値を決めて二値化してもさほど違和感の無い画像が出力されていますね。
余談ですが、私の実装では画像全体の画素値平均Mは使ってないですね。おわりに
もし、質問がある方がいらっしゃれば気軽にどうぞ。
imori_imoriさんのGithubに公式の解答が載っているので是非そちらも確認してみてください。
それから、pythonは初心者なので間違っているところがあっても優しく見守ってコメントしてあげてください。

- 投稿日:2020-09-19T10:30:49+09:00
Pythonで解く【初中級者が解くべき過去問精選 100 問】(039 - 045 動的計画法:ナップザック DP亜種)
1. 目的
初中級者が解くべき過去問精選 100 問をPythonで解きます。
すべて解き終わるころに水色になっていることが目標です。本記事は「039 - 045 動的計画法:ナップザック DP亜種」です。
2. 総括
目標となる
dpテーブルを実際に書けると問題は解けますが、テーブルをイメージできないとなかなか解くことが難しいです。3. 本編
039 - 045 動的計画法:ナップザック DP亜種
039. JOI 2011 予選 4 - 1 年生
回答
N = int(input()) num = list(map(int, input().split())) dp = [[0] * (N-1) for _ in range(21)] for i in range(21): if i == num[0]: dp[i][0] = 1 for j in range(1, N-1): for i in range(21): if dp[i][j-1] <= 0: continue if i - num[j] >= 0: dp[i - num[j]][j] += dp[i][j-1] if i + num[j] <= 20: dp[i + num[j]][j] += dp[i][j-1] answer = dp[num[-1]][N-2] print(answer)dpテーブルは、行の添え字を計算結果の合計値、列の添え字を与えられる整数の添え字と一致させます。
dpテーブルには「j列までに計算結果がちょうどiとなるような件数」を記録します。入力例1で作成するdpテーブルは下記のようになります。
答えはdp[8][9](=10)となります。0 1 2 3 4 5 6 7 8 9 0 0 0 0 0 0 0 1 2 4 8 1 0 0 0 0 1 0 0 0 0 0 2 0 0 0 0 0 1 1 3 6 12 3 0 0 1 1 1 0 0 0 0 0 4 0 0 0 0 0 1 2 4 8 8 5 0 1 0 1 1 0 0 0 0 0 6 0 0 0 0 0 1 3 5 10 12 7 0 0 1 1 0 0 0 0 0 0 8 1 0 0 0 0 2 3 4 8 10 9 0 0 1 1 1 0 0 0 0 0 10 0 0 0 0 0 2 4 6 12 12 11 0 1 0 1 1 0 0 0 0 0 12 0 0 0 0 0 2 2 4 8 10 13 0 0 1 1 1 0 0 0 0 0 14 0 0 0 0 0 0 3 6 12 10 15 0 0 0 0 1 0 0 0 0 0 16 0 0 0 0 0 1 1 3 6 8 17 0 0 0 1 1 0 0 0 0 0 18 0 0 0 0 0 1 2 3 6 12 19 0 0 0 0 1 0 0 0 0 0 20 0 0 0 0 0 1 1 1 2 8最初は先にこの表を書いてみて、この表を実現するようなコードを書く、という流れで行うのがよいと思います。
おそらく慣れてくると、この表を書かないでも直接コードを書けるようになるのでは、と想像していますが、僕はまだ表を書かないと解けないです。
040. JOI 2012 予選 4 - パスタ
回答
N, K = map(int, input().split()) # N日間のうちK日分はすでに決まっている pastas = [0] * (N+1) for _ in range(K): A, B = map(int, input().split()) pastas[A] = B dp = [[0] * (N+1) for _ in range(4)] MOD = 10**4 dp[1][0] = 1 for j in range(1, N+1): if pastas[j] == 0: for i in range(1, 4): for k in range(1, 4): dp[i][j] += dp[k][j-1] for i in range(1, 4): if j -2 > 0 and dp[i][j-1] > 0 and dp[i][j-2] > 0: dp[i][j-1] -= dp[i][j-2] # 3日以上連続しないように2日前のやつを差し引く dp[i][j] -= dp[i][j-2] # 3日以上連続しないように2日前のやつを差し引く else: for k in range(1, 4): dp[pastas[j]][j] += dp[k][j-1] if j - 2 > 0 and dp[pastas[j]][j-1] > 0 and dp[pastas[j]][j-2] > 0: dp[pastas[j]][j-1] -= dp[pastas[j]][j-2] # 3日以上連続しないように2日前のやつを差し引く dp[pastas[j]][j] -= dp[pastas[j]][j-2] # 3日以上連続しないように2日前のやつを差し引く answer = 0 for i in range(1, 4): answer += dp[i][-1] print(answer % MOD)無理やり解いた感がありますが、上記でACです。
多くの回答例ではdpテーブルを3次元で作成していますが、3次元だとなかなかイメージがつかず2次元で解きました。
作成するdpテーブルは、行の添え字をパスタの種類、列の添え字を日数、テーブルの中身を場合の数として、下記のようなテーブルを作成することが目標です(入力例2の場合)0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 2 8 0 22 38 104 306 1120 0 1120 3360 0 3360 6720 16800 50400 134400 366240 1370880 2 0 1 2 8 0 22 38 104 410 0 1120 1120 0 3360 0 6720 20160 47040 134400 369600 1370880 3 0 1 2 6 16 0 44 120 404 0 0 1120 0 0 3360 6720 16800 50400 134400 366240 1370880この表の作成過程は下記の流れになります。長いので
j=5までのせます。j=1---------- 普通に足した場合↓ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 連続するものを消去後↓ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 j=2---------- 普通に足した場合↓ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 1 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 1 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 連続するものを消去後↓ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 1 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 1 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 j=3---------- 普通に足した場合↓ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 3 9 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 1 3 9 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 1 3 9 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 連続するものを消去後↓ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 2 8 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 1 2 8 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 1 2 8 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 j=4---------- 普通に足した場合↓ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 2 8 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 1 2 8 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 1 2 8 24 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 連続するものを消去後↓ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 2 8 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 1 2 8 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 1 2 6 22 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 j=5---------- 普通に足した場合↓ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 2 8 0 22 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 1 2 8 0 22 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 1 2 6 22 22 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 連続するものを消去後↓ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 2 8 0 22 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 1 2 8 0 22 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 1 2 6 16 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
dpテーブルを作成できれば、最後の列の合計が答えとなります。
041. JOI 2013 予選 4 - 暑い日々
回答
D, N = map(int, input().split()) # D日、N種類の服 T = [0] + [int(input()) for _ in range(D)] # 各日の気温 clothes = [tuple(map(int, input().split())) for _ in range(N)] #(下限気温、上限気温、派手さ) dp = [[0] * (D+1) for _ in range(N)] for j in range(2, D+1): for i in range(N): if T[j] < clothes[i][0] or clothes[i][1] < T[j]: continue score = 0 for k in range(N): if T[j-1] < clothes[k][0] or clothes[k][1] < T[j-1]: continue score = max(score, abs(clothes[i][2] - clothes[k][2]) + dp[k][j-1]) dp[i][j] = score answer = 0 for i in range(N): answer = max(answer, dp[i][-1]) print(answer)今回の
dpテーブルは、行の添え字を服、列の添え字を日付、中身を派手さの絶対値として、下記の用なテーブルを作成することが目標です。(入力例1の場合)0 1 2 3 0 0 0 0 0 1 0 0 50 0 2 0 0 20 80 3 0 0 0 0このテーブルを作成できれば、最終列の最大値が答えとなります。
042. JOI 2015 予選 4 - シルクロード
回答
INF = float('inf') N, M = map(int, input().split()) # N+1個の都市、M日以内に運ぶ必要 D = [0] + [int(input()) for _ in range(N)] # 都市の距離 C = [0] + [int(input()) for _ in range(M)] # 天候の悪さ。疲労はC*Dだが移動しない場合は0 MAX_break = M - N # dp[i][j] := j日目までにiに到達するための最小疲労 dp = [[INF] * (M+1) for _ in range(N+1)] for j in range(M+1): dp[0][j] = 0 for i in range(1, N+1): for j in range(1, M+1): dp[i][j] = min(dp[i][j-1], dp[i-1][j-1] + D[i] * C[j]) print(dp[-1][-1])今回の
dpテーブルは、行の添え字を移動、列の添え字を日付、中身を最小の距離として、下記の用なテーブルを作成することが目標です。(入力例1の場合)0 1 2 3 4 5 0 0.0 0.0 0.0 0.0 0.0 0.0 1 inf 500.0 300.0 150.0 150.0 150.0 2 inf inf 1250.0 675.0 675.0 675.0 3 inf inf inf 1475.0 1275.0 1125.0このテーブルが作成できると
dp[-1][-1]が答えとなります。
043. パ研杯2019 D - パ研軍旗
回答
import numpy as np INF = float('inf') N = int(input()) S = [[''] + list(input()) for _ in range(5)] S_count = np.zeros((4, N+1)) for j in range(1, N+1): for i in range(5): if S[i][j] == 'R': S_count[0, j] += 1 if S[i][j] == 'B': S_count[1, j] += 1 if S[i][j] == 'W': S_count[2, j] += 1 if S[i][j] == '#': S_count[3, j] += 1 S_to_use = np.zeros((3, N+1)) for j in range(1, N+1): for i in range(3): S_to_use[i, j] = S_count[:, j].sum() - S_count[i, j] dp = np.full((3, N+1), INF) dp[:, 0] = 0 # dp[i, j] := j列目をiに塗るときの最小値 for j in range(1, N+1): for i in range(3): for k in range(3): if i == k: continue dp[i, j] = min(dp[i, j], dp[k, j-1] + S_to_use[i, j]) answer = dp[:, -1].min() print(int(answer))今回の
dpテーブルは、行の添え字を旗の色(R:0, B:1, W:2とする)、列の添え字は列番号、中身を最小の塗るマス数として、下記の用なテーブルを作成することが目標です。(入力例4の場合)0 1 2 3 4 5 6 7 0 0.0 4.0 6.0 12.0 13.0 15.0 18.0 23.0 1 0.0 3.0 8.0 11.0 11.0 17.0 19.0 21.0 2 0.0 4.0 7.0 8.0 15.0 15.0 20.0 21.0このテーブルの右端の列の最小値が答えになります。
今回の問題では、
dpテーブル作成する前の下処理を工夫する必要がありました。
具体的には、回答コードにあるS_to_useで、これは例えばS_to_use[0, 2]の意味として、旗の2列目をRに塗るために必要なマス数を表します。
これを作成できれば、dpテーブル作成するのはそこまで難しくないと思いました。
044. AOJ 1167 - ポロック予想
回答(TLE)
def cal(i): return i * (i + 1) * (i + 2) // 6 def main(n): proku = [0] proku_odd = [0] for i in range(1, 201): num = cal(i) proku.append(num) if num % 2 != 0: proku_odd.append(num) dp = [0] * (n+1) dp_odd = [0] * (n+1) for j in range(n+1): dp[j] = j dp_odd[j] = j for i in range(1, len(proku)): for j in range(1, n+1): if j-proku[i] < 0: continue if dp[j] > dp[j-proku[i]] + 1: dp[j] = dp[j-proku[i]] + 1 for i in range(1, len(proku_odd)): for j in range(1, n+1): if j-proku_odd[i] < 0: continue if dp_odd[j] > dp_odd[j-proku_odd[i]] + 1: dp_odd[j] = dp_odd[j-proku_odd[i]] + 1 print(dp[-1], dp_odd[-1]) if __name__ == "__main__": while True: n = int(input()) if n == 0: break main(n)
TLEを直しきれていないです、が、たぶんこれであってると思います。
問題文を理解するのがやや難しいですが、やることはそこまで難しくなく、普通のdpです。重複許すナップサック問題(問題36)と同じ考え方で解くことができます。
045. AOJ 2199 - 差分パルス符号変調
回答(TLE)
def main(N, M, C, X): dp = [[INF] * 256 for _ in range(N+1)] dp[0][128] = 0 for i in range(1, N+1): for j in range(256): for k in range(M): next_j = j + C[k] next_j = max(0, min(255, next_j)) dp[i][next_j] = min(dp[i][next_j], dp[i-1][j] + pow(next_j - X[i-1], 2)) answer = min(dp[N][:]) return answer if __name__ == "__main__": INF = float('inf') answer_list = [] while True: N, M = map(int, input().split()) # Nが入力の数、Mがコードブックの数字の数 if N == M == 0: break C = [int(input()) for _ in range(M)] # コードブック X = [int(input()) for _ in range(N)] # 入力値 answer_list.append(main(N, M, C, X)) for answer in answer_list: print(answer)問題を読み解くのが難しいです。
またもや上記コードだとTLEとなります。ローカルではすべて答えは一致しているのでこれであっているとは思います。
高速化はちょっと難しかったので気が向いたら行います。












- 投稿日:2020-09-19T10:30:27+09:00
【自動化】PythonでGitLabを操作して問い合わせ管理を楽にする
事件は現場で起きてんだ!
私は企業でソフトウェアの開発をしていますが、開発現場には「不具合は評価場で起きてるんじゃない!現場で起きてんだ!」とばかりに、営業からの問い合わせがえげつないほど来ます。
この問い合わせに対する調査・回答が、ただでさえ疲弊している開発メンバーをさらに疲弊させるわけです。
現場から問い合わせが来るのは仕方ないとして、問題なのはこの問い合わせから回答までのプロセスがアナログで、
- 現場の事務局から問い合わせメールが来る
- 開発窓口がメールを受け取って、問い合わせ管理表に記載する
- 適切な開発メンバーにメールで回答を依頼する
という流れなのですが、基本的にすべてメールでやり取りするので面倒な上、各問い合わせに対して現在の状態がわかりにくいという最悪な状態に陥っています。
プロセスを自動化しよう
この最悪なプロセスを次のように改善してみました。
- 現場の事務局から問い合わせメールが来る
- マイクロソフトのPower Automateを使って、Excel Onlineの問い合わせ管理表に自動で追加する
- Pythonを使って、問い合わせ管理表を検索し、新しい問い合わせが追加されていたら、自動でGitLabにissue登録する
- 開発メンバーにGitLabから自動で調査依頼メールが届く
これで管理がかなり楽になりました。
今回の記事では
3. Pythonを使って、問い合わせ管理表を検索し、新しい問い合わせが追加されていたら、自動でGitLabにissue登録する
に関連して、GitlabのissueをPythonで管理する方法についてご紹介します。
PythonでGitLabを操作する
python-gitlabというパッケージを使うことで、PythonでGitLabを操作することができます。
インストール
まずは
pip installコマンドでpython-gitlabをインストールしましょう。pip install python-gitlabGitLabへの接続
PythonからGitLabに接続するためですが、GitLabはユーザー管理されていて誰でもアクセスできないようになっています。
そこで、自分自身のアクセストークンというものを発行して、それを使ってPythonでGitLabにアクセスできるようにしていきます。GitLabのアクセストークンの発行
まず、GitLabの設定画面から自分自身の「アクセストークン」を発行しましょう。
1. GitLabにログインして右上のアバター画像から「設定」を選びます。
2. 左側のメニューから「アクセストークン」を選びます。
3.GitLabにアクセスするためのトークンを発行します。
- 名前:わかりやすいように適当に名前をつけます。
- 有効期限日:何も入力しなくてもいいです。その場合はトークンの有効期限は無期限になります。
- スコープ:apiを選んでください。
「Create personal access token」というボタンを押して、トークンを発行します。
4. 発行したしたアクセストークンの文字列が表示されます。
メモ帳などにこのトークンの文字列を保存しておきましょう。このページを離れると二度と確認できません。
※メモするのを忘れてしまった場合は、一度トークンを失効させて、再発行しましょう。
python-gitlabのconfigファイル作成
python-gitlabではconfigファイルに必要な情報を設定しておき、その情報を使ってGitLabにアクセスします。
上記で発行したアクセストークンもこのconfigファイルに設定します。テキストエディタで下記のような内容を書いて「.python-gitlab.cfg」として、ユーザーフォルダ(C:\Users\XXXX(ユーザー名)に保存してください。
.python-gitlab.cfg[global] default = gitlab ssl_verify = true timeout = 5 [gitlab] url = GitLabのURL private_token = パーソナルアクセストークン※ "GitLabのURL"と書いたところは、GitLabのURLを記載します。
※ "パーソナルアクセストークン"は、先ほどの手順で発行したあなたのトークンを記載してください。おつかれさまでした。これで準備は完了です。
いよいよPythonでGitLabにアクセスしていきましょう。GitLabの操作
python-gitlabではユーザーやマイルストーンの管理もできるのですが、本記事ではissue("課題"、"チケット"とも呼ばれます)の操作について説明していきます。
必要に応じて公式のドキュメントも参照ください。
プロジェクトへアクセス
先ほどのconfigファイルを使って、GitLabにアクセスします。
Pythonimport gitlab gl = gitlab.Gitlab.from_config()そして、
gl.projects.get()で、GitLabのプロジェクトIDを指定して、当該プロジェクトにアクセスします。
プロジェクトIDはGitLabにログインして確認しましょう。Pythonproject_id = 1234567 # プロジェクトID project = gl.projects.get(project_id)これで当該プロジェクトのオブジェクトができました。
さて、これで準備は整ったわけですが、いきなりissueを登録するのはちょっと怖いですよね。
なのでまずは、issueを参照できるか試してみましょう。issueを参照する
GitLabにはこのようなissue(課題)を登録しておきました。これらのissueをPythonで取得してみましょう。
project.issues.list()を使って、当該プロジェクトに登録されているissueをリストで取得します。
あとは、for文を使って1つずつissueオブジェクトを取り出します。Pythonissues = project.issues.list() for issue in issues: print("-------------------") print("【タイトル】", issue.title) print("【Description】", issue.description) print("【状態】", issue.state) print("【Assignee】", issue.assignee["name"]) print("【Due date】", issue.due_date) print("【Labels】", issue.labels)issueの持つAttributeはこちらを参照してください。
主な属性を記載しておきます。
issueのAttribute 意味 id ID title タイトル description Description state 状態(オープン/クローズ) assignee Assignee due_date 期限 labels ラベル 実行結果------------------- 【タイトル】 関先生のお店訪問! 【Description】 大変! 今度、関先生がマジョリカとお店のことについて話がしたいんだって! なんとかしなくちゃ! 【状態】 closed 【Assignee】 Doremi 【Due date】 2020-09-13 【Labels】 [] ------------------- 【タイトル】 仕入れ値の高騰 【Description】 今月は先月に比べて仕入れ値が倍以上になってます。 デラがぼったくっている気がするけど…最近魔法会の物価が高騰しているという話もあります。 仕入先の変更も視野に入れて来月以降の対策を検討させてください。 【状態】 opened 【Assignee】 Doremi 【Due date】 2020-09-18 【Labels】 ['経営'] ------------------- 【タイトル】 不審な人物の件 【Description】 最近オヤジーデらしい怪しい人物がMAHO堂の周りをうろついているという噂を聞きました。 何か対策を打ちませんか? 【状態】 opened 【Assignee】 Doremi 【Due date】 2020-09-25 【Labels】 []うまく取得することができましたね。
issueを登録する
では、本題のissue登録です。
issueの登録にはproject.issues.create()を使います。Python# チケットの登録 new_issue = project.issues.create({"title":"秋の東北旅行(出張販売)", "description":"今年も恒例、秋の旅行という名の出張販売に行きます。", "due_date":"2020-10-20"}) print(new_issue.id)実行結果71385002
ちゃんと登録できましたね!
機械で出来ることは機械にやらせよう
受信メールをウォッチしたり、管理表に書き込んだり状態を管理したりといったことは、人間よりも機械の方が得意なことです。
プログラムさえ間違っていなければ、機械の方が早く正確で、24時間働いても文句も言いません。こんな便利な機械と一緒に働くことができる時代に生きる私たちはとても幸せだと思います。
ぜひ機械(プログラム)を活用して、退屈な仕事から自分や仲間を解放しましょう!
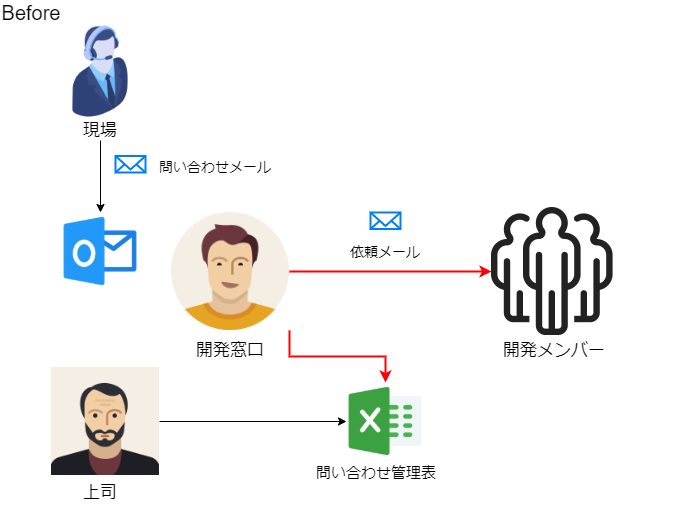
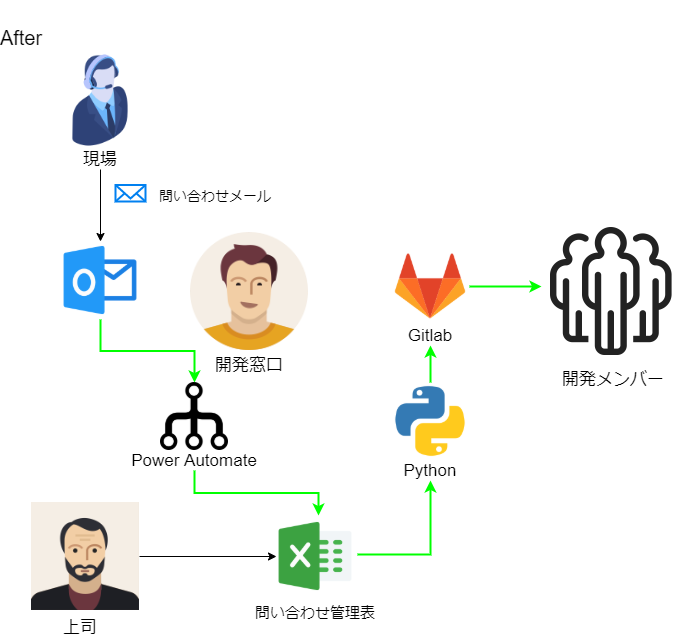
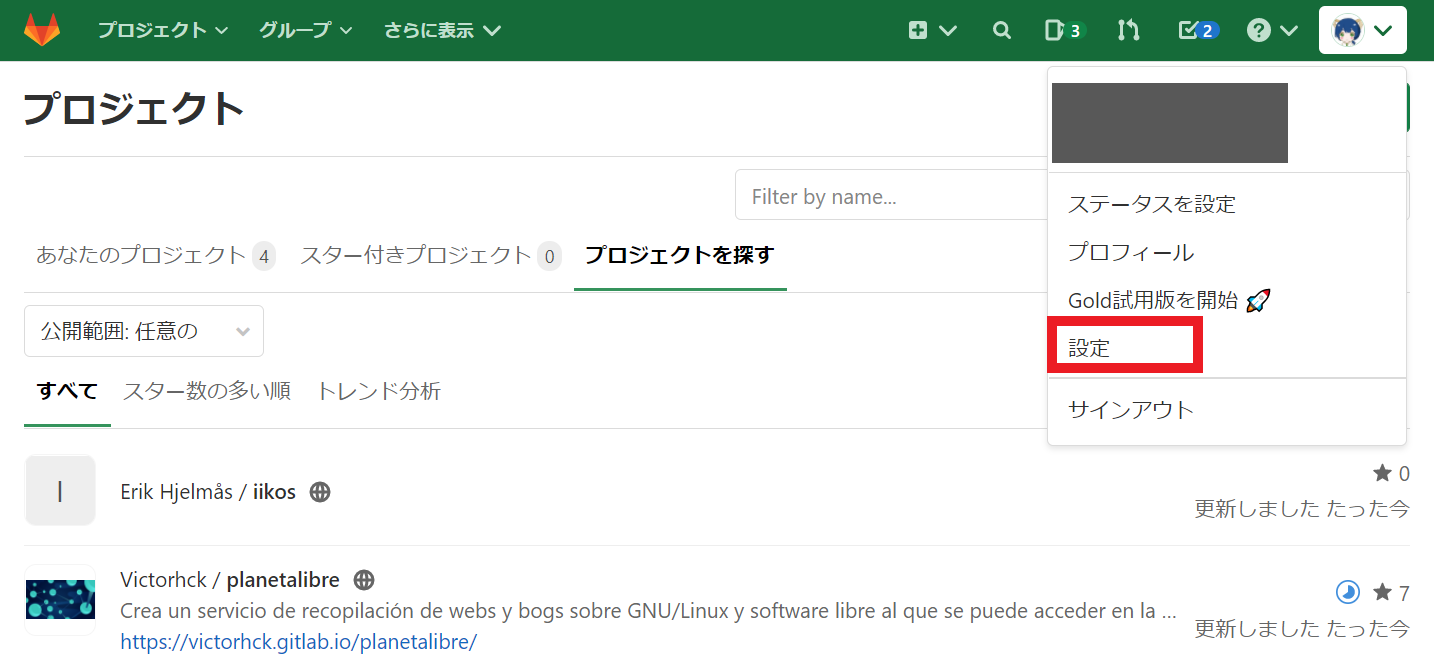
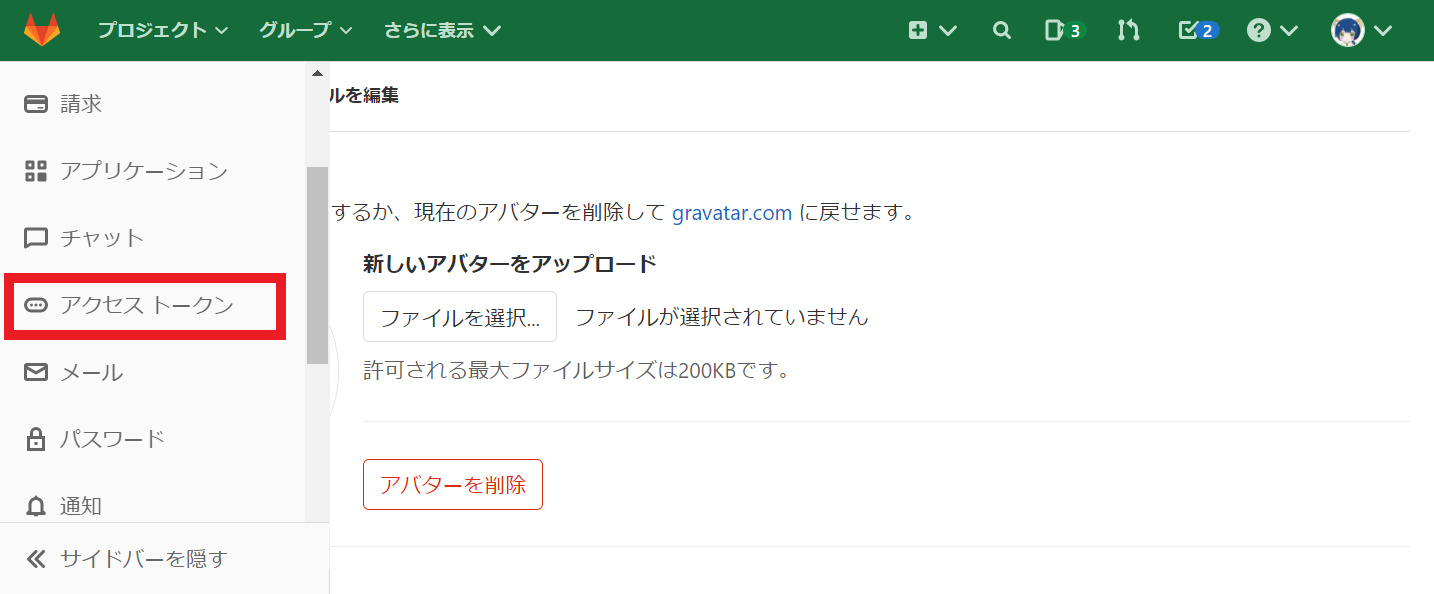
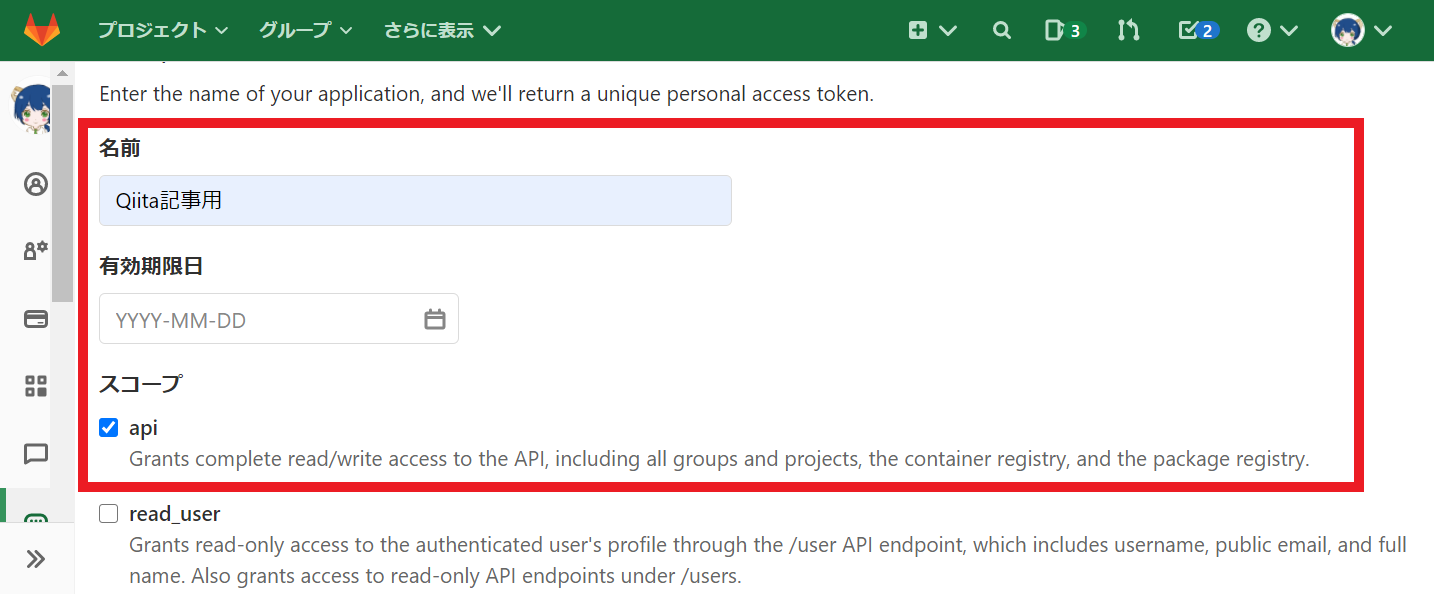
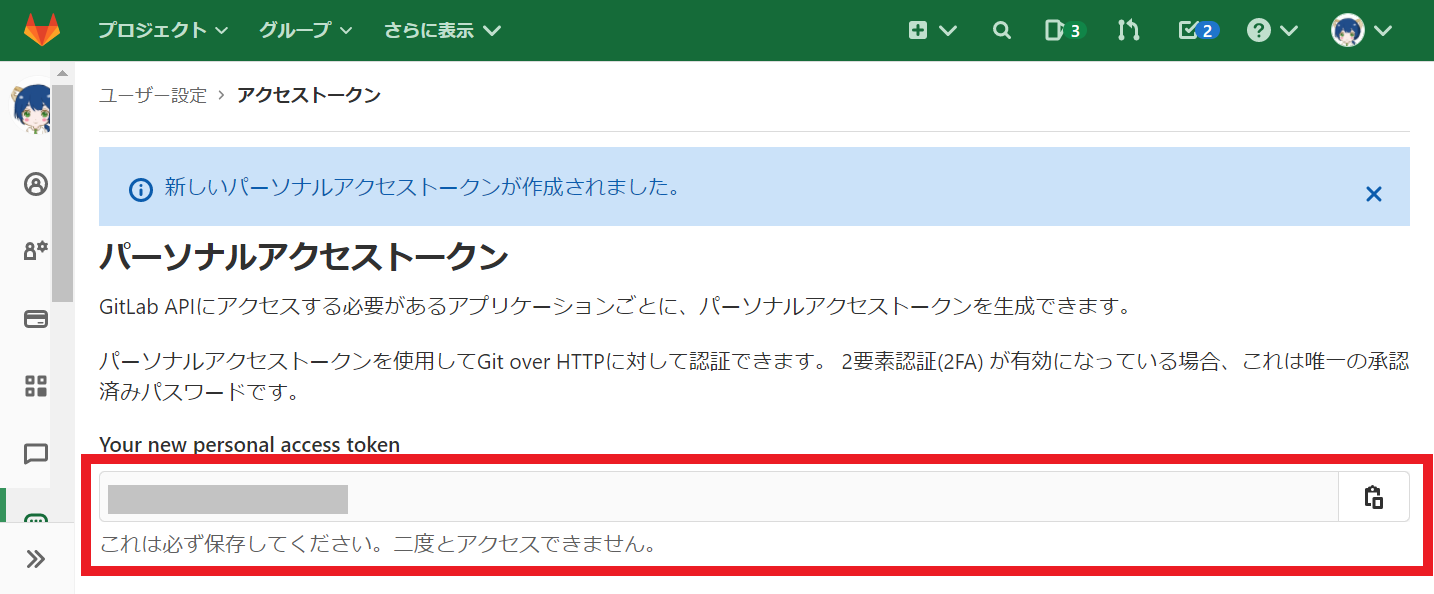
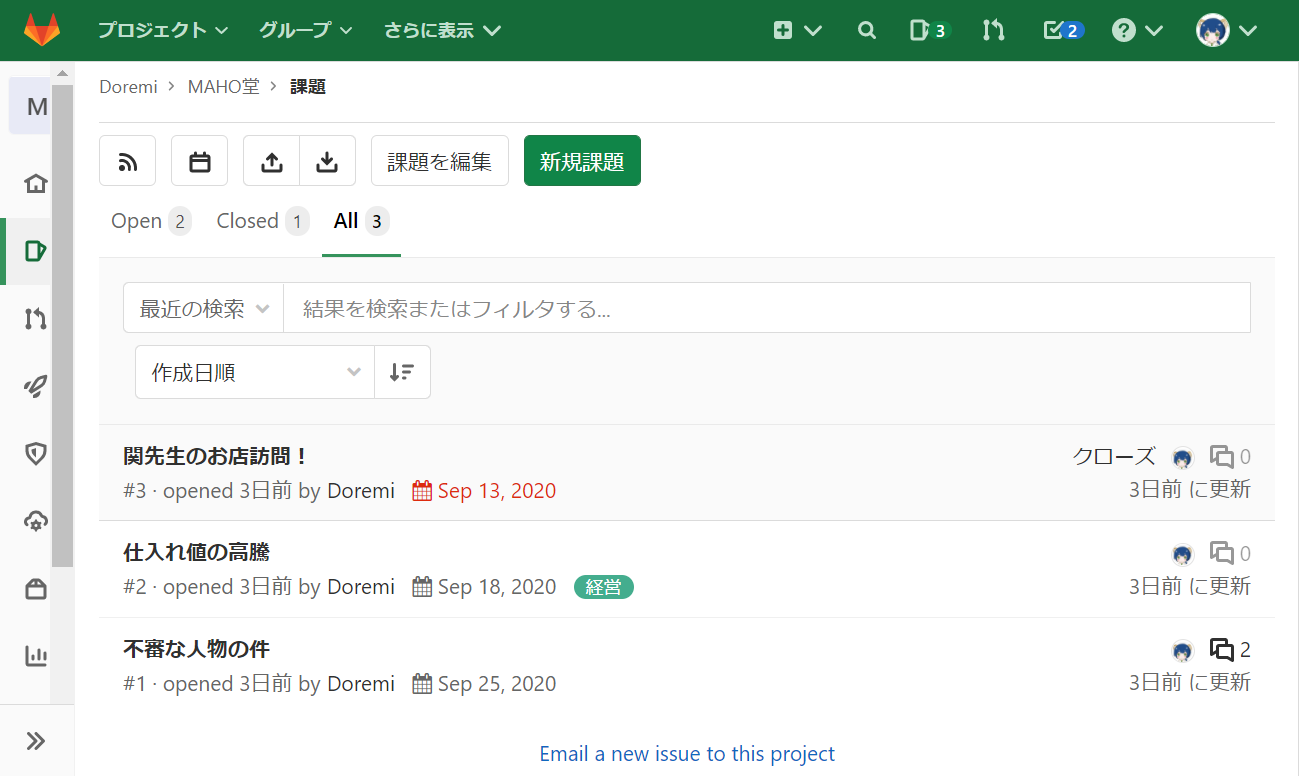
- 投稿日:2020-09-19T09:40:09+09:00
Python,AI関連の英語のための英英辞書対決
目的
英語を覚えるために英英辞書を使ってみるとして、
どれがいいか、英英辞書対決。候補は、
- ロングマン
- ケンブリッジ
- オックスフォード
- 後、おまけで、変な?語源のサイト
技術用語中心なので、やる前から、ロングマンは負けるのに決まっていますが、、、、
逆に、何か、面白いことがあるかも。。。LONGMAN
https://www.ldoceonline.com/Cambridge
https://dictionary.cambridge.org/Oxford
https://www.oxfordlearnersdictionaries.com/etymology
https://www.etymonline.com/ラウンド1(調査対象:placeholder)
■LONGMAN
欠席(技術用語を調べることが多いので、休みがちになると思います。すまない。)■Cambridge
a symbol or piece of text in a mathematical expression or computer instruction that can be replaced by particular pieces of information
↓
Google翻訳(ママ)
特定の情報に置き換えることができる数式またはコンピュータ命令のシンボルまたはテキストの一部
■Oxford
(specialist) a symbol or piece of text that temporarily replaces something that is missing
↓
Google翻訳(ママ)
欠けているものを一時的に置き換えるシンボルまたはテキストの一部
■etymology
place-holder (n.)
also placeholder, 1550s, "one who acts as a deputy for another," from place (n.) + holder (n.).↓
Google翻訳(ママ)プレースホルダー(n。)
また、プレースホルダー(1550年代)、プレース(n。)+ホルダー(n。)からの「別の代理人」。ラウンド2(調査対象:done)
以下のdone
(https://arxiv.org/abs/2006.07159)
Are we done with ImageNet?■LONGMAN
somebody is done (with something) (=someone has finished doing or using something)
■Cambridge
If something is done, or you are done with it, it is finished, or you have finished doing, using it, etc.:
↓
Google翻訳(ママ) <-- 不調
何かが行われた場合、またはあなたがそれを終えた場合、それが終了した場合、またはあなたがそれを実行したか、それを使用した場合など:
■Oxford
finished; completed
■etymology
done
past participle of do (v.); from Old English past participle gedon (a vestige of the prefix is in ado). As a past-participle adjective meaning "completed, finished, performed, accomplished" from early 15c. As a word of acceptance of a deal or wager, 1590s.U.S. Southern use of done in phrases such as done gone (or "Octopots done got Albert!") is attested by 1827, according to OED: "a perfective auxiliary or with adverbial force in the sense 'already; completely.' " Century Dictionary writes that it was "originally causal after have or had, followed by an object infinitive ; in present use the have or had is often omitted and the infinitive turned into a preterit, leaving done as a mere preterit sign" and calls it "a characteristic of negro idiom."
To be done in "exhausted" is by 1917. Slang done for "doomed" is by 1803 (colloquial do for "ruin, damage" is from 1740). To have done it "to have been very foolish, made a mess of things" is from 1837.
↓
Google翻訳(ママ)終わった
doの過去分詞(v。); 古い英語の過去分詞gedonから(接頭辞の痕跡はadoにあります)。 過去分詞形容詞としての意味は、15cの初めから「完了、終了、実行、達成」です。 契約または賭けの受け入れの言葉として、1590年代。OEDによると、done gone(または「Octopots done got Albert!」)などのフレーズで行われた米国南部での使用は、1827年までに「完全な補助または副詞的な力で、「すでに、完全に」という意味で証明されています。 「Century Dictionaryは、それが「もともと持っているか持っていた後に因果関係があり、その後にオブジェクト不定詞が続いた」と書いています。現在の使用では、持っているか持っていることがしばしば省略され、不定詞が前置記号になり、単なる前置記号として完了したままになっています。 「黒人イディオムの特徴。」
「使い果たされた」で行われるのは1917年までです。「悲惨な」で行われた俗語は1803年までです(「破滅、損傷」の俗語は1740年からです)。 「非常にばかだったこと、めちゃくちゃにしたこと」をしたのは1837年からです。
評価点(最も良いものに2。面白いのとか加点したいのがあれば、それに1。)
LONG Camb Oxf Ety 備考 placeholder 0 0 2 0 done 2 1 0 1 まとめ
特にありません。
- 投稿日:2020-09-19T09:16:05+09:00
PyTorchのモジュールでlibcusparse.so.10がないと言われる
自分用メモ
OS : Ubuntu 18.04 LTS
PyTorch : 1.50, 1.60
CUDA : 10.2
NVIDIA-driver : 440もともとは,PyTorch Geometricをimportしたときに起きたエラー.公式の通りにインストールしたのにおかしいな...と思ったが,結論から言うと,NVIDIA-driverはちゃんとインストールされていたが,NVCCがインストールされていなかったため.
症例
import torch_geometric.transforms as T OSError: libcusparse.so.10: cannot open shared object file: No such file or directorytensorflow-gpuで libcublas.so.10.0のImportError
https://qiita.com/Uejun/items/fbb579374eafab8633d6こちらも似たような症例だが,単にパスを通すだけで済むらしい.しかし,私のパソコンには,どこを探しても,libcusparse.so.10なるライブラリはなかった.
公式のissueにこのようなものがあった.libcusparse.so.10 error when importing
https://github.com/rusty1s/pytorch_geometric/issues/1092問題の状況は違うけど,
/usr/local/cuda/lib64下に,libcusparse.so.10があること,また,$ nvcc -Vがちゃん通ることが必要なようである.私の場合,$ nvcc -Vがそもそも通っていなかった.このコマンドを叩いたときには,$ nvcc -V Command 'nvcc' not found, but can be installed with: sudo apt install nvidia-cuda-toolkitと表示されるが,これでは目的のライブラリは入らない.それ以前に,cuda10.2をインストールする必要があるらしい.
解決策
cuda10.2を入れ直す.
$ sudo apt purge nvidia-cuda-*の後(なくてもいけるが念の為),公式をもとに,cuda10.2をインストールする.これに関しては,各デバイスごとに違うと思うので割愛.この後,.bashrcに
export PATH="/usr/local/cuda/bin:$PATH" export LD_LIBRARY_PATH="/usr/local/cuda/lib64:$LD_LIBRARY_PATH"を書き込んだら,
$ nvcc -Vが通り,PyTorch Geometricも使えるようになった.また,libucusparse.so.10.0などのモジュールがある場合は$ ln -s libucusparse.so.10.0 libucusparse.so.10などの対処で行ける場合もあるらしいが,自分の場合はエラーが起きた.
- 投稿日:2020-09-19T06:35:59+09:00
Selenium + WebDriver(Chrome) + Python | スクレイピングするための環境構築
経緯
やりたかった事と、最初の状況
Webページ( js展開後のhtml ) をスクレイピングしたい。
※Python使ったことほぼない。
※Seleniumについては全く知らなかった状態。調査開始
curlやphpでスクレイピングしようと思っていましたが、
curlではjs後のソースは拾ってこれないと分かり困りました。そこで調べたところ、以下ふたつが候補にあがります。
phantomjs
たくさんの情報があり、それなりに有効な気がしましたが、2018年6月で開発終了、サポートも終了していたことがわかりました。
Selenium + WebDriver
調べると情報量も多く、新しめの記事も多いので、ひとまずSeleniumでやってみることにしました。
環境準備
必要なもの
python pip chromedriver seleniumMacを使用していて標準でPythonが入っているため、Pythonのインストールについては割愛します。
pipをインストール
$ curl -kL https://bootstrap.pypa.io/get-pip.py | python実行結果
$ curl -kL https://bootstrap.pypa.io/get-pip.py | python % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 1841k 100 1841k 0 0 4630k 0 --:--:-- --:--:-- --:--:-- 4649k DEPRECATION: Python 2.7 reached the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 is no longer maintained. pip 21.0 will drop support for Python 2.7 in January 2021. More details about Python 2 support in pip can be found at https://pip.pypa.io/en/latest/development/release-process/#python-2-support pip 21.0 will remove support for this functionality. Defaulting to user installation because normal site-packages is not writeable Collecting pip Downloading pip-20.2.3-py2.py3-none-any.whl (1.5 MB) |████████████████████████████████| 1.5 MB 4.0 MB/s Collecting wheel Downloading wheel-0.35.1-py2.py3-none-any.whl (33 kB) Installing collected packages: pip, wheel WARNING: The scripts pip, pip2 and pip2.7 are installed in '/Users/xxx/Library/Python/2.7/bin' which is not on PATH. Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location. WARNING: The script wheel is installed in '/Users/xxx/Library/Python/2.7/bin' which is not on PATH. Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location. Successfully installed pip-20.2.3 wheel-0.35.1パスを通せというメッセージがあるので、パスを通す
$ export PATH="$HOME/Library/Python/2.7/bin:$PATH" $ echo 'export PATH="$HOME/Library/Python/2.7/bin:$PATH"' >> ~/.bash_profileパスが通っているか確認
$ echo $PATH /Users/xxx/Library/Python/2.7/bin:/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin $ cat ~/.bash_profile export PATH="$HOME/Library/Python/2.7/bin:$PATH"これでpipコマンドが使えるようになったので、確認
$ pip -V pip 20.2.3 from /Users/xxx/Library/Python/2.7/lib/python/site-packages/pip (python 2.7)Chromedriverをインストール
まず、現在パソコンで使用しているChromeのバージョンを確認する。
バージョン: 85.0.4181.101ということで、以下のコマンドを使う
pip install chromedriver-binary==85.*実行結果
$ pip install chromedriver-binary==85.* DEPRECATION: Python 2.7 reached the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 is no longer maintained. pip 21.0 will drop support for Python 2.7 in January 2021. More details about Python 2 support in pip can be found at https://pip.pypa.io/en/latest/development/release-process/#python-2-support pip 21.0 will remove support for this functionality. Defaulting to user installation because normal site-packages is not writeable Collecting chromedriver-binary==85.* Downloading chromedriver-binary-85.0.4183.87.0.tar.gz (3.6 kB) Building wheels for collected packages: chromedriver-binary Building wheel for chromedriver-binary (setup.py) ... done Created wheel for chromedriver-binary: filename=chromedriver_binary-85.0.4183.87.0-py2-none-any.whl size=7722067 sha256=901454e21156aef8f8bf4b0e302098747ea378a435c801330ea46d03ed Stored in directory: /Users/xxx/Library/Caches/pip/wheels/12/27/b7/69d38bfd65642b45a64e7e97e3160aba20f20be91cd5a Successfully built chromedriver-binary Installing collected packages: chromedriver-binary Successfully installed chromedriver-binary-85.0.4183.87.0 $Seleniumをインストール
使用コマンド
pip install selenium実行結果
$ pip install selenium DEPRECATION: Python 2.7 reached the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 is no longer maintained. pip 21.0 will drop support for Python 2.7 in January 2021. More details about Python 2 support in pip can be found at https://pip.pypa.io/en/latest/development/release-process/#python-2-support pip 21.0 will remove support for this functionality. Defaulting to user installation because normal site-packages is not writeable Collecting selenium Downloading selenium-3.141.0-py2.py3-none-any.whl (904 kB) |████████████████████████████████| 904 kB 5.2 MB/s Collecting urllib3 Downloading urllib3-1.25.10-py2.py3-none-any.whl (127 kB) |████████████████████████████████| 127 kB 10.7 MB/s Installing collected packages: urllib3, selenium Successfully installed selenium-3.141.0 urllib3-1.25.10 $これで準備は完了です。
Pythonで動かしてみる
Pythonファイルを作成
test.pyimport chromedriver_binary from selenium import webdriver options = webdriver.ChromeOptions() # options.add_argument('--incognito') # options.add_argument('--headless') print('connect...try...connect...try...') driver = webdriver.Chrome(options=options) driver.get('https://qiita.com') print(driver.current_url) # driver.quit()実行
$ python test.pyこれでChromeのブラウザが立ち上がってくれます。
めでたしめでたし。シークレットウインドウで立ち上げるには、以下のコメントアウトを外してください。
options.add_argument('--incognito')ヘッドレスブラウザで行う場合は、以下のコメントアウトを外してください。
options.add_argument('--headless')あとは、Seleniumやxpathなどを調べていけば誰でもスクレイピングできると思います。
補足
今回Macに入っていたpythonのversionは2.7でしたので少し古く2020年1月でサポートが終了してます。普段Pythonを使わないのでそのままにしてますが、各コマンドの実行結果のところで、2.7に対するメッセージ(DEPRECATION)が出てしまっています。ご容赦くださいm(_ _)m
参考記事
pipインストール
https://qiita.com/suzuki_y/items/3261ffa9b67410803443
https://qiita.com/tom-u/items/134e2b8d4e11feea8e12Seleniumセットアップ
https://qiita.com/Chanmoro/items/9a3c86bb465c1cce738aSeleniumで要素を選択する方法まとめ
https://qiita.com/VA_nakatsu/items/0095755dc48ad7e86e2fスクレイピング Xpath
https://qiita.com/rllllho/items/cb1187cec0fb17fc650a
- 投稿日:2020-09-19T03:08:37+09:00
連続隠れマルコフモデルのpythonによる実装
今回はせっかくqiitaも投稿始めたので、数ヶ月前に苦労して実装したpythonによる連続隠れマルコフモデルの実装について書こうと思います。
備忘録として自分が勉強した順に基本から書いていこうと思います。
また、この結果はおそらくできているだろうと思っていますが、動作怪しい部分もあるのでもし何かお気付きの方は教えていただけると幸いです。マルコフモデルとは
マルコフモデルとはマルコフ過程に基づいて作られるモデルのことで、マルコフ過程とはマルコフ性を持つ確率過程のことです。
マルコフたくさん出てきてなかなか理解できなかったので自分なりの理解を説明してみます。
まず以下のようなグラフ理論のような図を考えてみます。
この図ではある一定時間後に矢印が向いている方向に状態が確率的に遷移し、その確率は矢印に添えられている数字だとします。
今状態Aだとすると0.3の確率で状態Bへ、0.7の確率で状態Cに遷移します。
もしA状態にXからきてもYからきても状態Aから状態Bまたは状態Cへの遷移確率は変わりません。
つまり、次の状態(BまたはC)への遷移確率は今の状態(A)のみに依存しているような性質をマルコフ性というとのことです。
確率過程とは、"時間とともに変化する確率変数のことである。-wikipedia-"と書いてありこの場合は状態を取る確率が時間によって変わるために確率過程と言えると考えています。すみません厳密な定義は他の情報サイトに譲ります
このような考え方で作られるモデルがマルコフモデルと言えます。隠れマルコフモデル
隠れマルコフモデルとは先ほどのマルコフモデルのようなモデルですが状態がわからない代わりに状態に依存したある値(出力)を持っている時に使われるモデルです。
自然言語処理を元に具体的に例を作ってみます。
まず、”I book a film”(私は映画を予約する)という例文(出力)を考える。この時”I"、"film"は名詞、"book"は動詞、"a"は冠詞である。このような品詞はこの文章からはわからないため隠れ状態と考えられます。
この文の品詞を機械に決めさせたいとします。しかし"I"や"a"はほぼ一意に決まるが"book"や"film"は名詞である本や映画を撮るといいた動詞の使い方もできます。そこで隠れマルコフモデルを用いてうまく品詞分類できないか考えてみます。英文は5文型等ある程度品詞の順番が決まっています。そのため品詞の移り変わりのしやすさは以下の表のようになりそうです。(自分の感覚で値決めています)
文頭 名詞 動詞 冠詞 文末 文頭 0 0.6 0.2 0.2 0 名詞 0 0.3 0.5 0.1 0.1 動詞 0 0.6 0 0.3 0.1 冠詞 0 1 0 0 0 文末 0 0 0 0 0 左が今の状態上が次の状態を示していると考えてください。一つ例をあげると名詞の次に名詞がくる確率は0.3、動詞が来る確率は0.5、冠詞が来る確率は0.1、文末が来る確率は0.1のような感じで見てください。
確率に0を使うのはゼロ頻度問題的によくないのですが
そして各状態の時次のような確率で出力をとるとする。
つまり名詞の時は"I"を0.4、"a"を0.0、"book"を0.3、"film"を0.2の確率でとるということです。
この時の状態遷移の仕方は次のようになります。(遷移確率が0の状態はあらかじめ削っています)
そして、単語数がn個、単語列(観測可能なもの)を$W=w_1,w_2,...,w_n$とし、品詞列(観測できないもの:状態)を$T=t_1,t_2,...,t_n$とするとある一つのルートを決めた時のこのモデルが出す確率は
$P(w)= \prod_{i=1}^{n}P(t_i|t_{i-1})P(w_i|t_i)$で表すことができる。つまり前の状態から今の状態へと変わる確率$P(t_i|t_{i-1})$である遷移確率とある品詞の状態の時にその単語を出力する確率$P(w_i|t_i)$である出現確率の積を総乗することで求めることができる。
今回のモデルでは最初の状態(初期状態)は文頭でした。今回は最初の状態が文頭であることは自明であるが、他のデータに適応する時は最初の状態がどの状態から始まりやすいか(初期確率)も確率に大きく関わって来る。
そのため、このモデルが結果として出す確率は初期確率を$\pi_i$、遷移確率を$a_{i,j}$、出力関数を$b_j(w_t)$(ただしi,jはある状態を表し、tは出力の順番を示す。)と置き、状態の順番が$I=i_1,i_2,...,i_n$の時の確率は
$P(w)=\pi_{i_0}\prod_{t=1}^{n}a_{i_{t-1},i_t}b_{i_t}(w_t)$(ただし、今回使用した文章の例だと$w_0$は空白、$w_1$は'I',...,$w_n$は空白のようになります。)
そしてこの確率がもっとも高い遷移の仕方を求めるとこの文の品詞を予測することができる。
ちなみにこの例の場合はわかりやすく偏らせたためと言えるが文頭→名詞→動詞→冠詞→名詞→文末といった順番で遷移する確率がもっとも高くなり、正しく品詞分類できていると考えられます。余談ーーー
これからも初期確率は$\pi$
、遷移確率は$a_{i,j}$、出現確率は$b_j(w)$のような書き方で進めていきます。
ーーーーー連続隠れマルコフモデル
先ほどの隠れマルコフモデルは4つの単語について考えていたため出力は4値の出力として考えることができる。そのため出力は離散した値でした。そのため離散隠れマルコフモデルと言えます。
そのため気温のような連続した値を用いる場合の隠れマルコフモデルを連続隠れマルコフモデルというようです。
先ほどの離散マルコフモデルでは各状態の出現確率をそれぞれに求めていくが、連続値に対して全て値を振ることは現実的ではないので、混合ガウス分布を用いて出現確率を定義していきます。
連続隠れマルコフモデルの実装に入る前にまず混合ガウス分布について書いていこうと思います。ガウス分布・混合ガウス分布
混合ガウス分布とはガウス分布をいくつも足し合わせて確率分布を表現したものです。
そもそもガウス分布とは正規分布とも言われるもので、
$N(x| \mu,\sigma)=\frac{1}{\sqrt{2 \pi\sigma^2}}\exp(-\frac{(x-\mu)^2}{2\sigma^2})$で表されます。
-画像はwikipediaより拝借しました-
このグラフからわかるようにこのxが平均$\mu$(この図では0)に近いほど大きな値を取ることがわかります。そして分散が大きければ平べったい形になります。つまり、この値を確率と考えればxの値が平均$\mu$に近ければ近いほど高い値を取り、分散が大きければ平均から離れていてもその値をとる可能性はありうるようになると言えます。また混合ガウス分布はこの正規分布を複数足し合わせたようなもので、もしK個のガウス分布を合わせた混合ガウス分布の式は
$P(x|\pi,\mu,\sigma)=\sum_{k=1}^{K}\pi_kN(x|\mu_k,\sigma_k)$ただし、$\sum_{k=1}^K\pi_k=1$の条件があります。
で表されます。これを図示してみると
このようになります。
混合ガウス分布によるクラスタリング
今後連続隠れマルコフモデルを実装するにあたってデータ点からガウス分布を特定する必要があります。そこで混合ガウス分布によるソフトクラスタリングの実装を行うことでその流れを見ていこうと思います。
まず、3つのガウス分布を元に点をプロットして見ます。
これがそのプロットになります。これらの点はどのガウス分布から生成されたのかわかっている状態です。(完全データ)
しかし、実際にクラスタリングするときはどの分布から生成されたのかわかりません。(不完全データ)
そのため、今からガウス分布に従ってもっともよく3つにわけられるように3つのガウス分布からなる混合ガウス分布のパラメータを調整していきます。どのようにしたらうまく3つに分けることができるのか、それは求める混合ガウス分布による全ての点の同時確率がもっとも高くなれば良いということになります。つまり
$ln(p(X|\pi,\mu,\sigma))= ln(\prod_{i=1}^{n}\sum_{k=1}^K \pi_kN(x_i|\mu_k,\sigma_k))=\sum_{i=1}^nln(\sum_{k=1}^K\pi_kN(x_i|\mu_k,\sigma_k))$$X=[x_1,x_2,...,x_n]$・・・各データ点
$K$・・・モデルの数(クラスタの数)がもっとも高くなるようにパラメータを調整してきます。またこれを対数尤度関数と呼びます。
この関数を最大化するようにパラメータを変えたいのですが総和の総和が出現し、解析的に解くことが難しいためEMアルゴリズムを用いて解いていきます。EMアルゴリズムのやり方としては
Eステップ:期待値の計算
Mステップ:期待値が最大となるようにパラメータの調整
を繰り返すことで最適解を見つけるという方法です。今回の流れは
- $\pi,\mu,\sigma$の初期値を決める
- 負担率を計算する(Eステップ)
- パラメータ $\pi ,\mu,\sigma$の値を調節する。
- 尤度に差が見られなければ終了。まだ変わるのであれば2に戻る。
という流れで行います。
初期値
最初の初期値は適当に決めます。(当たり前ですが、この値をなんとなくわかっているなら調整すると早く収束したりするようです。)
Eステップ
次にEステップです。
ここで負担率という言葉が出てきますが、これはある点xがモデルkより発生した確率です。
先ほどのプロットで考えると、どのガウス分布モデルから生まれた点かわかりませんでした。そのためどのモデルから生まれた点かを示す潜在変数zを考えます。もし$z_{i,k}=1$なら点$x_i$はモデルkから生まれた点であると言えます。これを式にすると
$p(z_{i,k}=1|x_i)=\frac{p(z_{i,x}=1,x_i)}{p(x_i)}$また、
$p(x_i|x_{i,k}=1)=\frac{p(z_{i,k}=1,x_i)}{p(z_{i,k}=1)}$であるため
$p(z_{i,k}=1|x_i)=\frac{p(x_i|z_{i,k}=1)p(z_{i,z}=1)}{p(x_i)}$である。(ベイズの定理)
また$p(x_i)$はzについて周辺化した値であるため混合ガウス分布の式で表され、
$p(z_{i,k}=1|x_i)=\frac{p(x_i|z_{i,k}=1)p(z_{i,k}=1)}{\sum_{k=1}^{K}\pi_kN(x|\mu_k,\sigma_k)}=\gamma(z_{i,k})$となります。
ここで、$p(x_i|z_{i,k}=1)$はモデルkより$x_i$が生まれた確率なのでモデルkの正規分布$N(x_i|\mu_k,\sigma_k)$です。
そして、$p(z_{i,k}=1)=\pi_k$であるため
$\gamma(z_{i,k})=\frac{\pi_kN(x|\mu_k,\sigma_k)}{\sum_{k=1}^{K}\pi_kN(x|\mu_k,\sigma_k)}$
となります。( なぜ$p(z_{i,k}=1)=\pi_k$となるかは、自分の理解が追いついていないのですが、これはあくまでxに関係無い値で、どれだけモデルkに属しやすいかを比べる量とするなら確かにそうなるかもしれないという所感です。)
なぜこれが負担率と言われるかですが、モデルkがどのくらい混合ガウス分布の割合を占めているかを示すからだと考えています。
二つ前の図を見てもらうとなんとなくイメージできるかと思います。Mステップ
続いてパラメータの更新です。
個々の方針は$\mu,\sigma$については尤度関数がもっとも高くなればいいので微分してその値が0となる点を探すと言う方針で進めます。
また、$\pi$は$\sum_{k=1}^K\pi_k=1$の条件があるため、ラグランジェの未定乗数法で解いていきます。この微分の導出はEMアルゴリズム徹底解説ので他の方がとてもわかりやすく説明されているので結果だけをまとめます。
個人的に導出して見ましたがとても大変でした
結果
$\mu_k*=\frac{1}{N_k}\sum_{i=1}^N\gamma(z_{i,k})x_i$
$\sigma_k*=\frac{1}{N_k}\sum_{i=1}^N\gamma(z_{i,k})(x_i-\mu_k)(x_i-\mu_k)^T$
$\pi_k*=\frac{N_k}{N}=\frac{\sum_{n=1}^N\gamma(z_{i,k})}{N}$という結果になります。
混合ガウス分布の実装
導出についてまとまったので実際に混合ガウス分布のクラスタリングを実装して見ました。
ex_gmm.pyimport numpy as np import matplotlib.pyplot as plt #difine data_num = 100 model_num = 3 dim = 2 color = ['#ff0000','#00ff00','#0000ff'] epsilon = 1.0e-3 check = False # if not check == False #gaussian calculator def cal_gauss(x,mu,sigma): return np.exp(-np.dot((x-mu),np.dot(np.linalg.inv(sigma),(x-mu).T))/2)/np.sqrt(2*np.pi*abs(np.linalg.det(sigma))) #init create param mu =[] sigma = [] for i in range(model_num): mu.append([np.random.rand()*10 ,np.random.rand()*10]) temp = np.random.rand()-np.random.rand() sigma.append([[np.random.rand()+1,temp],[temp,np.random.rand()+1]]) #create data values = [] for i in range(model_num): values.append(np.random.multivariate_normal(mu[i],sigma[i],data_num)) for i in range(model_num): plt.scatter(values[i][:,0],values[i][:,1],c=color[i],marker='+') plt.show() #create training data train_values =values[0] for i in range(model_num-1): train_values = np.concatenate([train_values,values[i+1]]) plt.scatter(train_values[:,0],train_values[:,1],marker='+') #init model param model_mu =[] model_sigma =[] for i in range(model_num): model_mu.append([np.random.rand()*10 ,np.random.rand()*10]) temp = np.random.rand()-np.random.rand() model_sigma.append([[np.random.rand()+1,temp],[temp,np.random.rand()+1]]) model_mu = np.array(model_mu) model_sigma = np.array(model_sigma) for i in range(model_num): plt.scatter(model_mu[i,0],model_mu[i,1],c=color[i],marker='o') #plot pre train mu temp = [] for i in range(model_num): temp.append(np.random.rand()) model_pi = np.zeros_like(temp) for i in range(model_num): model_pi[i] = temp[i]/np.sum(temp) plt.show() #training old_L = 1 new_L = 0 gamma = np.zeros((data_num*model_num,model_num)) while(epsilon<abs(new_L-old_L)): #gamma calculation for i in range(data_num*model_num): result_gauss = [] for j in range(model_num): result_gauss.append(cal_gauss(train_values[i,:],model_mu[j],model_sigma[j])) result_gauss = np.array(result_gauss) old_L = np.sum(model_pi*result_gauss) #old_L calculation for j in range(model_num): gamma[i,j] = (model_pi[j]*result_gauss[j])/np.sum(model_pi*result_gauss,axis=0) N_k =np.sum(gamma,axis=0) #calculation sigma for i in range(model_num): temp = np.zeros((dim,dim)) for j in range(data_num*model_num): temp+=gamma[j,i]*np.dot((train_values[j,:]-model_mu[i]).reshape(-1,1),(train_values[j,:]-model_mu[i]).reshape(1,-1)) model_sigma[i] = temp/N_k[i] #calculation mu for i in range(model_num): model_mu[i] = np.sum(gamma[:,i].reshape(-1,1)*train_values,axis=0)/N_k[i] #calculation pi for i in range(model_num): model_pi[i]=N_k[i]/(data_num*model_num) #check plot if(check == True ): gamma_crasta = np.argmax(gamma,axis=1) for i in range(data_num*model_num): color_temp = color[gamma_crasta[i]] plt.scatter(train_values[i,0],train_values[i,1],c=color_temp,marker='+') for i in range(model_num): plt.scatter(model_mu[i,0],model_mu[i,1],c=color[i],marker='o') plt.show() ##new_Lcalculation for i in range(data_num*model_num): result_gauss = [] for j in range(model_num): result_gauss.append(cal_gauss(train_values[i,:],model_mu[j],sigma[j])) result_gauss = np.array(result_gauss) new_L = np.sum(model_pi*result_gauss) gamma_crasta = np.argmax(gamma,axis=1) for i in range(data_num*model_num): color_temp = color[gamma_crasta[i]] plt.scatter(train_values[i,0],train_values[i,1],c=color_temp,marker='+') for i in range(model_num): plt.scatter(model_mu[i,0],model_mu[i,1],c=color[i],marker='o') plt.show()このような感じで動くはずです。
このプログラムではパラメータが全部ランダムで出しているため、うまくクラスタリングできないこともあります。実際そのようなデータがきたらクラスタリングできないので……連続隠れマルコフモデルの実装
かなり遠回りしてしまいましたが、これから連続マルコフモデルの実装を見ていきたいと思います。
連続マルコフモデルである観測情報y={$y_1,y_2,...,y_t$}が得られた時、このモデルがこの値を想起する確率$p(y|M)$はトレリスアルゴリズムでもとめることができます。トレリスアルゴリズムは
$p(y|M) = \sum_{i}\alpha(i,T)$ (ただしこのiは最終状態)で求められます。
そしてこの$\alpha(i,t)$は\begin{eqnarray} \alpha_{i,t}=\left\{ \begin{array}{ll} \ \pi_i & (t=0) \\ \ \sum_j \alpha(j,t-1)a_{j,i}・b_{i}(y_t) & (|l-k|=1) \\ \end{array} \right. \end{eqnarray}です。そしてここで出てくる$a_{j,i}$と$b_{j,i}(y_t)$は少し前の話になりますが、隠れマルコフモデルでも出てきた遷移確率と出現確率を示しています。(この話は少し学習とは関係無かったです……)
この$\alpha(i,t)$は前から確率を辿っていきます(フォワード関数)が、これを最後から辿っていく関数(バックワード関数)を定義します。\begin{eqnarray} \beta_{i,T}=\left\{ \begin{array}{ll} \ 1 & (最終状態) \\ \ 0 & (最終状態では無い) \\ \end{array} \right. \end{eqnarray}\beta(i,t)=\sum_{j}a_{i,j}・b_{i}(y_t)・\beta(j,t+1) \qquad (t=T,T-1,...,1)隠れマルコフモデルのモデルパラメータの学習にはEMアルゴリズムの一種であるバウム・ウェルチアルゴリズムを用いて学習することができます。
バウムウェルチアルゴリズムでEステップで計算するのが、
$\gamma(i,j,t)=\frac{\alpha(i,t-1)・a_{i,j}・b_{j}・\beta(j,t)}{p(y|M)}$この値です。この値は時間tの時状態iからjへ遷移し、かつ$y_t$を出力する時の確率をこのモデルでyが生起する確率で割ったものと考えられます。
そして、パラメータの推定(更新)式は
$\pi*=\frac{\sum_j\gamma(i,j,1)}{\sum_i\sum_j\gamma(i,j,1)}$
$a_{i,j}*=\frac{\sum_t\gamma(i,j,t)}{\sum_t\sum_j\gamma(i,j,t)}$
となり、
bはガウス分布であるため、$\mu_{i,j}*=\frac{\sum_{t=1}^T\gamma(i,j,t)y_t}{\sum_{t=1}^T\gamma(i,j,t)}$
$\sigma_{i,j}=\frac{\sum_{t=1}^T \gamma(i,j,t)(y_t-\mu_j)(y_t-\mu_j)^t}{\sum_{t=1}^T\gamma(i,j,t)}$
で求められます。
それではコードです。
逐次調整を行なっていたためガウス分布の実装ファイル。隠れマルコフモデルのファイル、実行ファイルの3つに分けています。
(今回当初はGMMーHMMで作る予定だったので実装無駄な部分が多いです。GMMーHMMがうまくいき次第また更新しますので少々お待ちください。)class_b.pyimport numpy as np import matplotlib.pyplot as plt import math import sys #construct #c = mixing coefficient #mu = mean #sigma = dispersion #m = model num #size = datasize #x = data ##method #gaussian(x) : calculation gaussian:x=data #updata(x) : update gmm :x=data #output(x) : gmm output:x=data (size=1) class function_b: upsilon = 1.0e-50 def __init__(self,c,mu,sigma,m,size,x): self.c = np.array(c) self.c = self.c.reshape((-1,1)) self.mu = np.array(mu) self.mu = self.mu.reshape((-1,1)) self.sigma = np.array(sigma) self.sigma = self.sigma.reshape((-1,1)) self.size = size self.model_num = m self.x = np.array(x).reshape(1,-1) self.ganma = np.zeros((self.model_num,self.size)) self.sum_gaus = 0 self.N_k=np.zeros(self.model_num) def gaussian(self,x): return np.exp(-((x-self.mu)**2)/(2*self.sigma))/np.sqrt(2*math.pi*self.sigma) def update(self,pre_ganma): #x=[x1~xt] self.ganma = np.zeros((self.model_num,self.size)) #calculate ganma for m in range(self.model_num): self.ganma[m] = pre_ganma*((self.c[m]*self.gaussian(self.x)[m]+function_b.upsilon)/np.sum(self.c*self.gaussian(self.x)+function_b.upsilon,axis=0))+function_b.upsilon for m in range(self.model_num): self.N_k[m] = np.sum(self.ganma[m]) #calculate c for m in range(self.model_num): self.c[m]=self.N_k[m]/np.sum(self.N_k) #calculate sigma for m in range(self.model_num): self.sigma[m]=np.sum(self.ganma[m]*((self.x-self.mu[m])**2))/self.N_k[m] #calculate mu for m in range(self.model_num): self.mu[m]=np.sum(self.ganma[m]*self.x)/self.N_k[m] def output(self,x): return np.sum(self.c.reshape((1,-1))*self.gaussian(x).reshape((1,-1)))class_hmm_gmm.pyimport numpy as np import sys import matplotlib.pyplot as plt from class_b import function_b import copy #construct #s = state num #x = data #pi = init prob #a = transition prob #c = gmm mixing coefficient #mu = gmm mean #sigma = gmm dispersion #m = gmm model num #method #cal_alpha() : calculation alpha #cal_beta() : calculation beta #cal_exp() : calculation expected value(?) #update() : update prams #makestatelist : make statelist #viterbi : viterbi algorithm class Hmm_Gmm(): upsilon=1.0e-300 def __init__(self,s,x,pi,a,c,mu,sigma,m): self.s = s self.x = x self.a = np.array(a) self.size=len(x) self.b=[] for i in range(s): self.b.append(function_b(c[i],mu[i],sigma[i],m,self.size,x)) self.pi = np.array(pi) self.alpha = np.zeros((self.s,self.size)) self.beta = np.zeros((self.s,self.size)) self.prob = None self.kusai = np.zeros((self.s,self.s,self.size-1)) self.ganma = np.zeros((self.s,self.size)) self.preganma = None self.delta = None self.phi = None self.F = None self.P = None self.max_statelist=None def cal_alpha(self): for t in range(self.size): for j in range(self.s): if t==0: self.alpha[j,t]=self.pi[j]*self.b[j].output(self.x[t]) else: self.alpha[j,t]=0 for i in range(self.s): self.alpha[j,t]+=self.alpha[i,t-1]*self.a[i,j]*self.b[j].output(self.x[t]) self.prob =0 for i in range(self.s): self.prob+=self.alpha[i,self.size-1]+Hmm_Gmm.upsilon def cal_beta(self): for t in reversed(range(self.size)): for i in range(self.s): if t ==self.size-1: self.beta[i,t]=1 else: self.beta[i,t]=0 for j in range(self.s): self.beta[i,t]+=self.beta[j,t+1]*self.a[i,j]*self.b[j].output(self.x[t+1]) def cal_exp(self): for t in range(self.size-1): for i in range(self.s): for j in range(self.s): self.kusai[i,j,t] = ((self.alpha[i,t]*self.a[i,j]*self.b[j].output(self.x[t+1])*self.beta[j,t+1])+(Hmm_Gmm.upsilon/(self.s)))/self.prob for t in range(self.size): for i in range(self.s): #self.ganma[i,t] = (self.alpha[i,t]*self.beta[i,t])/self.prob #self.ganma[i,t] = (self.alpha[i,t]*self.beta[i,t])/self.prob + Hmm_Gmm.uplilon self.ganma[i,t] = ((self.alpha[i,t]*self.beta[i,t])+(Hmm_Gmm.upsilon))/self.prob def update(self): #cal exp self.cal_alpha() self.cal_beta() self.cal_exp() #cal pi self.pi = self.ganma[:,0] #cal a for i in range(self.s): for j in range(self.s): #self.a[i,j]=np.sum(self.ganma[i,:]) self.a[i,j]=np.sum(self.kusai[i,j,:])/np.sum(self.ganma[i,:]) #self.a[i,j]=np.sum(self.kusai[i,j,:]) #cal b #cal preganma self.preganma = np.zeros((self.s,self.size)) for t in range(self.size): temp = self.alpha[:,t]*self.beta[:,t]+self.upsilon self.preganma[:,t] = temp/np.sum(temp) for i in range(self.s): self.b[i].update(np.array(self.preganma[i])) def makestatelist(self,f,size): statelist = np.zeros(size) for t in reversed(range(size)): if t == size-1: statelist[t] = f else: statelist[t] = self.phi[statelist[t+1],t+1] return statelist def viterbi(self,x): data=np.array(x) self.delta = np.zeros((self.s,data.shape[0])) self.phi = np.zeros((self.s,data.shape[0])) for t in range(data.shape[0]): for i in range(self.s): if t == 0: self.phi[i,t] = np.nan self.delta[i,t] = np.log(self.pi[i]) else: self.phi[i,t] = np.argmax(self.delta[:,t-1]+np.log(self.a[:,i])) self.delta[i,t] = np.max(self.delta[:,t-1]+np.log(self.a[:,i]*self.b[i].output(data[t])+self.upsilon)) self.F = np.argmax(self.delta[:,data.shape[0]-1]) self.P = np.max(self.delta[:,data.shape[0]-1]) #print(self.makestatelist(self.F,data.shape[0])) self.max_statelist=self.makestatelist(self.F,data.shape[0])ex_hmm_demo.pyimport numpy as np import matplotlib.pyplot as plt import sys from class_hmm_gmm import Hmm_Gmm model_num = 1 state_num = 4 color=['#ff0000','#00ff00','#0000ff','#888888'] value_size = int(10*model_num*state_num) create_mu = [] create_sigma= [] create_pi =[] for i in range(state_num): temp = [] temp1 = [] temp2=[] for j in range(model_num): temp.extend([(np.random.rand()*30-np.random.rand()*30)]) temp1.extend([np.random.rand()+1]) temp2.extend([np.random.rand()]) create_mu.append(temp) create_sigma.append(temp1) create_pi.append((temp2/np.sum(temp2)).tolist()) #create data values = [] for i in range(state_num): temp = [] for it in range(int(value_size/state_num/model_num)): for j in range(model_num): temp.extend(np.random.normal(create_mu[i][j],create_sigma[i][j],1).tolist()) values.append(temp) x_plot = np.linspace(0,value_size,value_size) for i in range(state_num): plt.scatter(x_plot[i*len(values[0]):i*len(values[0])+len(values[0])],values[i],c=color[i],marker='+') for i in range(state_num): for j in range(model_num): plt.plot(x_plot[i*len(values[0]):i*len(values[0])+len(values[0])],np.full(len(values[0]),create_mu[i][j]),c=color[i]) plt.show() train_values=[] for i in range(state_num): train_values.extend(values[i]) train_mu = [] train_sigma= [] train_pi =[] for i in range(state_num): temp = [] temp1 = [] temp2=[] for j in range(model_num): temp.extend([np.random.rand()*30-np.random.rand()*30]) temp1.extend([np.random.rand()+1]) temp2.extend([np.random.rand()]) train_mu.append(temp) train_sigma.append(temp1) train_pi.append((temp2/np.sum(temp2)).tolist()) ##backup train b_train_mu = train_mu b_train_sigma = train_sigma plt.scatter(x_plot,train_values,c="#000000",marker='+') for i in range(state_num): for j in range(model_num): plt.plot(x_plot[i*len(values[0]):i*len(values[0])+len(values[0])],np.full(len(values[0]),train_mu[i][j]),c=color[i]) plt.show() #init a a = [] for j in range(state_num): temp = [] for i in range(state_num): temp.append(np.random.rand()) a.append(temp) for i in range(state_num): for j in range(state_num): #a[j][i] = a[j][i]/np.sum(np.array(a)[:,i]) a = (np.array(a)/np.sum(np.array(a),axis=0)).tolist() #init init_prob init_prob = [] for j in range(state_num): temp2.extend([np.random.rand()]) #temp2[0]+=1 init_prob.extend((temp2/np.sum(temp2)).tolist()) #init Hmm_Gmm model hmm_gmm = Hmm_Gmm(state_num,train_values,init_prob,a,train_pi,train_mu,train_sigma,model_num) #train roop print(create_mu) print(a) count = 0 while(count != 100): hmm_gmm.update() count +=1 #viterbi hmm_gmm.viterbi(train_values) print(hmm_gmm.max_statelist) #************************************* plt.scatter(x_plot,train_values,c="#000000",marker='+') ##plot of init train mu for i in range(state_num): for j in range(model_num): plt.plot(x_plot[i*len(values[0]):i*len(values[0])+len(values[0])],np.full(len(values[0]),b_train_mu[i][j]),c="#dddddd") for i in range(state_num): for j in range(model_num): plt.plot(x_plot[i*len(values[0]):i*len(values[0])+len(values[0])],np.full(len(values[0]),hmm_gmm.b[i].mu[j]),c=color[i]) plt.show()結果
初期$\mu$の値とガウス分布から出力された点です。今回は4つの状態を仮定していて4つのガウス分布からそれぞれ点が生成されています。それぞれの状態を最初から順に状態1(赤)、状態2(緑)、状態3(青)、状態4(灰)と呼んでおきます。
平均値 $\mu$を乱数でリセットしました。
これに対して学習を行なっていきます。100回アップデートした結果です。
学習結果です。
状態は最初から順に状態2、状態1、状態4、状態3の順番で状態づきましたが、結果としてうまくいっているように感じます。最後に
今回は隠れマルコフモデルについて自分なりにまとめてみましたが、思った以上に量が多く、数ヶ月前に実装したのにどうやって考えるのか忘れてしまうところも多く早めにアウトプットしていくことは大事だなととても感じました。その影響もあってビタービアルゴリズムや、状態リストの関数など説明できてないので。また後日改めてまとめます。
(文章力なくて入れ込めなかった原因もありますが……)
また、このプログラムでもきちんとガウス分布がうまくはまらないこともあり、自分のプログラムが原因なのか、局所最適解に落ちているのかもう少し考えたいと思います。
また、GMM-HMMの実装も行なってみたのですが(model_numを変更するとGMMになる)、うまく状態つかなくて、ここも再度どこでうまくいっていないのか(もしくは局所最適解に落ちているのか)もう一度見直したいと考えています。
きちんと完成したものじゃなくて申し訳ないです。
また、局所最適解に落ちる問題を解決するための手法について書かれてそうな論文見つけたのでこちらも勉強していきます。[参考]
https://mieruca-ai.com/ai/markov_model_hmm/ 【技術解説】マルコフモデルと隠れマルコフモデル
https://qiita.com/kenmatsu4/items/59ea3e5dfa3d4c161efb EMアルゴリズム徹底解説
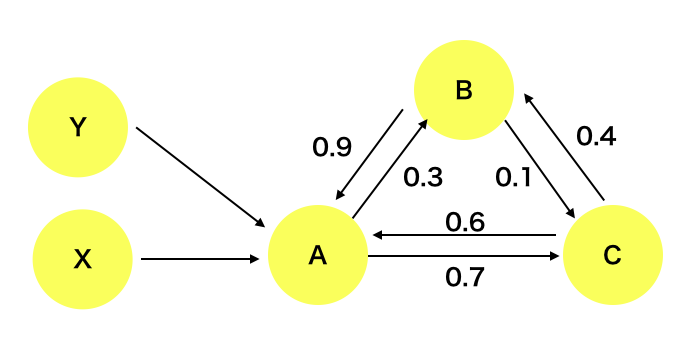
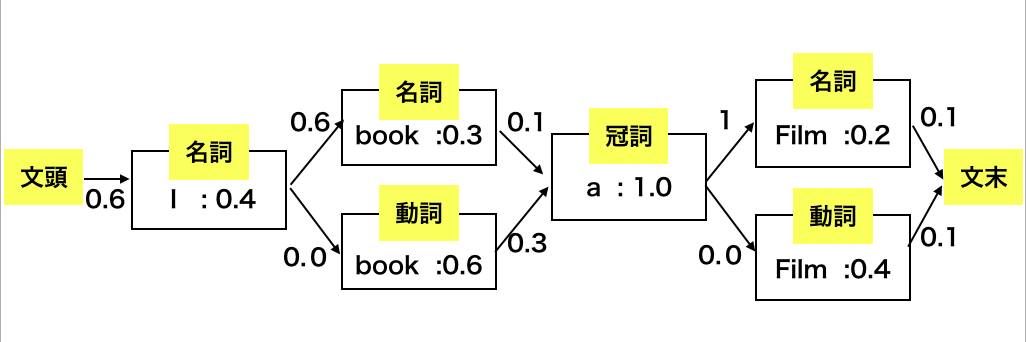
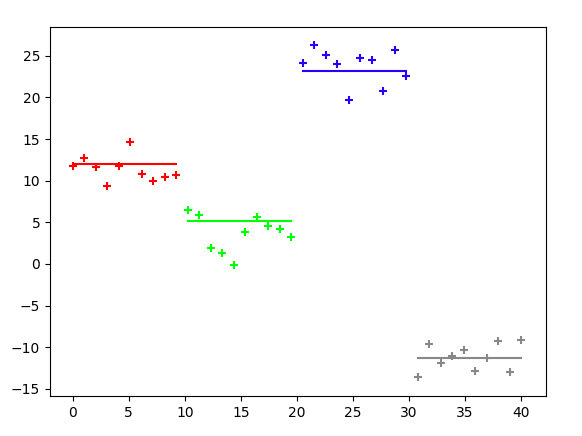
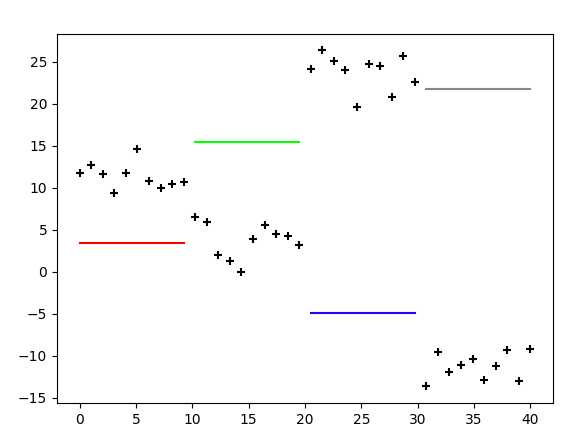
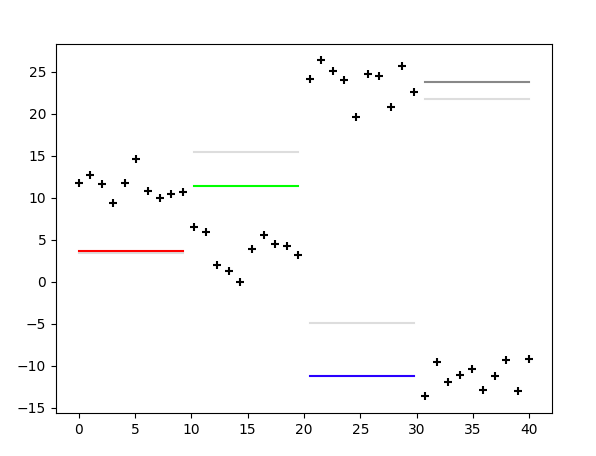
- 投稿日:2020-09-19T02:36:48+09:00
文字列配列を長さ&五十音順にソートする
はじめに
文字列でできた配列を単語の長さでソートし,かつ五十音順にしたいケースがあったのでメモとして残す。
解決方法
※ いただいたコメントを元に修正しました。shiracamusさんありがとうございます!!
words = ["にほん", "あめりか", "ろしあ", "ふらんす", "いたりあ", "ちゅうごく", "しんがぽーる", "おーすとらりあ", "たい", "ちり", "どいつ", "いぎりす"] words = sorted(words, key=lambda word: (len(word), word)) print(words)出力結果は次のようになります:
['たい', 'ちり', 'どいつ', 'にほん', 'ろしあ', 'あめりか', 'いぎりす', 'いたりあ', 'ふらんす', 'ちゅうごく', 'しんがぽーる', 'おーすとらりあ']簡単ですね。
もっと良い方法があれば教えてください。
- 投稿日:2020-09-19T01:17:40+09:00
tf.train.start_queue_runners()で0xC0000005エラーが発生した場合の対処法
tensorflowで非同期処理しようとしたらエラーでハマった。
対処法を探したが見つからなかったので誰かの参考になればと思います。現象
以下のコードを実行すると
tf.train.start_queue_runners()でエラーが発生するfilename_queue = tf.train.string_input_producer(["../dataset/sample1.tfrecord"]) reader = tf.TextLineReader() // ... 略 with tf.Session() as sess: # 入力 enqueue スレッド開始 coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord)[実行結果]
Process finished with exit code -1073741819 (0xC0000005)原因
ファイルパスの参照先が間違っていた。
(誤)filename_queue = tf.train.string_input_producer(["../dataset/sample1.tfrecord"]) (正)filename_queue = tf.train.string_input_producer(["../dataset/samples/sample1.tfrecord"])凡ミスだが地味にハマった。
tf.train.string_input_producer()でエラーが出てくれればいいのに…。
0xC0000005がそもそもメモリアクセス違反系のエラーなのでファイルなどの参照周りをまず怪しむべき。(参考)Tensorflowで非同期処理
以下の記事がわかりやすい。
https://qiita.com/antimon2/items/c7d2285d34728557e81d
https://qiita.com/ashigirl966/items/99b0f8d9713ee90db13a